2024年 第50卷 第2期
2024, 50(2): 211-240.
doi: 10.16383/j.aas.c230126
摘要:
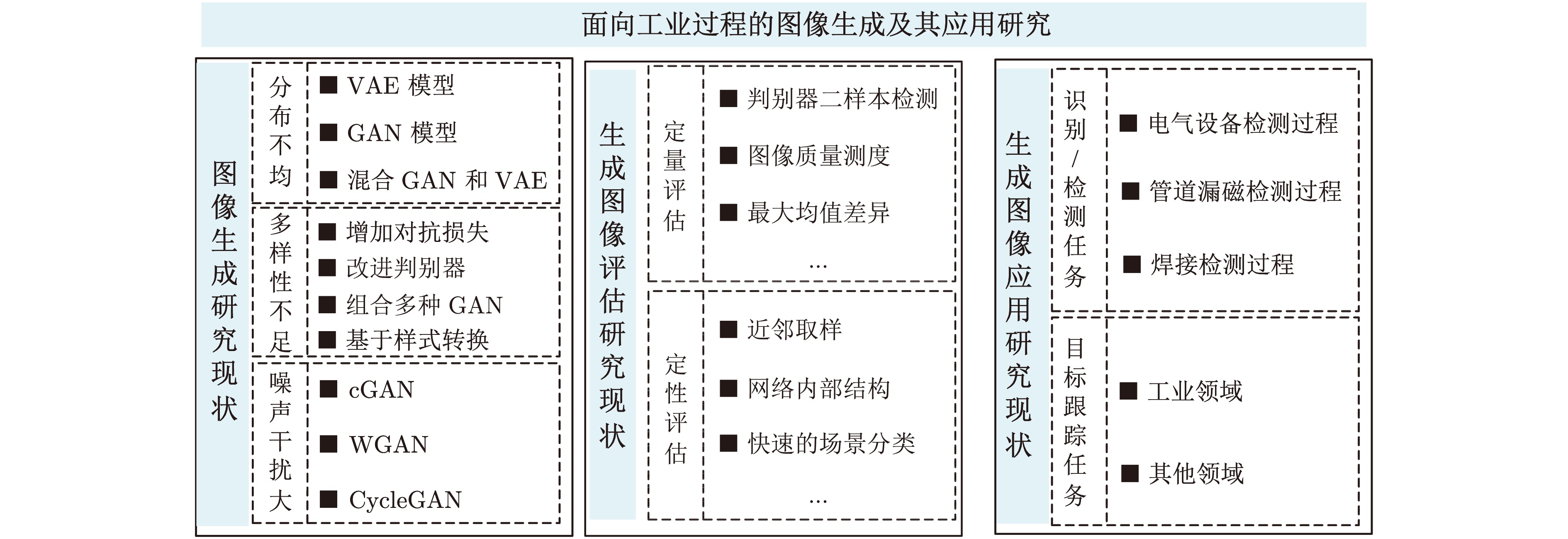
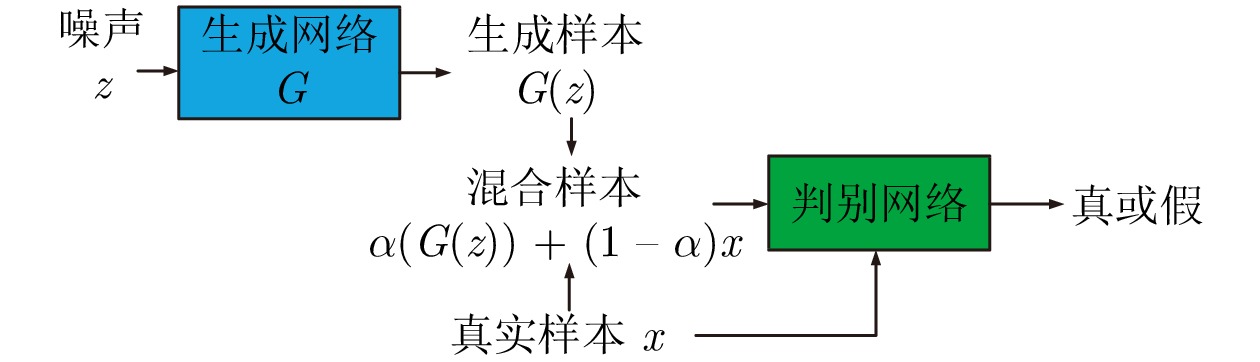
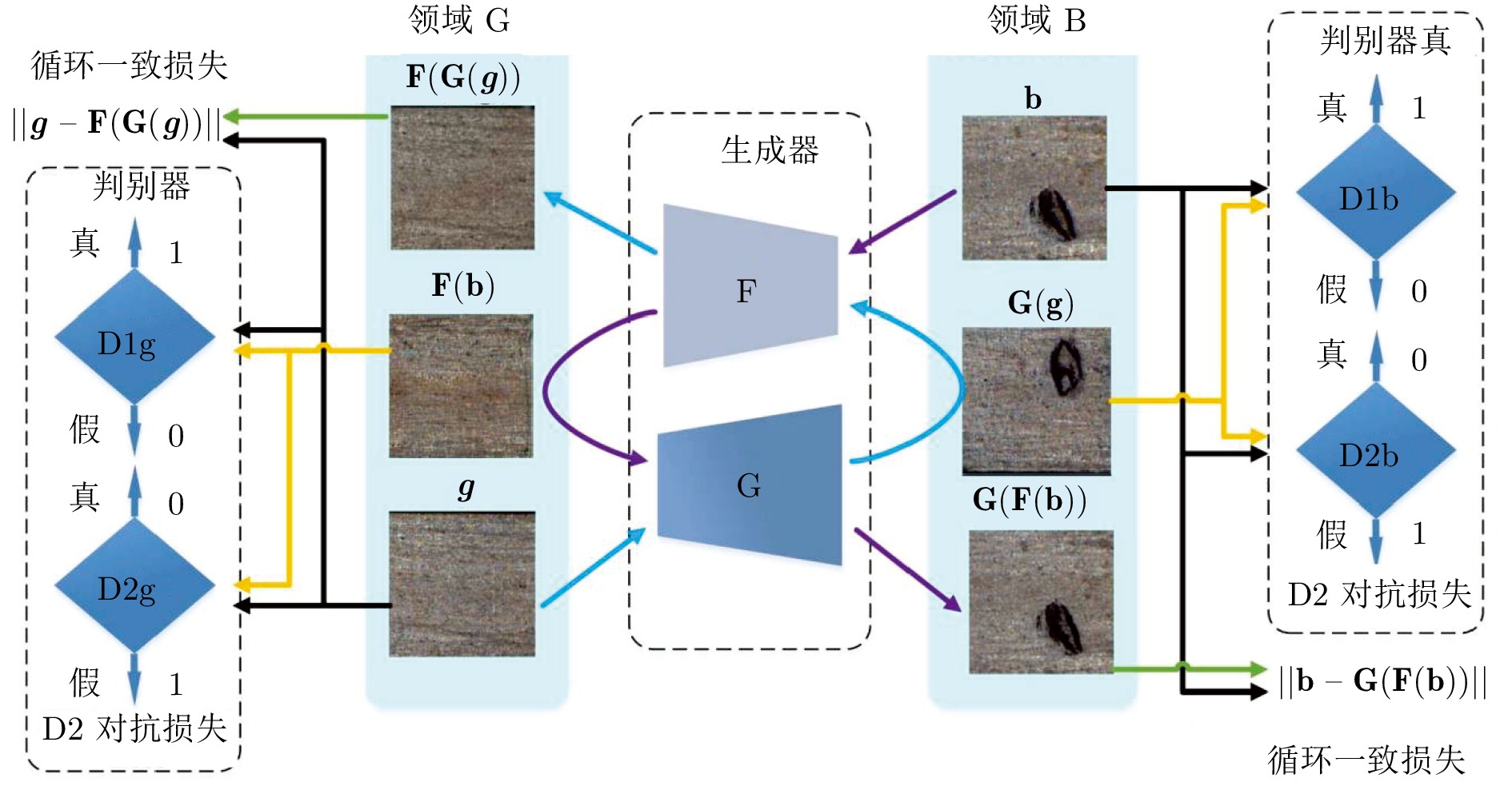
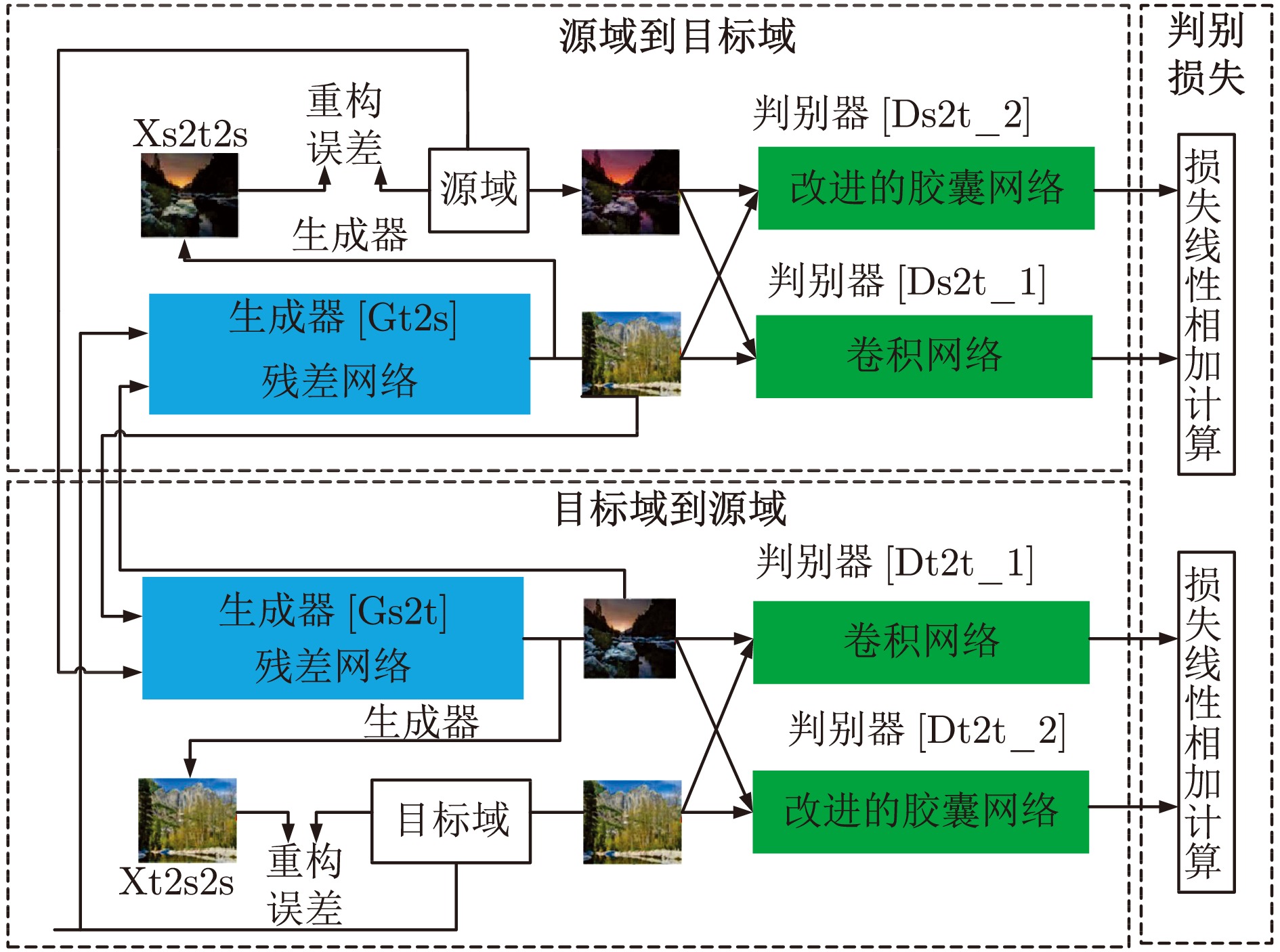
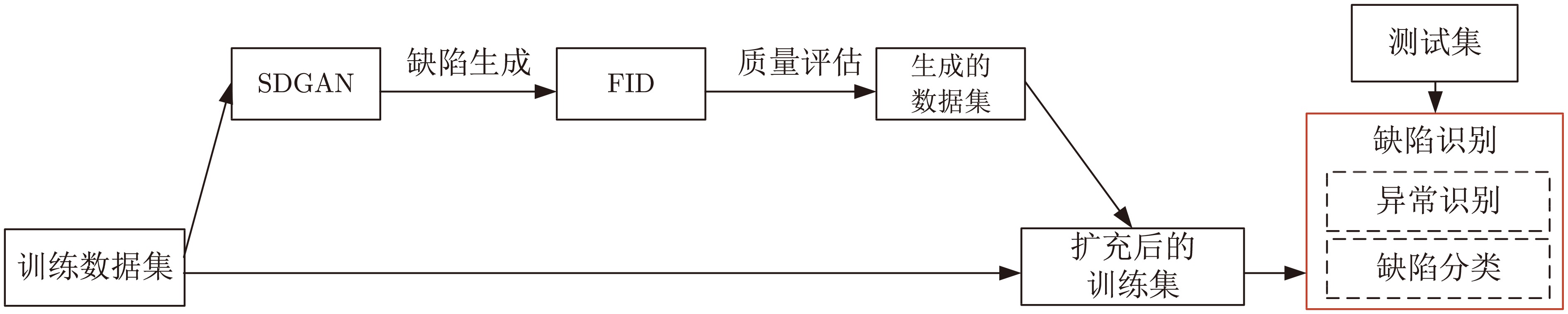
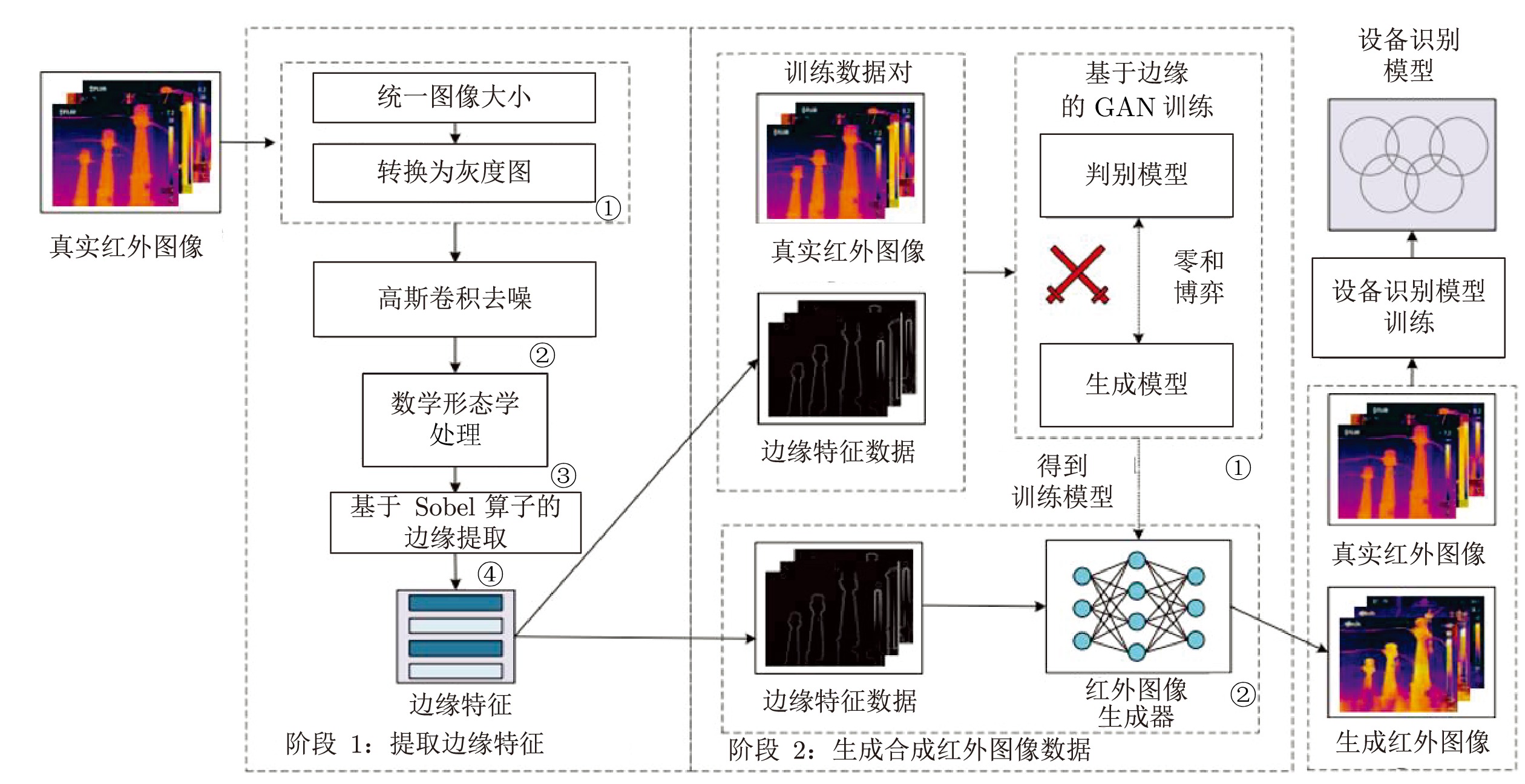
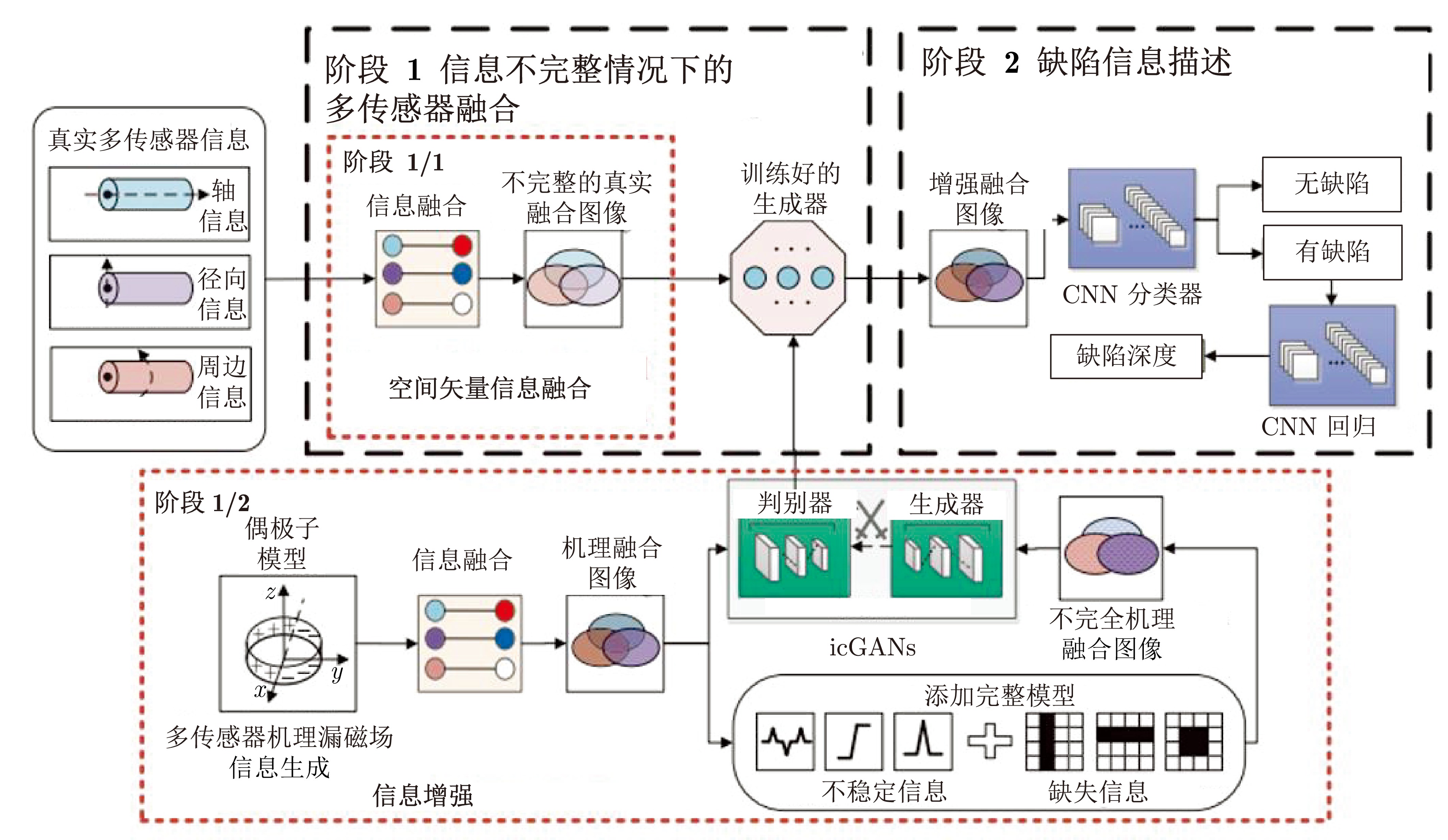
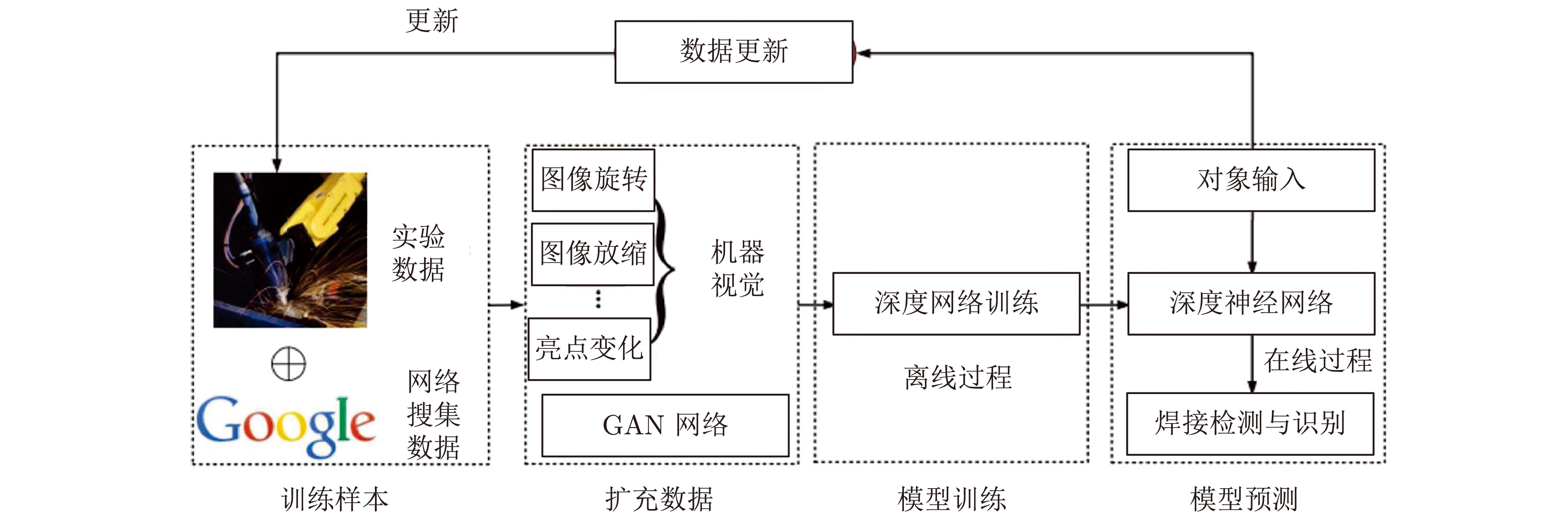
在面向工业过程的计算机视觉研究中, 智能感知模型能否实际应用取决于其对复杂工业环境的适应能力. 由于可利用的工业图像数据集存在分布不均、多样性不足和干扰严重等问题, 如何生成符合多工况分布的期望训练集是提高感知模型性能的关键. 为解决上述问题, 以城市固废焚烧(Municipal solid wastes incineration, MSWI)过程为背景, 综述目前面向工业过程的图像生成及其应用研究, 为进行面向工业图像的感知建模提供支撑. 首先, 梳理面向工业过程的图像生成定义和流程以及其应用需求; 随后, 分析在工业领域中具有潜在应用价值的图像生成算法; 接着, 从工业过程图像生成、生成图像评估和应用等视角进行现状综述; 然后, 对下一步研究方向进行讨论与分析; 最后, 对全文进行总结并指出未来挑战.
在面向工业过程的计算机视觉研究中, 智能感知模型能否实际应用取决于其对复杂工业环境的适应能力. 由于可利用的工业图像数据集存在分布不均、多样性不足和干扰严重等问题, 如何生成符合多工况分布的期望训练集是提高感知模型性能的关键. 为解决上述问题, 以城市固废焚烧(Municipal solid wastes incineration, MSWI)过程为背景, 综述目前面向工业过程的图像生成及其应用研究, 为进行面向工业图像的感知建模提供支撑. 首先, 梳理面向工业过程的图像生成定义和流程以及其应用需求; 随后, 分析在工业领域中具有潜在应用价值的图像生成算法; 接着, 从工业过程图像生成、生成图像评估和应用等视角进行现状综述; 然后, 对下一步研究方向进行讨论与分析; 最后, 对全文进行总结并指出未来挑战.











2024, 50(2): 241-281.
doi: 10.16383/j.aas.c230109
摘要:
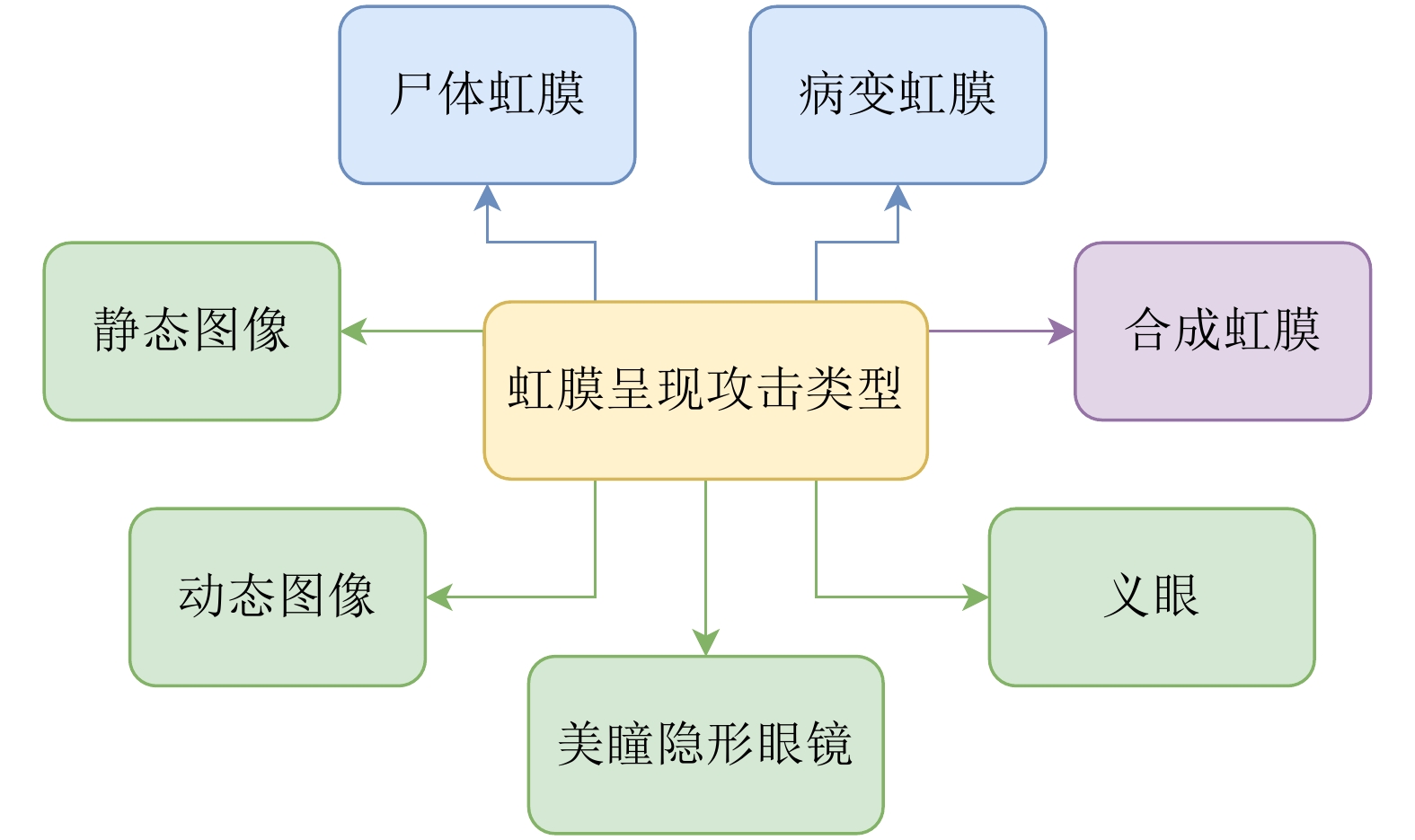
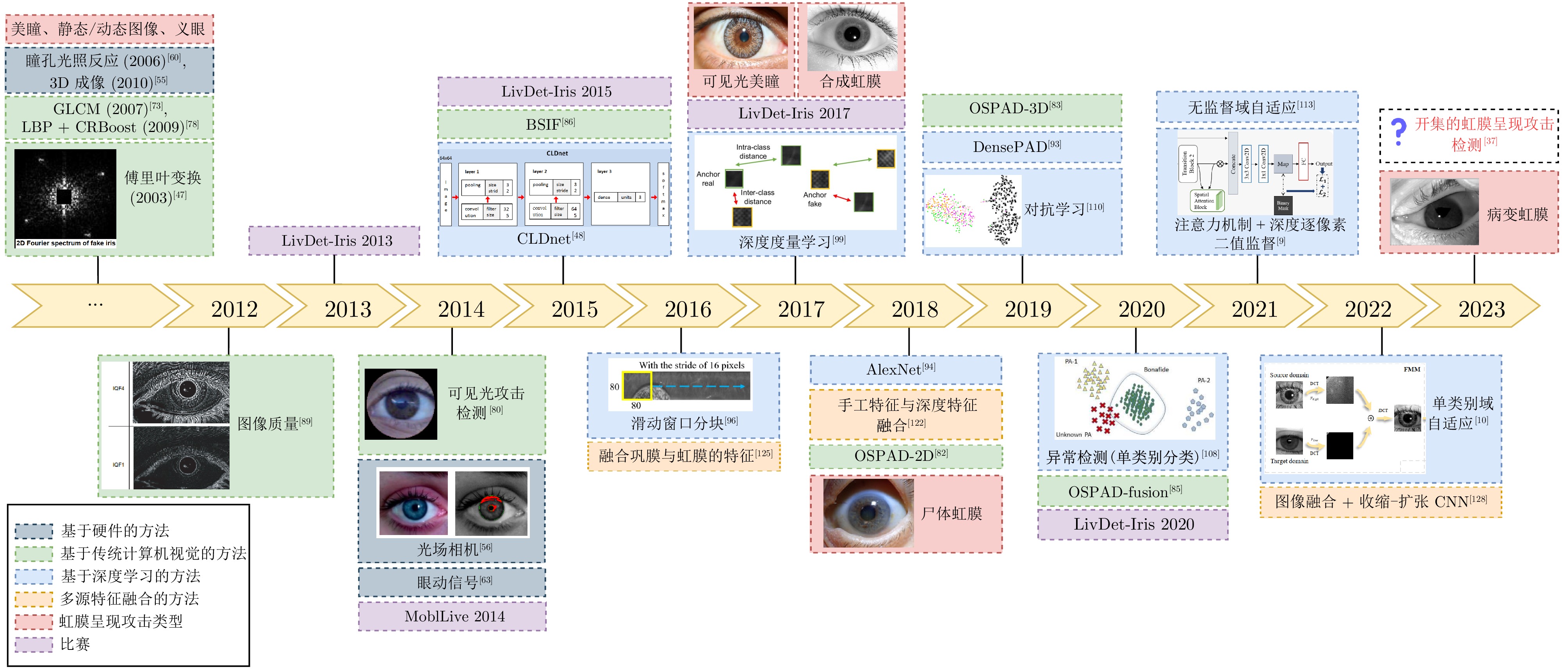
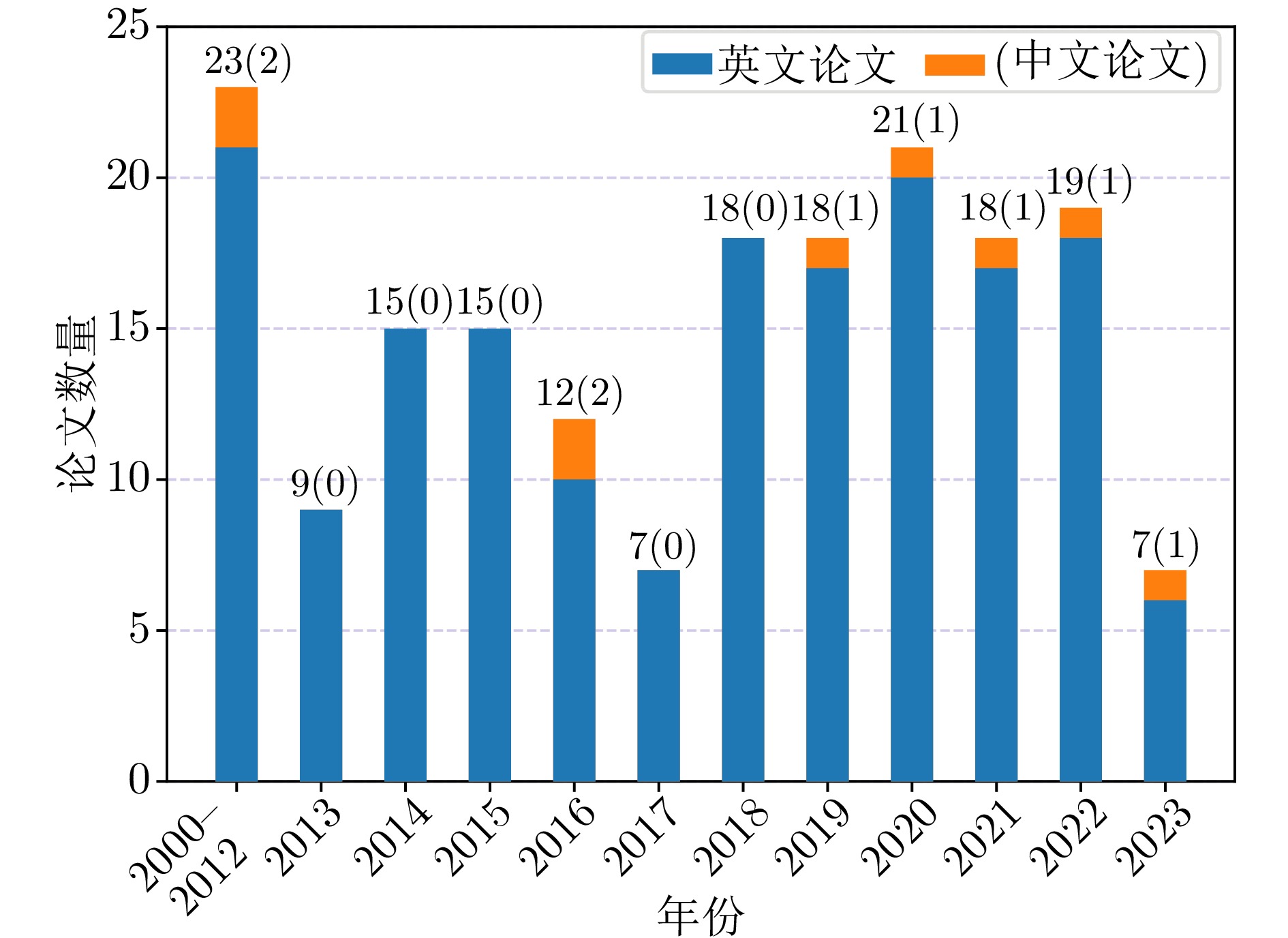
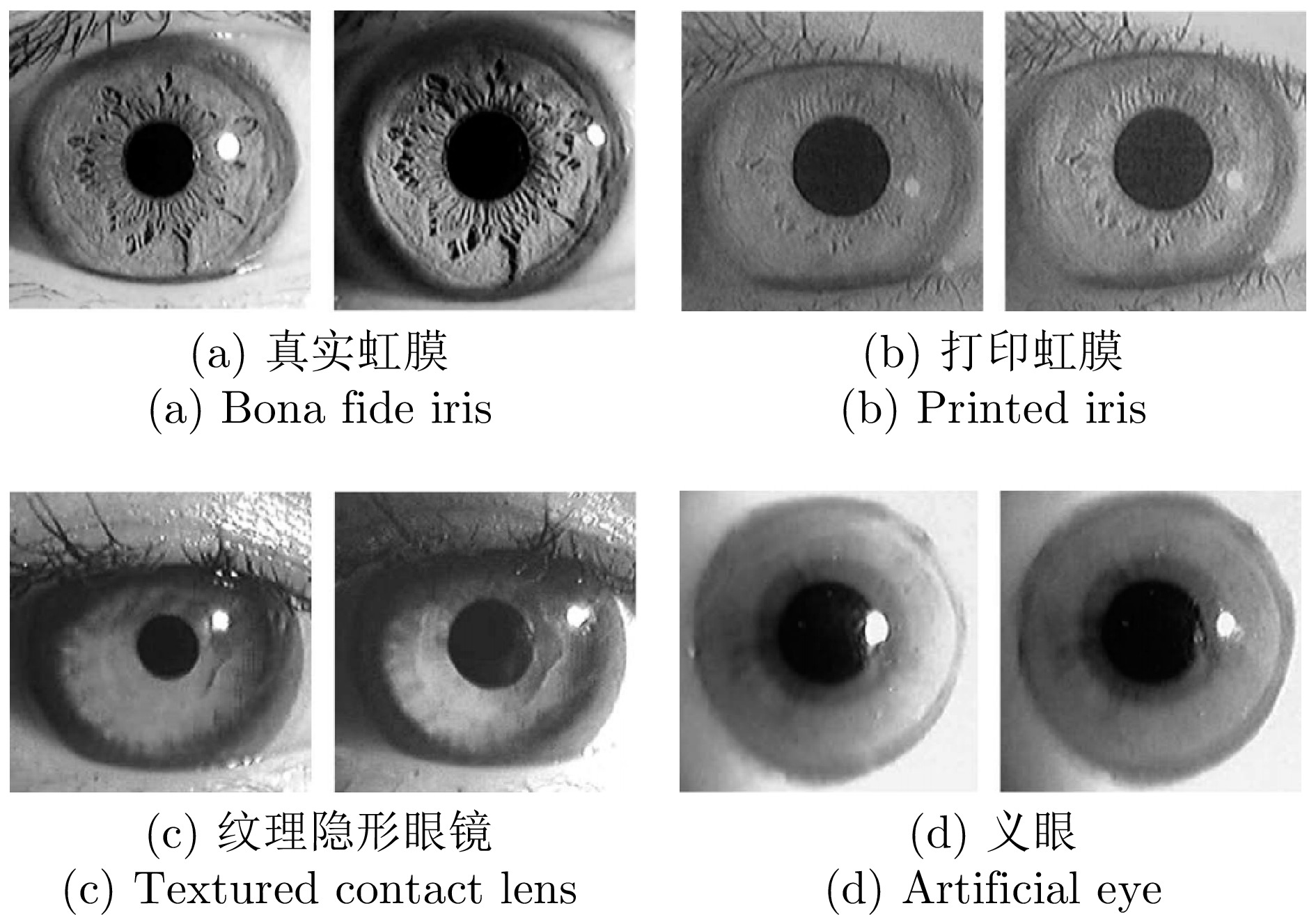
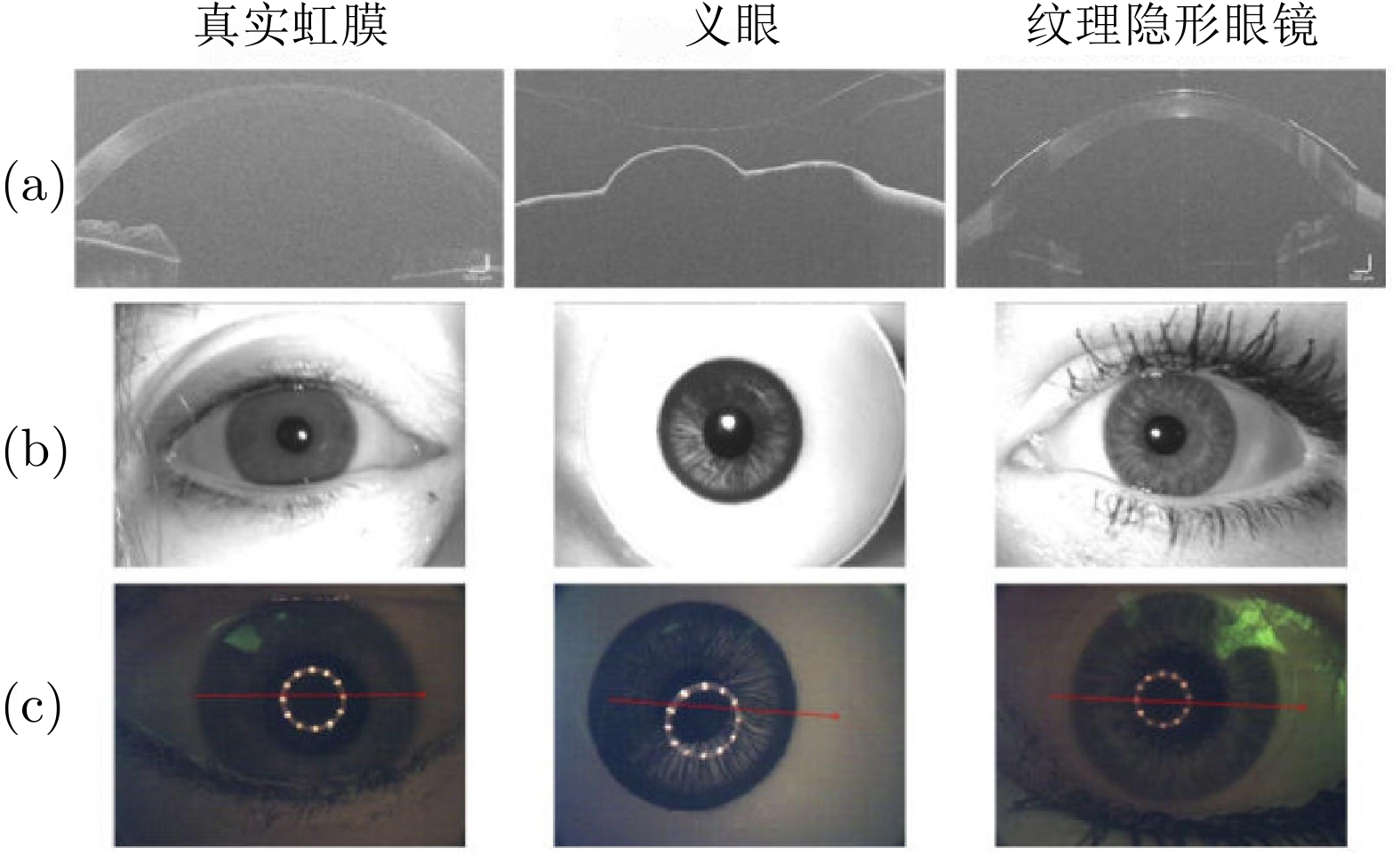
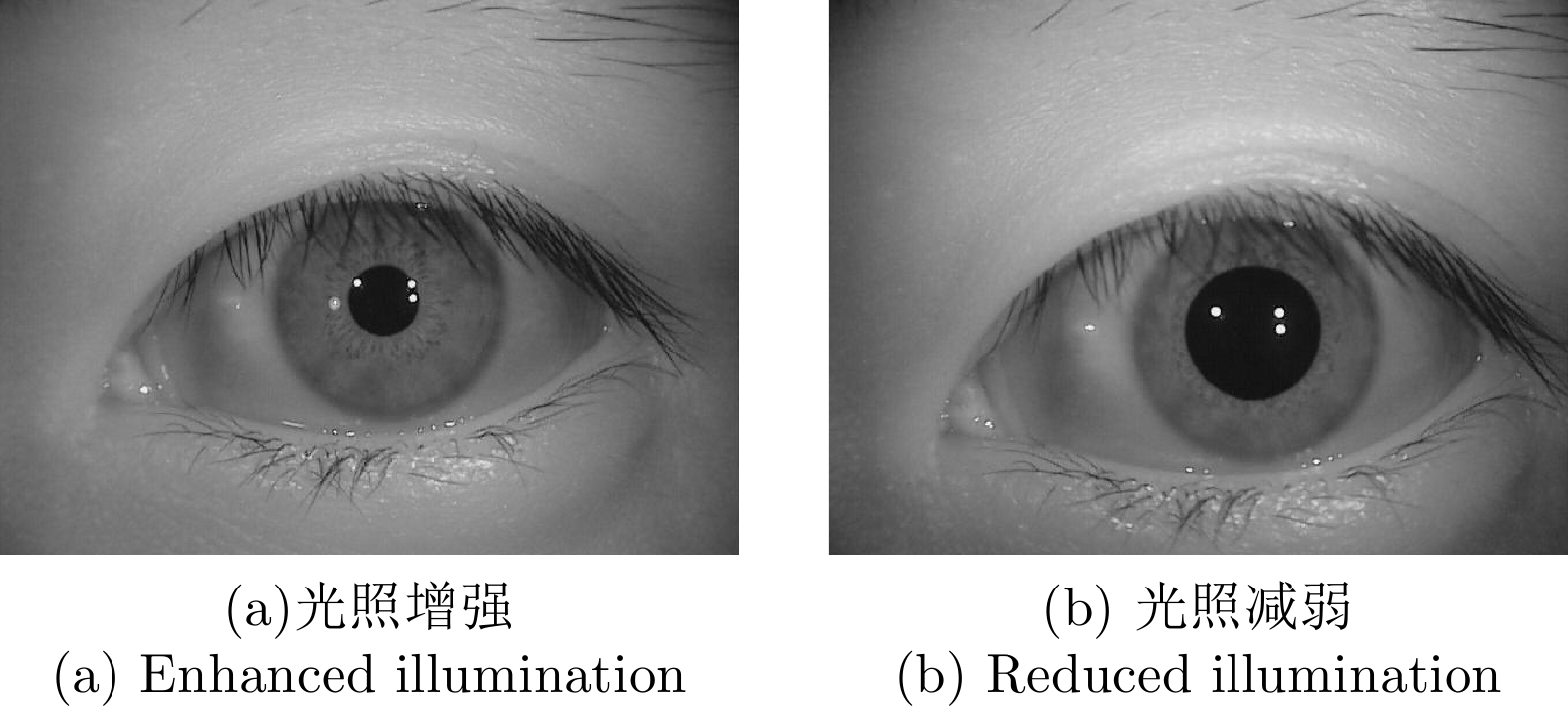
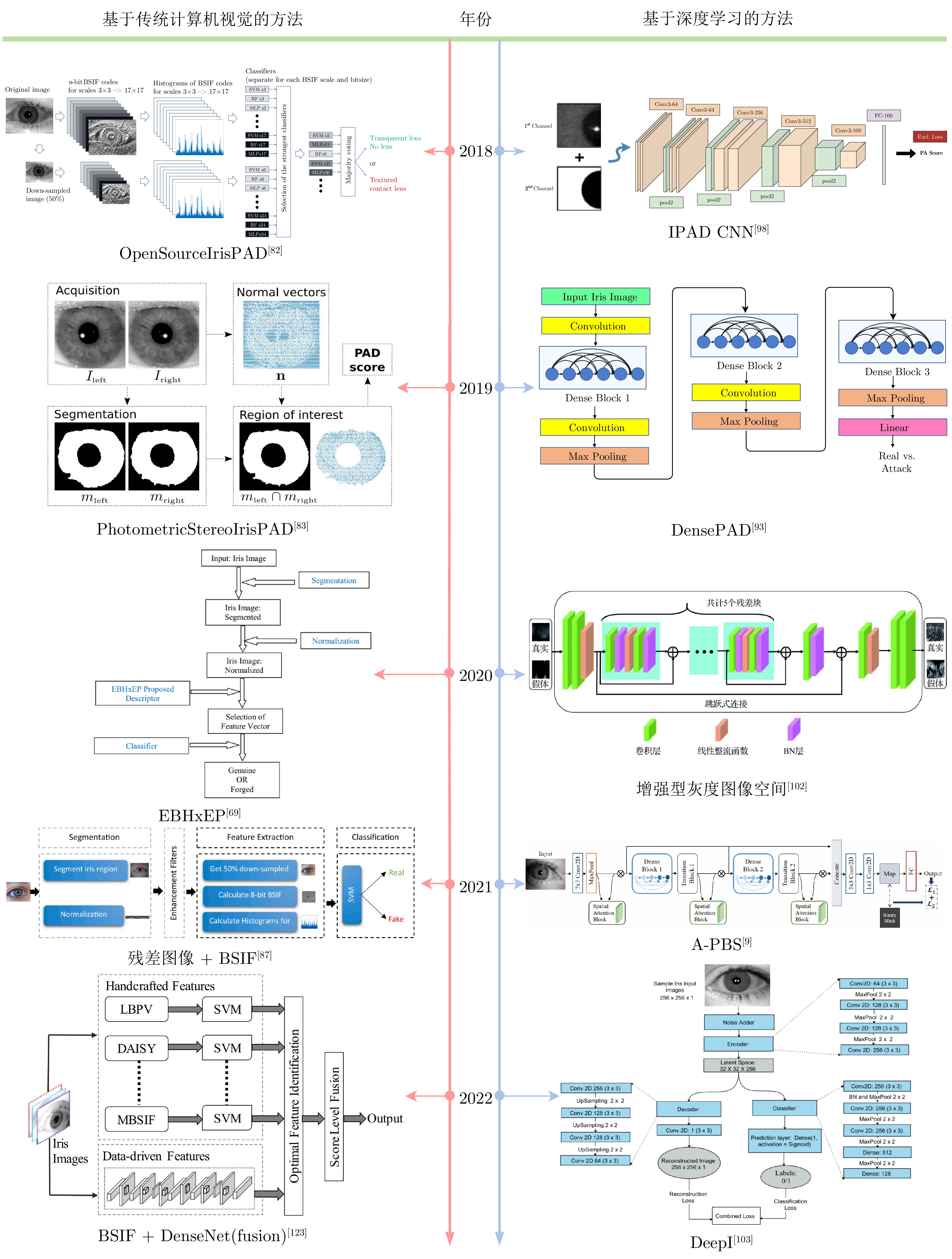
虹膜识别技术因唯一性、稳定性、非接触性、准确性等特性广泛应用于各类现实场景中. 然而, 现有的许多虹膜识别系统在认证过程中仍然容易遭受各种攻击的干扰, 导致安全性方面可能存在风险隐患. 在不同的攻击类型中, 呈现攻击(Presentation attacks, PAs)由于出现在早期的虹膜图像获取阶段, 且形式变化多端, 因而虹膜呈现攻击检测(Iris presentation attack detection, IPAD)成为虹膜识别技术中首先需要解决的安全问题之一, 得到了学术界和产业界的广泛重视. 本综述是目前已知第一篇虹膜呈现攻击检测领域的中文综述, 旨在帮助研究人员快速、全面地了解该领域的相关知识以及发展动态. 总体来说, 本文对虹膜呈现攻击检测的难点、术语和攻击类型、主流方法、公共数据集、比赛及可解释性等方面进行全面归纳. 具体而言, 首先介绍虹膜呈现攻击检测的背景、虹膜识别系统现存的安全漏洞与呈现攻击的目的. 其次, 按照是否使用额外硬件设备将检测方法分为基于硬件与基于软件的方法两大类, 并在基于软件的方法中按照特征提取的方式作出进一步归纳和分析. 此外, 还整理了开源方法、可申请的公开数据集以及概括了历届相关比赛. 最后, 对虹膜呈现攻击检测未来可能的发展方向进行了展望.
虹膜识别技术因唯一性、稳定性、非接触性、准确性等特性广泛应用于各类现实场景中. 然而, 现有的许多虹膜识别系统在认证过程中仍然容易遭受各种攻击的干扰, 导致安全性方面可能存在风险隐患. 在不同的攻击类型中, 呈现攻击(Presentation attacks, PAs)由于出现在早期的虹膜图像获取阶段, 且形式变化多端, 因而虹膜呈现攻击检测(Iris presentation attack detection, IPAD)成为虹膜识别技术中首先需要解决的安全问题之一, 得到了学术界和产业界的广泛重视. 本综述是目前已知第一篇虹膜呈现攻击检测领域的中文综述, 旨在帮助研究人员快速、全面地了解该领域的相关知识以及发展动态. 总体来说, 本文对虹膜呈现攻击检测的难点、术语和攻击类型、主流方法、公共数据集、比赛及可解释性等方面进行全面归纳. 具体而言, 首先介绍虹膜呈现攻击检测的背景、虹膜识别系统现存的安全漏洞与呈现攻击的目的. 其次, 按照是否使用额外硬件设备将检测方法分为基于硬件与基于软件的方法两大类, 并在基于软件的方法中按照特征提取的方式作出进一步归纳和分析. 此外, 还整理了开源方法、可申请的公开数据集以及概括了历届相关比赛. 最后, 对虹膜呈现攻击检测未来可能的发展方向进行了展望.








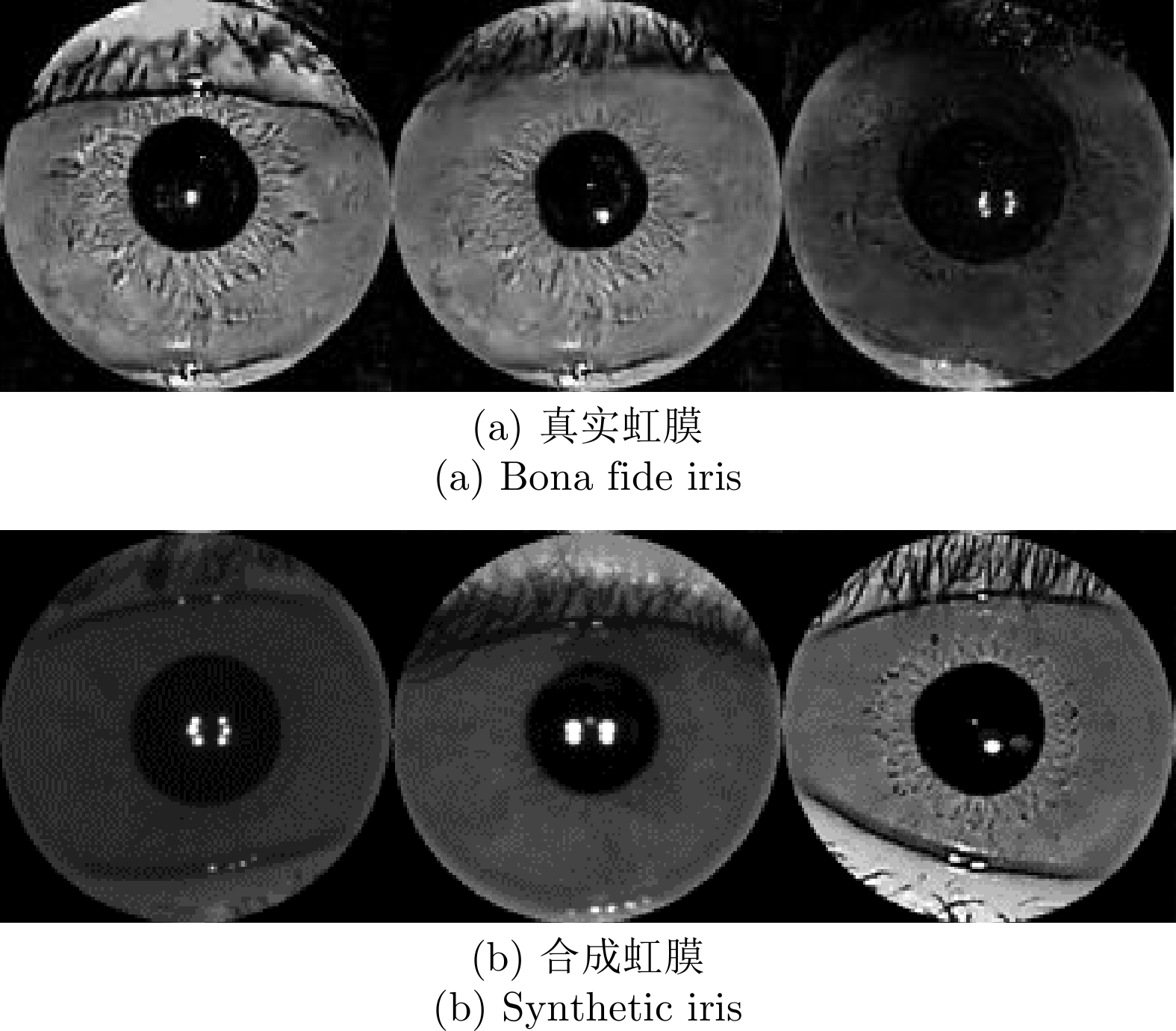

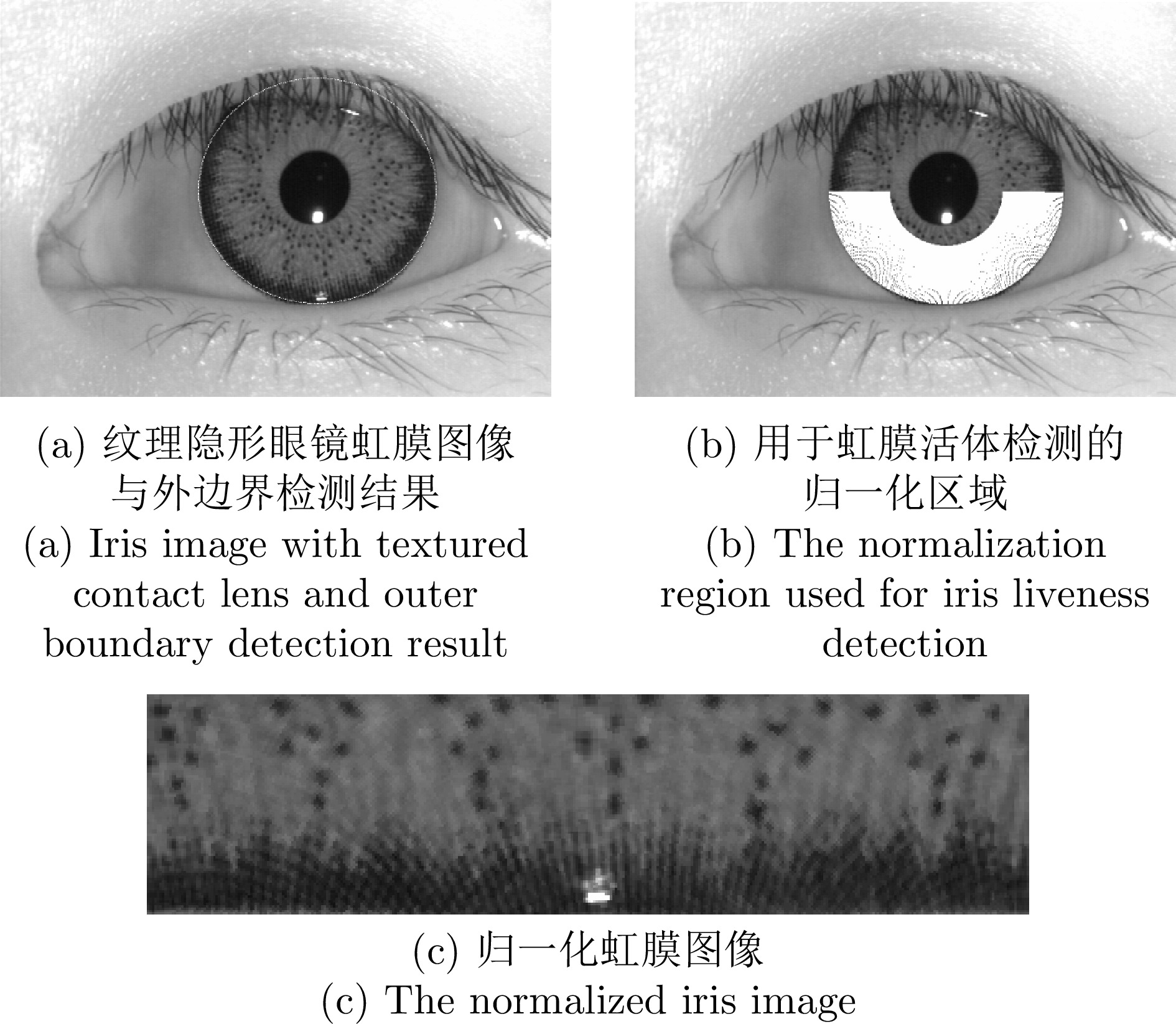


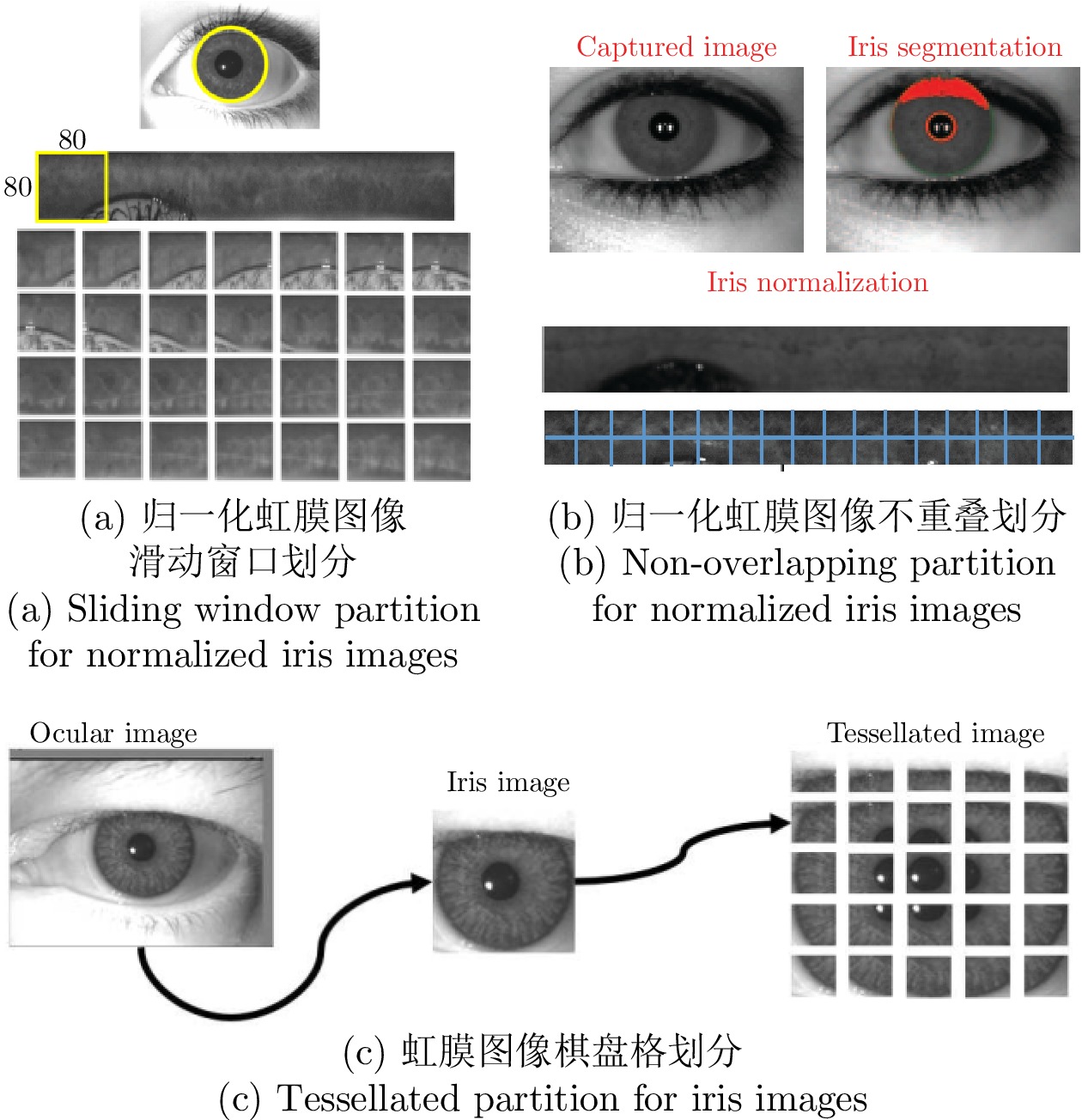






2024, 50(2): 282-294.
doi: 10.16383/j.aas.c211013
摘要:
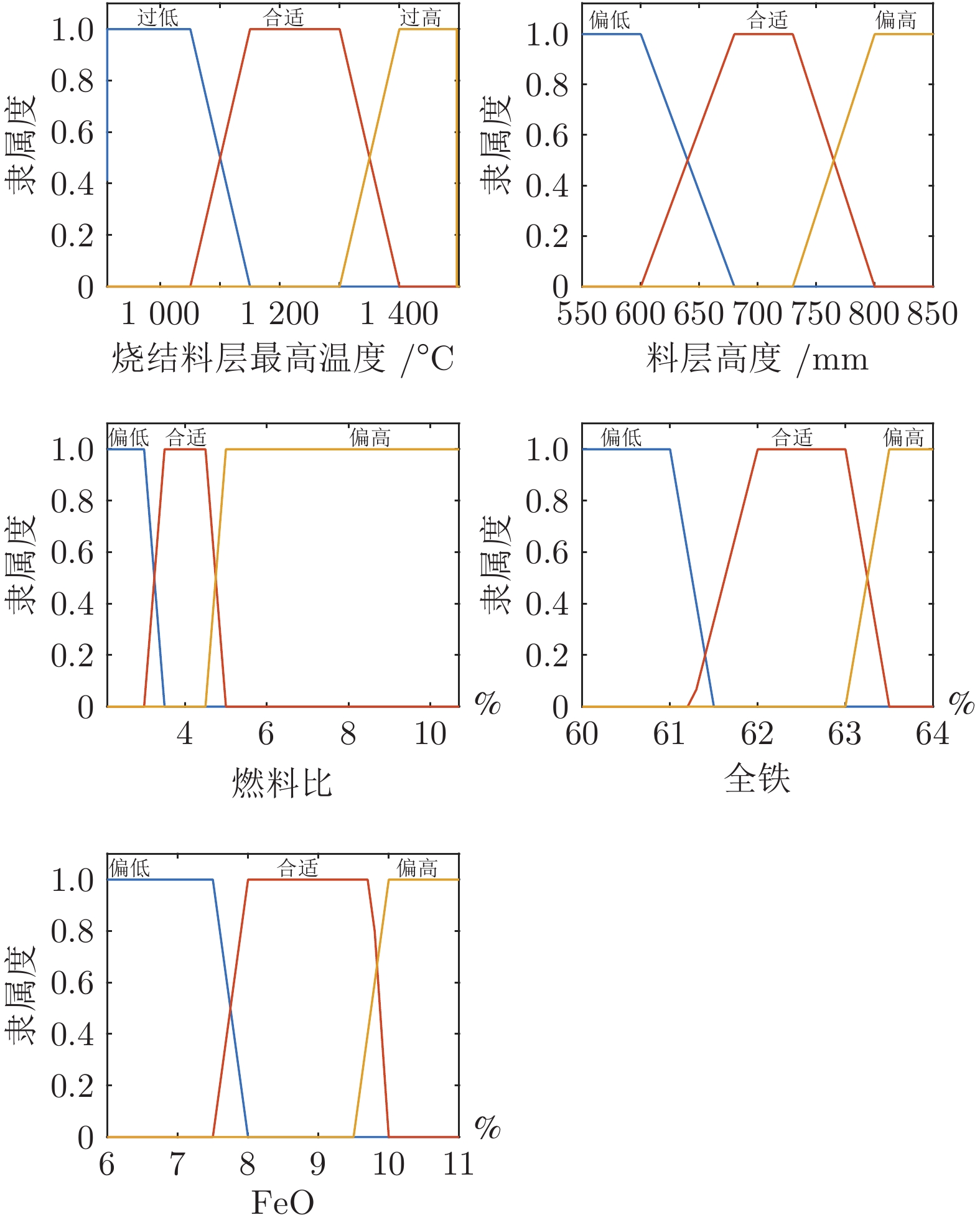
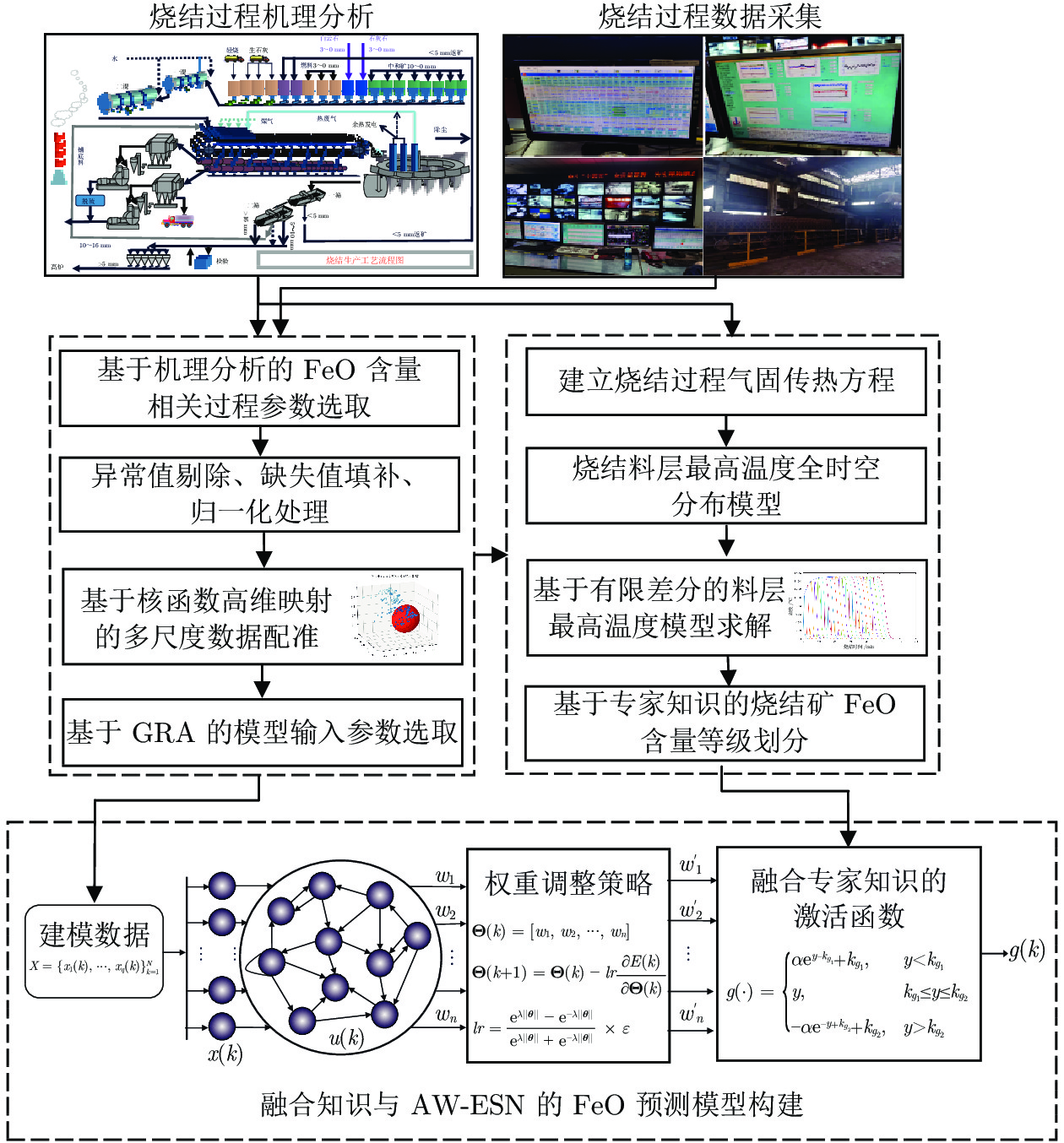
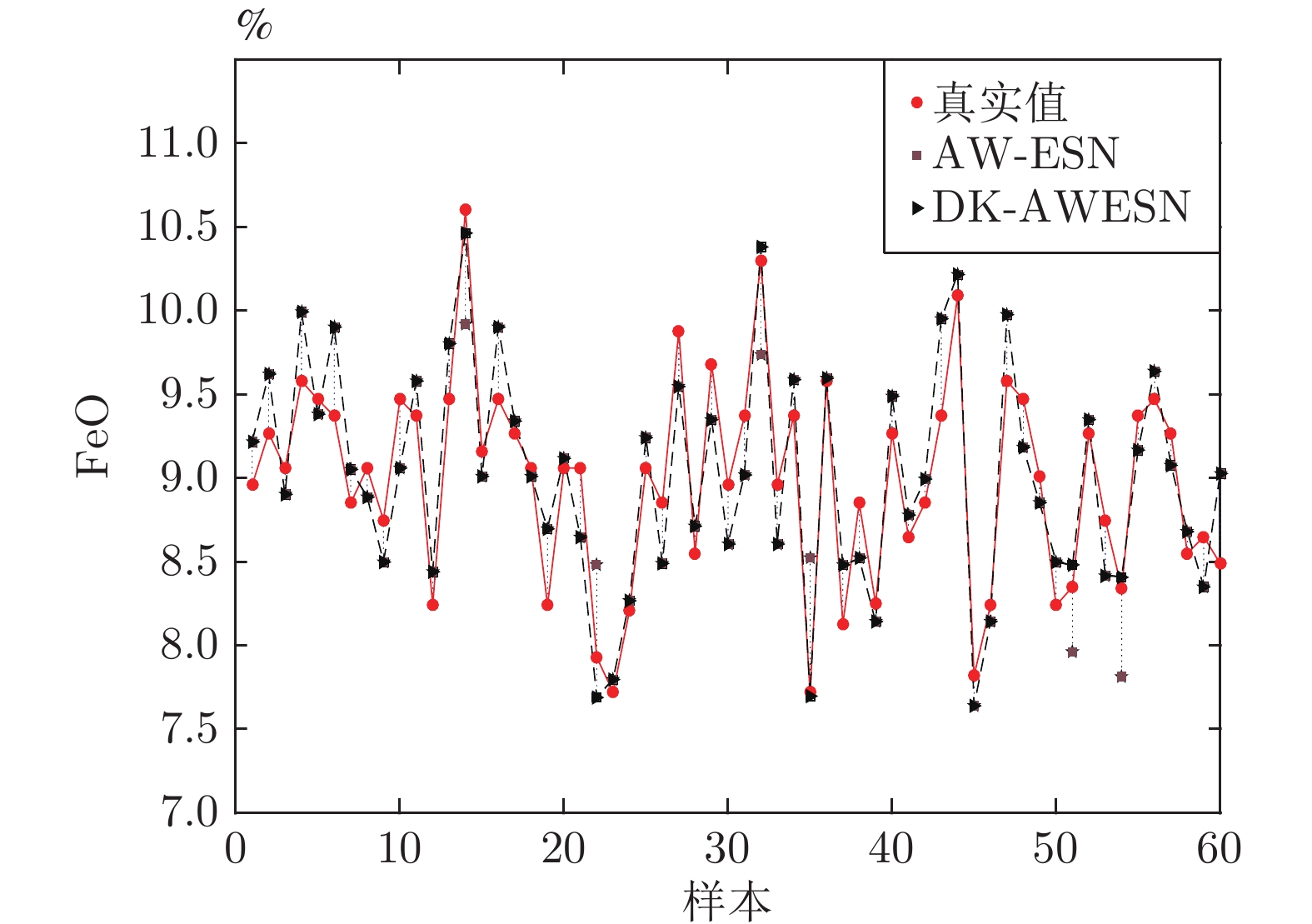
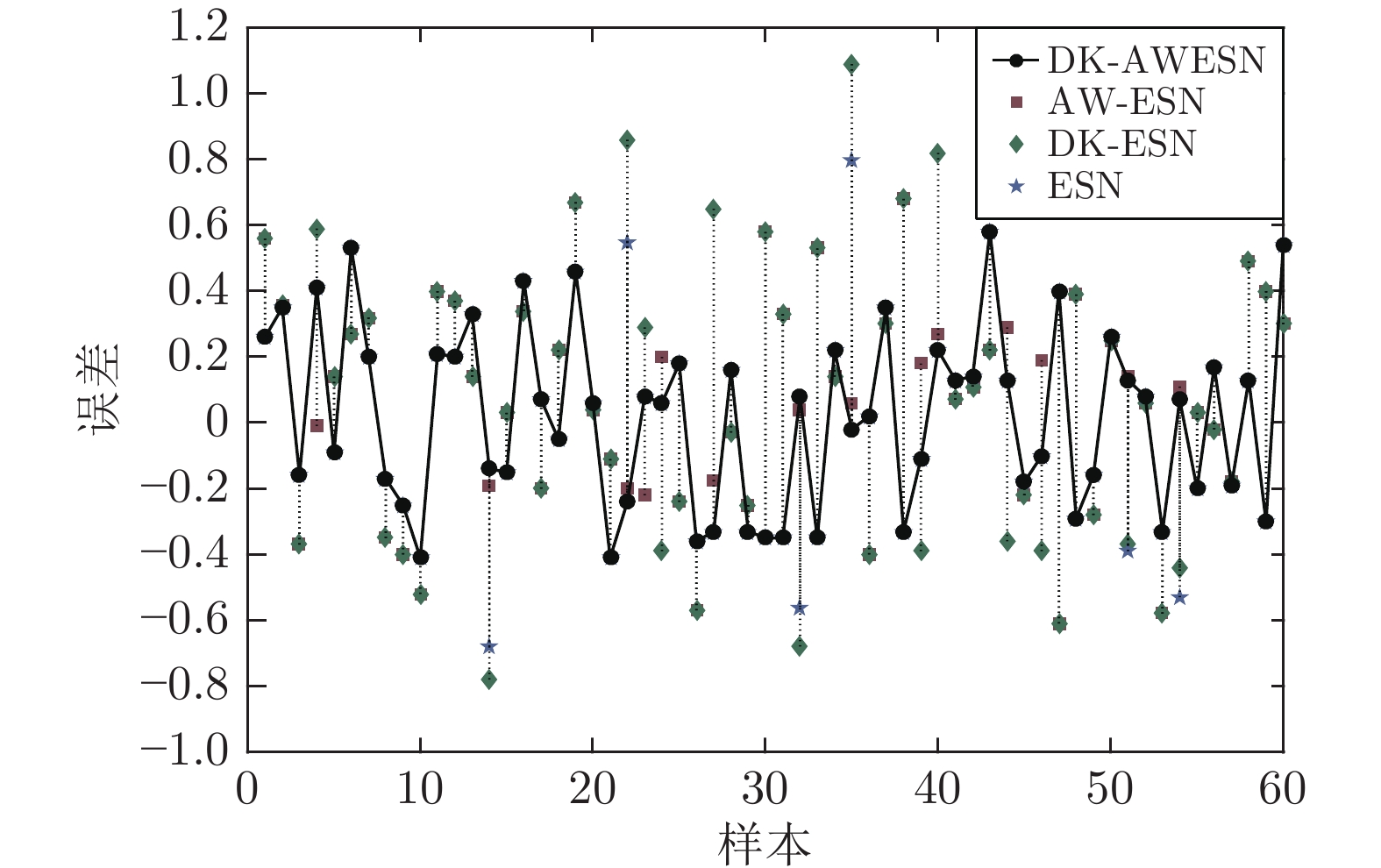
氧化亚铁(FeO)含量是衡量烧结矿强度和还原性的重要指标, 烧结过程FeO含量的实时准确预测对于提升烧结质量、优化烧结工艺具有重要意义. 然而烧结过程热状态参数缺失、过程参数波动频繁给FeO含量的高精度预测带来巨大的挑战, 为此, 提出一种基于知识与变权重回声状态网络融合(Fusion of data-knowledge and adaptive weight echo state network, DK-AWESN)的烧结过程FeO含量预测方法. 首先, 针对烧结过程热状态参数缺失的问题, 建立烧结料层最高温度分布模型, 实现基于料层温度分布特征的FeO含量等级划分; 其次, 针对烧结过程参数波动频繁的问题, 提出基于核函数高维映射的多尺度数据配准方法, 有效抑制离群点的影响, 提升建模数据的质量; 最后, 针对烧结过程数据驱动模型缺乏机理认知致使模型预测精度不高的问题, 将过程数据中提取得到的FeO含量等级知识与AW-ESN (Adaptive weight echo state network)结合, 建立DK-AWESN模型, 有效提升复杂工况下FeO含量的预测精度. 现场工业数据试验表明, 所提方法能实时准确地预测烧结过程FeO含量, 为烧结过程的智能化调控提供实时有效的FeO含量反馈信息.
氧化亚铁(FeO)含量是衡量烧结矿强度和还原性的重要指标, 烧结过程FeO含量的实时准确预测对于提升烧结质量、优化烧结工艺具有重要意义. 然而烧结过程热状态参数缺失、过程参数波动频繁给FeO含量的高精度预测带来巨大的挑战, 为此, 提出一种基于知识与变权重回声状态网络融合(Fusion of data-knowledge and adaptive weight echo state network, DK-AWESN)的烧结过程FeO含量预测方法. 首先, 针对烧结过程热状态参数缺失的问题, 建立烧结料层最高温度分布模型, 实现基于料层温度分布特征的FeO含量等级划分; 其次, 针对烧结过程参数波动频繁的问题, 提出基于核函数高维映射的多尺度数据配准方法, 有效抑制离群点的影响, 提升建模数据的质量; 最后, 针对烧结过程数据驱动模型缺乏机理认知致使模型预测精度不高的问题, 将过程数据中提取得到的FeO含量等级知识与AW-ESN (Adaptive weight echo state network)结合, 建立DK-AWESN模型, 有效提升复杂工况下FeO含量的预测精度. 现场工业数据试验表明, 所提方法能实时准确地预测烧结过程FeO含量, 为烧结过程的智能化调控提供实时有效的FeO含量反馈信息.


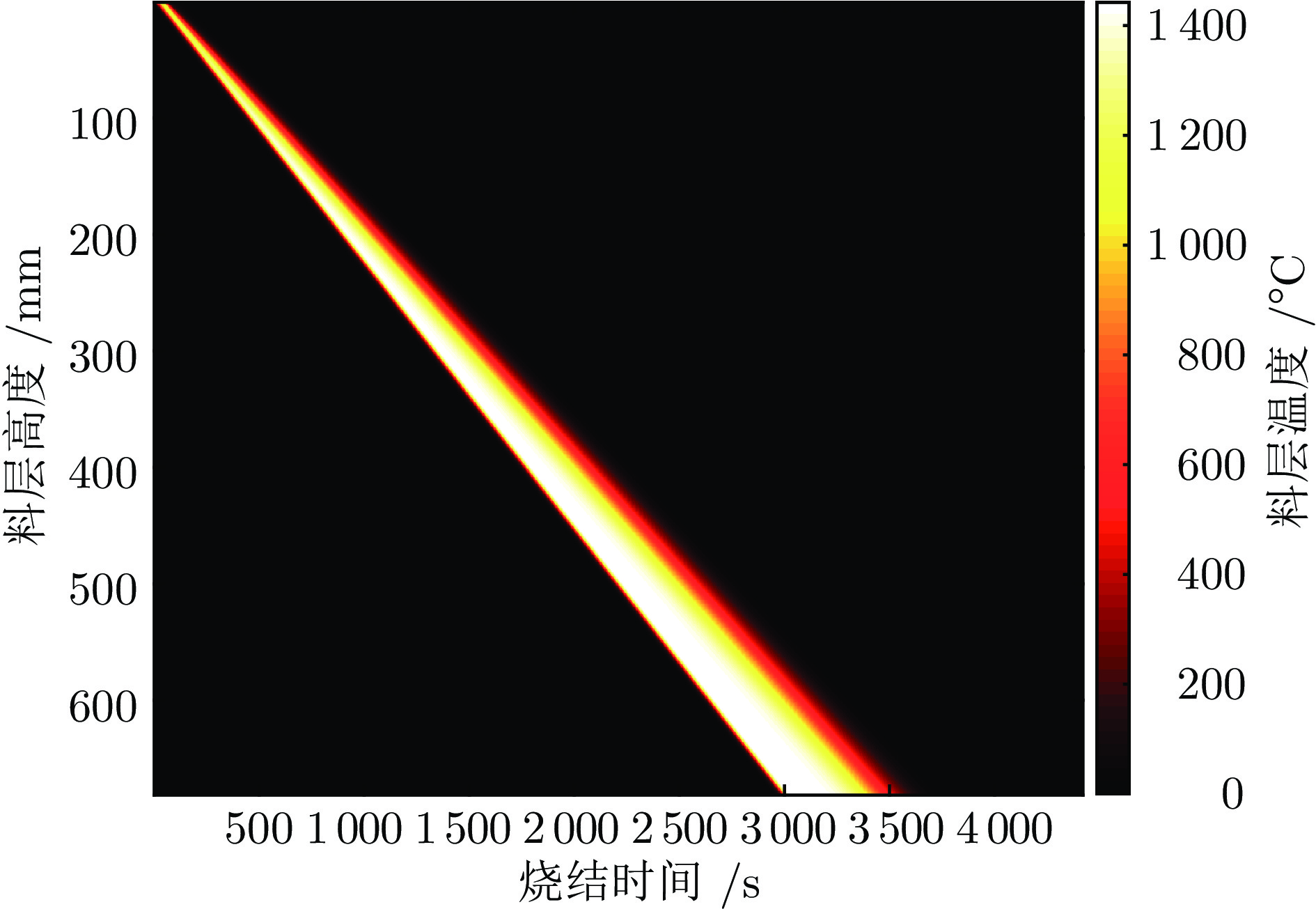



2024, 50(2): 295-307.
doi: 10.16383/j.aas.c221007
摘要:
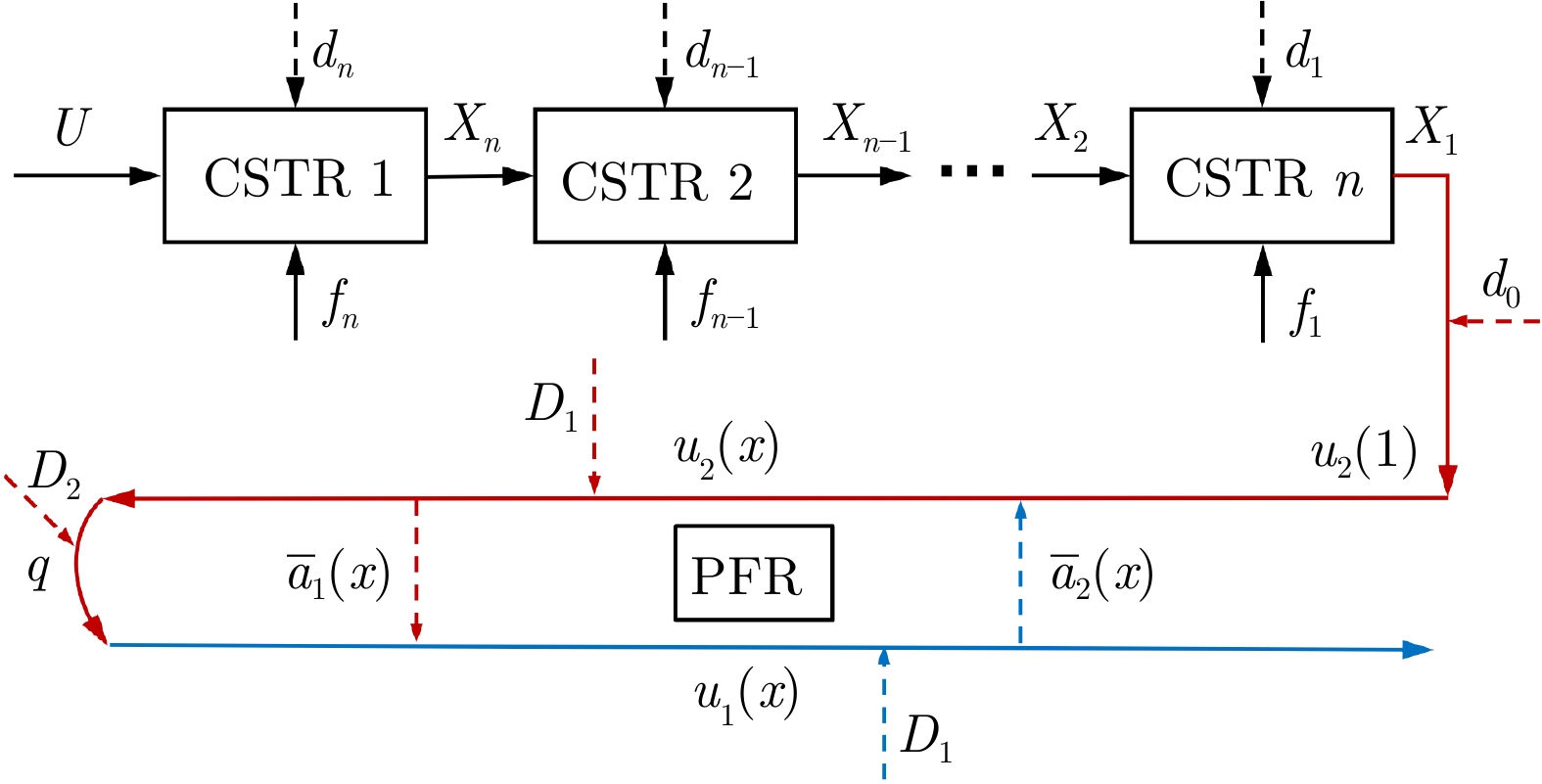
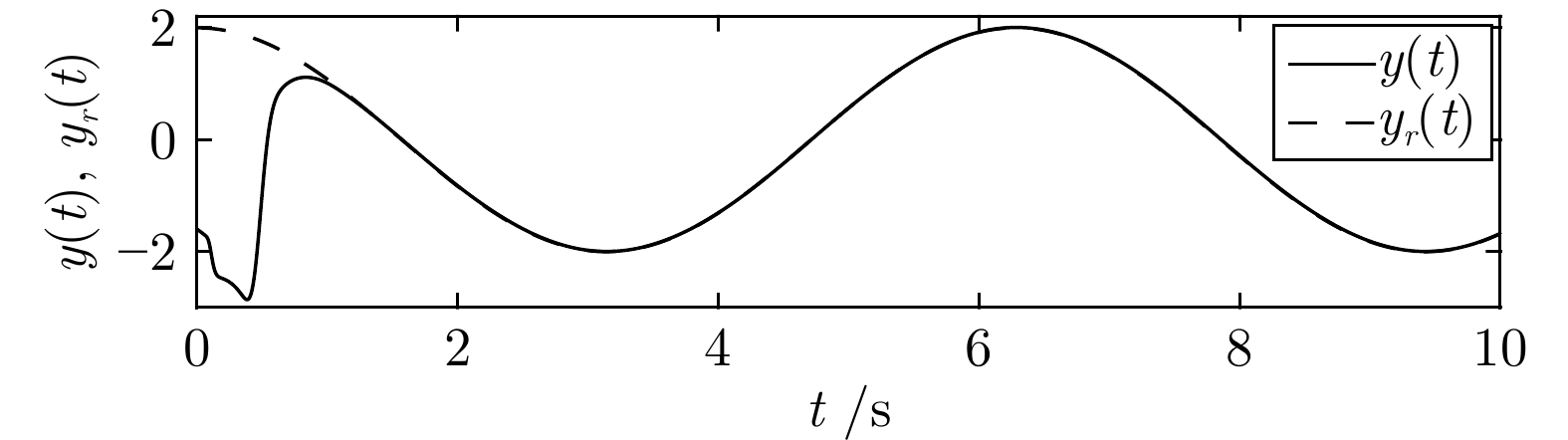
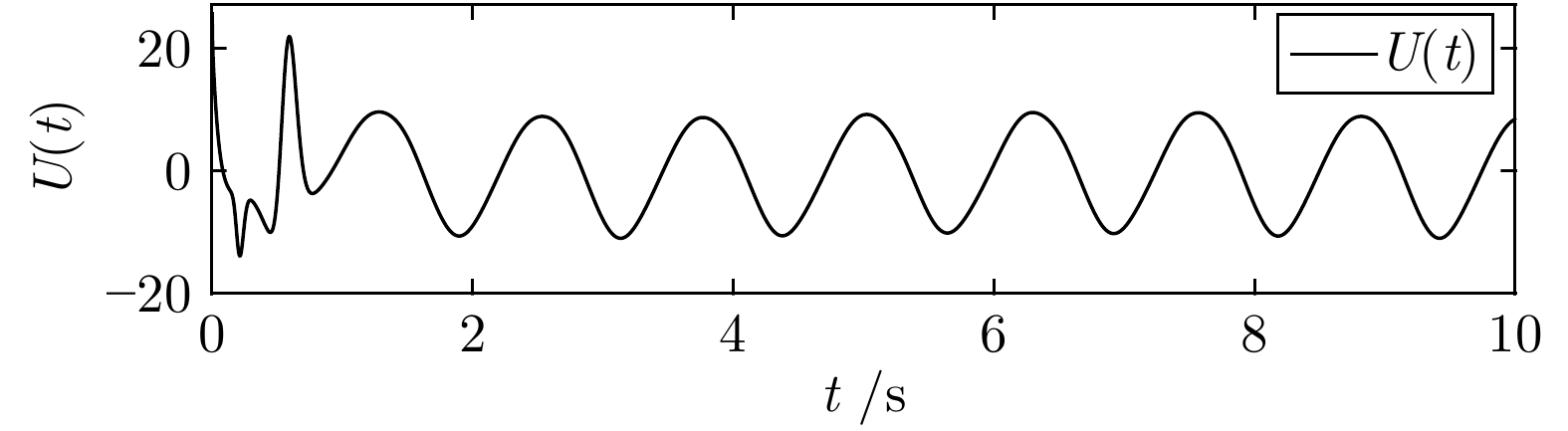
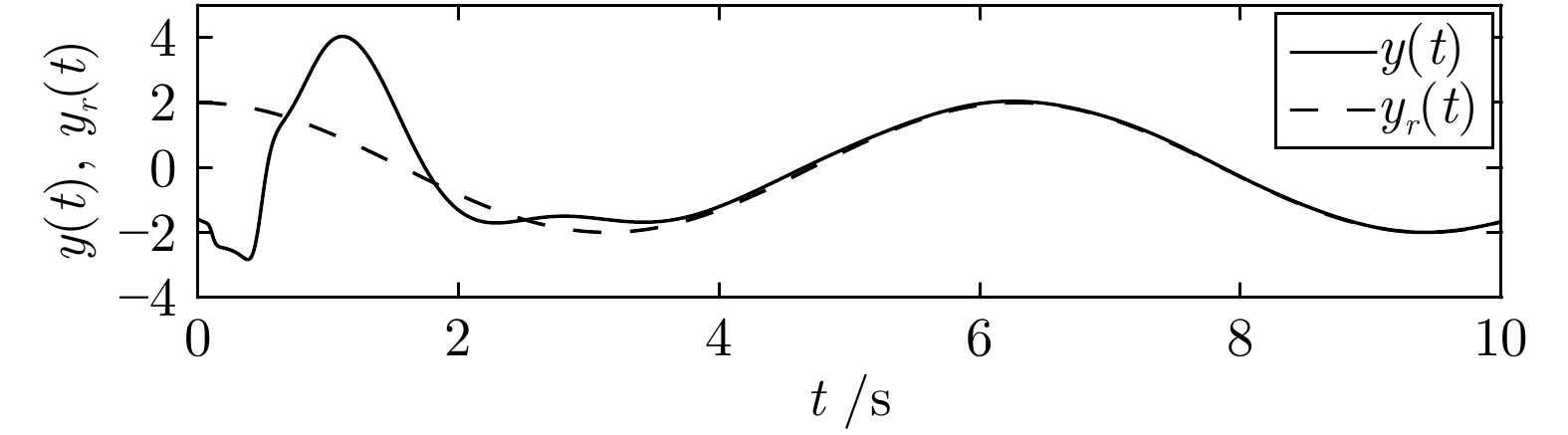
本文研究了一类具有边界执行器动态特性的双曲线型偏微分方程(Partial differential equation, PDE)系统的输出调节问题. 特别地, 执行器由一组非线性常微分方程(Ordinary differential equation, ODE)描述, 控制输入出现在执行器的一端而非直接作用在PDE系统上, 这使得控制任务变得相当困难. 基于几何设计方法和有限维与无限维反步法, 本文提出了显式表达的输出调节器, 实现了该类系统的扰动补偿及跟踪控制. 并且我们采用Lyapunov稳定性理论严格证明了闭环系统及跟踪误差在范数意义上的指数稳定性. 仿真实例对比验证了所提出控制方法的有效性.
本文研究了一类具有边界执行器动态特性的双曲线型偏微分方程(Partial differential equation, PDE)系统的输出调节问题. 特别地, 执行器由一组非线性常微分方程(Ordinary differential equation, ODE)描述, 控制输入出现在执行器的一端而非直接作用在PDE系统上, 这使得控制任务变得相当困难. 基于几何设计方法和有限维与无限维反步法, 本文提出了显式表达的输出调节器, 实现了该类系统的扰动补偿及跟踪控制. 并且我们采用Lyapunov稳定性理论严格证明了闭环系统及跟踪误差在范数意义上的指数稳定性. 仿真实例对比验证了所提出控制方法的有效性.


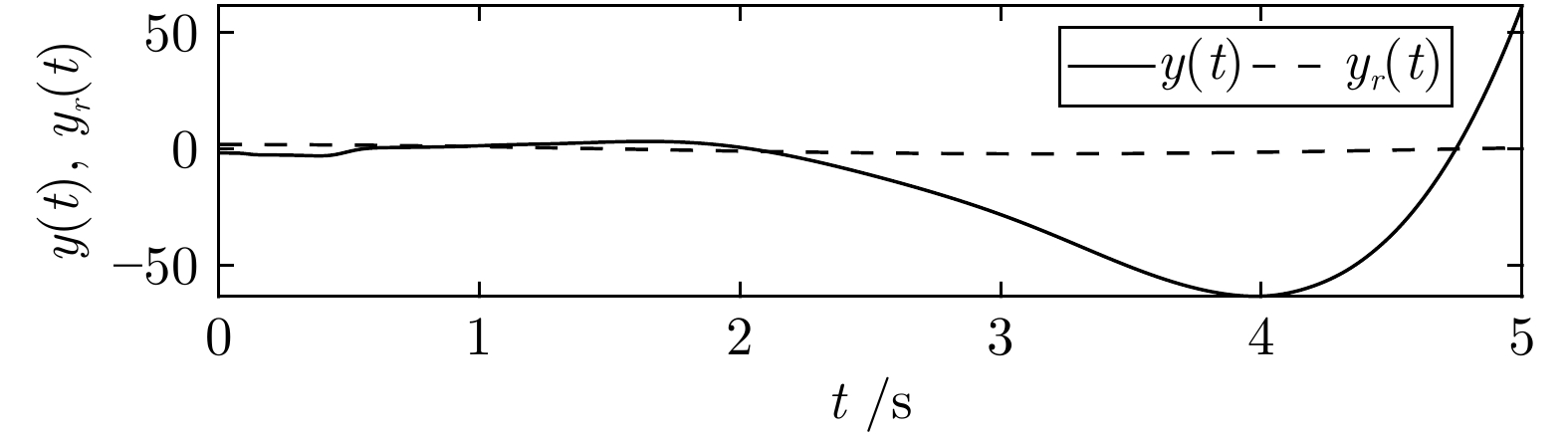
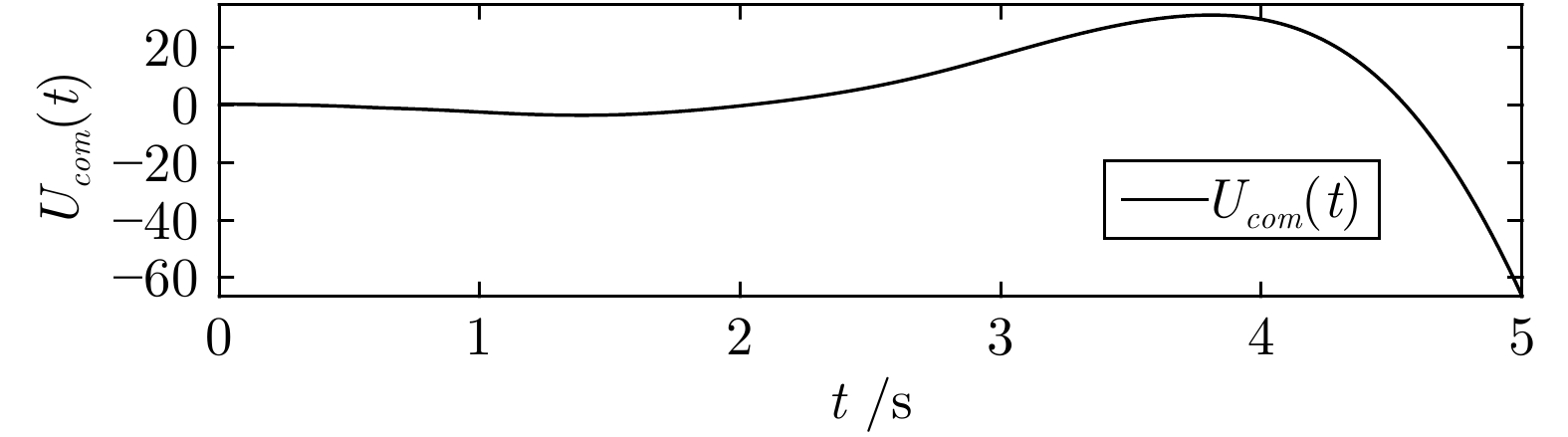
2024, 50(2): 308-319.
doi: 10.16383/j.aas.c220836
摘要:
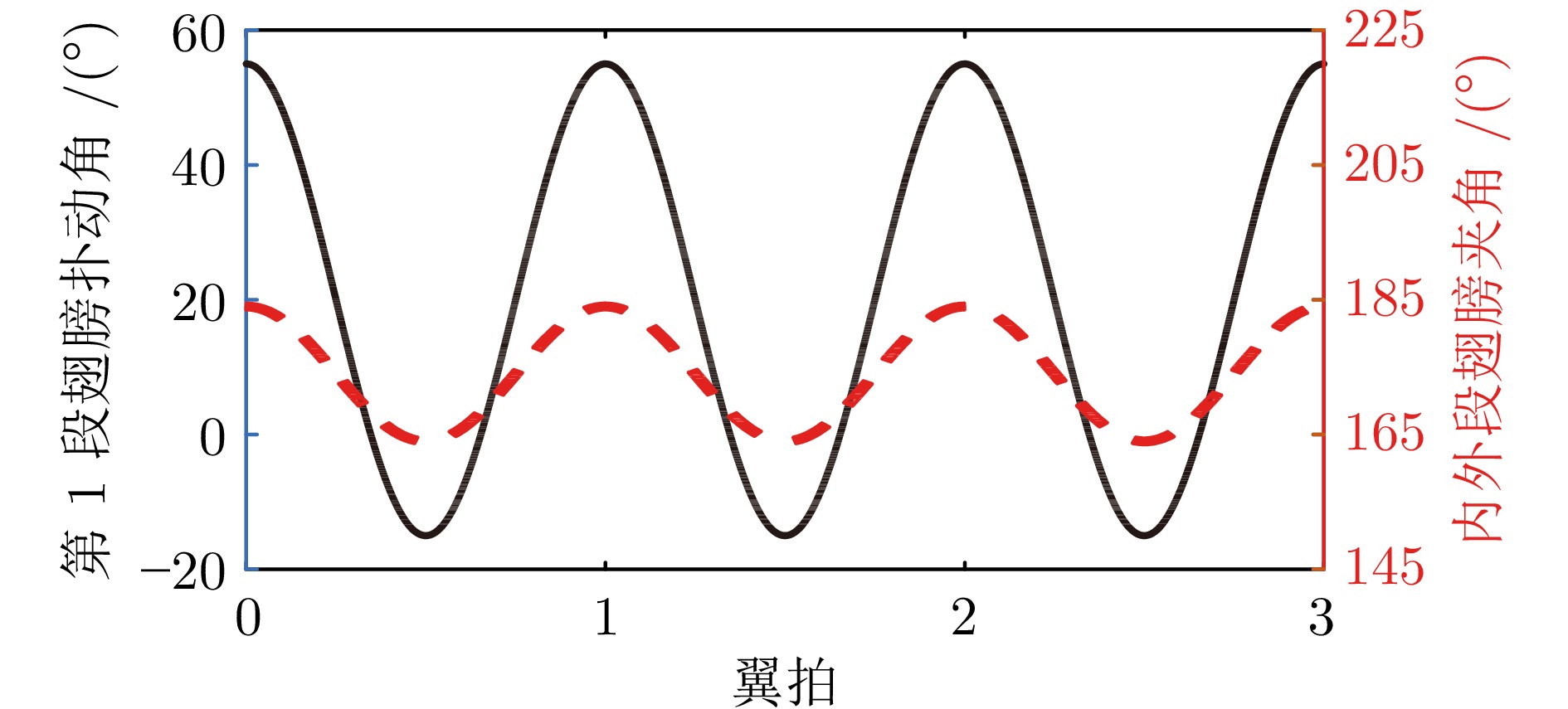
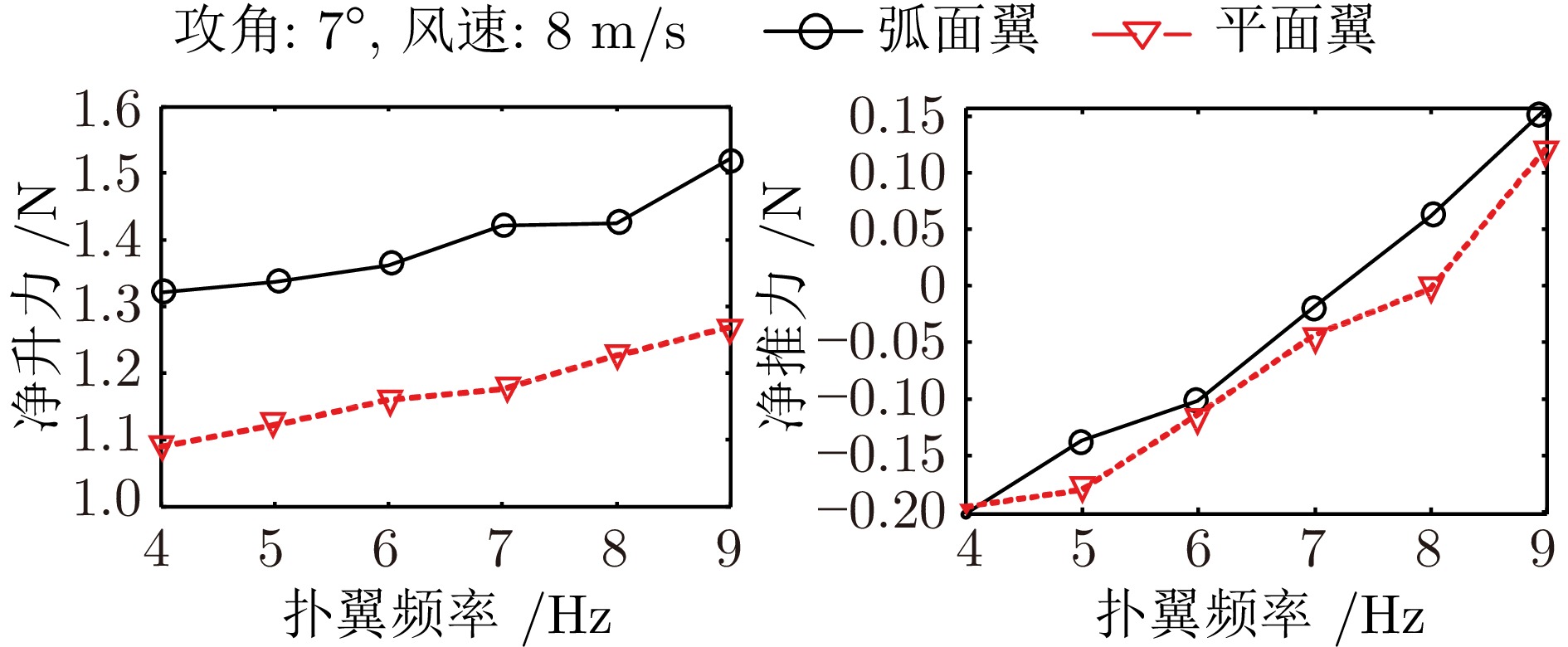
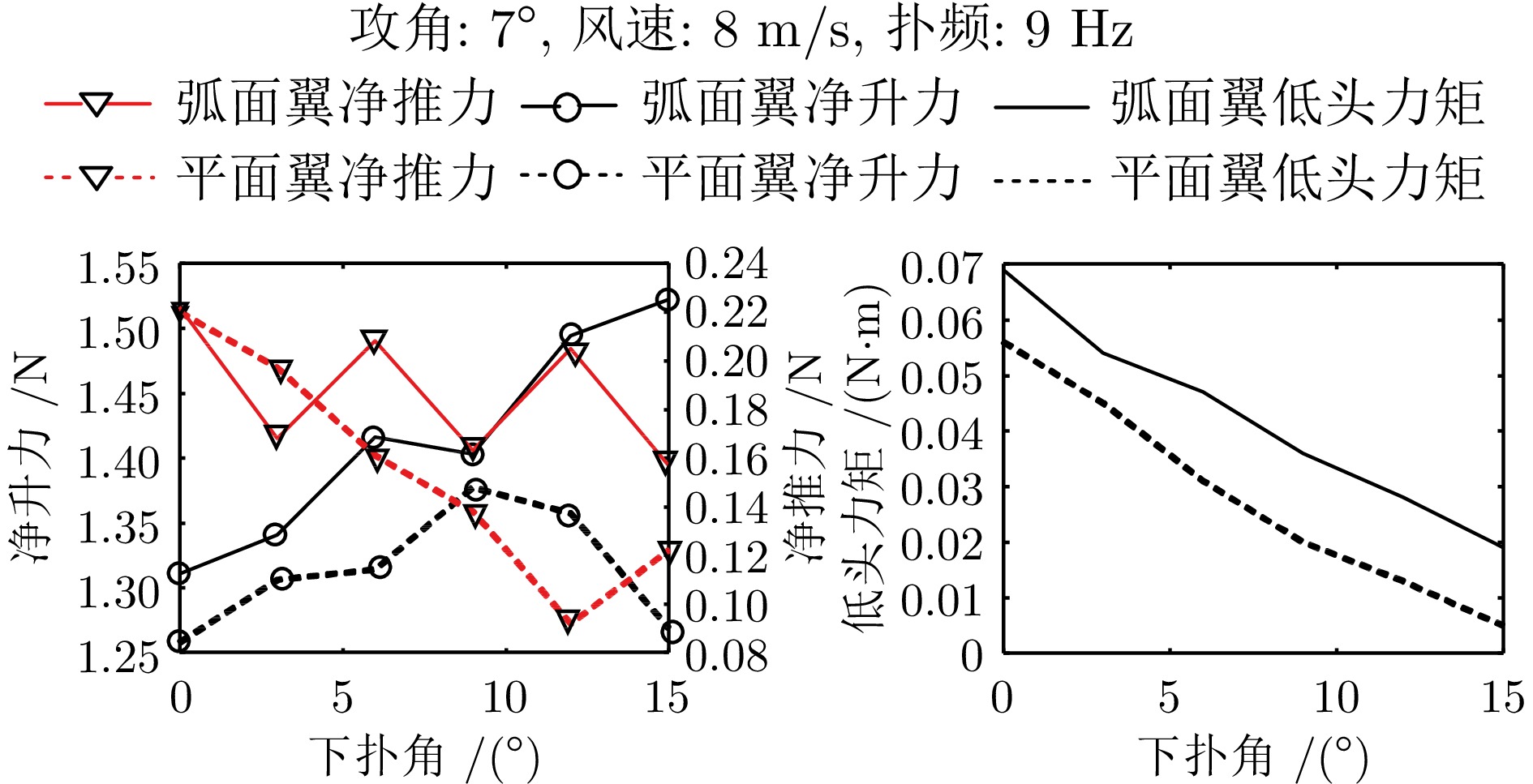
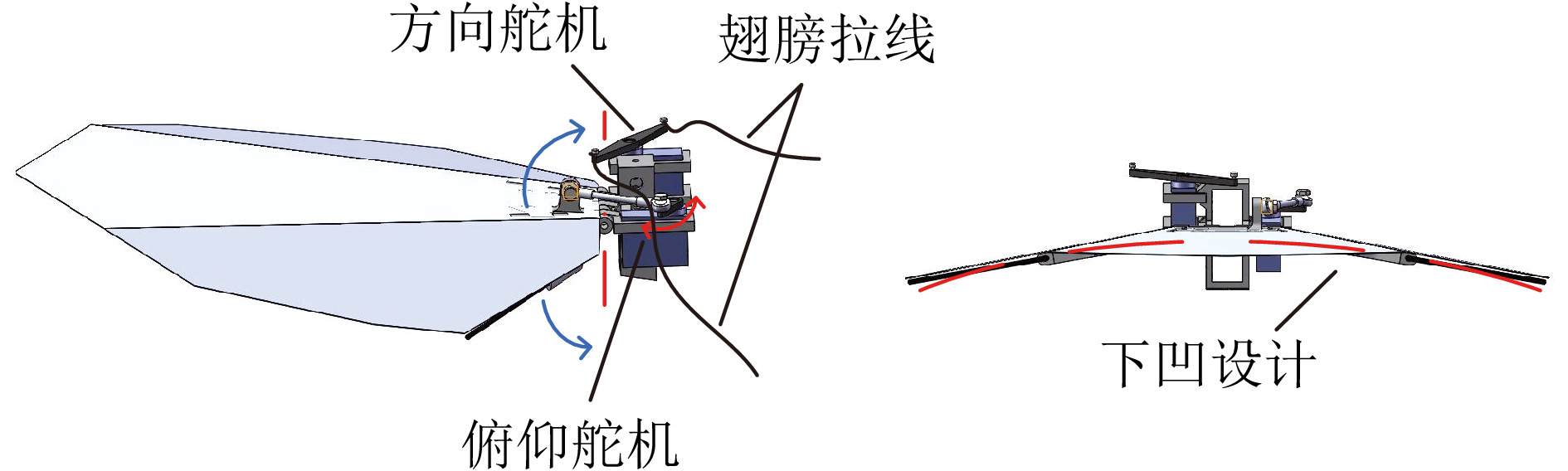
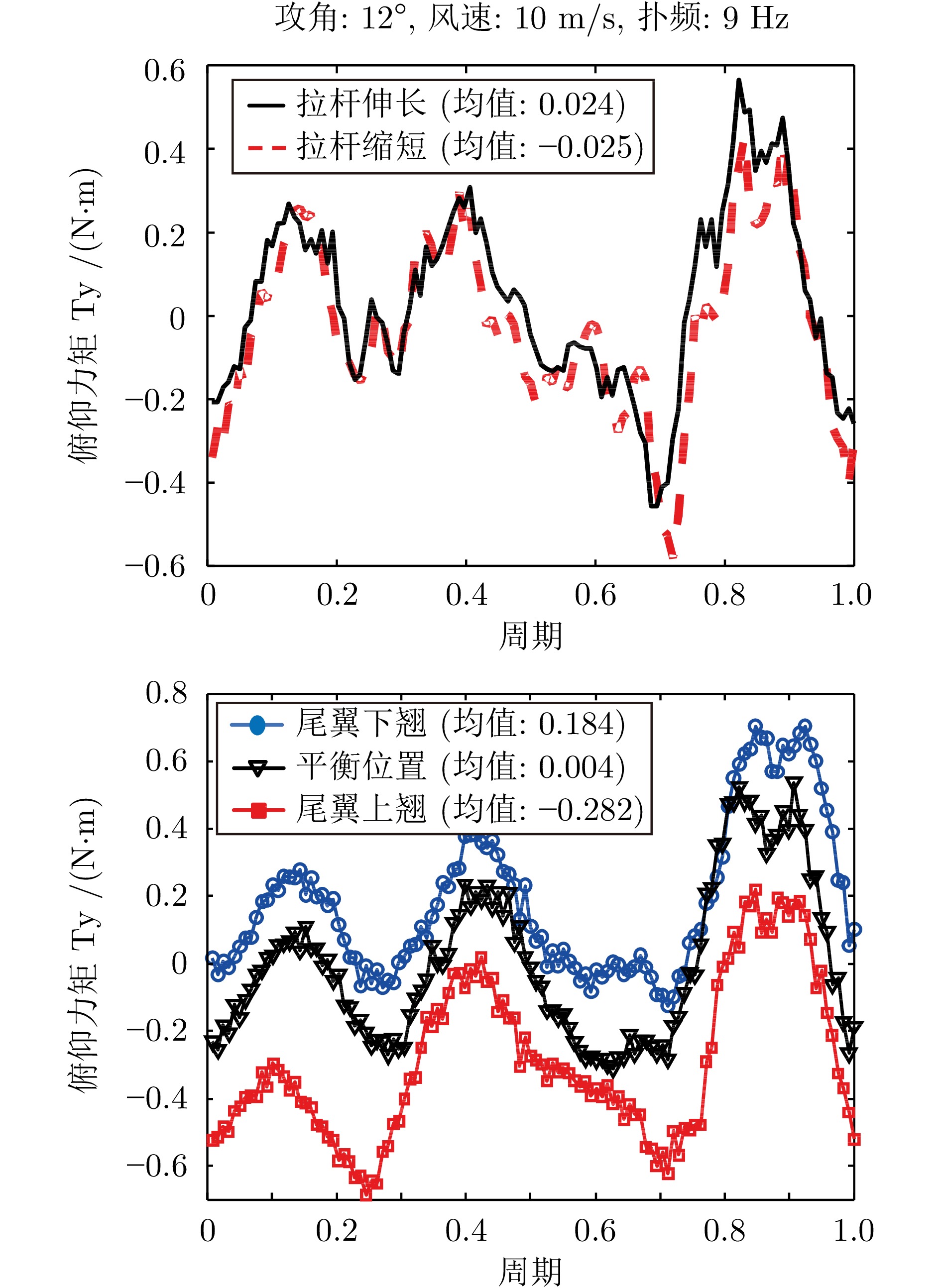
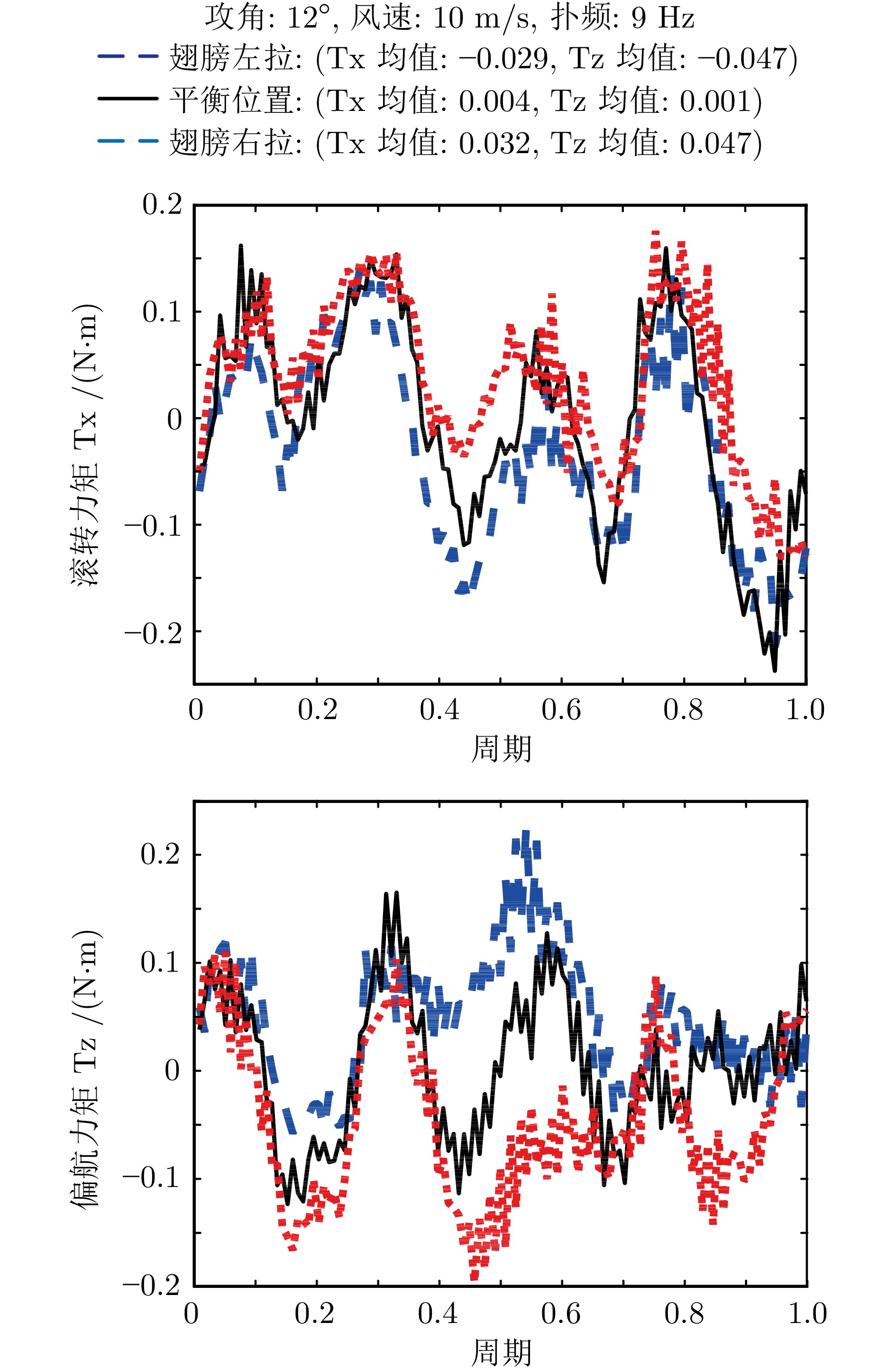
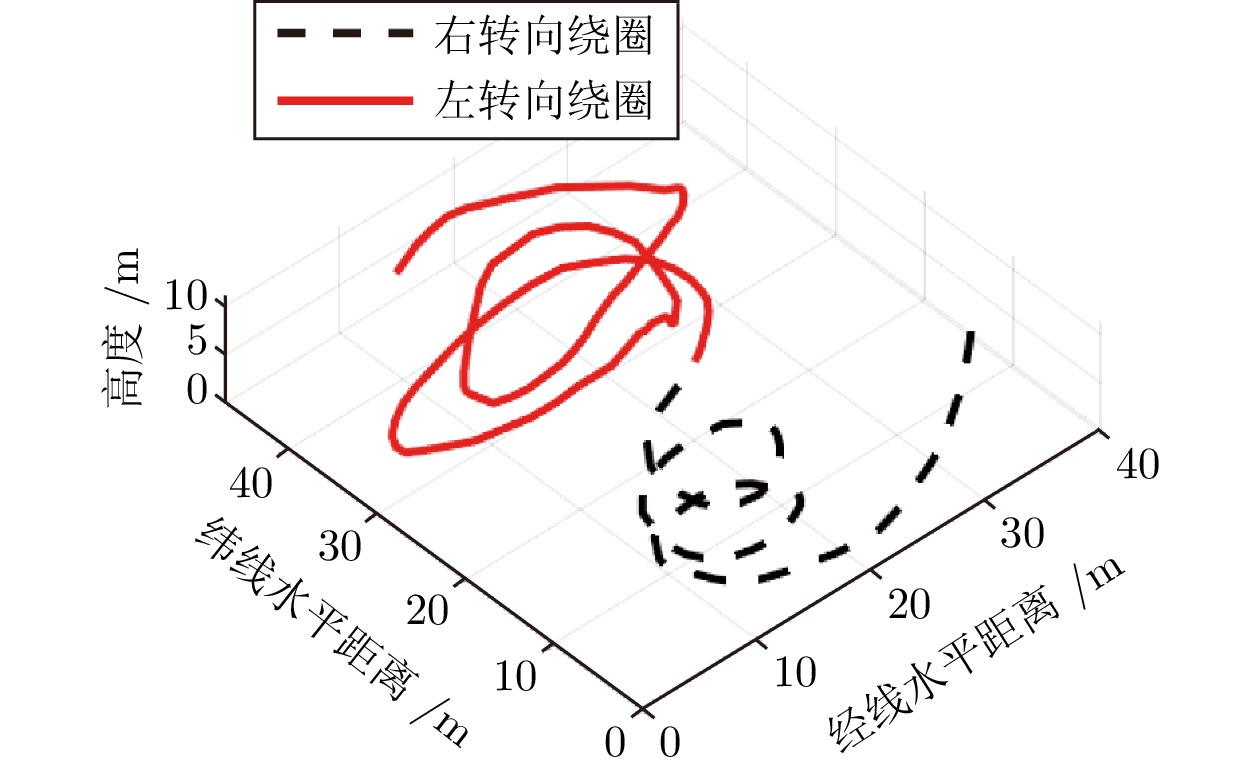
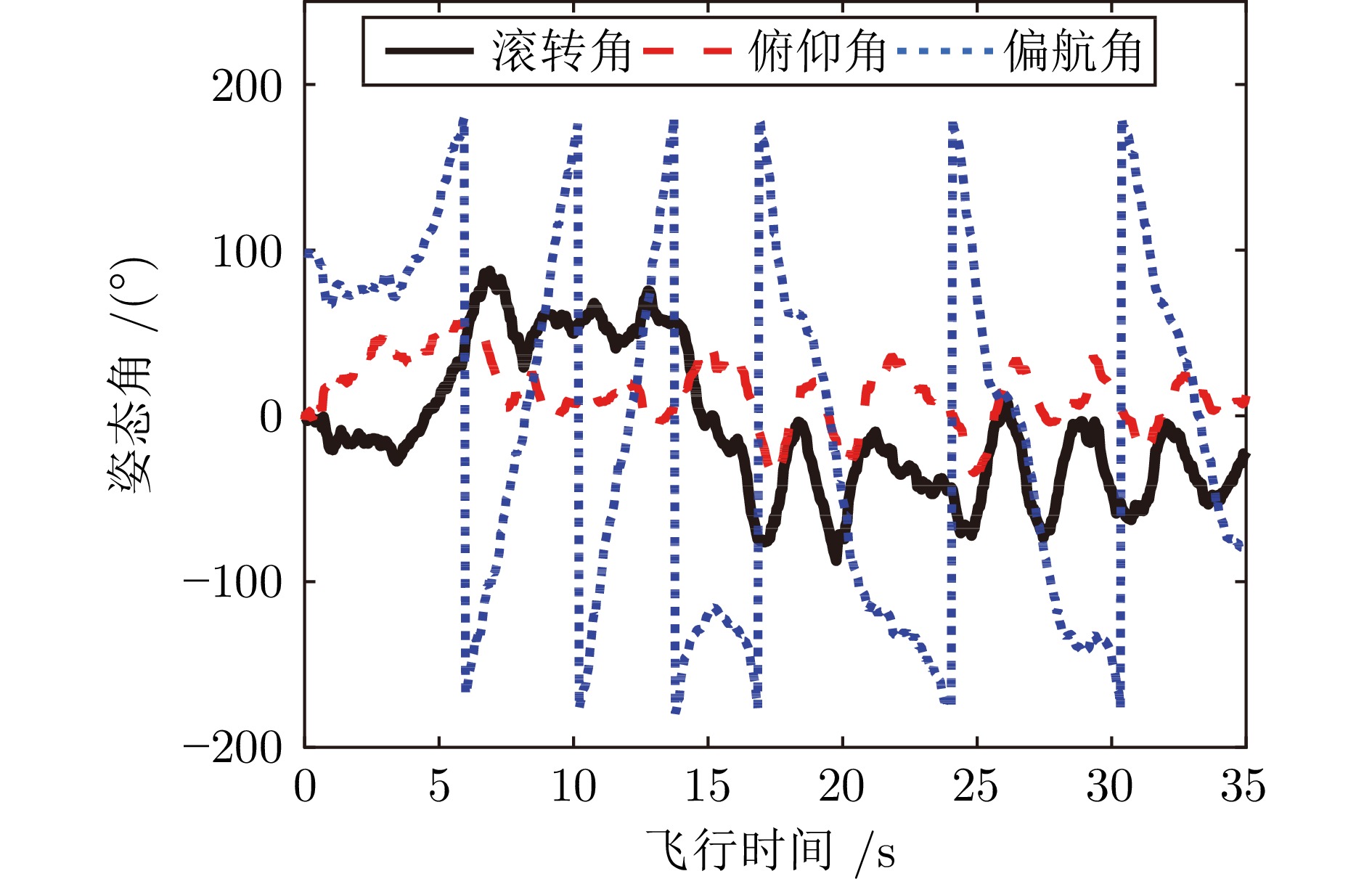
针对现有扑翼飞行机器人存在的飞行形态与实际鸟类相差较大, 以及翅膀、尾翼布局和俯仰、转向控制方式仿生度较低的问题, 提出一种形态布局与鸽子相仿的扑翼飞行机器人系统设计及实现方案. 通过设计弧面−折翼−后掠翅膀、仿鸟扇形尾翼以及尾翼挨近翅膀后缘布置的布局方式, 使扑翼机器人飞行形态更加接近真实鸟类, 提高扑翼机器人的形态仿生度. 在此基础上, 设计结合下扑角调控无需尾翼大角度上翘的俯仰控制方式, 以及不依赖于尾翼的翅膀收缩转向控制方式, 在提高仿生度的同时保证飞行控制的有效性. 在具体设计过程中, 首先参考鸽子翅膀型式选择不同类型翅膀并进行风洞测试, 确定出下扑角变化时仍能保持较优升推力性能的翅膀设计方案; 其次, 对各种尾翼型式进行分析和比较, 结合鸽子尾翼特点进行仿鸽尾翼及俯仰、转向控制机构设计, 并通过风洞测试验证; 最后, 设计飞控系统并装配整机, 进行外场飞行测试, 验证仿鸽扑翼飞行机器人平台的稳定性和可控性.
针对现有扑翼飞行机器人存在的飞行形态与实际鸟类相差较大, 以及翅膀、尾翼布局和俯仰、转向控制方式仿生度较低的问题, 提出一种形态布局与鸽子相仿的扑翼飞行机器人系统设计及实现方案. 通过设计弧面−折翼−后掠翅膀、仿鸟扇形尾翼以及尾翼挨近翅膀后缘布置的布局方式, 使扑翼机器人飞行形态更加接近真实鸟类, 提高扑翼机器人的形态仿生度. 在此基础上, 设计结合下扑角调控无需尾翼大角度上翘的俯仰控制方式, 以及不依赖于尾翼的翅膀收缩转向控制方式, 在提高仿生度的同时保证飞行控制的有效性. 在具体设计过程中, 首先参考鸽子翅膀型式选择不同类型翅膀并进行风洞测试, 确定出下扑角变化时仍能保持较优升推力性能的翅膀设计方案; 其次, 对各种尾翼型式进行分析和比较, 结合鸽子尾翼特点进行仿鸽尾翼及俯仰、转向控制机构设计, 并通过风洞测试验证; 最后, 设计飞控系统并装配整机, 进行外场飞行测试, 验证仿鸽扑翼飞行机器人平台的稳定性和可控性.
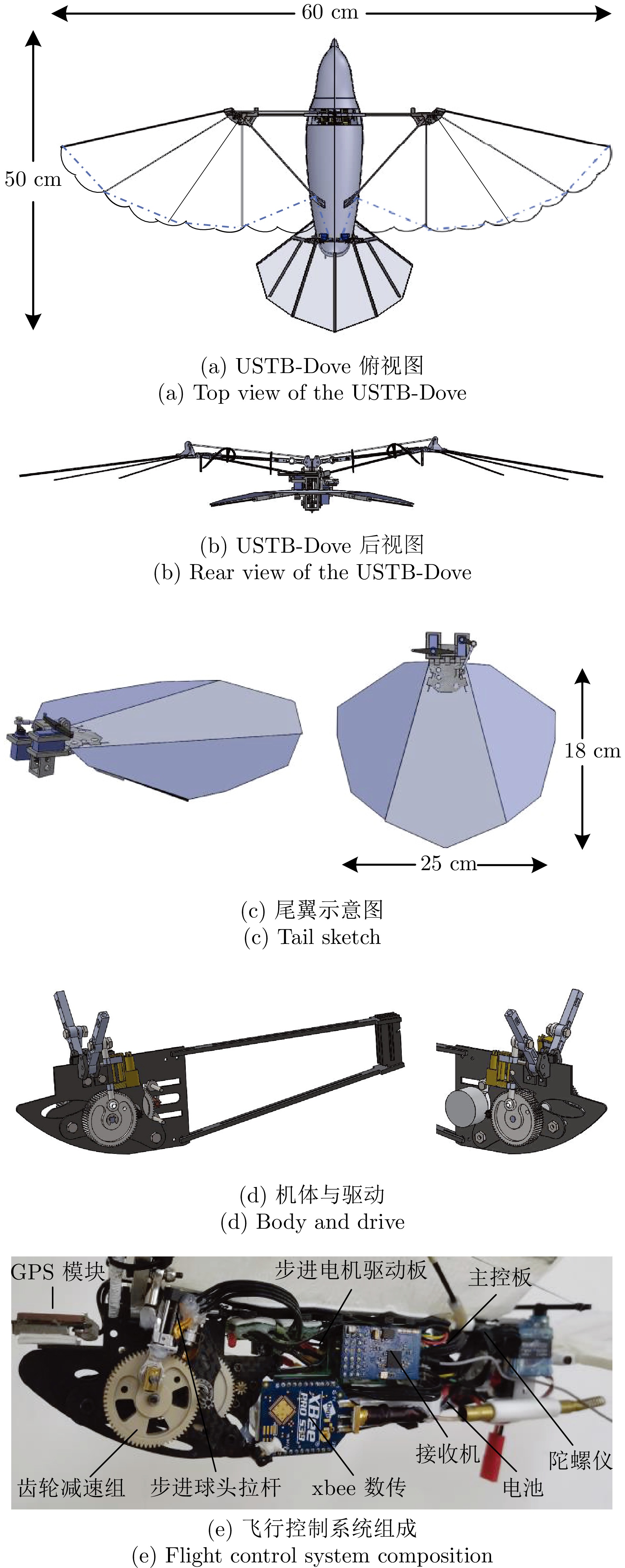


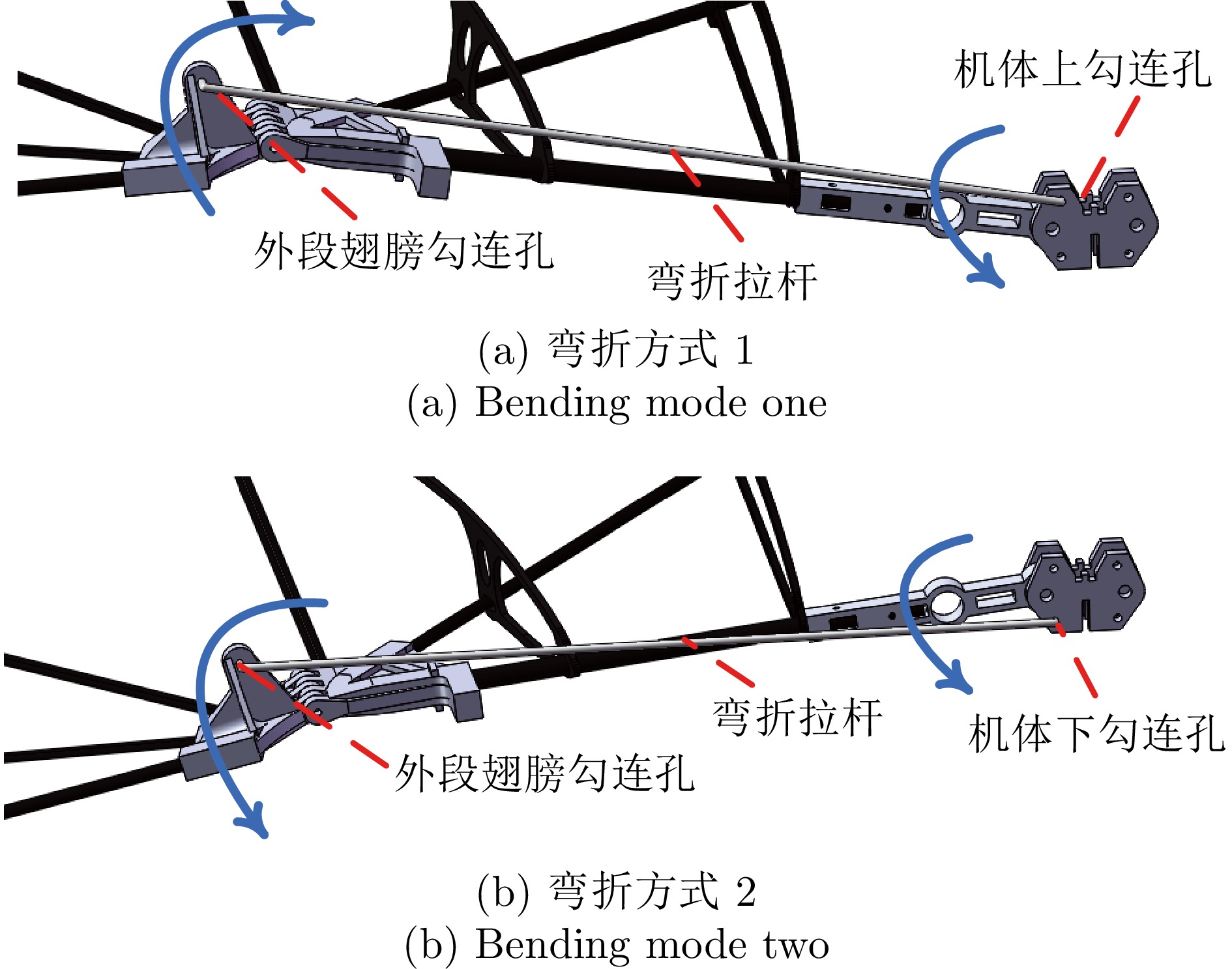











2024, 50(2): 320-333.
doi: 10.16383/j.aas.c230189
摘要:
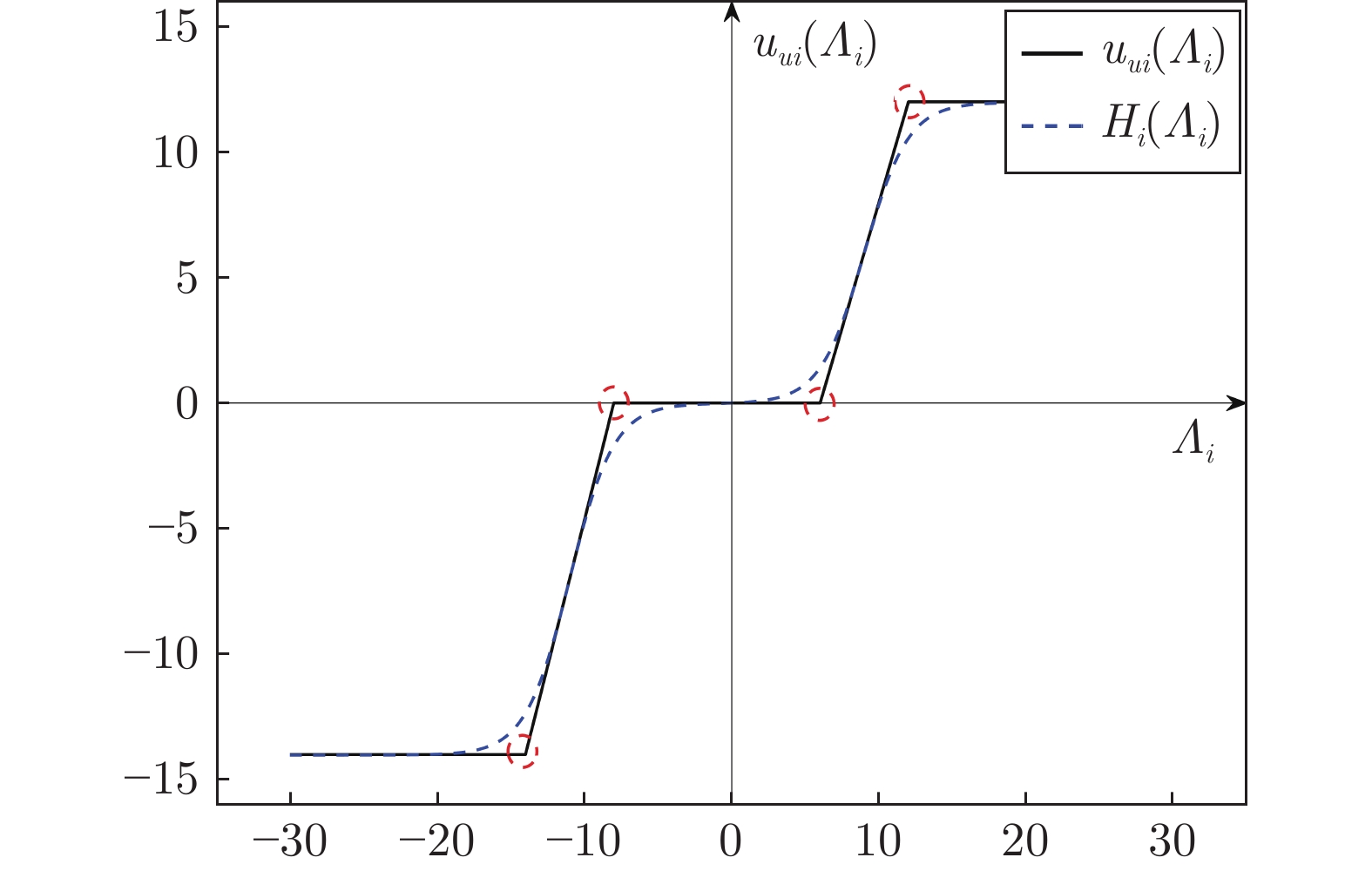
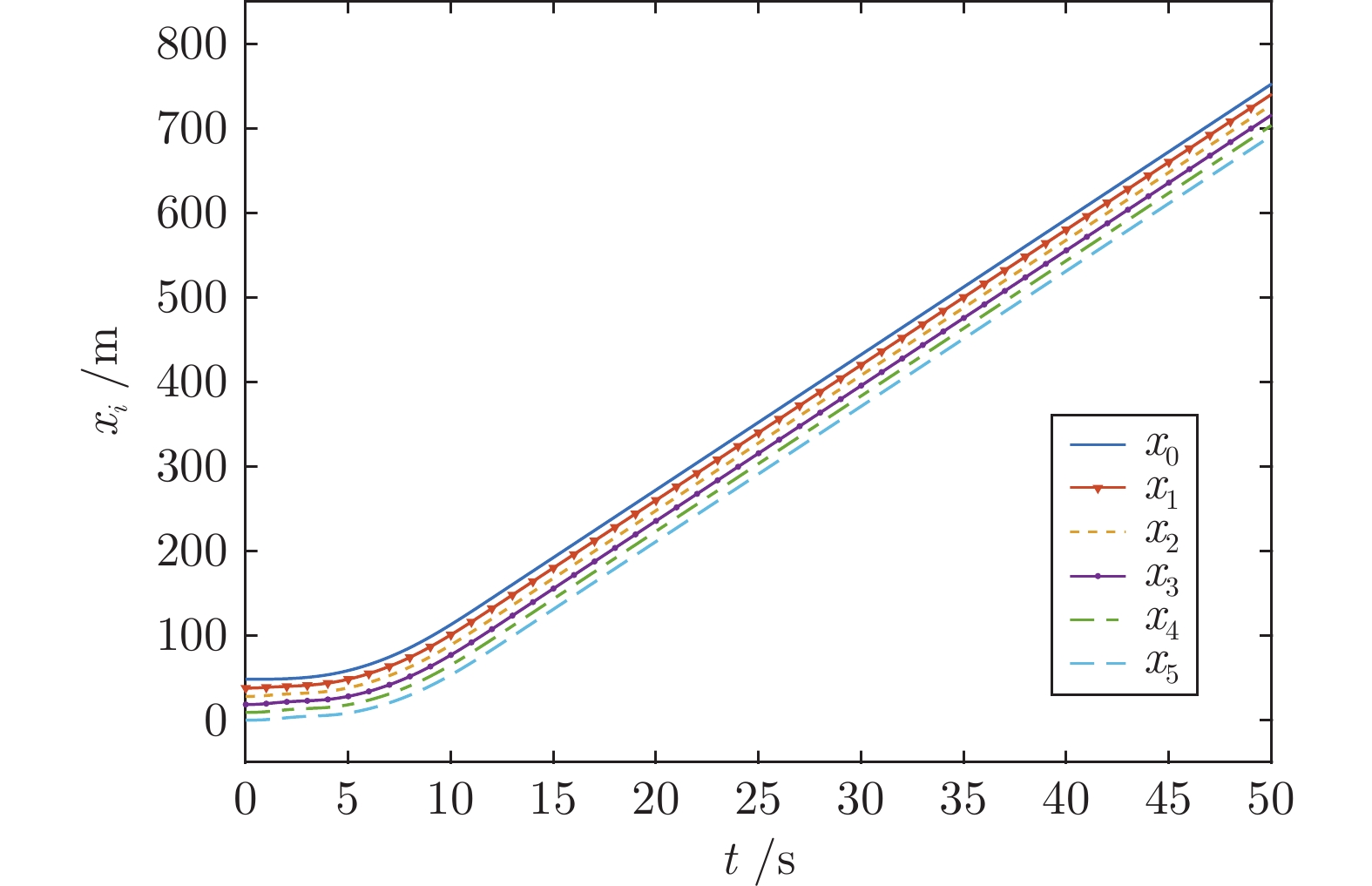
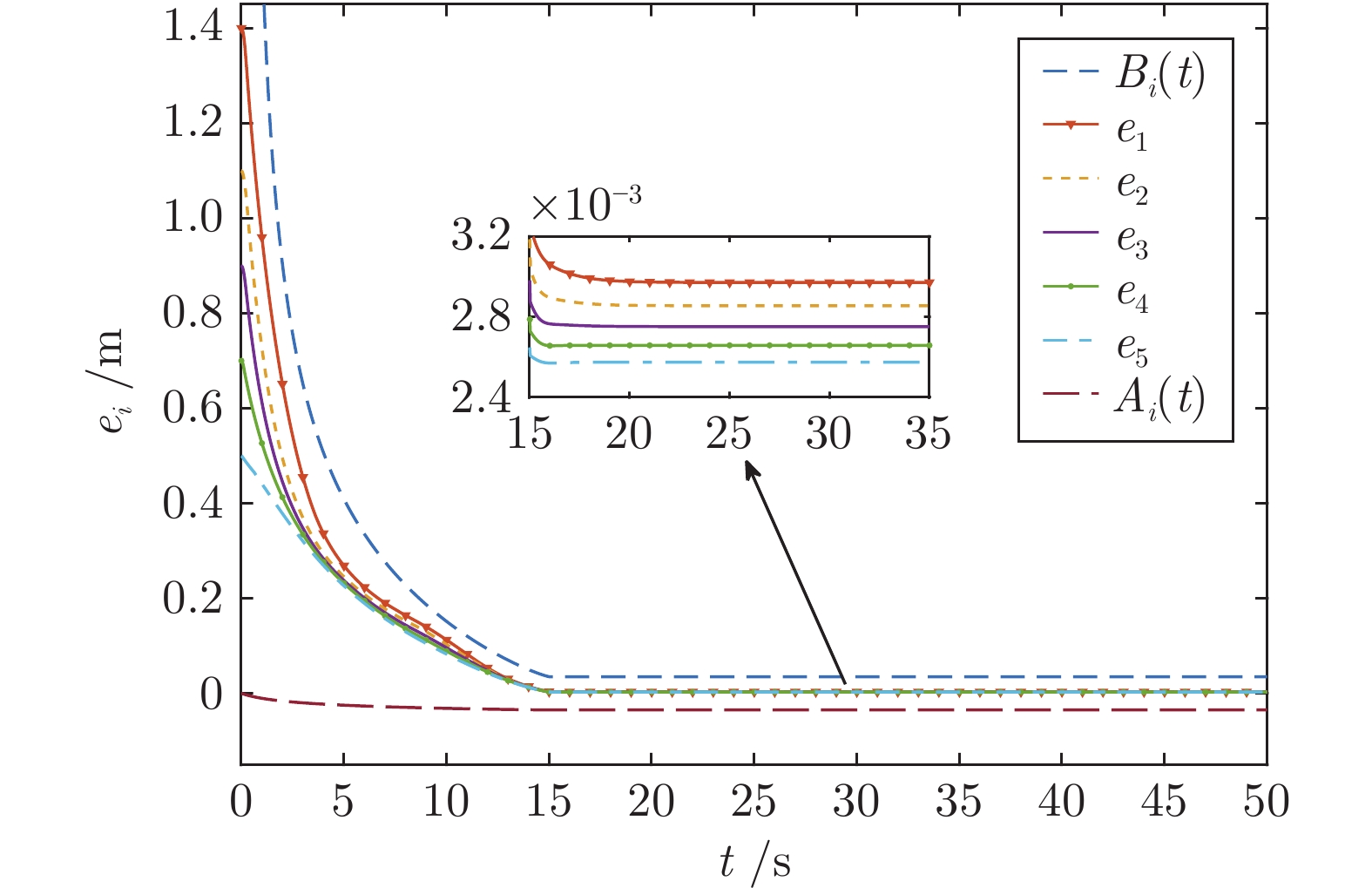
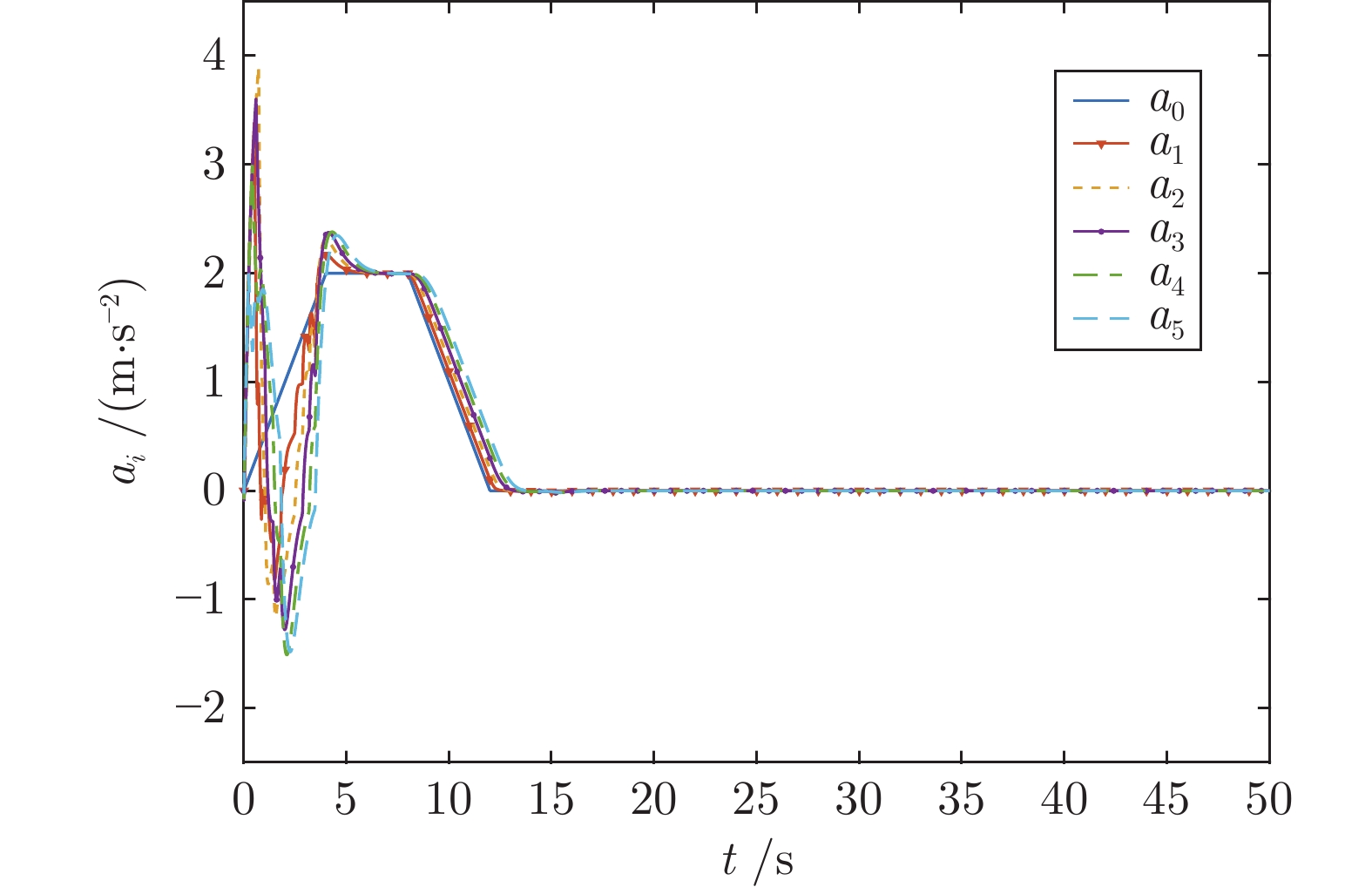
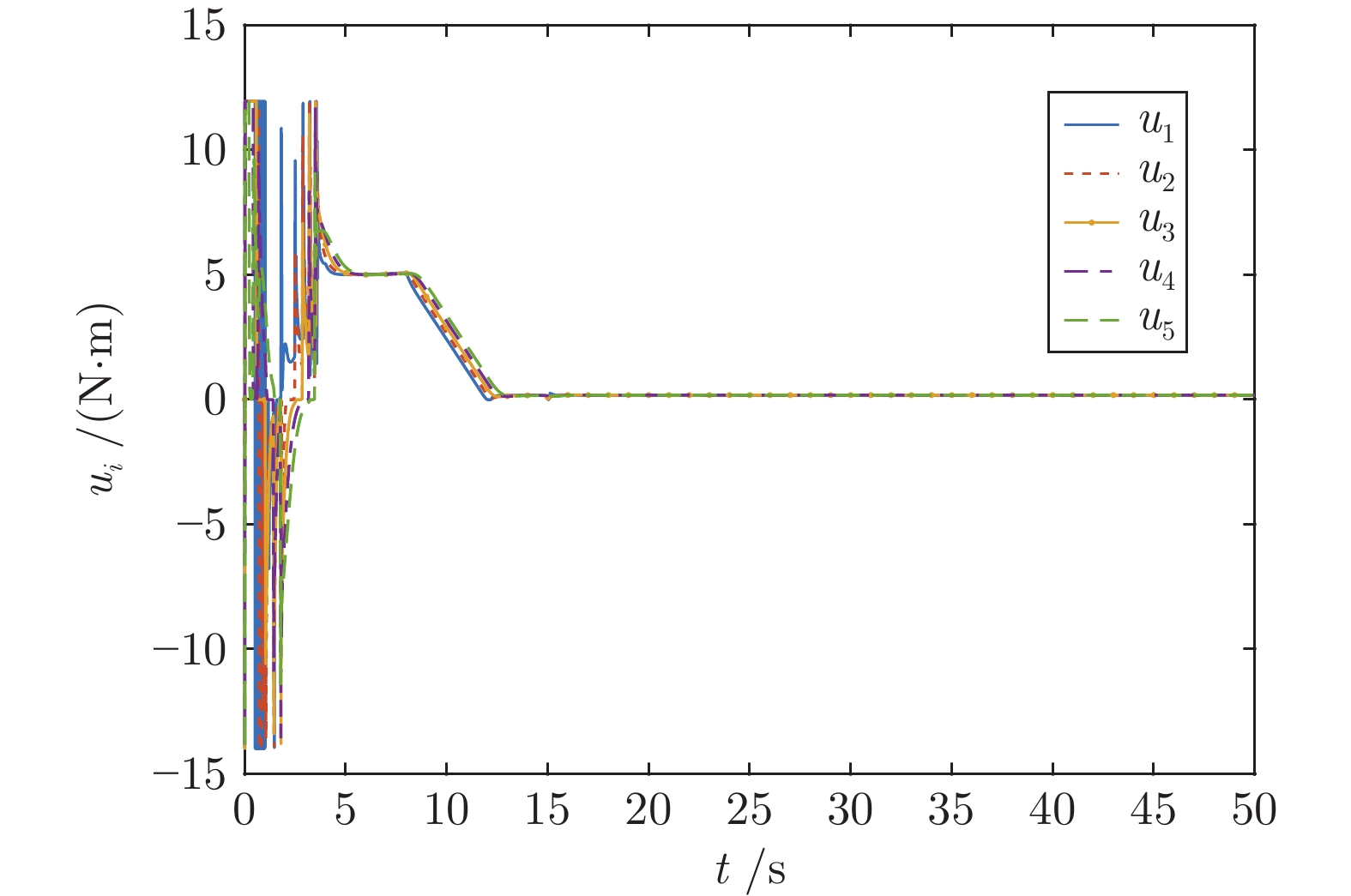
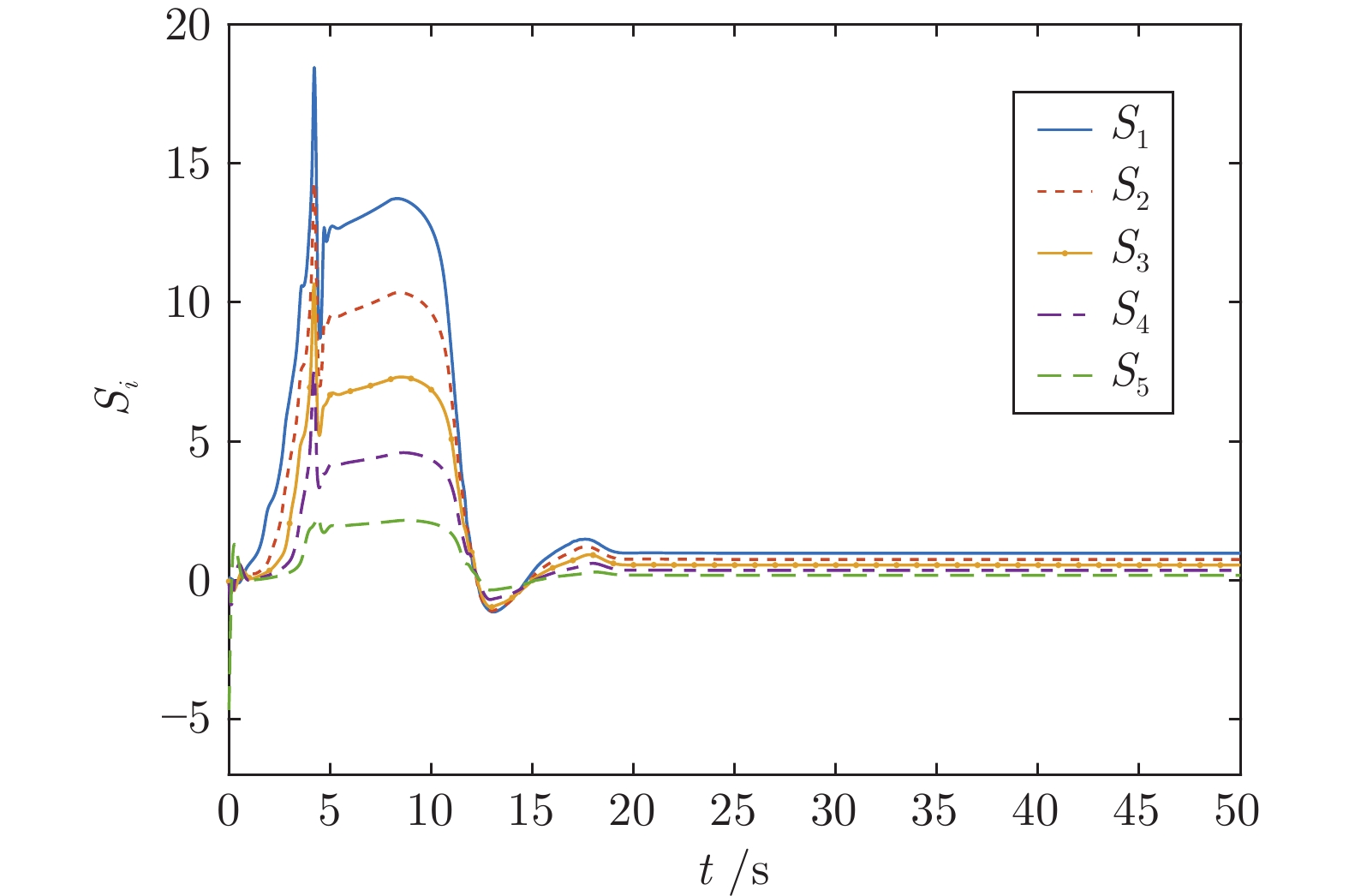
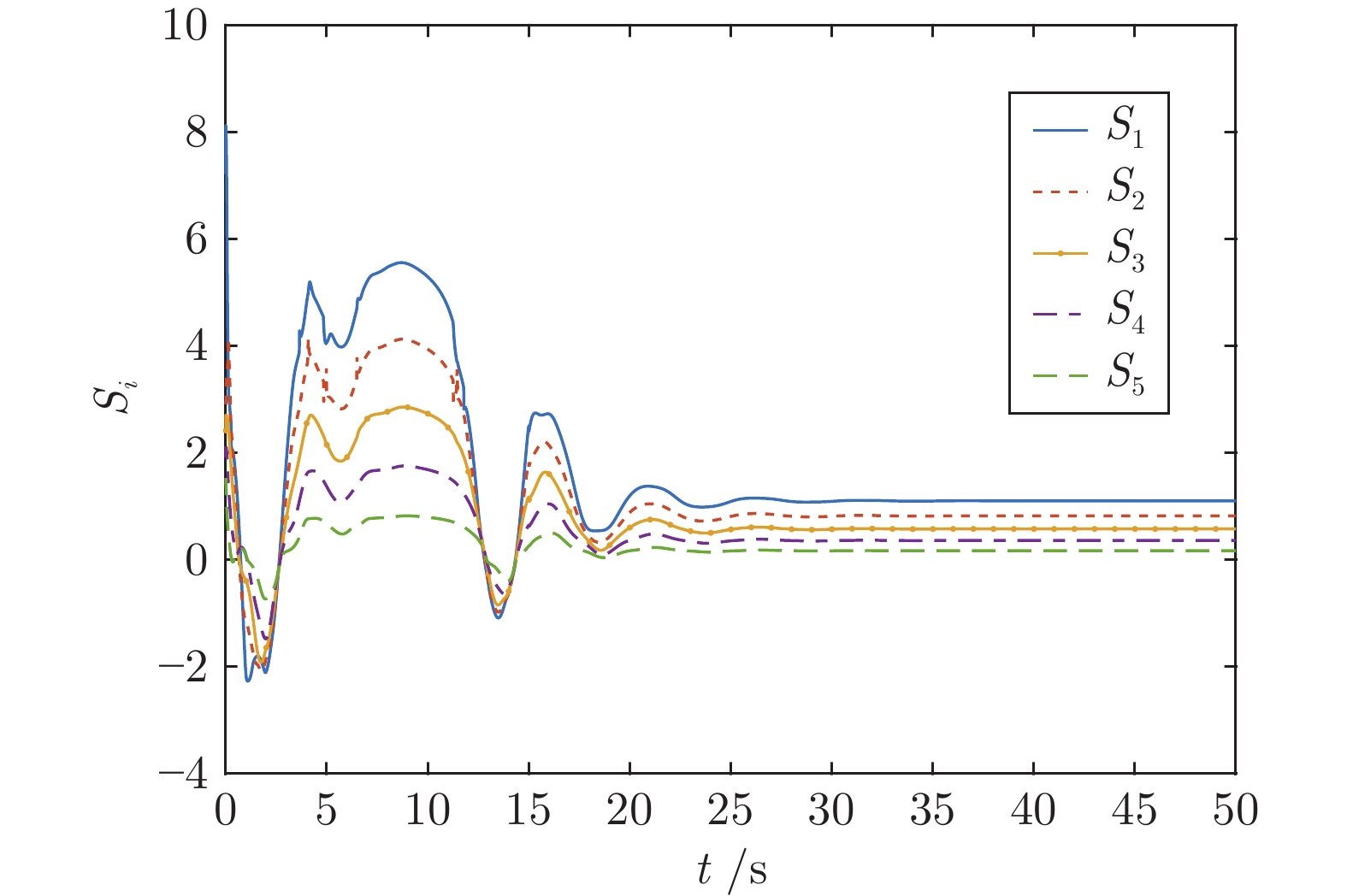
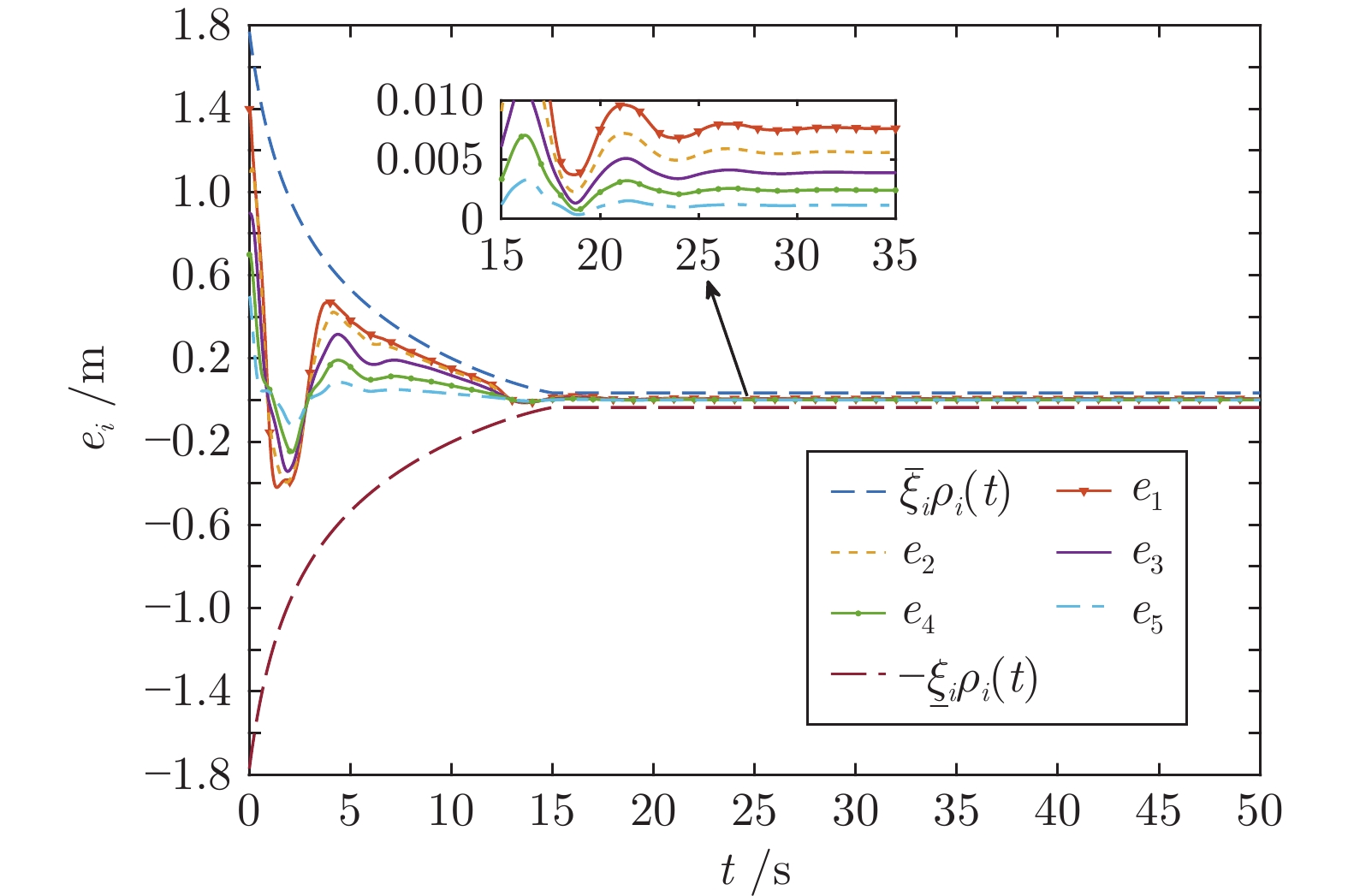
针对含有执行器非线性的车辆队列控制系统, 提出一种固定时间全局预设性能控制(Global prescribed performance control, GPPC) 控制方法. 首先, 设计一种平滑等效变换, 在同一框架下解决死区及饱和问题, 同时消除执行器非线性固有拐点问题. 其次, 构造两个新型性能函数, 并基于此提出一种全局预设性能控制算法, 实现如下目标: 1) 保证跟踪误差在固定时间内收敛到预定稳态区域; 2) 消除初始误差必须已知的限制; 3) 减小误差的超调量. 然后, 基于上述等效变换及预设性能控制算法, 设计一种固定时间滑模队列容错控制方案, 实现固定时间单车稳定及队列稳定. 最后, 通过 MATLAB 仿真实验, 验证了所提算法的有效性.
针对含有执行器非线性的车辆队列控制系统, 提出一种固定时间全局预设性能控制(Global prescribed performance control, GPPC) 控制方法. 首先, 设计一种平滑等效变换, 在同一框架下解决死区及饱和问题, 同时消除执行器非线性固有拐点问题. 其次, 构造两个新型性能函数, 并基于此提出一种全局预设性能控制算法, 实现如下目标: 1) 保证跟踪误差在固定时间内收敛到预定稳态区域; 2) 消除初始误差必须已知的限制; 3) 减小误差的超调量. 然后, 基于上述等效变换及预设性能控制算法, 设计一种固定时间滑模队列容错控制方案, 实现固定时间单车稳定及队列稳定. 最后, 通过 MATLAB 仿真实验, 验证了所提算法的有效性.



2024, 50(2): 334-347.
doi: 10.16383/j.aas.c230070
摘要:
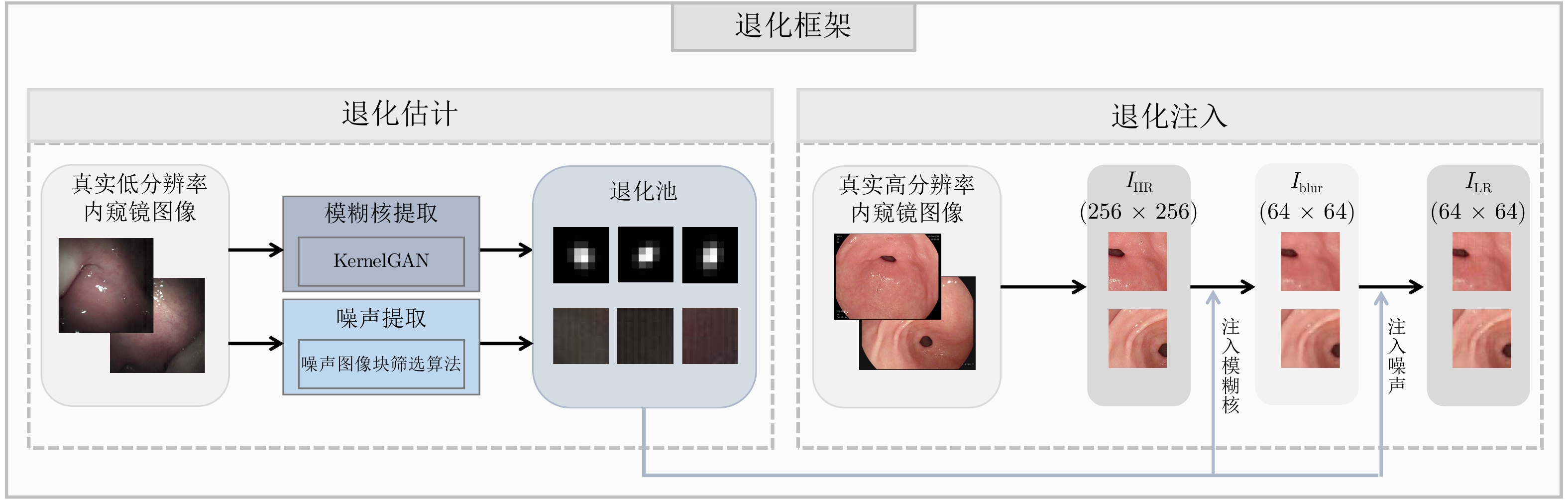
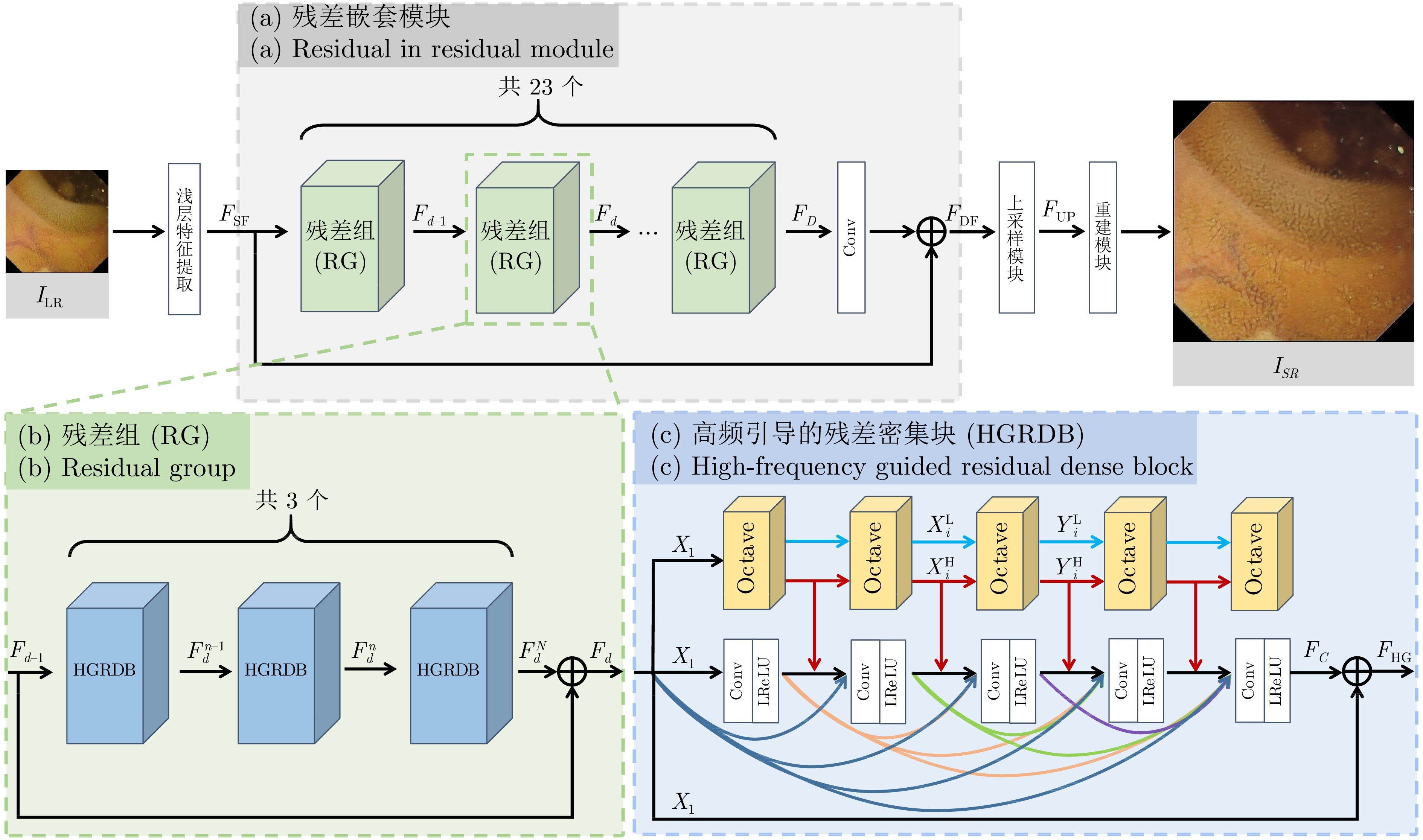
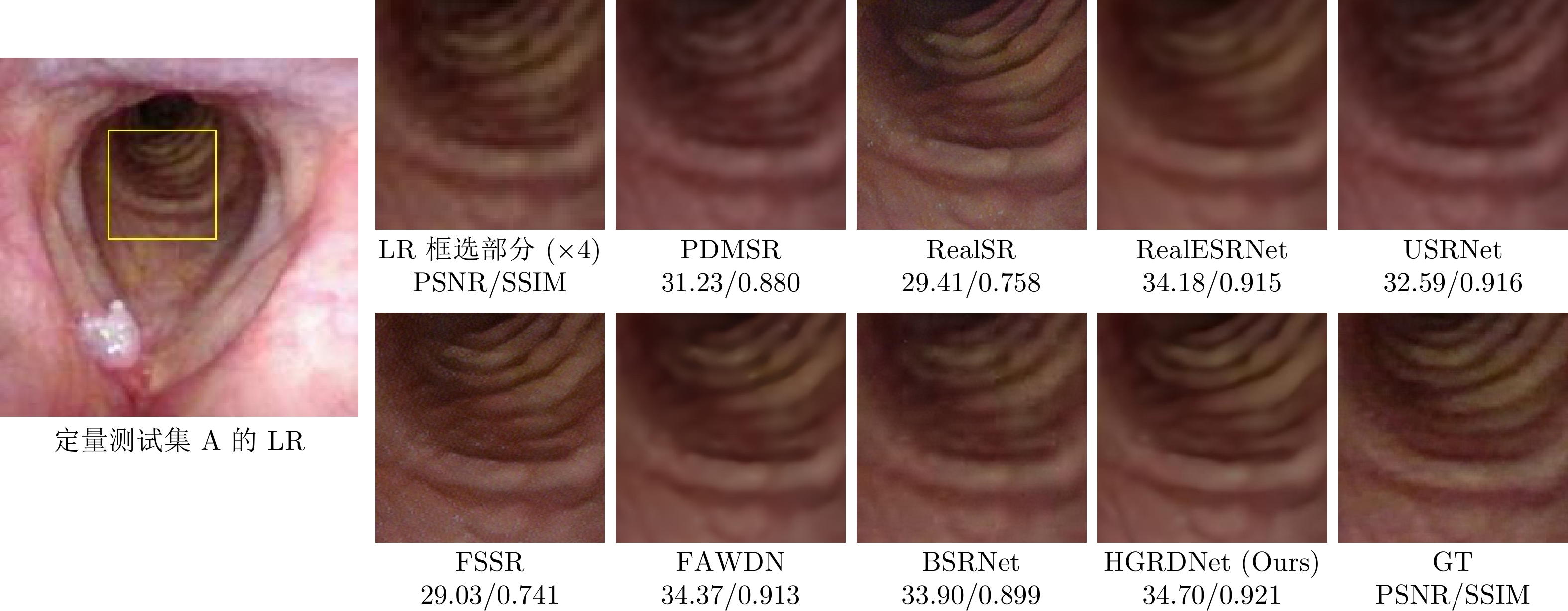
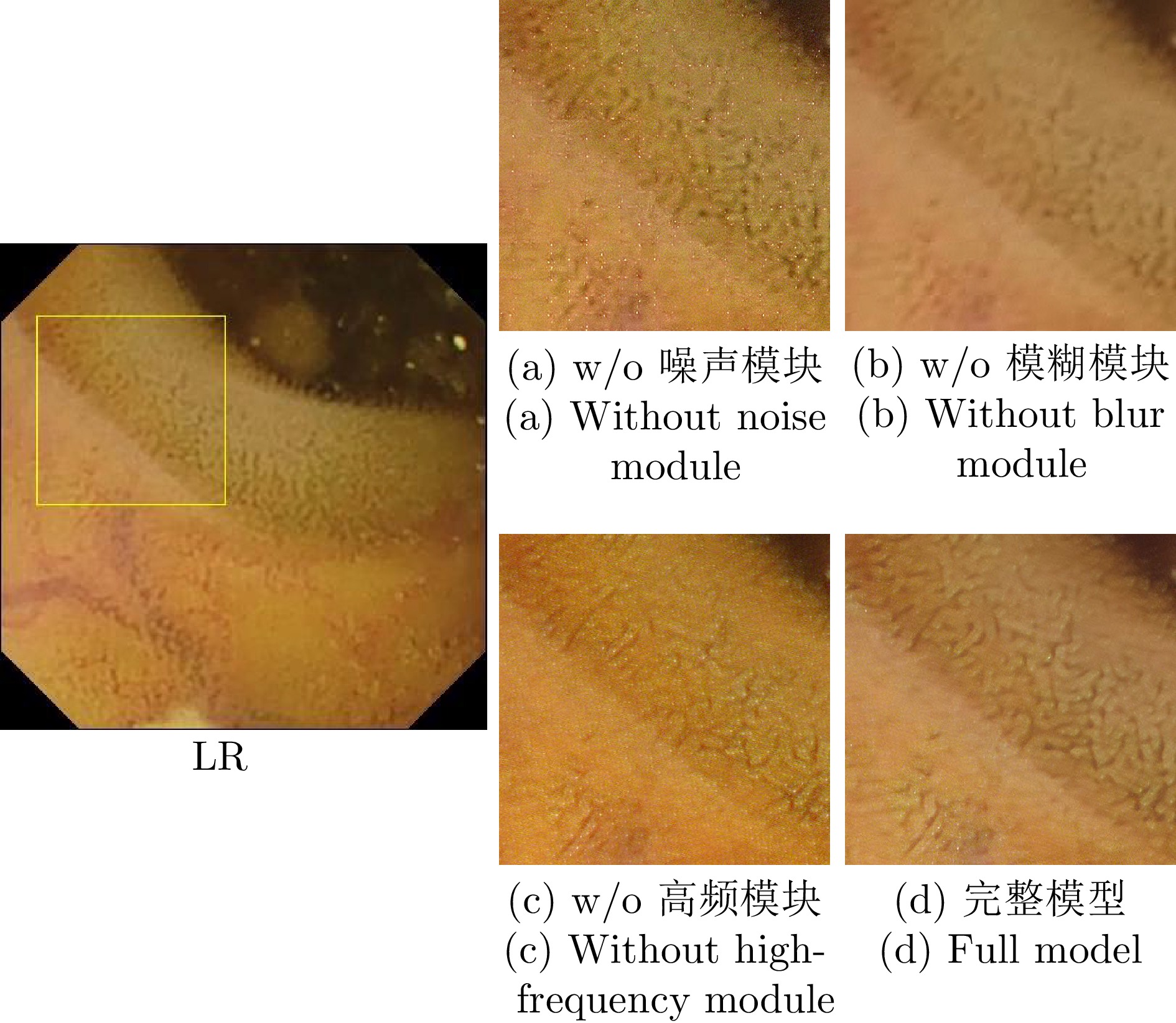
内窥镜是诊断人体器官疾病的重要医疗设备, 然而受人体内腔环境影响, 内窥镜图像分辨率一般较低, 需对其进行超分辨处理. 目前多数基于深度学习的超分辨算法直接使用双三次插值下采样从高质量图像中获取低分辨率(Low-resolution, LR)图像以进行配对训练, 此种方式会导致纹理细节丢失, 不适用于医学图像. 为解决该问题, 针对医学内窥镜图像开发了一种新颖的退化框架, 首先从真实低质量内窥镜图像中提取丰富多样的真实模糊核与噪声模式, 之后提出一种退化注入算法, 利用提取的真实模糊核与噪声将高分辨率(High-resolution, HR)内窥镜图像退化为符合真实域的低分辨率图像. 同时, 提出一种高频引导的残差密集超分辨网络, 采用基于双频率信息交互的频率分离策略, 并设计多层级融合机制, 将提取的多级高频信息逐层嵌入残差密集模块的多层特征, 以充分恢复内窥镜图像的高频细节和低频内容. 在合成与真实数据集上的大量实验表明, 我们的方法优于对比方法, 具有更好的主客观质量评价.
内窥镜是诊断人体器官疾病的重要医疗设备, 然而受人体内腔环境影响, 内窥镜图像分辨率一般较低, 需对其进行超分辨处理. 目前多数基于深度学习的超分辨算法直接使用双三次插值下采样从高质量图像中获取低分辨率(Low-resolution, LR)图像以进行配对训练, 此种方式会导致纹理细节丢失, 不适用于医学图像. 为解决该问题, 针对医学内窥镜图像开发了一种新颖的退化框架, 首先从真实低质量内窥镜图像中提取丰富多样的真实模糊核与噪声模式, 之后提出一种退化注入算法, 利用提取的真实模糊核与噪声将高分辨率(High-resolution, HR)内窥镜图像退化为符合真实域的低分辨率图像. 同时, 提出一种高频引导的残差密集超分辨网络, 采用基于双频率信息交互的频率分离策略, 并设计多层级融合机制, 将提取的多级高频信息逐层嵌入残差密集模块的多层特征, 以充分恢复内窥镜图像的高频细节和低频内容. 在合成与真实数据集上的大量实验表明, 我们的方法优于对比方法, 具有更好的主客观质量评价.



2024, 50(2): 348-355.
doi: 10.16383/j.aas.c230327
摘要:
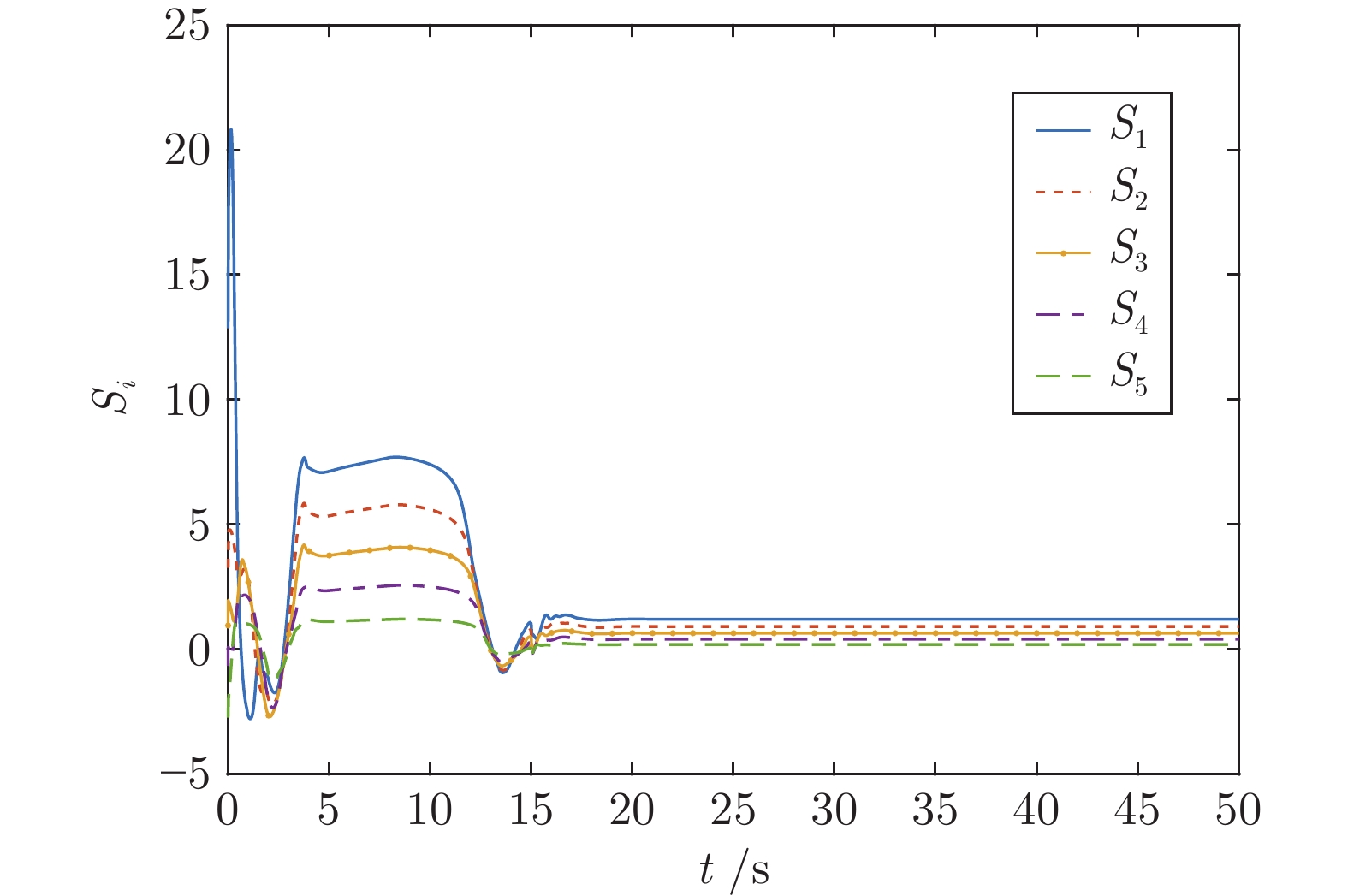
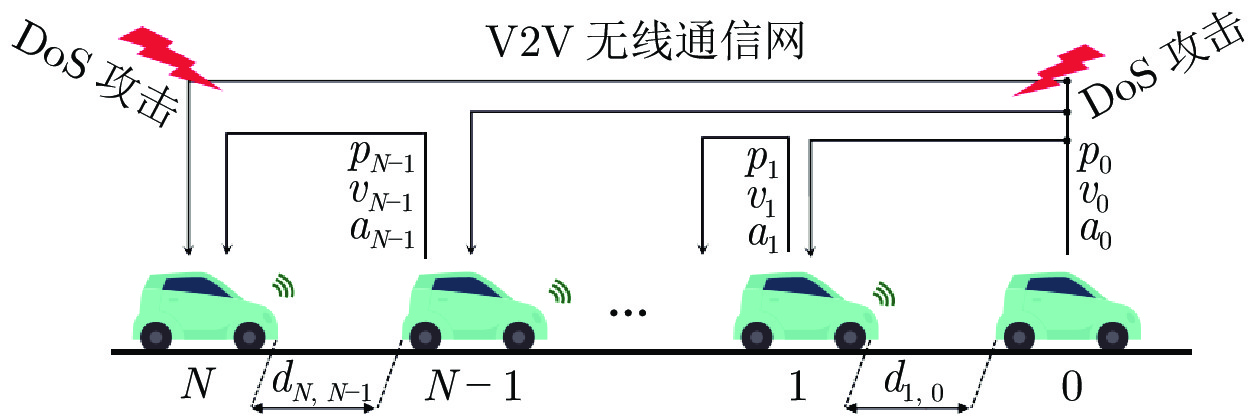
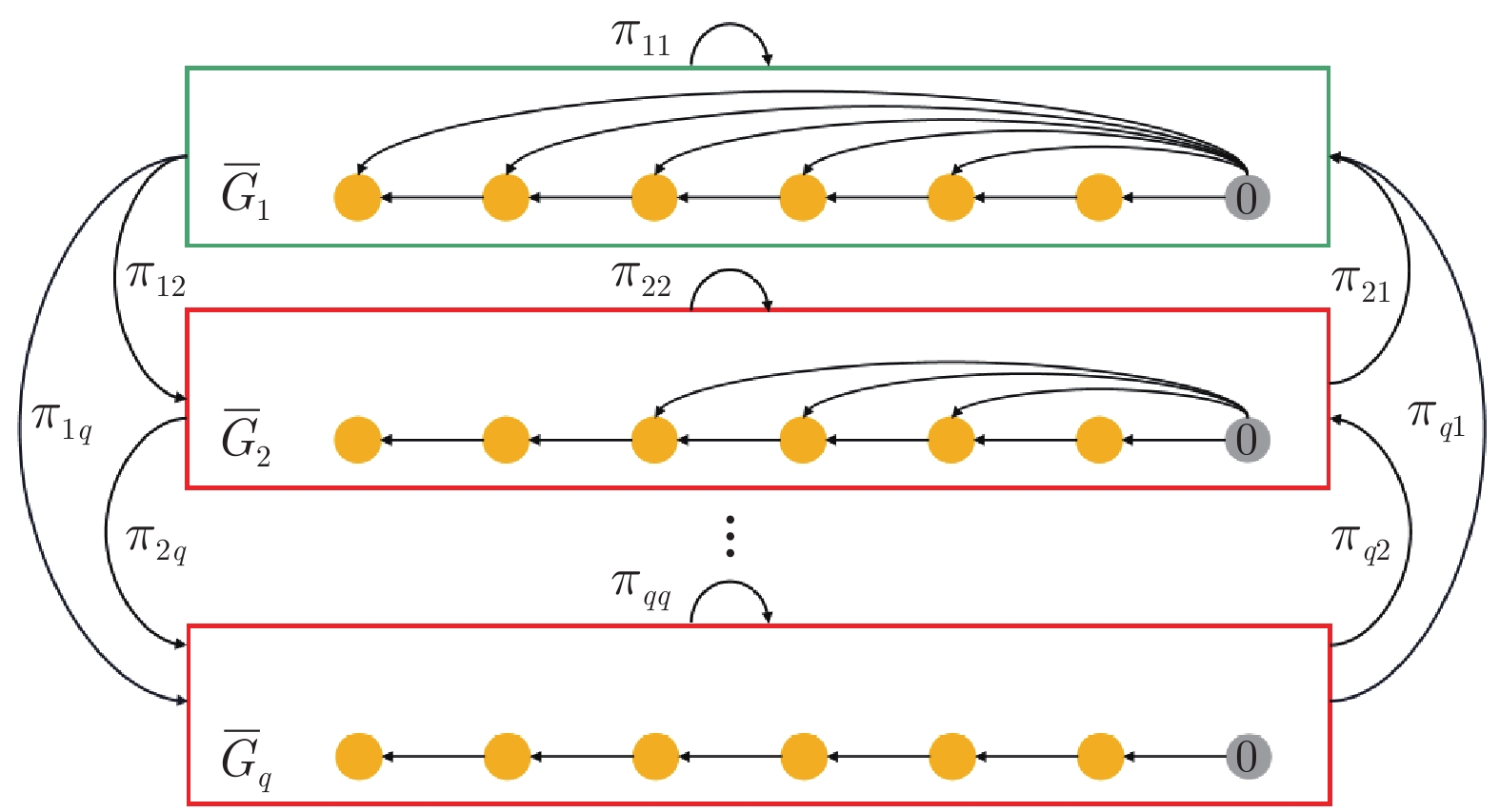
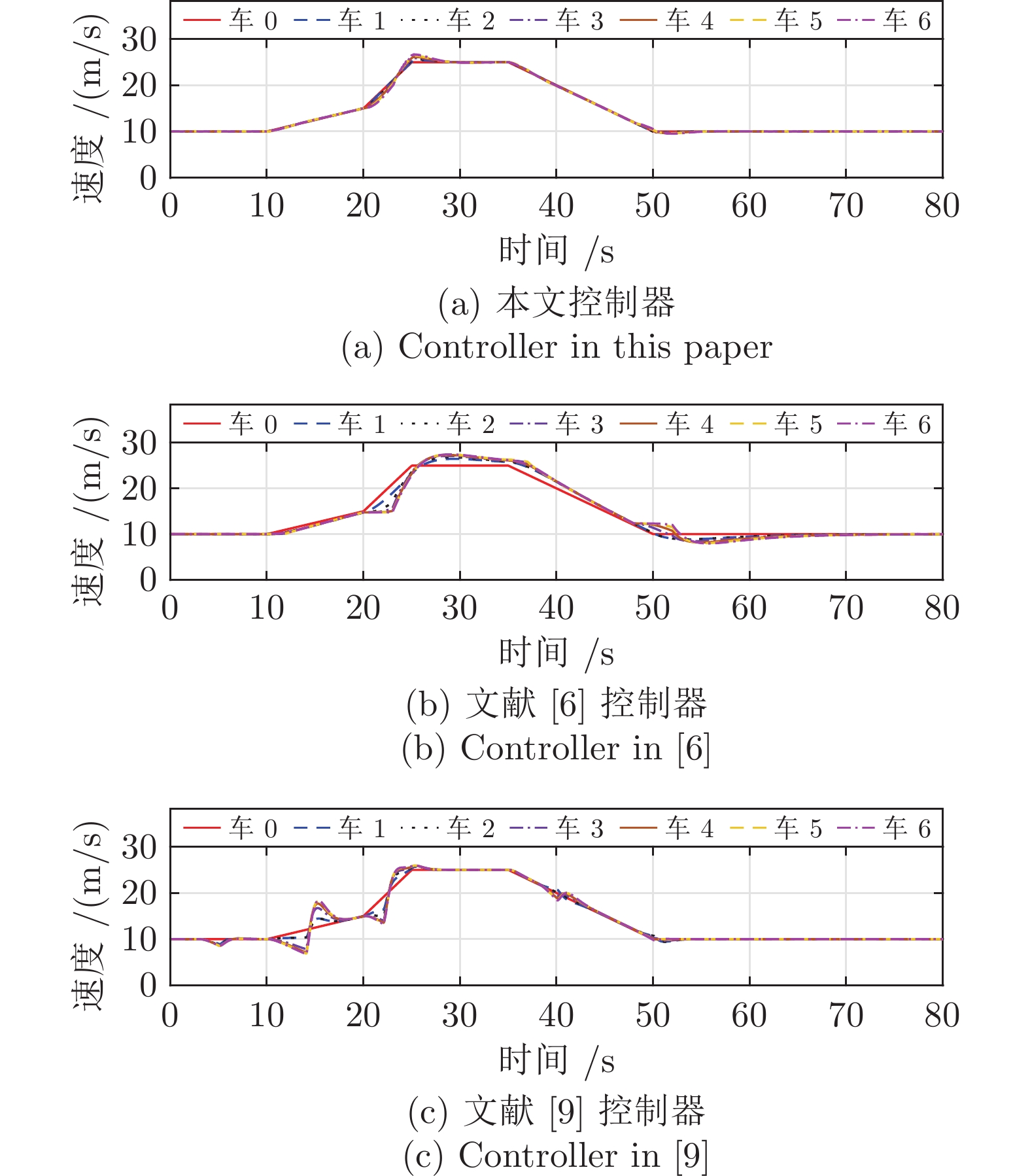
针对网联车队列系统易受到干扰和拒绝服务(Denial of service, DoS)攻击问题, 提出一种外部干扰和随机DoS攻击作用下的网联车安全H∞ 队列控制方法. 首先, 采用马尔科夫随机过程, 将网联车随机DoS攻击特性建模为一个随机通信拓扑切换模型, 据此设计网联车安全队列控制协议. 然后, 采用线性矩阵不等式(Linear matrix inequality, LMI)技术计算安全队列控制器参数, 并应用Lyapunov-Krasovskii稳定性理论, 建立在外部扰动和随机DoS攻击下队列系统稳定性充分条件. 在此基础上, 分析得到该队列闭环系统的弦稳定性充分条件. 最后, 通过7辆车组成的队列系统对比仿真实验, 验证该方法的优越性.
针对网联车队列系统易受到干扰和拒绝服务(Denial of service, DoS)攻击问题, 提出一种外部干扰和随机DoS攻击作用下的网联车安全H∞ 队列控制方法. 首先, 采用马尔科夫随机过程, 将网联车随机DoS攻击特性建模为一个随机通信拓扑切换模型, 据此设计网联车安全队列控制协议. 然后, 采用线性矩阵不等式(Linear matrix inequality, LMI)技术计算安全队列控制器参数, 并应用Lyapunov-Krasovskii稳定性理论, 建立在外部扰动和随机DoS攻击下队列系统稳定性充分条件. 在此基础上, 分析得到该队列闭环系统的弦稳定性充分条件. 最后, 通过7辆车组成的队列系统对比仿真实验, 验证该方法的优越性.



2024, 50(2): 356-371.
doi: 10.16383/j.aas.c220820
摘要:
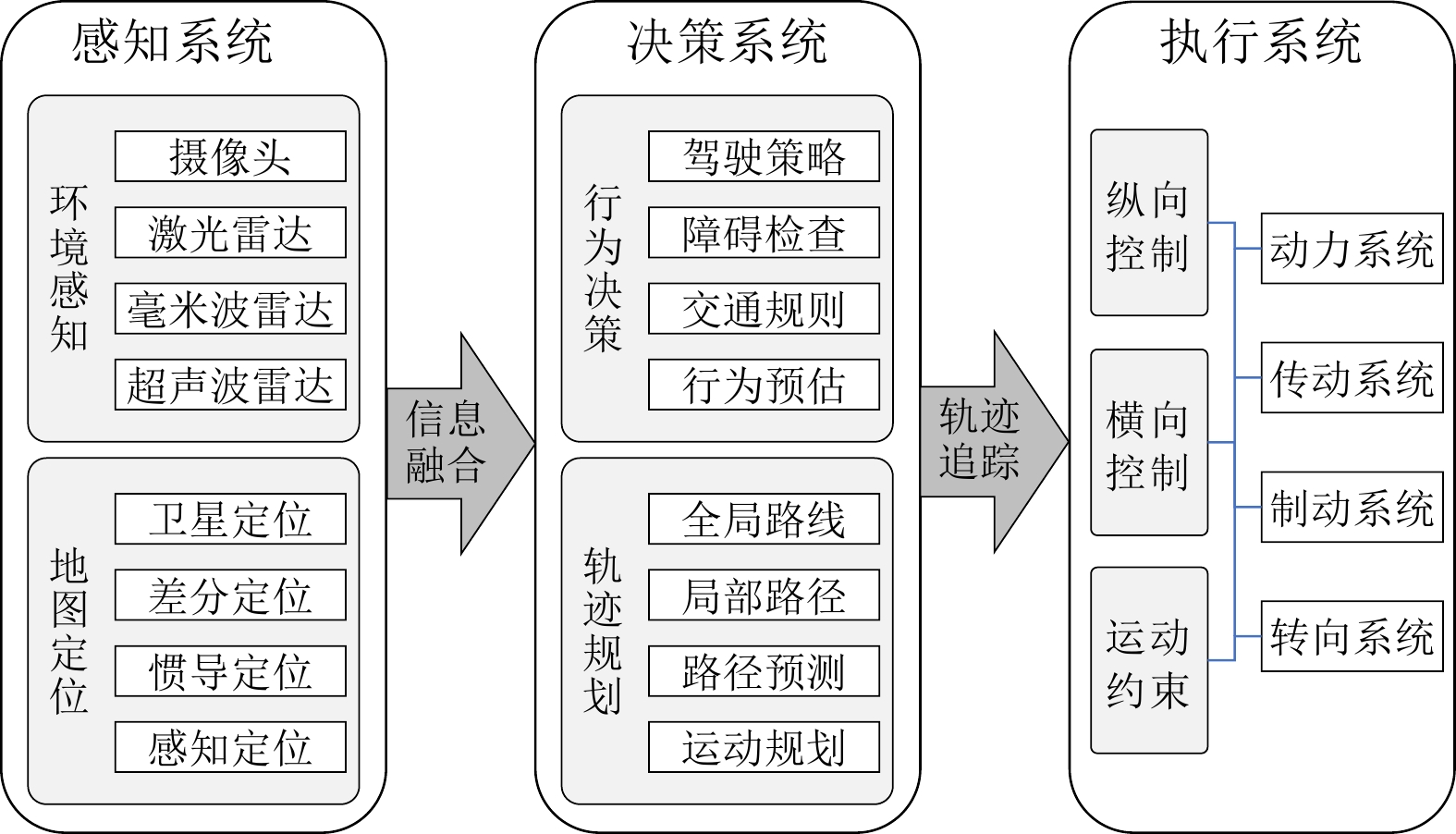
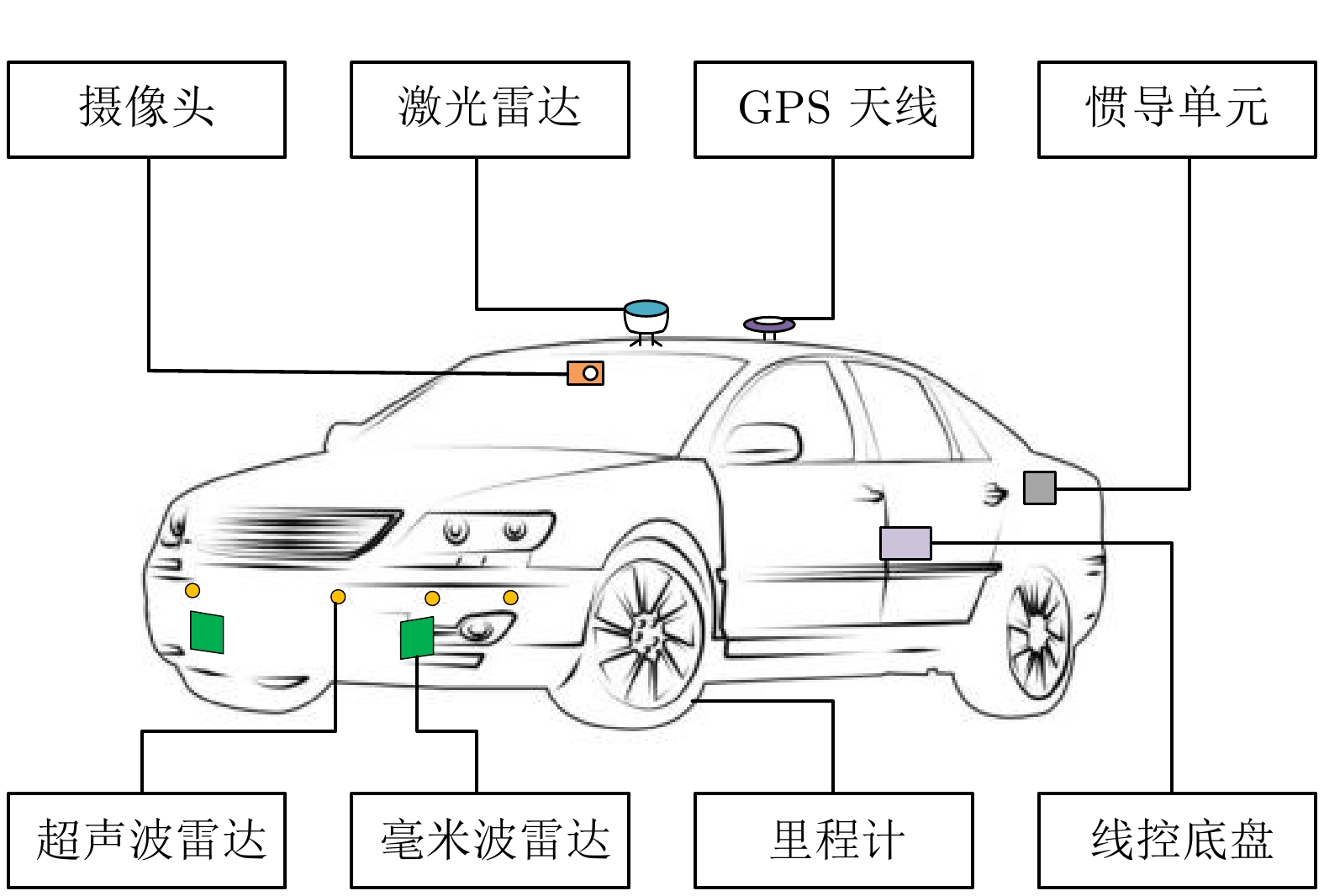
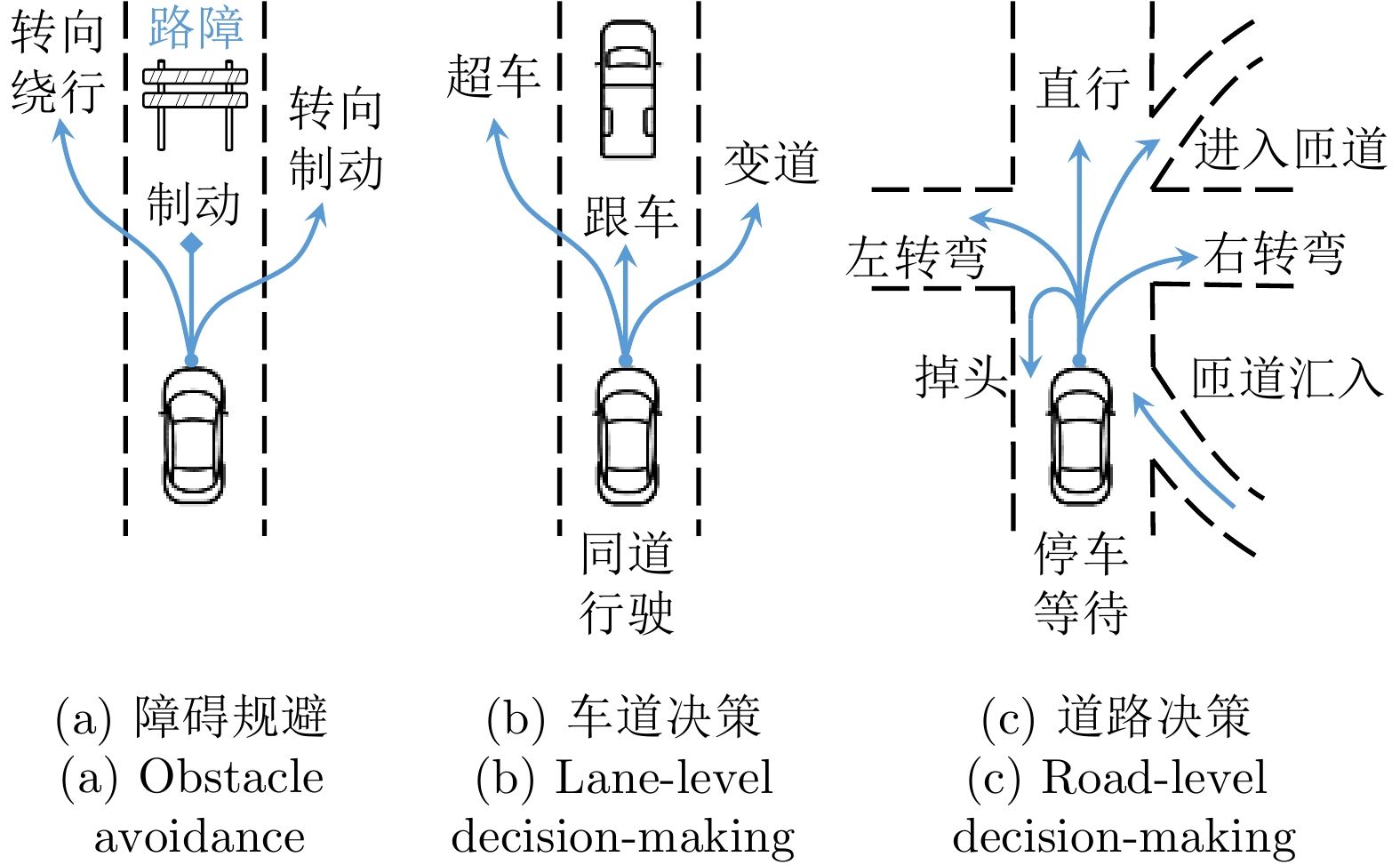
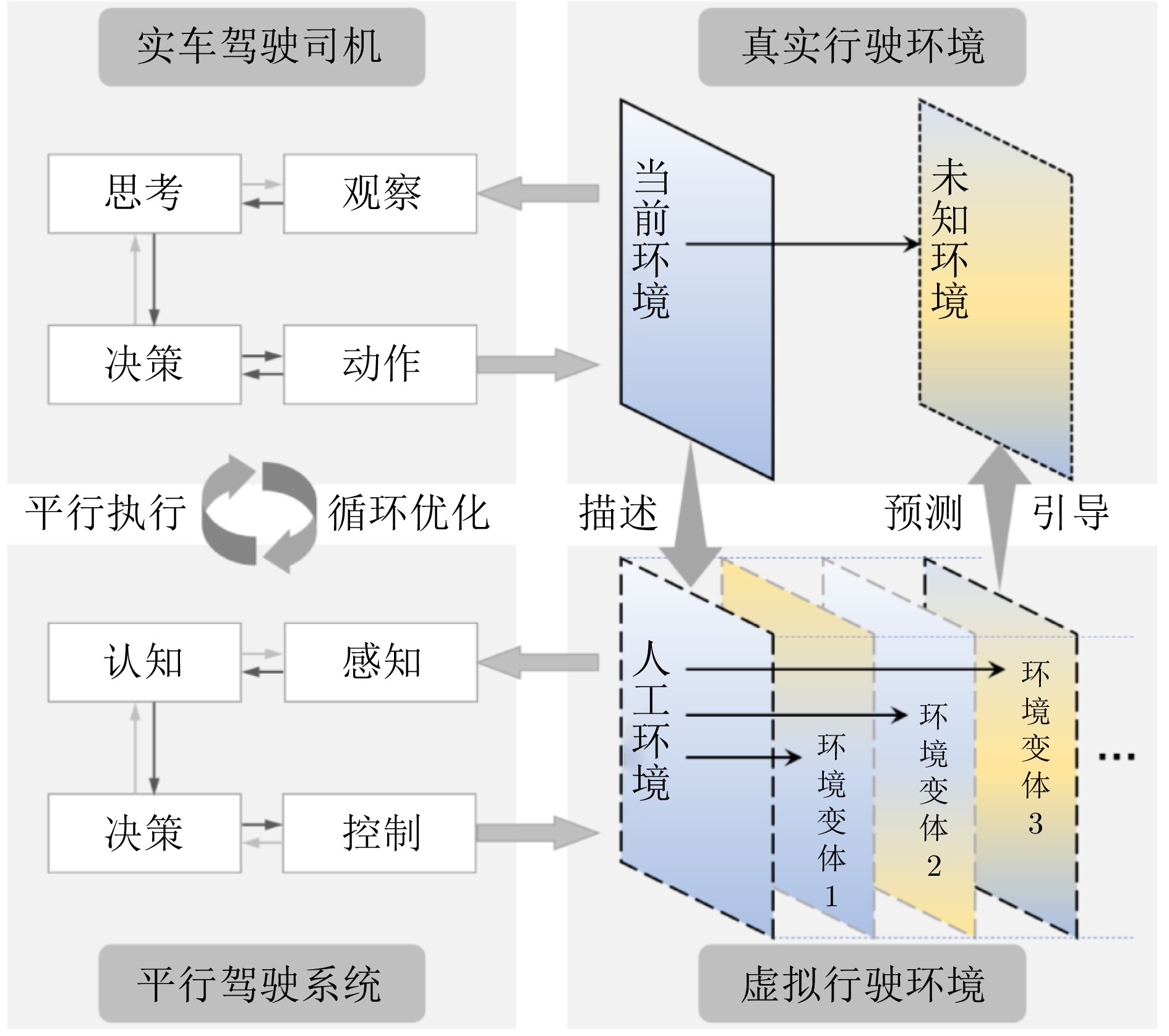
在大数据、云计算和机器学习等新一代人工智能技术的推动下, 自动驾驶的感知智能在近年来得到显著的提升与发展. 然而, 与人类驾驶过程中隐含的以自我目的实现为引导的自探索性和自主性相比, 现阶段自动驾驶技术主要以辅助驾驶功能为主, 还停留在以被动感知、规划与控制为主的初级智能自动驾驶阶段. 为实现车辆智能从数据驱动的环境感知、辅助决策、被动规划到知识驱动的场景认知、推理决策、主动规划的提升, 亟需增强车辆自身对复杂外界信息归纳提炼、推理决策、评价估计等类人能力. 首先回顾自动驾驶关键技术演化及其应用发展历程; 随后分析测试对车辆智能评估的效用; 然后基于平行测试理论, 提出自动驾驶车辆认知智能训练、测试与评估空间的构建方法, 并设计基于平行测试的认知自动驾驶智能训练框架. 该项研究工作预期能为推动自动驾驶从感知智能向认知智能的升级提供可行的技术支撑与实现路径.
在大数据、云计算和机器学习等新一代人工智能技术的推动下, 自动驾驶的感知智能在近年来得到显著的提升与发展. 然而, 与人类驾驶过程中隐含的以自我目的实现为引导的自探索性和自主性相比, 现阶段自动驾驶技术主要以辅助驾驶功能为主, 还停留在以被动感知、规划与控制为主的初级智能自动驾驶阶段. 为实现车辆智能从数据驱动的环境感知、辅助决策、被动规划到知识驱动的场景认知、推理决策、主动规划的提升, 亟需增强车辆自身对复杂外界信息归纳提炼、推理决策、评价估计等类人能力. 首先回顾自动驾驶关键技术演化及其应用发展历程; 随后分析测试对车辆智能评估的效用; 然后基于平行测试理论, 提出自动驾驶车辆认知智能训练、测试与评估空间的构建方法, 并设计基于平行测试的认知自动驾驶智能训练框架. 该项研究工作预期能为推动自动驾驶从感知智能向认知智能的升级提供可行的技术支撑与实现路径.




2024, 50(2): 372-385.
doi: 10.16383/j.aas.c230441
摘要:
针对输出受不对称时变约束的不确定高阶严反馈系统, 提出一种基于全驱系统方法的高阶自适应动态面输出约束控制方法. 所研究的高阶严反馈系统, 每个子系统都是高阶形式, 通过非线性转换函数将原输出约束系统转换为新的无约束系统, 从而将原系统输出约束问题转化为新系统输出有界的问题. 进一步结合全驱系统方法和自适应动态面控制, 直接将每个高阶子系统作为一个整体进行控制器设计, 而不需要将其转化为一阶系统形式, 有效简化了设计步骤; 同时通过引入一系列低通滤波器来获得虚拟控制律的高阶导数, 以代替复杂的微分运算. 基于Lyapunov稳定性理论证明闭环系统所有信号是一致最终有界的, 系统输出在满足约束的条件下能有效跟踪期望的参考信号, 且可通过调整参数使得系统跟踪误差收敛到零附近的足够小的邻域内. 最后, 通过对柔性关节机械臂系统进行仿真, 验证了所提出控制方法的有效性.
针对输出受不对称时变约束的不确定高阶严反馈系统, 提出一种基于全驱系统方法的高阶自适应动态面输出约束控制方法. 所研究的高阶严反馈系统, 每个子系统都是高阶形式, 通过非线性转换函数将原输出约束系统转换为新的无约束系统, 从而将原系统输出约束问题转化为新系统输出有界的问题. 进一步结合全驱系统方法和自适应动态面控制, 直接将每个高阶子系统作为一个整体进行控制器设计, 而不需要将其转化为一阶系统形式, 有效简化了设计步骤; 同时通过引入一系列低通滤波器来获得虚拟控制律的高阶导数, 以代替复杂的微分运算. 基于Lyapunov稳定性理论证明闭环系统所有信号是一致最终有界的, 系统输出在满足约束的条件下能有效跟踪期望的参考信号, 且可通过调整参数使得系统跟踪误差收敛到零附近的足够小的邻域内. 最后, 通过对柔性关节机械臂系统进行仿真, 验证了所提出控制方法的有效性.



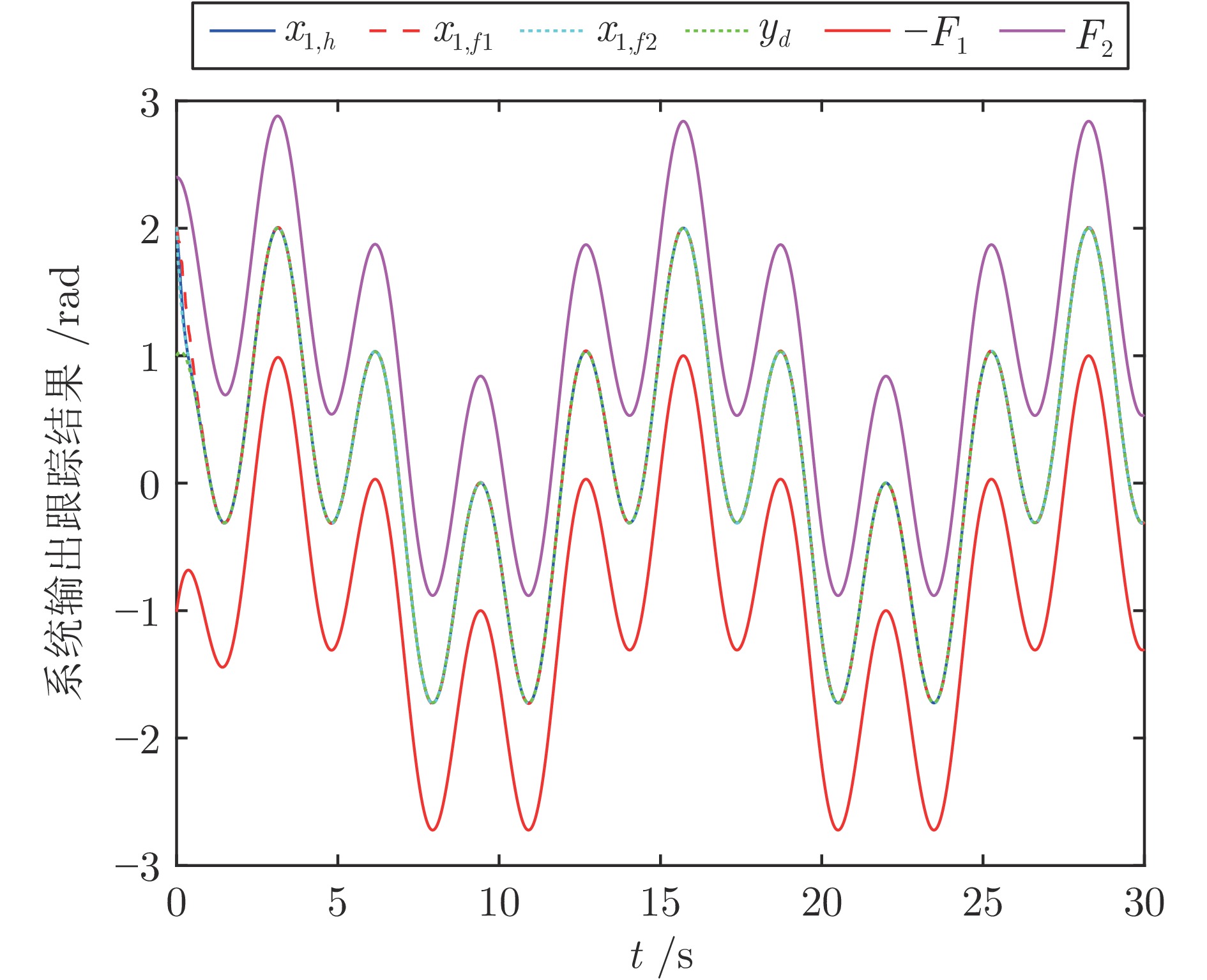
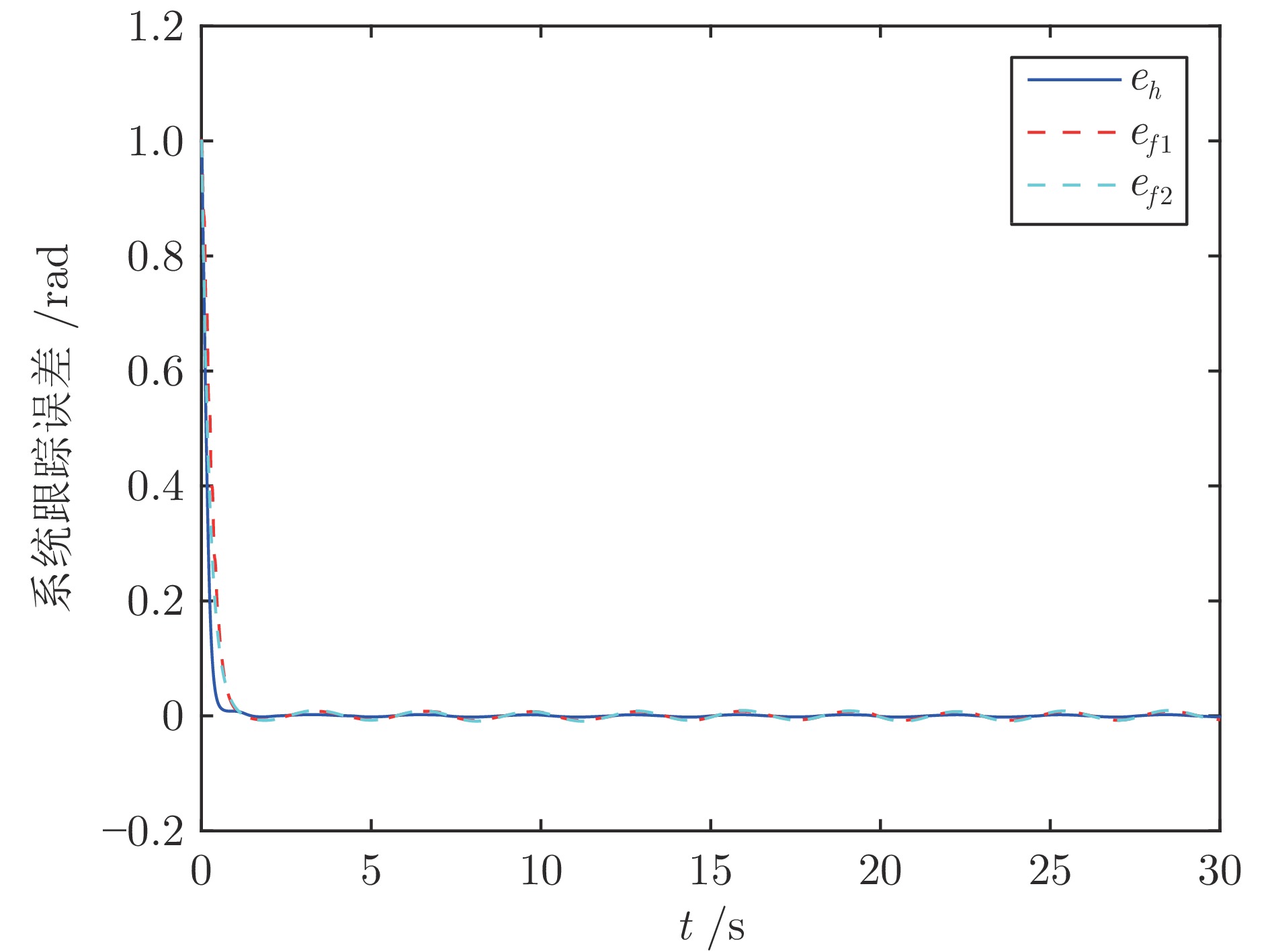
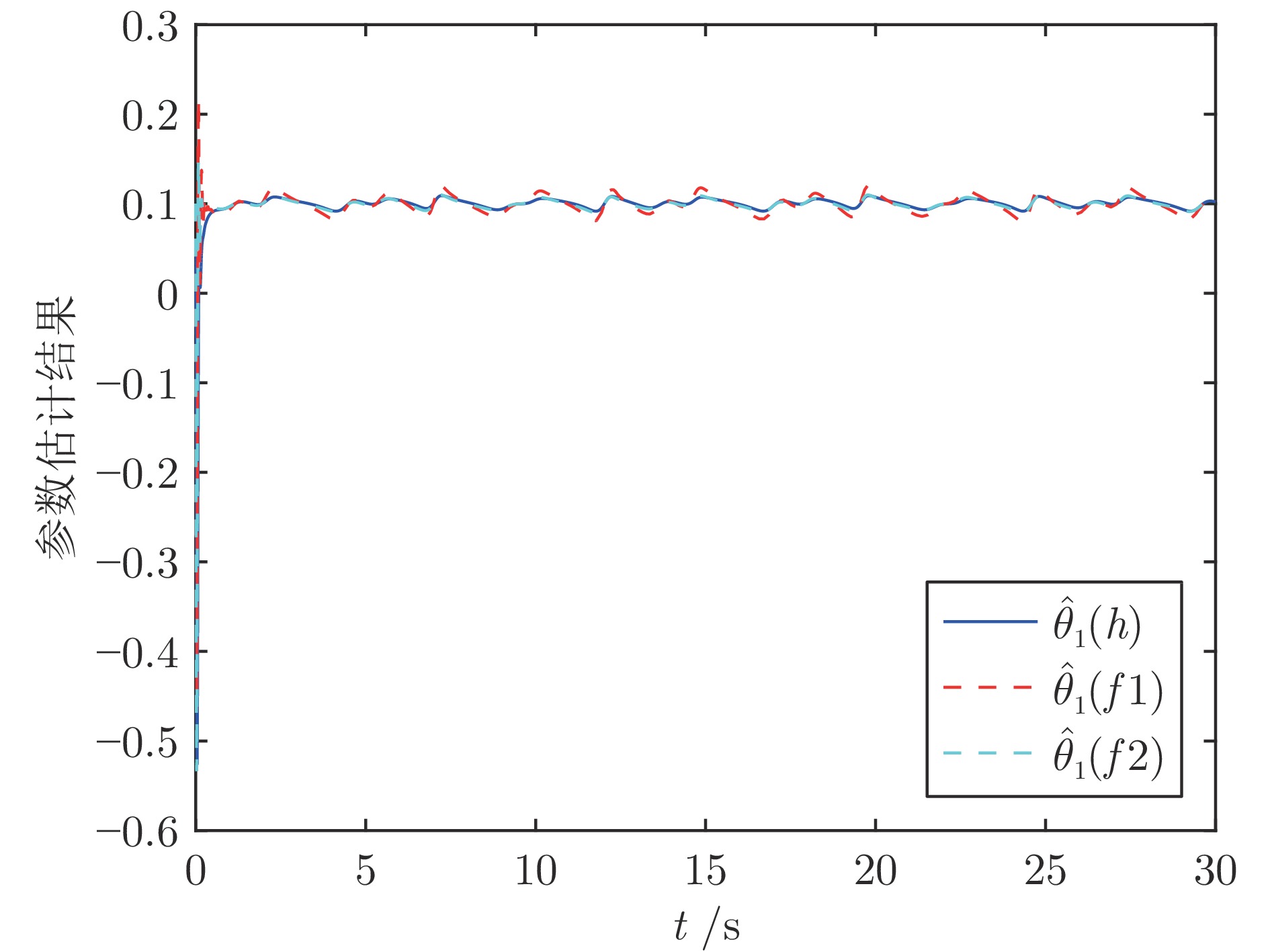

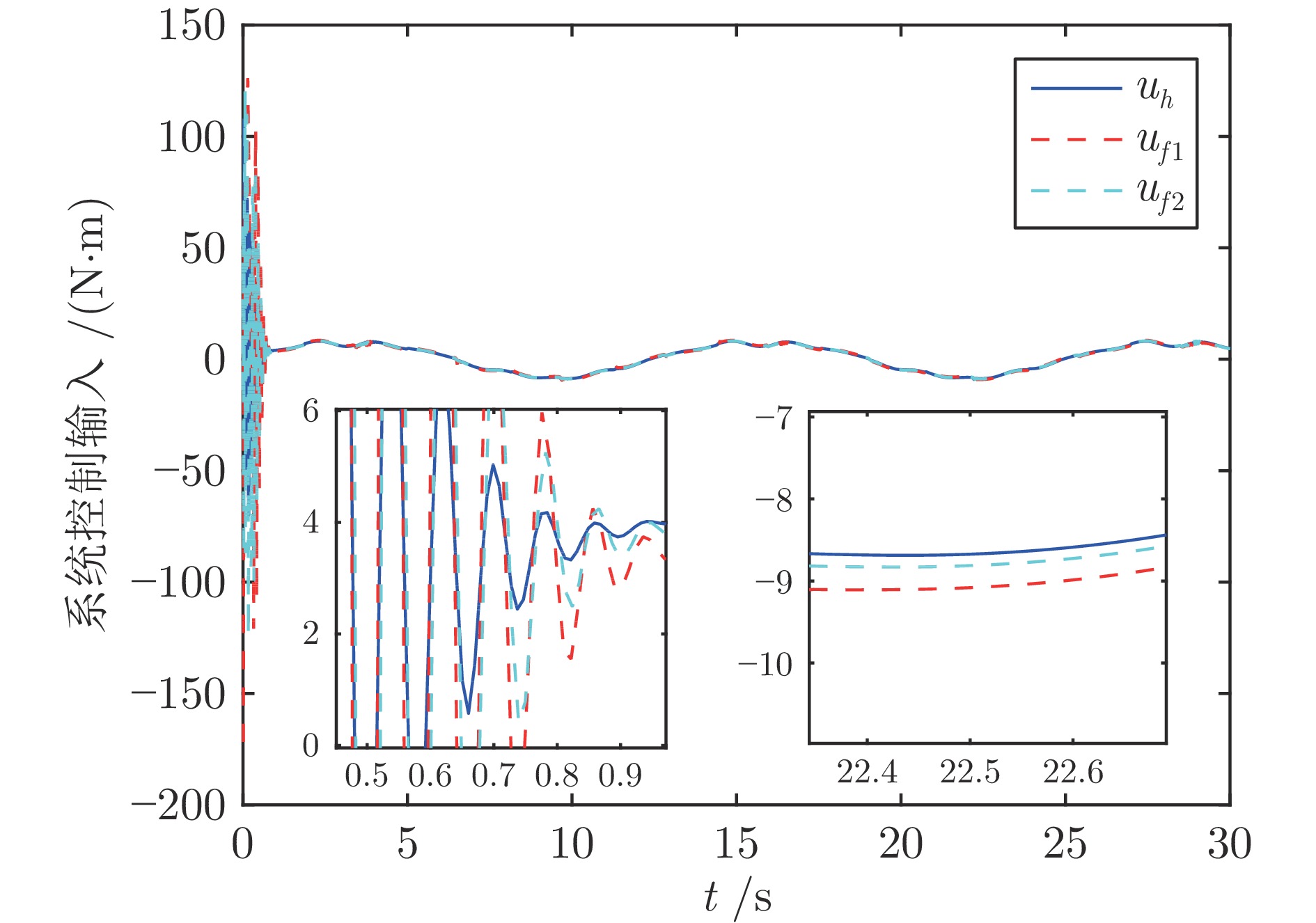
2024, 50(2): 386-402.
doi: 10.16383/j.aas.c210830
摘要:
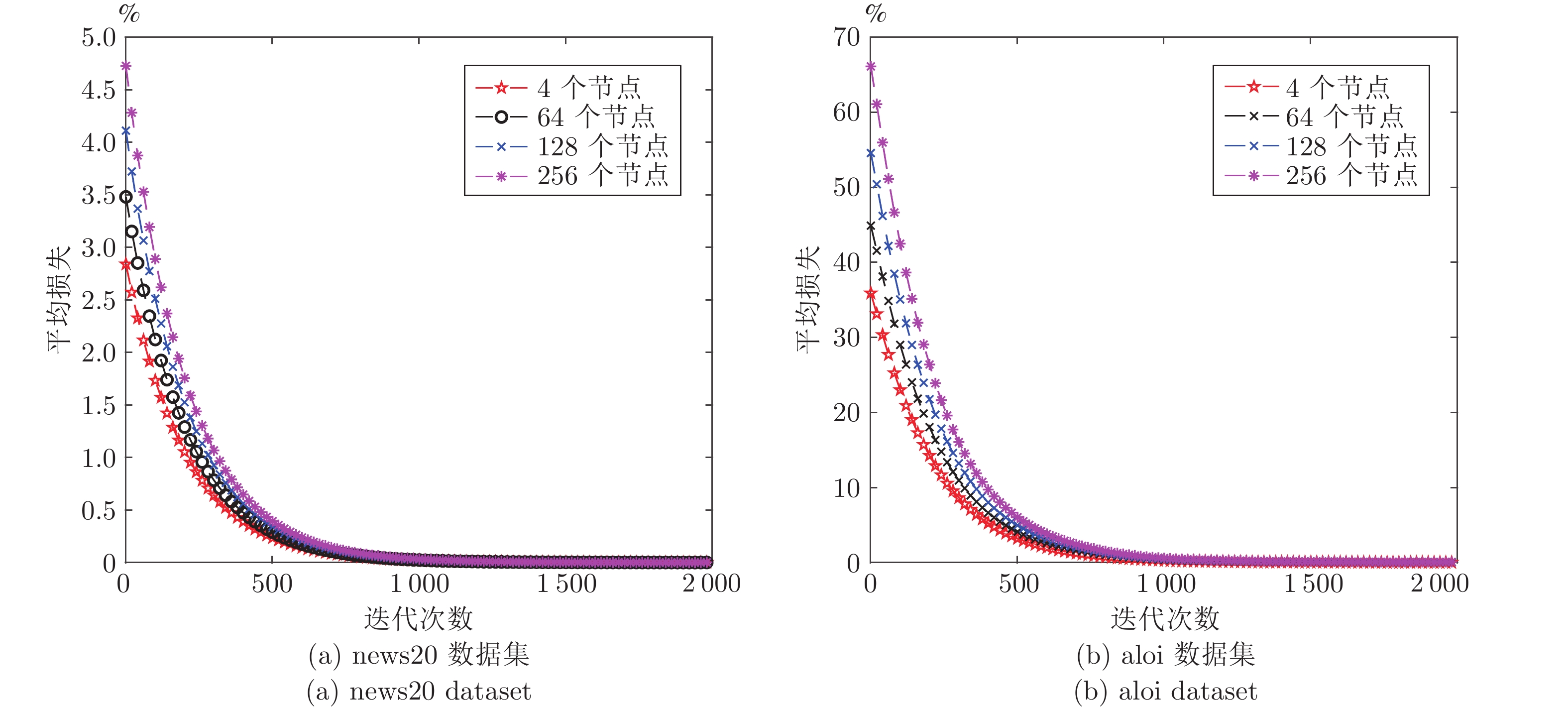
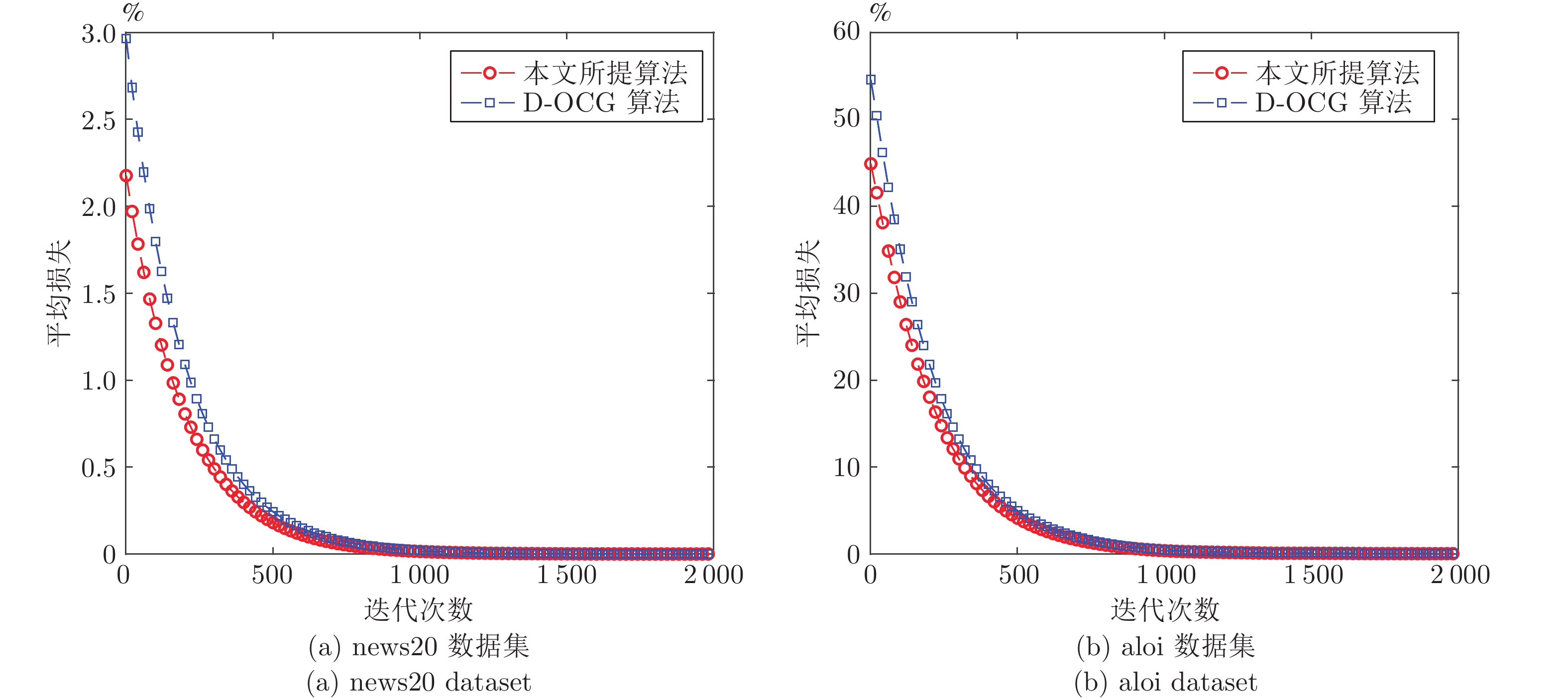
由于容易实施, 基于投影梯度的分布式在线优化模型逐渐成为一种主流的在线学习方法. 然而, 在处理大数据应用时, 投影步骤成为该方法的计算瓶颈. 近年来, 研究者提出了面向凸代价函数的分布式在线条件梯度算法, 其悔界为\begin{document}${\rm O}(T^{3/4})$\end{document} \begin{document}$T$\end{document} \begin{document}${\rm O}(\sqrt{T})$\end{document} \begin{document}${\rm O}(\sqrt{T})$\end{document} \begin{document}${\rm O}(\sqrt{T})$\end{document}
由于容易实施, 基于投影梯度的分布式在线优化模型逐渐成为一种主流的在线学习方法. 然而, 在处理大数据应用时, 投影步骤成为该方法的计算瓶颈. 近年来, 研究者提出了面向凸代价函数的分布式在线条件梯度算法, 其悔界为

2024, 50(2): 403-416.
doi: 10.16383/j.aas.c230252
摘要:
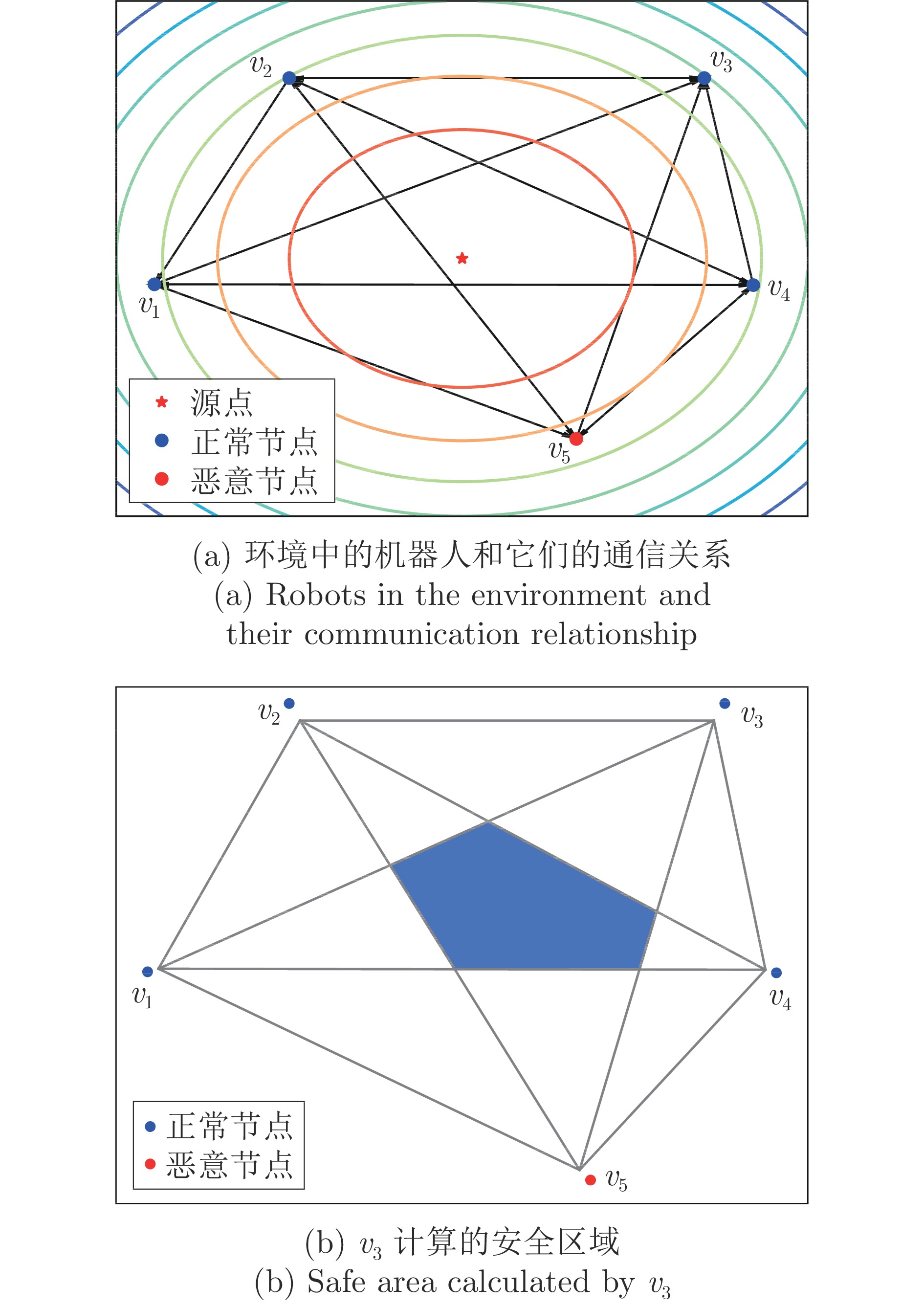
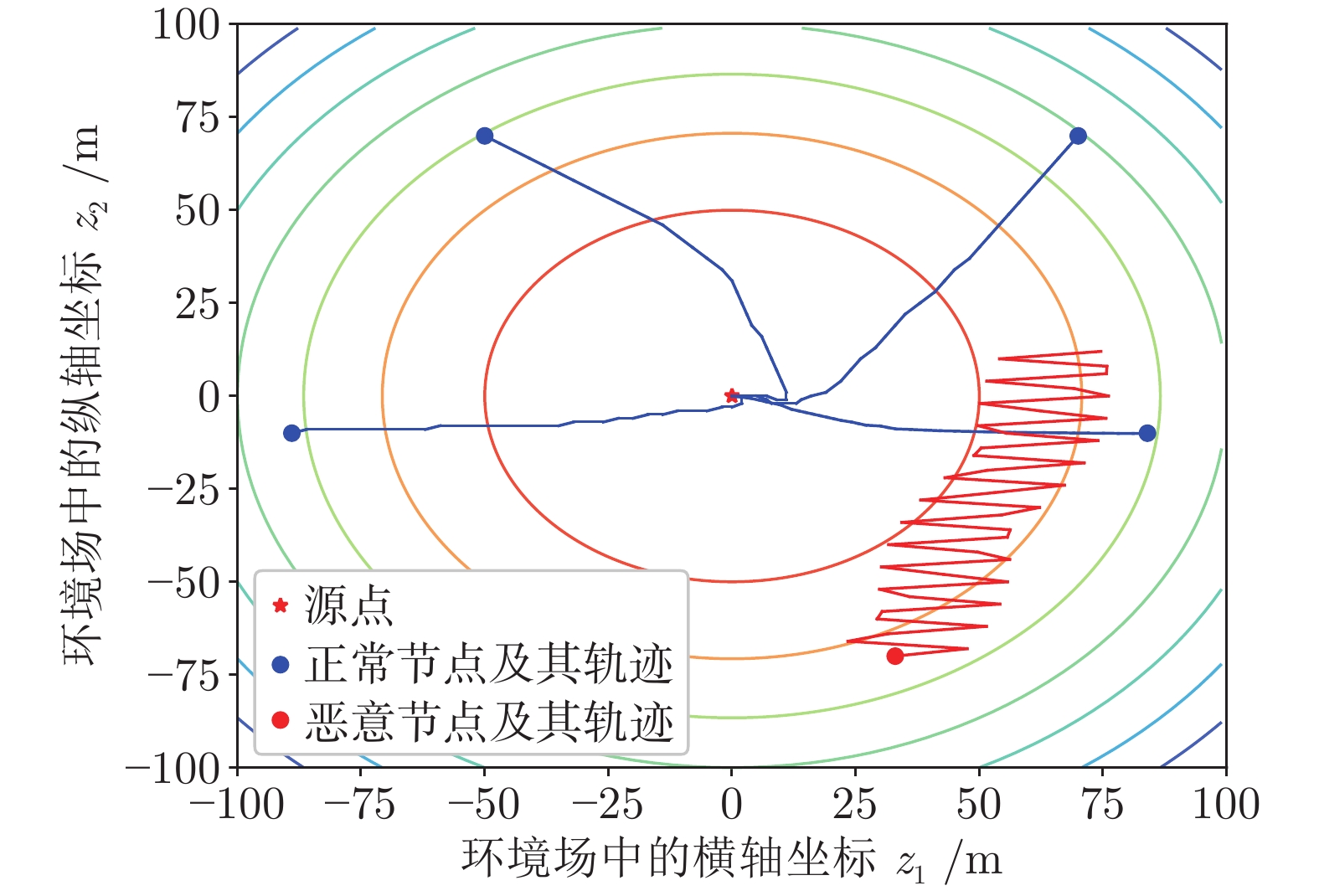
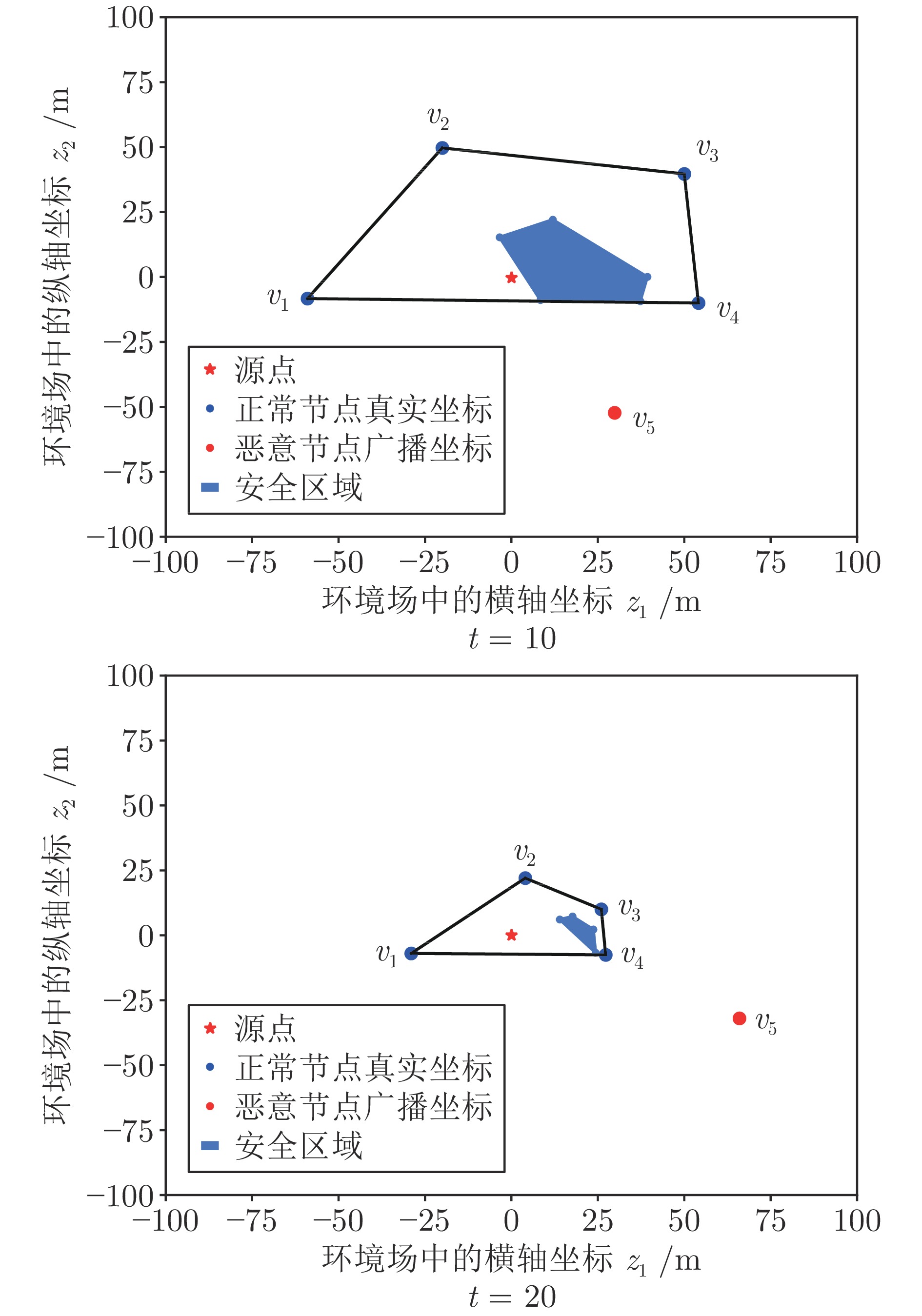
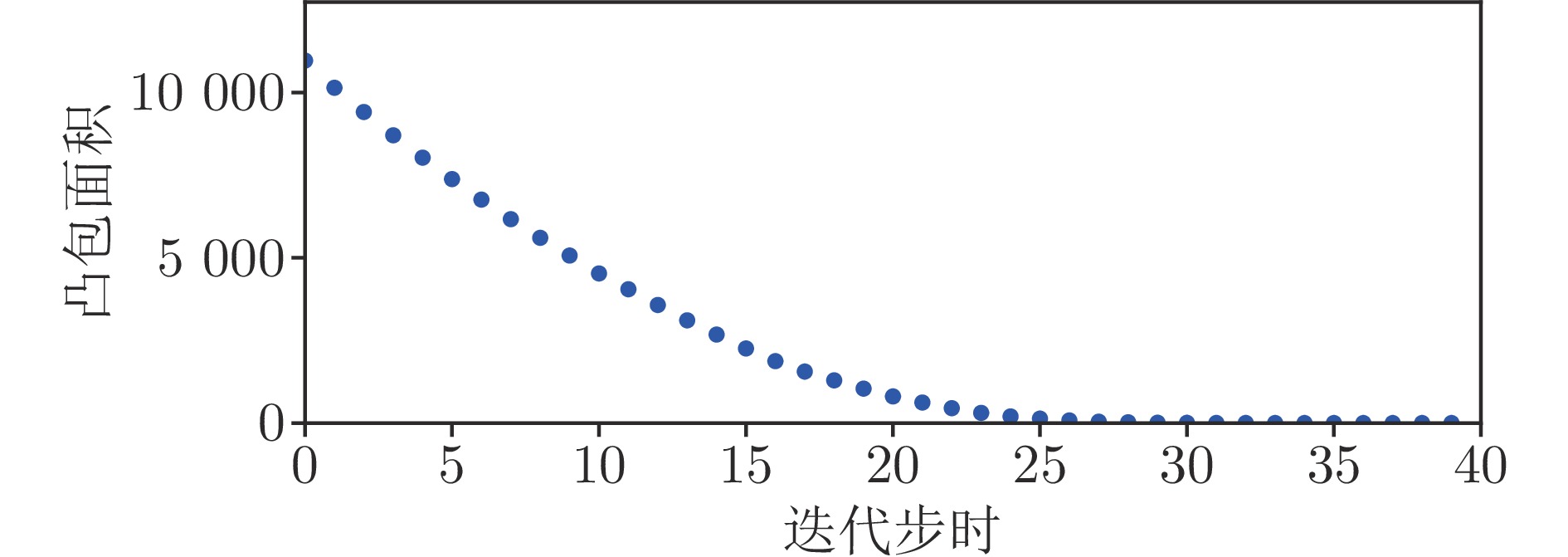
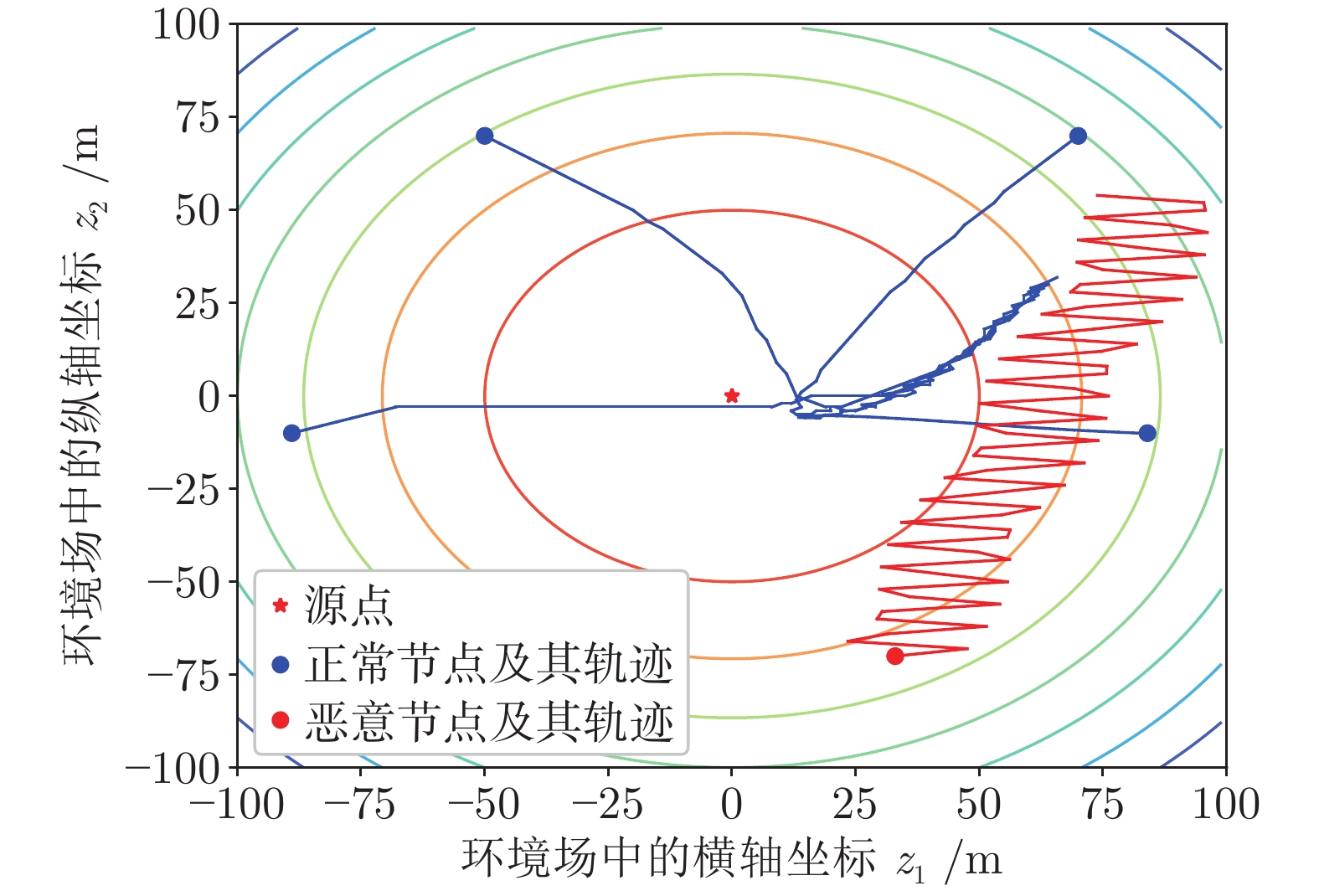
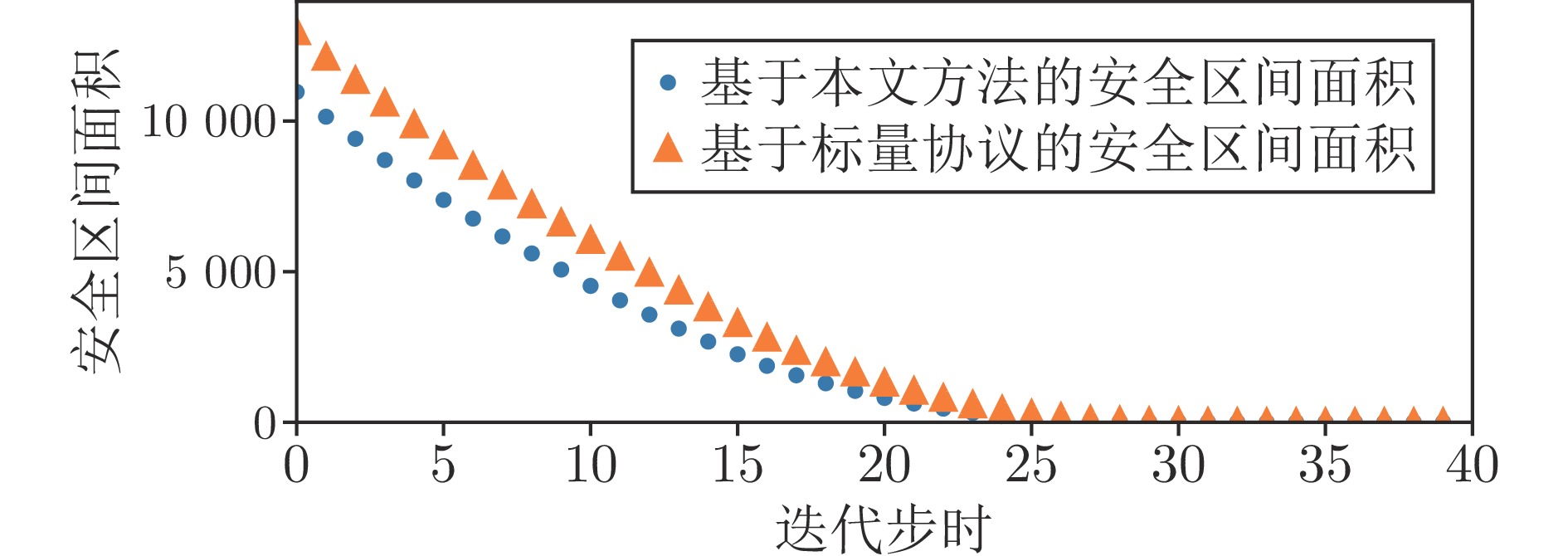
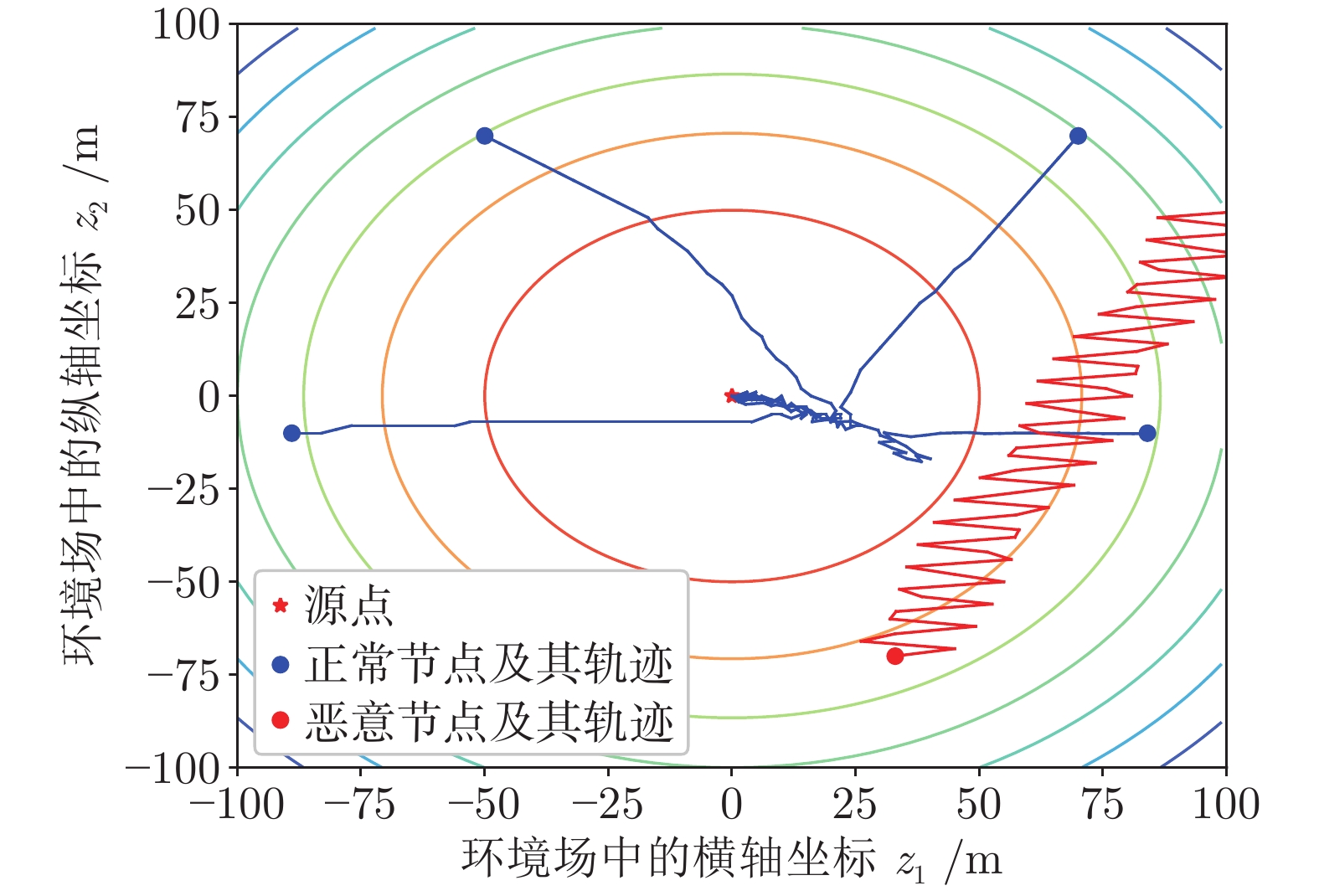
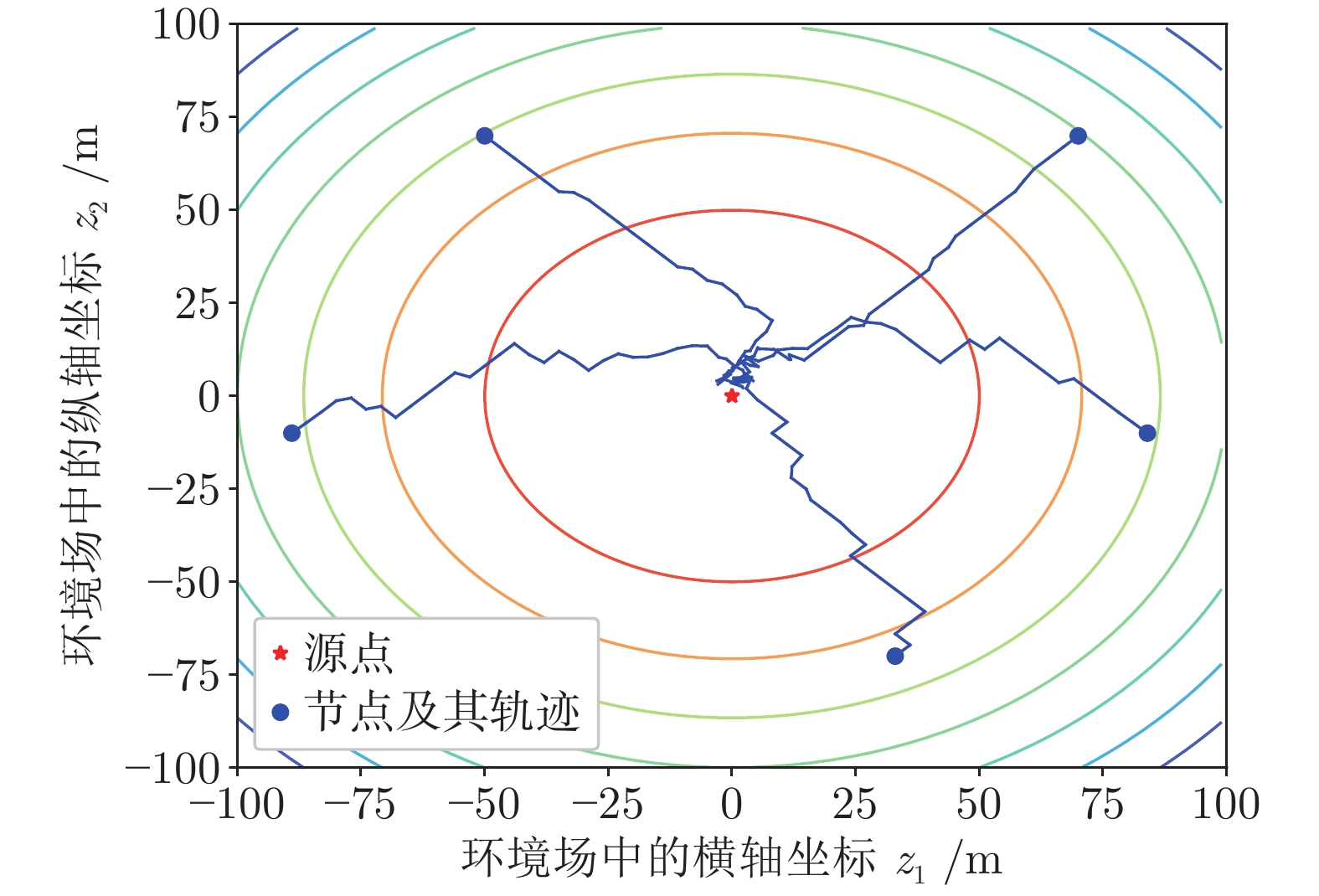
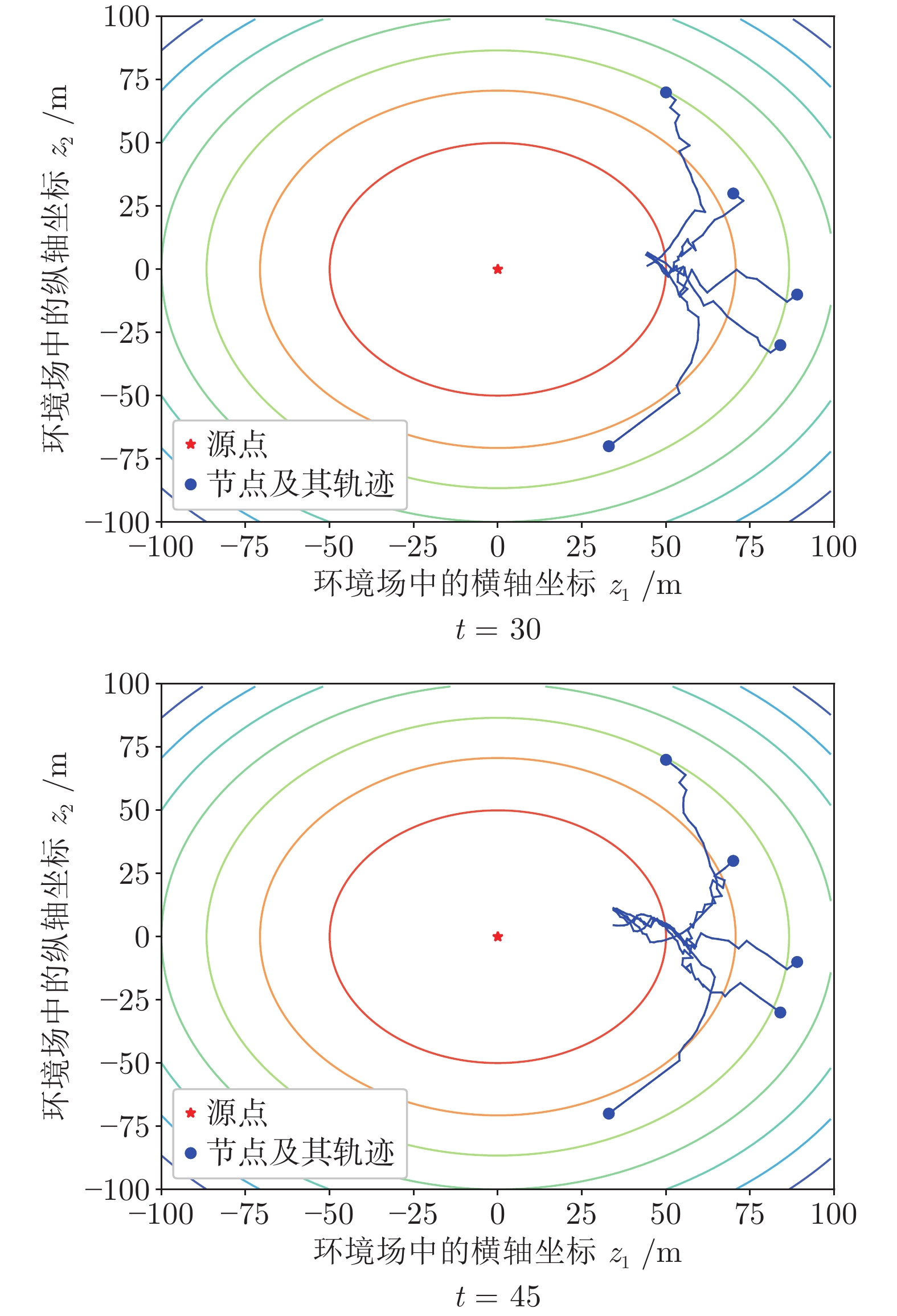
聚焦多机器人系统协同寻源问题, 即通过驱使多个机器人相互协同寻找未知环境中物理信号放射源的位置. 由于执行任务的机器人通常处于户外开放网络环境中, 攻击者在网络中生成的虚假数据注入攻击容易导致多机器人系统寻源任务的失败. 为在网络攻击情形下仍旧能够追寻到源点, 提出一种基于弹性向量趋同的多机器人系统协同多维寻源方法. 有别于现有文献在处理多维寻源时将向量分解成各个维度上的标量进而设计基于标量的弹性趋同协议, 所提出的多维寻源方法不仅能够有效抵御虚假数据注入攻击完成寻源任务, 而且其界定的安全区间相较于传统基于标量信息界定的安全区间更加严格和精准. 在假设f-局部有界(f-locally bounded) 虚假数据注入攻击模型下, 理论分析给出正常机器人在所设计的控制协议下追寻到源点的充分必要条件. 仿真结果表明, 该方法在分布式多机器人系统协作寻源和抵抗恶意攻击方面具有优越性.
聚焦多机器人系统协同寻源问题, 即通过驱使多个机器人相互协同寻找未知环境中物理信号放射源的位置. 由于执行任务的机器人通常处于户外开放网络环境中, 攻击者在网络中生成的虚假数据注入攻击容易导致多机器人系统寻源任务的失败. 为在网络攻击情形下仍旧能够追寻到源点, 提出一种基于弹性向量趋同的多机器人系统协同多维寻源方法. 有别于现有文献在处理多维寻源时将向量分解成各个维度上的标量进而设计基于标量的弹性趋同协议, 所提出的多维寻源方法不仅能够有效抵御虚假数据注入攻击完成寻源任务, 而且其界定的安全区间相较于传统基于标量信息界定的安全区间更加严格和精准. 在假设f-局部有界(f-locally bounded) 虚假数据注入攻击模型下, 理论分析给出正常机器人在所设计的控制协议下追寻到源点的充分必要条件. 仿真结果表明, 该方法在分布式多机器人系统协作寻源和抵抗恶意攻击方面具有优越性.





2024, 50(2): 417-430.
doi: 10.16383/j.aas.c230159
摘要:
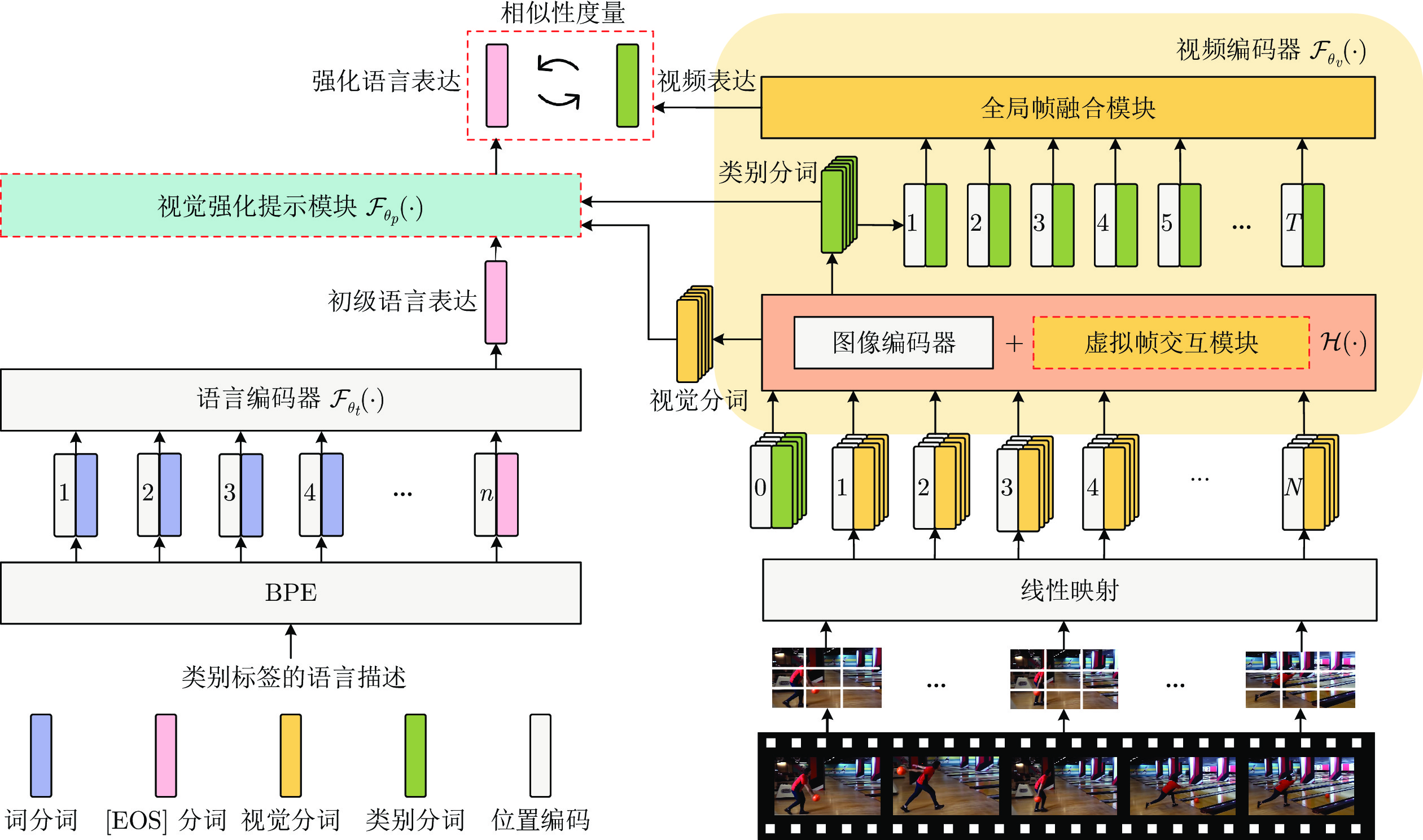
以对比语言−图像预训练(Contrastive language-image pre-training, CLIP)模型为基础, 提出一种面向视频行为识别的多模态模型, 该模型从视觉编码器的时序建模和行为类别语言描述的提示学习两个方面对CLIP模型进行拓展, 可更好地学习多模态视频表达. 具体地, 在视觉编码器中设计虚拟帧交互模块(Virtual-frame interaction module, VIM), 首先, 由视频采样帧的类别分词做线性变换得到虚拟帧分词; 然后, 对其进行基于时序卷积和虚拟帧分词移位的时序建模操作, 有效建模视频中的时空变化信息; 最后, 在语言分支上设计视觉强化提示模块(Visual-reinforcement prompt module, VPM), 通过注意力机制融合视觉编码器末端输出的类别分词和视觉分词所带有的视觉信息来获得经过视觉信息强化的语言表达. 在4个公开视频数据集上的全监督实验和2个视频数据集上的小样本、零样本实验结果, 验证了该多模态模型的有效性和泛化性.
以对比语言−图像预训练(Contrastive language-image pre-training, CLIP)模型为基础, 提出一种面向视频行为识别的多模态模型, 该模型从视觉编码器的时序建模和行为类别语言描述的提示学习两个方面对CLIP模型进行拓展, 可更好地学习多模态视频表达. 具体地, 在视觉编码器中设计虚拟帧交互模块(Virtual-frame interaction module, VIM), 首先, 由视频采样帧的类别分词做线性变换得到虚拟帧分词; 然后, 对其进行基于时序卷积和虚拟帧分词移位的时序建模操作, 有效建模视频中的时空变化信息; 最后, 在语言分支上设计视觉强化提示模块(Visual-reinforcement prompt module, VPM), 通过注意力机制融合视觉编码器末端输出的类别分词和视觉分词所带有的视觉信息来获得经过视觉信息强化的语言表达. 在4个公开视频数据集上的全监督实验和2个视频数据集上的小样本、零样本实验结果, 验证了该多模态模型的有效性和泛化性.