

FeO Content Prediction in Sintering Process Based on Fusion of Data-Knowledge and AW-ESN
-
摘要: 氧化亚铁(FeO)含量是衡量烧结矿强度和还原性的重要指标, 烧结过程FeO含量的实时准确预测对于提升烧结质量、优化烧结工艺具有重要意义. 然而烧结过程热状态参数缺失、过程参数波动频繁给FeO含量的高精度预测带来巨大的挑战, 为此, 提出一种基于知识与变权重回声状态网络融合(Fusion of data-knowledge and adaptive weight echo state network, DK-AWESN)的烧结过程FeO含量预测方法. 首先, 针对烧结过程热状态参数缺失的问题, 建立烧结料层最高温度分布模型, 实现基于料层温度分布特征的FeO含量等级划分; 其次, 针对烧结过程参数波动频繁的问题, 提出基于核函数高维映射的多尺度数据配准方法, 有效抑制离群点的影响, 提升建模数据的质量; 最后, 针对烧结过程数据驱动模型缺乏机理认知致使模型预测精度不高的问题, 将过程数据中提取得到的FeO含量等级知识与AW-ESN (Adaptive weight echo state network)结合, 建立DK-AWESN模型, 有效提升复杂工况下FeO含量的预测精度. 现场工业数据试验表明, 所提方法能实时准确地预测烧结过程FeO含量, 为烧结过程的智能化调控提供实时有效的FeO含量反馈信息.Abstract: FeO content is an important index to characterize the strength and reducibility of sinter. Real-time and accurate prediction of FeO content in sintering process is of great significance for improving sintering quality and optimizing sintering process. However, the lack of thermal state parameters in sintering process and the frequent fluctuation of process parameters bring great challenges to the high-precision prediction of FeO content. In order to alleviate these problems, a method of FeO content prediction in sintering process by fusing data-knowledge and adaptive weight echo state network (DK-AWESN) is proposed in this paper. Firstly, aiming at the problem of lacking thermal state parameters in sintering process, the temperature distribution model of sinter bed is established, and the state of FeO content can be obtained based on the temperature distribution characteristics of sinter bed; Secondly, aiming at the frequent fluctuation of sintering process parameters, a multi-scale data registration method based on kernel function high-dimensional mapping is proposed, which effectively suppresses the influence of outliers and improves the quality of modeling data; Finally, to alleviate the problem of low prediction accuracy of data-driven model due to the lack of mechanism knowledge, the expert knowledge extracted from the process data is fused with adaptive weight echo state network (AW-ESN) to establish DK-AWESN, which improves the FeO content prediction performance of the model under complex working conditions. Industrial verification shows that the proposed method can accurately predict the FeO content in real time and provide effective FeO content information for the intelligent control of the sintering process.
-

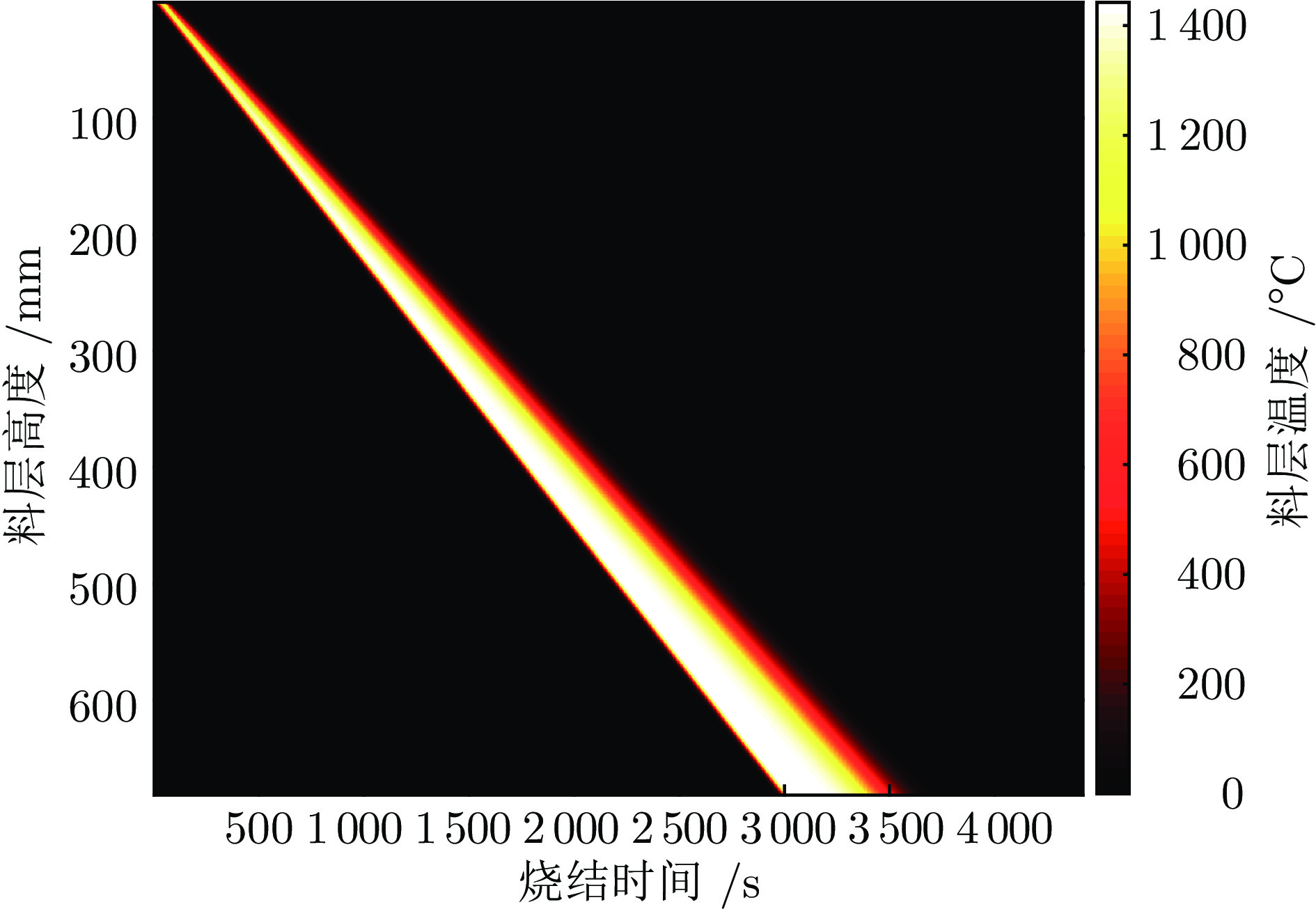
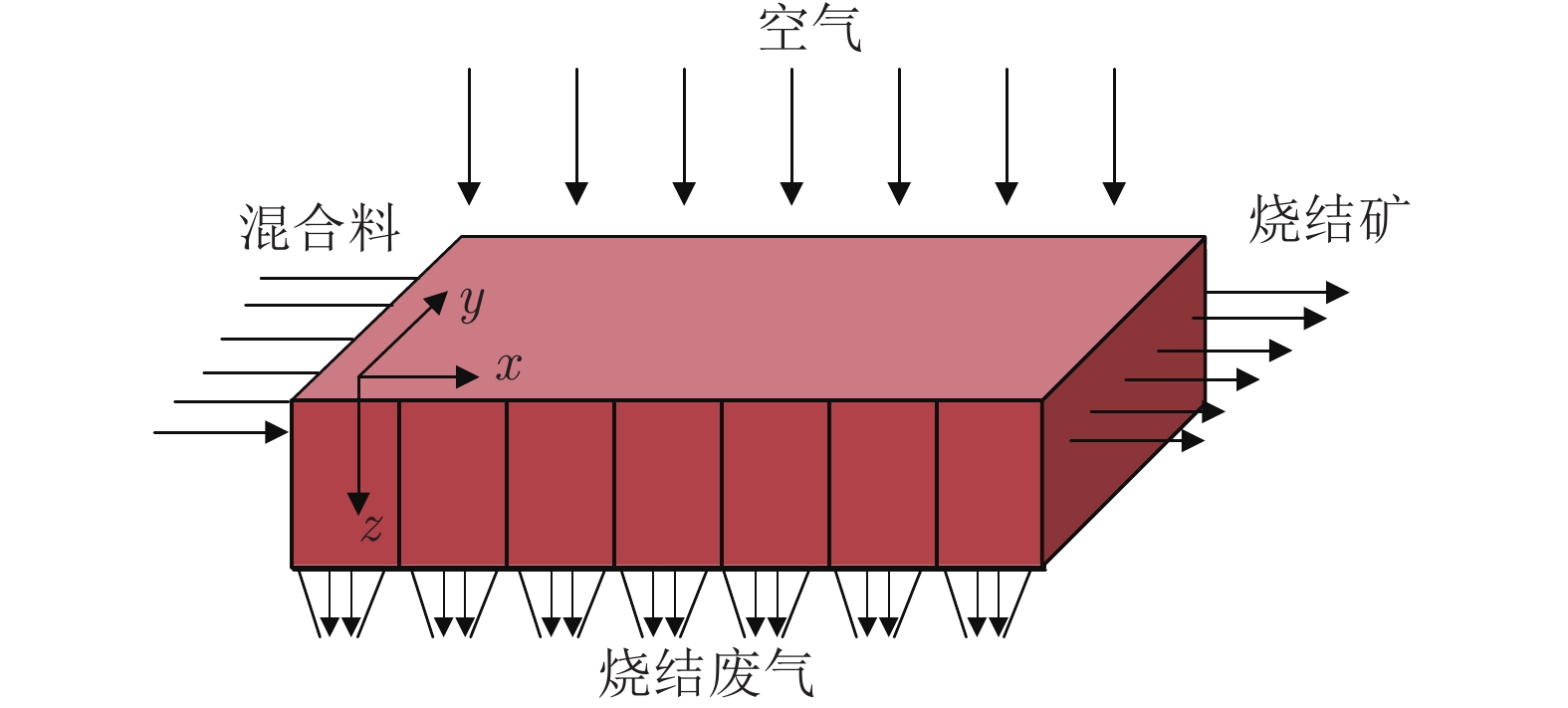
图 2 料层全时空最高温度分布
Fig. 2 Maximum temperature distribution of sinter bed in whole time and space
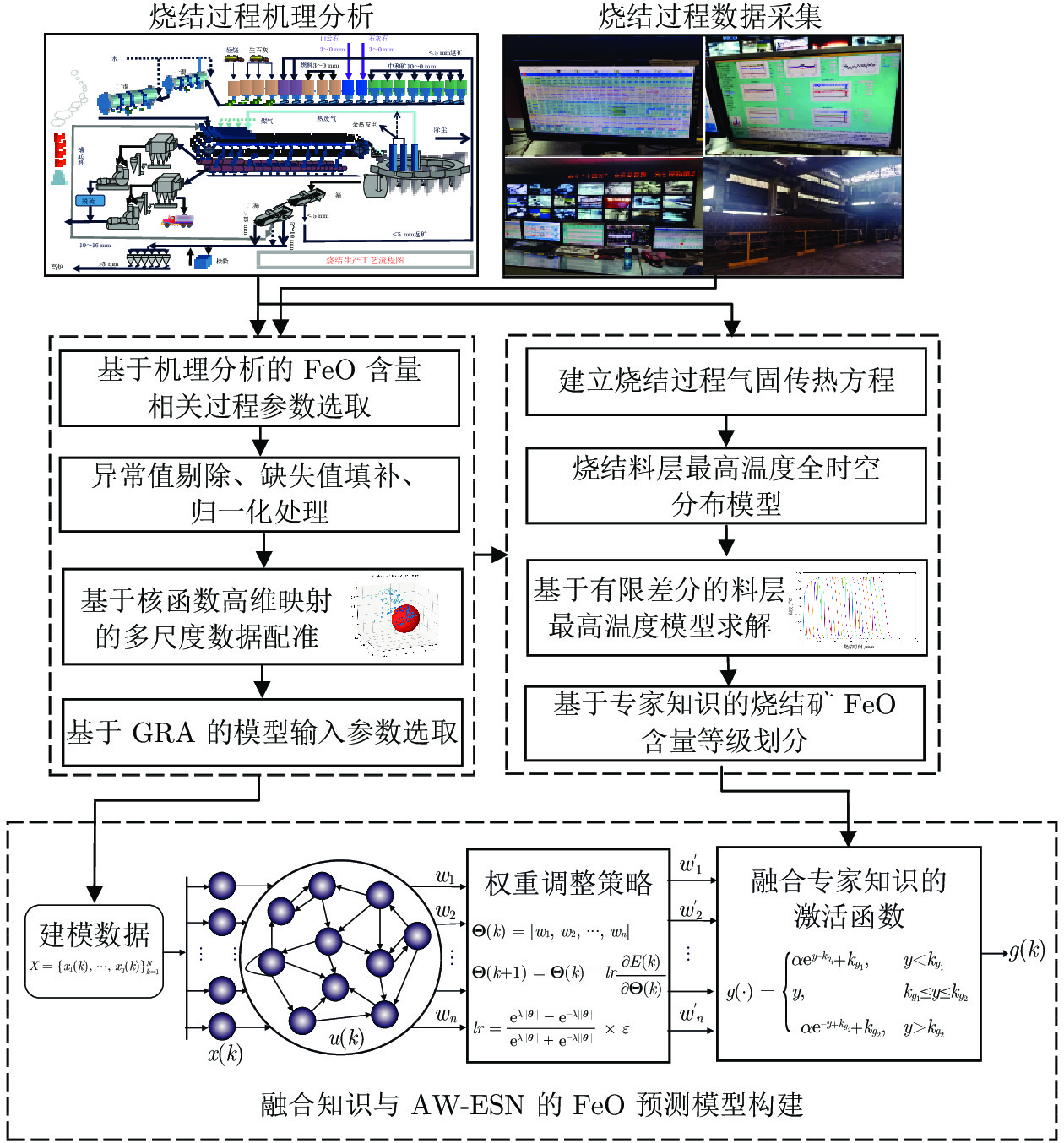
图 5 基于DK-AWESN的FeO含量预测方法框图
Fig. 5 Schematic of FeO content prediction method based on DK-AWESN
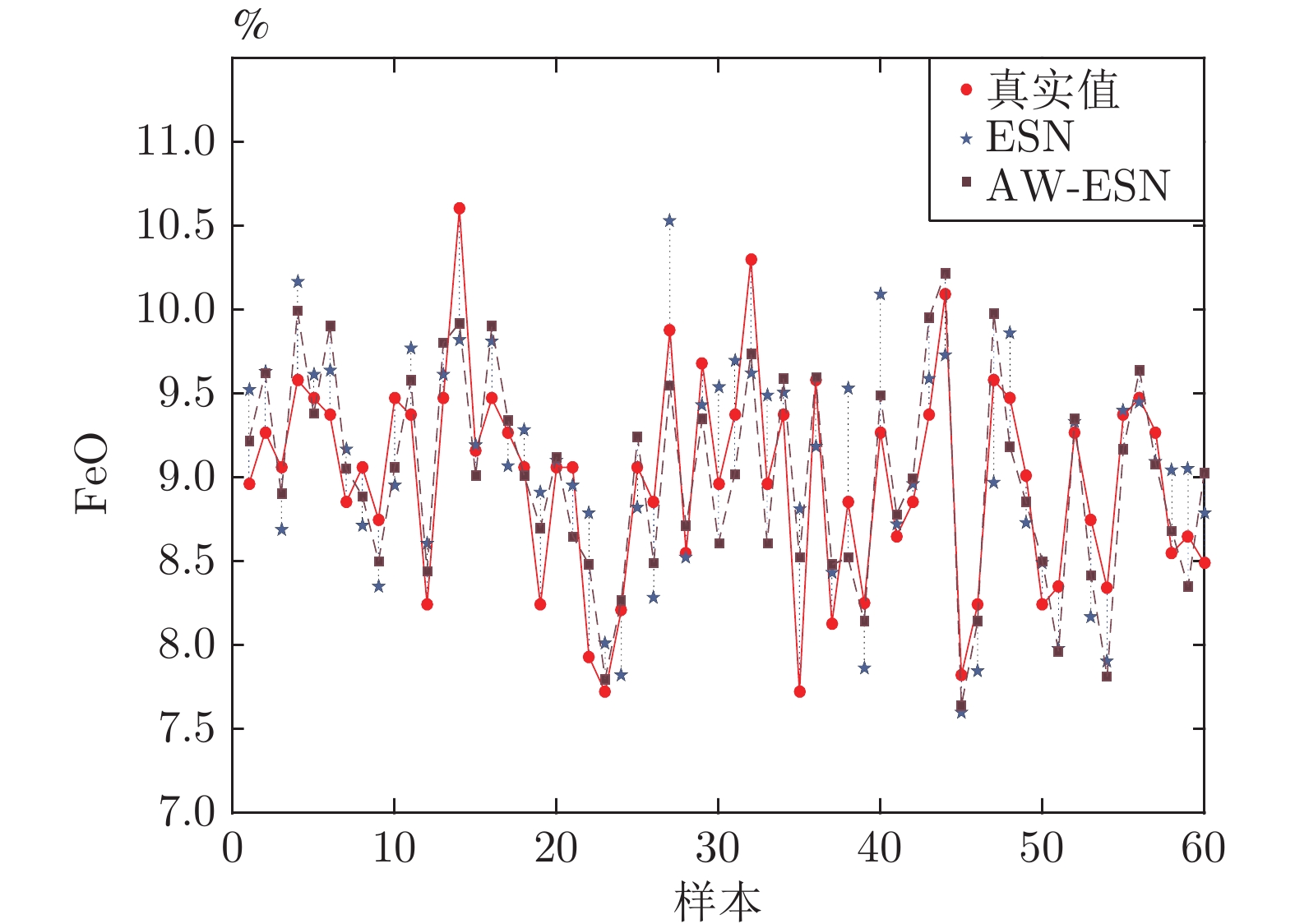
图 6 ESN和AW-ESN预测值与实际值对比
Fig. 6 Comparison between predicted values and actual values of ESN and AW-ESN

图 7 AW-ESN和DK-AWESN预测值与实际值对比
Fig. 7 Comparison between predicted values and actual values of AW-ESN and DK-AWESN

图 8 ESN和DK-ESN预测值与实际值对比
Fig. 8 Comparison between predicted values and actual values of ESN and DK-ESN
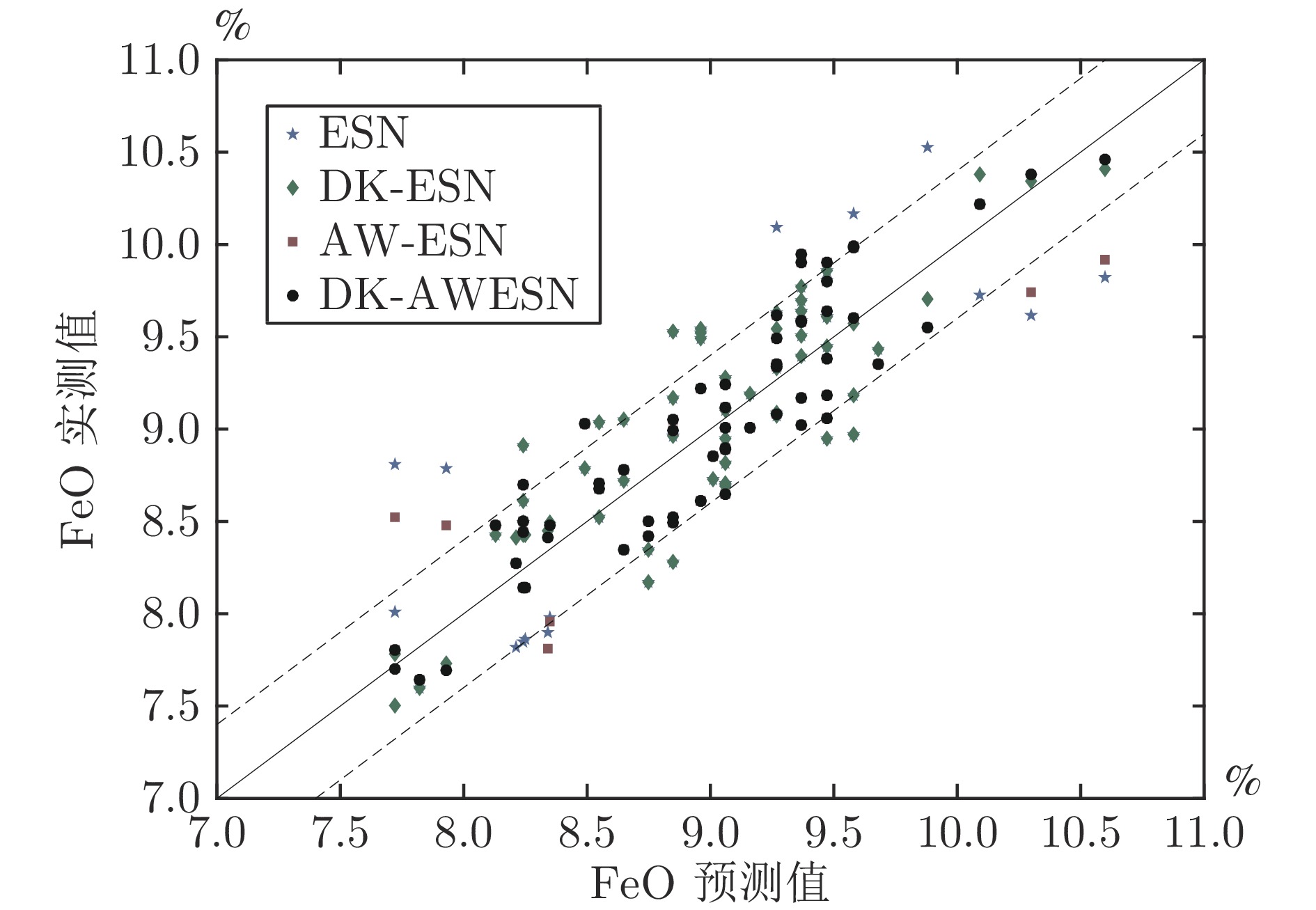
图 10 不同方法预测值和实测值的散点图
Fig. 10 Scatter plot of predicted values and measured values by different methods
表 1 反应速率计算参数表
Table 1 Reaction rate parameters
参数名称 符号 值 指前因子 $ k $ $6.89 \times {10^5} \sim 8.3 \times {10^5}\;{{\rm{s}}^{ - 1} }$ 反应活化能 $ E $ ${ {125.61 \sim 137.16\;{\rm{kJ} } } \mathord{\left/ {\vphantom { {125.61 \sim 137.16\;{\rm{kJ} } } { {\rm{mol} } } } } \right. } {{\rm{mol}}} }$ 比例系数 $ R $ $8.314\;{\rm{kJ}}/({\rm{mol}} \cdot {\rm{K}})$ 抽风负压 $ P $ ${\text{1} }{\text{.2} } \times {\text{1} }{ {\text{0} }^4}\;{\rm{Pa} }$ 料前氧分压 ${P_{ {{\rm{O}}_2}1} }$ ${\text{0} }{\text{.21} }\;{\rm{P} }$ 料后氧分压 ${P_{ {{\rm{O}}_2}2} }$ $0.09 \sim 0.11\;{\rm{P}}$ 总氧气扩散系数 ${D_{ {{\rm{O}}^2} } }$ $ {\text{2}}.03 \times {10^{ - 5}}{T^{1.87}} $ 雷诺数 $ Re $ $ {\text{2}} \times {\text{1}}{{\text{0}}^3} \sim 3.5 \times {10^4} $ 燃料孔隙率 $ {\varepsilon _c} $ $ {\text{0}}{\text{.39}} $ 有效孔隙率 $ B $ $ 0.15 $ 施密特数 $Sc$ $ {\text{0}}{{.6 \sim 2}}{\text{.5}} $ 氧气浓度 ${C_{ {{\rm{O}}_2} } }$ 9.735%  下载: 导出CSV
下载: 导出CSV
表 2 FeO含量等级推理结果与实际值对比
Table 2 Comparison of the inference results with measured values of FeO content
序号 料层最高温度 (℃) 料层高度 (mm) 燃料比 (%) 全铁 (%) 推理结果 化验数据 1 1 278.55 749.129 4.187 61.874 正常 正常 (8.96) 2 1 127.32 736.383 4.496 60.899 正常 正常 (9.27) 3 1 158.76 761.918 4.492 61.854 正常 正常 (9.06) 4 1 211.36 718.536 4.331 61.715 正常 正常 (9.47) 5 1 274.22 717.253 4.162 60.706 偏小 偏小 (7.37) $\vdots $ $\vdots $ $\vdots $ $\vdots $ $\vdots $ $\vdots $ $\vdots $ 558 1 160.56 649.579 4.561 63.755 正常 正常 (9.47) 559 1 176.76 650.864 4.305 60.802 偏大 偏大 (10.60) 600 1 308.99 710.711 4.286 61.067 正常 正常 (8.16)
下载: 导出CSV
表 3 各过程参数的灰色关联度
Table 3 The grey relational degree of process parameters
序号 变量名称 关联度 序号 变量名称 关联度 1 风箱废气温度 0.803 11 空支流量 0.559 2 烧结机机速 0.798 12 CMgO 0.557 3 料层高度 0.778 13 透气性 0.549 4 烧结终点 0.737 14 返矿比 0.539 5 $ {\rm{C}}_{{\rm{SiO}}_2}$ 0.733 15 风箱负压 0.527 6 碱度 0.703 16 CCaO 0.459 7 燃料配比 0.669 17 烟道压力 0.337 8 环冷机速度 0.641 18 风机入口温度 0.327 9 点火温度 0.618 19 混一温度 0.271 10 煤支流量 0.574 20 圆辊速度 0.249
下载: 导出CSV
表 4 模型输入变量
Table 4 The input variables of the model
序号 变量名称 序号 变量名称 1 风箱废气温度 9 空支流量 2 烧结机机速 10 CMgO 3 料层高度 11 透气性 4 烧结终点 12 返矿比 5 ${\rm{C}}_{{\rm{SiO}}_2} $ 13 风箱负压 6 碱度 14 燃料配比 7 环冷机速度 15 点火温度 8 煤支流量
下载: 导出CSV
表 5 储备池规模对DK-AWESN性能的影响
Table 5 Influence of reservoir size on the performance of DK-AWESN
储备池规模 训练时间 (s) 测试 NRMSE 平均值 标准差 50 21.821 0.425 0.0332 100 21.832 0.371 0.0258 150 21.840 0.332 0.0254 200 21.841 0.301 0.0218 250 21.850 0.343 0.0262 300 21.864 0.399 0.0246 350 21.866 0.435 0.0321 400 21.891 0.482 0.0326
下载: 导出CSV
表 6 各模型的预测性能指标比较
Table 6 Comparison of prediction performance indicators for different algorithms
性能指标 ESN DK-ESN AW-ESN DK-AWESN MAE 0.351 0.254 0.298 0.251 RMSE 0.420 0.316 0.345 0.301 HR (%) 70.00 83.33 78.33 86.67
下载: 导出CSV
-
[1] Usamentiaga R, García D F, Molleda J, Bulnes F G, Orgeira V G. Temperature tracking system for sinter material in a rotatory cooler based on infrared thermography. IEEE Transactions on Industry Applications, 2014, 50(5): 3095-3102 doi: 10.1109/TIA.2014.2306984 [2] Li Y X, Yang C J, Sun Y X. Dynamic time features expanding and extracting method for prediction model of sintering process quality index. IEEE Transactions on Industrial Informatics, 2022, 18(3): 1737-1745 doi: 10.1109/TII.2021.3086763 [3] Fernández-González D, Ruiz-Bustinza I, Mochón J, González-Gasca C, Verdeja L F. Iron ore sintering: Process. Mineral Processing and Extractive Metallurgy Review, 2017, 38(4): 215-227 doi: 10.1080/08827508.2017.1288115 [4] Fernández-González D, Ruiz-Bustinza I, Mochón I, González-Gasca C, Verdeja L F. Iron ore sintering: Raw materials and granulation. Mineral Processing and Extractive Metallurgy Review, 2017, 38(1): 36-46 doi: 10.1080/08827508.2016.1244059 [5] Huang Z C, Yi L Y, Jiang T, Zhang Y B. Hot airflow ignition with microwave heating for iron ore sintering. ISIJ International, 2012, 52(10): 1750-1756 doi: 10.2355/isijinternational.52.1750 [6] 李温鹏, 周平. 高炉铁水质量鲁棒正则化随机权神经网络建模. 自动化学报, 2020, 46(4): 721-733Li Wen-Peng, Zhou Ping. Robust regularized RVFLNs modeling of molten iron quality in blast furnace ironmaking. Acta Automatica Sinca, 2020, 46(4): 721-733 [7] Chen X X, Shi X H, Lan T. A semi-supervised linear-nonlinear prediction system for tumbler strength of iron ore sintering process with imbalanced data in multiple working modes. Control Engineering Practice, 2021, 110: Article No. 104766 doi: 10.1016/j.conengprac.2021.104766 [8] Umadevi T, Karthik P, Mahapatra P C, Prabhu M, Ranjan M. Optimisation of FeO in iron ore sinter at JSW Steel Limited. Ironmaking & Steelmaking, 2012, 39(3): 180-189 [9] 廖继勇, 何国强. 近五年烧结技术的进步与发展. 烧结球团, 2018, 43(5): 1-11, 19Liao Ji-Yong, He Guo-Qiang. Progress and development of sintering technologies during the last five years. Sintering and Pelletizing, 2018, 43(5): 1-11, 19 [10] Kawaguchi T, Sato S, Takata K. Development and application of an integrated simulation model for iron ore sintering. Iron Making Proceeding, 1987, 73(15): 1940-1947 [11] Yamaoka H, Kawaguchi T. Development of a 3-D sinter process mathematical simulation model. ISIJ International, 2005, 45(4): 522-531 doi: 10.2355/isijinternational.45.522 [12] 王悦祥. 烧结矿与球团矿生产. 北京: 冶金工业出版社, 2006.Wang Yue-Xiang. Sinter and Pellet Production. Beijing: Metallurgical Industry Press, 2006. [13] Jiang Z H, Guo Y H, Pan D, Gui W H, Maldague X. Polymorphic measurement method of FeO content of sinter based on heterogeneous features of infrared thermal images. IEEE Sensors Journal, 2021, 21(10): 12036-12047 doi: 10.1109/JSEN.2021.3065942 [14] Wu C, Wang F B, Chen X Z, Hou Q W, Chen Z K, Zhang M, et al. RGB color decomposition and image feature extraction of flame image in rear of sintering machine. In: Proceedings of the 36th Chinese Control Conference. Dalian, China: IEEE, 2017. 5640−5463 [15] 周雨润. 基于机尾断面图像和风箱温度的烧结质量等级在线评测系统的研究[硕士学位论文], 安徽大学, 中国, 2013.Zhou Yu-Run. The Research on Online Evaluation System for Sintering Quality Grade Based on Tail Section Image and Bellows Temperature [Master thesis], Anhui University, China, 2013. [16] Zhou H, Zhang H F, Yang C J. Hybrid-model-based intelligent optimization of ironmaking process. IEEE Transactions on Industrial Electronics, 2020, 67(3): 2469-2479 doi: 10.1109/TIE.2019.2903770 [17] Du S, Wu M, Chen L F, Zhou K L, Hu J, Cao W H, et al. A fuzzy control strategy of burn-through point based on the feature extraction of time-series trend for iron ore sintering process. IEEE Transactions on Industrial Informatics, 2020, 16(4): 2357-2368 doi: 10.1109/TII.2019.2935030 [18] 周平, 张丽, 李温鹏, 戴鹏, 柴天佑. 集成自编码与PCA的高炉多元铁水质量随机权神经网络建模. 自动化学报, 2018, 44(10): 1799-1811Zhou Ping, Zhang Li, Li Wen-Peng, Dai Peng, Chai Tian-You. Autoencoder and PCA based RVFLNs modeling for multivariate molten iron quality in blast furnace ironmaking. Acta Automatica Sinica, 2018, 44(10): 1799-1811 [19] 张舒, 高为民. 人工神经网络在烧结矿指标预测中的应用. 烧结球团, 2001, 26(4): 6-10Zhang Shu, Gao Wei-Min. Application of neural networks in the prediction of sinter quality. Sintering and Pelletizing, 2001, 26(4): 6-10 [20] Laitinen P J, Saxén H. A neural network based model of sinter quality and sinter plant performance indices. Ironmaking & Steelmaking, 2007, 34(2): 109-114 [21] 袁致强. 基于深度置信网络的烧结矿化学成分预测模型研究[硕士学位论文], 武汉科技大学, 中国, 2018.Yuan Zhi-Qiang. Study on Prediction Modeling of the Sinter Chemical Component Based on Deep Learning [Master thesis], Wuhan University of Science and Technology, China, 2018. [22] 蒋朝辉, 许川, 桂卫华, 蒋珂. 基于最优工况迁移的高炉铁水硅含量预测方法. 自动化学报, 2022, 48(1): 194-206Jiang Zhao-Hui, Xu Chuan, Gui Wei-Hua, Jiang Ke. Prediction method of hot metal silicon content in blast furnace based on optimal smelting condition migration. Acta Automatica Sinica, 2022, 48(1): 1194-206 [23] 李泽龙, 杨春节, 刘文辉, 周恒, 李宇轩. 基于LSTM-RNN模型的铁水硅含量预测. 化工学报, 2018, 69(3): 992-997Li Ze-Long, Yang Chun-Jie, Liu Wen-Hui, Zhou Heng, Li Yu-Xuan. Research on hot metal Si-content prediction based on LSTM-RNN. CIESC Journal, 2018, 69(3): 992-997 [24] 吴高昌, 刘强, 柴天佑, 秦泗钊. 基于时序图像深度学习的电熔镁炉异常工况诊断. 自动化学报, 2019, 45(8): 1475-1485Wu Gao-Chang, Liu Qiang, Chai Tian-You, Qin S J. Abnormal condition diagnosis through deep learning of image sequences for fused magnesium furnaces. Acta Automatica Sinica, 2019, 45(8): 1475-1485 [25] Fang Y J, Jiang Z H, Pan D, Gui W H, Chen Z P. Soft sensors based on adaptive stacked polymorphic model for silicon content prediction in ironmaking process. IEEE Transactions on Instrumentation and Measurement, 2021, 70: Article No. 2503412 [26] 王磊, 乔俊飞, 杨翠丽, 朱心新. 基于灵敏度分析的模块化回声状态网络修剪算法. 自动化学报, 2019, 45(6): 1136-1145Wang Lei, Qiao Jun-Fei, Yang Cui-Li, Zhu Xin-Xin. Pruning algorithm for modular echo state network based on sensitivity analysis. Acta Automatica Sinica, 2019, 45(6): 1136-1145 [27] 姜涛. 铁矿造块学. 长沙: 中南大学出版社, 2016.Jiang Tao. Principle and Technology of Agglomeration of Iron Ores. Changsha: Central South University Press, 2016. [28] Yao X S, Wang Z S. Broad echo state network for multivariate time series prediction. Journal of Franklin Institute, 2019, 356(9): 4888−4906 -

 下载:
下载:



计量
- 文章访问数: 984
- HTML全文浏览量: 497
- PDF下载量: 262
- 被引次数: 0
