

Multi-modal Video Action Recognition Method Based on Language-visual Contrastive Learning
-
摘要: 以对比语言−图像预训练(Contrastive language-image pre-training, CLIP)模型为基础, 提出一种面向视频行为识别的多模态模型, 该模型从视觉编码器的时序建模和行为类别语言描述的提示学习两个方面对CLIP模型进行拓展, 可更好地学习多模态视频表达. 具体地, 在视觉编码器中设计虚拟帧交互模块(Virtual-frame interaction module, VIM), 首先, 由视频采样帧的类别分词做线性变换得到虚拟帧分词; 然后, 对其进行基于时序卷积和虚拟帧分词移位的时序建模操作, 有效建模视频中的时空变化信息; 最后, 在语言分支上设计视觉强化提示模块(Visual-reinforcement prompt module, VPM), 通过注意力机制融合视觉编码器末端输出的类别分词和视觉分词所带有的视觉信息来获得经过视觉信息强化的语言表达. 在4个公开视频数据集上的全监督实验和2个视频数据集上的小样本、零样本实验结果, 验证了该多模态模型的有效性和泛化性.Abstract: This paper presents a novel multi-modal model for video action recognition, which is built upon the contrastive language-image pre-training (CLIP) model. The presented model extends the CLIP model in two ways, i.e., incorporating temporal modeling in the visual encoder and leveraging prompt learning for language descriptions of action classes, to better learn multi-modal video representations. Specifically, we design a virtual-frame interaction module (VIM) within the visual encoder that transforms class tokens of sampled video frames into virtual-frame tokens through linear transformation, and then temporal modeling operations based on temporal convolution and virtual-frame token shift are performed to effectively model the spatio-temporal change information in the video. In the language branch, we propose a visual-reinforcement prompt module (VPM) that leverages an attention mechanism to fuse the visual information, carried by the class token and visual token which are both output by the visual encoder, to enhance the language representations. Fully-supervised experiments conducted on four publicly available video datasets, as well as few-shot and zero-shot experiments conducted on two video datasets, demonstrate the effectiveness and generalization capabilities of the proposed multi-modal model.
-

图 1 基于语言−视觉对比学习的多模态模型
Fig. 1 Multi-modal model based on language-visual contrastive learning
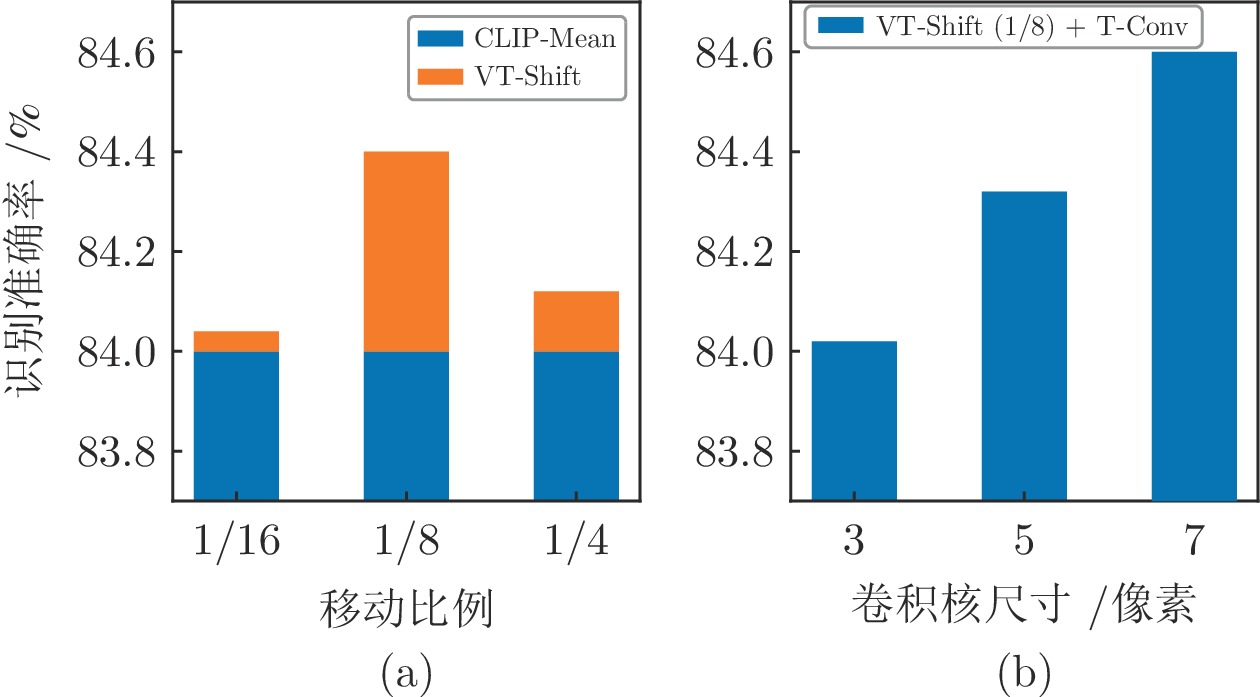
图 3 虚拟帧交互模块超参数消融实验结果
Fig. 3 Ablation studies of hyper-parameters of virtual frame interaction module

图 4 在K400数据集上, 本文模型与目前先进模型的识别准确率和浮点运算数比较
Fig. 4 Comparisons of accuracy and GFLOPs between the proposed model and state-of-the-art models on K400 dataset
表 1 模型具有/不具有语言信息的消融研究(%)
Table 1 Ablation studies of the model w/wo language information (%)
方法 第1识别准确率 前5识别准确率 单模态变体 82.7 94.0 本文模型 85.7 (提升3.0) 97.2 (提升3.2)  下载: 导出CSV
下载: 导出CSV
表 2 本文模块的消融实验结果 (%)
Table 2 Ablation studies of the proposed modules (%)
模块 第1识别准确率 基线(CLIP-Mean) 84.0 基线 + VIM 84.6 (提升0.6) 基线 + VIM + GBM 84.8 (提升0.8) 基线 + VIM + GBM + VPM 85.7 (提升1.7)
下载: 导出CSV
表 3 提示学习方法的比较 (%)
Table 3 Comparisons of prompt learning methods (%)
方法 第1识别准确率 前5识别准确率 无 84.8 97.0 ActionCLIP 84.9 96.9 CoOp 85.5 97.1 本文模型 85.7 (提升0.9) 97.2 (提升0.2)
下载: 导出CSV
表 4 K400数据集上, 全监督实验结果
Table 4 Fully-supervised experiment results on K400 dataset
类别 方法(骨干网络) 预训练数据集 帧数 第1识别准确率(%) 前5识别准确率(%) 时间剪辑$\times $空间裁剪 GFLOPs 3D CNN I3D NL ImageNet 32 77.7 93.3 $ 10\times 3 $ 359.0 CorrNet — 32 79.2 — $ 10\times 3 $ 224.0 SlowFast (R101-NL) — 16 + 64 79.8 93.9 $ 10\times 3 $ 234.0 X3D-XXL — 16 80.4 94.6 $ 10\times 3 $ 144.0 2D CNN TSM ImageNet 16 74.7 91.4 $ 10\times 3 $ 65.0 TEA ImageNet 16 76.1 92.5 $ 10\times 3 $ 70.0 TEINet ImageNet 16 76.2 92.5 $ 10\times 3 $ 66.0 TDN ImageNet 8 + 16 79.4 93.9 $ 10\times 3 $ 198.0 ViT VTN (ViT-B) ImageNet 250 78.6 93.7 $ 1\times 1 $ 4218.0 ViViT$({\rm{L} } /16\times 2)$ JFT 32 83.5 95.5 $ 4\times 3 $ 3992.0 TimeSformer (L) ImageNet 96 80.7 94.7 $ 1\times 3 $ 2380.0 MViT (B,$64\times 3)$ — 64 81.2 95.1 $ 3\times 3 $ 455.0 Swin (L) ImageNet 32 83.1 95.9 $ 4\times 3 $ 604.0 EVL (ViT-B/16) WIT 8 82.9 — $ 3\times 1 $ 444.0 AIM (ViT-B/16) WIT 8 83.9 96.3 $ 3\times 1 $ 606.0 语言−视觉
对比学习PromptCLIP (A6) WIT 16 76.9 93.5 $ 5\times 1 $ — ActionCLIP (ViT-B/32) WIT 8 78.4 94.3 $ 1\times 1 $ 35.0 ActionCLIP (ViT-B/16) WIT 8 81.1 95.5 $ 1\times 1 $ 141.0 ActionCLIP (ViT-B/16) WIT 16 82.6 96.2 $ 10\times 3 $ 282.0 ActionCLIP (ViT-B/16) WIT 32 83.8 97.1 $ 10\times 3 $ 563.0 X-CLIP (ViT-B/32) WIT 8 80.4 95.0 $ 4\times 3 $ 39.0 X-CLIP (ViT-B/32) WIT 16 81.1 95.5 $ 4\times 3 $ 75.0 X-CLIP (ViT-B/16) WIT 8 83.8 96.7 $ 4\times 3 $ 145.0 本文模型 本文模型(ViT-B/32) WIT 8 80.5 95.1 $ 4\times 3 $ 39.8 本文模型(ViT-B/32) WIT 16 81.4 95.5 $ 4\times 3 $ 75.6 本文模型(ViT-B/32) WIT 32 83.1 95.7 $ 4\times 3 $ 144.2 本文模型(ViT-B/16) WIT 8 84.1 96.7 $ 4\times 3 $ 145.8
下载: 导出CSV
表 5 HMDB51和UCF101数据集上, 全监督实验结果
Table 5 Fully-supervised experiment results on HMDB51 and UCF101 datasets
方法(骨干网络) 帧数 UCF101 (%) HMDB51 (%) TSN (2D R50) 8 91.7 64.7 TBN (2D R34) 8 93.6 69.4 PPAC (2D R152) 20 94.9 69.8 TCP (2D TSN R50) 8 95.1 72.5 ARTNet (3D R18) 16 94.3 70.9 R3D (3D R50) 16 92.9 69.4 MCL (R (2 + 1) D) 16 93.4 69.1 ActionCLIP (ViT-B/16) 32 97.1 76.2 X-CLIP (ViT-B/32) 8 95.3 72.8 X-CLIP (ViT-B/16) 8 97.4 75.6 本文模型(ViT-B/32) 8 96.1 74.3 本文模型(ViT-B/16) 8 97.6 76.7
下载: 导出CSV
表 6 HMDB51和UCF101数据集上, 小样本实验结果 (%)
Table 6 Few-shot experiment results on HMDB51 and UCF101 datasets (%)
方法(骨干网络) HMDB51 UCF101 K = 2 K = 4 K = 8 K = 16 K = 2 K = 4 K = 8 K = 16 TSM 17.5 20.9 18.4 31.0 25.3 47.0 64.4 61.0 TimeSformer 19.6 40.6 49.4 55.4 48.5 75.6 83.7 89.4 Swin (B) 20.9 41.3 47.9 56.1 53.3 74.1 85.8 88.7 ActionCLIP (ViT-B/16) 43.7 51.2 55.6 64.2 73.7 80.2 86.3 89.8 X-CLIP (ViT-B/16) 49.5 54.6 57.7 65.3 76.3 81.4 85.9 89.4 本文模型(ViT-B/16) 49.6 54.9 58.8 65.5 76.4 82.1 86.7 90.1
下载: 导出CSV
表 7 HMDB51和UCF101数据集上, 零样本实验结果(%)
Table 7 Zero-shot experiment results on HMDB51 and UCF101 datasets (%)
方法(骨干网络) HMDB51 UCF101 ZSECOC 22.6 15.1 UR 24.4 17.5 TS-GCN 23.2 34.2 E2E 32.7 48.0 ER-ZSAR 35.3 51.8 ActionCLIP 41.9 66.6 X-CLIP (ViT-B/16) 43.5 70.9 本文模型(ViT-B/16) 44.0 72.6
下载: 导出CSV
A1 模型训练超参数
A1 Hyper-parameters for model training
超参数 全监督 小样本 零样本 VPM $ \alpha $ 0.1 0.1 0.1 VPM $ \beta $ 0.1 0.1 0.1 优化器 AdamW AdamW — 优化器$ \beta $值 (0.90, 0.98) (0.90, 0.98) — 批大小 256 64 256 学习率策略 cosine cosine — 预热轮数 5 5 — 基础学习率 8 $ \times\;10^{-6} $ 2 $ \times\;10^{-6} $ — 最小学习率 8 $ \times\;10^{-8} $ 2 $ \times\;10^{-8} $ — 轮数 30 50 — 随机翻转 0.5 0.5 0.5 多尺度裁剪 (1, 0.875,
0.75, 0.66)(1, 0.875,
0.75, 0.66)(1, 0.875,
0.75, 0.66)颜色抖动 0.8 0.8 0.8 灰度值 0.2 0.2 0.2 标签平滑 0.1 0.1 0.1 混合 0.8 0.8 0.8 切割混合 1.0 1.0 1.0 权重衰减 0.001 0.001 0.001
下载: 导出CSV
C1 小样本实验使用的随机样本
C1 Random examples used in few-shot experiment
数据集 $ K $值 随机样本在第1种划分中的编号 HMDB51 2 [22, 25] 4 [69, 9, 21, 36] 8 [44, 47, 64, 67, 69, 9, 21, 6] 16 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15] UCF101 2 [21, 48] 4 [2, 16, 23, 44] 8 [14, 20, 60, 27, 33, 9, 21, 32] 16 [14, 20, 60, 27, 33, 9, 21, 32, 8, 15, 1, 26, 38,
44, 60, 48]
下载: 导出CSV
-
[1] 周波, 李俊峰. 结合目标检测的人体行为识别. 自动化学报, 2020, 46(9): 1961-1970 doi: 10.16383/j.aas.c180848Zhou Bo, Li Jun-Feng. Human action recognition combined with object detection. Acta Automatica Sinica, 2020, 46(9): 1961-1970 doi: 10.16383/j.aas.c180848 [2] 杨天金, 侯振杰, 李兴, 梁久祯, 宦娟, 郑纪翔. 多聚点子空间下的时空信息融合及其在行为识别中的应用. 自动化学报, 2022, 48(11): 2823-2835 doi: 10.16383/j.aas.c190327Yang Tian-Jin, Hou Zhen-Jie, Li Xing, Liang Jiu-Zhen, Huan Juan, Zheng Ji-Xiang. Recognizing action using multi-center subspace learning-based spatial-temporal information fusion. Acta Automatica Sinica, 2022, 48(11): 2823-2835 doi: 10.16383/j.aas.c190327 [3] 左国玉, 徐兆坤, 卢佳豪, 龚道雄. 基于结构优化的DDAG-SVM上肢康复训练动作识别方法. 自动化学报, 2020, 46(3): 549-561 doi: 10.16383/j.aas.c170724Zuo Guo-Yu, Xu Zhao-Kun, Lu Jia-Hao, Gong Dao-Xiong. A Structure-optimized DDAG-SVM Action Recognition Method for Upper Limb Rehabilitation Training. Acta Automatica Sinica, 2020, 46(3): 549-561 doi: 10.16383/j.aas.c170724 [4] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: 2014. 568−576 [5] Tran D, Bourdev L, Fergus R, Torresani L, Paluri M. Learning spatiotemporal features with 3D convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 4489−4497 [6] Carreira J, Zisserman A. Quo vadis, action recognition? A new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 4724−4733 [7] Qiu Z, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3D residual networks. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 5534−5542 [8] Du T, Wang H, Torresani L, Ray J, Paluri M. A closer look at spatio-temporal convolutions for action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6450−6459 [9] Xie S, Sun C, Huang J, Tu Z, Murphy K. Rethinking spatio-temporal feature learning: Speed-accuracy trade-offs in video classification. In: Proceedings of the European Conference on Computer Vision. Munich, Germany: Springer, 2018. 318−335 [10] Lin J, Gan C, Han S. TSM: Temporal shift module for efficient video understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 7082−7092 [11] Li Y, Ji B, Shi X T, Zhang J G, Kang B, Wang L M. TEA: Temporal excitation and aggregation for action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 909−918 [12] Liu Z Y, Wang L M, Wu W, Qian C, Lu T. TAM: Temporal adaptive module for video recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 13688−13698 [13] Neimark D, Bar O, Zohar M, Asselmann D. Video transformer network. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 3156−3165 [14] Arnab A, Dehghani M, Heigold G, Sun C, Lucic M, Schmid C. ViViT: A video vision transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 6816−6826 [15] Bertasius G, Wang H, Torresani L. Is space-time attention all you need for video understanding? In: Proceedings of the 38th International Conference on Machine Learning. Vienna, Austria: PMLR, 2021. 813−824 [16] Fan H Q, Xiong B, Mangalam K, Li Y H, Yan Z C, Malik J, et al. Multi-scale vision transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Mon-treal, Canada: IEEE, 2021. 6824−6835 [17] Liu Z, Ning J, Cao Y, Wei Y X, Zhang Z, Lin S, et al. Video swin transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 3192−3201 [18] Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. Vienna, Austria: PMLR, 2021. 8748−8763 [19] Jia C, Yang Y F, Xia Y, Chen Y T, Parekh Z, Pham H, et al. Scaling up visual and vision-language representation learning with noisy text supervision. In: Proceedings of the 38th International Conference on Machine Learning. Vienna, Austria: PMLR, 2021. 4904−4916 [20] Yuan L, Chen D D, Chen Y L, Codella N, Dai X Y, Gao J F, et al. Florence: A new foundation model for computer vision. arXiv preprint arXiv: 2111.11432, 2021. [21] Pan J T, Lin Z Y, Zhu X T, Shao J, Li H S. ST-Adapter: Parameter-efficient image-to-video transfer learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: MIT Press, 2022. 1−16 [22] Lin Z Y, Geng S J, Zhang R R, Gao P, Melo G D, Wang X G, et al. Frozen CLIP models are efficient video learners. In: Proceedings of the European Conference on Computer Vision. Tel-Aviv, Israel: Springer, 2022. 388−404 [23] Yang T J N, Zhu Y, Xie Y S, Zhang A, Chen C, Li M. AIM: Adapting image models for efficient video action recognition. In: Proceedings of the International Conference on Learning Representations. Kigali, Republic of Rwanda: 2023. 1−18 [24] Xu H, Ghosh G, Huang P Y, Okhonko D, Aghajanyan A, Metze F, et al. VideoCLIP: Contrastive pre-training for zero-shot video-text understanding. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Punta Cana, Dominican Republic: ACL, 2021. 6787−6800 [25] Ju C, Han T D, Zheng K H, Zhang Y, Xie W D. Prompting visual-language models for efficient video understanding. In: Proceedings of the European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 105−124 [26] Wang M M, Xing J Z, Liu Y. ActionCLIP: A new paradigm for video action recognition. arXiv preprint arXiv: 2109.08472, 2021. [27] Ni B L, Peng H W, Chen M H, Zhang S Y, Meng G F, Fu J L, et al. Expanding language-image pretrained models for general video recognition. In: Proceedings of the European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 1−18 [28] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, USA: 2017. 6000−6010 [29] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In: Proceedings of the International Conference on Learning Representations. Vien-na, Austria: 2021. 1−14 [30] Brown T B, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al. Language models are few-shot learners. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, USA: 2020. 1877−1901 [31] Gao T Y, Fisch A, Chen D Q. Making pre-trained language models better few-shot learners. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Bangkok, Thailand: ACL, 2021. 3816−3830 [32] Jiang Z B, Xu F F, Araki J, Neubig G. How can we know what language models know? Transactions of the Association for Computational Linguistics, 2020, 8: 423-438 doi: 10.1162/tacl_a_00324 [33] Schick T, Schütze H. Exploiting cloze questions for few shot text classification and natural language inference. In: Proceedings of the 16th Conference of the European Chapter of the Associat-ion for Computational Linguistics. Virtual Event: ACL, 2021. 255−269 [34] Shin T, Razeghi Y, Logan IV R L, Wallace E, Singh S. AutoPrompt: Eliciting knowledge from language models with automatically generated prompts. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Virtual Event: ACL, 2020. 4222−4235 [35] Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning. In: Proceedings of the Conferen-ce on Empirical Methods in Natural Language Processing. Punta Cana, Dominican Republic: ACL, 2021. 3045−3059 [36] Li X L, Liang P. Prefix-tuning: Optimizing continuous prompts for generation. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Virtual Event: ACL, 2021. 4582−4597 [37] Zhou K Y, Yang J K, Loy C C, Liu Z W. Learning to prompt for vision-language models. International Journal of Computer Vision, 2022, 130(9): 2337-2348 doi: 10.1007/s11263-022-01653-1 [38] Zhou K Y, Yang J K, Loy C C, Liu Z W. Conditional prompt learning for vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 16795−16804 [39] Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with sub-word units. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: ACL, 2016. 1715−1725 [40] Zhang H, Hao Y B, Ngo C W. Token shift transformer for video classification. In: Proceedings of the 29th ACM International Conference on Multimedia. New York, USA: ACM Press, 2021. 917−925 [41] Xie J T, Zeng R R, Wang Q L, Zhou Z Q, Li P H. SoT: Delving deeper into classification head for transformer. arXiv preprint arXiv: 2104.10935, 2021. [42] Kay W, Carreira J, Simonyan K, Zhang B, Hilier C, Vijayan-arasimhan S, et al. The kinetics human action video dataset. arXiv preprint arXiv: 1705.06950, 2017. [43] Soomro K, Zamir A R, Shah M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv: 1212.0402, 2012. [44] Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T. HMDB: A large video database for human motion recognition. In: Proceedings of the International Conference on Computer Vision. Barce-lona, Spain: IEEE, 2011. 2556−2563 [45] Wang L M, Xiong Y J, Wang Z, Qiao Y, Lin D H, Tang X O, et al. Temporal segment networks: Towards good practices for deep action recognition. In: Proceedings of the European Conference on Computer Vision. Amsterdam, Netherlands: Springer, 2016. 20−36 [46] Wang X L, Girshick R, Gupta A, He K M. Non-local neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7794−7803 [47] Wang H, Tran D, Torresani L, Feiszli M. Video modeling with correlation networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 349−358 [48] Feichtenhofer C, Fan H Q, Malik J, He K M. SlowFast networks for video recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 6201−6210 [49] Feichtenhofer C. X3D: Expanding architectures for efficient video recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 203−213 [50] Liu Z Y, Luo D H, Wang Y B, Wang L M, Tai Y, Wang C J, et al. TEINet: Towards an efficient architecture for video recognition. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11669-11676 doi: 10.1609/aaai.v34i07.6836 [51] Wang L M, Tong Z, Ji B, Wu G S. TDN: Temporal difference networks for efficient action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 1895−1904 [52] Li Y H, Song S J, Li Y Q, Liu J Y. Temporal bilinear networks for video action recognition. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence and the 31th Innovative Applications of Artificial Intelligence Conference and the 9th AAAI Symposium on Educational Advances in Artificial Intelligence. Hawaii, USA: AAAI, 2019. 8674−8681 [53] Long X, Melo G D, He D L, Li F, Chi Z Z, Wen S L, et al. Purely attention based local feature integration for video classification. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(4): 2140-2154 [54] Gao Z L, Wang Q L, Zhang B B, Hu Q H, Li P H. Temporal-attentive covariance pooling networks for video recognition. Advances in Neural Information Processing Systems, 2021, 34: 13587-13598 [55] Wang L M, Li W, Li W, Gool L V. Appearance-and-relation networks for video classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1430−1439 [56] Kataoka H, Wakamiya T, Hara K, Satoh Y. Would mega-scale datasets further enhance spatio-temporal 3D CNNs? In: Proce-edings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6546−6555 [57] Li R, Zhang Y H, Qiu Z F, Yao T, Liu D, Mei T. Motion-focused contrastive learning of video representations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 2105−2114 [58] Qin J, Liu L, Shao L, Shen F, Ni B B, Chen J X, et al. Zero-shot action recognition with error-correcting output codes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 1042−1051 [59] Zhu Y, Long Y, Guan Y, Newsam S, Shao L. Towards universal representation for unseen action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 9436−9445 [60] Gao J Y, Zhang T Z, Xu C S. I know the relationships: Zero-shot action recognition via two-stream graph convolutional networks and knowledge graphs. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 8303-8311 doi: 10.1609/aaai.v33i01.33018303 [61] Brattoli B, Tighe J, Zhdanov F, Perona P, Chalupka K. Rethinking zero-shot video classification: End-to-end training for realistic applications. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 4613−4623 [62] Chen S Z, Huang D. Elaborative rehearsal for zero-shot action recognition. In: Proceedings of the IEEE/CVF International Con-ference on Computer Vision. Montreal, Canada: IEEE, 2021. 13638−13647 -

 下载:
下载:


计量
- 文章访问数: 1997
- HTML全文浏览量: 757
- PDF下载量: 486
- 被引次数: 0
