
当期目录
2026年 第52卷 第7期
2026, 52(7): 1319-1333.
doi: 10.16383/j.aas.c250638
cstr: 32138.14.j.aas.c250638
摘要:
离线强化学习旨在利用预先采集的行为数据集优化智能体策略, 其面临的主要挑战是迭代优化的目标策略与产生数据集的行为策略之间存在分布偏移. 现有方法通常采用策略正则化以缓解该问题, 但其难以根据行为数据质量自适应地调整学习过程的约束强度, 并且难以有效建模行为策略中复杂的多峰分布. 针对上述问题, 提出基于流匹配策略优化(FMPO)的离线强化学习方法. FMPO利用流匹配模型对行为策略分布进行建模, 从流匹配策略中选择高优势动作以形成自适应约束, 引导学习策略在行为数据分布邻域内进行优化; 同时, 将流匹配策略生成的动作作为先验输入条件, 利用行为先验促进策略的高效学习. 通过基于流匹配策略的优化机制, FMPO能够在策略提升与满足数据集分布约束之间实现动态平衡. 实验结果表明, FMPO在D4RL基准任务上取得先进性能, 显著优于现有主流离线强化学习方法.
离线强化学习旨在利用预先采集的行为数据集优化智能体策略, 其面临的主要挑战是迭代优化的目标策略与产生数据集的行为策略之间存在分布偏移. 现有方法通常采用策略正则化以缓解该问题, 但其难以根据行为数据质量自适应地调整学习过程的约束强度, 并且难以有效建模行为策略中复杂的多峰分布. 针对上述问题, 提出基于流匹配策略优化(FMPO)的离线强化学习方法. FMPO利用流匹配模型对行为策略分布进行建模, 从流匹配策略中选择高优势动作以形成自适应约束, 引导学习策略在行为数据分布邻域内进行优化; 同时, 将流匹配策略生成的动作作为先验输入条件, 利用行为先验促进策略的高效学习. 通过基于流匹配策略的优化机制, FMPO能够在策略提升与满足数据集分布约束之间实现动态平衡. 实验结果表明, FMPO在D4RL基准任务上取得先进性能, 显著优于现有主流离线强化学习方法.







2026, 52(7): 1334-1346.
doi: 10.16383/j.aas.c250659
cstr: 32138.14.j.aas.c250659
摘要:
针对具有未知动力学的非线性多智能体系统, 研究事件触发神经网络自适应分布式优化控制问题. 通过结合神经网络与微分图博弈理论, 构建一种新型事件触发神经网络自适应分布式优化控制器. 为解决执行器频繁更新问题, 设计事件触发机制. 建立基于神经网络的强化学习算法, 学习优化控制器与哈密顿−雅可比−贝尔曼方程的解析解, 利用当前采样数据和历史存储数据设计评价网络的权重更新机制. 构造Lyapunov函数证明了被控非线性多智能体系统为渐近稳定并达到Nash均衡. 计算机仿真结果验证了所提分布式最优控制方案的有效性.
针对具有未知动力学的非线性多智能体系统, 研究事件触发神经网络自适应分布式优化控制问题. 通过结合神经网络与微分图博弈理论, 构建一种新型事件触发神经网络自适应分布式优化控制器. 为解决执行器频繁更新问题, 设计事件触发机制. 建立基于神经网络的强化学习算法, 学习优化控制器与哈密顿−雅可比−贝尔曼方程的解析解, 利用当前采样数据和历史存储数据设计评价网络的权重更新机制. 构造Lyapunov函数证明了被控非线性多智能体系统为渐近稳定并达到Nash均衡. 计算机仿真结果验证了所提分布式最优控制方案的有效性.





2026, 52(7): 1347-1359.
doi: 10.16383/j.aas.c250593
cstr: 32138.14.j.aas.c250593
摘要:
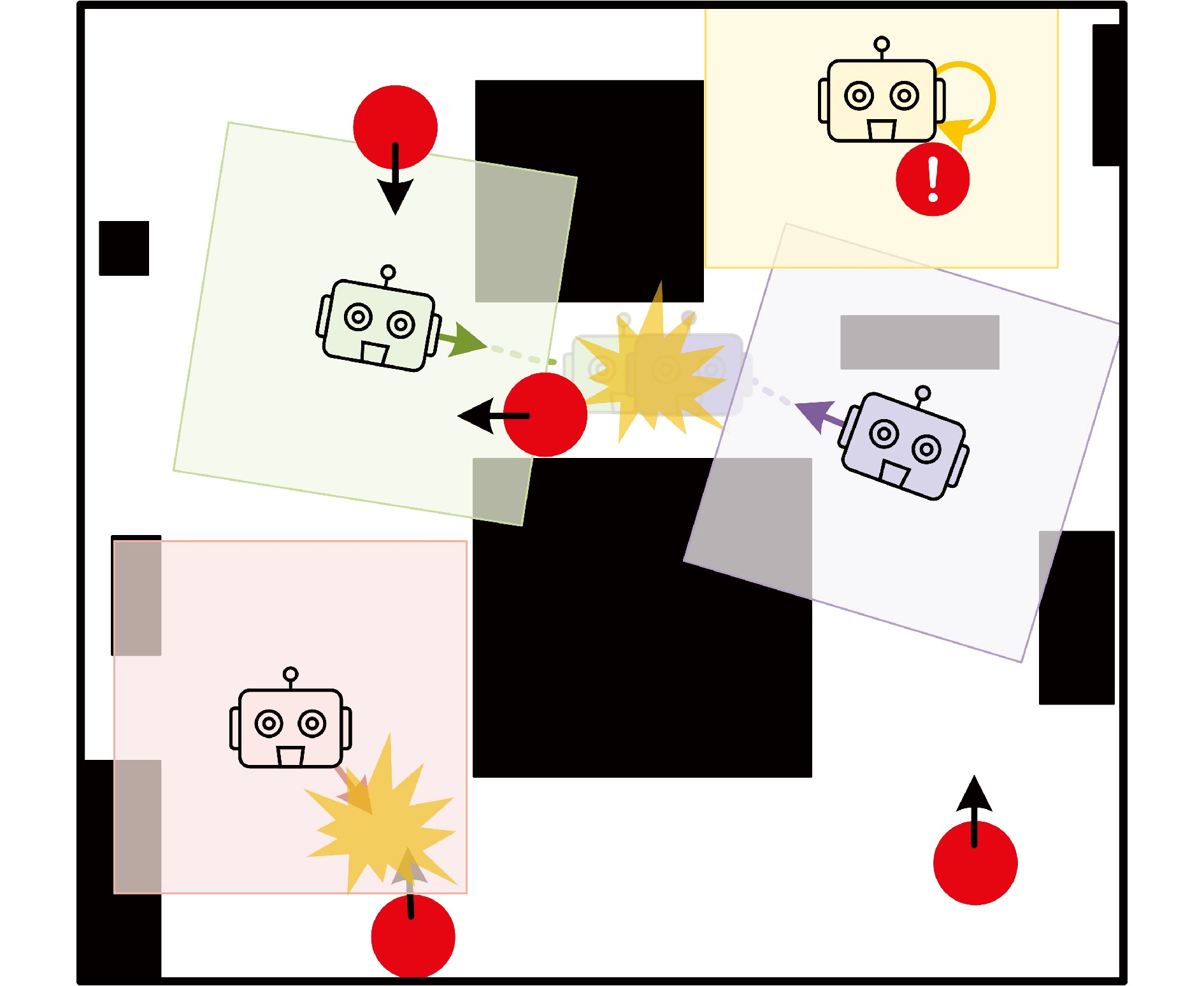
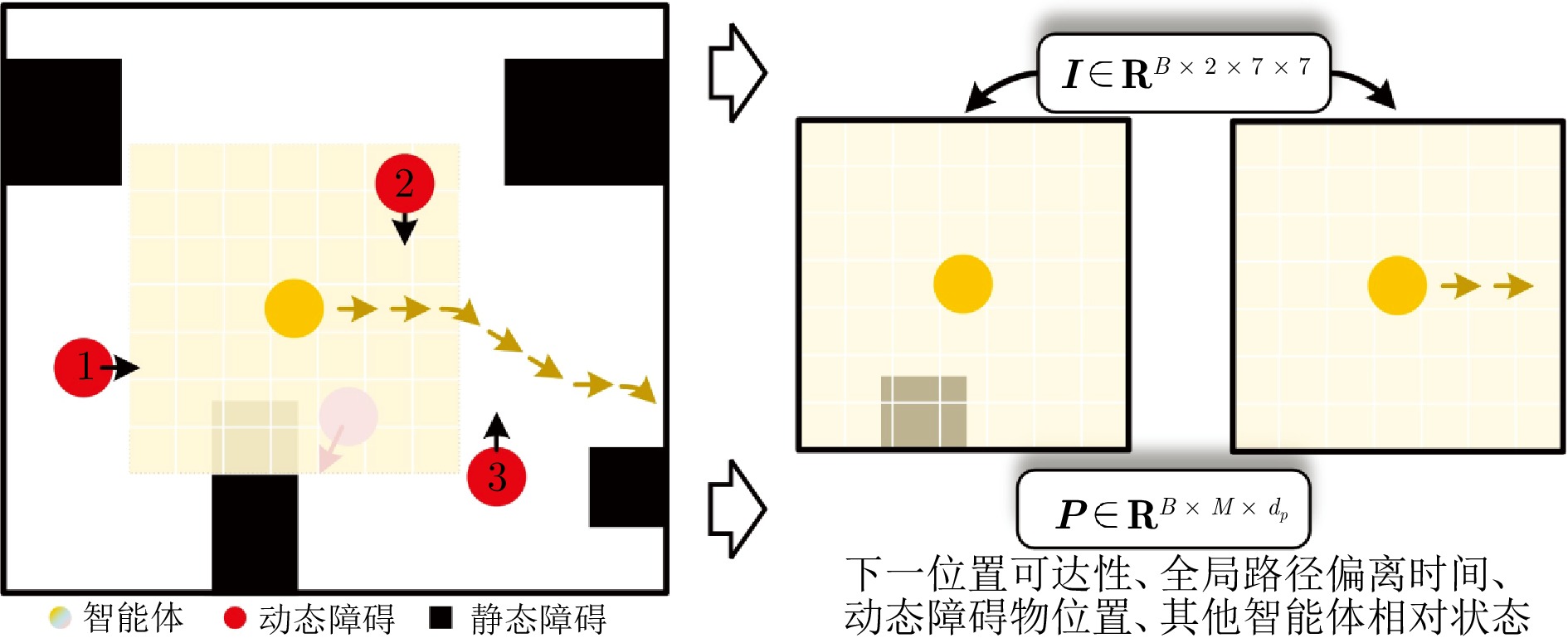
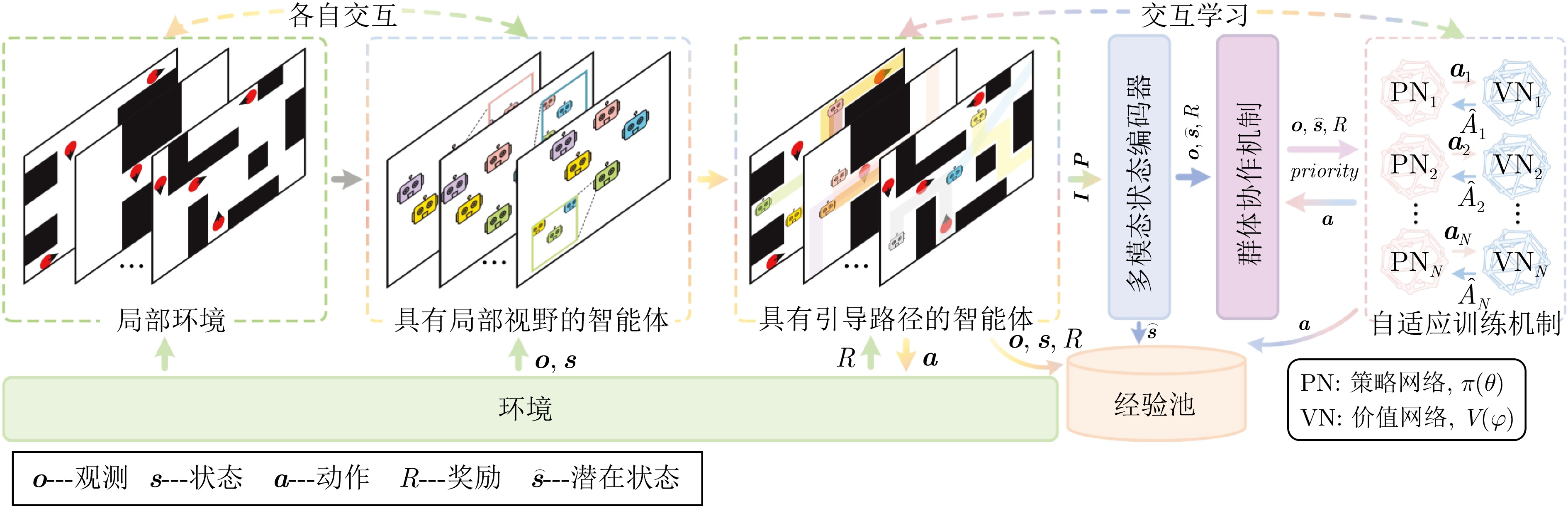
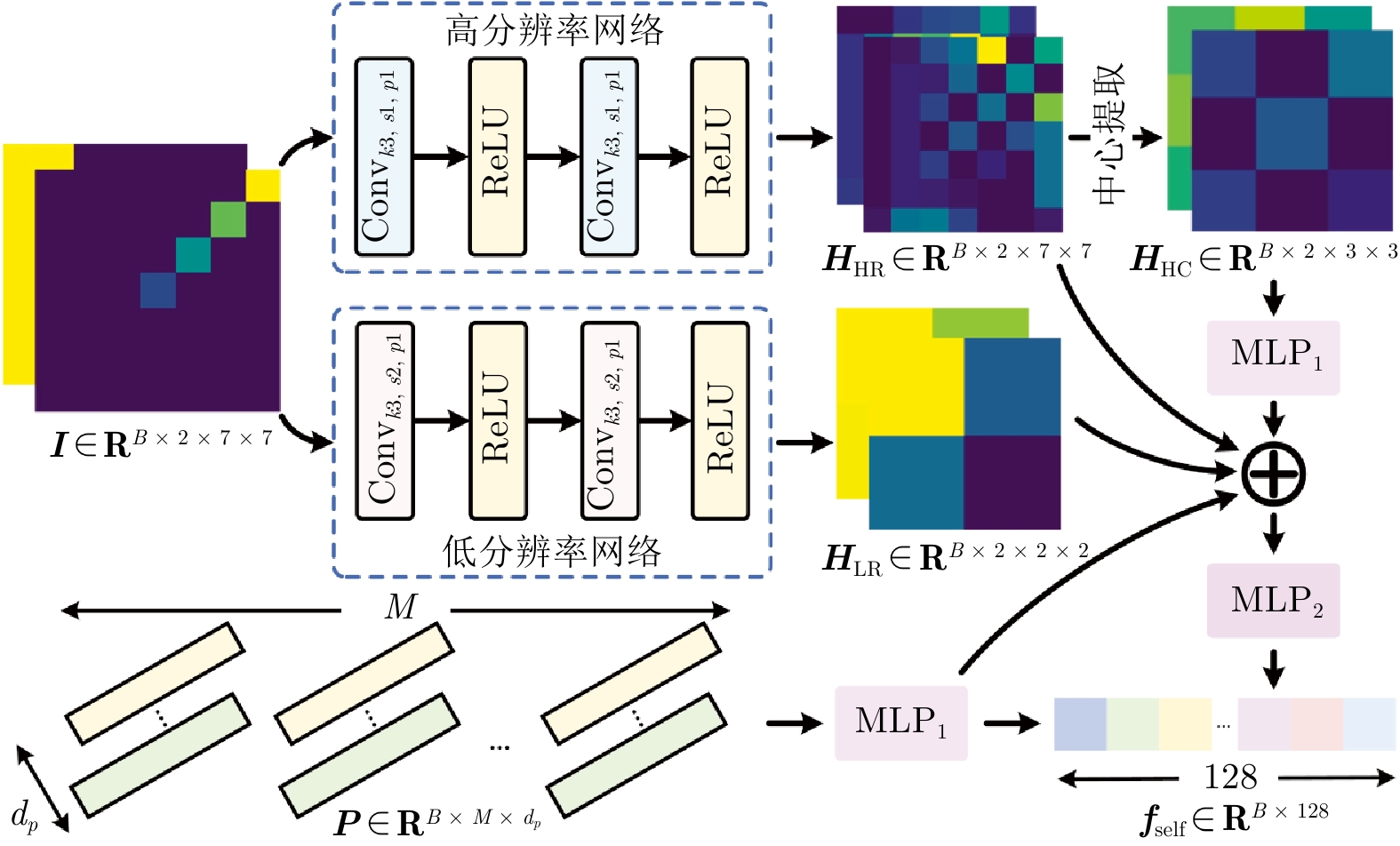
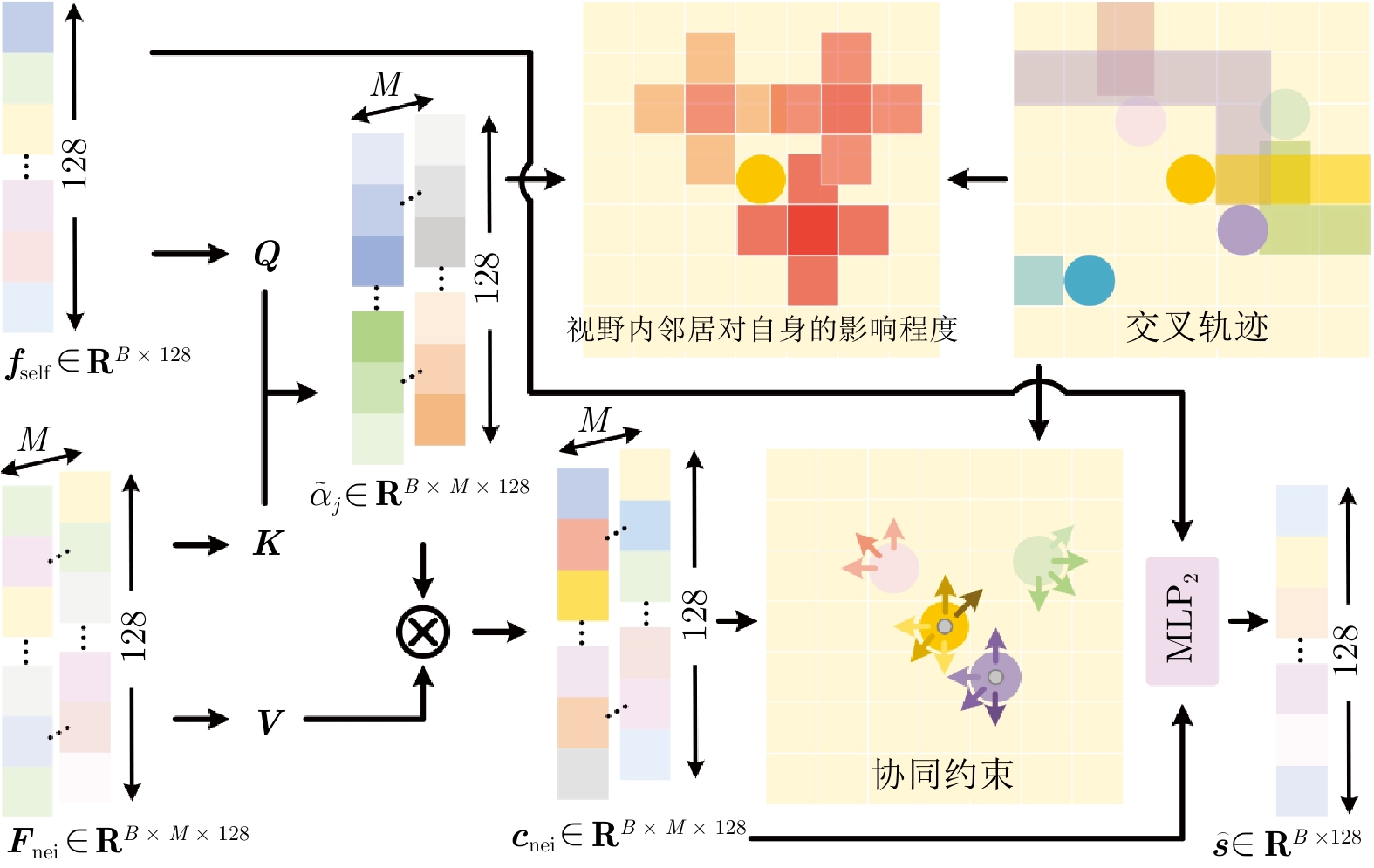
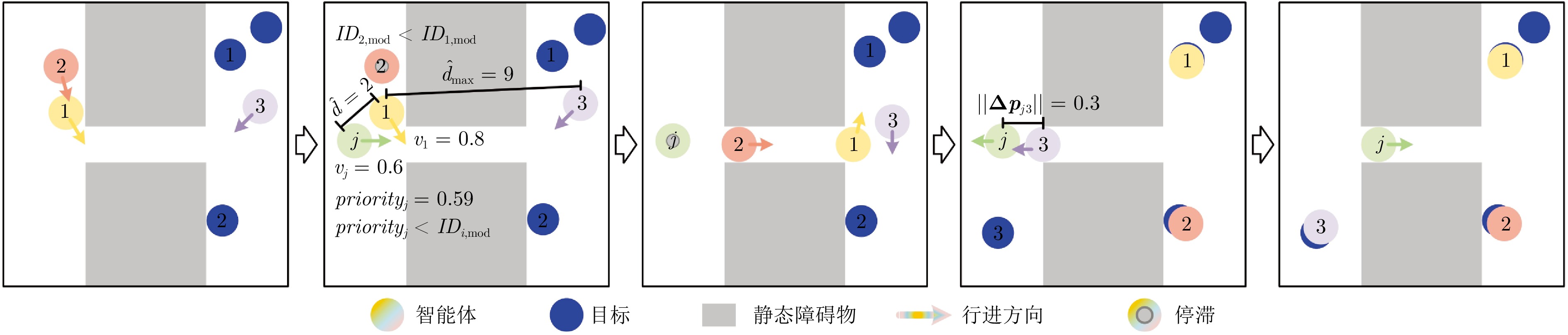
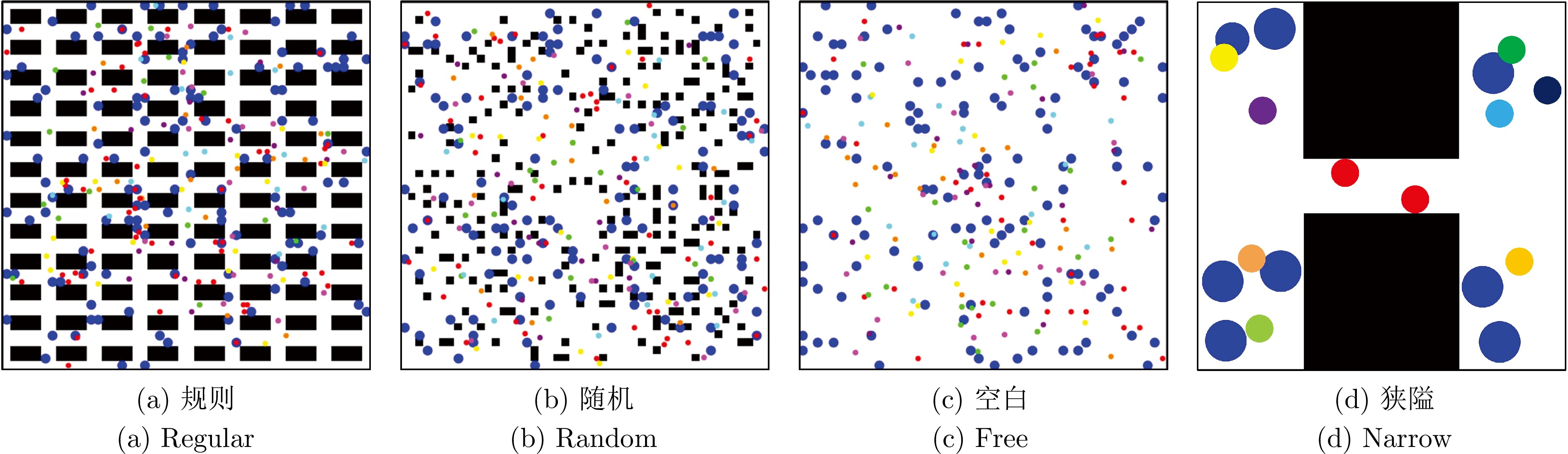
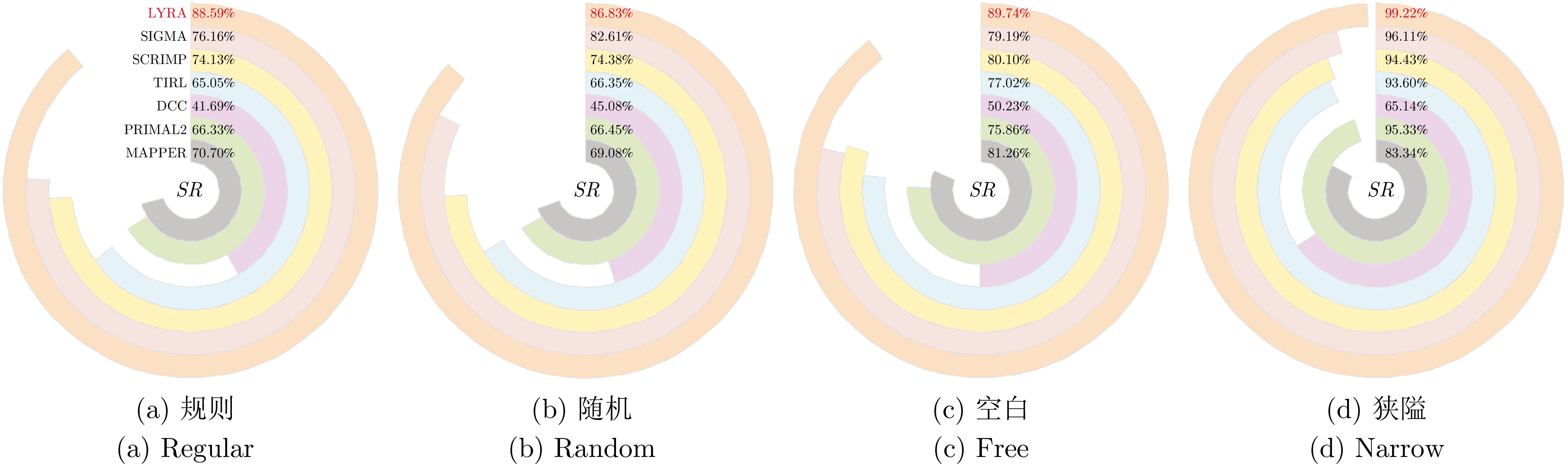
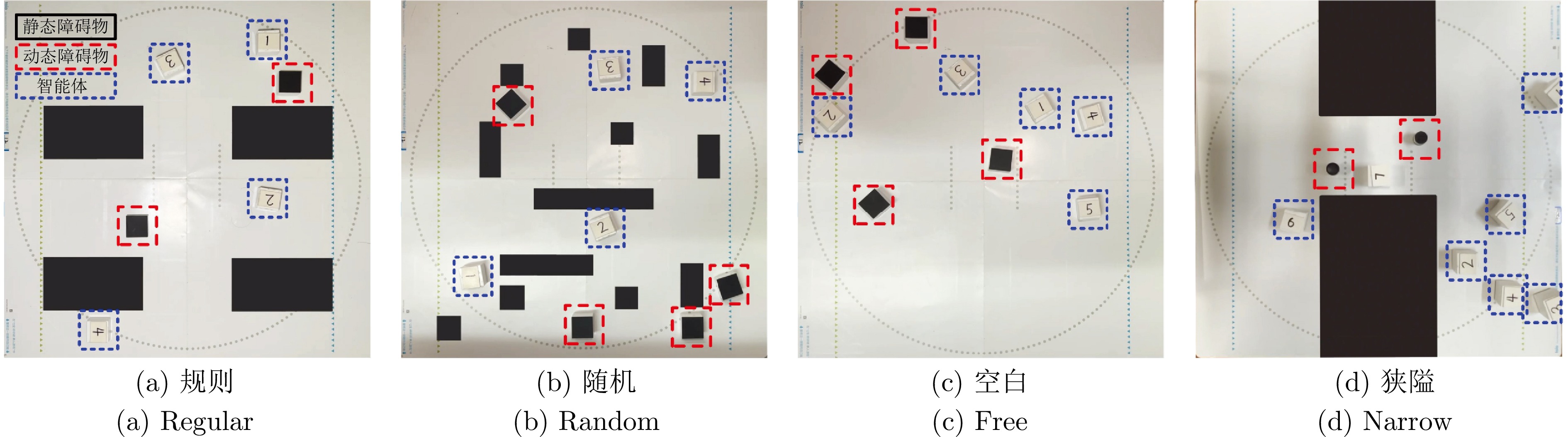
在部分可观测且动态变化的环境中, 深度强化学习(DRL) 为多智能体路径规划提供具备自学习、泛化与动态适应能力的分布式求解途径. 然而, DRL 在该问题中仍存在协调性不足与局部近视两个挑战: 智能体间的隐式交互易引发冲突, 仅依赖局部观测的反应式避障又导致路径冗长与全局目标偏离. 为此, 提出一种基于多模态特征融合与局部感知推理的分布式路径协作方法——LYRA. 该方法在分布式DRL 框架下构建从感知到决策的学习体系, 使智能体能依托局部观测实现推理与隐式让行. 多模态状态编码器融合局部碰撞线索与全局路径语义, 平衡即时避障与长期导航目标; 奖励引导的路径学习策略保证局部决策与全局任务一致; 群体协作机制通过隐式优先级推理化解局部冲突; 自适应学习率机制动态调节策略更新以提升训练稳定性. 实验结果表明, LYRA 在任务成功率和安全性上较基线方法有大幅提升, 在不同环境复杂度下保持良好泛化性, 为实现高效鲁棒的分布式多智能体路径规划提供了新范式.
在部分可观测且动态变化的环境中, 深度强化学习(DRL) 为多智能体路径规划提供具备自学习、泛化与动态适应能力的分布式求解途径. 然而, DRL 在该问题中仍存在协调性不足与局部近视两个挑战: 智能体间的隐式交互易引发冲突, 仅依赖局部观测的反应式避障又导致路径冗长与全局目标偏离. 为此, 提出一种基于多模态特征融合与局部感知推理的分布式路径协作方法——LYRA. 该方法在分布式DRL 框架下构建从感知到决策的学习体系, 使智能体能依托局部观测实现推理与隐式让行. 多模态状态编码器融合局部碰撞线索与全局路径语义, 平衡即时避障与长期导航目标; 奖励引导的路径学习策略保证局部决策与全局任务一致; 群体协作机制通过隐式优先级推理化解局部冲突; 自适应学习率机制动态调节策略更新以提升训练稳定性. 实验结果表明, LYRA 在任务成功率和安全性上较基线方法有大幅提升, 在不同环境复杂度下保持良好泛化性, 为实现高效鲁棒的分布式多智能体路径规划提供了新范式.

2026, 52(7): 1360-1371.
doi: 10.16383/j.aas.c250636
cstr: 32138.14.j.aas.c250636
摘要:
针对控制系统中数据经网络传输存在的隐私泄露以及隐私保护导致的性能损失问题, 本文研究一种具有隐私保护的切换系统最优控制方法. 首先, 根据混沌系统的非周期性及不可预测性, 开发一种基于混沌系统的数据加密方法. 将主混沌系统生成的伪随机序列添加到切换系统输出数据中, 能避免其经非理想网络传输时隐私的泄露. 其次, 设计一种基于粒子群优化算法的混沌形态同步控制器, 降低不确定项的影响, 保障主−从混沌系统的同步性, 确保解密后数据的可用性. 然后, 利用自适应动态规划算法对采用解密后数据构造的代价函数进行优化, 将预更新最优子系统的更新规则作为候选切换律. 通过对比候选切换律与当前切换律作用下系统的性能, 将性能好的切换律作为控制策略的一部分, 确保切换系统性能最优. 最后, 通过仿真对所提方法的可行性进行验证.
针对控制系统中数据经网络传输存在的隐私泄露以及隐私保护导致的性能损失问题, 本文研究一种具有隐私保护的切换系统最优控制方法. 首先, 根据混沌系统的非周期性及不可预测性, 开发一种基于混沌系统的数据加密方法. 将主混沌系统生成的伪随机序列添加到切换系统输出数据中, 能避免其经非理想网络传输时隐私的泄露. 其次, 设计一种基于粒子群优化算法的混沌形态同步控制器, 降低不确定项的影响, 保障主−从混沌系统的同步性, 确保解密后数据的可用性. 然后, 利用自适应动态规划算法对采用解密后数据构造的代价函数进行优化, 将预更新最优子系统的更新规则作为候选切换律. 通过对比候选切换律与当前切换律作用下系统的性能, 将性能好的切换律作为控制策略的一部分, 确保切换系统性能最优. 最后, 通过仿真对所提方法的可行性进行验证.








2026, 52(7): 1372-1386.
doi: 10.16383/j.aas.c250650
cstr: 32138.14.j.aas.c250650
摘要:
针对强噪声非平稳环境下滚动轴承故障信号关键特征易被淹没而导致诊断性能下降的难题, 提出一种双域抗噪编码与协同注意力混合解码模型. 首先, 该模型构建一个双域抗噪编码器, 其时域残差收缩分支可自适应学习阈值以抑制干扰, 同时波域可微分小波卷积分支用以捕获多尺度频率结构, 二者共同实现鲁棒的多域特征表示; 其次, 模型设计双域协同注意力模块, 通过双向交互与门控调节实现时域、波域特征的动态协同与自适应融合, 进而提升高噪声下的特征融合能力; 最后, 开发门控循环Transformer解码器组件, 将Transformer自注意力机制与GRU循环门控机制深度融合, 在统一的特征空间内同步实现全局建模与局部时序依赖提取的高效平衡. 基于凯斯西储大学与帕德博恩大学轴承数据集的实验表明, 该模型在标准工况下准确率达到100%, 且在强噪声下仍保持高准确率, 充分体现了其优越的抗噪性与鲁棒性.
针对强噪声非平稳环境下滚动轴承故障信号关键特征易被淹没而导致诊断性能下降的难题, 提出一种双域抗噪编码与协同注意力混合解码模型. 首先, 该模型构建一个双域抗噪编码器, 其时域残差收缩分支可自适应学习阈值以抑制干扰, 同时波域可微分小波卷积分支用以捕获多尺度频率结构, 二者共同实现鲁棒的多域特征表示; 其次, 模型设计双域协同注意力模块, 通过双向交互与门控调节实现时域、波域特征的动态协同与自适应融合, 进而提升高噪声下的特征融合能力; 最后, 开发门控循环Transformer解码器组件, 将Transformer自注意力机制与GRU循环门控机制深度融合, 在统一的特征空间内同步实现全局建模与局部时序依赖提取的高效平衡. 基于凯斯西储大学与帕德博恩大学轴承数据集的实验表明, 该模型在标准工况下准确率达到100%, 且在强噪声下仍保持高准确率, 充分体现了其优越的抗噪性与鲁棒性.













2026, 52(7): 1387-1400.
doi: 10.16383/j.aas.c250623
cstr: 32138.14.j.aas.c250623
摘要:
精准分割早期小病灶对疾病诊疗至关重要, 但现有方法面对特征稀疏、易受背景干扰的小病灶时性能显著下降. 受计算机断层扫描成像中X射线衰减物理原理启发, 发现小病灶在影像中呈现出中心亮、边缘渐弱的强度分布, 其轮廓与二维高斯分布高度吻合. 为此, 提出一种辐射衰减原理引导的显著性感知分割网络(RAP-Net). RAP-Net 将射线衰减导致的二维高斯分布作为相关滤波卷积核融入深度学习架构, 并设计专用于小病灶分割的多尺度感知特征网络. 该网络的核心显著特征感知提取模块利用多尺度高斯空洞卷积建模衰减特性, 实现稀疏特征的深度挖掘与背景抑制. 实验表明, RAP-Net在小肾结石与小肝脏钙化灶分割任务中的Dice系数和IoU提升至少18.05%和19.55%, 显著超越现有主流方法.
精准分割早期小病灶对疾病诊疗至关重要, 但现有方法面对特征稀疏、易受背景干扰的小病灶时性能显著下降. 受计算机断层扫描成像中X射线衰减物理原理启发, 发现小病灶在影像中呈现出中心亮、边缘渐弱的强度分布, 其轮廓与二维高斯分布高度吻合. 为此, 提出一种辐射衰减原理引导的显著性感知分割网络(RAP-Net). RAP-Net 将射线衰减导致的二维高斯分布作为相关滤波卷积核融入深度学习架构, 并设计专用于小病灶分割的多尺度感知特征网络. 该网络的核心显著特征感知提取模块利用多尺度高斯空洞卷积建模衰减特性, 实现稀疏特征的深度挖掘与背景抑制. 实验表明, RAP-Net在小肾结石与小肝脏钙化灶分割任务中的Dice系数和IoU提升至少18.05%和19.55%, 显著超越现有主流方法.












2026, 52(7): 1401-1412.
doi: 10.16383/j.aas.c250634
cstr: 32138.14.j.aas.c250634
摘要:
随着多光谱感知与智能视觉技术的发展, 如何在复杂环境中实现稳定而精确的目标检测已成为自动化视觉检测领域的重要研究方向. 针对传统单模态可见光目标检测在夜间、大雾及低照度等复杂环境中性能下降的问题, 提出一种基于频域特征细化导向的多光谱稀疏融合目标检测方法. 该方法利用共享权重的双分支编码器分别提取可见光与红外光特征, 并通过组稀疏自注意力模块实现跨模态长距离特征筛选, 以抑制冗余信息、增强显著特征表达. 同时, 设计频域自适应加权模块, 在频域空间中进行多光谱特征解耦与自适应融合, 实现不同光谱模态间的高效语义交互与动态权重分配. 该方法可在端到端框架下实现跨模态特征的高精度对齐与融合, 有效提升模型的检测精度与鲁棒性. 在M3FD和FLIR数据集上取得83.5%和81.6%的mAP50结果, 在 KAIST数据集上取得76.2%的AP50结果, 显著优于现有多光谱目标检测算法, 验证了所提方法在复杂场景下的优越性能和泛化能力.
随着多光谱感知与智能视觉技术的发展, 如何在复杂环境中实现稳定而精确的目标检测已成为自动化视觉检测领域的重要研究方向. 针对传统单模态可见光目标检测在夜间、大雾及低照度等复杂环境中性能下降的问题, 提出一种基于频域特征细化导向的多光谱稀疏融合目标检测方法. 该方法利用共享权重的双分支编码器分别提取可见光与红外光特征, 并通过组稀疏自注意力模块实现跨模态长距离特征筛选, 以抑制冗余信息、增强显著特征表达. 同时, 设计频域自适应加权模块, 在频域空间中进行多光谱特征解耦与自适应融合, 实现不同光谱模态间的高效语义交互与动态权重分配. 该方法可在端到端框架下实现跨模态特征的高精度对齐与融合, 有效提升模型的检测精度与鲁棒性. 在M3FD和FLIR数据集上取得83.5%和81.6%的mAP50结果, 在 KAIST数据集上取得76.2%的AP50结果, 显著优于现有多光谱目标检测算法, 验证了所提方法在复杂场景下的优越性能和泛化能力.







2026, 52(7): 1413-1425.
doi: 10.16383/j.aas.c250635
cstr: 32138.14.j.aas.c250635
摘要:
在铝电解过程中, 阳极效应是影响电能利用效率的典型异常工况, 其发生往往伴随阳极电阻的剧烈波动. 若能实现阳极电阻变化的实时预测, 即可对阳极效应进行前瞻性识别. 为此, 提出一种融合机理约束与数据驱动思想的多通道时空预测模型(卷积长短期记忆–二维卷积–多头注意力, ConvLSTM-Conv2D-MHA), 以联合刻画多槽系统的共性与差异特征. 模型利用堆叠ConvLSTM提取时序动态, 通过Conv2D分支强化空间特征表达, 并引入MHA机制捕捉长时依赖关系, 从而提升对趋势变化及早期波动的敏感度. 实验结果表明, 该模型在阳极电阻趋势预测中表现出更高的精度与稳定性, 较传统时序模型更能利用多槽间潜在的耦合关联.
在铝电解过程中, 阳极效应是影响电能利用效率的典型异常工况, 其发生往往伴随阳极电阻的剧烈波动. 若能实现阳极电阻变化的实时预测, 即可对阳极效应进行前瞻性识别. 为此, 提出一种融合机理约束与数据驱动思想的多通道时空预测模型(卷积长短期记忆–二维卷积–多头注意力, ConvLSTM-Conv2D-MHA), 以联合刻画多槽系统的共性与差异特征. 模型利用堆叠ConvLSTM提取时序动态, 通过Conv2D分支强化空间特征表达, 并引入MHA机制捕捉长时依赖关系, 从而提升对趋势变化及早期波动的敏感度. 实验结果表明, 该模型在阳极电阻趋势预测中表现出更高的精度与稳定性, 较传统时序模型更能利用多槽间潜在的耦合关联.













2026, 52(7): 1426-1437.
doi: 10.16383/j.aas.c250617
cstr: 32138.14.j.aas.c250617
摘要:
现代工业过程数据具有大容量、高维度及复杂相关性等特征, 单一多元统计监测方法难以兼顾不同类型特征的监测需求. 现有多模型融合方法与深度学习技术虽能提升故障检测性能, 但前者依赖模型库构建, 难以统一建模, 后者存在结构复杂与参数冗余问题. 针对上述问题, 提出一种基于两阶段多教师知识蒸馏的工业过程建模与故障检测方法. 该方法通过蒸馏框架将核主成分分析与独立成分分析提取的异构知识内化至学生自编码器模型中, 实现非线性与非高斯特征的统一建模, 并通过两阶段蒸馏协同优化特征空间与重构空间. 第一阶段在特征层蒸馏以引导学生模型学习教师模型的特征分布, 第二阶段在重构层蒸馏以提升模型对过程变化的表征与重构能力. 在田纳西−伊斯曼仿真过程及合成氨实际过程上的实验结果表明, 该方法能够有效提升故障检测的准确性与鲁棒性, 并通过离线知识蒸馏实现在线阶段的统一建模与高效监测.
现代工业过程数据具有大容量、高维度及复杂相关性等特征, 单一多元统计监测方法难以兼顾不同类型特征的监测需求. 现有多模型融合方法与深度学习技术虽能提升故障检测性能, 但前者依赖模型库构建, 难以统一建模, 后者存在结构复杂与参数冗余问题. 针对上述问题, 提出一种基于两阶段多教师知识蒸馏的工业过程建模与故障检测方法. 该方法通过蒸馏框架将核主成分分析与独立成分分析提取的异构知识内化至学生自编码器模型中, 实现非线性与非高斯特征的统一建模, 并通过两阶段蒸馏协同优化特征空间与重构空间. 第一阶段在特征层蒸馏以引导学生模型学习教师模型的特征分布, 第二阶段在重构层蒸馏以提升模型对过程变化的表征与重构能力. 在田纳西−伊斯曼仿真过程及合成氨实际过程上的实验结果表明, 该方法能够有效提升故障检测的准确性与鲁棒性, 并通过离线知识蒸馏实现在线阶段的统一建模与高效监测.









2026, 52(7): 1438-1448.
doi: 10.16383/j.aas.c250649
cstr: 32138.14.j.aas.c250649
摘要:
针对现有迭代学习控制方法中迭代次数依赖初始跟踪误差及系统不确定性影响控制精度等问题, 提出一种数据驱动鲁棒固定次迭代学习控制方法. 首先, 通过构造沿迭代轴的双曲正切型趋近律, 设计固定次迭代学习控制器, 推导出跟踪误差的稳态误差带并移除迭代次数上界依赖初始误差这一限制, 保证系统跟踪误差在固定迭代次数内收敛. 在此基础上, 基于系统输入输出数据设计沿迭代轴更新的参数自适应律与扩张状态观测器, 估计未知参数并补偿系统中未知干扰, 进而提高系统的鲁棒性与跟踪精度. 理论分析和仿真结果验证了所提方法的有效性.
针对现有迭代学习控制方法中迭代次数依赖初始跟踪误差及系统不确定性影响控制精度等问题, 提出一种数据驱动鲁棒固定次迭代学习控制方法. 首先, 通过构造沿迭代轴的双曲正切型趋近律, 设计固定次迭代学习控制器, 推导出跟踪误差的稳态误差带并移除迭代次数上界依赖初始误差这一限制, 保证系统跟踪误差在固定迭代次数内收敛. 在此基础上, 基于系统输入输出数据设计沿迭代轴更新的参数自适应律与扩张状态观测器, 估计未知参数并补偿系统中未知干扰, 进而提高系统的鲁棒性与跟踪精度. 理论分析和仿真结果验证了所提方法的有效性.








2026, 52(7): 1449-1462.
doi: 10.16383/j.aas.c250653
cstr: 32138.14.j.aas.c250653
摘要:
关键性能指标(KPI)预测对工业过程优化和安全至关重要. 然而, 在现实工业环境中传感器故障常导致推理阶段内生变量(预测目标)缺失, 引发信息不对称. 现有方法在推理阶段因缺乏内生变量的历史自回归信息, 难以建立鲁棒时空特征映射, 严重影响多步预测性能. 针对该挑战, 提出完备时空信息引导网络. 该网络采用包含“完备变量引导”和“外生变量学习”的双流架构, 基于贝叶斯理论将内生变量缺失下的预测问题转换为特征对齐任务, 通过分布对齐约束使网络在变量缺失时仍能学习到逼近完备变量提取的时空表征; 同时, 提出多尺度时空聚合模块, 结合图结构学习与注意力机制动态建模变量间的耦合关系, 并精炼特征空间, 有效捕获与KPI相关的复杂时空关联. 在电力变压器温度数据集和氧化铝回转窑烧结温度数据集上的实验表明, 在内生变量缺失下, 所提网络表现出良好的泛化能力和鲁棒的多步预测性能.
关键性能指标(KPI)预测对工业过程优化和安全至关重要. 然而, 在现实工业环境中传感器故障常导致推理阶段内生变量(预测目标)缺失, 引发信息不对称. 现有方法在推理阶段因缺乏内生变量的历史自回归信息, 难以建立鲁棒时空特征映射, 严重影响多步预测性能. 针对该挑战, 提出完备时空信息引导网络. 该网络采用包含“完备变量引导”和“外生变量学习”的双流架构, 基于贝叶斯理论将内生变量缺失下的预测问题转换为特征对齐任务, 通过分布对齐约束使网络在变量缺失时仍能学习到逼近完备变量提取的时空表征; 同时, 提出多尺度时空聚合模块, 结合图结构学习与注意力机制动态建模变量间的耦合关系, 并精炼特征空间, 有效捕获与KPI相关的复杂时空关联. 在电力变压器温度数据集和氧化铝回转窑烧结温度数据集上的实验表明, 在内生变量缺失下, 所提网络表现出良好的泛化能力和鲁棒的多步预测性能.











2026, 52(7): 1463-1476.
doi: 10.16383/j.aas.c250624
cstr: 32138.14.j.aas.c250624
摘要:
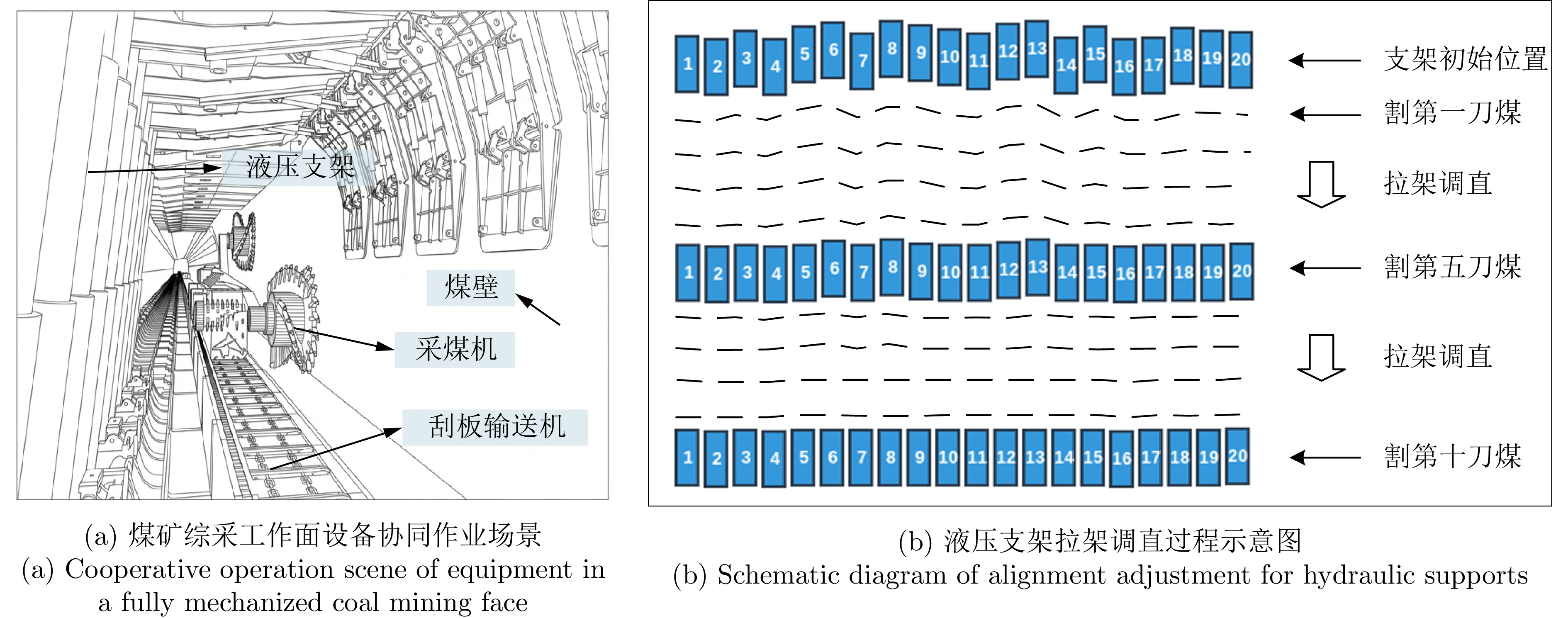
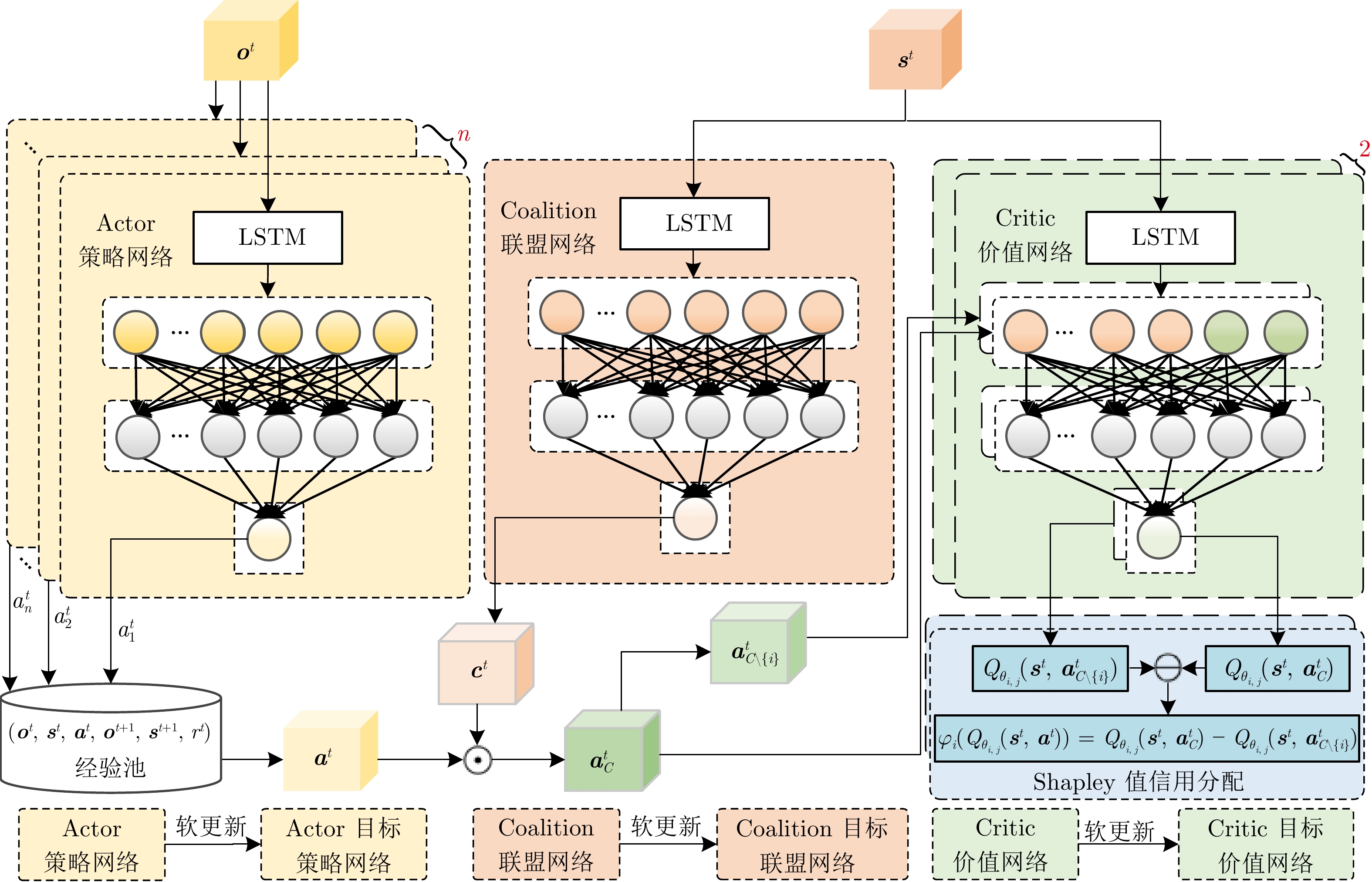
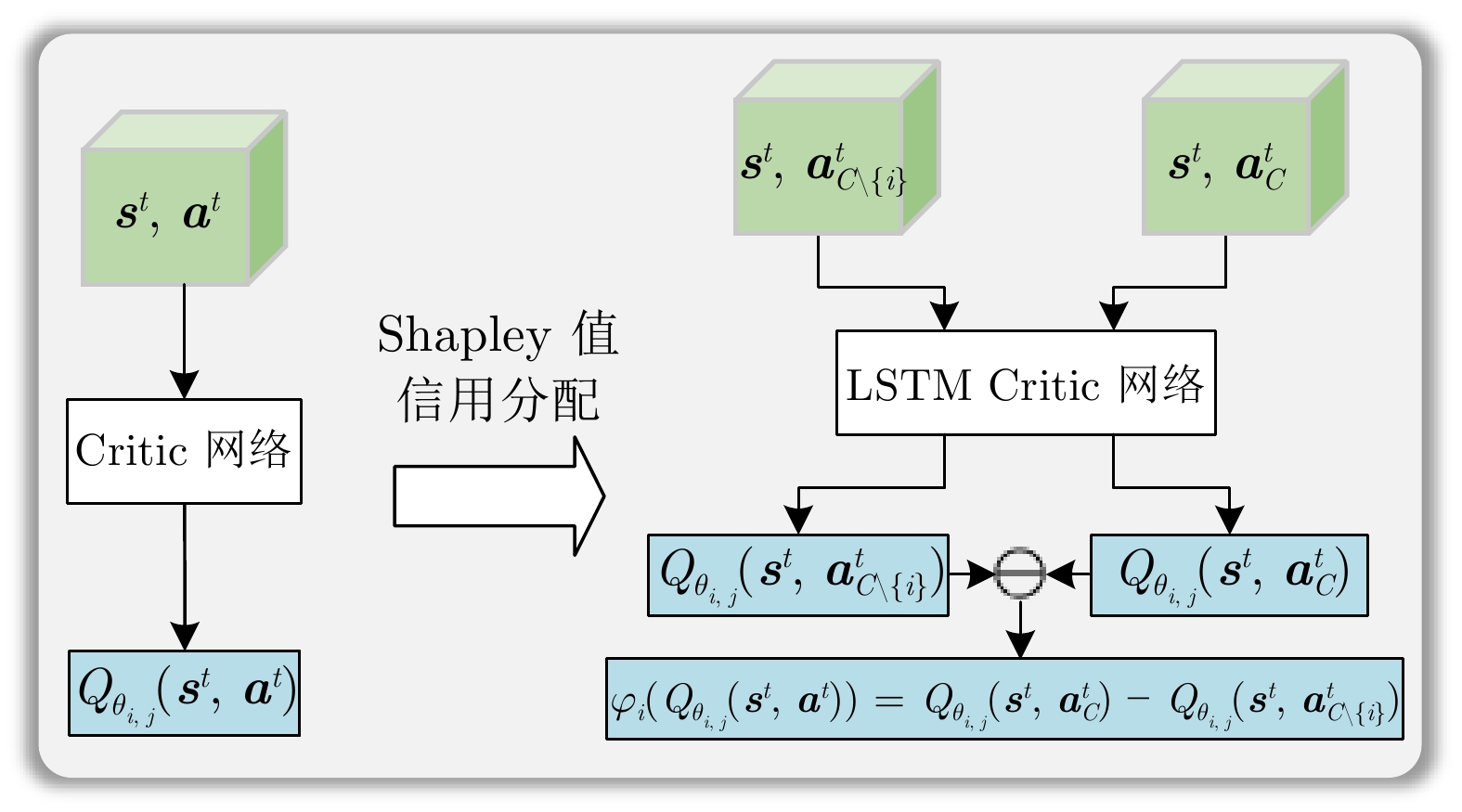
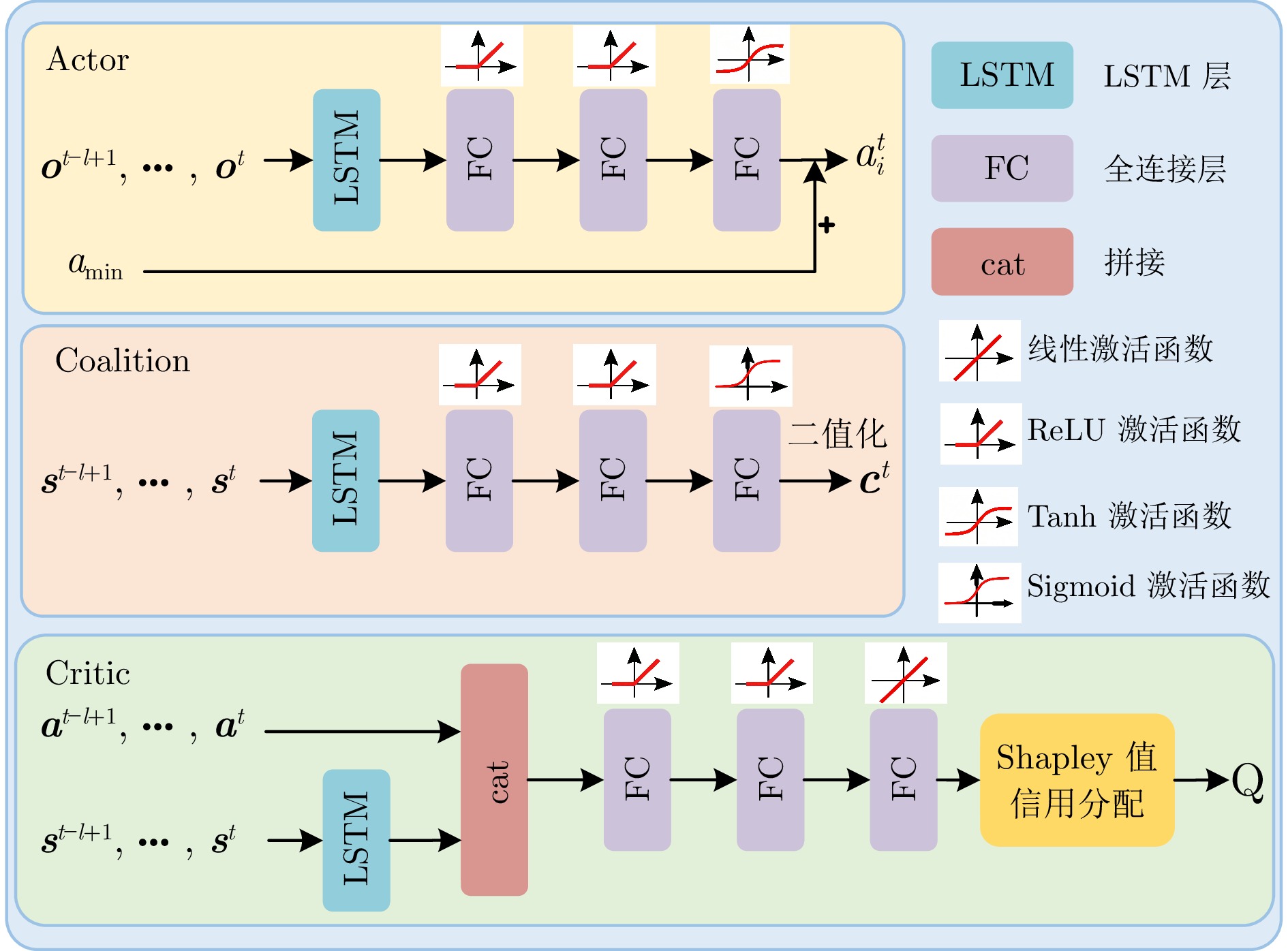
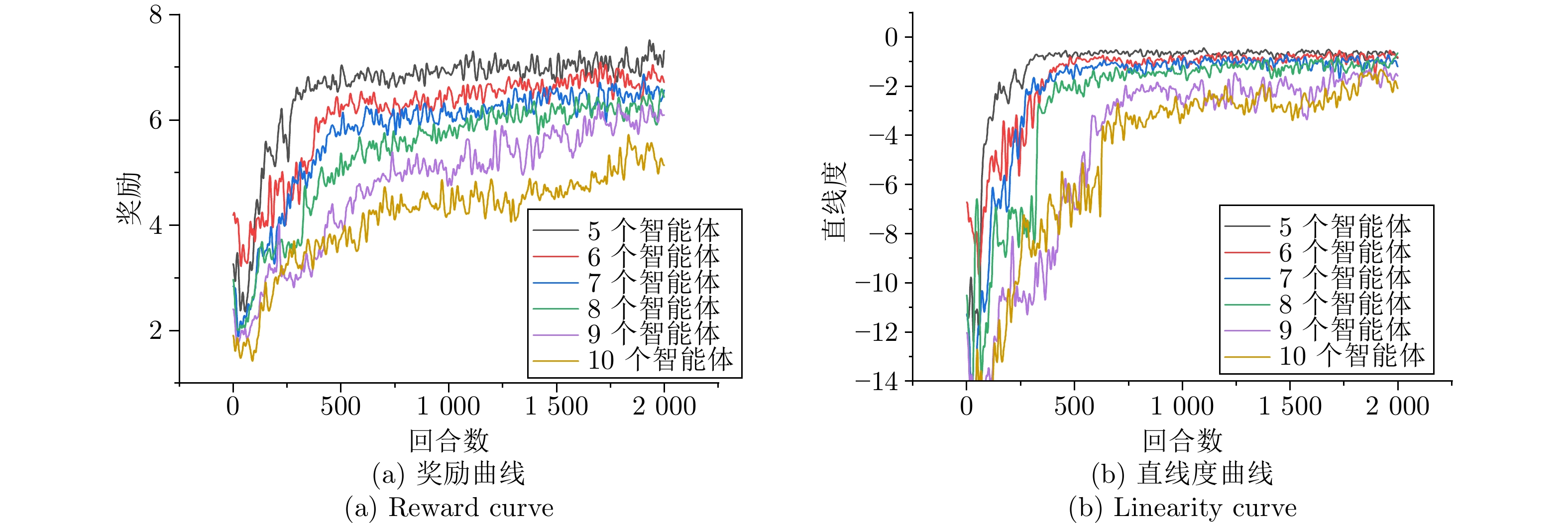
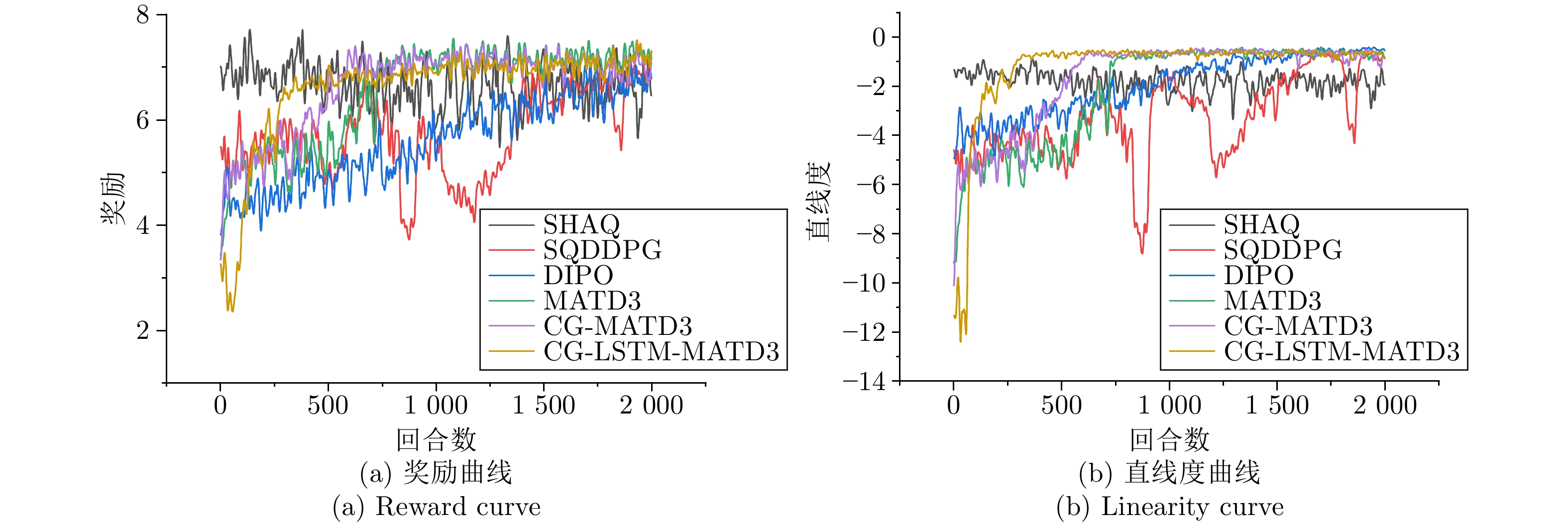
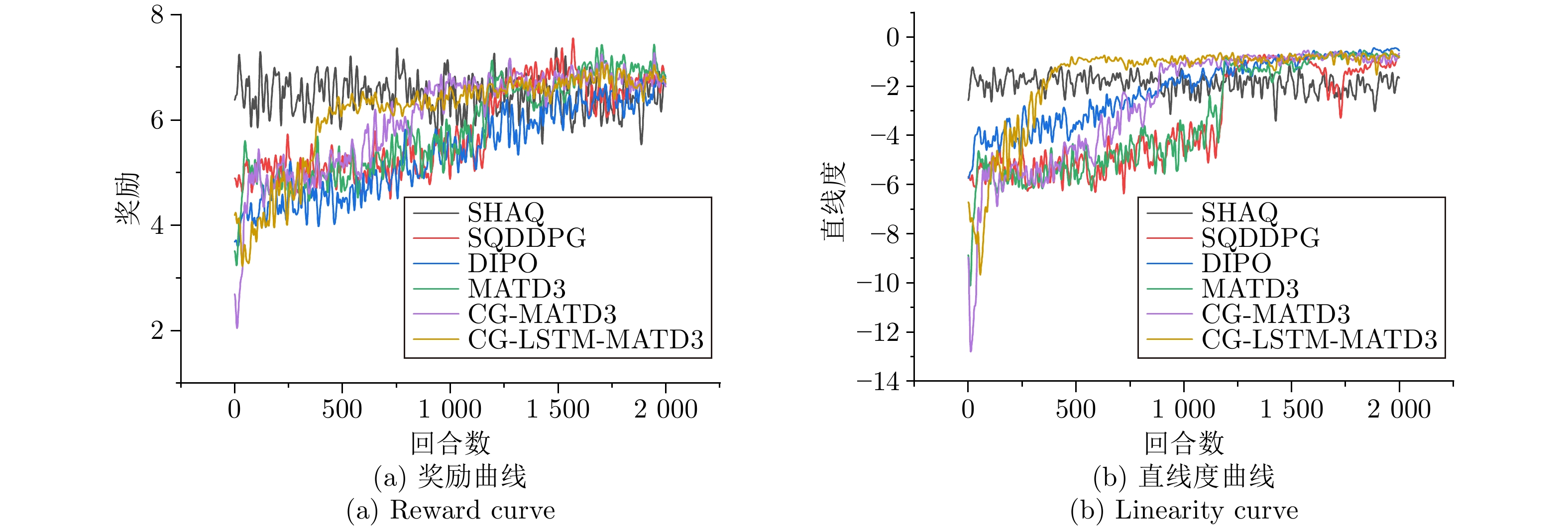
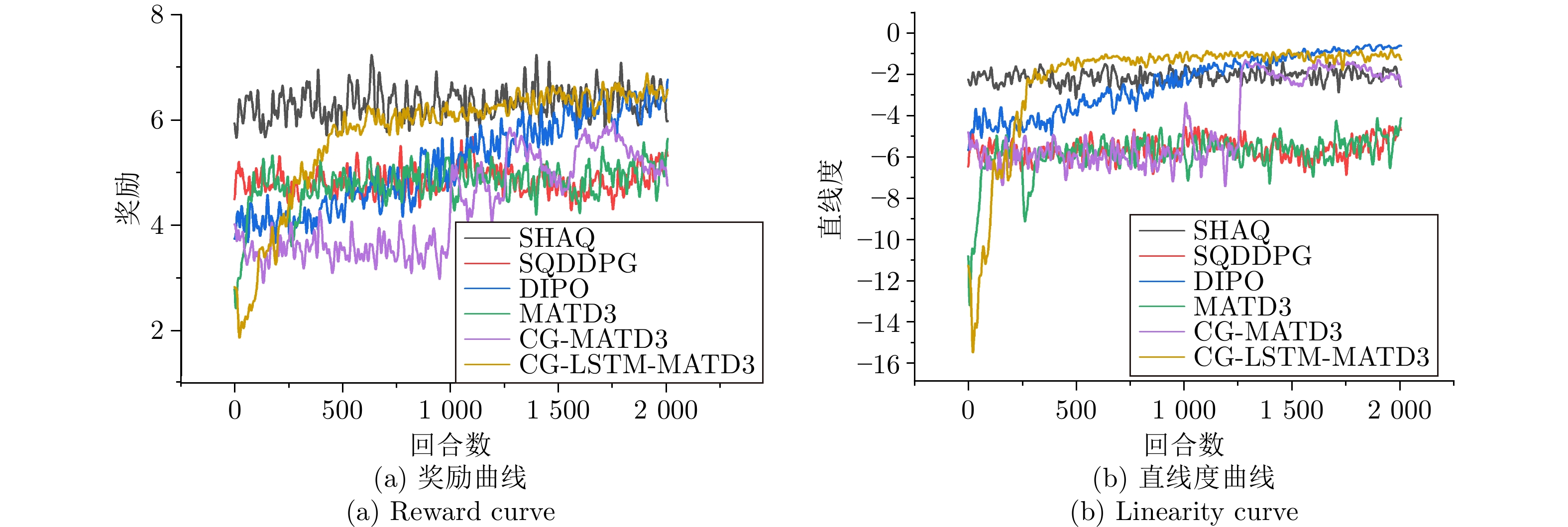
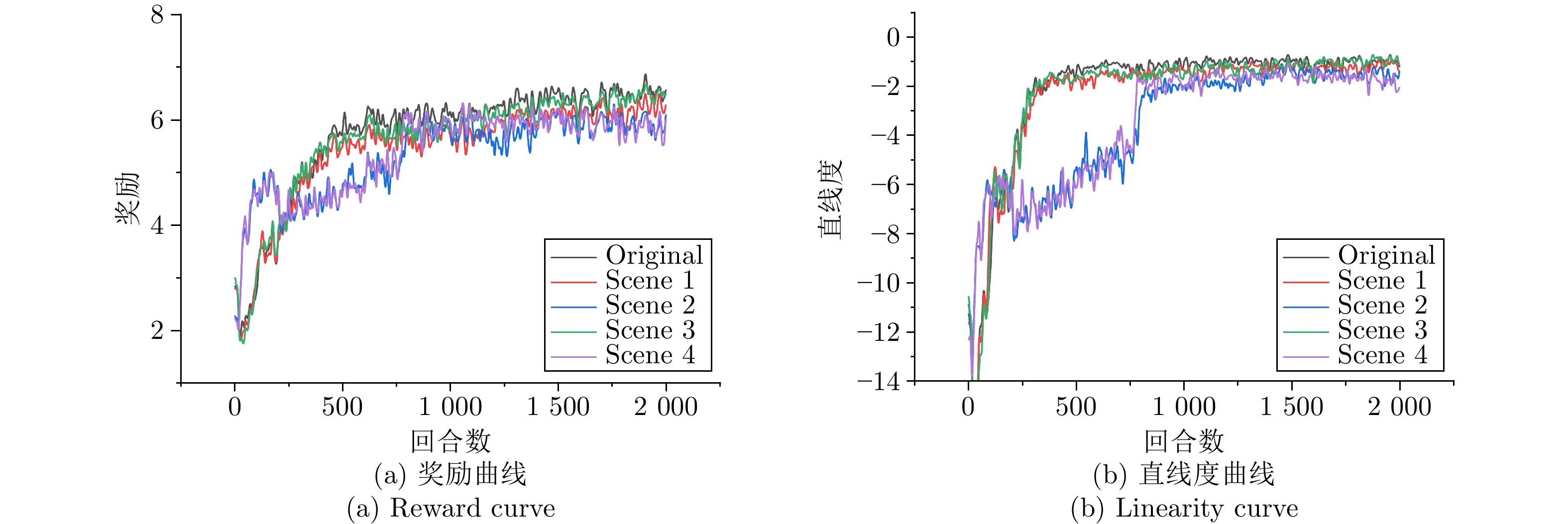
综采工作面液压支架群调直过程中, 支架群间的强耦合关系与液压缸摩擦−滑移非线性构成典型的“耦合−非线性”双重复杂性, 使传统控制方法难以有效建模. 现有多智能体强化学习方法能实现并行决策, 但面临全局奖励无法精确归因至各支架动作、仅依赖观测状态难以捕获支架群姿态的时序演化规律等问题, 阻碍策略的有效收敛. 为此, 提出融合合作博弈与长短期记忆网络(LSTM)的多智能体强化学习算法CG-LSTM-MATD3. 该算法基于去中心化部分可观测马尔科夫决策过程对液压支架调直过程建模, 引入Shapley值实现各液压支架边际贡献的合理归因, 并设计Coalition网络通过联盟生成降低计算复杂度. 其次, 在Actor、Critic以及Coalition网络中嵌入LSTM模块, 通过对状态序列等信息的记忆, 使模型能够捕获状态的时序依赖关系, 增强对环境动态特性和真实状态的感知能力. 实验结果表明, 该算法在七支架任务中直线度相对基线算法提升80.59%, 消融实验进一步证明了合作博弈机制与LSTM模块的有效性.
综采工作面液压支架群调直过程中, 支架群间的强耦合关系与液压缸摩擦−滑移非线性构成典型的“耦合−非线性”双重复杂性, 使传统控制方法难以有效建模. 现有多智能体强化学习方法能实现并行决策, 但面临全局奖励无法精确归因至各支架动作、仅依赖观测状态难以捕获支架群姿态的时序演化规律等问题, 阻碍策略的有效收敛. 为此, 提出融合合作博弈与长短期记忆网络(LSTM)的多智能体强化学习算法CG-LSTM-MATD3. 该算法基于去中心化部分可观测马尔科夫决策过程对液压支架调直过程建模, 引入Shapley值实现各液压支架边际贡献的合理归因, 并设计Coalition网络通过联盟生成降低计算复杂度. 其次, 在Actor、Critic以及Coalition网络中嵌入LSTM模块, 通过对状态序列等信息的记忆, 使模型能够捕获状态的时序依赖关系, 增强对环境动态特性和真实状态的感知能力. 实验结果表明, 该算法在七支架任务中直线度相对基线算法提升80.59%, 消融实验进一步证明了合作博弈机制与LSTM模块的有效性.
2026, 52(7): 1477-1490.
doi: 10.16383/j.aas.c250607
cstr: 32138.14.j.aas.c250607
摘要:
针对浮选精煤泡沫分割中因低质图像数据导致的目标漏检及误分割问题, 提出一种基于密度感知引导的煤泥浮选泡沫分割方法. 首先, 构建跨尺度区域密度感知模块, 设计层次化密度估计子模块提取多尺度差异化区域密度信息, 并提出基于全局语义引导的跨尺度聚合方式, 融合生成具有区域差异感知能力的密度引导表征. 其次, 设计基于密度引导的分支增强模块, 建立基于分布感知的动态密度注意力机制, 构成以密度分布为先验来动态调节双分支空间特征响应的增强策略, 降低泡沫漏检率. 最后, 设计基于密度引导的互信息约束优化模块, 提出以互信息最大化为目标的语义耦合策略, 形成强化密度与分割表征间统计依赖的联合优化方法, 提升泡沫边界的分割判别能力. 在两个实际浮选泡沫数据集上的实验结果表明, 所提方法有效提升了泡沫分割性能.
针对浮选精煤泡沫分割中因低质图像数据导致的目标漏检及误分割问题, 提出一种基于密度感知引导的煤泥浮选泡沫分割方法. 首先, 构建跨尺度区域密度感知模块, 设计层次化密度估计子模块提取多尺度差异化区域密度信息, 并提出基于全局语义引导的跨尺度聚合方式, 融合生成具有区域差异感知能力的密度引导表征. 其次, 设计基于密度引导的分支增强模块, 建立基于分布感知的动态密度注意力机制, 构成以密度分布为先验来动态调节双分支空间特征响应的增强策略, 降低泡沫漏检率. 最后, 设计基于密度引导的互信息约束优化模块, 提出以互信息最大化为目标的语义耦合策略, 形成强化密度与分割表征间统计依赖的联合优化方法, 提升泡沫边界的分割判别能力. 在两个实际浮选泡沫数据集上的实验结果表明, 所提方法有效提升了泡沫分割性能.




















