2019年 第45卷 第3期
2019, 45(3): 445-457.
doi: 10.16383/j.aas.c180586
cstr: 32138.14.j.aas.c180586
摘要:
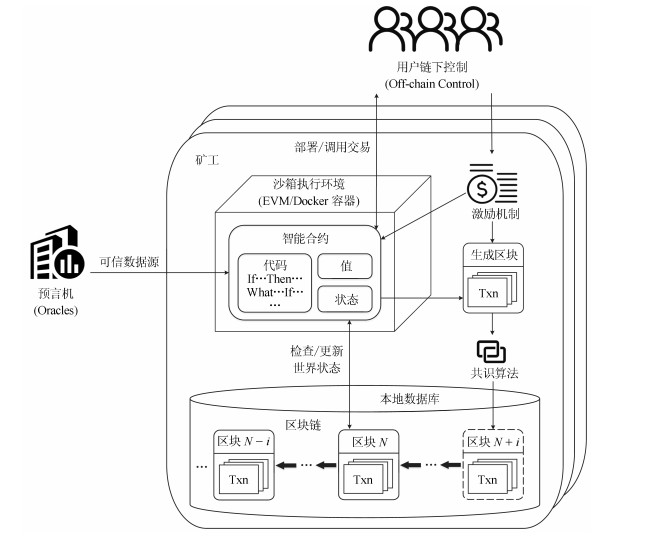
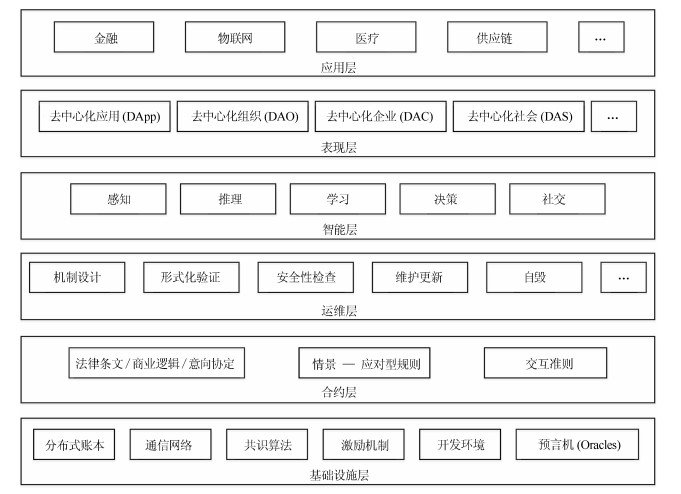
智能合约是一种无需中介、自我验证、自动执行合约条款的计算机交易协议,近年来随着区块链技术的日益普及而备受关注.区块链上的智能合约具有去中心化、去信任、可编程、不可篡改等特性,可灵活嵌入各种数据和资产,帮助实现安全高效的信息交换、价值转移和资产管理,最终有望深入变革传统商业模式和社会生产关系,为构建可编程资产、系统和社会奠定基础.本文致力于以区块链智能合约为研究对象,对已有的研究成果进行全面梳理和系统概述,提出了智能合约的基础架构模型并以此为研究框架阐述了智能合约的运行机制与基础架构,总结了智能合约的研究挑战与进展,介绍了智能合约的技术优势与典型应用领域,讨论了智能合约的发展趋势,以期为智能合约的后续研究提供参考.
智能合约是一种无需中介、自我验证、自动执行合约条款的计算机交易协议,近年来随着区块链技术的日益普及而备受关注.区块链上的智能合约具有去中心化、去信任、可编程、不可篡改等特性,可灵活嵌入各种数据和资产,帮助实现安全高效的信息交换、价值转移和资产管理,最终有望深入变革传统商业模式和社会生产关系,为构建可编程资产、系统和社会奠定基础.本文致力于以区块链智能合约为研究对象,对已有的研究成果进行全面梳理和系统概述,提出了智能合约的基础架构模型并以此为研究框架阐述了智能合约的运行机制与基础架构,总结了智能合约的研究挑战与进展,介绍了智能合约的技术优势与典型应用领域,讨论了智能合约的发展趋势,以期为智能合约的后续研究提供参考.

2019, 45(3): 458-470.
doi: 10.16383/j.aas.c180076
cstr: 32138.14.j.aas.c180076
摘要:
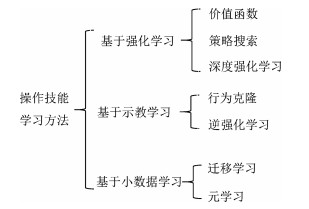
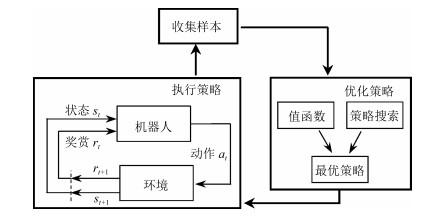
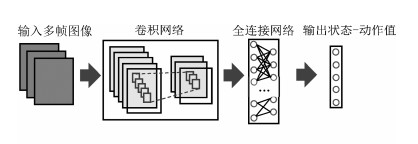
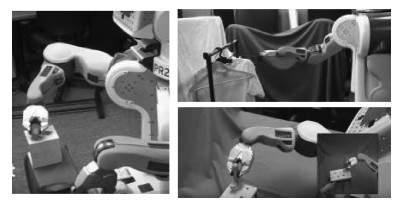
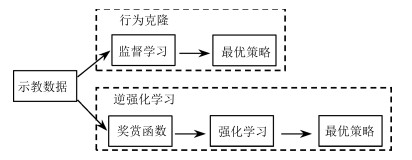
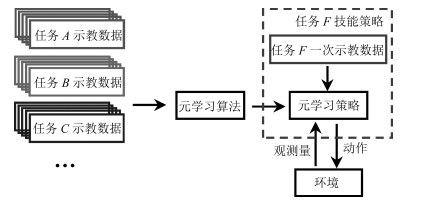
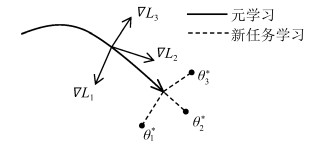
结合人工智能技术和机器人技术,研究具备一定自主决策和学习能力的机器人操作技能学习系统,已逐渐成为机器人研究领域的重要分支.本文介绍了机器人操作技能学习的主要方法及最新的研究成果.依据对训练数据的使用方式将机器人操作技能学习方法分为基于强化学习的方法、基于示教学习的方法和基于小数据学习的方法,并基于此对近些年的研究成果进行了综述和分析,最后列举了机器人操作技能学习的未来发展方向.
结合人工智能技术和机器人技术,研究具备一定自主决策和学习能力的机器人操作技能学习系统,已逐渐成为机器人研究领域的重要分支.本文介绍了机器人操作技能学习的主要方法及最新的研究成果.依据对训练数据的使用方式将机器人操作技能学习方法分为基于强化学习的方法、基于示教学习的方法和基于小数据学习的方法,并基于此对近些年的研究成果进行了综述和分析,最后列举了机器人操作技能学习的未来发展方向.






2019, 45(3): 471-479.
doi: 10.16383/j.aas.c170685
cstr: 32138.14.j.aas.c170685
摘要:
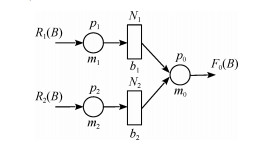
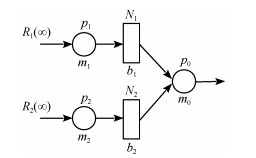
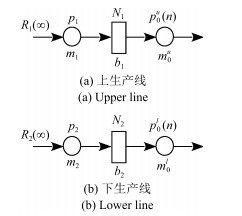
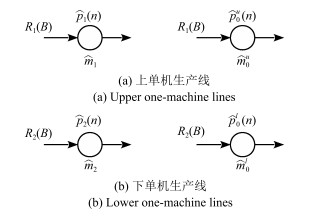
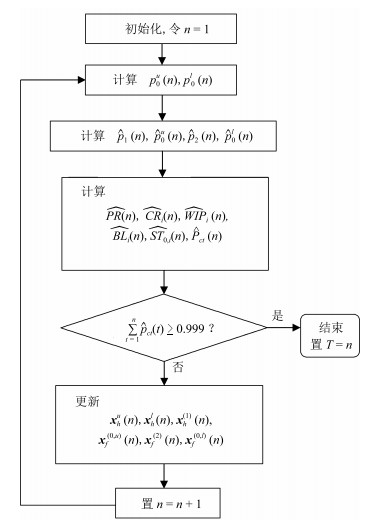
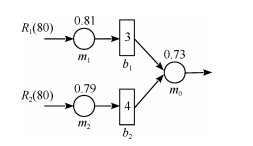
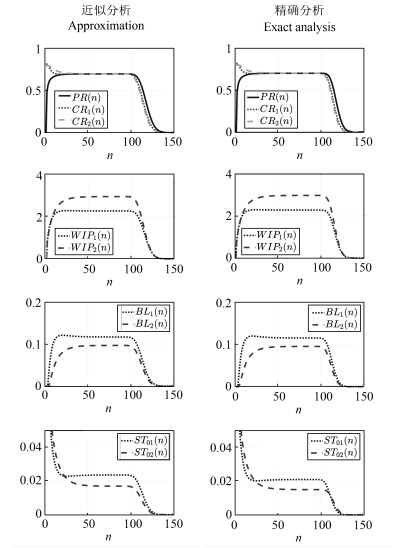
通常适用于大批量制造生产系统的稳态分析在过去几十年得到了广泛研究.然而,当生产量较小(例如,定制化有限小批量生产运行)时,暂态在生产过程中可能起到主要作用,稳态分析将变得不再适用.近年来,对有限小批量生产条件下的串行生产线的研究已经有了一些初步成果.与此同时,装配系统,其最终产品往往需要两个或者多个组件,也广泛用于实践生产中.本文中,在有限小批量生产运行的三机装配系统框架下,假设系统具有有限缓冲区容量,并且使用伯努利机器可靠性模型,研究了此类系统的性能评价问题.具体来说,首先推导出评价系统性能的数学模型和解析公式.然后,提出一种基于分解的方法来近似系统实时性能.最后,所提出的算法的准确性通过仿真数值实验进行了验证并通过一个数值实例进行了展示.
通常适用于大批量制造生产系统的稳态分析在过去几十年得到了广泛研究.然而,当生产量较小(例如,定制化有限小批量生产运行)时,暂态在生产过程中可能起到主要作用,稳态分析将变得不再适用.近年来,对有限小批量生产条件下的串行生产线的研究已经有了一些初步成果.与此同时,装配系统,其最终产品往往需要两个或者多个组件,也广泛用于实践生产中.本文中,在有限小批量生产运行的三机装配系统框架下,假设系统具有有限缓冲区容量,并且使用伯努利机器可靠性模型,研究了此类系统的性能评价问题.具体来说,首先推导出评价系统性能的数学模型和解析公式.然后,提出一种基于分解的方法来近似系统实时性能.最后,所提出的算法的准确性通过仿真数值实验进行了验证并通过一个数值实例进行了展示.
2019, 45(3): 480-489.
doi: 10.16383/j.aas.2018.c170237
cstr: 32138.14.j.aas.2018.c170237
摘要:
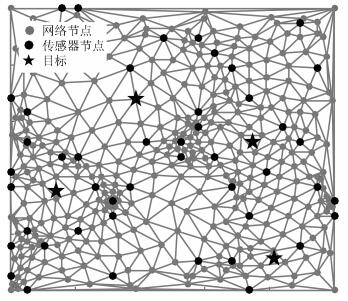
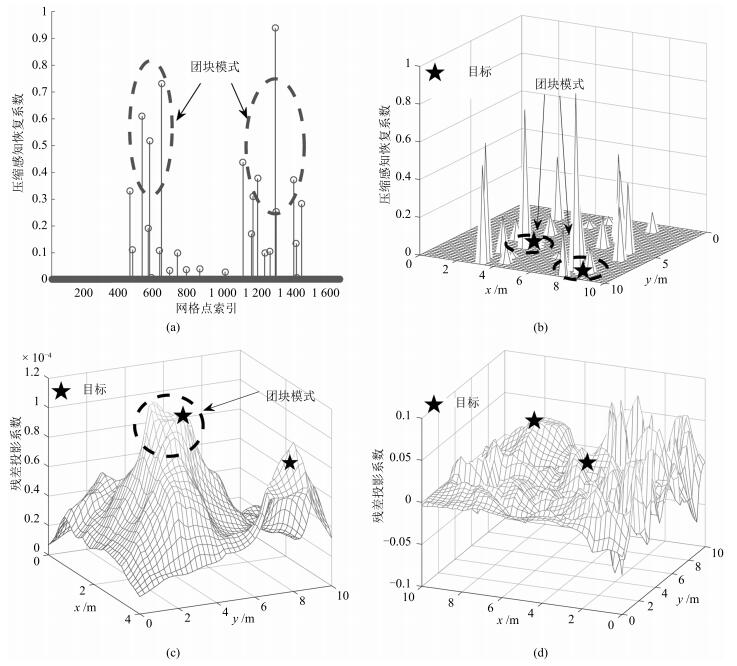
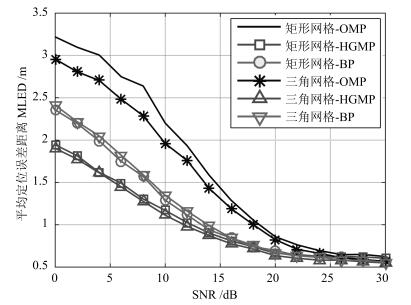
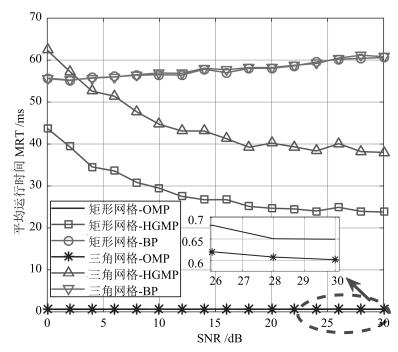
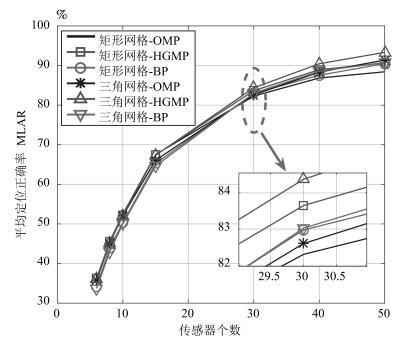
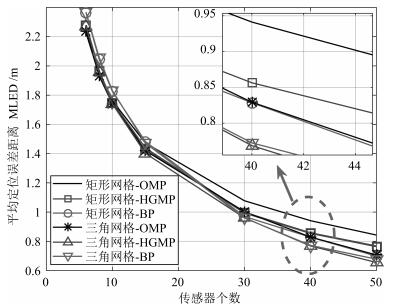
针对基于压缩感知(Compressive sensing,CS)的多目标定位问题,通过分析多目标场景中的隐含结构信息,本文提出一种层级的贪婪匹配追踪定位算法.该算法首先获得多目标在网格化空间中的可能位置作为全局估计层,然后利用该全局估计信息作为稀疏恢复层的输入信息,在网格化空间中重构多目标位置矢量.本文证明了文献中广泛采用的基于正交化的预处理方式实质上降低了信噪比(Signal to noise ratio,SNR),从而降低了定位性能.本文通过全局估计,预先排除了不可能的位置,等效于从观测子空间中分离出信号子空间,从而降低了观测噪声的影响.通过理论分析与计算机仿真,表明所提算法具有线性复杂度且在相同信噪比下具有更高的定位正确率和定位精度.
针对基于压缩感知(Compressive sensing,CS)的多目标定位问题,通过分析多目标场景中的隐含结构信息,本文提出一种层级的贪婪匹配追踪定位算法.该算法首先获得多目标在网格化空间中的可能位置作为全局估计层,然后利用该全局估计信息作为稀疏恢复层的输入信息,在网格化空间中重构多目标位置矢量.本文证明了文献中广泛采用的基于正交化的预处理方式实质上降低了信噪比(Signal to noise ratio,SNR),从而降低了定位性能.本文通过全局估计,预先排除了不可能的位置,等效于从观测子空间中分离出信号子空间,从而降低了观测噪声的影响.通过理论分析与计算机仿真,表明所提算法具有线性复杂度且在相同信噪比下具有更高的定位正确率和定位精度.

2019, 45(3): 490-504.
doi: 10.16383/j.aas.c170734
cstr: 32138.14.j.aas.c170734
摘要:
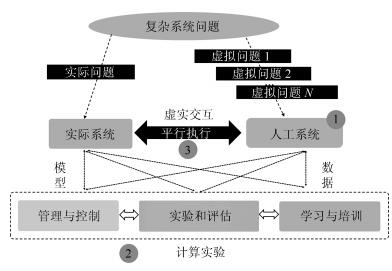
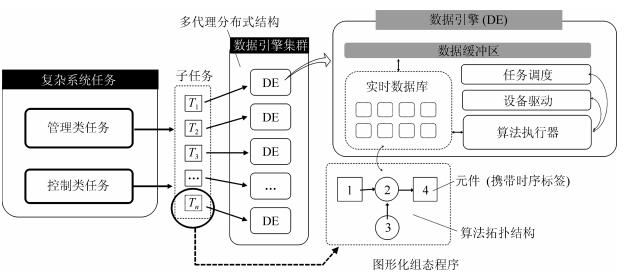
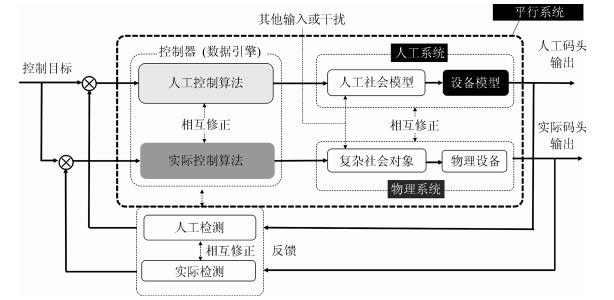
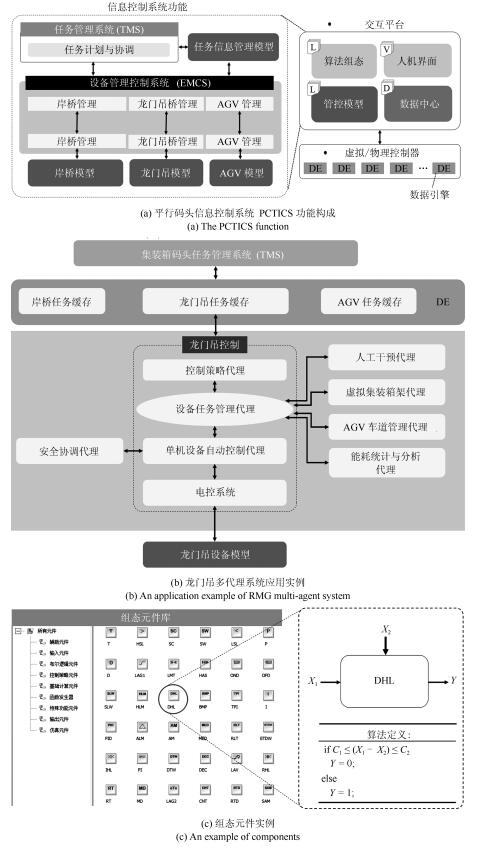
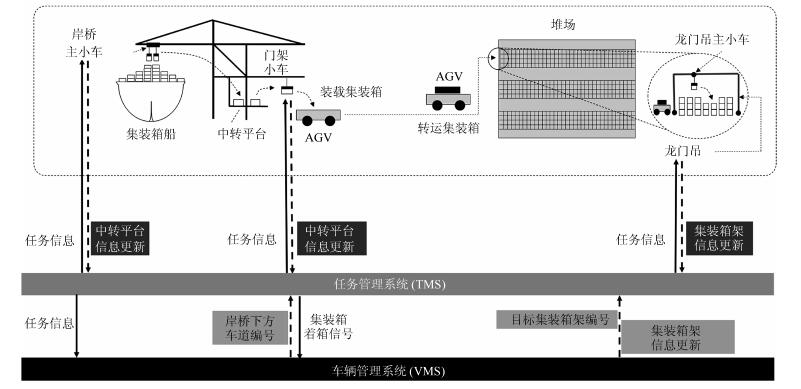
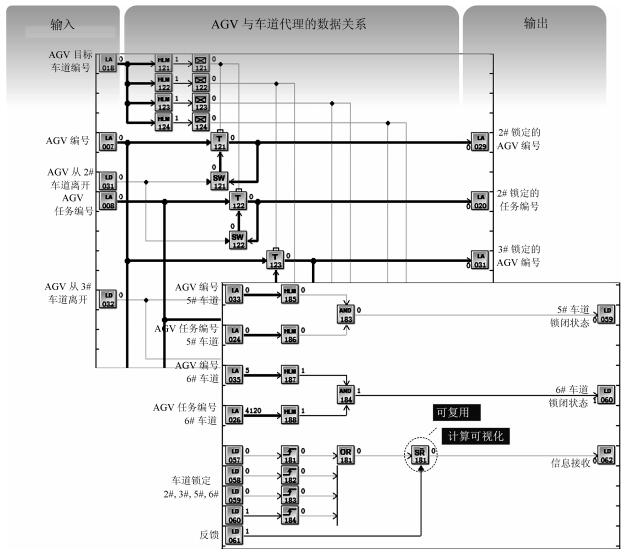
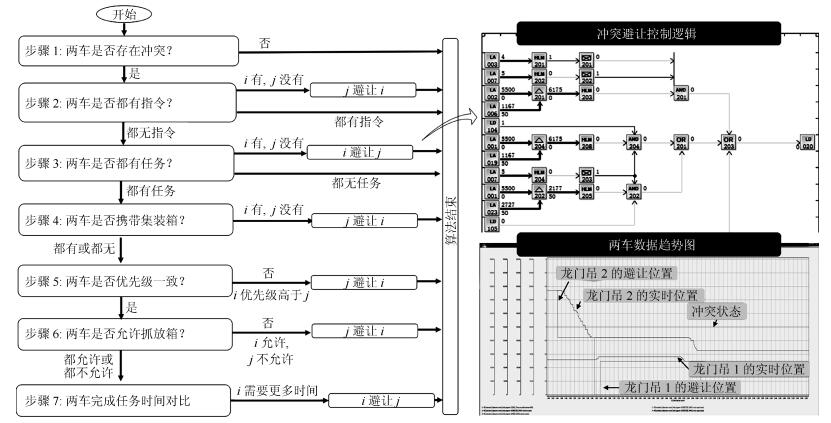
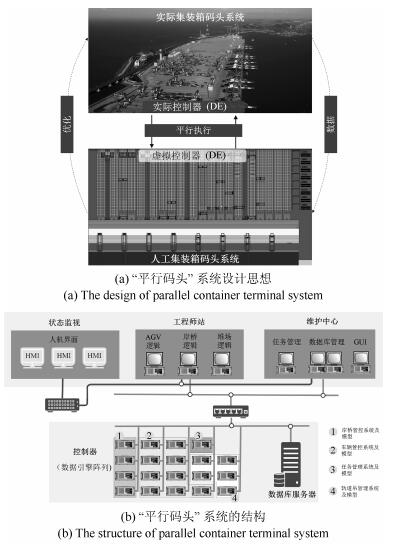
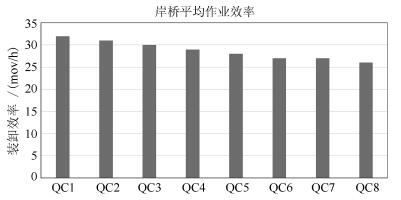
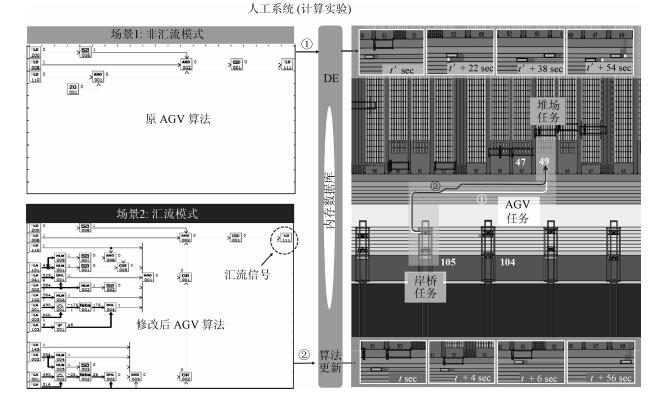
平行系统是一种建立在人工社会和计算实验基础上的科学研究方法,它的特点是既能真实反映现实系统的动态过程,又能实时优化现实系统的控制过程.自动化集装箱码头是一类典型的复杂系统,既存在不计其数的作业方案,同时也有大量的约束条件.如何在最短时间和最低能源消耗的前提下,完成具有间歇和批次特征的集装箱转运任务,是涉及到数学、控制、管理和计算机等多个学科的重大课题.本文采用数据引擎作为人工社会中的基本计算单元,构成一个复杂的平行系统,用于自动化集装箱码头信息控制系统的研究.数据引擎作为一种面向图形化元件组态的计算环境,非常适用于复杂系统的建模与计算.在可视化和动态重构技术的支持下,利用380个数据引擎对一个具有8台岸桥、25辆AGV和16台龙门吊组成的港机系统进行了自动化作业过程的计算实验.研究结果表明,数据引擎技术是实现平行系统的有效方法,由多数据引擎组成的计算环境,能够大幅度降低自动化集装箱码头信息控制系统建模的复杂程度,能够将码头系统的管理和控制过程无缝地融合在一起.该平行系统可直接与港机设备对接,建立“人工码头”和“物理码头”之间的平行关系,从而实现对港机设备的最优控制.
平行系统是一种建立在人工社会和计算实验基础上的科学研究方法,它的特点是既能真实反映现实系统的动态过程,又能实时优化现实系统的控制过程.自动化集装箱码头是一类典型的复杂系统,既存在不计其数的作业方案,同时也有大量的约束条件.如何在最短时间和最低能源消耗的前提下,完成具有间歇和批次特征的集装箱转运任务,是涉及到数学、控制、管理和计算机等多个学科的重大课题.本文采用数据引擎作为人工社会中的基本计算单元,构成一个复杂的平行系统,用于自动化集装箱码头信息控制系统的研究.数据引擎作为一种面向图形化元件组态的计算环境,非常适用于复杂系统的建模与计算.在可视化和动态重构技术的支持下,利用380个数据引擎对一个具有8台岸桥、25辆AGV和16台龙门吊组成的港机系统进行了自动化作业过程的计算实验.研究结果表明,数据引擎技术是实现平行系统的有效方法,由多数据引擎组成的计算环境,能够大幅度降低自动化集装箱码头信息控制系统建模的复杂程度,能够将码头系统的管理和控制过程无缝地融合在一起.该平行系统可直接与港机设备对接,建立“人工码头”和“物理码头”之间的平行关系,从而实现对港机设备的最优控制.


2019, 45(3): 505-517.
doi: 10.16383/j.aas.2018.c170438
cstr: 32138.14.j.aas.2018.c170438
摘要:
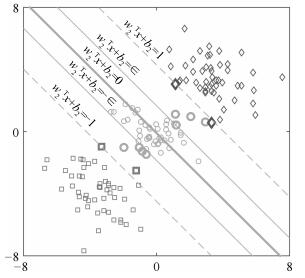
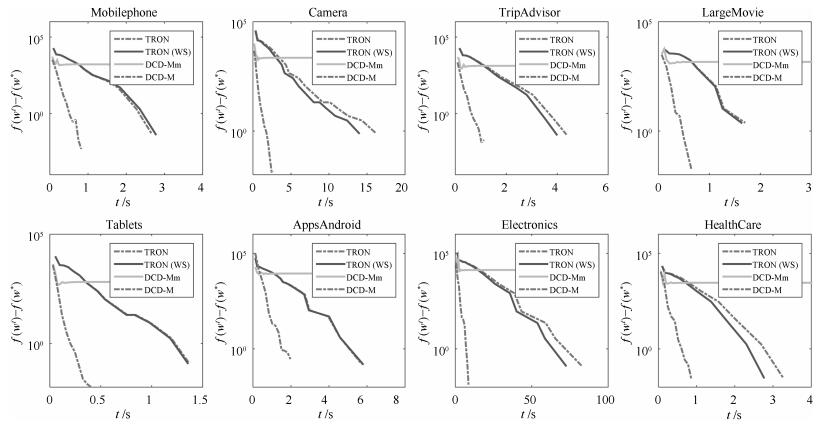
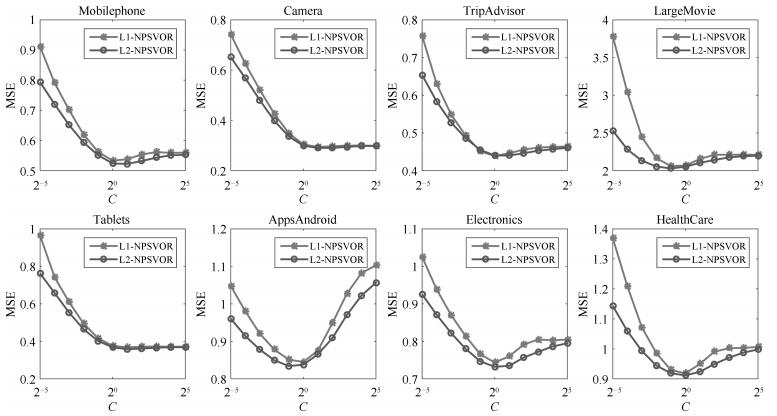
顺序回归是一种标签具有序信息的多分类问题,广泛存在于信息检索、推荐系统、情感分析等领域.随着互联网、移动通信等技术的发展,面对大量具有大规模、高维、稀疏等特征的数据,传统的顺序回归算法往往表现不足.非平行支持向量顺序回归模型具有适应性强,在性能上优于其他基于SVM的方法等优点,该文在此模型基础上提出基于L2损失的大规模线性非平行支持向量顺序回归模型,其中线性模型的设计可处理大规模数据,基于L2的损失可使标签偏离较大的样本得到更大惩罚.此外,该文从模型的两种不同角度分别设计了信赖域牛顿算法和坐标下降算法求解该线性模型,并比较了两种算法在性能上的差异.为验证模型的有效性,该文在大量数据集上对提出的模型及算法进行了分析,结果表明,该文提出的模型表现最优,尤其采用坐标下降算法求解的该模型在数据集上获得了最好的测试性能.
顺序回归是一种标签具有序信息的多分类问题,广泛存在于信息检索、推荐系统、情感分析等领域.随着互联网、移动通信等技术的发展,面对大量具有大规模、高维、稀疏等特征的数据,传统的顺序回归算法往往表现不足.非平行支持向量顺序回归模型具有适应性强,在性能上优于其他基于SVM的方法等优点,该文在此模型基础上提出基于L2损失的大规模线性非平行支持向量顺序回归模型,其中线性模型的设计可处理大规模数据,基于L2的损失可使标签偏离较大的样本得到更大惩罚.此外,该文从模型的两种不同角度分别设计了信赖域牛顿算法和坐标下降算法求解该线性模型,并比较了两种算法在性能上的差异.为验证模型的有效性,该文在大量数据集上对提出的模型及算法进行了分析,结果表明,该文提出的模型表现最优,尤其采用坐标下降算法求解的该模型在数据集上获得了最好的测试性能.

2019, 45(3): 518-529.
doi: 10.16383/j.aas.2018.c170245
cstr: 32138.14.j.aas.2018.c170245
摘要:
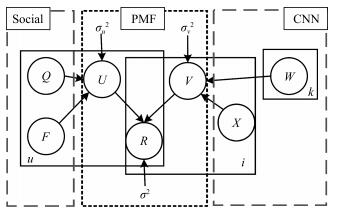
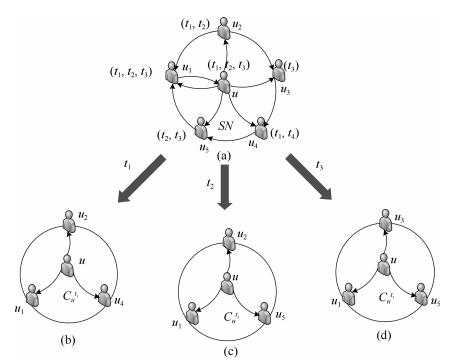
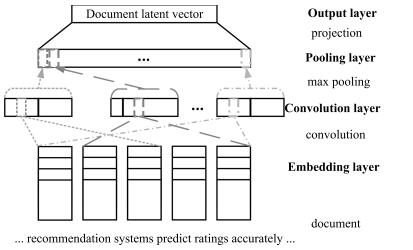
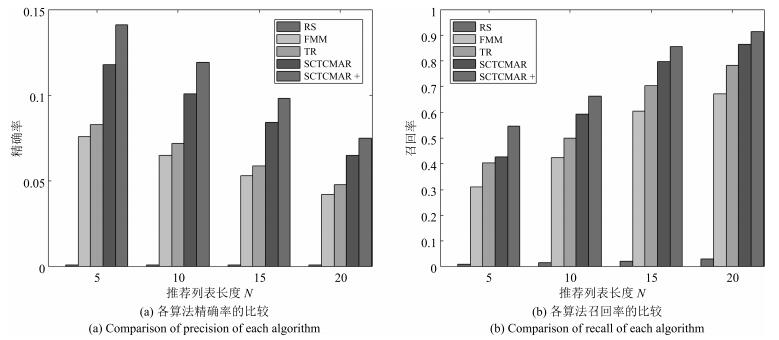
汽车作为较高价值和个性化的消费品,使得用户购车决策过程较一般商品更为复杂.本文主要研究社交环境和评论文本两方面对用户购车决策过程的影响,提出了融合社交因素和评论文本卷积网络的汽车推荐模型(Social and comment text CNN model based automobile recommendation,SCTCMAR).SCTCMAR首先定义了基于购买用途需求的社交圈,在此基础上提出了个人偏好计算方法,并引入了偏好相似度;其次,设计了卷积网络模型学习汽车评论文本的隐特征;然后将社交影响量化因素和评论文本特征有机融合注入推荐模型,并采用低阶矩阵分解技术进行模型计算.另外,本文使用GloVe预训练词嵌入模型,产生了SCTCMAR的另一个版本SCTCMAR+.最后,将SCTCMAR、SCTCMAR、FMM(Flexible mixture model)、TR(Trust rank)、Random sampling在课题组爬取后经清理、去重和整合的266995个用户、702辆汽车信息的真实数据集上进行精确率、召回率和平均倒序排名三个指标的多粒度实验比较,结果表明本文提出的SCTCMAR+和SCTCMAR具有良好的推荐性能.
汽车作为较高价值和个性化的消费品,使得用户购车决策过程较一般商品更为复杂.本文主要研究社交环境和评论文本两方面对用户购车决策过程的影响,提出了融合社交因素和评论文本卷积网络的汽车推荐模型(Social and comment text CNN model based automobile recommendation,SCTCMAR).SCTCMAR首先定义了基于购买用途需求的社交圈,在此基础上提出了个人偏好计算方法,并引入了偏好相似度;其次,设计了卷积网络模型学习汽车评论文本的隐特征;然后将社交影响量化因素和评论文本特征有机融合注入推荐模型,并采用低阶矩阵分解技术进行模型计算.另外,本文使用GloVe预训练词嵌入模型,产生了SCTCMAR的另一个版本SCTCMAR+.最后,将SCTCMAR、SCTCMAR、FMM(Flexible mixture model)、TR(Trust rank)、Random sampling在课题组爬取后经清理、去重和整合的266995个用户、702辆汽车信息的真实数据集上进行精确率、召回率和平均倒序排名三个指标的多粒度实验比较,结果表明本文提出的SCTCMAR+和SCTCMAR具有良好的推荐性能.


2019, 45(3): 530-539.
doi: 10.16383/j.aas.c170617
cstr: 32138.14.j.aas.c170617
摘要:
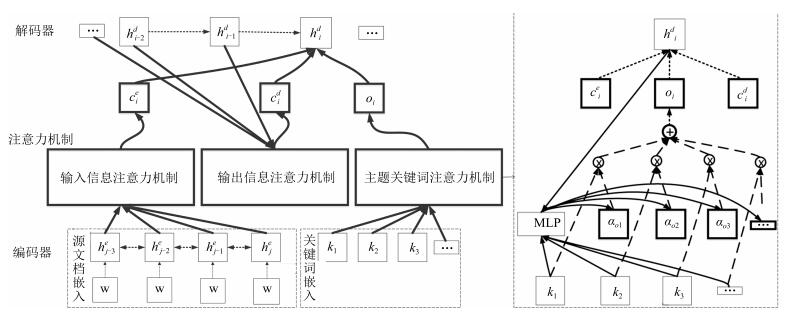
随着大数据和人工智能技术的迅猛发展,传统自动文摘研究正朝着从抽取式摘要到生成式摘要的方向演化,从中达到生成更高质量的自然流畅的文摘的目的.近年来,深度学习技术逐渐被应用于生成式摘要研究中,其中基于注意力机制的序列到序列模型已成为应用最广泛的模型之一,尤其在句子级摘要生成任务(如新闻标题生成、句子压缩等)中取得了显著的效果.然而,现有基于神经网络的生成式摘要模型绝大多数将注意力均匀分配到文本的所有内容中,而对其中蕴含的重要主题信息并没有细致区分.鉴于此,本文提出了一种新的融入主题关键词信息的多注意力序列到序列模型,通过联合注意力机制将文本中主题下重要的一些关键词语的信息与文本语义信息综合起来实现对摘要的引导生成.在NLPCC 2017的中文单文档摘要评测数据集上的实验结果验证了所提方法的有效性和先进性.
随着大数据和人工智能技术的迅猛发展,传统自动文摘研究正朝着从抽取式摘要到生成式摘要的方向演化,从中达到生成更高质量的自然流畅的文摘的目的.近年来,深度学习技术逐渐被应用于生成式摘要研究中,其中基于注意力机制的序列到序列模型已成为应用最广泛的模型之一,尤其在句子级摘要生成任务(如新闻标题生成、句子压缩等)中取得了显著的效果.然而,现有基于神经网络的生成式摘要模型绝大多数将注意力均匀分配到文本的所有内容中,而对其中蕴含的重要主题信息并没有细致区分.鉴于此,本文提出了一种新的融入主题关键词信息的多注意力序列到序列模型,通过联合注意力机制将文本中主题下重要的一些关键词语的信息与文本语义信息综合起来实现对摘要的引导生成.在NLPCC 2017的中文单文档摘要评测数据集上的实验结果验证了所提方法的有效性和先进性.

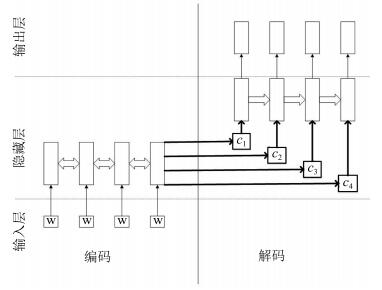
2019, 45(3): 540-552.
doi: 10.16383/j.aas.2018.c170549
cstr: 32138.14.j.aas.2018.c170549
摘要:
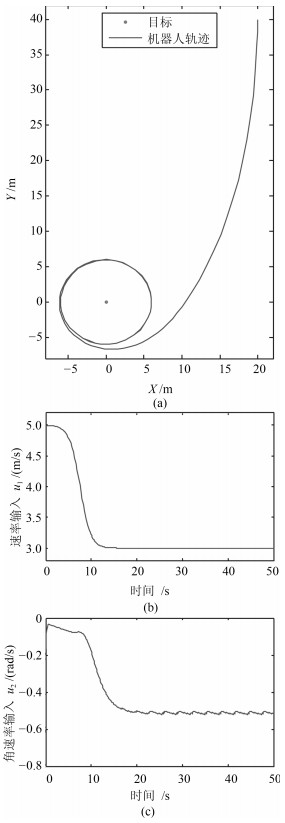
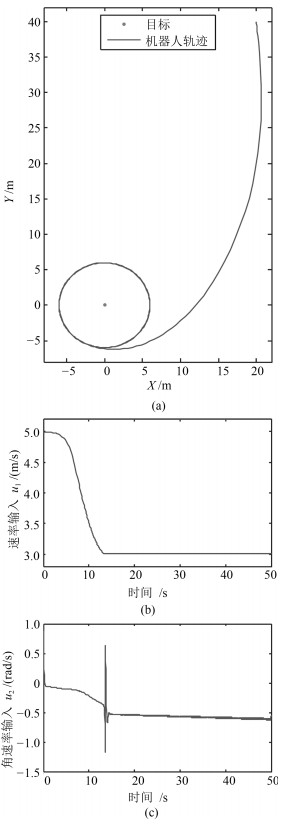
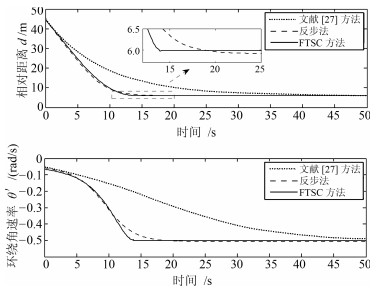
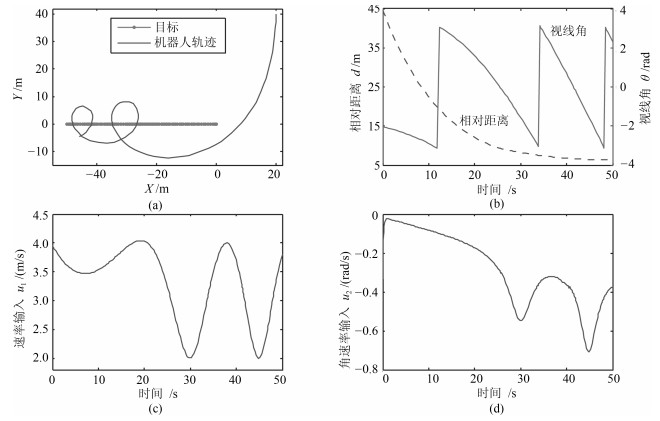
以二维运动目标的环航跟踪为背景,在非完整机器人速度受限情形下,设计了一类以规定环绕速率沿固定半径跟踪目标的控制器.首先,由极坐标系下的环航系统模型,利用反步法给出了一种使系统达到渐近稳定的控制器.进一步,考虑机器人在有限时间内达到跟踪要求的工程需求,利用饱和函数和Lyapunov稳定性理论,设计了一种使机器人运动轨迹在有限时间内收敛到期望轨迹的有限时间饱和控制器.最后,数值算例验证了所提控制律的有效性.
以二维运动目标的环航跟踪为背景,在非完整机器人速度受限情形下,设计了一类以规定环绕速率沿固定半径跟踪目标的控制器.首先,由极坐标系下的环航系统模型,利用反步法给出了一种使系统达到渐近稳定的控制器.进一步,考虑机器人在有限时间内达到跟踪要求的工程需求,利用饱和函数和Lyapunov稳定性理论,设计了一种使机器人运动轨迹在有限时间内收敛到期望轨迹的有限时间饱和控制器.最后,数值算例验证了所提控制律的有效性.
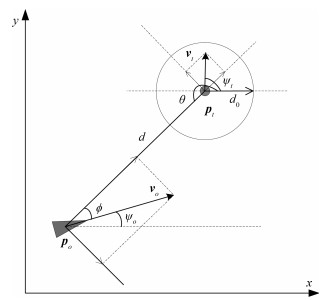
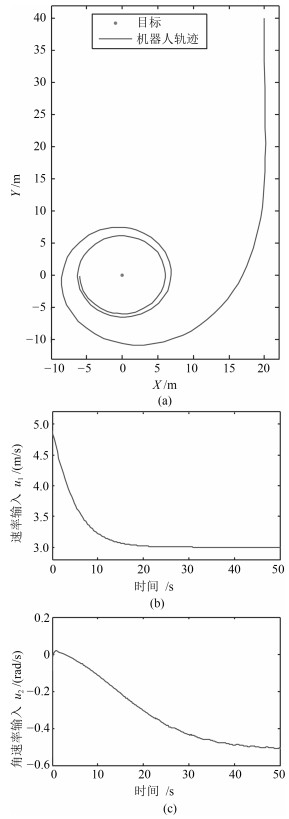

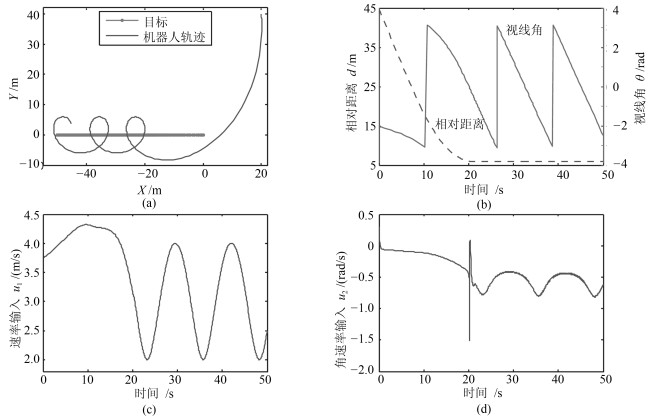
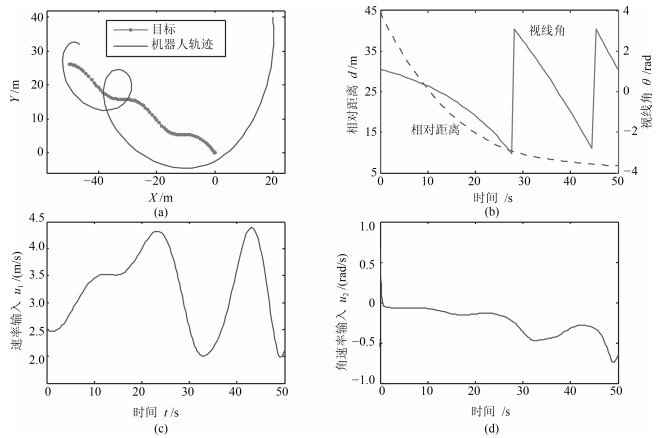
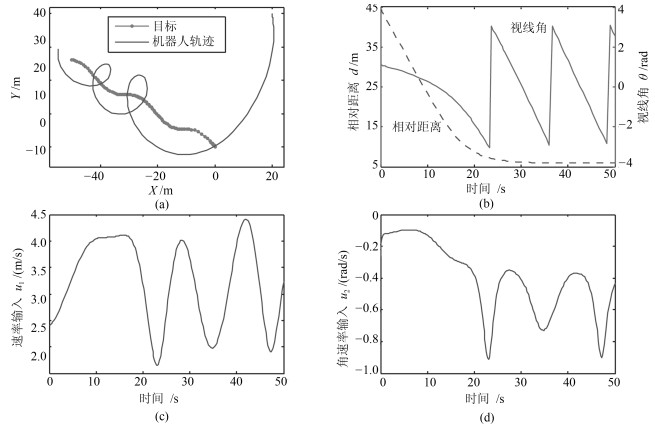
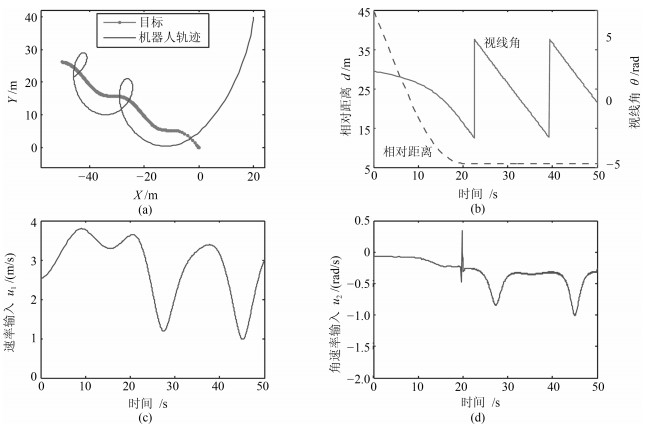
2019, 45(3): 553-565.
doi: 10.16383/j.aas.c170608
cstr: 32138.14.j.aas.c170608
摘要:
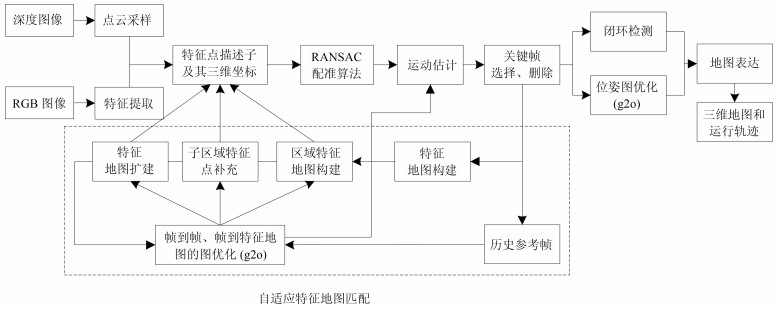
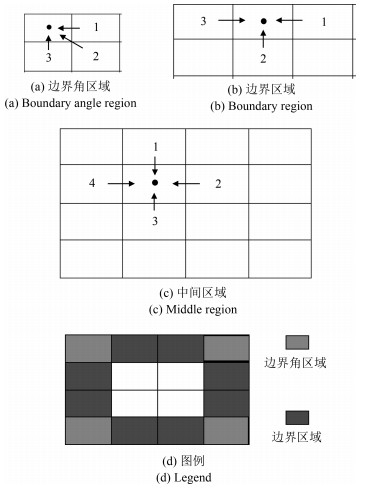
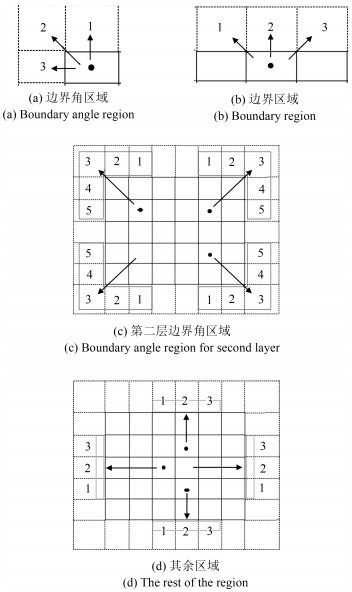
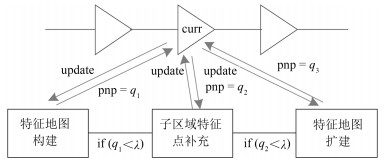
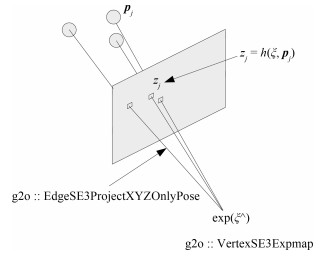
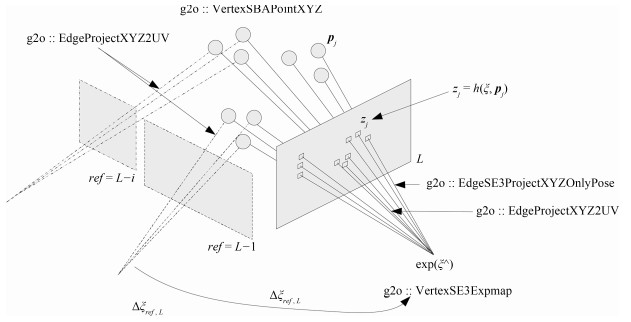
从提高机器人视觉同时定位与地图构建(Visual simultaneous localization and mapping,VSLAM)算法的实时性出发,在VSLAM的视觉里程计中提出一种自适应特征地图配准的算法.首先,针对视觉里程计中特征地图信息冗余、耗费计算资源的问题,划分特征地图子区域并作为结构单元,再根据角点响应强度指标大小提取子区域中少数高效的特征点,以较小规模的特征地图配准各帧:针对自适应地图配准时匹配个数不满足的情况,提出一种区域特征点补充和特征地图扩建的方法,快速实现该情形下当前帧的再次匹配:为了提高视觉里程计中位姿估计的精度,提出一种帧到帧、帧到模型的g2o(General graph optimization)特征地图优化模型,更加有效地更新特征地图的内点和外点.通用数据集的实验表明,所提方法的定位精度误差在厘米级,生成的点云地图清晰、漂移少,相比于其他算法,具有更好的实时性、定位精度以及建图能力.
从提高机器人视觉同时定位与地图构建(Visual simultaneous localization and mapping,VSLAM)算法的实时性出发,在VSLAM的视觉里程计中提出一种自适应特征地图配准的算法.首先,针对视觉里程计中特征地图信息冗余、耗费计算资源的问题,划分特征地图子区域并作为结构单元,再根据角点响应强度指标大小提取子区域中少数高效的特征点,以较小规模的特征地图配准各帧:针对自适应地图配准时匹配个数不满足的情况,提出一种区域特征点补充和特征地图扩建的方法,快速实现该情形下当前帧的再次匹配:为了提高视觉里程计中位姿估计的精度,提出一种帧到帧、帧到模型的g2o(General graph optimization)特征地图优化模型,更加有效地更新特征地图的内点和外点.通用数据集的实验表明,所提方法的定位精度误差在厘米级,生成的点云地图清晰、漂移少,相比于其他算法,具有更好的实时性、定位精度以及建图能力.

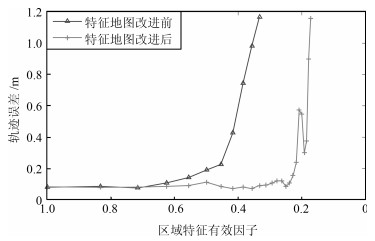


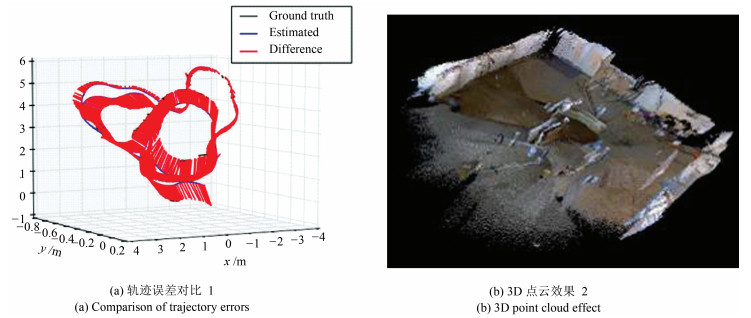
2019, 45(3): 566-576.
doi: 10.16383/j.aas.c170530
cstr: 32138.14.j.aas.c170530
摘要:
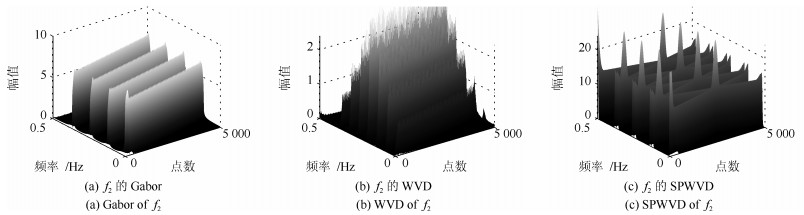
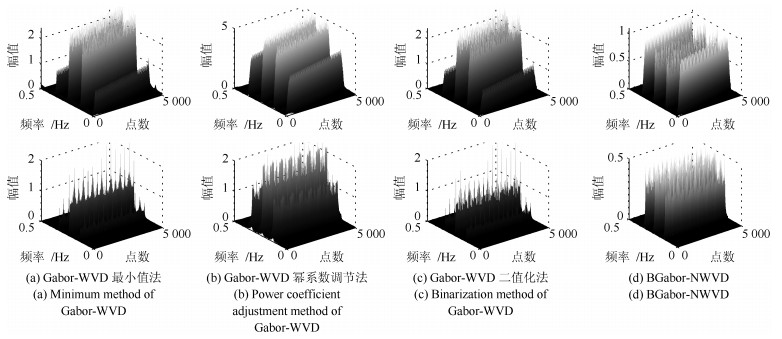
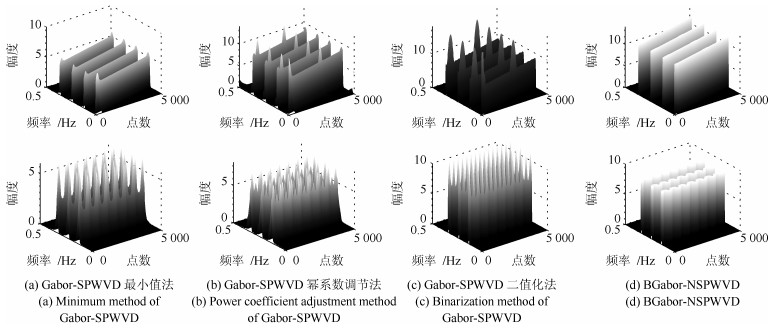
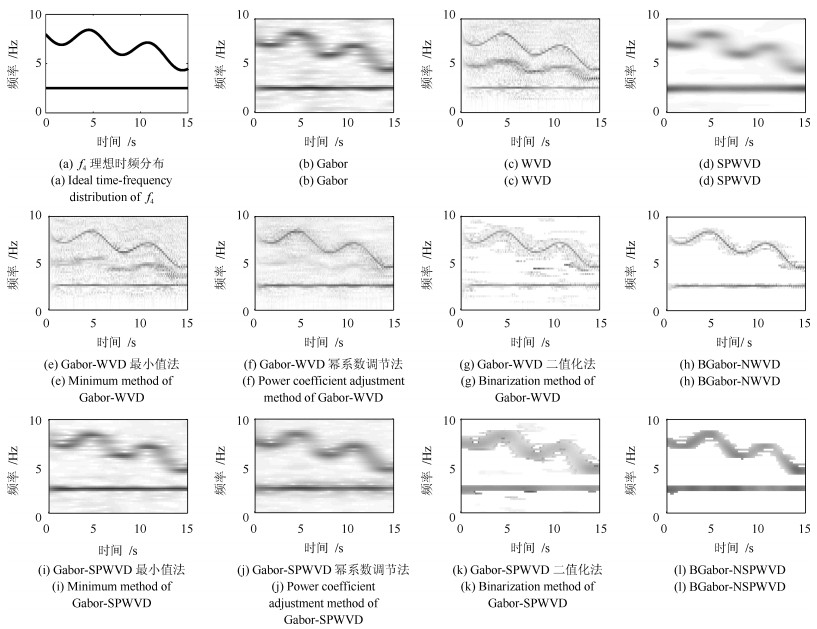
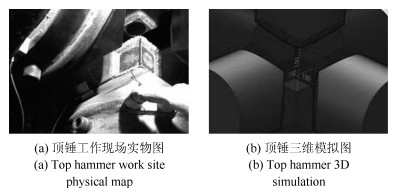
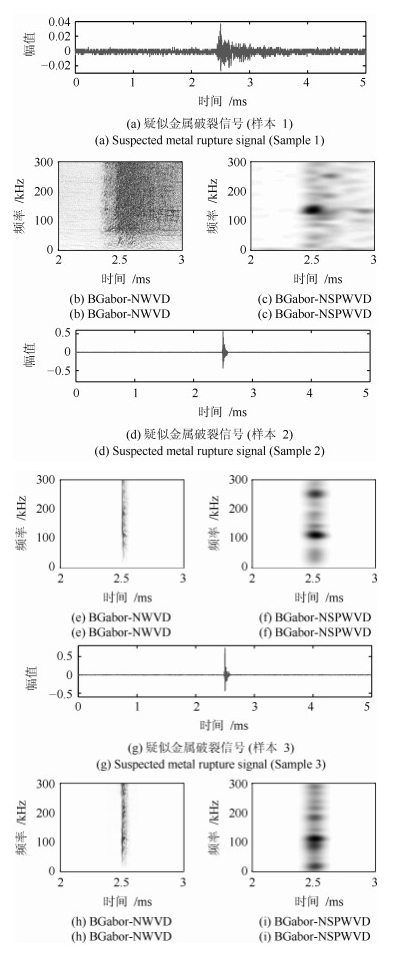
针对短时傅里叶变换(Short-time Fourier transform,STFT)、Gabor变换和魏格纳-维尔分布(Wigner-Ville distribution,WVD)出现的时频分辨率模糊和交叉项干扰,以及目前一些主流改进算法如STFT-WVD和Gabor-WVD存在的频率分量三维幅度失真,且抗噪性能及鲁棒性能不理想等问题,提出基于局部二值化、归一化处理再结合的二值化Gabor-归一化WVD(Binarized Gabor-normalized WVD,BGabor-NWVD)和二值化Gabor-归一化伪平滑WVD(Binarized Gabor-normalized smoothed pseudo WVD,BGabor-NSPWVD)算法.数值仿真实验结果表明,BGabor-NWVD和BGabor-NSPWVD算法较好地抑制了交叉项干扰,具有较高的时频锐化聚集度,且两种算法的抗噪性能和鲁棒性也较为理想.基于本文方法对硬质合金顶锤工作时产生的疑似破裂信号进行时频分析,在抑制噪声和交叉项的同时能够较为准确地寻找传感器的频率判别窗口,为金属破裂监测设备数据采集卡提供有效的阈值参考.
针对短时傅里叶变换(Short-time Fourier transform,STFT)、Gabor变换和魏格纳-维尔分布(Wigner-Ville distribution,WVD)出现的时频分辨率模糊和交叉项干扰,以及目前一些主流改进算法如STFT-WVD和Gabor-WVD存在的频率分量三维幅度失真,且抗噪性能及鲁棒性能不理想等问题,提出基于局部二值化、归一化处理再结合的二值化Gabor-归一化WVD(Binarized Gabor-normalized WVD,BGabor-NWVD)和二值化Gabor-归一化伪平滑WVD(Binarized Gabor-normalized smoothed pseudo WVD,BGabor-NSPWVD)算法.数值仿真实验结果表明,BGabor-NWVD和BGabor-NSPWVD算法较好地抑制了交叉项干扰,具有较高的时频锐化聚集度,且两种算法的抗噪性能和鲁棒性也较为理想.基于本文方法对硬质合金顶锤工作时产生的疑似破裂信号进行时频分析,在抑制噪声和交叉项的同时能够较为准确地寻找传感器的频率判别窗口,为金属破裂监测设备数据采集卡提供有效的阈值参考.
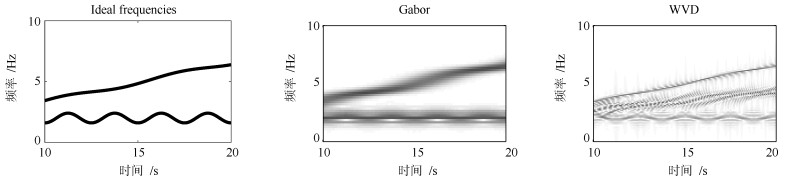

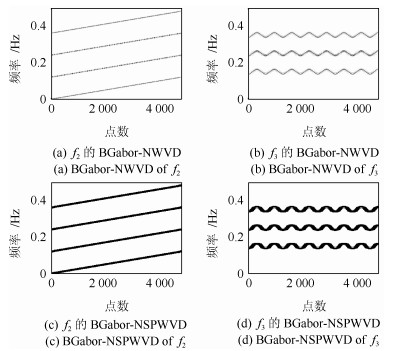

2019, 45(3): 577-592.
doi: 10.16383/j.aas.2018.c170441
cstr: 32138.14.j.aas.2018.c170441
摘要:
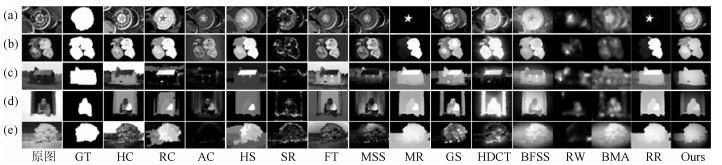
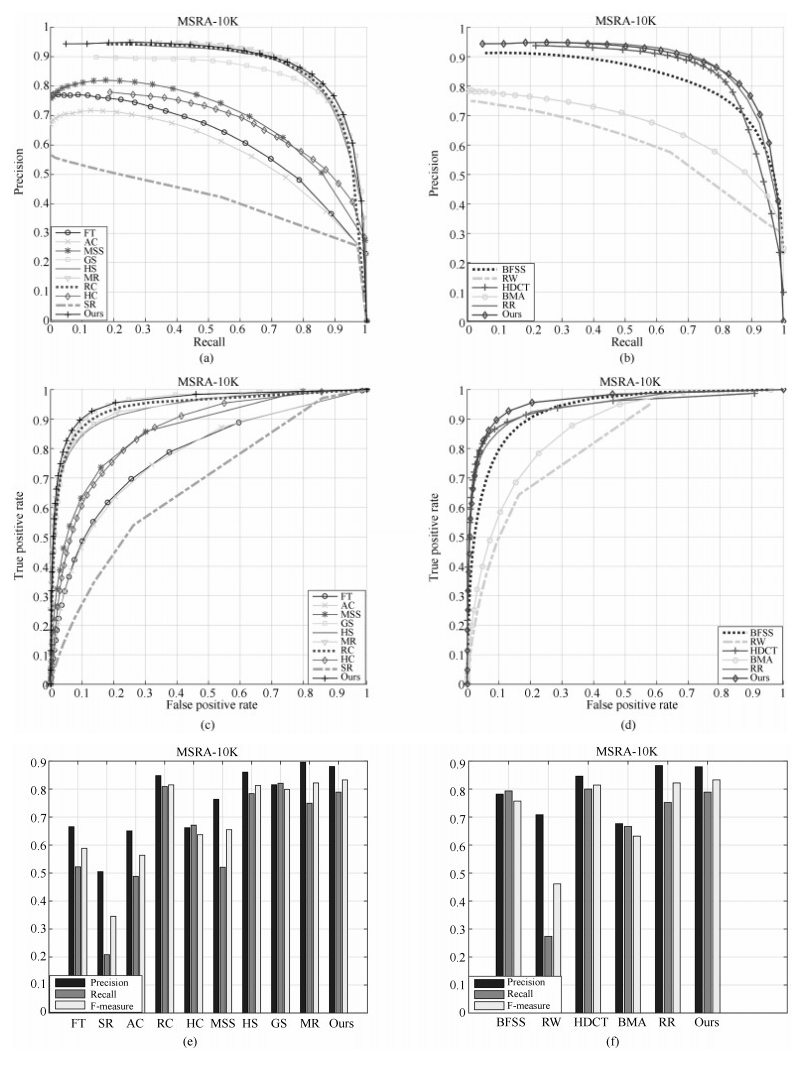
针对现有图像显著性检测算法中显著目标检测不完整和显著目标内部不均匀的问题,本文提出了一种基于多图流形排序的图像显著性检测算法.该算法以超像素为节点构造KNN图(K nearest neighbor graph)模型和K正则图(K regular graph)模型,分别在两种图模型上利用流形排序算法计算超像素节点的显著性值,并将每个图模型中超像素节点的显著值加权融合得到最终的显著图.在公开的MSRA-10K、SED2和ECSSD三个数据集上,将本文提出的算法与当前流行的14种算法进行对比,实验结果显示本文算法能够完整地检测出显著目标,并且显著目标内部均匀光滑.
针对现有图像显著性检测算法中显著目标检测不完整和显著目标内部不均匀的问题,本文提出了一种基于多图流形排序的图像显著性检测算法.该算法以超像素为节点构造KNN图(K nearest neighbor graph)模型和K正则图(K regular graph)模型,分别在两种图模型上利用流形排序算法计算超像素节点的显著性值,并将每个图模型中超像素节点的显著值加权融合得到最终的显著图.在公开的MSRA-10K、SED2和ECSSD三个数据集上,将本文提出的算法与当前流行的14种算法进行对比,实验结果显示本文算法能够完整地检测出显著目标,并且显著目标内部均匀光滑.






2019, 45(3): 593-603.
doi: 10.16383/j.aas.c170534
cstr: 32138.14.j.aas.c170534
摘要:
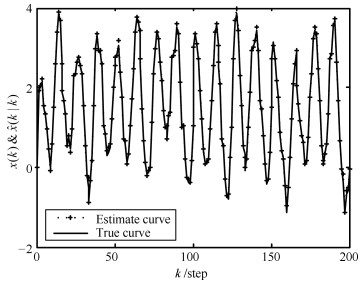
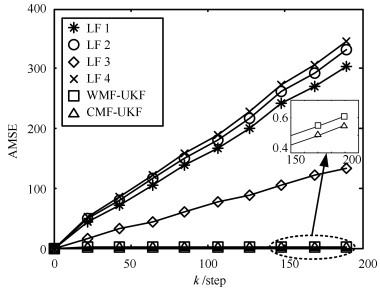
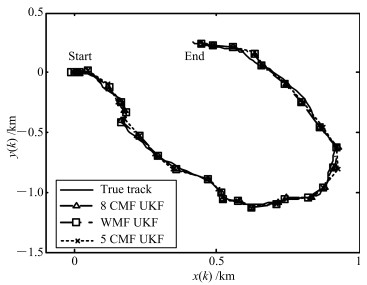
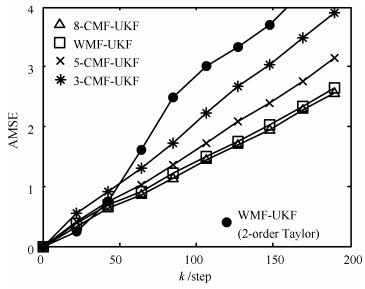
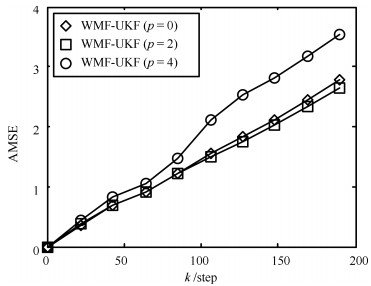
对非线性多传感器系统,基于Gauss-Hermite逼近方法和加权最小二乘法,提出了一种具有普适性的非线性加权观测融合算法.该算法可将一个高维观测压缩为一个低维观测.在此基础上,结合无迹Kalman滤波器(Unscented Kalman filter,UKF),提出了非线性加权观测融合无迹Kalman滤波器(WMF(Weighted measurement fusion)-UKF).与集中式融合UKF(CMF(Centralized measurement fusion)-UKF)相比,该算法计算负担小且具有逼近的估计精度.特别是在传感器数量较大时,该算法在计算量上的优势更加明显.仿真例子验证了算法的有效性.
对非线性多传感器系统,基于Gauss-Hermite逼近方法和加权最小二乘法,提出了一种具有普适性的非线性加权观测融合算法.该算法可将一个高维观测压缩为一个低维观测.在此基础上,结合无迹Kalman滤波器(Unscented Kalman filter,UKF),提出了非线性加权观测融合无迹Kalman滤波器(WMF(Weighted measurement fusion)-UKF).与集中式融合UKF(CMF(Centralized measurement fusion)-UKF)相比,该算法计算负担小且具有逼近的估计精度.特别是在传感器数量较大时,该算法在计算量上的优势更加明显.仿真例子验证了算法的有效性.

2019, 45(3): 604-616.
doi: 10.16383/j.aas.c170554
cstr: 32138.14.j.aas.c170554
摘要:
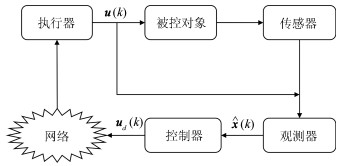
针对干扰作用下的非线性网络控制系统,给出了带一个自由控制作用的输出反馈预测控制方法.首先,利用区间二型T-S模糊模型描述具有参数不确定性的非线性对象,采用马尔科夫链描述系统中的随机丢包过程,由此建立了丢包网络环境下的非线性网络控制系统的数学模型.然后,通过引入二次有界技术得到了干扰作用下网络控制系统的稳定性描述方法,并在此基础上给出了状态观测器的线性矩阵不等式条件.最后,基于估计状态,通过将无穷时域控制作用参数化为一个自由控制作用加一个线性反馈律得到了输出反馈预测控制方法.论文的特色在于构建了在线更新误差椭圆集合的基本方法,满足了约束条件下输出反馈预测控制保证稳定性的要求.仿真例子验证了所提方法的有效性.
针对干扰作用下的非线性网络控制系统,给出了带一个自由控制作用的输出反馈预测控制方法.首先,利用区间二型T-S模糊模型描述具有参数不确定性的非线性对象,采用马尔科夫链描述系统中的随机丢包过程,由此建立了丢包网络环境下的非线性网络控制系统的数学模型.然后,通过引入二次有界技术得到了干扰作用下网络控制系统的稳定性描述方法,并在此基础上给出了状态观测器的线性矩阵不等式条件.最后,基于估计状态,通过将无穷时域控制作用参数化为一个自由控制作用加一个线性反馈律得到了输出反馈预测控制方法.论文的特色在于构建了在线更新误差椭圆集合的基本方法,满足了约束条件下输出反馈预测控制保证稳定性的要求.仿真例子验证了所提方法的有效性.

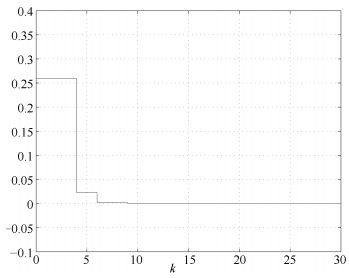
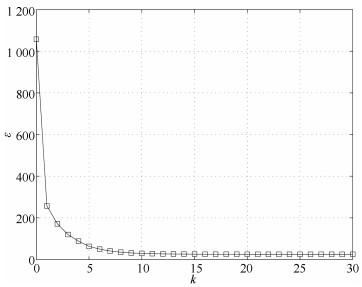
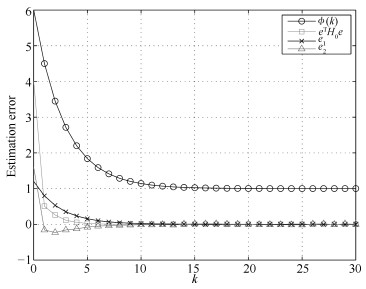

2019, 45(3): 617-625.
doi: 10.16383/j.aas.c170389
cstr: 32138.14.j.aas.c170389
摘要:
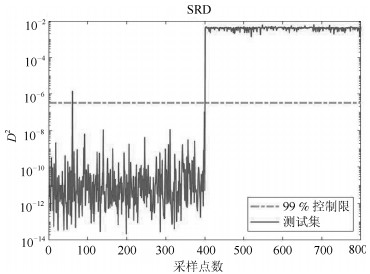
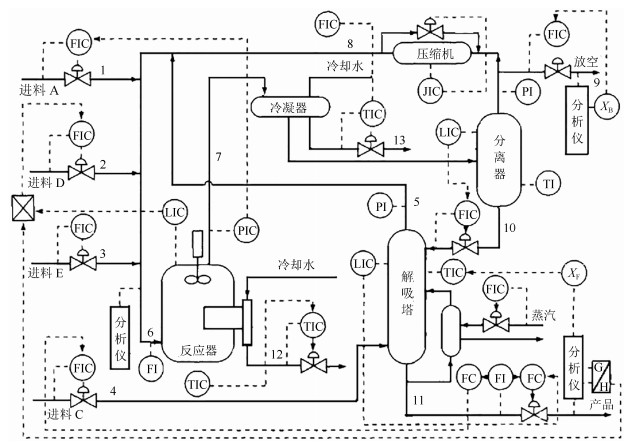
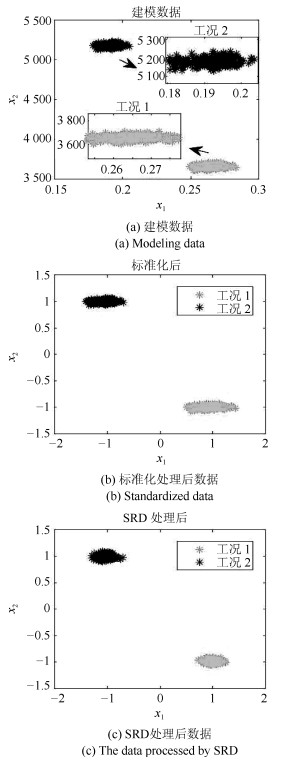
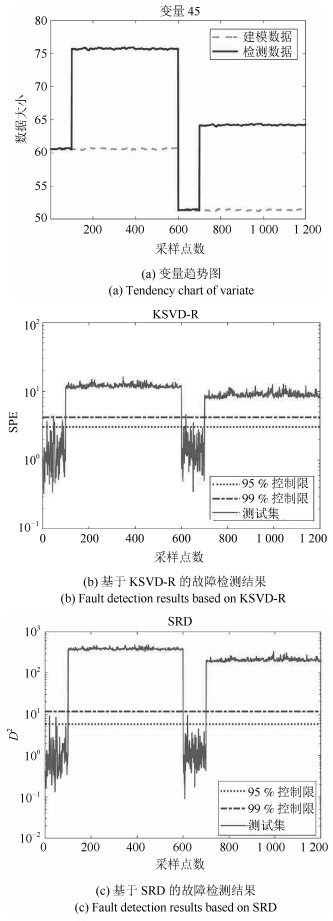
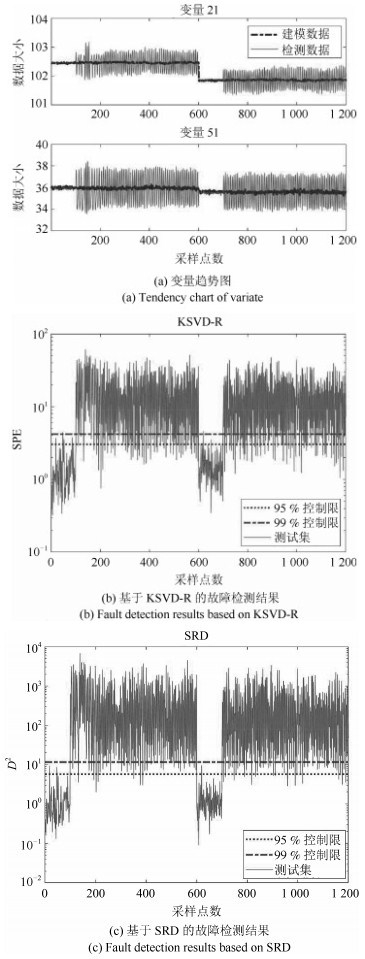
针对多工况过程,本文提出一种新的基于稀疏残差距离(Sparse residual distance,SRD)统计指标的故障检测方法.首先对正常的多工况标准化后数据直接进行稀疏分解,提取多个工况数据间相关关系,得到字典和对应的稀疏编码,以便构建全局检测模型,避免分工况且突出数据特征.然后计算正常多工况数据的近似值,构建稀疏残差空间,提出计算稀疏残差k近邻距离构建故障检测统计量,利用k近邻捕捉过程具有的非线性、多工况特征.最后通过数值案例和TE(Tennessee Eastman)生产过程进行仿真实验,验证了所提方法的有效性.
针对多工况过程,本文提出一种新的基于稀疏残差距离(Sparse residual distance,SRD)统计指标的故障检测方法.首先对正常的多工况标准化后数据直接进行稀疏分解,提取多个工况数据间相关关系,得到字典和对应的稀疏编码,以便构建全局检测模型,避免分工况且突出数据特征.然后计算正常多工况数据的近似值,构建稀疏残差空间,提出计算稀疏残差k近邻距离构建故障检测统计量,利用k近邻捕捉过程具有的非线性、多工况特征.最后通过数值案例和TE(Tennessee Eastman)生产过程进行仿真实验,验证了所提方法的有效性.
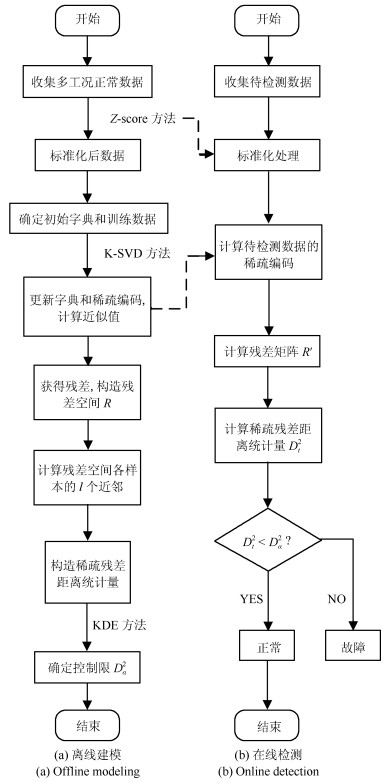

2019, 45(3): 626-636.
doi: 10.16383/j.aas.2018.c170294
cstr: 32138.14.j.aas.2018.c170294
摘要:
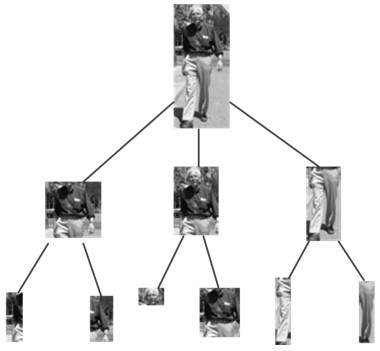
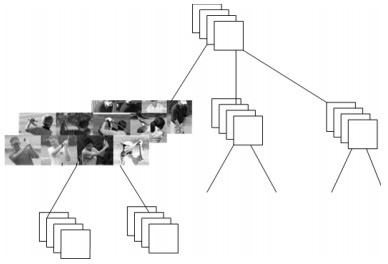
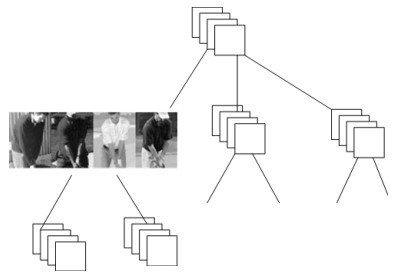
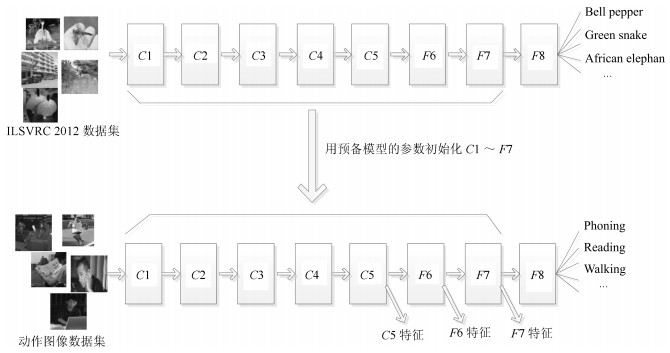
人体姿态是动作识别的重要语义线索,而CNN能够从图像中提取有很强判别能力的深度特征,本文从图像局部区域提取姿态特征,从整体图像中提取深度特征,探索两者在动作识别中的互补作用.首先介绍了一种姿态表示方法,每个肢体部件的姿态由描述该部件姿态的一组Poselet检测得分表示.为了抑制检测错误,设计了基于部件的模型作为检测上下文.为了从数量有限的数据集中训练CNN网络,本文使用了预训练和精细调节的方法.在两个数据集中的实验表明,本文介绍的姿态特征与深度特征混合使用,动作识别性能得到了极大提升.
人体姿态是动作识别的重要语义线索,而CNN能够从图像中提取有很强判别能力的深度特征,本文从图像局部区域提取姿态特征,从整体图像中提取深度特征,探索两者在动作识别中的互补作用.首先介绍了一种姿态表示方法,每个肢体部件的姿态由描述该部件姿态的一组Poselet检测得分表示.为了抑制检测错误,设计了基于部件的模型作为检测上下文.为了从数量有限的数据集中训练CNN网络,本文使用了预训练和精细调节的方法.在两个数据集中的实验表明,本文介绍的姿态特征与深度特征混合使用,动作识别性能得到了极大提升.