

-
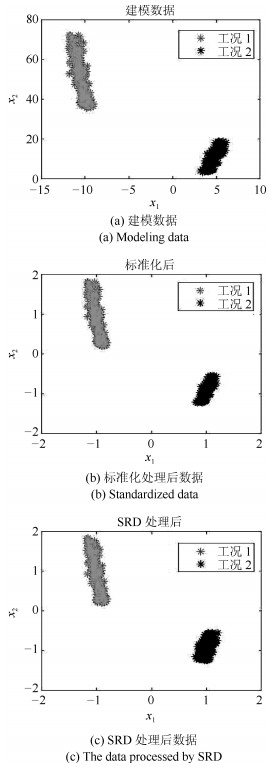
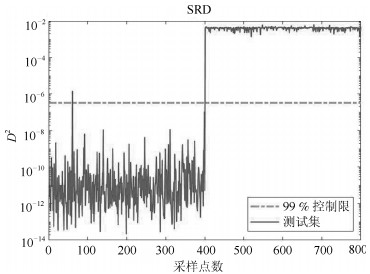
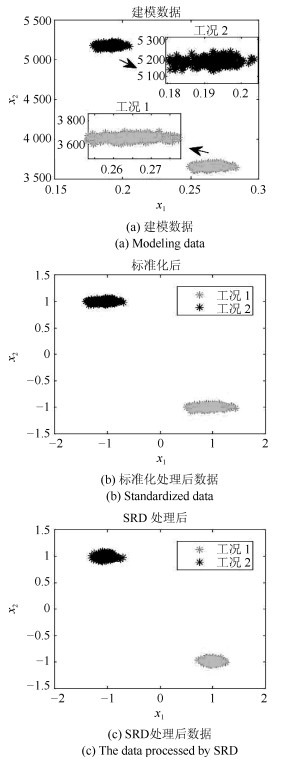
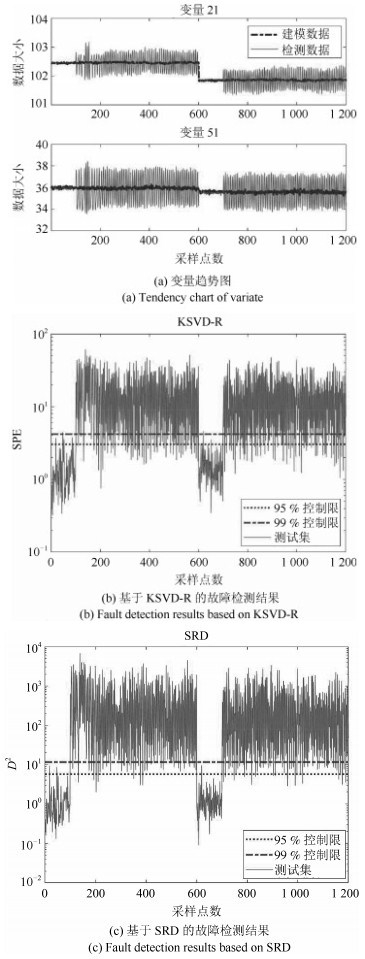
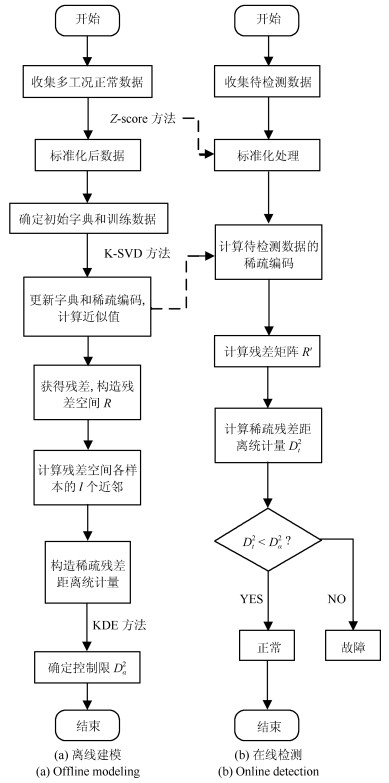
摘要: 针对多工况过程,本文提出一种新的基于稀疏残差距离(Sparse residual distance,SRD)统计指标的故障检测方法.首先对正常的多工况标准化后数据直接进行稀疏分解,提取多个工况数据间相关关系,得到字典和对应的稀疏编码,以便构建全局检测模型,避免分工况且突出数据特征.然后计算正常多工况数据的近似值,构建稀疏残差空间,提出计算稀疏残差k近邻距离构建故障检测统计量,利用k近邻捕捉过程具有的非线性、多工况特征.最后通过数值案例和TE(Tennessee Eastman)生产过程进行仿真实验,验证了所提方法的有效性.Abstract: For multi-mode processes, a new fault detection method employing sparse residual distance (SRD) is proposed in this paper. Firstly, standardized normal multi-mode process data is directly used for sparse decomposition to extract correlation between multi-mode data, and a global detection model is established using the obtained dictionary and corresponding sparse coding, so as to avoid distinguishing modes and highlight data characteristics. Then calculating the approximate value of the normal multi-mode process data to construct the sparse residual space, in which sparse residual k-nearest neighbor distance is proposed, thus the nonlinear and multi-mode features of the process can be captured further by using k-nearest neighbor. Finally, the effectiveness of the proposed method is verified by a numerical example and the Tennessee Eastman (TE) production process.1) 本文责任编委 王伟
-
表 1 TE过程故障
Table 1 Failures of TE process
故障编号 性质描述 变化类型 IDV 1 物料A/C进料比改变, 物料B含量不变 阶跃 IDV 2 物料A/C进料比不变, 物料B含量改变 阶跃 IDV 4 反应器冷却入口温度改变 阶跃 IDV 6 物料A进料损失 阶跃 IDV 7 物料C压力损失 阶跃 IDV 13 反应动力学参数改变 慢偏移 IDV 16 未知 未知  下载: 导出CSV
下载: 导出CSV
表 2 本文采用的TE过程生产模式
Table 2 TE process production model used in this paper
生产模式 G/H比率 产品生产率 1 50/50 7 038 kgh-1 G和7 038 kgh-1 H 3 90/10 1 000 kgh-1 G和1 111 kgh-1 H "kgh-1 G"表示"每小时生产多少千克的G产品", "kgh-1 H"表示"每小时生产多少千克的H产品".
下载: 导出CSV
表 3 误报率及检测率汇总表
Table 3 False alarm rate and detection rate summary table
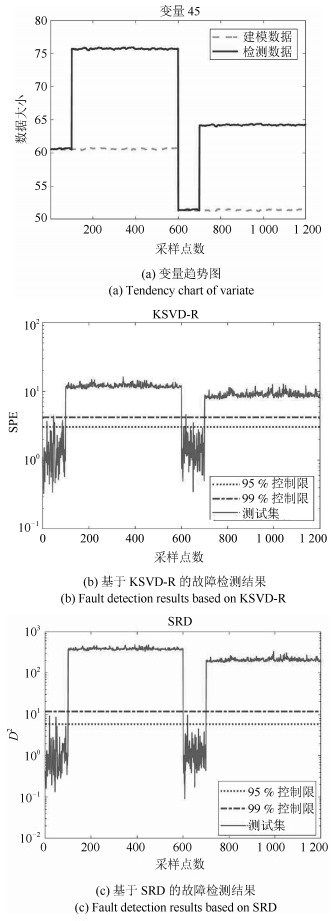
故障号 KSVD-R SRD 误报率(%) 检测率(%) 误报率(%) 检测率(%) 1 4.50 0.10 100 100 2.00 0 100 100 2 4.50 0.10 100 98.6 2.00 0 100 100 4 4.50 0.10 100 100 2.00 0 100 100 6 4.50 0.10 100 100 2.00 0 100 100 7 4.50 0.10 100 100 2.00 0 100 100 13 4.50 0.10 89.6 82.1 2.00 0 97.8 90.2 16 4.50 0.10 94.6 90.2 2.00 0 98.6 94.7 注1:表 3中误报率和漏报率下属两列数据, 靠前的一列为控制限为95%的数值, 靠后的一列为控制限为99%的数值
下载: 导出CSV
-
[1] 周东华, 李钢, 李元.数据驱动的工业过程故障诊断技术.北京:科学出版社, 2011.Zhou Dong-Hua, Li Gang, Li Yuan. Data-driven Based Process Fault Detection and Diagnosis Technology. Beijing:Science Press, 2011. [2] 卢春红.基于数据驱动的故障检测与诊断技术及其应用研究[博士学位论文], 江南大学, 中国, 2015Lu Chun-Hong. Research on Data-driven Fault Detection and Diagnosis Techniques and Their Applications[Ph.D. dissertation], Jiangnan University, China, 2015 [3] 许仙珍, 谢磊, 王树青.基于PCA混合模型的多工况过程监控.化工学报, 2011, 62(3):743-752 http://d.old.wanfangdata.com.cn/Periodical/hgxb201103023Xu Xian-Zhen, Xie Lie, Wang Shu-Qing. Multi-mode process monitoring method based on PCA mixture model. CIESC Journal, 2011, 62(3):743-752 http://d.old.wanfangdata.com.cn/Periodical/hgxb201103023 [4] 熊伟丽, 郭校根.一种基于多工况识别的过程在线监测方法研究.控制与决策, 2018, 33(3):403-412 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201803003.htmXiong Wei-Li, Guo Xiao-Gen. A process on-line monitoring method based on multi-mode identification. Control and Decision, 2018, 33(3):403-412 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201803003.htm [5] Ge Z Q, Song Z H. Bayesian inference and joint probability analysis for batch process monitoring. AIChE Journal, 2013, 59(10):3702-3713 doi: 10.1002/aic.14119 [6] Zhao C H. Concurrent phase partition and between-mode statistical analysis for multimode and multiphase batch process monitoring. AIChE Journal, 2014, 60(2):559-573 doi: 10.1002/aic.14282 [7] 孙贤昌, 田学民, 张妮.一种基于GMM的多工况过程故障诊断方法.计算机与应用化学, 2014, 31(1):33-39 http://d.old.wanfangdata.com.cn/Periodical/jsjyyyhx201401008Sun Xian-Chang, Tian Xue-Min, Zhang Ni. Multi-mode process fault diagnosis method based on GMM. Computers and Applied Chemistry, 2014, 31(1):33-39 http://d.old.wanfangdata.com.cn/Periodical/jsjyyyhx201401008 [8] 郭红杰, 徐春玲, 侍洪波.基于局部邻域标准化策略的多工况过程故障检测.上海交通大学学报, 2015, 49(6):868-875, 883 http://d.old.wanfangdata.com.cn/Periodical/shjtdxxb201506022Guo Hong-Jie, Xu Chun-Ling, Shi Hong-Bo. Multimode process monitoring based on local neighborhood standardization strategy. Journal of Shanghai Jiao Tong University, 2015, 49(6):868-875, 883 http://d.old.wanfangdata.com.cn/Periodical/shjtdxxb201506022 [9] 王国柱, 刘建昌, 李元, 商亮亮.加权k最近邻重构分析的工业过程故障诊断.控制理论与应用, 2015, 32(7):873-880 http://d.old.wanfangdata.com.cn/Periodical/kzllyyy201507003Wang Guo-Zhu, Liu Jian-Chang, Li Yuan, Shang Liang-Liang. Fault diagnosis of industrial processes based on weighted k-nearest neighbor reconstruction analysis. Control Theory & Applications, 2015, 32(7):873-880 http://d.old.wanfangdata.com.cn/Periodical/kzllyyy201507003 [10] Ge Z Q, Song Z H. Bagging support vector data description model for batch process monitoring. Journal of Process Control, 2013, 23(8):1090-1096 doi: 10.1016/j.jprocont.2013.06.010 [11] 钟娜, 邓晓刚, 徐莹.基于LECA的多工况过程故障检测方法.化工学报, 2015, 66(12):4929-4940 http://d.old.wanfangdata.com.cn/Periodical/hgxb201512029Zhong Na, Deng Xiao-Gang, Xu Ying. Fault detection method based on LECA for multimode process. CIESC Journal, 2015, 66(12):4929-4940 http://d.old.wanfangdata.com.cn/Periodical/hgxb201512029 [12] Ning C, Chen M Y, Zhou D H. Sparse contribution plot for fault diagnosis of multimodal chemical processes. IFAC-PapersOnLine, 2015, 48(21):619-626 doi: 10.1016/j.ifacol.2015.09.595 [13] 练秋生, 石保顺, 陈书贞.字典学习模型、算法及其应用研究进展.自动化学报, 2015, 41(2):240-260 http://www.aas.net.cn/CN/abstract/abstract18604.shtmlLian Qiu-Sheng, Shi Bao-Shun, Chen Shu-Zhen. Research advances on dictionary learning models, algorithms and applications. Acta Automatica Sinica, 2015, 41(2):240-260 http://www.aas.net.cn/CN/abstract/abstract18604.shtml [14] Tropp J A, Gilbert A C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Transactions on Information Theory, 2007, 53(12):4655-4666 doi: 10.1109/TIT.2007.909108 [15] 陈川.基于近邻规则的间歇过程故障检测算法研究[硕士学位论文], 电子科技大学, 中国, 2015Chen Chuan. Fault Detection Algorithm for Batch Process Based on Neareast Neighbor Rule[Master thesis], University of Electronic Science and Technology of China, China, 2015 [16] Ge Z Q, Song Z H. Multimode process monitoring based on Bayesian method. Journal of Chemometrics, 2009, 23(12):636-650 http://d.old.wanfangdata.com.cn/Periodical/cjce201206025 [17] Downs J J, Vogel E F. A plant-wide industrial process control problem. Computer & Chemical Engineering, 1993, 17(3):245-255 doi: 10.1016-0098-1354(93)80018-I/ -

 下载:
下载:


图(7) / 表(3)
计量
- 文章访问数: 2243
- HTML全文浏览量: 591
- PDF下载量: 636
- 被引次数: 0
