

-
摘要: 顺序回归是一种标签具有序信息的多分类问题,广泛存在于信息检索、推荐系统、情感分析等领域.随着互联网、移动通信等技术的发展,面对大量具有大规模、高维、稀疏等特征的数据,传统的顺序回归算法往往表现不足.非平行支持向量顺序回归模型具有适应性强,在性能上优于其他基于SVM的方法等优点,该文在此模型基础上提出基于L2损失的大规模线性非平行支持向量顺序回归模型,其中线性模型的设计可处理大规模数据,基于L2的损失可使标签偏离较大的样本得到更大惩罚.此外,该文从模型的两种不同角度分别设计了信赖域牛顿算法和坐标下降算法求解该线性模型,并比较了两种算法在性能上的差异.为验证模型的有效性,该文在大量数据集上对提出的模型及算法进行了分析,结果表明,该文提出的模型表现最优,尤其采用坐标下降算法求解的该模型在数据集上获得了最好的测试性能.Abstract: Ordinal regression, where the labels of the samples exhibit a natural ordering, is a kind of multi-classification problem. It has found wide applications in information retrieval, recommendation systems, and sentiment analysis. With the development of internet and mobile communication technology, traditional ordinal regression models often underperform when facing numerous large scale, high dimensional and sparse data. However, the nonparallel support vector ordinal regression model shows its advantages with strong adaptability and better performance compared with other SVM-based models. Based on this model, this paper presents a new L2-loss linear nonparallel support vector ordinal regression model, whose linear model could deal with large-scale problems and whose L2-loss could give a great punishment to the sample that deviates from the true label. Besides, two algorithms:trust region Newton method and the dual coordinate descent method (DCD) are developed in terms of different perspectives of the model and their performances are compared. To verify the effectiveness of the model, experiments are conducted on numerous datasets and the results show that the proposed model, especially the model with the DCD algorithm can achieve the state-of-art performance.
-
Key words:
- Ordinal regression /
- SVM /
- trust region Newton method /
- dual coordinate descent method
-
顺序回归旨在对具有顺序标签结构的样本进行分类.近些年随着数据挖掘和机器学习技术的发展, 顺序回归模型在情感分析、产品评论、信用评估、用户画像等领域得到了广泛应用[1-3].在这些领域中, 其样本标签包含顺序信息, 不同的错误样本代价往往不同.如用户画像领域中对年龄的预估, 20岁的青年用户被错分为30岁和50岁形成的用户画像有明显差异.再如在信用评估领域, 一个信用值极低的公司被错分为一般低和较高所影响的决策大相径庭.因此, 顺序回归问题受到越来越多的重视.顺序回归在机器学习领域中介于分类问题和回归问题之间.与分类问题不同, 顺序回归问题的标签集合具有顺序结构而不仅仅是一个多类别集合.再者, 与回归问题不同, 顺序回归问题的标签不具有度量信息.
顺序回归领域拥有多种模型. Gutiérrez等[4]对顺序回归模型做了一个比较全面的综述性调研并且对比了当前16种流行的顺序回归模型的性能.实验表明, 基于SVM的方法[5], 如支持向量顺序回归机(Support vector ordinal regression, SVOR)[6], 约简的SVM (Reduction applied to support vector machines, RedSVM)[7]和基于映射的顺序集成学习(Ordinal projection-based ensemble learning, OPBE)[8]在顺序回归数据上表现出良好的性能.但是, 这些方法均采用非线性核函数把样本点映射到一个高维特征空间.由于经非线性变换后的数据往往被表示成具有较高维度的向量, 那么在模型由于向量之间进行内积计算造成训练时间成本较高且内存消耗大.所以基于SVM的非线性方法只适合于小规模及低纬度数据.而在大量实际应用中, 数据往往表现出量多、特征维度多等特点, 如文本分类等.在文本分类中, 文本通过特征提取和特征值计算的方法, 如词袋特征(Bag-of-words, BOW), 词频–反文档频率(Term frequency-inverse document frequency, TF-IDF)等常被表示成高维向量.所以非线性顺序回归模型无法满足大规模数据的需求.此外, 研究表明[9]在大规模数据中, 线性模型和非线性模型在性能上没有较大差异.所以, 为了减少时间和内存消耗, 文本将提出基于SVM的线性顺序回归模型.文献[10]提出了非线性的非平行支持向量回归机模型(Nonparallel support vector ordinal regression, NPSVOR), 该模型采用Hinge损失函数建立.实验表明在非线性情况下, NPSVOR优于其他基于SVM的方法, 因此本文将研究可处理大规模数据的线性NPSVOR模型.
在解决顺序回归问题时一方面需要考虑顺序信息, 另一方面由于对不同分错样本的处理不同, 所以在构建模型时, 对损失项的特殊处理有助于使预测标签与实际标签尽可能接近, 提高模型的性能.如此, 为了使与真实标签产生较大偏差的样本得到更大的惩罚, 我们在建模中采用L2损失(均方Hinge损失)作为模型损失函数, 旨在最小化真实值与估计值的距离的平方, 使得训练的模型能更好地处理与真实标签间的差异.与此同时, L2损失对离群点较敏感, 一个合适的训练模型算法显得如此重要.针对求解算法, Hsieh等研究了标准的线性支持向量分类(Support vector classification, SVC)[11]和支持向量回归(Support vector regression, SVR)[12]求解算法, 并提出了相应处理大规模数据的求解算法如对偶坐标下降算法(DCD)和信赖域算法.虽然Hsieh等[11-12]的模型和算法被广泛应用在文本挖掘中, 但这些模型和算法主要解决了标准的多分类和回归问题, 而在顺序回归模型中还没有得到应用.所以该文提出能快速求解基于L2损失的非平行支持向量回归机的算法.
本文提出一种基于L2损失的线性非平行支持向量顺序回归模型.从目前研究来看, 这是在顺序回归领域中第一个处理大规模问题的相关工作.此外, 针对该模型, 该文设计了两种求解该模型的算法并比较了两种算法的性能表现.
本文组织结构如下:第1节介绍基于L1损失的NPSVOR模型.第2节介绍本文提出的基于L2损失的线性NPSVOR (L2-NPSVOR)模型, 并给出其对偶模型.第3节研究求解L2-NPSVOR模型的优化算法, 从原问题和对偶问题两个角度分别给出了信赖域牛顿算法和对偶坐标下降算法.第4节主要介绍数值实验, 将提出的L2-NPSVOR模型与其他相关模型进行分析比较, 验证模型的有效性.最后, 对本文研究工作进行总结.
1. 非平行支持向量回归机
在顺序回归问题中, 每个训练样本均由一个特征向量和一个有序标签组成.假设顺序回归问题有$p$个不同的具有有序结构的类别, 为不失一般性, 我们用连续整数$1, 2, \cdots, p$表示其类别, 用$n$表示样本的数量.则顺序回归样本集可以表示为:
$ \mathcal{S} = \{(\boldsymbol{x}_{i}, y_i)\}_{i=1, \cdots, n} $
其中$\boldsymbol{x}_{i} \in {\bf R}^m$是输入向量, 是$\boldsymbol{x}_i$的标签, 这里整数值的大小关系反应类别之间序关系.
文献[10]提出的非平行支持向量顺序回归模型(NPSVOR), 其可以在原空间上学习多个非平行的超平面, 对数据分布具有更好的适应性.并在性能上优于其他基于SVM的方法.对于$p$类的顺序回归问题, NPSVOR针对每个类别构建有序三元分解学习一个超平面, 即给定, 首先对每个索引$k$建立三个索引集: 其中$y_i$是$\boldsymbol{x}_i$的标签.然后, 学习一个映射${f_k}({\boldsymbol{x}}) = {\boldsymbol{w}}_k^{\rm T} {\boldsymbol{x}}+b_k$, 建立如下优化模型
$ \begin{equation}\label{L1-NPSVOR} \begin{array}{ll} \mathop {\min }\limits_{{{\boldsymbol{w}}_k}}\displaystyle &\frac{1}{2}{\boldsymbol{w}}_k^{\rm T} {{\boldsymbol{w}}_k}+ {C_1}\sum\limits_{i \in \mathcal{I}_k} {\max (0, |{\boldsymbol{w}}_k^{\rm T} {{\boldsymbol{x}}_i}+b_k| - \varepsilon )}+ \\ & {C_2}\sum\limits_{i \notin \mathcal{I}_k} {\max (0, 1 - \hat y_i^k({\boldsymbol{w}}_k^{\rm T}) {{\boldsymbol{x}}_i}+b_k)} \end{array} \end{equation} $
(1) 其中, $C_1, C_2 >0$是惩罚系数.由于模型中采用L1损失(Hinge损失)作为损失函数, 这里记该模型(1)为L1-NPSVOR.
在模型式(1)中, 第一项为正则项, 第二项和第三项为L1损失项, 其中第二项是要求学习的超平面尽可能考虑第$k$类样本, 第三项要求其他类样本离该超平面尽可能远, 且其中标签大于$k$的样本和标签小于$k$的样本分别位于该超平面两侧, 以更好地利用标签的有序信息.值得强调的是, 学习的$p$个子优化模型(1)相互独立, 因而可并行学习.
图 1是非平行支持向量回归机的几何解释.图 1中, "$\square$", "$\bigcirc$"和"$\lozenge$"分别表示类别1、类别2和类别3.该类的最优超平面应该离该类样本尽可能地近而离其他类的样本尽可能远.同时, 第1类和第3类的样本点应位居该类最优超平面的两侧.
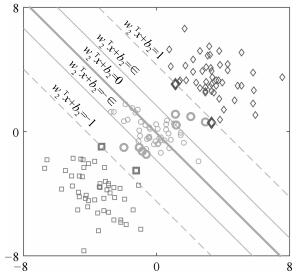 图 1 非平行支持向量顺序回归的几何解释(以类别2超平面构建为例)Fig. 1 Geometric interpretation of NPSVOR (It shows the construction of the $2$-th proximal hyperplane)
图 1 非平行支持向量顺序回归的几何解释(以类别2超平面构建为例)Fig. 1 Geometric interpretation of NPSVOR (It shows the construction of the $2$-th proximal hyperplane)若第$k$类对应的模型式(1)的解为${\boldsymbol{w}_k}^*, b_k^*$, 那么关于第$k$类的最优超平面即为, 其中$k=1, 2, \cdots, p$.预测准则被定义为:
$ \begin{eqnarray}\label{decisionfun} r({\boldsymbol{x}}) = 1 + \sum\limits_{i = 1}^{p - 1}[\kern-0.15em[ {f_k}({\boldsymbol{x}}) + {f_{k+1}}({\boldsymbol{x}}) > 0]\kern-0.15em] \end{eqnarray} $
(2) 其中$\left[\kern-0.15em\left[ \cdot\right]\kern-0.15em\right]$表示一个0-1示性函数, 即满足条件取1, 否则取0.实际上, 预测函数通过学习的$p$个类别超平面构建$p-1$有序二元分类的决策函数, 即, 然后以投票的方式进行决策.
2. 基于L2损失的线性非平行支持向量顺序回归机
本节将在NPSVOR模型基础上描述本文提出的基于L2损失(均方Hinge损失)的线性NPSVOR模型.考虑到模型(1)中L1损失对损失的惩罚是线性关系, 而顺序回归问题建模目标是使预测标签与真实标签尽可能接近, 这促使我们考虑采用L2损失函数, 其对于较大的损失给予更大惩罚, 使模型尽可能避免产生较大偏差预测.
据此, 我们考虑建立L2损失线性NPSVOR模型
$ \begin{align}\label{primal:L2-NPSVOR} \mathop {\min }\limits_{\boldsymbol{w}_k} {f}({\boldsymbol{w}_k}) =\, & \frac{1}{2}{{\boldsymbol{w}_k^{\rm T}} } {\boldsymbol{w}_k} +\nonumber\\ &{C_1}\sum\limits_{i \in \mathcal{I}_k} {\max {{(0, |{{\boldsymbol{w}_k^{\rm T}} } {{\boldsymbol{x}_{i}}}| - \varepsilon )}^2}}+\nonumber\\ &{C_2}\sum\limits_{i \notin \mathcal{I}_k} {\max {{(0, 1 - {{\hat y}_{i}^k}( {{\boldsymbol{w}_k^{\rm T}} }{{\boldsymbol{x}}_i}))}^2}} \end{align} $
(3) 其中$\hat y_i^k = \left\{ {{array}{*{20}{l}} 1, &{{y_i} > k}\\ { - 1}, &{{y_i} \leq k} {array}}\right. $, $C_1, C_2 >0$是惩罚系数.模型(3)相对于模型(1)区别就是损失项采用L2损失, 为了区别两个模型, 这里记基于L2损失的线性NPSVOR模型(3)为L2-NPSVOR.引入松弛变量, 模型(3)等价于如下形式
$ \begin{align}\label{primalWithConstrants:L2-NPSVOR} \mathop {\min }\limits_{{{\boldsymbol{w}}_k}, {\boldsymbol{\xi }}_k^ + , {\boldsymbol{\xi }}_k^ - , {{\boldsymbol{\xi }}_k}} &\frac{1}{2}{{\boldsymbol{w}_k^{\rm T}} }{\boldsymbol{w}_k} + {C_1}\sum\limits_{i \in {\mathcal{I}_k}} {({{(\xi _{ki}^ + )}^2} + {{(\xi _{ki}^ - )}^2})} +\nonumber\\ &\quad\quad\quad {C_2}\sum\limits_{i \notin {\mathcal{I}_k}} {{{({\xi _{ki}})}^2}} \nonumber\\ \text{s.t.}~~~~&- \varepsilon - \xi _{ki}^ - \le {\boldsymbol{w}}_k^{\rm T}{{\boldsymbol{x}}_i} \le \varepsilon + \xi _{ki}^ + , i \in {\mathcal{I}_k}\nonumber\\ & \hat y_i^k({\boldsymbol{w}}_k^{\rm T}{{\boldsymbol{x}}_i}) \ge 1 - {\xi _{^{ki}}}, i \notin {\mathcal{I}_k}\nonumber\\ & \xi _{ki}^ + , \xi _{ki}^ - \ge 0, i \in {\mathcal{I}_k}\nonumber\\ & {\xi _{^{ki}}} \ge 0, i \notin {\mathcal{I}_k} \end{align} $
(4) 其中, ${\boldsymbol{\xi }}_k^ - = {(\xi _{ki}^ - )_{i \in \mathcal{I}_k}}, {{\boldsymbol{\xi }}_k} = {({\xi _{ki}})_{i \notin \mathcal{I}_k}}$.在式(4)中对每个约束引入对偶因子, 根据Lagrangian函数, 利用Karush-Kuhn-Tucker定理, 得到原模型式(3)的对偶问题:
$ \begin{align}\label{L2dualmodel} &\mathop {\min }\limits_{\boldsymbol{\alpha }_k} \frac{1}{2}{{\boldsymbol{w}}_k^{\rm T}} {\boldsymbol{w}_k} + \sum\limits_{i \in \mathcal{I}_k} {\varepsilon (\alpha _{ki}^ + + \alpha _{ki}^ - )} - \sum\limits_{i \notin \mathcal{I}_k} {{\alpha _{ki}}}+\nonumber\\ & \qquad\left\{\frac{1}{{4{C_1}}}\sum\limits_{i \in \mathcal{I}_k} {\left[{{(\alpha _{ki}^ + )}^2} + {{(\alpha _{ki}^ - )}^2}\right]} + \frac{1}{{4{C_2}}}\sum\limits_{i \notin \mathcal{I}_k} {\alpha_{ki}^2} \right\}\nonumber\\ &\text{s.t.}~~ {\alpha_{ki}} \geq 0, \forall i \end{align} $
(5) 其中${{\boldsymbol{w}_k}}$与对偶变量$\alpha_k$相关
$ \begin{align}\label{eq:wAlpha} {\boldsymbol{w}_k} = - \sum\limits_{i \in \mathcal{I}_k} {(\alpha _{ki}^ + - \alpha _{ki}^ - ){{\boldsymbol{x}}_i}} + \sum\limits_{i \notin \mathcal{I}_k} {{{\hat y}_{i}^k}{\alpha _{ki}}{{\boldsymbol{x}}_i}} \end{align} $
(6) 对于具有$p$类的顺序回归问题, L2-NPSVOR由$p$个子优化模型式(3) (或对偶问题式(5))组成.
3. 训练算法
在本节中, 我们将针对L2-NPSVOR模型, 从原问题及其对偶问题两个角度, 分别设计了信赖域牛顿算法和对偶坐标下降算法求解该模型.由于不同$k$对应的原问题式(3)及其对偶问题式(5)具有相同形式, 为了方便讨论, 在不引起混淆的情况下, 我们将忽略模型式(3)和式(5)中的下标$k$.
3.1 信赖域牛顿法
信赖域牛顿算法(Trust region Newton method, TRON)[13]是一种求解可微的无约束或有界约束问题的广义优化算法. Ho和Lin等研究了L2损失SVC和SVR以及Logistic回归问题的TRON算法[12-14].这里将该算法应用于L2-NPSVOR模型的求解.
采用TRON算法求解原问题(3), 优化过程包含两层迭代:在第$t$步外迭代中, 给定$\boldsymbol{w}_t$, TRON算法构造在信赖域半径${\Delta _t}$下的二次优化问题, 即
$ \begin{equation}\label{L2-NPSVOR:subproblem} \mathop {\min }\limits_{\left\| {\boldsymbol{s}} \right\| \le {\Delta _{\rm{t}}}} {q_t}({\boldsymbol{s}}) \equiv \frac{1}{2}{{\boldsymbol{s}}^{\rm T} }{\nabla ^2}{f }({{\boldsymbol{w}}^t}){\boldsymbol{s}}{\rm{ + }}(\nabla {f}{({{\boldsymbol{w}}^t}))^{\rm T} }{\boldsymbol{s}} \end{equation} $
(7) 然后, 在内层迭代中, 求解该模型获得拟牛顿方向$\boldsymbol{s}$. TRON算法根据近似函数${q_t}({\boldsymbol{s}})$调整优化半径${\Delta _t}$, 具体调整方法参见文献[14].在构造二次优化问题时, 需要计算梯度$\nabla {f}({{\boldsymbol{w}}^t})$和Hessian矩阵.由于${f}({\boldsymbol{w}})$连续可微, 存在梯度
$ \begin{align*} \nabla {f}({\boldsymbol{w}}) =\,&{\boldsymbol{w}}{\rm{ + }}2{C_1}{({X_{{I_1}, :}})^{\rm T} }({X_{{I_1}, :}}{\boldsymbol{w}} - \varepsilon )+ \\ & 2{C_1}{({X_{{I_2}, :}})^{\rm T} }({X_{{I_2}, :}}{\boldsymbol{w}}{\rm{ + }}\varepsilon ) +\\ & 2{C_2}{({X_{{I_3}, :}})^{\rm T} }({X_{{I_3}, :}}{\boldsymbol{w}} - {\hat{\boldsymbol{y}}}_{{I_3}}) \end{align*} $
其中
$ \begin{align*} {I_1} &= \{ i \in \mathcal{I}|{{\boldsymbol{w}}^{\rm T}}{{\boldsymbol{x}}_i} > \varepsilon \}, {I_2} = \{ i \in \mathcal{I}|{{\boldsymbol{w}}^{\rm T}}{{\boldsymbol{x}}_i} < - \varepsilon \} \\ {I_3} &= \{ i \notin \mathcal{I}|1 - {\hat y_i}({{\boldsymbol{w}}^{\rm T}}{{\boldsymbol{x}}_i}) > 0\} \end{align*} $
这里$X=[\boldsymbol{x}_1, \cdots, \boldsymbol{x}_n]^{\rm T}$为样本矩阵, 每行代表一个样本向量, $I_1, I_2$和$I_3$为指标集, ${X_{I, :}}$表示$X$中指标集$I$对应的行组成的样本矩阵.这里二阶不可微, 不存在Hessian矩阵, 因而不能直接采用牛顿方向对变量更新.但${f }({\boldsymbol{w}})$几乎处处二阶可微, 且一阶导数Lipschitz连续, 因而根据文献[13]可定义广义Hessian矩阵, 即
$ \begin{equation}\label{L2-NPSVOR:HessianMatrix} B({\boldsymbol{w}}) = I + 2{X^{\rm T} }DX \end{equation} $
(8) 其中$I$为$m$阶的单位矩阵, $D$为$n$阶对角矩阵且
$ {D_{ii}} = \left\{ {\begin{array}{*{20}{l}} {{C_1}}, &{i \in {I_1}\cup I_2 }\\ {{C_2}}, &{i \in {I_3}}\\ 0, &{{\text{其他}}} \end{array}} \right. $
然后, 更新${{\boldsymbol{w}}^t}$和${\Delta _t}$.先考察
$ \begin{equation}\label{update_rhok} {\rho _t} = \frac{{f({{\boldsymbol{w}}^t} + {{\boldsymbol{s}}^t})}}{{{q_t}({{\boldsymbol{s}}^t})}} \end{equation} $
(9) 为原问题优化函数减少量与优化的二次函数${q_t}({\boldsymbol{s}})$减少量的比值.只要${\rho _t}$足够大便更新${{\boldsymbol{w}}^t}$, 否则不更新.设${\eta _0} > 0$是给定的阈值, 则更新${{\boldsymbol{w}}^t}$为
$ \begin{equation}\label{update_w} {{\boldsymbol{w}}^{t + 1}} = \left\{ {\begin{array}{*{20}{l}} {{{\boldsymbol{w}}^t} + {{\boldsymbol{s}}^t}}, &{{\rho _t} > {\eta _0}}\\ {{{\boldsymbol{w}}^t}}, &{{\rho _t} \le {\eta _0}} \end{array}} \right. \end{equation} $
(10) 关于更新信赖域半径${\Delta _t}$: Lin等[13]给出了如下更新规则, 即根据给定的两常数和${\eta _2}$且满足${\eta _1} < {\eta _2} < 1$, 的更新依赖于正数${\sigma _1}, {\sigma _2}$和满足${\sigma _1} < {\sigma _2} < 1 < {\sigma _3}$, 于是信赖域半径更新条件为
$ \begin{equation}\label{update_deltak} \begin{array}{*{20}{l}} {{\Delta _{t + 1}} \in [{\sigma _1}\min\{ \|{s^t}\|, {\Delta _t}\} , {\sigma _1}{\Delta _t}]}, &{{\rho _t} \le {\eta _1}}\\ {{\Delta _{t + 1}} \in [{\sigma _1}{\Delta _t}, {\sigma _3}{\Delta _t}]}, &{{\rho _t} \in ({\eta _1}, {\eta _2})}\\ {{\Delta _{t + 1}} \in [{\Delta _t}, {\sigma _3}{\Delta _t}]}, &{{\rho _t} \ge {\eta _2}} \end{array} \end{equation} $
(11) 式(11)仅给出了更新满足的范围, 文献[13]给出了只要满足以上更新条件算法收敛的证明.具体更新规则可以有多种方式, 这里我们采用与LIBLINEAR[15]中一致的TRON更新规则方式[14]:
$ \begin{align}\label{TRON:update_deltak} &{\Delta _{t + 1}} =\nonumber\\&\begin{subarray}{l} \left\{ {\begin{array}{*{20}{l}} {\min (\max({\alpha _t}, {\sigma _1})\|{{\boldsymbol{s}}^t}\|, {\sigma _2}{\Delta _t})}, &{\rho_t < {\eta _0}}\\ {\max ({\sigma _1}{\Delta _t}, \min ({\alpha _t}\|{{\boldsymbol{s}}^t}\|, {\sigma _2}{\Delta _t})}), &{{\rho _t} \in [{\eta _0}, {\eta _1}]}\\ {\max ({\sigma _1}{\Delta _t}, \min ({\alpha _t}\|{{\boldsymbol{s}}^t}\|, {\sigma _3}{\Delta _t})}), &{{\rho _t} \in ({\eta _1}, {\eta _2})}\\ {\max({\Delta _t}, \min ({\alpha _t}\|{{\boldsymbol{s}}^t}\|, {\sigma _3}{\Delta _t})}), &{{\rho _t} \ge {\eta _2}} \end{array}} \right.\end{subarray} \end{align} $
(12) 在更新规则(12)中, ${\alpha _t}\|{{\boldsymbol{s}}^t}\|$被引入作为的估计, 其中
$ \begin{equation}\label{TRON:update_alphak} {\alpha _t} = \frac{{ - (\nabla f{{({{\boldsymbol{w}}^t})})^{\rm T} }{{\boldsymbol{s}}^t}}}{{2(f({{\boldsymbol{w}}^t} + {{\boldsymbol{s}}^t}) - f({{\boldsymbol{w}}^t}) - (\nabla f{{({{\boldsymbol{w}}^t})})^{\rm T} }{{\boldsymbol{s}}^t})}} \end{equation} $
(13) 对于算法终止条件, 我们考察算法第$k$次迭代步时目标函数的梯度相对初始梯度$\nabla f({{\boldsymbol{w}}^0})$关系, 以及样本类别样本规模, 建立如下终止条件
$ \begin{equation}\label{TRON:stopCondition} \|\nabla f({{\boldsymbol{w}}^t})\| \le \varepsilon \cdot \frac{{\min (|\mathcal{I}|, n - |\mathcal{I}|)}}{n}\|\nabla f({{\boldsymbol{w}}^0})\| \end{equation} $
(14) 其中$\varepsilon $为给定终止精度, $|\mathcal{I}|$表示指标集$\mathcal{I}$元素个数, $n$为训练样本个数.
算法1给出了NPSVOR的信赖域牛顿法算法主要步骤.
算法1. TRON:信赖域牛顿算法求解L2-NPSVOR的子模型式(3)
1) 给定${{\boldsymbol{w}}^0}$, 子模型式(3)对应的类别$k$.
2) 根据类别$k$定义.
3) for $i = 1, 2, \cdots$ (外循环迭代):
共轭梯度算法近似求解信赖域子问题式(7)得到${{\boldsymbol{s}}^t}$.
根据式(9)更新$\rho^t$.
根据式(10)更新${{\boldsymbol{w}}^t}$为.
根据式(12)求解得到${\Delta _{t + 1}}$.
如果${\boldsymbol{w}^t}$满足终止条件式(14), 终止迭代.
算法1的效率主要依赖于是否能快速求解子优化问题式(7).由于目标函数的广义Hessian矩阵式(8)是阶, 对于高维问题直接计算该矩阵会使得内存难以存储.同时, 由于样本矩阵$X$高度稀疏, 可采用共轭梯度算法进行求解, 因此只需要在算法优化过程中计算和存储Hessian矩阵式(8)与向量的乘积, 即
$ \begin{align}\label{HessianWithVector} B({\boldsymbol{w}}){\boldsymbol{v}}&={\boldsymbol{v}} +2{C_1}({({X_{{I_1} \cup {I_2}, :}})^{\rm T} }({X_{{I_1} \cup {I_2}, :}}{\boldsymbol{v}}))\nonumber+\\ &\quad 2{C_2}({({X_{{I_3}, :}})^{\rm T} }({X_{{I_3}, :}}{\boldsymbol{v}})) \end{align} $
(15) 算法2给出了求解问题(7)的共轭梯度算法过程.
算法2. 共轭梯度算法近似求解信赖域子问题(7)
1) 给定${\xi _t} < 1, {\Delta _t} > 0$.令和.
2) for $i = 1, 2, \cdots$ (内循环迭代):
如果${\rm{||}}{{\boldsymbol{r}}^i}{\rm{||}} \le {\xi _t}{\rm{||}}\nabla f({{\boldsymbol{w}}^t}{\rm{)||}}$, 输出${{\boldsymbol{s}}^t} = {{\bar{\boldsymbol{s}}}^i}$, 并终止迭代.
如果$\|{{\bar{\boldsymbol{s}}}^{i + 1}}\| \ge {\Delta _t}$, 计算满足$\|{{\bar{\boldsymbol{s}}}^i} + \tau {{\boldsymbol{d}}^i}\|={\Delta _t}$, 那么输出, 终止算法.
${\beta _i} = ||{{\boldsymbol{r}}^{i + 1}}|{|^2}/||{{\boldsymbol{r}}^i}|{|^2}$
${{\boldsymbol{d}}^{i + 1}} = {{\boldsymbol{r}}^{i + 1}} + {\beta _i}{{\boldsymbol{d}}^i}$
3.2 对偶坐标下降算法
坐标下降算法(Coordinate descent method, CD)是一种无约束优化技术, 被用于求解大规模线性SVM模型. Chang等[9]利用CD算法求解L2损失的线性SVM模型的原始问题, 实验表明这种方法可以快速获取模型的解. Hsieh等[11]提出对偶坐标下降算法(Dual coordinate descent method, DCD)求解线性SVM模型, 即在L1和L2损失的线性SVM的对偶模型上利用CD算法, 并采用Shrinking和随机置换优化样本序列的加速技术.当数据的规模和特征维度规模都比较大时, CD算法比其他算法在求解线性SVM模型上能获得更好的效果[11, 16]. Yuan等[17]将DCD算法应用于求解L1正则化的优化问题. Tseng和Yun[18]系统讨论了L1正则优化问题的分解算法, 给出分解算法的一般性框架[12].将DCD算法扩展到求解大规模SVR问题中, 但采用了与文献[11]中不同的Shrinking准则和算法终止策略, 研究表明这种策略在回归问题中可以快速获得优化模型的解.本节将利用DCD算法求解基于L2损失的线性NPSVOR, 实现大规模顺序回归问题的求解.
忽略原问题式(3)的下标$k$, 其对偶问题式(5)可写为:
$ \begin{align}\label{L2 simple Dualmodel} &\mathop {\min }\limits_{\boldsymbol{\alpha }} \frac{1}{2}{{\boldsymbol{w}}^{\rm T}}{\boldsymbol{w}} + \sum\limits_{i \in \mathcal{I}} {\varepsilon (\alpha _i^ + + \alpha _i^ - )}- \sum\limits_{i \notin \mathcal{I}} {{\alpha _i}} \nonumber +\\ & \qquad\left(\frac{1}{{4{C_1}}}\sum\limits_{i \in \mathcal{I}} {({{(\alpha _i^ + )}^2} + {{(\alpha _i^ - )}^2})} + \frac{1}{{4{C_2}}}\sum\limits_{i \notin \mathcal{I}} {\alpha _i^2} \right)\\ \end{align} $
(16) $ \text{s.t.}~~{\alpha _i} \geq 0, \forall i $
(17) 其中${{\boldsymbol{w}}}$与对偶变量$\boldsymbol{\alpha}$相关
$ \begin{align} {\boldsymbol{w}} = - \sum\limits_{i \in \mathcal{I}} {(\alpha _i^ + - \alpha _i^ - ){{\boldsymbol{x}}_i}} + \sum\limits_{i \notin \mathcal{I}} {{{\hat y}_i}{\alpha _i}{{\boldsymbol{x}}_i}} \end{align} $
(18) 根据KKT条件可知, $\alpha _i^ + , \alpha _i^ - $不同时非零, 且有$\alpha _i^ + \alpha _i^ - = 0$, 因此, 在最优解条件下有
$ \begin{equation}\label{alphaiproperty} \alpha _i^ + {\rm{ + }}\alpha _i^ - {\rm{ = |}}\alpha _i^ + - \alpha _i^ - {\rm{|, (}}\alpha _i^ + {{\rm{)}}^2}{\rm{ + (}}\alpha _i^ - {{\rm{)}}^2}{\rm{ = (}}\alpha _i^ + - \alpha _i^ - {)^2} \end{equation} $
(19) 性质成立.令${\alpha _i} = \alpha _i^ + - \alpha _i^ - $, 对偶问题转变为
$ \begin{align}\label{dualproblem:simple} \mathop {\min }\limits_{\boldsymbol{\alpha }} ~~&\frac{1}{2}{{\boldsymbol{w}}^{\rm T} }{\boldsymbol{w}} + \sum\limits_{i \in \mathcal{I}} {\varepsilon {\rm{|}}{\alpha _i}{\rm{|}}} - \sum\limits_{i \notin \mathcal{I}} {{\alpha _i}}\nonumber + \\ &(\frac{1}{{4{C_1}}}\sum\limits_{i \in \mathcal{I}} {\alpha _i^2} + \frac{1}{{4{C_2}}}\sum\limits_{i \notin \mathcal{I}} {\alpha _i^2} )\\ \end{align} $
(20) $ \text{s.t.}~~ {\alpha _i} \geq 0, i \notin \mathcal{I} $
(21) 其中, 同时式(18)变为
$ \begin{equation}\label{eq:wAlpha:simple} {\boldsymbol{w}} = - \sum\limits_{i \in \mathcal{I}} {{\alpha _i}{{\boldsymbol{x}}_i}} + \sum\limits_{i \notin \mathcal{I}} {{{\hat y}_i}{\alpha _i}{{\boldsymbol{x}}_i}} \end{equation} $
(22) 对偶坐标下降算法, 每次仅更新一个变量, 同时固定其他变量.由于目标函数变量中关于${\alpha _i}, i \in \mathcal{I}$存在不可微项, 这里对$i \in \mathcal{I}$和$i \notin \mathcal{I}$的变量分别讨论.
1) 当$i \in \mathcal{I}$时, 令, 更新变量${\alpha _i}$得到如下单变量优化子问题
$ \begin{equation}\label{submodelI} \mathop {\min }\limits_s g(s) = \frac{1}{2}{\bar A_i}{s^2} - {B_i}s + \varepsilon |s| \end{equation} $
(23) 其中${\bar A_i} = {A_i} + {1}/({{2{C_1}}})$, 为常数, 且${B_i}$由最近一次更新变量得到.尽管优化目标函数$g(s)$不可微, 但可以通过软阈值方法得到闭式解.令$g(s)$左导数和右导数分别为
$ \begin{equation}\label{GpGn} {g'_p}(s) = \bar A_i s - {B_i} + \varepsilon , ~{g'_n}(s) =\bar A_is - {B_i} - \varepsilon \end{equation} $
(24) 根据软阈值的方法可知, 优化问题的解为
$ \begin{equation}\label{update:alphai:I} {\alpha _i} \leftarrow {\alpha _i}- d_i \end{equation} $
(25) 其中
$ \begin{equation}\label{update:alphai:di} d_i=\left\{ {\begin{array}{*{20}{l}} {\frac{{{{g'_p}}({\alpha _i})}}{\bar A}}, &{{{g'_p}}({\alpha _i}) < \bar A_i{\alpha _i}}\\ {\frac{{{{g'_n}}({\alpha _i})}}{\bar A}}, &{{{g'_n}}({\alpha _i}) >\bar A_i{\alpha _i}}\\ 0, &\text{其他}\end{array}} \right. \end{equation} $
(26) 在算法迭代中, 需要判断优化变量是否达到最优性条件, 定义优化目标函数关于$\alpha _i$的投影梯度为
$ \begin{equation}\label{inotI:vi} {v_i} = \left\{ {\begin{array}{*{20}{l}} {{{g'_p}}({\alpha _i})}, &{{\alpha _i} > 0}\\ {{{g'_n}}({\alpha _i})}, &{{\alpha _i} < 0}\\ {\max (0, {{g'_n}}({\alpha _i})) - \min (0, {{g'_p}}({\alpha _i}))}, &{{\alpha _i} = 0} \end{array}} \right. \end{equation} $
(27) 容易得到, ${\alpha _i}$为最优解当且仅当${v_i} = 0$.
2) 当$i \notin \mathcal{I}$时, 令, 更新变量${\alpha _i}$得到关于步长${d_i}$的优化子问题
$ \begin{equation}\label{submodel:inotI} \mathop {\min }\limits_{{d_i}} h({d_i}) = \frac{1}{2}{\bar A_i}d_i^2 + {G_i}{d_i}, ~~\text{s.t.}~~{\alpha _i} + {d_i} \ge 0 \end{equation} $
(28) 其中.令目标函数导数为0, 即$h'({d_i}){\rm{ = }}0$, 可得
$ \begin{equation}\label{submodel:inotI:di} {d_i} = \frac{{{G_i}}}{{{{\bar A}_i}}} \end{equation} $
(29) 此时, 对${\alpha _i}$更新
$ \begin{equation}\label{submodel:inotI:alpha_i} {\alpha _i} \leftarrow \max (0, {\alpha _i} + {d_i}) \end{equation} $
(30) 目标函数$h({d_i})$关于${\alpha _i}$的投影梯度为
$ \begin{equation}\label{submodel:inotI:vi} {v_i} = \left\{ {\begin{array}{*{20}{l}} {\max (0, - {G_i})}, &{{\alpha _i} = 0}\\ {{G_i}}, &{{\alpha _i} > 0} \end{array}} \right. \end{equation} $
(31) 同样, ${\alpha _i}$为最优点当且仅当${v_i}{\rm{ = }}0$.根据以上分析, 我们可以给出优化问题式(5)的DCD算法过程, 如算法3所示, 记该算法为DCD.
算法3. DCD:坐标下降法求解L2-NPSVOR的对偶问题(5)
1) 给定$\boldsymbol \alpha=\boldsymbol{0}$和${\boldsymbol{w}} = \boldsymbol{0}$.
2) 计算${A_i} = {\boldsymbol{x}}_i^{\rm T}{{\boldsymbol{x}}_i}, i=1, \cdots, n$.
3) while $\boldsymbol \alpha$不满足最优性条件: do (4)
4) for $i=1, \cdots, n$
定义${\hat y_i}$:
do步骤5), 6), 7).
5) if $y_i= k$:
${\bar A_i} = {A_i} + \frac{1}{{2{C_1}}}$
${G_p} = {\hat y_i}{{\boldsymbol{w}}^{\rm T}}{{\boldsymbol{x}}_i} + \varepsilon $和${G_n} = {\hat y_i}{{\boldsymbol{w}}^{\rm T}}{{\boldsymbol{x}}_i} - \varepsilon$,
根据式(26)更新$d_i$, 根据式(27)更新$v_i$.
if $v_i\neq 0$: ${\bar \alpha _i} \leftarrow {\alpha _i}$, ${\alpha _i} \leftarrow {\alpha _i}- d_i$.
6) else if $y_i\neq k$:
${\bar A_i} = {A_i} + \frac{1}{{2{C_2}}}$
$G = {\hat y_i}{{\boldsymbol{w}}^{\rm T}}{{\boldsymbol{x}}_i} - 1$
根据式(29)更新$d_i$, 根据式(31)更新$v_i$.
if $v_i\neq 0$: ,
7) ${\boldsymbol{w}} \leftarrow {\boldsymbol{w}} + ({\alpha _i} - {\bar \alpha _i}){\hat y_i}{{\boldsymbol{x}}_i}, $
关于终止条件, 我们可以采用文献[17]的终止条件, 即
$ \begin{equation}\label{StopCondition} {\left\| {{{\boldsymbol{v}}^t}} \right\|_1} < {\varepsilon _s}{\left\| {{{\boldsymbol{v}}^0}} \right\|_1} \end{equation} $
(32) 其中${{\boldsymbol{v}}^0}$和${{\boldsymbol{v}}^t}$分别是初始迭代的违反值(Violation)向量和第$t$步迭代的违反值向量.注意到, ${{\boldsymbol{v}}^t}$的分量值是通过式(27)和式(31)在第$t$次迭代中得到.
Shrinking策略[19], 是一种算法加速技术, 在算法迭代训练时删去一些值不变的变量, 通过减少优化问题的变量规模实现对算法的加速.该策略常被用于SVM的分解算法, 只是不同的算法和模型在具体操作上有所不同.在本文的DCD算法中, 也采用了该技术, 即考虑在算法的有序迭代中, 删除达到约束边界的最优变量(即)以及不可微点().对于变量$\alpha_i$, Shrinking条件为:
当$i\notin \mathcal{I}$时,
$ \begin{equation}\label{ShrinkingConditions_inotI} \alpha_i = 0 ~\text{且}~ v_i > M \end{equation} $
(33) 当$i\in \mathcal{I}$时,
$ \begin{align}\label{ShrinkingConditions} ~~~~~ {\alpha _i} = 0 ~\text{且}~ {g'_n}({\alpha _i}) < - M ~\text{且}~ {g'_p}({\alpha _i})>M \end{align} $
(34) 其中
$ \begin{equation}\label{Shrink_M} M = \mathop {\max }\limits_{\forall i} |v_i| \end{equation} $
(35) 这里$v_i$是上一次迭代的违反值.
这里取梯度违反值绝对值的最大值式(35)作为Shrinking阈值条件, 并考察梯度违反值$\boldsymbol{v}^t$与初始$\boldsymbol{v}^0$值缩小比例式(32)进行算法终止.在后面实验中, 我们将进一步对比在设计大规模线性SVM的DCD算法中提出的Shrinking技术和终止策略[11], 即对梯度违反值正负值分别维持阈值$M, m$, 然后并将$M-m<\epsilon$作为算法终止条件(具体见文献[11]), 以说明本文算法设计的合理性.
4. 数值实验
为验证提出的L2-NPSVOR模型及算法的有效性, 本文在多个数据集上与其他基于SVM的顺序回归模型进行了性能比较.其中比较的模型包括: L1-NPSVOR、SVM、SVR、RedSVM等.此外, 本文还比较了TRON和DCD在L2损失的NPSVOR模型的算法效率.最后本文分析了L2-NPSVOR模型对参数的敏感性. TRON和DCD算法均在LIBLINEAR框架基础上用C++实现1, 实验平台为Intel Xeon 2.0 GHz CPU (E5504), 4 MB cache, 内存4 GB, Linux系统.
1算法代码已上传至https://github.com/huadong2014/Lin-earNPSVOR/.
4.1 实验数据准备与评价标准
针对大规模高维稀疏的顺序回归问题, 目前还缺少相关的研究.这里我们收集并整理了部分文本顺序回归数据集, 这些数据来自情感分析、电影评论、Amazon商品评论等多个领域, 具体数据集如下:
1) TripAdvisor2, 是一个酒店评论数据集, 最早被用于文本潜在语义分析[20].每条评论有一个1至5颗星的打分.
2数据集取自http://www.cs.virgini.edu/~hw5x/dtset.html
2) Treeban3, 来自斯坦福大学构建的情感数据库Treebank, 每条数据对应一个来自{very negative, negative, neutral, positive, very positive}的标签.
3http://nlp.stnford.edu/sentiment/
3) MovieReview[21], 电影评论数据集4.顺序标签是从连续值$[0, 1]$离散化得到, 即a) rating $\leq0.3$, b) 0.4 $\leq$ rating $\leq 0.5$, c) 0.6 $\leq $ rating $\leq$ 0.7, d) 0.8 $\leq$ rating.该数据集常被用于情感分析.
4scle dtset v1.0: http://www.cs.cornell.edu/people/pbo/movie-review-dt/
4) LargeMovie5, 是一个包含8种情感类别的电影评论数据.
5http://i.stnford.edu/~ms/dt/sentiment/
5) Amazon产品评论, 有8个数据集, 来自两个数据资源网站:其中4个数据集来自文献[20], 包括AmazonMp3, VideoSurveillance, Mobilephone, Cameras6; 另外4个数据集(Electronics, HealthCare, AppsAndroid, HomeKitchen)[22-23]来自Amazon产品评论数据集7, 所有数据均是文本评论, 且有5个类别.由于实际数据集类别样本分布不均衡, 为了不影响模型测试表现, 这里对数据集进行降采样得到平衡数据集.
6http://sifk.cs.uiuc.edu/~wng296/Dt/index.html
7Amzon product reviews dtsets: http://jmculey.ucsd.edu/dt/mzon/
以上数据集均为文本数据, 故本文对这些数据进行下列预处理:词干化、去停用词、删除词频小于3次的词, 以及在所有文本出现的频率大于50 %或出现少于2次的词.此外, 我们采用unigram, bigram作为特征, 利用TF-IDF技术提取文本特征.为了方便实验算法分析和方法比较, 将每个数据集随机划分为两部分, 即取20 %条数据作为测试集, 剩余80 %条数据作为训练集.数据集的统计描述见表 1所示, 其特征包括样本规模、特征维数、训练集非零元素个数等.
表 1 数据集特征描述Table 1 Data statistics数据集 样本($n$) 特征($m$) 非零元素个数 类别 类别分布 AmazonMp3 10 391 65 487 1 004 435 5 ≈ 2 078 VideoSurveillance 22 281 119 793 1 754 092 5 ≈ 4 456 Tablets 35 166 201 061 3 095 663 5 ≈ 7 033 Mobilephone 69 891 265 432 5 041 894 5 ≈ 13 978 Cameras 138 011 654 268 14 308 676 5 ≈ 27 602 TripAdvisor 65 326 404 778 8 687 561 5 ≈ 13 065 Treebank 11 856 8 569 98 883 5 ≈ 2 371 MovieReview 5 007 55 020 961 379 4 ≈ 1 251 LargeMovie 50 000 309 362 6 588 192 8 ≈ 6 250 Electronics 409 041 1 422 181 37 303 259 5 ≈ 81 808 HealthCare 82 251 283 542 5 201 794 5 ≈ 16 450 AppsAndroid 220 566 253 932 6 602 522 5 ≈ 44 113 HomeKitchen 120 856 427 558 8 473 465 5 ≈ 24 171 关于评价标准, 由于顺序回归问题与普通多分类问题不同, 预测标准是预测标签与真实标签尽可能接近, 因此, 这里采用平均绝对误差(Mean absolute error, MAE)和平均均方误差(Mean square error, MSE)作为评价准则, 即给定预测标签$\{ {\hat y_1}, \cdots , {\hat y_n}\} $和实际标签$\{ {y_1}, \cdots , {y_n}\} $, MAE和MSE定义如下
$ \begin{equation}\label{MAEMSE} {\rm{MAE}} = \frac{1}{n}\sum\limits_{i = 1}^n|\hat{y_i} - {y_i}|, \quad {\rm{MSE}} = \frac{1}{n}\sum\limits_{i = 1}^n (\hat{y_i} - {y_i})^2 \end{equation} $
(36) 该指标被广泛用于刻画顺序回归模型预测与实际标签的接近程度[6-7, 24-25].
4.2 L2-NPSVOR与其他模型比较
本节我们测试线性L2-NPSVOR的泛化效果, 并与其他SVM相关方法比较, 比较方法具体如下:
1) SVC[11], 将顺序回归看成普通多分类问题处理的朴素方法.文献[11]给出了线性SVM模型的DCD算法, 在算法中采用了随机置换和Shinking加速技术.该算法已经实现并集成在著名的LIBLINEAR软件包中, 采用one-vs-all的方式策略进行多分类预测.
2) SVR[12], 将顺序回归标签看成普通数值, 采用数值回归的方式进行处理, 同样属于一种朴素方法. SVR模型预测值是连续的数值, 本文对预测后的连续数值按照相邻的整数离散成相应的类别标签.文献[12]给出了线性SVR的DCD求解算法, 并在LIBLINEAR中实现, 这里仅对预测函数作了修改.
3) RedSVM[7], 对于$p$类顺序回归问题, 其学习一个线性映射将样本映射到一维实数轴上, 在该数轴上寻找$p-1$个具有最大划分间隔的阈值点, 将直线分成$p$个连续的区间段进行预测.文献[7]提出一种处理顺序回归的框架, 将顺序回归问题转化为一个二元分类问题, 对样本通过扩展将其转化为二分类样本$(({\boldsymbol{x}}_i^{\rm T}, {\boldsymbol{e}}_k^{\rm T}), {\hat y_i^k})$ $(\forall i;k = 1, \cdots , p - 1)$, 其中${\hat y_i^k} = -1$当$y_i<k$, 否则${\hat y_i^k} = 1$.
4) L1-NPSVOR[10], 基于L1损失的NPSVOR, 属于有序分解模型, 根据标签有序信息, 对每个类别均构造一个三划分并学习一个超平面, 从而构建了优化模型式(1), 可直接将文献[11]的DCD算法直接扩展求解其对偶问题.
5) L2-NPSVOR (TRON), 即L2损失的NPSVOR, 采用信赖域牛顿法(见算法1)求解, 共轭梯度算法(算法2)求解信赖域子问题式(7).
6) L2-NPSVOR (DCD), 即L2损失的NPSVOR, 采用对偶坐标下降法(见算法3)求解, 终止条件为式(32), Shrinking策略为式(33)和式(34).
该实验在训练集上进行5-折交叉验证进行参数选择, 参数选择范围设定在$\{2^{-5}, 2^{-4}, \cdots, 2^{5}\}$.以MAE作为交叉验证选参的标准, 通过参数选择后的最优参数作为模型训练的参数.关于实验参数设置方面, 基于DCD算法求解的模型终止精度均设为0.1, $\boldsymbol{\alpha}$和$\boldsymbol{w}$均采用0向量作为初始化, TRON的终止精度设定为0.001.另外, 为公平起见, 在NPSVOR算法中该实验固定参数$\epsilon$值为0.1, $C_1=C_2$, 并与其他模型中的$C$采用同样的选参方式, 除RedSVM模型8, 其他模型均采用有偏置项模型.实验数据集如表 1所示. 表 2给出了各模型在不同数据集上MAE、MSE值和训练时间(Time), 表中每行最好的结果均已经加粗显示. 表 2的最后列出了各方法在所有数据集上关于MAE、MSE和训练时间的平均排序, 以方便比较各模型之间的性能.
8需要注意的是, 因为目前还没有针对顺序回归问题提出的大规模求解算法, RedSVM模型只有非线性模型的求解算法, 故本文对线性RedSVM算法求解时采用文献[7]中DCD算法对RedSVM的线性版本进行实现.
表 2 方法在各数据集上测试结果, 包括MAE、MSE和最优参数下的训练时间(s)Table 2 Test results for each dataset and method, including MAE, MSE and training time (s)数据集 指标 L1-SVC L2-SVC SVR RedSVM NPSVOR L2-NPSVOR (TRON) L2-NPSVOR (DCD) AmazonMp3 MAE 0.564 0.557 0.534 0.535 0.488 0.481 0.481 MSE 0.996 0.987 0.732 0.735 0.699 0.670 0.683 TIME 0.209 0.660 0.031 0.186 0.165 0.830 0.144 VideoSurveillance MAE 0.404 0.391 0.426 0.446 0.376 0.371 0.372 MSE 0.709 0.668 0.578 0.592 0.511 0.493 0.491 TIME 0.433 1.708 0.087 0.551 0.492 1.996 0.402 Tablets MAE 0.306 0.299 0.334 0.346 0.280 0.278 0.278 MSE 0.514 0.496 0.444 0.444 0.373 0.362 0.363 TIME 0.821 3.400 0.198 1.029 0.948 2.958 0.674 Mobilephone MAE 0.431 0.419 0.450 0.444 0.391 0.388 0.385 MSE 0.736 0.705 0.604 0.587 0.536 0.524 0.522 TIME 1.811 7.574 0.353 1.909 2.330 6.724 1.605 Cameras MAE 0.246 0.240 0.273 0.301 0.227 0.232 0.226 MSE 0.394 0.381 0.357 0.375 0.296 0.299 0.298 TIME 9.552 34.480 1.401 6.016 6.341 30.132 5.388 TripAdvisor MAE 0.398 0.388 0.433 0.429 0.365 0.365 0.366 MSE 0.611 0.583 0.539 0.523 0.445 0.449 0.452 TIME 2.331 12.778 0.807 2.110 2.857 9.238 3.505 Treebank MAE 0.907 0.841 0.784 0.752 0.763 0.806 0.756 MSE 1.652 1.455 1.116 1.049 1.126 1.229 1.068 TIME 0.025 0.040 0.004 0.015 0.026 0.035 0.024 MovieReview MAE 0.501 0.490 0.448 0.447 0.432 0.436 0.431 MSE 0.615 0.582 0.486 0.485 0.476 0.476 0.475 TIME 0.121 0.429 0.029 0.133 0.130 0.373 0.125 LargeMovie MAE 1.205 1.176 1.182 1.093 0.992 1.008 1.002 MSE 3.617 3.502 2.469 2.225 2.046 2.075 2.020 TIME 3.311 10.416 0.328 1.965 2.569 7.523 2.493 Electronics MAE 0.592 0.590 0.606 0.620 0.529 0.526 0.520 MSE 1.069 1.050 0.840 0.848 0.747 0.736 0.731 TIME 22.316 168.141 4.878 10.736 23.075 116.586 18.062 HealthCare MAE 0.637 0.621 0.660 0.681 0.591 0.590 0.589 MSE 1.338 1.282 1.004 1.062 0.945 0.920 0.929 TIME 2.098 7.429 0.439 2.686 2.954 6.365 2.673 AppsAndroid MAE 0.640 0.616 0.656 0.659 0.584 0.590 0.584 MSE 1.179 1.106 0.922 0.920 0.844 0.872 0.859 TIME 4.043 14.924 0.634 1.603 4.574 11.423 6.290 HomeKitchen MAE 0.585 0.574 0.597 0.609 0.519 0.519 0.510 MSE 1.050 1.015 0.829 0.842 0.745 0.723 0.720 TIME 5.587 19.393 0.896 1.786 5.171 19.560 4.475 平均排序 MAE 5.64 4.57 5.64 5.86 2.50 2.21 1.57 MSE 7.00 6.00 4.36 4.29 2.36 2.29 1.64 TIME 3.57 6.79 1.00 3.29 4.07 6.21 3.07 从表 2的结果中, 通过观察可以得到以下几点结论:
1) 根据各方法在所有数据集上平均排序可以看出, L2-NPSVOR较其他方法在MAE和MSE上, 取得了最好的预测效果.虽然L2-NPSVOR在TRON和DCD算法得到的预测效果接近, 但DCD在总体上得到了更好的MAE和MSE值, 算法的训练时间相对TRON优势明显.
2) RedSVM模型在非线性情况下表现突出[4], 但在大规模数据集的表现略低于朴素方法线性L1/L2-SVC.
3) 对比L1-NPSVOR和L2-NPSVOR, 采用L2损失的模型在MAE、MSE优于L1-NPSVOR模型, 这与我们的预期一致, 即顺序回归问题预测要求预测标签与实际标签尽可能接近, L2损失对于损失偏差较大的样本给予更大的惩罚, 可得到预测偏差更小的模型.此外, 基于L2损失的NPSVOR在DCD算法下可以得到更快的优化速度.
4) 在算法的训练时间上, 基于DCD算法的L2-NPSVOR获得了除SVR外最快的训练速度.尽管SVR在时间上具有优势, 但其在顺序回归上的预测结果相对较差, 这也说明将顺序回归问题等同于数值回归存在一定的缺陷.
4.3 TRON与DCD算法比较
本文针对NPSVOR提出了信赖域牛顿算法和对偶坐标下降算法, 这里我们对算法效率进行比较.假设原问题的优化目标函数为$f(\boldsymbol{w})$, 通过观察算法训练过程中目标函数值$f(\boldsymbol{w})$与最优值目标函数值$f(\boldsymbol{w}^*)$的接近程度, 即$f(\boldsymbol{w})-f(\boldsymbol{w}^*)$来比较算法效率.为说明本文算法设计的合理性, 考虑以下四种情形:
TRON: 即本文给出的信赖域牛顿算法1, 在算法中NPSVOR各子模型独立求解, 均初始化$\boldsymbol{w}=\boldsymbol{0}$, 可分布并行求解各子模型.为方便比较, 这里仅考虑串行求解方式.
TRON (WS): 在利用TRON算法求解NPSVOR各子模型时, 可采用暖启动策略(Warm start, WS).由于在NPSVOR模型中, 每个子模型的超平面是基于有序三元分解建立的, 其是根据标签的有序结构信息得到, 因而相邻类别对应的超平面相对比较接近, 对应的解具有相似的结构, 即$\boldsymbol{w}_{k}\approx\boldsymbol{w}_{k+1}$.如果依次求解$k=1, \cdots, p$对应的模型, 在求解第$k+1$个子模型$\boldsymbol{w}_{k+1}$时, 可以利用第$k$个模型的解$\boldsymbol{w}_{k}$作为其初始解, 这样可以利用顺序回归的特有性质来加速模型的求解.
DCD-M: 即本文给出的对偶坐标下降算法3.算法中采用了Yuan等[17]给出的终止准则和Shrinking策略, 即采用最优梯度违反值的绝对值最大值式(35)作为判断最优性条件的阈值.
DCD-Mm: Hsieh等[11]在设计线性SVM的对偶坐标下降算法中, 根据梯度投影的最大幅度值作为终止条件的判断依据, 并根据上下振幅值作为Shrinking阈值, 将该策略应用到文本的DCD算法中, 即Shrinking条件为, 当$i\in \mathcal{I}$时,
$ \begin{align} {\alpha _i} = 0 ~\text{且}~ {g'_n}({\alpha _i}) < - m ~\text{且}~ {g'_p}({\alpha _i})>M \end{align} $
(37) 其中这里$v_i$是上一次迭代的违反值.终止条件为:
$ \begin{equation} M-m < \epsilon \end{equation} $
(38) 该实验选择数据集中样本规模较大的8个数据集, 固定参数$C=1$, 模型NPSVOR中的参数$\epsilon$固定值为$0.1$. TRON算法和DCD算法的终止精度分别设为0.01和0.001. TRON的其他参数选择与文献[14]相同, 即
$ \begin{array}{l} {\eta _0} = 0, {\eta _1} = 0.25, {\eta _2} = 0.75\\ {\sigma _1} = 0.25, {\sigma _2} = 0.5, {\sigma _3} = 4 \end{array} $
在训练集上进行训练, 记录目标函数值变化情况.由于L2-NPSVOR对于每个类别均需要求解一个子优化模型, 图 2仅展示类别3对应的子优化模型(即$k=3$)绝对目标函数差训练时间的变化.
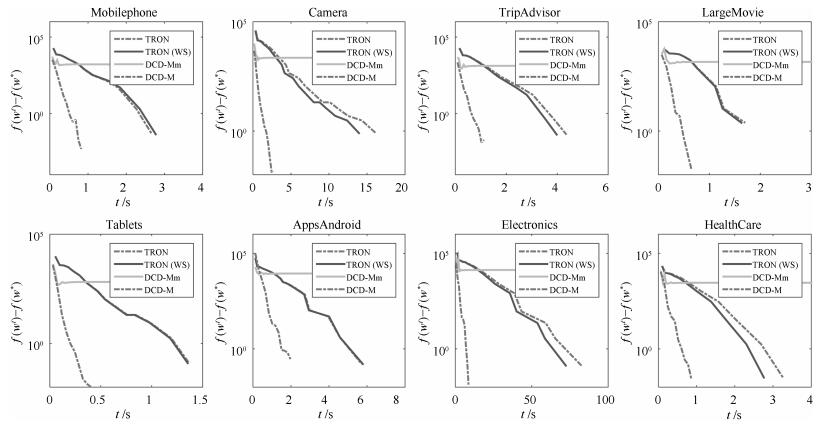 图 2 TRON, TRON (WS), DCD-M and DCD-Mm在8个数据集上的比较(这里展示了类别3对应的优化问题).横坐标是时间$t$, 纵坐标为L2-NPSVOR原问题目标函数的$f(\boldsymbol{w}^t)-f(\boldsymbol{w}^*)$的值Fig. 2 Comparison of TRON, TRON (WS), DCD-M and DCD-Mm on eight datasets (Show the optimization model for rank 3). The horizontal axis is training time in seconds and the vertical axis is the difference between $f(\boldsymbol{w}^t)$ and $f(\boldsymbol{w}^*$)
图 2 TRON, TRON (WS), DCD-M and DCD-Mm在8个数据集上的比较(这里展示了类别3对应的优化问题).横坐标是时间$t$, 纵坐标为L2-NPSVOR原问题目标函数的$f(\boldsymbol{w}^t)-f(\boldsymbol{w}^*)$的值Fig. 2 Comparison of TRON, TRON (WS), DCD-M and DCD-Mm on eight datasets (Show the optimization model for rank 3). The horizontal axis is training time in seconds and the vertical axis is the difference between $f(\boldsymbol{w}^t)$ and $f(\boldsymbol{w}^*$)从图 2中, 我们可以观察到: 1)采用暖启动的TRON算法TRON (WS)在其中6个数据集上有较为明显的加速, 但在短的训练时间内, 加速不明显. 2)目标函数的$f(\boldsymbol{w}^t)-f(\boldsymbol{w}^*)$在DCD-M算法优化下在给出的8个数据集中比TRON算法高效并且获得了更低的目标函数值, DCD-M算法优势明显. 3) DCD-Mm采用文献[11]的终止条件和Shrinking策略, 实验表明目标函数值过早趋于平稳, 并且不能够及时有效终止算法.
4.4 L1-NPSVOR和L2-NPSVOR参数敏感性
参数选择通常十分耗时, 故我们期望得到的模型对参数不敏感, 即参数值的变化不会有较大的测试结果变化.本节实验将比较L1-NPSVOR和L2-NPSVOR关于MAE和MSE随参数值$C$改变的变化情况(限定$C_1=C_2$并记为$C$), 采用DCD算法求解.实验选择与第4.3节相同的8个数据集进行实验, 参数$C$的变化范围设定为$\{2^{-5}, 2^{-4}, \cdots, 2^5\}$, 采用5折交叉验证得到每个参数值下的测试MAE/MSE值. MAE和MSE变化趋势分别如图 3和图 4所示.
 图 3 L1/L2-NPSVOR的MAE分别随参数$C$变化Fig. 3 Test MAE results of L1/L2-NPSVOR change with parameter $C$ on eight datasets
图 3 L1/L2-NPSVOR的MAE分别随参数$C$变化Fig. 3 Test MAE results of L1/L2-NPSVOR change with parameter $C$ on eight datasets 图 4 L1/L2-NPSVOR的MSE分别随参数$C$变化Fig. 4 Test MSE results of L1/L2-NPSVOR change with parameter $C$ on eight datasets
图 4 L1/L2-NPSVOR的MSE分别随参数$C$变化Fig. 4 Test MSE results of L1/L2-NPSVOR change with parameter $C$ on eight datasets从图 3和图 4中可以观察得到, 基于L2损失的NPSVOR在MAE/MSE上随参数$C$变化相对平稳, 变化幅度均低于采用L1损失的对应结果, 尤其是在参数值$C$较小的情况下, 在此情形下, L1-/L2-NPSVOR均在训练数据集上出现欠拟合问题, 但是由于L2损失对损失的惩罚要高于L1损失, 故欠拟合问题严重性相对较弱一些.另外, 从图 4中最后3个数据集(Apps Android、Electronics和Health Care)对比看出, L2损失在MSE上有显著地提高.以上结果表明, L2损失对参数$C$的敏感性低于L1损失, 即利用L2损失, 可以更容易选出较合适的参数.
5. 结束语
本文针对大规模、高维、稀疏的顺序回归问题, 考虑到L2损失的引入对偏离较大的点给予更大的惩罚, 使得预测标签与真实标签更加接近, 而线性模型的提出能成功解决大规模数据面对的速度及内存消耗问题, 所以本文提出基于L2损失的线性非平行支持向量顺序回归模型—L2-NPSVOR.另外本文从原问题及其对偶问题两个角度, 分别设计了信赖域牛顿算法和对偶坐标下降算法求解该模型.其中在TRON算法中, 考虑到顺序回归相邻的超平面具有相似的解, 在算法求解时提出暖启动的方法.最后, 为验证模型及算法的有效性, 本文在收集的大量文本顺序回归数据上对提出的模型及算法进行了分析和比较.结果表明, 相比其他基于SVM的顺序回归模型, L2-NPSVOR在性能上表现最优; 关于求解算法, TRON算法能够获得比DCD更加精确的解, 但当样本维数远远高于样本数时, DCD算法比TRON更加高效.
-
图 1 非平行支持向量顺序回归的几何解释(以类别2超平面构建为例)
Fig. 1 Geometric interpretation of NPSVOR (It shows the construction of the $2$-th proximal hyperplane)
图 2 TRON, TRON (WS), DCD-M and DCD-Mm在8个数据集上的比较(这里展示了类别3对应的优化问题).横坐标是时间$t$, 纵坐标为L2-NPSVOR原问题目标函数的$f(\boldsymbol{w}^t)-f(\boldsymbol{w}^*)$的值
Fig. 2 Comparison of TRON, TRON (WS), DCD-M and DCD-Mm on eight datasets (Show the optimization model for rank 3). The horizontal axis is training time in seconds and the vertical axis is the difference between $f(\boldsymbol{w}^t)$ and $f(\boldsymbol{w}^*$)
图 3 L1/L2-NPSVOR的MAE分别随参数$C$变化
Fig. 3 Test MAE results of L1/L2-NPSVOR change with parameter $C$ on eight datasets
图 4 L1/L2-NPSVOR的MSE分别随参数$C$变化
Fig. 4 Test MSE results of L1/L2-NPSVOR change with parameter $C$ on eight datasets
表 1 数据集特征描述
Table 1 Data statistics
数据集 样本($n$) 特征($m$) 非零元素个数 类别 类别分布 AmazonMp3 10 391 65 487 1 004 435 5 ≈ 2 078 VideoSurveillance 22 281 119 793 1 754 092 5 ≈ 4 456 Tablets 35 166 201 061 3 095 663 5 ≈ 7 033 Mobilephone 69 891 265 432 5 041 894 5 ≈ 13 978 Cameras 138 011 654 268 14 308 676 5 ≈ 27 602 TripAdvisor 65 326 404 778 8 687 561 5 ≈ 13 065 Treebank 11 856 8 569 98 883 5 ≈ 2 371 MovieReview 5 007 55 020 961 379 4 ≈ 1 251 LargeMovie 50 000 309 362 6 588 192 8 ≈ 6 250 Electronics 409 041 1 422 181 37 303 259 5 ≈ 81 808 HealthCare 82 251 283 542 5 201 794 5 ≈ 16 450 AppsAndroid 220 566 253 932 6 602 522 5 ≈ 44 113 HomeKitchen 120 856 427 558 8 473 465 5 ≈ 24 171  下载: 导出CSV
下载: 导出CSV
表 2 方法在各数据集上测试结果, 包括MAE、MSE和最优参数下的训练时间(s)
Table 2 Test results for each dataset and method, including MAE, MSE and training time (s)
数据集 指标 L1-SVC L2-SVC SVR RedSVM NPSVOR L2-NPSVOR (TRON) L2-NPSVOR (DCD) AmazonMp3 MAE 0.564 0.557 0.534 0.535 0.488 0.481 0.481 MSE 0.996 0.987 0.732 0.735 0.699 0.670 0.683 TIME 0.209 0.660 0.031 0.186 0.165 0.830 0.144 VideoSurveillance MAE 0.404 0.391 0.426 0.446 0.376 0.371 0.372 MSE 0.709 0.668 0.578 0.592 0.511 0.493 0.491 TIME 0.433 1.708 0.087 0.551 0.492 1.996 0.402 Tablets MAE 0.306 0.299 0.334 0.346 0.280 0.278 0.278 MSE 0.514 0.496 0.444 0.444 0.373 0.362 0.363 TIME 0.821 3.400 0.198 1.029 0.948 2.958 0.674 Mobilephone MAE 0.431 0.419 0.450 0.444 0.391 0.388 0.385 MSE 0.736 0.705 0.604 0.587 0.536 0.524 0.522 TIME 1.811 7.574 0.353 1.909 2.330 6.724 1.605 Cameras MAE 0.246 0.240 0.273 0.301 0.227 0.232 0.226 MSE 0.394 0.381 0.357 0.375 0.296 0.299 0.298 TIME 9.552 34.480 1.401 6.016 6.341 30.132 5.388 TripAdvisor MAE 0.398 0.388 0.433 0.429 0.365 0.365 0.366 MSE 0.611 0.583 0.539 0.523 0.445 0.449 0.452 TIME 2.331 12.778 0.807 2.110 2.857 9.238 3.505 Treebank MAE 0.907 0.841 0.784 0.752 0.763 0.806 0.756 MSE 1.652 1.455 1.116 1.049 1.126 1.229 1.068 TIME 0.025 0.040 0.004 0.015 0.026 0.035 0.024 MovieReview MAE 0.501 0.490 0.448 0.447 0.432 0.436 0.431 MSE 0.615 0.582 0.486 0.485 0.476 0.476 0.475 TIME 0.121 0.429 0.029 0.133 0.130 0.373 0.125 LargeMovie MAE 1.205 1.176 1.182 1.093 0.992 1.008 1.002 MSE 3.617 3.502 2.469 2.225 2.046 2.075 2.020 TIME 3.311 10.416 0.328 1.965 2.569 7.523 2.493 Electronics MAE 0.592 0.590 0.606 0.620 0.529 0.526 0.520 MSE 1.069 1.050 0.840 0.848 0.747 0.736 0.731 TIME 22.316 168.141 4.878 10.736 23.075 116.586 18.062 HealthCare MAE 0.637 0.621 0.660 0.681 0.591 0.590 0.589 MSE 1.338 1.282 1.004 1.062 0.945 0.920 0.929 TIME 2.098 7.429 0.439 2.686 2.954 6.365 2.673 AppsAndroid MAE 0.640 0.616 0.656 0.659 0.584 0.590 0.584 MSE 1.179 1.106 0.922 0.920 0.844 0.872 0.859 TIME 4.043 14.924 0.634 1.603 4.574 11.423 6.290 HomeKitchen MAE 0.585 0.574 0.597 0.609 0.519 0.519 0.510 MSE 1.050 1.015 0.829 0.842 0.745 0.723 0.720 TIME 5.587 19.393 0.896 1.786 5.171 19.560 4.475 平均排序 MAE 5.64 4.57 5.64 5.86 2.50 2.21 1.57 MSE 7.00 6.00 4.36 4.29 2.36 2.29 1.64 TIME 3.57 6.79 1.00 3.29 4.07 6.21 3.07
下载: 导出CSV
-
[1] Nakov P, Ritter A, Rosenthal S, Sebastiani F, Stoyanov V. SemEval-2016 task 4:sentiment analysis in Twitter. In:Proceedings of the 10th International Workshop on Semantic Evaluation. San Diego, CA, USA:ACL, 2016. 1-18 [2] Dikkers H, Rothkrantz L. Support vector machines in ordinal classification:An application to corporate credit scoring. Neural Network World, 2005, 15(6):491 http://cn.bing.com/academic/profile?id=24de1d6567f75a19b2e740ee74907f6e&encoded=0&v=paper_preview&mkt=zh-cn [3] Chang K Y, Chen C S, Hung Y P. Ordinal hyperplanes ranker with cost sensitivities for age estimation. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA:IEEE, 2011. 585-592 https://www.researchgate.net/publication/224254798_Ordinal_hyperplanes_ranker_with_cost_sensitivities_for_age_estimation [4] Gutiérrez P A, Pérez-Ortiz M, Sánchez-Monedero J, Fernández-Navarro F, Hervás-Martínez C. Ordinal regression methods:survey and experimental study. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(1):127-146 doi: 10.1109/TKDE.2015.2457911 [5] 张学工.关于统计学习理论与支持向量机.自动化学报, 2000, 26(1):32-42 doi: 10.3969/j.issn.1003-8930.2000.01.008Zhang Xue-Gong. Introduction to statistical learning theory and support vector machines. Acta Automatica Sinica, 2000, 26(1):32-42 doi: 10.3969/j.issn.1003-8930.2000.01.008 [6] Chu W, Keerthi S S. Support vector ordinal regression. Neural Computation, 2007, 19(3):792-815 doi: 10.1162/neco.2007.19.3.792 [7] Lin H T, Li L. Reduction from cost-sensitive ordinal ranking to weighted binary classification. Neural Computation, 2012, 24(5):1329-1367 doi: 10.1162/NECO_a_00265 [8] Pérez-Ortiz M, Gutiérrez P A, Hervás-Martínez C. Projection-based ensemble learning for ordinal regression. IEEE Transactions on Cybernetics, 2014, 44(5):681-694 doi: 10.1109/TCYB.2013.2266336 [9] Chang K W, Hsieh C J, Lin C J. Coordinate descent method for large-scale L2-loss linear support vector machines. The Journal of Machine Learning Research, 2008, 9:1369-1398 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=CC0210084282 [10] Wang H D, Shi Y, Niu L F, Tian Y J. Nonparallel support vector ordinal regression. IEEE Transactions on Cybernetics, 2017, 47(10):3306-3317 doi: 10.1109/TCYB.2017.2682852 [11] Hsieh C J, Chang K W, Lin C J, Keerthi S S, Sundararajan S. A dual coordinate descent method for large-scale linear SVM. In:Proceedings of the 25th International Conference on Machine Learning. New York, USA:ACM, 2008. 408-415 https://www.researchgate.net/publication/215601307_A_Dual_Coordinate_Descent_Method_for_Large-scale_Linear_SVM [12] Ho C H, Lin C J. Large-scale linear support vector regression. The Journal of Machine Learning Research, 2012, 13(1):3323-3348 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0231088023/ [13] Lin C J, Moré J J. Newton's method for large bound-constrained optimization problems. SIAM Journal on Optimization, 1999, 9(4):1100-1127 doi: 10.1137/S1052623498345075 [14] Lin C J, Weng R C, Keerthi S S. Trust region newton method for logistic regression. The Journal of Machine Learning Research, 2008, 9:627-650 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=CC024921794 [15] Hsia C Y, Zhu Y, Lin C J. A study on trust region update rules in newton methods for large-scale linear classification. In:Proceedings of the 9th Asian Conference on Machine Learning (ACML). Seoul, South Korea:ACML, 2017 [16] Chiang W L, Lee M C, Lin C J. Parallel Dual coordinate descent method for large-scale linear classification in multi-core environments. In:Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, USA:ACM, 2016. 1485-1494 https://www.researchgate.net/publication/310825079_Parallel_Dual_Coordinate_Descent_Method_for_Large-scale_Linear_Classification_in_Multi-core_Environments [17] Yuan G X, Chang K W, Hsieh C J, Lin C J. A comparison of optimization methods and software for large-scale l1-regularized linear classification. The Journal of Machine Learning Research, 2010, 11:3183-3234 http://cn.bing.com/academic/profile?id=37aed315925f78d33806d3741e753dbb&encoded=0&v=paper_preview&mkt=zh-cn [18] Tseng P, Yun S. A coordinate gradient descent method for nonsmooth separable minimization. Mathematical Programming, 2009, 117(1-2):387-423 doi: 10.1007/s10107-007-0170-0 [19] Joachims T. Making Large-scale SVM Learning Practical, Technical Report, SFB 475:Komplexitätsreduktion in Multivariaten Datenstrukturen, Universität Dortmund, Germany, 1998 [20] Wang H N, Lu Y, Zhai C X. Latent aspect rating analysis on review text data:a rating regression approach. In:Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Washington, DC, USA:ACM, 2010. 783-792 https://www.researchgate.net/publication/221653225_Latent_Aspect_Rating_Analysis_on_Review_Text_Data_A_Rating_Regression_Approach [21] Pang B, Lee L. Seeing stars:exploiting class relationships for sentiment categorization with respect to rating scales. In:Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics. Ann Arbor, USA:ACL, 2005. 115-124 [22] McAuley J, Targett C, Shi Q F, van den Hengel A. Image-based recommendations on styles and substitutes. In:Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. Santiago, Chile:ACM, 2015. 43-52 https://www.researchgate.net/publication/278734421_Image-Based_Recommendations_on_Styles_and_Substitutes [23] McAuley J, Pandey R, Leskovec J. Inferring networks of substitutable and complementary products. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney, Australia:ACM, 2015. 785-794 https://dl.acm.org/citation.cfm?id=2783381 [24] Tang D Y, Qin B, Liu T. Document modeling with gated recurrent neural network for sentiment classification. In:Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal:ACL, 2015. 1422-1432 [25] Diao Q M, Qiu M H, Wu C Y, Smola A J, Jiang J, Wang C. Jointly modeling aspects, ratings and sentiments for movie recommendation (JMARS). In:Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA:ACM, 2014. 193-202 -

 下载:
下载:
计量
- 文章访问数: 2280
- HTML全文浏览量: 353
- PDF下载量: 429
- 被引次数: 0
