

-
摘要: 人体姿态是动作识别的重要语义线索,而CNN能够从图像中提取有很强判别能力的深度特征,本文从图像局部区域提取姿态特征,从整体图像中提取深度特征,探索两者在动作识别中的互补作用.首先介绍了一种姿态表示方法,每个肢体部件的姿态由描述该部件姿态的一组Poselet检测得分表示.为了抑制检测错误,设计了基于部件的模型作为检测上下文.为了从数量有限的数据集中训练CNN网络,本文使用了预训练和精细调节的方法.在两个数据集中的实验表明,本文介绍的姿态特征与深度特征混合使用,动作识别性能得到了极大提升.Abstract: Body pose is an important semantic cue for action recognition, and CNN can extract strong discriminative depth feature. This paper extracts pose feature from local image patches and gets depth feature from holistic image, then exploits their complementary relationship in action recognition. A pose representation is introduced, in which pose of a body part is represented by a collection of poselets which describe its pose variability. To suppress detection ambiguity, part-based model is designed as the context of detection for each poselet. CNN is trained through pre-training and fine tuning on the data set with very limited images. Empirical results demonstrate aggressive performance improvement by concatenating pose feature and depth feature.
-
Key words:
- Action recognition /
- pose feature /
- poselet /
- depth feature
1) 本文责任编委 赖剑煌 -
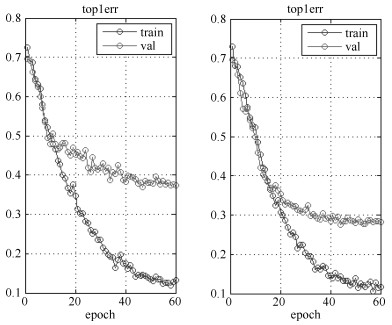
图 9 使用预备模型前后CNN训练过程top1错误率比较
Fig. 9 Comparison of top1 error between whether using pre trained model

图 10 姿态特征识别正确而深度特征识别错误的图像
Fig. 10 Some images recognized accurately by pose feature but falsely by deep feature

图 11 深度特征识别正确而姿态特征识别错误的图像
Fig. 11 Some images recognized accurately by deep feature but falsely by pose feature
表 3 静止图像数据集姿态特征、CNN及混合后性能比较(%)
Table 3 Precision comparison on static image data set (%)
方法 舞蹈 打高尔夫球 跑步 坐 行走 平均 姿态特征 69 65 74 65 59 66.4 CNN 72.4 76.4 70.2 73.9 65.6 71.7 姿态特征+ C5 79.4 68.8 79.9 77.4 72.0 75.5 姿态特征+ F6 78.5 70.2 77.9 78.3 74.5 75.8 姿态特征+ F7 75.3 68.9 76.2 79.3 72.4 74.4  下载: 导出CSV
下载: 导出CSV
表 4 视频截图数据集姿态特征、CNN及混合后精度比较(%)
Table 4 Precision comparision on video data set (%)
方法 舞蹈 打高尔夫球 跑步 坐 行走 平均 姿态特征 52.1 91.5 83.6 39.4 51.4 63.6 CNN 62.2 58.9 76.2 63.9 58.9 64.0 姿态特征+ C5 63.4 65.7 82.3 61.5 65.5 67.6 姿态特征+ F6 69.8 64.6 84.5 64.3 66.3 69.9 姿态特征+ F7 67.5 64.1 82.5 63.7 65.8 68.7
下载: 导出CSV
-
[1] Aggarwal J K, Ryoo M S. Human activity analysis:a review. ACM Computing Surveys, 2011, 43(3):Article No.16 http://d.old.wanfangdata.com.cn/Periodical/dlkxjz201407009 [2] Jiang Y G, Wu Z X, Wang J, Xue X Y, Chang S F. Exploiting feature and class relationships in video categorization with regularized deep neural networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(2):352-364 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=Arxiv000001111697 [3] Wu Z X, Jiang Y G, Wang X, Ye H, Xue X Y. Multi-stream multi-class fusion of deep networks for video classification. In:Proceedings of the 2016 ACM on Multimedia Conference. Amsterdam, The Netherlands:ACM, 2016. 791-800 [4] 朱煜, 赵江坤, 王逸宁, 郑兵兵.基于深度学习的人体行为识别算法综述.自动化学报, 2016, 42(6):848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtmlZhu Yu, Zhao Jiang-Kun, Wang Yi-Ning, Zheng Bing-Bing. A review of human action recognition based on deep learning. Acta Automatica Sinica, 2016, 42(6):848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtml [5] 关秋菊, 罗晓牧, 郭雪梅, 王国利.基于隐马尔科夫模型的人体动作压缩红外分类.自动化学报, 2017, 43(3):398-406 http://www.aas.net.cn/CN/abstract/abstract19018.shtmlGuan Qiu-Ju, Luo Xiao-Mu, Guo Xue-Mei, Wang Guo-Li. Compressive infrared classification of human motion using HMM. Acta Automatica Sinica, 2017, 43(3):398-406 http://www.aas.net.cn/CN/abstract/abstract19018.shtml [6] Guo G D, Lai A. A survey on still image based human action recognition. Pattern Recognition, 2014, 47(10):3343-3361 doi: 10.1016/j.patcog.2014.04.018 [7] Maji S, Bourdev L, Malik J. Action recognition from a distributed representation of pose and appearance. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, USA:IEEE, 2011. 3177-3184 [8] Yao B P, Li F F. Action recognition with exemplar based 2.5D graph matching. In:Proceedings of the 12th European Conference on Computer Vision. Florence, Italy:Springer, 2012. 173-186 [9] Yao B P, Jiang X Y, Khosla A, Lin A L, Guibas L, Li F F. Human action recognition by learning bases of action attributes and parts. In:Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain:IEEE, 2011. 1331-1338 [10] Delaitre V, Laptev I, Sivic J. Recognizing human actions in still images:a study of bag-of-features and part-based representations. In:Proceedings of the 21st British Machine Vision Conference. Aberystwyth, UK:BMVC Press, 2010. 1-11 [11] Ikizler-Cinbis N, Cinbis R G, Sclaroff S. Learning actions from the Web. In:Proceedings of the 2009 IEEE 12th International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 995-1002 [12] Wang Y, Jiang H, Drew M S, Li Z N, Mori G. Unsupervised discovery of action classes. In:Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA:IEEE, 2006. 1654-1661 [13] Felzenszwalb P F, Huttenlocher D P. Pictorial structures for object recognition. International Journal of Computer Vision, 2005, 61(1):55-79 doi: 10.1023/B:VISI.0000042934.15159.49 [14] Yang Y, Ramanan D. Articulated pose estimation with flexible mixtures-of-parts. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, USA:IEEE, 2011. 1385-1392 [15] Bourdev L, Malik J. Poselets:body part detectors trained using 3D human pose annotations. In:Proceedings of IEEE the 12th International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 1365-1372 [16] Bourdev L, Maji S, Brox T, Malik J. Detecting people using mutually consistent poselet activations. In:Proceedings of the 11th European Conference on Computer Vision. Heraklion, Crete, Greece:Springer, 2010. 168-181 [17] Yang W L, Wang Y, Mori G. Recognizing human actions from still images with latent poses. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, USA:IEEE, 2010. 2030-2037 [18] Wang Y, Tran D, Liao Z C, Forsyth D. Discriminative hierarchical part-based models for human parsing and action recognition. Journal of Machine Learning Research, 2012, 13(1):3075-3102 http://cn.bing.com/academic/profile?id=b01a8d0fa4dfaa33e7d60d84dc664875&encoded=0&v=paper_preview&mkt=zh-cn [19] Ni B B, Moulin P, Yang X K, Yan S C. Motion part regularization:improving action recognition via trajectory group selection. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015. 3698-3706 [20] Wang H, Schmid C. Action recognition with improved trajectories. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 3551-3558 [21] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In:Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA:ACM, 2012. 84-90 [22] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In:Proceedings of the 2014 Advances in Neural Information Processing Systems. Montrál, Canada:NIPS, 2014. 1-8 [23] Goodale M A, Milner A D. Separate visual pathways for perception and action. Trends in Neurosciences, 1992, 15(1):20-25 doi: 10.1016/0166-2236(92)90344-8 [24] Gkioxari G, Malik J. Finding action tubes. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015. 759-768 [25] Cheron G, Laptev I, Schmid C. P-CNN:pose-based CNN features for action recognition. In:Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile:IEEE, 2015. 3218-3226 [26] Chen J W, Wu J, Konrad J, Ishwar P. Semi-coupled two-stream fusion ConvNets for action recognition at extremely low resolutions. In:Proceedings of 2017 IEEE Winter Conference on Applications of Computer Vision. Santa Rosa, CA, USA:IEEE, 2017. 139-147 [27] Shi Y M, Tian Y H, Wang Y W, Huang T J. Sequential deep trajectory descriptor for action recognition with three-stream CNN. IEEE Transactions on Multimedia, 2017, 19(7):1510-1520 doi: 10.1109/TMM.2017.2666540 [28] Tu Z G, Cao J, Li Y K, Li B X. MSR-CNN:applying motion salient region based descriptors for action recognition. In:Proceedings of the 23rd International Conference on Pattern Recognition. Cancun, Mexico:IEEE, 2016. 3524-3529 [29] Mikolajczyk K, Choudhury R, Schmid C. Face detection in a video sequence-a temporal approach. In:Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, HI, USA:IEEE, 2001. Ⅱ-96-Ⅱ-101 [30] Ramanan D. Dual coordinate solvers for large-scale structural SVMs. USA:UC Irvine, 2013 [31] Donahue J, Jia Y Q, Vinyals O, Hoffman J, Zhang N, Tzeng E, et al. DeCAF:a deep convolutional activation feature for generic visual recognition. In:Proceedings of the 31st International Conference on Machine Learning. Beijing, China:ICML, 2014. 647-655 [32] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA:IEEE, 2014. 580-587 [33] Niebles J C, Han B, Ferencz A, Li F F. Extracting moving people from internet videos. In:Proceedings of the 10th European Conference on Computer Vision. Marseille, France:Springer, 2008. 527-540 -

 下载:
下载:





计量
- 文章访问数: 2709
- HTML全文浏览量: 760
- PDF下载量: 851
- 被引次数: 0
