

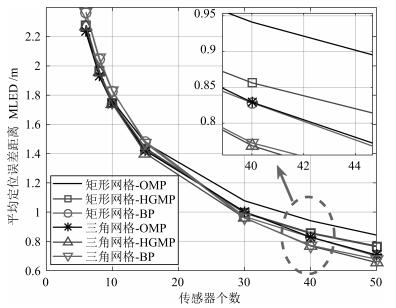
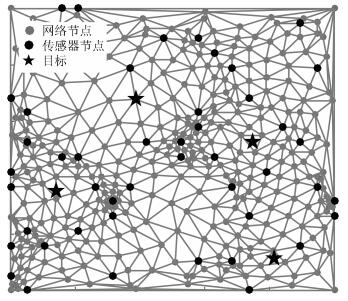
Hierarchical Greedy Matching Pursuit for Multi-target Localization in Wireless Sensor Networks Using Compressive Sensing
-
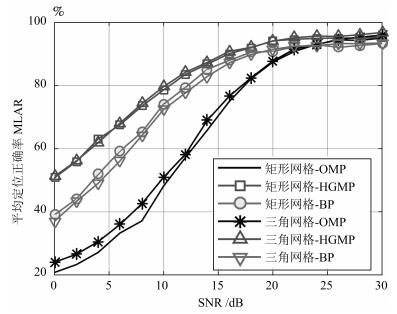
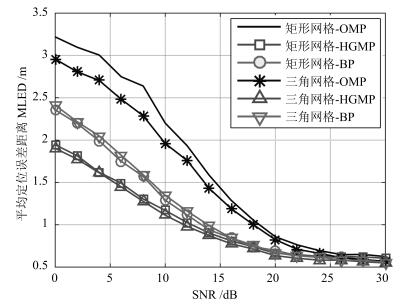
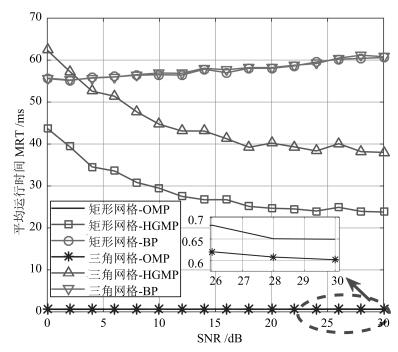
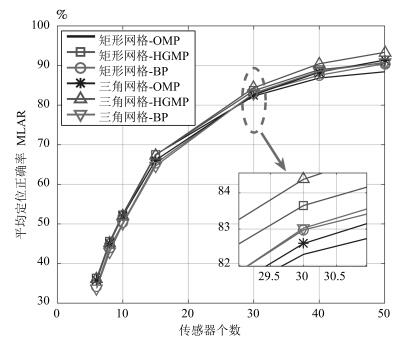
摘要: 针对基于压缩感知(Compressive sensing,CS)的多目标定位问题,通过分析多目标场景中的隐含结构信息,本文提出一种层级的贪婪匹配追踪定位算法.该算法首先获得多目标在网格化空间中的可能位置作为全局估计层,然后利用该全局估计信息作为稀疏恢复层的输入信息,在网格化空间中重构多目标位置矢量.本文证明了文献中广泛采用的基于正交化的预处理方式实质上降低了信噪比(Signal to noise ratio,SNR),从而降低了定位性能.本文通过全局估计,预先排除了不可能的位置,等效于从观测子空间中分离出信号子空间,从而降低了观测噪声的影响.通过理论分析与计算机仿真,表明所提算法具有线性复杂度且在相同信噪比下具有更高的定位正确率和定位精度.Abstract: This paper addresses the problem of multi-target localization in wireless sensor networks using compressive sensing (CS). We first analyze the ample implicit structured information contained in the multi-target localization scenario. Then, a hierarchical greedy matching pursuit (HGMP) approach for multi-target localization is proposed. In the proposed HGMP algorithm, the possible positions of targets in the meshing space are obtained as the global estimation layer, and subsequently the global estimation information is used as the input information to the sparse recovery layer to reconstruct the multi-target localization vector in the meshing space. Moreover, we prove that the orthogonality-based preprocessing operation widely adopted in the literature reduces the signal-to-noise ratio (SNR), degrades the localization performance, a problem that has never been addressed before. Through the global estimation layer, impossible positions are preliminarily removed, which is equivalent to separating the signal subspace from the observation subspace, thus reducing the influence of the observed noise. Finally, theoretical analysis and computer simulations show that the proposed algorithm enjoys a linear computational complexity and a higher localization accuracy at the same SNR.
-
许多现实采样的数据特征复杂,呈非线性分布,变量之间存在高度非线性相关性.大部分情况下,图像数据被视为一种具有非线性结构的数据.因图像易受外界因素的干扰,使得数据具有很强的不确定性.例如人脸图像会受光照、表情和姿态等因素的影响,通常导致图像中的像素值发生非线性的变化.同样,现实中采集到的基因表达数据也常呈现出高维、小样本、多噪声和非线性等特征,且大部分数据不含类别信息,因此聚类技术作为一种典型无监督技术而被广泛使用.故本文从非线性角度研究图像数据和基因表达数据的聚类问题.
近年来,子空间聚类作为一种热点聚类方法被广泛研究,并被应用到机器视觉领域,如图像分割领域[1]、动态分割领域[2]和人脸聚类领域[3];此外图像表达[4]和混合识别系统[5]等图像处理领域中,子空间聚类方法也被成功使用.目前,已有许多经典的子空间聚类算法被提出,如稀疏子空间聚类(Sparsesubspace clustering,SSC)[6]、 低秩表达(Low rankrepresentation,LRR)[7] 和最小二乘子空间聚类(Least squaresregression,LSR)[8] 等,三者都是基于谱聚类的子空间聚类算法.SSC可实现从全局角度自动选择近邻点,消除数据之间的相关性;LRR保持仿射矩阵的低秩性;LSR保持数据的聚集性.在这些方法基础之上改进得到鲁棒潜在低秩表达子空间聚类(Robustlatent low rank representation,RLLRR)[9]、光滑表达子空间聚类(Smooth representation clustering,SMR)[10]、 鲁棒SSC (Robust SSC,R-SSC)[11]、块对角SSC (Block-diagonal SSC,BD-SSC)和块对角LRR (Block-diagonalLRR,BD-LRR)[12]等.
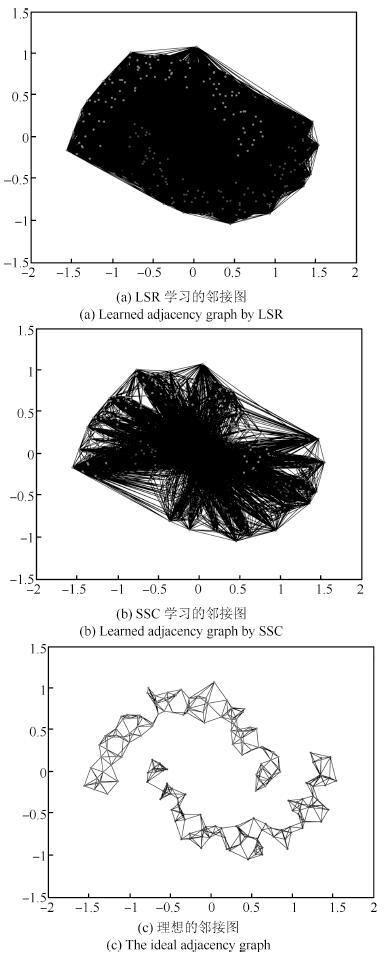
上述的大部分方法都以数据全局线性为前提,每个样本点可以利用其余样本点线性重构.从回归模拟角度来看,上述方法可看作线性回归模型.故SSC是LASSO (Least absolute shrinkageand selectionator operator)[13]的变形,LSR是岭回归 (Ridgeregression)[14]的变形.LASSO以l1范数作为惩罚项来压缩模型回归系数,l1范数在原点处不可导,通常采用迭代方法求解模型的回归系数.因求解会得到许多为0的回归系数,所对应的回归变量在线性回归模型中不起作用,以此达到压缩变量的目的[15]. 但对有较多变量的模型来说,压缩变量的效果会变差.岭回归是一种较稳定的连续型模型,但它不能压缩变量,这导致模型中变量过多,不能得到一个简单且解释性强的模型.对于线性相关程度大的数据,LASSO和岭回归的效果较好; 反之,这两种方法的回归效果较差.在子空间聚类方法中,SSC和LSR也保持着同样的优缺点.因此对于非线性数据,SSC和LSR的聚类效果不理想,如图 1 所示.
图 1是LSR和SSC在双月形数据上学习得到的仿射矩阵画出的邻接图.由图 1(a)可见,LSR用除本身外的其余点做线性表示,不能将两类数据区分开.由图 1(b)中亦可见,SSC虽然能自动选取样本点进行线性表示,但样本点的选取不理想.可见LSR和SSC都不能达到图 1(c)的理想效果,二者不能够将两类数据准确地区分开,因此不适合对非线性数据进行聚类.
流形学习是近年来处理流形数据和非线性数据的常用方法,许多经典流形学习方法被提出,如局部保持投影(Locality preservingprojections,LPP)[16]、 局部线性嵌入(Locally linearembedding,LLE)[17]和近邻保持嵌入(Neighborhood preservingembedding,NPE)[18]等. LPP、 LLE和NPE有一个共同点就是假设数据是局部线性的,每个样本点均可利用其近邻样本进行线性表示.同样,在聚类问题中,相互靠近的样本点往往被视为同类,这样便可以利用近邻点对数据线性表示.因此,受流形学习局部线性表示思想的启发,结合子空间聚类,本文提出局部子空间聚类算法(Local subspace clustering,LSC),并应用于图像和基因表达谱等具有明显非线性特征的高维数据.
本文提出的局部子空间聚类利用样本点的k个近邻进行线性表示.值得注意的是:1) k近邻法的关键是近邻参数k的选取,本文提出的子空间聚类方法能够自适应地调整近邻点个数. 2) 通常采用k近邻法只选取适当少的近邻点,但局部子空间聚类算法既可以取适当少,也可以取适当多的近邻点.当选取适当少的近邻点时,可剔除大量样本点,计算便捷; 当选取适当多的近邻点时,可剔除一些噪声点,使算法更具鲁棒性.
1. 子空间聚类
子空间聚类目标是将样本数据分割或聚集成几个簇,每个簇对应一个子空间,因此也称为子空间分割.
定义 1[8]. 子空间聚类(Subspace clustering):给定的从c个子空间{Si}i=1c采样的数据向量集合 $X=[{{X}_{1}},{{X}_{2}},\cdots ,{{X}_{c}}]=[{{x}_{1}},{{x}_{2}},\cdots ,{{x}_{n}}]\in {{\mathbf{R}}^{d\times n}},{{X}_{i}}$ 是从子空间Si中采样的ni个数据向量构成的集合,.子空间聚类的目标是根据它们采样的基子空间分割数据.
子空间聚类算法根据表示方式不同可以粗略分为四类[8]:代数方法、 迭代方法、 统计方法和谱聚类方法,本文重点研究最后一种.基于谱聚类的子空间聚类方法核心在于求解仿射矩阵Z=(zij)n×n,zij用来度量两个样本xi 和xj的相似度.典型的相似度度量zij=exp(-||xi-xj||2/σ),σ>0不能很好地刻画数据的本质特征[8].稀疏子空间聚类SSC、低秩表达子空间聚类LRR和最小二乘回归子空间聚类LSR提出了新的仿射矩阵计算方法.这些方法将每个样本点xi表示为其他样本点的线性组合:
$x_i=\sum_{jeq i}x_jz_{ij} $
(1) 其中zij是表示权重的常数.利用表示系数(|zij|+|zji|)/2度量xi和xj之间的相似度.
SSC的目标函数:
$\begin{align} & \min_z \| Z \|_1\\ & {\rm s.t.} \quad X=XZ,\quad {\rm diag}{Z}=0 \end{align}$
(2) 其中,||Z||1是Z的l1范数,定义为仿射矩阵Z的所有元素的绝对值之和.文献[6]还将SSC扩展到噪声模型,目标函数如下:
$\begin{align} &\min_z \frac{\lambda}{2} \| X-XZ \|^2_F+ \| Z \|_1\\ & {\rm s.t.} \quad {\rm diag}{Z}=0 \end{align}$
(3) LSR最小化Z的Frobenius范数:
$\begin{align} & \min_z \| Z \|^2_F\\ & {\rm s.t.} \quad X=XZ,\quad {\rm diag}{Z}=0 \end{align}$
(4) 对于有噪声的模型,可以扩展为
$\begin{align} &\min_z \| X-XZ \|^2_F+\lambda \| Z \|^2_F\\ & {\rm s.t.} \quad {\rm diag}{Z}=0 \end{align}$
(5) 去除约束条件 ,扩展为
$ \min_z \| X-XZ \|^2_F+\lambda \| Z \|^2_F$
(6) 其中,λ >0,||Z||F是矩阵Z的Frobenius范数.
2. 局部子空间聚类
为解决子空间聚类方法不能直接应用于非线性图像数据的不足,本文引入k近邻局部线性表示思想,将其分别与经典子空间聚类方法SSC和LSR相结合,提出局部子空间聚类(Local subspace clustering,LSC),其中k近邻局部线性表示与LSR结合,命名为局部最小二乘回归子空间聚类(Local least squares regression,LLSR); 与SSC结合,命名为局部稀疏子空间聚类(Local sparse subspaceclustering,LSSC).
2.1 局部最小二乘回归子空间聚类
LLSR算法主要利用k近邻[18]求取k个近邻点,以局部线性为依据对数据进行线性表示.具体步骤如下:
1) 以样本点间的欧氏距离作为相似性度量,距离越小表示样本相似性越高.样本点xi的k个近邻点(不包含自身)集用Nk(xi)={xi1,xi2,…,xik}表示.
模型(3)和模型(5)中,对角为0的约束本质上是从样本点xi用除自身以外的样本点线性表示得来,即zii=0 (i=1,2,…,n),因此k个近邻点中不包含xi自身的目的是为保持模型中对角元素为0的约束.
2) LLSR子空间聚类的目标函数为
$ \min_z \sum_i {\| x_i-\sum_{x_j\in N_k(x_i)}x_jz_{ij} \|^2_F}+\lambda \| Z \|^2_F$
(7) 其中若xj∉ Nk(xi),则令zij=0.由于每个xi相互独立,故上式亦可表示为
$ \min_{\tilde{z}_i} \| x_i-N_k(x_i)\tilde{z}_{i} \|^2_F+\lambda \| \tilde{z}_i \|^2_F$
(8) 利用最小二乘思想求解式(8),得到解析解为
$\tilde{z}_i=(N_k(x_i)^{\rm T}N_k(x_i)+\lambda I)^{-1}N_k(x_i)^{\rm T}x_i $
(9) 对于每个样本点xi,LLSR都可求解出一个解 ${{\tilde{z}}_{i}}$ .对任意 $i,z_{i{{i}_{m}}}^{*}={{\tilde{z}}_{i{{i}_{m}}}}\$,\$m=1,2,\cdots ,k$ ,其余为0,故可得到模型(7)的解Z*.
2.2 局部稀疏子空间聚类
由于近邻参数k值固定,不能根据样本点分布的疏密自主确定近邻点个数,导致第2.1节提出的LLSR方法存在局限,为此本节提出局部稀疏子空间聚类LSSC. LSSC利用l1范数具有稀疏的性质,在k近邻点选取过程中可自适应地调整近邻点个数.由于SSC与LSR的正则参数项位置不同,为了让正则参数项的作用统一,将SSC改写成:
$ \min_z \frac{1}{2} \| X-XZ \|^2_F+\lambda \| Z \|_1$
(10) 此式可利用交替方向乘子法(Alternating direction method ofmultipliers,ADMM)[19]的思想求解.本文的LSSC在式(10)上进行局部线性化改进,其算法步骤与LLSR相同.先选取每个样本点 的k个近邻点,再从近邻点中二次筛选,自动调整近邻. LSSC目标函数如下:
$ \min_z \frac{1}{2} \sum_i {\| x_i-\sum_{x_j\in N_k(x_i)}x_jz_{ij} \|^2_F}+\lambda \| Z \|_1$
(11) 其中,若xjotin Nk(xi),则令zij=0.同样,每个xi相互独立,故式(11)亦可为
$ \min_{\tilde{z}_i} \frac{1}{2} \| x_i-N_k(x_i){\tilde{z}_i} \|^2_F+\lambda \| {\tilde{z}_i} \|_1$
(12) 此目标函数与LASSO的回归模型等价,利用ADMM,目标函数(12)转化为
$\begin{align} &\min_{\tilde{z}_i}\frac{1}{2} \| x_i-N_k(x_i)\tilde{z}_i \|^2_F+\lambda \| \beta \|_1\\ & {\rm s.t.} \quad \tilde{z_i}-\beta=0 \end{align}$
(13) 其中β是对偶变量.进一步可写成:
$\begin{align} & \min_{\tilde{z}_i,\beta,U} \frac{1}{2} \|x_i-N_k(x_i)\tilde{z}_i\|^2_F+\lambda \| \beta \|_1+\\ & \quad\quad \|\frac{\rho}{2}\| \tilde{z}_i-\beta-U \|^2_F \end{align}$
(14) 其中ρ是拉格朗日乘子,在实验中设为常数1,U是对偶变量.模型(14)的ADMM步骤如下:
$\begin{align} & {\tilde{z}_i}^{K+1}:=(N_k(x_i)^{\rm T}N_k(x_i)+\rho I)^{-1}(N_k(x_i)x_i+\\ & \quad\quad \quad \quad \rho \beta^K-U^K)\\ & \beta^{K+1}:=S_{\frac{\lambda}{\rho}}({\tilde{z}_i}^{K+1}+\frac{U^K}{\rho}) \\ & U^{K+1}:=U^K+\rho(\tilde{z}_i^{K+1}-\beta^{K+1})\end{align}$
(15) 其中K是更新次数, ${{S}_{\alpha }}(v)={{(v-\alpha )}_{+}}-{{(-v-\alpha )}_{+}}$ ,具体算法参见文献[19],由此可求得 ${{\tilde{z}}_{i}}$ .对任意i,在相应位置上 $z_{i{{i}_{m}}}^{*}={{\tilde{z}}_{i{{i}_{m}}}},m=1,2,\cdots ,k$ ,其余为0,可得到LSSC 模型(11)的解矩阵Z*.
2.3 局部子空间聚类算法
类似于SSC、LRR和LSR,局部子空间聚类算法LSC也是基于谱聚类的子空间聚类方法. LSC算法如下:
算法 1. 局部子空间聚类算法
输入. 数据矩阵X,正则参数λ,近邻点个数k,类数c.
输出. c个类簇.
1) 利用k近邻求每个样本点的k个近邻;
2) 通过LLSR目标函数(7)或LSSC目标函数(11)求解矩阵Z*;
3) 计算仿射矩阵(|Z*|+|(Z*)T|)/2;
4) 应用标准分割方法[20]将数据分成c个子空间.}
值得注意的是,文献[8]证明了LSR具有聚集性,同样我们可以证明LLSR具有局部聚集性.
定理 1. 给定向量y∈ Rd ,矩阵Nk(y)∈ Rd× k和参数λ >0,假设Nk(y)={y(1),y(2),…,y(k)}已经按列标准化,z*是如下LLSR 问题的解:
$ \min_z \| y-N_k(y)z^* \|^2_2+\lambda \| z \|^2_2$
(16) 那么
$\frac{\| z^*_{(i)}-z^*_{(j)} \|_2}{\| y \|_2}\leq\frac{1}{\lambda}\sqrt{2(1-r)} $
(17) 其中r=y(i)T y(j)是样本相关系数.
证明 . 令 $L(z)=\|y-{{N}_{k}}(y){{z}^{*}}\|_{2}^{2}+\lambda \|z\|_{2}^{2}$ ,且
$ \frac{\partial L(z^*)}{\partial z_k}=0$
(18) 有:
$-2y_{(i)}^{\text{T}}(y-{{N}_{k}}(y){{z}^{*}})+2\lambda z_{(i)}^{*}=0$
(19) $-2y^{\rm T}_{(j)}(y-N_k(y)z^* )+2\lambda z^*_{(j)}=0 $
(20) 由式(19)和式(20)得
$z^*_{(i)}-z^*_{(j)}=\frac{1}{\lambda}(y^{\rm T}_{(i)}-y^{\rm T}_{(j)})(y-N_k(y)z^* ) $
(21) 且Nk(y)已经按列标准化,r=y(i)T y(j),得
$\| y_{(i)}-y_{(j)} \|_2=\sqrt{2(1-r)} $
(22) 又因为z*是问题(16)的最优解,得
$\| y-N_k(y)z^* \|^2_2 +\lambda \| z^* \|^2_2=L(z^*)\leq L(0)=\| y\|^2_2 $
(23) 因此 ,结合式(21)和式(22)可得
$\frac{\| z^*_{(i)}-z^*_{(j)} \|_2}{\| y \|_2}\leq\frac{1}{\lambda}\sqrt{2(1-r)} $
(24) 定理 1 证明了LLSR的局部聚集能力.假如y(i)和y(j)是高度相关的,如r=1,则定理1表明y(i)和y(j)对应的系数z(i)和z(j)的差异性接近为0,这样y(i)和y(j)就会聚成相同的簇.
3. 实验
为验证局部子空间聚类方法的有效性,本节选用经典聚类方法:K均值(K-means)、层次聚类方法(Hierarchical clustering,HC),以及子空间聚类方法: SSC[6]、 LRR[7]、LSR[8]、 BD-LRR[12]、RLLRR[9]和SMR[10],与本文提出的LLSR和LSSC进行比较,并从聚类准确率(Accuracy,ACC)[21]的角度对比各种方法的聚类能力,其中ACC 定义如下:
对给定样本,令ri和si分别为聚类算法得到的类标签和样本自带的类标签,准确率计算公式为
$ACC=\frac{\sum\limits_{i=1}^{n} \delta(s_i,map(r_i))}{n} $
(25) 其中,n为样本总数,δ(x,y) 是一个函数,当x=y 时,值为1,否则为0. map(ri)是一置换函数,将每个类标签ri映射成与样本自带的类标签等价的类标签.
本文采用双月形数据、图像数据集和基因表达数据集,其中图像数据集包括:ORL10P1、 PIX10P1、PIE10P1、Umist[22]、 USP-S[10]、COIL202;基因数据集3包括: Leukemia1、 SRBCT、 Lung_Cancer、 Prostate_Tumor. 在参数设置方面,LRR、 LSR和LLSR的正则参数λ取值为 {0.0001,0.001,0.005,0.01,0.05,0.1,0.5,1,10}, SSC和LSSC的λ取值为 {0.0001,0.001,0.005,0.01,0.05,0.1}; BD-LRR、 RLLRR和SMR的参数取 {0.08,0.1,0.5,1,5,10,50,100,500,1000};近邻点个数k取3~10.每个算法运行10次,取聚类准确率的平均值.本文的实验环境为Winows 7系统,内存4GB和i5处理器,所有方法都用Matlab2012b编程实现.
3.1 人造数据
利用人造双月形实验数据说明LSC的有效性,同时展示近邻点k值和正则参数λ的选取对聚类准确率的影响.
双月形数据是由两类数据组成的非线性数据,形状如两个弯月,如图 2所示.我们的目标是希望能找到一个好的仿射矩阵,将数据准确地分成两类.利用LLSR和LSSC学习得到的邻接图如图 3所示.
 图 3 LSC在双月形数据学习得到的邻接图Fig. 3 Learned adjacency graph by LSC on the two-moon synthetic data
图 3 LSC在双月形数据学习得到的邻接图Fig. 3 Learned adjacency graph by LSC on the two-moon synthetic data结合图 1和图 3,易知LLSR和LSSC能够很好地将两类数据分开,便于聚类.比较图 3中LLSR 和 LSSC的邻接图,后者以稀疏为目的能够自动筛选近邻点,故邻接边较少.表 1给出各对比方法在双月形数据上的聚类准确率(参数)和运行时间.由表 1可以看出LLSR和LSSC很大程度地提升了聚类准确率,二者均能达到100\%的准确率,而其余方法基本在50\%左右.比较SSC和LSSC运行时间可以看出,LSSC利用局部线性的思想明显提升了运行速度. LSSC和LLSR的运行时间包括近邻点计算的耗时. 得的仿射矩阵效果并不理想; 反观,LLSR和LSSC两种方法都能得到对角形式的仿射矩阵,且LSSC能得到更稀疏的仿射矩阵.综上,对于双月形数据,原有LSR和SSC方法受全局线性限制,不能得到理想结果,而局部子空间聚类LSC的两种方法利用局部线性思想得到较好的结果,更好地解决非线性数据的聚类问题.
表 1 双月形数据上聚类准确率(%)和运行时间(s)的对比Table 1 Clustering accuracy (%) and running time (s)comparison on the two-moon synthetic dataHC K-means LRR SSC LSR BD-LRR RLLRR SMR LSSC LLSR ACC 100.00 72.00 53.50 53.50 50.00 50.00 52.00 51.50 100.00 100.00 (0.001) (0.005) (0.0001) (0.08) (0.1) (0.001) (0.0001,5) (0.0001,5) Time 0.0010 0.0026 1.89 4.80 0.0008 19.15 0.33 0.045 0.94 0.10 图 4给出LSR、 SSC、 LLSR和LSSC四种方法的仿射矩阵图.对于双月形数据,LSR和SSC所
在双月形数据实验中研究正则参数λ和近邻点k的选取对聚类准确率的影响,结果如图 5所示.
 图 5 在双月形数据上LSC的参数学习Fig. 5 Study on the LSC's parameters on the two-moon synthetic data
图 5 在双月形数据上LSC的参数学习Fig. 5 Study on the LSC's parameters on the two-moon synthetic data由图 5(a)可知,将LSR和SSC应用在非线性数据上,正则参数λ的改变不会使聚类准确率发生较大变化; 而对于LLSR,由于采用局部线性思想,相当于在很大程度上剔除了许多不相关点,因此λ 的变化也不会影响其聚类准确率; LSSC也是如此,在大部分λ取值下,得到的结果是稳定的,但当λ取值越大时,l1 范数的作用越大,会导致最终获得的近邻点减少,甚至近邻点个数为0,得到的仿射矩阵为0矩阵,影响了聚类准确率.所以,图 5(a)中SSC和LSSC在取较大正则参数时,聚类准确率均发生下降,甚至在过大的正则参数下无法进行有效聚类.图 5(b)显示近邻点个数的变化会导致聚类准确率的变化,当k取过小或过大,都会使得聚类准确率降低,当k取5~7时,LLSR和LSSC会得到较好的结果. LLSR整体上比LSSC更稳定,有更高的聚类准确率.在选取近邻点时,LSSC的k值一般比LLSR小.且实验中发现,LSSC虽然能自动调整近邻点,但当近邻点数k过大时,l1 范数自动调整近邻点的效果变差.
3.2 图像数据
本实验采用的6个图像数据中,前4个是人脸图像数据,第5个是手写数字图像数据,第6个为物品数据.数据集描述如表 2.且图 6列出6个图像数据集中的部分样本图像.
表 2 数据集描述Table 2 Summary of the data sets数据集 样本 长 宽 类别 ORL10P 100 112 92 10 PIX10P 100 100 100 10 PIE10P 210 55 44 10 Umist 575 28 23 20 USPS 1 000 16 16 10 COIL20 1 440 32 32 20 3.2.1 聚类准确率
实验时,使用PCA统一将6个图像数据降至60维.实验结果如表 3.
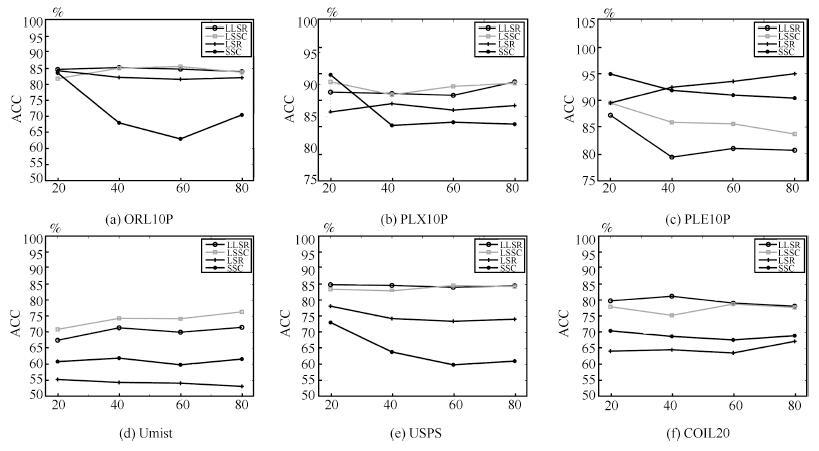
表 3 聚类准确率Table 3 Clustering accuracy (%)HC K-means LRR SSC LSR BD-LRR RLLRR SMR LSSC LLSR ORL10P 41.00 73.40 79.00 71.00 83.00 70.30 74.70 78.00 86.00 87.00 PIX10P 77.00 79.90 87.00 86.00 85.00 76.80 56.10 88.00 96.00 97.00 PIE10P 70.95 32.95 100.00 90.00 90.00 80.00 79.43 100.00 98.57 100.00 Umist 45.57 47.58 52.17 61.57 52.35 48.35 50.96 69.91 76.87 74.09 USPS 10.90 73.14 78.60 60.80 71.30 63.90 65.50 77.10 81.20 91.20 COIL20 53.47 60.10 65.69 72.01 63.40 67.72 68.80 67.15 78.26 79.58 由表 3可知,局部子空间聚类方法 LLSR 和 LSSC利用局部线性思想,在所有测试数据集上都取得最好结果.在大部分图像数据中,LSC的聚类准确率提高明显.对比两种不同的局部子空间聚类方法可以发现:LLSR的聚类准确率除Umist 数据集外均优于LSSC,较好地改进了最小二乘子空间聚类算法.值得注意的是,在PIE10P实验中,其他传统子空间聚类方法也取得90\%以上较高的聚类准确率,说明该数据集的线性相关度非常高,因此k 值选取较大,局部近邻点几乎包括全部样本数据.由此可见LSC还具有剔除噪声点的作用.在其余5个数据集中,近邻点k都在5~7之间.实验结果表明局部子空间聚类方法能更好地处理具有非线性特征的图像数据,可以更好地反映图像数据的本质结构.
3.2.2 运行时间
表 4给出几种对比算法的运行时间,数据集按样本数由少到多排列.由表 4可以看出随着样本数的增大,各算法的运行时间也相应增加.几种子空间聚类方法中LSR速度最快,最慢的方法是SSC.在大部分实验中,LSC的两个方法会比SSC、 LRR、BD-LRR和RLLRR快.特别是由SSC改进而来的LSSC,仅选取少数近邻点学习仿射矩阵,其计算量明显减少,因此运行时间比SSC节省很多,且随着数据集规模的增大,LSSC较之SSC的优势也更明显.
表 4 运行时间的对比(s)Table 4 Running time (s) comparisonHC K-means LRR SSC LSR BD-LRR RLLRR SMR LSSC LLSR ORL10P 0.0011 0.0071 0.54 0.21 0.00078 7.29 1.69 0.014 0.14 0.034 PIX10P 0.00095 0.0062 1.04 0.33 0.00073 7.60 1.72 0.012 1.25 0.035 PIE10P 0.0023 0.011 4.51 2.53 0.0015 22.23 2.14 0.057 0.32 0.13 Umist 0.011 0.037 25.14 62.27 0.015 240.70 13.48 0.71 1.52 0.92 USPS 0.034 0.091 130.61 124.57 0.044 884.42 120.33 4.53 3.57 2.75 COIL20 0.072 0.071 423.54 2.51 1446.67 926.78 134.86 18.92 18.97 5.69 3.2.3 PCA对聚类准确率的影响
PCA是一种线性降维方法,使得数据在降维后既能尽量保持原有数据信息,又能使算法更快运行,因此被广泛使用.由于图像高维性的限制,若直接采用原始图像数据会因计算机内存不足而导致算法无法执行,故本实验先对图像数据进行PCA降维.针对本文提出的局部子空间聚类算法,讨论PCA降维对局部子空间聚类算法的影响.分别将6个图像数据集降至20,40,60和80维,实验结果如图 7.
图 7中LSSC和LLSR取固定的近邻数 k (k=5).由图 7可知,在数据为20,40,60和80维时,LLSR和LSSC 大部分都能取得最好的结果.SSC在大部分维数高的情况下,聚类准确率反而下降,而LSSC与SSC相反; LLSR不随维数的变化而产生大变化,说明其是一种比较稳定的算法.图 7(d)是侧脸渐变数据,正脸与侧脸的样本数据差异较大; 用原始SSC和LSR算法所得的聚类准确率不高,说明该数据全局线性相关性不强,而LSSC和LLSR的聚类准确率会随着维数的增高而增加.
3.3 基因数据
实验时,用PCA统一将4个基因表达数据降至60维.4个基因数据主要信息如表 5所示.
表 5 数据集描述Table 5 Summary of the data sets数据集 样本 基因 类别 Leukemia1 72 5 327 3 SRBCT 83 2 308 4 Lung_Cancer 203 12 600 5 Prostate_Tumor 102 10 509 2 由表 6给出的各类算法的聚类准确率可知,在4个基因表达数据集上,局部子空间聚类方法LLSR和LSSC都取得最好的聚类效果.且在大部分数据集上,LLSR和LSSC的聚类准确率比其他方法提高10%.一般情况下参数设置为k取5到7.特别对于Lung_Cancer数据,LSR的聚类准确率达92%,这说明数据全局线性相关,故选取较大k值.实验结果表明,局部子空间聚类方法在基因表达数据上也能取得更好的聚类结果.
表 6 聚类准确率(%)Table 6 Clustering accuracy (%)HC K-means LRR SSC LSR BD-LRR RLLRR SMR LSSC LLSR Leukemia1 54.17 69.31 86.11 58.33 77.78 79.17 54.17 77.78 90.28 90.28 SRBCT 36.14 53.73 68.43 40.12 54.22 60.24 46.99 63.68 74.70 74.46 Lung_Cancer 78.33 83.50 87.39 83.74 92.61 85.22 84.24 90.64 91.63 92.61 Prostate_Tumor 51.96 63.73 62.75 56.86 62.75 60.78 60.78 59.80 66.67 69.61 3.4 参数选择
LSC模型有两个参数: 正则参数 和近邻数k. 从图 5(a)可以看出, LSC聚类准确率对参数λ的变化不敏感,主要因为剔除大量不相关样本点,使得参数λ对实验结果的影响减弱,但还是建议将λ选在0.001~0.1之间.因为λ过大,LSSC求出的仿射矩阵将是0矩阵.另一个参数k通常取5~7之间能取得理想结果,大部分情况下k过大或过小可能导致准确率降低;而对于线性相关程度较大的数据,k 值可取较大值,这样可起到剔除噪声点的作用.综上,对于大部分数据集,λ取0.001~0.1 且k取5~7 时,LSC会得到较为理想的聚类结果.
4. 结论
考虑到实际应用中很多数据具有非线性特征,将k近邻局部线性表示引入子空间聚类,分别提出LSSC 和LLSR两种局部子空间聚类算法,两种算法均能较好克服原有算法全局线性的局限,较好地应用于非线性数据.同时,证明了LLSR模型具有局部聚集性,能够聚集局部样本.在图像数据和基因表达数据的实验中,发现LSSC 和LLSR均优于传统子空间聚类方法和其他对比方法,不仅在聚类准确率上有较大提高,且在运行时间上LSSC也取得明显改进.研究中发现LLSR和LSSC的聚类效果受k值影响,如何高效选取近邻数k将在以后的研究中给出.
-
[1] Suo H, Wan J F, Huang L, Zou G F. Issues and challenges of wireless sensor networks localization in emerging applications. In:Proceedings of the 2012 IEEE International Conference on Computer Science and Electronics Engineering. Hangzhou, China:IEEE, 2012. 447-451 https://www.researchgate.net/publication/261315118_Issues_and_Challenges_of_Wireless_Sensor_Networks_Localization_in_Emerging_Applications [2] Goldoni E, Savioli A, Risi M, Gamba P. Experimental analysis of RSSI-based indoor localization with IEEE 802.15.4. In:Proceedings of the 2010 European Wireless Conference. Lucca, Italy:IEEE, 2010. 71-77 [3] 罗旭, 柴利, 杨君.无线传感器网络下静态水体中的近岸污染源定位.自动化学报, 2014, 40 (5):849-861 http://www.aas.net.cn/CN/abstract/abstract18353.shtmlLuo Xu, Chai Li, Yang Jun. Offshore pollution source localization in static water using wireless sensor networks. Acta Automatica Sinica, 2014, 40 (5):849-861 http://www.aas.net.cn/CN/abstract/abstract18353.shtml [4] 彭宇, 罗清华, 王丹, 彭喜元.基于区间数聚类的无线传感器网络定位方法.自动化学报, 2012, 38 (7):1190-1199 http://www.aas.net.cn/CN/abstract/abstract13552.shtmlPeng Yu, Luo Qing-Hua, Wang Dan, Peng Xi-Yuan. WSN localization method using interval data clustering. Acta Automatica Sinica, 2012, 38 (7):1190-1199 http://www.aas.net.cn/CN/abstract/abstract13552.shtml [5] Liu D X, Kuang Y J, Wei W. Research and improvement of DVHOP localization algorithm in wireless sensor networks. In:Proceedings of the 2010 International Conference on Computational Problem-Solving. Lijiang, China:IEEE, 2010. 47-50 https://www.researchgate.net/publication/308733981_Research_and_improvement_of_DV_HOP_localization_algorithm_in_wireless_sensor_networks [6] 杨小军.多跳无线传感器网络下信道感知的目标定位方法.自动化学报, 2013, 39 (7):1110-1116 http://www.aas.net.cn/CN/abstract/abstract18139.shtmlYang Xiao-Jun. Channel aware target localization in multi-hop wireless sensor networks. Acta Automatica Sinica, 2013, 39 (7):1110-1116 http://www.aas.net.cn/CN/abstract/abstract18139.shtml [7] Bahl P, Padmanabhan V N. RADAR:an in-building RF-based user location and tracking system. In:Proceedings of the 19th Annual Joint Conference of the IEEE Computer and Communications Societies INFOCOM. Tel Aviv, Israel:IEEE, 2000. 775-784 https://www.researchgate.net/publication/3842777_RADAR_An_in-building_RF-based_user_location_and_tracking_system [8] Zhang W, Liu K, Zhang W D, Zhang Y M, Gu J. Wi-Fi positioning based on deep learning. In:Proceedings of the 2014 IEEE International Conference on Information and Automation. Hailar, China:IEEE, 2014. 1176-1179 https://www.researchgate.net/publication/286573524_Wi-Fi_positioning_based_on_deep_learning [9] Candes E J, Wakin M B. An introduction to compressive sampling. IEEE Signal Processing Magazine, 2008, 25 (2):21-30 doi: 10.1109/MSP.2007.914731 [10] Feng C, Valaee S, Tan Z H. Multiple target localization using compressive sensing. In:Proceedings of the 2009 IEEE Global Telecommunications Conference. Honolulu, HI, USA:IEEE, 2009. 1-6 https://www.researchgate.net/publication/221287682_Multiple_Target_Localization_Using_Compressive_Sensing [11] Zhang B W, Cheng X Z, Zhang N, Cui Y, Li Y S, Liang Q L. Sparse target counting and localization in sensor networks based on compressive sensing. In:Proceedings of the 2011 IEEE INFOCOM. Shanghai, China:IEEE, 2011. 2255-2263 https://www.researchgate.net/publication/224243922_Sparse_target_counting_and_localization_in_sensor_networks_based_on_compressive_sensing [12] Cevher V, Duarte M F, Baraniuk R G. Distributed target localization via spatial sparsity. In:Proceedings of the 6th European Signal Processing Conference. Lausanne, Switzerland:IEEE, 2008. 1-5 https://www.researchgate.net/publication/46146266_Distributed_target_localization_via_spatial_sparsity [13] Cevher V, Boufounos P, Baraniuk R G, Gilbert A C, Strauss M J. Near-optimal Bayesian localization via incoherence and sparsity. In:Proceedings of the 2009 International Conference on Information Processing in Sensor Networks. San Francisco, CA, USA:IEEE, 2009. 205-216 https://www.researchgate.net/publication/46146271_Near-Optimal_Bayesian_Localization_via_Incoherence_and_Sparsity [14] Lin X F, You K Y, Guo W B. Delaunay triangulation and mesh grid combining algorithm for multiple targets localization using compressive sensing. In:Proceedings of the 19th International Symposium on Wireless Personal Multimedia Communications. Shenzhen, China:IEEE, 2017. 25-30 https://ieeexplore.ieee.org/document/7954448/ [15] Candés E J, Romberg J K, Tao T. Stable signal recovery from incomplete and inaccurate measurement. Communications on Pure and Applied Mathematics, 2006, 59 (8):1207-1223 doi: 10.1002/(ISSN)1097-0312 [16] Yang S X, Guo Y, Liu X, Niu D W, Sun B M. A localization algorithm based on compressive sensing by K-nearest neighbor classification. In:Proceedings of the 13th International Conference on Signal Processing. Chengdu, China:IEEE, 2017. 863-867 https://www.researchgate.net/publication/315512511_A_localization_algorithm_based_on_compressive_sensing_by_K-nearest_Neighbor_classification [17] Needell D, Vershynin R. Signal recovery from incomplete and inaccurate measurements via regularized orthogonal matching pursuit. IEEE Journal of Selected Topics in Signal Processing, 2010, 4 (2), 310-316 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0223736356/ [18] Wang Y, Feng S L, Zhang P. Cluster-based multi-target localization under partial observations. In:Proceedings of the 81st Vehicular Technology Conference. Glasgow, UK:IEEE, 2015. 1-6 https://www.researchgate.net/publication/283103190_Cluster-Based_Multi-Target_Localization_under_Partial_Observations -

 下载:
下载:


 下载:
下载:
计量
- 文章访问数: 1712
- HTML全文浏览量: 429
- PDF下载量: 547
- 被引次数: 0
