

-
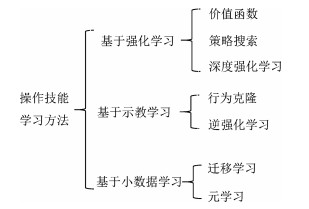
摘要: 结合人工智能技术和机器人技术,研究具备一定自主决策和学习能力的机器人操作技能学习系统,已逐渐成为机器人研究领域的重要分支.本文介绍了机器人操作技能学习的主要方法及最新的研究成果.依据对训练数据的使用方式将机器人操作技能学习方法分为基于强化学习的方法、基于示教学习的方法和基于小数据学习的方法,并基于此对近些年的研究成果进行了综述和分析,最后列举了机器人操作技能学习的未来发展方向.Abstract: Designing a robot manipulation skill learning system with autonomous reasoning and learning ability has gradually become an important branch of robotics research field in combination with artificial intelligence and robotics technology. In this paper, the main methods and the latest research results of robot manipulation skills learning methods are introduced. We divide the learning methods into three categories, namely reinforcement learning approach, demonstration learning approach, and few data learning approach. Achievements of the robot manipulation skills learning areas based on these methods are discussed thoroughly. Finally, the future research directions are listed.
-
Key words:
- Robots /
- manipulation skills /
- reinforcement learning /
- imitation learning /
- few data learning
1) 本文责任编委 魏庆来 -
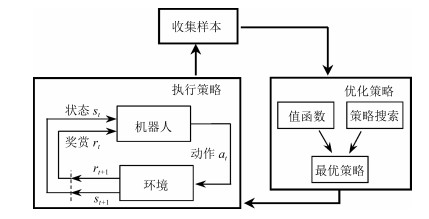
图 2 基于强化学习的操作技能学习示意图
Fig. 2 Illustration of manipulation skills learning method based on reinforcement learning

图 3 基于值函数强化学习的操作技能
Fig. 3 Manipulation skills based on value function of reinforcement learning

图 4 基于策略搜索强化学习的操作技能
Fig. 4 Manipulation skills based on policy search of reinforcement learning

表 1 机器人和其他应用中强化学习比较
Table 1 Comparison of reinforcement learning methods applied in robotics and other fields
项目 机器人应用 其他应用 状态、动作空间 均为高维、连续空间 大多为低维、离散空间 训练数据获取 真实环境:数据获取会损耗硬件, 有潜在危险, 成本高; 虚拟环境:数据获取方便 不损耗硬件不存在危险性 训练成本 仿真环境低, 真实环境高 低 主流方法 大多基于策略搜索 大多基于价值函数 其他方面 不确定性因素多, 训练过程受诸多条件约束, 学习过程需要人的参与 -  下载: 导出CSV
下载: 导出CSV
表 2 三类操作技能学习方法特点对比
Table 2 Comparison of three kinds of manipulation skills learning methods
对比项目 基于强化学习 基于示教学习 小数据学习 数据量 不需提供示教数据但需大量机器人与环境的交互数据 需提供较多示教数据 需大量数据面对新任务需少量数据 学习效率 低, 需不断试错 较高 高 学习成本 高 高 低
下载: 导出CSV
-
[1] Goldberg K. Editorial:"One Robot is robotics, ten robots is automation". IEEE Transactions on Automation Science and Engineering, 2016, 13(4):1418-1419 doi: 10.1109/TASE.2016.2606859 [2] 谭民, 王硕.机器人技术研究进展.自动化学报, 2013, 39(7):963-972 http://www.aas.net.cn/CN/abstract/abstract18124.shtmlTan Min, Wang Shuo. Research progress on robotics. Acta Automatica Sinica, 2013, 39(7):963-972 http://www.aas.net.cn/CN/abstract/abstract18124.shtml [3] Rozo L, Jaquier N, Calinon S, Caldwell D G. Learning manipulability ellipsoids for task compatibility in robot manipulation. In: Proceedings of the 30th International Conference on Intelligent Robots and Systems (IROS). Vancouver, Canada: IEEE, 2017. 3183-3189 [4] Siciliano B, Khatib O. Springer Handbook of Robotics. Berlin: Springer, 2016. 357-398 [5] Connell J H, Mahadevan S. Robot Learning. Boston: Springer, 1993. 1-17 [6] Dang H, Allen P K. Robot learning of everyday object manipulations via human demonstration. In: Proceedings of the 23rd IEEE International Conference on Intelligent Robots and Systems (IROS). Taipei, China: IEEE, 2010. 1284-1289 [7] Gu S X, Holly E, Lillicrap T, Levine S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In: Proceedings of the 35th IEEE International Conference on Robotics and Automation (ICRA). Singapore, Singapore: IEEE, 2017. 3389-3396 [8] Li D Y, Ma G F, He W, Zhang W, Li C J, Ge S S. Distributed coordinated tracking control of multiple Euler-Lagrange systems by state and output feedback. IET Control Theory and Applications, 2017, 11(14):2213-2221 doi: 10.1049/iet-cta.2017.0188 [9] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Eraz T, Tassa Y, et al. Continuous control with deep reinforcement learning. arXiv: 1509.02971, 2015. [10] Heess N, Dhruva T B, Sriram S, Lemmon J, Merel J, Wayne G, et al. Emergence of locomotion behaviours in rich environments. arXiv: 1707.02286, 2017. [11] Levine S, Abbeel P. Learning neural network policies with guided policy search under unknown dynamics. In: Proceedings of the 28th Advances in Neural Information Processing Systems (NIPS). Montreal, Canada: NIPS Press, 2014. 1071-1079 [12] Levine S, Finn C, Darrell T, Abbeel P. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research, 2016, 17(1):1334-1373 http://cn.bing.com/academic/profile?id=3eb0ad9e289b5e3b52ba8e173dda9e10&encoded=0&v=paper_preview&mkt=zh-cn [13] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv: 1707. 06347, 2017. [14] Al-Shedivat M, Bansal T, Burda Y, Sutskever I, Mordatch I, Abbeel P. Continuous adaptation via meta-learning in nonstationary and competitive environments. In: Proceedings of the 6th International conference on Learning Representations (ICLR). Vancouver, Canada: ICLR, 2018. [15] Levine S, Pastor P, Krizhevsky A, Quillen D. Learning hand-eye coordination for robotic grasping with large-scale data collection. In: Proceedings of the 25th International Symposium on Experimental Robotics. Cham: Springer, 2016. 173-184 [16] Calinon S. Robot learning with task-parameterized generative models. Robotics Research. Cham: Springer, 2018. 111-126 [17] Billard A, Grollman D. Robot learning by demonstration. Scholarpedia, 2013, 8(12):3824 doi: 10.4249/scholarpedia.3824 [18] Wiering M, van Otterlo M. Reinforcement Learning: State-of-the-Art. Berlin: Springer-Verlag, 2015. 79-100 [19] Sutton R S, Barto A G. Reinforcement Learning: An Introduction (Second edition). Cambridge: MIT Press, 1998. [20] Bellman R. On the theory of dynamic programming. Proceedings of the National Academy of Sciences of the United States of America, 1952, 38(8):716-719 doi: 10.1073/pnas.38.8.716 [21] Lioutikov R, Paraschos A, Peters J, Neumann G. Sample-based informationl-theoretic stochastic optimal control. In: Proceedings of the 32nd IEEE International Conference on Robotics and Automation (ICRA). Hong Kong, China: IEEE, 2014. 3896-3902 [22] Schenck C, Tompson J, Fox D, Levine S. Learning robotic manipulation of granular media. In: Proceedings of the 1st Conference on Robot Learning (CORL). Mountain View, USA: CORL, 2017. [23] Hester T, Quinlan M, Stone P. Generalized model learning for reinforcement learning on a humanoid robot. In: Proceedings of the 28th IEEE International Conference on Robotics and Automation (ICRA). Alaska, USA: IEEE, 2010. 2369-2374 [24] Kocsis L, Szepesvári C. Bandit based Monte-Carlo planning. In: Proceedings of the 2006 European Conference on Machine Learning. Berlin, Germany: Springer, 2006. 282-293 [25] Hasselt H, Mahmood A R, Sutton R S. Off-policy TD(λ) with a true online equivalence. In: Proceedings of the 30th Conference on Uncertainty in Artificial Intelligence. Quebec City, Canada: UAI, 2014. [26] Park K H, Kim Y J, Kim J H. Modular Q-learning based multi-agent cooperation for robot soccer. Robotics and Autonomous Systems, 2001, 35(2):109-122 doi: 10.1016/S0921-8890(01)00114-2 [27] Ramachandran D, Gupta R. Smoothed Sarsa: reinforcement learning for robot delivery tasks. In: Proceedings of the 27th IEEE International Conference on Robotics and Automation (ICRA). Kobe, Japan: IEEE, 2009. 2125-2132 [28] Konidaris G, Kuindersma S, Grupen R, Barto A. Autonomous skill acquisition on a mobile manipulator. In: Proceedings of the 25th AAAI Conference on Artificial Intelligence (AAAI). San Francisco, California, USA: AAAI Press, 2011. 1468-1473 [29] Konidaris G, Kuindersma S, Barto A G, Grupen R A. Constructing skill trees for reinforcement learning agents from demonstration trajectories. In: Proceedings of the 24th Advances in Neural Information Processing Systems (NIPS). Vancouver Canada: NIPS Press, 2010. 1162-1170 [30] Asada M, Noda S, Tawaratsumida S, Hosoda K. Purposive behavior acquisition for a real robot by vision-based reinforcement learning. Machine Learning, 1996, 23(2-3):279-303 doi: 10.1007/BF00117447 [31] Kroemer O B, Detry R, Piater J, Peters J. Combining active learning and reactive control for robot grasping. Robotics and Autonomous Systems, 2010, 58(9):1105-1116 doi: 10.1016/j.robot.2010.06.001 [32] Gass S I, Fu M C. Encyclopedia of Operations Research and Management Science. Boston, MA: Springer, 2013. 326-333 [33] Iruthayarajan M W, Baskar S. Covariance matrix adaptation evolution strategy based design of centralized PID controller. Expert Systems with Applications, 2010, 37(8):5775-5781 doi: 10.1016/j.eswa.2010.02.031 [34] Endo G, Morimoto J, Matsubara T, Nakanishi J, Cheng G. Learning CPG-based biped locomotion with a policy gradient method:application to a humanoid robot. The International Journal of Robotics Research, 2008, 27(2):213-228 doi: 10.1177/0278364907084980 [35] Peters J, Schaal S. Reinforcement learning of motor skills with policy gradients. Neural Networks, 2008, 21(4):682-697 doi: 10.1016/j.neunet.2008.02.003 [36] Deisenroth M P, Rasmussen C E, Fox D. Learning to control a low-cost manipulator using data-efficient reinforcement learning. Robotics: Science and Systems VⅡ. Cambridge: MIT Press, 2011. 57-64 [37] Deisenroth M P, Rasmussen C E. PILCO: a model-based and data-efficient approach to policy search. In: Proceedings of the 28th International Conference on Machine Learning (ICML). Washington, USA: Omnipress, 2011. 465-472 [38] Deisenroth M P, Neumann G, Peters J. A survey on policy search for robotics. Foundations and Trends in Robotics, 2013, 2(1-2):1-142 [39] 赵冬斌, 邵坤, 朱圆恒, 李栋, 陈亚冉, 王海涛, 等.深度强化学习综述:兼论计算机围棋的发展.控制理论与应用, 2016, 33(6):701-717 http://d.old.wanfangdata.com.cn/Periodical/kzllyyy201606001Zhao Dong-Bin, Shao Kun, Zhu Yuan-Heng, Li Dong, Chen Ya-Ran, Wang Hai-Tao, et al. Review of deep reinforcement learning and discussions on the development of computer Go. Control Theory and Applications, 2016, 33(6):701-717 http://d.old.wanfangdata.com.cn/Periodical/kzllyyy201606001 [40] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemareet M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540):529-533 doi: 10.1038/nature14236 [41] Silver D, Huang A, Maddison C, Guez A, Sifre L, van den Driessche G, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587):484-489 doi: 10.1038/nature16961 [42] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of Go without human knowledge. Nature, 2017, 550(7587):354-359 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=8e9716babb5853bbe194883f34681a51 [43] van Hasselt H, Guez A, Silver D. Deep reinforcement learning with double Q-learning. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Arizona, USA: AAAI Press, 2016. 2094-2100 [44] Wang Z Y, Schaul T, Hessel M, van Hasselt H, Lanctot M, de Freitas N. Dueling network architectures for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York City, USA: JMLR, 2016. 1995-2003 [45] Hausknecht M, Stone P. Deep recurrent Q-learning for partially observable MDPs. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Texas, USA: AAAI Press, 2015 [46] Zhang F Y, Leitner J, Milford M, Upcroft B, Corke P. Towards vision-based deep reinforcement learning for robotic motion control. arXiv: 1511.03791, 2015. [47] Zhang F Y, Leitner J, Milford M, Corke P. Modular deep Q networks for Sim-to-real transfer of visuo-motor policies. arXiv: 1610.06781, 2016. [48] Gu S X, Lillicrap T, Sutskever I, Levine S. Continuous deep Q-learning with model-based acceleration. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). New York City, USA: JMLR, 2016. 2829-2838 [49] Silver D, Lever G, Heess N, Degris T, Wierstra D, Riedmiller M. Deterministic policy gradient algorithms. In: Proceedings of the 31st International Conference on International Conference on Machine Learning (ICML). Beijing, China: JMLR, 2014. 387-395 [50] Schulman J, Levine S, Moritz P, Jordan M, Abbeel P. Trust region policy optimization. In: Proceedings of the 32nd International Conference on Machine Learning (ICML). Lille, France: JMLR, 2015. 1889-1897 [51] Mnih V, Badia A P, Mirza M, Graves A, Lillicrap T, Harley T, et al. Asynchronous methods for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). New York City, USA: JMLR, 2016. 1928-1937 [52] Levine S, Koltun V. Guided policy search. In: Proceedings of the 30th International Conference on Machine Learning (ICML). Atlanta, USA: JMLR, 2013. 1-9 [53] Levine S, Koltun V. Learning complex neural network policies with trajectory optimization. In: Proceedings of the 31st International Conference on Machine Learning (ICML). Beijing, China: JMLR, 2014. 829-837 [54] Malekzadeh M, Queißer J, Steil J J. Imitation learning for a continuum trunk robot. In: Proceedings of the 25th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN). Bruges, Belgium: ESANN, 2017. [55] Ross S, Gordon G J, Bagnell D. A reduction of imitation learning and structured prediction to no-regret online learning. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA: JMLR, 2011. 627-635 [56] Ng A Y, Russell S J. Algorithms for inverse reinforcement learning. In: Proceedings of the 17th International Conference on Machine Learning (ICML). Stanford, USA: Morgan Kaufmann Publishers Inc., 2000. 663-670 [57] 周志华.机器学习.北京: 清华大学出版社, 2016.Zhou Zhi-Hua. Machine Learning. Beijing: Tsinghua University Press, 2016. [58] Takeda T, Hirata Y, Kosuge K. Dance step estimation method based on HMM for dance partner robot. IEEE Transactions on Industrial Electronics, 2007, 54(2):699-706 doi: 10.1109/TIE.2007.891642 [59] Calinon S, Guenter F, Billard A. On learning, representing, and generalizing a task in a humanoid robot. IEEE Transactions on Systems, Man and Cybernetics, Part B (Cybernetics), 2007, 37(2):286-298 doi: 10.1109/TSMCB.2006.886952 [60] Calinon S, Billard A. Incremental learning of gestures by imitation in a humanoid robot. In: Proceedings of the 2nd ACM/IEEE International Conference on Human-robot Interaction. Arlington, VA, USA: IEEE, 2007. 255-262 [61] Rahmatizadeh R, Abolghasemi P, Behal A, Bölöni L. From virtual demonstration to real-world manipulation using LSTM and MDN. arXiv: 1603.03833, 2016. [62] Calinon S, DHalluin F, Sauser E L, Caldwell D G, Billard A G. Learning and reproduction of gestures by imitation. IEEE Robotics and Automation Magazine, 2010, 17(2):44-54 doi: 10.1109/MRA.2010.936947 [63] Zhang T H, McCarthy Z, Jow O, Lee D, Chen X, Goldberg K, et al. Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In: Proceedings of the 36th International Conference on Robotics and Automation (ICRA). Brisbane, Australia: IEEE, 2018. [64] Abbeel P, Ng A Y. Apprenticeship learning via inverse reinforcement learning. In: Proceedings of the 21st International Conference on Machine Learning (ICML). Alberta, Canada: ACM, 2004. [65] Ratliff N D, Bagnell J A, Zinkevich M A. Maximum margin planning. In: Proceedings of the 23rd International Conference on Machine Learning (ICML). Pennsylvania, USA: ACM, 2006. 729-736 [66] Ziebart B D, Maas A, Bagnell J A, Dey A K. Maximum entropy inverse reinforcement learning. In: Proceedings of the 23rd AAAI Conference on Artificial Intelligence (AAAI). Illinois, USA: AAAI Press, 2008. 1433-1438 [67] Levine S, Popovićí Z, Koltun V. Nonlinear inverse reinforcement learning with Gaussian processes. In: Proceedings of the 24th International Conference on Neural Information Processing Systems (NIPS). Granada, Spain: Curran Associates, 2011. 19-27 [68] Ratliff N D, Bradley D M, Bagnell J A, Chestnutt J E. Boosting structured prediction for imitation learning. In: Proceedings of the 19th Advances in Neural Information Processing Systems (NIPS). British Columbia, Canada: Curran Associates, 2006. 1153-1160 [69] Xia C, El Kamel A. Neural inverse reinforcement learning in autonomous navigation. Robotics and Autonomous Systems, 2016, 84:1-14 doi: 10.1016/j.robot.2016.06.003 [70] Wulfmeier M, Ondruska P, Posner I. Maximum entropy deep inverse reinforcement learning. arXiv: 1507.04888, 2015. [71] Finn C, Levine S, Abbeel P. Guided cost learning: deep inverse optimal control via policy optimization. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). New York City, USA: JMLR, 2016. 49-58 [72] Ho J, Ermon S. Generative adversarial imitation learning. In: Proceedings of the 30th Advances in Neural Information Processing Systems (NIPS). Barcelona, Spain: Curran Associates, 2016. 4565-4573 [73] Peng X B, Abeel P, Levine S, van de Panne M. DeepMimic: example-guided deep reinforcement learning of physics-based character skills. arXiv: 1804.02717, 2018. [74] Zhu Y K, Wang Z Y, Merel J, Rusu A, Erez T, Cabi S, et al. Reinforcement and imitation learning for diverse visuomotor skills. arXiv: 1802.09564, 2018. [75] Hester T, Vecerik M, Pietquin O, Lanctot M, Schaul T, Piot B, et al. Deep Q-learning from demonstrations. In: Proceedings of the 32th Association for the Advancement of Artificial Intelligence (AAAI). Louisiana USA: AAAI Press, 2018. [76] Lemke C, Budka M, Gabrys B. Metalearning:a survey of trends and technologies. Artificial Intelligence Review, 2015, 44(1):117-130 doi: 10.1007/s10462-013-9406-y [77] Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10):1345-1359 doi: 10.1109/TKDE.2009.191 [78] Tzeng E, Hoffman J, Zhang N, Saenko K, Darrell T. Deep domain confusion: maximizing for domain invariance. arXiv: 1412.3474, 2014. [79] Shi Z Y, Siva P, Xiang T. Transfer learning by ranking for weakly supervised object annotation. arXiv: 1705.00873, 2017. [80] Gupta A, Devin C, Liu Y X, Abbeel P, Levine S. Learning invariant feature spaces to transfer skills with reinforcement learning. In: Proceedings of the 5th International Conference on Learning Representations (ICLR). Toulon, France: ICLR, 2017. [81] Stadie B C, Abbeel P, Sutskever I. Third-person imitation learning. In: Proceedings of the 5th International Conference on Learning Representations (ICLR). Toulon, France: ICLR, 2017. [82] Ammar H B, Eaton E, Ruvolo P, Taylor M E. Online multi-task learning for policy gradient methods. In: Proceedings of the 31st International Conference on International Conference on Machine Learning (ICML). Beijing, China: JMLR, 2014. 1206-1214 [83] Gupta A, Devin C, Liu Y X, Abbeel P, Levine S. Learning invariant feature spaces to transfer skills with reinforcement learning. arXiv: 1703.02949, 2017. [84] Tzeng E, Devin C, Hoffman J, Finn C, Peng X C, Levine S, et al. Towards adapting deep visuomotor representations from simulated to real environments. arXiv: 1511.07111, 2015. [85] Vinyals O, Blundell C, Lillicrap T, Kavukcuoglu K, Wierstra D. Matching networks for one shot learning. In: Proceedings of the 30th Advances in Neural Information Processing Systems (NIPS). Barcelona, Spain: Curran Associates, 2016. 3630-3638 [86] Santoro A, Bartunov S, Botvinick M, Wierstra D, Lillicrap T. Meta-learning with memory-augmented neural networks. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). New York City, USA: JMLR, 2016. 1842-1850 [87] Ravi S, Larochelle H. Optimization as a model for few-shot learning. In: Proceedings of the 5th International Conference on Learning Representations (ICLR). Toulon, France: ICLR, 2017. [88] Edwards H, Storkey A. Towards a neural statistician. In: Proceedings of the 5th International Conference on Learning Representations (ICLR). Toulon, France: ICLR, 2017. [89] Rezende D, Mohamed S, Danihelka I, Gregor K, Wierstra D. One-shot generalization in deep generative models. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). New York City, USA: JMLR, 2016. [90] Duan Y, Schulman J, Chen X, Bartlett P L, Sutskever I, Abbeel P. RL2: fast reinforcement learning via slow reinforcement learning. arXiv: 1611.02779, 2016. [91] Wang J X, Kurth-Nelson Z, Tirumala D, Soyer H, Leibo J Z, Munoset R, et al. Learning to reinforcement learn. arXiv: 1611.05763, 2016. [92] Duan Y, Andrychowicz M, Stadie B C, Ho J, Schneider J, Sutskever I, et al. One-shot imitation learning. arXiv: 1703. 07326, 2017. [93] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks. arXiv: 1703.03400, 2017. [94] Xu D F, Nair S, Zhu Y K, Gao J L, Garg A, Li F F, et al. Neural task programming: learning to generalize across hierarchical tasks. arXiv: 1710.01813, 2017. [95] Reed S, de Freitas N. Neural programmer-interpreters. arXiv: 1511.06279, 2015. [96] Tobin J, Fong R, Ray A, Schneider J, Zaremba W, Abbeel P. Domain randomization for transferring deep neural networks from simulation to the real world. In: Proceedings of the 30th International Conference on Intelligent Robots and Systems (IROS). Vancouver, Canada: IEEE, 2017. 23-30 -

 下载:
下载:




计量
- 文章访问数: 6285
- HTML全文浏览量: 3179
- PDF下载量: 3079
- 被引次数: 0
