2026, 52(7): 1319-1333.
doi: 10.16383/j.aas.c250638
cstr: 32138.14.j.aas.c250638
摘要:
离线强化学习旨在利用预先采集的行为数据集优化智能体策略, 其面临的主要挑战是迭代优化的目标策略与产生数据集的行为策略之间存在分布偏移. 现有方法通常采用策略正则化以缓解该问题, 但其难以根据行为数据质量自适应地调整学习过程的约束强度, 并且难以有效建模行为策略中复杂的多峰分布. 针对上述问题, 提出基于流匹配策略优化(FMPO)的离线强化学习方法. FMPO利用流匹配模型对行为策略分布进行建模, 从流匹配策略中选择高优势动作以形成自适应约束, 引导学习策略在行为数据分布邻域内进行优化; 同时, 将流匹配策略生成的动作作为先验输入条件, 利用行为先验促进策略的高效学习. 通过基于流匹配策略的优化机制, FMPO能够在策略提升与满足数据集分布约束之间实现动态平衡. 实验结果表明, FMPO在D4RL基准任务上取得先进性能, 显著优于现有主流离线强化学习方法.
离线强化学习旨在利用预先采集的行为数据集优化智能体策略, 其面临的主要挑战是迭代优化的目标策略与产生数据集的行为策略之间存在分布偏移. 现有方法通常采用策略正则化以缓解该问题, 但其难以根据行为数据质量自适应地调整学习过程的约束强度, 并且难以有效建模行为策略中复杂的多峰分布. 针对上述问题, 提出基于流匹配策略优化(FMPO)的离线强化学习方法. FMPO利用流匹配模型对行为策略分布进行建模, 从流匹配策略中选择高优势动作以形成自适应约束, 引导学习策略在行为数据分布邻域内进行优化; 同时, 将流匹配策略生成的动作作为先验输入条件, 利用行为先验促进策略的高效学习. 通过基于流匹配策略的优化机制, FMPO能够在策略提升与满足数据集分布约束之间实现动态平衡. 实验结果表明, FMPO在D4RL基准任务上取得先进性能, 显著优于现有主流离线强化学习方法.







2026, 52(7): 1334-1346.
doi: 10.16383/j.aas.c250659
cstr: 32138.14.j.aas.c250659
摘要:
针对具有未知动力学的非线性多智能体系统, 研究事件触发神经网络自适应分布式优化控制问题. 通过结合神经网络与微分图博弈理论, 构建一种新型事件触发神经网络自适应分布式优化控制器. 为解决执行器频繁更新问题, 设计事件触发机制. 建立基于神经网络的强化学习算法, 学习优化控制器与哈密顿−雅可比−贝尔曼方程的解析解, 利用当前采样数据和历史存储数据设计评价网络的权重更新机制. 构造Lyapunov函数证明了被控非线性多智能体系统为渐近稳定并达到Nash均衡. 计算机仿真结果验证了所提分布式最优控制方案的有效性.
针对具有未知动力学的非线性多智能体系统, 研究事件触发神经网络自适应分布式优化控制问题. 通过结合神经网络与微分图博弈理论, 构建一种新型事件触发神经网络自适应分布式优化控制器. 为解决执行器频繁更新问题, 设计事件触发机制. 建立基于神经网络的强化学习算法, 学习优化控制器与哈密顿−雅可比−贝尔曼方程的解析解, 利用当前采样数据和历史存储数据设计评价网络的权重更新机制. 构造Lyapunov函数证明了被控非线性多智能体系统为渐近稳定并达到Nash均衡. 计算机仿真结果验证了所提分布式最优控制方案的有效性.





2026, 52(7): 1347-1359.
doi: 10.16383/j.aas.c250593
cstr: 32138.14.j.aas.c250593
摘要:
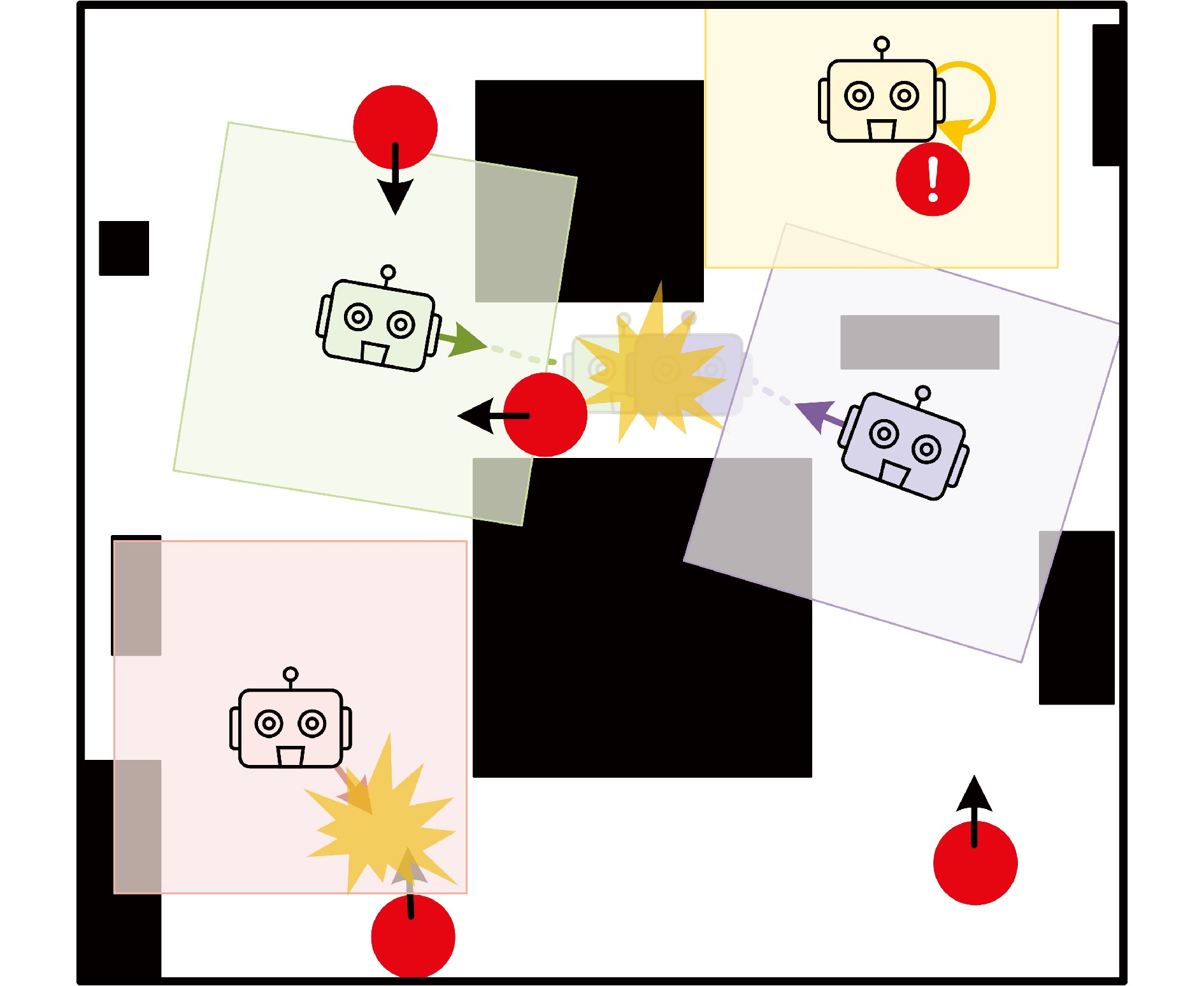
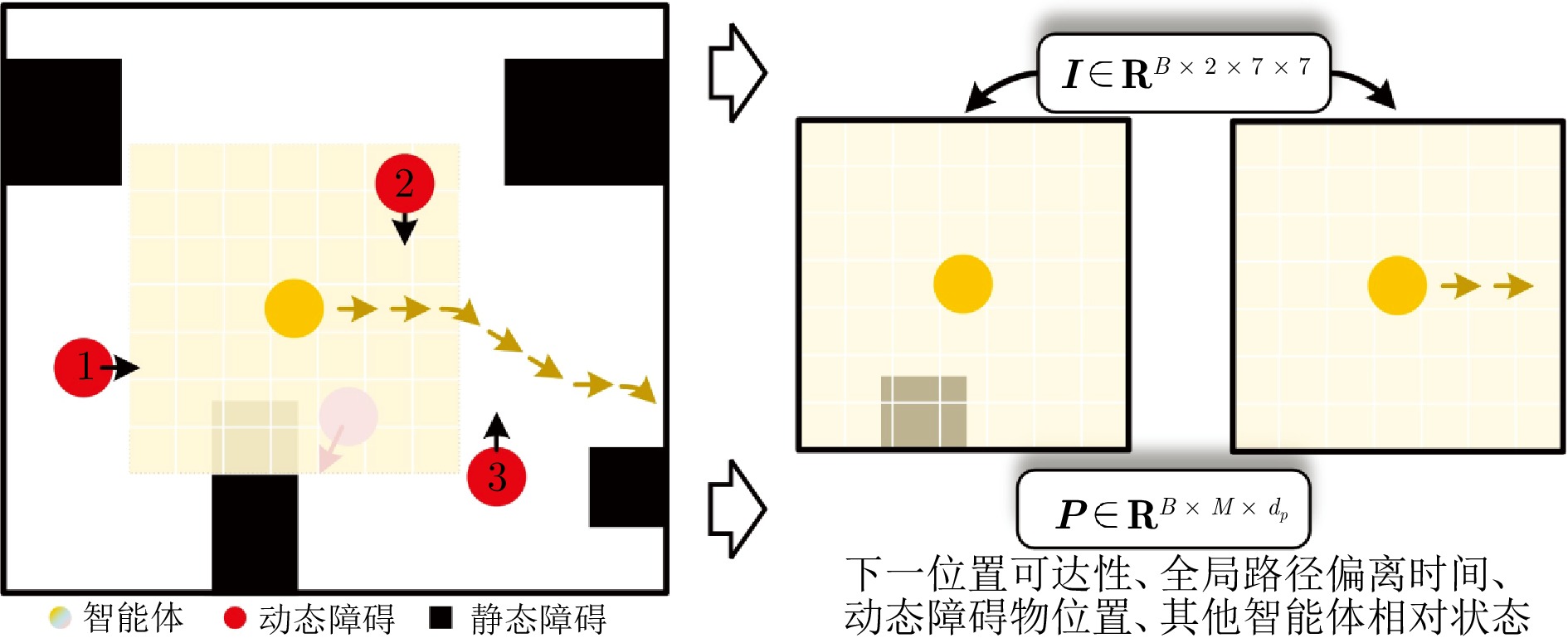
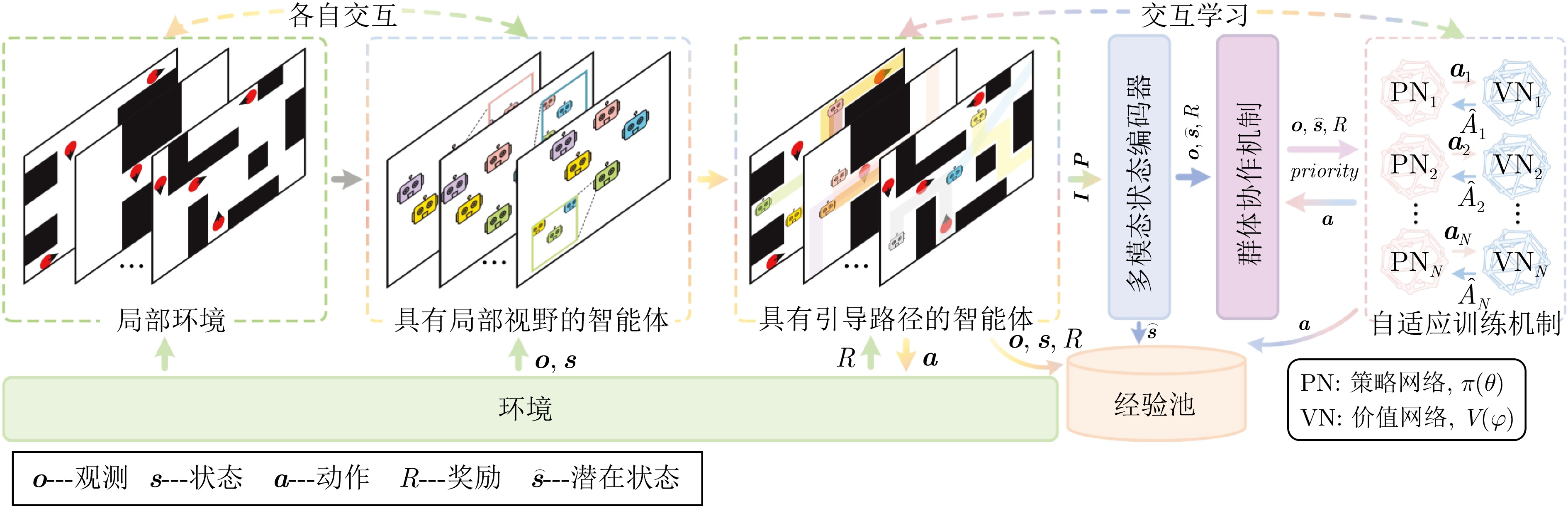
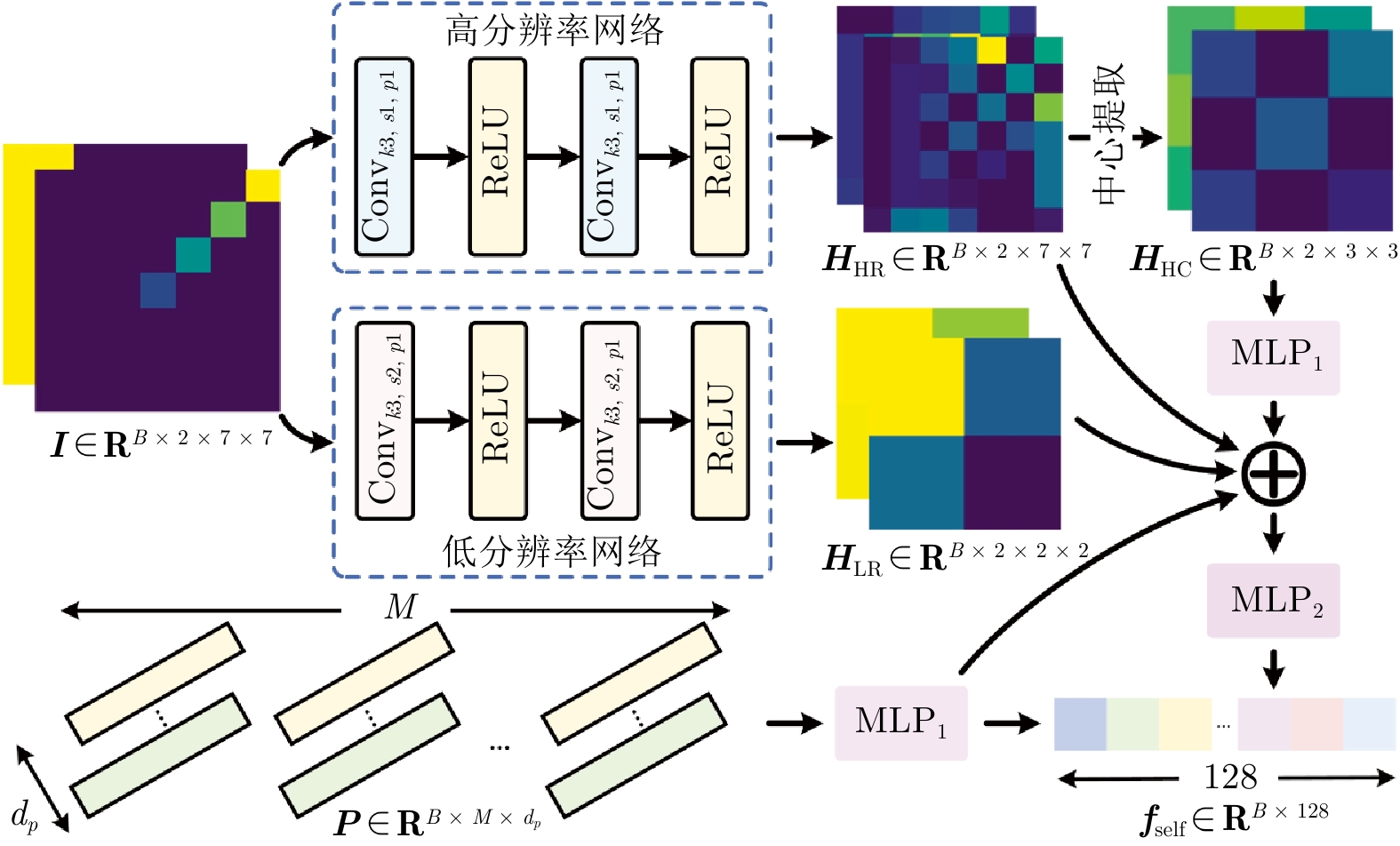
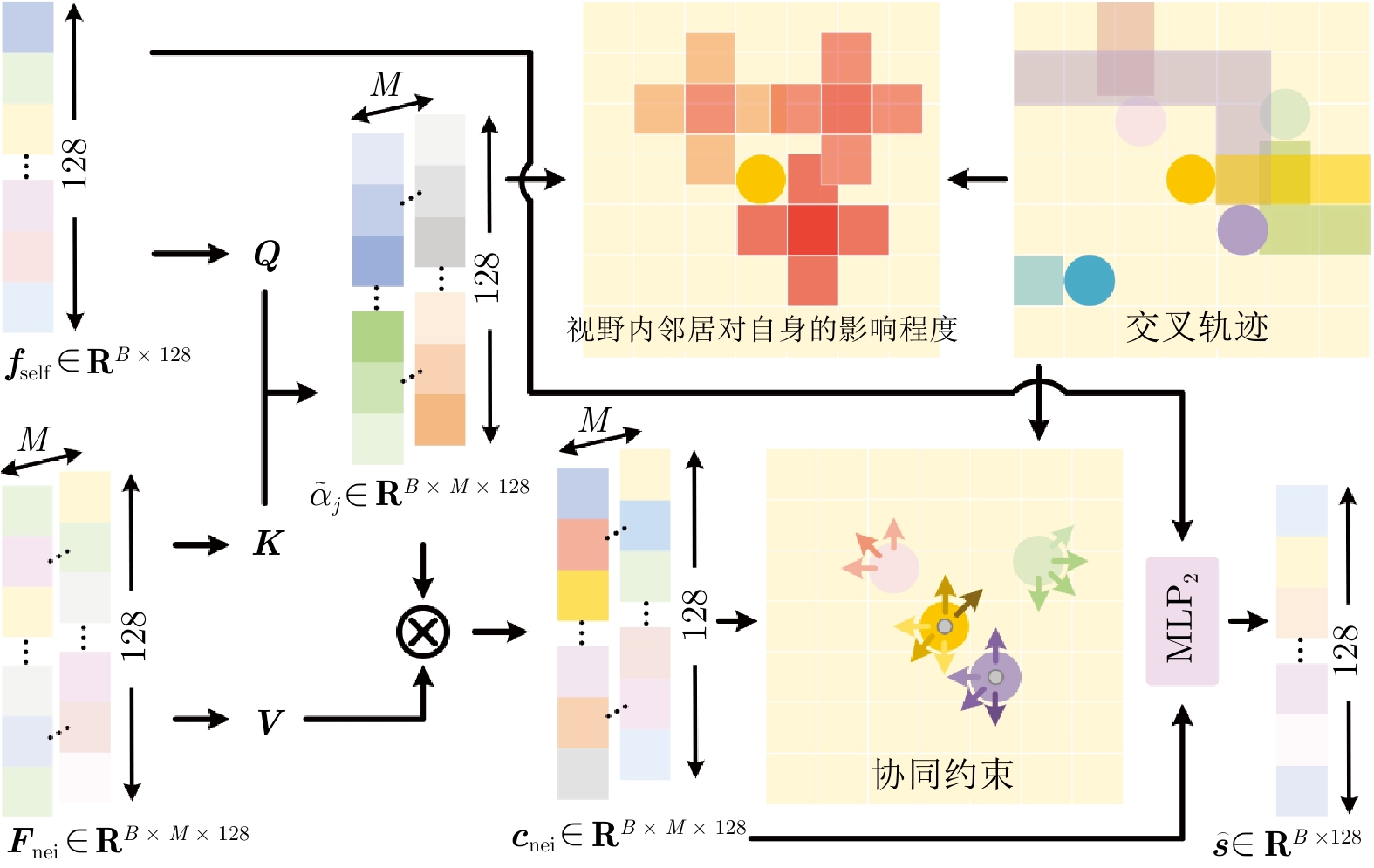
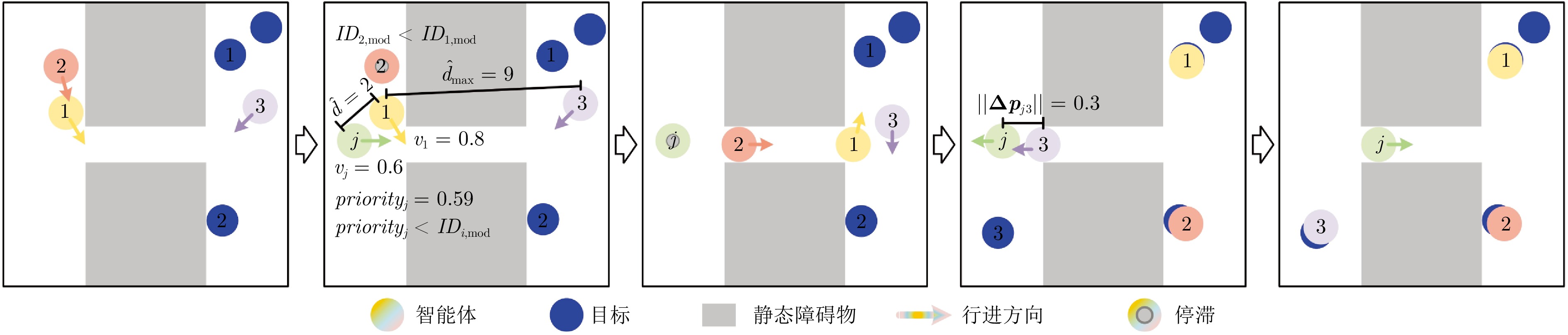
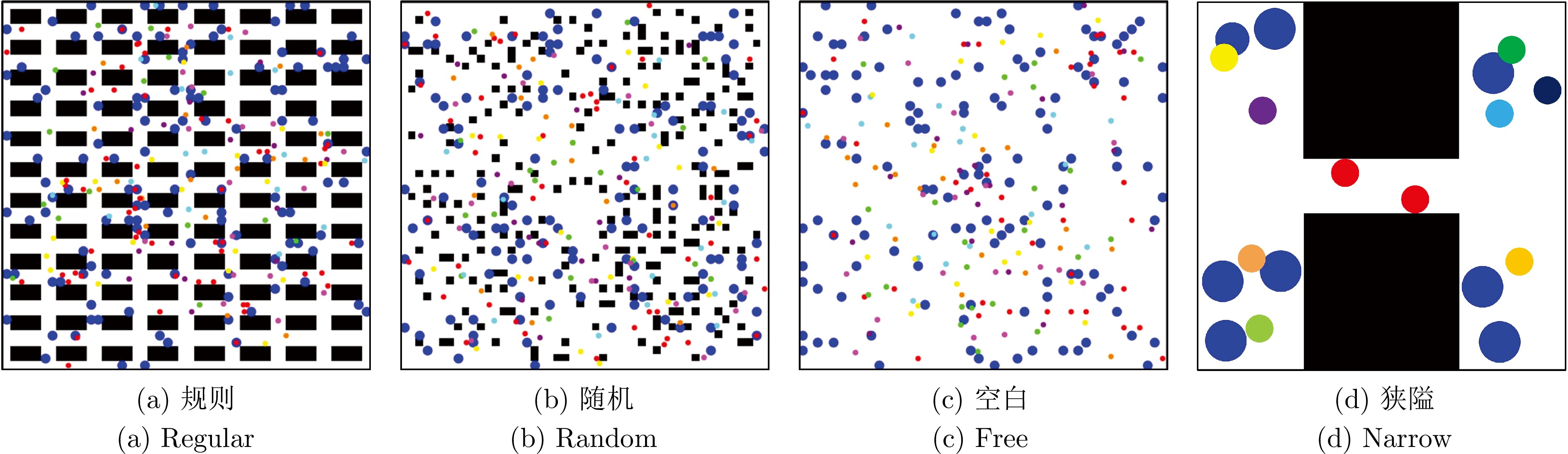
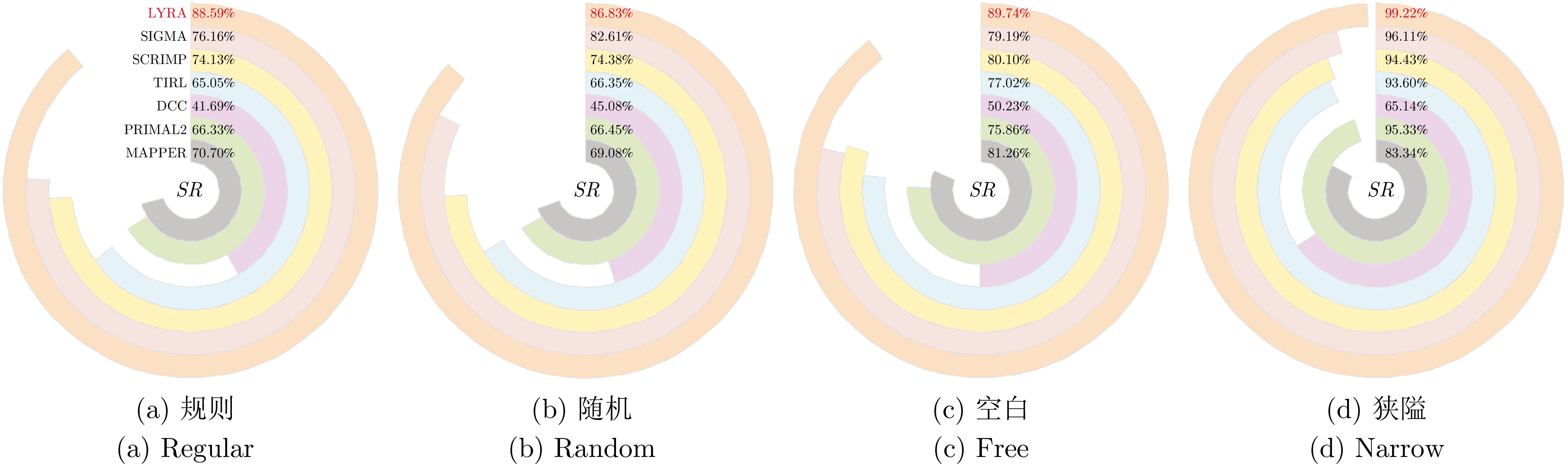
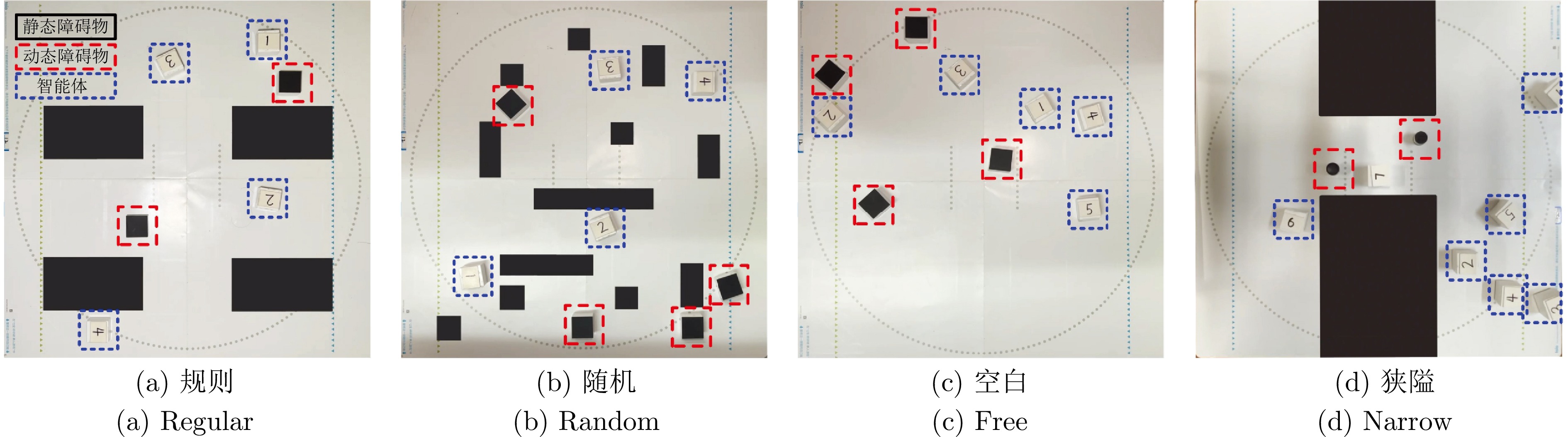
在部分可观测且动态变化的环境中, 深度强化学习(DRL) 为多智能体路径规划提供具备自学习、泛化与动态适应能力的分布式求解途径. 然而, DRL 在该问题中仍存在协调性不足与局部近视两个挑战: 智能体间的隐式交互易引发冲突, 仅依赖局部观测的反应式避障又导致路径冗长与全局目标偏离. 为此, 提出一种基于多模态特征融合与局部感知推理的分布式路径协作方法——LYRA. 该方法在分布式DRL 框架下构建从感知到决策的学习体系, 使智能体能依托局部观测实现推理与隐式让行. 多模态状态编码器融合局部碰撞线索与全局路径语义, 平衡即时避障与长期导航目标; 奖励引导的路径学习策略保证局部决策与全局任务一致; 群体协作机制通过隐式优先级推理化解局部冲突; 自适应学习率机制动态调节策略更新以提升训练稳定性. 实验结果表明, LYRA 在任务成功率和安全性上较基线方法有大幅提升, 在不同环境复杂度下保持良好泛化性, 为实现高效鲁棒的分布式多智能体路径规划提供了新范式.
在部分可观测且动态变化的环境中, 深度强化学习(DRL) 为多智能体路径规划提供具备自学习、泛化与动态适应能力的分布式求解途径. 然而, DRL 在该问题中仍存在协调性不足与局部近视两个挑战: 智能体间的隐式交互易引发冲突, 仅依赖局部观测的反应式避障又导致路径冗长与全局目标偏离. 为此, 提出一种基于多模态特征融合与局部感知推理的分布式路径协作方法——LYRA. 该方法在分布式DRL 框架下构建从感知到决策的学习体系, 使智能体能依托局部观测实现推理与隐式让行. 多模态状态编码器融合局部碰撞线索与全局路径语义, 平衡即时避障与长期导航目标; 奖励引导的路径学习策略保证局部决策与全局任务一致; 群体协作机制通过隐式优先级推理化解局部冲突; 自适应学习率机制动态调节策略更新以提升训练稳定性. 实验结果表明, LYRA 在任务成功率和安全性上较基线方法有大幅提升, 在不同环境复杂度下保持良好泛化性, 为实现高效鲁棒的分布式多智能体路径规划提供了新范式.

2026, 52(7): 1360-1371.
doi: 10.16383/j.aas.c250636
cstr: 32138.14.j.aas.c250636
摘要:
针对控制系统中数据经网络传输存在的隐私泄露以及隐私保护导致的性能损失问题, 本文研究一种具有隐私保护的切换系统最优控制方法. 首先, 根据混沌系统的非周期性及不可预测性, 开发一种基于混沌系统的数据加密方法. 将主混沌系统生成的伪随机序列添加到切换系统输出数据中, 能避免其经非理想网络传输时隐私的泄露. 其次, 设计一种基于粒子群优化算法的混沌形态同步控制器, 降低不确定项的影响, 保障主−从混沌系统的同步性, 确保解密后数据的可用性. 然后, 利用自适应动态规划算法对采用解密后数据构造的代价函数进行优化, 将预更新最优子系统的更新规则作为候选切换律. 通过对比候选切换律与当前切换律作用下系统的性能, 将性能好的切换律作为控制策略的一部分, 确保切换系统性能最优. 最后, 通过仿真对所提方法的可行性进行验证.
针对控制系统中数据经网络传输存在的隐私泄露以及隐私保护导致的性能损失问题, 本文研究一种具有隐私保护的切换系统最优控制方法. 首先, 根据混沌系统的非周期性及不可预测性, 开发一种基于混沌系统的数据加密方法. 将主混沌系统生成的伪随机序列添加到切换系统输出数据中, 能避免其经非理想网络传输时隐私的泄露. 其次, 设计一种基于粒子群优化算法的混沌形态同步控制器, 降低不确定项的影响, 保障主−从混沌系统的同步性, 确保解密后数据的可用性. 然后, 利用自适应动态规划算法对采用解密后数据构造的代价函数进行优化, 将预更新最优子系统的更新规则作为候选切换律. 通过对比候选切换律与当前切换律作用下系统的性能, 将性能好的切换律作为控制策略的一部分, 确保切换系统性能最优. 最后, 通过仿真对所提方法的可行性进行验证.








2026, 52(7): 1372-1386.
doi: 10.16383/j.aas.c250650
cstr: 32138.14.j.aas.c250650
摘要:
针对强噪声非平稳环境下滚动轴承故障信号关键特征易被淹没而导致诊断性能下降的难题, 提出一种双域抗噪编码与协同注意力混合解码模型. 首先, 该模型构建一个双域抗噪编码器, 其时域残差收缩分支可自适应学习阈值以抑制干扰, 同时波域可微分小波卷积分支用以捕获多尺度频率结构, 二者共同实现鲁棒的多域特征表示; 其次, 模型设计双域协同注意力模块, 通过双向交互与门控调节实现时域、波域特征的动态协同与自适应融合, 进而提升高噪声下的特征融合能力; 最后, 开发门控循环Transformer解码器组件, 将Transformer自注意力机制与GRU循环门控机制深度融合, 在统一的特征空间内同步实现全局建模与局部时序依赖提取的高效平衡. 基于凯斯西储大学与帕德博恩大学轴承数据集的实验表明, 该模型在标准工况下准确率达到100%, 且在强噪声下仍保持高准确率, 充分体现了其优越的抗噪性与鲁棒性.
针对强噪声非平稳环境下滚动轴承故障信号关键特征易被淹没而导致诊断性能下降的难题, 提出一种双域抗噪编码与协同注意力混合解码模型. 首先, 该模型构建一个双域抗噪编码器, 其时域残差收缩分支可自适应学习阈值以抑制干扰, 同时波域可微分小波卷积分支用以捕获多尺度频率结构, 二者共同实现鲁棒的多域特征表示; 其次, 模型设计双域协同注意力模块, 通过双向交互与门控调节实现时域、波域特征的动态协同与自适应融合, 进而提升高噪声下的特征融合能力; 最后, 开发门控循环Transformer解码器组件, 将Transformer自注意力机制与GRU循环门控机制深度融合, 在统一的特征空间内同步实现全局建模与局部时序依赖提取的高效平衡. 基于凯斯西储大学与帕德博恩大学轴承数据集的实验表明, 该模型在标准工况下准确率达到100%, 且在强噪声下仍保持高准确率, 充分体现了其优越的抗噪性与鲁棒性.













2026, 52(7): 1387-1400.
doi: 10.16383/j.aas.c250623
cstr: 32138.14.j.aas.c250623
摘要:
精准分割早期小病灶对疾病诊疗至关重要, 但现有方法面对特征稀疏、易受背景干扰的小病灶时性能显著下降. 受计算机断层扫描成像中X射线衰减物理原理启发, 发现小病灶在影像中呈现出中心亮、边缘渐弱的强度分布, 其轮廓与二维高斯分布高度吻合. 为此, 提出一种辐射衰减原理引导的显著性感知分割网络(RAP-Net). RAP-Net 将射线衰减导致的二维高斯分布作为相关滤波卷积核融入深度学习架构, 并设计专用于小病灶分割的多尺度感知特征网络. 该网络的核心显著特征感知提取模块利用多尺度高斯空洞卷积建模衰减特性, 实现稀疏特征的深度挖掘与背景抑制. 实验表明, RAP-Net在小肾结石与小肝脏钙化灶分割任务中的Dice系数和IoU提升至少18.05%和19.55%, 显著超越现有主流方法.
精准分割早期小病灶对疾病诊疗至关重要, 但现有方法面对特征稀疏、易受背景干扰的小病灶时性能显著下降. 受计算机断层扫描成像中X射线衰减物理原理启发, 发现小病灶在影像中呈现出中心亮、边缘渐弱的强度分布, 其轮廓与二维高斯分布高度吻合. 为此, 提出一种辐射衰减原理引导的显著性感知分割网络(RAP-Net). RAP-Net 将射线衰减导致的二维高斯分布作为相关滤波卷积核融入深度学习架构, 并设计专用于小病灶分割的多尺度感知特征网络. 该网络的核心显著特征感知提取模块利用多尺度高斯空洞卷积建模衰减特性, 实现稀疏特征的深度挖掘与背景抑制. 实验表明, RAP-Net在小肾结石与小肝脏钙化灶分割任务中的Dice系数和IoU提升至少18.05%和19.55%, 显著超越现有主流方法.












2026, 52(7): 1401-1412.
doi: 10.16383/j.aas.c250634
cstr: 32138.14.j.aas.c250634
摘要:
随着多光谱感知与智能视觉技术的发展, 如何在复杂环境中实现稳定而精确的目标检测已成为自动化视觉检测领域的重要研究方向. 针对传统单模态可见光目标检测在夜间、大雾及低照度等复杂环境中性能下降的问题, 提出一种基于频域特征细化导向的多光谱稀疏融合目标检测方法. 该方法利用共享权重的双分支编码器分别提取可见光与红外光特征, 并通过组稀疏自注意力模块实现跨模态长距离特征筛选, 以抑制冗余信息、增强显著特征表达. 同时, 设计频域自适应加权模块, 在频域空间中进行多光谱特征解耦与自适应融合, 实现不同光谱模态间的高效语义交互与动态权重分配. 该方法可在端到端框架下实现跨模态特征的高精度对齐与融合, 有效提升模型的检测精度与鲁棒性. 在M3FD和FLIR数据集上取得83.5%和81.6%的mAP50结果, 在 KAIST数据集上取得76.2%的AP50结果, 显著优于现有多光谱目标检测算法, 验证了所提方法在复杂场景下的优越性能和泛化能力.
随着多光谱感知与智能视觉技术的发展, 如何在复杂环境中实现稳定而精确的目标检测已成为自动化视觉检测领域的重要研究方向. 针对传统单模态可见光目标检测在夜间、大雾及低照度等复杂环境中性能下降的问题, 提出一种基于频域特征细化导向的多光谱稀疏融合目标检测方法. 该方法利用共享权重的双分支编码器分别提取可见光与红外光特征, 并通过组稀疏自注意力模块实现跨模态长距离特征筛选, 以抑制冗余信息、增强显著特征表达. 同时, 设计频域自适应加权模块, 在频域空间中进行多光谱特征解耦与自适应融合, 实现不同光谱模态间的高效语义交互与动态权重分配. 该方法可在端到端框架下实现跨模态特征的高精度对齐与融合, 有效提升模型的检测精度与鲁棒性. 在M3FD和FLIR数据集上取得83.5%和81.6%的mAP50结果, 在 KAIST数据集上取得76.2%的AP50结果, 显著优于现有多光谱目标检测算法, 验证了所提方法在复杂场景下的优越性能和泛化能力.







2026, 52(7): 1413-1425.
doi: 10.16383/j.aas.c250635
cstr: 32138.14.j.aas.c250635
摘要:
在铝电解过程中, 阳极效应是影响电能利用效率的典型异常工况, 其发生往往伴随阳极电阻的剧烈波动. 若能实现阳极电阻变化的实时预测, 即可对阳极效应进行前瞻性识别. 为此, 提出一种融合机理约束与数据驱动思想的多通道时空预测模型(卷积长短期记忆–二维卷积–多头注意力, ConvLSTM-Conv2D-MHA), 以联合刻画多槽系统的共性与差异特征. 模型利用堆叠ConvLSTM提取时序动态, 通过Conv2D分支强化空间特征表达, 并引入MHA机制捕捉长时依赖关系, 从而提升对趋势变化及早期波动的敏感度. 实验结果表明, 该模型在阳极电阻趋势预测中表现出更高的精度与稳定性, 较传统时序模型更能利用多槽间潜在的耦合关联.
在铝电解过程中, 阳极效应是影响电能利用效率的典型异常工况, 其发生往往伴随阳极电阻的剧烈波动. 若能实现阳极电阻变化的实时预测, 即可对阳极效应进行前瞻性识别. 为此, 提出一种融合机理约束与数据驱动思想的多通道时空预测模型(卷积长短期记忆–二维卷积–多头注意力, ConvLSTM-Conv2D-MHA), 以联合刻画多槽系统的共性与差异特征. 模型利用堆叠ConvLSTM提取时序动态, 通过Conv2D分支强化空间特征表达, 并引入MHA机制捕捉长时依赖关系, 从而提升对趋势变化及早期波动的敏感度. 实验结果表明, 该模型在阳极电阻趋势预测中表现出更高的精度与稳定性, 较传统时序模型更能利用多槽间潜在的耦合关联.













2026, 52(7): 1426-1437.
doi: 10.16383/j.aas.c250617
cstr: 32138.14.j.aas.c250617
摘要:
现代工业过程数据具有大容量、高维度及复杂相关性等特征, 单一多元统计监测方法难以兼顾不同类型特征的监测需求. 现有多模型融合方法与深度学习技术虽能提升故障检测性能, 但前者依赖模型库构建, 难以统一建模, 后者存在结构复杂与参数冗余问题. 针对上述问题, 提出一种基于两阶段多教师知识蒸馏的工业过程建模与故障检测方法. 该方法通过蒸馏框架将核主成分分析与独立成分分析提取的异构知识内化至学生自编码器模型中, 实现非线性与非高斯特征的统一建模, 并通过两阶段蒸馏协同优化特征空间与重构空间. 第一阶段在特征层蒸馏以引导学生模型学习教师模型的特征分布, 第二阶段在重构层蒸馏以提升模型对过程变化的表征与重构能力. 在田纳西−伊斯曼仿真过程及合成氨实际过程上的实验结果表明, 该方法能够有效提升故障检测的准确性与鲁棒性, 并通过离线知识蒸馏实现在线阶段的统一建模与高效监测.
现代工业过程数据具有大容量、高维度及复杂相关性等特征, 单一多元统计监测方法难以兼顾不同类型特征的监测需求. 现有多模型融合方法与深度学习技术虽能提升故障检测性能, 但前者依赖模型库构建, 难以统一建模, 后者存在结构复杂与参数冗余问题. 针对上述问题, 提出一种基于两阶段多教师知识蒸馏的工业过程建模与故障检测方法. 该方法通过蒸馏框架将核主成分分析与独立成分分析提取的异构知识内化至学生自编码器模型中, 实现非线性与非高斯特征的统一建模, 并通过两阶段蒸馏协同优化特征空间与重构空间. 第一阶段在特征层蒸馏以引导学生模型学习教师模型的特征分布, 第二阶段在重构层蒸馏以提升模型对过程变化的表征与重构能力. 在田纳西−伊斯曼仿真过程及合成氨实际过程上的实验结果表明, 该方法能够有效提升故障检测的准确性与鲁棒性, 并通过离线知识蒸馏实现在线阶段的统一建模与高效监测.









2026, 52(7): 1438-1448.
doi: 10.16383/j.aas.c250649
cstr: 32138.14.j.aas.c250649
摘要:
针对现有迭代学习控制方法中迭代次数依赖初始跟踪误差及系统不确定性影响控制精度等问题, 提出一种数据驱动鲁棒固定次迭代学习控制方法. 首先, 通过构造沿迭代轴的双曲正切型趋近律, 设计固定次迭代学习控制器, 推导出跟踪误差的稳态误差带并移除迭代次数上界依赖初始误差这一限制, 保证系统跟踪误差在固定迭代次数内收敛. 在此基础上, 基于系统输入输出数据设计沿迭代轴更新的参数自适应律与扩张状态观测器, 估计未知参数并补偿系统中未知干扰, 进而提高系统的鲁棒性与跟踪精度. 理论分析和仿真结果验证了所提方法的有效性.
针对现有迭代学习控制方法中迭代次数依赖初始跟踪误差及系统不确定性影响控制精度等问题, 提出一种数据驱动鲁棒固定次迭代学习控制方法. 首先, 通过构造沿迭代轴的双曲正切型趋近律, 设计固定次迭代学习控制器, 推导出跟踪误差的稳态误差带并移除迭代次数上界依赖初始误差这一限制, 保证系统跟踪误差在固定迭代次数内收敛. 在此基础上, 基于系统输入输出数据设计沿迭代轴更新的参数自适应律与扩张状态观测器, 估计未知参数并补偿系统中未知干扰, 进而提高系统的鲁棒性与跟踪精度. 理论分析和仿真结果验证了所提方法的有效性.








2026, 52(7): 1449-1462.
doi: 10.16383/j.aas.c250653
cstr: 32138.14.j.aas.c250653
摘要:
关键性能指标(KPI)预测对工业过程优化和安全至关重要. 然而, 在现实工业环境中传感器故障常导致推理阶段内生变量(预测目标)缺失, 引发信息不对称. 现有方法在推理阶段因缺乏内生变量的历史自回归信息, 难以建立鲁棒时空特征映射, 严重影响多步预测性能. 针对该挑战, 提出完备时空信息引导网络. 该网络采用包含“完备变量引导”和“外生变量学习”的双流架构, 基于贝叶斯理论将内生变量缺失下的预测问题转换为特征对齐任务, 通过分布对齐约束使网络在变量缺失时仍能学习到逼近完备变量提取的时空表征; 同时, 提出多尺度时空聚合模块, 结合图结构学习与注意力机制动态建模变量间的耦合关系, 并精炼特征空间, 有效捕获与KPI相关的复杂时空关联. 在电力变压器温度数据集和氧化铝回转窑烧结温度数据集上的实验表明, 在内生变量缺失下, 所提网络表现出良好的泛化能力和鲁棒的多步预测性能.
关键性能指标(KPI)预测对工业过程优化和安全至关重要. 然而, 在现实工业环境中传感器故障常导致推理阶段内生变量(预测目标)缺失, 引发信息不对称. 现有方法在推理阶段因缺乏内生变量的历史自回归信息, 难以建立鲁棒时空特征映射, 严重影响多步预测性能. 针对该挑战, 提出完备时空信息引导网络. 该网络采用包含“完备变量引导”和“外生变量学习”的双流架构, 基于贝叶斯理论将内生变量缺失下的预测问题转换为特征对齐任务, 通过分布对齐约束使网络在变量缺失时仍能学习到逼近完备变量提取的时空表征; 同时, 提出多尺度时空聚合模块, 结合图结构学习与注意力机制动态建模变量间的耦合关系, 并精炼特征空间, 有效捕获与KPI相关的复杂时空关联. 在电力变压器温度数据集和氧化铝回转窑烧结温度数据集上的实验表明, 在内生变量缺失下, 所提网络表现出良好的泛化能力和鲁棒的多步预测性能.











2026, 52(7): 1463-1476.
doi: 10.16383/j.aas.c250624
cstr: 32138.14.j.aas.c250624
摘要:
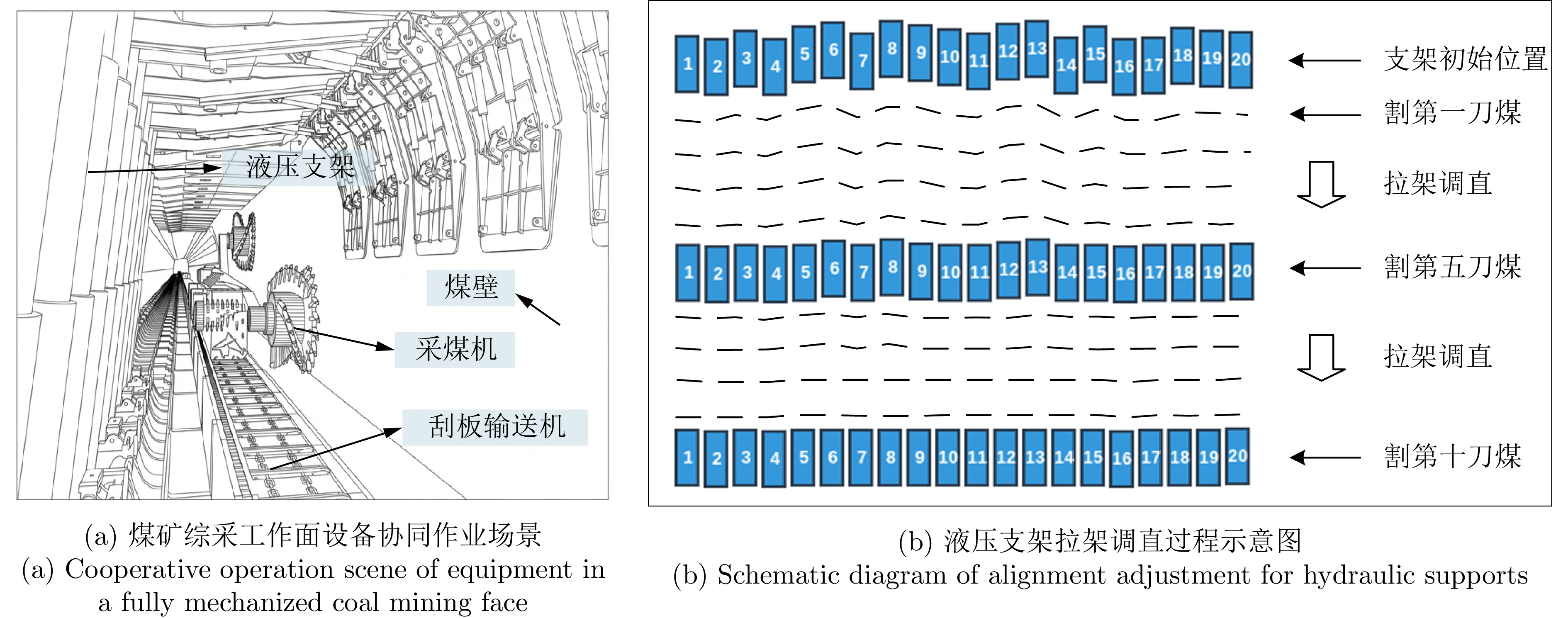
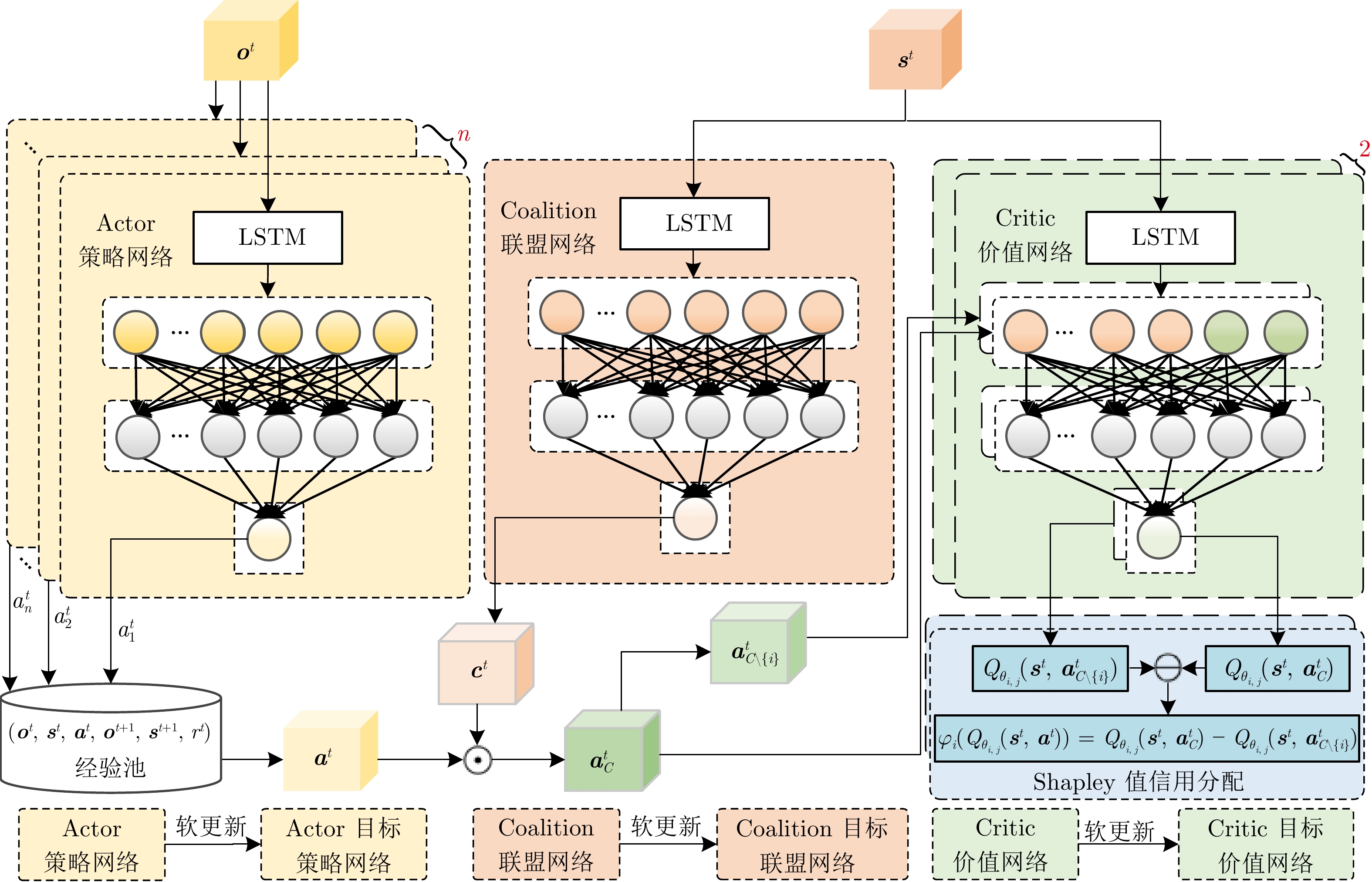
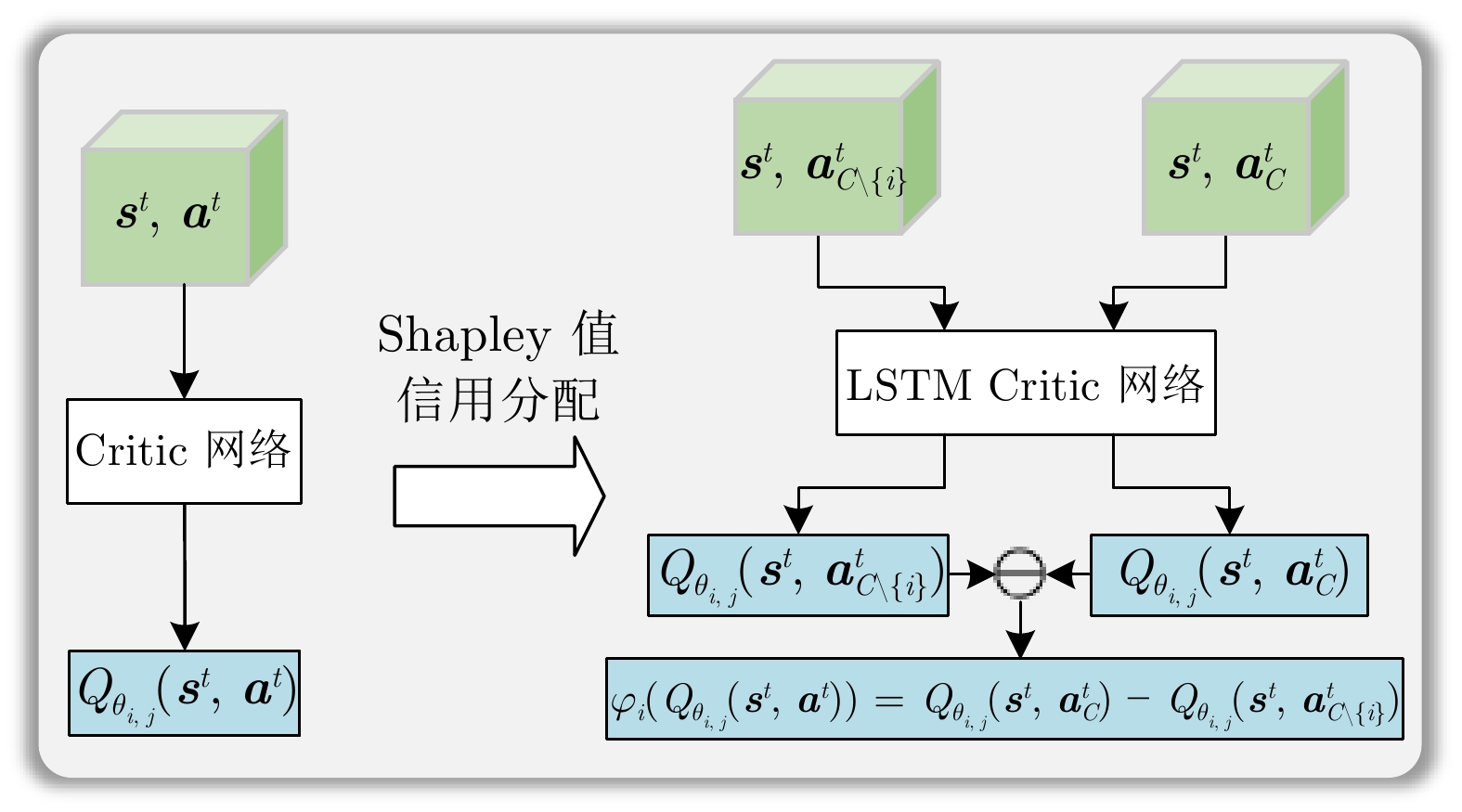
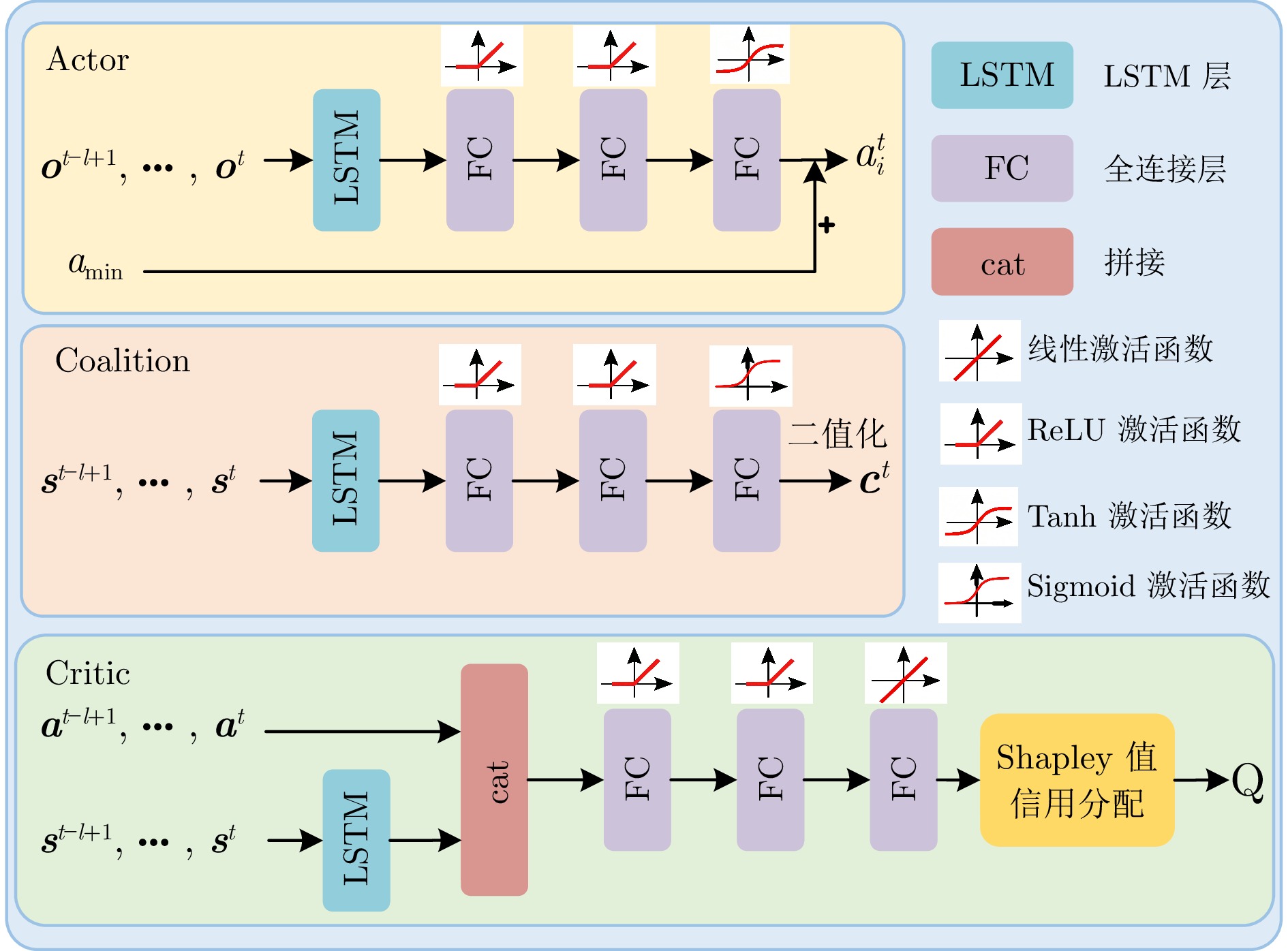
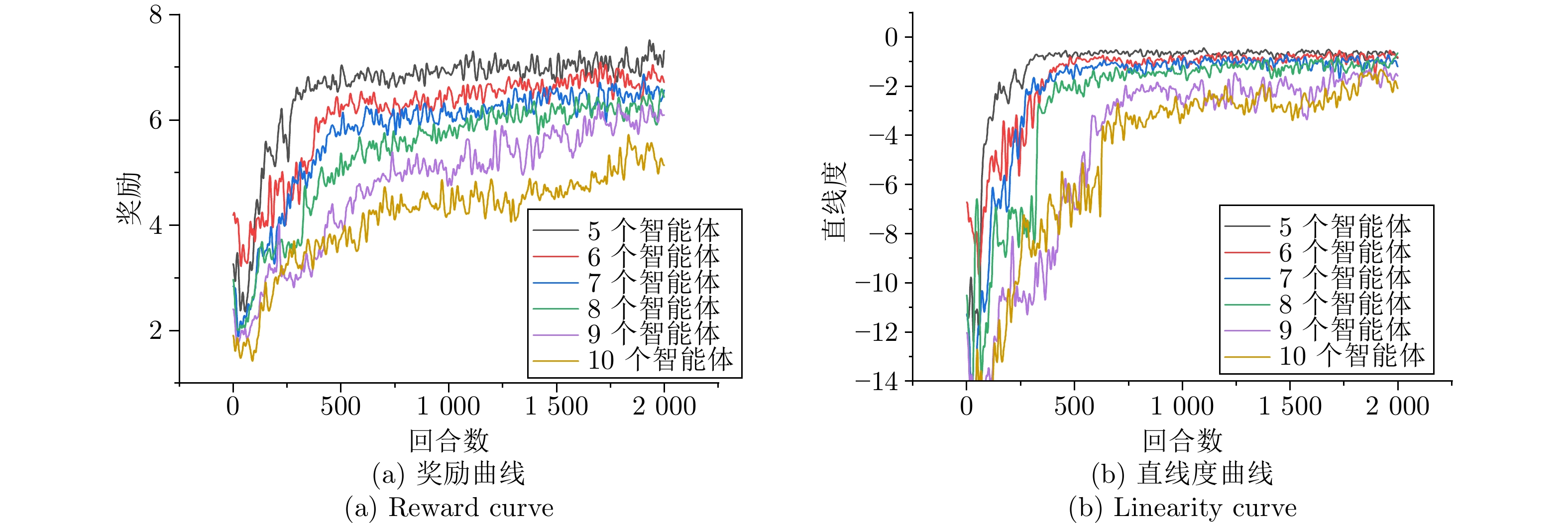
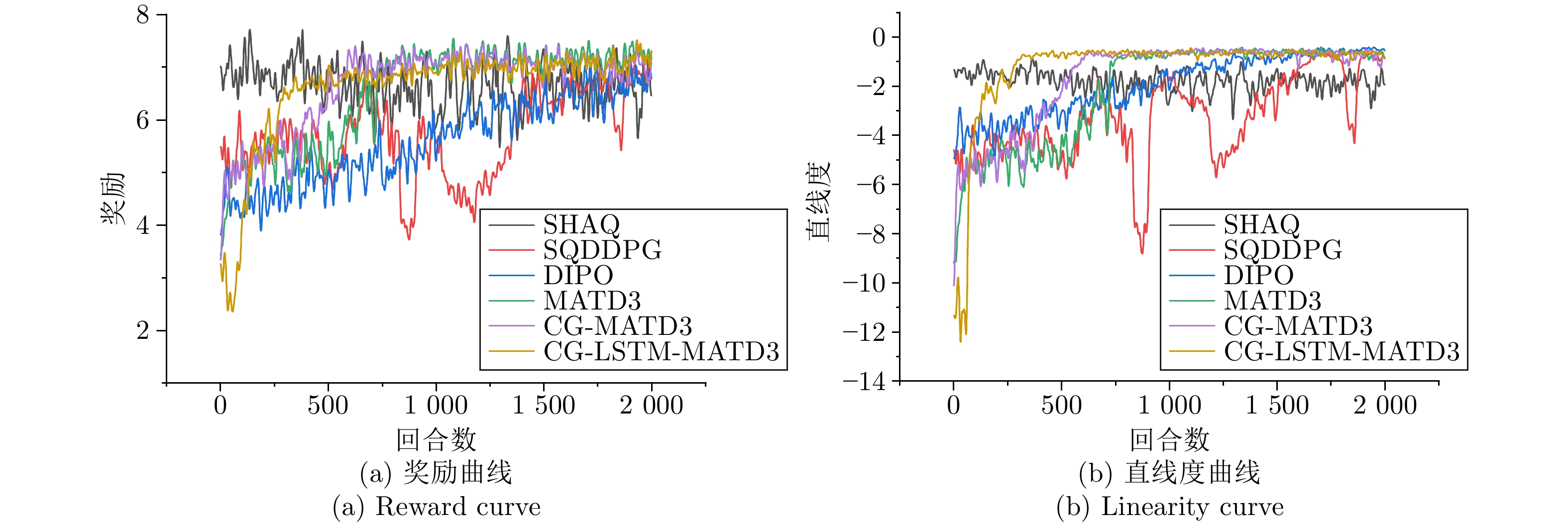
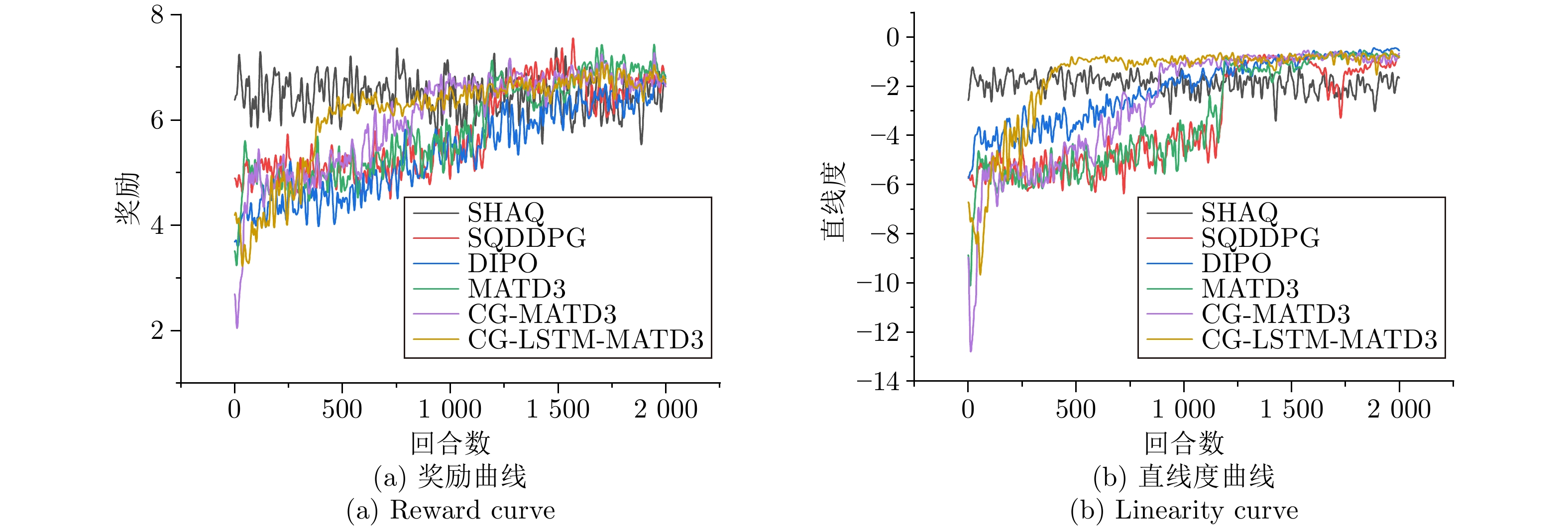
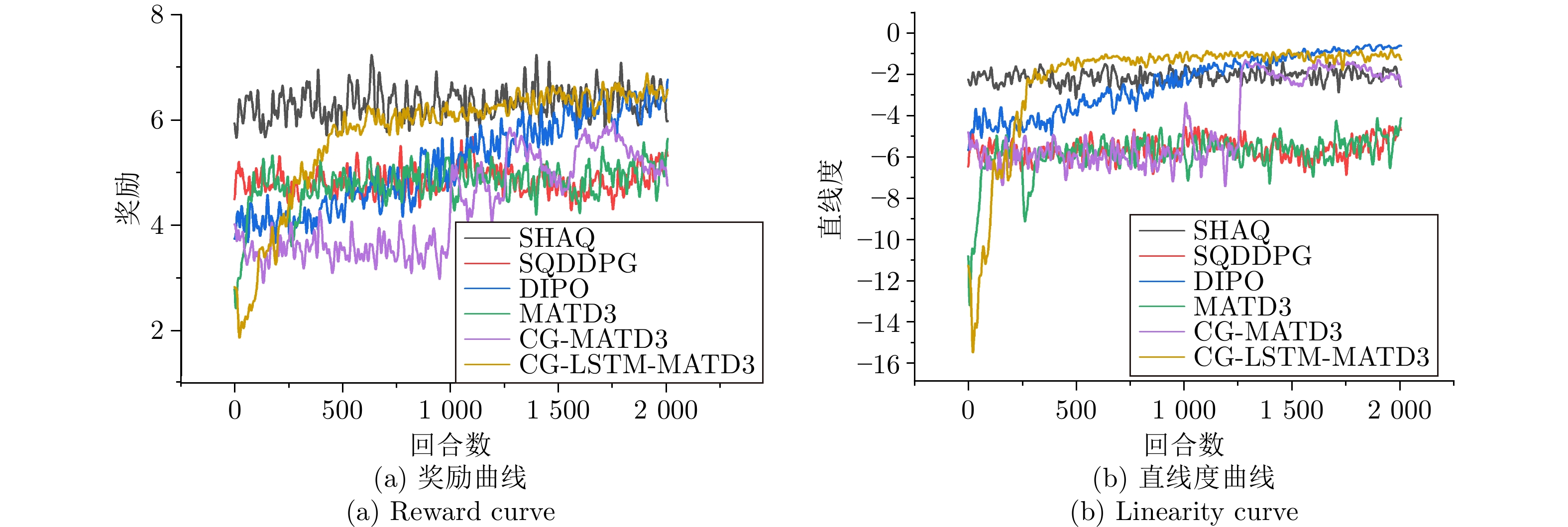
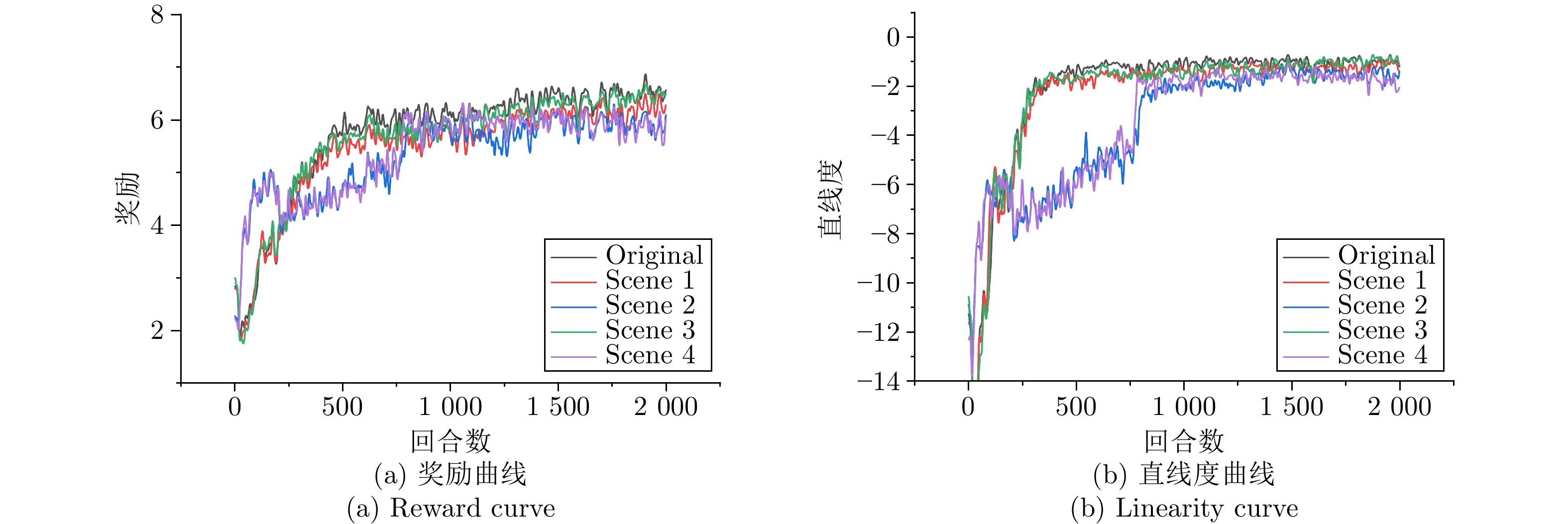
综采工作面液压支架群调直过程中, 支架群间的强耦合关系与液压缸摩擦−滑移非线性构成典型的“耦合−非线性”双重复杂性, 使传统控制方法难以有效建模. 现有多智能体强化学习方法能实现并行决策, 但面临全局奖励无法精确归因至各支架动作、仅依赖观测状态难以捕获支架群姿态的时序演化规律等问题, 阻碍策略的有效收敛. 为此, 提出融合合作博弈与长短期记忆网络(LSTM)的多智能体强化学习算法CG-LSTM-MATD3. 该算法基于去中心化部分可观测马尔科夫决策过程对液压支架调直过程建模, 引入Shapley值实现各液压支架边际贡献的合理归因, 并设计Coalition网络通过联盟生成降低计算复杂度. 其次, 在Actor、Critic以及Coalition网络中嵌入LSTM模块, 通过对状态序列等信息的记忆, 使模型能够捕获状态的时序依赖关系, 增强对环境动态特性和真实状态的感知能力. 实验结果表明, 该算法在七支架任务中直线度相对基线算法提升80.59%, 消融实验进一步证明了合作博弈机制与LSTM模块的有效性.
综采工作面液压支架群调直过程中, 支架群间的强耦合关系与液压缸摩擦−滑移非线性构成典型的“耦合−非线性”双重复杂性, 使传统控制方法难以有效建模. 现有多智能体强化学习方法能实现并行决策, 但面临全局奖励无法精确归因至各支架动作、仅依赖观测状态难以捕获支架群姿态的时序演化规律等问题, 阻碍策略的有效收敛. 为此, 提出融合合作博弈与长短期记忆网络(LSTM)的多智能体强化学习算法CG-LSTM-MATD3. 该算法基于去中心化部分可观测马尔科夫决策过程对液压支架调直过程建模, 引入Shapley值实现各液压支架边际贡献的合理归因, 并设计Coalition网络通过联盟生成降低计算复杂度. 其次, 在Actor、Critic以及Coalition网络中嵌入LSTM模块, 通过对状态序列等信息的记忆, 使模型能够捕获状态的时序依赖关系, 增强对环境动态特性和真实状态的感知能力. 实验结果表明, 该算法在七支架任务中直线度相对基线算法提升80.59%, 消融实验进一步证明了合作博弈机制与LSTM模块的有效性.
2026, 52(7): 1477-1490.
doi: 10.16383/j.aas.c250607
cstr: 32138.14.j.aas.c250607
摘要:
针对浮选精煤泡沫分割中因低质图像数据导致的目标漏检及误分割问题, 提出一种基于密度感知引导的煤泥浮选泡沫分割方法. 首先, 构建跨尺度区域密度感知模块, 设计层次化密度估计子模块提取多尺度差异化区域密度信息, 并提出基于全局语义引导的跨尺度聚合方式, 融合生成具有区域差异感知能力的密度引导表征. 其次, 设计基于密度引导的分支增强模块, 建立基于分布感知的动态密度注意力机制, 构成以密度分布为先验来动态调节双分支空间特征响应的增强策略, 降低泡沫漏检率. 最后, 设计基于密度引导的互信息约束优化模块, 提出以互信息最大化为目标的语义耦合策略, 形成强化密度与分割表征间统计依赖的联合优化方法, 提升泡沫边界的分割判别能力. 在两个实际浮选泡沫数据集上的实验结果表明, 所提方法有效提升了泡沫分割性能.
针对浮选精煤泡沫分割中因低质图像数据导致的目标漏检及误分割问题, 提出一种基于密度感知引导的煤泥浮选泡沫分割方法. 首先, 构建跨尺度区域密度感知模块, 设计层次化密度估计子模块提取多尺度差异化区域密度信息, 并提出基于全局语义引导的跨尺度聚合方式, 融合生成具有区域差异感知能力的密度引导表征. 其次, 设计基于密度引导的分支增强模块, 建立基于分布感知的动态密度注意力机制, 构成以密度分布为先验来动态调节双分支空间特征响应的增强策略, 降低泡沫漏检率. 最后, 设计基于密度引导的互信息约束优化模块, 提出以互信息最大化为目标的语义耦合策略, 形成强化密度与分割表征间统计依赖的联合优化方法, 提升泡沫边界的分割判别能力. 在两个实际浮选泡沫数据集上的实验结果表明, 所提方法有效提升了泡沫分割性能.











本刊经同行评议拟录用的文章,目前在编校阶段,尚未确定卷期及页码,已有DOI。
显示方式:
摘要:
个性化自适应学习是当前智能教育发展的核心. 以往的学习模型在识别学习者个体差异、整合认知与情感因素、适应多样学习任务等方面存在理论瓶颈, 导致个性化学习在教育场景中缺乏解释力、泛化性与适应性, 难以充分满足个性化学习的复杂情境. 为此, 首先梳理个性化学习与人工智能技术融合的发展历程, 分析认知、情感与任务三大因素在个性化自适应学习中的关键作用以及以往研究存在的局限. 在此基础上提出认知−情感−任务(CAT)学习理论模型, 并通过多模态数据采集与分析方法, 在外语学习场景中分析不同任务难度下学习者认知与情感加工状态的变化, 对CAT学习理论模型进行初步的实证. 该理论为个性化自适应学习研究提供更具整合性的理论支撑, 对当前的智能教育发展具有一定的指导意义.
个性化自适应学习是当前智能教育发展的核心. 以往的学习模型在识别学习者个体差异、整合认知与情感因素、适应多样学习任务等方面存在理论瓶颈, 导致个性化学习在教育场景中缺乏解释力、泛化性与适应性, 难以充分满足个性化学习的复杂情境. 为此, 首先梳理个性化学习与人工智能技术融合的发展历程, 分析认知、情感与任务三大因素在个性化自适应学习中的关键作用以及以往研究存在的局限. 在此基础上提出认知−情感−任务(CAT)学习理论模型, 并通过多模态数据采集与分析方法, 在外语学习场景中分析不同任务难度下学习者认知与情感加工状态的变化, 对CAT学习理论模型进行初步的实证. 该理论为个性化自适应学习研究提供更具整合性的理论支撑, 对当前的智能教育发展具有一定的指导意义.




摘要:
针对受多重输入非线性影响的机电系统轨迹跟踪问题, 提出一种MIMO无模型最优预设时间和精度控制方法. 首先, 为实现无模型控制, 提出分数阶MIMO极局部模型在极小时间窗口内重构被控系统; 进而基于准时延估计和分数阶滑模控制提出MIMO无模型分数阶控制. 然后, 引入不受初值影响的改进性能函数, 实现对跟踪误差的预设时间和精度约束, 并设计有限时间控制稳定闭环系统, 进而提出MIMO无模型分数阶预设性能有限时间控制. 进一步, 使用海洋捕食者算法优化控制输入增益矩阵参数. 最后, 使用李雅普诺夫方法证明了闭环系统稳定性. 应用于三自由度机械臂的联合仿真表明, 所提方法的平均IAE性能指标相比于基于特征建模的智能自适应控制和无模型预设性能固定时间控制分别减小88.1%和62.1%. 此外相较于矩阵参数人工整定和灰狼优化, 经海洋捕食者算法优化后所提方法的平均IAE性能指标分别能降低74.6%和53.6%. 最后, 应用于七自由度外骨骼的联合仿真进一步验证了所提方法在更复杂系统中的有效性.
针对受多重输入非线性影响的机电系统轨迹跟踪问题, 提出一种MIMO无模型最优预设时间和精度控制方法. 首先, 为实现无模型控制, 提出分数阶MIMO极局部模型在极小时间窗口内重构被控系统; 进而基于准时延估计和分数阶滑模控制提出MIMO无模型分数阶控制. 然后, 引入不受初值影响的改进性能函数, 实现对跟踪误差的预设时间和精度约束, 并设计有限时间控制稳定闭环系统, 进而提出MIMO无模型分数阶预设性能有限时间控制. 进一步, 使用海洋捕食者算法优化控制输入增益矩阵参数. 最后, 使用李雅普诺夫方法证明了闭环系统稳定性. 应用于三自由度机械臂的联合仿真表明, 所提方法的平均IAE性能指标相比于基于特征建模的智能自适应控制和无模型预设性能固定时间控制分别减小88.1%和62.1%. 此外相较于矩阵参数人工整定和灰狼优化, 经海洋捕食者算法优化后所提方法的平均IAE性能指标分别能降低74.6%和53.6%. 最后, 应用于七自由度外骨骼的联合仿真进一步验证了所提方法在更复杂系统中的有效性.


















摘要:
复杂运动的稳定性与社会环境的适应性是人形机器人实现自然交互与任务执行的核心能力, 而高质量、高协调的仿人运动是保障其高效稳定运行的基础. 腰部自由度作为上下肢协调控制的关键枢纽, 对整体动态稳定性与动作流畅性具有显著影响. 然而, 现有研究在腰部自由度建模与控制方面关注不足, 导致机器人在仿人行走中易出现姿态畸变甚至运动失稳. 为此, 提出一种虚拟腰部自由度引导的多关节主动补偿控制框架. 该框架首先利用动作捕捉系统采集人体多维关节点数据, 并通过关节空间映射实现运动风格的高保真迁移. 随后, 针对人体腰部与机器人结构间的自由度差异, 构建融合俯仰与滚转虚拟关节的上下肢动力学模型, 提出多关节主动补偿机制以实现对虚拟腰部自由度的协同补偿. 进一步地, 将虚拟关节引入特权观测空间, 构建对抗式动作先验风格奖励与任务执行奖励的可变融合策略, 从而实现全身协调的仿人运动控制. 实验基于Isaac Gym训练平台与MuJoCo仿真环境, 在多速率运动指令 (0.2–1.6 m/s) 下开展测试, 结果表明所提方法能显著提升人形机器人的仿人运动自然度与泛化能力, 相较现有腰部受限方法具有更优性能.
复杂运动的稳定性与社会环境的适应性是人形机器人实现自然交互与任务执行的核心能力, 而高质量、高协调的仿人运动是保障其高效稳定运行的基础. 腰部自由度作为上下肢协调控制的关键枢纽, 对整体动态稳定性与动作流畅性具有显著影响. 然而, 现有研究在腰部自由度建模与控制方面关注不足, 导致机器人在仿人行走中易出现姿态畸变甚至运动失稳. 为此, 提出一种虚拟腰部自由度引导的多关节主动补偿控制框架. 该框架首先利用动作捕捉系统采集人体多维关节点数据, 并通过关节空间映射实现运动风格的高保真迁移. 随后, 针对人体腰部与机器人结构间的自由度差异, 构建融合俯仰与滚转虚拟关节的上下肢动力学模型, 提出多关节主动补偿机制以实现对虚拟腰部自由度的协同补偿. 进一步地, 将虚拟关节引入特权观测空间, 构建对抗式动作先验风格奖励与任务执行奖励的可变融合策略, 从而实现全身协调的仿人运动控制. 实验基于Isaac Gym训练平台与MuJoCo仿真环境, 在多速率运动指令 (0.2–1.6 m/s) 下开展测试, 结果表明所提方法能显著提升人形机器人的仿人运动自然度与泛化能力, 相较现有腰部受限方法具有更优性能.













摘要:
视听目标分割任务旨在依据音频信号对视频中的发声物体进行像素级分割, 但在处理复杂动态场景时, 现有方法面临音视频特征交互不充分与像素级样本分布失衡两大挑战.为此, 提出结合状态空间模型与动态焦点损失的视听分割网络MambaAVS, 构建跨时间音频查询生成与跨模态音视频交互两大核心模块.首先, 利用跨时间音频查询生成机制提取关键频域信息以增强音频表征; 随后, 通过跨模态音视频交互模块动态捕捉音视频模态间的长距离依赖与语义对应关系, 实现特征的深度对齐与交互.此外, 针对训练过程中存在的难易样本分布不均与正负比例悬殊问题, 提出动态焦点损失, 通过自适应调节难易样本权重与梯度表征, 有效缓解了模型优化偏差.在 AVSBench-Object 与 AVSBench-Semantic 数据集上的实验结果表明, 所提 MambaAVS 在单声源、多声源及视听语义分割数据集上的mIoU比分别达到82.86%、62.56%和36.79%; 与同类先进方法 AVSegFormer 相比, MambaAVS在3个数据集上的精度分别提升了0.80%、4.20%和0.13%, 验证了其在复杂视听场景下的有效性.
视听目标分割任务旨在依据音频信号对视频中的发声物体进行像素级分割, 但在处理复杂动态场景时, 现有方法面临音视频特征交互不充分与像素级样本分布失衡两大挑战.为此, 提出结合状态空间模型与动态焦点损失的视听分割网络MambaAVS, 构建跨时间音频查询生成与跨模态音视频交互两大核心模块.首先, 利用跨时间音频查询生成机制提取关键频域信息以增强音频表征; 随后, 通过跨模态音视频交互模块动态捕捉音视频模态间的长距离依赖与语义对应关系, 实现特征的深度对齐与交互.此外, 针对训练过程中存在的难易样本分布不均与正负比例悬殊问题, 提出动态焦点损失, 通过自适应调节难易样本权重与梯度表征, 有效缓解了模型优化偏差.在 AVSBench-Object 与 AVSBench-Semantic 数据集上的实验结果表明, 所提 MambaAVS 在单声源、多声源及视听语义分割数据集上的mIoU比分别达到82.86%、62.56%和36.79%; 与同类先进方法 AVSegFormer 相比, MambaAVS在3个数据集上的精度分别提升了0.80%、4.20%和0.13%, 验证了其在复杂视听场景下的有效性.





摘要:
为满足供电可靠性、经济性和安全性等运行要求, 智能电网通常涉及微电网孤岛运行、并网运行以及两种运行模式之间的动态切换. 本文提出了一种考虑不同运行模式下系统数据隐私保护需求的智能电网分布式经济调度算法. 首先将微-主网通信机制融入所提算法中, 实现了微电网与主网之间信息的双向交互. 进一步地, 为克服现有隐私保护方法存在的收敛精度不足以及需收集全局信息等问题, 引入基于混合信息的隐私保护机制, 其中混合信息由节点状态及其功率信息构成, 各节点通过接收混合信息完成自身状态更新. 利用Perron-Frobenius定理、矩阵扰动理论以及Karush-Kuhn-Tucker条件证明了所提算法无需收集全局信息即可使系统状态精确收敛至全局最优解. 同时, 考虑两种典型的窃听者模型, 对所提算法在孤岛与并网两种运行模式下经济调度的隐私性进行了分析. 最后, 通过不同运行条件下的仿真实验, 验证了所提算法的可行性和优越性.
为满足供电可靠性、经济性和安全性等运行要求, 智能电网通常涉及微电网孤岛运行、并网运行以及两种运行模式之间的动态切换. 本文提出了一种考虑不同运行模式下系统数据隐私保护需求的智能电网分布式经济调度算法. 首先将微-主网通信机制融入所提算法中, 实现了微电网与主网之间信息的双向交互. 进一步地, 为克服现有隐私保护方法存在的收敛精度不足以及需收集全局信息等问题, 引入基于混合信息的隐私保护机制, 其中混合信息由节点状态及其功率信息构成, 各节点通过接收混合信息完成自身状态更新. 利用Perron-Frobenius定理、矩阵扰动理论以及Karush-Kuhn-Tucker条件证明了所提算法无需收集全局信息即可使系统状态精确收敛至全局最优解. 同时, 考虑两种典型的窃听者模型, 对所提算法在孤岛与并网两种运行模式下经济调度的隐私性进行了分析. 最后, 通过不同运行条件下的仿真实验, 验证了所提算法的可行性和优越性.











摘要:
针对现有一阶赢者通吃竞争模型难以同时刻画惯性效应、状态约束与严格优化解释, 本文研究资源总量守恒与箱体约束下的分布式非凸资源分配问题. 为此, 针对 Hill 型效用函数引入对数障碍正则化, 并以图边流动量为中间状态构建二阶惯性边流竞争模型. 所建模型能够利用局部边际效用信息实现分布式交互. 随后, 通过构造能量函数并运用 LaSalle 不变性原理, 证明可行内点集具有正不变性、系统能量单调耗散, 且系统轨迹收敛至平衡点集合. 在此基础上, 进一步建立动力学平衡点与正则化问题 KKT 条件之间的对应关系, 并证明当障碍参数趋于零且相关对偶变量保持有界时, 平衡点极限能够恢复原问题的 KKT 结构. 此外, 针对智能体处于 Hill 边际效用饱和区的情形, 给出能力参数与稳态资源分配之间的条件排序性质. 数值结果表明, 所建模型能够在保持约束的同时形成有界优势资源集聚. 其中, 惯性环节在收敛速度与峰值边流强度之间提供可调折中, 网络拓扑主要影响边际效用一致化速度, 而总资源规模则改变优势资源集聚强度.
针对现有一阶赢者通吃竞争模型难以同时刻画惯性效应、状态约束与严格优化解释, 本文研究资源总量守恒与箱体约束下的分布式非凸资源分配问题. 为此, 针对 Hill 型效用函数引入对数障碍正则化, 并以图边流动量为中间状态构建二阶惯性边流竞争模型. 所建模型能够利用局部边际效用信息实现分布式交互. 随后, 通过构造能量函数并运用 LaSalle 不变性原理, 证明可行内点集具有正不变性、系统能量单调耗散, 且系统轨迹收敛至平衡点集合. 在此基础上, 进一步建立动力学平衡点与正则化问题 KKT 条件之间的对应关系, 并证明当障碍参数趋于零且相关对偶变量保持有界时, 平衡点极限能够恢复原问题的 KKT 结构. 此外, 针对智能体处于 Hill 边际效用饱和区的情形, 给出能力参数与稳态资源分配之间的条件排序性质. 数值结果表明, 所建模型能够在保持约束的同时形成有界优势资源集聚. 其中, 惯性环节在收敛速度与峰值边流强度之间提供可调折中, 网络拓扑主要影响边际效用一致化速度, 而总资源规模则改变优势资源集聚强度.




摘要:
摘要应涵盖全文. 摘要内容包括研究目的、方法、结果等, 注意不是标题的罗列, 能独立成文, 不能出现公式号和文献号. 英文摘要的书写, 请按英语习惯, 无文法及拼写错误, 用词准确. 无人机技术的普及与滥用带来严峻空防挑战, 民用无人机“黑飞”威胁公共安全与基础设施, 军用无人机及蜂群作战突破传统防空体系, 单一防御手段已难以应对, 提升对非合作无人机的协同跟踪与处置能力迫在眉睫. 飞网协同围捕技术作为无人机反制核心方案之一, 要求多无人机协同估计目标轨迹中心并自主编队完成捕获, 而分布式平均跟踪是实现该目标的关键理论. 本文针对此问题, 提出无需相对速度测量和变量初始化的集群无人机系统动态事件触发分布式平均跟踪算法; 理论分析证实, 该算法可实现分布式平均跟踪目标且闭环系统不存在芝诺现象; 最后以集群无人机跟踪非合作无人机集群为实例, 验证了算法的有效性与实用性.
摘要应涵盖全文. 摘要内容包括研究目的、方法、结果等, 注意不是标题的罗列, 能独立成文, 不能出现公式号和文献号. 英文摘要的书写, 请按英语习惯, 无文法及拼写错误, 用词准确. 无人机技术的普及与滥用带来严峻空防挑战, 民用无人机“黑飞”威胁公共安全与基础设施, 军用无人机及蜂群作战突破传统防空体系, 单一防御手段已难以应对, 提升对非合作无人机的协同跟踪与处置能力迫在眉睫. 飞网协同围捕技术作为无人机反制核心方案之一, 要求多无人机协同估计目标轨迹中心并自主编队完成捕获, 而分布式平均跟踪是实现该目标的关键理论. 本文针对此问题, 提出无需相对速度测量和变量初始化的集群无人机系统动态事件触发分布式平均跟踪算法; 理论分析证实, 该算法可实现分布式平均跟踪目标且闭环系统不存在芝诺现象; 最后以集群无人机跟踪非合作无人机集群为实例, 验证了算法的有效性与实用性.







摘要:
文本属性图基础模型(TAG-FM)旨在通过在大规模图数据集上预训练, 实现稳健的跨域泛化能力. 尽管TAG-FM已在多项下游任务中展现出良好的性能, 但是通过深入分析发现, 其在泛化能力方面仍存在关键弱点: 域适应阈值效应, 即, 当预训练域与测试域之间的分布偏移超过某一临界阈值时, 模型性能将出现显著退化. 由于基础模型复杂度高且测试数据稀缺, 引入测试时自适应方法成为缓解该问题的可行方案. 然而现有测试时自适应方法在实例层和域层均存在局限, 严重制约着TAG-FM对分布外数据的适应性能. 针对此问题, 提出一种面向TAG-FM的“检索−分治”测试时自适应方法, 该方法通过检索增强的特征共形融合模块生成融合图结构和节点文本语义的统一特征, 并引入一种分而治之的测试时自适应策略, 通过渐进式自适应过程学习泛化性语义. 在7个基准文本属性图数据集和12个严重域偏移文本属性图数据集上的实验结果表明, 本文方法能够显著增强TAG-FM的跨域泛化能力.
文本属性图基础模型(TAG-FM)旨在通过在大规模图数据集上预训练, 实现稳健的跨域泛化能力. 尽管TAG-FM已在多项下游任务中展现出良好的性能, 但是通过深入分析发现, 其在泛化能力方面仍存在关键弱点: 域适应阈值效应, 即, 当预训练域与测试域之间的分布偏移超过某一临界阈值时, 模型性能将出现显著退化. 由于基础模型复杂度高且测试数据稀缺, 引入测试时自适应方法成为缓解该问题的可行方案. 然而现有测试时自适应方法在实例层和域层均存在局限, 严重制约着TAG-FM对分布外数据的适应性能. 针对此问题, 提出一种面向TAG-FM的“检索−分治”测试时自适应方法, 该方法通过检索增强的特征共形融合模块生成融合图结构和节点文本语义的统一特征, 并引入一种分而治之的测试时自适应策略, 通过渐进式自适应过程学习泛化性语义. 在7个基准文本属性图数据集和12个严重域偏移文本属性图数据集上的实验结果表明, 本文方法能够显著增强TAG-FM的跨域泛化能力.














摘要:
电子固废处理析取过程涉及多变量强耦合的多相反应, 其原料异质性使工艺变量间呈现动态因果特性, 导致表征反应平衡的溶解氧浓度难以准确预测. 为解决该问题, 设计一种电子固废处理析取过程溶解氧浓度自适应因果推理预测模型. 首先, 提出一种基于多头注意力的自适应因果发现方法, 更新工艺变量的因果注意力分布, 实现动态因果结构的建模. 其次, 设计一种基于动态掩码的因果干预策略, 抑制工艺参数的虚假因果相关, 实现模型真实因果关系重构. 最后, 构建一种基于元更新的门控网络结构, 调节时空特征与因果特征的门控融合权重, 实现析取过程溶解氧浓度的稳定预测. 在电子固废处理析取过程数据集上验证该预测模型, 实验结果表明, 该模型能够准确描述工艺变量间动态因果关系, 提升溶解氧浓度的预测精度.
电子固废处理析取过程涉及多变量强耦合的多相反应, 其原料异质性使工艺变量间呈现动态因果特性, 导致表征反应平衡的溶解氧浓度难以准确预测. 为解决该问题, 设计一种电子固废处理析取过程溶解氧浓度自适应因果推理预测模型. 首先, 提出一种基于多头注意力的自适应因果发现方法, 更新工艺变量的因果注意力分布, 实现动态因果结构的建模. 其次, 设计一种基于动态掩码的因果干预策略, 抑制工艺参数的虚假因果相关, 实现模型真实因果关系重构. 最后, 构建一种基于元更新的门控网络结构, 调节时空特征与因果特征的门控融合权重, 实现析取过程溶解氧浓度的稳定预测. 在电子固废处理析取过程数据集上验证该预测模型, 实验结果表明, 该模型能够准确描述工艺变量间动态因果关系, 提升溶解氧浓度的预测精度.






摘要:
针对大规模网络化无人艇集群面临的通信资源受限、成员收益最大化问题, 提出一种基于边分组通信机制的博弈编队控制方案. 首先, 构造具有时变纳什均衡点的代价函数, 使编队成员能够通过动态博弈过程最大化自身收益, 并逐步形成期望的编队构型; 同时, 为每个成员设计分布式状态估计器, 以降低博弈过程对全局信息的依赖. 其次, 考虑大规模集群系统多边并发通信易导致信道拥塞、延迟、丢包等问题, 边分组通信机制将通信边划分成组, 并由各组自主生成相互交错的通信时间序列, 使各边通信错峰进行, 在各自的通信时刻避免竞争. 最后, 通过理论分析与数值仿真验证了所提控制方案的有效性与优越性.
针对大规模网络化无人艇集群面临的通信资源受限、成员收益最大化问题, 提出一种基于边分组通信机制的博弈编队控制方案. 首先, 构造具有时变纳什均衡点的代价函数, 使编队成员能够通过动态博弈过程最大化自身收益, 并逐步形成期望的编队构型; 同时, 为每个成员设计分布式状态估计器, 以降低博弈过程对全局信息的依赖. 其次, 考虑大规模集群系统多边并发通信易导致信道拥塞、延迟、丢包等问题, 边分组通信机制将通信边划分成组, 并由各组自主生成相互交错的通信时间序列, 使各边通信错峰进行, 在各自的通信时刻避免竞争. 最后, 通过理论分析与数值仿真验证了所提控制方案的有效性与优越性.























摘要:
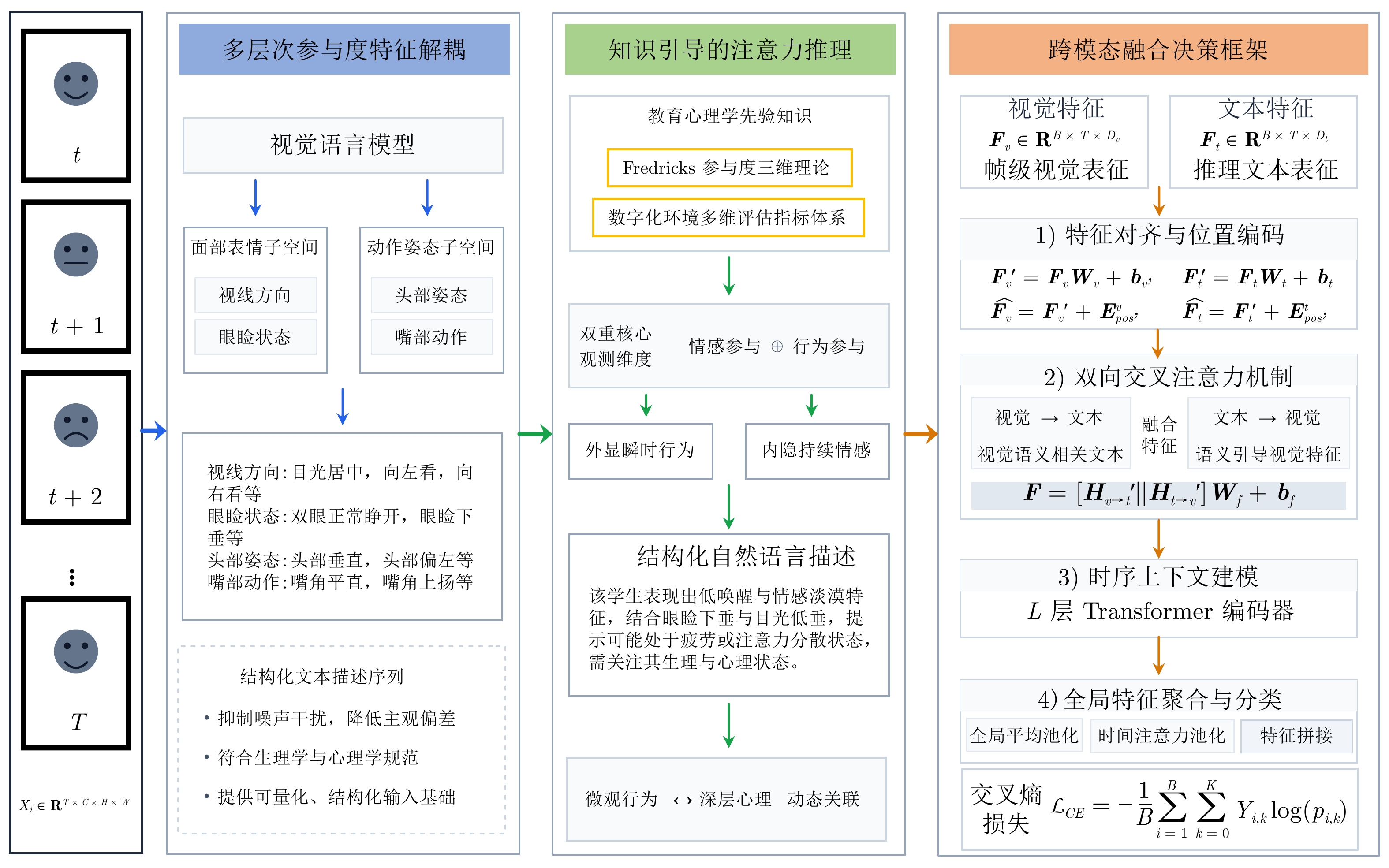
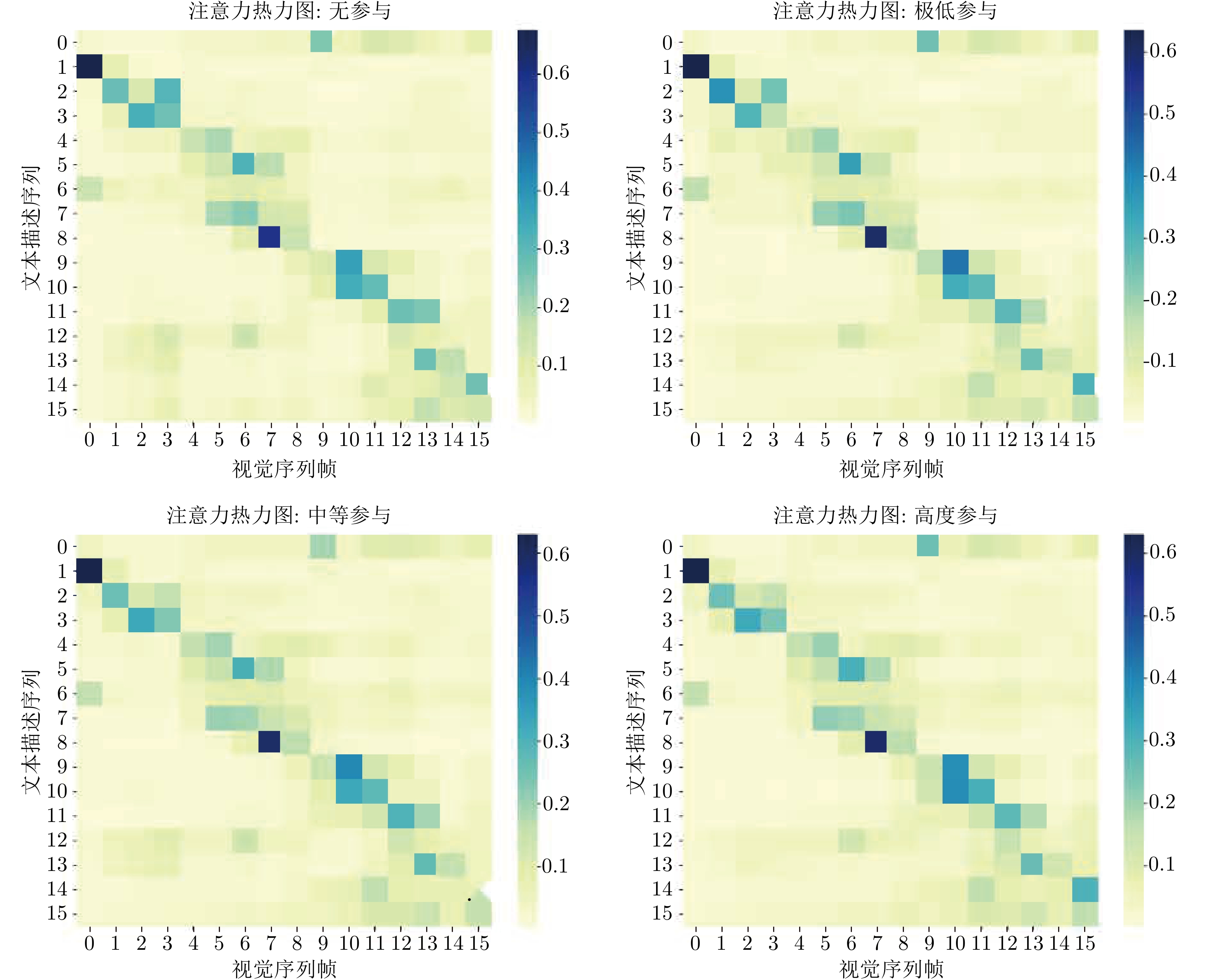
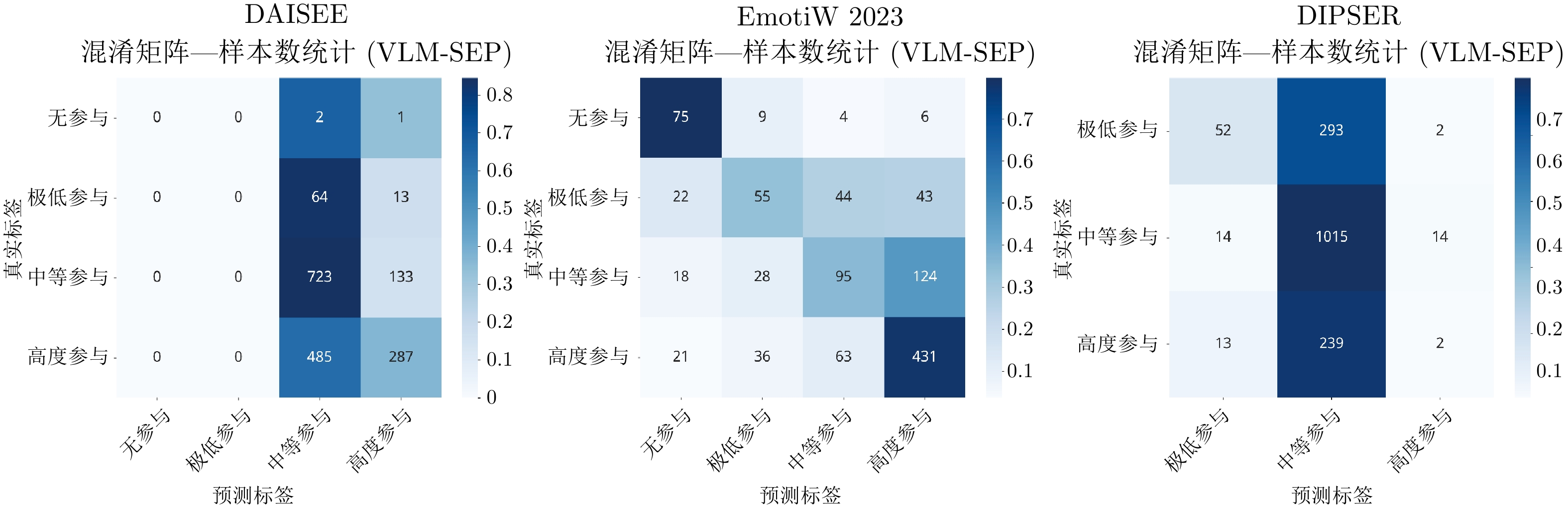
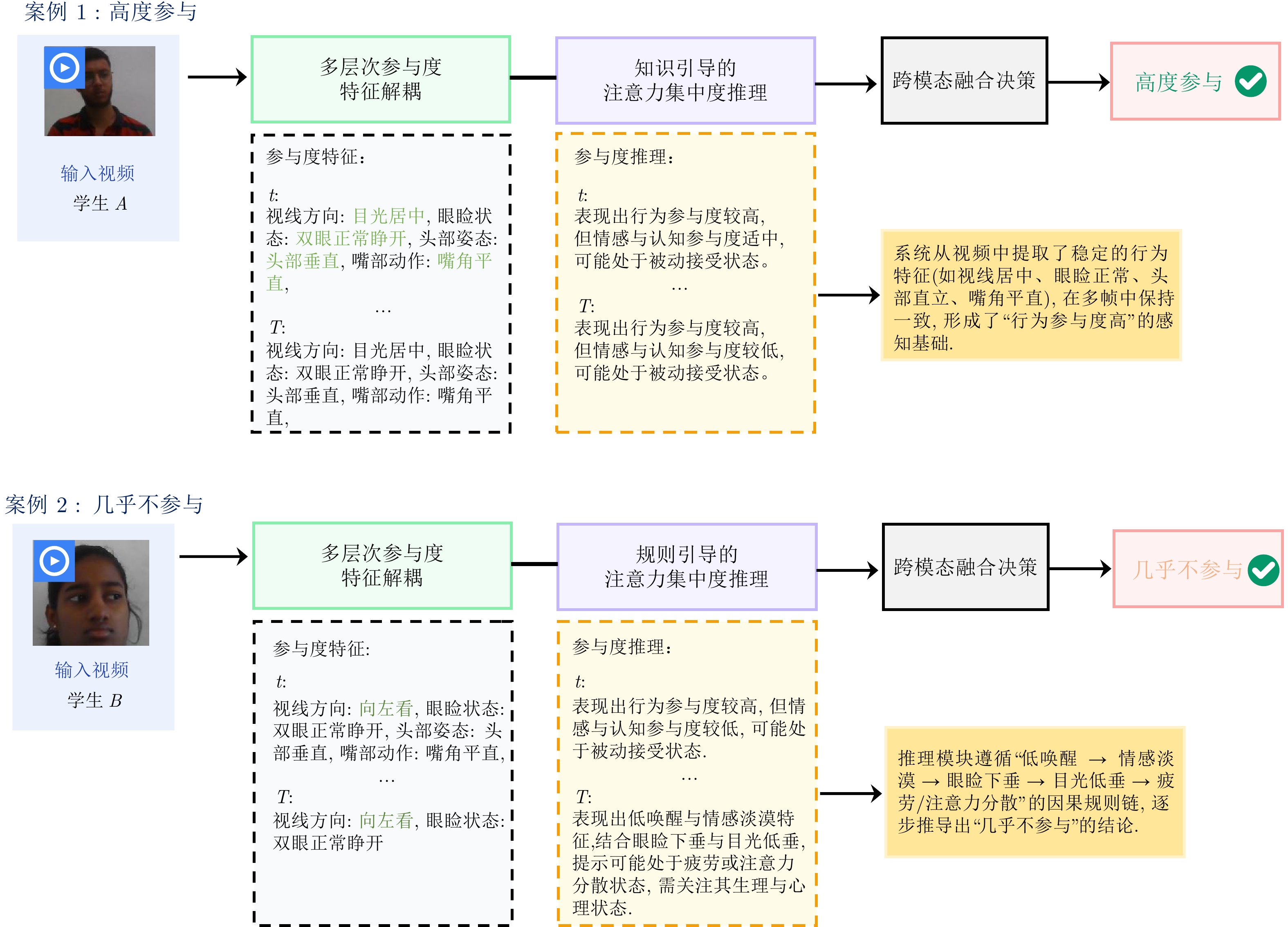
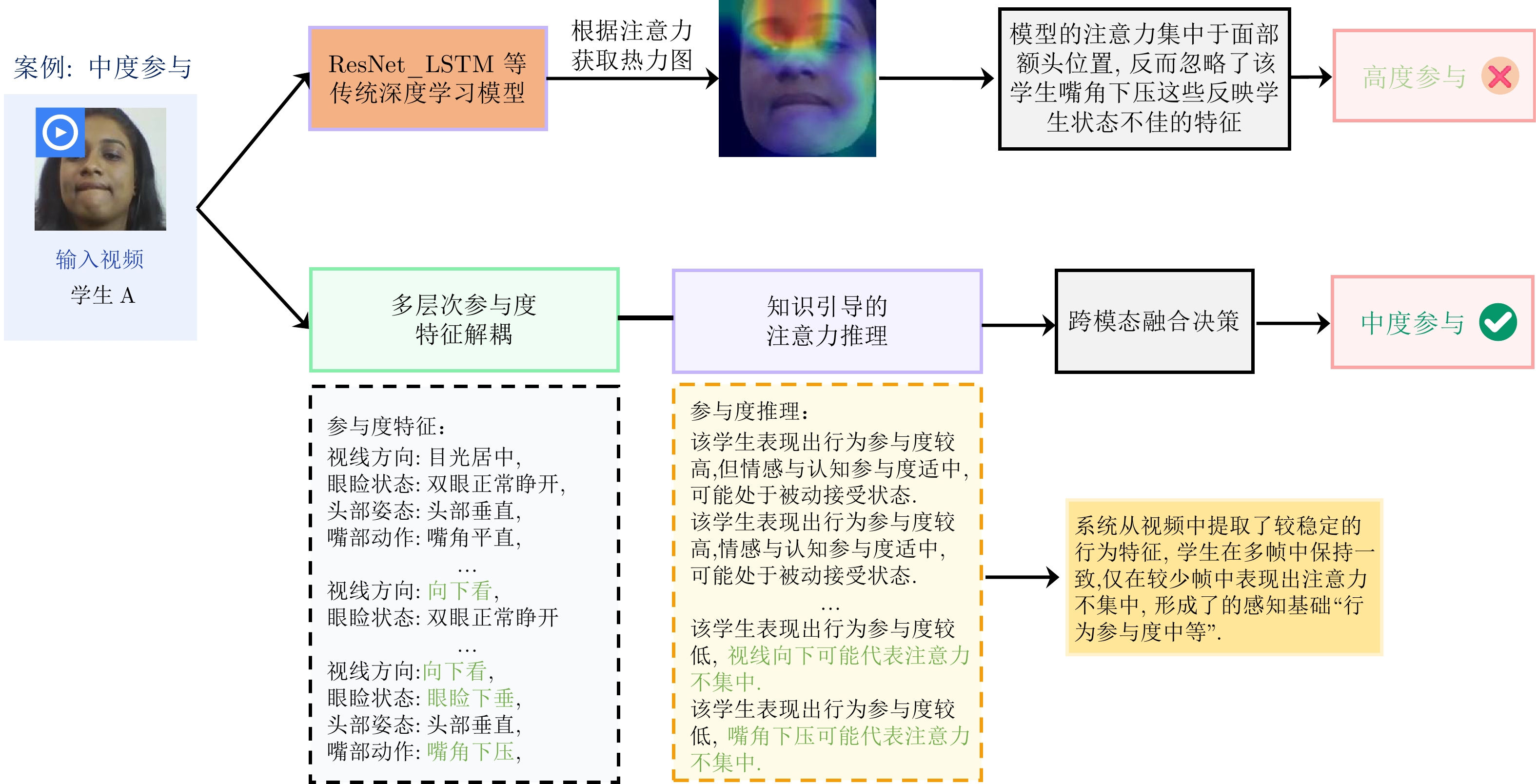
随着在线教育的普及, 学生参与度预测(SEP)已成为评估教学效能的核心任务. 尽管视觉语言模型(VLMs)在通用多模态表征学习中表现卓越, 但直接迁移至SEP领域时, 受限于对细粒度面部微表情及特定教学语境下宏观情绪的感知瓶颈, 难以实现视觉特征与高层语义标签的精准对齐. 为此, 提出基于VLMs的多模态学生参与度预测方法VLM-SEP. 该方法先进行多层次参与度特征解耦, 从面部表情与动作姿态中提取结构化参与度特征; 再引入知识引导的注意力集中度推理, 建立离散视觉特征与参与度状态语言描述的显式映射; 最后通过跨模态融合决策, 结合视觉与文本信息实现参与度精准判别. 在三个公开数据集上的实验结果表明, 该方法有效提升了VLMs在SEP领域的适配性, 为学生参与度预测提供可解释解决方案.
随着在线教育的普及, 学生参与度预测(SEP)已成为评估教学效能的核心任务. 尽管视觉语言模型(VLMs)在通用多模态表征学习中表现卓越, 但直接迁移至SEP领域时, 受限于对细粒度面部微表情及特定教学语境下宏观情绪的感知瓶颈, 难以实现视觉特征与高层语义标签的精准对齐. 为此, 提出基于VLMs的多模态学生参与度预测方法VLM-SEP. 该方法先进行多层次参与度特征解耦, 从面部表情与动作姿态中提取结构化参与度特征; 再引入知识引导的注意力集中度推理, 建立离散视觉特征与参与度状态语言描述的显式映射; 最后通过跨模态融合决策, 结合视觉与文本信息实现参与度精准判别. 在三个公开数据集上的实验结果表明, 该方法有效提升了VLMs在SEP领域的适配性, 为学生参与度预测提供可解释解决方案.


摘要:
肝脏肿瘤精准分割是计算机辅助诊断中的关键任务, 但现有深度学习方法高度依赖大规模像素级标注, 而医学图像标注需要专业放射科医生参与, 成本高且耗时, 限制了临床应用. 为此, 提出AutoSynth-Liver, 一种基于自回归模型的肝脏肿瘤合成增强框架. 该框架通过学习真实肿瘤的外观特征与空间分布规律, 生成多样化且逼真的合成肿瘤, 并自然融合到健康肝脏区域, 从而构建大量带精确标注的训练数据, 实现低标注条件下的高性能分割. 具体包括: 1)基于PixelCNN或VQ-VAE结合Transformer的自回归肿瘤生成模块, 用于建模肿瘤纹理与边界特征; 2)条件图像合成模块, 用于保证肿瘤融合的解剖学合理性; 3)混合监督分割训练模块, 通过联合使用合成数据与少量真实标注数据提升分割性能. 在LiTS17、3DIRCADb和CHAOS数据集上的实验表明, 仅使用合成数据训练时, AutoSynth-Liver的DSC即可达到66.2%, 相当于全监督方法(71.2%)的93.0%; 结合10%真实标注数据后, DSC提升至69.1%, 接近全监督水平. 同时, 该框架将人工标注工作量减少90%以上, 并在病灶检测率和体积测量等临床指标上达到可接受水平.
肝脏肿瘤精准分割是计算机辅助诊断中的关键任务, 但现有深度学习方法高度依赖大规模像素级标注, 而医学图像标注需要专业放射科医生参与, 成本高且耗时, 限制了临床应用. 为此, 提出AutoSynth-Liver, 一种基于自回归模型的肝脏肿瘤合成增强框架. 该框架通过学习真实肿瘤的外观特征与空间分布规律, 生成多样化且逼真的合成肿瘤, 并自然融合到健康肝脏区域, 从而构建大量带精确标注的训练数据, 实现低标注条件下的高性能分割. 具体包括: 1)基于PixelCNN或VQ-VAE结合Transformer的自回归肿瘤生成模块, 用于建模肿瘤纹理与边界特征; 2)条件图像合成模块, 用于保证肿瘤融合的解剖学合理性; 3)混合监督分割训练模块, 通过联合使用合成数据与少量真实标注数据提升分割性能. 在LiTS17、3DIRCADb和CHAOS数据集上的实验表明, 仅使用合成数据训练时, AutoSynth-Liver的DSC即可达到66.2%, 相当于全监督方法(71.2%)的93.0%; 结合10%真实标注数据后, DSC提升至69.1%, 接近全监督水平. 同时, 该框架将人工标注工作量减少90%以上, 并在病灶检测率和体积测量等临床指标上达到可接受水平.








摘要:
配电网高阻接地故障下, 故障初始电流微弱且常伴有非线性电弧, 暂态特征微弱, 短时内故障难以可靠辨识, 存在电气火灾与人身触电事故风险. 为此, 提出改进小波基与分尺度跨线路注意力融合的配电网高阻接地故障辨识方法. 建立分尺度特征跨线路辨识模型, 利用汉明窗滤波器抑制频谱泄漏, 提取具有高物理显著性的小波关键系数, 提升故障特征在信号中的对比度; 引入尺度内编码机制, 将长序列特征按尺度等效降维, 形成低维度嵌入向量; 构建分尺度跨线处理模型, 改进注意力机制, 显式捕捉故障线路与健全线路间的差异性, 提高配电网高阻接地故障的辨识准确率. 仿真实验表明, 所提方法相较其他模型, 高阻接地故障辨识准确率最高提升36.6%;动模实验和真型实验表明, 即使面对训练阶段未出现的新拓扑, 所提方法在真实链路情况下的辨识准确率仍超95%, 验证了该方法在真实工况环境下的适用性与一定的鲁棒性.
配电网高阻接地故障下, 故障初始电流微弱且常伴有非线性电弧, 暂态特征微弱, 短时内故障难以可靠辨识, 存在电气火灾与人身触电事故风险. 为此, 提出改进小波基与分尺度跨线路注意力融合的配电网高阻接地故障辨识方法. 建立分尺度特征跨线路辨识模型, 利用汉明窗滤波器抑制频谱泄漏, 提取具有高物理显著性的小波关键系数, 提升故障特征在信号中的对比度; 引入尺度内编码机制, 将长序列特征按尺度等效降维, 形成低维度嵌入向量; 构建分尺度跨线处理模型, 改进注意力机制, 显式捕捉故障线路与健全线路间的差异性, 提高配电网高阻接地故障的辨识准确率. 仿真实验表明, 所提方法相较其他模型, 高阻接地故障辨识准确率最高提升36.6%;动模实验和真型实验表明, 即使面对训练阶段未出现的新拓扑, 所提方法在真实链路情况下的辨识准确率仍超95%, 验证了该方法在真实工况环境下的适用性与一定的鲁棒性.
















摘要:
2017年, 宋永端教授团队于Automatica发表高阶非线性系统预设时间控制的原创性工作. 不同于传统控制方法, 该策略能够人为预先设定系统收敛的时间, 同时具备出色的扰动抑制性能, 成果面世后迅速成为研究热点, 国内外学者围绕该方向已开展大量深入研究. 本文从系统稳定性相关的基本概念出发, 系统辨析有限时间、固定时间、预定时间与预设时间稳定性之间的联系与区别, 进而聚焦于预设时间控制的实现途径. 以经典的比例制导、终端约束最优控制、滑模控制等为基础, 梳理其理论渊源, 重点阐述状态变换、时间尺度变换、复合反馈及周期时滞反馈等核心设计框架. 通过比较不同方法的收敛性能, 进一步分析增强或削弱反馈信号对系统性能与工程可实现性的影响. 此外, 还讨论预设时间控制中存在的数值奇异和噪声敏感等挑战, 总结多种解决方案, 并对未来在理论融合、智能控制、跨领域应用验证等方面的发展方向进行展望. 预设时间控制在航空航天、机器人、多智能体等对动态性能与时间精度要求严苛的领域中展现出重要应用潜力, 其进一步发展将推动高可靠控制系统的工程实现.
2017年, 宋永端教授团队于Automatica发表高阶非线性系统预设时间控制的原创性工作. 不同于传统控制方法, 该策略能够人为预先设定系统收敛的时间, 同时具备出色的扰动抑制性能, 成果面世后迅速成为研究热点, 国内外学者围绕该方向已开展大量深入研究. 本文从系统稳定性相关的基本概念出发, 系统辨析有限时间、固定时间、预定时间与预设时间稳定性之间的联系与区别, 进而聚焦于预设时间控制的实现途径. 以经典的比例制导、终端约束最优控制、滑模控制等为基础, 梳理其理论渊源, 重点阐述状态变换、时间尺度变换、复合反馈及周期时滞反馈等核心设计框架. 通过比较不同方法的收敛性能, 进一步分析增强或削弱反馈信号对系统性能与工程可实现性的影响. 此外, 还讨论预设时间控制中存在的数值奇异和噪声敏感等挑战, 总结多种解决方案, 并对未来在理论融合、智能控制、跨领域应用验证等方面的发展方向进行展望. 预设时间控制在航空航天、机器人、多智能体等对动态性能与时间精度要求严苛的领域中展现出重要应用潜力, 其进一步发展将推动高可靠控制系统的工程实现.











摘要:
针对传统图像级标注的弱监督语义分割方法仍依赖目标数据集的图像级标注, 进而难以获取精细空间监督信号的问题, 提出一种无需目标域标注的自监督CLIP提示引导方法. 该方法利用预训练CLIP模型的强大泛化能力, 通过自监督适应机制挖掘无标注数据的内在结构. 主要解决三个问题: 一是传统监督缺乏像素级空间约束; 二是初始伪标签受限于分类特征的传导偏差; 三是预训练特征与分割任务存在语义失配. 对此, 提出三点解决方案: 1)设计自监督提示学习机制, 替代传统固定的文本模板, 利用跨模态注意力动态生成包含图像上下文的可学习提示向量, 在不依赖人工标注的情况下实现类别语义的精准激活; 2)提出基于损失响应梯度的动态裁剪策略, 利用深度神经网络的“早期记忆效应”过滤高梯度的噪声区域, 优化伪标签边界精度; 3)构建基于Transformer自注意力的类感知亲和图, 增强分割结果的空间一致性. 在PASCAL VOC 2012和MS COCO 2014数据集上的实验结果表明, 所提方法在未见目标域标注的设定下, mIoU指标优于现有的无人工标注弱监督语义分割方法, 且在边界保持与背景抑制方面具有显著优势.
针对传统图像级标注的弱监督语义分割方法仍依赖目标数据集的图像级标注, 进而难以获取精细空间监督信号的问题, 提出一种无需目标域标注的自监督CLIP提示引导方法. 该方法利用预训练CLIP模型的强大泛化能力, 通过自监督适应机制挖掘无标注数据的内在结构. 主要解决三个问题: 一是传统监督缺乏像素级空间约束; 二是初始伪标签受限于分类特征的传导偏差; 三是预训练特征与分割任务存在语义失配. 对此, 提出三点解决方案: 1)设计自监督提示学习机制, 替代传统固定的文本模板, 利用跨模态注意力动态生成包含图像上下文的可学习提示向量, 在不依赖人工标注的情况下实现类别语义的精准激活; 2)提出基于损失响应梯度的动态裁剪策略, 利用深度神经网络的“早期记忆效应”过滤高梯度的噪声区域, 优化伪标签边界精度; 3)构建基于Transformer自注意力的类感知亲和图, 增强分割结果的空间一致性. 在PASCAL VOC 2012和MS COCO 2014数据集上的实验结果表明, 所提方法在未见目标域标注的设定下, mIoU指标优于现有的无人工标注弱监督语义分割方法, 且在边界保持与背景抑制方面具有显著优势.





摘要:
针对城市固废焚烧(Municipal solid waste incineration, MSWI)过程炉膛温度、烟气含氧量等关键工艺参数难以精准控制问题, 文中提出了一种数据驱动的多变量自适应预测控制方法. 首先, 通过引入操作变量约束和设计加权障碍函数, 构造无约束形式的目标函数以降低优化求解的复杂度. 其次, 提出了一种稀疏在线牛顿(Sparsified online Newton, SoNew)算法, 通过稀疏分解海森矩阵, 实现控制律的高效求解. 同时, 设计了针对多变量控制的加权系数动态分配策略, 能够根据实际运行状态自适应调整炉膛温度和烟气含氧量的权重, 进一步提升了控制效果. 此外, 对所提控制方法的可行性和稳定性进行了分析, 以确保其在实际应用中的可靠性. 最后, 采用MSWI厂实际运行数据验证了所提控制方法的可行性和有效性.
针对城市固废焚烧(Municipal solid waste incineration, MSWI)过程炉膛温度、烟气含氧量等关键工艺参数难以精准控制问题, 文中提出了一种数据驱动的多变量自适应预测控制方法. 首先, 通过引入操作变量约束和设计加权障碍函数, 构造无约束形式的目标函数以降低优化求解的复杂度. 其次, 提出了一种稀疏在线牛顿(Sparsified online Newton, SoNew)算法, 通过稀疏分解海森矩阵, 实现控制律的高效求解. 同时, 设计了针对多变量控制的加权系数动态分配策略, 能够根据实际运行状态自适应调整炉膛温度和烟气含氧量的权重, 进一步提升了控制效果. 此外, 对所提控制方法的可行性和稳定性进行了分析, 以确保其在实际应用中的可靠性. 最后, 采用MSWI厂实际运行数据验证了所提控制方法的可行性和有效性.












摘要:
跨视图定位技术正经历从通用框架向面向自动驾驶的专有化架构深刻转变. 为系统梳理这一领域, 首先回顾其从粗略检索到精准3-DoF姿态估计的发展脉络. 进而, 提出一个从“输入数据、模型架构、评价指标、损失函数”四个核心维度出发的分析框架, 以此对主流方法进行系统性解构与归因, 揭示不同技术路径的设计权衡. 此外, 详细评述自动驾驶跨视图定位数据集, 并指出当前评估在泛化能力考量上的不足; 为此, 构建新的包含结构化道路与越野场景的CSC-Shanmao数据集, 作为评估模型环境适应性的新基准, 并在其上验证了多种代表性方法, 结果表明面向自动驾驶设计的方法在精度与鲁棒性上优势显著, 但同时也暴露出精度、效率与泛化性之间的突出矛盾. 最后, 总结该技术在轻量化部署、多模态融合可靠性及评估体系等方面面临的严峻挑战, 并展望轻量化设计、可信评估基准及主动感知等未来关键研究方向.
跨视图定位技术正经历从通用框架向面向自动驾驶的专有化架构深刻转变. 为系统梳理这一领域, 首先回顾其从粗略检索到精准3-DoF姿态估计的发展脉络. 进而, 提出一个从“输入数据、模型架构、评价指标、损失函数”四个核心维度出发的分析框架, 以此对主流方法进行系统性解构与归因, 揭示不同技术路径的设计权衡. 此外, 详细评述自动驾驶跨视图定位数据集, 并指出当前评估在泛化能力考量上的不足; 为此, 构建新的包含结构化道路与越野场景的CSC-Shanmao数据集, 作为评估模型环境适应性的新基准, 并在其上验证了多种代表性方法, 结果表明面向自动驾驶设计的方法在精度与鲁棒性上优势显著, 但同时也暴露出精度、效率与泛化性之间的突出矛盾. 最后, 总结该技术在轻量化部署、多模态融合可靠性及评估体系等方面面临的严峻挑战, 并展望轻量化设计、可信评估基准及主动感知等未来关键研究方向.







摘要:
视觉−语言−动作(VLA)模型是实现具身智能的重要技术路径. 针对现有方法普遍依赖大规模数据与高算力平台, 难以适应边缘侧等资源受限场景的瓶颈, 本文提出覆盖“数据−模型−训练−部署”全周期的优化框架. 在数据层面, 剖析真实采集、仿真生成与视频迁移三类路径的协同优化机制; 在设计层面, 梳理轻量化架构、状态空间模型、分层双系统、条件计算及流匹配等高效模型技术; 在系统层面, 重点探讨输入侧剪枝、模型压缩、动态推理路径及软硬件协同优化等部署加速策略. 最后, 对资源受限VLA模型的未来研究方向与应用前景进行展望.
视觉−语言−动作(VLA)模型是实现具身智能的重要技术路径. 针对现有方法普遍依赖大规模数据与高算力平台, 难以适应边缘侧等资源受限场景的瓶颈, 本文提出覆盖“数据−模型−训练−部署”全周期的优化框架. 在数据层面, 剖析真实采集、仿真生成与视频迁移三类路径的协同优化机制; 在设计层面, 梳理轻量化架构、状态空间模型、分层双系统、条件计算及流匹配等高效模型技术; 在系统层面, 重点探讨输入侧剪枝、模型压缩、动态推理路径及软硬件协同优化等部署加速策略. 最后, 对资源受限VLA模型的未来研究方向与应用前景进行展望.








摘要:
实际工业数据因检测方式不同, 过程变量与质量指标往往采样速率各异, 受低采样率数据影响, 可有效利用的样本稀缺, 传统建模精度难以提升. 此外, 因过程响应特性及传感器部署分布差异使各过程变量相对最终产品质量指标存在不同程度时滞, 但实际现场无法进行阶跃测试使得过程时滞难以测量, 进一步增加了建模难度. 为此, 本文提出一种面向多速率难测时滞工业过程的质量指标建模方法, 该方法首先设计基于核Copula熵的数据依赖结构时滞估计方法, 通过核Copula熵定量分析过程数据依赖结构关联强度, 将时滞参数估计问题转化为寻找最大依赖结构关联度问题, 引入专家经验约束依赖结构寻优过程, 保证时滞参数符合工业现场情况并修正数据时序对应关系. 进一步, 提出一种多速率采样数据时空约束网络模型, 该模型通过融合数据的时序特性与空间关联性, 构建时序因果的邻近样本质量指标的时空距离相似度约束矩阵, 据此充分挖掘无质量指标标签样本信息辅助模型构建, 提升软测量建模精度, 并且证明了网络模型的收敛性. 最后, 基于数值仿真和实际磨矿数据工业实验验证了所提方法的可行性和有效性
实际工业数据因检测方式不同, 过程变量与质量指标往往采样速率各异, 受低采样率数据影响, 可有效利用的样本稀缺, 传统建模精度难以提升. 此外, 因过程响应特性及传感器部署分布差异使各过程变量相对最终产品质量指标存在不同程度时滞, 但实际现场无法进行阶跃测试使得过程时滞难以测量, 进一步增加了建模难度. 为此, 本文提出一种面向多速率难测时滞工业过程的质量指标建模方法, 该方法首先设计基于核Copula熵的数据依赖结构时滞估计方法, 通过核Copula熵定量分析过程数据依赖结构关联强度, 将时滞参数估计问题转化为寻找最大依赖结构关联度问题, 引入专家经验约束依赖结构寻优过程, 保证时滞参数符合工业现场情况并修正数据时序对应关系. 进一步, 提出一种多速率采样数据时空约束网络模型, 该模型通过融合数据的时序特性与空间关联性, 构建时序因果的邻近样本质量指标的时空距离相似度约束矩阵, 据此充分挖掘无质量指标标签样本信息辅助模型构建, 提升软测量建模精度, 并且证明了网络模型的收敛性. 最后, 基于数值仿真和实际磨矿数据工业实验验证了所提方法的可行性和有效性









摘要:
设计了高阶全驱系统的一种无模型控制器. 首先, 将无模型控制问题转化为不确定系统的输出反馈半全局镇定问题; 随后, 基于参量Lyapunov设计方法, 构造基于观测器的动态输出反馈. 进一步地, 阐明由原系统与观测器误差系统构成的增广闭环系统是一类弱耦合互联系统, 通过分析该系统特性, 完成闭环系统渐近稳定性与吸引域分析. 最后, 论证该输出反馈控制器构成高阶全驱系统的无模型控制器. 与传统基于模型的控制器相比, 所设计控制器不仅能够适应系统存在未建模动态及控制增益未知的情形, 还具有显式表达式, 且参数调节简便(对于n阶系统, 仅需调整3个参数). 通过船舶航向控制系统与柔性关节机械臂系统的仿真, 验证所设计无模型控制器的有效性.
设计了高阶全驱系统的一种无模型控制器. 首先, 将无模型控制问题转化为不确定系统的输出反馈半全局镇定问题; 随后, 基于参量Lyapunov设计方法, 构造基于观测器的动态输出反馈. 进一步地, 阐明由原系统与观测器误差系统构成的增广闭环系统是一类弱耦合互联系统, 通过分析该系统特性, 完成闭环系统渐近稳定性与吸引域分析. 最后, 论证该输出反馈控制器构成高阶全驱系统的无模型控制器. 与传统基于模型的控制器相比, 所设计控制器不仅能够适应系统存在未建模动态及控制增益未知的情形, 还具有显式表达式, 且参数调节简便(对于n阶系统, 仅需调整3个参数). 通过船舶航向控制系统与柔性关节机械臂系统的仿真, 验证所设计无模型控制器的有效性.




摘要:
随着航空航天、能源动力与智能制造等领域对结构安全与运行可靠性要求的不断提升, 缺陷无损检测的重要性日益凸显. 然而传统方法受限于固定采集、人工依赖及泛化能力不足等因素制约, 难以满足复杂场景下高精度效率与智能化的需求. 具身智能在智能体自主移动、多模态感知与闭环决策控制方面, 提供了新路径. 通过将环境感知与缺陷检测模块集成于智能体平台, 并结合物理建模及主动规划等算法, 可实现由被动采集向主动信息获取的转变, 显著提升检测的可达性、自主性与数据质量. 围绕这一范式, 系统梳理具身智能缺陷无损检测的概念内涵与整体组成框架, 从传感器体系、无人系统平台及核心算法三个层面构建统一技术体系, 并结合典型工作对不同具身载体下的实现路径进行综合分析. 在此基础上, 归纳当前该领域在复杂环境适应、多模态协同与自主决策等方面面临的关键挑战, 并对未来发展趋势进行展望, 为具身智能缺陷无损检测技术的进一步研究与工程应用提供系统性参考.
随着航空航天、能源动力与智能制造等领域对结构安全与运行可靠性要求的不断提升, 缺陷无损检测的重要性日益凸显. 然而传统方法受限于固定采集、人工依赖及泛化能力不足等因素制约, 难以满足复杂场景下高精度效率与智能化的需求. 具身智能在智能体自主移动、多模态感知与闭环决策控制方面, 提供了新路径. 通过将环境感知与缺陷检测模块集成于智能体平台, 并结合物理建模及主动规划等算法, 可实现由被动采集向主动信息获取的转变, 显著提升检测的可达性、自主性与数据质量. 围绕这一范式, 系统梳理具身智能缺陷无损检测的概念内涵与整体组成框架, 从传感器体系、无人系统平台及核心算法三个层面构建统一技术体系, 并结合典型工作对不同具身载体下的实现路径进行综合分析. 在此基础上, 归纳当前该领域在复杂环境适应、多模态协同与自主决策等方面面临的关键挑战, 并对未来发展趋势进行展望, 为具身智能缺陷无损检测技术的进一步研究与工程应用提供系统性参考.












摘要:
针对无人机集群在突发环境变化下易出现性能退化的问题, 提出一种基于动态性能均衡的元学习控制方法, 以实现集群系统高效、可靠的在线自适应协同控制. 首先, 基于无人机不确定动力学模型, 结合轨迹跟踪、集群协同与动态障碍物规避等多重约束, 构建一类能够有效抵御系统不确定性与外部扰动的自适应控制策略. 其次, 为解决瞬态响应与稳态精度之间的性能冲突, 并克服传统优化算法计算耗时高的局限, 构建元学习控制架构. 该方法通过离线训练习得具备强泛化能力的初始化参数, 使系统在线仅需利用少量历史数据和单步梯度更新, 即可实现毫秒级自适应并快速收敛至满足动态性能均衡要求的最优增益. 实验结果验证了该方法在动态障碍物及剧烈环境变化场景下的显著适应能力, 实现了兼具鲁棒性、安全性与高性能的协同控制.
针对无人机集群在突发环境变化下易出现性能退化的问题, 提出一种基于动态性能均衡的元学习控制方法, 以实现集群系统高效、可靠的在线自适应协同控制. 首先, 基于无人机不确定动力学模型, 结合轨迹跟踪、集群协同与动态障碍物规避等多重约束, 构建一类能够有效抵御系统不确定性与外部扰动的自适应控制策略. 其次, 为解决瞬态响应与稳态精度之间的性能冲突, 并克服传统优化算法计算耗时高的局限, 构建元学习控制架构. 该方法通过离线训练习得具备强泛化能力的初始化参数, 使系统在线仅需利用少量历史数据和单步梯度更新, 即可实现毫秒级自适应并快速收敛至满足动态性能均衡要求的最优增益. 实验结果验证了该方法在动态障碍物及剧烈环境变化场景下的显著适应能力, 实现了兼具鲁棒性、安全性与高性能的协同控制.










摘要:
情境化习题是联系数学概念与真实世界的重要载体, 对培养学生数学建模与应用能力具有关键作用. 然而, 现有基于大语言模型的习题编制方法容易使情境设计流于形式, 导致题干冗长花哨或偏离数学本质, 同时缺乏对学生认知差异的建模, 生成或改编而成的习题难以适配不同发展阶段. 因此, 提出一种基于多智能体协同与迭代优化策略的习题情境化改编框架, 以解决通用方法存在的情境失真、认知失配等困境. 该框架深度融合问题解决理论与教学支架理论, 首先定义多种类型的学生认知特征, 并系统梳理学生在解题各阶段可能出现的常见错误类型, 将其归因并映射为多种教学支架. 在此基础上, 构建包含习题生成、学生模拟与诊断、习题改进三大智能体的协同架构, 从教学支架视角为习题改进提供理论化、可操作的动作空间, 结合多种优化策略将情境化习题命制任务形式化为一个序列决策问题. 实验结果表明, 本框架改编形成的习题在情境相关、知识迁移、认知适配等方面均显著优于基线方法, 相关模块的设计在创设情境的同时能有效降低各类学生的非必要认知错误, 从而提升情境化习题质量, 以充分发挥其育人功能.
情境化习题是联系数学概念与真实世界的重要载体, 对培养学生数学建模与应用能力具有关键作用. 然而, 现有基于大语言模型的习题编制方法容易使情境设计流于形式, 导致题干冗长花哨或偏离数学本质, 同时缺乏对学生认知差异的建模, 生成或改编而成的习题难以适配不同发展阶段. 因此, 提出一种基于多智能体协同与迭代优化策略的习题情境化改编框架, 以解决通用方法存在的情境失真、认知失配等困境. 该框架深度融合问题解决理论与教学支架理论, 首先定义多种类型的学生认知特征, 并系统梳理学生在解题各阶段可能出现的常见错误类型, 将其归因并映射为多种教学支架. 在此基础上, 构建包含习题生成、学生模拟与诊断、习题改进三大智能体的协同架构, 从教学支架视角为习题改进提供理论化、可操作的动作空间, 结合多种优化策略将情境化习题命制任务形式化为一个序列决策问题. 实验结果表明, 本框架改编形成的习题在情境相关、知识迁移、认知适配等方面均显著优于基线方法, 相关模块的设计在创设情境的同时能有效降低各类学生的非必要认知错误, 从而提升情境化习题质量, 以充分发挥其育人功能.


摘要:
针对多模态大模型在抽象度示意图(如几何、电路、科学图表)理解中面临的视觉感知静态化挑战, 提出一种基于前瞻性机制的多视角视觉推理框架. 该方法旨在模拟人类“慢思考”的认知机理, 通过引入相对注意力与信息增益门控, 实现对关键视觉线索的主动搜索与去噪; 利用逻辑置信度与视觉相关性进行双维质量评估, 构建“观察–假设–验证”的动态闭环推理系统. 实验表明, 该方法在多学科的示意图推理数据集上显著优于现有主流方法, 在并未引入过多计算开销的同时, 大幅提升了复杂示意图问答的准确率与鲁棒性.
针对多模态大模型在抽象度示意图(如几何、电路、科学图表)理解中面临的视觉感知静态化挑战, 提出一种基于前瞻性机制的多视角视觉推理框架. 该方法旨在模拟人类“慢思考”的认知机理, 通过引入相对注意力与信息增益门控, 实现对关键视觉线索的主动搜索与去噪; 利用逻辑置信度与视觉相关性进行双维质量评估, 构建“观察–假设–验证”的动态闭环推理系统. 实验表明, 该方法在多学科的示意图推理数据集上显著优于现有主流方法, 在并未引入过多计算开销的同时, 大幅提升了复杂示意图问答的准确率与鲁棒性.





摘要:
随着大规模视觉-语言预训练模型的不断发展, 零样本异常检测逐渐成为一个重要的研究方向. 该任务要求模型能够直接对类别未知的异常样本进行有效检测与定位, 而无需依赖目标领域的训练数据. 由于异常检测与异常定位任务分别需要全局和局部不同粒度的语义信息, 现有方法共享文本提示的设计使模型无法同时满足二者的需求, 导致性能难以兼顾. 为此, 提出一种基于文本解耦的零样本异常检测方法, 其核心是为两个任务分别设计独立的提示并进行优化. 同时, 针对模型在异常定位任务中跨数据集泛化能力较弱的问题, 提出了原型对齐模块. 该模块通过优化图像块特征与原型之间的距离, 提升模型的异常定位能力. 此外, 考虑到仅依赖图像的全局特征难以充分识别细微异常, 进一步设计了异常特征增强策略, 通过聚焦于潜在的异常区域以提升异常检测的性能. 实验结果表明, 所提出方法在MVTec AD、ISIC、BrainMRI等公开数据集上均取得了优良性能, 验证了其有效性与泛化能力.
随着大规模视觉-语言预训练模型的不断发展, 零样本异常检测逐渐成为一个重要的研究方向. 该任务要求模型能够直接对类别未知的异常样本进行有效检测与定位, 而无需依赖目标领域的训练数据. 由于异常检测与异常定位任务分别需要全局和局部不同粒度的语义信息, 现有方法共享文本提示的设计使模型无法同时满足二者的需求, 导致性能难以兼顾. 为此, 提出一种基于文本解耦的零样本异常检测方法, 其核心是为两个任务分别设计独立的提示并进行优化. 同时, 针对模型在异常定位任务中跨数据集泛化能力较弱的问题, 提出了原型对齐模块. 该模块通过优化图像块特征与原型之间的距离, 提升模型的异常定位能力. 此外, 考虑到仅依赖图像的全局特征难以充分识别细微异常, 进一步设计了异常特征增强策略, 通过聚焦于潜在的异常区域以提升异常检测的性能. 实验结果表明, 所提出方法在MVTec AD、ISIC、BrainMRI等公开数据集上均取得了优良性能, 验证了其有效性与泛化能力.








摘要:
人格特质作为个体在思想、情感和行为模式上独特且相对稳定的心理特征, 是理解和预测人类行为的重要维度. 多模态人格评分预测研究已成为心理学、社会学与计算科学交叉融合的前沿热点. 然而, 现有评分预测方法在捕捉个体稳定人格特质时, 常因行为表现中的非典型成分(如停顿、思考或环境噪声)而产生偏差, 影响了人格特质多维度评分预测的准确性. 针对这一问题, 受认知−情感人格系统(Cognitive-Affective Personality System, CAPS)理论启发, 提出一种多模态人格评分预测框架EBPNet(Emotion-Behavior-based Personality Network). 该框架充分利用社会情境对人格表现的调节作用, 通过构建上下文情境感知模块, 系统整合视频数据中的动态情境发展过程, 减少了非典型行为对人格特质评分预测的影响. 同时, 框架融合视觉大模型的细粒度情感分析能力, 精确提取情绪演变轨迹与微表情特征, 并与语音转录文本形成多类型数据的协同评分预测, 提升了对个体情感-行为时序模式的建模能力. 通过显式建模社会情境与多模态行为数据的交互关系, 该框架实现了人格特质的多维度评分预测. 实验结果表明, EBPNet在目前广泛认可的多模态人格分析数据集First Impressions V2上的表现优于现有基线模型, 验证了社会心理学启发的多维度评分预测方法的有效性.
人格特质作为个体在思想、情感和行为模式上独特且相对稳定的心理特征, 是理解和预测人类行为的重要维度. 多模态人格评分预测研究已成为心理学、社会学与计算科学交叉融合的前沿热点. 然而, 现有评分预测方法在捕捉个体稳定人格特质时, 常因行为表现中的非典型成分(如停顿、思考或环境噪声)而产生偏差, 影响了人格特质多维度评分预测的准确性. 针对这一问题, 受认知−情感人格系统(Cognitive-Affective Personality System, CAPS)理论启发, 提出一种多模态人格评分预测框架EBPNet(Emotion-Behavior-based Personality Network). 该框架充分利用社会情境对人格表现的调节作用, 通过构建上下文情境感知模块, 系统整合视频数据中的动态情境发展过程, 减少了非典型行为对人格特质评分预测的影响. 同时, 框架融合视觉大模型的细粒度情感分析能力, 精确提取情绪演变轨迹与微表情特征, 并与语音转录文本形成多类型数据的协同评分预测, 提升了对个体情感-行为时序模式的建模能力. 通过显式建模社会情境与多模态行为数据的交互关系, 该框架实现了人格特质的多维度评分预测. 实验结果表明, EBPNet在目前广泛认可的多模态人格分析数据集First Impressions V2上的表现优于现有基线模型, 验证了社会心理学启发的多维度评分预测方法的有效性.




摘要:
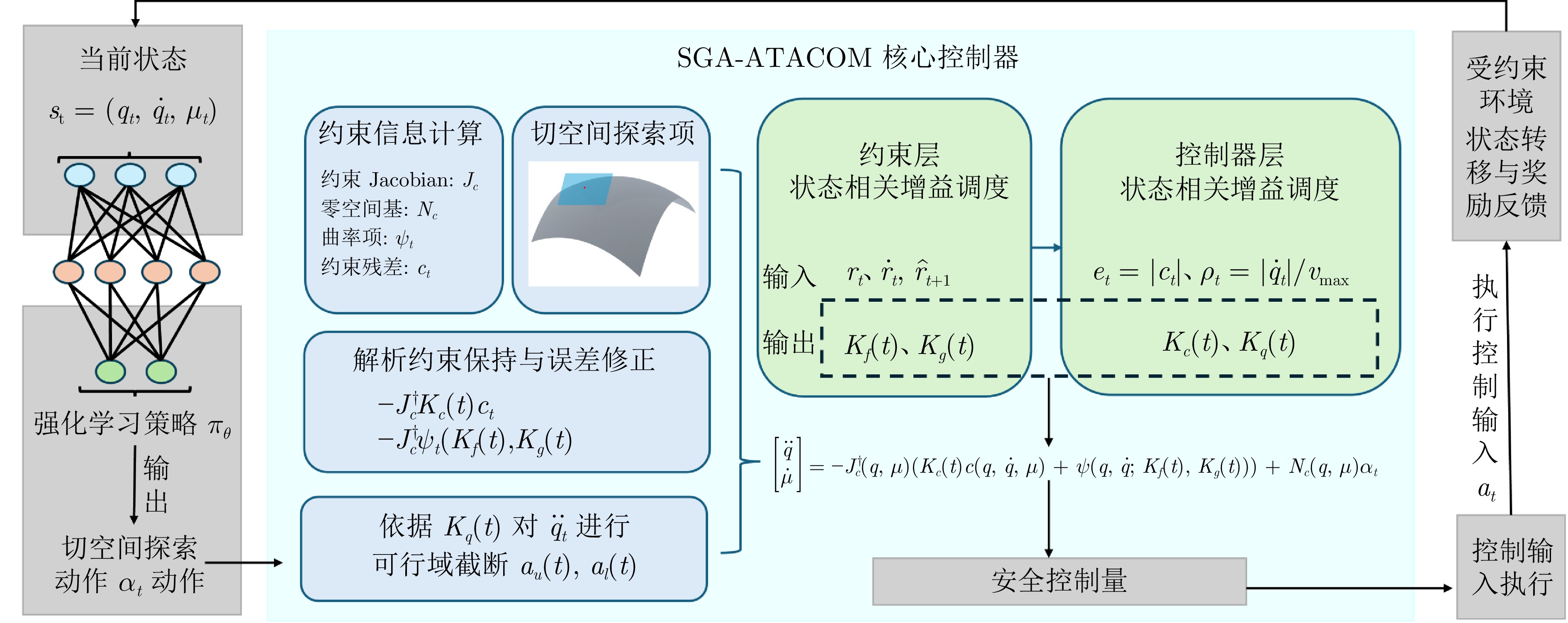
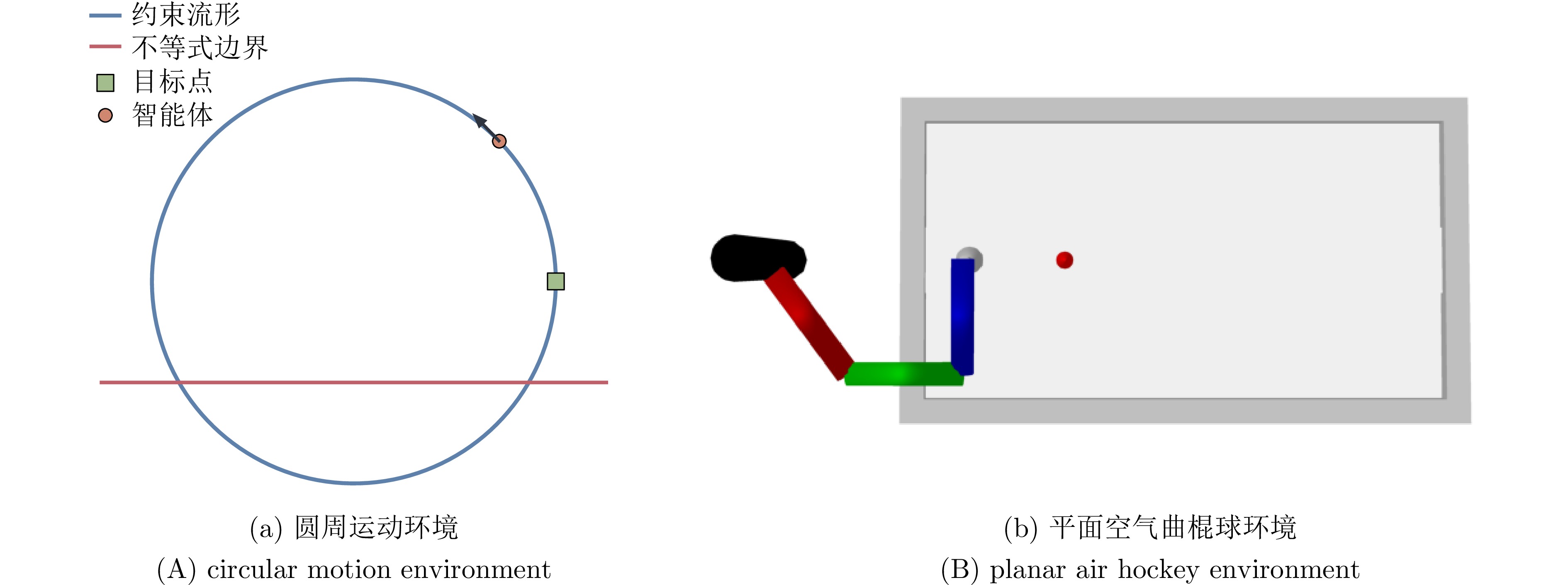
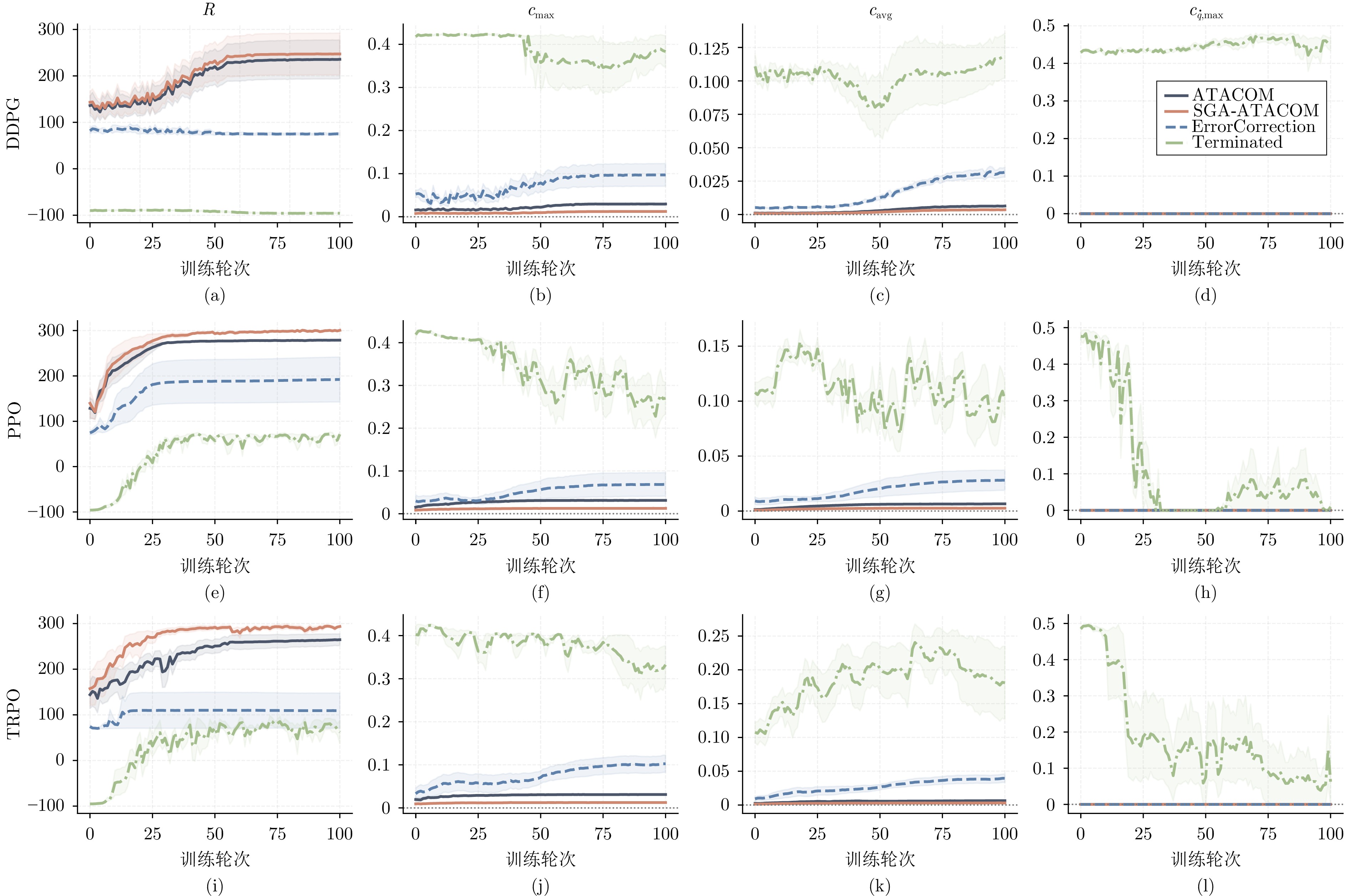
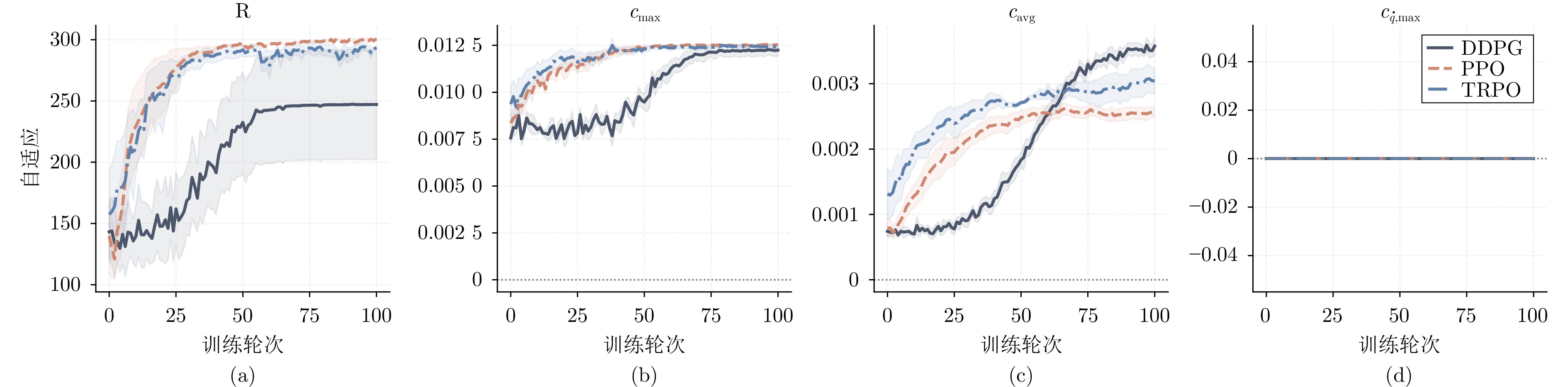
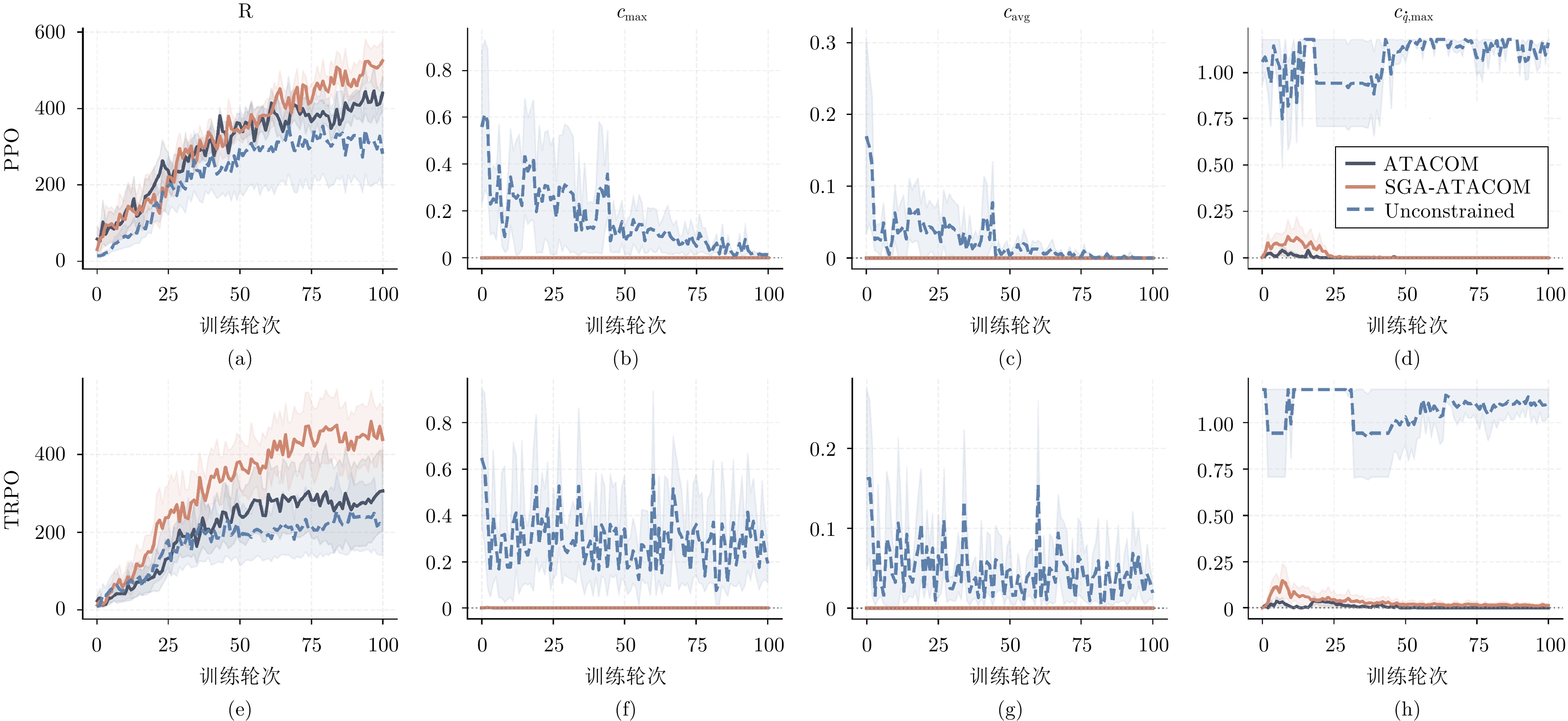
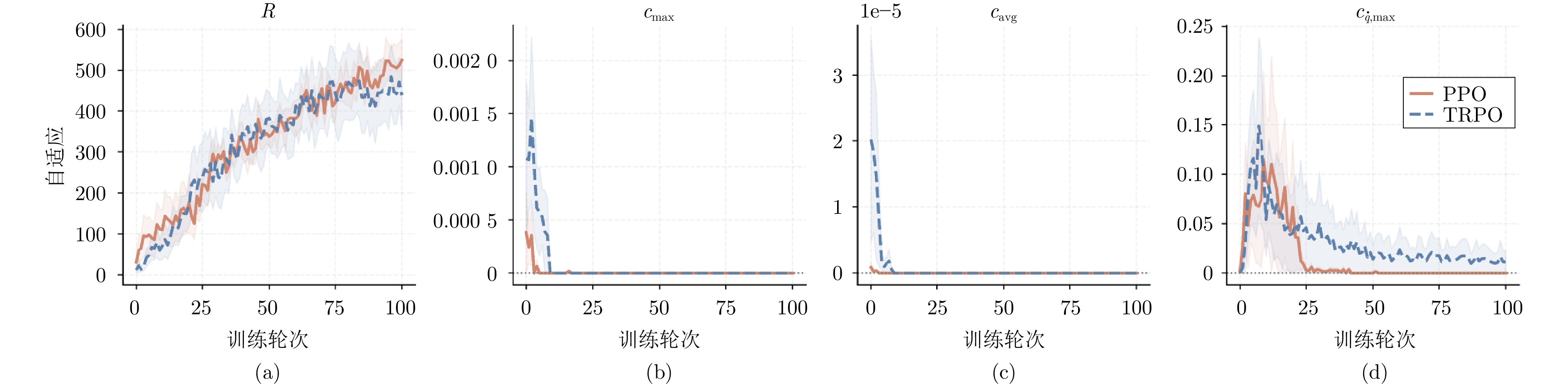
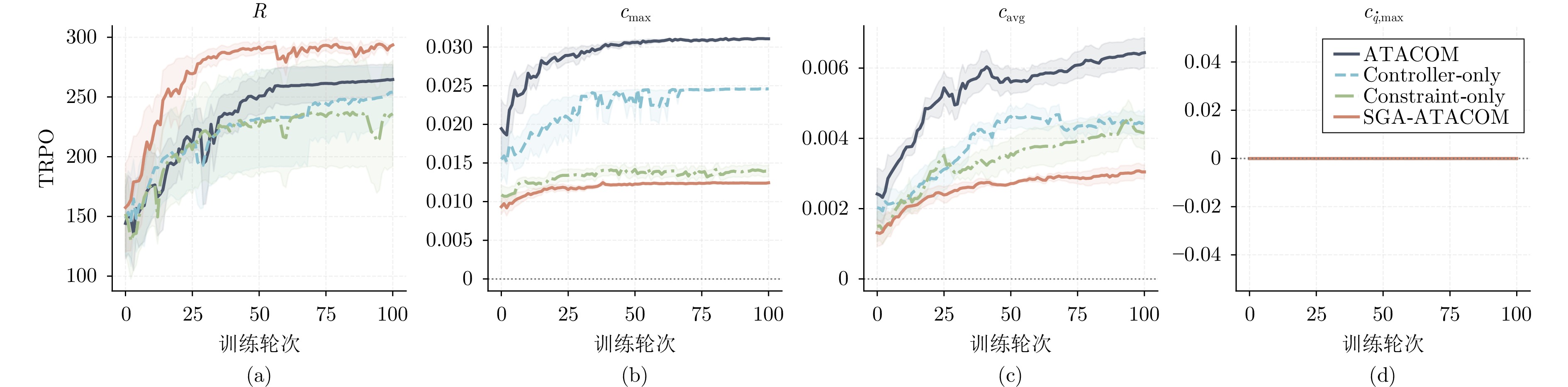
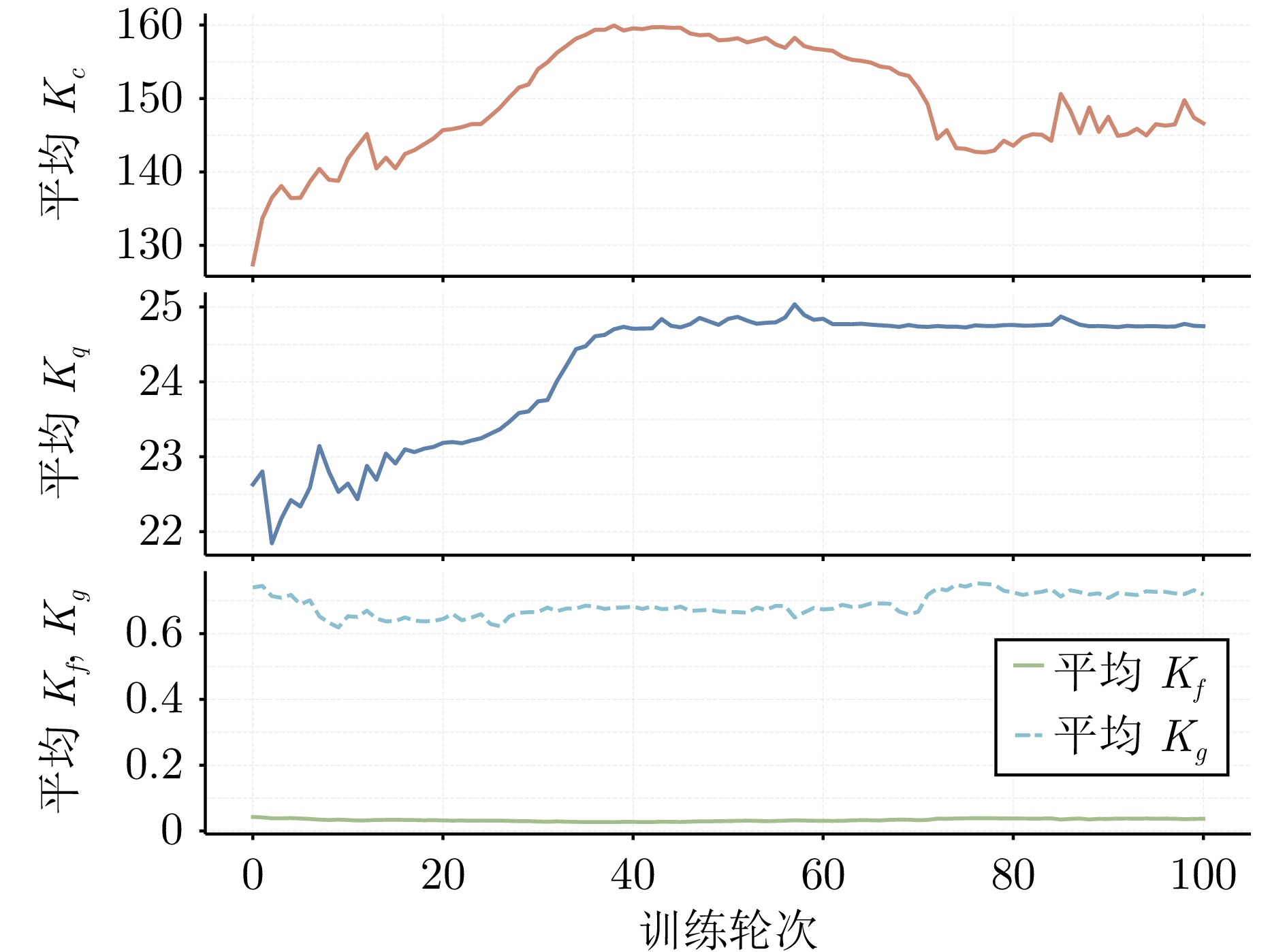
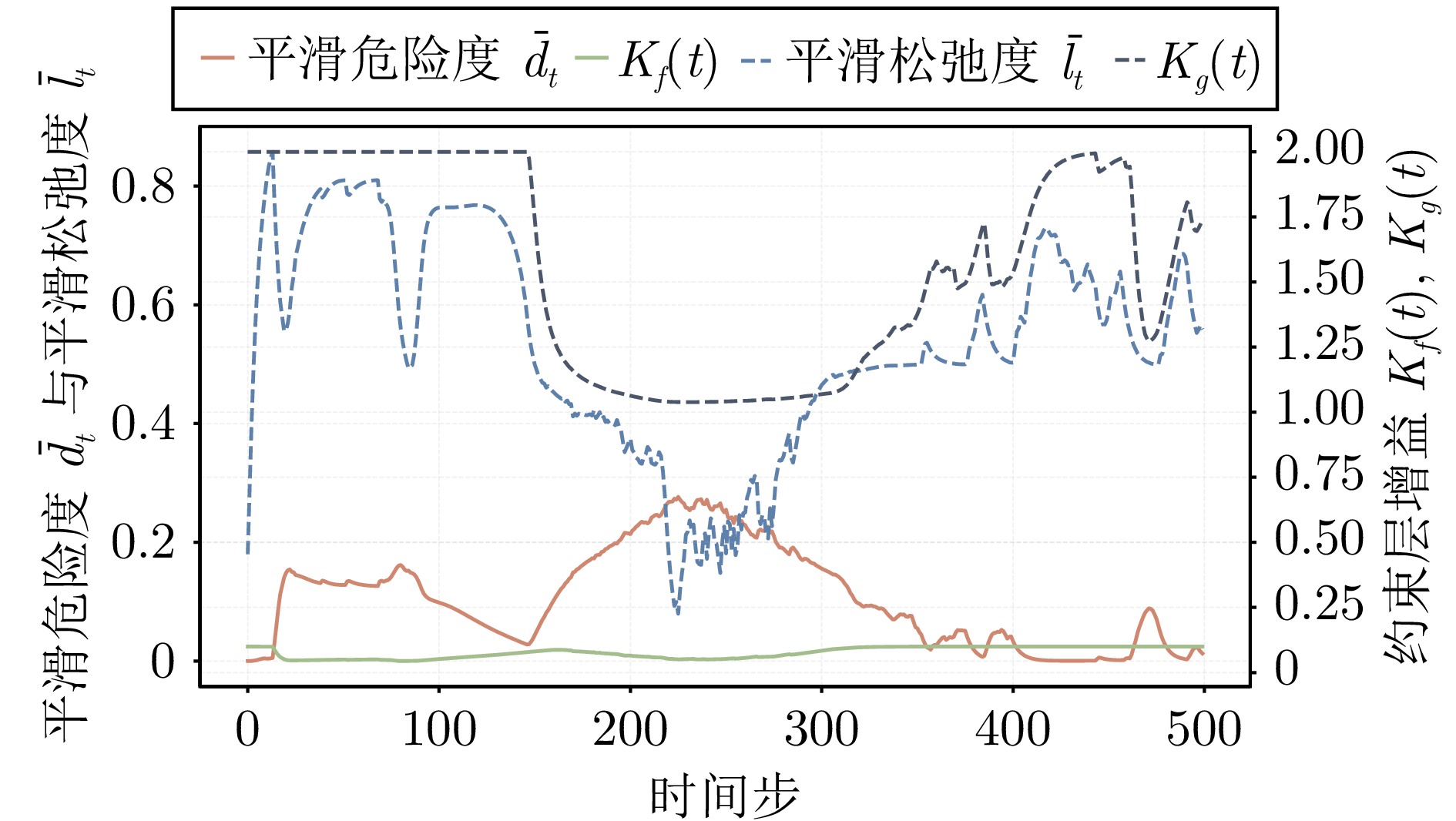
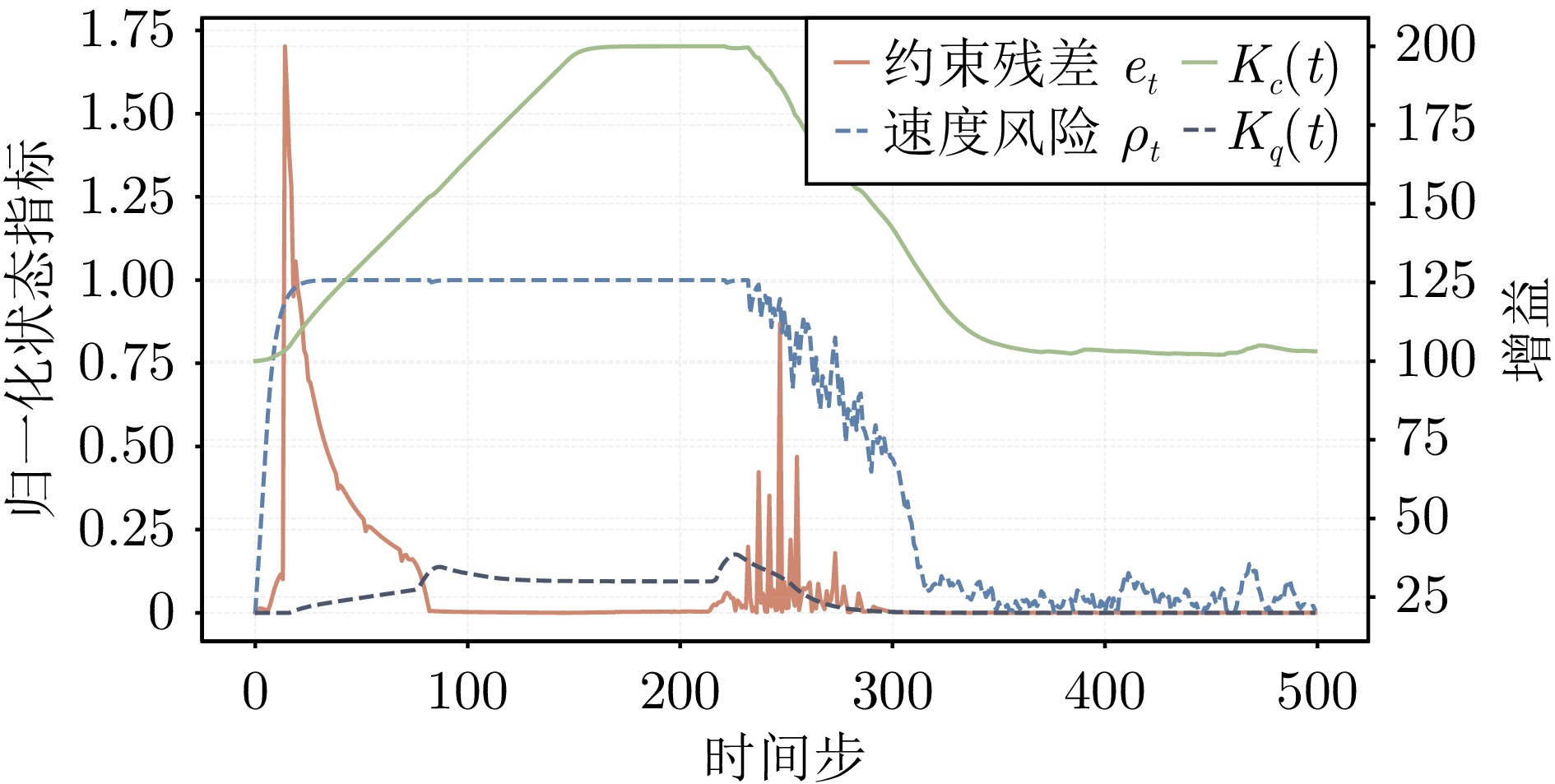
在机器人走向实际场景的过程中, 如何在严格满足安全约束的同时兼顾学习探索效率, 已成为制约智能机器人实用化的重要挑战.现有安全学习方法依赖固定控制增益参数的设计范式, 难以在训练过程中动态平衡探索效率与约束满足, 易导致过度保守或约束保持不足.为此, 提出一种面向安全-性能动态平衡的状态相关增益调度自适应 ATACOM 方法, 简称 SGA-ATACOM. 在保持 ATACOM 原有的约束流形切空间探索、解析约束保持和误差修正控制结构不变的基础上, 构建约束层与控制器层的双层在线调度机制. 其中, 约束层依据当前约束状态、变化趋势及短时预测结果, 自适应调节可行性约束参数; 控制器层结合约束残差与速度风险指标, 在线更新误差修正增益和速度可行域增益, 从而实现在风险指标较高时增强约束回拉与速度保护、在风险指标较低时释放更有效的探索空间的自适应协调. 为验证所提方法的有效性, 分别在 CircularMotion 任务和 Planar Air Hockey 机械臂任务上, 结合不同强化学习算法开展仿真实验. 实验结果表明, 该算法在不同任务场景和不同强化学习算法下均表现出良好的通用性, 能够在维持较低约束违反的同时取得更优的安全−性能平衡.消融实验进一步验证了约束层调度与控制器层调度的互补作用. 该算法为受约束强化学习中的安全−性能协同优化提供了一种具有几何可解释性和结构保持性的改进方案.
在机器人走向实际场景的过程中, 如何在严格满足安全约束的同时兼顾学习探索效率, 已成为制约智能机器人实用化的重要挑战.现有安全学习方法依赖固定控制增益参数的设计范式, 难以在训练过程中动态平衡探索效率与约束满足, 易导致过度保守或约束保持不足.为此, 提出一种面向安全-性能动态平衡的状态相关增益调度自适应 ATACOM 方法, 简称 SGA-ATACOM. 在保持 ATACOM 原有的约束流形切空间探索、解析约束保持和误差修正控制结构不变的基础上, 构建约束层与控制器层的双层在线调度机制. 其中, 约束层依据当前约束状态、变化趋势及短时预测结果, 自适应调节可行性约束参数; 控制器层结合约束残差与速度风险指标, 在线更新误差修正增益和速度可行域增益, 从而实现在风险指标较高时增强约束回拉与速度保护、在风险指标较低时释放更有效的探索空间的自适应协调. 为验证所提方法的有效性, 分别在 CircularMotion 任务和 Planar Air Hockey 机械臂任务上, 结合不同强化学习算法开展仿真实验. 实验结果表明, 该算法在不同任务场景和不同强化学习算法下均表现出良好的通用性, 能够在维持较低约束违反的同时取得更优的安全−性能平衡.消融实验进一步验证了约束层调度与控制器层调度的互补作用. 该算法为受约束强化学习中的安全−性能协同优化提供了一种具有几何可解释性和结构保持性的改进方案.
摘要:
随着人工智能技术的快速发展, 传统以单点自动化为特征的制造体系, 在应对高度动态化、个性化与系统级协同需求方面日益显现局限. 大模型与具身智能作为新一代人工智能的重要方向, 正在为制造业的智能化转型提供全新路径. 大模型具备跨模态表征、知识泛化和持续学习能力, 具身智能强调智能体与物理环境的动态交互与闭环反馈, 两者融合不仅强化了多模态感知与知识驱动决策的统一性, 还提升了虚实迁移的稳定性与群体智能的协同能力, 从而为复杂工业场景下的自主优化与系统级智能提供系统性支撑. 基于此, 系统梳理相关理论与关键技术, 结合流程制造与离散制造的典型场景, 探讨机理知识融合、多模态感知、符号--神经推理、数字孪生演化和人机共融交互等前沿方向, 为工业人工智能构建结构化框架和系统化方案提供参考, 推动制造业由局部探索迈向系统级深度融合.
随着人工智能技术的快速发展, 传统以单点自动化为特征的制造体系, 在应对高度动态化、个性化与系统级协同需求方面日益显现局限. 大模型与具身智能作为新一代人工智能的重要方向, 正在为制造业的智能化转型提供全新路径. 大模型具备跨模态表征、知识泛化和持续学习能力, 具身智能强调智能体与物理环境的动态交互与闭环反馈, 两者融合不仅强化了多模态感知与知识驱动决策的统一性, 还提升了虚实迁移的稳定性与群体智能的协同能力, 从而为复杂工业场景下的自主优化与系统级智能提供系统性支撑. 基于此, 系统梳理相关理论与关键技术, 结合流程制造与离散制造的典型场景, 探讨机理知识融合、多模态感知、符号--神经推理、数字孪生演化和人机共融交互等前沿方向, 为工业人工智能构建结构化框架和系统化方案提供参考, 推动制造业由局部探索迈向系统级深度融合.









摘要:
近年来, 随着大模型在多模态领域的快速发展, 文本属性图学习也迎来了新的范式. 文本属性图中包含图结构与丰富的节点/边文本属性信息, 广泛存在于社交网络、论文引用网络与知识图谱等场景. 然而, 传统图神经网络通常依赖浅层文本嵌入作为初始节点表示, 难以充分捕捉上下文依赖与复杂语义信息, 并在图结构与文本语义的融合上存在天然局限. 为克服这一瓶颈, 近年来研究者开始探索利用大模型强大的语言理解、知识记忆与推理能力来提升文本属性图学习的效果, 推动了该领域的新一轮发展. 本文系统梳理大模型驱动的文本属性图学习研究进展, 围绕图生成、图预测、图推理三大核心任务, 回顾代表性方法与主要范式, 并总结现有研究中常用的数据集与评测基准. 在文本属性图研究中, 当前在图生成、图预测与图推理三大任务中分别面临结构与属性表达效率不足、生成方法匮乏, 评估体系与可扩展性不完善, 以及复杂关系建模与多跳推理受限等挑战. 本文结合上述问题提出未来发展方向, 期望为后续研究提供系统化参考与整体性视角, 进一步促进大模型与图学习的深度耦合.
近年来, 随着大模型在多模态领域的快速发展, 文本属性图学习也迎来了新的范式. 文本属性图中包含图结构与丰富的节点/边文本属性信息, 广泛存在于社交网络、论文引用网络与知识图谱等场景. 然而, 传统图神经网络通常依赖浅层文本嵌入作为初始节点表示, 难以充分捕捉上下文依赖与复杂语义信息, 并在图结构与文本语义的融合上存在天然局限. 为克服这一瓶颈, 近年来研究者开始探索利用大模型强大的语言理解、知识记忆与推理能力来提升文本属性图学习的效果, 推动了该领域的新一轮发展. 本文系统梳理大模型驱动的文本属性图学习研究进展, 围绕图生成、图预测、图推理三大核心任务, 回顾代表性方法与主要范式, 并总结现有研究中常用的数据集与评测基准. 在文本属性图研究中, 当前在图生成、图预测与图推理三大任务中分别面临结构与属性表达效率不足、生成方法匮乏, 评估体系与可扩展性不完善, 以及复杂关系建模与多跳推理受限等挑战. 本文结合上述问题提出未来发展方向, 期望为后续研究提供系统化参考与整体性视角, 进一步促进大模型与图学习的深度耦合.













摘要:
本文对流形上的几何状态估计方法进行全面的梳理. 首先介绍流形上一般滤波器设计的思路, 然后从保持几何性质的观测器角度讨论流形空间中滤波器设计的思路以及带来的几何性质优势.流形上的几何状态估计器设计主要包括不变扩展卡尔曼滤波和等变滤波两个阶段.流形上的几何状态估计方法提供了一种通用的理论框架来进行滤波器设计, 通过灵活的群构造和群作用的选择, 可以针对不同观测类型设计保持系统几何结构的滤波器.在利用系统几何结构的基础上可以从根本上解决传统滤波器存在的不一致性问题, 并有望减少线性化误差, 从而提高了状态估计的精度和鲁棒性.最后本文对未来发展方向进行了展望.
本文对流形上的几何状态估计方法进行全面的梳理. 首先介绍流形上一般滤波器设计的思路, 然后从保持几何性质的观测器角度讨论流形空间中滤波器设计的思路以及带来的几何性质优势.流形上的几何状态估计器设计主要包括不变扩展卡尔曼滤波和等变滤波两个阶段.流形上的几何状态估计方法提供了一种通用的理论框架来进行滤波器设计, 通过灵活的群构造和群作用的选择, 可以针对不同观测类型设计保持系统几何结构的滤波器.在利用系统几何结构的基础上可以从根本上解决传统滤波器存在的不一致性问题, 并有望减少线性化误差, 从而提高了状态估计的精度和鲁棒性.最后本文对未来发展方向进行了展望.





















摘要:
本文研究多智能体系统的避碰安全控制问题, 目标是在尽量保持标称控制性能的同时, 确保任意智能体对之间始终保持安全距离. 针对二阶系统中安全约束函数相对度为2、传统控制障碍函数难以直接施加控制约束的问题, 本文引入高阶控制障碍函数框架构造碰撞避免条件, 并将其转化为最小侵入的二次规划控制器. 进一步地, 利用安全约束项的对称性, 将原本耦合的不等式约束分解为各智能体可独立求解的线性约束. 在此基础上, 本文将所提方法推广至含有不确定项的多智能体系统, 设计鲁棒控制障碍函数及构建可实现的鲁棒控制器, 并证明了系统安全集的前向不变性. 数值仿真结果表明, 所提方法可使得系统保持安全性并维持良好的跟踪性能.
本文研究多智能体系统的避碰安全控制问题, 目标是在尽量保持标称控制性能的同时, 确保任意智能体对之间始终保持安全距离. 针对二阶系统中安全约束函数相对度为2、传统控制障碍函数难以直接施加控制约束的问题, 本文引入高阶控制障碍函数框架构造碰撞避免条件, 并将其转化为最小侵入的二次规划控制器. 进一步地, 利用安全约束项的对称性, 将原本耦合的不等式约束分解为各智能体可独立求解的线性约束. 在此基础上, 本文将所提方法推广至含有不确定项的多智能体系统, 设计鲁棒控制障碍函数及构建可实现的鲁棒控制器, 并证明了系统安全集的前向不变性. 数值仿真结果表明, 所提方法可使得系统保持安全性并维持良好的跟踪性能.




摘要:
为更好地利用人类经验并遵循人类意愿,提出一种引入人机共驾领导者的多农机容错协同编队控制方法. 首先,建立包含运动学和动力学的农机系统模型,其中领导者控制输入由驾驶员控制和驾驶辅助控制组成. 其次,结合预瞄等行为特征构建驾驶员控制模型,并基于模型预测控制设计领导者驾驶辅助控制系统,设计模糊规则动态调整驾驶员和辅助系统之间的控制权限. 然后,针对人机共驾领导者的控制输入未知的问题,基于对领导者横向速度和转向角的分布式估计,设计一种位置编队线性控制方法. 最后,通过仿真验证该方法的有效性.
为更好地利用人类经验并遵循人类意愿,提出一种引入人机共驾领导者的多农机容错协同编队控制方法. 首先,建立包含运动学和动力学的农机系统模型,其中领导者控制输入由驾驶员控制和驾驶辅助控制组成. 其次,结合预瞄等行为特征构建驾驶员控制模型,并基于模型预测控制设计领导者驾驶辅助控制系统,设计模糊规则动态调整驾驶员和辅助系统之间的控制权限. 然后,针对人机共驾领导者的控制输入未知的问题,基于对领导者横向速度和转向角的分布式估计,设计一种位置编队线性控制方法. 最后,通过仿真验证该方法的有效性.








当前状态:
, 最新更新时间: ,
doi: 10.16383/j.aas.c250547
摘要:
针对无向网络拓扑设计中存在着定义适用性差或设计目标单一等问题, 本文得到了如下主要结果1)给出了一种新的网络能量定义; 借此并基于Wiener指数, 给出了一种新的网络效率定义; 2)给出了简单无向连通图的对称性定义及其度量指标; 首次给出了无向高效网络和无向\begin{document}$ k{\text{-}}$\end{document} \begin{document}$ k{\text{-}}$\end{document} \begin{document}$ k{\text{-}}$\end{document} \begin{document}$ k{\text{-}}$\end{document}
针对无向网络拓扑设计中存在着定义适用性差或设计目标单一等问题, 本文得到了如下主要结果1)给出了一种新的网络能量定义; 借此并基于Wiener指数, 给出了一种新的网络效率定义; 2)给出了简单无向连通图的对称性定义及其度量指标; 首次给出了无向高效网络和无向

摘要:
针对机械臂在狭窄空间中路径规划效率与成功率低、碰撞检测耗时占比高的问题, 提出一种基于高维构型空间快速碰撞检测的在线路径规划算法. 该算法以RRT-Connect为基线路径搜索框架, 并行运行基于高维构型在线聚类的快速碰撞检测模块. 其中, 后者包括高维构型数据集均衡采样与快速碰撞检测模型在线训练两个阶段. 具体而言, 数据集在线构建阶段通过引入启发式策略以充分挖掘狭窄通道内的自由构型, 克服仅通过均匀采样获取的数据集中碰撞构型、自由构型数量不均衡的问题, 为后续快速碰撞检测模型训练提供可靠的数据支撑; 数据集构建完成后, 通过对碰撞、自由构型在线聚类, 以簇的形式表征高维构型空间下两类构型的分布; 基于训练得到的簇模型, 将基线算法中基于包围盒的碰撞检测转化为采样构型与聚类簇间的距离计算, 极大降低单次碰撞检测耗时, 进而有效提升算法整体搜索效率. 通过在简单、开放、封闭三类狭窄环境下的仿真测试与实验验证, 表明所提算法在路径搜索效率和成功率方面具有显著优势.
针对机械臂在狭窄空间中路径规划效率与成功率低、碰撞检测耗时占比高的问题, 提出一种基于高维构型空间快速碰撞检测的在线路径规划算法. 该算法以RRT-Connect为基线路径搜索框架, 并行运行基于高维构型在线聚类的快速碰撞检测模块. 其中, 后者包括高维构型数据集均衡采样与快速碰撞检测模型在线训练两个阶段. 具体而言, 数据集在线构建阶段通过引入启发式策略以充分挖掘狭窄通道内的自由构型, 克服仅通过均匀采样获取的数据集中碰撞构型、自由构型数量不均衡的问题, 为后续快速碰撞检测模型训练提供可靠的数据支撑; 数据集构建完成后, 通过对碰撞、自由构型在线聚类, 以簇的形式表征高维构型空间下两类构型的分布; 基于训练得到的簇模型, 将基线算法中基于包围盒的碰撞检测转化为采样构型与聚类簇间的距离计算, 极大降低单次碰撞检测耗时, 进而有效提升算法整体搜索效率. 通过在简单、开放、封闭三类狭窄环境下的仿真测试与实验验证, 表明所提算法在路径搜索效率和成功率方面具有显著优势.













摘要:
深度学习软测量(DLSS)已成为解决复杂工业过程关键变量测量难题的有效方法, 但其极易遭受肉眼难以察觉的对抗攻击而输出虚假预测结果, 进而危害生产安全. 现有对抗攻击检测方法对微小扰动对抗样本(SPAS)普遍难以检出, 且对抗训练防御方法仍广泛存在对抗鲁棒过拟合现象. 针对上述问题, 提出一种对抗训练与攻击检测融合(ATADI)的对抗防御方法: 首先理论证明了仅采用SPAS进行对抗训练更有助于缓解对抗鲁棒过拟合, 其次在此基础上提出一种基于SPAS的特征锚定式对抗训练(FAAT)方案, 即SPAS-FAAT. ATADI中的攻击检测器在防御过程中仅检测较大扰动对抗样本(LPAS)以规避其难以检出SPAS的不足, SPAS则被输入经SPAS-FAAT后的DLSS以获得最终软测量结果. 最后在转子热变形软测量对抗攻防案例上进行了实验: 结构消融结果显示, 将对抗训练与攻击检测相融合可作为DLSS对抗防御的有效手段, 各类攻击产生的LPAS均能以高于98%的准确率被检出, 且经SPAS-FAAT后的DLSS在SPAS与正常样本上的软测量结果均满足精度要求. ATADI方法显著增强了DLSS的对抗鲁棒性, 为对抗防御方法的研究提供了新思路.
深度学习软测量(DLSS)已成为解决复杂工业过程关键变量测量难题的有效方法, 但其极易遭受肉眼难以察觉的对抗攻击而输出虚假预测结果, 进而危害生产安全. 现有对抗攻击检测方法对微小扰动对抗样本(SPAS)普遍难以检出, 且对抗训练防御方法仍广泛存在对抗鲁棒过拟合现象. 针对上述问题, 提出一种对抗训练与攻击检测融合(ATADI)的对抗防御方法: 首先理论证明了仅采用SPAS进行对抗训练更有助于缓解对抗鲁棒过拟合, 其次在此基础上提出一种基于SPAS的特征锚定式对抗训练(FAAT)方案, 即SPAS-FAAT. ATADI中的攻击检测器在防御过程中仅检测较大扰动对抗样本(LPAS)以规避其难以检出SPAS的不足, SPAS则被输入经SPAS-FAAT后的DLSS以获得最终软测量结果. 最后在转子热变形软测量对抗攻防案例上进行了实验: 结构消融结果显示, 将对抗训练与攻击检测相融合可作为DLSS对抗防御的有效手段, 各类攻击产生的LPAS均能以高于98%的准确率被检出, 且经SPAS-FAAT后的DLSS在SPAS与正常样本上的软测量结果均满足精度要求. ATADI方法显著增强了DLSS的对抗鲁棒性, 为对抗防御方法的研究提供了新思路.









摘要:
工业时间序列数据常伴随缺失、漂移等异常情况, 给准确预测带来挑战. 提出一种结合迁移学习的ESN-AR模型以应对这些问题. 具体而言, 将异常数据集作为目标域, 首先采用动态时间规整筛选源域数据. 不同于仅利用源域数据进行参数初始化的传统迁移学习方法, 将源域数据的自回归特征引入ESN储备池. 该储备池统一处理目标域与源域数据的状态更新, 使源域健康的趋势信息能够持续参与目标域的预测过程. 这一设计增强了对趋势信息的关注, 从而提高了模型在数据异常时的预测鲁棒性. 接着, 通过递归最小二乘法在线更新跨域共享的输出权重, 实现知识的有效迁移. 最后, 基于风电场风电功率数据的实验结果表明, 即使在数据漂移、缺失以及低相似度的情况下, 该方法仍能保持优异的预测性能.
工业时间序列数据常伴随缺失、漂移等异常情况, 给准确预测带来挑战. 提出一种结合迁移学习的ESN-AR模型以应对这些问题. 具体而言, 将异常数据集作为目标域, 首先采用动态时间规整筛选源域数据. 不同于仅利用源域数据进行参数初始化的传统迁移学习方法, 将源域数据的自回归特征引入ESN储备池. 该储备池统一处理目标域与源域数据的状态更新, 使源域健康的趋势信息能够持续参与目标域的预测过程. 这一设计增强了对趋势信息的关注, 从而提高了模型在数据异常时的预测鲁棒性. 接着, 通过递归最小二乘法在线更新跨域共享的输出权重, 实现知识的有效迁移. 最后, 基于风电场风电功率数据的实验结果表明, 即使在数据漂移、缺失以及低相似度的情况下, 该方法仍能保持优异的预测性能.












摘要:
针对一类带有全局耦合等式约束的分布式非合作博弈问题, 提出一种适用于二阶多智能体系统的预设时间分布式寻优算法. 研究目标是确保在强连通有向图拓扑下, 所有智能体能在预设时间内协同收敛至广义纳什均衡. 为克服通信拓扑权重不平衡带来的系统偏差, 算法采用两阶段收敛策略: 第一阶段利用一致性机制精确估计拉普拉斯矩阵的左特征向量, 实现拓扑补偿; 第二阶段通过引入阻尼项保障二阶积分型系统的可控性, 并结合拉格朗日乘子法处理全局约束, 同时利用基于领导−跟随一致性协议的估计器重构对手的决策信息, 以实现伪梯度的分布式更新. 此外, 针对权重平衡有向图这一特殊情形, 给出算法的简化实现形式. 在博弈映射满足强单调性假设下, 通过引入时间变换函数并构造新型李雅普诺夫函数, 从理论上严格证明系统能够在预设时间内收敛至广义纳什均衡, 并确保收敛后的持续稳定性. 最后, 数值仿真实验验证了算法在不同拓扑结构下的有效性与收敛精度.
针对一类带有全局耦合等式约束的分布式非合作博弈问题, 提出一种适用于二阶多智能体系统的预设时间分布式寻优算法. 研究目标是确保在强连通有向图拓扑下, 所有智能体能在预设时间内协同收敛至广义纳什均衡. 为克服通信拓扑权重不平衡带来的系统偏差, 算法采用两阶段收敛策略: 第一阶段利用一致性机制精确估计拉普拉斯矩阵的左特征向量, 实现拓扑补偿; 第二阶段通过引入阻尼项保障二阶积分型系统的可控性, 并结合拉格朗日乘子法处理全局约束, 同时利用基于领导−跟随一致性协议的估计器重构对手的决策信息, 以实现伪梯度的分布式更新. 此外, 针对权重平衡有向图这一特殊情形, 给出算法的简化实现形式. 在博弈映射满足强单调性假设下, 通过引入时间变换函数并构造新型李雅普诺夫函数, 从理论上严格证明系统能够在预设时间内收敛至广义纳什均衡, 并确保收敛后的持续稳定性. 最后, 数值仿真实验验证了算法在不同拓扑结构下的有效性与收敛精度.










摘要:
烟气脱硫处理是聚焦污染防治、实现节能减排的重要举措, 其安全、稳定运行直接影响着经济社会可持续发展与居民生命健康. 然而, 长期运行下的烟气脱硫设备往往不可避免地出现故障且难以预测, 进而导致连锁反应甚至事故. 鉴于此, 本文提出一种基于深度模糊推理模型(DFIM)的烟气脱硫设备运行状态预测方法. 首先, 构建数据驱动的深度模糊信念网络(DFBN), 通过模糊特征学习算法将传感器获取的原始数据映射为抗干扰的模糊语义特征, 并实现模糊特征的预测输出. 其次, 建立推理门控层, 进一步对输出模糊特征进行识别, 并聚焦设备故障模式. 然后, 结合操作经验和运行环境, 对标设备运行状态和故障模式, 给出处置方案. 最后, 以实际烟气脱硫系统循环泵内浆液pH和轴承温度为设备运行状态变量为例, 测试DFIM在烟气脱硫设备运行状态预测中的有效性, 实验结果表明所提出的DFIM在预测精度、稳定性与快速性等方面均优于现有方法, 对设备运维与管理具有重要的指导意义.
烟气脱硫处理是聚焦污染防治、实现节能减排的重要举措, 其安全、稳定运行直接影响着经济社会可持续发展与居民生命健康. 然而, 长期运行下的烟气脱硫设备往往不可避免地出现故障且难以预测, 进而导致连锁反应甚至事故. 鉴于此, 本文提出一种基于深度模糊推理模型(DFIM)的烟气脱硫设备运行状态预测方法. 首先, 构建数据驱动的深度模糊信念网络(DFBN), 通过模糊特征学习算法将传感器获取的原始数据映射为抗干扰的模糊语义特征, 并实现模糊特征的预测输出. 其次, 建立推理门控层, 进一步对输出模糊特征进行识别, 并聚焦设备故障模式. 然后, 结合操作经验和运行环境, 对标设备运行状态和故障模式, 给出处置方案. 最后, 以实际烟气脱硫系统循环泵内浆液pH和轴承温度为设备运行状态变量为例, 测试DFIM在烟气脱硫设备运行状态预测中的有效性, 实验结果表明所提出的DFIM在预测精度、稳定性与快速性等方面均优于现有方法, 对设备运维与管理具有重要的指导意义.













摘要:
具有治疗师般个性化、柔顺且安全交互的康复机器人可有效防止二次伤害并提升康复效率. 本文提出一种基于双臂机器人的新型上肢康复框架, 用于实现机器人治疗师般的交互. 首先, 以安全性为首要目标, 建立七自由度上肢运动学模型, 用于评估上肢末端以及前臂后端的可达训练空间; 利用双臂康复的优势, 提出一种非冗余逆运动学方法以约束关节运动角度, 进而构建任务-关节双重约束下的安全机制. 其次, 考虑个性化与柔顺交互, 设计了一种基于势场的按需辅助控制策略, 使双臂机器人能够从单次演示中学习治疗师的个性化牵引特性, 并根据上肢的运动能力和训练参与度提供自适应柔顺辅助. 实验结果表明, 所提方法兼具末端牵引式康复机器人动作适应性高、接触少以及外骨骼式康复机器人精准空间训练的特点, 并能够根据上肢训练状态实施按需辅助. 随着双臂及人形机器人的应用越来越广泛, 所提出的方法为机器人在医院和家庭环境中实现治疗师般个性化、柔顺且安全的康复训练提供了一条新途径.
具有治疗师般个性化、柔顺且安全交互的康复机器人可有效防止二次伤害并提升康复效率. 本文提出一种基于双臂机器人的新型上肢康复框架, 用于实现机器人治疗师般的交互. 首先, 以安全性为首要目标, 建立七自由度上肢运动学模型, 用于评估上肢末端以及前臂后端的可达训练空间; 利用双臂康复的优势, 提出一种非冗余逆运动学方法以约束关节运动角度, 进而构建任务-关节双重约束下的安全机制. 其次, 考虑个性化与柔顺交互, 设计了一种基于势场的按需辅助控制策略, 使双臂机器人能够从单次演示中学习治疗师的个性化牵引特性, 并根据上肢的运动能力和训练参与度提供自适应柔顺辅助. 实验结果表明, 所提方法兼具末端牵引式康复机器人动作适应性高、接触少以及外骨骼式康复机器人精准空间训练的特点, 并能够根据上肢训练状态实施按需辅助. 随着双臂及人形机器人的应用越来越广泛, 所提出的方法为机器人在医院和家庭环境中实现治疗师般个性化、柔顺且安全的康复训练提供了一条新途径.












摘要:
本文研究大规模变频空调集群参与需求响应中的最优功率调度问题. 针对现有研究侧重运行经济性最优, 忽略用户舒适需求、快速动态响应能力及用户满意度等关键工程因素的不足, 构建了兼顾舒适约束与动态性能的优化调度框架. 为刻画用户舒适需求, 基于实时室内温度、设定温度及可容许温度偏差构建统一的用户舒适指标, 实现舒适水平的定量表征. 基于此, 提出一种预定义时间最优调度策略, 通过协调各空调单元功率消耗, 确保在满足用户舒适约束的前提下, 集群总功率于预定义时间内精确跟踪需求功率并实现用户满意度最优. 进一步地, 将该方法扩展至阶跃需求情形, 以增强对动态需求目标的适应能力. 最后, 基于李雅普诺夫理论证明了系统收敛性, 数值仿真验证了所提方法的有效性与工程可行性.
本文研究大规模变频空调集群参与需求响应中的最优功率调度问题. 针对现有研究侧重运行经济性最优, 忽略用户舒适需求、快速动态响应能力及用户满意度等关键工程因素的不足, 构建了兼顾舒适约束与动态性能的优化调度框架. 为刻画用户舒适需求, 基于实时室内温度、设定温度及可容许温度偏差构建统一的用户舒适指标, 实现舒适水平的定量表征. 基于此, 提出一种预定义时间最优调度策略, 通过协调各空调单元功率消耗, 确保在满足用户舒适约束的前提下, 集群总功率于预定义时间内精确跟踪需求功率并实现用户满意度最优. 进一步地, 将该方法扩展至阶跃需求情形, 以增强对动态需求目标的适应能力. 最后, 基于李雅普诺夫理论证明了系统收敛性, 数值仿真验证了所提方法的有效性与工程可行性.







摘要:
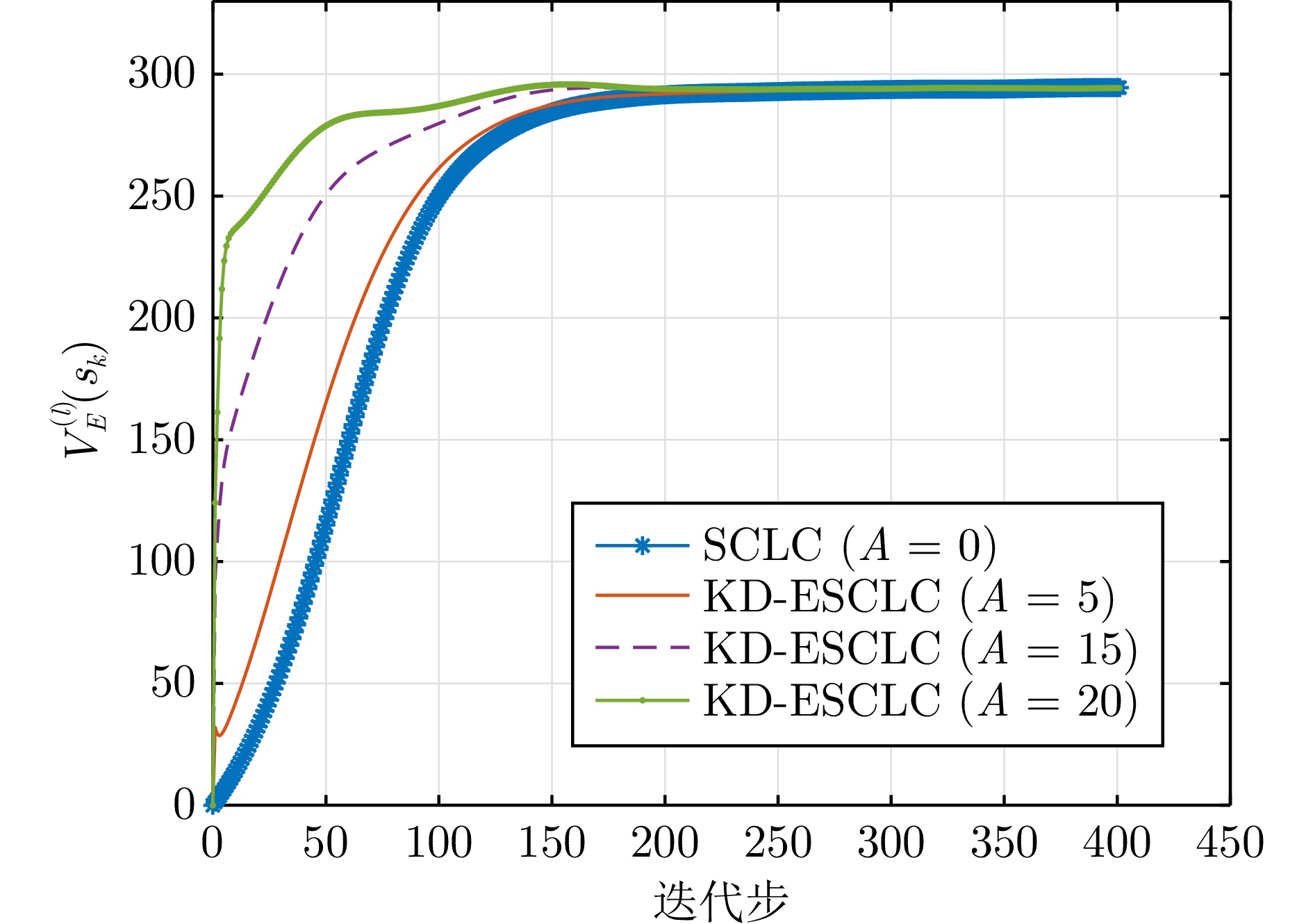
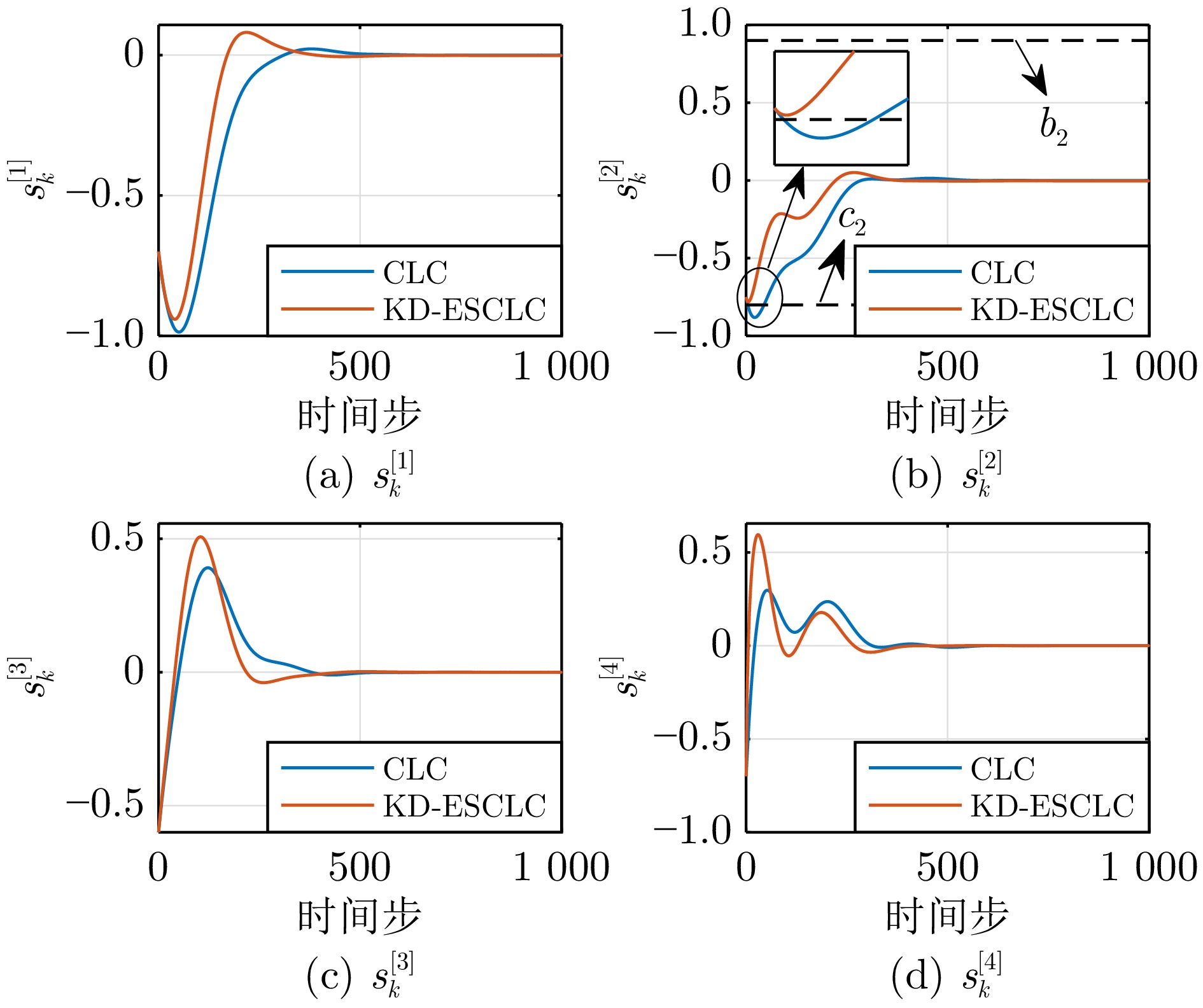
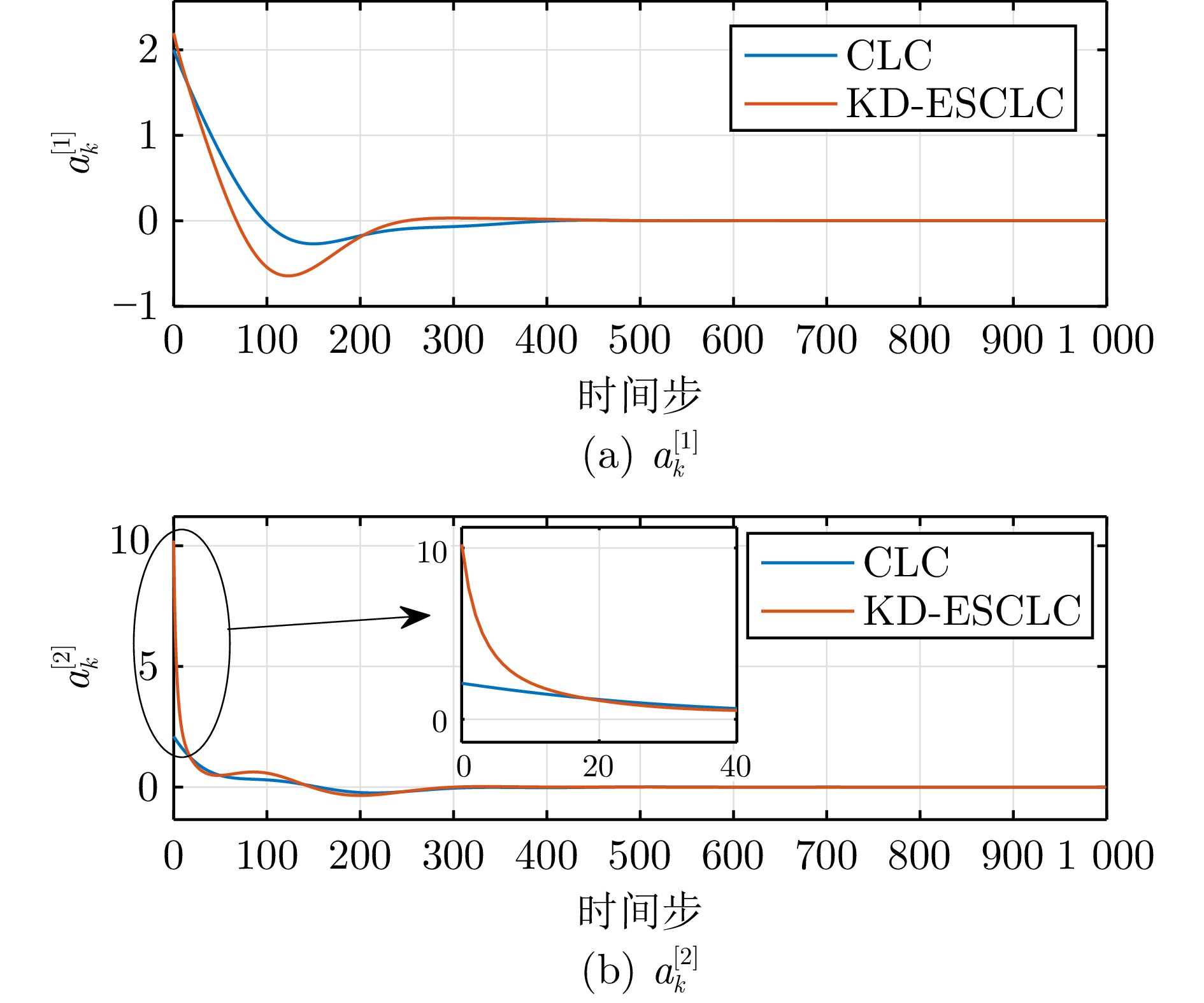
针对具有状态约束的离散时间非线性系统, 开发一种知识驱动高效安全评判学习控制算法. 首先, 基于知识迁移技术, 利用历史任务中的先验知识来改善评判学习控制算法在当前目标任务的学习效率. 同时, 构造一类单调递减的衰减函数以避免先验知识影响控制策略的最优性. 其次, 通过设计合适的障碍函数, 成功将具有状态约束的最优调节问题转化为无约束最优调节问题, 进而建立一种安全评判学习控制框架. 利用所提控制算法, 可高效求解一类具有状态约束的非线性系统最优控制问题. 此外, 为提供严谨的理论支持, 给出了所提控制算法的收敛性证明以及控制策略的稳定性判别准则. 最后, 利用两个数值仿真实例验证了所提算法的有效性.
针对具有状态约束的离散时间非线性系统, 开发一种知识驱动高效安全评判学习控制算法. 首先, 基于知识迁移技术, 利用历史任务中的先验知识来改善评判学习控制算法在当前目标任务的学习效率. 同时, 构造一类单调递减的衰减函数以避免先验知识影响控制策略的最优性. 其次, 通过设计合适的障碍函数, 成功将具有状态约束的最优调节问题转化为无约束最优调节问题, 进而建立一种安全评判学习控制框架. 利用所提控制算法, 可高效求解一类具有状态约束的非线性系统最优控制问题. 此外, 为提供严谨的理论支持, 给出了所提控制算法的收敛性证明以及控制策略的稳定性判别准则. 最后, 利用两个数值仿真实例验证了所提算法的有效性.
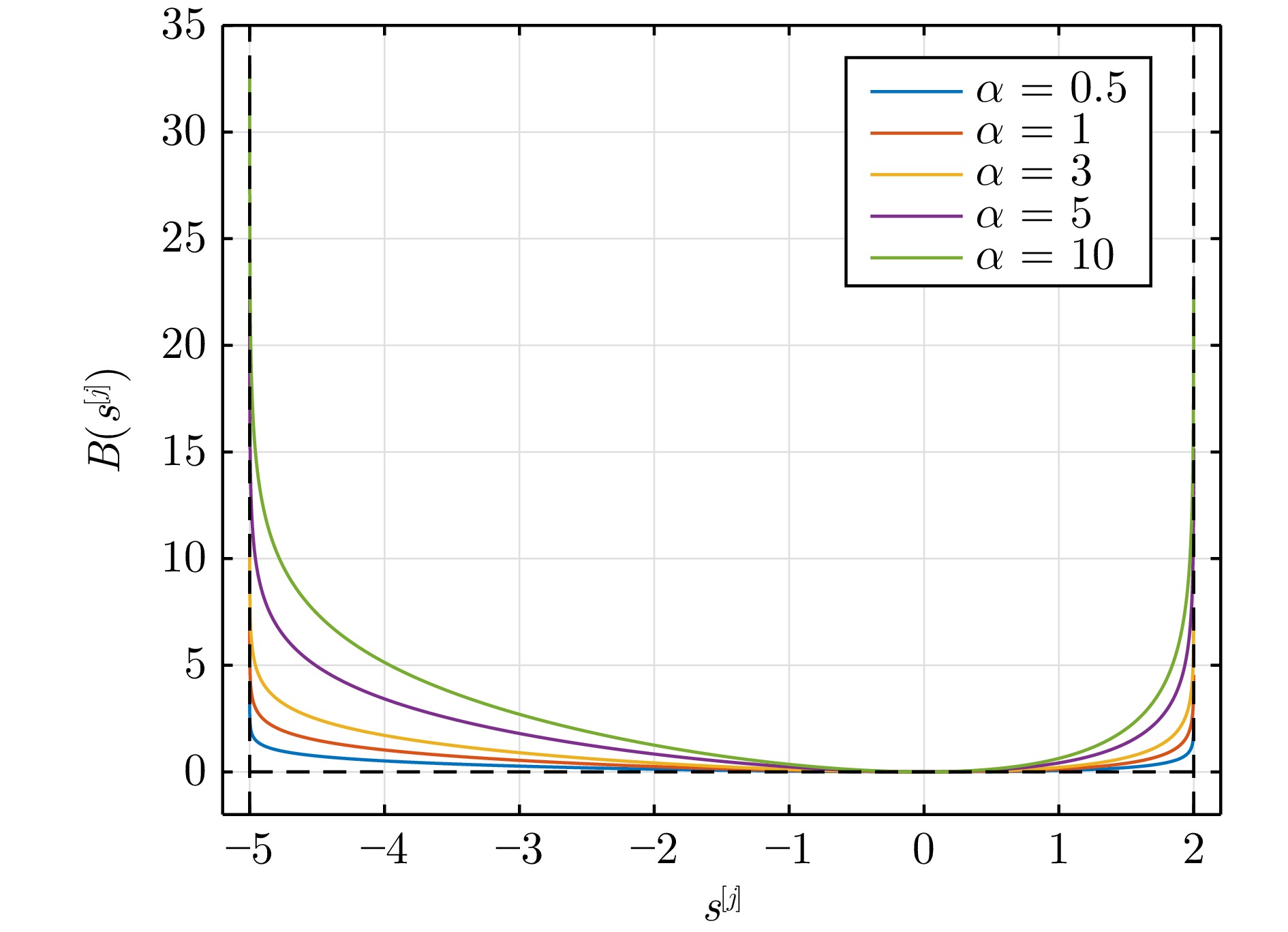
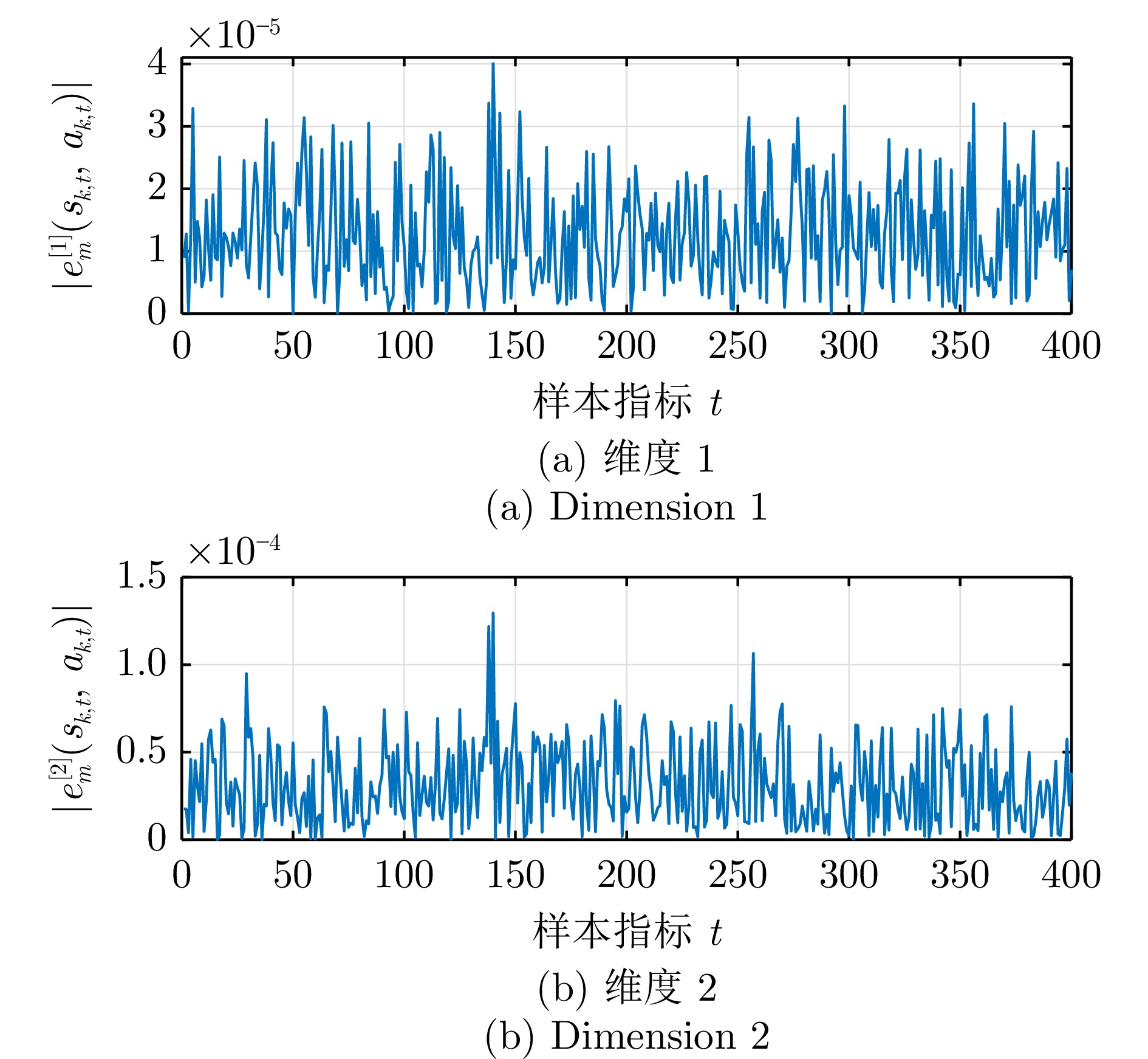
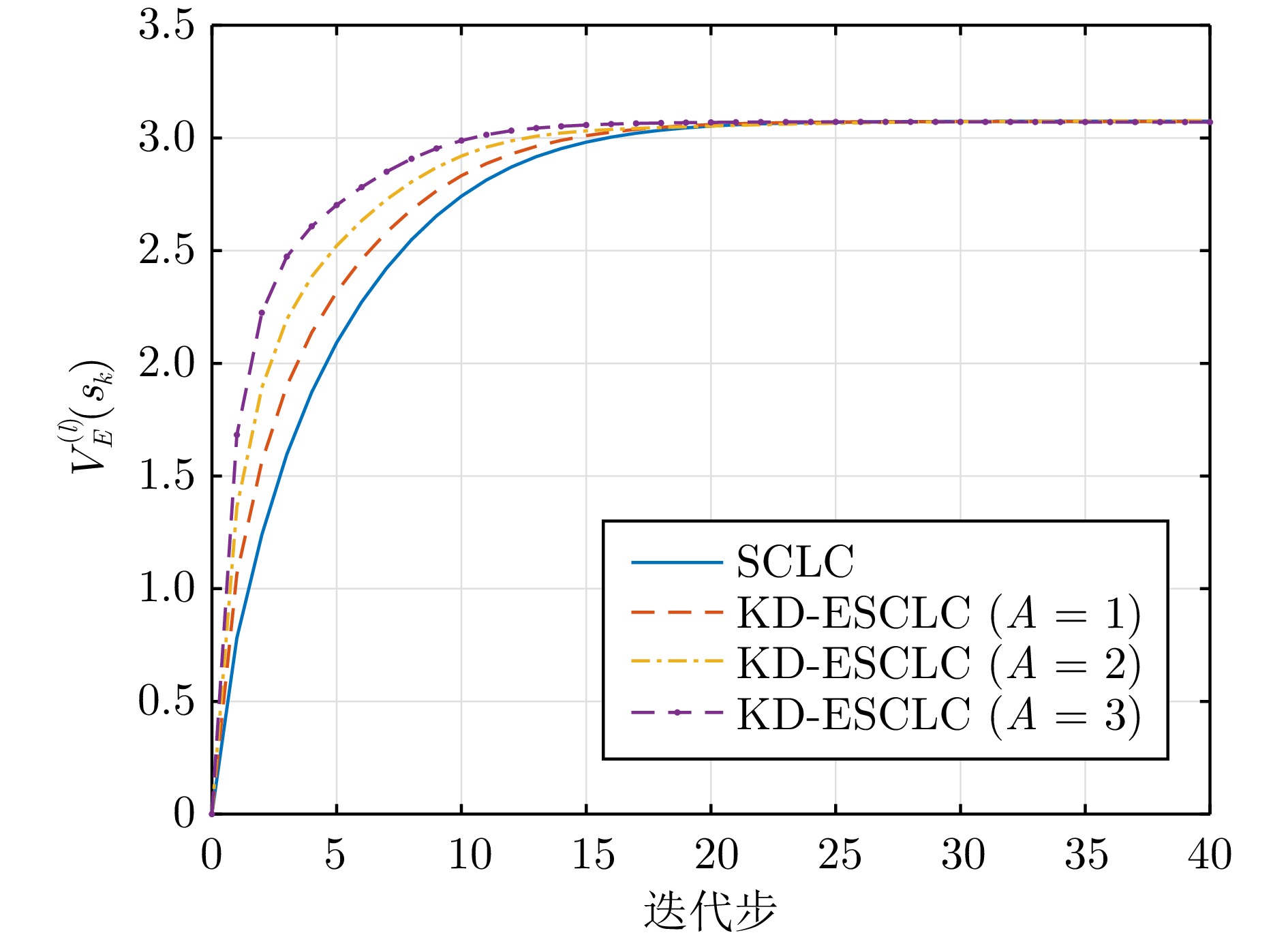
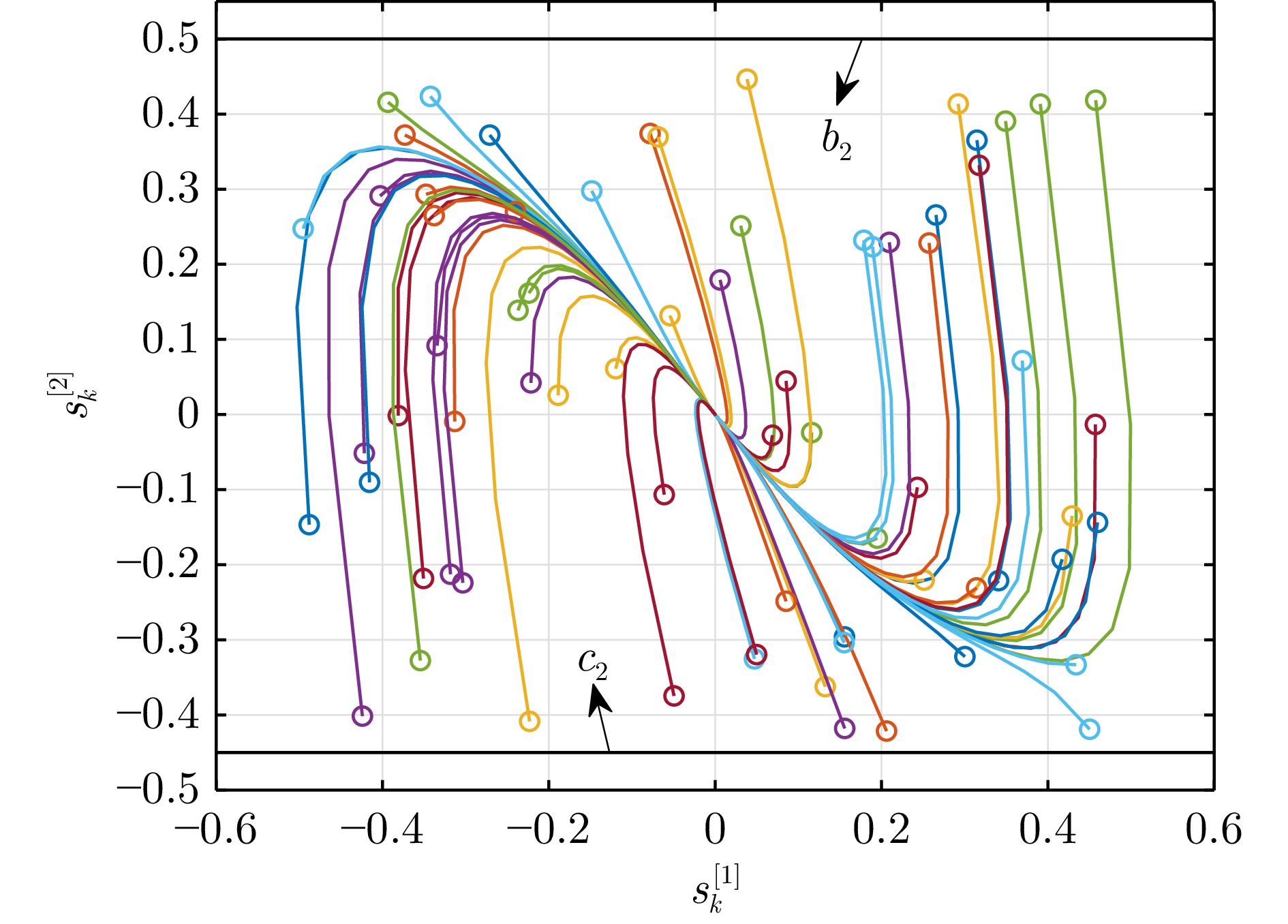
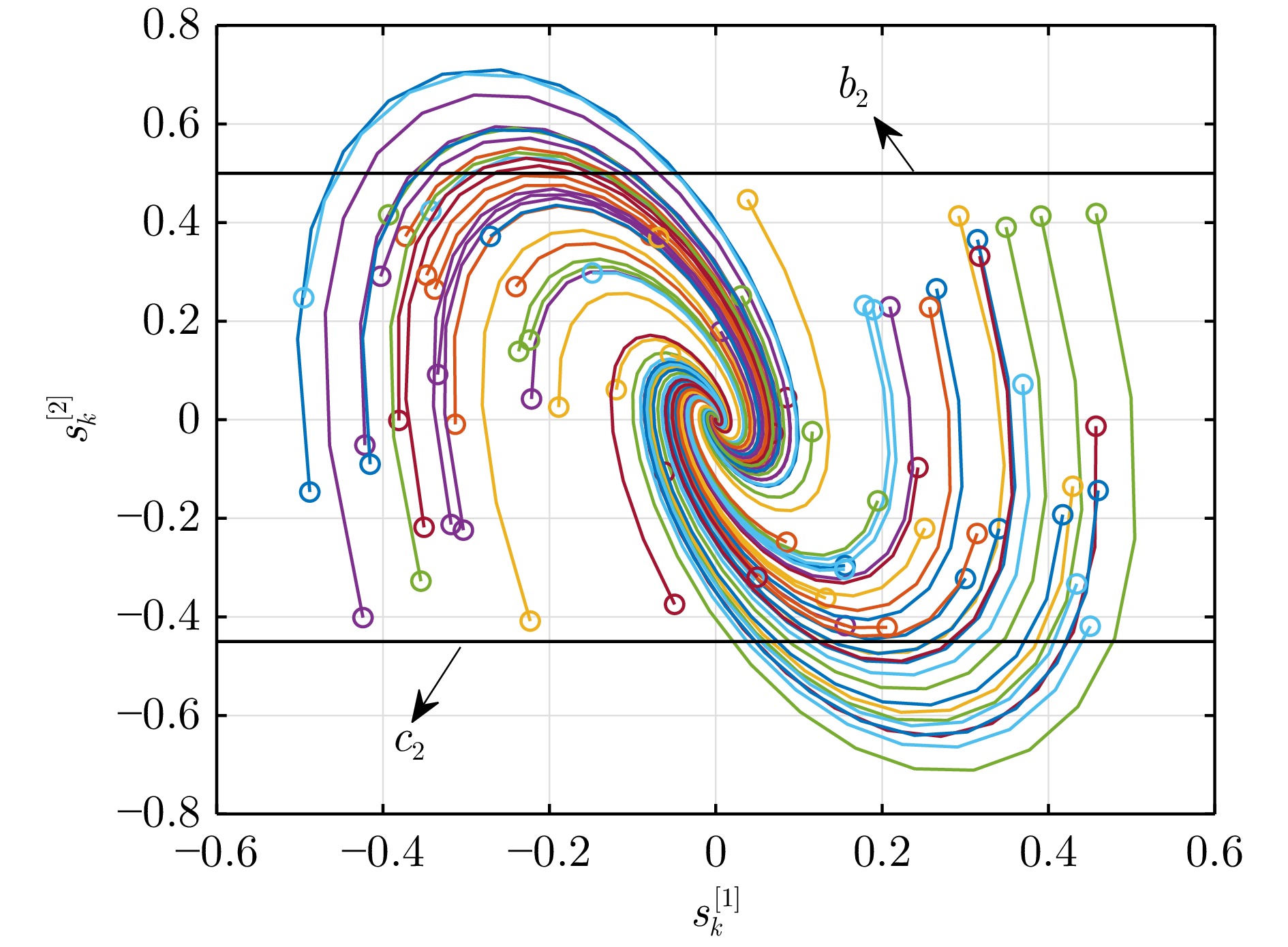
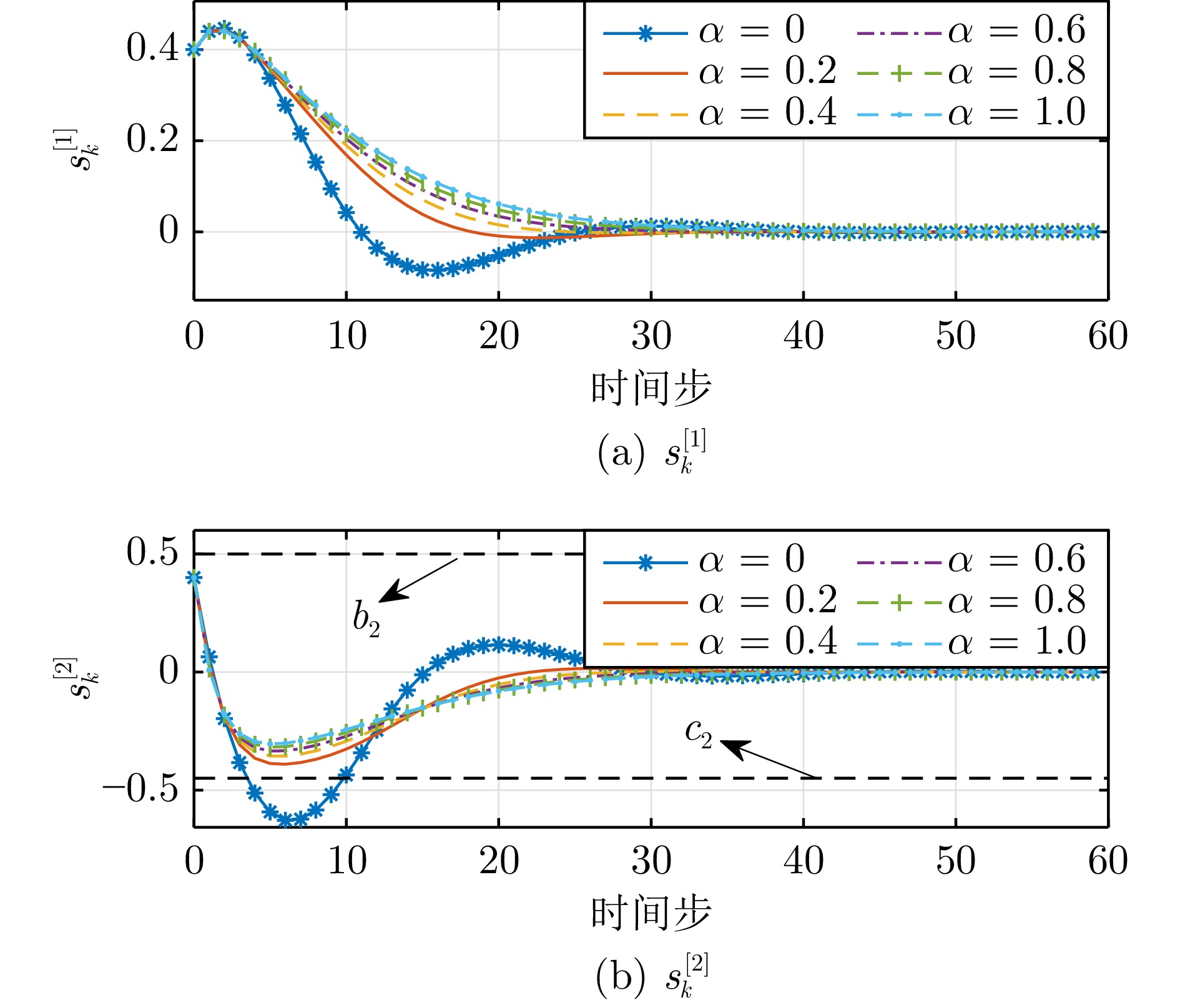
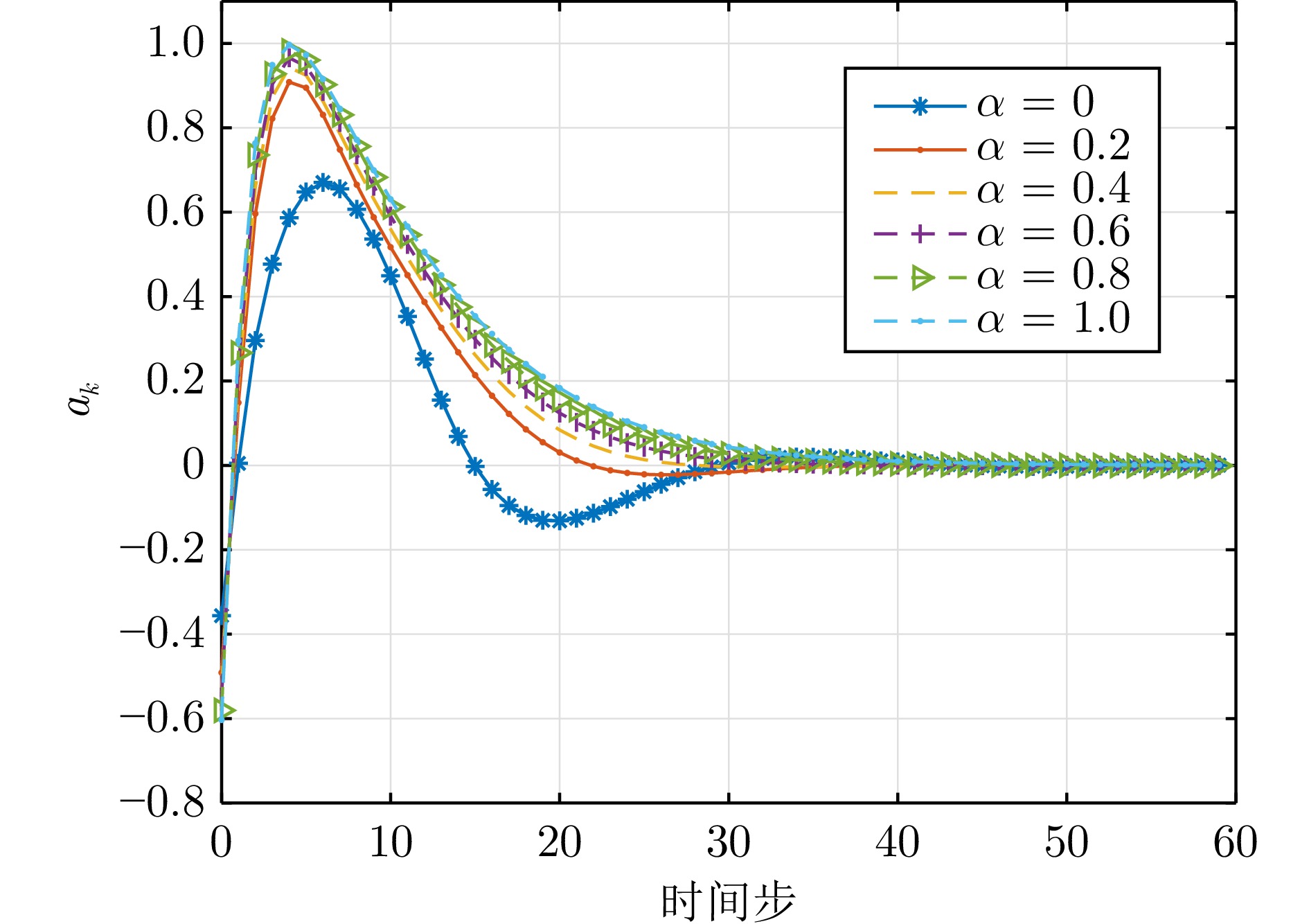
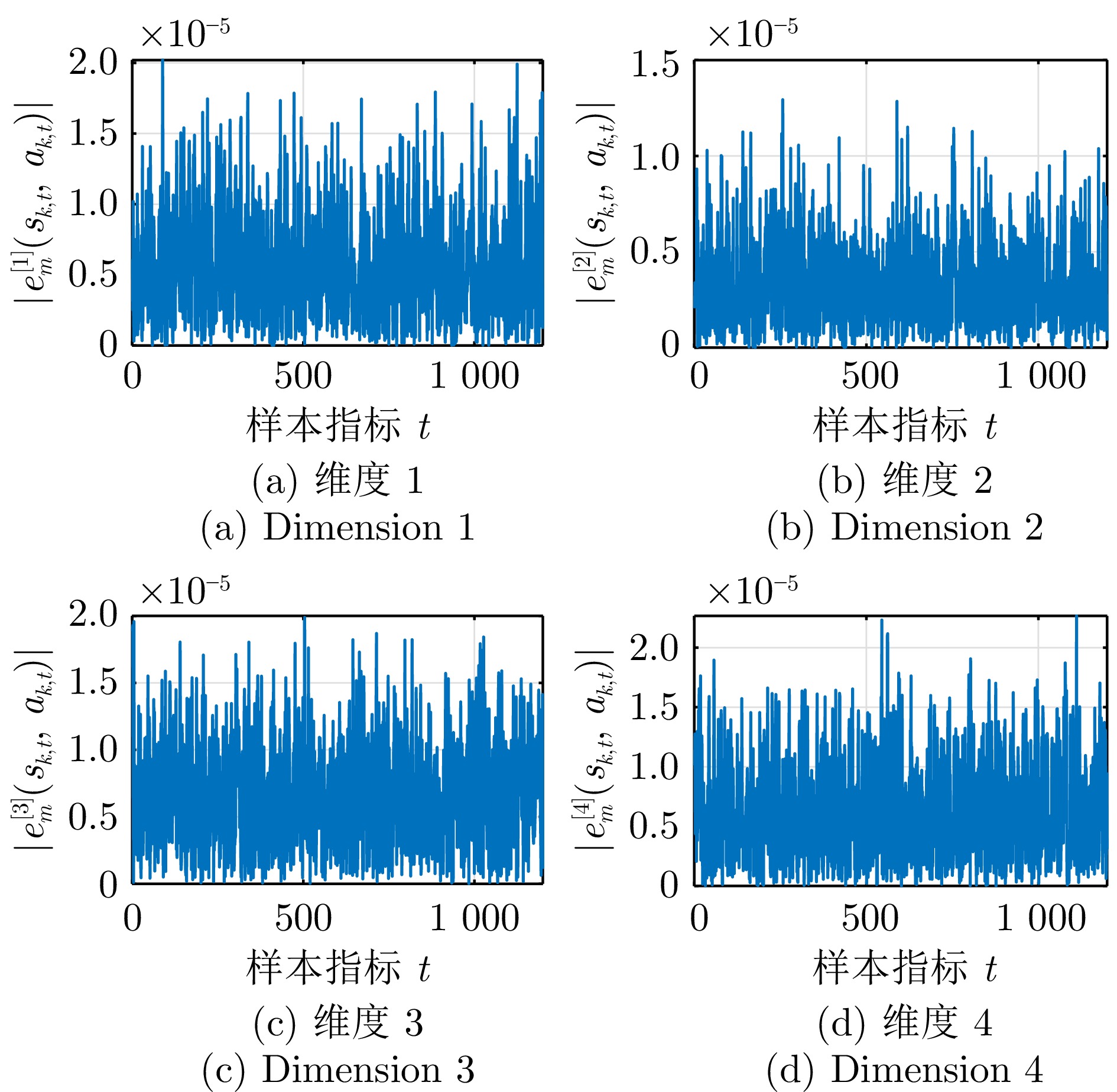
摘要:
大气湍流是由大气折射率随机起伏引起的复杂光学退化现象, 通常导致成像过程中产生几何畸变、模糊及闪烁等问题, 严重制约远距离成像系统的视觉质量与机器感知性能. 本文系统综述基于深度学习的大气湍流抑制研究, 详细探讨基于卷积神经网络、生成对抗网络、Transformer、扩散模型以及 Mamba 的多种核心方法, 并从建模能力、鲁棒性与计算效率等方面对各类代表性方法进行对比分析. 最后, 围绕复杂场景、实时处理、高分辨率成像等关键问题进行总结与展望, 为未来研究提供参考.
大气湍流是由大气折射率随机起伏引起的复杂光学退化现象, 通常导致成像过程中产生几何畸变、模糊及闪烁等问题, 严重制约远距离成像系统的视觉质量与机器感知性能. 本文系统综述基于深度学习的大气湍流抑制研究, 详细探讨基于卷积神经网络、生成对抗网络、Transformer、扩散模型以及 Mamba 的多种核心方法, 并从建模能力、鲁棒性与计算效率等方面对各类代表性方法进行对比分析. 最后, 围绕复杂场景、实时处理、高分辨率成像等关键问题进行总结与展望, 为未来研究提供参考.




摘要:
在集群机器人系统中, 通信、控制与计算模块的协同设计已成为提升系统整体性能的关键, 对推动离散制造自动化向智能化、集成化方向发展具有重要促进作用. 首先, 从集群机器人“通−控−算”联合系统架构出发, 通过梳理国内外在“通−控”、“通−算”、“控−算”融合技术方面的研究现状, 揭示子系统之间的耦合关系, 强调“通−控−算”联合设计对提升集群机器人整体作业性能的重要性. 接着, 以集群机器人系统在“通−控−算”软件仿真、硬件在环仿真及实物测试验证平台为例, 总结具体实施中的关键技术. 最后, 对集群机器人“通−控−算”系统联合设计的未来研究方向进行总结与展望.
在集群机器人系统中, 通信、控制与计算模块的协同设计已成为提升系统整体性能的关键, 对推动离散制造自动化向智能化、集成化方向发展具有重要促进作用. 首先, 从集群机器人“通−控−算”联合系统架构出发, 通过梳理国内外在“通−控”、“通−算”、“控−算”融合技术方面的研究现状, 揭示子系统之间的耦合关系, 强调“通−控−算”联合设计对提升集群机器人整体作业性能的重要性. 接着, 以集群机器人系统在“通−控−算”软件仿真、硬件在环仿真及实物测试验证平台为例, 总结具体实施中的关键技术. 最后, 对集群机器人“通−控−算”系统联合设计的未来研究方向进行总结与展望.








当前状态:
, 最新更新时间: ,
doi: 10.16383/j.aas.c250726
摘要:
针对存在外部扰动的非线性不确定时滞分布参数多智能体系统一致性问题, 提出一种\begin{document}$H_{\infty}$\end{document} \begin{document}$H_{\infty}$\end{document} \begin{document}$H_{\infty}$\end{document}
针对存在外部扰动的非线性不确定时滞分布参数多智能体系统一致性问题, 提出一种





摘要:
矿物磨选过程运行优化控制通常采用基础回路层和运行层双层结构, 涉及不同时间尺度被控对象, 其运行层动态机理复杂难以建模, 且层级间具有不同采样速率与通信丢包问题, 进一步增加了控制设计难度. 因此, 针对矿物磨选过程运行优化中存在的多速率、不可靠通信问题, 提出一种带有通信补偿的多速率分层学习控制方法. 该方法在基础回路层采用提升技术和模型预测控制实现多速率下的设定值跟踪; 在此基础上, 通过递归提升将回路动态引入运行层, 采用强化学习技术, 结合史密斯预估器的思想, 设计带有通信补偿的快慢耦合逆学习控制算法, 以解决性能指标权重参数依赖人工经验设定、调参困难的问题, 利用演示运行数据逆向学习性能指标权重参数的同时在线更新回路设定值, 进而实现运行指标的优化控制. 理论分析和工业应用验证了所提方法的有效性.
矿物磨选过程运行优化控制通常采用基础回路层和运行层双层结构, 涉及不同时间尺度被控对象, 其运行层动态机理复杂难以建模, 且层级间具有不同采样速率与通信丢包问题, 进一步增加了控制设计难度. 因此, 针对矿物磨选过程运行优化中存在的多速率、不可靠通信问题, 提出一种带有通信补偿的多速率分层学习控制方法. 该方法在基础回路层采用提升技术和模型预测控制实现多速率下的设定值跟踪; 在此基础上, 通过递归提升将回路动态引入运行层, 采用强化学习技术, 结合史密斯预估器的思想, 设计带有通信补偿的快慢耦合逆学习控制算法, 以解决性能指标权重参数依赖人工经验设定、调参困难的问题, 利用演示运行数据逆向学习性能指标权重参数的同时在线更新回路设定值, 进而实现运行指标的优化控制. 理论分析和工业应用验证了所提方法的有效性.















摘要:
针对由涵盖执行器部分至完全失效的多级故障所导致的网联车队决策?执行层协调失配问题, 提出一种融合跟踪精度与收敛速度监督的协同变道容错控制方法. 首先, 针对变道决策规划参数不当引发的快速性与平稳性冲突问题, 设计一种基于可变安全时窗的目标轨迹规划机制, 规避相邻车道动态障碍车碰撞风险, 实现变道过程快速响应与乘客舒适性的动态权衡. 其次, 针对多级故障、饱和输入与欺骗攻击耦合造成的执行层轨迹跟踪失控问题, 构建一种集成分布式扰动近似技术的性能监督容错跟踪控制策略, 确保队列跟踪精度与收敛速度在预设时间内恢复到指定范围内, 消除对故障因子非零的强假设条件. 接着, 针对多级故障过渡阶段安全时窗非光滑突变引发的决策−执行层协调失配问题, 提出一种基于性能过渡映射的自适应协同变道控制方法, 确保决策层与执行层动态双向交互调节, 保障车队一致跟踪目标轨迹并安全完成变道. 最后, 通过仿真实验验证了所提方法的有效性.
针对由涵盖执行器部分至完全失效的多级故障所导致的网联车队决策?执行层协调失配问题, 提出一种融合跟踪精度与收敛速度监督的协同变道容错控制方法. 首先, 针对变道决策规划参数不当引发的快速性与平稳性冲突问题, 设计一种基于可变安全时窗的目标轨迹规划机制, 规避相邻车道动态障碍车碰撞风险, 实现变道过程快速响应与乘客舒适性的动态权衡. 其次, 针对多级故障、饱和输入与欺骗攻击耦合造成的执行层轨迹跟踪失控问题, 构建一种集成分布式扰动近似技术的性能监督容错跟踪控制策略, 确保队列跟踪精度与收敛速度在预设时间内恢复到指定范围内, 消除对故障因子非零的强假设条件. 接着, 针对多级故障过渡阶段安全时窗非光滑突变引发的决策−执行层协调失配问题, 提出一种基于性能过渡映射的自适应协同变道控制方法, 确保决策层与执行层动态双向交互调节, 保障车队一致跟踪目标轨迹并安全完成变道. 最后, 通过仿真实验验证了所提方法的有效性.





















摘要:
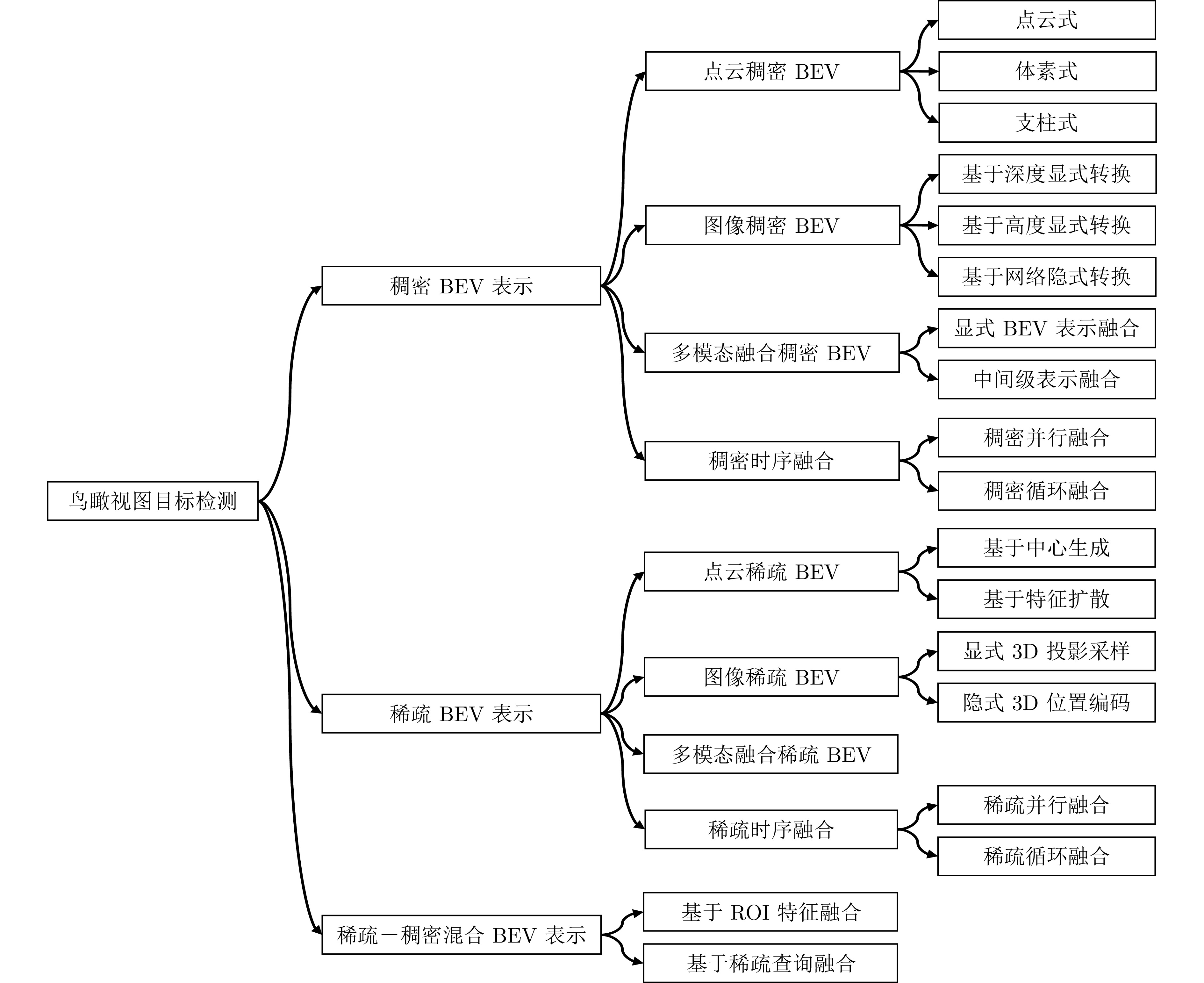
鸟瞰视图表征基于统一的空间坐标系, 能够实现多传感器时空对齐与特征融合, 在自动驾驶领域三维目标检测任务中展现出显著优势. 首先, 阐述BEV表征的优势以及常用自动驾驶3D目标检测数据集与评价指标. 其次, 不同于现有综述文献的输入模态特性或模态特征融合的分析视角, 基于BEV表征, 从其稠密程度切入, 分别从稀疏表示、稠密表示、稀疏−稠密混合表示角度系统梳理现有研究工作, 指出现有方法在时空消耗与表征完备性之间的权衡困境. 最后, 从全天候鲁棒感知、相机参数无关的自适应几何建模、自动驾驶开放世界检测等角度, 指出实现低成本、高精度自动驾驶BEV目标检测的研究趋势, 希望为从事BEV感知研究的学者提供启发, 推动自动驾驶技术的发展.
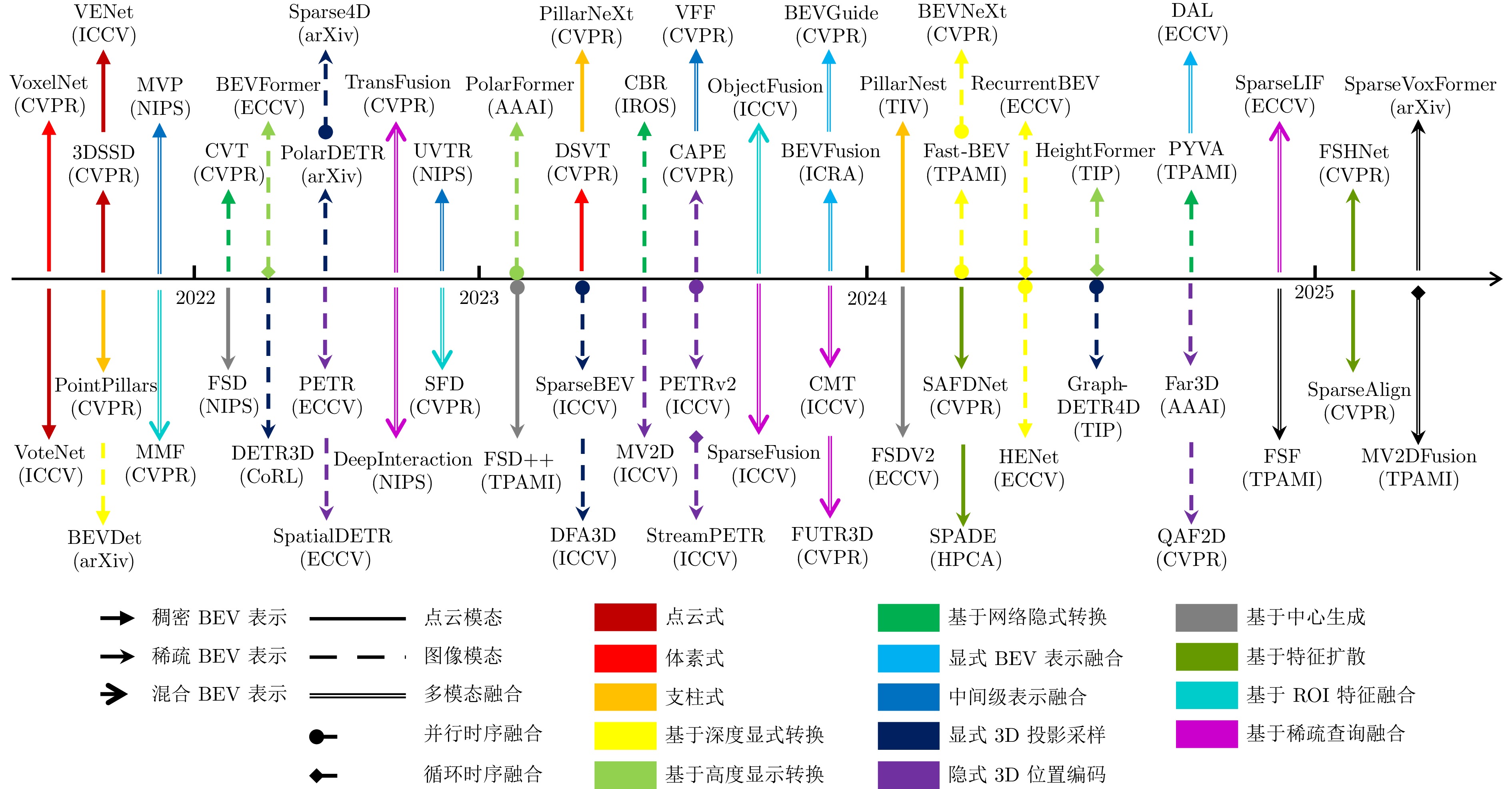
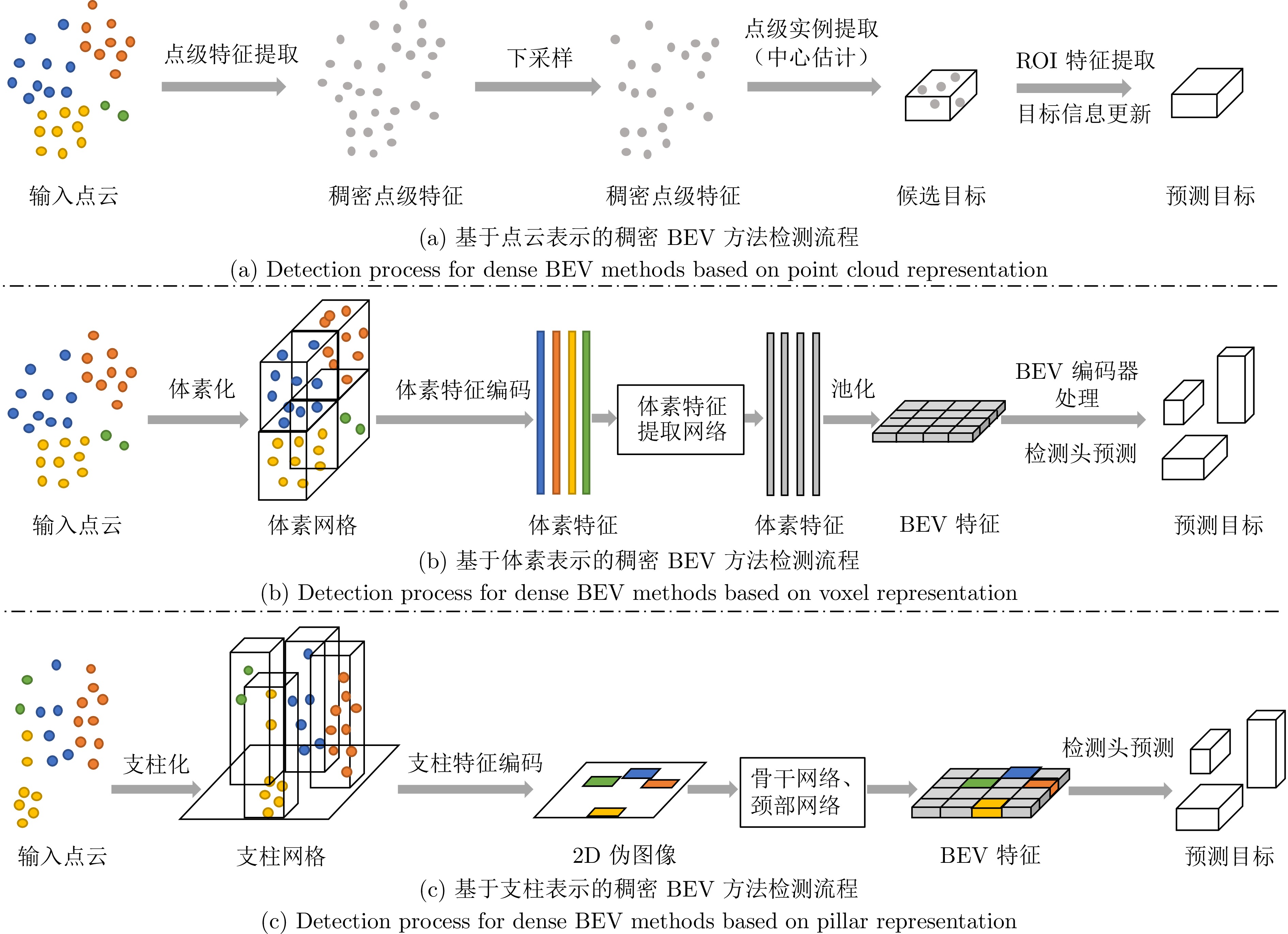
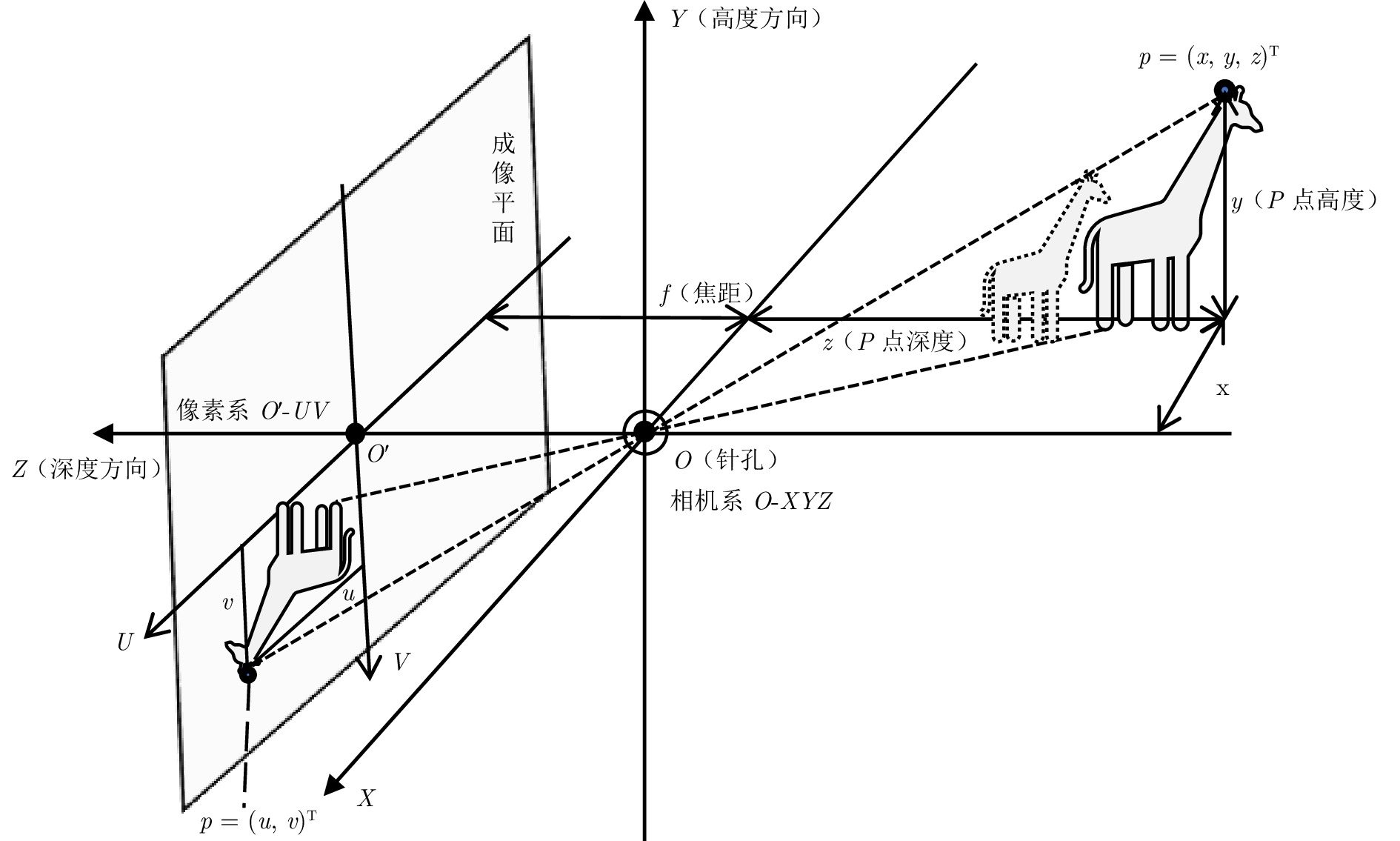
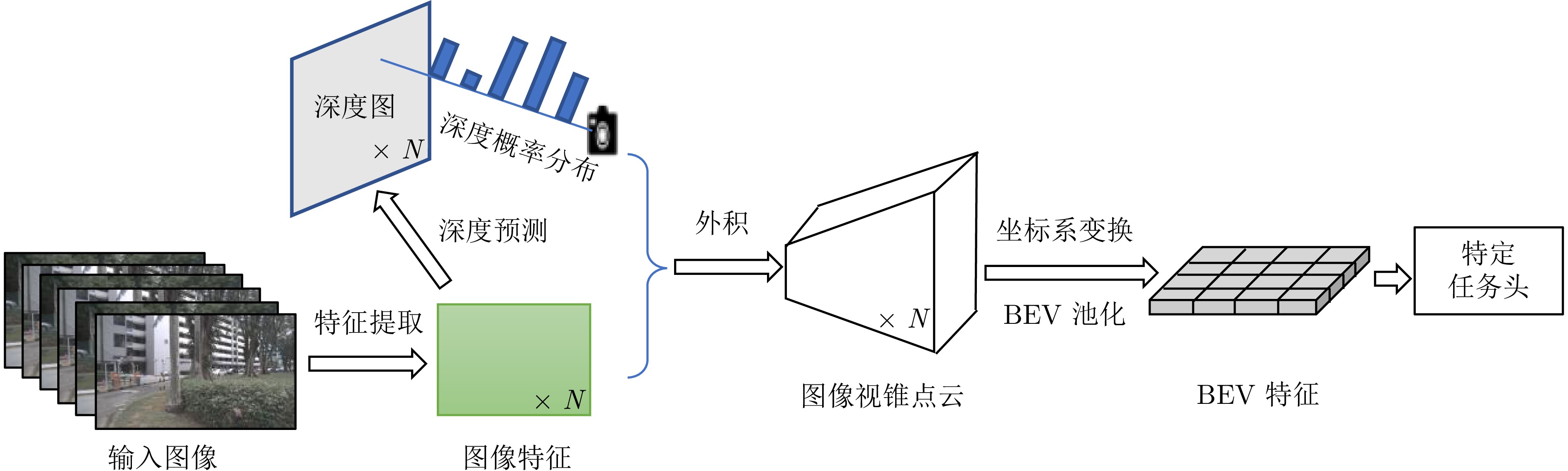
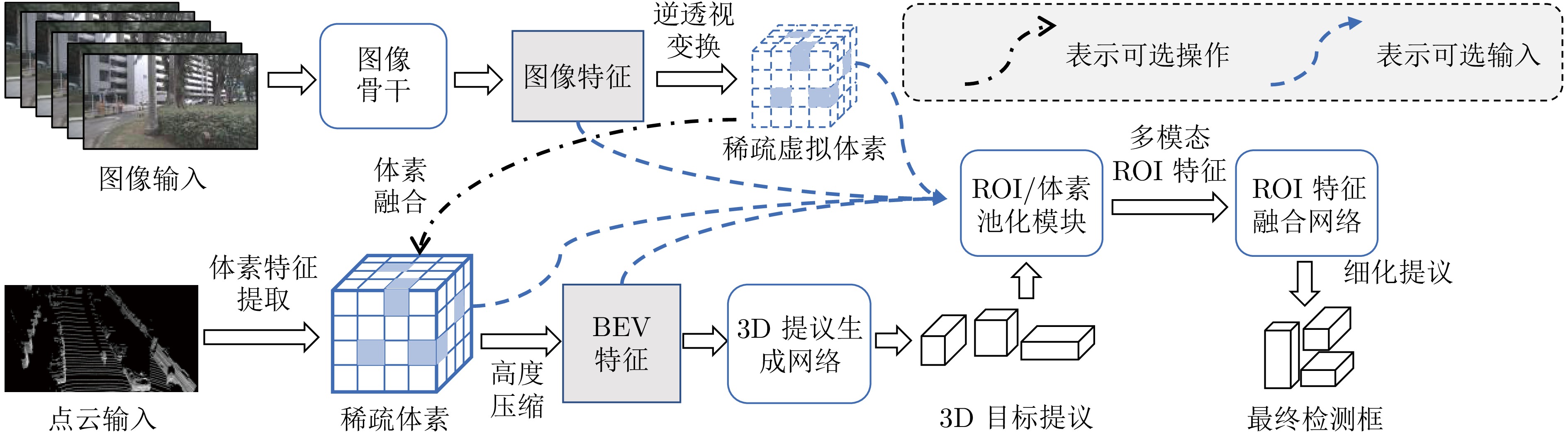
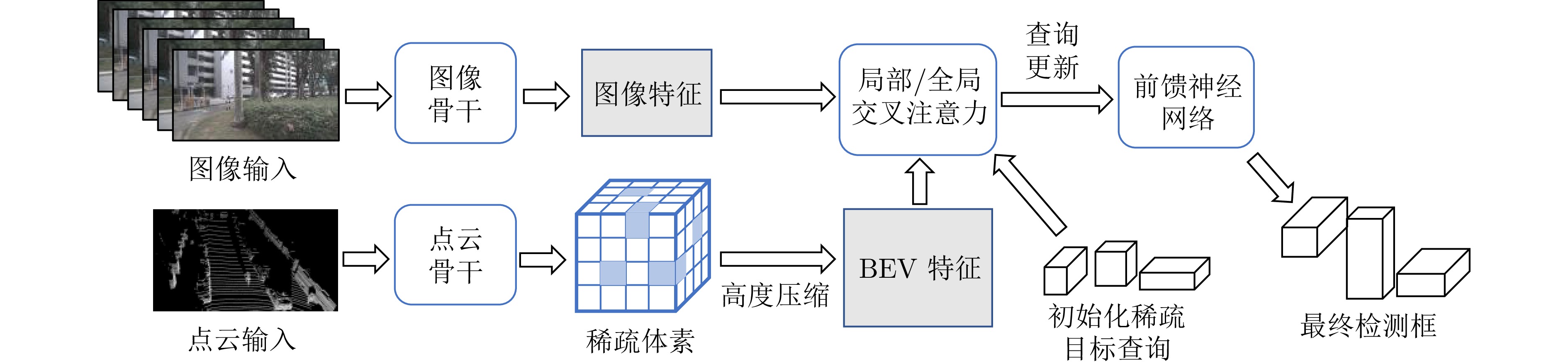
鸟瞰视图表征基于统一的空间坐标系, 能够实现多传感器时空对齐与特征融合, 在自动驾驶领域三维目标检测任务中展现出显著优势. 首先, 阐述BEV表征的优势以及常用自动驾驶3D目标检测数据集与评价指标. 其次, 不同于现有综述文献的输入模态特性或模态特征融合的分析视角, 基于BEV表征, 从其稠密程度切入, 分别从稀疏表示、稠密表示、稀疏−稠密混合表示角度系统梳理现有研究工作, 指出现有方法在时空消耗与表征完备性之间的权衡困境. 最后, 从全天候鲁棒感知、相机参数无关的自适应几何建模、自动驾驶开放世界检测等角度, 指出实现低成本、高精度自动驾驶BEV目标检测的研究趋势, 希望为从事BEV感知研究的学者提供启发, 推动自动驾驶技术的发展.

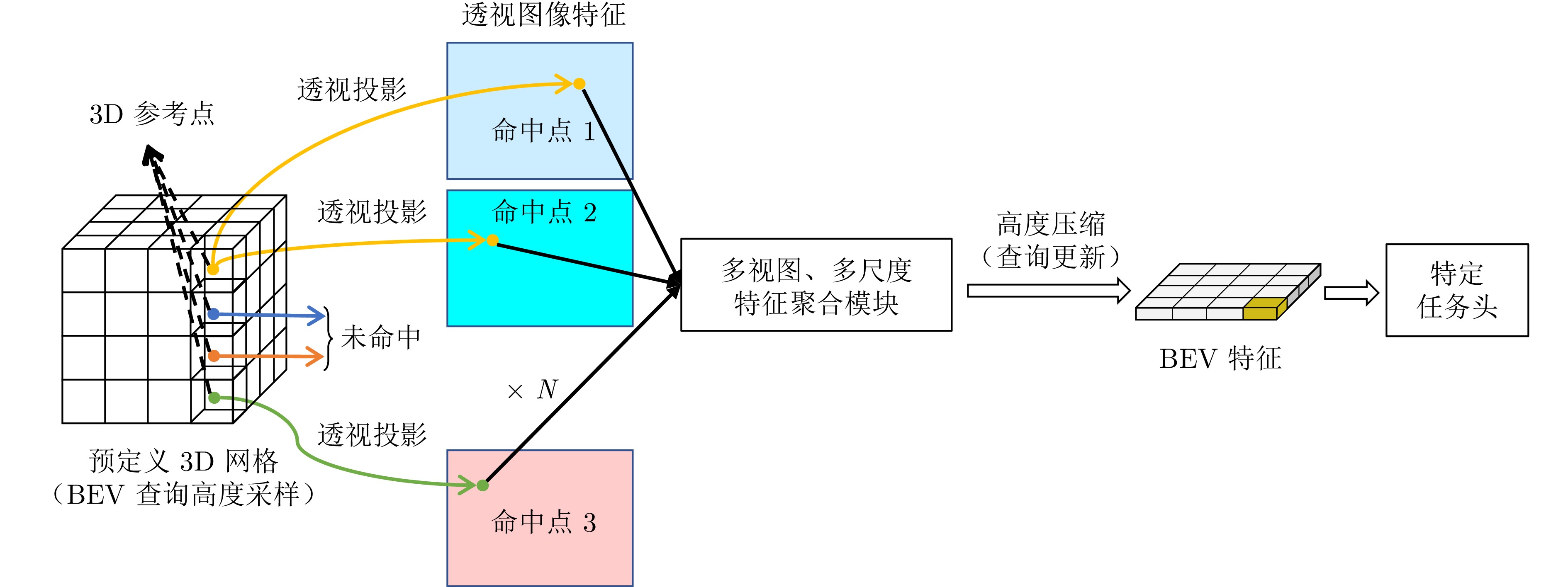
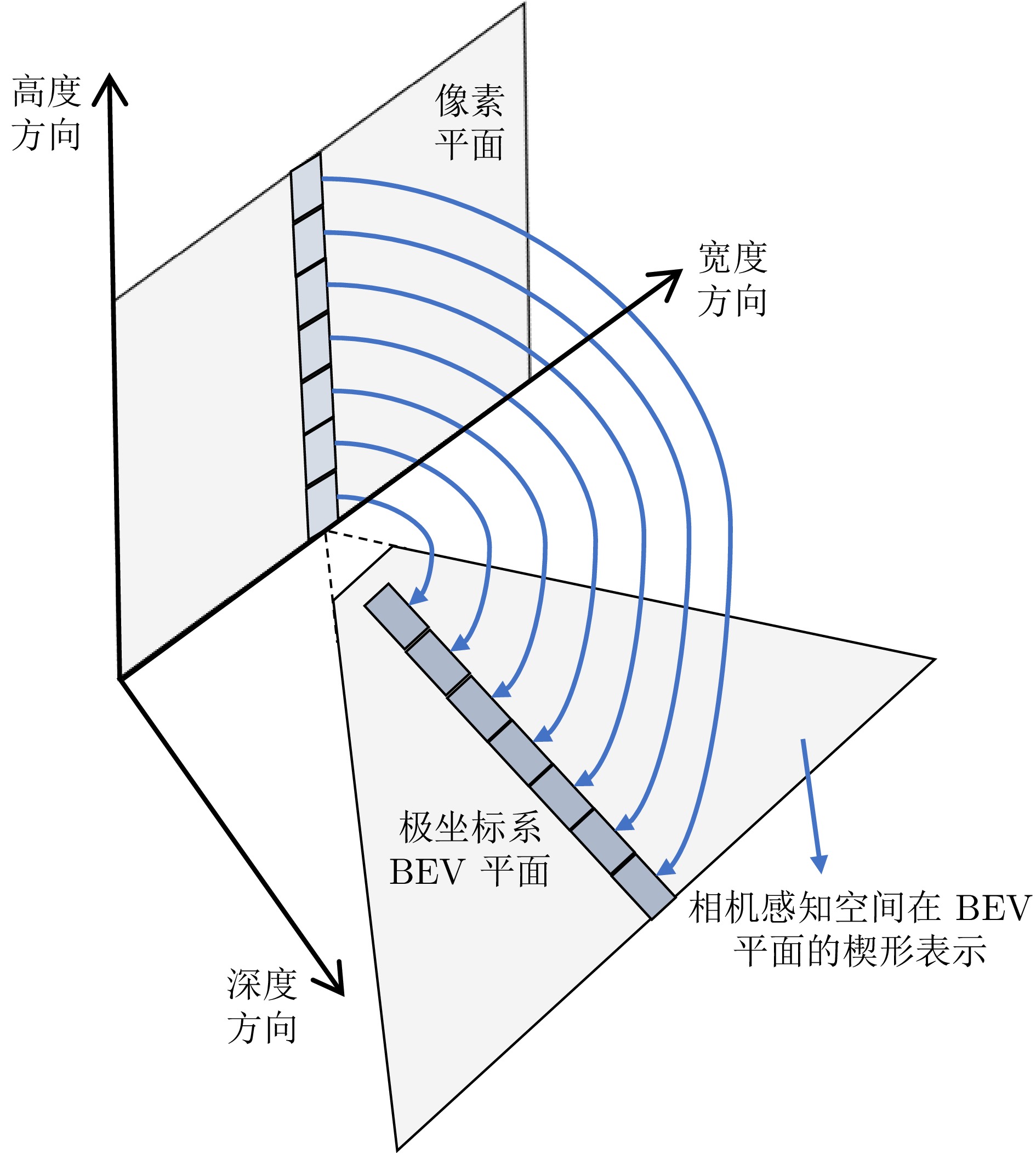
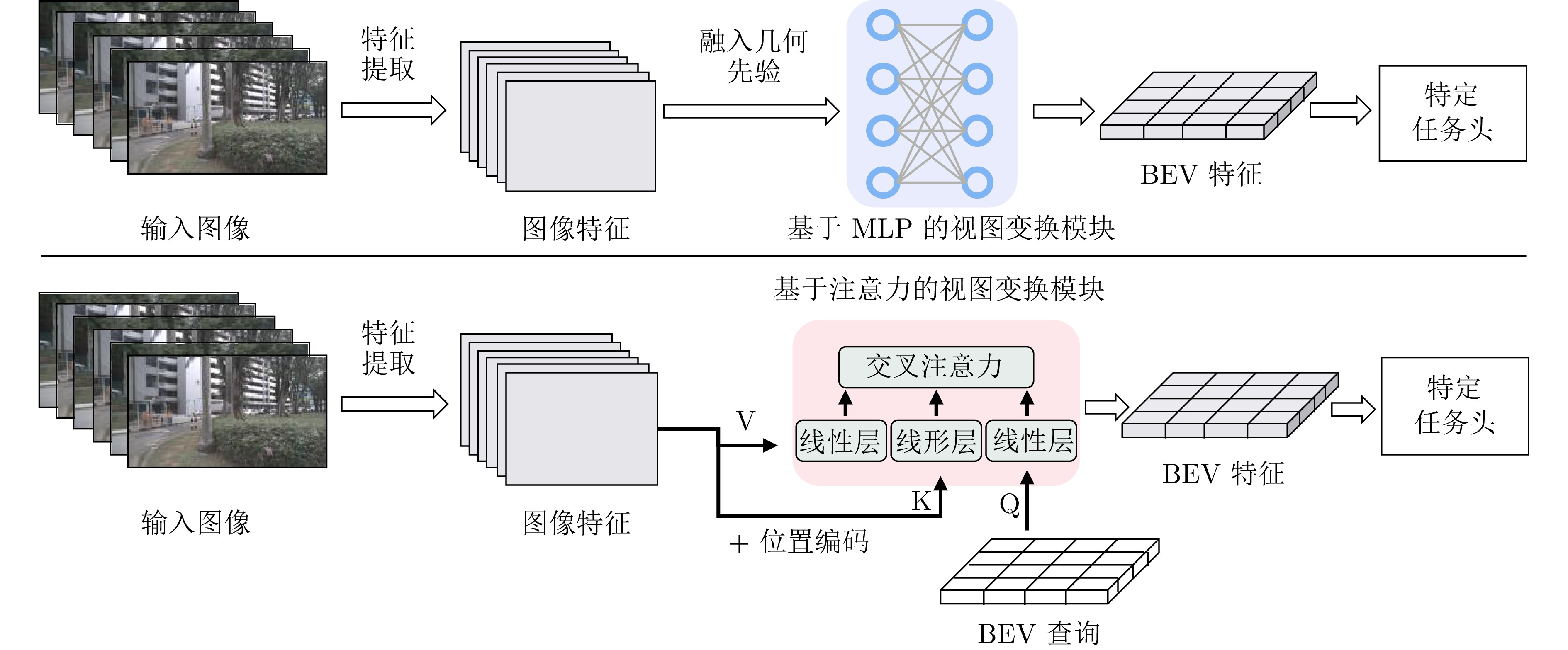
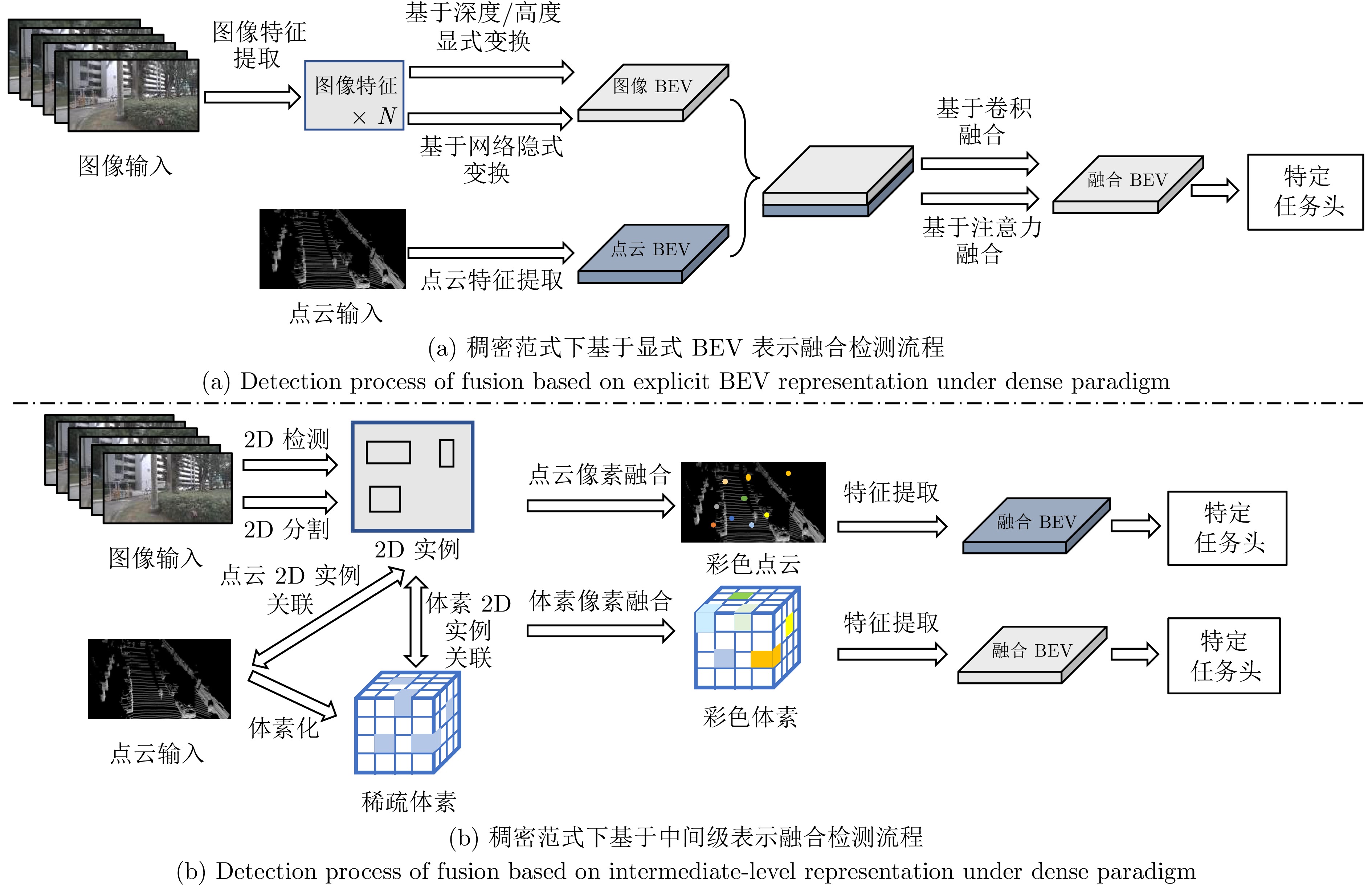
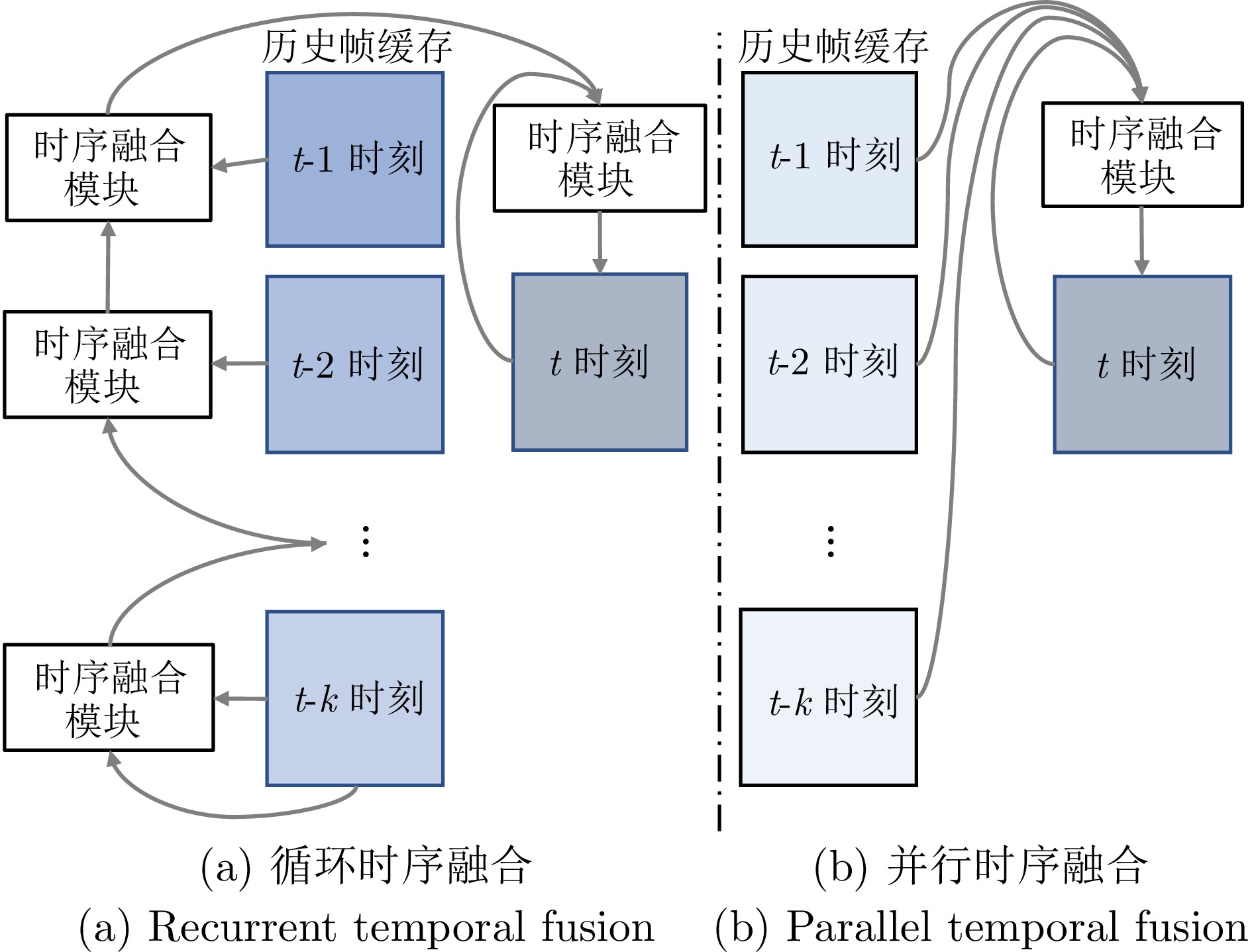
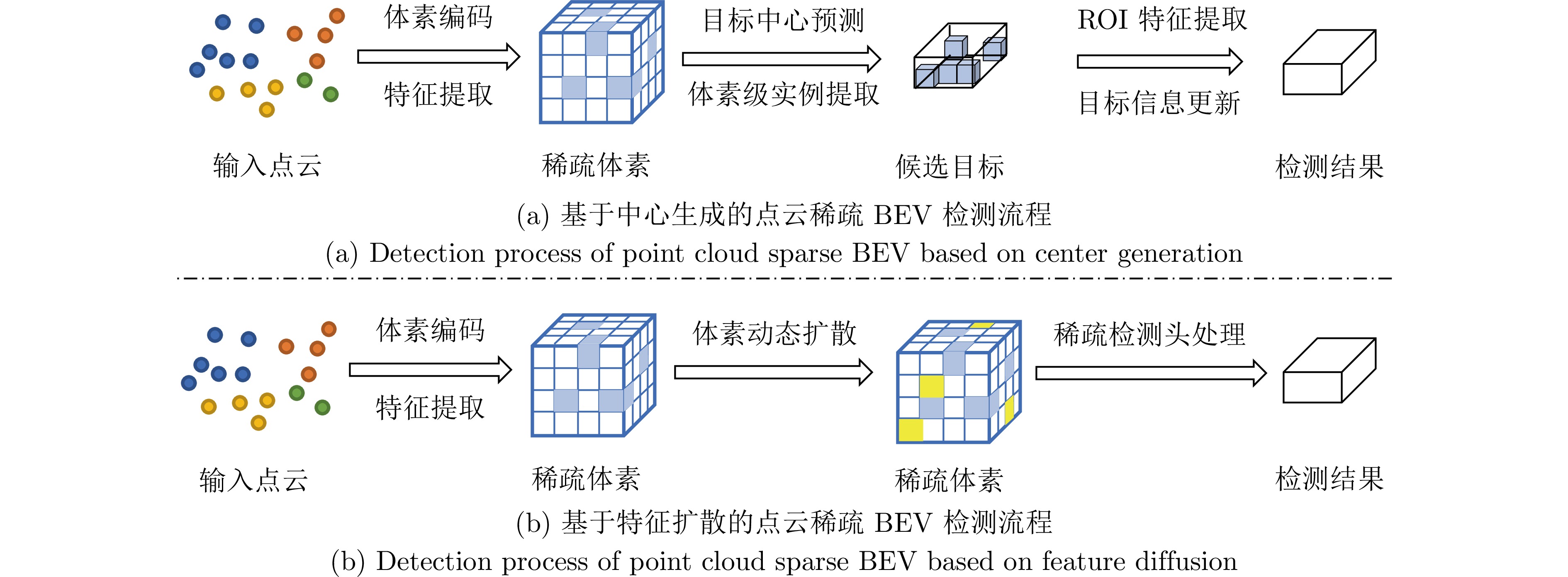
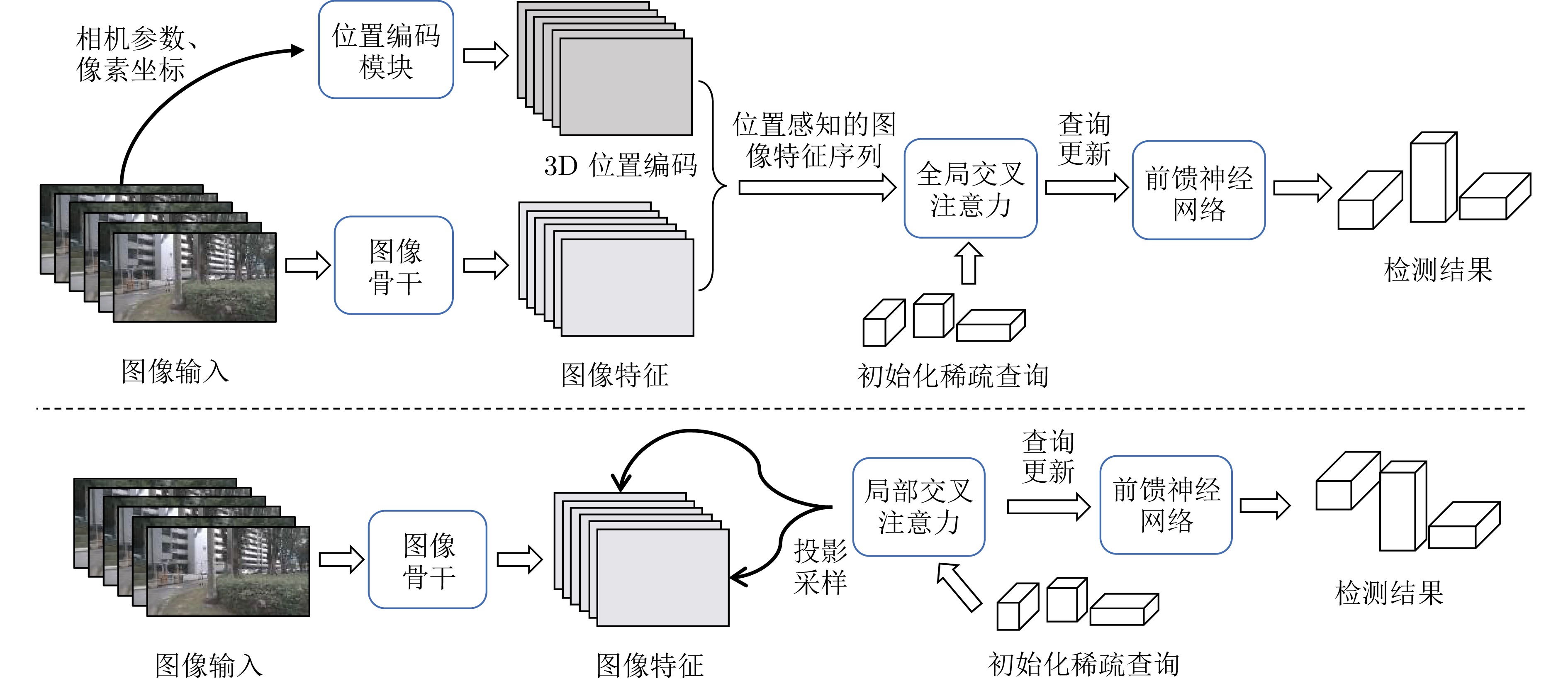
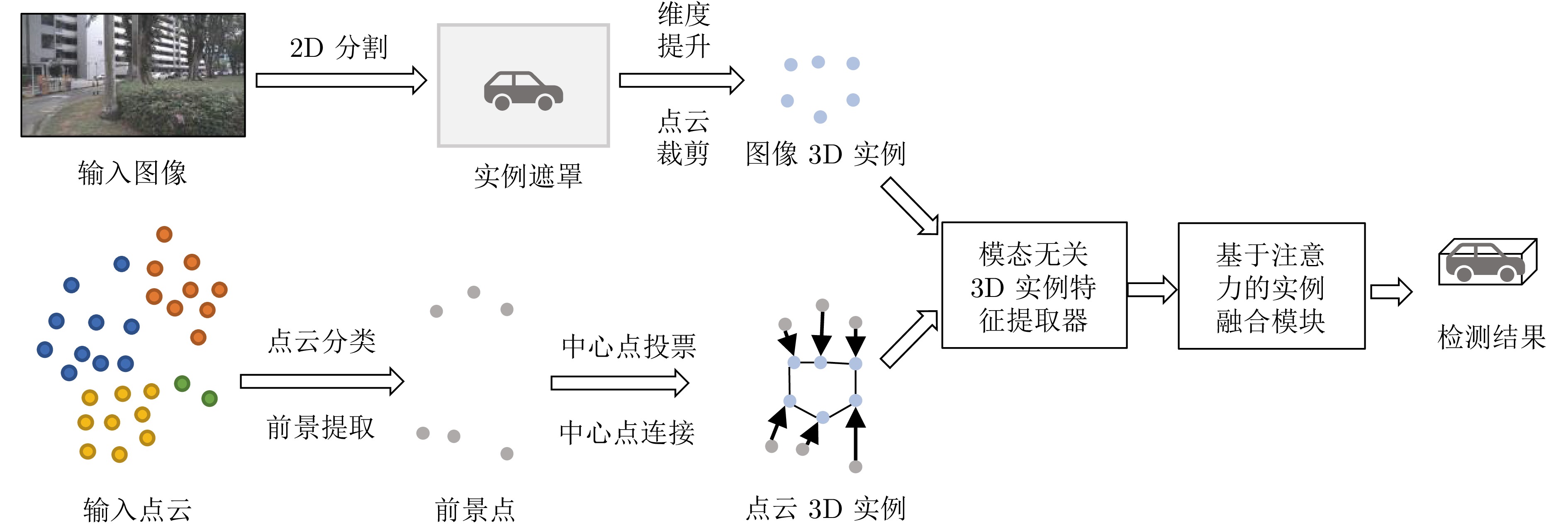
摘要:
本文研究了一类同时存在软、硬输出约束的不确定非线性系统跟踪控制问题. 其中, 安全相关的输出约束被建模为不可违背的硬约束, 而期望的跟踪性能则通过可调节的软约束加以刻画. 针对软、硬约束可能发生冲突的情形, 引入一种光滑过渡函数, 并基于此构造凸组合算子对软约束边界进行直接修正, 从而保证其与硬约束的兼容性. 在此基础上, 将硬约束与修正后的软约束进行统一整合, 构造具有光滑边界的约束结构. 基于该约束结构并结合漏斗控制技术, 提出一种低复杂度鲁棒控制算法, 确保系统同时满足硬约束与修正后的软约束. 与现有基于辅助动态系统的软约束间接调整方法不同, 所提策略无需引入额外动态系统, 从而得到结构简洁、易于实现的静态控制器. 此外, 在软、硬约束冲突发生时, 该方法能够将软约束的违背量严格限制在硬约束所必需的最小违背量之上的预设容差范围内, 且在有限时间内实现约束解耦, 优先确保硬约束的严格满足. 仿真结果验证了该方法的有效性.
本文研究了一类同时存在软、硬输出约束的不确定非线性系统跟踪控制问题. 其中, 安全相关的输出约束被建模为不可违背的硬约束, 而期望的跟踪性能则通过可调节的软约束加以刻画. 针对软、硬约束可能发生冲突的情形, 引入一种光滑过渡函数, 并基于此构造凸组合算子对软约束边界进行直接修正, 从而保证其与硬约束的兼容性. 在此基础上, 将硬约束与修正后的软约束进行统一整合, 构造具有光滑边界的约束结构. 基于该约束结构并结合漏斗控制技术, 提出一种低复杂度鲁棒控制算法, 确保系统同时满足硬约束与修正后的软约束. 与现有基于辅助动态系统的软约束间接调整方法不同, 所提策略无需引入额外动态系统, 从而得到结构简洁、易于实现的静态控制器. 此外, 在软、硬约束冲突发生时, 该方法能够将软约束的违背量严格限制在硬约束所必需的最小违背量之上的预设容差范围内, 且在有限时间内实现约束解耦, 优先确保硬约束的严格满足. 仿真结果验证了该方法的有效性.






摘要:
多智能体系统执行任务过程中需规避障碍、分布式交互信息, 以保证作业安全性、可靠性, 使得其作业空间受到防碰撞及障碍躲避的安全区域、通信连通性保持的智能体间有限相对位置约束. 为此, 本文研究在上述复杂空间约束下的多智能体预设时间一致性控制问题. 根据智能体与障碍物之间的安全距离, 区分多智能体系统作业过程为障碍规避模态及协同作业模态进行全作业过程描述. 在障碍规避模态, 除传统的智能体间及与障碍物碰撞安全距离约束外, 设计有通信距离约束的避障控制律, 保障在复杂空间障碍环境协同穿越情况下的作业安全性, 以及穿越障碍物后的分布式通信连通性, 防止协同避障后部分智能体断联、中断协同作业任务. 在协同作业模态, 针对传统有限时间稳定相关方法的收敛时间依赖系统初值的缺陷, 提出含时变增益的预设时间控制器设计方法, 实现在协同避障后初值不确定情况下的收敛时间预设, 提高了多智能体系统作业可靠性. 最后, 以二阶多智能体系统为例进行数值仿真, 验证了提出方法的有效性.
多智能体系统执行任务过程中需规避障碍、分布式交互信息, 以保证作业安全性、可靠性, 使得其作业空间受到防碰撞及障碍躲避的安全区域、通信连通性保持的智能体间有限相对位置约束. 为此, 本文研究在上述复杂空间约束下的多智能体预设时间一致性控制问题. 根据智能体与障碍物之间的安全距离, 区分多智能体系统作业过程为障碍规避模态及协同作业模态进行全作业过程描述. 在障碍规避模态, 除传统的智能体间及与障碍物碰撞安全距离约束外, 设计有通信距离约束的避障控制律, 保障在复杂空间障碍环境协同穿越情况下的作业安全性, 以及穿越障碍物后的分布式通信连通性, 防止协同避障后部分智能体断联、中断协同作业任务. 在协同作业模态, 针对传统有限时间稳定相关方法的收敛时间依赖系统初值的缺陷, 提出含时变增益的预设时间控制器设计方法, 实现在协同避障后初值不确定情况下的收敛时间预设, 提高了多智能体系统作业可靠性. 最后, 以二阶多智能体系统为例进行数值仿真, 验证了提出方法的有效性.















当前状态:
, 最新更新时间: ,
doi: 10.16383/j.aas.c260096
摘要:
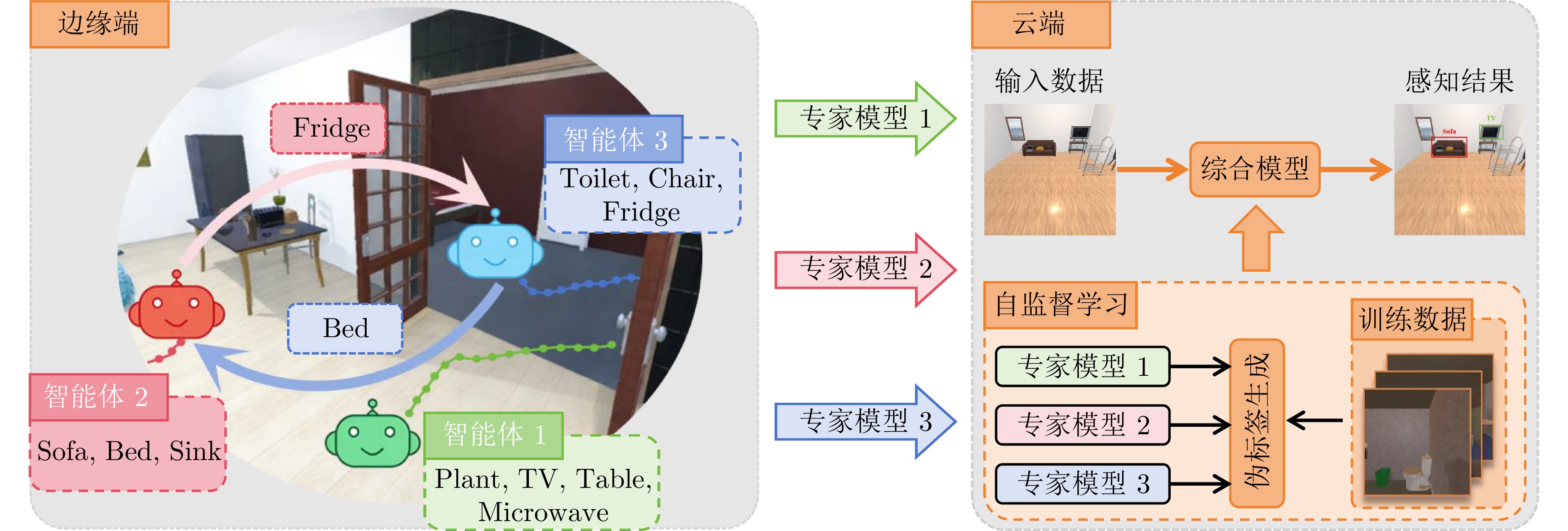
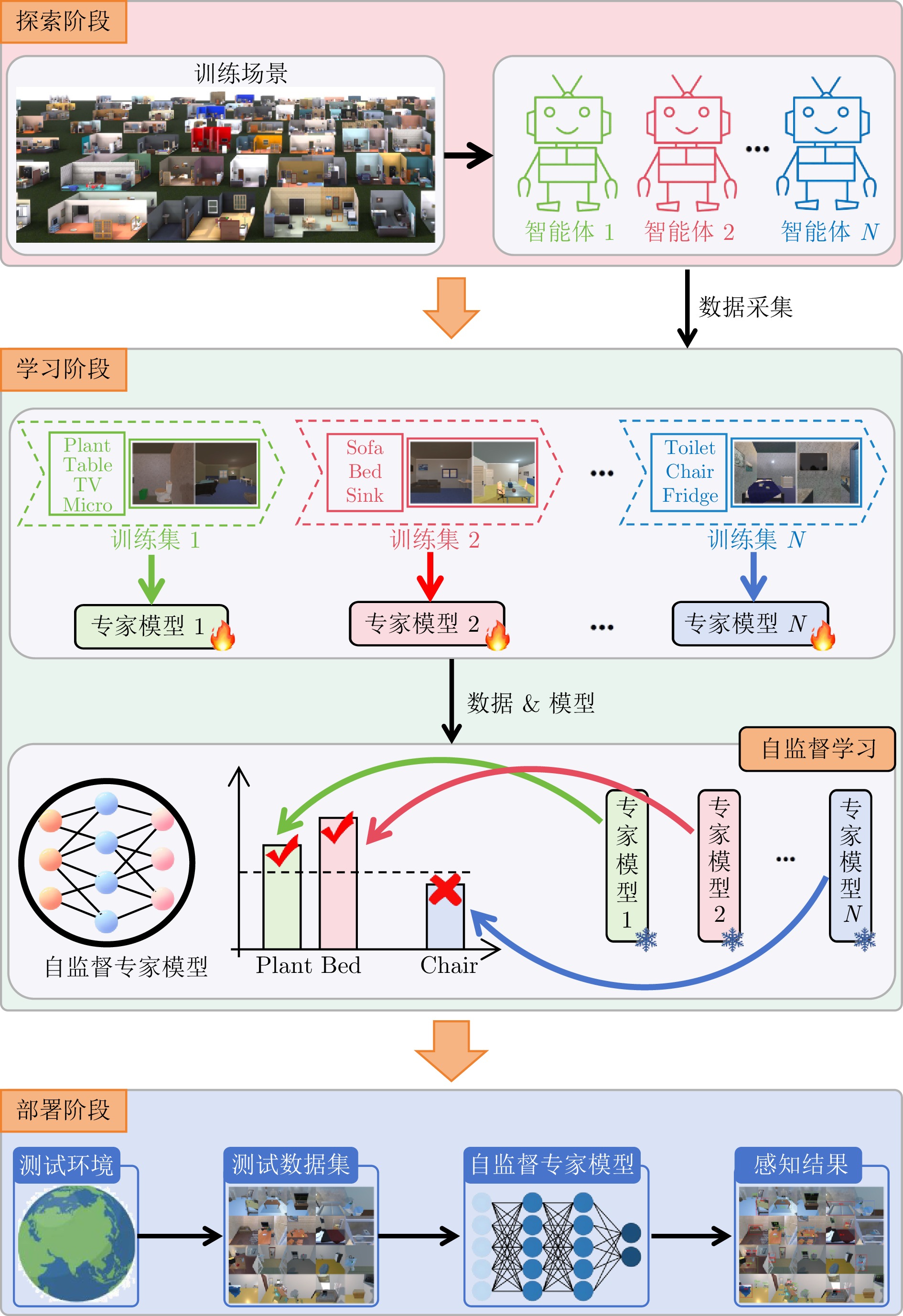
具身学习通过智能体与环境的主动交互与数据采集, 结合模型迭代更新, 实现自主智能. 然而, 随着环境复杂度和任务规模增加, 传统单智能体方法面临数据采集效率低、样本利用效率低、训练效率低等瓶颈, 严重制约了系统可扩展性. 针对上述问题, 提出一种云边协同的多智能体具身学习框架, 充分利用视觉?语言模型的高级推理能力, 在无需额外训练的前提下实现多智能体高效在线探索与协同数据采集. 具体地, 各智能体通过视觉?语言模型对观测数据及感知信息进行解析, 构建融合语义与空间状态的好奇心地图, 以指导短期目标选择, 实现语义驱动的高价值区域利用与空间驱动的未知区域探索的协同推进; 在短期探索任务完成后, 智能体能够基于全局空间状态与共享语义信息开展长期探索规划, 以保障探索的全面性与战略性. 所有智能体完成全场景探索后, 边缘端利用采集数据进行本地模型训练, 并将更新参数和少量数据上传云端, 由云端进行多源知识聚合, 生成全局优化模型. 实验结果表明, 所提方法显著优于基线方法, 为大规模复杂环境下多机器人自主智能学习提供新的有效范式.
具身学习通过智能体与环境的主动交互与数据采集, 结合模型迭代更新, 实现自主智能. 然而, 随着环境复杂度和任务规模增加, 传统单智能体方法面临数据采集效率低、样本利用效率低、训练效率低等瓶颈, 严重制约了系统可扩展性. 针对上述问题, 提出一种云边协同的多智能体具身学习框架, 充分利用视觉?语言模型的高级推理能力, 在无需额外训练的前提下实现多智能体高效在线探索与协同数据采集. 具体地, 各智能体通过视觉?语言模型对观测数据及感知信息进行解析, 构建融合语义与空间状态的好奇心地图, 以指导短期目标选择, 实现语义驱动的高价值区域利用与空间驱动的未知区域探索的协同推进; 在短期探索任务完成后, 智能体能够基于全局空间状态与共享语义信息开展长期探索规划, 以保障探索的全面性与战略性. 所有智能体完成全场景探索后, 边缘端利用采集数据进行本地模型训练, 并将更新参数和少量数据上传云端, 由云端进行多源知识聚合, 生成全局优化模型. 实验结果表明, 所提方法显著优于基线方法, 为大规模复杂环境下多机器人自主智能学习提供新的有效范式.
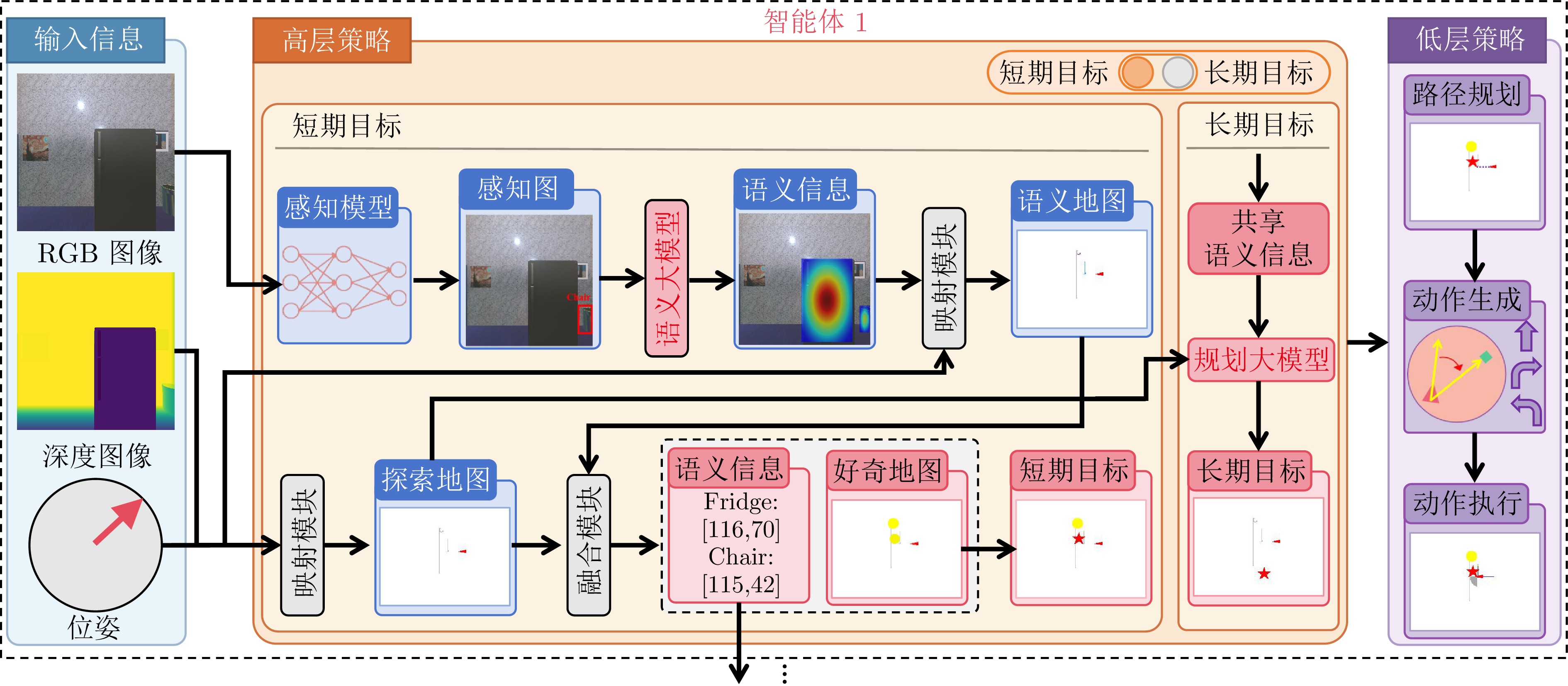
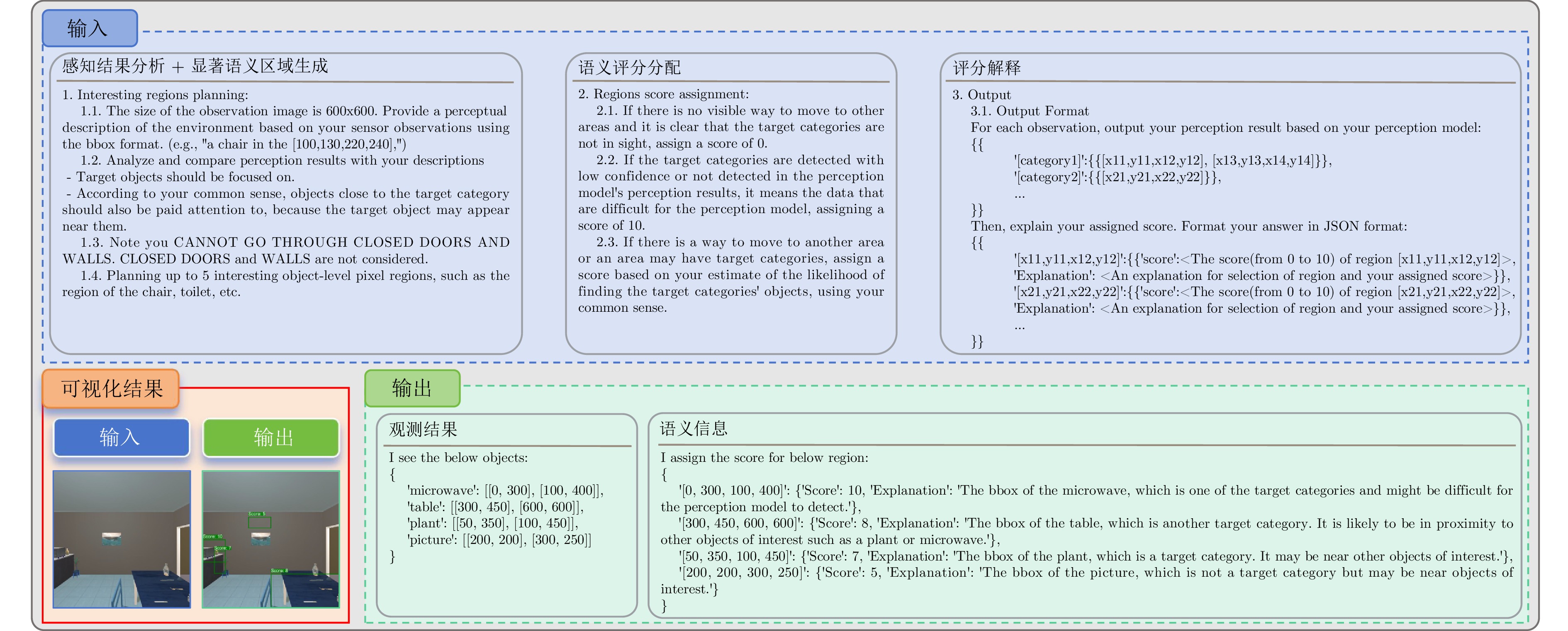





摘要:
针对基于萃取机理的稀土萃取工艺流程模拟难以符合实际萃取生产工况的问题, 提出一种基于多分支回归生成对抗网络的稀土萃取分离流程模拟方法, 实现稀土萃取分离各级萃取槽稀土元素组分含量的精准计算. 首先, 针对稀土萃取生产现场有效样本数量较少, 采用生成对抗网络(GAN)构造生成对抗模型, 依据稀土萃取工艺串级分离特点, 使用多分支深层网络构造GAN的生成器, 逐级学习萃取级间数据深层特征; 提出判别器与回归器的浅层特征共享机制, 回归器复用判别器首层卷积特征以提升预测性能, 并通过回归一致性约束以生成更真实的样本; 根据多分支网络结构特点, 设计一种递归渐近式对抗训练策略, 固定前一分支子GAN模型学习到的网络参数并作为下一分支子GAN的共同特征, 各分支子GAN内部生成器、判别器、回归器三者循环对抗训练, 在保证模型稳定收敛的同时, 精准捕捉级间耦合特征. 仿真结果表明了本文所提方法的有效性.
针对基于萃取机理的稀土萃取工艺流程模拟难以符合实际萃取生产工况的问题, 提出一种基于多分支回归生成对抗网络的稀土萃取分离流程模拟方法, 实现稀土萃取分离各级萃取槽稀土元素组分含量的精准计算. 首先, 针对稀土萃取生产现场有效样本数量较少, 采用生成对抗网络(GAN)构造生成对抗模型, 依据稀土萃取工艺串级分离特点, 使用多分支深层网络构造GAN的生成器, 逐级学习萃取级间数据深层特征; 提出判别器与回归器的浅层特征共享机制, 回归器复用判别器首层卷积特征以提升预测性能, 并通过回归一致性约束以生成更真实的样本; 根据多分支网络结构特点, 设计一种递归渐近式对抗训练策略, 固定前一分支子GAN模型学习到的网络参数并作为下一分支子GAN的共同特征, 各分支子GAN内部生成器、判别器、回归器三者循环对抗训练, 在保证模型稳定收敛的同时, 精准捕捉级间耦合特征. 仿真结果表明了本文所提方法的有效性.


















摘要:
动态点云视频时空耦合复杂, 现有端到端方法仅支持特定数据集与任务验证, 跨场景、跨任务泛化能力不足, 需重复训练. 为了能够挖掘可迁移的通用先验, 本文将研究视角重新聚焦于静态点云基础模型. 首先分析现有迁移学习方法存在的两大掣肘, 即密集计算与冗余设计. 为了实现轻量、紧凑的目标, 提出一种基于渐进式适配器的跨模态高效迁移学习方法. 该方法通过无重叠的3D滑动窗口注意力, 将自注意力复杂度由二次降为线性. 引入洗牌希尔伯特-Z序双向扫描曲线, 将动态点云视频约束为兼容Mamba的特征序列, 并以渐进式门控融合实现基础模型与新增适配器的高效协同. 整体方法不改变基础模型权重, 不依赖外部辅助设计. 在MSR-Action3D、HOI4D和SHREC'17上的实验结果表明, 仅微调1.8%参数即可获得超越现有基线模型的性能, 验证了该方法的优越性.
动态点云视频时空耦合复杂, 现有端到端方法仅支持特定数据集与任务验证, 跨场景、跨任务泛化能力不足, 需重复训练. 为了能够挖掘可迁移的通用先验, 本文将研究视角重新聚焦于静态点云基础模型. 首先分析现有迁移学习方法存在的两大掣肘, 即密集计算与冗余设计. 为了实现轻量、紧凑的目标, 提出一种基于渐进式适配器的跨模态高效迁移学习方法. 该方法通过无重叠的3D滑动窗口注意力, 将自注意力复杂度由二次降为线性. 引入洗牌希尔伯特-Z序双向扫描曲线, 将动态点云视频约束为兼容Mamba的特征序列, 并以渐进式门控融合实现基础模型与新增适配器的高效协同. 整体方法不改变基础模型权重, 不依赖外部辅助设计. 在MSR-Action3D、HOI4D和SHREC'17上的实验结果表明, 仅微调1.8%参数即可获得超越现有基线模型的性能, 验证了该方法的优越性.






摘要:
针对复杂动态场景下大规模无人集群拦截任务, 提出一种基于图注意力机制与动态分组的集群协同拦截框架. 现有基于规则或优化的方法在实时性、泛化性与目标分配效能方面存在局限, 而多智能体强化学习在复杂动态场景下面临维度爆炸、策略泛化性不足等挑战. 为提升复杂动态场景下集群拦截策略学习效率以及跨场景泛化能力, 创新性地设计了目标动态分组模块、图注意力模块与改进多智能体强化学习(MARL)模块, 并融合成一套闭环算法框架: 1)目标分组模块通过周期性聚类将敌方集群分解为低维战术小组, 敌方小组信息作为节点传输给图注意力模块, 降低状态-动作维度; 2)图注意力模块利用敌方小组节点信息, 基于图注意力网络进行特征融合并构建敌我智能体-小组间相对关系, 生成目标重要性权重以引导差异化奖励函数设计, 提升策略目标分配与泛化能力; 3)MARL模块结合差异化奖励函数与融合特征, 基于SAC算法与对抗性训练机制进行策略学习, 进一步增强策略泛化性. 仿真实验表明该框架显著提升复杂动态场景下集群拦截效率以及跨场景泛化能力.
针对复杂动态场景下大规模无人集群拦截任务, 提出一种基于图注意力机制与动态分组的集群协同拦截框架. 现有基于规则或优化的方法在实时性、泛化性与目标分配效能方面存在局限, 而多智能体强化学习在复杂动态场景下面临维度爆炸、策略泛化性不足等挑战. 为提升复杂动态场景下集群拦截策略学习效率以及跨场景泛化能力, 创新性地设计了目标动态分组模块、图注意力模块与改进多智能体强化学习(MARL)模块, 并融合成一套闭环算法框架: 1)目标分组模块通过周期性聚类将敌方集群分解为低维战术小组, 敌方小组信息作为节点传输给图注意力模块, 降低状态-动作维度; 2)图注意力模块利用敌方小组节点信息, 基于图注意力网络进行特征融合并构建敌我智能体-小组间相对关系, 生成目标重要性权重以引导差异化奖励函数设计, 提升策略目标分配与泛化能力; 3)MARL模块结合差异化奖励函数与融合特征, 基于SAC算法与对抗性训练机制进行策略学习, 进一步增强策略泛化性. 仿真实验表明该框架显著提升复杂动态场景下集群拦截效率以及跨场景泛化能力.







摘要:
针对高超声速变形飞行器在变形过程中面临的模型不确定性、强外部扰动及执行器饱和问题,提出一种复合控制方法. 该方法集成预设时间扰动观测器、抗饱和辅助系统与自适应动态规划.首先, 设计基于模糊系统的预设时间扰动观测器, 实现对集总扰动的快速精确估计与前馈补偿; 其次, 引入动态抗饱和辅助变量, 在控制量饱和后调整收敛轨迹从而减轻饱和, 并在饱和结束后引导系统收敛, 保障系统闭环稳定性; 进一步, 构建包含跟踪误差与控制能耗的综合代价函数, 采用自适应动态规划在线逼近最优控制律, 通过输入到状态稳定性理论证明闭环系统所有信号一致最终有界. 仿真结果表明, 所提控制方法在强扰动与执行器饱和条件下, 能实现姿态跟踪误差的预设时间收敛, 相比传统的抗扰控制与纯数据驱动方法, 具备更快的动态响应、更高的跟踪精度与更优的饱和抑制能力.
针对高超声速变形飞行器在变形过程中面临的模型不确定性、强外部扰动及执行器饱和问题,提出一种复合控制方法. 该方法集成预设时间扰动观测器、抗饱和辅助系统与自适应动态规划.首先, 设计基于模糊系统的预设时间扰动观测器, 实现对集总扰动的快速精确估计与前馈补偿; 其次, 引入动态抗饱和辅助变量, 在控制量饱和后调整收敛轨迹从而减轻饱和, 并在饱和结束后引导系统收敛, 保障系统闭环稳定性; 进一步, 构建包含跟踪误差与控制能耗的综合代价函数, 采用自适应动态规划在线逼近最优控制律, 通过输入到状态稳定性理论证明闭环系统所有信号一致最终有界. 仿真结果表明, 所提控制方法在强扰动与执行器饱和条件下, 能实现姿态跟踪误差的预设时间收敛, 相比传统的抗扰控制与纯数据驱动方法, 具备更快的动态响应、更高的跟踪精度与更优的饱和抑制能力.














摘要:
随着大语言模型的发展, 多智能体虚拟课堂正成为低风险教学实验与策略验证的重要工具. 然而, 现有方法往往忽视真实课堂中的话语结构、学生潜在状态与同伴交互机制, 缺乏对教学互动真实性及干预效果的系统建模与评估. 为此, 提出IRF-Smi框架: 以发起–应答–反馈话语链条约束教学对话, 结合第一视角潜在状态建模与小世界社交网络, 刻画师生行为的动态演化及同伴影响. 同时构建教学互动真实性评测基准, 并采用Pearson相关系数、组内相关系数及平均绝对误差对模拟结果进行量化评估. 在50节K-12课堂数据上的实验表明, IRF-Smi相比AutoGen与MetaGPT在师生行为分布一致性方面表现更优; 此外, 游戏化教学策略带来显著收益, 验证了该框架用于教学机制研究与智能体行为验证的潜力.
随着大语言模型的发展, 多智能体虚拟课堂正成为低风险教学实验与策略验证的重要工具. 然而, 现有方法往往忽视真实课堂中的话语结构、学生潜在状态与同伴交互机制, 缺乏对教学互动真实性及干预效果的系统建模与评估. 为此, 提出IRF-Smi框架: 以发起–应答–反馈话语链条约束教学对话, 结合第一视角潜在状态建模与小世界社交网络, 刻画师生行为的动态演化及同伴影响. 同时构建教学互动真实性评测基准, 并采用Pearson相关系数、组内相关系数及平均绝对误差对模拟结果进行量化评估. 在50节K-12课堂数据上的实验表明, IRF-Smi相比AutoGen与MetaGPT在师生行为分布一致性方面表现更优; 此外, 游戏化教学策略带来显著收益, 验证了该框架用于教学机制研究与智能体行为验证的潜力.














摘要:
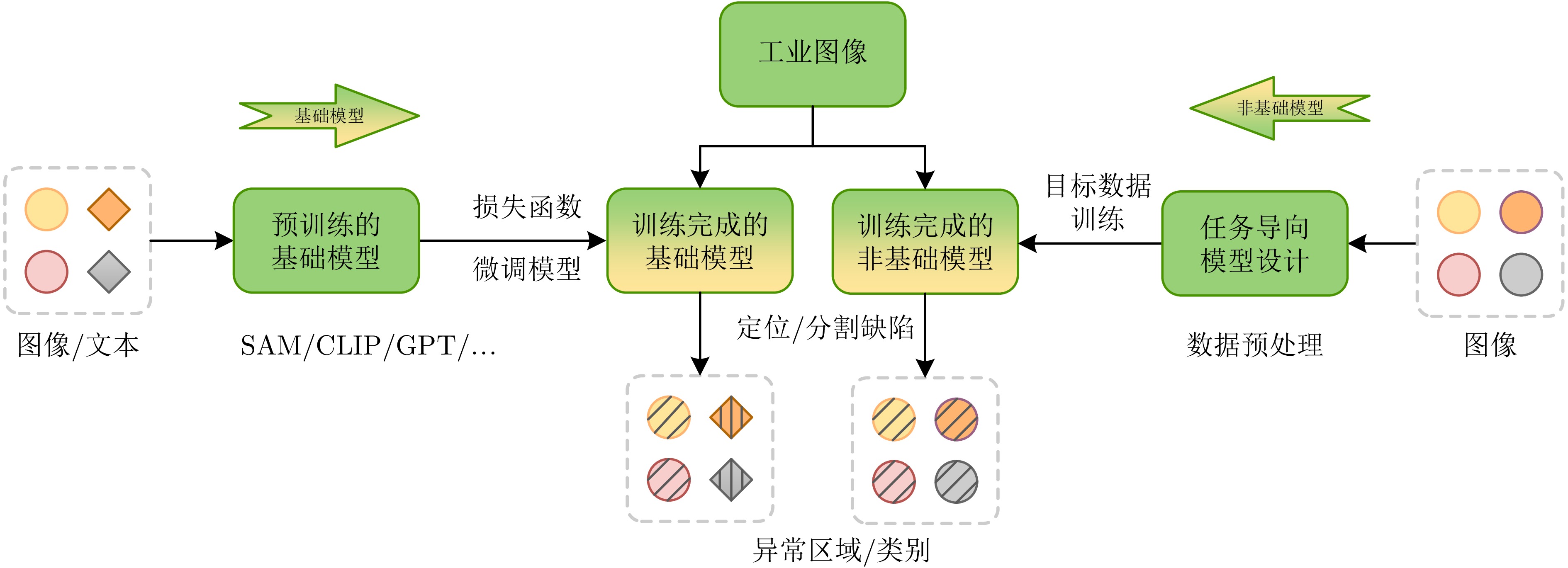
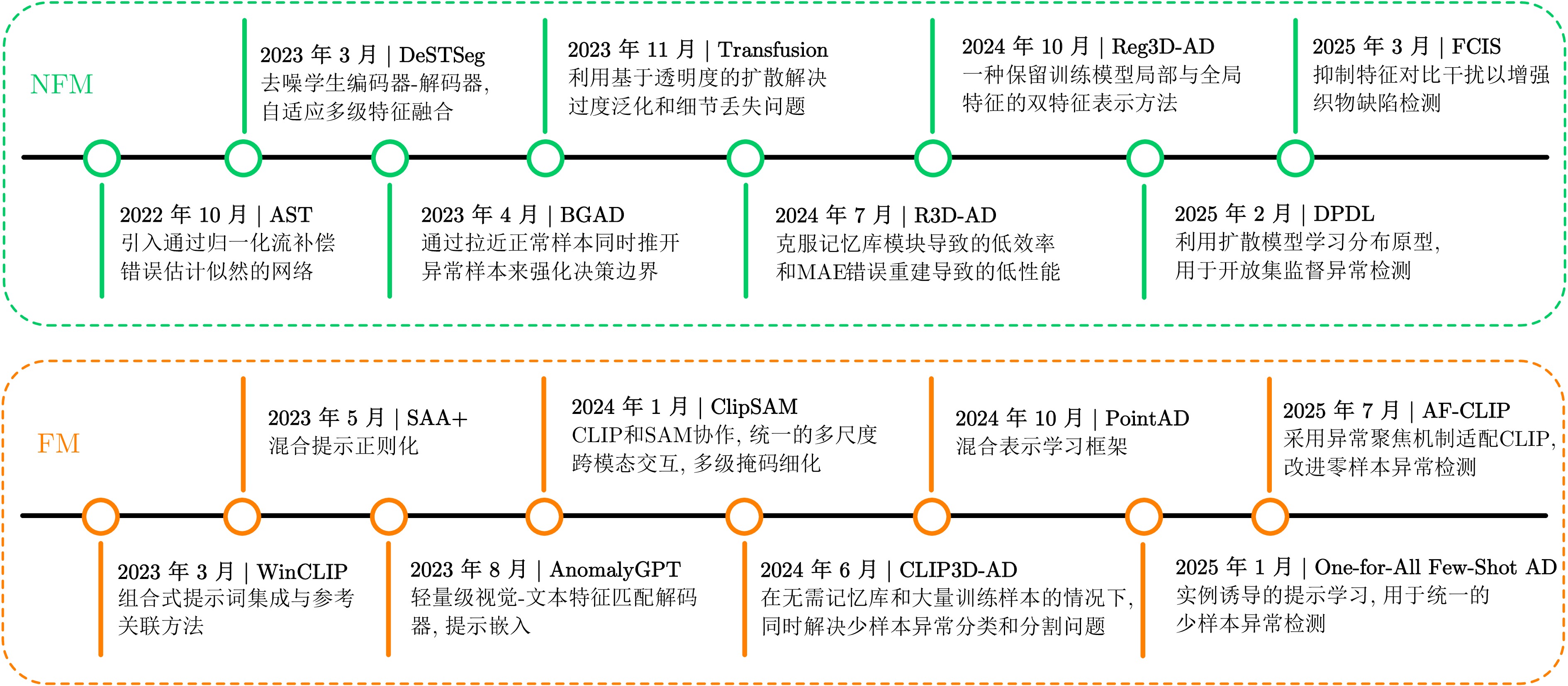
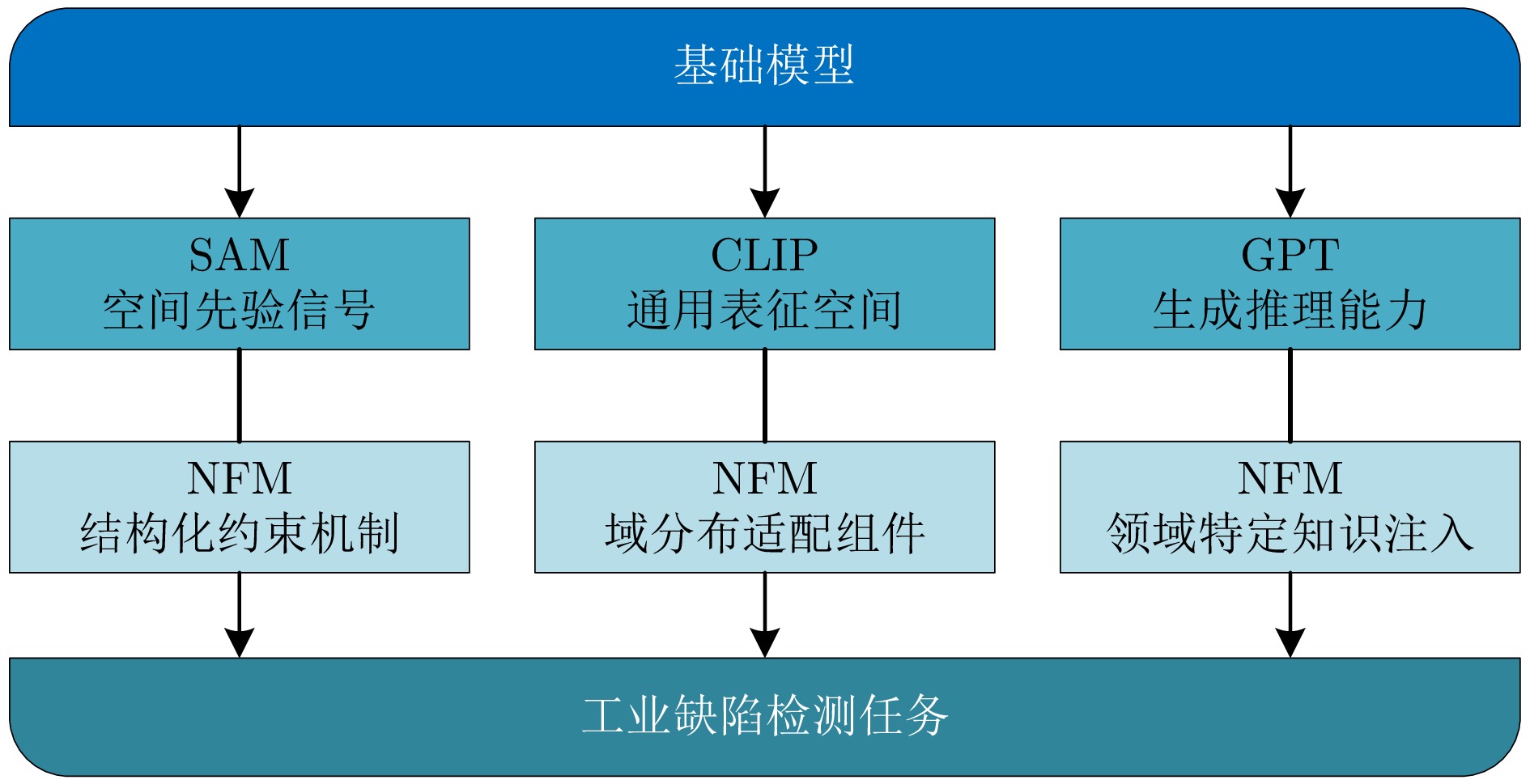
随着工业产品日益丰富且精密复杂, 视觉工业缺陷检测技术备受关注. 近年来, 基础模型(FM)凭借其从海量数据中获取的广博先验知识, 在泛化能力及少样本与零样本场景中展现出强大的潜力. 然而, 梳理现有方法可以发现一个值得关注的现象:当前许多先进的FM方法, 其性能的显著提升并非单纯依赖FM的应用, 而是通过将FM强大的通用表征能力与非基础模型(NFM)方法中成熟、高效的任务导向型原理(例如对比学习、知识蒸馏和异常合成)进行战略性融合. 为系统性地分析并揭示这一协同范式, 首先分别对NFM和FM方法进行系统性综述, 并从多维度比较两种方法, 分析各自的优势与局限. 在此基础上, 深入剖析NFM策略如何从其原始架构中解耦出来, 并被重新用于增强基础模型在工业应用中的性能, 同时构建协同机制适配性矩阵. 此外, 进一步探讨该范式在实际场景中的落地局限. 在对比数据的支持下, 分析结果表明, FM的通用知识与NFM的任务特化优势之间存在巨大的协同潜力, 这为未来的研究指明一条有效的借鉴思路.
随着工业产品日益丰富且精密复杂, 视觉工业缺陷检测技术备受关注. 近年来, 基础模型(FM)凭借其从海量数据中获取的广博先验知识, 在泛化能力及少样本与零样本场景中展现出强大的潜力. 然而, 梳理现有方法可以发现一个值得关注的现象:当前许多先进的FM方法, 其性能的显著提升并非单纯依赖FM的应用, 而是通过将FM强大的通用表征能力与非基础模型(NFM)方法中成熟、高效的任务导向型原理(例如对比学习、知识蒸馏和异常合成)进行战略性融合. 为系统性地分析并揭示这一协同范式, 首先分别对NFM和FM方法进行系统性综述, 并从多维度比较两种方法, 分析各自的优势与局限. 在此基础上, 深入剖析NFM策略如何从其原始架构中解耦出来, 并被重新用于增强基础模型在工业应用中的性能, 同时构建协同机制适配性矩阵. 此外, 进一步探讨该范式在实际场景中的落地局限. 在对比数据的支持下, 分析结果表明, FM的通用知识与NFM的任务特化优势之间存在巨大的协同潜力, 这为未来的研究指明一条有效的借鉴思路.
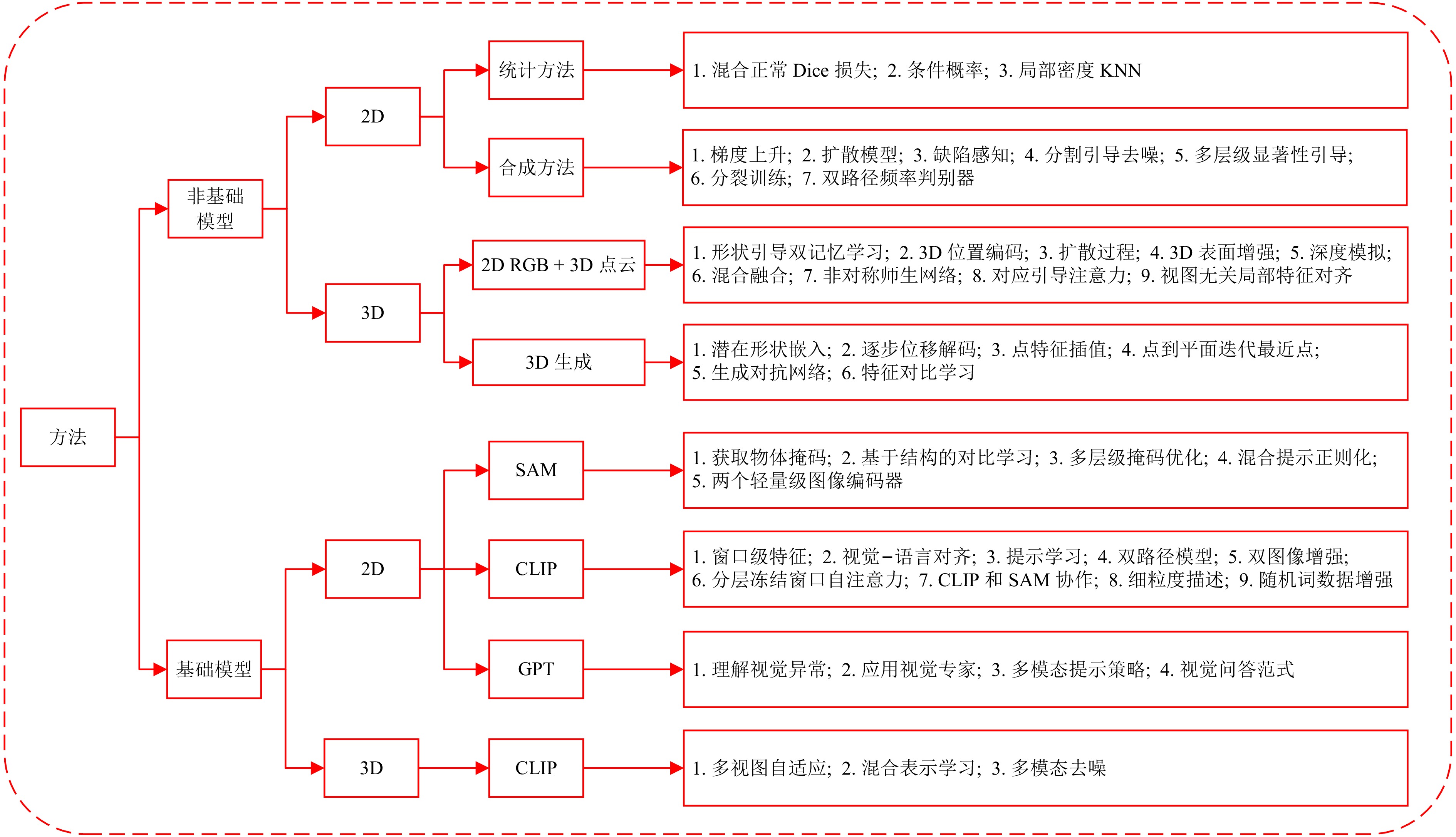
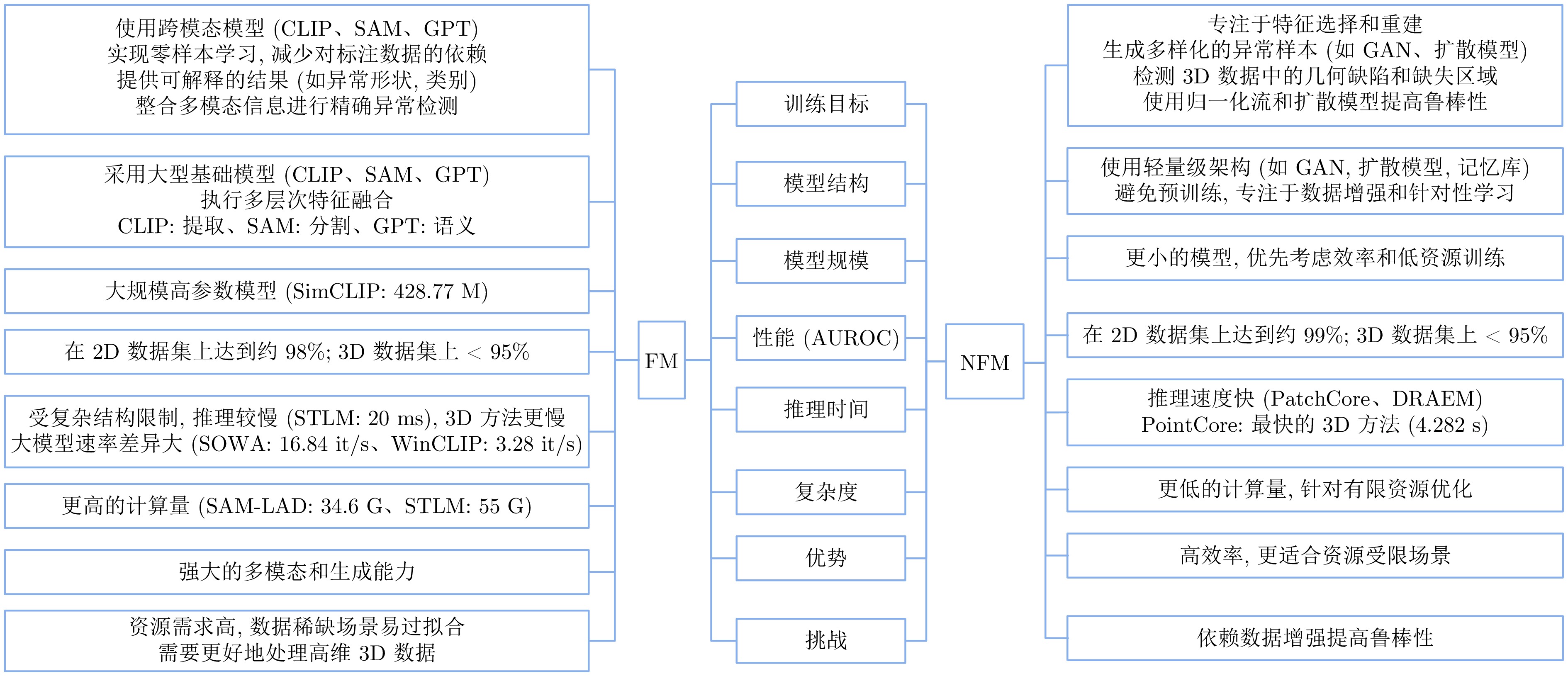

摘要:
针对多无人机在多重约束下的协同任务分配问题, 提出一种面向多无人机协同任务分配的多策略融合海鸥优化算法(MFSOA). 该算法由时间代价、能耗代价、负载均衡、任务时序及多约束条件构建多无人机协同任务分配目标优化模型. 为提升算法寻优效率, 采用Tent混沌映射增强种群多样性, 结合精英进化策略优化迭代过程中的种群质量; 通过设计多方向自适应迁徙策略增强算法全局寻优能力, 避免算法陷入局部最优; 构建基于精英个体的攻击策略平衡算法的全局探索与局部开发能力, 提升算法的寻优稳定性. 实验结果表明, MFSOA在多场景下均表现出优异的综合性能, 其寻优能力相较对比算法提升约3%~13%, 验证了该算法求解多无人机协同任务分配问题的有效性与可靠性.
针对多无人机在多重约束下的协同任务分配问题, 提出一种面向多无人机协同任务分配的多策略融合海鸥优化算法(MFSOA). 该算法由时间代价、能耗代价、负载均衡、任务时序及多约束条件构建多无人机协同任务分配目标优化模型. 为提升算法寻优效率, 采用Tent混沌映射增强种群多样性, 结合精英进化策略优化迭代过程中的种群质量; 通过设计多方向自适应迁徙策略增强算法全局寻优能力, 避免算法陷入局部最优; 构建基于精英个体的攻击策略平衡算法的全局探索与局部开发能力, 提升算法的寻优稳定性. 实验结果表明, MFSOA在多场景下均表现出优异的综合性能, 其寻优能力相较对比算法提升约3%~13%, 验证了该算法求解多无人机协同任务分配问题的有效性与可靠性.










摘要:
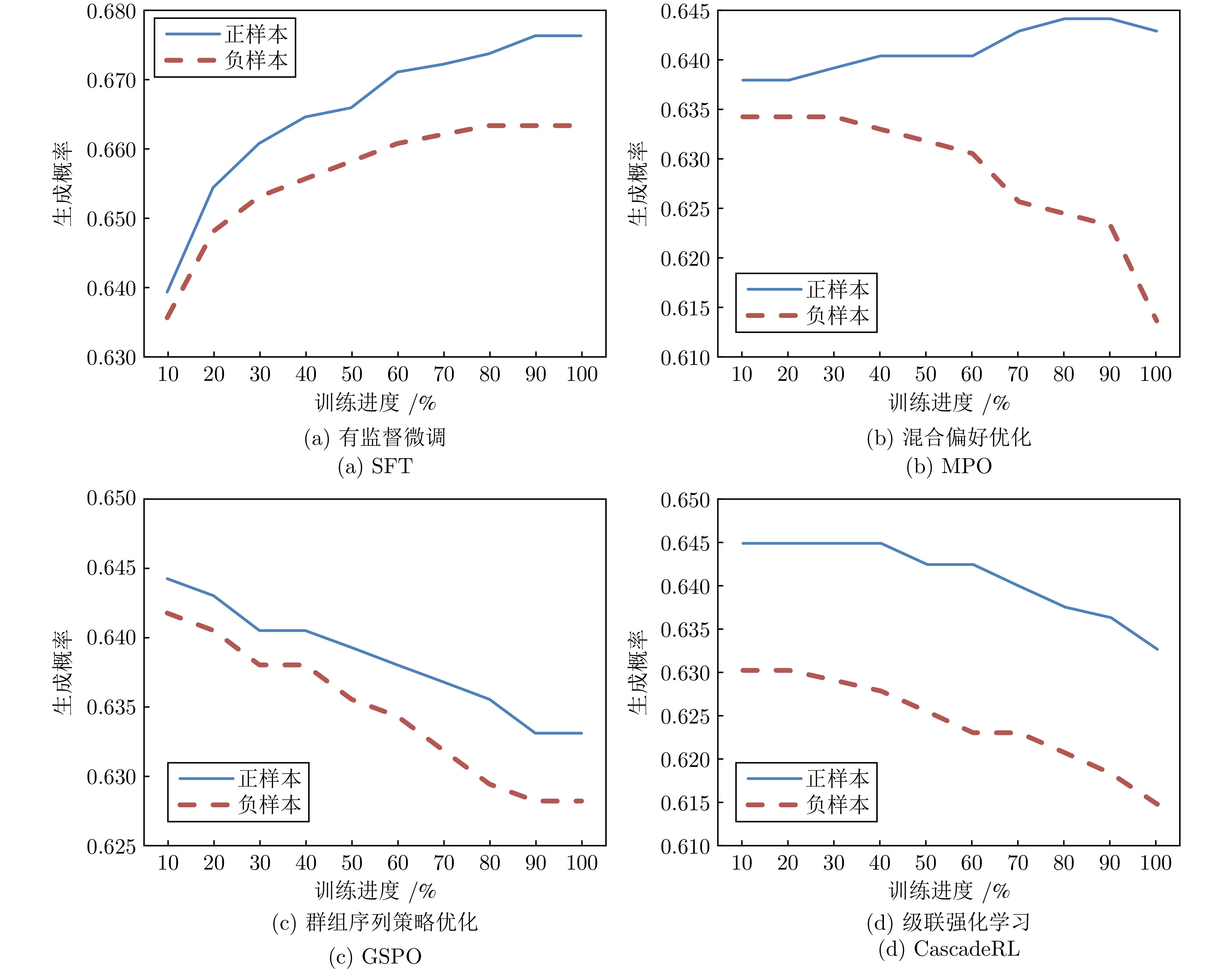
强化学习在提升多模态大语言模型的推理能力上展现出巨大潜力, 逐渐成为模型训练过程中的关键步骤. 然而, 在线强化学习算法需要策略模型在训练过程中实时采样, 且收敛速度较慢, 因此训练成本昂贵; 离线强化学习虽然整体成本更低, 但是也牺牲了性能上限. 本文尝试将离线强化学习训练成本低的特性与在线强化学习性能上限高的优势相结合, 提出一种新的训练策略--级联强化学习. 这套训练策略包含离线强化学习和在线强化学习两个训练阶段, 其中离线强化学习阶段用于加速模型收敛并提升后续训练的稳定性; 在线强化学习阶段对模型进行了更精细的训练, 进一步提升其性能上限. 本文通过一系列定量分析实验证明了相比单一的在线强化学习算法, 级联强化学习可以通过一半的训练成本达到更高的性能上限. 这种简单有效的训练策略将InternVL3.5-8B-Instruct和InternVL3.5-241B-A28B-Instruct在七个多模态推理评测基准上的平均准确率分别提升了6.7%和6.5%, 证明了这一策略的有效性和可扩展性.
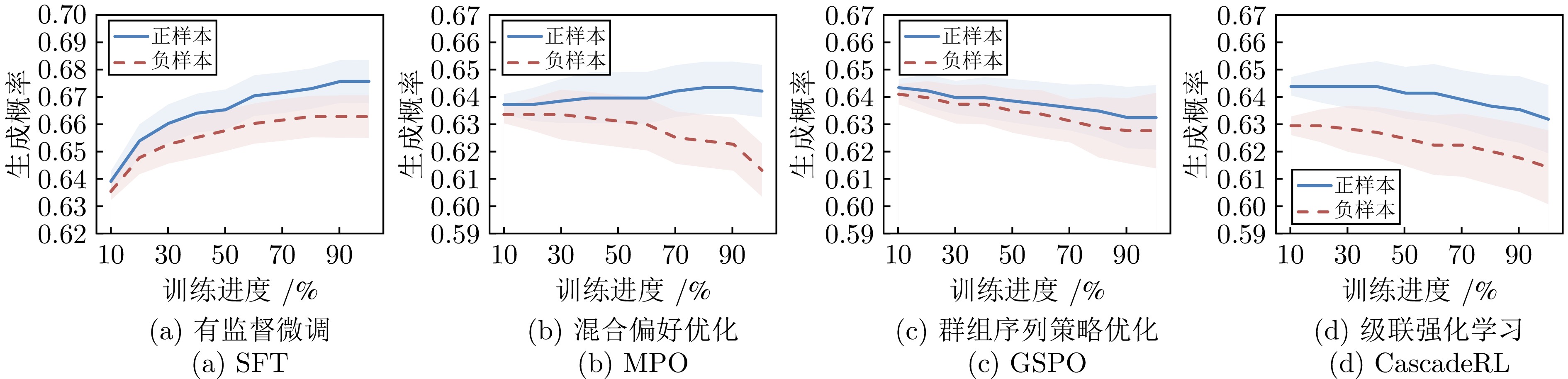
强化学习在提升多模态大语言模型的推理能力上展现出巨大潜力, 逐渐成为模型训练过程中的关键步骤. 然而, 在线强化学习算法需要策略模型在训练过程中实时采样, 且收敛速度较慢, 因此训练成本昂贵; 离线强化学习虽然整体成本更低, 但是也牺牲了性能上限. 本文尝试将离线强化学习训练成本低的特性与在线强化学习性能上限高的优势相结合, 提出一种新的训练策略--级联强化学习. 这套训练策略包含离线强化学习和在线强化学习两个训练阶段, 其中离线强化学习阶段用于加速模型收敛并提升后续训练的稳定性; 在线强化学习阶段对模型进行了更精细的训练, 进一步提升其性能上限. 本文通过一系列定量分析实验证明了相比单一的在线强化学习算法, 级联强化学习可以通过一半的训练成本达到更高的性能上限. 这种简单有效的训练策略将InternVL3.5-8B-Instruct和InternVL3.5-241B-A28B-Instruct在七个多模态推理评测基准上的平均准确率分别提升了6.7%和6.5%, 证明了这一策略的有效性和可扩展性.



摘要:
大规模预训练模型已经在自然语言处理等领域展现出强大的能力. 为更好地适配下游任务, 微调预训练模型是一个常用的方法. 然而, 大模型的全参数微调面临计算成本高昂、存储需求巨大等严峻挑战. 参数高效微调(PEFT)作为解决这些问题的关键技术范式, 仅引入或选择极少量可训练参数, 在显著降低计算和存储开销的同时, 有效保持模型的能力. 该综述系统梳理PEFT领域的主流方法体系、关键技术进展与发展趋势. 首先, 将现有方法归纳为四大范式: 添加式、局部式、重参数化式以及融合式, 并深入剖析各类方法的核心机理、性能特征、应用场景及策略优势. 进而, 重点探讨PEFT的技术演进, 从技术变化中分析出现该发展的内在本质规律, 总结出PEFT 方法从单一方法创新向存储、计算、性能三元权衡, 以及自动化、智能化、软硬件协同等统一框架发展的技术趋势. 更进一步, 该综述对各类PEFT中的代表性方法进行系统性的定量比较, 在统一的模型与数据集上评估其性能与参数效率. 此外, 本综述还涵盖PEFT 技术在视觉、语音及跨模态模型等领域的拓展应用, 展现其广泛的适用性. 最后, 总结并探讨未来研究方向, 以推动更高效、更适应多样化任务的大型模型微调技术的发展.
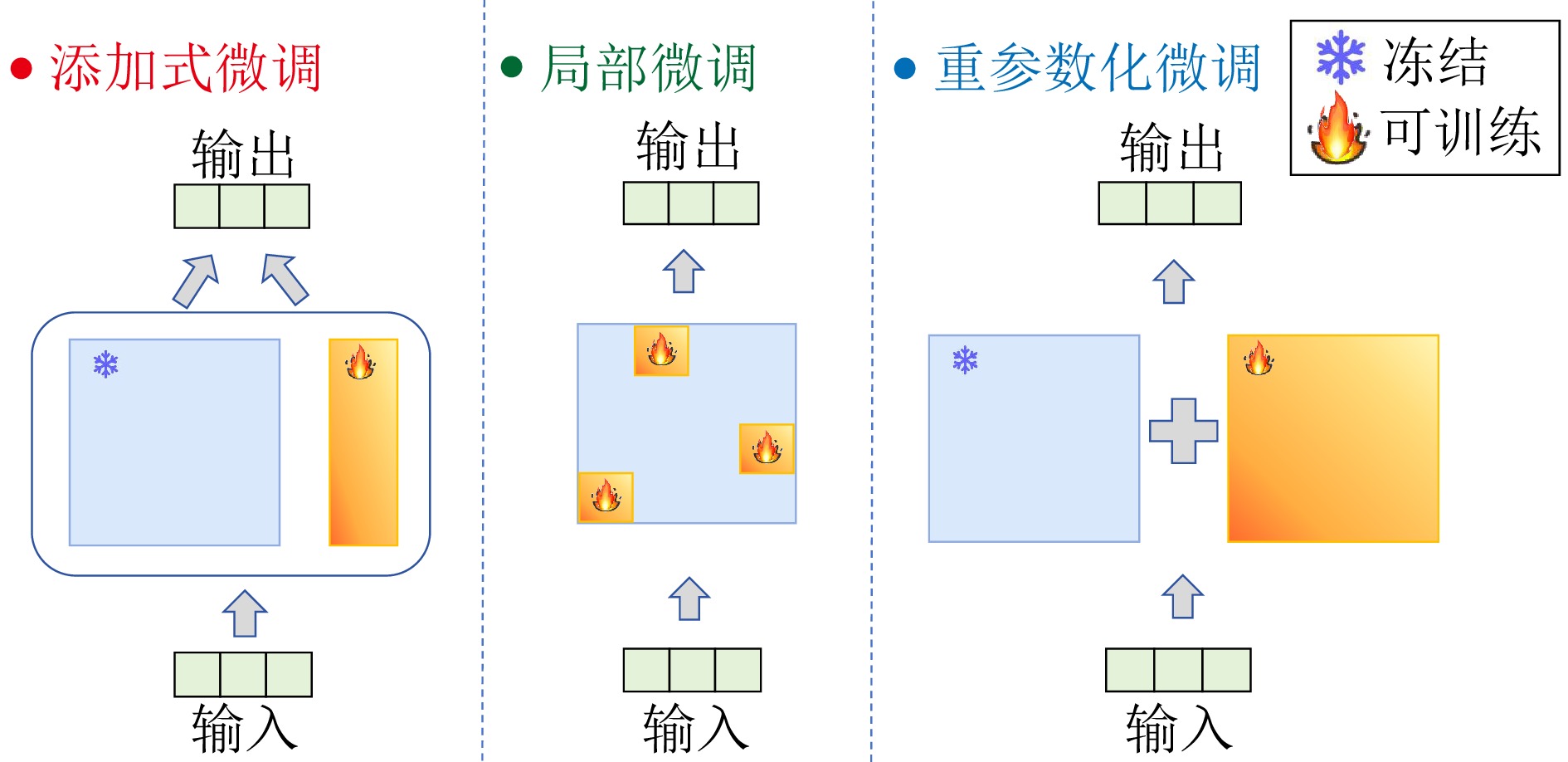
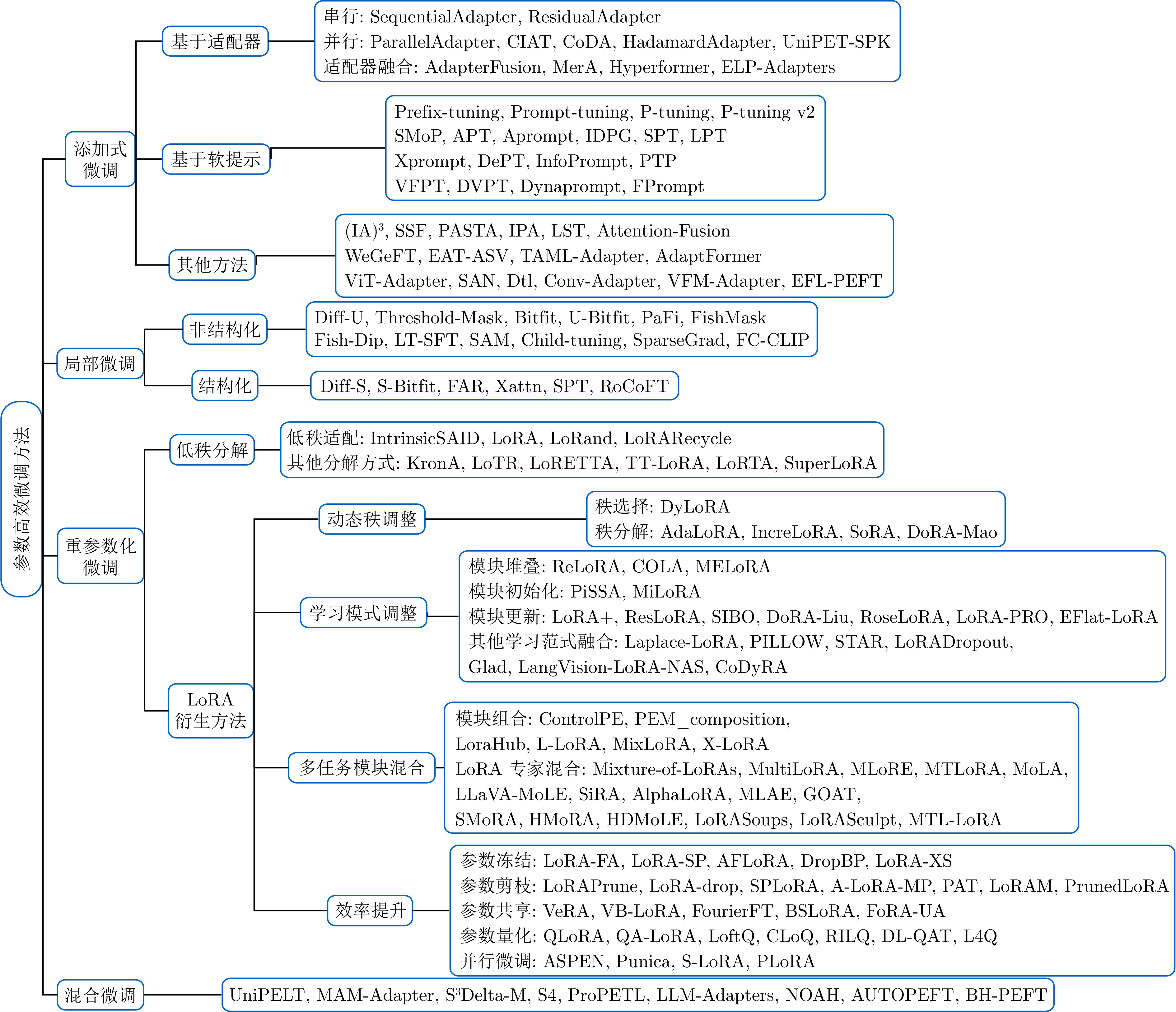
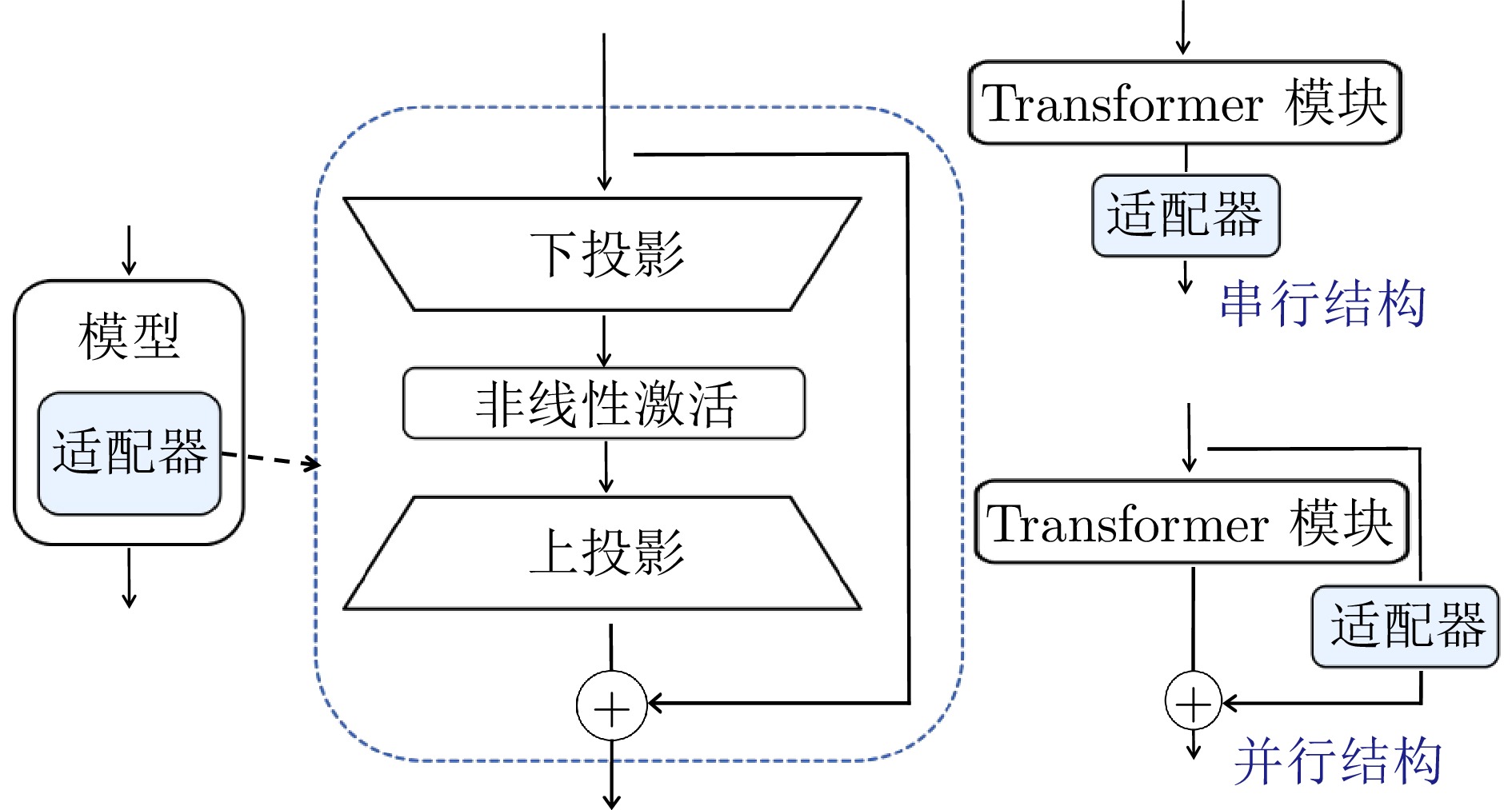
大规模预训练模型已经在自然语言处理等领域展现出强大的能力. 为更好地适配下游任务, 微调预训练模型是一个常用的方法. 然而, 大模型的全参数微调面临计算成本高昂、存储需求巨大等严峻挑战. 参数高效微调(PEFT)作为解决这些问题的关键技术范式, 仅引入或选择极少量可训练参数, 在显著降低计算和存储开销的同时, 有效保持模型的能力. 该综述系统梳理PEFT领域的主流方法体系、关键技术进展与发展趋势. 首先, 将现有方法归纳为四大范式: 添加式、局部式、重参数化式以及融合式, 并深入剖析各类方法的核心机理、性能特征、应用场景及策略优势. 进而, 重点探讨PEFT的技术演进, 从技术变化中分析出现该发展的内在本质规律, 总结出PEFT 方法从单一方法创新向存储、计算、性能三元权衡, 以及自动化、智能化、软硬件协同等统一框架发展的技术趋势. 更进一步, 该综述对各类PEFT中的代表性方法进行系统性的定量比较, 在统一的模型与数据集上评估其性能与参数效率. 此外, 本综述还涵盖PEFT 技术在视觉、语音及跨模态模型等领域的拓展应用, 展现其广泛的适用性. 最后, 总结并探讨未来研究方向, 以推动更高效、更适应多样化任务的大型模型微调技术的发展.
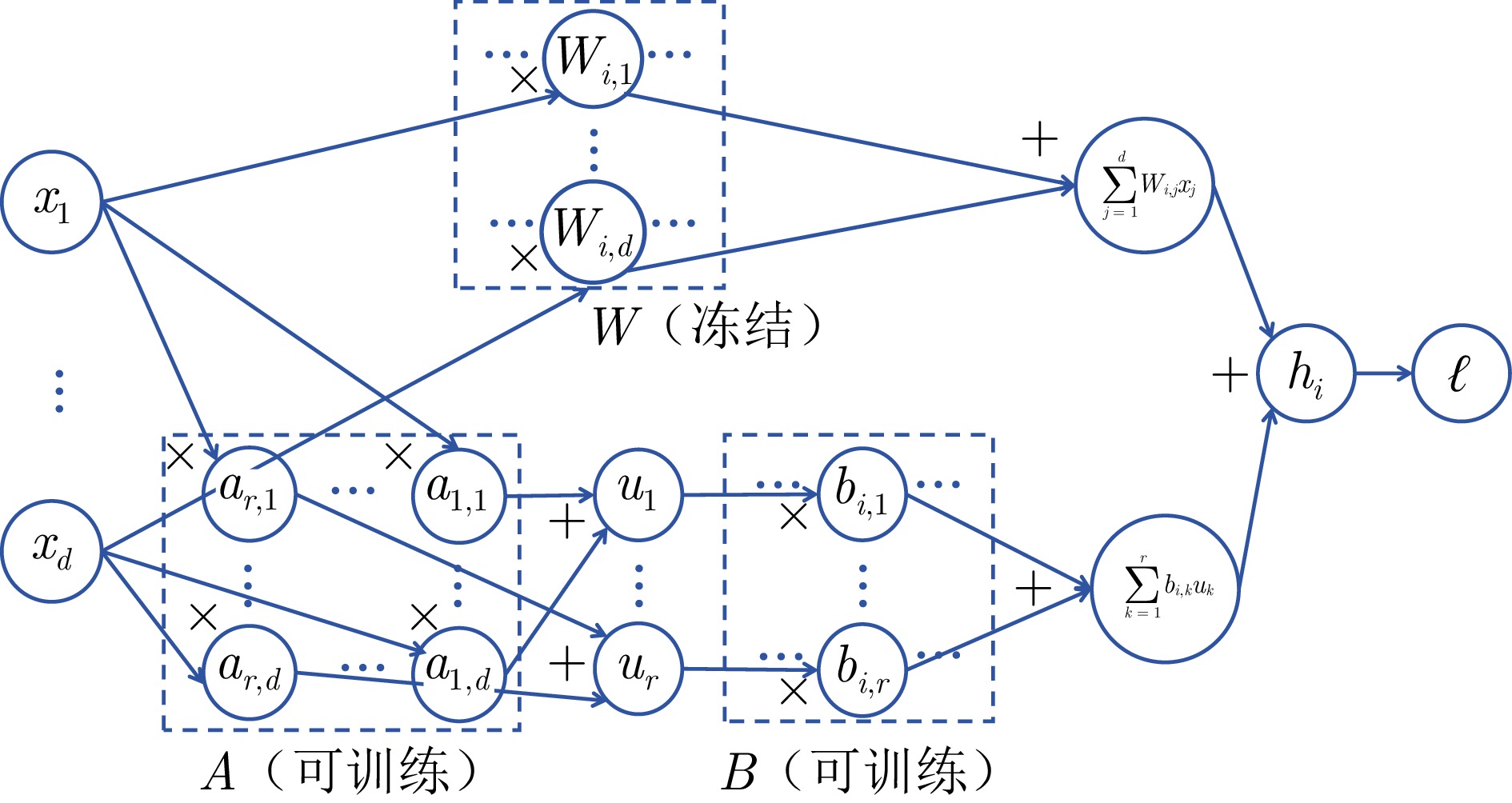
摘要:
针对表面肌电信号和人体运动等模型误差引起的运动估计性能下降问题, 提出一种基于门控渐进高斯滤波网络(gated progressive Gaussian filtering network, GPGF-net) 的人体运动估计方法, 以实现对模型误差的补偿以及提升运动估计的精度. 首先, 设计门控记忆机制来调控信息流, 以学习出系统状态的长期依赖与观测信号的时变特性, 从而动态调整误差补偿项的分布参数. 其次, 通过融合贝叶斯滤波与深度学习的优势, 引入渐进式观测更新策略到GPGF-net, 以减小非线性近似误差以及增强模型鲁棒性. 最后, 通过人体肢体运动估计实验表明, 相较于现有方法, GPGF-net显著提高了估计精度, 均方根误差降低15.62 %, 相关系数R2提升5.08 %, 验证了所提方法的有效性.
针对表面肌电信号和人体运动等模型误差引起的运动估计性能下降问题, 提出一种基于门控渐进高斯滤波网络(gated progressive Gaussian filtering network, GPGF-net) 的人体运动估计方法, 以实现对模型误差的补偿以及提升运动估计的精度. 首先, 设计门控记忆机制来调控信息流, 以学习出系统状态的长期依赖与观测信号的时变特性, 从而动态调整误差补偿项的分布参数. 其次, 通过融合贝叶斯滤波与深度学习的优势, 引入渐进式观测更新策略到GPGF-net, 以减小非线性近似误差以及增强模型鲁棒性. 最后, 通过人体肢体运动估计实验表明, 相较于现有方法, GPGF-net显著提高了估计精度, 均方根误差降低15.62 %, 相关系数R2提升5.08 %, 验证了所提方法的有效性.







摘要:
随着全球航班规模与运行密度提升, 传统人工监控方法在应对复杂动态飞行环境方面逐渐显现出局限性. 近年来, 数据驱动的智能监控方法成为提升飞行安全与运行效率的研究热点. 本文对基于时序大数据的飞行安全状态评估方法进行综述, 从飞行数据的时序特性出发, 梳理三类面向不同时间维度的关键方法: 异常检测、征兆挖掘以及趋势跟踪与预测, 涵盖飞行异常状态的识别与潜在风险事件的早期预警与预测. 首先, 对上述三类评估方法进行系统定义, 可覆盖“过去−现在−未来”的安全保障. 其次, 介绍各类方法的代表性研究进展与存在问题; 以高风险进近阶段为典型场景, 分析评估方法的应用现状与协同机制, 并回顾其技术支撑, 包括数据通信和软件平台. 最后, 总结当前挑战和未来方向, 包括异常检测的可解释性、征兆事件的动态表征与定位、趋势预测与因果推理的融合, 以及大模型应用潜力等.
随着全球航班规模与运行密度提升, 传统人工监控方法在应对复杂动态飞行环境方面逐渐显现出局限性. 近年来, 数据驱动的智能监控方法成为提升飞行安全与运行效率的研究热点. 本文对基于时序大数据的飞行安全状态评估方法进行综述, 从飞行数据的时序特性出发, 梳理三类面向不同时间维度的关键方法: 异常检测、征兆挖掘以及趋势跟踪与预测, 涵盖飞行异常状态的识别与潜在风险事件的早期预警与预测. 首先, 对上述三类评估方法进行系统定义, 可覆盖“过去−现在−未来”的安全保障. 其次, 介绍各类方法的代表性研究进展与存在问题; 以高风险进近阶段为典型场景, 分析评估方法的应用现状与协同机制, 并回顾其技术支撑, 包括数据通信和软件平台. 最后, 总结当前挑战和未来方向, 包括异常检测的可解释性、征兆事件的动态表征与定位、趋势预测与因果推理的融合, 以及大模型应用潜力等.









摘要:
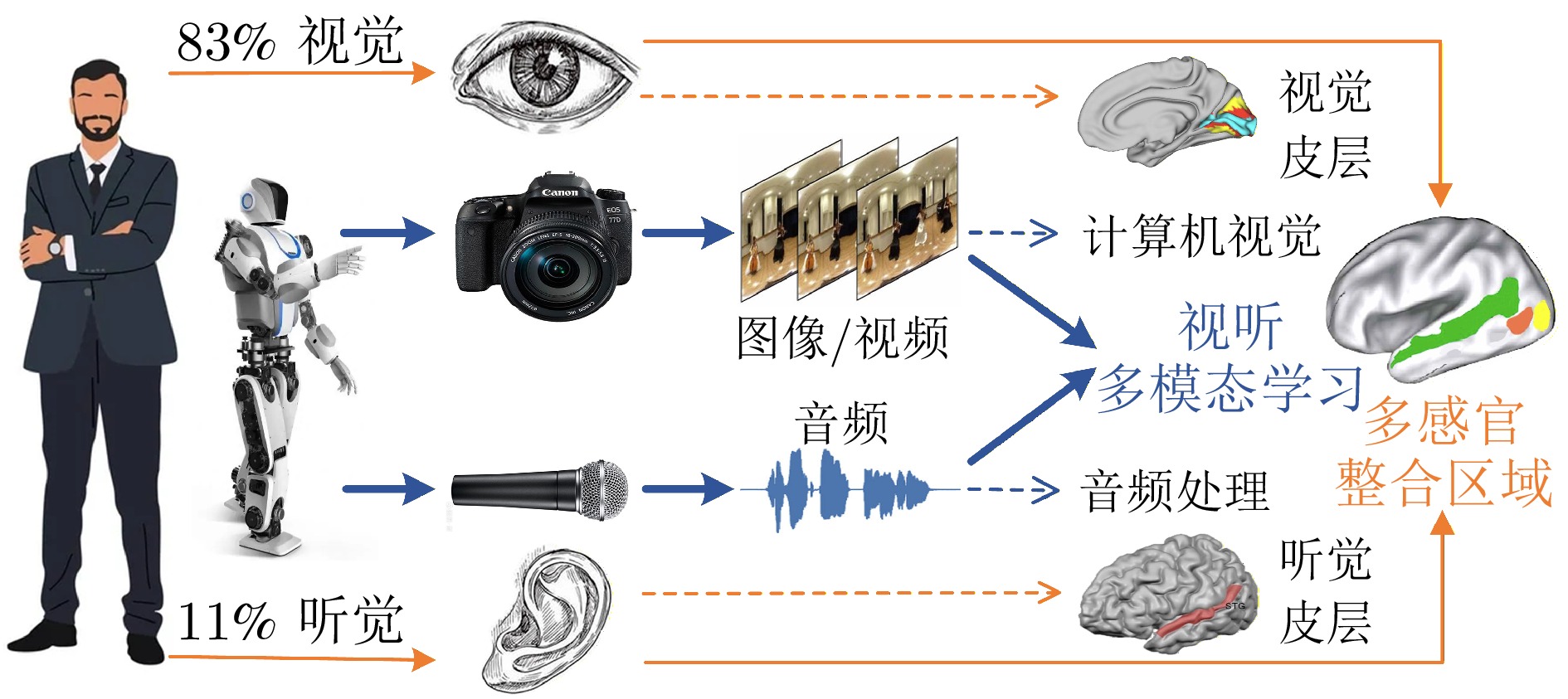
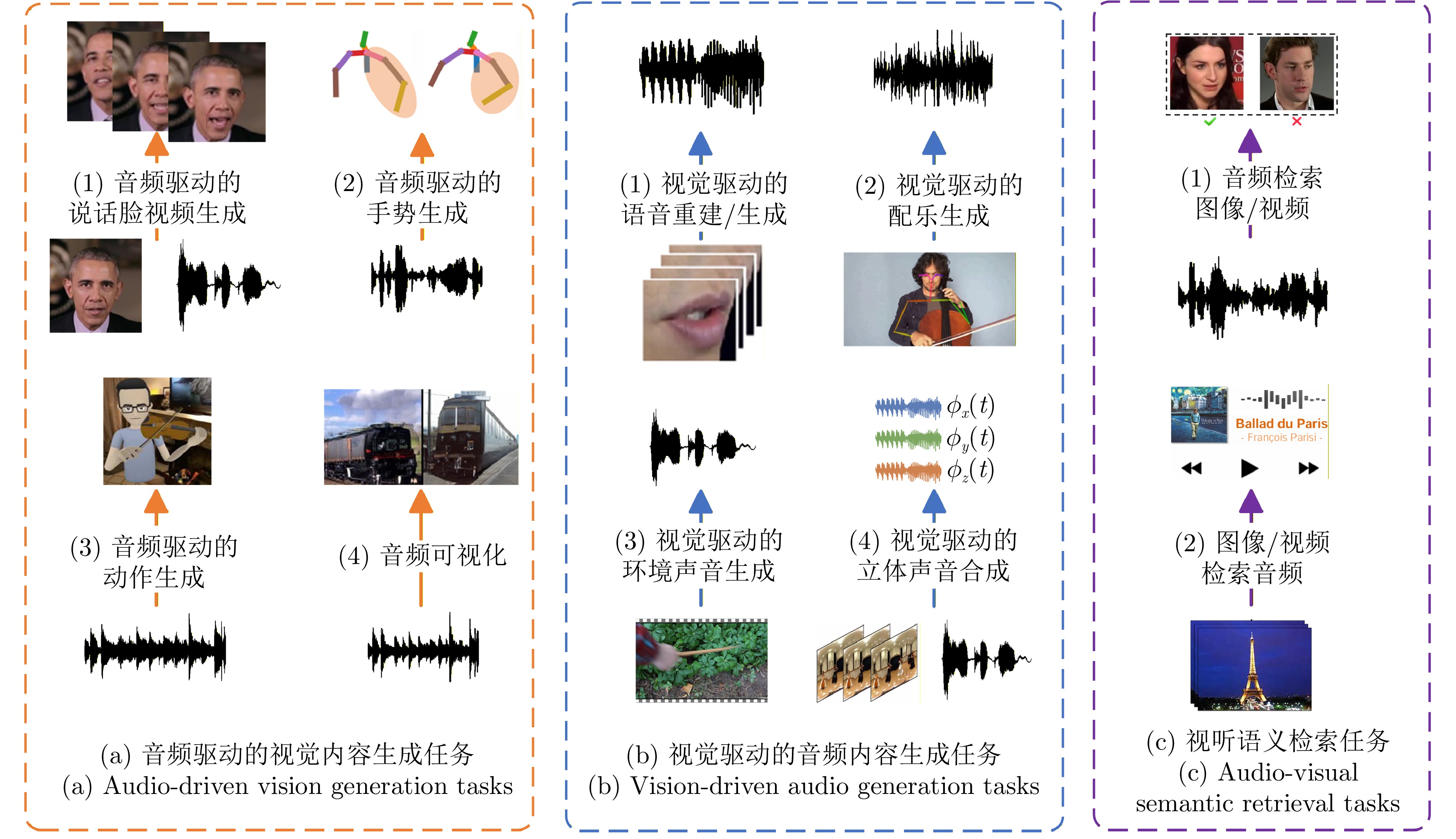
在人类信息获取过程中, 视听觉扮演着重要角色, 大脑通过整合视听信息, 形成统一、连贯且稳定的知觉体验. 视听多模态学习旨在模拟人类的视听多感官整合能力, 近年来受到研究者的广泛关注. 然而, 该领域在应用场景、任务目标和技术方法上呈现出显著的多样性, 目前尚且缺乏对视听多模态学习领域系统性回顾和分析的综合性中文综述. 基于人类的多感官整合机制在视听认知中的重要性以及不同视听多模态学习任务间的内在关联性, 提出一个统一框架, 将现有研究归纳为三类: 视听增强通过引入音频或视觉信息实现对初始单模态任务的增强效应; 跨模态交互旨在探索视听信息间的相互转换; 视听协作致力于探索视听信息的综合理解方法及其协同效应. 在此基础上, 对该领域中的最新研究进展进行系统性综述和总结. 此外, 深入剖析当前视听多模态学习研究所面临的五大核心共性问题和挑战---视听表征、对齐、转换、融合和共同学习; 并探讨大模型背景下视听多模态学习的发展现状.
在人类信息获取过程中, 视听觉扮演着重要角色, 大脑通过整合视听信息, 形成统一、连贯且稳定的知觉体验. 视听多模态学习旨在模拟人类的视听多感官整合能力, 近年来受到研究者的广泛关注. 然而, 该领域在应用场景、任务目标和技术方法上呈现出显著的多样性, 目前尚且缺乏对视听多模态学习领域系统性回顾和分析的综合性中文综述. 基于人类的多感官整合机制在视听认知中的重要性以及不同视听多模态学习任务间的内在关联性, 提出一个统一框架, 将现有研究归纳为三类: 视听增强通过引入音频或视觉信息实现对初始单模态任务的增强效应; 跨模态交互旨在探索视听信息间的相互转换; 视听协作致力于探索视听信息的综合理解方法及其协同效应. 在此基础上, 对该领域中的最新研究进展进行系统性综述和总结. 此外, 深入剖析当前视听多模态学习研究所面临的五大核心共性问题和挑战---视听表征、对齐、转换、融合和共同学习; 并探讨大模型背景下视听多模态学习的发展现状.






摘要:
本文系统回顾美国、欧洲及我国在宇航用处理器领域的技术演进, 重点分析了基于PowerPC架构的美国代表性处理器产品以及采用SPARC架构的欧洲与我国典型处理器方案. 研究揭示, 未来宇航用处理器的发展将显著分化为通用型与智能型两大技术路线. 通用型宇航用处理器将呈现高性能(如提升多核并行计算能力)、高集成度(如实现系统级芯片SoC)、高可靠性(如强化抗辐射设计)及低功耗的协同发展趋势; 而智能型处理器则将侧重于提升在轨实时智能信息处理能力.
本文系统回顾美国、欧洲及我国在宇航用处理器领域的技术演进, 重点分析了基于PowerPC架构的美国代表性处理器产品以及采用SPARC架构的欧洲与我国典型处理器方案. 研究揭示, 未来宇航用处理器的发展将显著分化为通用型与智能型两大技术路线. 通用型宇航用处理器将呈现高性能(如提升多核并行计算能力)、高集成度(如实现系统级芯片SoC)、高可靠性(如强化抗辐射设计)及低功耗的协同发展趋势; 而智能型处理器则将侧重于提升在轨实时智能信息处理能力.










摘要:
在工业4.0时代, 大语言模型向工业边缘异构集群的迁移已成为一项关键技术挑战.边缘设备计算与存储资源受限、动态负载波动、异构架构复杂以及网络高延迟等特性, 使得传统推理框架难以满足工业场景对实时性、鲁棒性和隐私保护的需求.提出一种动态弹性推理框架(Dynama), 设计全域心跳被动感知器和实时弹性量化调度算法.该框架采用管道环并行结构, 实现模型层动态分配与懒加载; 通过被动监测设备延迟向量, 触发实时弹性量化调度算法在不改变层分配前提下优化量化版本, 平衡延迟最小化和精度损失. Dynama通过优化数据传输与量化策略, 显著提升高延迟网络环境下的推理效率, 适应工业边缘的动态环境变化.实验结果表明, Dynama在工业边缘异构集群中展现出优异的实时性与鲁棒性, 为工业智能的落地应用提供高效、可靠的解决方案.
在工业4.0时代, 大语言模型向工业边缘异构集群的迁移已成为一项关键技术挑战.边缘设备计算与存储资源受限、动态负载波动、异构架构复杂以及网络高延迟等特性, 使得传统推理框架难以满足工业场景对实时性、鲁棒性和隐私保护的需求.提出一种动态弹性推理框架(Dynama), 设计全域心跳被动感知器和实时弹性量化调度算法.该框架采用管道环并行结构, 实现模型层动态分配与懒加载; 通过被动监测设备延迟向量, 触发实时弹性量化调度算法在不改变层分配前提下优化量化版本, 平衡延迟最小化和精度损失. Dynama通过优化数据传输与量化策略, 显著提升高延迟网络环境下的推理效率, 适应工业边缘的动态环境变化.实验结果表明, Dynama在工业边缘异构集群中展现出优异的实时性与鲁棒性, 为工业智能的落地应用提供高效、可靠的解决方案.







摘要:
近年来, 视频扩散模型在相机可控的图像到视频生成任务中取得了突破性进展. 然而, 现有方法在维持3D空间结构一致性方面仍面临显著挑战, 其生成视频普遍存在空间结构模糊化、多视角下物体形态畸变等缺陷, 这些问题严重制约了生成视频的视觉可信度. 为解决这一问题, 提出在视频扩散模型的训练和推理阶段均引入额外的3D空间先验信息, 以增强生成视频的空间结构一致性. 具体而言, 在模型训练阶段, 设计基于视角形变映射的条件嵌入方法(Warp-Injection), 通过进行逐帧视角形变映射与图像补全构建具备高度空间一致性的参考帧序列, 并将其作为结构先验条件嵌入扩散模型的训练过程. 在推理阶段, 首先提出初始噪声空间几何校正策略(Warp-Init): 对条件图像加噪进行首帧初始化, 此后通过迭代式视角形变映射构建符合3D一致性约束的初始噪声序列. 在此基础上, 进一步在去噪过程中引入基于视角形变先验的能量函数引导策略(Warp-Guidance), 通过减小生成帧与视角形变映射后的预期目标视频之间的距离来实现对视频3D空间一致性的校正. 在标准RealEstate10K数据集上的实验结果表明, 相较于当前最优模型, 本文方法在FVD指标上取得18.03的显著优化, 同时将3D结构估计的失败率(COLMAP error rate) 降低至5.20%. 可视化分析进一步证明, 本文方法能有效维持生成视频的3D空间结构一致性.
近年来, 视频扩散模型在相机可控的图像到视频生成任务中取得了突破性进展. 然而, 现有方法在维持3D空间结构一致性方面仍面临显著挑战, 其生成视频普遍存在空间结构模糊化、多视角下物体形态畸变等缺陷, 这些问题严重制约了生成视频的视觉可信度. 为解决这一问题, 提出在视频扩散模型的训练和推理阶段均引入额外的3D空间先验信息, 以增强生成视频的空间结构一致性. 具体而言, 在模型训练阶段, 设计基于视角形变映射的条件嵌入方法(Warp-Injection), 通过进行逐帧视角形变映射与图像补全构建具备高度空间一致性的参考帧序列, 并将其作为结构先验条件嵌入扩散模型的训练过程. 在推理阶段, 首先提出初始噪声空间几何校正策略(Warp-Init): 对条件图像加噪进行首帧初始化, 此后通过迭代式视角形变映射构建符合3D一致性约束的初始噪声序列. 在此基础上, 进一步在去噪过程中引入基于视角形变先验的能量函数引导策略(Warp-Guidance), 通过减小生成帧与视角形变映射后的预期目标视频之间的距离来实现对视频3D空间一致性的校正. 在标准RealEstate10K数据集上的实验结果表明, 相较于当前最优模型, 本文方法在FVD指标上取得18.03的显著优化, 同时将3D结构估计的失败率(COLMAP error rate) 降低至5.20%. 可视化分析进一步证明, 本文方法能有效维持生成视频的3D空间结构一致性.






摘要:
近年来, 大语言模型研究取得了突破性进展. 本文针对大模型分布式训练中通信开销高、算力利用率低的问题, 提出了一种基于Adam-mini优化器的单比特通信压缩算法——单比特Adam-mini. 该算法通过减少二阶动量参数, 使得能够以较小的通信代价精确计算全局二阶动量, 从而简化了通信误差补偿机制的设计. 单比特Adam-mini不仅避免了现有单比特Adam算法中通信开销较大的预热阶段, 还具备可证明的线性加速性质, 确保了分布式训练的高效性. 实验结果表明, 该算法在多种任务上表现优异, 并且可以兼容稀疏压缩器, 为大模型训练提供了更高效的解决方案.
近年来, 大语言模型研究取得了突破性进展. 本文针对大模型分布式训练中通信开销高、算力利用率低的问题, 提出了一种基于Adam-mini优化器的单比特通信压缩算法——单比特Adam-mini. 该算法通过减少二阶动量参数, 使得能够以较小的通信代价精确计算全局二阶动量, 从而简化了通信误差补偿机制的设计. 单比特Adam-mini不仅避免了现有单比特Adam算法中通信开销较大的预热阶段, 还具备可证明的线性加速性质, 确保了分布式训练的高效性. 实验结果表明, 该算法在多种任务上表现优异, 并且可以兼容稀疏压缩器, 为大模型训练提供了更高效的解决方案.




摘要:
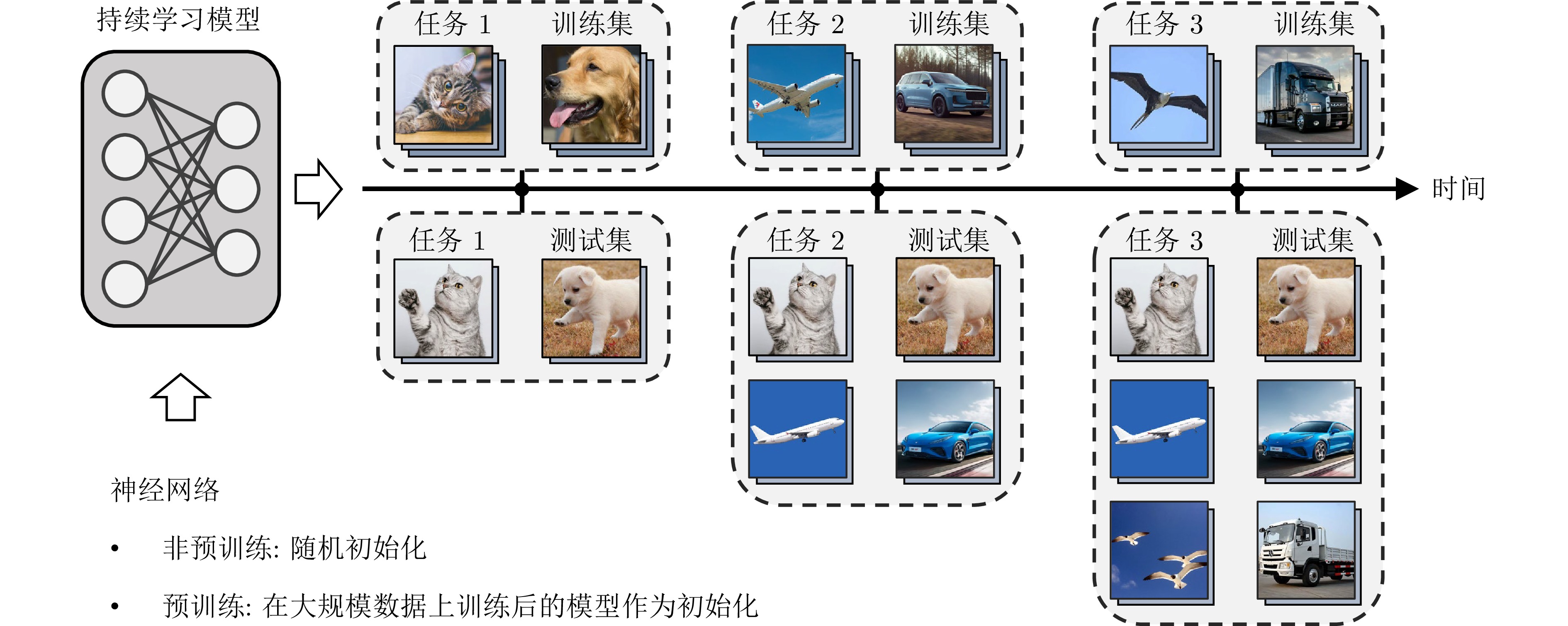
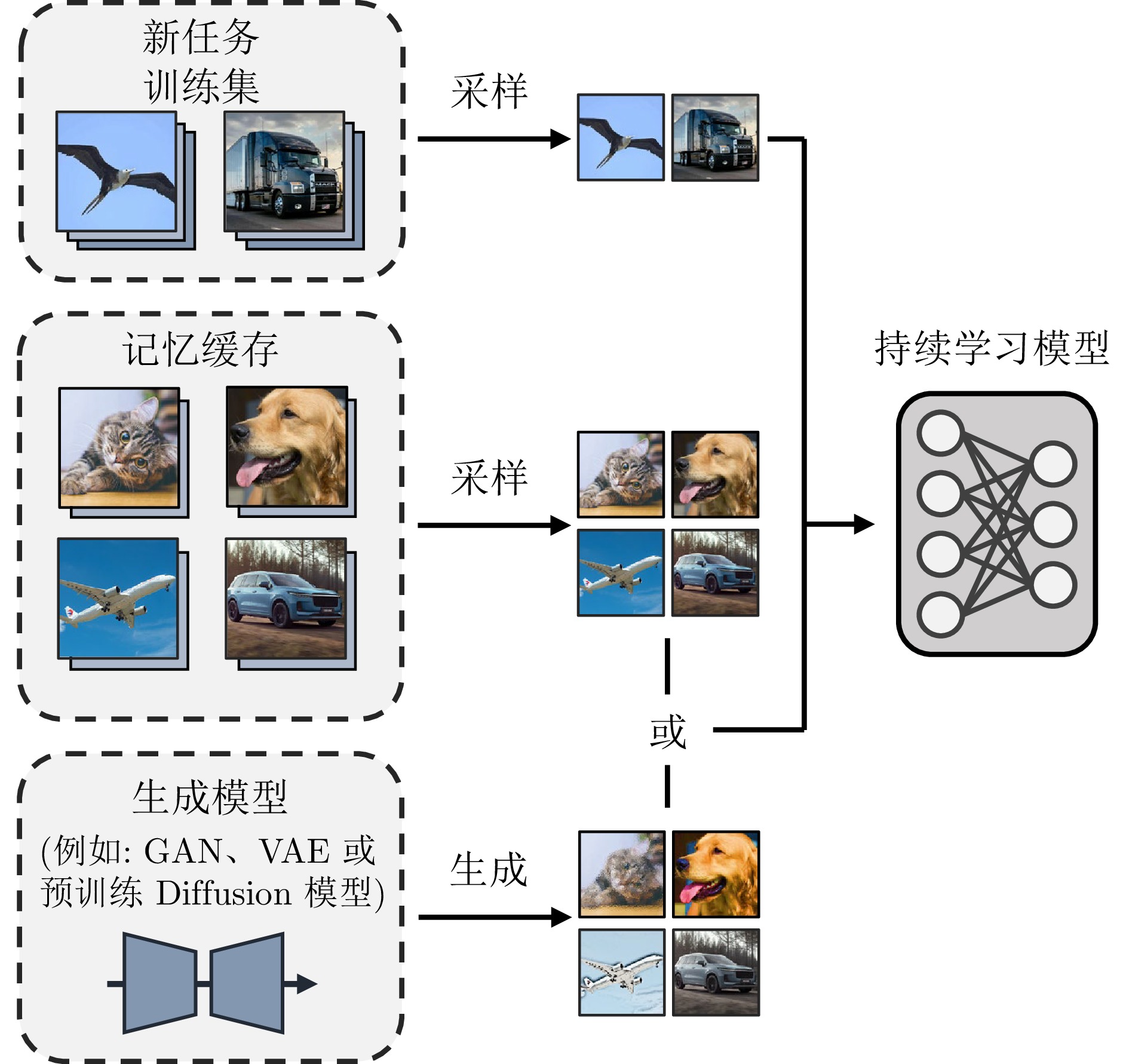
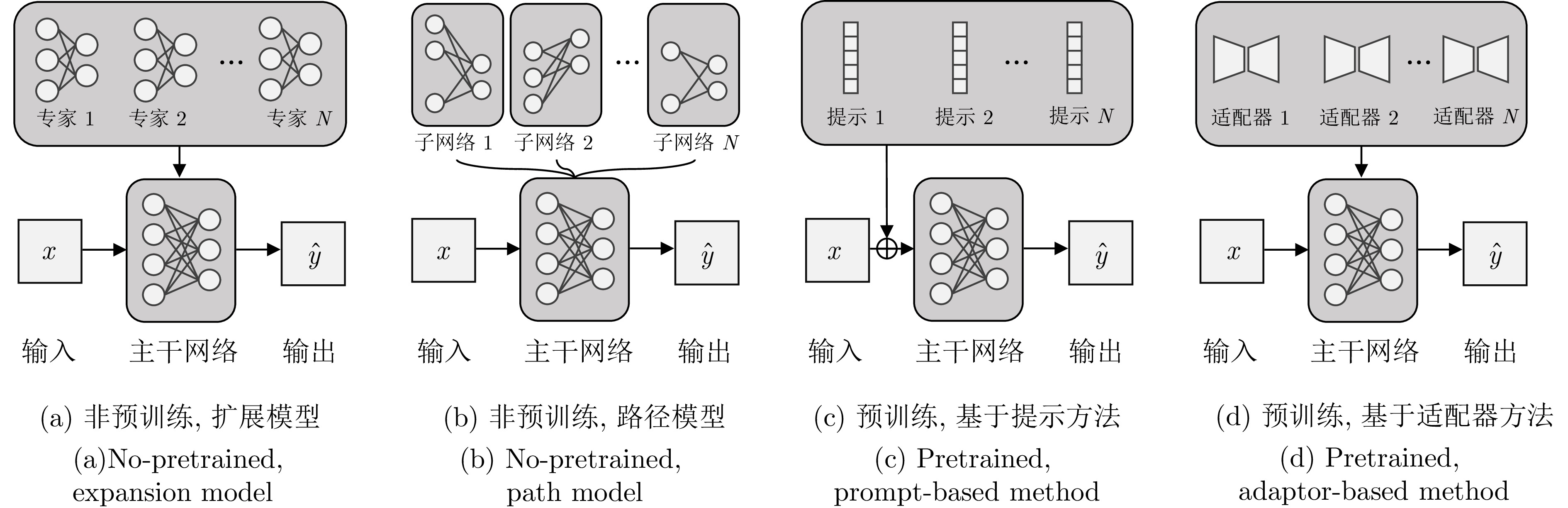
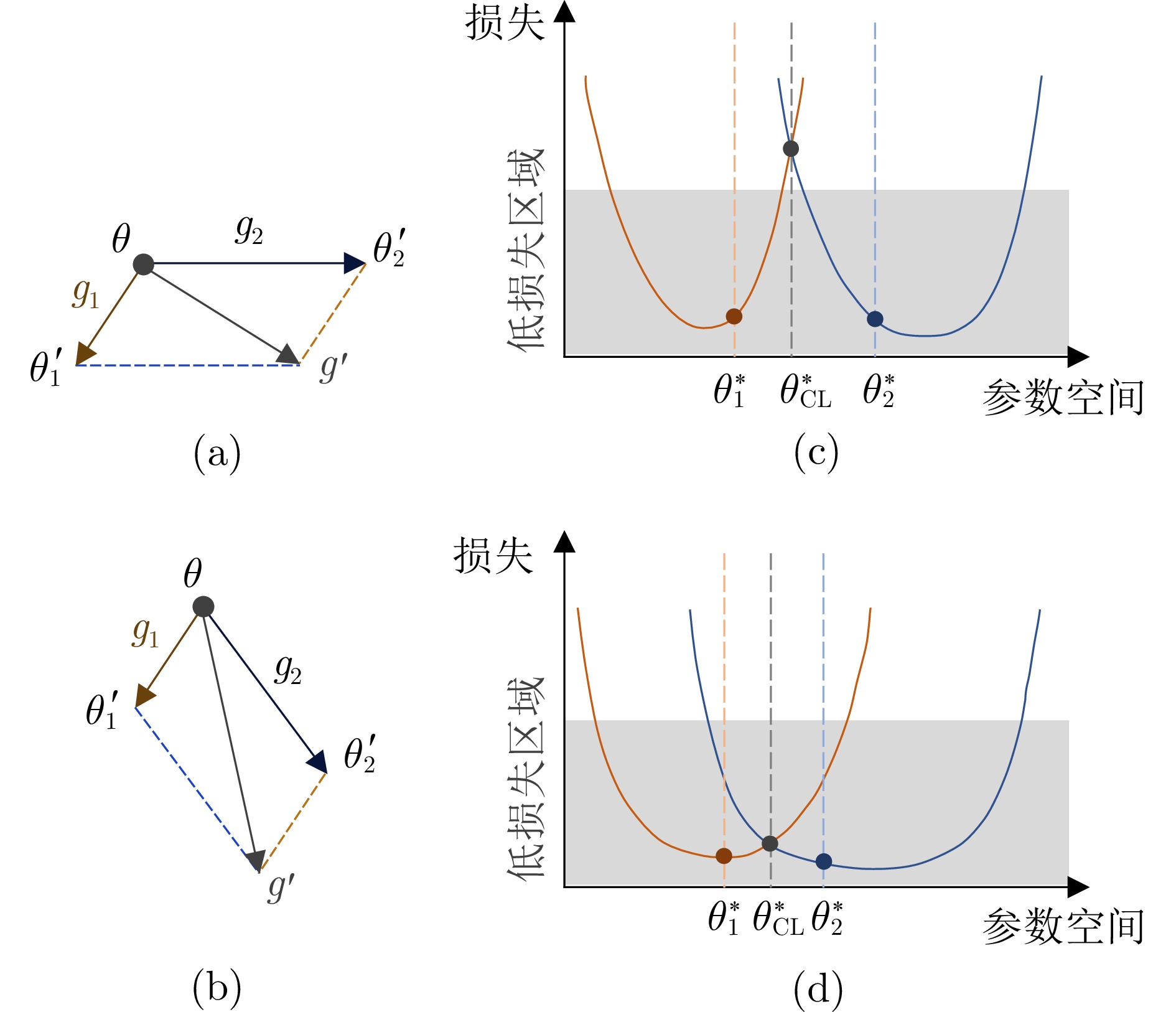
以深度学习为代表的机器学习方法已经在多个领域取得显著进展, 然而大多方法局限于静态场景, 难以像人类一样在开放世界的动态场景中不断学习新知识, 同时保持已经学过的知识. 为解决该挑战, 持续学习受到越来越多的关注. 现有的持续学习方法大致可以分为两类, 即传统的非预训练模型持续学习方法以及大模型时代下逐步演进的预训练模型持续学习方法. 本文旨在对这两类方法的研究进展进行详细的综述, 主要从四个层面对比非预训练模型和预训练模型方法的异同点, 即数据层面、模型层面、损失/优化层面以及理论层面. 着重分析从应用非预训练模型的方法发展到应用预训练模型的方法的技术变化, 并分析出现此类差异的内在本质. 最后, 总结并展望未来持续学习发展的趋势.
以深度学习为代表的机器学习方法已经在多个领域取得显著进展, 然而大多方法局限于静态场景, 难以像人类一样在开放世界的动态场景中不断学习新知识, 同时保持已经学过的知识. 为解决该挑战, 持续学习受到越来越多的关注. 现有的持续学习方法大致可以分为两类, 即传统的非预训练模型持续学习方法以及大模型时代下逐步演进的预训练模型持续学习方法. 本文旨在对这两类方法的研究进展进行详细的综述, 主要从四个层面对比非预训练模型和预训练模型方法的异同点, 即数据层面、模型层面、损失/优化层面以及理论层面. 着重分析从应用非预训练模型的方法发展到应用预训练模型的方法的技术变化, 并分析出现此类差异的内在本质. 最后, 总结并展望未来持续学习发展的趋势.
当前状态:
, 最新更新时间: ,
doi: 10.16383/j.aas.c190277
摘要:
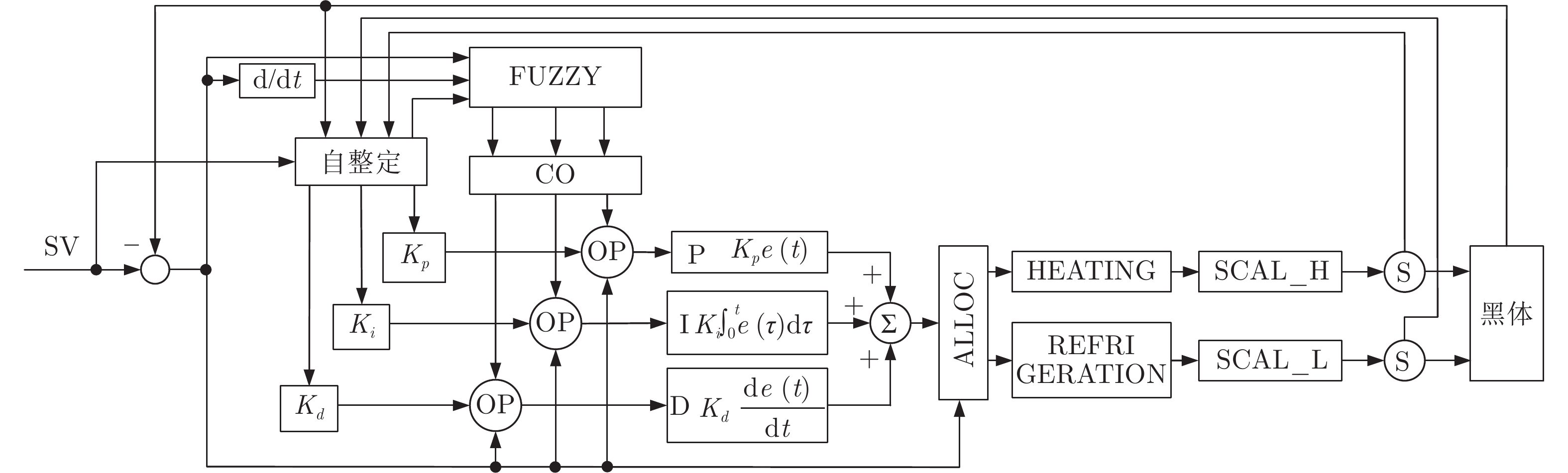
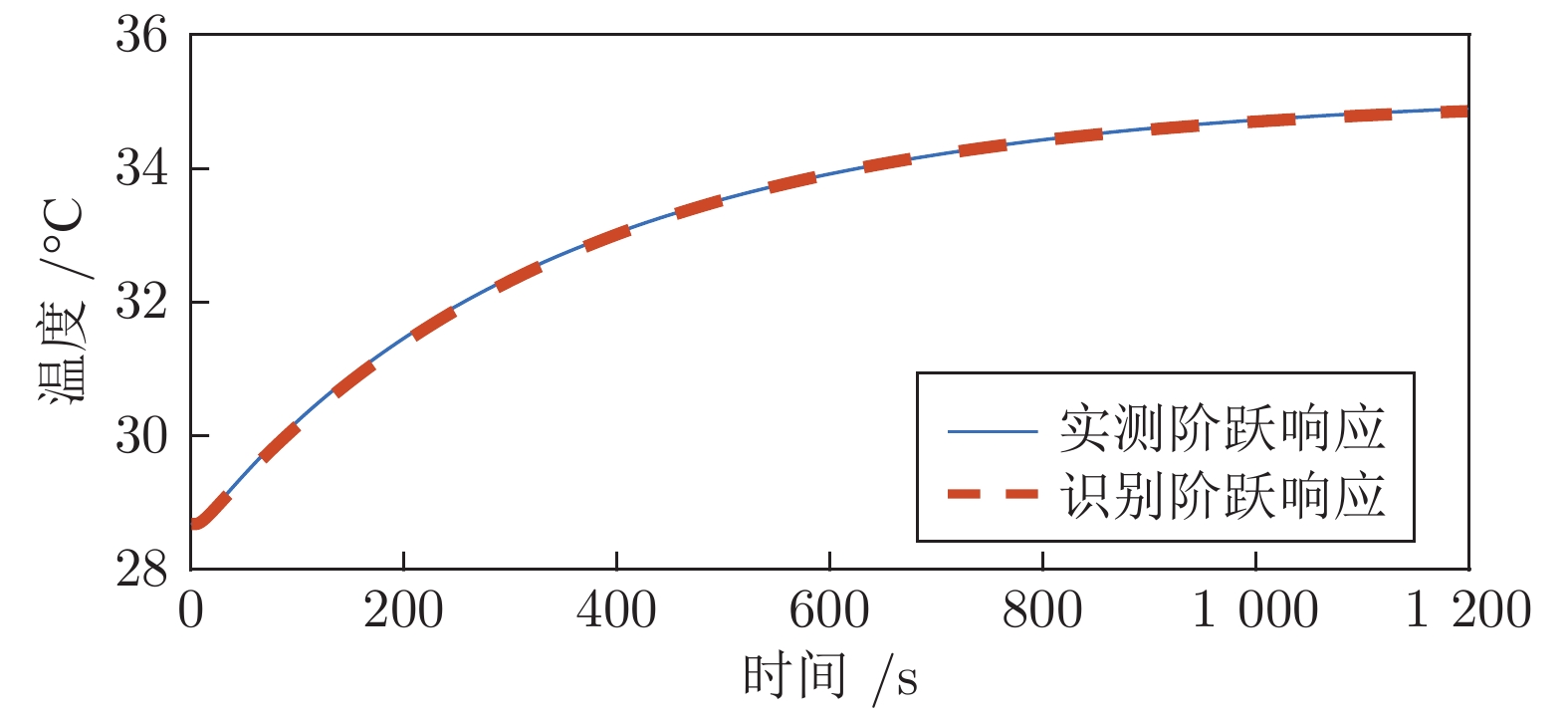
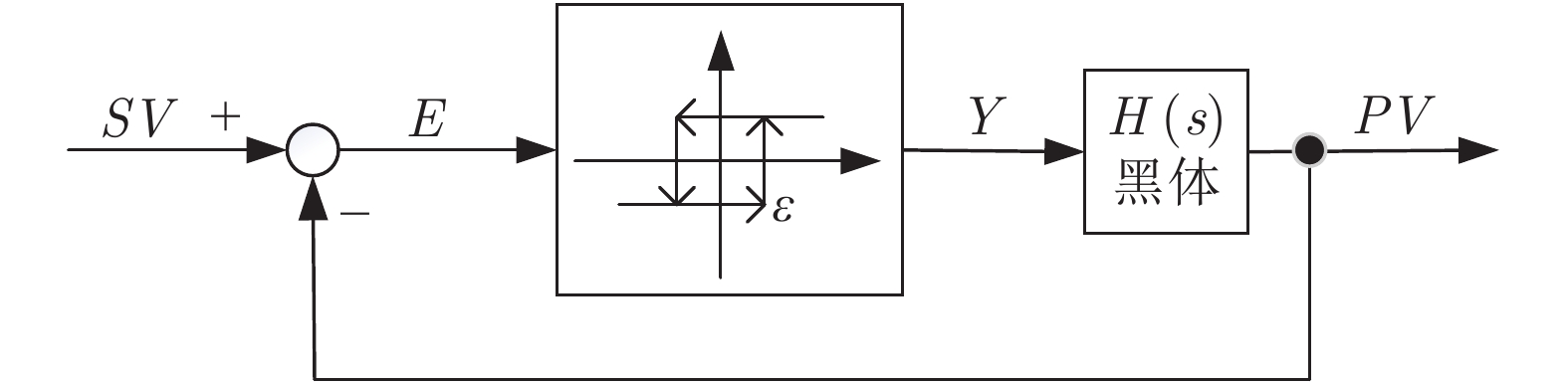
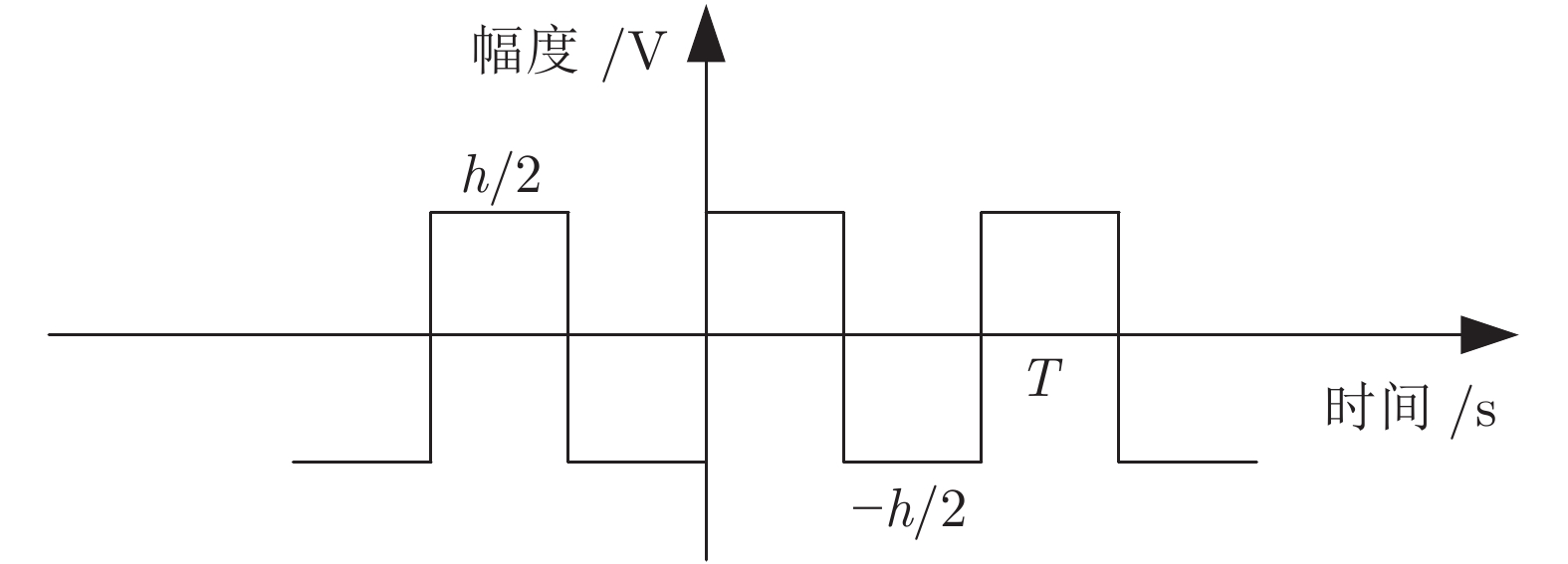
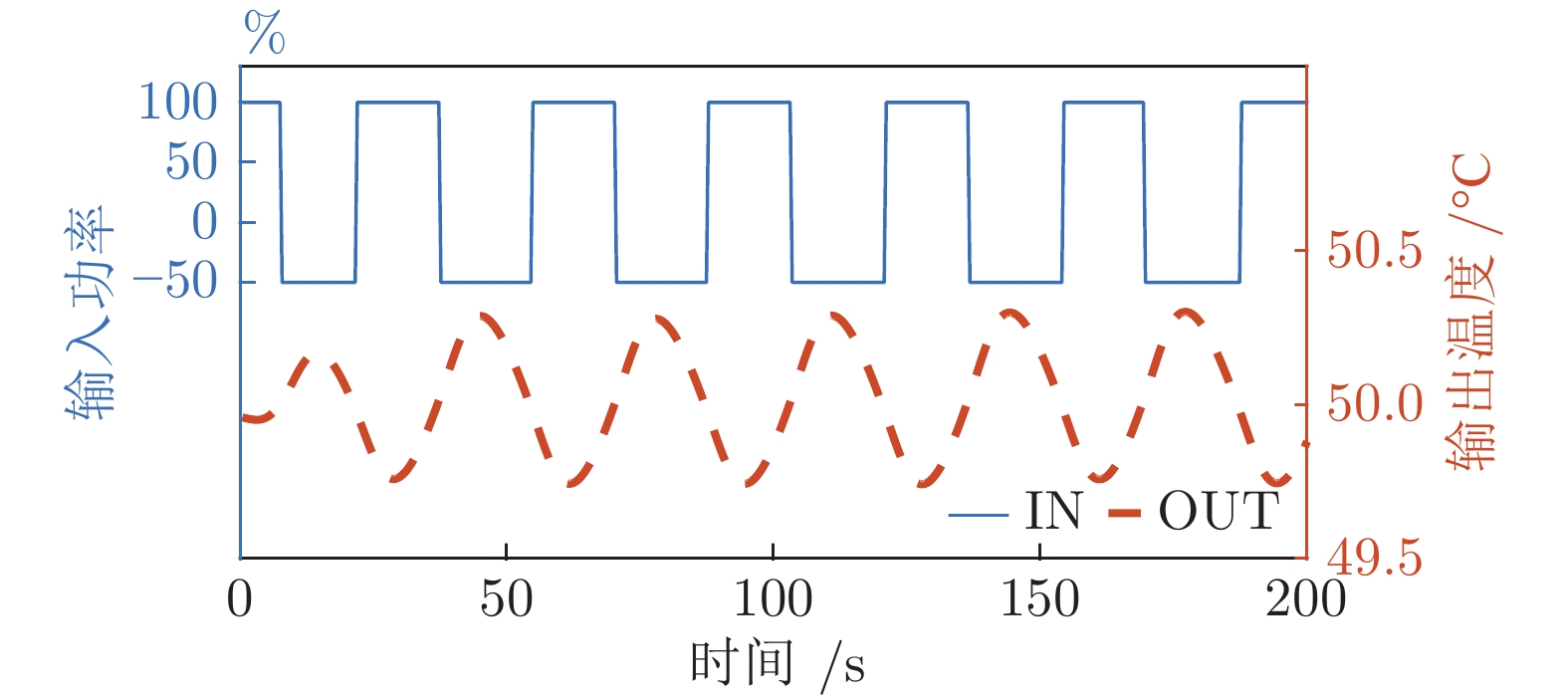
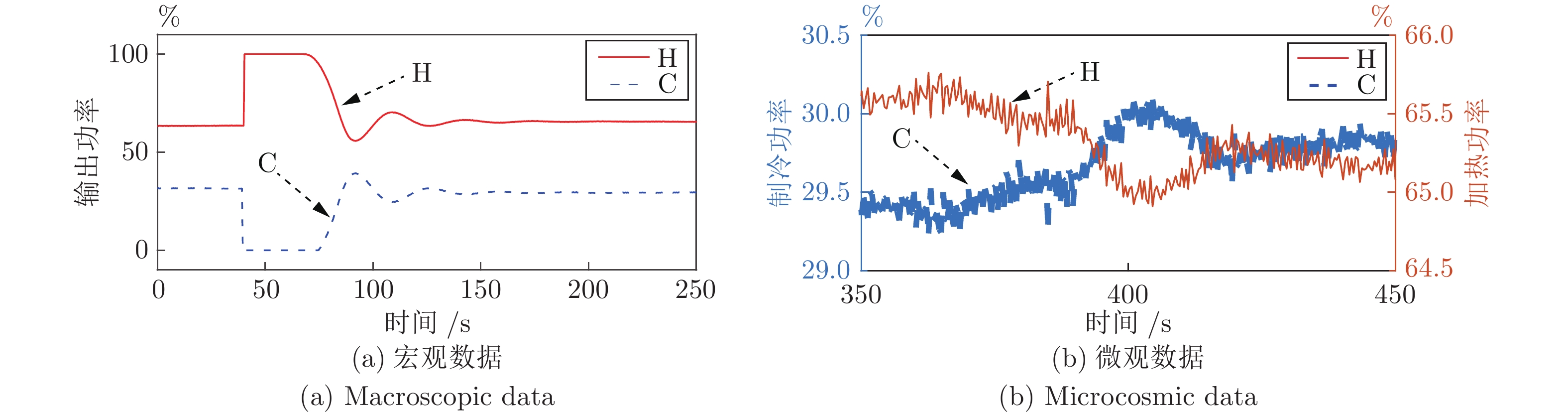
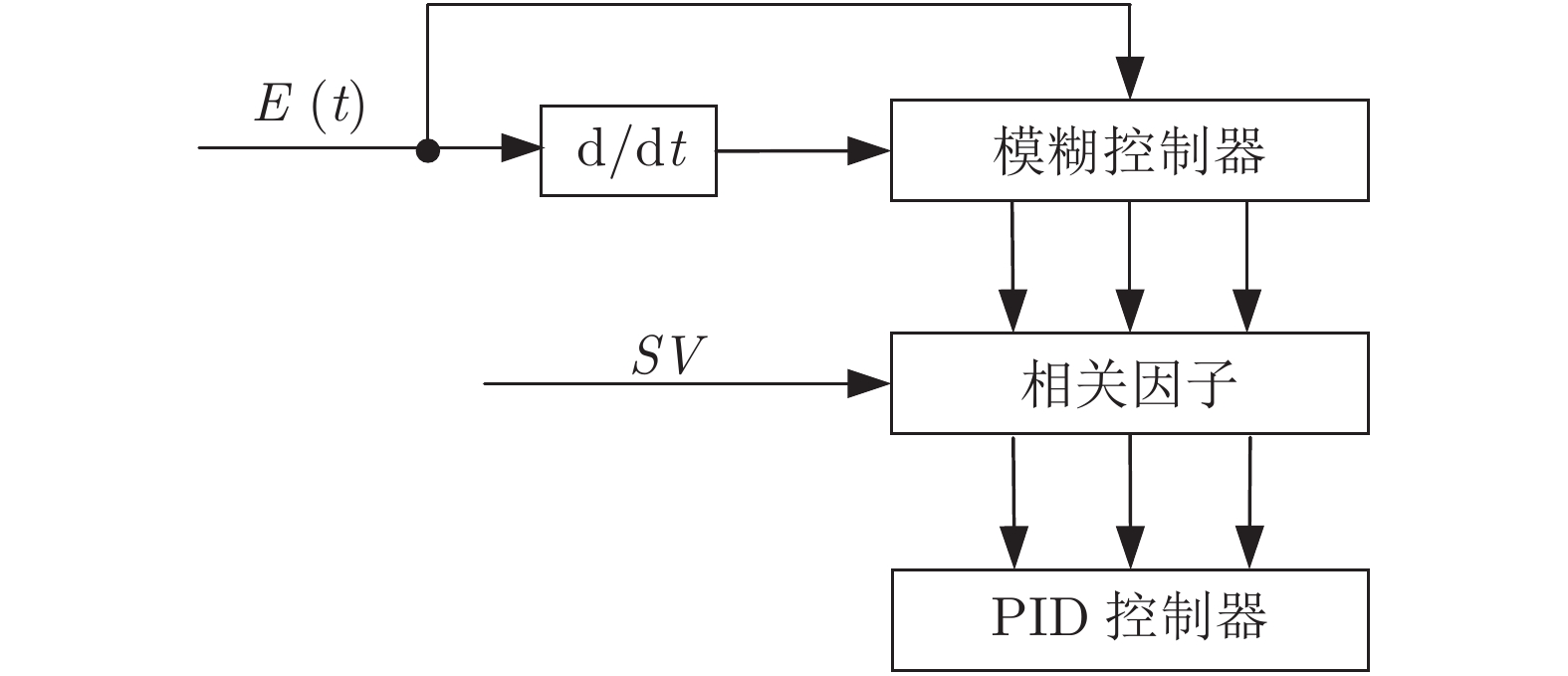
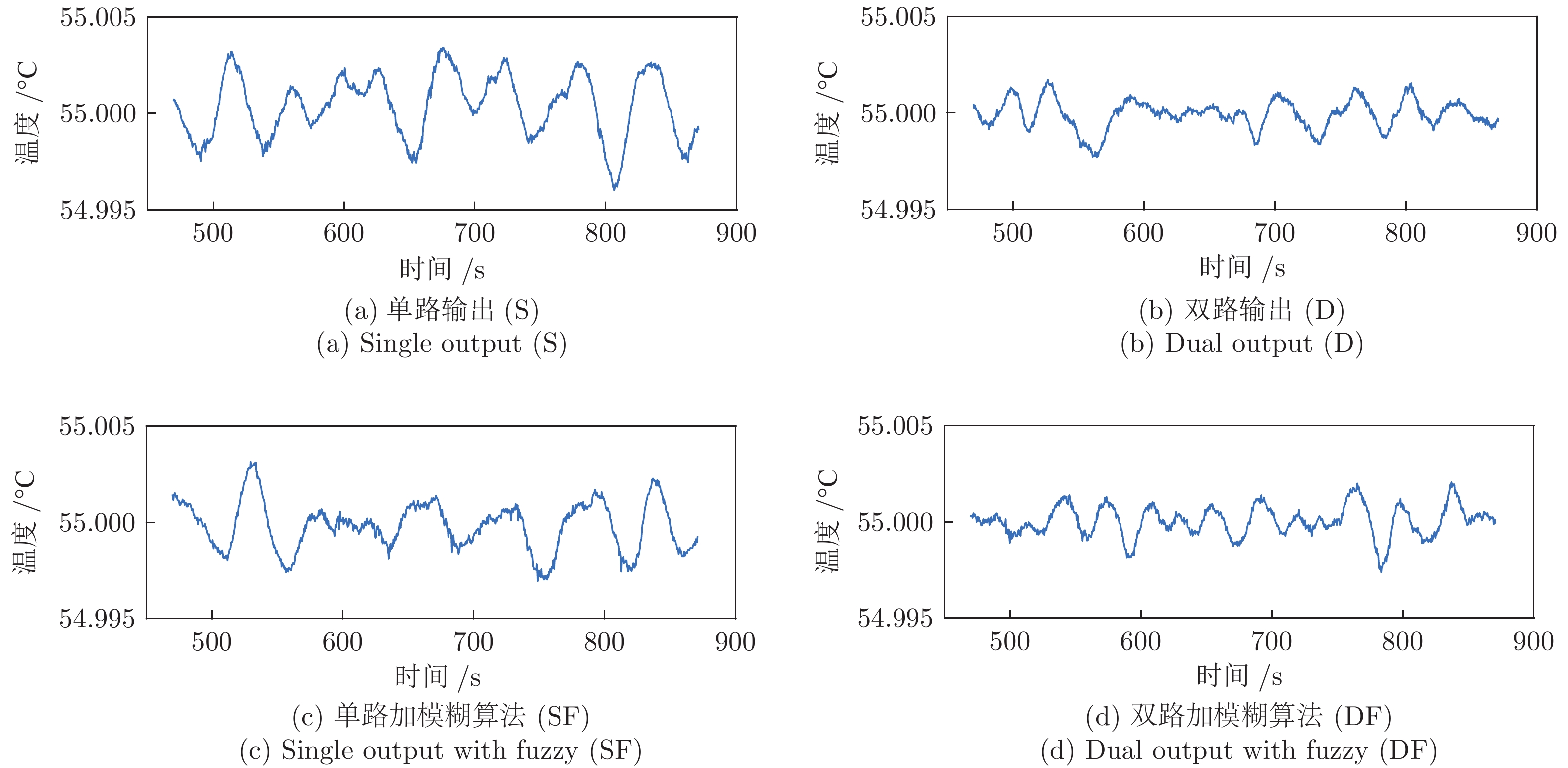
首先, 通过分析黑体温度控制系统的物理模型, 推演出黑体传递函数的表达式.推演过程中得知黑体易受环境温度和空气散热的影响, 所以黑体温度控制系统是个非线性时变系统.结合实验黑体的阶跃响应数据, 采用阶跃响应法对传递函数进行近似计算, 得出黑体温控系统的传递函数是极点在左半轴的二阶系统, 该系统等效于二阶低通滤波器.经过低通滤波器的信号, 会滤除高频部分, 当用继电器法进行参数自整定时, 仅需计算能量较大的基波信号.通过对基波信号进行比较, 得出继电器法的整定公式, 并参照Ziegler-Nichols整定法则计算出PID参数.同时, 本文针对黑体加热器具有双路输出的特点, 提出了一种双路动态输出法, 通过理论分析了该方法可以消除环境对黑体温度的影响.对于环境温度变化较大的, 采用继电器法PID参数自整定的方式来消除; 对于黑体运行过程中环境温度变化较小的, 采用双路动态输出法来减少影响.最后, 结合实验数据, 引入性能指标, 验证了本文所述方法对黑体的温度控制性能有一定的提升.
首先, 通过分析黑体温度控制系统的物理模型, 推演出黑体传递函数的表达式.推演过程中得知黑体易受环境温度和空气散热的影响, 所以黑体温度控制系统是个非线性时变系统.结合实验黑体的阶跃响应数据, 采用阶跃响应法对传递函数进行近似计算, 得出黑体温控系统的传递函数是极点在左半轴的二阶系统, 该系统等效于二阶低通滤波器.经过低通滤波器的信号, 会滤除高频部分, 当用继电器法进行参数自整定时, 仅需计算能量较大的基波信号.通过对基波信号进行比较, 得出继电器法的整定公式, 并参照Ziegler-Nichols整定法则计算出PID参数.同时, 本文针对黑体加热器具有双路输出的特点, 提出了一种双路动态输出法, 通过理论分析了该方法可以消除环境对黑体温度的影响.对于环境温度变化较大的, 采用继电器法PID参数自整定的方式来消除; 对于黑体运行过程中环境温度变化较小的, 采用双路动态输出法来减少影响.最后, 结合实验数据, 引入性能指标, 验证了本文所述方法对黑体的温度控制性能有一定的提升.



当前状态:
, 最新更新时间: ,
doi: 10.16383/j.aas.c200007
摘要:
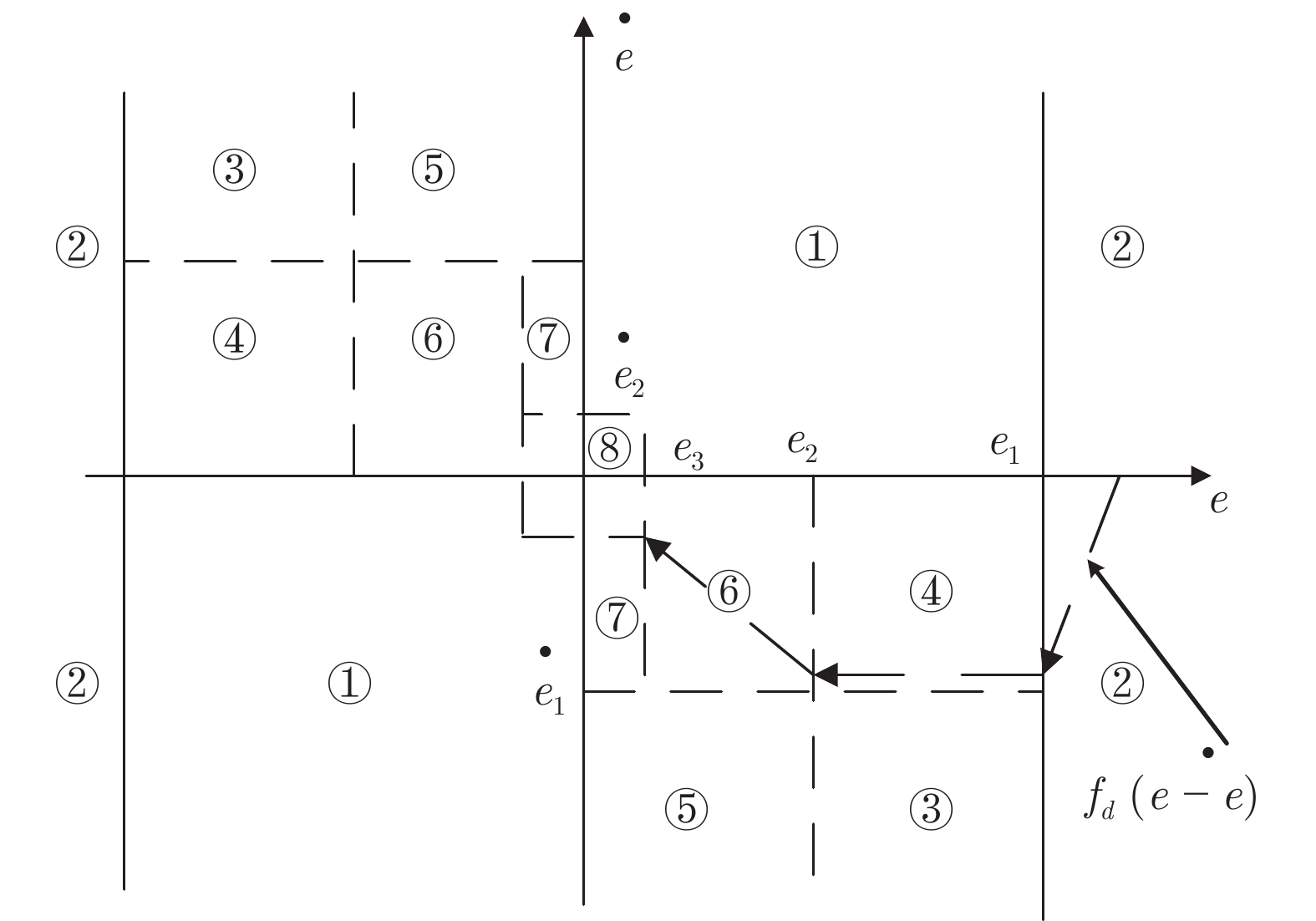
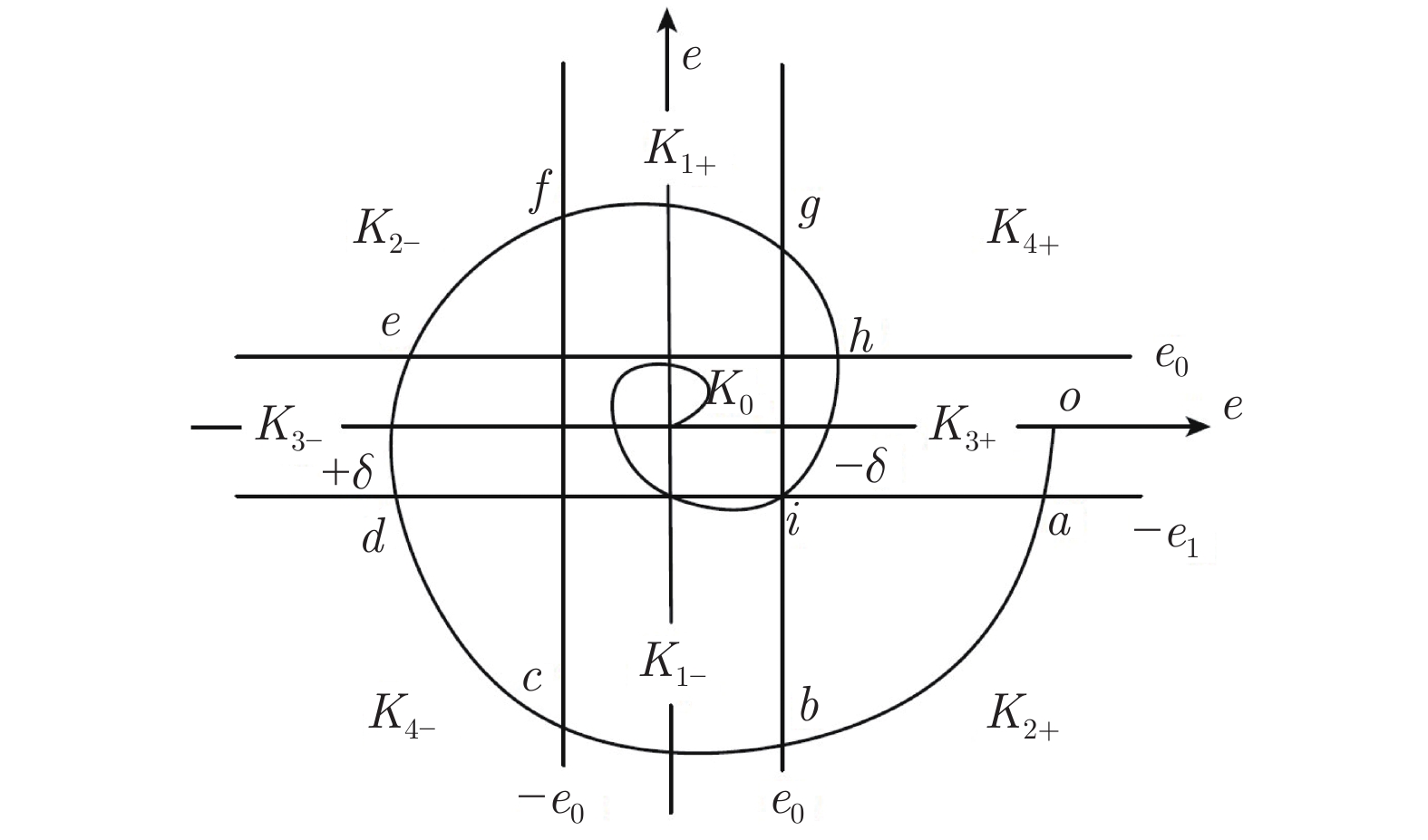
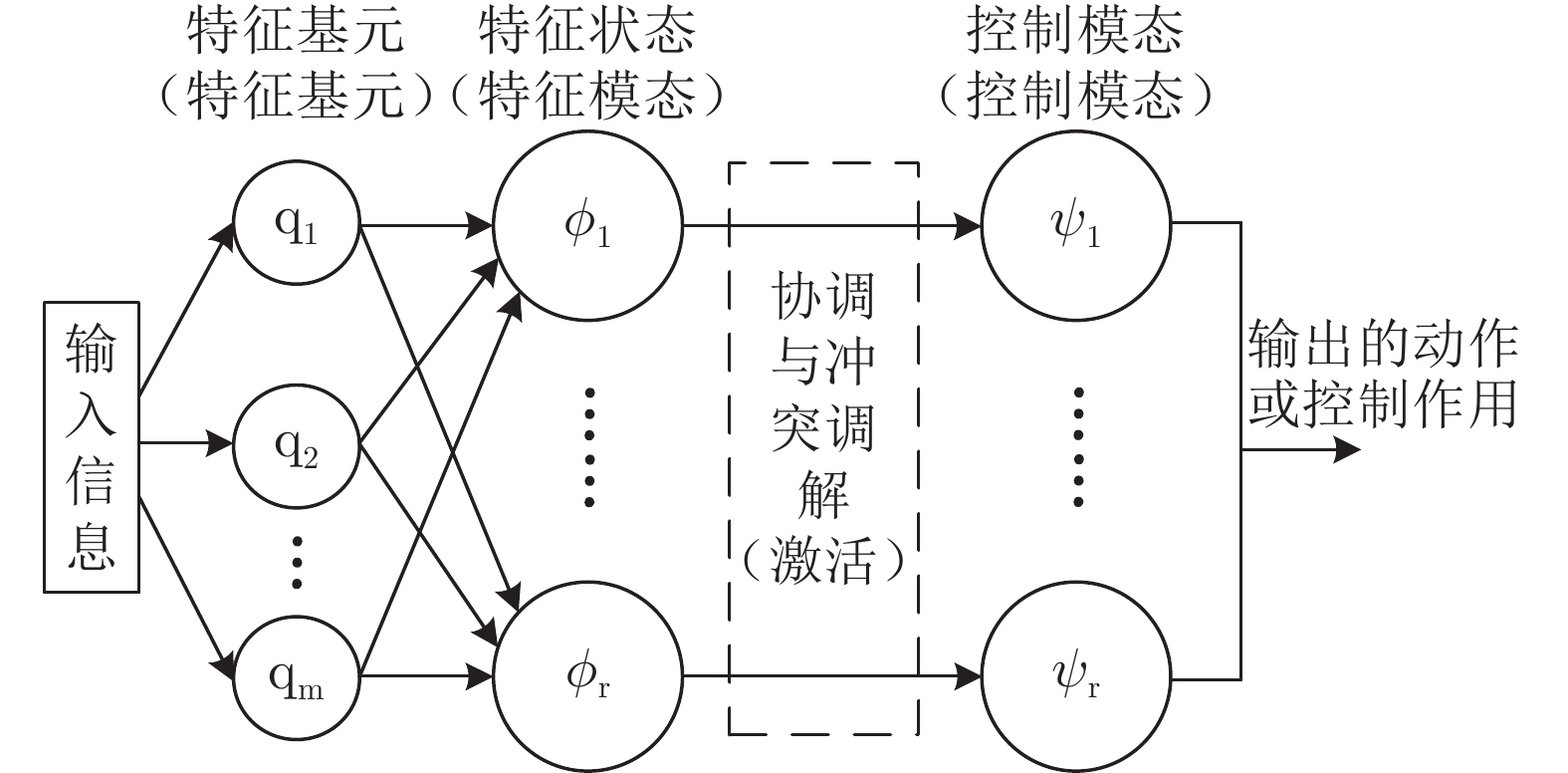
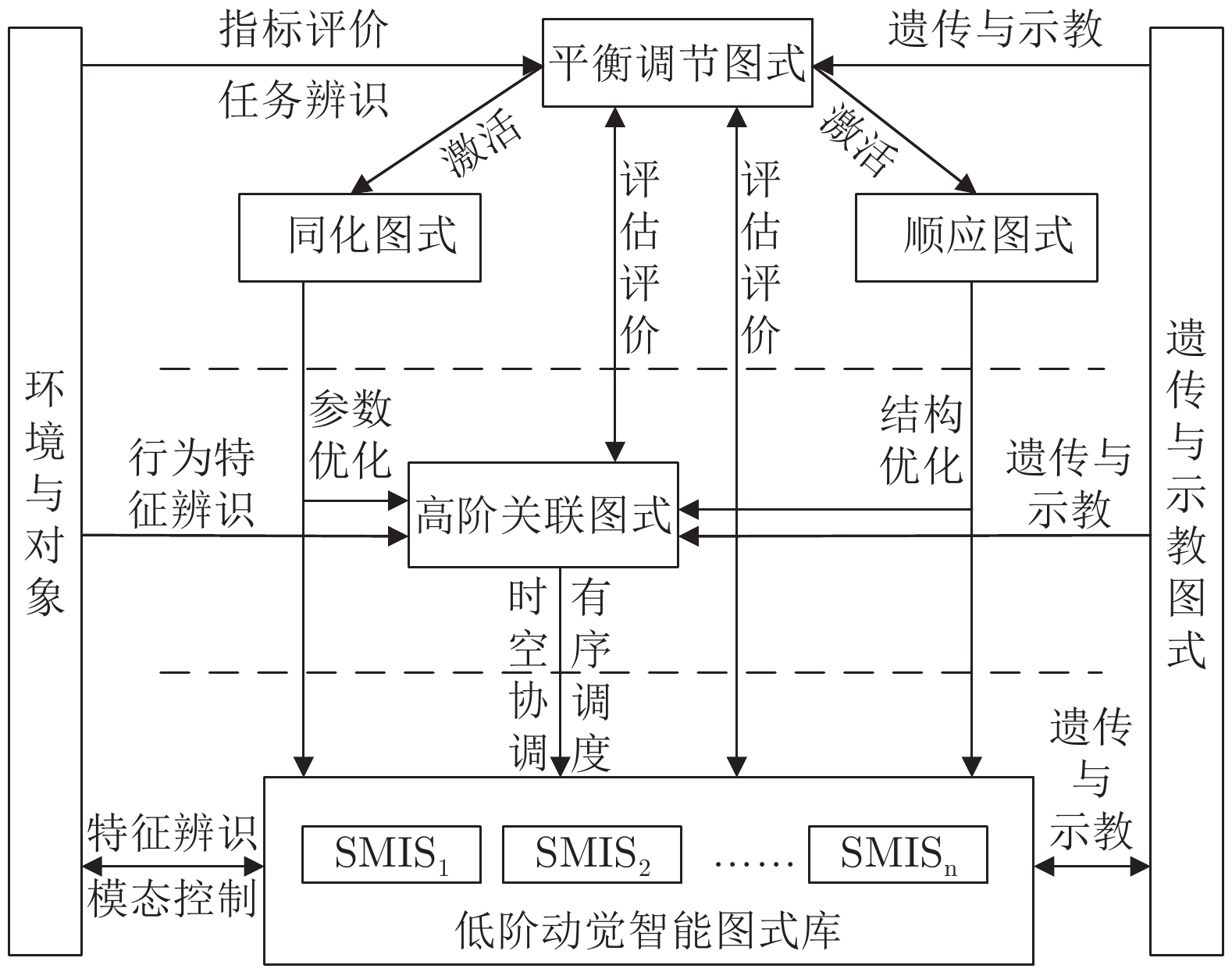
仿人智能控制是现代智能控制理论之一, 利用分层递阶的控制结构与多控制模态为强非线性、大迟滞、难建模问题提供了切实可行的解决方案, 近些年来发展迅速并且得到学术界的持续关注, 但缺乏对该理论研究进展系统性的总结. 本文通过系统的梳理仿人智能控制的理论基础和发展脉络, 将其划分为三代控制模型, 分别从每一代控制模型的算法描述、研究进展与应用进展三个角度进行综述, 同时, 结合当前的研究进展讨论仿人智能控制在控制模型、结构功能、参数校正方面进一步研究的方向.
仿人智能控制是现代智能控制理论之一, 利用分层递阶的控制结构与多控制模态为强非线性、大迟滞、难建模问题提供了切实可行的解决方案, 近些年来发展迅速并且得到学术界的持续关注, 但缺乏对该理论研究进展系统性的总结. 本文通过系统的梳理仿人智能控制的理论基础和发展脉络, 将其划分为三代控制模型, 分别从每一代控制模型的算法描述、研究进展与应用进展三个角度进行综述, 同时, 结合当前的研究进展讨论仿人智能控制在控制模型、结构功能、参数校正方面进一步研究的方向.
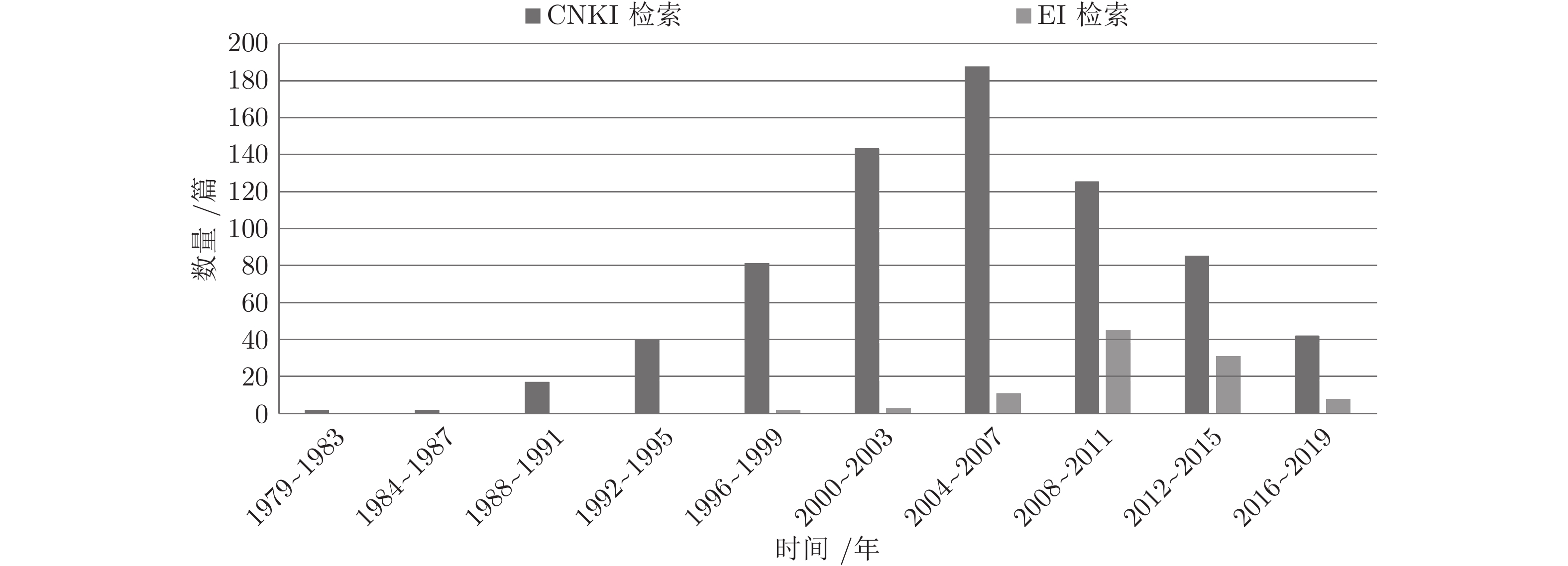
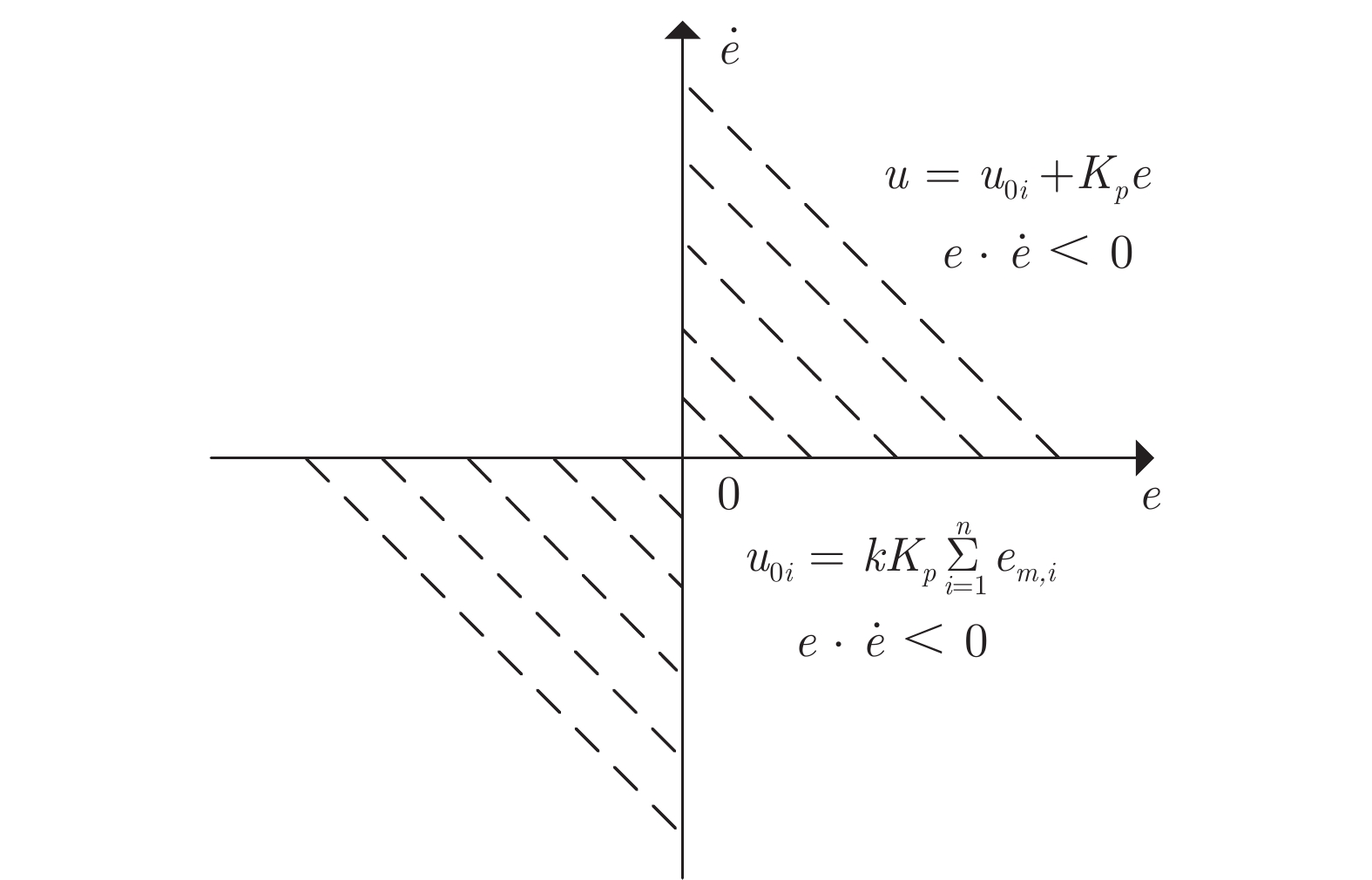
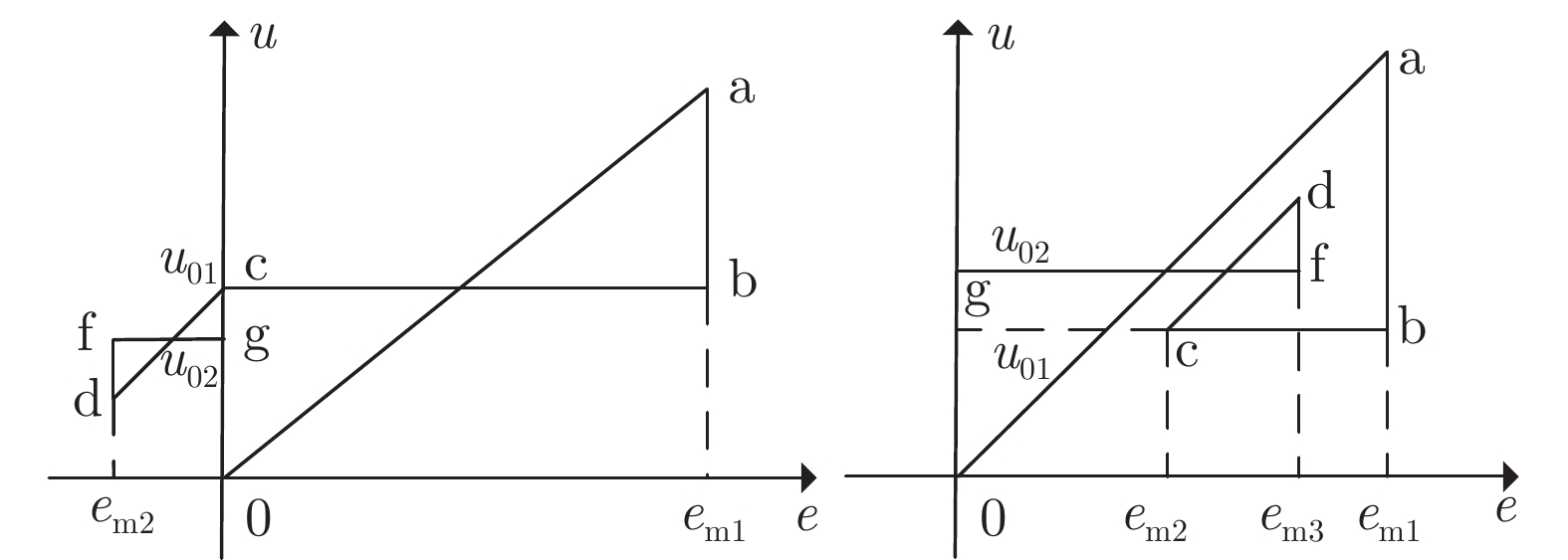
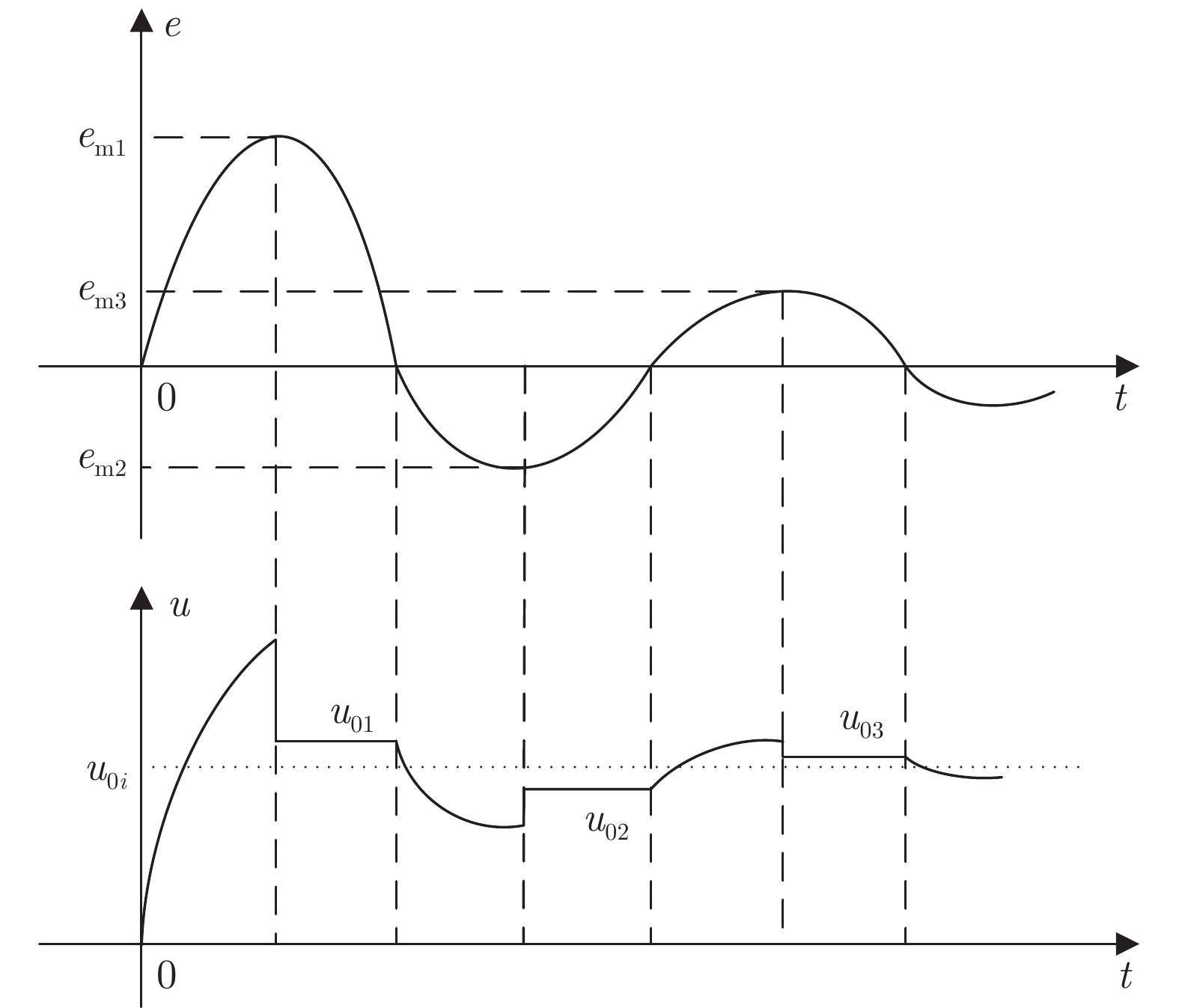


当前状态:
, 最新更新时间: ,
doi: 10.16383/j.aas.2020.c200033
摘要:
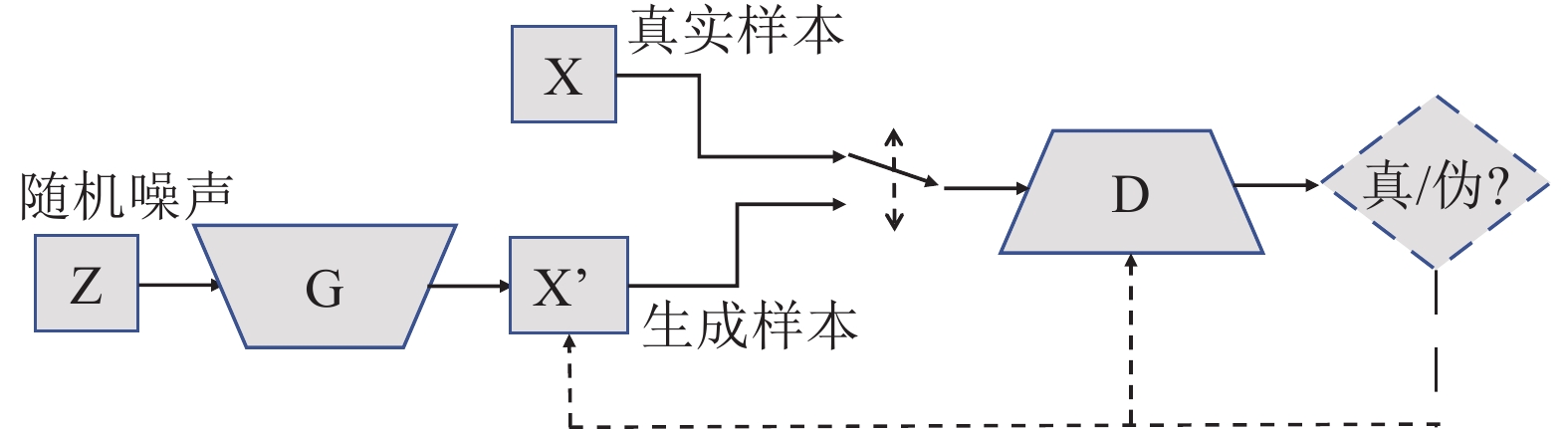
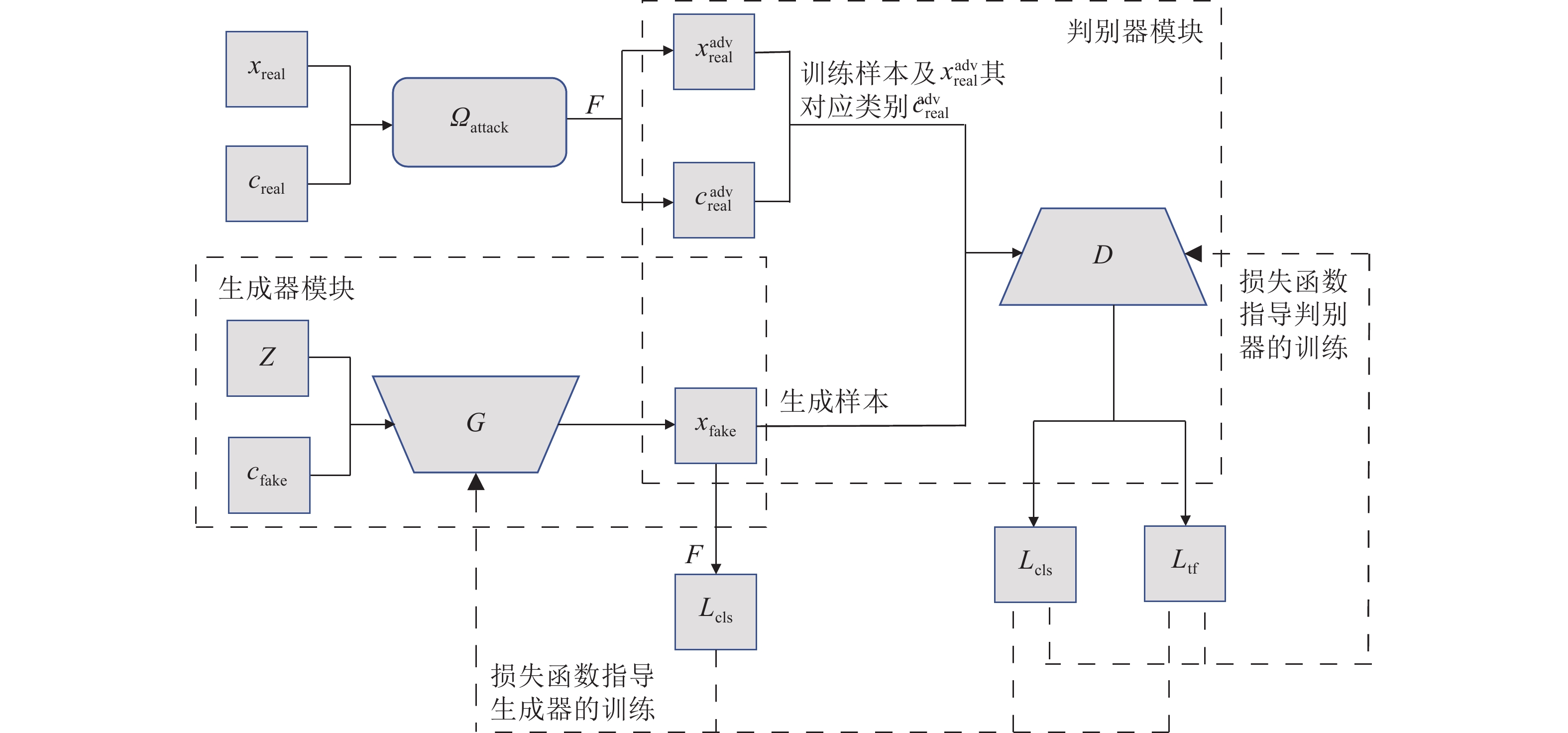
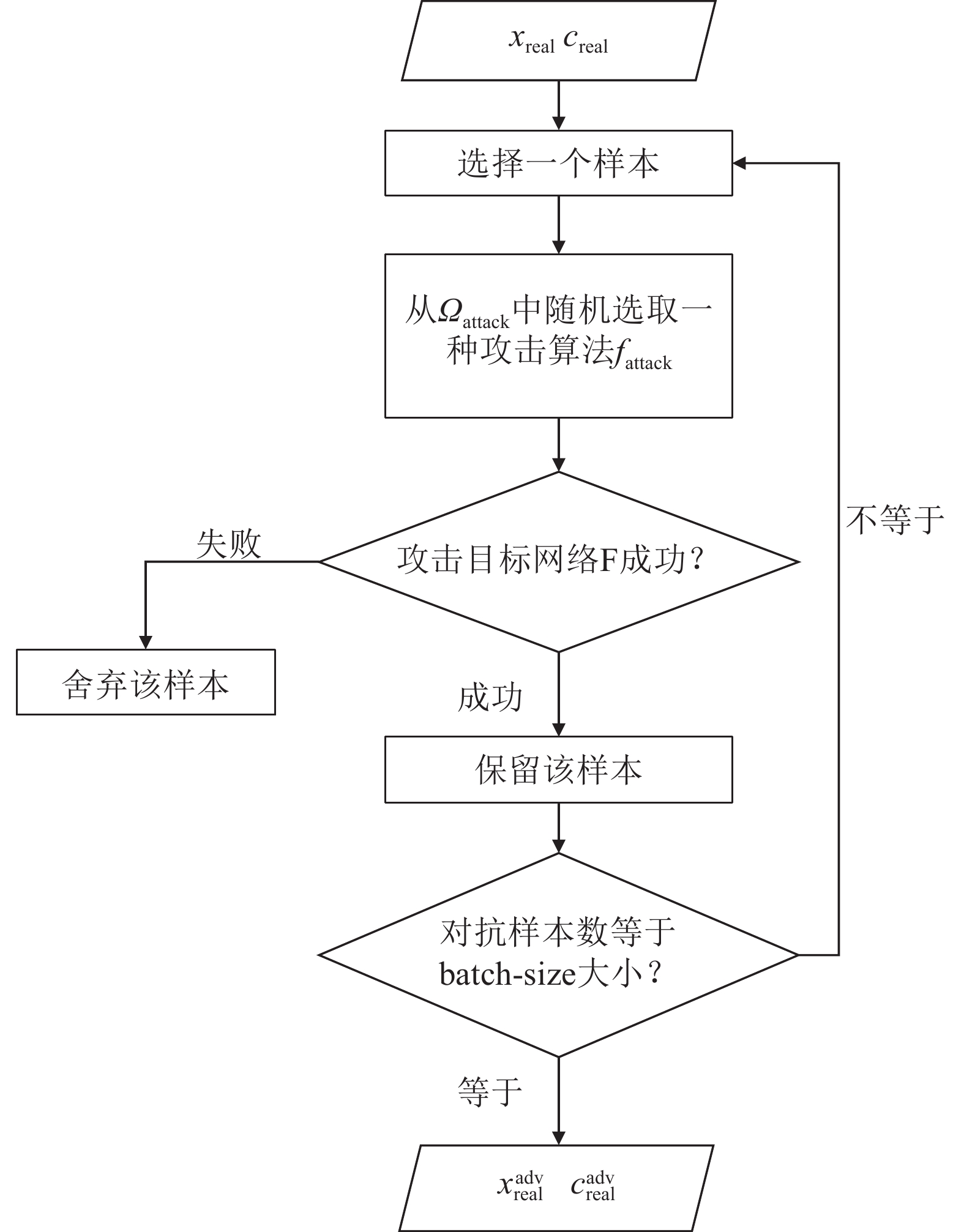
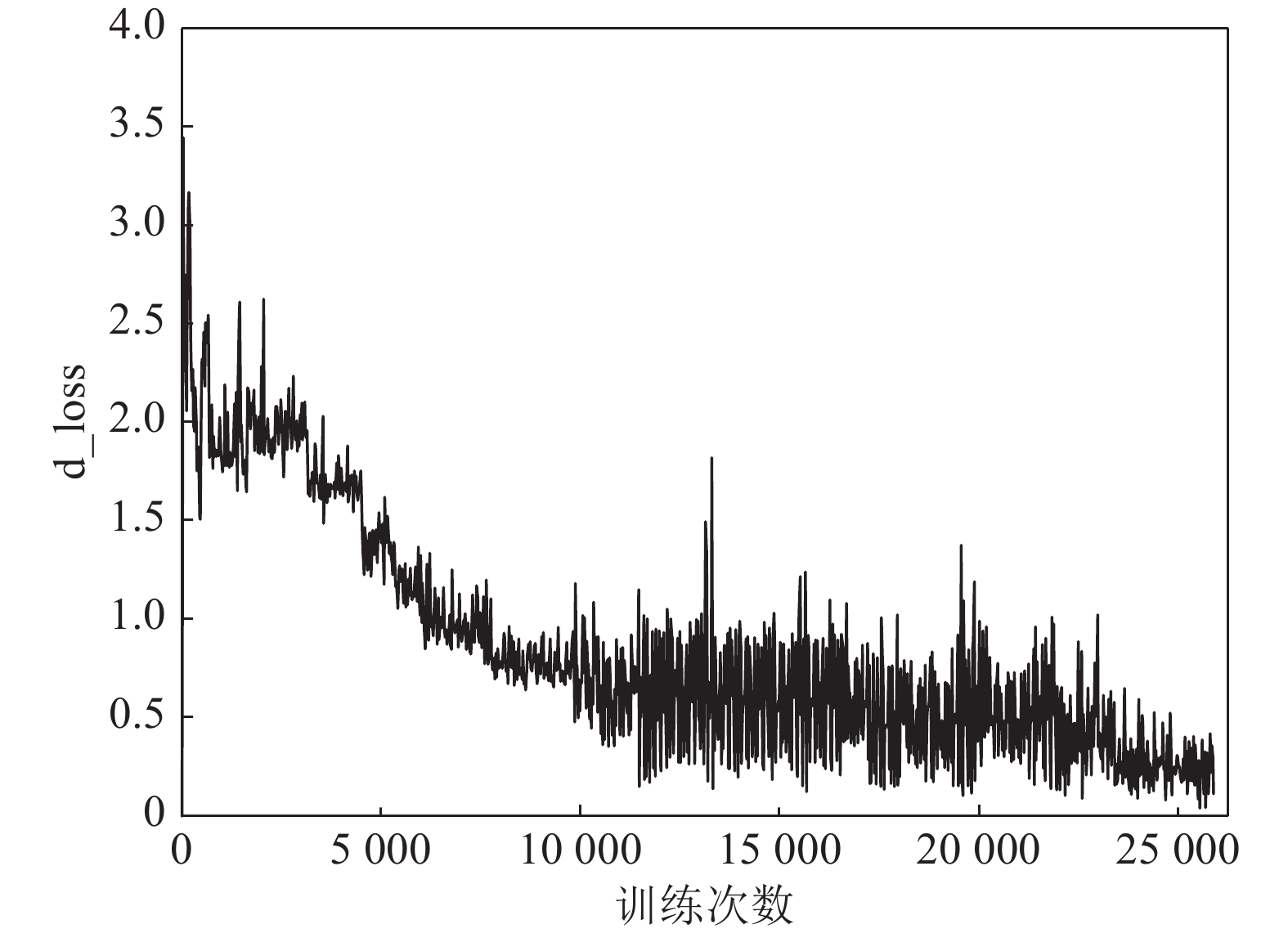
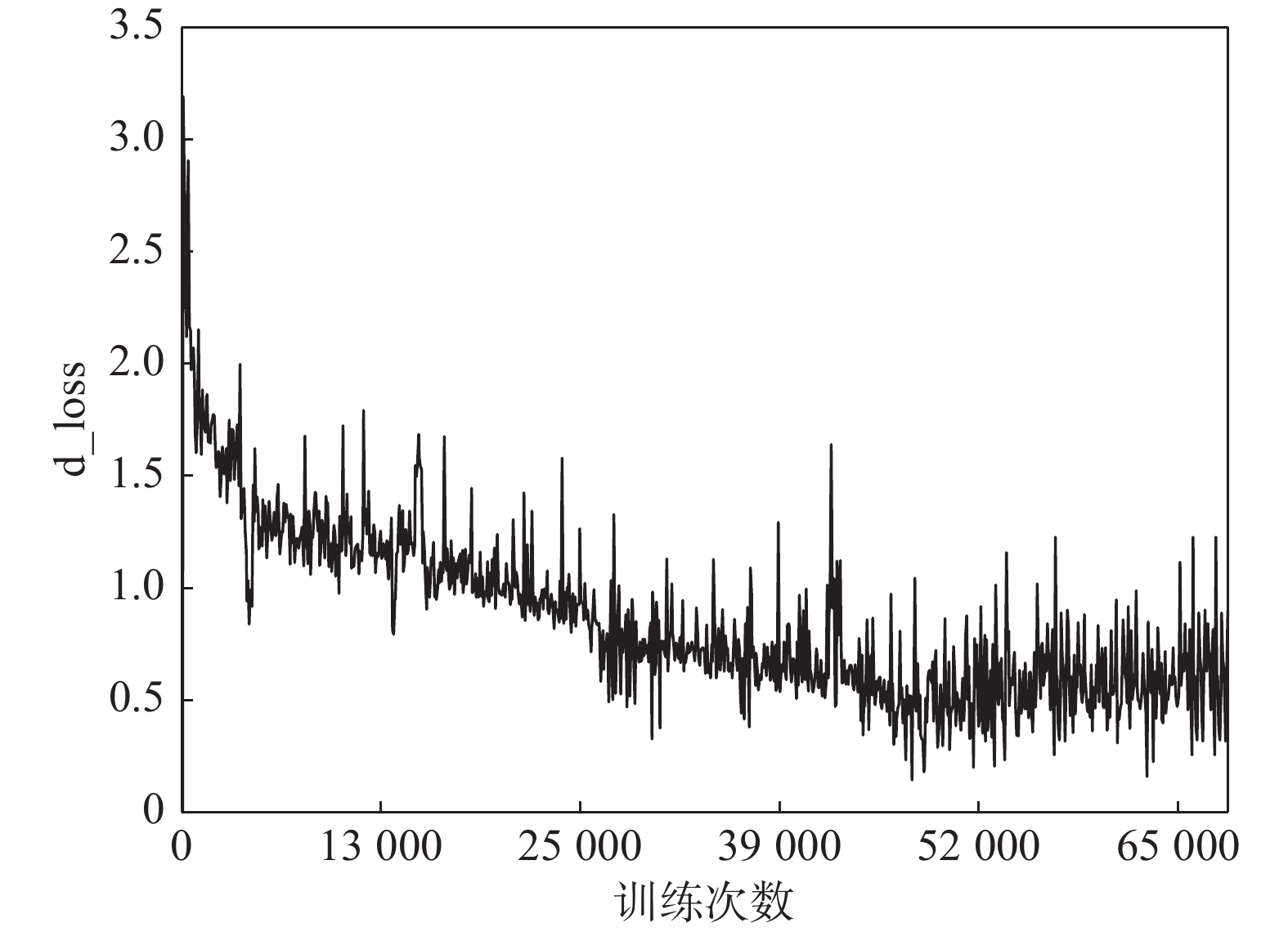
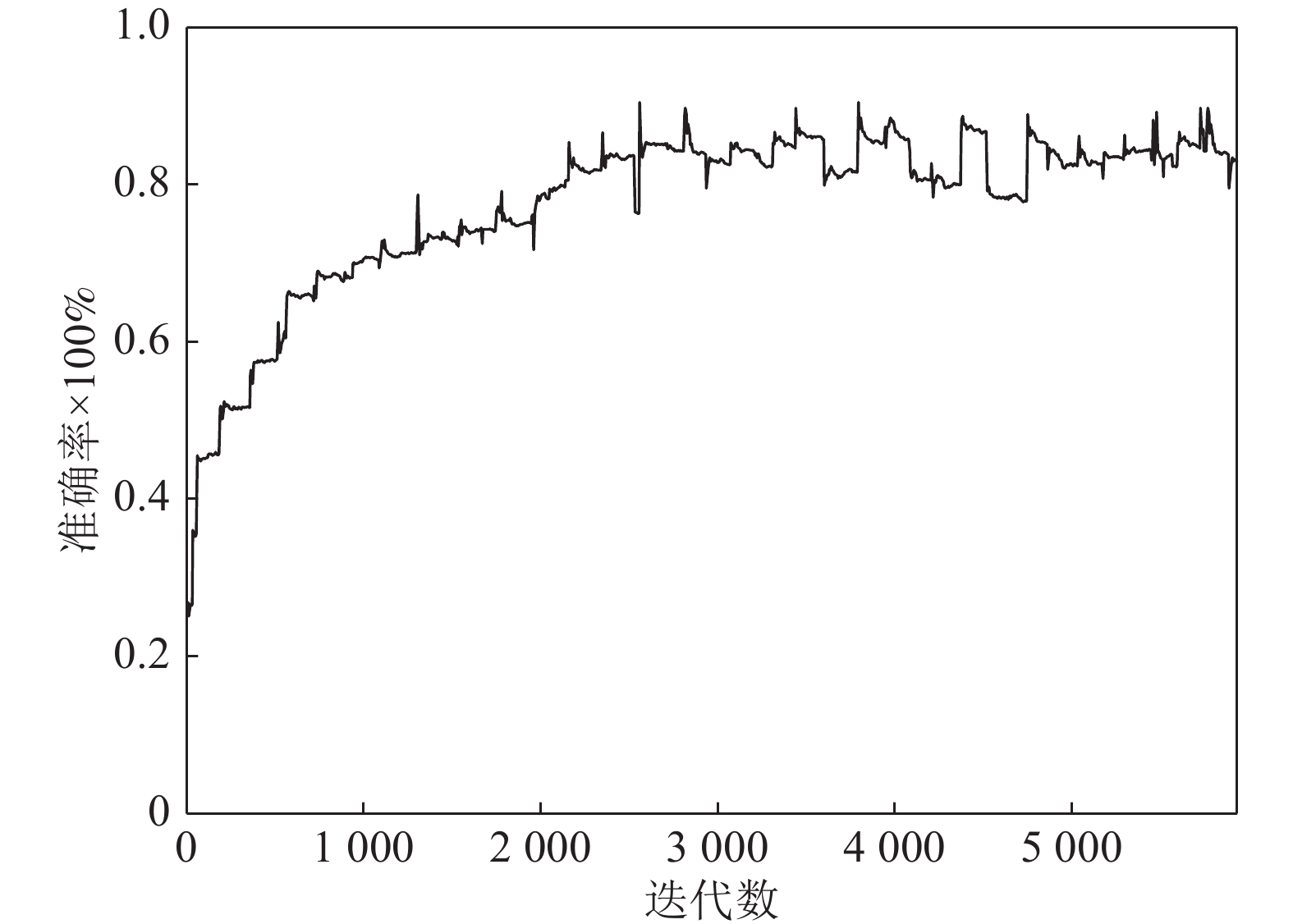
深度神经网络在解决复杂问题方面取得了惊人的成功, 广泛应用于生活中各个领域, 但是最近的研究表明, 深度神经网络容易受到精心设计的对抗样本的攻击, 导致网络模型输出错误的预测结果, 这对于深度学习网络的安全性是一种极大的挑战. 对抗攻击是深度神经网络发展过程中必须克服的一大障碍, 设计一种高效且能够防御多种对抗攻击算法, 且具有强鲁棒性的防御模型是有效推动对抗攻击防御的方向之一, 探究能否利用对抗性攻击来训练网络分类器从而提高其鲁棒性具有重要意义. 本文将生成对抗网络(Generative adversarial networks, GAN)和现有的攻击算法结合, 提出一种基于生成对抗网络的对抗攻击防御模型(AC-DefGAN), 利用对抗攻击算法生成攻击样本作为GAN的训练样本, 同时在网络中加入条件约束来稳定模型的训练过程, 利用分类器对生成器所生成样本的分类来指导GAN的训练过程, 通过自定义分类器需要防御的攻击算法来生成对抗样本以完成判别器的训练, 从而得到能够防御多种对抗攻击的分类器. 通过在MNIST、CIFAR-10和ImageNet数据集上进行实验, 证明训练完成后, AC-DefGAN可以直接对原始样本和对抗样本进行正确分类, 对各类对抗攻击算法达到很好的防御效果, 且比已有方法防御效果好、鲁棒性强.
深度神经网络在解决复杂问题方面取得了惊人的成功, 广泛应用于生活中各个领域, 但是最近的研究表明, 深度神经网络容易受到精心设计的对抗样本的攻击, 导致网络模型输出错误的预测结果, 这对于深度学习网络的安全性是一种极大的挑战. 对抗攻击是深度神经网络发展过程中必须克服的一大障碍, 设计一种高效且能够防御多种对抗攻击算法, 且具有强鲁棒性的防御模型是有效推动对抗攻击防御的方向之一, 探究能否利用对抗性攻击来训练网络分类器从而提高其鲁棒性具有重要意义. 本文将生成对抗网络(Generative adversarial networks, GAN)和现有的攻击算法结合, 提出一种基于生成对抗网络的对抗攻击防御模型(AC-DefGAN), 利用对抗攻击算法生成攻击样本作为GAN的训练样本, 同时在网络中加入条件约束来稳定模型的训练过程, 利用分类器对生成器所生成样本的分类来指导GAN的训练过程, 通过自定义分类器需要防御的攻击算法来生成对抗样本以完成判别器的训练, 从而得到能够防御多种对抗攻击的分类器. 通过在MNIST、CIFAR-10和ImageNet数据集上进行实验, 证明训练完成后, AC-DefGAN可以直接对原始样本和对抗样本进行正确分类, 对各类对抗攻击算法达到很好的防御效果, 且比已有方法防御效果好、鲁棒性强.