

-
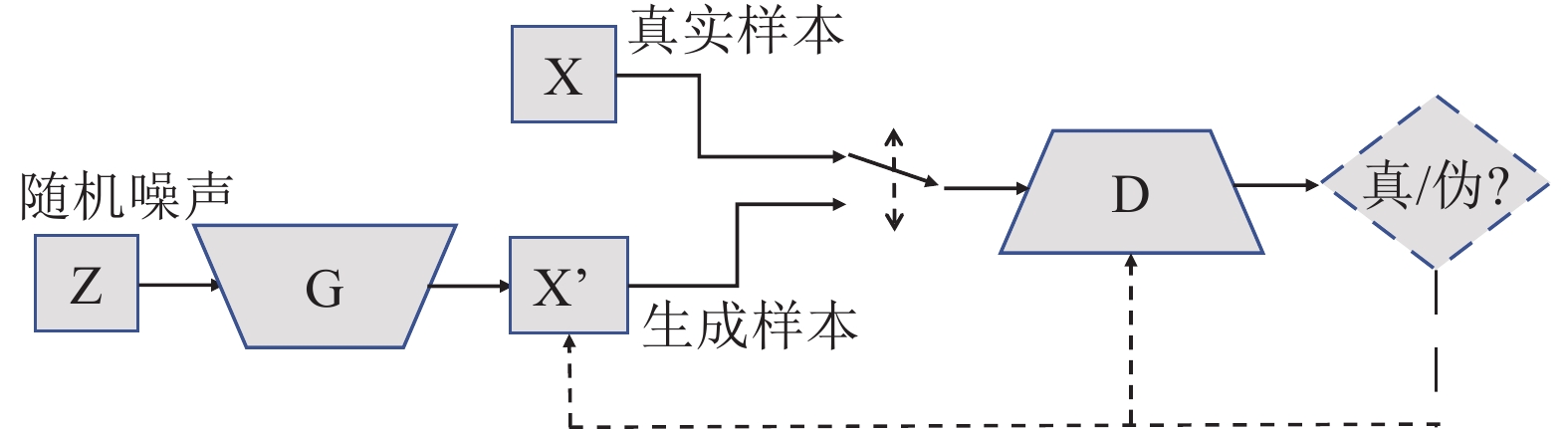
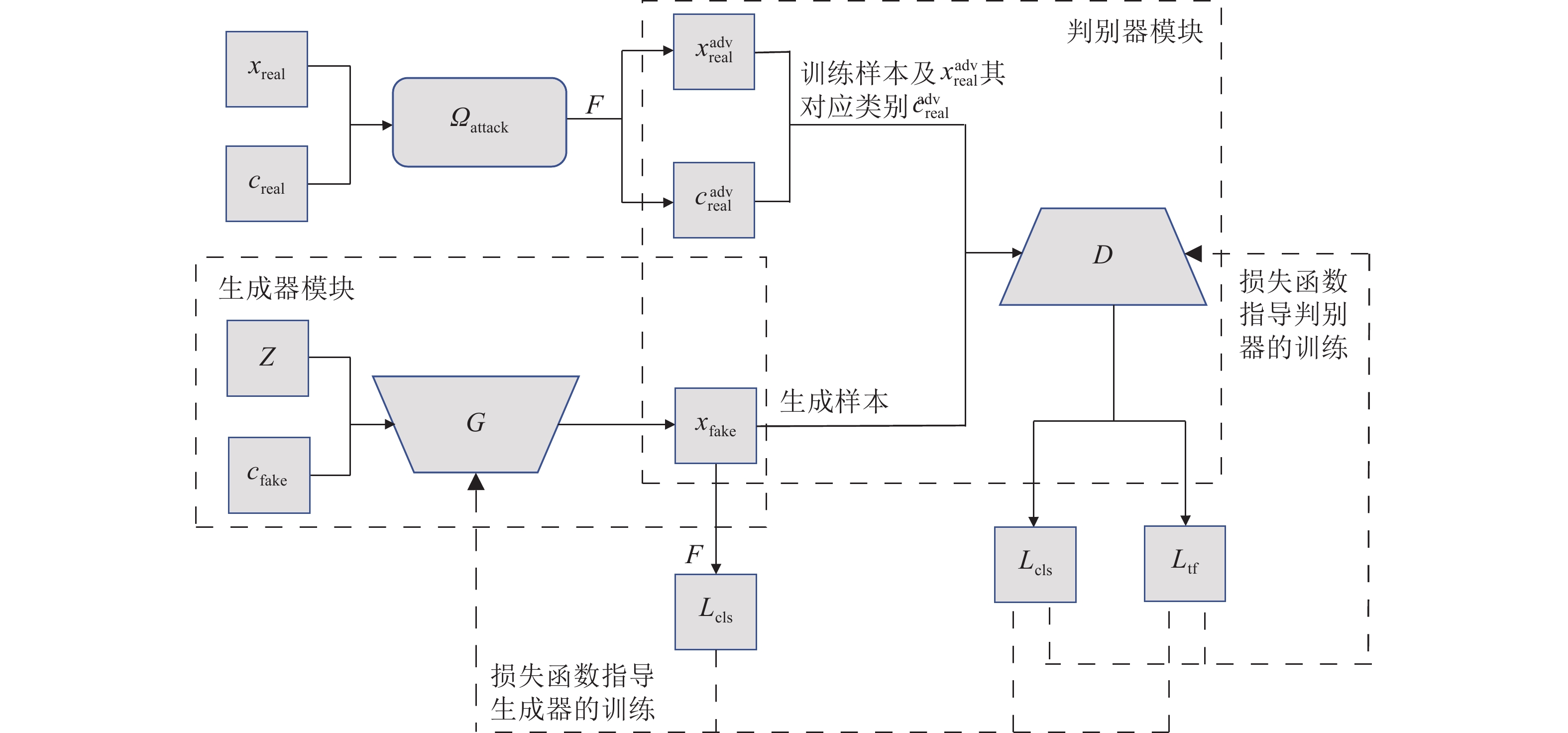
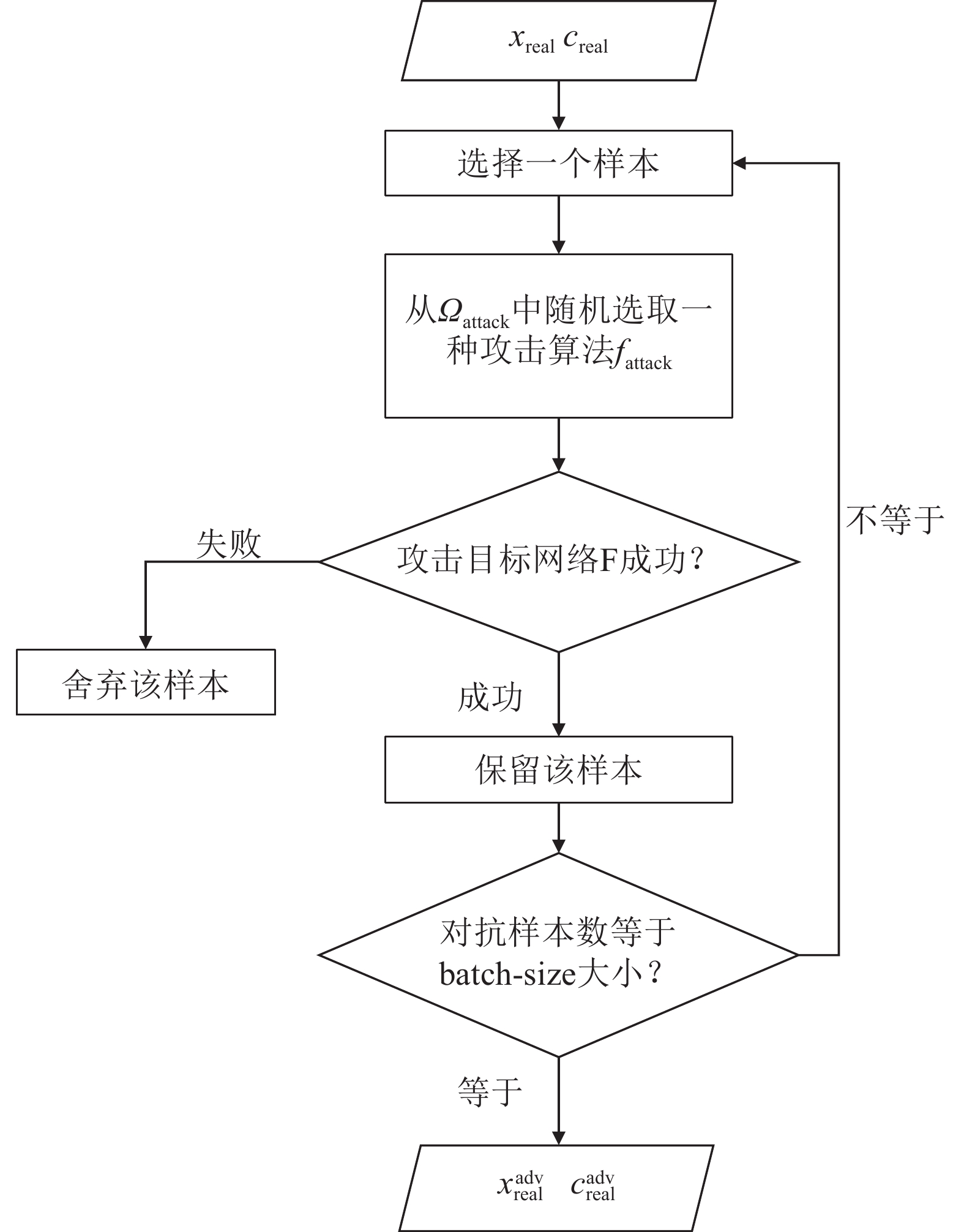
摘要: 深度神经网络在解决复杂问题方面取得了惊人的成功, 广泛应用于生活中各个领域, 但是最近的研究表明, 深度神经网络容易受到精心设计的对抗样本的攻击, 导致网络模型输出错误的预测结果, 这对于深度学习网络的安全性是一种极大的挑战. 对抗攻击是深度神经网络发展过程中必须克服的一大障碍, 设计一种高效且能够防御多种对抗攻击算法, 且具有强鲁棒性的防御模型是有效推动对抗攻击防御的方向之一, 探究能否利用对抗性攻击来训练网络分类器从而提高其鲁棒性具有重要意义. 本文将生成对抗网络(Generative adversarial networks, GAN)和现有的攻击算法结合, 提出一种基于生成对抗网络的对抗攻击防御模型(AC-DefGAN), 利用对抗攻击算法生成攻击样本作为GAN的训练样本, 同时在网络中加入条件约束来稳定模型的训练过程, 利用分类器对生成器所生成样本的分类来指导GAN的训练过程, 通过自定义分类器需要防御的攻击算法来生成对抗样本以完成判别器的训练, 从而得到能够防御多种对抗攻击的分类器. 通过在MNIST、CIFAR-10和ImageNet数据集上进行实验, 证明训练完成后, AC-DefGAN可以直接对原始样本和对抗样本进行正确分类, 对各类对抗攻击算法达到很好的防御效果, 且比已有方法防御效果好、鲁棒性强.Abstract: Deep neural networks have achieved amazing success in solving complex problems and are widely used in various fields of life. However, recent research has shown that deep neural networks are vulnerable to well-designed adversarial samples, which can cause the network model to output incorrect prediction results. This is a great challenge for the security of deep learning networks. Adversarial attacks are a major obstacle that must be overcome during the development of deep neural networks. Designing an efficient and robust defense model that is capable of defending against a variety of adversarial attacks is one of the directions to effectively promote the defense against attacks. It is of great significance to explore whether it is possible to use adversarial attacks to train a network classifier to improve its robustness. In this paper, by combining generative adversarial networks with existing attack algorithms, we propose an adversarial attack defense model AC-DefGAN. We use the adversarial attack model to generate attack samples as training samples, and the classification of samples generated by the generator is used to guide the training process of GAN, and then we add the conditional constraints to stabilize the model training process. Once our model is trained, it can effectively defend the corresponding adversarial attacks. The experimental results on the MNIST, CIFAR-10 and ImageNet datasets show that AC-DefGAN can directly correctly classify the original samples and the adversarial samples after training. It can defend a variety of adversarial attack algorithms, and has better defense effect and robustness than existing defense methods.
-
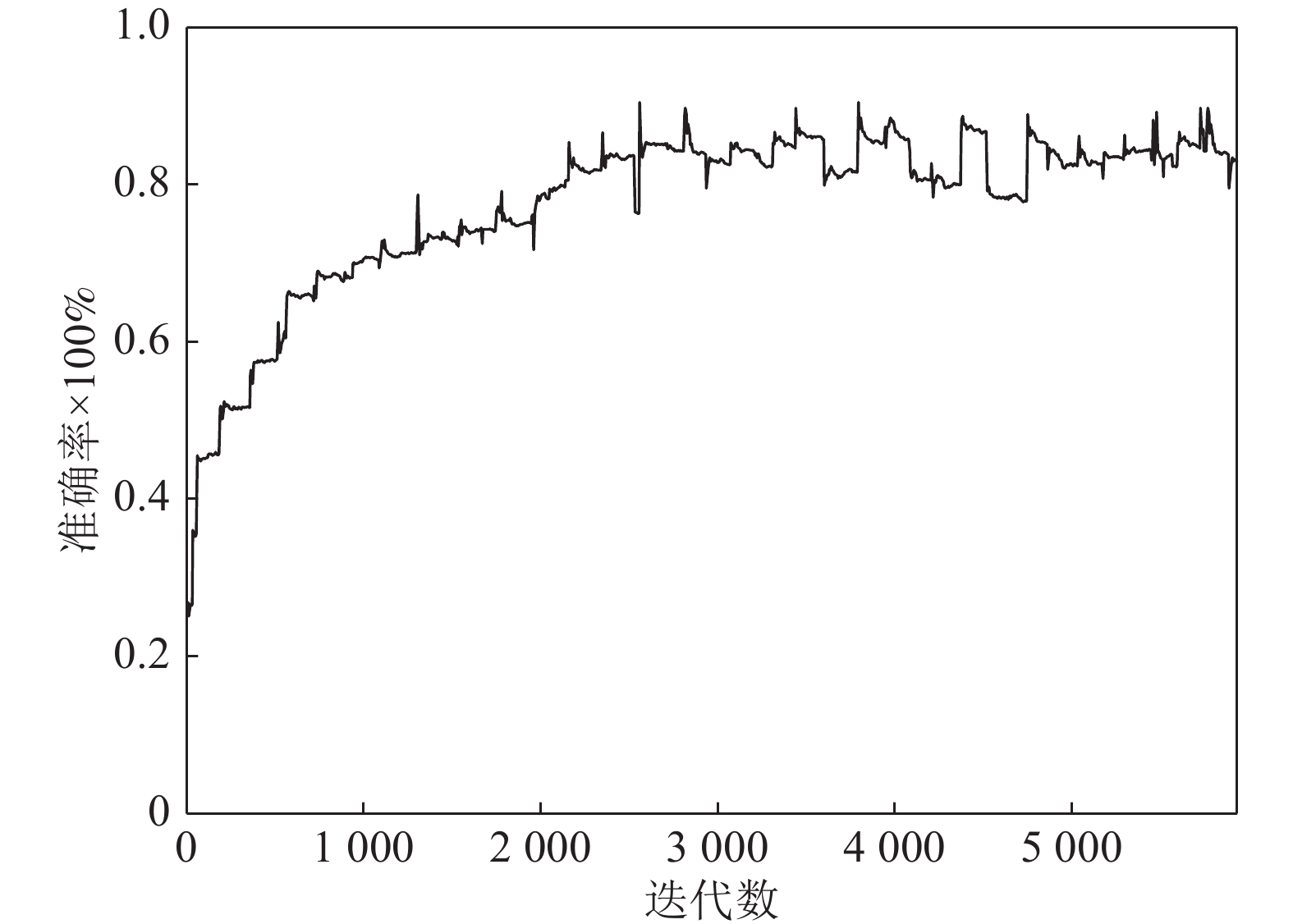
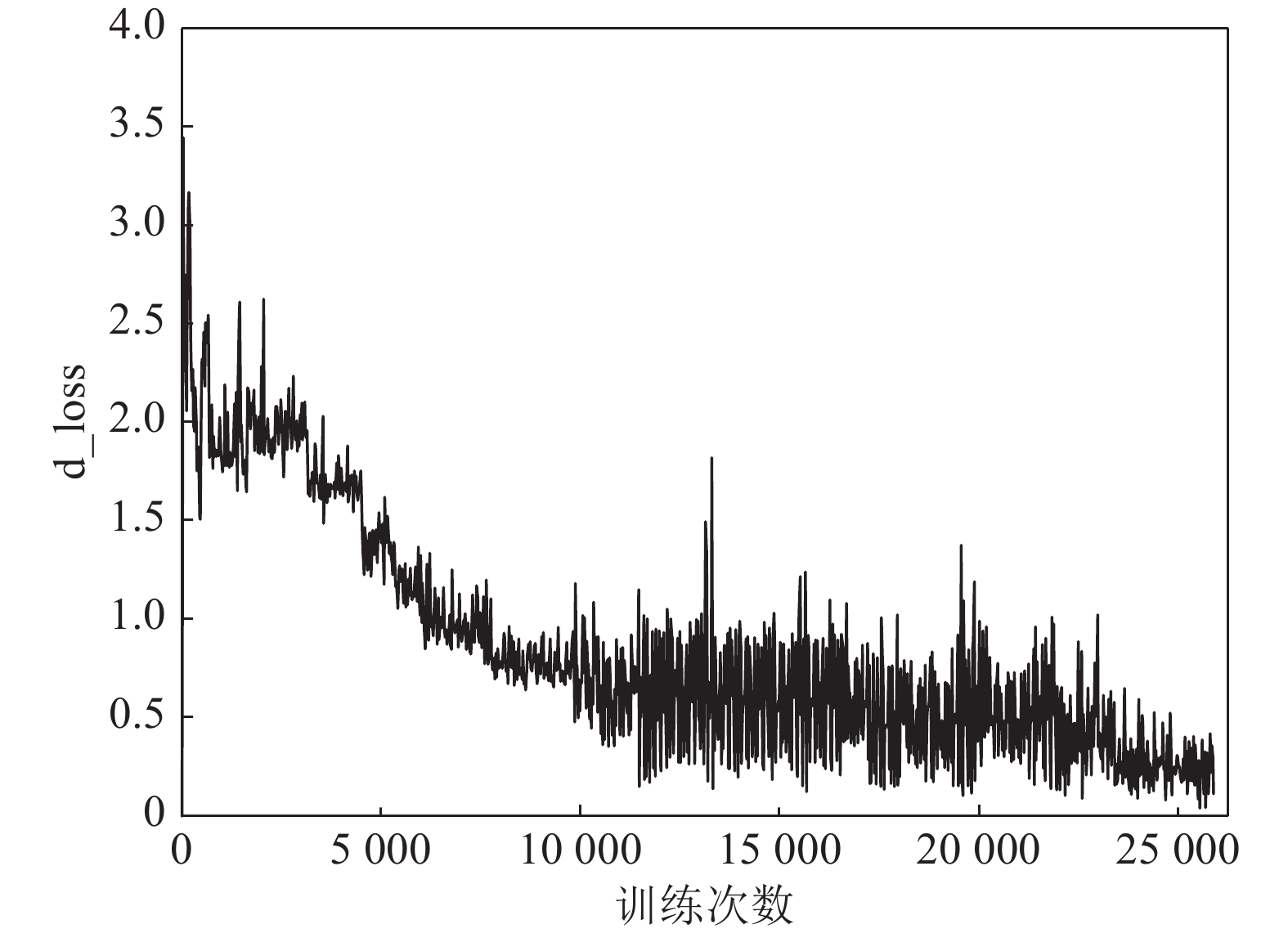
图 8 CIFAR-10数据集下AC-DefGAN判别器识别对抗样本
$x_{real}^{adv}$ 的准确率Fig. 8 Accuracy of AC-DefGAN discriminator in identifying adversarial samples
$x_{real}^{adv}$ 表 1 MNIST数据集中各目标网络、AC-DefGAN对各类对抗样本的误分类率
Table 1 Misclassification rates of various adversarial examples for target models and AC-DefGAN on MNIST
攻击方法 VGG11 ResNet-18 Dense-Net40 InceptionV3 Target model AC-DefGAN Target model AC-DefGAN Target model AC-DefGAN Target model AC-DefGAN FGSM(%) 95.31 0.66 87.83 0.58 79.32 0.56 92.91 0.61 BIM(%) 95.70 0.78 88.51 0.69 82.01 0.64 93.12 0.73 DeepFool(%) 96.24 1.42 89.74 1.13 88.61 1.10 93.80 1.25 C&W(%) 99.37 1.79 97.52 1.71 96.21 1.68 98.93 1.75 PGD(%) 98.13 1.61 95.81 1.52 93.26 1.37 97.15 1.58  下载: 导出CSV
下载: 导出CSV
表 2 MNIST数据集中AC-DefGAN对各攻击算法所生成对抗样本的误分类率
Table 2 Misclassification rates of multiple adversarial examples for AC-DefGAN on MNIST
攻击方法 VGG11 ResNet-18 Dense-Net40 InceptionV3 BIM、FGSM(%) 0.69 0.64 0.59 0.67 BIM、DeepFool(%) 1.11 0.91 0.87 1.01 FGSM、DeepFool(%) 1.05 0.86 0.81 0.93 BIM、FGSM、DeepFool(%) 1.01 0.84 0.79 0.89
下载: 导出CSV
表 3 MNIST数据集中AC-DefGAN与各防御模型对各类对抗样本的误分类率
Table 3 Misclassification rates of various adversarial examplesfor AC-DefGAN and other defense strategies on MNIST
攻击方法 MagNet Adv. training APE-GANm Defence-GAN-Rec AC-DefGAN FGSM(%) 80.91 18.40 2.80 1.11 0.66 BIM(%) 83.09 19.21 2.91 1.24 0.78 DeepFool(%) 89.93 23.16 2.43 1.53 1.42 C&W(%) 93.18 62.23 1.74 2.29 1.67 粗体表示最优值.
下载: 导出CSV
表 4 MNIST数据集中目标网络、AC-DefGAN对不同扰动阈值
$\varepsilon $ 的FGSM所产生对抗样本的误分类率(%)Table 4 Misclassification rates of adversarial examples generated from FGSM with different
$\varepsilon $ for target model and AC-DefGAN on MNIST (%)FGSM的扰动阈值 $\varepsilon $ 目标网络 AC-DefGAN $\varepsilon = 0.1$ 96.29 0.68 $\varepsilon = 0.2$ 96.98 0.83 $\varepsilon = 0.3$ 97.35 0.91 $\varepsilon = 0.4$ 98.76 1.69
下载: 导出CSV
表 5 CIFAR-10数据集中各目标网络、AC-DefGAN对各类对抗样本的误分类率
Table 5 Misclassification rates of various adversarial examples for target models and AC-DefGAN on CIFAR-10
攻击方法 VGG19 ResNet-18 Dense-Net40 InceptionV3 Target model AC-DefGAN Target model AC-DefGAN Target model AC-DefGAN Target model AC-DefGAN FGSM(%) 77.81 16.95 74.92 13.07 73.37 13.74 76.74 15.49 BIM(%) 84.73 19.80 75.74 14.27 76.44 13.83 79.52 18.93 DeepFool(%) 88.52 23.47 83.48 22.55 86.16 21.79 88.26 23.15 C&W(%) 98.94 31.13 92.79 30.24 96.68 29.85 97.43 30.97 PGD(%) 87.13 28.37 86.41 26.29 86.28 25.91 87.04 26.74
下载: 导出CSV
表 6 CIFAR-10数据集中AC-DefGAN对各攻击算法所生成对抗样本的误分类率
Table 6 Misclassification rates of multiple adversarial examples for AC-DefGAN on CIFAR-10
攻击方法 VGG19 ResNet-18 Dense-Net40 InceptionV3 BIM、FGSM(%) 19.62 13.73 13.18 16.45 BIM、DeepFool(%) 21.71 18.65 17.42 22.14 FGSM、DeepFool(%) 20.95 15.21 16.35 19.78 BIM、FGSM、DeepFool(%) 21.37 17.56 16.93 20.81
下载: 导出CSV
表 7 CIFAR-10数据集中AC-DefGAN与各防御模型对各类对抗样本的误分类率
Table 7 Misclassification rates of various adversarial examplesfor AC-DefGAN and other defense strategies on CIFAR-10
攻击方法 目标网络F Adv. training APE-GANm Defence-GAN-Rec AC-DefGAN FGSM(%) 82.83 32.68 26.41 22.50 16.91 BIM(%) 89.75 39.49 24.33 21.72 19.83 DeepFool(%) 93.54 44.71 25.29 28.09 25.56 C&W(%) 98.71 78.23 30.50 32.21 30.24 粗体表示最优值.
下载: 导出CSV
表 8 CIFAR-10数据集中目标网络、AC-DefGAN对不同扰动阈值
$\varepsilon $ 的FGSM所产生对抗样本的误分类率(%)Table 8 Misclassification rates of adversarial examples generated from FGSM with different
$\varepsilon $ for target model and AC-DefGAN on CIFAR-10 (%)FGSM的扰动阈值 $\varepsilon $ 目标网络 AC-DefGAN $\varepsilon = 0.1$ 77.82 12.92 $\varepsilon = 0.2$ 80.89 17.47 $\varepsilon = 0.3$ 82.33 18.86 $\varepsilon = 0.4$ 84.74 24.13
下载: 导出CSV
表 9 ImageNet数据集中各类目标网络、AC-DefGAN对各类对抗样本的误分类率
Table 9 Misclassification rates of various adversarial examples for target models and AC-DefGAN on ImageNet
攻击方法 VGG19 ResNet-18 Dense-Net40 InceptionV3 Target model AC-DefGAN Target model AC-DefGAN Target model AC-DefGAN Target model AC-DefGAN FGSM(%) 71.21 39.42 69.14 38.52 68.42 37.92 69.65 38.77 DeepFool(%) 88.45 44.80 85.73 42.96 86.24 43.17 87.67 44.63 C&W(%) 97.39 39.13 96.19 36.75 95.84 36.74 96.43 38.68
下载: 导出CSV
表 10 ImageNet数据集中AC-DefGAN与各防御模型对各攻击算法对抗样本的误分类率(%)
Table 10 Misclassification rates of various adversarial examples for AC-DefGAN and other defense strategies on ImageNet (%)
攻击方法 目标网络 APE-GANm AC-DefGAN FGSM 72.92 40.14 38.94 C&W 97.84 38.70 36.52 BIM 76.79 41.28 40.78 DeepFool 94.71 45.93 44.31 粗体表示最优值.
下载: 导出CSV
-
[1] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436−444 doi: 10.1038/nature14539 [2] Hinton G E. What kind of a graphical model is the brain? In: Proceedings of the 19th International Joint Conference on Artificial Intelligence. Burlington, USA: Morgan Kaufmann, 2005. 1765−1775 [3] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504 −507 doi: 10.1126/science.1127647 [4] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Piscataway, NJ, USA: IEEE, 2011. 315−323 [5] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2012. 1097−1105 [6] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 818−833 [7] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv: 1409.1556v6, 2015. [8] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D. Going deeper with convolutions. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. IEEE: Boston, USA: 2015. 1−9 [9] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. IEEE: Las Vegas, USA: 2016. 770−778 [10] Chakraborty A, Alam M, Dey V, et al. Adversarial Attacks and Defences: A Survey. arXiv preprint arXiv: 1810.00069, 2018. [11] Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I J, Fergus R. Intriguing properties of neural networks. arXiv preprint arXiv: 1312. 6199, 2014. [12] Akhtar N, Mian A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access, 2018, 6: 14410−14430 doi: 10.1109/ACCESS.2018.2807385 [13] G oodfellow I J, Shlens J, and Szegedy C. Explaining and Harnessing Adversarial Examples. arXiv preprint arXiv: 1412.6572, 2015. [14] Kurakin A, Goodfellow I J, Bengio S. Adversarial examples in the physical world. arXiv preprint, arXiv: 1607.02533v4, 2017. [15] Tramer F, Kurakin A, Papernot N, et al. Ensemble adversarial training: Attacks and defenses. arXiv preprint, arXiv: 1705.07204v5, 2020. [16] Moosavi-Dezfooli S M, Fawzi A, Frossard P. Deepfool: a simple and accurate method to fool deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016. 2574−2582 [17] Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv: 1706.06083v4, 2019. [18] Lyu C, Huang K Z, and Liang H N. A Unified Gradient Regularization Family for Adversarial Examples. In: Proceedings of 2015 IEEE International Conference on Data Mining. IEEE, 2015. 301−309 [19] Shaham U, Yamada Y, Negahban S. Understanding adversarial training: Increasing local stability of supervised models through robust optimization. Neurocomputing, 2018, 307: 195−204 doi: 10.1016/j.neucom.2018.04.027 [20] Nayebi A, Ganguli S. Biologically inspired protection of deep networks from adversarial attacks. arXiv preprint arXiv: 1703.09202, 2017. [21] Dziugaite G K, Ghahramani Z, Roy D M. A study of the effect of jpg compression on adversarial images. arXiv preprint arXiv: 1608.00853, 2016. [22] Guo C, Rana M, Cisse M, et al. Countering adversarial images using input transformations. arXiv preprint arXiv: 1711.00117v3, 2018. [23] Das N, Shanbhogue M, Chen S T, et al. Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression. arXiv preprint arXiv: 1705.02900, 2017. [24] Xie C, Wang J, Zhang Z, et al. Adversarial examples for semantic segmentation and object detection. In: Proceedings of the IEEE International Conference on Computer Vision, 2017. 1369−1378 [25] Gu S, Rigazio L. Towards deep neural network architectures robust to adversarial examples. arXiv preprint arXiv: 1412.5068v4, 2015. [26] Papernot N, McDaniel P, Wu X, et al. Distillation as a defense to adversarial perturbations against deep neural networks. In: Proceedings of 2016 IEEE Symposium on Security and Privacy (SP). IEEE, 2016. 582−597 [27] Ross A S, Doshi-Velez F. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In Thirty-second AAAI conference on artificial intelligence. 2018. [28] Cisse M, Adi Y, Neverova N, et al. Houdini: Fooling deep structured prediction models. arXiv preprint arXiv: 1707.05373, 2017. [29] Akhtar N, Liu J, Mian A. Defense against universal adversarial perturbations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3389−3398 [30] Samangouei P, Kabkab M, Chellappa R. Defense-gan: Protecting classifiers against adversarial attacks using generative models. arXiv preprint arXiv: 1805.06605, 2018. [31] Meng D, Chen H. Magnet: a two-pronged defense against adversarial examples. In: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 2017: 135−147 [32] Xu W, Evans D, Qi Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv preprint arXiv: 1704.01155, 2017. [33] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets. In: Proceedings of Advances in Neural Information Processing Systems. 2014: 2672−2680 [34] Yu Y, Gong Z, Zhong P, et al. Unsupervised representation learning with deep convolutional neural network for remote sensing images. In: Proceedings of International Conference on Image and Graphics. Springer, Cham, 2017: 97−108 [35] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint arXiv: 1411.1784, 2014. [36] Odena A, Olah C, Shlens J. Conditional image synthesis with auxiliary classifier gans. In: Proceedings of International Conference on Machine Learning. 2017: 2642−2651 [37] 林懿伦, 戴星原, 李力, 王晓, 王飞跃. 人工智能研究的新前线: 生成式对抗网络. 自动化学报, 2018, 44(5): 775−792Lin Yi-Lun, Dai Xing-Yuan, Li Li, Wang Xiao, Wang FeiYue. The new frontier of AI research: generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 775−792 [38] Shen S, Jin G, Gao K, et al. Ape-gan: Adversarial perturbation elimination with gan. arXiv preprint arXiv: 1707.05474, 2017. [39] 王坤峰, 左旺孟, 谭营, 秦涛, 李力, 王飞跃. 生成式对抗网络: 从生成数据到创造智能. 自动化学报, 2018, 44(5): 769−774Wang Kun-Feng, Zuo Wang-Meng, Tan Ying, Qin Tao, Li Li, Wang Fei-Yue. Generative adversarial networks: from generating data to creating intelligence. Acta Automatica Sinica, 2018, 44(5): 769−774 [40] 孔锐, 黄钢. 基于条件约束的胶囊生成对抗网络. 自动化学报, 2020, 46(1): 94−107KONG Rui, HUANG Gang. Conditional Generative Adversarial Capsule Networks. Acta Automatica Sinica, 2020, 46(1): 94−107 [41] Zhang H, Chen H, Song Z, et al. The limitations of adversarial training and the blind-spot attack. arXiv preprint arXiv: 1901.04684, 2019. [42] 唐贤伦, 杜一铭, 刘雨微, 李佳歆, 马艺玮. 基于条件深度卷积生成对抗网络的图像识别方法. 自动化学报, 2018, 44(5): 855−864TANG Xian-Lun, DU Yi-Ming, LIU Yu-Wei, LI Jia-Xin, MA Yi-Wei. Image Recognition With Conditional Deep Convolutional Generative Adversarial Networks. Acta Automatica Sinica, 2018, 44(5): 855−864 [43] Kussul E, Baidyk T. Improved method of handwritten digit recognition tested on MNIST database. Image and Vision Computing, 2004, 22(12): 971−981 doi: 10.1016/j.imavis.2004.03.008 [44] Hinton G E, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv: 1207.0580, 2012. [45] Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database. In: Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009. 248−255 [46] Carlini N, Wagner D. Towards evaluating the robustness of neural networks. In: Proceedings of 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017. 39−57 -

 下载:
下载:





















计量
- 文章访问数: 4003
- HTML全文浏览量: 2517
- 被引次数: 0
