2016年 第42卷 第6期
2016, 42(6): 807-818.
doi: 10.16383/j.aas.2016.c150674
摘要:
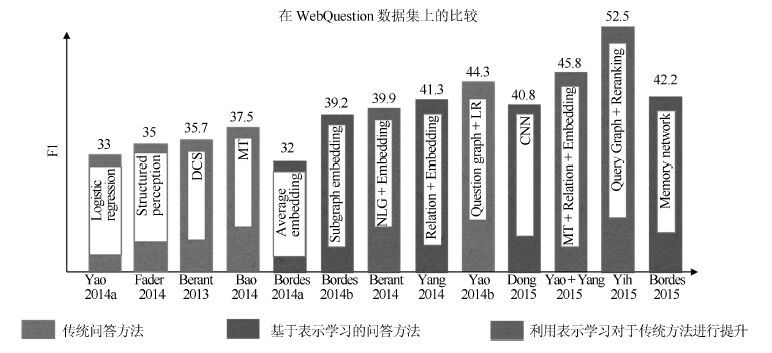
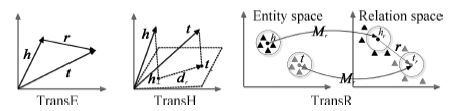
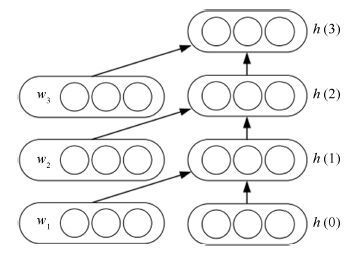
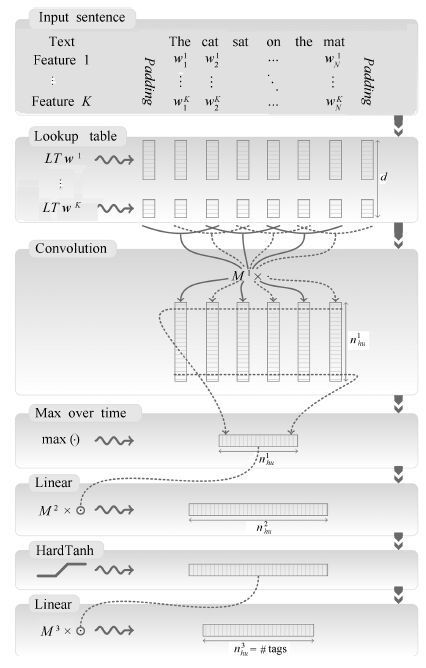
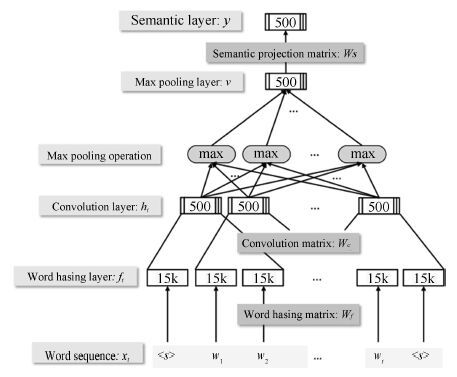
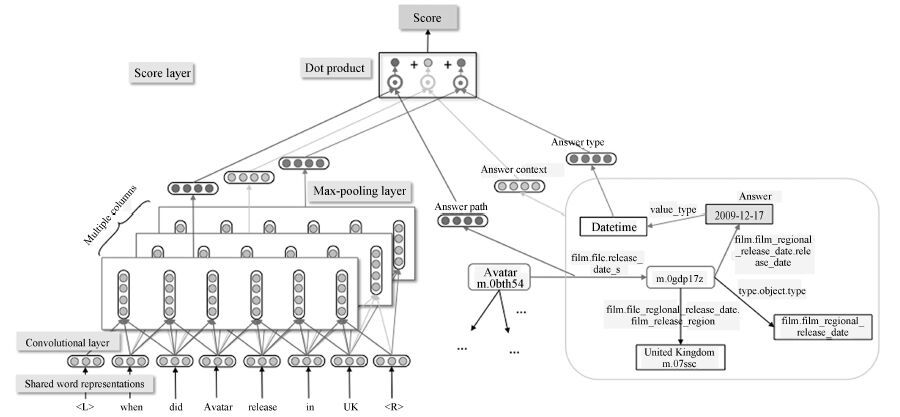
面向知识库的问答(Question answering over knowledge base, KBQA)是问答系统的重要组成. 近些年, 随着以深度学习为代表的表示学习技术在多个领域的成功应用, 许多研究者开始着手研究基于表示学习的知识库问答技术. 其基本假设是把知识库问答看做是一个语义匹配的过程. 通过表示学习知识库以及用户问题的语义表示, 将知识库中的实体、关系以及问句文本转换为一个低维语义空间中的数值向量, 在此基础上, 利用数值计算, 直接匹配与用户问句语义最相似的答案. 从目前的结果看, 基于表示学习的知识库问答系统在性能上已经超过传统知识库问答方法. 本文将对现有基于表示学习的知识库问答的研究进展进行综述, 包括知识库表示学习和问句(文本)表示学习的代表性工作, 同时对于其中存在难点以及仍存在的研究问题进行分析和讨论.
面向知识库的问答(Question answering over knowledge base, KBQA)是问答系统的重要组成. 近些年, 随着以深度学习为代表的表示学习技术在多个领域的成功应用, 许多研究者开始着手研究基于表示学习的知识库问答技术. 其基本假设是把知识库问答看做是一个语义匹配的过程. 通过表示学习知识库以及用户问题的语义表示, 将知识库中的实体、关系以及问句文本转换为一个低维语义空间中的数值向量, 在此基础上, 利用数值计算, 直接匹配与用户问句语义最相似的答案. 从目前的结果看, 基于表示学习的知识库问答系统在性能上已经超过传统知识库问答方法. 本文将对现有基于表示学习的知识库问答的研究进展进行综述, 包括知识库表示学习和问句(文本)表示学习的代表性工作, 同时对于其中存在难点以及仍存在的研究问题进行分析和讨论.




2016, 42(6): 819-833.
doi: 10.16383/j.aas.2016.c150734
摘要:
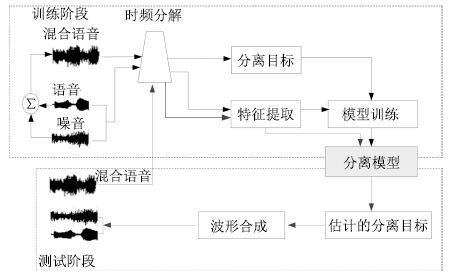
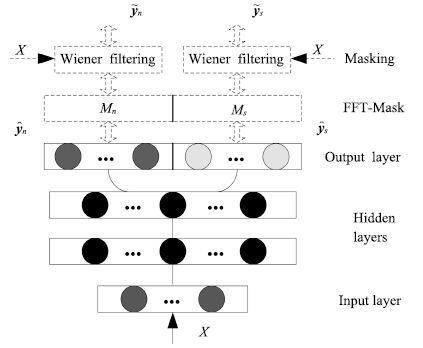
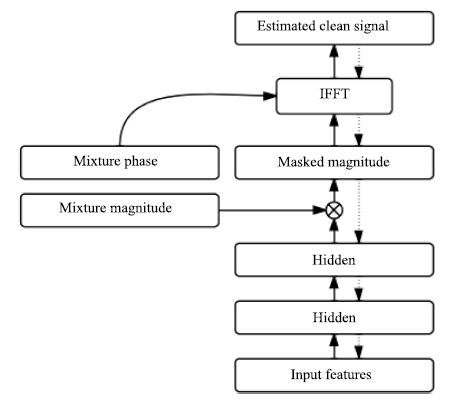
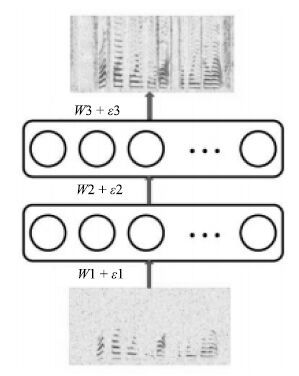
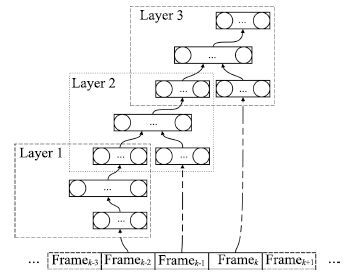
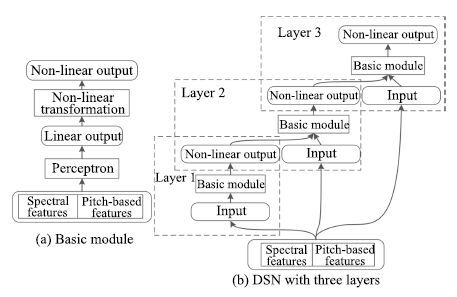
现阶段, 语音交互技术日益在现实生活中得到广泛的应用, 然而, 由于干扰的存在, 现实环境中的语音交互技术远没有达到令人满意的程度. 针对加性噪音的语音分离技术是提高语音交互性能的有效途径, 几十年来, 全世界范围内的许多研究者为此投入了巨大的努力, 提出了很多实用的方法. 特别是近年来, 由于深度学习研究的兴起, 基于深度学习的语音分离技术日益得到了广泛关注和重视, 显露出了相当光明的应用前景, 逐渐成为语音分离中一个新的研究趋势. 目前已有很多基于深度学习的语音分离方法被提出, 但是, 对于深度学习语音分离技术一直以来都缺乏一个系统的分析和总结, 不同方法之间的联系和区分也很少被研究. 针对这个问题, 本文试图对语音分离的主要流程和整体框架进行细致的分析和总结, 从特征、模型以及目标三个方面对现有的前沿研究进展进行全面而深入的综述, 最后对语音分离技术进行展望.
现阶段, 语音交互技术日益在现实生活中得到广泛的应用, 然而, 由于干扰的存在, 现实环境中的语音交互技术远没有达到令人满意的程度. 针对加性噪音的语音分离技术是提高语音交互性能的有效途径, 几十年来, 全世界范围内的许多研究者为此投入了巨大的努力, 提出了很多实用的方法. 特别是近年来, 由于深度学习研究的兴起, 基于深度学习的语音分离技术日益得到了广泛关注和重视, 显露出了相当光明的应用前景, 逐渐成为语音分离中一个新的研究趋势. 目前已有很多基于深度学习的语音分离方法被提出, 但是, 对于深度学习语音分离技术一直以来都缺乏一个系统的分析和总结, 不同方法之间的联系和区分也很少被研究. 针对这个问题, 本文试图对语音分离的主要流程和整体框架进行细致的分析和总结, 从特征、模型以及目标三个方面对现有的前沿研究进展进行全面而深入的综述, 最后对语音分离技术进行展望.

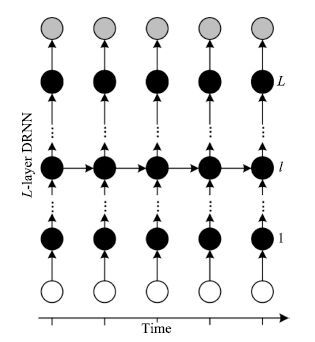
2016, 42(6): 834-847.
doi: 10.16383/j.aas.2016.c150705
摘要:
视频目标跟踪是计算机视觉的重要研究课题, 在视频监控、机器人、人机交互等方面具有广泛应用. 大数据时代的到来及深度学习方法的出现, 为视频目标跟踪的研究提供了新的契机. 本文首先阐述了视频目标跟踪的基本研究框架. 对新时期视频目标跟踪研究的特点与趋势进行了分析, 介绍了国际上新兴的数据平台、评测方法. 重点介绍了目前发展迅猛的深度学习方法, 包括堆叠自编码器、卷积神经网络等在视频目标跟踪中的最新具体应用情况并进行了深入分析与总结. 最后对深度学习方法在视频目标跟踪中的未来应用与发展方向进行了展望.
视频目标跟踪是计算机视觉的重要研究课题, 在视频监控、机器人、人机交互等方面具有广泛应用. 大数据时代的到来及深度学习方法的出现, 为视频目标跟踪的研究提供了新的契机. 本文首先阐述了视频目标跟踪的基本研究框架. 对新时期视频目标跟踪研究的特点与趋势进行了分析, 介绍了国际上新兴的数据平台、评测方法. 重点介绍了目前发展迅猛的深度学习方法, 包括堆叠自编码器、卷积神经网络等在视频目标跟踪中的最新具体应用情况并进行了深入分析与总结. 最后对深度学习方法在视频目标跟踪中的未来应用与发展方向进行了展望.


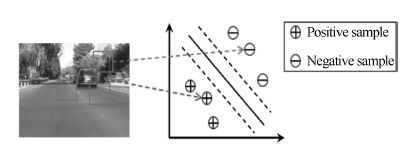

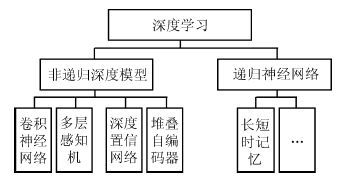
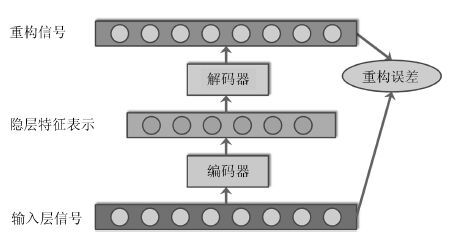

2016, 42(6): 848-857.
doi: 10.16383/j.aas.2016.c150710
摘要:
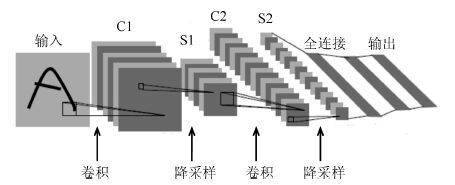
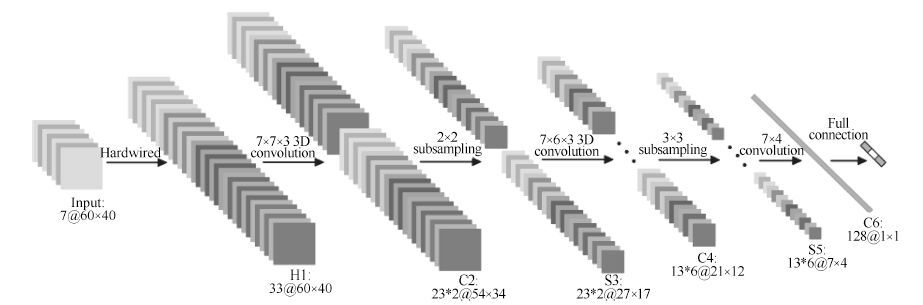
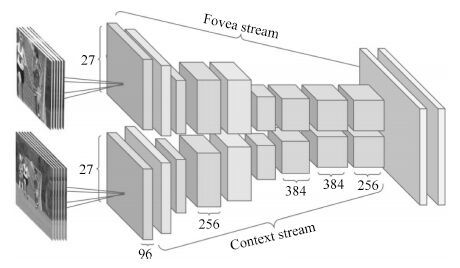
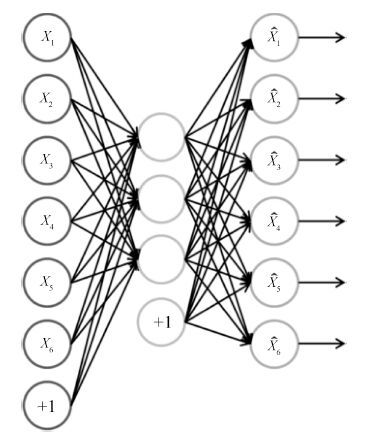
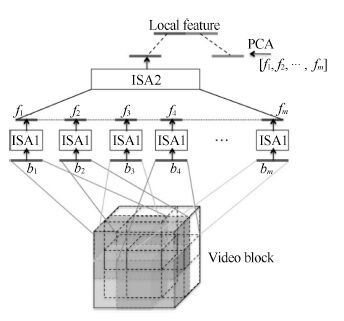
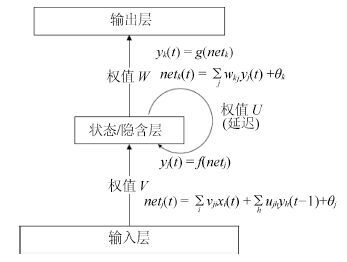
人体行为识别和深度学习理论是智能视频分析领域的研究热点, 近年来得到了学术界及工程界的广泛重视, 是智能视频分析与理解、视频监控、人机交互等诸多领域的理论基础. 近年来, 被广泛关注的深度学习算法已经被成功运用于语音识别、图形识别等各个领域.深度学习理论在静态图像特征提取上取得了卓著成就, 并逐步推广至具有时间序列的视频行为识别研究中. 本文在回顾了基于时空兴趣点等传统行为识别方法的基础上, 对近年来提出的基于不同深度学习框架的人体行为识别新进展进行了逐一介绍和总结分析; 包括卷积神经网络(Convolution neural network, CNN)、独立子空间分析(Independent subspace analysis, ISA)、限制玻尔兹曼机(Restricted Boltzmann machine, RBM)以及递归神经网络(Recurrent neural network, RNN)及其在行为识别中的模型建立, 对模型性能、成果进展及各类方法的优缺点进行了分析和总结.
人体行为识别和深度学习理论是智能视频分析领域的研究热点, 近年来得到了学术界及工程界的广泛重视, 是智能视频分析与理解、视频监控、人机交互等诸多领域的理论基础. 近年来, 被广泛关注的深度学习算法已经被成功运用于语音识别、图形识别等各个领域.深度学习理论在静态图像特征提取上取得了卓著成就, 并逐步推广至具有时间序列的视频行为识别研究中. 本文在回顾了基于时空兴趣点等传统行为识别方法的基础上, 对近年来提出的基于不同深度学习框架的人体行为识别新进展进行了逐一介绍和总结分析; 包括卷积神经网络(Convolution neural network, CNN)、独立子空间分析(Independent subspace analysis, ISA)、限制玻尔兹曼机(Restricted Boltzmann machine, RBM)以及递归神经网络(Recurrent neural network, RNN)及其在行为识别中的模型建立, 对模型性能、成果进展及各类方法的优缺点进行了分析和总结.







2016, 42(6): 858-865.
doi: 10.16383/j.aas.2016.c150658
摘要:
为提高性别分类准确率, 在传统卷积神经网络(Convolutional neural network, CNN)的基础上, 提出一个跨连卷积神经网络(Cross-connected CNN, CCNN)模型. 该模型是一个9层的网络结构, 包含输入层、6个由卷积层和池化层交错构成的隐含层、全连接层和输出层, 其中允许第2个池化层跨过两个层直接与全连接层相连接. 在10个人脸数据集上的性别分类实验结果表明, 跨连卷积网络的准确率均不低于传统卷积网络.
为提高性别分类准确率, 在传统卷积神经网络(Convolutional neural network, CNN)的基础上, 提出一个跨连卷积神经网络(Cross-connected CNN, CCNN)模型. 该模型是一个9层的网络结构, 包含输入层、6个由卷积层和池化层交错构成的隐含层、全连接层和输出层, 其中允许第2个池化层跨过两个层直接与全连接层相连接. 在10个人脸数据集上的性别分类实验结果表明, 跨连卷积网络的准确率均不低于传统卷积网络.


2016, 42(6): 866-874.
doi: 10.16383/j.aas.2016.c150663
摘要:
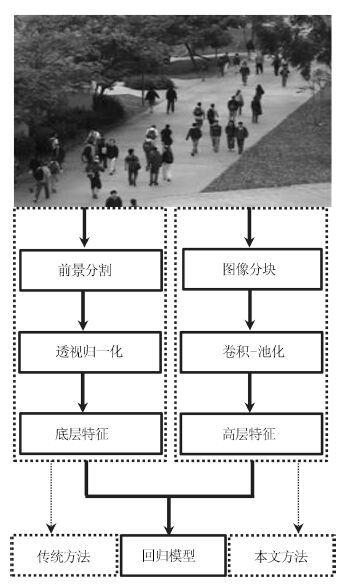
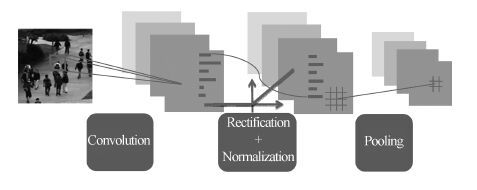
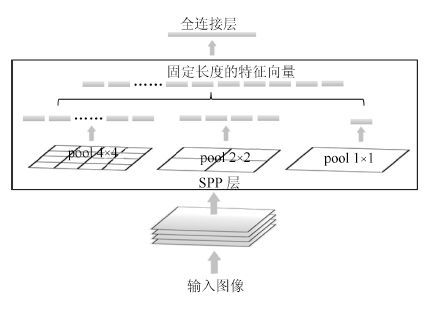
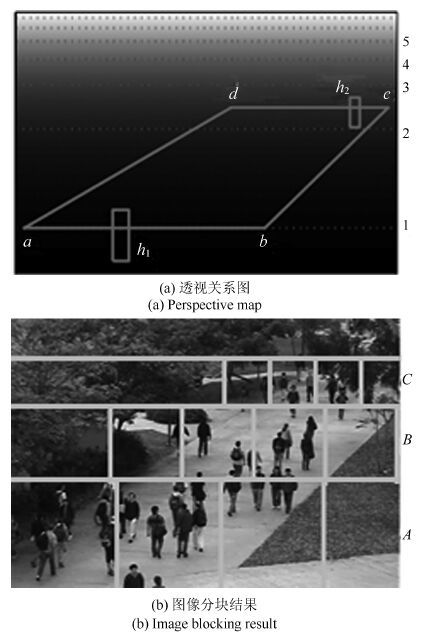
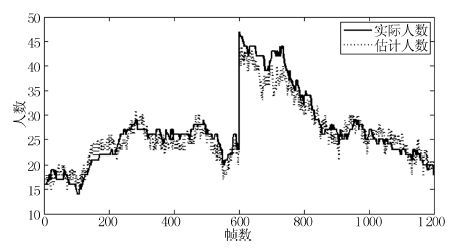
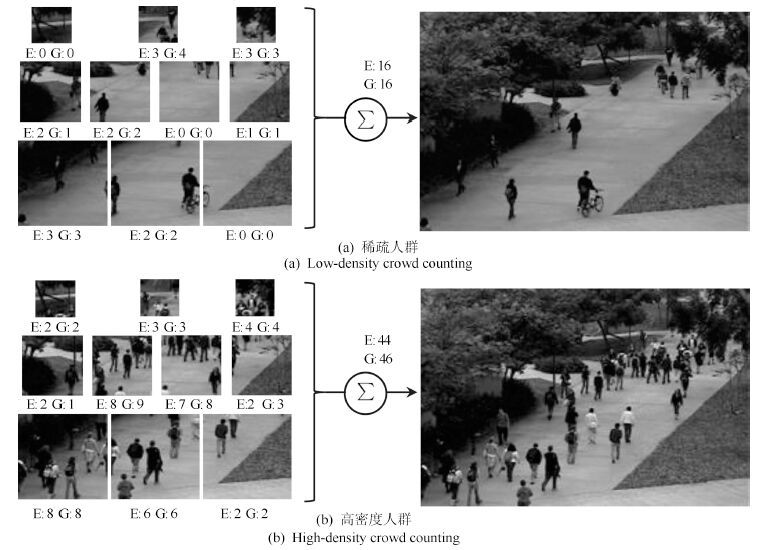
视频中的人群计数在智能监控领域具有重要价值. 由于摄像机透视效果、图像背景、人群密度分布不均匀和行人遮挡等干扰因素的制约, 基于底层特征的传统计数方法准确率较低. 本文提出一种基于序的空间金字塔池化(Rank-based spatial pyramid pooling, RSPP)网络的人群计数方法. 该方法将原图像分成多个具有相同透视范围的子区域并在各个子区域分别取不同尺度的子图像块, 采用基于序的空间金字塔池化网络估计子图像块人数, 然后相加所有子图像块人数得出原图像人数. 提出的图像分块方法有效地消除了摄像机透视效果和人群密度分布不均匀对计数的影响. 提出的基于序的空间金字塔池化不仅能够处理多种尺度的子图像块, 而且解决了传统池化方法易损失大量重要信息和易过拟合的问题. 实验结果表明, 本文方法相比于传统方法具有准确率高和鲁棒性好的优点.
视频中的人群计数在智能监控领域具有重要价值. 由于摄像机透视效果、图像背景、人群密度分布不均匀和行人遮挡等干扰因素的制约, 基于底层特征的传统计数方法准确率较低. 本文提出一种基于序的空间金字塔池化(Rank-based spatial pyramid pooling, RSPP)网络的人群计数方法. 该方法将原图像分成多个具有相同透视范围的子区域并在各个子区域分别取不同尺度的子图像块, 采用基于序的空间金字塔池化网络估计子图像块人数, 然后相加所有子图像块人数得出原图像人数. 提出的图像分块方法有效地消除了摄像机透视效果和人群密度分布不均匀对计数的影响. 提出的基于序的空间金字塔池化不仅能够处理多种尺度的子图像块, 而且解决了传统池化方法易损失大量重要信息和易过拟合的问题. 实验结果表明, 本文方法相比于传统方法具有准确率高和鲁棒性好的优点.



2016, 42(6): 875-882.
doi: 10.16383/j.aas.2016.c150741
摘要:
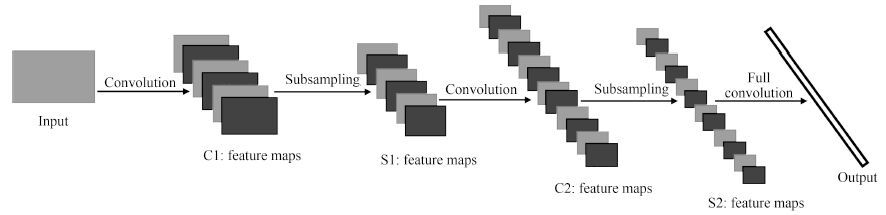
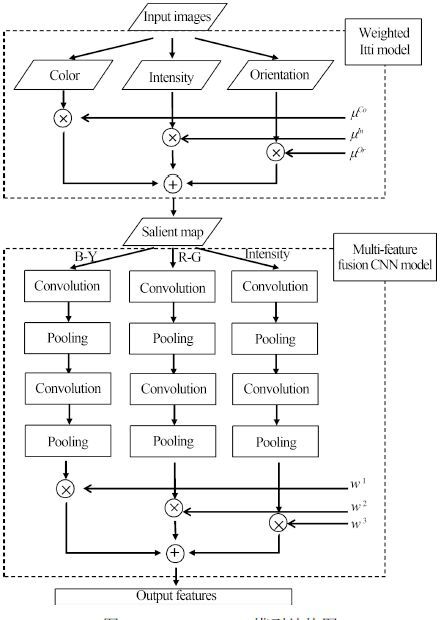
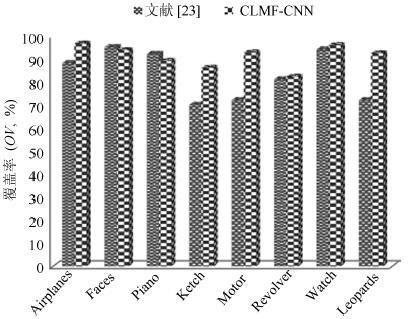
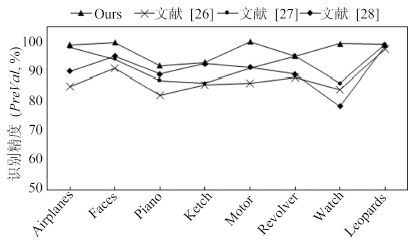
针对传统人工特征提取模型难以满足复杂场景下目标识别的需求, 提出了一种基于CLMF的深度卷积神经网络(Convolutional neural networks with candidate location and multi-feature fusion, CLMF-CNN).该模型结合视觉显著性、多特征融合和CNN模型实现目标对象的识别. 首先, 利用加权Itti模型获取目标候选区; 然后, 利用CNN模型从颜色、亮度多特征角度提取目标对象的特征, 经过加权融合供目标识别; 最后, 与单一特征以及目前的流行算法进行对比实验, 结果表明本文模型不仅在同等条件下正确识别率得到了提高, 同时, 达到实时性要求.
针对传统人工特征提取模型难以满足复杂场景下目标识别的需求, 提出了一种基于CLMF的深度卷积神经网络(Convolutional neural networks with candidate location and multi-feature fusion, CLMF-CNN).该模型结合视觉显著性、多特征融合和CNN模型实现目标对象的识别. 首先, 利用加权Itti模型获取目标候选区; 然后, 利用CNN模型从颜色、亮度多特征角度提取目标对象的特征, 经过加权融合供目标识别; 最后, 与单一特征以及目前的流行算法进行对比实验, 结果表明本文模型不仅在同等条件下正确识别率得到了提高, 同时, 达到实时性要求.




2016, 42(6): 883-891.
doi: 10.16383/j.aas.2016.c150638
摘要:
深度神经网络已经被证明在图像、语音、文本领域具有挖掘数据深层潜在的分布式表达特征的能力. 通过在多个面部情感数据集上训练深度卷积神经网络和深度稀疏校正神经网络两种深度学习模型, 对深度神经网络在面部情感分类领域的应用作了对比评估. 进而, 引入了面部结构先验知识, 结合感兴趣区域(Region of interest, ROI)和K最近邻算法(K-nearest neighbors, KNN), 提出一种快速、简易的针对面部表情分类的深度学习训练改进方案——ROI-KNN, 该训练方案降低了由于面部表情训练数据过少而导致深度神经网络模型泛化能力不佳的问题, 提高了深度学习在面部表情分类中的鲁棒性, 同时, 显著地降低了测试错误率.
深度神经网络已经被证明在图像、语音、文本领域具有挖掘数据深层潜在的分布式表达特征的能力. 通过在多个面部情感数据集上训练深度卷积神经网络和深度稀疏校正神经网络两种深度学习模型, 对深度神经网络在面部情感分类领域的应用作了对比评估. 进而, 引入了面部结构先验知识, 结合感兴趣区域(Region of interest, ROI)和K最近邻算法(K-nearest neighbors, KNN), 提出一种快速、简易的针对面部表情分类的深度学习训练改进方案——ROI-KNN, 该训练方案降低了由于面部表情训练数据过少而导致深度神经网络模型泛化能力不佳的问题, 提高了深度学习在面部表情分类中的鲁棒性, 同时, 显著地降低了测试错误率.

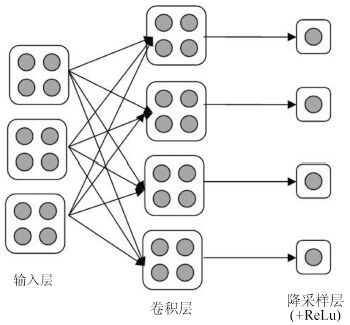
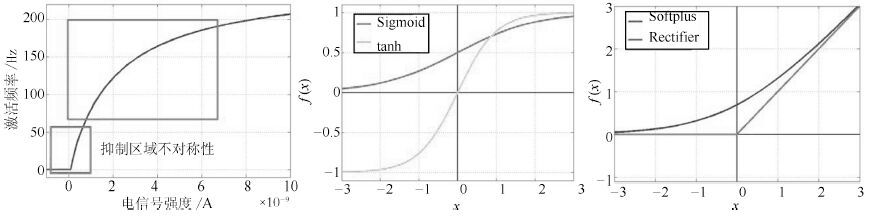
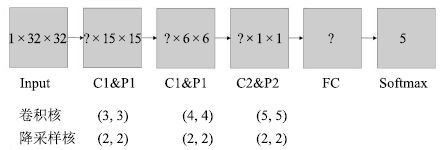
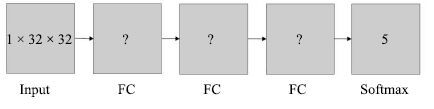
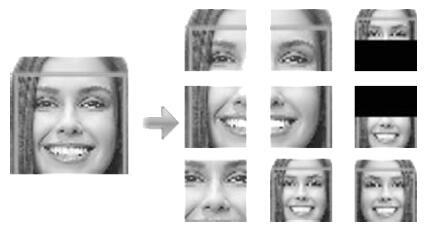
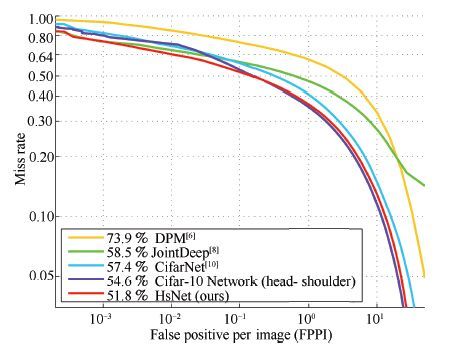
2016, 42(6): 892-903.
doi: 10.16383/j.aas.2016.c150729
摘要:
复杂监控视频中事件检测是一个具有挑战性的难题, 而TRECVID-SED评测使用的数据集取自机场的实际监控视频,以高难度著称. 针对TRECVID-SED评测集, 提出了一种基于卷积神经网络(Convolutional neural network, CNN)级联网络和轨迹分析的监控视频事件检测综合方案. 在该方案中, 引入级联CNN网络在拥挤场景中准确地检测行人, 为跟踪行人奠定了基础; 采用CNN网络检测具有关键姿态的个体事件, 引入轨迹分析方法检测群体事件. 该方案在国际评测中取得了很好的评测排名: 在6个事件检测的评测中, 3个事件检测排名第一.
复杂监控视频中事件检测是一个具有挑战性的难题, 而TRECVID-SED评测使用的数据集取自机场的实际监控视频,以高难度著称. 针对TRECVID-SED评测集, 提出了一种基于卷积神经网络(Convolutional neural network, CNN)级联网络和轨迹分析的监控视频事件检测综合方案. 在该方案中, 引入级联CNN网络在拥挤场景中准确地检测行人, 为跟踪行人奠定了基础; 采用CNN网络检测具有关键姿态的个体事件, 引入轨迹分析方法检测群体事件. 该方案在国际评测中取得了很好的评测排名: 在6个事件检测的评测中, 3个事件检测排名第一.
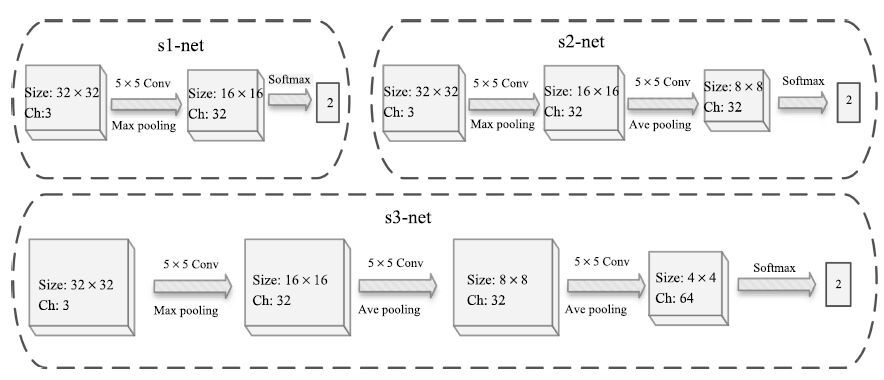







2016, 42(6): 904-914.
doi: 10.16383/j.aas.2016.c150718
摘要:
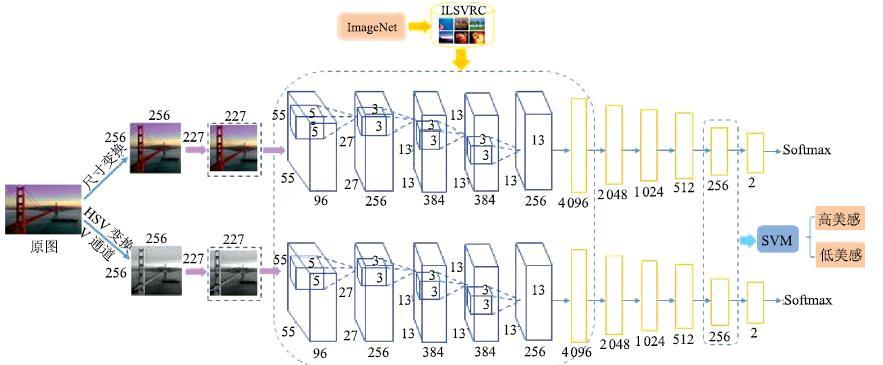
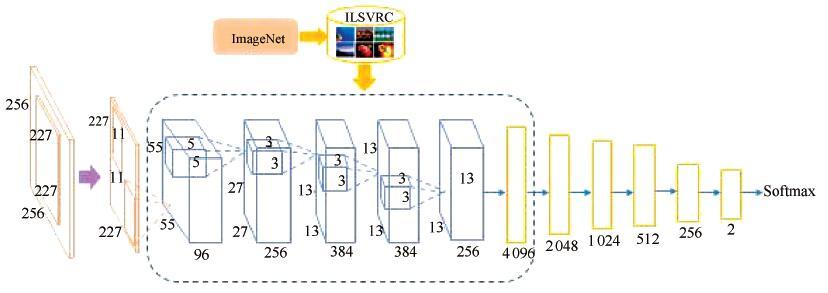
随着计算机和社交网络的飞速发展, 图像美感的自动评价产生了越来越大的需求并受到了广泛关注. 由于图像美感评价的主观性和复杂性, 传统的手工特征和局部特征方法难以全面表征图像的美感特点, 并准确量化或建模. 本文提出一种并行深度卷积神经网络的图像美感分类方法, 从同一图像的不同角度出发, 利用深度学习网络自动完成特征学习, 得到更为全面的图像美感特征描述; 然后利用支持向量机训练特征并建立分类器, 实现图像美感分类. 通过在两个主流的图像美感数据库上的实验显示, 本文方法与目前已有的其他算法对比, 获得了更好的分类准确率.
随着计算机和社交网络的飞速发展, 图像美感的自动评价产生了越来越大的需求并受到了广泛关注. 由于图像美感评价的主观性和复杂性, 传统的手工特征和局部特征方法难以全面表征图像的美感特点, 并准确量化或建模. 本文提出一种并行深度卷积神经网络的图像美感分类方法, 从同一图像的不同角度出发, 利用深度学习网络自动完成特征学习, 得到更为全面的图像美感特征描述; 然后利用支持向量机训练特征并建立分类器, 实现图像美感分类. 通过在两个主流的图像美感数据库上的实验显示, 本文方法与目前已有的其他算法对比, 获得了更好的分类准确率.



2016, 42(6): 915-922.
doi: 10.16383/j.aas.2016.c150715
摘要:
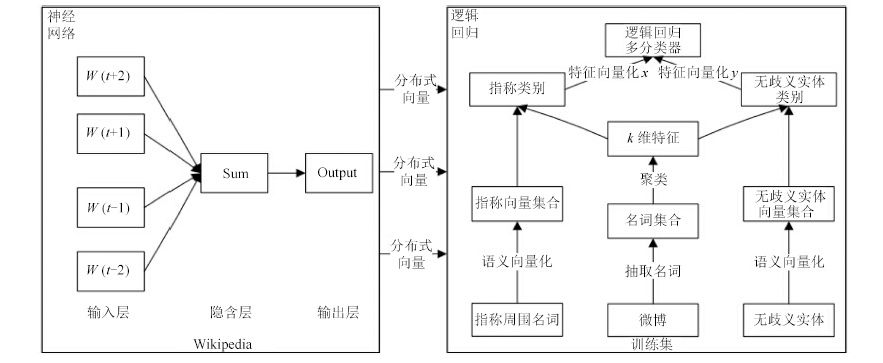
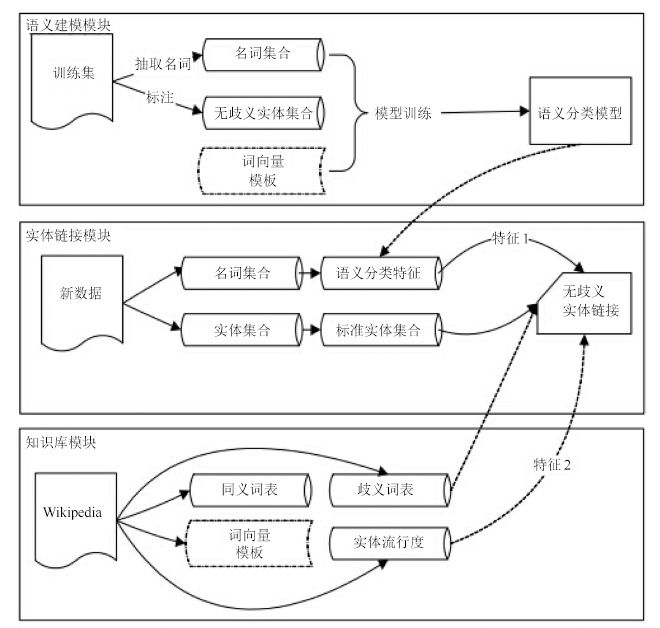
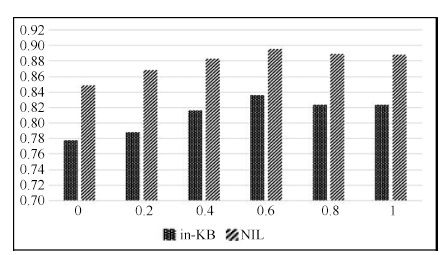
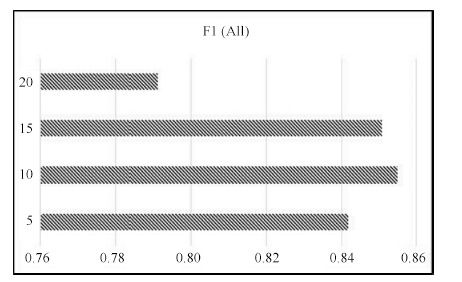
微博实体链接是把微博中给定的指称链接到知识库的过程,广泛应用于信息抽取、自动问答等自然语言处理任务(Natural language processing,NLP). 由于微博内容简短,传统长文本实体链接的算法并不能很好地用于微博实体链接任务. 以往研究大都基于实体指称及其上下文构建模型进行消歧,难以识别具有相似词汇和句法特征的候选实体. 本文充分利用指称和候选实体本身所含有的语义信息,提出在词向量层面对任务进行抽象建模,并设计一种基于词向量语义分类的微博实体链接方法. 首先通过神经网络训练词向量模板,然后通过实体聚类获得类别标签作为特征,再通过多分类模型预测目标实体的主题类别来完成实体消歧. 在NLPCC2014公开评测数据集上的实验结果表明,本文方法的准确率和召回率均高于此前已报道的最佳结果,特别是实体链接准确率有显著提升.
微博实体链接是把微博中给定的指称链接到知识库的过程,广泛应用于信息抽取、自动问答等自然语言处理任务(Natural language processing,NLP). 由于微博内容简短,传统长文本实体链接的算法并不能很好地用于微博实体链接任务. 以往研究大都基于实体指称及其上下文构建模型进行消歧,难以识别具有相似词汇和句法特征的候选实体. 本文充分利用指称和候选实体本身所含有的语义信息,提出在词向量层面对任务进行抽象建模,并设计一种基于词向量语义分类的微博实体链接方法. 首先通过神经网络训练词向量模板,然后通过实体聚类获得类别标签作为特征,再通过多分类模型预测目标实体的主题类别来完成实体消歧. 在NLPCC2014公开评测数据集上的实验结果表明,本文方法的准确率和召回率均高于此前已报道的最佳结果,特别是实体链接准确率有显著提升.

2016, 42(6): 923-930.
doi: 10.16383/j.aas.2016.c150726
摘要:
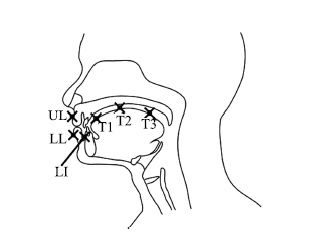
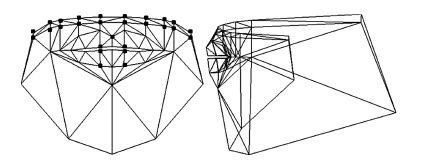
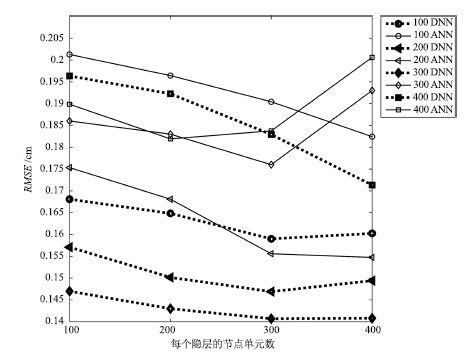
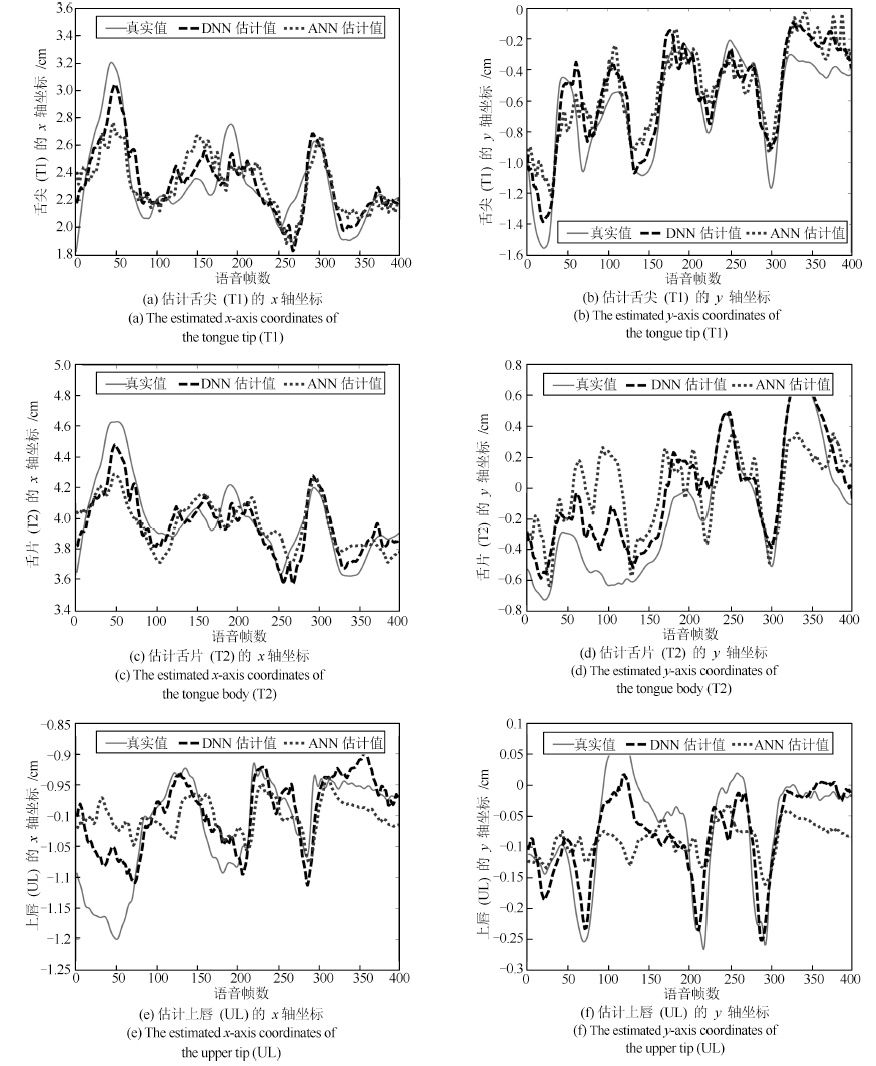
实现一种基于深度神经网络的语音驱动发音器官运动合成的方法,并应用于语音驱动虚拟说话人动画合成. 通过深度神经网络(Deep neural networks, DNN)学习声学特征与发音器官位置信息之间的映射关系,系统根据输入的语音数据估计发音器官的运动轨迹,并将其体现在一个三维虚拟人上面. 首先,在一系列参数下对比人工神经网络(Artificial neural network, ANN)和DNN的实验结果,得到最优网络; 其次,设置不同上下文声学特征长度并调整隐层单元数,获取最佳长度; 最后,选取最优网络结构,由DNN 输出的发音器官运动轨迹信息控制发音器官运动合成,实现虚拟人动画. 实验证明,本文所实现的动画合成方法高效逼真.
实现一种基于深度神经网络的语音驱动发音器官运动合成的方法,并应用于语音驱动虚拟说话人动画合成. 通过深度神经网络(Deep neural networks, DNN)学习声学特征与发音器官位置信息之间的映射关系,系统根据输入的语音数据估计发音器官的运动轨迹,并将其体现在一个三维虚拟人上面. 首先,在一系列参数下对比人工神经网络(Artificial neural network, ANN)和DNN的实验结果,得到最优网络; 其次,设置不同上下文声学特征长度并调整隐层单元数,获取最佳长度; 最后,选取最优网络结构,由DNN 输出的发音器官运动轨迹信息控制发音器官运动合成,实现虚拟人动画. 实验证明,本文所实现的动画合成方法高效逼真.
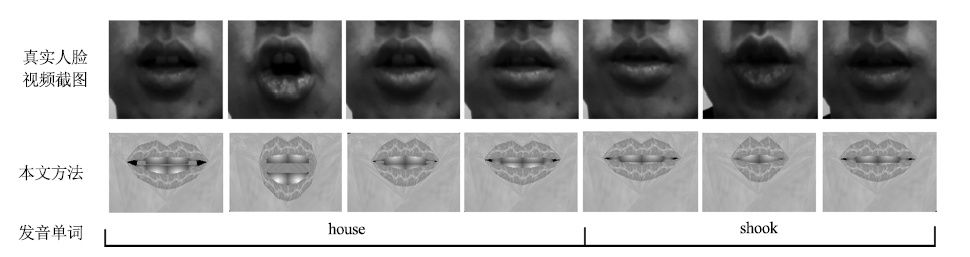
2016, 42(6): 931-942.
doi: 10.16383/j.aas.2016.c150645
摘要:
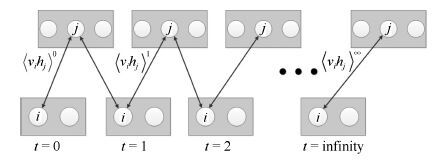
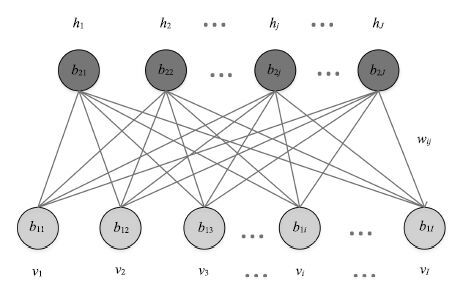
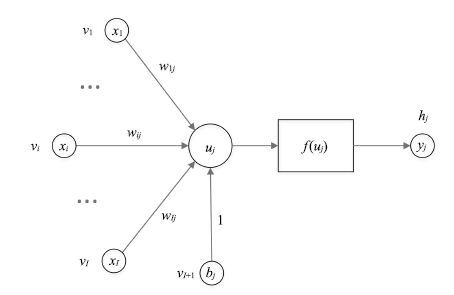
目前大部分受限玻尔兹曼机(Restricted Boltzmann machines, RBMs)训练算法都是以多步Gibbs采样为基础的采样算法. 本文针对多步Gibbs采样过程中出现的采样发散和训练速度过慢的问题,首先, 对问题进行实验描述,给出了问题的具体形式; 然后, 从马尔科夫采样的角度对多步Gibbs采样的收敛性质进行了理论分析, 证明了多步Gibbs采样在受限玻尔兹曼机训练初期较差的收敛性质是造成采样发散和训练速度过慢的主要原因; 最后, 提出了动态Gibbs采样算法,给出了对比仿真实验.实验结果表明, 动态Gibbs采样算法可以有效地克服采样发散的问题,并且能够以微小的运行时间为代价获得更高的训练精度.
目前大部分受限玻尔兹曼机(Restricted Boltzmann machines, RBMs)训练算法都是以多步Gibbs采样为基础的采样算法. 本文针对多步Gibbs采样过程中出现的采样发散和训练速度过慢的问题,首先, 对问题进行实验描述,给出了问题的具体形式; 然后, 从马尔科夫采样的角度对多步Gibbs采样的收敛性质进行了理论分析, 证明了多步Gibbs采样在受限玻尔兹曼机训练初期较差的收敛性质是造成采样发散和训练速度过慢的主要原因; 最后, 提出了动态Gibbs采样算法,给出了对比仿真实验.实验结果表明, 动态Gibbs采样算法可以有效地克服采样发散的问题,并且能够以微小的运行时间为代价获得更高的训练精度.
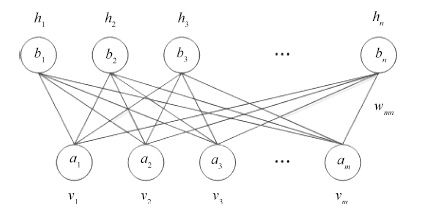

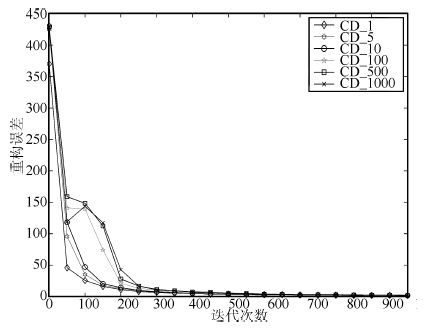
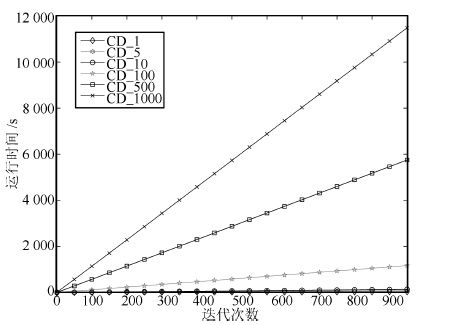










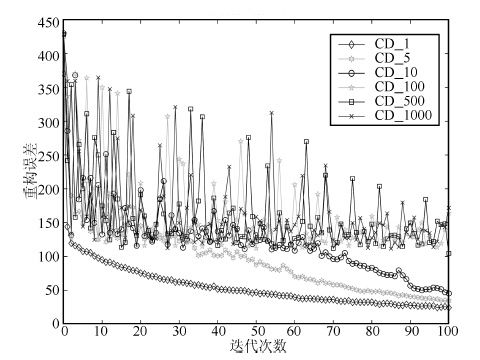
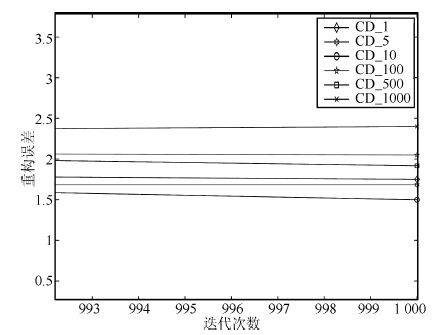
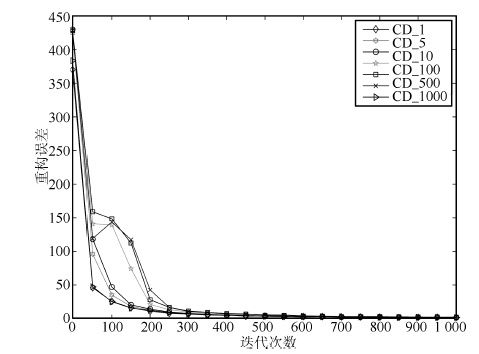
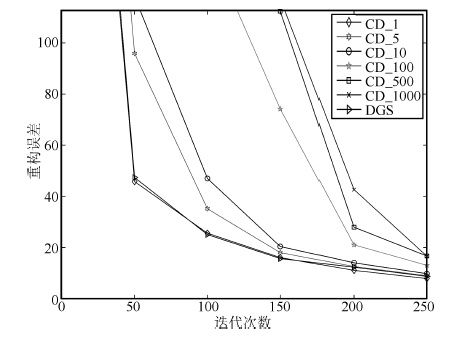











2016, 42(6): 943-952.
doi: 10.16383/j.aas.2016.c150727
摘要:
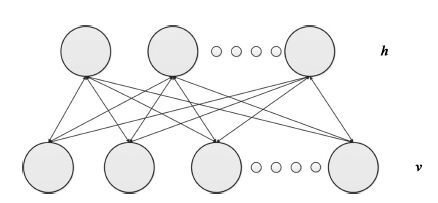
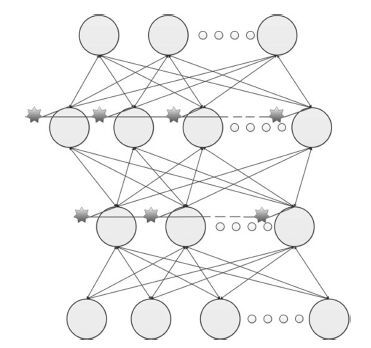
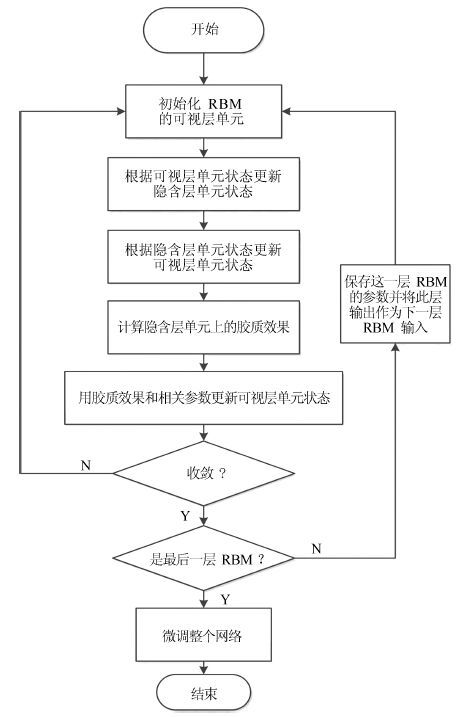
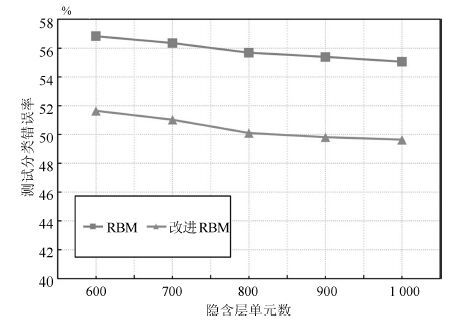
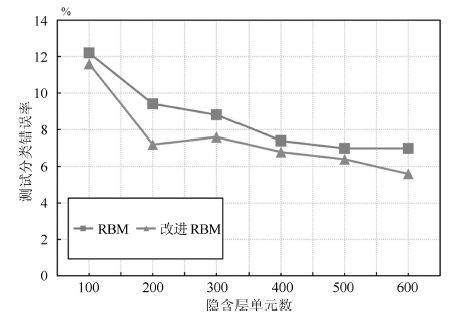
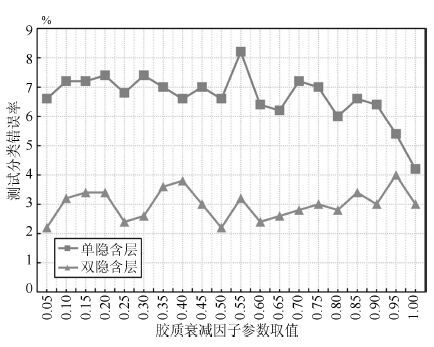
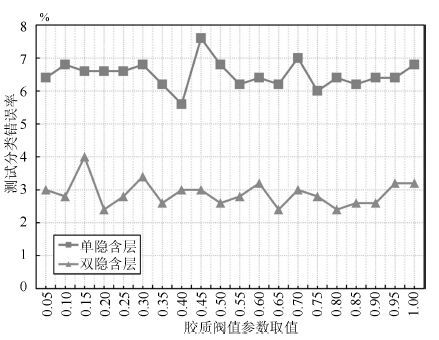
深度信念网络(Deep belief network, DBN) 是一种从无标签数据学习特征的多层结构模型. 在同一层单元间缺少连接, 导致数据中的深度关联特征难以提取. 受到人脑中胶质神经细胞机制的启示, 提出一种基于胶质细胞链的改进 DBN 模型及其学习算法, 以提取更多数据信息. 在标准图像分类数据集上的实验结果表明, 与其他几种模型相比, 本文提出的改进 DBN 模型可以提取更为优秀的图像特征, 提高分类准确率.
深度信念网络(Deep belief network, DBN) 是一种从无标签数据学习特征的多层结构模型. 在同一层单元间缺少连接, 导致数据中的深度关联特征难以提取. 受到人脑中胶质神经细胞机制的启示, 提出一种基于胶质细胞链的改进 DBN 模型及其学习算法, 以提取更多数据信息. 在标准图像分类数据集上的实验结果表明, 与其他几种模型相比, 本文提出的改进 DBN 模型可以提取更为优秀的图像特征, 提高分类准确率.


2016, 42(6): 953-958.
doi: 10.16383/j.aas.2016.c150681
摘要:
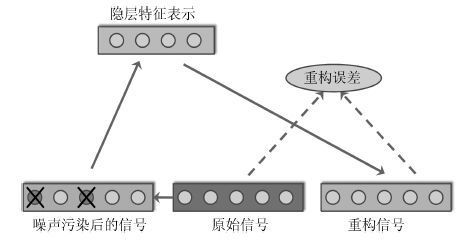
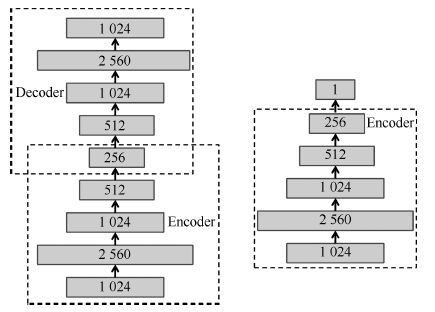
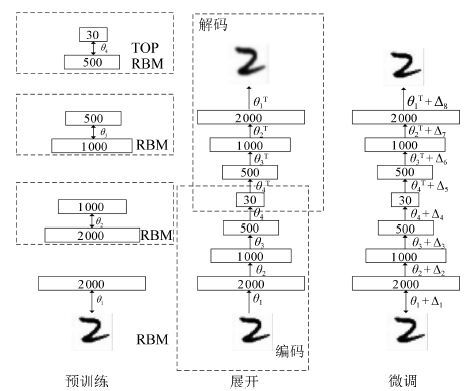
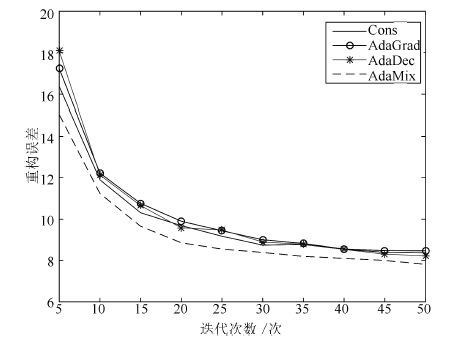
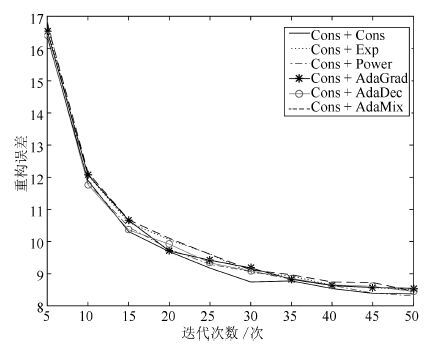
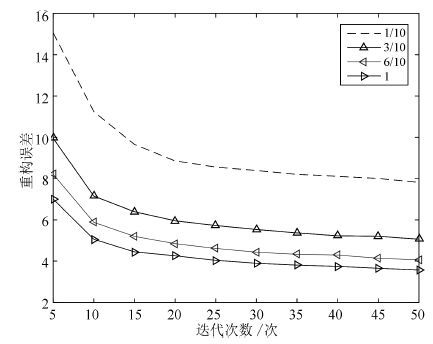
一个设计良好的学习率策略可以显著提高深度学习模型的收敛速度, 减少模型的训练时间. 本文针对AdaGrad和AdaDec学习策略只对模型所有参数提供单一学习率方式的问题, 根据模型参数的特点, 提出了一种组合型学习策略: AdaMix. 该策略为连接权重设计了一个仅与当前梯度有关的学习率, 为偏置设计使用了幂指数型学习率.利用深度学习模型Autoencoder对图像数据库MNIST进行重构, 以模型反向微调过程中测试阶段的重构误差作为评价指标, 验证几种学习策略对模型收敛性的影响.实验结果表明, AdaMix比AdaGrad和AdaDec的重构误差小并且计算量也低, 具有更快的收敛速度.
一个设计良好的学习率策略可以显著提高深度学习模型的收敛速度, 减少模型的训练时间. 本文针对AdaGrad和AdaDec学习策略只对模型所有参数提供单一学习率方式的问题, 根据模型参数的特点, 提出了一种组合型学习策略: AdaMix. 该策略为连接权重设计了一个仅与当前梯度有关的学习率, 为偏置设计使用了幂指数型学习率.利用深度学习模型Autoencoder对图像数据库MNIST进行重构, 以模型反向微调过程中测试阶段的重构误差作为评价指标, 验证几种学习策略对模型收敛性的影响.实验结果表明, AdaMix比AdaGrad和AdaDec的重构误差小并且计算量也低, 具有更快的收敛速度.


2016, 42(6): 959-964.
doi: 10.16383/j.aas.2016.c150672
摘要:
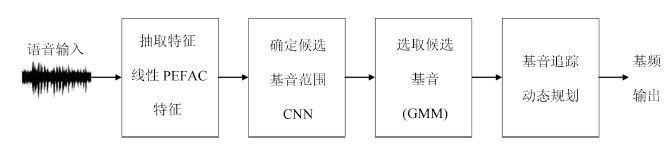
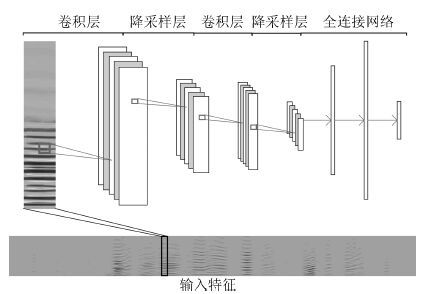
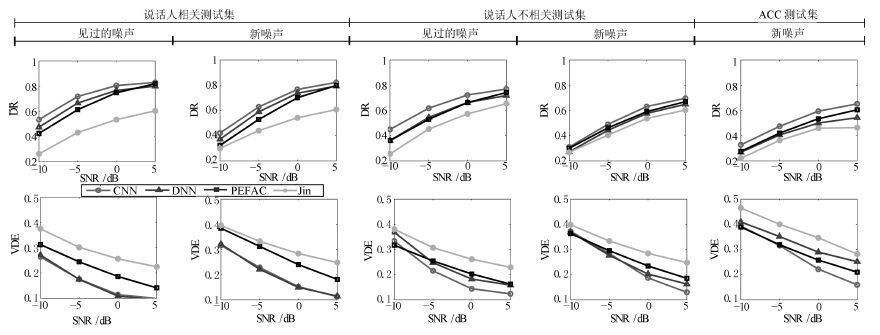
在语音信号中, 基音是一个重要参数, 且有重要用途. 然而, 检测噪声环境中语音的基音却是一项难度较大的工作. 由于卷积神经网络(Convolutional neural network, CNN)具有平移不变性, 能够很好地刻画语谱图中的谐波结构, 因此我们提出使用CNN来完成这项工作. 具体地, 我们使用CNN来选取候选基音, 再用动态规划方法(Dynamic programming, DP)进行基音追踪, 生成连续的基音轮廓. 实验表明, 与其他方法相比, 本文的方法具有明显的性能优势, 并且 对新的说话人和噪声有很好的泛化性能, 具有更好的鲁棒性.
在语音信号中, 基音是一个重要参数, 且有重要用途. 然而, 检测噪声环境中语音的基音却是一项难度较大的工作. 由于卷积神经网络(Convolutional neural network, CNN)具有平移不变性, 能够很好地刻画语谱图中的谐波结构, 因此我们提出使用CNN来完成这项工作. 具体地, 我们使用CNN来选取候选基音, 再用动态规划方法(Dynamic programming, DP)进行基音追踪, 生成连续的基音轮廓. 实验表明, 与其他方法相比, 本文的方法具有明显的性能优势, 并且 对新的说话人和噪声有很好的泛化性能, 具有更好的鲁棒性.