

-
摘要: 复杂监控视频中事件检测是一个具有挑战性的难题, 而TRECVID-SED评测使用的数据集取自机场的实际监控视频,以高难度著称. 针对TRECVID-SED评测集, 提出了一种基于卷积神经网络(Convolutional neural network, CNN)级联网络和轨迹分析的监控视频事件检测综合方案. 在该方案中, 引入级联CNN网络在拥挤场景中准确地检测行人, 为跟踪行人奠定了基础; 采用CNN网络检测具有关键姿态的个体事件, 引入轨迹分析方法检测群体事件. 该方案在国际评测中取得了很好的评测排名: 在6个事件检测的评测中, 3个事件检测排名第一.Abstract: It is well-known that event detection in real-world surveillance videos is a challenging task. The corpus of TRECVID-SED evaluation is acquired from the surveillance video of London Gatwick International Airport and it is well known for its high difficulties. We propose a comprehensive event detection framework based on an effective part-based deep network cascade——head-shoulder networks (HsNet) and trajectory analysis. On the one hand, the deep network detects pedestrians very precisely, laying a foundation for tracking pedestrians. On the other hand, convolutional neural networks (CNNs) are good at detecting key-pose-based single events. Trajectory analysis is introduced for group events. In TRECVID-SED15 evaluation, our approach outperformed others in 3 out of 6 events, demonstrating the power of our proposal.
-
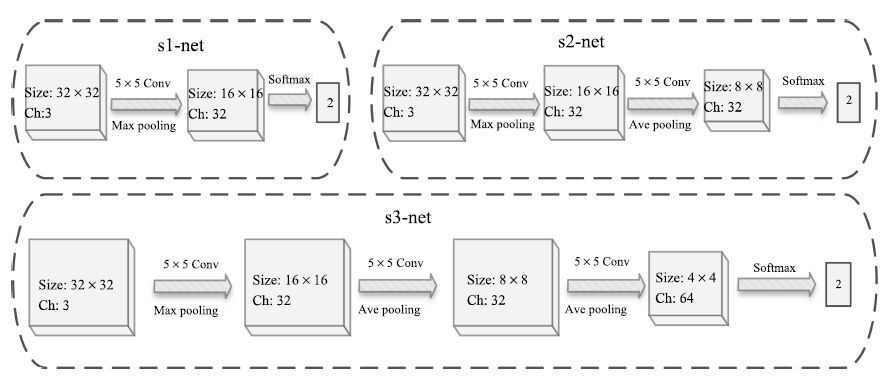

图 5 ObjectPut和PersonRuns事件关键姿态检测的网络结构
Fig. 5 The architecture of CNN for ObjectPut and PersonRuns key-pose detection
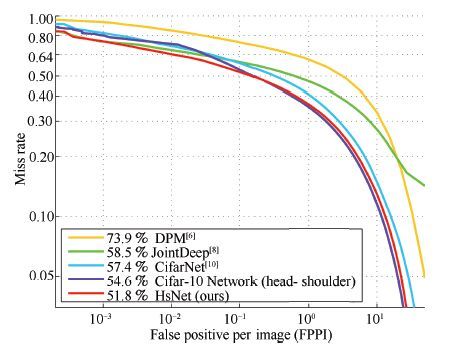

表 1 2015年TRECVID-SED评测结果
Table 1 Evaluation Results of TRECVID-SED 2015
排名 其他团队最好成绩(ADCR) ADCR #Targ #CorDet #FA #Miss Embrace 1 0.8680 0.7909 138 36 90 102 ObjectPut 1 1.0160 1.0120 289 2 33 287 PeopleMeet 4 0.8939 1.0426 256 30 278 226 PeopleSplitUp 2 0.8934 0.9387 152 24 168 128 PersonRuns 2 0.5768 0.9700 50 4 87 46 Pointing 1 1.0140 1.0040 794 16 42 778  下载: 导出CSV
下载: 导出CSV
-
[1] Text Retrieval Conference (TREC)[Online], available: http://trec.nist.gov/, April 5, 2016 [2] National Institute of Standards and Technology (NIST)[Online], available: http://www.nist.gov/index.html, April 5, 2016 [3] TREC Video Retrieval Evaluation (TRECVID)[Online], available: http://www-nlpir.nist.gov/projects/trecvid/, April 5, 2016 [4] Dollar P, Wojek C, Schiele B, Perona P. Pedestrian detection: an evaluation of the state of the art. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743-761 [5] Benenson R, Omran M, Hosang J, Schiele B. Ten years of pedestrian detection, what have we learned? In: Proceedings of the 12th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 613-627 [6] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, USA: IEEE, 2005. 886-893 [7] Felzenszwalb P, McAllester D, Ramanan D. A discriminatively trained, multiscale, deformable part model. In: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, Alaska, USA: IEEE, 2008. 1-8 [8] Ouyang W, Wang X. Joint deep learning for pedestrian detection. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 2056-2063 [9] Luo P, Tian Y, Wang X, Tang X. Switchable deep network for pedestrian detection. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, Ohio, USA: IEEE, 2014. 899-906 [10] Hosang J, Omran M, Benenson R, Schiele B. Taking a deeper look at pedestrians. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 4073-4082 [11] Cuda-convnet. High-performance C++/CUDA implementation of convolutional neural networks[Online], available: https://code.google.com/p/cuda-convnet/, April 5, 2016 [12] Huang C, Wu B, Nevatia R. Robust object tracking by hierarchical association of detection responses. In: Proceedings of the 10th European Conference on Computer Vision. Marseille, France: Springer, 2008. 788-801 [13] Yang B, Nevatia R. Multi-target tracking by online learning of non-linear motion patterns and robust appearance models. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 1918-1925 [14] Soomro K, Zamir A R, Shah M. UCF101: A Dataset of 101 Human Actions Classes from Videos in the Wild, Technical Report CRCV-TR-12-01, Center for Research in Computer Vision, University of Central Florida, USA, 2012. [15] Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T. HMDB: a large video database for human motion recognition. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 2556-2563 [16] Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Li F F. Large-scale video classification with convolutional neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, Ohio, USA: IEEE, 2014. 1725-1732 [17] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In: Proceedings of the 2014 Conference and Workshop on Neural Information Processing Systems. Montreal, Canada, 2014. 568-576 [18] Over P, Awad G, Fiscus J, Michel M, Smeaton A F, Kraaij W. TRECVID 2009-goals, tasks, data, evaluation mechanisms and metrics. In: TRECVid Workshop 2009. Gaithersburg, MD, USA: NIST, 2010. 1-42 [19] Du X Z, Cai Y, Zhao Y C, Li H, Yang Y, Hauptmann A. Informedia@trecvid 2014: surveillance event detection. TRECVid video retrieval evaluation workshop[Online], available:http://www-nlpir.nist.gov/projects/tvpubs/tv14.papers/cmu.pdf, April 5, 2016 [20] Cheng Y, Brown L, Fan Q F, Liu J J, Feris R, Choudhary A, Pankanti S. IBM-Northwestern@TRECVID 2014: Surveillance Event Detection. TRECVid video retrieval evaluation workshop[Online], available: http://www.nlpir.nist.gov/projects/tvpubs/tv14.papers/ibm.pdf, April 5, 2016 [21] Laptev I. On space-time interest points. International Journal of Computer Vision, 2005, 64(2-3): 107-123 [22] Chen M Y, Hauptmann A. MoSIFT: Recognizing Human Actions in Surveillance Videos, Technical Report CMU-CS-09-161, Department of Computer Science, Mellon University, USA, 2009. [23] Lawrence S, Giles C L, Tsoi A C, Back A D. Face recognition: a convolutional neural-network approach. IEEE Transactions on Neural Networks, 1997, 8(1): 98-113 [24] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 2012 Advances in Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates, Inc., 2012. 1097-1105 [25] Jia Y Q, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T. Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM International Conference on Multimedia. Orlando, USA: ACM, 2014. 675-678 [26] Chen Q, Jiang W H, Zhao Y Y, Su F. Part-based deep network for pedestrian detection in surveillance videos. In: Proceedings of the 2015 IEEE International Conference on Visual Communications and Image Processing. Singapore: IEEE, 2015. 1-4 [27] 李澜博. 纸币面值识别及监控视频跟踪算法[硕士学位论文], 北京邮电大学, 中国, 2015.Li Lan-Bo. Currency Recognition and Multi-Target Tracking Algorithm[Master dissertation], Beijing University of Posts and Communications, China, 2015. [28] Prince S J D. Computer Vision: Models, Learning, and Inference. Cambridge: Cambridge University Press, 2012. [29] SED Pedestrian Dataset (SED-PD)[Online], available: http://www.bupt-mcprl.net/datadownload.php, April 5, 2016 [30] TRECVID Surveillance Event Detection (SED) Evaluation Plan[Online], available: ftp://jaguar.ncsl.nist.gov/pub/SED15_EvaluationPlan.pdf, April 5, 2016 -

 下载:
下载:






图(10) / 表(1)
计量
- 文章访问数: 3503
- HTML全文浏览量: 1616
- PDF下载量: 1155
- 被引次数: 0
