

-
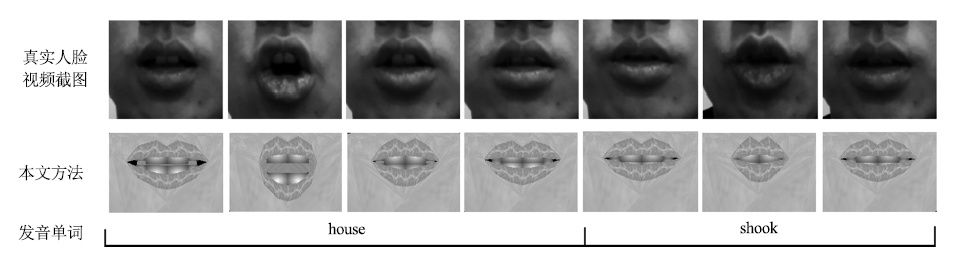
摘要: 实现一种基于深度神经网络的语音驱动发音器官运动合成的方法,并应用于语音驱动虚拟说话人动画合成. 通过深度神经网络(Deep neural networks, DNN)学习声学特征与发音器官位置信息之间的映射关系,系统根据输入的语音数据估计发音器官的运动轨迹,并将其体现在一个三维虚拟人上面. 首先,在一系列参数下对比人工神经网络(Artificial neural network, ANN)和DNN的实验结果,得到最优网络; 其次,设置不同上下文声学特征长度并调整隐层单元数,获取最佳长度; 最后,选取最优网络结构,由DNN 输出的发音器官运动轨迹信息控制发音器官运动合成,实现虚拟人动画. 实验证明,本文所实现的动画合成方法高效逼真.Abstract: This paper implements a deep neural networks (DNN) approach for speech-driven articulator motion synthesis, which is applied to speech-driven talking avatar animation synthesis. We realize acoustic-articulatory mapping by DNN. The input of the system is acoustic speech and the output is the estimated articulatory movements on a three-dimensional avatar. First, through comparison on the performance between ANN and DNN under a series of parameters, the optimal network is obtained. Second, for different context acoustic length configurations, the number of hidden layer units is tuned for best performance. So we get the best context length. Finally, we select the optimal network structure and realize the avatar animation by using the articulatory motion trajectory information output from the DNN to control the articulator motion synthesis. The experiment proves that the method can vividly and efficiently realize talking avatar animation synthesis.
-
Key words:
- Deep neural networks (DNN) /
- speech-driven /
- motion synthesis /
- talking avatar
-
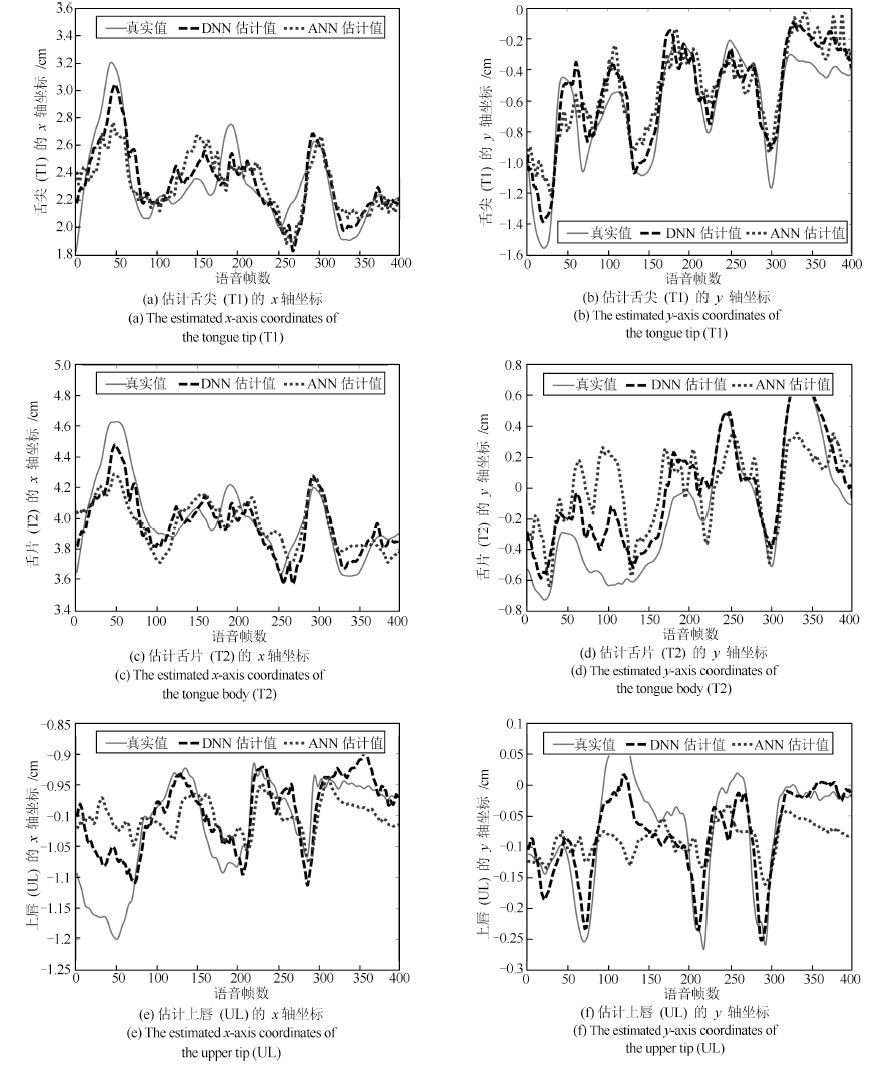
图 6 比较ANN 和DNN 估计的发音器官运动轨迹
Fig. 6 Comparison on the estimated articulatory motion trajectories between ANN and DNN
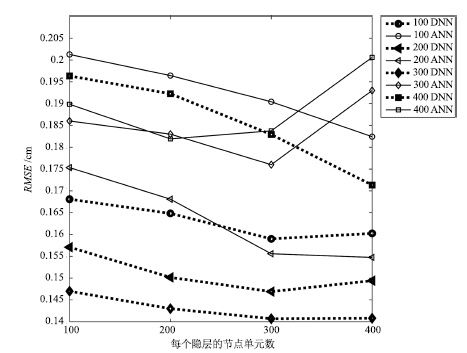
表 1 上下文窗的长度对RMSE 的影响
Table 1 E®ect of the length of the context window on the RMSE
上下文长度(帧数) RMSE (cm) 6 0.149 10 0.141 14 0.138 18 0.135 22 0.134 26 0.134 30 0.136  下载: 导出CSV
下载: 导出CSV
-
[1] Liu J, You M Y, Chen C, Song M L. Real-time speech-driven animation of expressive talking faces. International Journal of General Systems, 2011, 40(4): 439-455 [2] Le B H, Ma X H, Deng Z G. Live speech driven head-and-eye motion generators. IEEE Transactions on Visualization and Computer Graphics, 2012, 18(11): 1902-1914 [3] Han W, Wang L J, Soong F, Yuan B. Improved minimum converted trajectory error training for real-time speech-to-lips conversion. In: Proceedings of the 2012 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Kyoto, Japan: IEEE, 2012. 4513-4516 [4] Ben-Youssef A, Shimodaira H, Braude D A. Speech driven talking head from estimated articulatory features. In: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Florence, Italy: IEEE, 2014. 4573-4577 [5] Ding C, Zhu P C, Xie L, Jiang D M, Fu Z H. Speech-driven head motion synthesis using neural networks. In: Proceedings of the 2014 Annual Conference of the International Speech Communication Association (INTERSPEECH). Singapore, Singapore: ISCA, 2014. 2303-2307 [6] Richmond K, King S, Taylor P. Modelling the uncertainty in recovering articulation from acoustics. Computer Speech and Language, 2003, 17(2-3): 153-172 [7] Zhang L, Renals S. Acoustic-articulatory modeling with the trajectory HMM. IEEE Signal Processing Letters, 2008, 15: 245-248 [8] Toda T, Black A W, Tokuda K. Statistical mapping between articulatory movements and acoustic spectrum using a Gaussian mixture model. Speech Communication, 2008, 50(3): 215-227 [9] Xie L, Liu Z Q. Realistic mouth-synching for speech-driven talking face using articulatory modelling. IEEE Transactions on Multimedia, 2007, 9(3): 500-510 [10] Uria B, Renals S, Richmond K. A deep neural network for acoustic-articulatory speech inversion. In: Proceedings of the 2011 NIPSWorkshop on Deep Learning and Unsupervised Feature Learning. Granada, Spain: NIPS, 2011. 1-9 [11] Zhao K, Wu Z Y, Cai L H. A real-time speech driven talking avatar based on deep neural network. In: Proceedings of the 2013 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA). Kaohsiung, China: IEEE, 2013. 1-4 [12] Tang H, Fu Y, Tu J L, Hasegawa J M, Huang T S. Humanoid audio-visual avatar with emotive text-to-speech synthesis. IEEE Transactions on Multimedia, 2008, 10(6): 969-981 [13] Fu Y, Li R X, Huang T S, Danielsen M. Real-time multimodal human-avatar interaction. IEEE Transactions on Circuits and Systems for Video Technology, 2008, 18(4): 467-477 [14] Schreer O, Englert R, Eisert P, Tanger R. Real-time vision and speech driven avatars for multimedia applications. IEEE Transactions on Multimedia, 2008, 10(3): 352-360 [15] Liu K, Ostermann J. Realistic facial expression synthesis for an image-based talking head. In: Proceedings of the 2011 IEEE International Conference on Multimedia and Expo (ICME). Barcelona, Spain: IEEE, 2011. 1-6 [16] 杨逸,侯进,王献.基于运动轨迹分析的3D唇舌肌肉控制模型.计算机应用研究,2013, 30(7): 2236-2240Yang Yi, Hou Jin, Wang Xian. Mouth and tongue model controlled by muscles based on motion trail analyzing. Application Research of Computers, 2013, 30(7): 2236-2240 [17] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504-507 [18] Hinton G E. A practical guide to training restricted Boltzmann machines. Neural Networks: Tricks of the Trade (2nd Edition). Berlin: Springer-Verlag, 2012. 599-619 [19] Tieleman T. Training restricted Boltzmann machines using approximations to the likelihood gradient. In: Proceedings of the 25th International Conference on Machine Learning (ICML). New York, USA: ACM, 2008. 1064-1071 [20] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7): 1527-1554 [21] Hinton G, Deng L, Yu D, Dahl G E, Mohamed A R, Jaitly N, Senior A, Vanhoucke V, Nguyen P, Sainath T N, Kingsbury B. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Processing Magazine, 2012, 29(6): 82-97 [22] Richmond K, Hoole P, King S. Announcing the electromagnetic articulography (day 1) subset of the mngu0 articulatory. In: Proceedings of the 2001 Annual Conference of the International Speech Communication Association (INTERSPEECH). Florence, Italy: ISCA, 2011. 1505-1508 [23] Kawahara H, Estill J, Fujimura O. Aperiodicity extraction and control using mixed mode excitation and group delay manipulation for a high quality speech analysis, modification and synthesis system STRAIGHT. In: Proceedings of the 2nd International Workshop Models and Analysis of Vocal Emissions for Biomedical Application (MAVEBA). Firenze, Italy, 2001. 59-64 [24] 李皓,陈艳艳,唐朝京.唇部子运动与权重函数表征的汉语动态视位.信号处理,2012, 28(3): 322-328Li Hao, Chen Yan-Yan, Tang Chao-Jing. Dynamic Chinese visemes implemented by lip sub-movements and weighting function. Signal Processing, 2012, 28(3): 322-328 [25] Deng L, Li J Y, Huang J T, Yao K S, Yu D, Seide F, Seltzer M, Zweig G, He X D, Williams J, Gong Y F, Acero A. Recent advances in deep learning for speech research at Microsoft. In: Proceedings of the 2013 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Vancouver, Canada: IEEE, 2013. 8604-8608 -

 下载:
下载:




图(7) / 表(2)
计量
- 文章访问数: 2465
- HTML全文浏览量: 545
- PDF下载量: 1298
- 被引次数: 0
