

-
摘要: 深度信念网络(Deep belief network, DBN) 是一种从无标签数据学习特征的多层结构模型. 在同一层单元间缺少连接, 导致数据中的深度关联特征难以提取. 受到人脑中胶质神经细胞机制的启示, 提出一种基于胶质细胞链的改进 DBN 模型及其学习算法, 以提取更多数据信息. 在标准图像分类数据集上的实验结果表明, 与其他几种模型相比, 本文提出的改进 DBN 模型可以提取更为优秀的图像特征, 提高分类准确率.Abstract: Deep belief network (DBN) is a hierarchical model for learning feature representations from unlabeled data. However, there are no interconnections among the neural units in the same layer and the mutual information of different neural units may be ignored. Inspired by functions of glia cells in the neural network structure of human brain, we propose a variant structure of DBN and an improved learning algorithm to extract more information of the data. Experimental results based on benchmark image datasets have shown that the proposed DBN model can acquire better features and achieve lower error rates than a traditional DBN and other compared learning algorithms.
-
Key words:
- Deep belief network (DBN) /
- glia cells /
- unsupervised learning /
- feature extraction
-

图 3 胶质细胞链改进的RBM 及其组成的DBN 模型
Fig. 3 Improved RBMs based on glia chains and a DBN composed of these RBMs

图 5 RBM (上) 和胶质细胞链改进的RBM (下) 学习特征的可视化
Fig. 5 Visualization of features learned by RBM (above) and improved RBM (below)
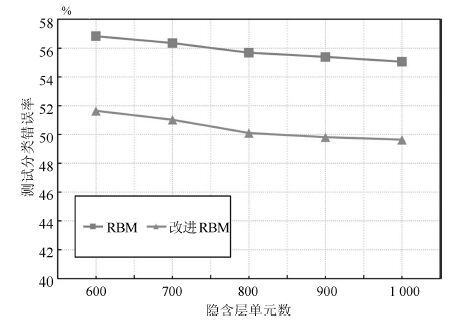
图 6 RBM 及胶质细胞改进RBM 在CIFAR-10 数据集上的测试分类错误率
Fig. 6 Test error rate of RBM and RBM with glia chain on CIFAR-10 dataset

图 7 Rectangles images 数据集上RBM 及胶质细胞改进 RBM 的测试分类错误率
Fig. 7 Test error rate of RBM and RBM with glia chain on Rectangles images dataset
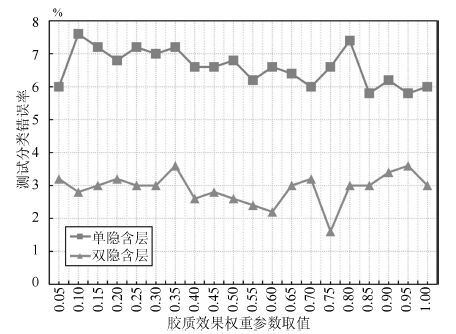
图 8 胶质效果权重参数不同取值下改进DBN 模型的测试分类错误率
Fig. 8 Testing error rate of improved DBN with diαerent values of glia eαect weight

图 9 胶质衰减因子参数不同取值下改进DBN 模型的测试分类错误率
Fig. 9 Testing error rate of improved DBN with diαerent values of attenuation factor
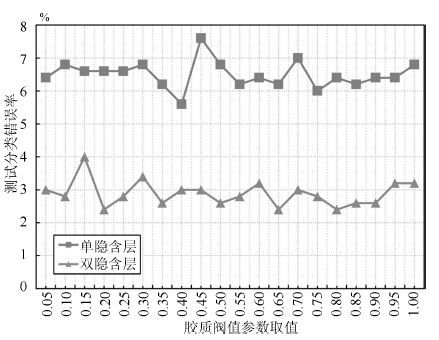
图 10 胶质阈值参数不同取值下改进DBN 模型的测试分类错误率
Fig. 10 Testing error rate of improved DBN with diαerent values of glia threshold
表 1 MNIST 数据集上不同模型的测试结果
Table 1 Testing results of diαerent models on MNIST dataset
模型 200 隐含单元 300 隐含单元 500 隐含单元 测试 收敛 测试 收敛 测试 收敛 错误率 时间 错误率 时间 错误率 时间 (%) (s) (%) (s) (%) (s) RBM 3.03 70.06 2.83 94.48 2.55 146.23 Sparse auto-encoder 3.34 121.01 2.91 153.67 2.59 198.21 BP neural network 4.57 142.42 4.35 187.17 4.1 215.88 RBM + Glial chain 2.82 65.27 2.62 90.42 2.4 137.91  下载: 导出CSV
下载: 导出CSV
表 2 MNIST 数据集上传统DBN 及改进DBN 的训练及测试错误率及收敛时间
Table 2 Training, testing error rate and convergence time of DBN and improved DBN on MNIST dataset
模型 训练错误率(%) 测试错误率(%) 收敛时间(s) DBN 1.69 2.59 184.07 改进DBN 1.05 1.53 176.72
下载: 导出CSV
表 3 MNIST 数据集上传统DBN 及改进DBN 的FP 及FN 数据
Table 3 FP and FN data of DBN and improved DBN on MNIST dataset
模型 类别1 类别2 类别3 FP FN FP FN FP FN DBN 145 10 137 13 133 24 改进DBN 28 9 12 10 33 16
下载: 导出CSV
表 4 MNIST 数据集上改进DBN 取得的最优结果与其他模型已有结果的比较
Table 4 Comparison of DBN and other models0 bestresults on MNIST dataset
模型 测试错误率(%) 1 000 RBF + Linear classifer 3.60[20] DBN,using SparseRBMs pre-training a 784-500-500-2 000 network 1.87[26] Boosted trees (17 leaves) 1.53[27] 3-layer NN,500 + 300 HU,softmax,cross-entropy,weight decay 1.51[28] SVM,Gaussian kernel 1.40[29] DBN,using RBMs pre-training a 784-500-500-2 000 network 1.20[2] DBN,using RBMs with glial chain pre-training a 784-500-500-2 000 network 1.09
下载: 导出CSV
表 5 CIFAR-10 数据集上DBN 及胶质细胞改进DBN 的训练和测试分类错误率及收敛时间
Table 5 Training, testing error rate and convergence time of DBN and improved DBN on CIFAR-10 dataset
模型 训练错误率(%) 测试错误率(%) 收敛时间(s) DBN 32.67 50.07 474.21 改进DBN 30.4 46.19 463.19
下载: 导出CSV
表 6 CIFAR-10 数据集上DBN 及胶质细胞改进DBN 的FP 和FN 数据
Table 6 FP and FN data of DBN and improved DBN on CIFAR-10 dataset
类别 Airplane Automobile Bird FP FN FP FN FP FN DBN 8 781 421 8 017 800 7 817 1 000 改进DBN 4 986 36 5 074 333 4 731 676
下载: 导出CSV
表 7 Rectangles images 数据集上DBN 及胶质细胞改进DBN 的训练和测试错误率、收敛时间、FP 和FN 数据
Table 7 Training, testing error rate, convergence time, and FP, FN data of DBN and improved DBN on Rectangles images dataset
模型 训练错误率(%) 测试错误率(%) 收敛时间(s) FP FN DBN 1.61 3.22 90.03 7 9 改进DBN 0.59 1.4 46.3 5 2
下载: 导出CSV
-
[1] Kruger N, Janssen P, Kalkan S, Lappe M, Leonardis A, Piater J, Rodriguez-Sanchez A J, Wiskott L. Deep hierarchies in the primate visual cortex: what can we learn for computer vision. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1847-1871 [2] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504-507 [3] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7): 1527-1554 [4] Bengio Y, Lamblin P, Popovici D, Larochelle H. Greedy layer-wise training of deep networks. In: Proceedings of Advances in Neural Information Processing Systems 19. Cambridge: MIT Press, 2007. 153-160 [5] Lee H, Grosse R, Ranganath R, Ng A Y. Unsupervised learning of hierarchical representations with convolutional deep belief networks. Communications of the ACM, 2011, 54(10): 95-103 [6] Huang G B, Lee H, Learned-Miller E. Learning hierarchical representations for face verification with convolutional deep belief networks. In: Proceedings of the 2012 IEEE Conference on Computer Vision&Pattern Recognition. Providence, RI: IEEE, 2012. 2518-2525 [7] Liu P, Han S Z, Meng Z B, Tong Y. Facial expression recognition via a boosted deep belief network. In: Proceedings of the 2014 IEEE Conference on Computer Vision&Pattern Recognition. Columbus, OH: IEEE, 2014. 1805-1812 [8] Roy P P, Chherawala Y, Cheriet M. Deep-belief-network based rescoring approach for handwritten word recognition. In: Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition. Heraklion: IEEE, 2014. 506-511 [9] Mohamed A R, Dahl G E, Hinton G. Acoustic modeling using deep belief networks. IEEE Transactions on Audio, Speech,&Language Processing, 2012, 20(1): 14-22 [10] Kang S Y, Qian X J, Meng H L. Multi-distribution deep belief network for speech synthesis. In: Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Vancouver, BC: IEEE, 2013. 8012-8016 [11] Haydon P G. GLIA: listening and talking to the synapse. Nature Reviews Neuroscience, 2001, 2(3): 185-193 [12] Ikuta C, Uwate Y, Nishio Y. Investigation of multi-layer perceptron with pulse glial chain. IEICE Technical Report Nonlinear Problems, 2011, 111(62): 45-48 (in Japanese) [13] Fischer A, Igel C. An introduction to restricted Boltzmann machines. In: Proceedings of the 17th Iberoamerican Congress on Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications. Lecture Notes in Computer Science. Buenos Aires, Argentina: Springer, 2012. 14-36 [14] Deng L, Yu D. Deep learning: methods and applications. Foundations&Trends® in Signal Processing, 2013, 7(3-4): 197-387 [15] Hinton G E. Training products of experts by minimizing contrastive divergence. Neural Computation, 2002, 14(8): 1771-1800 [16] Bengio Y. Learning deep architectures for AI. Foundations&Trends® in Machine Learning, 2009, 2(1): 1-127 [17] Ikuta C, Uwate Y, Nishio Y. Multi-layer perceptron with positive and negative pulse glial chain for solving two-spirals problem. In: Proceedings of the 2012 International Joint Conference on Neural Networks. Brisbane, QLD: IEEE, 2012. 1-6 [18] Hinton G, Deng L, Yu D, Dahl G E, Mohamed A R, Jaitly N, Senior A, Vanhoucke V, Nguyen P, Sainath T N, Kingsbury B. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Processing Magazine, 2012, 29(6): 82-97 [19] Hinton G E. A practical guide to training restricted Boltzmann machines. Neural Networks: Tricks of the Trade (2nd edition). Berlin Heidelberg: Springer, 2012. 599-619 [20] Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278-2324 [21] Krizhevsky A, Hinton G. Learning Multiple Layers of Features from Tiny Images, Technical Report, University of Toronto, Canada, 2009. [22] Larochelle H, Erhan D, Courville A, Bergstra J, Bengio Y, Ghahramani Z. An empirical evaluation of deep architectures on problems with many factors of variation. In: Proceedings of the 24th International Conference on Machine Learning. Oregon, USA: ICML, 2007. 473-480 [23] Luo Y X, Wan Y. A novel efficient method for training sparse auto-encoders. In: Proceedings of the 6th International Congress on Image&Signal Processing. Hangzhou, China: IEEE, 2013. 1019-1023 [24] Rumelhart D E, Hinton G E, Williams R J. Learning internal representations by error propagation. Neurocomputing: Foundations of Research. Cambridge: MIT Press, 1988. 673-695 [25] Platt J C. Using analytic Qp and sparseness to speed training of support vector machines. In: Proceedings of Advances in Neural Information Processing Systems 11. Cambridge: MIT Press, 1999. 557-563 [26] Swersky K, Chen B, Marlin B, de Freitas N. A tutorial on stochastic approximation algorithms for training restricted Boltzmann machines and deep belief nets. In: Proceedings of the 2010 Information Theory and Applications Workshop (ITA). San Diego, USA: IEEE, 2010. 1-10 [27] Kégl B, Busa-Fekete R. Boosting products of base classifiers. In: Proceedings of the 26th International Conference on Machine Learning. Montreal, Canada: ACM, 2009. 497-504 [28] Hinton G E. What kind of a graphical model is the brain. In: Proceedings of the 19th International Joint Conference on Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2005. 1765-1775 [29] Cortes C, Vapnik V. Support-vector networks. Machine Learning, 1995, 20(3): 273-297 -

 下载:
下载:


计量
- 文章访问数: 2004
- HTML全文浏览量: 296
- PDF下载量: 1357
- 被引次数: 0
