

-
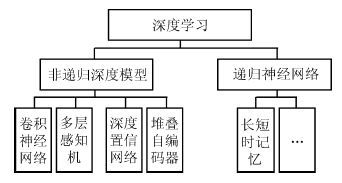
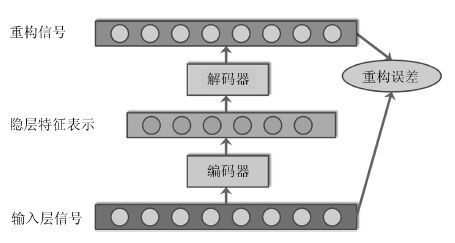
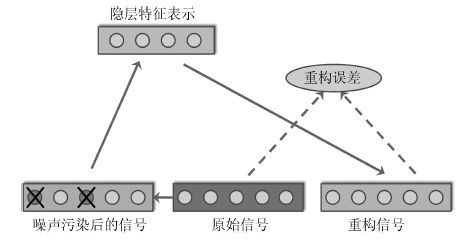
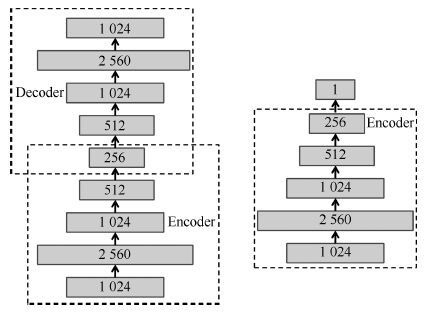
摘要: 视频目标跟踪是计算机视觉的重要研究课题, 在视频监控、机器人、人机交互等方面具有广泛应用. 大数据时代的到来及深度学习方法的出现, 为视频目标跟踪的研究提供了新的契机. 本文首先阐述了视频目标跟踪的基本研究框架. 对新时期视频目标跟踪研究的特点与趋势进行了分析, 介绍了国际上新兴的数据平台、评测方法. 重点介绍了目前发展迅猛的深度学习方法, 包括堆叠自编码器、卷积神经网络等在视频目标跟踪中的最新具体应用情况并进行了深入分析与总结. 最后对深度学习方法在视频目标跟踪中的未来应用与发展方向进行了展望.Abstract: Video object tracking is an important research topic of computer vision with numerous applications including surveillance, robotics, human-computer interface, etc. The coming of big data era and the rise of deep learning methods have offered new opportunities for the research of tracking. Firstly, we present the general framework for video object tracking research. Then, we introduce new arisen datasets and evaluation methodology. We highlight the application of the rapid-developing deep-learning methods including stacked autoencoder and convolutional neural network on video object tracking. Finally, we have a discussion and provide insights for future.
-
Key words:
- Object tracking /
- video analysis /
- online learning /
- deep learning /
- big data
-
-
[1] Comaniciu D, Ramesh V, Meer P. Real-time tracking of non-rigid objects using mean shift. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. Hilton Head Island, SC: IEEE, 2000. 142-149 [2] Risfic B, Arulampalam S, Gordon N. Beyond the Kalman filter-book review. IEEE Aerospace and Electronic Systems Magazine, 2004, 19(7) : 37-38 [3] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2001. I-511-I-518 [4] Pérez P, Hue C, Vermaak J, Gangnet M. Color-based probabilistic tracking. In: Proceedings of the 7th European Conference on Computer Vision. Copenhagen, Denmark: Springer, 2002. 661-675 [5] Possegger H, Mauthner T, Bischof H. In defense of color-based model-free tracking. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 2113-2120 [6] Danelljan M, Khan F S, Felsberg M, van de Weijer J. Adaptive color attributes for real-time visual tracking. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 1090-1097 [7] Ojala T, Pietikainen M, Harwood D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions. In: Proceedings of the 12th IAPR International Conference on Pattern Processing. Jerusalem: IEEE, 1994. 582-585 [8] Zhou H Y, Yuan Y, Shi C M. Object tracking using SIFT features and mean shift. Computer Vision and Image Understanding, 2009, 113(3) : 345-352 [9] Miao Q, Wang G J, Shi C B, Lin X G, Ruan Z W. A new framework for on-line object tracking based on SURF. Pattern Recognition, 2011, 32(13) : 1564-1571 [10] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA: IEEE, 2005. 886-893 [11] Lucas B D, Kanade T. An iterative image registration technique with an application to stereo vision. In: Proceedings of the 7th International Joint Conference on Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1981. 674-679 [12] Horn B K P, Schunck B G. Determining optical flow. Artificial Intelligence, 1981, 17(2) : 185-203 [13] Kalal Z, Mikolajczyk K, Matas J. Tracking-learning-detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(7) : 1409-1422 [14] Kalal Z, Mikolajczyk K, Matas J. Forward-backward error: automatic detection of tracking failures. In: Proceedings of the 20th IEEE International Conference on Pattern Recognition. Istanbul: IEEE, 2010. 2756-2759 [15] Li X, Hu W M, Shen C H, Zhang Z F, Dick A, van den Hengel A. A survey of appearance models in visual object tracking. ACM Transactions on Intelligent Systems and Technology, 2013, 4(4) : Article No.58 [16] 张焕龙, 胡士强, 杨国胜. 基于外观模型学习的视频目标跟踪方法综述. 计算机研究与发展, 2015, 52(1) : 177-190Zhang Huan-Long, Hu Shi-Qiang, Yang Guo-Sheng. Video object tracking based on appearance models learning. Journal of Computer Research and Development, 2015, 52(1) : 177-190 [17] 侯志强, 韩崇昭. 视觉跟踪技术综述. 自动化学报, 2006, 32(4) : 603-617Hou Zhi-Qiang, Han Chong-Zhao. A survey of visual tracking. Acta Automatica Sinica, 2006, 32(4) : 603-617 [18] Adam A, Rivlin E, Shimshoni I. Robust fragments-based tracking using the integral histogram. In: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, NY, USA: IEEE, 2006. 798-805 [19] Alt N, Hinterstoisser S, Navab N. Rapid selection of reliable templates for visual tracking. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 1355-1362 [20] He S F, Yang Q X, Lau R W H, Wang J, Yang M H. Visual tracking via locality sensitive histograms. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 2427-2434 [21] Black M J, Jepson A D. EigenTracking: robust matching and tracking of articulated objects using a view-based representation. International Journal of Computer Vision, 1998, 26(1) : 63-84 [22] Ross D A, Lim J, Lin R S, Yang M H. Incremental learning for robust visual tracking. International Journal of Computer Vision, 2008, 77(1-3) : 125-141 [23] Zhang T Z, Liu S, Xu C S, Yan S C, Ghanem B, Ahuja N, Yang M H. Structural sparse tracking. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 150-158 [24] Jia X, Lu H C, Yang M H. Visual tracking via adaptive structural local sparse appearance model. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 1822-1829 [25] Zhang T Z, Ghanem B, Liu S, Ahuja N. Robust visual tracking via multi-task sparse learning. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 2042-2049 [26] Zhang S P, Yao H X, Sun X, Lu X S. Sparse coding based visual tracking: review and experimental comparison. Pattern Recognition, 2013, 46(7) : 1772-1788 [27] Wright J, Ma Y, Mairal J, Sapiro G, Huang T S, Yan S C. Sparse representation for computer vision and pattern recognition. Proceedings of the IEEE, 2010, 98(6) : 1031-1044 [28] Mei X, Ling H B. Robust visual tracking using L1 minimization. In: Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto: IEEE, 2009. 1436-1443 [29] Hare S, Saffari A, Torr P H S. Struck: structured output tracking with kernels. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona: IEEE, 2011. 263-270 [30] Avidan S. Support vector tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(8) : 1064-1072 [31] Bai Y C, Tang M. Robust tracking via weakly supervised ranking SVM. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 1854-1861 [32] Grabner H, Grabner M, Bischof H. Real-time tracking via on-line boosting. In: Proceedings of the British Machine Vision Conference. Edinburgh, UK: BMVA Press, 2006. 47-56 [33] Grabner H, Leistner C, Bischof H. Semi-supervised on-line boosting for robust tracking. In: Proceedings of the 10th European Conference on Computer Vision. Marseille, France: Springer, 2008. 234-247 [34] Stalder S, Grabner H, van Gool L. Beyond semi-supervised tracking: tracking should be as simple as detection, but not simpler than recognition. In: Proceedings of the 12th IEEE International Conference on Computer Vision Workshops. Kyoto: IEEE, 2009. 1409-1416 [35] Babenko B, Yang M H, Belongie S. Visual tracking with online multiple instance learning. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009. 983-990 [36] Henriques J F, Caseiro R, Martins P, Batista J. Exploiting the circulant structure of tracking-by-detection with kernels. In: Proceedings of the 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012. 702-715 [37] Henriques J F, Caseiro R, Martins P, Batista J. High-speed tracking with kernelized correlation filters. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3) : 583-596 [38] Zhang K H, Zhang L, Yang M H. Real-time compressive tracking. In: Proceedings of 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012. 864-877 [39] 黄凯奇, 任伟强, 谭铁牛. 图像物体分类与检测算法综述. 计算机学报, 2014, 37(6) : 1225-1240Huang Kai-Qi, Ren Wei-Qiang, Tan Tie-Niu. A review on image object classification and detection. Chinese Journal of Computers, 2014, 37(6) : 1225-1240 [40] Deng J, Dong W, Socher R, Li J J, Li K, Li F F. ImageNet: a large-scale hierarchical image database. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009. 248-255 [41] Everingham M, Van Gool L, Williams C K I, Winn J, Zisserman A. The PASCAL visual object classes (VOC) challenge. International Journal of Computer Vision, 2010, 88(2) : 303-338 [42] Smeaton A F, Over P, Kraaij W. Evaluation campaigns and TRECVid. In: Proceedings of the 8th ACM International Workshop on Multimedia Information Retrieval. Santa Barbara, CA, USA: ACM, 2006. 321-330 [43] Wu Y, Lim J, Yang M H. Online object tracking: a benchmark. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 2411-2418 [44] Wu Y, Lim J, Yang M H. Object tracking benchmark. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9) : 1834-1848 [45] Kristan M, Matas J, Leonardis A, Felsberg M, Cehovin L, Fernández G, Vojír T, Häger G, Nebehay G, Pflugfelder R. The visual object tracking VOT2015 challenge results. In: Proceedings of the 2015 IEEE International Conference on Computer Vision Workshops. Santiago: IEEE, 2015. 564-586 [46] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088) : 533-536 [47] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786) : 504-507 [48] Hinton G, Deng L, Yu D, Dahl G E, Mohamed A R, Jaitly N, Senior A, Vanhoucke V, Nguyen P, Sainath T N, Kingsbury B. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Processing Magazine, 2012, 29(6) : 82-97 [49] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceeding of Advances in Neural Information Processing Systems. Nevada, USA: MIT Press, 2012. 1097-1105 [50] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 580-587 [51] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. In: Proceeding of Advances in Neural Information Processing Systems. Montréal, Canada: MIT Press, 2015. 91-99 [52] Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Li F F. Large-scale video classification with convolutional neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 1725-1732 [53] Ji S W, Xu W, Yang M, Yu K. 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1) : 221-231 [54] Lee T S, Mumford D, Romero R, Lamme V A F. The role of the primary visual cortex in higher level vision. Vision Research, 1998, 38(15-16) : 2429-2454 [55] Lee T S, Mumford D. Hierarchical Bayesian inference in the visual cortex. Journal of the Optical Society of America A: Optics Image Science and Vision, 2003, 20(7) : 1434-1448 [56] Jia Y Q, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T. Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM International Conference on Multimedia. Orlando, FL, USA: ACM, 2014. 675-678 [57] Bergstra J, Bastien F, Breuleux O, Lamblin P, Pascanu R, Delalleau O, Desjardins G, Warde-Farley D, Goodfellow I J, Bergeron A, Bengio Y. Theano: deep learning on GPUS with python. In: Advances in Neural Information Processing Systems Workshops. Granada, Spain: MIT Press, 2011. 1-4 [58] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7) : 1527-1554 [59] Vincent P, Larochelle H, Bengio Y, Manzagol P A. Extracting and composing robust features with denoising autoencoders. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008. 1096-1103 [60] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11) : 2278-2324 [61] Jozefowicz R, Zaremba W, Sutskever I. An empirical exploration of recurrent network architectures. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR, 2015. 2342-2350 [62] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8) : 1735-1780 [63] Gers F A, Schraudolph N N, Schmidhuber J. Learning precise timing with LSTM recurrent networks. The Journal of Machine Learning Research, 2003, 3: 115-143 [64] Graves A, Liwicki M, Fernández S, Bertolami R, Bunke H, Schmidhuber J. A novel connectionist system for unconstrained handwriting recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(5) : 855-868 [65] Wang N Y, Yeung D Y. Learning a deep compact image representation for visual tracking. In: Proceeding of Advances in Neural Information Processing Systems. Nevada, USA: MIT Press, 2013. 809-817 [66] Torralba A, Fergus R, Freeman W T. 80 million tiny images: a large data set for nonparametric object and scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(11) : 1958-1970 [67] Zhou X Z, Xie L, Zhang P, Zhang Y N. An ensemble of deep neural networks for object tracking. In: Proceedings of the 2014 IEEE International Conference on Image Processing. Paris, France: IEEE, 2014. 843-847 [68] Kuen J, Lim K M, Lee C P. Self-taught learning of a deep invariant representation for visual tracking via temporal slowness principle. Pattern Recognition, 2015, 48(10) : 2964-2982 [69] Ding J W, Huang Y Z, Liu W, Huang K Q. Severely blurred object tracking by learning deep image representations. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 26(2) : 319-331 [70] Dai L, Zhu Y S, Luo G B, He C. A low-complexity visual tracking approach with single hidden layer neural networks. In: Proceedings of the 13th IEEE International Conference on Control Automation Robotics and Vision. Singapore: IEEE, 2014. 810-814 [71] Hubel D H, Wiesel T N. Receptive fields, binocular interaction and functional architecture in the cat's visual cortex. Journal of Physiology, 1962, 160(1) : 106-154 [72] Fukushima K. Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 1980, 36(4) : 193-202 [73] LeCun Y, Boser B, Denker J S, Henderson D, Howard R E, Hubbard W, Jackel L D. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989, 1(4) : 541-551 [74] LeCun Y, Kavukcuoglu K, Farabet C. Convolutional networks and applications in vision. In: Proceedings of 2010 IEEE International Symposium on Circuits and Systems. Paris, France: IEEE, 2010. 253-256 [75] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 1-9 [76] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv: 1409.1556, 2014. [77] Jin J, Dundar A, Bates J, Farabet C, Culurciello E. Tracking with deep neural networks. In: Proceedings of the 47th Annual Conference on Information Sciences and Systems (CISS). Baltimore, MD, USA: IEEE, 2013. 1-5 [78] Wang L, Liu T, Wang G, Chan K L, Yang Q X. Video tracking using learned hierarchical features. IEEE Transactions on Image Processing, 2015, 24(4) : 1424-1435 [79] Wang N Y, Li S Y, Gupta A, Yeung D Y. Transferring rich feature hierarchies for robust visual tracking. arXiv: 1501.04587, 2015. [80] Hong S, You T, Kwak S, Han B. Online tracking by learning discriminative saliency map with convolutional neural network. In: Proceedings of the 32th International Conference on Machine Learning. Lille, France: JMLR, 2015. 597-606 [81] Wang L J, Ouyang W L, Wang X G, Lu H C. Visual tracking with fully convolutional networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015. 3119-3127 [82] Ma C, Huang J B, Yang X K, Yang M H. Hierarchical convolutional features for visual tracking. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015. 3074-3082 [83] Li H X, Li Y, Porikli F. DeepTrack: learning discriminative feature representations online for robust visual tracking. IEEE Transactions on Image Processing, 2016, 25(4) : 1834-1848 [84] Li H X, Li Y, Porikli F. Robust online visual tracking with a single convolutional neural network. In: Proceedings of the 12th Asian Conference on Computer Vision. Singapore: Springer, 2015. 194-209 [85] He Y, Dong Z, Yang M, Chen L, Pei M T, Jia Y D. Visual tracking using multi-stage random simple features. In: Proceedings of the 22nd International Conference on Pattern Recognition. Stockholm: IEEE, 2014. 4104-4109 [86] Danelljan M, Häger G, Khan F S, Felsberg M. Convolutional features for correlation filter based visual tracking. In: Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop. Santiago: IEEE, 2015. 621-629 [87] Wang N Y, Shi J P, Yeung D Y, Jia J Y. Understanding and diagnosing visual tracking systems. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015. 3101-3109 [88] Hong Z B, Chen Z, Wang C H, Mei X, Prokhorov D, Tao D C. MUlti-Store tracker (MUSTer): a cognitive psychology inspired approach to object tracking. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 749-758 -

 下载:
下载:





图(10)
计量
- 文章访问数: 5673
- HTML全文浏览量: 3851
- PDF下载量: 6645
- 被引次数: 0
