2024年 第50卷 第10期
2024, 50(10): 1877-1905.
doi: 10.16383/j.aas.c230445
cstr: 32138.14.j.aas.c230445
摘要:
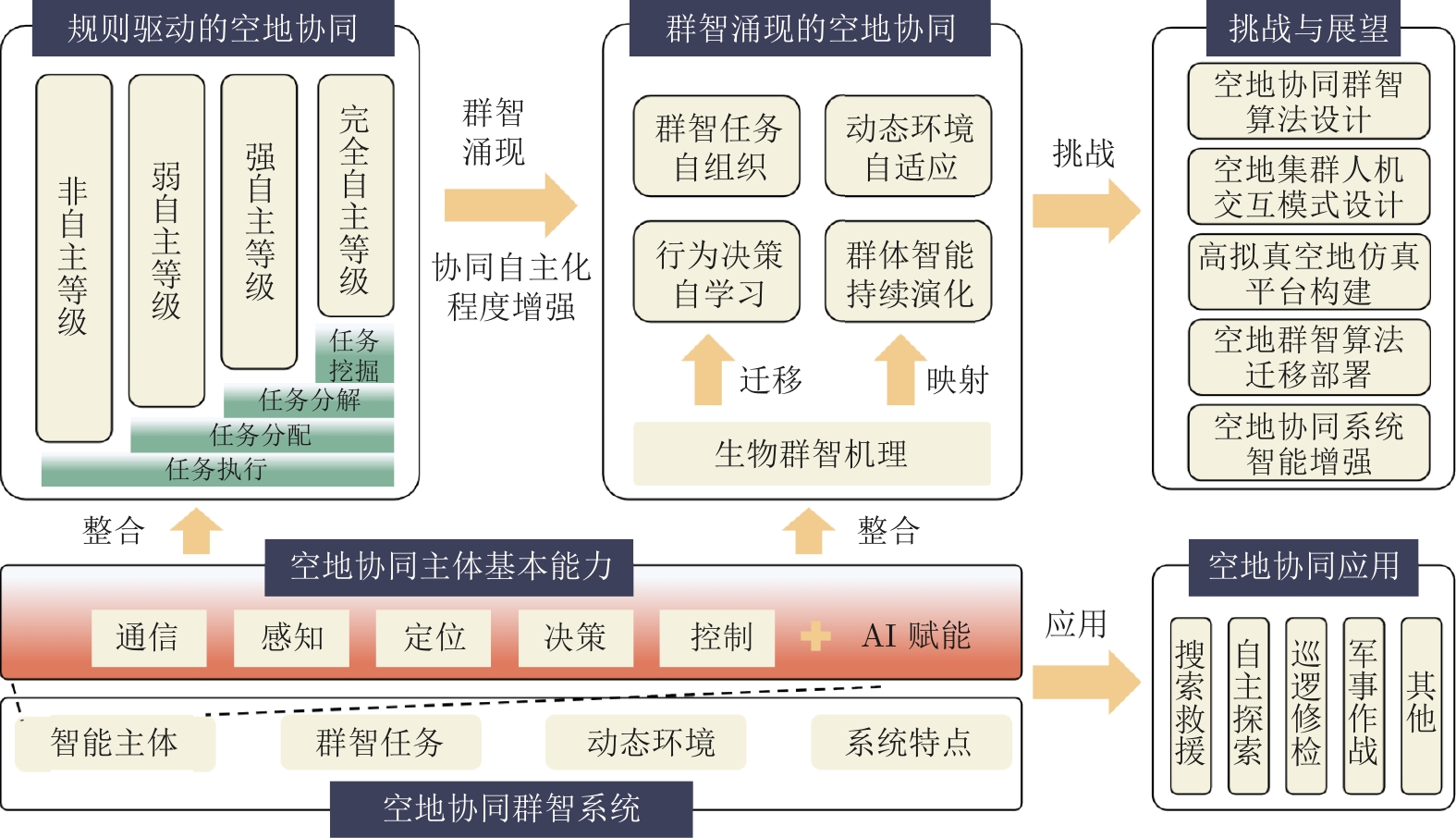
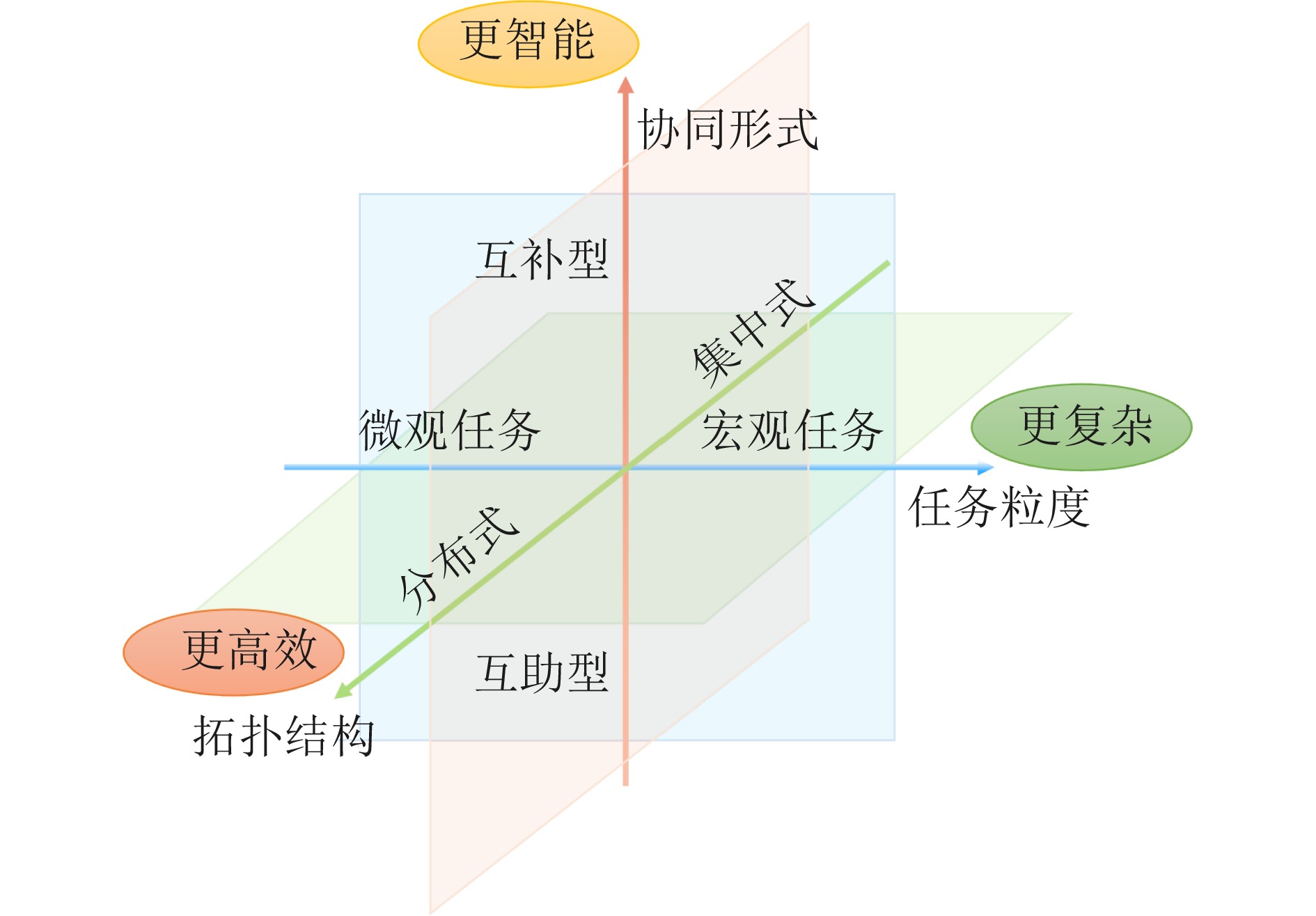
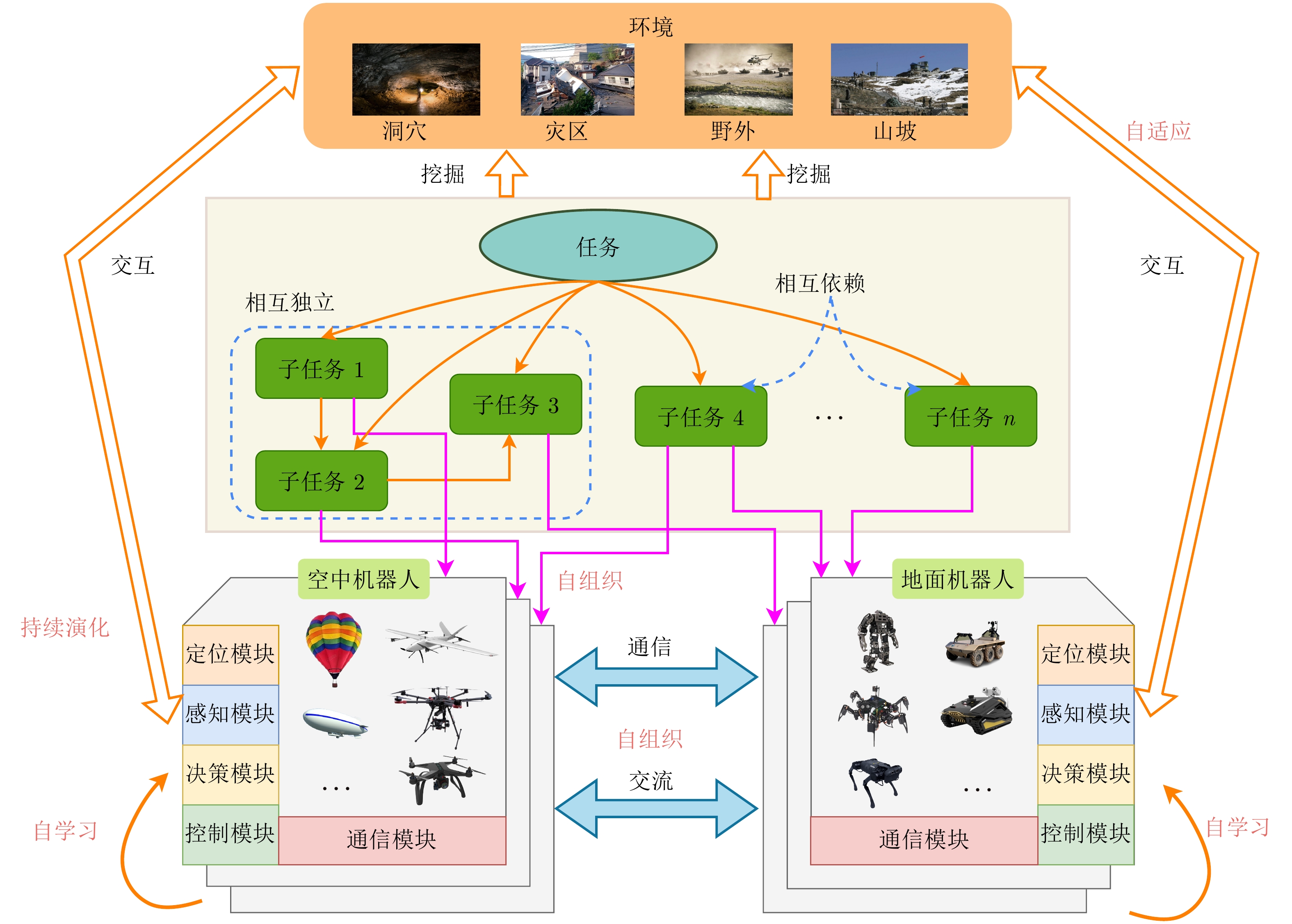
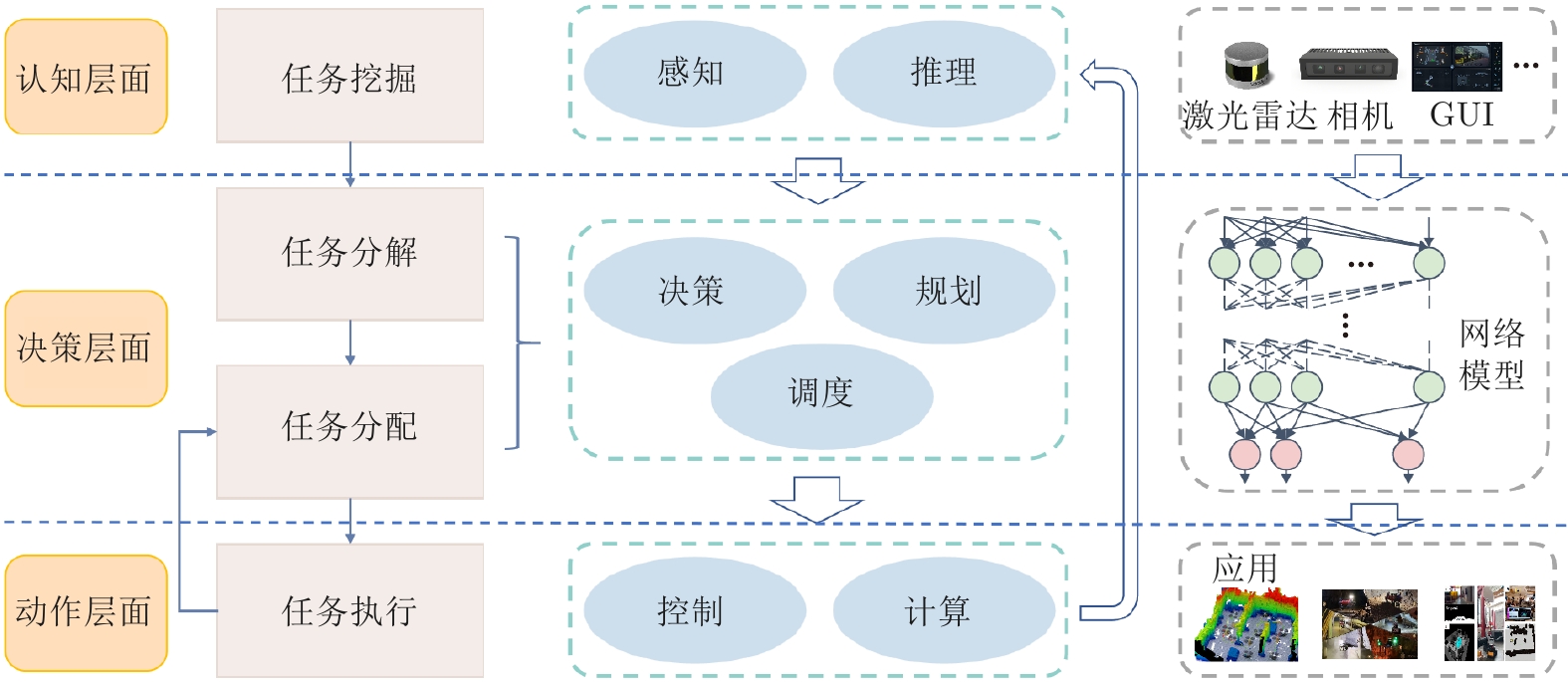
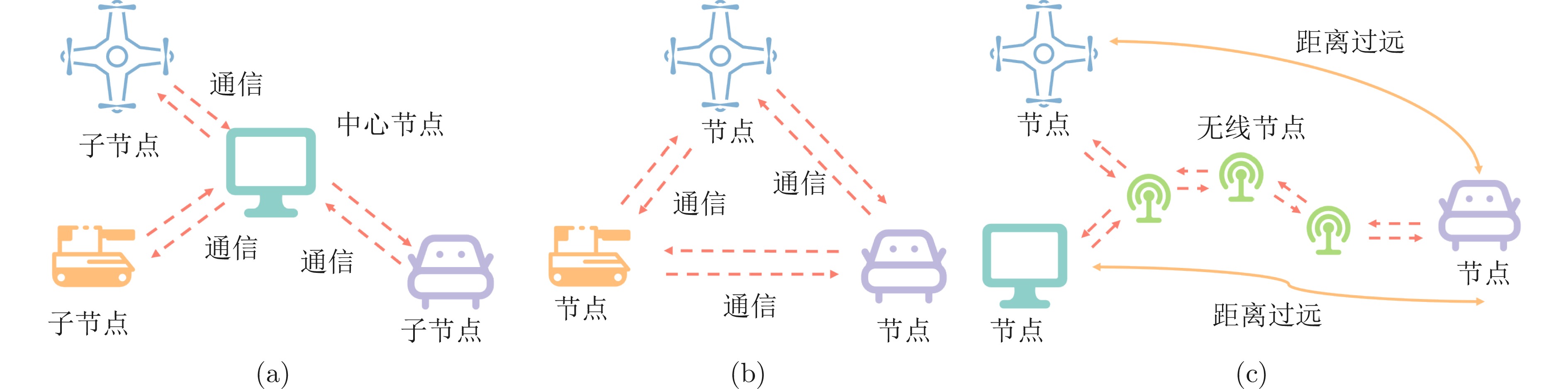
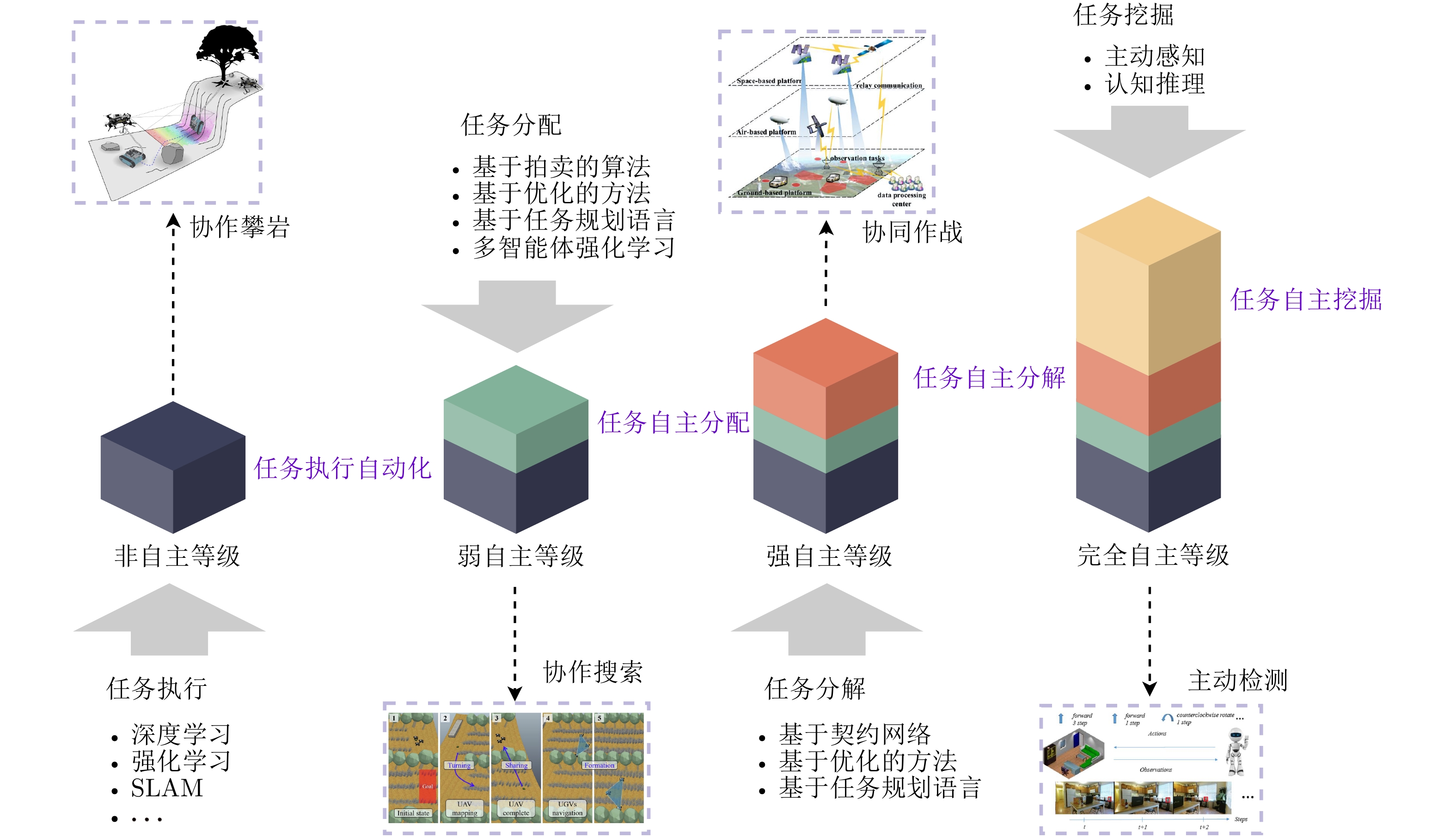
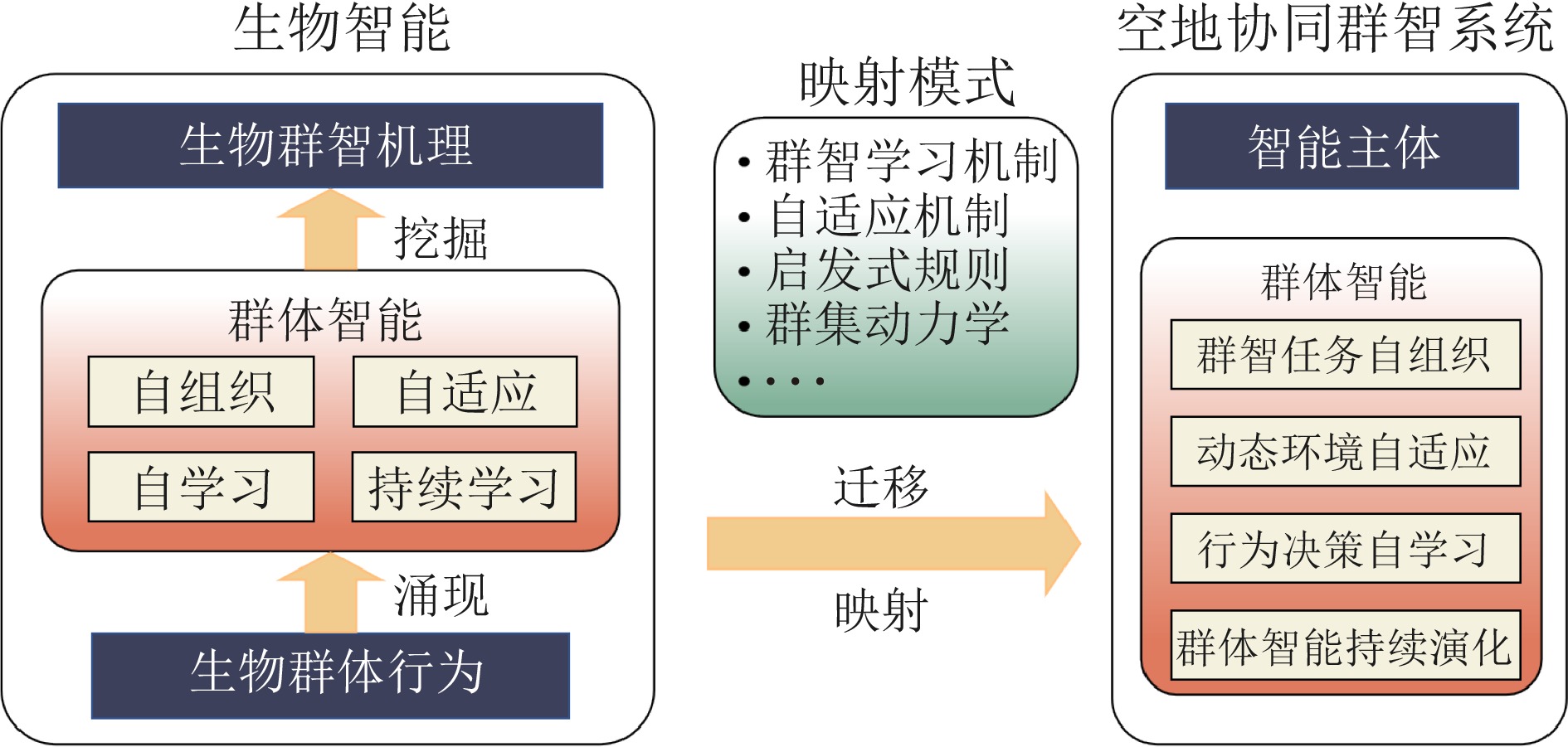
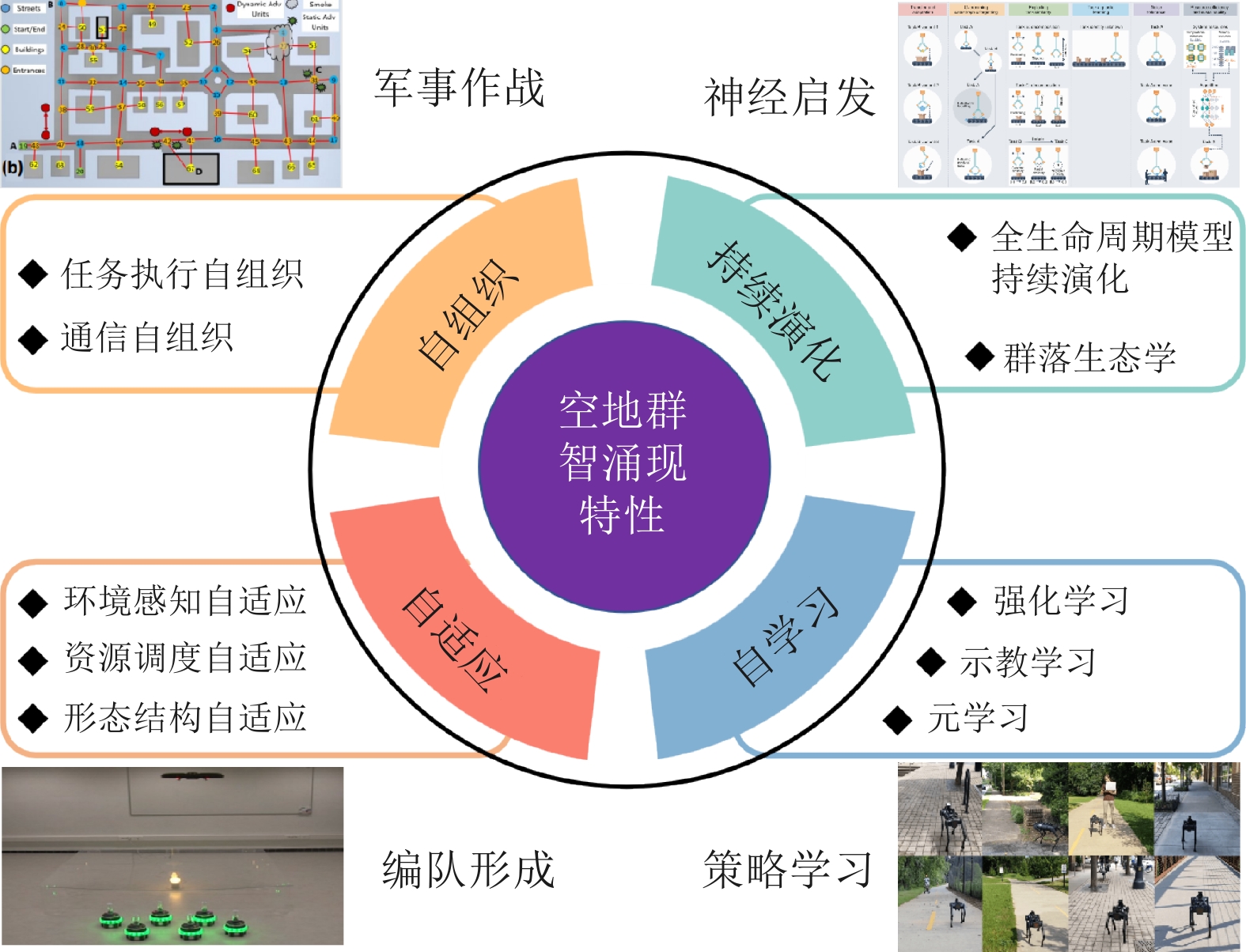
多机器人空地协同系统作为一种在搜索救援、自主探索等领域具有广泛应用前景的异构机器人协作系统, 近年来受到研究者的高度关注. 针对限制空地协同系统自治性能的低智能性、弱自主性挑战, 如何增强个体智能、提高群体协同自主性是加快空地系统应用落地亟需解决的关键问题. 近年来, 随着以深度学习、群体智能为代表的人工智能(Artificial intelligence, AI)算法在感知、决策等领域的不断发展, 将其应用于空地协同系统成为了当前的研究热点. 基于空地协同的自主化程度, 总结从规则驱动到群智涌现不同协作水平下的空地协同工作, 强调通过增强个体智能涌现群体智慧. 同时, 构建并拓宽空地协同群智系统的概念及要素, 阐述其自组织、自适应、自学习与持续演化的群智特性. 最后, 通过列举空地协同代表性应用场景, 总结空地协同所面临的挑战, 并展望未来方向.
多机器人空地协同系统作为一种在搜索救援、自主探索等领域具有广泛应用前景的异构机器人协作系统, 近年来受到研究者的高度关注. 针对限制空地协同系统自治性能的低智能性、弱自主性挑战, 如何增强个体智能、提高群体协同自主性是加快空地系统应用落地亟需解决的关键问题. 近年来, 随着以深度学习、群体智能为代表的人工智能(Artificial intelligence, AI)算法在感知、决策等领域的不断发展, 将其应用于空地协同系统成为了当前的研究热点. 基于空地协同的自主化程度, 总结从规则驱动到群智涌现不同协作水平下的空地协同工作, 强调通过增强个体智能涌现群体智慧. 同时, 构建并拓宽空地协同群智系统的概念及要素, 阐述其自组织、自适应、自学习与持续演化的群智特性. 最后, 通过列举空地协同代表性应用场景, 总结空地协同所面临的挑战, 并展望未来方向.

2024, 50(10): 1906-1927.
doi: 10.16383/j.aas.c230808
cstr: 32138.14.j.aas.c230808
摘要:
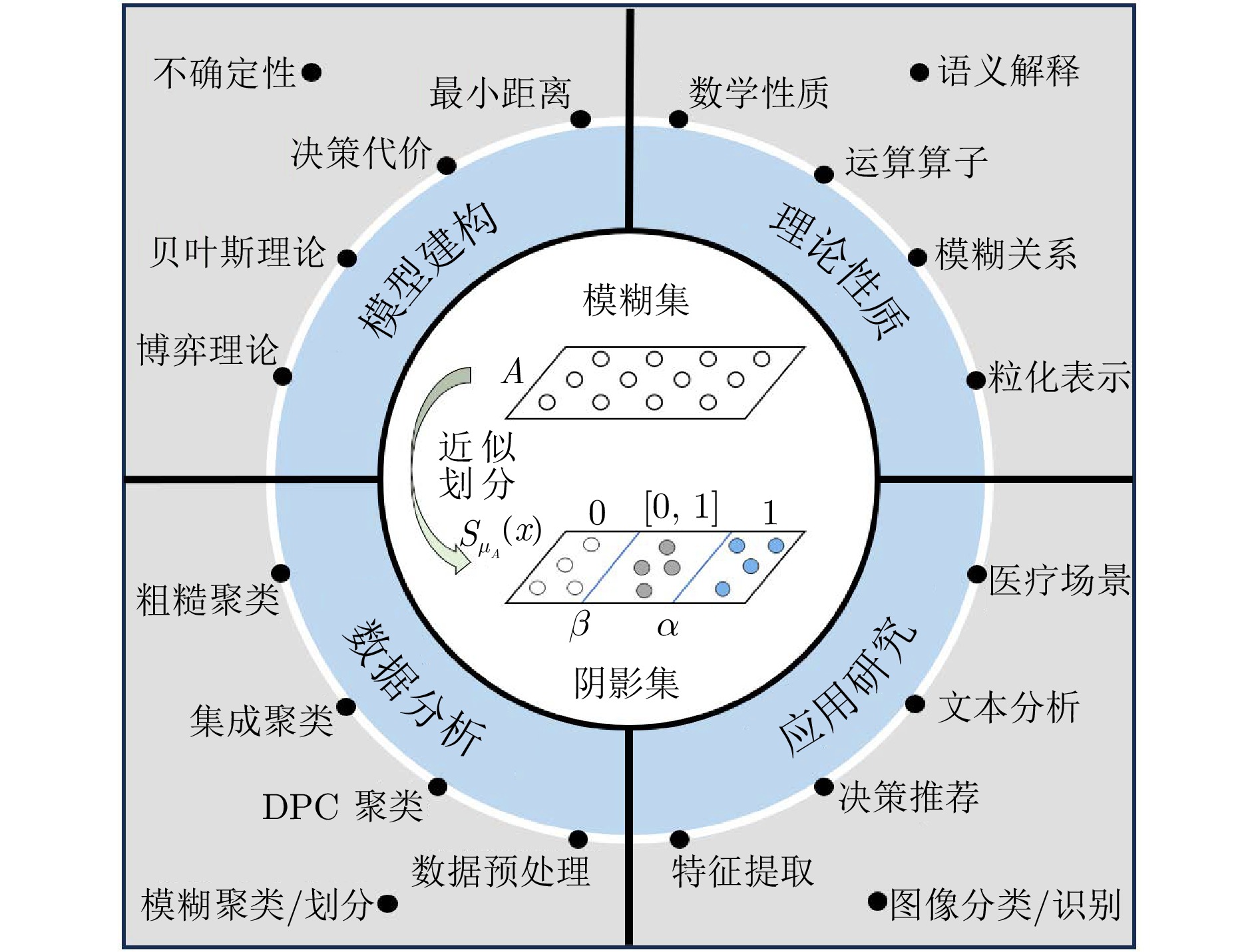
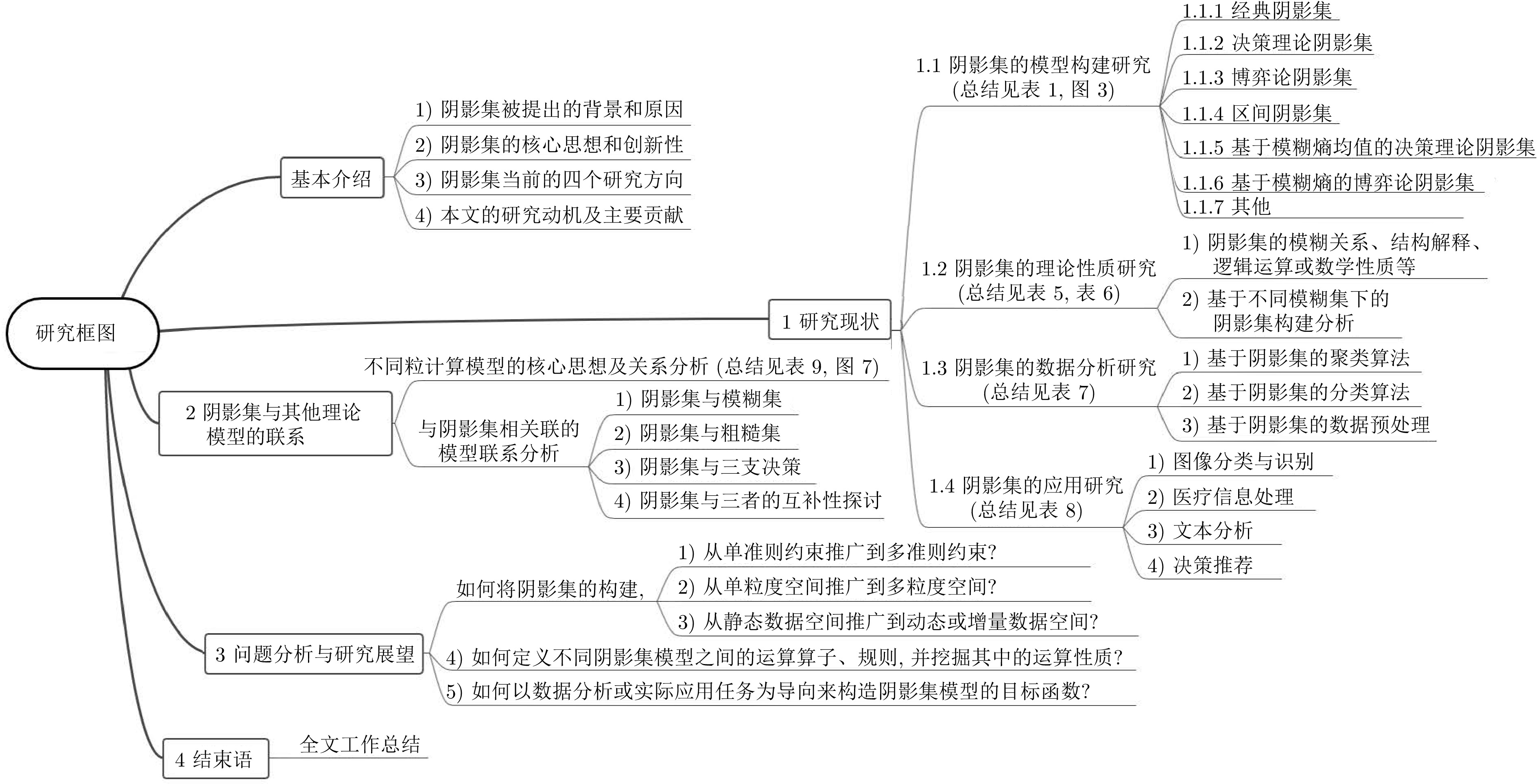
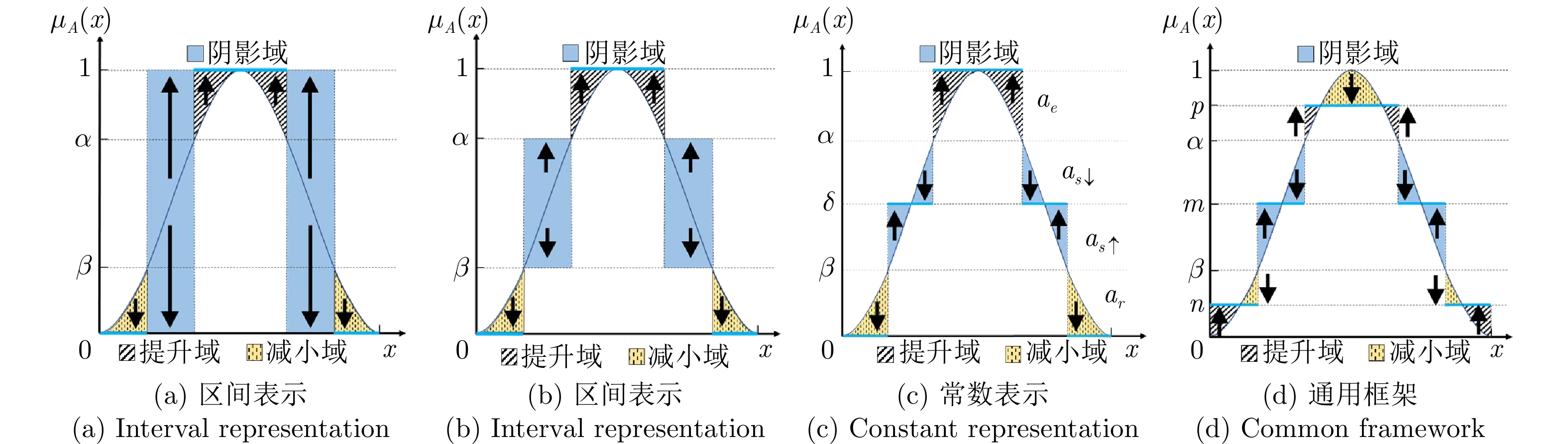
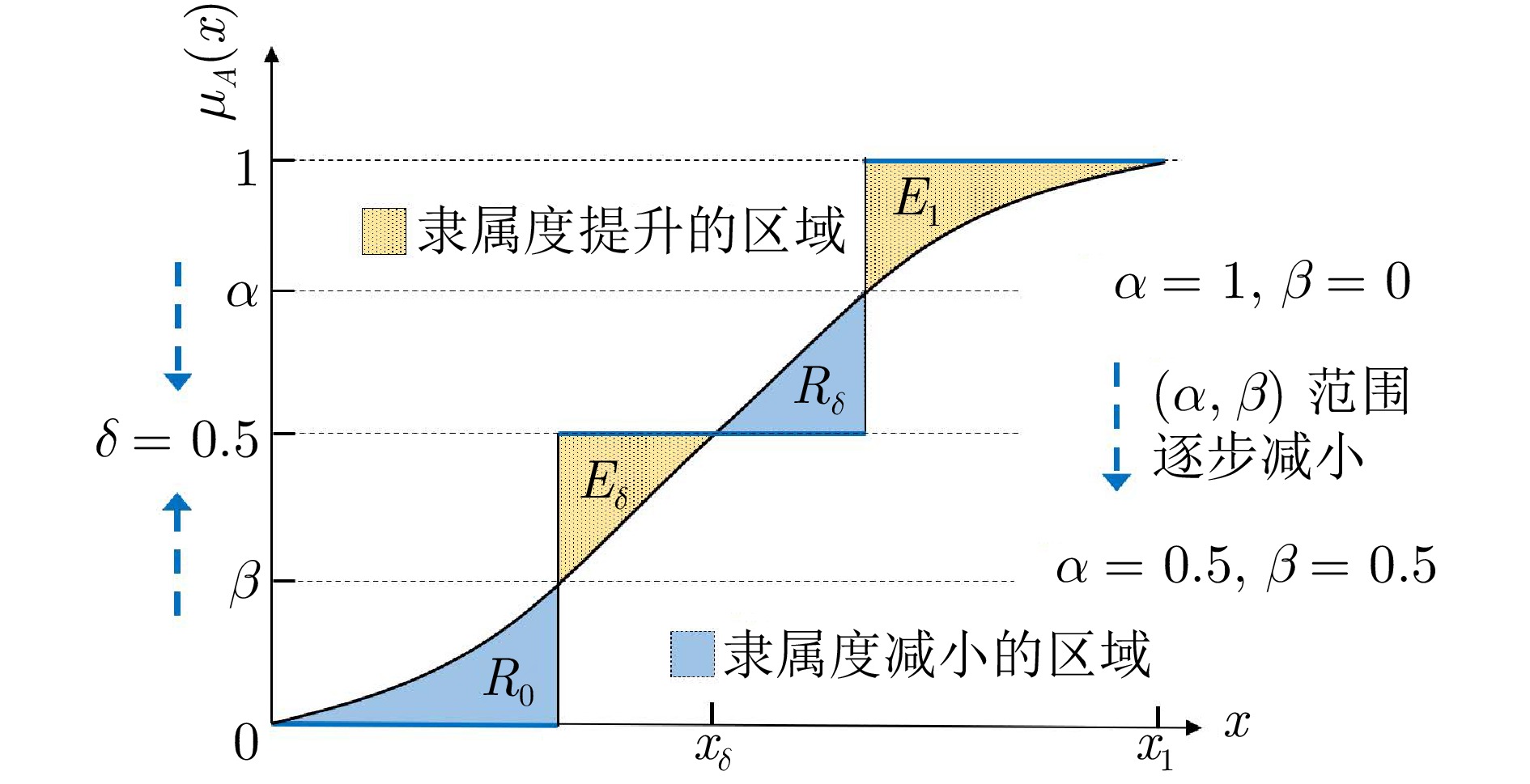
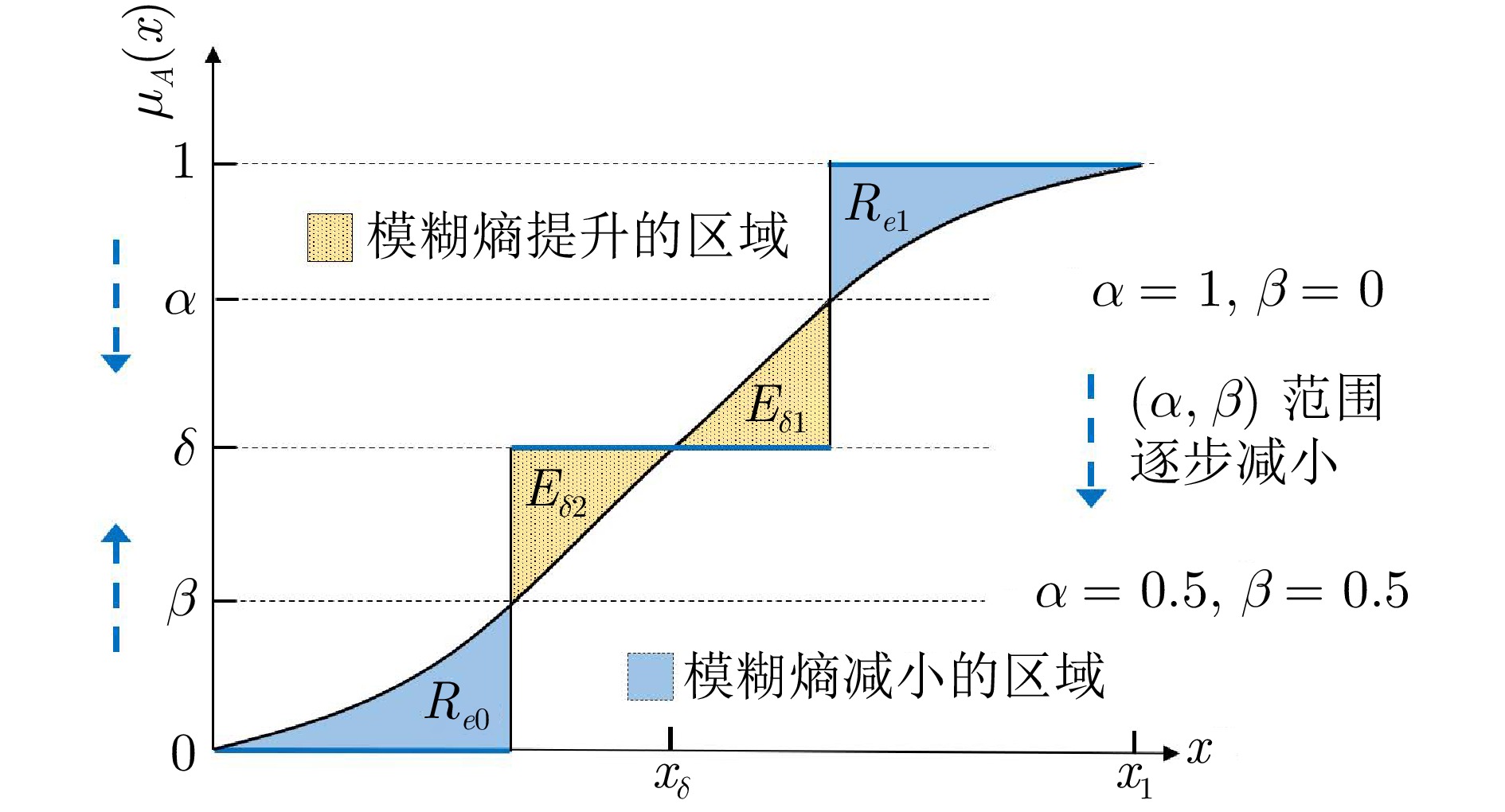
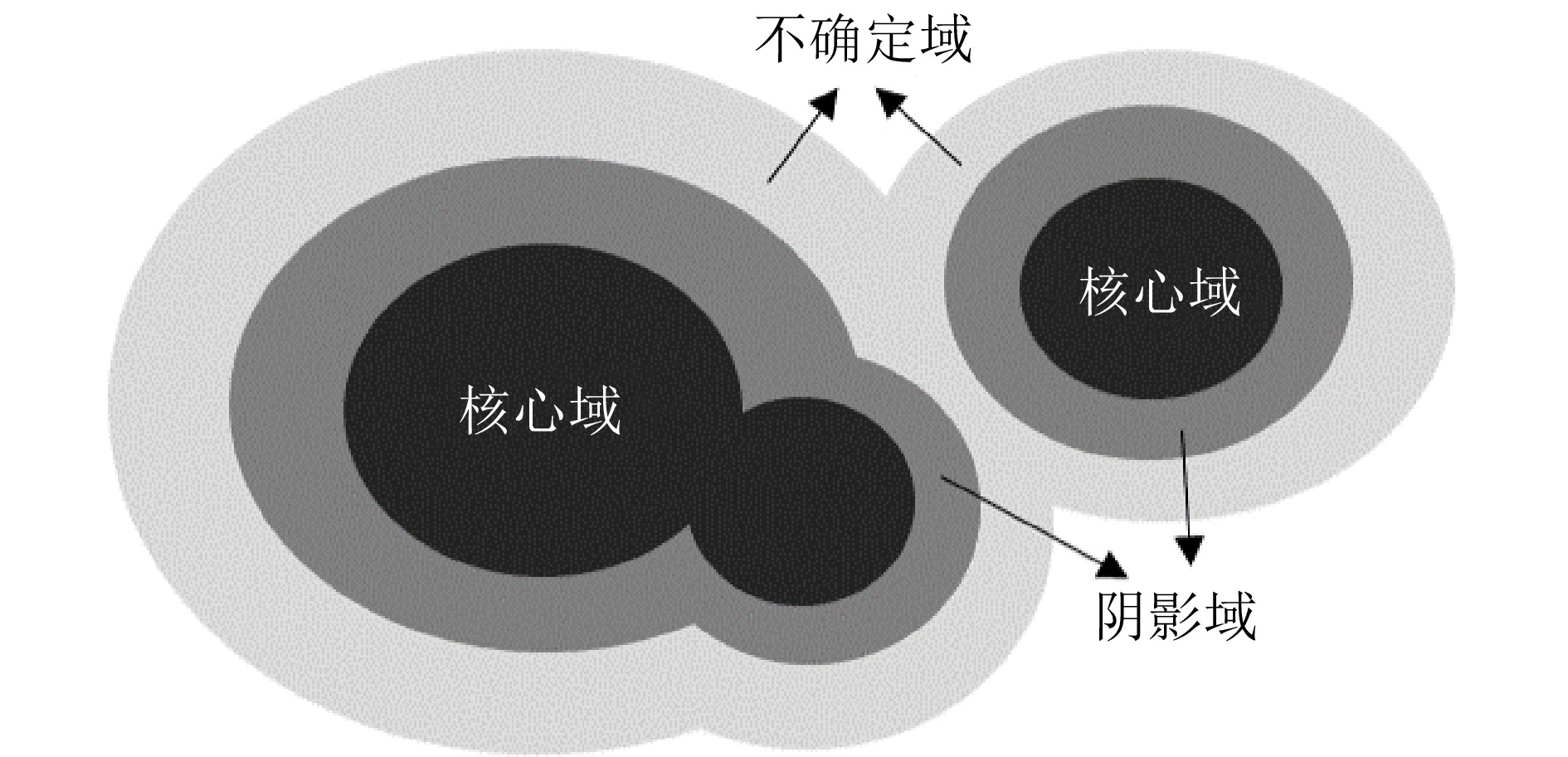
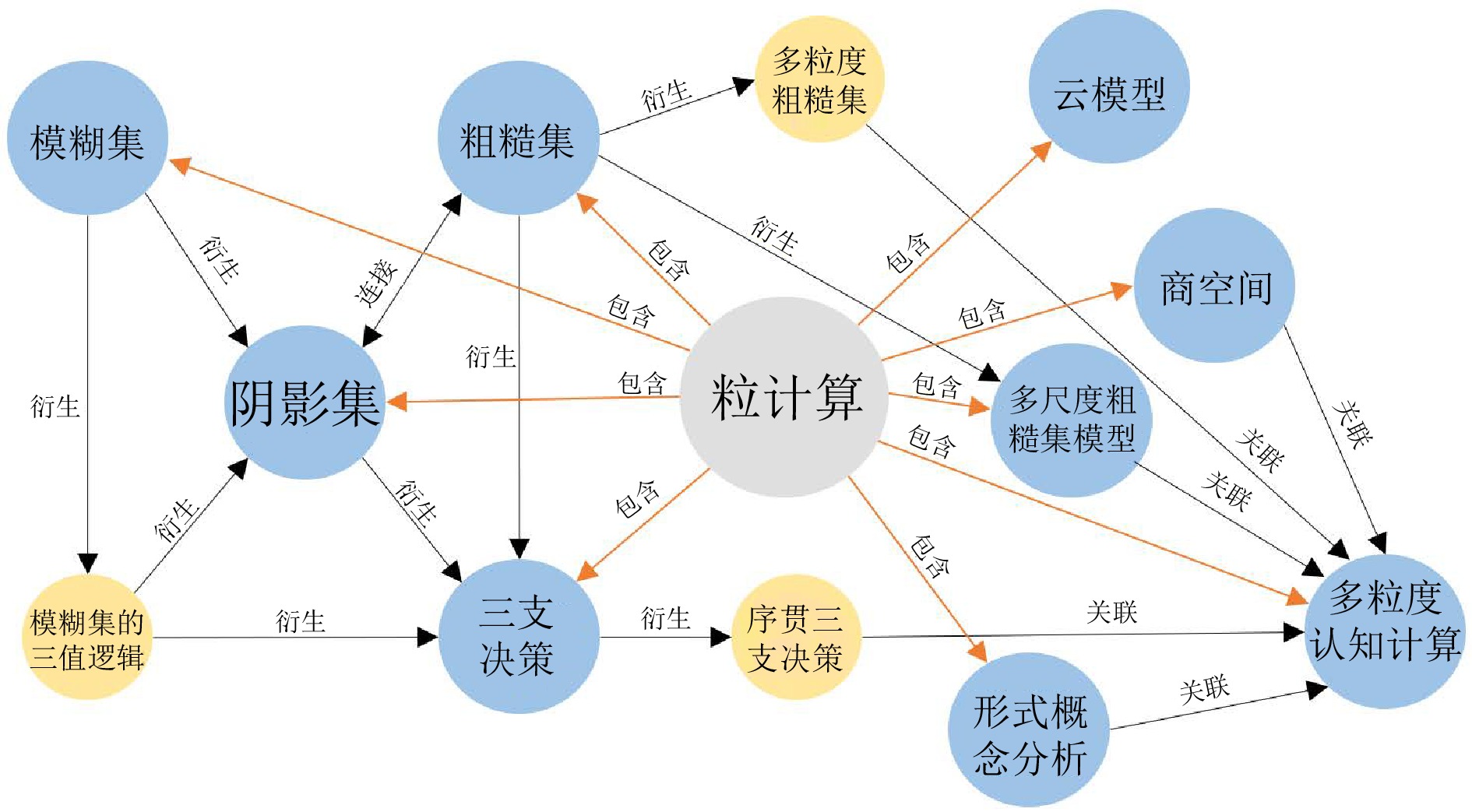
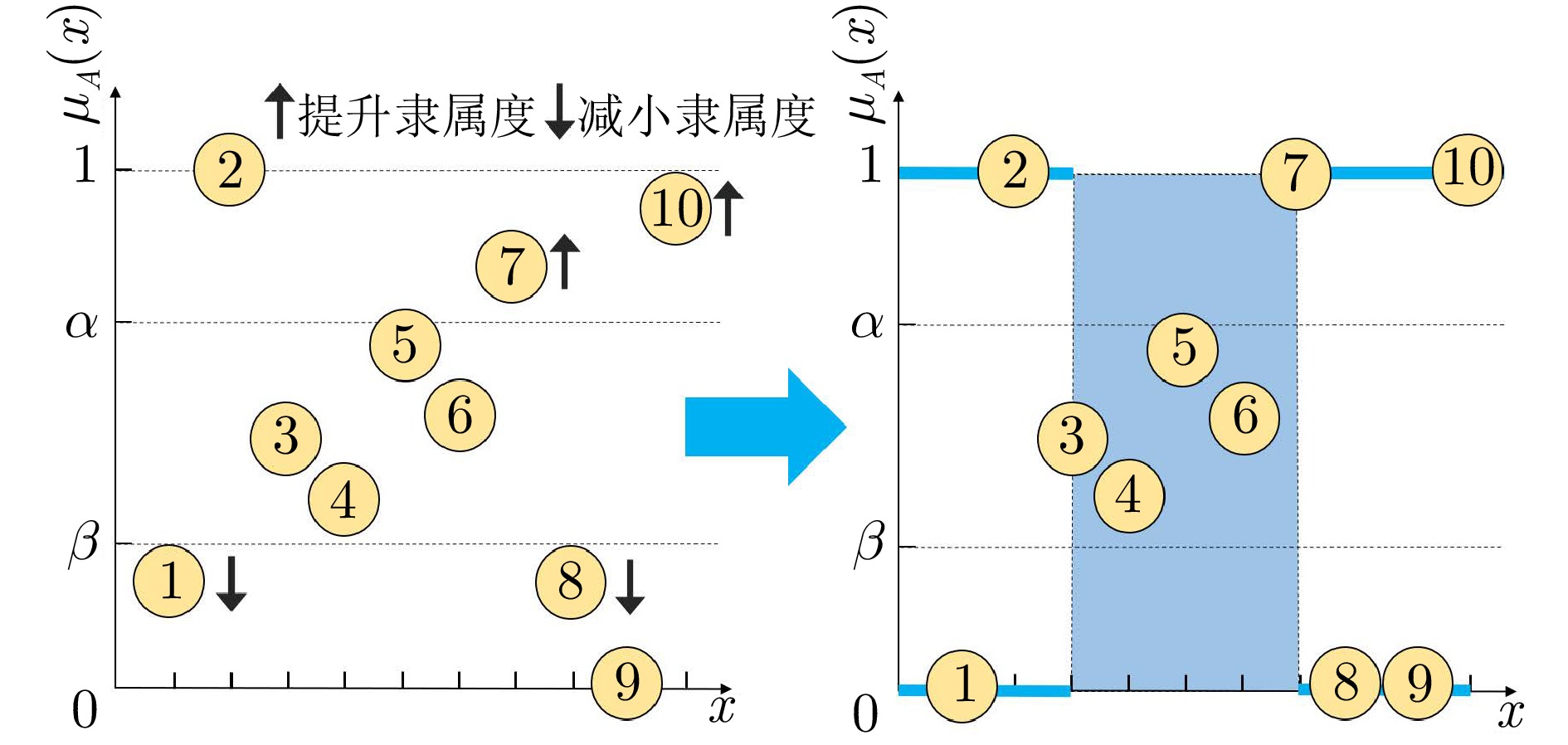
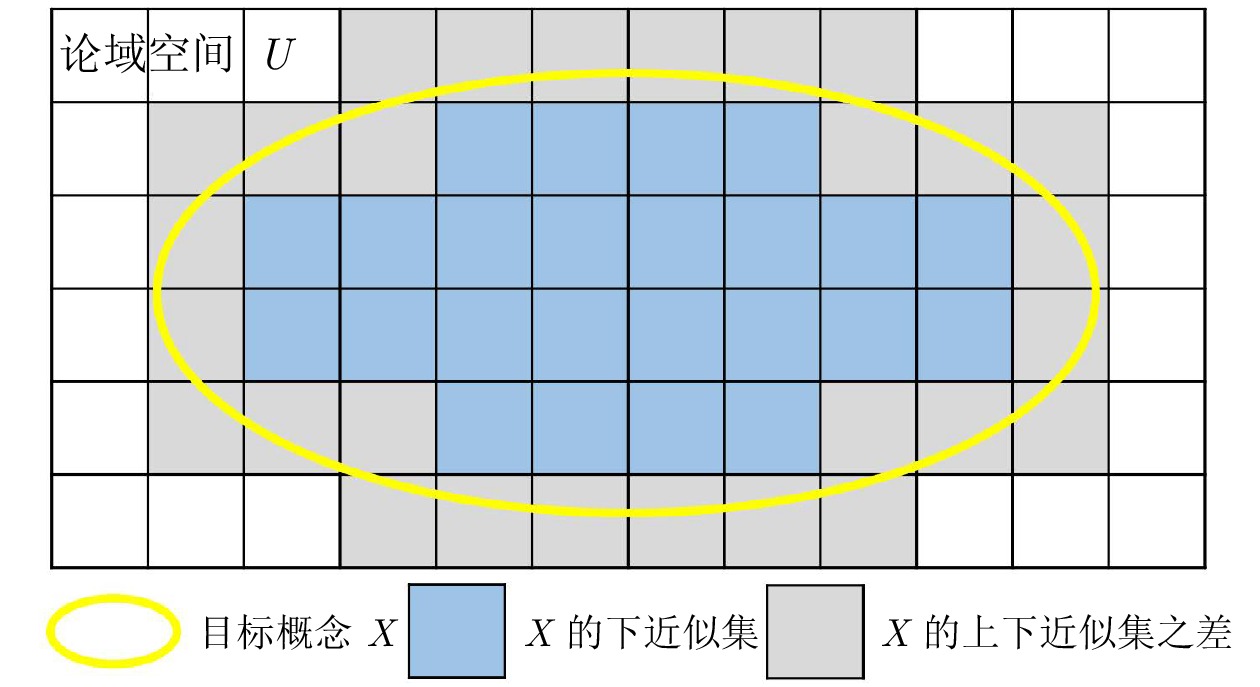
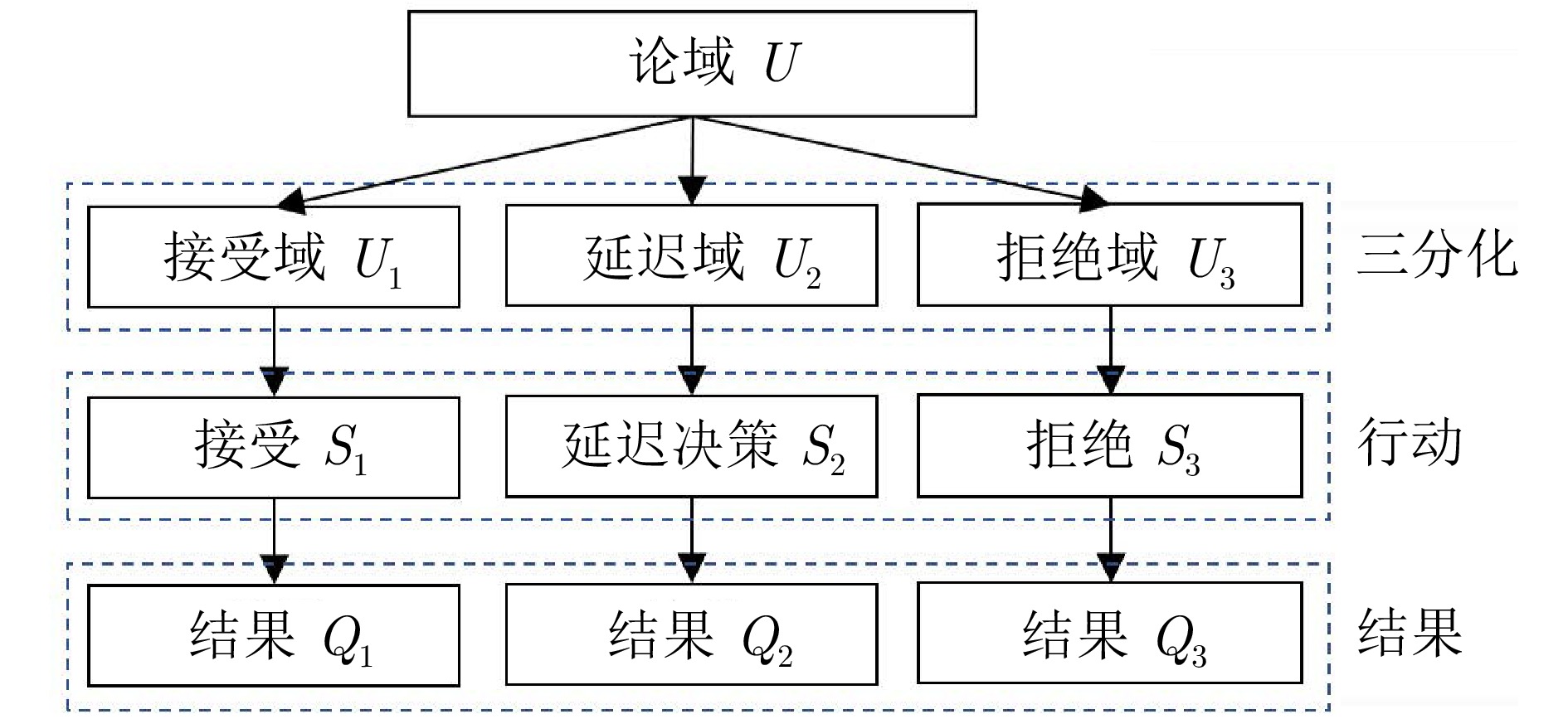
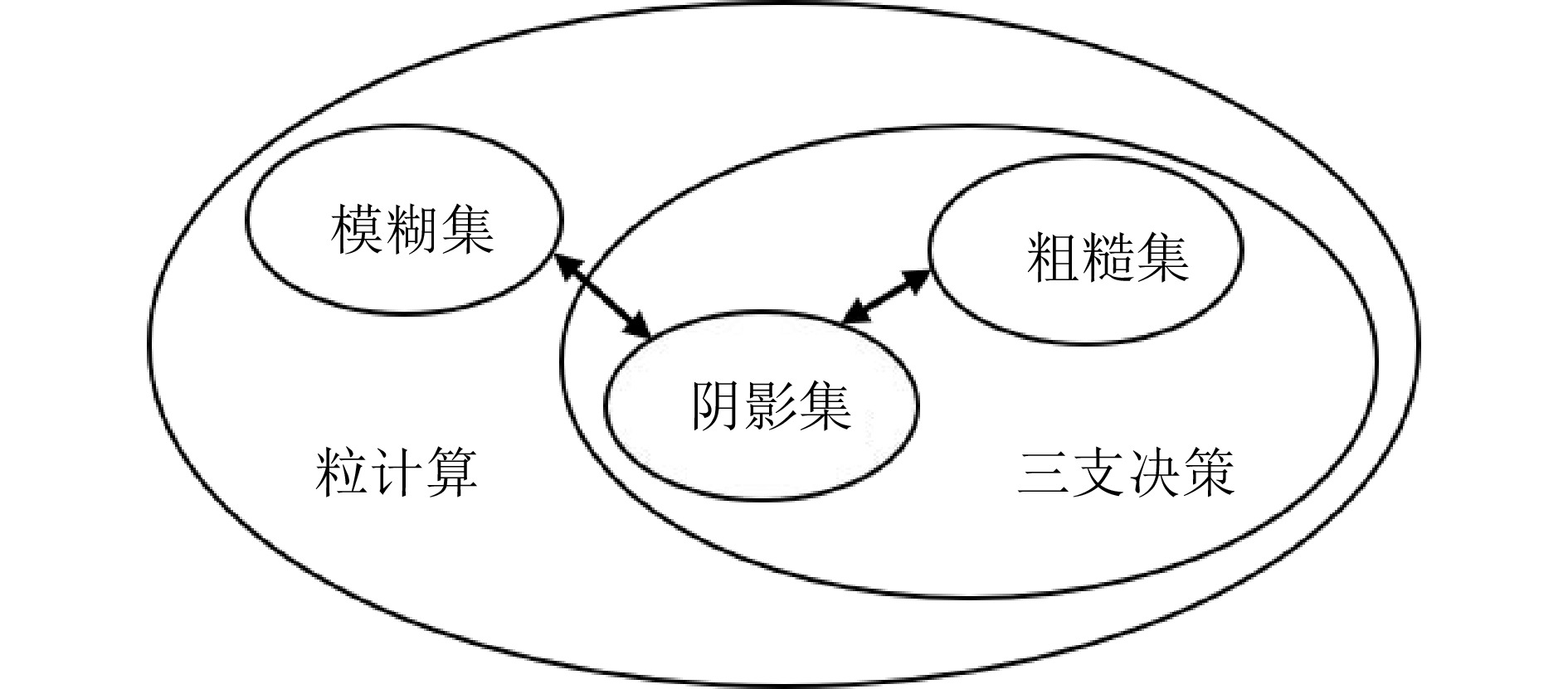
阴影集(Shadowed set, SS)是一种对模糊集进行三支近似处理的不确定性知识发现模型, 其能够对模糊集中具有精确值的不确定性对象进行有效的近似和划分, 从而减少模糊决策过程中不确定性对象的决策划分成本和计算损耗. 首先, 回顾阴影集的发展历程, 并从四个方面介绍其研究现状及内容, 即阴影集的模型构建、理论性质、数据分析以及应用研究. 通过总结分析它们的核心思想、方法体系、相互关系和区别等, 为该领域的后续研究提供借鉴. 随后, 讨论分析阴影集理论与其他不确定性问题处理理论模型的联系, 尤其是阴影集与模糊集、粗糙集和三支决策理论之间的区别、联系以及互补性. 最后, 围绕上述四个研究方面, 对当前若干具有挑战性的研究问题进行分析和展望.
阴影集(Shadowed set, SS)是一种对模糊集进行三支近似处理的不确定性知识发现模型, 其能够对模糊集中具有精确值的不确定性对象进行有效的近似和划分, 从而减少模糊决策过程中不确定性对象的决策划分成本和计算损耗. 首先, 回顾阴影集的发展历程, 并从四个方面介绍其研究现状及内容, 即阴影集的模型构建、理论性质、数据分析以及应用研究. 通过总结分析它们的核心思想、方法体系、相互关系和区别等, 为该领域的后续研究提供借鉴. 随后, 讨论分析阴影集理论与其他不确定性问题处理理论模型的联系, 尤其是阴影集与模糊集、粗糙集和三支决策理论之间的区别、联系以及互补性. 最后, 围绕上述四个研究方面, 对当前若干具有挑战性的研究问题进行分析和展望.
2024, 50(10): 1928-1937.
doi: 10.16383/j.aas.c230685
cstr: 32138.14.j.aas.c230685
摘要:
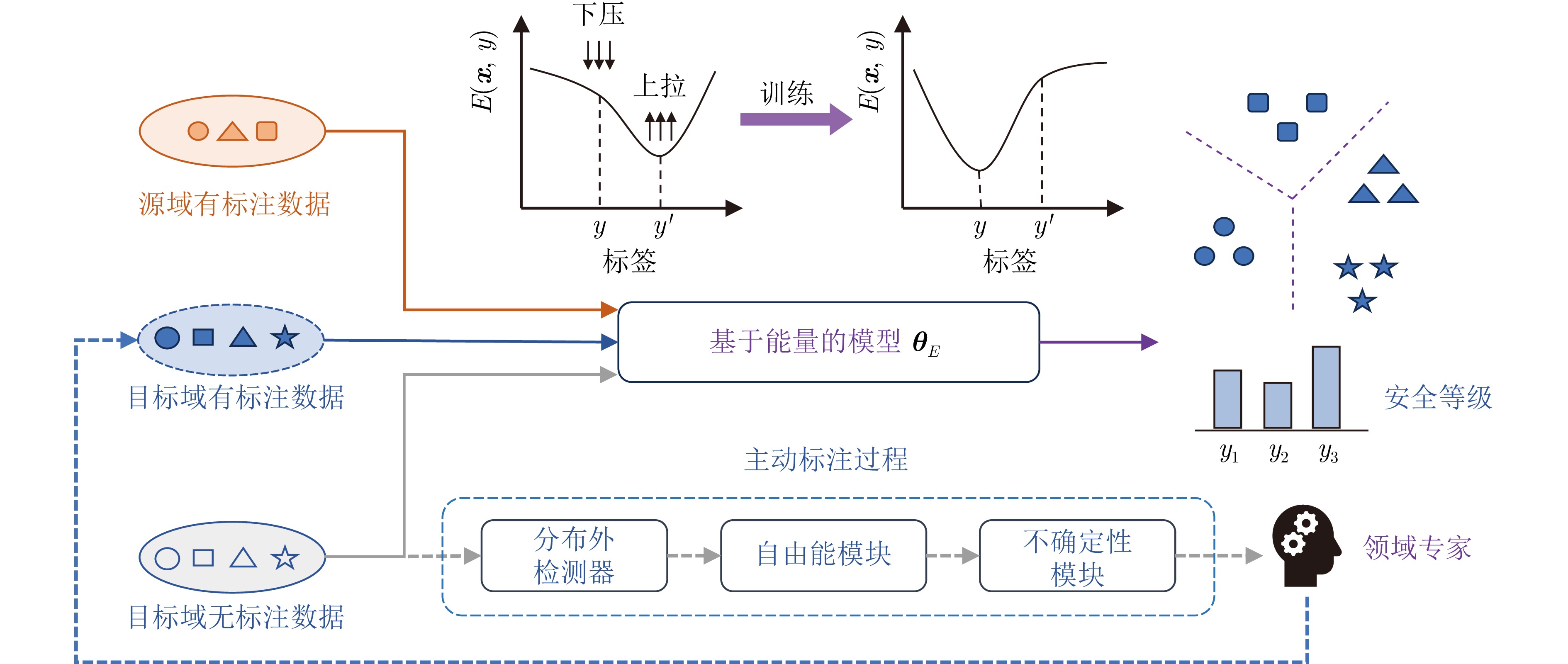
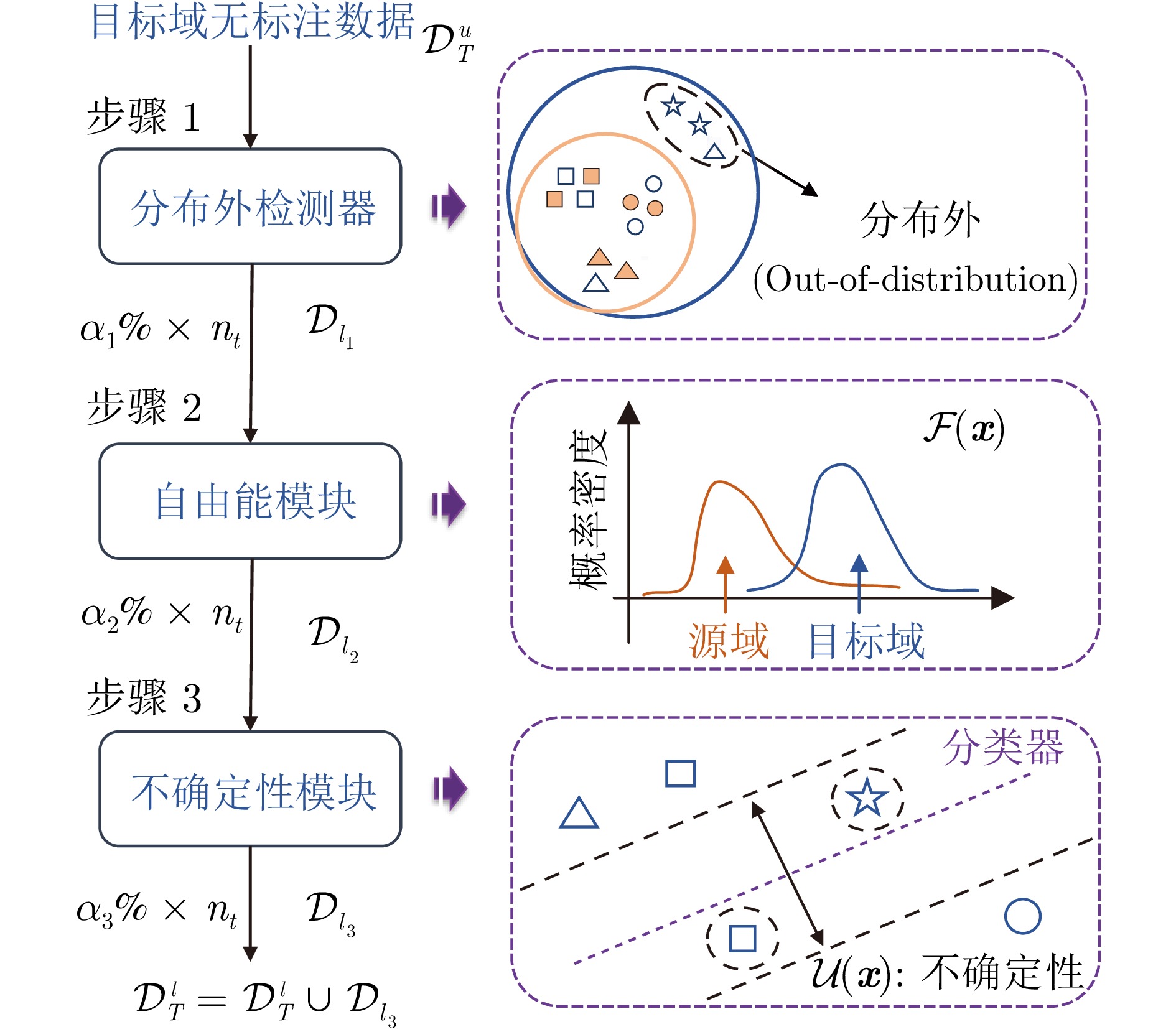
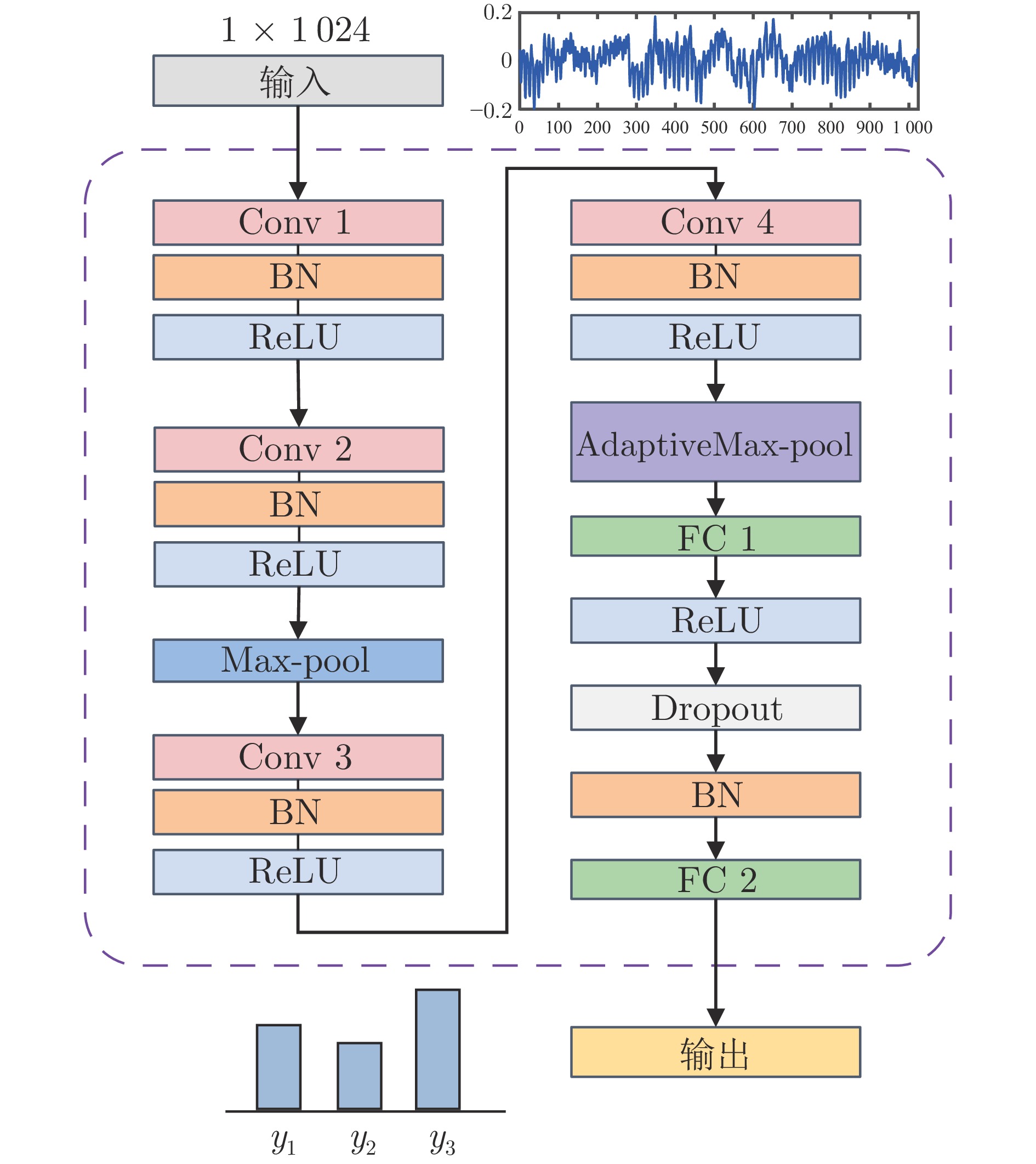
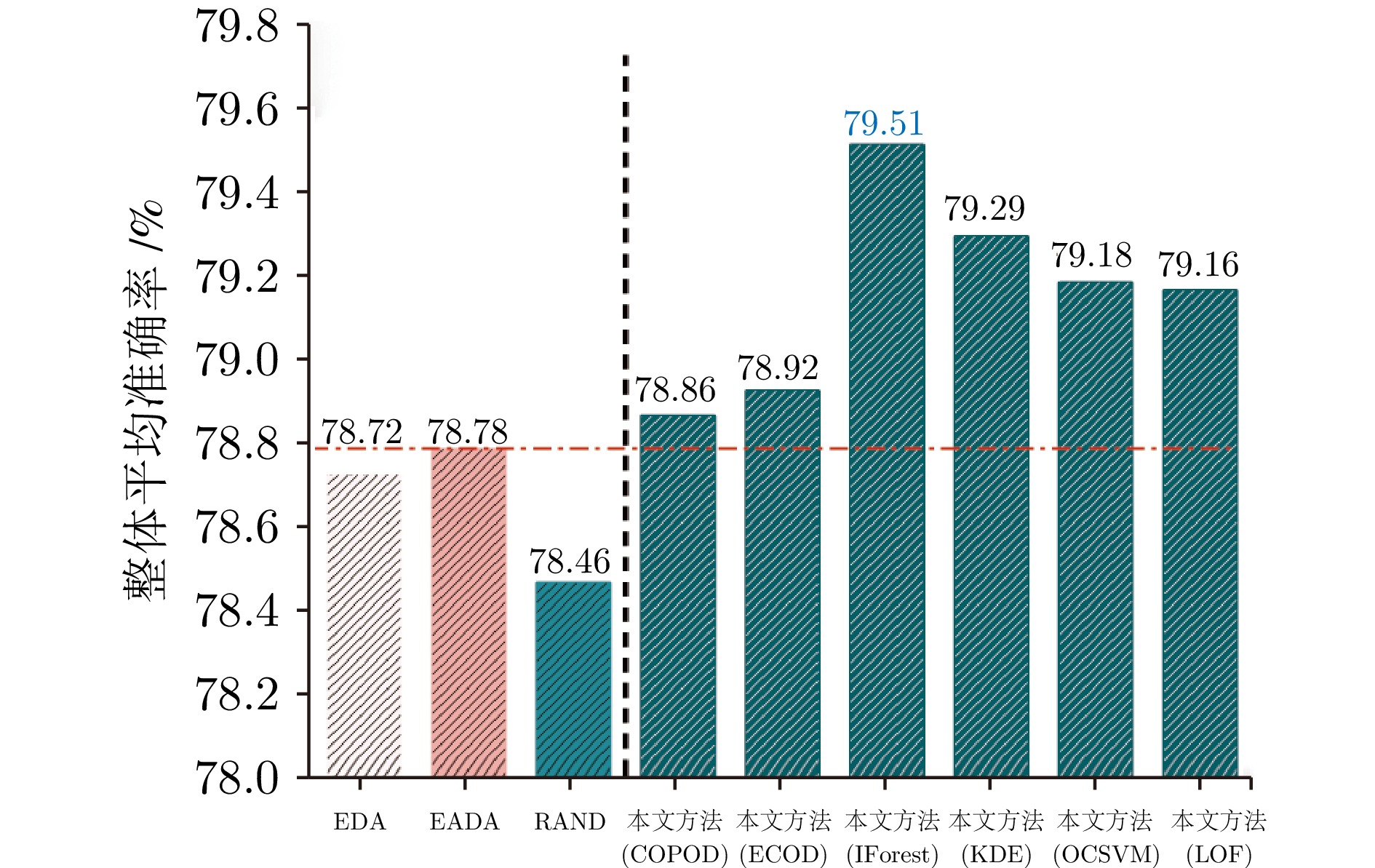
复杂动态系统运行过程中的在线安全性评估至关重要且富有挑战性. 构建有效的数据驱动模型需要大量有标注数据, 但这在实际中通常难以获得. 此外, 考虑到系统不同的运行工况, 安全性评估模型应该具有良好的泛化能力. 域自适应(Domain adaptation, DA)可以将模型从数据标注丰富的源域迁移到具有不同但相似数据分布的目标域. 然而, 源域中没有出现过的任务相关未知情景会降低模型的性能, 是目前尚未解决的挑战. 主动域自适应通过结合域自适应与主动学习技术, 为解决上述挑战提供了思路. 本文研究目标域存在任务相关未知情景的主动域自适应安全性评估问题, 提出一种基于改进能量模型的主动域自适应方法. 在所提方法中融合分布外检测器, 在此基础上主动选择目标域中具有代表性的无标注样本进行标注, 作为训练数据以提高域自适应模型的性能. 最后, 通过基于轴承数据的案例研究, 验证所提方法的有效性和适用性.
复杂动态系统运行过程中的在线安全性评估至关重要且富有挑战性. 构建有效的数据驱动模型需要大量有标注数据, 但这在实际中通常难以获得. 此外, 考虑到系统不同的运行工况, 安全性评估模型应该具有良好的泛化能力. 域自适应(Domain adaptation, DA)可以将模型从数据标注丰富的源域迁移到具有不同但相似数据分布的目标域. 然而, 源域中没有出现过的任务相关未知情景会降低模型的性能, 是目前尚未解决的挑战. 主动域自适应通过结合域自适应与主动学习技术, 为解决上述挑战提供了思路. 本文研究目标域存在任务相关未知情景的主动域自适应安全性评估问题, 提出一种基于改进能量模型的主动域自适应方法. 在所提方法中融合分布外检测器, 在此基础上主动选择目标域中具有代表性的无标注样本进行标注, 作为训练数据以提高域自适应模型的性能. 最后, 通过基于轴承数据的案例研究, 验证所提方法的有效性和适用性.

2024, 50(10): 1938-1952.
doi: 10.16383/j.aas.c211244
cstr: 32138.14.j.aas.c211244
摘要:
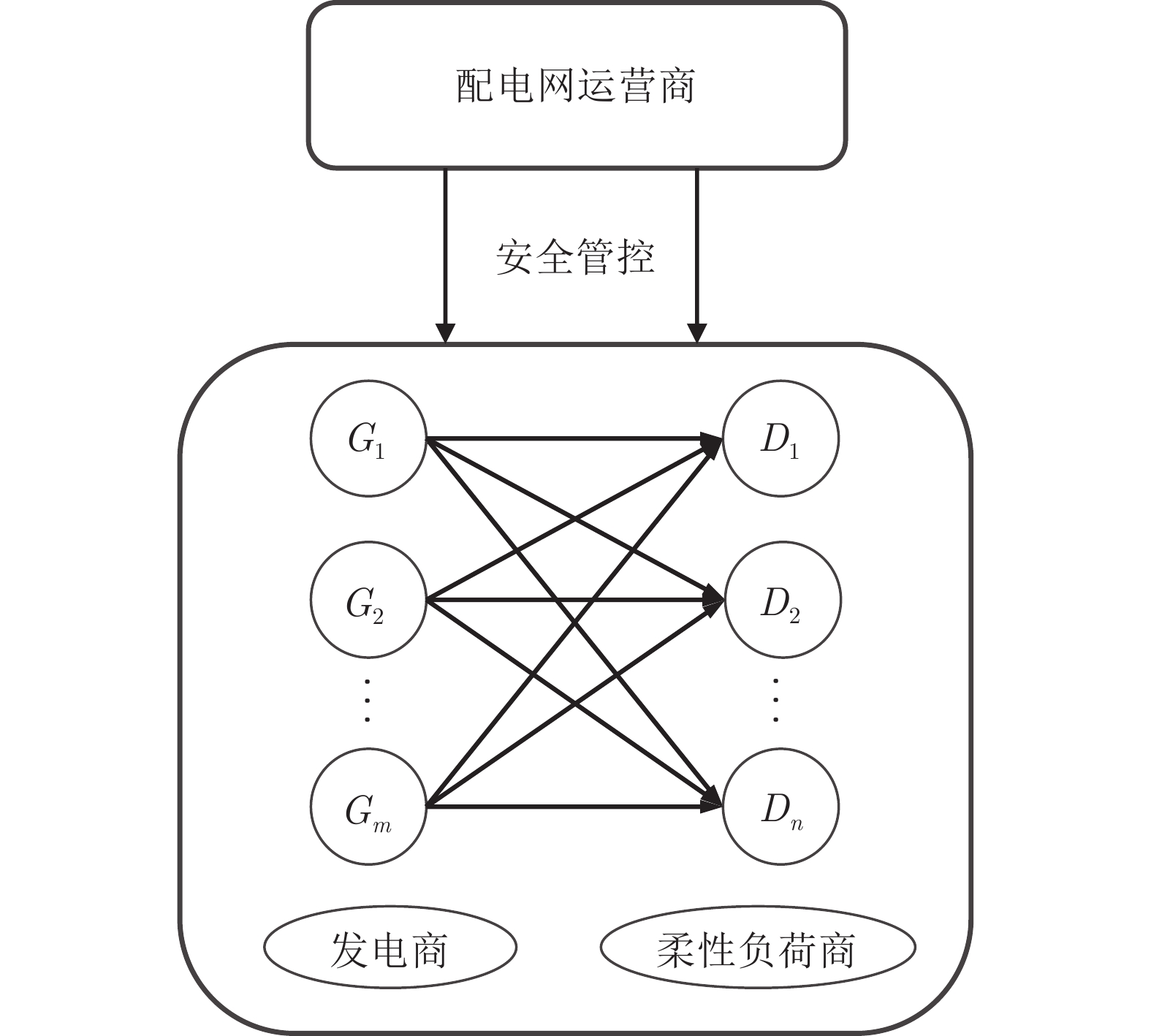
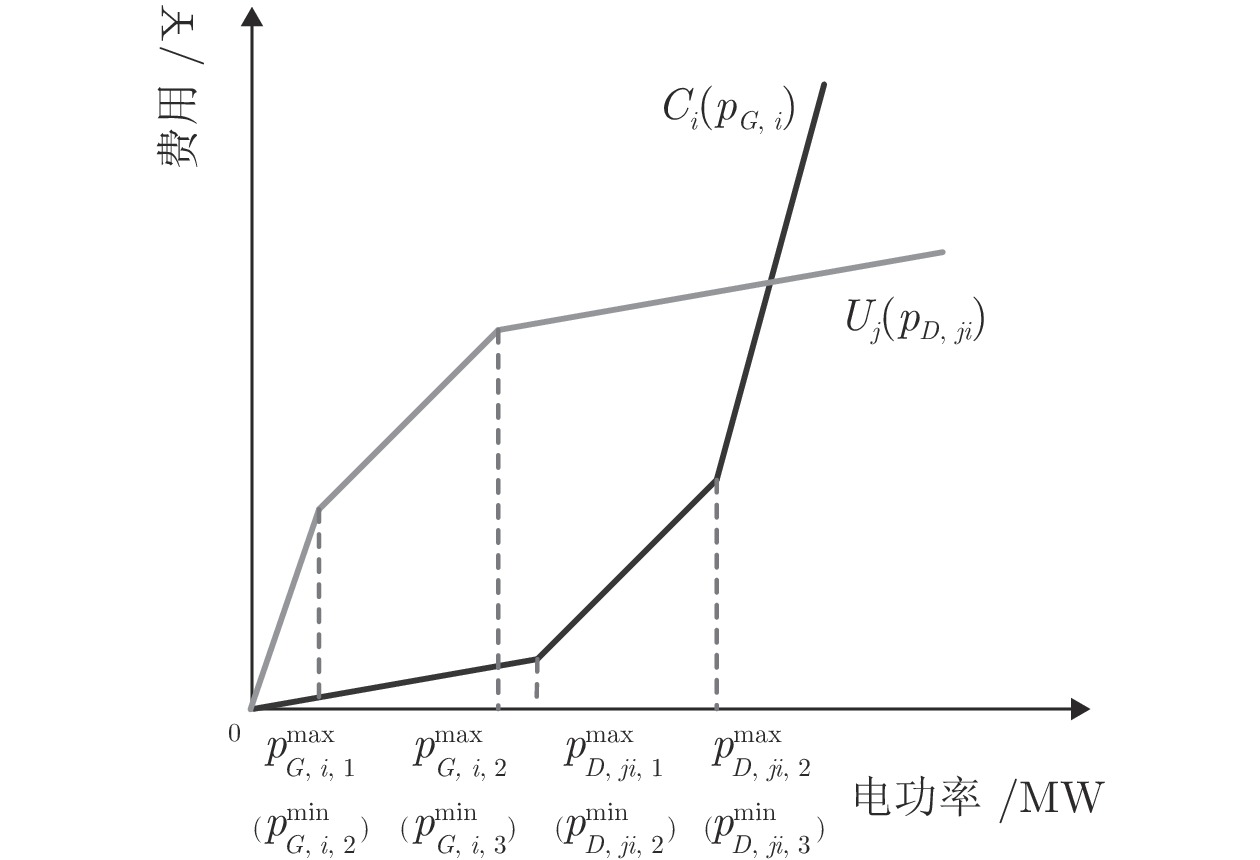
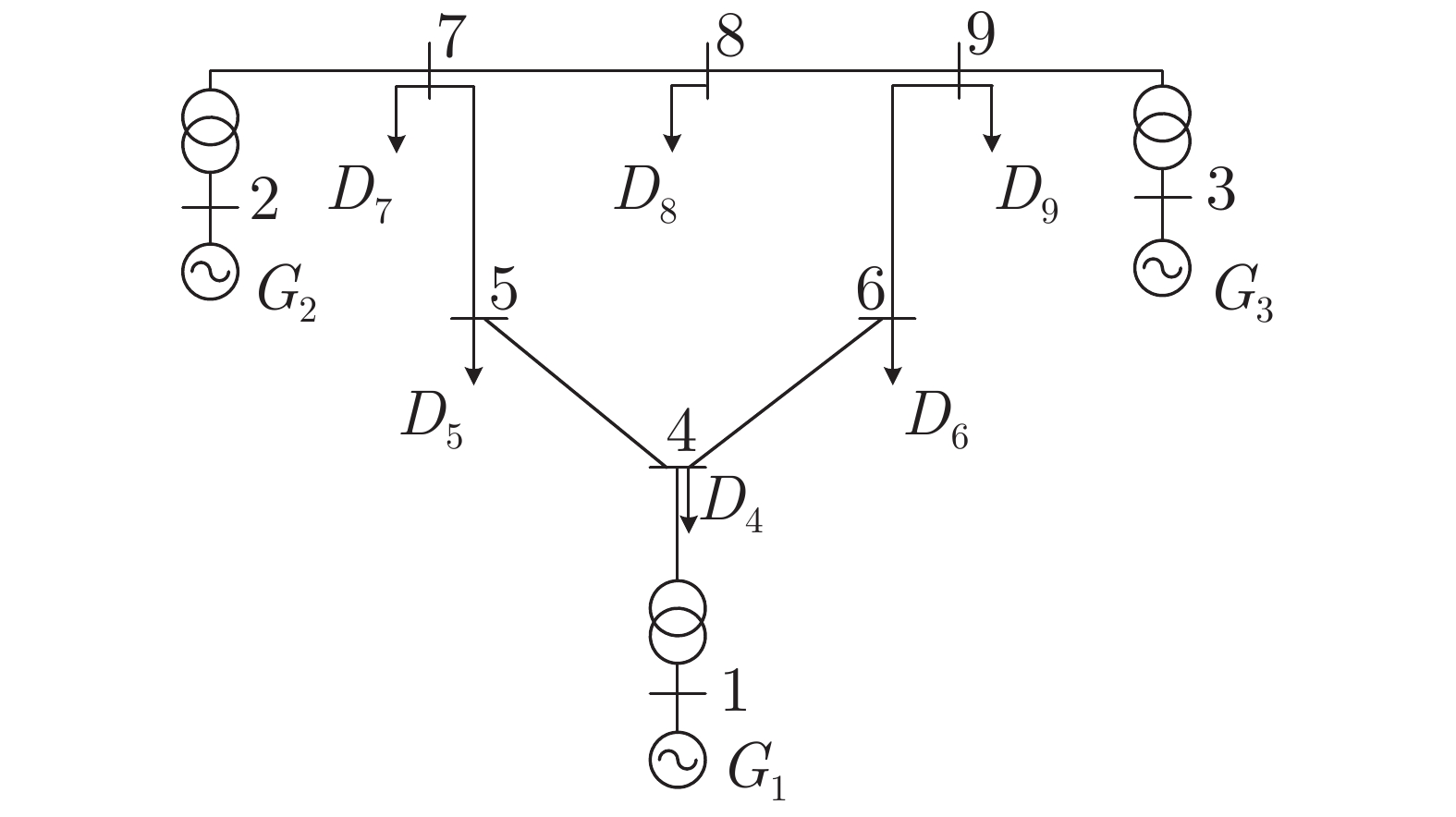
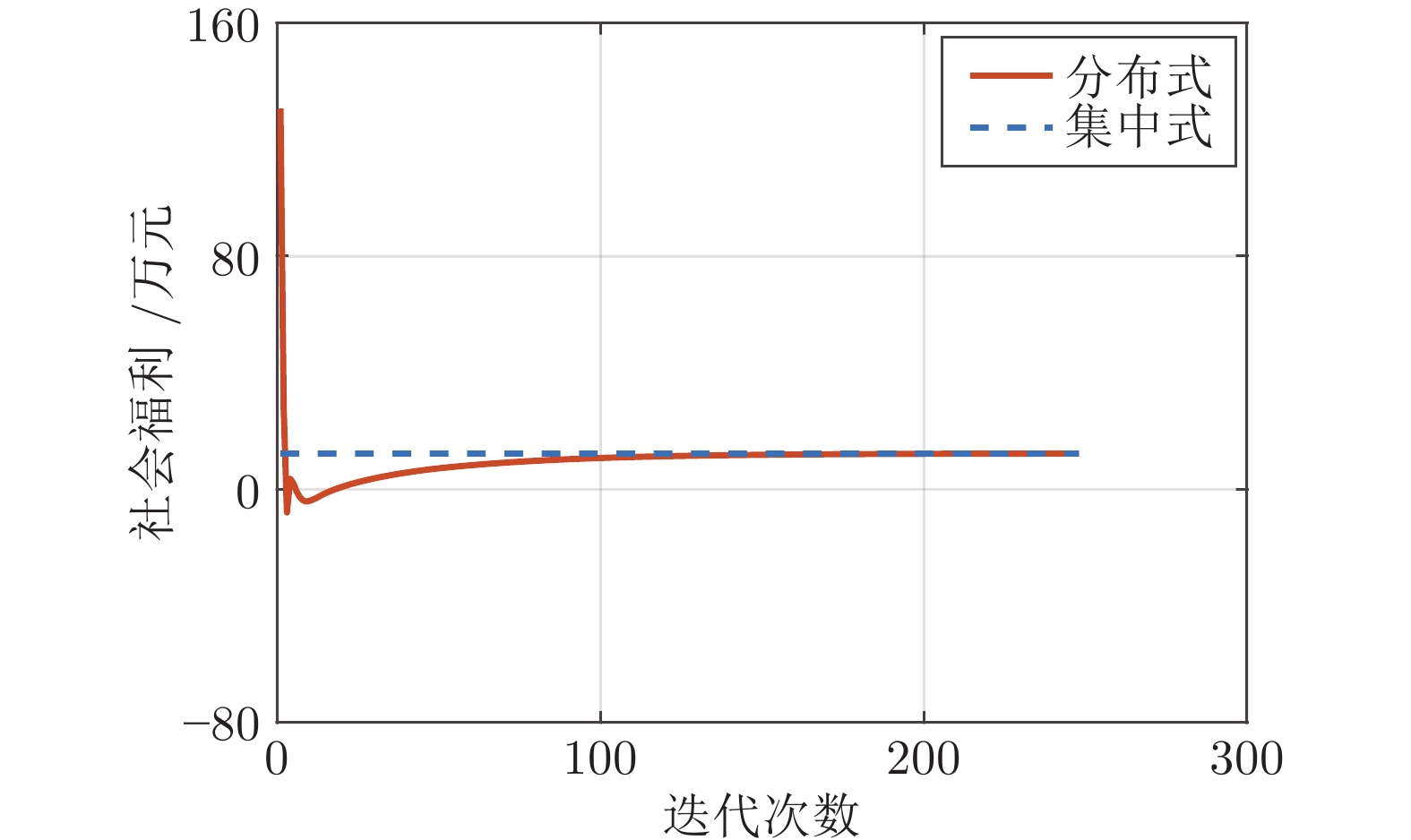
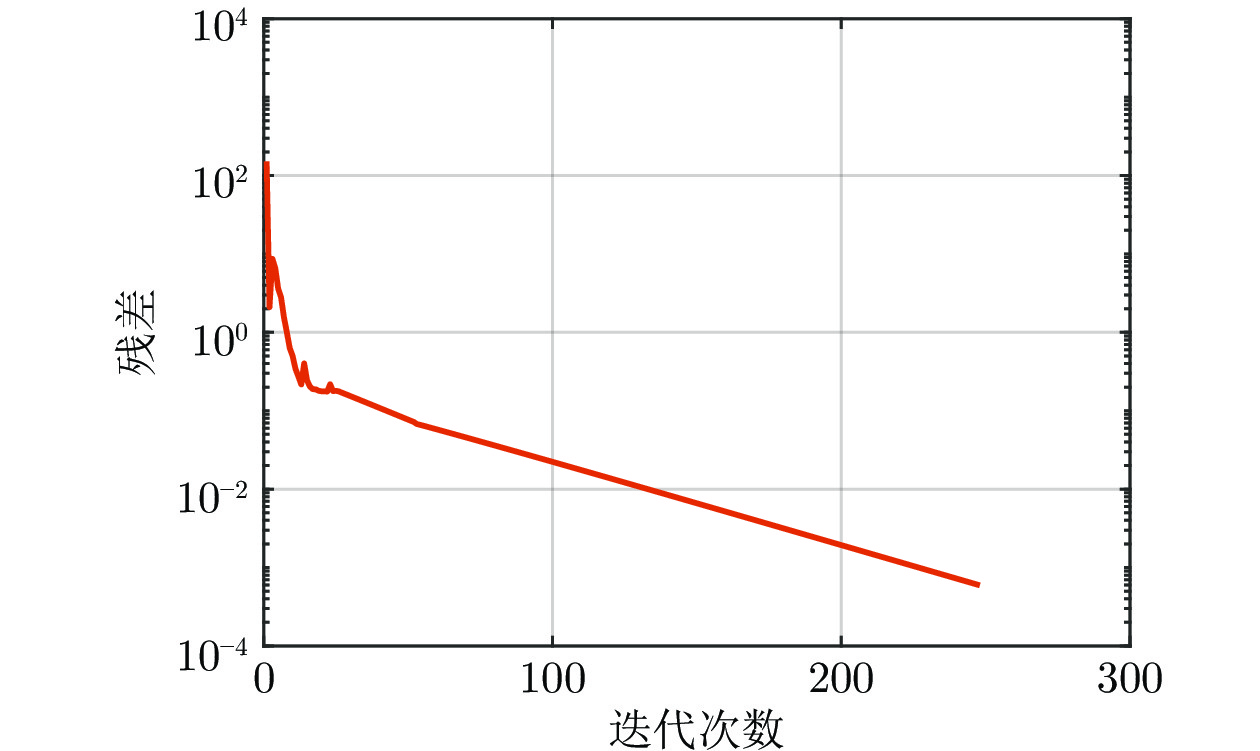
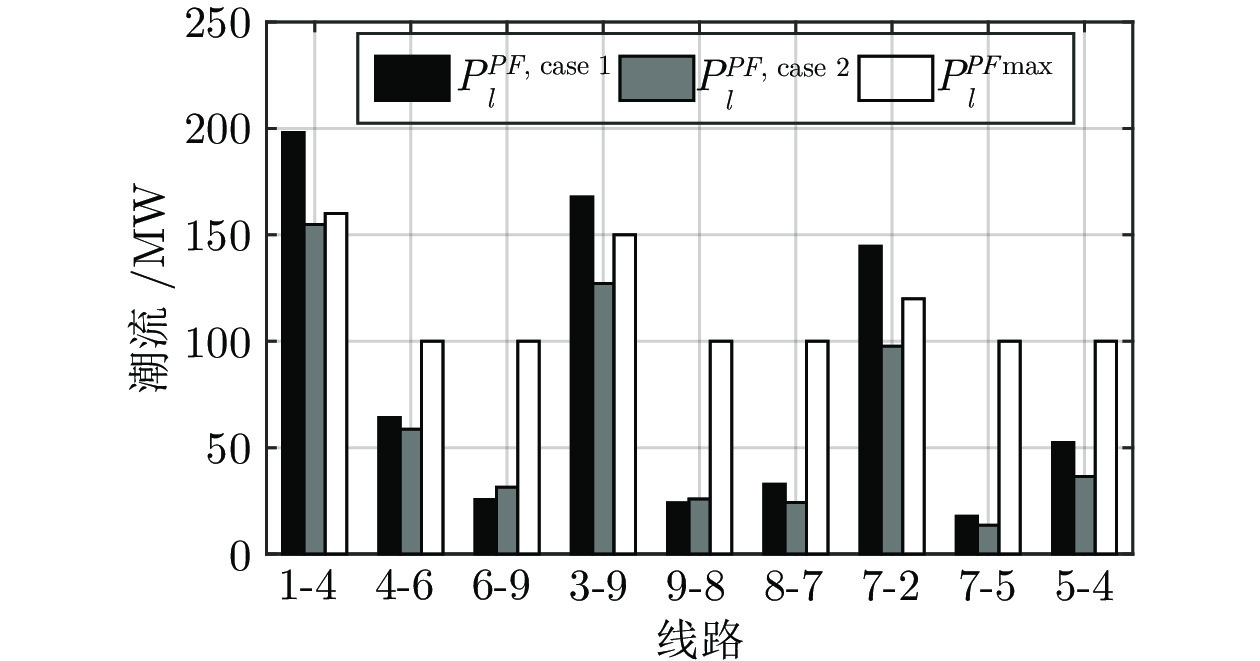
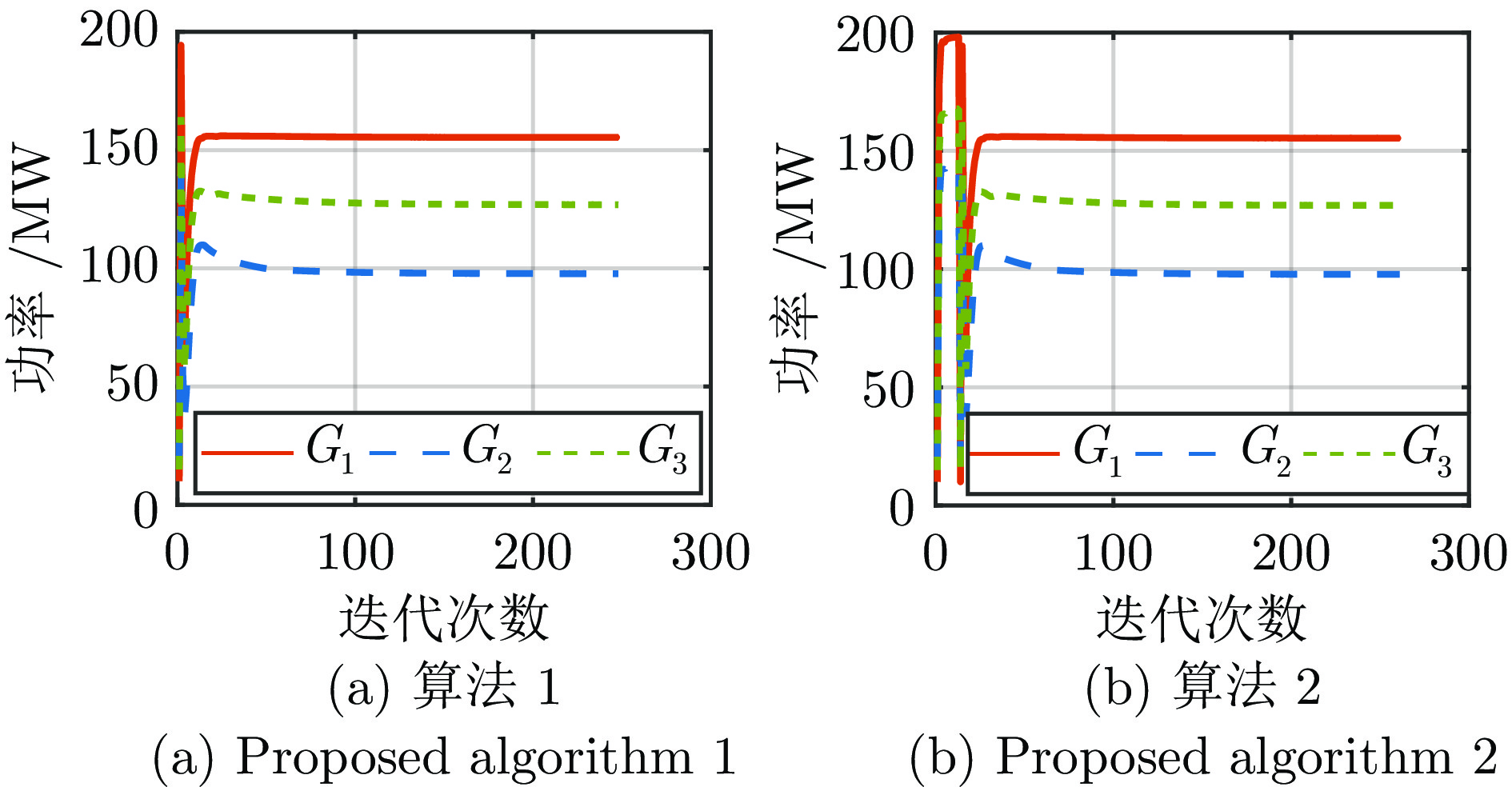
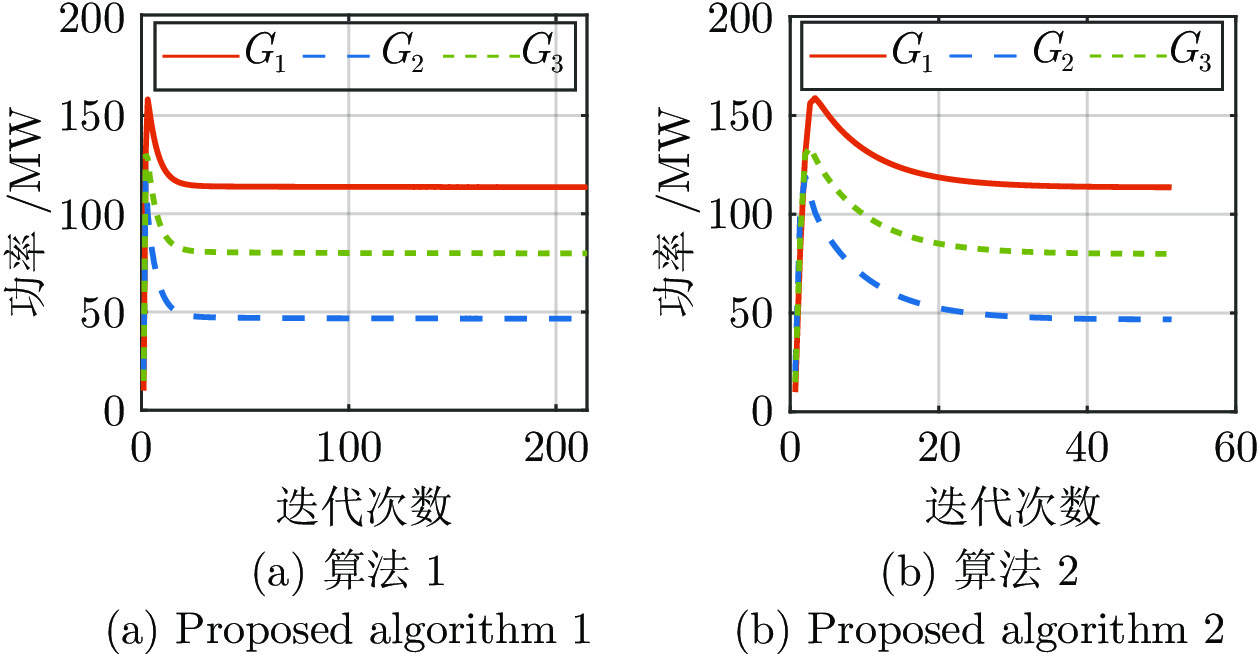
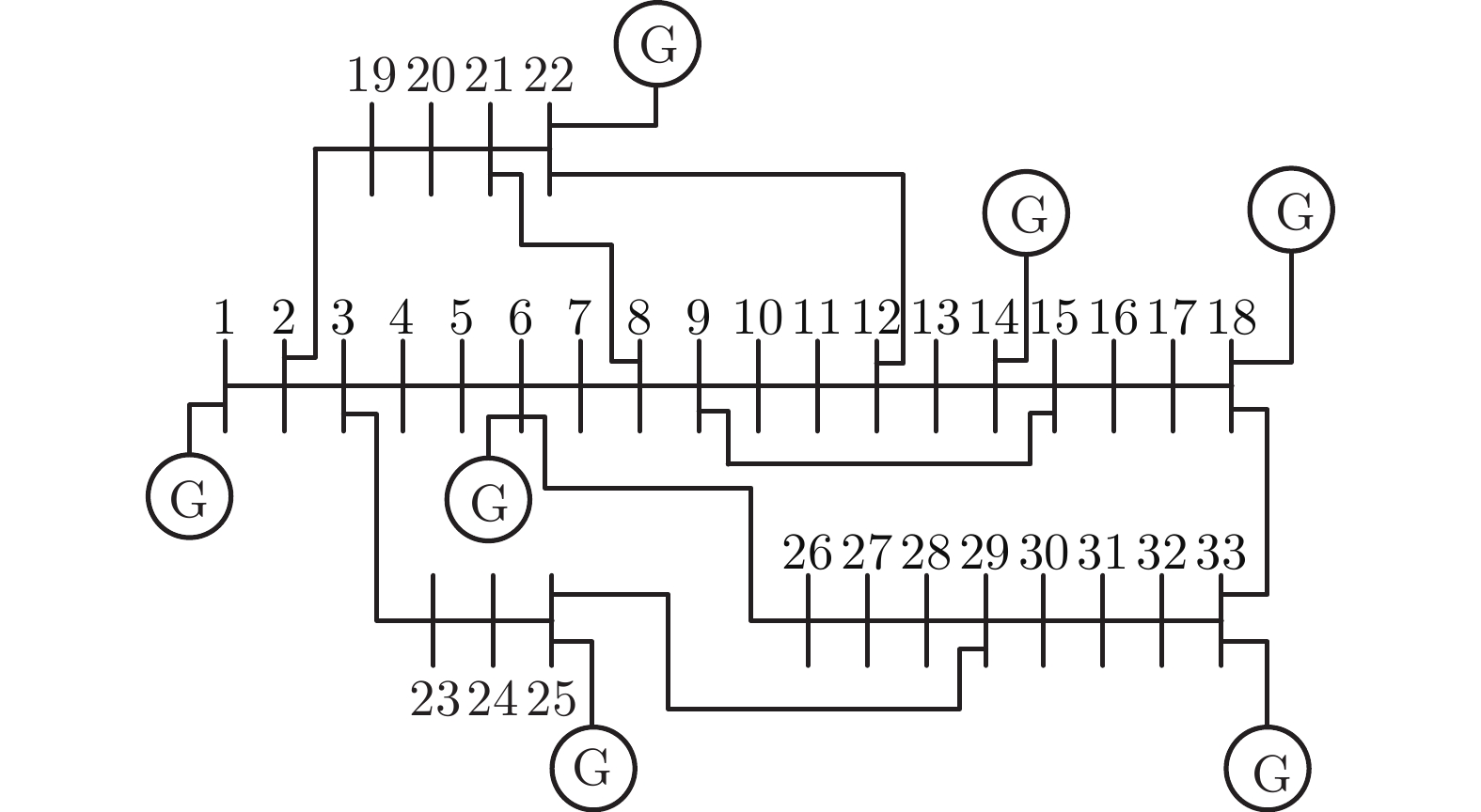
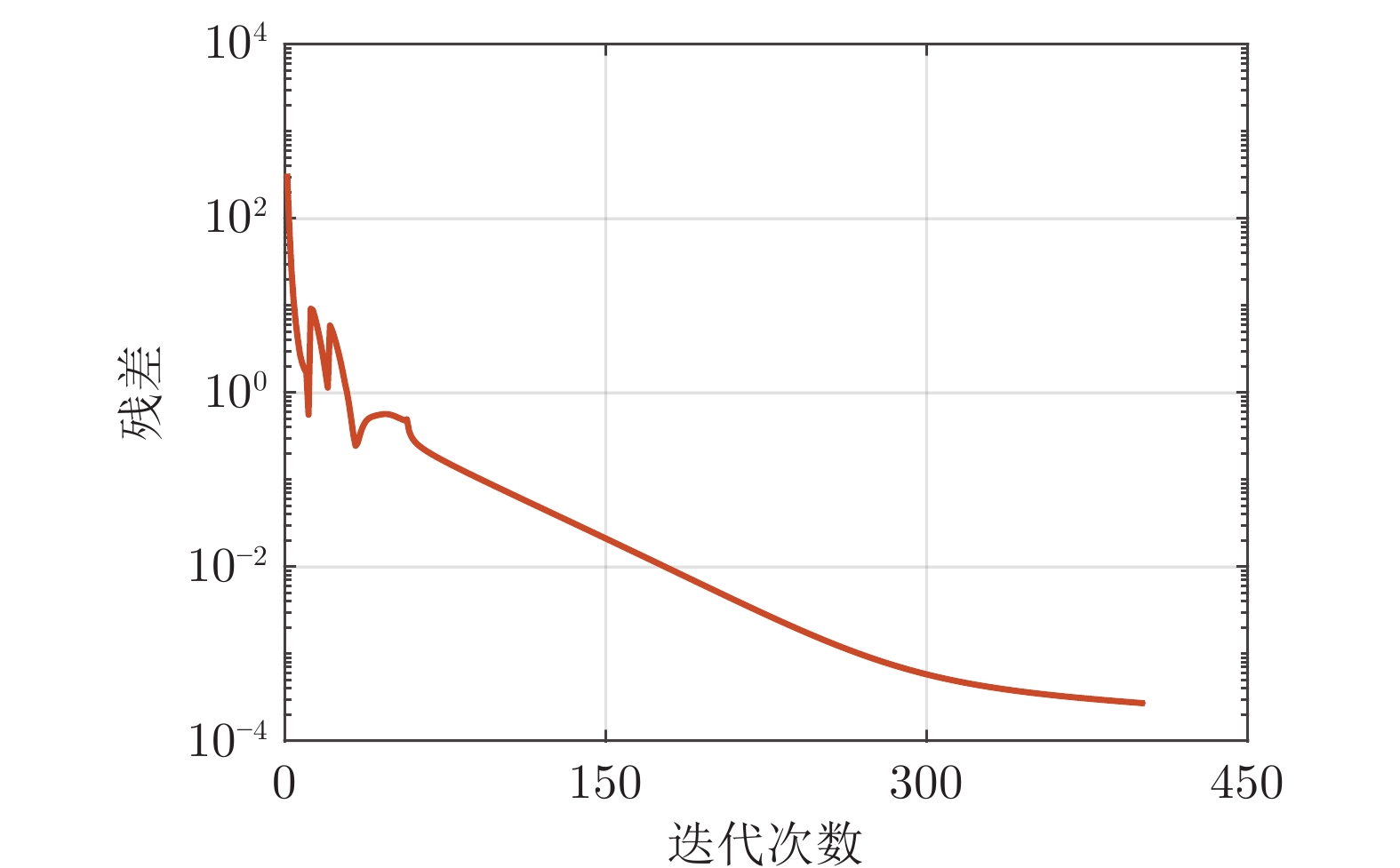
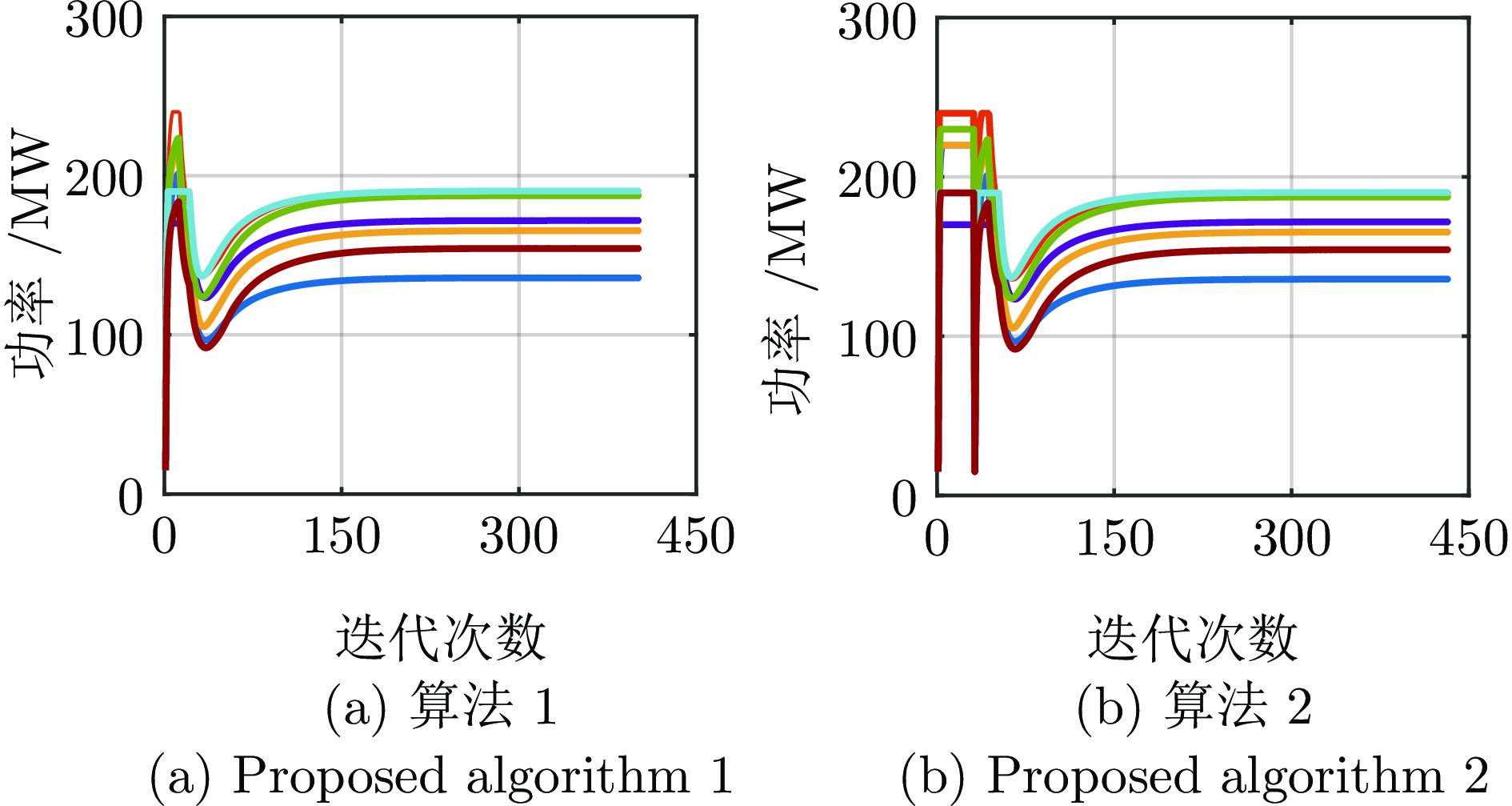
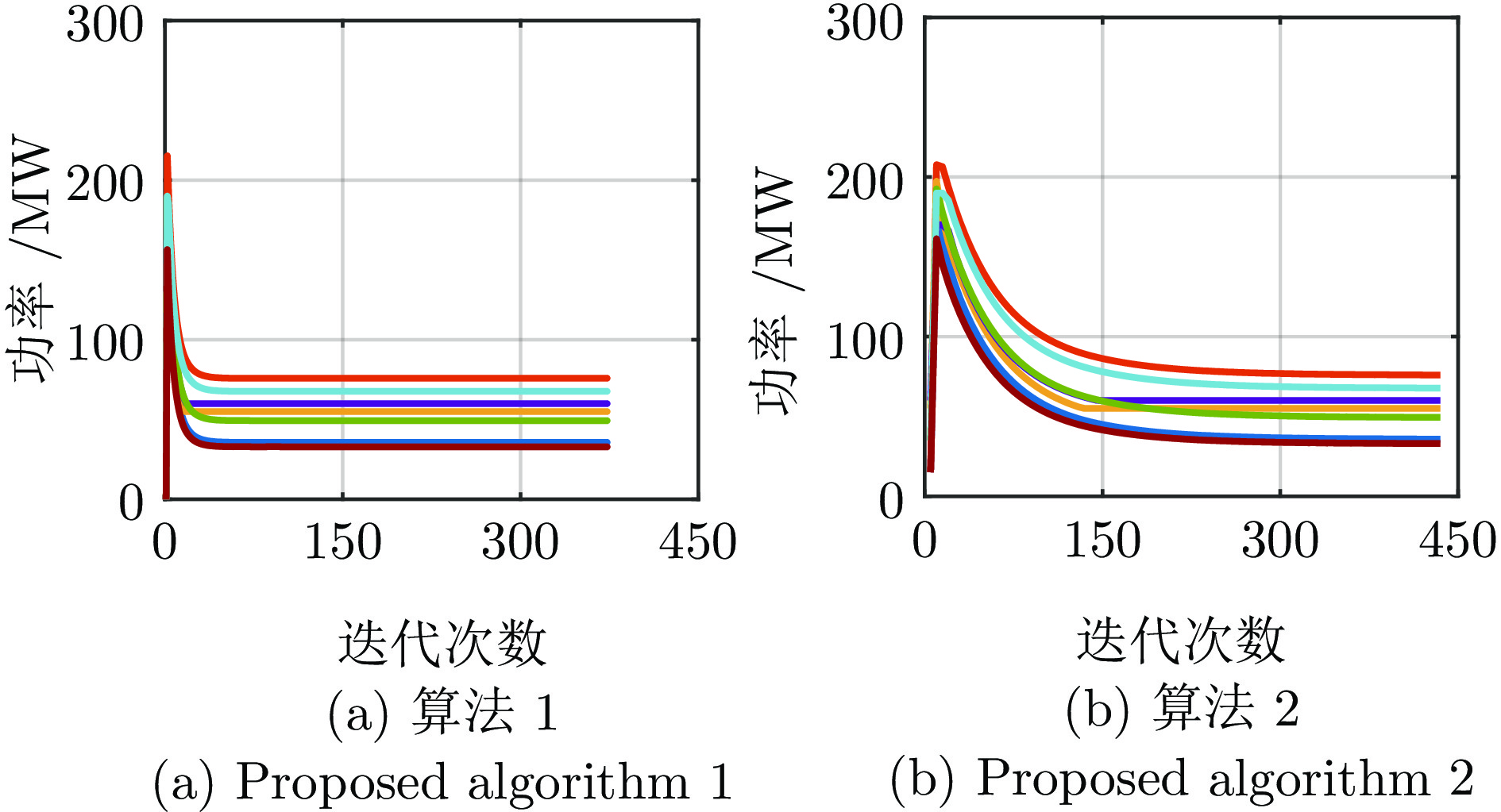
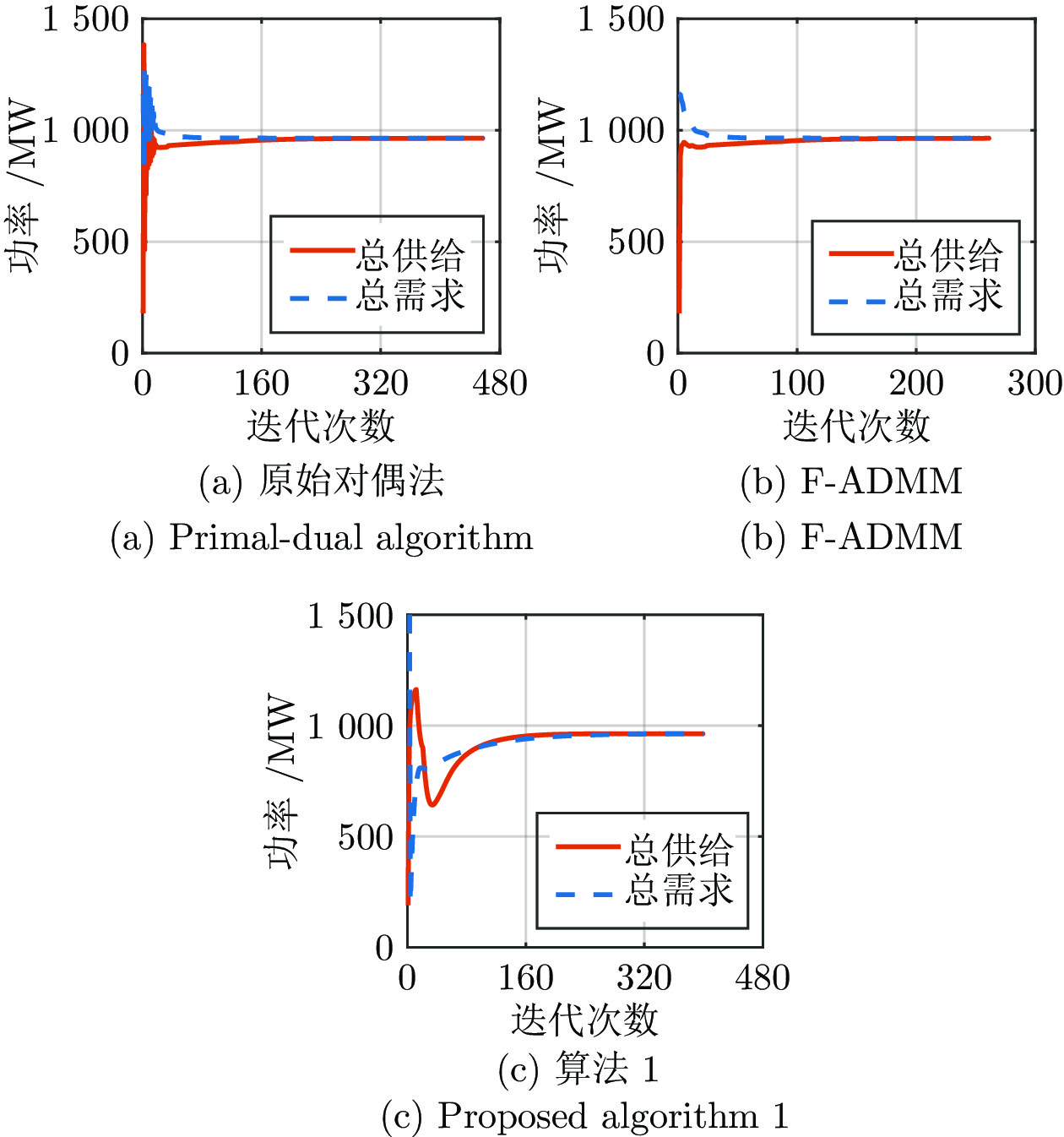
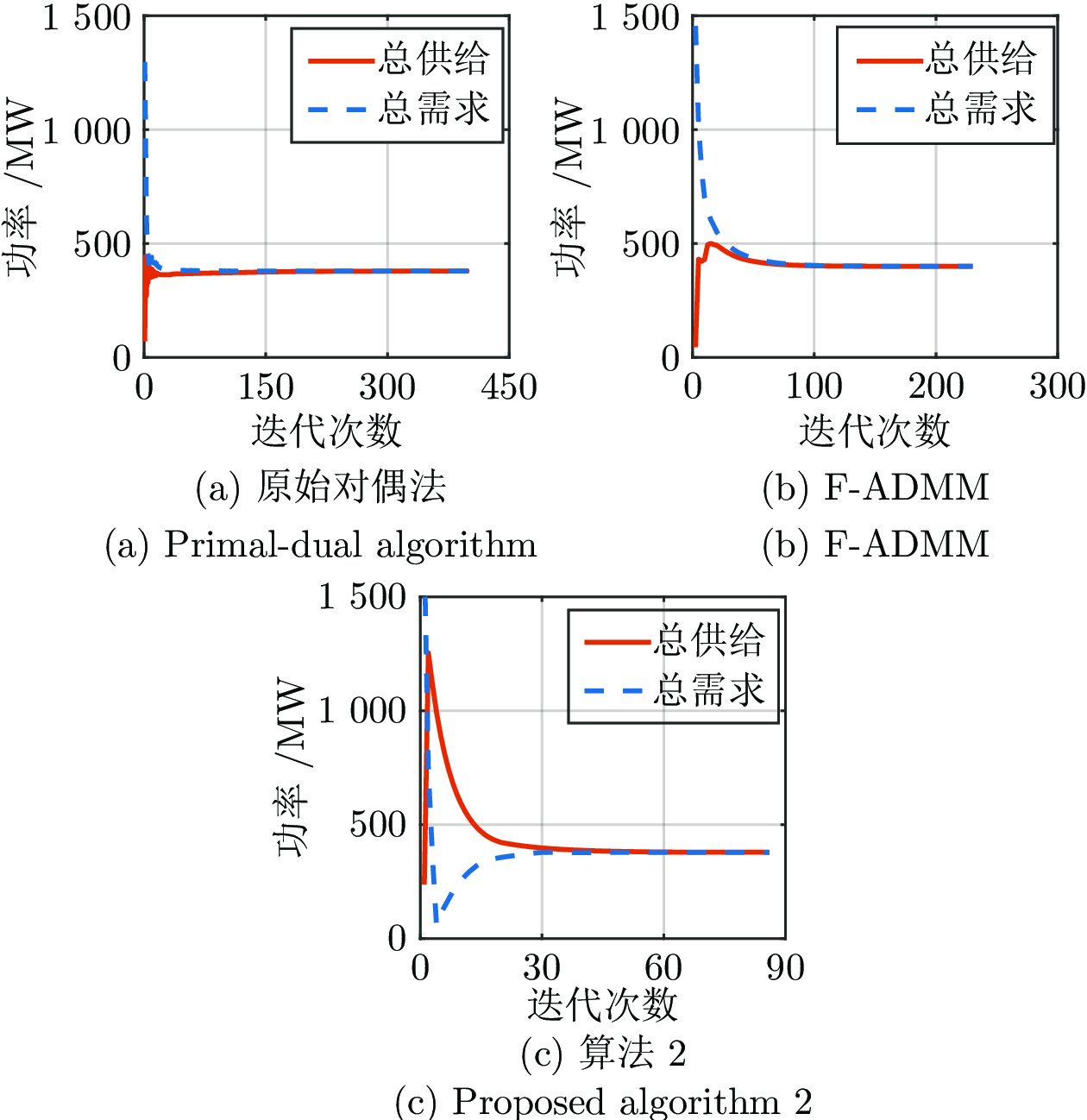
电力市场分布式交易模型可有效缓解传统集中模型下市场主体的隐私安全等问题, 但难以在保障市场主体收益和电力系统安全稳定运行的同时, 实现社会福利最大化. 因此, 基于电网线路传输安全, 首先以社会福利最大化为目标, 构建集中式交易模型, 并采用拉格朗日乘子法和对偶定理, 将其等价分解为各市场主体自身利益最大化的分布式交易模型. 在此基础上, 设计2种适用于不同情形的分布式交易方法及其求解算法, 并构造电网安全成本影响市场主体的决策, 从而保证电网线路传输安全. 最后, 基于算例分析, 验证了2种交易方法的有效性.
电力市场分布式交易模型可有效缓解传统集中模型下市场主体的隐私安全等问题, 但难以在保障市场主体收益和电力系统安全稳定运行的同时, 实现社会福利最大化. 因此, 基于电网线路传输安全, 首先以社会福利最大化为目标, 构建集中式交易模型, 并采用拉格朗日乘子法和对偶定理, 将其等价分解为各市场主体自身利益最大化的分布式交易模型. 在此基础上, 设计2种适用于不同情形的分布式交易方法及其求解算法, 并构造电网安全成本影响市场主体的决策, 从而保证电网线路传输安全. 最后, 基于算例分析, 验证了2种交易方法的有效性.
2024, 50(10): 1953-1962.
doi: 10.16383/j.aas.c220966
cstr: 32138.14.j.aas.c220966
摘要:
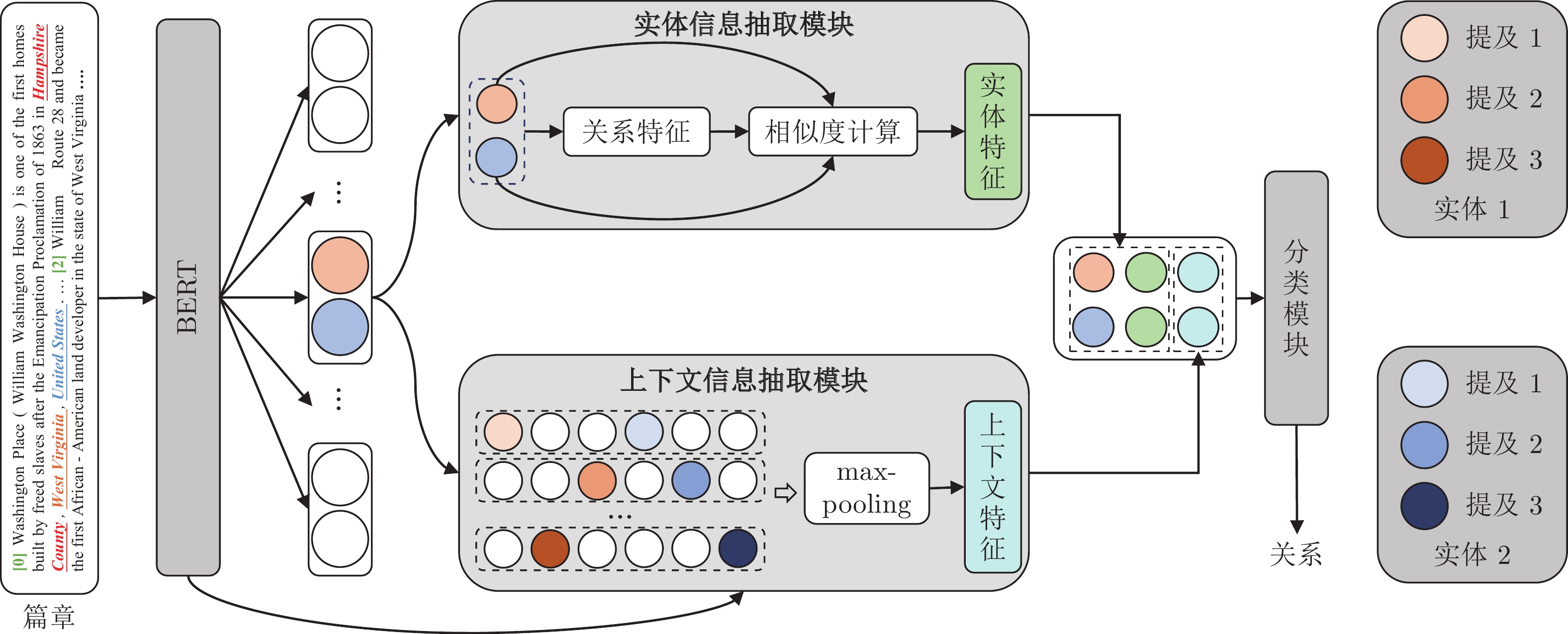
篇章关系抽取旨在识别篇章中实体对之间的关系. 相较于传统的句子级别关系抽取, 篇章级别关系抽取任务更加贴近实际应用, 但是它对实体对的跨句子推理和上下文信息感知等问题提出了新的挑战. 本文提出融合实体和上下文信息(Fuse entity and context information, FECI)的篇章关系抽取方法, 它包含两个模块, 分别是实体信息抽取模块和上下文信息抽取模块. 实体信息抽取模块从两个实体中自动地抽取出能够表示实体对关系的特征. 上下文信息抽取模块根据实体对的提及位置信息, 从篇章中抽取不同的上下文关系特征. 本文在三个篇章级别的关系抽取数据集上进行实验, 效果得到显著提升.
篇章关系抽取旨在识别篇章中实体对之间的关系. 相较于传统的句子级别关系抽取, 篇章级别关系抽取任务更加贴近实际应用, 但是它对实体对的跨句子推理和上下文信息感知等问题提出了新的挑战. 本文提出融合实体和上下文信息(Fuse entity and context information, FECI)的篇章关系抽取方法, 它包含两个模块, 分别是实体信息抽取模块和上下文信息抽取模块. 实体信息抽取模块从两个实体中自动地抽取出能够表示实体对关系的特征. 上下文信息抽取模块根据实体对的提及位置信息, 从篇章中抽取不同的上下文关系特征. 本文在三个篇章级别的关系抽取数据集上进行实验, 效果得到显著提升.


2024, 50(10): 1963-1976.
doi: 10.16383/j.aas.c230649
cstr: 32138.14.j.aas.c230649
摘要:
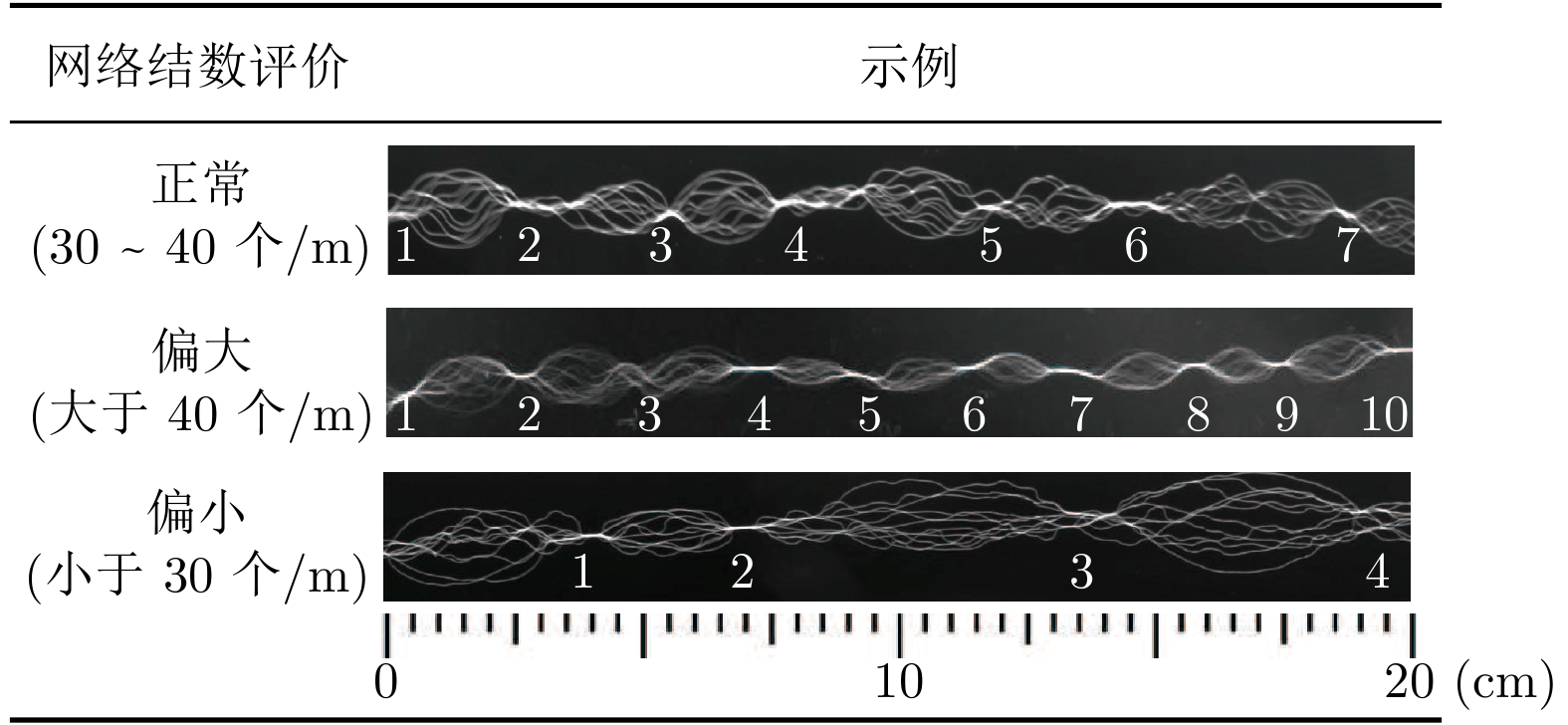
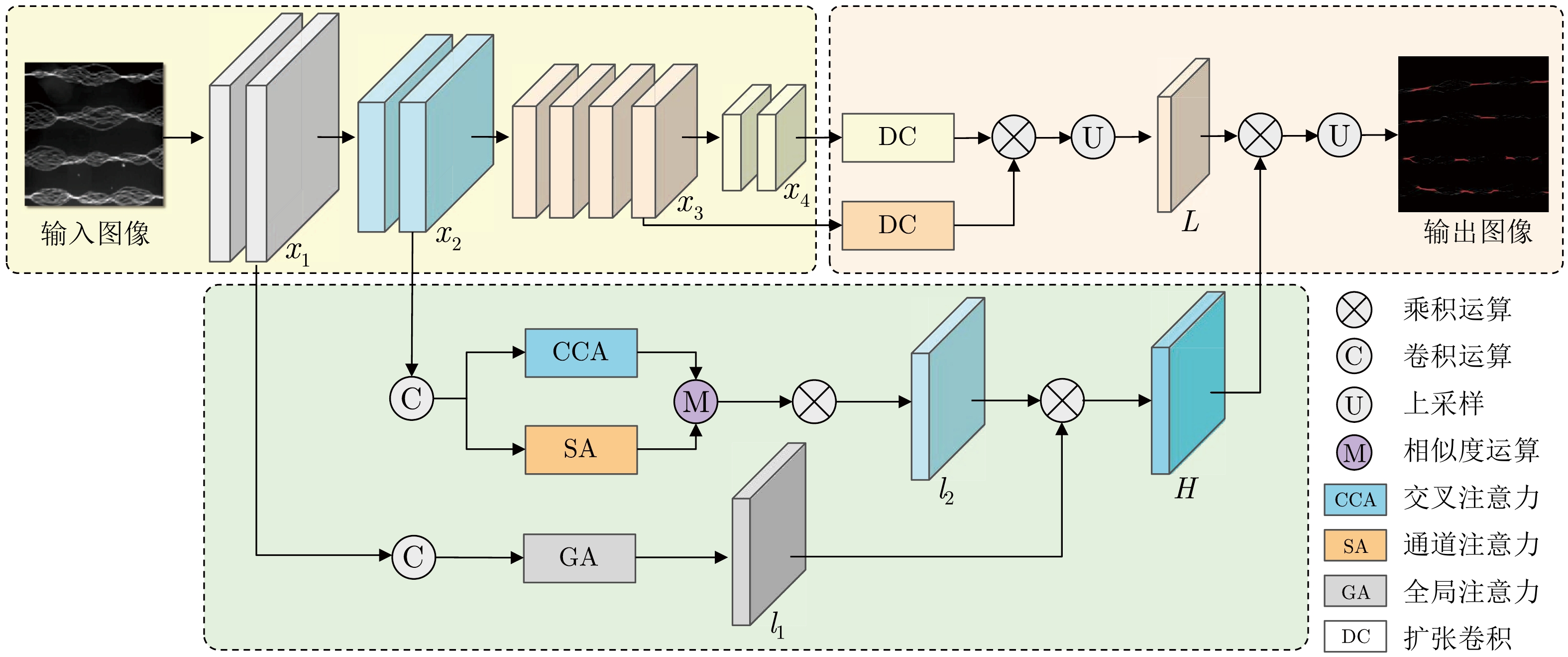
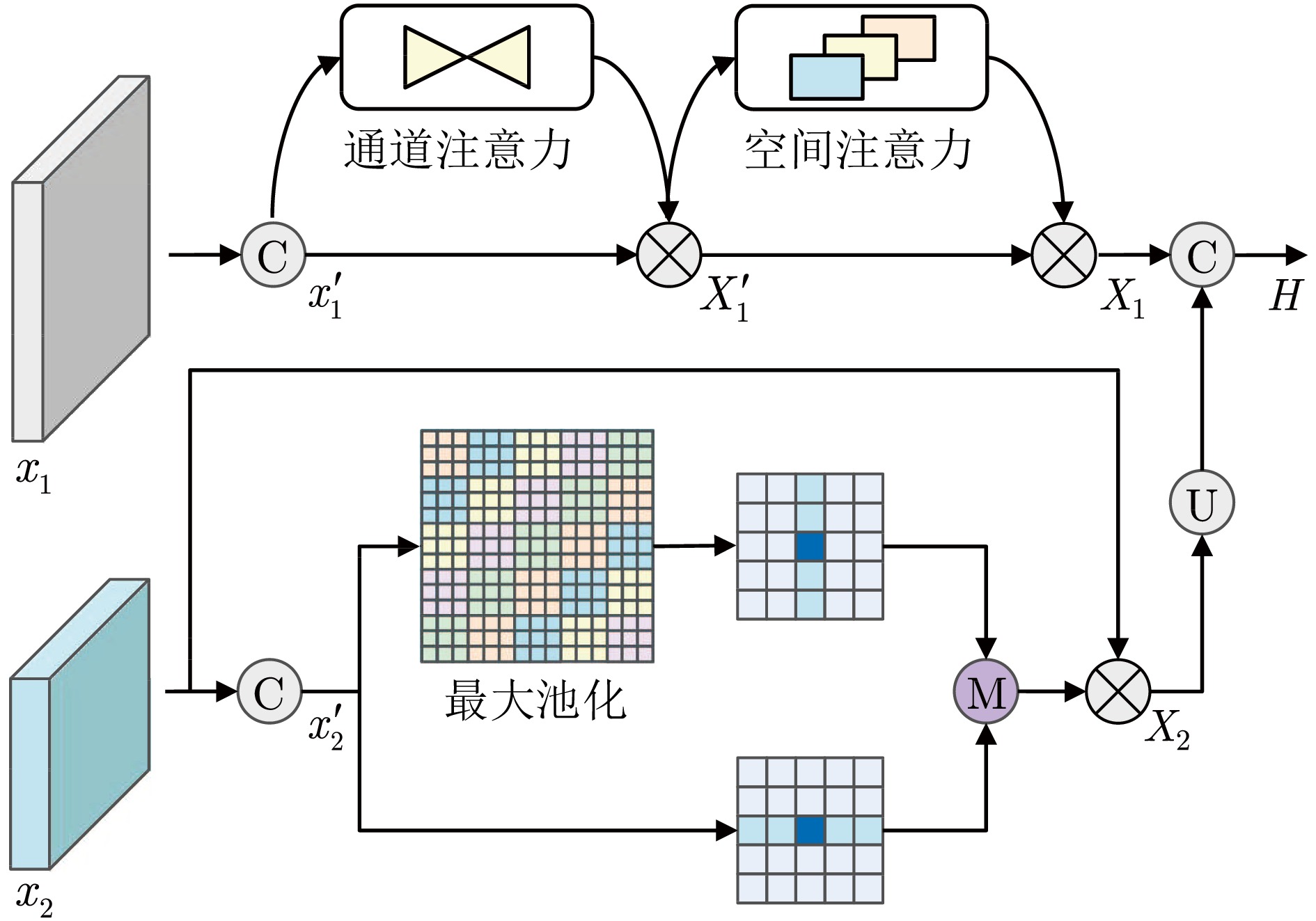
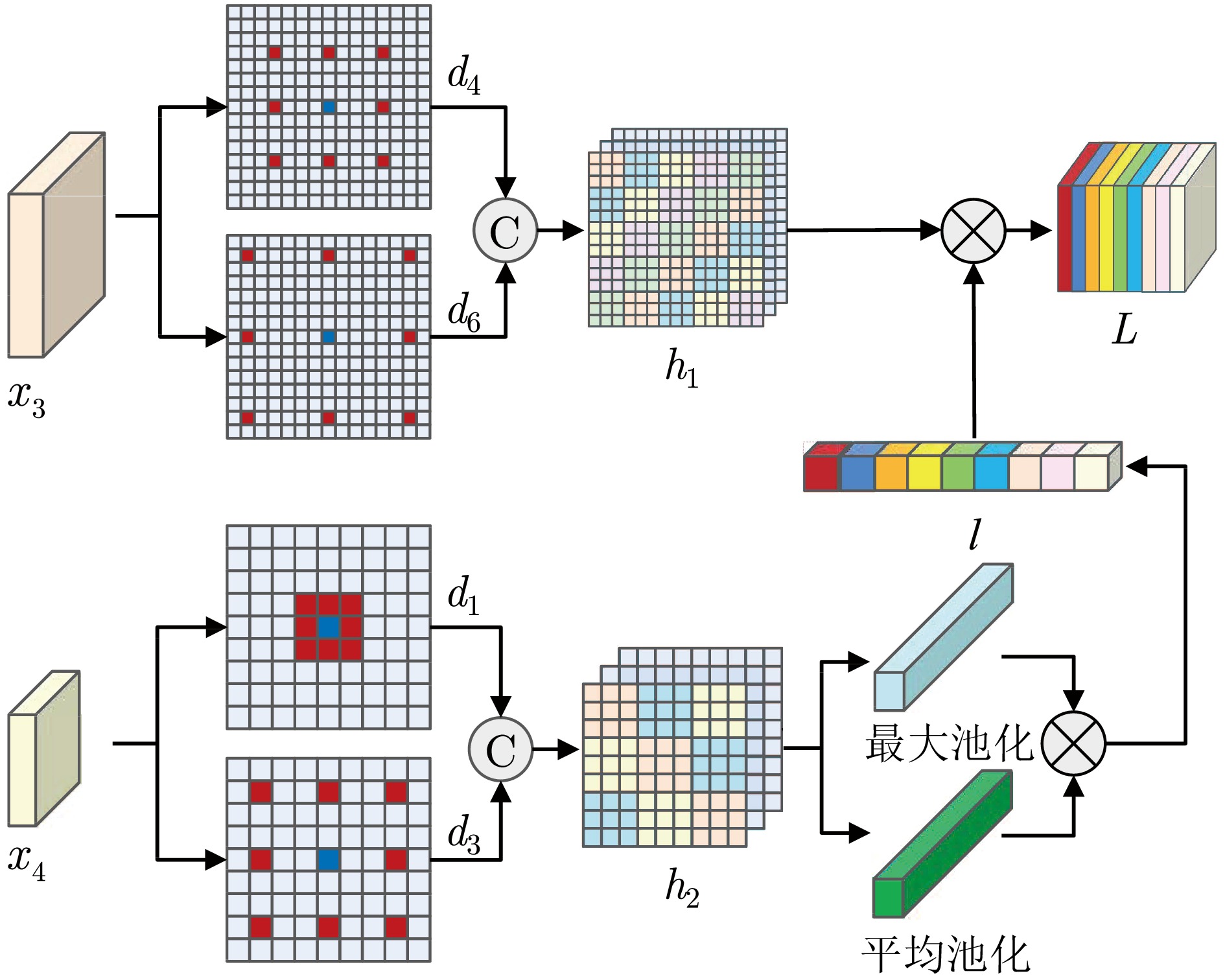
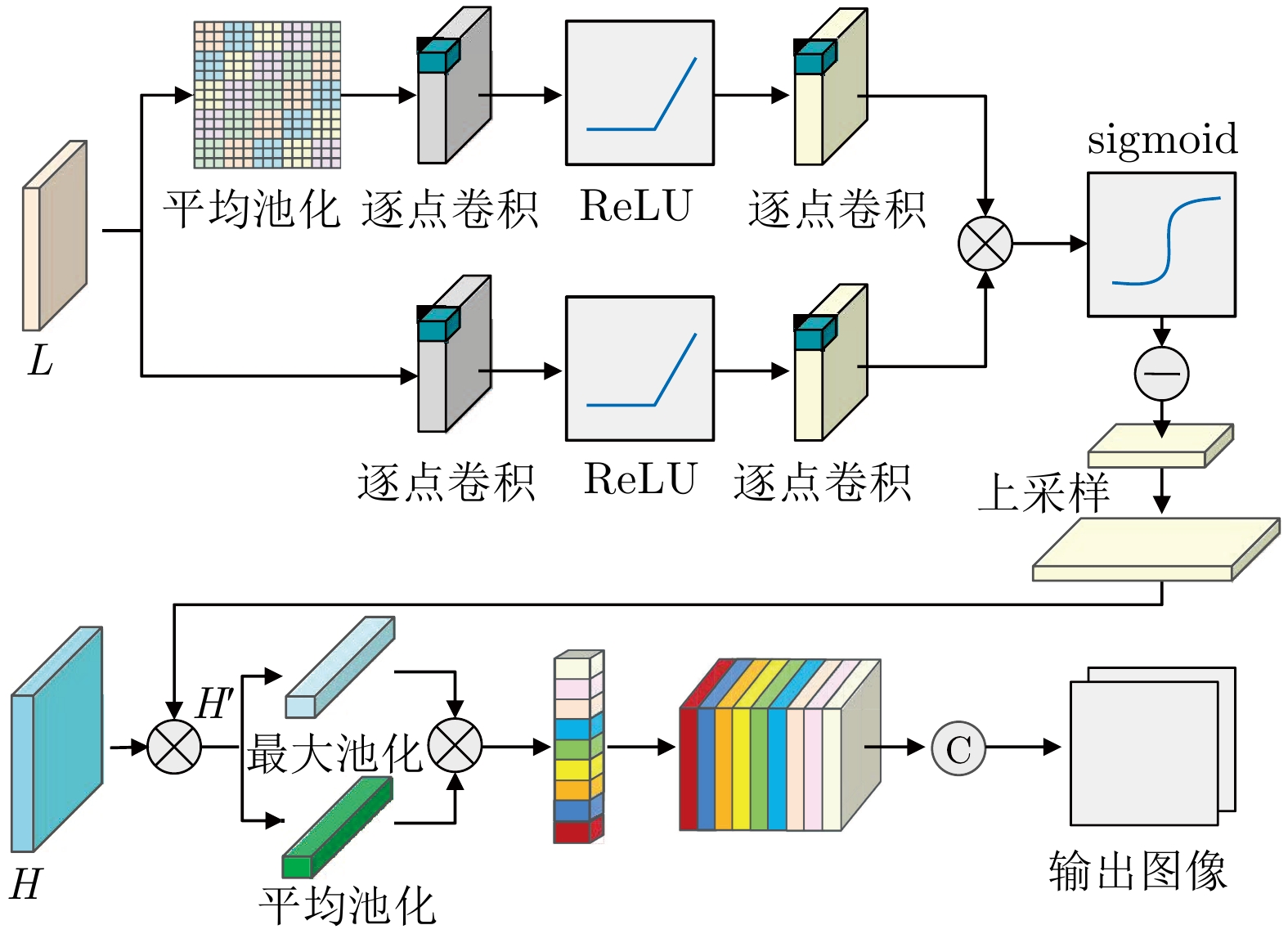
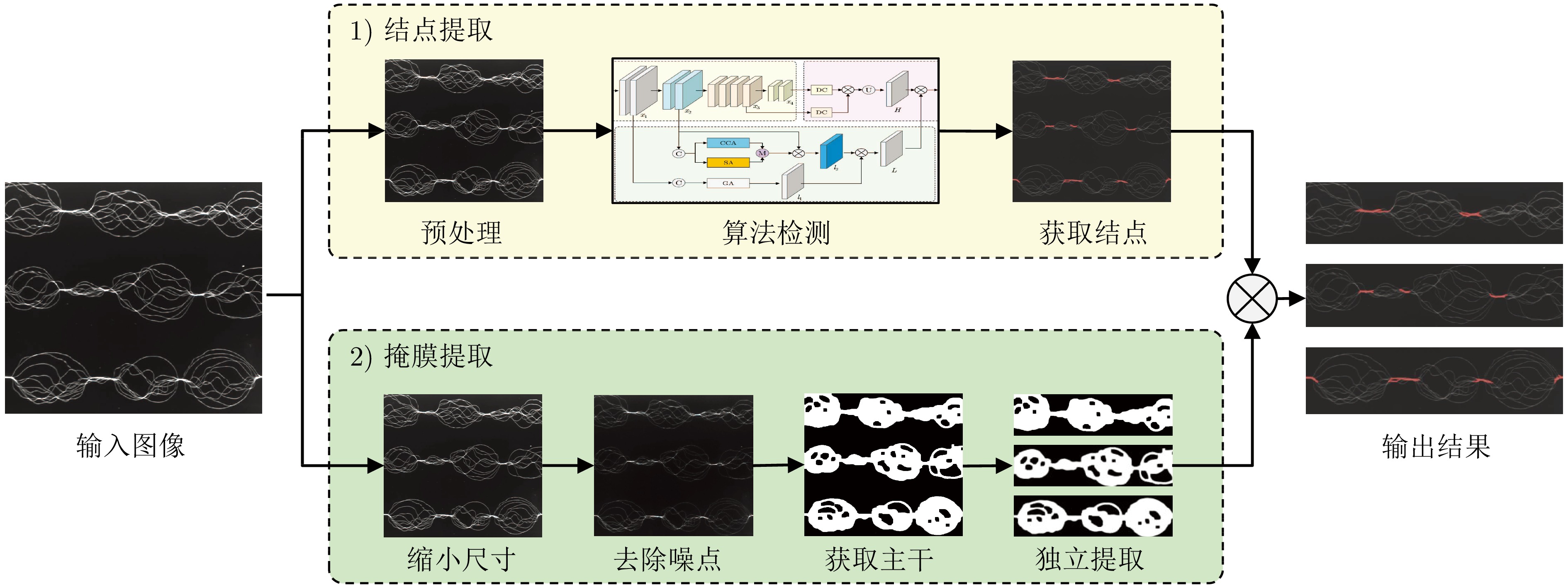
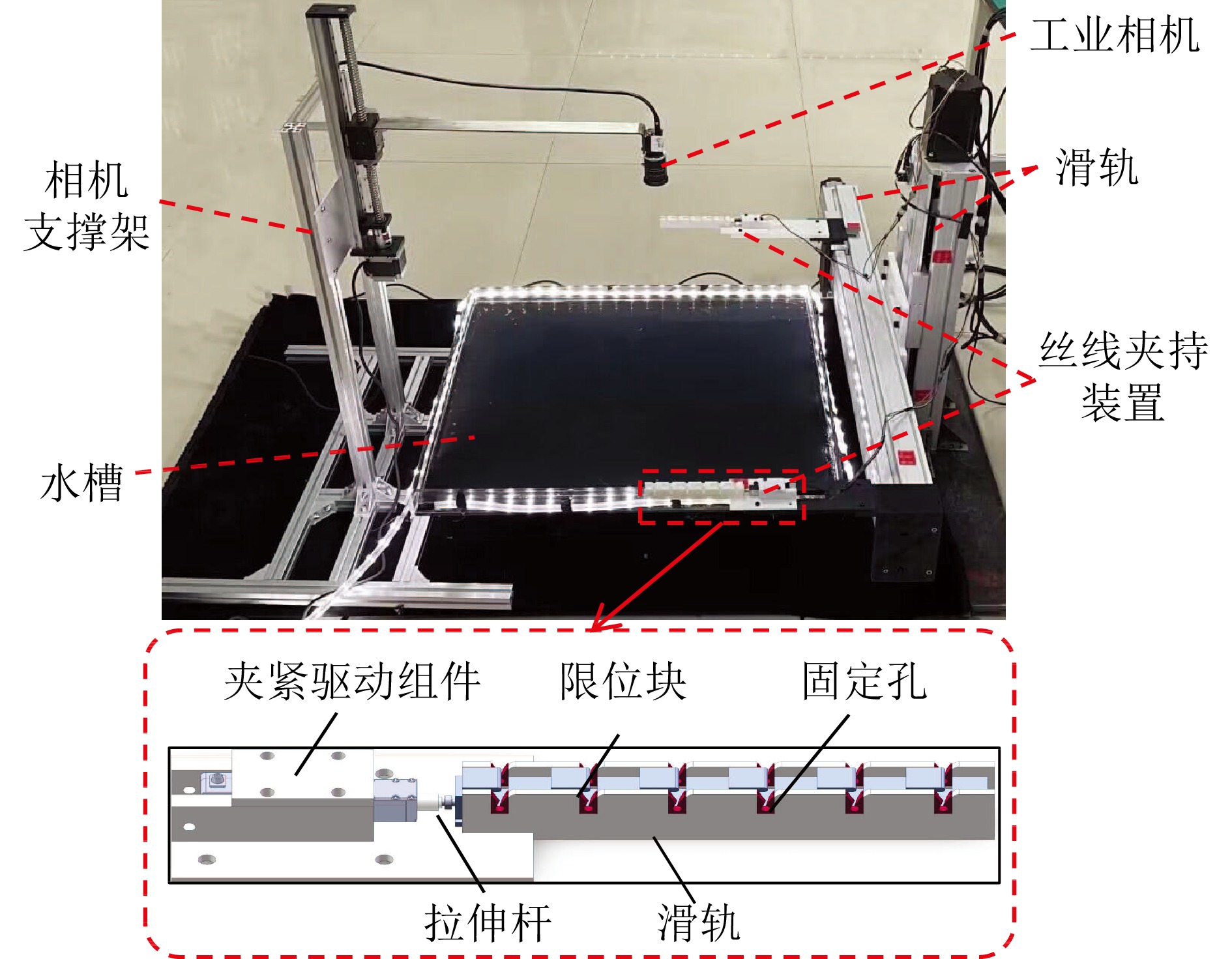
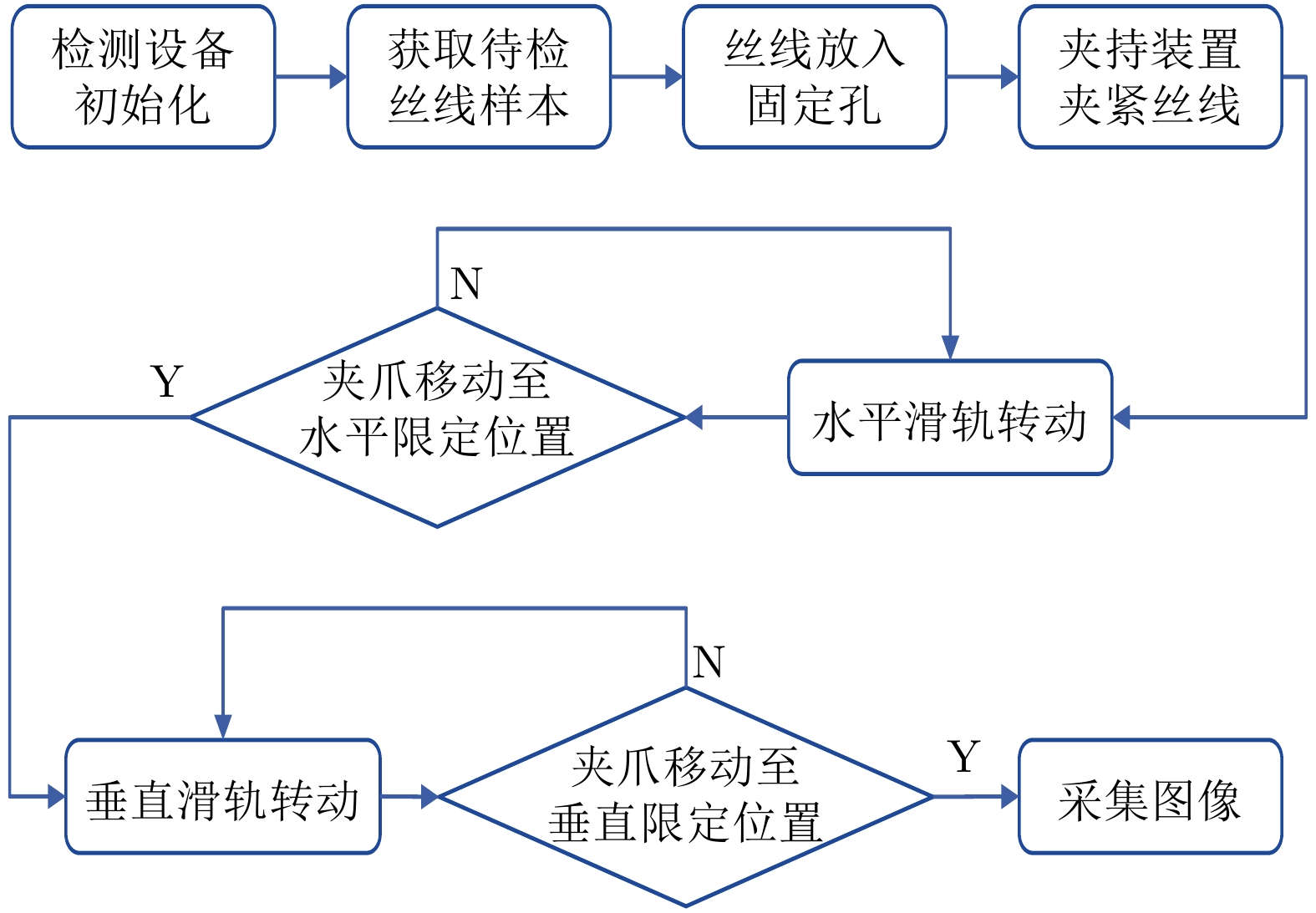
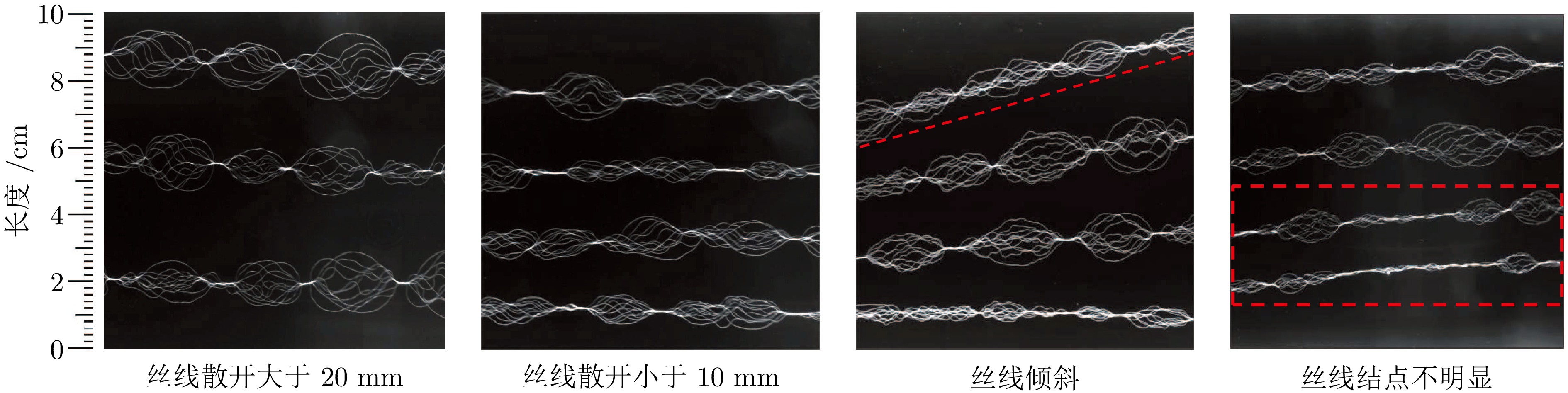
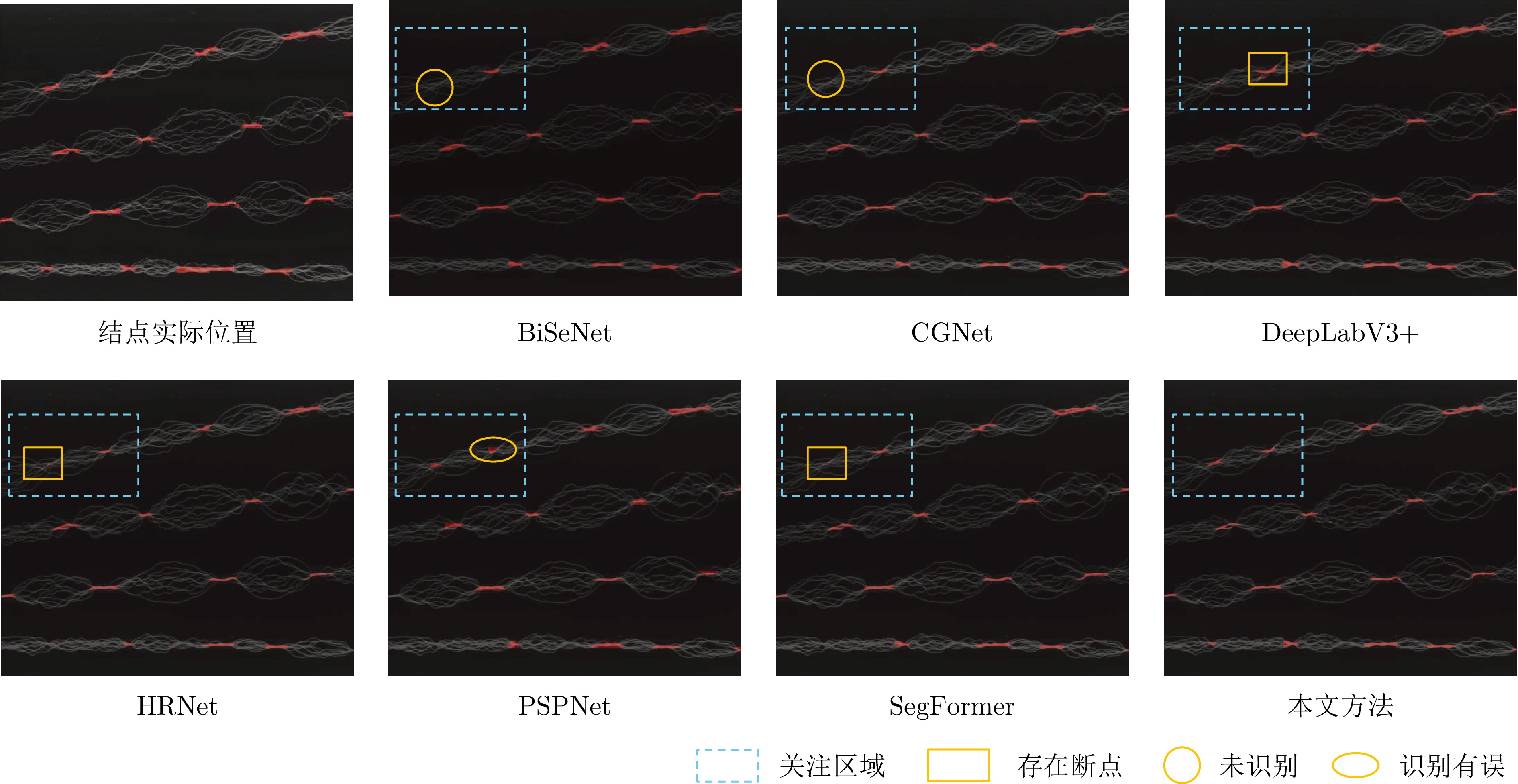
网络度是衡量化纤丝线及化纤织物性能的重要指标之一, 在生产车间中通常采用人工方式进行检测. 为解决人工检测误检率较高的问题, 提出一种基于语义信息增强的化纤丝线网络度并行检测方法. 首先, 为提升单根化纤丝线网络结点识别的准确度, 使用基于MobileNetV2优化的主干网络结构提取语义信息, 以提高模型的运算速度. 在所提主干网络的基础上, 设计语义信息增强模块和多级特征扩张模块处理主干网络的特征信息, 同时, 设计像素级注意力掩膜对特征信息进行加权和融合, 以提高网络度检测的准确性. 然后, 为实现多根化纤丝线网络度的批量计算, 基于所提语义信息增强算法, 设计网络度并行检测方法. 使用算法检测丝线网络结点, 同时使用连通域分析及掩膜提取的方法并行检测, 提取视野内每条丝线的独立区域. 随后, 将并行检测结果融合, 以准确获取每根丝线的网络度检测结果. 为验证所提方法的有效性, 使用自主研发的网络度检测设备建立了化纤丝线数据集, 并进行了实验验证. 结果表明, 所提出的方法能够有效地提高检测的准确性.
网络度是衡量化纤丝线及化纤织物性能的重要指标之一, 在生产车间中通常采用人工方式进行检测. 为解决人工检测误检率较高的问题, 提出一种基于语义信息增强的化纤丝线网络度并行检测方法. 首先, 为提升单根化纤丝线网络结点识别的准确度, 使用基于MobileNetV2优化的主干网络结构提取语义信息, 以提高模型的运算速度. 在所提主干网络的基础上, 设计语义信息增强模块和多级特征扩张模块处理主干网络的特征信息, 同时, 设计像素级注意力掩膜对特征信息进行加权和融合, 以提高网络度检测的准确性. 然后, 为实现多根化纤丝线网络度的批量计算, 基于所提语义信息增强算法, 设计网络度并行检测方法. 使用算法检测丝线网络结点, 同时使用连通域分析及掩膜提取的方法并行检测, 提取视野内每条丝线的独立区域. 随后, 将并行检测结果融合, 以准确获取每根丝线的网络度检测结果. 为验证所提方法的有效性, 使用自主研发的网络度检测设备建立了化纤丝线数据集, 并进行了实验验证. 结果表明, 所提出的方法能够有效地提高检测的准确性.




2024, 50(10): 1977-1987.
doi: 10.16383/j.aas.c230545
cstr: 32138.14.j.aas.c230545
摘要:
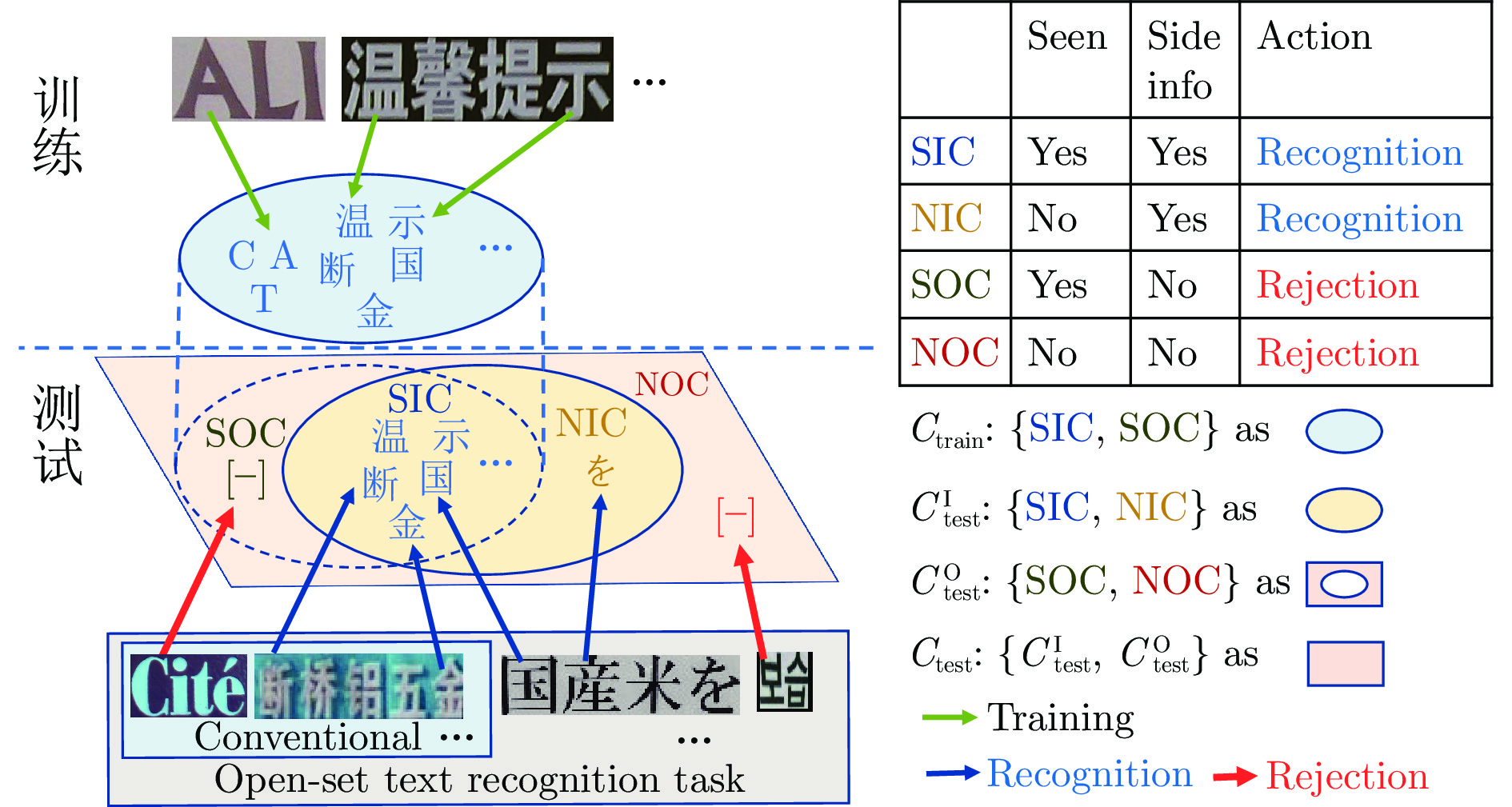
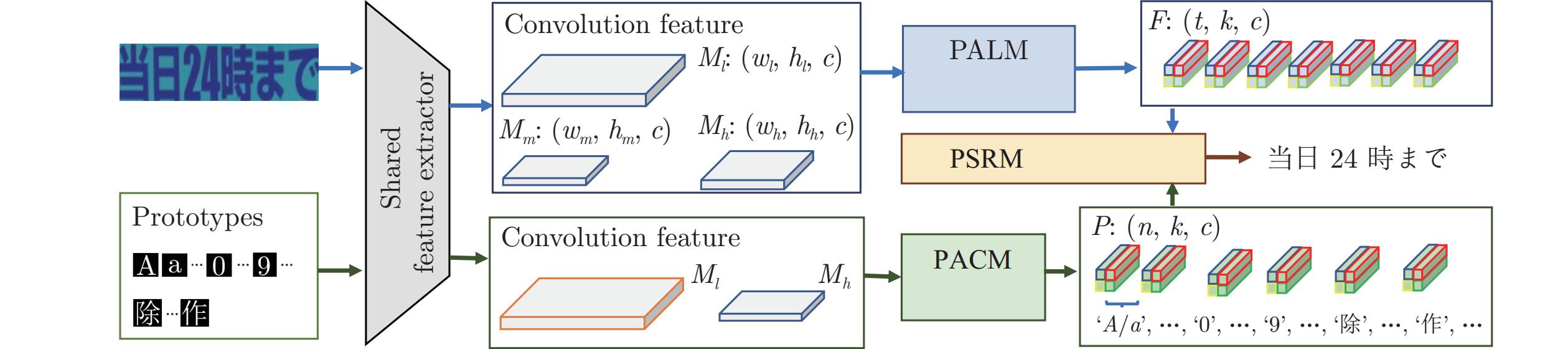
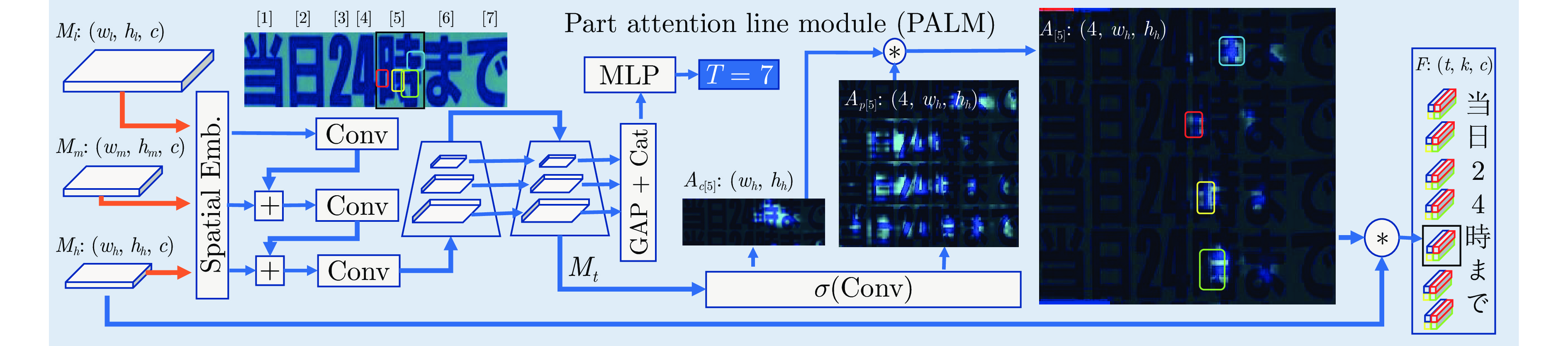
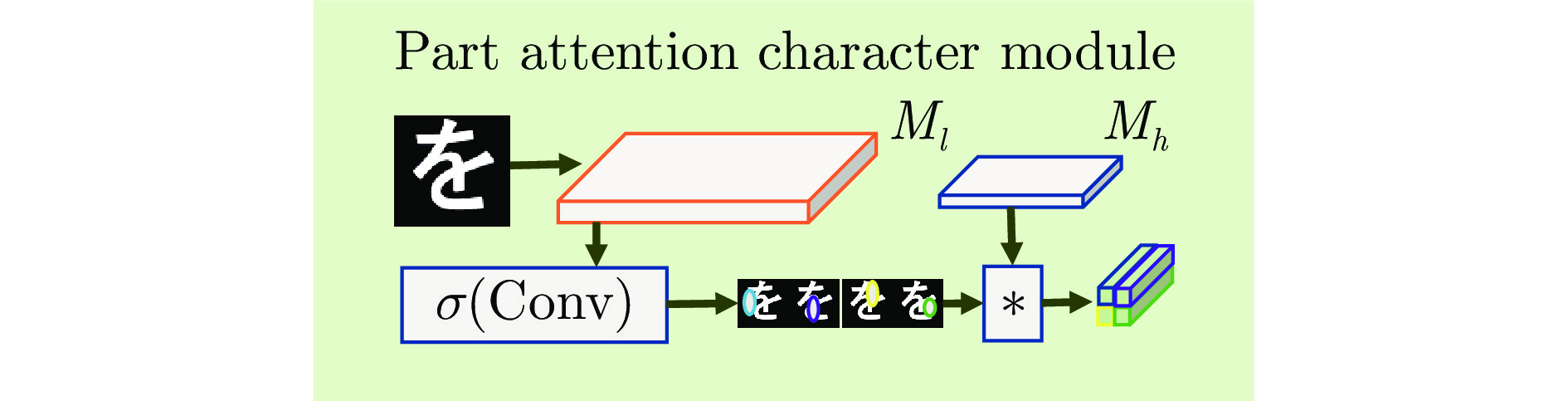
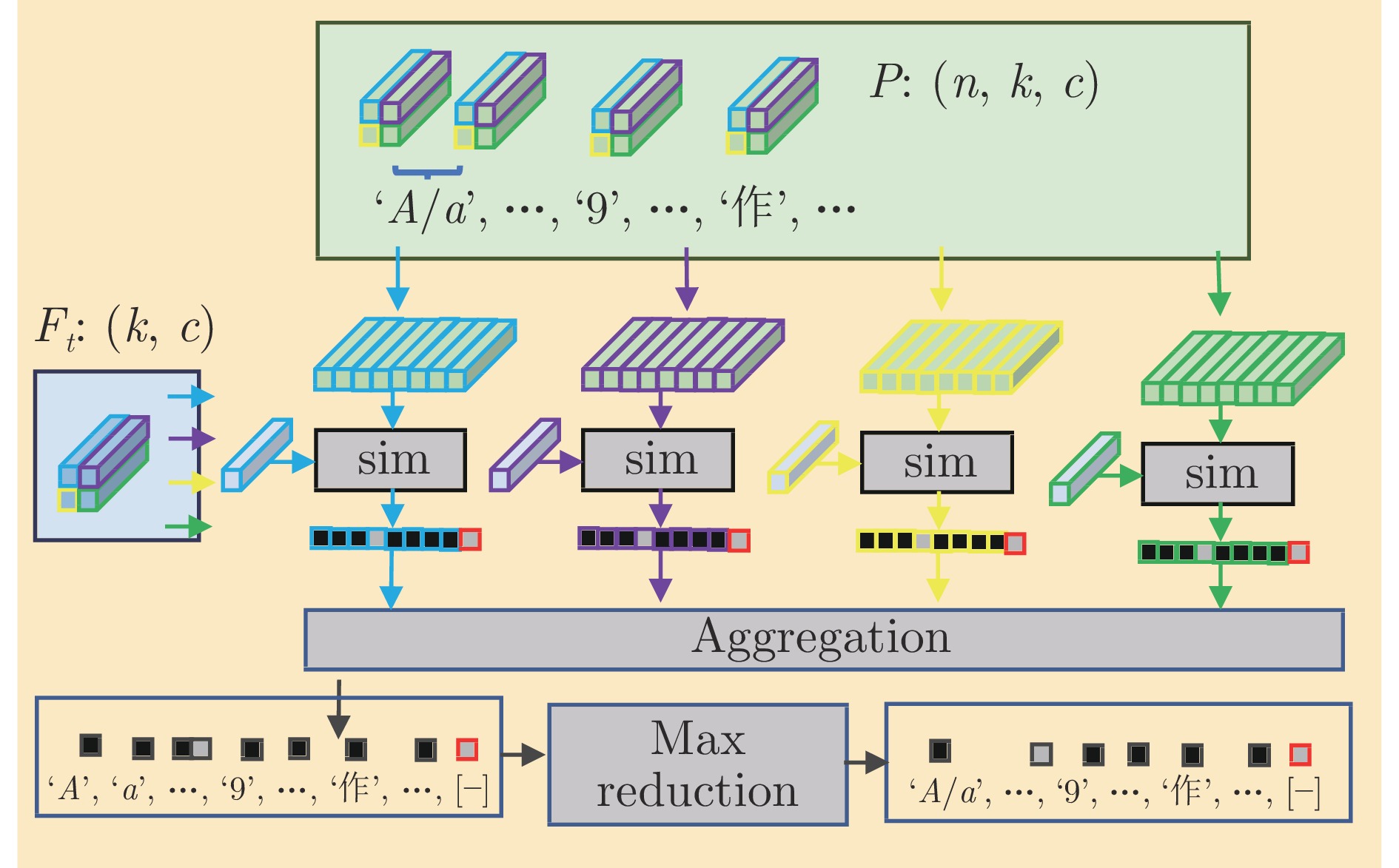
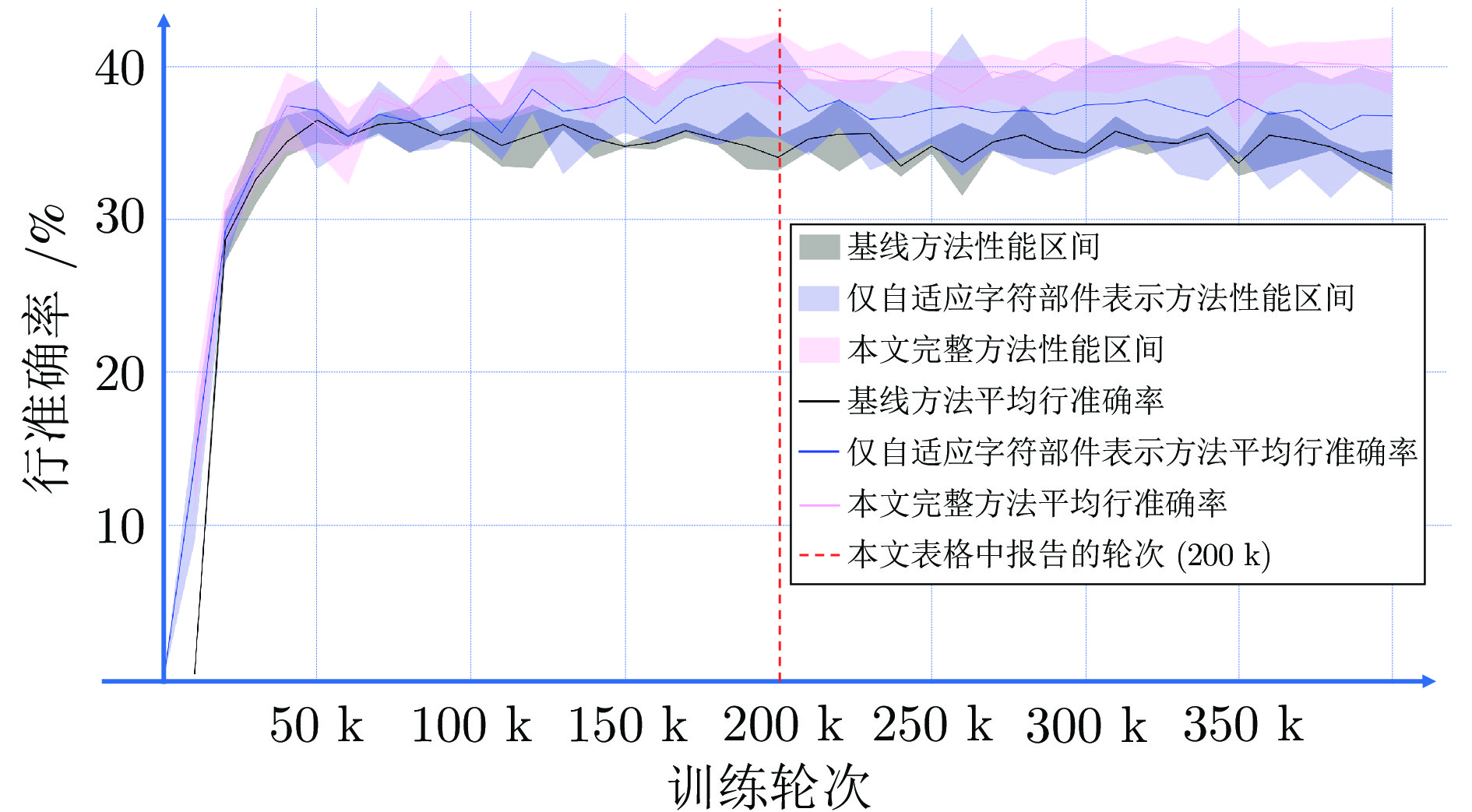
开放集文字识别 (Open-set text recognition, OSTR) 是一项新任务, 旨在解决开放环境下文字识别应用中的语言模型偏差及新字符识别与拒识问题. 最近的 OSTR 方法通过将上下文信息与视觉信息分离来解决语言模型偏差问题. 然而, 这些方法往往忽视了字符视觉细节的重要性. 考虑到上下文信息的偏差, 局部细节信息在区分视觉上接近的字符时变得更加重要. 本文提出一种基于自适应字符部件表示的开放集文字识别框架, 构建基于文字局部结构相似度量的开放集文字识别方法, 通过对不同字符部件进行显式建模来改进对局部细节特征的建模能力. 与基于字根 (Radical) 的方法不同, 所提出的框架采用数据驱动的部件设计, 具有语言无关的特性和跨语言泛化识别的能力. 此外, 还提出一种局部性约束正则项来使模型训练更加稳定. 大量的对比实验表明, 本文方法在开放集、传统闭集文字识别任务上均具有良好的性能.
开放集文字识别 (Open-set text recognition, OSTR) 是一项新任务, 旨在解决开放环境下文字识别应用中的语言模型偏差及新字符识别与拒识问题. 最近的 OSTR 方法通过将上下文信息与视觉信息分离来解决语言模型偏差问题. 然而, 这些方法往往忽视了字符视觉细节的重要性. 考虑到上下文信息的偏差, 局部细节信息在区分视觉上接近的字符时变得更加重要. 本文提出一种基于自适应字符部件表示的开放集文字识别框架, 构建基于文字局部结构相似度量的开放集文字识别方法, 通过对不同字符部件进行显式建模来改进对局部细节特征的建模能力. 与基于字根 (Radical) 的方法不同, 所提出的框架采用数据驱动的部件设计, 具有语言无关的特性和跨语言泛化识别的能力. 此外, 还提出一种局部性约束正则项来使模型训练更加稳定. 大量的对比实验表明, 本文方法在开放集、传统闭集文字识别任务上均具有良好的性能.





2024, 50(10): 1988-2001.
doi: 10.16383/j.aas.c220994
cstr: 32138.14.j.aas.c220994
摘要:
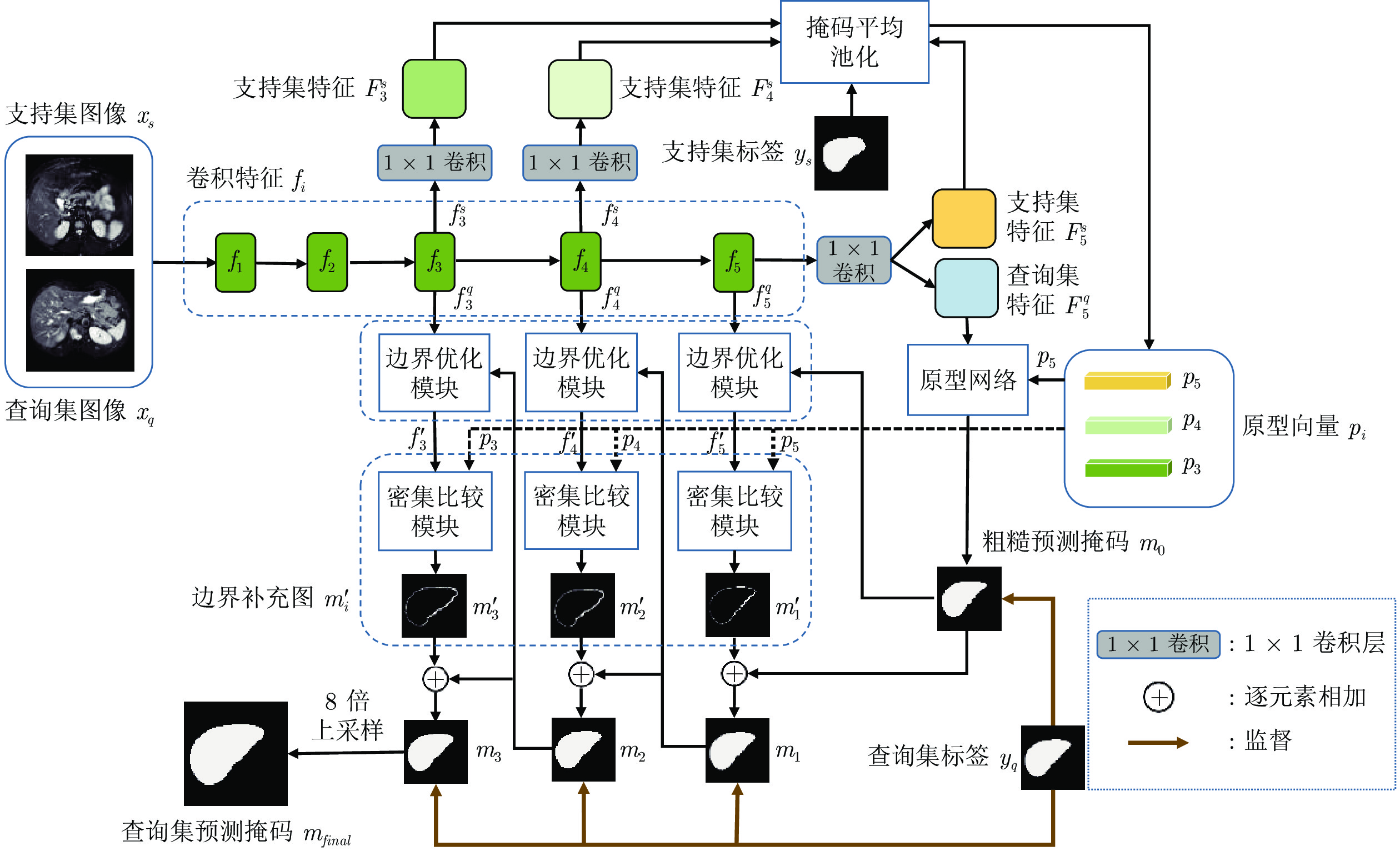
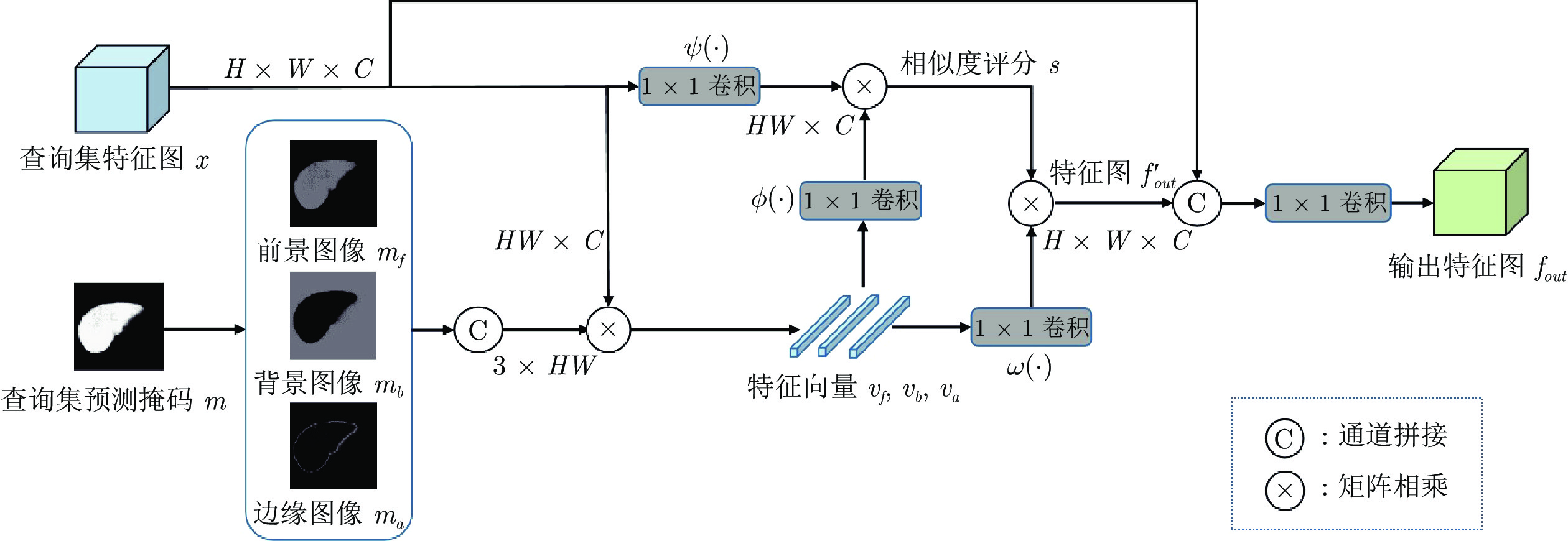
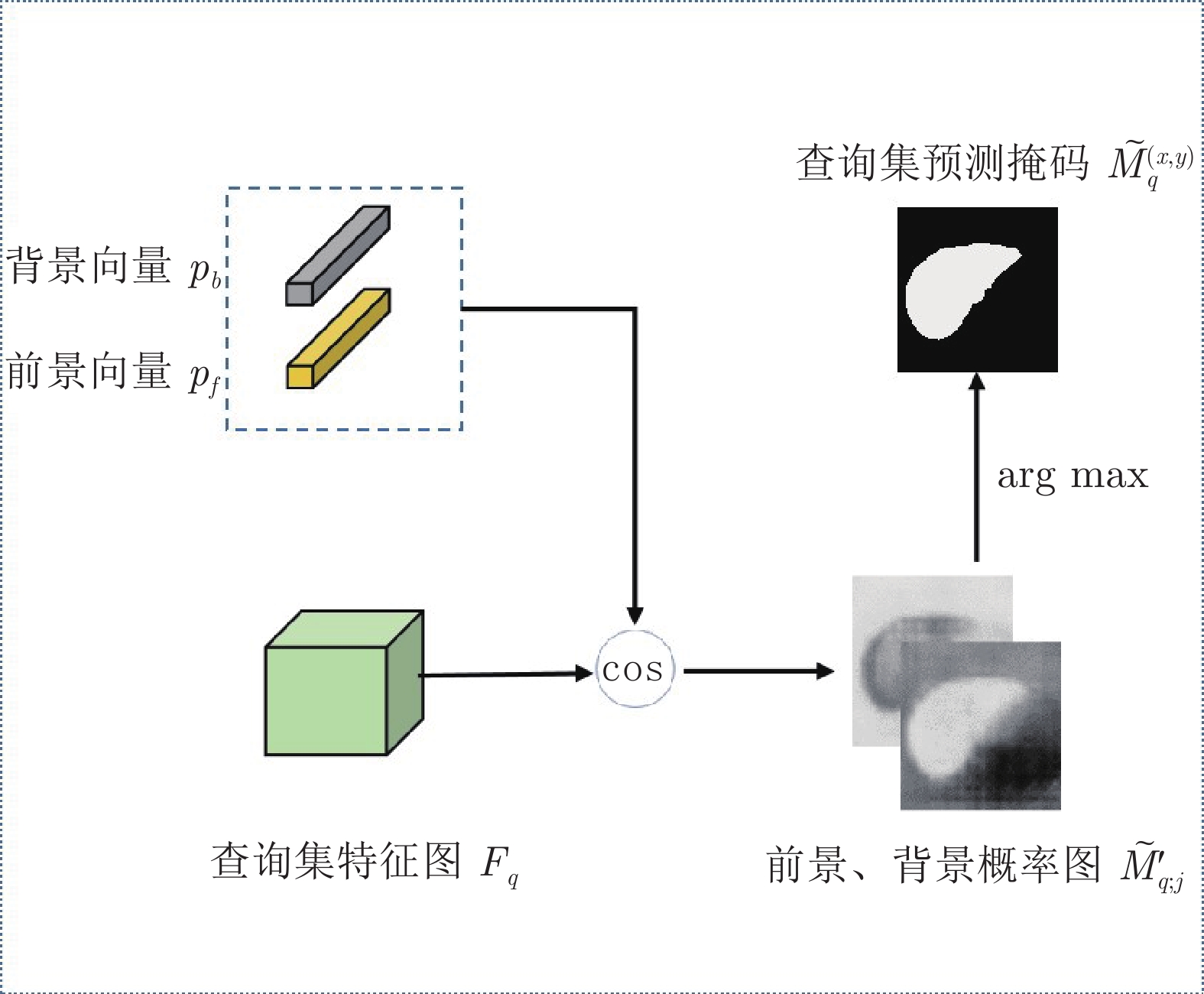
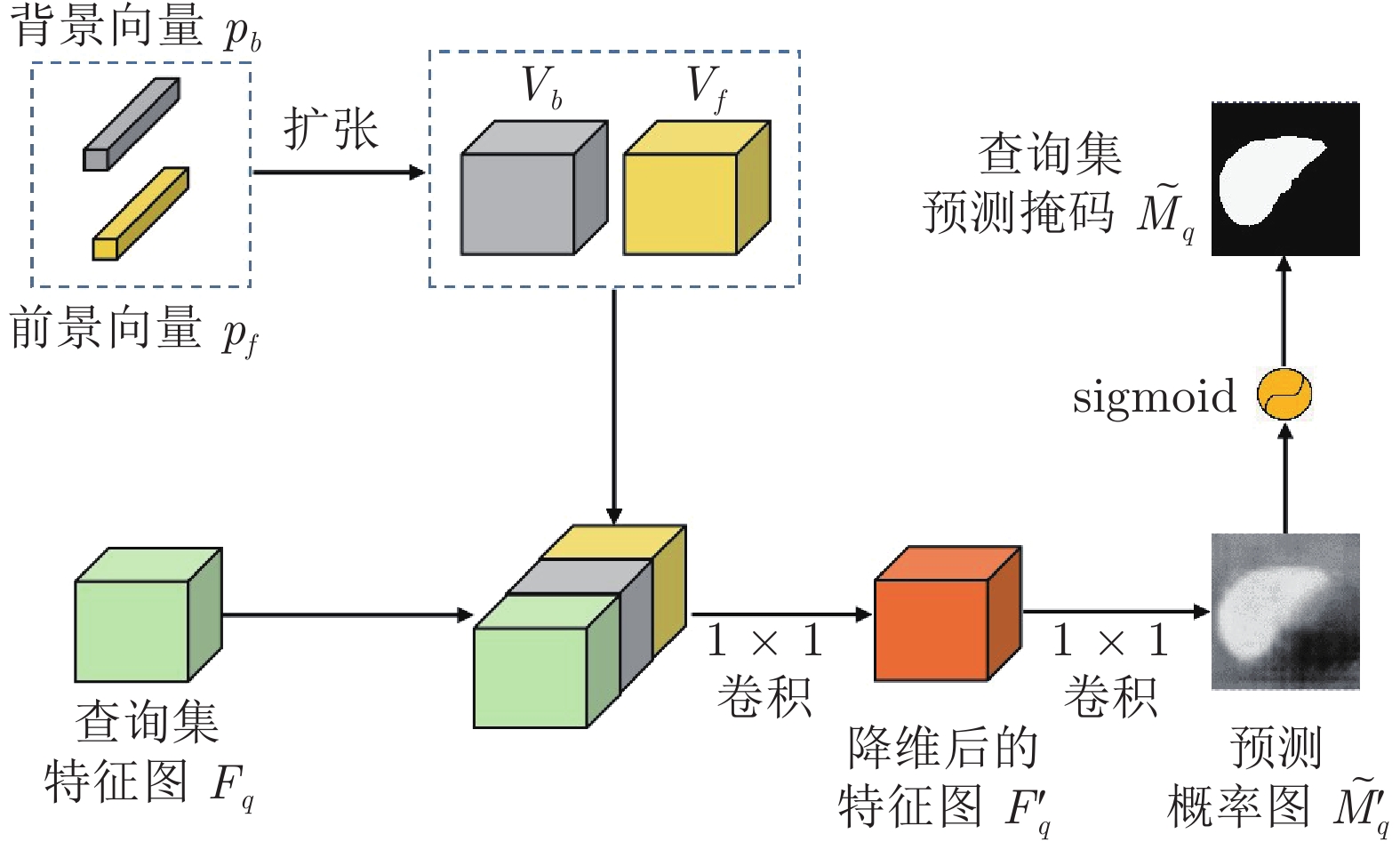
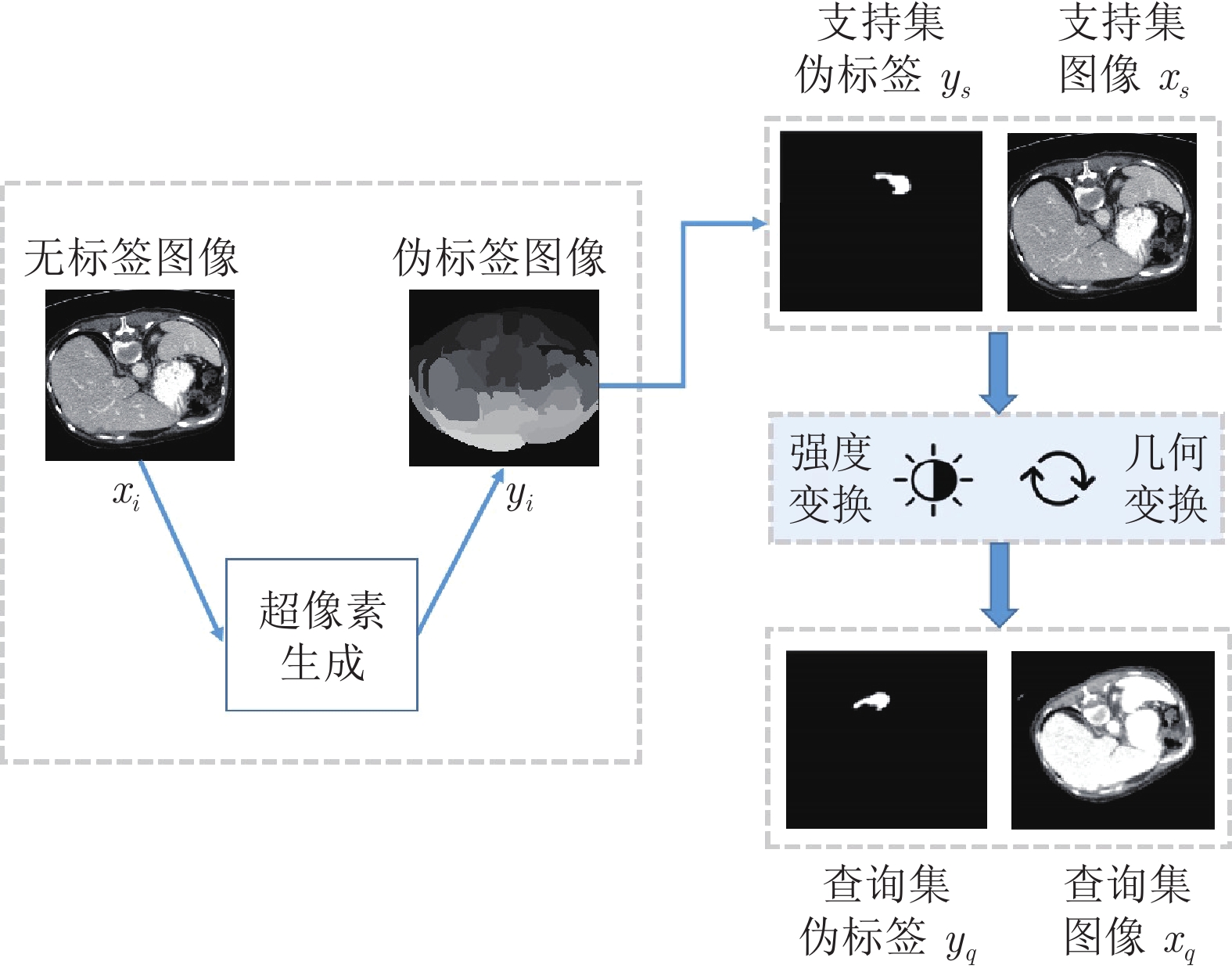
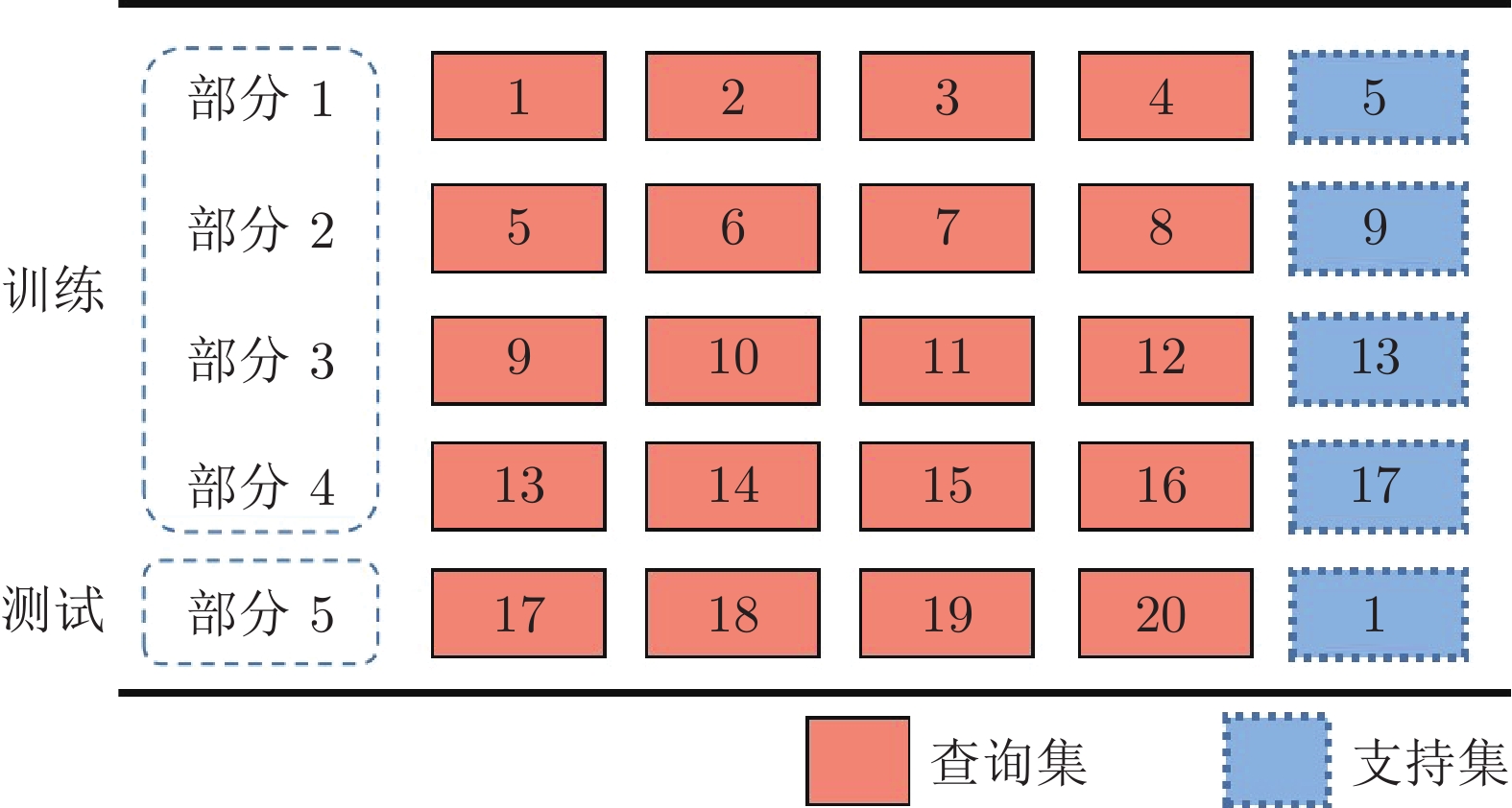
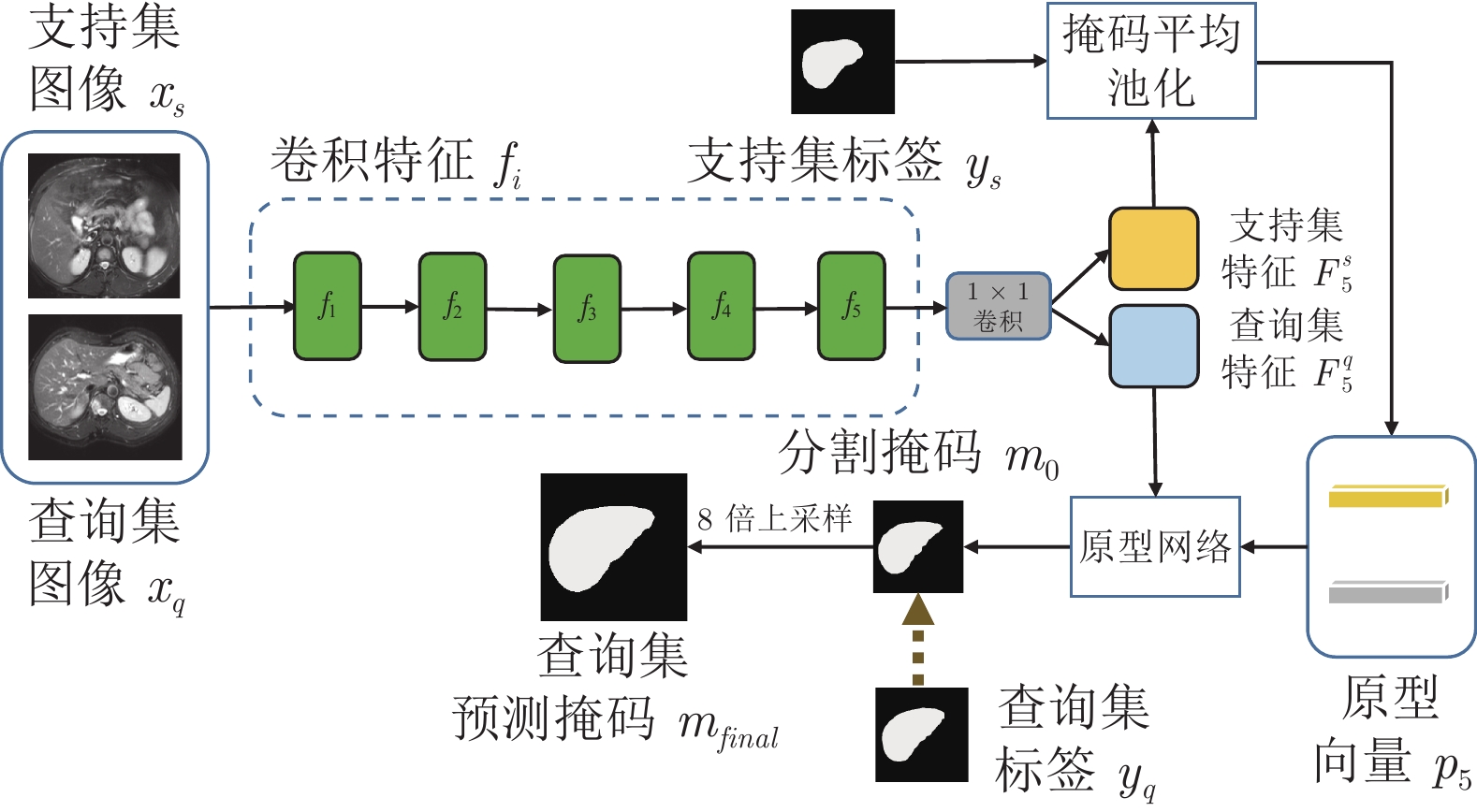
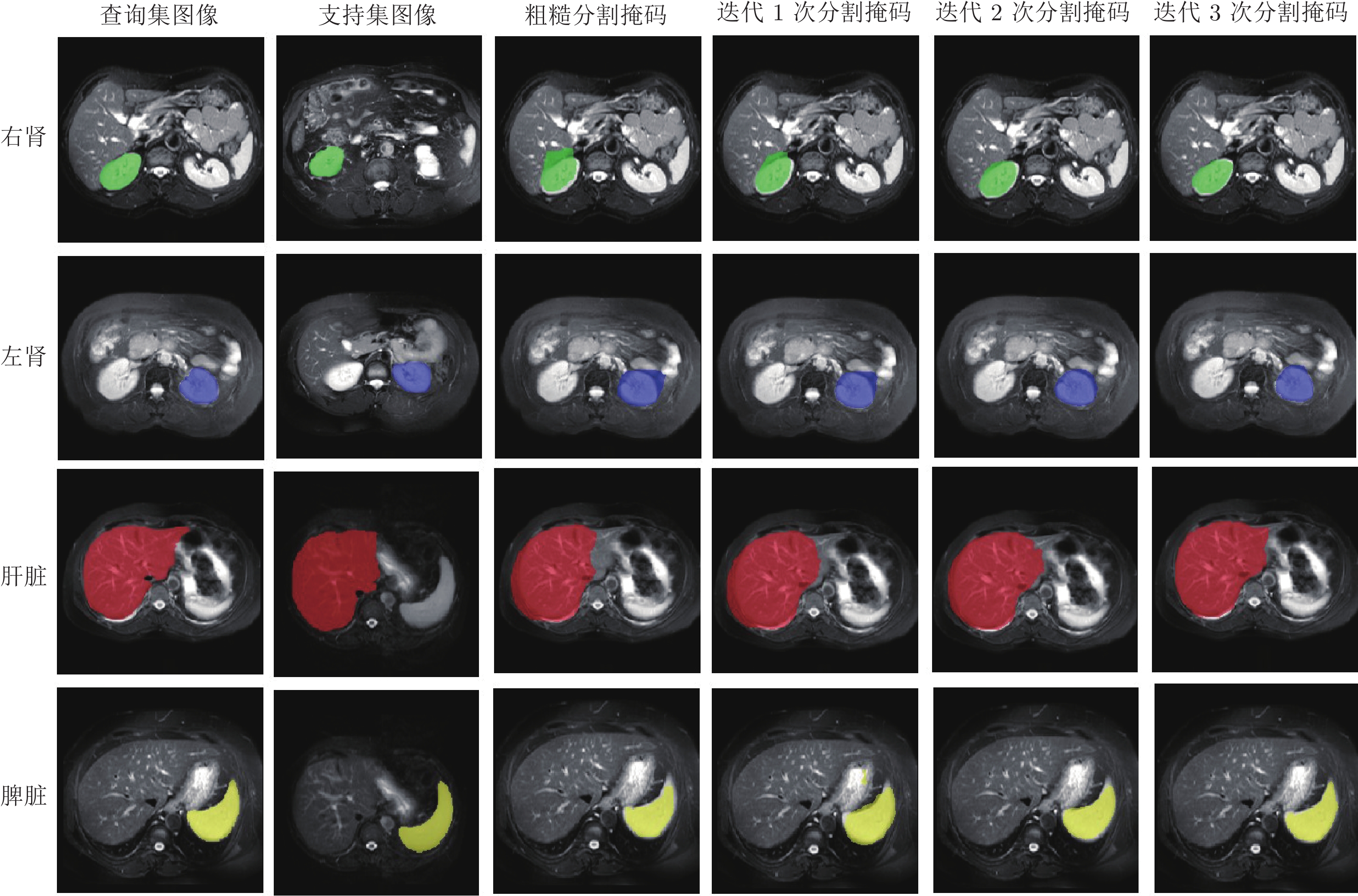
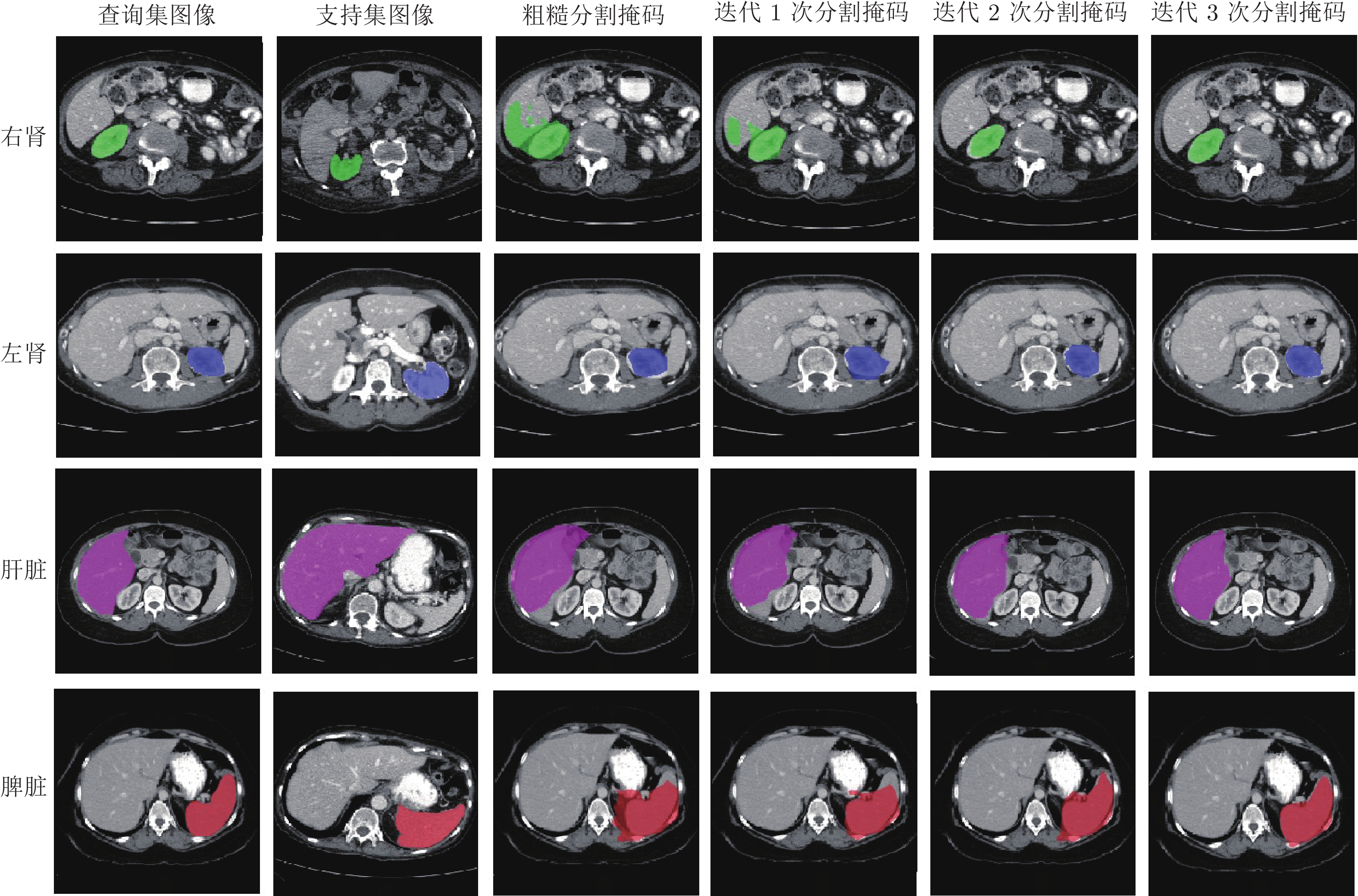
精准的医学图像自动分割是临床影像学诊断和影像三维重建的重要基础. 但医学图像数据的目标对象间对比度差异小、受器官运动影响大, 加之标注样本规模小, 因此在小样本下建立高性能的医学分割模型仍是目前的难点问题. 针对主流原型学习小样本分割网络对医学图像边界分割性能差的问题, 提出一种迭代边界优化的小样本分割网络(Iterative boundary refinement based few-shot segmentation network, IBR-FSS-Net). 以双分支原型学习的小样本分割框架为基础, 引入类别注意力机制和密集比较模块(Dense comparison module, DCM), 对粗分割掩码进行迭代优化, 引导分割模型在多次迭代学习过程中关注边界, 从而提升边界分割精度. 为进一步克服医学图像训练样本少且多样性不足问题, 使用超像素方法生成伪标签, 扩充训练数据以提升模型泛化性. 在ABD-MR和ABD-CT医学图像分割公共数据集上进行实验, 与现有多种先进的医学图像小样本分割方法进行对比分析和消融实验. 实验结果表明, 该方法有效提升了未见医学类别的分割性能.
精准的医学图像自动分割是临床影像学诊断和影像三维重建的重要基础. 但医学图像数据的目标对象间对比度差异小、受器官运动影响大, 加之标注样本规模小, 因此在小样本下建立高性能的医学分割模型仍是目前的难点问题. 针对主流原型学习小样本分割网络对医学图像边界分割性能差的问题, 提出一种迭代边界优化的小样本分割网络(Iterative boundary refinement based few-shot segmentation network, IBR-FSS-Net). 以双分支原型学习的小样本分割框架为基础, 引入类别注意力机制和密集比较模块(Dense comparison module, DCM), 对粗分割掩码进行迭代优化, 引导分割模型在多次迭代学习过程中关注边界, 从而提升边界分割精度. 为进一步克服医学图像训练样本少且多样性不足问题, 使用超像素方法生成伪标签, 扩充训练数据以提升模型泛化性. 在ABD-MR和ABD-CT医学图像分割公共数据集上进行实验, 与现有多种先进的医学图像小样本分割方法进行对比分析和消融实验. 实验结果表明, 该方法有效提升了未见医学类别的分割性能.
2024, 50(10): 2002-2012.
doi: 10.16383/j.aas.c210174
cstr: 32138.14.j.aas.c210174
摘要:
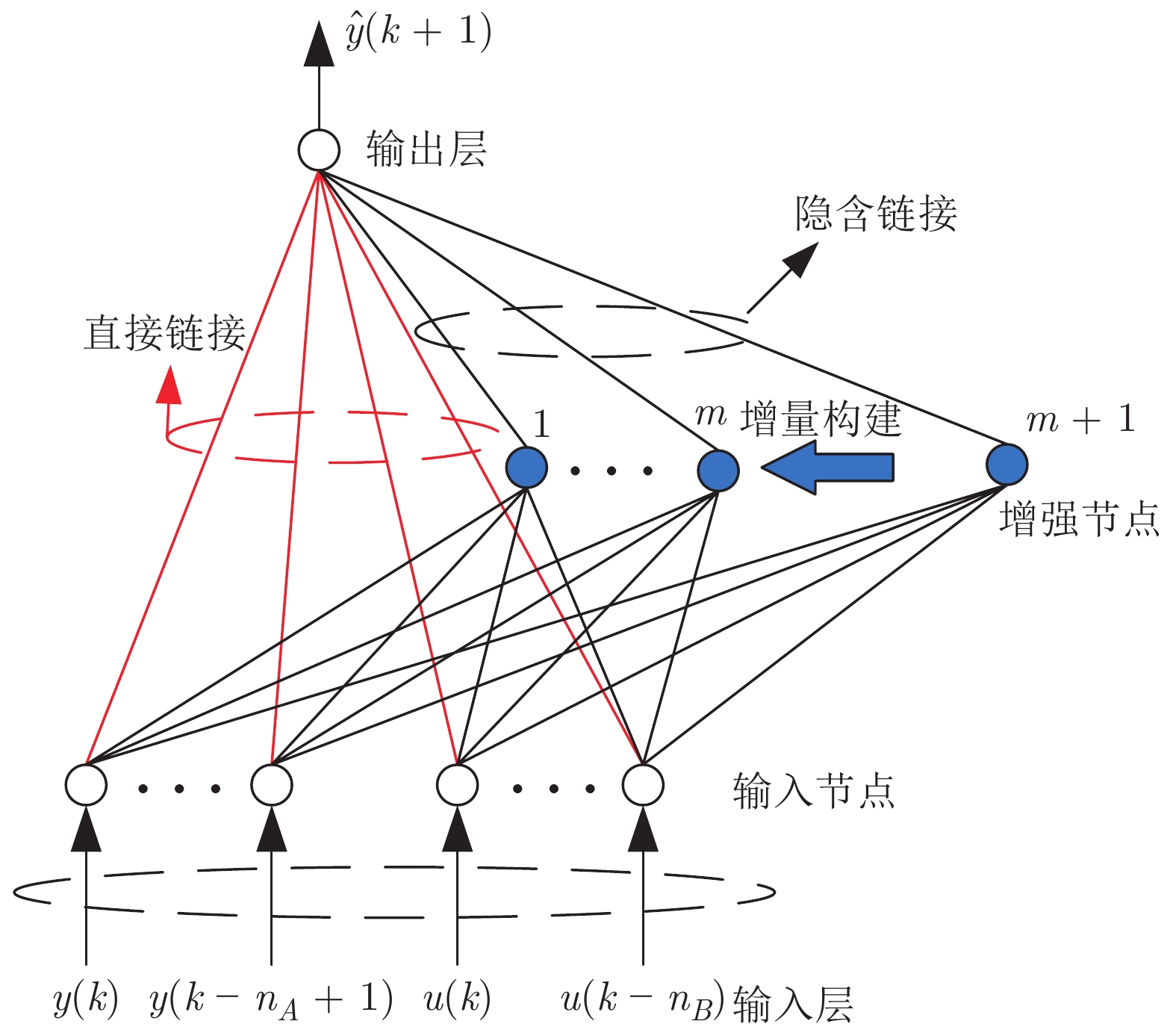
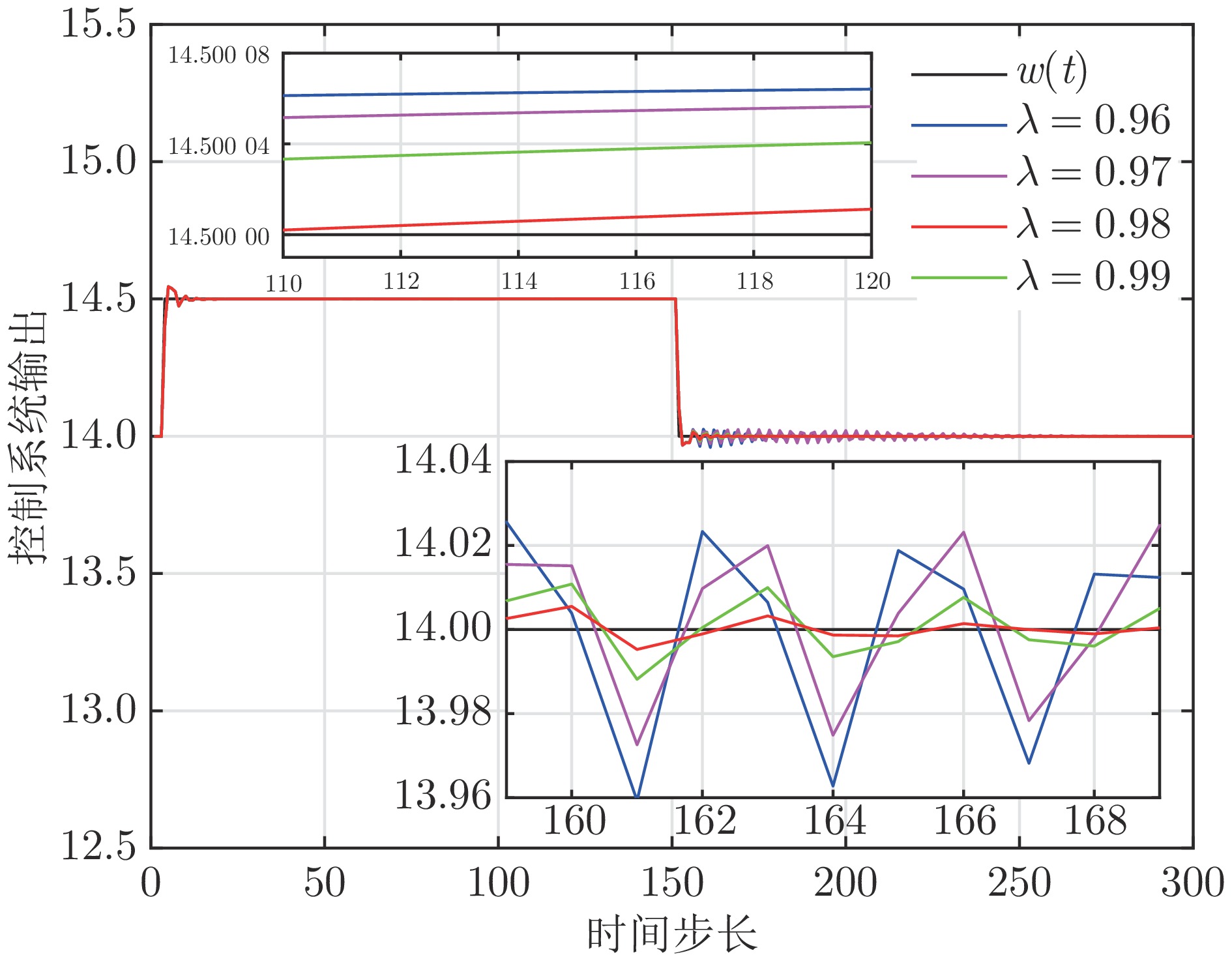
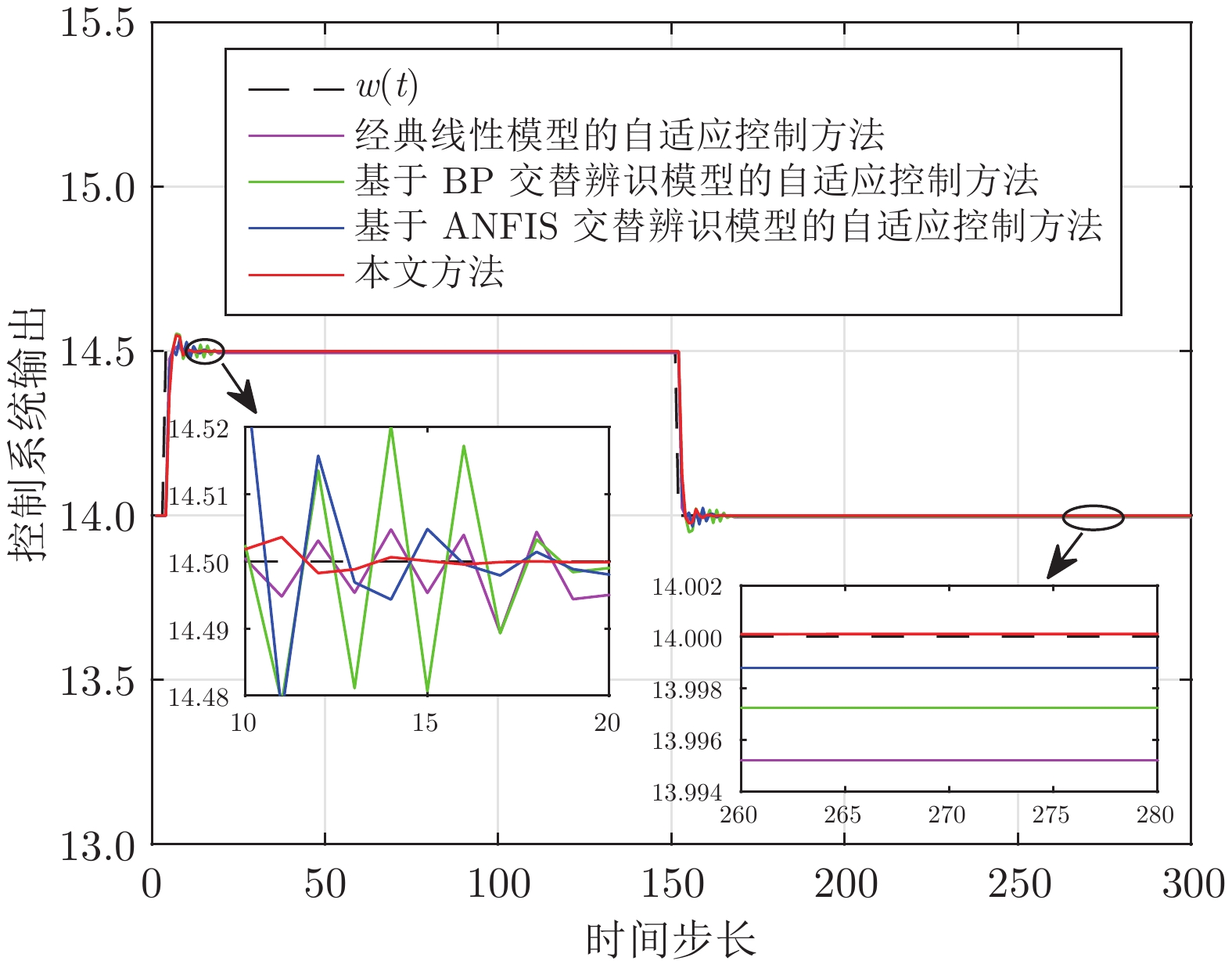
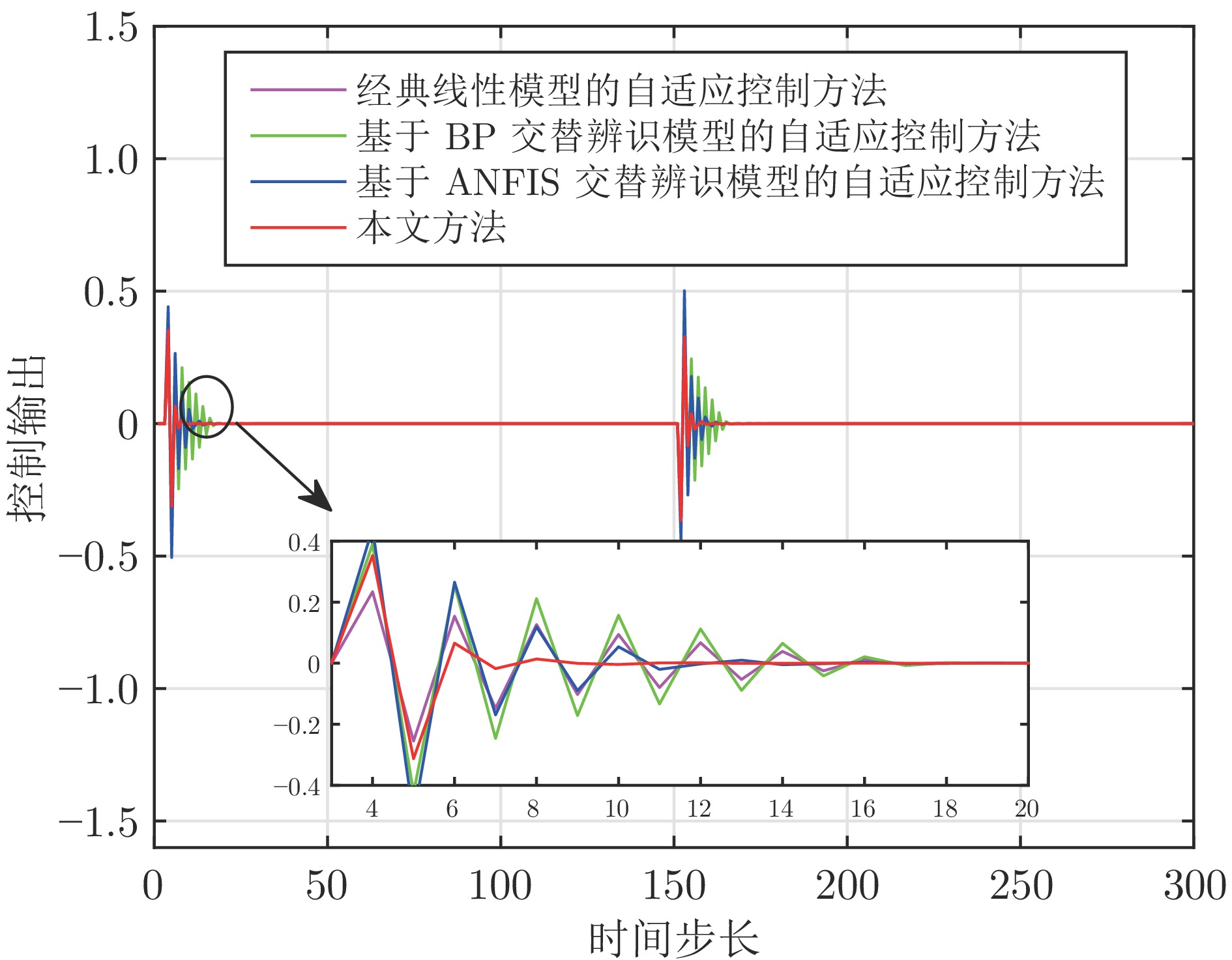
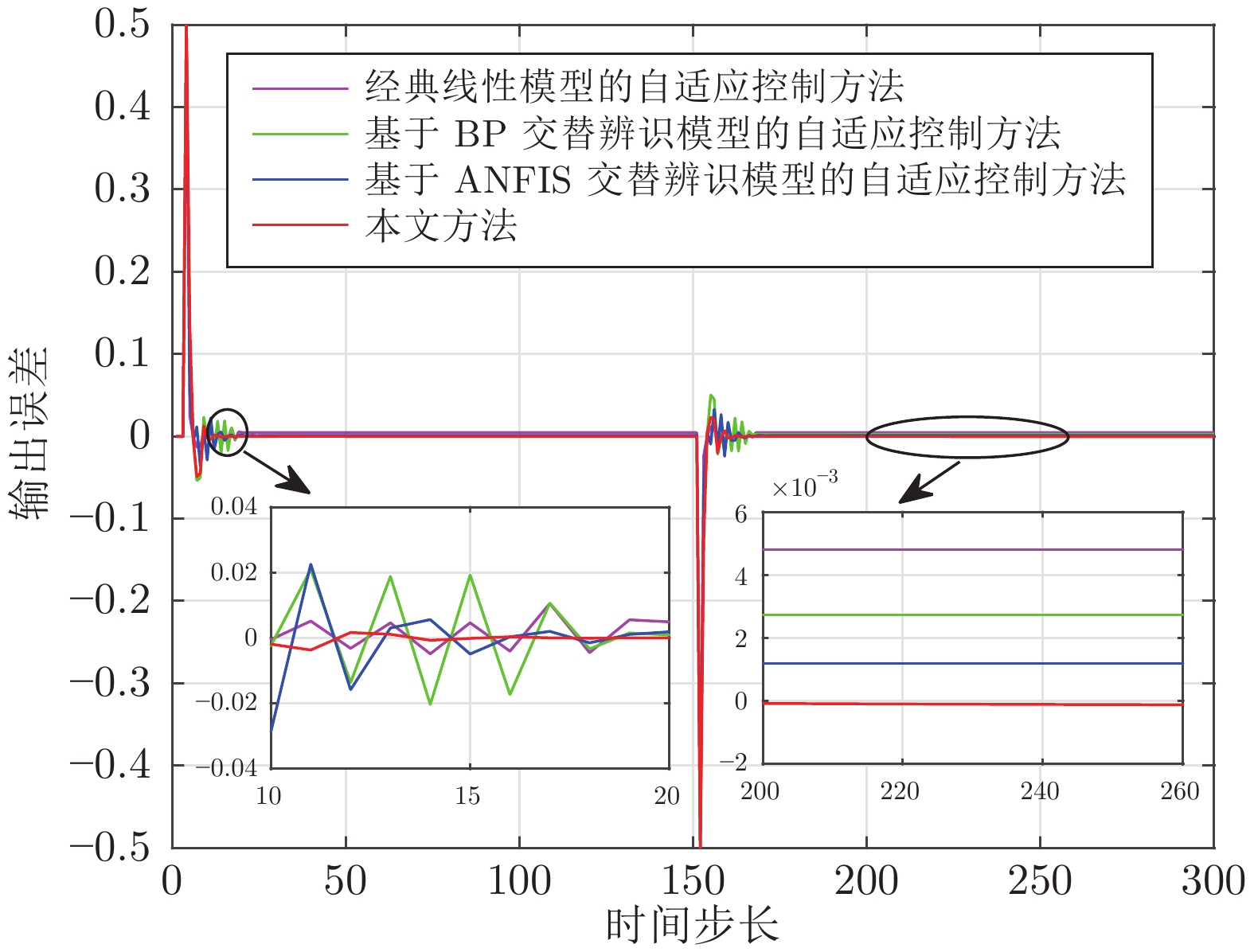
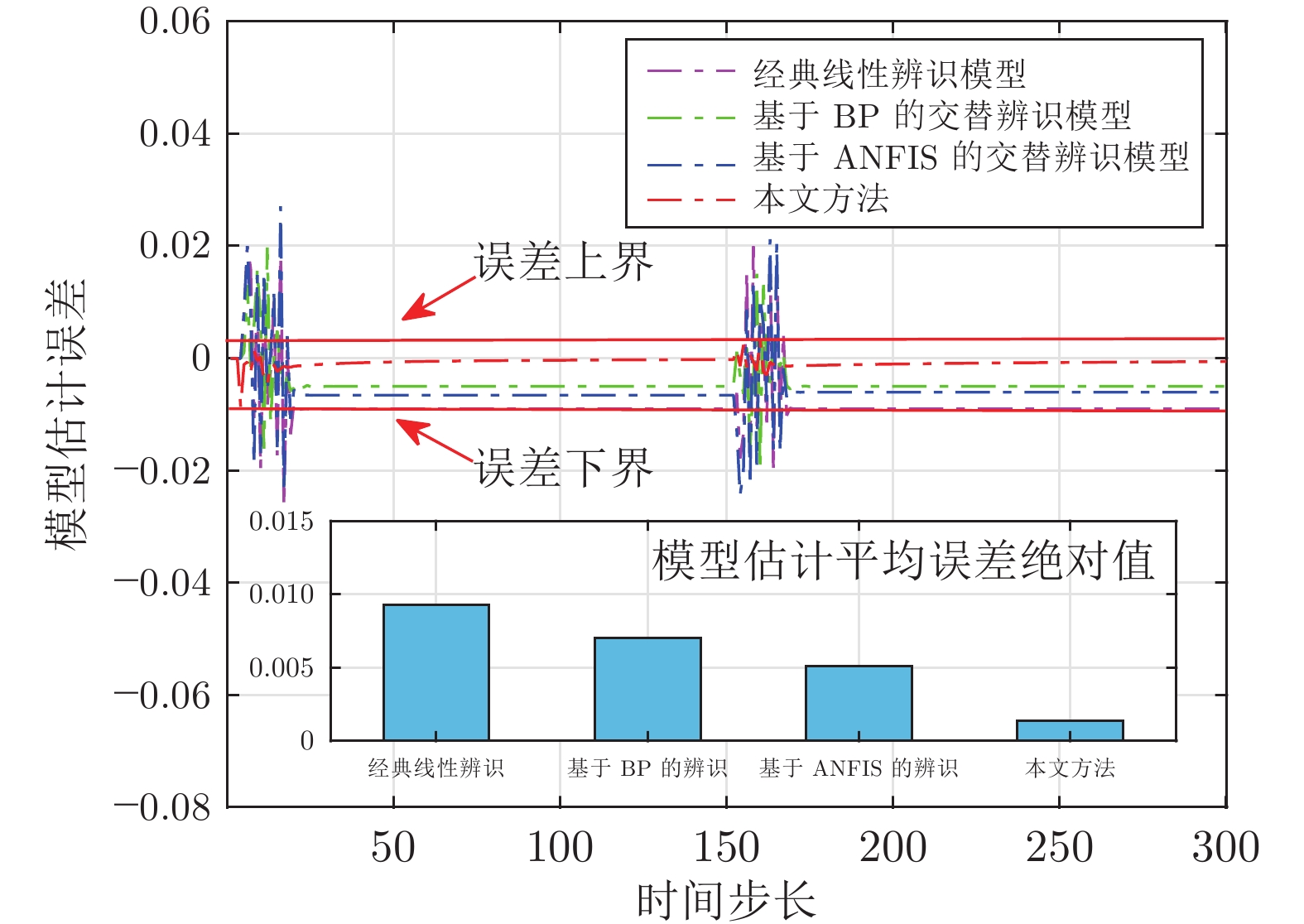
针对一类难以建立精确模型的单输入单输出(Single-input single-output, SISO) 非线性离散动态系统, 提出了一种数据驱动模型的自适应控制方法. 所提方法首先设计具有直链与增强结构的随机配置网络(Stochastic configuration network, SCN), 建立了一种可同时表征非线性系统低阶线性部分与高阶非线性项(未建模动态)的数据驱动模型, 并采用增量学习方法与监督机制, 对模型结构与模型参数进行同步更新优化, 保证了数据驱动模型的无限逼近能力, 解决了传统自适应控制采用交替辨识算法存在的建模精度低、模型收敛性无法保证的问题. 进而利用直链部分与增强部分, 分别设计了线性控制器及虚拟未建模动态补偿器, 建立了基于SCN 数据驱动模型的自适应控制新方法, 分析了其稳定性与收敛性, 通过数值仿真实验和采用交替辨识算法的传统自适应控制方法进行对比, 实验结果表明了所提方法的有效性.
针对一类难以建立精确模型的单输入单输出(Single-input single-output, SISO) 非线性离散动态系统, 提出了一种数据驱动模型的自适应控制方法. 所提方法首先设计具有直链与增强结构的随机配置网络(Stochastic configuration network, SCN), 建立了一种可同时表征非线性系统低阶线性部分与高阶非线性项(未建模动态)的数据驱动模型, 并采用增量学习方法与监督机制, 对模型结构与模型参数进行同步更新优化, 保证了数据驱动模型的无限逼近能力, 解决了传统自适应控制采用交替辨识算法存在的建模精度低、模型收敛性无法保证的问题. 进而利用直链部分与增强部分, 分别设计了线性控制器及虚拟未建模动态补偿器, 建立了基于SCN 数据驱动模型的自适应控制新方法, 分析了其稳定性与收敛性, 通过数值仿真实验和采用交替辨识算法的传统自适应控制方法进行对比, 实验结果表明了所提方法的有效性.

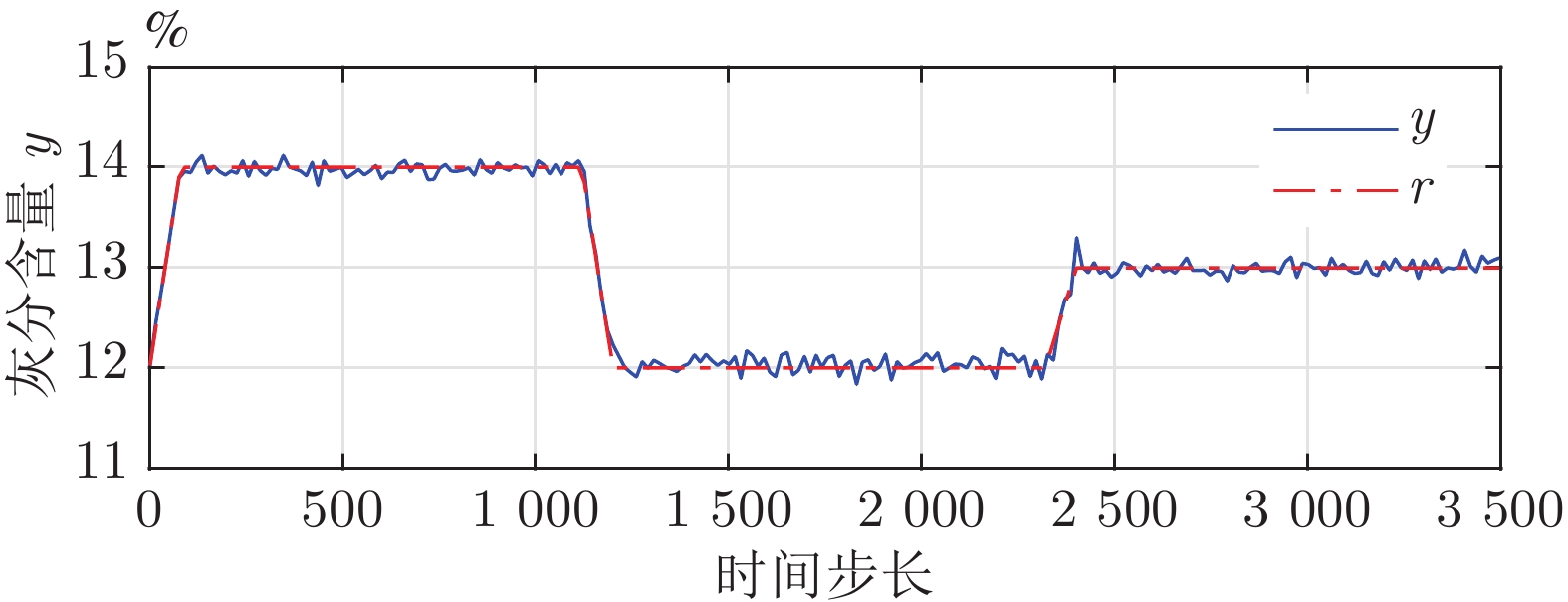
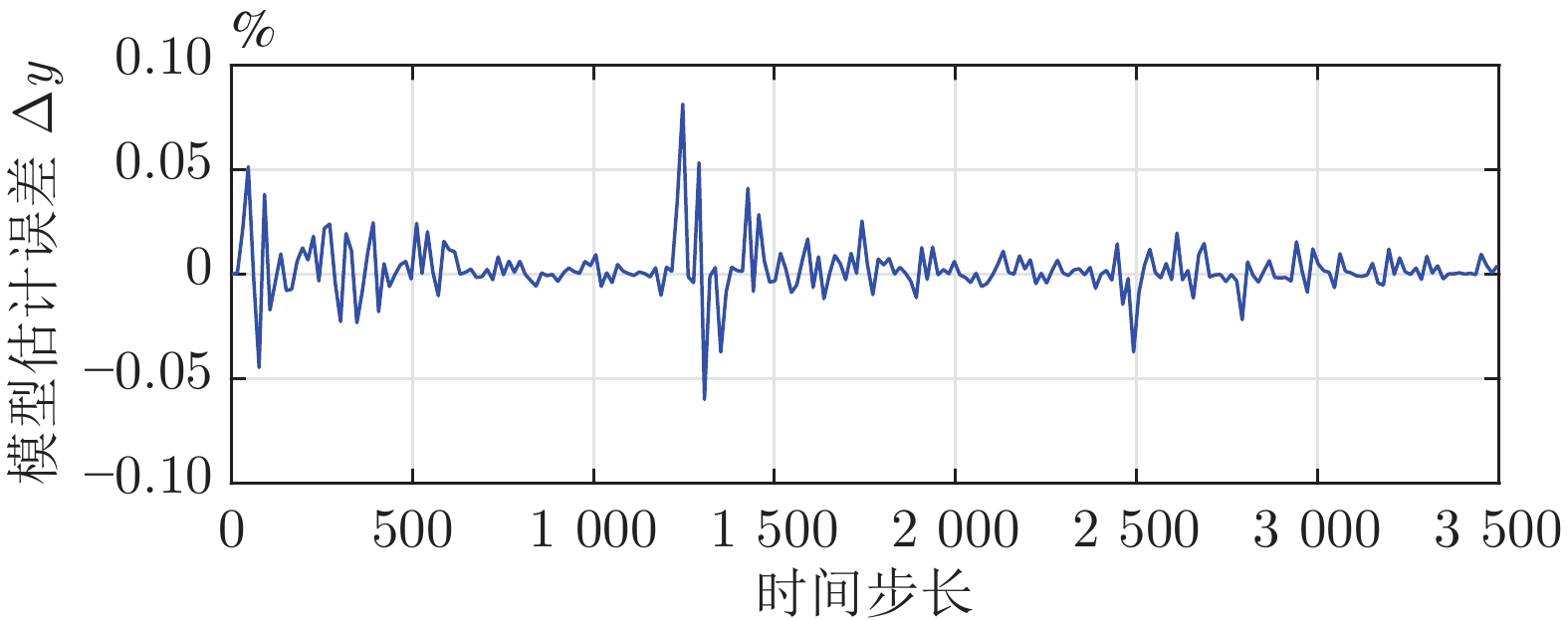
2024, 50(10): 2013-2021.
doi: 10.16383/j.aas.c210303
cstr: 32138.14.j.aas.c210303
摘要:
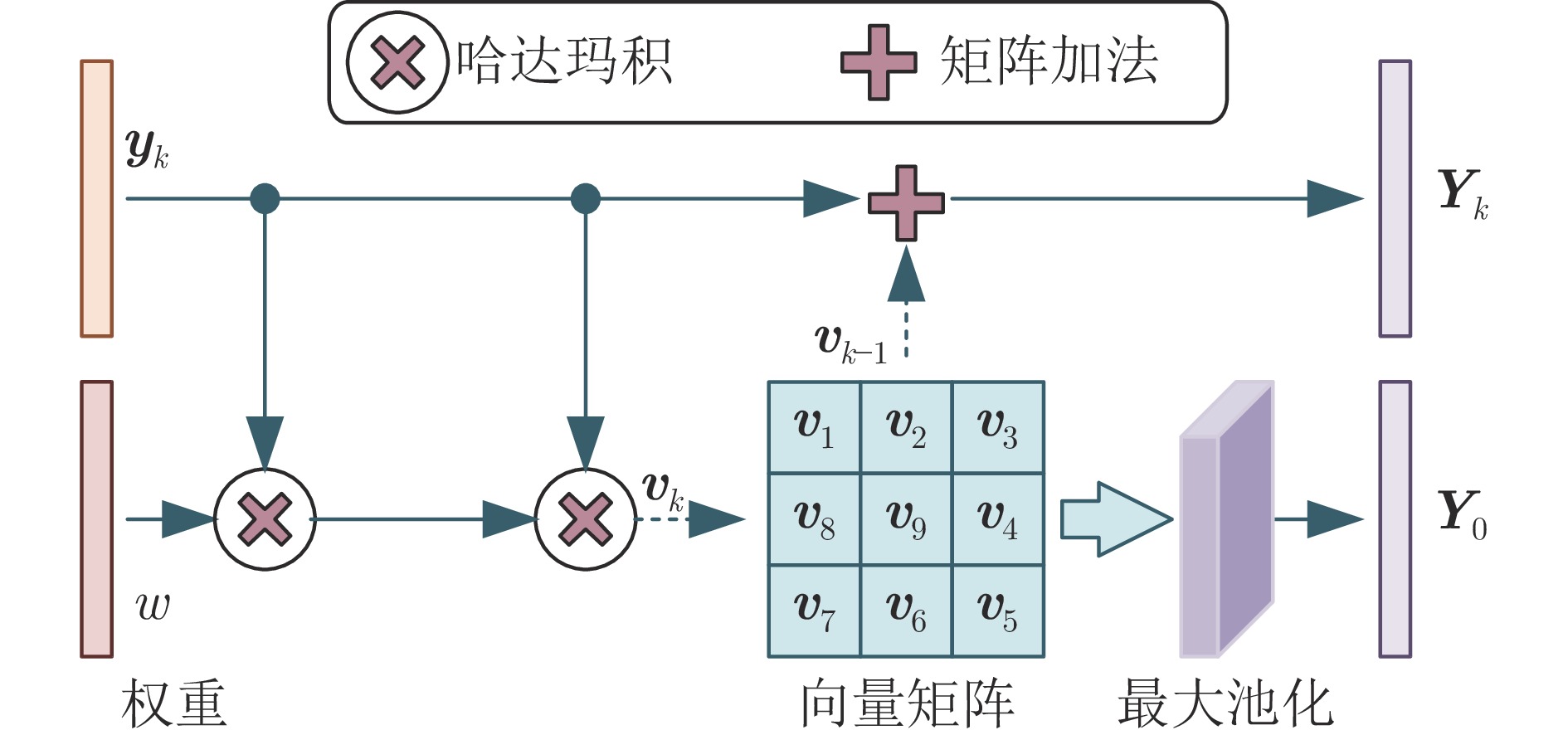
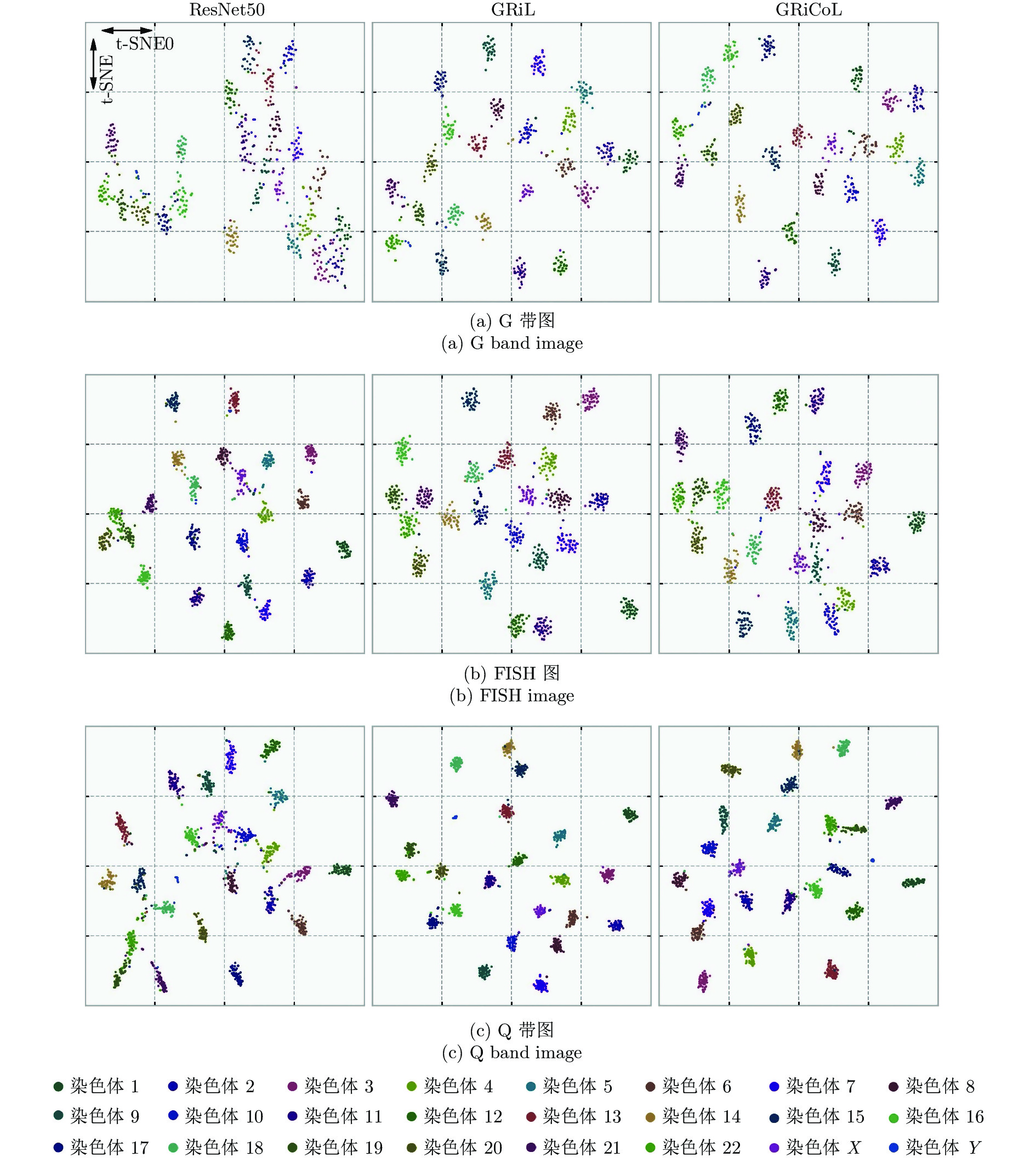
染色体的分类是核型分析的重要任务之一. 因其柔软易弯曲, 且类间差异小、类内差异大等特点, 其精准分类仍然是一个具有挑战性的难题. 对此, 提出一种基于网格重构学习(Grid reconstruction learning, GRiCoL)的染色体分类模型. 该模型首先将染色体图像网格化, 提取局部分类特征; 然后通过重构网络对全局特征进行二次提取; 最后完成分类. 相比于现有几种先进方法, GRiCoL同时兼顾局部和全局特征提取更有效的分类特征, 有效改善染色体弯曲导致的分类性能下降, 参数规模合理. 通过基于G带、荧光原位杂交 (Fluorescence in situ hybridization, FISH)、Q带染色体公开数据集的实验表明: GRiCoL能够更好地弱化染色体弯曲带来的影响, 在不同数据集上的分类准确度均优于现有分类方法.
染色体的分类是核型分析的重要任务之一. 因其柔软易弯曲, 且类间差异小、类内差异大等特点, 其精准分类仍然是一个具有挑战性的难题. 对此, 提出一种基于网格重构学习(Grid reconstruction learning, GRiCoL)的染色体分类模型. 该模型首先将染色体图像网格化, 提取局部分类特征; 然后通过重构网络对全局特征进行二次提取; 最后完成分类. 相比于现有几种先进方法, GRiCoL同时兼顾局部和全局特征提取更有效的分类特征, 有效改善染色体弯曲导致的分类性能下降, 参数规模合理. 通过基于G带、荧光原位杂交 (Fluorescence in situ hybridization, FISH)、Q带染色体公开数据集的实验表明: GRiCoL能够更好地弱化染色体弯曲带来的影响, 在不同数据集上的分类准确度均优于现有分类方法.
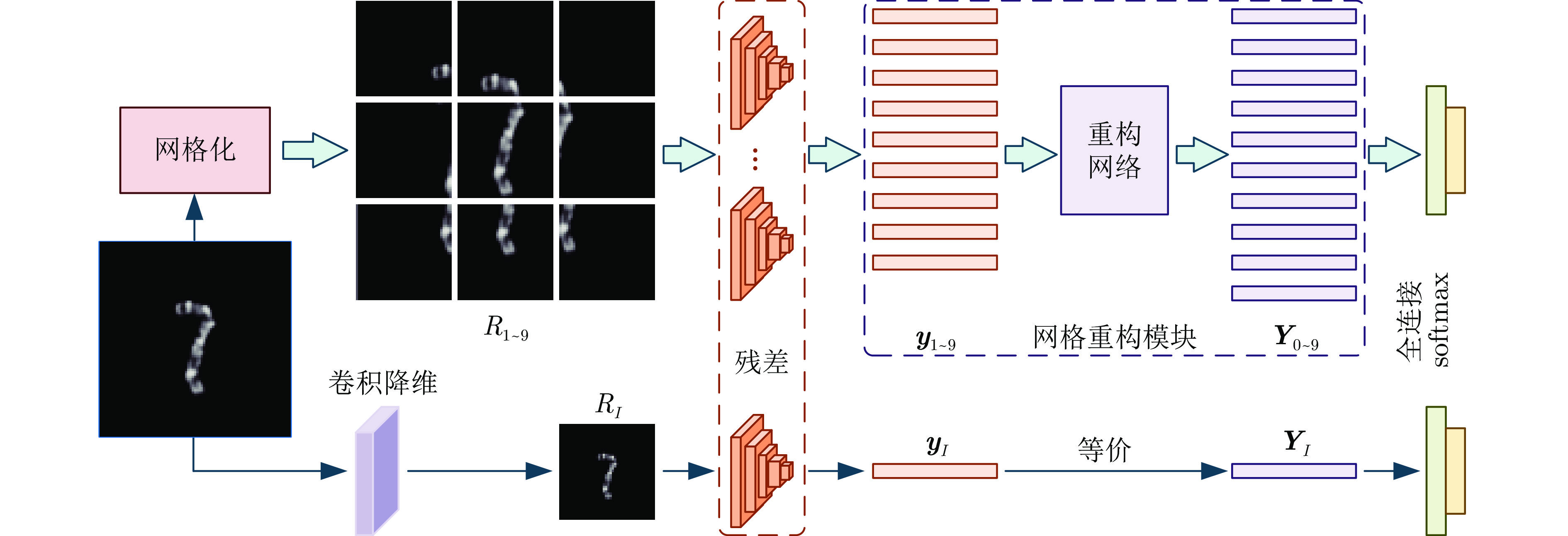
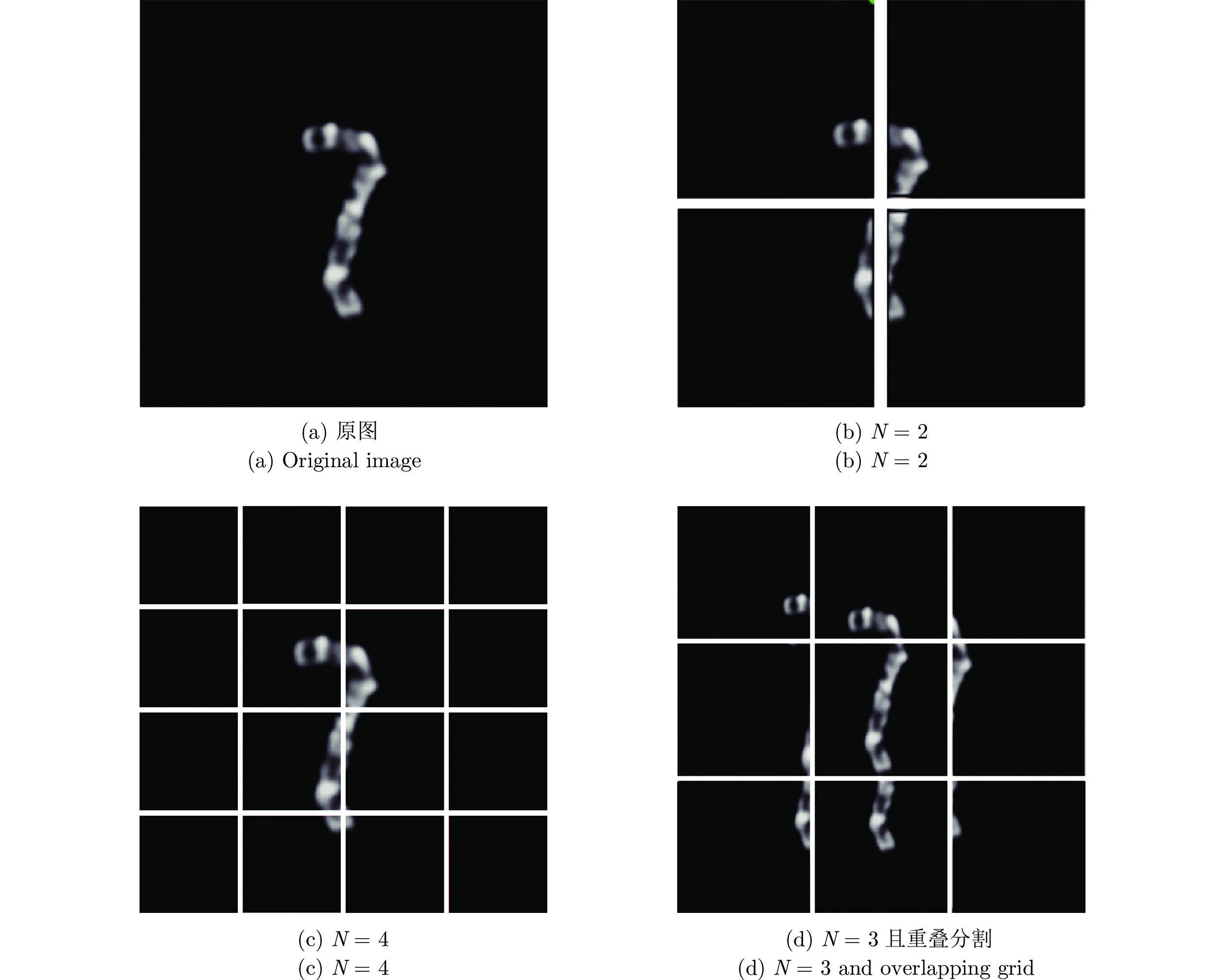


2024, 50(10): 2022-2035.
doi: 10.16383/j.aas.c230624
cstr: 32138.14.j.aas.c230624
摘要:
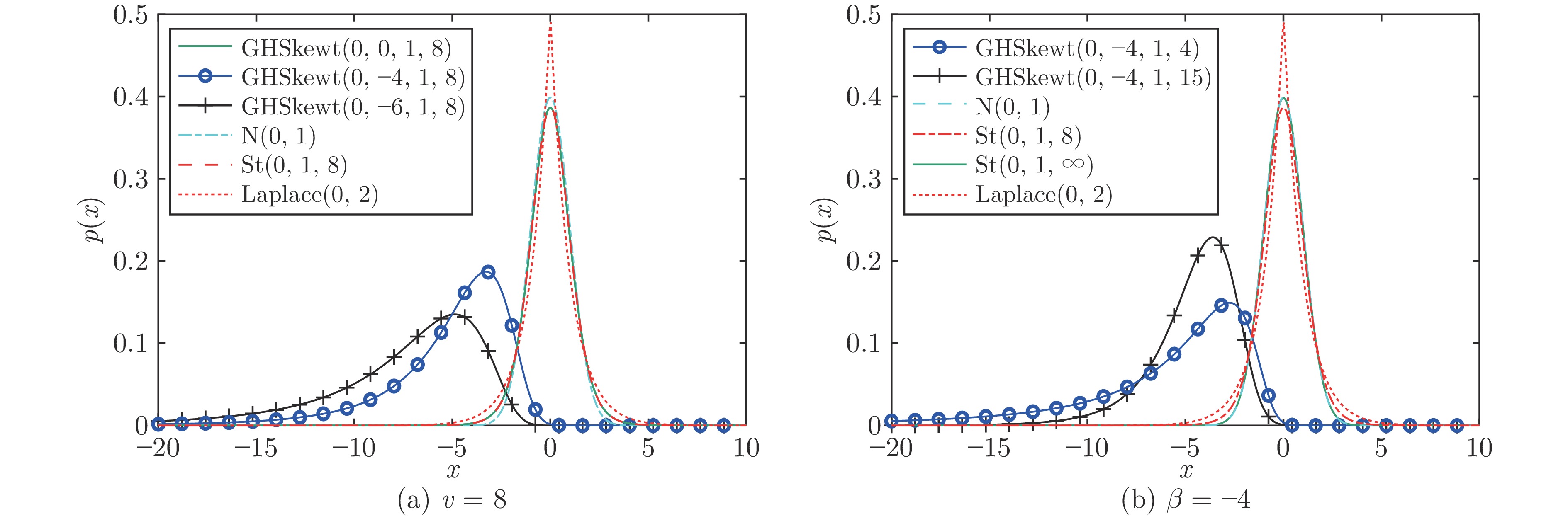
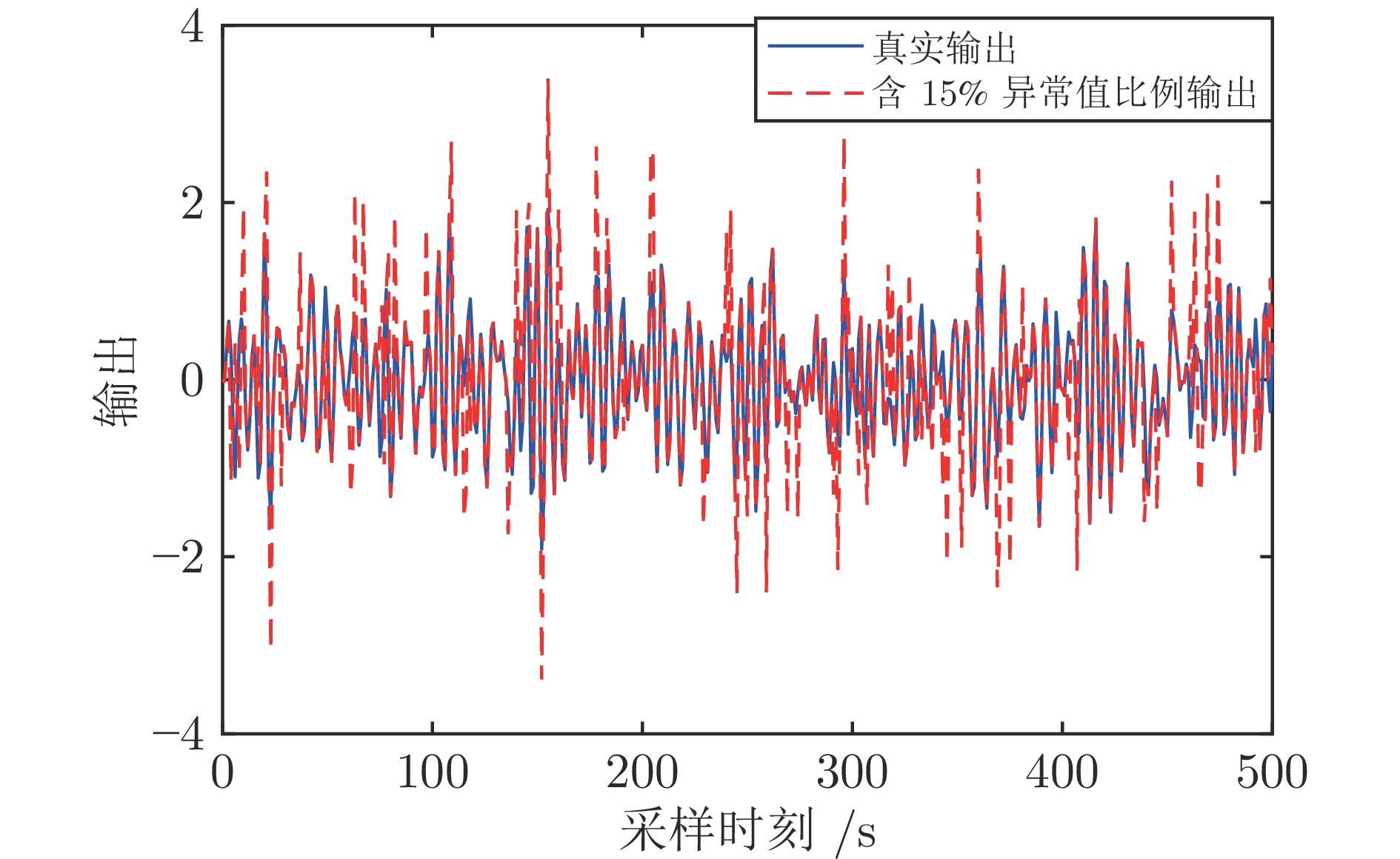
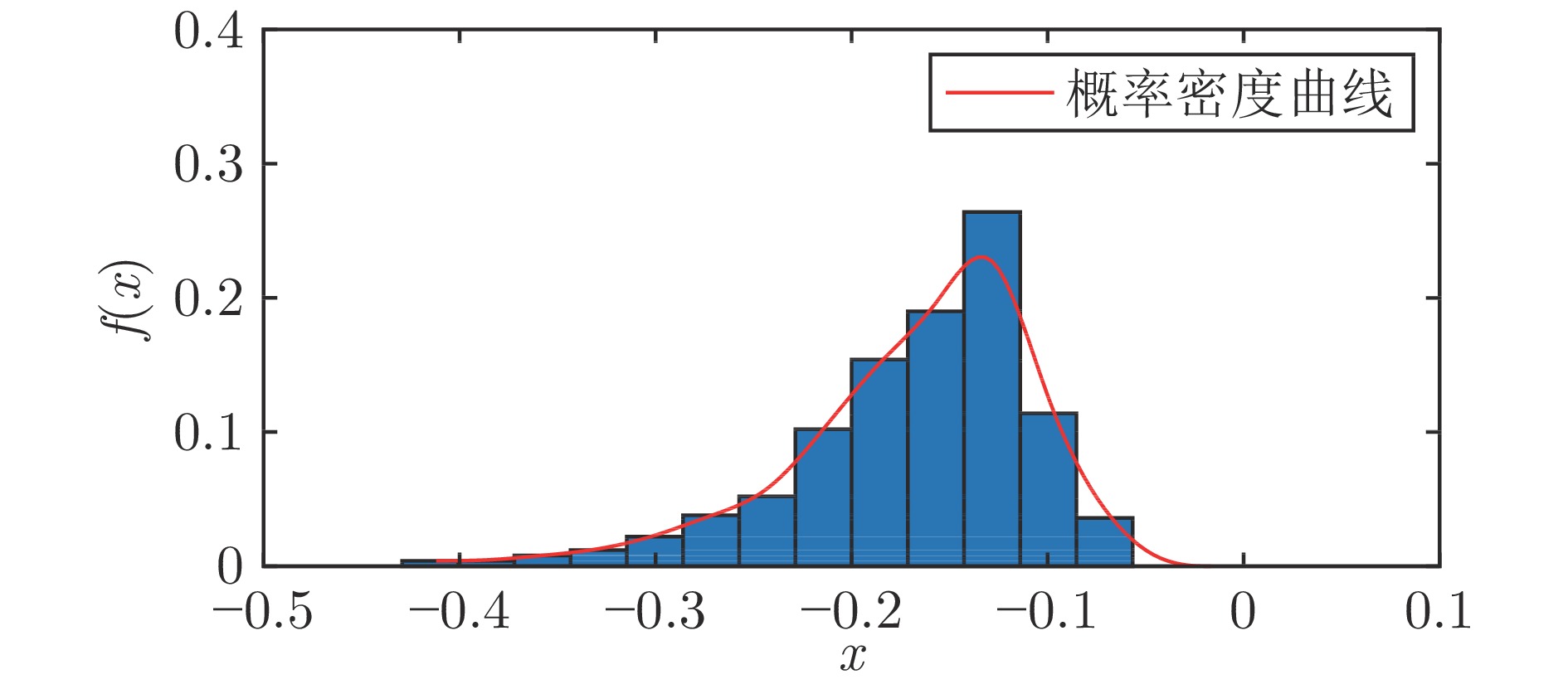
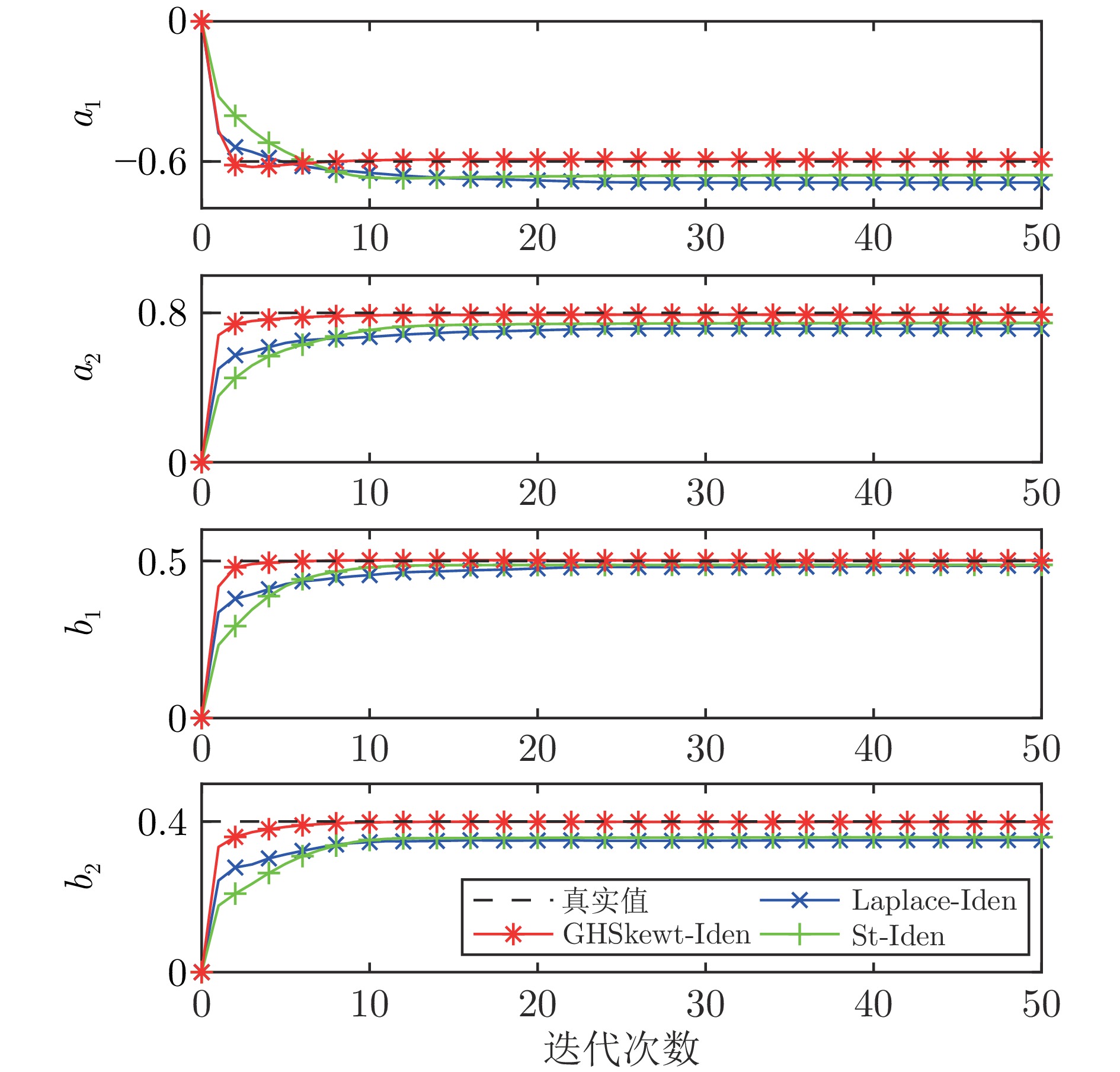
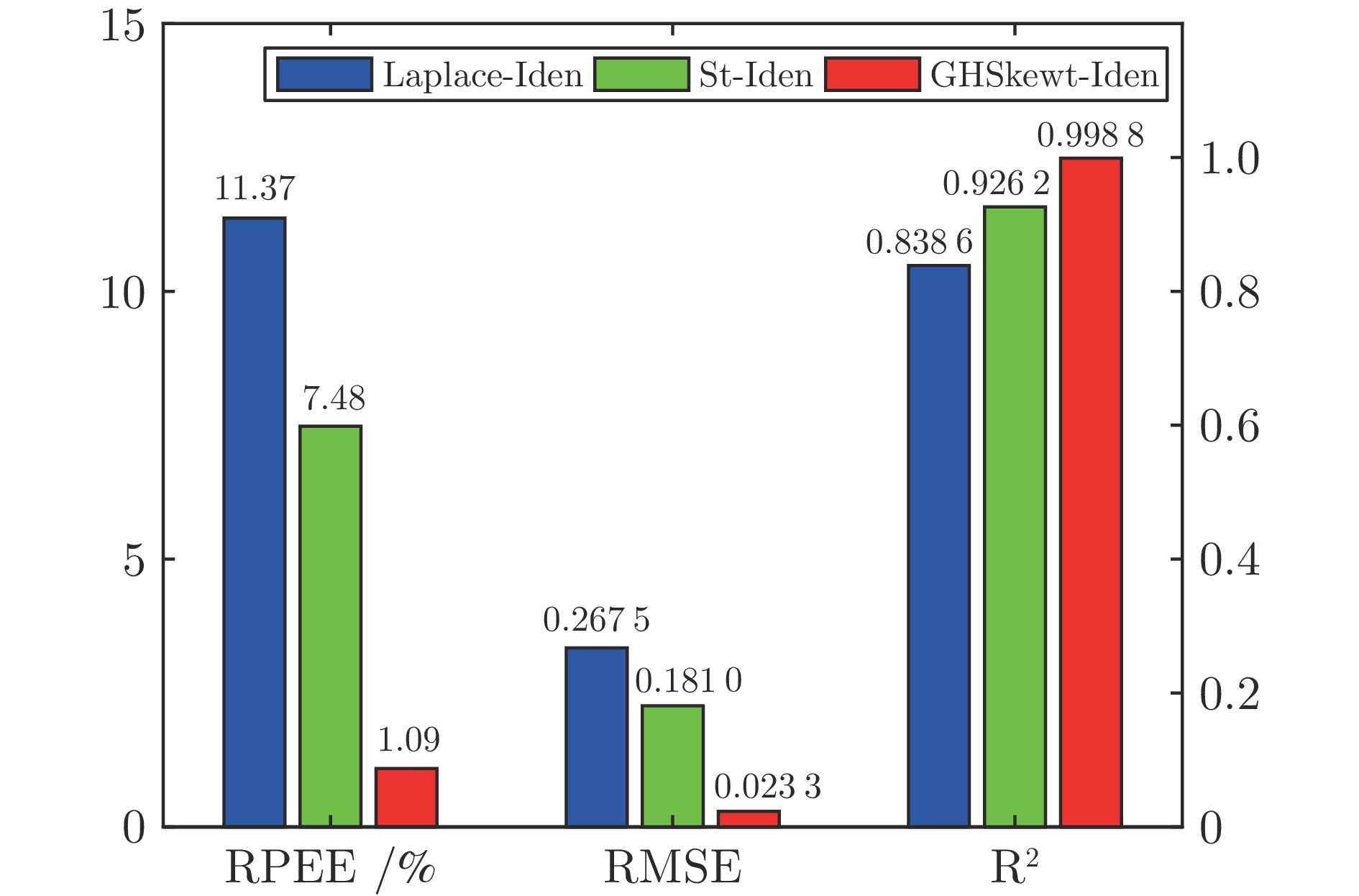
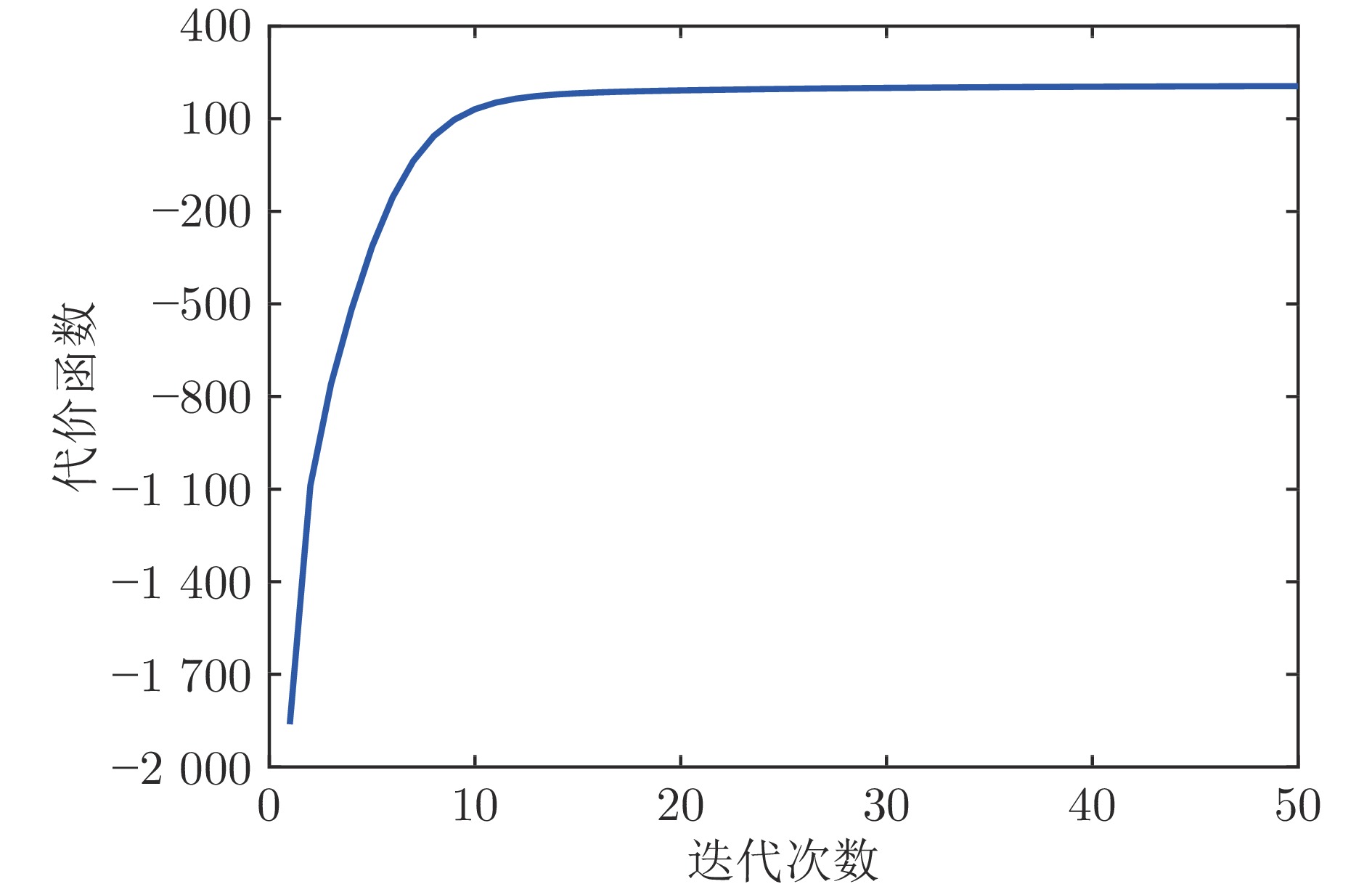
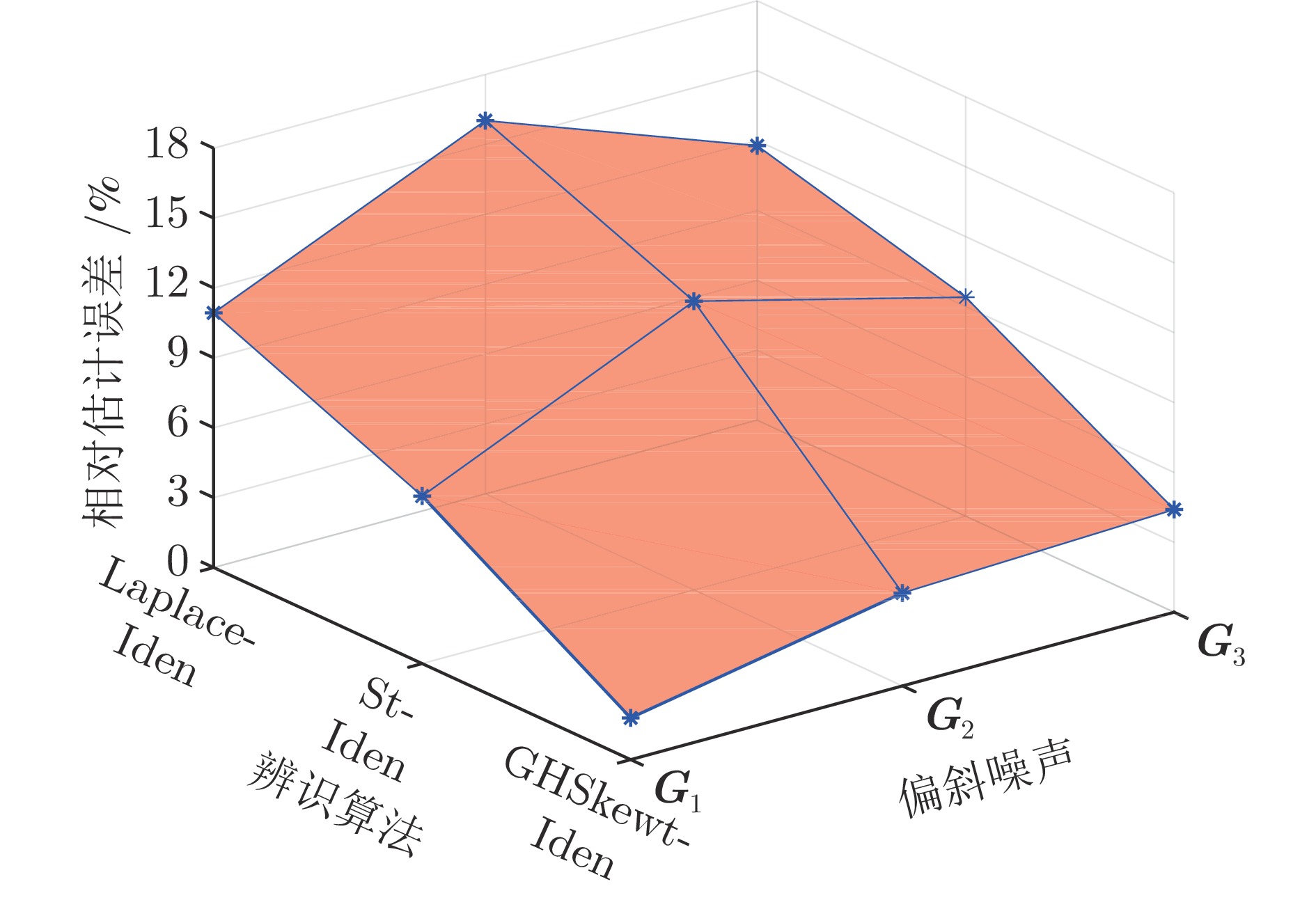
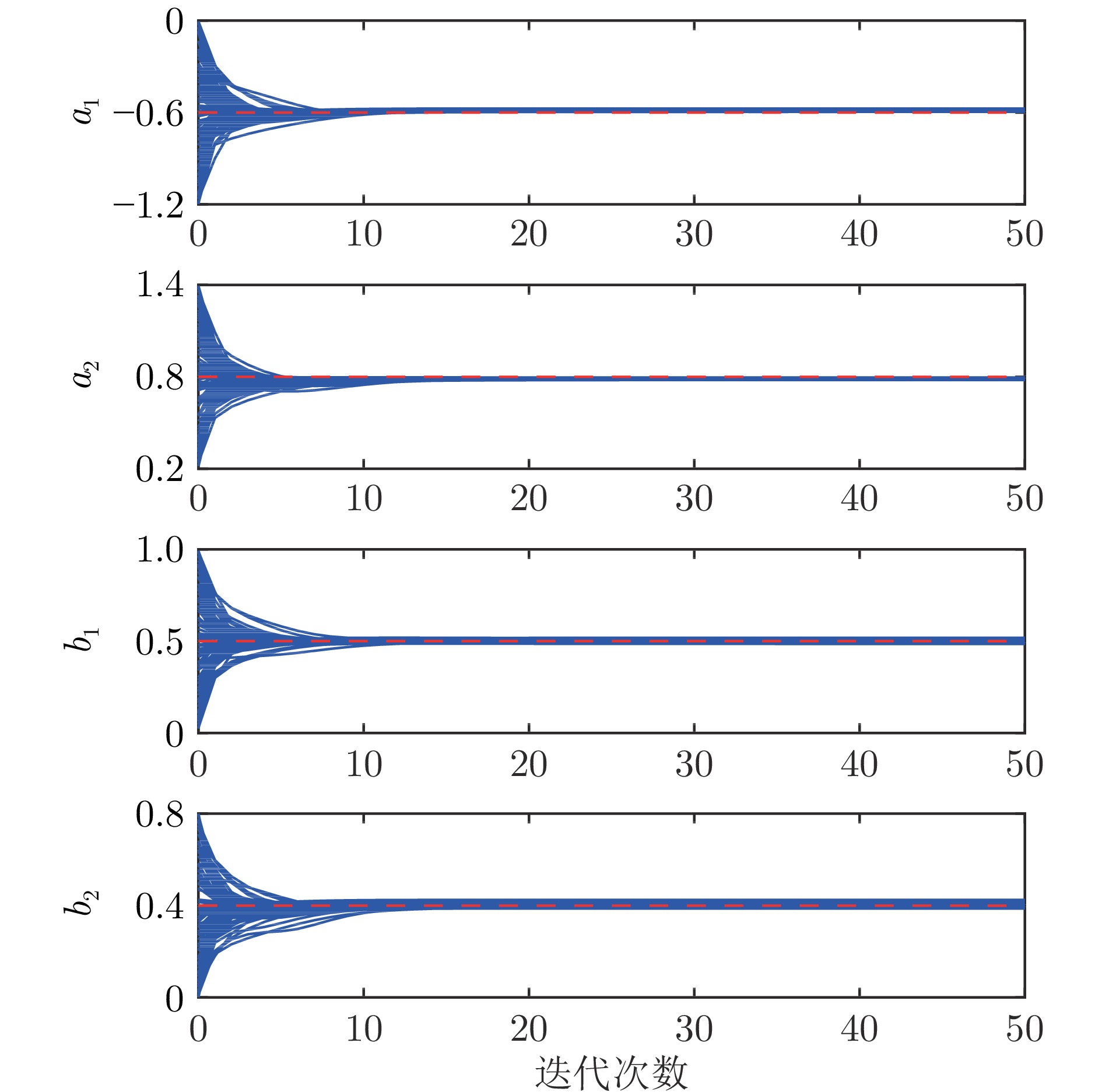
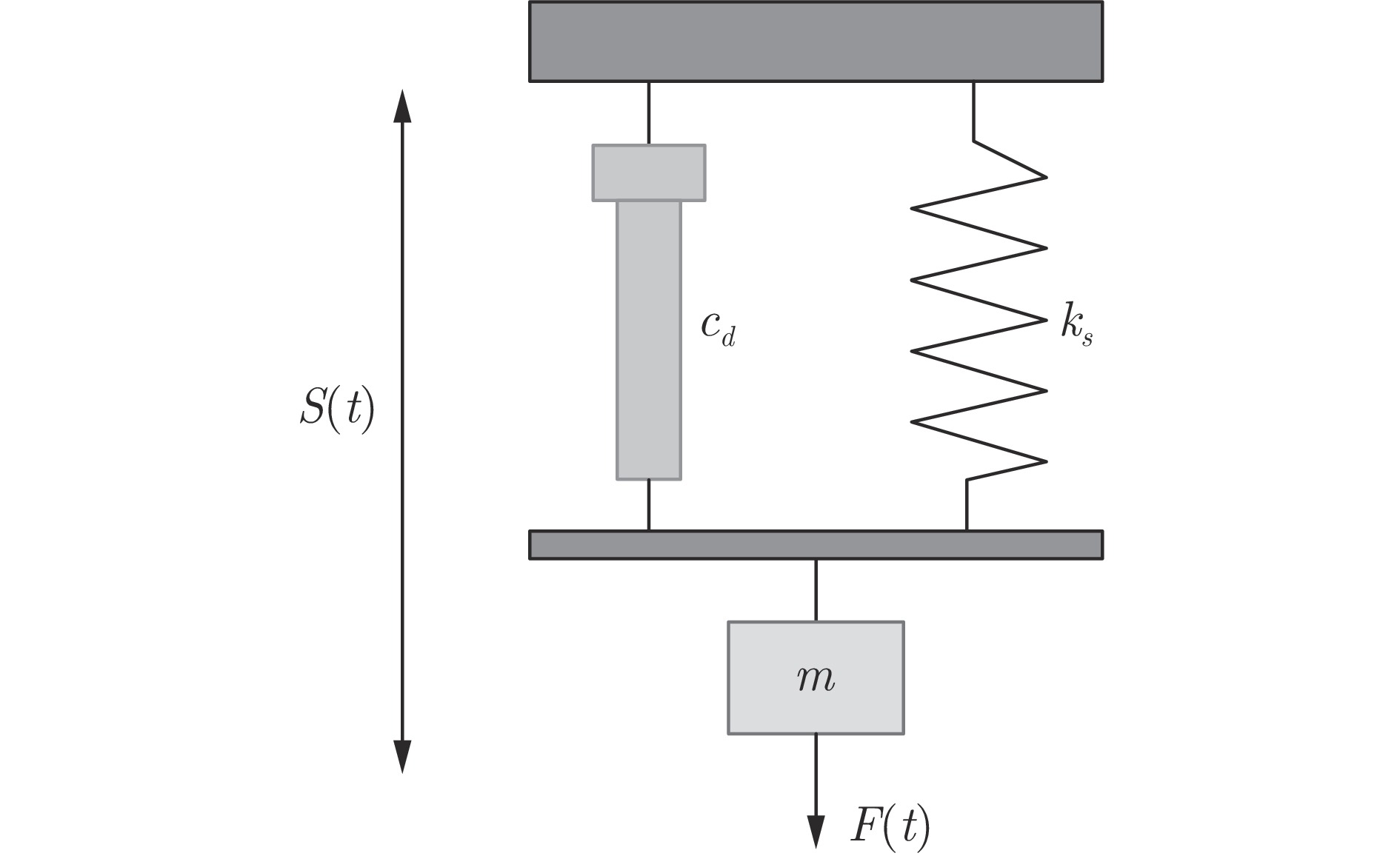
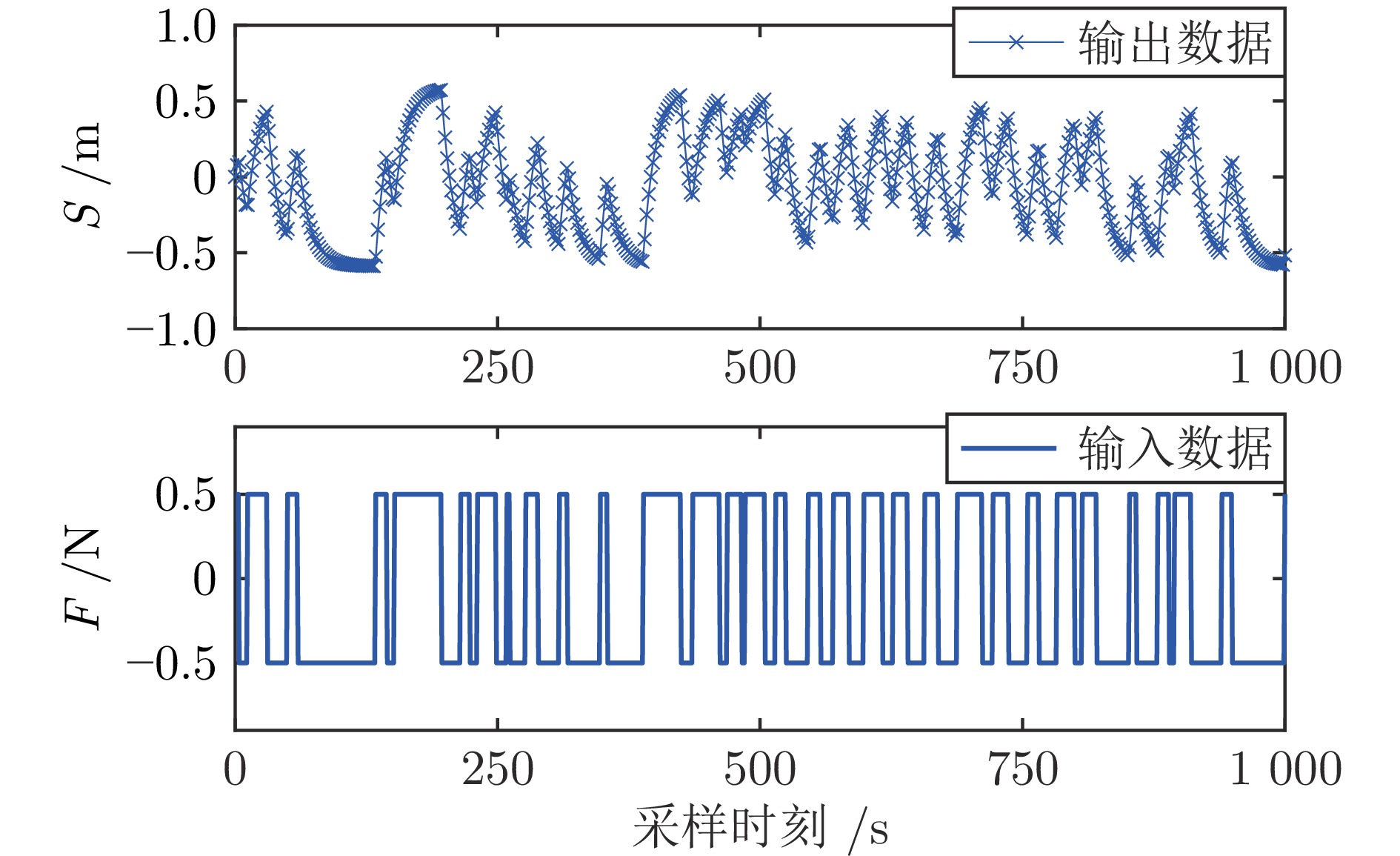
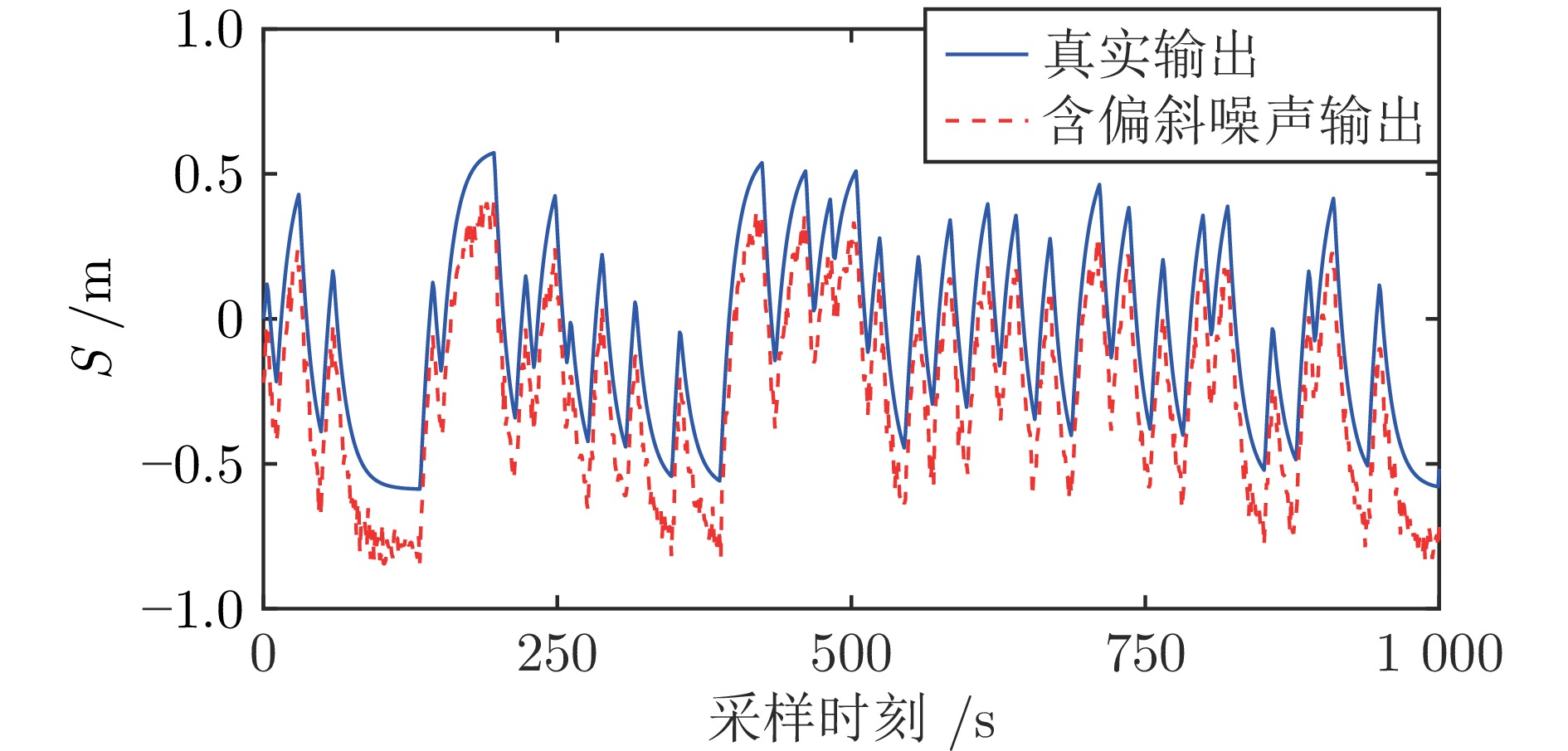
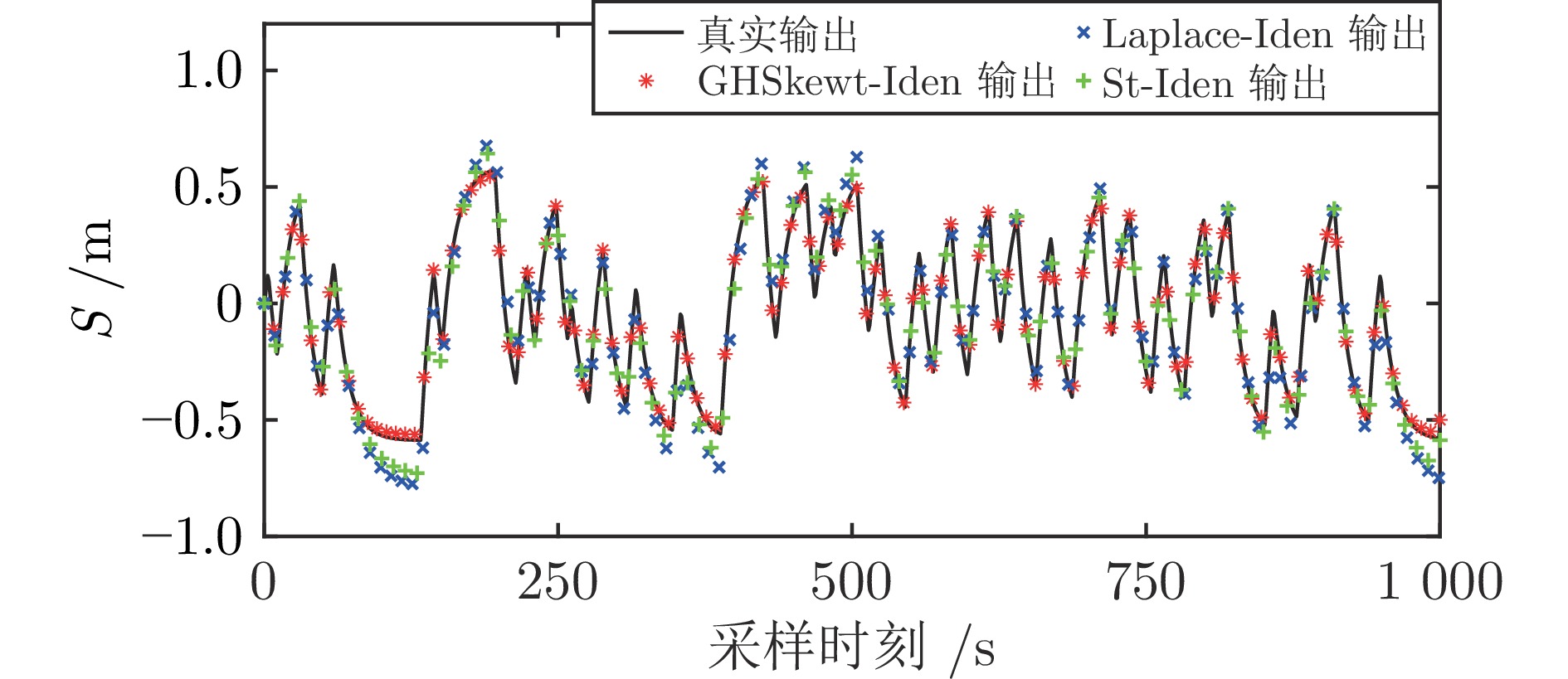
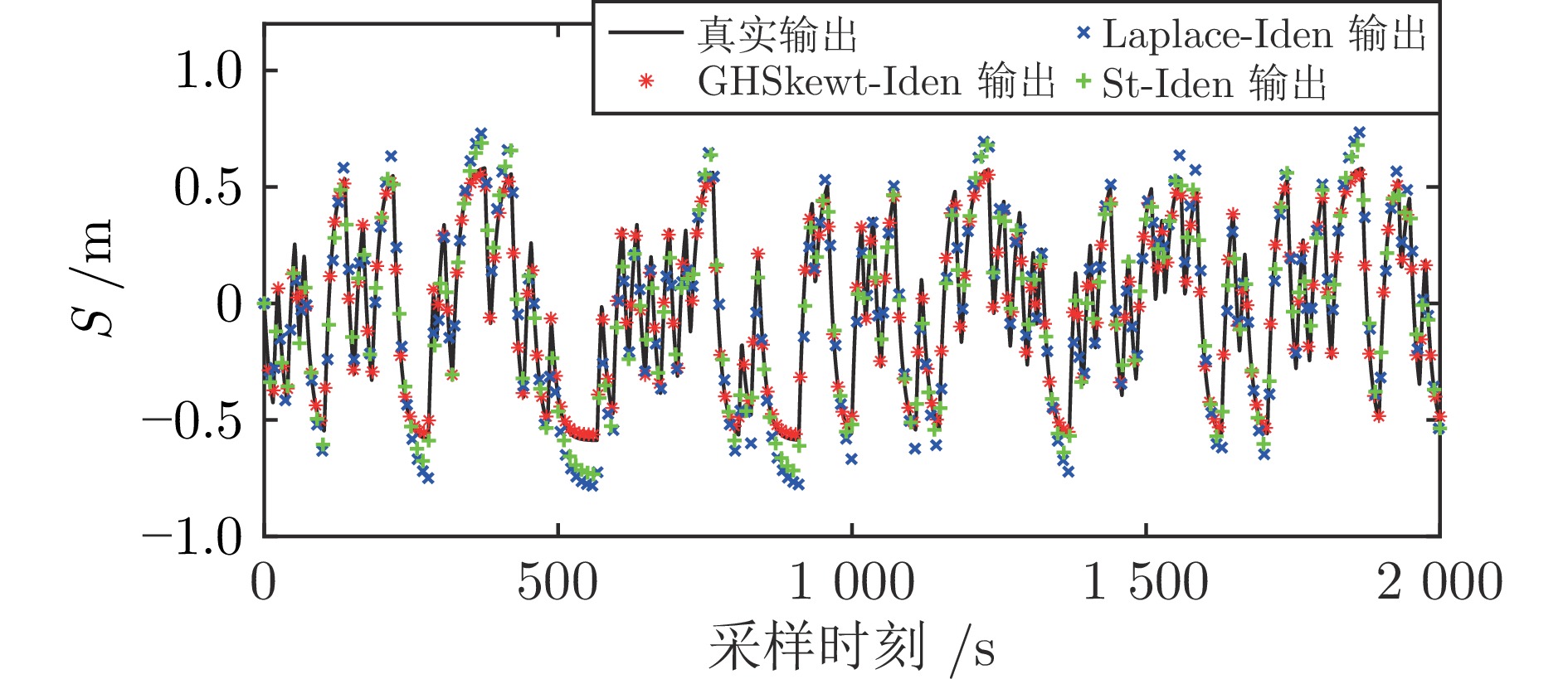
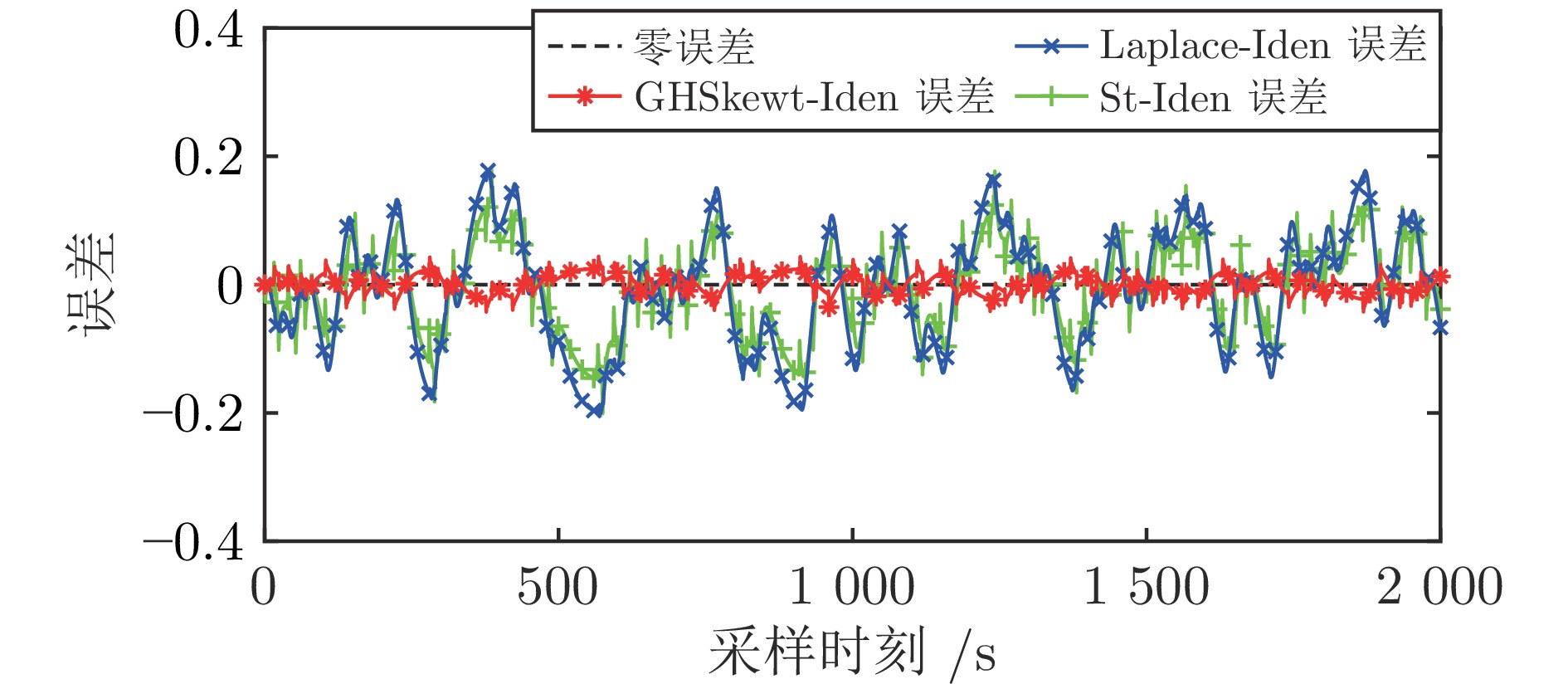
在现有的系统辨识算法中, 常用的高斯、学生氏t (Student's t, St)、拉普拉斯等噪声分布均呈现出对称的统计特性, 难以描述非对称性、有偏的输出噪声, 使得在非对称偏斜噪声条件下算法的性能下降. 基于此, 研究一类广义双曲倾斜学生氏t (Generalized hyperbolic skew student's t, GHSkewt)分布, 并在非对称偏斜噪声条件下, 提出一种线性系统鲁棒辨识算法. 首先, 对GHSkewt分布的重尾特性和偏斜特性进行详细阐述, 数学上证明了标准学生氏t分布可看作是GHSkewt分布的一个特例; 其次, 引入隐含变量将GHSkewt分布进行数学分解, 以方便算法的推导和实现; 最后, 在期望最大化(Expectation-maximization, EM)算法下, 重构具有隐含变量系统的代价函数, 通过迭代优化的方式, 不断从被污染数据集中学习过程的动态特性和噪声分布, 实现噪声参数和模型参数的联合估计.
在现有的系统辨识算法中, 常用的高斯、学生氏t (Student's t, St)、拉普拉斯等噪声分布均呈现出对称的统计特性, 难以描述非对称性、有偏的输出噪声, 使得在非对称偏斜噪声条件下算法的性能下降. 基于此, 研究一类广义双曲倾斜学生氏t (Generalized hyperbolic skew student's t, GHSkewt)分布, 并在非对称偏斜噪声条件下, 提出一种线性系统鲁棒辨识算法. 首先, 对GHSkewt分布的重尾特性和偏斜特性进行详细阐述, 数学上证明了标准学生氏t分布可看作是GHSkewt分布的一个特例; 其次, 引入隐含变量将GHSkewt分布进行数学分解, 以方便算法的推导和实现; 最后, 在期望最大化(Expectation-maximization, EM)算法下, 重构具有隐含变量系统的代价函数, 通过迭代优化的方式, 不断从被污染数据集中学习过程的动态特性和噪声分布, 实现噪声参数和模型参数的联合估计.
2024, 50(10): 2036-2048.
doi: 10.16383/j.aas.c211112
cstr: 32138.14.j.aas.c211112
摘要:
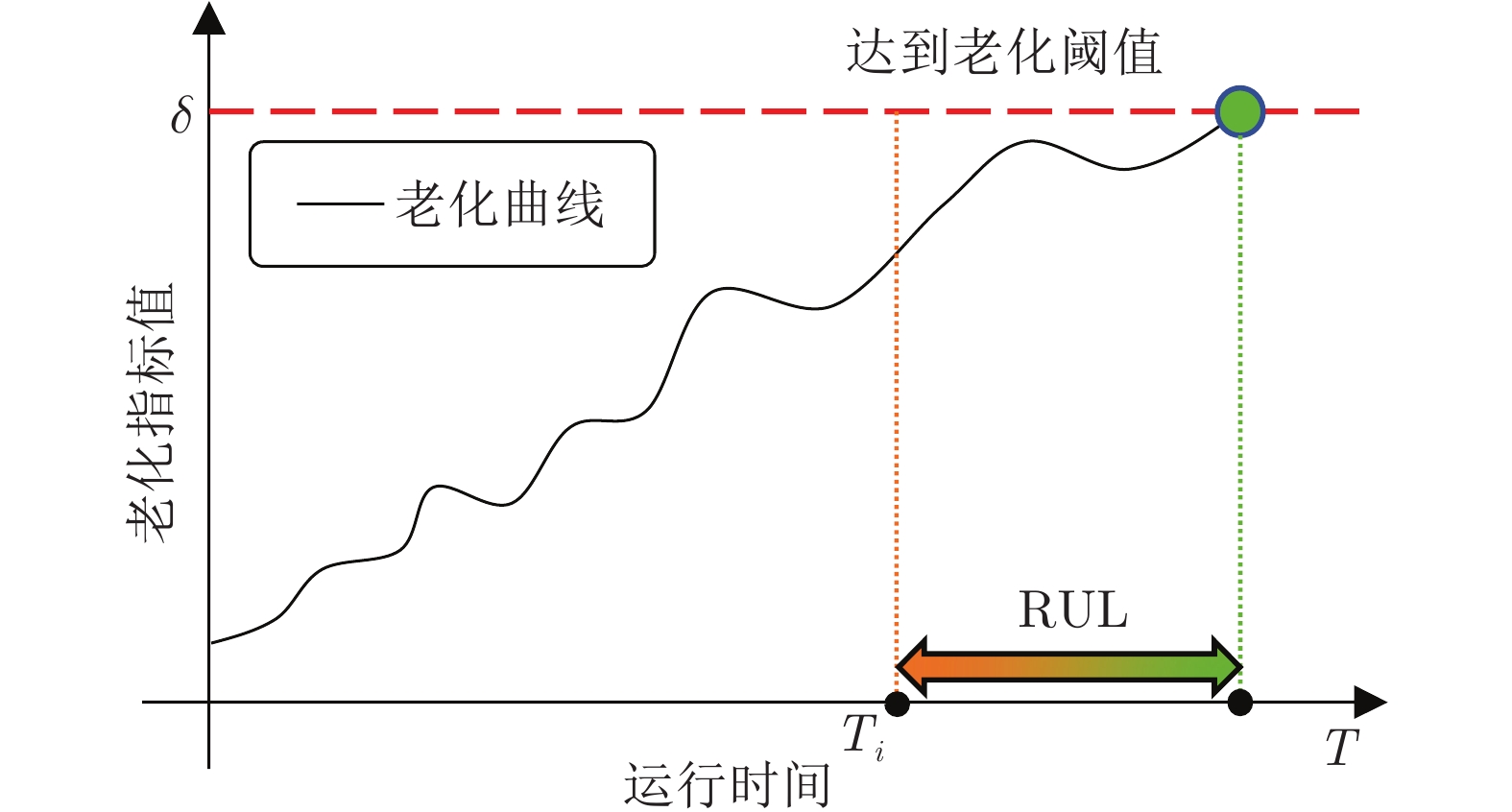
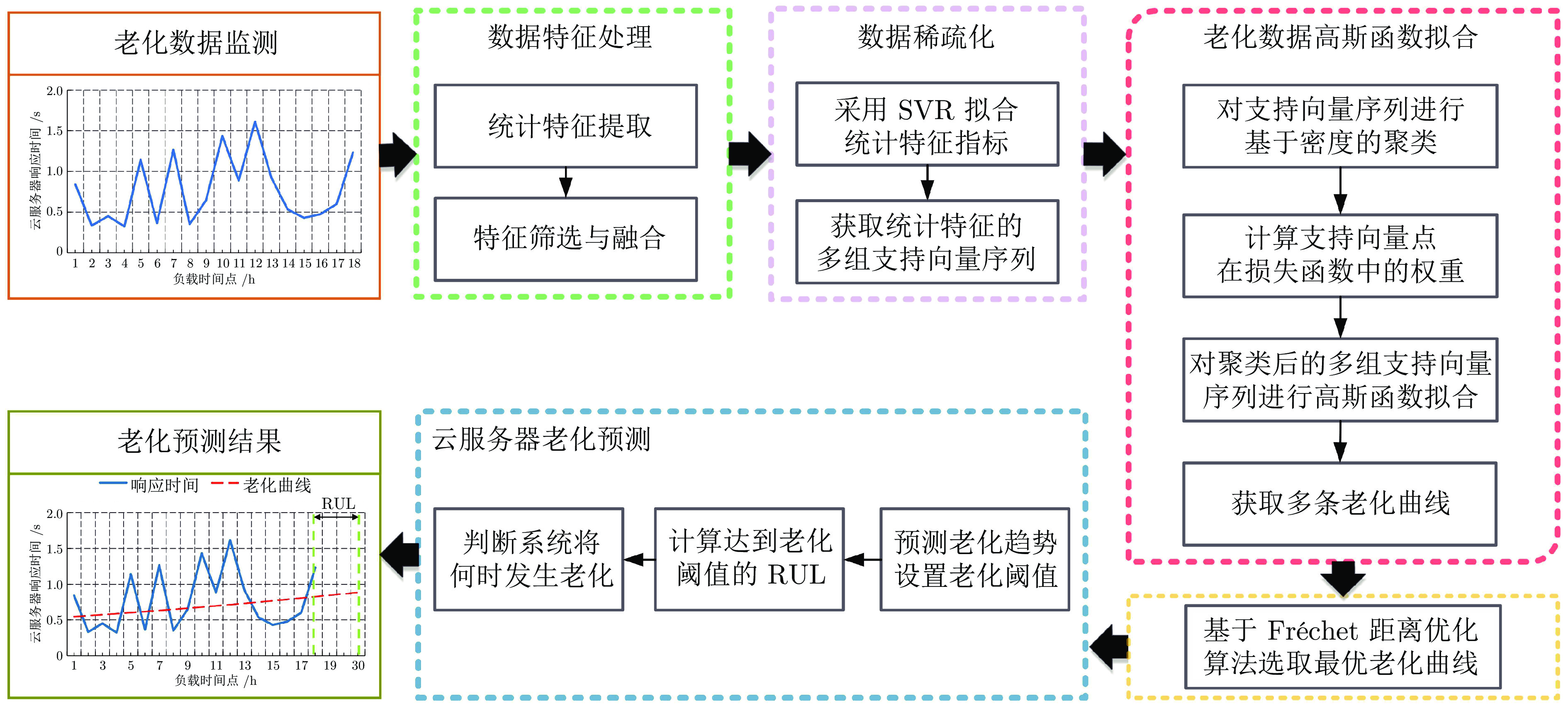
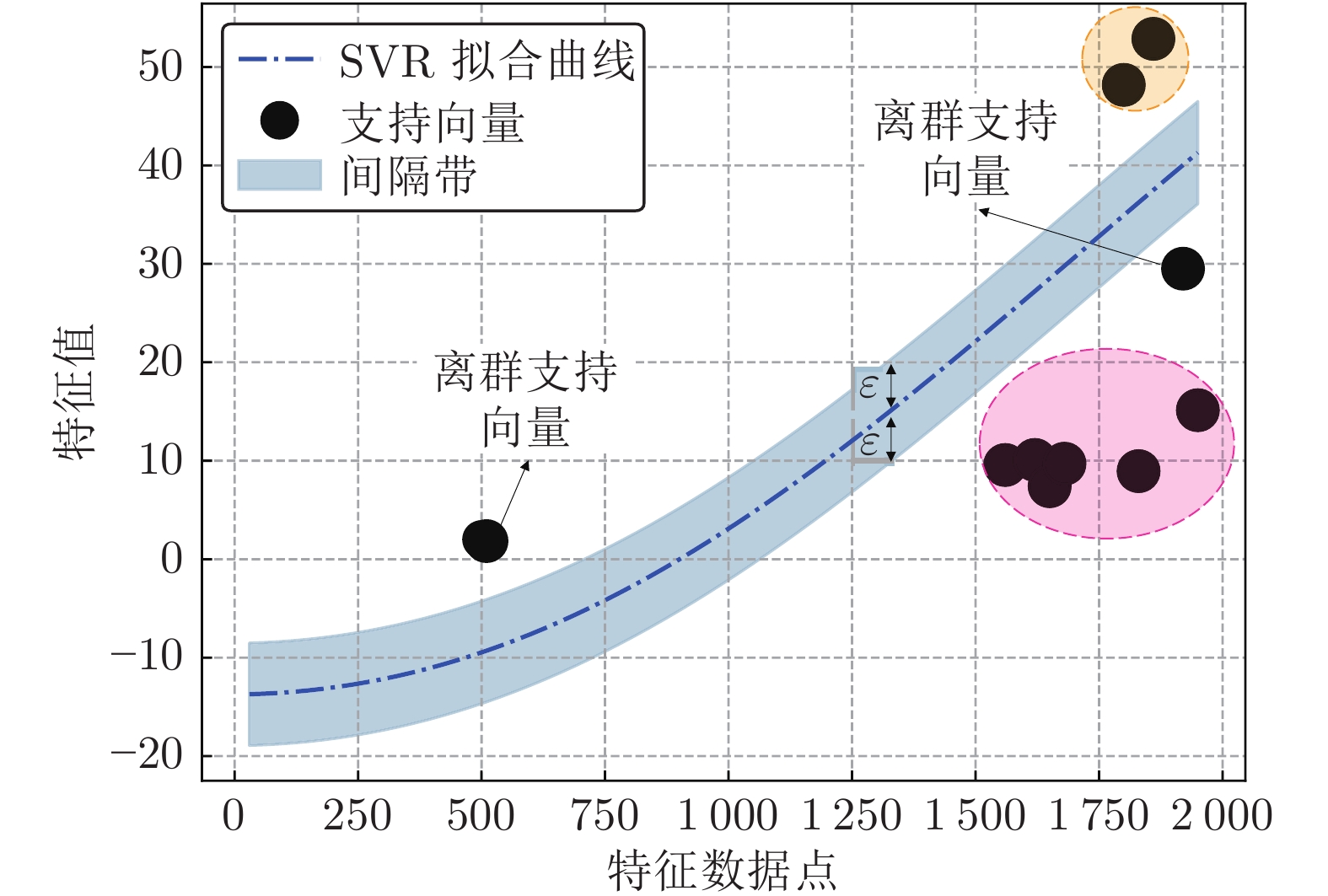
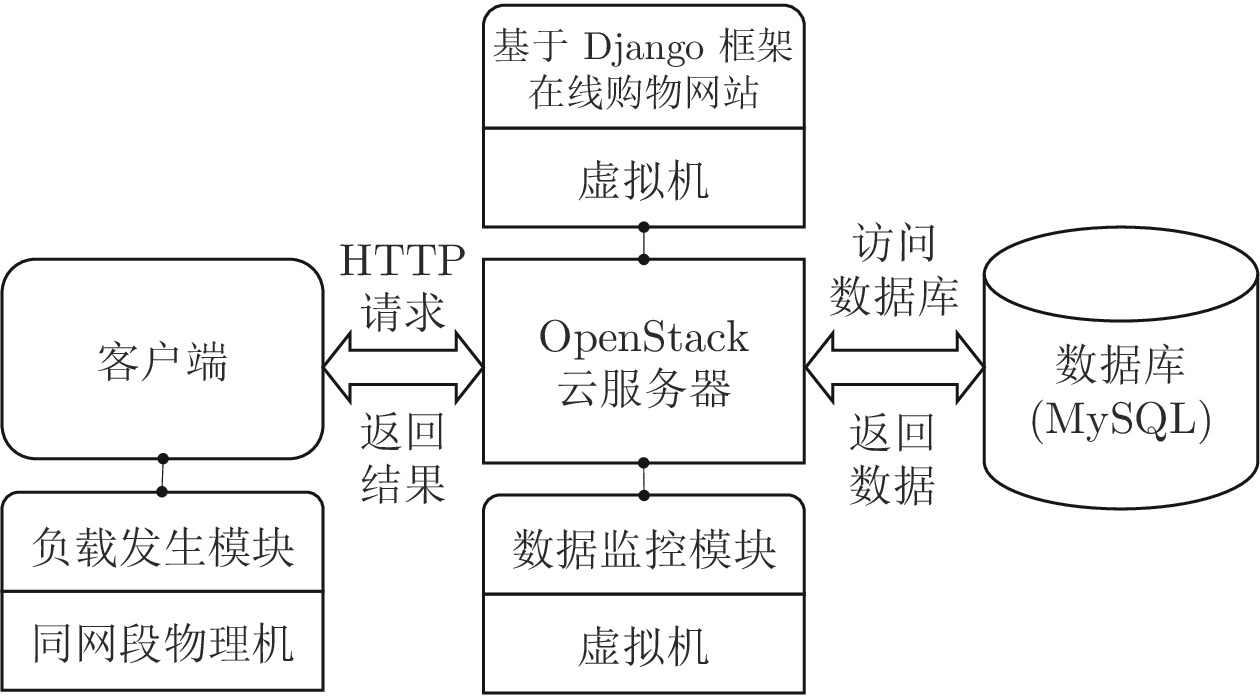
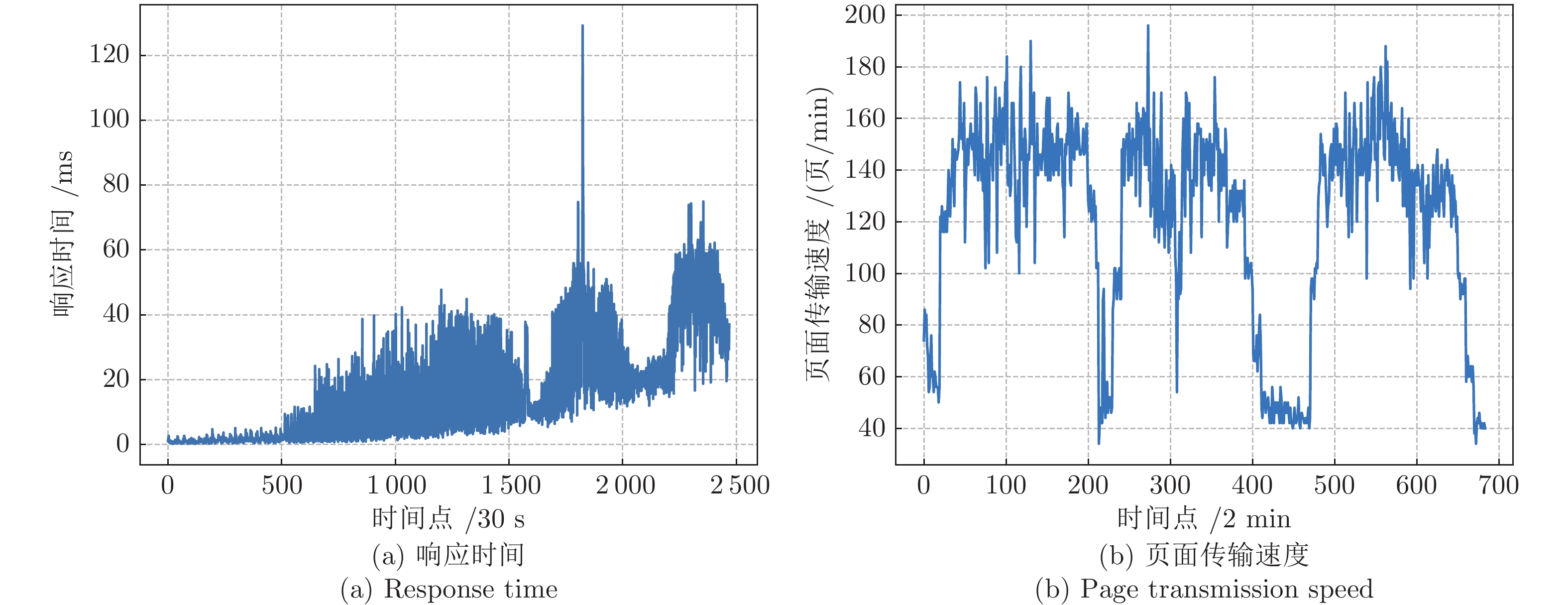
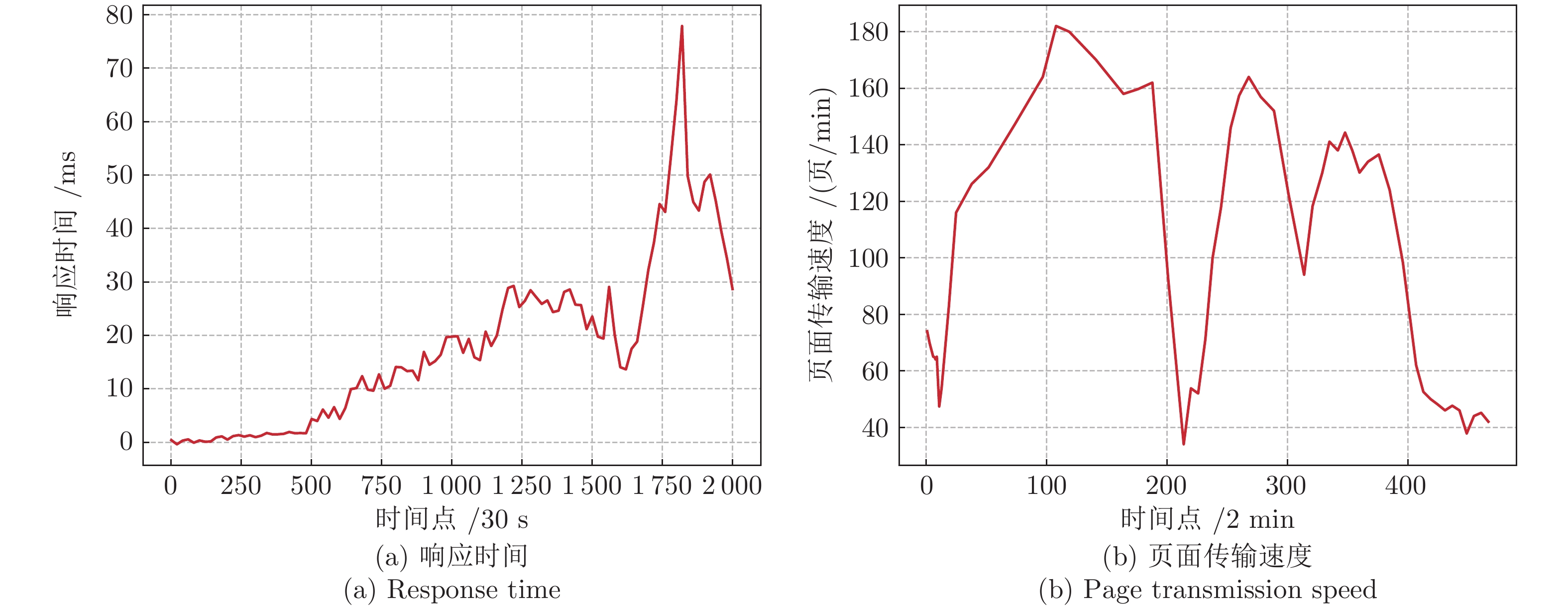
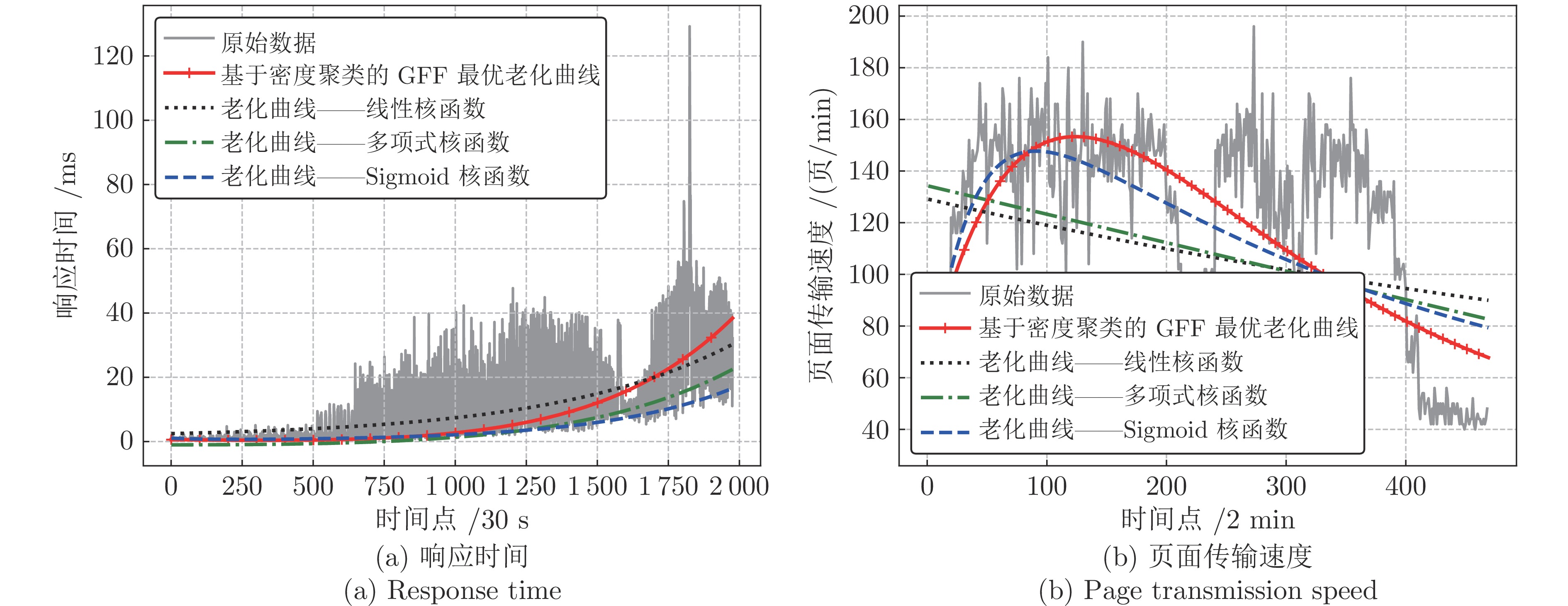
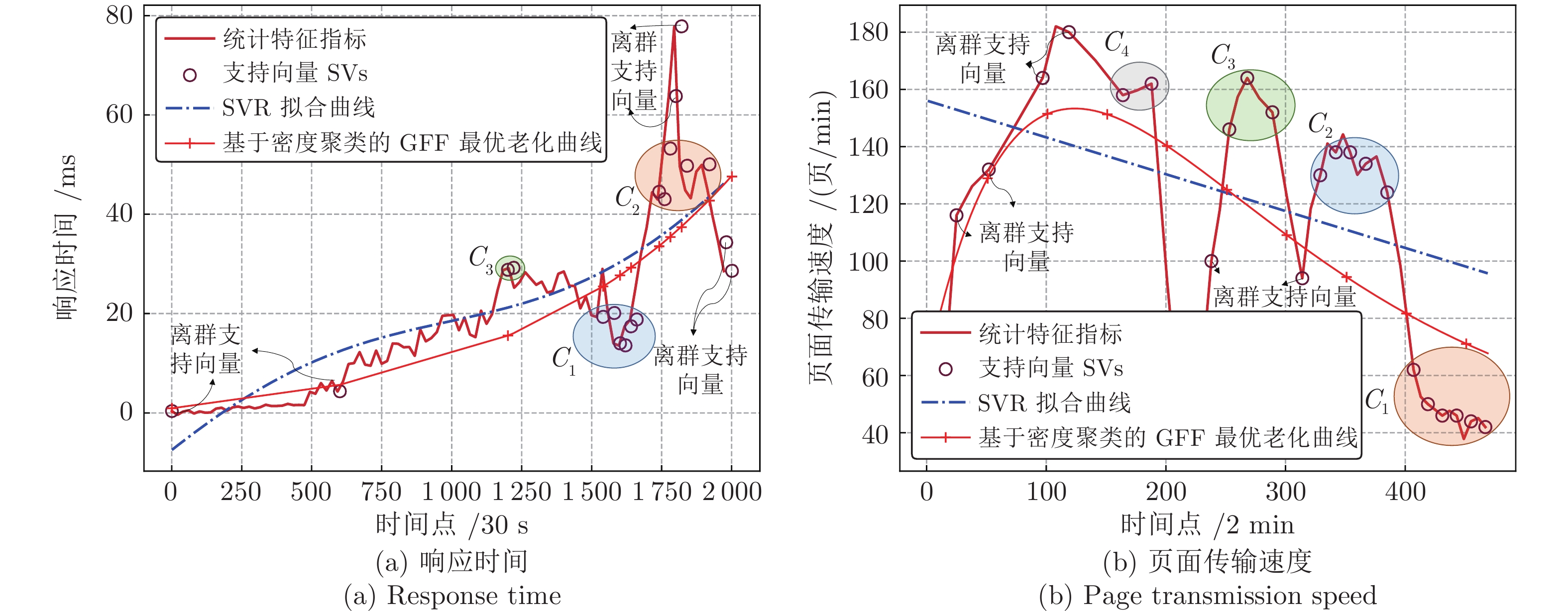
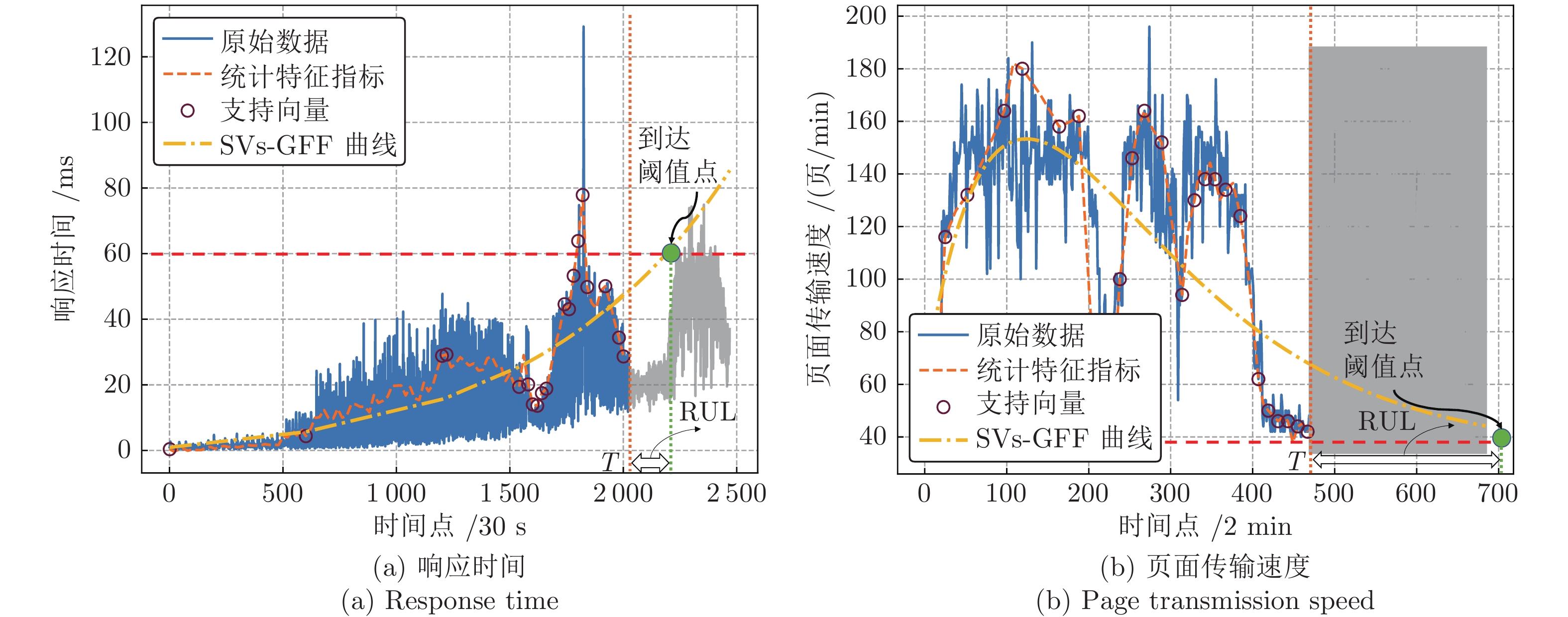
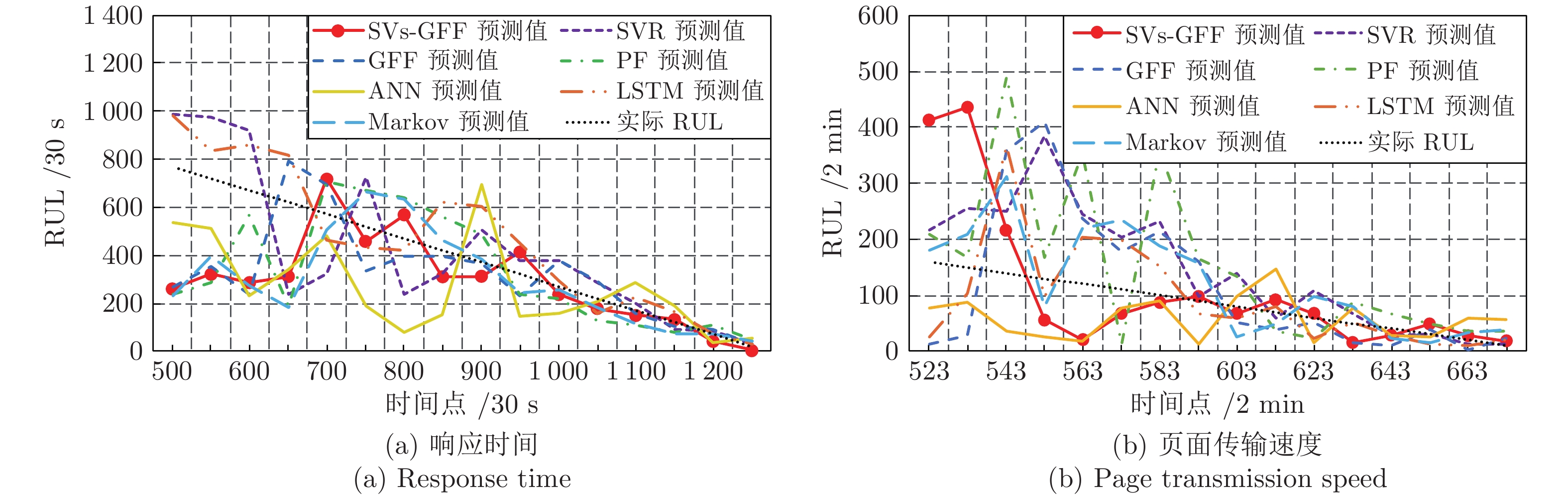
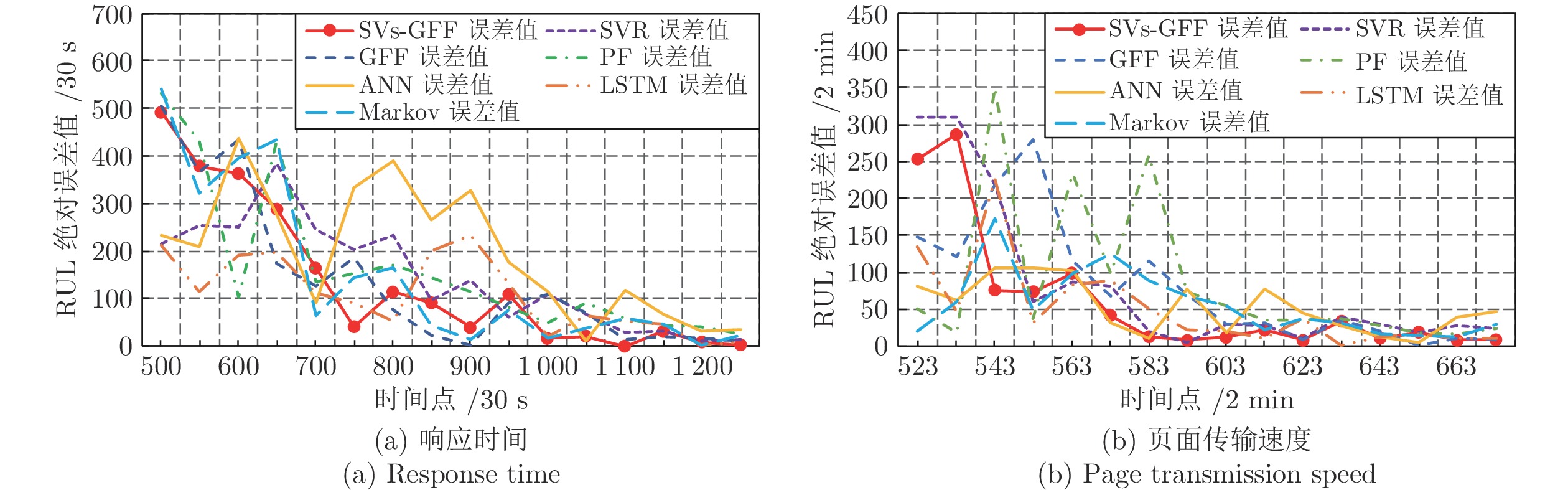
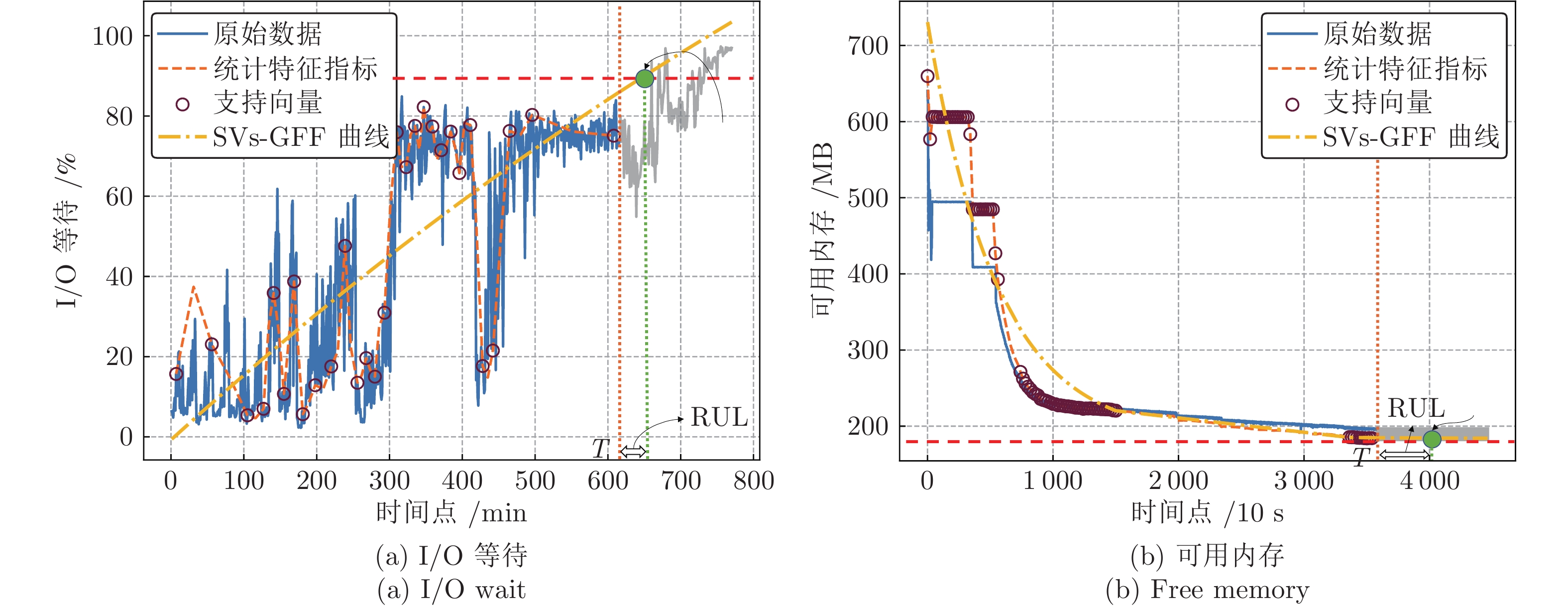
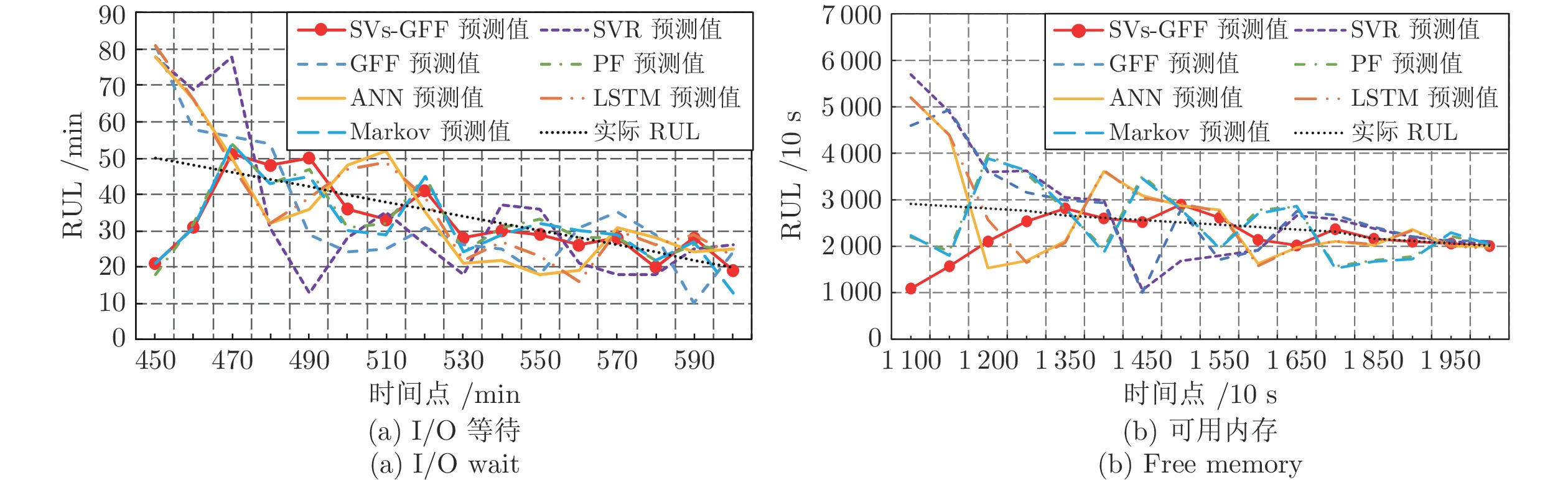
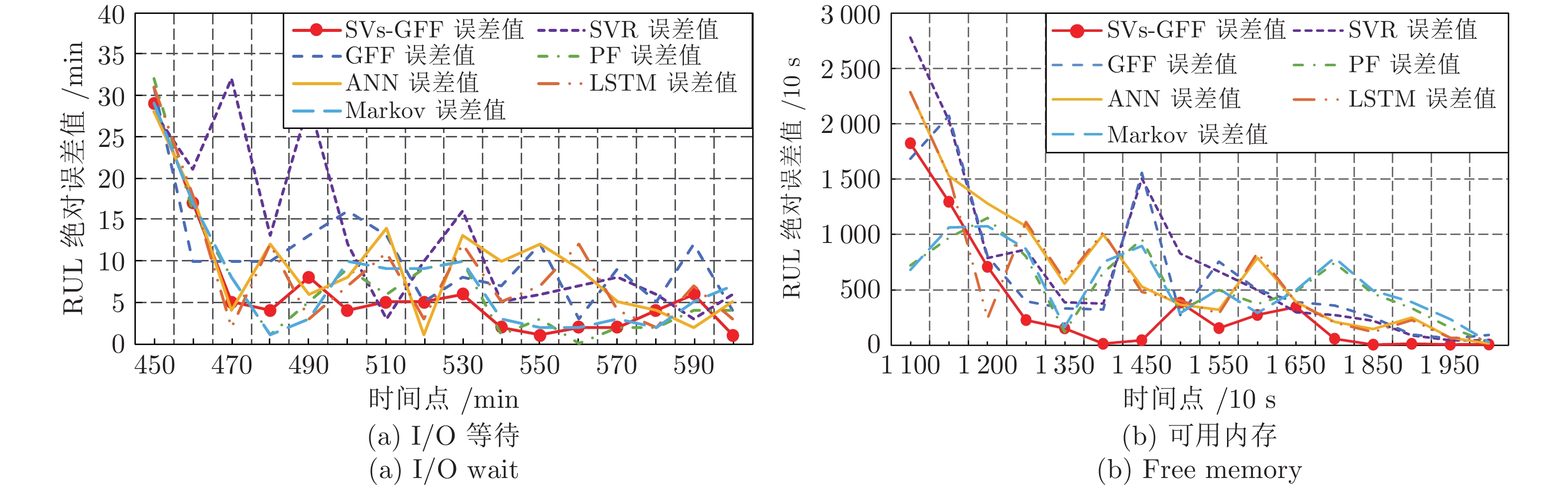
针对云服务器中存在软件老化现象, 将造成系统性能衰退与可靠性下降问题, 借鉴剩余使用寿命(Remaining useful life, RUL)概念, 提出基于支持向量和高斯函数拟合(Support vectors and Gaussian function fitting, SVs-GFF)的老化预测方法. 首先, 提取云服务器老化数据的统计特征指标, 并采用支持向量回归(Support vector regression, SVR)对统计特征指标进行数据稀疏化处理, 得到支持向量(Support vectors, SVs)序列数据; 然后, 建立基于密度聚类的高斯函数拟合(Gaussian function fitting, GFF)模型, 对不同核函数下的支持向量序列数据进行老化曲线拟合, 并采用Fréchet距离优化算法选取最优老化曲线; 最后, 基于最优老化曲线, 评估系统到达老化阈值前的RUL, 以预测系统何时发生老化. 在OpenStack云服务器4个老化数据集上的实验结果表明, 基于RUL和SVs-GFF的云服务器老化预测方法与传统预测方法相比, 具有更高的预测精度和更快的收敛速度.
针对云服务器中存在软件老化现象, 将造成系统性能衰退与可靠性下降问题, 借鉴剩余使用寿命(Remaining useful life, RUL)概念, 提出基于支持向量和高斯函数拟合(Support vectors and Gaussian function fitting, SVs-GFF)的老化预测方法. 首先, 提取云服务器老化数据的统计特征指标, 并采用支持向量回归(Support vector regression, SVR)对统计特征指标进行数据稀疏化处理, 得到支持向量(Support vectors, SVs)序列数据; 然后, 建立基于密度聚类的高斯函数拟合(Gaussian function fitting, GFF)模型, 对不同核函数下的支持向量序列数据进行老化曲线拟合, 并采用Fréchet距离优化算法选取最优老化曲线; 最后, 基于最优老化曲线, 评估系统到达老化阈值前的RUL, 以预测系统何时发生老化. 在OpenStack云服务器4个老化数据集上的实验结果表明, 基于RUL和SVs-GFF的云服务器老化预测方法与传统预测方法相比, 具有更高的预测精度和更快的收敛速度.
2024, 50(10): 2049-2062.
doi: 10.16383/j.aas.c230651
cstr: 32138.14.j.aas.c230651
摘要:
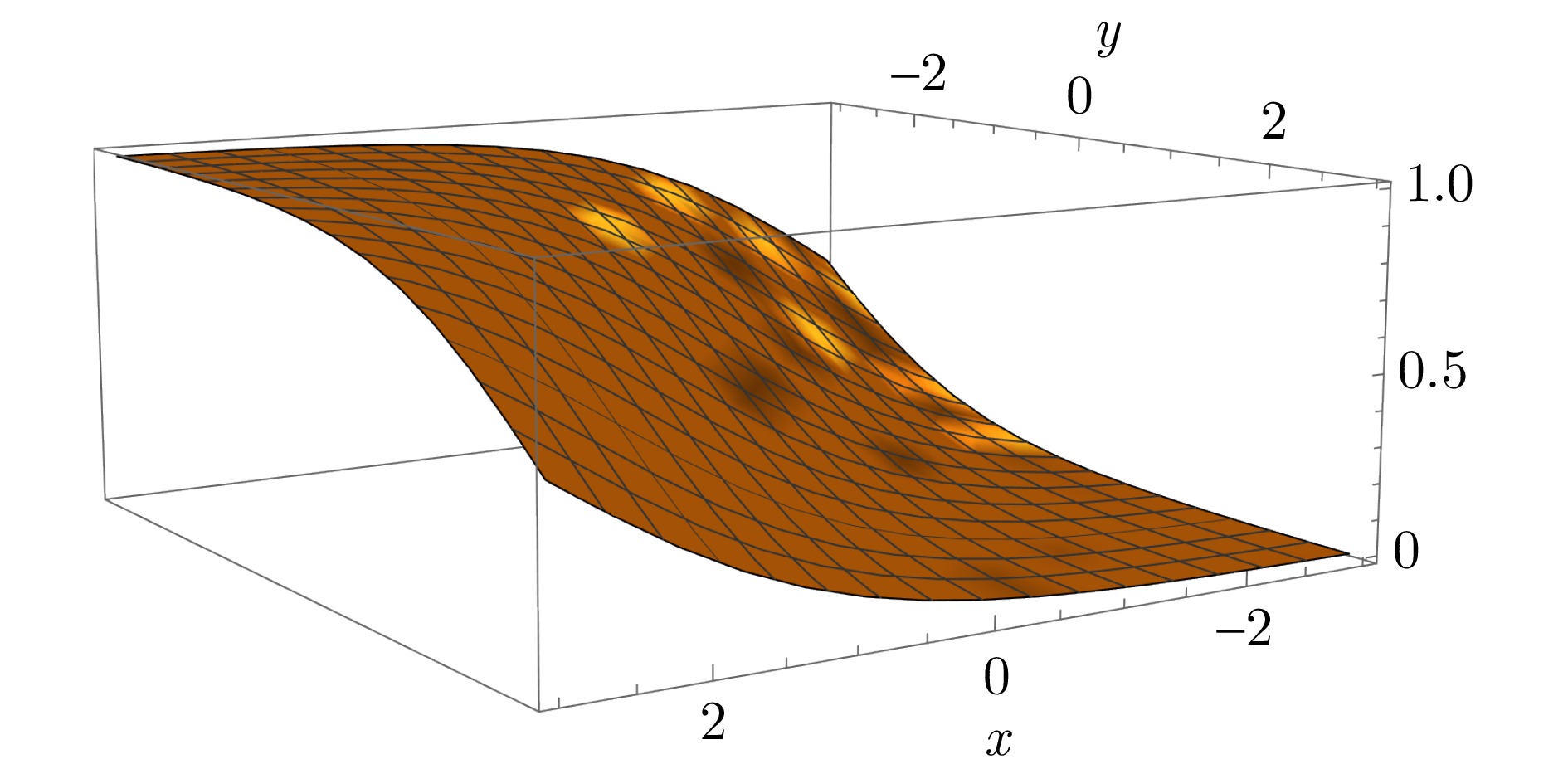
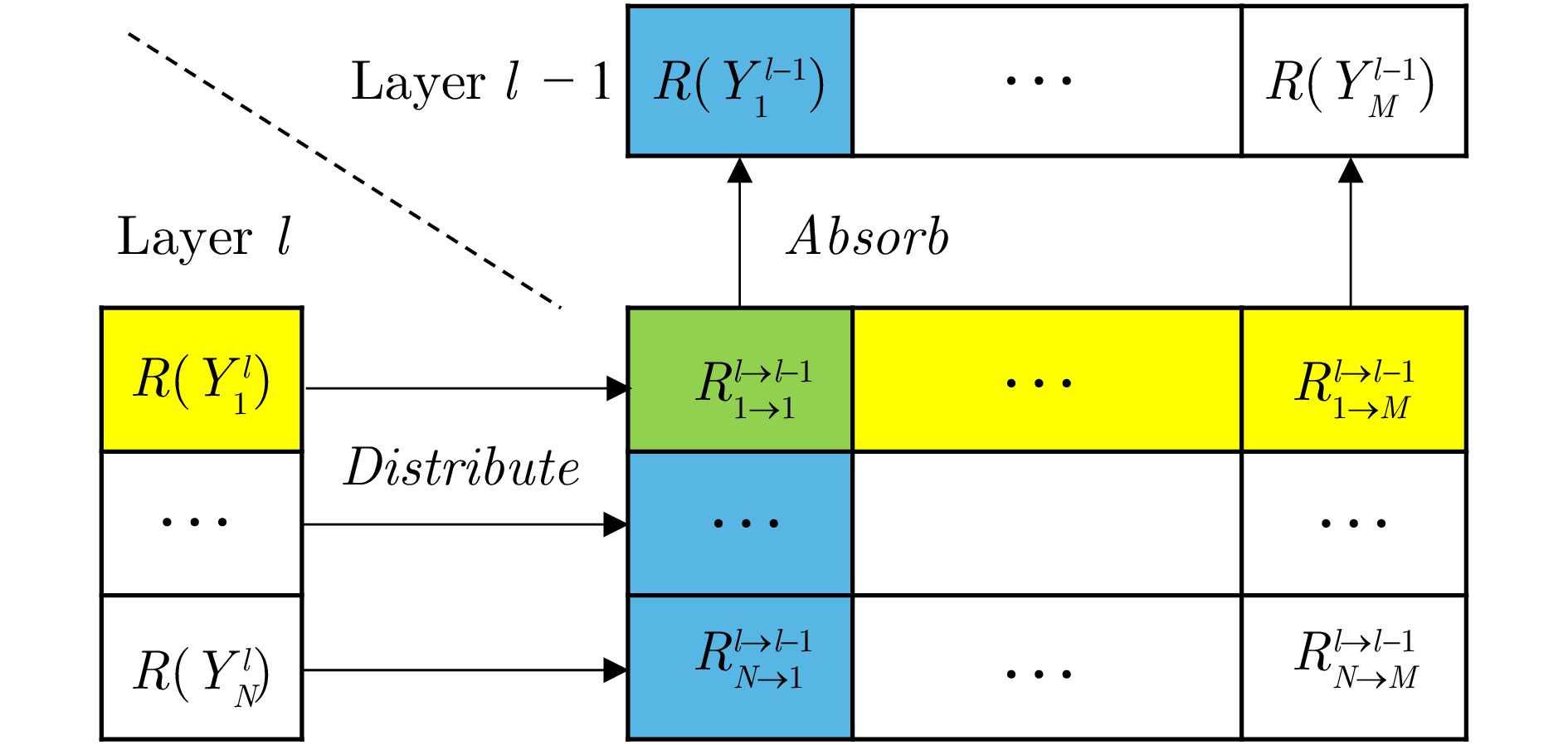
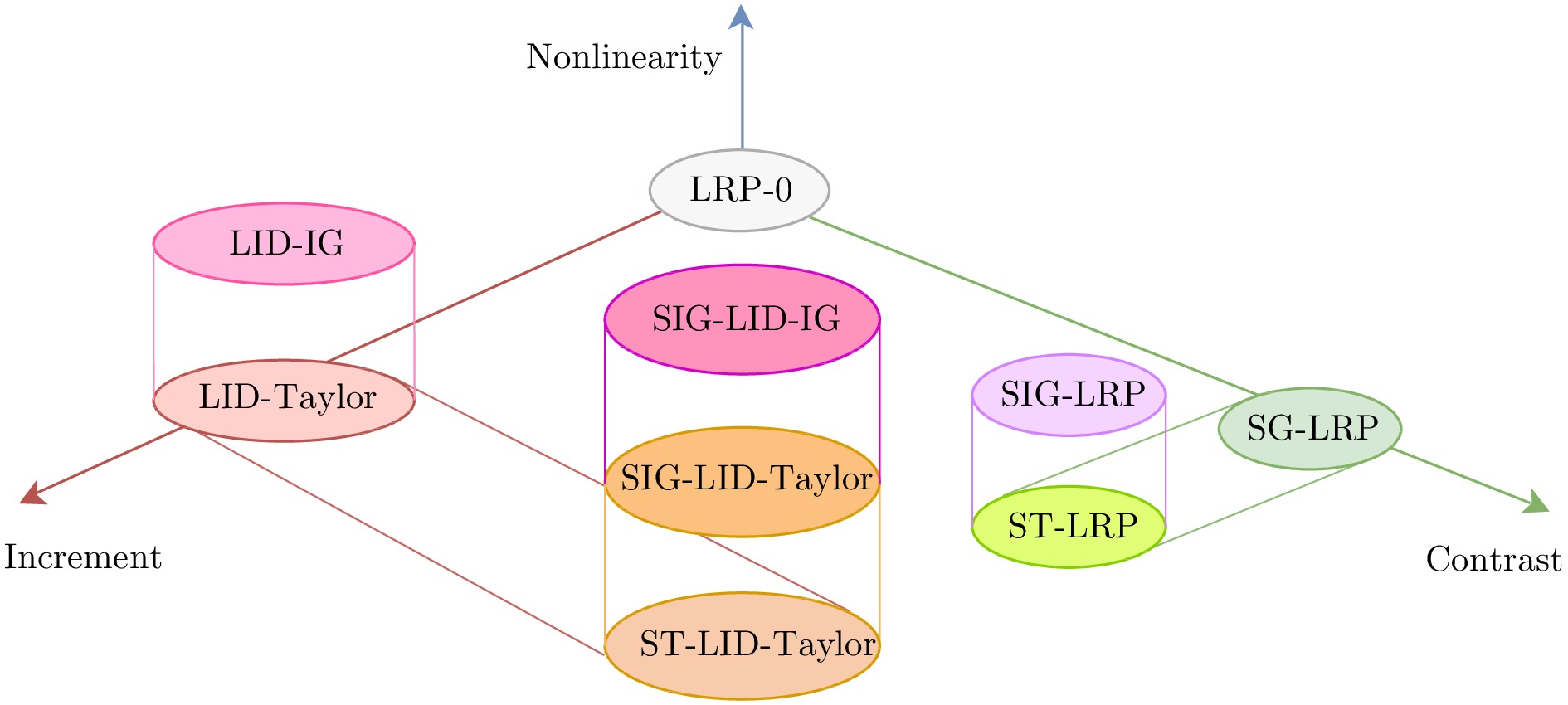
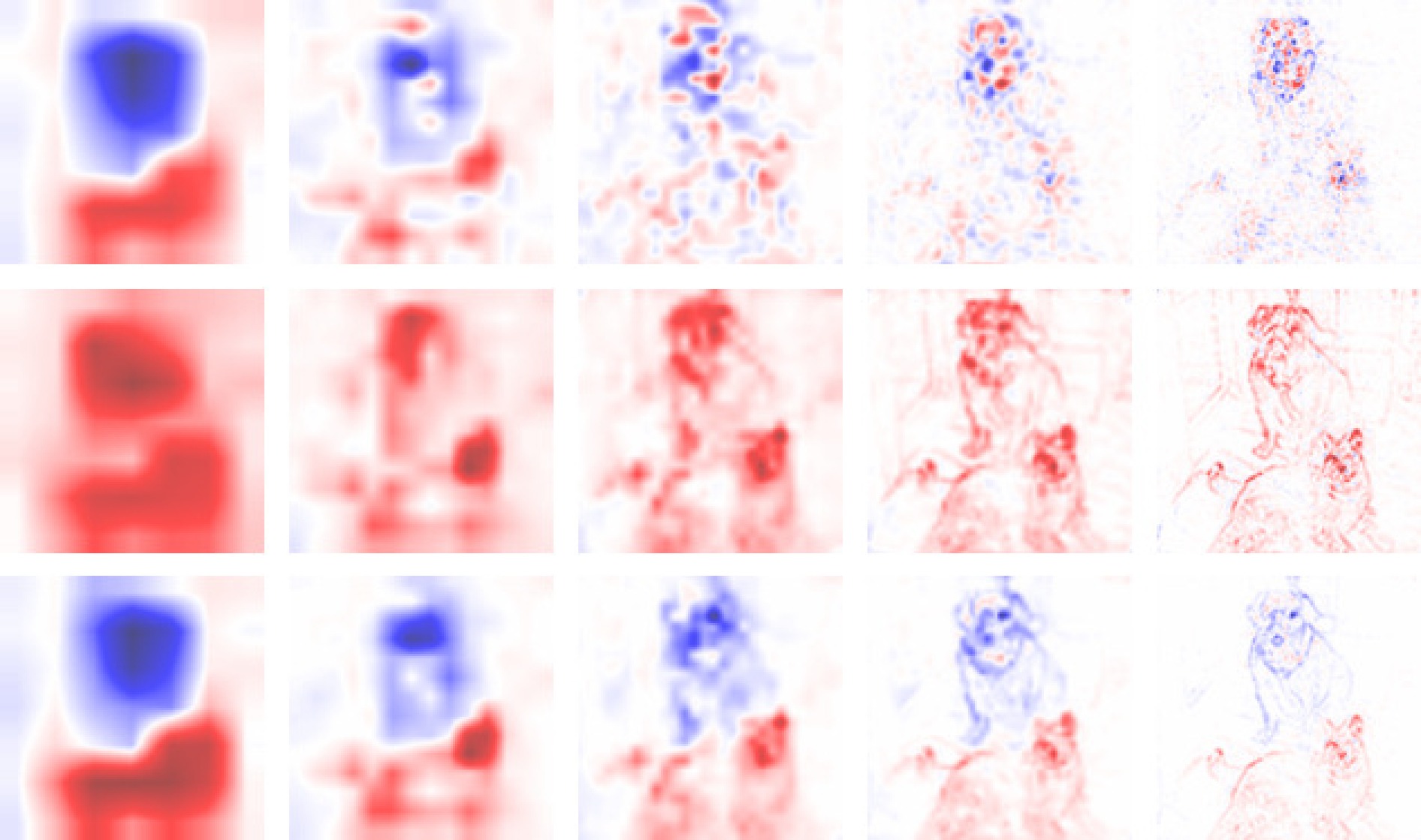
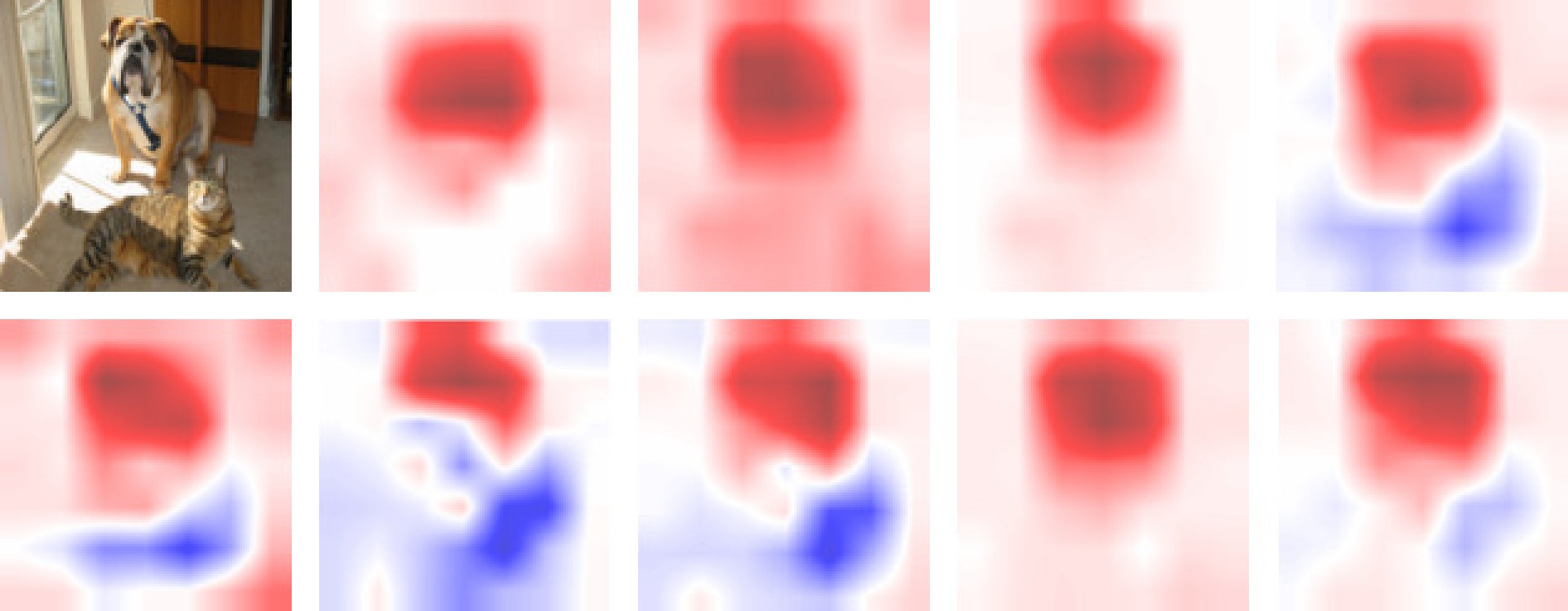
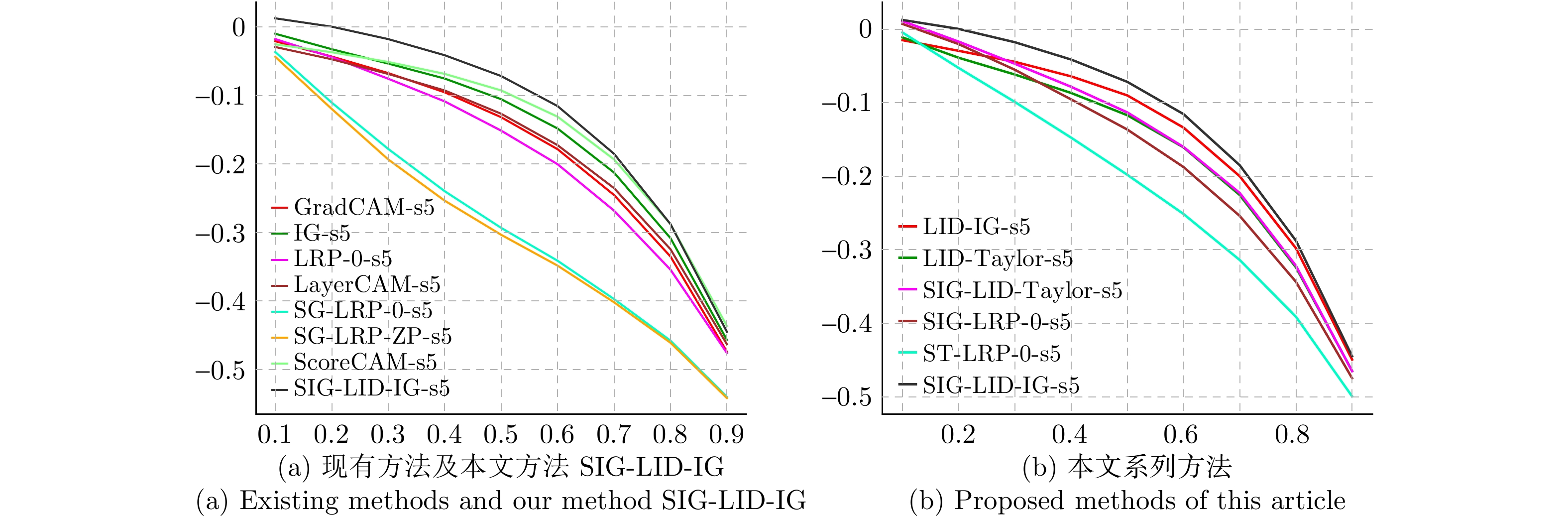
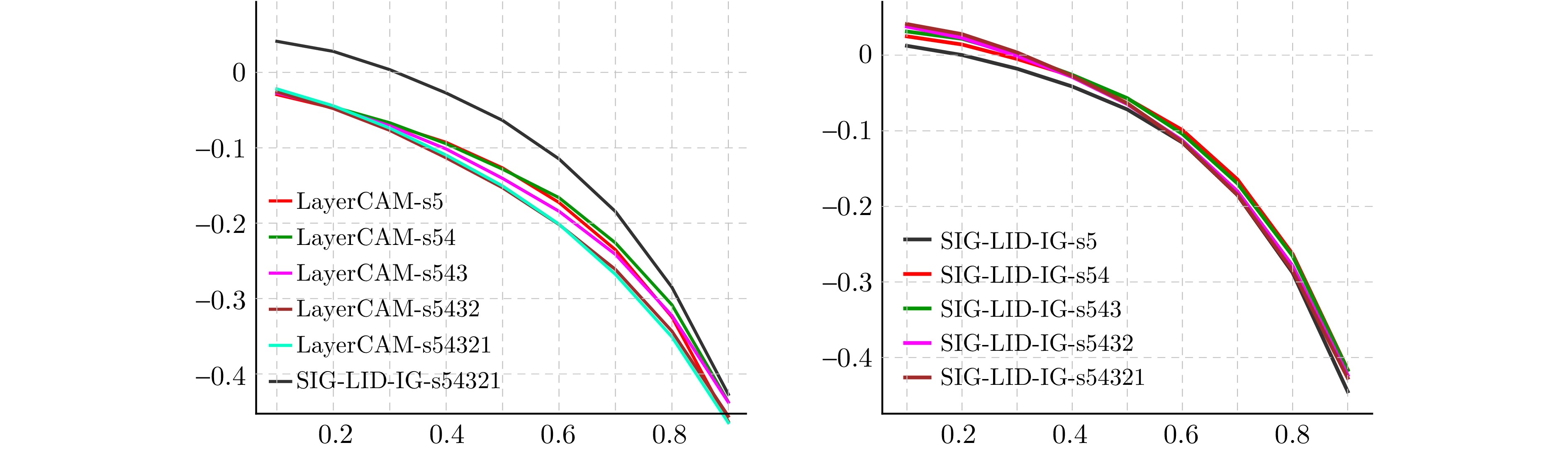
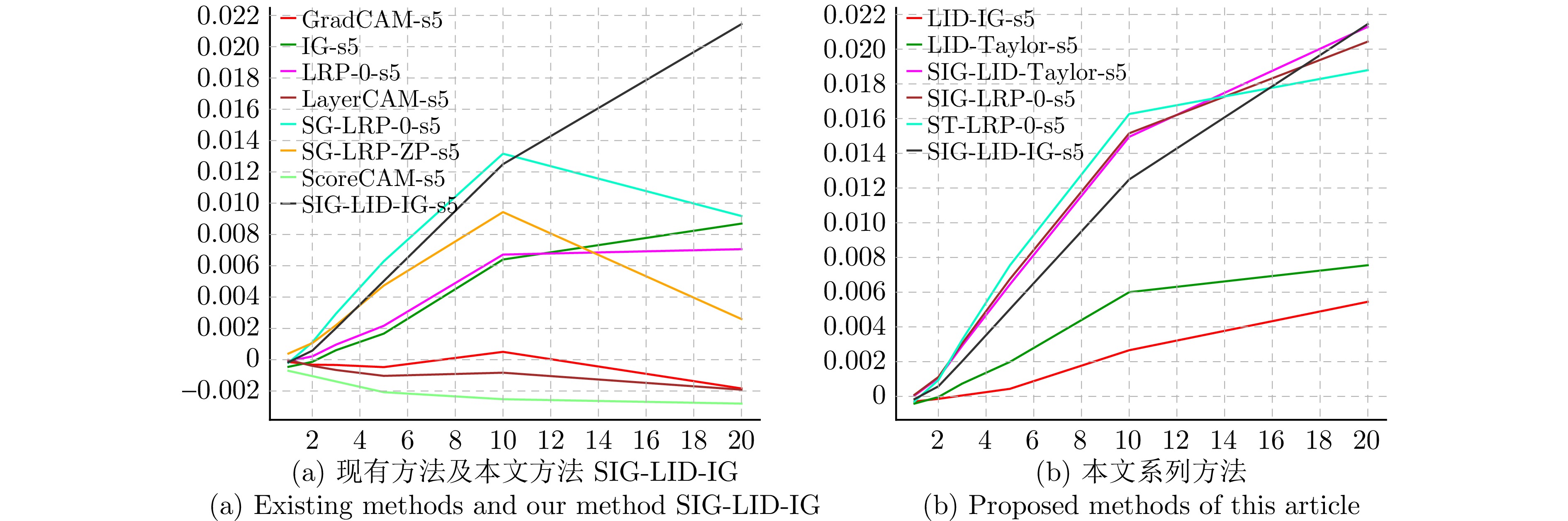
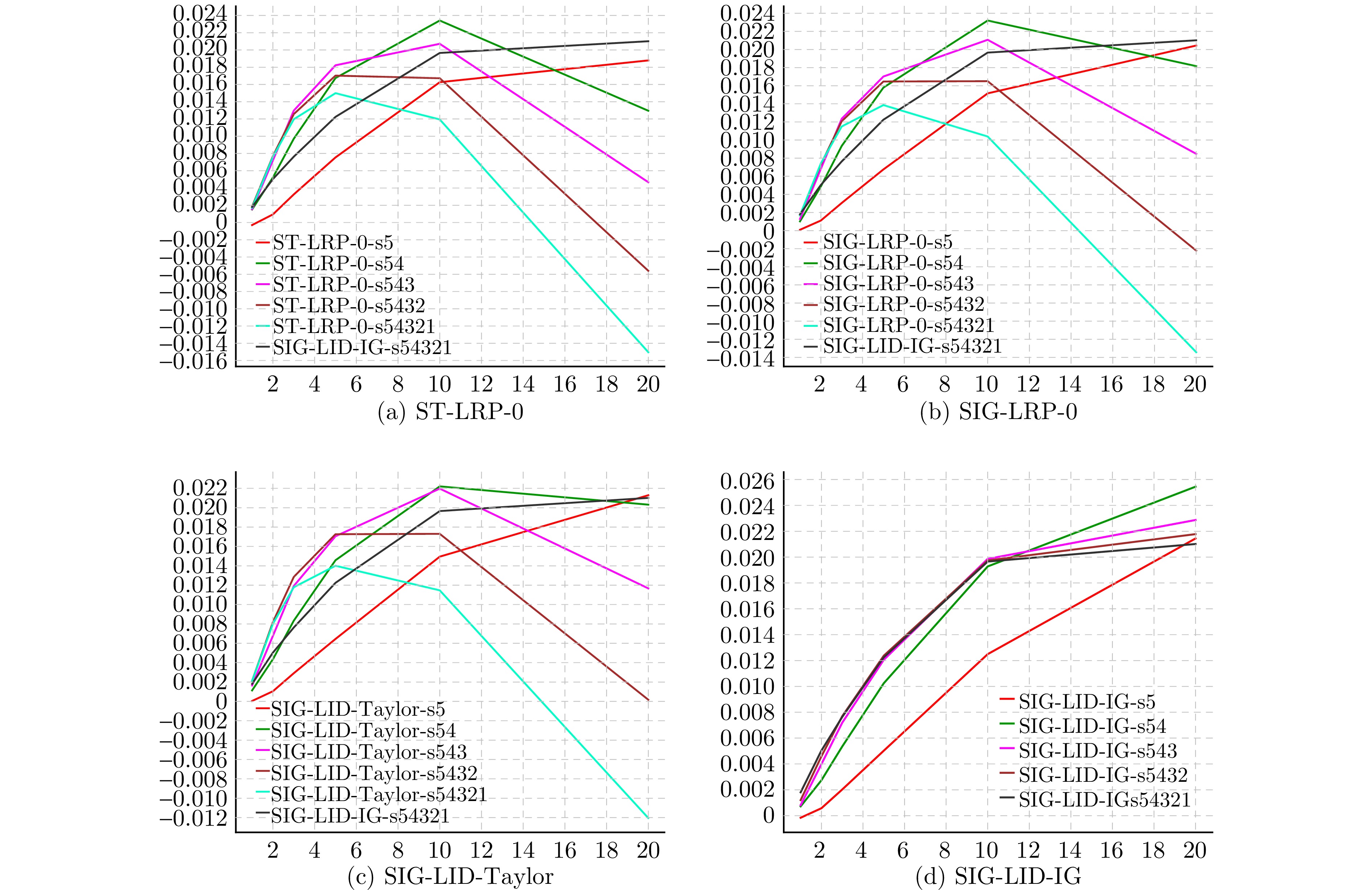
神经网络的黑箱特性严重阻碍了人们关于网络决策的直观分析与理解. 尽管文献报道了多种基于神经元贡献度分配的决策解释方法, 但是现有方法的解释一致性难以保证, 鲁棒性更是有待改进. 本文从神经元相关性概念入手, 提出一种基于逐层增量分解的神经网络解释新方法LID-Taylor (Layer-wise increment decomposition), 且在此基础上先后引入针对顶层神经元相关性的对比提升策略, 以及针对所有层神经元相关性的非线性提升策略, 最后利用交叉组合策略得到最终方法SIG-LID-IG, 实现了决策归因性能的鲁棒跃升. 通过热力图对现有工作与提出方法的决策归因性能做了定性定量评估. 结果显示, SIG-LID-IG在神经元的正、负相关性的决策归因合理性上均可媲美甚至优于现有工作. SIG-LID-IG在多尺度热力图下同样取得了精确性更高、鲁棒性更强的决策归因.
神经网络的黑箱特性严重阻碍了人们关于网络决策的直观分析与理解. 尽管文献报道了多种基于神经元贡献度分配的决策解释方法, 但是现有方法的解释一致性难以保证, 鲁棒性更是有待改进. 本文从神经元相关性概念入手, 提出一种基于逐层增量分解的神经网络解释新方法LID-Taylor (Layer-wise increment decomposition), 且在此基础上先后引入针对顶层神经元相关性的对比提升策略, 以及针对所有层神经元相关性的非线性提升策略, 最后利用交叉组合策略得到最终方法SIG-LID-IG, 实现了决策归因性能的鲁棒跃升. 通过热力图对现有工作与提出方法的决策归因性能做了定性定量评估. 结果显示, SIG-LID-IG在神经元的正、负相关性的决策归因合理性上均可媲美甚至优于现有工作. SIG-LID-IG在多尺度热力图下同样取得了精确性更高、鲁棒性更强的决策归因.





2024, 50(10): 2063-2078.
doi: 10.16383/j.aas.c211089
cstr: 32138.14.j.aas.c211089
摘要:
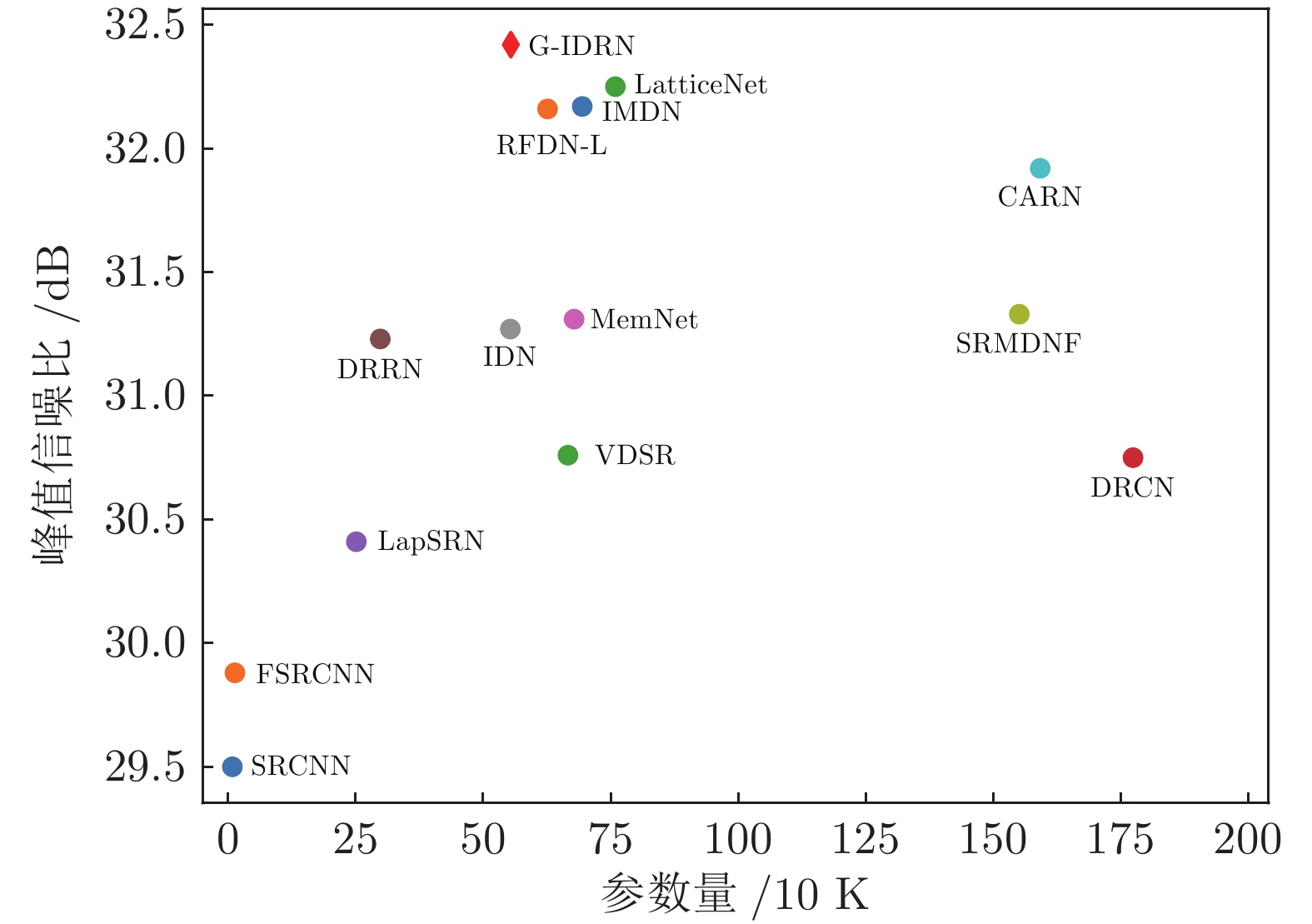
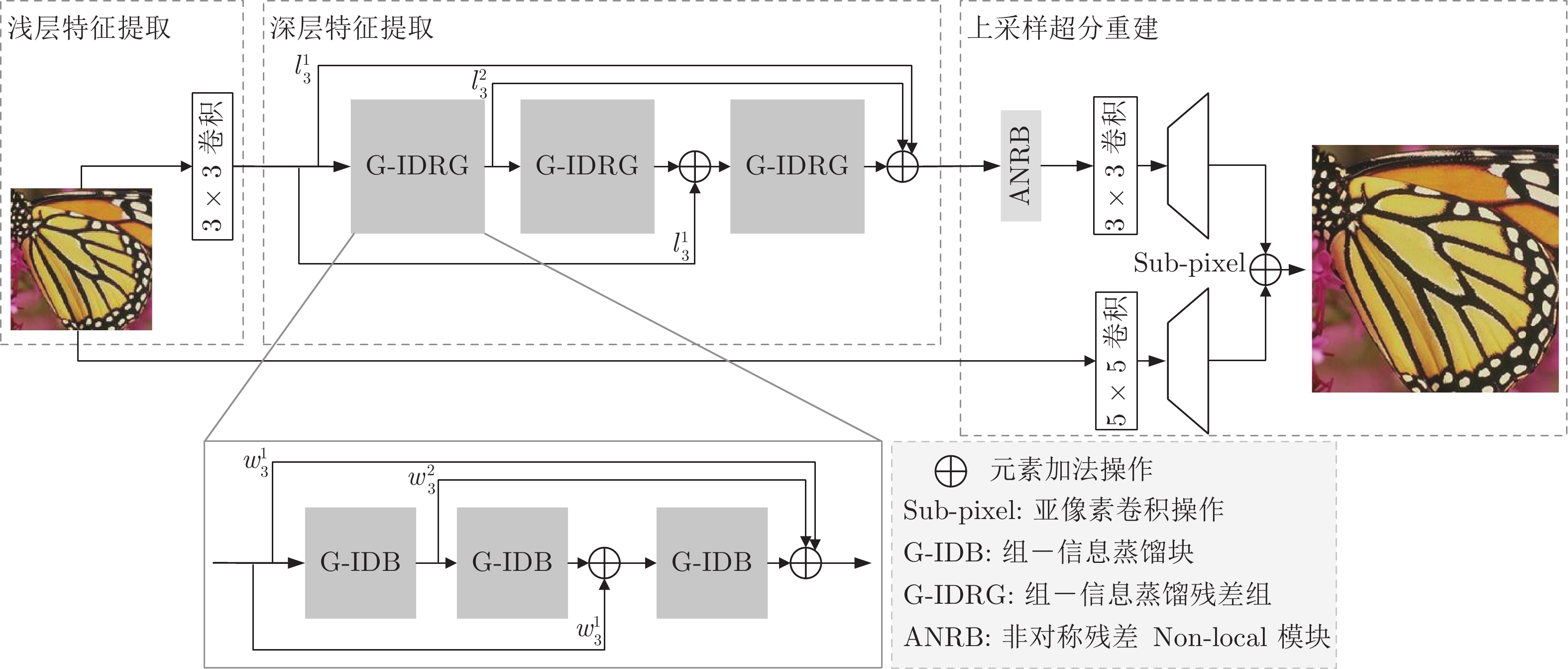
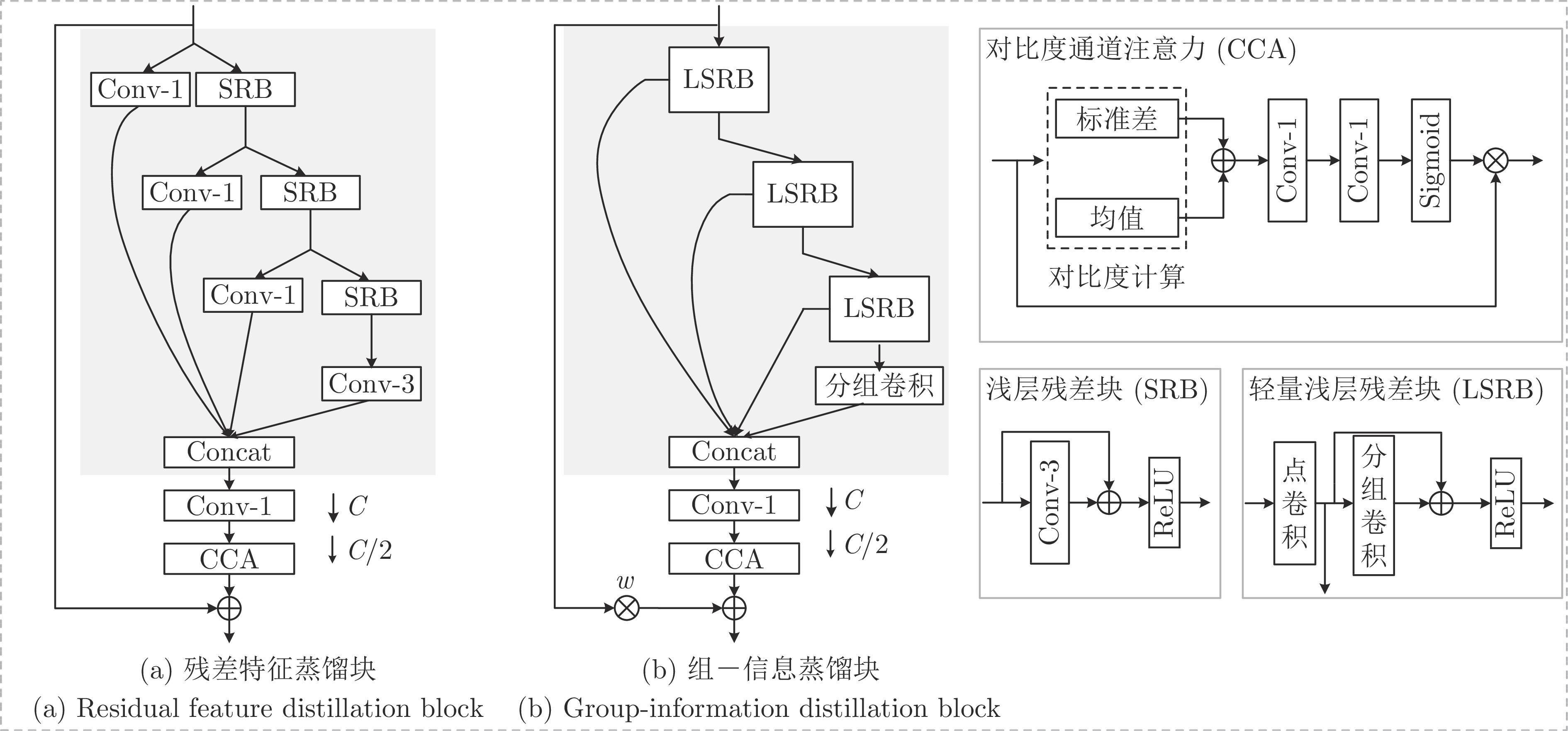
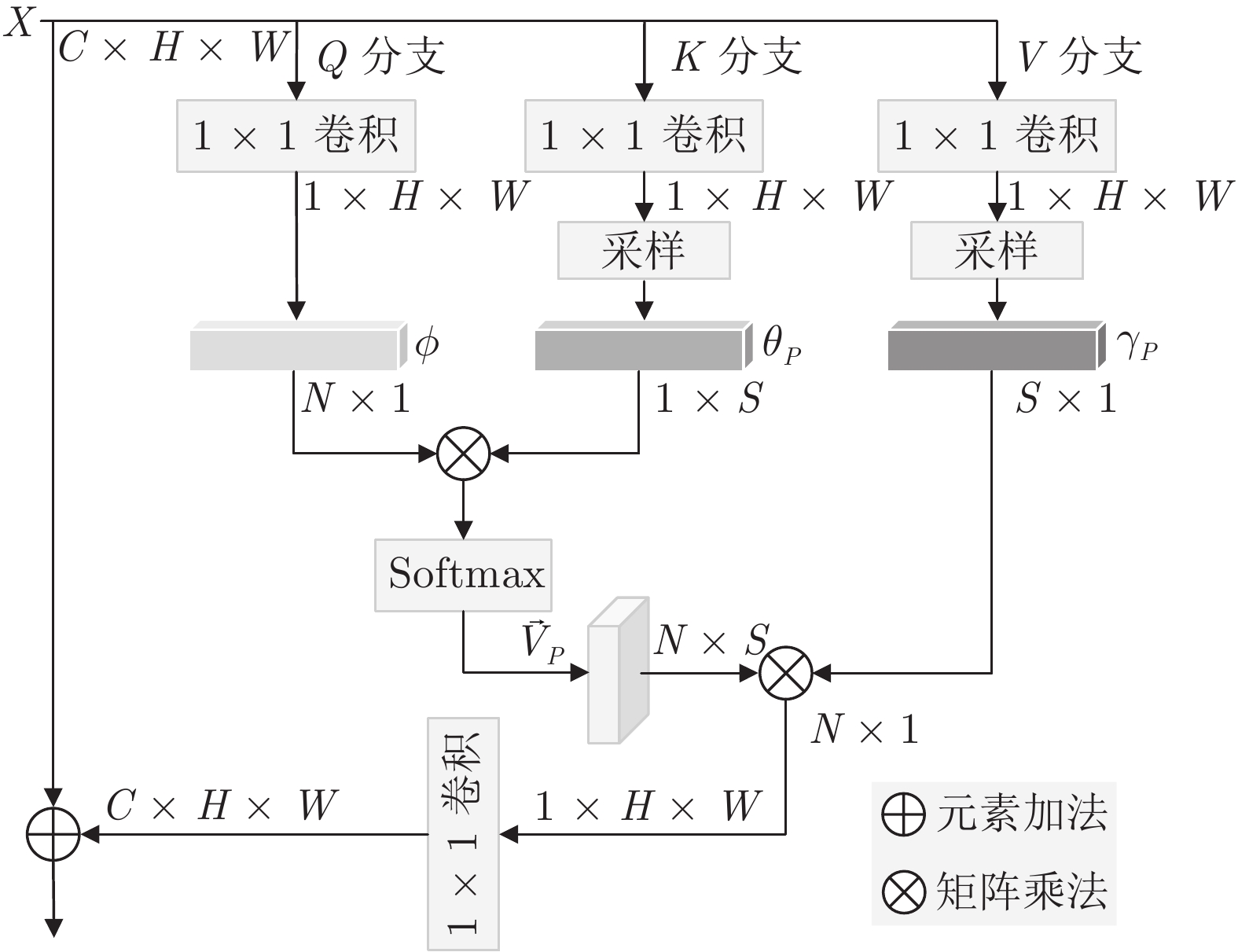
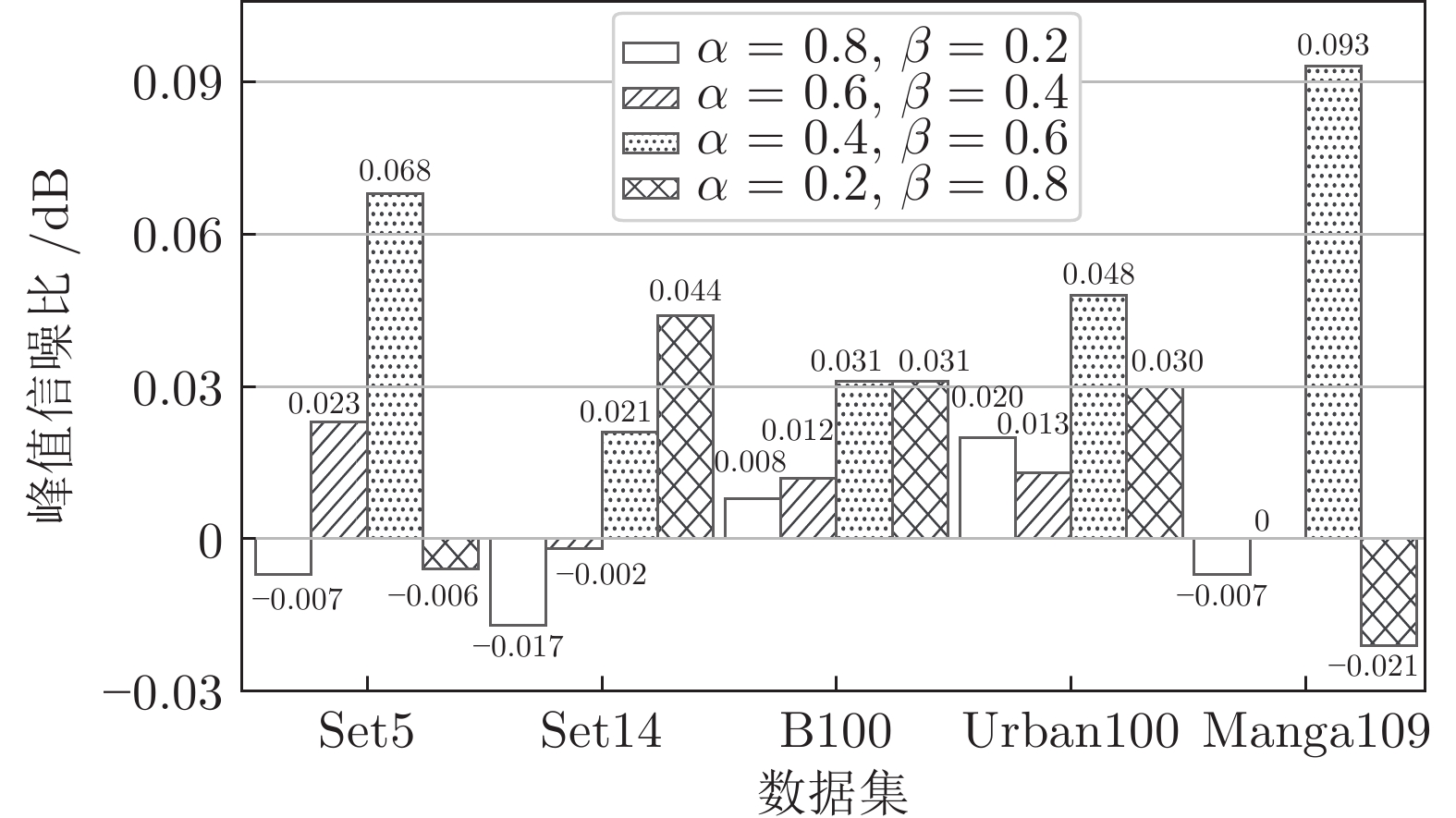
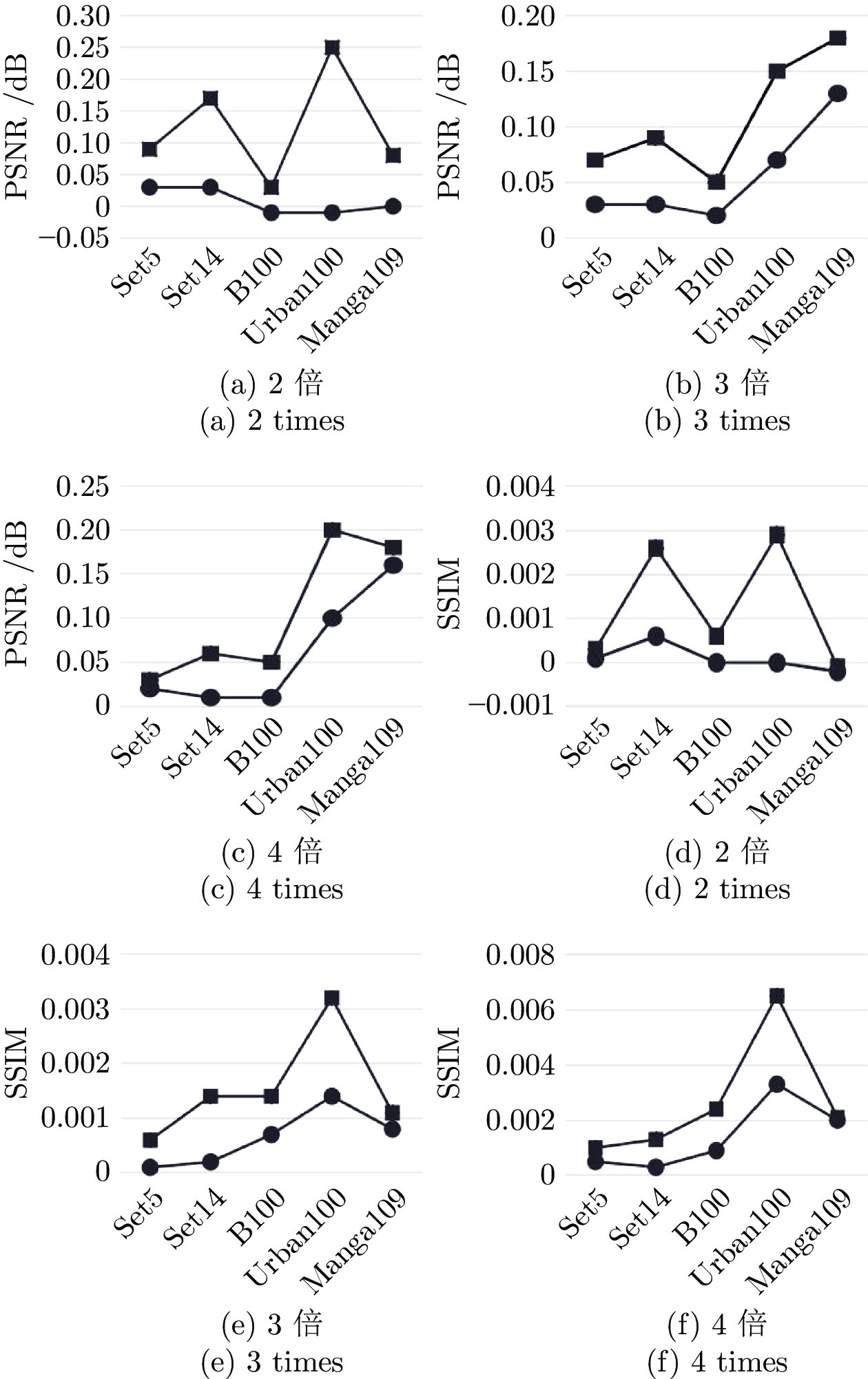
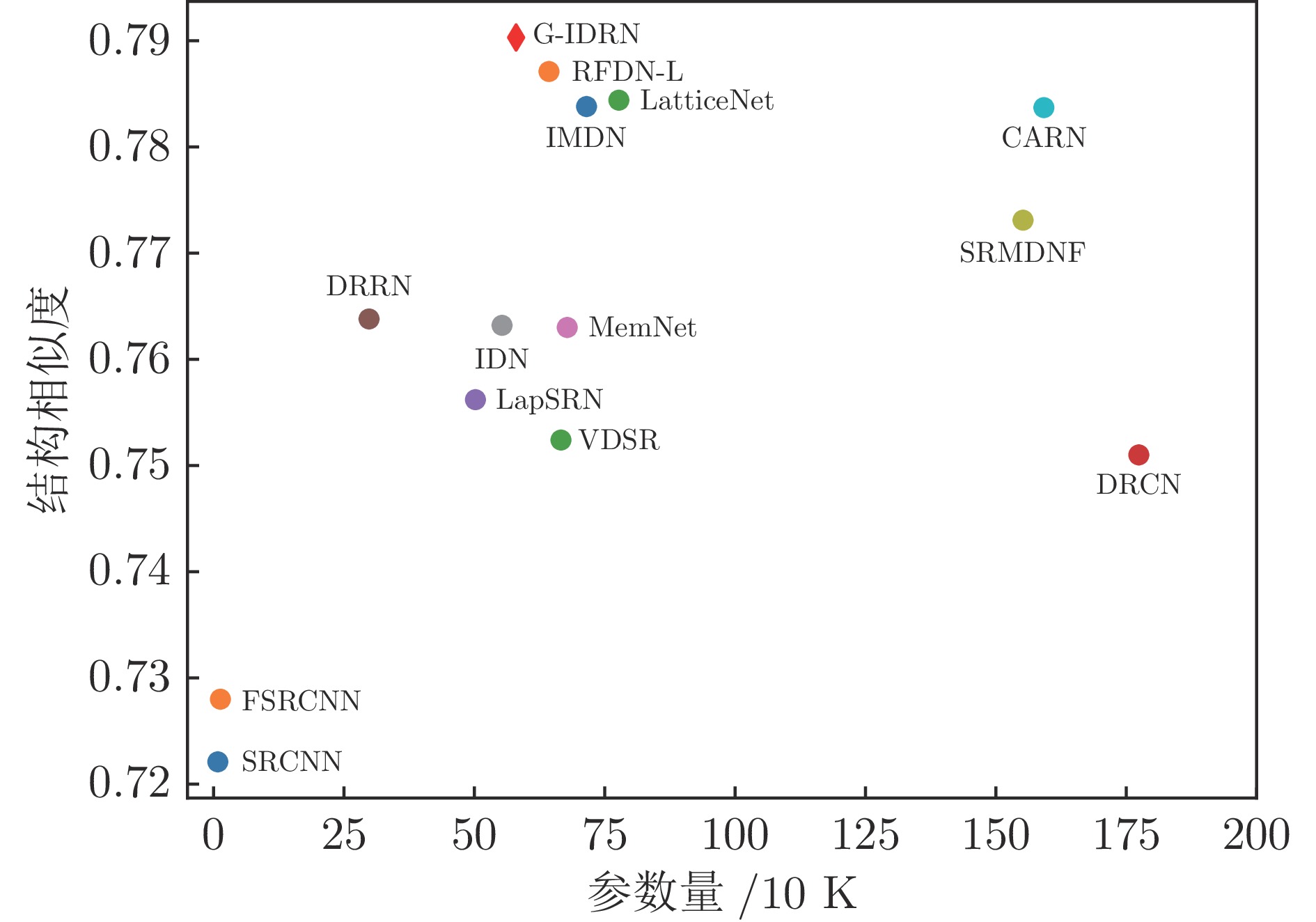
目前, 基于深度学习的超分辨算法已经取得了很好性能, 但这些方法通常具有较大内存消耗和较高计算复杂度, 很难应用到低算力或便携式设备上. 为了解决这个问题, 设计一种轻量级的组−信息蒸馏残差网络(Group-information distillation residual network, G-IDRN)用于快速且精确的单图像超分辨率任务. 具体地, 提出一个更加有效的组−信息蒸馏模块(Group-information distillation block, G-IDB)作为网络特征提取基本块. 同时, 引入密集快捷连接, 对多个基本块进行组合, 构建组−信息蒸馏残差组(Group-information distillation residual group, G-IDRG), 捕获多层级信息和有效重利用特征. 另外, 还提出一个轻量的非对称残差Non-local模块, 对长距离依赖关系进行建模, 进一步提升超分性能. 最后, 设计一个高频损失函数, 去解决像素损失带来图像细节平滑的问题. 大量实验结果表明, 该算法相较于其他先进方法, 可以在图像超分辨率性能和模型复杂度之间取得更好平衡, 其在公开测试数据集B100上, 4倍超分速率达到56 FPS, 比残差注意力网络快15倍.
目前, 基于深度学习的超分辨算法已经取得了很好性能, 但这些方法通常具有较大内存消耗和较高计算复杂度, 很难应用到低算力或便携式设备上. 为了解决这个问题, 设计一种轻量级的组−信息蒸馏残差网络(Group-information distillation residual network, G-IDRN)用于快速且精确的单图像超分辨率任务. 具体地, 提出一个更加有效的组−信息蒸馏模块(Group-information distillation block, G-IDB)作为网络特征提取基本块. 同时, 引入密集快捷连接, 对多个基本块进行组合, 构建组−信息蒸馏残差组(Group-information distillation residual group, G-IDRG), 捕获多层级信息和有效重利用特征. 另外, 还提出一个轻量的非对称残差Non-local模块, 对长距离依赖关系进行建模, 进一步提升超分性能. 最后, 设计一个高频损失函数, 去解决像素损失带来图像细节平滑的问题. 大量实验结果表明, 该算法相较于其他先进方法, 可以在图像超分辨率性能和模型复杂度之间取得更好平衡, 其在公开测试数据集B100上, 4倍超分速率达到56 FPS, 比残差注意力网络快15倍.