

-
摘要: 强化学习作为一类重要的人工智能方法, 广泛应用于解决复杂的控制和决策问题, 其在众多领域的应用已展示出巨大潜力. 近年来, 强化学习从单智能体决策逐渐扩展到多智能体协作与博弈, 形成多智能体强化学习这一研究热点. 多智能体系统由多个具有自主感知和决策能力的实体组成, 有望解决传统单智能体方法难以应对的大规模复杂问题. 多智能体强化学习不仅需要考虑环境的动态性, 还需要应对其他智能体策略的不确定性, 从而增加学习和决策过程的复杂度. 为此, 梳理多智能体强化学习在控制与决策领域的研究, 分析其面临的主要问题与挑战, 从控制理论与自主决策两个层次综述现有的研究成果与进展, 并对未来的研究方向进行展望. 通过分析, 期望为未来多智能体强化学习的研究提供有价值的参考和启示.Abstract: Reinforcement learning, as an important method in artificial intelligence, has been widely used to solve complex control and decision-making problems and has shown great potential in various fields. Recently, multi-agent reinforcement learning has evolved from single-agent decision-making to multi-agent cooperation and competition, forming a research hotspot in the field. Multi-agent systems consist of multiple entities with autonomous perception and decision-making capabilities, which hold promise for solving large-scale complex problems that traditional single-agent methods struggle to address. Multi-agent reinforcement learning must not only account for the dynamic nature of the environment, but also deal with uncertainties in the strategies of other agents, adding complexity to the learning and decision-making processes. This paper reviews the research on multi-agent reinforcement learning in the fields of control and decision-making, analyzes the major problems and challenges, summarizes existing results and advances from the perspectives of control theory and decision-making, and looks forward to future research directions. Through this survey, the paper aims to provide valuable references and insights for future research in multi-agent reinforcement learning.
-
[1] 刘全, 翟建伟, 章宗长, 钟珊, 周倩, 章鹏, 等. 深度强化学习综述. 计算机学报, 2018, 41(1): 1−27 doi: 10.11897/SP.J.1016.2019.00001Liu Quan, Zhai Jian-Wei, Zhang Zong-Chang, Zhong Shan, Zhou Qian, Zhang Peng, et al. A survey on deep reinforcement learning. Chinese Journal of Computers, 2018, 41(1): 1−27 doi: 10.11897/SP.J.1016.2019.00001 [2] Zhou F, Luo B, Wu Z K, Huang T W. SMONAC: Supervised multiobjective negative actor-critic for sequential recommendation. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(12): 18525−18537 doi: 10.1109/TNNLS.2023.3317353 [3] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den driessche G, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484−489 doi: 10.1038/nature16961 [4] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of Go without human knowledge. Nature, 2017, 550(7676): 354−359 doi: 10.1038/nature24270 [5] Huang X Y, Li Z Y, Xiang Y Z, Ni Y M, Chi Y F, Li Y H, et al. Creating a dynamic quadrupedal robotic goalkeeper with reinforcement learning. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Detroit, USA: IEEE, 2023. 2715−2722 [6] Perolat J, de Vylder B, Hennes D, Tarassov E, Strub F, de Boer V, et al. Mastering the game of stratego with model-free multiagent reinforcement learning. Science, 2022, 378(6623): 990−996 doi: 10.1126/science.add4679 [7] Fawzi A, Balog M, Huang A, Hubert T, Romera-Paredes B, Barekatain M, et al. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature, 2022, 610(7930): 47−53 doi: 10.1038/s41586-022-05172-4 [8] Zhou Q, Wang W, Liang H J, Basin M V, Wang B H. Observer-based event-triggered fuzzy adaptive bipartite containment control of multiagent systems with input quantization. IEEE Transactions on Fuzzy Systems, 2021, 29(2): 372−384 doi: 10.1109/TFUZZ.2019.2953573 [9] Wu H N, Luo B. Neural network based online simultaneous policy update algorithm for solving the HJI equation in nonlinear H∞ control. IEEE Transactions on Neural Networks and Learning Systems, 2012, 23(12): 1884−1895 doi: 10.1109/TNNLS.2012.2217349 [10] Vrabie D, Vamvoudakis K G, Lewis F L. Optimal Adaptive Control and Differential Games by Reinforcement Learning Principles. London: Institution of Engineering and Technology, 2012. [11] Luo B, Wu H N, Huang T W. Off-policy reinforcement learning for H∞ control design. IEEE Transactions on Cybernetics, 2015, 45(1): 65−76 doi: 10.1109/TCYB.2014.2319577 [12] Luo B, Huang T W, Wu H N, Yang X. Data-driven H∞ control for nonlinear distributed parameter systems. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(11): 2949−2961 doi: 10.1109/TNNLS.2015.2461023 [13] Fu Y, Fu J, Chai T Y. Robust adaptive dynamic programming of two-player zero-sum games for continuous-time linear systems. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(12): 3314−3319 doi: 10.1109/TNNLS.2015.2461452 [14] Liu Q Y, Wang Z D, He X, Zhou D H. Event-based H∞ consensus control of multi-agent systems with relative output feedback: The finite-horizon case. IEEE Transactions on Automatic Control, 2015, 60(9): 2553−2558 doi: 10.1109/TAC.2015.2394872 [15] Vamvoudakis K G, Lewis F L. Online solution of nonlinear two-player zero-sum games using synchronous policy iteration. International Journal of Robust and Nonlinear Control, 2012, 22(13): 1460−1483 doi: 10.1002/rnc.1760 [16] Luo B, Yang Y, Liu D R. Policy iteration Q-learning for data-based two-player zero-sum game of linear discrete-time systems. IEEE Transactions on Cybernetics, 2021, 51(7): 3630−3640 doi: 10.1109/TCYB.2020.2970969 [17] van der Schaft A J. L2-gain analysis of nonlinear systems and nonlinear state-feedback H∞ control. IEEE Transactions on Automatic Control, 1992, 37(6): 770−784 doi: 10.1109/9.256331 [18] Luo B, Wu H N. Computationally efficient simultaneous policy update algorithm for nonlinear H∞ state feedback control with Galerkin's method. International Journal of Robust and Nonlinear Control, 2013, 23(9): 991−1012 doi: 10.1002/rnc.2814 [19] Sun J L, Long T. Event-triggered distributed zero-sum differential game for nonlinear multi-agent systems using adaptive dynamic programming. ISA Transactions, 2021, 110: 39−52 doi: 10.1016/j.isatra.2020.10.043 [20] Zhou Y, Zhou J L, Wen G H, Gan M G, Yang T. Distributed minmax strategy for consensus tracking in differential graphical games: A model-free approach. IEEE Systems, Man, and Cybernetics Magazine, 2023, 9(4): 53−68 doi: 10.1109/MSMC.2023.3282774 [21] Sun J L, Liu C S. Distributed zero-sum differential game for multi-agent systems in strict-feedback form with input saturation and output constraint. Neural Networks, 2018, 106: 8−19 doi: 10.1016/j.neunet.2018.06.007 [22] Li M H, Wang D, Qiao J F. Neural critic learning for tracking control design of constrained nonlinear multi-person zero-sum games. Neurocomputing, 2022, 512: 456−465 doi: 10.1016/j.neucom.2022.09.103 [23] Jiao Q, Modares H, Xu S Y, Lewis F L, Vamvoudakis K G. Multi-agent zero-sum differential graphical games for disturbance rejection in distributed control. Automatica, 2016, 69: 24−34 doi: 10.1016/j.automatica.2016.02.002 [24] Chen C, Lewis F L, Xie K, Lyu Y, Xie S L. Distributed output data-driven optimal robust synchronization of heterogeneous multi-agent systems. Automatica, 2023, 153: Article No. 111030 doi: 10.1016/j.automatica.2023.111030 [25] Zhang H, Li Y, Wang Z P, Ding Y, Yan H C. Distributed optimal control of nonlinear system based on policy gradient with external disturbance. IEEE Transactions on Network Science and Engineering, 2024, 11(1): 872−885 doi: 10.1109/TNSE.2023.3309816 [26] An C L, Su H S, Chen S M. H∞ consensus for discrete-time fractional-order multi-agent systems with disturbance via Q-learning in zero-sum games. IEEE Transactions on Network Science and Engineering, 2022, 9(4): 2803−2814 doi: 10.1109/TNSE.2022.3169792 [27] Ma Y J, Meng Q Y, Jiang B, Ren H. Fault-tolerant control for second-order nonlinear systems with actuator faults via zero-sum differential game. Engineering Applications of Artificial Intelligence, 2023, 123: Article No. 106342 doi: 10.1016/j.engappai.2023.106342 [28] Wu Y, Chen M, Li H Y, Chadli M. Mixed-zero-sum-game-based memory event-triggered cooperative control of heterogeneous MASs against DoS attacks. IEEE Transactions on Cybernetics, 2024, 54(10): 5733−5745 doi: 10.1109/TCYB.2024.3369975 [29] 李梦花, 王鼎, 乔俊飞. 不对称约束多人非零和博弈的自适应评判控制. 控制理论与应用, 2023, 40(9): 1562−1568Li Meng-Hua, Wang Ding, Qiao Jun-Fei. Adaptive critic control for multi-player non-zero-sum games with asymmetric constraints. Control Theory and Applications, 2023, 40(9): 1562−1568 [30] 吕永峰, 田建艳, 菅垄, 任雪梅. 非线性多输入系统的近似动态规划H∞ 控制. 控制理论与应用, 2021, 38(10): 1662−1670 doi: 10.7641/CTA.2021.00559Lv Yong-Feng, Tian Jian-Yan, Jian Long, Ren Xue-Mei. Approximate-dynamic-programming H∞ controls for multi-input nonlinear system. Control Theory and Applications, 2021, 38(10): 1662−1670 doi: 10.7641/CTA.2021.00559 [31] 洪成文, 富月. 基于自适应动态规划的非线性鲁棒近似最优跟踪控制. 控制理论与应用, 2018, 35(9): 1285−1292 doi: 10.7641/CTA.2018.80075Hong Cheng-Wen, Fu Yue. Nonlinear robust approximate optimal tracking control based on adaptive dynamic programming. Control Theory and Applications, 2018, 35(9): 1285−1292 doi: 10.7641/CTA.2018.80075 [32] Vamvoudakis K G, Lewis F L. Multi-player non-zero-sum games: Online adaptive learning solution of coupled Hamilton-Jacobi equations. Automatica, 2011, 47(8): 1556−1569 doi: 10.1016/j.automatica.2011.03.005 [33] Song R Z, Lewis F L, Wei Q L. Off-policy integral reinforcement learning method to solve nonlinear continuous-time multiplayer nonzero-sum games. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3): 704−713 doi: 10.1109/TNNLS.2016.2582849 [34] Kamalapurkar R, Klotz J R, Dixon W E. Concurrent learning-based approximate feedback-Nash equilibrium solution of N-player nonzero-sum differential games. IEEE/CAA Journal of Automatica Sinica, 2014, 1(3): 239−247 doi: 10.1109/JAS.2014.7004681 [35] Zhao Q T, Sun J, Wang G, Chen J. Event-triggered ADP for nonzero-sum games of unknown nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(5): 1905−1913 doi: 10.1109/TNNLS.2021.3071545 [36] Yang X D, Zhang H, Wang Z P. Data-based optimal consensus control for multiagent systems with policy gradient reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(8): 3872−3883 doi: 10.1109/TNNLS.2021.3054685 [37] Abouheaf M I, Lewis F L, Vamvoudakis K G, Haesaert S, Babuska R. Multi-agent discrete-time graphical games and reinforcement learning solutions. Automatica, 2014, 50(12): 3038−3053 doi: 10.1016/j.automatica.2014.10.047 [38] Vamvoudakis K G, Lewis F L, Hudas G R. Multi-agent differential graphical games: Online adaptive learning solution for synchronization with optimality. Automatica, 2012, 48(8): 1598−1611 doi: 10.1016/j.automatica.2012.05.074 [39] Yang N, Xiao J W, Xiao L, Wang Y W. Non-zero sum differential graphical game: Cluster synchronisation for multi-agents with partially unknown dynamics. International Journal of Control, 2019, 92(10): 2408−2419 doi: 10.1080/00207179.2018.1441550 [40] Odekunle A, Gao W, Davari M, Jiang Z P. Reinforcement learning and non-zero-sum game output regulation for multi-player linear uncertain systems. Automatica, 2020, 112: Article No. 108672 doi: 10.1016/j.automatica.2019.108672 [41] Wang Y, Xue H W, Wen J W, Liu J F, Luan X L. Efficient off-policy Q-learning for multi-agent systems by solving dual games. International Journal of Robust and Nonlinear Control, 2024, 34(6): 4193−4212 doi: 10.1002/rnc.7189 [42] Su H G, Zhang H G, Liang Y L, Mu Y F. Online event-triggered adaptive critic design for non-zero-sum games of partially unknown networked systems. Neurocomputing, 2019, 368: 84−98 doi: 10.1016/j.neucom.2019.07.029 [43] Yu M M, Hong S H. A real-time demand-response algorithm for smart grids: A Stackelberg game approach. IEEE Transactions on Smart Grid, 2016, 7(2): 879−888 [44] Yang B, Li Z Y, Chen S M, Wang T, Li K Q. Stackelberg game approach for energy-aware resource allocation in data centers. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(12): 3646−3658 doi: 10.1109/TPDS.2016.2537809 [45] Yoon S G, Choi Y J, Park J K, Bahk S. Stackelberg-game-based demand response for at-home electric vehicle charging. IEEE Transactions on Vehicular Technology, 2016, 65(6): 4172−4184 doi: 10.1109/TVT.2015.2440471 [46] Lin M D, Zhao B, Liu D R. Event-triggered robust adaptive dynamic programming for multiplayer Stackelberg-Nash games of uncertain nonlinear systems. IEEE Transactions on Cybernetics, 2024, 54(1): 273−286 doi: 10.1109/TCYB.2023.3251653 [47] Li M, Qin J H, Ma Q C, Zheng W X, Kang Y. Hierarchical optimal synchronization for linear systems via reinforcement learning: A Stackelberg-Nash game perspective. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(4): 1600−1611 doi: 10.1109/TNNLS.2020.2985738 [48] Yan L, Liu J H, Lai G Y, Chen C L P, Wu Z Z, Liu Z. Adaptive optimal output-feedback consensus tracking control of nonlinear multiagent systems using two-player Stackelberg game. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024, 54(9): 5377−5387 doi: 10.1109/TSMC.2024.3404147 [49] Li D D, Dong J X. Output-feedback optimized consensus for directed graph multi-agent systems based on reinforcement learning and subsystem error derivatives. Information Sciences, 2023, 649: Article No. 119577 doi: 10.1016/j.ins.2023.119577 [50] Zhang D F, Yao Y, Wu Z J. Reinforcement learning based optimal synchronization control for multi-agent systems with input constraints using vanishing viscosity method. Information Sciences, 2023, 637: Article No. 118949 doi: 10.1016/j.ins.2023.118949 [51] Li Q, Xia L N, Song R Z, Liu J. Leader-follower bipartite output synchronization on signed digraphs under adversarial factors via data-based reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(10): 4185−4195 doi: 10.1109/TNNLS.2019.2952611 [52] Luo A, Zhou Q, Ren H R, Ma H, Lu R Q. Reinforcement learning-based consensus control for MASs with intermittent constraints. Neural Networks, 2024, 172: Article No. 106105 doi: 10.1016/j.neunet.2024.106105 [53] Yu J L, Dong X W, Li Q D, Lv J H, Ren Z. Adaptive practical optimal time-varying formation tracking control for disturbed high-order multi-agent systems. IEEE Transactions on Circuits and Systems I: Regular Papers, 2022, 69(6): 2567−2578 doi: 10.1109/TCSI.2022.3151464 [54] Lan J, Liu Y J, Yu D X, Wen G X, Tong S C, Liu L. Time-varying optimal formation control for second-order multiagent systems based on neural network observer and reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(3): 3144−3155 doi: 10.1109/TNNLS.2022.3158085 [55] Wang Z K, Zhang L J. Distributed optimal formation tracking control based on reinforcement learning for underactuated AUVs with asymmetric constraints. Ocean Engineering, 2023, 280: Article No. 114491 doi: 10.1016/j.oceaneng.2023.114491 [56] Cheng M, Liu H, Gao Q, Lu J H, Xia X H. Optimal containment control of a quadrotor team with active leaders via reinforcement learning. IEEE Transactions on Cybernetics, 2024, 54(8): 4502−4512 doi: 10.1109/TCYB.2023.3284648 [57] Zuo S, Song Y D, Lewis F L, Davoudi A. Optimal robust output containment of unknown heterogeneous multiagent system using off-policy reinforcement learning. IEEE Transactions on Cybernetics, 2018, 48(11): 3197−3207 doi: 10.1109/TCYB.2017.2761878 [58] Wang F Y, Cao A, Yin Y H, Liu Z X. Model-free containment control of fully heterogeneous linear multiagent systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024, 54(4): 2551−2562 doi: 10.1109/TSMC.2023.3344786 [59] Qin J H, Li M, Shi Y, Ma Q C, Zheng W X. Optimal synchronization control of multiagent systems with input saturation via off-policy reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(1): 85−96 doi: 10.1109/TNNLS.2018.2832025 [60] Mu C X, Zhao Q, Gao Z K, Sun C Y. Q-learning solution for optimal consensus control of discrete-time multiagent systems using reinforcement learning. Journal of the Franklin Institute, 2019, 356(13): 6946−6967 doi: 10.1016/j.jfranklin.2019.06.007 [61] Bai W W, Li T S, Long Y, Chen C L P. Event-triggered multigradient recursive reinforcement learning tracking control for multiagent systems. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(1): 366−379 doi: 10.1109/TNNLS.2021.3094901 [62] Sun J Y, Ming Z Y. Cooperative differential game-based distributed optimal synchronization control of heterogeneous nonlinear multiagent systems. IEEE Transactions on Cybernetics, 2023, 53(12): 7933−7942 doi: 10.1109/TCYB.2023.3240983 [63] Ji L H, Wang C H, Zhang C J, Wang H W, Li H Q. Optimal consensus model-free control for multi-agent systems subject to input delays and switching topologies. Information Sciences, 2022, 589: 497−515 doi: 10.1016/j.ins.2021.12.125 [64] Guang W W, Wang X, Tan L H, Sun J, Huang T W. Prescribed-time optimal consensus for switched stochastic multiagent systems: Reinforcement learning strategy. IEEE Transactions on Emerging Topics in Computational Intelligence, 2025, 9(1): 75−86 [65] Wang Z S, Liu Y Y, Zhang H G. Two-layer reinforcement learning for output consensus of multiagent systems under switching topology. IEEE Transactions on Cybernetics, 2024, 54(9): 5463−5472 doi: 10.1109/TCYB.2024.3380001 [66] Liu D Y, Liu H, Lv J H, Lewis F L. Time-varying formation of heterogeneous multiagent systems via reinforcement learning subject to switching topologies. IEEE Transactions on Circuits and Systems I: Regular Papers, 2023, 70(6): 2550−2560 doi: 10.1109/TCSI.2023.3250516 [67] Qin J H, Ma Q C, Yu X H, Kang Y. Output containment control for heterogeneous linear multiagent systems with fixed and switching topologies. IEEE Transactions on Cybernetics, 2019, 49(12): 4117−4128 doi: 10.1109/TCYB.2018.2859159 [68] Li H Y, Wu Y, Chen M. Adaptive fault-tolerant tracking control for discrete-time multiagent systems via reinforcement learning algorithm. IEEE Transactions on Cybernetics, 2021, 51(3): 1163−1174 doi: 10.1109/TCYB.2020.2982168 [69] Zhao W B, Liu H, Valavanis K P, Lewis F L. Fault-tolerant formation control for heterogeneous vehicles via reinforcement learning. IEEE Transactions on Aerospace and Electronic Systems, 2022, 58(4): 2796−2806 doi: 10.1109/TAES.2021.3139260 [70] Li T S, Bai W W, Liu Q, Long Y, Chen C L P. Distributed fault-tolerant containment control protocols for the discrete-time multiagent systems via reinforcement learning method. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(8): 3979−3991 doi: 10.1109/TNNLS.2021.3121403 [71] Liu D H, Mao Z H, Jiang B, Xu L. Simplified ADP-based distributed event-triggered fault-tolerant control of heterogeneous nonlinear multiagent systems with full-state constraints. IEEE Transactions on Circuits and Systems I: Regular Papers, 2024, 71(8): 3820−3832 doi: 10.1109/TCSI.2024.3389740 [72] Zhang Y W, Zhao B, Liu D R, Zhang S C. Distributed fault tolerant consensus control of nonlinear multiagent systems via adaptive dynamic programming. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(7): 9041−9053 doi: 10.1109/TNNLS.2022.3217774 [73] Xu Y, Wu Z G. Data-based collaborative learning for multiagent systems under distributed denial-of-service attacks. IEEE Transactions on Cognitive and Developmental Systems, 2024, 16(1): 75−85 doi: 10.1109/TCDS.2022.3172937 [74] Zhang L J, Chen Y. Distributed finite-time ADP-based optimal control for nonlinear multiagent systems. IEEE Transactions on Circuits and Systems II: Express Briefs, 2023, 70(12): 4534−4538 [75] Wang P, Yu C P, Lv M L, Cao J D. Adaptive fixed-time optimal formation control for uncertain nonlinear multiagent systems using reinforcement learning. IEEE Transactions on Network Science and Engineering, 2024, 11(2): 1729−1743 doi: 10.1109/TNSE.2023.3330266 [76] Zhang Y, Chadli M, Xiang Z R. Prescribed-time formation control for a class of multiagent systems via fuzzy reinforcement learning. IEEE Transactions on Fuzzy Systems, 2023, 31(12): 4195−4204 doi: 10.1109/TFUZZ.2023.3277480 [77] Peng Z N, Luo R, Hu J P, Shi K B, Ghosh B K. Distributed optimal tracking control of discrete-time multiagent systems via event-triggered reinforcement learning. IEEE Transactions on Circuits and Systems I: Regular Papers, 2022, 69(9): 3689−3700 doi: 10.1109/TCSI.2022.3177407 [78] Xu Y, Sun J, Pan Y J, Wu Z G. Optimal tracking control of heterogeneous MASs using event-driven adaptive observer and reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(4): 5577−5587 doi: 10.1109/TNNLS.2022.3208237 [79] Tan M J, Liu Z, Chen C L P, Zhang Y, Wu Z Z. Optimized adaptive consensus tracking control for uncertain nonlinear multiagent systems using a new event-triggered communication mechanism. Information Sciences, 2022, 605: 301−316 doi: 10.1016/j.ins.2022.05.030 [80] Li H Y, Wu Y, Chen M, Lu R Q. Adaptive multigradient recursive reinforcement learning event-triggered tracking control for multiagent systems. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(1): 144−156 doi: 10.1109/TNNLS.2021.3090570 [81] Zhao H R, Shan J J, Peng L, Yu H N. Adaptive event-triggered bipartite formation for multiagent systems via reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(12): 17817−17828 doi: 10.1109/TNNLS.2023.3309326 [82] Xiao W B, Zhou Q, Liu Y, Li H Y, Lu R Q. Distributed reinforcement learning containment control for multiple nonholonomic mobile robots. IEEE Transactions on Circuits and Systems I: Regular Papers, 2022, 69(2): 896−907 doi: 10.1109/TCSI.2021.3121809 [83] Xiong C P, Ma Q, Guo J, Lewis F L. Data-based optimal synchronization of heterogeneous multiagent systems in graphical games via reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(11): 15984−15992 doi: 10.1109/TNNLS.2023.3291542 [84] Zhang Q C, Zhao D B, Lewis F L. Model-free reinforcement learning for fully cooperative multi-agent graphical games. In: Proceedings of the International Joint Conference on Neural Networks (IJCNN). Rio de Janeiro, Brazil: IEEE, 2018. 1−6 [85] Li J N, Modares H, Chai T Y, Lewis F L, Xie L H. Off-policy reinforcement learning for synchronization in multiagent graphical games. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(10): 2434−2445 doi: 10.1109/TNNLS.2016.2609500 [86] Wang H, Li M. Model-free reinforcement learning for fully cooperative consensus problem of nonlinear multiagent systems. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(4): 1482−1491 doi: 10.1109/TNNLS.2020.3042508 [87] Ming Z Y, Zhang H G, Zhang J, Xie X P. A novel actor-critici-dentifier architecture for nonlinear multiagent systems with gradient descent method. Automatica, 2023, 155: Article No. 111128 doi: 10.1016/j.automatica.2023.111128 [88] 梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦, 等. 多Agent深度强化学习综述. 自动化学报, 2020, 46(12): 2537−2557Liang Xing-Xing, Feng Yang-He, Ma Yang, Cheng Guang-Quan, Huang Jin-Cai, Wang Qi, et al. Deep multi-agent reinforcement learning: A survey. Acta Automatica Sinica, 2020, 46(12): 2537−2557 [89] Bellman R. A Markovian decision process. Journal of Mathematics and Mechanics, 1957, 6(5): 679−684 [90] Howard R A. Dynamic Programming and Markov Processes. Cambridge: MIT Press, 1960. [91] Watkins C J C H, Dayan P. Q-learning. Machine Learning, 1992, 8(3): 279−292 [92] Rummery G A, Niranjan M. On-Line Q-Learning Using Connectionist Systems. Cambridge: University of Cambridge, 1994. [93] Sutton R S, McAllester D, Singh S, Mansour Y. Policy gradient methods for reinforcement learning with function approximation. In: Proceedings of the 13th International Conference on Neural Information Processing Systems. Denver, USA: MIT Press, 1999. 1057−1063 [94] Silver D, Lever G, Heess N, Degris T, Wierstra D, Riedmiller M. Deterministic policy gradient algorithms. In: Proceedings of the 31st International Conference on Machine Learning. Beijing, China: ACM, 2014. I-387−I-395 [95] Luo B, Wu Z K, Zhou F, Wang B C. Human-in-the-loop reinforcement learning in continuous-action space. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(11): 15735−15744 doi: 10.1109/TNNLS.2023.3289315 [96] Shapley L S. Stochastic games. Proceedings of the National Academy of Sciences of the United States of America, 1953, 39(10): 1095−1100 [97] Hansen E A, Bernstein D S, Zilberstein S. Dynamic programming for partially observable stochastic games. In: Proceedings of the 19th AAAI Conference on Artificial Intelligence. San Jose, USA: AAAI, 2004. 709−715 [98] Smallwood R D, Sondik E J. The optimal control of partially observable Markov processes over a finite horizon. Operations Research, 1973, 21(5): 1071−1088 doi: 10.1287/opre.21.5.1071 [99] Tampuu A, Matiisen T, Kodelja D, Kuzovkin I, Korjus K, Aru J, et al. Multiagent cooperation and competition with deep reinforcement learning. PLoS One, 2017, 12(4): Article No. e0172395 doi: 10.1371/journal.pone.0172395 [100] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529−533 doi: 10.1038/nature14236 [101] Chen Y F, Liu M, Everett M, How J P. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Singapore: IEEE, 2017. 285−292 [102] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301−1312Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301−1312 [103] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, USA: ICLR, 2016. [104] Gupta J K, Egorov M, Kochenderfer M. Cooperative multi-agent control using deep reinforcement learning. In: Proceedings of the Conference on Autonomous Agents and Multiagent Systems. São Paulo, Brazil: Springer, 2017. 66−83 [105] Kraemer L, Banerjee B. Multi-agent reinforcement learning as a rehearsal for decentralized planning. Neurocomputing, 2016, 190: 82−94 doi: 10.1016/j.neucom.2016.01.031 [106] Bhatnagar S, Sutton R S, Ghavamzadeh M, Lee M. Natural actor-critic algorithms. Automatica, 2009, 45(11): 2471−2482 doi: 10.1016/j.automatica.2009.07.008 [107] Degris T, White M, Sutton R S. Off-policy actor-critic. In: Proceedings of the 29th International Conference on Machine Learning. Edinburgh, UK: ACM, 2012. 179−186 [108] Sunehag P, Lever G, Gruslys A, Czarnecki W M, Zambaldi V, Jaderberg M, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward. In: Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems. Stockholm, Sweden: ACM, 2018. 2085−2087 [109] Lowe R, Wu Y I, Tamar A, Harb J, Pieter A, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 6382−6393 [110] Gronauer S, Diepold K. Multi-agent deep reinforcement learning: A survey. Artificial Intelligence Review, 2022, 55(2): 895−943 doi: 10.1007/s10462-021-09996-w [111] Iqbal S, Sha F. Actor-attention-critic for multi-agent reinforcement learning. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 2961−2970 [112] Yu C, Velu A, Vnitsky E, Gao J X, Wang Y, Bayen A, et al. The surprising effectiveness of PPO in cooperative multi-agent games. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 1787 [113] Mnih V, Heess N, Graves A, Kavukcuoglu K. Recurrent models of visual attention. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2204−2212 [114] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6000−6010 [115] Tan M. Multi-agent reinforcement learning: Independent versus cooperative agents. In: Proceedings of the 10th International Conference on Machine Learning. Amherst, USA: ACM, 1993. 330−337 [116] Sen S, Sekaran M, Hale J. Learning to coordinate without sharing information. In: Proceedings of the 12th AAAI Conference on Artificial Intelligence. Seattle, USA: AAAI, 1994. 426−431 [117] Matignon L, Laurent G J, Le Fort-Piat N. Independent reinforcement learners in cooperative Markov games: A survey regarding coordination problems. The Knowledge Engineering Review, 2012, 27(1): 1−31 doi: 10.1017/S0269888912000057 [118] Foerster J, Nardelli N, Farquhar G, Afouras T, Torr P H S, Kohli P, et al. Stabilising experience replay for deep multi-agent reinforcement learning. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ACM, 2017. 1146−1155 [119] Raileanu R, Denton E, Szlam A, Fergus R. Modeling others using oneself in multi-agent reinforcement learning. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 4254−4263 [120] Kaelbling L P, Littman M L, Cassandra A R. Planning and acting in partially observable stochastic domains. Artificial Intelligence, 1998, 101(1−2): 99−134 doi: 10.1016/S0004-3702(98)00023-X [121] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735−1780 doi: 10.1162/neco.1997.9.8.1735 [122] Cho K, van Merrienboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: ACL, 2014. 1724−1734 [123] Hausknecht M, Stone P. Deep recurrent Q-learning for partially observable MDPs. In: Proceedings of the AAAI Fall Symposium. Arlington, USA: AAAI, 2015. 29−37 [124] Matignon L, Laurent G J, Le Fort-Piat N. Hysteretic Q-learning: An algorithm for decentralized reinforcement learning in cooperative multi-agent teams. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. San Diego, USA: IEEE, 2007. 64−69 [125] Omidshafiei S, Pazis J, Amato C, How J P, Vian J. Deep decentralized multi-task multi-agent reinforcement learning under partial observability. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ACM, 2017. 2681−2690 [126] Foerster J N, Assael Y M, de Freitas N, Whiteson S. Learning to communicate to solve riddles with deep distributed recurrent Q-networks. arXiv preprint arXiv: 1602.02672, 2016. [127] Sukhbaatar S, Fergus R, Fergus R. Learning multiagent communication with backpropagation. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc., 2016. 2252−2260 [128] Singh A, Jain T, Sukhbaatar S. Individualized controlled continuous communication model for multiagent cooperative and competitive tasks. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: OpenReview, 2019. 1−16Singh A, Jain T, Sukhbaatar S. Individualized controlled continuous communication model for multiagent cooperative and competitive tasks. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: OpenReview, 2019. 1−16 [129] Chen J D, Lan T, Joe-Wong C. RGMComm: Return gap minimization via discrete communications in multi-agent reinforcement learning. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 17327−17336 [130] Sheng J J, Wang X F, Jin B, Yan J C, Li W H, Chang T H, et al. Learning structured communication for multi-agent reinforcement learning. Autonomous Agents and Multi-Agent Systems, 2022, 36(2): Article No. 50 doi: 10.1007/s10458-022-09580-8 [131] Foerster J N, Assael Y M, de Freitas N, Whiteson S. Learning to communicate with deep multi-agent reinforcement learning. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc., 2016. 2145−2153 [132] Peng P, Wen Y, Yang Y D, Yuan Q, Tang Z K, Long H T, et al. Multiagent bidirectionally-coordinated nets: Emergence of human-level coordination in learning to play starcraft combat games. arXiv preprint arXiv: 1703.10069, 2017. [133] 吴俊锋, 王文, 汪亮, 陶先平, 胡昊, 吴海军. 基于两阶段意图共享的多智能体强化学习方法. 计算机学报, 2023, 46(9): 1820−1837 doi: 10.11897/SP.J.1016.2023.01820Wu Jun-Feng, Wang Wen, Wang Liang, Tao Xian-Ping, Hu Hao, Wu Hai-Jun. Multi-agent reinforcement learning with two step intention sharing. Chinese Journal of Computers, 2023, 46(9): 1820−1837 doi: 10.11897/SP.J.1016.2023.01820 [134] Mao H Y, Zhang Z C, Xiao Z, Gong Z B, Ni Y. Learning agent communication under limited bandwidth by message pruning. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 5142−5149 [135] Kim D, Moon S, Hostallero D, Kang W J, Lee T, Son K, et al. Learning to schedule communication in multi-agent reinforcement learning. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: OpenReview, 2019. 1−11 [136] Das A, Gervet T, Romoff J, Batra D, Parikh D, Rabbat M, et al. TarMAC: Targeted multi-agent communication. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: ICML, 2019. 1538−1546 [137] Niu Y R, Paleja R, Gombolay M. Multi-agent graph-attention communication and teaming. In: Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems. Virtual Event: ACM, 2021. 964−973Niu Y R, Paleja R, Gombolay M. Multi-agent graph-attention communication and teaming. In: Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems. Virtual Event: ACM, 2021. 964−973 [138] Lhaksmana K M, Murakami Y, Ishida T. Role-based modeling for designing agent behavior in self-organizing multi-agent systems. International Journal of Software Engineering and Knowledge Engineering, 2018, 28(1): 79−96 doi: 10.1142/S0218194018500043 [139] Wang T H, Dong H, Lesser V, Zhang C J. ROMA: Multi-agent reinforcement learning with emergent roles. In: Proceedings of the 37th International Conference on Machine Learning. Vienna, Australia: ACM, 2020. Article No. 916Wang T H, Dong H, Lesser V, Zhang C J. ROMA: Multi-agent reinforcement learning with emergent roles. In: Proceedings of the 37th International Conference on Machine Learning. Vienna, Australia: ACM, 2020. Article No. 916 [140] Wang T H, Gupta T, Mahajan A, Peng B, Whiteson S, Zhang C J. RODE: Learning roles to decompose multi-agent tasks. In: Proceedings of the 9th International Conference on Learning Representations. Vienna, Australia: OpenReview, 2021. 1−24Wang T H, Gupta T, Mahajan A, Peng B, Whiteson S, Zhang C J. RODE: Learning roles to decompose multi-agent tasks. In: Proceedings of the 9th International Conference on Learning Representations. Vienna, Australia: OpenReview, 2021. 1−24 [141] Hu Z C, Zhang Z Z, Li H X, Chen C L, Ding H Y, Wang Z. Attention-guided contrastive role representations for multi-agent reinforcement learning. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Australia: OpenReview, 2024. 1−23 [142] Zambaldi V, Raposo D, Santoro A, Bapst V, Li Y J, Babuschkin I, et al. Relational deep reinforcement learning. arXiv preprint arXiv: 1806.01830, 2018. [143] Jiang H, Liu Y T, Li S Z, Zhang J Y, Xu X H, Liu D H. Diverse effective relationship exploration for cooperative multi-agent reinforcement learning. In: Proceedings of the 31st ACM International Conference on Information and Knowledge Management. Atlanta, USA: ACM, 2022. 842−851 [144] Wang W X, Yang T P, Liu Y, Hao J Y, Hao X T, Hu Y J. Action semantics network: Considering the effects of actions in multiagent systems. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: OpenReview, 2020. 1−18 [145] Ackermann J, Gabler V, Osa T, Sugiyama M. Reducing overestimation bias in multi-agent domains using double centralized critics. arXiv preprint arXiv: 1910.01465, 2019. [146] van Hasselt H, Guez A, Silver D. Deep reinforcement learning with double Q-learning. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI, 2016. 2094−2100 [147] Pan L, Rashid T, Peng B, Huang L B, Whiteson S. Regularized softmax deep multi-agent Q-learning. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 105Pan L, Rashid T, Peng B, Huang L B, Whiteson S. Regularized softmax deep multi-agent Q-learning. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 105 [148] Liu J R, Zhong Y F, Hu S Y, Fu H B, Fu Q, Chang X J, et al. Maximum entropy heterogeneous-agent reinforcement learning. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Australia: OpenReview, 2024. 1−12 [149] Na H, Seo Y, Moon I C. Efficient episodic memory utilization of cooperative multi-agent reinforcement learning. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Australia: OpenReview, 2024. 1−13 [150] Mahajan A, Rashid T, Samvelyan M, Whiteson S. MAVEN: Multi-agent variational exploration. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2019. Article No. 684 [151] Liu I J, Jain U, Yeh R A, Schwing A G. Cooperative exploration for multi-agent deep reinforcement learning. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: ICML, 2021. 6826−6836Liu I J, Jain U, Yeh R A, Schwing A G. Cooperative exploration for multi-agent deep reinforcement learning. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: ICML, 2021. 6826−6836 [152] Chen Z H, Luo B, Hu T M, Xu X D. LJIR: Learning joint-action intrinsic reward in cooperative multi-agent reinforcement learning. Neural Networks, 2023, 167: 450−459 doi: 10.1016/j.neunet.2023.08.016 [153] Hao J Y, Hao X T, Mao H Y, Wang W X, Yang Y D, Li D, et al. Boosting multiagent reinforcement learning via permutation invariant and permutation equivariant networks. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview, 2023. 1−12 [154] Yang Y D, Luo R, Li M N, Zhou M, Zhang W N, Wang J. Mean field multi-agent reinforcement learning. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: ICML, 2018. 5567−5576 [155] Subramanian S G, Poupart P, Taylor M E, Hegde N. Multi type mean field reinforcement learning. In: Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems. Auckland, New Zealand: ACM, 2020. 411−419 [156] Mondal W U, Agarwal M, Aggarwal V, Ukkusuri S V. On the approximation of cooperative heterogeneous multi-agent reinforcement learning (MARL) using mean field control (MFC). The Journal of Machine Learning Research, 2022, 23(1): Article No. 129 [157] Chang Y H, Ho T, Kaelbling L P. All learning is local: Multi-agent learning in global reward games. In: Proceedings of the 17th International Conference on Neural Information Processing Systems. Whistler, Canada: MIT Press, 2003. 807−814 [158] Rashid T, Samvelyan M, de Witt C S, Farquhar G, Foerster J N, Whiteson S. QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: ICML, 2018. 4292−4301 [159] Zhou M, Liu Z Y, Sui P W, Li Y X, Chung Y Y. Learning implicit credit assignment for cooperative multi-agent reinforcement learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 994 [160] Rashid T, Farquhar G, Peng B, Whiteson S. Weighted QMIX: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 855 [161] Yang Y D, Hao J Y, Liao B, Shao K, Chen G Y, Liu W L, et al. Qatten: A general framework for cooperative multiagent reinforcement learning. arXiv preprint arXiv: 2002.03939, 2020. [162] Son K, Kim D, Kang W J, Hostallero D, Yi Y. QTRAN: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: ICML, 2019. 5887−5896 [163] Foerster J, Farquhar G, Afouras T, Nardelli N, Whiteson S. Counterfactual multi-agent policy gradients. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 2974−2982 [164] Wolpert D H, Tumer K. Optimal payoff functions for members of collectives. Advances in Complex Systems, 2001, 4(2−3): 265−279 doi: 10.1142/S0219525901000188 [165] Wang J H, Zhang Y, Kim T K, Gu Y J. Shapley Q-value: A local reward approach to solve global reward games. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 7285−7292 [166] Shapley L. A value for N-person games. Contributions to the Theory of Games II. Princeton: Princeton University Press, 1953. 307−317 [167] Li J H, Kuang K, Wang B X, Liu F R, Chen L, Wu F, et al. Shapley counterfactual credits for multi-agent reinforcement learning. In: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Virtual Event: ACM, 2021. 934−942Li J H, Kuang K, Wang B X, Liu F R, Chen L, Wu F, et al. Shapley counterfactual credits for multi-agent reinforcement learning. In: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Virtual Event: ACM, 2021. 934−942 [168] 徐诚, 殷楠, 段世红, 何昊, 王然. 基于奖励滤波信用分配的多智能体深度强化学习算法. 计算机学报, 2022, 45(11): 2306−2320 doi: 10.11897/SP.J.1016.2022.02306Xu Cheng, Yin Nan, Duan Shi-Hong, He Hao, Wang Ran. Reward-filtering-based credit assignment for multi-agent deep reinforcement learning. Chinese Journal of Computers, 2022, 45(11): 2306−2320 doi: 10.11897/SP.J.1016.2022.02306 [169] Chen S R, Zhang Z W, Yang Y D, Du Y L. STAS: Spatial-temporal return decomposition for solving sparse rewards problems in multi-agent reinforcement learning. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 17337−17345 [170] Littman M L. Markov games as a framework for multi-agent reinforcement learning. In: Proceedings of the 11th International Conference on Machine Learning. New Brunswick, USA: ACM, 1994. 157−163 [171] Zhang K Q, Yang Z R, Liu H, Zhang T, Basar T. Finite-sample analysis for decentralized batch multiagent reinforcement learning with networked agents. IEEE Transactions on Automatic Control, 2021, 66(12): 5925−5940 doi: 10.1109/TAC.2021.3049345 [172] Fan J Q, Wang Z R, Xie Y C, Yang Z R. A theoretical analysis of deep Q-learning. In: Proceedings of the 2nd Annual Conference on Learning for Dynamics and Control. Berkeley, USA: PMLR, 2020. 486−489 [173] Heinrich J, Lanctot M, Silver D. Fictitious self-play in extensive-form games. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ACM, 2015. 805−813 [174] Berger U. Brown's original fictitious play. Journal of Economic Theory, 2007, 135(1): 572−578 doi: 10.1016/j.jet.2005.12.010 [175] Heinrich J, Silver D. Deep reinforcement learning from self-play in imperfect-information games. arXiv preprint arXiv: 1603.01121, 2016. [176] Zhang L, Chen Y X, Wang W, Han Z L, Li S J, Pan Z J, et al. A Monte Carlo neural fictitious self-play approach to approximate Nash equilibrium in imperfect-information dynamic games. Frontiers of Computer Science, 2021, 15(5): Article No. 155334 doi: 10.1007/s11704-020-9307-6 [177] Lanctot M, Zambaldi V, Gruslys A, Lazaridou A, Tuyls K, Pérolat J, et al. A unified game-theoretic approach to multiagent reinforcement learning. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 4193−4206 [178] McAleer S, Lanier J, Fox R, Baldi P. Pipeline PSRO: A scalable approach for finding approximate Nash equilibria in large games. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 1699 [179] Muller P, Omidshafiei S, Rowland M, Tuyls K, Pérolat J, Liu S Q, et al. A generalized training approach for multiagent learning. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. [180] 徐浩添, 秦龙, 曾俊杰, 胡越, 张琪. 基于深度强化学习的对手建模方法研究综述. 系统仿真学报, 2023, 35(4): 671−694Xu Hao-Tian, Qin Long, Zeng Jun-Jie, Hu Yue, Zhang Qi. Research progress of opponent modeling based on deep reinforcement learning. Journal of System Simulation, 2023, 35(4): 671−694 [181] He H, Boyd-Graber J, Kwok K, Daumé III H. Opponent modeling in deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: ACM, 2016. 1804−1813 [182] Everett R, Roberts S J. Learning against non-stationary agents with opponent modelling and deep reinforcement learning. In: Proceedings of the AAAI Spring Symposium. Palo Alto, USA: AAAI, 2018. 621−626 [183] Foerster J, Chen R Y, Al-Shedivat M, Whiteson S, Abbeel P, Mordatch I. Learning with opponent-learning awareness. In: Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems. Stockholm, Sweden: ACM, 2018. 122−130 [184] Long P X, Fan T X, Liao X Y, Liu W X, Zhang H, Pan J. Towards optimally decentralized multi-robot collision avoidance via deep reinforcement learning. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Brisbane, Australia: IEEE, 2018. 6252−6259 [185] Willemsen D, Coppola M, de Croon G C H E. MAMBPO: Sample-efficient multi-robot reinforcement learning using learned world models. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Prague, Czech Republic: IEEE, 2021. 5635−5640 [186] Yue L F, Lv M L, Yan M D, Zhao X R, Wu A, Li L Y, et al. Improving cooperative multi-target tracking control for UAV swarm using multi-agent reinforcement learning. In: Proceedings of the 9th International Conference on Control, Automation and Robotics (ICCAR). Beijing, China: IEEE, 2023. 179−186 [187] Xue Y T, Chen W S. Multi-agent deep reinforcement learning for UAVs navigation in unknown complex environment. IEEE Transactions on Intelligent Vehicles, 2024, 9(1): 2290−2303 doi: 10.1109/TIV.2023.3298292 [188] Mou Z Y, Zhang Y, Gao F F, Wang H G, Zhang T, Han Z. Deep reinforcement learning based three-dimensional area coverage with UAV swarm. IEEE Journal on Selected Areas in Communications, 2021, 39(10): 3160−3176 doi: 10.1109/JSAC.2021.3088718 [189] Hou Y K, Zhao J, Zhang R Q, Cheng X, Yang L Q. UAV swarm cooperative target search: A multi-agent reinforcement learning approach. IEEE Transactions on Intelligent Vehicles, 2024, 9(1): 568−578 doi: 10.1109/TIV.2023.3316196 [190] Cui J J, Liu Y W, Nallanathan A. Multi-agent reinforcement learning-based resource allocation for UAV networks. IEEE Transactions on Wireless Communications, 2020, 19(2): 729−743 doi: 10.1109/TWC.2019.2935201 [191] Wang Z Y, Gombolay M. Learning scheduling policies for multi-robot coordination with graph attention networks. IEEE Robotics and Automation Letters, 2020, 5(3): 4509−4516 doi: 10.1109/LRA.2020.3002198 [192] Johnson D, Chen G, Lu Y Q. Multi-agent reinforcement learning for real-time dynamic production scheduling in a robot assembly cell. IEEE Robotics and Automation Letters, 2022, 7(3): 7684−7691 doi: 10.1109/LRA.2022.3184795 [193] Paul S, Ghassemi P, Chowdhury S. Learning scalable policies over graphs for multi-robot task allocation using capsule attention networks. In: Proceedings of the International Conference on Robotics and Automation (ICRA). Philadelphia, USA: IEEE, 2022. 8815−8822 [194] Shalev-Shwartz S, Shammah S, Shashua A. Safe, multi-agent, reinforcement learning for autonomous driving. arXiv preprint arXiv: 1610.03295, 2016. [195] Yu C, Wang X, Xu X, Zhang M J, Ge H W, Ren J K, et al. Distributed multiagent coordinated learning for autonomous driving in highways based on dynamic coordination graphs. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(2): 735−748 doi: 10.1109/TITS.2019.2893683 [196] Liu B, Ding Z T, Lv C. Platoon control of connected autonomous vehicles: A distributed reinforcement learning method by consensus. IFAC-PapersOnLine, 2020, 53(2): 15241−15246 doi: 10.1016/j.ifacol.2020.12.2310 [197] Liang Z X, Cao J N, Jiang S, Saxena D, Xu H F. Hierarchical reinforcement learning with opponent modeling for distributed multi-agent cooperation. In: Proceedings of the 42nd IEEE International Conference on Distributed Computing Systems (ICDCS). Bologna, Italy: IEEE, 2022. 884−894 [198] Candela E, Parada L, Marques L, Georgescu T A, Demiris Y, Angeloudis P. Transferring multi-agent reinforcement learning policies for autonomous driving using sim-to-real. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Kyoto, Japan: IEEE, 2022. 8814−8820 [199] Chu T S, Wang J, Codecà L, Li Z J. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(3): 1086−1095 doi: 10.1109/TITS.2019.2901791 [200] Jiang S, Huang Y F, Jafari M, Jalayer M. A distributed multi-agent reinforcement learning with graph decomposition approach for large-scale adaptive traffic signal control. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(9): 14689−14701 doi: 10.1109/TITS.2021.3131596 [201] Wang X Q, Ke L J, Qiao Z M, Chai X H. Large-scale traffic signal control using a novel multiagent reinforcement learning. IEEE Transactions on Cybernetics, 2021, 51(1): 174−187 doi: 10.1109/TCYB.2020.3015811 [202] Wang K, Mu C X. Learning-based control with decentralized dynamic event-triggering for vehicle systems. IEEE Transactions on Industrial Informatics, 2023, 19(3): 2629−2639 doi: 10.1109/TII.2022.3168034 [203] Xu Y, Wu Z G, Pan Y J. Perceptual interaction-based path tracking control of autonomous vehicles under DoS attacks: A reinforcement learning approach. IEEE Transactions on Vehicular Technology, 2023, 72(11): 14028−14039 [204] Shen G Q, Lei L, Zhang X T, Li Z L, Cai S S, Zhang L J. Multi-UAV cooperative search based on reinforcement learning with a digital twin driven training framework. IEEE Transactions on Vehicular Technology, 2023, 72(7): 8354−8368 [205] Cheng M, Liu H, Wen G H, Lv J H, Lewis F L. Data-driven time-varying formation-containment control for a heterogeneous air-ground vehicle team subject to active leaders and switching topologies. Automatica, 2023, 153: Article No. 111029 doi: 10.1016/j.automatica.2023.111029 [206] Zhao W B, Liu H, Wan Y, Lin Z L. Data-driven formation control for multiple heterogeneous vehicles in air-ground coordination. IEEE Transactions on Control of Network Systems, 2022, 9(4): 1851−1862 doi: 10.1109/TCNS.2022.3181254 [207] Zhao J, Yang C, Wang W D, Xu B, Li Y, Yang L Q, et al. A game-learning-based smooth path planning strategy for intelligent air-ground vehicle considering mode switching. IEEE Transactions on Transportation Electrification, 2022, 8(3): 3349−3366 doi: 10.1109/TTE.2022.3142150 [208] Song W T, Tong S C. Fuzzy optimal tracking control for nonlinear underactuated unmanned surface vehicles. Ocean Engineering, 2023, 287: Article No. 115700 doi: 10.1016/j.oceaneng.2023.115700 [209] Chen L, Dong C, He S D, Dai S L. Adaptive optimal formation control for unmanned surface vehicles with guaranteed performance using actor-critic learning architecture. International Journal of Robust and Nonlinear Control, 2023, 33(8): 4504−4522 doi: 10.1002/rnc.6623 [210] Bai W W, Zhang W J, Cao L, Liu Q. Adaptive control for multi-agent systems with actuator fault via reinforcement learning and its application on multi-unmanned surface vehicle. Ocean Engineering, 2023, 280: Article No. 114545 doi: 10.1016/j.oceaneng.2023.114545 [211] Chen H Z, Yan H C, Wang Y Y, Xie S R, Zhang D. Reinforcement learning-based close formation control for underactuated surface vehicle with prescribed performance and time-varying state constraints. Ocean Engineering, 2022, 256: Article No. 111361 doi: 10.1016/j.oceaneng.2022.111361 [212] Weng P J, Tian X H, Liu H T, Mai Q. Distributed edge-based event-triggered optimal formation control for air-sea heterogeneous multiagent systems. Ocean Engineering, 2023, 288: Article No. 116066 doi: 10.1016/j.oceaneng.2023.116066 [213] Jaderberg M, Czarnecki W M, Dunning I, Marris L, Lever G, Castañeda A G, et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science, 2019, 364(6443): 859−865 doi: 10.1126/science.aau6249 [214] Xu X, Jia Y W, Xu Y, Xu Z, Chai S J, Lai C S. A multi-agent reinforcement learning-based data-driven method for home energy management. IEEE Transactions on Smart Grid, 2020, 11(4): 3201−3211 doi: 10.1109/TSG.2020.2971427 [215] Ahrarinouri M, Rastegar M, Seifi A R. Multiagent reinforcement learning for energy management in residential buildings. IEEE Transactions on Industrial Informatics, 2021, 17(1): 659−666 doi: 10.1109/TII.2020.2977104 [216] Zhang Y, Yang Q Y, An D, Li D H, Wu Z Z. Multistep multiagent reinforcement learning for optimal energy schedule strategy of charging stations in smart grid. IEEE Transactions on Cybernetics, 2023, 53(7): 4292−4305 doi: 10.1109/TCYB.2022.3165074 [217] Zhao X Y, Wu C. Large-scale machine learning cluster scheduling via multi-agent graph reinforcement learning. IEEE Transactions on Network and Service Management, 2022, 19(4): 4962−4974 doi: 10.1109/TNSM.2021.3139607 [218] Yu T, Huang J, Chang Q. Optimizing task scheduling in human-robot collaboration with deep multi-agent reinforcement learning. Journal of Manufacturing Systems, 2021, 60: 487−499 doi: 10.1016/j.jmsy.2021.07.015 [219] Jing X, Yao X F, Liu M, Zhou J J. Multi-agent reinforcement learning based on graph convolutional network for flexible job shop scheduling. Journal of Intelligent Manufacturing, 2024, 35(1): 75−93 doi: 10.1007/s10845-022-02037-5 [220] 邝祝芳, 陈清林, 李林峰, 邓晓衡, 陈志刚. 基于深度强化学习的多用户边缘计算任务卸载调度与资源分配算法. 计算机学报, 2022, 45(4): 812−824 doi: 10.11897/SP.J.1016.2022.00812Kuang Zhu-Fang, Chen Qing-Lin, Li Lin-Feng, Deng Xiao-Heng, Chen Zhi-Gang. Multi-user edge computing task offloading scheduling and resource allocation based on deep reinforcement learning. Chinese Journal of Computers, 2022, 45(4): 812−824 doi: 10.11897/SP.J.1016.2022.00812 [221] Adibi M, van der Woude J. Secondary frequency control of microgrids: An online reinforcement learning approach. IEEE Transactions on Automatic Control, 2022, 67(9): 4824−4831 doi: 10.1109/TAC.2022.3162550 [222] Liu Y L, Qie T H, Yu Y, Wang Y X, Chau T K, Zhang X N. A novel integral reinforcement learning-based H∞ control strategy for proton exchange membrane fuel cell in DC Microgrids. IEEE Transactions on Smart Grid, 2023, 14(3): 1668−1681 doi: 10.1109/TSG.2022.3206281 [223] Zhang H F, Yue D, Dou C X, Xie X P, Li K, Hancke G P. Resilient optimal defensive strategy of TSK fuzzy-model-based microgrids' system via a novel reinforcement learning approach. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(4): 1921−1931 doi: 10.1109/TNNLS.2021.3105668 [224] Duan J J, Yi Z H, Shi D, Lin C, Lu X, Wang Z W. Reinforcement-learning-based optimal control of hybrid energy storage systems in hybrid AC-DC microgrids. IEEE Transactions on Industrial Informatics, 2019, 15(9): 5355−5364 doi: 10.1109/TII.2019.2896618 [225] Dong X, Zhang H G, Xie X P, Ming Z Y. Data-driven distributed H∞ current sharing consensus optimal control of DC microgrids via reinforcement learning. IEEE Transactions on Circuits and Systems I: Regular Papers, 2024, 71(6): 2824−2834 doi: 10.1109/TCSI.2024.3366942 [226] Fang H Y, Zhang M G, He S P, Luan X L, Liu F, Ding Z T. Solving the zero-sum control problem for tidal turbine system: An online reinforcement learning approach. IEEE Transactions on Cybernetics, 2023, 53(12): 7635−7647 doi: 10.1109/TCYB.2022.3186886 [227] Dong H Y, Zhao X W. Wind-farm power tracking via preview-based robust reinforcement learning. IEEE Transactions on Industrial Informatics, 2022, 18(3): 1706−1715 doi: 10.1109/TII.2021.3093300 [228] Xie J J, Dong H Y, Zhao X W, Lin S Y. Wind turbine fault-tolerant control via incremental model-based reinforcement learning. IEEE Transactions on Automation Science and Engineering, 2025, 22: 1958−1969 doi: 10.1109/TASE.2024.3372713 [229] Park J S, O'Brien J, Cai C J, Morris M R, Liang P, Bernstein M S. Generative agents: Interactive simulacra of human behavior. In: Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. San Francisco, USA: ACM, 2023. Article No. 2 [230] Wang H Q, Chen J H, Huang W S, Ben Q W, Wang T, Mi B Y, et al. GRUtopia: Dream general robots in a city at scale. arXiv preprint arXiv: 2407.10943, 2024. [231] 王涵, 俞扬, 姜远. 基于通信的多智能体强化学习进展综述. 中国科学: 信息科学, 2022, 52(5): 742−764 doi: 10.1360/SSI-2020-0180Wang Han, Yu Yang, Jiang Yuan. Review of the progress of communication-based multi-agent reinforcement learning. Science Sinica Information, 2022, 52(5): 742−764 doi: 10.1360/SSI-2020-0180 [232] Hu T M, Luo B. PA2D-MORL: Pareto ascent directional decomposition based multi-objective reinforcement learning. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 12547−12555 [233] Xu M, Song Y H, Wang J Y, Qiao M L, Huo L Y, Wang Z L. Predicting head movement in panoramic video: A deep reinforcement learning approach. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(11): 2693−2708 doi: 10.1109/TPAMI.2018.2858783 [234] Skalse J, Hammond L, Griffin C, Abate A. Lexicographic multi-objective reinforcement learning. In: Proceedings of the 31st International Joint Conference on Artificial Intelligence. Vienna, Austria: IJCAI, 2022. 3430−3436 [235] Hu T M, Luo B, Yang C H, Huang T W. MO-MIX: Multi-objective multi-agent cooperative decision-making with deep reinforcement learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 12098−12112 doi: 10.1109/TPAMI.2023.3283537 [236] 王雪松, 王荣荣, 程玉虎. 安全强化学习综述. 自动化学报, 2023, 49(9): 1813−1835Wang Xue-Song, Wang Rong-Rong, Cheng Yu-Hu. Safe reinforcement learning: A survey. Acta Automatica Sinica, 2023, 49(9): 1813−1835 -

 下载:
下载:
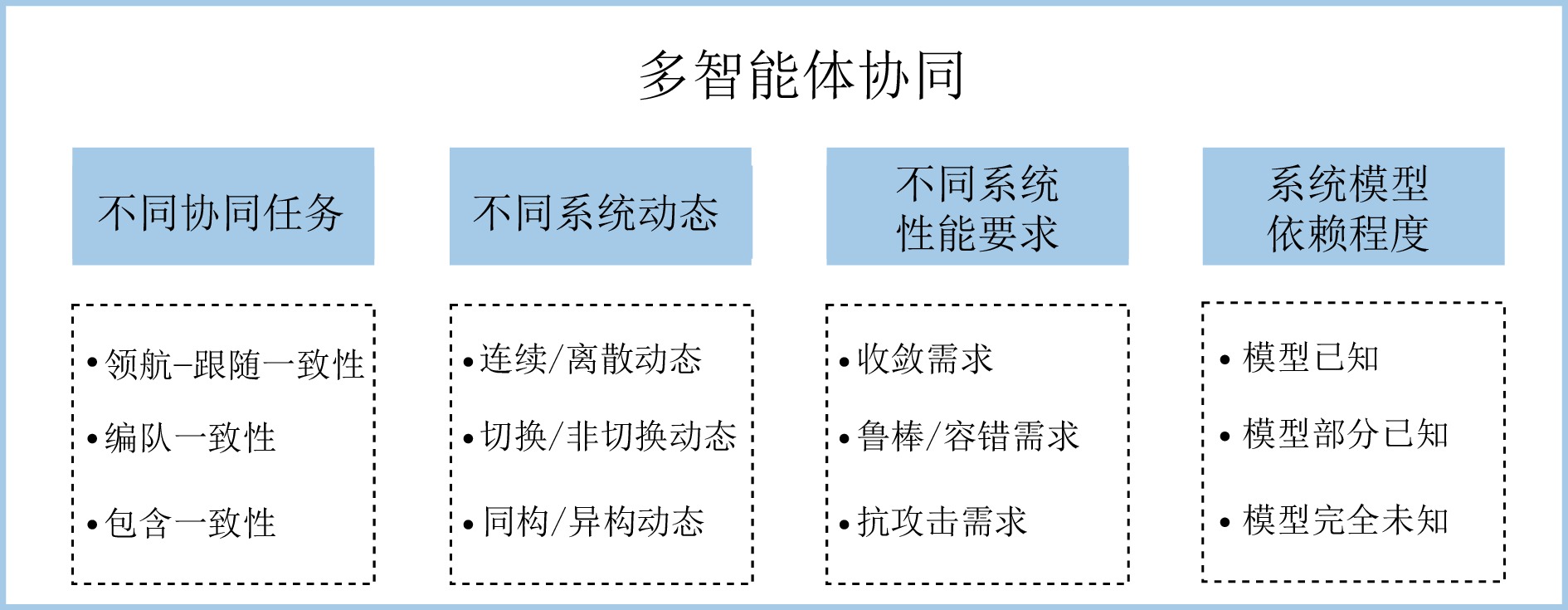
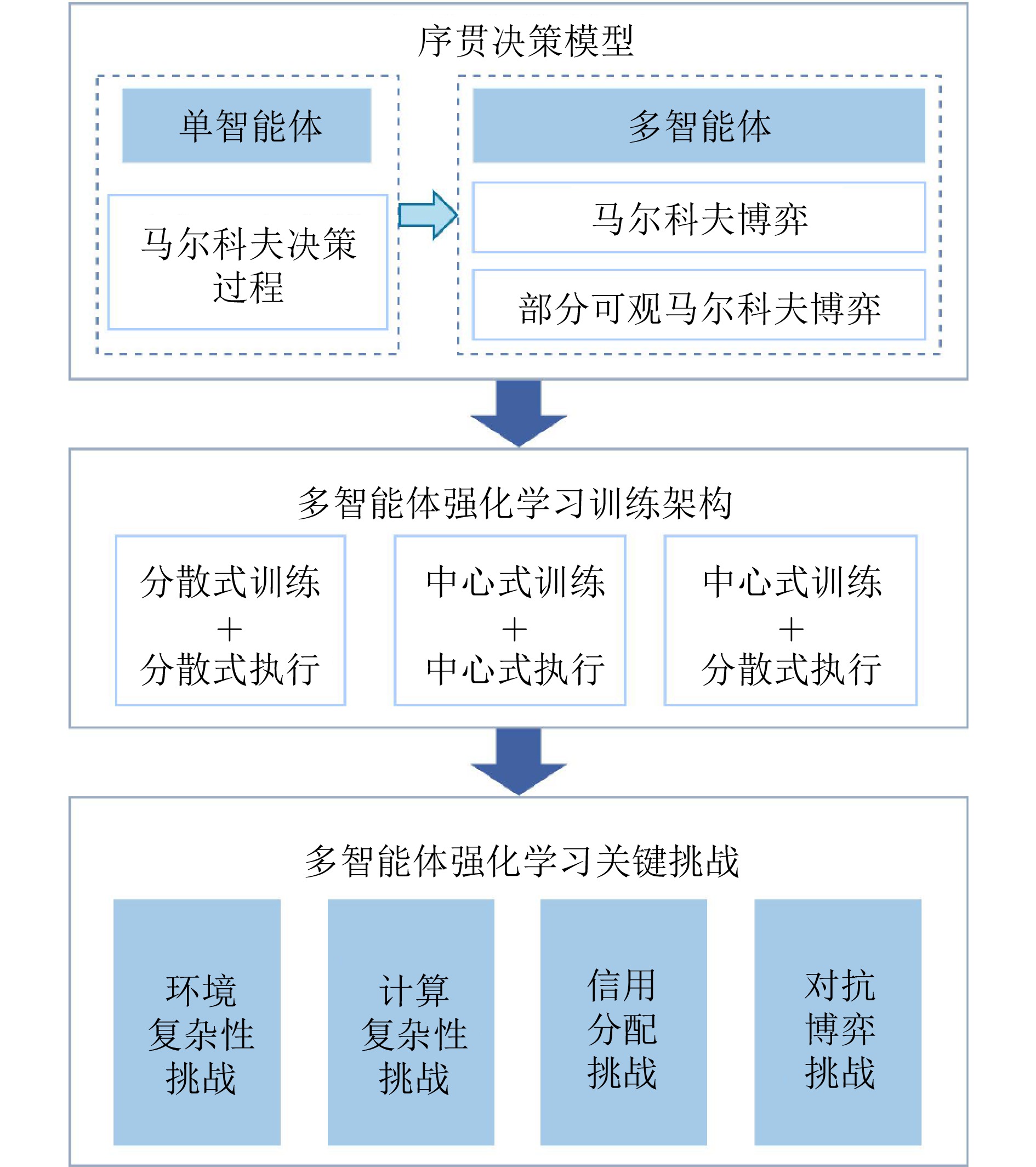
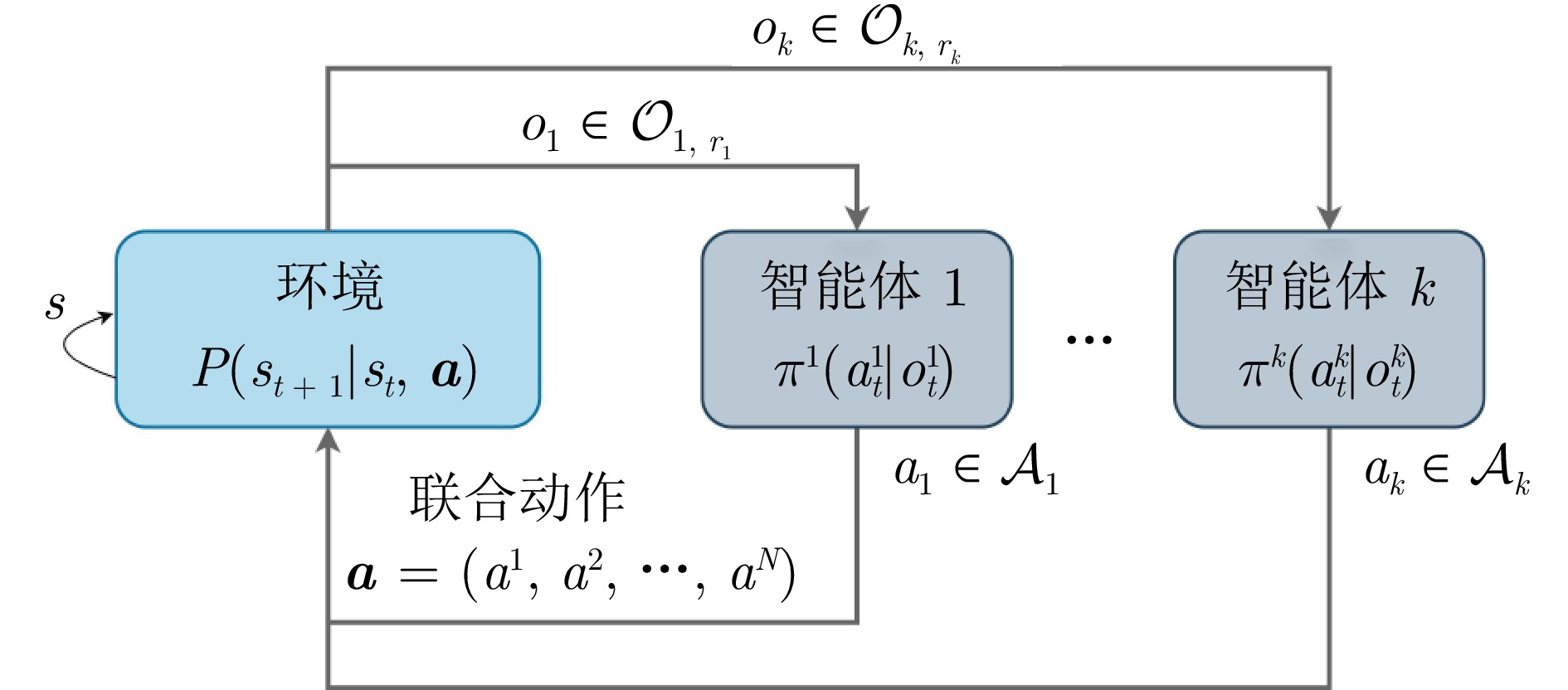

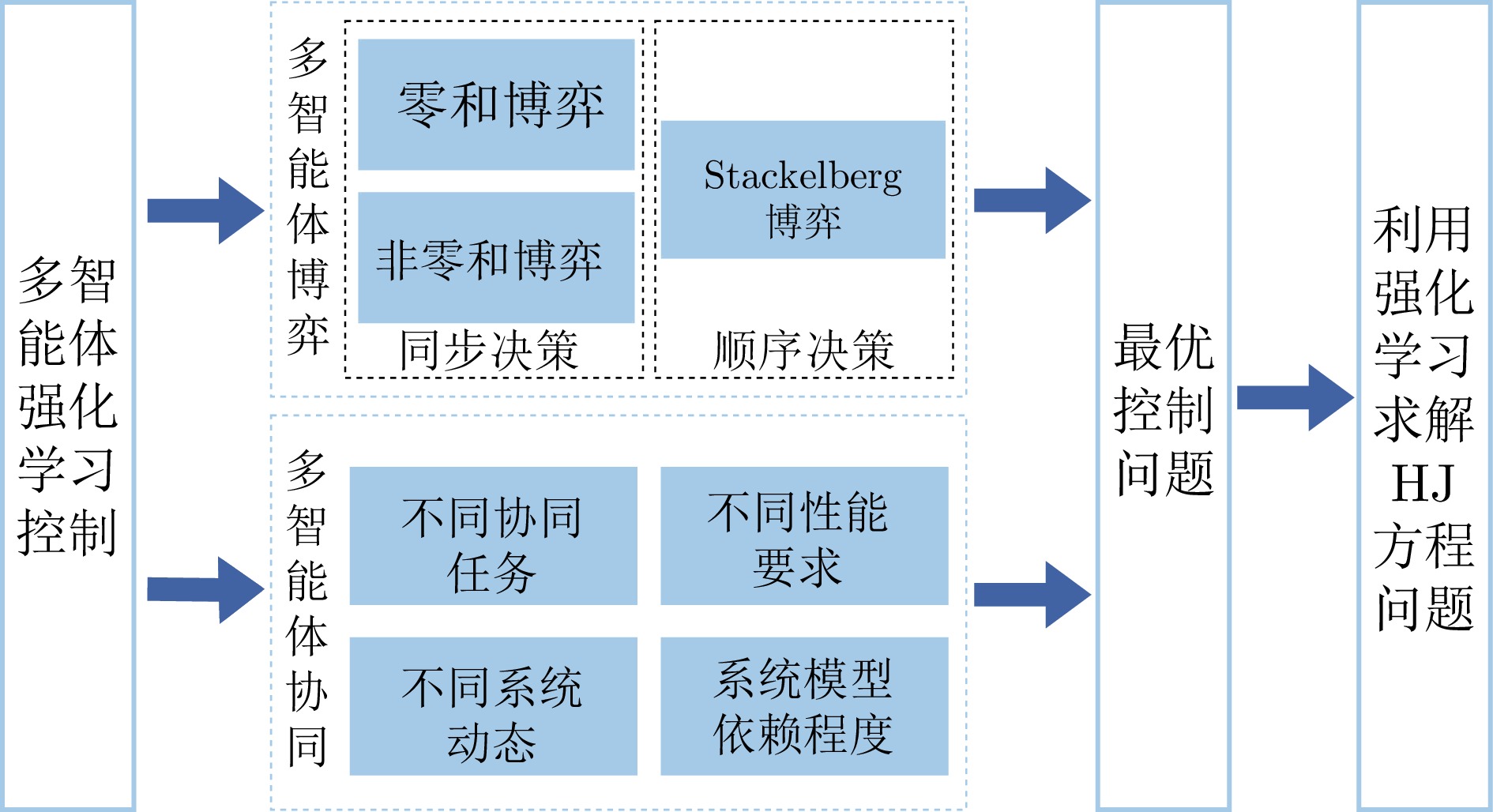
图(4)
计量
- 文章访问数: 12109
- HTML全文浏览量: 6863
- PDF下载量: 1893
- 被引次数: 0
