
2025年 第51卷 第3期
2025, 51(3): 489-509.
doi: 10.16383/j.aas.c240508
cstr: 32138.14.j.aas.c240508
摘要:
多智能体协同应用广泛, 并被列为新一代人工智能(Artificial intelligence, AI)基础理论亟待突破的重要内容之一, 对其开展研究具有鲜明的科学价值和工程意义. 随着人工智能技术的进步, 传统的单一控制视角下的多智能体协同已无法满足执行大规模复杂任务的需求, 融合博弈与控制的多智能体协同应运而生. 在这一框架下, 多智能体协同具有更高的灵活性、适应性和扩展性, 为多智能体系统的发展带来更多可能性. 鉴于此, 首先从协同角度入手, 回顾多智能体协同控制与估计领域的进展. 接着, 围绕博弈与控制的融合, 介绍博弈框架的基本概念, 重点讨论在微分博弈下多智能体协同问题的建模与分析, 并简要总结如何应用强化学习算法求解博弈均衡. 选取多机器人导航和电动汽车充电调度这两个典型的多智能体协同场景, 介绍博弈与控制融合的思想如何用于解决相关领域的难点问题. 最后, 对博弈与控制融合框架下的多智能体协同进行总结和展望.
多智能体协同应用广泛, 并被列为新一代人工智能(Artificial intelligence, AI)基础理论亟待突破的重要内容之一, 对其开展研究具有鲜明的科学价值和工程意义. 随着人工智能技术的进步, 传统的单一控制视角下的多智能体协同已无法满足执行大规模复杂任务的需求, 融合博弈与控制的多智能体协同应运而生. 在这一框架下, 多智能体协同具有更高的灵活性、适应性和扩展性, 为多智能体系统的发展带来更多可能性. 鉴于此, 首先从协同角度入手, 回顾多智能体协同控制与估计领域的进展. 接着, 围绕博弈与控制的融合, 介绍博弈框架的基本概念, 重点讨论在微分博弈下多智能体协同问题的建模与分析, 并简要总结如何应用强化学习算法求解博弈均衡. 选取多机器人导航和电动汽车充电调度这两个典型的多智能体协同场景, 介绍博弈与控制融合的思想如何用于解决相关领域的难点问题. 最后, 对博弈与控制融合框架下的多智能体协同进行总结和展望.


2025, 51(3): 510-539.
doi: 10.16383/j.aas.c240392
cstr: 32138.14.j.aas.c240392
摘要:
强化学习作为一类重要的人工智能方法, 广泛应用于解决复杂的控制和决策问题, 其在众多领域的应用已展示出巨大潜力. 近年来, 强化学习从单智能体决策逐渐扩展到多智能体协作与博弈, 形成多智能体强化学习这一研究热点. 多智能体系统由多个具有自主感知和决策能力的实体组成, 有望解决传统单智能体方法难以应对的大规模复杂问题. 多智能体强化学习不仅需要考虑环境的动态性, 还需要应对其他智能体策略的不确定性, 从而增加学习和决策过程的复杂度. 为此, 梳理多智能体强化学习在控制与决策领域的研究, 分析其面临的主要问题与挑战, 从控制理论与自主决策两个层次综述现有的研究成果与进展, 并对未来的研究方向进行展望. 通过分析, 期望为未来多智能体强化学习的研究提供有价值的参考和启示.
强化学习作为一类重要的人工智能方法, 广泛应用于解决复杂的控制和决策问题, 其在众多领域的应用已展示出巨大潜力. 近年来, 强化学习从单智能体决策逐渐扩展到多智能体协作与博弈, 形成多智能体强化学习这一研究热点. 多智能体系统由多个具有自主感知和决策能力的实体组成, 有望解决传统单智能体方法难以应对的大规模复杂问题. 多智能体强化学习不仅需要考虑环境的动态性, 还需要应对其他智能体策略的不确定性, 从而增加学习和决策过程的复杂度. 为此, 梳理多智能体强化学习在控制与决策领域的研究, 分析其面临的主要问题与挑战, 从控制理论与自主决策两个层次综述现有的研究成果与进展, 并对未来的研究方向进行展望. 通过分析, 期望为未来多智能体强化学习的研究提供有价值的参考和启示.




2025, 51(3): 540-558.
doi: 10.16383/j.aas.c240478
cstr: 32138.14.j.aas.c240478
摘要:
多智能体强化学习(Multi-agent reinforcement learning, MARL)作为博弈论、控制论和多智能体学习的交叉研究领域, 是多智能体系统(Multi-agent systems, MASs)研究中的前沿方向, 赋予智能体在动态多维的复杂环境中通过交互和决策完成多样化任务的能力. 多智能体强化学习正在向应用对象开放化、应用问题具身化、应用场景复杂化的方向发展, 并逐渐成为解决现实世界中博弈决策问题的最有效工具. 本文对基于多智能体强化学习的博弈进行系统性综述. 首先, 介绍多智能体强化学习的基本理论, 梳理多智能体强化学习算法与基线测试环境的发展进程. 其次, 针对合作、对抗以及混合三种多智能体强化学习任务, 从提高智能体合作效率、提升智能体对抗能力的维度来介绍多智能体强化学习的最新进展, 并结合实际应用探讨混合博弈的前沿研究方向. 最后, 对多智能体强化学习的应用前景和发展趋势进行总结与展望.
多智能体强化学习(Multi-agent reinforcement learning, MARL)作为博弈论、控制论和多智能体学习的交叉研究领域, 是多智能体系统(Multi-agent systems, MASs)研究中的前沿方向, 赋予智能体在动态多维的复杂环境中通过交互和决策完成多样化任务的能力. 多智能体强化学习正在向应用对象开放化、应用问题具身化、应用场景复杂化的方向发展, 并逐渐成为解决现实世界中博弈决策问题的最有效工具. 本文对基于多智能体强化学习的博弈进行系统性综述. 首先, 介绍多智能体强化学习的基本理论, 梳理多智能体强化学习算法与基线测试环境的发展进程. 其次, 针对合作、对抗以及混合三种多智能体强化学习任务, 从提高智能体合作效率、提升智能体对抗能力的维度来介绍多智能体强化学习的最新进展, 并结合实际应用探讨混合博弈的前沿研究方向. 最后, 对多智能体强化学习的应用前景和发展趋势进行总结与展望.


2025, 51(3): 559-569.
doi: 10.16383/j.aas.c240416
cstr: 32138.14.j.aas.c240416
摘要:
研究了高维线性时不变动力学系统构成的具有加权有向的多智能体网络拓扑变化可辨识性. 这些网络智能体动力学和内耦合矩阵均具有异构性. 分析异构内耦合矩阵对网络拓扑可辨识性的影响, 并发现网络拓扑结构的可辨识性与智能体之间的内耦合矩阵相关. 当内耦合矩阵由同构变为异构时, 网络拓扑的可辨识性可能发生变化, 既可能由可辨识变为不可辨识, 也可能由不可辨识变为可辨识. 针对一般网络结构, 提出充分和必要的条件以验证拓扑变化的可辨识性. 此外, 针对有向链状网络、有向星型网络以及有向环状网络等几种典型网络结构, 分别给出相应的可辨识性条件. 通过实际案例验证了所提条件的合理性和有效性.
研究了高维线性时不变动力学系统构成的具有加权有向的多智能体网络拓扑变化可辨识性. 这些网络智能体动力学和内耦合矩阵均具有异构性. 分析异构内耦合矩阵对网络拓扑可辨识性的影响, 并发现网络拓扑结构的可辨识性与智能体之间的内耦合矩阵相关. 当内耦合矩阵由同构变为异构时, 网络拓扑的可辨识性可能发生变化, 既可能由可辨识变为不可辨识, 也可能由不可辨识变为可辨识. 针对一般网络结构, 提出充分和必要的条件以验证拓扑变化的可辨识性. 此外, 针对有向链状网络、有向星型网络以及有向环状网络等几种典型网络结构, 分别给出相应的可辨识性条件. 通过实际案例验证了所提条件的合理性和有效性.








2025, 51(3): 570-576.
doi: 10.16383/j.aas.c240474
cstr: 32138.14.j.aas.c240474
摘要:
针对无领航者多智能体系统(Multi-agent systems, MASs)以及领航−跟随多智能体系统执行器故障问题, 设计基于PI结构的容错控制律. 考虑到传统的比例型控制律无法消除加性干扰影响下的稳态误差, 引入积分环节, 在一致性控制律中融入状态的积分项, 用于改善多智能体系统一致性过程的稳态性能. 针对领航者输入不为零的情况, 设计非线性的一致性控制律, 并借助黎卡提方程以及Lyapunov函数, 进行多智能体系统在故障情况下的一致性分析和控制律设计. 最后, 通过一系列对比仿真, 说明了所设计控制律在改善系统稳态性能方面的优势.
针对无领航者多智能体系统(Multi-agent systems, MASs)以及领航−跟随多智能体系统执行器故障问题, 设计基于PI结构的容错控制律. 考虑到传统的比例型控制律无法消除加性干扰影响下的稳态误差, 引入积分环节, 在一致性控制律中融入状态的积分项, 用于改善多智能体系统一致性过程的稳态性能. 针对领航者输入不为零的情况, 设计非线性的一致性控制律, 并借助黎卡提方程以及Lyapunov函数, 进行多智能体系统在故障情况下的一致性分析和控制律设计. 最后, 通过一系列对比仿真, 说明了所设计控制律在改善系统稳态性能方面的优势.










2025, 51(3): 577-589.
doi: 10.16383/j.aas.c240288
cstr: 32138.14.j.aas.c240288
摘要:
本文研究了严格反馈多智能体系统的最优一致性问题, 旨在局部信息交互的条件下, 使所有智能体收敛至全局代价函数的最优解. 首先, 针对权重非平衡有向图, 提出一种新的分布式比例积分(Proportional-integral, PI)变量, 将最优一致性问题转化为PI调节问题, 使得经典的控制技术能够通过调节PI变量的方式来处理更加复杂的多智能体系统. 然后, 结合所提出的分布式PI变量和预设性能控制, 设计一类基于PI调节的分布式控制算法, 使得带有死区输入非线性和有界扰动的严格反馈多智能体系统实现近似最优一致性. 最后, 通过仿真实验验证了所设计算法的有效性.
本文研究了严格反馈多智能体系统的最优一致性问题, 旨在局部信息交互的条件下, 使所有智能体收敛至全局代价函数的最优解. 首先, 针对权重非平衡有向图, 提出一种新的分布式比例积分(Proportional-integral, PI)变量, 将最优一致性问题转化为PI调节问题, 使得经典的控制技术能够通过调节PI变量的方式来处理更加复杂的多智能体系统. 然后, 结合所提出的分布式PI变量和预设性能控制, 设计一类基于PI调节的分布式控制算法, 使得带有死区输入非线性和有界扰动的严格反馈多智能体系统实现近似最优一致性. 最后, 通过仿真实验验证了所设计算法的有效性.
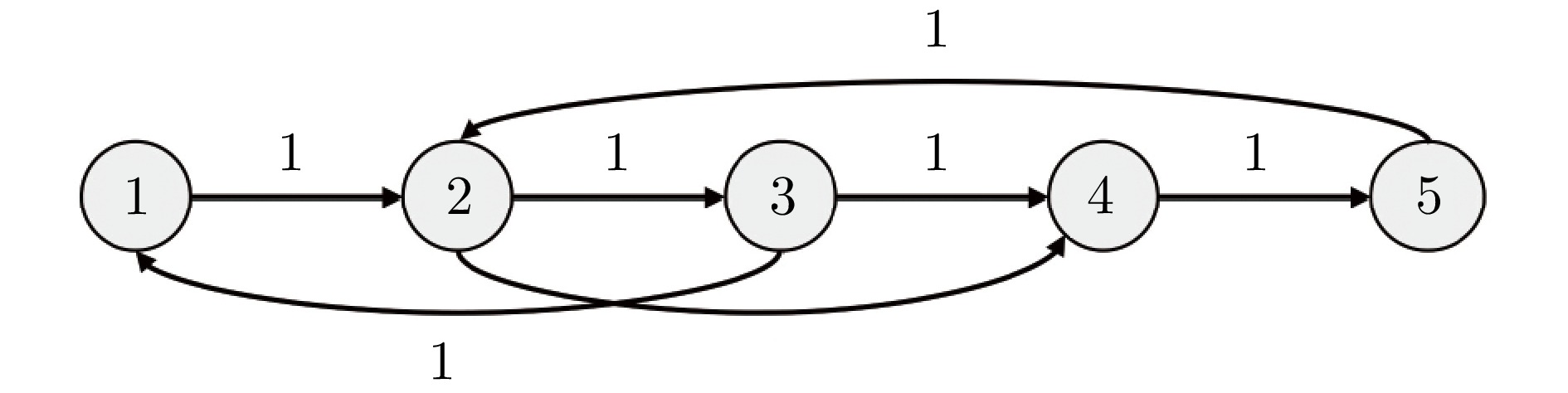
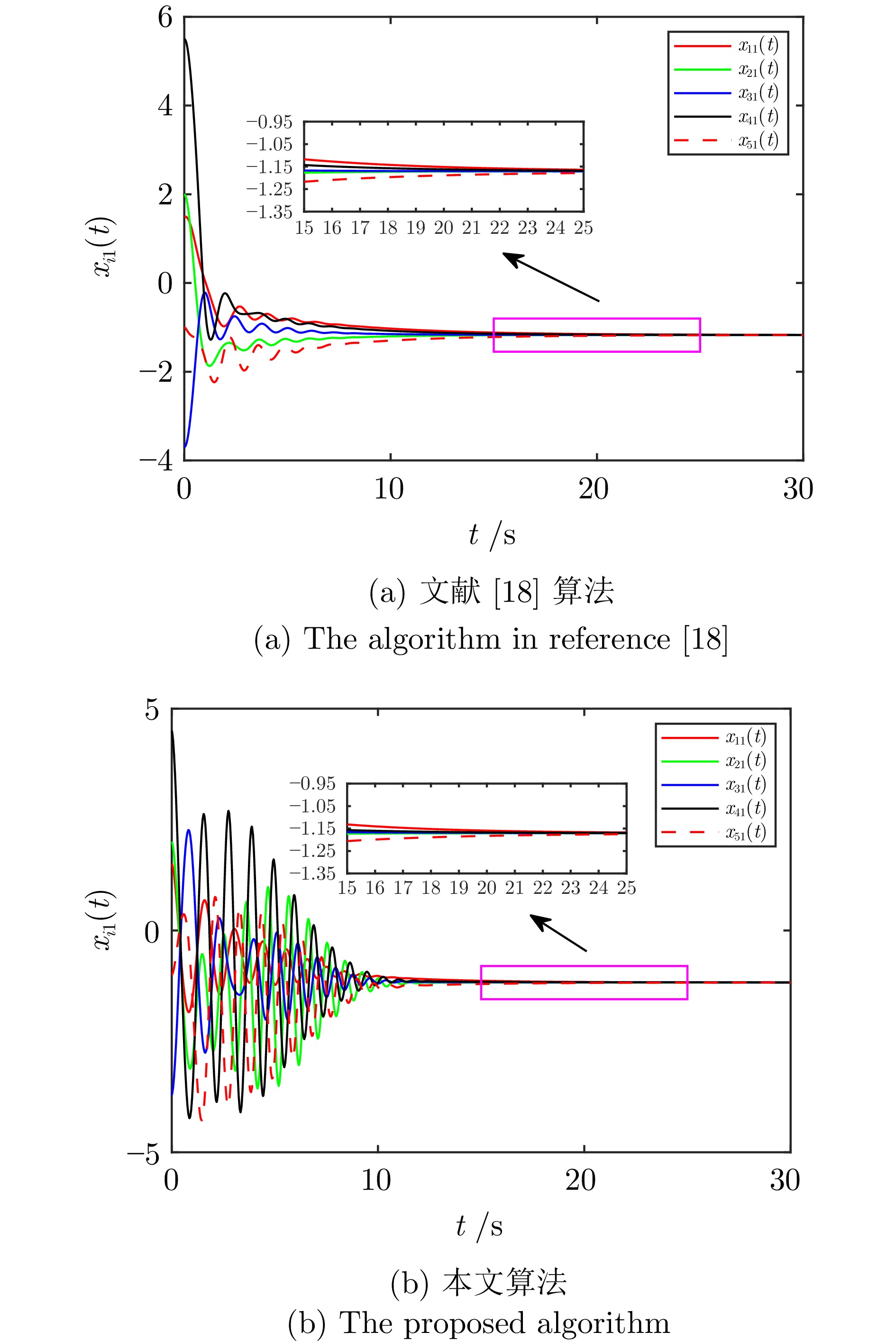
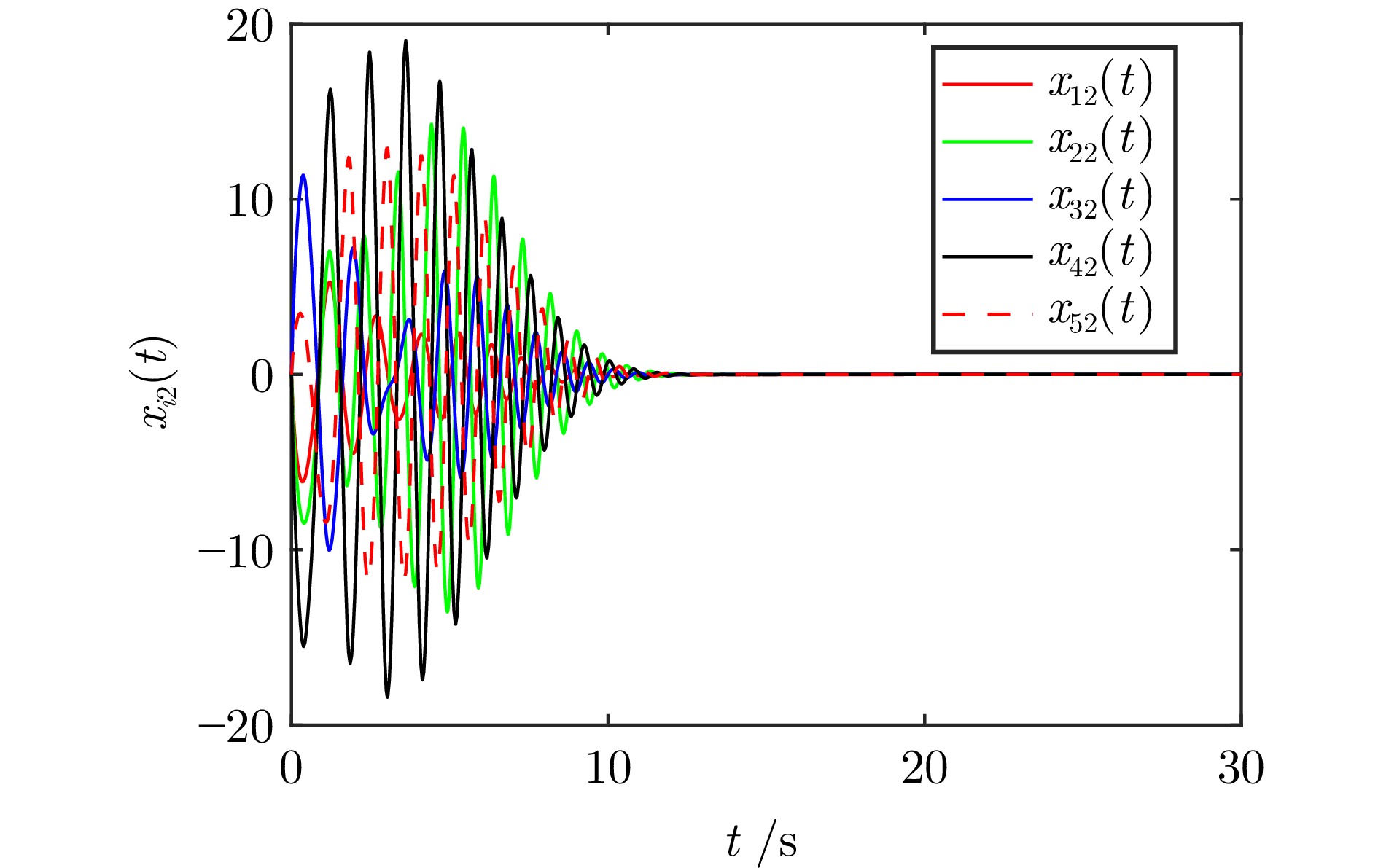
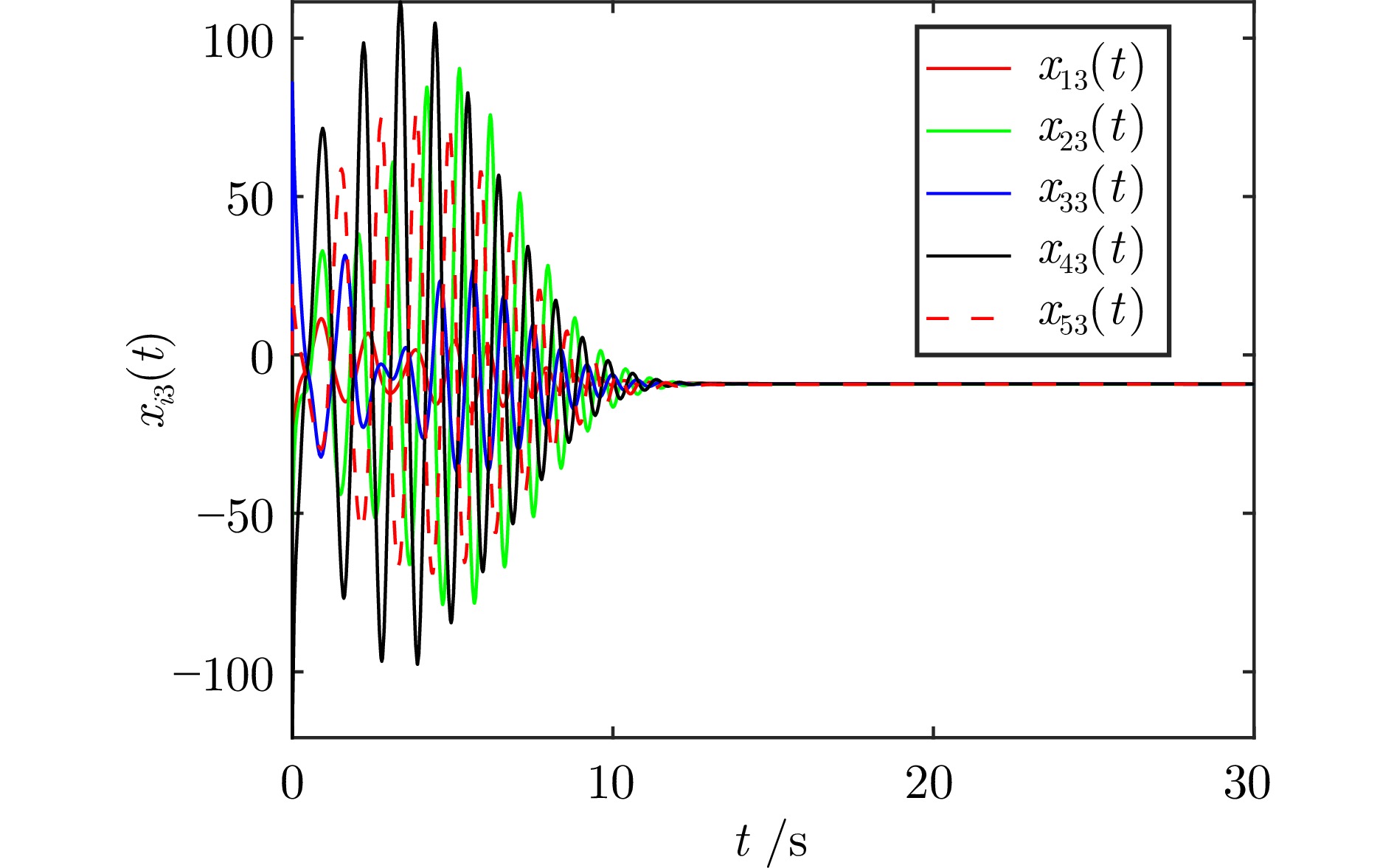
2025, 51(3): 590-603.
doi: 10.16383/j.aas.c240451
cstr: 32138.14.j.aas.c240451
摘要:
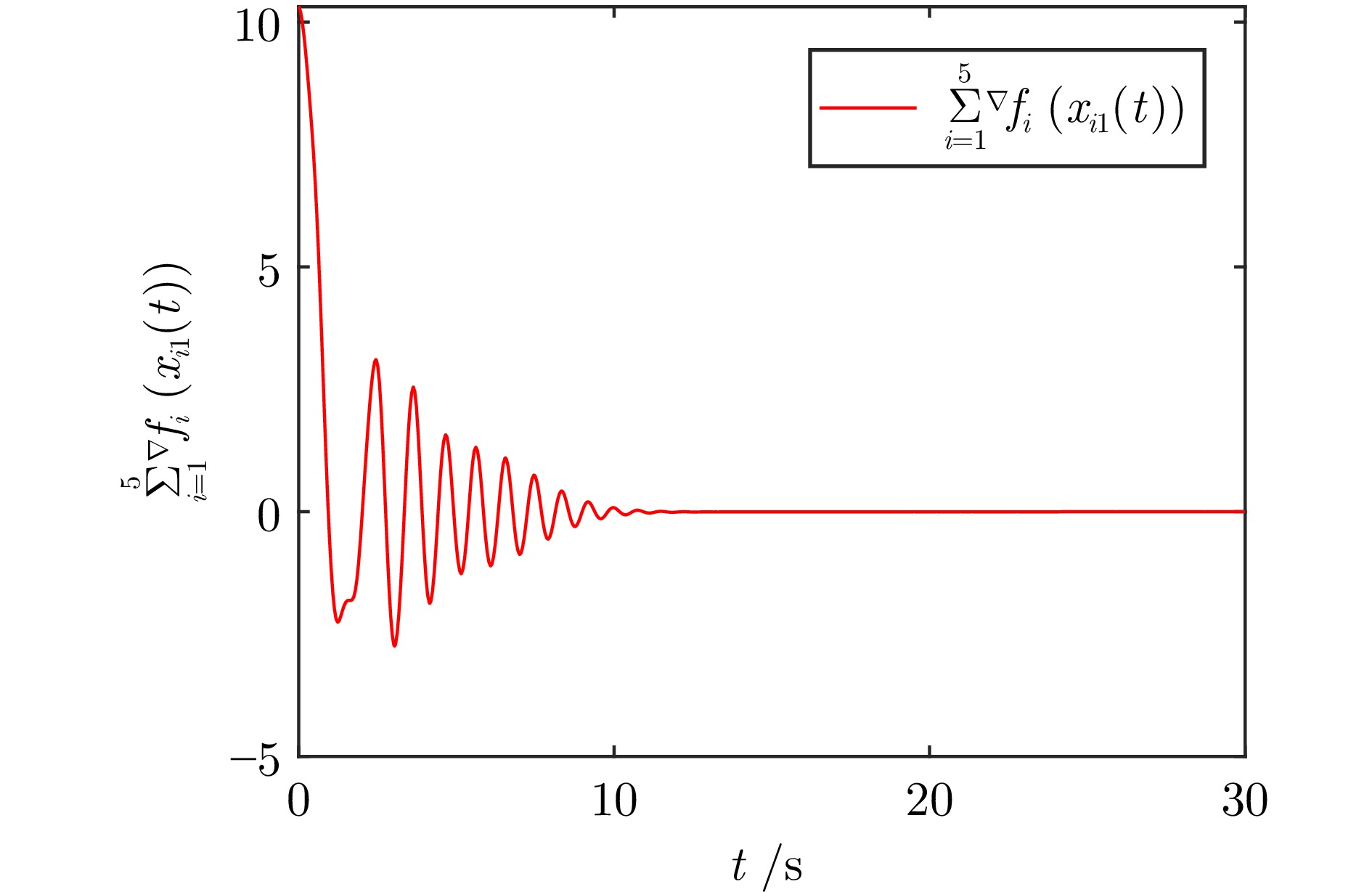
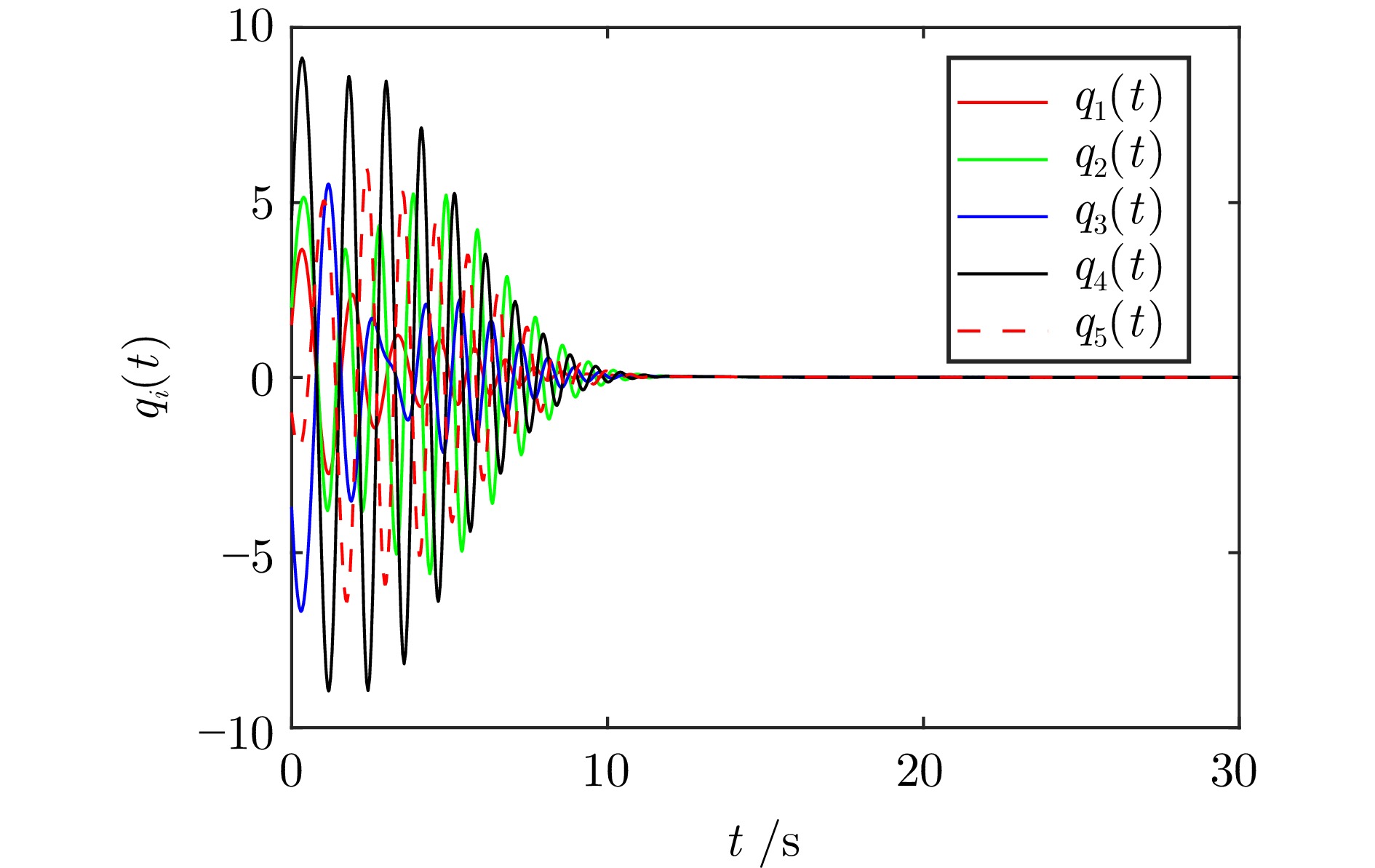
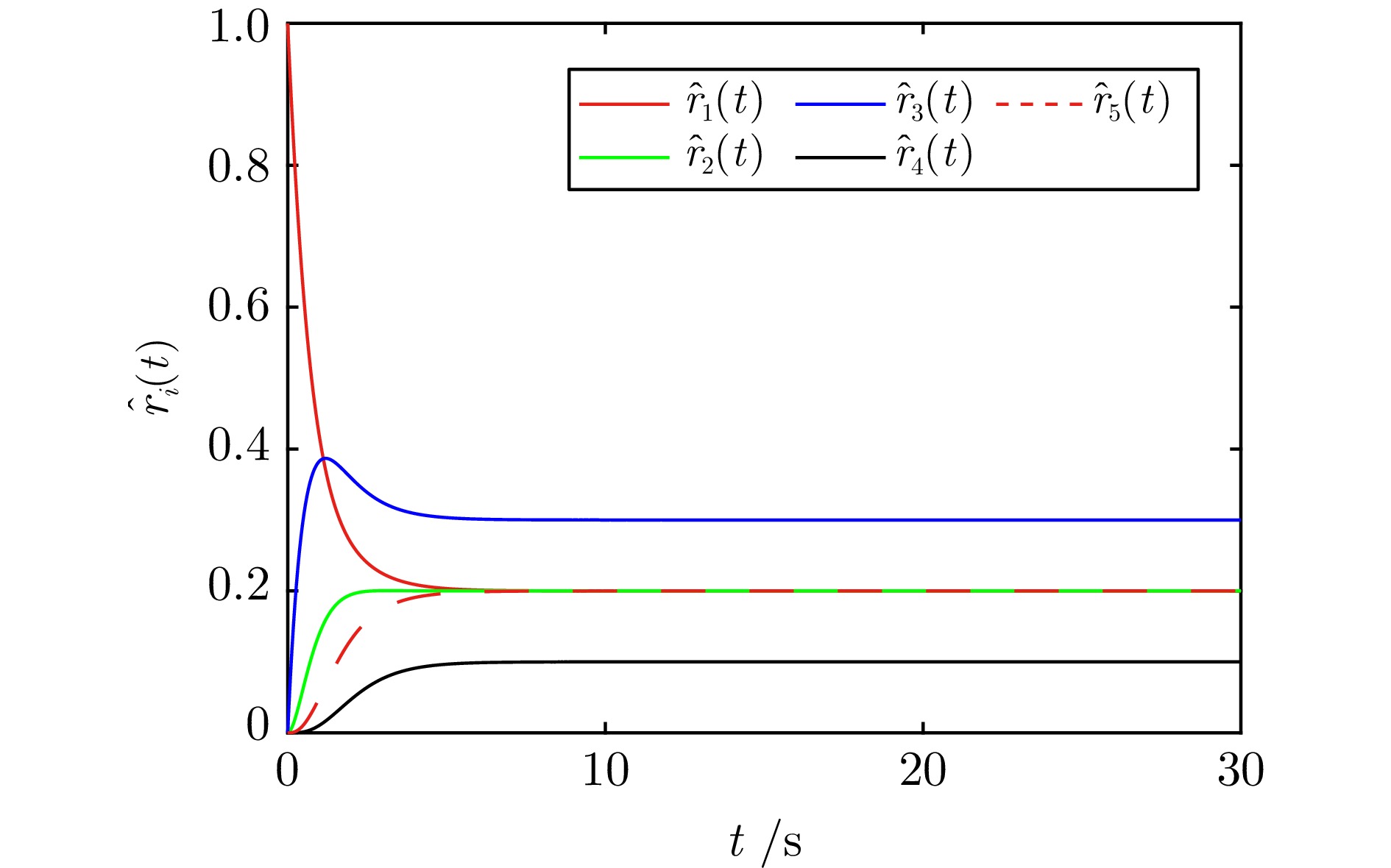
针对多智能体系统分布式一致性控制问题, 提出一种新的融合动态模糊神经网络(Dynamic fuzzy neural network, DFNN)和自适应动态规划(Adaptive dynamic programming, ADP)算法的无模型自适应控制方法. 类似于强化学习中执行者−评论家结构, DFNN和神经网络(Neural network, NN)分别逼近控制策略和性能指标. 每个智能体的DFNN执行者从零规则开始, 通过在线学习, 与其局部邻域的智能体交互而生成和合并规则. 最终, 每个智能体都有一个独特的DFNN控制器, 具有不同的结构和参数, 实现了最优的分布式同步控制律. 仿真结果表明, 本文提出的在线算法在非线性多智能体系统分布式一致性控制中优于传统基于NN的ADP算法.
针对多智能体系统分布式一致性控制问题, 提出一种新的融合动态模糊神经网络(Dynamic fuzzy neural network, DFNN)和自适应动态规划(Adaptive dynamic programming, ADP)算法的无模型自适应控制方法. 类似于强化学习中执行者−评论家结构, DFNN和神经网络(Neural network, NN)分别逼近控制策略和性能指标. 每个智能体的DFNN执行者从零规则开始, 通过在线学习, 与其局部邻域的智能体交互而生成和合并规则. 最终, 每个智能体都有一个独特的DFNN控制器, 具有不同的结构和参数, 实现了最优的分布式同步控制律. 仿真结果表明, 本文提出的在线算法在非线性多智能体系统分布式一致性控制中优于传统基于NN的ADP算法.










2025, 51(3): 604-616.
doi: 10.16383/j.aas.c240459
cstr: 32138.14.j.aas.c240459
摘要:
针对异构非线性多智能体系统(Multi-agent system, MAS)的输出一致性控制难题, 设计了一种基于同胚分布式控制协议的无模型方法. 通过将输出反馈线性化理论与自适应动态规划相结合, 可以在不需要精确系统模型的情况下实现非线性智能体的线性化, 简化分布式控制器的设计复杂性. 具体而言, 设计一种双层分布式控制结构, 在物理空间层通过无模型反馈线性化方法实现未知系统线性化, 在微分同构空间层利用线性控制技术进行分布式共识控制. 通过两个实验验证了所提方法在处理未知异构非线性多智能体系统中的有效性, 将传统的线性分布式控制方法扩展到未知非线性多智能体系统的控制器设计.
针对异构非线性多智能体系统(Multi-agent system, MAS)的输出一致性控制难题, 设计了一种基于同胚分布式控制协议的无模型方法. 通过将输出反馈线性化理论与自适应动态规划相结合, 可以在不需要精确系统模型的情况下实现非线性智能体的线性化, 简化分布式控制器的设计复杂性. 具体而言, 设计一种双层分布式控制结构, 在物理空间层通过无模型反馈线性化方法实现未知系统线性化, 在微分同构空间层利用线性控制技术进行分布式共识控制. 通过两个实验验证了所提方法在处理未知异构非线性多智能体系统中的有效性, 将传统的线性分布式控制方法扩展到未知非线性多智能体系统的控制器设计.








2025, 51(3): 617-630.
doi: 10.16383/j.aas.c240446
cstr: 32138.14.j.aas.c240446
摘要:
针对执行器饱和的离散时间线性多智能体系统(Multi-agent systems, MASs)有限时域一致性控制问题, 将低增益反馈(Low gain feedback, LGF)方法与Q学习相结合, 提出采用后向时间迭代的模型无关控制方法. 首先, 将执行器饱和的有限时域一致性控制问题的求解转化为执行器饱和的单智能体有限时域最优控制问题的求解, 并证明可以通过求解修正的时变黎卡提方程 (Modified time-varying Riccati equation, MTVRE)实现有限时域最优控制. 随后, 引入时变参数化Q函数(Time-varying parameterized Q-function, TVPQF), 并提出基于Q学习的模型无关后向时间迭代算法, 可以更新低增益参数, 同时实现逼近求解MTVRE. 另外, 证明所提迭代求解算法得到的LGF控制矩阵收敛于MTVRE的最优解, 也可以实现全局有限时域一致性控制. 最后, 通过仿真实验结果验证了该方法的有效性.
针对执行器饱和的离散时间线性多智能体系统(Multi-agent systems, MASs)有限时域一致性控制问题, 将低增益反馈(Low gain feedback, LGF)方法与Q学习相结合, 提出采用后向时间迭代的模型无关控制方法. 首先, 将执行器饱和的有限时域一致性控制问题的求解转化为执行器饱和的单智能体有限时域最优控制问题的求解, 并证明可以通过求解修正的时变黎卡提方程 (Modified time-varying Riccati equation, MTVRE)实现有限时域最优控制. 随后, 引入时变参数化Q函数(Time-varying parameterized Q-function, TVPQF), 并提出基于Q学习的模型无关后向时间迭代算法, 可以更新低增益参数, 同时实现逼近求解MTVRE. 另外, 证明所提迭代求解算法得到的LGF控制矩阵收敛于MTVRE的最优解, 也可以实现全局有限时域一致性控制. 最后, 通过仿真实验结果验证了该方法的有效性.












2025, 51(3): 631-642.
doi: 10.16383/j.aas.c240426
cstr: 32138.14.j.aas.c240426
摘要:
现有基于偏微分方程(Partial differential equation, PDE)的多智能体系统(Multi-agent system, MAS)编队控制方法要求智能体必须是密集分布的, 为打破这一限制, 提出一种新的基于常微分−偏微分方程(Ordinary differential equation-partial differential equation, ODE-PDE)的分析方法, 以解决稀疏−密集混合分布的大规模异构MAS编队问题. 首先, 通过设计特定的通信协议, 并基于空间离散系统部分连续化方法, 将原始大量的异构MAS的ODE动力学模型转化为由一个PDE 和少数几个ODE耦合而成的ODE-PDE 模型. 为更符合实际复杂场景, 将拓扑权值规定为半马尔科夫切换的, 且稀疏分布和密集分布智能体遵循不一致的切换规则. 其次, 针对无时滞和有时滞两种情形, 设计两种异步边界控制策略, 利用Lyapunov方法得到保证误差系统实际有限时间稳定的充分条件, 并得到停息时间和稳定阈值的计算规则. 最后, 两个广义的数值仿真进一步验证了所提方法的有效性.
现有基于偏微分方程(Partial differential equation, PDE)的多智能体系统(Multi-agent system, MAS)编队控制方法要求智能体必须是密集分布的, 为打破这一限制, 提出一种新的基于常微分−偏微分方程(Ordinary differential equation-partial differential equation, ODE-PDE)的分析方法, 以解决稀疏−密集混合分布的大规模异构MAS编队问题. 首先, 通过设计特定的通信协议, 并基于空间离散系统部分连续化方法, 将原始大量的异构MAS的ODE动力学模型转化为由一个PDE 和少数几个ODE耦合而成的ODE-PDE 模型. 为更符合实际复杂场景, 将拓扑权值规定为半马尔科夫切换的, 且稀疏分布和密集分布智能体遵循不一致的切换规则. 其次, 针对无时滞和有时滞两种情形, 设计两种异步边界控制策略, 利用Lyapunov方法得到保证误差系统实际有限时间稳定的充分条件, 并得到停息时间和稳定阈值的计算规则. 最后, 两个广义的数值仿真进一步验证了所提方法的有效性.







2025, 51(3): 643-657.
doi: 10.16383/j.aas.c240445
cstr: 32138.14.j.aas.c240445
摘要:
针对多智能体系统中邻居间通信存在通信路径损耗的情况, 研究距离−变权重通信拓扑下非线性多智能体系统固定时间防碰防离编队控制问题, 充分考虑通信路径损耗所引起的拓扑变化的不确定性和距离相关性、系统中未知非线性动力学特性以及固定时间收敛的控制性能要求等. 为解决以上问题, 首先结合通信理论中的通信损耗模型和数学图论知识, 对通信路径损耗下的拓扑结构进行量化建模. 其次, 基于人工势场原理, 设计一套新的预设时间防碰防离策略, 以确保每个智能体在预设时间内离开碰撞与离群预警区, 避免碰撞与离群现象. 同时, 提出一种新的具有自适应增益的分层滑模面结构, 进一步改善系统的动态性能. 在此基础上, 结合自适应技术, 构建一套自适应分层滑模固定时间防碰防离编队控制方案. 所提方案不仅解决了系统本身以及通信路径损耗所引起的非线性动态耦合问题, 而且保证了通信路径损耗情况下多智能体系统的编队任务在固定时间内完成, 同时没有碰撞和离群现象. 最后, 给出严格的理论分析以及对比仿真结果, 证明了所提控制方法的有效性和优越性.
针对多智能体系统中邻居间通信存在通信路径损耗的情况, 研究距离−变权重通信拓扑下非线性多智能体系统固定时间防碰防离编队控制问题, 充分考虑通信路径损耗所引起的拓扑变化的不确定性和距离相关性、系统中未知非线性动力学特性以及固定时间收敛的控制性能要求等. 为解决以上问题, 首先结合通信理论中的通信损耗模型和数学图论知识, 对通信路径损耗下的拓扑结构进行量化建模. 其次, 基于人工势场原理, 设计一套新的预设时间防碰防离策略, 以确保每个智能体在预设时间内离开碰撞与离群预警区, 避免碰撞与离群现象. 同时, 提出一种新的具有自适应增益的分层滑模面结构, 进一步改善系统的动态性能. 在此基础上, 结合自适应技术, 构建一套自适应分层滑模固定时间防碰防离编队控制方案. 所提方案不仅解决了系统本身以及通信路径损耗所引起的非线性动态耦合问题, 而且保证了通信路径损耗情况下多智能体系统的编队任务在固定时间内完成, 同时没有碰撞和离群现象. 最后, 给出严格的理论分析以及对比仿真结果, 证明了所提控制方法的有效性和优越性.











2025, 51(3): 658-668.
doi: 10.16383/j.aas.c240444
cstr: 32138.14.j.aas.c240444
摘要:
运动受速度和加速度嵌套饱和约束, 而反应式躲避安全机制下分布式编队互联的移动机器人更易触发该嵌套饱和, 从而引起编队的剧烈振荡, 所以需要研究该情况下多移动机器人平滑安全协同及其自适应振荡抑制方法. 故以分布式网络中的移动机器人为研究对象, 首先构建基于视线和速度的低触发势能函数, 实现邻近编队机器人近距排斥作用下的避碰保持; 引入驱动机器人绕过障碍物的安全加速度包络, 并复合近距排斥的弱能量、低触发势能, 避免与非合作障碍物的碰撞. 其次, 嵌入复合自适应辅助动态系统, 平滑躲避过程中触发的嵌套运动饱和与安全加速度约束引起的轨迹振荡; 设计复合非线性反馈框架下的分布式编队控制器, 融合混合的躲避和振荡抑制机制, 实现多机器人障碍环境下的安全编队. 最后, 与现有安全编队方法进行对比仿真和实验验证, 结果表明该方法在嵌套运动饱和约束下可显著提升编队的平滑和安全性能.
运动受速度和加速度嵌套饱和约束, 而反应式躲避安全机制下分布式编队互联的移动机器人更易触发该嵌套饱和, 从而引起编队的剧烈振荡, 所以需要研究该情况下多移动机器人平滑安全协同及其自适应振荡抑制方法. 故以分布式网络中的移动机器人为研究对象, 首先构建基于视线和速度的低触发势能函数, 实现邻近编队机器人近距排斥作用下的避碰保持; 引入驱动机器人绕过障碍物的安全加速度包络, 并复合近距排斥的弱能量、低触发势能, 避免与非合作障碍物的碰撞. 其次, 嵌入复合自适应辅助动态系统, 平滑躲避过程中触发的嵌套运动饱和与安全加速度约束引起的轨迹振荡; 设计复合非线性反馈框架下的分布式编队控制器, 融合混合的躲避和振荡抑制机制, 实现多机器人障碍环境下的安全编队. 最后, 与现有安全编队方法进行对比仿真和实验验证, 结果表明该方法在嵌套运动饱和约束下可显著提升编队的平滑和安全性能.








2025, 51(3): 669-677.
doi: 10.16383/j.aas.c240473
cstr: 32138.14.j.aas.c240473
摘要:
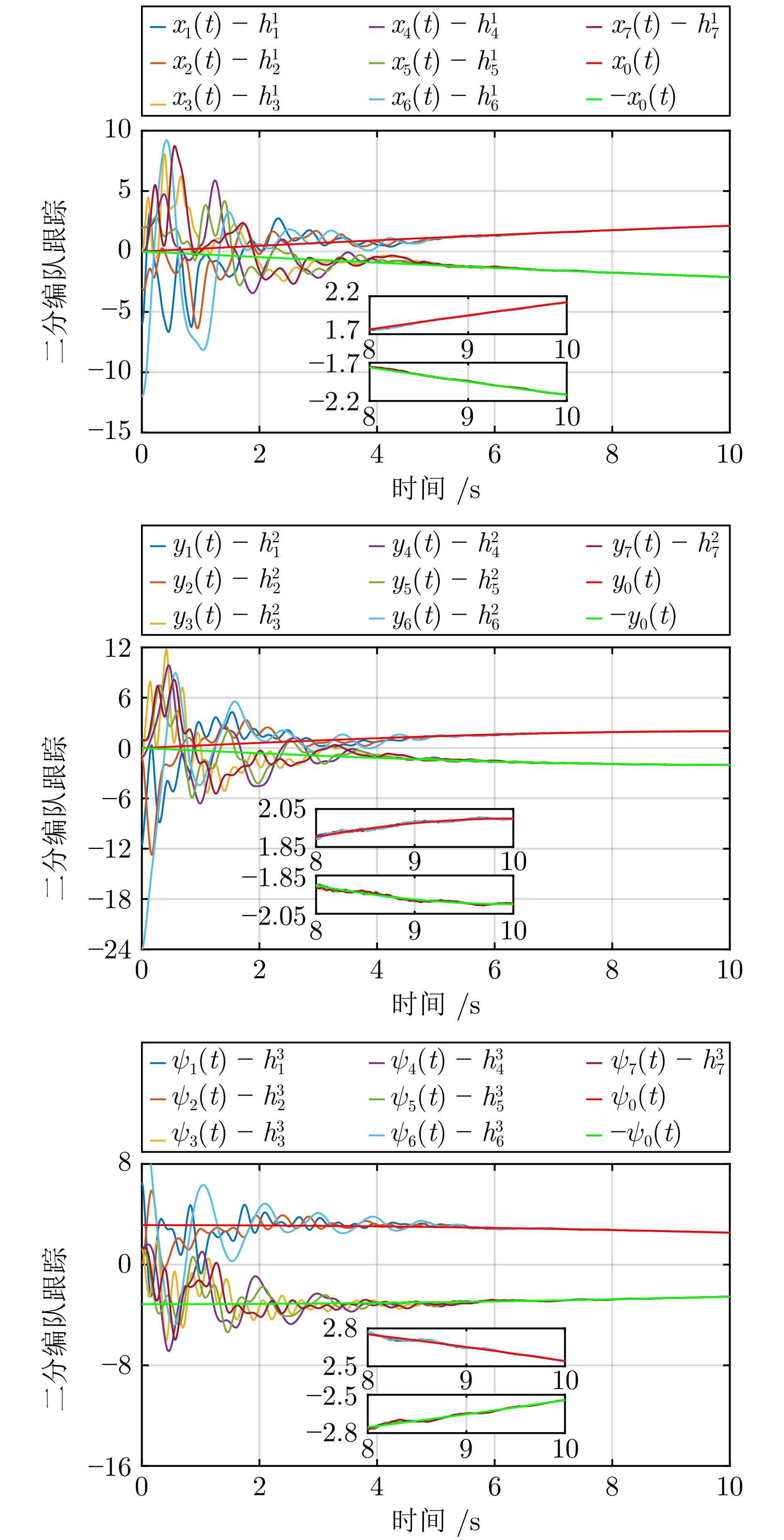
针对模型参数不确定下多无人艇(Multiple unmanned surface vehicle, Multi-USV)系统的固定时间二分编队跟踪控制问题, 通过将命令滤波与复合学习技术融合到反推控制方法中, 提出一种新型分布式固定时间二分编队跟踪控制协议. 首先, 将命令滤波引入到反推控制中, 进而分别设计虚拟控制协议与真实控制协议. 在此基础上, 为估计未知参数设计了参数复合学习律, 利用在线记录的数据和即时数据来产生预测误差, 并利用跟踪误差和预测误差来更新参数估计. 结果表明, 在严格弱于持续激励(Persistent excitation, PE)条件的区间激励(Interval excitation, IE)条件下, 本文提出的控制方案不仅能够保证编队误差的固定时间收敛性, 也能够保证参数估计误差的固定时间收敛性, 同时解决了多无人艇系统的固定时间二分编队跟踪控制问题. 最后, 通过仿真实验验证了本文提出的控制协议的有效性.
针对模型参数不确定下多无人艇(Multiple unmanned surface vehicle, Multi-USV)系统的固定时间二分编队跟踪控制问题, 通过将命令滤波与复合学习技术融合到反推控制方法中, 提出一种新型分布式固定时间二分编队跟踪控制协议. 首先, 将命令滤波引入到反推控制中, 进而分别设计虚拟控制协议与真实控制协议. 在此基础上, 为估计未知参数设计了参数复合学习律, 利用在线记录的数据和即时数据来产生预测误差, 并利用跟踪误差和预测误差来更新参数估计. 结果表明, 在严格弱于持续激励(Persistent excitation, PE)条件的区间激励(Interval excitation, IE)条件下, 本文提出的控制方案不仅能够保证编队误差的固定时间收敛性, 也能够保证参数估计误差的固定时间收敛性, 同时解决了多无人艇系统的固定时间二分编队跟踪控制问题. 最后, 通过仿真实验验证了本文提出的控制协议的有效性.
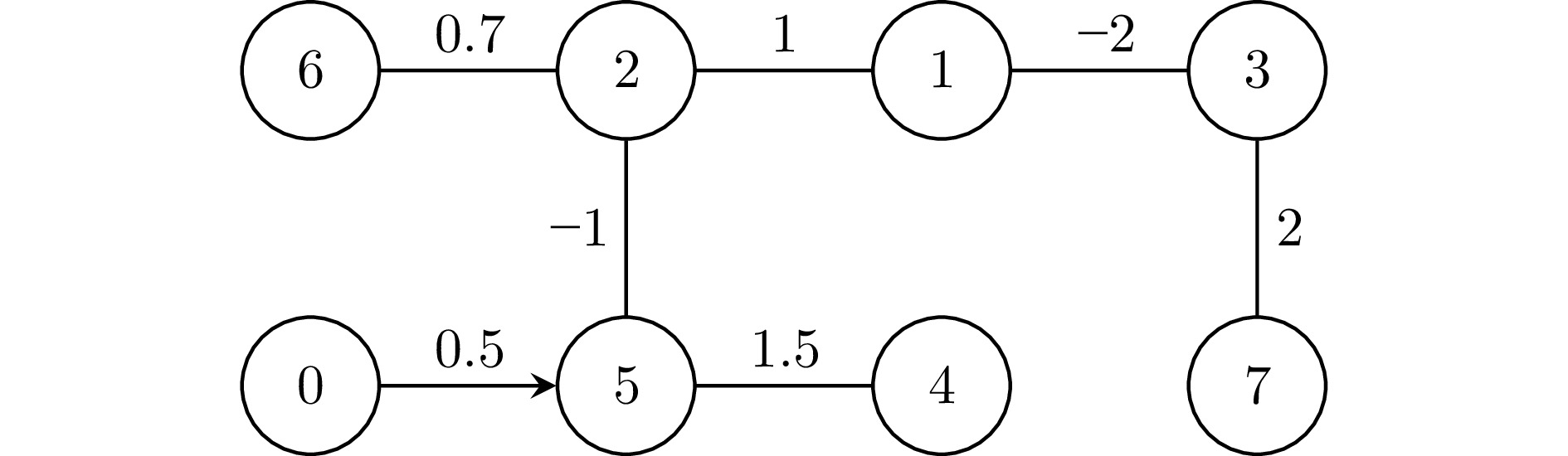
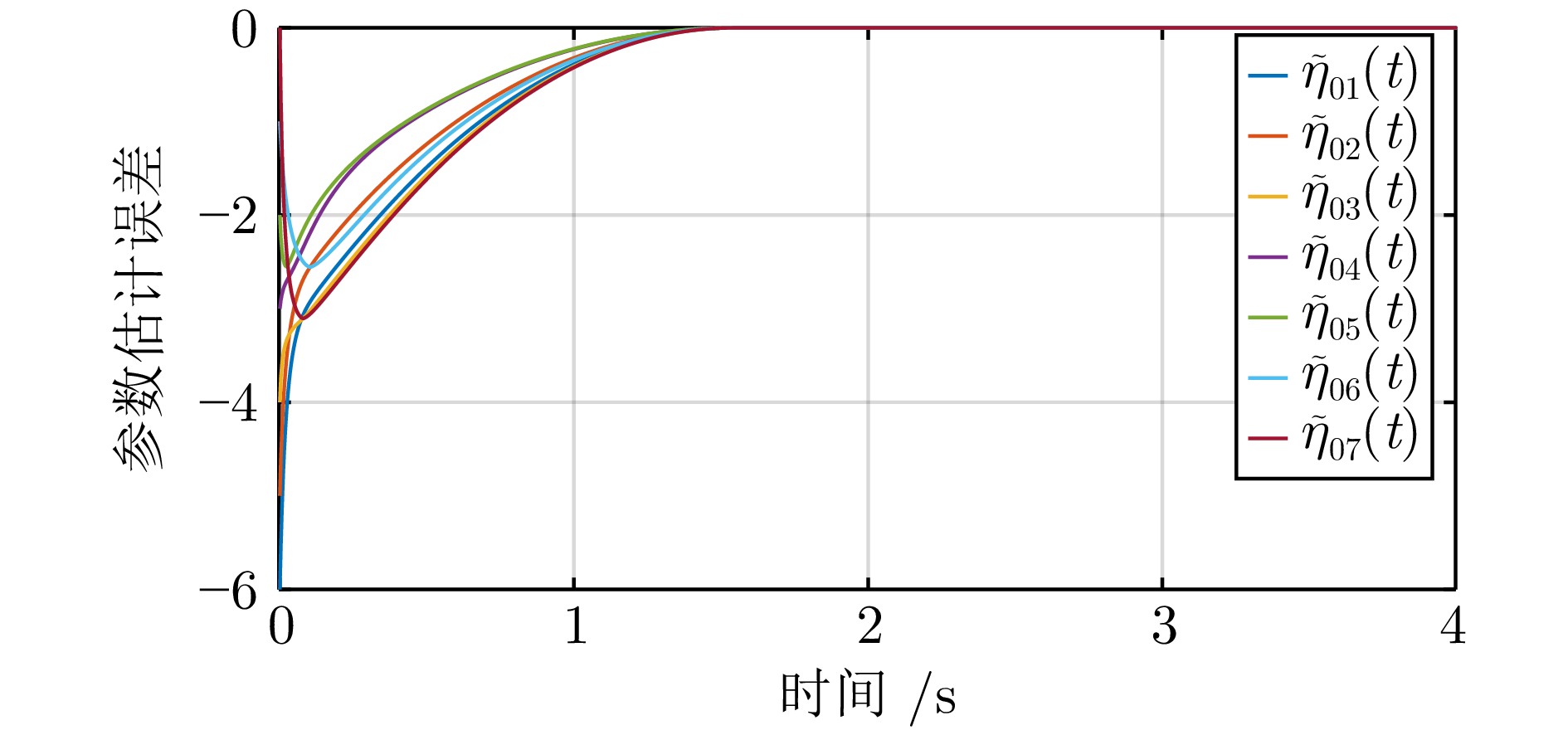
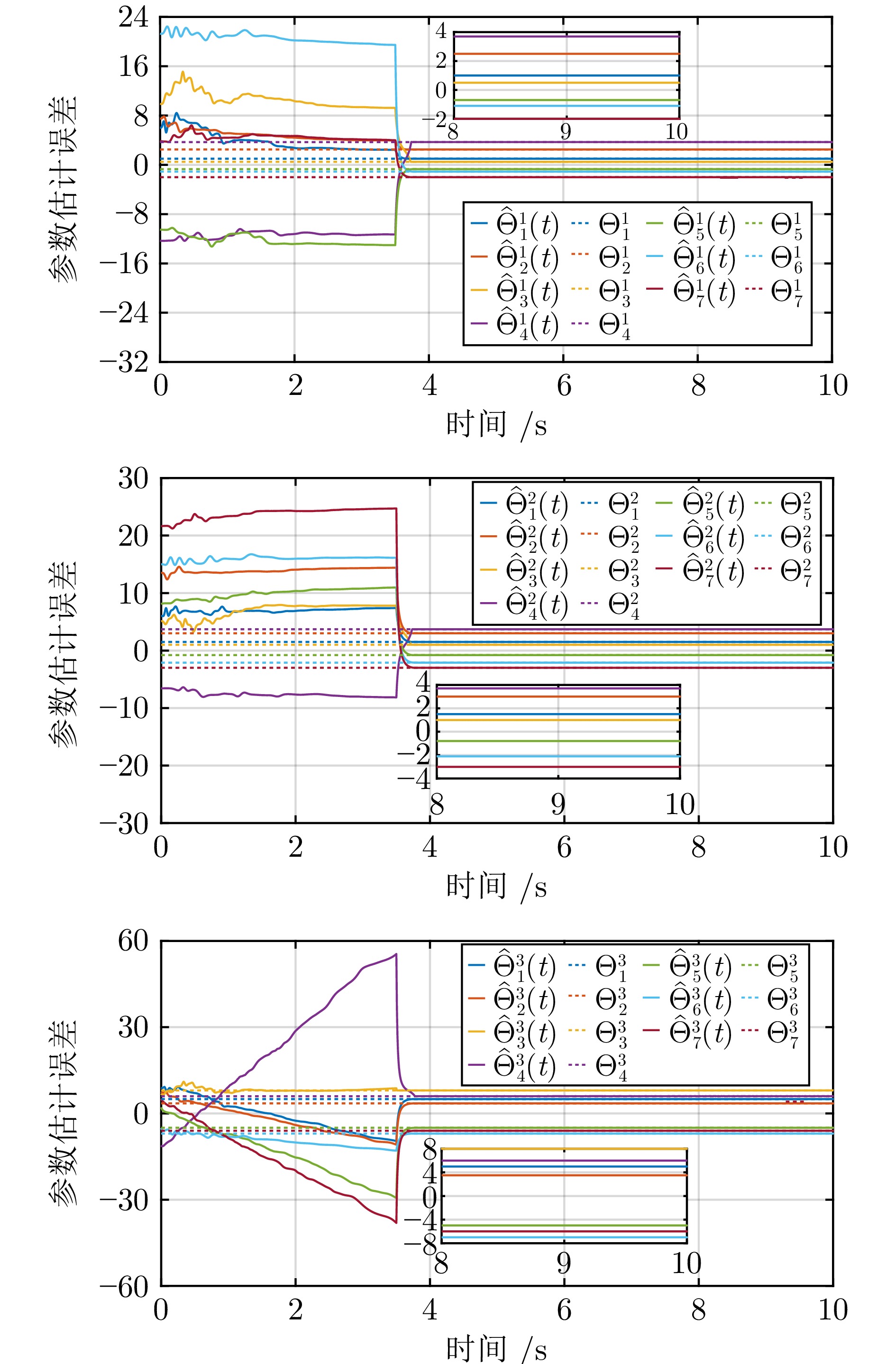
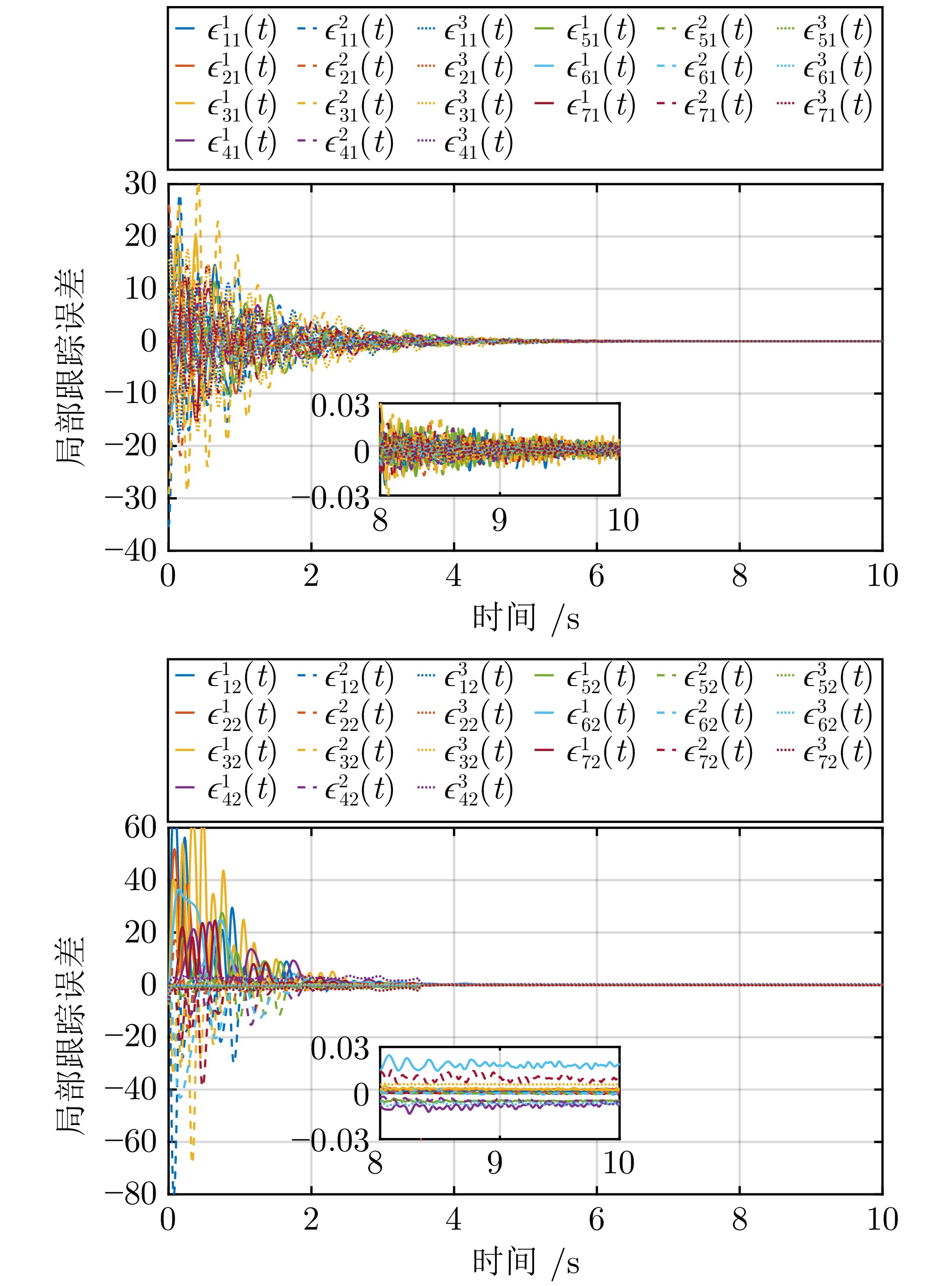
2025, 51(3): 678-691.
doi: 10.16383/j.aas.c240371
cstr: 32138.14.j.aas.c240371
摘要:
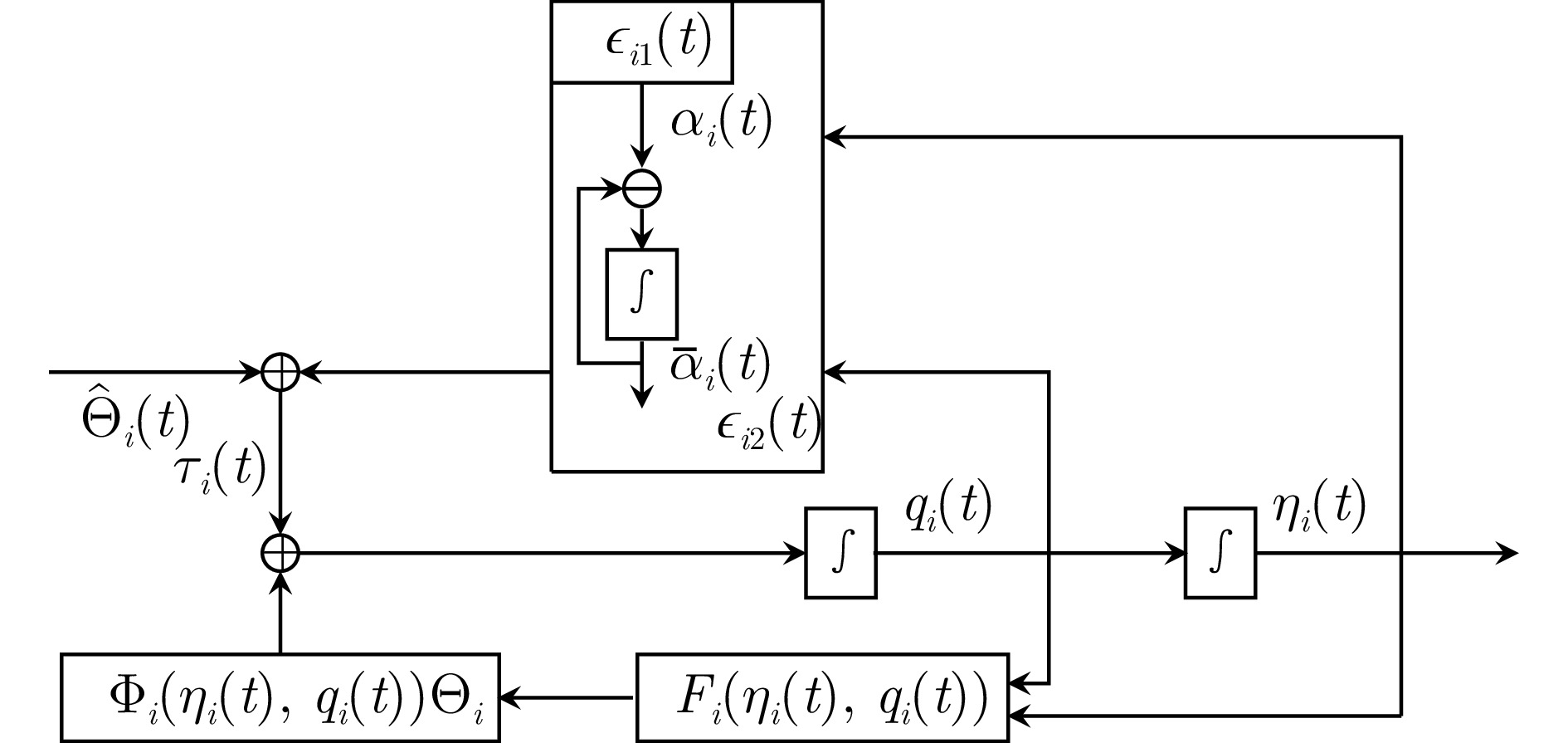
针对离散时间多智能体系统的协同最优输出调节问题, 在不依赖多智能体系统矩阵精确信息的条件下提出分布式数据驱动自适应控制策略. 基于自适应动态规划和分布式自适应内模, 通过引入值迭代和策略迭代两种强化学习算法, 利用在线数据学习最优控制器, 实现多智能体系统的协同输出调节. 考虑到跟随者只能访问领导者的估计值进行在线学习, 对闭环系统的稳定性和学习算法的收敛性进行严格的理论分析, 证明所学习的控制增益可以收敛到最优控制增益. 仿真结果验证了所提控制方法的有效性.
针对离散时间多智能体系统的协同最优输出调节问题, 在不依赖多智能体系统矩阵精确信息的条件下提出分布式数据驱动自适应控制策略. 基于自适应动态规划和分布式自适应内模, 通过引入值迭代和策略迭代两种强化学习算法, 利用在线数据学习最优控制器, 实现多智能体系统的协同输出调节. 考虑到跟随者只能访问领导者的估计值进行在线学习, 对闭环系统的稳定性和学习算法的收敛性进行严格的理论分析, 证明所学习的控制增益可以收敛到最优控制增益. 仿真结果验证了所提控制方法的有效性.












2025, 51(3): 692-704.
doi: 10.16383/j.aas.c240295
cstr: 32138.14.j.aas.c240295
摘要:
针对持续扰动下的分布式状态耦合非线性系统, 提出一种新的多耦合分布式经济模型预测控制(Economic model predictive control, EMPC)策略. 由于耦合非线性系统的经济性能函数的非凸性和非正定性, 首先引入关于经济最优平衡点的正定辅助函数和相应的辅助优化问题. 接着, 利用辅助函数的最优值函数构造原始分布式EMPC的一类隐式收缩约束. 然后, 建立状态耦合分布式EMPC的递推可行性和闭环系统关于最优经济平衡点的输入到状态稳定性(Input-to-state stability, ISS). 最后, 以耦合的四个连续搅拌釜反应器(Continuous stirred tank reactors, CSTRs)为例, 验证本文所提策略的有效性.
针对持续扰动下的分布式状态耦合非线性系统, 提出一种新的多耦合分布式经济模型预测控制(Economic model predictive control, EMPC)策略. 由于耦合非线性系统的经济性能函数的非凸性和非正定性, 首先引入关于经济最优平衡点的正定辅助函数和相应的辅助优化问题. 接着, 利用辅助函数的最优值函数构造原始分布式EMPC的一类隐式收缩约束. 然后, 建立状态耦合分布式EMPC的递推可行性和闭环系统关于最优经济平衡点的输入到状态稳定性(Input-to-state stability, ISS). 最后, 以耦合的四个连续搅拌釜反应器(Continuous stirred tank reactors, CSTRs)为例, 验证本文所提策略的有效性.


























