

Distance Information Based Pursuit-evasion Strategy: Continuous Stochastic Game With Belief State
-
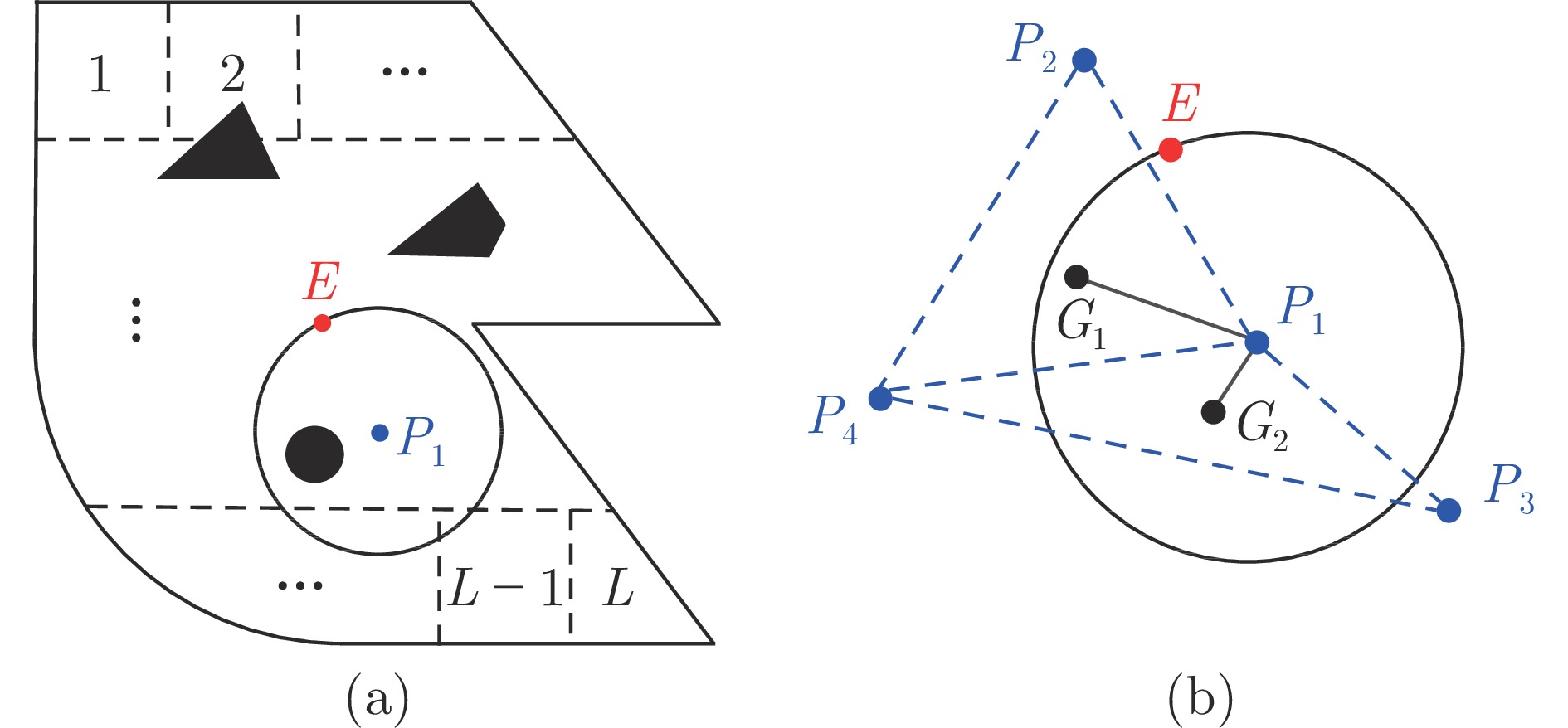
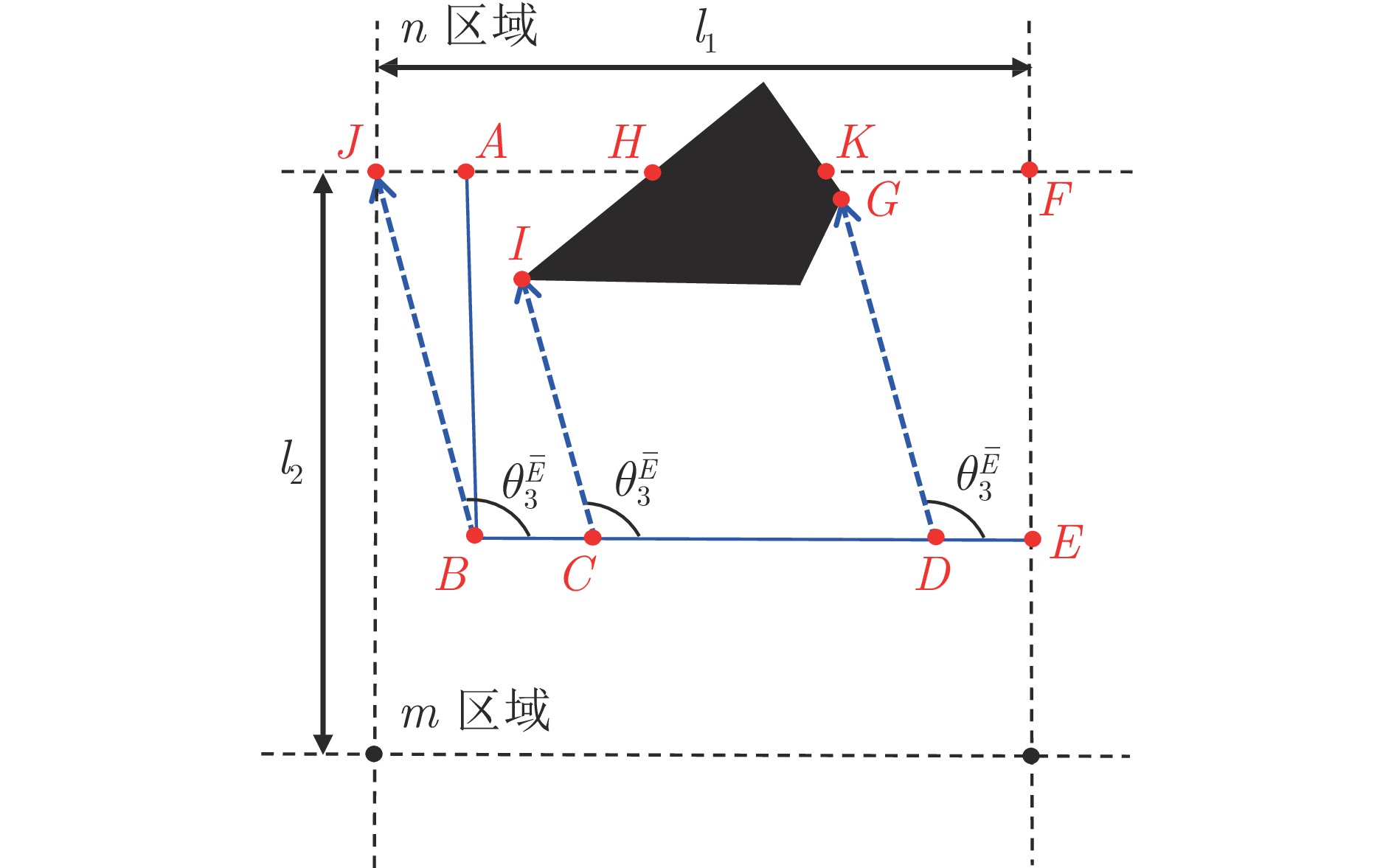
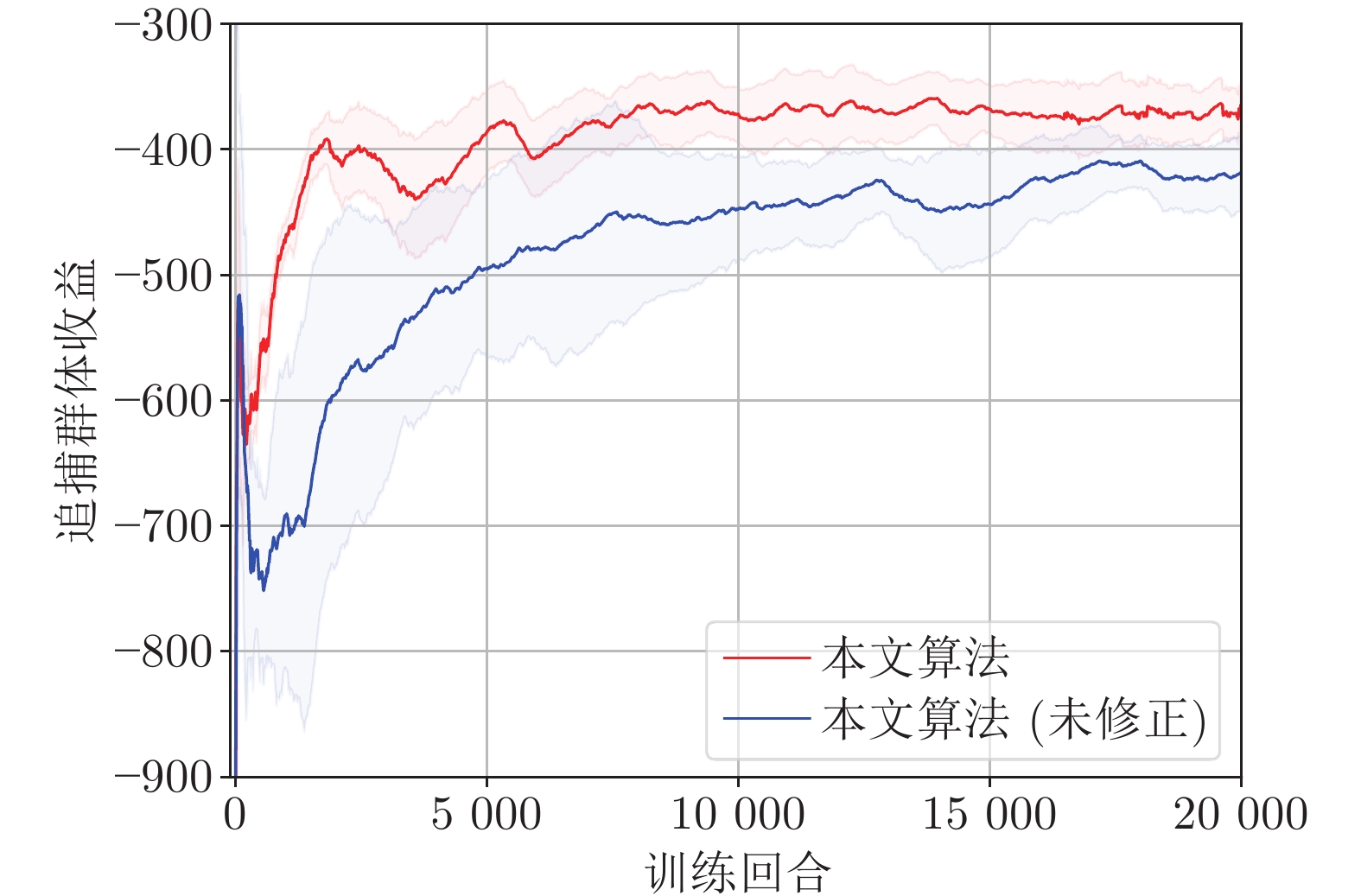
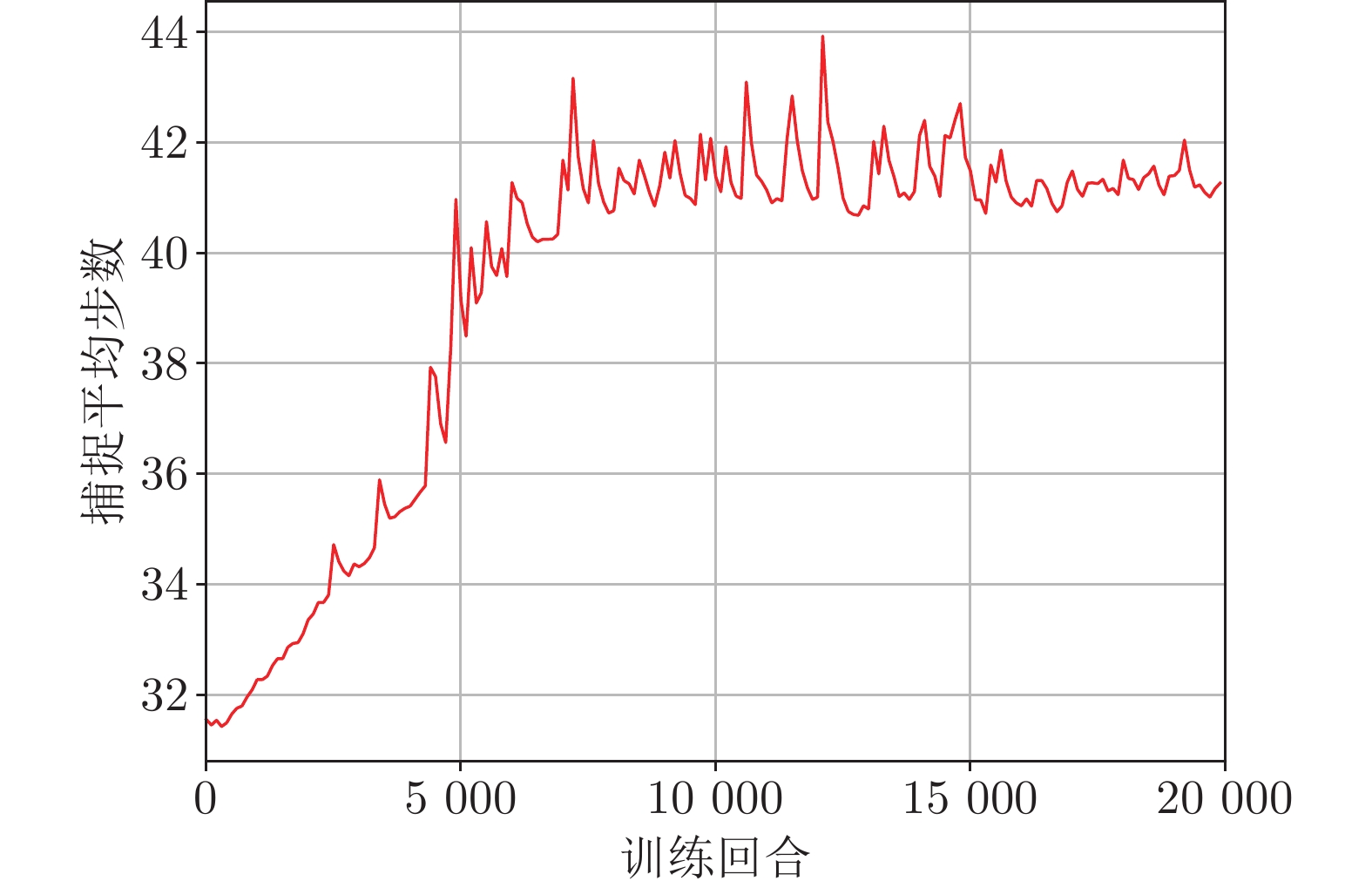
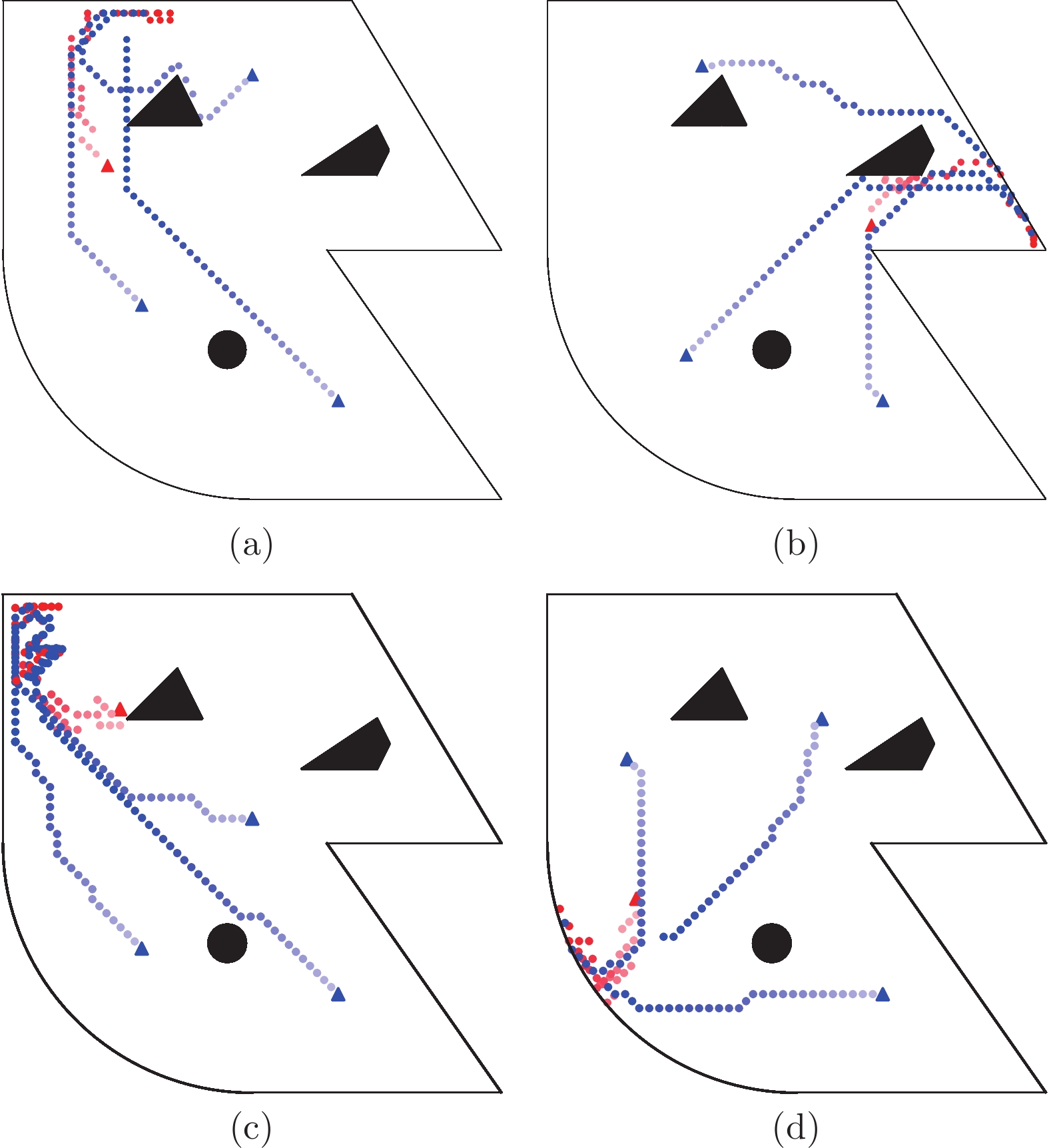
摘要: 追逃问题的研究在对抗、追踪以及搜查等领域极具现实意义. 借助连续随机博弈与马尔科夫决策过程(Markov decision process, MDP), 研究使用测量距离求解多对一追逃问题的最优策略. 在此追逃问题中, 追捕群体仅领导者可测量与逃逸者间的相对距离, 而逃逸者具有全局视野. 追逃策略求解被分为追博弈与马尔科夫决策两个过程. 在求解追捕策略时, 通过分割环境引入信念区域状态以估计逃逸者位置, 同时使用测量距离对信念区域状态进行修正, 构建起基于信念区域状态的连续随机追博弈, 并借助不动点定理证明了博弈平稳纳什均衡策略的存在性. 在求解逃逸策略时, 逃逸者根据全局信息建立混合状态下的马尔科夫决策过程及相应的最优贝尔曼方程. 同时给出了基于强化学习的平稳追逃策略求解算法, 并通过案例验证了该算法的有效性.Abstract: The pursuit-evasion problem is of great importance in the fields of confrontation, tracking and searching. In this paper, we are focused on the study of optimal strategies for solving the multi-pursuits and single-evader problem with only measured distances within the framework of continuous stochastic game and Markov decision process (MDP). In such problem, only the leader of pursuits can measure its relative distance with respect to the evader, while the evader has a global view. The strategies of the pursuits and evader are established via two steps: The pursuit game and the MDP. For the pursuits' strategy, the belief region state is introduced by partitioning the environment to estimate the evader's position, and the belief region state is further corrected by using the measured distances. A continuous stochastic pursuit game is then formed based on the belief region state, and the existence of stationary Nash equilibrium strategies is shown through the fixed-point theorem. For the evader's strategy, an MDP with the global states is established and the underlying optimal Bellman equation is devised. Moreover, a reinforcement learning based algorithm is presented for stationary pursuit-evasion strategies computation, and an example is also included to exhibit the effectiveness of the current method.
-
[1] 杜永浩, 邢立宁, 蔡昭权. 无人飞行器集群智能调度技术综述. 自动化学报, 2020, 46(2): 222−241Du Yong-Hao, Xing Li-Ning, Cai Zhao-Quan. Survey on intelligent scheduling technologies for unmanned flying craft clusters. Acta Automatica Sinica, 2020, 46(2): 222−241 [2] 寇立伟, 项基. 基于输出反馈线性化的多移动机器人目标包围控制. 自动化学报, 2022, 48(5): 1285−1291Kou Li-Wei, Xiang Ji. Target fencing control of multiple mobile robots using output feedback linearization. Acta Automatica Sinica, 2022, 48(5): 1285−1291 [3] Ferrari S, Fierro R, Perteet B, Cai C H, Baumgartner K. A geometric optimization approach to detecting and intercepting dynamic targets using a mobile sensor network. SIAM Journal on Control and Optimization, 2009, 48(1): 292−320 doi: 10.1137/07067934X [4] Isaacs R. Differential Games. New York: Wiley, 1965. [5] Osborne M J, Rubinstein A. A Course in Game Theory. Cambridge: MIT Press, 1994. [6] 施伟, 冯旸赫, 程光权, 黄红蓝, 黄金才, 刘忠, 等. 基于深度强化学习的多机协同空战方法研究. 自动化学报, 2021, 47(7): 1610−1623Shi Wei, Feng Yang-He, Cheng Guang-Quan, Huang Hong-Lan, Huang Jin-Cai, Liu Zhong, et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(7): 1610−1623 [7] 耿远卓, 袁利, 黄煌, 汤亮. 基于终端诱导强化学习的航天器轨道追逃博弈. 自动化学报, 2023, 49(5): 974−984Geng Yuan-Zhuo, Yuan Li, Huang Huang, Tang Liang. Terminal-guidance based reinforcement-learning for orbital pursuit-evasion game of the spacecraft. Acta Automatica Sinica, 2023, 49(5): 974−984 [8] Engin S, Jiang Q Y, Isler V. Learning to play pursuit-evasion with visibility constraints. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Prague, Czech Republic: IEEE, 2021. 3858−3863 [9] Al-Talabi A A. Multi-player pursuit-evasion differential game with equal speed. In: Proceedings of the IEEE International Automatic Control Conference (CACS). Pingtung, Taiwan, China: IEEE, 2017. 1−6 [10] Selvakumar J, Bakolas E. Feedback strategies for a reach-avoid game with a single evader and multiple pursuers. IEEE Transactions on Cybernetics, 2021, 51(2): 696−707 doi: 10.1109/TCYB.2019.2914869 [11] de Souza C, Newbury R, Cosgun A, Castillo P, Vidolov B, Kulić D. Decentralized multi-agent pursuit using deep reinforcement learning. IEEE Robotics and Automation Letters, 2021, 6(3): 4552−4559 doi: 10.1109/LRA.2021.3068952 [12] Zhou Z J, Xu H. Decentralized optimal large scale multi-player pursuit-evasion strategies: A mean field game approach with reinforcement learning. Neurocomputing, 2022, 484: 46−58 doi: 10.1016/j.neucom.2021.01.141 [13] Garcia E, Casbeer D W, Von Moll A, Pachter M. Multiple pursuer multiple evader differential games. IEEE Transactions on Automatic Control, 2021, 66(5): 2345−2350 doi: 10.1109/TAC.2020.3003840 [14] Pierson A, Wang Z J, Schwager M. Intercepting rogue robots: An algorithm for capturing multiple evaders with multiple pursuers. IEEE Robotics and Automation Letters, 2017, 2(2): 530−537 doi: 10.1109/LRA.2016.2645516 [15] Gibbons R. A Primer in Game Theory. Harlow: Prentice Education Limited, 1992. [16] Parthasarathy T. Discounted, positive, and noncooperative stochastic games. International Journal of Game Theory, 1973, 2(1): 25−37 doi: 10.1007/BF01737555 [17] Maitra A, Parthasarathy T. On stochastic games. Journal of Optimization Theory and Applications, 1970, 5(4): 289−300 doi: 10.1007/BF00927915 [18] Liu S Y, Zhou Z Y, Tomlin C, Hedrick K. Evasion as a team against a faster pursuer. In: Proceedings of the American Control Conference. Washington, USA: IEEE, 2013. 5368−5373 [19] Huang L N, Zhu Q Y. A dynamic game framework for rational and persistent robot deception with an application to deceptive pursuit-evasion. IEEE Transactions on Automation Science and Engineering, 2022, 19(4): 2918−2932 doi: 10.1109/TASE.2021.3097286 [20] Qi D D, Li L Y, Xu H L, Tian Y, Zhao H Z. Modeling and solving of the missile pursuit-evasion game problem. In: Proceedings of the 40th Chinese Control Conference (CCC). Shanghai, China: IEEE, 2021. 1526−1531 [21] 刘坤, 郑晓帅, 林业茗, 韩乐, 夏元清. 基于微分博弈的追逃问题最优策略设计. 自动化学报, 2021, 47(8): 1840−1854Liu Kun, Zheng Xiao-Shuai, Lin Ye-Ming, Han Le, Xia Yuan-Qing. Design of optimal strategies for the pursuit-evasion problem based on differential game. Acta Automatica Sinica, 2021, 47(8): 1840−1854 [22] Xu Y H, Yang H, Jiang B, Polycarpou M M. Multiplayer pursuit-evasion differential games with malicious pursuers. IEEE Transactions on Automatic Control, 2022, 67(9): 4939−4946 doi: 10.1109/TAC.2022.3168430 [23] Lin W, Qu Z H, Simaan M A. Nash strategies for pursuit-evasion differential games involving limited observations. IEEE Transactions on Aerospace and Electronic Systems, 2015, 51(2): 1347−1356 doi: 10.1109/TAES.2014.130569 [24] Fang X, Wang C, Xie L H, Chen J. Cooperative pursuit with multi-pursuer and one faster free-moving evader. IEEE Transactions on Cybernetics, 2022, 52(3): 1405−1414 doi: 10.1109/TCYB.2019.2958548 [25] Lopez V G, Lewis F L, Wan Y, Sanchez E N, Fan L L. Solutions for multiagent pursuit-evasion games on communication graphs: Finite-time capture and asymptotic behaviors. IEEE Transactions on Automatic Control, 2020, 65(5): 1911−1923 doi: 10.1109/TAC.2019.2926554 [26] 郑延斌, 樊文鑫, 韩梦云, 陶雪丽. 基于博弈论及Q学习的多Agent协作追捕算法. 计算机应用, 2020, 40(6): 1613−1620Zheng Yan-Bin, Fan Wen-Xin, Han Meng-Yun, Tao Xue-Li. Multi-agent collaborative pursuit algorithm based on game theory and Q-learning. Journal of Computer Applications, 2020, 40(6): 1613−1620 [27] Zhu J G, Zou W, Zhu Z. Learning evasion strategy in pursuit-evasion by deep Q-network. In: Proceedings of the 24th International Conference on Pattern Recognition (ICPR). Beijing, China: IEEE, 2018. 67−72 [28] Bilgin A T, Kadioglu-Urtis E. An approach to multi-agent pursuit evasion games using reinforcement learning. In: Proceedings of the International Conference on Advanced Robotics (ICAR). Istanbul, Turkey: IEEE, 2015. 164−169 [29] Wang Y D, Dong L, Sun C Y. Cooperative control for multi-player pursuit-evasion games with reinforcement learning. Neurocomputing, 2020, 412: 101−114 doi: 10.1016/j.neucom.2020.06.031 [30] Zhang R L, Zong Q, Zhang X Y, Dou L Q, Tian B L. Game of drones: Multi-UAV pursuit-evasion game with online motion planning by deep reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2022.3146976 [31] Coleman D, Bopardikar S D, Tan X B. Observability-aware target tracking with range only measurement. In: Proceedings of the American Control Conference (ACC). New Orleans, USA: IEEE, 2021. 4217−4224 [32] Chen W, Sun R S. Range-only SLAM for underwater navigation system with uncertain beacons. In: Proceedings of the 10th International Conference on Modelling, Identification and Control (ICMIC). Guiyang, China: IEEE, 2018. 1−5 [33] Bopardikar S D, Bullo F, Hespanha J P. A pursuit game with range-only measurements. In: Proceedings of the 47th IEEE Conference on Decision and Control. Cancun, Mexico: IEEE, 2008. 4233−4238 [34] Lima R, Ghose D. Target localization and pursuit by sensor-equipped UAVs using distance information. In: Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS). Miami, USA: IEEE, 2017. 383−392 [35] Fidan B, Kiraz F. On convexification of range measurement based sensor and source localization problems. Ad Hoc Networks, 2014, 20: 113−118 doi: 10.1016/j.adhoc.2014.04.003 [36] Chaudhary G, Sinha A. Capturing a target with range only measurement. In: Proceedings of the European Control Conference (ECC). Zurich, Switzerland: IEEE, 2013. 4400−4405 [37] Güler S, Fidan B. Target capture and station keeping of fixed speed vehicles without self-location information. European Journal of Control, 2018, 43: 1−11 doi: 10.1016/j.ejcon.2018.06.003 [38] Sutton R S, Barto A G. Reinforcement Learning: An Introduction (Second edition). Cambridge: MIT Press, 2018. [39] Kreyszig E. Introductory Functional Analysis With Applications. New York: John Wiley & Sons, 1991. [40] Yu C, Velu A, Vinitsky E, Gao J X, Wang Y, Bayen A, et al. The surprising effectiveness of PPO in cooperative multi-agent games. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: NIPS, 2022. [41] Haarnoja T, Zhou A, Abbeel P, Levine S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 1861−1870 [42] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: ICLR, 2015. -

 下载:
下载:






图(10) / 表(1)
计量
- 文章访问数: 1642
- HTML全文浏览量: 892
- PDF下载量: 289
- 被引次数: 0
