

Terminal-guidance Based Reinforcement-learning for Orbital Pursuit-evasion Game of the Spacecraft
-
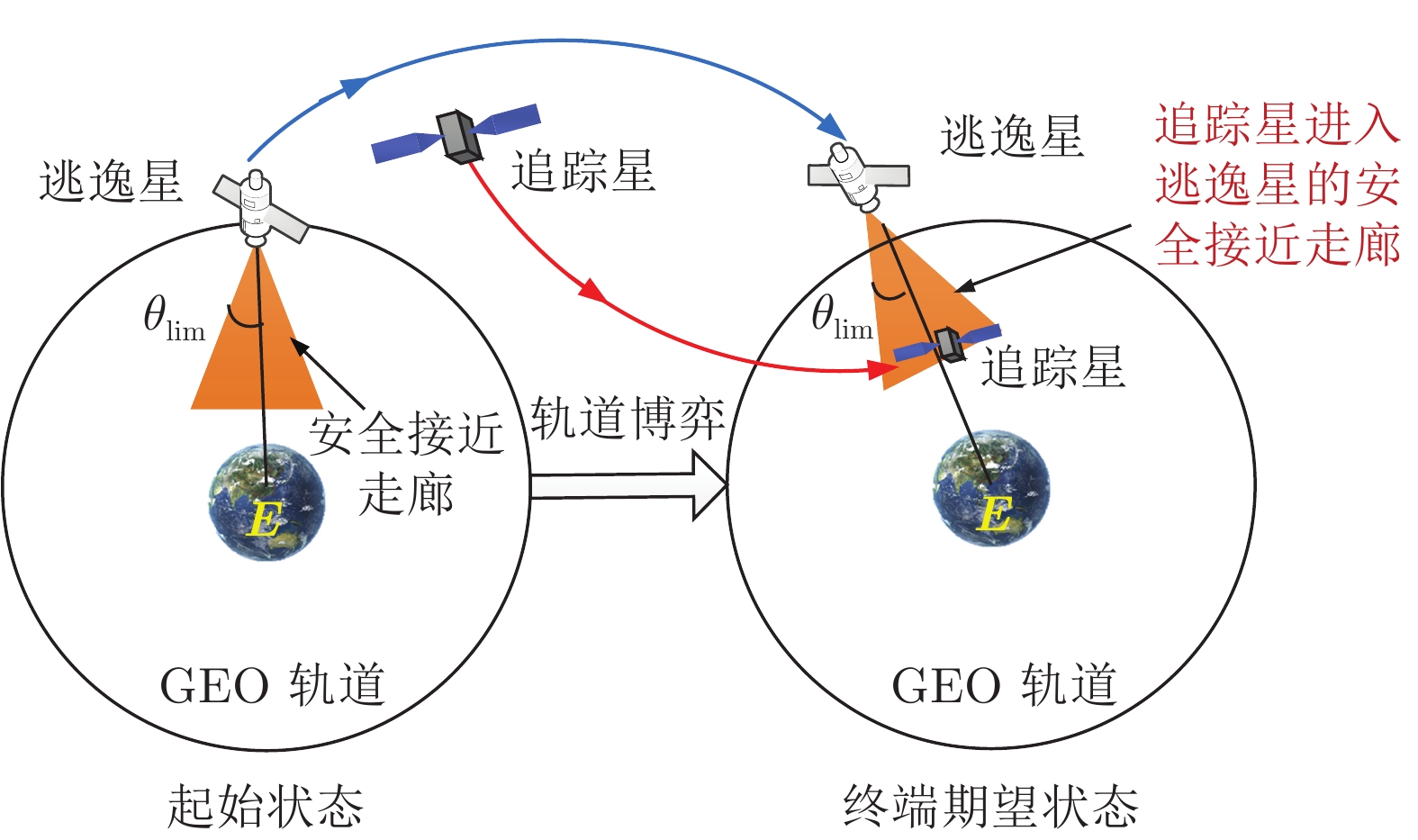
摘要: 针对脉冲推力航天器轨道追逃博弈问题, 提出一种基于强化学习的决策方法, 实现追踪星在指定时刻抵近至逃逸星的特定区域, 其中两星都具备自主博弈能力. 首先, 充分考虑追踪星和逃逸星的燃料约束、推力约束、决策周期约束、运动范围约束等实际约束条件, 建立锥形安全接近区及追逃博弈过程的数学模型; 其次, 为了提升航天器面对不确定博弈对抗场景的自主决策能力, 以近端策略优化 (Proximal policy optimization, PPO) 算法框架为基础, 采用左右互搏的方式同时训练追踪星和逃逸星, 交替提升两星的决策能力; 在此基础上, 为了在指定时刻完成追逃任务, 提出一种终端诱导的奖励函数设计方法, 基于CW (Clohessy Wiltshire)方程预测两星在终端时刻的相对误差, 并将该预测误差引入奖励函数中, 有效引导追踪星在指定时刻进入逃逸星的安全接近区. 与现有基于当前误差设计奖励函数的方法相比, 所提方法能够有效提高追击成功率. 最后, 通过与其他学习方法仿真对比, 验证提出的训练方法和奖励函数设计方法的有效性和优越性.Abstract: This paper addresses the problem of orbital pursuit-evasion of two multi-impulse satellites with strong maneuver ability. A reinforcement-learning based approach is proposed to train two satellites such that the pursuer can reach to a specific region adjacent to the evader at the appointed time. First, by taking fuel limits, control force limits, control frequency, and range of motion into consideration, the model for conical approach region and orbital dynamics of relative motion between two satellites is established. Based on this model, to enhance the ability of confronting with the situations with high uncertainties, the proximal policy optimization (PPO) scheme is adopted to train the pursuer and the evader alternately. Moreover, to accomplish the pursuit or evasion at the appointed time, a new kind of reward function is designed based on the final predicted error, which guides the pursuer to approach the evader approximately at the prescribed time. Compared with existing reward function design methods based on the current error, the proposed method in this paper can effectively enhance the success rate of pursuit. Finally, the simulation comparisons are conducted to show the superiority of the terminal-guidance reward function proposed in this paper over traditional reward function design approaches.
-
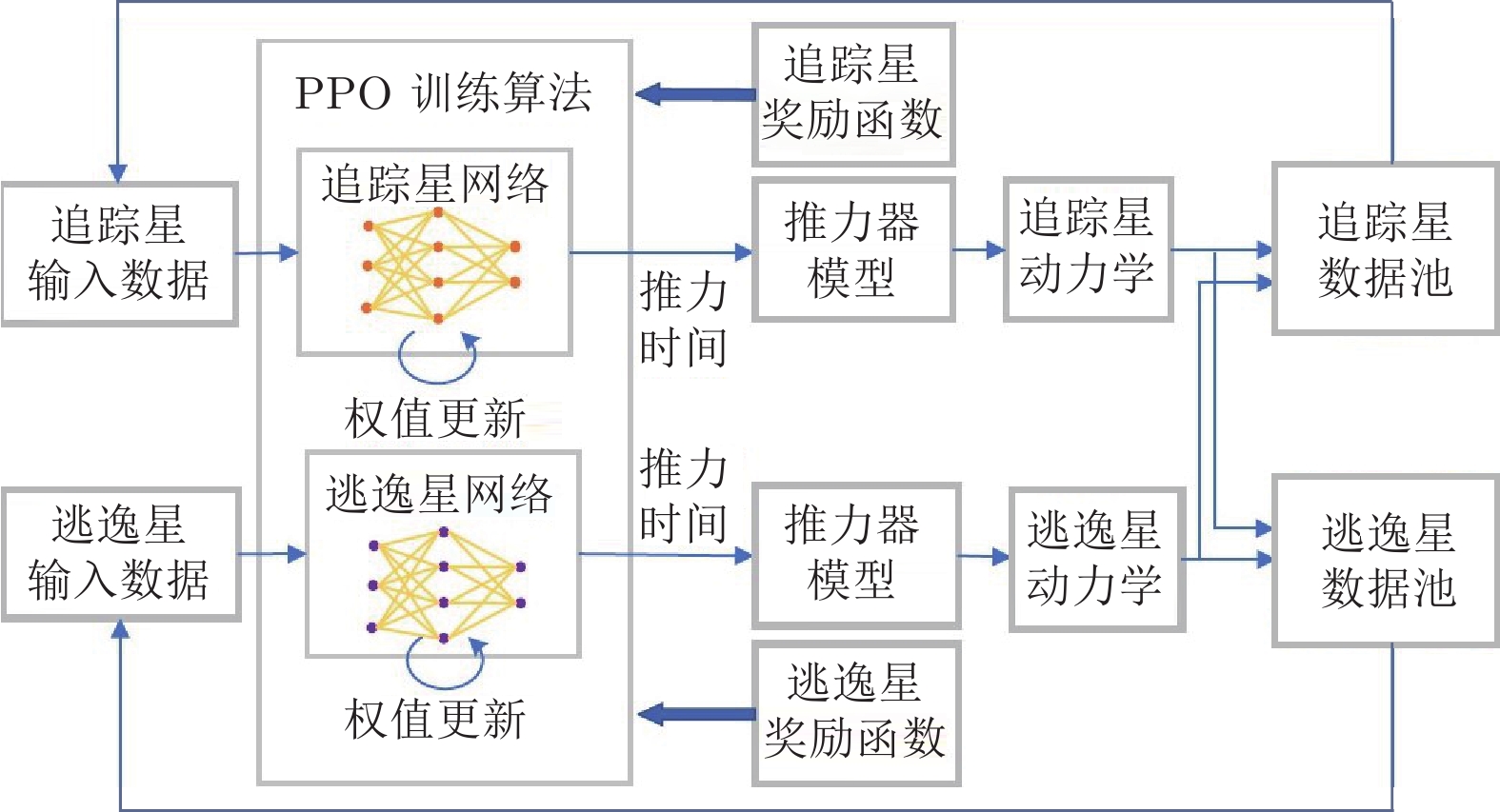
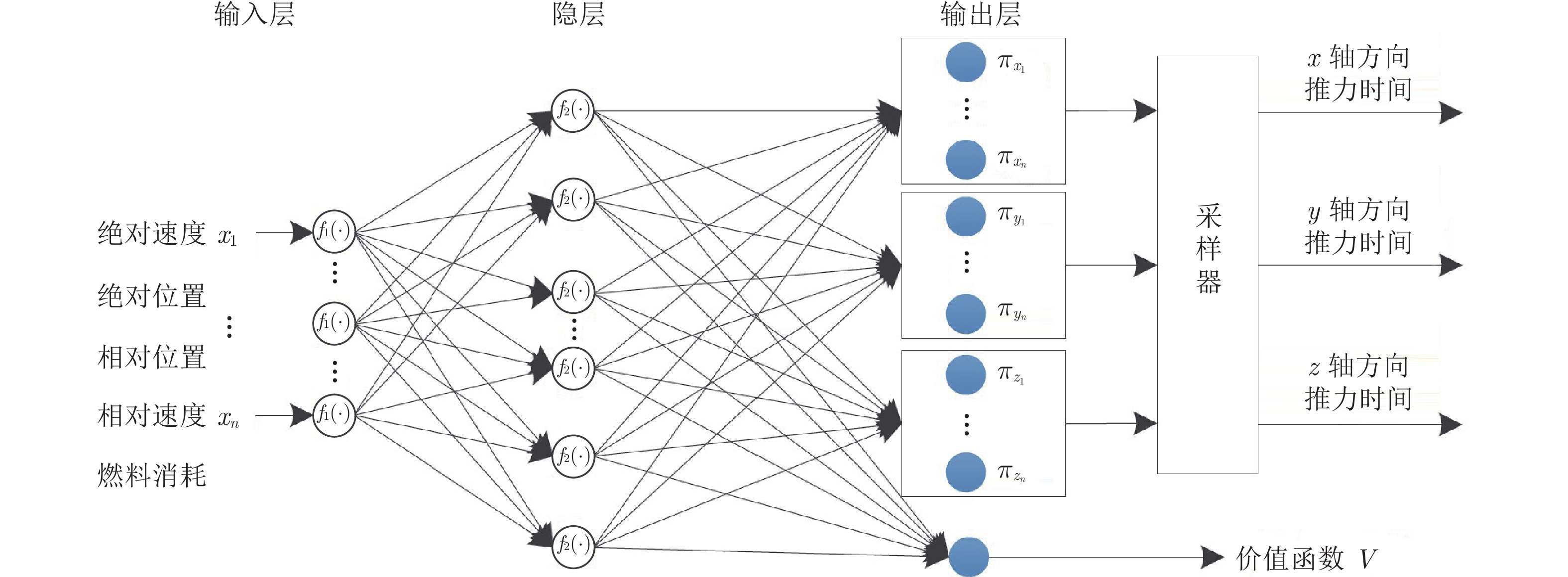
图 3 两星训练框架示意图
Fig. 3 The schematic diagram for training framework of the two spacecraft
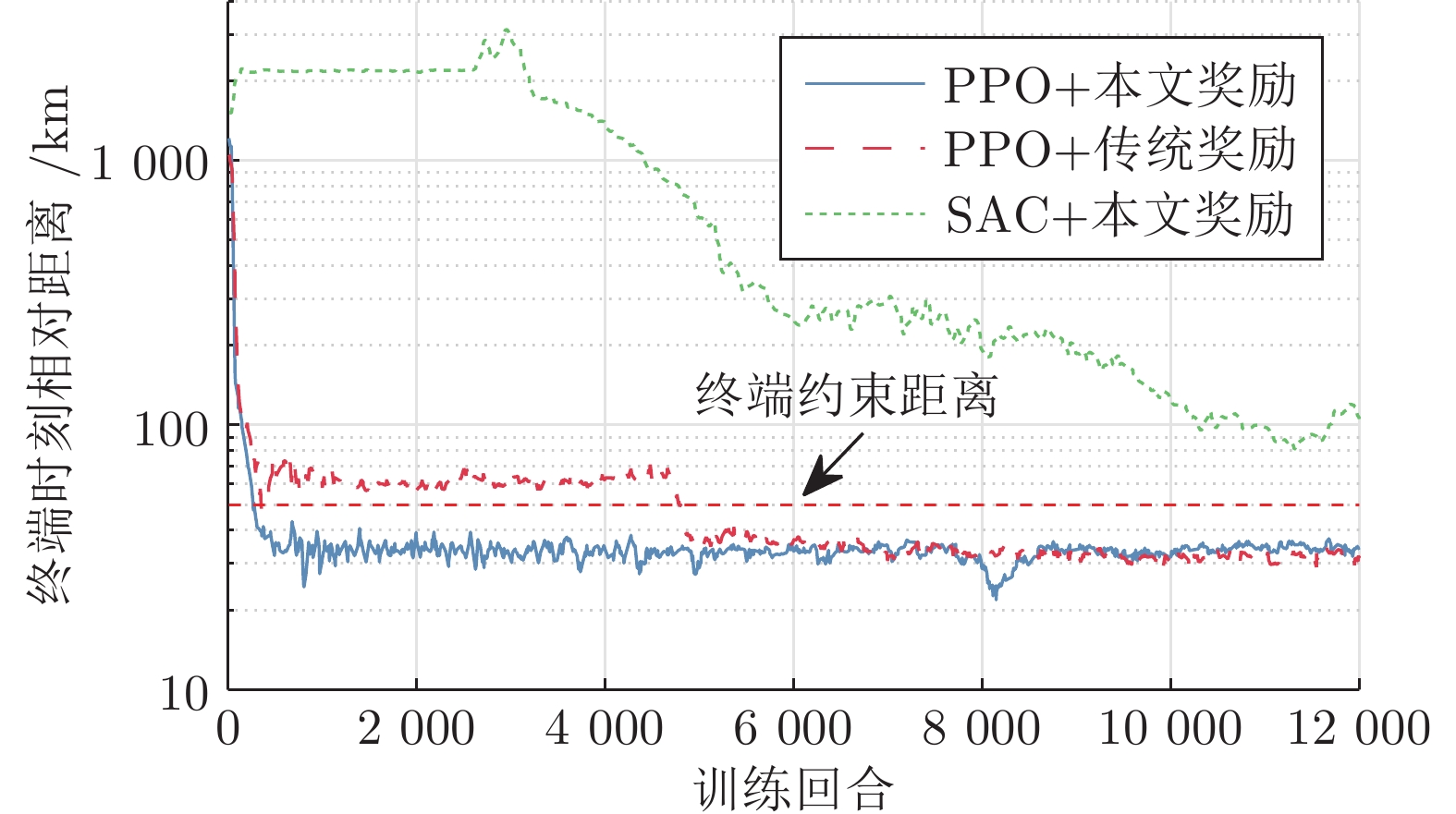
图 8 训练过程中两星终端相对距离
Fig. 8 The final distance between pursuer and evader during the training

图 9 训练过程中终端时刻两星与安全接近区域中心线夹角
Fig. 9 The final angle between the pursuer-evader direction and the conic center axis during the training

图 10 基于本文奖励函数设计方法的多局打靶结果
Fig. 10 The Monte-Carlo results for the reward function design method in this paper
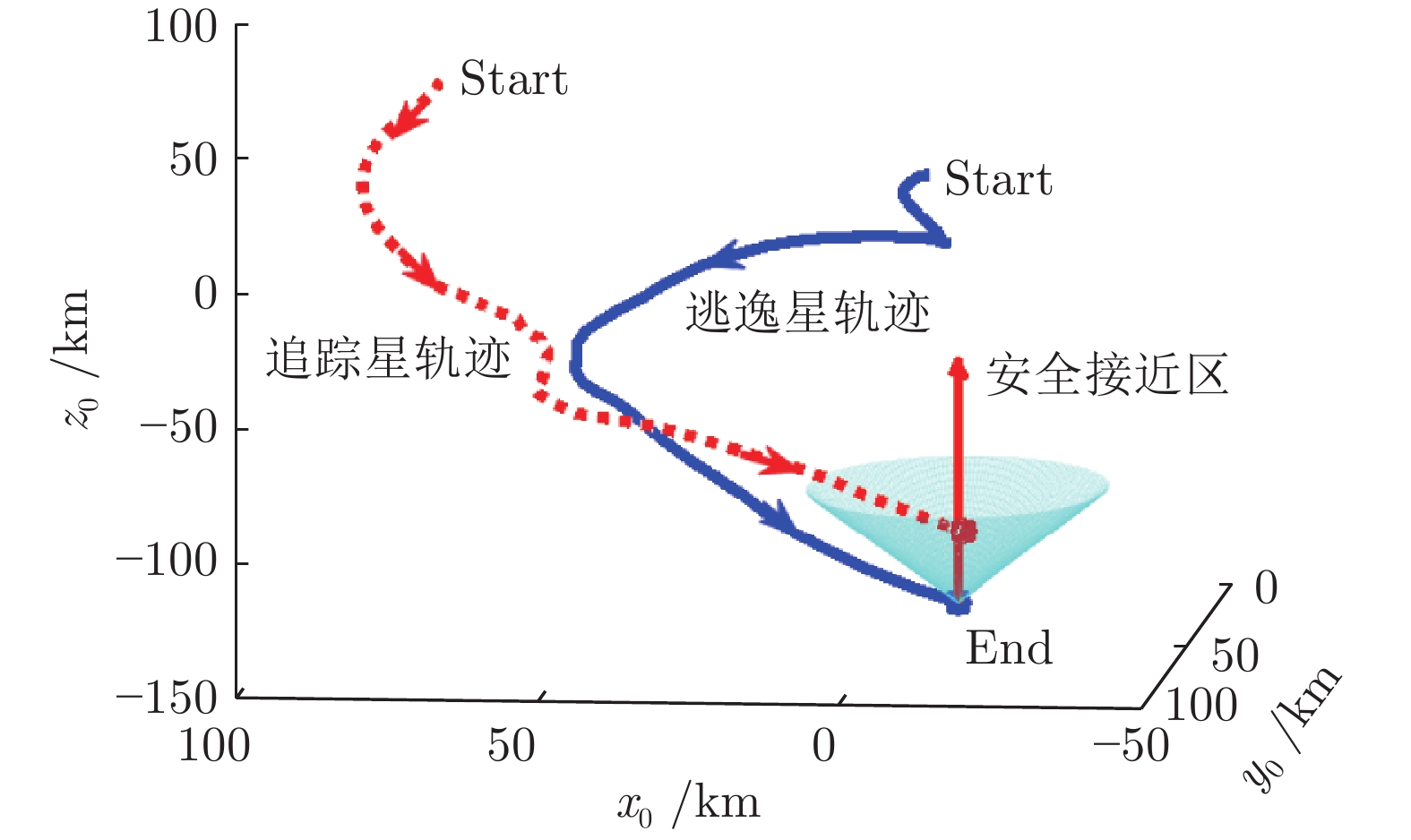
图 11 本文奖励函数对应的一局轨迹
Fig. 11 The trajectory in one episode based on the reward function designed in this paper

图 12 基于传统奖励函数设计方法的多局打靶结果
Fig. 12 The Monte-Carlo results for the traditional reward function design method
表 1 追踪星和逃逸星参数设置
Table 1 Parameters of the pursuer and evader
博弈对象 决策周期 (s) 各轴推质比(N/kg) 各轴单次速度增量上限 (m/s) 总速度增量上限 (m/s) 追踪星 600 20/500 1.6 320 逃逸星 600 20/500 1.6 240  下载: 导出CSV
下载: 导出CSV
表 2 PPO算法相关参数
Table 2 Parameters for the PPO algorithm
参数描述 参数数值 学习率 $\alpha_{lr}=0.0002$ 损失函数相关参数 $\varepsilon=0.1, c_1=0.5, c_2=0.01$ 训练所需轨迹条数 $\mathrm{Batch_{-}n=128}$ 追踪星奖励函数参数 $\delta_{c1}=1$, $\delta_{c2}=0.1$, $\alpha_c=4\times10^{-6}$, $\beta_c=1/\pi$, $\lambda_c=0.5$ 逃逸星奖励函数参数 $\delta_{t1}=1$, $\delta_{t2}=0.1$, $\alpha_t=4\times10^{-6}$, $\beta_t=1/\pi$, $\lambda_t=5/6$
下载: 导出CSV
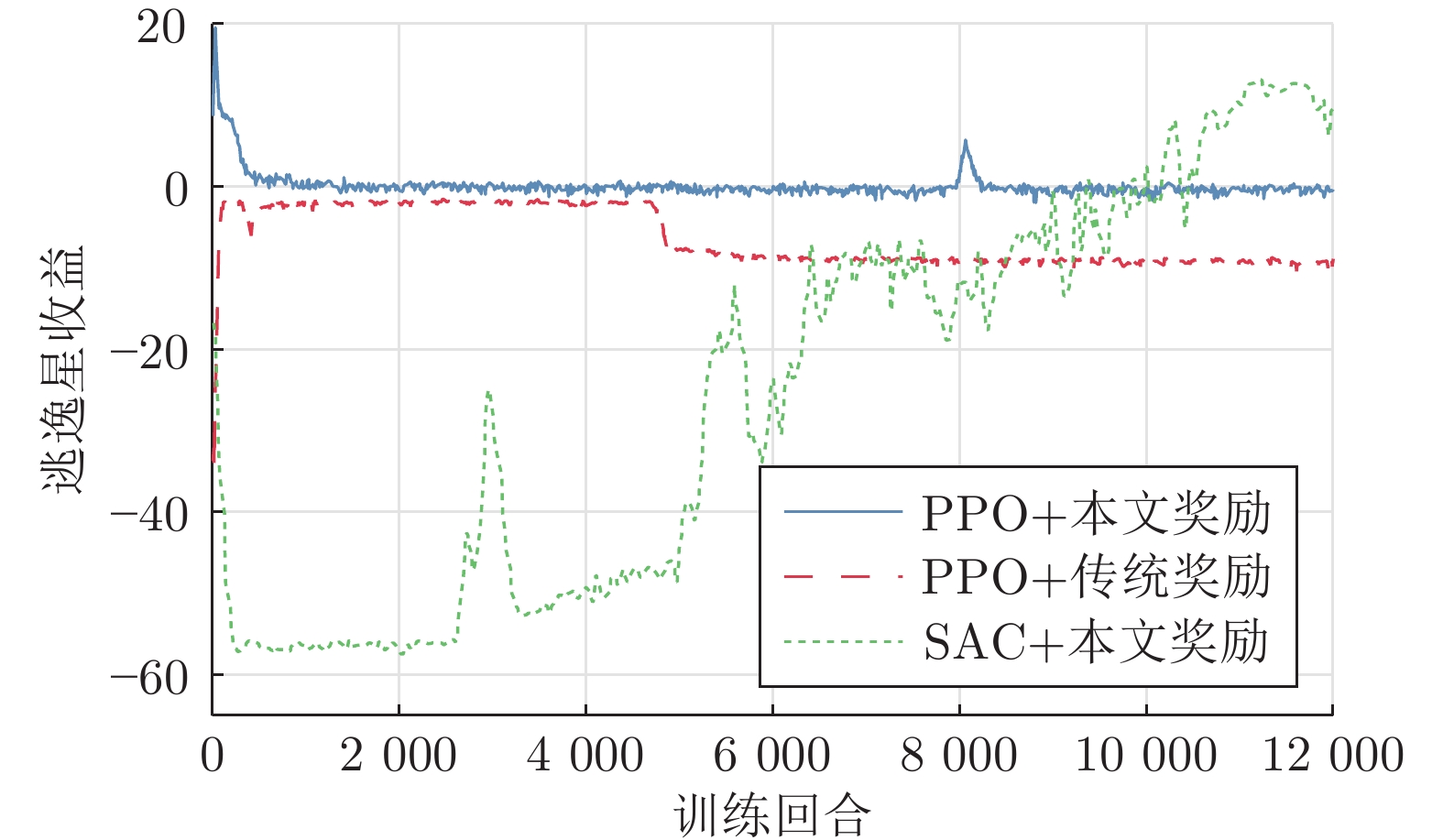
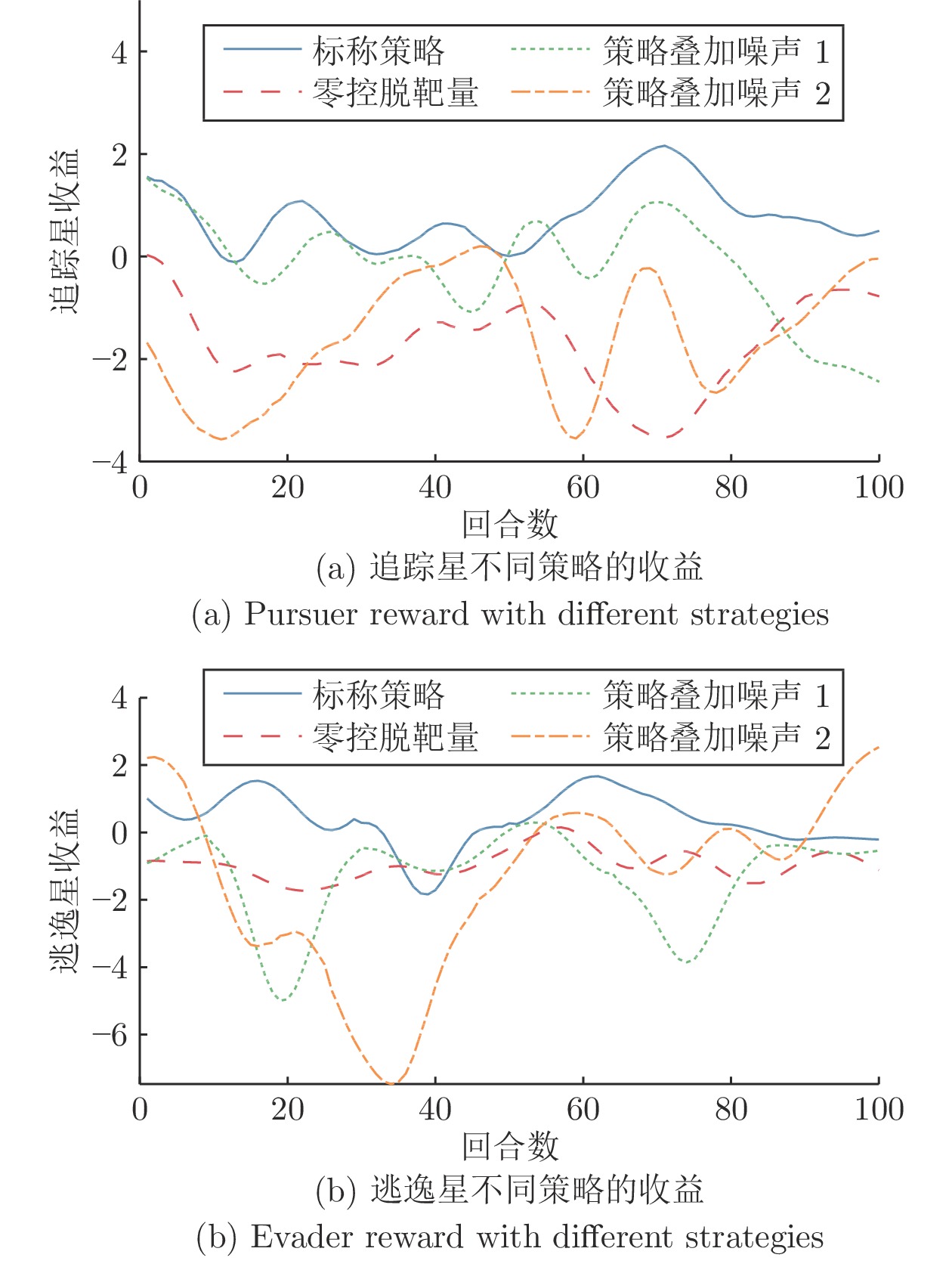
表 3 不同追逃策略的追踪成功率
Table 3 Success rate of the pursuer for different pursuing and evasion strategies
逃逸星 追踪星 PPO+本文奖励 PPO+传统奖励 SAC+本文奖励 零控脱靶量法 PPO+本文奖励 $97{\text{%}}$ $89{\text{%}}$ $0{\text{%}}$ $92{\text{%}}$ PPO+传统奖励 $99{\text{%}}$ $92{\text{%}}$ $2{\text{%}}$ $98{\text{%}}$ SAC+本文奖励 $100{\text{%}}$ $61{\text{%}}$ $7{\text{%}}$ $100{\text{%}}$ 零控脱靶量法 $99{\text{%}}$ $99{\text{%}}$ $9{\text{%}}$ $98{\text{%}}$
下载: 导出CSV
-
[1] 袁利. 面向不确定环境的航天器智能自主控制技术.宇航学报, 2021, 42(7): 839-849 doi: 10.3873/j.issn.1000-1328.2021.07.004Yuan Li. Spacecraft intelligent autonomous control technology toward uncertain environment. Journal of Astronautics, 2021, 42(7): 839-849 doi: 10.3873/j.issn.1000-1328.2021.07.004 [2] 赵力冉, 党朝辉, 张育林. 空间轨道博弈: 概念, 原理与方法. 指挥与控制学报, 7(3): 215-224 doi: 10.3969/j.issn.2096-0204.2021.03.0215Zhao Li-Ran, Dang Zhao-Hui, Zhang Yu-Lin. Orbital game: Concepts, principles and methods. Journal of Command and Control, 2021, 7(3): 215-224 doi: 10.3969/j.issn.2096-0204.2021.03.0215 [3] Isaacs R. Differential Games: A Mathematical Theory With Applications to Warfare and Pursuit, Control and Optimization. London: John Wiley, 1999. [4] Chertovskih R, Karamzin D, Khalil N T, Pereira F L. An indirect method for regular state-constrained optimal control problems in flow fields. IEEE Transactions on Automatic Control, 2020, 66(2): 787-793 [5] 郝志伟, 孙松涛, 张秋华, 谌颖. 半直接配点法在航天器追逃问题求解中的应用. 宇航学报, 2019, 40(6): 628-635 doi: 10.3873/j.issn.1000-1328.2019.06.003Hao Zhi-Wei, Sun Song-Tao, Zhang Qiu-Hua, Chen Ying. Application of semi-direct collocation method for solving pursuit-evasion problems of spacecraft. Journal of Astronautics, 2019, 40(6): 628-635 doi: 10.3873/j.issn.1000-1328.2019.06.003 [6] Li Y, Chen W, Yang L. Multistage linear gauss pseudospectral method for piecewise continuous nonlinear optimal control problems. IEEE Transactions on Aerospace and Electronic Systems, 2021, 57(4): 2298-2310 doi: 10.1109/TAES.2021.3054074 [7] 罗亚中, 李振瑜, 祝海. 航天器轨道追逃微分对策研究综述. 中国科学: 技术科学, 2020, 50(12): 1533-1545 doi: 10.1360/SST-2019-0174Luo Ya-Zhong, Li Zhen-Yu, Zhu Hai. Survey on spacecraft orbital pursuit-evasion differential games. Scientia Sinica Technologica, 2020, 50(12): 1533-1545 doi: 10.1360/SST-2019-0174 [8] Hafer W T, Reed H L, Turner J D, Pham K. Sensitivity methods applied to orbital pursuit evasion. Journal of Guidance, Control, and Dynamics, 2015, 38(6): 1118-1126 doi: 10.2514/1.G000832 [9] Oyler D W, Kabamba P T, Girard A R. Pursuit-evasion games in the presence of obstacles. Automatica, 2016, 65: 1-11 doi: 10.1016/j.automatica.2015.11.018 [10] Shen H X, Casalino L. Revisit of the three-dimensional orbital pursuit-evasion game. Journal of Guidance, Control, and Dynamics, 2018, 41(8): 1823—1831 doi: 10.2514/1.G003127 [11] Li Z, Zhu H, Yang Z, Luo Y Z. Saddle point of orbital pursuit-evasion game under J2-perturbed dynamics. Journal of Guidance, Control, and Dynamics, 2020, 43(9): 1733-1739 doi: 10.2514/1.G004459 [12] Perelman A, Shima T, Rusnak I. Cooperative differential games strategies for active aircraft protection from a homing missile. Journal of Guidance, Control, and Dynamics, 2011, 34(3): 761-773 doi: 10.2514/1.51611 [13] 刘坤, 郑晓帅, 林业茗, 韩乐, 夏元清. 基于微分博弈的追逃问题最优策略设计. 自动化学报, 2021, 47(8): 1840-1854 doi: 10.16383/j.aas.c200979Liu Kun, Zheng Xiao-Shuai, Lin Ye-Ming, Han Le, Xia Yuan-Qing. Design of optimal strategies for the pursuit-evasion problem based on differential game. Acta Automatica Sinica, 2021, 47(8): 1840-1854 doi: 10.16383/j.aas.c200979 [14] Venigalla C, Scheeres D J. Delta-V-based analysis of spacecraft pursuit-evasion games. Journal of Guidance, Control, and Dynamics, 2021, 44(11): 1961-1971 doi: 10.2514/1.G005901 [15] 于大腾. 空间飞行器安全防护规避机动方法研究 [博士论文], 国防科技大学, 中国, 2017Yu Da-Teng. Approaches for the Spacecraft Security Defense and Evasion Maneuver Method [Ph.D. dissertation], National University of Defense Technology, China, 2017 [16] 李臻, 范家璐, 姜艺, 柴天佑. 一种基于Off-Policy的无模型输出数据反馈 $H_{\infty}$ 控制方法. 自动化学报, 2021, 47(9): 2182-2193Li Zhen, Fan Jia-Lu, Jiang Yi, Chai Tian-You. A model-free$H_{\infty}$ control method based on off-policy with output data feedback. Acta Automatica Sinica, 2021, 47(9): 2182-2193[17] Schulman J, Levine S, Moritz P, Jordan M I, Abbeel P. Trust region policy optimization. In: Proceedings of the International Conference on Machine Learning. Guangzhou, China: International Machine Learning Society (IMLS), 2015. 1889−1897 [18] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017. [19] Han M, Zhang L, Wang J, Pan W. Actor-critic reinforcement learning for control with stability guarantee. IEEE Robotics and Automation Letters, 2020, 5(4): 6217-6224 doi: 10.1109/LRA.2020.3011351 [20] Izzo D, Simoes L F, de Croon G C H E. An evolutionary robotics approach for the distributed control of satellite formations. Evolutionary Intelligence, 2014, 7(2): 107-118 doi: 10.1007/s12065-014-0111-9 [21] Shirobokov M, Trofimov S, Ovchinnikov M. Survey of machine learning techniques in spacecraft control design. Acta Astronautica, 2021, 186: 87-97 doi: 10.1016/j.actaastro.2021.05.018 [22] Gaudet B, Linares R, Furfaro R. Adaptive guidance and integrated navigation with reinforcement meta-learning. Acta Astronautica, 2020, 169: 180-190 doi: 10.1016/j.actaastro.2020.01.007 [23] Gaudet B, Linares R, Furfaro R. Deep reinforcement learning for six degree-of-freedom planetary landing. Advances in Space Research, 2020, 65(7): 1723-1741 doi: 10.1016/j.asr.2019.12.030 [24] Hovell K, Ulrich S. Deep reinforcement learning for spacecraft proximity operations guidance. Journal of Spacecraft and Rockets, 2021, 58(2): 254-264 doi: 10.2514/1.A34838 [25] Zavoli A, Federici L. Reinforcement learning for robust trajectory design of interplanetary missions. Journal of Guidance, Control, and Dynamics, 2021, 44(8): 1440-1453 doi: 10.2514/1.G005794 [26] Koch W, Mancuso R, West R, Bestavros A. Reinforcement learning for UAV attitude control. ACM Transactions on Cyber-Physical Systems, 2019, 3(2): 1-21 [27] Furfaro R, Scorsoglio A, Linares R, Massari M. Adaptive generalized ZEM-ZEV feedback guidance for planetary landing via a deep reinforcement learning approach. Acta Astronautica, 2020, 171: 156-171 doi: 10.1016/j.actaastro.2020.02.051 [28] Wang X, Shi P, Wen C, Zhao Y. Design of parameter-self-tuning controller based on reinforcement learning for tracking noncooperative targets in space. IEEE Transactions on Aerospace and Electronic Systems, 2020, 56(6): 4192-4208 doi: 10.1109/TAES.2020.2988170 [29] 施伟, 冯旸赫, 程光权, 黄红蓝, 黄金才, 刘忠, 等. 基于深度强化学习的多机协同空战方法研究. 自动化学报, 2021, 47(7): 1610-1623 doi: 10.16383/j.aas.c201059Shi Wei, Feng Yang-He, Cheng Guang-Quan, Huang Hong-Lan, Huang Jin-Cai, Liu Zhong, et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(7): 1610-1623 doi: 10.16383/j.aas.c201059 [30] 赵毓, 郭继峰, 颜鹏, 白成超. 稀疏奖励下多航天器规避决策自学习仿真. 系统仿真学报, 2021, 33(8): 1766-1774 doi: 10.16182/j.issn1004731x.joss.21-0432Zhao Yu, Guo Ji-Feng, Yan Peng, Bai Cheng-chao. Self-learning-based multiple spacecraft evasion decision making simulation under sparse reward condition. Journal of System Simulation, 2021, 33(8): 1766-1774 doi: 10.16182/j.issn1004731x.joss.21-0432 [31] 刘冰雁, 叶雄兵, 高勇, 王新波, 倪蕾, 等. 基于分支深度强化学习的非合作目标追逃博弈策略求解. 航空学报, 2020, 41(10): 348—358Liu Bing-Yan, Ye Xiong-Bing, Gao Yong, Wang Xin-Bo, Ni Lei, et al. Strategy solution of non-coorerative target pursuit-evasion game based on branching deep reinforcement learning. Acta Aeronautica et Astronautica Sinica, 2020, 41(10): 348-358 [32] 王淳宝, 叶东, 孙兆伟, 孙楚琦. 航天器末端拦截自适应博弈策略. 宇航学报, 2020, 41(3): 309-318 doi: 10.3873/j.issn.1000-1328.2020.03.007Wang Chun-Bao, Ye Dong, Sun Zhao-Wei, Sun Chu-Qi. Adaptive game strategy of spacecraft terminal interception. Journal of Astronautics, 2020, 41(3): 309-318 doi: 10.3873/j.issn.1000-1328.2020.03.007 -

 下载:
下载:





计量
- 文章访问数: 3125
- HTML全文浏览量: 1585
- PDF下载量: 582
- 被引次数: 0
