

-
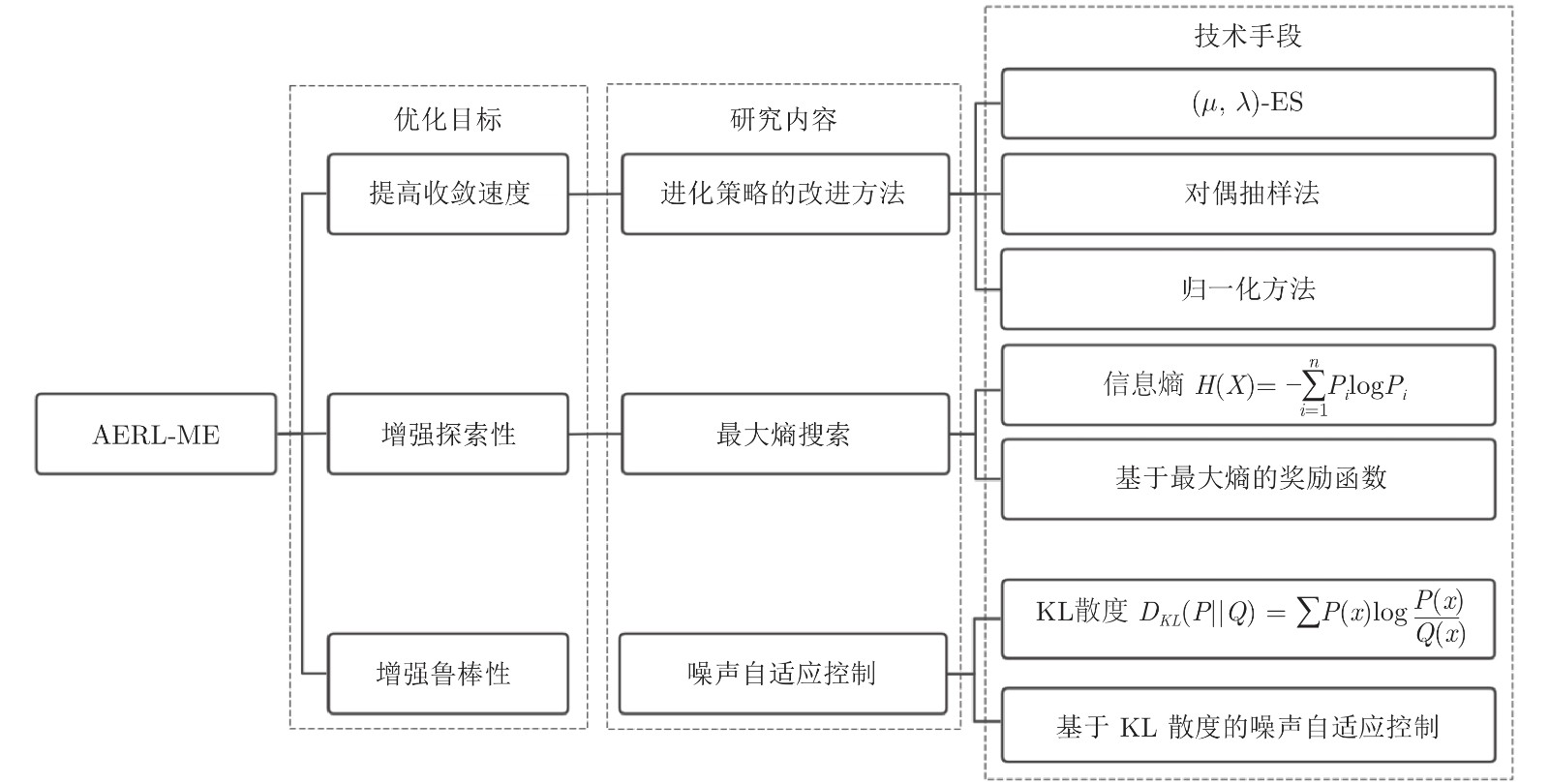
摘要: 近年来, 进化策略由于其无梯度优化和高并行化效率等优点, 在深度强化学习领域得到了广泛的应用. 然而, 传统基于进化策略的深度强化学习方法存在着学习速度慢、容易收敛到局部最优和鲁棒性较弱等问题. 为此, 提出了一种基于自适应噪声的最大熵进化强化学习方法. 首先, 引入了一种进化策略的改进办法, 在“优胜”的基础上加强了“劣汰”, 从而提高进化强化学习的收敛速度; 其次, 在目标函数中引入了策略最大熵正则项, 来保证策略的随机性进而鼓励智能体对新策略的探索; 最后, 提出了自适应噪声控制的方式, 根据当前进化情形智能化调整进化策略的搜索范围, 进而减少对先验知识的依赖并提升算法的鲁棒性. 实验结果表明, 该方法较之传统方法在学习速度、最优性收敛和鲁棒性上有比较明显的提升.Abstract: Recently, evolution strategies have been widely investigated in the field of deep reinforcement learning due to their promising properties of derivative-free optimization and high parallelization efficiency. However, traditional evolutionary reinforcement learning methods suffer from several problems, including the slow learning speed, the tendency toward local optima, and the poor robustness. A systematic method is proposed, named adaptive noise-based evolutionary reinforcement learning with maximum entropy, to tackle these problems. First, the canonical evolution strategies is introduced to enhance the influence of well-behaved individuals and weaken the impact of those with bad performance, thus improving the learning speed of evolutionary reinforcement learning. Second, a regularization term of maximizing the policy entropy is incorporated into the objective function, which ensures moderate stochastically of actions and encourages the exploration to new promising solutions. Third, the exploration noise is proposed to automatically adapt according to the current evolutionary situation, which reduces the dependence on prior knowledge and promotes the robustness of evolution. Experimental results show that this method achieves faster learning speed, better convergence to global optima, and improved robustness, compared to traditional approaches.
-
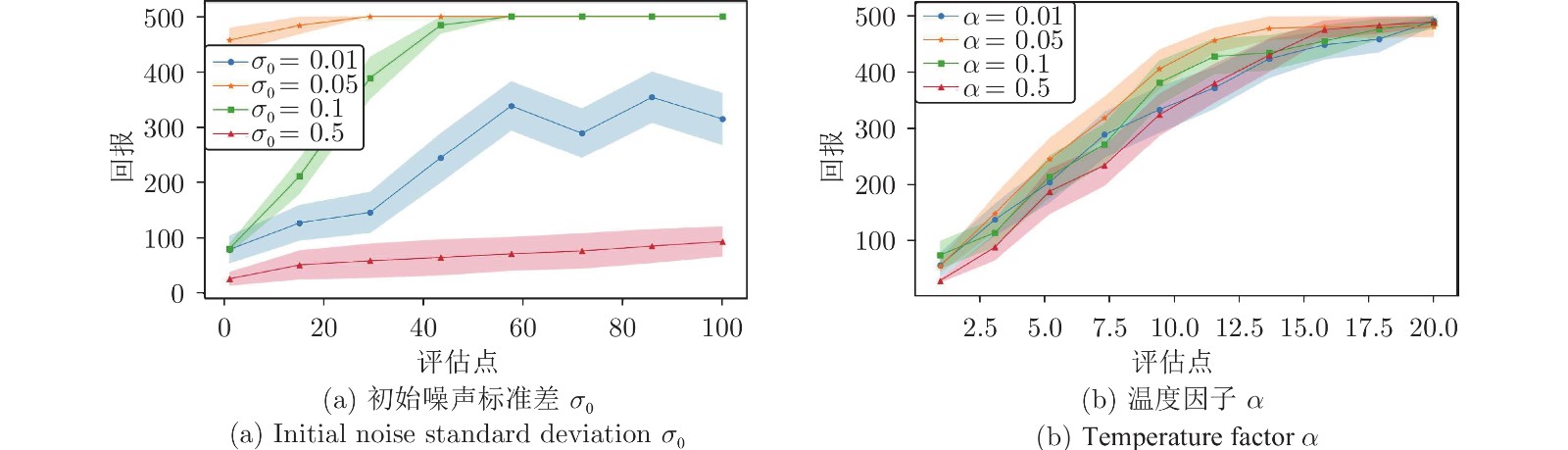
图 6 初始噪声标准差
$ \sigma_0 $ 和温度因子$ \alpha $ 的灵敏度分析Fig. 6 Sensitivity analysis of initial noise standard deviation
$ \sigma_0 $ and temperature factor$ \alpha $ 表 1 以平均回报表示的数值结果
Table 1 The numerical results in terms of average received returns
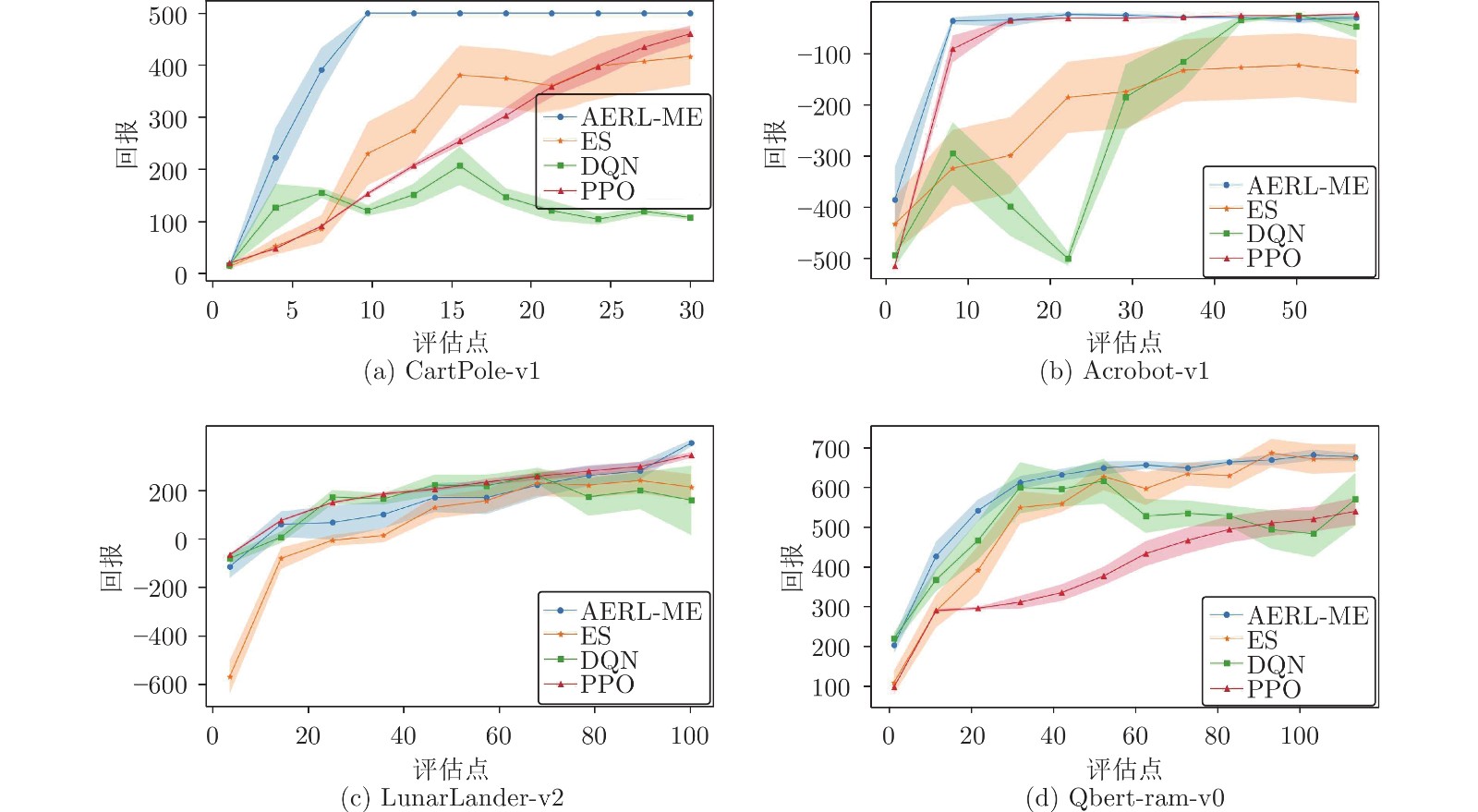
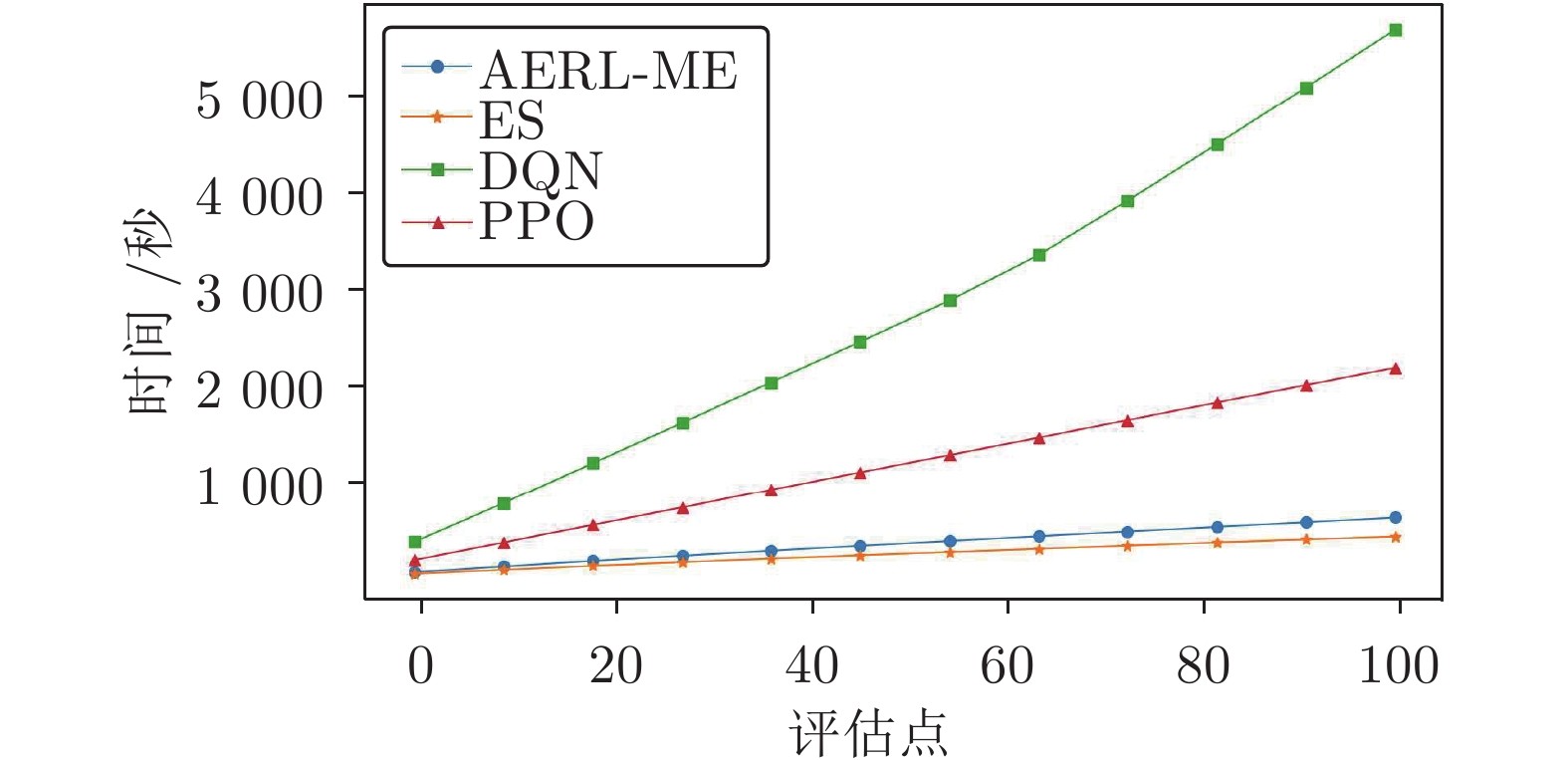
环境 AERL-ME ES DQN PPO CP 500.0 ± 0.0 416.1 ± 54.0 108.3 ± 3.6 460.4 ± 15.8 AB −83.9 ± 4.5 −173.7 ± 52.9 −98.6 ± 18.5 −77.8 ± 0.5 LL 245.0 ± 11.8 82.8 ± 47.8 35.2 ± 126.9 201.2 ± 10.4 Qbert 677.5 ± 10.3 675.0 ± 34.6 571.0 ± 65.9 540.4 ± 34.0  下载: 导出CSV
下载: 导出CSV
-
[1] Sutton R S, Barto A G. Reinforcement Learning: An Introduction (2nd edition). Cambridge: MIT Press, 2018. [2] Li H, Zhang Q, Zhao D. Deep reinforcement learning-based automatic exploration for navigation in unknown environment. IEEE Transactions on Neural Networks and Learning Systems, 2019, 31(6): 2064—2076 [3] Li D, Zhao D, Zhang Q, Chen Y. Reinforcement learning and deep learning based lateral control for autonomous driving[application notes]. IEEE Computational Intelligence Magazine, 2019, 14(2): 83—98 doi: 10.1109/MCI.2019.2901089 [4] Yang W, Shi Y, Gao Y, Yang M. Online multi-view subspace learning via group structure analysis for visual object tracking. Distributed and Parallel Databases, 2018, 36(3): 485—509 doi: 10.1007/s10619-018-7227-3 [5] Luo B, Liu D, Huang T, Wang D. Model-free optimal tracking control via critic-only Q-learning. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(10): 2134—2144 doi: 10.1109/TNNLS.2016.2585520 [6] 姚红革, 张玮, 杨浩琪, 喻钧. 深度强化学习联合回归目标定位. 自动化学报, 2020, 41: 1—10 doi: 10.16383/j.aas.c200045Yao Hong-Ge, Zhang Wei, Yang Hao-Qi, Yu Jun. Joint regression object localization based on deep reinforcement learning. Acta Automatica Sinica, 2020, 41: 1—10 doi: 10.16383/j.aas.c200045 [7] Zhang Z, Zhao D, Gao J, Wang D. FMRQ—A multiagent reinforcement learning algorithm for fully cooperative tasks. IEEE Transactions on Cybernetics, 2016, 47(6): 1367—1379 [8] 李凯文, 张涛, 王锐, 覃伟健, 贺惠晖, 黄鸿. 基于深度强化学习的组合优化研究进展. 自动化学报, 2021, 47(11): 2521—2537 doi: 10.16383/j.aas.c200551Li Kai-Wen, Zhang Tao, Wang Rui, Qin Wei-Jian, He Hui-Hui, Huang Hong. Research reviews of combinatorial optimization methods based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(11): 2521—2537 doi: 10.16383/j.aas.c200551 [9] 王云鹏, 郭戈. 基于深度强化学习的有轨电车信号优先控制. 自动化学报, 2019, 45(12): 2366—2377Wang Yun-Peng, Guo Ge. Signal priority control for trams using deep reinforcement learning. Acta Automatica Sinica, 2019, 45(12): 2366—2377 [10] 吴晓光, 刘绍维, 杨磊, 邓文强, 贾哲恒. 基于深度强化学习的双足机器人斜坡步态控制方法. 自动化学报, 2021, 47(8): 1976—1987 doi: 10.16383/j.aas.c190547Wu Xiao-Guang, Liu Shao-Wei, Yang Lei, Deng Wen-Qiang, Jia Zhe-Heng. A gait control method for biped robot on slope based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(8): 1976—1987 doi: 10.16383/j.aas.c190547 [11] 赵冬斌, 邵坤, 朱圆恒, 李栋, 陈亚冉, 王海涛, 等. 深度强化学习综述: 兼论计算机围棋的发展. 控制理论与应用, 2016, 33(6): 701—717 doi: 10.7641/CTA.2016.60173Zhao Dong-Bin, Shao Kun, Zhu Yuan-Heng, Li Dong, Chen Ya-Ran, Wang Hai-Tao, et al. Review of deep reinforcement learning and discussions on the development of computer Go. Control Theory and Applications, 2016, 33(6): 701—717 doi: 10.7641/CTA.2016.60173 [12] 刘建伟, 高峰, 罗雄麟. 基于值函数和策略梯度的深度强化学习综述. 计算机学报, 2019, 42(6): 1406—1438 doi: 10.11897/SP.J.1016.2019.01406Liu Jian-Wei, Gao Feng, Luo Xiong-Lin. Survey of Deep Reinforcement Learning Based on Value Function and Policy Gradient. Chinese Journal of Computers, 2019, 42(6): 1406—1438 doi: 10.11897/SP.J.1016.2019.01406 [13] Xu X, Hu D, Lu X. Kernel-based least squares policy iteration for reinforcement learning. IEEE Transactions on Neural Networks, 2007, 18(4): 973—992 doi: 10.1109/TNN.2007.899161 [14] Zhu Y, Zhao D, Yang X, Zhang Q. Policy iteration for H∞ optimal control of polynomial nonlinear systems via sum of squares programming. IEEE Transactions on Cybernetics, 2017, 48(2): 500—509 [15] Liu D, Wu J, Xu X. Multi-agent reinforcement learning using ordinal action selection and approximate policy iteration. International Journal of Wavelets, Multiresolution and Information Processing, 2016, 14(6): 1650053 doi: 10.1142/S0219691316500533 [16] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms [Online], available: https://arxiv.org/abs/1707.06347v2, August 28, 2017 [17] Gu Y, Cheng Y, Chen C L P, Wang X. Proximal Policy Optimization With Policy Feedback. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021, 52(7): 4600—4610 [18] Cheng Y, Huang L, Wang X. Authentic boundary proximal policy optimization. IEEE Transactions on Cybernetics, to be published [19] Wang X, Li T, Cheng Y. Proximal parameter distribution optimization. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 51(6): 3771—3780 [20] Salimans T, Ho J, Chen X, Sidor S, Sutskever I. Evolution strategies as a scalable alternative to reinforcement learning [Online], available: https://arxiv.org/abs/1703.03864v2, Septe-mber 7, 2017 [21] Such F P, Madhavan V, Conti E, Lehman J, Stanley K O, Clune J. Deep neuroevolution: Genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning [Online], available: https://arxiv.org/abs/1712. 06567v3, April 20, 2018 [22] Lehman J, Chen J, Clune J, Stanley K O. Es is more than just a traditional finite difference approximator. In: Proceedings of the Genetic and Evolutionary Computation Conference. Kyoto, Japan, 2018. 450−457 [23] Zhang X, Clune J, Stanley K O. On the relationship between the openai evolution strategy and stochastic gradient descent [Online], available: https://arxiv.org/abs/1712.06564, December 18, 2017 [24] Khadka S, Tumer K. Evolution-guided policy gradient in reinforcement learning. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Mont-réal, Canada, 2018. 1196−1208 [25] Shi L, Li S, Zheng Q, Cao L, Yang L, Pan G. Maximum entropy reinforcement learning with evolution strategies. In: Proceedings of the International Joint Conference on Neural Networks. Glasgow, United Kingdom: IEEE, 2020. 1−8 [26] Song X, Gao W, Yang Y, Choromanski K, Pacchiano A, Tang Y. Es-maml: Simple hessian-free meta learning. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia, 2020 [27] Majumdar S, Khadka S, Miret S, Mcaleer S, Tumer K. Evolutionary reinforcement learning for sample-efficient multiagent coordination. In: Proceedings of the 37th International Conference on Machine Learning. New York, USA: 2020. 6651−6660 [28] Long Q, Zhou Z, Gupta A, Fang F, Wu Y, Wang X. Evolutionary population curriculum for scaling multi-agent reinforcement learning. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia, 2020 [29] Wang Z, Chen C, Dong D. Instance weighted incremental evolution strategies for reinforcement learning in dynamic environments [Online], available: https://arxiv.org/abs/2010.04605v2, March 31, 2022 [30] Wierstra D, Schaul T, Glasmachers T, Sun Y, Peters J, Schmidhuber J. Natural evolution strategies. The Journal of Machine Learning Research, 2014, 15(1): 949—980 [31] Conti E, Madhavan V, Such F P, Lehman J, Stanley K, Clune J. Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada, 2018. 5032− 5043 [32] Lehman J, Chen J, Clune J, Stanley K O. Safe mutations for deep and recurrent neural networks through output gradients. In: Proceedings of the Genetic and Evolutionary Computation Conference. Kyoto, Japan, 2018. 117−124 [33] Choromanski K, Pacchiano A, Parker-Holder J, Tang Y, Jain D Yang Y, et al. Provably robust blackbox optimization for reinforcement learning. In: Proceedings of the Conference on Robot Learning. New York, USA: 2020. 683−696 [34] Chrabaszcz P, Loshchilov I, Hutter F. Back to basics: Benchmarking canonical evolution strategies for playing Atari. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden, 2018. 1419−1426 [35] Haarnoja T, Zhou A, Hartikainen K, Tucker g, Ha S, Tan J, et al. Soft actor-critic algorithms and applications [Online], available: https://arxiv.org/abs/1812.05905v2, January 29, 2019 [36] 张化祥, 陆晶. 基于Q学习的适应性进化规划算法. 自动化学报, 2008, 34(7): 819—822Zhang Hua-Xiang, Lu Jing. An adaptive evolutionary programming algorithm based on Q learning. Acta Automatica Sinica, 2008, 34(7): 819—822 [37] Zhu Y, Zhao D, Li X. Iterative adaptive dynamic programming for solving unknown nonlinear zero-sum game based on online data. IEEE Transactions on Neural Networks and Learning Systems, 2016, 28(3): 714—725 [38] Plappert M, Houthooft R, Dhariwal P, Sidor S, Chen R Y, Chen X, et al. Parameter space noise for exploration [Online], available: https://arxiv.org/abs/1706.01905v2, January 31, 2018 [39] Naumov M, Blagov A. Development of the heuristic method of evolutionary strategies for reinforcement learning problems solving. In: Proceedings of the 6th International Conference on Information Technology and Nanotechnology. Samara, Russia, 2020. 19−22 [40] 王柳静, 张贵军, 周晓根. 基于状态估计反馈的策略自适应差分进化算法. 自动化学报, 2020, 46(4): 752—766 doi: 10.16383/j.aas.2018.c170338Wang Liu-Jing, Zhang Gui-Jun, Zhou Xiao-Gen. Strategy self-adaptive differential evolution algorithm based on state estimation feedback. Acta Automatica Sinica, 2020, 46(4): 752—766 doi: 10.16383/j.aas.2018.c170338 [41] Schulman J, Levine S, Abbeel P, Jordan M, Moritz P. Trust region policy optimization. In: Proceedings of the 32th International Conference on Machine Learning. Lille, France: 2015. 1889−1897 [42] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529—533 doi: 10.1038/nature14236 -

 下载:
下载:








图(6) / 表(1)
计量
- 文章访问数: 1743
- HTML全文浏览量: 1426
- PDF下载量: 463
- 被引次数: 0
