

Key Problems and Progress of Vision Transformers: The State of the Art and Prospects
-
摘要: Transformer所具备的长距离建模能力和并行计算能力使其在自然语言处理领域取得了巨大成功并逐步拓展至计算机视觉等领域. 本文以分类任务为切入, 介绍了典型视觉Transformer的基本原理和结构, 并分析了Transformer与卷积神经网络在连接范围、权重动态性和位置表示能力三方面的区别与联系; 同时围绕计算代价、性能提升、训练优化以及结构设计四个方面总结了视觉Transformer研究中的关键问题以及研究进展; 并提出了视觉Transformer的一般性框架; 然后针对检测和分割两个领域, 介绍了视觉Transformer在特征学习、结果产生和真值分配等方面给上层视觉模型设计带来的启发和改变; 并对视觉Transformer未来发展方向进行了展望.
-
关键词:
- 视觉Transformer /
- 图像分类 /
- 目标检测 /
- 图像分割 /
- 计算机视觉
Abstract: Due to its long-range sequence modeling and parallel computing capability, Transformers have achieved significant success in natural language processing and are gradually expanding to computer vision area. Starting from image classification, we introduce the architecture of classic vision Transformer and compare it with convolutional neural networks in connection range, dynamic weights and position representation ability. Then, we summarize existing problems and corresponding solutions in vision Transformers including computational efficiency, performance improvement, optimization and architecture design. Besides, we propose a general architecture of Vision Transformers. For object detection and image segmentation, we discuss Transformer-based models and their roles on feature extraction, result generation and ground-truth assignment. Finally, we point out the development trends of vision Transformers.-
Key words:
- Vision Transformers /
- image classification /
- object detection /
- image segmentation /
- computer vision
-
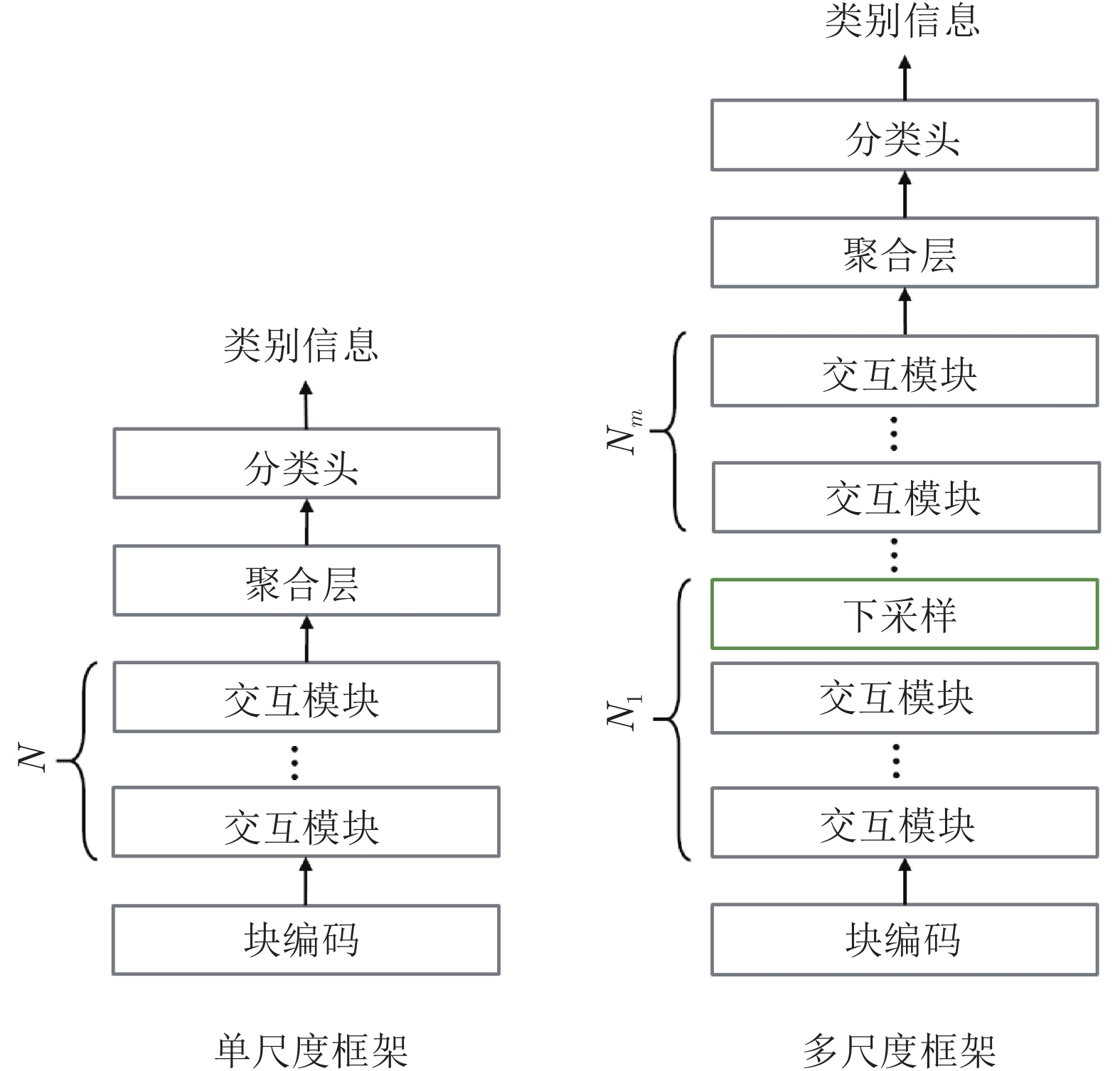
图 4 单尺度与多尺度结构对比
Fig. 4 The comparison of single-scale framework and multi-scale framework
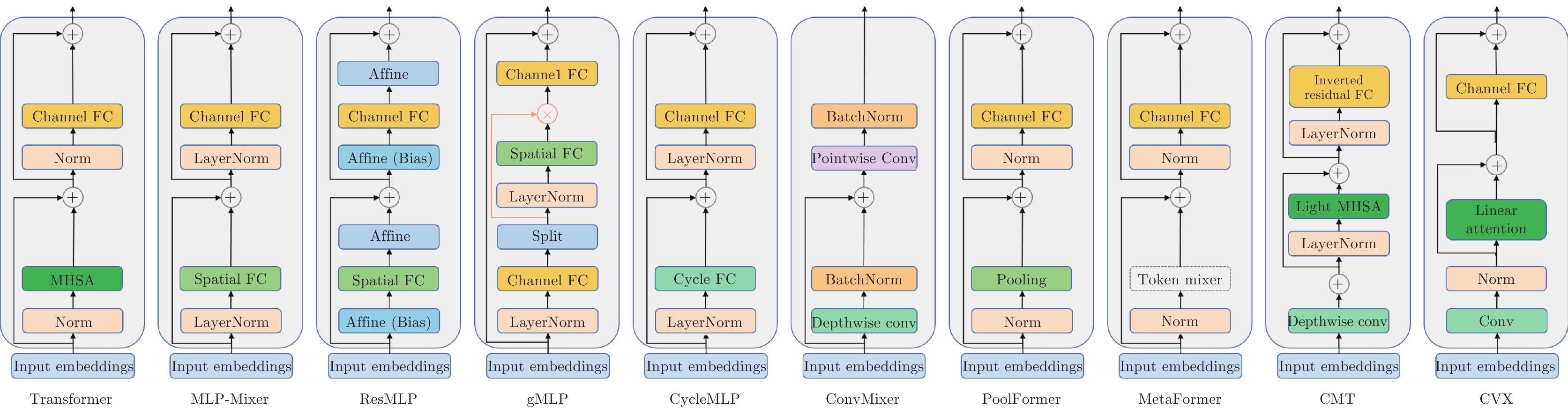
图 5 类Transformer方法的交互模块结构对比(Transformer[8], MLP-Mixer[85], ResMLP[86], gMLP[87], CycleMLP[88], ConvMixer[89], PoolFormer[90], MetaFormer[90], CMT[34], CVX[91])
Fig. 5 The comparison of mixing blocks of Transformer-like methods (Transformer[8], MLP-Mixer[85], ResMLP[86], gMLP[87], CycleMLP[88], ConvMixer[89], PoolFormer[90], MetaFormer[90], CMT[34], CVX[91])
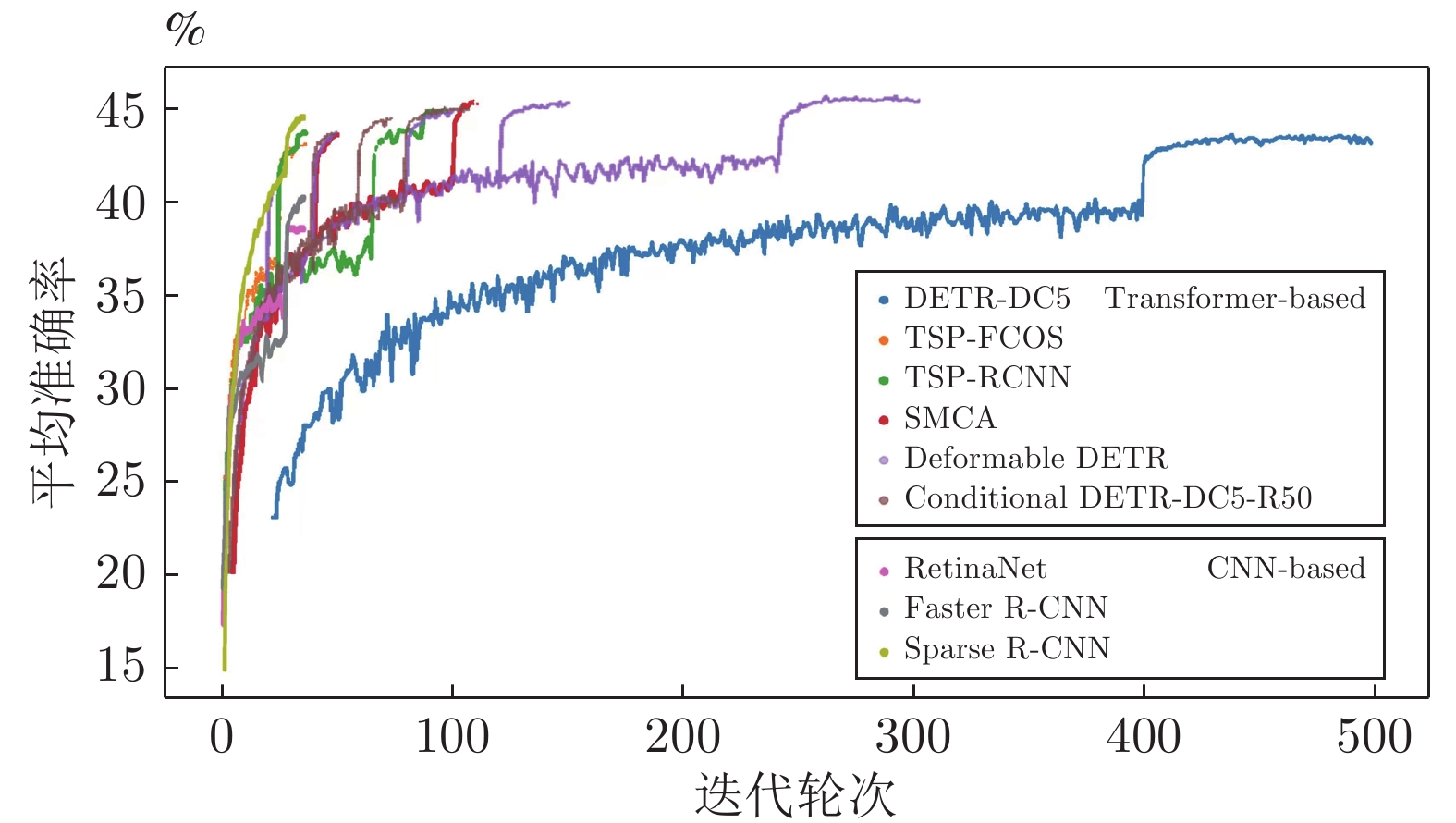
图 8 基于Transformer和CNN的目标检测器的收敛速度对比(DETR-DC5[16], TSP-FCOS[115], TSP-RCNN[115], SMCA[110], Deformable DETR[24], Conditional DETR-DC5-R50[111], RetinaNet[104], Faster R-CNN[95], Sparse R-CNN[108])
Fig. 8 The comparison of converge speed among object detectors based on Transformer and CNN (DETR-DC5[16], TSP-FCOS[115], TSP-RCNN[115], SMCA[110], Deformable DETR[24], Conditional DETR-DC5-R50[111], RetinaNet[104], Faster R-CNN[95], Sparse R-CNN[108])
表 1 不同Transformer自注意力机制以及卷积的时间和空间复杂度(
$ N $ ,$ d $ ,$ s $ 分别表示序列长度、特征维度和局部窗口尺寸, 其中$s<N$ )Table 1 The time and space complexity of different Transformer frameworks (
$N$ ,$ d $ ,$ s $ denote the length, dimension and local window size respectively)名称 时间复杂度 空间复杂度 Convolution $ {\rm{O}}(Nd^2s) $ $ {\rm{O}}(Ns^2d^2+Nd) $ Transformer[8] $ {\rm{O}}(N^2d) $ $ {\rm{O}}(N^2+Nd) $ Sparse Transformers[49] $ {\rm{O}}(N\sqrt{N}d) $ — Reformer[50] $ {\rm{O}}(N\log Nd) $ $ {\rm{O}}(N\log N+Ld) $ Linear Transformer[33] $ {\rm{O}}(Nd^2) $ $ {\rm{O}}(Nd+d^2) $ Performer[54] $ {\rm{O}}(Nd^2\log d) $ $ {\rm{O}}(Nd\log d+d^2\log d) $ AFT-simple[56] $ {\rm{O}}(Nd) $ $ {\rm{O}}(Nd) $ AFT-full[56] $ {\rm{O}}(N^2d) $ $ {\rm{O}}(Nd) $ AFT-local (1D)[56] $ {\rm{O}}(Nsd) $ $ {\rm{O}}(Nd) $ Swin Transformer (2D)[23] ${\rm{O}}(Ns^2d)$ —  下载: 导出CSV
下载: 导出CSV
表 2 视觉Transformer算法在ImageNet-1k上的Top-1准确率比较
Table 2 The comparison of Top-1 accuracy of different vision Transformers on ImageNet-1k dataset
方法名称 迭代轮次 批处理大小 参数量 (×106) 计算量 (GFLOPs) 图像尺寸 Top-1 准确率 训练 测试 ViT-B/16[15] 300 4 096 86 743 224 384 77.9 ViT-L/16[15] 307 5172 224 384 76.5 DeiT-Ti[58] 300 1 024 5 1.3 224 224 72.2 DeiT-S[58] 22 4.6 224 224 79.8 DeiT-B[58] 86 17.6 224 224 81.8 DeiT-B$ \uparrow $[58] 86 52.8 224 384 83.1 ConViT-Ti[60] 300 512 6 1 224 224 73.1 ConViT-S[60] 27 5.4 224 224 81.3 ConViT-B[60] 86 17 224 224 82.4 LocalViT-T[61] 300 1 024 5.9 1.3 224 224 74.8 LocalViT-S[61] 22.4 4.6 224 224 80.8 CeiT-T[73] 300 1 024 6.4 1.2 224 224 76.4 CeiT-S[73] 24.2 4.5 224 224 82.0 CeiT-S$ \uparrow $[73] 24.2 12.9 224 384 83.3 ResT-Small[53] 300 2 048 13.66 1.9 224 224 79.6 ResT-Base[53] 30.28 4.3 224 224 81.6 ResT-Large[53] 51.63 7.9 224 224 83.6 Swin-T[23] 300 1 024 29 4.5 224 224 81.3 Swin-S[23] 50 8.7 224 224 83.0 Swin-B[23] 88 15.4 224 224 83.3 Swin-B$ \uparrow $[23] 88 47.0 224 384 84.2 VOLO-D1[68] 300 1 024 27 6.8 224 224 84.2 VOLO-D2[68] 59 14.1 224 224 85.2 VOLO-D3[68] 86 20.6 224 224 85.4 VOLO-D4[68] 193 43.8 224 224 85.7 VOLO-D5[68] 296 69.0 224 224 86.1 VOLO-D5$ \uparrow $[68] 296 304 224 448 87.0 PVT-Tiny[22] 300 128 13.2 1.9 224 224 75.1 PVT-Small[22] 24.5 3.8 224 224 79.8 PVT-Medium[22] 44.2 6.7 224 224 81.2 PVT-Large[22] 61.4 9.8 224 224 81.7 DeepViT-S[66] 300 256 27 6.2 224 224 82.3 DeepViT-L[66] 55 12.5 224 224 83.1 Refined-ViT-S[59] 300 256 25 7.2 224 224 83.6 Refined-ViT-M[59] 55 13.5 224 224 84.6 Refined-ViT-L[59] 81 19.1 224 224 84.9 Refined-ViT-L$ \uparrow $[59] 512 81 69.1 224 384 85.7 CrossViT-9[63] 300 4 096 8.6 1.8 224 224 73.9 CrossViT-15[63] 27.4 5.8 224 224 81.5 CrossViT-18[63] 43.3 9.0 224 224 82.5
下载: 导出CSV
表 3 基于Transformer和基于CNN的目标检测算法在COCO 2017 val数据集上的检测精度比较. 其中C. 表示基于CNN的算法, T. 表示基于Transformer的算法
Table 3 The comparison of detection performance of Transformer-based and CNN-based detectors on COCO 2017 val set. C. denotes CNN-based methods, T. denotes Transformer-based methods
类型 方法名称 迭代轮次 计算量 (GFLOPs) 参数量 (×106) 帧数 (FPS) 多尺度输入 $ AP $ $ AP_{50} $ $ AP_{75} $ $ AP_{S} $ $ AP_{M} $ $ AP_{L} $ C. FCOS[116] 36 177 — 17 √ 41.0 59.8 44.1 26.2 44.6 52.2 Faster R-CNN[95] 36 180 42 26 √ 40.2 61.0 43.8 24.2 43.5 52.0 Faster R-CNN+[95] 108 180 42 26 √ 42.0 62.1 45.5 26.6 45.4 53.4 Mask R-CNN[99] 36 260 44 — √ 41.0 61.7 44.9 — — — Cascade Mask R-CNN[105] 36 739 82 18 √ 46.3 64.3 50.5 — — — T. ViT-B/16-FRCNN$ \ddagger $[117] 21 — — — — 36.6 56.3 39.3 17.4 40.0 55.5 ViT-B/16-FRCNN*[117] 21 — — — — 37.8 57.4 40.1 17.8 41.4 57.3 DETR-R50[16] 500 86 41 28 — 42.0 62.4 44.2 20.5 45.8 61.1 DETR-DC5-R50[16] 500 187 41 12 — 43.3 63.1 45.9 22.5 47.3 61.1 ACT-MTKD (L=16)[113] — 156 — 14 — 40.6 — — 18.5 44.3 59.7 ACT-MTKD (L=32)[113] — 169 — 16 — 43.1 — — 22.2 47.1 61.4 Deformable DETR[24] 50 78 34 27 — 39.7 60.1 42.4 21.2 44.3 56.0 Deformable DETR-DC5[24] 50 128 34 22 — 41.5 61.8 44.9 24.1 45.3 56.0 Deformable DETR[24] 50 173 40 19 √ 43.8 62.6 47.7 26.4 47.1 58.0 Two-Stage Deformable DETR[24] 50 173 40 19 √ 46.2 65.2 50.0 28.8 49.2 61.7 SMCA[110] 50 152 40 22 — 41.0 — — 21.9 44.3 59.1 SMCA+[110] 108 152 40 22 — 42.7 — — 22.8 46.1 60.0 SMCA[110] 50 152 40 10 √ 43.7 63.6 47.2 24.2 47.0 60.4 SMCA+[110] 108 152 40 10 √ 45.6 65.5 49.1 25.9 49.3 62.6 Efficient DETR[109] 36 159 32 — √ 44.2 62.2 48.0 28.4 47.5 56.6 Efficient DETR*[109] 36 210 35 — √ 45.1 63.1 49.1 28.3 48.4 59.0 Conditional DETR[111] 108 90 44 — — 43.0 64.0 45.7 22.7 46.7 61.5 Conditional DETR-DC5[111] 108 195 44 — — 45.1 65.4 48.5 25.3 49.0 62.2 UP-DETR[112] 150 86 41 28 — 40.5 60.8 42.6 19.0 44.4 60.0 UP-DETR+[112] 300 86 41 28 — 42.8 63.0 45.3 20.8 47.1 61.7 TSP-FCOS[115] 36 189 51.5 15 √ 43.1 62.3 47.0 26.6 46.8 55.9 TSP-RCNN[115] 36 188 64 11 √ 43.8 63.3 48.3 28.6 46.9 55.7 TSP-RCNN+[115] 96 188 64 11 √ 45.0 64.5 49.6 29.7 47.7 58.0 YOLOS-S[114] 150 200 30.7 7 — 36.1 56.4 37.1 15.3 38.5 56.1 YOLOS-S[114] 150 179 27.9 5 √ 37.6 57.6 39.2 15.9 40.2 57.3 YOLOS-B[114] 150 537 127 — — 42.0 62.2 44.5 19.5 45.3 62.1
下载: 导出CSV
表 4 基于Transformer的语义分割算法在ADE20K val数据集上的语义分割精度比较. 其中, 1k表示ImageNet-1k, 22k表示ImageNet-1k和ImageNet-21k的结合
Table 4 The comparison of semantic segmentation performance of Transformer-based methods on ADE20K val set. 1k denotes ImageNet-1k dataset, 22k denotes the combination of ImageNet-1k and ImageNet-21k
方法名称 骨干网络 预训练数据集 图像尺寸 参数量 (×106) 计算量 (GFLOPs) 帧数 (FPS) 多尺度输入 mIoU UperNet[122] R-50 1k 512 — — 23.4 √ 42.8 R-101 1k 512 86 1 029 20.3 √ 44.9 Swin-T 1k 512 60 236 18.5 √ 46.1 Swin-S 1k 512 81 259 15.2 √ 49.3 Swin-B 22k 640 121 471 8.7 √ 51.6 Swin-L 22k 640 234 647 6.2 √ 53.5 Segformer[25] MiT-B3 1k 512 47.3 79 — √ 50.0 MiT-B4 1k 512 64.1 95.7 15.4 √ 51.1 MiT-B5 1k 512 84.7 183.3 9.8 √ 51.8 Segmenter[124] ViT-S/16 1k 512 37.0 — 34.8 √ 46.9 ViT-B/16 1k 512 106 — 24.1 √ 50.0 ViT-L/16 22k 640 334 — — √ 53.6 MaskFormer[125] R-50 1k 512 41 53 24.5 √ 46.7 R-101 1k 512 60 73 19.5 √ 47.2 Swin-T 1k 512 42 55 22.1 √ 48.8 Swin-S 1k 512 63 79 19.6 √ 51.0 Swin-B 22k 640 102 195 12.6 √ 53.9 Swin-L 22k 640 212 375 7.9 √ 55.6 Mask2Former[26] R-50 1k 512 — — — √ 49.2 R-101 1k 512 — — — √ 50.1 Swin-S 1k 512 — — — √ 52.4 Swin-B 22k 640 — √ 55.1 Swin-L 22k 640 — — — √ 57.3
下载: 导出CSV
表 5 基于Transformer的实例分割方法和基于CNN算法在COCO test-dev数据集上的实例分割精度比较
Table 5 The comparison of instance segmentation performance of Transformer-based and typical CNN-based methods on COCO test-dev dataset
方法名称 骨干网络 迭代轮次 帧数 (FPS) $ Ap^m $ $ Ap_S^m $ $ Ap_M^m $ $ Ap_L^m $ $ Ap^b $ Mask R-CNN[99] R-50-FPN 36 15.3 37.5 21.1 39.6 48.3 41.3 R-101-FPN 36 11.8 38.8 21.8 41.4 50.5 43.1 Blend Mask[96] R-50-FPN 36 15.0 37.8 18.8 40.9 53.6 43.0 R-101-FPN 36 11.5 39.6 22.4 42.2 51.4 44.7 SOLO v2[97] R-50-FPN 36 10.5 38.2 16.0 41.2 55.4 40.7 R-101-FPN 36 9.0 39.7 17.3 42.9 57.4 42.6 ISTR[127] R-50-FPN 36 13.8 38.6 22.1 40.4 50.6 46.8 R-101-FPN 36 11.0 39.9 22.8 41.9 52.3 48.1 SOLQ[98] R-50 50 — 39.7 21.5 42.5 53.1 47.8 R-101 50 — 40.9 22.5 43.8 54.6 48.7 Swin-L 50 — 45.9 27.8 49.3 60.5 55.4 QueryInst[126] R-50-FPN 36 7.0 40.6 23.4 42.5 52.8 45.6 R-101-FPN 36 6.1 41.7 24.2 43.9 53.9 47.0 Swin-L 50 3.3 49.1 31.5 51.8 63.2 56.1 Mask2Former[26] R-50 50 — 43.7 — — — 30.6 R-101 50 — 44.2 — — — 31.1 Swin-T 50 — 45.0 — — — 31.8 Swin-L 50 — 50.1 — — — 36.2
下载: 导出CSV
表 6 基于Transformer的全景分割算法在COCO panoptic minval数据集上的全景分割精度比较
Table 6 The comparison of panoptic segmentation performance of Transformer-based methods on COCO panoptic minival dataset
方法名称 骨干网络 迭代轮次 参数量 (×106) 计算量 (GFLOPs) $ PQ $ $ PQ^{Th} $ $ PQ^{St} $ DETR[16] R-50 150+25 42.8 137 43.4 48.2 36.3 R-101 61.8 157 45.1 50.5 37 MaxDeepLab[123] Max-S 54 61.9 162 48.4 53.0 41.5 Max-L 451 1 846 51.1 57.0 42.2 MaskFormer[125] R-50 300 45 181 46.5 51.0 39.8 R-101 64 248 47.6 52.5 40.3 Swin-T 42 179 47.7 51.7 41.7 Swin-S 63 259 49.7 54.4 42.6 Swin-B 102 411 51.1 56.3 43.2 Swin-L 212 792 52.7 58.5 44.0 Panoptic SegFormer[128] R-50 12 51.0 214 48.0 52.3 41.5 R-50 24 51.0 214 49.6 54.4 42.4 R-101 69.9 286 50.6 55.5 43.2 Swin-L 221.4 816 55.8 61.7 46.9
下载: 导出CSV
-
[1] 张慧, 王坤峰, 王飞跃. 深度学习在目标视觉检测中的应用进展与展望. 自动化学报, 2017, 43(8): 1289-1305Zhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(8): 1289-1305 [2] 陈伟宏, 安吉尧, 李仁发, 李万里. 深度学习认知计算综述. 自动化学报, 2017, 43(11): 1886-1897Chen Wei-Hong, An Ji-Yao, Li Ren-Fa, Li Wan-Li. Review on deep-learning-based cognitive computing. Acta Automatica Sinica, 2017, 43(11): 1886-1897 [3] LeCun Y, Boser B, Denker J S, Henderson D, Howard R E, Hubbard W, et al. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989, 1(4): 541-551 doi: 10.1162/neco.1989.1.4.541 [4] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: Curran Associates Inc., 2012. 1097−1105 [5] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [6] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [7] Chung J, Gulcehre C, Cho K H, Bengio Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv: 1412.3555, 2014. [8] Vaswani A, Shazeer N, Parmar N, Uszkoreit U, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6000−6010 [9] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA, 2015. [10] Gehring J, Auli M, Grangier D, Yarats D, Dauphin Y N. Convolutional sequence to sequence learning. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: JMLR.org, 2017. 1243−1252 [11] Jozefowicz R, Vinyals O, Schuster M, Shazeer N, Wu Y H. Exploring the limits of language modeling. arXiv preprint arXiv: 1602.02410, 2016. [12] Luong T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: The Association for Computational Linguistics, 2015. 1412−1421 [13] Devlin J, Chang M W, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, Minnesota, USA: Association for Computational Linguistics, 2018. 4171−4186 [14] Brown T B, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al. Language models are few-shot learners. In: Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems. 2020. [15] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event, Austria: OpenReview.net, 2020. [16] Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 213−229 [17] Han K, Wang Y H, Chen H T, Chen X H, Guo J Y, Liu Z H, et al. A survey on vision transformer. IEEE Transactions on Pattern Analysis and Machine Intelligence, DOI: 10.1109/TPAMI.2022.3152247 [18] Liu Y, Zhang Y, Wang Y X, Hou F, Yuan J, Tian J, et al. A survey of visual transformers. arXiv preprint arXiv: 2111.06091, 2021. [19] Khan S, Naseer M, Hayat M, Zamir S W, Khan, F S, Shah M. Transformers in vision: A survey. arXiv preprint arXiv: 2101.01169, 2021. [20] Selva J, Johansen A S, Escalera S, Nasrollahi K, Moeslund T B, Clapés A. Video transformers: A survey. arXiv preprint arXiv: 2201.05991, 2022. [21] Shamshad F, Khan S, Zamir S W, Khan M H, Hayat M, Khan F S, et al. Transformers in medical imaging: A survey. arXiv preprint arXiv: 2201.09873, 2022. [22] Wang W H, Xie E Z, Li X, Fan D P, Song K T, Liang D, et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 548−558 [23] Liu Z, Lin Y T, Cao Y, Hu H, Wei Y X, Zhang Z, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 9992−10002 [24] Zhu X Z, Su W J, Lu L W, Li B, Wang X G, Dai J F. Deformable DETR: Deformable transformers for end-to-end object detection. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event, Austria: OpenReview.net, 2021. [25] Xie E Z, Wang W H, Yu Z D, Anandkumar A, Alvarez J M, Luo P. SegFormer: Simple and efficient design for semantic segmentation with transformers. arXiv preprint arXiv: 2105.15203, 2021. [26] Cheng B W, Misra I, Schwing A G, Kirillov A, Girdhar R. Masked-attention mask transformer for universal image segmentation. arXiv preprint arXiv: 2112.01527, 2021. [27] Zhou L W, Zhou Y B, Corso J J, Socher R, Xiong C M. End-to-end dense video captioning with masked transformer. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8739−8748 [28] Zeng Y H, Fu J L, Chao H Y. Learning joint spatial-temporal transformations for video inpainting. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 528−543 [29] Jiang Y F, Chang S Y, Wang Z Y. TransGAN: Two transformers can make one strong gan. arXiv preprint arXiv: 2102.07074, 2021. [30] Zhao H, Jiang L, Jia J, Torr P H, Koltun V. Point transformer. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 16259−16268 [31] Guo M H, Cai J X, Liu Z N, Mu T J, Martin R R, Hu S M. PCT: Point cloud transformer. Computational Visual Media, 2021, 7(2): 187-199 doi: 10.1007/s41095-021-0229-5 [32] Shen Z R, Zhang M Y, Zhao H Y, Yi S, Li H S. Efficient attention: Attention with linear complexities. In: Proceedings of the 2021 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Waikoloa, USA: IEEE, 2021. 3530−3538 [33] Katharopoulos A, Vyas A, Pappas N, François F. Transformers are rNNS: Fast autoregressive transformers with linear attention. In: Proceedings of the 37th International Conference on Machine Learning. PMLR, 2020. 5156−5165 [34] Guo J Y, Han K, Wu H, Xu C, Tang Y H, Xu C J, et al. CMT: Convolutional neural networks meet vision transformers. arXiv preprint arXiv: 2107.06263, 2021. [35] Xiao T, Singh M, Mintun E, Darrell T, Dollár P, Girshick R. Early convolutions help transformers see better. In: Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021). 2021. [36] Kolesnikov A, Beyer L, Zhai X H, Puigcerver J, Yung J, Gelly S, et al. Big transfer (BiT): General visual representation learning. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 491−507 [37] Mahajan D, Girshick R, Ramanathan V, He K M, Paluri M, Li Y X, et al. Exploring the limits of weakly supervised pretraining. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 185−201 [38] Touvron H, Vedaldi A, Douze M, Jégou H. Fixing the train-test resolution discrepancy. In: Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019). Vancouver, Canada, 2019. 8250−8260 [39] Xie Q Z, Luong M T, Hovy E, Le Q V. Self-training with noisy student improves ImageNet classification. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 10684−10695 [40] Ba J L, Kiros J R, Hinton G E. Layer normalization. arXiv preprint arXiv: 1607.06450, 2016. [41] Kim Y, Denton C, Hoang L, Rush A M. Structured attention networks. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: OpenReview.net, 2017. [42] Buades A, Coll B, Morel J M. A non-local algorithm for image denoising. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR′′05). San Diego, USA: IEEE, 2005. 60−65 [43] Wang X L, Girshick R, Gupta A, He K M. Non-local neural networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7794−7803 [44] Han Q, Fan Z J, Dai Q, Sun L Cheng M M, Liu J Y, et al. Demystifying local vision transformer: Sparse connectivity, weight sharing, and dynamic weight. arXiv preprint arXiv: 2106.04263, 2021. [45] Chen L C, Papandreou G, Kokkinos I, Murphy K, Yuille A L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848 doi: 10.1109/TPAMI.2017.2699184 [46] De Brabandere B, Jia X, Tuytelaars T, Van Gool L. Dynamic filter networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc., 2016. 667−675 [47] Islam A, Jia S, Bruce N D B. How much position information do convolutional neural networks encode? In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: OpenReview.net, 2020. [48] Tay Y, Dehghani M, Bahri D, Metzler D. Efficient transformers: A survey. arXiv preprint arXiv: 2009.06732, 2020. [49] Child R, Gray S, Radford A, Sutskever I. Generating long sequences with sparse transformers. arXiv preprint arXiv: 1904.10509, 2019. [50] Kitaev N, Kaiser L, Levskaya A. Reformer: The efficient transformer. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: OpenReview.net, 2020. [51] Rao Y M, Zhao W L, Liu B L, Lu J W, Zhou J, Hsieh C J. DynamicViT: Efficient vision transformers with dynamic token sparsification. arXiv preprint arXiv: 2106.02034, 2021. [52] Wang W X, Yao L, Chen L, Lin B B, Cai D, He X F, et al. CrossFormer: A versatile vision transformer hinging on cross-scale attention. arXiv preprint arXiv: 2108.00154, 2021. [53] Zhang Q L, Yang B B. ResT: An efficient transformer for visual recognition. arXiv preprint arXiv: 2105.13677, 2021. [54] Choromanski K M, Likhosherstov V, Dohan D, Song X Y, Gane A, Sarlás T, et al. Rethinking attention with performers. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event, Austria: OpenReview.net, 2021. [55] Tsai Y H H, Bai S J, Yamada M, Morency L P, Salakhutdinov R. Transformer dissection: An unified understanding for transformer$'$s attention via the lens of kernel. arXiv preprint arXiv: 1908.11775, 2019. [56] Zhai S F, Talbott W, Srivastava N, Huang C, Goh H, Zhang R X, et al. An attention free transformer. arXiv preprint arXiv: 2015.14103, 2021. [57] Lu J C, Yao J H, Zhang J G, Zhu X T, Xu H, Gao W G, et al. SOFT: Softmax-free transformer with linear complexity. In: Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021). 2021. [58] Touvron H, Cord M, Douze M, Francisco M, Sablayrolles A, Jégou H. Training data-efficient image transformers & distillation through attention. In: Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. 10347−10357 [59] Zhou D Q, Shi Y J, Kang B Y, Yu W H, Jiang Z H, Li Y, et al. Refiner: Refining self-attention for vision transformers. arXiv preprint arXiv: 2106.03714, 2021. [60] d′′Ascoli S, Touvron H, Leavitt M L, Morcos A S, Biroli G, Sagun L. ConViT: Improving vision transformers with soft convolutional inductive biases. In: Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. 2286−2296 [61] Li Y W, Zhang K, Cao J Z, Timofte R, Van Gool L. LocalViT: Bringing locality to vision transformers. arXiv preprint arXiv: 2104.05707, 2021. [62] Lin T Y, Dollár P, Girshick R, He K M, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 936-−944 [63] Chen C F, Fan Q F, Panda R. CrossViT: Cross-attention multi-scale vision transformer for image classification. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 347−356 [64] Gong C Y, Wang D L, Li M, Chandra V, Liu Q. Improve vision transformers training by suppressing over-smoothing. arXiv preprint arXiv: 2104.12753, 2021. [65] Yun S, Han D, Chun S, Oh S J, Yoo Y, Choe J. CutMix: Regularization strategy to train strong classifiers with localizable features. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 6022−6031 [66] Zhou D Q, Kang B Y, Jin X J, Yang L J, Lian X C, Hou Q B, et al. DeepViT: Towards deeper vision transformer. arXiv preprint arXiv: 2103.11886, 2021. [67] Tay Y, Bahri D, Metzler D, Juan D C, Zhao Z, Zheng C. Synthesizer: Rethinking self-attention for transformer models. In: Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. 10183−10192 [68] Yuan L, Hou Q B, Jiang Z H, Feng J S, Yan S C. VOLO: Vision outlooker for visual recognition. arXiv preprint arXiv: 2106.13112, 2021. [69] Mihcak M K, Kozintsev I, Ramchandran K, Moulin P. Low-complexity image denoising based on statistical modeling of wavelet coefficients. IEEE Signal Processing Letters, 1999, 6(12): 300-303 doi: 10.1109/97.803428 [70] He K M, Sun J, Tang X O. Guided image filtering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(6): 1397-1409 doi: 10.1109/TPAMI.2012.213 [71] Criminisi A, Pérez P, Toyama K. Region filling and object removal by exemplar-based image inpainting. IEEE Transactions on Image Processing, 2004, 13(9): 1200-1212 doi: 10.1109/TIP.2004.833105 [72] Raghu M, Unterthiner T, Kornblith S, Zhang C Y, Dosovitskiy A. Do vision transformers see like convolutional neural networks? In: Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021). 2021. [73] Yuan K, Guo S P, Liu Z W, Zhou A J, Yu F W, Wu W. Incorporating convolution designs into visual transformers. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 559−568 [74] Chen Y P, Dai X Y, Chen D D, Liu M C, Dong X Y, Yuan L, et al. Mobile-former: Bridging MobileNet and transformer. arXiv preprint arXiv: 2108.05895, 2021. [75] Mehta S, Rastegari M. MobileViT: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv preprint arXiv: 2110.02178, 2021. [76] Peng Z L, Huang W, Gu S Z, Xie L X, Wang Y W, Jiao J B, et al. Conformer: Local features coupling global representations for visual recognition. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 357−366 [77] Yan H, Deng B C, Li X N, Qiu X P. TENER: Adapting transformer encoder for named entity recognition. arXiv preprint arXiv: 1911.04474, 2019. [78] Shaw P, Uszkoreit J, Vaswani A. Self-attention with relative position representations. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New Orleans, USA: Association for Computational Linguistics, 2018. 464−468 [79] Dai Z H, Yang Z L, Yang Y M, Carbonell J G, Le Q V, Salakhutdinov R. Transformer-XL: Attentive language models beyond a fixed-length context. In: Proceedings of the 57th Conference of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 2978−2988 [80] Huang Z H, Liang D, Xu P, Xiang B. Improve transformer models with better relative position embeddings. In: Proceedings of the Findings of the Association for Computational Linguistics: EMNLP. Association for Computational Linguistics, 2020. 3327−3335 [81] Parmar N, Ramachandran P, Vaswani A, Bello I, Levskaya A, Shlens J. Stand-alone self-attention in vision models. In: Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems. Vancouver, Canada, 2019. 68−80 [82] Wu K, Peng H W, Chen M H, Fu J L, Chao H Y. Rethinking and improving relative position encoding for vision transformer. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 10013−10021 [83] Deng J, Dong W, Socher R, Li L J, Li K, Li F F. ImageNet: A large-scale hierarchical image database. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 248−255 [84] Zhao Y C, Wang G T, Tang C X, Luo C, Zeng W J, Zha Z J. A battle of network structures: An empirical study of CNN, transformer, and MLP. arXiv preprint arXiv: 2108.13002, 2021. [85] Tolstikhin I, Houlsby N, Kolesnikov A, Beyer L, Zhai X H, Unterthiner T, et al. MLP-Mixer: An all-MLP architecture for vision. arXiv preprint arXiv: 2105.01601, 2021. [86] Touvron H, Bojanowski P, Caron M, Cord M, El-Nouby A, Grave E, et al. ResMLP: Feedforward networks for image classification with data-efficient training. arXiv preprint arXiv: 2105.03404, 2021. [87] Liu H X, Dai Z H, So D R, Le Q V. Pay attention to MLPs. In: Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021). 2021. [88] Chen S F, Xie E Z, Ge C J, Chen R J, Liang D, Luo P. CycleMLP: A MLP-like architecture for dense prediction. arXiv preprint arXiv: 2107.10224, 2021. [89] Ng D, Chen Y Q, Tian B, Fu Q, Chng E S. ConvMixer: Feature interactive convolution with curriculum learning for small footprint and noisy far-field keyword spotting. arXiv preprint arXiv: 2201.05863, 2022. [90] Yu W H, Luo M, Zhou P, Si C Y, Zhou Y C, Wang X C, et al. MetaFormer is actually what you need for vision. arXiv preprint arXiv: 2111.11418, 2021. [91] Jeevan P, Sethi A. Convolutional xformers for vision. arXiv preprint arXiv: 2201.10271, 2022. [92] Liu Z, Mao H Z, Wu C Y, Feichtenhofer C, Darrell T, Xie S N. A ConvNet for the 2020s. arXiv preprint arXiv: 2201.03545, 2022. [93] Ding X H, Zhang X Y, Zhou Y Z, Han J G, Ding G G, Sun J. Scaling up your kernels to 31x31: Revisiting large kernel design in CNNs. arXiv preprint arXiv: 2203.06717, 2022. [94] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA, 2014. [95] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015. Montreal, Canada, 2015. 91−99 [96] Chen H, Sun K Y, Tian Z, Shen C H, Huang Y M, Yan Y L. BlendMask: Top-down meets bottom-up for instance segmentation. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 8570−8578 [97] Wang X L, Zhang R F, Kong T, Li L, Shen C H. SOLOv2: Dynamic and fast instance segmentation. In: Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020). Vancouver, Canada, 2020. [98] Dong B, Zeng F G, Wang T C, Zhang X Y, Wei Y C. SOLQ: Segmenting objects by learning queries. In: Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021). 2021. [99] He K M, Gkioxari G, Dollár P, Girshick R B. Mask R-CNN. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2980−2988 [100] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, et al. SSD: Single shot MultiBox detector. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 21−37 [101] Law H, Deng J. CornerNet: Detecting objects as paired keypoints. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 765−781 [102] Zhou X Y, Wang D Q, Krähenbühl P. Objects as points. arXiv preprint arXiv: 1904.07850, 2019. [103] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 740−755 [104] Lin T Y, Goyal P, Girshick R, He K M, Dollár P. Focal loss for dense object detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2999−3007 [105] Cai Z W, Vasconcelos N. Cascade R-CNN: Delving into high quality object detection. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6154−6162 [106] Zhang S F, Chi C, Yao Y Q, Lei Z, Li S Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 9756−9765 [107] Chen Y H, Zhang Z, Cao Y, Wang L W, Lin S, Hu H. RepPoints v2: Verification meets regression for object detection. In: Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020. 2020. [108] Sun P Z, Zhang R F, Jiang Y, Kong T, Xu C F, Zhan W, et al. Sparse R-CNN: End-to-end object detection with learnable proposals. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 14449−14458 [109] Yao Z Y, Ai J B, Li B X, Zhang C. Efficient DETR: Improving end-to-end object detector with dense prior. arXiv preprint arXiv: 2104.01318, 2021. [110] Gao P, Zheng M H, Wang X G, Dai J F, Li H S. Fast convergence of DETR with spatially modulated co-attention. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 3601−3610 [111] Meng D P, Chen X K, Fan Z J, Zeng G, Li H Q, Yuan Y H, et al. Conditional DETR for fast training convergence. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 3631−3640 [112] Dai Z G, Cai B L, Lin Y G, Chen J Y. UP-DETR: Unsupervised pre-training for object detection with transformers. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 1601−1610 [113] Zheng M H, Gao P, Zhang R R, Li K C, Wang X G, Li H S, et al. End-to-end object detection with adaptive clustering transformer. arXiv preprint arXiv: 2011.09315, 2020. [114] Fang Y X, Liao B C, Wang X G, Fang J M, Qi J Y, Wu R, et al. You only look at one sequence: Rethinking transformer in vision through object detection. arXiv preprint arXiv: 2106.00666, 2021. [115] Sun Z Q, Cao S C, Yang Y M, Kitani K. Rethinking transformer-based set prediction for object detection. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 3591−3600 [116] Tian Z, Shen C H, Chen H, He T. FCOS: Fully convolutional one-stage object detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 9626−9635 [117] Beal J, Kim E, Tzeng E, Park D H, Zhai A, Kislyuk D. Toward transformer-based object detection. arXiv preprint arXiv: 2012.09958, 2020. [118] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1440−1448 [119] Minaee S, Boykov Y Y, Porikli F, Plaza A J, Kehtarnavaz N, Terzopoulos D. Image segmentation using deep learning: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, DOI: 10.1109/TPAMI.2021.3059968 [120] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 3431−3440 [121] Zheng S X, Lu J C, Zhao H S, Zhu X T, Luo Z K, Wang Y B, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 6877−6886 [122] Xiao T T, Liu Y C, Zhou B L, Jiang Y N, Sun J. Unified perceptual parsing for scene understanding. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 432−448 [123] Wang H Y, Zhu Y K, Adam H, Yuille A, Chen L C. MaX-DeepLab: End-to-end panoptic segmentation with mask transformers. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 5459−5470 [124] Strudel R, Garcia R, Laptev I, Schmid C. Segmenter: Transformer for semantic segmentation. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 7242−7252 [125] Cheng B W, Schwing A, Kirillov A. Per-pixel classification is not all you need for semantic segmentation. In: Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021). 2021. [126] Fang Y X, Yang S S, Wang X G, Li Y, Fang C, Shan Y, et al. QueryInst: Parallelly supervised mask query for instance segmentation. arXiv preprint arXiv: 2105.01928, 2021. [127] Hu J, Cao L J, Yan L, Zhang S C, Wang Y, Li K, et al. ISTR: End-to-end instance segmentation with transformers. arXiv preprint arXiv: 2105.00637, 2021. [128] Li Z Q, Wang W H, Xie E Z, Yu Z D, Anandkumar A, Alvarez J M, et al. Panoptic SegFormer: Delving deeper into panoptic segmentation with transformers. arXiv preprint arXiv: 2109.03814, 2022. -

 下载:
下载:












计量
- 文章访问数: 8977
- HTML全文浏览量: 7380
- PDF下载量: 6660
- 被引次数: 0
