

Analysis and Application of Bounded Confidence Opinion Dynamics With Universal Gravitation-like
-
摘要: 在社会网络中, Hegselmann-Krause模型描述了置信阈值内不同邻居对个体的观点影响权重都相同且邻居对个体的吸引力与它们的观点差值成正比, 这是不切实际的. 为了克服经典Hegselmann-Krause模型的不足, 提出具有类万有引力的有界置信观点动力学模型, 描述个体观点的更新依赖于观点之间的差值和邻居的权威性, 且不同邻居对个体的观点影响权重不同. 根据置信矩阵的性质证明观点的收敛性, 并分析具有衰减置信阈值的观点动力学行为, 给出观点收敛速率的显式解. 最后, 利用提出的观点动力学模型, 研究社会心理学中的“权威效应”和“非零和效应”. 仿真结果表明, 邻居的权威性有利于观点达成一致.Abstract: In the social networks, the Hegselmann-Krause model describes that the different neighbors within the confidence threshold have the same influence weight on the individual's opinion, and the attractiveness of neighbors to the individual is proportional to the opinion distance, which is unrealistic. In order to overcome the shortcoming of the classical Hegselmann-Krause model, we propose a bounded confidence opinion dynamics model with universal gravitation-like in this paper, which captures the update of the individual opinion depending on both the opinion distance and the authority of neighbors, and it is shown that different neighbors have different influence weights on individual opinions. The convergence of opinions is proved in terms of the property of confidence matrix, and moreover, the dynamic behavior of the opinion with decaying confidence threshold is analyzed and the explicit solution of the opinion convergence rate is given. Finally, by employing our proposed opinion dynamics model, we study the authority effect and the non-zero-sum effect in social psychology. Simulation analyses reveal that the authority of the neighbor is beneficial to opinion achieving consensus.
-
Key words:
- Opinion dynamics /
- universal gravitation-like /
- bounded confidence /
- social networks /
- convergence
-
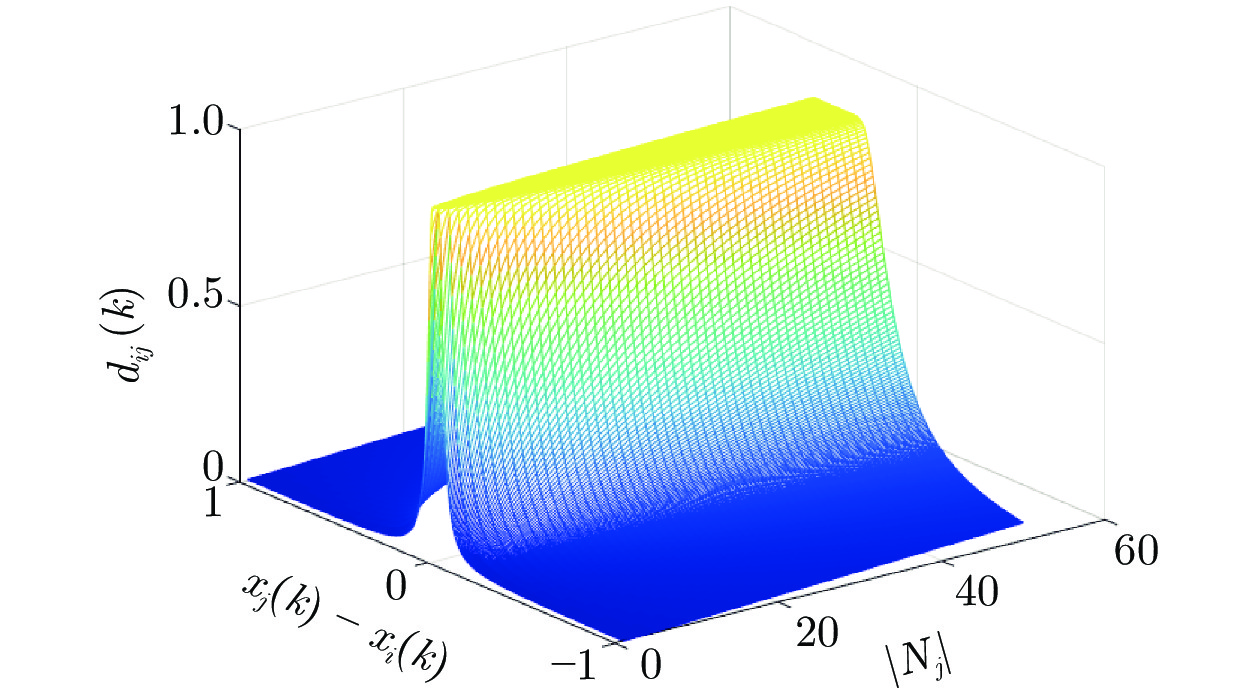
图 1 $d_{ij}(k)$关于$\vert N_j\vert$和$x_j(k)-x_i(k)$的函数图
Fig. 1 The trajectories of $d_{ij}(k)$ with respect to $\vert N_j\vert$ and $x_j(k)-x_i(k)$
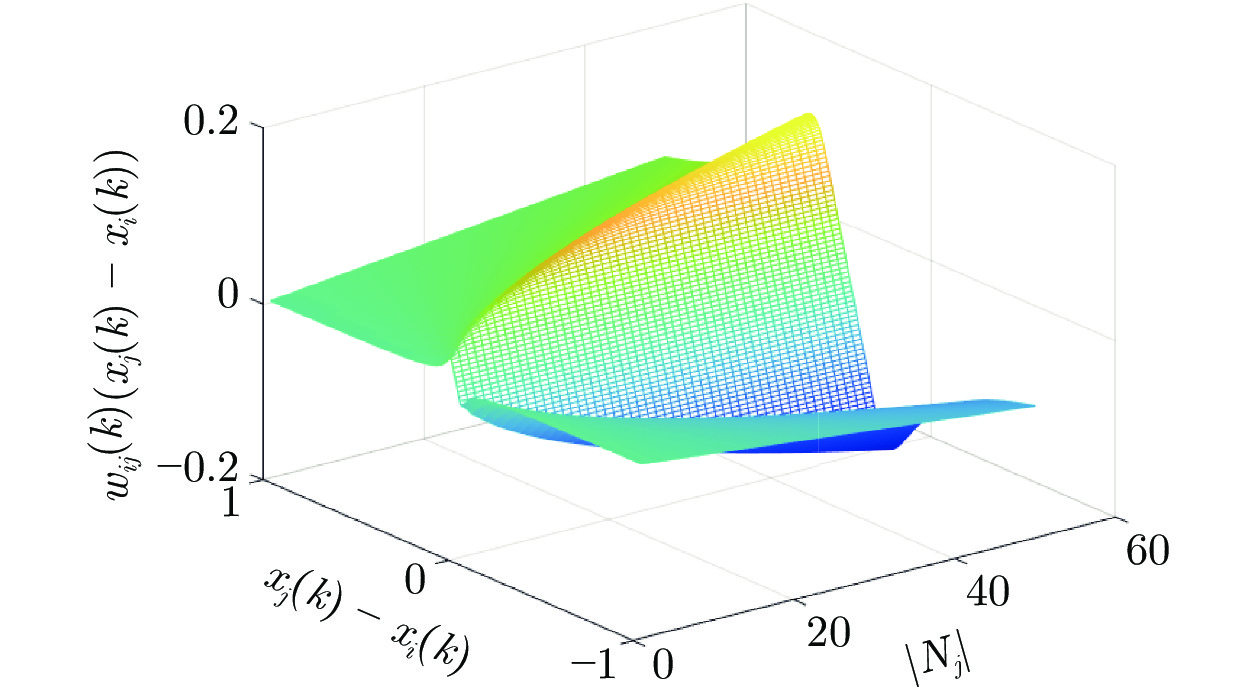
图 2 个体$j$对个体$i$观点的影响
Fig. 2 The influence of individual $j$ on the opinion of individual $i$
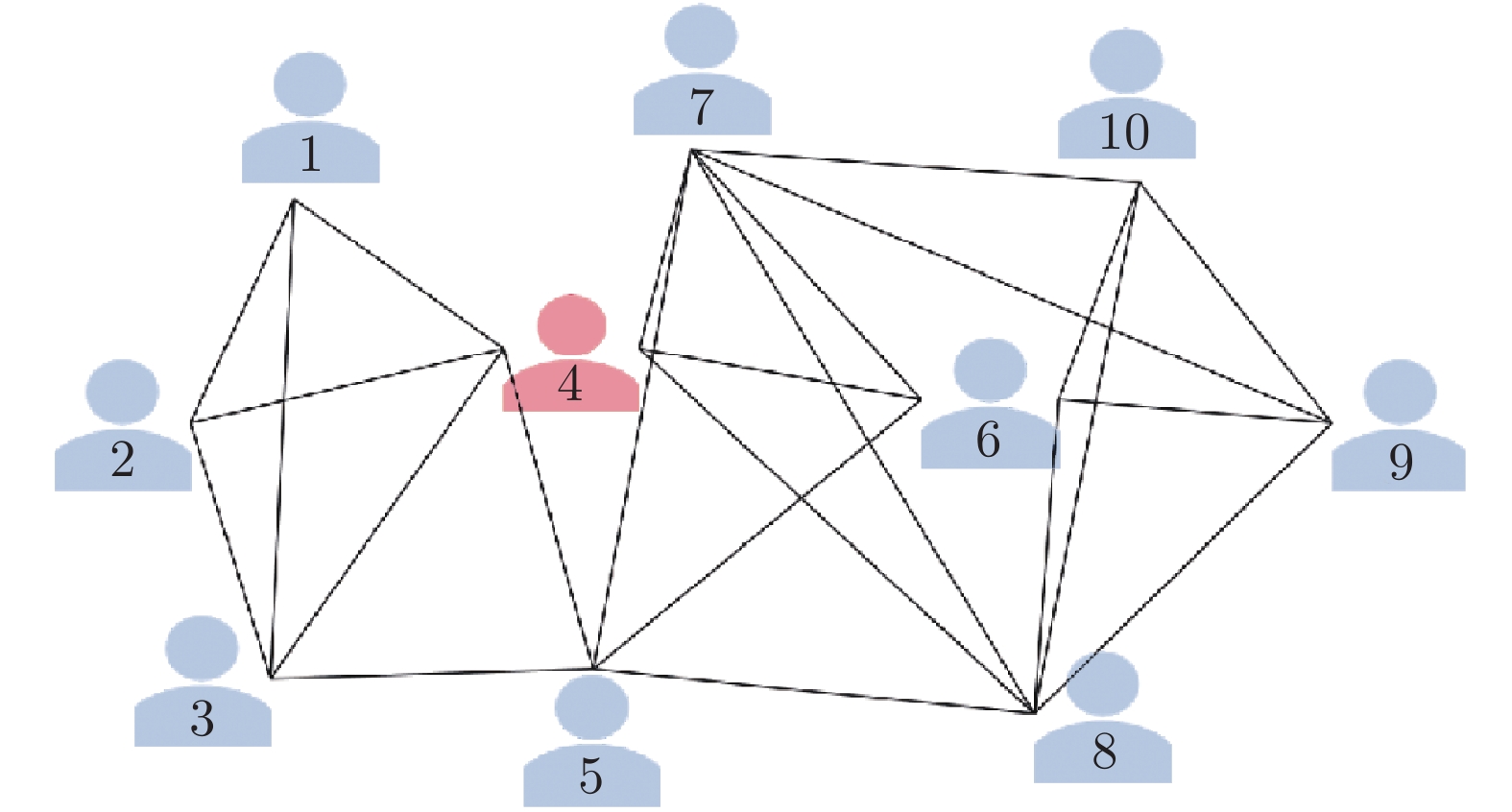
图 3 网络拓扑结构 (个体4为权威个体)
Fig. 3 Network structure (individual 4 is the authoritative individual)

图 4 权威效应 (个体4为权威个体)
Fig. 4 Authority effect (individual 4 is the authoritative individual)
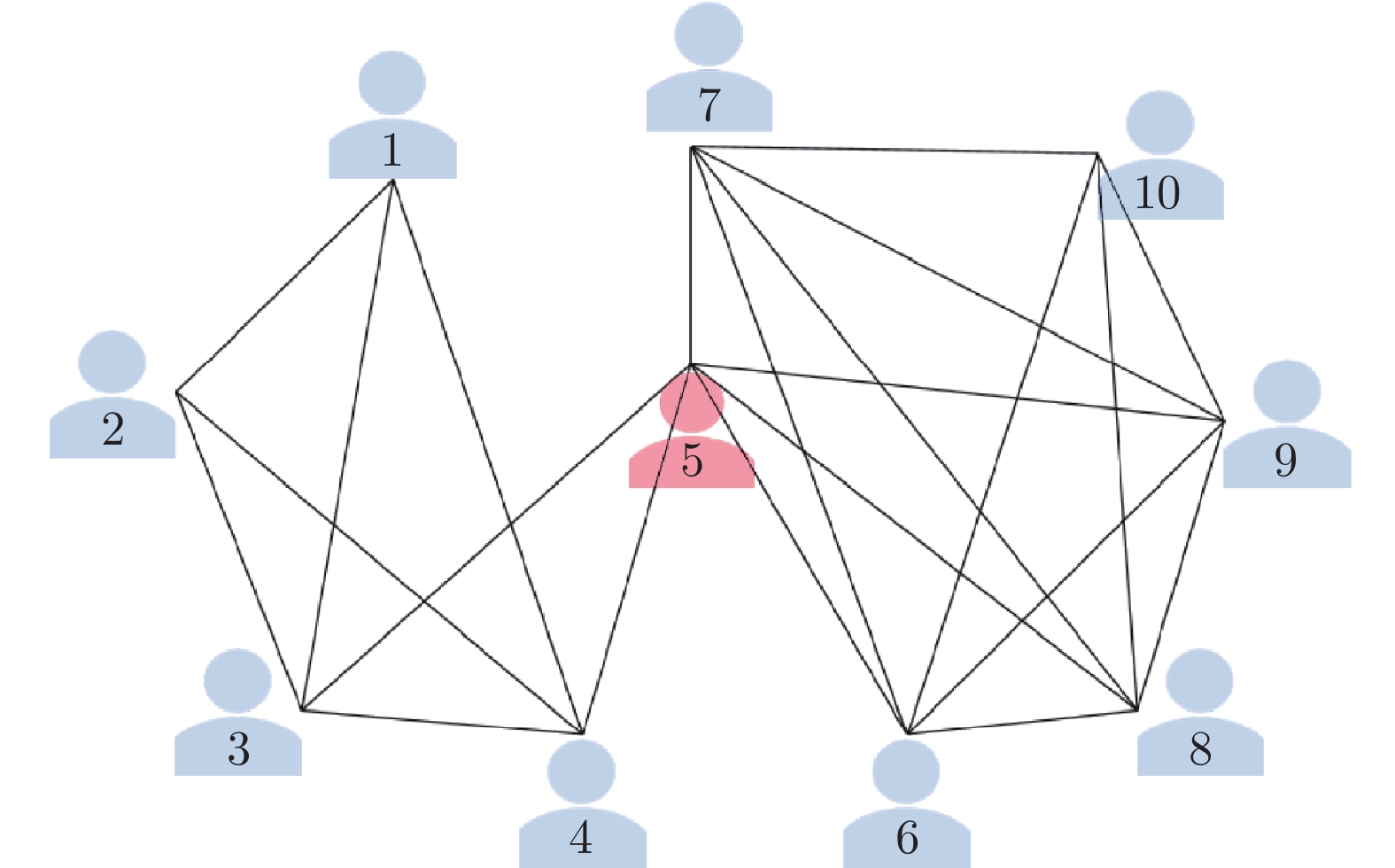
图 5 网络拓扑结构 (个体5为权威个体)
Fig. 5 Network structure (individual 5 is the authoritative individual)
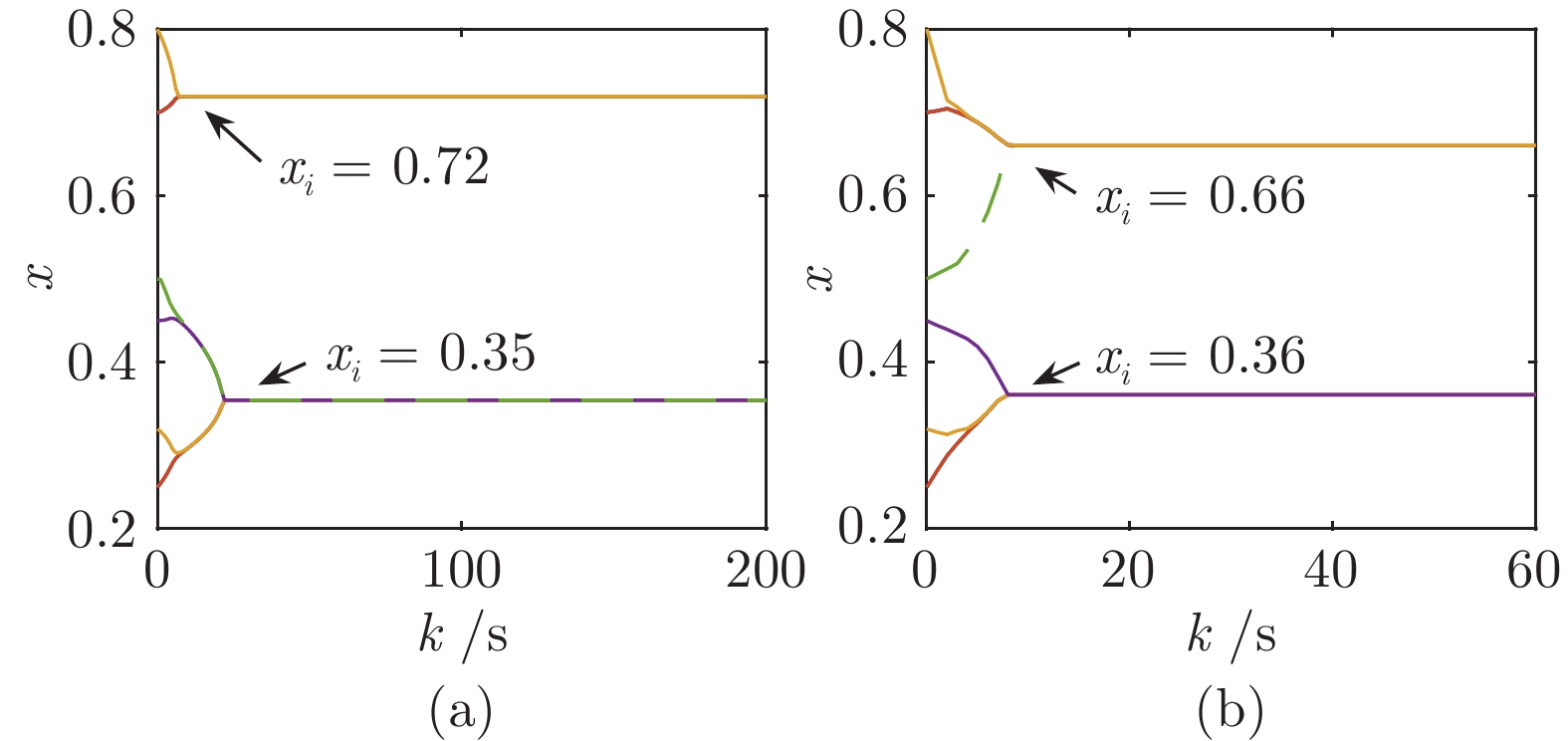
图 6 权威效应 (个体5为权威个体)
Fig. 6 Authority effect (individual 5 is the authoritative individual)
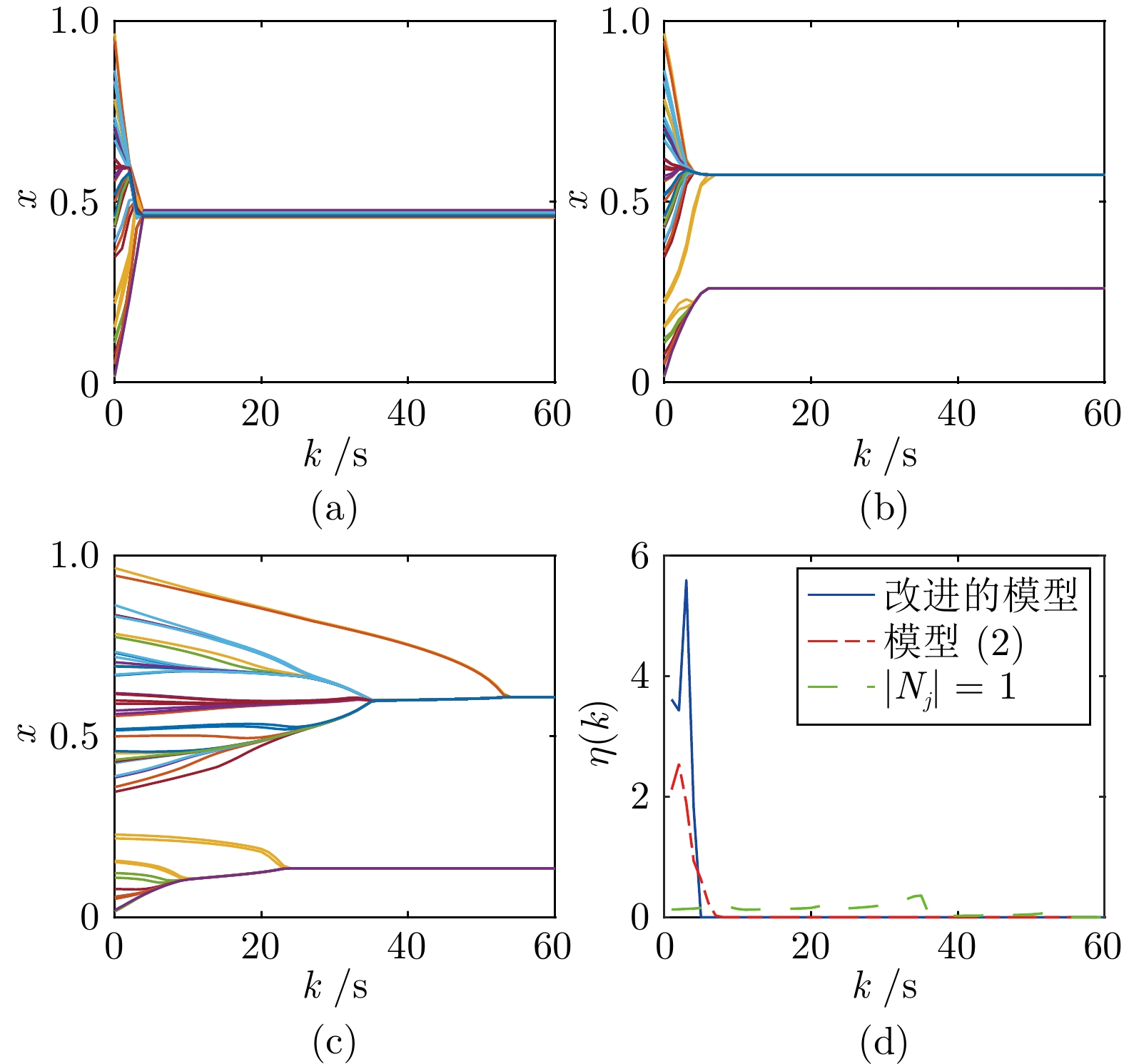
图 8 初值为均匀分布时的观点演化
Fig. 8 Opinion evolution when the initial value is uniformly distributed
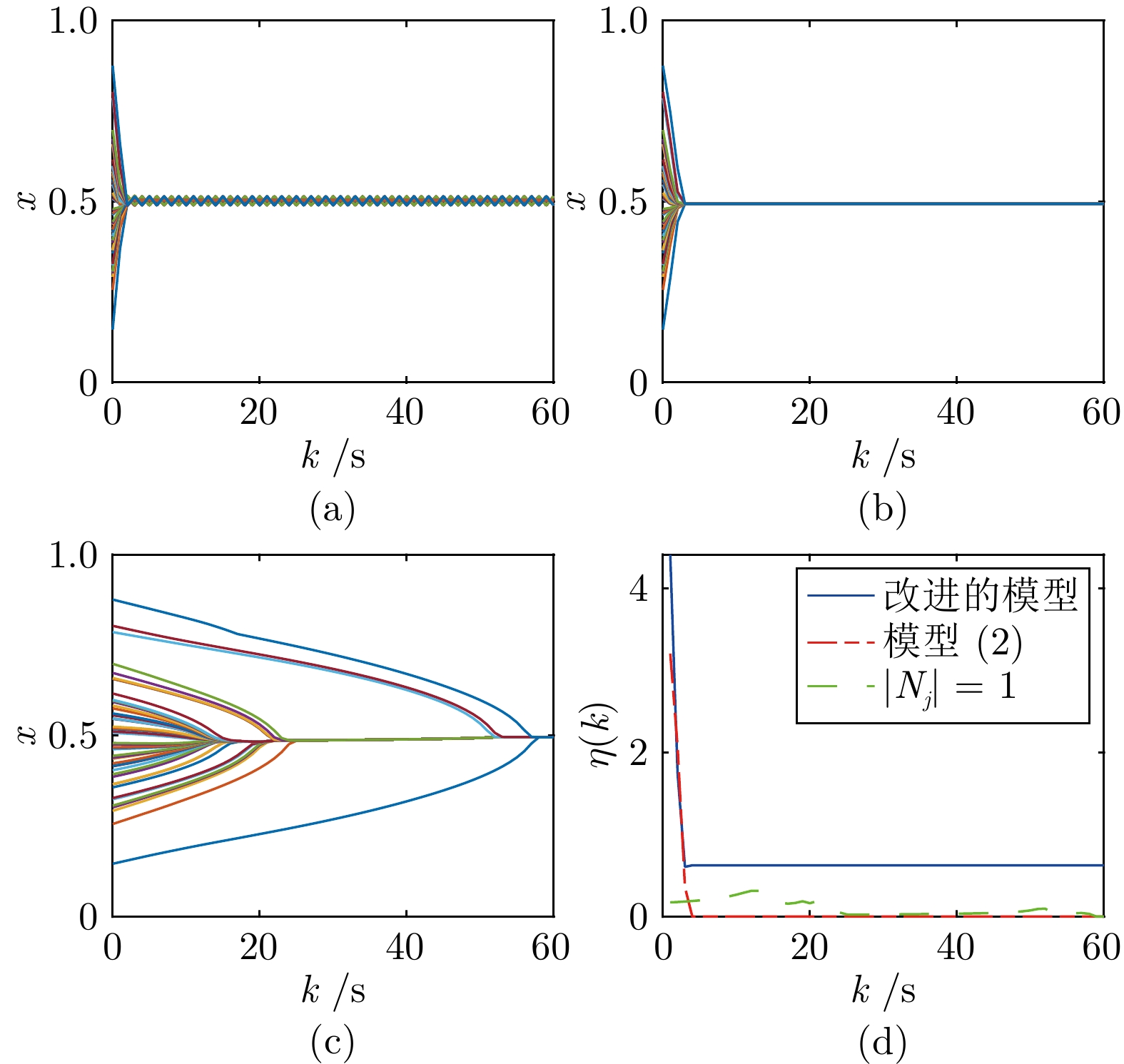
图 9 初值为正态分布时的观点演化
Fig. 9 Opinion evolution when the initial value is normally distributed
-
[1] Zhou B, Lin Z. Consensus of high-order multi-agent systems with large input and communication delays. Automatica, 2014, 50: 452-464 doi: 10.1016/j.automatica.2013.12.006 [2] 陈世明, 邵赛, 姜根兰. 基于事件触发二阶多智能体系统的固定时间比例一致性. 自动化学报, 2022, 48(1): 261-270Chen Shi-Ming, Shao Sai, Jiang Gen-Lan. Distributed event-triggered fixed-time scaled consensus control for second-order multi-agent systems. Acta Automatica Sinica, 2022, 48(1): 261-270 [3] Zhou B. Consensus of delayed multi-agent systems by reduced-order observer-based truncated predictor feedback protocols. IET Control Theory & Applications, 2014, 8(16): 1741-1751 [4] 王龙, 田野, 杜金铭. 社会网络上的观念动力学. 中国科学: 信息科学, 2018, 48(1): 3-23 doi: 10.1360/N112017-00096Wang Long, Tian Ye, Du Jin-Ming. Opinion dynamics in social networks. Scientia Sinica: Informationis, 2018, 48(1): 3-23 doi: 10.1360/N112017-00096 [5] Ghaderi J, Srikant R. Opinion dynamics in social networks with stubborn agents: Equilibrium and convergence rate. Automatica, 2014, 50(12): 3209-3215 doi: 10.1016/j.automatica.2014.10.034 [6] Xia W, Ye M, Liu J, Cao M, Sun X M. Analysis of a nonlinear opinion dynamics model with biased assimilation. Automatica, 2020, 120: 109113 doi: 10.1016/j.automatica.2020.109113 [7] Liu C, Wu X, Niu R, Aziz-Alaoui M A, Lü J. Opinion diffusion in two-layer interconnected networks. IEEE Transactions on Circuits and Systems I: Regular Papers, 2021, 68(9): 3772-3783 doi: 10.1109/TCSI.2021.3093537 [8] Ye M, Qin Y, Govaert A, Anderson B D, Cao M. An influence network model to study discrepancies in expressed and private opinions. Automatica, 2019, 107: 371-381 doi: 10.1016/j.automatica.2019.05.059 [9] 刘青松, 李明鹏, 柴利. 具有遗忘群体的社会网络多维观点动力学分析与应用. 自动化学报, 2022, DOI: 10.16383/j.aas.c210091Liu Qing-Song, Li Ming-Peng, Chai Li, Analysis and application of multidimensional opinion dynamics on social networks with oblivion individuals. Acta Automatica Sinica, 2022, DOI: 10.16383/j.aas.c210091 [10] Hou J, Li W, Jiang M. Opinion dynamics in modified expressed and private model with bounded confidence. Physica A: Statistical Mechanics and its Applications, 2021, 574: 125968 doi: 10.1016/j.physa.2021.125968 [11] 郑维, 张志明, 刘和鑫, 张明泉, 孙富春. 基于线性变换的领导-跟随多智能体系统动态反馈均方一致性控制. 自动化学报, 2021, DOI: 10.16383/j.aas.c200850Zheng Wei, Zhang Zhi-Ming, Liu He-Xin, Zhang Ming-Quan, Sun Fu-Chun. Dynamic feedback mean square consensus control based on linear transformation for leader-follower multi-agent systems. Acta Automatica Sinica, 2021, DOI: 10.16383/j.aas.c200850 [12] Yi J W, Chai L, Zhang J. Average consensus by graph filtering: new approach, explicit convergence rate, and optimal design. IEEE Transactions on Automatic Control, 2020, 65(1): 191-206 doi: 10.1109/TAC.2019.2907410 [13] Liu Q, Zhou B. Consensus of discrete-time multiagent systems with state, input, and communication delays. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 50(11): 4425-4437 doi: 10.1109/TSMC.2018.2852944 [14] Liu Q. Pseudo-predictor feedback control for multiagent systems with both state and input delays. IEEE/CAA Journal of Automatica Sinica, 2021, 8(11): 1827-1836 doi: 10.1109/JAS.2021.1004180 [15] French Jr J R. A formal theory of social power. Psychological Review, 1956, 63(3): 181-194 doi: 10.1037/h0046123 [16] DeGroot M H. Reaching a consensus. Journal of the American Statistical Association, 1974, 69(345): 118-121 doi: 10.1080/01621459.1974.10480137 [17] Friedkin N, Johnsen E. Social influence networks and opinion change. Advances Group Processes, 1999, 16: 1-29 [18] Parsegov S E, Proskurnikov A V, Tempo R, Friedkin N E. Novel multidimensional models of opinion dynamics in social networks. IEEE Transactions on Automatic Control, 2017, 62(5): 2270-2285 doi: 10.1109/TAC.2016.2613905 [19] Tian Y, Wang L. Opinion dynamics in social networks with stubborn agents: An issue-based perspective. Automatica, 2018, 96: 213-223 doi: 10.1016/j.automatica.2018.06.041 [20] Deffuant G, Neau D, Amblard F, Weisbuch G. Mixing beliefs among interacting agents. Advances in Complex Systems, 2000, 3: 87-98 doi: 10.1142/S0219525900000078 [21] Zhang J, Hong Y. Opinion evolution analysis for short-range and long-range Deffuant–Weisbuch models. Physica A: Statistical Mechanics and its Applications, 2013, 392(21): 5289-5297 doi: 10.1016/j.physa.2013.07.014 [22] Dong Y, Ding Z, Martínez L, Herrera F. Managing consensus based on leadership in opinion dynamics. Information Sciences, 2017, 397: 187-205 [23] Mei W, Friedkin N E, Lewis K, Bullo F. Dynamic models of appraisal networks explaining collective learning. IEEE Transactions on Automatic Control, 2018, 63(9): 2898-2912 doi: 10.1109/TAC.2017.2775963 [24] Hegselmann R, Krause U. Opinion dynamics and bounded confidence models, analysis, and simulation. Journal of Artificial Societies and Social Simulation, 2002, 5(3): 1-33 [25] Bullo F, Cortes J, Martinez S. Distributed Control of Robotic Networks. Princeton: Princeton University Press, 2009. [26] Cody W F. Authoritative effect of FDA regulations. The Business Lawyer, 1969, 24: 479-491 [27] Chen Z, Lan H. Dynamics of public opinion: Diverse media and audiences’ choices. Journal of Artificial Societies and Social Simulation, 2021, 24(2): 1-21 doi: 10.18564/jasss.4518 [28] Canuto C, Fagnani F, Tilli P. An Eulerian approach to the analysis of Krause's consensus models. SIAM Journal on Control and Optimization, 2012, 50(1): 243-265 doi: 10.1137/100793177 [29] Su W, Chen G, Hong Y. Noise leads to quasi-consensus of Hegselmann–Krause opinion dynamics. Automatica, 2017, 85: 448-454 doi: 10.1016/j.automatica.2017.08.008 [30] Yang Y, Dimarogonas D V, Hu X. Opinion consensus of modified Hegselmann–Krause models. Automatica, 2014, 50(2): 622-627 doi: 10.1016/j.automatica.2013.11.031 [31] Haskovec J. A simple proof of asymptotic consensus in the Hegselmann-Krause and Cucker-Smale models with normalization and delay. SIAM Journal on Applied Dynamical Systems, 2021, 20(1): 130-148 doi: 10.1137/20M1341350 [32] Vasca F, Bernardo C, Iervolino R. Practical consensus in bounded confidence opinion dynamics. Automatica, 2021, 129: 109683 doi: 10.1016/j.automatica.2021.109683 [33] Gerrig R J. Psychology and Life (20th Edition). New York: Pearson, 2013. [34] Mei W, Bullo F, Chen G, Hendrickx J, Dörfler F. Rethinking the micro-foundation of opinion dynamics: Rich consequences of the weighted-median mechanism [Online], available: https://arxiv.org//abs/1909.06474, January 26, 2022 [35] Swingle P G, Santi A. Communication in non-zero-sum games. Journal of Personality and Social Psychology, 1972, 23 (1), 54-63 doi: 10.1037/h0032878 [36] Lorenz J. A stabilization theorem for dynamics of continuous opinions. Physica A: Statistical Mechanics and its Applications, 2005, 355(1): 217-223 doi: 10.1016/j.physa.2005.02.086 [37] Morarescu I C, Girard A. Opinion dynamics with decaying confidence: Application to community detection in graphs. IEEE Transactions on Automatic Control, 2011, 56(8): 1862-1873 doi: 10.1109/TAC.2010.2095315 -

 下载:
下载:

计量
- 文章访问数: 948
- HTML全文浏览量: 379
- PDF下载量: 138
- 被引次数: 0
