

Huapu-CP: From Knowledge Graphs to a Data Central-Platform
-
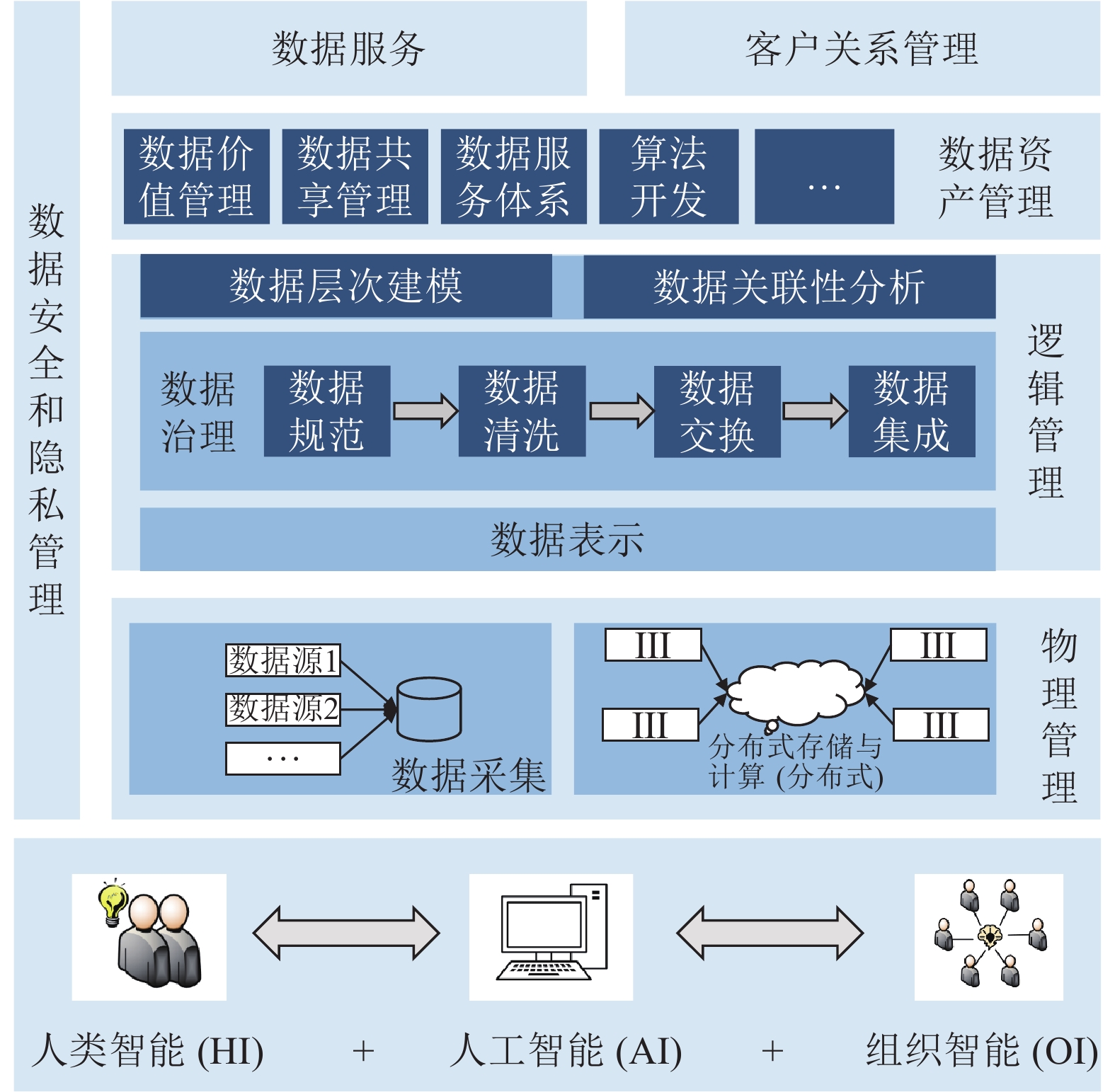
摘要: 针对碎片化的各姓氏家谱数据, 华谱系统通过构建家谱知识图谱的数据中台, 能够解决数据孤岛、烟囱式开发等问题. “数据中台”是一个源自国内的新近技术概念, 在华谱系统建设中, 我们通过家谱知识图谱的构建和应用, 对这个概念进行了正式定义. 基于这个定义和对应的7项核心功能, 本文提出一种用于家谱数据分析的数据中台建设架构Huapu-CP (华谱系统), 并通过该架构详细介绍面向家谱领域的数据中台核心技术, 分析数据中台构建的关键问题.Abstract: With fragmented family tree data, Huapu aims to solve the problems of data islands and chimney development by building a data central-platform based on genealogical knowledge graphs. Data central-platform is a new technology that has recently emerged in China. During the construction of the Huapu system, we started with knowledge graph construction and analytics, and then formulated a formal definition for this technology concept. Based on this definition and its corresponding 7 key components, this paper proposes a Huapu-CP (or Huapu for short) framework for genealogical data analytics and presents the core techniques and key challenges in building such a genealogical data platform.
-
Key words:
- Genealogy /
- data central-platform /
- data governance /
- knowledge graph
-
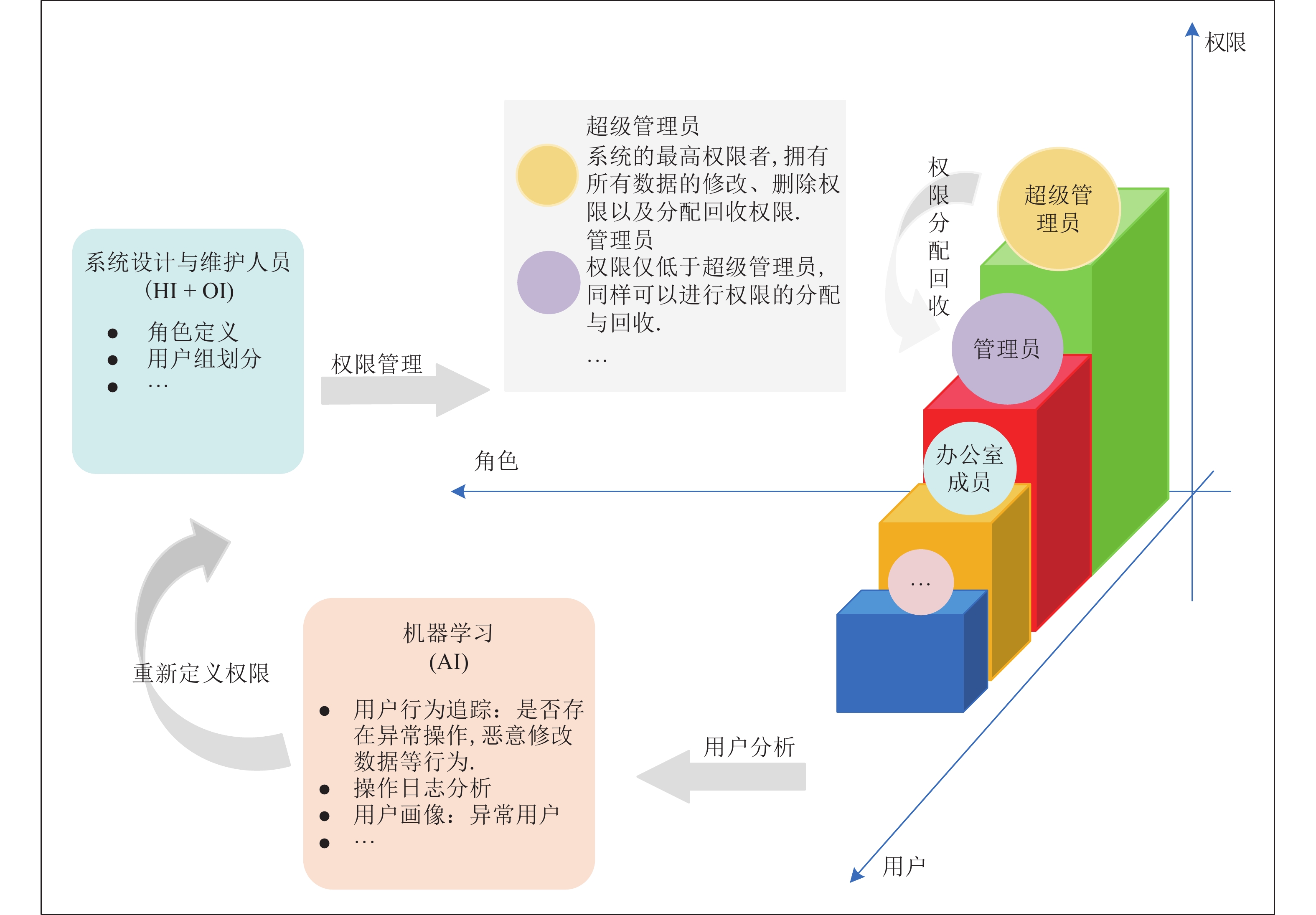
表 1 角色表
Table 1 Role table
角色类型 角色诞生及身份转变方式 普通用户 注册华谱系统的普通用户, 可进行创建家谱、查看公开数据等. 普通家谱成员 普通用户向某一共建家谱申请成为家谱成员, 只拥有针对该家谱的最基本权限, 例如查看该家谱中的基本信息. 家谱共建者 家谱成员向家谱创建者或核心修谱成员申请成为家谱共建者, 拥有上传数据、对本人上传的数据以及其他用户分享的数据拥有基本修改权限. 若涉及家谱主树结构变化, 需经过审核. 数据合作拥有者 包含部分、全部合作拥有者, 家谱成员向数据拥有者申请数据增加、修改等权限, 成为数据合作拥有者. 数据拥有者 家谱成员保存个人家谱数据, 成为数据拥有者, 拥有数据的全部权限, 且在共建家谱中其权限可转让或共享. 核心修谱成员 家谱成员向家谱创建者申请成为核心修谱成员. 拥有对该家谱数据的大部分权限, 包括查看、编辑、审核本家谱所有家谱人物. 不具备指定核心修谱成员、修改家谱名称等少数信息的权限. 家谱创建者 拥有该家谱的所有权限, 可指定每位家谱成员的权限级别.  下载: 导出CSV
下载: 导出CSV
表 2 数据权限表
Table 2 Data authority table
数据类型公开级 相关描述 完全公开10 如公开家谱、百度百科人物;
所有人可进行查看、编辑完全公开9 如公开家谱、百度百科人物;
所有人可进行查看.8 针 对 共
建 家 谱
而 言部分用户可查看 7 部分用户可修改人物信息 6 部分用户可修改人物关系 5 部分用户可删除人物 4 仅数据录入者可修改 3 私有家谱 2 普通管理员可修改查看 1 超级管理员可修改、查看
下载: 导出CSV
-
[1] 陈宁宁. 家谱研究历史现状. 图书馆杂志, 1998, 17(2): 12−1318Chen Ning-Ning. History and current status of genealogical research. Library Journal, 1998, 17(2): 12−1318 [2] Carolina N, Nils G, Hilary C, and Alexander L. Lineage: Visualizing Multivariate Clinical Data in Genealogy Graphs. IEEE Transactions on Visualization and Computer Graphics, 2019, 25(1): 544−554 [3] Hayden E C. Colossal family tree reveals environment's influence on lifespan. Nature, 2018. [4] 湛庐. 家谱中的文献问题. 北京大学学报(哲学社会科学版), 2007, (1): 150−151Zhan Lu. Literature questions in genealogy. Journal of Peking University (Philosophy and Social Sciences), 2007, (1): 150−151 [5] 欧阳康. 大数据与人文社会科学研究的变革与创新. 光明日报, 2016-11-10(016).Ou Yang-Kang. The reform and innovation of big data and humanities and social science research. Guangming Daily, 2016-11-10(016). [6] 孙建军. 大数据时代人文社会科学如何发展. 光明日报, 2014-07-07(011).Sun Jian-Jun. How to develop humanities and social sciences in the age of big data. Guangming Daily, 2014-07-07(011). [7] Wu X D, Chen H H, Wu G Q, et al. Knowledge engineering with big data. IEEE Intelligent Systems, 2015, 30(5): 46−55 [8] Wu X D, Zhu X Q, Wu G Q, Ding W. Data mining with big data. IEEE Transactions on Knowledge and Data Engineering. 2014, 36(1): 97−107. [9] 吴信东, 何进, 陆汝钤, 郑南宁. 从大数据到大知识: HACE+BigKE. 自动化学报, 2016, 42(7): 965−982Wu Xin-Dong, He Jin, Lu Ru-Qian, Zheng Nan-Ning. From big data to big knowledge: HACE + BigKE. Acta Automatica Sinica, 2016, 42(7): 965−982 [10] Wu M H, Wu X D. On big wisdom. Knowledge and Information Systems, 2018, 58(1): 1−8 [11] 钟华. 企业IT架构转型之道: 阿里巴巴中台战略思想与架构实战. 北京: 机械工业出版社, 2017.Zhong Hua. The Transformation of IT Framework in Enterprises: the Strategic Thinking and Framework of Alibaba. Beijing: China Machine Press, 2017. [12] 付登坡, 江敏, 任寅姿等. 数据中台: 让数据用起来. 北京: 机械工业出版社, 2020.Fu Deng-Po, Jiang Min, Ren Yin-Zi, etc. Data Middle Office: Make Data Valuable. Beijing: China Machine Press, 2020. [13] 陈新宇, 罗家鹰, 邓通, 江威. 中台战略: 中台建设与数字商业. 北京: 机械工业出版社, 2019.Chen Xin-Yu, Luo Jia-Ying, Deng Tong, Jiang Wei. Middle-Platform Strategy: Middle-Platform Construction and Digital Commerce. Beijing: China Machine Press, 2019. [14] 吴信东, 董丙冰, 堵新政, 杨威. 数据治理技术. 软件学报, 2019, 30(9): 2830−2856Wu Xin-Dong, Dong Bing-Bing, Du Xin-Zheng, Yang Wei. Data governance technology. Ruan Jian Xue Bao/Journal of Software, 2019, 30(9): 2830−2856 [15] 吴信东, 嵇圣硙. MapReduce与Spark用于大数据分析之比较. 软件学报, 2018, 29(6): 260−281Wu Xin-Dong, Ji Sheng-Wei. Comparative study on MapReduce and Spark for big data analytics. Ruan Jian Xue Bao/Journal of Software, 2018, 29(6): 260−281 [16] Ji S W, Bu C Y, Li L, W XD. Local graph edge partitioning with a two-Stage heuristic method. In: Proceedings of the 39th IEEE International Conference on Distributed Computing Systems. Dallas, Texas, USA. IEEE, 2019. [17] 吴共庆, 胡骏, 李莉, 徐喆昊, 刘鹏程, 胡学钢, 吴信东. 基于标签路径特征融合的在线Web新闻内容抽取. 软件学报, 2016, 27(3): 714−735Wu Gong-Qing, Hu Jun, Li Li, Xu Zhe-Hao, Liu Peng-Cheng, Hu Xue-Gang, Wu Xin-Dong. Online web news extraction via tag path feature fusion. Ruan Jian Xue Bao/Journal of Software, 2016, 27(3): 714−735 [18] 吴信东, 李娇, 周鹏, 卜晨阳. 碎片化家谱数据的融合技术. 软件学报. http://www.jos.org.cn/1000-9825/6010.htm.Wu Xin-Dong, Li Jiao, Zhou Peng, Bu Chen-Yang. A fusion technique for fragmented genealogy data. Ruan Jian Xue Bao/Journal of Software, 2020 http://www.jos.org.cn/1000-9825/6010.htm. [19] Liu X J, Zhu Y, Ji S W. Web log analysis in genealogy system. In: Proceedings of the 11th IEEE International Conference on Knowledge Graph. Nanjing, China. IEEE, 2020. -

 下载:
下载:







图(12) / 表(2)
计量
- 文章访问数: 4665
- HTML全文浏览量: 1018
- PDF下载量: 668
- 被引次数: 0
