2020年 第46卷 第10期
2020, 46(10): 2005-2012.
doi: 10.16383/j.aas.c200796
摘要:
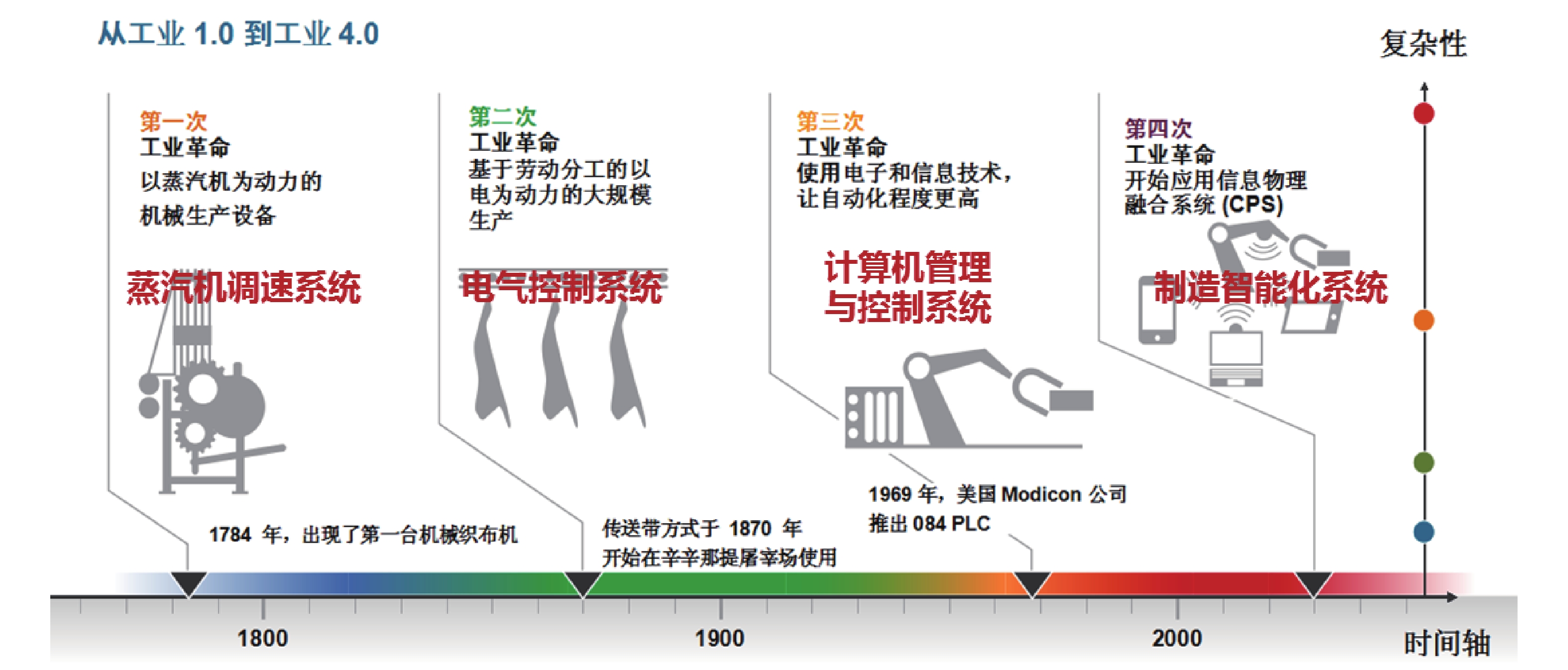
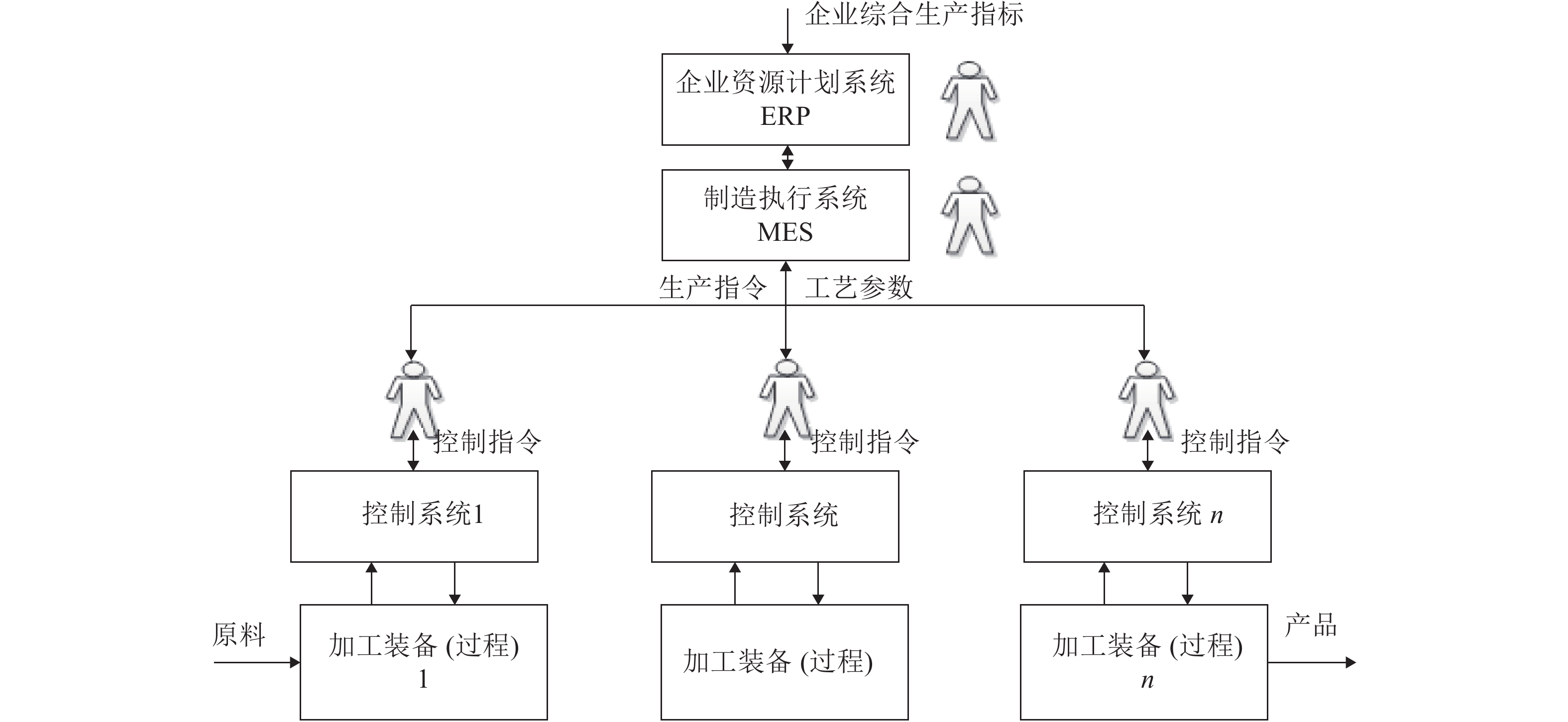
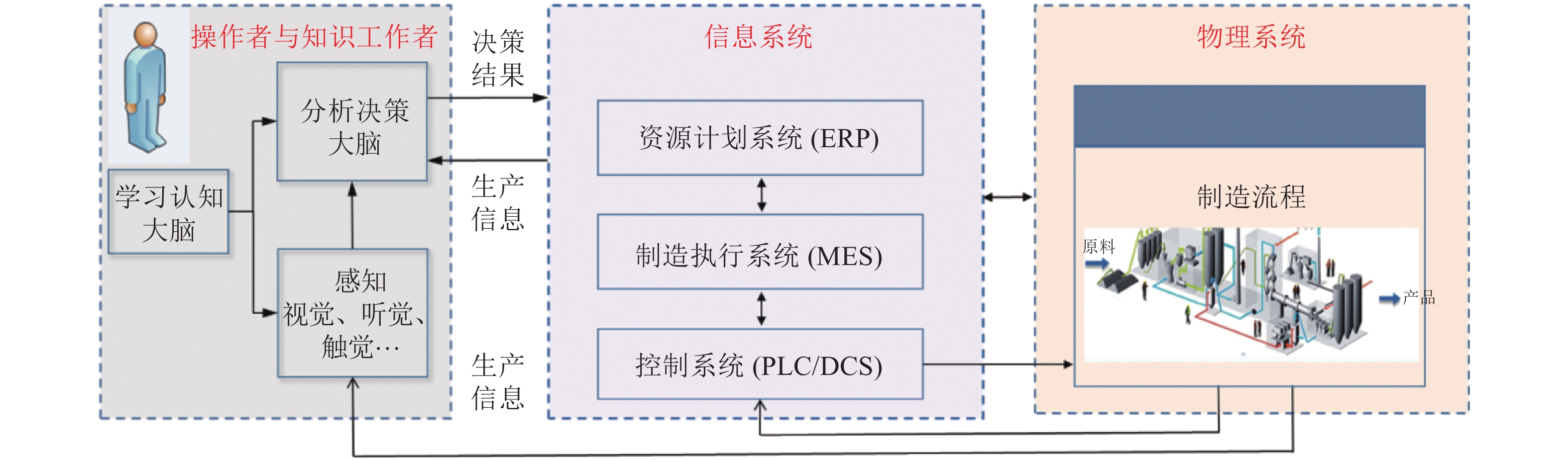
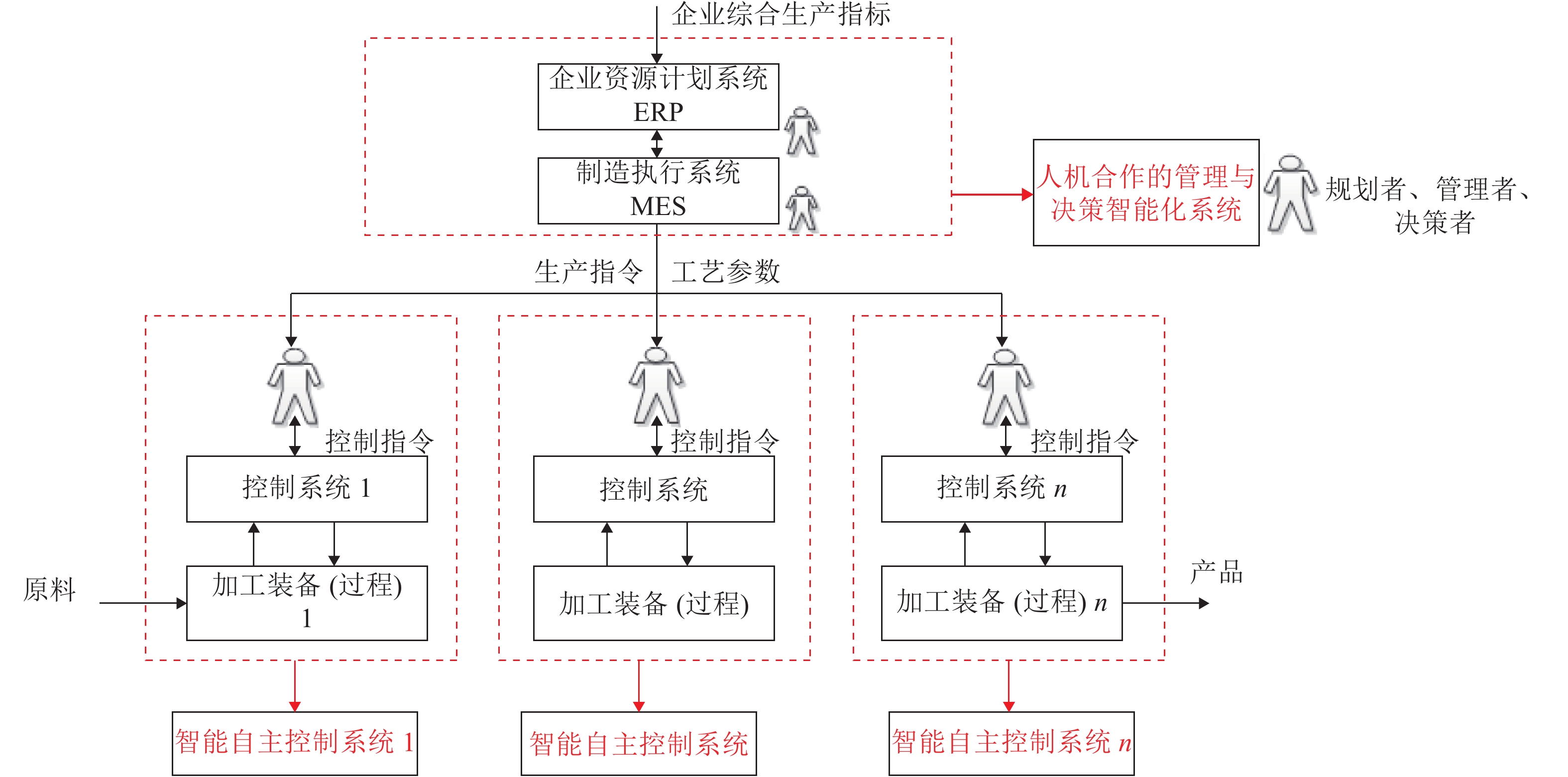
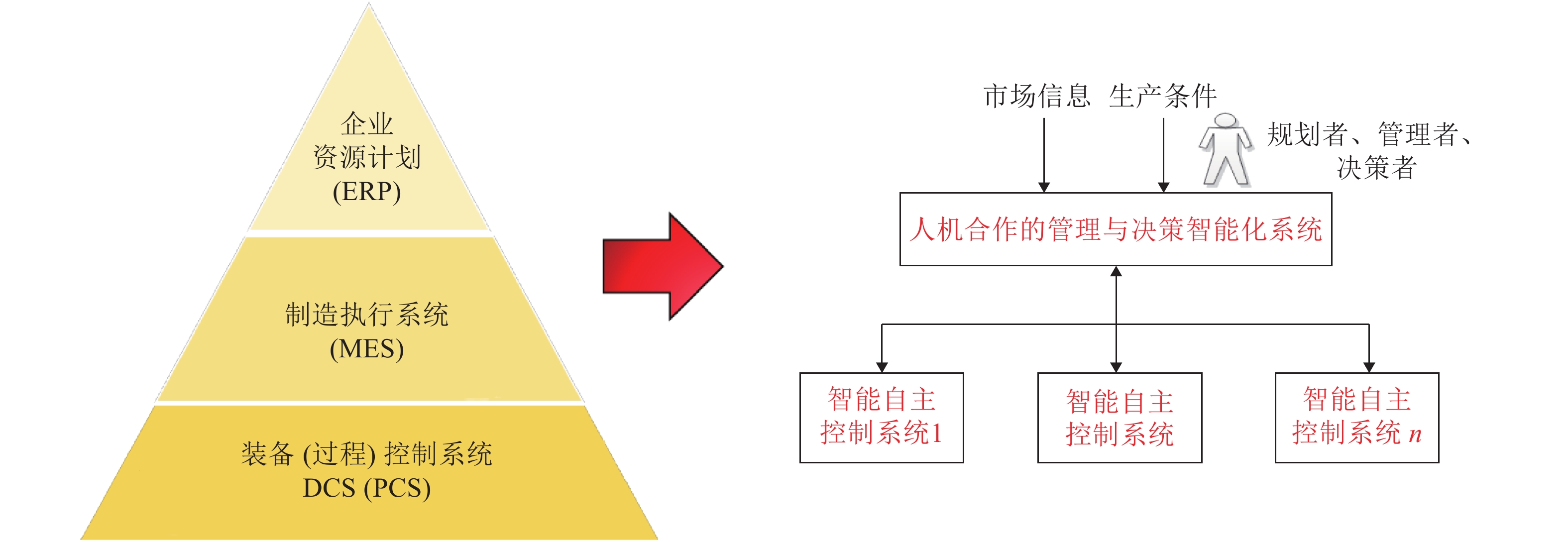
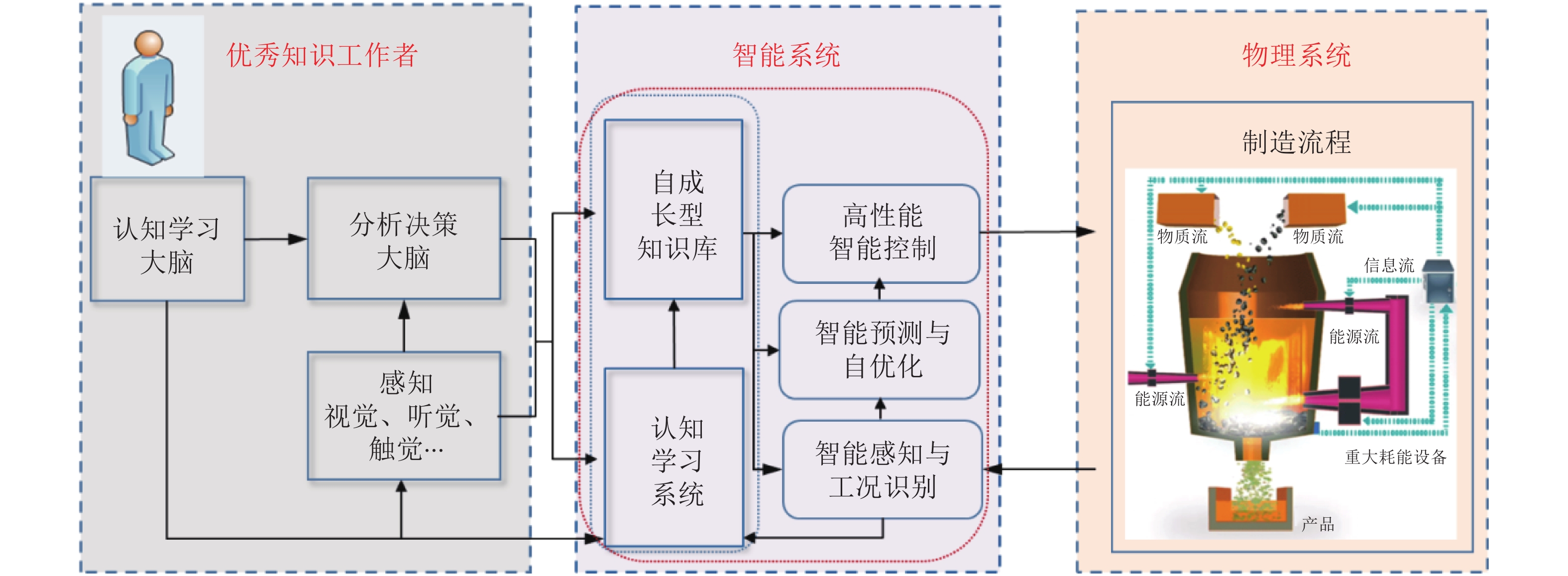
本文结合工业自动化和信息技术在工业革命中的作用以及制造与生产全流程决策、控制以及运行管理的现状和智能化发展方向的分析, 提出了发展工业人工智能的必要性. 通过对人工智能技术的涵义、发展简史和发展方向的分析以及自动化与人工智能研究与应用的核心目标、实现方式、研究对象与研究方法等方面的对比分析, 提出了工业人工智能技术的涵义. 通过对工业人工智能和工业自动化的研究对象与研究目标对比分析, 提出了工业人工智能的研究方向和研究思路与方法.
本文结合工业自动化和信息技术在工业革命中的作用以及制造与生产全流程决策、控制以及运行管理的现状和智能化发展方向的分析, 提出了发展工业人工智能的必要性. 通过对人工智能技术的涵义、发展简史和发展方向的分析以及自动化与人工智能研究与应用的核心目标、实现方式、研究对象与研究方法等方面的对比分析, 提出了工业人工智能技术的涵义. 通过对工业人工智能和工业自动化的研究对象与研究目标对比分析, 提出了工业人工智能的研究方向和研究思路与方法.
2020, 46(10): 2013-2030.
doi: 10.16383/j.aas.c200333
摘要:
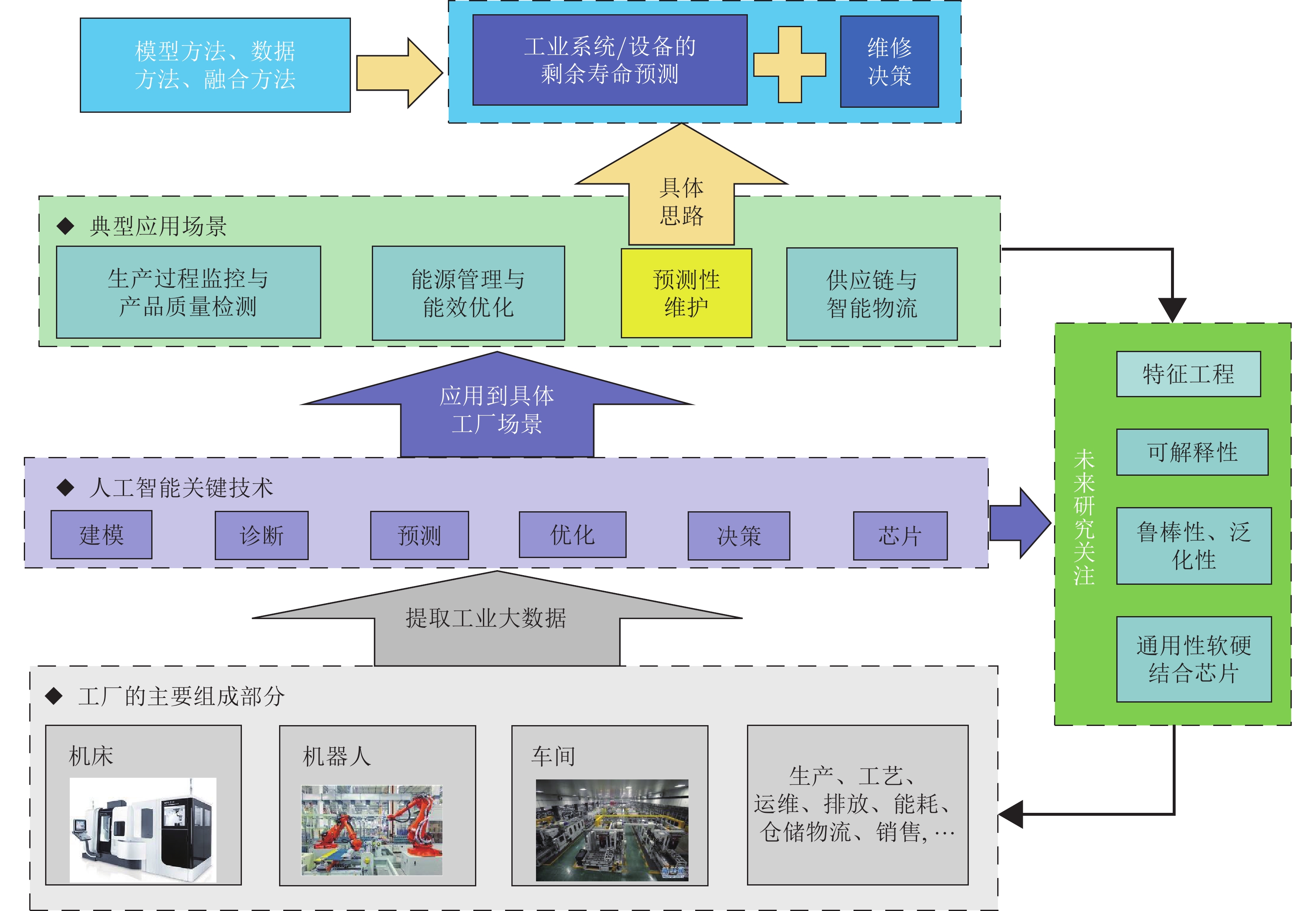
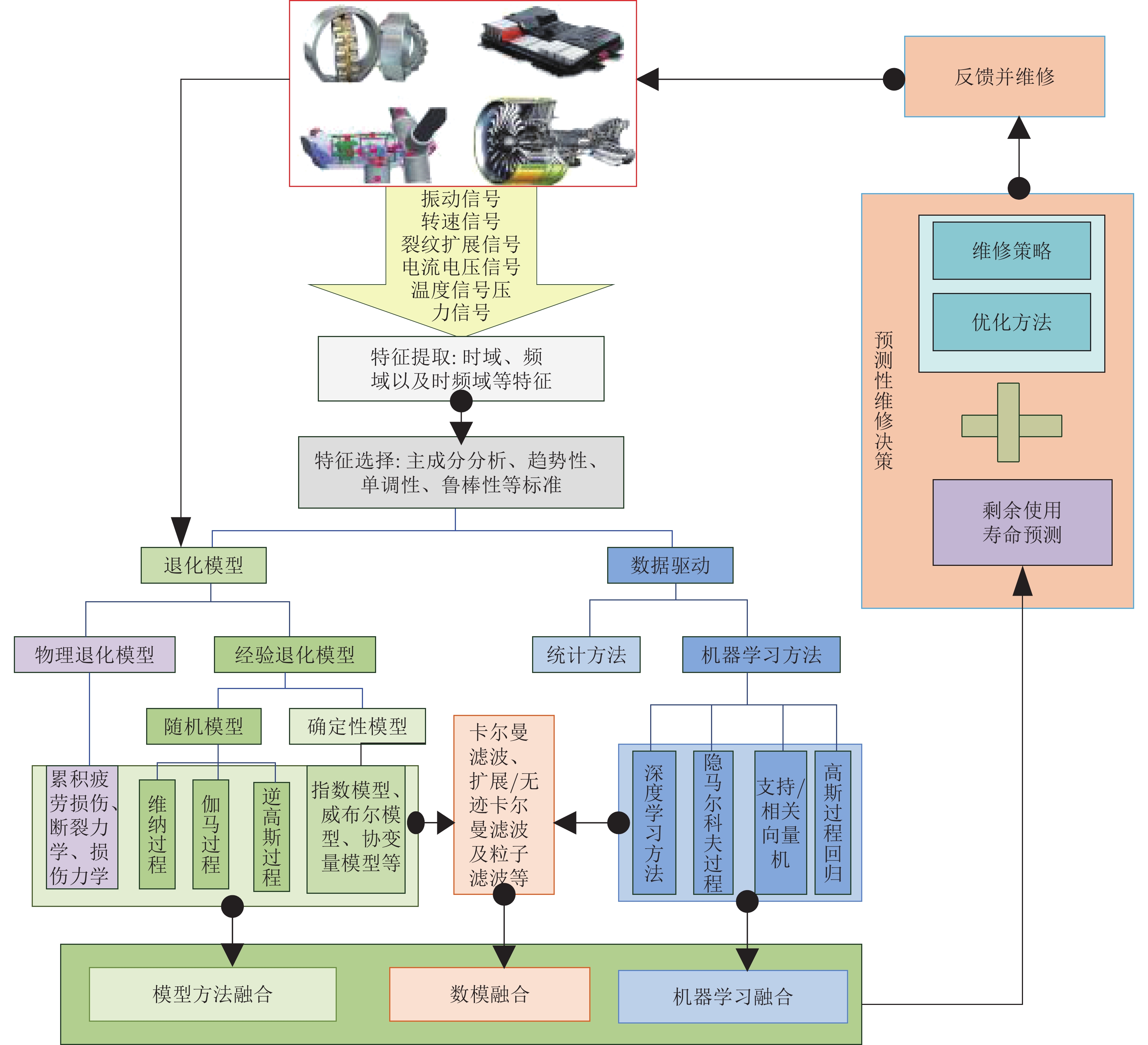
随着人工智能技术的快速发展及其在工业系统中卓有成效的应用, 工业智能化成为当前工业生产转型的一个重要趋势. 论文提炼了工业人工智能(Industrial artificial intelligence, IAI)的建模、诊断、预测、优化、决策以及智能芯片等共性关键技术, 总结了生产过程监控与产品质量检测等4个主要应用场景. 同时, 论文选择预测性维护作为工业人工智能的典型应用场景, 以工业设备的闭环智能维护形式, 分别从模型方法、数据方法以及融合方法出发, 系统的总结和分析了设备的寿命预测技术和维护决策理论, 展示了人工智能技术在促进工业生产安全、降本、增效、提质等方面的重要作用. 最后, 探讨了工业人工智能研究所面临的问题以及未来的研究方向.
随着人工智能技术的快速发展及其在工业系统中卓有成效的应用, 工业智能化成为当前工业生产转型的一个重要趋势. 论文提炼了工业人工智能(Industrial artificial intelligence, IAI)的建模、诊断、预测、优化、决策以及智能芯片等共性关键技术, 总结了生产过程监控与产品质量检测等4个主要应用场景. 同时, 论文选择预测性维护作为工业人工智能的典型应用场景, 以工业设备的闭环智能维护形式, 分别从模型方法、数据方法以及融合方法出发, 系统的总结和分析了设备的寿命预测技术和维护决策理论, 展示了人工智能技术在促进工业生产安全、降本、增效、提质等方面的重要作用. 最后, 探讨了工业人工智能研究所面临的问题以及未来的研究方向.
2020, 46(10): 2031-2044.
doi: 10.16383/j.aas.200501
摘要:
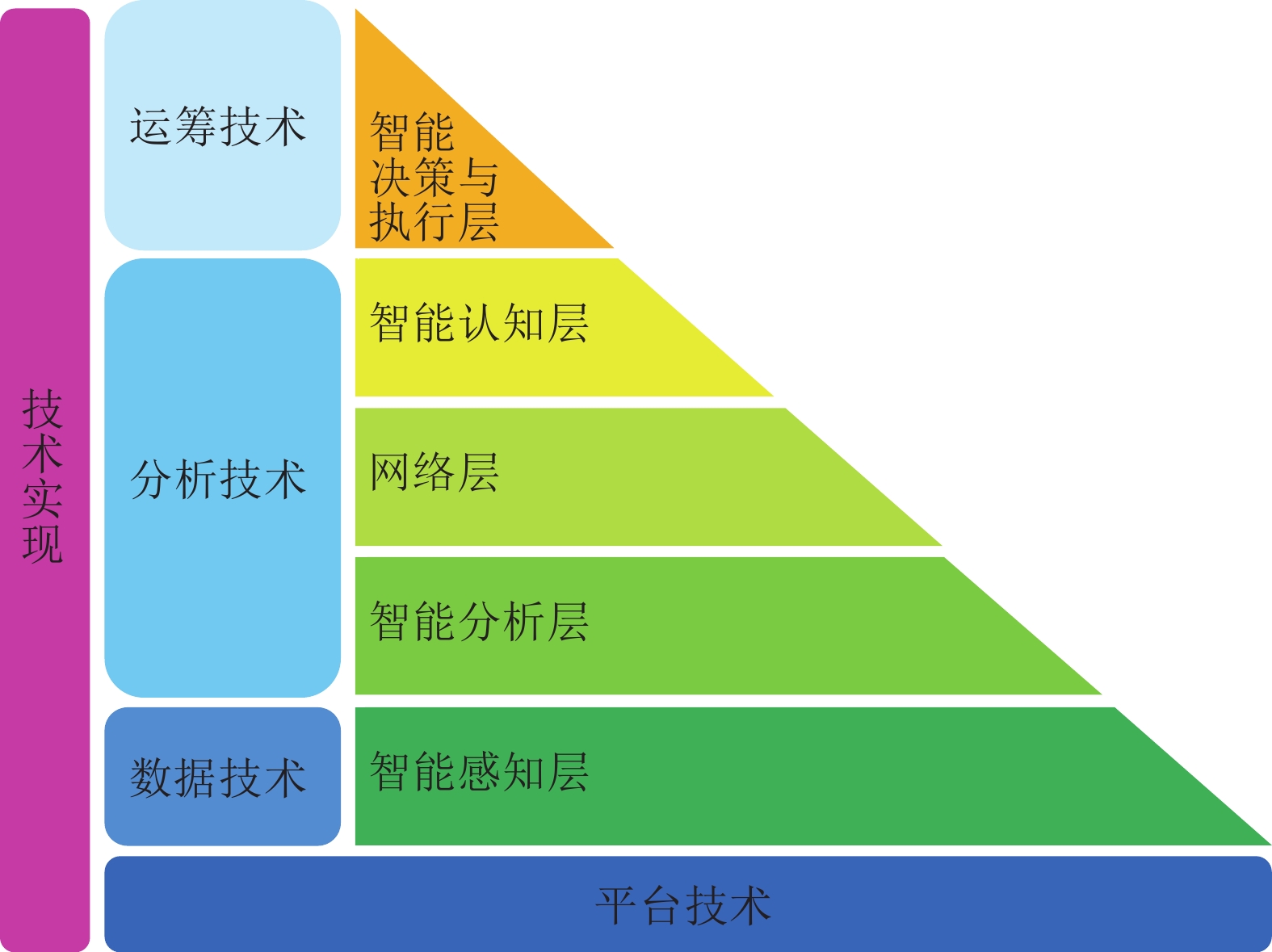
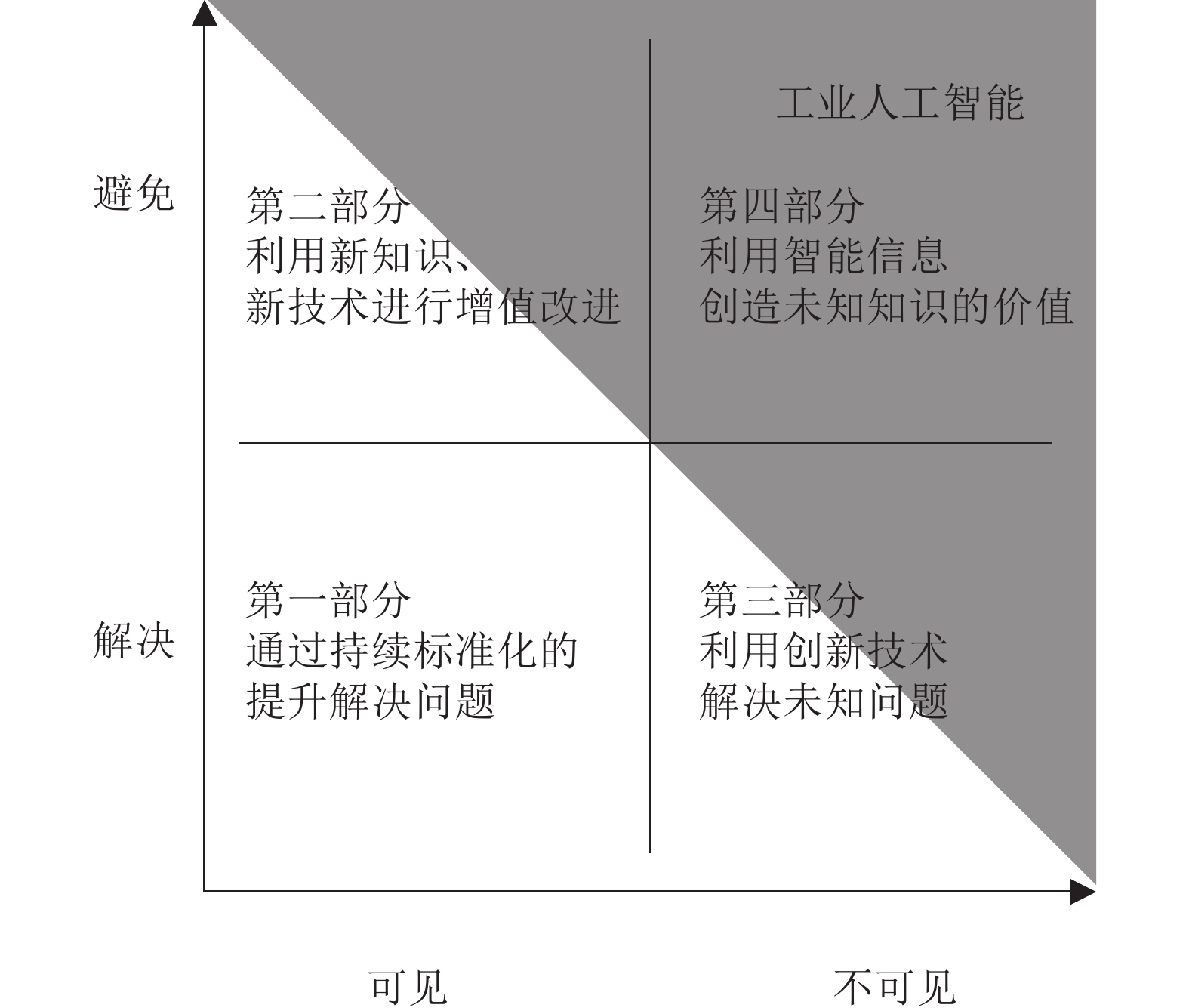
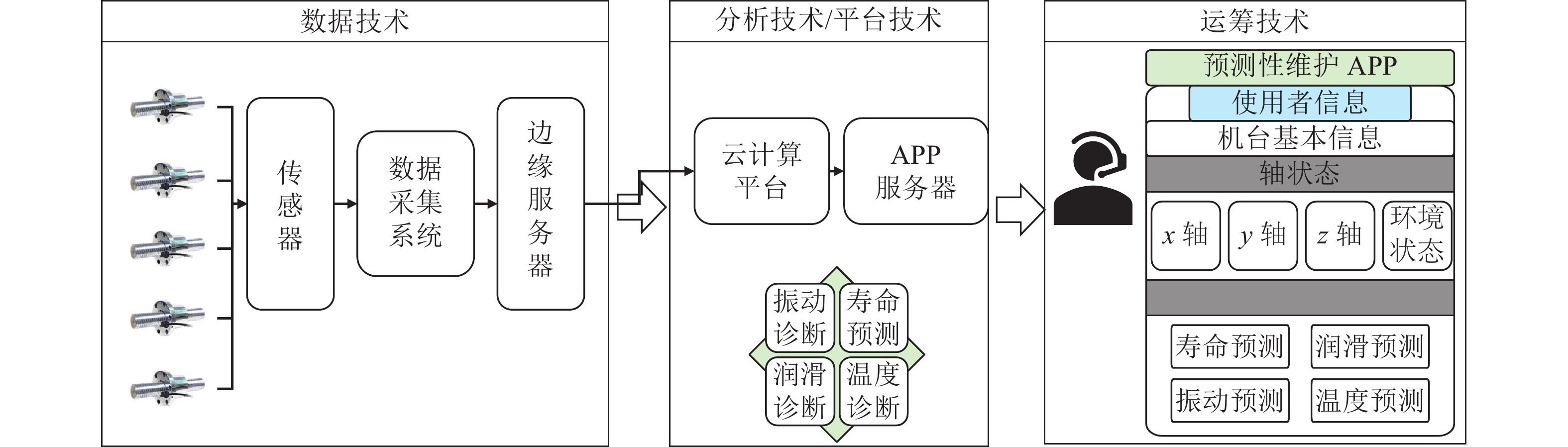
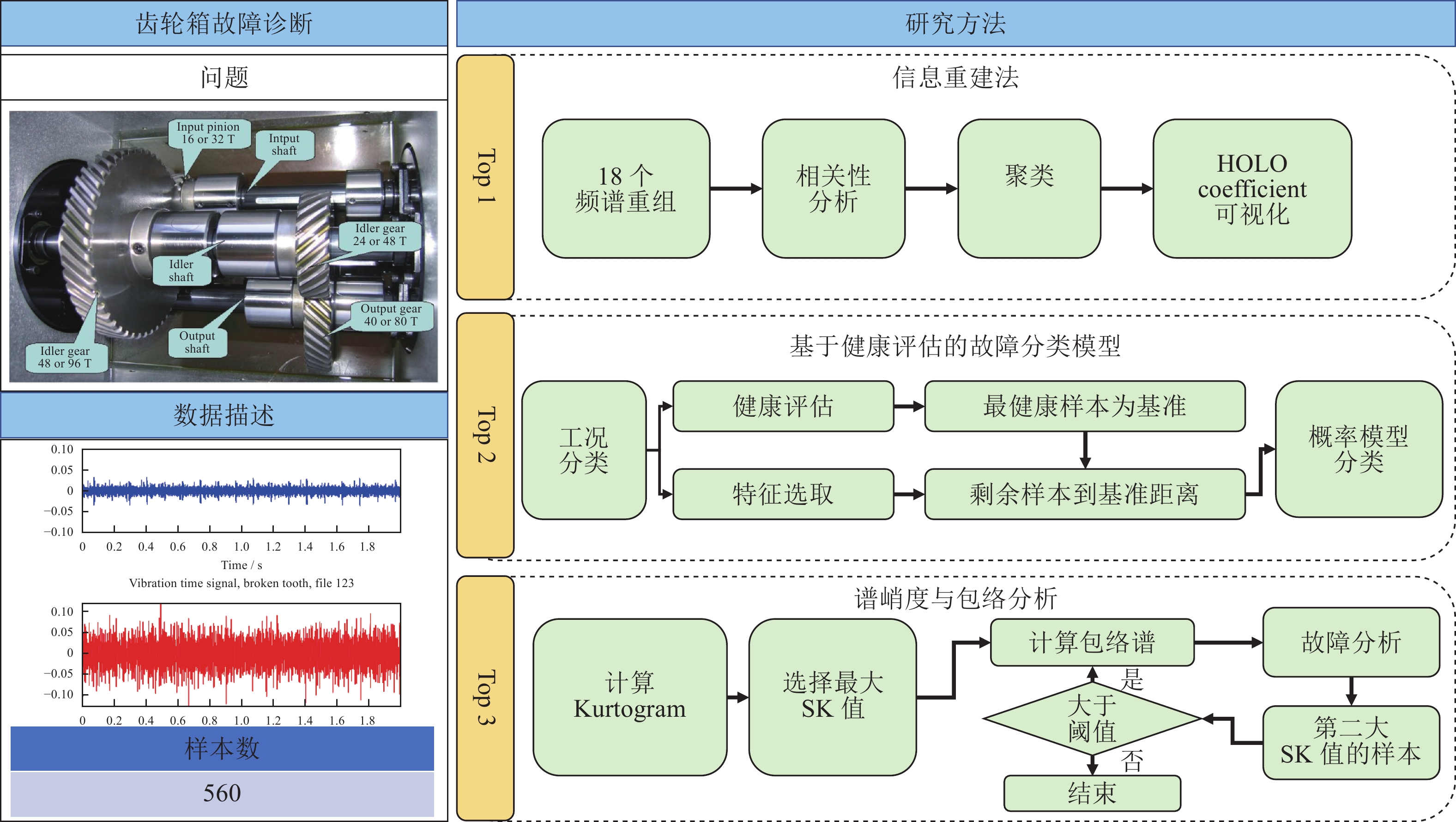
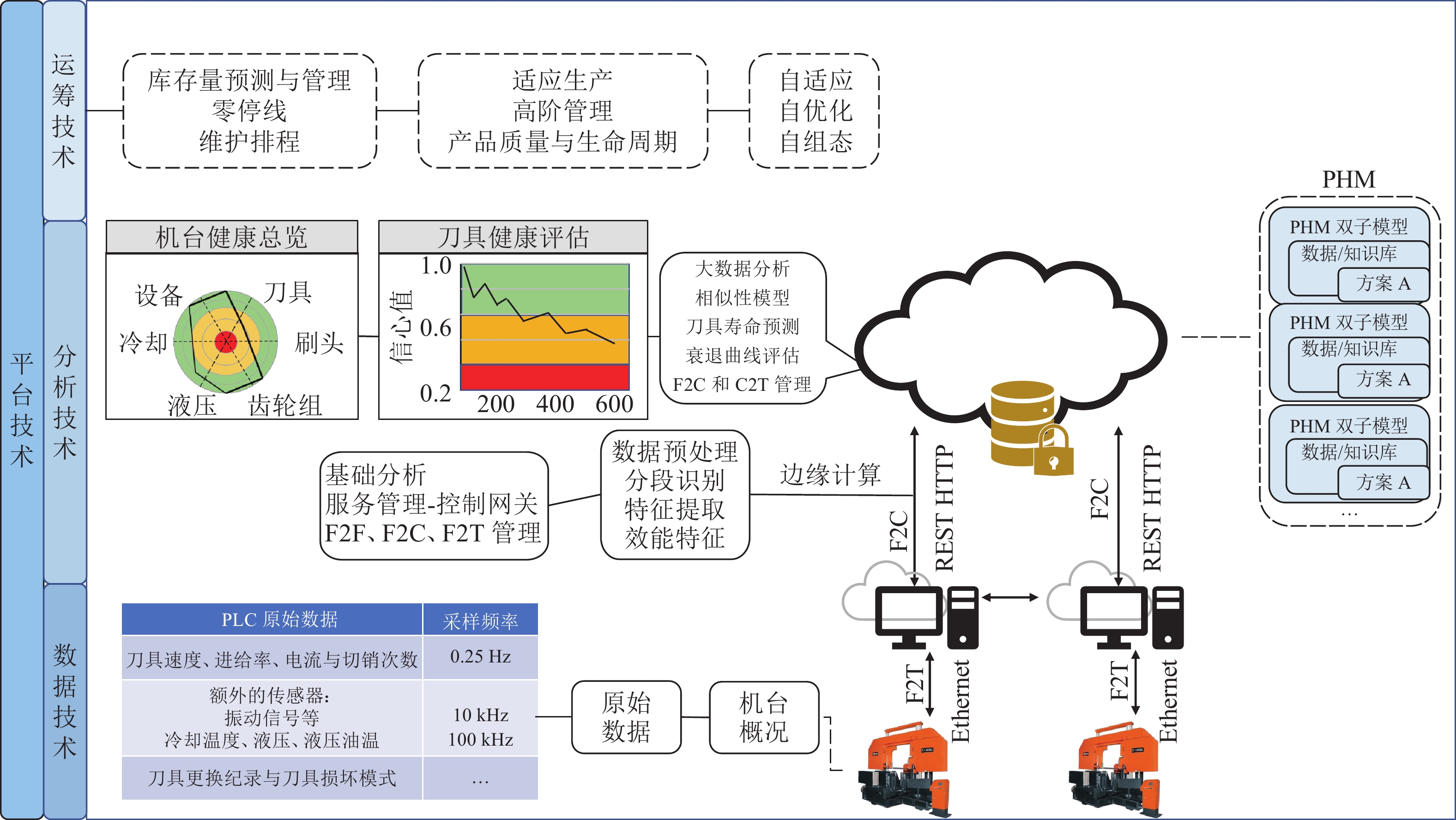
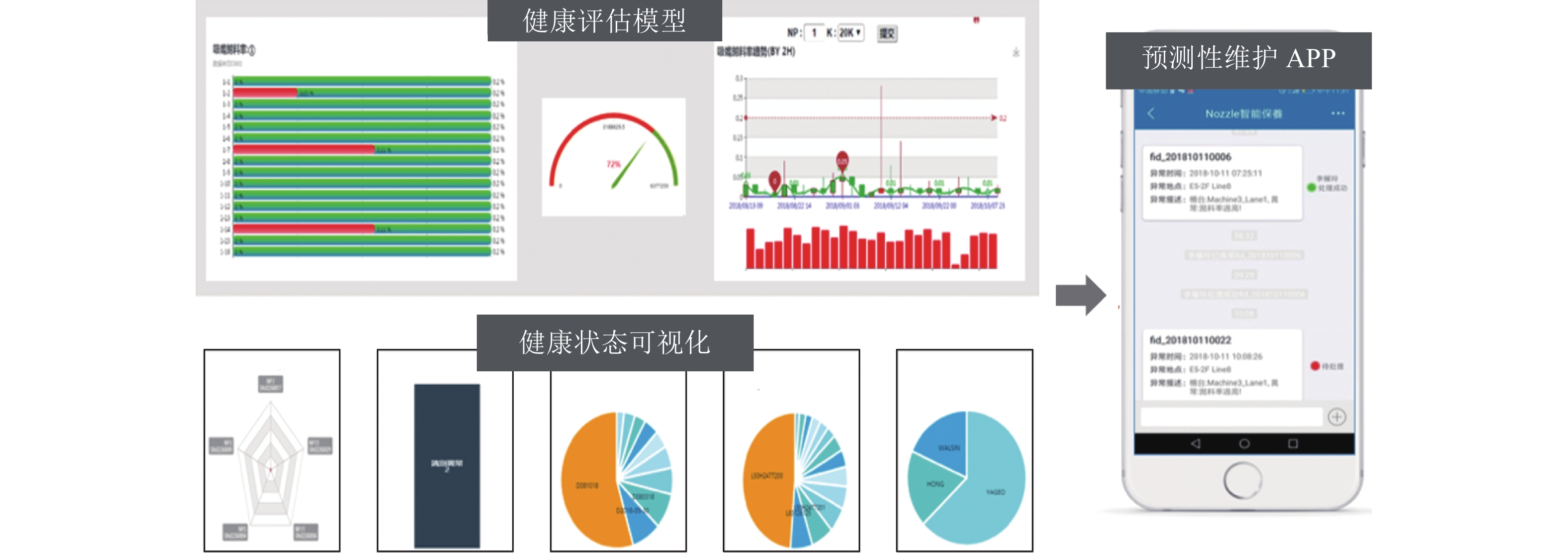
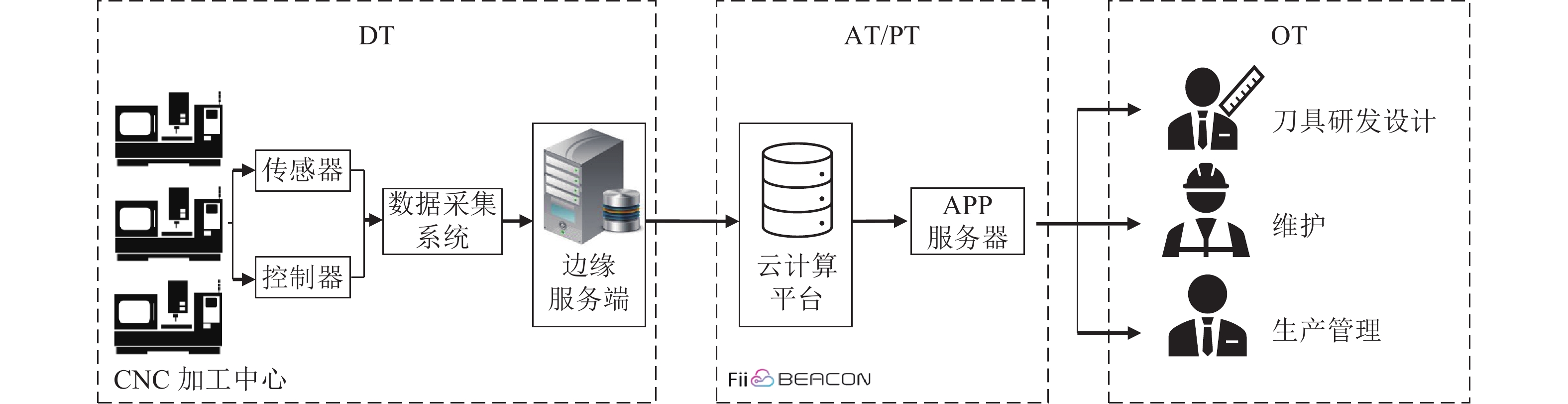
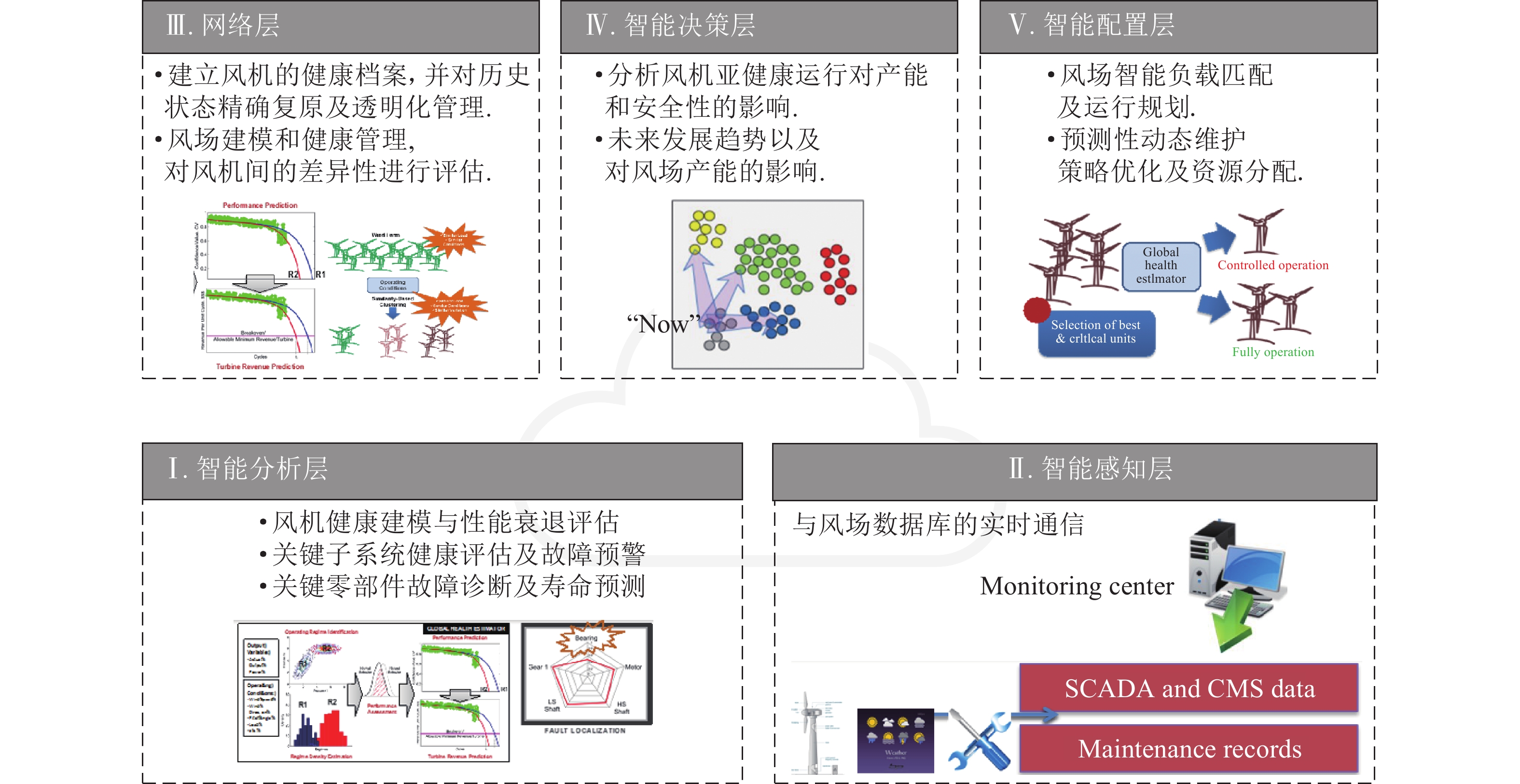
工业4.0将工业制造流程以及产品质量优化从以前依照经验和观察进行判断转变为以事实为基础, 通过分析数据进而挖掘潜在价值的完整智能系统. 人工智能技术的快速发展在工业4.0的实现中扮演着关键的角色. 然而, 传统的人工智能技术通常着眼于日常生活、社会交流和金融场景, 而非解決工业界实际所遇到的问题. 相比而言, 工业人工智能技术基于工业领域的具体问题, 利用智能系统提升生产效率、系统可靠性并优化生产过程, 更加适合解决特定的工业问题同时帮助从业人员发现隐性问题, 并让工业设备有自主能力来实现弹性生产并最终创造更大价值. 本文首先介绍工业人工智能的相关概念, 并通过实际的工业应用案例如元件级的滚珠丝杠、设备级的带锯加工机与机器群等不同层次的问题来展示工业人工智能架构的可行性与应用前景.
工业4.0将工业制造流程以及产品质量优化从以前依照经验和观察进行判断转变为以事实为基础, 通过分析数据进而挖掘潜在价值的完整智能系统. 人工智能技术的快速发展在工业4.0的实现中扮演着关键的角色. 然而, 传统的人工智能技术通常着眼于日常生活、社会交流和金融场景, 而非解決工业界实际所遇到的问题. 相比而言, 工业人工智能技术基于工业领域的具体问题, 利用智能系统提升生产效率、系统可靠性并优化生产过程, 更加适合解决特定的工业问题同时帮助从业人员发现隐性问题, 并让工业设备有自主能力来实现弹性生产并最终创造更大价值. 本文首先介绍工业人工智能的相关概念, 并通过实际的工业应用案例如元件级的滚珠丝杠、设备级的带锯加工机与机器群等不同层次的问题来展示工业人工智能架构的可行性与应用前景.


2020, 46(10): 2045-2059.
doi: 10.16383/j.aas.c200502
摘要:
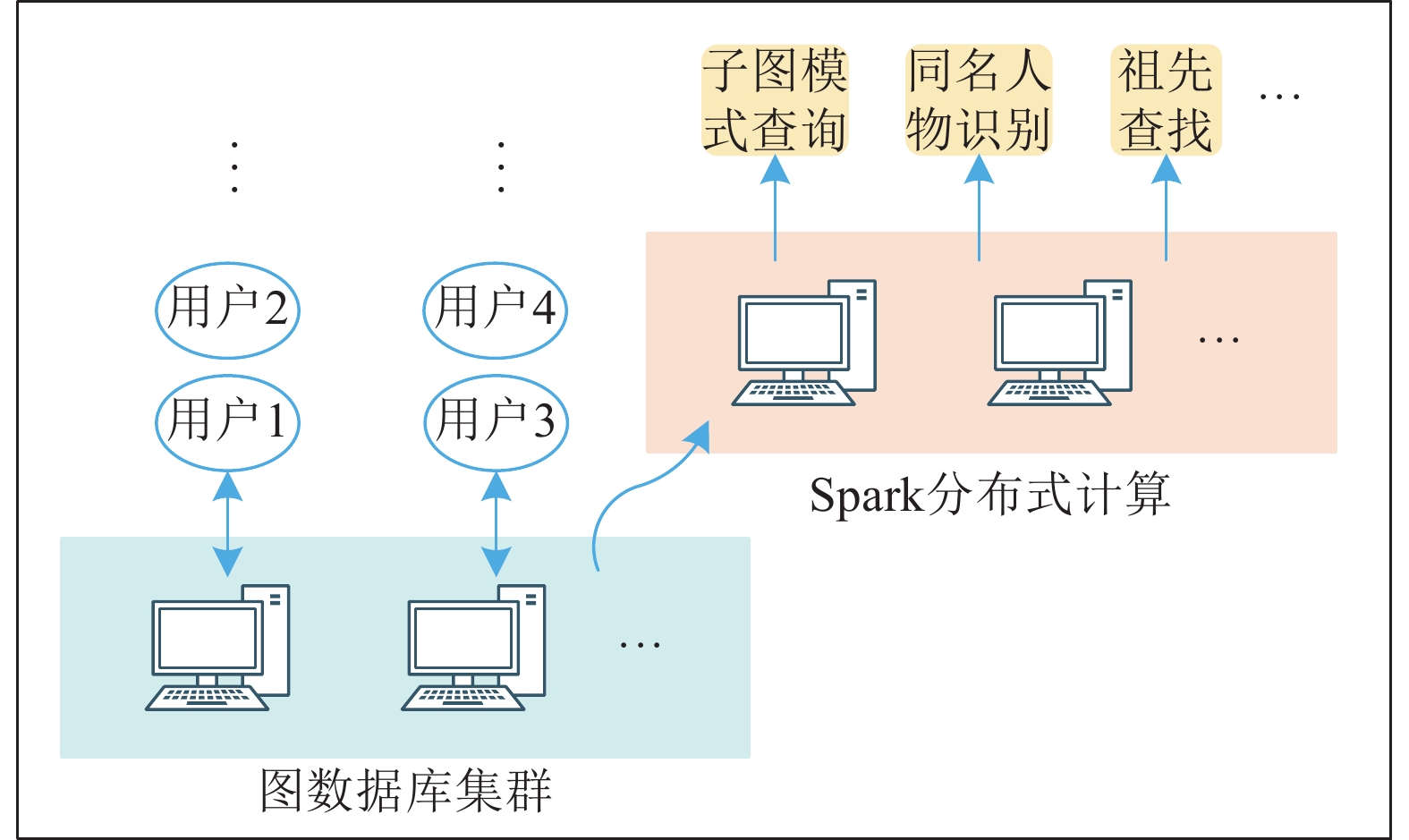
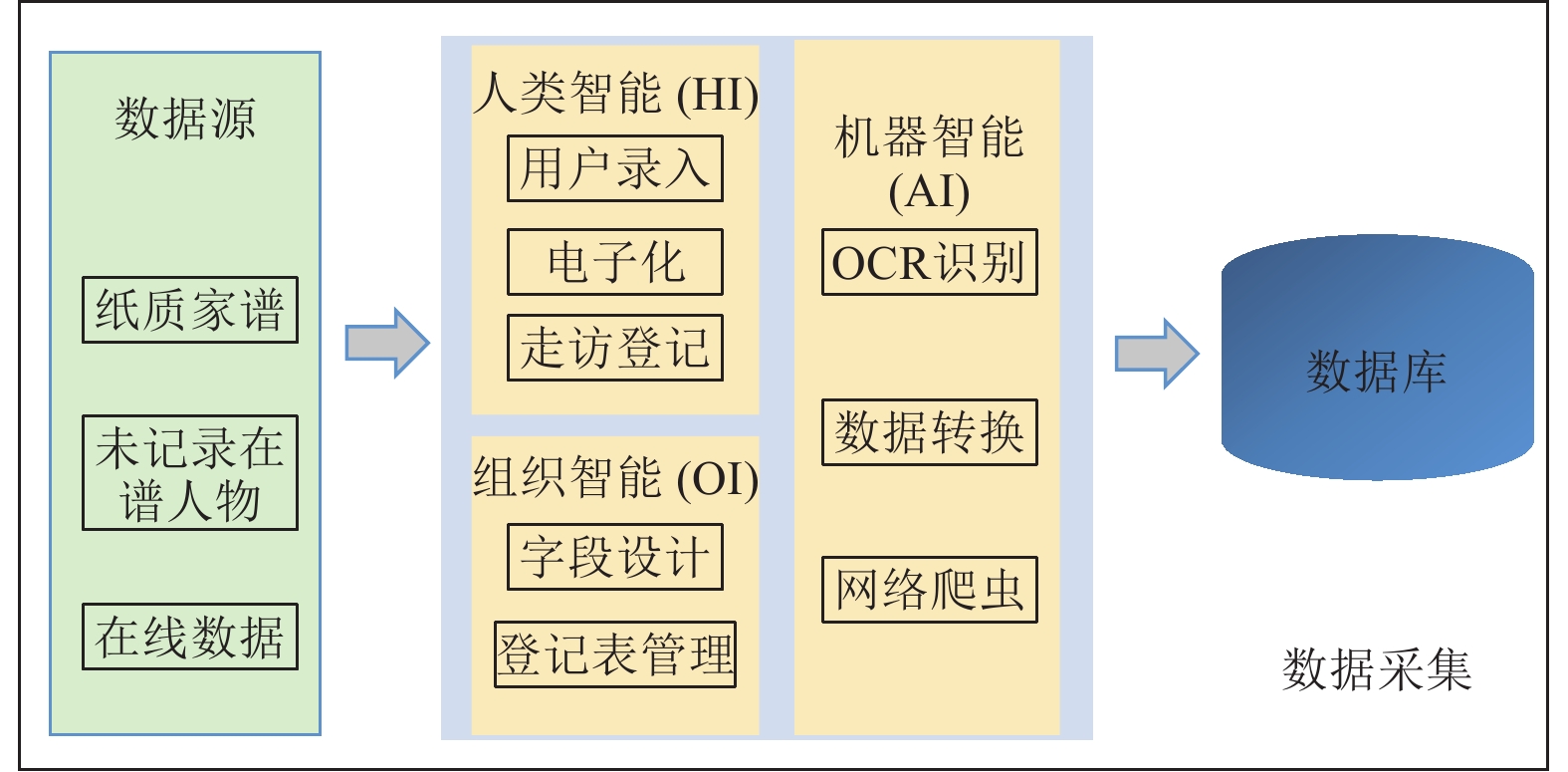
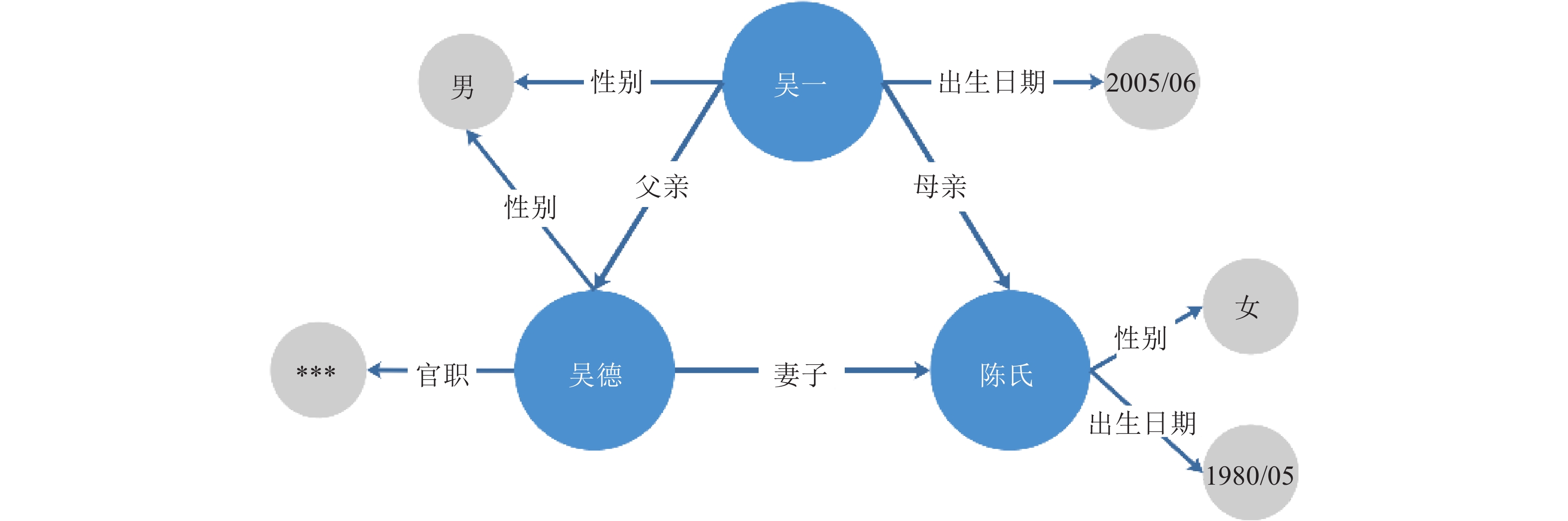
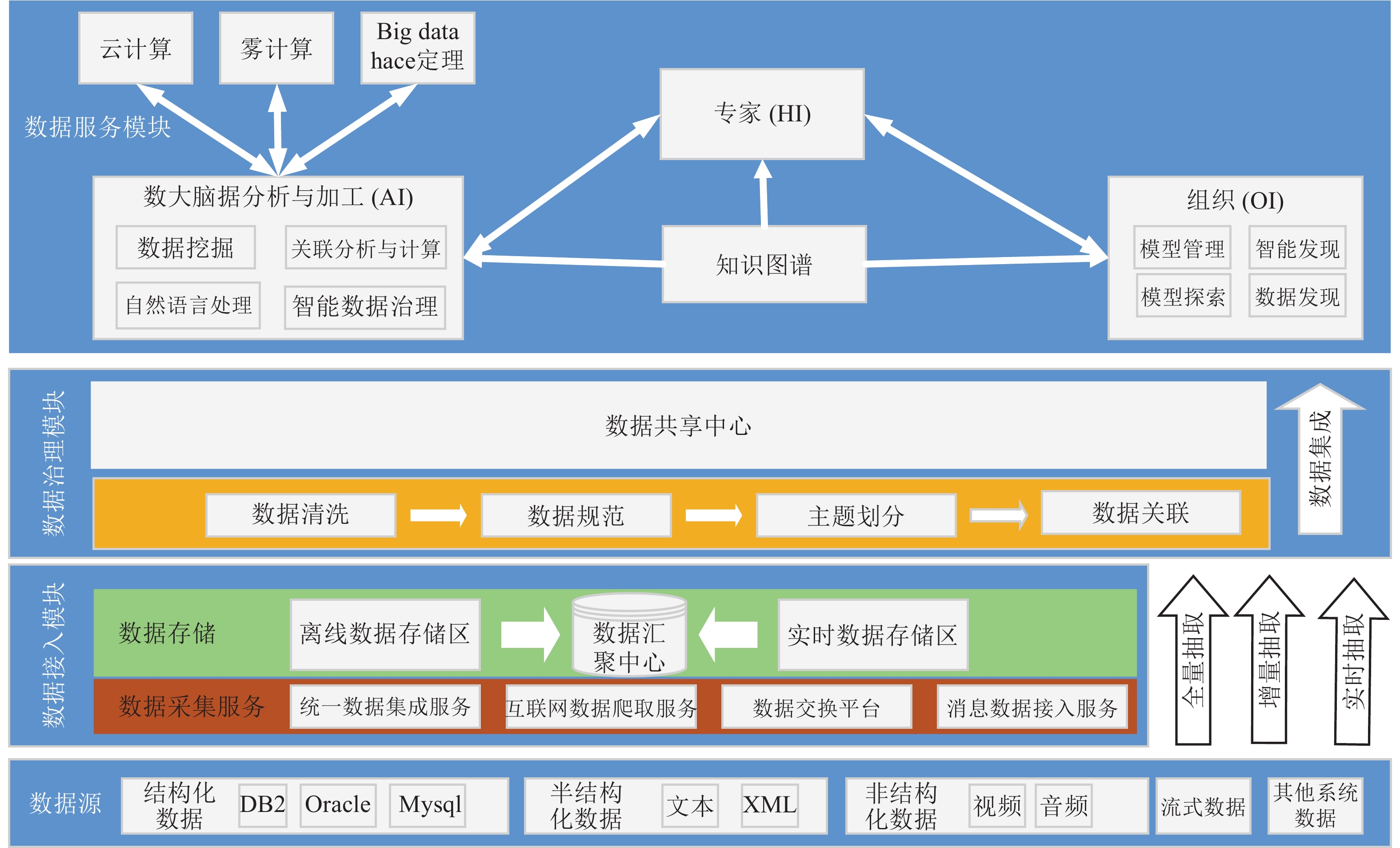
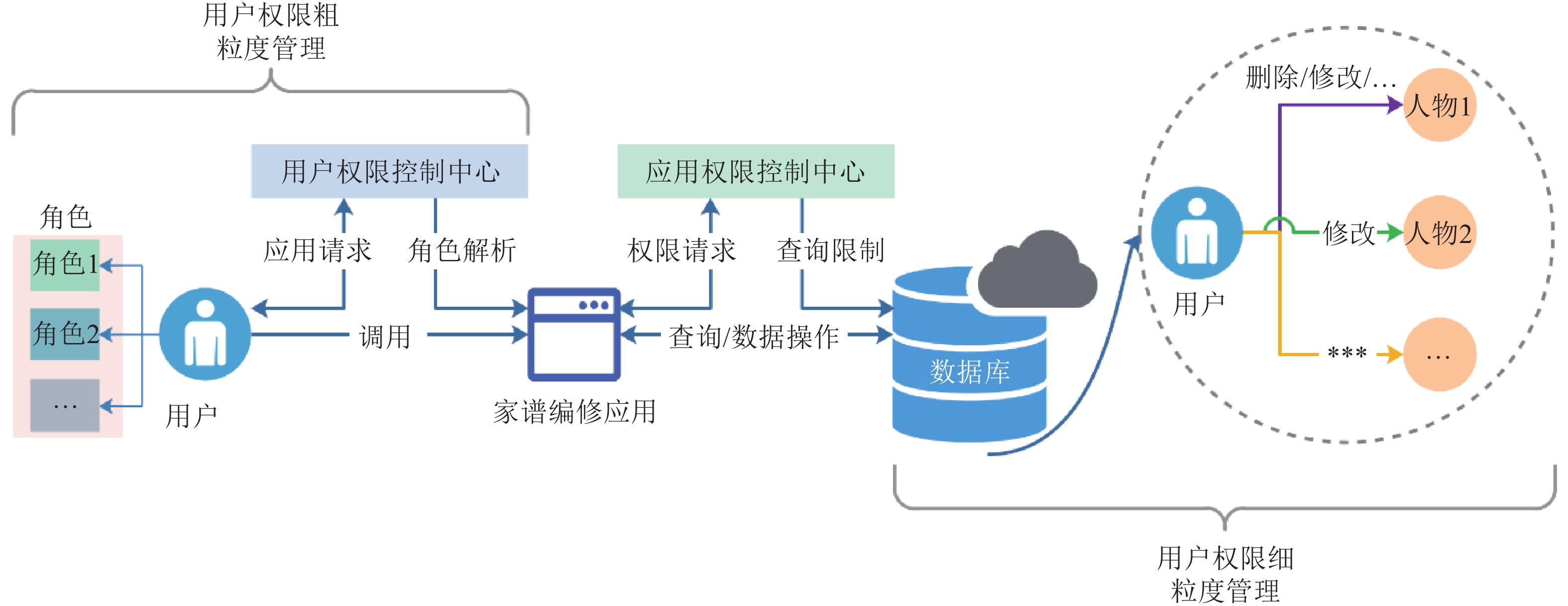
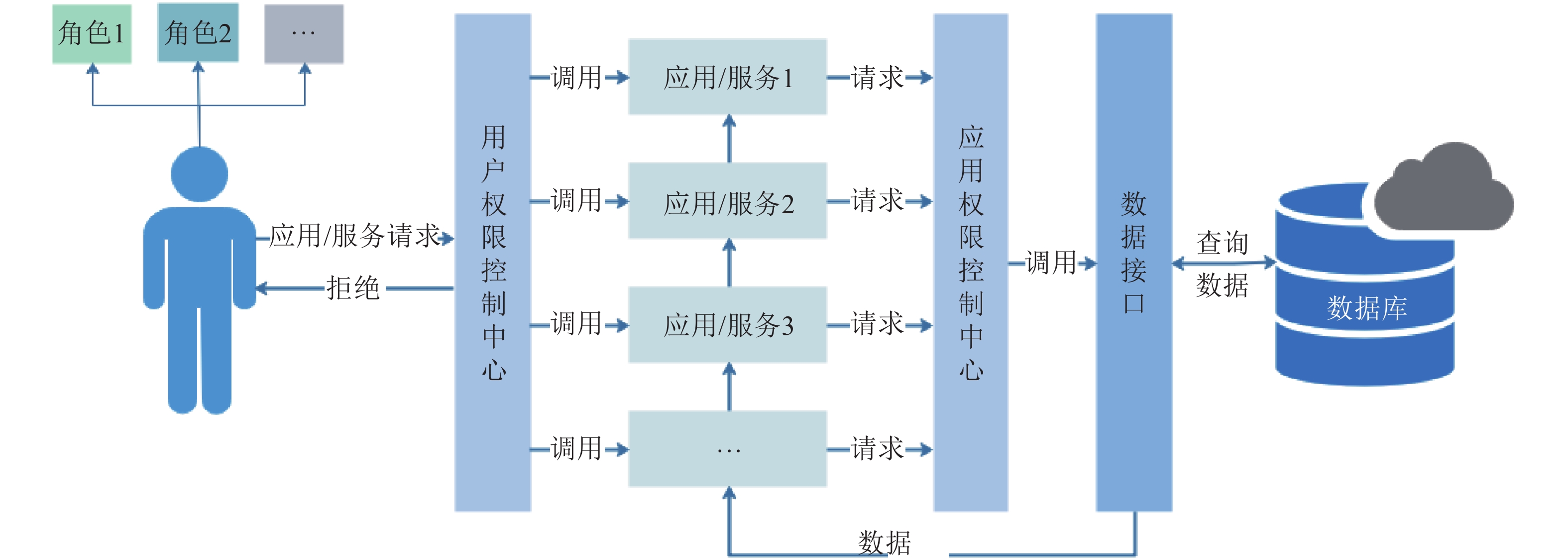
针对碎片化的各姓氏家谱数据, 华谱系统通过构建家谱知识图谱的数据中台, 能够解决数据孤岛、烟囱式开发等问题. “数据中台”是一个源自国内的新近技术概念, 在华谱系统建设中, 我们通过家谱知识图谱的构建和应用, 对这个概念进行了正式定义. 基于这个定义和对应的7项核心功能, 本文提出一种用于家谱数据分析的数据中台建设架构Huapu-CP (华谱系统), 并通过该架构详细介绍面向家谱领域的数据中台核心技术, 分析数据中台构建的关键问题.
针对碎片化的各姓氏家谱数据, 华谱系统通过构建家谱知识图谱的数据中台, 能够解决数据孤岛、烟囱式开发等问题. “数据中台”是一个源自国内的新近技术概念, 在华谱系统建设中, 我们通过家谱知识图谱的构建和应用, 对这个概念进行了正式定义. 基于这个定义和对应的7项核心功能, 本文提出一种用于家谱数据分析的数据中台建设架构Huapu-CP (华谱系统), 并通过该架构详细介绍面向家谱领域的数据中台核心技术, 分析数据中台构建的关键问题.






2020, 46(10): 2060-2071.
doi: 10.16383/j.aas.c200555
摘要:
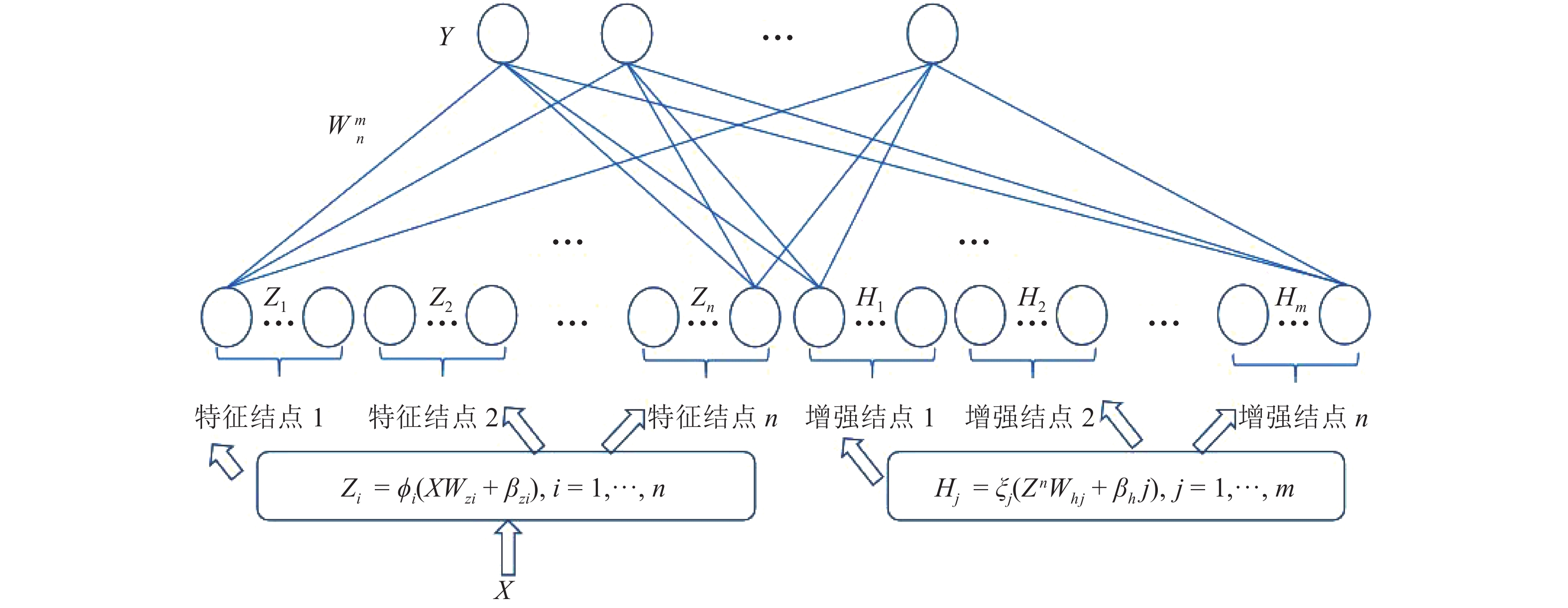
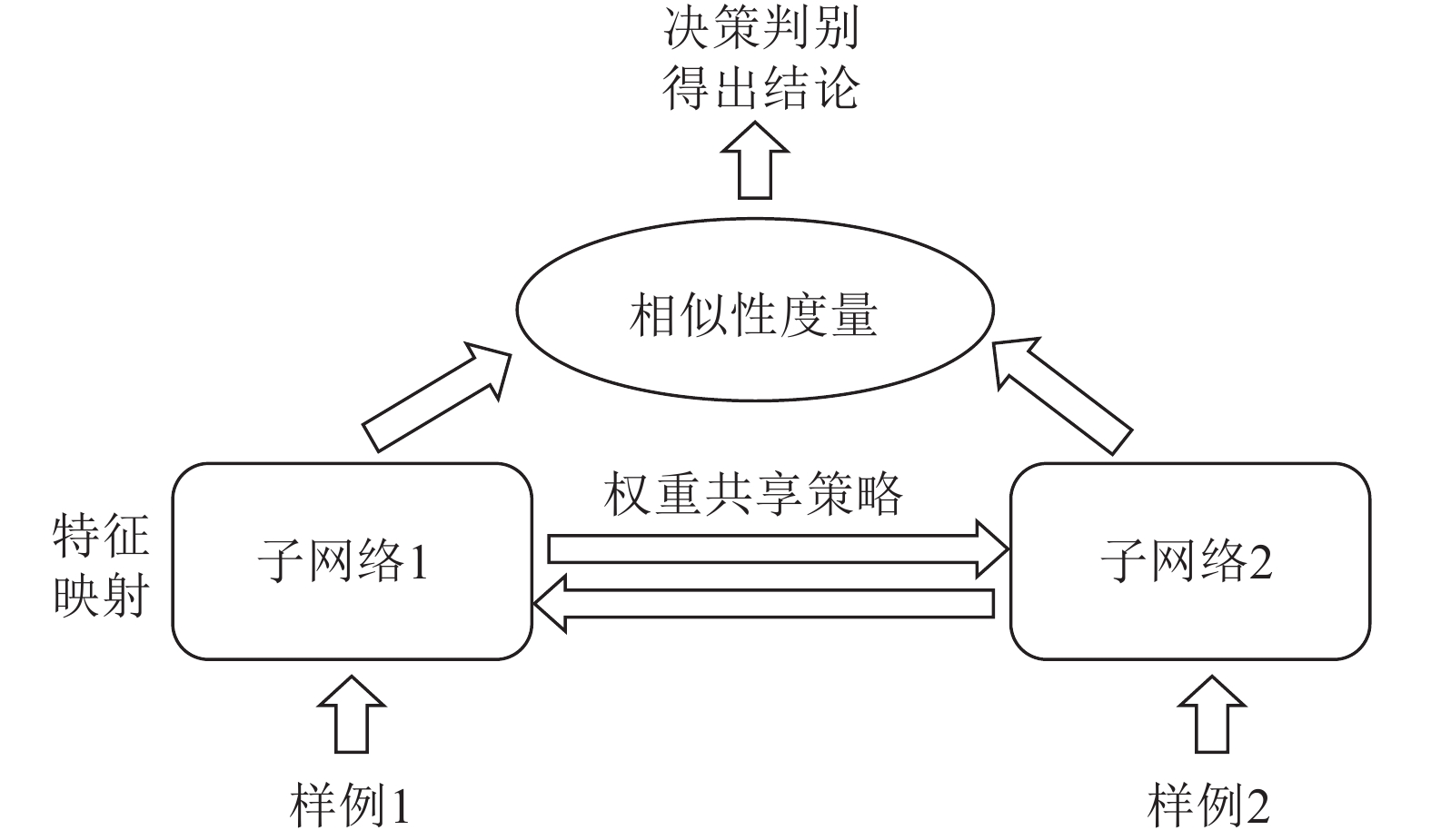
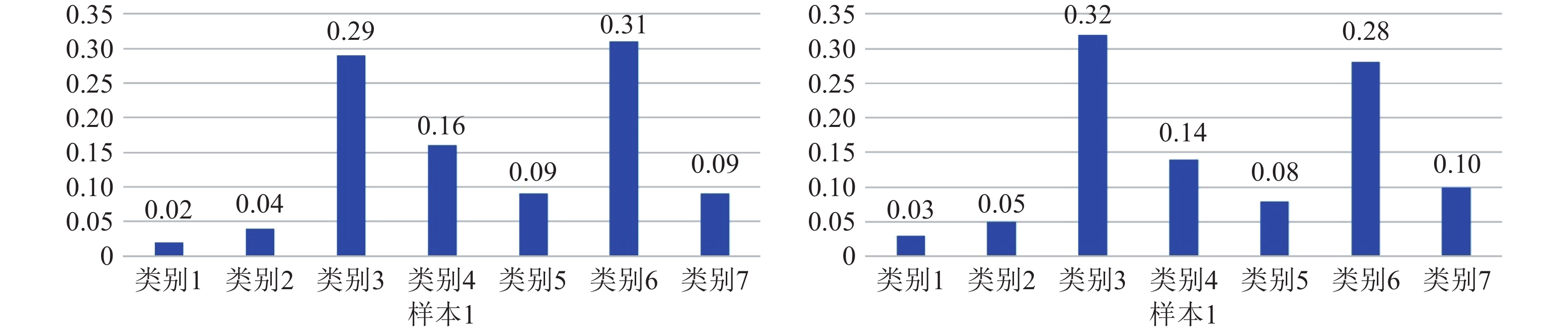
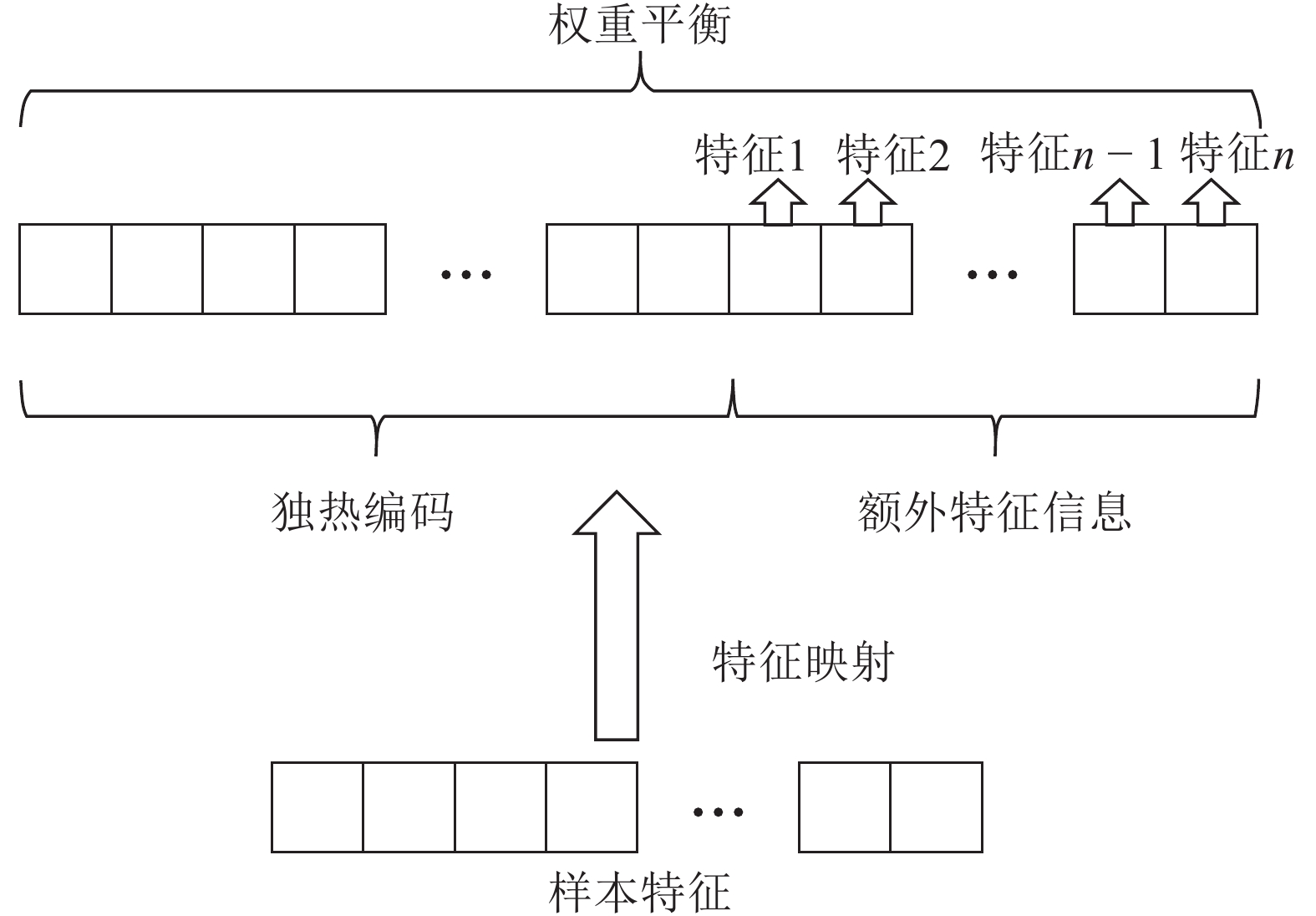
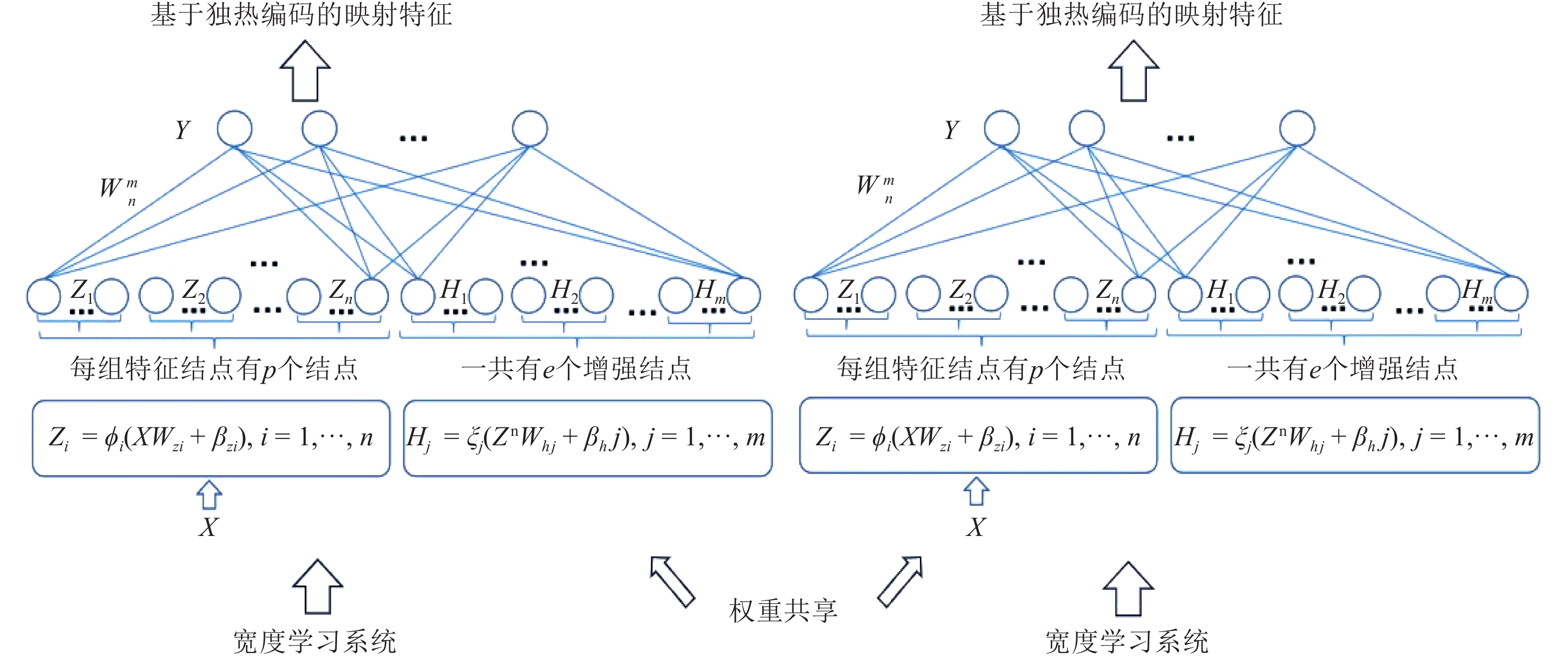
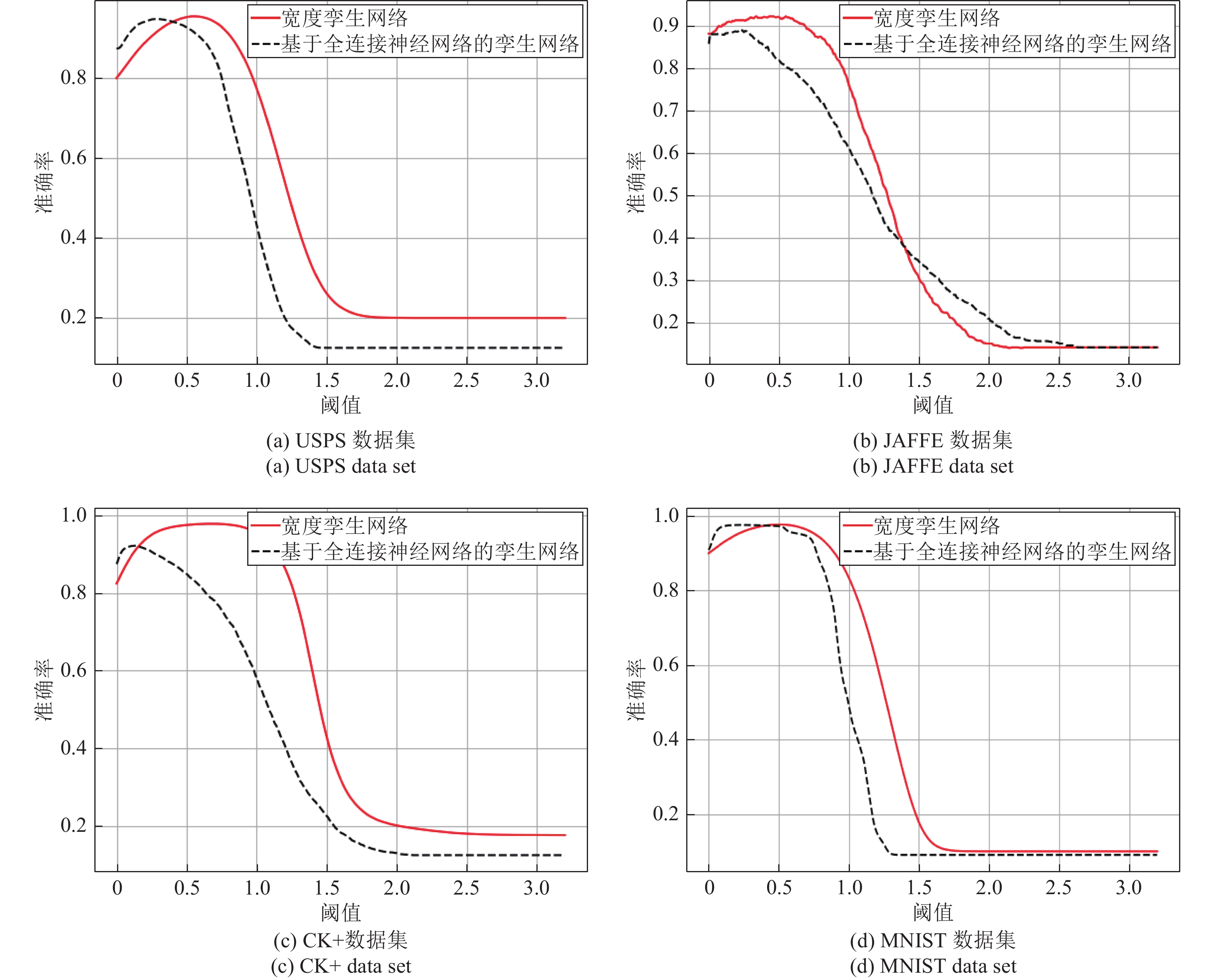
边缘计算是将计算、存储、通信等任务分配到网络边缘的计算模式. 它强调在用户终端附近执行数据处理过程, 以达到降低延迟, 减少能耗, 保护用户隐私等目的. 然而网络边缘的计算、存储、能源资源有限, 这给边缘计算应用的推广带来了新的挑战. 随着边缘智能的兴起, 人们更希望将边缘计算应用与人工智能技术结合起来, 为我们的生活带来更多的便利. 许多人工智能方法, 如传统的深度学习方法, 需要消耗大量的计算、存储资源, 并且伴随着巨大的时间开销. 这不利于强调低延迟的边缘计算应用的推广. 为了解决这个问题, 我们提出将宽度学习系统(Broad learning system, BLS)等浅层网络方法应用到边缘计算应用领域, 并且设计了一种宽度孪生网络算法. 我们将宽度学习系统与孪生网络结合起来用于解决分类问题. 实验结果表明我们的方法能够在取得与传统深度学习方法相似精度的情况下降低时间和资源开销, 从而更好地提高边缘计算应用的性能.
边缘计算是将计算、存储、通信等任务分配到网络边缘的计算模式. 它强调在用户终端附近执行数据处理过程, 以达到降低延迟, 减少能耗, 保护用户隐私等目的. 然而网络边缘的计算、存储、能源资源有限, 这给边缘计算应用的推广带来了新的挑战. 随着边缘智能的兴起, 人们更希望将边缘计算应用与人工智能技术结合起来, 为我们的生活带来更多的便利. 许多人工智能方法, 如传统的深度学习方法, 需要消耗大量的计算、存储资源, 并且伴随着巨大的时间开销. 这不利于强调低延迟的边缘计算应用的推广. 为了解决这个问题, 我们提出将宽度学习系统(Broad learning system, BLS)等浅层网络方法应用到边缘计算应用领域, 并且设计了一种宽度孪生网络算法. 我们将宽度学习系统与孪生网络结合起来用于解决分类问题. 实验结果表明我们的方法能够在取得与传统深度学习方法相似精度的情况下降低时间和资源开销, 从而更好地提高边缘计算应用的性能.





2020, 46(10): 2072-2091.
doi: 10.16383/j.aas.c190586
摘要:
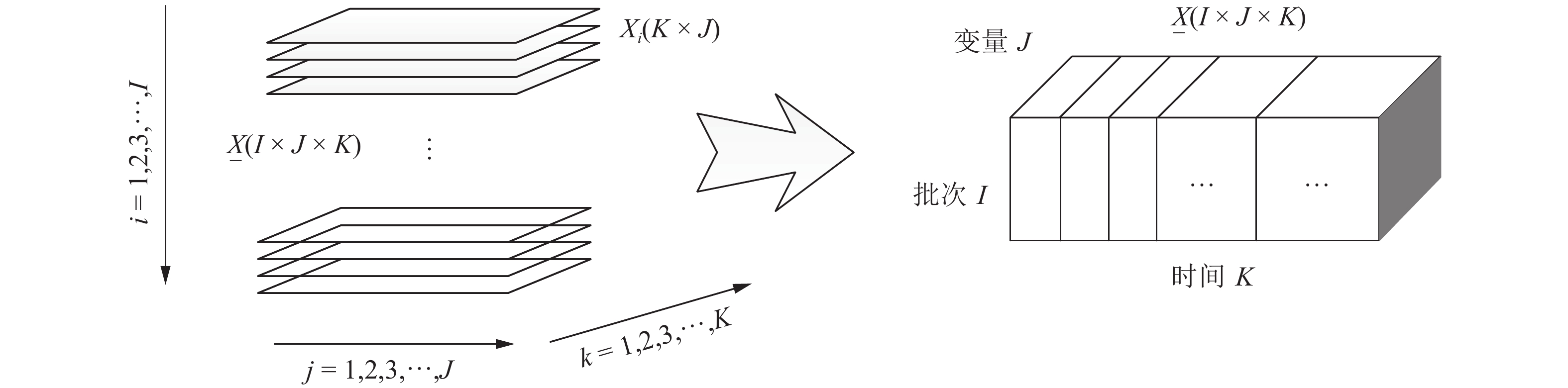
间歇过程作为制造业的重要生产方式之一, 其高效运行是智能制造的优先主题. 为了保障生产过程的高效运行, 面向间歇生产的过程数据解析与状态监控算法在最近三十年间得到大家的广泛关注, 发展速度稳步提升. 但由于间歇过程本身的多重时变大范围非平稳运行复杂特性, 以及对状态监控与故障诊断要求的提高, 现有的理论和方法仍面临着挑战. 本文从分析间歇过程的特性出发, 从数据解析的角度, 总结了近三十年来非平稳间歇过程高性能监控研究的发展. 一方面对间歇过程监控领域几种经典的方法体系进行了总结和梳理, 另一方面揭示了尚存在的问题以及未来可能的研究思路和发展脉络.
间歇过程作为制造业的重要生产方式之一, 其高效运行是智能制造的优先主题. 为了保障生产过程的高效运行, 面向间歇生产的过程数据解析与状态监控算法在最近三十年间得到大家的广泛关注, 发展速度稳步提升. 但由于间歇过程本身的多重时变大范围非平稳运行复杂特性, 以及对状态监控与故障诊断要求的提高, 现有的理论和方法仍面临着挑战. 本文从分析间歇过程的特性出发, 从数据解析的角度, 总结了近三十年来非平稳间歇过程高性能监控研究的发展. 一方面对间歇过程监控领域几种经典的方法体系进行了总结和梳理, 另一方面揭示了尚存在的问题以及未来可能的研究思路和发展脉络.

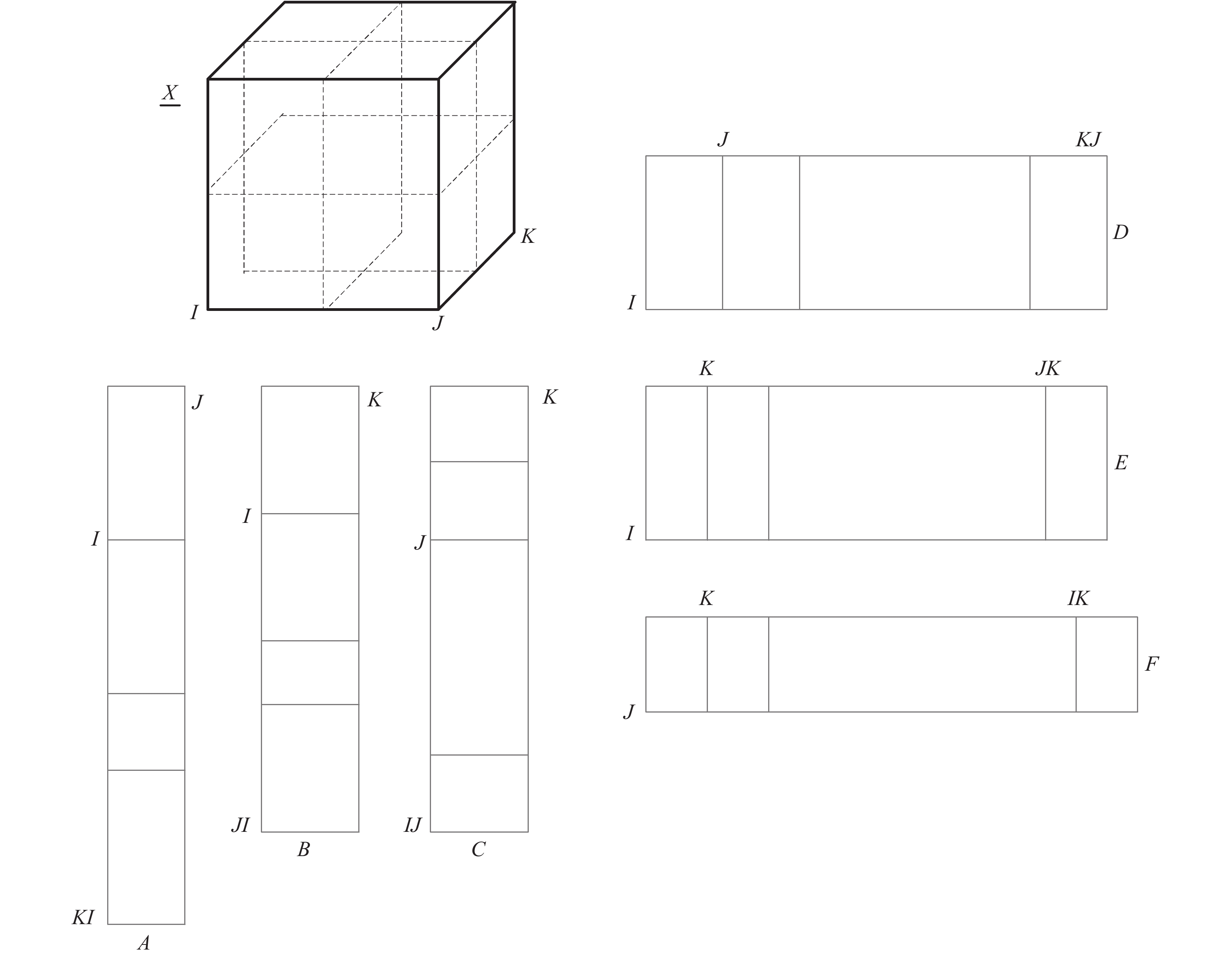



2020, 46(10): 2092-2108.
doi: 10.16383/j.aas.c200294
摘要:
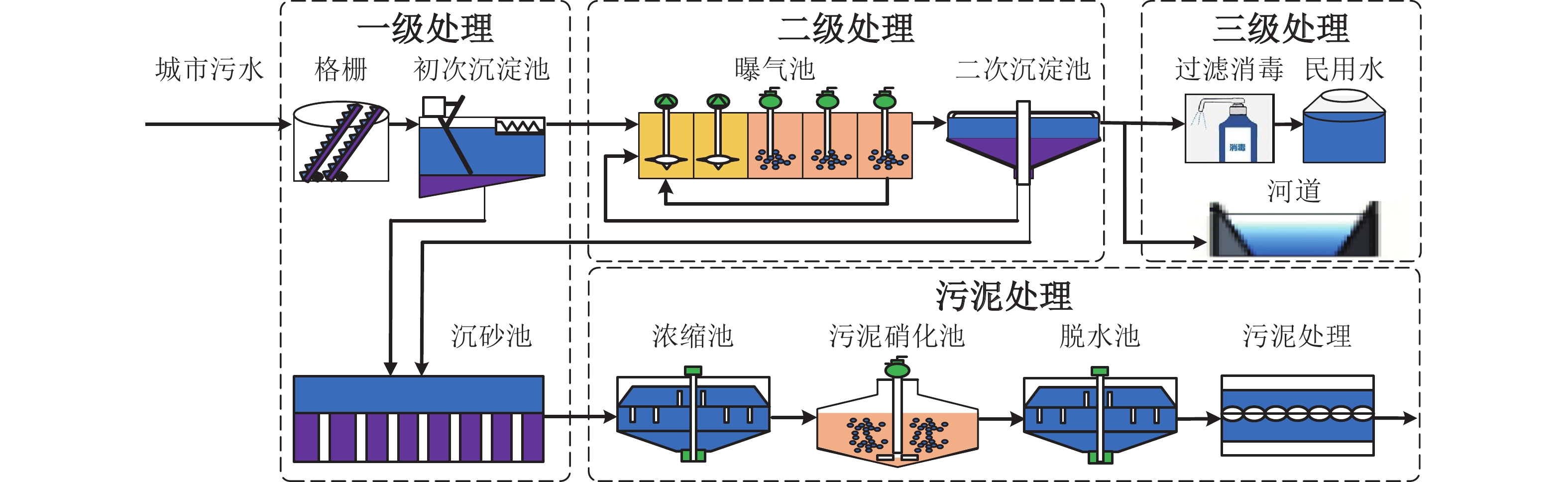
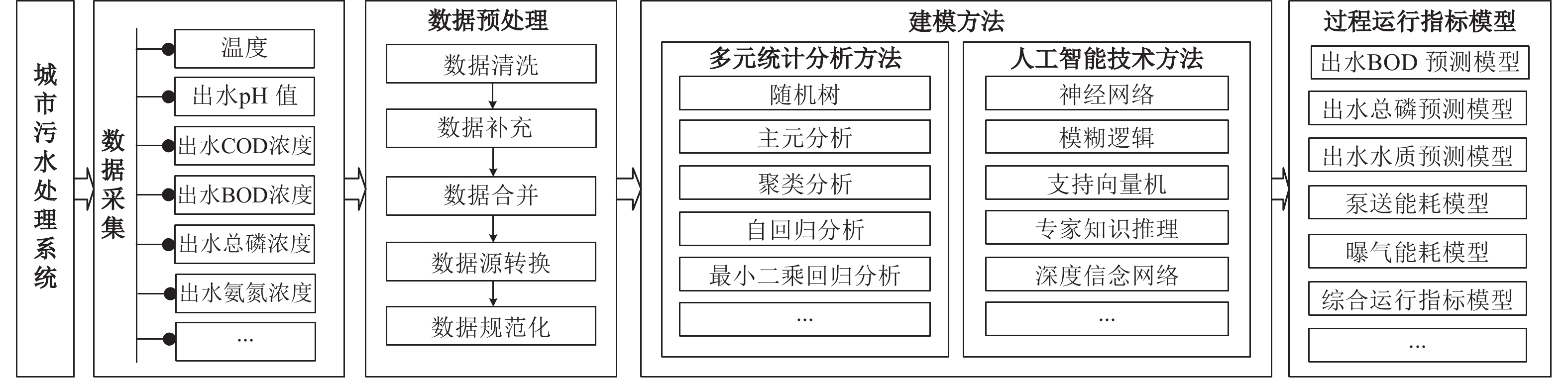
城市污水处理过程优化运行的目标是保证出水水质达标, 降低运行成本. 为了实现该目标, 需要动态更新污水处理过程操作变量的最优设定值. 由于城市污水处理过程具有多变量、多冲突、多目标、多约束、动态、时变等特点, 如何设计精确的污水处理过程运行指标模型, 如何优化过程操作变量的最优设定值, 是实现城市污水处理过程优化运行亟待解决的难题. 本文梳理了城市污水处理过程优化设定方法的研究进展. 首先, 介绍了城市污水处理过程特性和过程优化设定问题; 其次, 分别概述了基于机理和基于数据驱动的城市污水处理过程运行指标建模方法; 然后, 分别讨论了城市污水处理过程单运行指标和多运行指标的操作变量设定值寻优算法; 最后, 展望了城市污水处理过程优化设定问题的未来研究方向.
城市污水处理过程优化运行的目标是保证出水水质达标, 降低运行成本. 为了实现该目标, 需要动态更新污水处理过程操作变量的最优设定值. 由于城市污水处理过程具有多变量、多冲突、多目标、多约束、动态、时变等特点, 如何设计精确的污水处理过程运行指标模型, 如何优化过程操作变量的最优设定值, 是实现城市污水处理过程优化运行亟待解决的难题. 本文梳理了城市污水处理过程优化设定方法的研究进展. 首先, 介绍了城市污水处理过程特性和过程优化设定问题; 其次, 分别概述了基于机理和基于数据驱动的城市污水处理过程运行指标建模方法; 然后, 分别讨论了城市污水处理过程单运行指标和多运行指标的操作变量设定值寻优算法; 最后, 展望了城市污水处理过程优化设定问题的未来研究方向.

2020, 46(10): 2109-2120.
doi: 10.16383/j.aas.c180563
摘要:
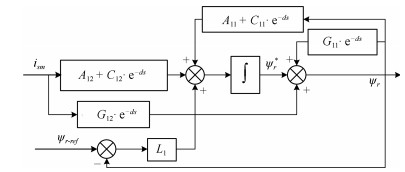
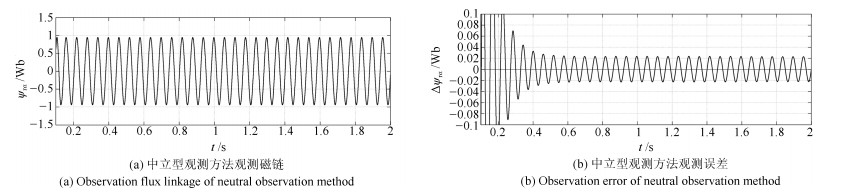
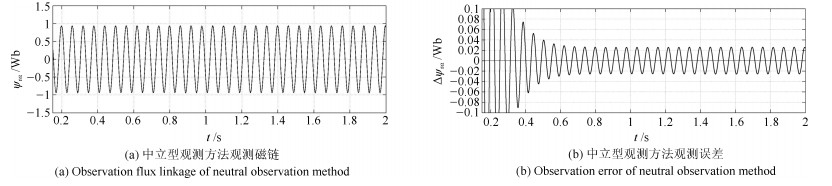
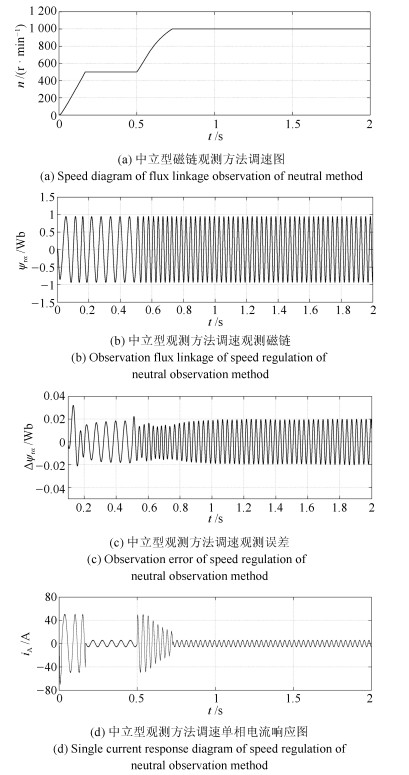
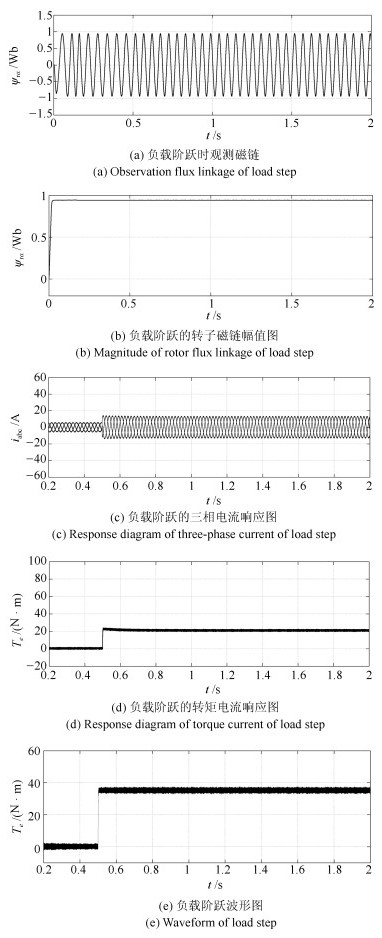
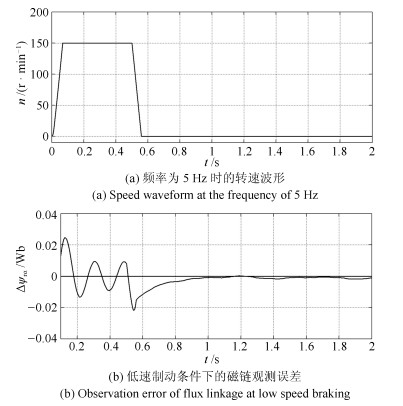
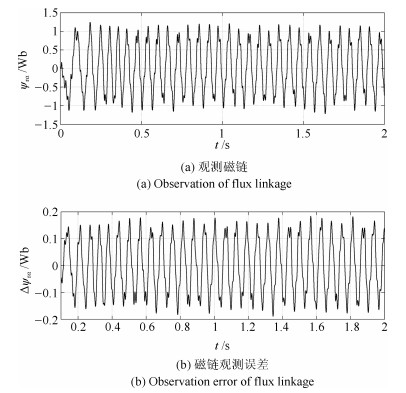
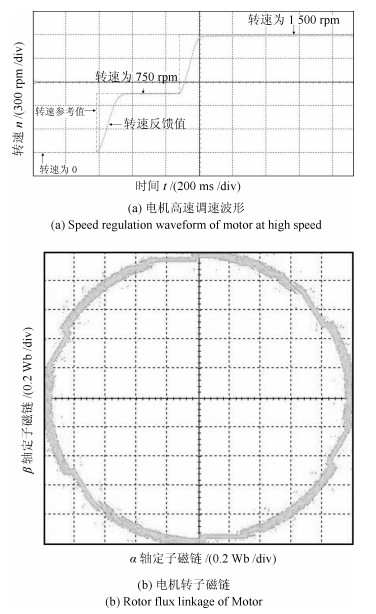
针对感应电机交流传动控制系统磁链观测模型不精确, 忽略控制中的延时问题, 转子磁链观测一般具有观测精度不高、易受电机参数变化影响等问题, 运用中立型理论, 建立中立型感应电机观测模型, 提出一种基于中立型的转子磁链观测方法, 设计了中立型转子磁链观测器.该磁链观测器具有观测精度高、受电机参数变化影响小、鲁棒性好的优点, 通过建立精确的观测模型, 解决控制中延时问题对磁链观测精度的影响.对感应电机中立型磁链观测模型进行了稳定性分析.仿真和实验结果证明了所设计中立型转子磁链观测器的可行性和有效性.
针对感应电机交流传动控制系统磁链观测模型不精确, 忽略控制中的延时问题, 转子磁链观测一般具有观测精度不高、易受电机参数变化影响等问题, 运用中立型理论, 建立中立型感应电机观测模型, 提出一种基于中立型的转子磁链观测方法, 设计了中立型转子磁链观测器.该磁链观测器具有观测精度高、受电机参数变化影响小、鲁棒性好的优点, 通过建立精确的观测模型, 解决控制中延时问题对磁链观测精度的影响.对感应电机中立型磁链观测模型进行了稳定性分析.仿真和实验结果证明了所设计中立型转子磁链观测器的可行性和有效性.
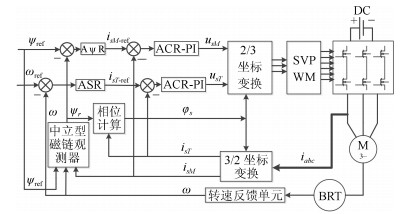
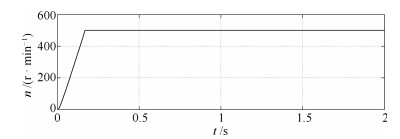
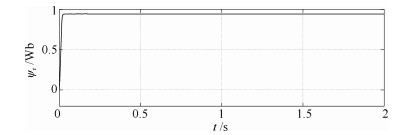
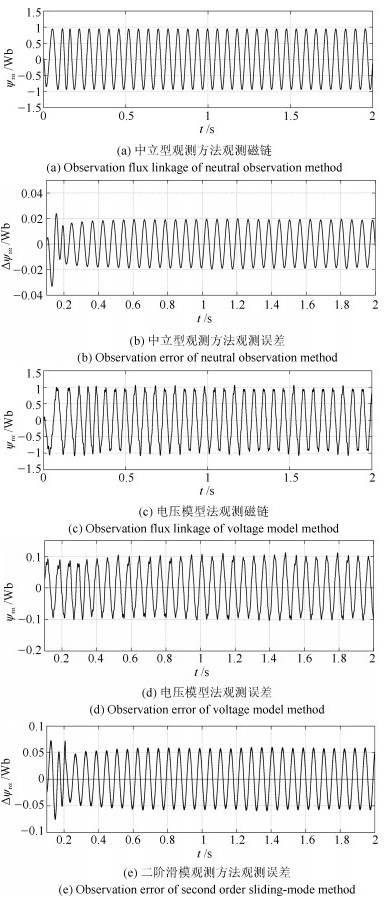




2020, 46(10): 2121-2128.
doi: 10.16383/j.aas.c180555
摘要:
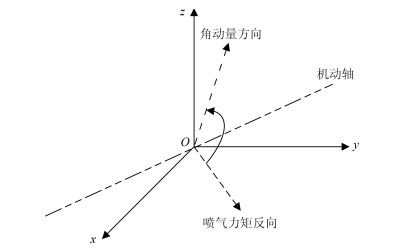
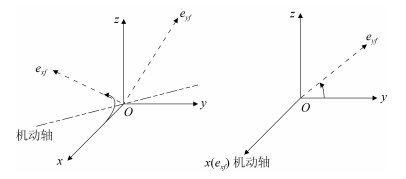
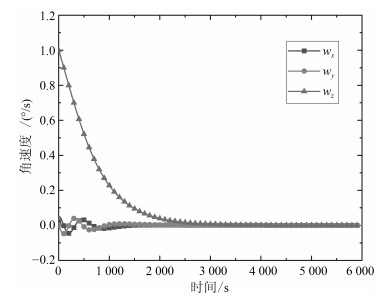
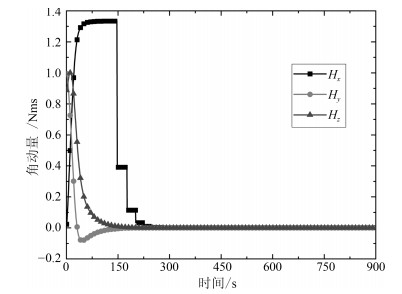
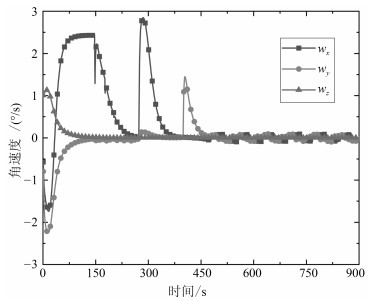
欠驱动航天器的姿态控制能够增强航天器的可靠性.本文针对欠驱动航天器姿态控制, 从喷气姿态阻尼的角动量等效原理出发, 推导脉宽调制公式, 得到燃料消耗最小时给定姿态、非给定姿态两种情况下的喷气最优组合方案.同时, 为了实现喷气全局最优, 提出欠驱动飞轮姿态控制策略, 实现了运动航天器机动至预期姿态.进一步分析欠驱动飞轮航天器的姿态控制原理及稳定性, 提出了共面双飞轮-单喷气的配置方案, 通过双飞轮组合稳定航天器的角速度, 使得航天器到达预期姿态机动时燃料全局最省.结合绕两个旋转轴的姿态机动路径规划方法, 通过姿态机动时序关系的实时分配可实现航天器姿态机动与稳定控制.最后, 通过航天器姿态控制仿真和对比分析, 发现共面双飞轮-单喷气的欠驱动姿态阻尼及姿轨控制方案能够在较少硬件配置下实现对航天器的姿态控制, 且消耗燃料最少.
欠驱动航天器的姿态控制能够增强航天器的可靠性.本文针对欠驱动航天器姿态控制, 从喷气姿态阻尼的角动量等效原理出发, 推导脉宽调制公式, 得到燃料消耗最小时给定姿态、非给定姿态两种情况下的喷气最优组合方案.同时, 为了实现喷气全局最优, 提出欠驱动飞轮姿态控制策略, 实现了运动航天器机动至预期姿态.进一步分析欠驱动飞轮航天器的姿态控制原理及稳定性, 提出了共面双飞轮-单喷气的配置方案, 通过双飞轮组合稳定航天器的角速度, 使得航天器到达预期姿态机动时燃料全局最省.结合绕两个旋转轴的姿态机动路径规划方法, 通过姿态机动时序关系的实时分配可实现航天器姿态机动与稳定控制.最后, 通过航天器姿态控制仿真和对比分析, 发现共面双飞轮-单喷气的欠驱动姿态阻尼及姿轨控制方案能够在较少硬件配置下实现对航天器的姿态控制, 且消耗燃料最少.




2020, 46(10): 2129-2136.
doi: 10.16383/j.aas.c190246
摘要:
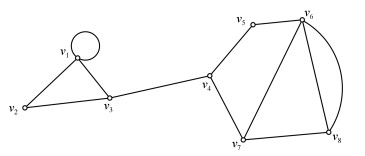
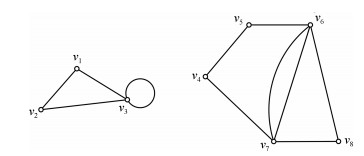
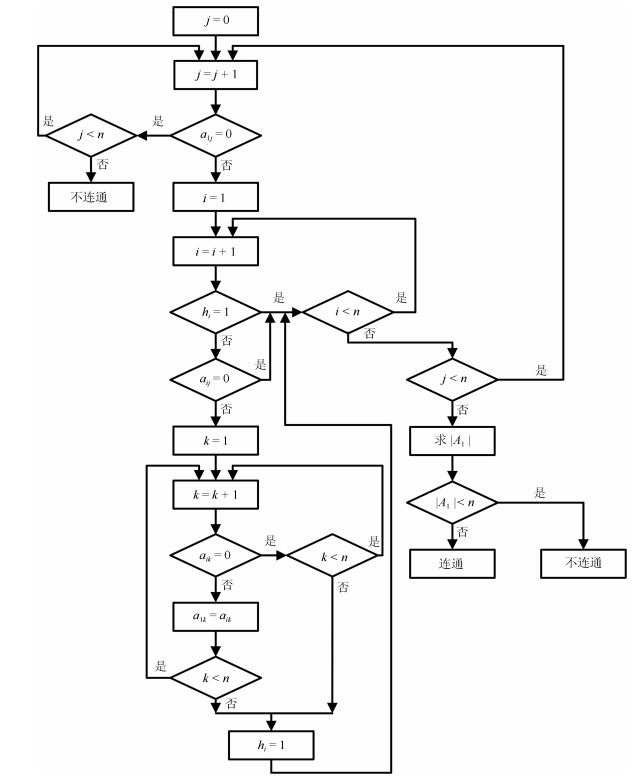
通信网络的拓扑结构连通性是多智能体系统一致性控制或编队控制等的理论前提.以往, 各种多智能体系统一致性控制或编队控制方面的文献仅侧重于控制协议、智能体动力学模型和控制律设计, 而缺乏对多智能体通信网络拓扑结构的连通性研究.网络连通性高效判定算法不仅是大规模多智能体系统一致性控制或编队控制的保证, 而且在图论、现代移动通信、计算机与交通等各种网络中有着重要和广泛的应用.针对复杂无向网络的连通性问题, 本文给出了一种新的高效判定算法、以及该算法的时间复杂度和空间复杂度的上界.该算法具有非常低的时间复杂度和空间复杂度, 且便于计算机实现, 因而具有重要的理论意义和广泛的实用价值.
通信网络的拓扑结构连通性是多智能体系统一致性控制或编队控制等的理论前提.以往, 各种多智能体系统一致性控制或编队控制方面的文献仅侧重于控制协议、智能体动力学模型和控制律设计, 而缺乏对多智能体通信网络拓扑结构的连通性研究.网络连通性高效判定算法不仅是大规模多智能体系统一致性控制或编队控制的保证, 而且在图论、现代移动通信、计算机与交通等各种网络中有着重要和广泛的应用.针对复杂无向网络的连通性问题, 本文给出了一种新的高效判定算法、以及该算法的时间复杂度和空间复杂度的上界.该算法具有非常低的时间复杂度和空间复杂度, 且便于计算机实现, 因而具有重要的理论意义和广泛的实用价值.
2020, 46(10): 2137-2147.
doi: 10.16383/j.aas.c180107
摘要:
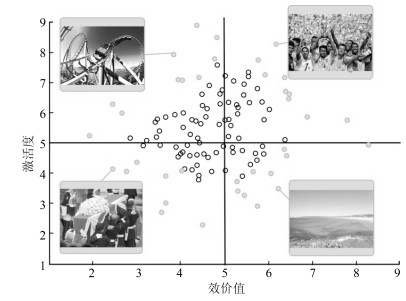
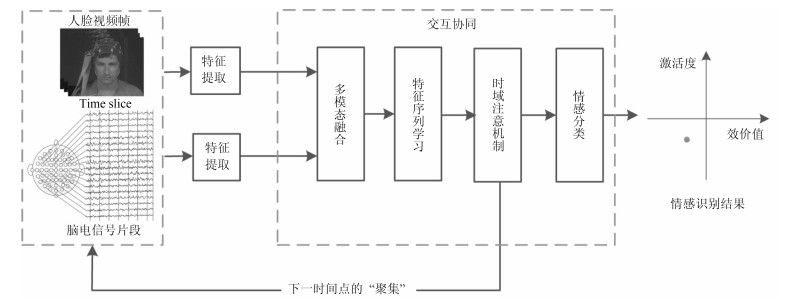
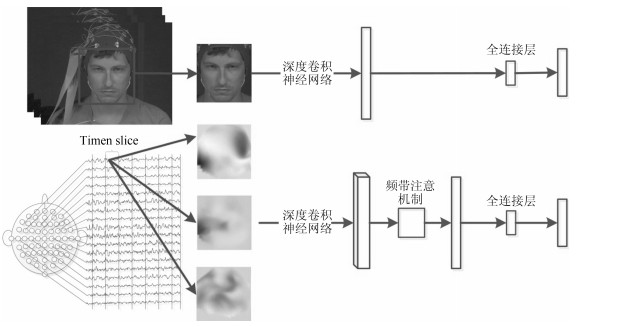
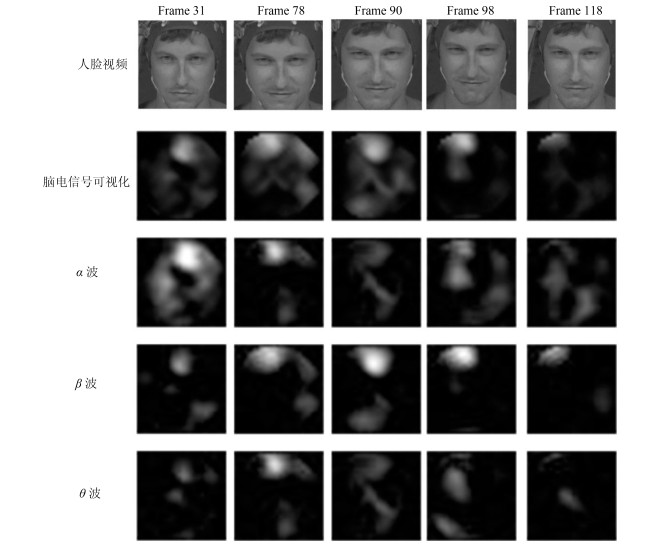
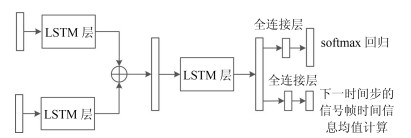
基于视频-脑电信号交互协同的情感识别是人机交互重要而具有挑战性的研究问题.本文提出了基于长短记忆神经网络(Long-short term memory, LSTM)和注意机制(Attention mechanism)的视频-脑电信号交互协同的情感识别模型.模型的输入是实验参与人员观看情感诱导视频时采集到的人脸视频与脑电信号, 输出是实验参与人员的情感识别结果.该模型在每一个时间点上同时提取基于卷积神经网络(Convolution neural network, CNN)的人脸视频特征与对应的脑电信号特征, 通过LSTM进行融合并预测下一个时间点上的关键情感信号帧, 直至最后一个时间点上计算出情感识别结果.在这一过程中, 该模型通过空域频带注意机制计算脑电信号\begin{document}${\alpha}$\end{document} \begin{document}${\beta}$\end{document} \begin{document}${\theta}$\end{document}
基于视频-脑电信号交互协同的情感识别是人机交互重要而具有挑战性的研究问题.本文提出了基于长短记忆神经网络(Long-short term memory, LSTM)和注意机制(Attention mechanism)的视频-脑电信号交互协同的情感识别模型.模型的输入是实验参与人员观看情感诱导视频时采集到的人脸视频与脑电信号, 输出是实验参与人员的情感识别结果.该模型在每一个时间点上同时提取基于卷积神经网络(Convolution neural network, CNN)的人脸视频特征与对应的脑电信号特征, 通过LSTM进行融合并预测下一个时间点上的关键情感信号帧, 直至最后一个时间点上计算出情感识别结果.在这一过程中, 该模型通过空域频带注意机制计算脑电信号



2020, 46(10): 2148-2164.
doi: 10.16383/j.aas.c180695
摘要:
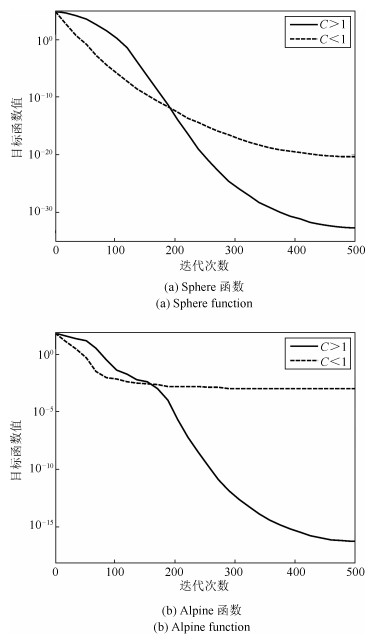
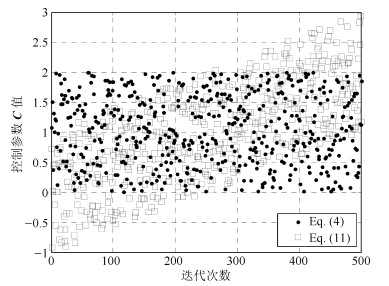
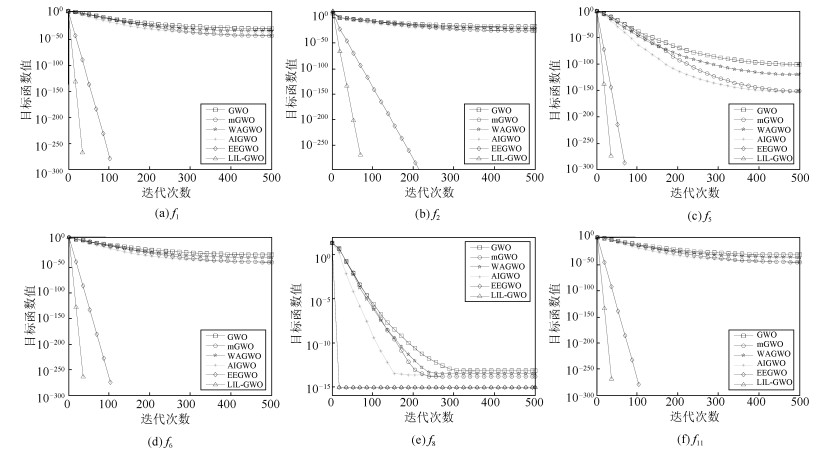
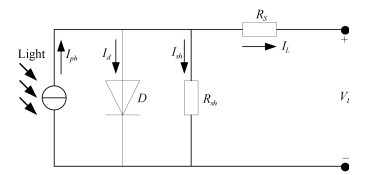
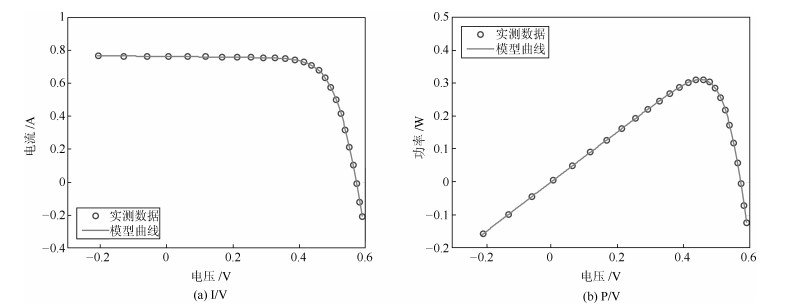
在灰狼优化算法中,\begin{document}$ {{\pmb C}} $\end{document} \begin{document}$ {{\pmb C}} $\end{document} \begin{document}$\alpha$\end{document} \begin{document}$\beta$\end{document} \begin{document}$\delta$\end{document} \begin{document}$ {{\pmb C}} $\end{document} \begin{document}$\pmb C$\end{document}
在灰狼优化算法中,


2020, 46(10): 2165-2176.
doi: 10.16383/j.aas.c190007
摘要:
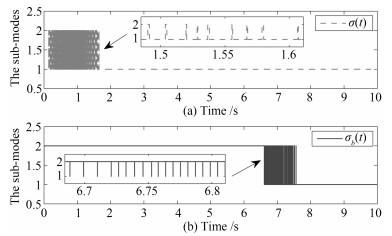
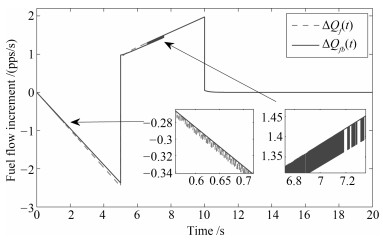
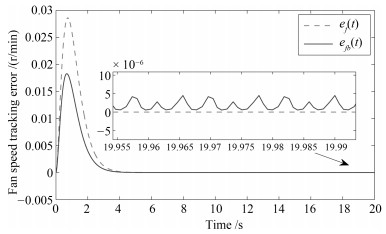
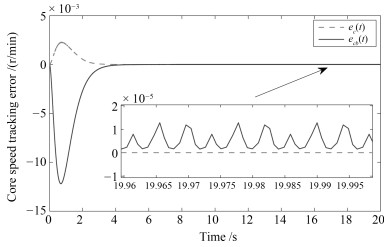
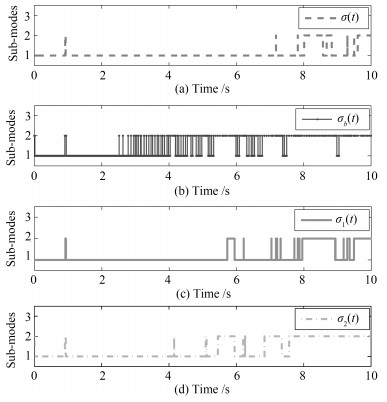
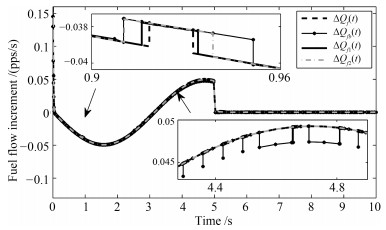
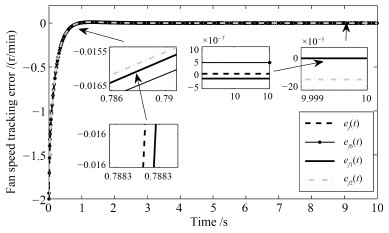
利用多Lyapunov函数方法, 本文研究了一类切换线性系统的状态跟踪无扰切换控制问题.首先, 刻画了控制信号在切换时刻处的抖振抑制水平.其次, 通过控制器与切换律的同时设计, 实现了系统的状态跟踪和控制信号抖振抑制.最后, 将所提出的状态跟踪无扰切换控制策略应用于一个涡扇航空发动机模型的控制设计上, 说明了所提出方法的有效性.
利用多Lyapunov函数方法, 本文研究了一类切换线性系统的状态跟踪无扰切换控制问题.首先, 刻画了控制信号在切换时刻处的抖振抑制水平.其次, 通过控制器与切换律的同时设计, 实现了系统的状态跟踪和控制信号抖振抑制.最后, 将所提出的状态跟踪无扰切换控制策略应用于一个涡扇航空发动机模型的控制设计上, 说明了所提出方法的有效性.

2020, 46(10): 2177-2190.
doi: 10.16383/j.aas.c180251
摘要:
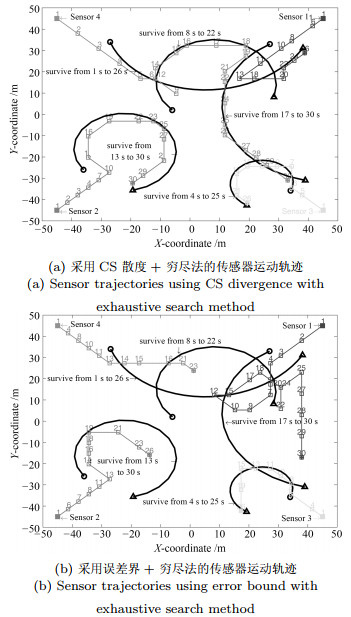
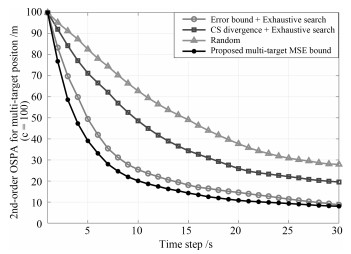
提出了一种新的基于集中式处理结构的有约束多传感器控制算法.该算法将多目标均方误差界作为传感器控制的代价函数.为了应用信息不等式得到该误差界, 2阶最优子模式分配测度被用于度量状态集和其估计集间的误差, 并采用δ-广义标签多伯努利滤波器执行多目标Bayes递推.混合罚函数法和复合形法被用来降低求解该有约束优化问题的计算量.仿真结果表明对于由多个不同观测性能传感器组成的带约束条件的控制系统, 本方法的跟踪精度显著优于柯西-施瓦茨散度法; 并且当传感器个数较多时, 混合罚函数和复合形法的计算时间相比穷尽搜索法显著缩短而跟踪精度损失很小.
提出了一种新的基于集中式处理结构的有约束多传感器控制算法.该算法将多目标均方误差界作为传感器控制的代价函数.为了应用信息不等式得到该误差界, 2阶最优子模式分配测度被用于度量状态集和其估计集间的误差, 并采用δ-广义标签多伯努利滤波器执行多目标Bayes递推.混合罚函数法和复合形法被用来降低求解该有约束优化问题的计算量.仿真结果表明对于由多个不同观测性能传感器组成的带约束条件的控制系统, 本方法的跟踪精度显著优于柯西-施瓦茨散度法; 并且当传感器个数较多时, 混合罚函数和复合形法的计算时间相比穷尽搜索法显著缩短而跟踪精度损失很小.
2020, 46(10): 2191-2213.
doi: 10.16383/j.aas.c190012
摘要:
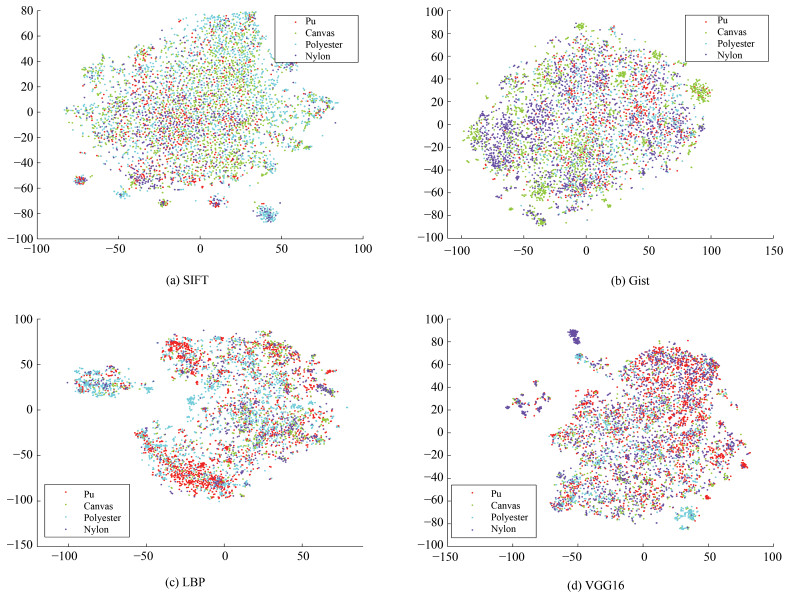
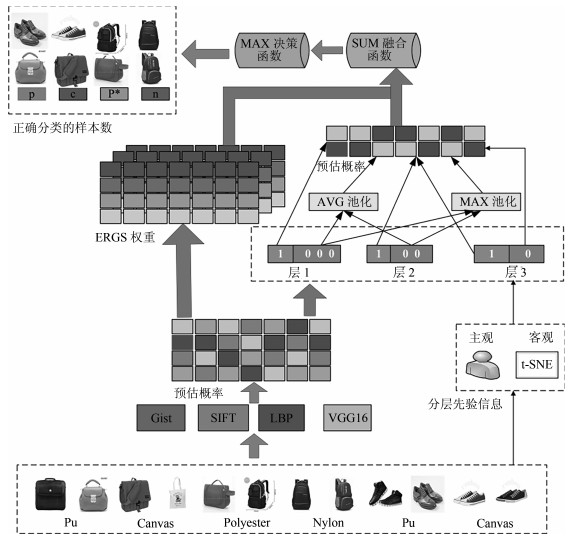
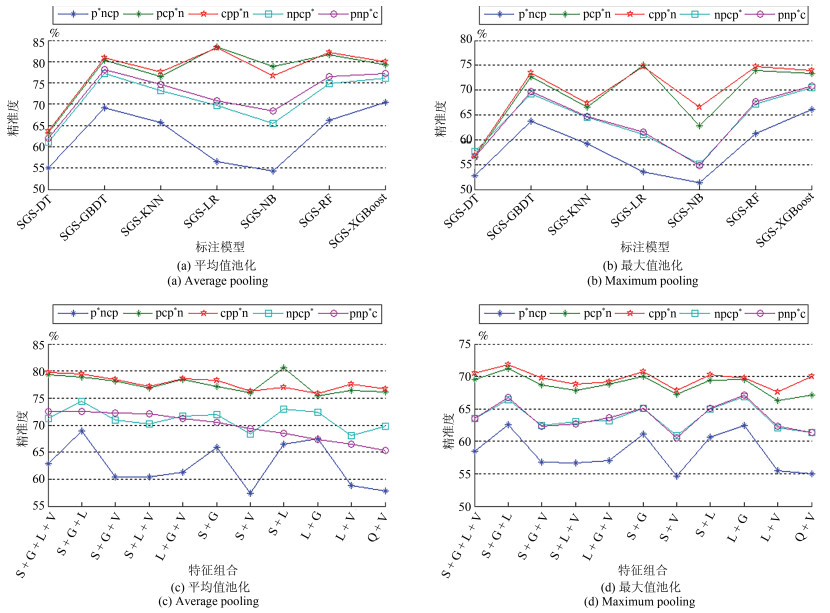
图像材质属性标注在电商平台、机器人视觉、工业检测等领域都具有广阔的应用前景.准确利用特征间的互补性及分类模型的决策能力是提升标注性能的关键.提出分层基因优选多特征融合(Stratified gene selection multi-feature fusion, SGSMFF)算法:提取图像传统及深度学习特征; 采用分类模型计算特征预估概率; 改进有效区域基因优选(Effective range based gene selection, ERGS)算法, 并在其中融入分层先验信息(Stratified priori information, SPI), 逐层、动态地为预估概率计算ERGS权重; 池化预估概率并做ERGS加权, 实现多特征融合.在MattrSet和Fabric两个数据集上完成实验, 结果表明: SGSMFF算法中可加入任意分类模型, 并实现多特征融合; 平均值池化方法、分层先验信息所提供的难分样本信息、"S + G + L"及"S + V"特征组合等均有助于改善材质属性标注性能.在上述两个数据集上, SGSMFF算法的精准度较最强基线分别提升18.70%、15.60%.
图像材质属性标注在电商平台、机器人视觉、工业检测等领域都具有广阔的应用前景.准确利用特征间的互补性及分类模型的决策能力是提升标注性能的关键.提出分层基因优选多特征融合(Stratified gene selection multi-feature fusion, SGSMFF)算法:提取图像传统及深度学习特征; 采用分类模型计算特征预估概率; 改进有效区域基因优选(Effective range based gene selection, ERGS)算法, 并在其中融入分层先验信息(Stratified priori information, SPI), 逐层、动态地为预估概率计算ERGS权重; 池化预估概率并做ERGS加权, 实现多特征融合.在MattrSet和Fabric两个数据集上完成实验, 结果表明: SGSMFF算法中可加入任意分类模型, 并实现多特征融合; 平均值池化方法、分层先验信息所提供的难分样本信息、"S + G + L"及"S + V"特征组合等均有助于改善材质属性标注性能.在上述两个数据集上, SGSMFF算法的精准度较最强基线分别提升18.70%、15.60%.

2020, 46(10): 2214-2220.
doi: 10.16383/j.aas.c180141
摘要:
信息准则在发展主子空间跟踪算法中具有十分重要的意义.目前, 主子空间信息准则还不多见, 为此本文提出了一种新型的主子空间跟踪信息准则.当且仅当神经网络权矩阵收敛到信号主子空间的一个正交基时, 该信息准则取得唯一全局极大值.通过梯度上升法对该信息准则求极值导出了一个主子空间跟踪算法.最后通过仿真实验和实际应用证明了所提算法的正确性和实用性.
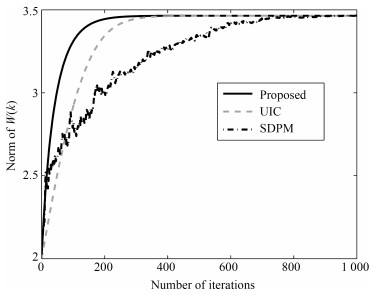
信息准则在发展主子空间跟踪算法中具有十分重要的意义.目前, 主子空间信息准则还不多见, 为此本文提出了一种新型的主子空间跟踪信息准则.当且仅当神经网络权矩阵收敛到信号主子空间的一个正交基时, 该信息准则取得唯一全局极大值.通过梯度上升法对该信息准则求极值导出了一个主子空间跟踪算法.最后通过仿真实验和实际应用证明了所提算法的正确性和实用性.



2020, 46(10): 2221-2228.
doi: 10.16383/j.aas.c180479
摘要:
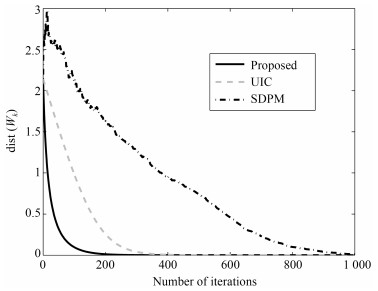
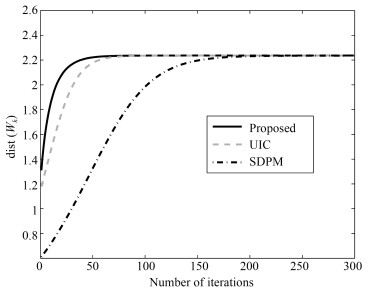
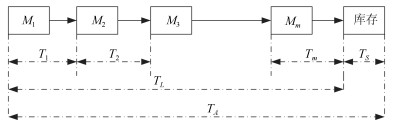
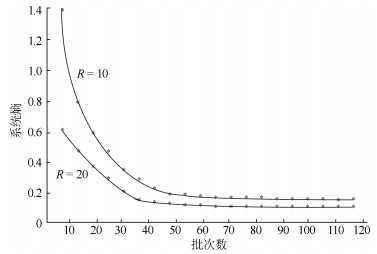
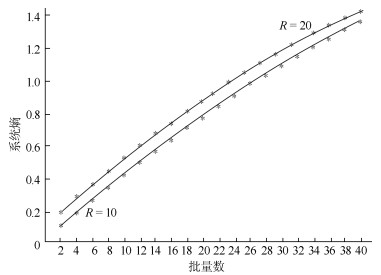
流水车间生产中, 批量及批次的信息量测度意味着对描述不同批量及批次在工作站的状态所需信息量的度量, 即求解批量及批次的信息熵表达.现有批量及批次信息控制研究主要集中在批量调度问题上, 鲜有针对生产中的批量及批次与管理生产所需信息量关系的研究, 造成研究结论很难为决策者从信息管理角度选择生产方式提供理论依据.针对上述问题, 在分析信息熵度量特性基础上, 理论上首次建立流水车间生产线不同批次相同加工时间条件下的批量及批次的信息熵函数, 作为度量生产系统状态所需信息量的基础, 并由此提出生产批次与熵函数变化关系两个定理, 即:生产批次的信息熵函数单调递减; 批次趋于无穷大时, 系统信息熵趋于零.采用求导法与极值法分别对所提定理给予充分证明, 从而理论上证明了流水车间的加工批次增加(或批量减小), 则系统的信息熵降低.分别取工作站数量为10和20进行实证研究, 以图示表达的结果再次验证了所提定理的正确性.批量与批次的信息量测度理论研究, 对实际流水车间生产批量与批次的作业安排及最终生产方式的选择, 都具有重要的理论支撑和现实指导意义.
流水车间生产中, 批量及批次的信息量测度意味着对描述不同批量及批次在工作站的状态所需信息量的度量, 即求解批量及批次的信息熵表达.现有批量及批次信息控制研究主要集中在批量调度问题上, 鲜有针对生产中的批量及批次与管理生产所需信息量关系的研究, 造成研究结论很难为决策者从信息管理角度选择生产方式提供理论依据.针对上述问题, 在分析信息熵度量特性基础上, 理论上首次建立流水车间生产线不同批次相同加工时间条件下的批量及批次的信息熵函数, 作为度量生产系统状态所需信息量的基础, 并由此提出生产批次与熵函数变化关系两个定理, 即:生产批次的信息熵函数单调递减; 批次趋于无穷大时, 系统信息熵趋于零.采用求导法与极值法分别对所提定理给予充分证明, 从而理论上证明了流水车间的加工批次增加(或批量减小), 则系统的信息熵降低.分别取工作站数量为10和20进行实证研究, 以图示表达的结果再次验证了所提定理的正确性.批量与批次的信息量测度理论研究, 对实际流水车间生产批量与批次的作业安排及最终生产方式的选择, 都具有重要的理论支撑和现实指导意义.

2020, 46(10): 2229-2238.
doi: 10.16383/j.aas.c180163
摘要:
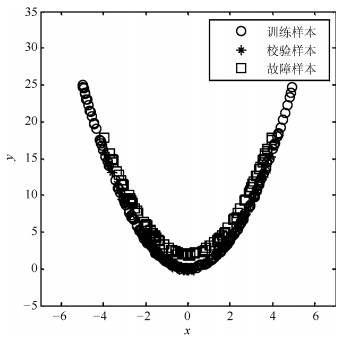
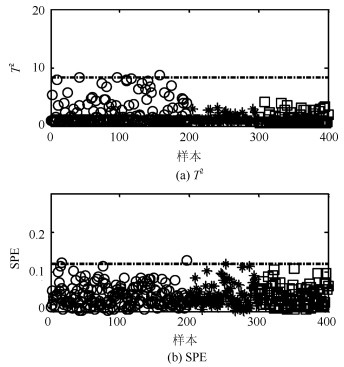
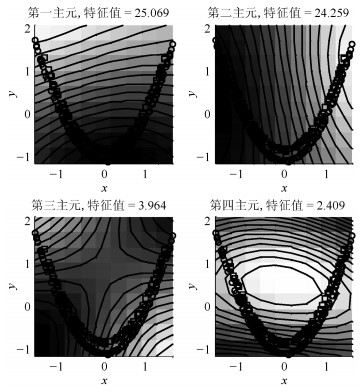
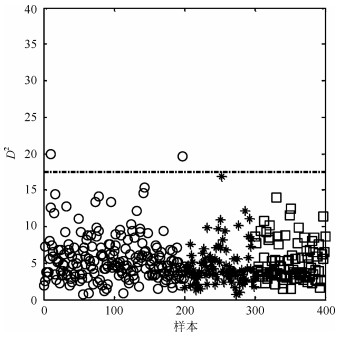
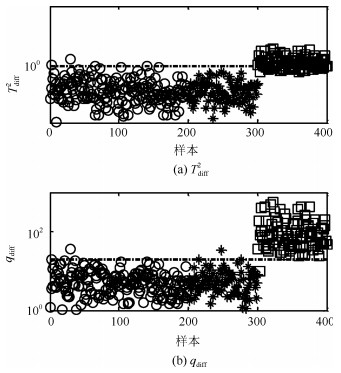
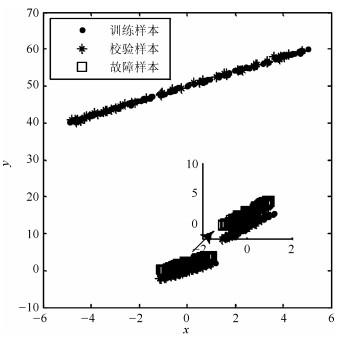
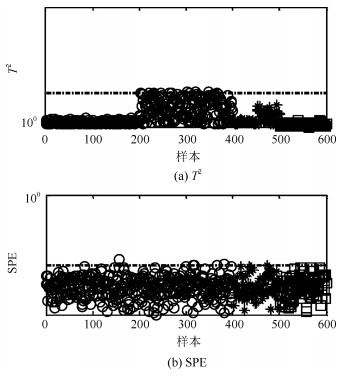
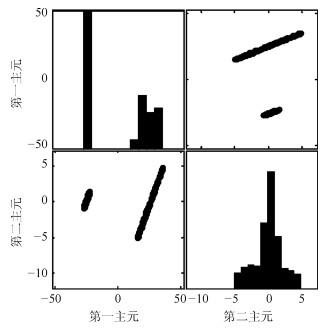
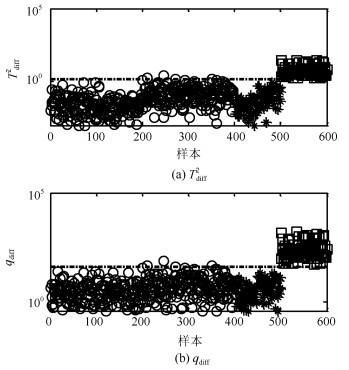
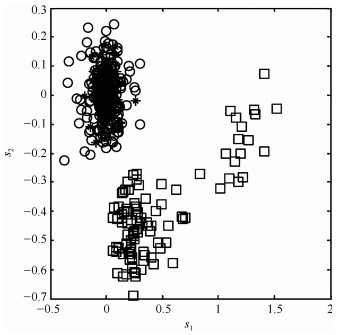
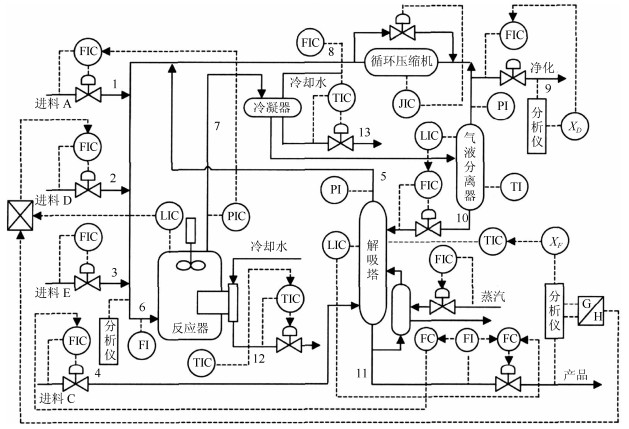
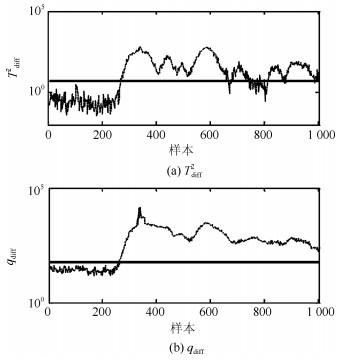
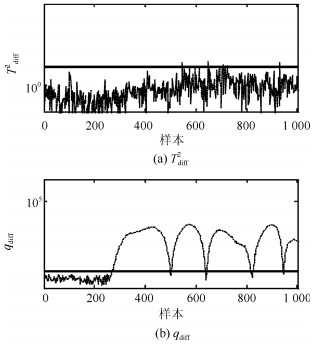
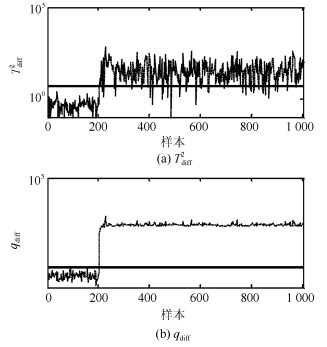
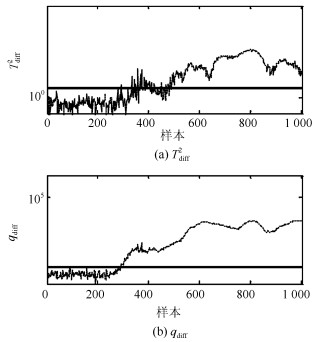
针对具有非线性和多模态特征过程的故障检测问题, 本文提出一种基于k近邻主元得分差分的故障检测策略.首先, 通过主元分析(Principal component analysis, PCA)方法计算样本的真实得分.然后, 应用样本的k近邻均值计算样本估计得分.接下来, 通过上述两种得分计算样本的得分差分矩阵和残差矩阵, 其中残差矩阵由样本的估计得分计算得到,这区别于传统方法.最后, 在差分子空间和残差子空间中分别建立新的统计指标进行故障检测.值得注意的是本文的得分差分方法能够消除数据结构对过程故障检测的影响, 同时, 新的统计量能够提高过程的故障检测率.将本文方法在两个模拟例子和Tennessee Eastman (TE)过程中进行测试, 并与传统方法如PCA、KPCA、DPCA和~FD-kNN等进行对比分析, 测试结果证明了本文方法的有效性.
针对具有非线性和多模态特征过程的故障检测问题, 本文提出一种基于k近邻主元得分差分的故障检测策略.首先, 通过主元分析(Principal component analysis, PCA)方法计算样本的真实得分.然后, 应用样本的k近邻均值计算样本估计得分.接下来, 通过上述两种得分计算样本的得分差分矩阵和残差矩阵, 其中残差矩阵由样本的估计得分计算得到,这区别于传统方法.最后, 在差分子空间和残差子空间中分别建立新的统计指标进行故障检测.值得注意的是本文的得分差分方法能够消除数据结构对过程故障检测的影响, 同时, 新的统计量能够提高过程的故障检测率.将本文方法在两个模拟例子和Tennessee Eastman (TE)过程中进行测试, 并与传统方法如PCA、KPCA、DPCA和~FD-kNN等进行对比分析, 测试结果证明了本文方法的有效性.