

-
摘要: 大量基于深度学习的视频目标分割方法存在两方面局限性: 1)单帧编码特征直接输入网络解码器, 未能充分利用多帧特征, 导致解码器输出的目标表观特征难以自适应复杂场景变化; 2)常采用前馈网络结构, 阻止了后层特征反馈前层进行补充学习, 导致学习到的表观特征判别力受限. 为此, 本文提出了反馈高斯表观网络, 通过建立在线高斯模型并反馈后层特征到前层来充分利用多帧、多尺度特征, 学习鲁棒的视频目标分割表观模型. 网络结构包括引导、查询与分割三个分支. 其中, 引导与查询分支通过共享权重来提取引导与查询帧的特征, 而分割分支则由多尺度高斯表观特征提取模块与反馈多核融合模块构成. 前一个模块通过建立在线高斯模型融合多帧、多尺度特征来增强对外观的表征力, 后一个模块则通过引入反馈机制进一步增强模型的判别力. 最后, 本文在三个标准数据集上进行了大量评测, 充分证明了本方法的优越性能.Abstract: There are two limitations in existing deep learning based video object segmentation methods: 1) the single frame encoding features are directly input into the network decoder, which fails to make full use of the multi-frame features, resulting in the difficulty in adapting complex scene changes of the target appearance features of the decoded output; 2) the feedforward network structure is adopted to prevent the feature feedback of the latter layer from the former layer for complementary learning. Therefore, this paper proposes a feedback Gaussian appearance network. By building an online Gaussian model and feedback the features of the back layer to the front layer, we can make full use of the multi-frame and multi-scale features to learn a robust video object segmentation model. Network structure includes three branches: guidance, query and segmentation branches. The guidance and the query branches extract the features of the guidance frame and the query frame by sharing the weights of the network, while the segmentation branch is composed of the multi-scale Gaussian appearance feature extraction module and the feedback multi-kernel fusion module. The former module enhances the representation of the appearance by building an online Gaussian model to fuse the multi-frame and multi-scale features, and the second module further enhances the discriminative capability of the model by introducing a feedback mechanism. Finally, experiments are carried out on three benchmark datasets, which fully proves the superiority of this method.
-
Key words:
- Video object segmentation /
- appearance model /
- feedback mechanism /
- deep learning
-
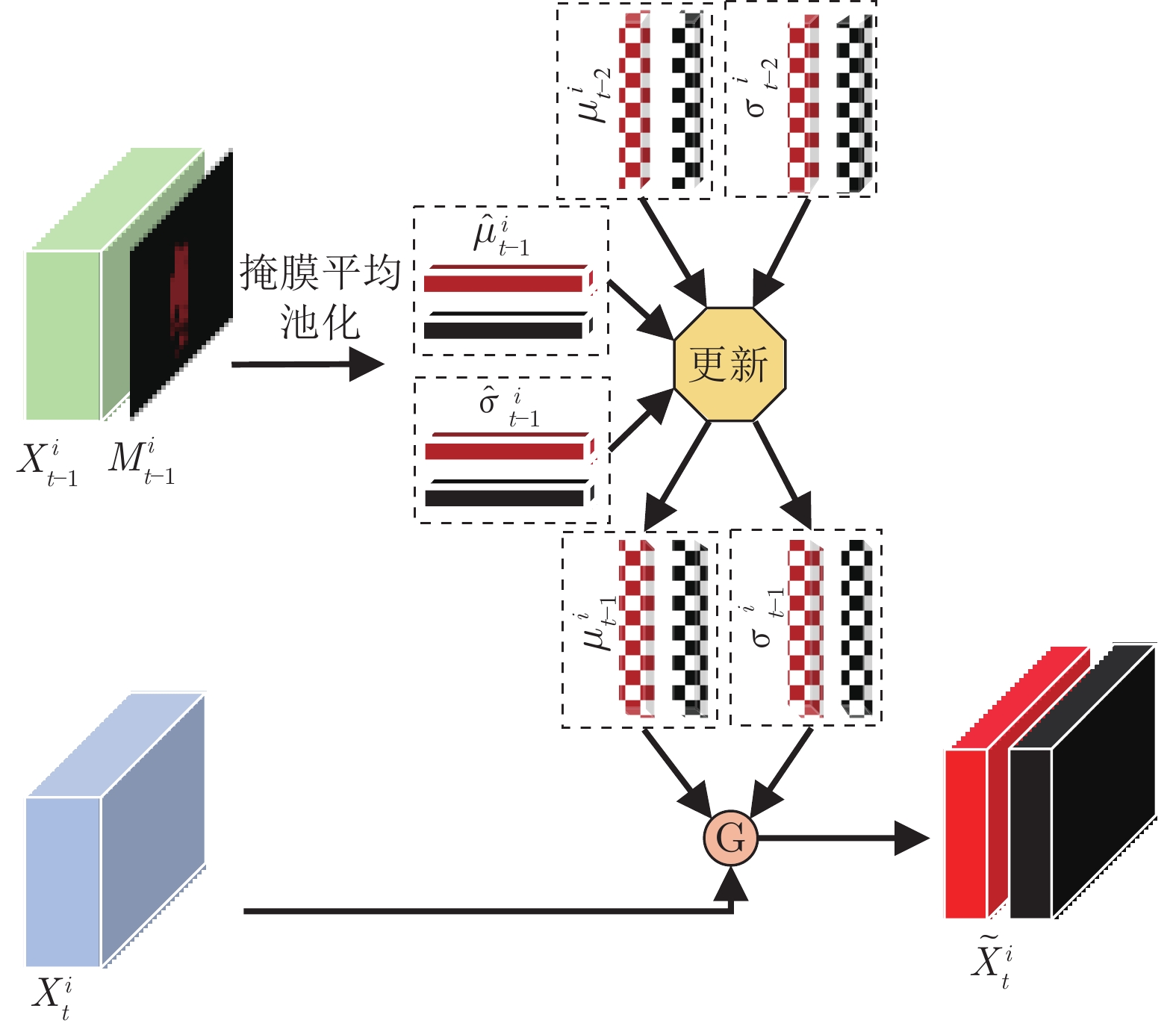
图 2 高斯表观特征提取模块 (G表示高斯模型)
Fig. 2 Gaussian appearance feature extraction module (G denotes Gaussian model)
表 1 不同方法在DAVIS 2016验证集的评估结果
Table 1 Evaluation results of different methods on DAVIS 2016 validation dataset
方法 在线 $J{\rm{\& }}F$ ${J_{{\rm{Mean}}}}$ ${J_{ {\rm{ {\rm{Re} } } } \rm{call}} }$ ${J_{{\rm{Decay}}}}$ ${F_{{\rm{Mean}}}}$ ${F_{{\rm{{\rm{Re}}}} {\rm{call}}}}$ ${F_{{\rm{Decay}}}}$ $T\;({\rm{s}})$ MSK[2] √ 77.6 79.7 93.1 8.9 75.4 87.1 9.0 12 LIP[37] √ 78.5 78.0 88.6 5.0 79.0 86.8 6.0 — OSVOS[1] √ 80.2 79.8 93.6 14.9 80.6 92.6 15.0 9 Lucid[17] √ 83.6 84.8 — 82.3 — — > 30 STCNN[38] √ 83.8 83.8 96.1 4.9 83.8 91.5 6.4 3.9 CINM[39] √ 84.2 83.4 94.9 12.3 85.0 92.1 14.7 > 30 OnAVOS[13] √ 85.5 86.1 96.1 5.2 84.9 89.7 5.8 13 OSVOSS[21] √ 86.6 85.6 96.8 5.5 87.5 95.9 8.2 4.5 PReMVOS[22] √ 86.8 84.9 96.1 8.8 88.6 94.7 9.8 > 30 MHP[14] √ 86.9 85.7 96.6 — 88.1 94.8 — > 14 VPN[40] × 67.9 70.2 82.3 12.4 65.5 69.0 14.4 0.63 OSMN[4] × 73.5 74.0 87.6 9.0 72.9 84.0 10.6 0.14 VM[24] × — 81.0 — — — — — 0.32 FAVOS[41] × 81.0 82.4 96.5 4.5 79.5 89.4 5.5 1.8 FEELVOS[25] × 81.7 81.1 90.5 13.7 82.2 86.6 14.1 0.45 RGMP[16] × 81.8 81.5 91.7 10.9 82.0 90.8 10.1 0.13 AGAM[15] × 81.8 81.4 93.6 9.4 82.1 90.2 9.8 0.07 RANet[3] × 85.5 85.5 97.2 6.2 85.4 94.9 5.1 0.03 本文算法 × 85.0 84.6 97.1 5.8 85.3 93.3 7.2 0.1  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在DAVIS 2017验证集的评估结果
Table 2 Evaluation results of different methods on DAVIS 2017 validation dataset
方法 在线 $J$ $F$ $T\;({\rm{s}})$ MSK[2] √ 51.2 57.3 15 OSVOS[1] √ 56.6 63.9 11 LIP[37] √ 59.0 63.2 — STCNN[38] √ 58.7 64.6 6 OnAVOS[13] √ 61.6 69.1 26 OSVOSS[21] √ 64.7 71.3 8 CINM[39] √ 67.2 74.0 50 MHP[14] √ 71.8 78.8 20 OSMN[4] × 52.5 57.1 0.28 FAVOS[41] × 54.6 61.8 1.2 VM[24] × 56.6 68.2 0.35 RANet[3] × 63.2 68.2 — RGMP[16] × 64.8 68.6 0.28 AGSS[42] × 64.9 69.9 — AGAM[15] × 67.2 72.7 — DMMNet[43] × 68.1 73.3 0.13 FEELVOS[25] × 69.1 74.0 0.51 本文算法 × 70.7 76.2 0.14
下载: 导出CSV
表 3 不同方法在DAVIS 2017测试集的评估结果
Table 3 Evaluation results of different methods on DAVIS 2017 test-dev dataset
下载: 导出CSV
表 4 不同方法在YouTube-VOS验证集的评估结果
Table 4 Evaluation results of different methods on YouTube-VOS validation dataset
方法 在线 $G$ ${J_S}$ ${F_s}$ ${J_u}$ ${F_u}$ MSK[2] √ 53.1 59.9 59.5 45.0 47.9 OnAVOS[13] √ 55.2 60.1 62.7 46.6 51.4 OSVOS[1] √ 58.8 59.8 60.5 54.2 60.7 S2S[45] √ 64.4 71.0 70.0 55.5 61.2 OSMN[4] × 51.2 60.0 60.1 40.6 44.0 DMMNet[43] × 51.7 58.3 60.7 41.6 46.3 RGMP[16] × 53.8 59.5 — 45.2 — RVOS[46] × 56.8 63.6 67.2 45.5 51.0 S2S[45] × 57.6 66.7 — 48.2 — Capsule[44] × 62.3 67.3 68.1 53.7 59.9 PTSNet[47] × 63.2 69.1 — 53.5 — AGAM[15] × 66.0 66.9 — 61.2 — 本文算法 × 68.1 69.9 72.3 62.1 68.3
下载: 导出CSV
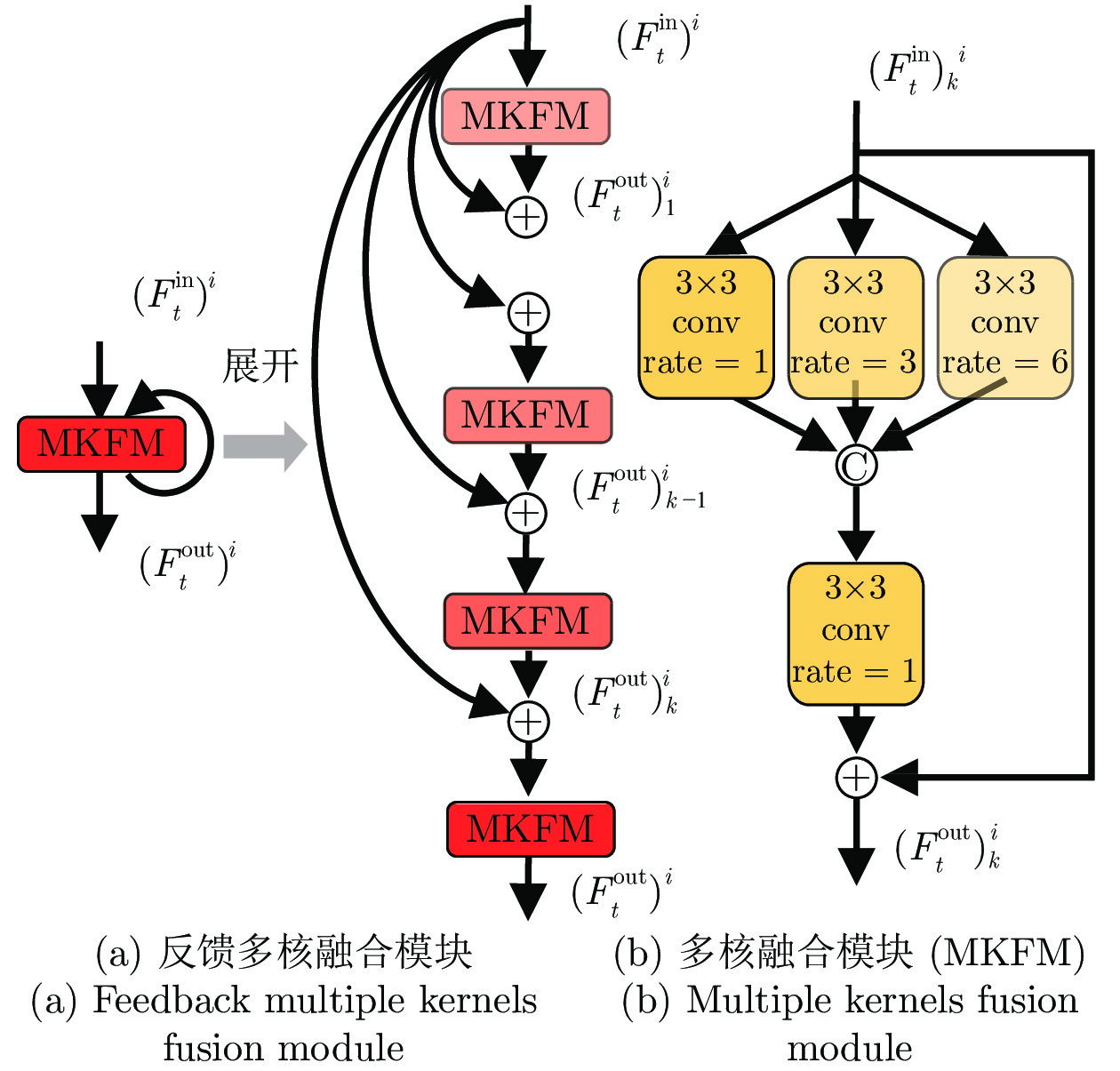
表 5 消融实验(M, F和f分别代表多尺度高斯表观特征提取模块、反馈多核融合模块和反馈机制)
Table 5 Ablative experiments (M, F, f, denotes the multi-level Gaussian feature module, feedback multi-kernel fusion module and feedback mechanism, respectively)
算法变体 本文算法 ${\rm{ - }}M$ ${\rm{ - }}F$ ${\rm{ - }}f$ ${\rm{ - }}M{\rm{ - }}F$ $J \;({\text{%} })$ 70.7 62.2 66.6 69.1 59.8
下载: 导出CSV
表 6 不同反馈次数对比
Table 6 Comparisons with different numbers of feedback
反馈次数 k 0 1 2 3 4 $J$ (%) 69.1 69.9 70.3 70.7 70.7 $T\;(\text {ms})$ 132 135 137 140 142
下载: 导出CSV
-
[1] Caelles S, Maninis K, Ponttuset J, Lealtaixe L, Cremers D, Van Gool L. One-shot video object segmentation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 221−230 [2] Perazzi F, Khoreva A, Benenson R, Schiele B, Sorkinehornung A. Learning video object segmentation from static images. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 2663−2672 [3] Wang Z Q, Xu J, Liu L, Zhu F, Shao L. Ranet: Ranking attention network for fast video object segmentation. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019. 3978−3987 [4] Yang L J, Wang Y R, Xiong X H, Yang J C, Katsaggelos A K. Efficient video object segmentation via network modulation. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6499−6507 [5] 薄一航, Hao Jiang. 视频中旋转与尺度不变的人体分割方法. 自动化学报, 2017, 43(10): 1799--1809.Bo Yi-Hang, Hao Jiang. A rotation- and scale-invariant human parts segmentation in videos. Acta Automatica Sinica, 2017, 43(10): 1799--1809. [6] 褚一平, 张引, 叶修梓, 张三元. 基于隐条件随机场的自适应视频分割算法[J]. 自动化学报, 2007, 33(12): 1252—1258.Chu Yi-Ping, Zhang Yin, Ye Xiu-Zi, Zhang San-Yuan. Adaptive Video Segmentation Algorithm Using Hidden Conditional Random Fields. Acta Automatica Sinica, 2007, 33(12): 1252--1258. [7] Li Y, Sun J, Shum H Y. Video object cut and paste. In: Proceedings of the 2005 Special Interest Group on Computer Graphics and Interactive Techniques Conference. Los Angeles, USA: ACM, 2005. 595−600 [8] Wang W G, Shen J B, and Porikli F. Selective video object cutout. In: IEEE Transactions on Image Processing, 2017, 26(12): 5645--5655. doi: 10.1109/TIP.2017.2745098 [9] Wang Q, Zhang L, Bertinetto L, Hu W M, Torr P H. Fast online object tracking and segmentation: A unifying approach. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 1328−1338 [10] Yeo D H, Son J, Han B Y, Hee Han J. Superpixelbased tracking-by-segmentation using markov chains. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 1812−1821 [11] Guo J M, Li Z W, Cheong L F, Zhou S Z. Video co-segmentation for meaningful action extraction. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 2232−2239 [12] 钱银中, 沈一帆. 姿态特征与深度特征在图像动作识别中的混合应用. 自动化学报, 2019, 45(3): 626--636.Qian Yin-Zhong, Shen Yi-Fan. Hybrid of pose feature and depth feature for action recognition in static image. Acta Automatica Sinica, 2019, 45(3): 626--636. [13] Voigtlaender P, Leibe B. Online adaptation of convolutional neural networks for video object segmentation, ArXiv Preprint, ArXiv: 1706.09364, 2017. [14] Xu S J, Liu D Z, Bao L C, Liu W, Zhou P. Mhpvos: Multiple hypotheses propagation for video object segmentation. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 314−323 [15] Johnander J, Danelljan M, Brissman E, Khan F S, Felsberg M. A generative appearance model for end to-end video object segmentation. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 8953−8962 [16] Oh S W, Lee J, Sunkavalli K, Kim S J. Fast video object segmentation by reference-guided mask propagation. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7376−7385 [17] Khoreva A, Benenson R, Ilg E, Brox T, Schiele B. Lucid data dreaming for object tracking. DAVIS Challenge on Video Object Segmentation, 2017. [18] Oh S W, Lee J, Xu N, Kim S J. Video object segmentation using space-time memory networks. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019. 9226−9235 [19] Cao C S, Liu X M, Yang Y, Yu Y, Wang J, Wang Z L, Huang Y Z, Wang L, Huang C, Xu W, Ramanan D, Huang T S. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2956−2964 [20] Zamir A R, Wu T L, Sun L, Shen W B, Shi B E, Malik J, Savarese S. Feedback networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 1308−1317 [21] Maninis K, Caelles S, Chen Y H, Ponttuset J, Lealtaixe L, Cremers D, Van Gool L. Video object segmentation without temporal information. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(6): 1515−1530 [22] Luiten J, Voigtlaender P, Leibe B. Premvos: Proposal-generation, refinement and merging for video object segmentation. In: Proceedings of the 2018 Asian Conference on Computer Vision. Perth Australia: Springer, 2018. 565−580 [23] Caelles S, Montes A, Maninis K, Chen Y H, Van Gool L, Perazzi F, Ponttuset J. The 2018 DAVIS challenge on video object segmentation. ArXiv preprint: ArXiv: 1803.00557, 2018. [24] Hu Y T, Huang J B, Schwing A G. Videomatch: Matching based video object segmentation. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Spring, 2018. 54−70 [25] Voigtlaender P, Chai Y N, Schroff F, Adam H, Leibe B, Chen L C. Feelvos: Fast end-to-end embedding learning for video object segmentation. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 9481−9490 [26] Robinson A, Lawin F J, Danelljan M, Khan F S, Felsberg M. Discriminative online learning for fast video object segmentation, ArXiv preprint: ArXiv: 1904.08630, 2019. [27] Li Z, Yang J L, Liu Z, Yang X M, Jeon G, Wu W. Feedback network for image super-resolution. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 3867−3876 [28] Wei J, Wang S H, Huang Q M. F3net: Fusion, feedback and focus for salient object detection. In: Proceedings of the 2019 AAAI Conference on Artificial Intelligence. Hilton Hawaiian Village, Honolulu, Hawaii, USA: Spring, 2019. [29] Sam D B, Babu R V. Top-down feedback for crowd counting convolutional neural network. In: Proceedings of the 2018 AAAI Conference on Artificial Intelligence. New Orleans, USA: Spring, 2018. [30] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 2015 International Conference on Medical Image Computing and Computer-assisted Intervention. Munich, Germany: Springer, Cham, 2015. 234−241 [31] Zhang K H and Song H H. Real-time visual tracking via online weighted multiple instance learning. Pattern Recognition, 2013, 46(1): 397—411. doi: 10.1016/j.patcog.2012.07.013 [32] Chen L C, Papandreou G, Kokkinos I, Murphy K, and Yuille A L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(4), 834--848. doi: 10.1109/TPAMI.2017.2699184 [33] Ponttuset J, Perazzi F, Caelles S, Arbelaez P, Sorkinehornung A, Van G L. The 2017 DAVIS challenge on video object segmentation. ArXiv Preprint, ArXiv: 1704.00675, 2017. [34] Xu N, Yang L J, Fan Y C, Yue D C, Liang Y C, Yang J C, Huang T S. Youtube-vos: A large-scale video object segmentation benchmark. ArXiv preprint: ArXiv: 1809.03327, 2018. [35] Kingma D P, Ba J. Adam: A method for stochastic optimization. ArXiv preprint ArXiv: 1412.6980, 2014. [36] Perazzi F, Ponttuset J, Mcwilliams B, Van Gool L, Gross M, Sorkinehornung A. A benchmark dataset and evaluation methodology for video object segmentation. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA, IEEE: 2016. 724−732 [37] Lv Y, Vosselman G, Xia G S, Ying Y M. Lip: Learning instance propagation for video object segmentation. In: Proceedings of the 2019 IEEE International Conference on Computer Vision Workshops. Seoul, Korea (South): IEEE, 2019. [38] Xu K, Wen L Y, Li G R, Bo L F, Huang Q M. Spatiotemporal CNN for video object segmentation. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 1379−1388 [39] Bao L C, Wu B Y, Liu W. CNN in MRF: Video object segmentation via inference in a CNN-based higher-order spatio-temporal MRF. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5977−5986 [40] Jampani V, Gadde R, Gehler P V. Video propagation networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 451−461 [41] Cheng J C, Tsai Y H, Hung W C, Wang S J, Yang M H. Fast and accurate online video object segmentation via tracking parts. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7415−7424 [42] Lin H J, Qi X J, Jia J Y. AGSS-VOS: Attention guided single-shot video object segmentation. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019. 3948−3956 [43] Zeng X H, Liao R J, Gu L, Xiong Y W, Fidler S, Urtasun R. DMM-net: Differentiable mask-matching network for video object segmentation. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019. 3929−3938 [44] Duarte K, Rawat Y S, Shah M. Capsulevos: Semisupervised video object segmentation using capsule routing. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019. 8480−8489 [45] Xu N, Yang L J, Fan Y C, Yang J C, Yue D C, Liang Y C, Cohen S, Huang T. Youtubevos: Sequence-to-sequence video object segmentation. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Spring, 2018. 585−601 [46] Ventura C, Bellver M, Girbau A, Salvador A, Marques F, Giroinieto X. Rvos: End-to-end recurrent network for video object segmentation. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 5277−5286 [47] Zhou Q, Huang Z L, Huang L C, Gong Y C, Shen H, Huang C, Liu W Y, Wang X. Proposal, tracking and segmentation (PTS): A cascaded network for video object segmentation. ArXiv Preprint ArXiv: 1907.01203, 2019. -

 下载:
下载:



计量
- 文章访问数: 1374
- HTML全文浏览量: 564
- PDF下载量: 167
- 被引次数: 0
