2022年 第48卷 第3期
2022, 48(3): 627-643.
doi: 10.16383/j.aas.c210118
摘要:
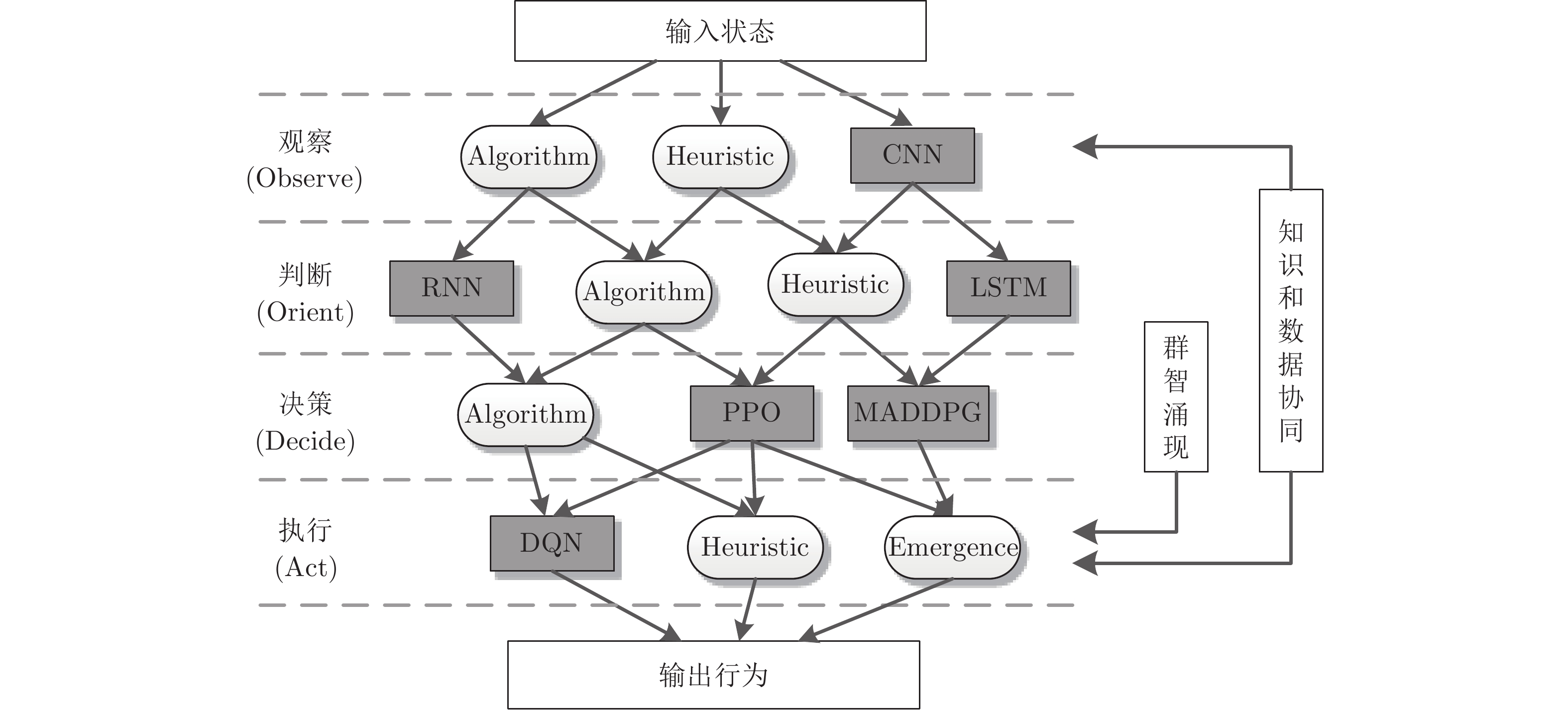
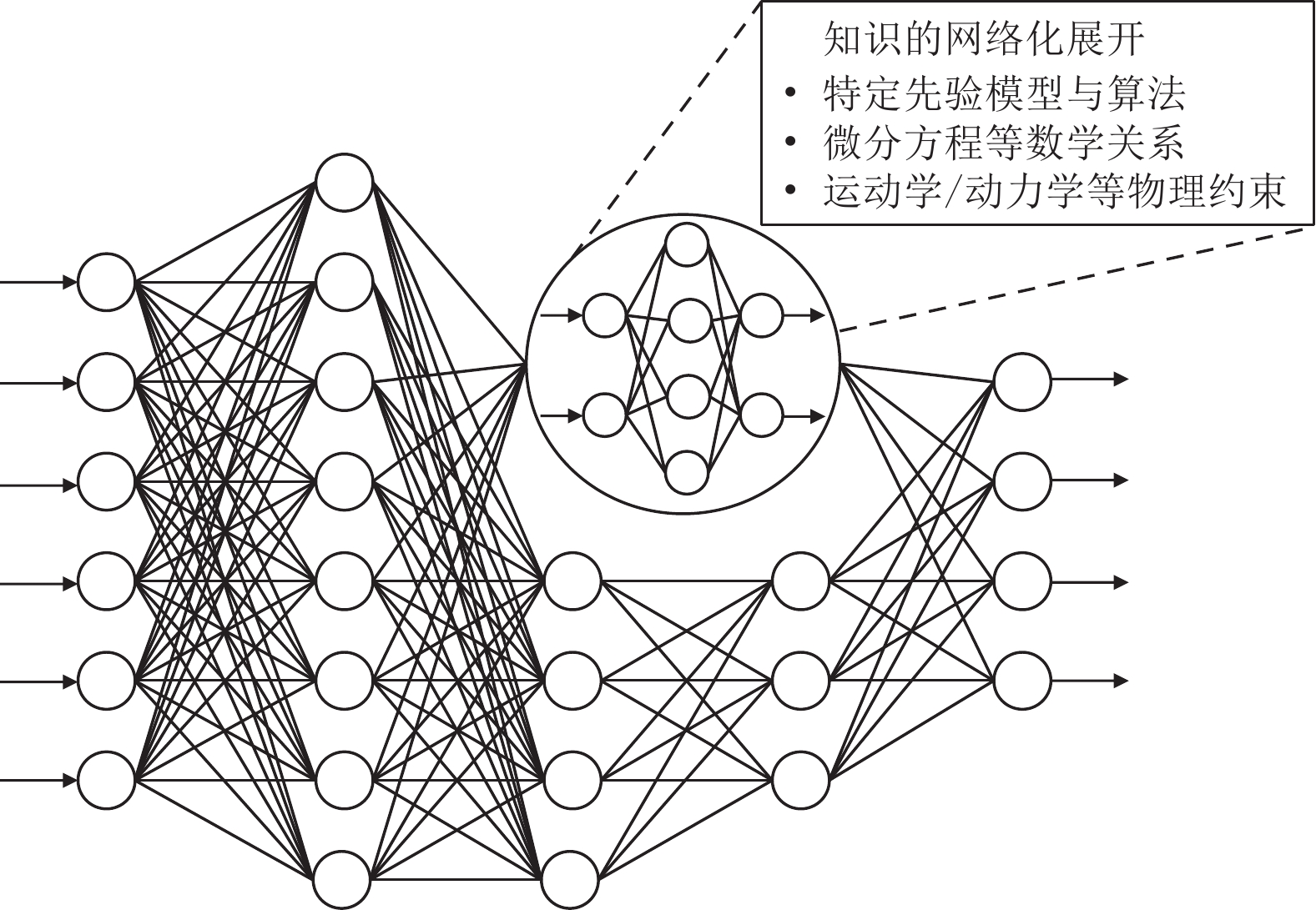
群体智能(Collectire intelligence, CI)系统具有广泛的应用前景. 当前的群体智能决策方法主要包括知识驱动、数据驱动两大类, 但各自存在优缺点. 本文指出, 知识与数据协同驱动将为群体智能决策提供新解法. 本文系统梳理了知识与数据协同驱动可能存在的不同方法路径, 从知识与数据的架构级协同、算法级协同两个层面对典型方法进行了分类, 同时将算法级协同方法进一步划分为算法的层次化协同和组件化协同, 前者包含神经网络树、遗传模糊树、分层强化学习等层次化方法; 后者进一步总结为知识...
群体智能(Collectire intelligence, CI)系统具有广泛的应用前景. 当前的群体智能决策方法主要包括知识驱动、数据驱动两大类, 但各自存在优缺点. 本文指出, 知识与数据协同驱动将为群体智能决策提供新解法. 本文系统梳理了知识与数据协同驱动可能存在的不同方法路径, 从知识与数据的架构级协同、算法级协同两个层面对典型方法进行了分类, 同时将算法级协同方法进一步划分为算法的层次化协同和组件化协同, 前者包含神经网络树、遗传模糊树、分层强化学习等层次化方法; 后者进一步总结为知识...





2022, 48(3): 644-663.
doi: 10.16383/j.aas.c200270
摘要:
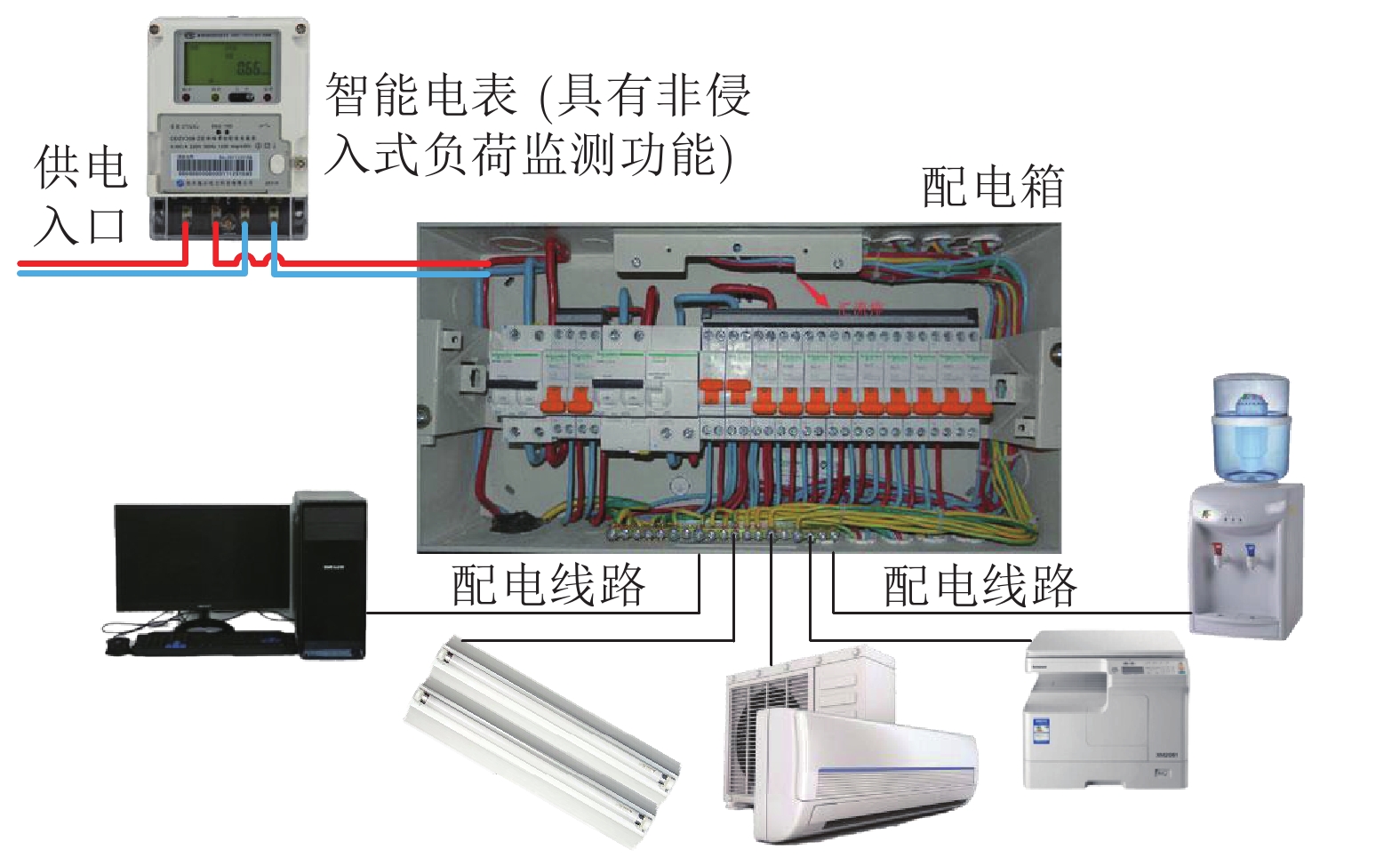
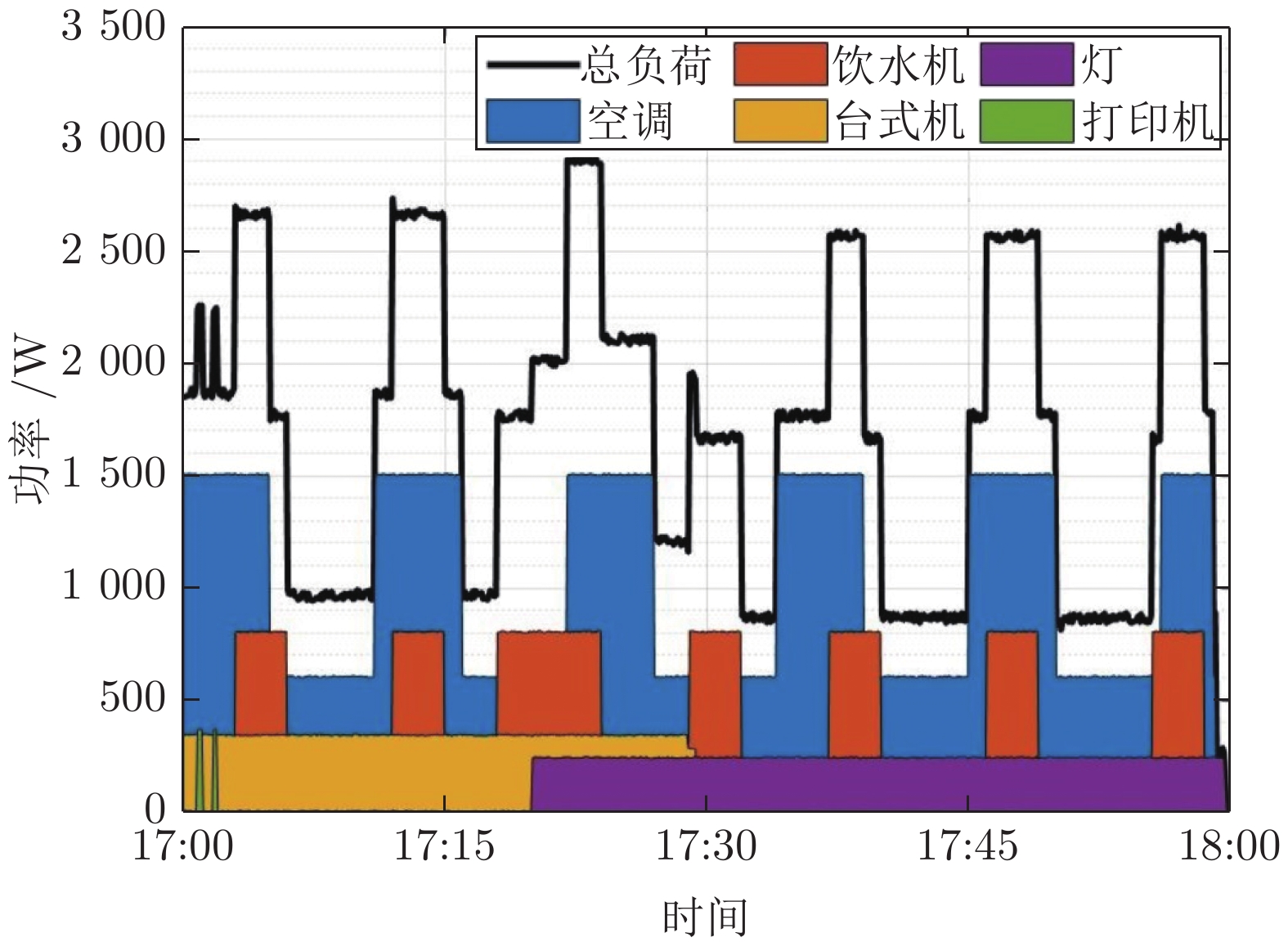
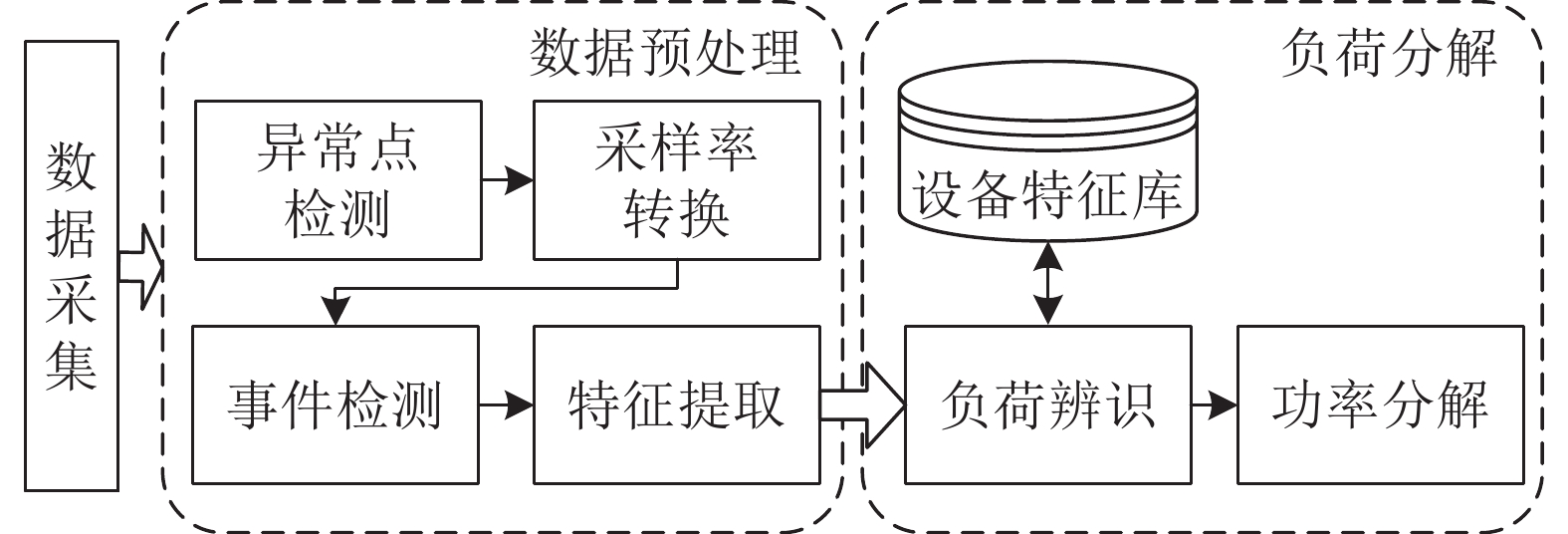
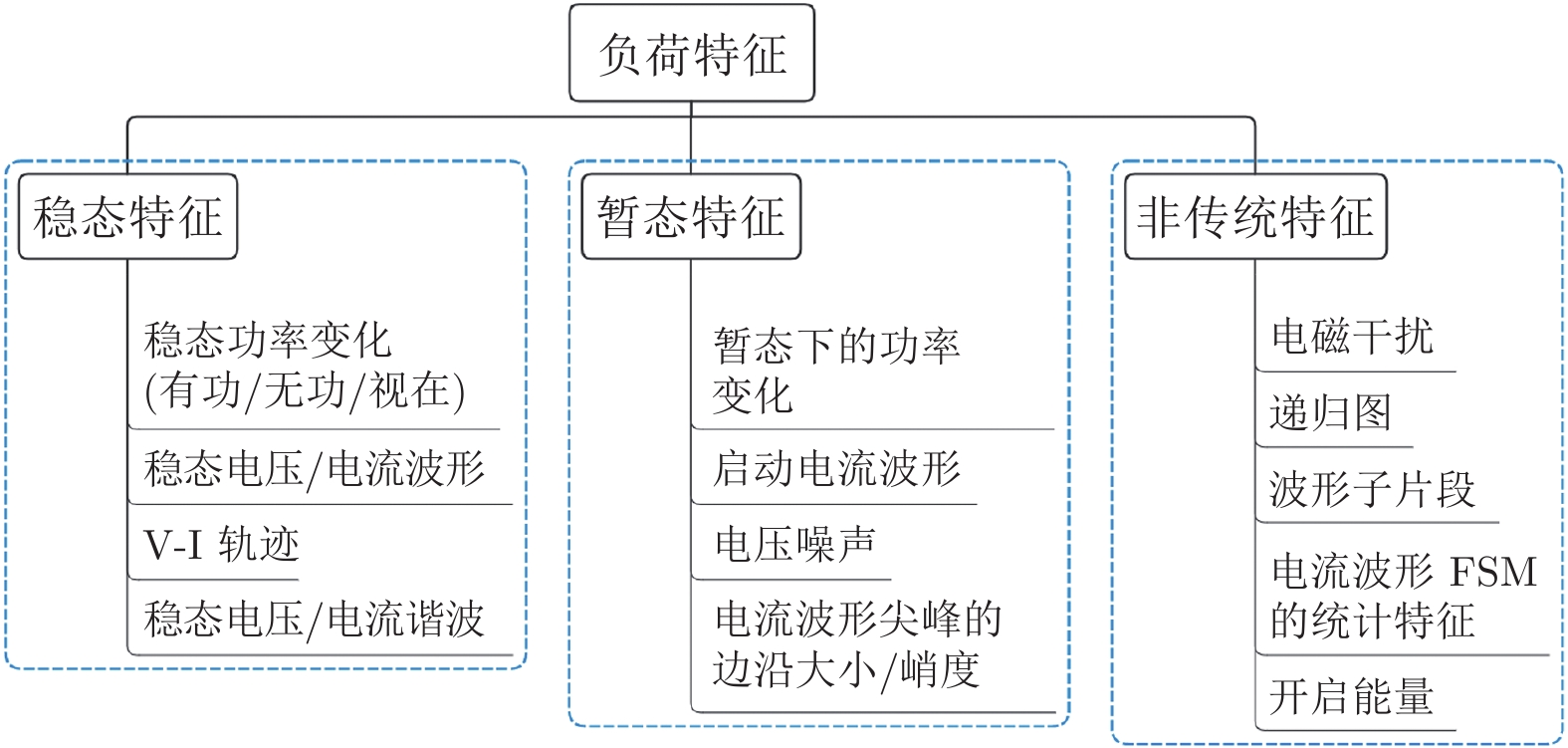
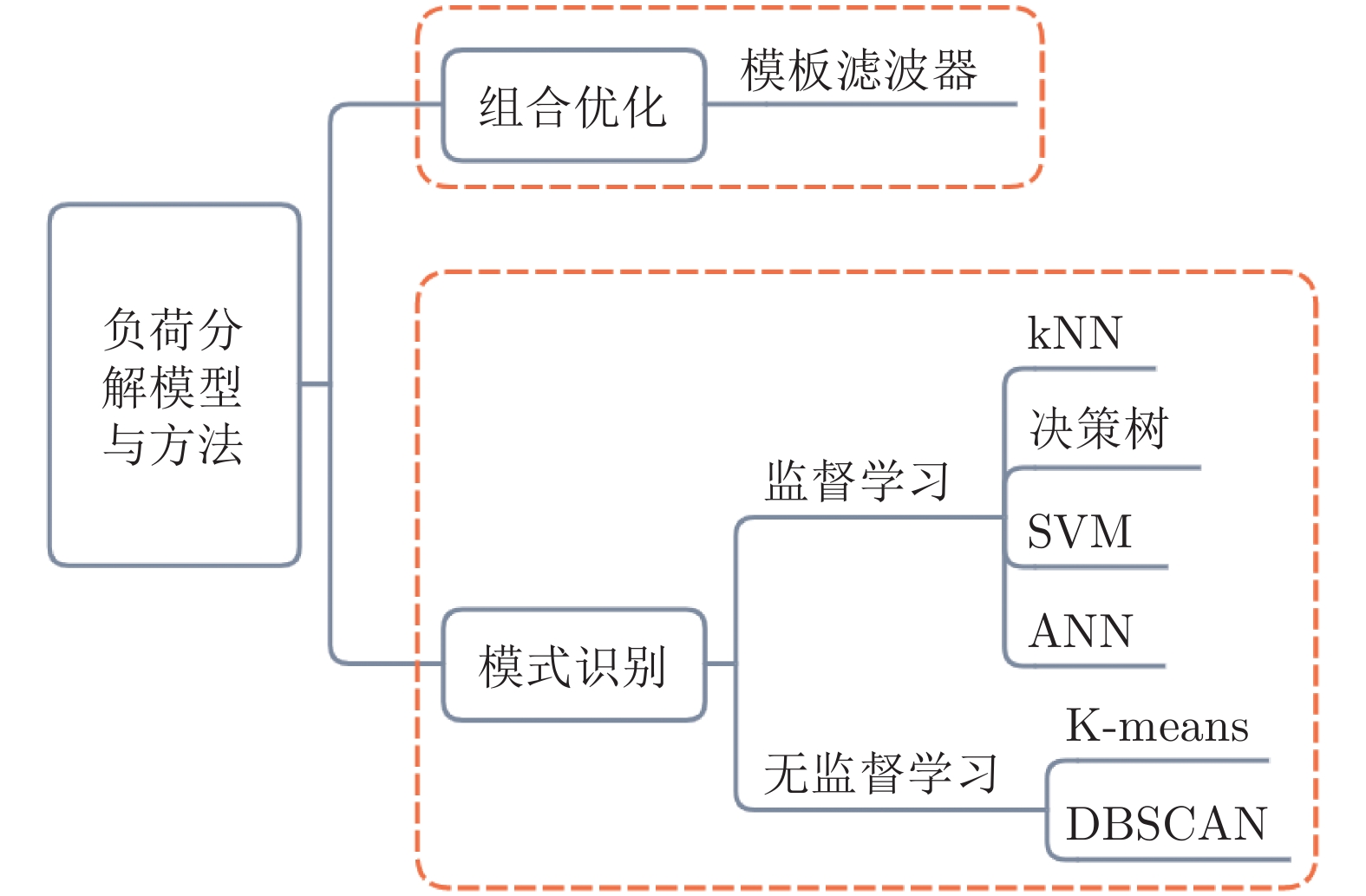
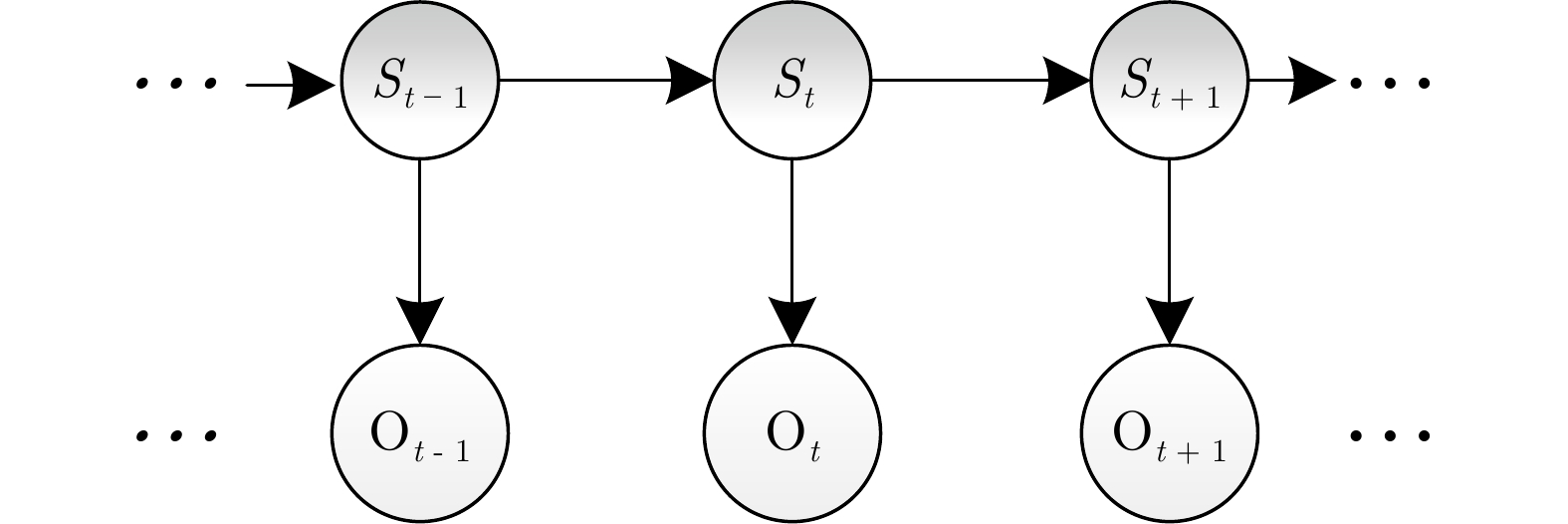
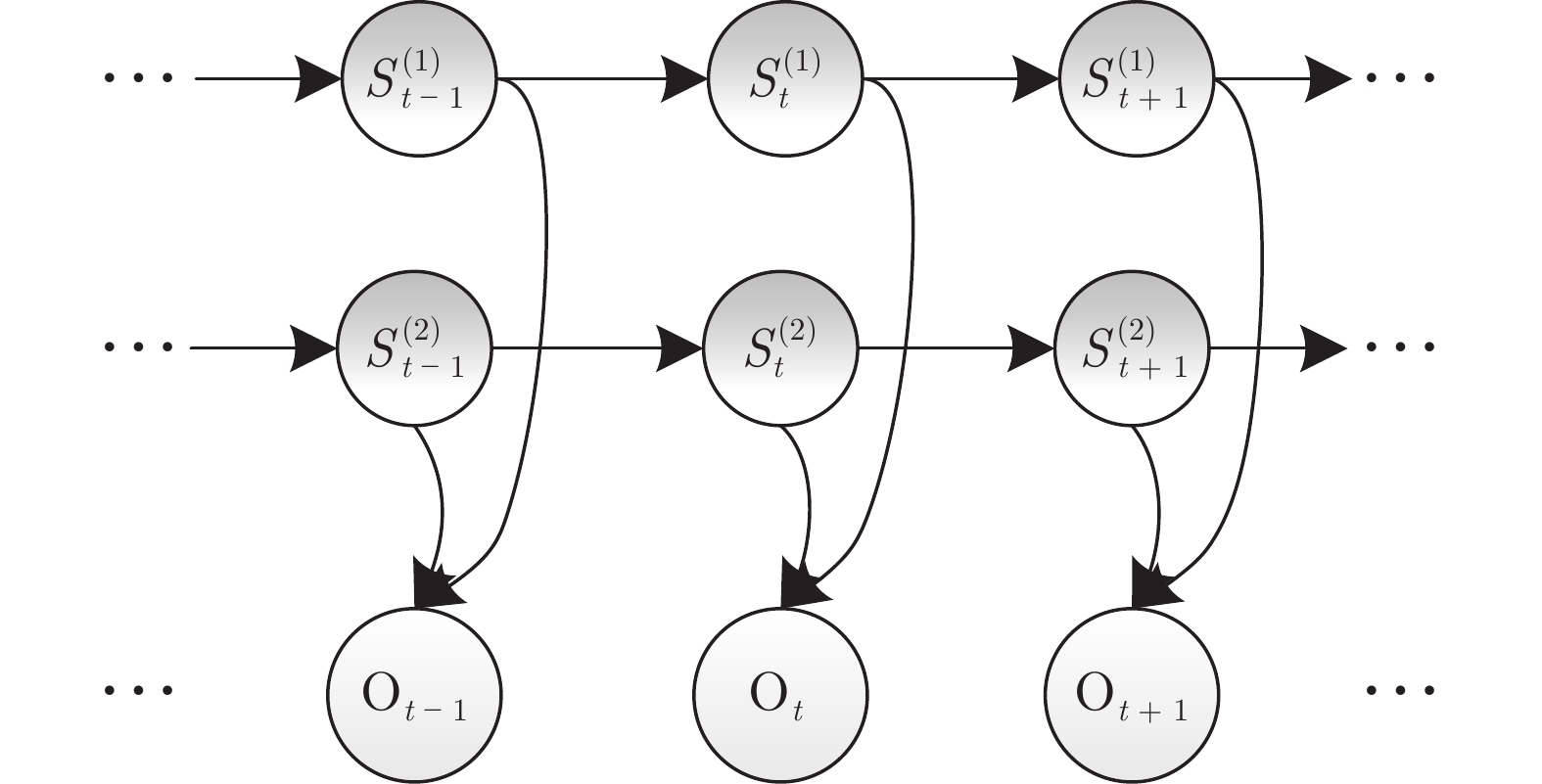
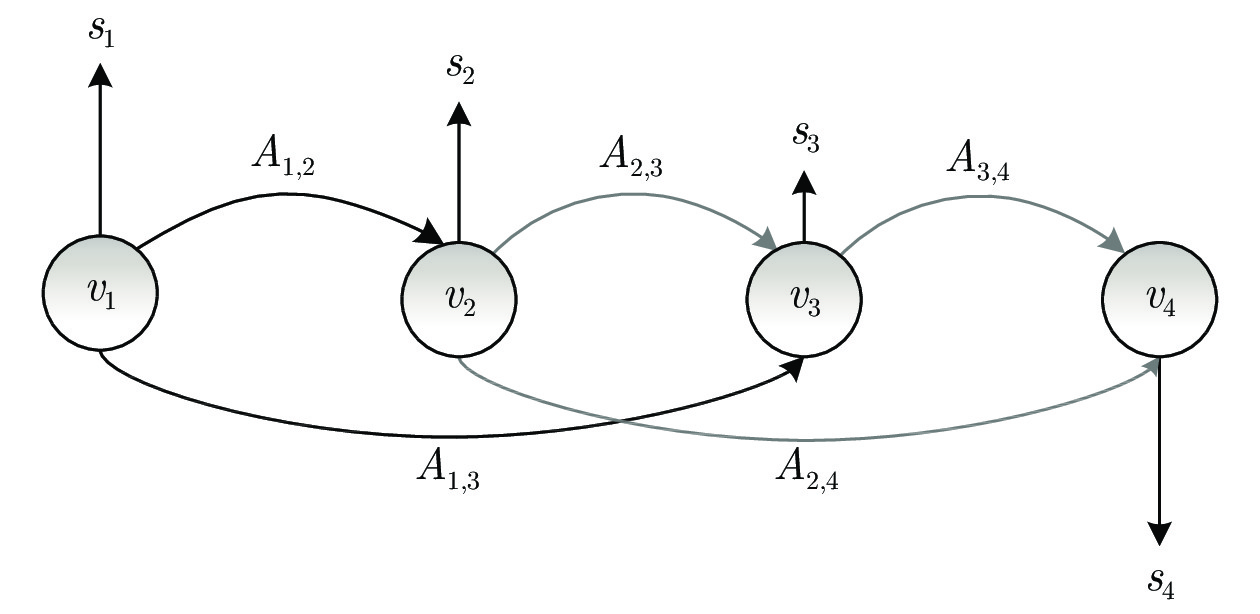
非侵入式负荷监测通过对总负荷电表数据进行分析处理, 能够实现对各个用电设备及其工作状态的辨识, 可广泛应用于建筑节能、智慧城市、智能电网等领域. 近年来, 随着智能电表的大规模部署以及各类机器学习算法的广泛应用, 非侵入式负荷监测引起了学术界与工业界的共同关注. 本文对非侵入式负荷监测方面的研究进行综述. 首先提炼非侵入式负荷监测的问题模型及基本框架; 然后分别对非侵入式负荷监测的数据采集与预处理过程、负荷分解模型与方法、常用数据集及评估指标进行归纳总结; 最后, 对目前研究中存在的挑战进行分析...
非侵入式负荷监测通过对总负荷电表数据进行分析处理, 能够实现对各个用电设备及其工作状态的辨识, 可广泛应用于建筑节能、智慧城市、智能电网等领域. 近年来, 随着智能电表的大规模部署以及各类机器学习算法的广泛应用, 非侵入式负荷监测引起了学术界与工业界的共同关注. 本文对非侵入式负荷监测方面的研究进行综述. 首先提炼非侵入式负荷监测的问题模型及基本框架; 然后分别对非侵入式负荷监测的数据采集与预处理过程、负荷分解模型与方法、常用数据集及评估指标进行归纳总结; 最后, 对目前研究中存在的挑战进行分析...


2022, 48(3): 664-688.
doi: 10.16383/j.aas.c200521
摘要:
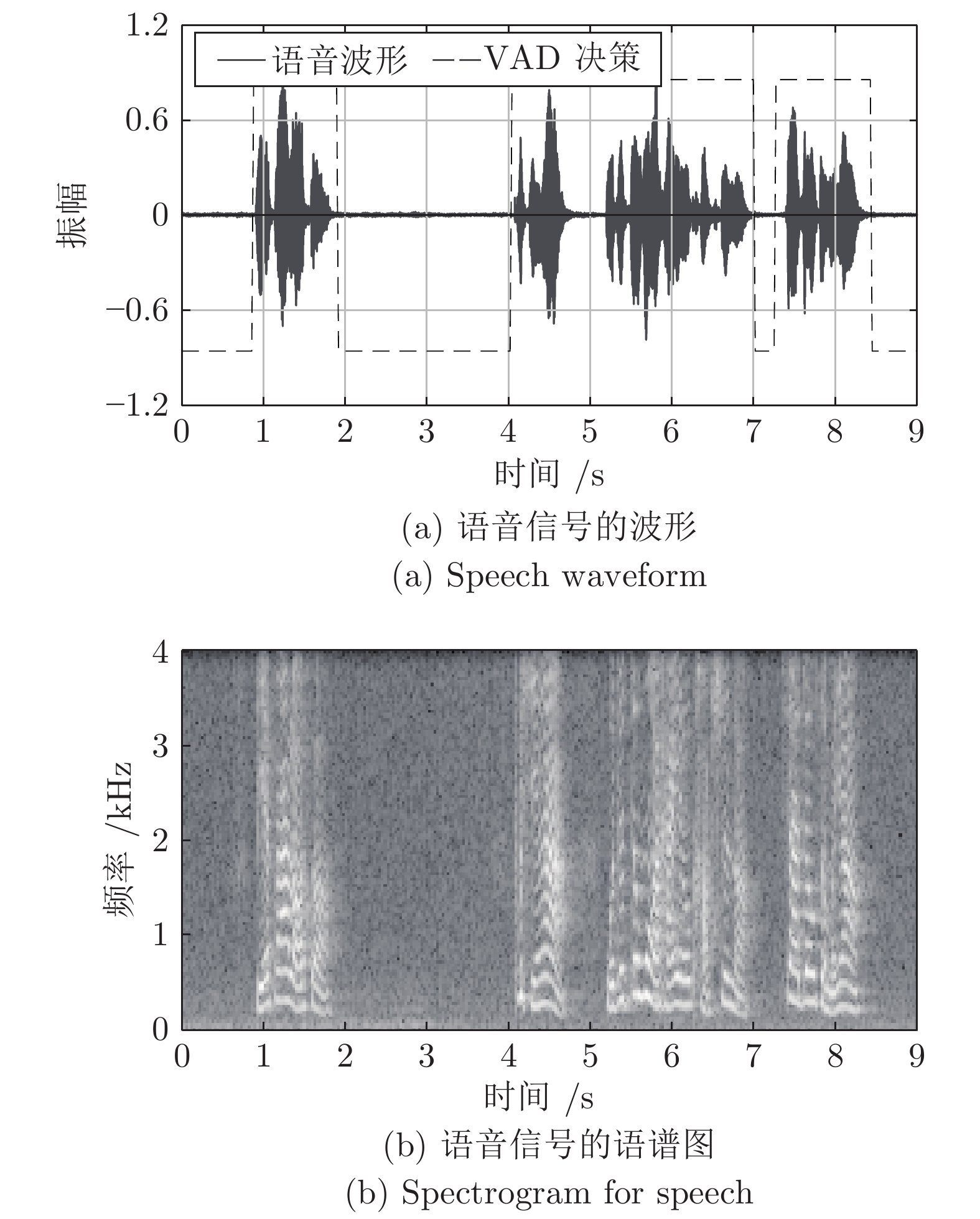
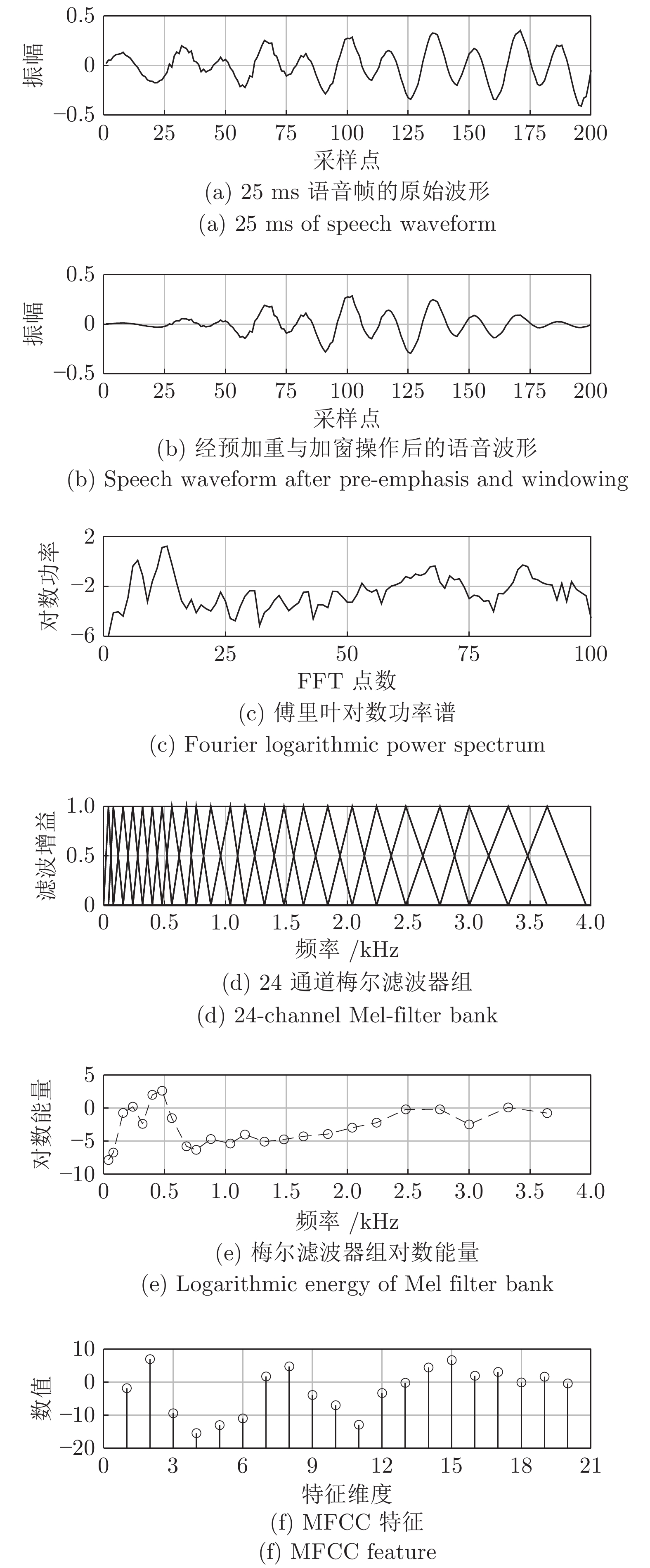
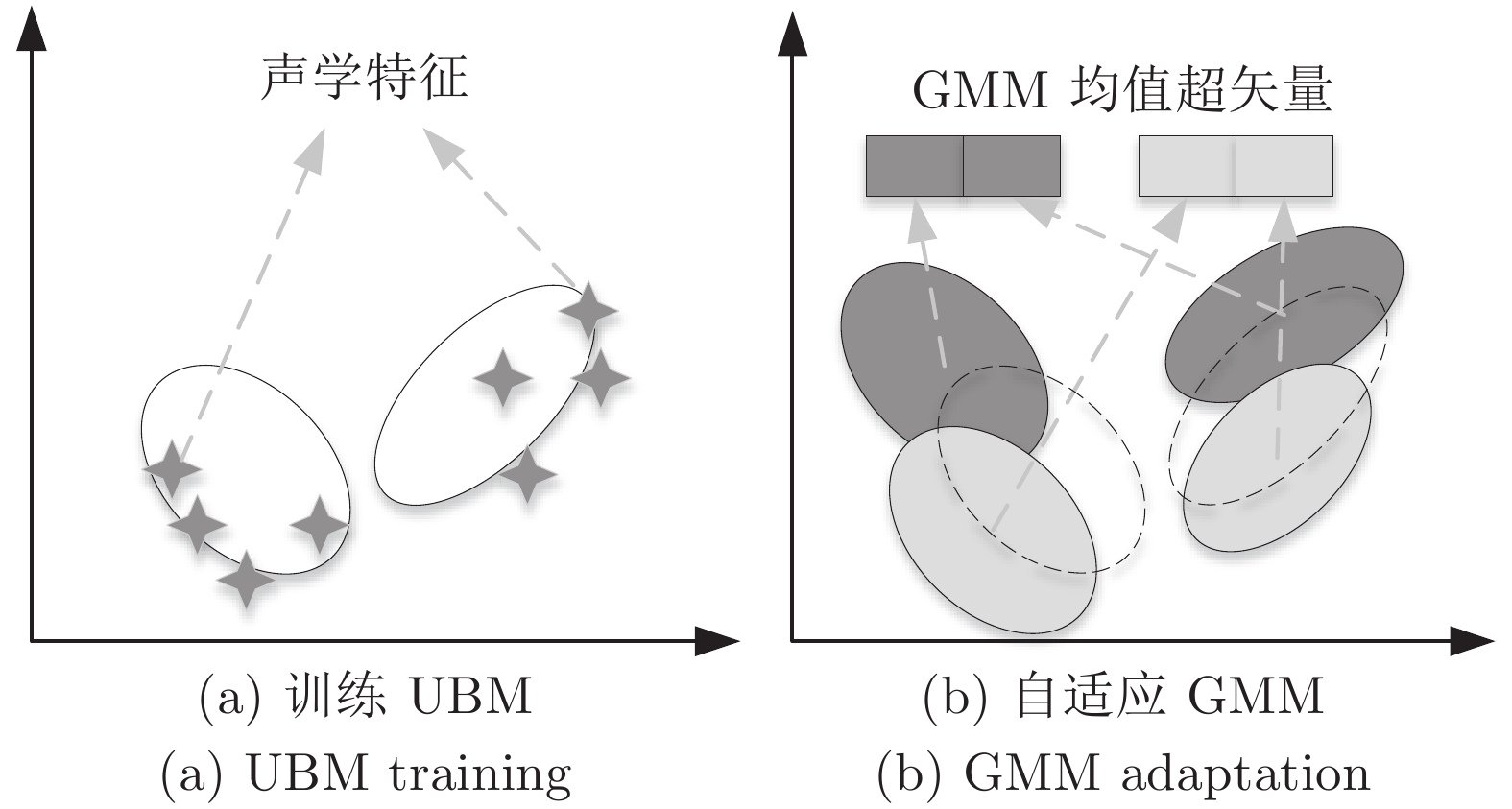
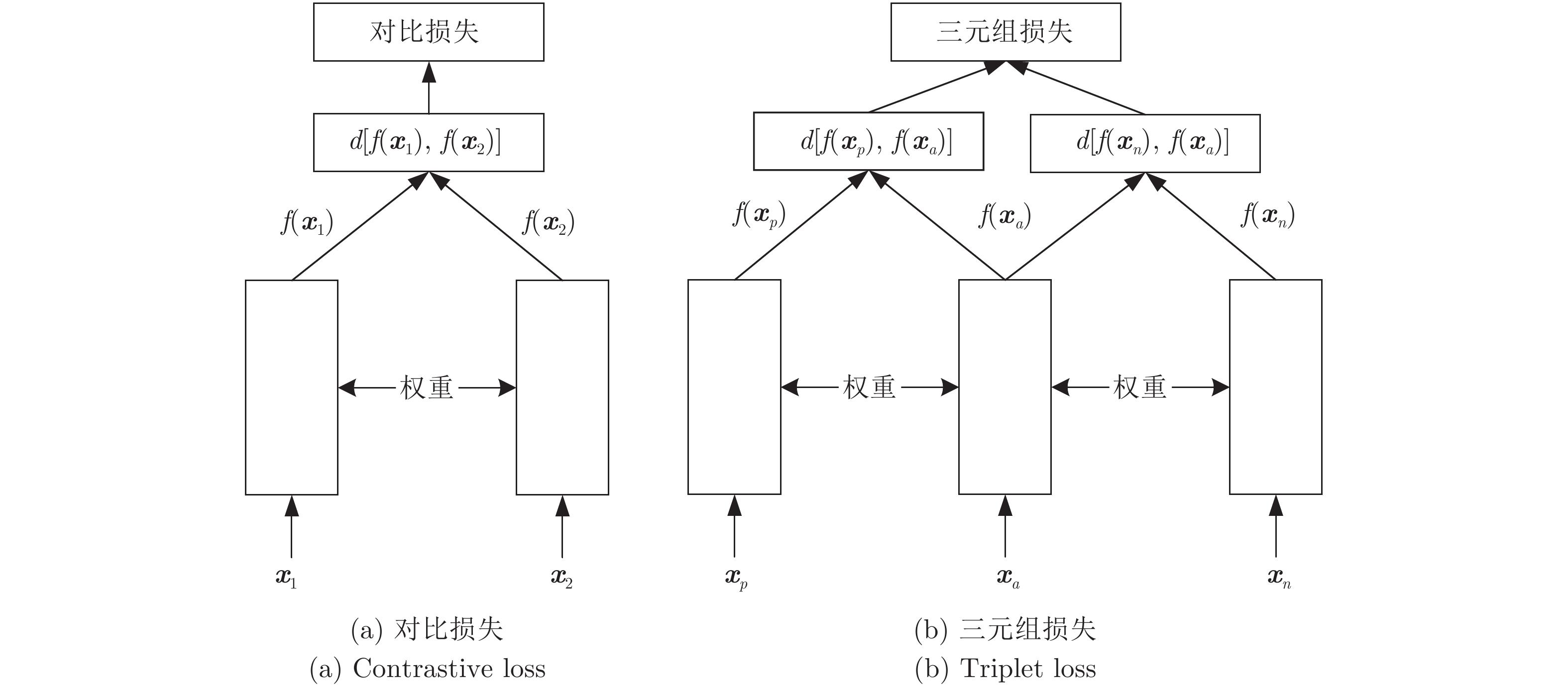
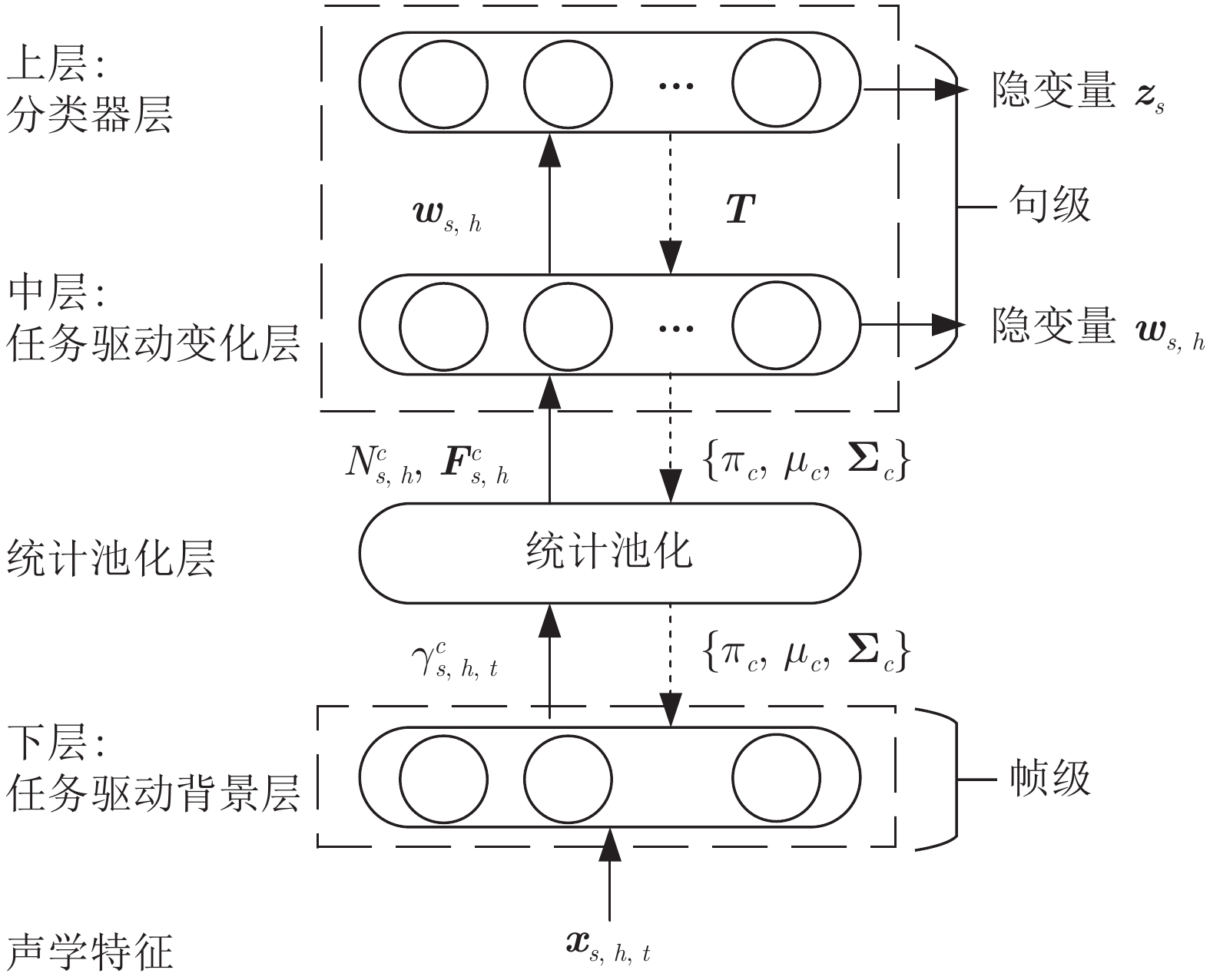
句级 (Utterance-level) 特征提取是文本无关说话人识别领域中的重要研究方向之一. 与只能刻画短时语音特性的帧级 (Frame-level) 特征相比, 句级特征中包含了更丰富的说话人个性信息; 且不同时长语音的句级特征均具有固定维度, 更便于与大多数常用的模式识别方法相结合. 近年来, 句级特征提取的研究取得了很大的进展, 鉴于其在说话人识别中的重要地位, 本文对近期具有代表性的句级特征提取方法与技术进行整理与综述, 并分别从前端处理、基于任务分段式与驱动式策略的特征提取方法, ...
句级 (Utterance-level) 特征提取是文本无关说话人识别领域中的重要研究方向之一. 与只能刻画短时语音特性的帧级 (Frame-level) 特征相比, 句级特征中包含了更丰富的说话人个性信息; 且不同时长语音的句级特征均具有固定维度, 更便于与大多数常用的模式识别方法相结合. 近年来, 句级特征提取的研究取得了很大的进展, 鉴于其在说话人识别中的重要地位, 本文对近期具有代表性的句级特征提取方法与技术进行整理与综述, 并分别从前端处理、基于任务分段式与驱动式策略的特征提取方法, ...


2022, 48(3): 689-711.
doi: 10.16383/j.aas.c201030
摘要:
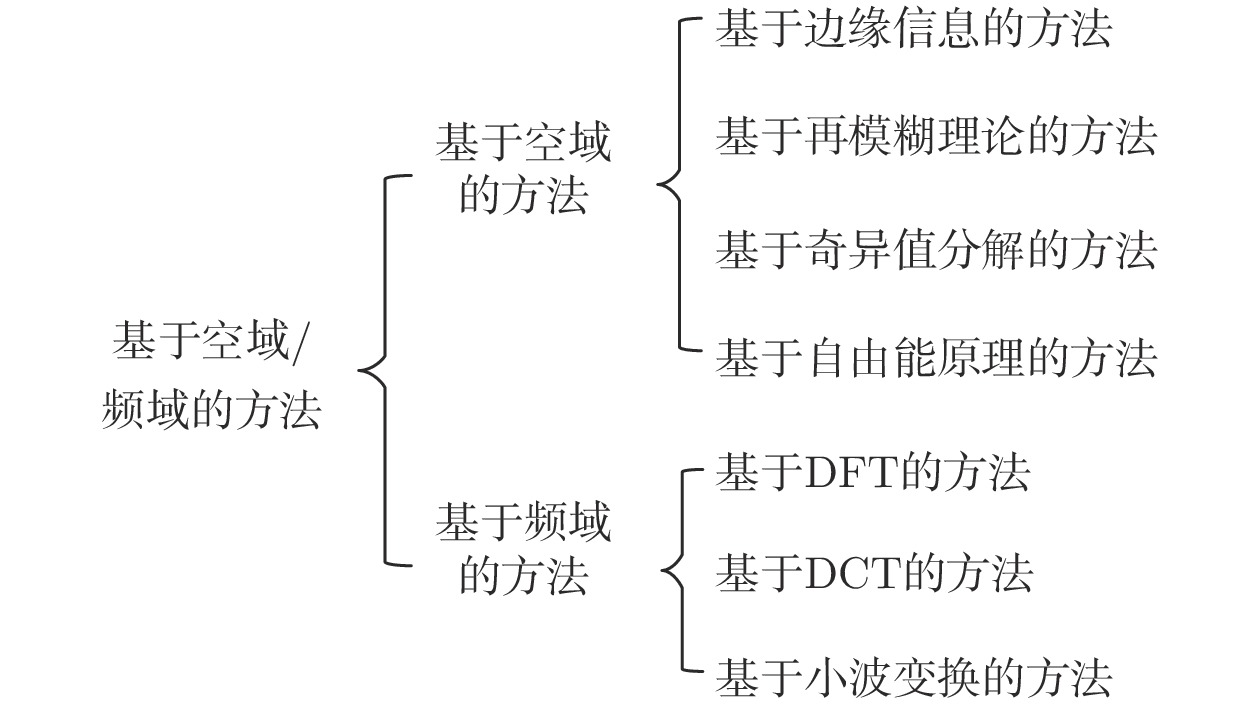
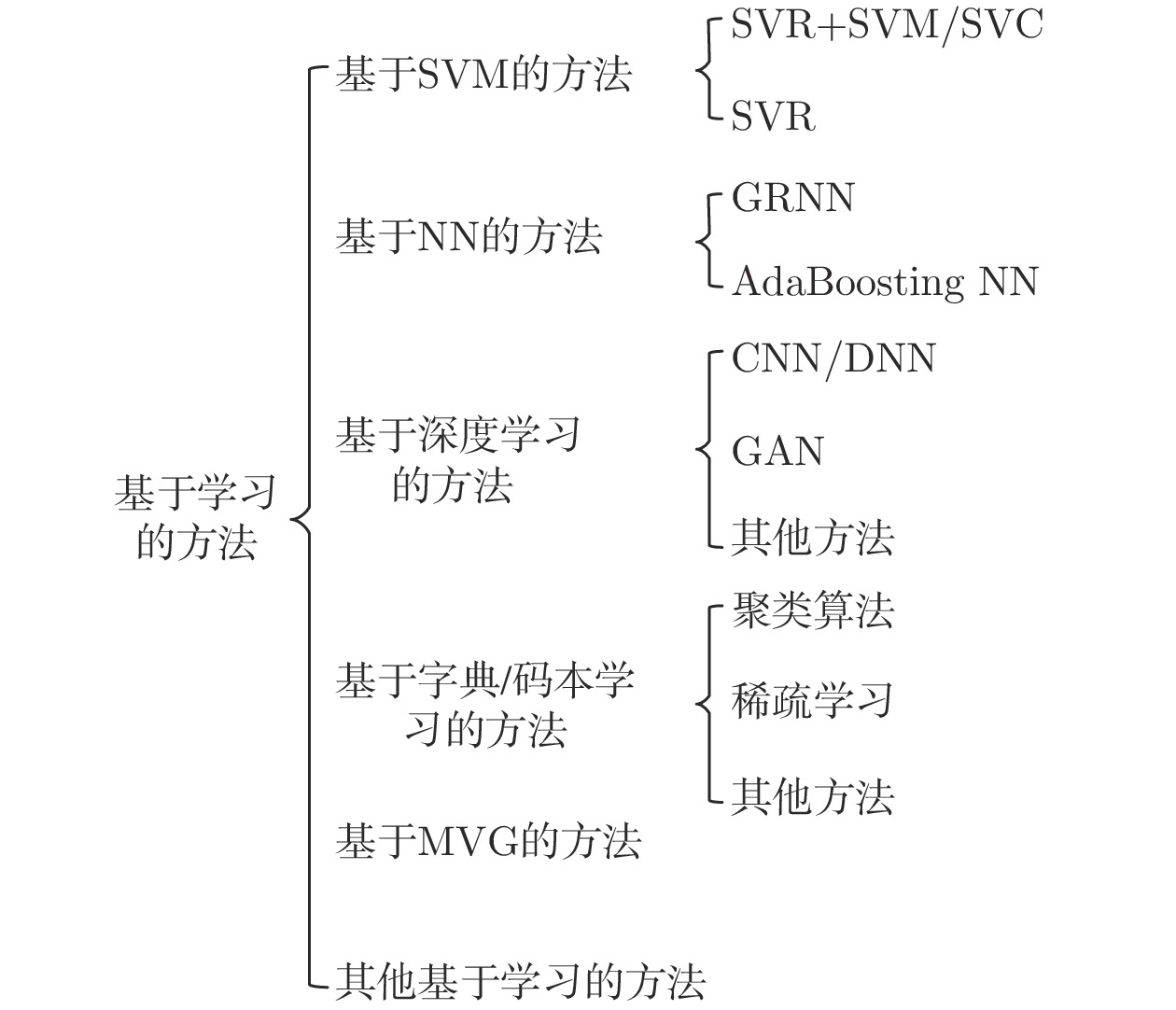
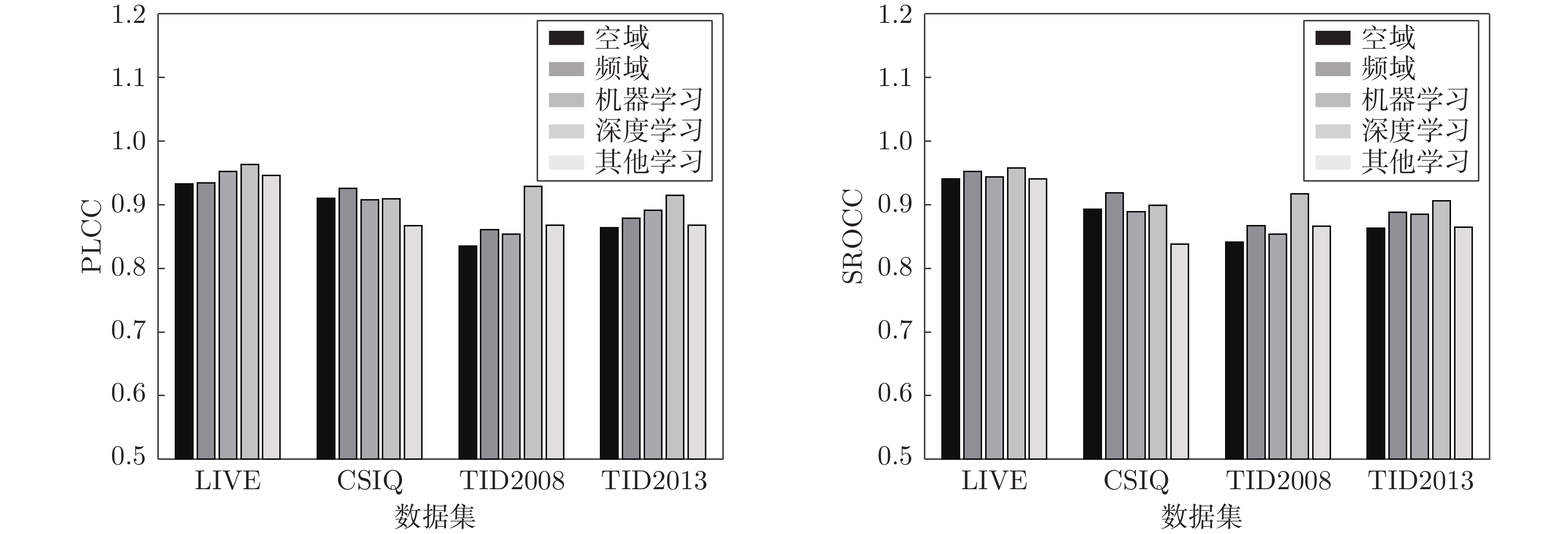
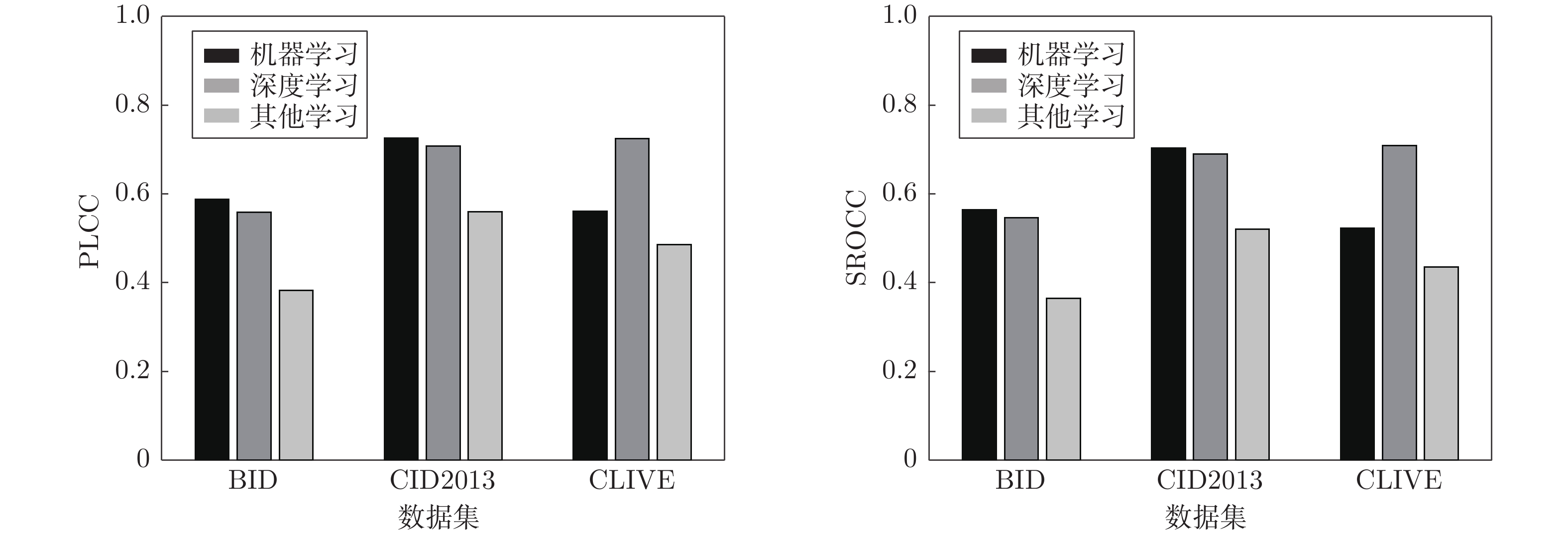
图像的模糊问题影响人们对信息的感知、获取及图像的后续处理. 无参考模糊图像质量评价是该问题的主要研究方向之一. 本文分析了近20年来无参考模糊图像质量评价相关技术的发展. 首先, 本文结合主要数据集对图像模糊失真进行分类说明; 其次, 对主要的无参考模糊图像质量评价方法进行分类介绍与详细分析; 随后, 介绍了用来比较无参考模糊图像质量评价方法性能优劣的主要评价指标; 接着, 选择典型数据集及评价指标, 并采用常见的无参考模糊图像质量评价方法进行性能比较; 最后, 对无参考模糊图像质量评价的相关技...
图像的模糊问题影响人们对信息的感知、获取及图像的后续处理. 无参考模糊图像质量评价是该问题的主要研究方向之一. 本文分析了近20年来无参考模糊图像质量评价相关技术的发展. 首先, 本文结合主要数据集对图像模糊失真进行分类说明; 其次, 对主要的无参考模糊图像质量评价方法进行分类介绍与详细分析; 随后, 介绍了用来比较无参考模糊图像质量评价方法性能优劣的主要评价指标; 接着, 选择典型数据集及评价指标, 并采用常见的无参考模糊图像质量评价方法进行性能比较; 最后, 对无参考模糊图像质量评价的相关技...

2022, 48(3): 712-723.
doi: 10.16383/j.aas.c190273
摘要:
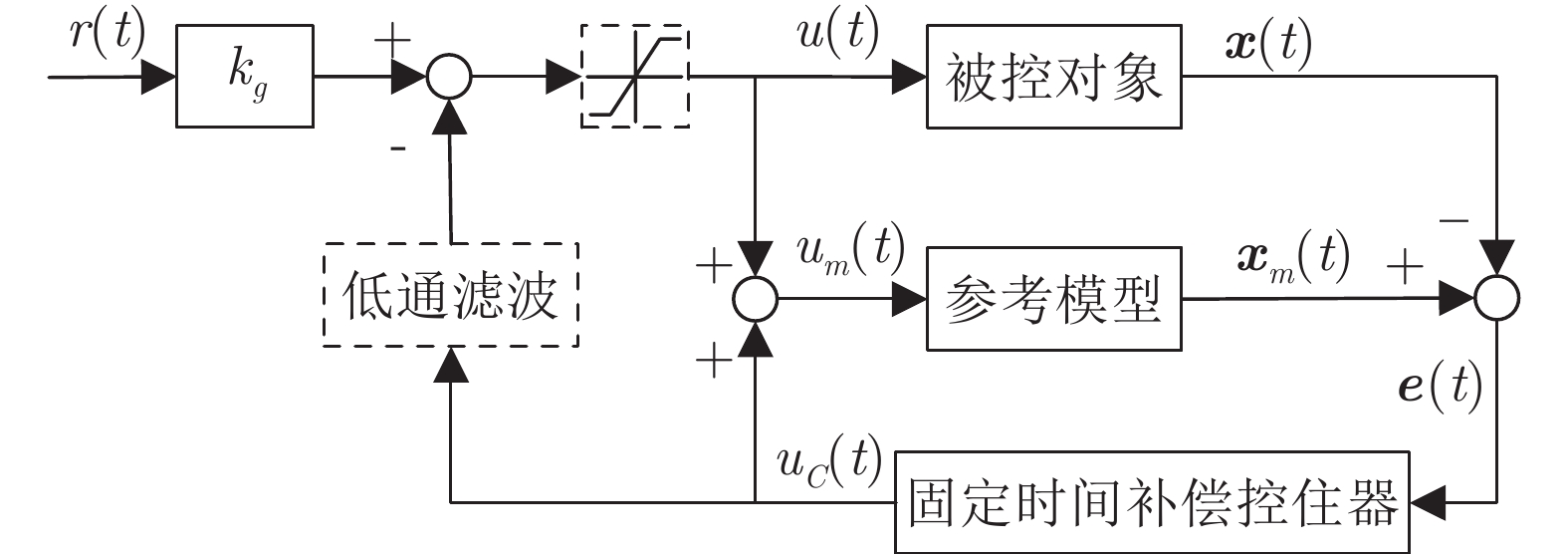
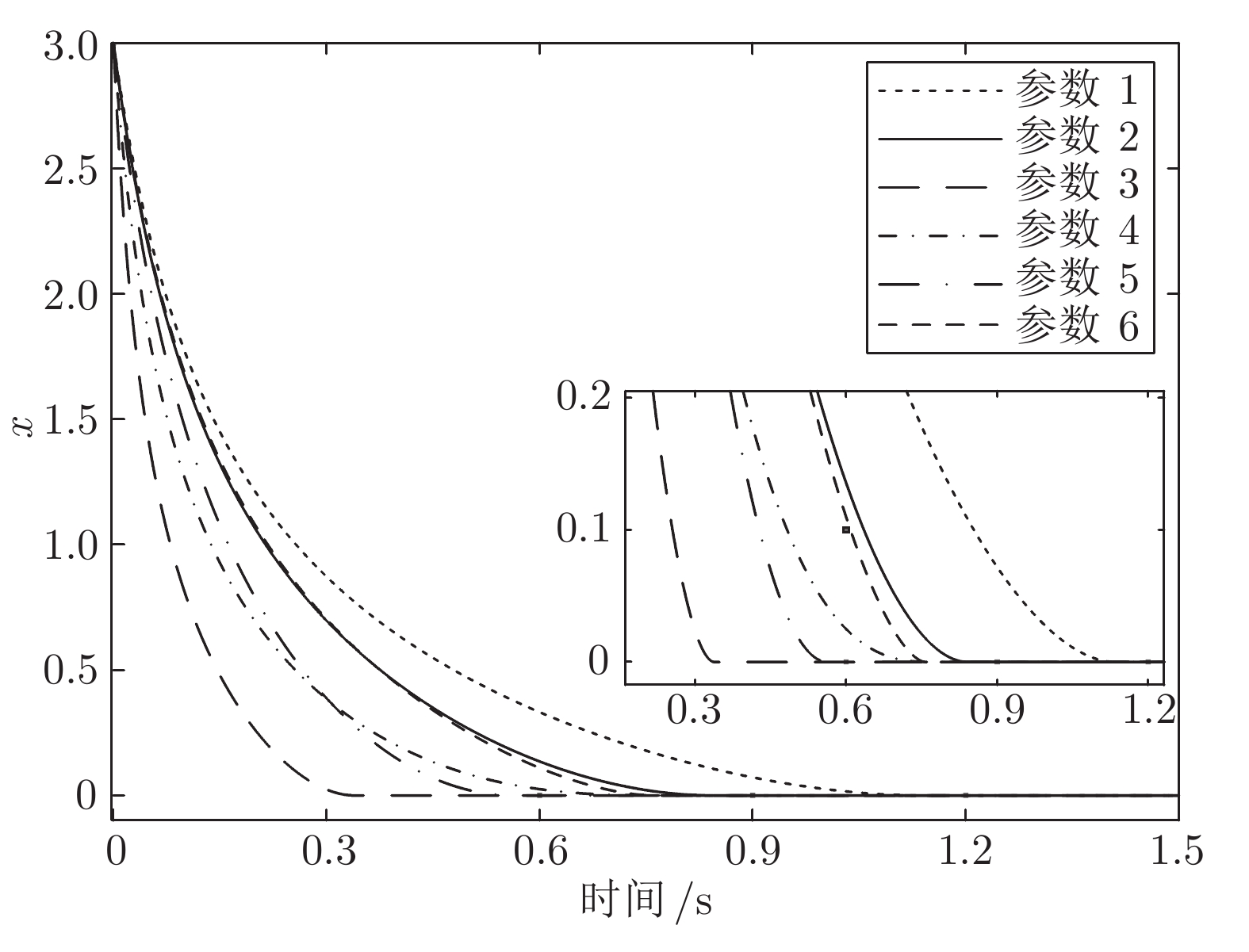
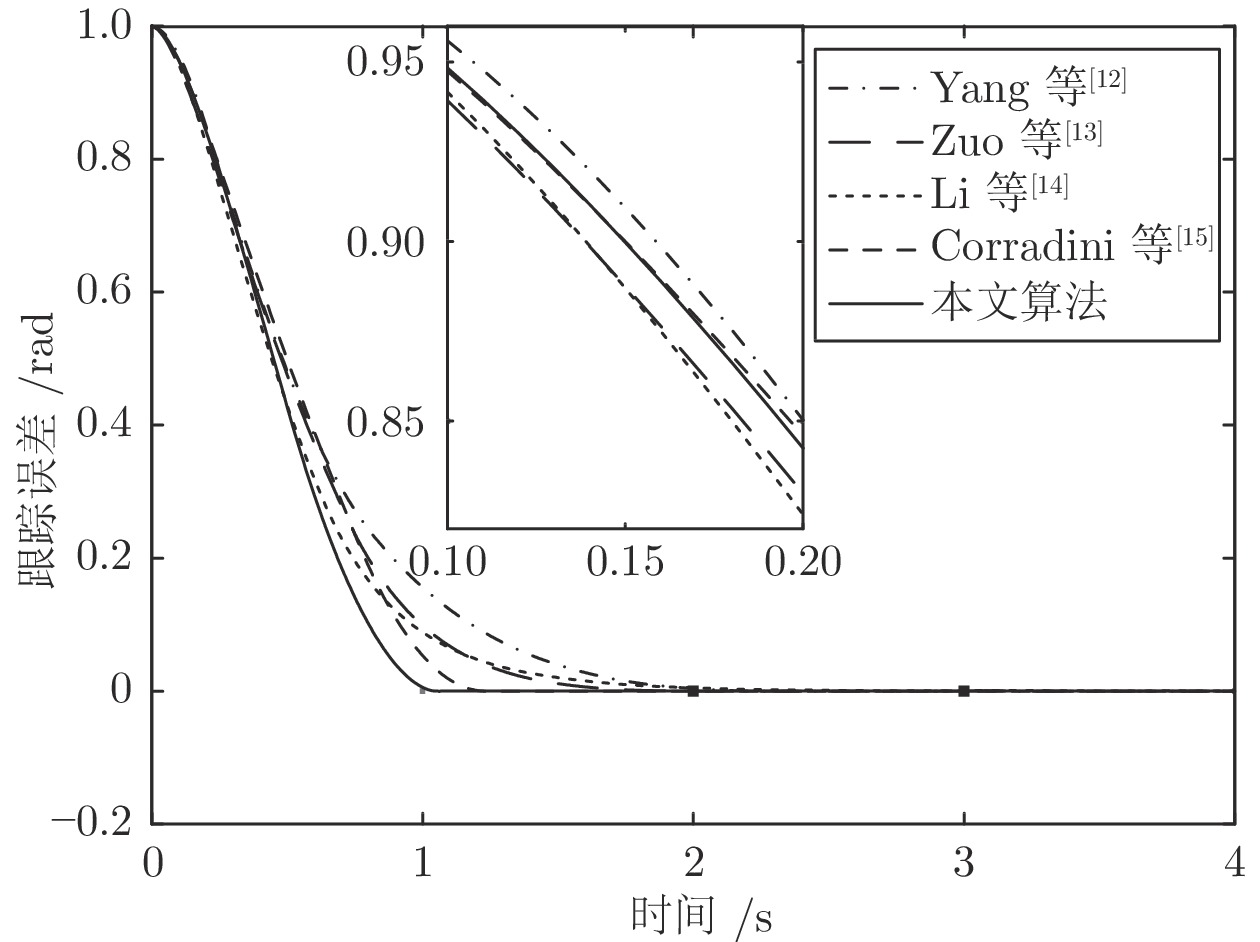
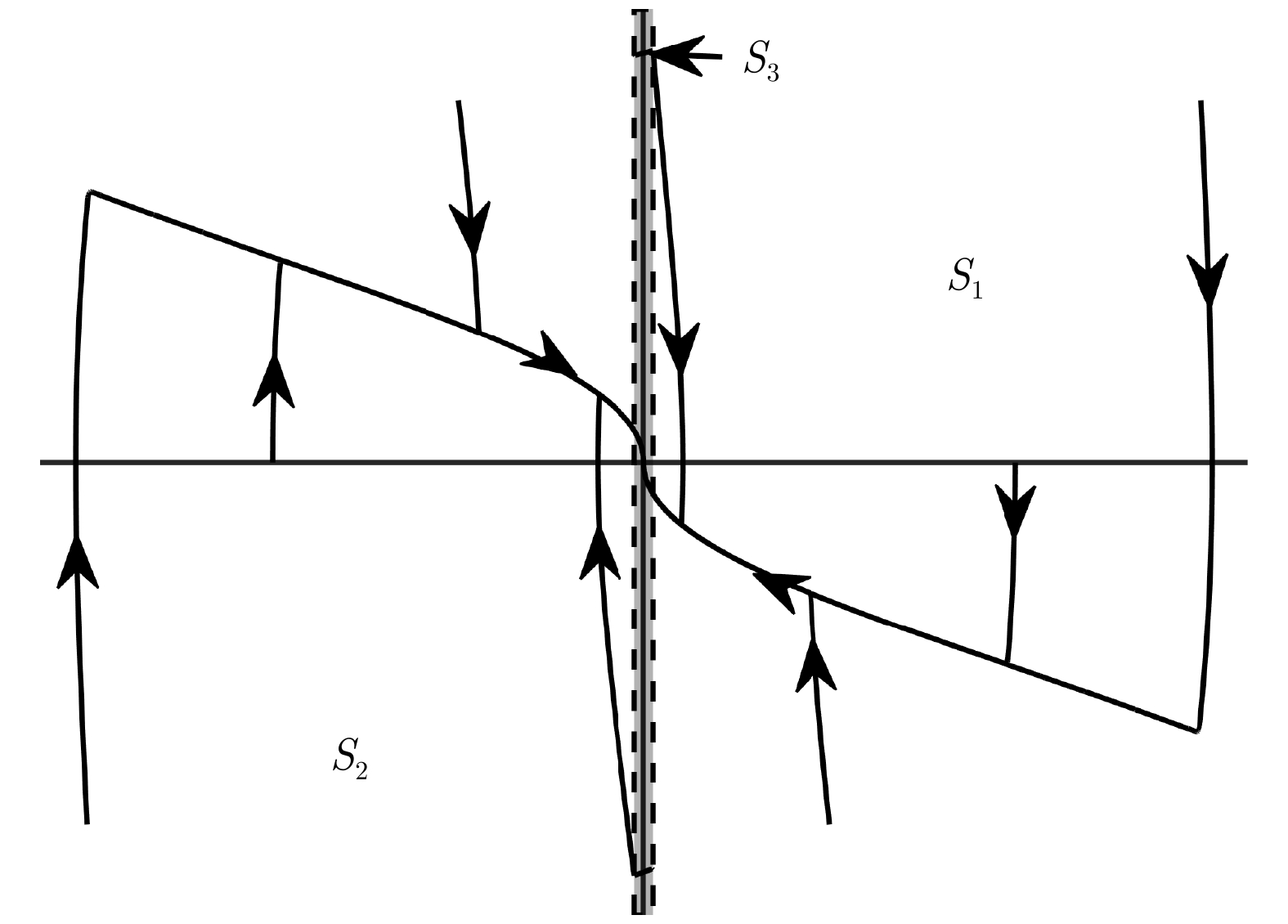
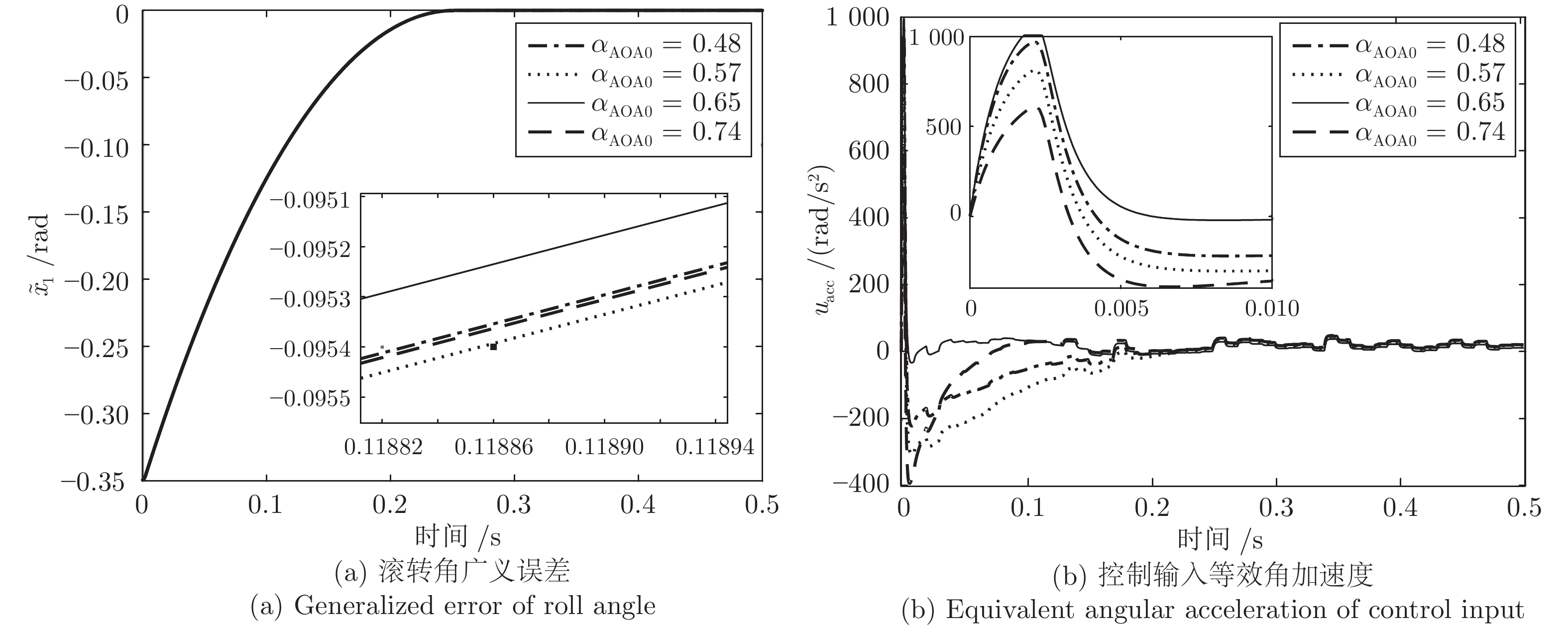
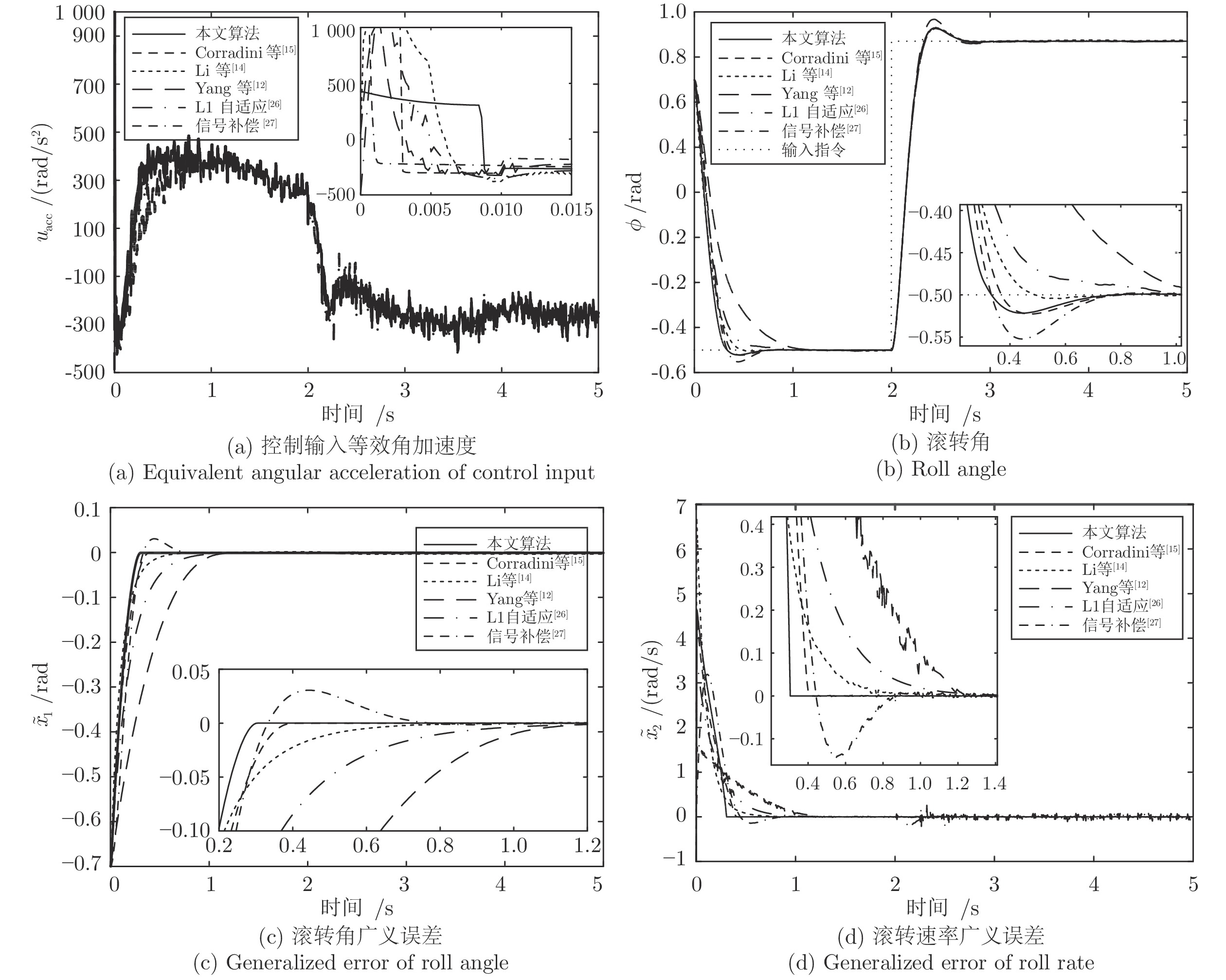
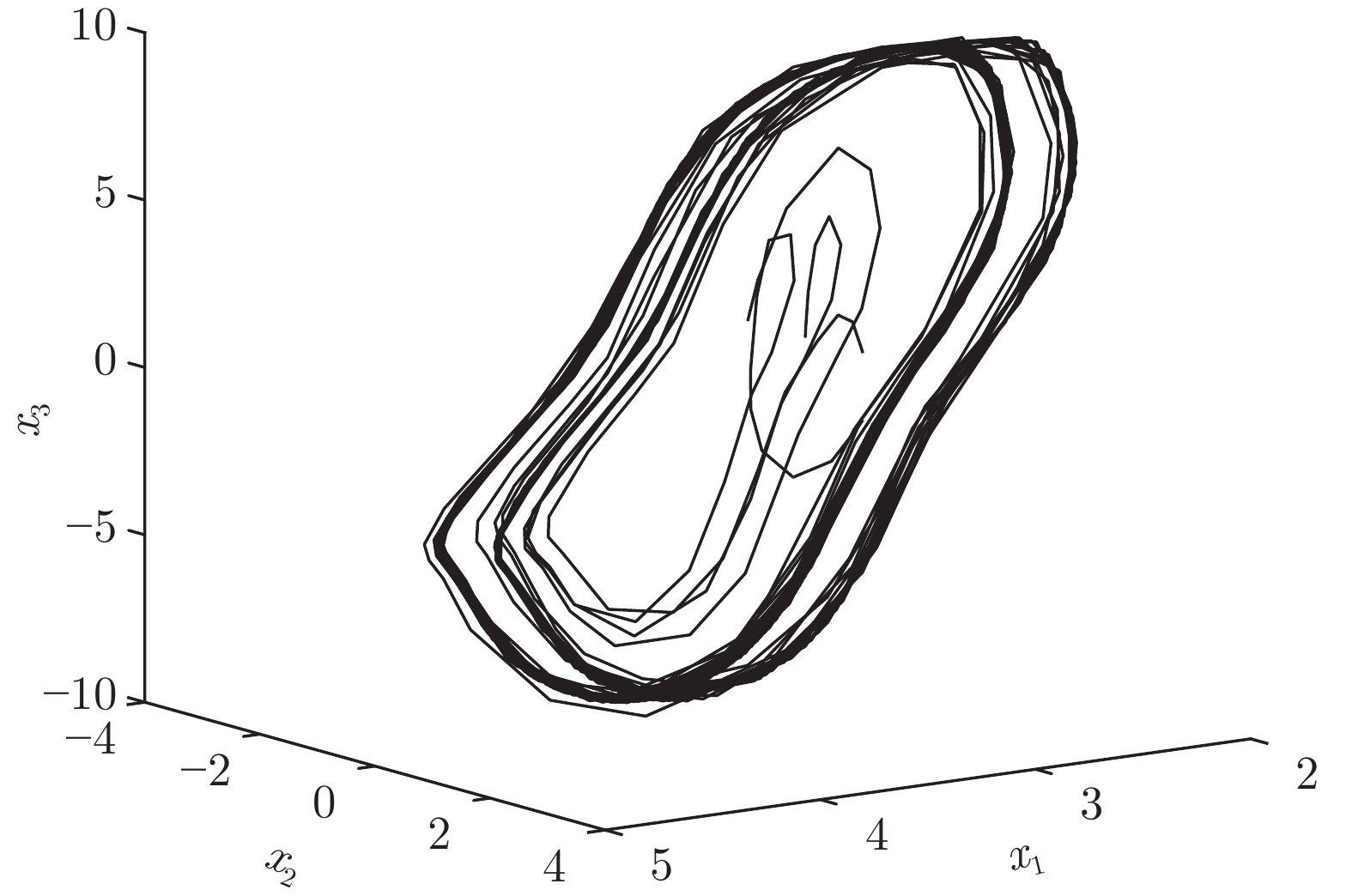
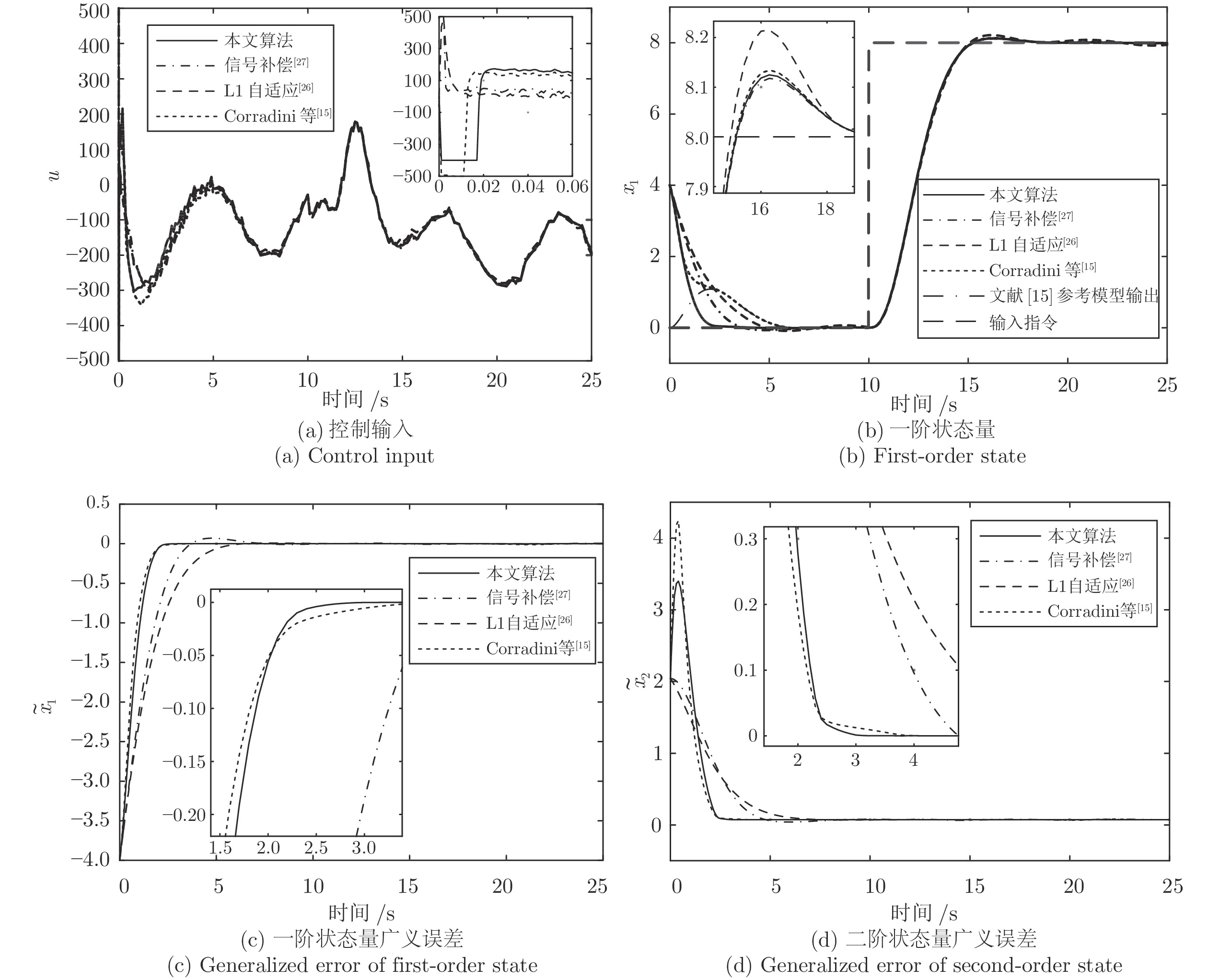
针对一类具有模型不确定性和外部扰动的时变非线性系统, 基于模型参考控制方法, 设计了具有固定时间收敛特性的终端滑模控制器. 首先, 提出一种带有输入饱和限幅和补偿信号滤波的模型参考控制结构; 然后针对广义误差信号, 采用新型终端滑模面设计了补偿控制器, 较好地平衡靠近和远离平衡点的收敛速度. 基于李雅普诺夫方法证明了闭环系统的稳定性和固定时间收敛特性, 并给出了收敛时间上界. 最后将该方法应用到含有极限环的非线性系统跟踪控制中, 仿真结果验证了该方法的有效性.
针对一类具有模型不确定性和外部扰动的时变非线性系统, 基于模型参考控制方法, 设计了具有固定时间收敛特性的终端滑模控制器. 首先, 提出一种带有输入饱和限幅和补偿信号滤波的模型参考控制结构; 然后针对广义误差信号, 采用新型终端滑模面设计了补偿控制器, 较好地平衡靠近和远离平衡点的收敛速度. 基于李雅普诺夫方法证明了闭环系统的稳定性和固定时间收敛特性, 并给出了收敛时间上界. 最后将该方法应用到含有极限环的非线性系统跟踪控制中, 仿真结果验证了该方法的有效性.


2022, 48(3): 724-734.
doi: 10.16383/j.aas.c190307
摘要:
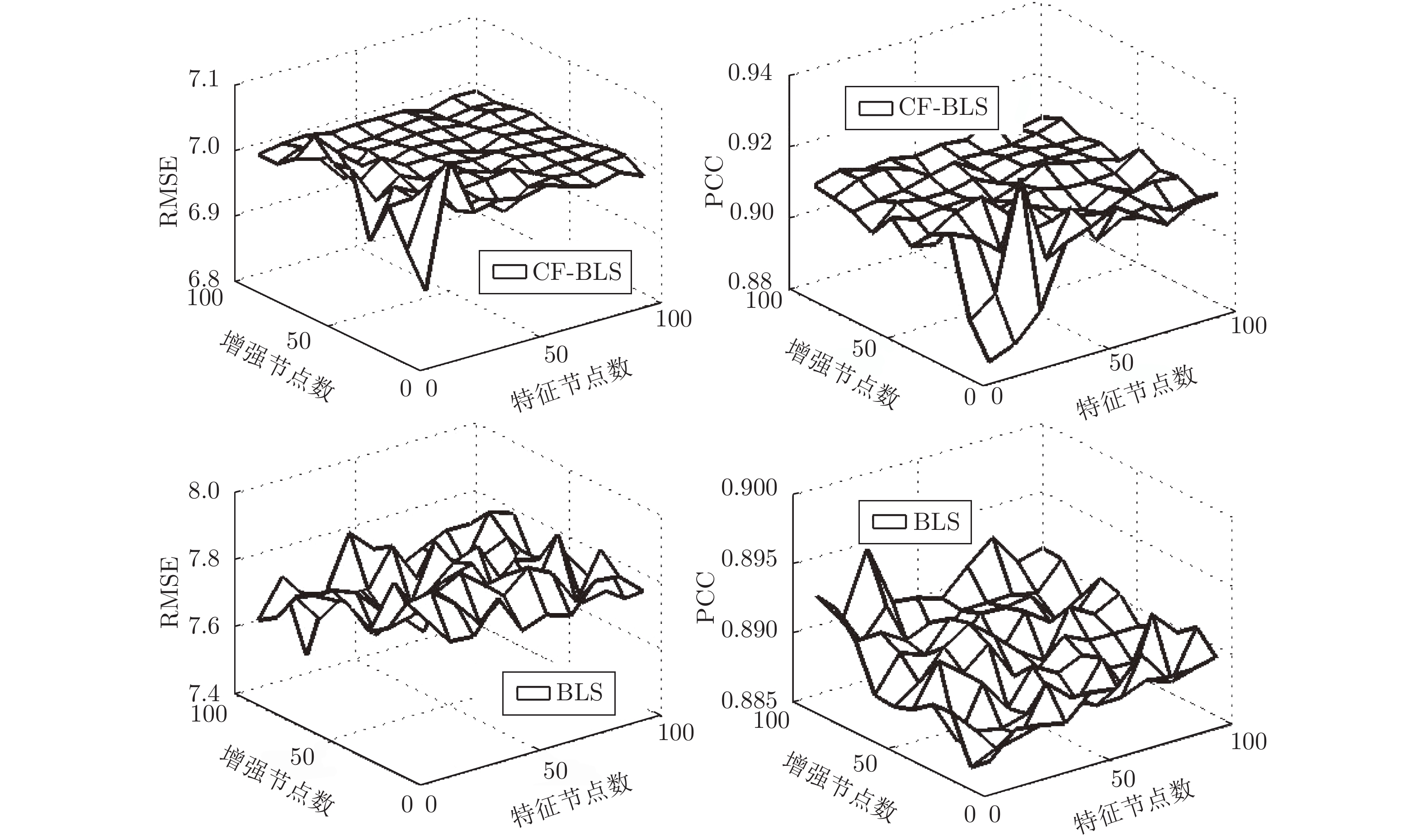
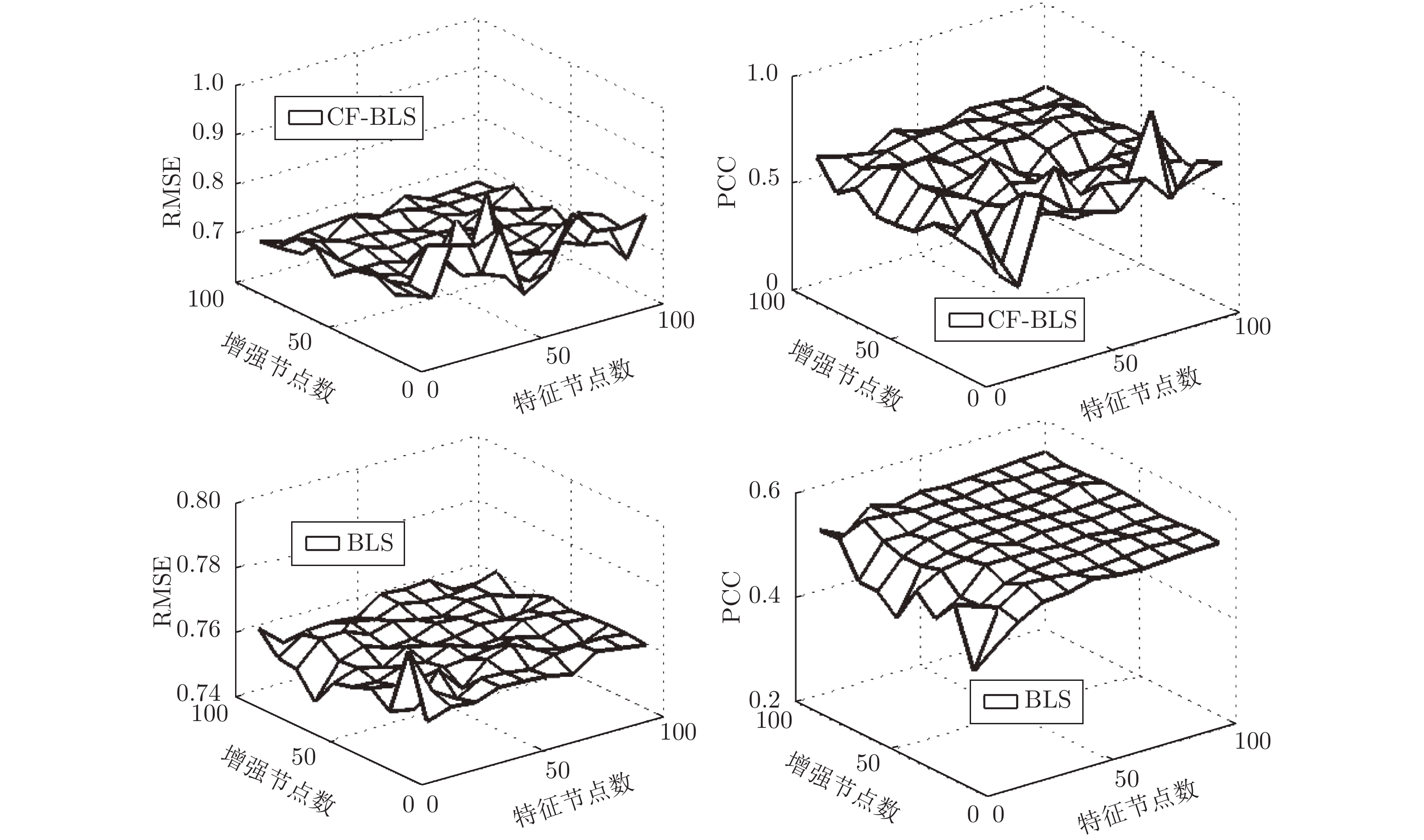
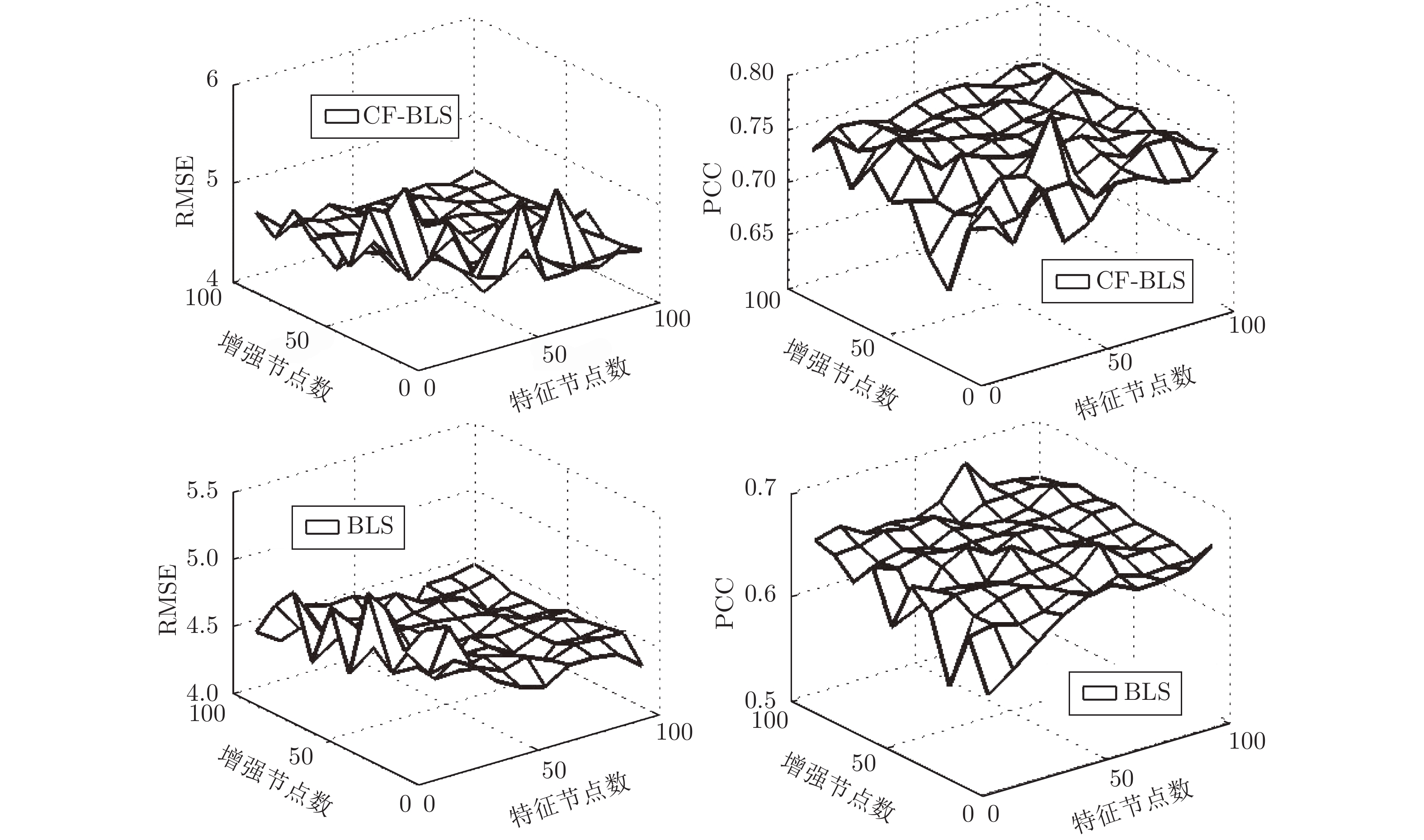
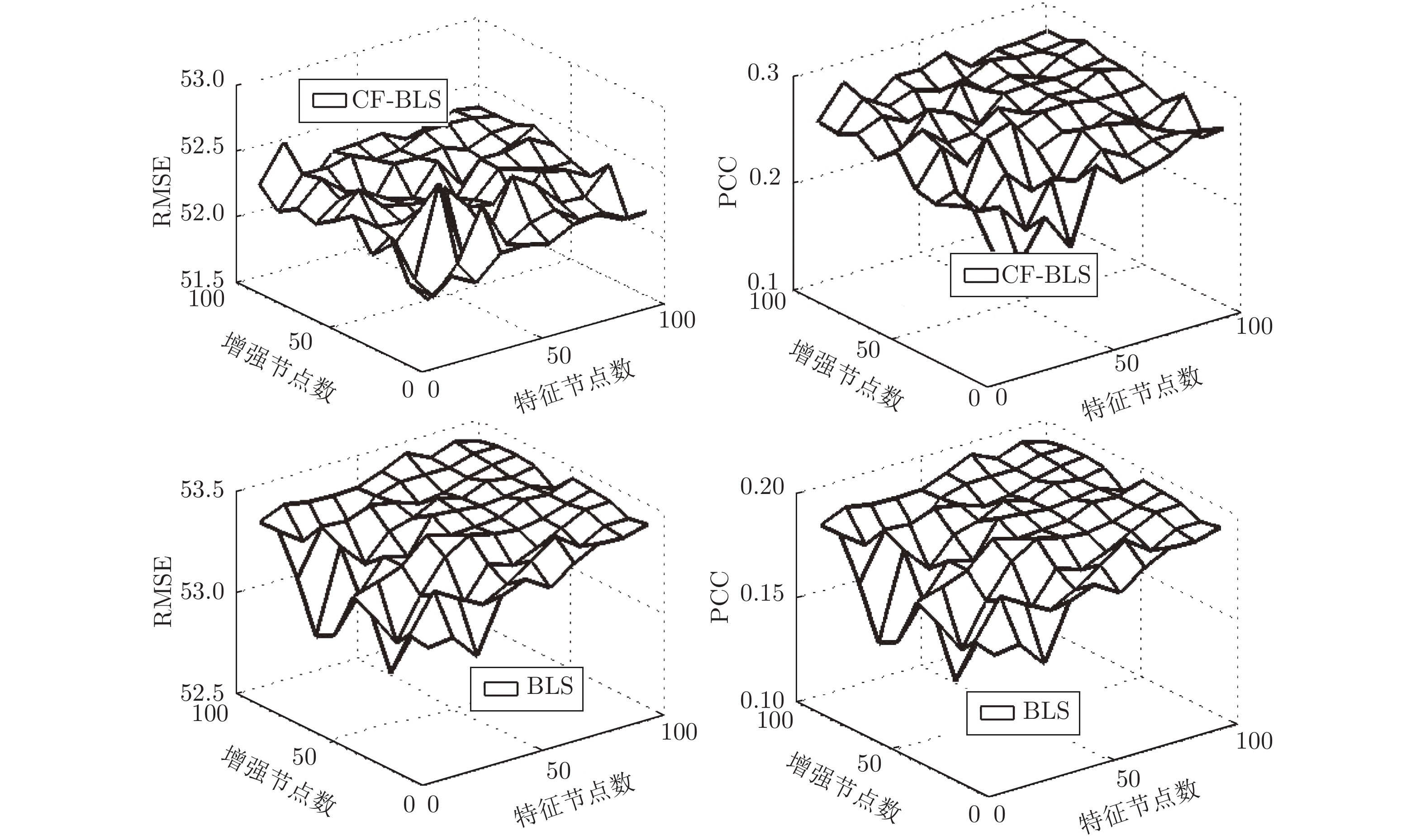
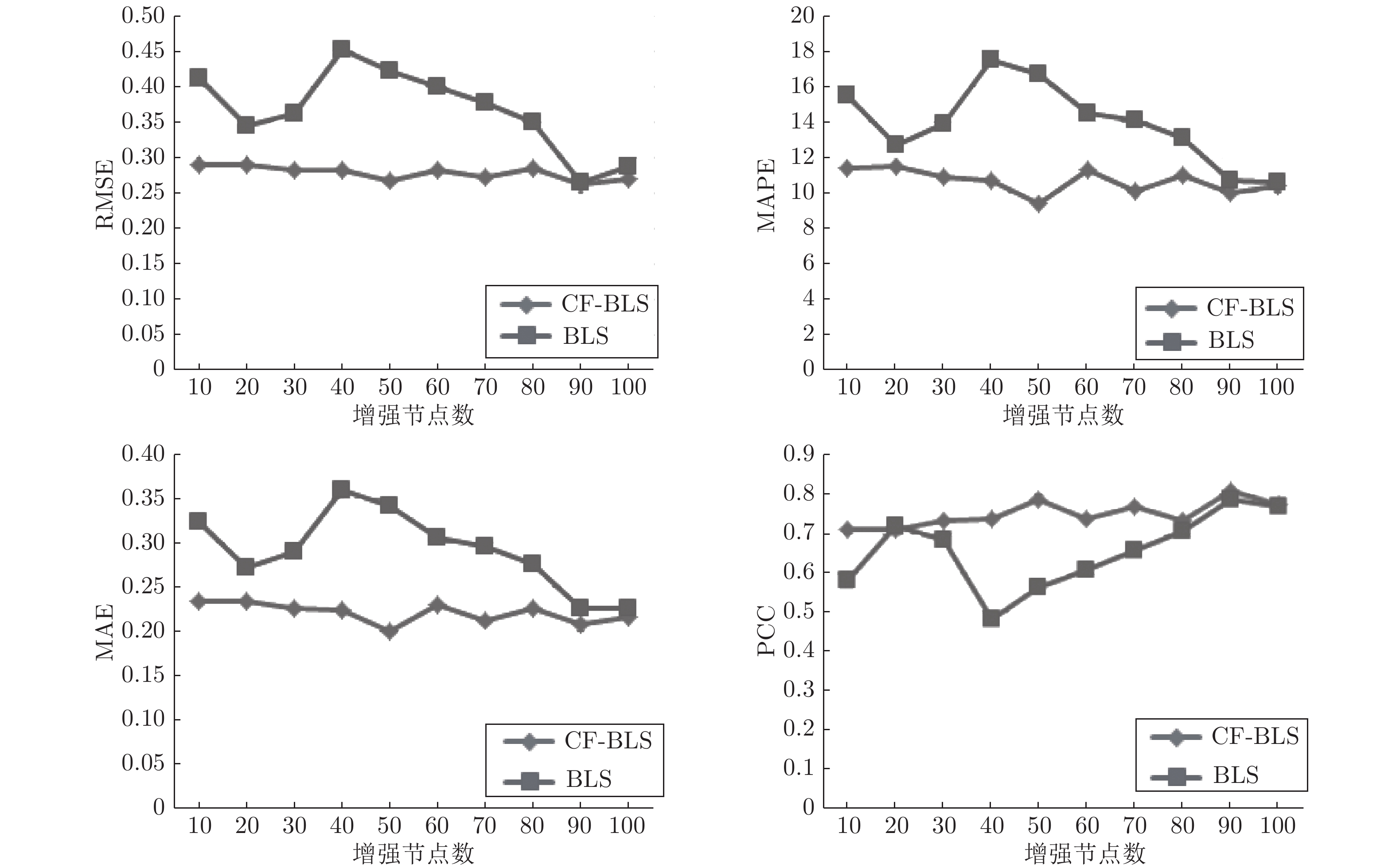
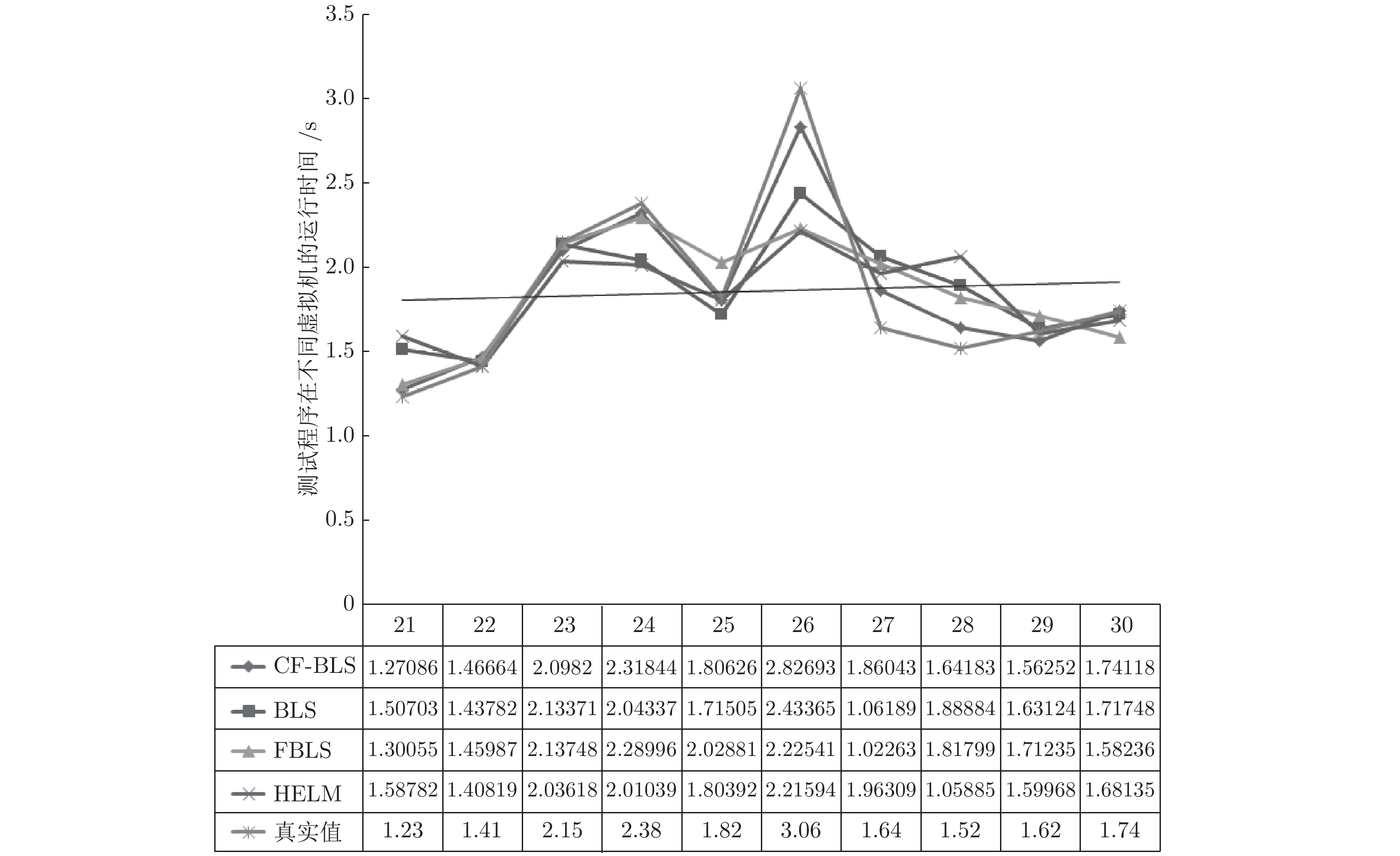
在基于基础设施即服务的云服务模式下, 精准的虚拟机性能预测, 对于用户在众多资源提供商之间进行虚拟机租用策略的制定具有十分重要的意义. 针对基于宽度学习系统(Broad learning system, BLS)的预测模型存在许多降低虚拟机性能预测准确性和效率的冗余节点, 通过引入压缩因子, 构建基于压缩因子的宽度学习系统, 使预测结果更逼近输出样本, 能够减少BLS的冗余特征节点与增强节点, 从而加快BLS的网络收敛速度, 提高BLS的泛化性能.
在基于基础设施即服务的云服务模式下, 精准的虚拟机性能预测, 对于用户在众多资源提供商之间进行虚拟机租用策略的制定具有十分重要的意义. 针对基于宽度学习系统(Broad learning system, BLS)的预测模型存在许多降低虚拟机性能预测准确性和效率的冗余节点, 通过引入压缩因子, 构建基于压缩因子的宽度学习系统, 使预测结果更逼近输出样本, 能够减少BLS的冗余特征节点与增强节点, 从而加快BLS的网络收敛速度, 提高BLS的泛化性能.


2022, 48(3): 735-746.
doi: 10.16383/j.aas.c190279
摘要:
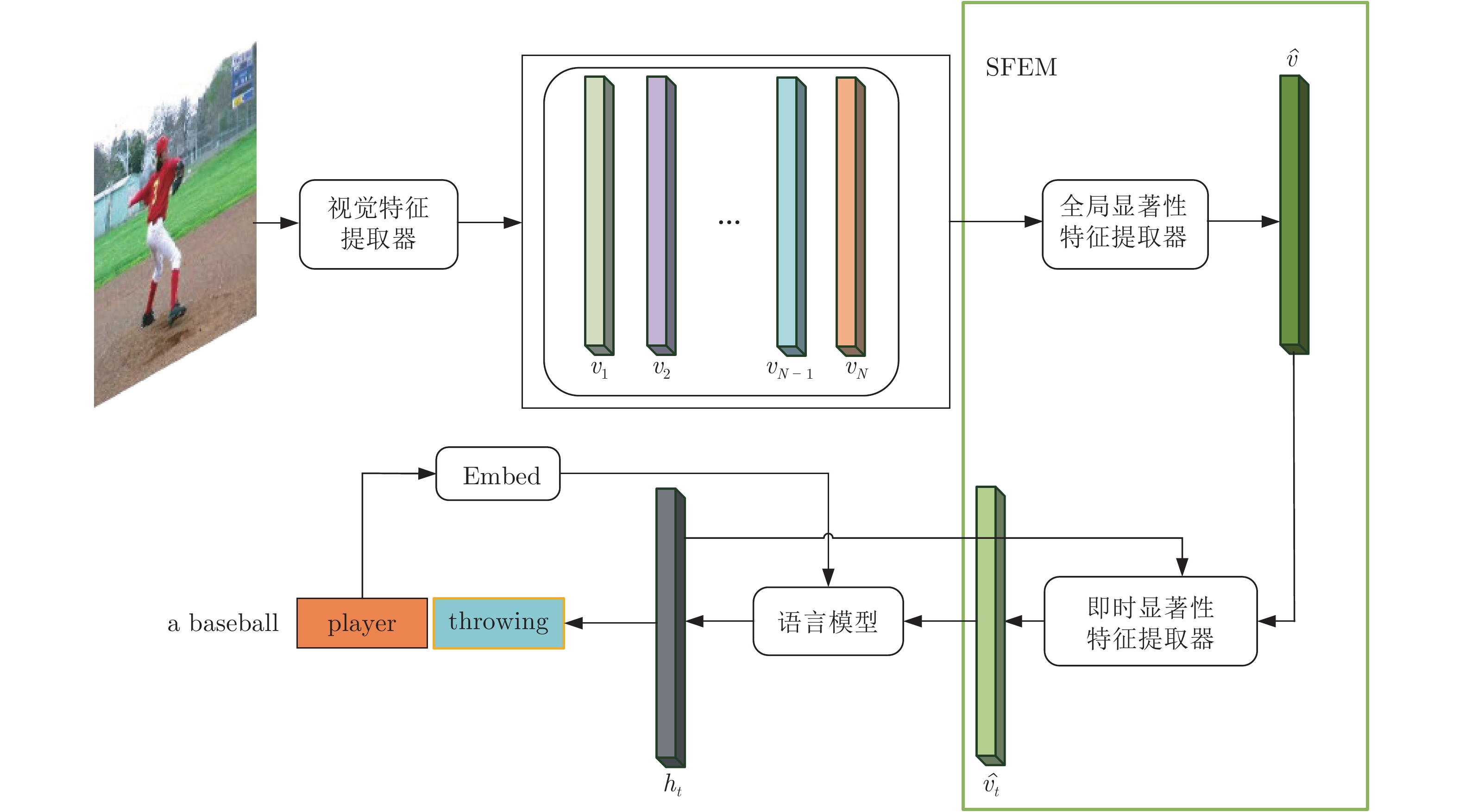
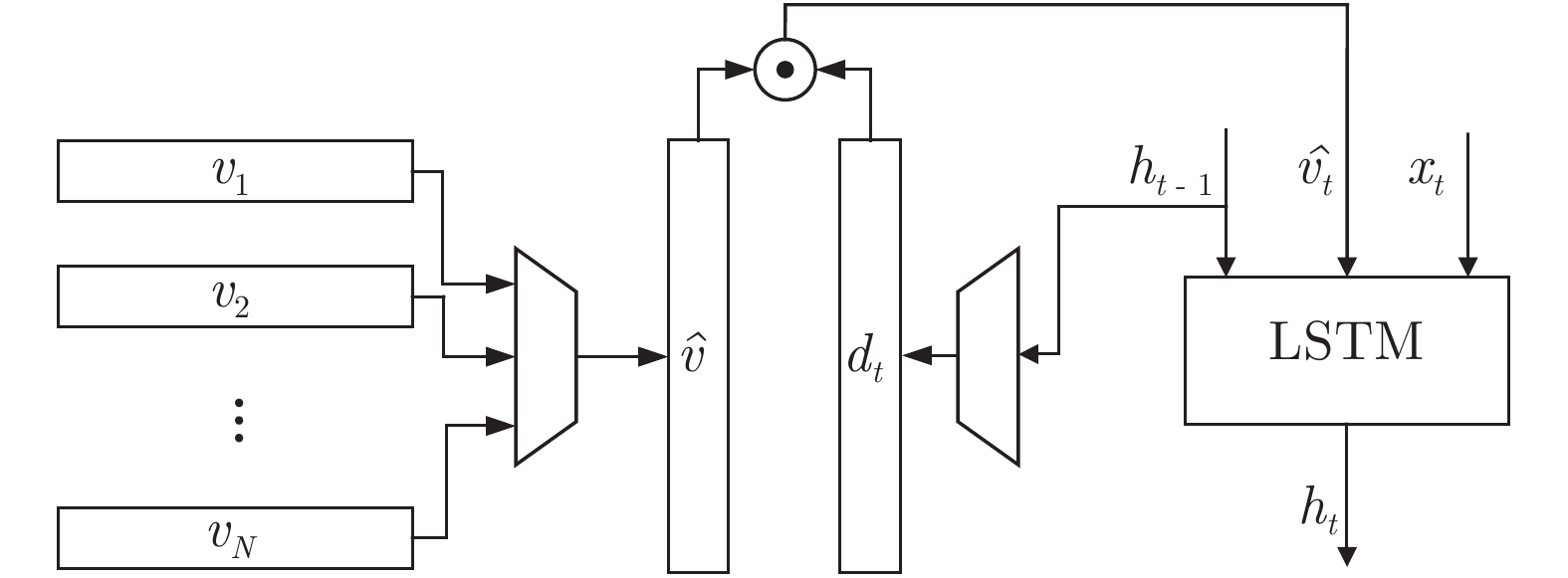
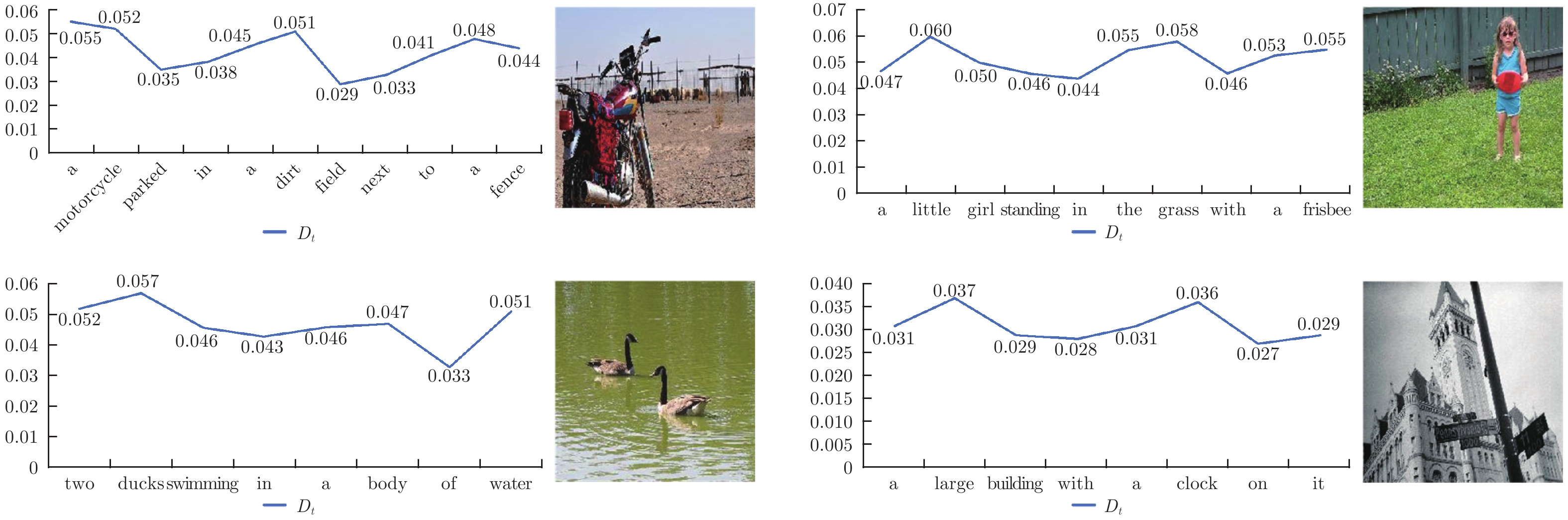
图像描述(Image captioning)是一个融合了计算机视觉和自然语言处理这两个领域的研究方向, 本文为图像描述设计了一种新颖的显著性特征提取机制(Salient feature extraction mechanism, SFEM), 能够在语言模型预测每一个单词之前快速地向语言模型提供最有价值的视觉特征来指导单词预测, 有效解决了现有方法对视觉特征选择不准确以及时间性能不理想的问题. SFEM包含全局显著性特征提取器和即时显著性特征提取器这两个部分: 全局显著性特征提取器能够从多个局部...
图像描述(Image captioning)是一个融合了计算机视觉和自然语言处理这两个领域的研究方向, 本文为图像描述设计了一种新颖的显著性特征提取机制(Salient feature extraction mechanism, SFEM), 能够在语言模型预测每一个单词之前快速地向语言模型提供最有价值的视觉特征来指导单词预测, 有效解决了现有方法对视觉特征选择不准确以及时间性能不理想的问题. SFEM包含全局显著性特征提取器和即时显著性特征提取器这两个部分: 全局显著性特征提取器能够从多个局部...



2022, 48(3): 747-761.
doi: 10.16383/j.aas.c210668
摘要:
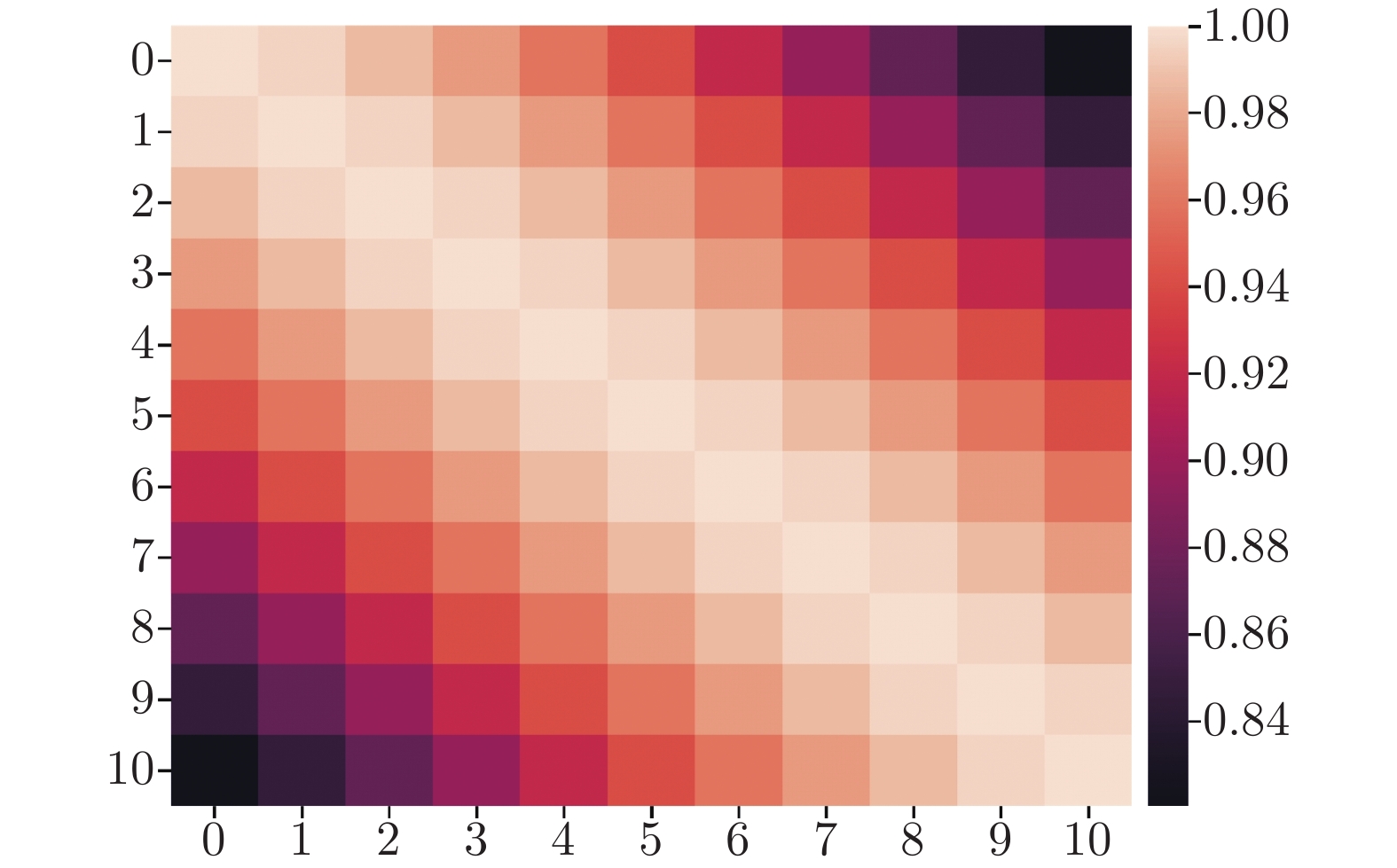
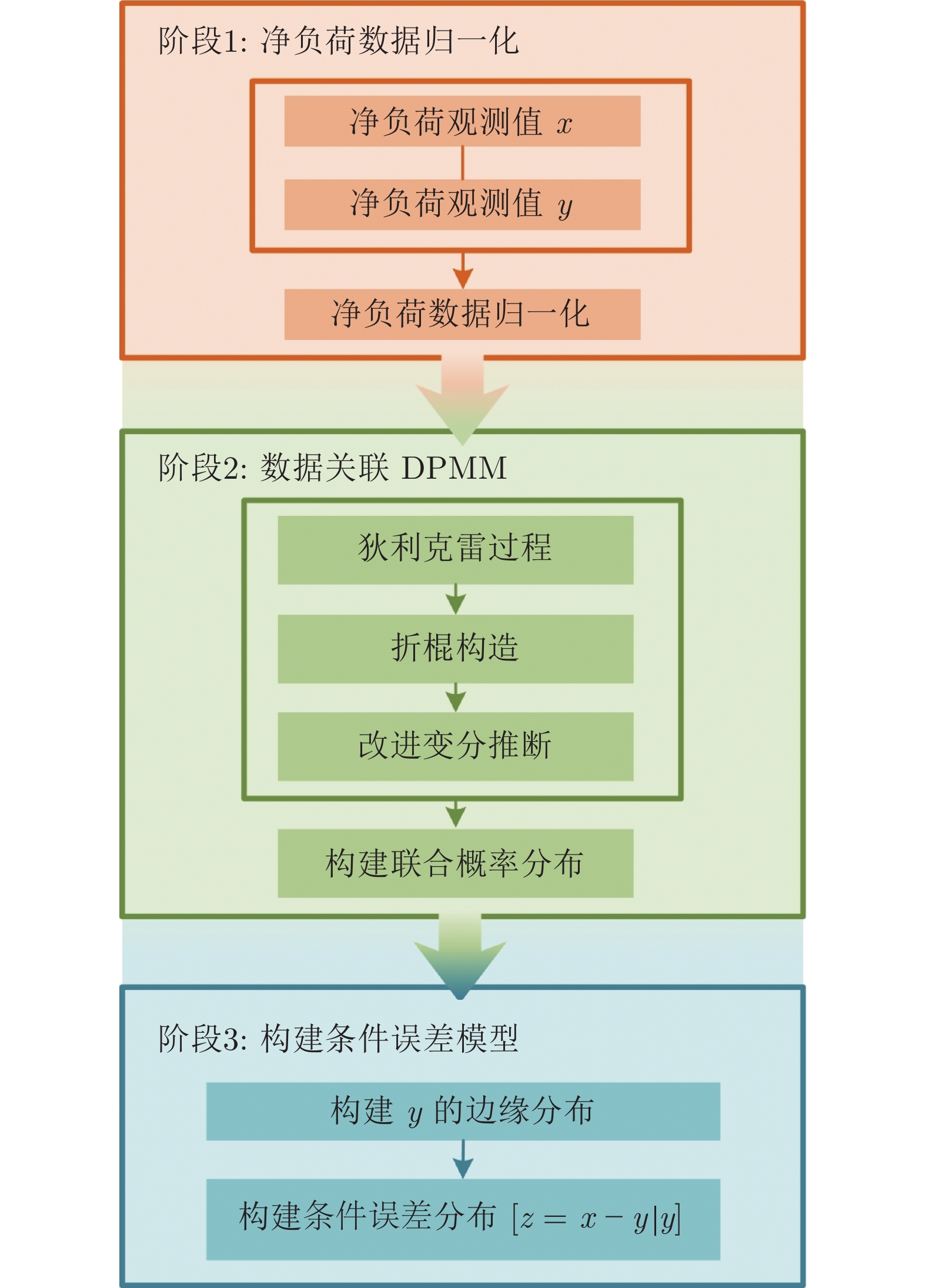
针对电网净负荷时序数据关联的特点, 提出基于数据关联的狄利克雷混合模型 (Data-relevance Dirichlet process mixture model, DDPMM)来表征净负荷的不确定性. 首先, 使用狄利克雷混合模型对净负荷的观测数据与预测数据进行拟合, 得到其混合概率模型; 然后, 提出考虑数据关联的变分贝叶斯推断方法, 改进后验分布对该混合概率模型进行求解, 从而得到混合模型的最优参数; 最后, 根据净负荷预测值的大小得到其对应的预测误差边缘概率分布, 实现不确定性表征....
针对电网净负荷时序数据关联的特点, 提出基于数据关联的狄利克雷混合模型 (Data-relevance Dirichlet process mixture model, DDPMM)来表征净负荷的不确定性. 首先, 使用狄利克雷混合模型对净负荷的观测数据与预测数据进行拟合, 得到其混合概率模型; 然后, 提出考虑数据关联的变分贝叶斯推断方法, 改进后验分布对该混合概率模型进行求解, 从而得到混合模型的最优参数; 最后, 根据净负荷预测值的大小得到其对应的预测误差边缘概率分布, 实现不确定性表征....
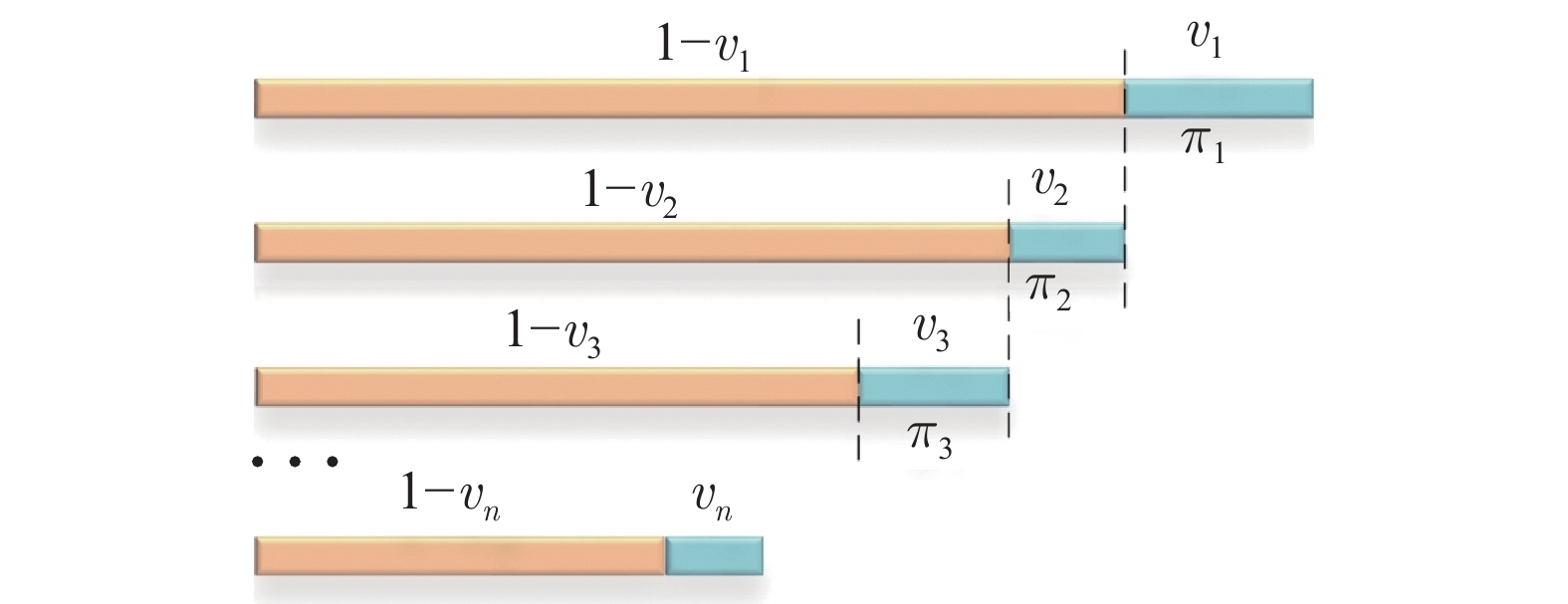
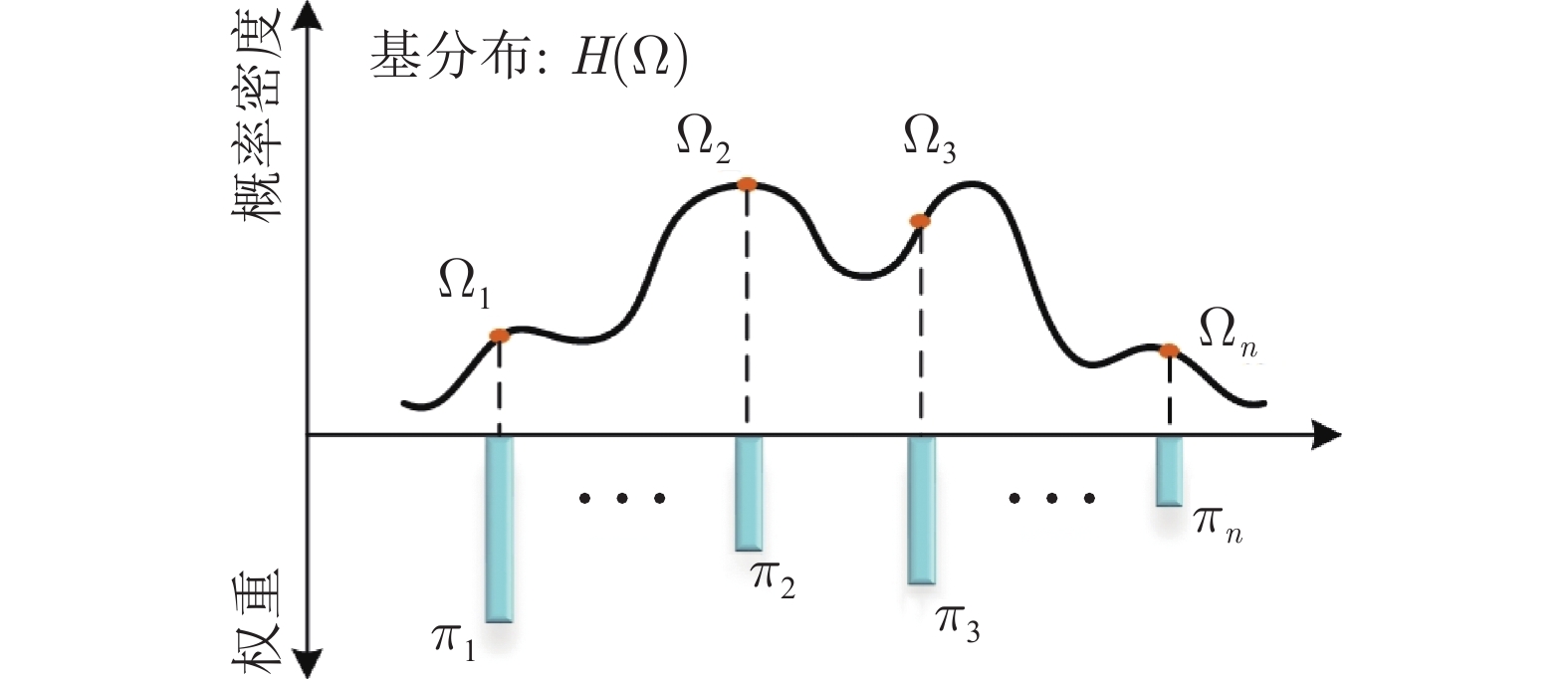

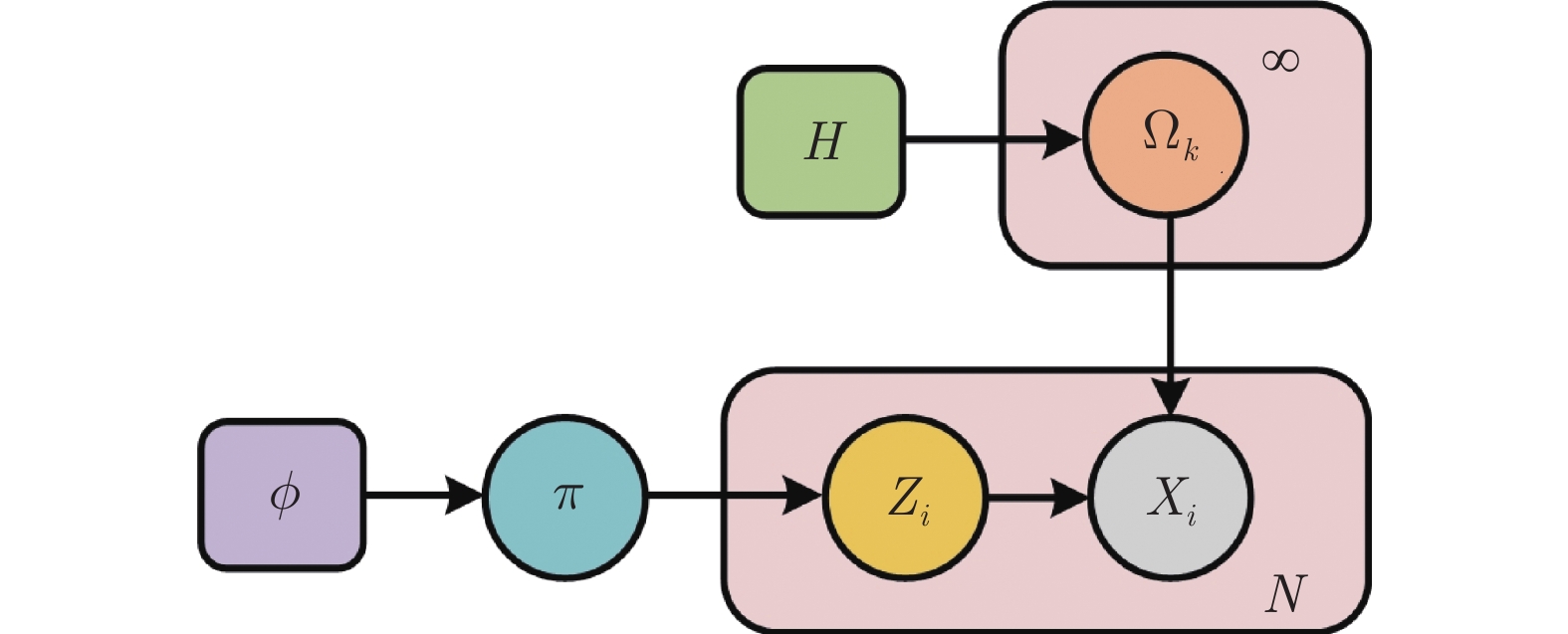

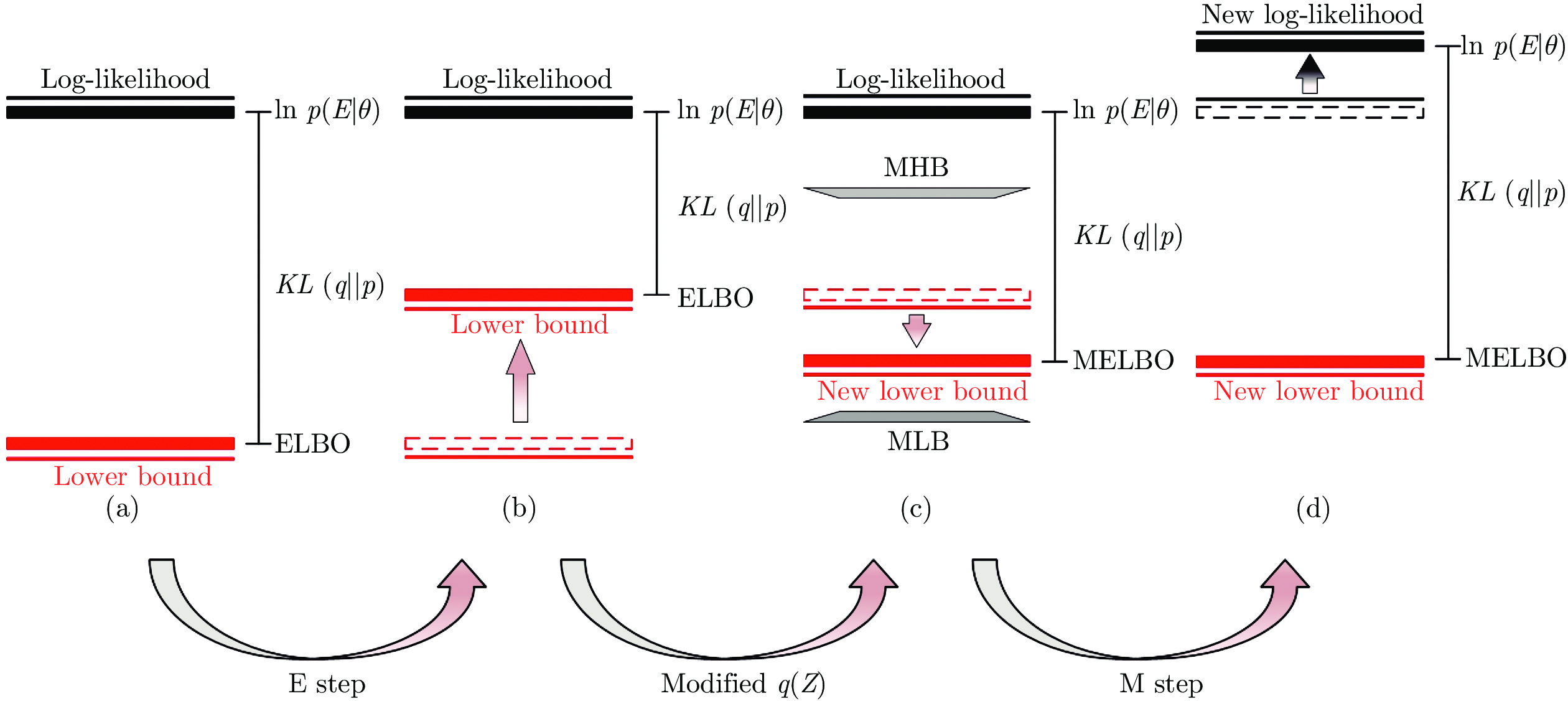

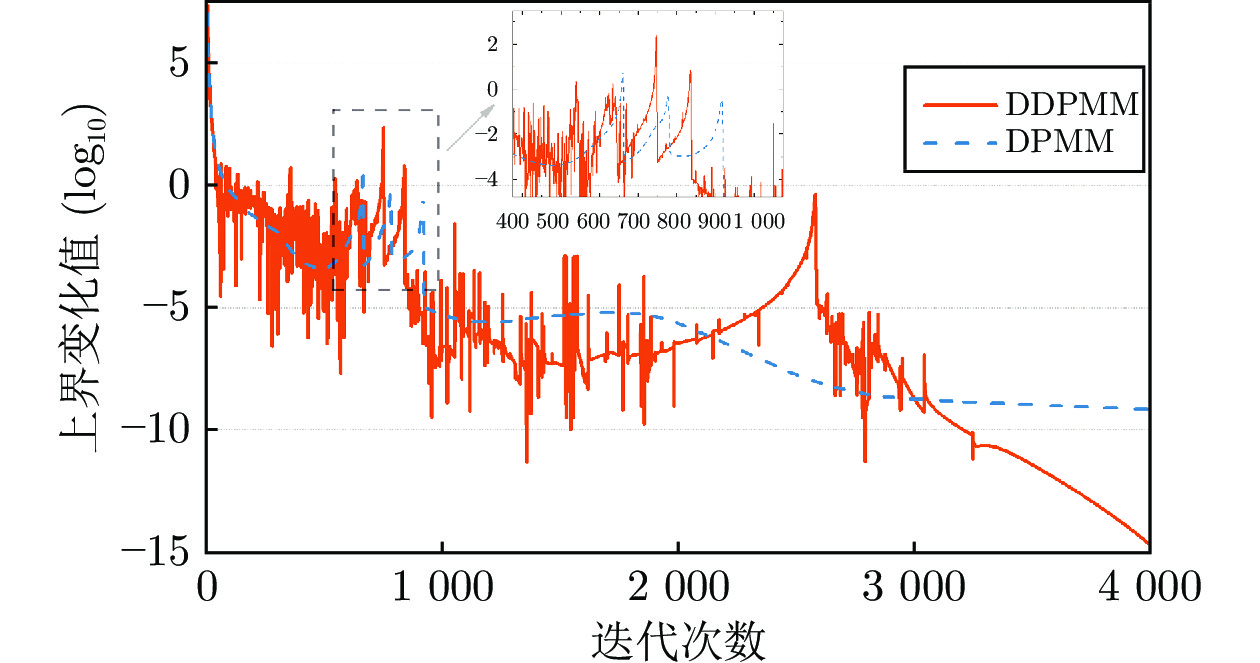

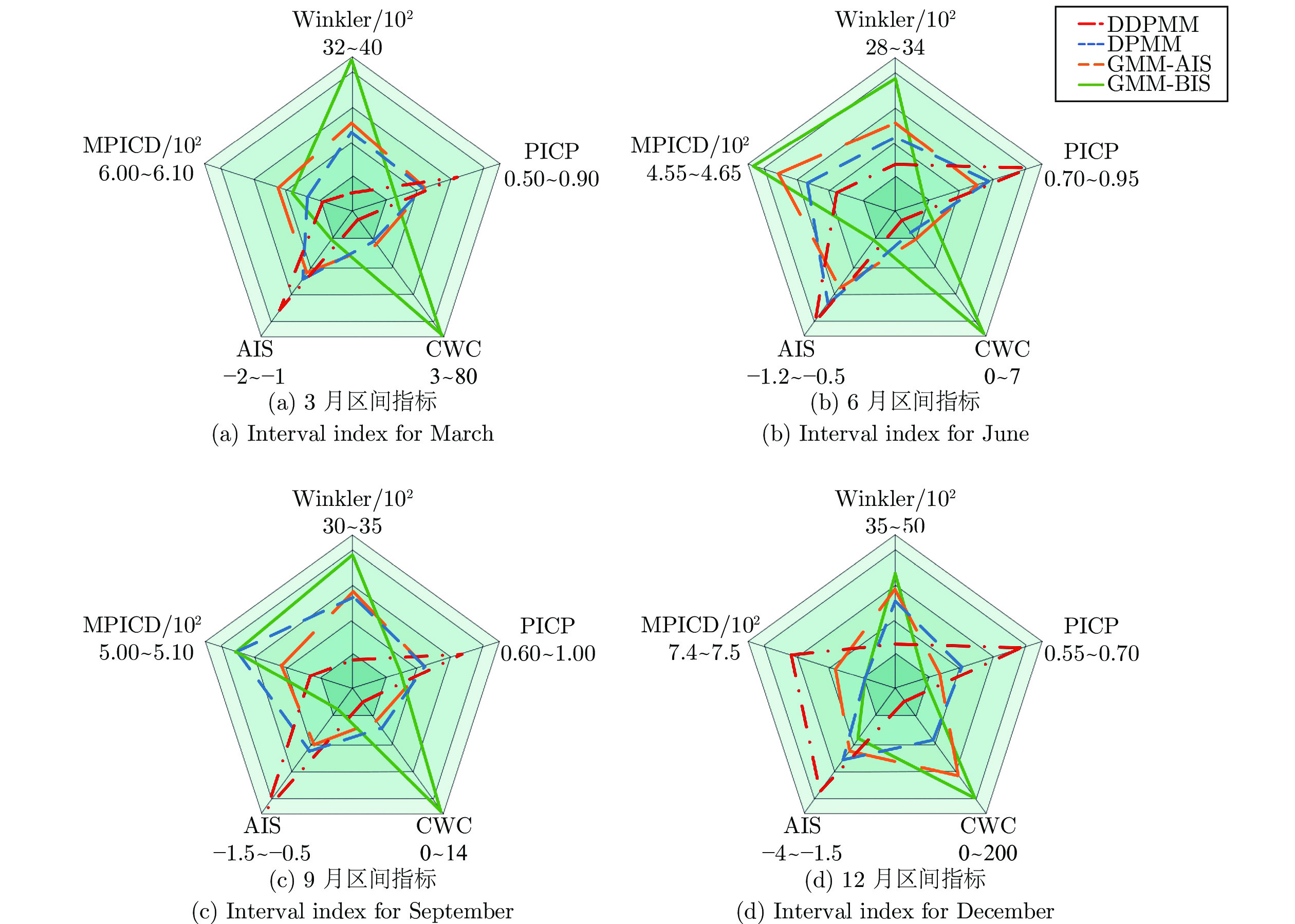
2022, 48(3): 762-773.
doi: 10.16383/j.aas.c210690
摘要:
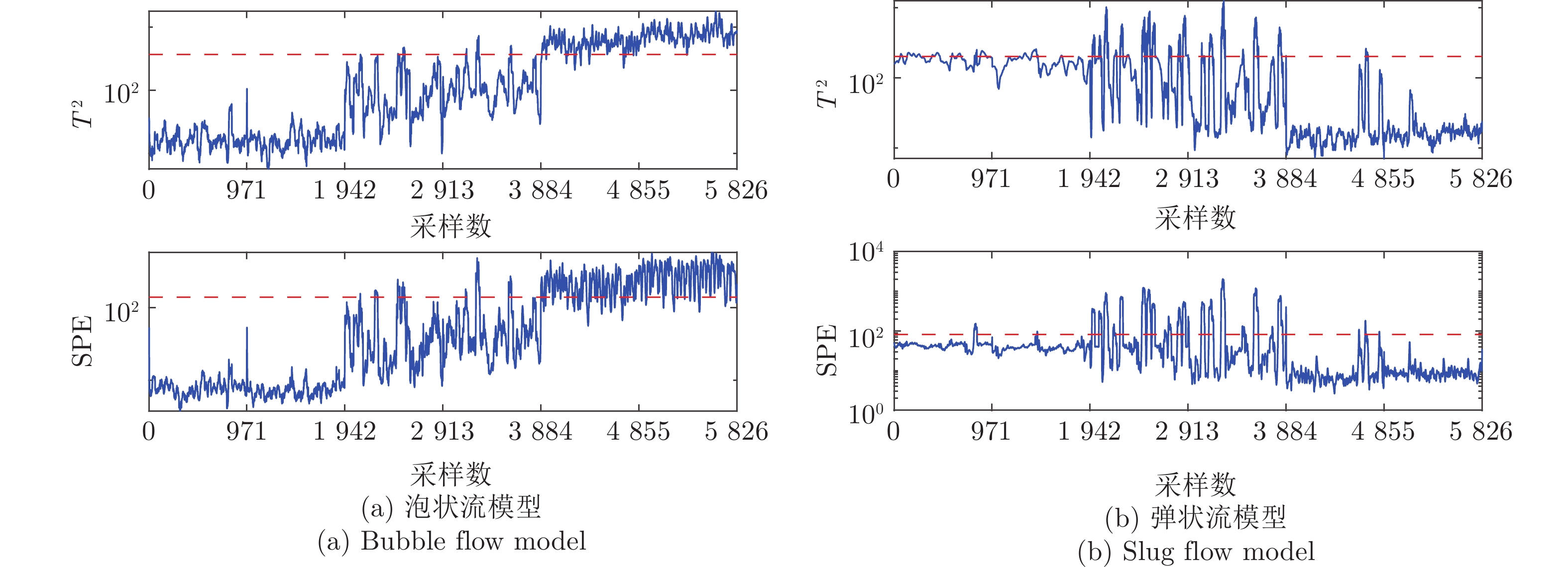
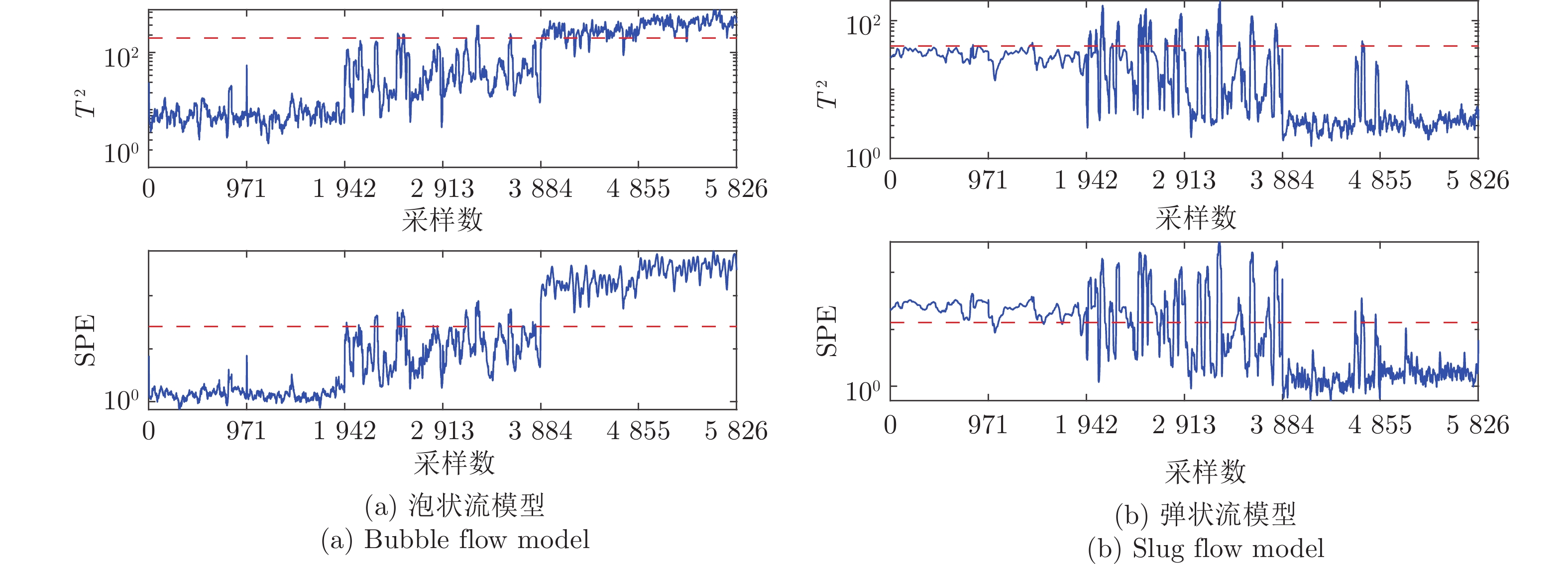
气液两相流流动过程作为一种非平稳过程, 其状态的变化具有时变性、非线性、随机性等复杂流动过程的特点, 其流动状态的实时监测对掌握其流动过程的产生、发展及转化, 保障实际生产的安全稳定运行具有重要意义. 特别是流动状态的过渡过程反映了流动状态的发展及演化, 其流动结构非常复杂. 针对气液两相流的3种典型流动状态及过渡转化过程, 在多传感器获取流动状态测试数据的基础上, 提出一种多模态动态核主成分分析方法. 通过采用动态自相关、互相关方法提取流动过程测试数据中的动态特性, 采用核方法提取非线性特性,...
气液两相流流动过程作为一种非平稳过程, 其状态的变化具有时变性、非线性、随机性等复杂流动过程的特点, 其流动状态的实时监测对掌握其流动过程的产生、发展及转化, 保障实际生产的安全稳定运行具有重要意义. 特别是流动状态的过渡过程反映了流动状态的发展及演化, 其流动结构非常复杂. 针对气液两相流的3种典型流动状态及过渡转化过程, 在多传感器获取流动状态测试数据的基础上, 提出一种多模态动态核主成分分析方法. 通过采用动态自相关、互相关方法提取流动过程测试数据中的动态特性, 采用核方法提取非线性特性,...
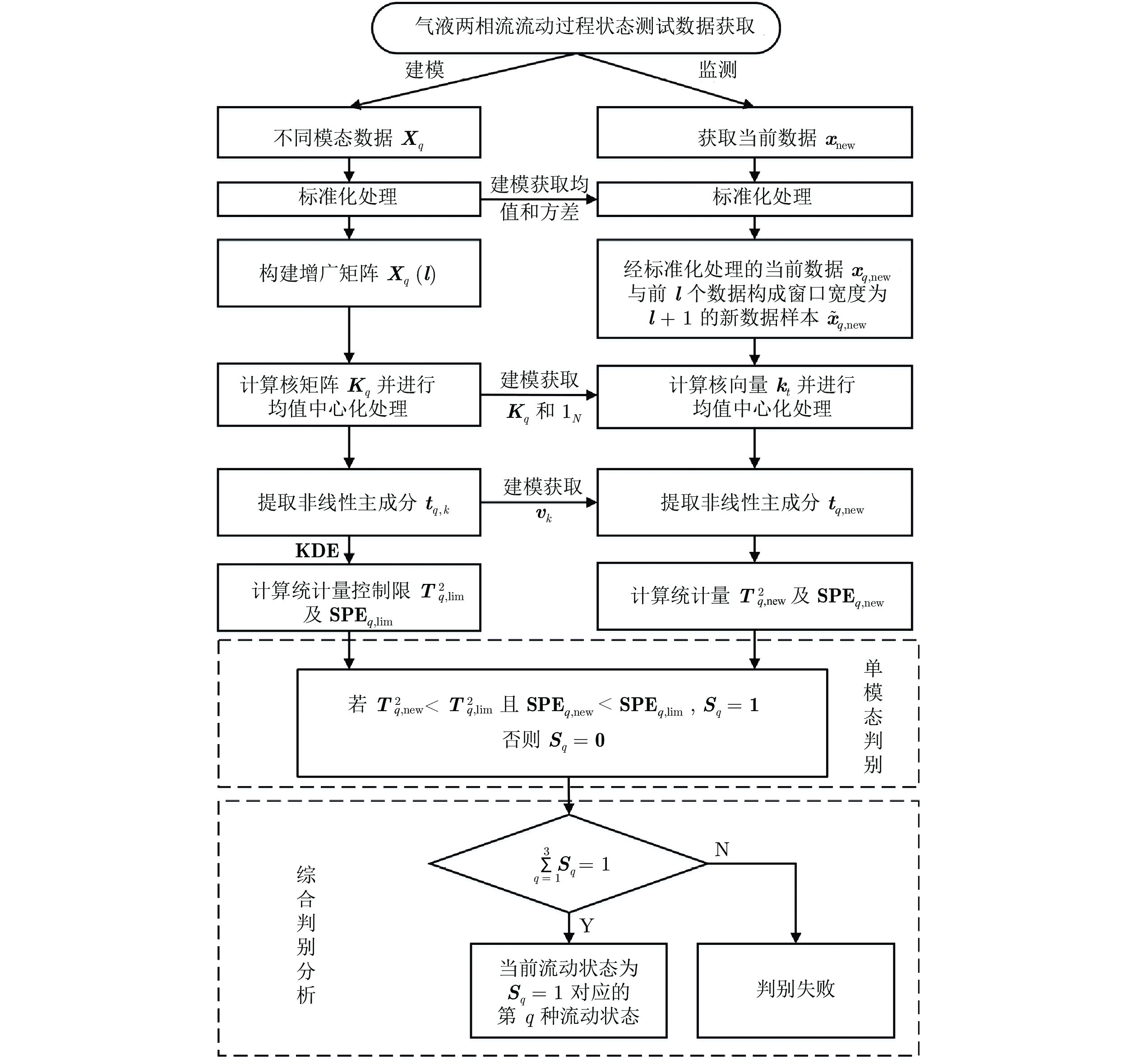
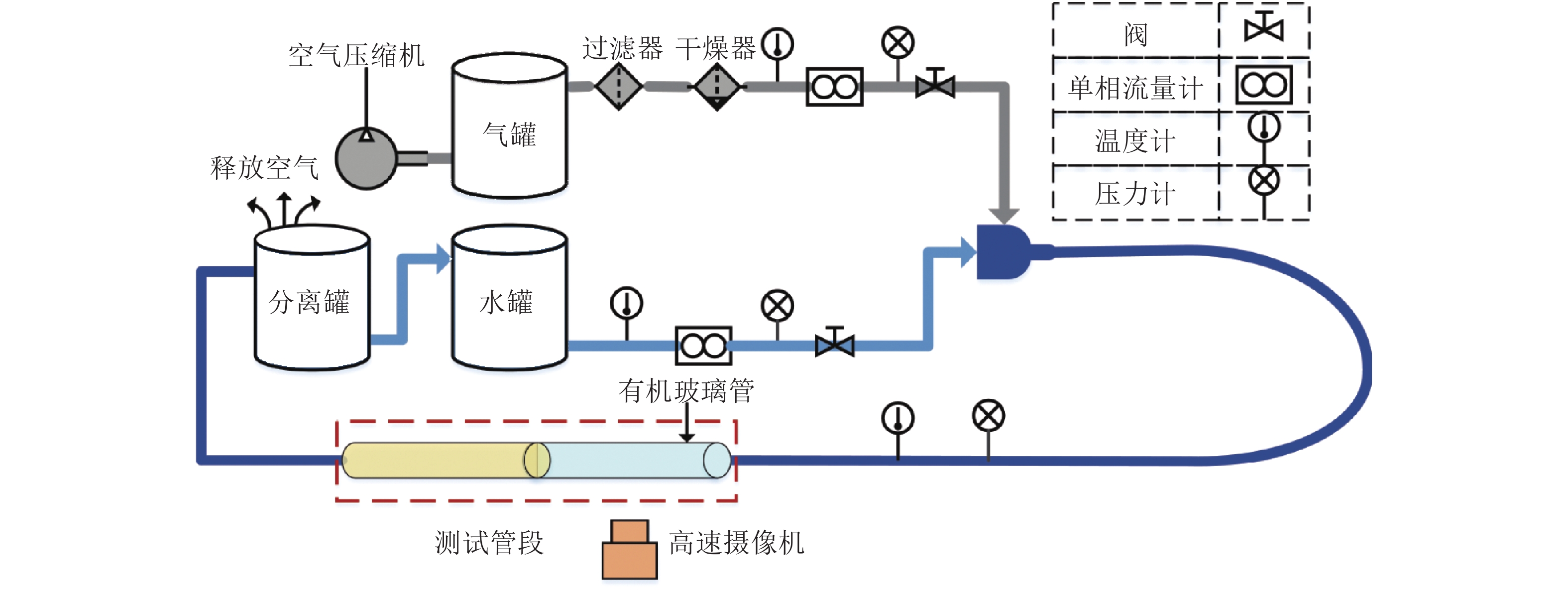
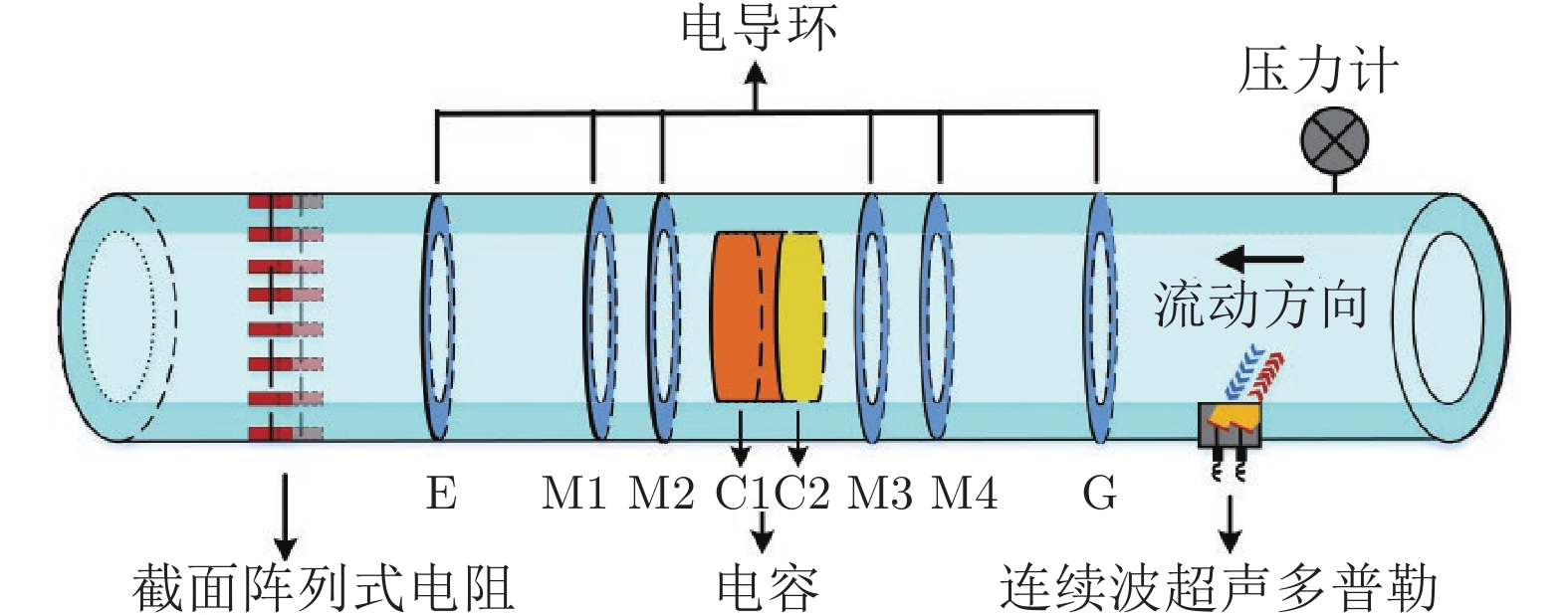
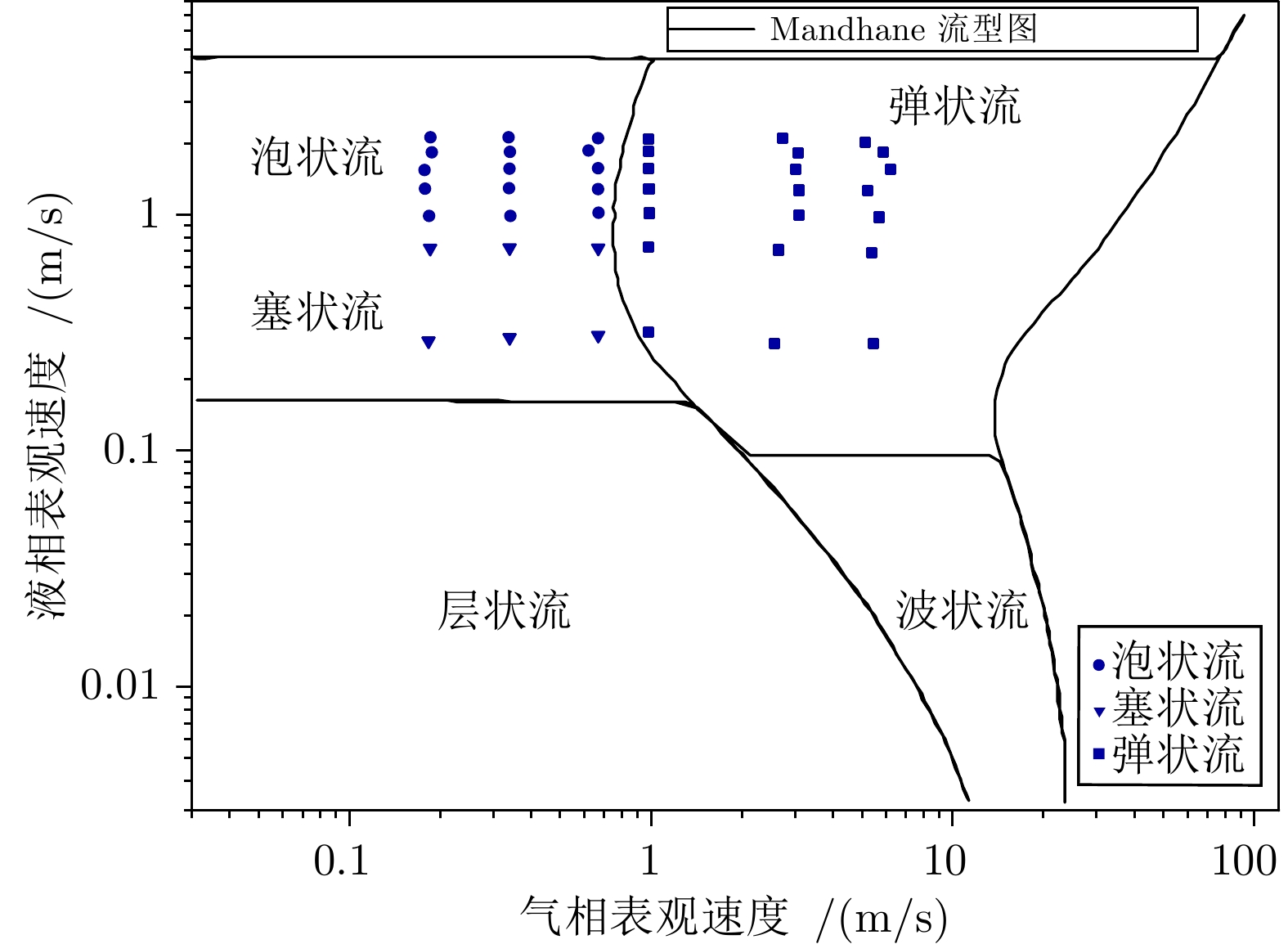


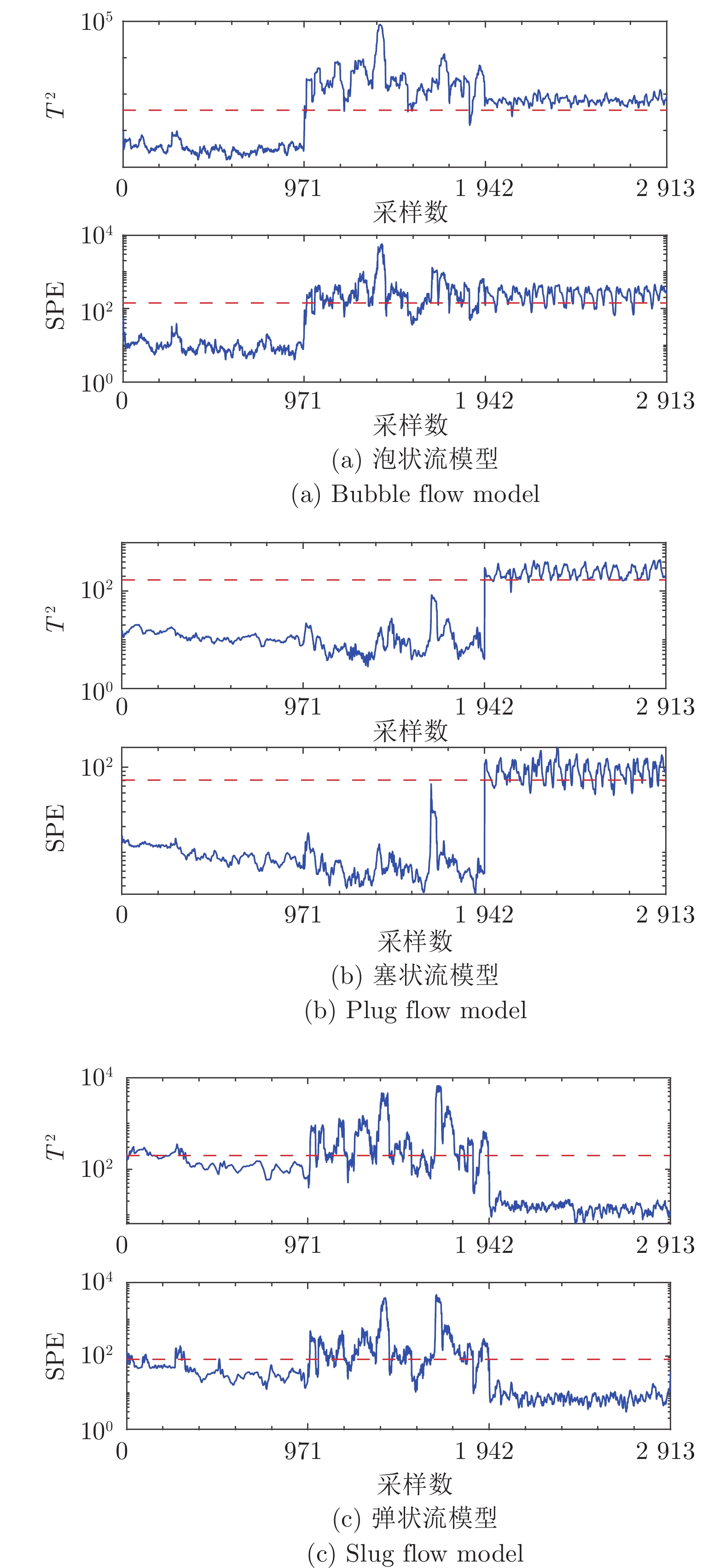


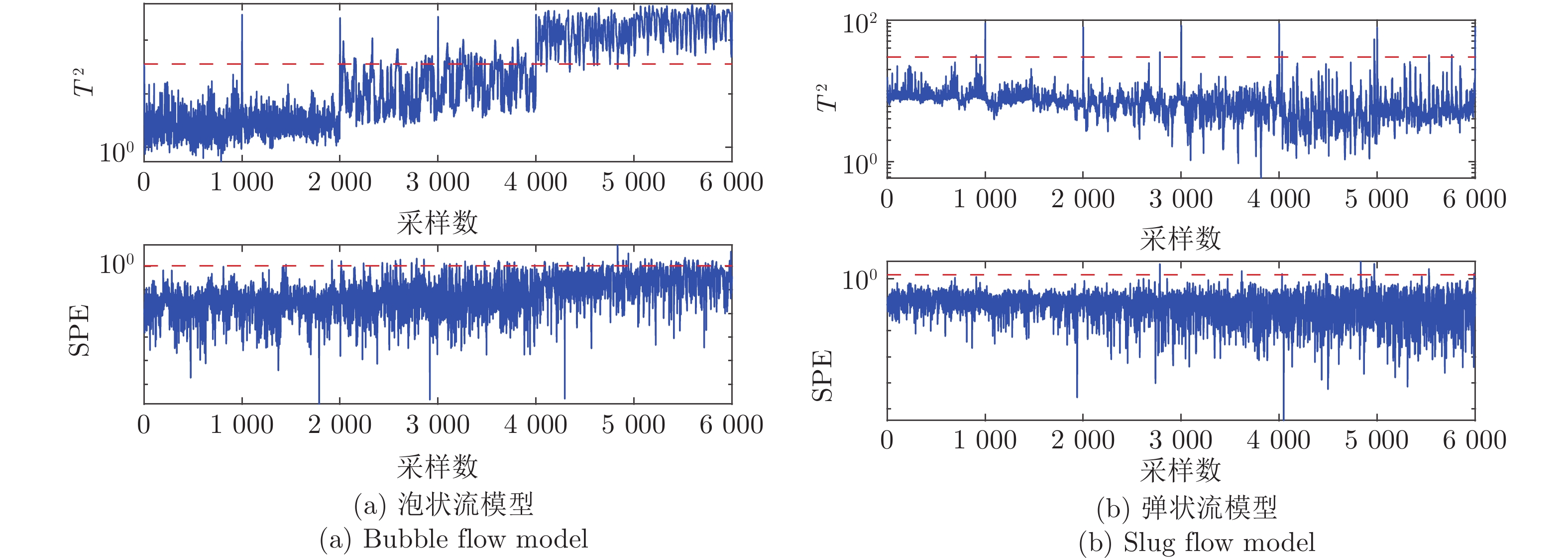
2022, 48(3): 774-786.
doi: 10.16383/j.aas.c190375
摘要:
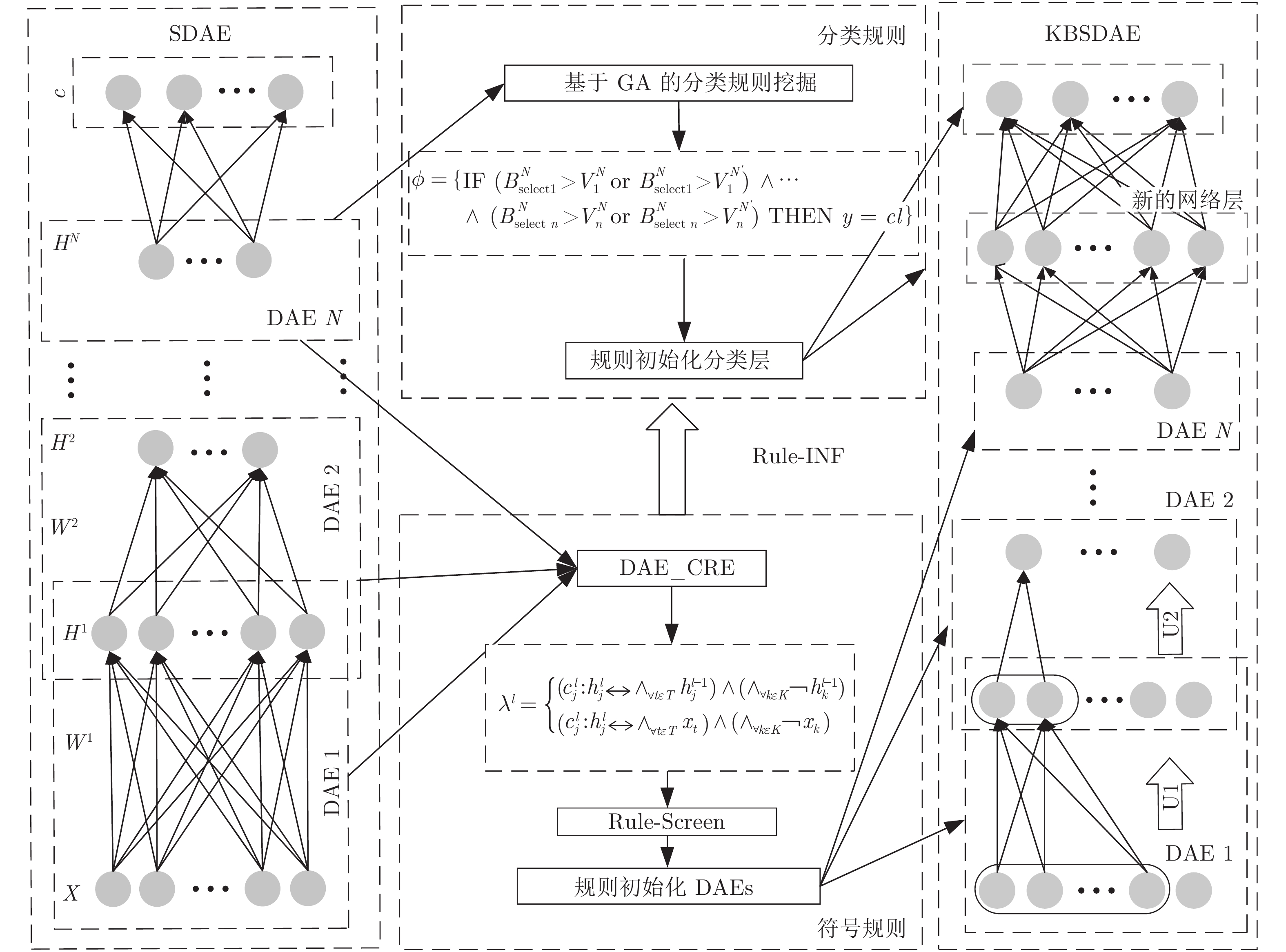
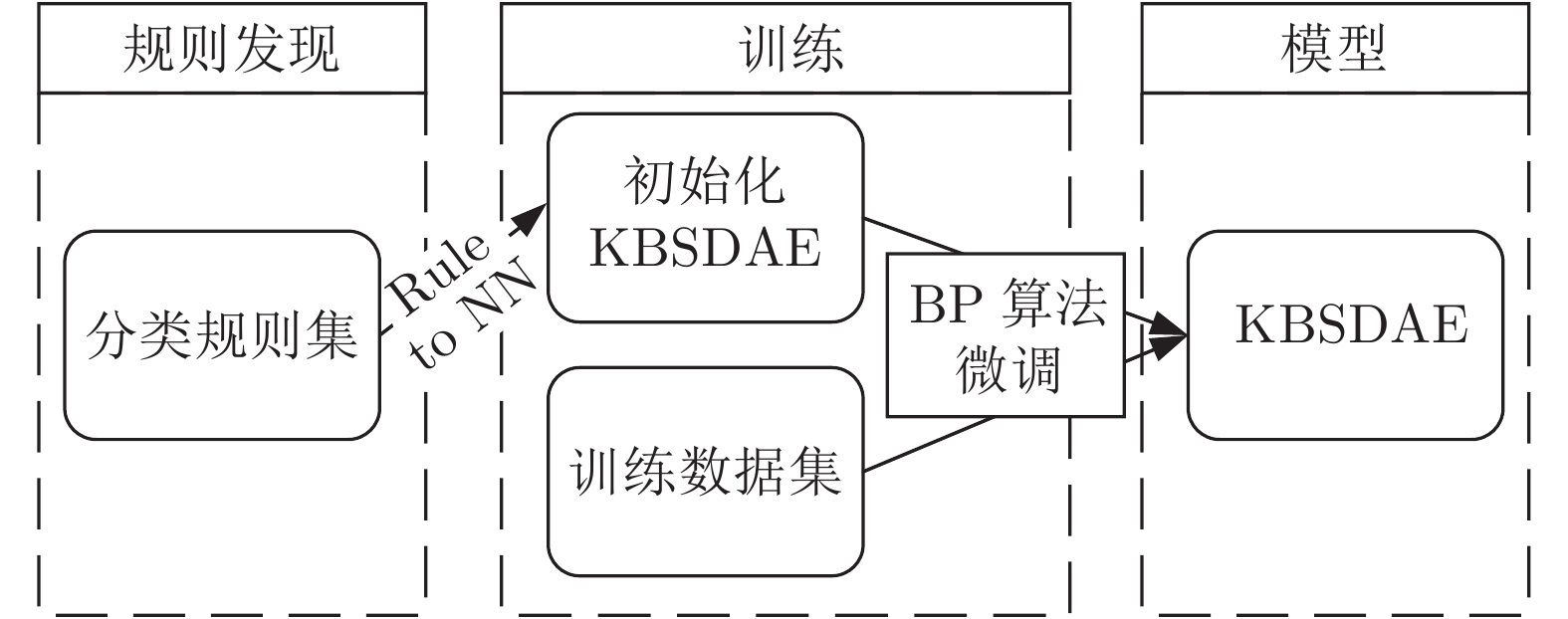
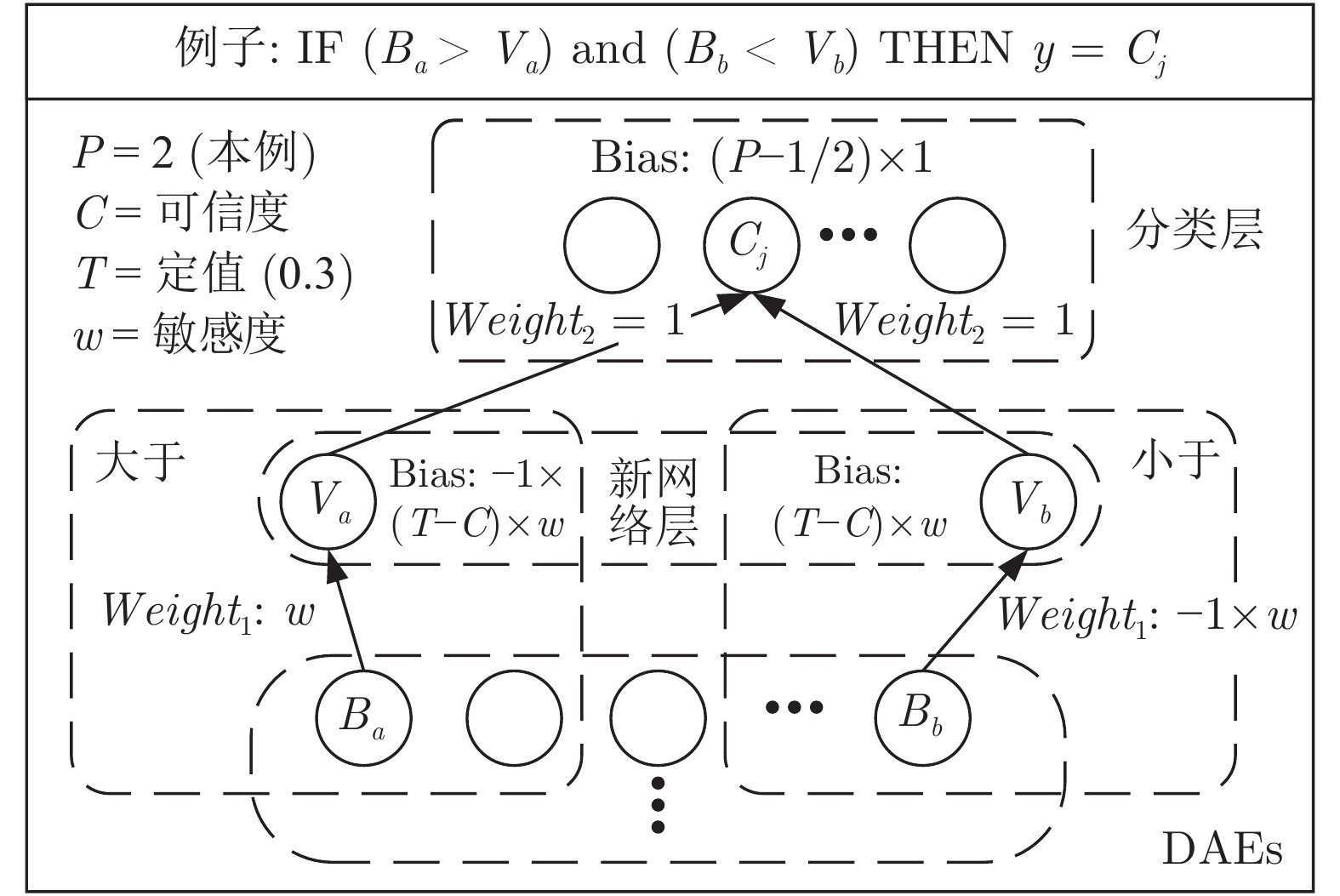
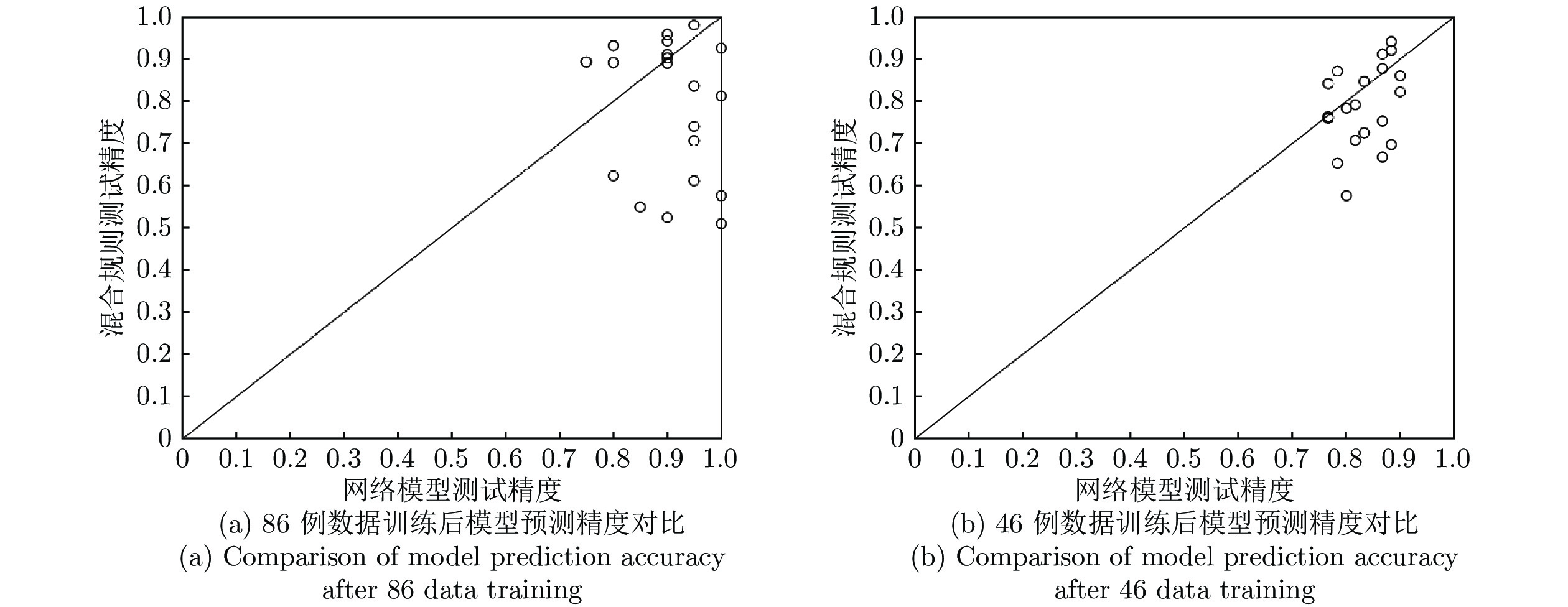
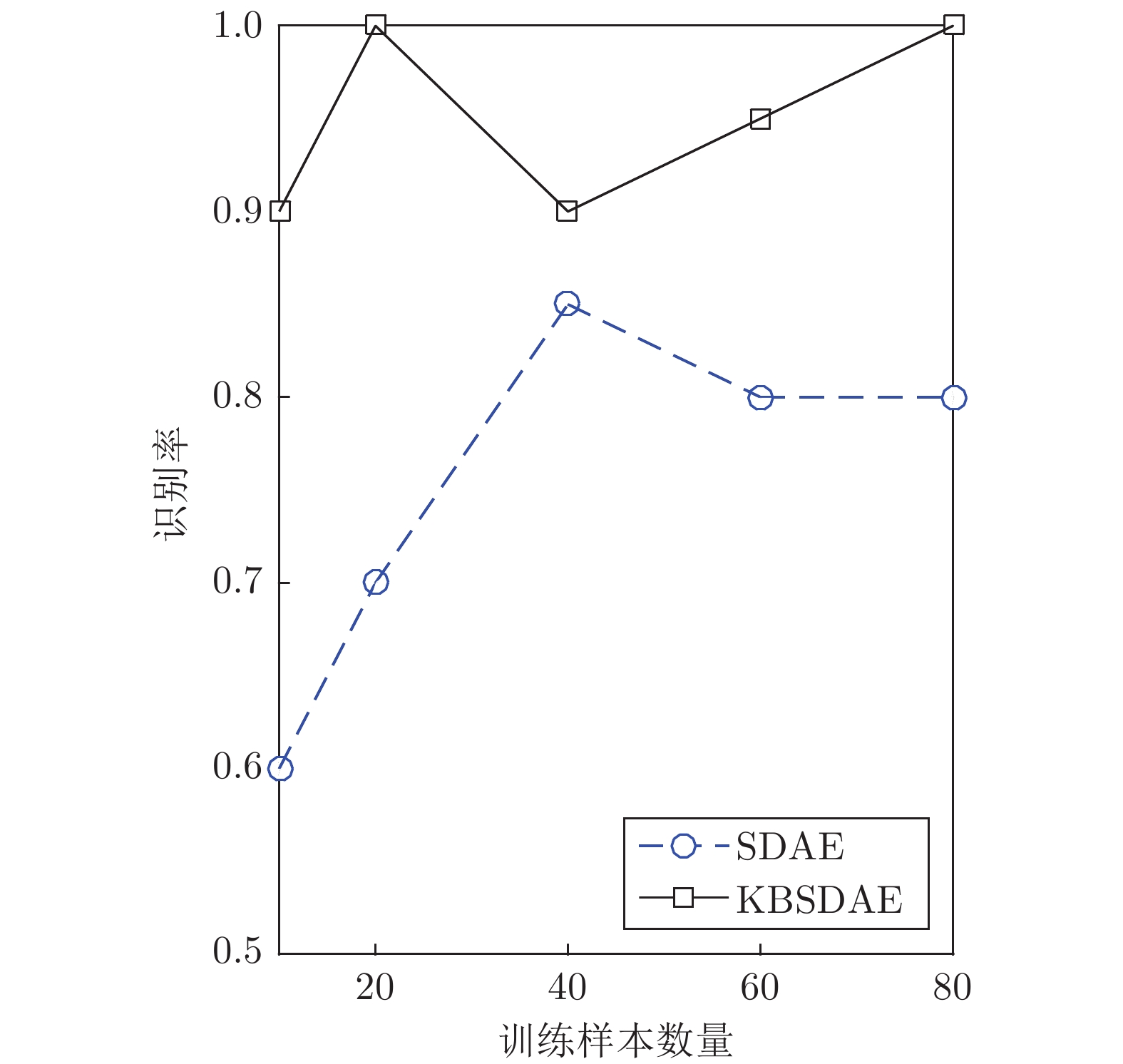
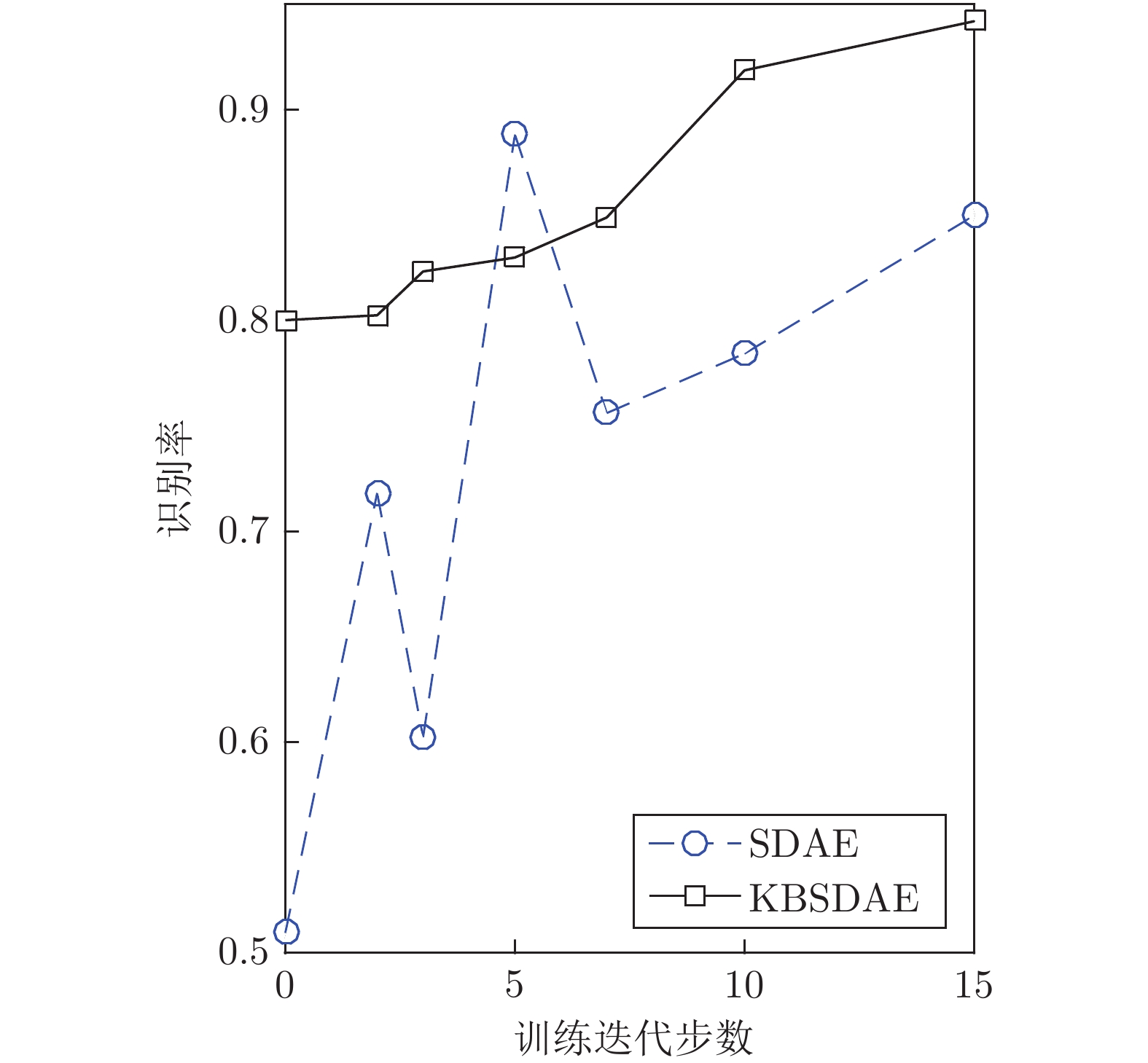
深度神经网络是具有复杂结构和多个非线性处理单元的模型, 广泛应用于计算机视觉、自然语言处理等领域. 但是, 深度神经网络存在不可解释这一致命缺陷, 即“黑箱问题”, 这使得深度学习在各个领域的应用仍然存在巨大的障碍. 本文提出了一种新的深度神经网络模型 —— 知识堆叠降噪自编码器(Knowledge-based stacked denoising autoencoder, KBSDAE). 尝试以一种逻辑语言的方式有效解释网络结构及内在运作机理, 同时确保逻辑规则可以进行深度推导. 进一步通过插...
深度神经网络是具有复杂结构和多个非线性处理单元的模型, 广泛应用于计算机视觉、自然语言处理等领域. 但是, 深度神经网络存在不可解释这一致命缺陷, 即“黑箱问题”, 这使得深度学习在各个领域的应用仍然存在巨大的障碍. 本文提出了一种新的深度神经网络模型 —— 知识堆叠降噪自编码器(Knowledge-based stacked denoising autoencoder, KBSDAE). 尝试以一种逻辑语言的方式有效解释网络结构及内在运作机理, 同时确保逻辑规则可以进行深度推导. 进一步通过插...


2022, 48(3): 787-796.
doi: 10.16383/j.aas.c190292
摘要:
提出了一种基于注意力机制的视频分割网络及其全局信息优化训练方法. 该方法包含一个改进的视频分割网络, 在对视频中的物体进行分割后, 利用初步分割的结果作为先验信息对网络优化, 再次分割得到最终结果. 该分割网络是一种双流卷积网络, 以视频图像和光流图像作为输入, 分别提取图像的表观信息和运动信息, 最终融合得到分割掩膜(Segmentation mask). 网络中嵌入了一个新的卷积注意力模块, 应用于卷积网络的高层次特征与相邻低层次特征之间, 使得高层语义特征可以定位低层特征中的重要区域, 提...
提出了一种基于注意力机制的视频分割网络及其全局信息优化训练方法. 该方法包含一个改进的视频分割网络, 在对视频中的物体进行分割后, 利用初步分割的结果作为先验信息对网络优化, 再次分割得到最终结果. 该分割网络是一种双流卷积网络, 以视频图像和光流图像作为输入, 分别提取图像的表观信息和运动信息, 最终融合得到分割掩膜(Segmentation mask). 网络中嵌入了一个新的卷积注意力模块, 应用于卷积网络的高层次特征与相邻低层次特征之间, 使得高层语义特征可以定位低层特征中的重要区域, 提...
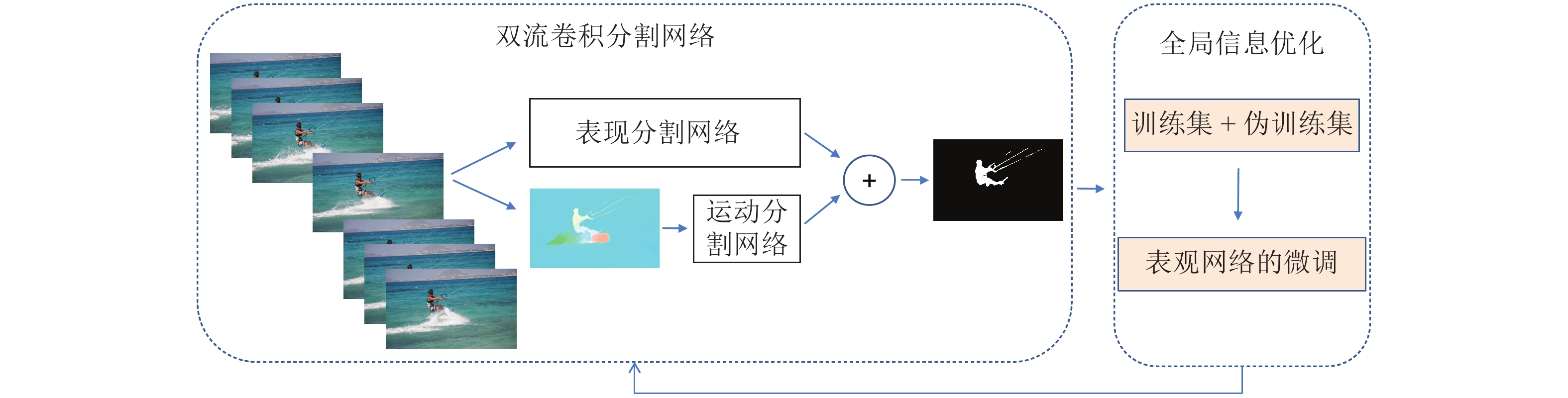
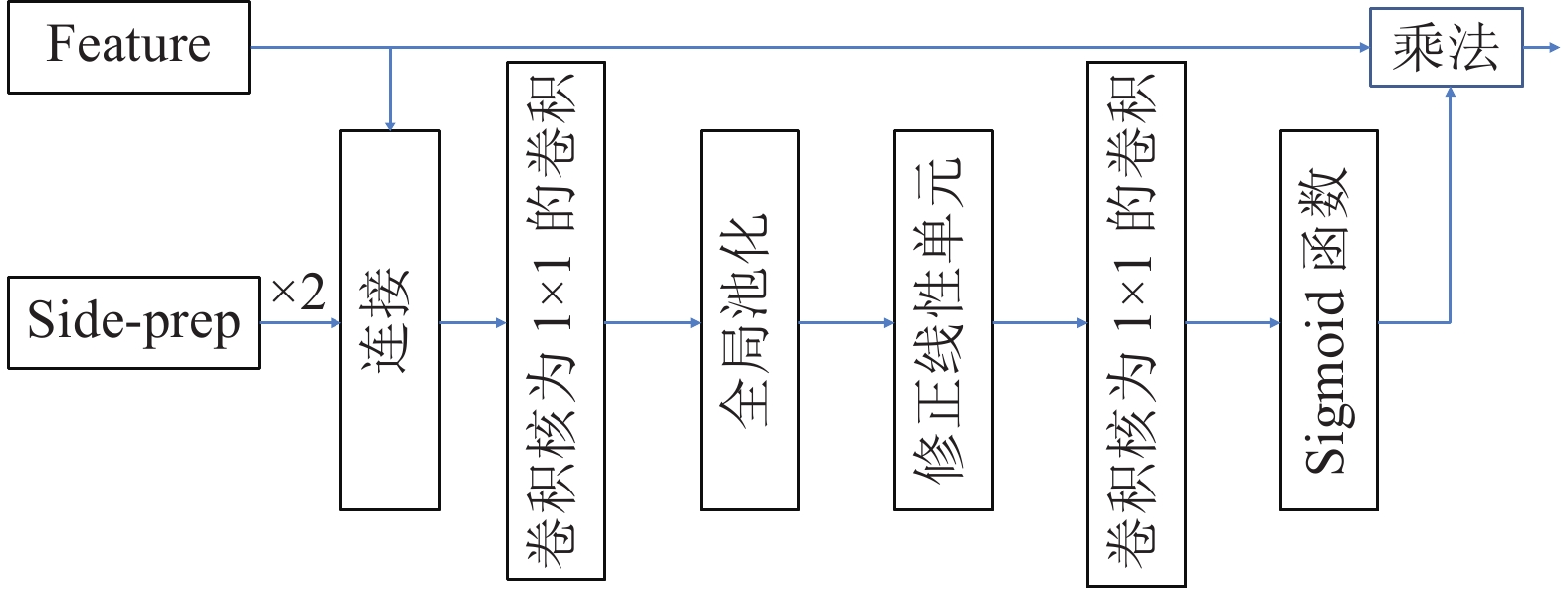
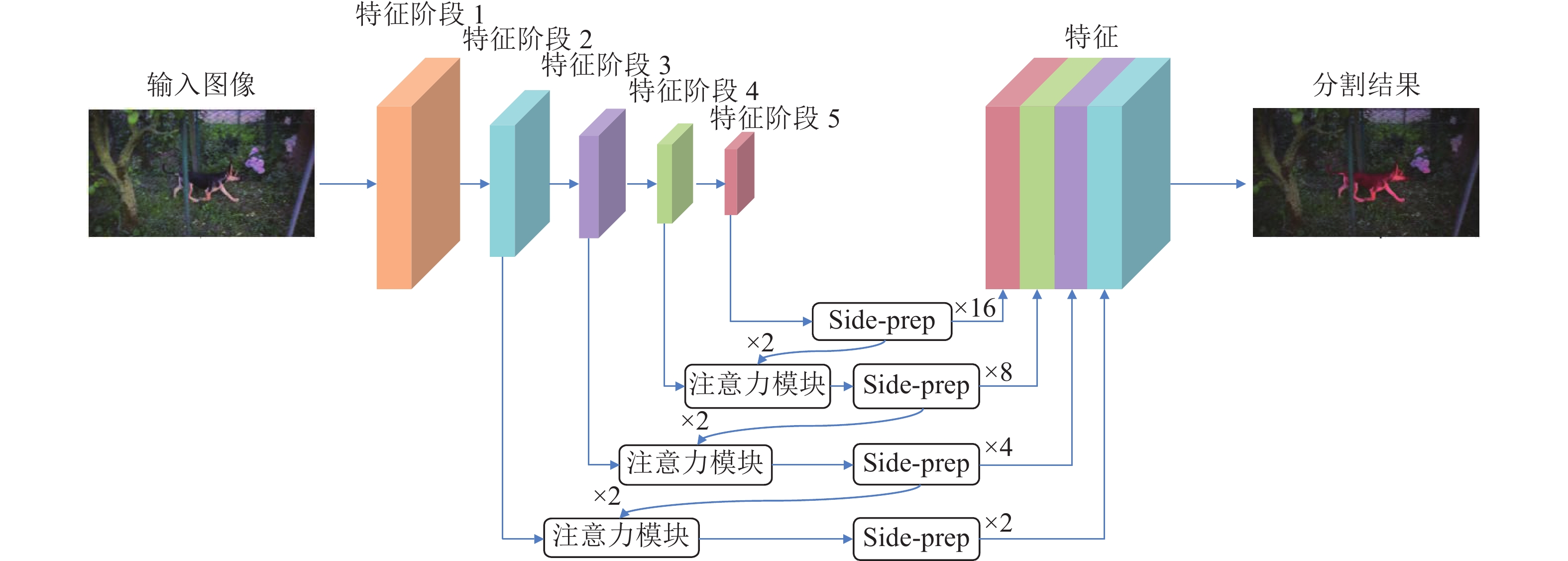


2022, 48(3): 797-807.
doi: 10.16383/j.aas.c190376
摘要:
自然场景图像质量易受光照及采集设备的影响, 且其背景复杂, 图像中文字颜色、尺度、排列方向多变, 因此, 自然场景文字检测具有很大的挑战性. 本文提出一种基于全卷积网络的端对端文字检测器, 集中精力在网络结构和损失函数的设计, 通过设计感受野模块并引入 Focalloss、GIoUloss 进行像素点分类和文字包围框回归, 从而获得更加稳定且准确的多方向文字检测器. 实验结果表明本文方法与现有先进方法相比, 无论是在多方向场景文字数据集还是水平场景文字数据集均取得了具有可比性的成绩.
自然场景图像质量易受光照及采集设备的影响, 且其背景复杂, 图像中文字颜色、尺度、排列方向多变, 因此, 自然场景文字检测具有很大的挑战性. 本文提出一种基于全卷积网络的端对端文字检测器, 集中精力在网络结构和损失函数的设计, 通过设计感受野模块并引入 Focalloss、GIoUloss 进行像素点分类和文字包围框回归, 从而获得更加稳定且准确的多方向文字检测器. 实验结果表明本文方法与现有先进方法相比, 无论是在多方向场景文字数据集还是水平场景文字数据集均取得了具有可比性的成绩.

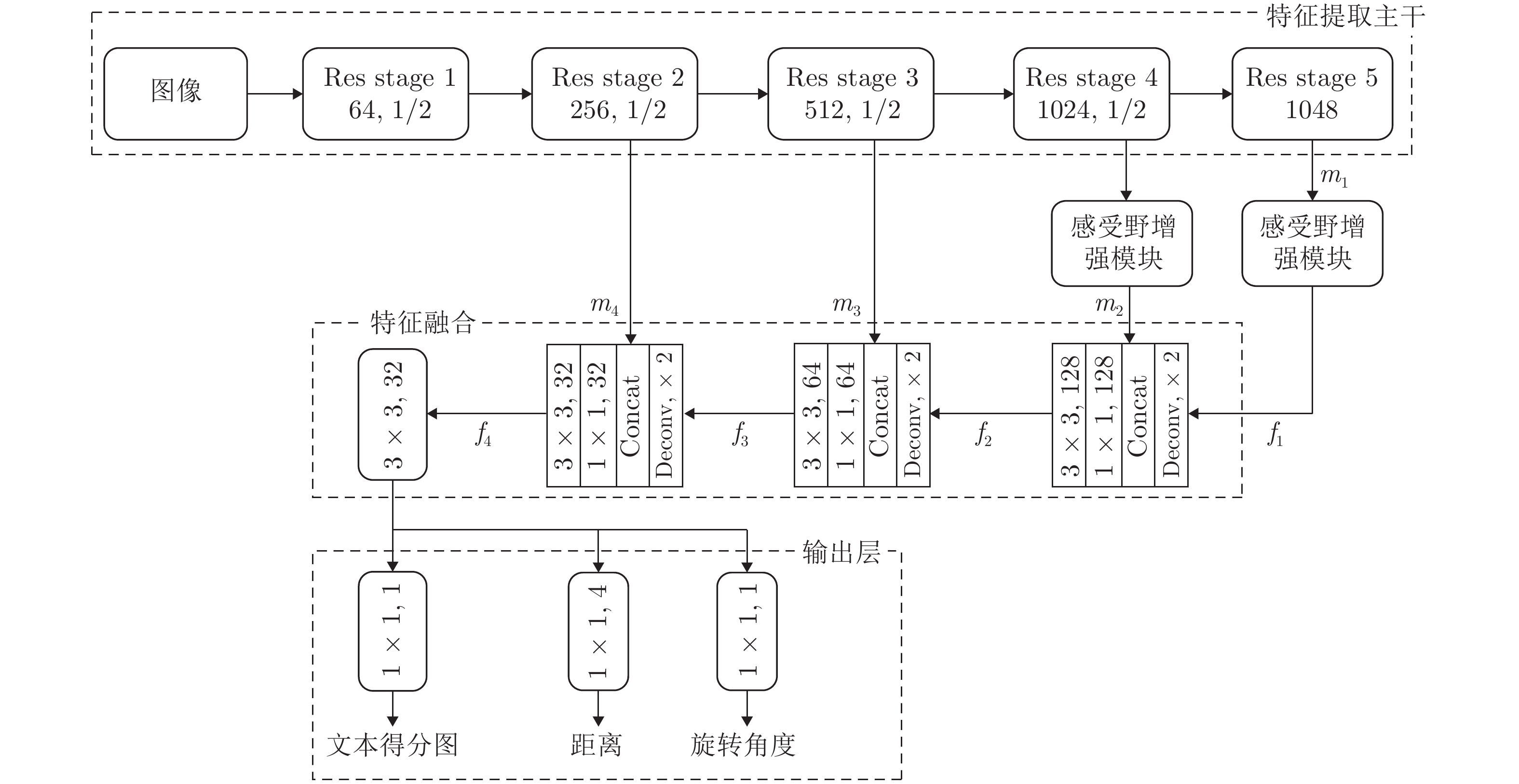



2022, 48(3): 808-819.
doi: 10.16383/j.aas.c190345
摘要:
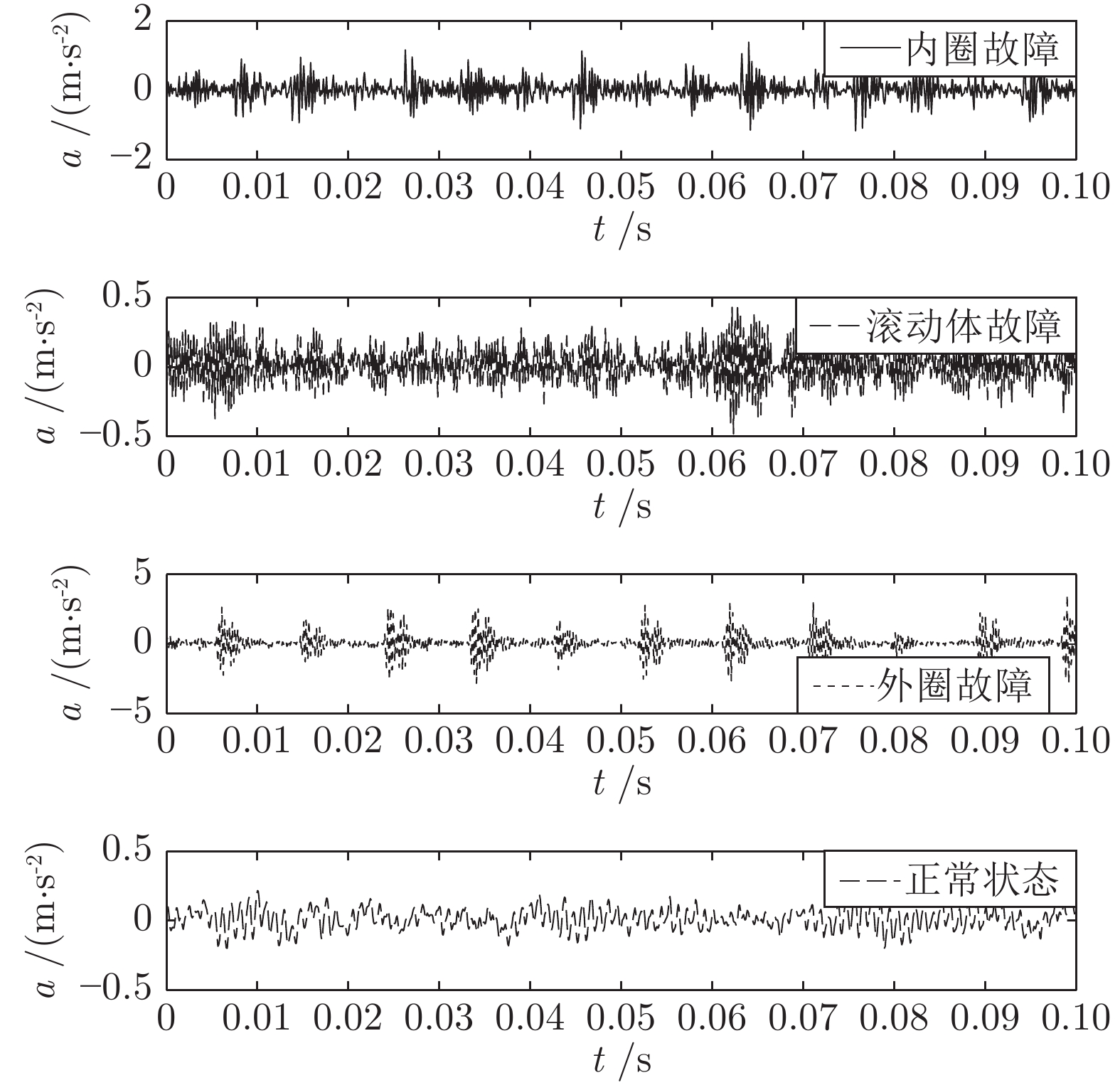
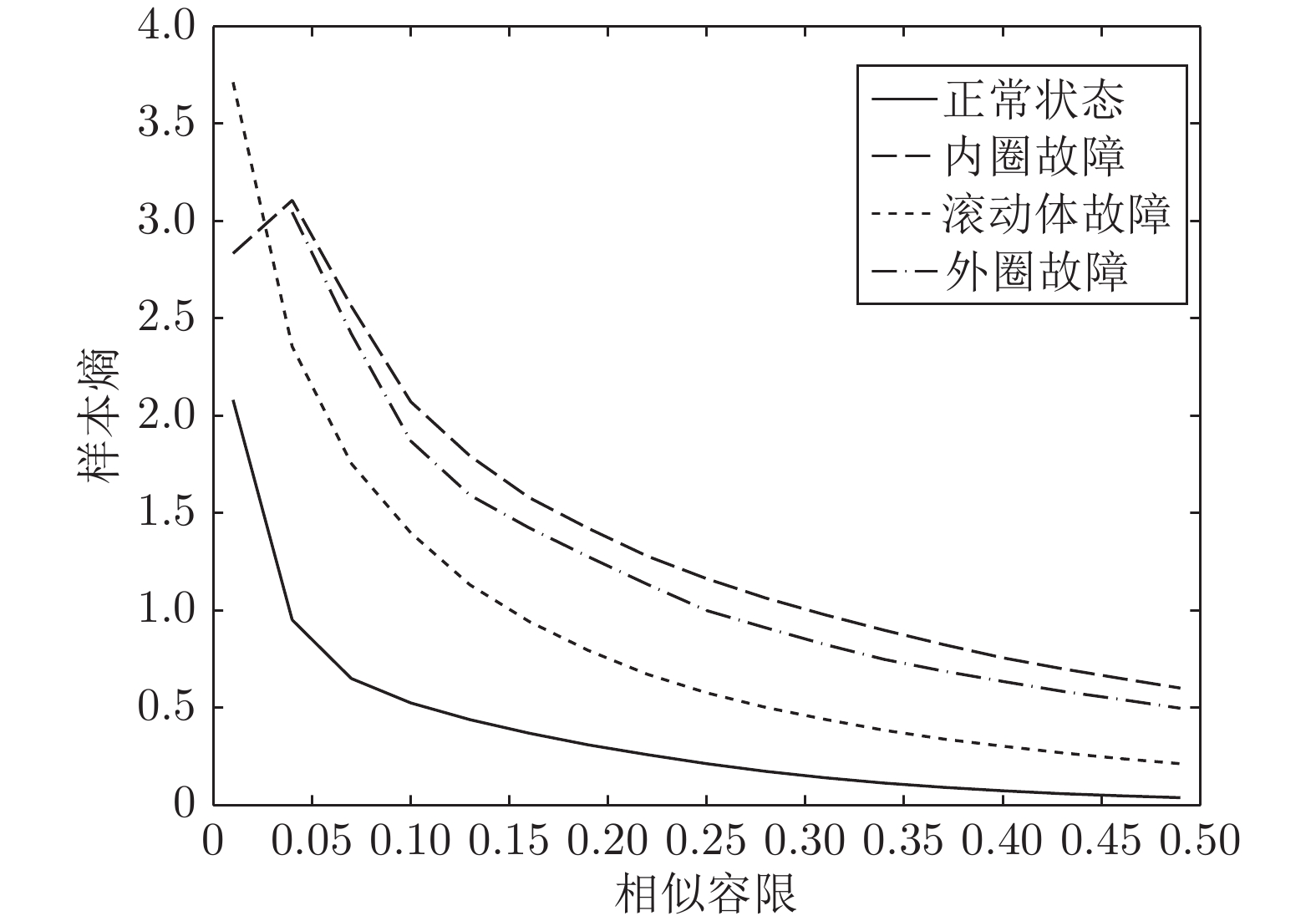
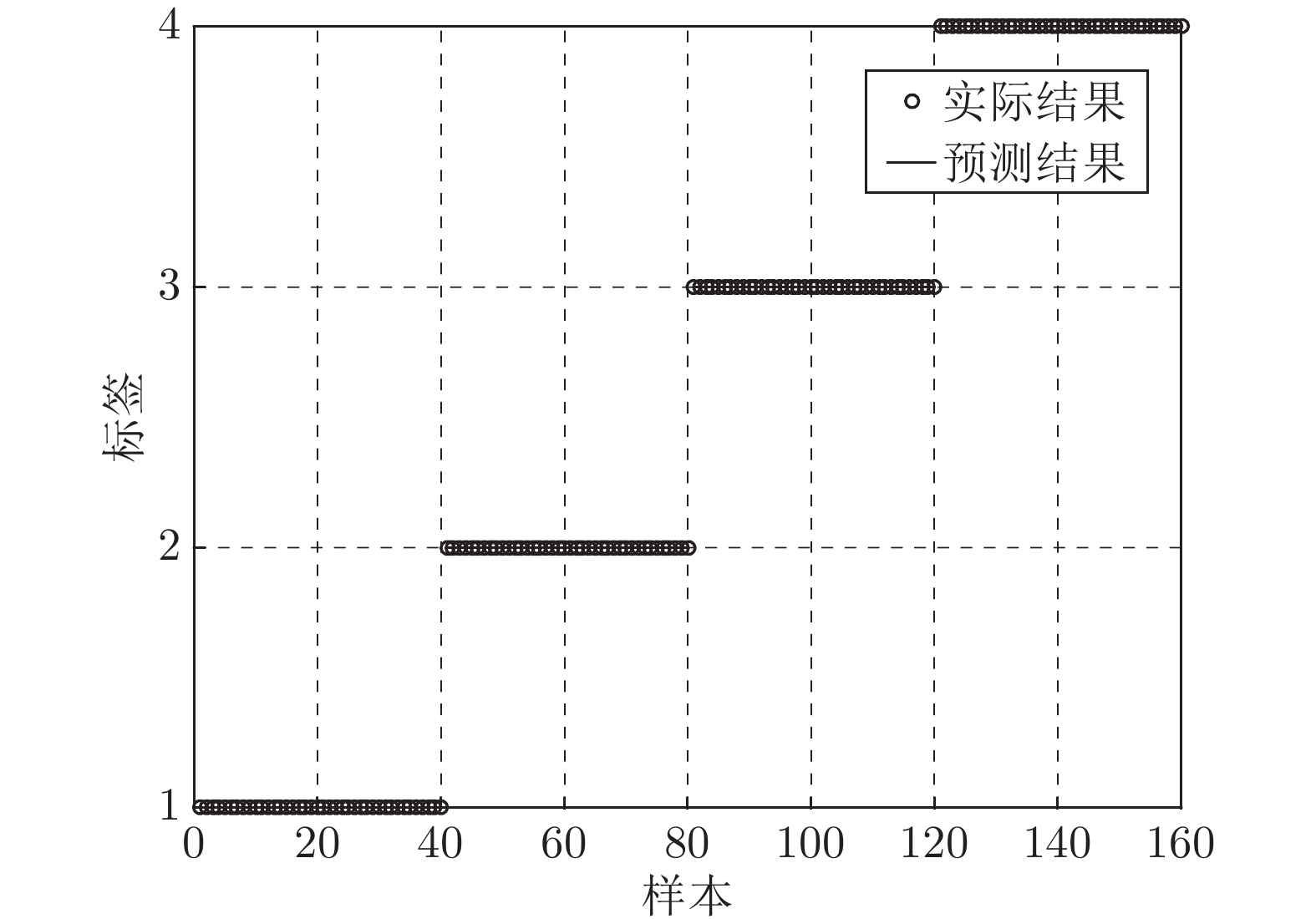
针对滚动轴承故障特征提取不丰富而导致的诊断识别率低的情况, 提出了基于参数优化变分模态分解(Variational mode decomposition, VMD)和样本熵的特征提取方法, 采用支持向量机(Support vector machine, SVM)进行故障识别. VMD方法的分解效果受限于分解个数和惩罚因子的选取, 本文分析了这两个影响参数选取的不规律性, 采用遗传变异粒子群算法进行参数优化, 利用参数优化的VMD方法处理故障信号. 样本熵在衡量滚动轴承振动信号的复杂度时, 得到的...
针对滚动轴承故障特征提取不丰富而导致的诊断识别率低的情况, 提出了基于参数优化变分模态分解(Variational mode decomposition, VMD)和样本熵的特征提取方法, 采用支持向量机(Support vector machine, SVM)进行故障识别. VMD方法的分解效果受限于分解个数和惩罚因子的选取, 本文分析了这两个影响参数选取的不规律性, 采用遗传变异粒子群算法进行参数优化, 利用参数优化的VMD方法处理故障信号. 样本熵在衡量滚动轴承振动信号的复杂度时, 得到的...
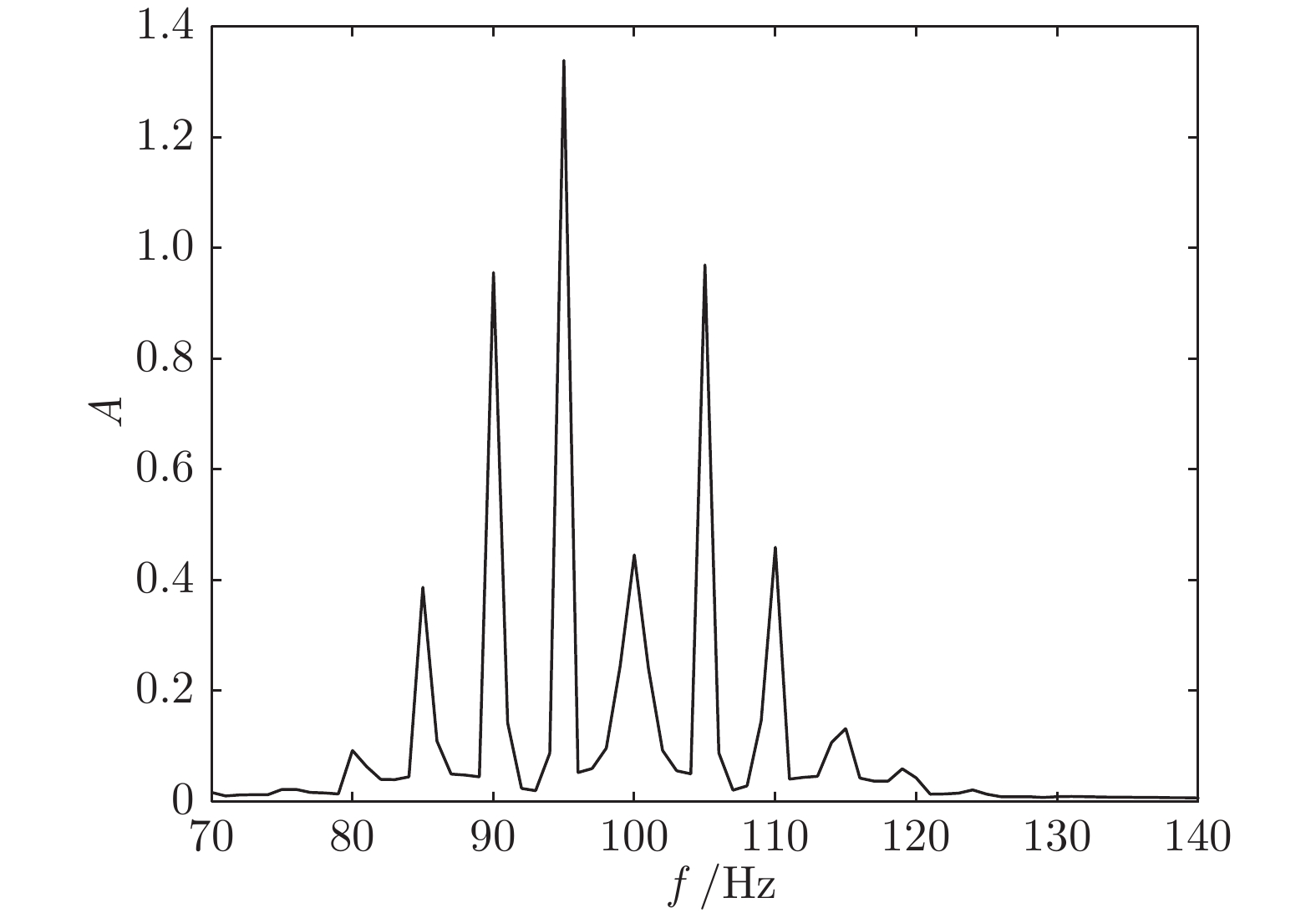
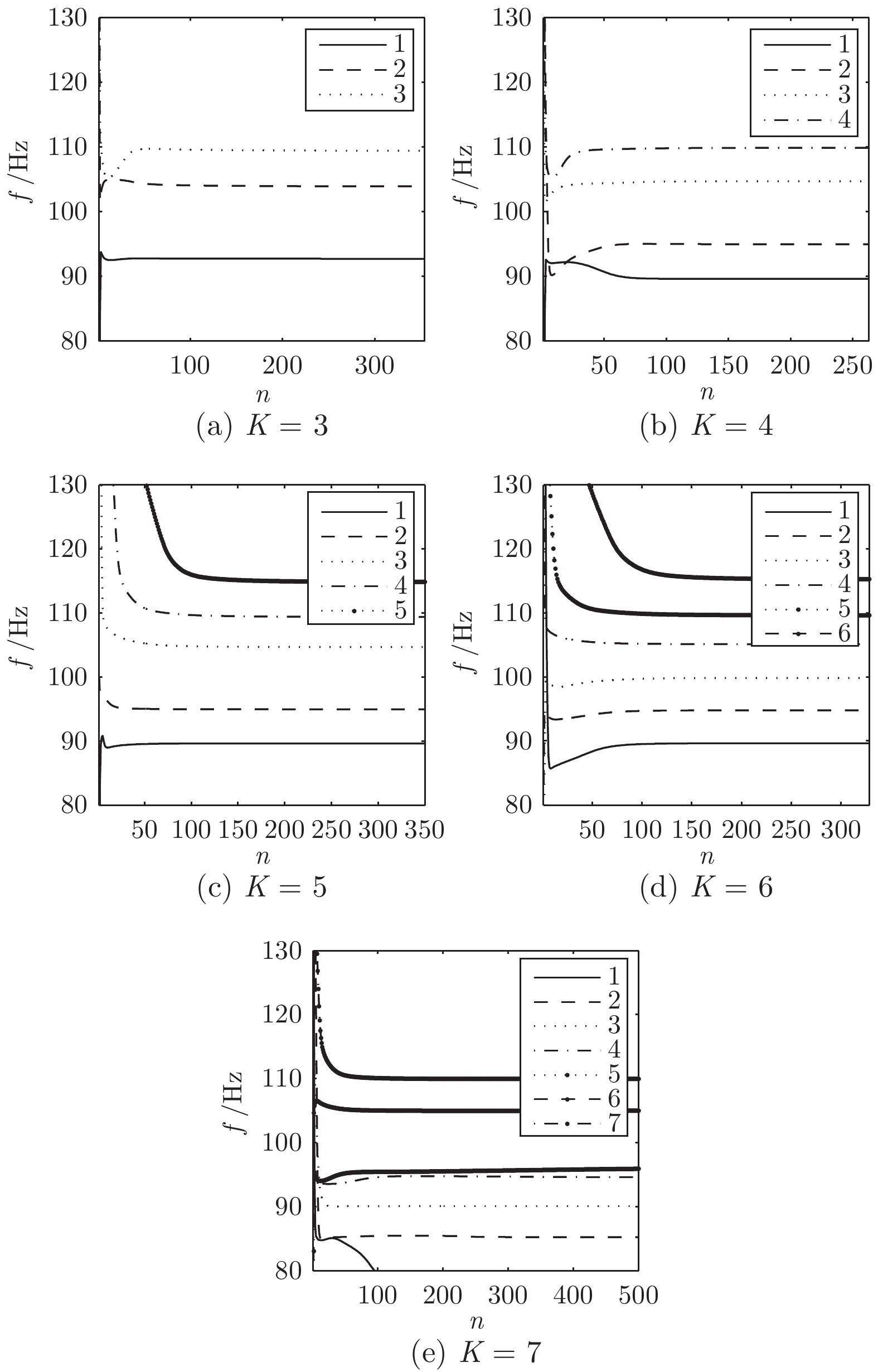
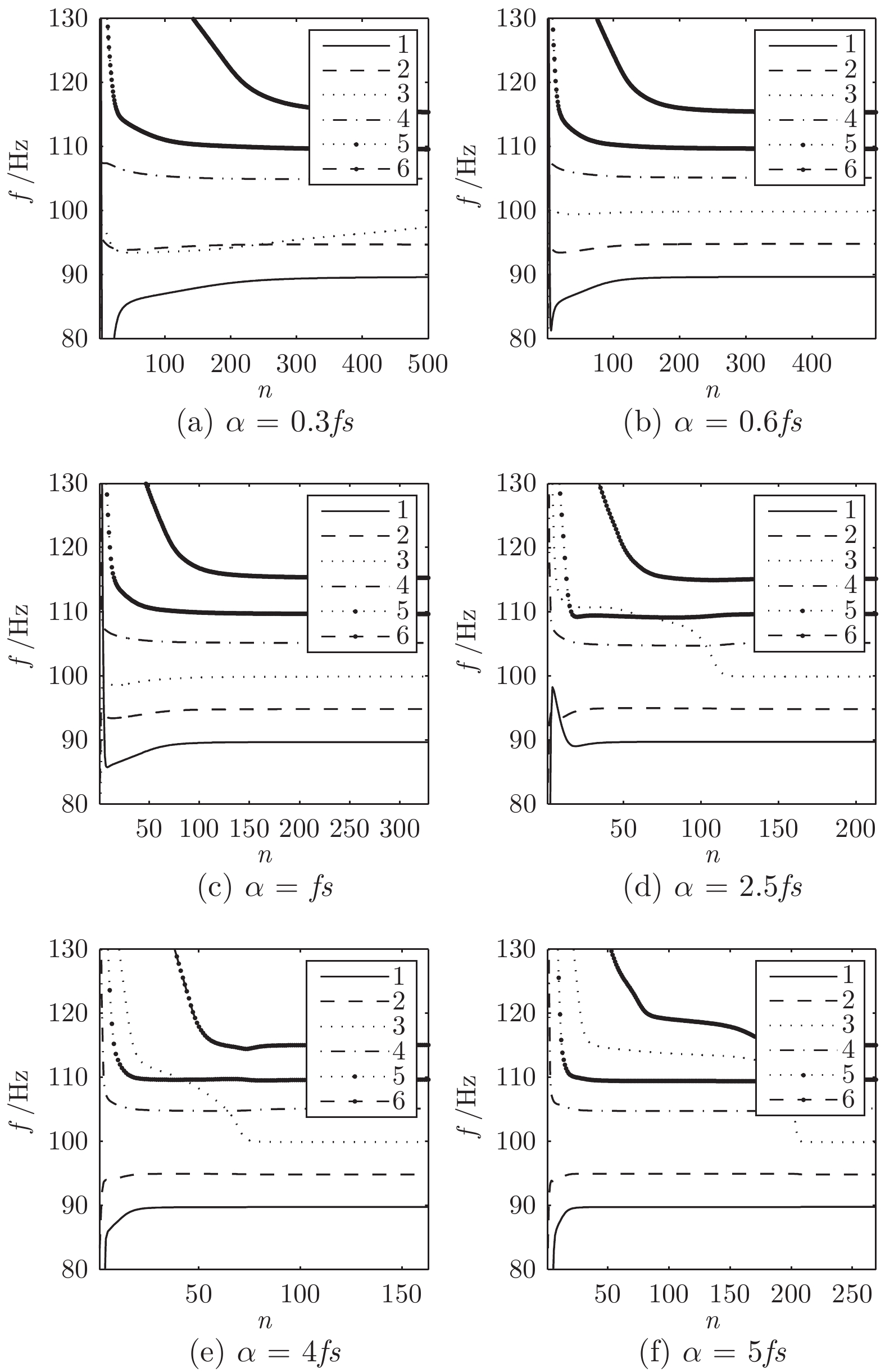
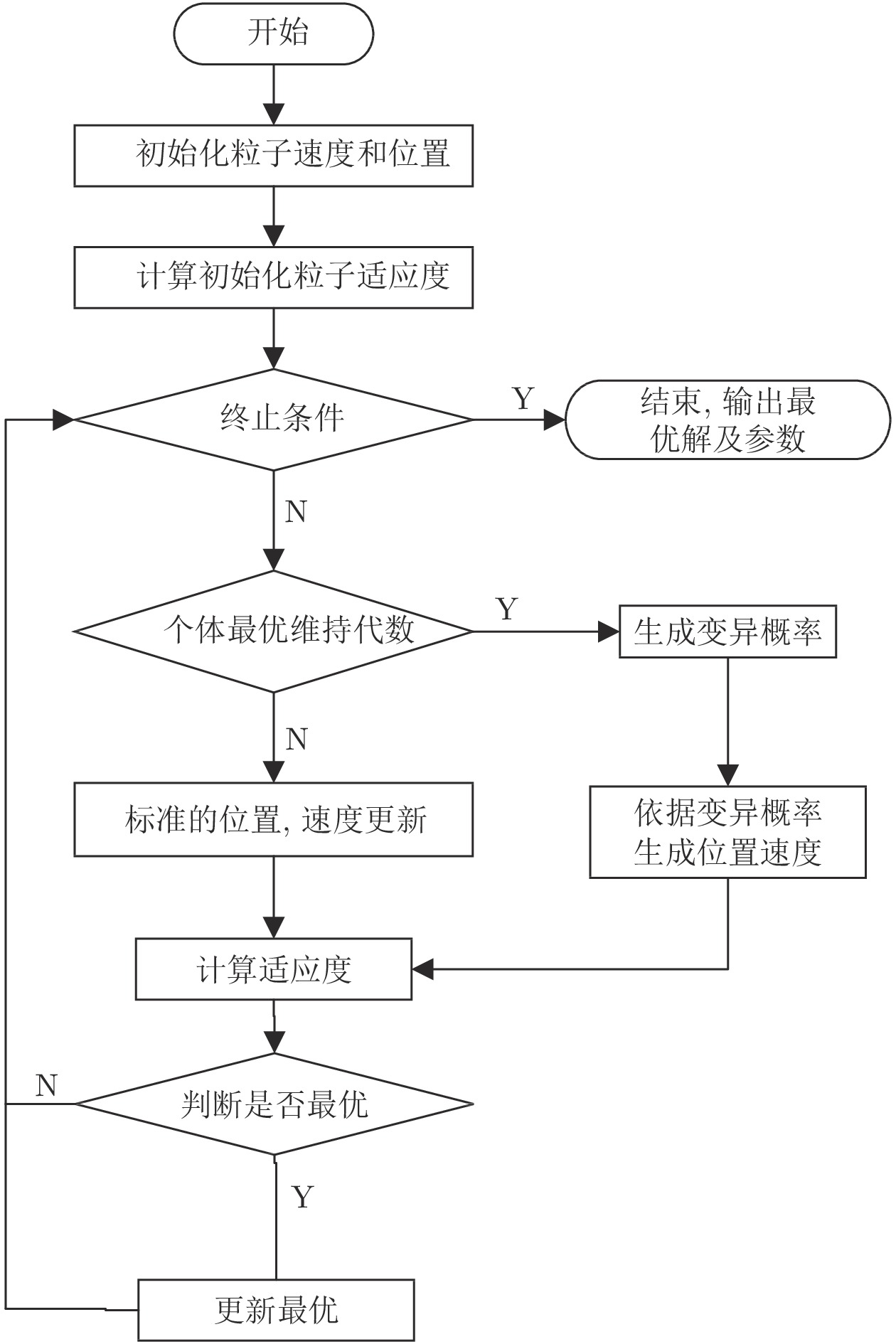
2022, 48(3): 820-833.
doi: 10.16383/j.aas.c200046
摘要:
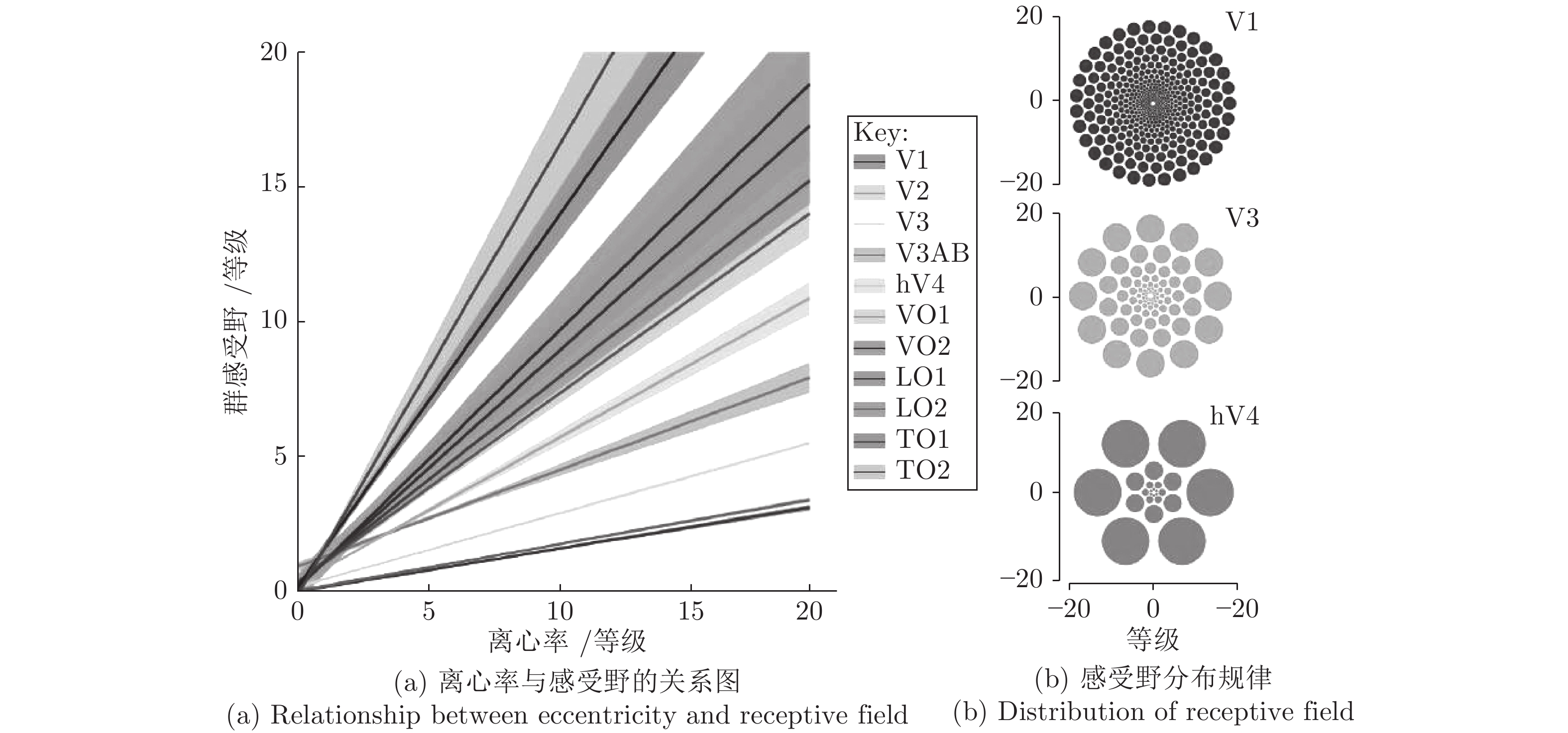
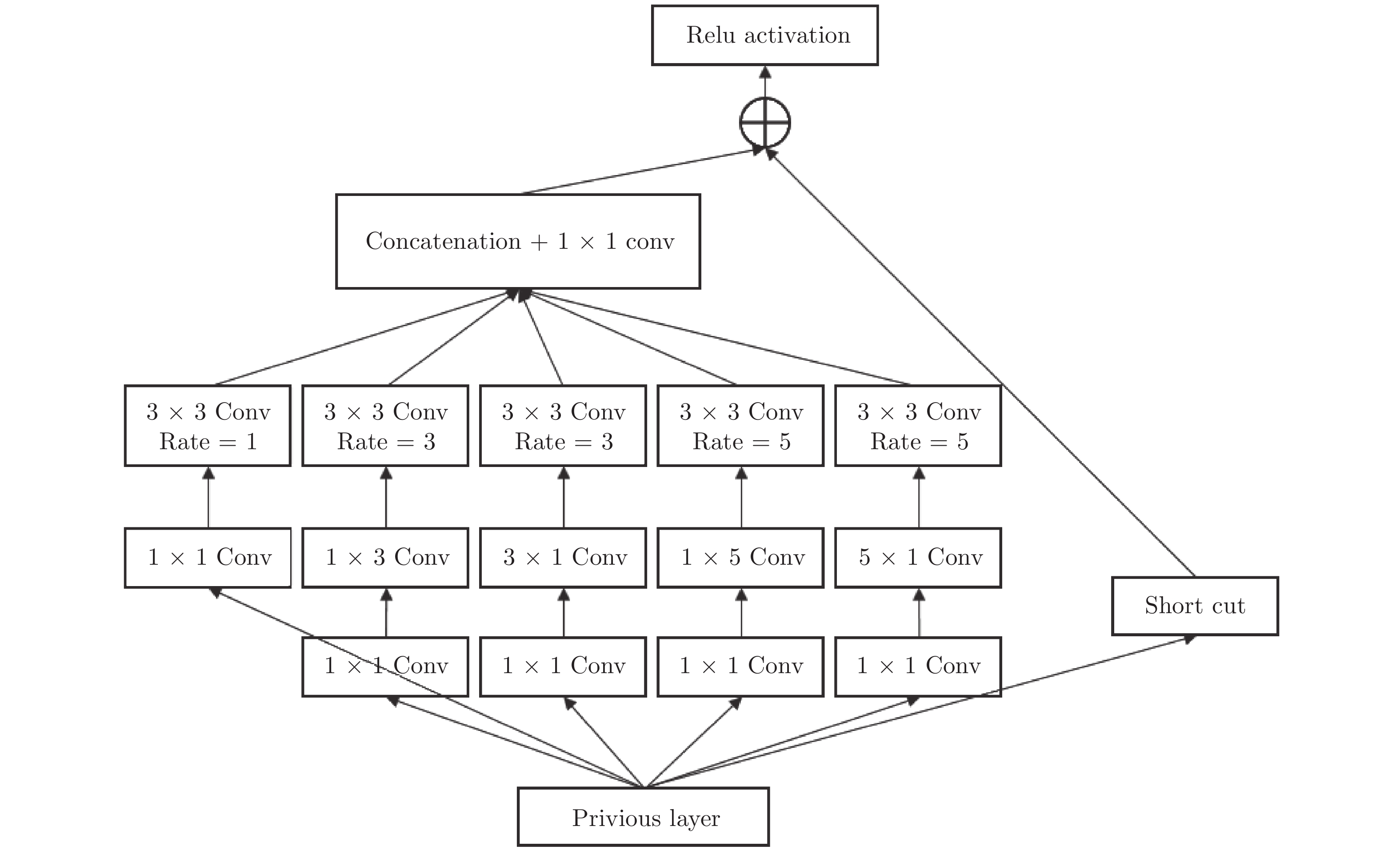
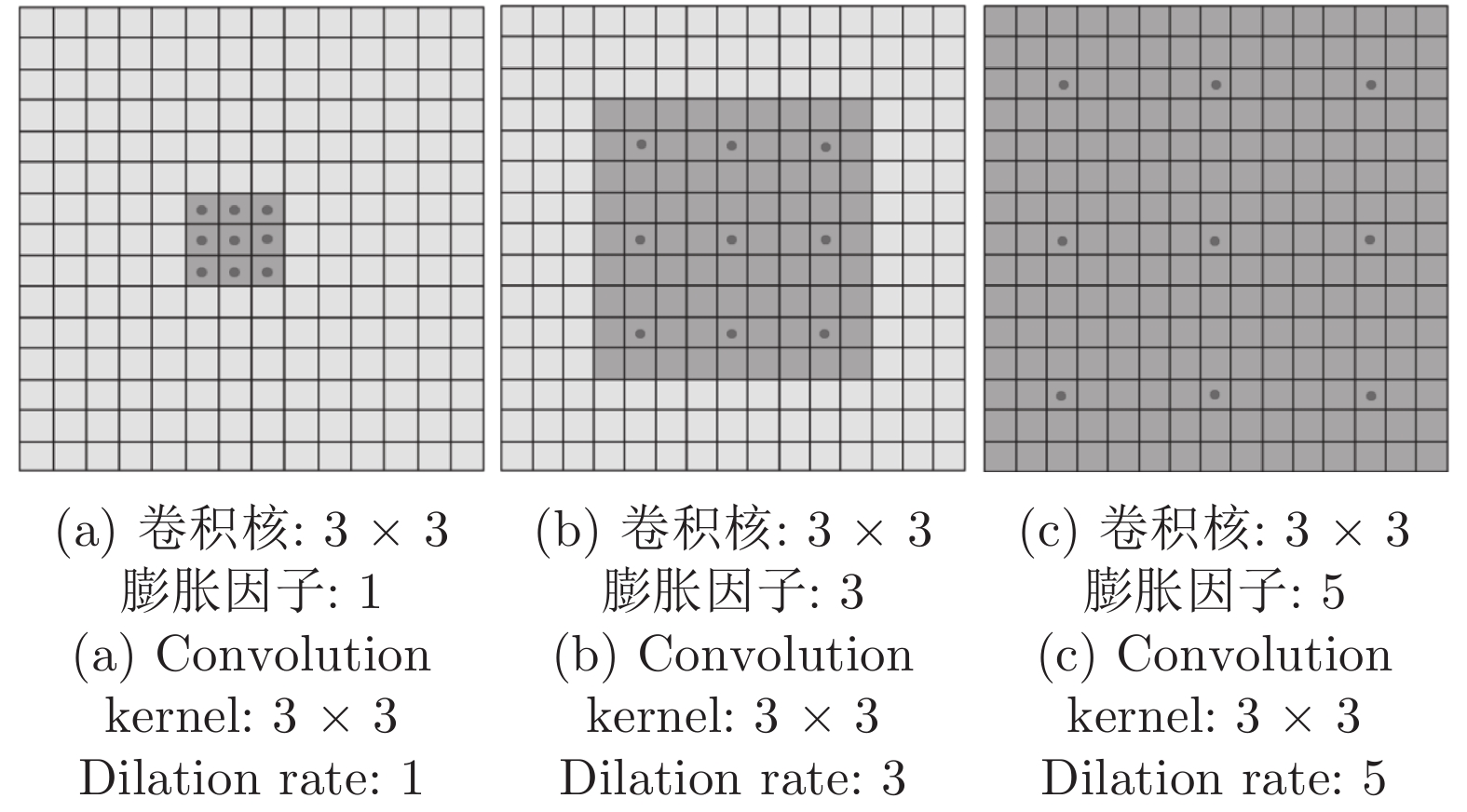
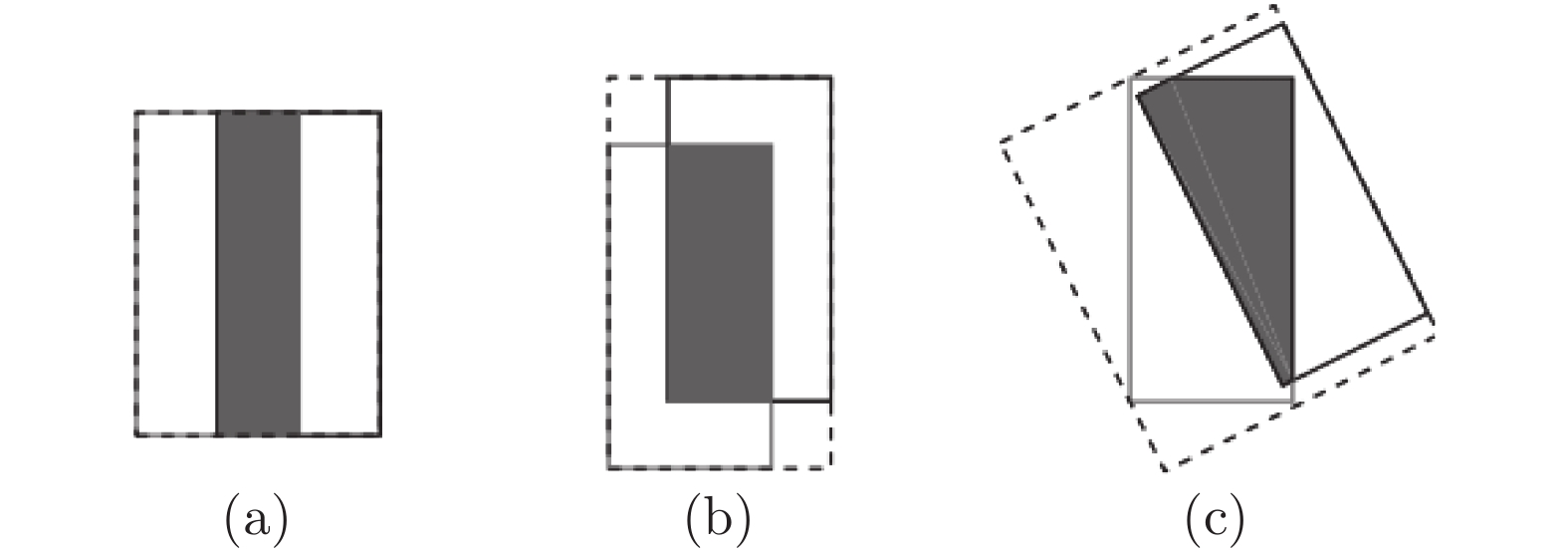
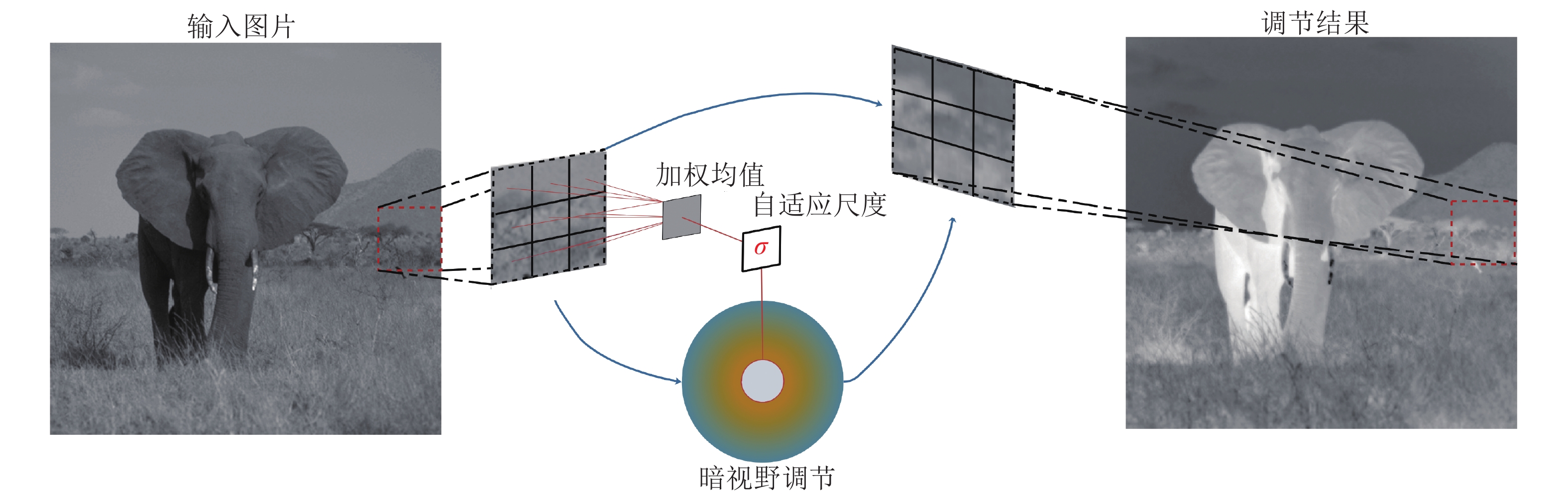
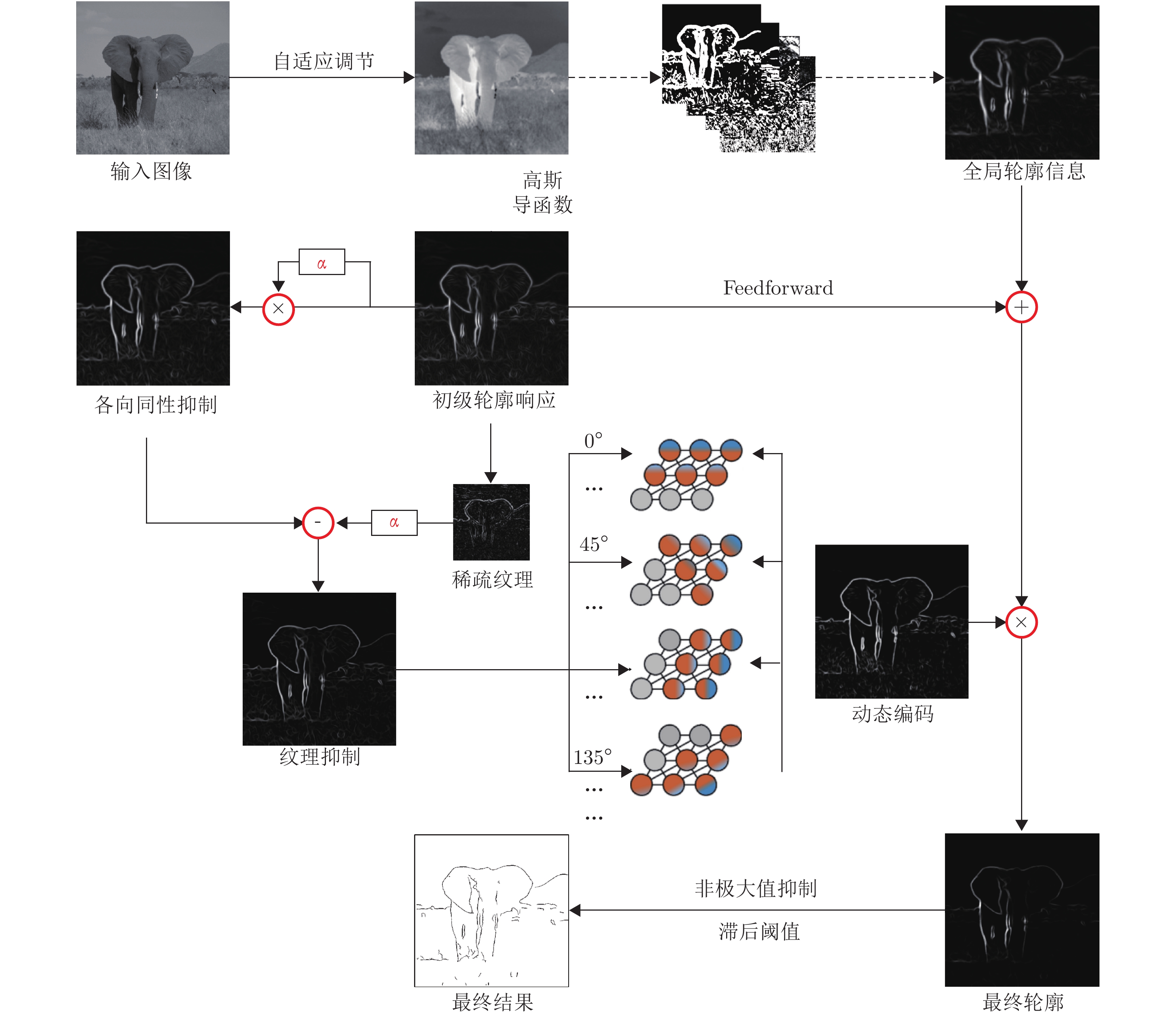
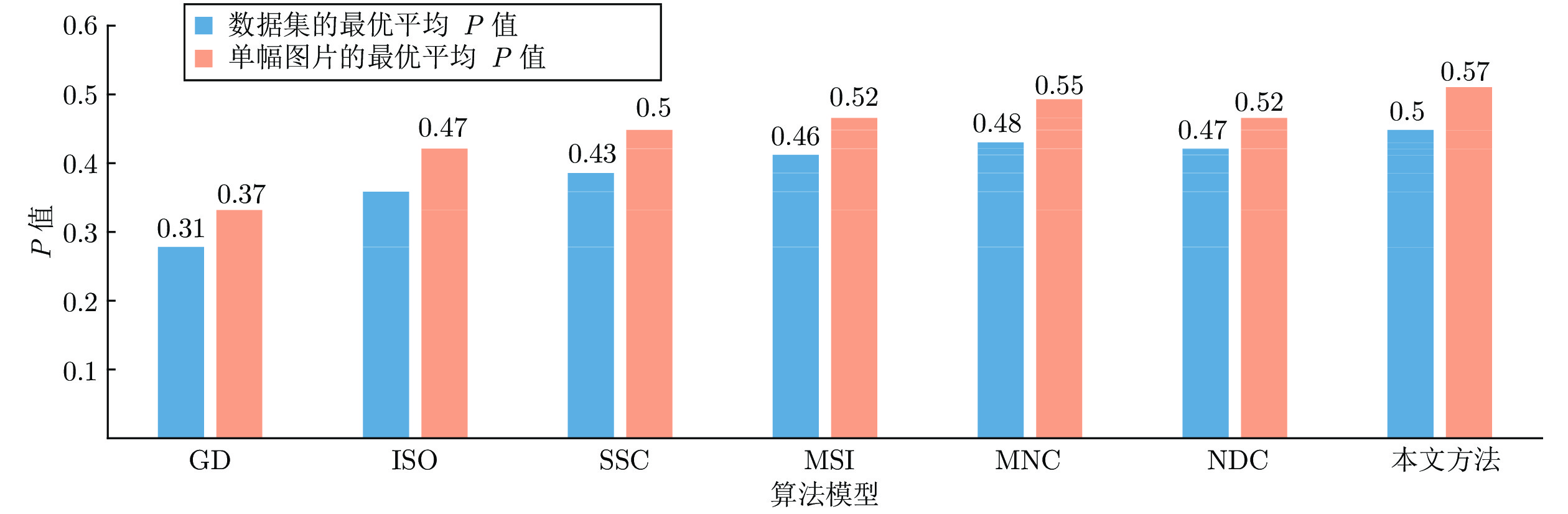
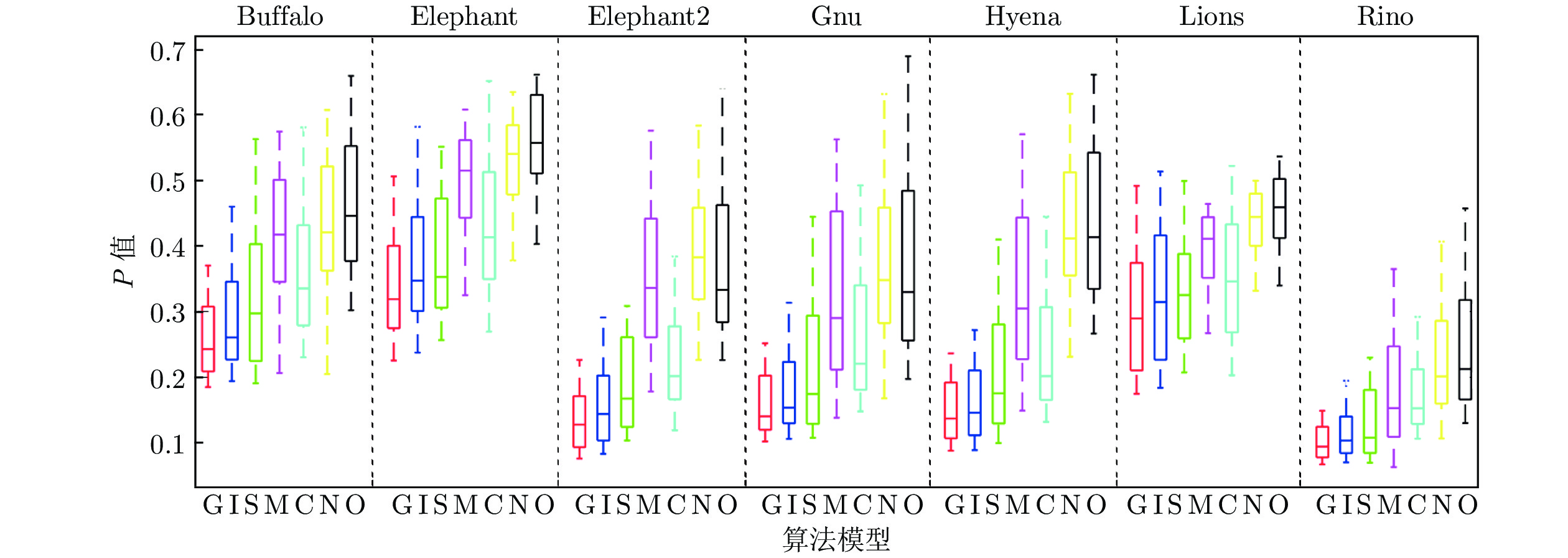
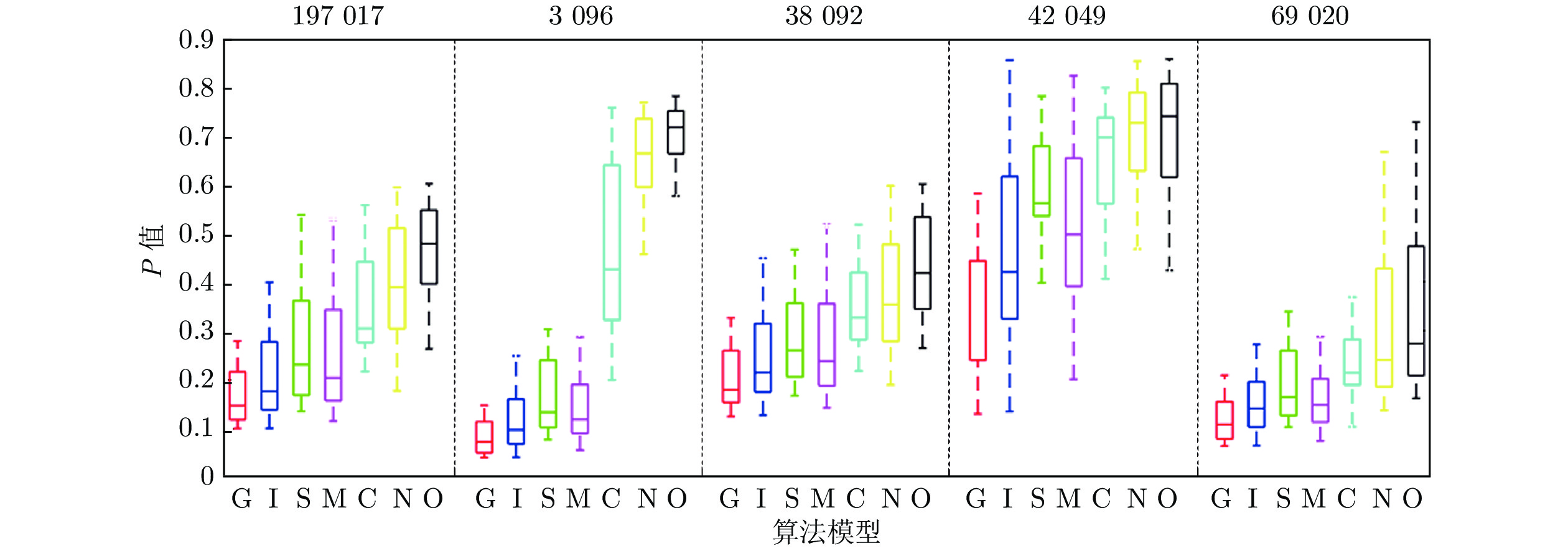
基于视通路结构分级响应与动态传递的方式, 本文提出了一种图像轮廓检测的新方法. 针对视网膜感光细胞的暗视觉特性, 建立亮度自适应的暗视野调节模型, 利用多尺度经典感受野的方位选择性, 构建高级轮廓与全局轮廓的检测路径; 模拟外侧膝状体(Lateral geniculate nucleus, LGN)细胞特性对信息进行纹理稀疏编码, 并结合非经典感受野的侧抑制作用抑制背景强纹理; 另外在LGN区提出微动整合机制, 减少纹理冗余信息, 再经适应性突触实现信息关联传递; 最后将初级轮廓响应跨视区前馈至...
基于视通路结构分级响应与动态传递的方式, 本文提出了一种图像轮廓检测的新方法. 针对视网膜感光细胞的暗视觉特性, 建立亮度自适应的暗视野调节模型, 利用多尺度经典感受野的方位选择性, 构建高级轮廓与全局轮廓的检测路径; 模拟外侧膝状体(Lateral geniculate nucleus, LGN)细胞特性对信息进行纹理稀疏编码, 并结合非经典感受野的侧抑制作用抑制背景强纹理; 另外在LGN区提出微动整合机制, 减少纹理冗余信息, 再经适应性突触实现信息关联传递; 最后将初级轮廓响应跨视区前馈至...



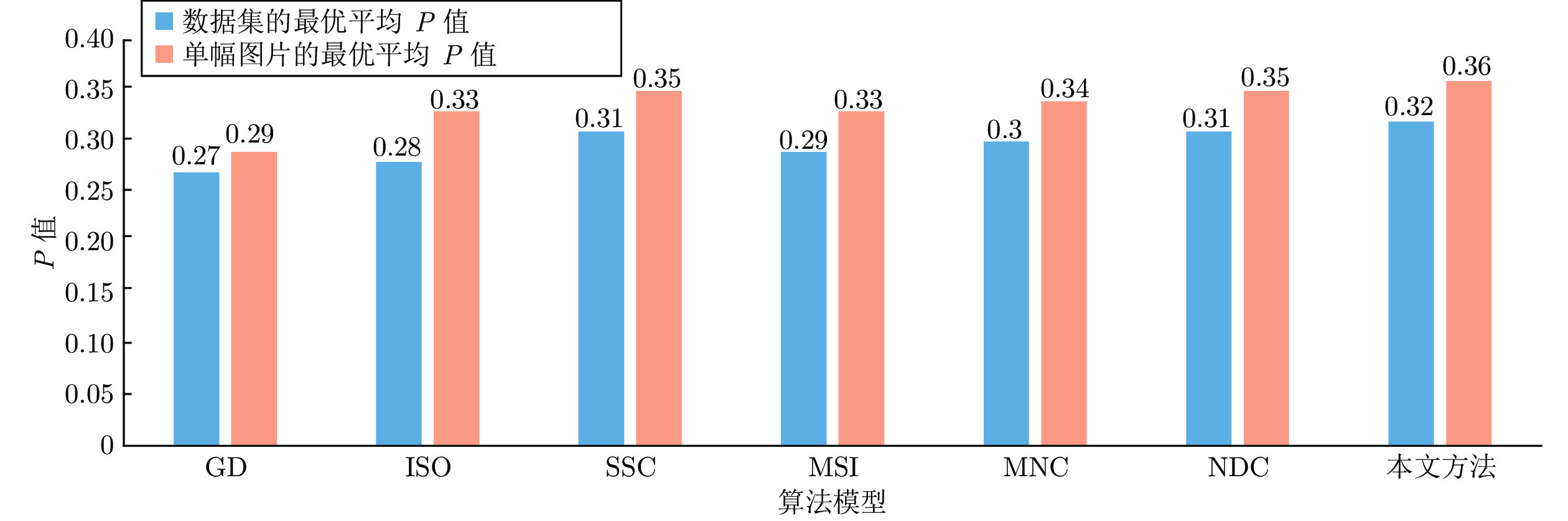
2022, 48(3): 834-842.
doi: 10.16383/j.aas.c200288
摘要:
大量基于深度学习的视频目标分割方法存在两方面局限性: 1)单帧编码特征直接输入网络解码器, 未能充分利用多帧特征, 导致解码器输出的目标表观特征难以自适应复杂场景变化; 2)常采用前馈网络结构, 阻止了后层特征反馈前层进行补充学习, 导致学习到的表观特征判别力受限. 为此, 本文提出了反馈高斯表观网络, 通过建立在线高斯模型并反馈后层特征到前层来充分利用多帧、多尺度特征, 学习鲁棒的视频目标分割表观模型. 网络结构包括引导、查询与分割三个分支. 其中, 引导与查询分支通过共享权重来提取引导与查询...
大量基于深度学习的视频目标分割方法存在两方面局限性: 1)单帧编码特征直接输入网络解码器, 未能充分利用多帧特征, 导致解码器输出的目标表观特征难以自适应复杂场景变化; 2)常采用前馈网络结构, 阻止了后层特征反馈前层进行补充学习, 导致学习到的表观特征判别力受限. 为此, 本文提出了反馈高斯表观网络, 通过建立在线高斯模型并反馈后层特征到前层来充分利用多帧、多尺度特征, 学习鲁棒的视频目标分割表观模型. 网络结构包括引导、查询与分割三个分支. 其中, 引导与查询分支通过共享权重来提取引导与查询...
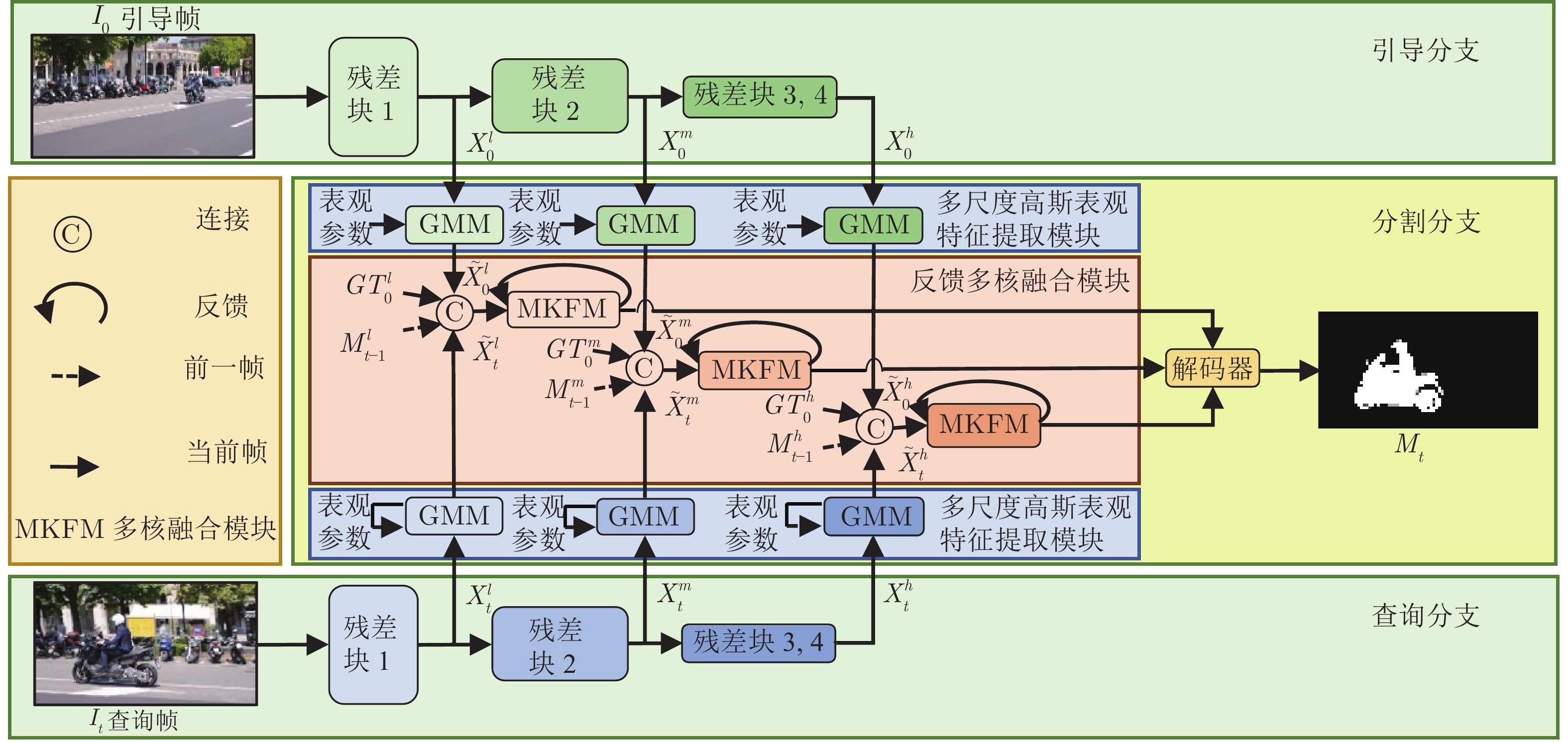
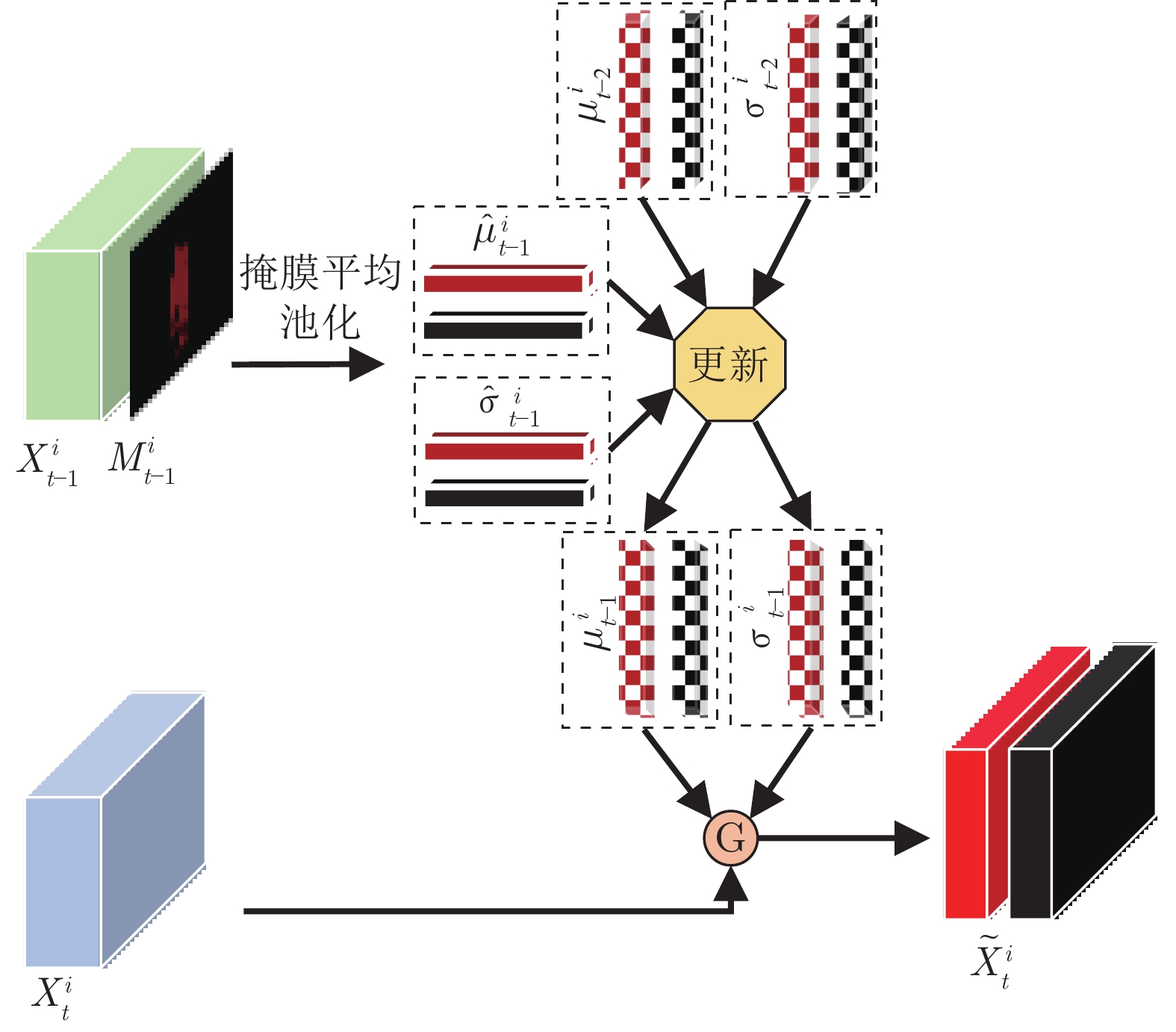
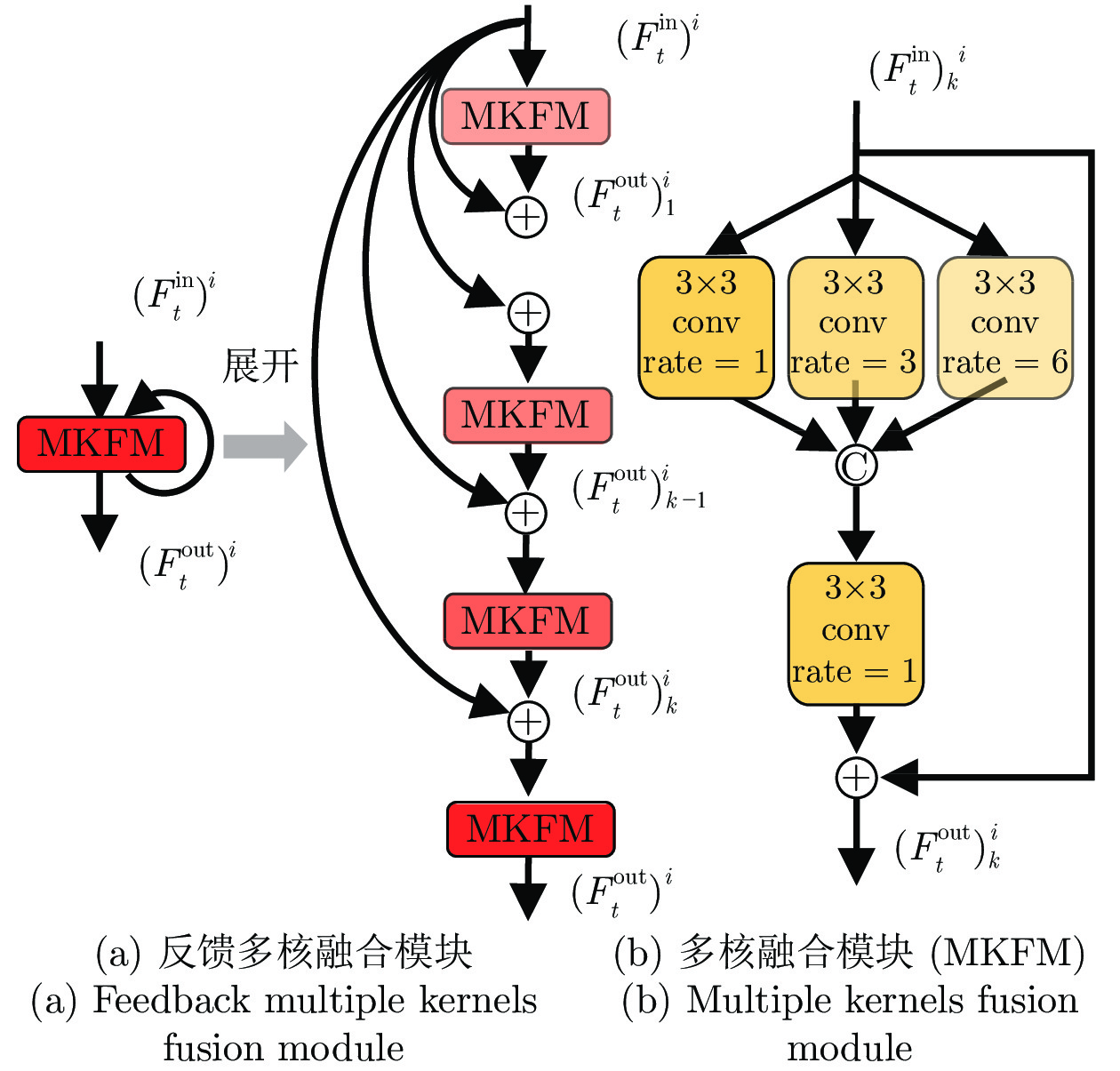

2022, 48(3): 843-852.
doi: 10.16383/j.aas.c190305
摘要:
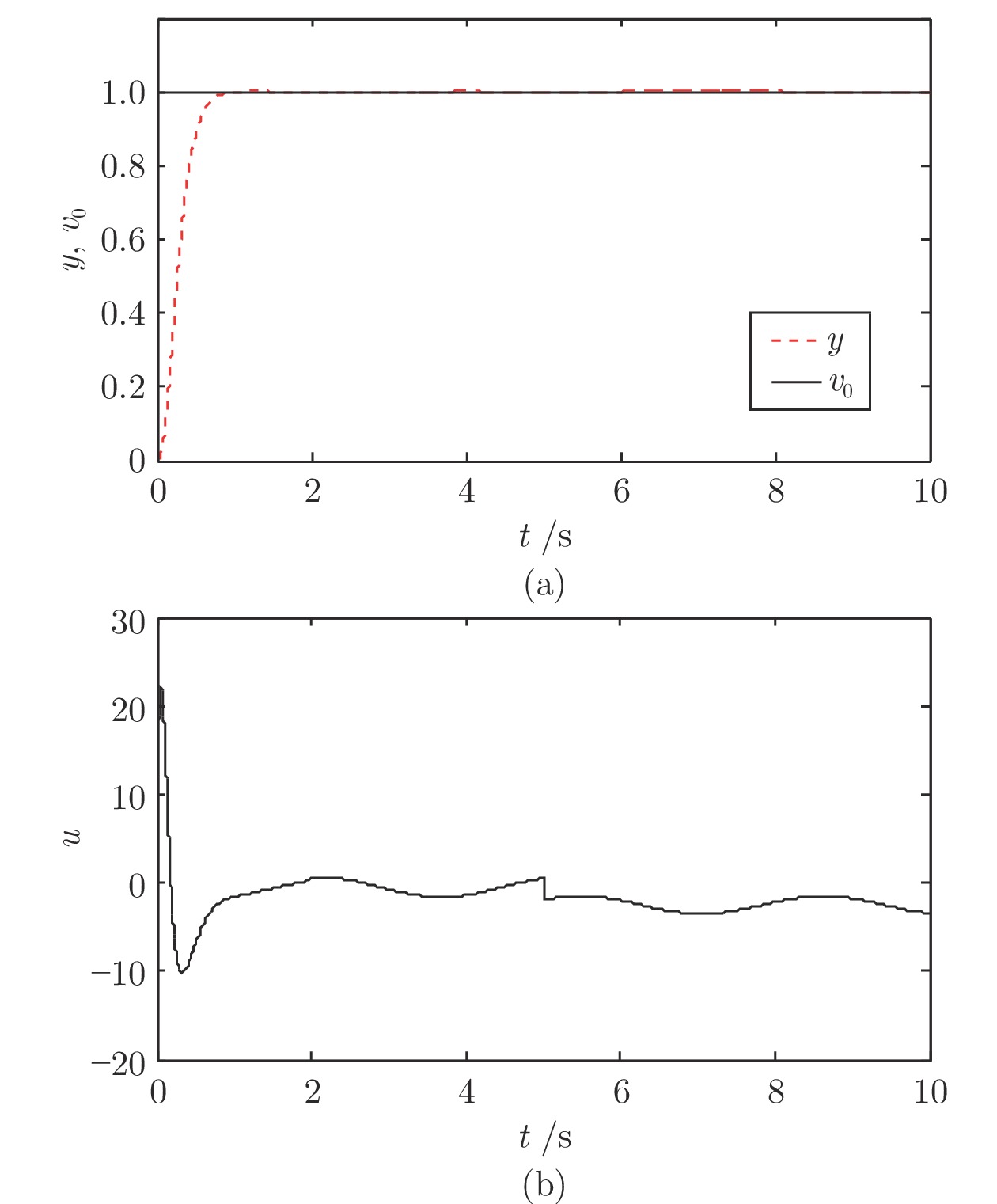
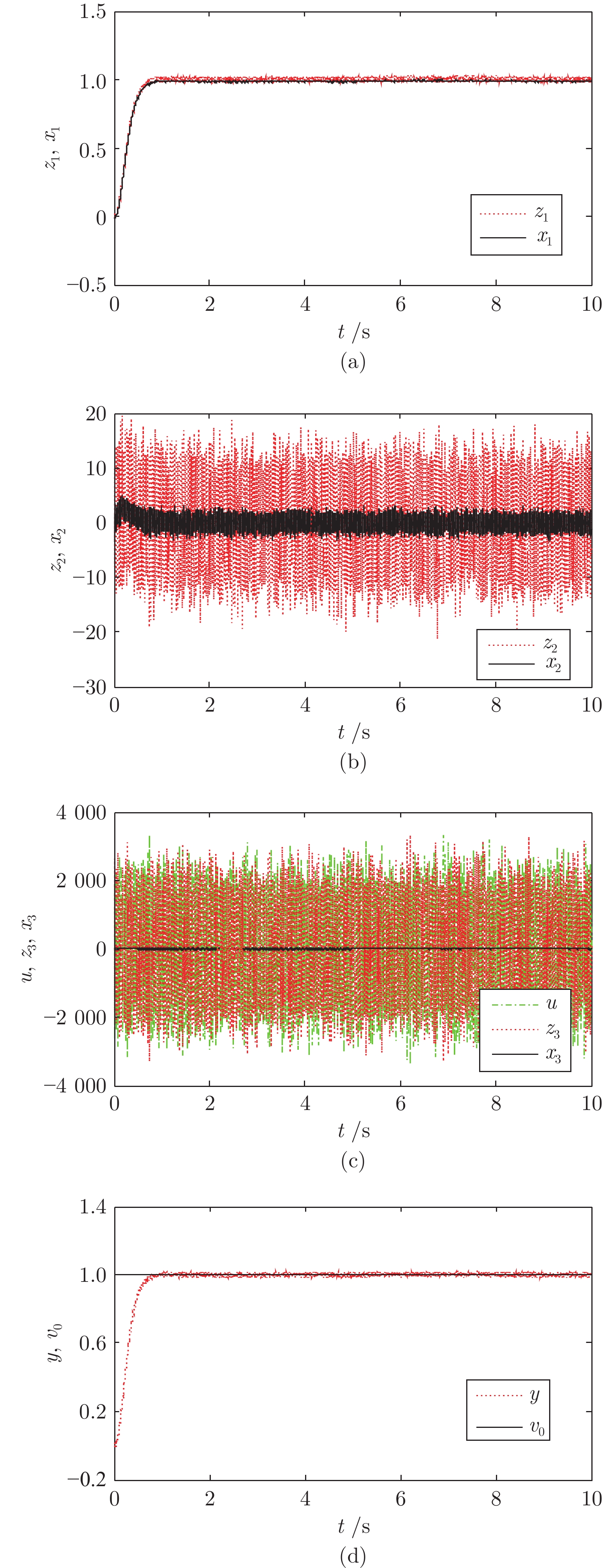
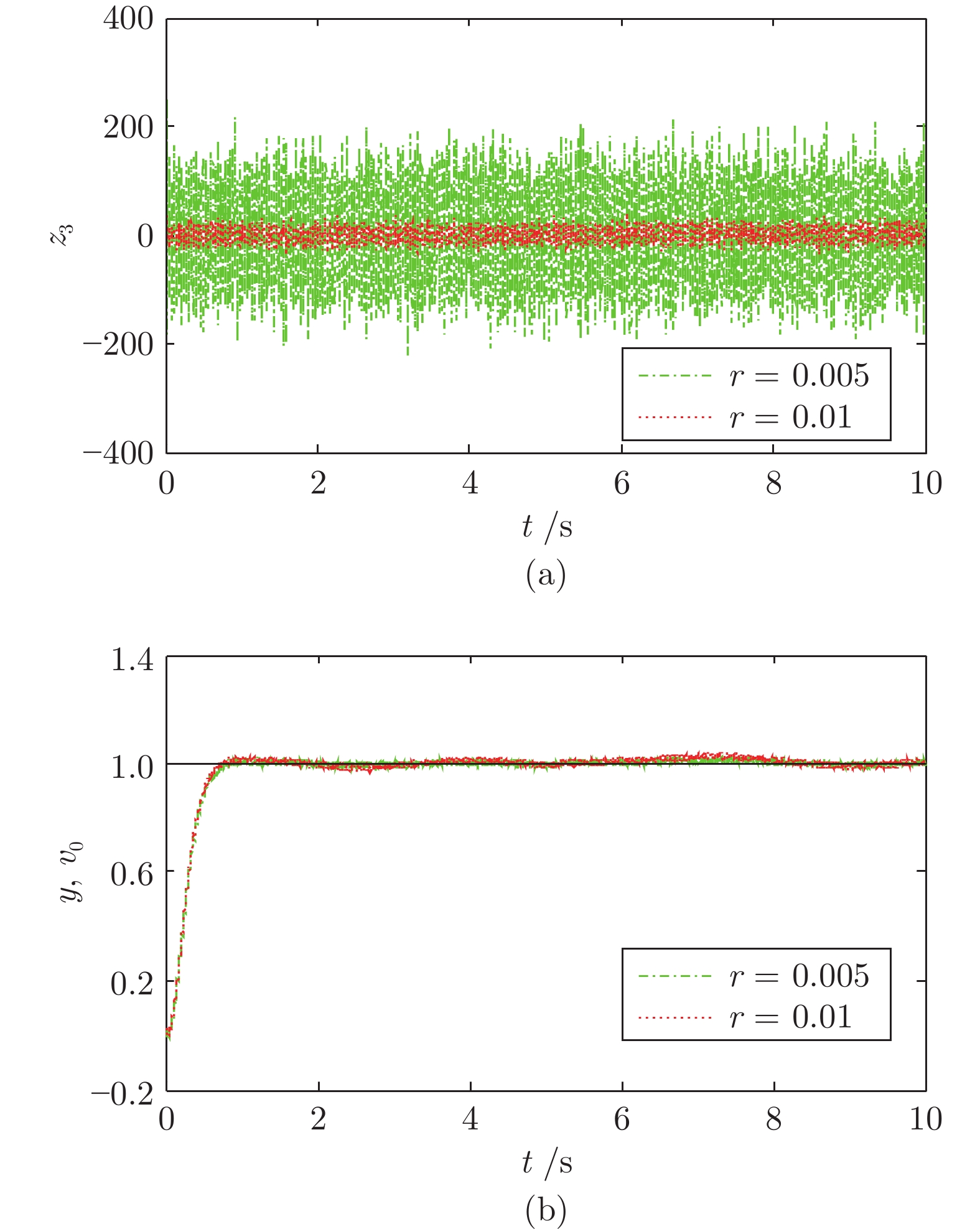
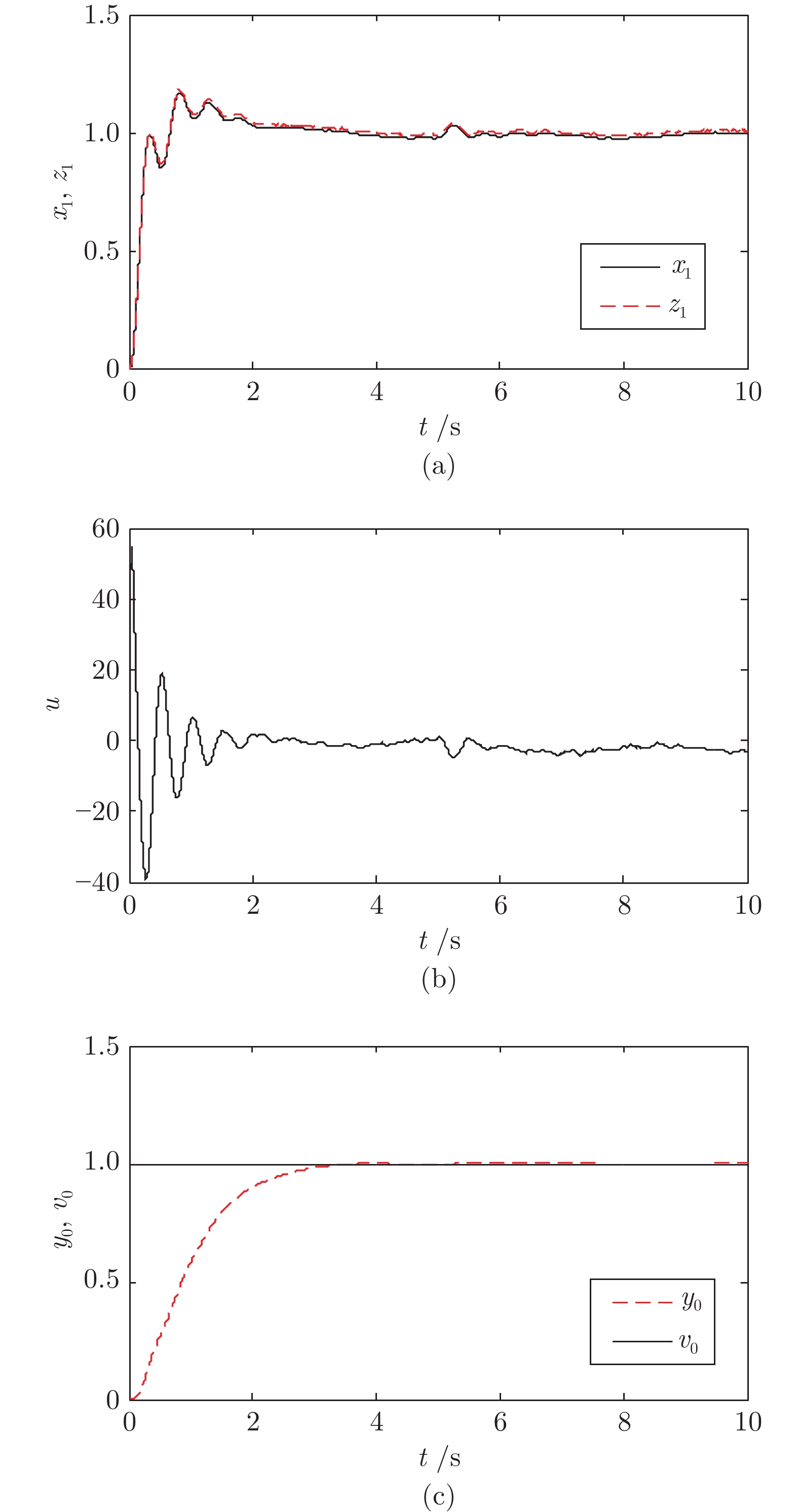
针对一类具有输入约束和输出噪声的SISO (Single input single output)不确定非线性系统, 提出了一种基于误差补偿和工程滤波的抗饱和级联线性自抗扰控制(Linear active disturbance rejection control, LADRC)方法. 首先针对高频量测噪声, 分析了线性扩张状态观测器(Linear extended state observer, LESO)对噪声的放大机理及其与观测器增益的定量关系, 进而设计了一种基于工程滤波器的级联LADR...
针对一类具有输入约束和输出噪声的SISO (Single input single output)不确定非线性系统, 提出了一种基于误差补偿和工程滤波的抗饱和级联线性自抗扰控制(Linear active disturbance rejection control, LADRC)方法. 首先针对高频量测噪声, 分析了线性扩张状态观测器(Linear extended state observer, LESO)对噪声的放大机理及其与观测器增益的定量关系, 进而设计了一种基于工程滤波器的级联LADR...




2022, 48(3): 853-864.
doi: 10.16383/j.aas.c190752
摘要:
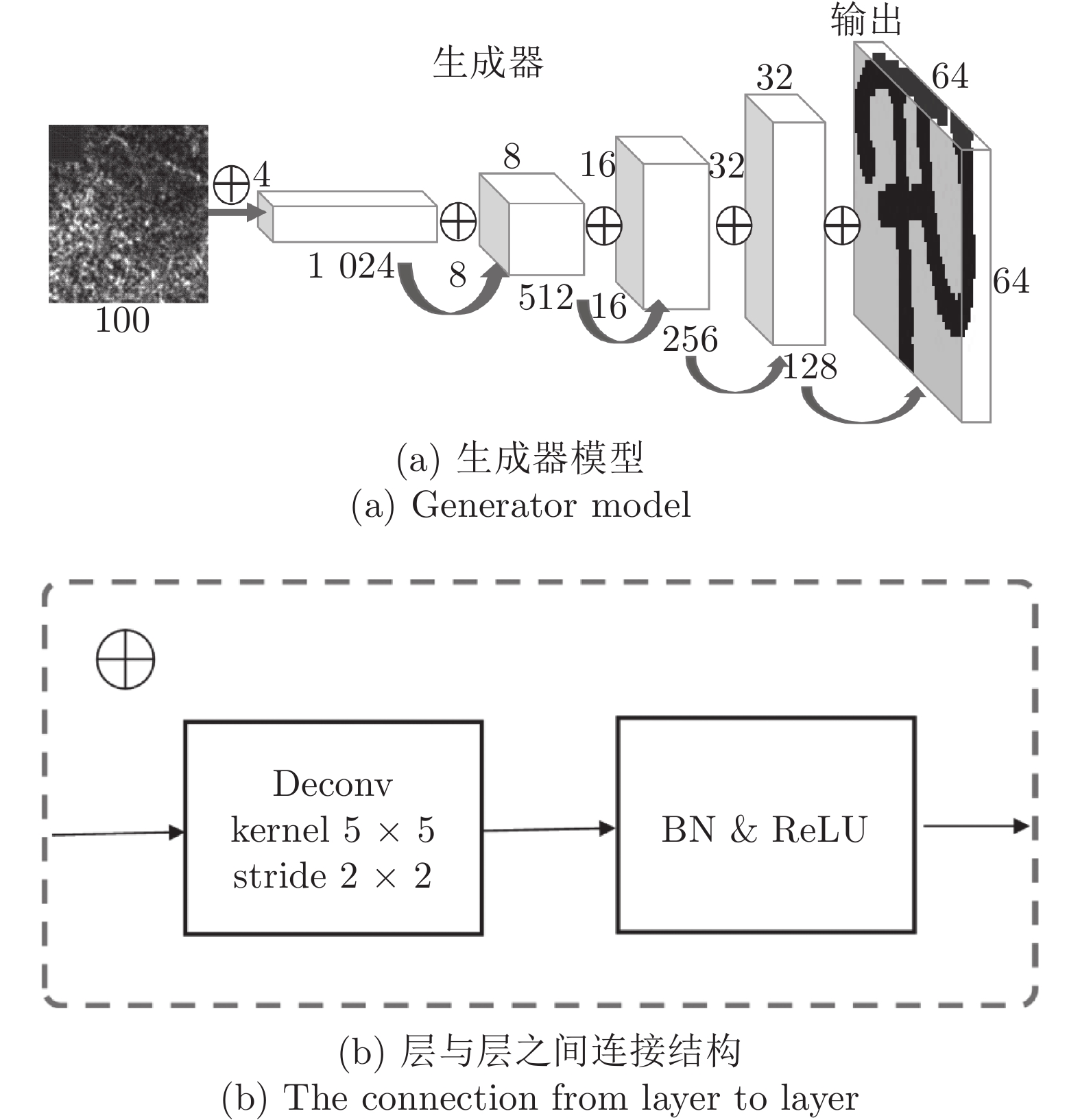
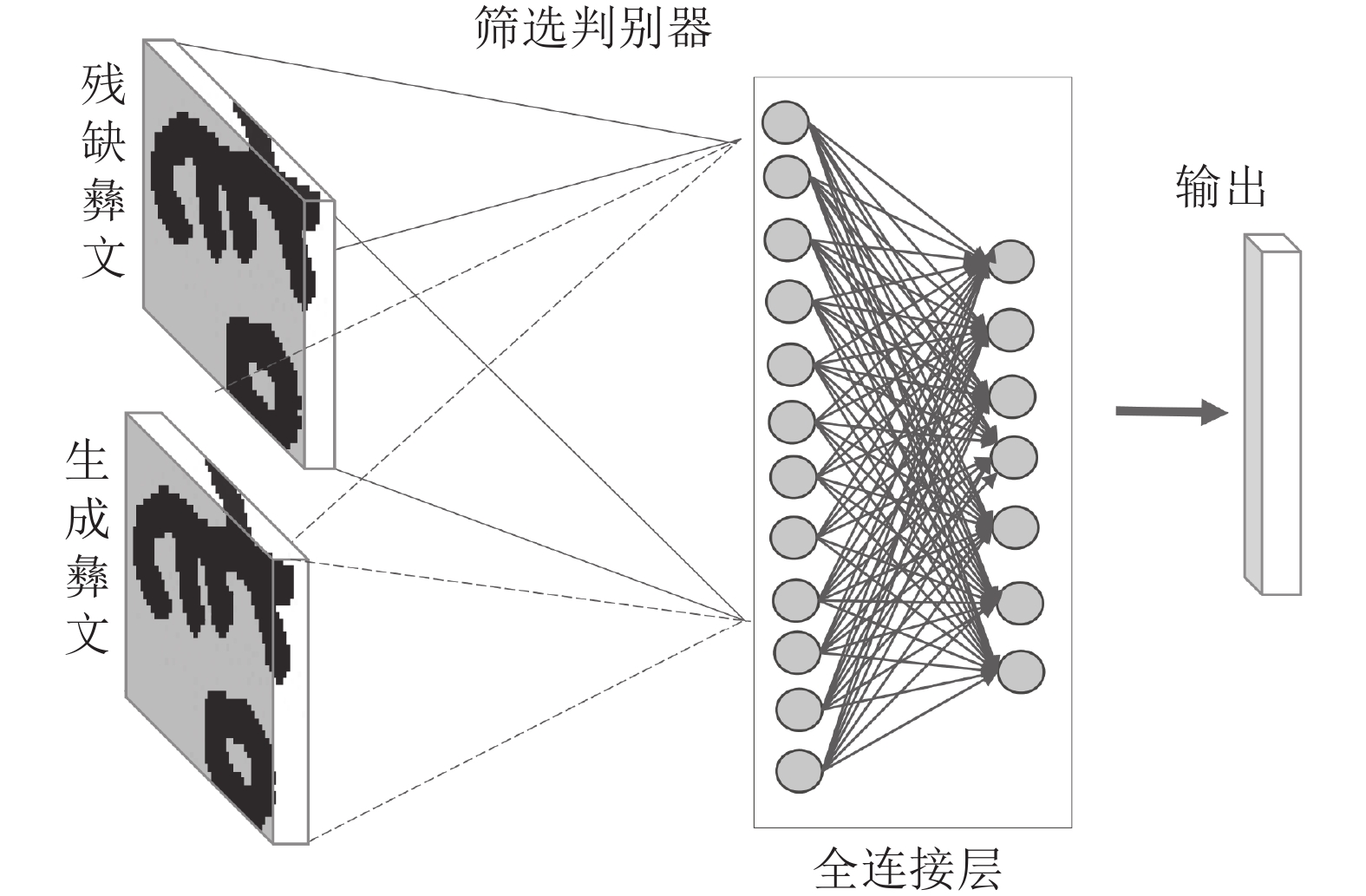
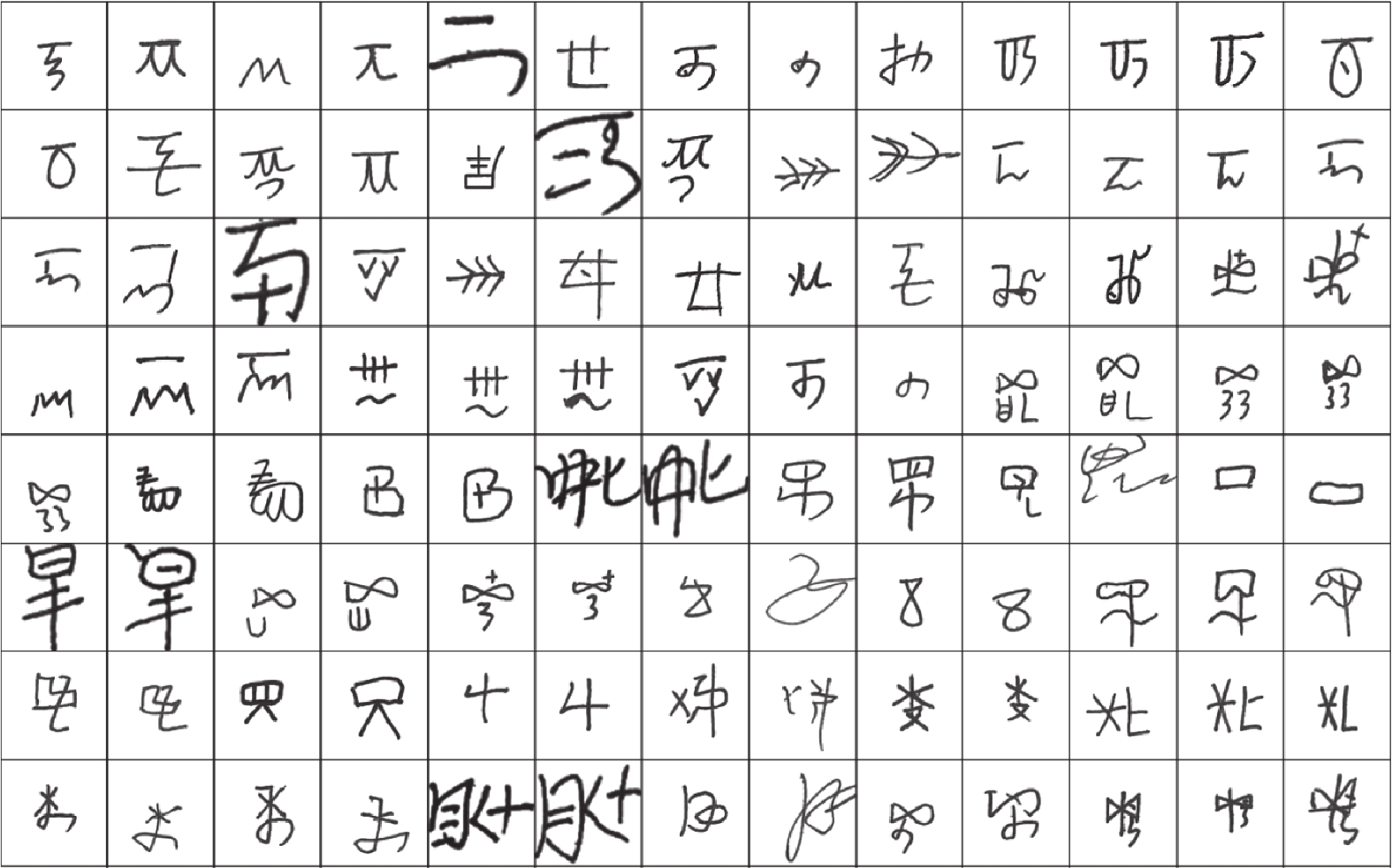
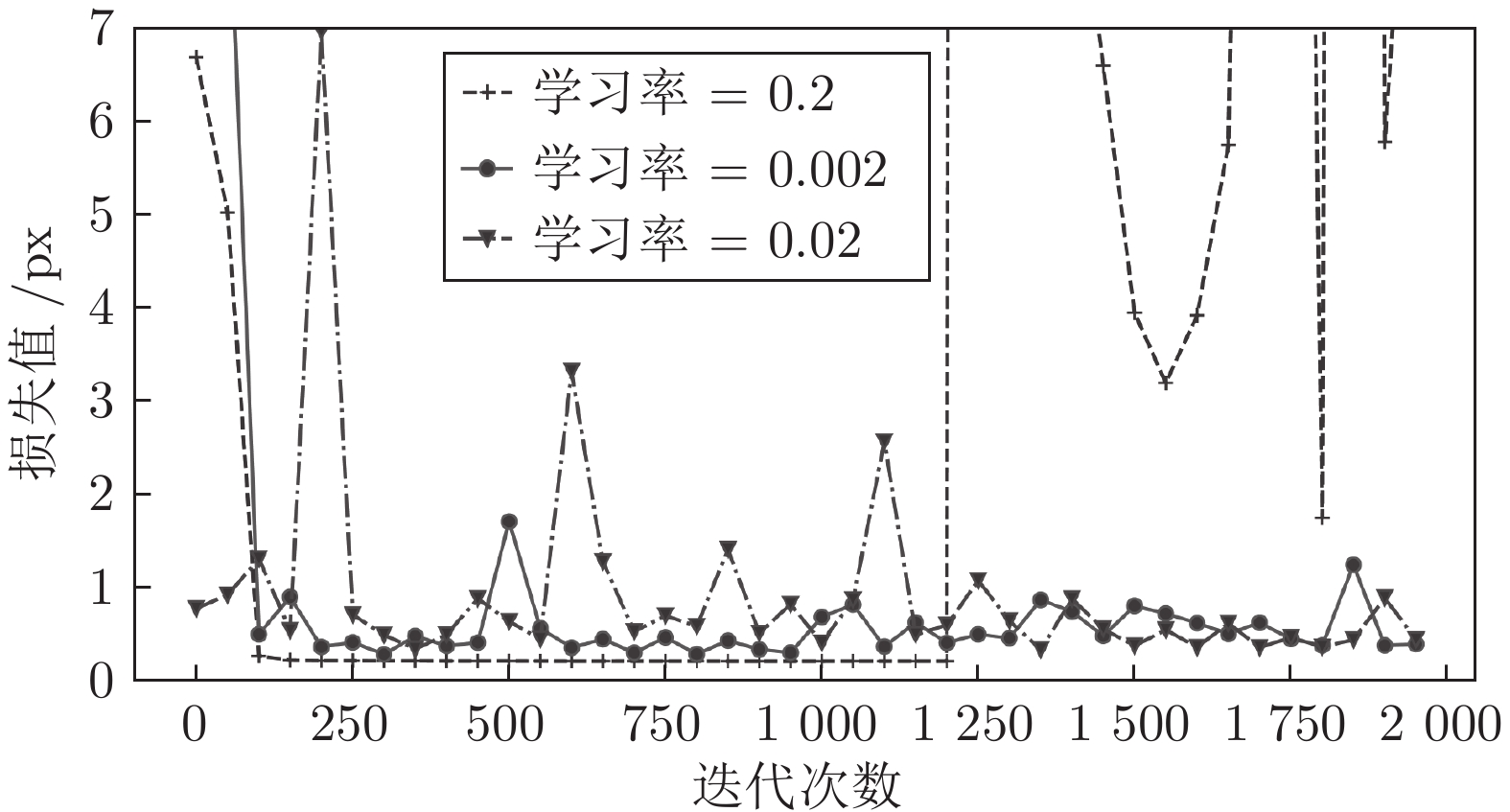
在中国, 彝文古籍文献日益流失而且损毁严重, 由于通晓古彝文的研究人员缺乏, 使得古籍恢复工作进展十分缓慢. 人工智能在图像文本领域的应用, 为古籍文献的自动修复提供可能. 本文设计了一种双判别器生成对抗网络(Generative adversarial networks with dual discriminator,D2GAN), 以还原古代彝族字符中的缺失部分. D2GAN是在深度卷积生成对抗网络的基础上, 增加一个古彝文筛选判别器. 通过三个阶段的训练来迭代地优化古彝文字符生成网络, 以...
在中国, 彝文古籍文献日益流失而且损毁严重, 由于通晓古彝文的研究人员缺乏, 使得古籍恢复工作进展十分缓慢. 人工智能在图像文本领域的应用, 为古籍文献的自动修复提供可能. 本文设计了一种双判别器生成对抗网络(Generative adversarial networks with dual discriminator,D2GAN), 以还原古代彝族字符中的缺失部分. D2GAN是在深度卷积生成对抗网络的基础上, 增加一个古彝文筛选判别器. 通过三个阶段的训练来迭代地优化古彝文字符生成网络, 以...

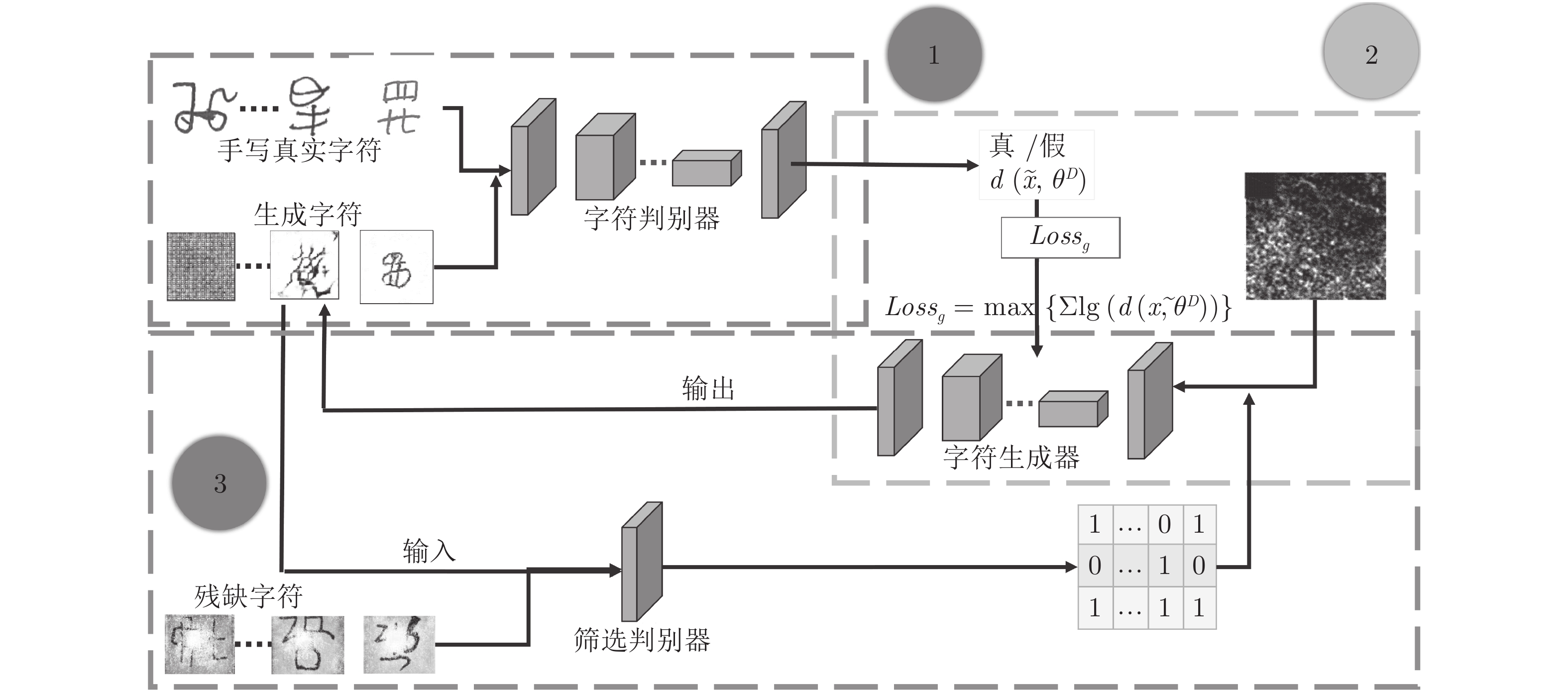
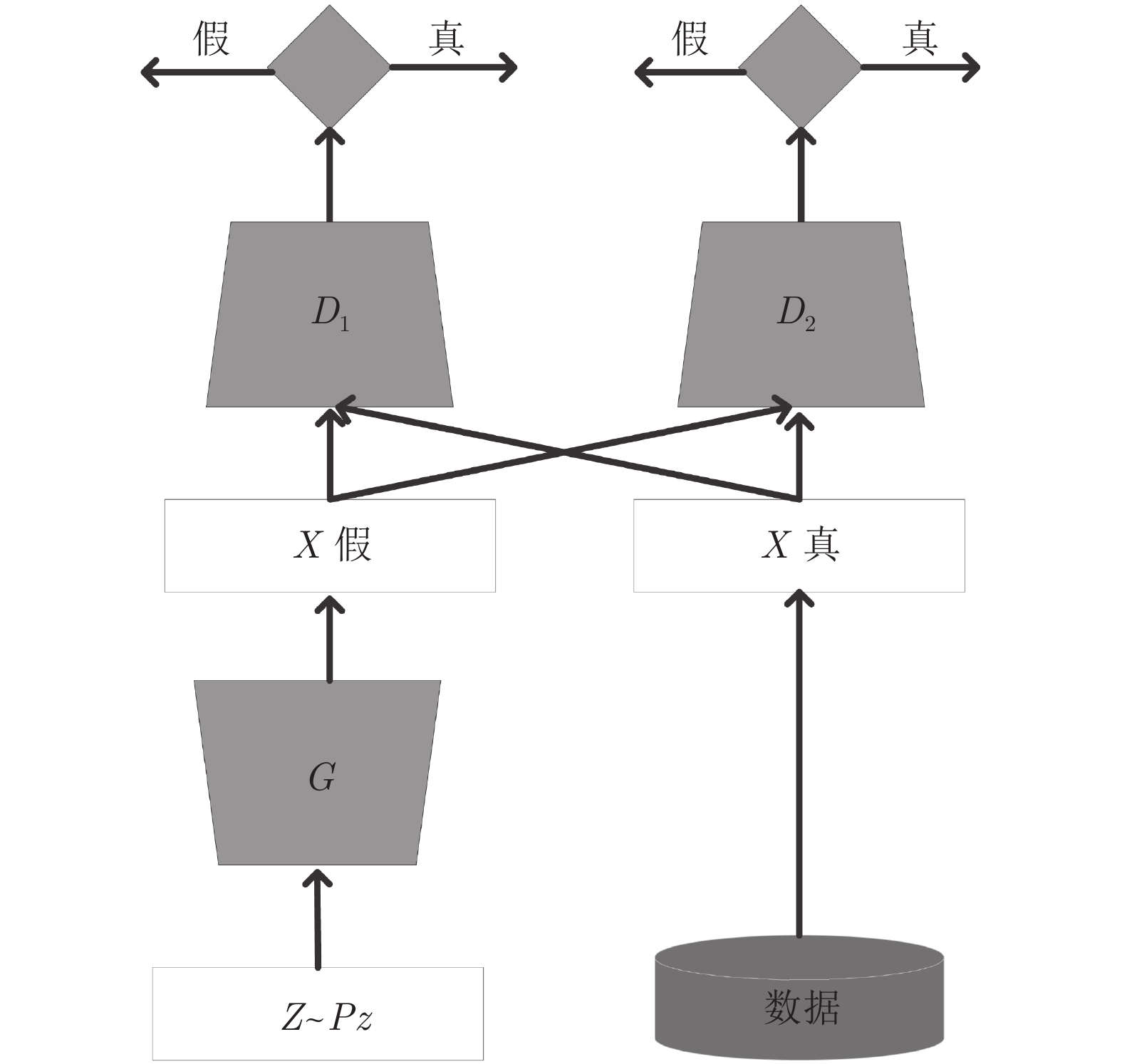
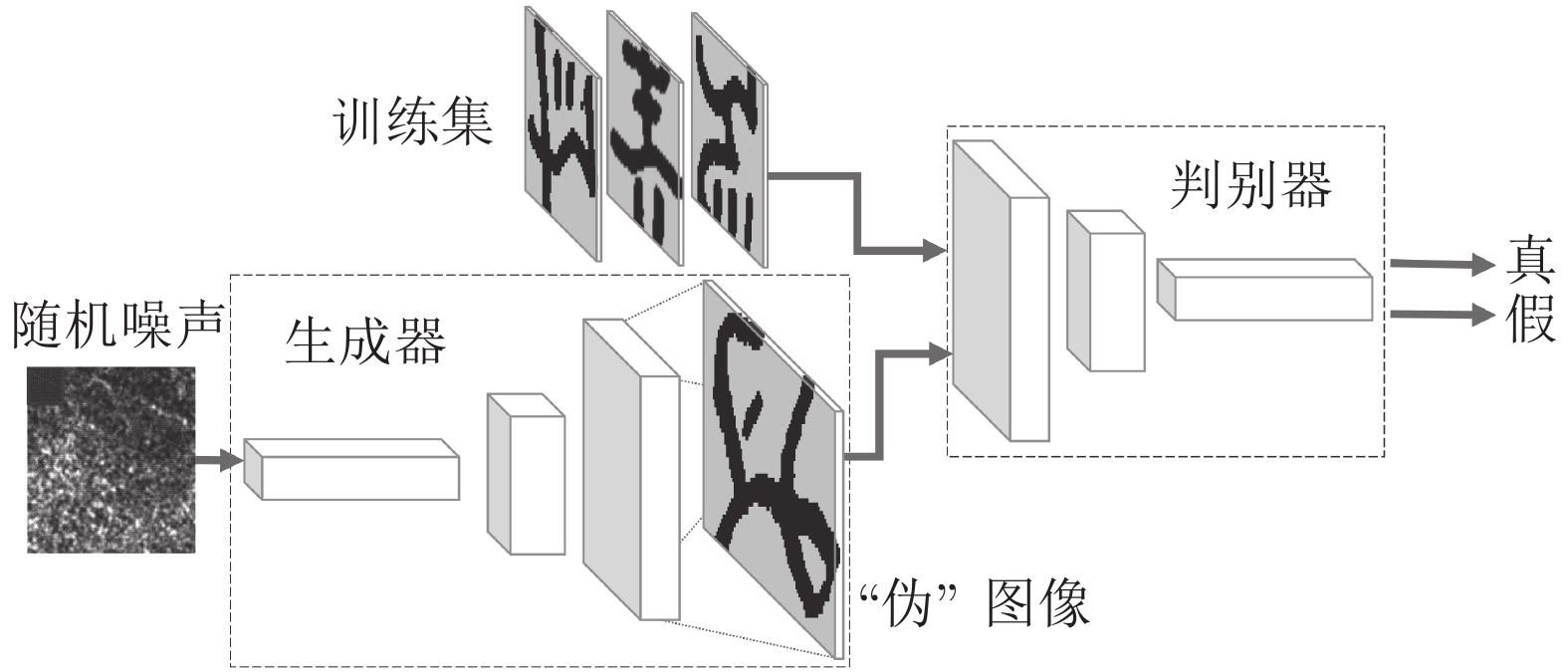
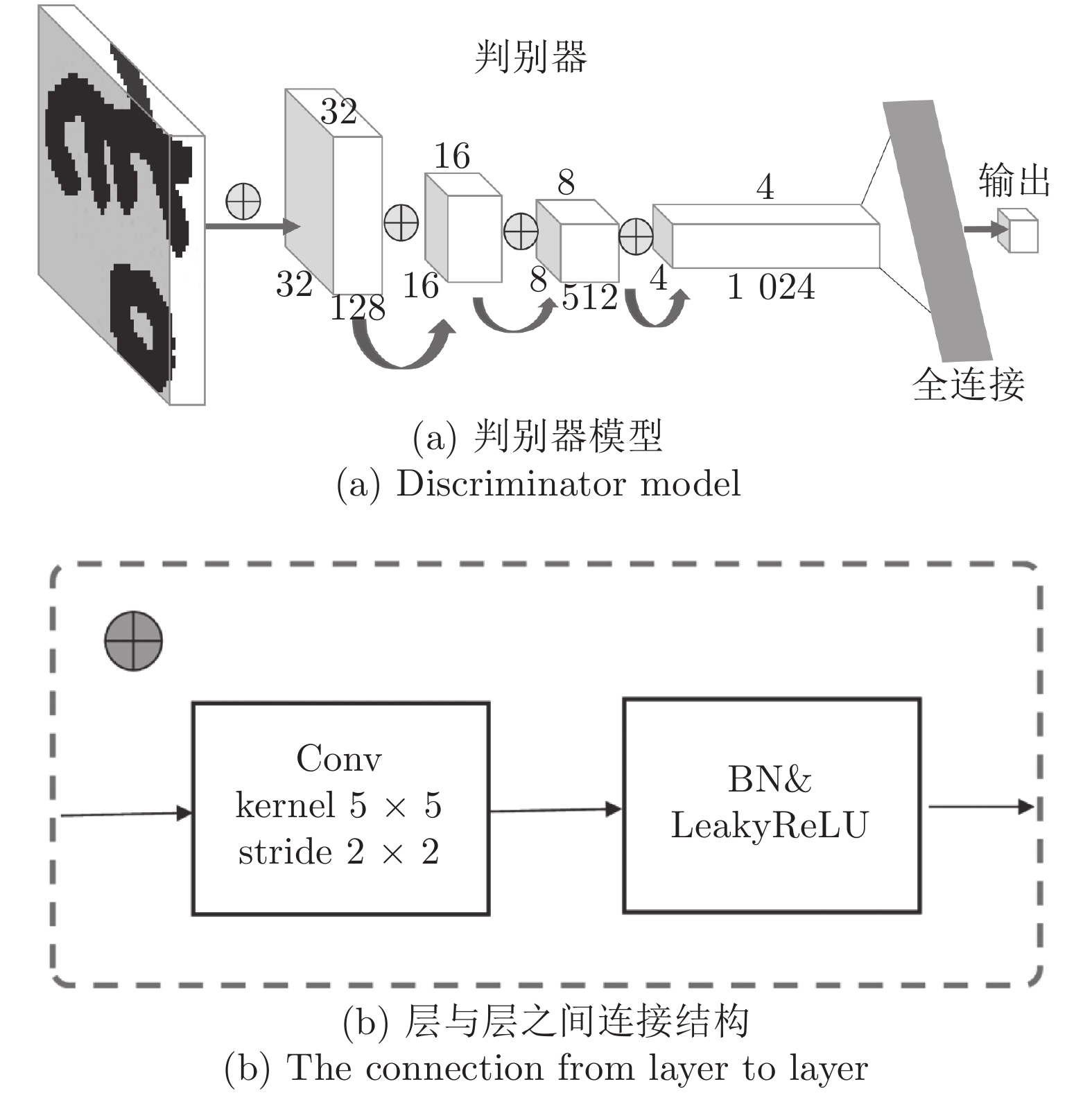






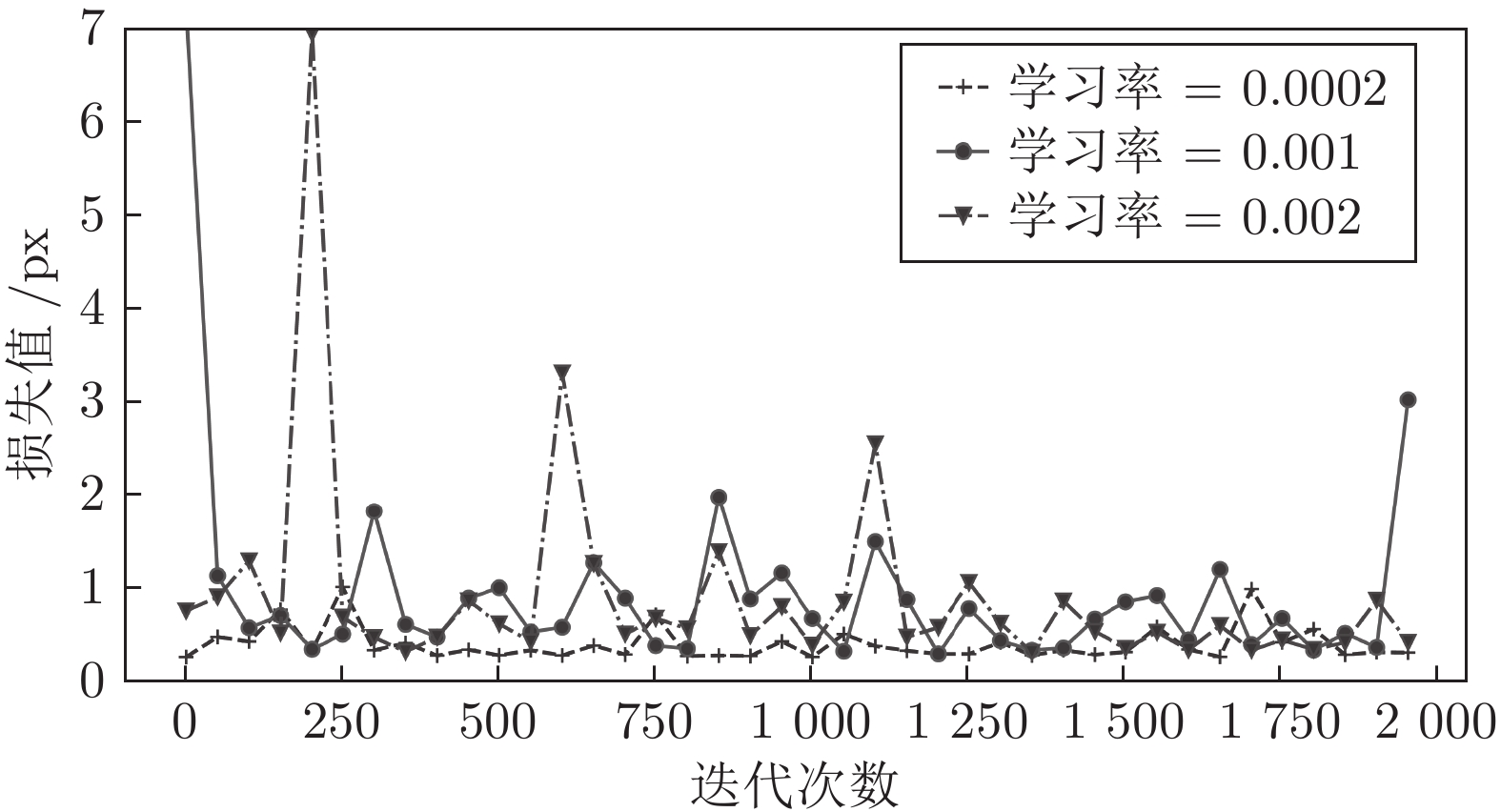
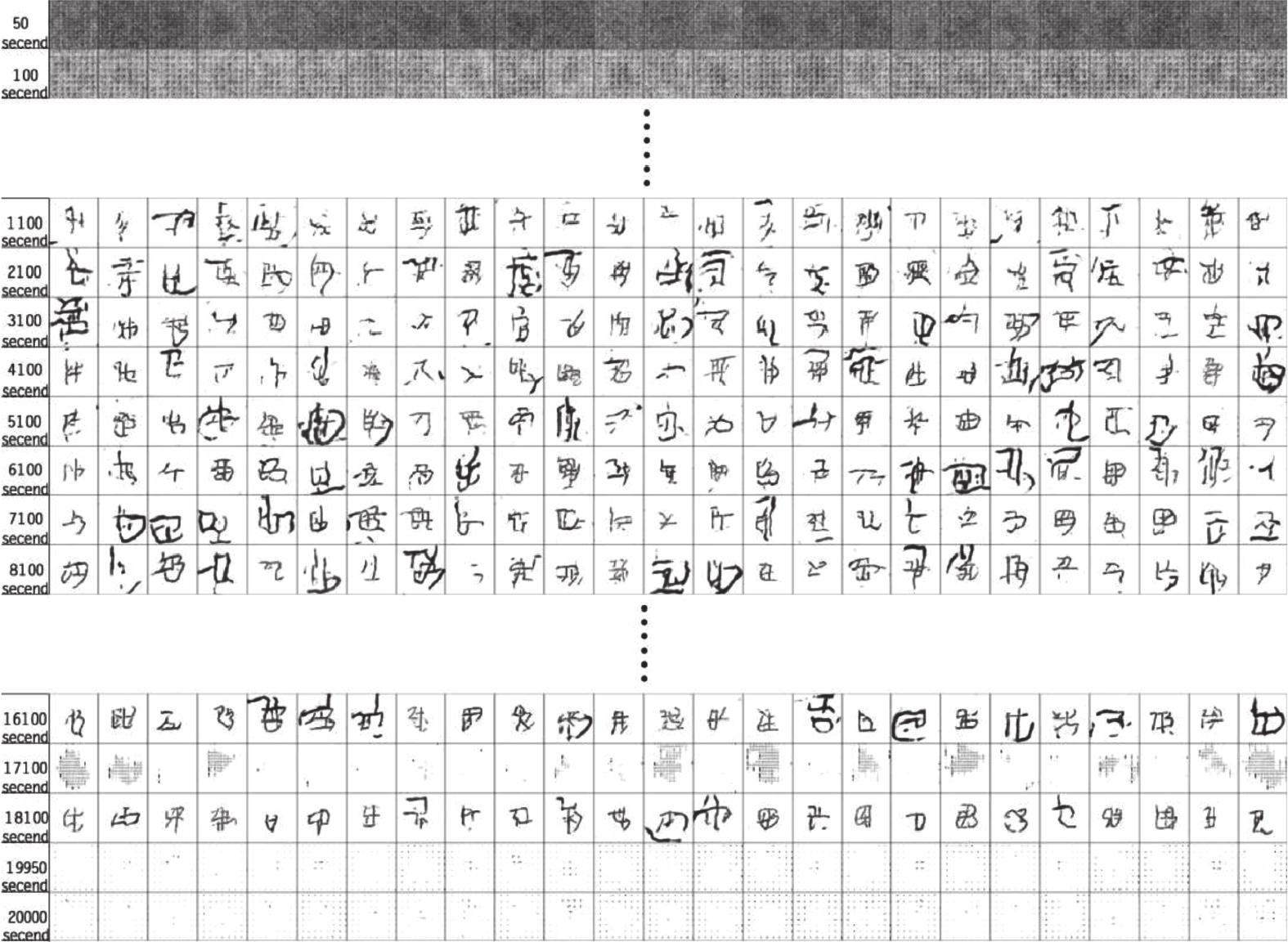
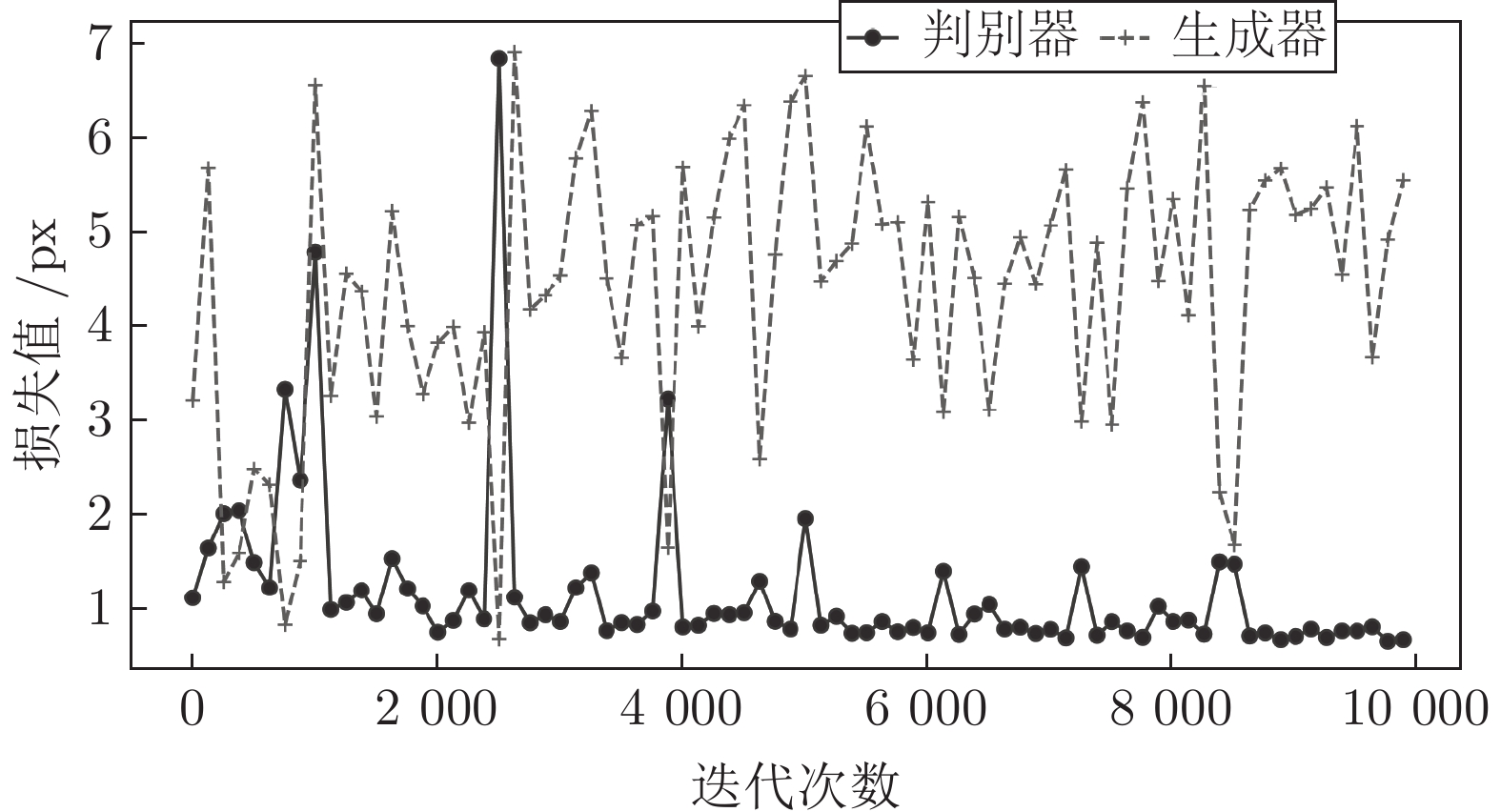

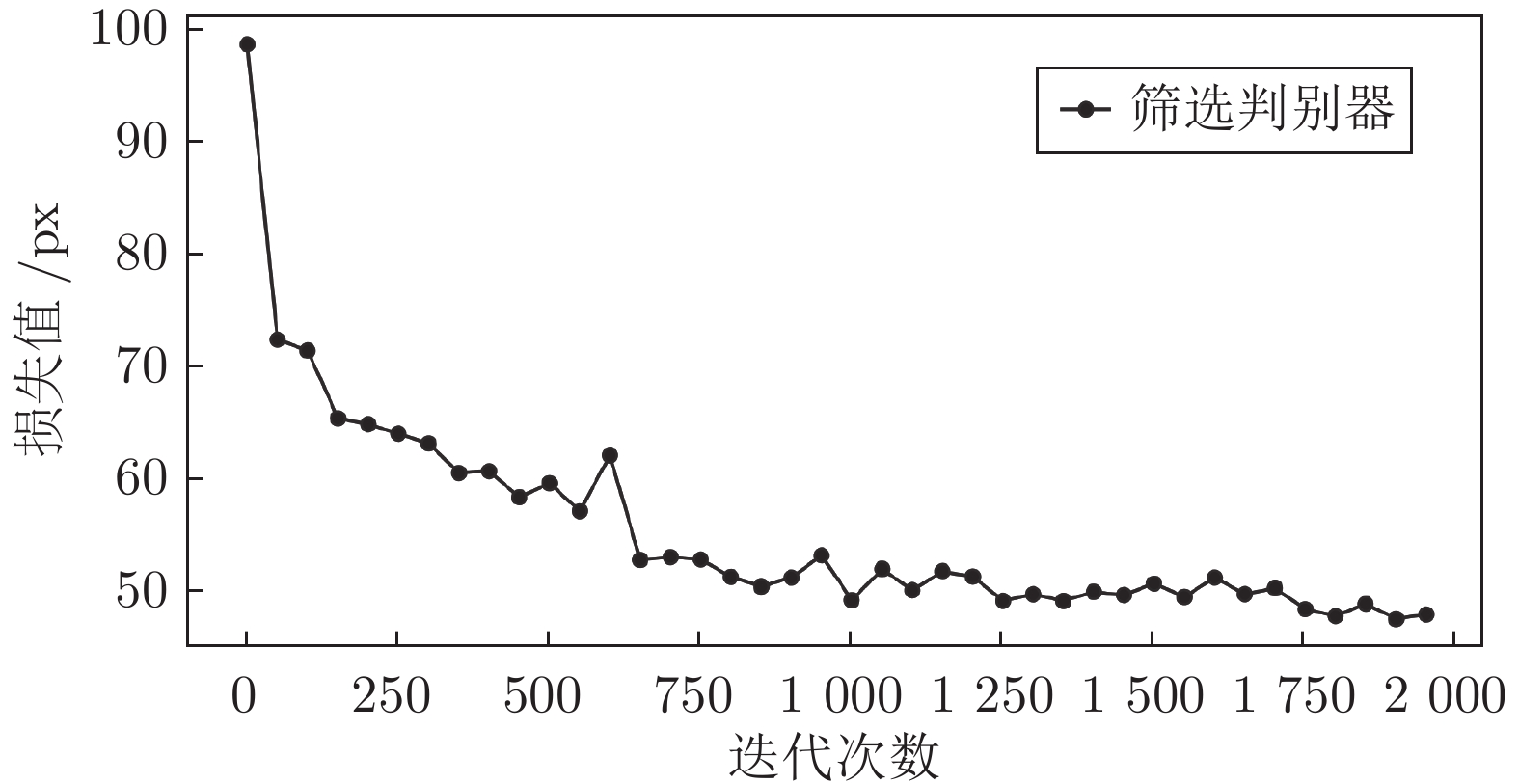





2022, 48(3): 865-876.
doi: 10.16383/j.aas.c190860
摘要:
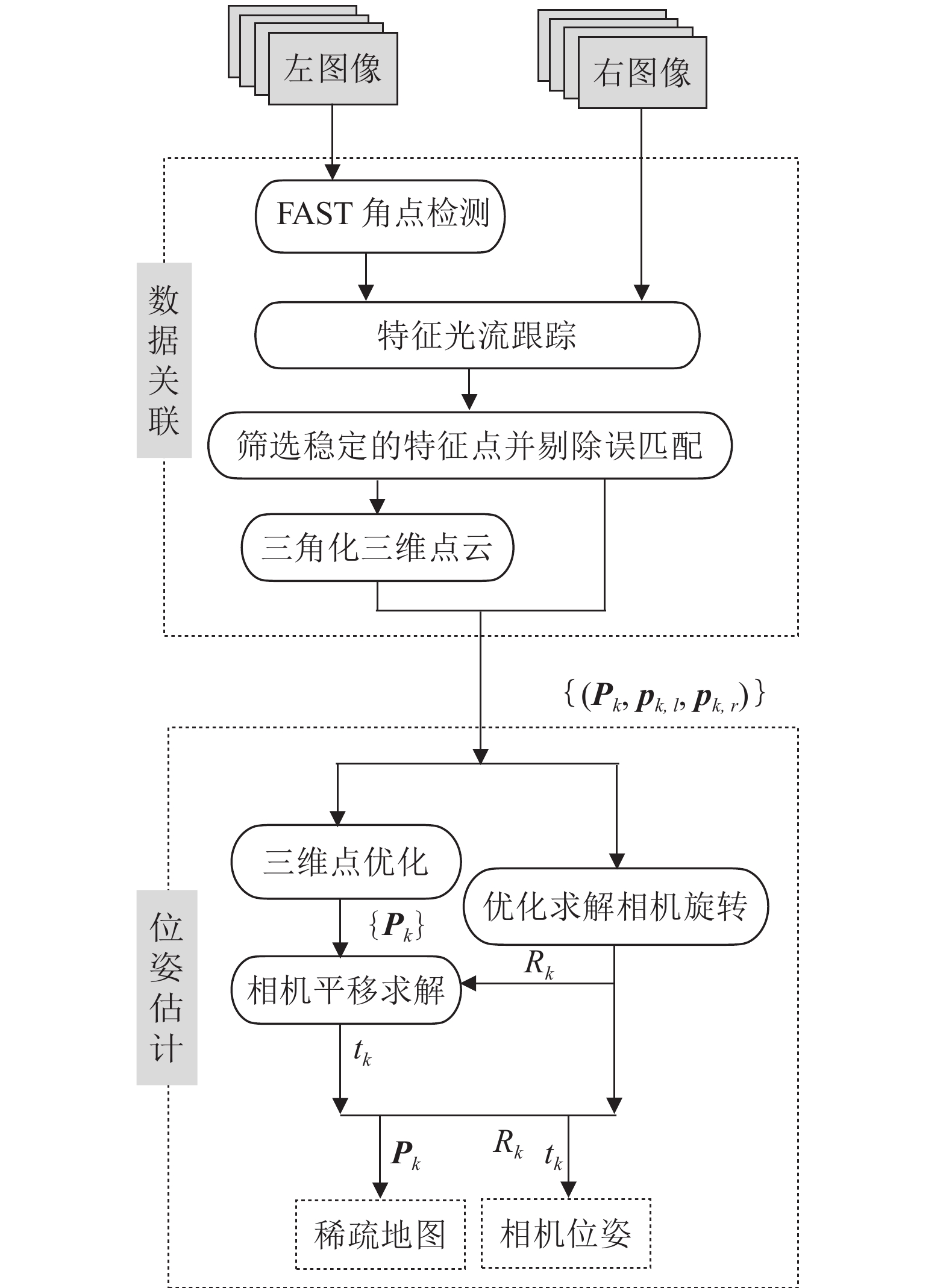
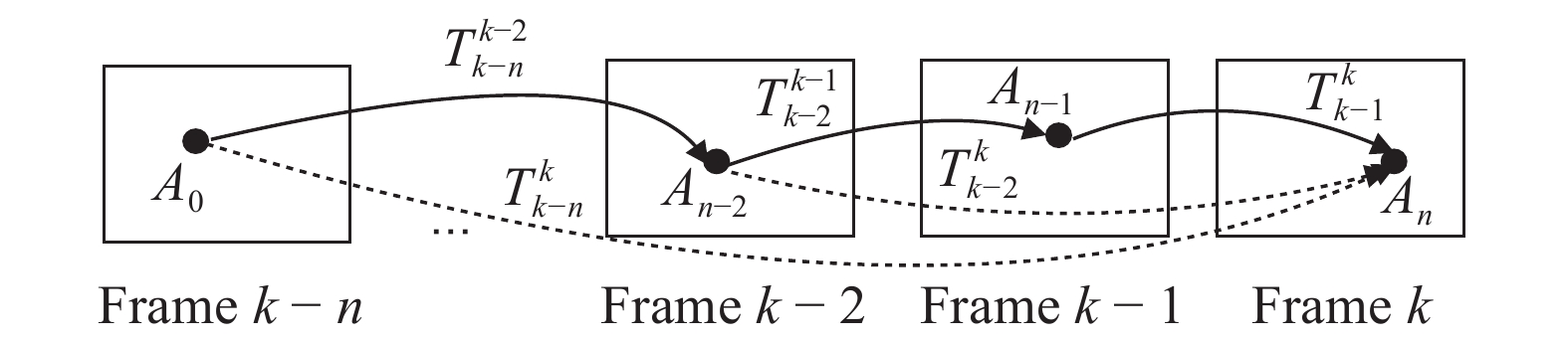
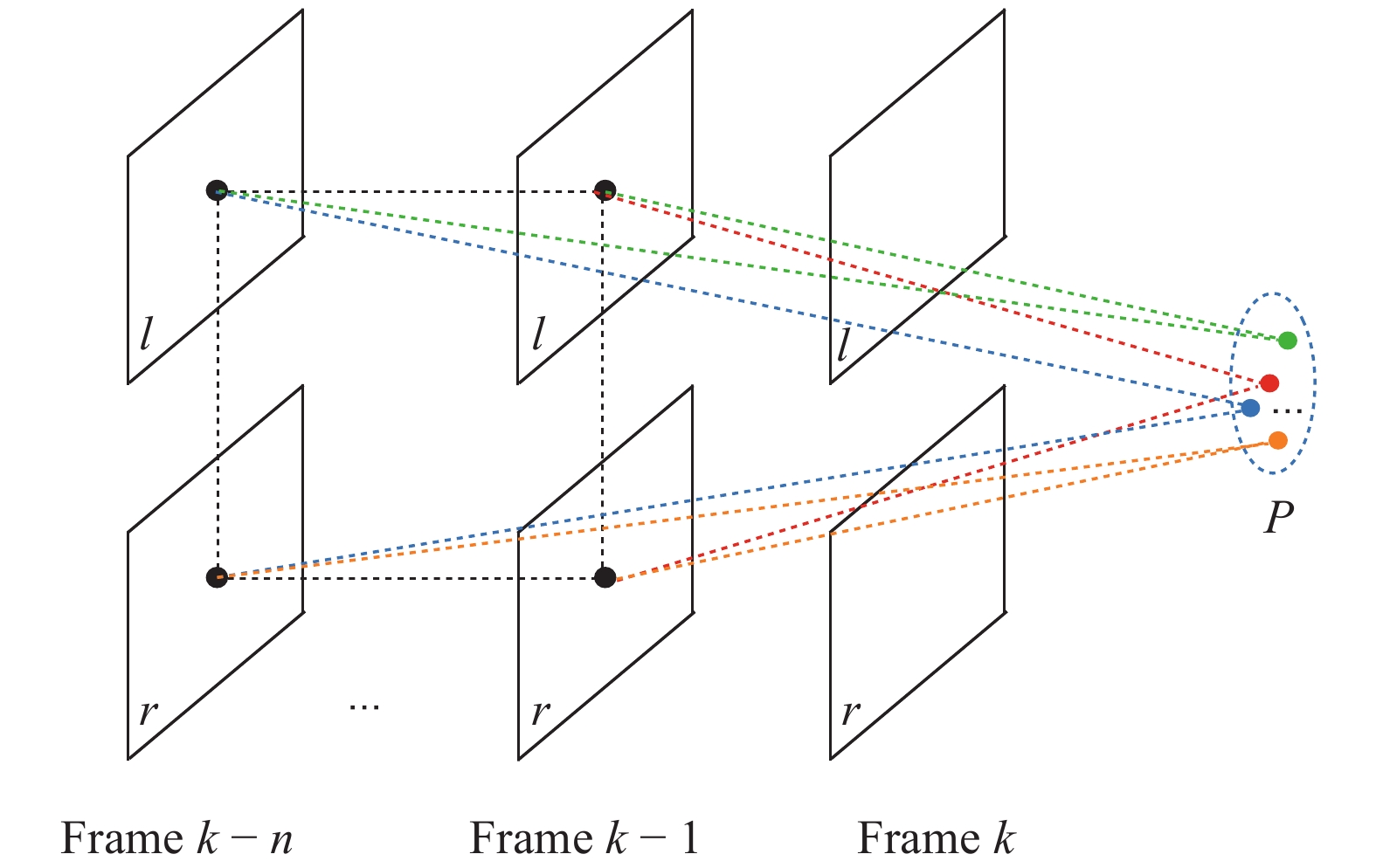
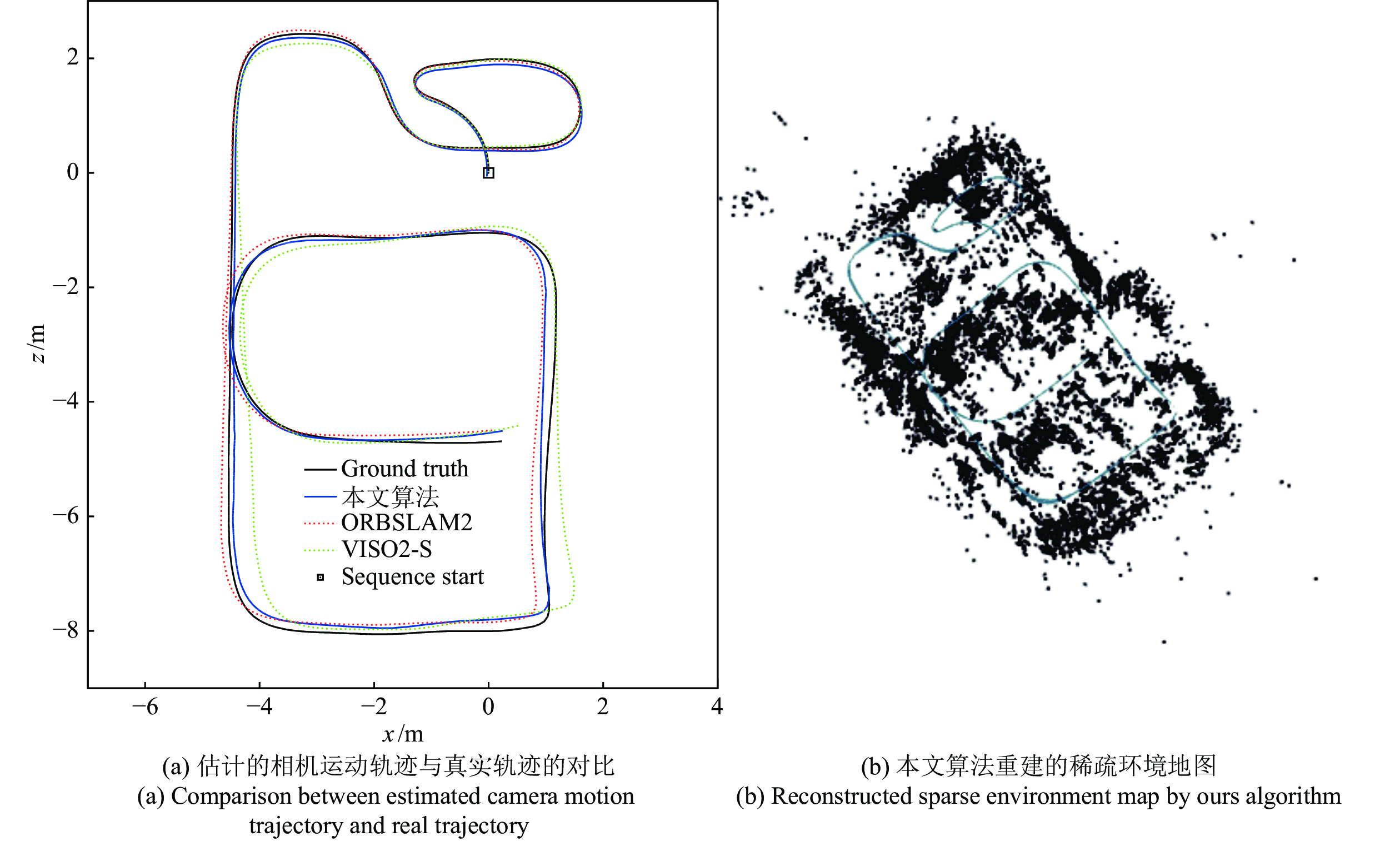
针对相机在未知环境中定位及其周围环境地图重建的问题, 本文基于拉普拉斯分布提出了一种快速精确的双目视觉里程计算法. 在使用光流构建数据关联时结合使用三个策略: 平滑的运动约束、环形匹配以及视差一致性检测来剔除错误的关联以提高数据关联的精确性, 并在此基础上筛选稳定的特征点. 本文单独估计相机的旋转与平移. 假设相机旋转、三维空间点以及相机平移的误差都服从拉普拉斯分布, 在此 假设下优化得到最优的相机位姿估计与三维空间点位置. 在KITTI和New Tsukuba数据集上的实验结果表明, 本文算法...
针对相机在未知环境中定位及其周围环境地图重建的问题, 本文基于拉普拉斯分布提出了一种快速精确的双目视觉里程计算法. 在使用光流构建数据关联时结合使用三个策略: 平滑的运动约束、环形匹配以及视差一致性检测来剔除错误的关联以提高数据关联的精确性, 并在此基础上筛选稳定的特征点. 本文单独估计相机的旋转与平移. 假设相机旋转、三维空间点以及相机平移的误差都服从拉普拉斯分布, 在此 假设下优化得到最优的相机位姿估计与三维空间点位置. 在KITTI和New Tsukuba数据集上的实验结果表明, 本文算法...




2022, 48(3): 877-886.
doi: 10.16383/j.aas.c190256
摘要:
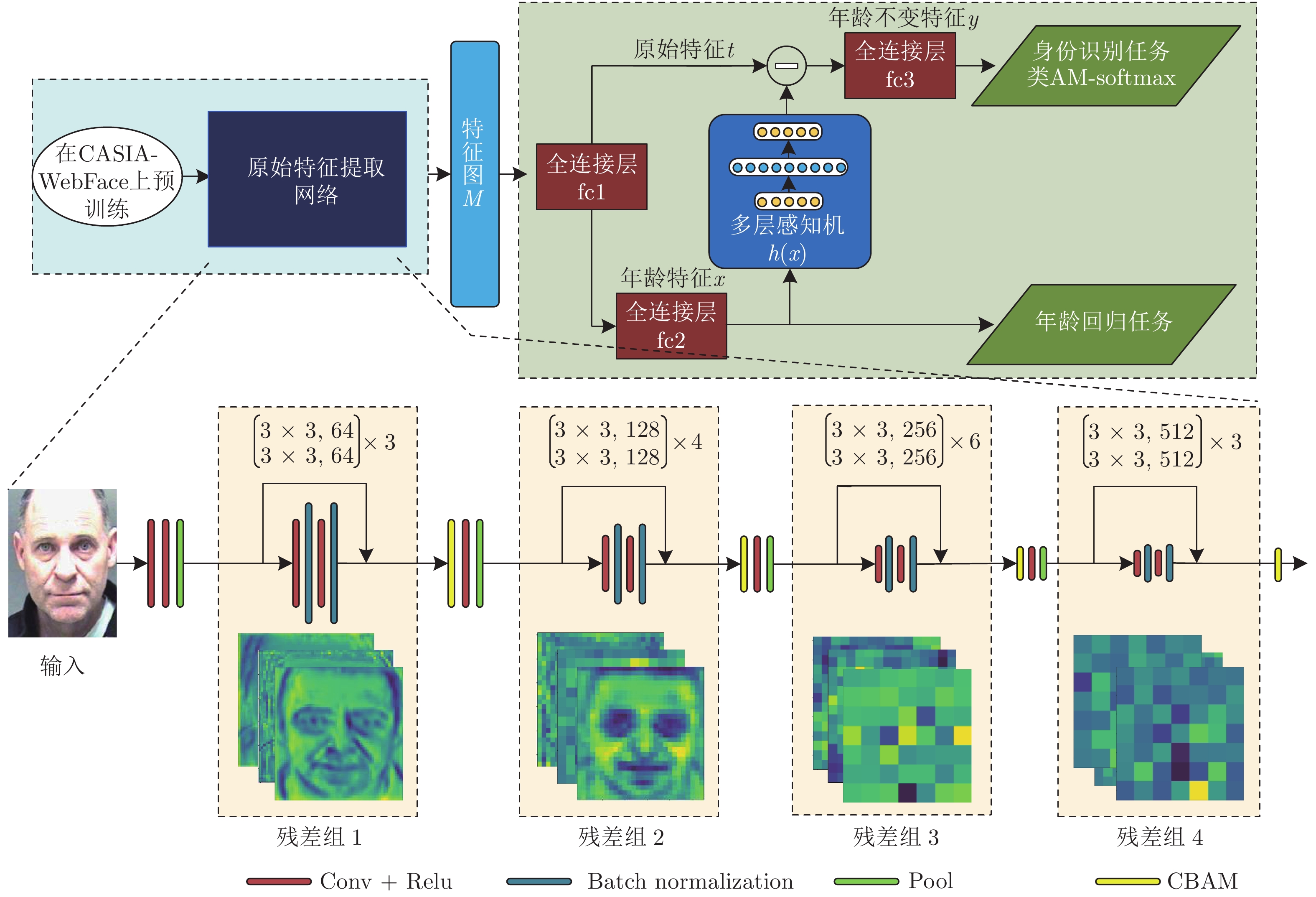
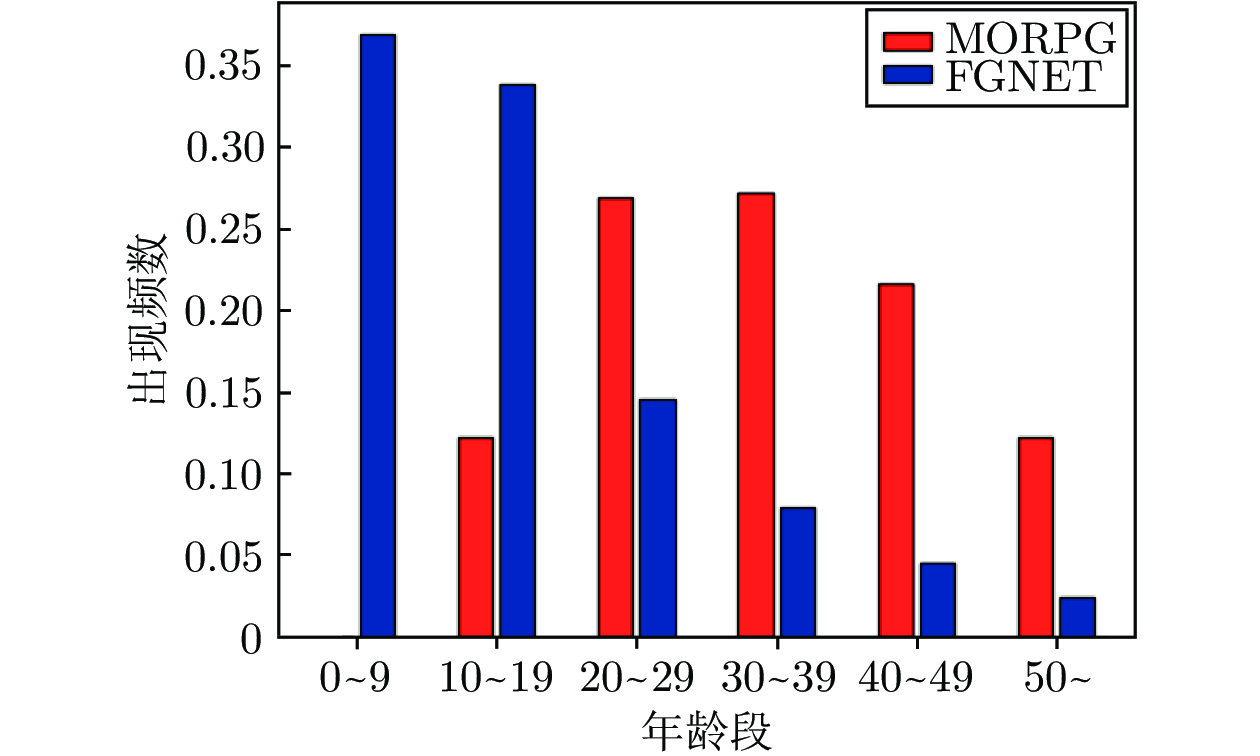
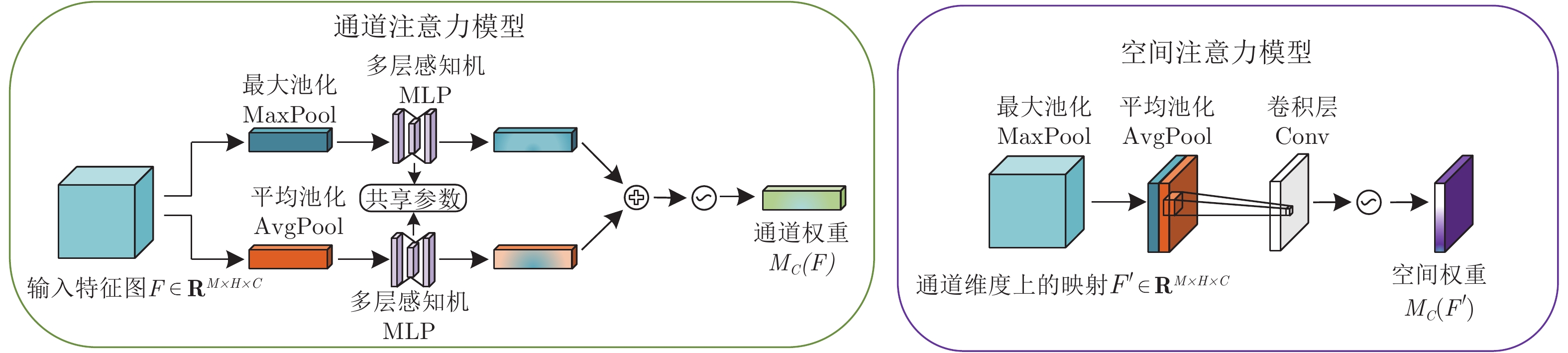
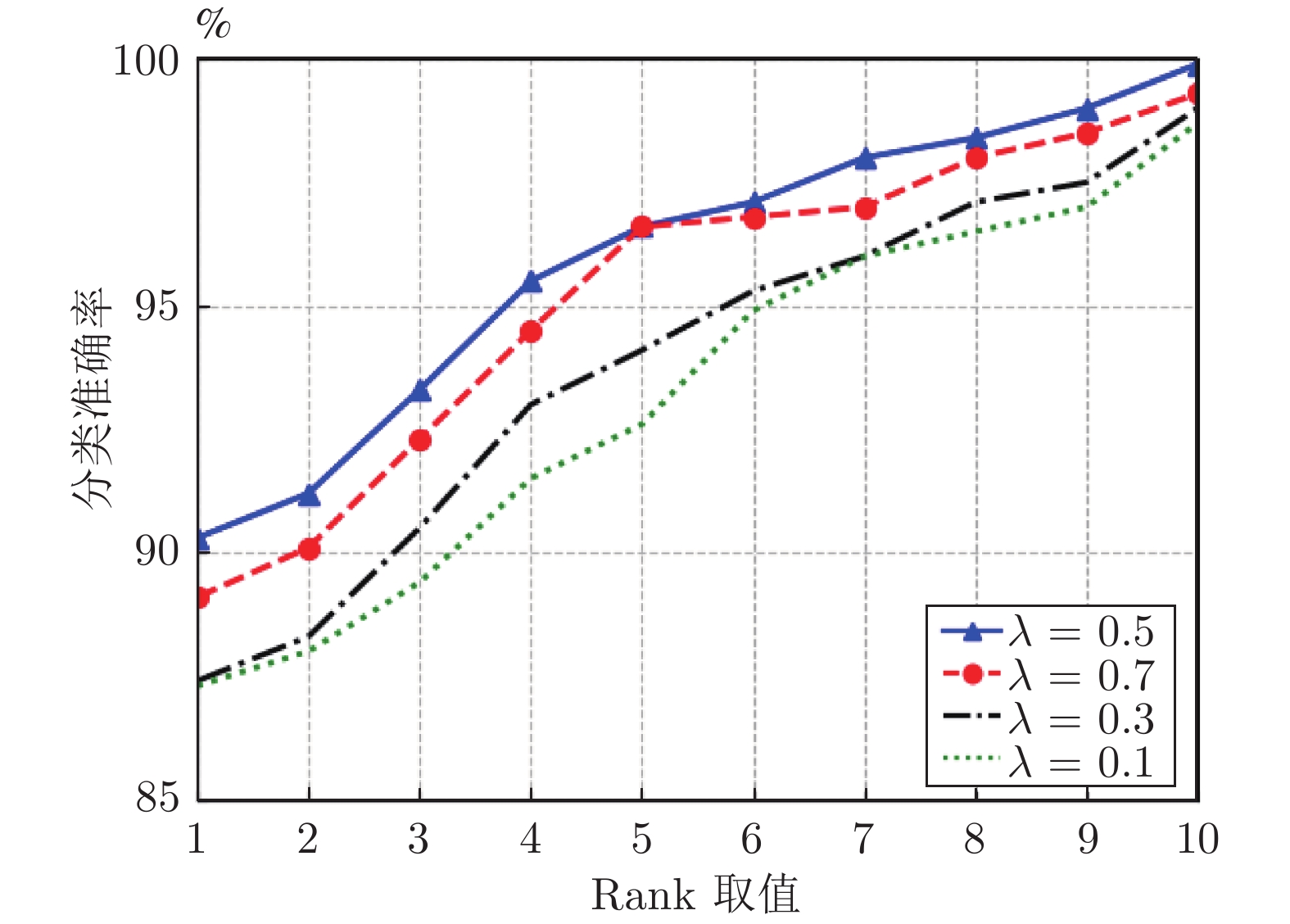
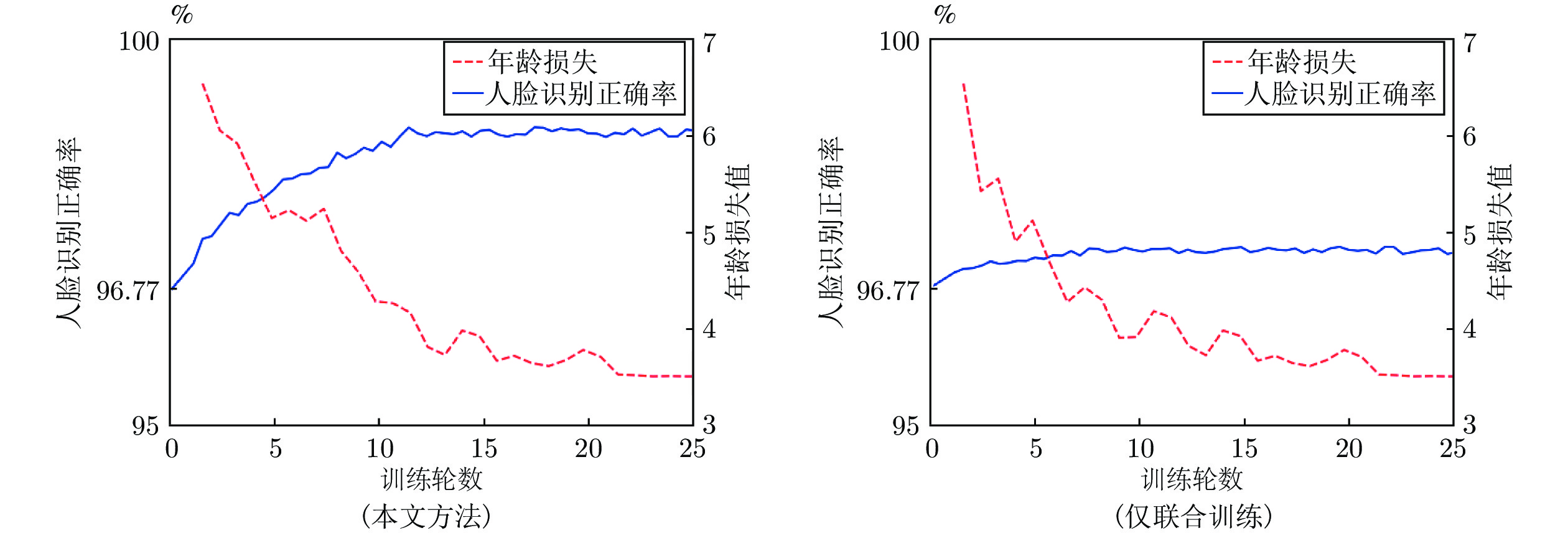
随着年龄的增长, 人脸的形状、纹理等特征会随之发生较明显的改变从而造成显著的类内干扰, 这使得人脸识别的性能大大降低. 为了解决上述问题, 本文基于深度卷积神经网络将年龄估计任务和人脸识别任务相结合, 提出了一种抗年龄干扰的人脸识别新方法AD-CNN (Age decomposition convolution neural network), 首先将卷积块注意力模型(Convolutional block attention module, CBAM)嵌入到残差网络中以学习更具有代表性的面部特...
随着年龄的增长, 人脸的形状、纹理等特征会随之发生较明显的改变从而造成显著的类内干扰, 这使得人脸识别的性能大大降低. 为了解决上述问题, 本文基于深度卷积神经网络将年龄估计任务和人脸识别任务相结合, 提出了一种抗年龄干扰的人脸识别新方法AD-CNN (Age decomposition convolution neural network), 首先将卷积块注意力模型(Convolutional block attention module, CBAM)嵌入到残差网络中以学习更具有代表性的面部特...




2022, 48(3): 887-895.
doi: 10.16383/j.aas.c190286
摘要:
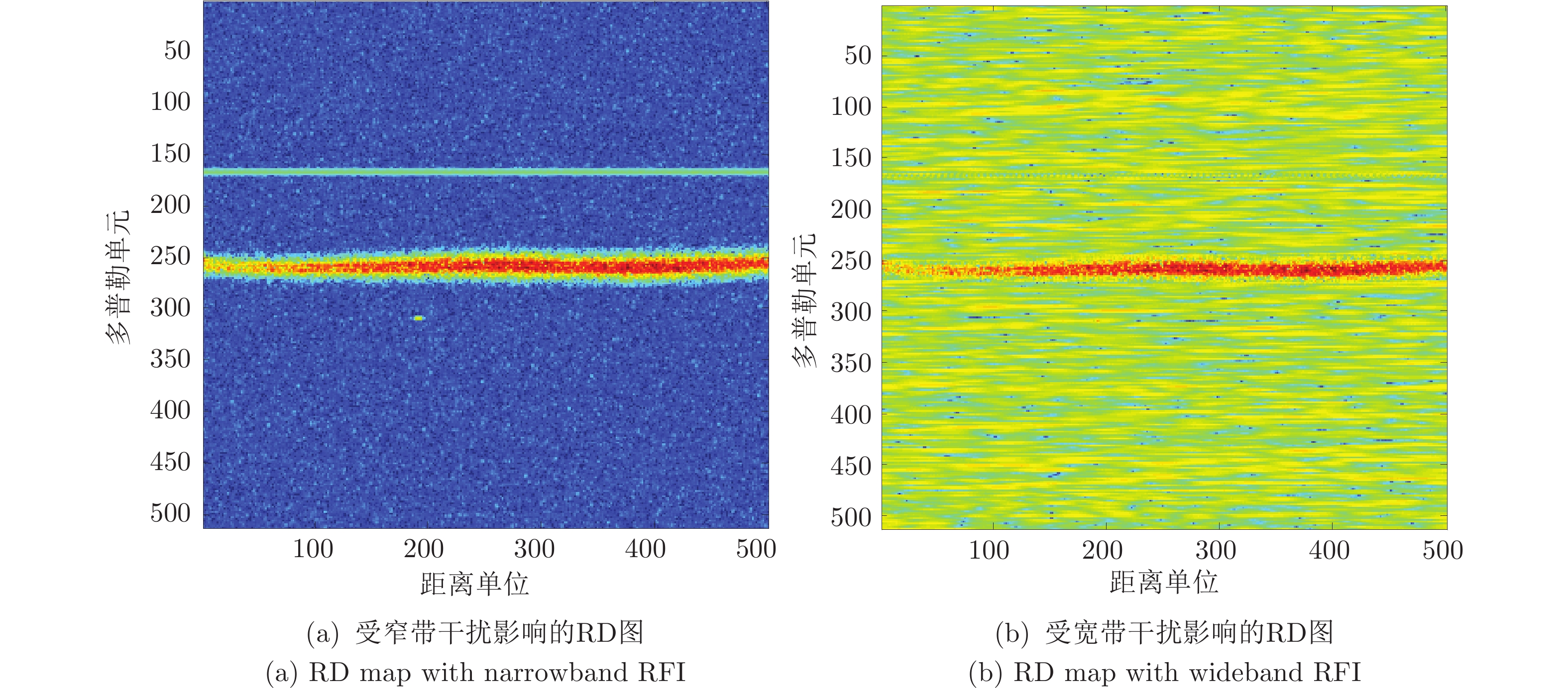
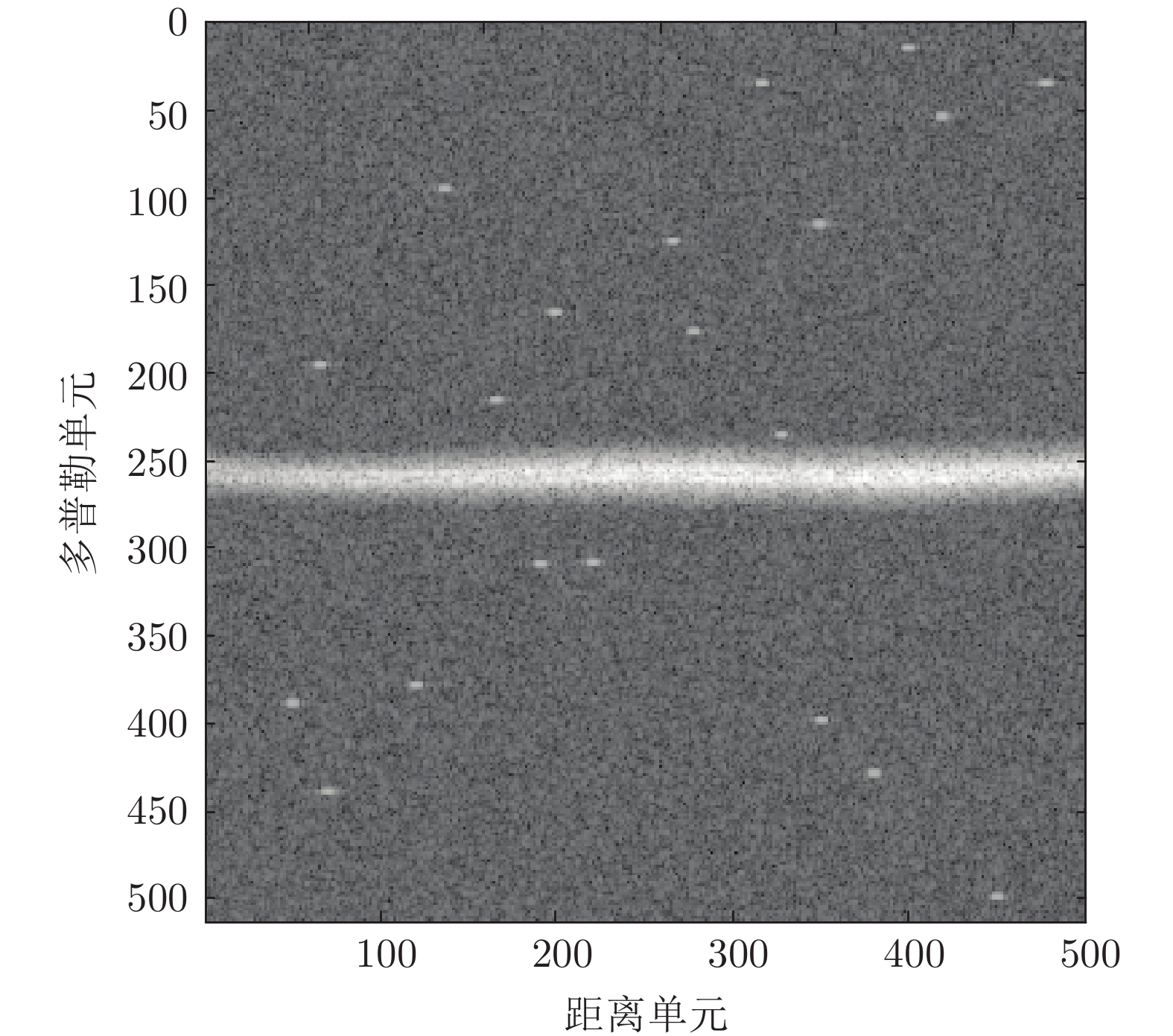
针对OTH (Over-the-horizon) 雷达距离−多普勒(Range-Doppler, RD)图, 本文首次提出采用纹理粗糙度作为RD图质量的评价指标, 即计算RD图所转化灰度图的Tamura纹理粗糙度. 分析表明, 粗糙度指标能准确反映RD图受干扰情况, 对于不同灰度转换函数具有稳健性. 作为应用举例, 本文将图像粗糙度用于改进射频干扰抑制算法, 使干扰抑制达到自适应优化. 实验结果表明, Tamura粗糙度能够正确反映RD图干扰抑制情况, 优化粗糙度指标能够使干扰抑制自适应达到最优...
针对OTH (Over-the-horizon) 雷达距离−多普勒(Range-Doppler, RD)图, 本文首次提出采用纹理粗糙度作为RD图质量的评价指标, 即计算RD图所转化灰度图的Tamura纹理粗糙度. 分析表明, 粗糙度指标能准确反映RD图受干扰情况, 对于不同灰度转换函数具有稳健性. 作为应用举例, 本文将图像粗糙度用于改进射频干扰抑制算法, 使干扰抑制达到自适应优化. 实验结果表明, Tamura粗糙度能够正确反映RD图干扰抑制情况, 优化粗糙度指标能够使干扰抑制自适应达到最优...


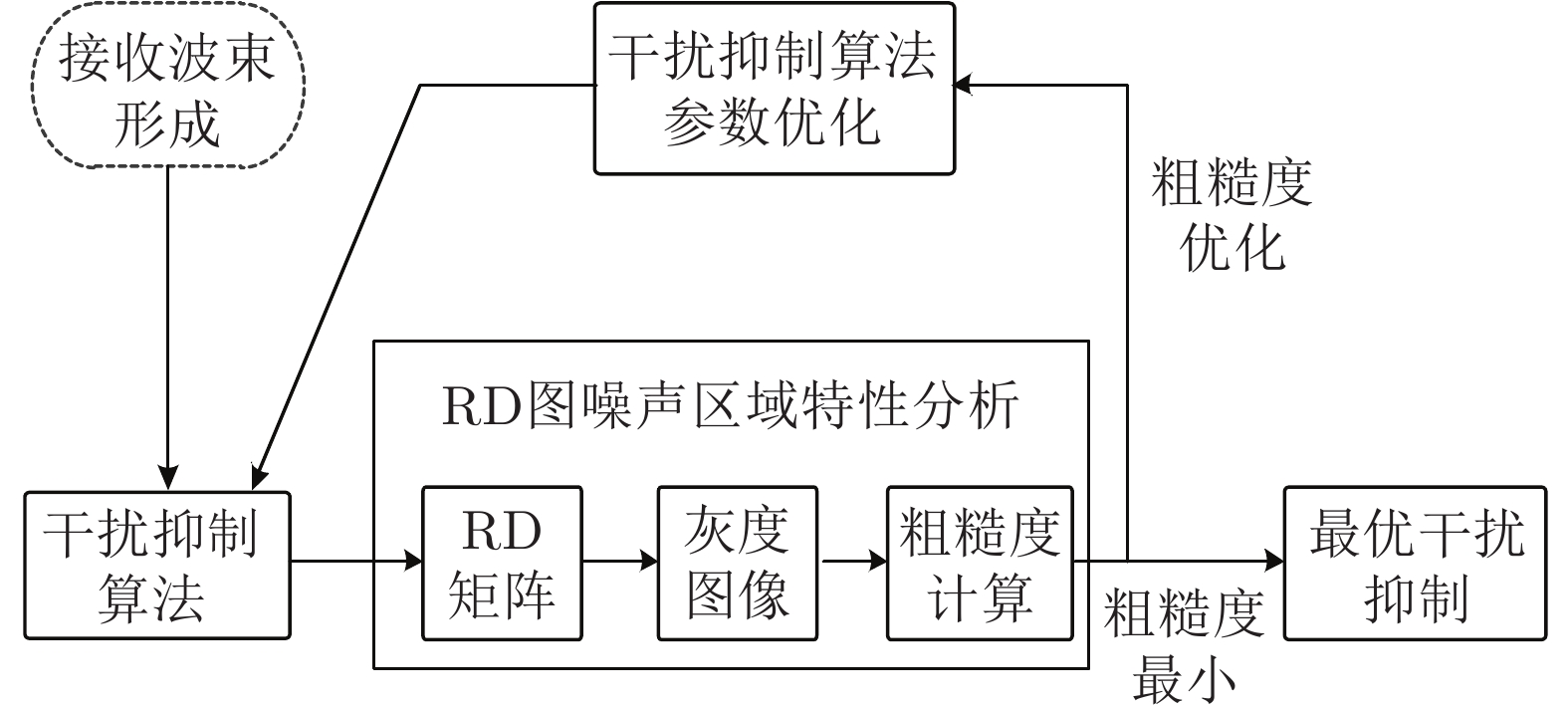

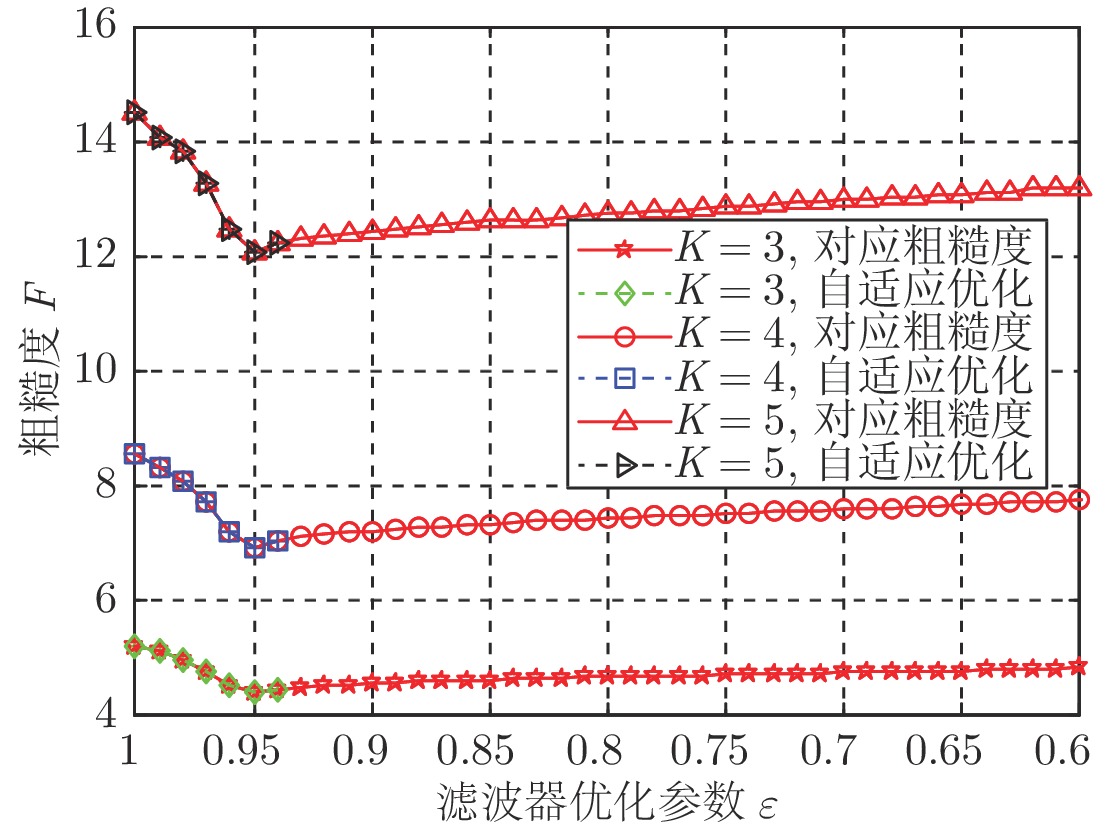
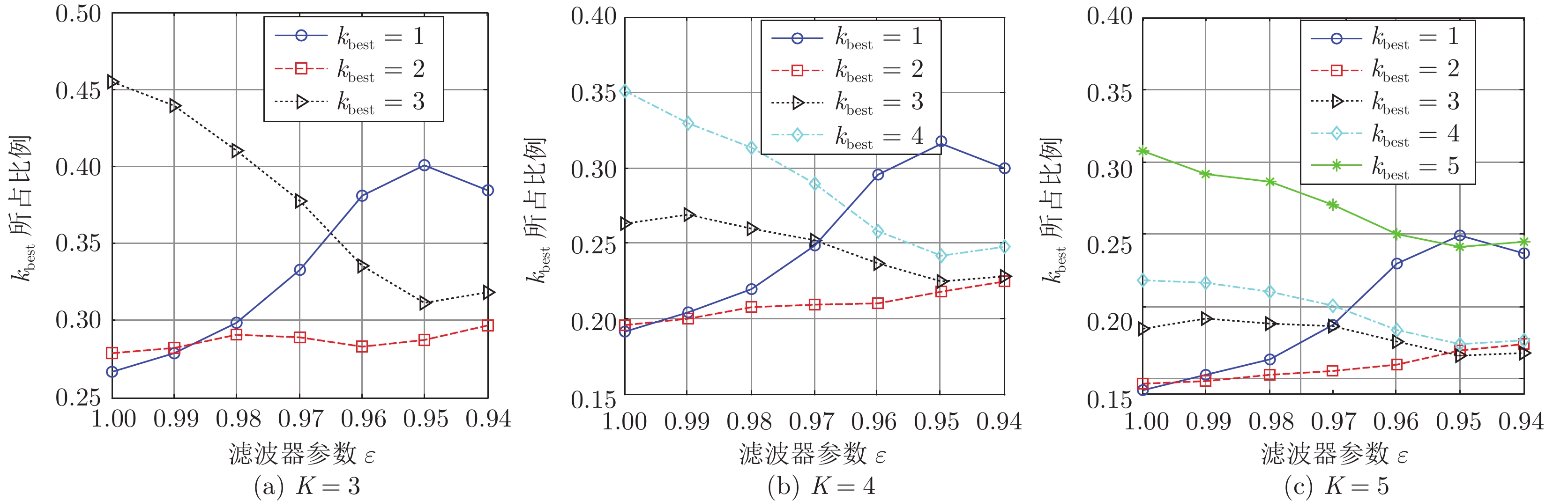
2022, 48(3): 896-908.
doi: 10.16383/j.aas.c190090
摘要:
时间、生产质量和成本是加工制造中相互制约的重要参数, 平衡此参数使制造工艺最优是一个NP (Non-deterministic polynomial)难题, 对此出现了许多优秀的调度方法. 然而这些方法的优化对象均为线性工艺, 对于普遍存在的非线性工艺却无法调度优化. 针对此不足, 本文以非线性工艺为优化对象提出了三层虚拟工作流模型Three-VMG (Three-virtual model graph)及其优化算法Three-OVMG (Three-optimal virtual model ...
时间、生产质量和成本是加工制造中相互制约的重要参数, 平衡此参数使制造工艺最优是一个NP (Non-deterministic polynomial)难题, 对此出现了许多优秀的调度方法. 然而这些方法的优化对象均为线性工艺, 对于普遍存在的非线性工艺却无法调度优化. 针对此不足, 本文以非线性工艺为优化对象提出了三层虚拟工作流模型Three-VMG (Three-virtual model graph)及其优化算法Three-OVMG (Three-optimal virtual model ...
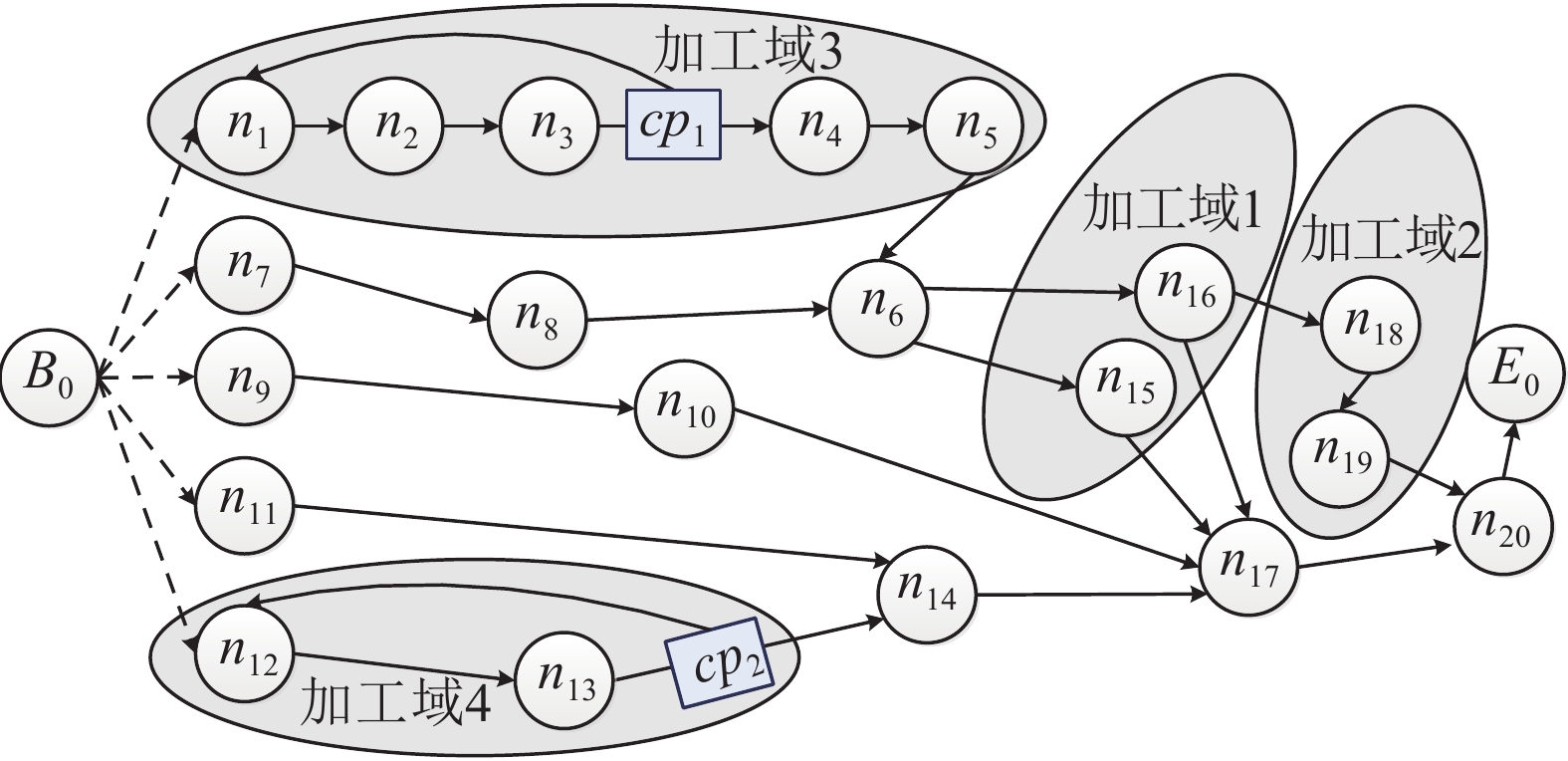

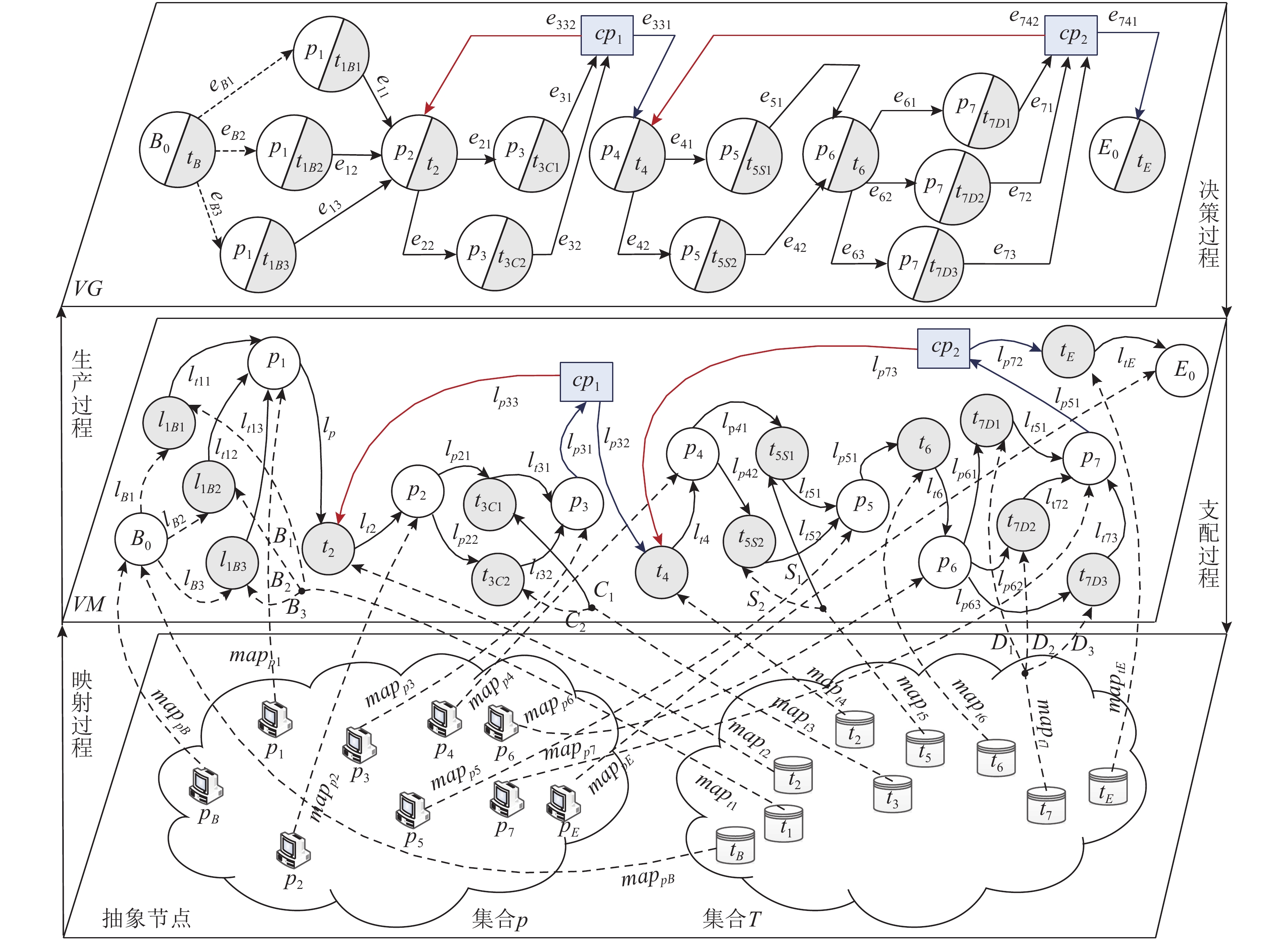
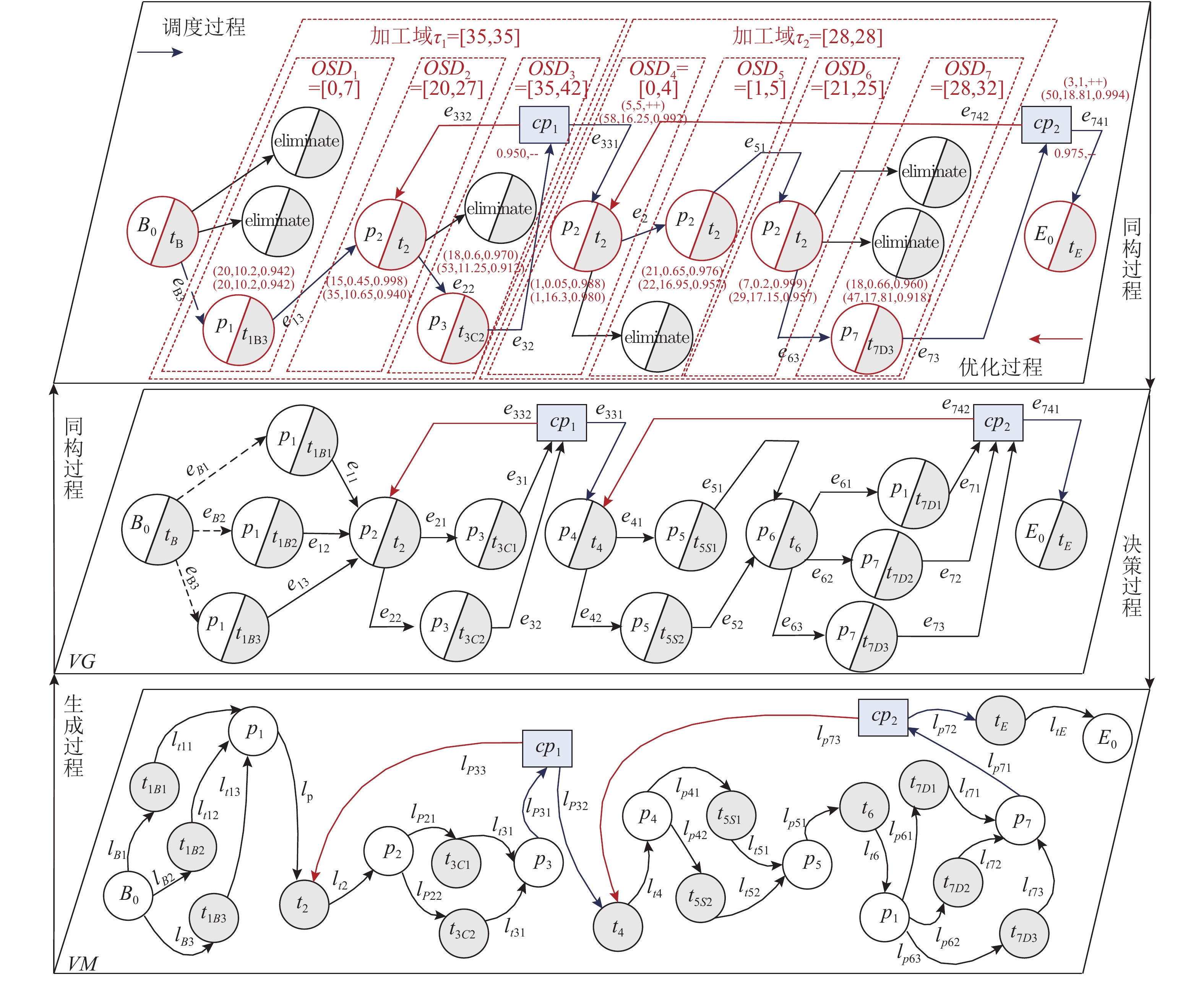
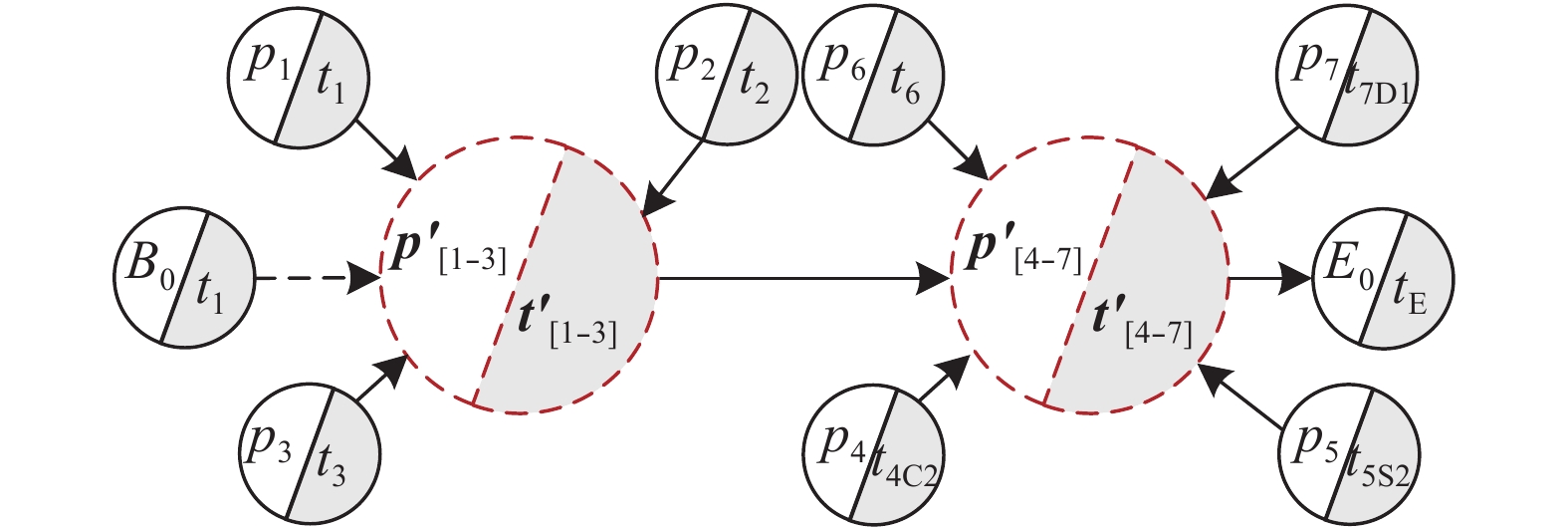
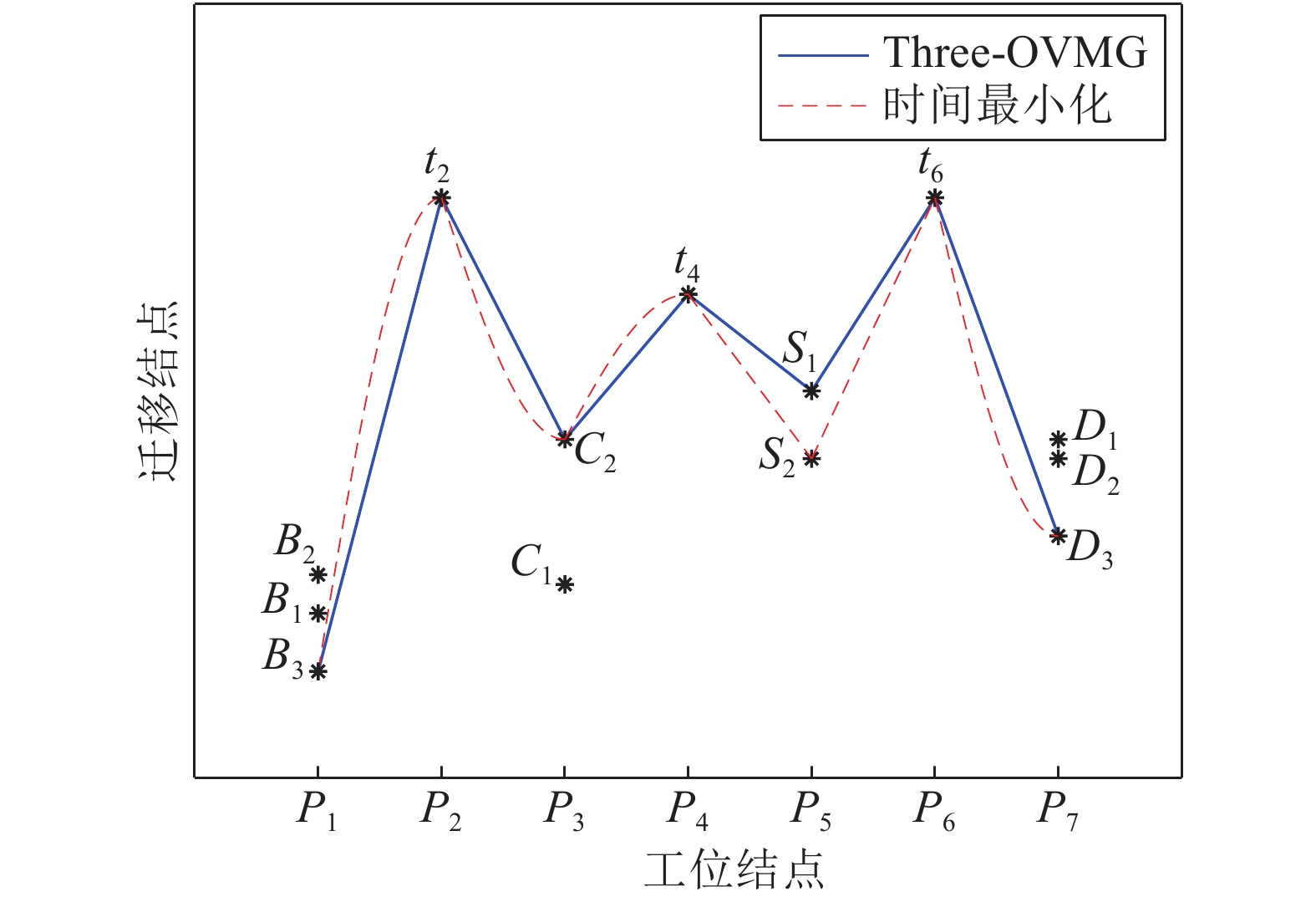
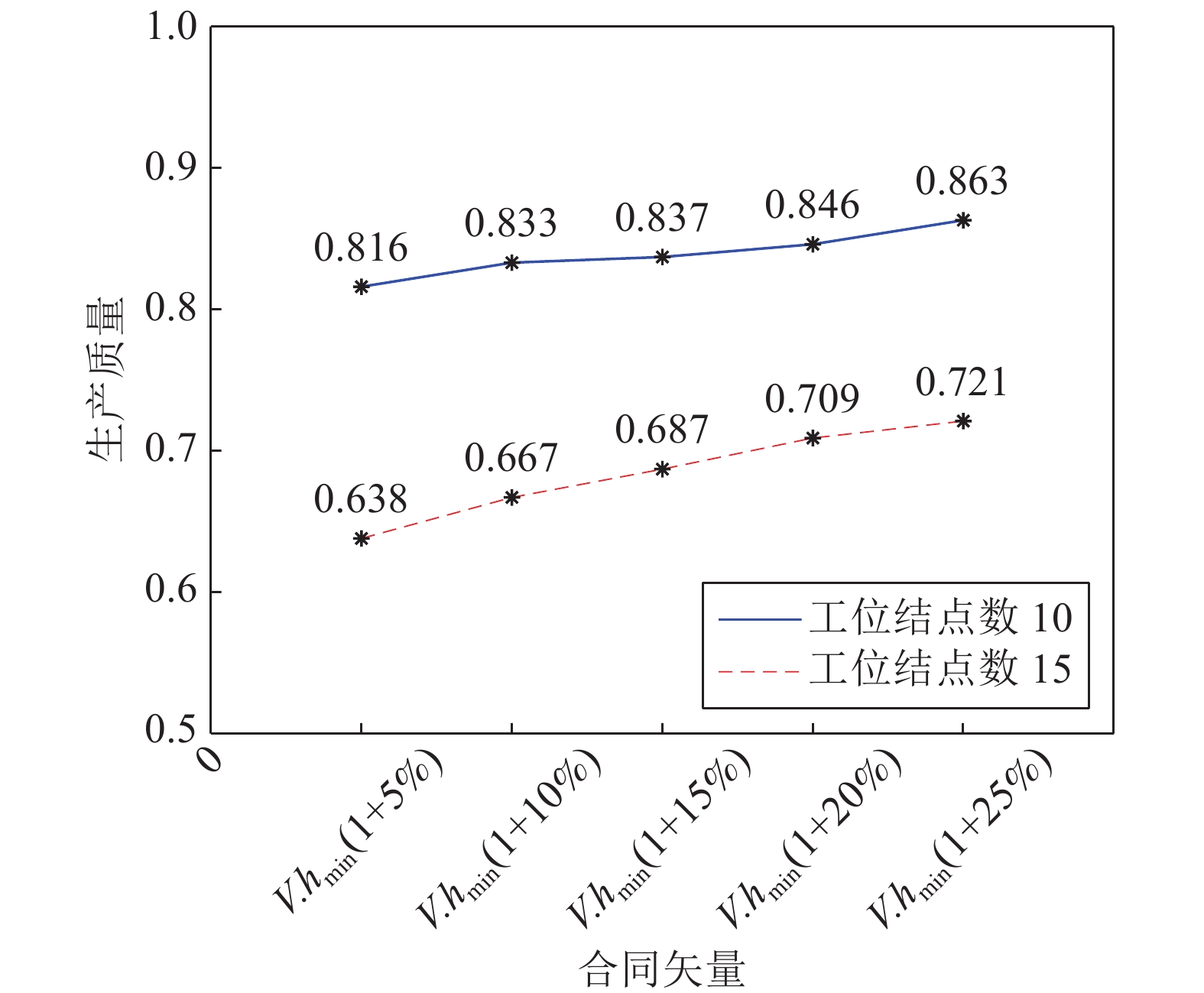
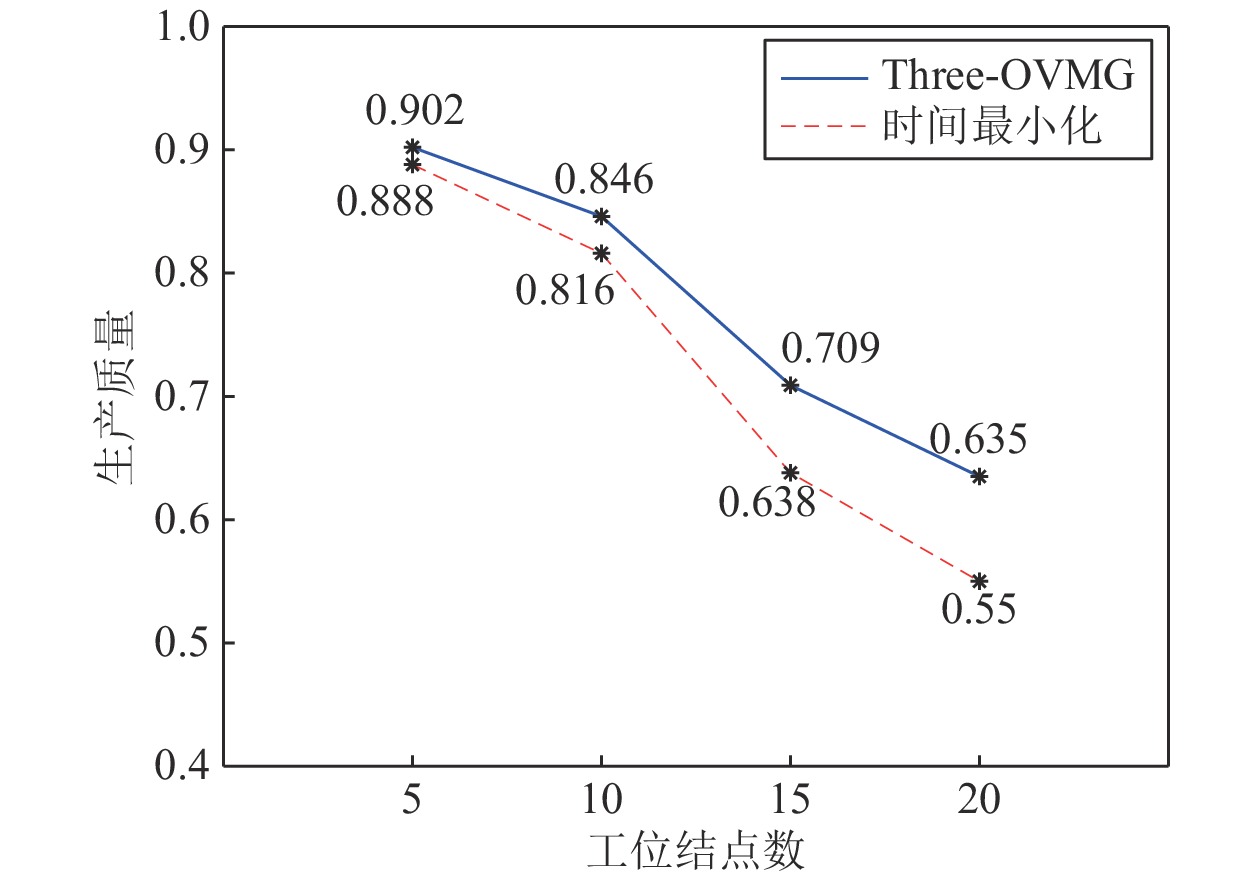
2022, 48(3): 909-916.
doi: 10.16383/j.aas.c190251
摘要:
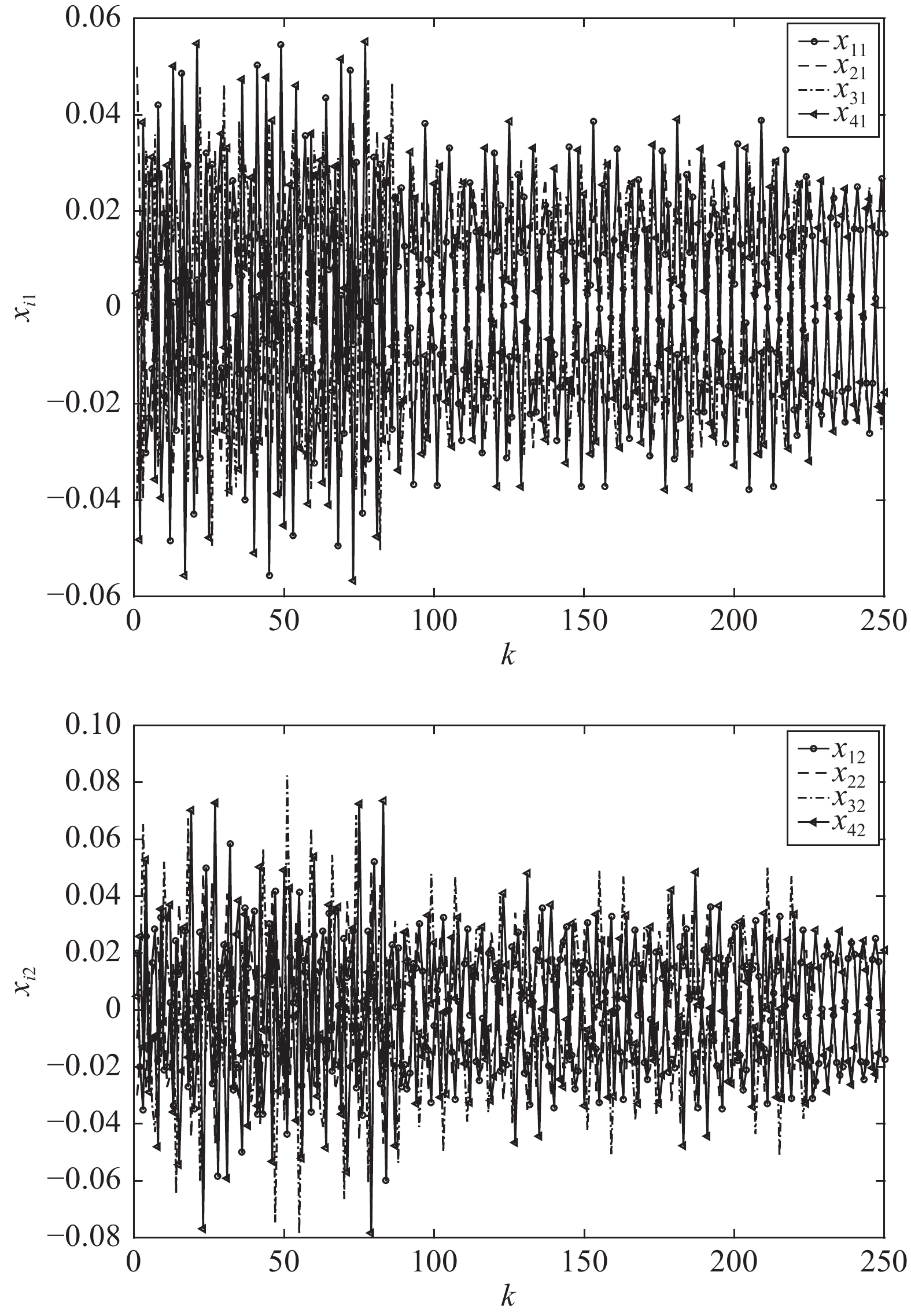
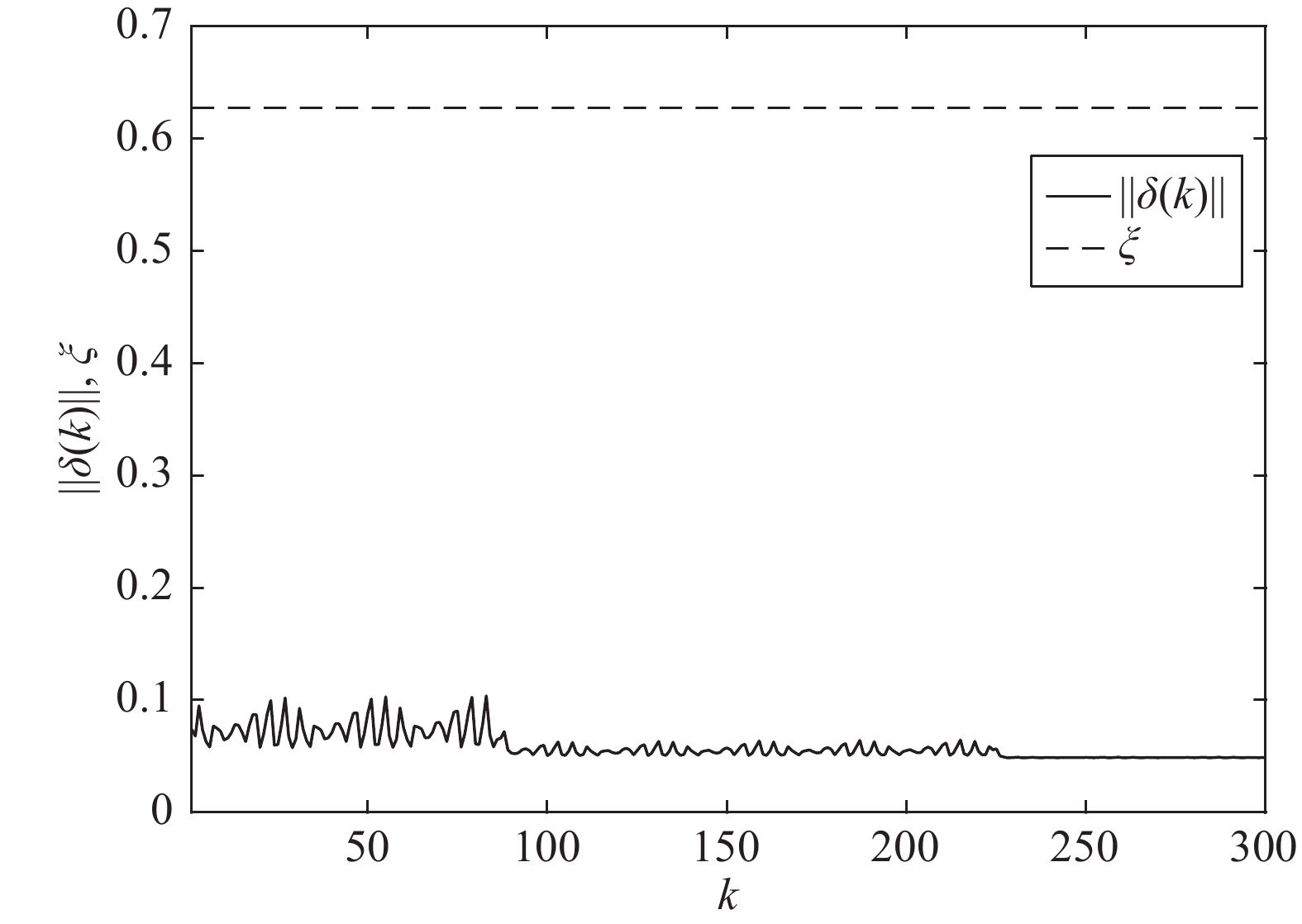
针对含有对抗关系和时变拓扑的耦合离散系统, 本文研究了这类系统有界双向同步问题(Bounded bipartite synchronization, BBS). 考虑了以下两种情形: 1)在某时刻所有个体不能划分为两个敌对阵营; 2)尽管在每一个时刻所有个体都可以被划分为两个敌对阵营, 但每个阵营中的成员随着时间的推移而改变. 对于以上两种情形, 耦合系统不能达到双向同步, 可以在一定条件下达到有界双向同步. 本文得到了使耦合离散系统达到有界双向同步的一些充分条件, 并通过一个数值例子验证了所得...
针对含有对抗关系和时变拓扑的耦合离散系统, 本文研究了这类系统有界双向同步问题(Bounded bipartite synchronization, BBS). 考虑了以下两种情形: 1)在某时刻所有个体不能划分为两个敌对阵营; 2)尽管在每一个时刻所有个体都可以被划分为两个敌对阵营, 但每个阵营中的成员随着时间的推移而改变. 对于以上两种情形, 耦合系统不能达到双向同步, 可以在一定条件下达到有界双向同步. 本文得到了使耦合离散系统达到有界双向同步的一些充分条件, 并通过一个数值例子验证了所得...
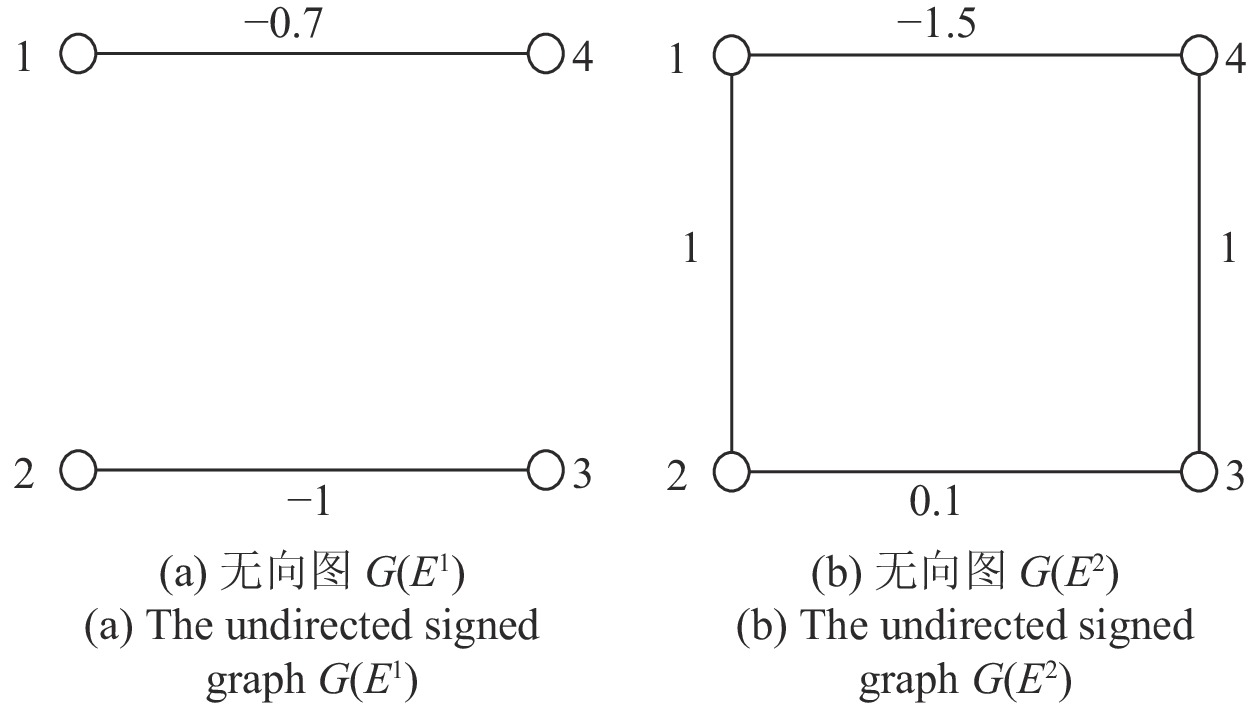
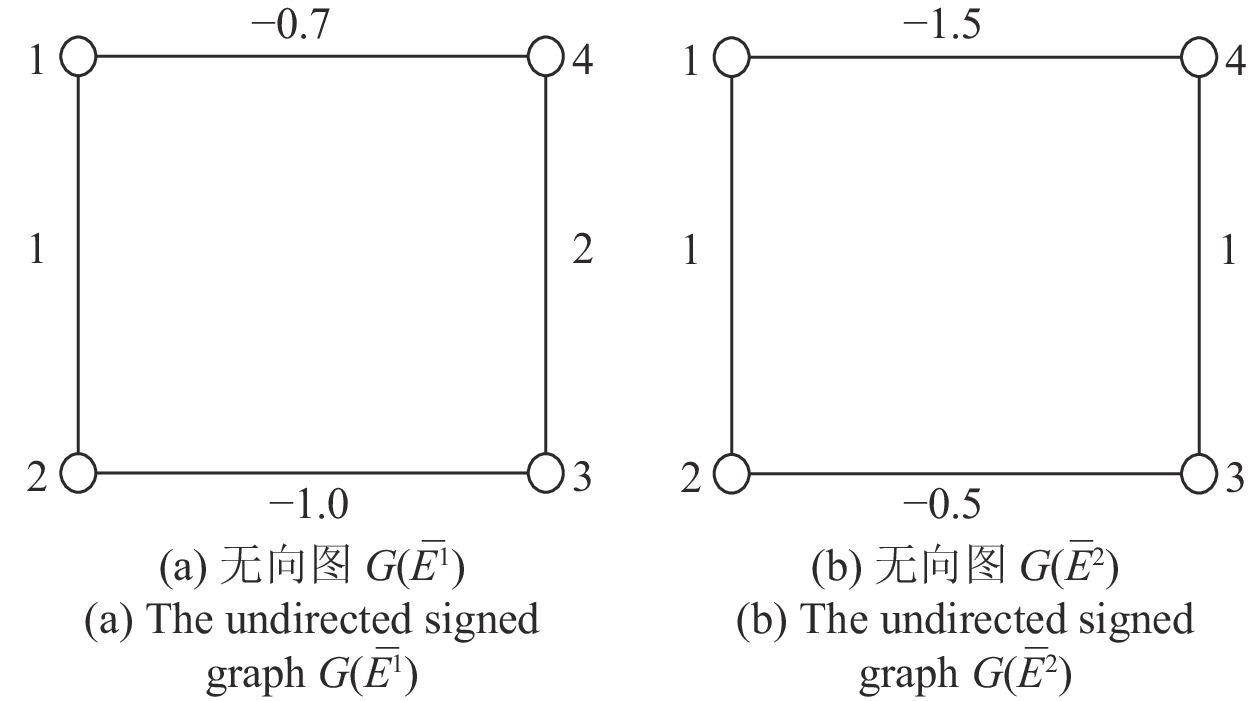

2022, 48(3): 917-925.
doi: 10.16383/j.aas.c190357
摘要:
情感作为人脑的高级功能, 对人们的个性特征和心理健康有很大的影响, 利用网上公开的脑电情感数据库(DEAP (Database for emotion analysis using physiological signals)数据库), 根据心理效价和激励唤醒度等级进行情感划分, 对压力和平静等5种情感进行研究分析. 针对脑电信号时空特征结合的特点, 把深度学习中的卷积神经网络(Convolutional neural network, CNN)和长短期记忆网络(Long short term ...
情感作为人脑的高级功能, 对人们的个性特征和心理健康有很大的影响, 利用网上公开的脑电情感数据库(DEAP (Database for emotion analysis using physiological signals)数据库), 根据心理效价和激励唤醒度等级进行情感划分, 对压力和平静等5种情感进行研究分析. 针对脑电信号时空特征结合的特点, 把深度学习中的卷积神经网络(Convolutional neural network, CNN)和长短期记忆网络(Long short term ...



2022, 48(3): 926-934.
doi: 10.16383/j.aas.c190561
摘要:
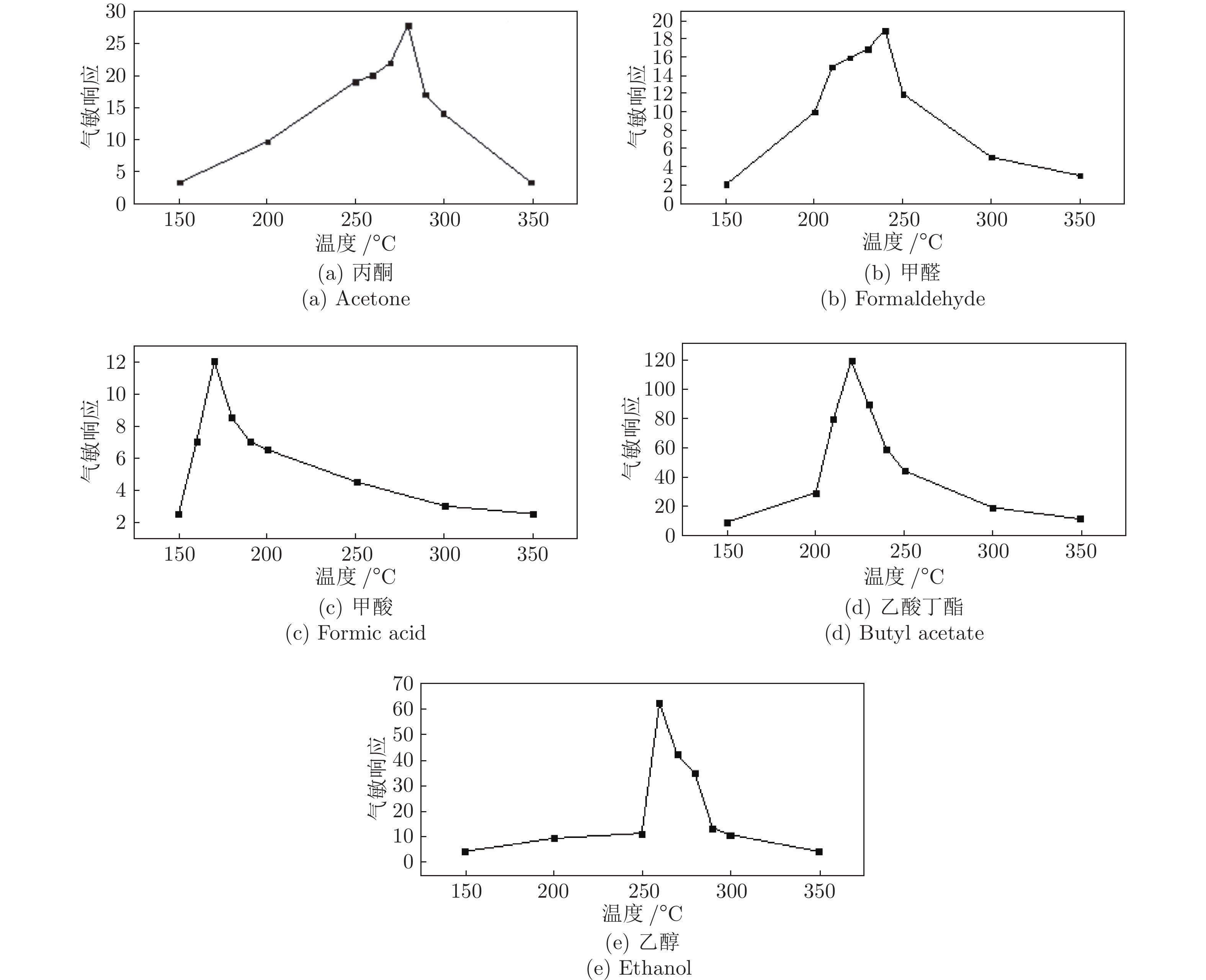
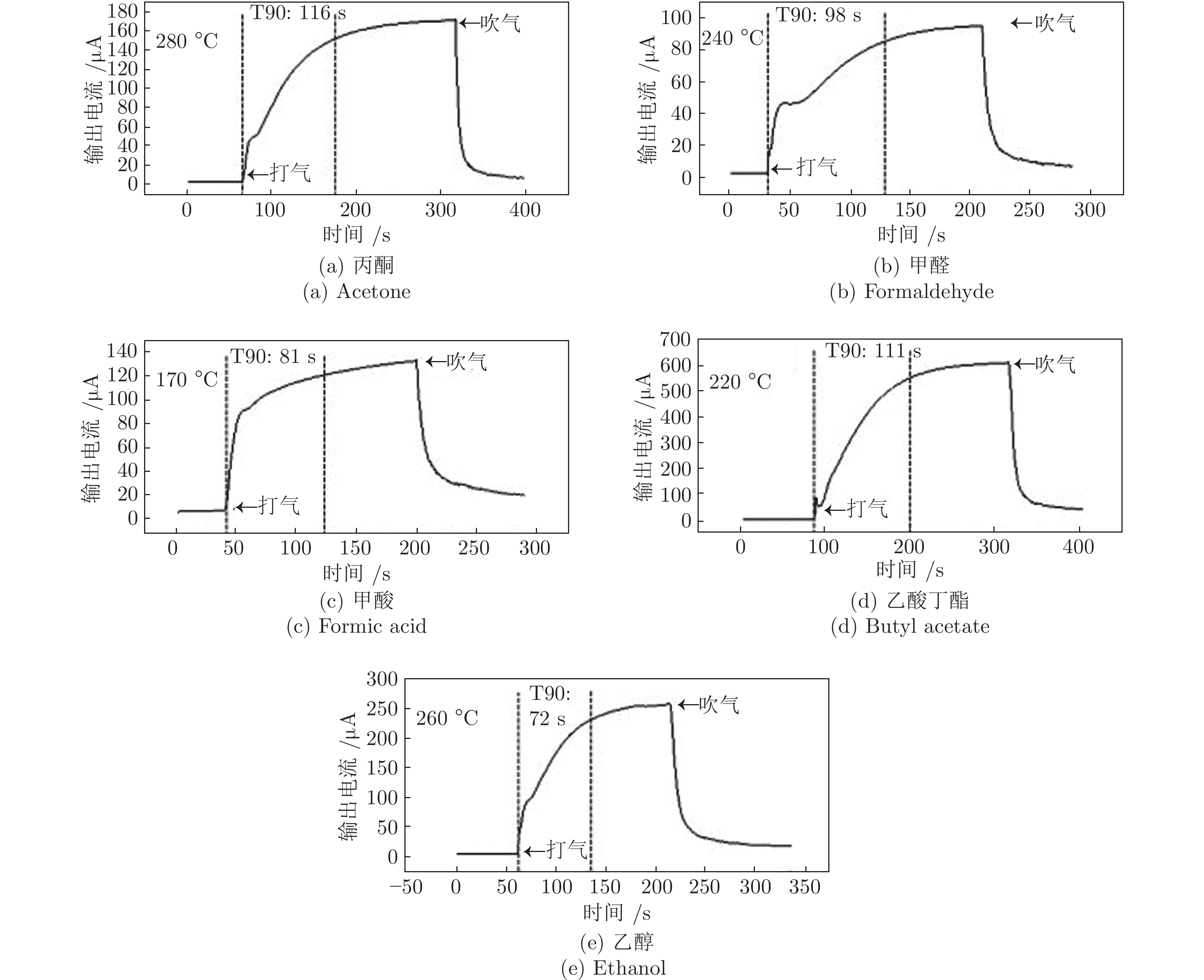
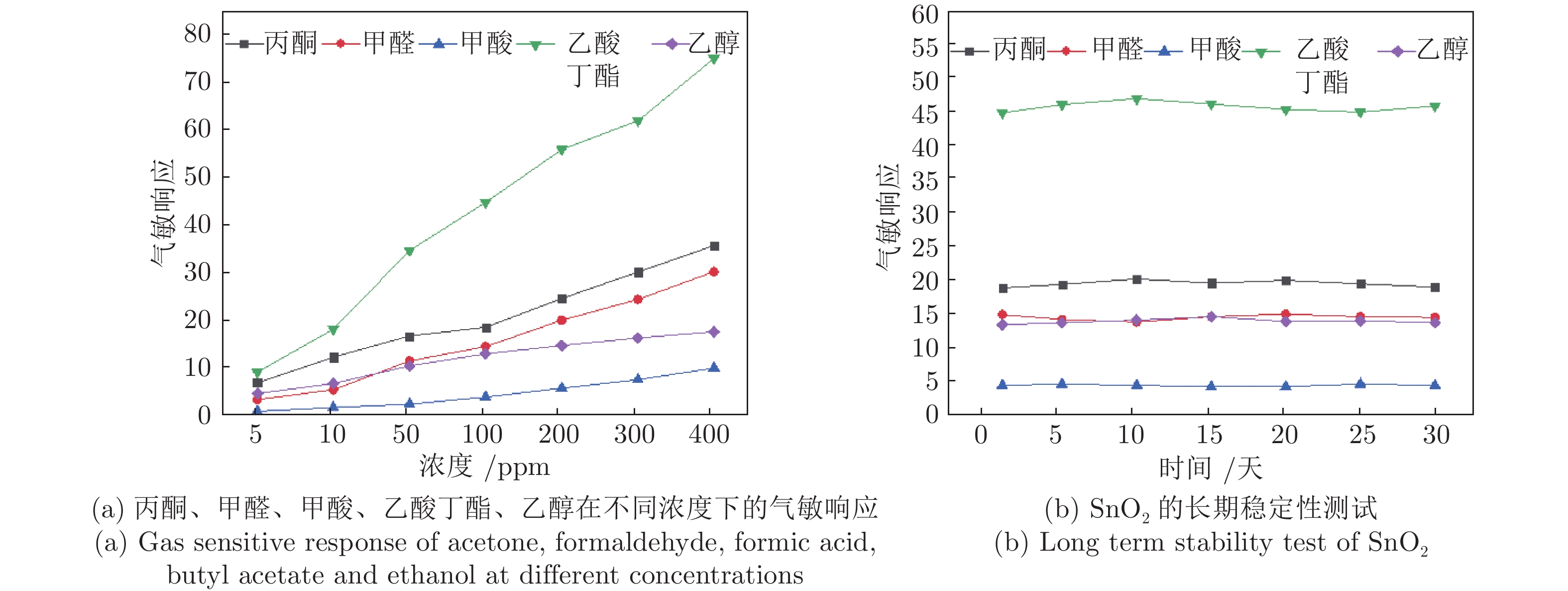
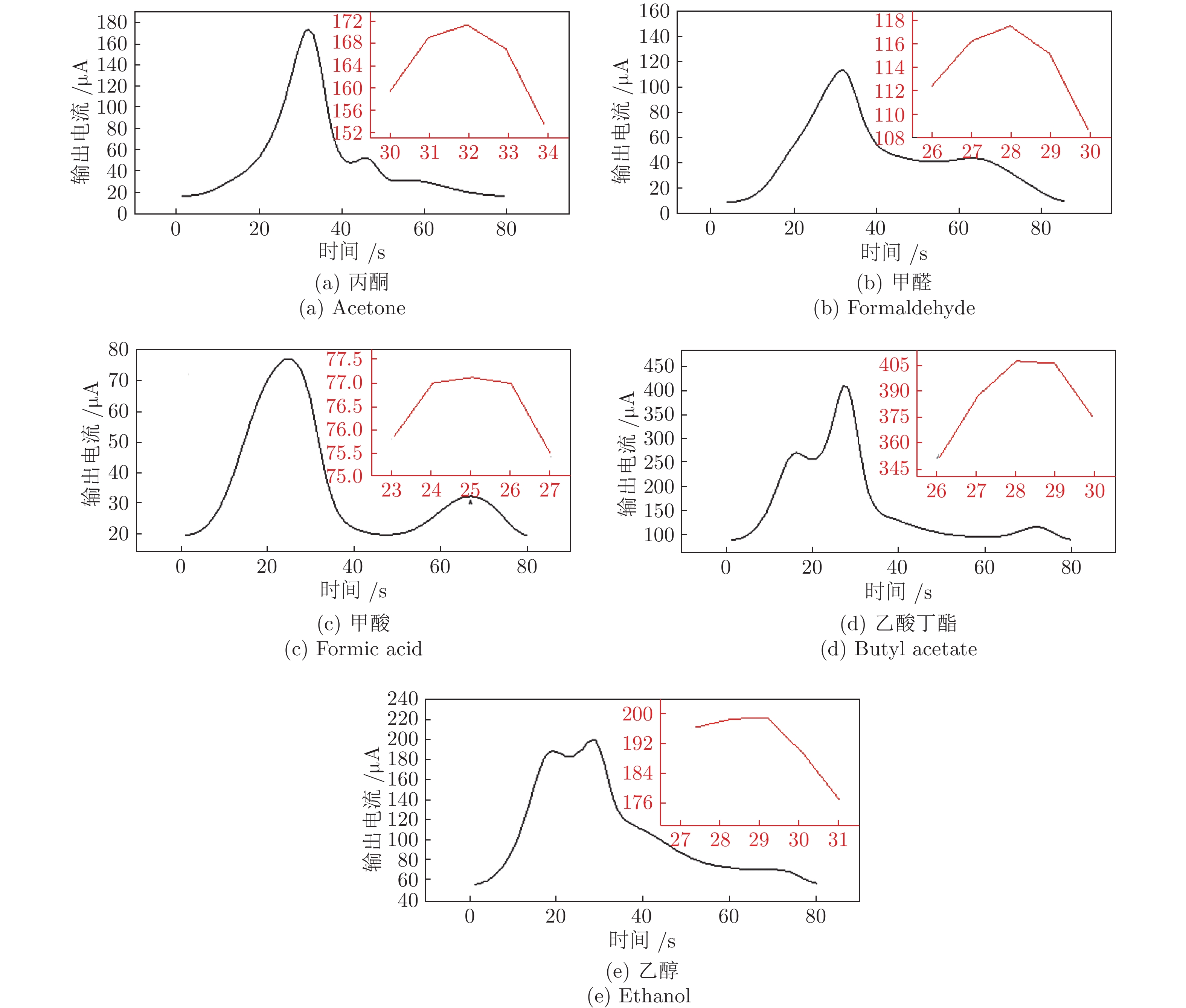
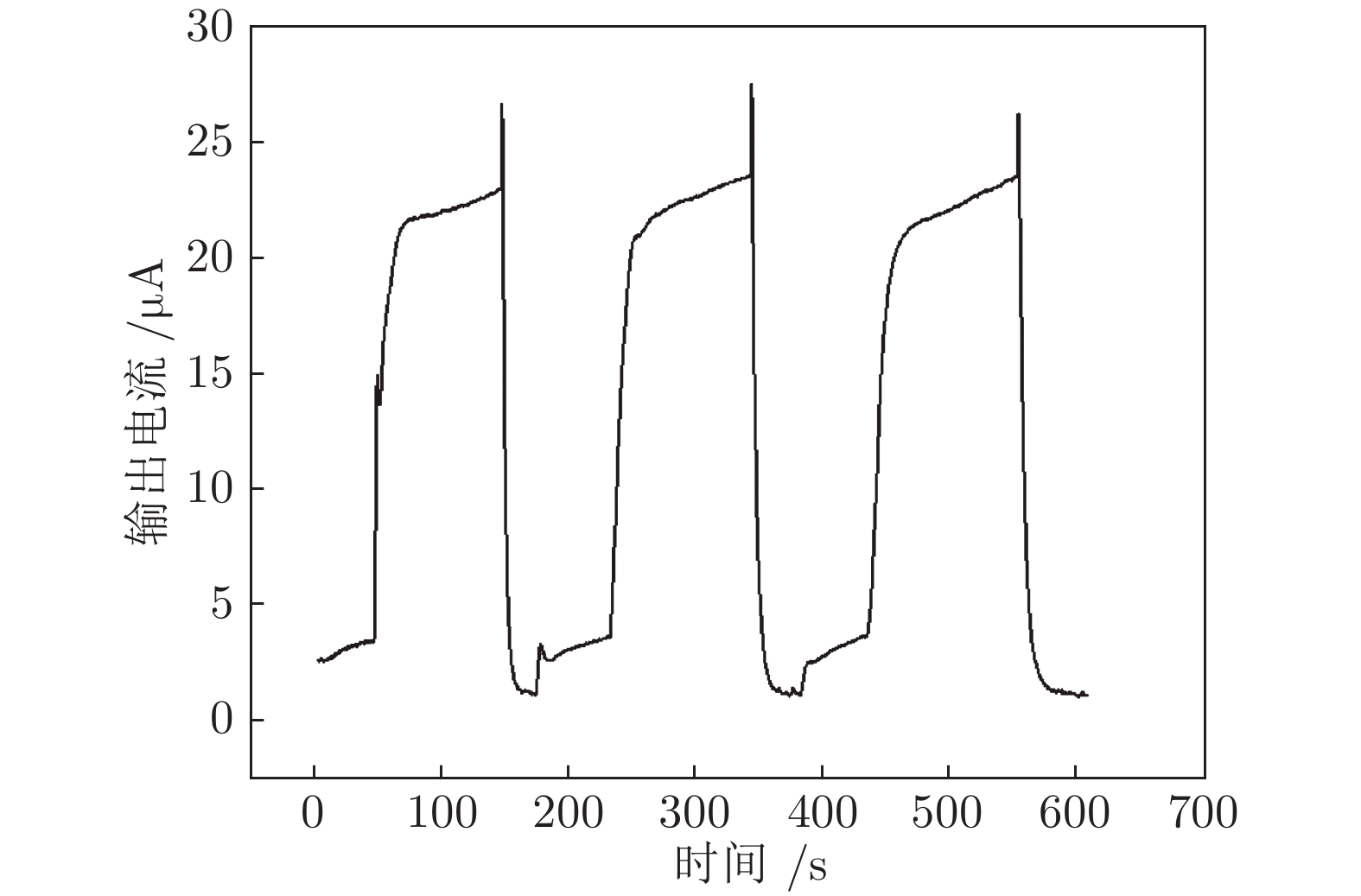
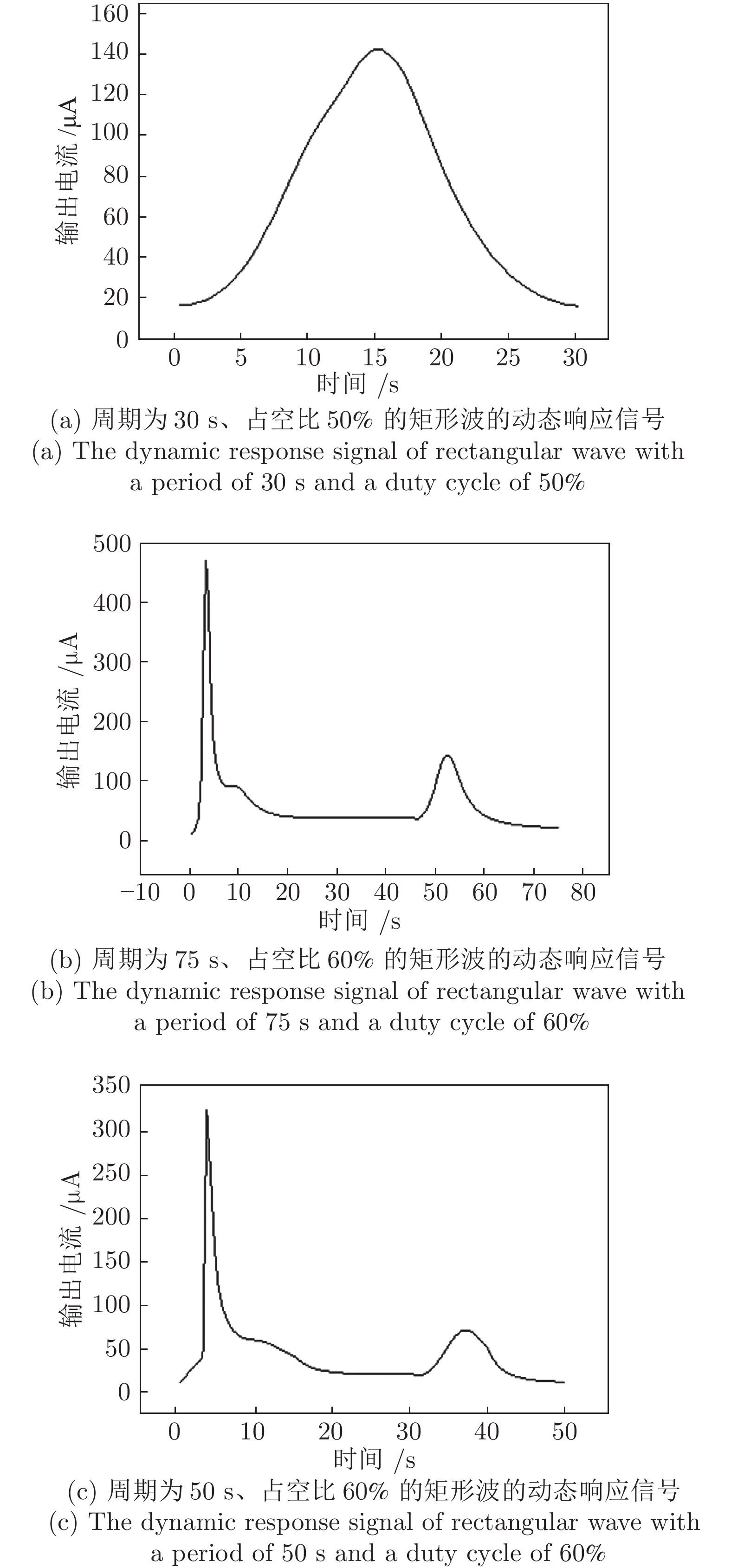
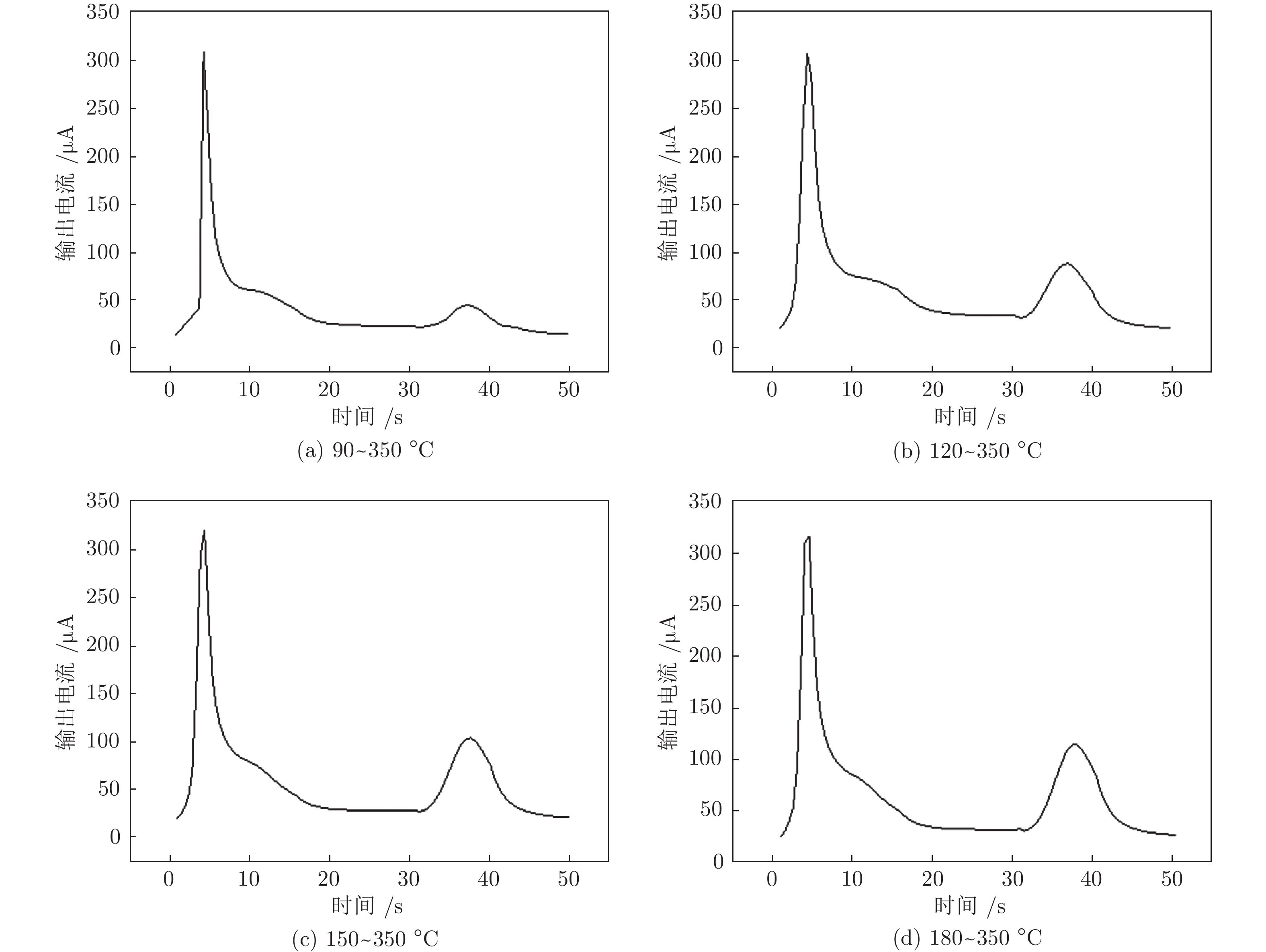
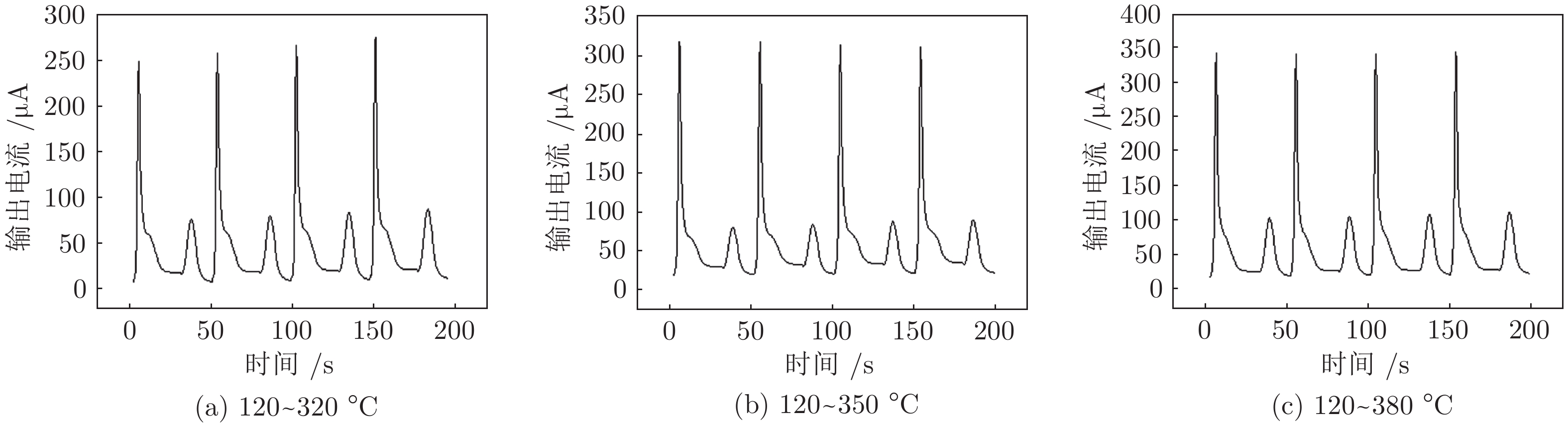
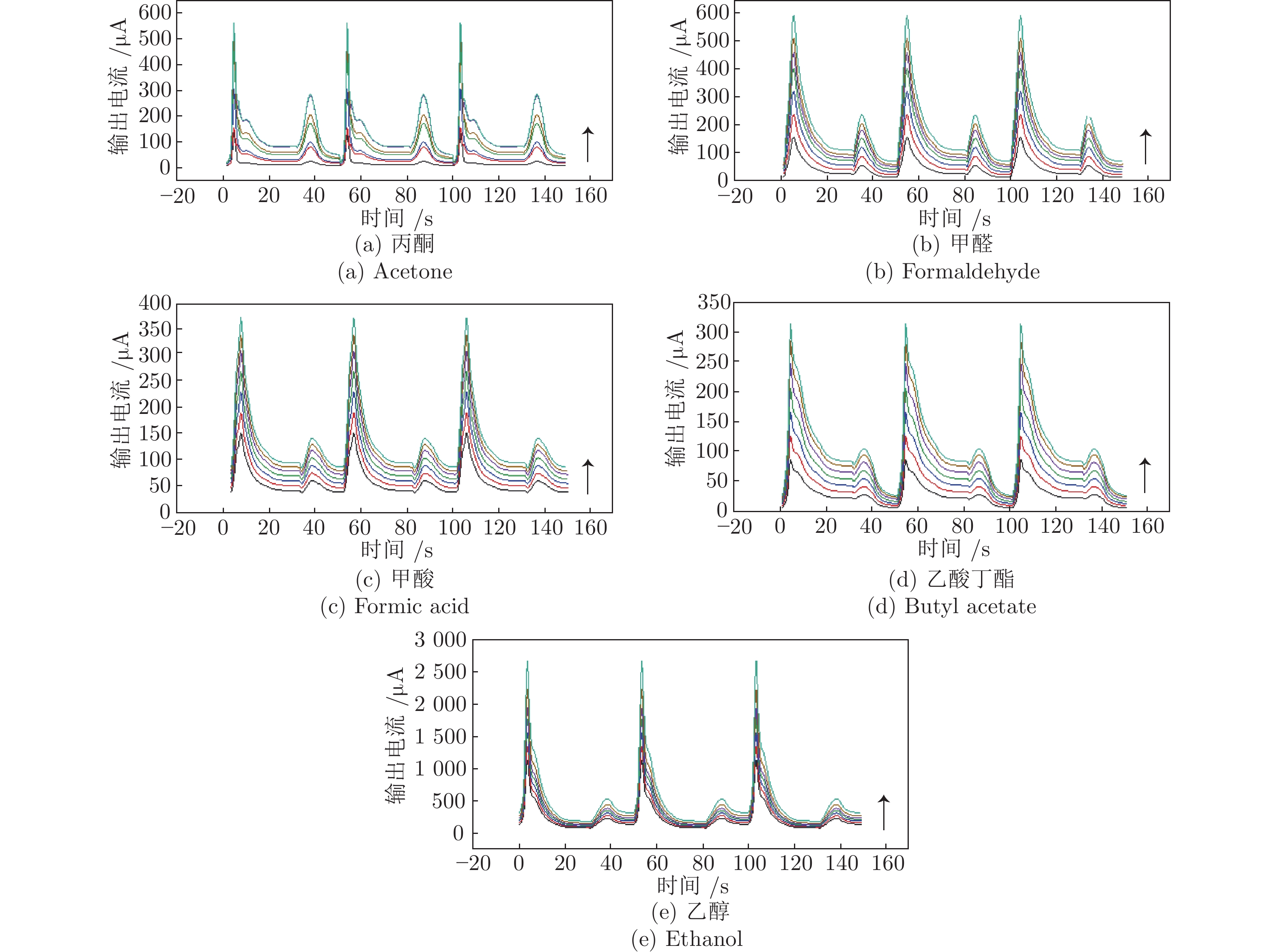
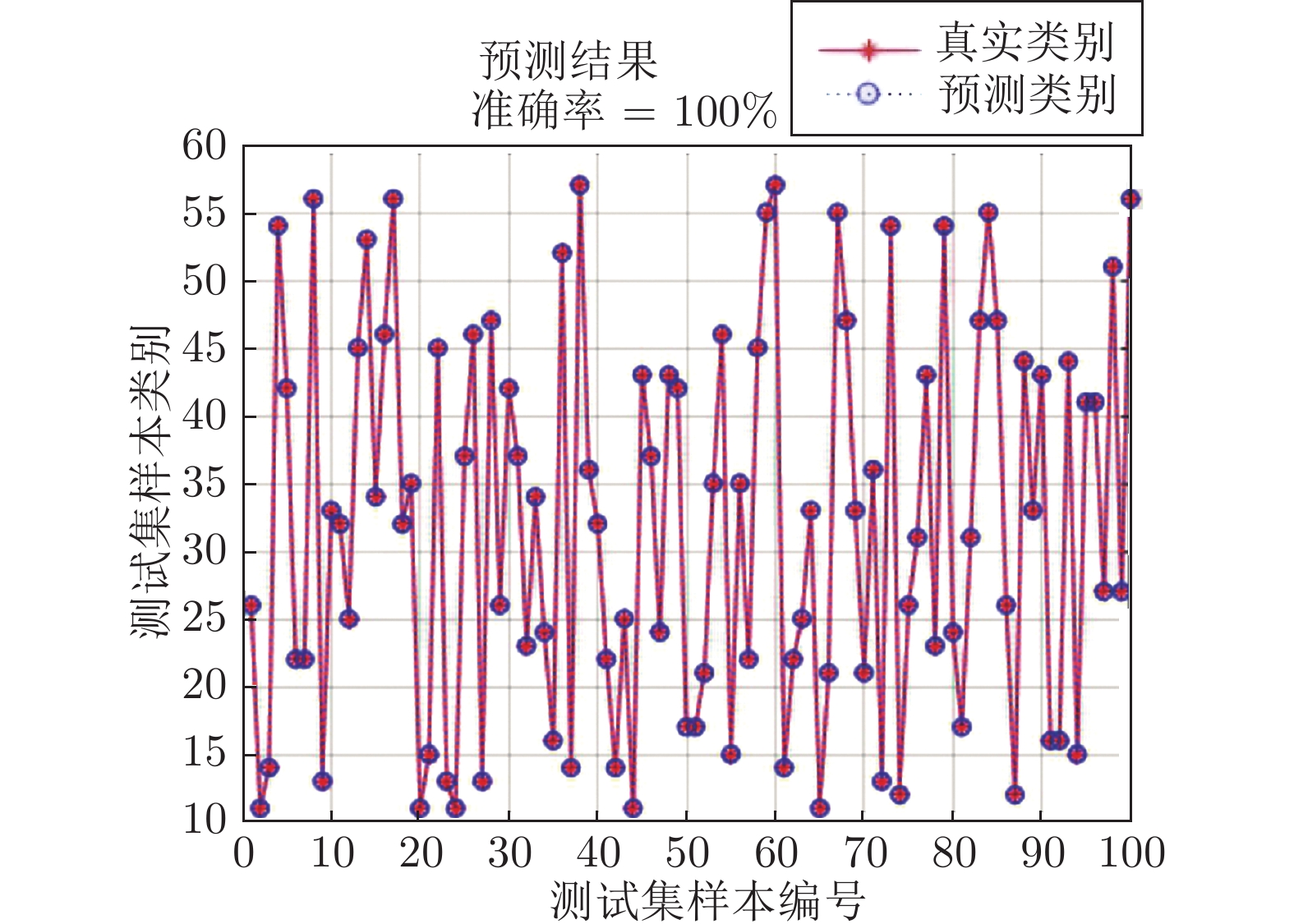
温度调制的动态测试是解决金属氧化物传感器选择性差的一种常用方法, 但至今尚未有明确的方法控制动态响应信号的波形以达到预期期望. 本文首先从静态测试的角度出发, 描述了静态性能指标与动态响应信号的对应关系, 提出了适合于动态测试的半导体传感器的选择方法. 然后以矩形波为例, 通过对其周期、占空比、工作温度范围的调整, 在不降低动态响应信号品质的前提下, 缩短在实际应用中的响应时间和功耗. 最后, 利用支持向量机算法验证了动态响应信号的品质, 在不同种类不同浓度的气体中, 识别率高达100%.
温度调制的动态测试是解决金属氧化物传感器选择性差的一种常用方法, 但至今尚未有明确的方法控制动态响应信号的波形以达到预期期望. 本文首先从静态测试的角度出发, 描述了静态性能指标与动态响应信号的对应关系, 提出了适合于动态测试的半导体传感器的选择方法. 然后以矩形波为例, 通过对其周期、占空比、工作温度范围的调整, 在不降低动态响应信号品质的前提下, 缩短在实际应用中的响应时间和功耗. 最后, 利用支持向量机算法验证了动态响应信号的品质, 在不同种类不同浓度的气体中, 识别率高达100%.