

-
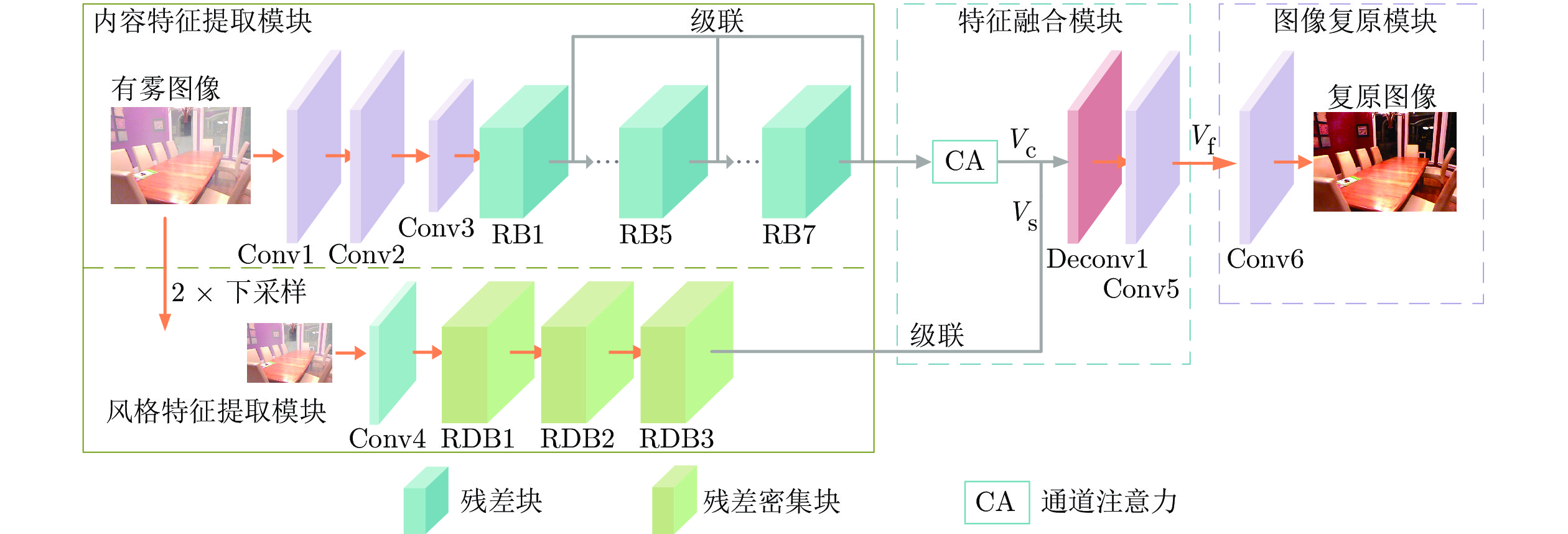
摘要: 基于深度学习的方法在去雾领域已经取得了很大进展, 但仍然存在去雾不彻底和颜色失真等问题. 针对这些问题, 本文提出一种基于内容特征和风格特征相融合的单幅图像去雾网络. 所提网络包括特征提取、特征融合和图像复原三个子网络, 其中特征提取网络包括内容特征提取模块和风格特征提取模块, 分别用于学习图像内容和图像风格以实现去雾的同时可较好地保持原始图像的色彩特征. 在特征融合子网络中, 引入注意力机制对内容特征提取模块输出的特征图进行通道加权实现对图像主要特征的学习, 并将加权后的内容特征图与风格特征图通过卷积操作相融合. 最后, 图像复原模块对融合后的特征图进行非线性映射得到去雾图像. 与已有方法相比, 所提网络对合成图像和真实图像均可取得理想的去雾结果, 同时可有效避免去雾后的颜色失真问题.Abstract: Although recent research has shown the potential of using deep learning to accomplish single image dehazing, existing methods still have some problems, such as poor visibility and color distortion. To overcome these shortcomings, we present a content feature and style feature fusion network for single image dehazing. The dehazing network consists of three parts: Feature extraction sub-network, feature fusion sub-network and image restoration sub-network. The feature extraction sub-network consists of a content feature extraction module and a style feature extraction module, which can learn image content and image style respectively to achieve pleasing dehazing results and maintain original color characteristics simultaneously. In the feature fusion sub-network, the channel-wise attention mechanism is adopted to weight the feature maps generated from the content feature extraction module in order to learn the most important features of the image, and then the weighted content feature map and style feature map are fused by convolution operation. Finally, a non-linear mapping is performed to recover the dehazed image. Compared with the existing approaches, the proposed network can obtain superior results on synthetic and real images, and can avoid the color distortion effectively.
-

图 5 合成有雾图的实验结果(MSD) ((a) 有雾图; (b) DCP; (c) DehazeNet; (d) MSCNN; (e) AOD-Net; (f) DCPDN; (g) EPDN; (h) FFA-Net; (i) Y-Net; (j)本文方法; (k) 清晰图像)
Fig. 5 Experimental results of the synthetic hazy images (MSD) ((a) Hazy images; (b) DCP; (c) DehazeNet; (d) MSCNN; (e) AOD-Net; (f) DCPDN; (g) EPDN; (h) FFA-Net; (i) Y-Net; (j) Proposed; (k) Clear images)

图 7 真实场景有雾图的实验结果 ((a) 有雾图; (b) DCP; (c) DehazeNet; (d) MSCNN; (e) AOD-Net; (f) DCPDN; (g) EPDN; (h) FFA-Net; (i) Y-Net; (j)本文方法)
Fig. 7 Experimental results of real outdoor hazy images ((a) Hazy images; (b) DCP; (c) DehazeNet; (d) MSCNN; (e) AOD-Net; (f) DCPDN; (g) EPDN; (h) FFA-Net; (i) Y-Net; (j) Proposed)

图 4 合成有雾图的实验结果(SOTS) ((a) 有雾图; (b) DCP; (c) DehazeNet; (d) MSCNN; (e) AOD-Net; (f) DCPDN; (g) EPDN; (h) FFA-Net; (i) Y-Net; (j)本文方法; (k) 清晰图像)
Fig. 4 Experimental results of the synthetic hazy images (SOTS) ((a) Hazy images; (b) DCP; (c) DehazeNet; (d) MSCNN; (e) AOD-Net; (f) DCPDN; (g) EPDN; (h) FFA-Net; (i) Y-Net; (j) Proposed; (k) Clear images)

图 6 去雾结果图及其对应的特征图 ((a) 有雾图; (b) 去雾图像; (c) 内容特征图(RB1_index 59); (d)内容特征图(RB7_index 13); (e) 风格特征图(RDB3_index 10); (f) 融合后的特征图(index 53))
Fig. 6 Dehazed results and corresponding feature maps ((a) Hazy image; (b) Dehazed image; (c) Content feature map (RB1_index 59); (d) Content feature map (RB7_index 13); (e) Style feature map (RDB3_index 10); (f) Fused feature map (index 53))

图 8 消融实验结果比较 ((a) 有雾图; (b) CF; (c) WCF; (d) WC-SF; (e) SF-WCF; (f) 清晰图像)
Fig. 8 Comparison of ablation experiments ((a) Hazy image; (b) CF; (c) WCF; (d) WC-SF; (e) SF-WCF; (f) Clear image)
表 1 在合成数据集上PSNR和SSIM结果
Table 1 Comparison of PSNR and SSIM tested on synthetic hazy images
方法 室内图像 室外图像 PSNR (dB) SSIM PSNR (dB) SSIM DCP[5] 16.62 0.8179 19.13 0.8148 DehazeNet[9] 21.14 0.8472 22.46 0.8514 MSCNN[10] 17.57 0.8102 22.06 0.9078 AOD-Net[12] 19.06 0.8504 20.29 0.8765 DCPDN[11] 15.85 0.8175 19.93 0.8449 EPDN[15] 25.06 0.9232 22.57 0.8630 FFA-Net[16] 36.39 0.9886 33.57 0.9840 FS-Net[17] 26.61 0.9561 24.07 0.8741 Y-Net[18] 19.04 0.8465 25.02 0.9012 本文方法 31.10 0.9776 30.74 0.9774  下载: 导出CSV
下载: 导出CSV
表 2 在SOTS室内数据集上PSNR和SSIM结果比较
Table 2 Comparison of PSNR and SSIM tested on SOTS (indoor dataset)
实验项目 PSNR (dB) SSIM CF 28.57 0.9703 WCF 29.76 0.9730 WC-SF 29.85 0.9774 SF-WCF 31.10 0.9776
下载: 导出CSV
-
[1] 吴迪, 朱青松. 图像去雾的最新研究进展. 自动化学报, 2015, 41(2): 221-239.Wu Di, Zhu Qing-Song. The latest research progress of image dehazing. Acta Automatica Sinica, 2015, 41(2): 221-239. [2] Xu H T, Zhai G T, Wu X L, Yang X K. Generalized equalization model for image enhancement. IEEE Transactions on Multimedia, 2014, 16(1): 68-82. doi: 10.1109/TMM.2013.2283453 [3] Jiang B, Woodell G A, Jobson D J. Novel multi-scale retinex with color restoration on graphics processing unit. Journal of Real-Time Image Processing, 2015, 10(2): 239-253. doi: 10.1007/s11554-014-0399-9 [4] Narasimhan S G, Nayar S K. Vision and the atmosphere. International Journal of Computer Vision, 2002, 48(3): 233-254. doi: 10.1023/A:1016328200723 [5] He K M, Sun J, Tang X O. Single image haze removal using dark channel prior. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 33(12): 2341-2353. [6] Berman D, Treibitz T, Avidan S. Non-local image dehazing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 1674−1682 [7] Zhu Q S, Mai J M, Shao L. A fast single image haze removal algorithm using color attenuation prior. IEEE Transactions on Image Processing, 2015, 24(11): 3522-3533. doi: 10.1109/TIP.2015.2446191 [8] 杨燕, 陈高科, 周杰. 基于高斯权重衰减的迭代优化去雾算法. 自动化学报, 2019, 45(4): 819-828.Yang Yan, Chen Gao-Ke, Zhou Jie. Iterative optimization defogging algorithm using gaussian weight decay. Acta Automatica Sinica, 2019, 45(4): 819-828. [9] Cai B L, Xu X M, Jia K, Qing C M, Tao D C. DehazeNet: an end-to-end system for single image haze removal. IEEE Transactions on Image Processing, 2016, 25(11): 5187-5198. doi: 10.1109/TIP.2016.2598681 [10] Ren W Q, Liu S, Zhang H, Pan J S, Cao X C, Yang M H. Single image dehazing via multi-scale convolutional neural networks. In: Proceedings of the European Conference on Computer Vision. Amsterdam, Netherlands: Springer, 2016. 154−169 [11] Zhang H, Patel V M. Densely connected pyramid dehazing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 3194−3203 [12] Li B Y, Peng X L, Wang Z Y, Xu J Z, Feng D. AOD-Net: All-in-one dehazing network. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 4780−4788 [13] Ren W Q, Ma L, Zhang J W, Pan J S, Cao X C, Liu W, et al. Gated fusion network for single image dehazing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 3253−3261 [14] Li R D, Pan J S, Li Z C, Tang J H. Single image dehazing via conditional generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 8202−8211 [15] Qu Y Y, Chen Y Z, Huang J Y, Xie Y. Enhanced pix2pix dehazing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019. 8160−8168 [16] Qin X, Wang Z L, Bai Y C, Xie X D, Jia H Z. FFA-Net: Feature fusion attention network for single image dehazing. In: Proceedings of the Association for the Advance of Artificial Intelligence. Hilton Midtown, New York, USA: AAAI Press, 2020. 11908−11915 [17] Guo F, Zhao X, Tang J, Peng H, Liu L J, Zou B J, et al. Single image dehazing based on fusion strategy. Neurocomputing, 2020, 378: 9-23. doi: 10.1016/j.neucom.2019.09.094 [18] Yang H H, Yang C H H, Tsai Y C J. Y-net: Multi-scale feature aggregation network with wavelet structure similarity loss function for single image dehazing. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Barcelona, Spain: IEEE, 2020. 2628−2632 [19] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 770−778 [20] Zhang Y L, Tian Y P, Kong Y, Zhong B N, Fu Y. Residual dense network for image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 2472−2481 [21] Chen L, Zhang H W, Xiao J, Nie L Q, Shao J, Liu W, et al. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 6298−6306 [22] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3): 211-252. doi: 10.1007/s11263-015-0816-y [23] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, CA, USA: ICLR, 2015. 1−14 [24] Li B Y, Ren W Q, Fu D P, Tao D C, Feng D, Zeng W J, et al. Benchmarking single image dehazing and beyond. IEEE Transactions on Image Processing, 2019, 28(1): 492-505. doi: 10.1109/TIP.2018.2867951 [25] Scharstein D, Pal C. Learning conditional random fields for stereo. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, MN, USA: IEEE, 2007. 18−23 -

 下载:
下载:


计量
- 文章访问数: 1849
- HTML全文浏览量: 742
- PDF下载量: 323
- 被引次数: 0
