

-
摘要: 利用无人机载的热红外图像开展行人及车辆检测, 在交通监控、智能安防、防灾应急等领域中, 具有巨大的应用潜力. 热红外图像能够在夜间或者光照条件不理想的情况对场景目标清晰成像, 但也往往存在对比度低、纹理特征弱的缺点. 为此, 本文提出使用热红外图像的显著图来进行图像增强, 作为目标检测器的注意力机制, 并研究仅使用热红外图像和其显著图提高目标检测性能的方法. 此外, 针对无人机内存不足、算力有限的特点, 设计使用轻量化网络YOLOv3-MobileNetv2作为目标检测模型. 在实验中, 本文训练了YOLOv3网络作为检测的评价基准网络. 使用BASNet生成显著图, 通过通道替换和像素级加权融合两种方案将热红外图像与其对应的显著图进行融合增强, 比较了不同方案下YOLOv3-MobileNetv2模型的检测性能. 统计结果显示, 行人及车辆的平均精确度(Average precision, AP)相对于基准分别提升了6.7%和5.7%, 同时检测速度提升了60%, 模型大小降低了58%. 该算法模型为开拓无人机载热红外图像的应用领域提供了可靠的技术支撑.
-
关键词:
- 显著图 /
- 无人机 /
- 热红外图像 /
- 目标检测 /
- YOLOv3-MobileNetv2
Abstract: Using thermal images obtained from unmanned aerial vehicles (UAV) for pedestrian and vehicle detection has great potential in the fields of traffic monitoring, intelligent security, disaster prevention, and emergency response. Thermal images can clearly observe objects at night or under bad lighting conditions, but they also have the disadvantages of low contrast and weak texture features. For these reasons, this paper proposes to use the saliency map of the thermal image for image enhancement as the attention mechanism of the object detector. The technology to improve the performance of object detection using only thermal images and their saliency maps is studied. In addition, considering the computing power of UAV platforms, a lightweight network YOLOv3-MobileNetv2 was designed as the object detection model. In the paper, YOLOv3 network is trained as a detection benchmark; BASNet is used to generate saliency maps. We fuse thermal images with their corresponding saliency maps through channel replacement and pixel-level weighted fusion schemes. In our experiments, the detection performances of YOLOv3-MobileNetv2 model with different schemes are compared. The statistical results show that the average precision (AP) of pedestrians and vehicles are increased by 6.7% and 5.7% respectively, compared with the benchmark. The detection speed is increased by 60%, while the model size is reduced by 58%. This model provides reliable technical support for the application of thermal images with UAV platforms.-
Key words:
- Saliency map /
- unmanned aerial vehicles (UAV) /
- thermal image /
- object detection /
- YOLOv3-MobileNetv2
-
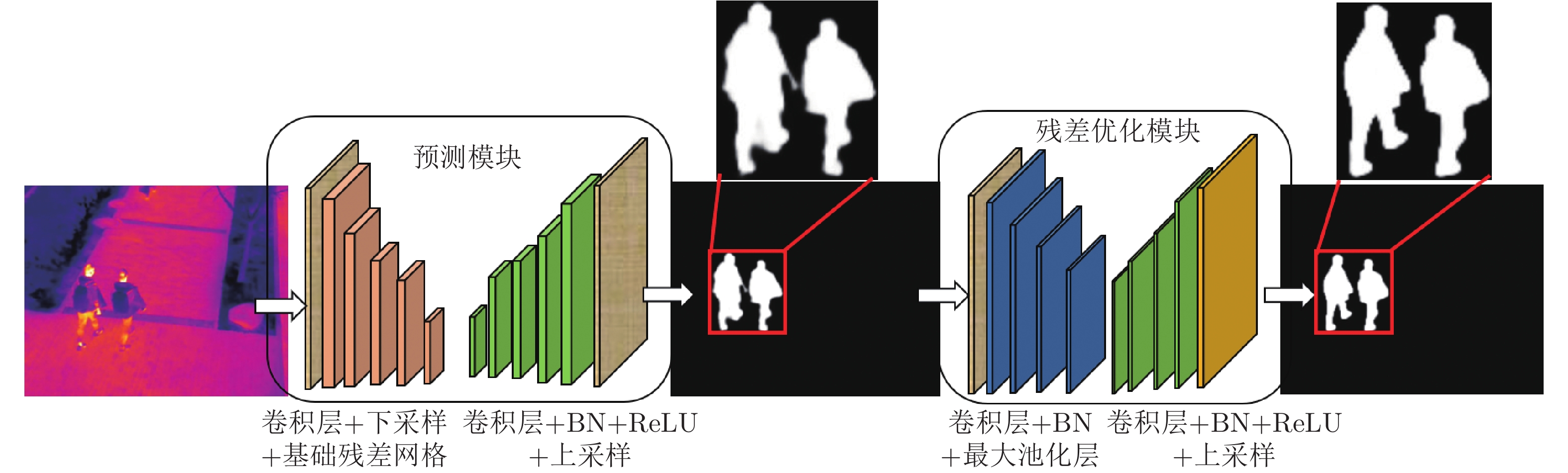
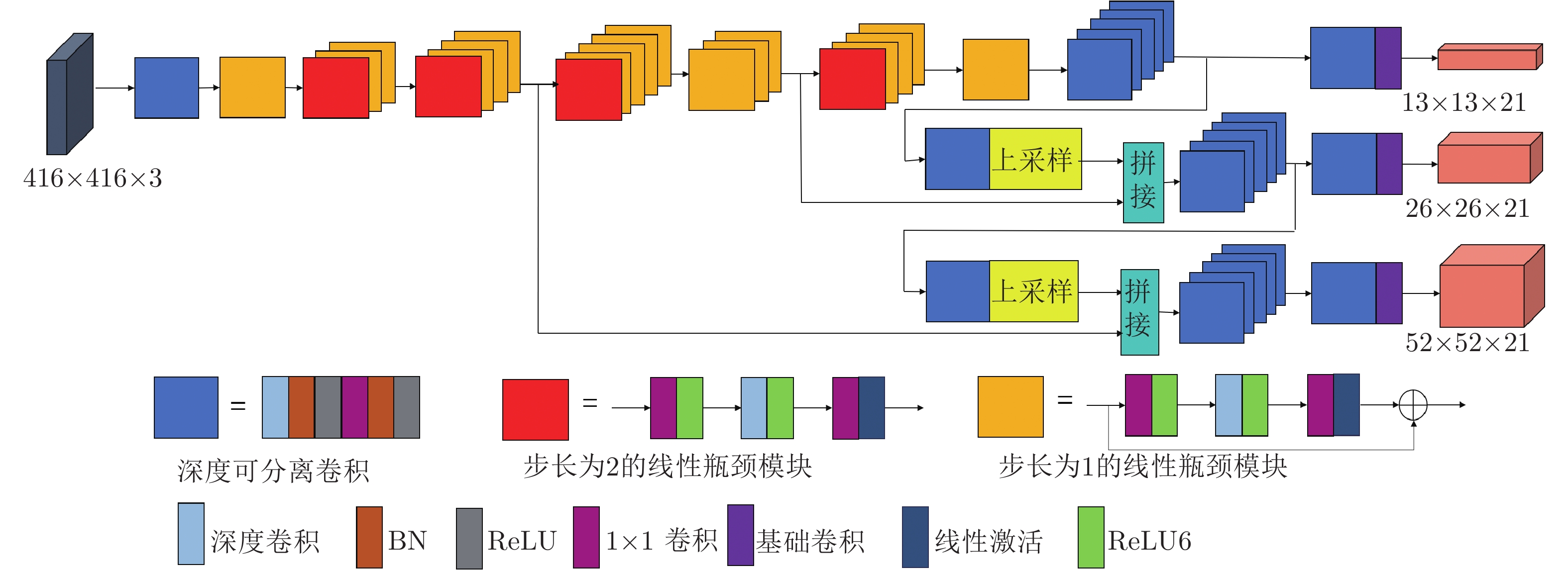
图 1 BASNet网络结构
Fig. 1 Architecture of boundary-aware salient object detection network: BASNet
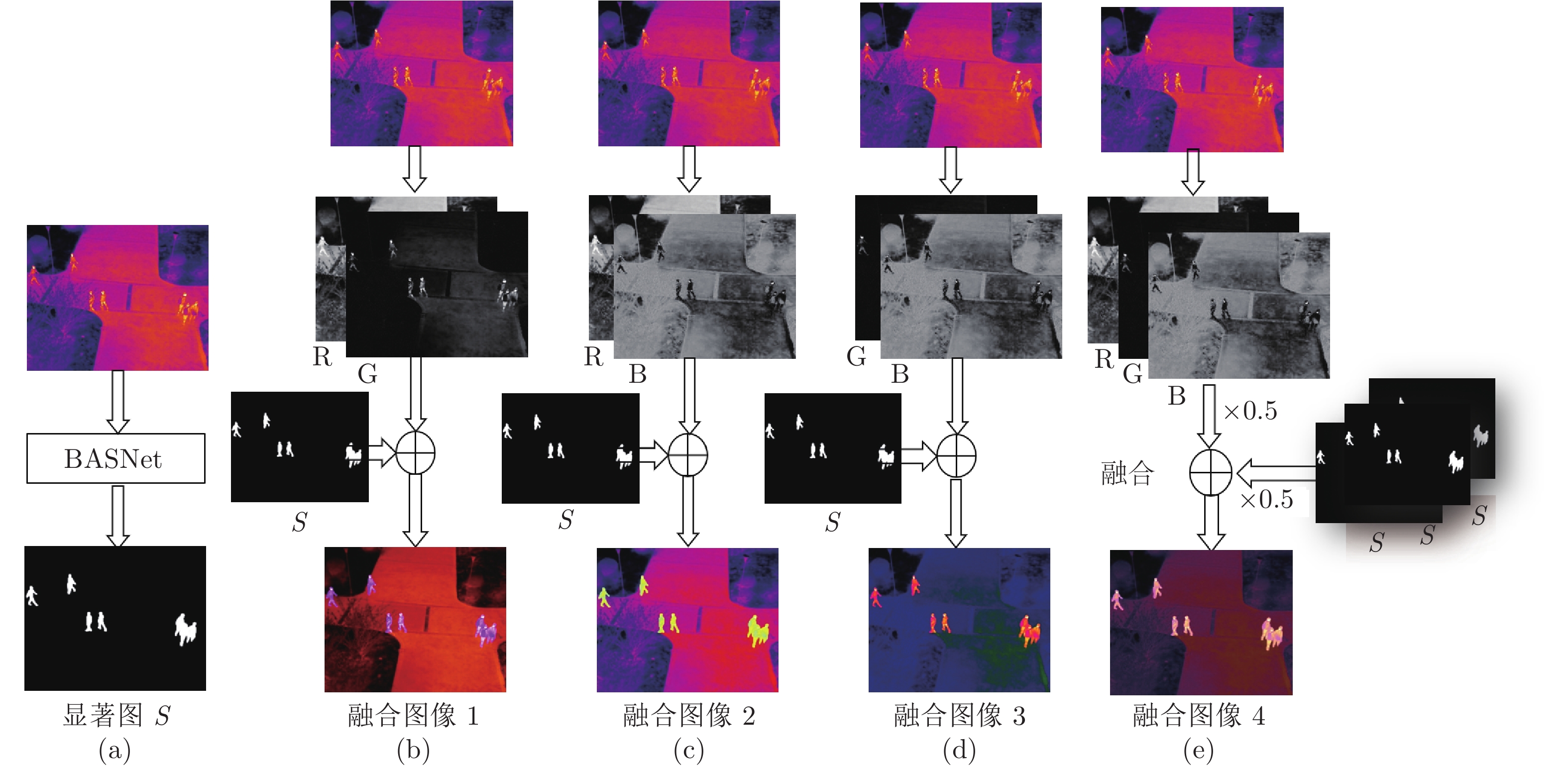
图 2 使用显著图增强热红外图像的流程
((a)使用BASNet网络生成热红外图像的显著图; (b)~(d)分别是用显著图替换热红外图像三通道中的一个通道; (e)将显著图与热红外图像在三个通道分别进行像素级别上直接融合)
Fig. 2 The fusion of the thermal image and its saliency map
((a) Using BASNet to generate the saliency map of a thermal image; (b) to (d) replacing each of three channels of the thermal image with the saliency map; (e) Fusion of the thermal image and the duplicated saliency maps at pixel-level)

图 3 测试集中使用显著图增强的热红外行人(第1行和第2行)及车辆(第3行和第4行)图像
((a)原始热红外图像; (b)显著图; (c)使用显著图替换热红外图像R通道; (d)使用显著图替换热红外图像G通道; (e)使用显著图替换热红外图像B通道; (f)热红外图像与显著图的三个通道分别进行像素级直接融合)
Fig. 3 Thermal images and generated saliency maps for pedestrian (top 2 rows) and vehicle (bottom 2 rows) images from the test set
((a) Original thermal images; (b) Saliency maps; (c) Replacing red channel of thermal images with saliency maps; (d) Replacing green channel of thermal images with saliency maps; (e) Replacing blue channel of thermal images with saliency maps; (f) Direct fusion of saliency maps and thermal images at pixel-level)

图 5 行人及车辆热红外数据集标注示例
Fig. 5 Sample annotations from pedestrian and vehicle thermal dataset
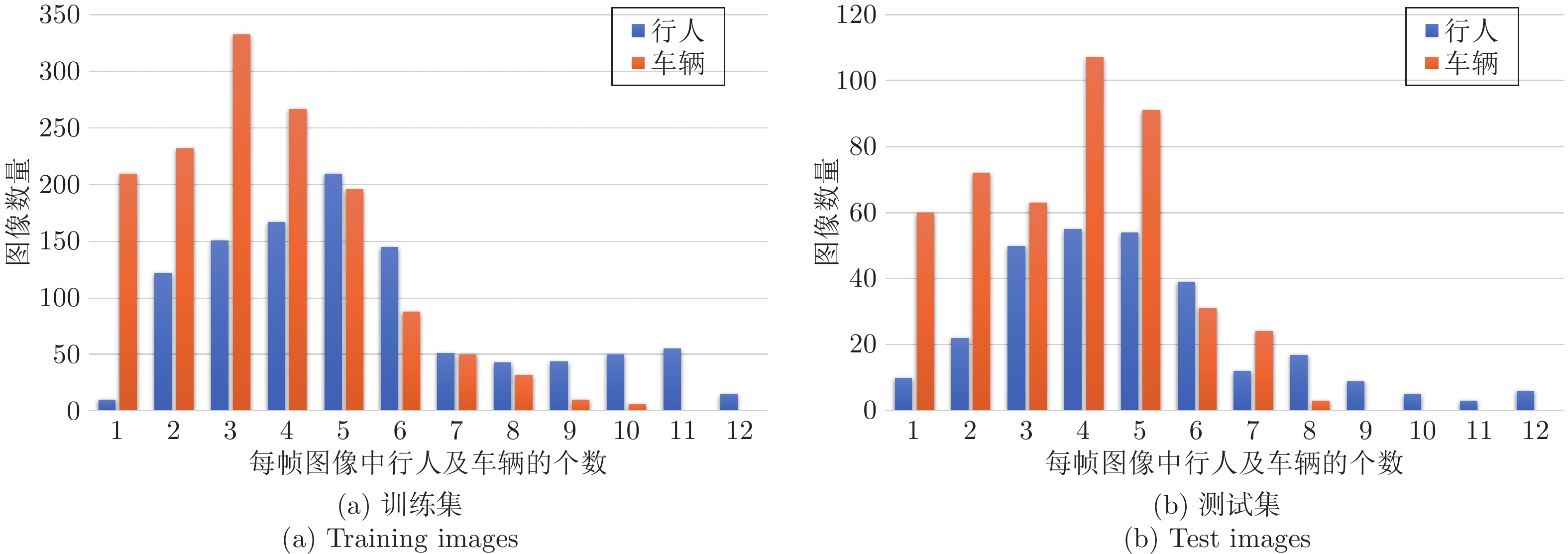
图 6 训练集和测试集中行人及车辆的分布
Fig. 6 Distribution of pedestrian and vehicle in training images and test images

图 8 行人及车辆检测示例(1 ~ 3列为行人, 4、5列为车辆)
((a)原始热红外图像+YOLOv3; (b)原始热红外图像+YOLOv3-MobileNetv2; (c)显著图+YOLOv3-MobileNetv2; (d) ~ (f)分别是使用显著图替换热红外图像R、G、B通道+YOLOv3-MobileNetv2; (g)热红外图像与显著图进行像素级直接融合+YOLOv3-MobileNetv2)
Fig. 8 Sample results from pedestrian detection on images 1 ~ 3 and vehicle detection on images 4 and 5 from methods: ((a) Thermal images + YOLOv3; (b) Thermal images + YOLOv3-MobileNetv2; (c) Saliency maps + YOLOv3 -MobileNetv2; (d) ~ (f) represent replacing one of R, G, and B channel of thermal images by saliency maps + YOLOv3 -MobileNetv2; (g) Direct fusion of saliency maps and thermal images at pixel-level + YOLOv3-MobileNetv2)
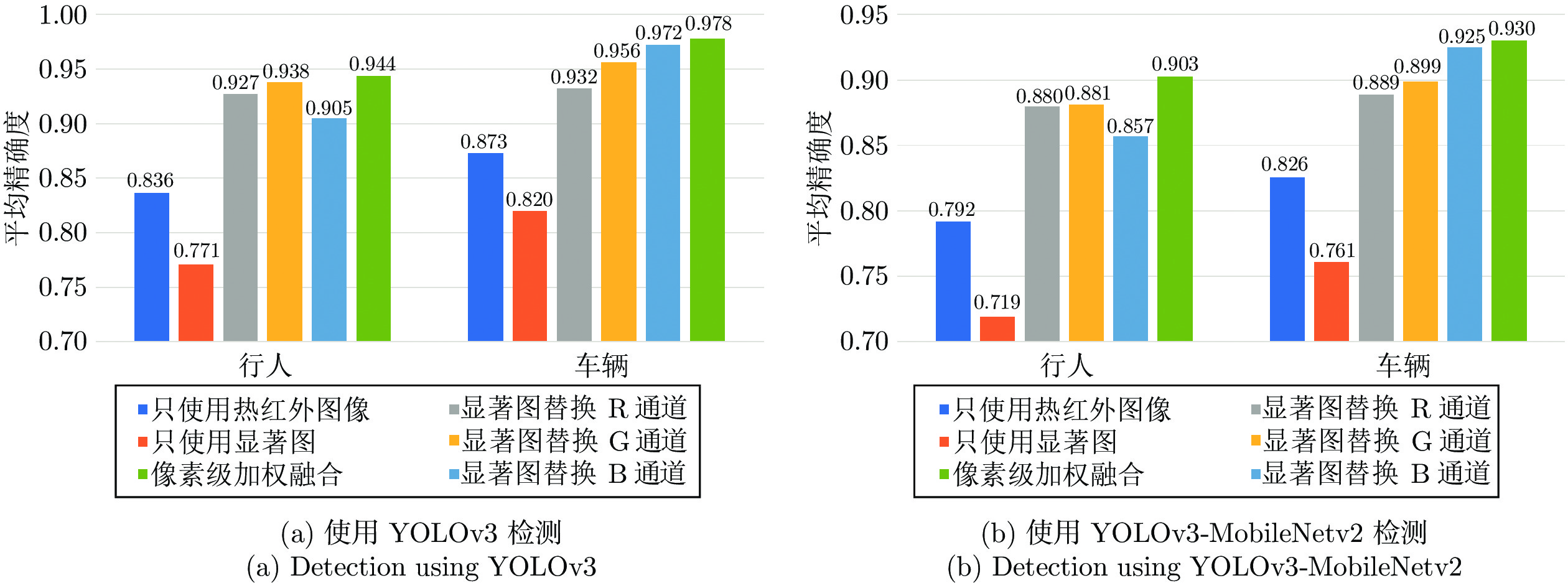
图 7 不同检测模型的平均精确度比较
Fig. 7 Comparison of average precisions of different detection models
表 1 采用不同方法所得到结果的比较
Table 1 Comparison of results from different techniques
类别 指标 行人 车辆 模型大小 (MB) AP FPS AP FPS 使用的数据和方法 热红外图像 YOLOv3 0.836 20 0.873 20 235 YOLOv3-MobileNetv2 0.792 32 0.826 32 97 显著图 YOLOv3 0.771 21 0.820 21 235 YOLOv3-MobileNetv2 0.719 34 0.761 34 97 替换 R 通道融合 YOLOv3 0.927 20 0.932 20 235 YOLOv3-MobileNetv2 0.880 32 0.889 32 97 替换 G 通道融合 YOLOv3 0.938 18 0.956 18 235 YOLOv3-MobileNetv2 0.881 30 0.899 30 97 替换 B 通道融合 YOLOv3 0.905 19 0.972 19 235 YOLOv3-MobileNetv2 0.857 31 0.925 31 97 像素级加权融合 YOLOv3 0.944 20 0.978 20 235 YOLOv3-MobileNetv2 0.903 32 0.930 32 97  下载: 导出CSV
下载: 导出CSV
-
[1] 刘智嘉, 贾鹏, 夏寅辉, 林昱, 徐长彬. 基于红外与可见光图像融合技术发展与性能评价. 激光与红外, 2019, 49(5): 633-640 doi: 10.3969/j.issn.1001-5078.2019.05.021Liu Zhi-Jia, Jia Peng, Xia Yin-Hui, Lin Yu, Xu Chang-Bin. Development and performance evaluation of infrared and visual image fusion technology. Laser & Infrared, 2019, 49(5): 633-640 doi: 10.3969/j.issn.1001-5078.2019.05.021 [2] Koch C, Ullman S. Shifts in selective visual attention: Towards the underlying neural circuitry. Human Neurobiology, 1985, 4(4): 219-227 [3] Redmon J, Farhadi A. YOLOv3: An incremental improvement [Online], available: https://arxiv.org/abs/1804.02767, April 8, 2018 [4] Qin X B, Zhang Z C, Huang C Y, Gao C, Dehghan M, Jagersand M. BASNet: Boundary-aware salient object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 7479−7489 [5] Sandler M, Howard A, Zhu M L, Zhmoginov A, Chen L C. MobileNetV2: Inverted residuals and linear bottlenecks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 4510−4520 [6] Lin T Y, Goyal P, Girshick R, He K M, Dollár P. Focal loss for dense object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327 doi: 10.1109/TPAMI.2018.2858826 [7] Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278-2324 doi: 10.1109/5.726791 [8] 于雪松, 刘家锋, 唐降龙, 黄剑华. 基于概率模型的行人四肢自遮挡的检测. 自动化学报, 2010, 36(4): 610-615 doi: 10.3724/SP.J.1004.2010.00610Yu Xue-Song, Liu Jia-Feng, Tang Xiang-Long, Huang Jian-Hua. Estimating the pedestrian 3D motion indoor via hybrid tracking model. Acta Automatica Sinica, 2010, 36(4): 610-615 doi: 10.3724/SP.J.1004.2010.00610 [9] Dollár P, Tu Z W, Perona P, Belongie S. Integral channel features. In: Proceedings of the 2009 British Machine Vision Conference (BMVC). London, UK: BMVA Press, 2009. 91.1−91.11 [10] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, USA: IEEE, 2014. 580−587 [11] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1440−1448 [12] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149 doi: 10.1109/TPAMI.2016.2577031 [13] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 779−788 [14] Redmon J, Farhadi A. YOLO9000: Better, faster, stronger [Online], available: https://arxiv.org/abs/1612.08242, December 25, 2016 [15] Ruhé M, Kühne R, Ernst I, Zuev S, Hipp E. Air borne systems and datafusion for traffic surveillance and forecast for the soccer world cup, In: Proceedings of the 86th Annual Meeting of Transportation Research Board (TRB 2017), Washington, DC, USA, 2007. [16] Portmann J, Lynen S, Chli M, Siegwart R. People detection and tracking from aerial thermal views. In: Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA). Hong Kong, China: IEEE, 2014. 1794−1800 [17] 董培, 石繁槐. 基于小型无人机航拍图像的道路检测方法. 计算机工程, 2015, 41(12): 36-39 doi: 10.3969/j.issn.1000-3428.2015.12.007Dong Pei, Shi Fan-Huai. Road detection method based on small unmanned aerial vehicle image. Computer Engineering, 2015, 41(12): 36-39 doi: 10.3969/j.issn.1000-3428.2015.12.007 [18] 张秀伟, 张艳宁, 杨涛, 张新功, 邵大培. 基于co-motion的可见光-热红外图像序列自动配准算法. 自动化学报, 2010, 36(9): 1220-1231 doi: 10.3724/SP.J.1004.2010.01220Zhang Xiu-Wei, Zhang Yan-Ning, Yang Tao, Zhang Xin-Gong, Shao Da-Pei. Automatic visual-thermal image sequence registration based on co-motion. Acta Automatica Sinica, 2010, 36(9): 1220-1231 doi: 10.3724/SP.J.1004.2010.01220 [19] Li C Y, Song D, Tong R F, Tang M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognition, 2019, 85: 161-171 doi: 10.1016/j.patcog.2018.08.005 [20] Xu D, Ouyang W L, Ricci E, Wang X G, Sebe N. Learning cross-modal deep representations for robust pedestrian detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 5363−5371 [21] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254-1259 doi: 10.1109/34.730558 [22] Hou X D, Zhang L Q. Saliency detection: A spectral residual approach. In: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Minneapolis, USA: IEEE, 2007. 1−8 [23] He S F, Lau R W H, Liu W X, Huang Z, Yang Q X. SuperCNN: A superpixelwise convolutional neural network for salient object detection. International Journal of Computer Vision, 2015, 115(3): 330-344 doi: 10.1007/s11263-015-0822-0 [24] Hou Q B, Cheng M M, Hu X W, Borji A, Tu Z W, Torr P. Deeply supervised salient object detection with short connections. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 3203−3212 [25] 张芳, 王萌, 肖志涛, 吴骏, 耿磊, 童军, 等. 基于全卷积神经网络与低秩稀疏分解的显著性检测. 自动化学报, 2019, 45(11): 2148-2158Zhang Fang, Wang Meng, Xiao Zhi-Tao, Wu Jun, Geng Lei, Tong Jun, et al. Saliency detection via full convolution neural network and low rank sparse decomposition. Acta Automatica Sinica, 2019, 45(11): 2148-2158 [26] Iandola F N, Han S, Moskewicz M W, Ashraf K, Dally W J, Keutzer K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size [Online], available: https://arxiv.org/abs/1602.07360, November 4, 2016 [27] Zhang X Y, Zhou X Y, Lin M X, Sun J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices [Online], available: https://arxiv.org/abs/1707.01083, December 7, 2017 [28] Howard A G, Zhu M L, Chen B, Kalenichenko D, Wang W J, Weyand T, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications [Online], available: https://arxiv.org/abs/1704.04861, April 17, 2017 [29] Howard A, Sandler M, Chu G, Chen L C, Chen B, Tan M X, et al. Searching for MobileNetV3 [Online], available: https://arxiv.org/abs/1905.02244?context=cs, November 20, 2019 [30] 方青云, 王兆魁. 基于改进YOLOv3网络的遥感目标快速检测方法. 上海航天, 2019, 36(5): 21-27, 34Fang Qing-Yun, Wang Zhao-Kui. Efficient object detection method based on improved YOLOv3 network for remote sensing images. Aerospace Shanghai, 2019, 36(5): 21-27, 34 -

 下载:
下载:

计量
- 文章访问数: 2769
- HTML全文浏览量: 3141
- PDF下载量: 679
- 被引次数: 0
