

-
摘要: 在模糊核未知的情况下对模糊图像进行复原称为盲解卷积问题, 这是一个欠定逆问题, 现有的大部分盲解卷积算法利用图像的各种先验知识约束问题的解空间. 由于清晰图像的跨尺度自相似性强于模糊图像的跨尺度自相似性, 且降采样模糊图像与清晰图像具有更强的相似性, 本文提出了一种基于跨尺度低秩约束的单幅图像盲解卷积算法, 利用图像跨尺度自相似性, 在降采样图像中搜索相似图像块构成相似图像块组, 从整体上对相似图像块组进行低秩约束, 作为正则项加入到图像盲解卷积的目标函数中, 迫使重建图像的边缘接近清晰图像的边缘. 本文算法没有对噪声进行特殊处理, 由于低秩约束更好地表示了数据的全局结构特性, 因此避免了盲解卷积过程受噪声的干扰. 在模糊图像和模糊有噪图像上的实验验证了本文的算法能够解决大尺寸模糊核的盲复原并对噪声具有良好的鲁棒性.Abstract: Blind image deconvolution aims to recover the sharp image from a blurred one when the blur kernel is unknown. To solve this underdetermined inverse problem, most existing methods exploit various image priors to constrain the solution. Our work is inspired by the observation that the cross-scale self-similarity of the sharp image will diminish after blurring, and the down-sampled blurry image has stronger similarity with the sharp image than the blurry image. In this paper, we propose a blind deconvolution method based on cross-scale low rank prior, in which the similar image patch group is formed from sharper patches sampled from the down-sampled image, and the low rank matrix approximation is used to explore the low rank structure of this group. By introducing the cross-scale low rank prior as the regularization constraint, the intermediate latent image is enforced to contain the sharp edges and fine details. The low rank matrix approximation elegantly indicates the global structure of data, allowing for the noise-avoiding kernel estimation without acquiring any additional handling of noise. Experimental results on blurry images and blurred-noisy images demonstrate that our method can estimate accurate large blur kernels, meanwhile, it has good robustness to noise.
-
Key words:
- Self-similarity /
- cross-scale /
- low rank /
- blind deconvolution /
- deblurring
1) 1 后面的内容涉及到范数的表示和导数计算, 为了方便表达, 需要将公式写为矩阵向量的形式, 因此, 对于空域卷积, 本文近似使用列向量的形式表示.2) 1 根据统计, 细节块约占图像块总数的10%. -

图 3 模糊图像和降采样模糊图像分别与清晰图像的相似性比较
Fig. 3 Comparison of similarities between the blurry image and the down-sampled blurry image related the sharp image
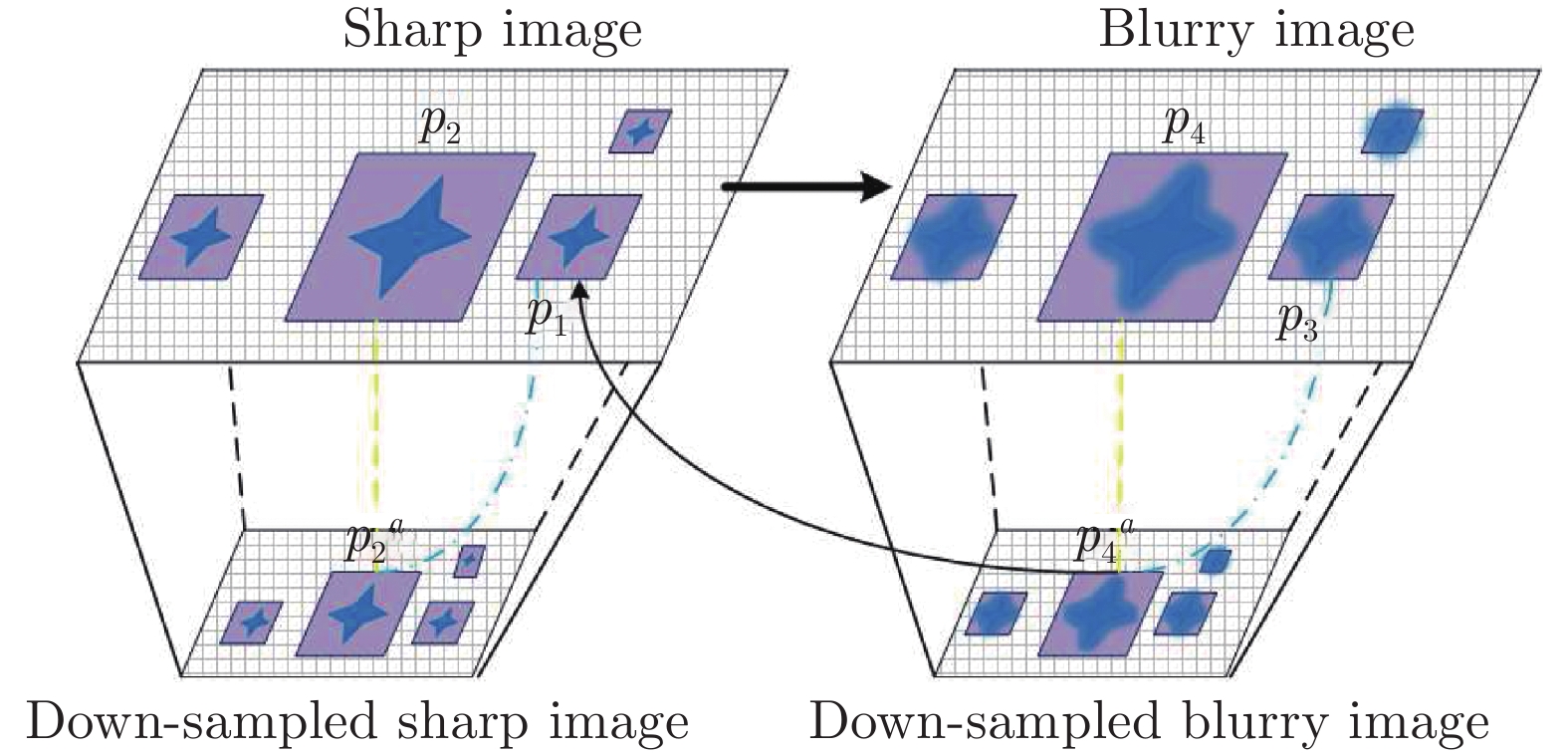
图 4 跨尺度自相似性用于图像盲复原的解释
Fig. 4 Interpretation of cross-scale self-similarity for blind image restoration
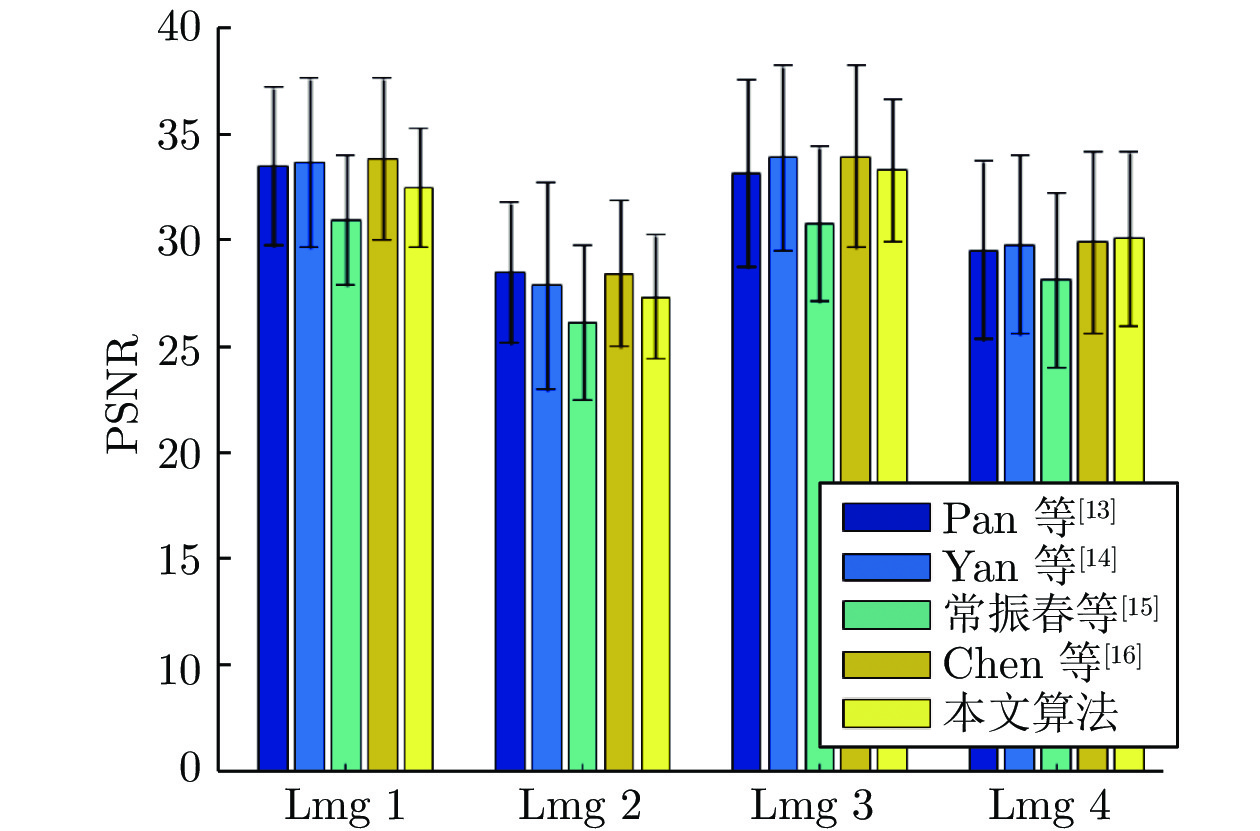
图 6 Kohler数据集PSNR的平均值与标准差
Fig. 6 Mean and standard deviation of PSNR on Kohler dataset

图 7 各个算法对Kohler数据集中一幅小模糊图像复原结果的比较
Fig. 7 Comparison of the results deblurred by some state-of-the-art methods on a weakly blurred image from Kohler dataset

图 8 各个算法对Kohler数据集中一幅大模糊图像复原结果的比较
Fig. 8 Comparison of the results deblurred by some state-of-the-art methods on a severely blurred image from Kohler dataset

图 9 加噪Kohler数据集PSNR的平均值与标准差
Fig. 9 Mean and standard deviation of PSNR on noisy Kohler dataset

图 10 各个算法对加噪Kohler数据集中一幅图像复原结果的比较
Fig. 10 Comparison of the results deblurred by some state-of-the-art methods on a blurred-noisy image from noisy Kohler dataset

图 11 各个算法对加噪Kohler数据集中另一幅图像复原结果的比较
Fig. 11 Comparison of the results deblurred by some state-of-the-art methods on another blurred-noisy image from noisy Kohler dataset

图 12 各个算法对一幅真实模糊图像复原结果的比较
Fig. 12 Visual comparisons with some state-of-the-art methods on one real-world photo

图 13 各个算法对另一幅真实模糊图像复原结果的比较
Fig. 13 Visual comparisons with some state-of-the-art methods on another real-world photo

图 14 各个算法在一幅真实模糊有噪图像上的实验结果
Fig. 14 Visual comparisons with state-of-the-art some methods on a real blurred-noisy image

图 15 各个算法在另一幅真实模糊有噪图像上的实验结果
Fig. 15 Visual comparisons with some state-of-the-art methods on another real blurred-noisy image
-
[1] Jia J Y. Single image motion deblurring using transparency. In: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, MN, USA: IEEE, 2007. 1−8 [2] Joshi N, Szeliski R, Kriegman D J. PSF estimation using sharp edge prediction. In: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK, USA: IEEE, 2008. 1−8 [3] Cho S, Lee S. Fast motion deblurring. ACM Transactions on Graphics, 2009, 28(5): 89-97 [4] Xu L, Jia J Y. Two-phase kernel estimation for robust motion deblurring. In: Proceedings of the 11th European Conference on Computer Vision. Heraklion, Crete, Greece: Springer Berlin Heidelberg, 2010. 157−170 [5] Chan T, Wong C. Total variation blind deconvolution. IEEE Transactions on Image Processing, 1998, 7(3): 370-375 doi: 10.1109/83.661187 [6] Levin A, Weiss Y, Durand F, Freeman W T. Efficient marginal likelihood optimization in blind deconvolution. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2011. 2657−2664 [7] Fergus R, Singh B, Hertzmann A, Rowels S T, Freeman W T. Removing camera shake from a single photograph. ACM Transactions on Graphics, 2006, 25(3): 787-794 doi: 10.1145/1141911.1141956 [8] Levin A, Weiss Y, Durand F, Freeman W T. Understanding and evaluating blind deconvolution algorithms. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009. 1964−1971 [9] Perrone D, Favaro P. Total variation blind deconvolution: The devil is in the details. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 2909−2916 [10] Michaeli T, Irani M. Blind deblurring using internal patch recurrence. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer Cham, 2014. 783−798 [11] Zhang H C, Yang J C, Zhang Y N, Nasrabadi N M, Huang T S. Close the loop: Joint blind image restoration and recognition with sparse representation prior. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 770−777 [12] Ren W, Cao X, Pan J, Guo X, Zuo W, Yang M. Image deblurring via enhanced low-rank prior. IEEE Transactions on Image Processing, 2016, 25(7): 3426-3437 doi: 10.1109/TIP.2016.2571062 [13] Pan J, Sun D, Pfister H, Yan M. Deblurring images via dark channel prior. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(10): 2315-2328 doi: 10.1109/TPAMI.2017.2753804 [14] Yan Y Y, Ren W Q, Guo Y F, Wang R, Cao X C. Image deblurring via extreme channels prior. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 6978−6986 [15] 常振春, 禹晶, 肖创柏, 孙卫东. 基于稀疏表示和结构自相似性的单幅图像盲解卷积算法. 自动化学报, 2017, 43(11): 1908-1919Chang Zhen-Chun, Yu Jing, Xiao Chuang-Bai, Sun Wei-Dong. Single image blind deconvolution using sparse representation and structural self-similarity. Acta Automatica Sinica, 2017, 43(11): 1908-1919 [16] Chen L, Fang F M, Wang T T, Zhang G X. Blind image deblurring with local maximum gradient prior. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019. 1742−1750 [17] Pan L Y, Hartley R, Liu M M, Dai Y C. Phase-only image based kernel estimation for single image blind deblurring. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019. 6027−6036 [18] Kotera J, Sroubek F. Motion estimation and deblurring of fast moving objects. In: Proceedings of the 2018 IEEE International Conference on Image Processing. Athens, Greece: IEEE, 2018. 2860−2864 [19] Aharon M, Elad M, Bruckstein A. K-SVD : An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Transactions on Signal Processing, 2006, 54(11): 4311-4322 doi: 10.1109/TSP.2006.881199 [20] Su S C, Delbracio M, Wang J, Sapiro G, Heidrich W, Wang O. Deep video deblurring for hand-held cameras. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 237−246 [21] Yan R, Shao L. Blind image blur estimation via deep learning. IEEE Transactions on Image Processing, 2016, 25(4): 1910-1921 [22] Sun J, Cao W F, Xu Z B, Ponce J. Learning a convolutional neural network for non-uniform motion blur removal. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 769−777 [23] Kupyn O, Budzan V, Mykhailych M, Matas J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 8183−8192 [24] 林懿伦, 戴星原, 李力, 王晓, 王飞跃. 人工智能研究的新前线: 生成式对抗网络. 自动化学报, 2018, 44(5): 775-792Lin Yi-Lun, Dai Xing-Yuan, Li Li, Wang Xiao, Wang Fei-Yue. The new frontier of AI research: Generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 775-792 [25] 潘宗序, 禹晶, 胡少兴, 孙卫东. 基于多尺度结构自相似性的单幅图像超分辨率算法. 自动化学报, 2014, 40(4): 594-603Pan Zong-Xu, Yu Jing, Hu Shao-Xing, Sun Wei-Dong. Single image super resolution based on multi-scale structural self-similarity. Acta Automatica Sinica, 2014, 40(4): 594-603 [26] Glasner D, Bagon S, Irani M. Super-resolution from a single image. In: Proceedings of the 2009 IEEE International Conference on Computer Vision. Kyoto, Japan: IEEE, 2009. 349−356 [27] Sun L B, Cho S, Wang J, Hays J. Edge-based blur kernel estimation using patch priors. In: Proceedings of the 2013 IEEE International Conference on Computational Photography. Cambridge, MA, USA: IEEE, 2013. 1−8 [28] Cai J, Candes E, Shen Z. A singular value thresholding algorithm for matrix completion.SIAM Journal on Optimization, 2010, 20(4): 1956-1982 doi: 10.1137/080738970 [29] Lucy L. An iterative technique for the rectification of observed distributions. Astronomical Journal, 1974, 79(6): 745-754 [30] Hu Z, Cho S, Wang J, Yang M H. Deblurring low-light images with light streaks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(10): 2329-2341 doi: 10.1109/TPAMI.2017.2768365 [31] Yuan L, Sun J, Quan L, Shum H Y. Progressive inter-scale and intra-scale non-blind image deconvolution. ACM Transactions on Graphics, 2008, 27(3): 74:1-74:10 [32] Liu D, Chen X Y, Liu X. An improved Richardson-Lucy algorithm for star image deblurring. In: Proceedings of the 2019 IEEE International Instrumentation and Measurement Technology Conference. Auckland, New Zealand: IEEE, 2019. 1−5 [33] Zoran D, Weiss Y. From learning models of natural image patches to whole image restoration. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 479-486 [34] Mosleh A, Elmi Sola Y, Zargari F, Onzon E, Langlois J M P. Explicit ringing removal in image deblurring. IEEE Transactions on Image Processing, 2018, 27(2): 580-593 doi: 10.1109/TIP.2017.2764625 [35] Ortega G, Garzon E M, Vazquez F. The biconjugate gradient method on GPUs. Journal of Supercomputing, 2013, 64(1): 49-58 doi: 10.1007/s11227-012-0761-2 [36] Dabov K, Foi A, Katkovnik V, Egiazarian K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Transactions on Image Processing, 2007, 16(8): 2080-2095 doi: 10.1109/TIP.2007.901238 [37] Kohler R, Hirsch M, Mohler B. Recording and playback of camera shake: Benchmarking blind deconvolution with a real-world database. In: Proceedings of the 12th European Conference on Computer Vision. Florence, Italy: Springer Berlin Heidelberg 2012. 27−40 -

 下载:
下载:






计量
- 文章访问数: 1693
- HTML全文浏览量: 613
- PDF下载量: 232
- 被引次数: 0
