2022年 第48卷 第10期
2022, 48(10): 2361-2373.
doi: 10.16383/j.aas.c210377
摘要:
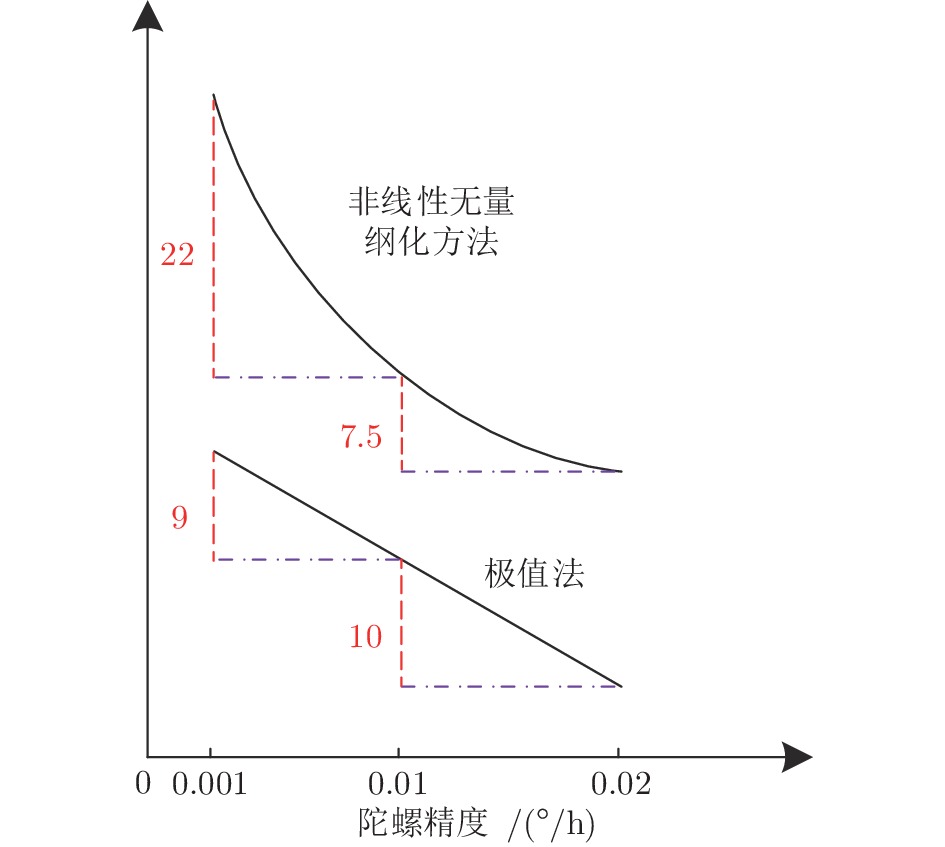
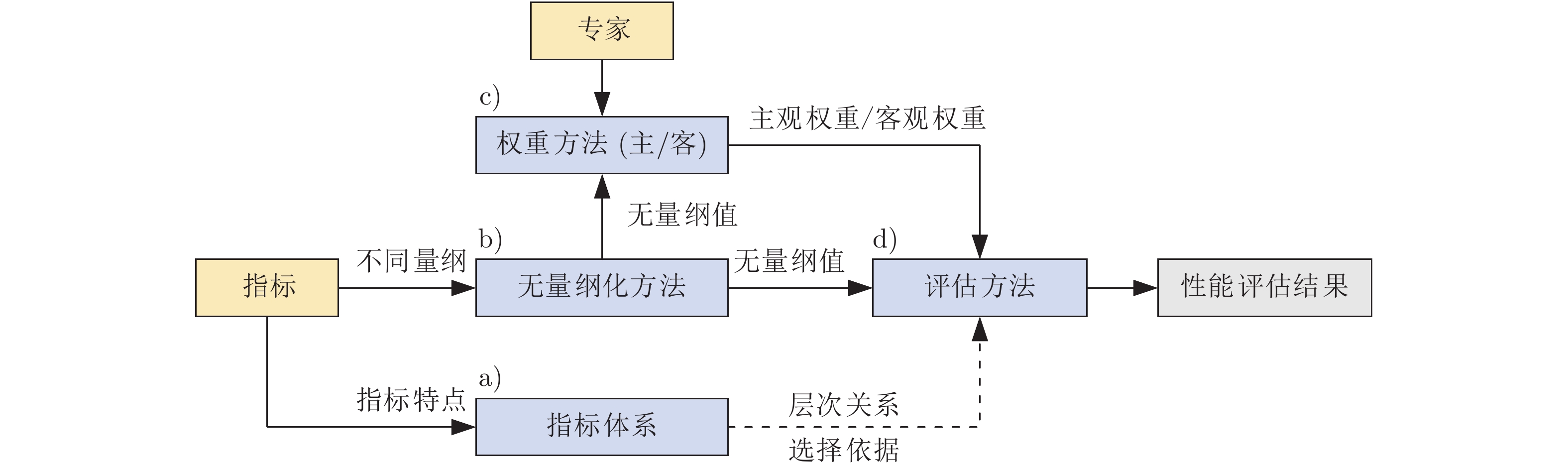
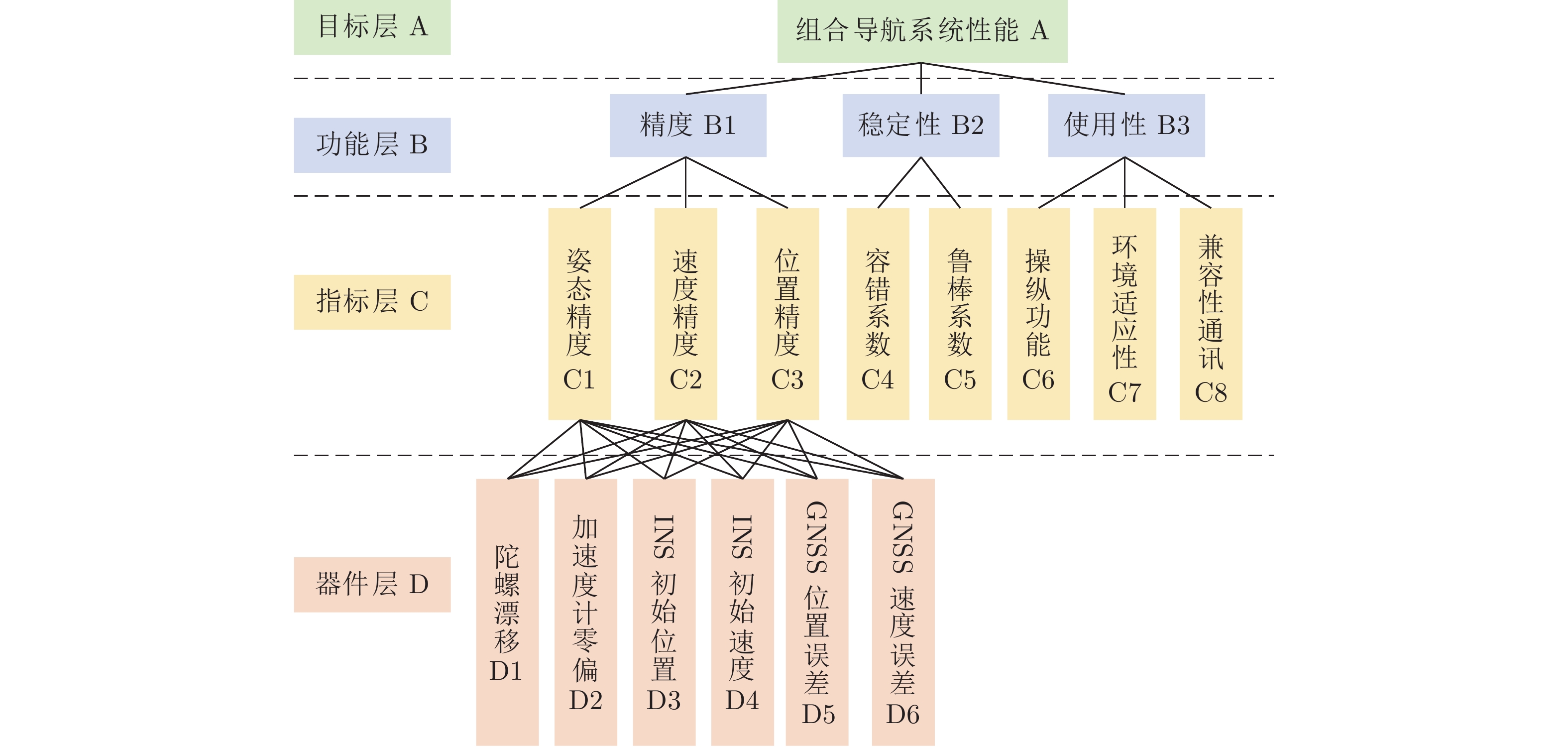
性能评估方法能够解决试验法无法评估定性指标, 以及试验难以开展时无法评估性能的问题, 已成为支撑各类军民装备现代化的重要技术手段. 然而, 性能评估方法的指标体系, 无量纲化方法及权重方法均存在不足, 难以满足精确性的要求. 对于指标具有模糊性和不可公度性, 且包含多个指标, 指标间具有多层次关系的系统而言, 例如, 惯性组合导航系统, 性能评估方法精确性尤为重要. 本文梳理了惯性组合导航系统性能评估方法研究进展. 首先, 介绍了惯性组合导航系统性能评估方法概述, 包括性能评估方法概念分析, 惯性组合导航系统特殊性讨论及惯性组合导航系统与性能评估方法关系分析. 其次, 分析了惯性组合导航系统指标体系, 无量纲化方法, 组合权重方法及评估方法等内容. 最后, 阐述惯性组合导航系统性能评估方法存在的问题及未来研究方向.
性能评估方法能够解决试验法无法评估定性指标, 以及试验难以开展时无法评估性能的问题, 已成为支撑各类军民装备现代化的重要技术手段. 然而, 性能评估方法的指标体系, 无量纲化方法及权重方法均存在不足, 难以满足精确性的要求. 对于指标具有模糊性和不可公度性, 且包含多个指标, 指标间具有多层次关系的系统而言, 例如, 惯性组合导航系统, 性能评估方法精确性尤为重要. 本文梳理了惯性组合导航系统性能评估方法研究进展. 首先, 介绍了惯性组合导航系统性能评估方法概述, 包括性能评估方法概念分析, 惯性组合导航系统特殊性讨论及惯性组合导航系统与性能评估方法关系分析. 其次, 分析了惯性组合导航系统指标体系, 无量纲化方法, 组合权重方法及评估方法等内容. 最后, 阐述惯性组合导航系统性能评估方法存在的问题及未来研究方向.
2022, 48(10): 2374-2391.
doi: 10.16383/j.aas.c200916
摘要:
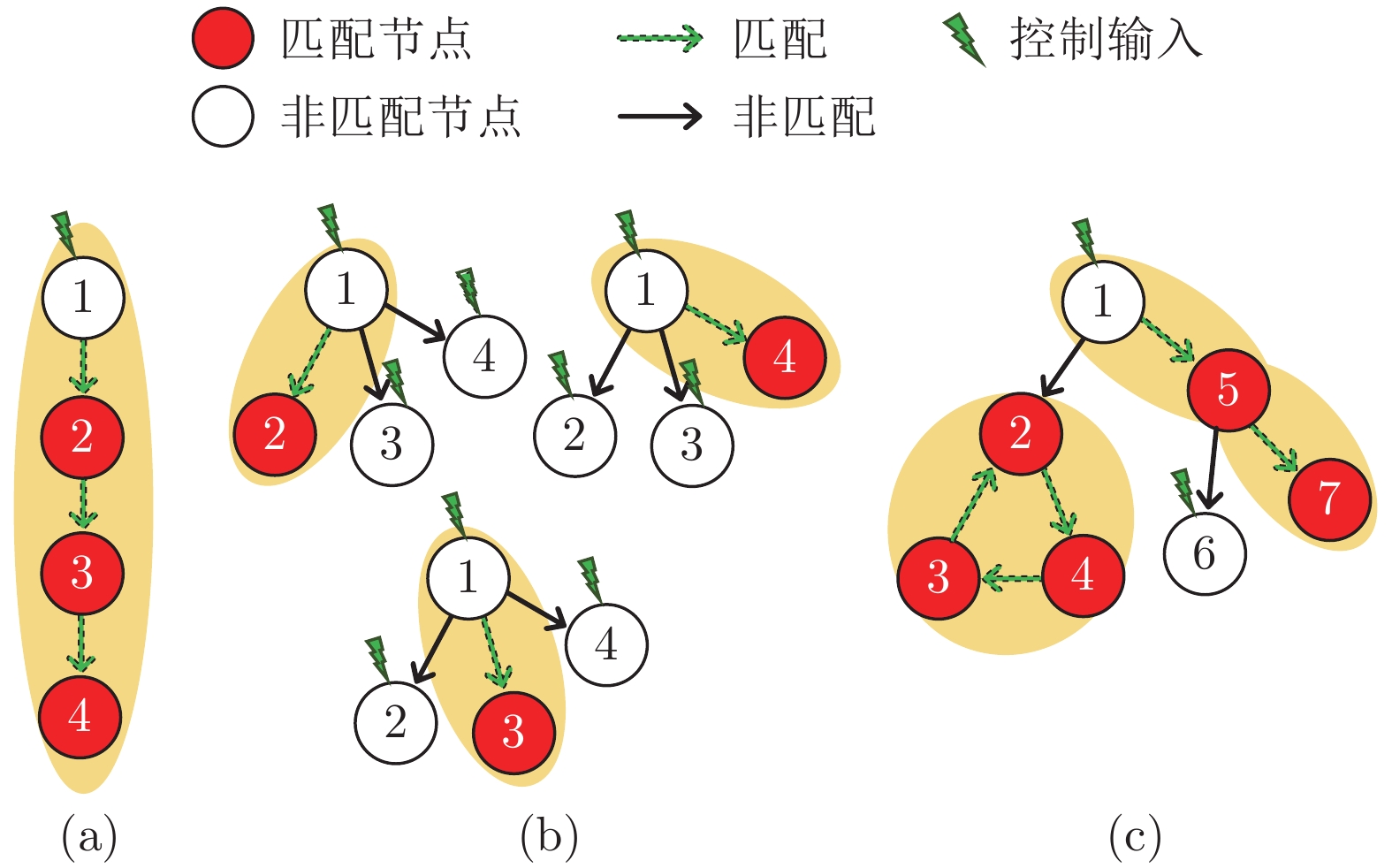
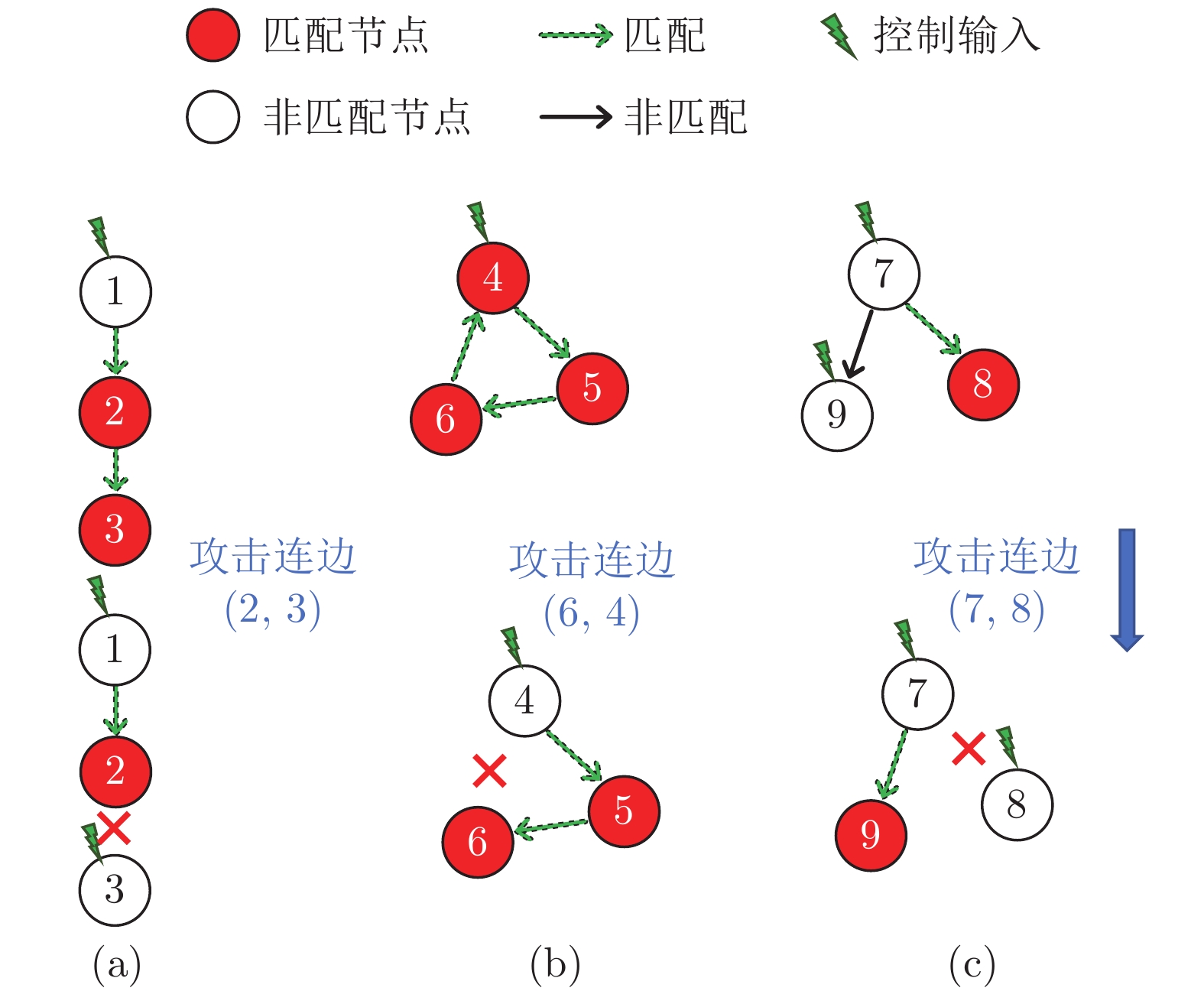
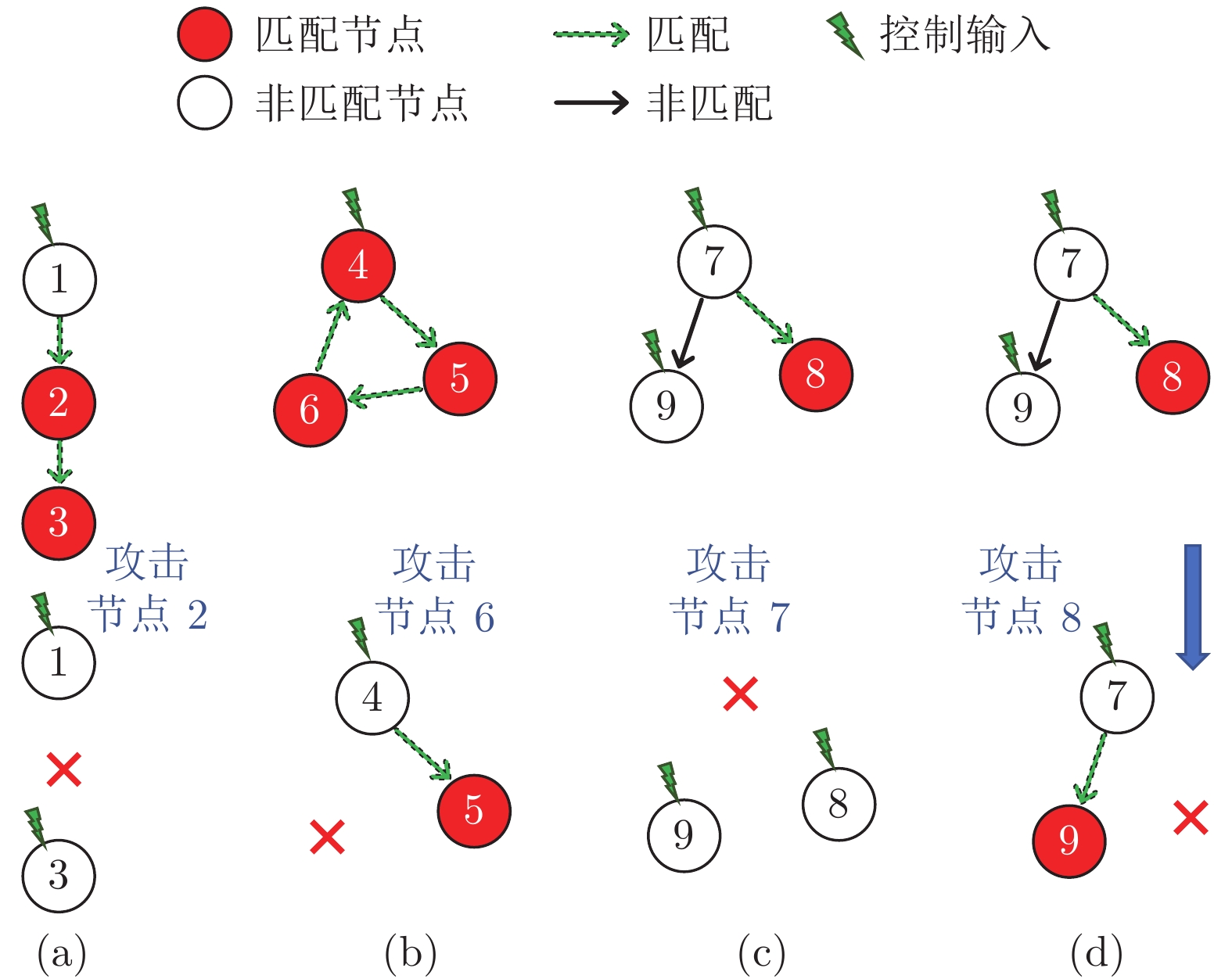
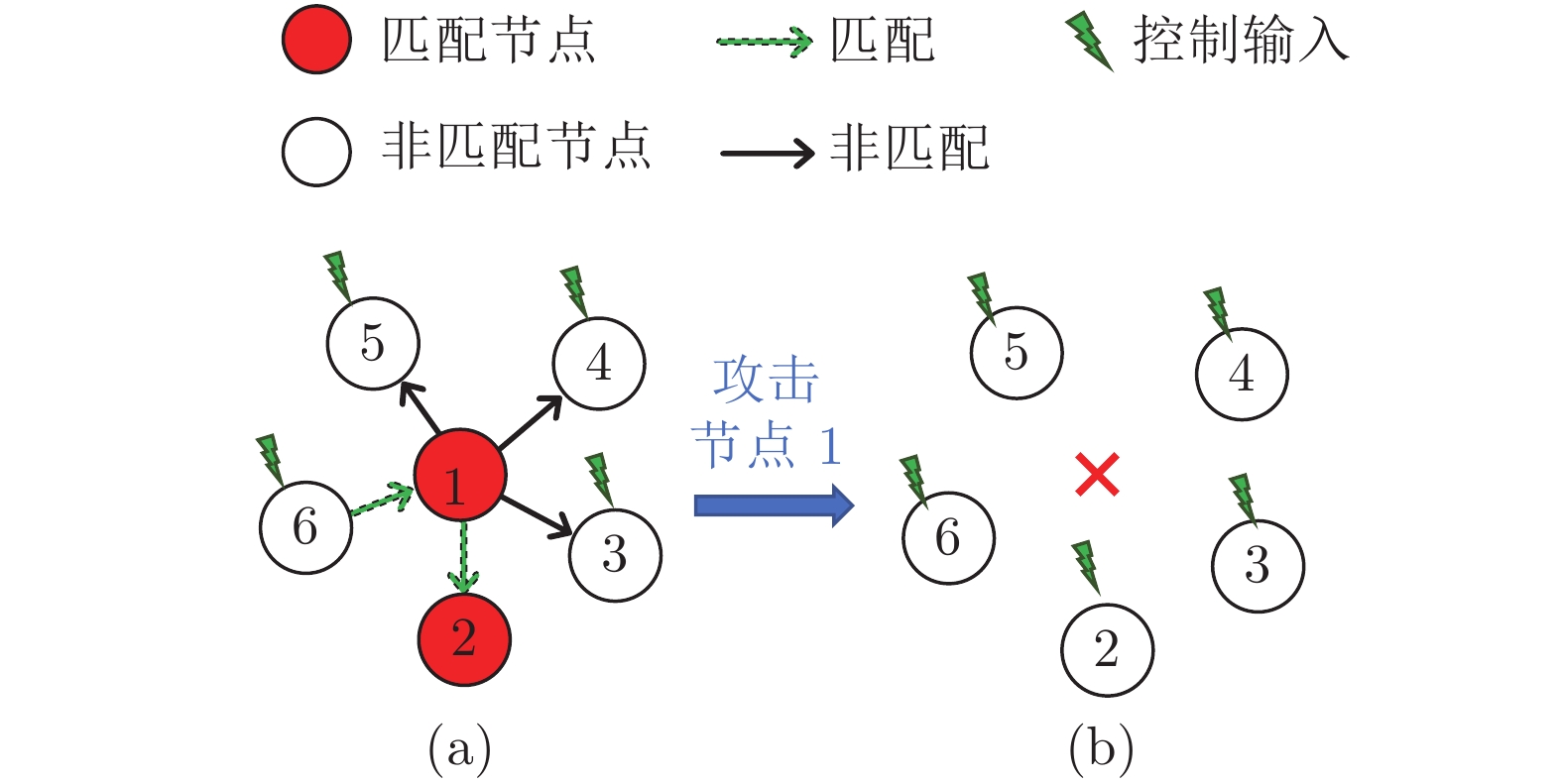
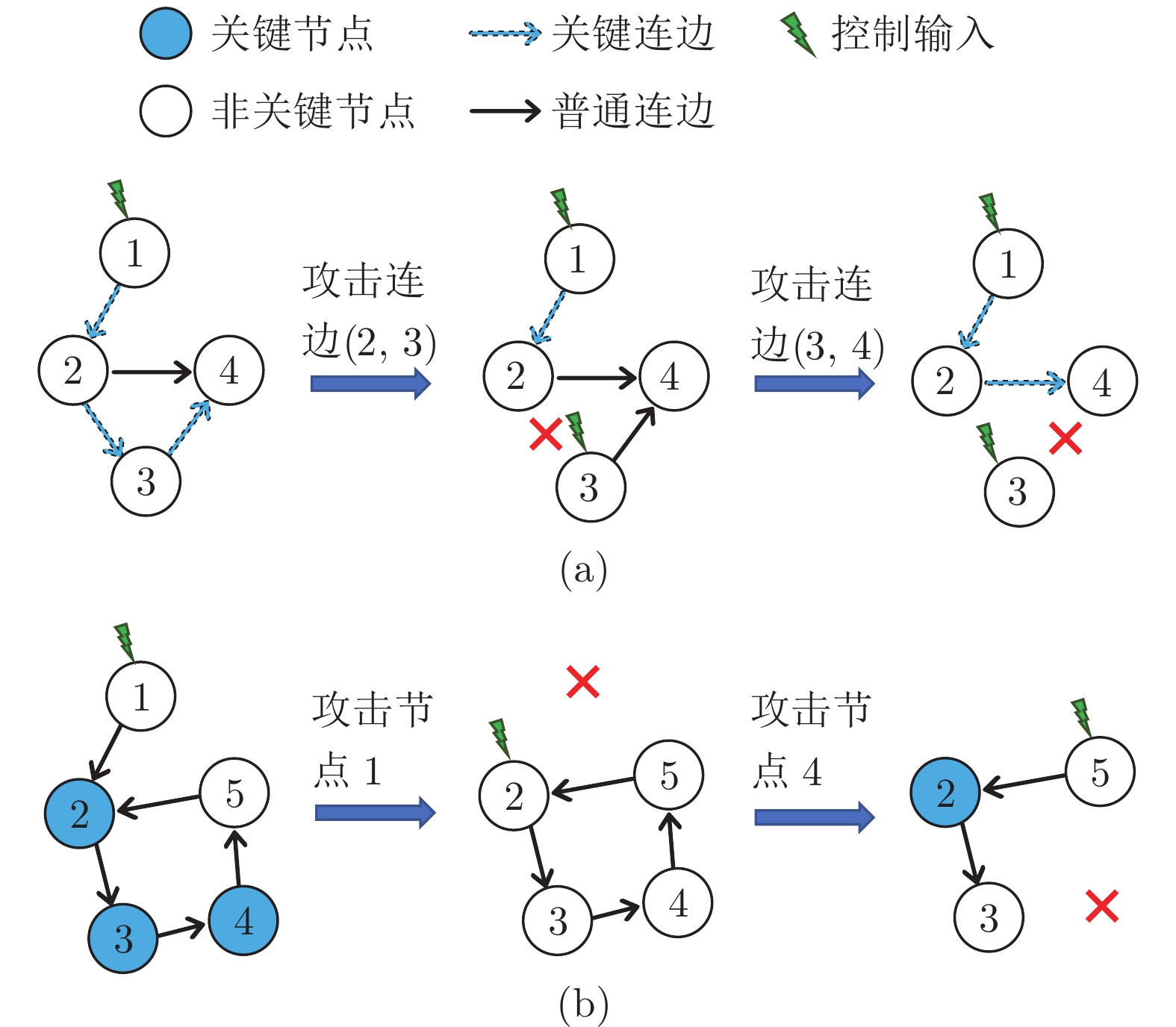
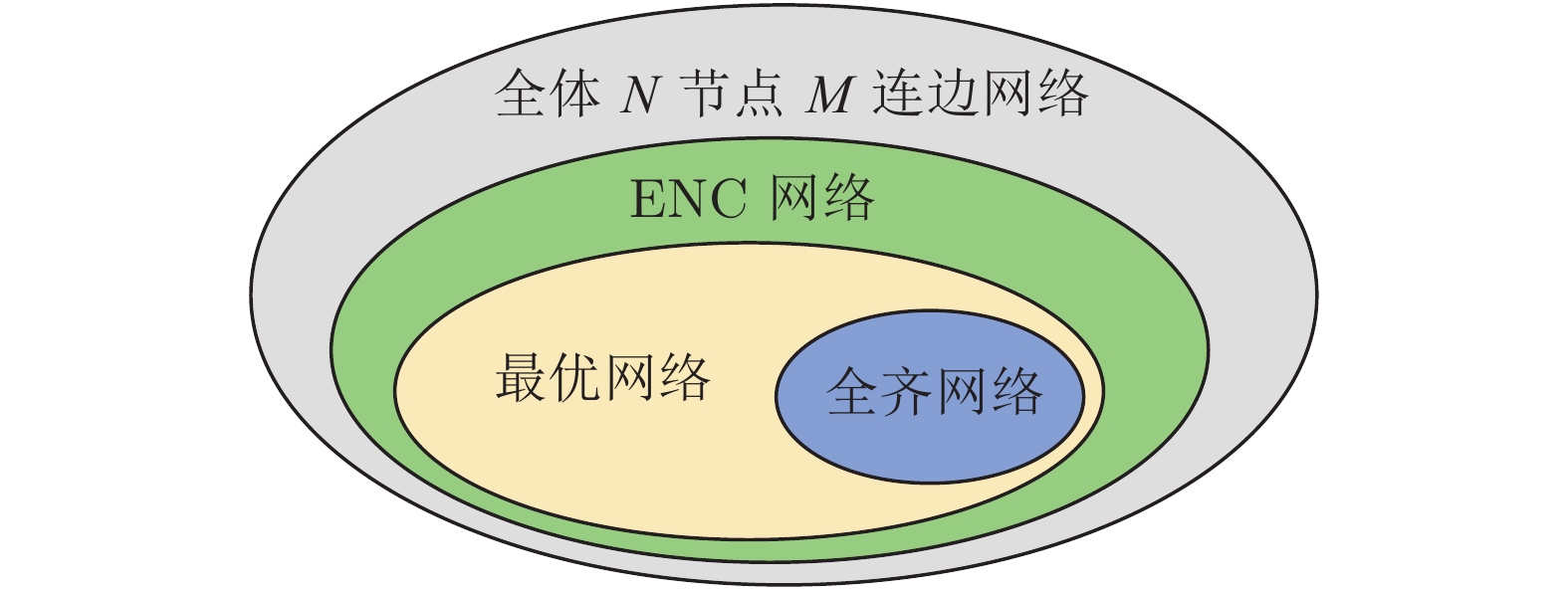
研究复杂网络能控性鲁棒性对包括社会网络、生物和技术网络等在内的复杂系统的控制和应用具有重要价值. 复杂网络的能控性是指: 可通过若干控制节点和适当的输入, 在有限时间内将系统状态驱动至任意目标状态. 能控性鲁棒性则是指在受到攻击的情况下, 复杂网络依然维持能控性的能力. 设计具有优异能控性鲁棒性的复杂网络模型和优化实际网络的能控性鲁棒性一直是复杂网络领域的重要研究内容. 本文首先比较了常用的能控性鲁棒性定义及度量, 接着从攻击策略的角度分析了3类攻击的特点及效果, 包括随机攻击、基于特征的蓄意攻击和启发式攻击. 然后比较了常见模型网络的能控性鲁棒性. 介绍了常用优化策略, 包括模型设计和重新连边等. 目前的研究在攻击策略和拓扑结构优化方面都取得了进展, 也为进一步理论分析提供条件. 最后总结全文并提出潜在研究方向.
研究复杂网络能控性鲁棒性对包括社会网络、生物和技术网络等在内的复杂系统的控制和应用具有重要价值. 复杂网络的能控性是指: 可通过若干控制节点和适当的输入, 在有限时间内将系统状态驱动至任意目标状态. 能控性鲁棒性则是指在受到攻击的情况下, 复杂网络依然维持能控性的能力. 设计具有优异能控性鲁棒性的复杂网络模型和优化实际网络的能控性鲁棒性一直是复杂网络领域的重要研究内容. 本文首先比较了常用的能控性鲁棒性定义及度量, 接着从攻击策略的角度分析了3类攻击的特点及效果, 包括随机攻击、基于特征的蓄意攻击和启发式攻击. 然后比较了常见模型网络的能控性鲁棒性. 介绍了常用优化策略, 包括模型设计和重新连边等. 目前的研究在攻击策略和拓扑结构优化方面都取得了进展, 也为进一步理论分析提供条件. 最后总结全文并提出潜在研究方向.


2022, 48(10): 2392-2405.
doi: 10.16383/j.aas.c190785
摘要:
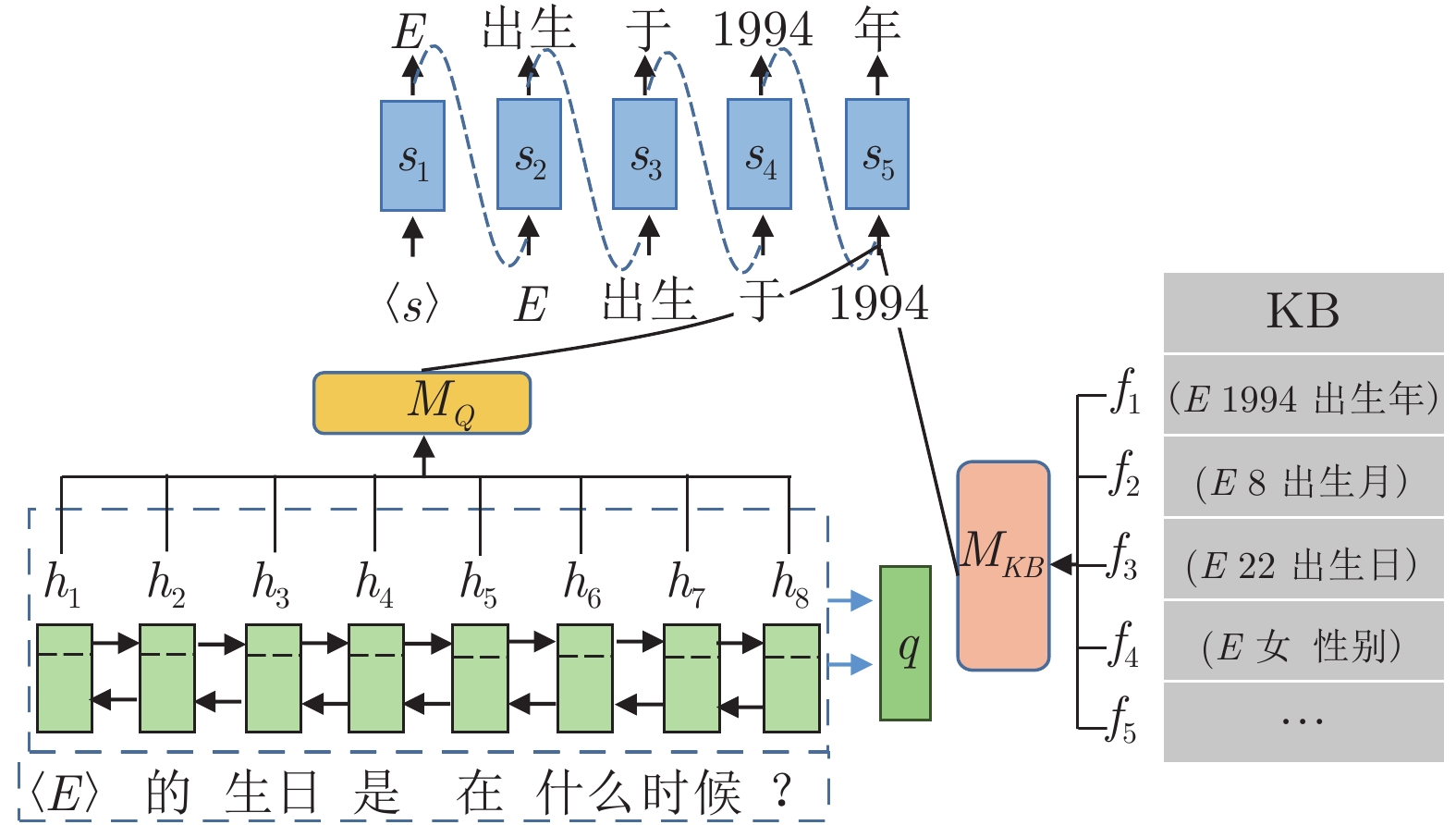
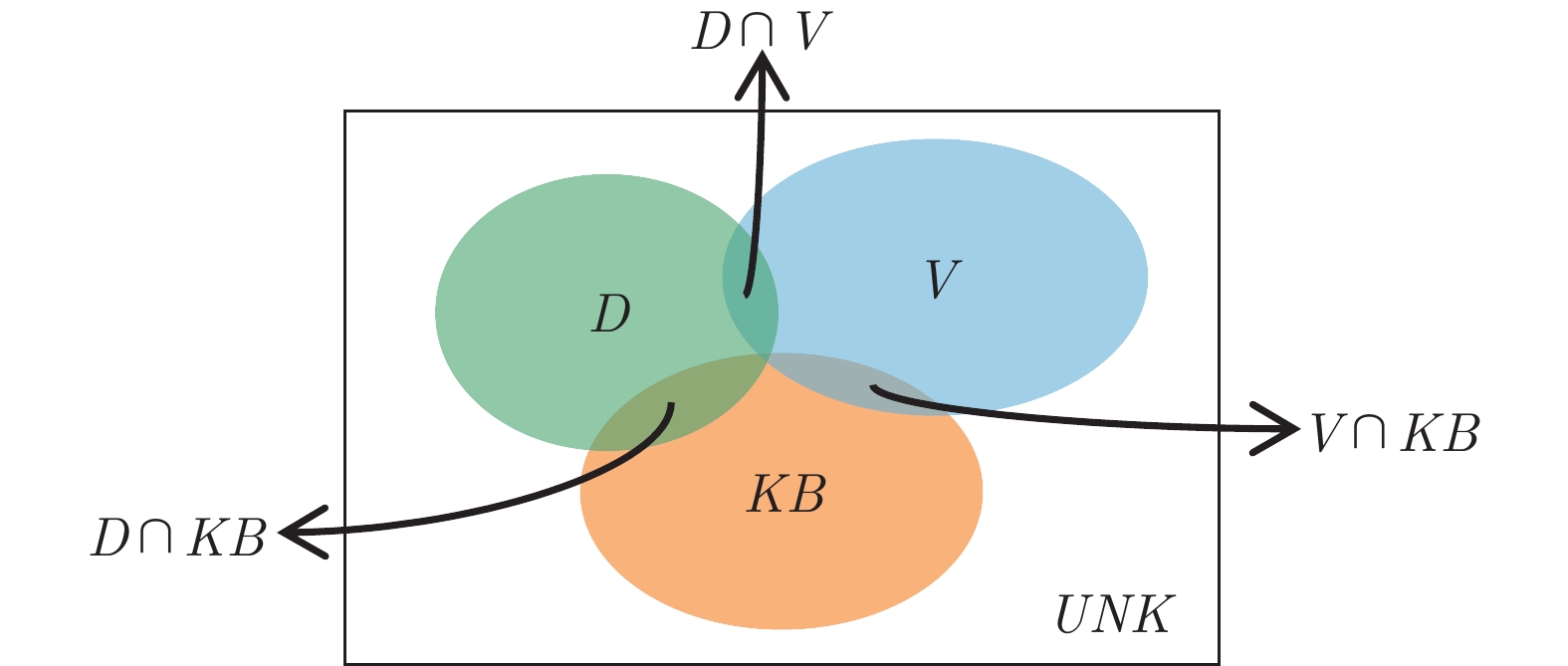
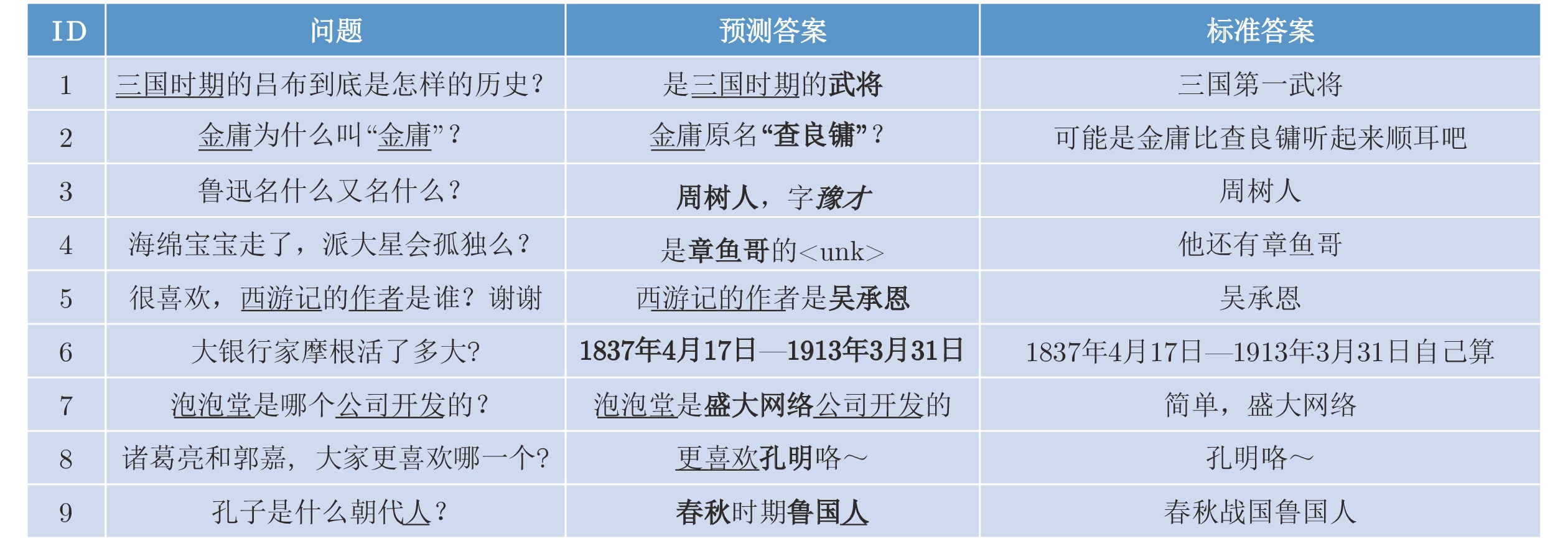
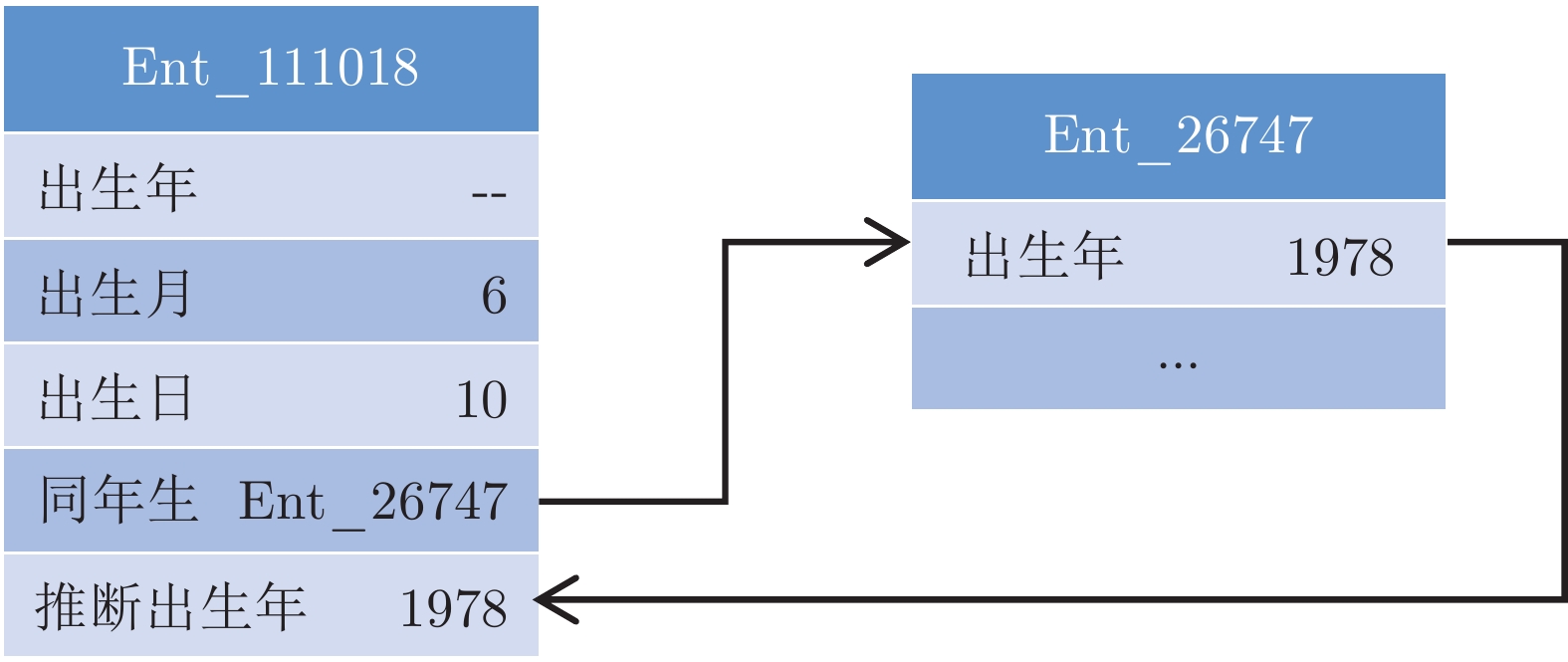
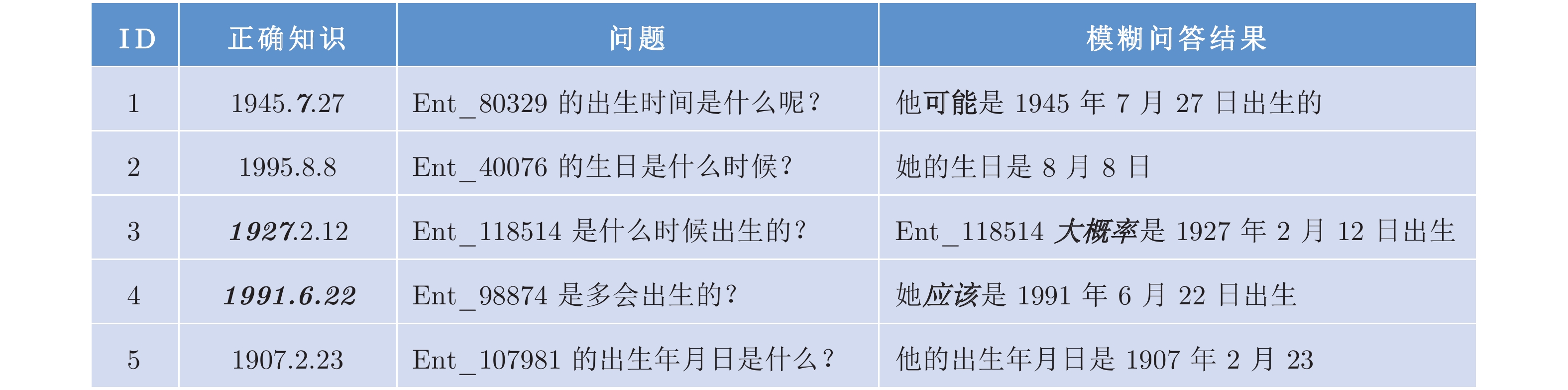
针对现有生成式问答模型中陌生词汇导致答案准确率低下的问题和模式混乱导致的词汇重复问题, 本文提出引入知识表示学习结果的方法提高模型识别陌生词汇的能力, 提高模型准确率. 同时本文提出使用全局覆盖机制以平衡不同模式答案生成的概率, 减少由预测模式混乱导致的重复输出问题, 提高答案的质量. 本文在知识问答模型基础上结合知识表示学习的推理结果, 使模型具备模糊回答的能力. 在合成数据集和现实世界数据集上的实验证明了本模型能够有效地提高生成答案的质量, 能对推理知识进行模糊回答.
针对现有生成式问答模型中陌生词汇导致答案准确率低下的问题和模式混乱导致的词汇重复问题, 本文提出引入知识表示学习结果的方法提高模型识别陌生词汇的能力, 提高模型准确率. 同时本文提出使用全局覆盖机制以平衡不同模式答案生成的概率, 减少由预测模式混乱导致的重复输出问题, 提高答案的质量. 本文在知识问答模型基础上结合知识表示学习的推理结果, 使模型具备模糊回答的能力. 在合成数据集和现实世界数据集上的实验证明了本模型能够有效地提高生成答案的质量, 能对推理知识进行模糊回答.


2022, 48(10): 2406-2415.
doi: 10.16383/j.aas.c190880
摘要:
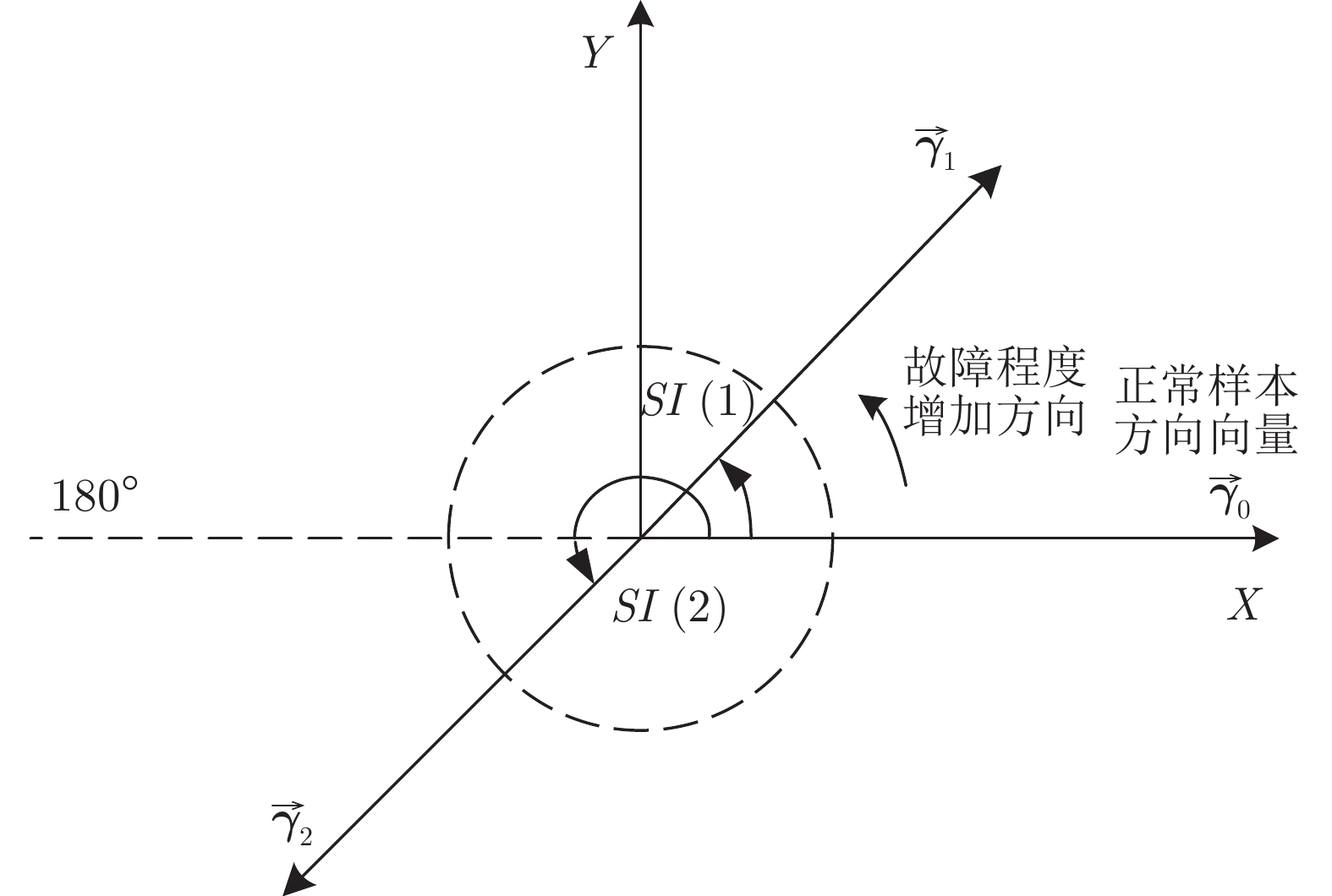
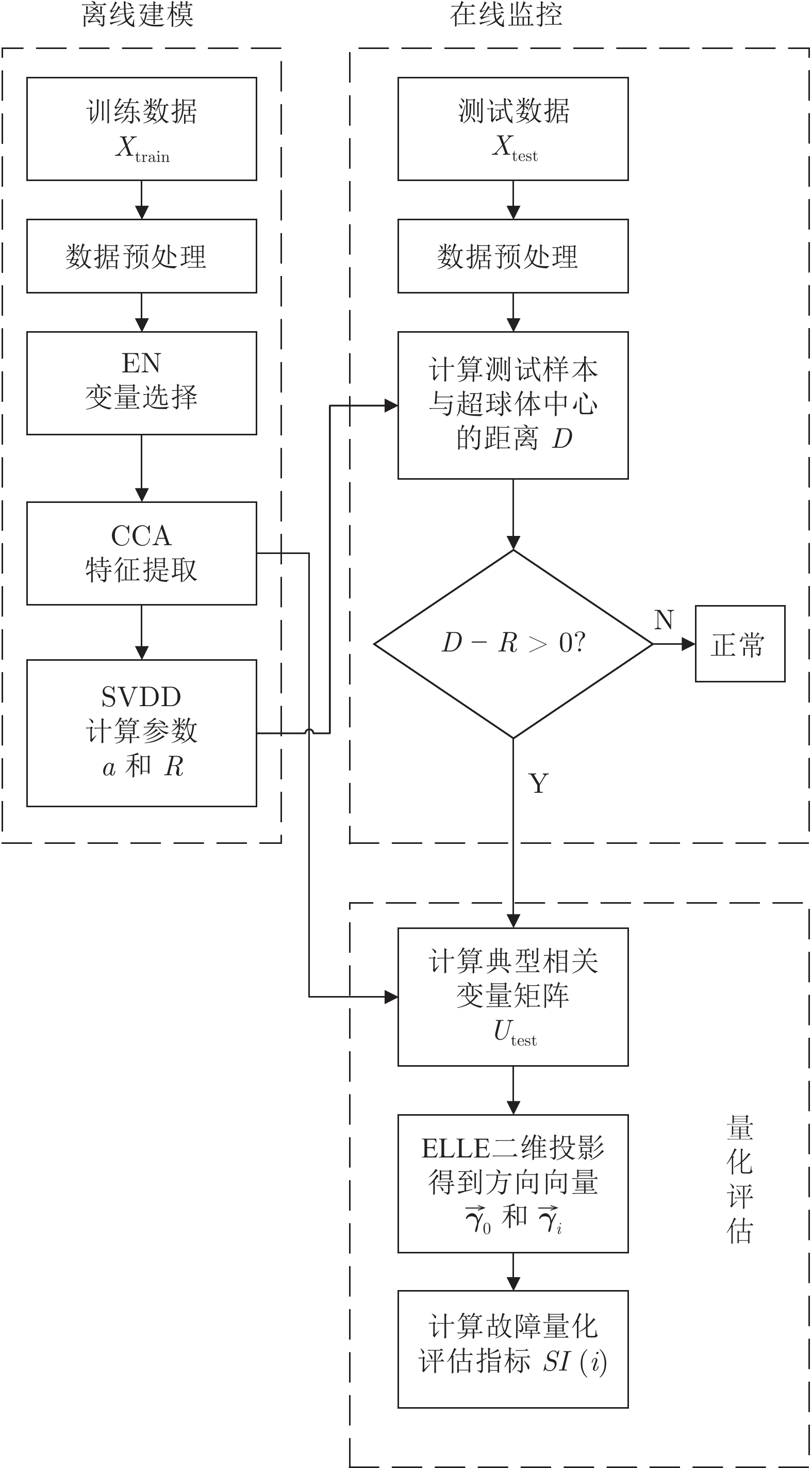
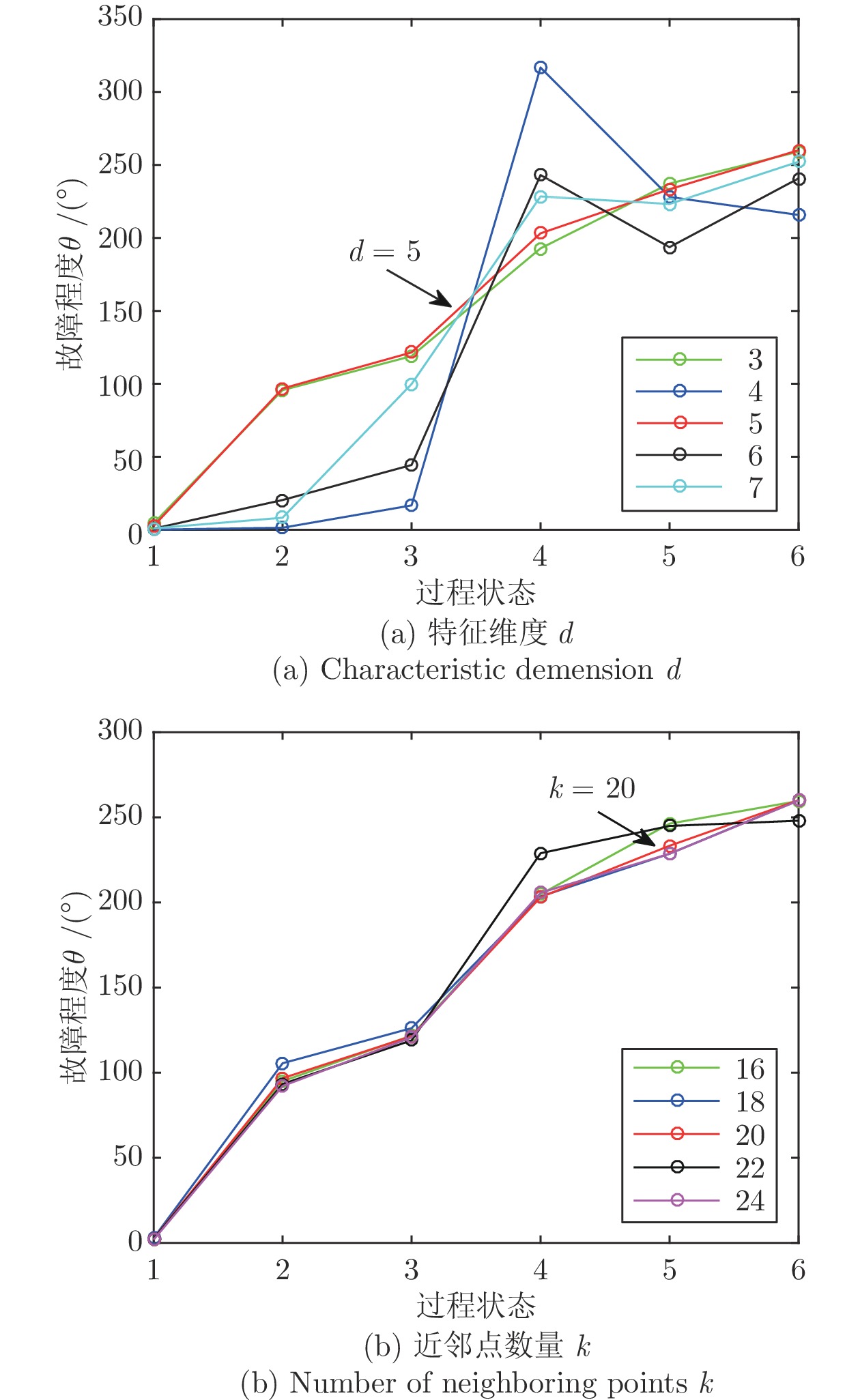
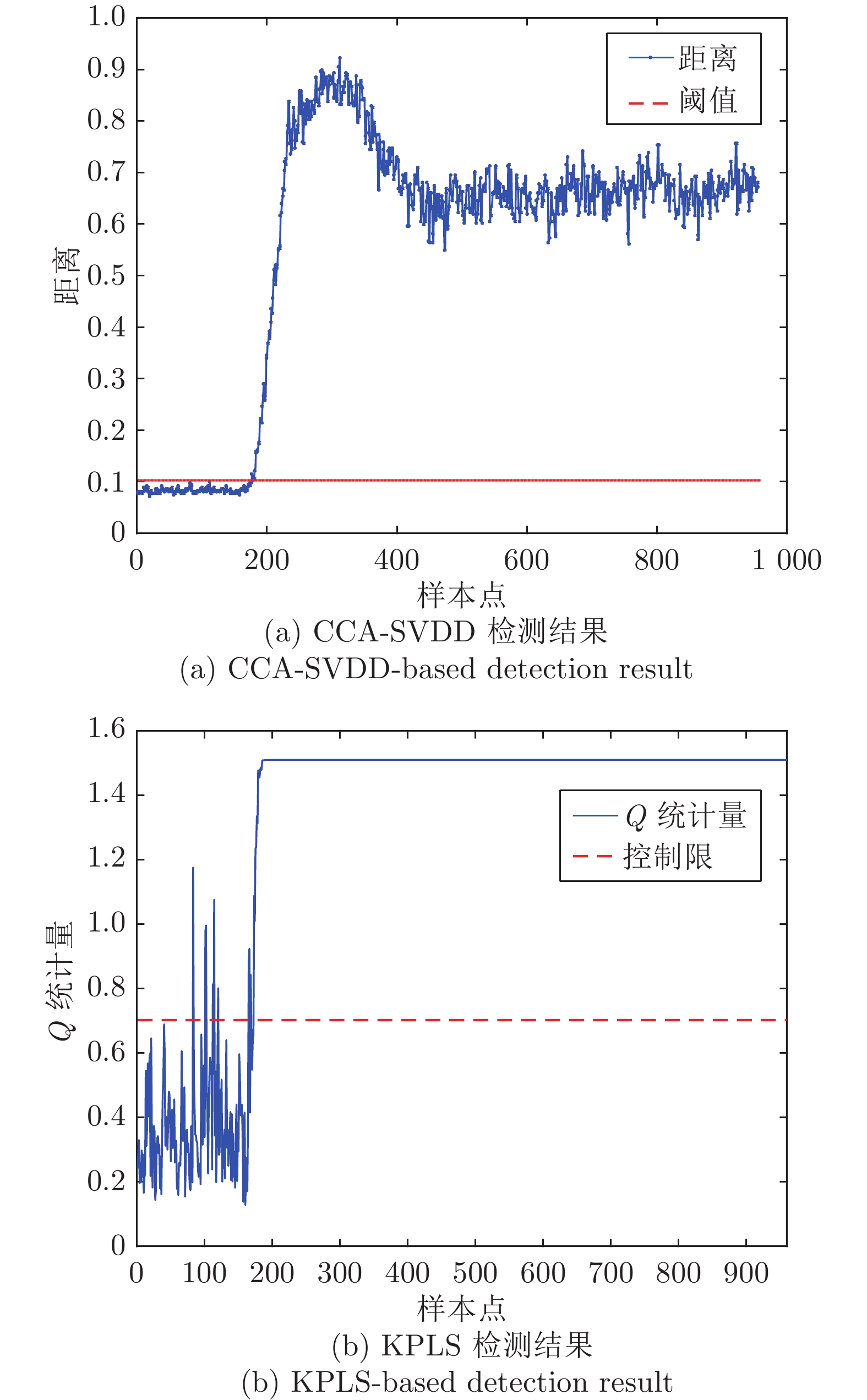
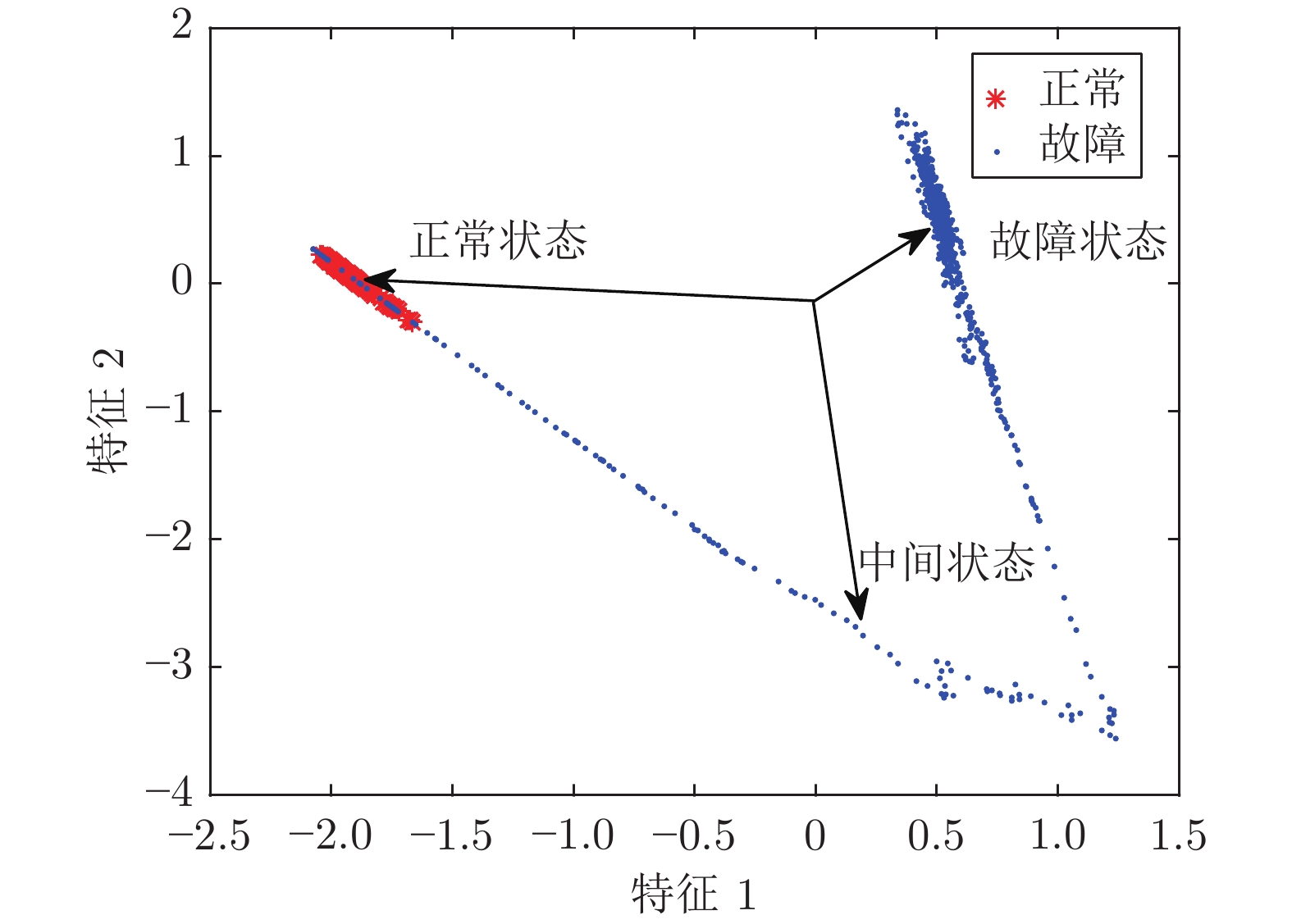
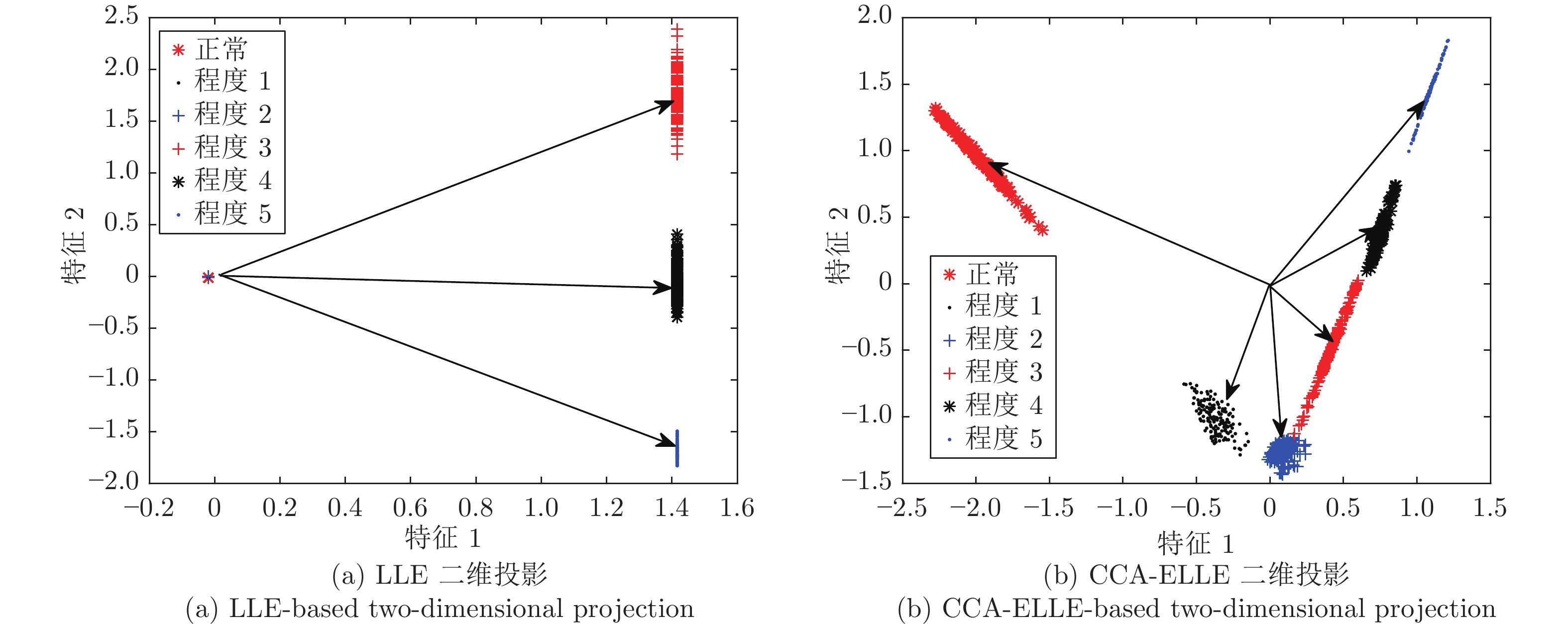
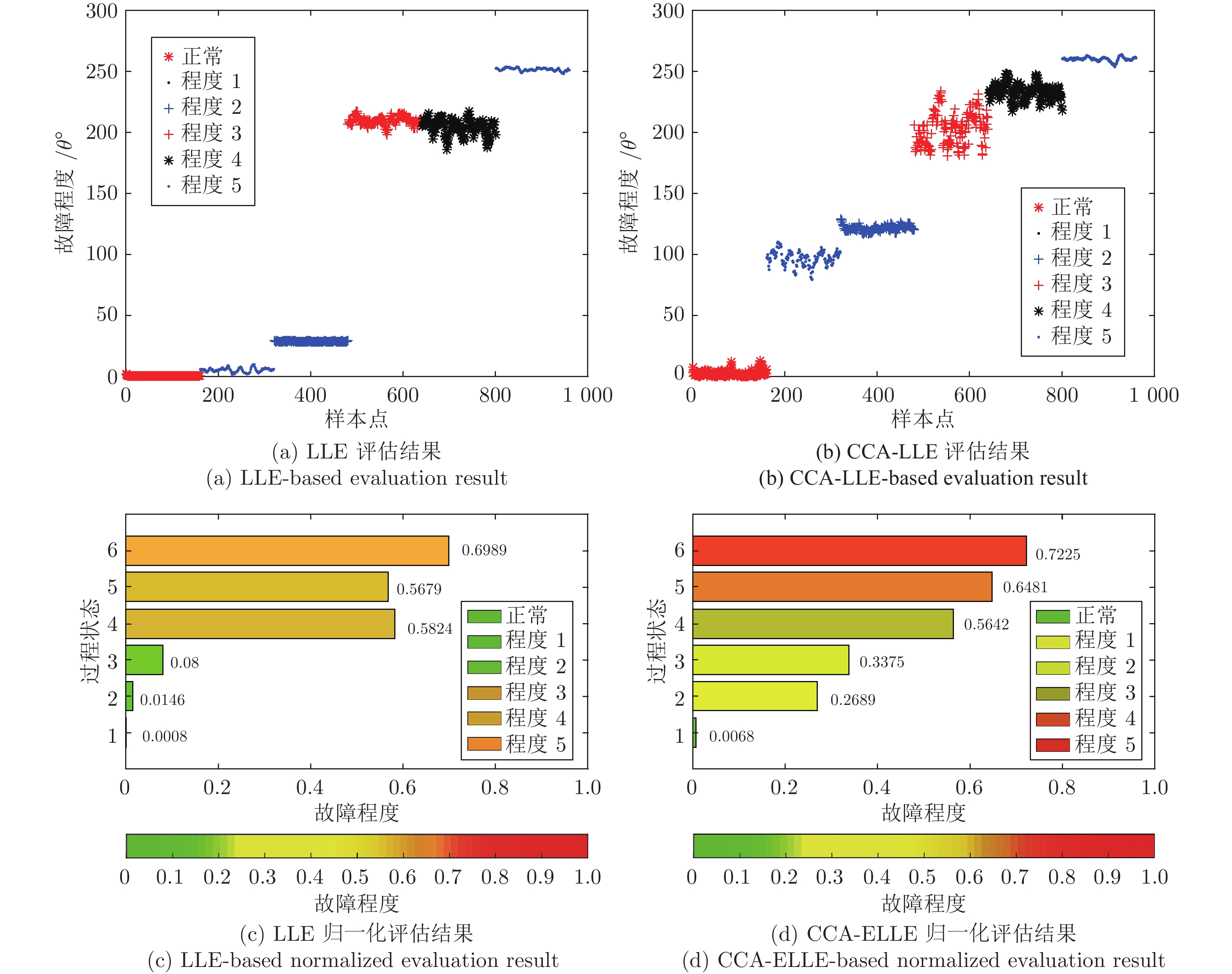
质量异常检测(Quality abnormality detection, QAD)与故障量化评估(Fault quantitative assessment, FQA)作为工业过程监控的关键环节, 是故障诊断领域的研究热点. 本文提出了一种新的工业过程质量异常检测与故障量化评估方法. 首先, 采用弹性网络(Elastic net, EN)算法构建了质量相关的变量候选集, 借助典型相关分析(Canonical correlation analysis, CCA)构建了质量相关的特征向量, 并引入支持向量数据描述(Support vector data description, SVDD)实现质量异常检测. 其次, 从优化近邻点距离的角度提出了增强局部线性嵌入(Enhanced local linear embedding, ELLE)算法, 并提出了基于CCA-ELLE的质量异常故障量化评估方法. 最后, 通过田纳西−伊斯曼(Tennessee-Eastman, TE)过程进行仿真验证, 并与传统的方法进行对比分析, 实验结果验证了所提方法的优越性和有效性.
质量异常检测(Quality abnormality detection, QAD)与故障量化评估(Fault quantitative assessment, FQA)作为工业过程监控的关键环节, 是故障诊断领域的研究热点. 本文提出了一种新的工业过程质量异常检测与故障量化评估方法. 首先, 采用弹性网络(Elastic net, EN)算法构建了质量相关的变量候选集, 借助典型相关分析(Canonical correlation analysis, CCA)构建了质量相关的特征向量, 并引入支持向量数据描述(Support vector data description, SVDD)实现质量异常检测. 其次, 从优化近邻点距离的角度提出了增强局部线性嵌入(Enhanced local linear embedding, ELLE)算法, 并提出了基于CCA-ELLE的质量异常故障量化评估方法. 最后, 通过田纳西−伊斯曼(Tennessee-Eastman, TE)过程进行仿真验证, 并与传统的方法进行对比分析, 实验结果验证了所提方法的优越性和有效性.
2022, 48(10): 2416-2428.
doi: 10.16383/j.aas.c220003
摘要:
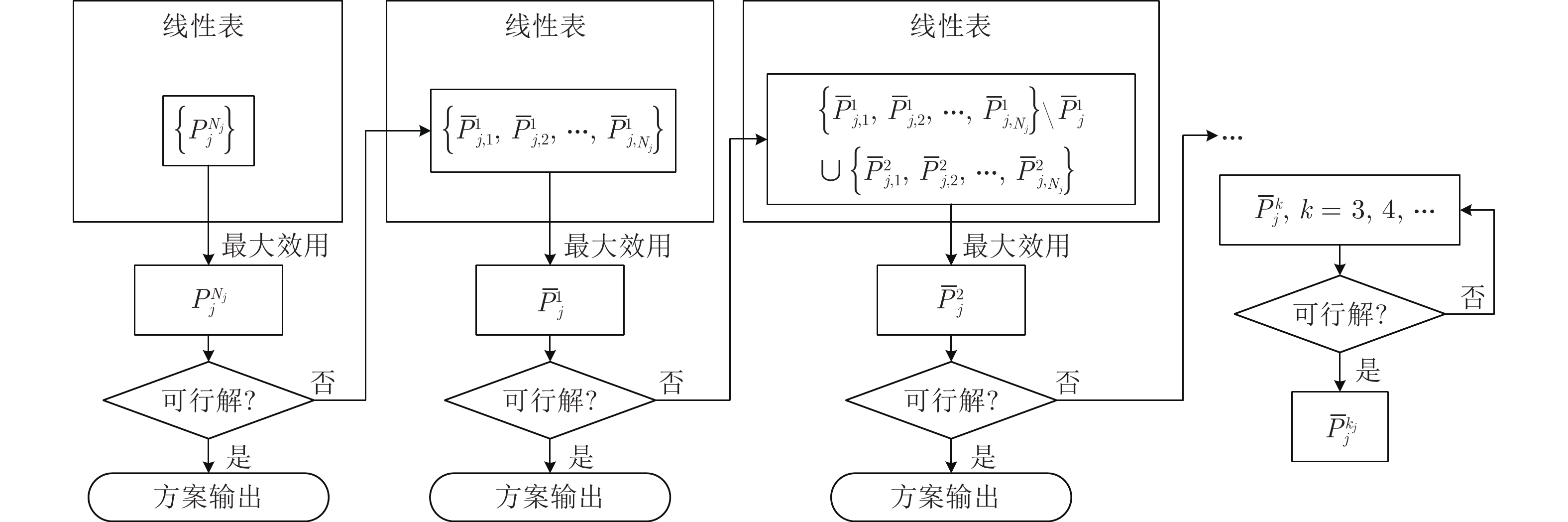
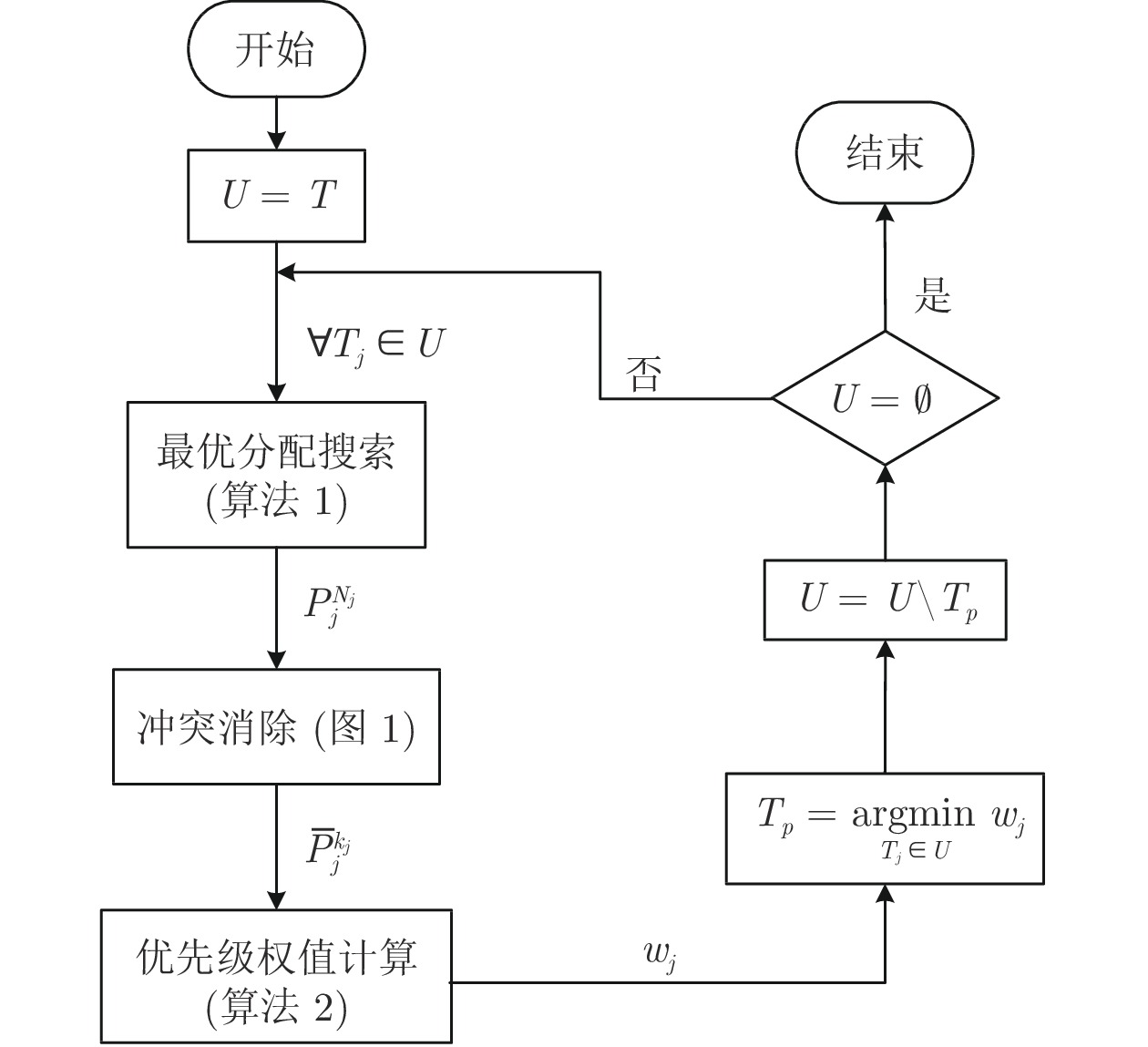
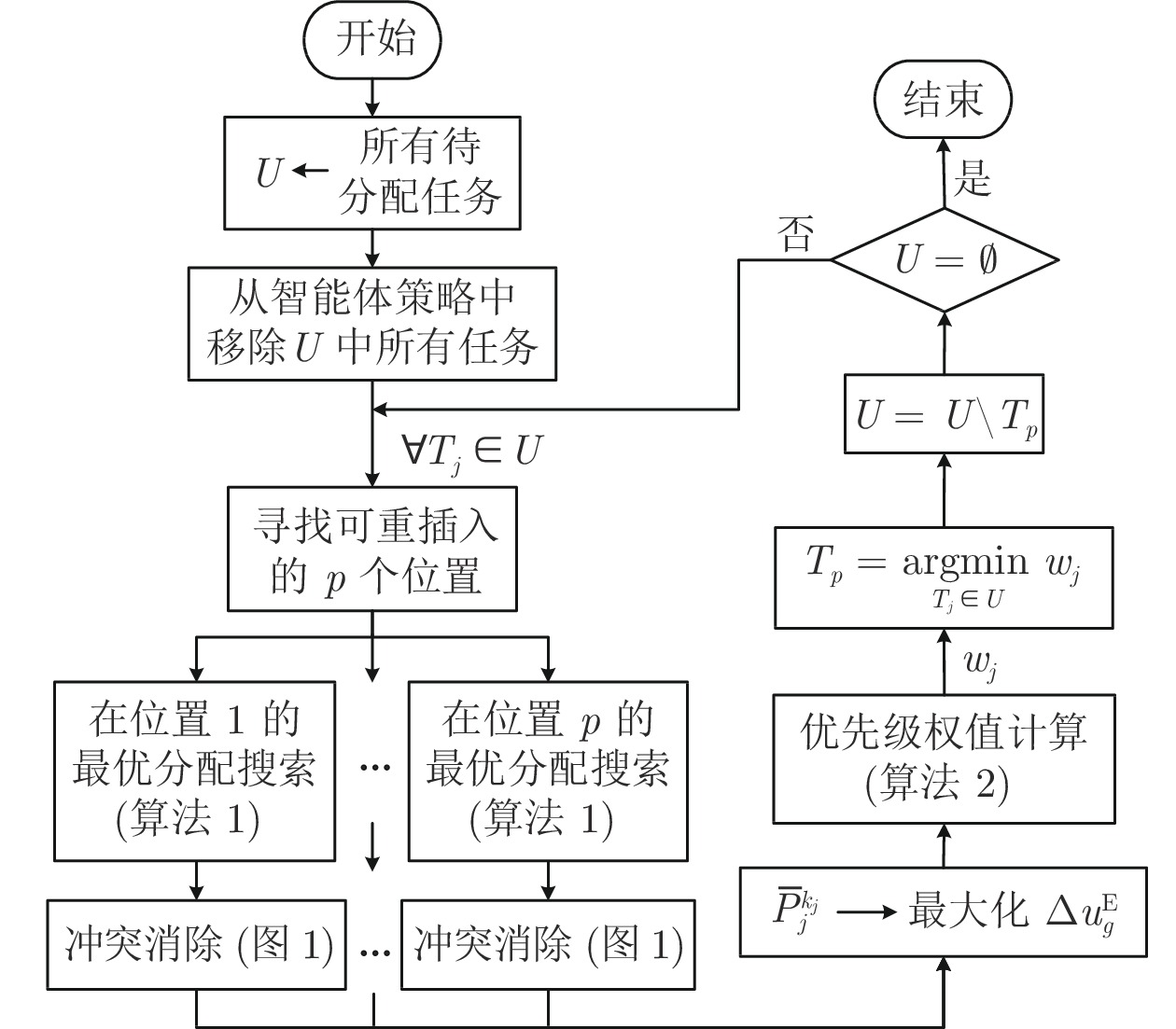
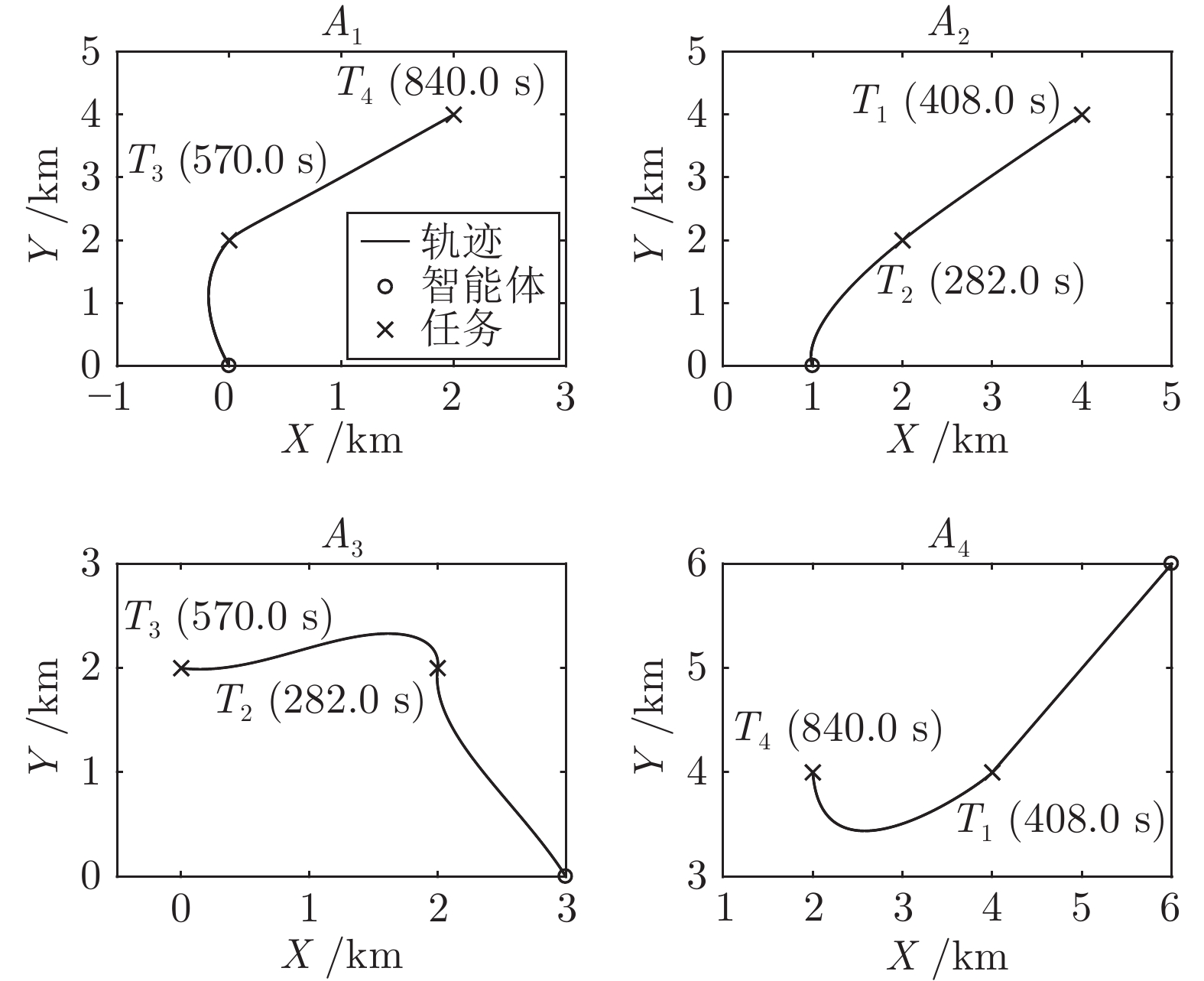
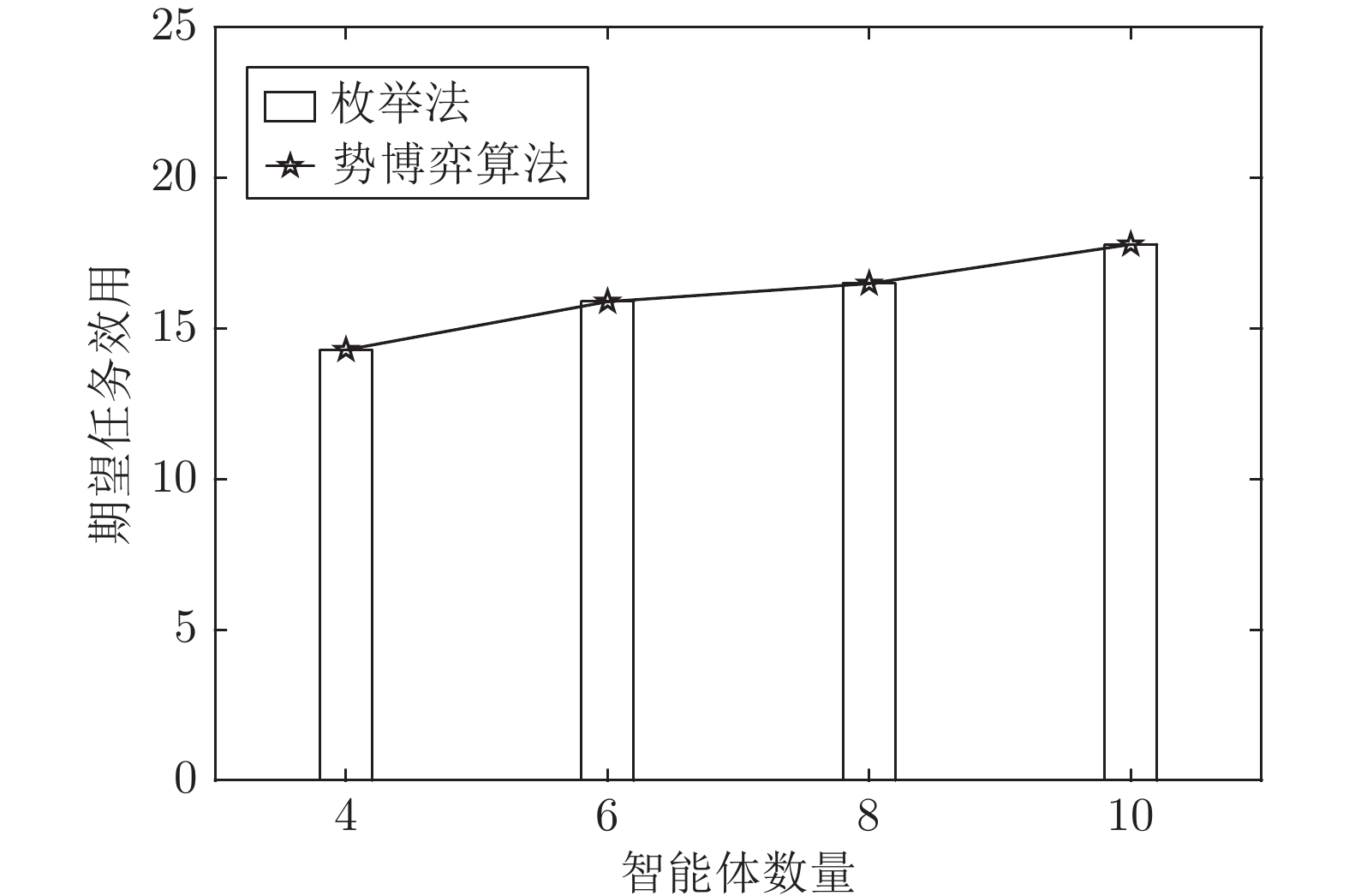
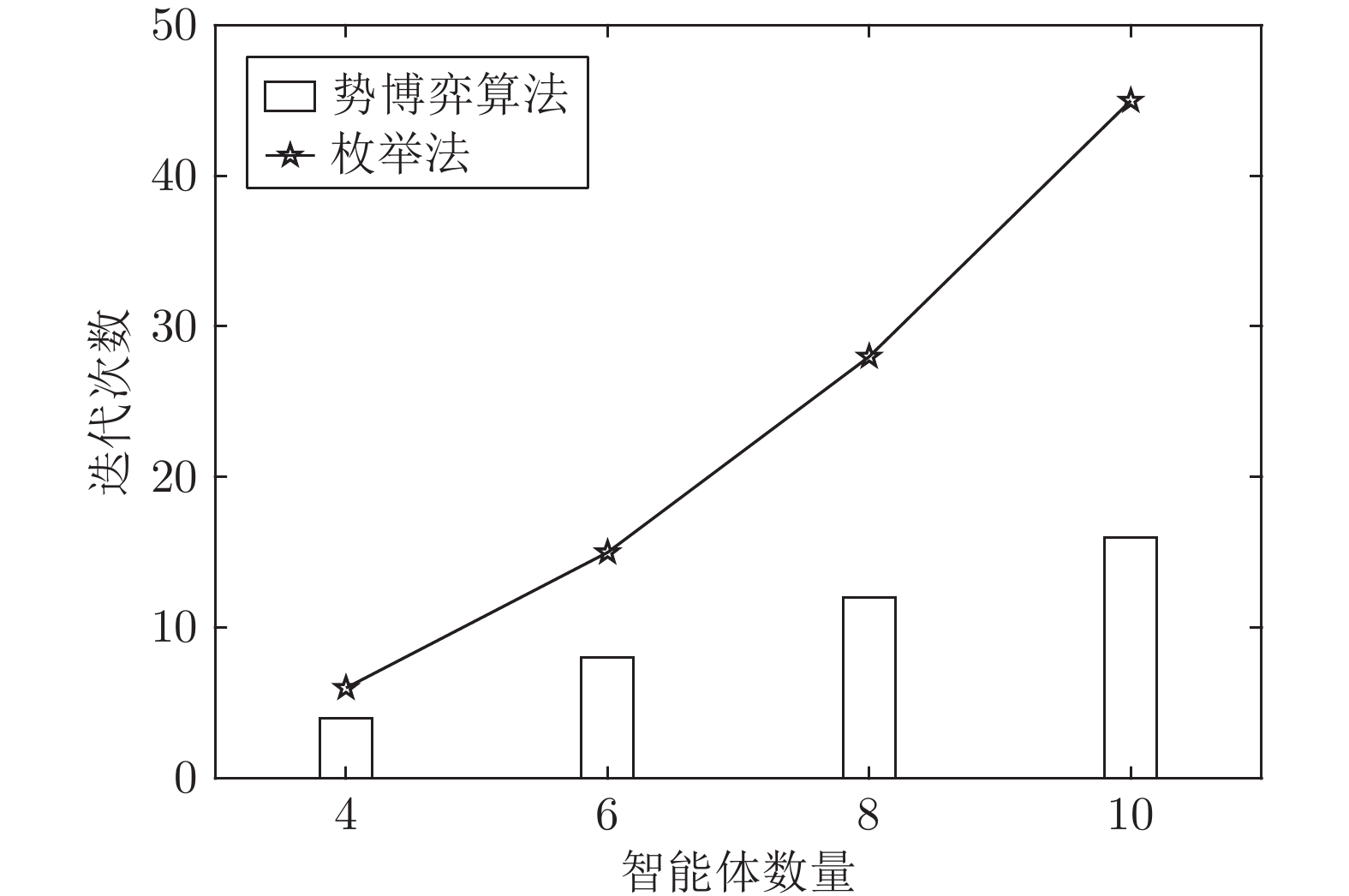
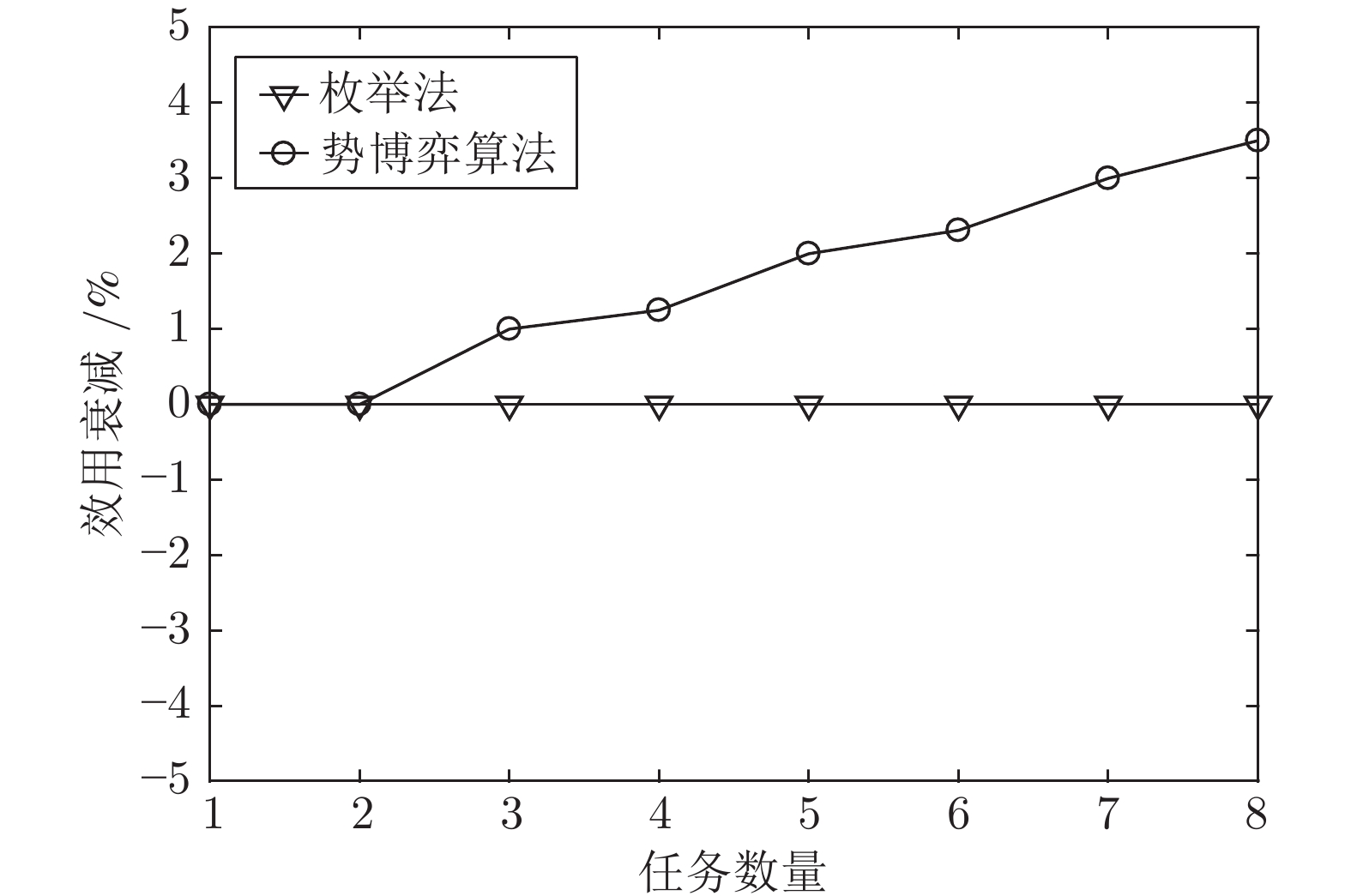
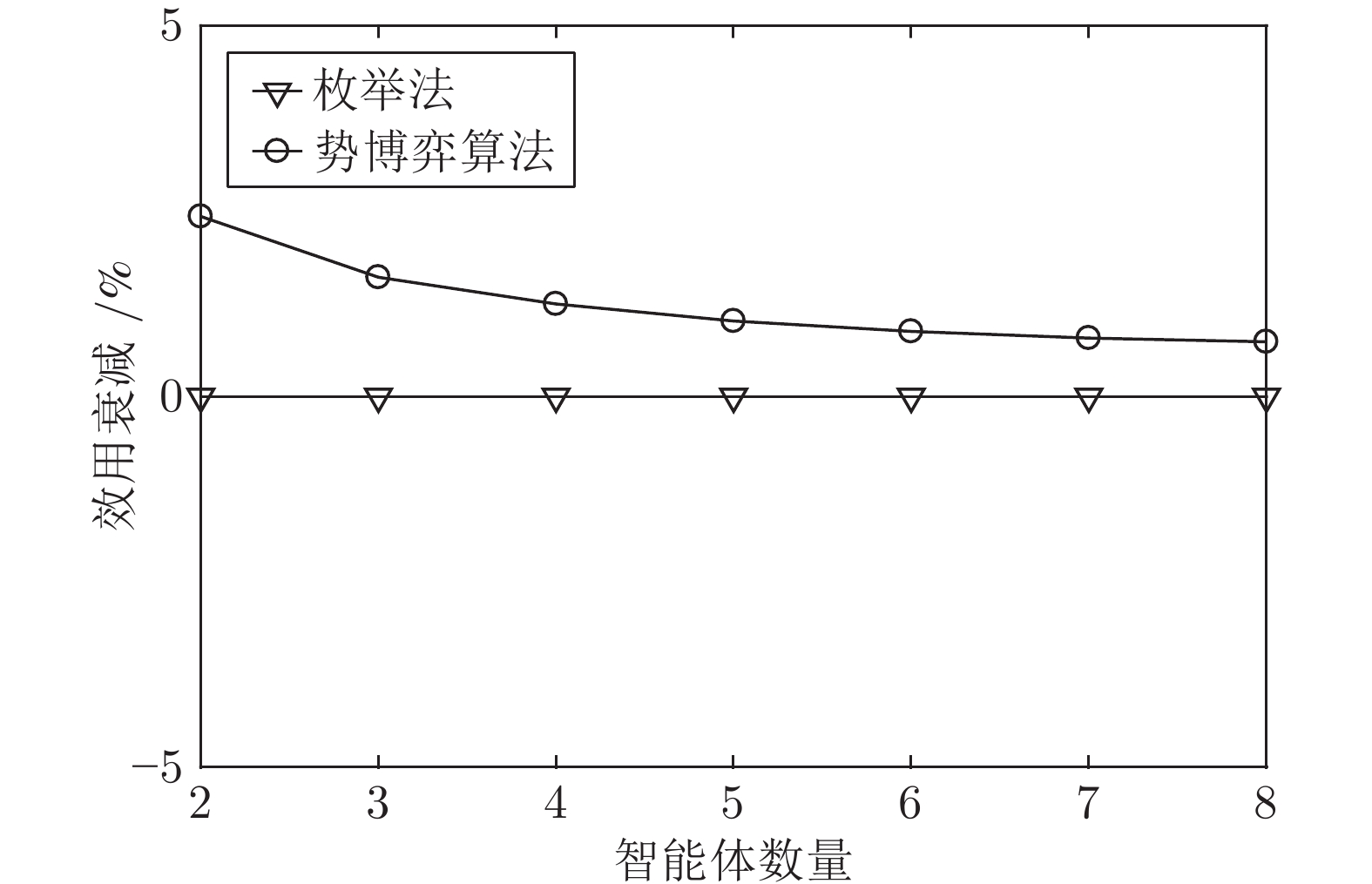
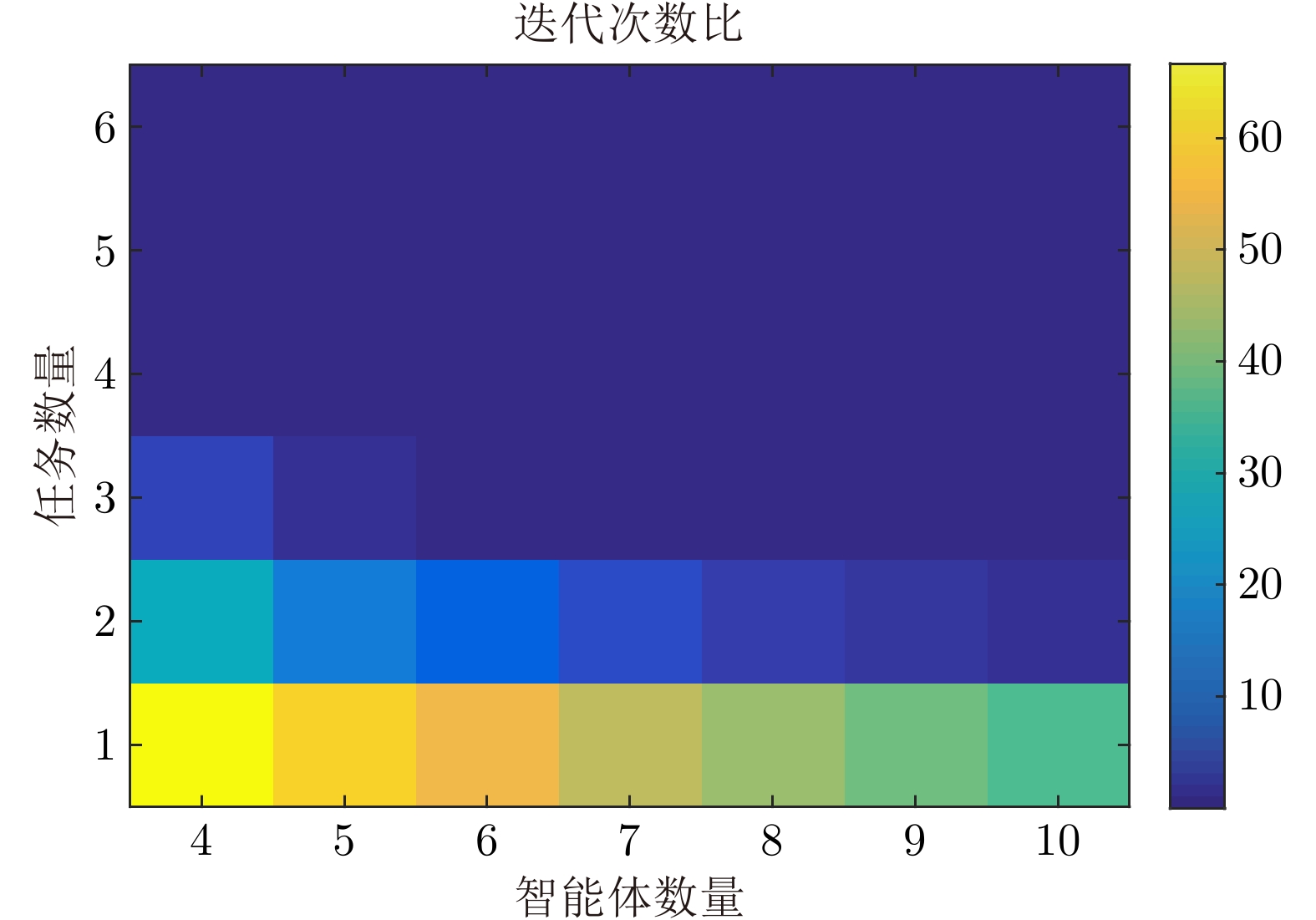
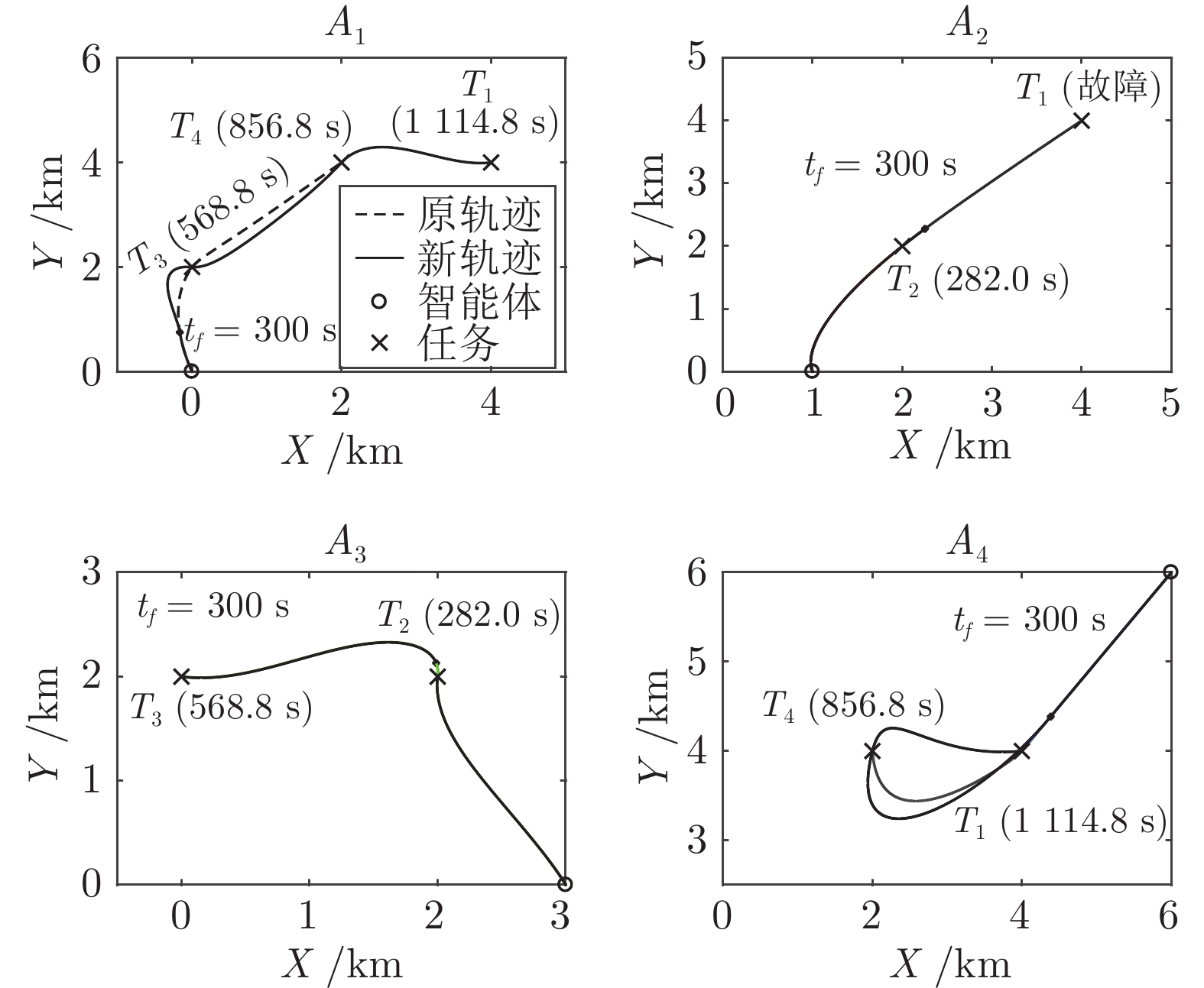
针对异构多智能体系统, 基于势博弈理论提出一种新的任务分配和重分配算法. 考虑任务执行同步性和任务时效性的多重约束, 导致异构多智能体系统中各个体任务执行时间受到多种限制, 建立一个基于势博弈的算法结构, 使系统以分布式方式工作. 在此基础上, 基于势博弈理论设计任务分配算法, 保证在较低复杂度的同时, 可以得到近似最大化期望全局效用的良好分配方案, 并且随后将所提出的方法推广到任务重分配方案实现故障下的容错. 最后, 针对攻击任务场景对所提算法进行仿真验证, 结果表明, 在期望全局效用、容错能力和算法复杂度方面具有全面的性能.
针对异构多智能体系统, 基于势博弈理论提出一种新的任务分配和重分配算法. 考虑任务执行同步性和任务时效性的多重约束, 导致异构多智能体系统中各个体任务执行时间受到多种限制, 建立一个基于势博弈的算法结构, 使系统以分布式方式工作. 在此基础上, 基于势博弈理论设计任务分配算法, 保证在较低复杂度的同时, 可以得到近似最大化期望全局效用的良好分配方案, 并且随后将所提出的方法推广到任务重分配方案实现故障下的容错. 最后, 针对攻击任务场景对所提算法进行仿真验证, 结果表明, 在期望全局效用、容错能力和算法复杂度方面具有全面的性能.
2022, 48(10): 2429-2441.
doi: 10.16383/j.aas.c190574
摘要:
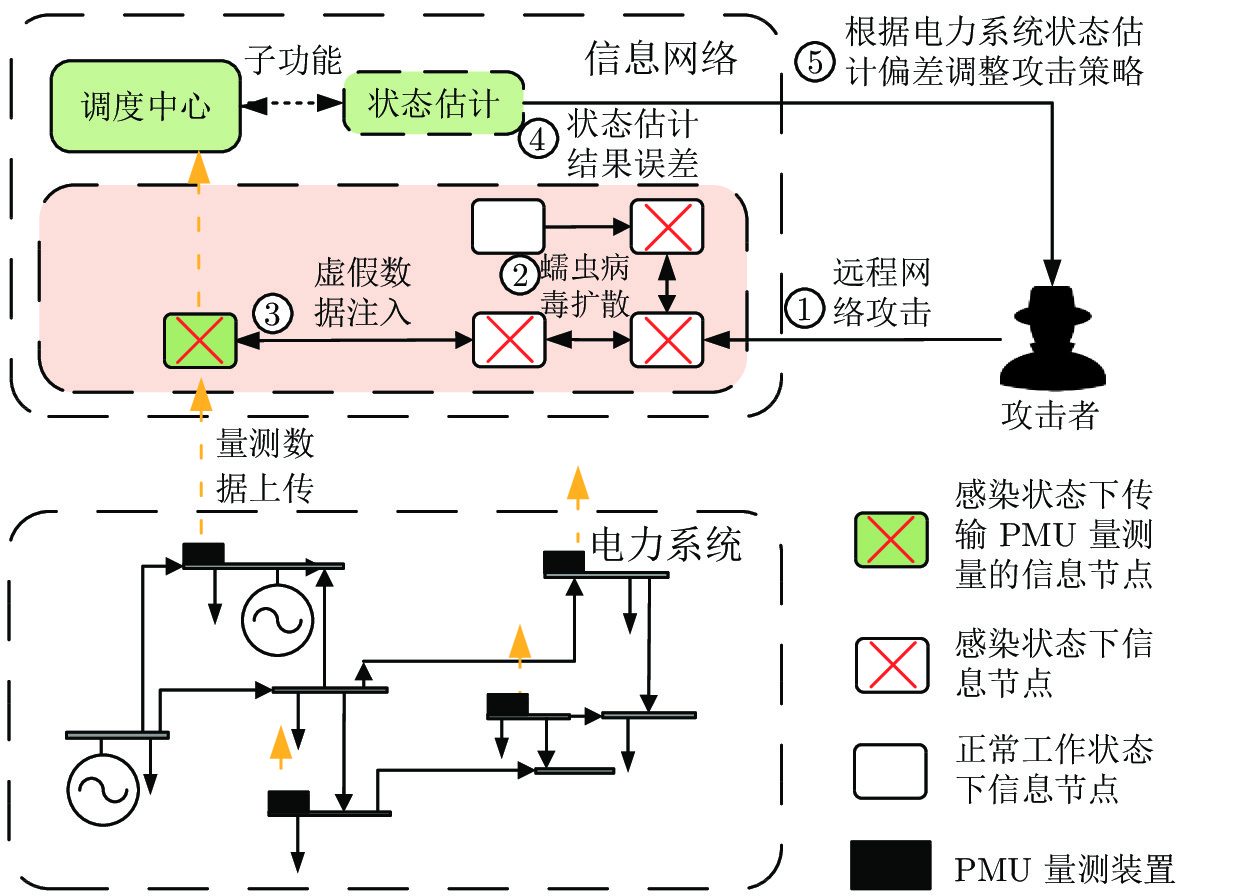
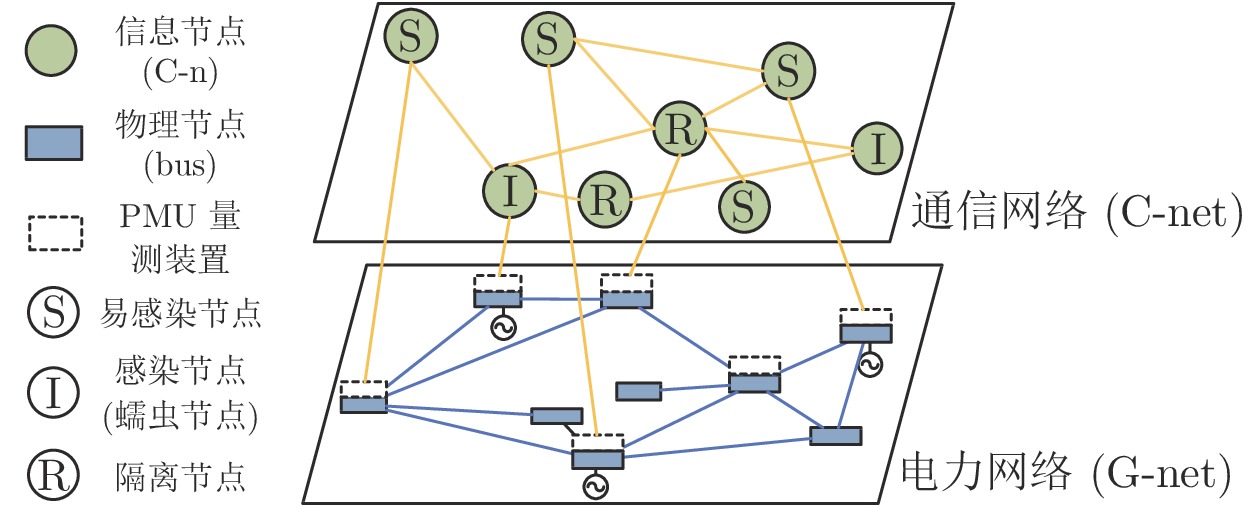
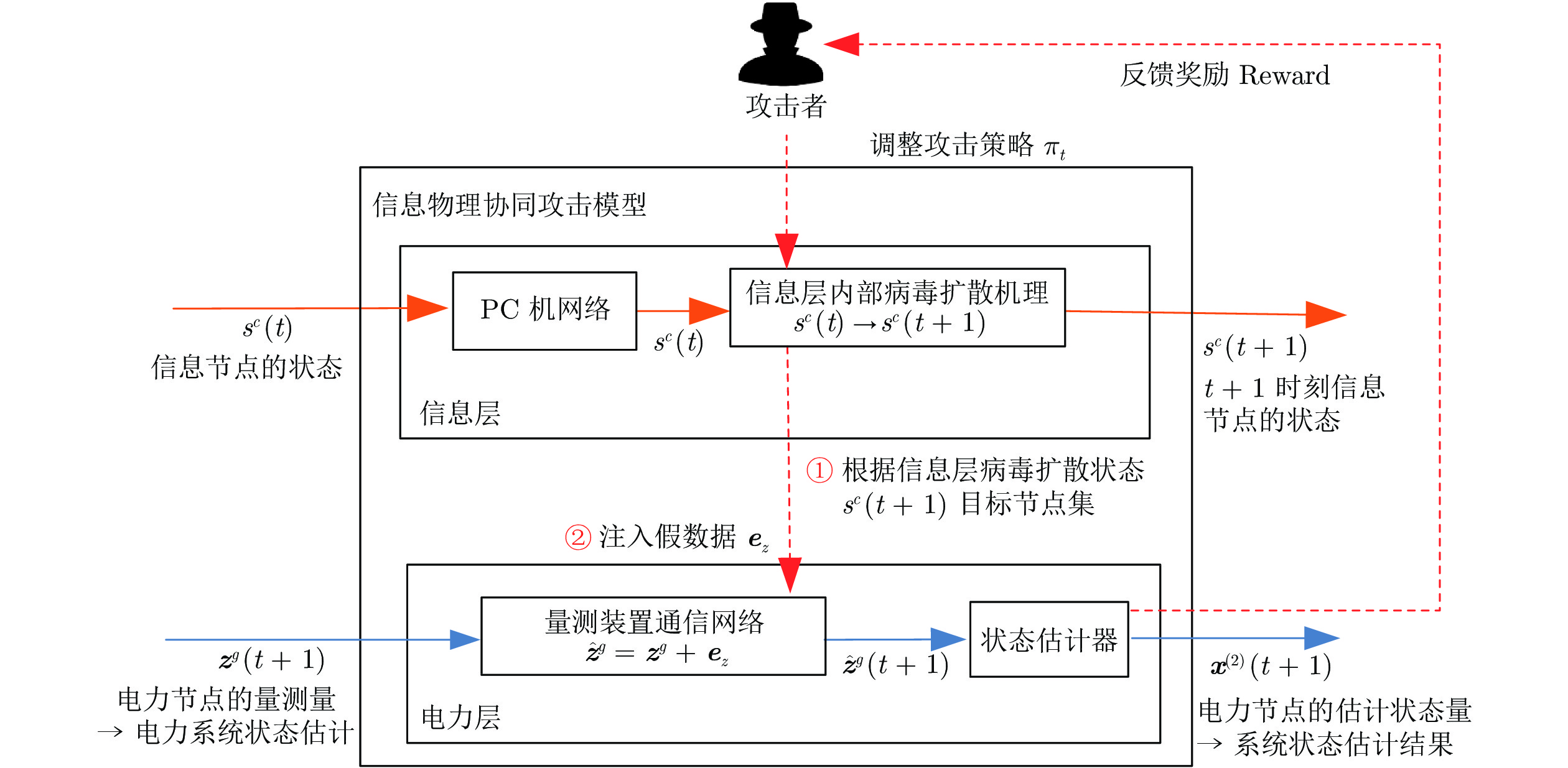
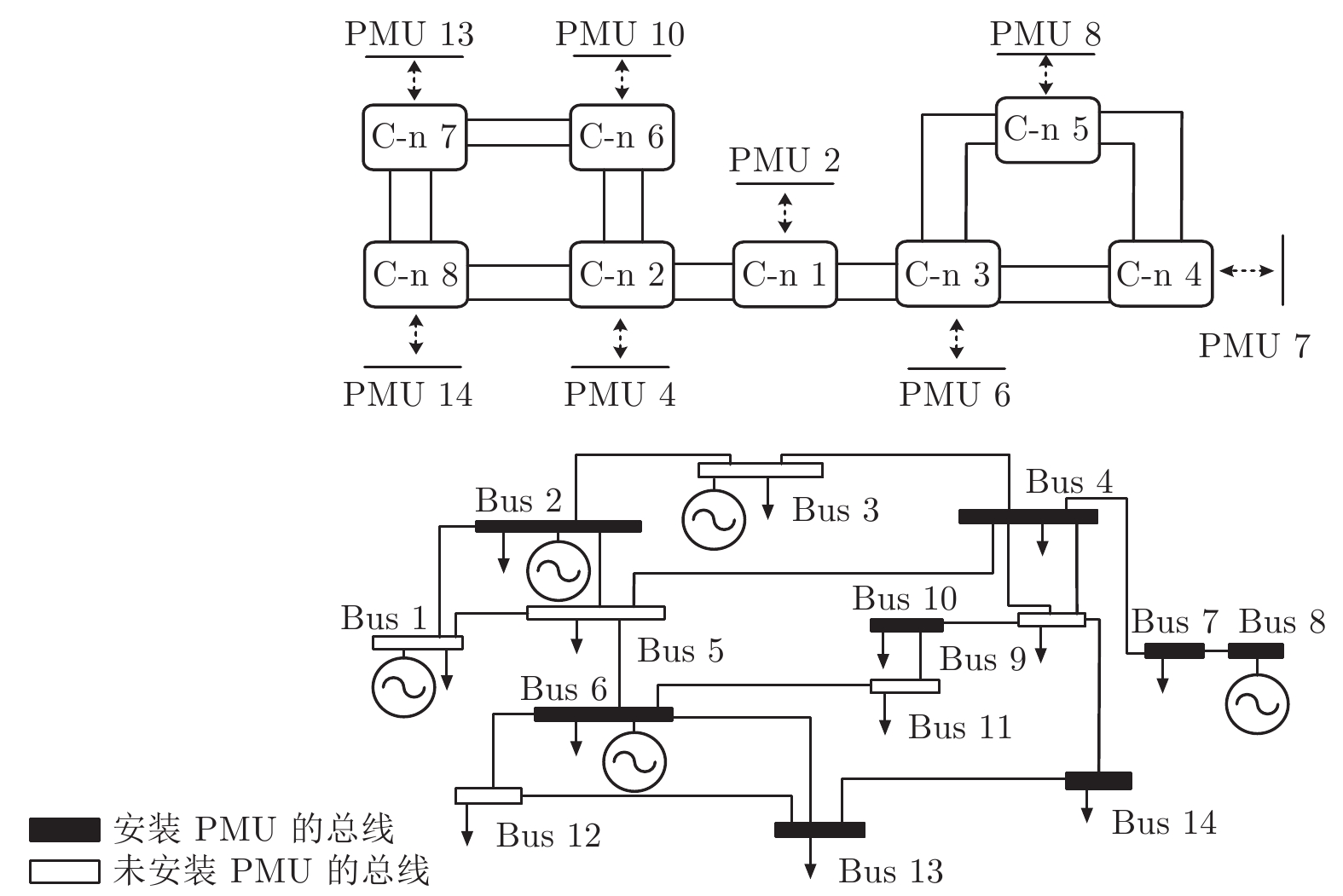
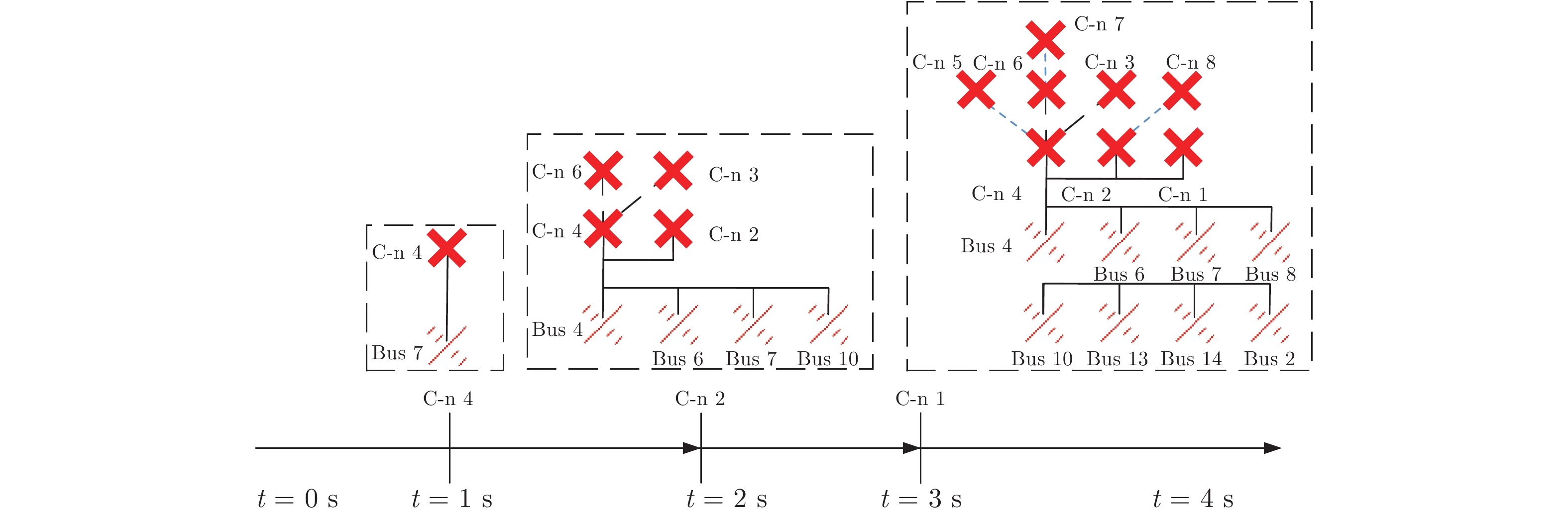
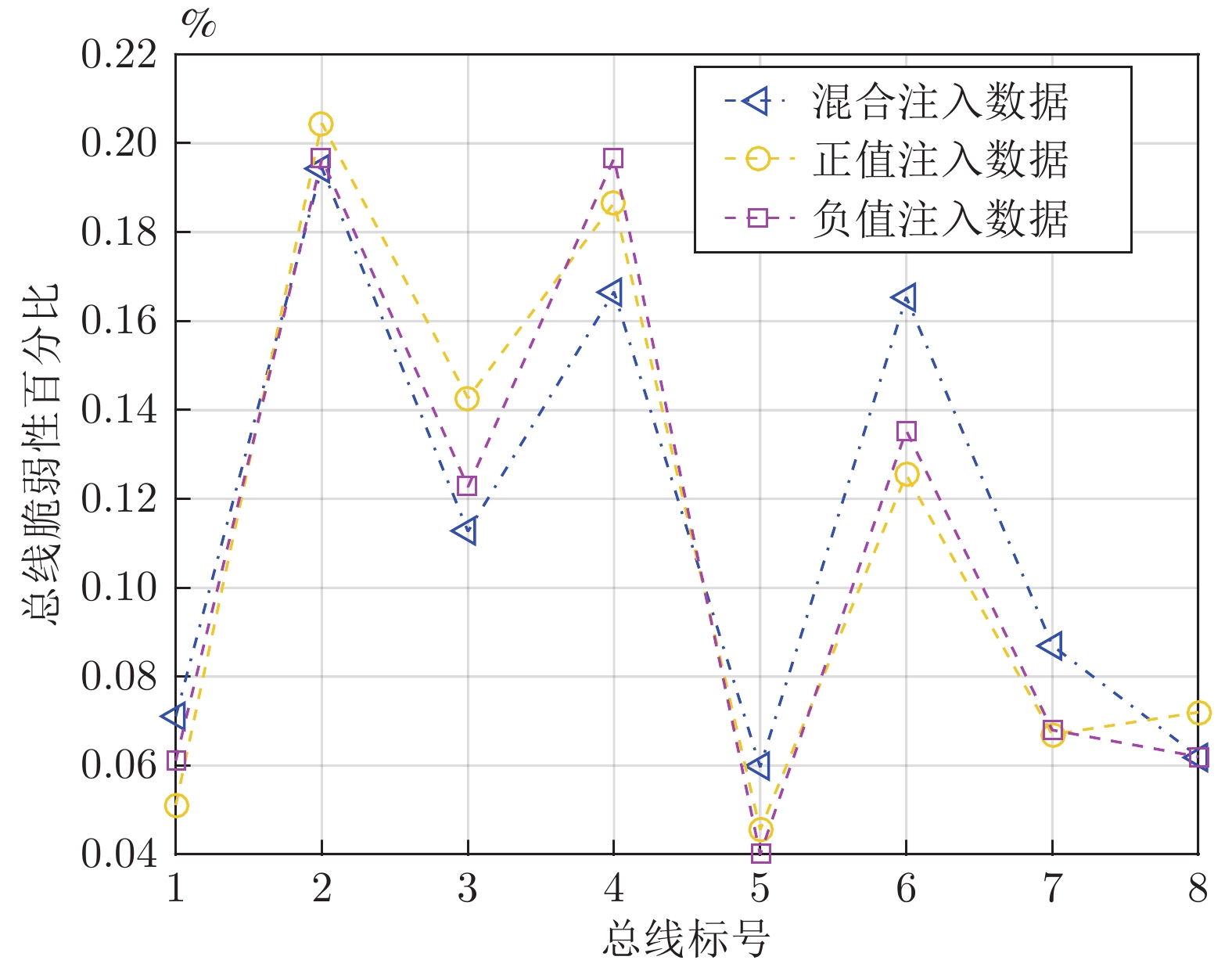
随着信息技术与现代电力系统的结合日趋紧密, 通信系统异常和网络攻击均可能影响到电力系统的安全稳定运行. 为了研究工控蠕虫病毒对电网带来的安全隐患, 本文首次建立了基于马尔科夫决策过程(Markov decision process, MDP)的电力信息物理系统跨空间协同攻击模型, 该模型同时考虑通信设备漏洞被利用的难易程度为代价以及对电力网络的破坏程度为收益两方面因素, 能够更有效地识别系统潜在风险. 其次, 采用Q学习算法求解在该模型下的最优攻击策略, 并依据电力系统状态估计的误差值来评定该攻击行为对电力系统造成的破坏程度. 最后, 本文在通信8节点−电力14节点的耦合系统上进行联合仿真, 对比结果表明相较单一攻击方式, 协同攻击对电网的破坏程度更大. 与传统的不考虑通信网络的电力层攻击研究相比, 本模型辨识出的薄弱节点也考虑了信息层的关键节点的影响, 对防御资源的分配有指导作用.
随着信息技术与现代电力系统的结合日趋紧密, 通信系统异常和网络攻击均可能影响到电力系统的安全稳定运行. 为了研究工控蠕虫病毒对电网带来的安全隐患, 本文首次建立了基于马尔科夫决策过程(Markov decision process, MDP)的电力信息物理系统跨空间协同攻击模型, 该模型同时考虑通信设备漏洞被利用的难易程度为代价以及对电力网络的破坏程度为收益两方面因素, 能够更有效地识别系统潜在风险. 其次, 采用Q学习算法求解在该模型下的最优攻击策略, 并依据电力系统状态估计的误差值来评定该攻击行为对电力系统造成的破坏程度. 最后, 本文在通信8节点−电力14节点的耦合系统上进行联合仿真, 对比结果表明相较单一攻击方式, 协同攻击对电网的破坏程度更大. 与传统的不考虑通信网络的电力层攻击研究相比, 本模型辨识出的薄弱节点也考虑了信息层的关键节点的影响, 对防御资源的分配有指导作用.

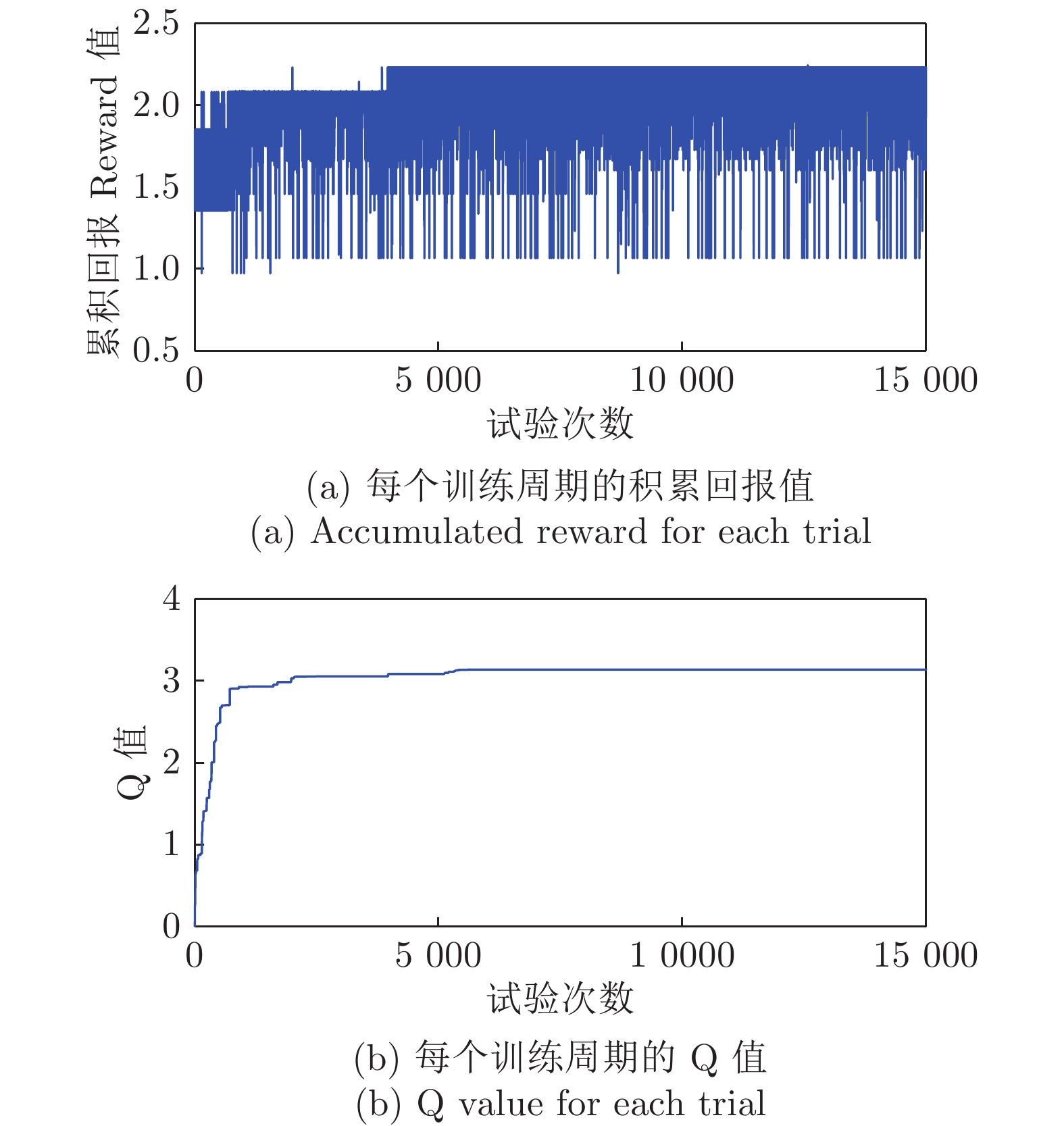

2022, 48(10): 2442-2461.
doi: 10.16383/j.aas.c190673
摘要:
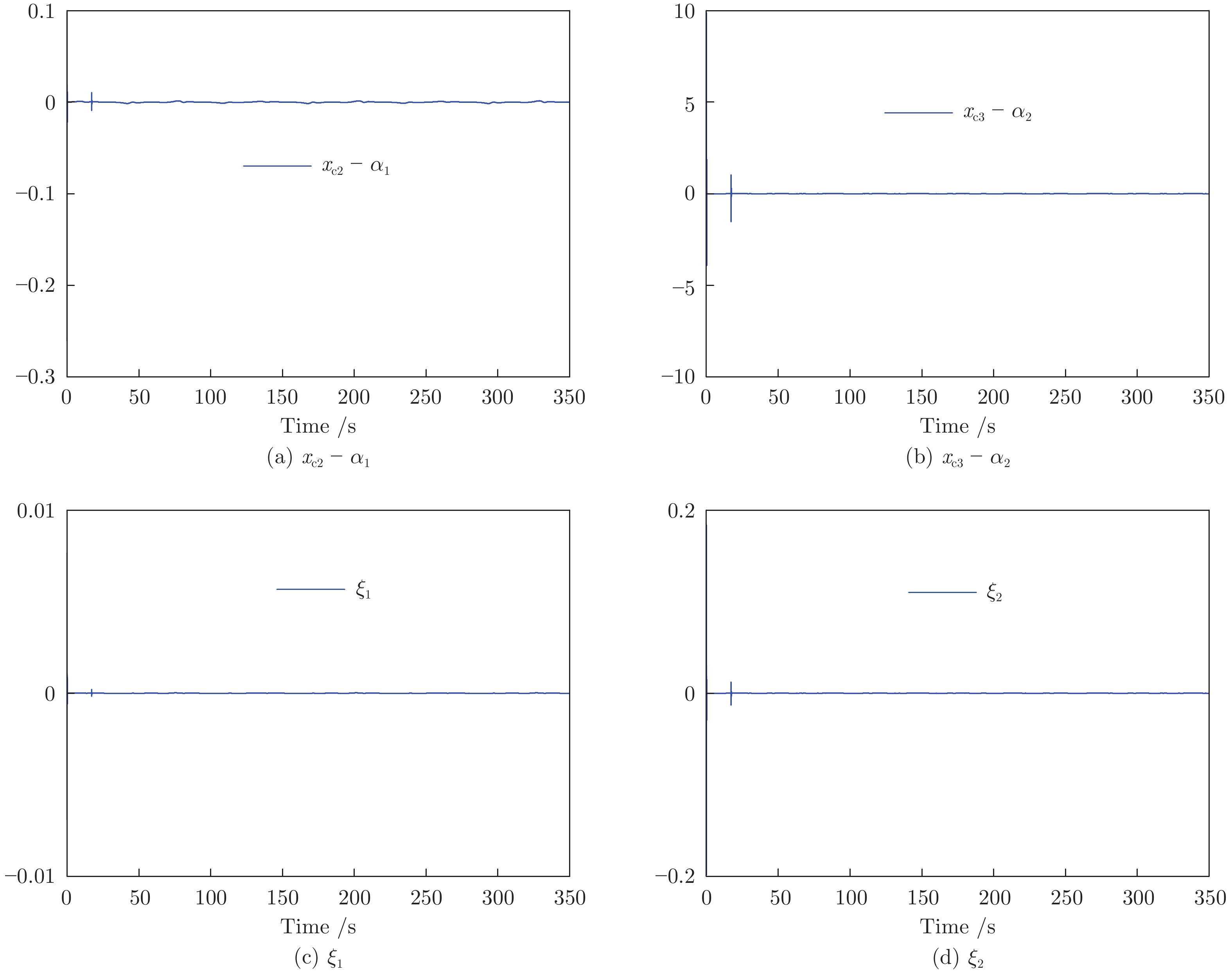
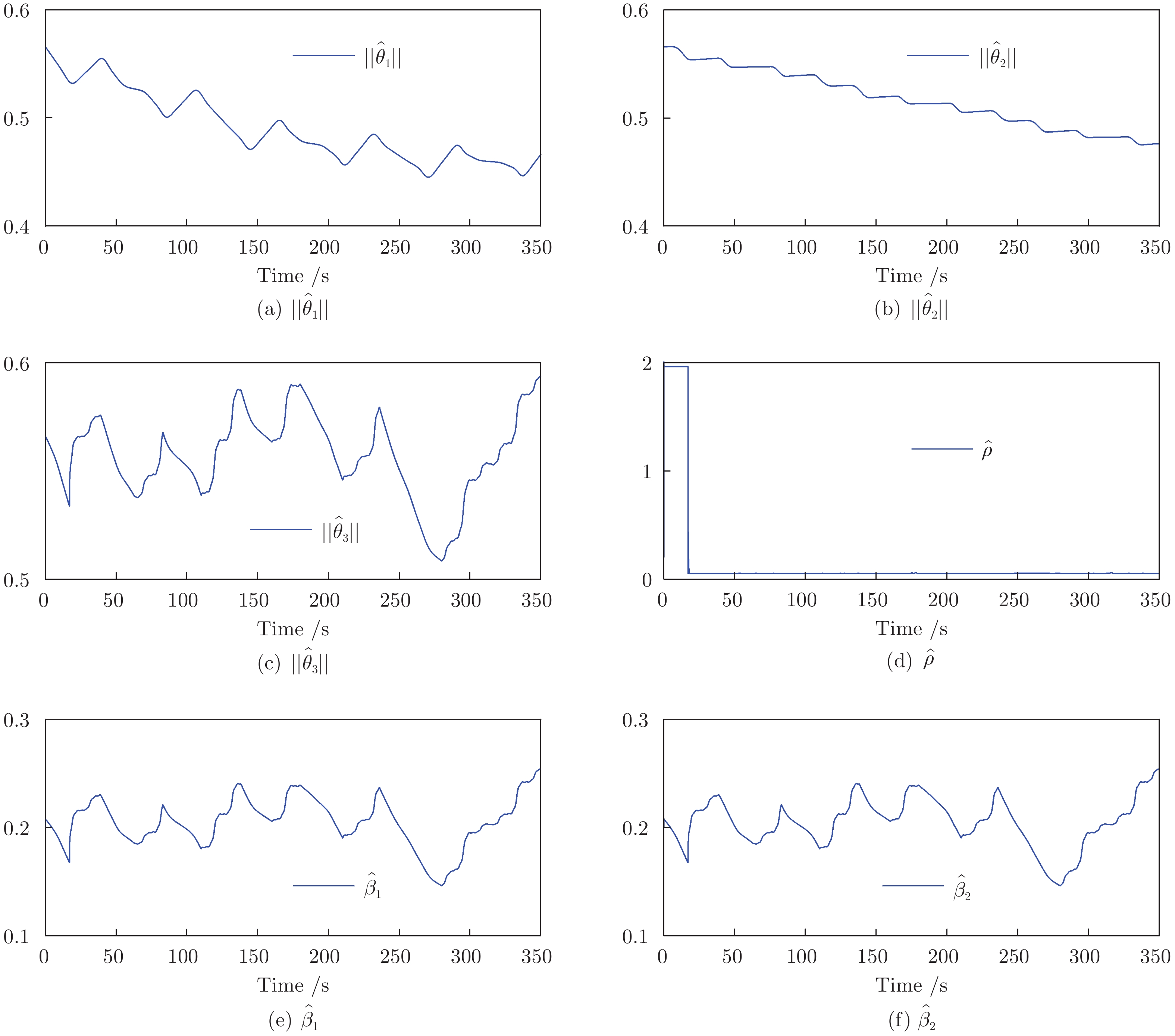
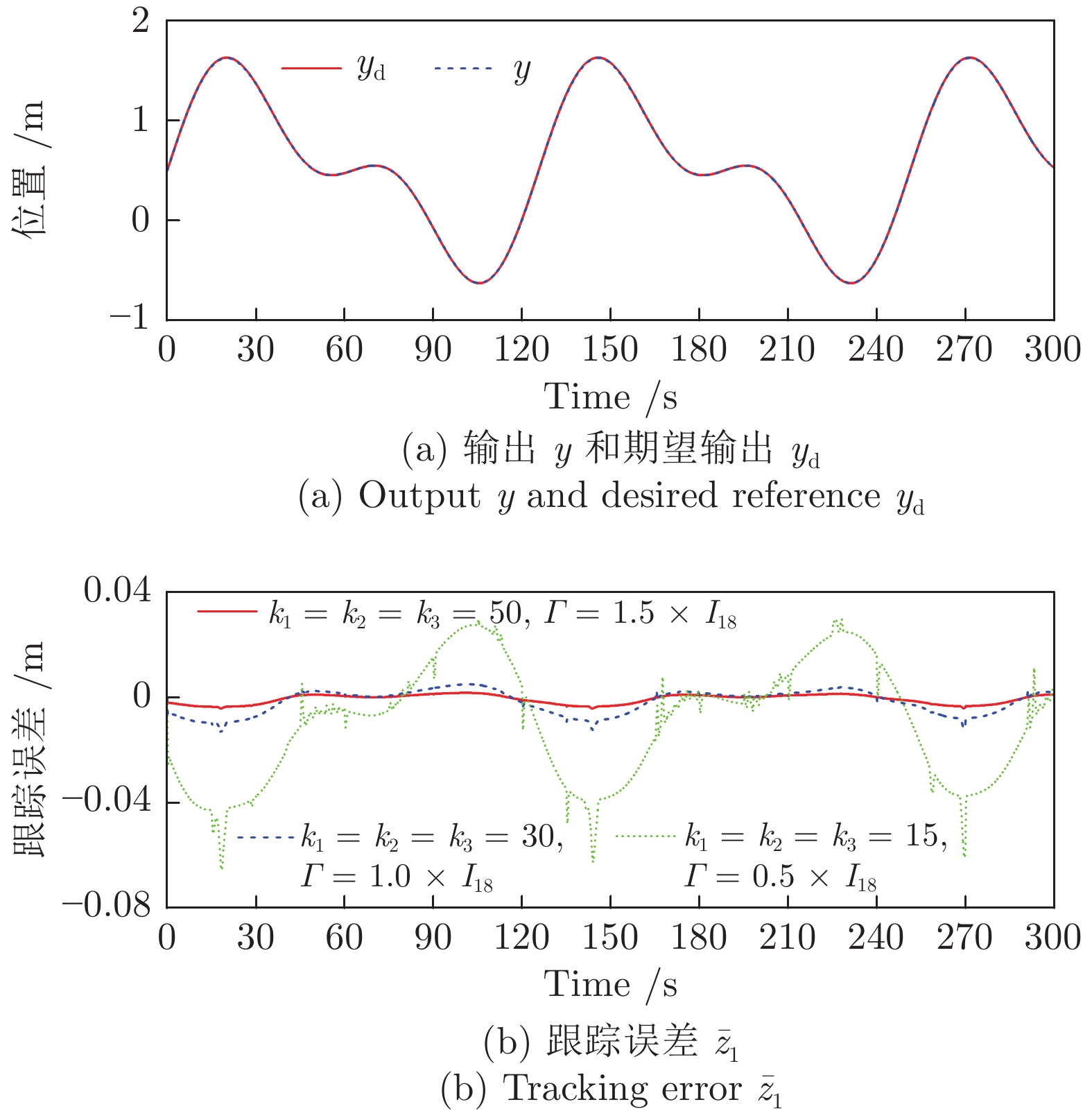
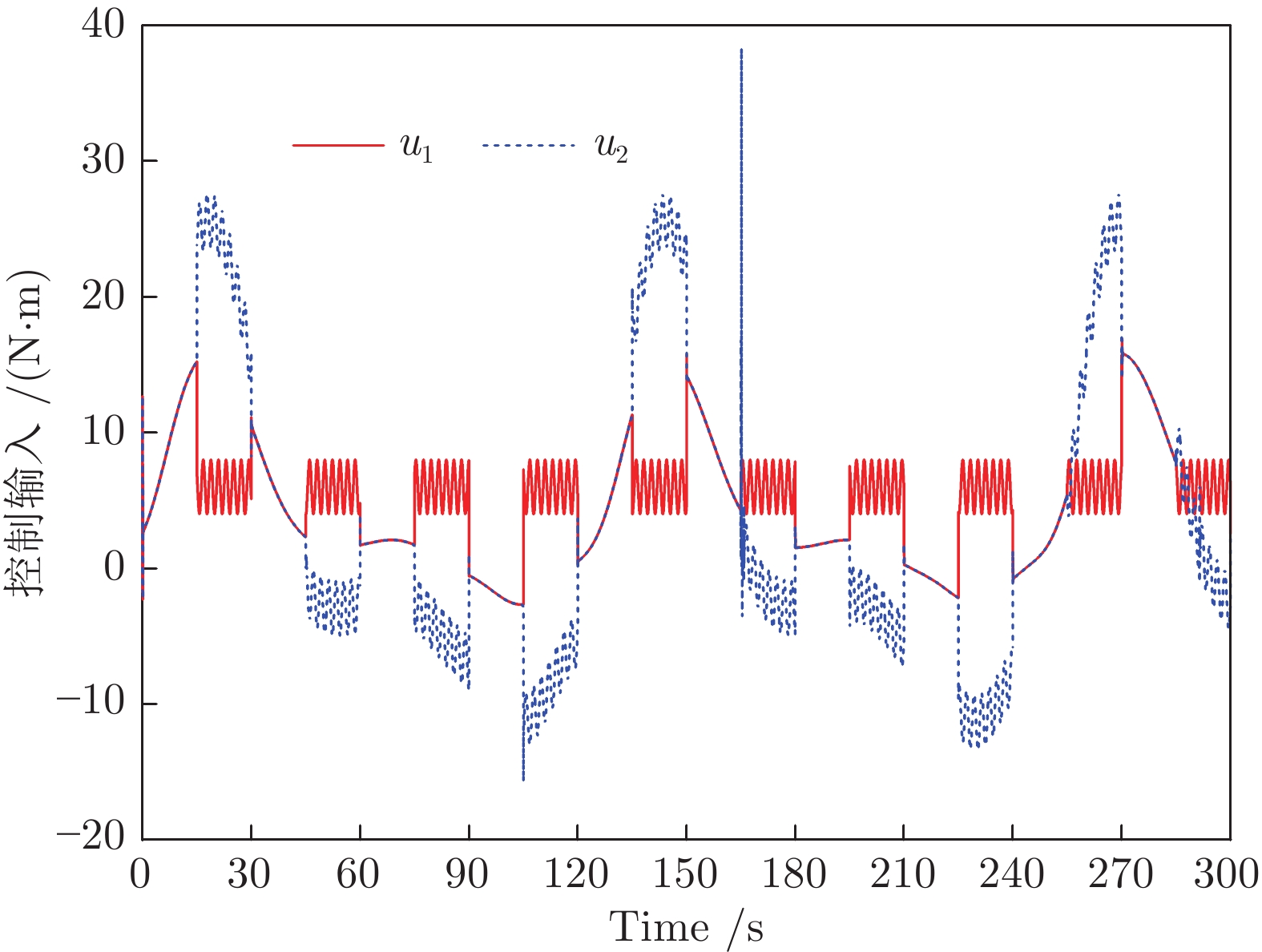
控制系统的执行器经常发生各种未知的间歇性故障. 如何有效地处理这些故障对系统的影响是一个难题. 针对一类不确定严格反馈非线性系统, 提出一种自适应CFB (Command filtered backstepping) 控制方案解决了间歇性执行器故障的补偿问题. 利用神经网络逼近控制器中的未知函数, 并采用投影算子实时在线更新控制器中的估计参数使得参数估计值随着故障次数的累积而不断增加的问题被消除. 提出改进的Lyapunov函数证明了所提出的方案能够保证所有闭环信号的有界性, 同时建立了跟踪误差与Lyapunov函数跳变幅度, 最小故障时间间隔, 设计参数之间的关系. 如果Lyapunov函数的跳变幅度越小以及两个连续故障之间的时间间隔越长, 系统的稳态跟踪指标越好. 通过迭代计算建立了暂态跟踪误差指标的均方根型界. 该界表明了通过选择恰当的设计参数, 可改善系统的暂态指标. 仿真结果表明了所提方案的有效性.
控制系统的执行器经常发生各种未知的间歇性故障. 如何有效地处理这些故障对系统的影响是一个难题. 针对一类不确定严格反馈非线性系统, 提出一种自适应CFB (Command filtered backstepping) 控制方案解决了间歇性执行器故障的补偿问题. 利用神经网络逼近控制器中的未知函数, 并采用投影算子实时在线更新控制器中的估计参数使得参数估计值随着故障次数的累积而不断增加的问题被消除. 提出改进的Lyapunov函数证明了所提出的方案能够保证所有闭环信号的有界性, 同时建立了跟踪误差与Lyapunov函数跳变幅度, 最小故障时间间隔, 设计参数之间的关系. 如果Lyapunov函数的跳变幅度越小以及两个连续故障之间的时间间隔越长, 系统的稳态跟踪指标越好. 通过迭代计算建立了暂态跟踪误差指标的均方根型界. 该界表明了通过选择恰当的设计参数, 可改善系统的暂态指标. 仿真结果表明了所提方案的有效性.

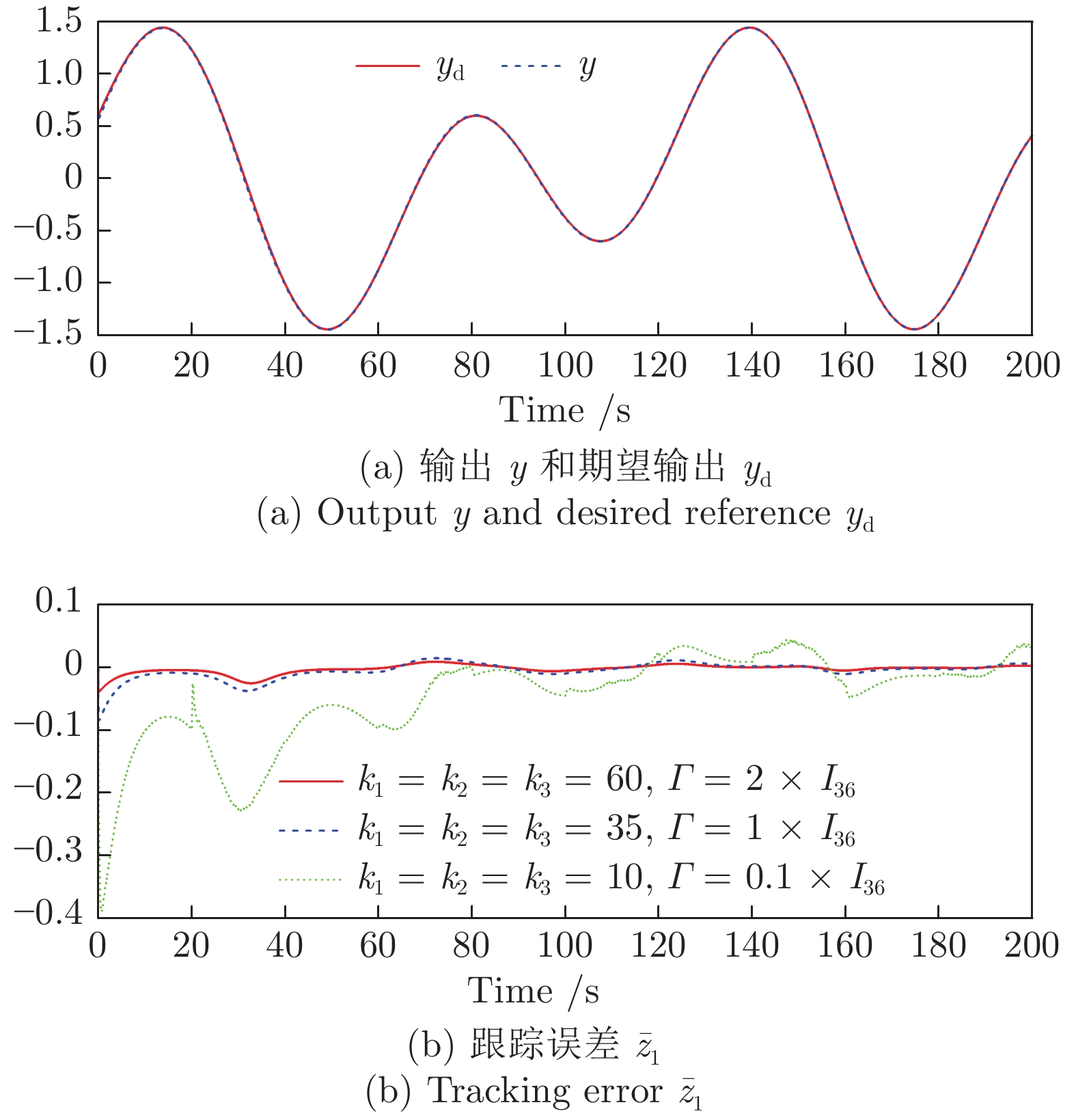
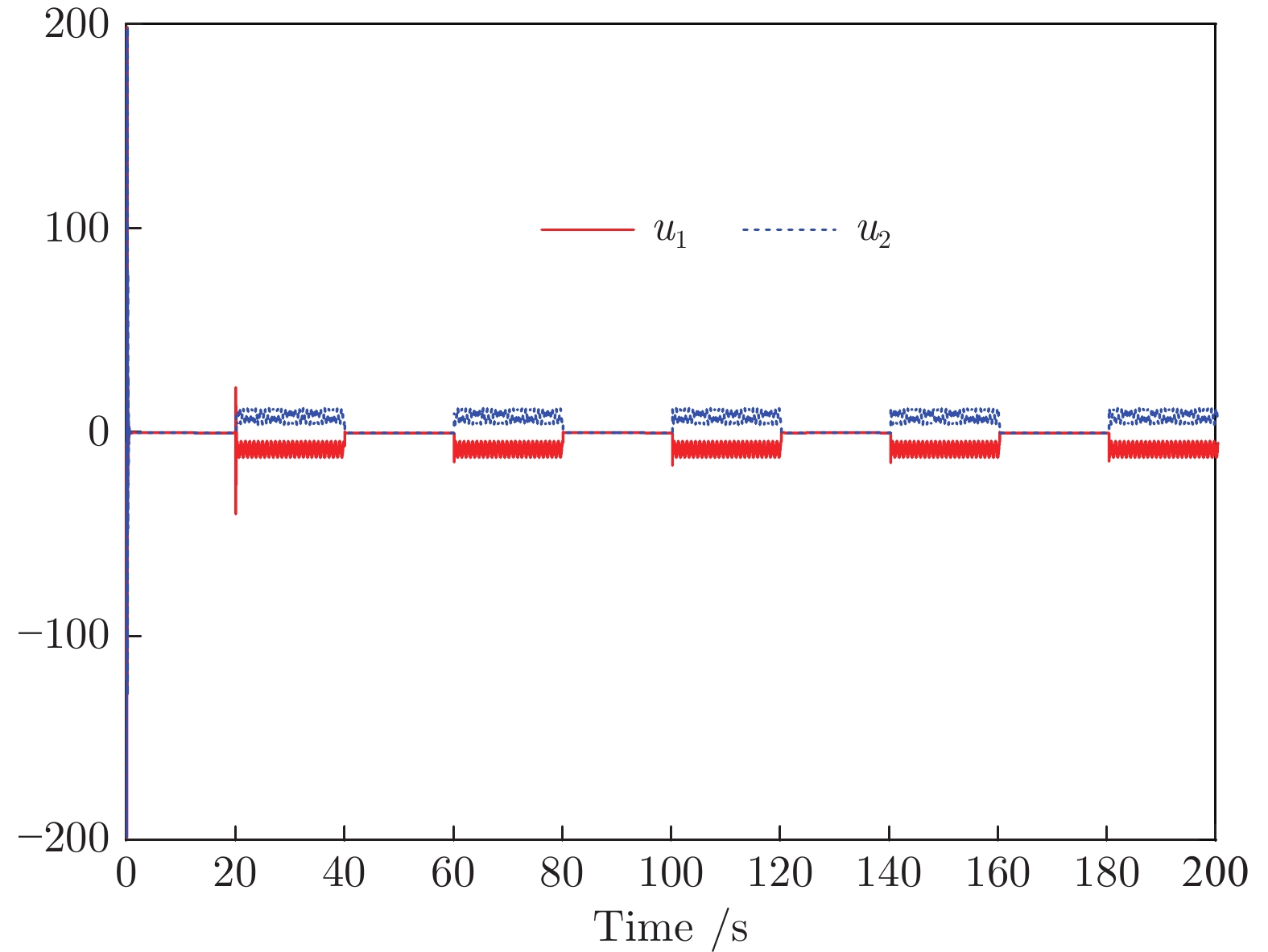
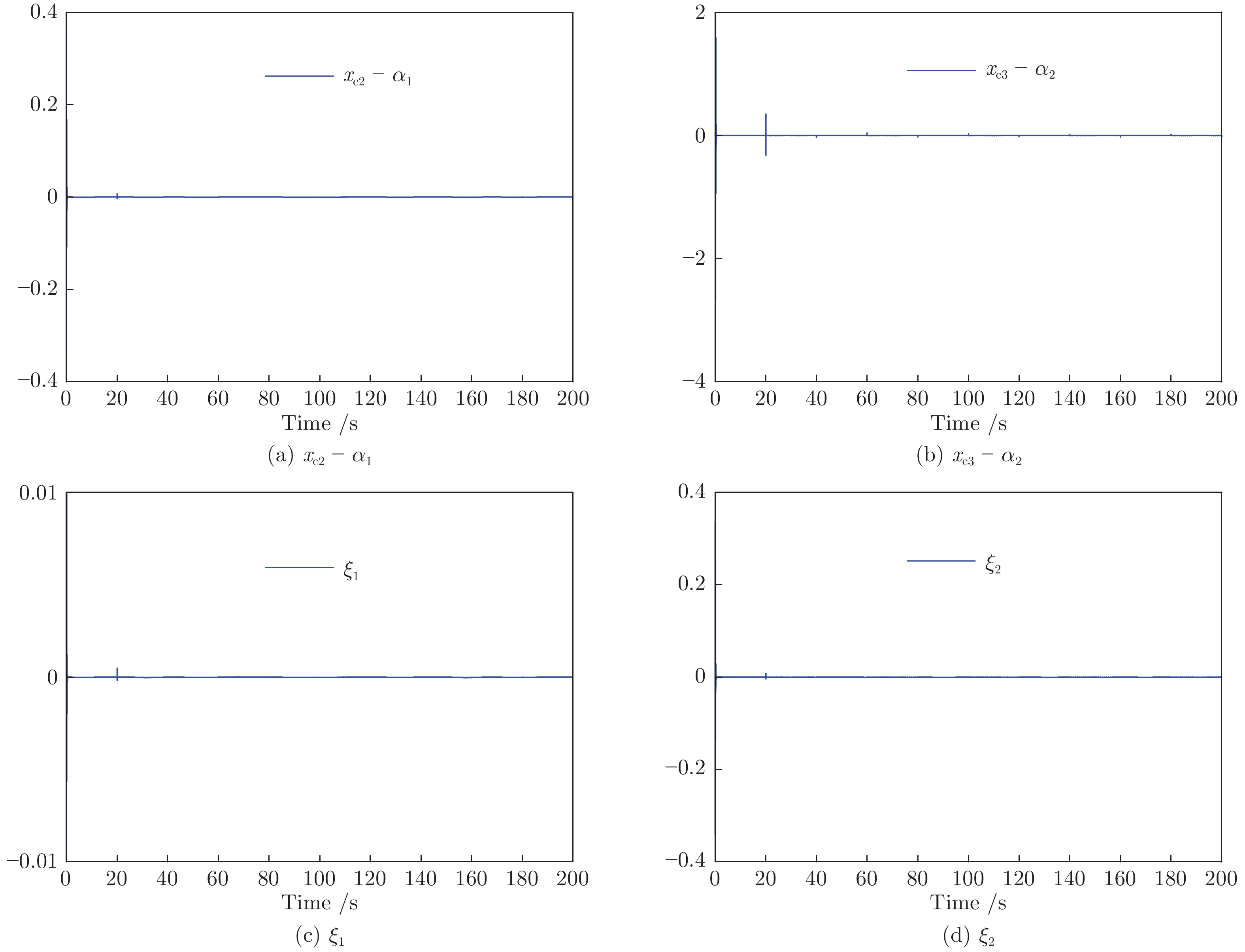
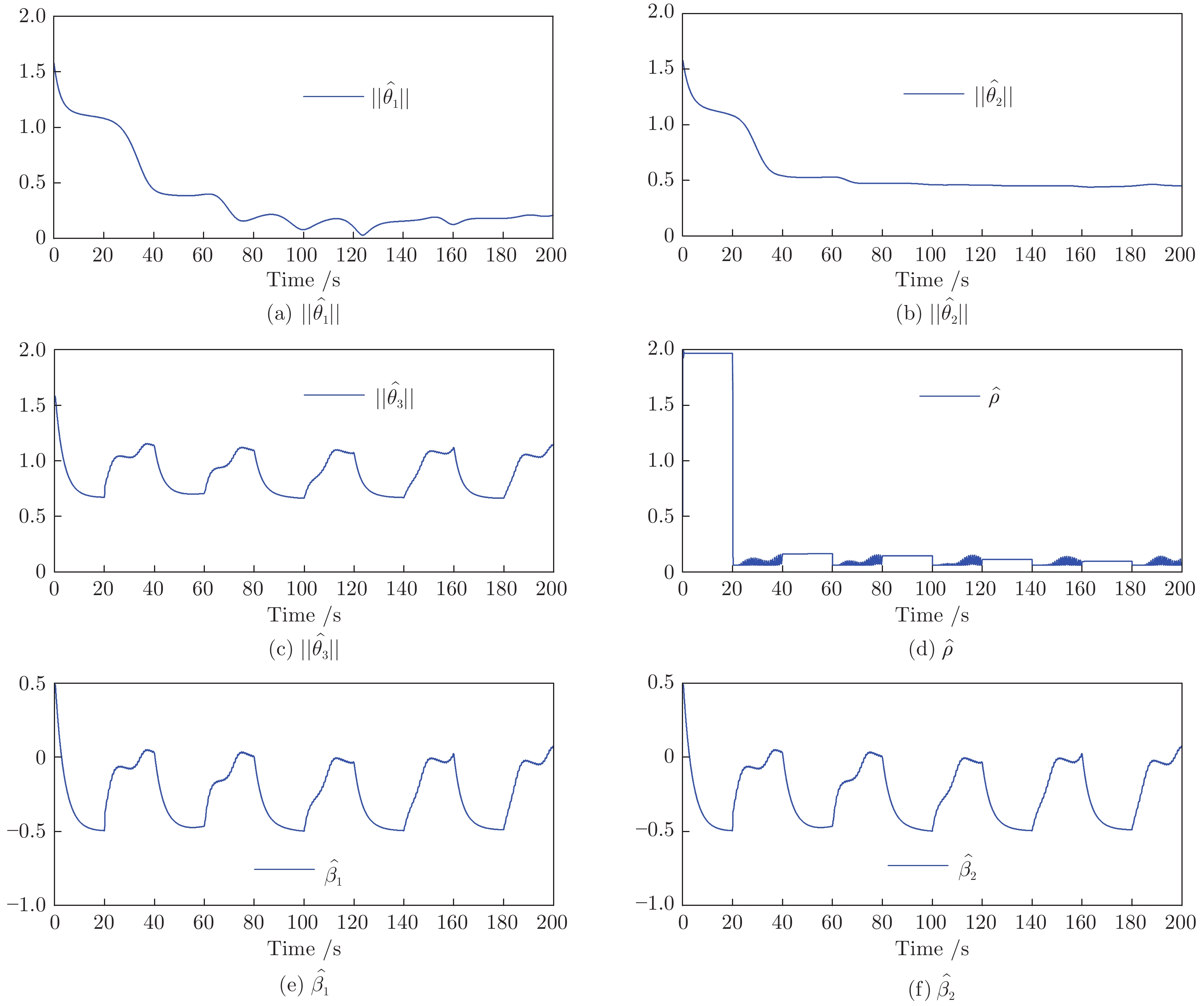

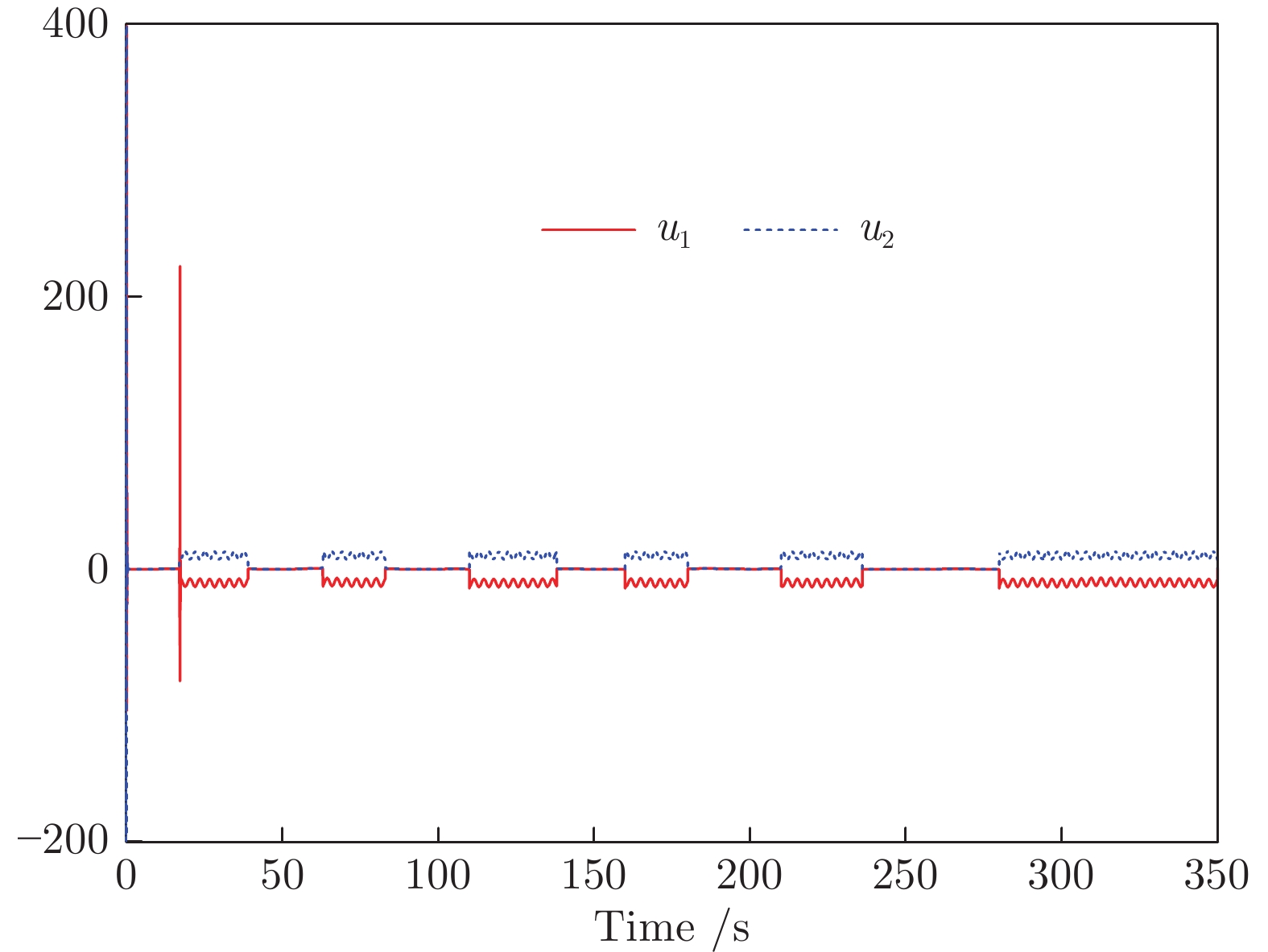
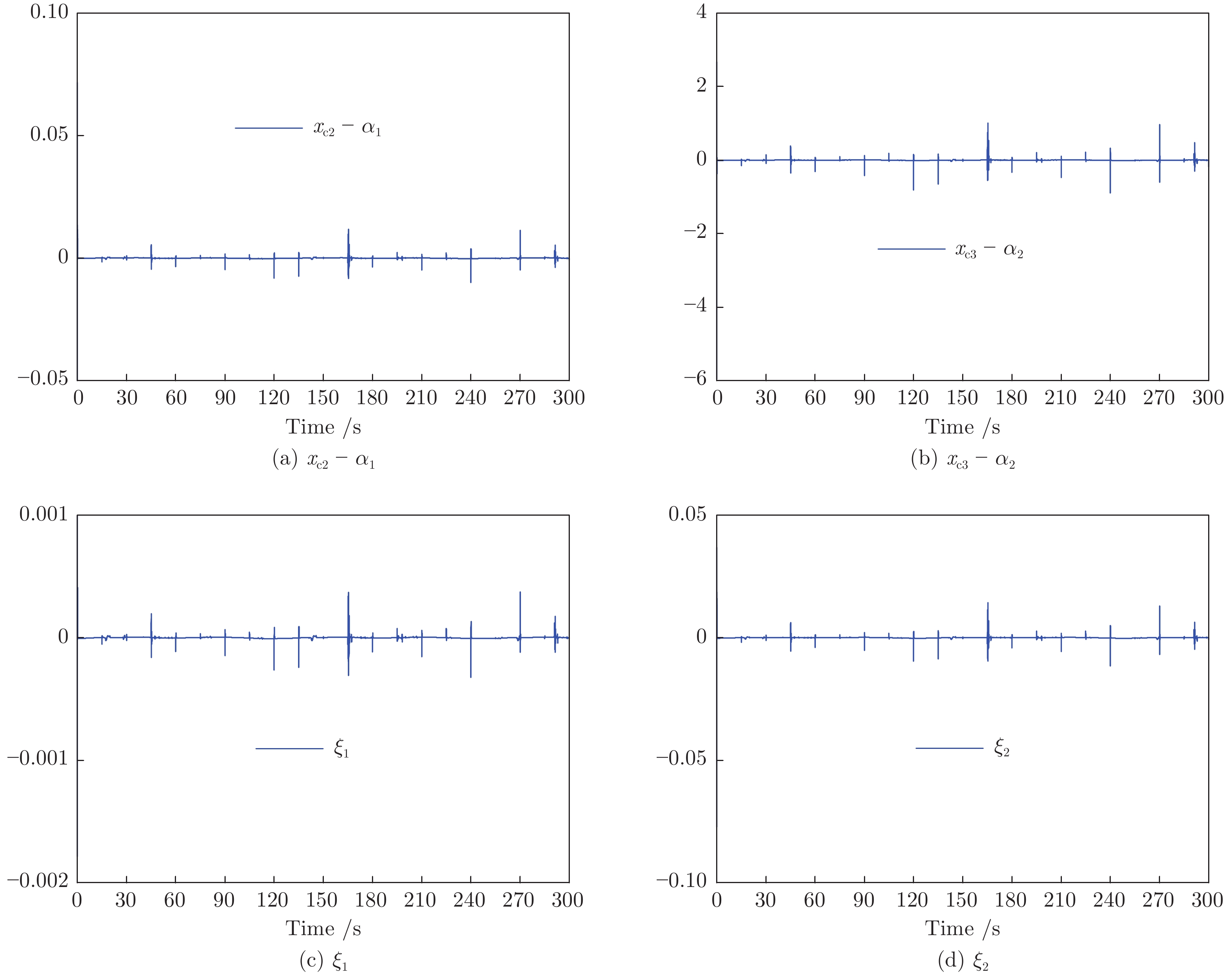
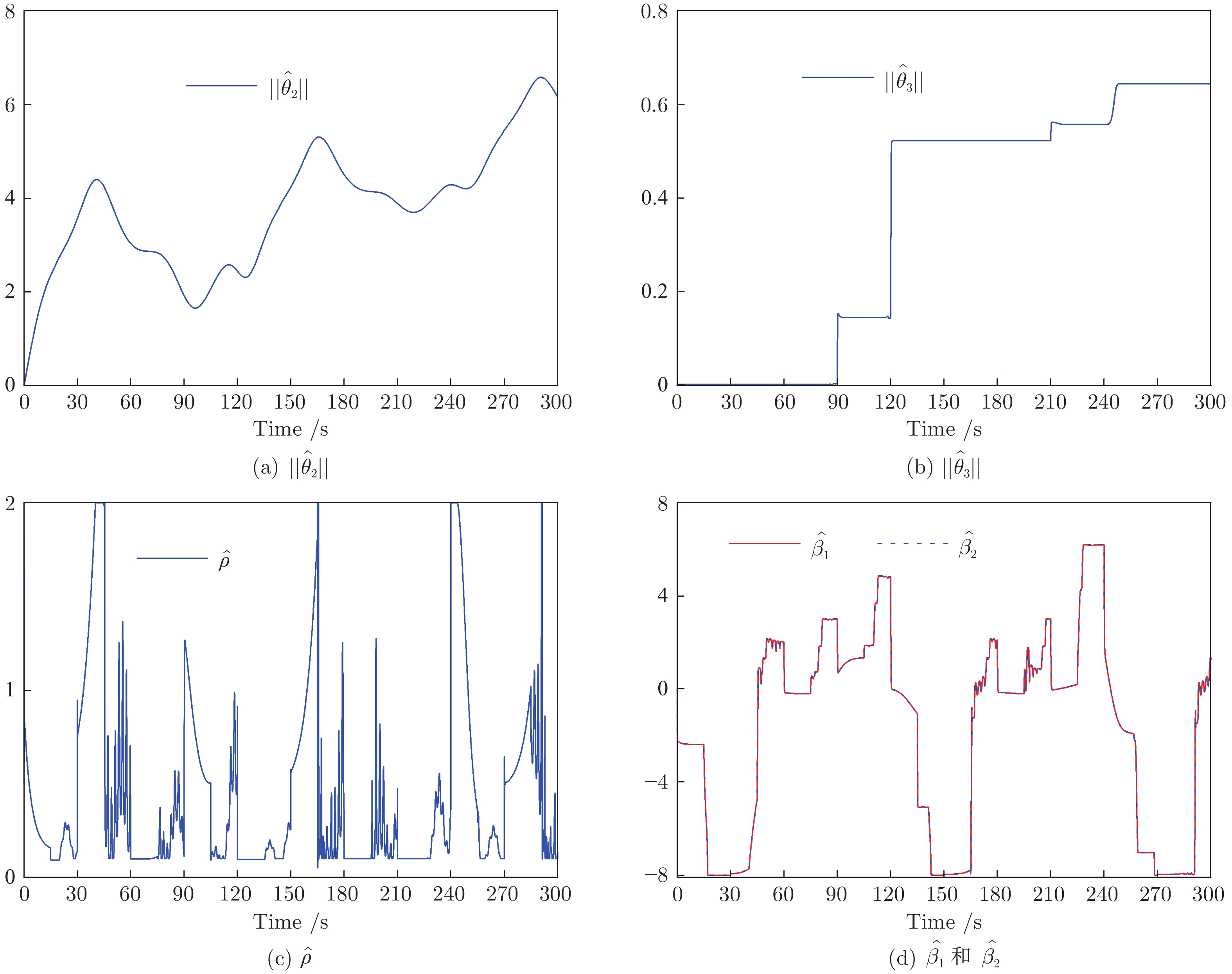
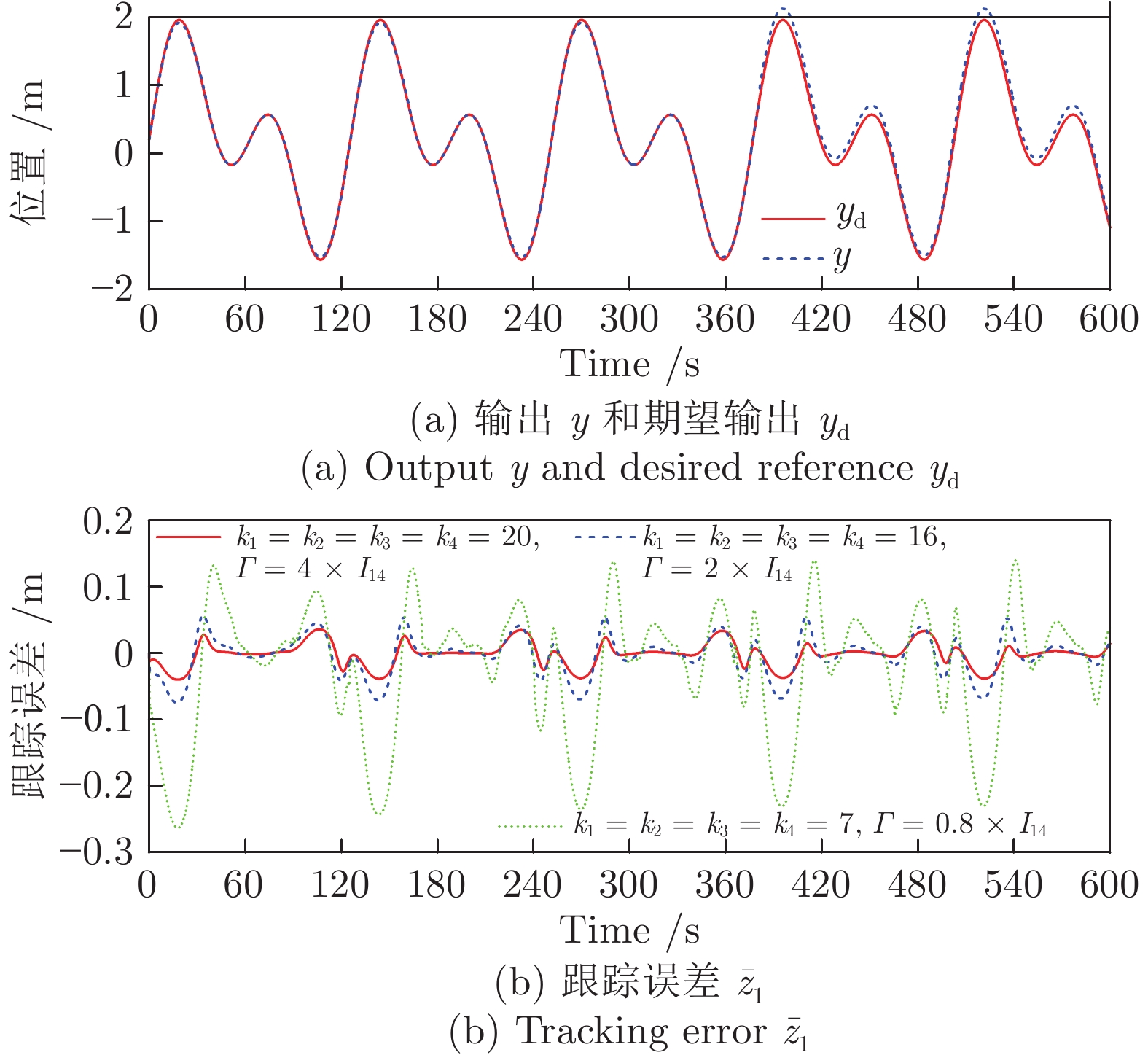
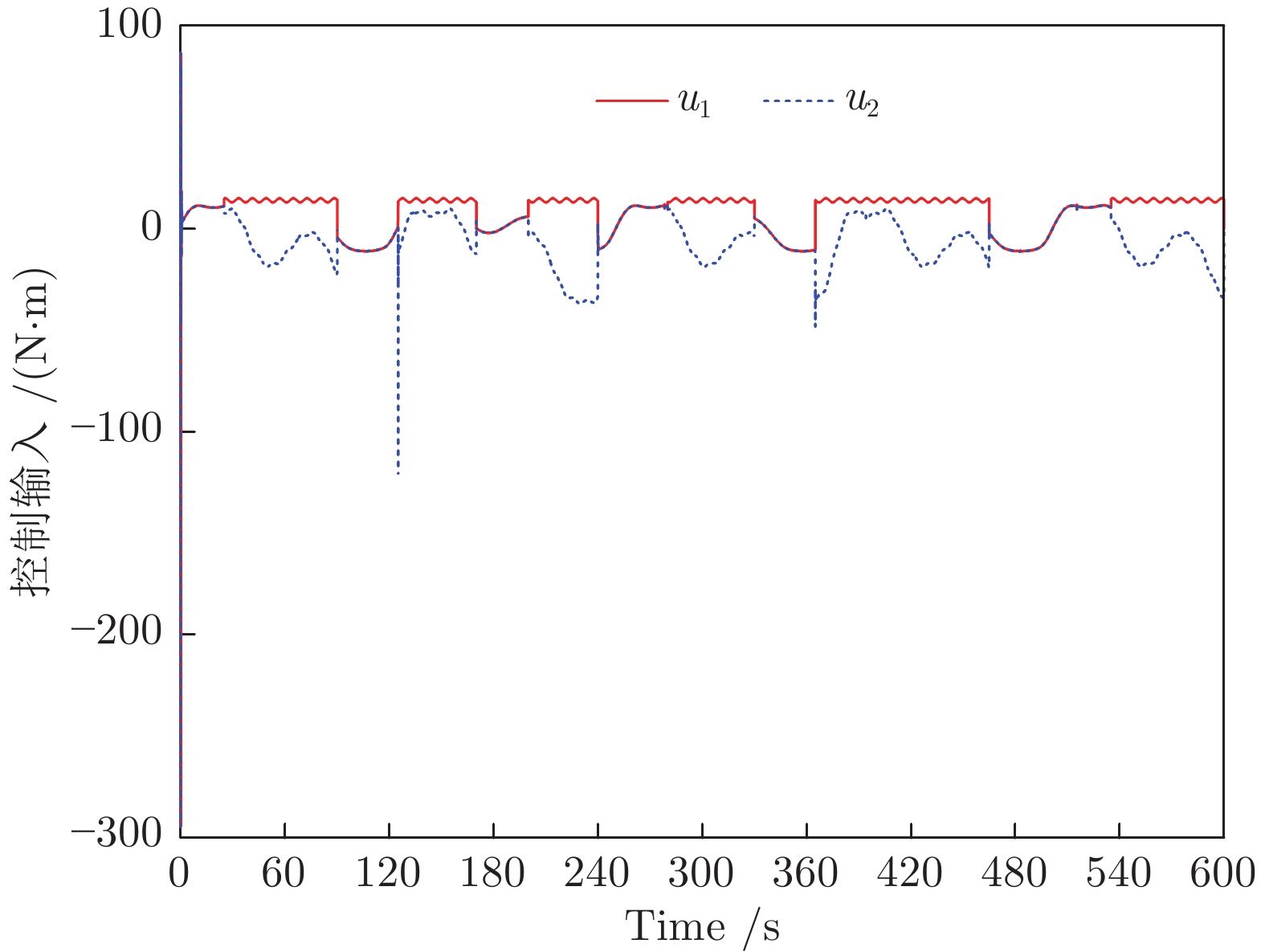

2022, 48(10): 2462-2473.
doi: 10.16383/j.aas.c211003
摘要:
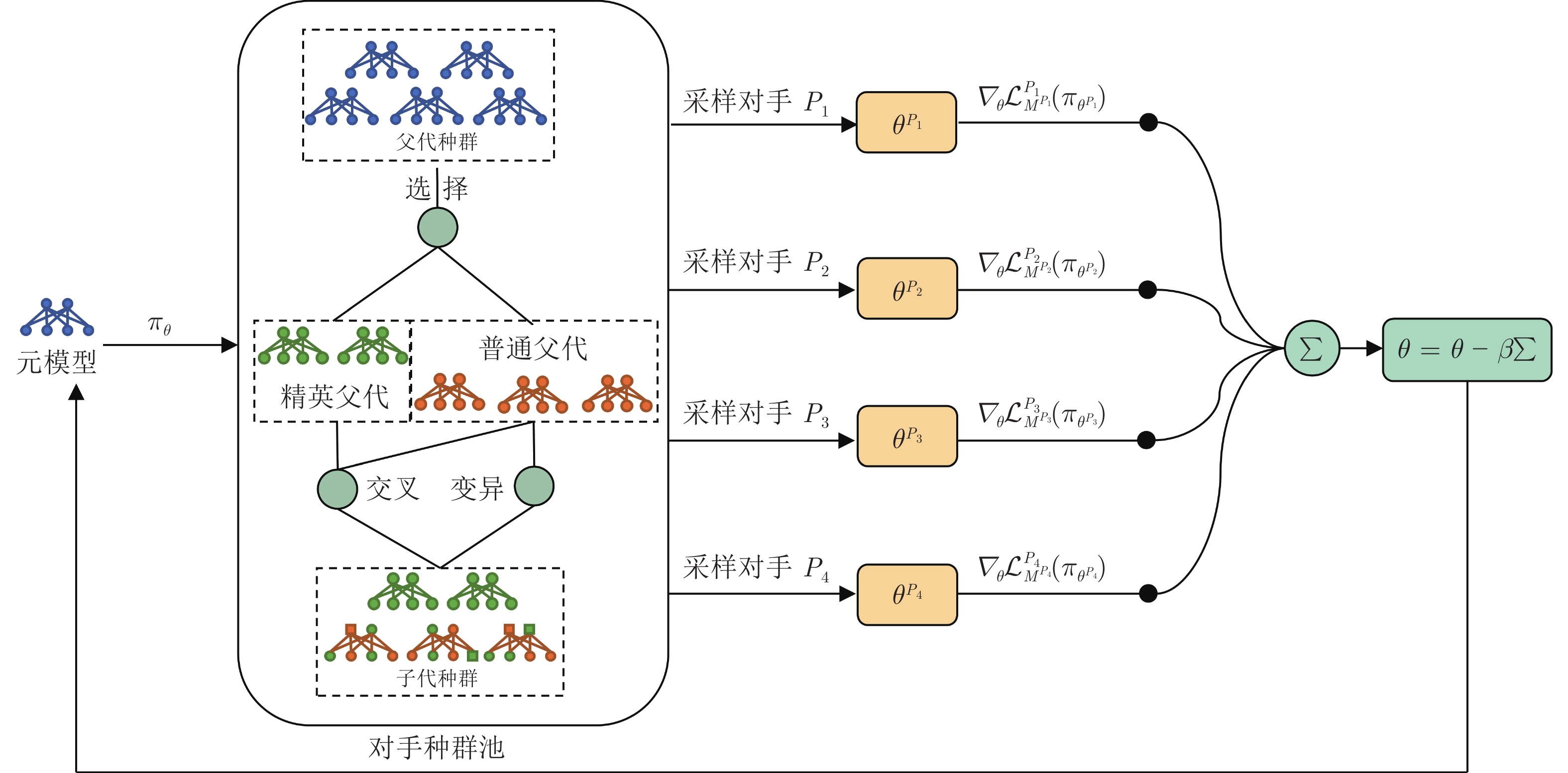
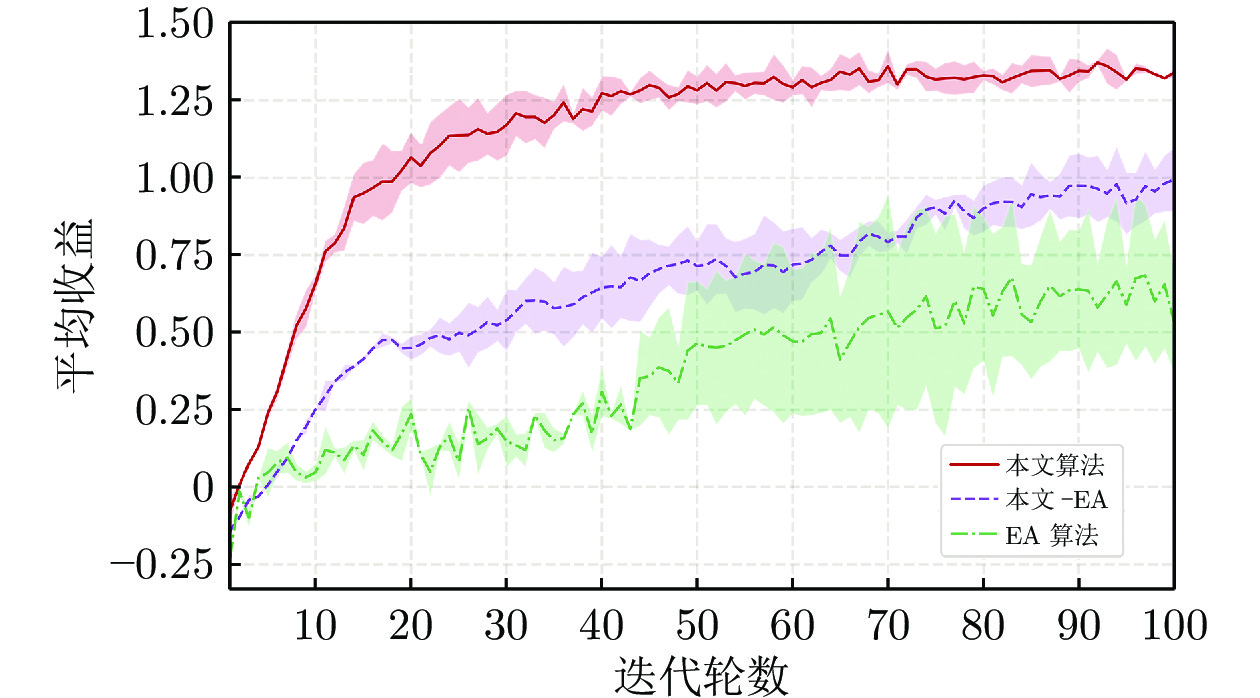
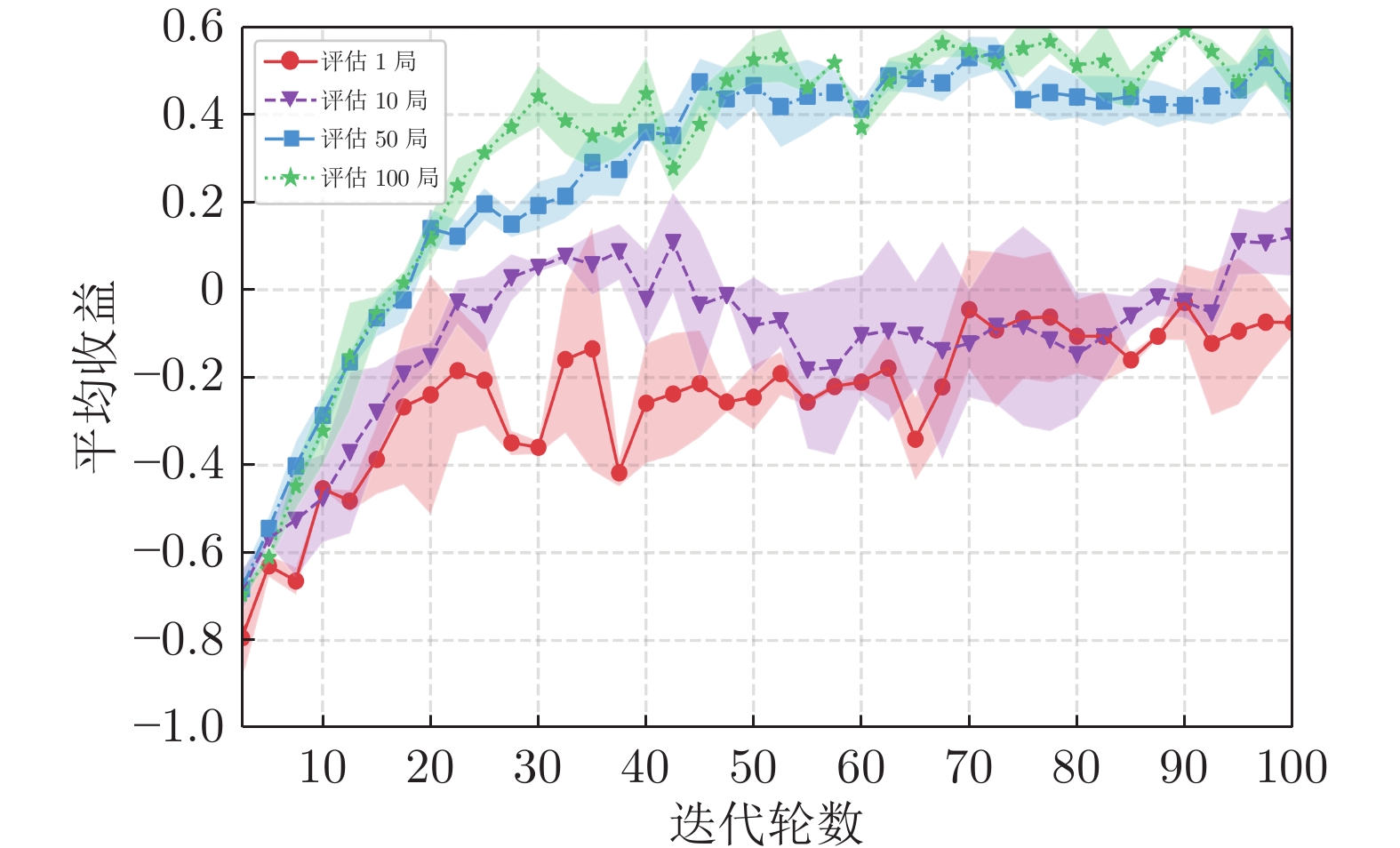
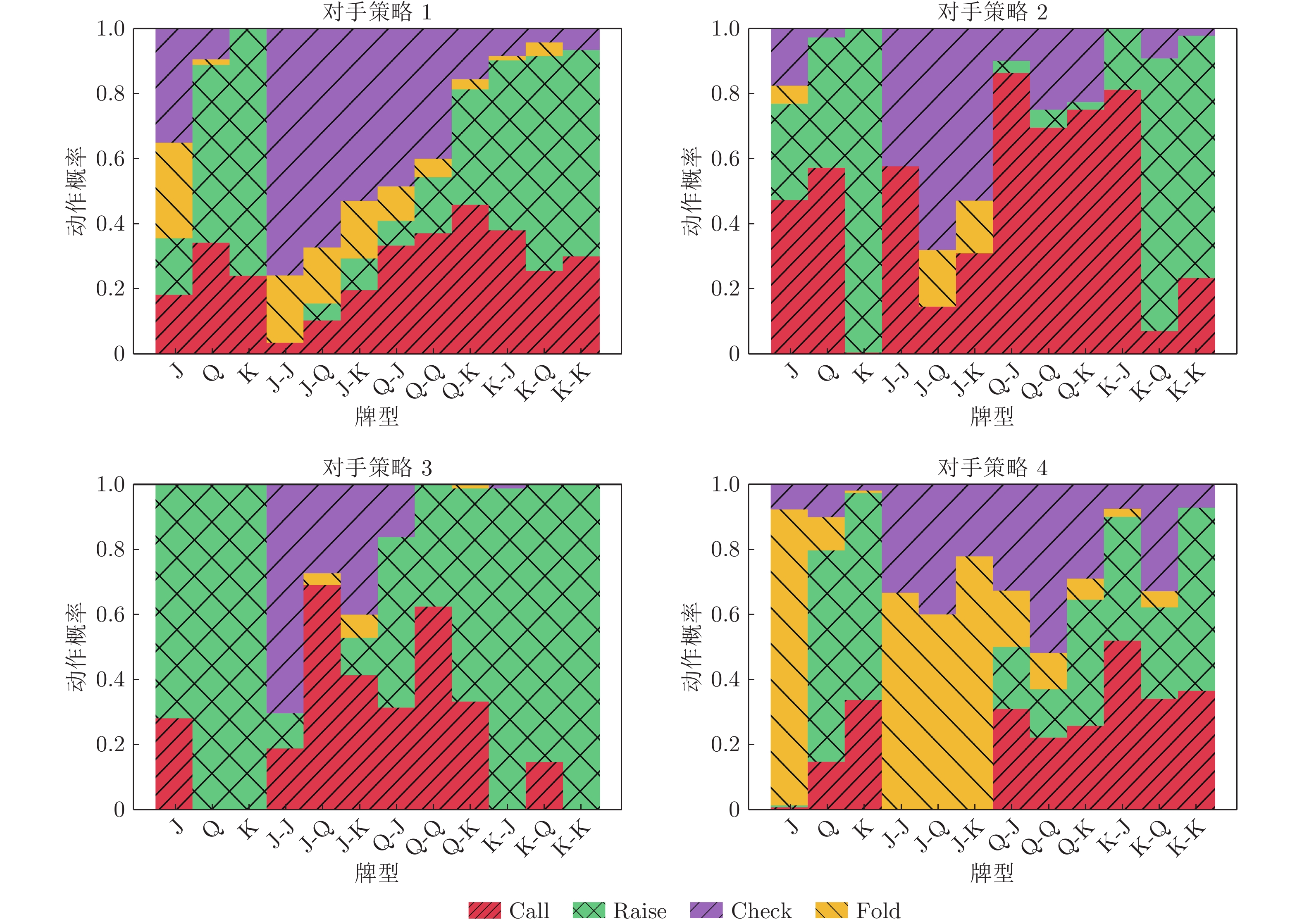
围绕两人零和博弈所开展的一系列研究, 近年来在围棋、德州扑克等问题中取得了里程碑式的突破. 现有的两人零和博弈求解方案大多在理性对手的假设下围绕纳什均衡解开展, 是一种力求不败的保守型策略, 但在实际博弈中由于对手非理性等原因并不能保证收益最大化. 对手建模为最大化博弈收益提供了一种新途径, 但仍存在建模困难等问题. 结合元学习的思想提出了一种能够快速适应对手策略的元策略演化学习求解框架. 在训练阶段, 首先通过种群演化的方法不断生成风格多样化的博弈对手作为训练数据, 然后利用元策略更新方法来调整元模型的网络权重, 使其获得快速适应的能力. 在Leduc扑克、两人有限注德州扑克(Heads-up limit Texas Hold'em, LHE)和RoboSumo上的大量实验结果表明, 该算法能够有效克服现有方法的弊端, 实现针对未知风格对手的快速适应, 从而为两人零和博弈收益最大化求解提供了一种新思路.
围绕两人零和博弈所开展的一系列研究, 近年来在围棋、德州扑克等问题中取得了里程碑式的突破. 现有的两人零和博弈求解方案大多在理性对手的假设下围绕纳什均衡解开展, 是一种力求不败的保守型策略, 但在实际博弈中由于对手非理性等原因并不能保证收益最大化. 对手建模为最大化博弈收益提供了一种新途径, 但仍存在建模困难等问题. 结合元学习的思想提出了一种能够快速适应对手策略的元策略演化学习求解框架. 在训练阶段, 首先通过种群演化的方法不断生成风格多样化的博弈对手作为训练数据, 然后利用元策略更新方法来调整元模型的网络权重, 使其获得快速适应的能力. 在Leduc扑克、两人有限注德州扑克(Heads-up limit Texas Hold'em, LHE)和RoboSumo上的大量实验结果表明, 该算法能够有效克服现有方法的弊端, 实现针对未知风格对手的快速适应, 从而为两人零和博弈收益最大化求解提供了一种新思路.

2022, 48(10): 2474-2485.
doi: 10.16383/j.aas.c200850
摘要:
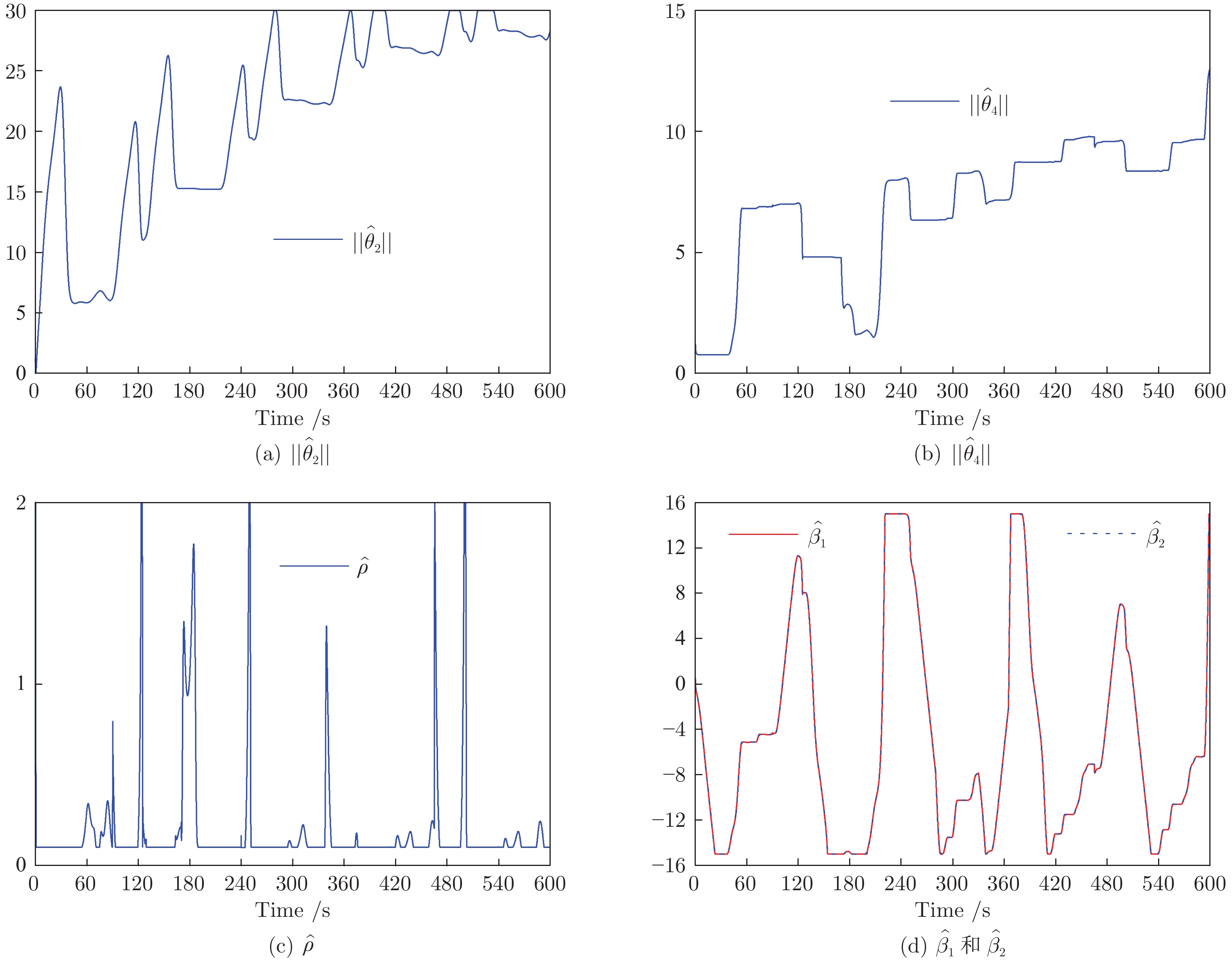
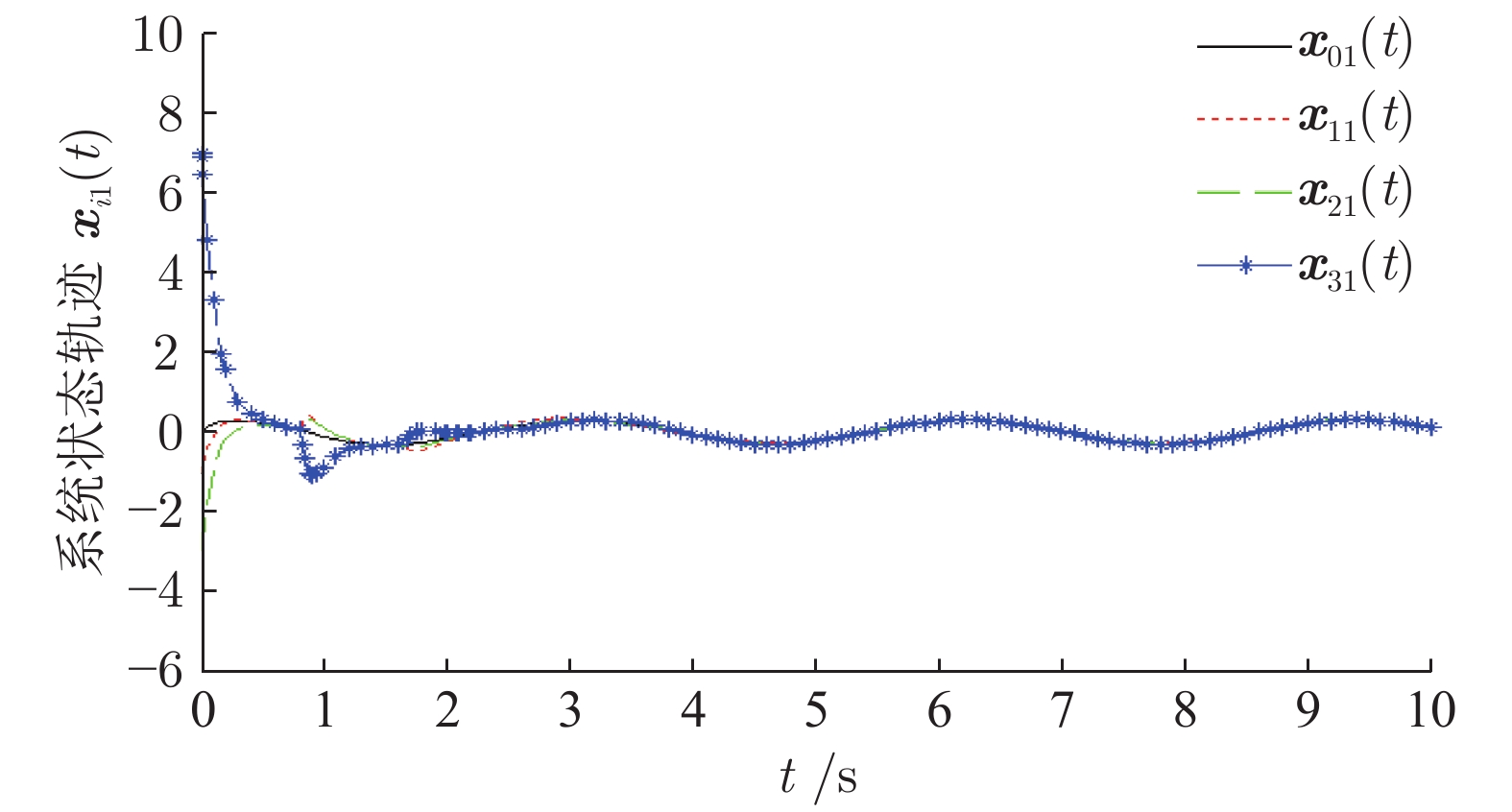
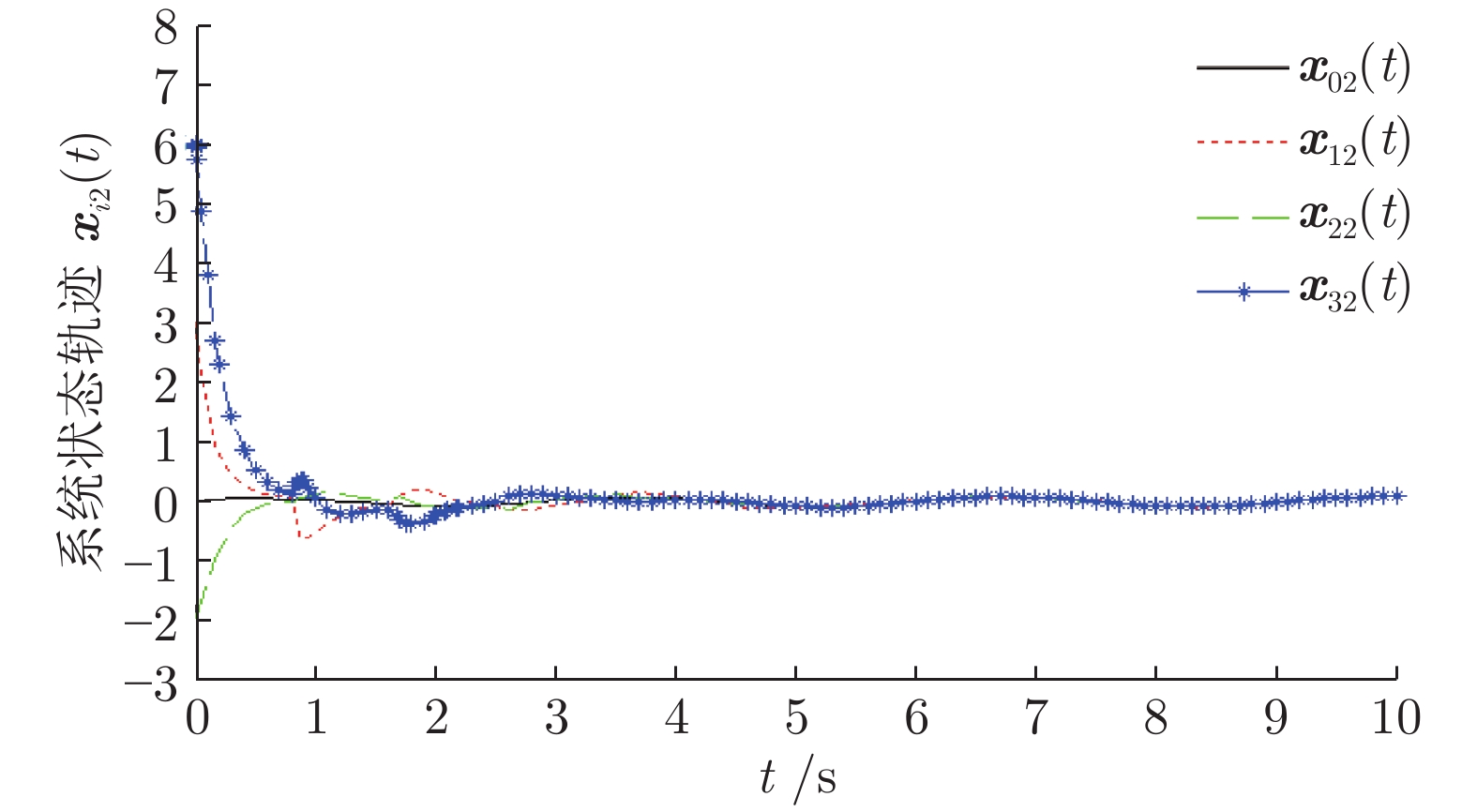
研究了基于半马尔科夫(Markov)跳变的领导−跟随多智能体系统(Multi-agent system, MAS)的均方一致性控制问题. 首先, 针对多智能体系统同时存在通信时滞和执行器故障的问题, 提出基于线性变换的动态反馈控制策略. 其次, 将实现领导−跟随多智能体系统的均方一致性问题转化为多智能体误差系统的稳定性控制问题. 再次, 设计动态反馈控制器, 利用李亚谱诺夫(Lyapunov)函数抑制系统的非线性特性, 解决由控制器未知增益矩阵产生的非线性问题. 使领导−跟随多智能体系统达到均方一致, 并给出系统的\begin{document}$ {H_{\infty} }$\end{document} ![]()
![]()
研究了基于半马尔科夫(Markov)跳变的领导−跟随多智能体系统(Multi-agent system, MAS)的均方一致性控制问题. 首先, 针对多智能体系统同时存在通信时滞和执行器故障的问题, 提出基于线性变换的动态反馈控制策略. 其次, 将实现领导−跟随多智能体系统的均方一致性问题转化为多智能体误差系统的稳定性控制问题. 再次, 设计动态反馈控制器, 利用李亚谱诺夫(Lyapunov)函数抑制系统的非线性特性, 解决由控制器未知增益矩阵产生的非线性问题. 使领导−跟随多智能体系统达到均方一致, 并给出系统的



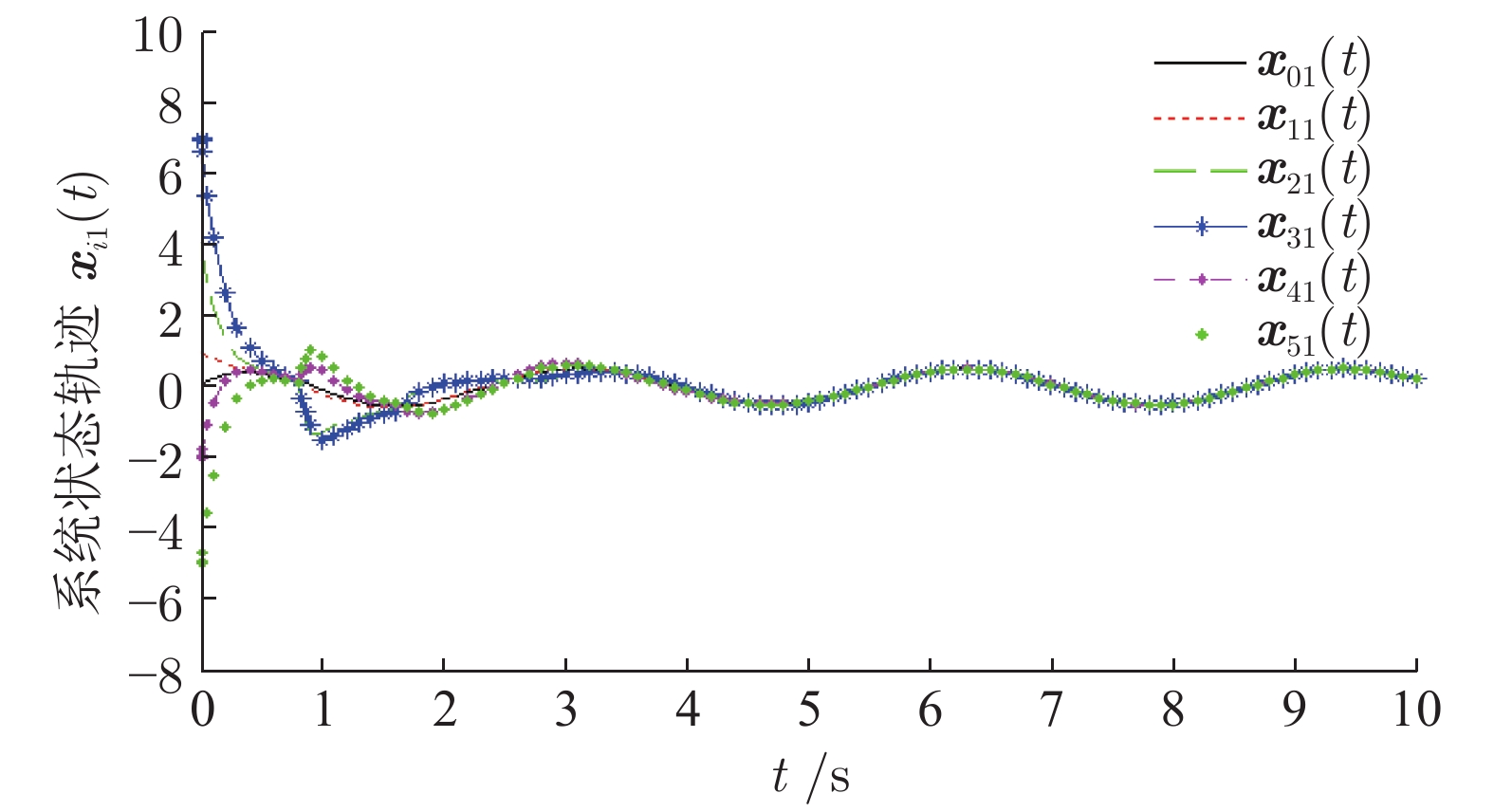
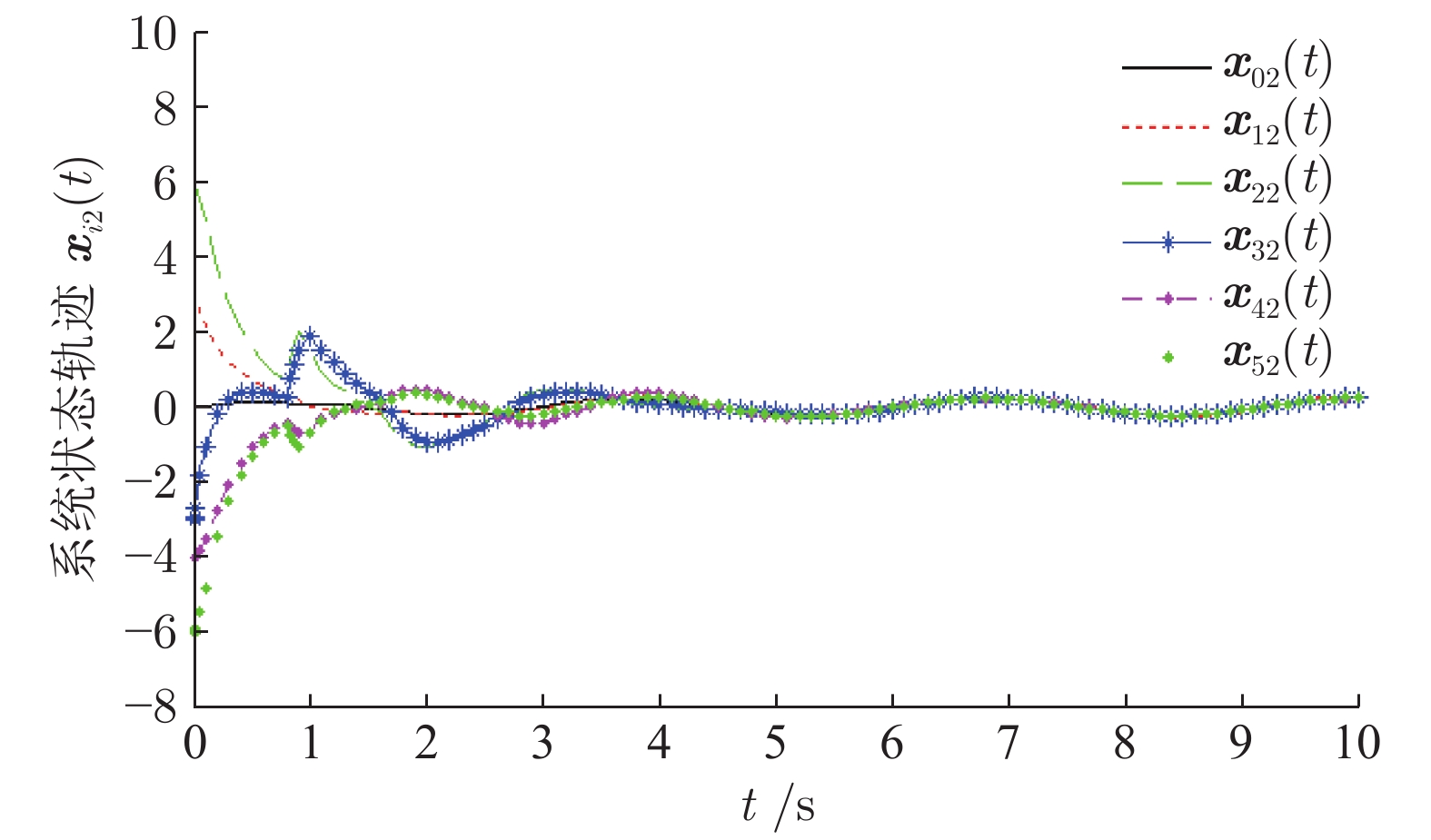

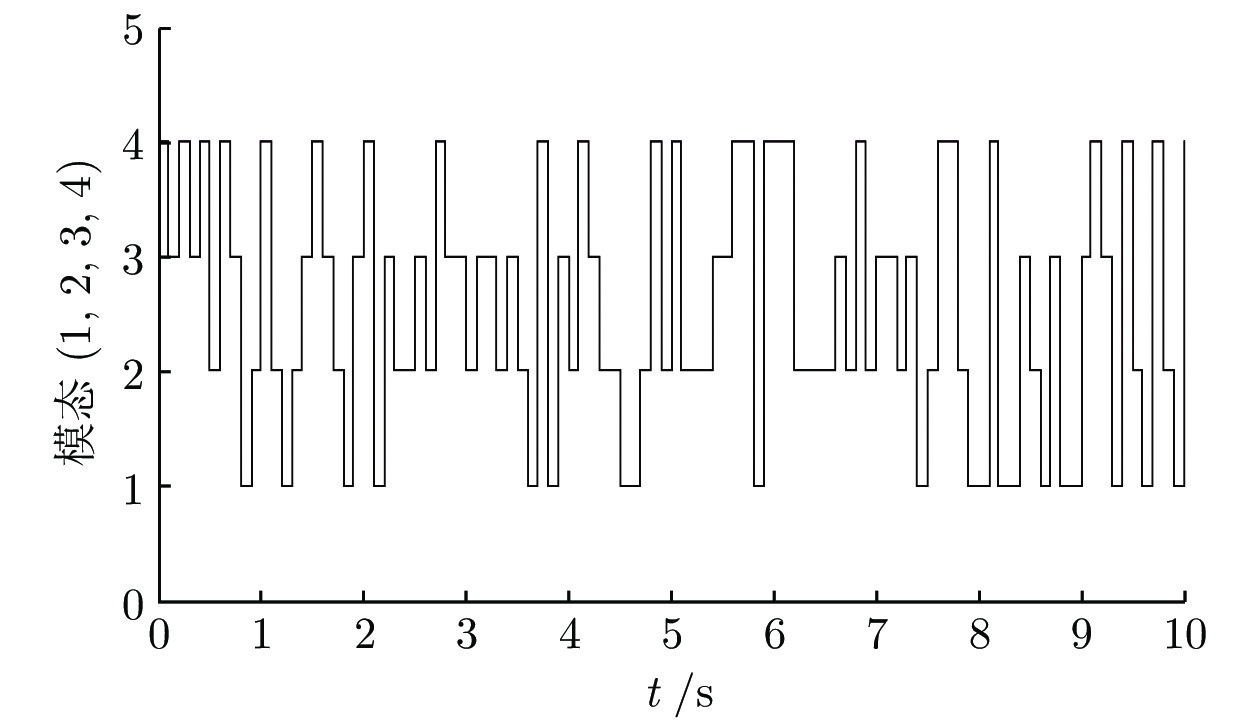
2022, 48(10): 2486-2495.
doi: 10.16383/j.aas.c200407
摘要:
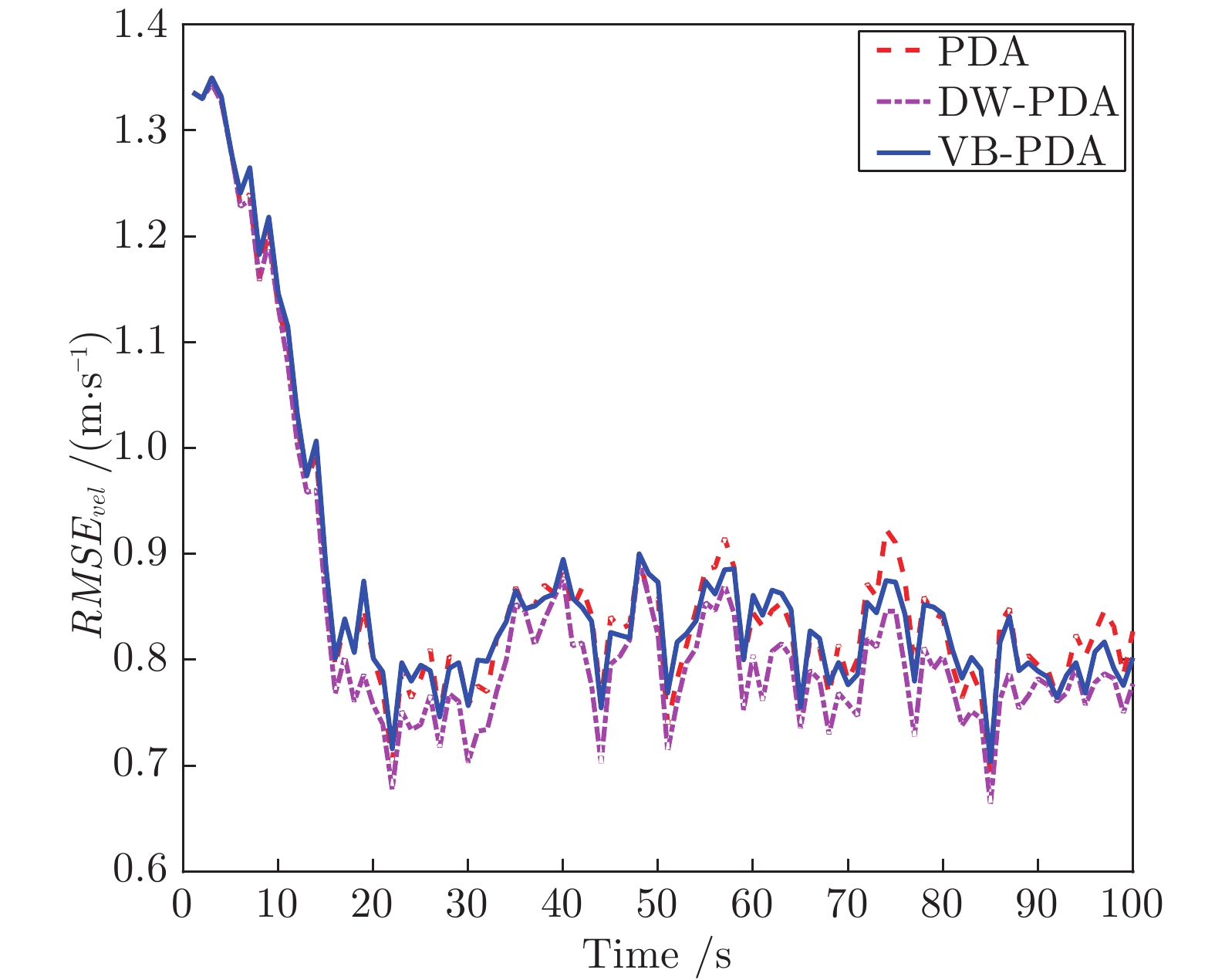
针对杂波环境下的目标跟踪问题, 提出了一种基于变分贝叶斯的概率数据关联算法(Variational Bayesian based probabilistic data association algorithm, VB-PDA). 该算法首先将关联事件视为一个随机变量并利用多项分布对其进行建模, 随后基于数据集、目标状态、关联事件的联合概率密度函数求取关联事件的后验概率密度函数, 最后将关联事件的后验概率密度函数引入变分贝叶斯框架中以获取状态近似后验概率密度函数. 相比于概率数据关联算法, VB-PDA算法在提高算法实时性的同时在权重Kullback-Leibler (KL)平均准则下获取了近似程度更高的状态后验概率密度函数. 相关仿真实验对提出算法的有效性进行了验证.
针对杂波环境下的目标跟踪问题, 提出了一种基于变分贝叶斯的概率数据关联算法(Variational Bayesian based probabilistic data association algorithm, VB-PDA). 该算法首先将关联事件视为一个随机变量并利用多项分布对其进行建模, 随后基于数据集、目标状态、关联事件的联合概率密度函数求取关联事件的后验概率密度函数, 最后将关联事件的后验概率密度函数引入变分贝叶斯框架中以获取状态近似后验概率密度函数. 相比于概率数据关联算法, VB-PDA算法在提高算法实时性的同时在权重Kullback-Leibler (KL)平均准则下获取了近似程度更高的状态后验概率密度函数. 相关仿真实验对提出算法的有效性进行了验证.
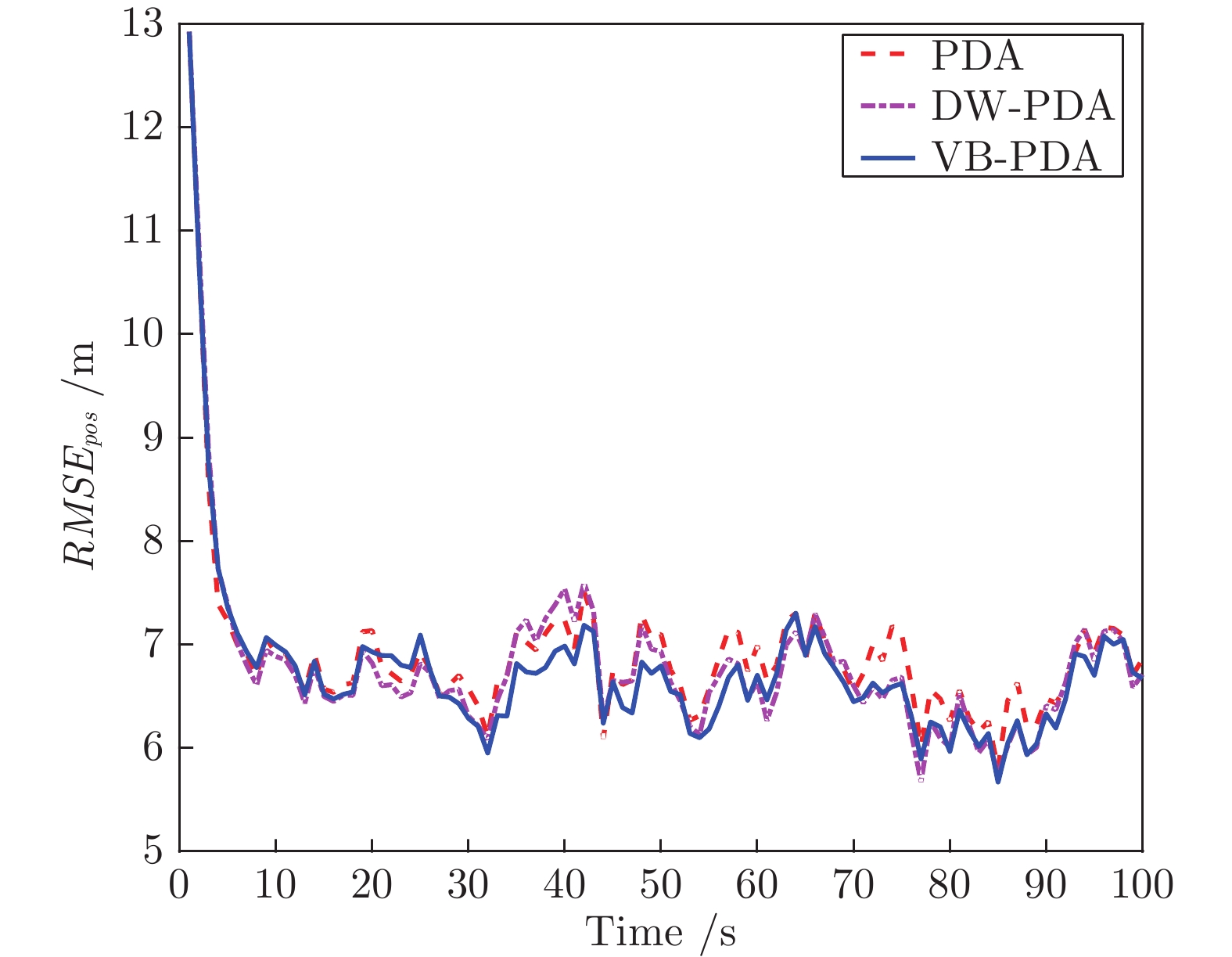


2022, 48(10): 2496-2507.
doi: 10.16383/j.aas.c190594
摘要:
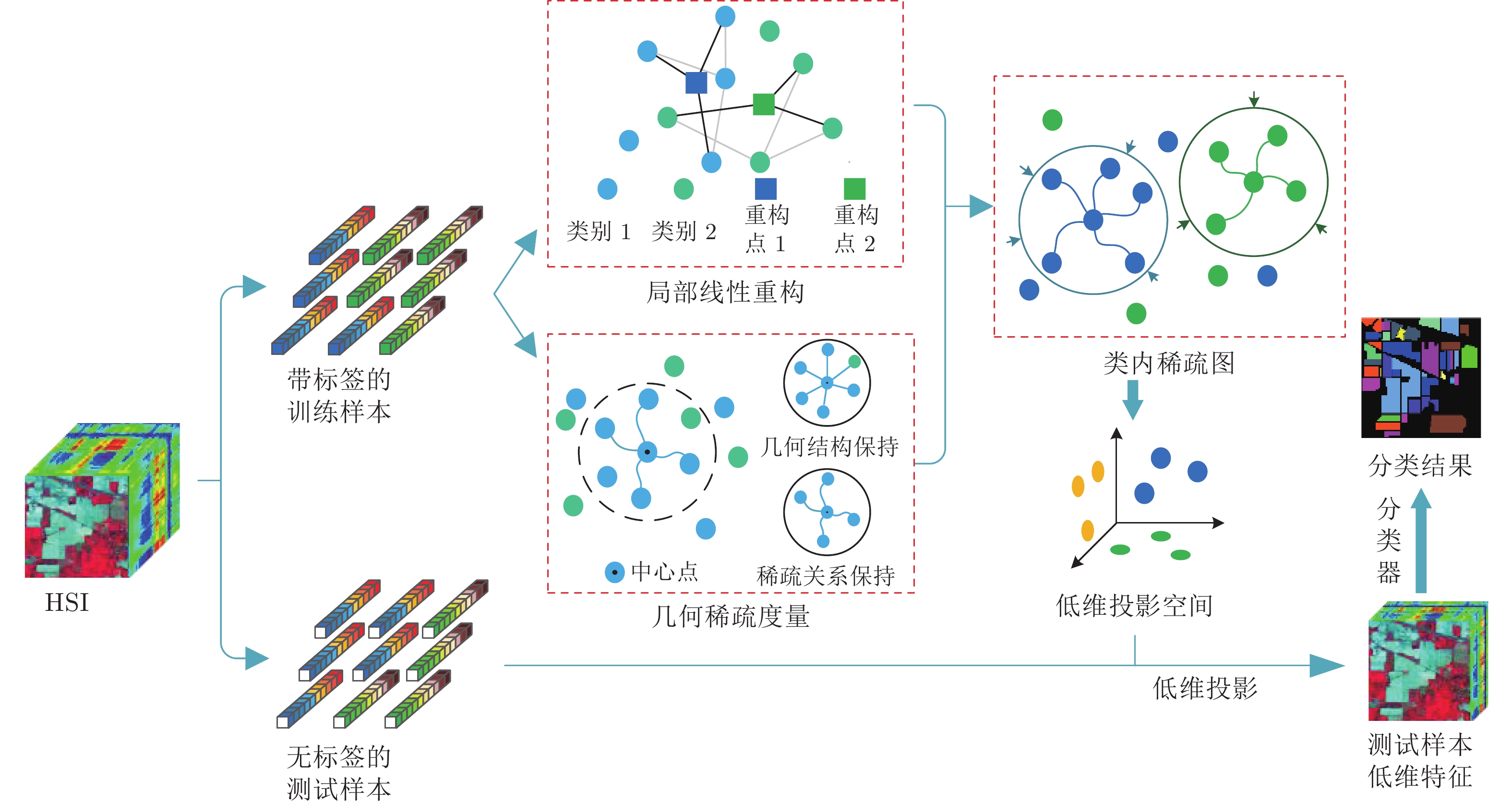
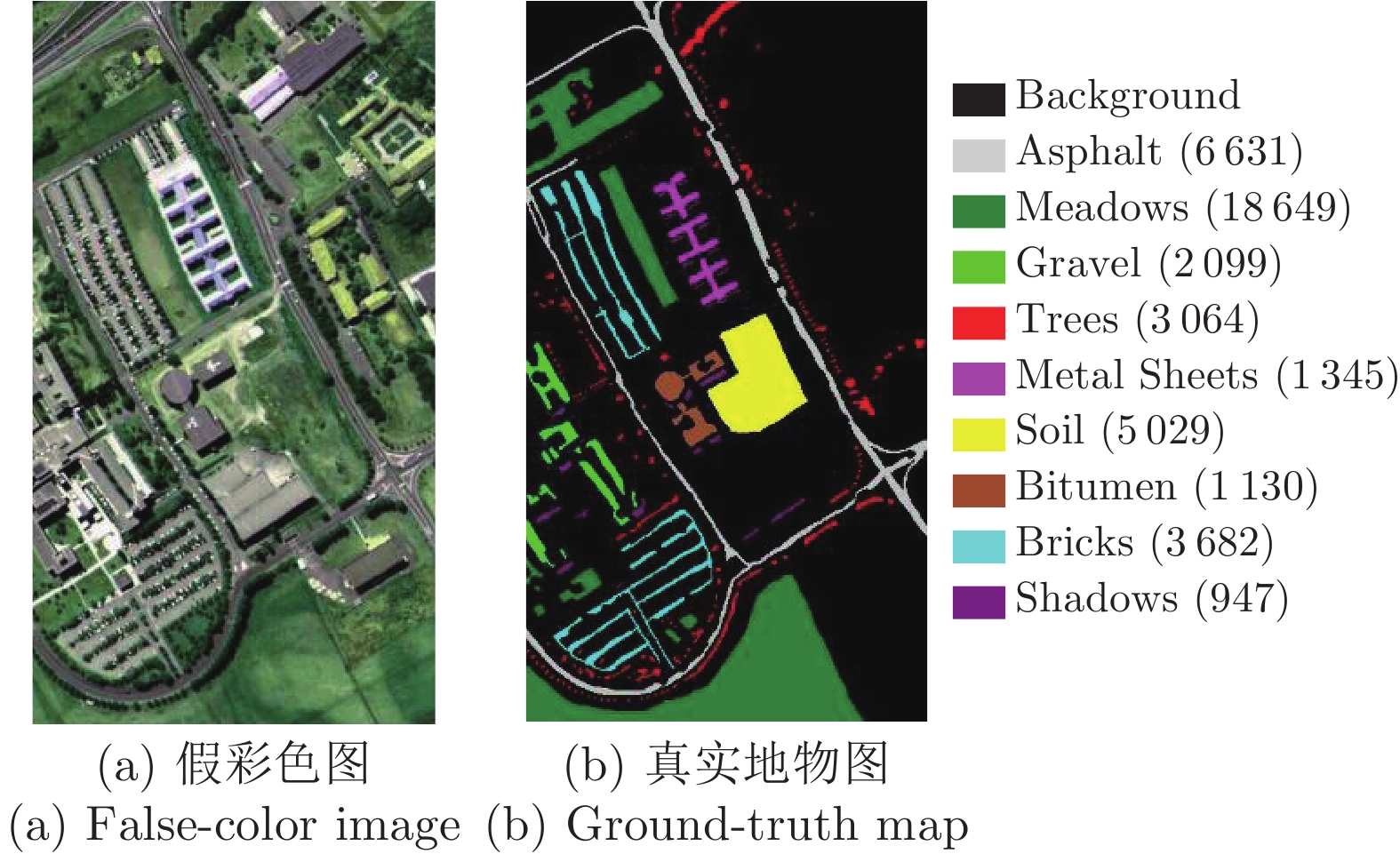
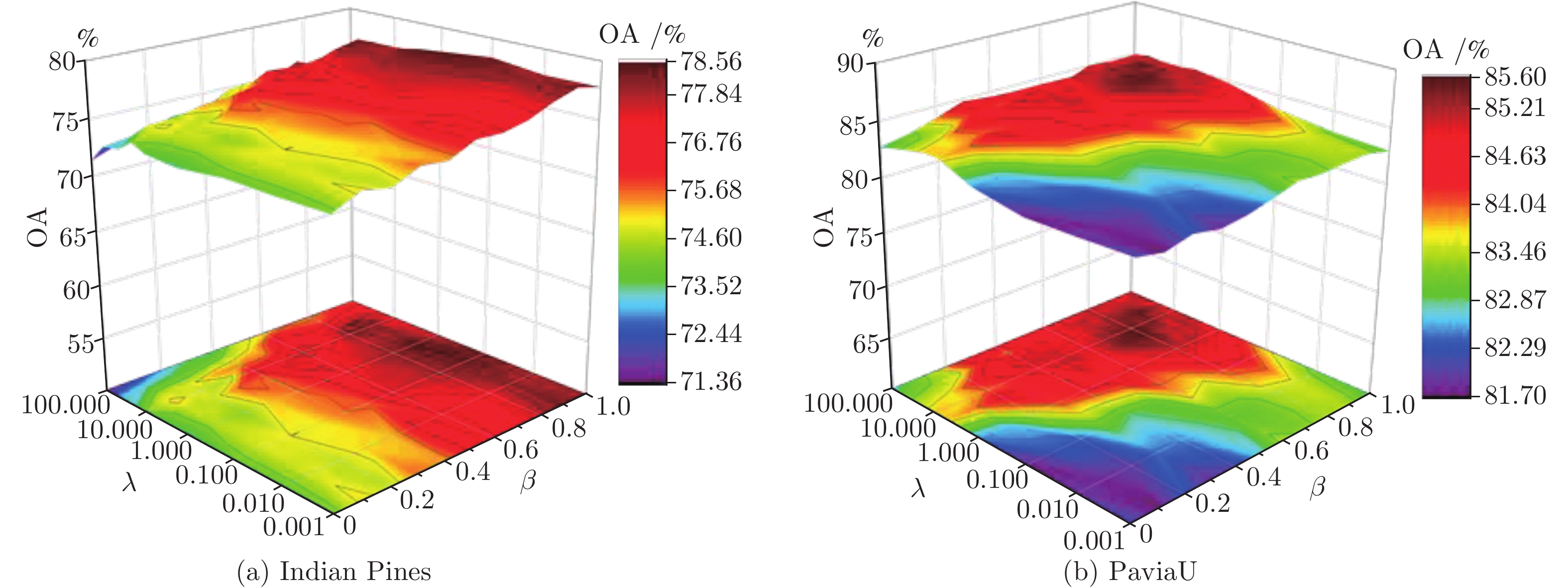
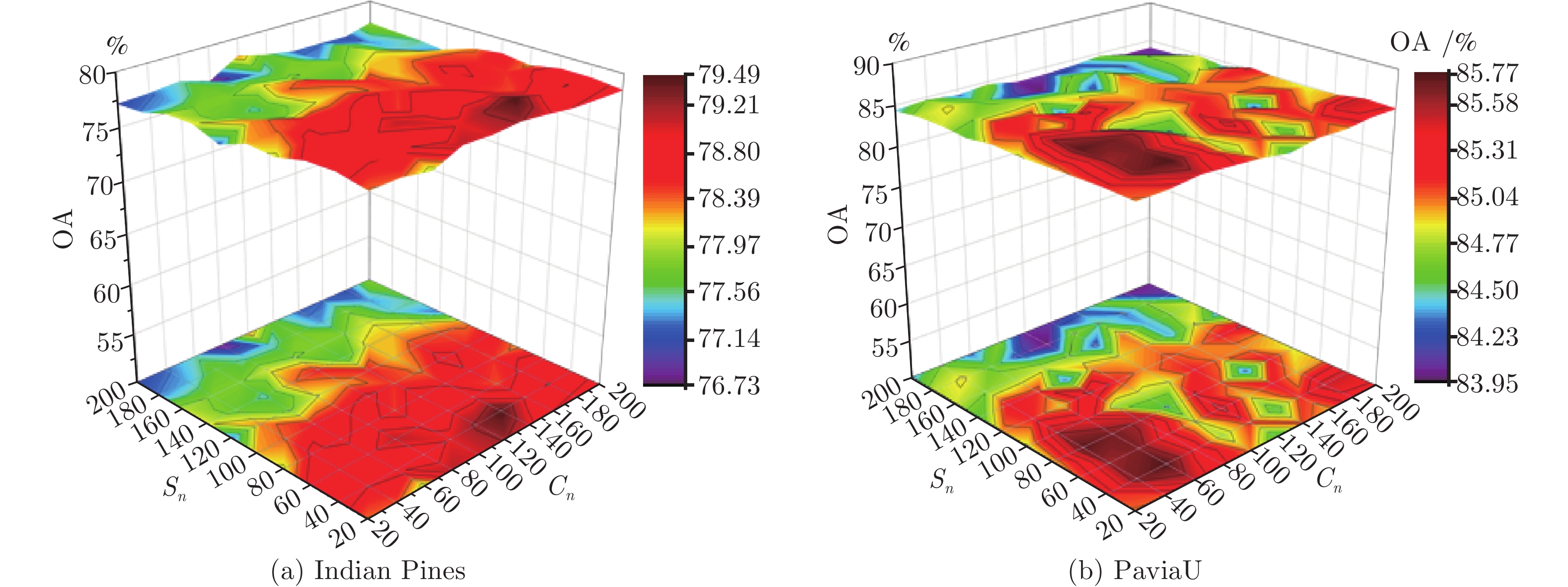
大量维数约简(Dimensionality reducion, DR)方法表明保持数据间稀疏特性的同时, 确保几何结构的保持能更有效提取出具有鉴别性的特征, 为此本文提出一种联合局部几何近邻结构和局部稀疏流形的维数约简方法. 该方法首先通过局部线性嵌入方法重构每个样本以保持数据的局部线性关系, 同时计算样本邻域内的局部稀疏流形结构, 在此基础上通过图嵌入框架保持数据的局部几何近邻结构和稀疏结构, 最后在低维嵌入空间中使类内数据尽可能聚集, 提取低维鉴别特征, 从而提升地物分类性能. 在Indian Pines和PaviaU高光谱数据集上的实验结果表明, 本文方法相较于传统维数约简方法能明显提高地物的分类性能, 总体分类可达到83.02%和91.20%, 有利于实际应用.
大量维数约简(Dimensionality reducion, DR)方法表明保持数据间稀疏特性的同时, 确保几何结构的保持能更有效提取出具有鉴别性的特征, 为此本文提出一种联合局部几何近邻结构和局部稀疏流形的维数约简方法. 该方法首先通过局部线性嵌入方法重构每个样本以保持数据的局部线性关系, 同时计算样本邻域内的局部稀疏流形结构, 在此基础上通过图嵌入框架保持数据的局部几何近邻结构和稀疏结构, 最后在低维嵌入空间中使类内数据尽可能聚集, 提取低维鉴别特征, 从而提升地物分类性能. 在Indian Pines和PaviaU高光谱数据集上的实验结果表明, 本文方法相较于传统维数约简方法能明显提高地物的分类性能, 总体分类可达到83.02%和91.20%, 有利于实际应用.



2022, 48(10): 2508-2525.
doi: 10.16383/j.aas.c190845
摘要:
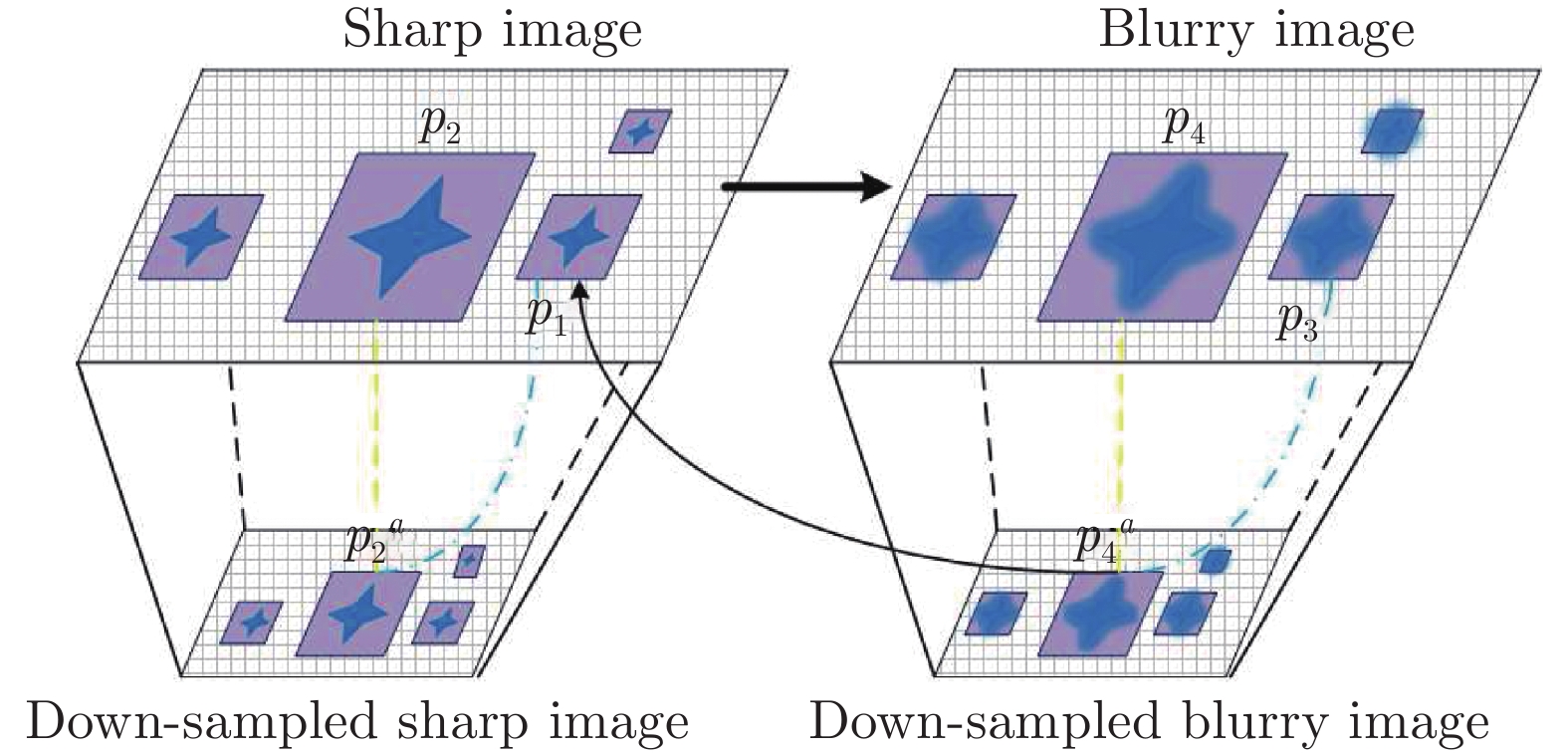
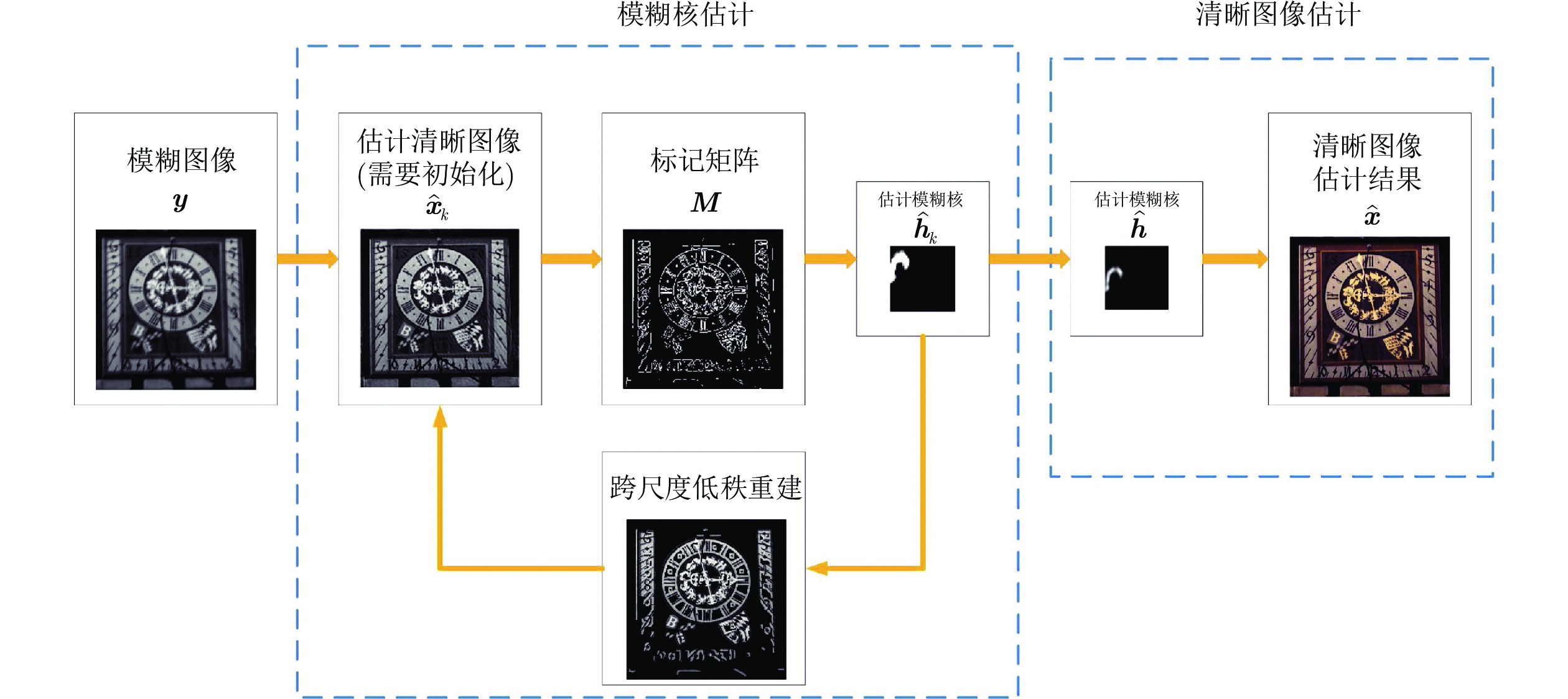
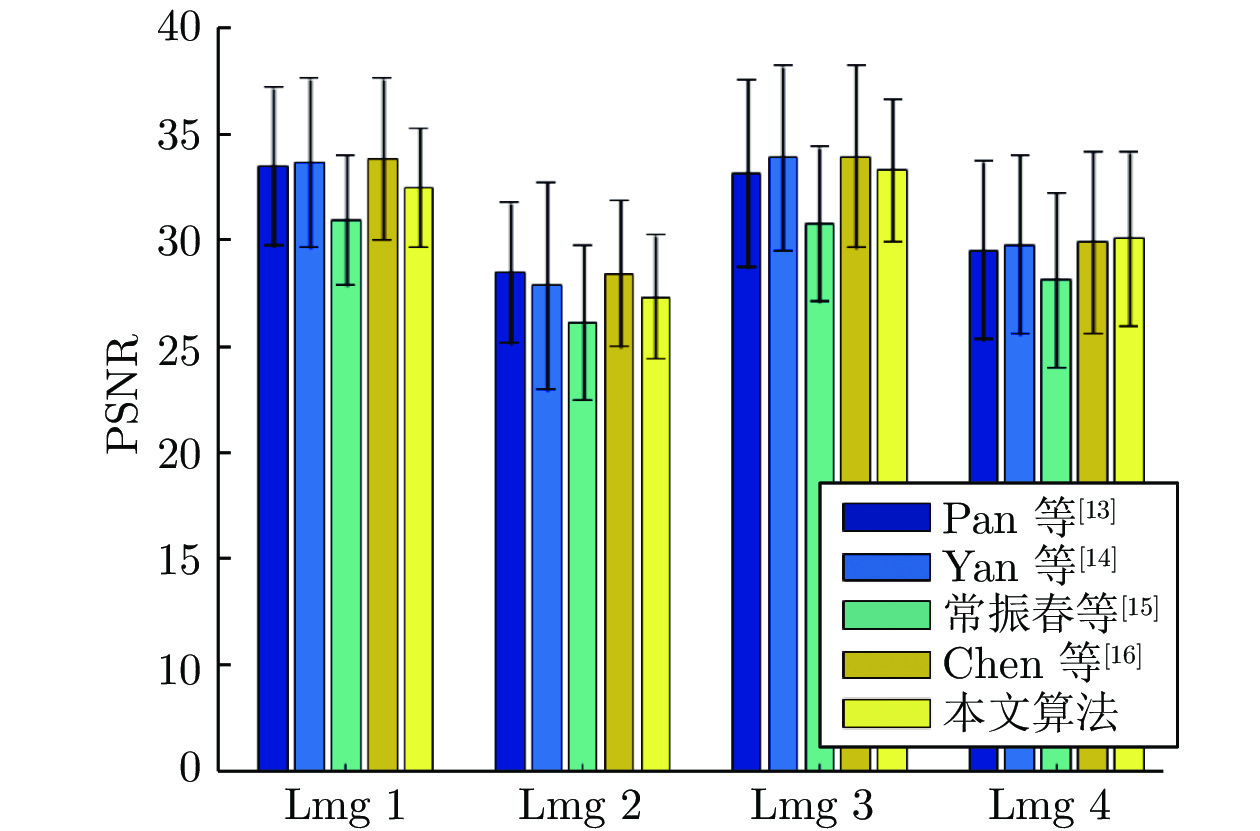
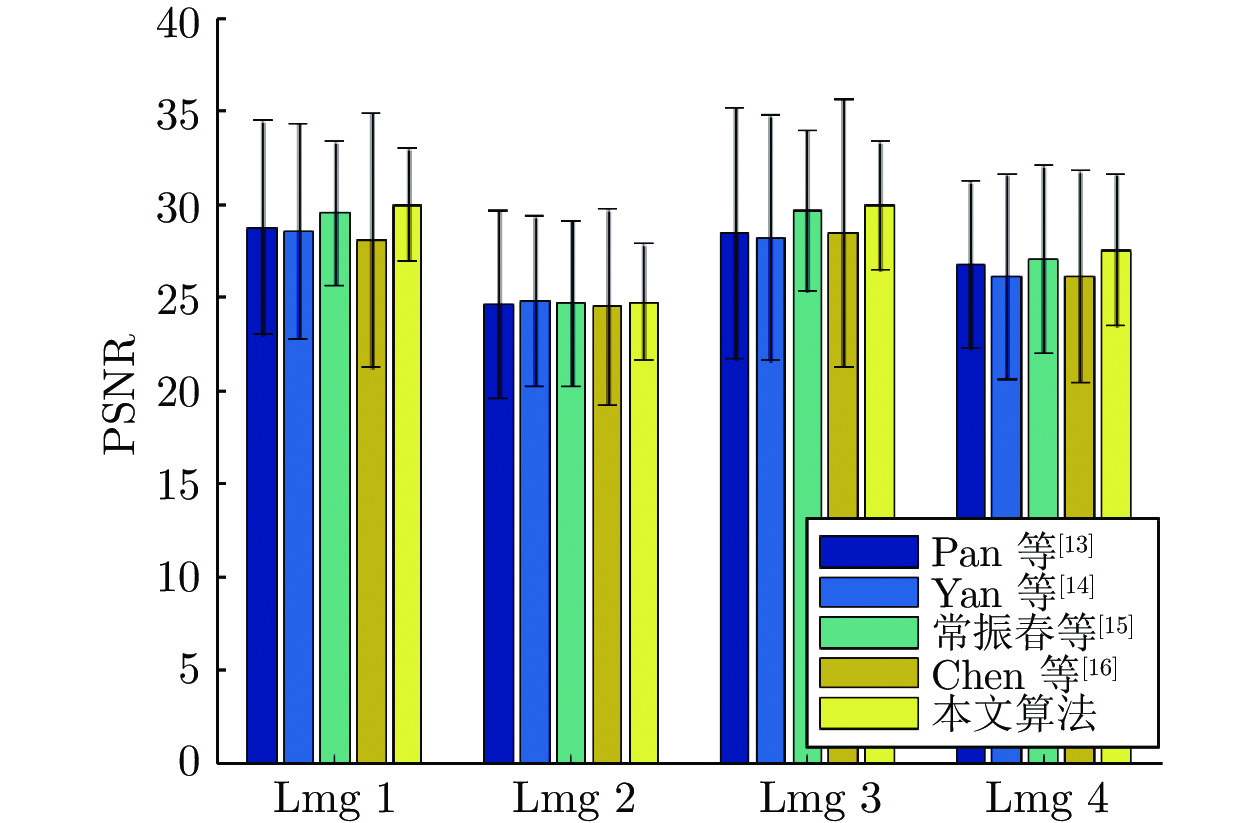
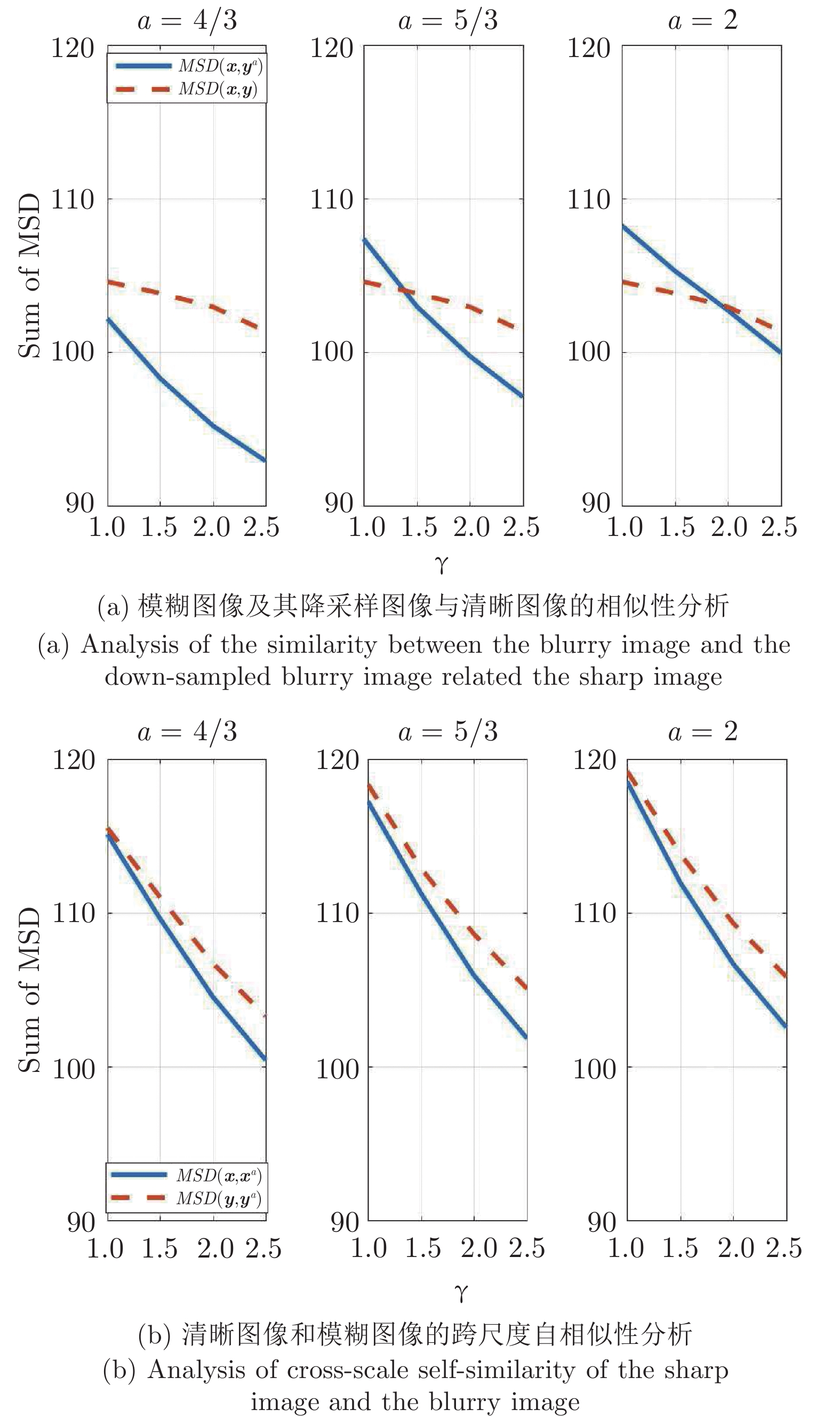
在模糊核未知的情况下对模糊图像进行复原称为盲解卷积问题, 这是一个欠定逆问题, 现有的大部分盲解卷积算法利用图像的各种先验知识约束问题的解空间. 由于清晰图像的跨尺度自相似性强于模糊图像的跨尺度自相似性, 且降采样模糊图像与清晰图像具有更强的相似性, 本文提出了一种基于跨尺度低秩约束的单幅图像盲解卷积算法, 利用图像跨尺度自相似性, 在降采样图像中搜索相似图像块构成相似图像块组, 从整体上对相似图像块组进行低秩约束, 作为正则项加入到图像盲解卷积的目标函数中, 迫使重建图像的边缘接近清晰图像的边缘. 本文算法没有对噪声进行特殊处理, 由于低秩约束更好地表示了数据的全局结构特性, 因此避免了盲解卷积过程受噪声的干扰. 在模糊图像和模糊有噪图像上的实验验证了本文的算法能够解决大尺寸模糊核的盲复原并对噪声具有良好的鲁棒性.
在模糊核未知的情况下对模糊图像进行复原称为盲解卷积问题, 这是一个欠定逆问题, 现有的大部分盲解卷积算法利用图像的各种先验知识约束问题的解空间. 由于清晰图像的跨尺度自相似性强于模糊图像的跨尺度自相似性, 且降采样模糊图像与清晰图像具有更强的相似性, 本文提出了一种基于跨尺度低秩约束的单幅图像盲解卷积算法, 利用图像跨尺度自相似性, 在降采样图像中搜索相似图像块构成相似图像块组, 从整体上对相似图像块组进行低秩约束, 作为正则项加入到图像盲解卷积的目标函数中, 迫使重建图像的边缘接近清晰图像的边缘. 本文算法没有对噪声进行特殊处理, 由于低秩约束更好地表示了数据的全局结构特性, 因此避免了盲解卷积过程受噪声的干扰. 在模糊图像和模糊有噪图像上的实验验证了本文的算法能够解决大尺寸模糊核的盲复原并对噪声具有良好的鲁棒性.












2022, 48(10): 2526-2536.
doi: 10.16383/j.aas.c190566
摘要:
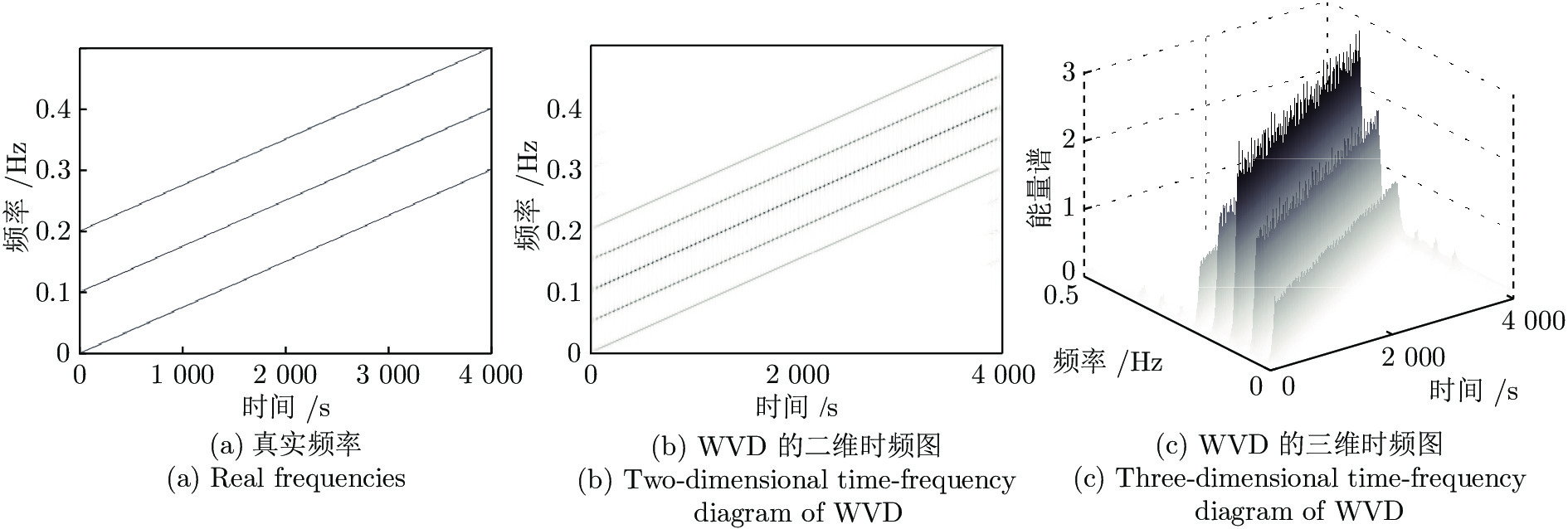
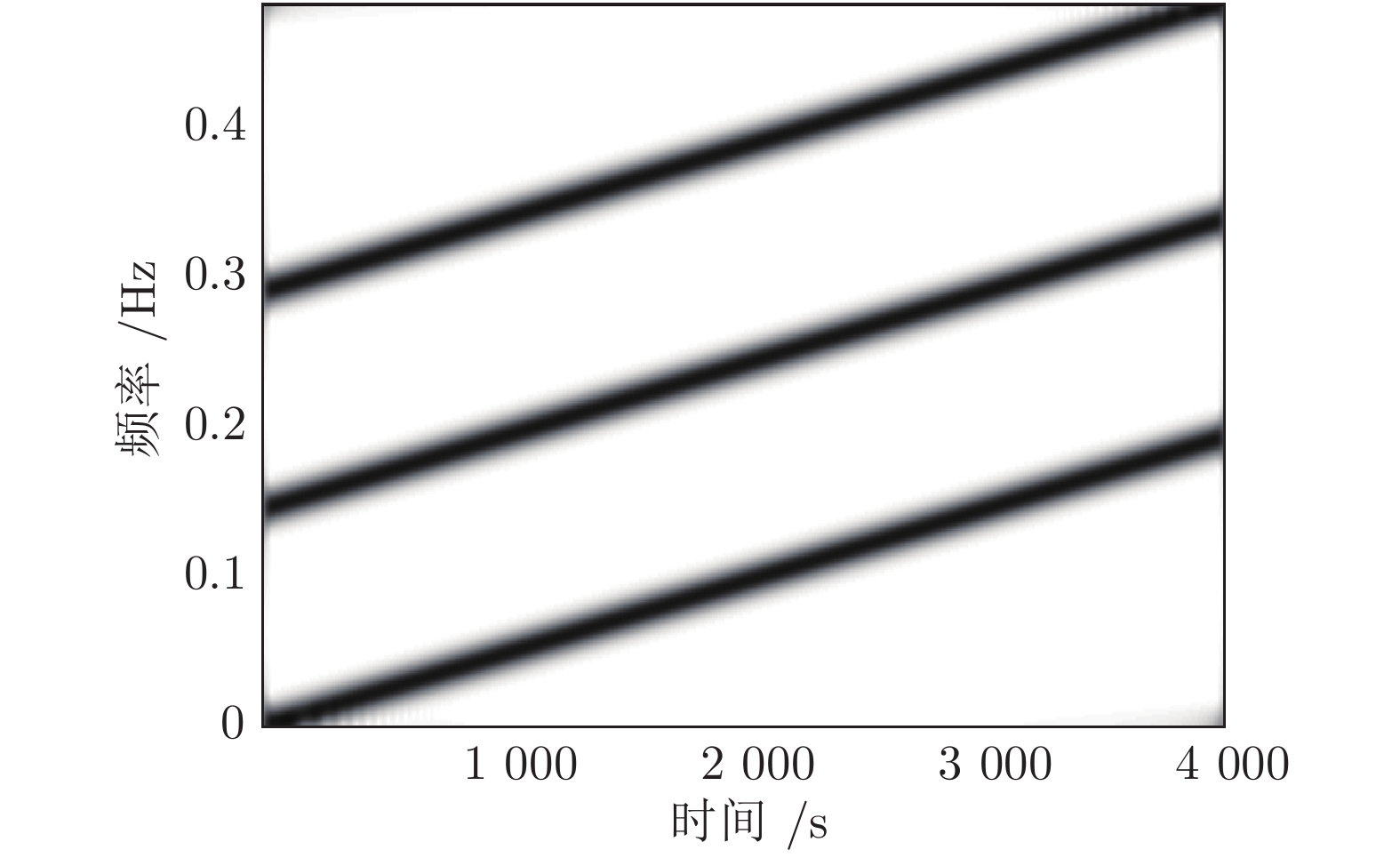
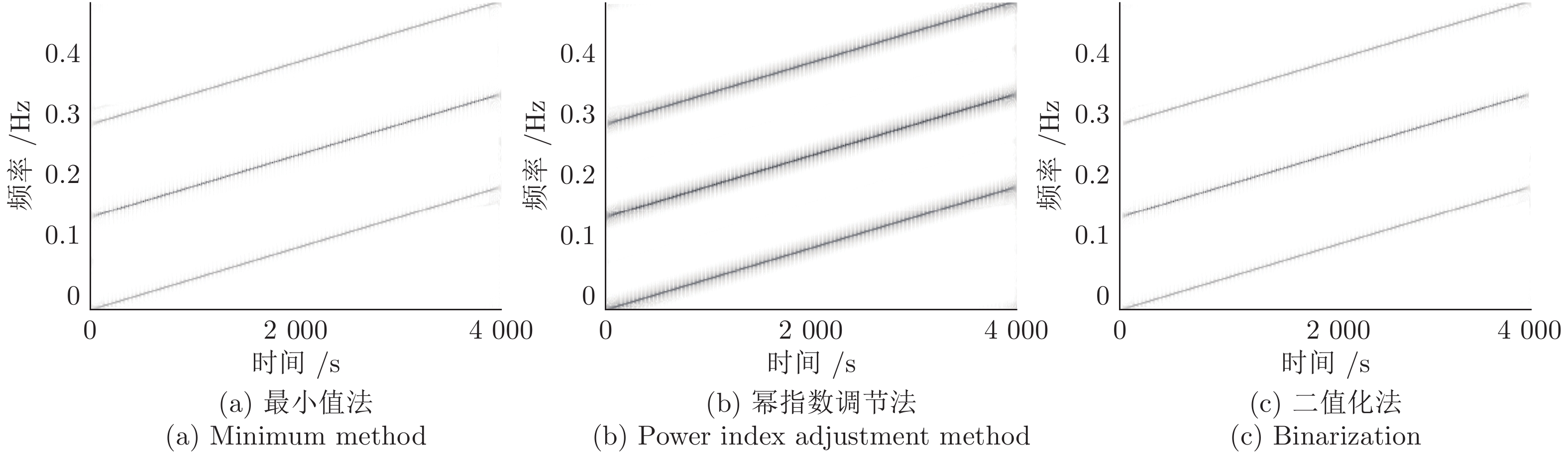
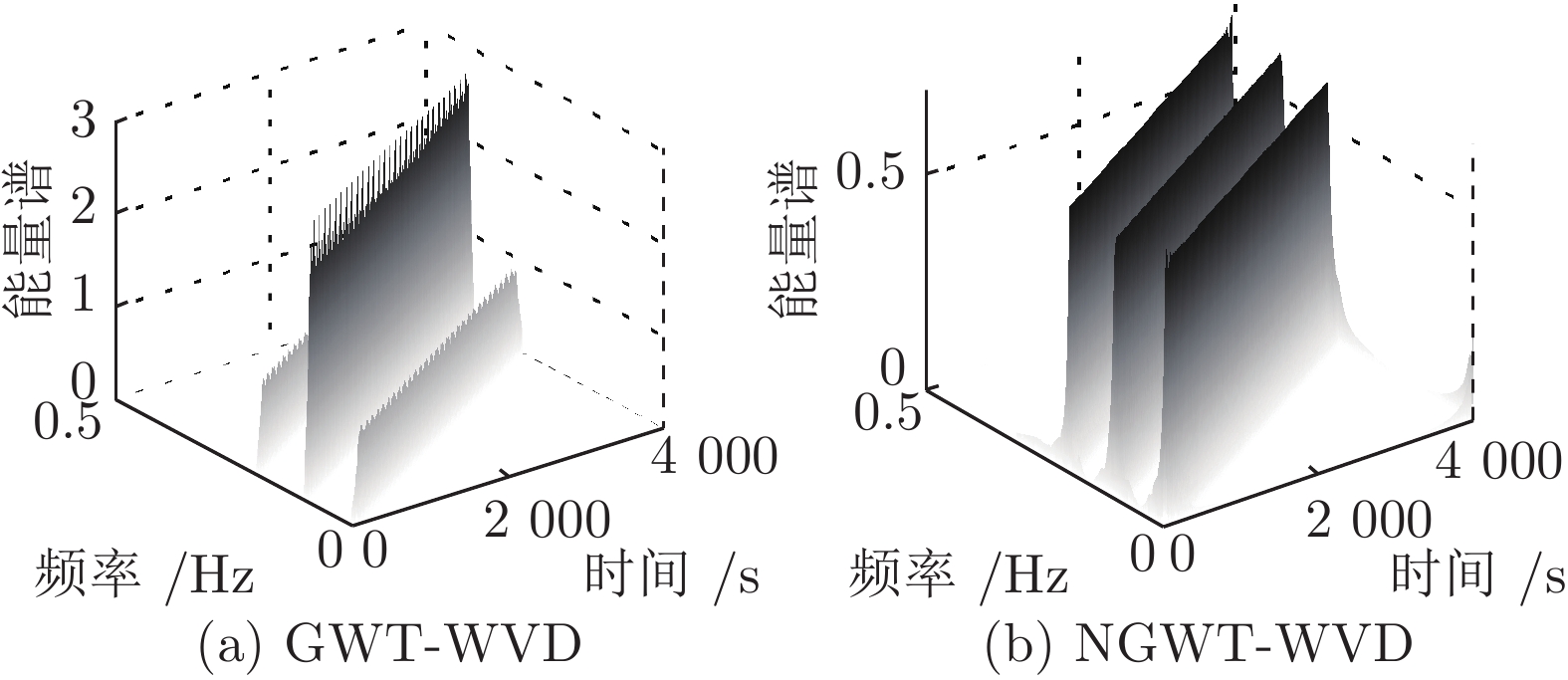
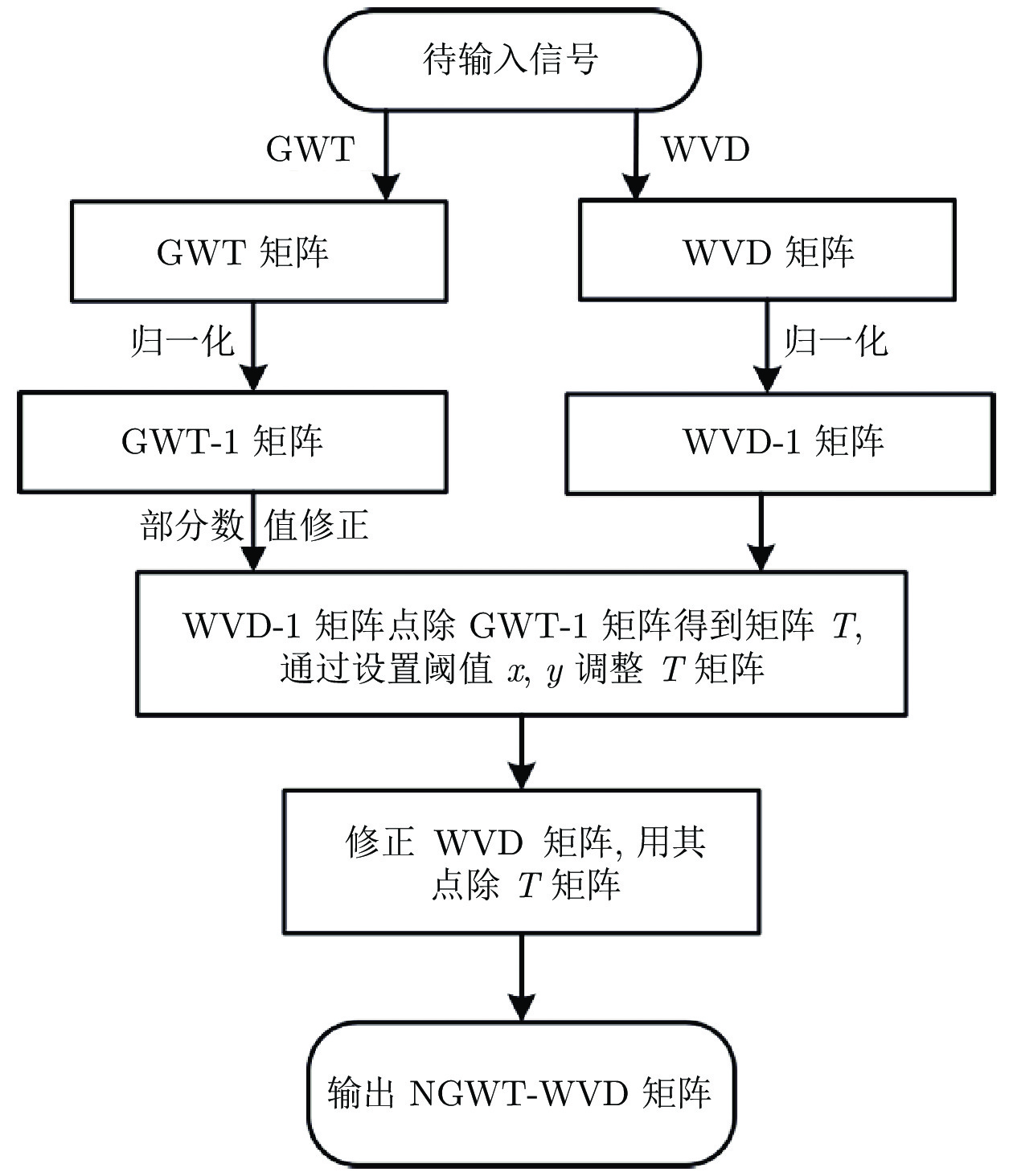
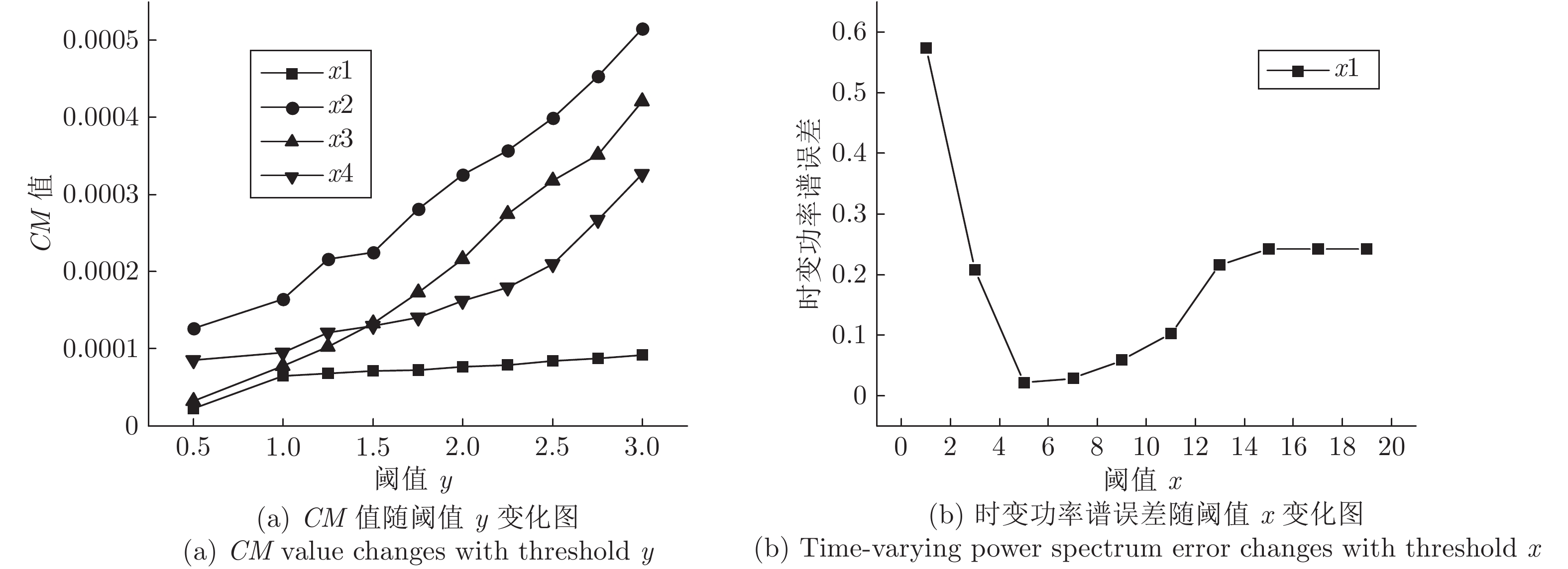
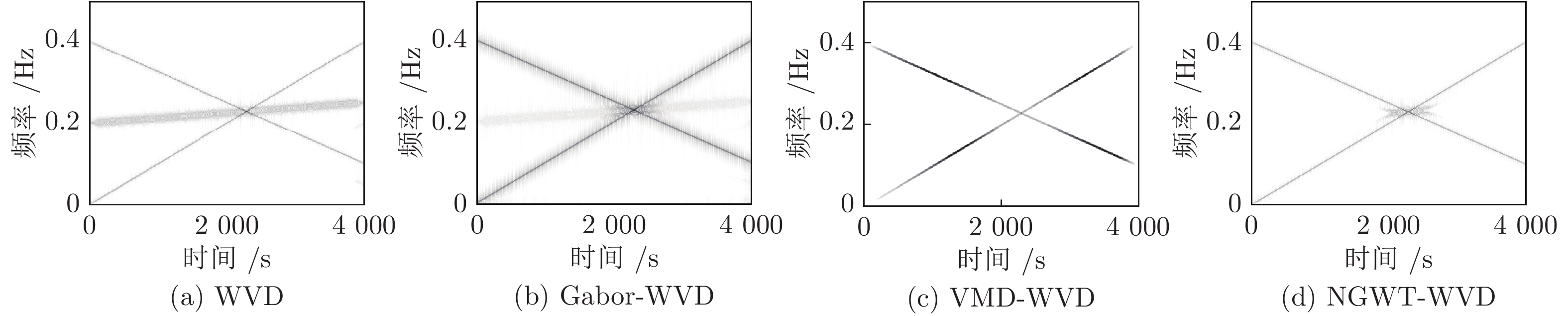
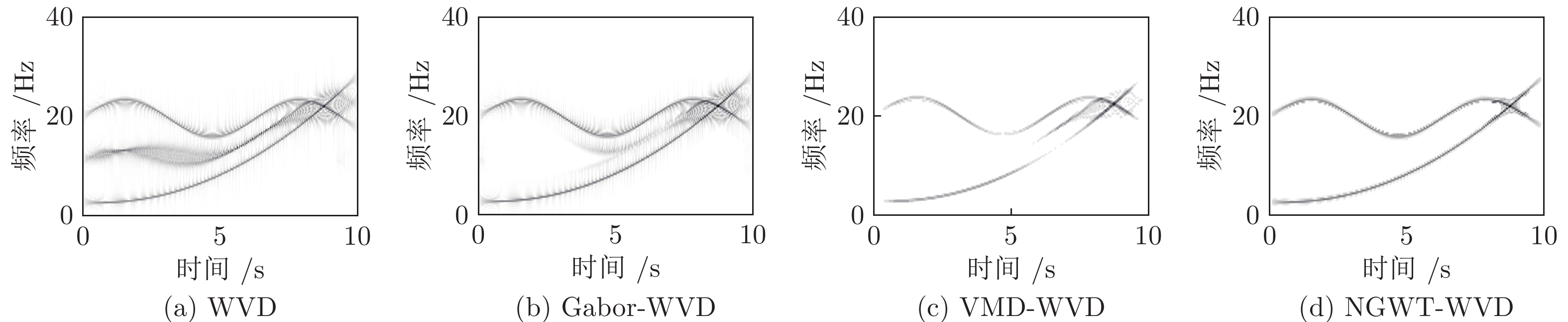
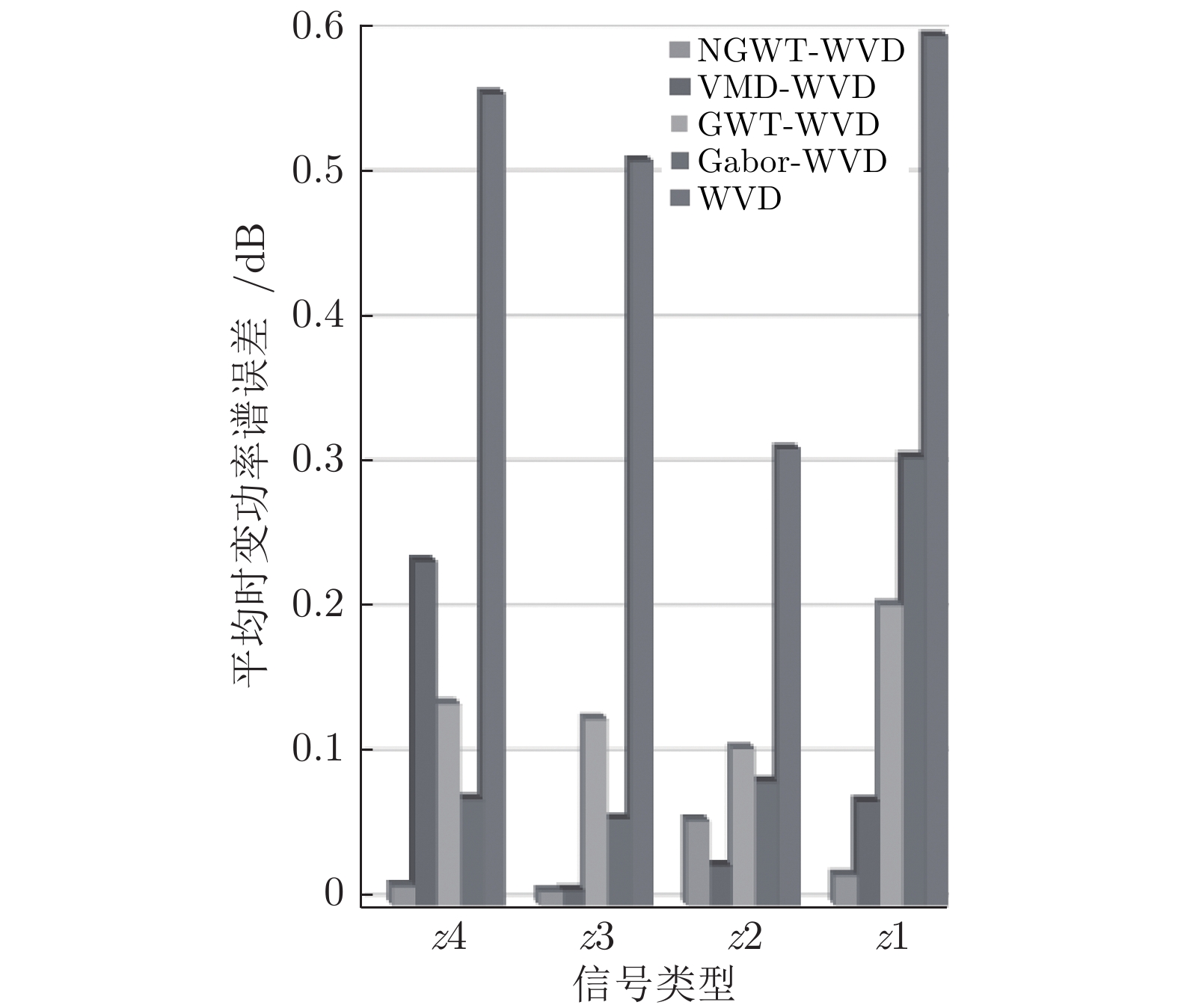
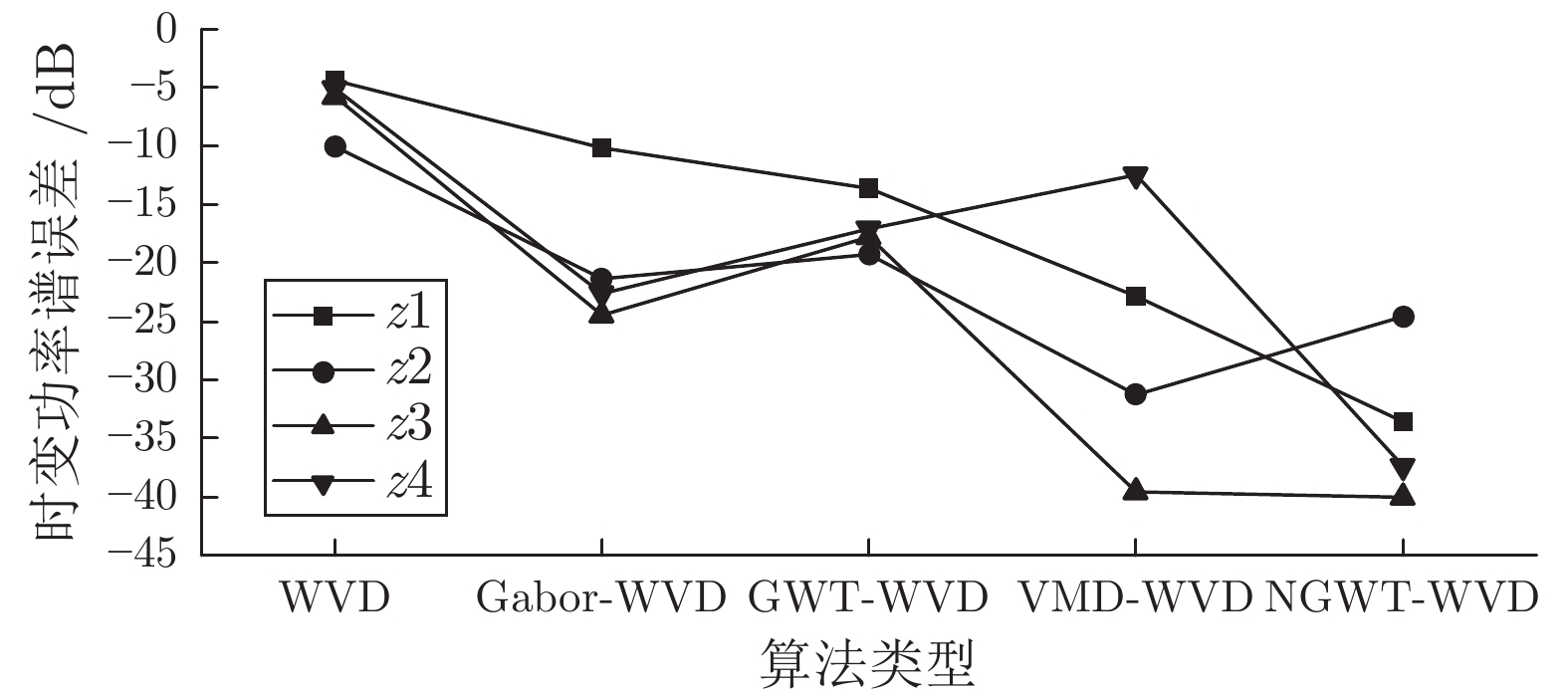
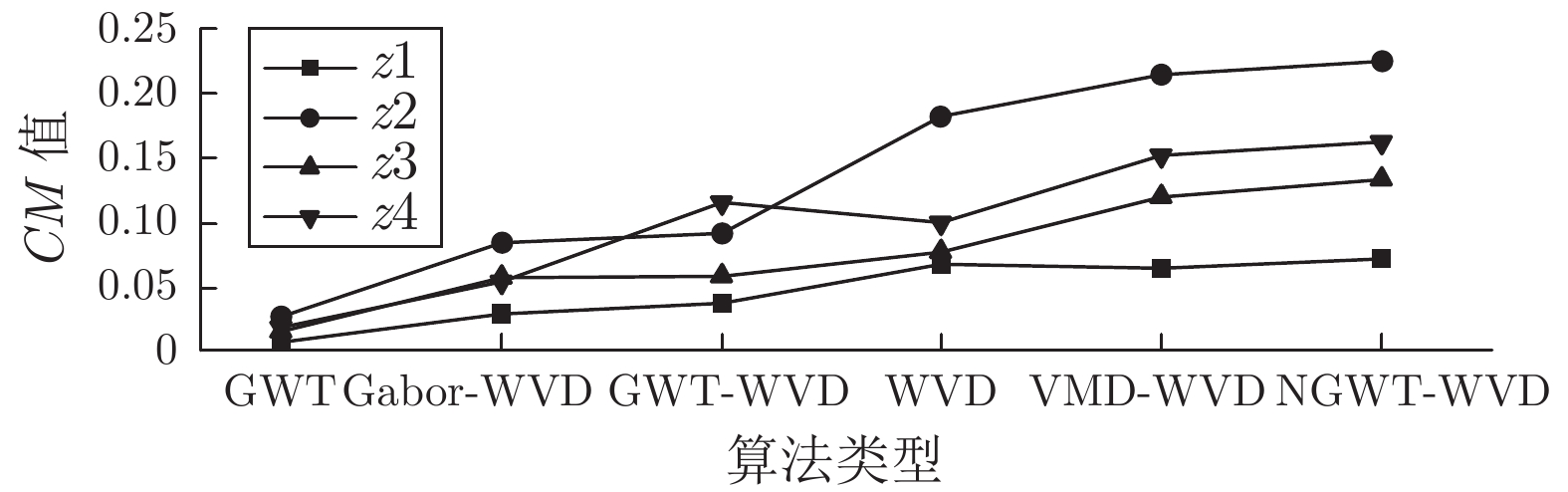
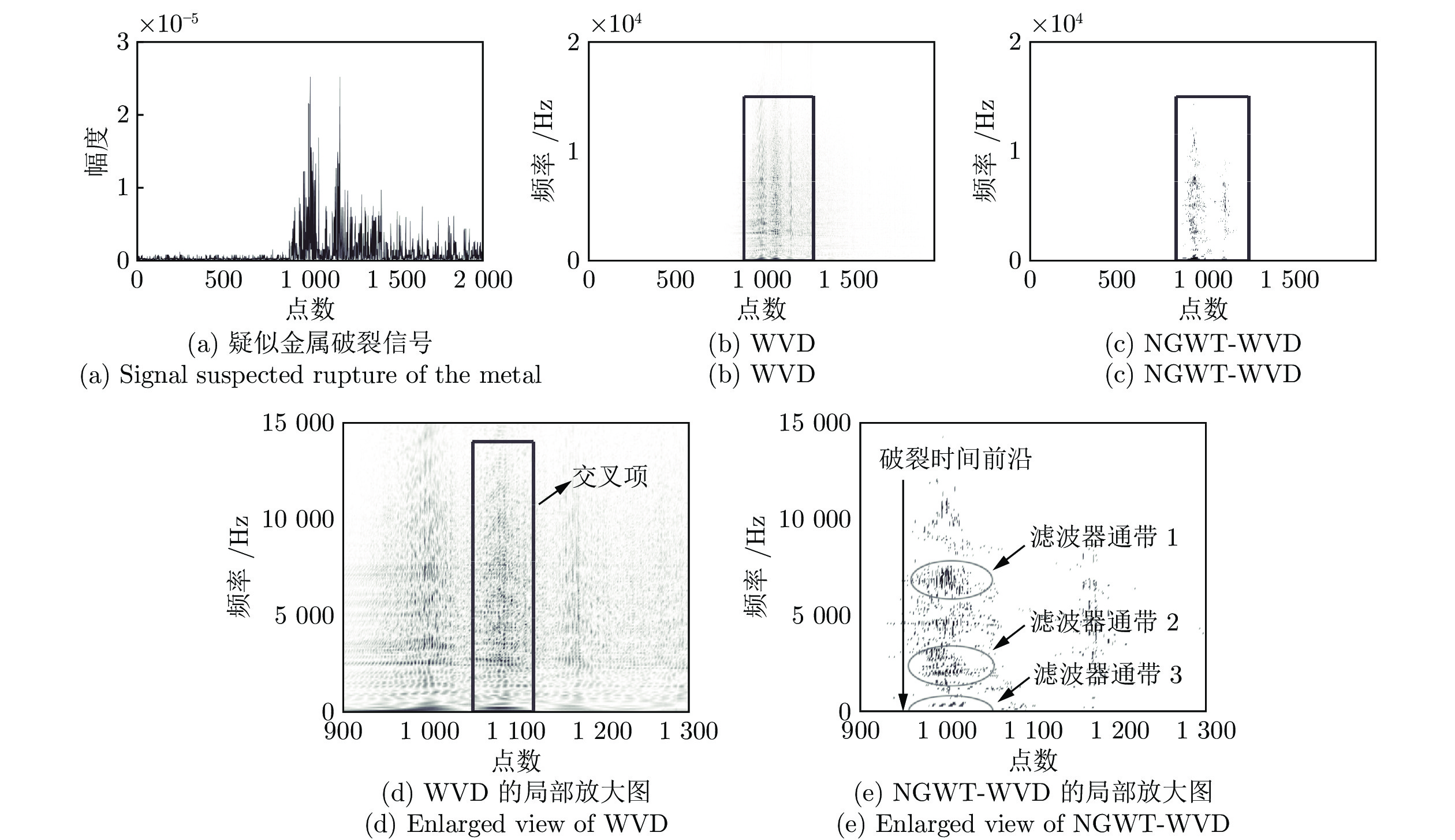
针对高聚集度Wigner-Ville distribution (WVD)时频分析方法存在严重的交叉项干扰问题, 利用广义Warblet变换(Generalized Warblet transform, GWT)不产生虚假频率分量的特点, 提出了WVD与GWT相结合的归一化广义Warblet-WVD (Normalized generalized Warblet-WVD, NGWT-WVD)算法. 该算法将GWT与WVD进行矩阵运算, 实现滤波效应, 抑制WVD产生的新交叉项以及混入自项的交叉项, 提高WVD的时频分析质量. 实验结果表明, NGWT-WVD方法有效地去除了多分量信号的交叉项干扰, 提高信号分析结果的时频聚集度, 还原多分量信号的真实时频分布. 采用NGWT-WVD方法处理金属疑似破裂样本信号, 获取破裂发生区间的时间和频率标志段, 为监测传感器设置有效门限值提供判据, 取得了良好效果.
针对高聚集度Wigner-Ville distribution (WVD)时频分析方法存在严重的交叉项干扰问题, 利用广义Warblet变换(Generalized Warblet transform, GWT)不产生虚假频率分量的特点, 提出了WVD与GWT相结合的归一化广义Warblet-WVD (Normalized generalized Warblet-WVD, NGWT-WVD)算法. 该算法将GWT与WVD进行矩阵运算, 实现滤波效应, 抑制WVD产生的新交叉项以及混入自项的交叉项, 提高WVD的时频分析质量. 实验结果表明, NGWT-WVD方法有效地去除了多分量信号的交叉项干扰, 提高信号分析结果的时频聚集度, 还原多分量信号的真实时频分布. 采用NGWT-WVD方法处理金属疑似破裂样本信号, 获取破裂发生区间的时间和频率标志段, 为监测传感器设置有效门限值提供判据, 取得了良好效果.



2022, 48(10): 2537-2548.
doi: 10.16383/j.aas.c220093
摘要:
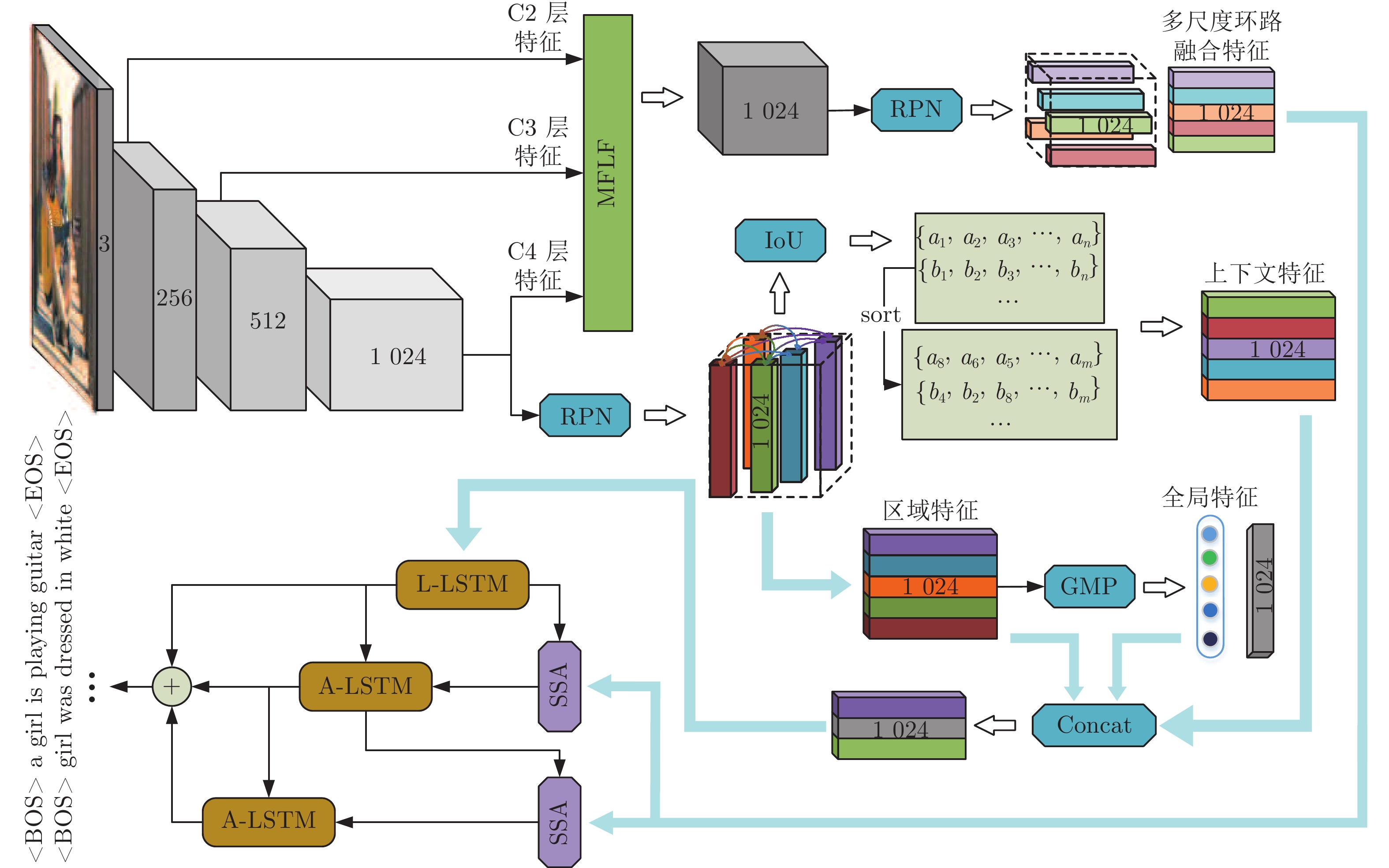
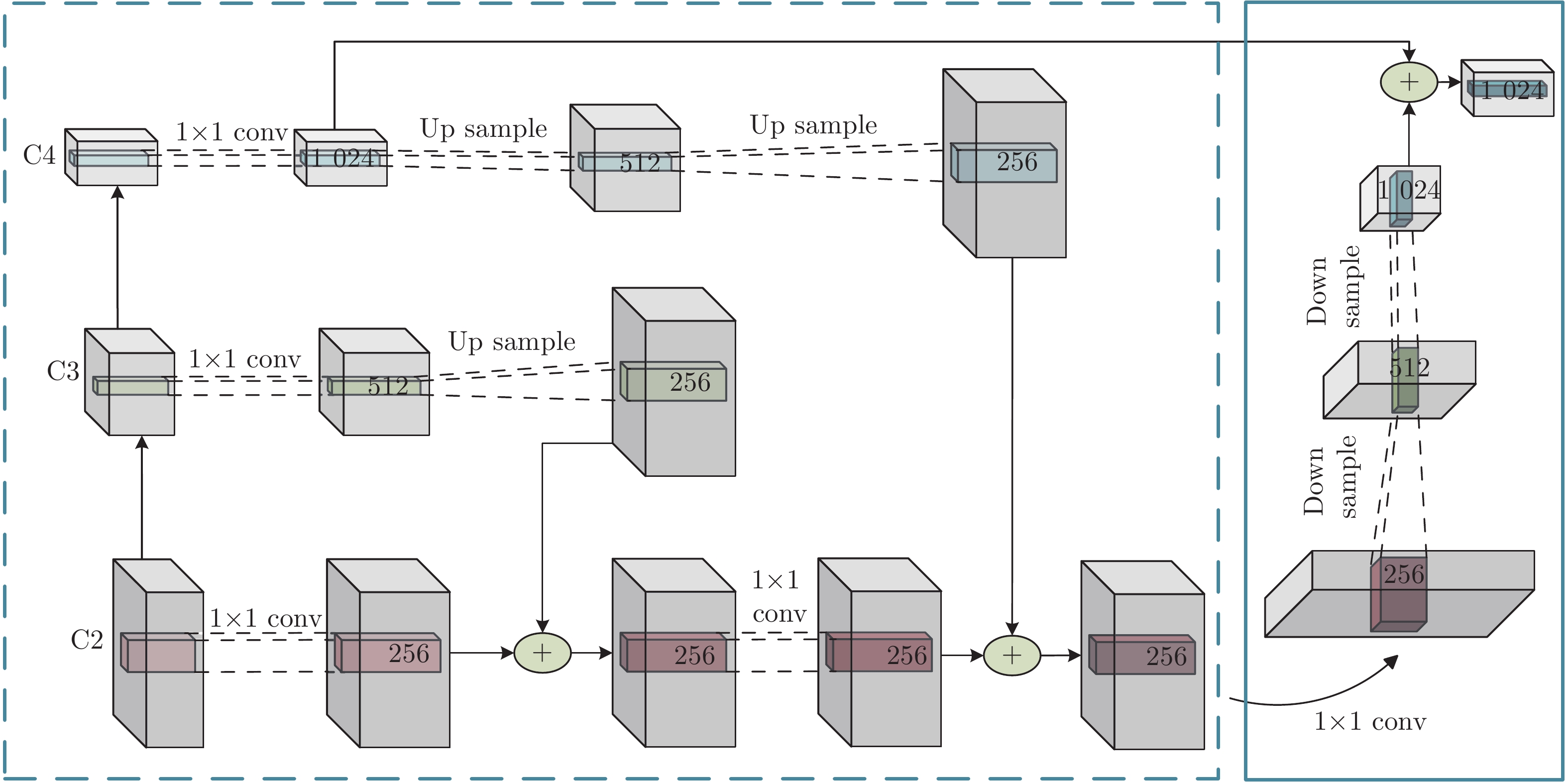
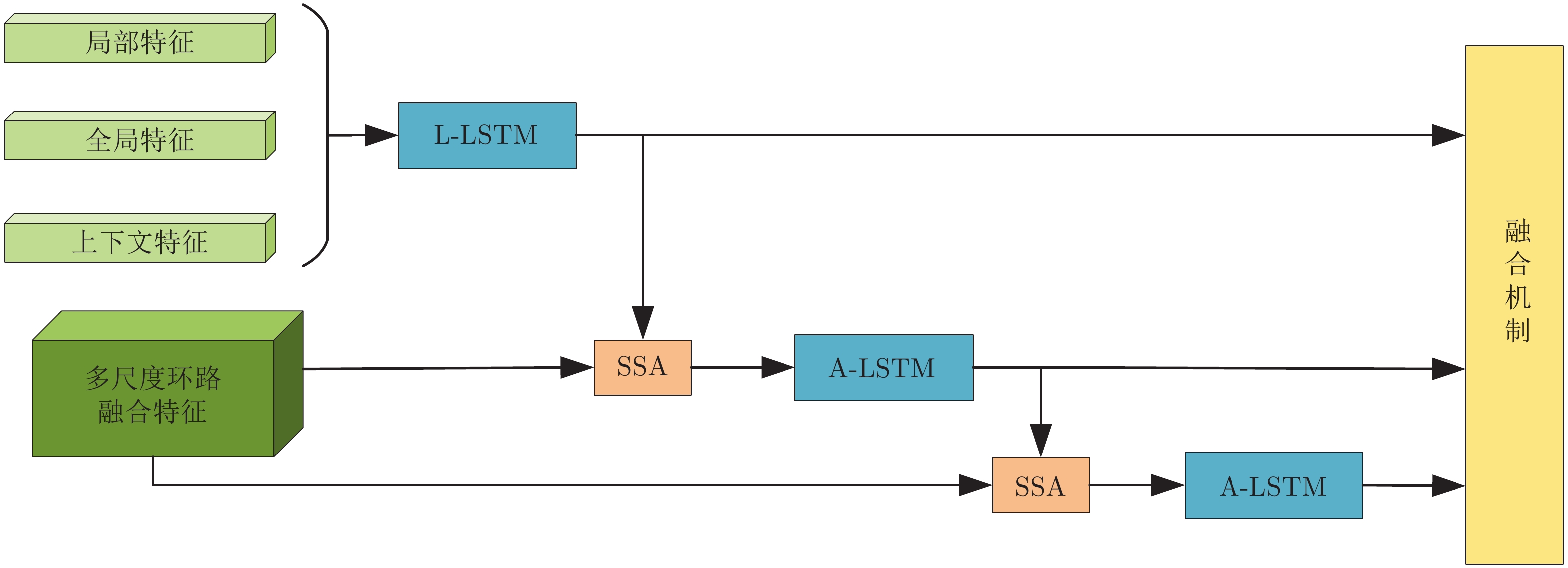
图像密集描述旨在为复杂场景图像提供细节描述语句. 现有研究方法虽已取得较好成绩, 但仍存在以下两个问题: 1)大多数方法仅将注意力聚焦在网络所提取的深层语义信息上, 未能有效利用浅层视觉特征中的几何信息; 2)现有方法致力于改进感兴趣区域间上下文信息的提取, 但图像内物体空间位置信息尚不能较好体现. 为解决上述问题, 提出一种基于多重注意结构的图像密集描述生成方法—MAS-ED (Multiple attention structure-encoder decoder). MAS-ED通过多尺度特征环路融合(Multi-scale feature loop fusion, MFLF) 机制将多种分辨率尺度的图像特征进行有效集成, 并在解码端设计多分支空间分步注意力(Multi-branch spatial step attention, MSSA)模块, 以捕捉图像内物体间的空间位置关系, 从而使模型生成更为精确的密集描述文本. 实验在Visual Genome数据集上对MAS-ED进行评估, 结果表明MAS-ED能够显著提升密集描述的准确性, 并可在文本中自适应加入几何信息和空间位置信息. 基于长短期记忆网络(Long-short term memory, LSTM)解码网络框架, MAS-ED方法性能在主流评价指标上优于各基线方法.
图像密集描述旨在为复杂场景图像提供细节描述语句. 现有研究方法虽已取得较好成绩, 但仍存在以下两个问题: 1)大多数方法仅将注意力聚焦在网络所提取的深层语义信息上, 未能有效利用浅层视觉特征中的几何信息; 2)现有方法致力于改进感兴趣区域间上下文信息的提取, 但图像内物体空间位置信息尚不能较好体现. 为解决上述问题, 提出一种基于多重注意结构的图像密集描述生成方法—MAS-ED (Multiple attention structure-encoder decoder). MAS-ED通过多尺度特征环路融合(Multi-scale feature loop fusion, MFLF) 机制将多种分辨率尺度的图像特征进行有效集成, 并在解码端设计多分支空间分步注意力(Multi-branch spatial step attention, MSSA)模块, 以捕捉图像内物体间的空间位置关系, 从而使模型生成更为精确的密集描述文本. 实验在Visual Genome数据集上对MAS-ED进行评估, 结果表明MAS-ED能够显著提升密集描述的准确性, 并可在文本中自适应加入几何信息和空间位置信息. 基于长短期记忆网络(Long-short term memory, LSTM)解码网络框架, MAS-ED方法性能在主流评价指标上优于各基线方法.





2022, 48(10): 2549-2563.
doi: 10.16383/j.aas.c200034
摘要:
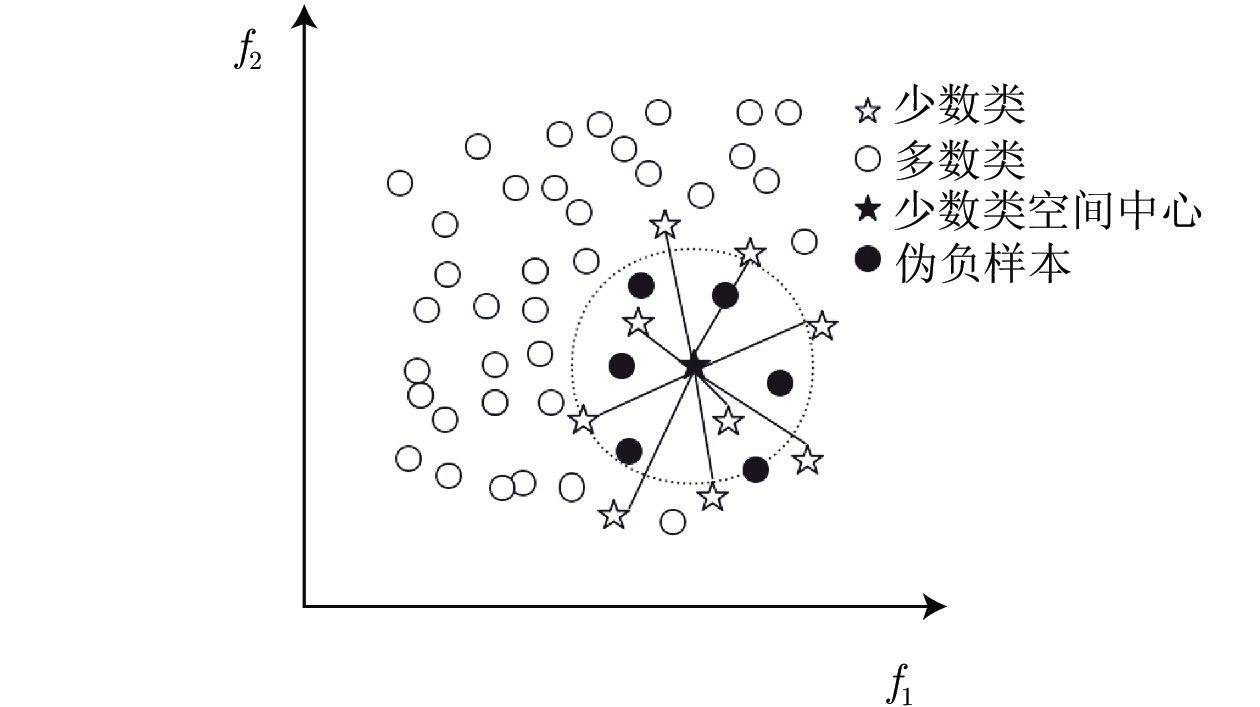
不平衡数据是机器学习中普遍存在的问题并得到广泛研究, 即少数类的样本数量远远小于多数类样本的数量. 传统基于最小化错误率方法的不足在于: 分类结果会倾向于多数类, 造成少数类的精度降低, 通常还存在时间复杂度较高的问题. 为解决上述问题, 提出一种基于样本空间分布的数据采样方法, 伪负样本采样方法. 伪负样本指被标记为负样本(多数类)但与正样本(少数类)有很大相关性的样本. 算法主要包括3个关键步骤: 1)计算正样本的空间分布中心并得到每个正样本到空间中心的平均距离; 2)以同样的距离计算方法计算每个负样本到空间分布中心的距离, 并与平均距离进行比较, 将其距离小于平均距离的负样本标记为伪负样本; 3)将伪负样本从负样本集中删除并加入到正样本集中. 算法的优势在于不改变原始数据集的数量, 因此不会引入噪声样本或导致潜在信息丢失; 在不降低整体分类精度的情况下, 提高少数类的精确度. 此外, 其时间复杂度较低. 经过13个数据进行多角度实验, 表明伪负样本采样方法具有较高的预测准确性.
不平衡数据是机器学习中普遍存在的问题并得到广泛研究, 即少数类的样本数量远远小于多数类样本的数量. 传统基于最小化错误率方法的不足在于: 分类结果会倾向于多数类, 造成少数类的精度降低, 通常还存在时间复杂度较高的问题. 为解决上述问题, 提出一种基于样本空间分布的数据采样方法, 伪负样本采样方法. 伪负样本指被标记为负样本(多数类)但与正样本(少数类)有很大相关性的样本. 算法主要包括3个关键步骤: 1)计算正样本的空间分布中心并得到每个正样本到空间中心的平均距离; 2)以同样的距离计算方法计算每个负样本到空间分布中心的距离, 并与平均距离进行比较, 将其距离小于平均距离的负样本标记为伪负样本; 3)将伪负样本从负样本集中删除并加入到正样本集中. 算法的优势在于不改变原始数据集的数量, 因此不会引入噪声样本或导致潜在信息丢失; 在不降低整体分类精度的情况下, 提高少数类的精确度. 此外, 其时间复杂度较低. 经过13个数据进行多角度实验, 表明伪负样本采样方法具有较高的预测准确性.


2022, 48(10): 2564-2584.
doi: 10.16383/j.aas.c200791
摘要:
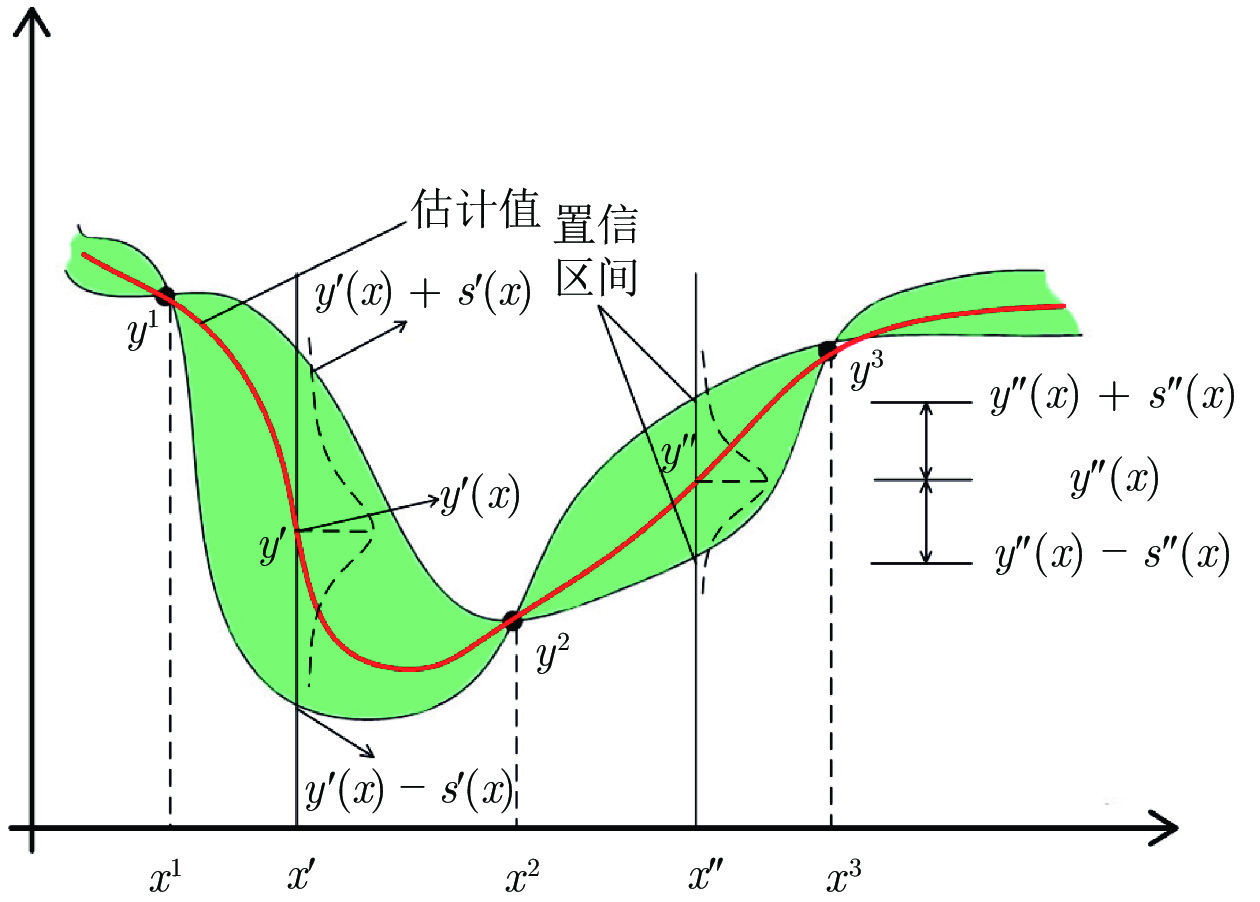
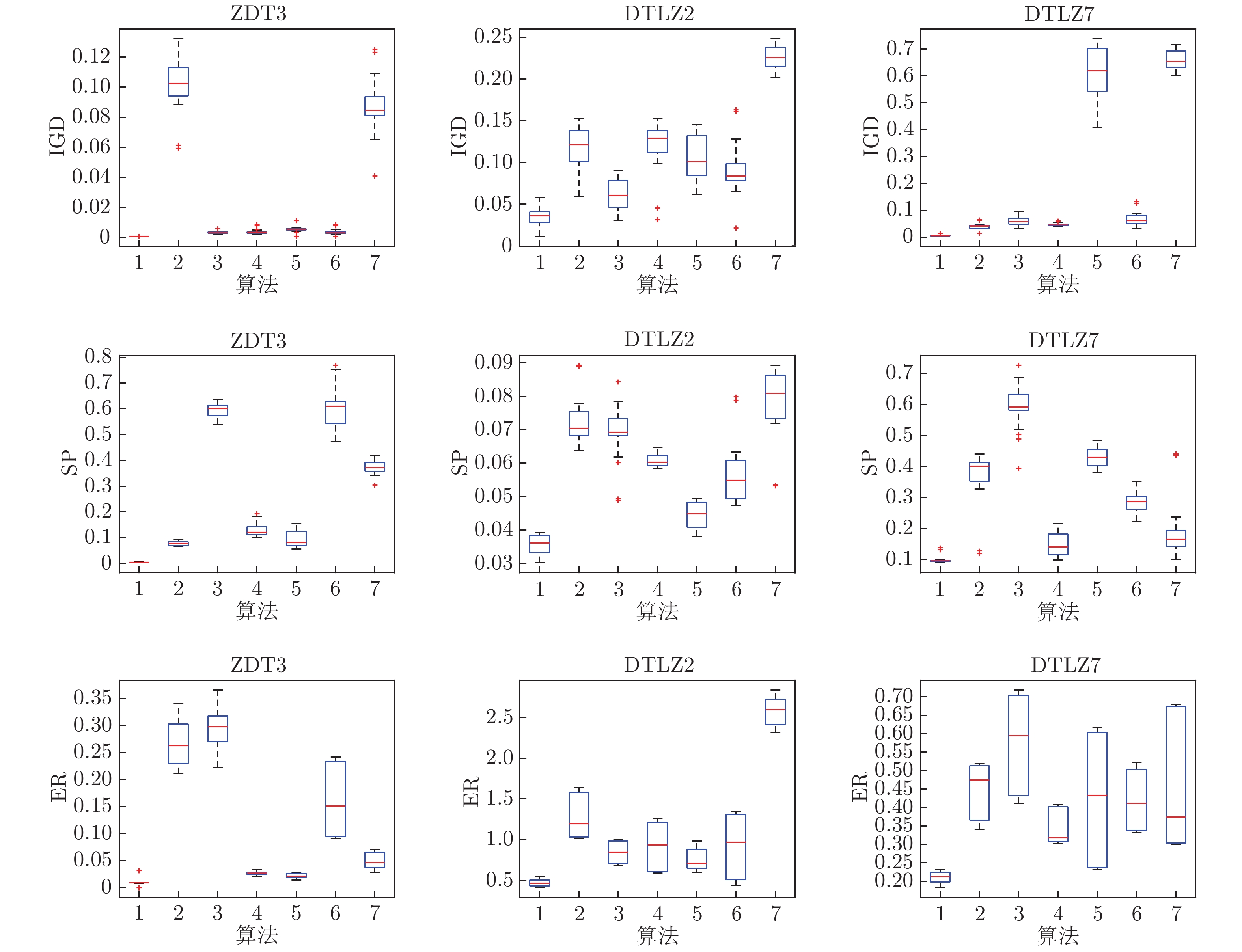
为了解决难以建立精确数学模型或者真实评估实验成本高昂的多目标优化问题, 提出了一种基于径向空间划分的昂贵多目标进化算法. 首先算法使用高斯回归作为代理模型逼近目标函数; 然后将目标空间的个体投影到径向空间, 结合目标空间和径向空间信息保留对种群贡献更高的个体; 之后由径向空间中个体的位置分布决定下一步应该选择哪些个体进行真实评估; 最后, 采用一种双档案管理策略维护代理模型的质量. 数值实验和现实问题上的结果表明, 与5种先进算法相比, 该算法在解决昂贵多目标优化问题时能够提供更高质量的解.
为了解决难以建立精确数学模型或者真实评估实验成本高昂的多目标优化问题, 提出了一种基于径向空间划分的昂贵多目标进化算法. 首先算法使用高斯回归作为代理模型逼近目标函数; 然后将目标空间的个体投影到径向空间, 结合目标空间和径向空间信息保留对种群贡献更高的个体; 之后由径向空间中个体的位置分布决定下一步应该选择哪些个体进行真实评估; 最后, 采用一种双档案管理策略维护代理模型的质量. 数值实验和现实问题上的结果表明, 与5种先进算法相比, 该算法在解决昂贵多目标优化问题时能够提供更高质量的解.
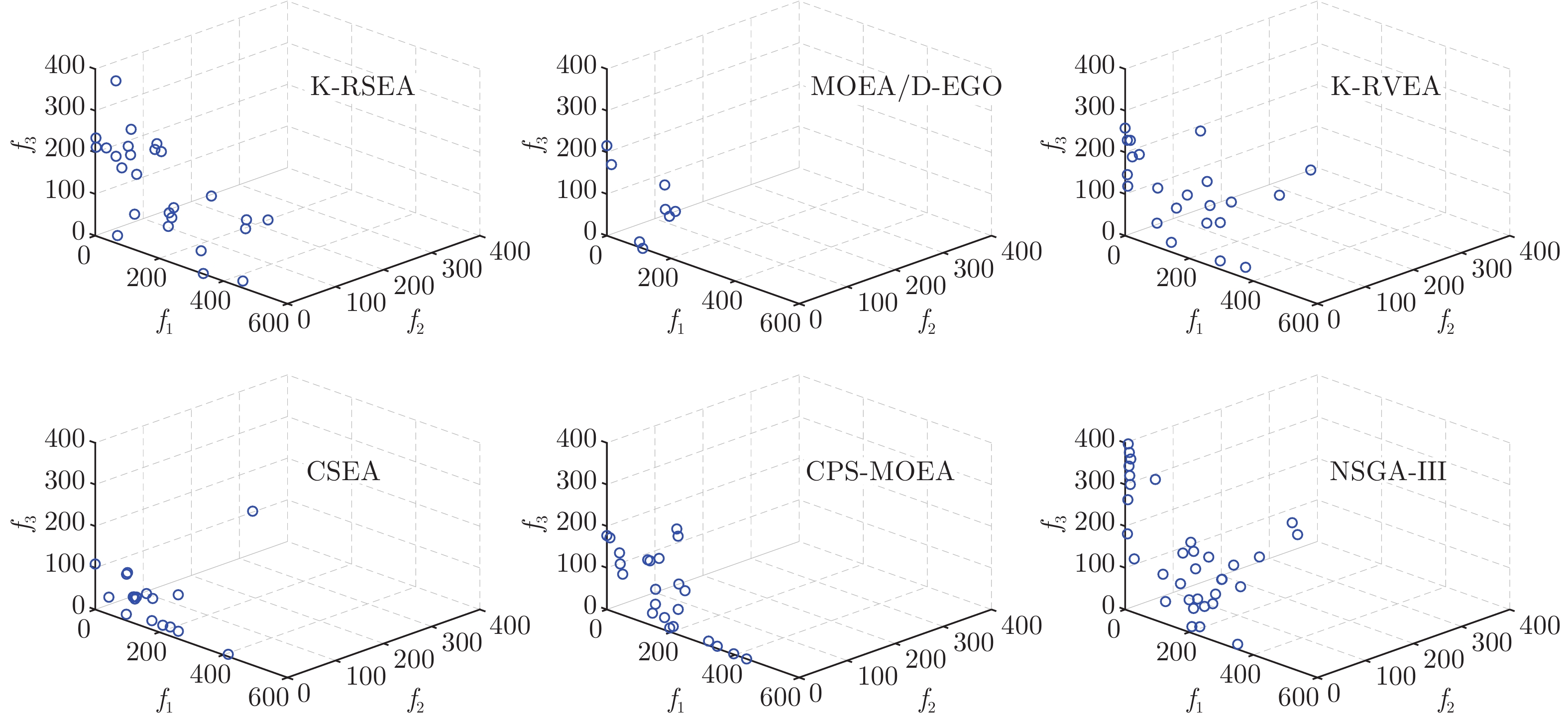


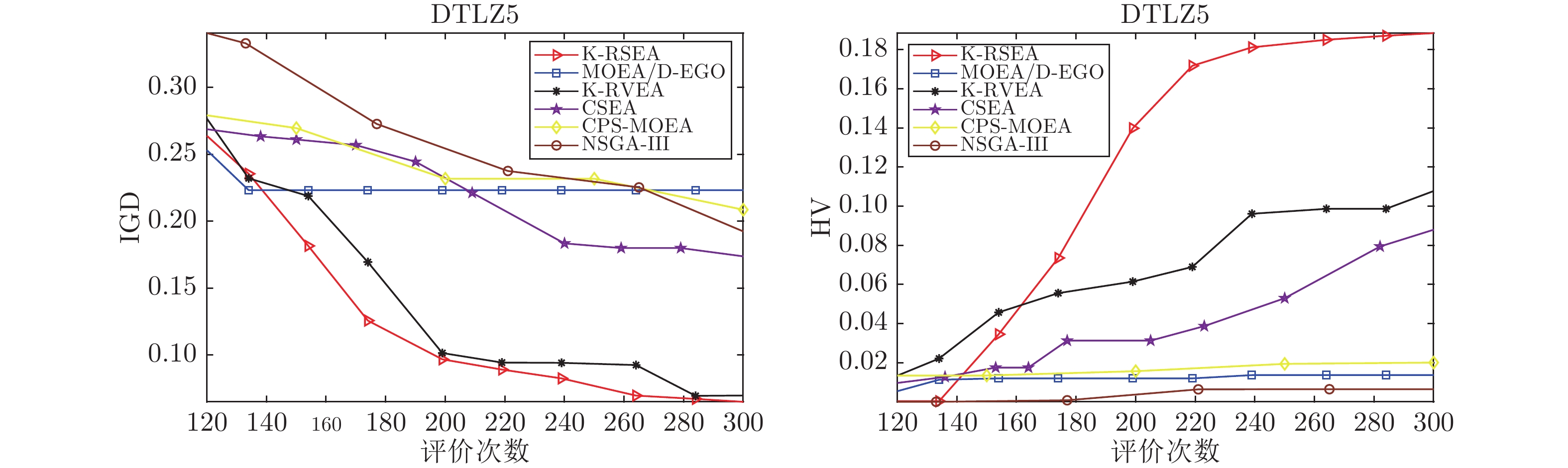
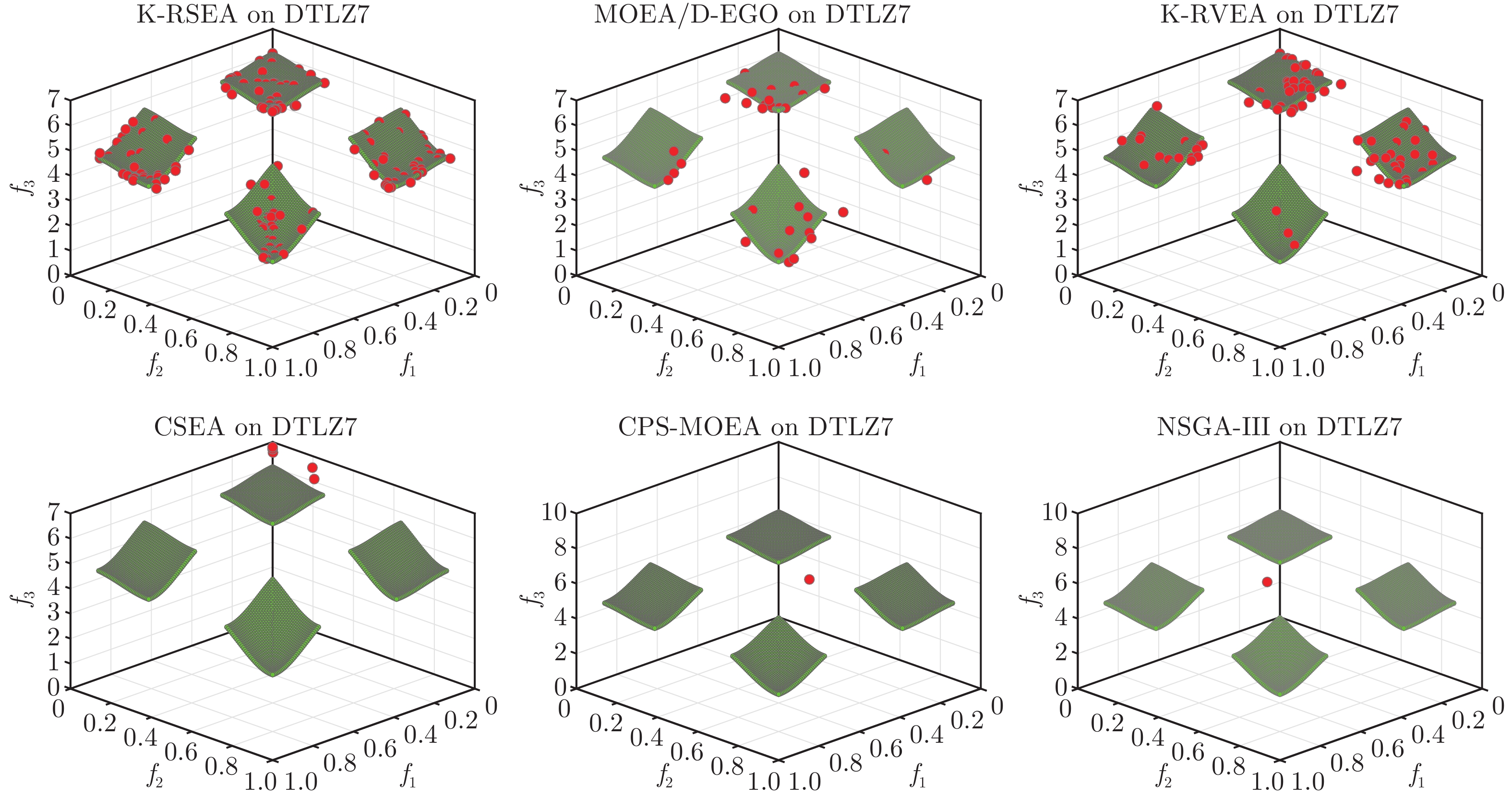
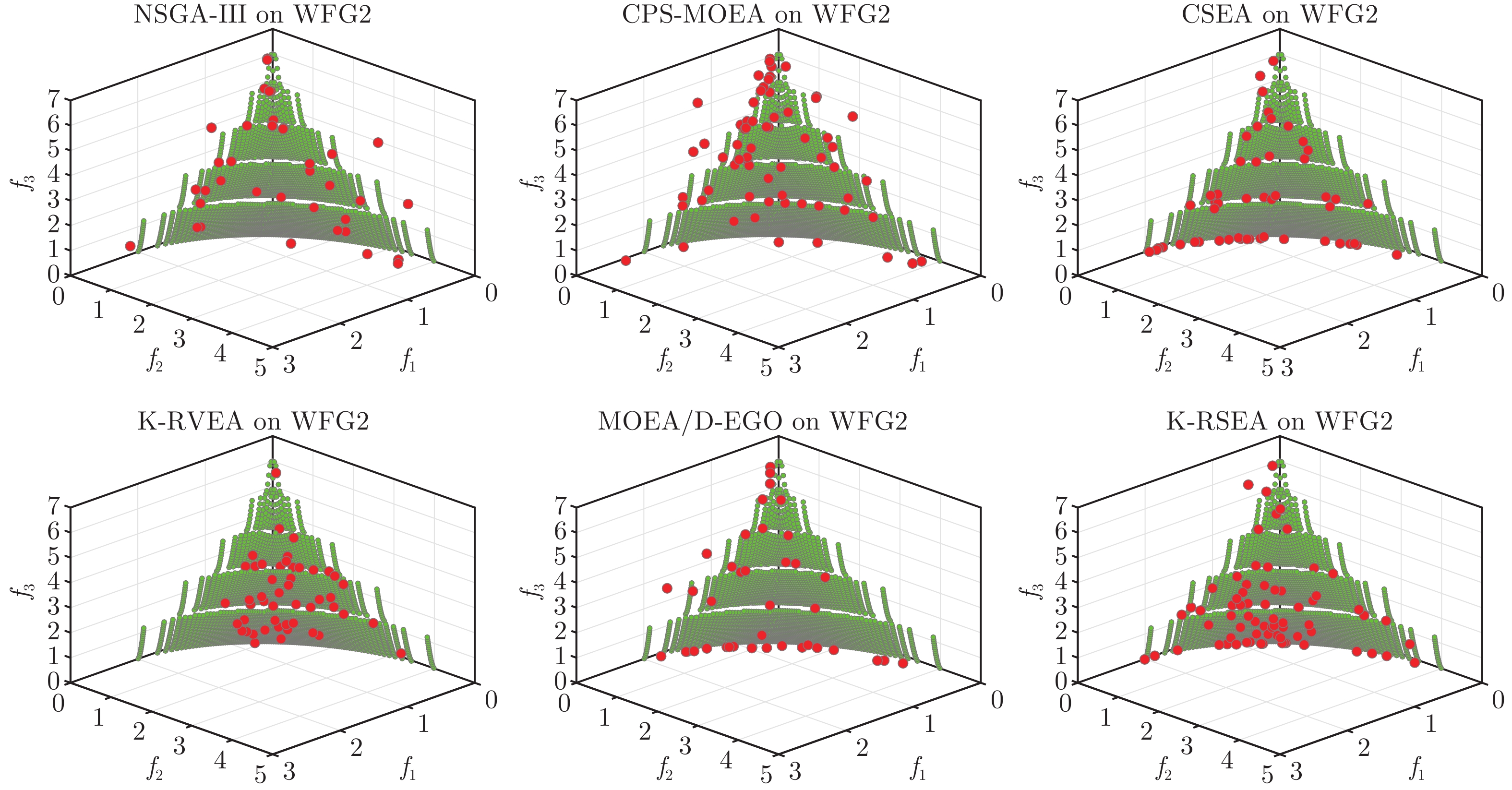

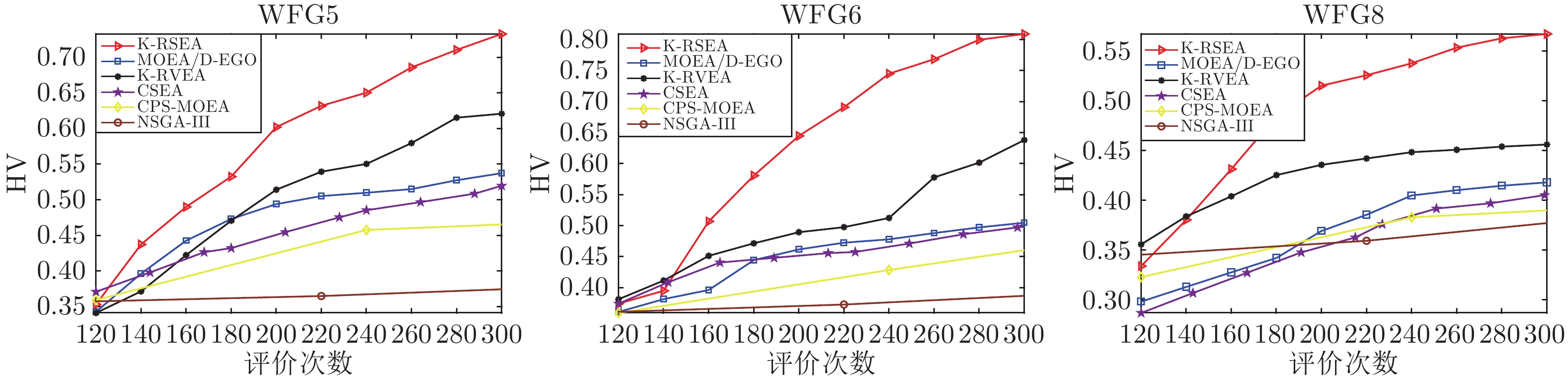

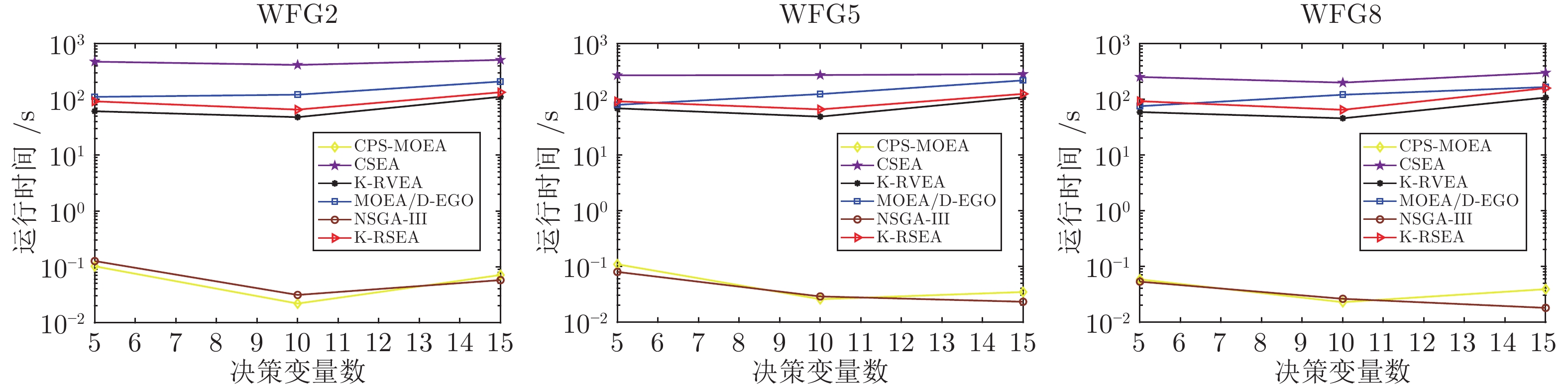
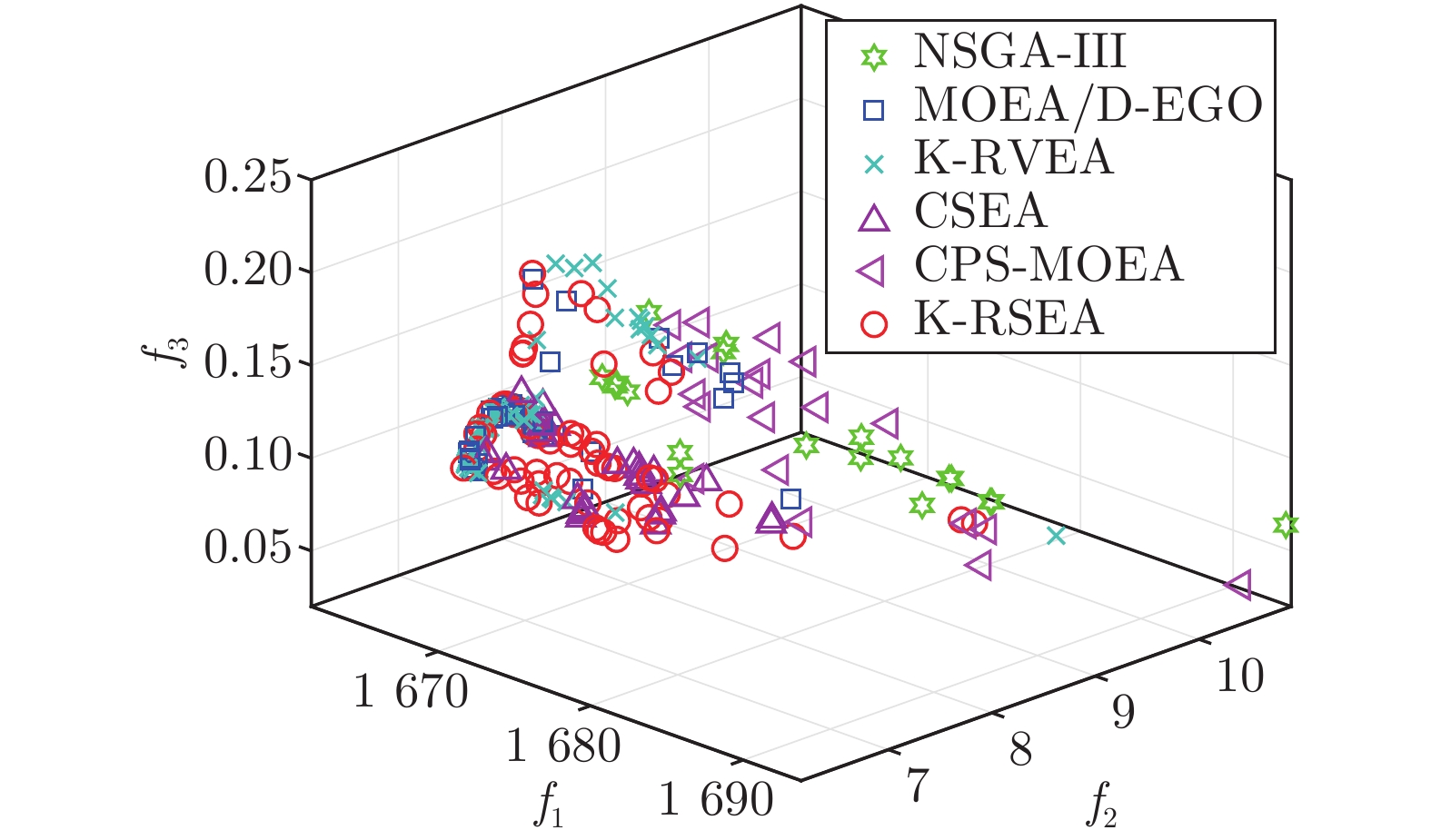
2022, 48(10): 2585-2599.
doi: 10.16383/j.aas.c200307
摘要:
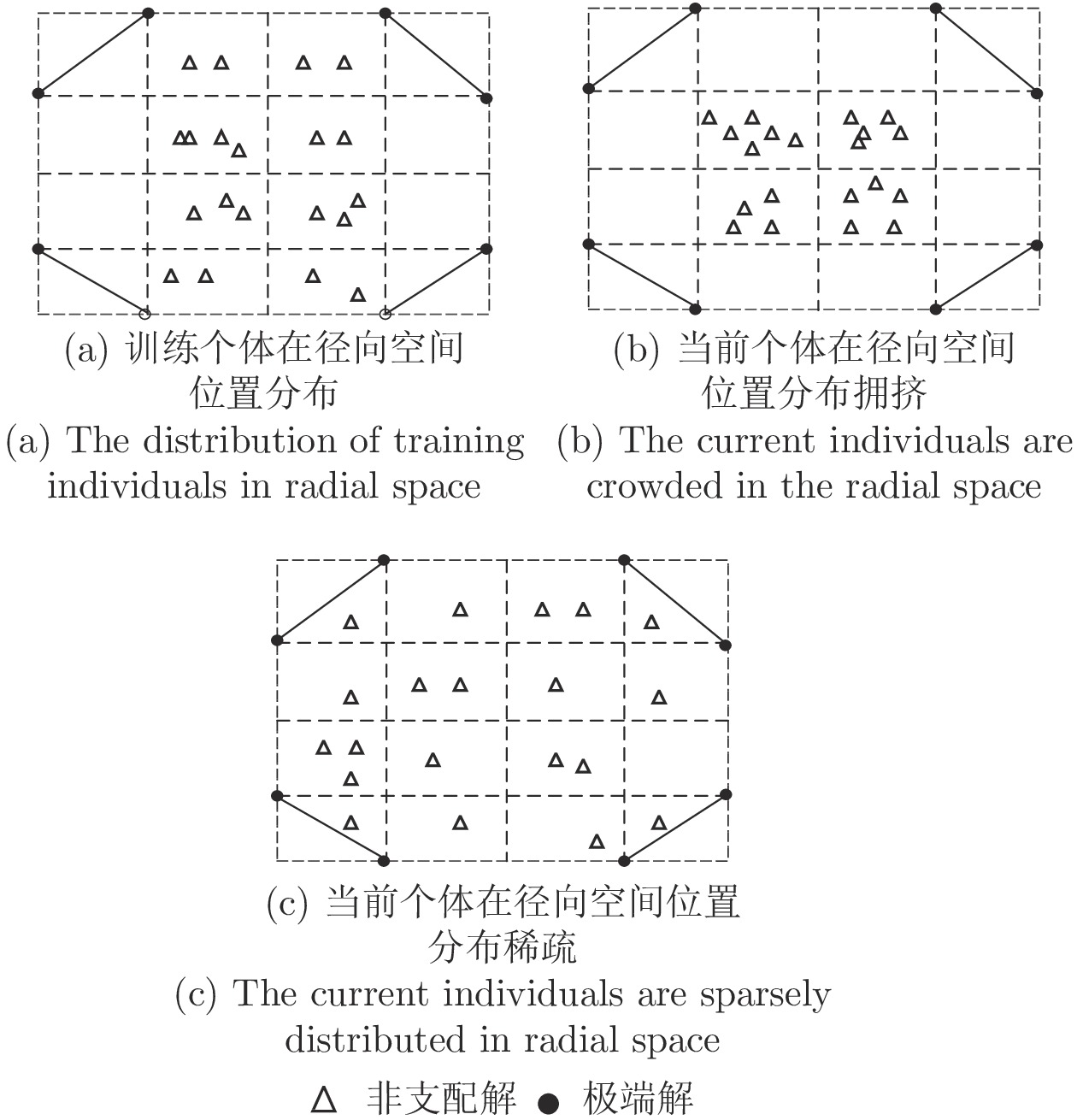
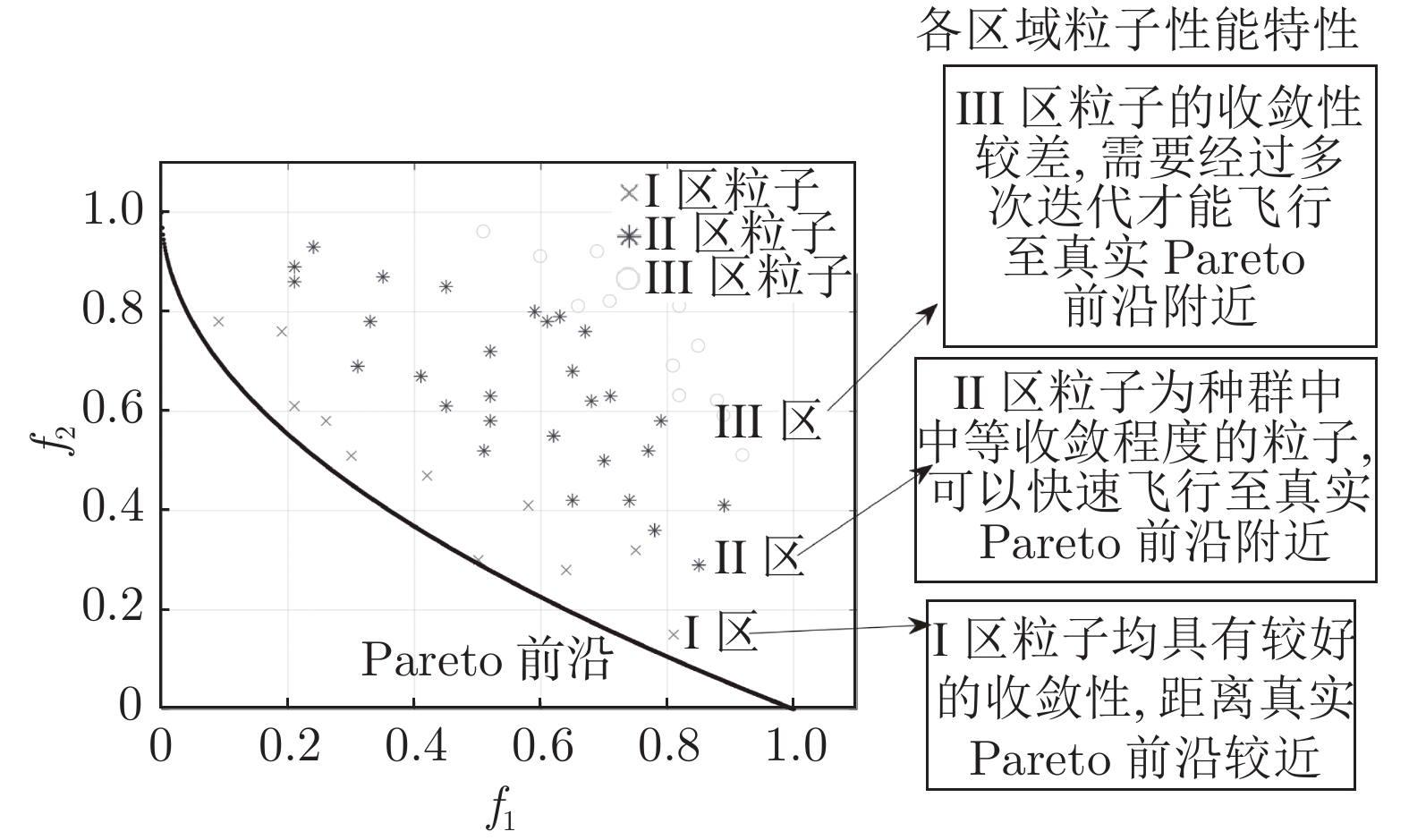
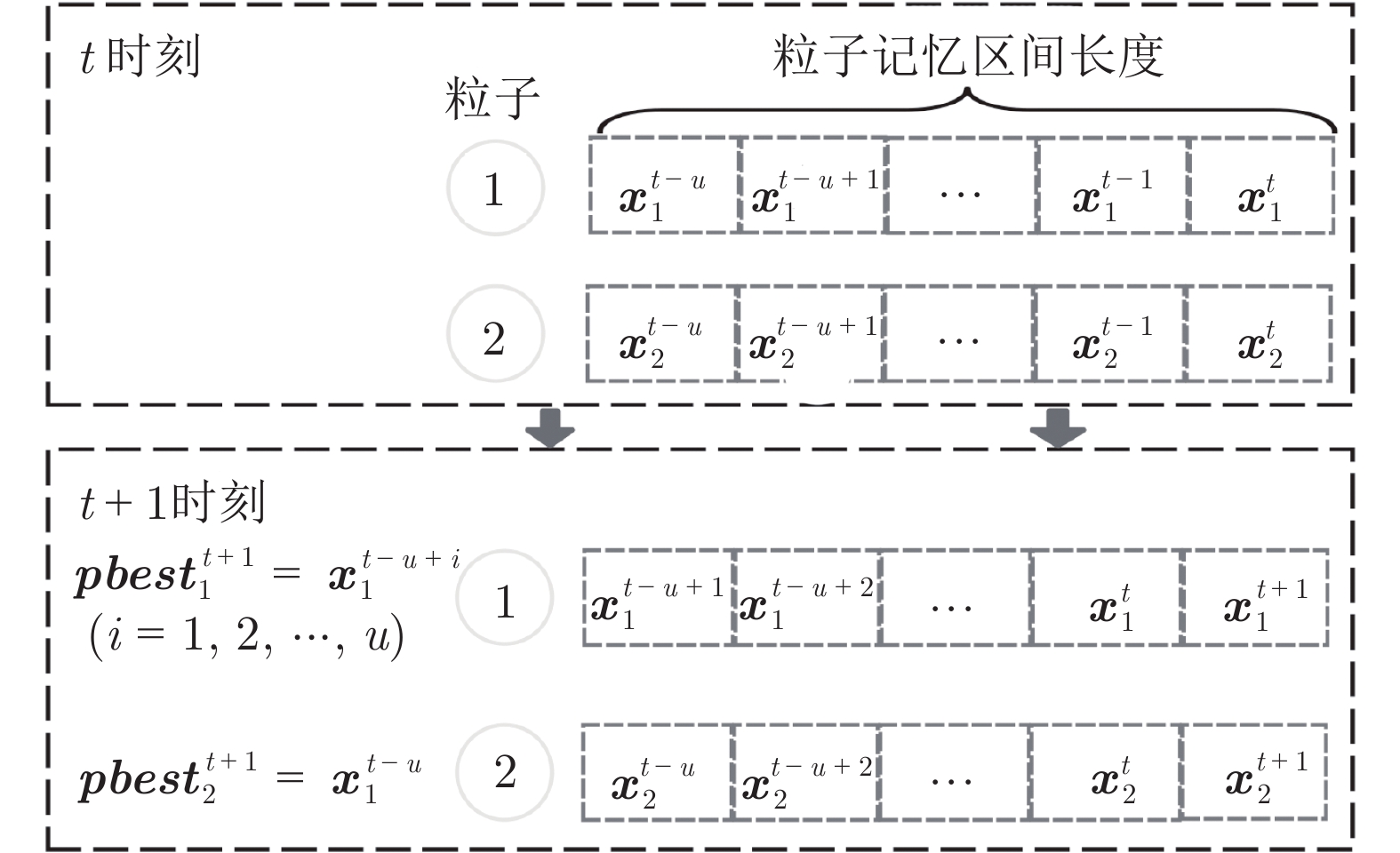
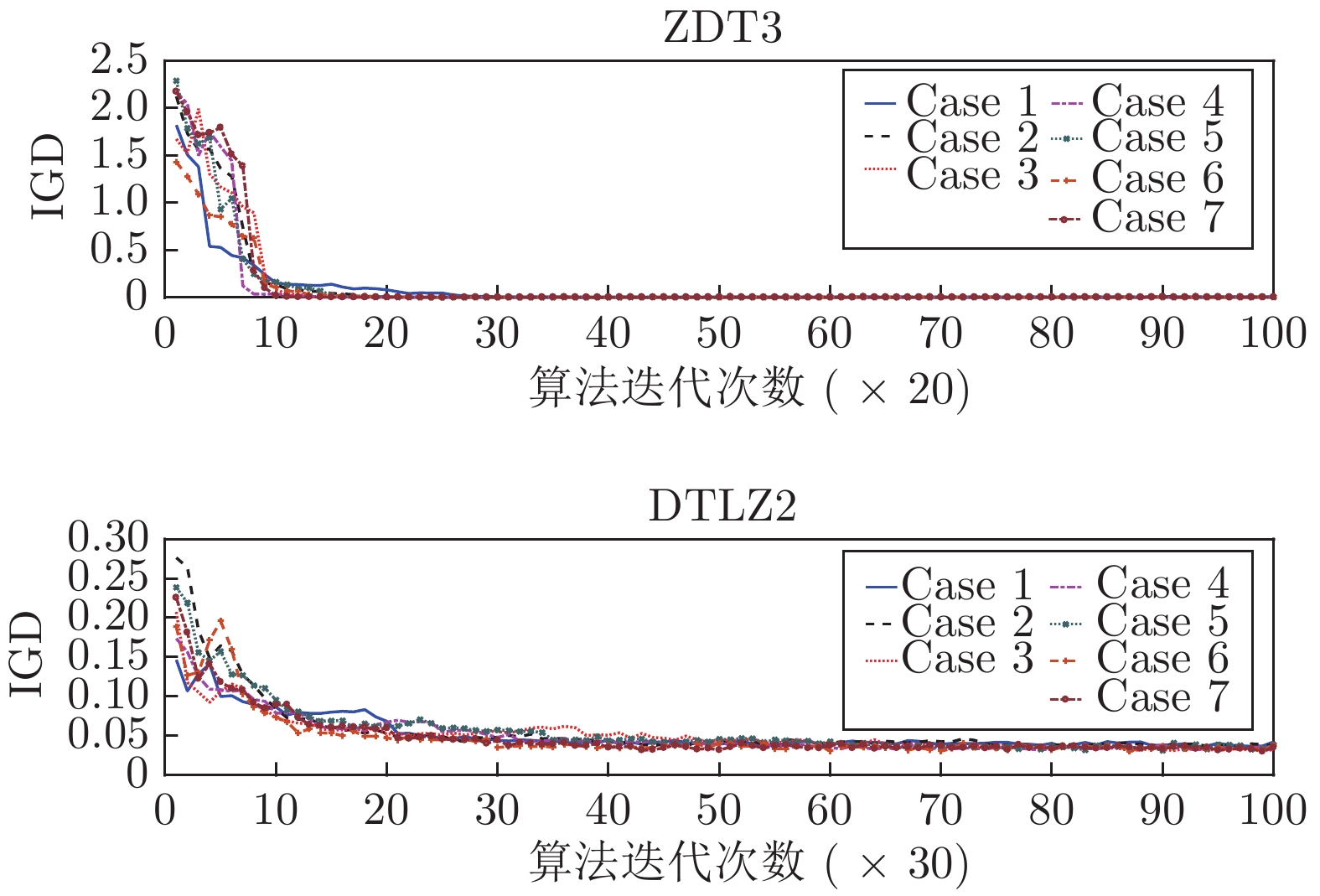
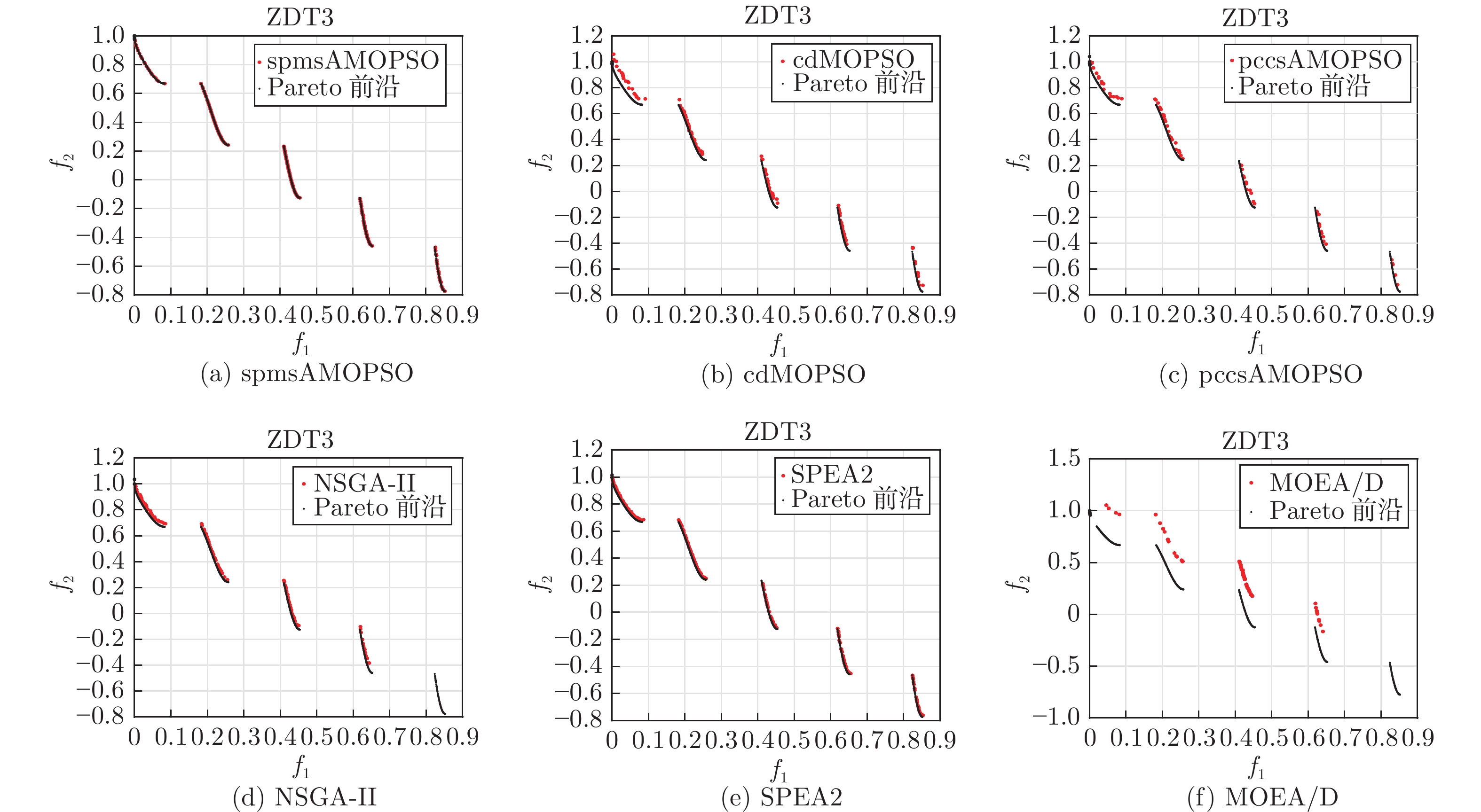
在多目标粒子群优化算法中, 平衡算法收敛性和多样性是获得良好分布和高精度Pareto前沿的关键, 多数已提出的方法仅依靠一种策略引导粒子搜索, 在解决复杂问题时算法收敛性和多样性不足. 为解决这一问题, 提出一种基于种群分区的多策略自适应多目标粒子群优化算法. 采用粒子收敛性贡献对算法环境进行检测, 自适应调整粒子的探索和开发过程; 为准确制定不同性能的粒子的搜索策略, 提出一种多策略的全局最优粒子选取方法和多策略的变异方法, 根据粒子的收敛性评价指标, 将种群划分为3个区域, 将粒子性能与算法寻优过程结合, 提升种群中各个粒子的搜索效率; 为解决因选取的个体最优粒子不能有效指导粒子飞行方向, 使算法停滞, 陷入局部最优的问题, 提出一种带有记忆区间的个体最优粒子选取方法, 提升个体最优粒子选取的可靠性并加快粒子收敛过程; 采用包含双性能测度的融合指标维护外部存档, 避免仅根据粒子密度对外部存档维护时, 删除收敛性较好的粒子, 导致种群产生退化, 影响粒子开发能力. 仿真实验结果表明, 与其他几种多目标优化算法相比, 该算法具有良好的收敛性和多样性.
在多目标粒子群优化算法中, 平衡算法收敛性和多样性是获得良好分布和高精度Pareto前沿的关键, 多数已提出的方法仅依靠一种策略引导粒子搜索, 在解决复杂问题时算法收敛性和多样性不足. 为解决这一问题, 提出一种基于种群分区的多策略自适应多目标粒子群优化算法. 采用粒子收敛性贡献对算法环境进行检测, 自适应调整粒子的探索和开发过程; 为准确制定不同性能的粒子的搜索策略, 提出一种多策略的全局最优粒子选取方法和多策略的变异方法, 根据粒子的收敛性评价指标, 将种群划分为3个区域, 将粒子性能与算法寻优过程结合, 提升种群中各个粒子的搜索效率; 为解决因选取的个体最优粒子不能有效指导粒子飞行方向, 使算法停滞, 陷入局部最优的问题, 提出一种带有记忆区间的个体最优粒子选取方法, 提升个体最优粒子选取的可靠性并加快粒子收敛过程; 采用包含双性能测度的融合指标维护外部存档, 避免仅根据粒子密度对外部存档维护时, 删除收敛性较好的粒子, 导致种群产生退化, 影响粒子开发能力. 仿真实验结果表明, 与其他几种多目标优化算法相比, 该算法具有良好的收敛性和多样性.
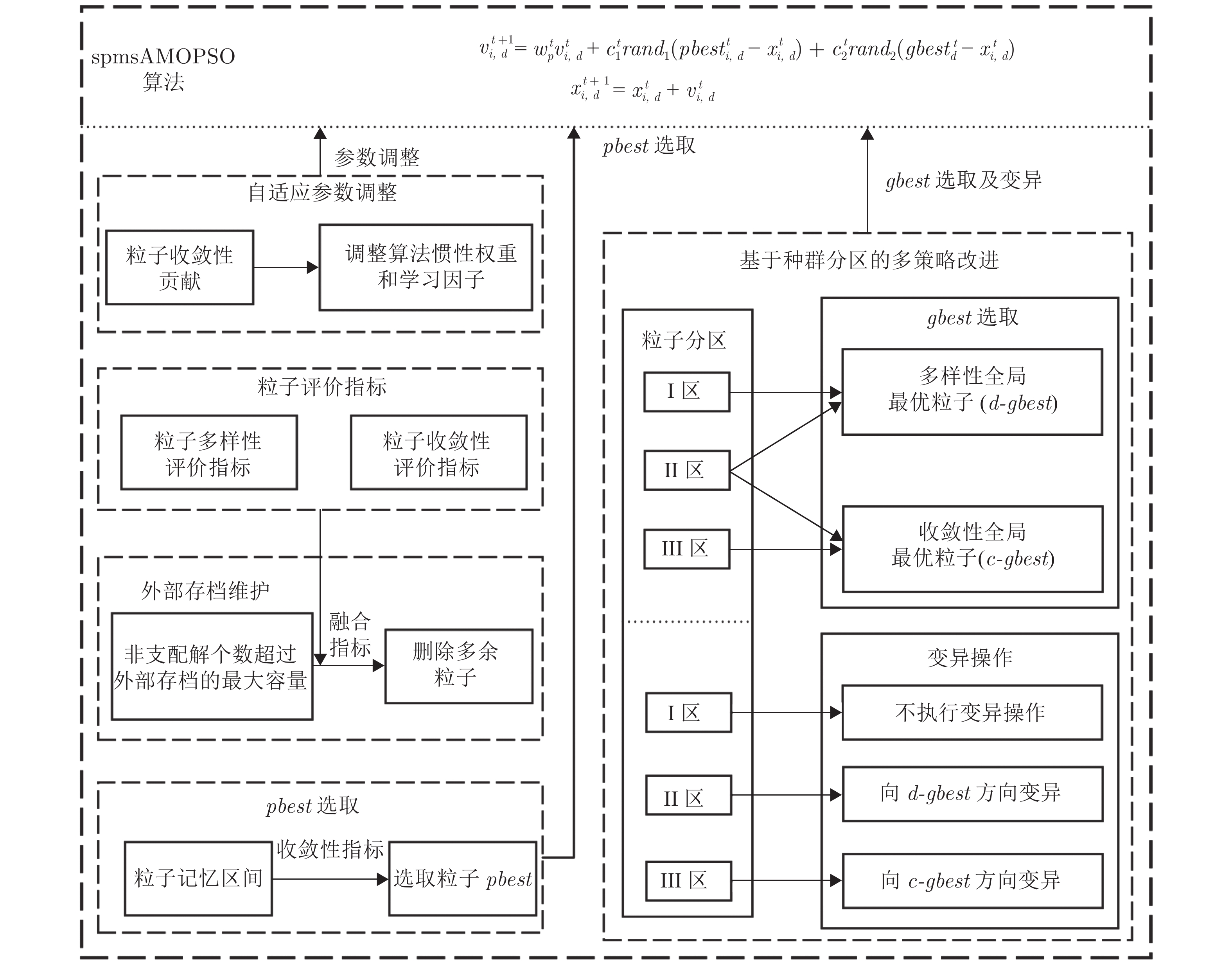



2022, 48(10): 2600-2610.
doi: 10.16383/j.aas.c200927
摘要:
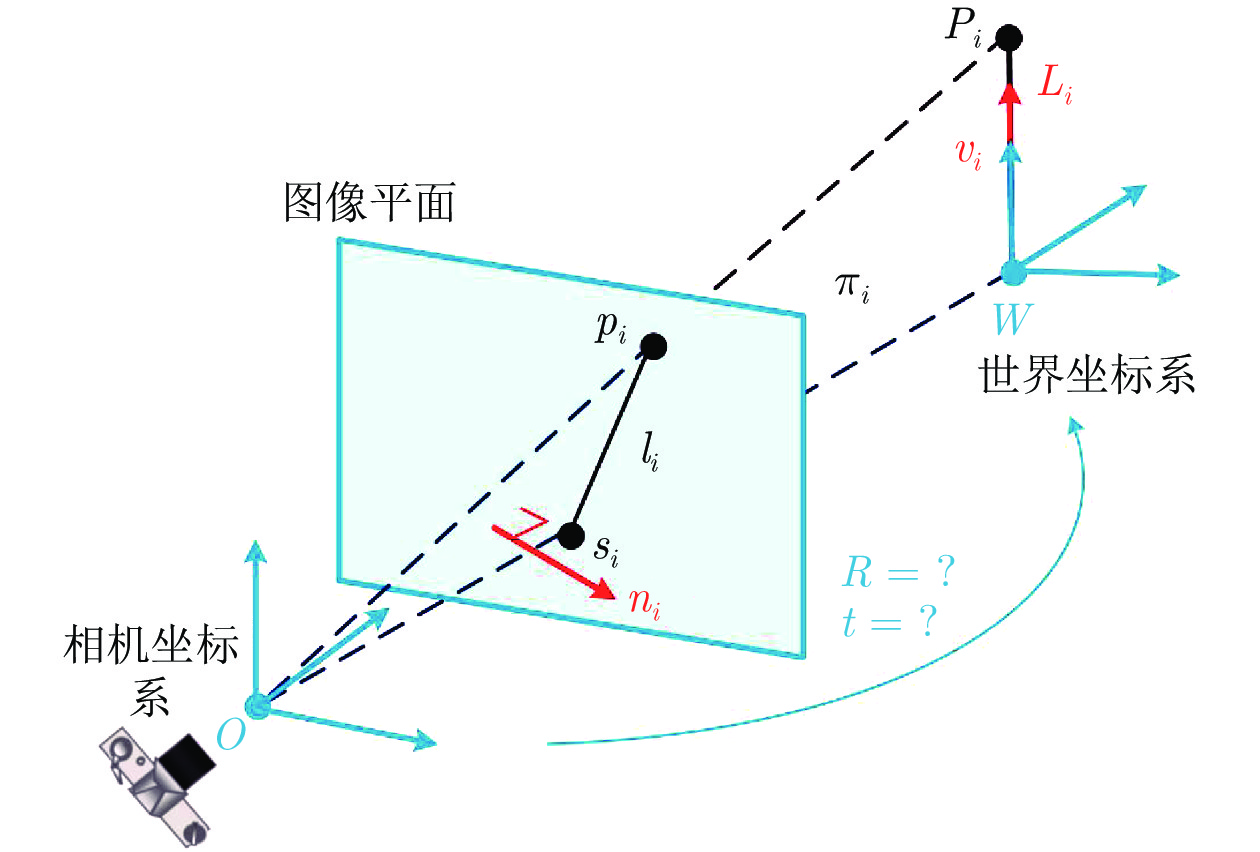
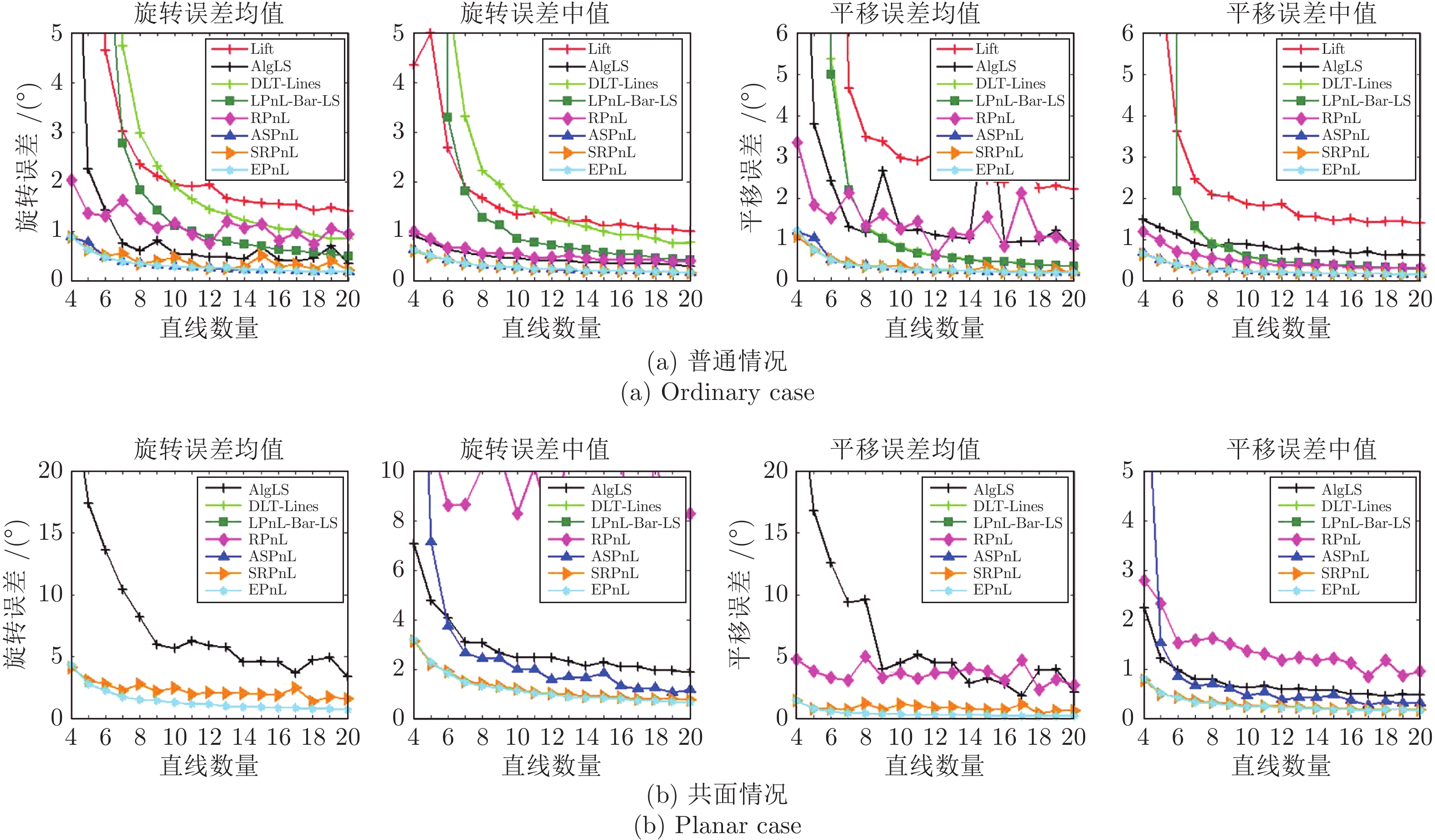
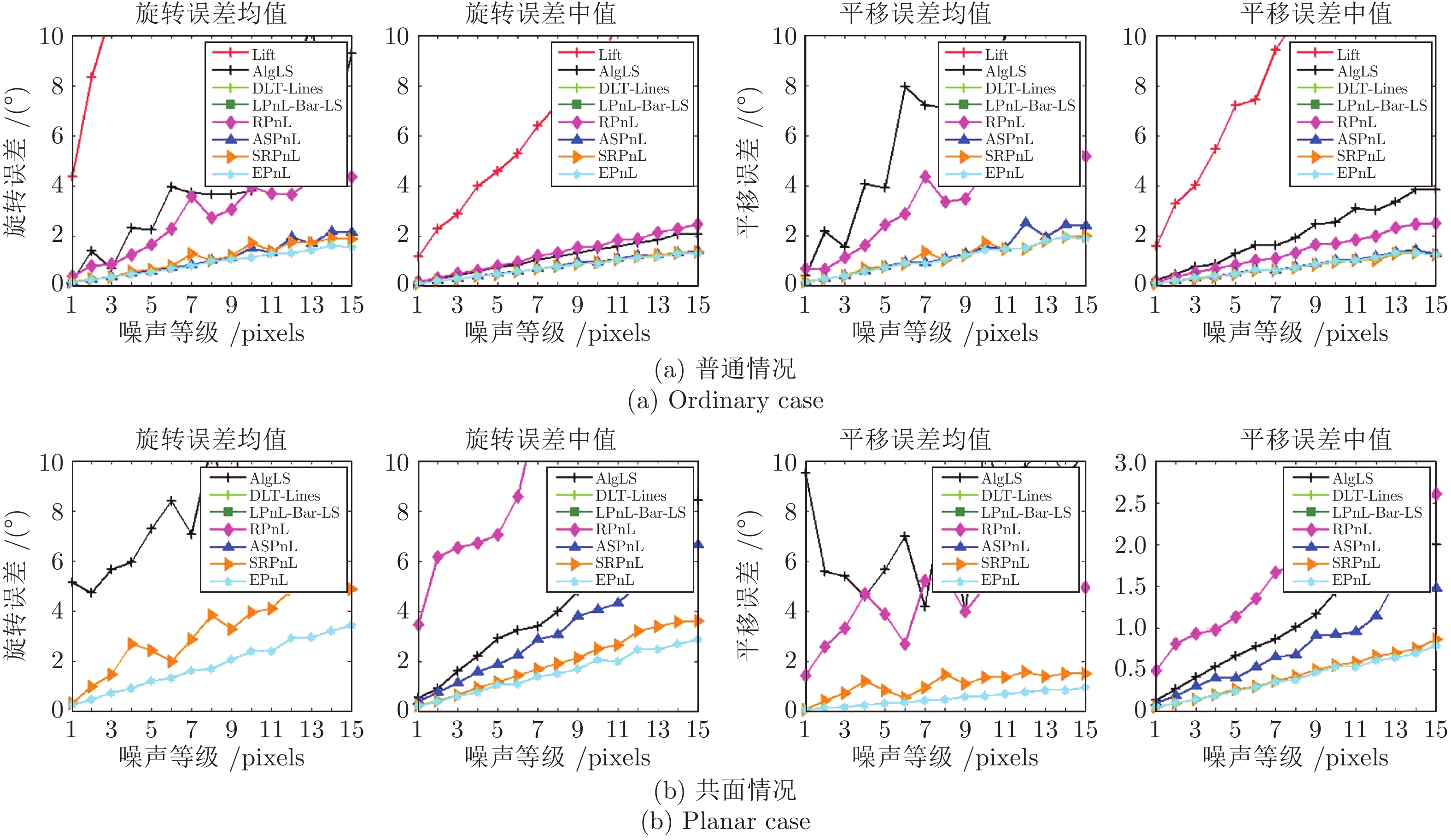
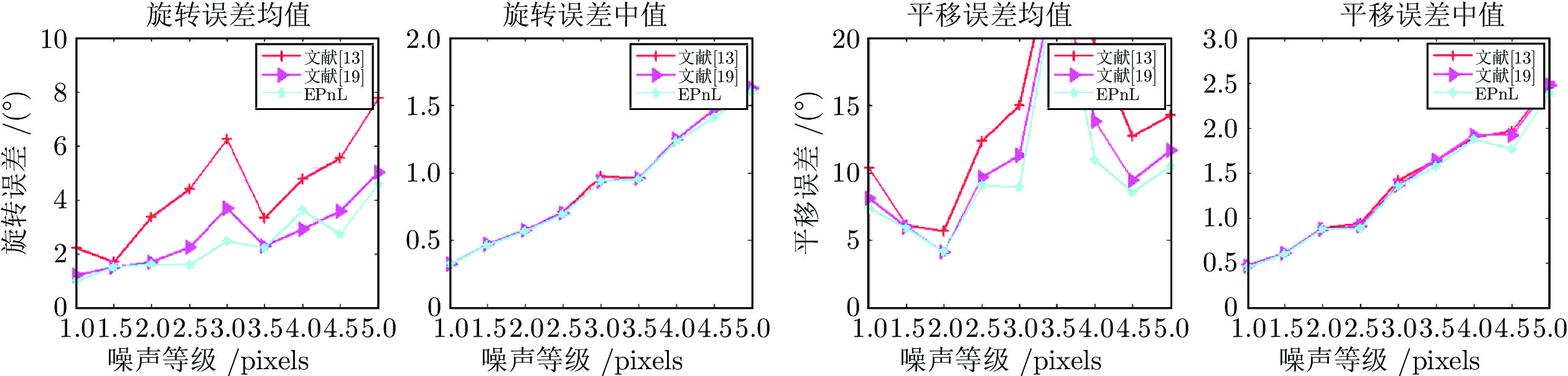
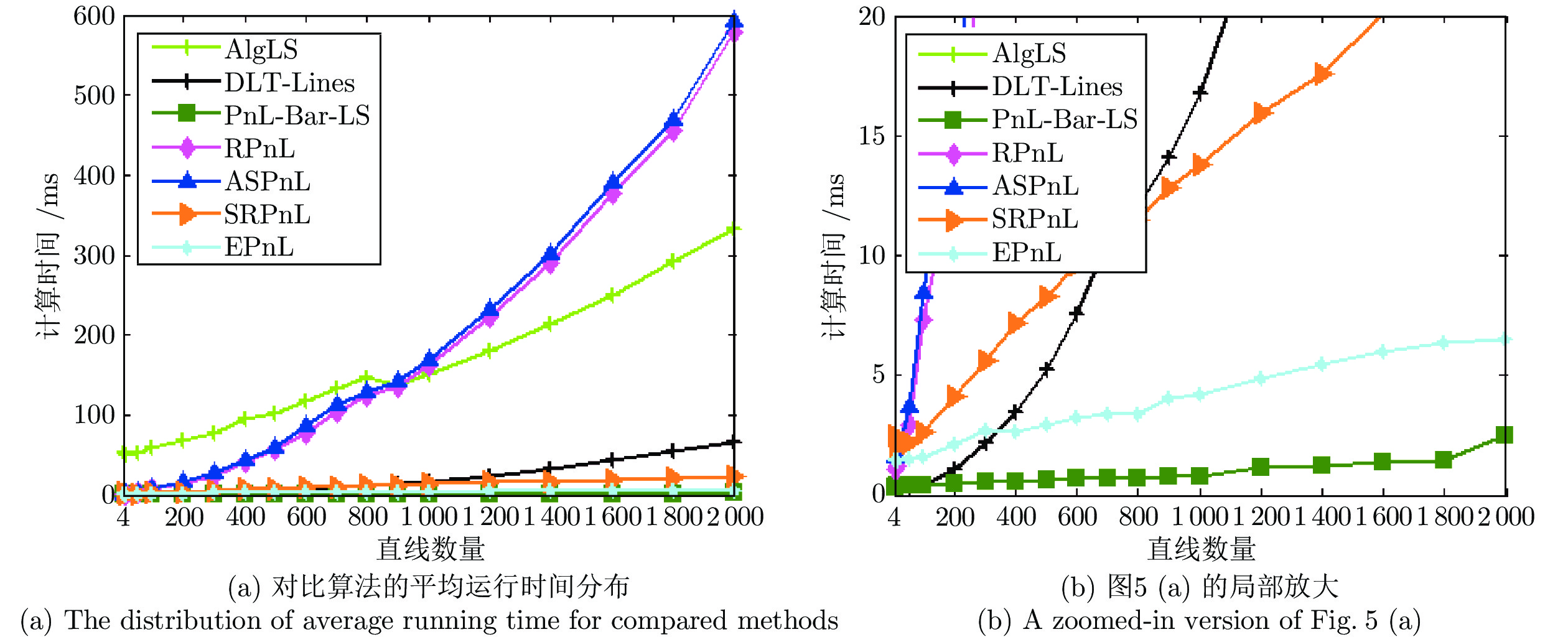
现有Perspective-n-line (PnL)问题求解算法无法在获得高求解精度的同时保证高求解效率. 为解决这个缺点, 提出了同时兼具求解效率和求解精度算法EPnL. 该方法首先将PnL问题转换为求二次曲面方程组交点的问题, 然后利用单位四元数中变量不同时为零的特性, 分类参数化PnL问题中的旋转矩阵. 最后, 为克服常规优化方法可靠性和效率较低的问题, 同时兼具求解效率和求解精度算法利用二次曲面方程组自身的结构信息, 采用低次项参数化高次项的方式将二次曲面方程组的求解问题转换为单变量多项式的求解问题. 实验表明, 相比于现有算法, 该算法在具有高求解精度的同时也兼具有高求解效率.
现有Perspective-n-line (PnL)问题求解算法无法在获得高求解精度的同时保证高求解效率. 为解决这个缺点, 提出了同时兼具求解效率和求解精度算法EPnL. 该方法首先将PnL问题转换为求二次曲面方程组交点的问题, 然后利用单位四元数中变量不同时为零的特性, 分类参数化PnL问题中的旋转矩阵. 最后, 为克服常规优化方法可靠性和效率较低的问题, 同时兼具求解效率和求解精度算法利用二次曲面方程组自身的结构信息, 采用低次项参数化高次项的方式将二次曲面方程组的求解问题转换为单变量多项式的求解问题. 实验表明, 相比于现有算法, 该算法在具有高求解精度的同时也兼具有高求解效率.