

Abnormal Behavior Detection Algorithm With Video-bag Attention Mechanism in Surveillance Video
-
摘要: 针对监控视频中行人非正常行走状态的异常现象, 提出了一个端到端的异常行为检测网络, 以视频包为输入, 输出异常得分. 时空编码器提取视频包时空特征后, 利用基于隐向量的注意力机制对包级特征进行加权处理, 最后用包级池化映射出视频包得分. 本文整合了4个常用的异常行为检测数据集, 在整合数据集上进行算法测试并与其他异常检测算法进行对比. 多项客观指标结果显示, 本文算法在异常事件检测方面有着显著的优势.Abstract: Aiming at the detection of the abnormal behavior pedestrians in surveillance videos, this paper proposes an end-to-end abnormal behavior detection network. It takes video bags as input, and anomaly score as output. The spatio-temporal encoder is used to extract the features of the video bag, then use the attention mechanism based on the hidden vector to weight the different elements in the bag-level feature, and finally use the bag-level pooling to obtain the video bag anomaly score. Four commonly used anomaly detection datasets are integrated and used to test and compare the performance of different anomaly detection algorithm. The results of multiple objective indicators show that our algorithm has significant advantages in anomaly detection.
-
Key words:
- Anomaly detection /
- video-bag /
- spatiotemporal feature /
- attention mechanism
-
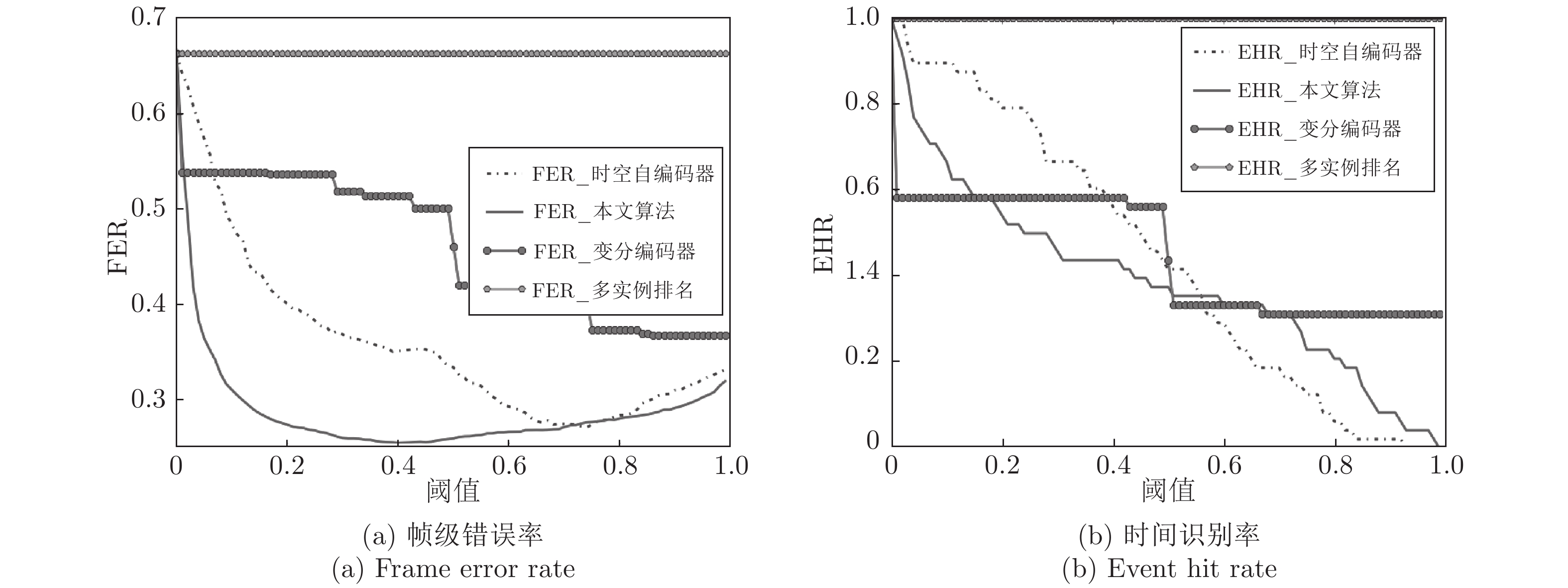
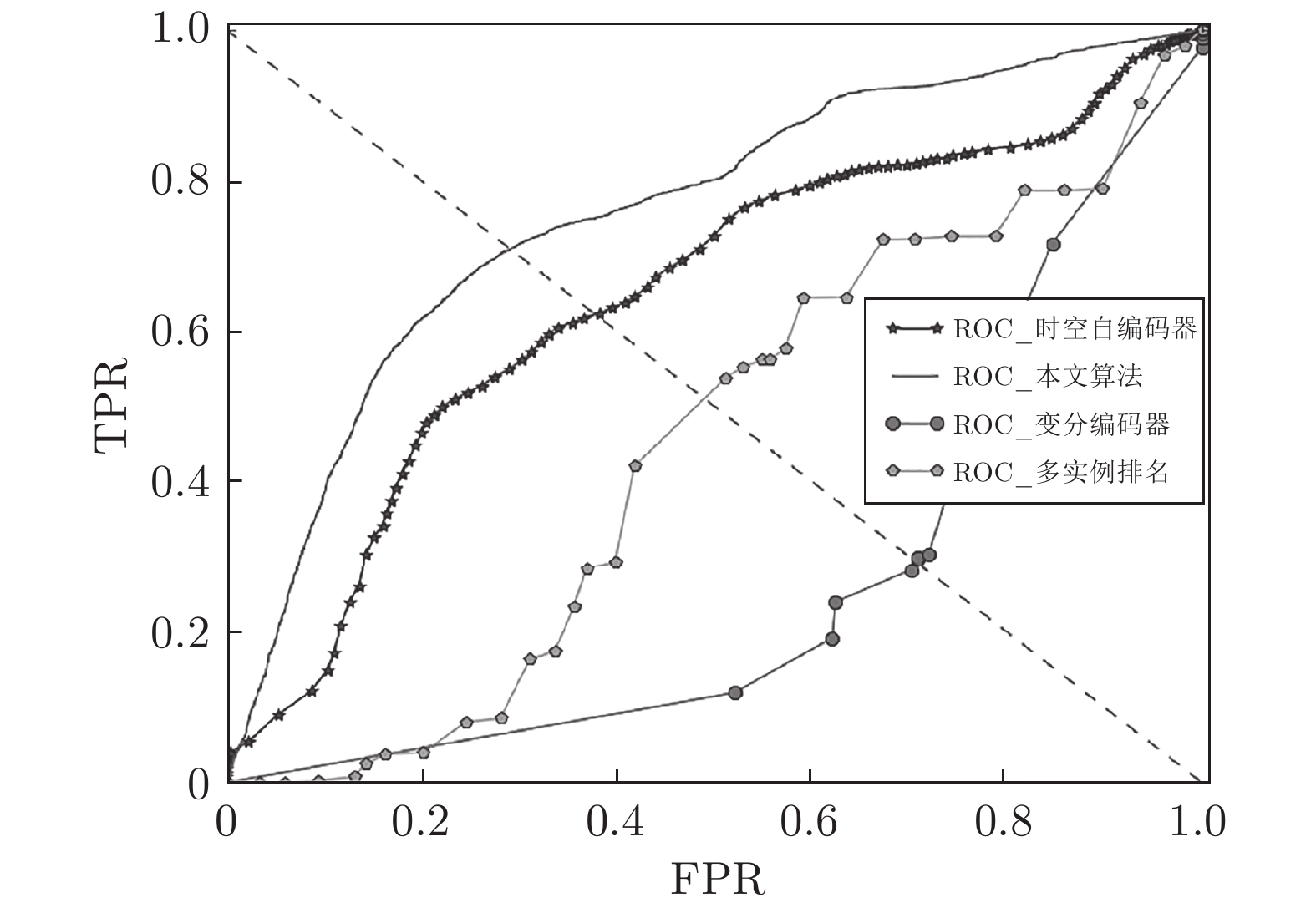
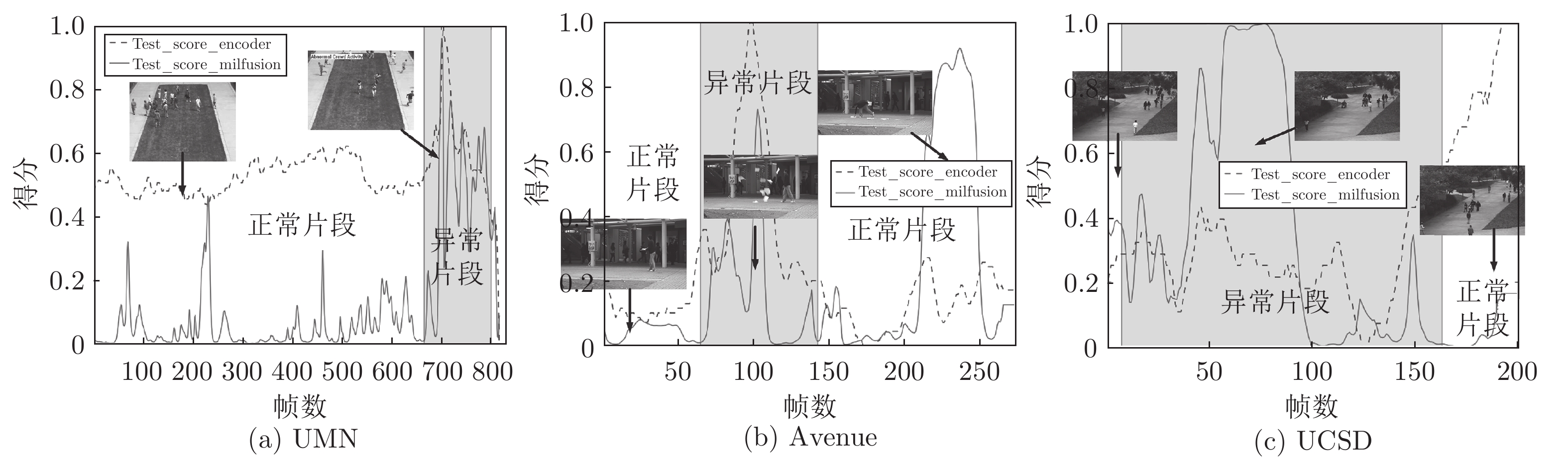
图 7 异常检测算法在帧级及事件级指标对比图
Fig. 7 The frame-level and event-level index of different algorithms
表 1 异常检测算法AUC及EER指标
Table 1 The AUC and EER of different algorithms
 下载: 导出CSV
下载: 导出CSV
表 2 算法处理时间(CPU) (ms)
Table 2 The processing time of algorithms (CPU) (ms)
时空自编码器 变分编码器 本文算法 238 245 173
下载: 导出CSV
-
[1] Xiao T, Zhang C, Zha H B, Wei F Y. Anomaly detection via local coordinate factorization and spatio-temporal pyramid. In: Proceedings of the 12th Asian Conference on Computer Vision. Singapore, Singapore: Springer, 2015. 66−82 [2] Reddy V, Sanderson C, Lovell B C. Improved anomaly detection in crowded scenes via cell-based analysis of foreground speed, size and texture. In: Proceedings of the 2011 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Colorado Springs, CO, USA: IEEE, 2011. 55−61 [3] 肖进胜, 朱力, 赵博强, 雷俊锋, 王莉. 基于主成分分析的分块视频噪声估计. 自动化学报, 2018, 44(09): 1618-1625Xiao Jin-Sheng, Zhu Li, Zhao Bo-Qiang, Lei Jun-Feng, Wang Li. Block-based video noise estimation algorithm via principal component analysis. Acta Automatica Sinica, 2018, 44(09): 1618-1625 [4] 罗会兰, 王婵娟. 行为识别中一种基于融合特征的改进VLAD编码方法. 电子学报, 2019, 47(01): 49-58 doi: 10.3969/j.issn.0372-2112.2019.01.007Luo Hui-Lan, Wang Chan-Juan. An improved VLAD coding method based on fusion feature in action recognition. Acta Electronica Sinica, 2019, 47(01): 49-58 doi: 10.3969/j.issn.0372-2112.2019.01.007 [5] Xiao J, Shen M, Lei J, Zhou J, Klette R, Sui H. Single image dehazing based on learning of haze layers. Neurocomputing, 2020, (DOI: 10.1016/j.neucom.2020.01.007) [6] Zhou Y Z, Sun X Y, Zha Z J, Zeng W J. MiCT: Mixed 3D/2D convolutional tube for human action recognition. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 449−458 [7] Ionescu R T, Khan F S, Georgescu M I, Shao L. Object-centric auto-encoders and dummy anomalies for abnormal event detection in video. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019. 7834−7843 [8] 蔡瑞初, 谢伟浩, 郝志峰, 王丽娟, 温雯. 基于多尺度时间递归神经网络的人群异常检测. 软件学报, 2015, 26(11): 2884-2896Cai Rui-Chu, Xie Wei-Hao, Hao Zhi-Feng, Wang Li-Juan, Wen Wen. Abnormal crowd detection based on multi-scale recurrent neural network. Journal of Software, 2015, 26(11): 2884-2896 [9] 袁非牛, 章琳, 史劲亭, 夏雪, 李钢. 自编码神经网络理论及应用综述. 计算机学报, 2019, 42(01): 203-230Yuan Fei-Niu, Zhang Lin, Shi Jin-Ting, Xia Xue, Li Gang. Theories and applications of auto-encoder neural networks: a literature survey. Chinese Journal of Computers, 2019, 42(01): 203-230 [10] Chong Y S, Tay Y H. Abnormal event detection in videos using spatiotemporal autoencoder. International Symposium on Neural Networks, 2017, (10262): 189-196 [11] Shi X J, Chen Z R, Wang H, Yeang D Y. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Quebec, Canada: MIT Press, 2015. 802−810 [12] An J, Cho S. Variational autoencoder based anomaly detection using reconstruction probability. SNU Data Mining Center, Korea, Spe. Lec. on IE, 2015, 2: 1−18 [13] 袁静, 章毓晋. 融合梯度差信息的稀疏去噪自编码网络在异常行为检测中的应用. 自动化学报, 2017, 43(4): 604-610Yuan Jing, Zhang Yu-Jin. Application of sparse denoising auto encoder network with gradient difference information for abnormal action detection. Acta Automatica Sinica, 2017, 43(4): 604-610 [14] Sultani W, Chen C, Shah M. Real-world anomaly detection in surveillance videos. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 6479−6488 [15] Tran D, Bourdev L, Fergus R, Torresani L, Paluri M. Learning spatiotemporal features with 3D convolutional networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 4489−4497 [16] 肖进胜, 周景龙, 雷俊锋, 刘恩雨, 舒成. 基于霾层学习的单幅图像去雾算法. 电子学报, 2019, 47(10): 2142-2148 doi: 10.3969/j.issn.0372-2112.2019.10.016Xiao Jin-Sheng, Zhou Jing-Long, Lei Jun-Feng, Liu EnYu, Shu Cheng. Single image dehazing algorithm based on the learning of hazy layers. Acta Electronica Sinica, 2019, 47(10): 2142-2148 doi: 10.3969/j.issn.0372-2112.2019.10.016 [17] Lu C W, Shi J P, Jia J Y. Abnormal event detection at 150 FPS in MATLAB. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013. 2720−2727 [18] Unusual crowd activity dataset of University of Minnesota [Online], available: http://mha.cs.umn.edu/Movies/Crowdctivity-All. avi, October 25, 2006 [19] Mahadevan V, Li W X, Bhalodia V, Vasconcelos N. Anomaly detection in crowded scenes. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 1975−1981 [20] Saligrama V, Chen Z. Video anomaly detection based on local statistical aggregates. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 2112−2119 -

 下载:
下载:


图(8) / 表(2)
计量
- 文章访问数: 2525
- HTML全文浏览量: 1320
- PDF下载量: 394
- 被引次数: 0
