

-
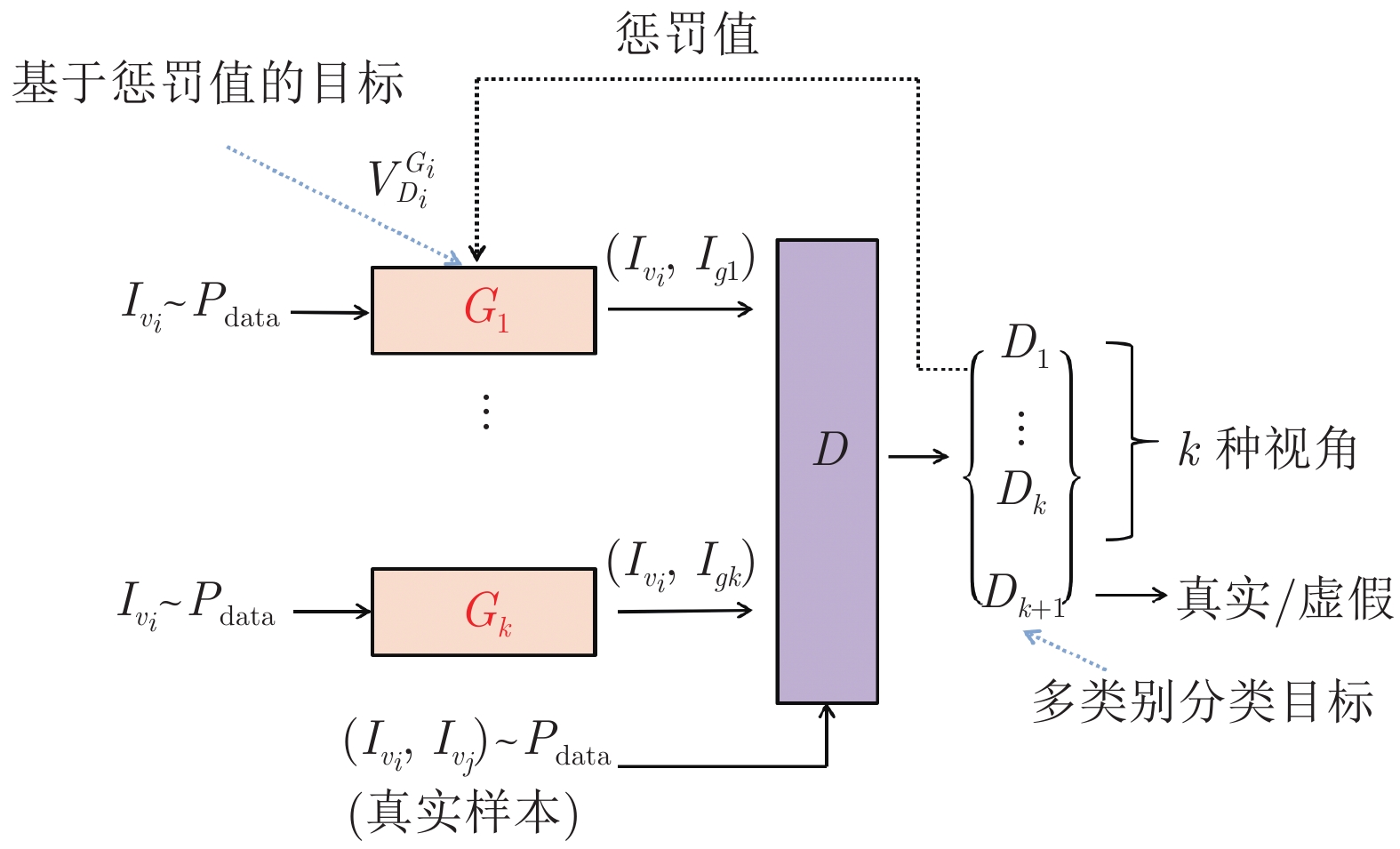
摘要: 多视角图像生成即基于某个视角图像生成其他多个视角图像, 是多视角展示和虚拟现实目标建模等领域的基本问题, 已引起研究人员的广泛关注. 近年来, 生成对抗网络(Generative adversarial network, GAN)在多视角图像生成任务上取得了不错的成绩, 但目前的主流方法局限于固定领域, 很难迁移至其他场景, 且生成的图像存在模糊、失真等弊病. 为此本文提出了一种基于混合对抗生成网络的多视角图像生成模型ViewGAN, 它包括多个生成器和一个多类别判别器, 可灵活迁移至多视角生成的多个场景. 在ViewGAN中, 多个生成器被同时训练, 旨在生成不同视角的图像. 此外, 本文提出了一种基于蒙特卡洛搜索的惩罚机制来促使每个生成器生成高质量的图像, 使得每个生成器更专注于指定视角图像的生成. 在DeepFashion, Dayton, ICG Lab6数据集上的大量实验证明: 我们的模型在Inception score和Top-k accuracy上的性能优于目前的主流模型, 并且在结构相似性(Structural similarity, SSIM)上的分数提升了32.29%, 峰值信噪比(Peak signal-to-noise ratio, PSNR)分数提升了14.32%, SD (Sharpness difference)分数提升了10.18%.Abstract: Cross-view image translation aims at synthesizing new image from one to another. It is a fundamental issue in areas such as multi-view presentations and object modeling in virtual reality, which has been gaining a lot interest from researchers around the world. Recently, generative adversarial network (GAN) has shown promising results in image generation. However, the state-of-the-arts are limited to flxed flelds, and it is di–cult to migrate to other scenes, and the generated images are ambiguous and distorted. In this paper, we propose a novel framework- ViewGAN that makes it possible to generate realistic-looking images with difierent views. The ViewGAN can be flexibly migrated to multiple scenarios of the multi-view image generation task, which has multiple generators and one multi-class discriminator. The multiple generators are trained simultaneously, aiming at generating images from difierent views. Moreover, we propose a penalty mechanism based on Monte Carlo search to make each generator focus on generating its own images of a speciflc view accurately. Extensive experiments on DeepFashion, Dayton and ICG Lab6 datasets demonstrate that our model performs better on inception score and top-k accuracy than several state-of-the-arts, and the SSIM (structural similarity) increased by 32.29%, the PSNR (peak signal-to-noise ratio) increased by 14.32%, and the SD (sharpness difference) increased by 10.18%.
-
Key words:
- Deep learning /
- computer vision /
- image translation /
- multi-view images generation
1) 收稿日期 2019-10-25 录用日期 2020-02-23 Manuscript received October 25, 2019; accepted February 23,2020 2020年安徽省自然科学基金联合基金(2008085UD08), 安徽省重点研发计划项目(201904d08020008, 202004a05020004), 合肥工业大学智能制造技术研究院智能网联及新能源汽车技术成果转化及产业化项目(IMIWL2019003, IMIDC2019002)资助 Supported by Joint Fund of Natural Science Foundation of Anhui Province in 2020 (2008085UD08), Anhui Provincial Key Research and Development Program (201904d08020008, 202004a05020004), and Intelligent Networking and New Energy Vehicle Special Project of Intelligent Manufacturing Institute of Hefei University of Technology (IMIWL2019003, IMIDC2019002) 本文责任编委 吴建鑫 Recommended by Associate Editor WU Jian-Xin 1. 合肥工业大学计算机与信息学院 合肥 2306012) 1. School of Computer and Information, Hefei University of Technology, Hefei 230601 -

图 1 本文模型ViewGAN在DeepFashion、Dayton和ICG Lab6数据集上的测试样例
Fig. 1 Examples of ViewGAN on three datasets, i.e., DeepFashion, Dayton and ICG Lab6

图 4 各模型在DeepFashion数据集上的测试样例
Fig. 4 Results generated by different models on DeepFashion dataset

图 5 各模型在Dayton数据集上的测试样例
Fig. 5 Results generated by different models on Dayton dataset

图 6 各模型在ICG Lab6数据集上的测试样例
Fig. 6 Results generated by different models on ICG Lab6 dataset

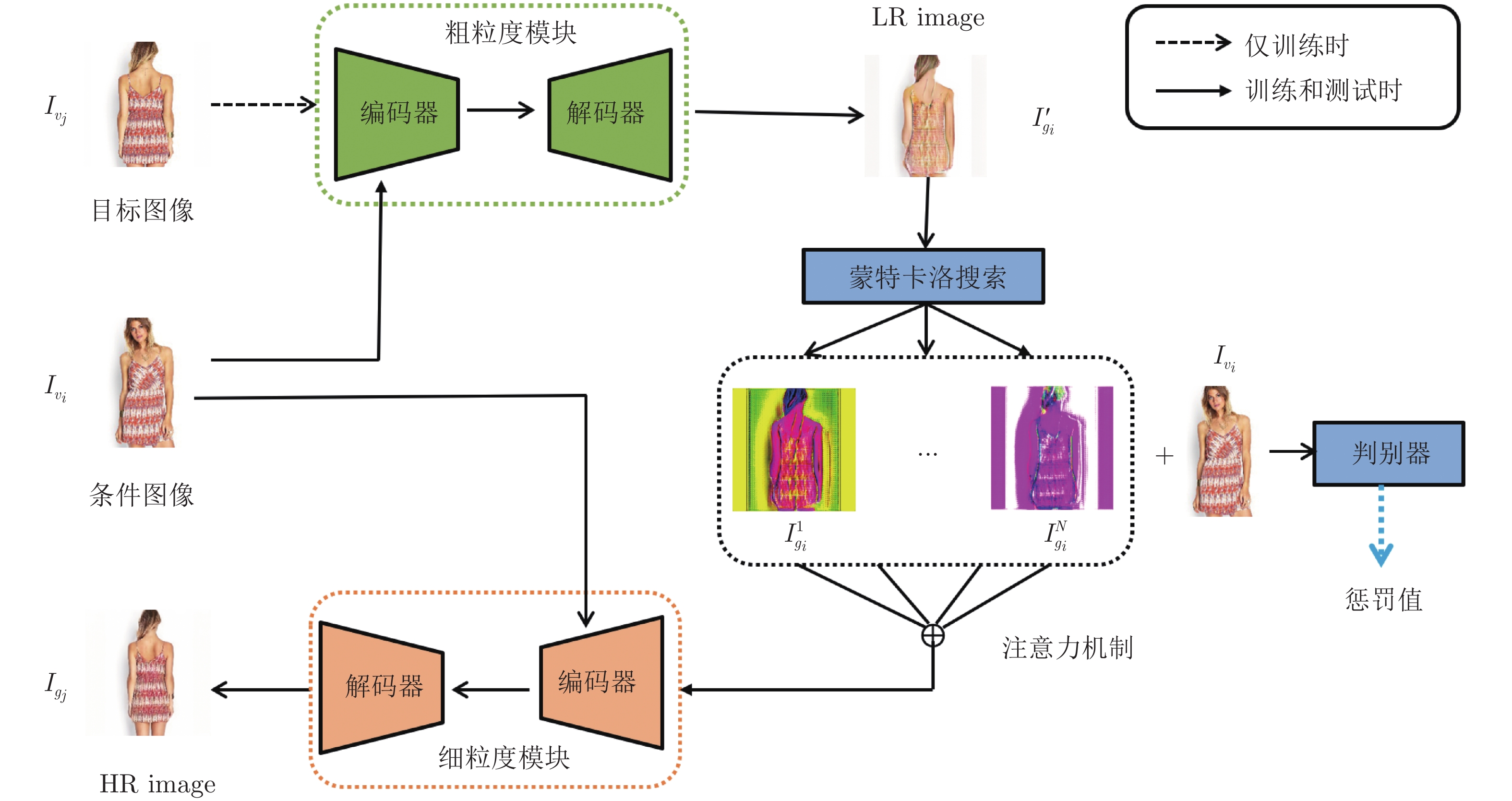
图 7 ViewGAN生成图像的可视化过程((a)输入图像; (b)粗粒度模块合成的低分辨率目标图像;(c)蒙特卡洛搜索的结果; (d)细粒度模块合成的高分辨率目标图像)
Fig. 7 Visualization of the process of ViewGAN generating images ((a) The input image; (b) The LR image generated by coarse image module; (c) Intermediate results generated by Monte Carlo search module; (d) The HR image generated by fine image module)
表 1 生成器网络结构
Table 1 Generator network architecture
网络 层次 输入 输出 Down-Sample CONV(N64, K4×4, S1, P3)-BN-Leaky Relu (256, 256, 3) (256, 256, 64) CONV(N128, K4×4, S2, P1)-BN-Leaky Relu (256, 256, 64) (128, 128, 128) CONV(N256, K4×4, S2, P1)-BN-Leaky Relu (128, 128, 128) (64, 64, 256) CONV(N512, K4×4, S2, P1)-BN-Leaky Relu (64, 64, 256) (32, 32, 512) Residual Block CONV(N512, K4×4, S1, P1)-BN-Leaky Relu (32, 32, 512) (32, 32, 512) CONV(N512, K4×4, S1, P1)-BN-Leaky Relu (32, 32, 512) (32, 32, 512) CONV(N512, K4×4, S1, P1)-BN-Leaky Relu (32, 32, 512) (32, 32, 512) CONV(N512, K4×4, S1, P1)-BN-Leaky Relu (32, 32, 512) (32, 32, 512) CONV(N512, K4×4, S1, P1)-BN-Leaky Relu (32, 32, 512) (32, 32, 512) Up-Sample DECONV(N256, K4×4, S2, P1)-BN-Leaky Relu (32, 32, 512) (64, 64, 256) DECONV(N128, K4×4, S2, P1)-BN-Leaky Relu (64, 64, 256) (128, 128, 128) DECONV(N64, K4×4, S1, P3)-BN-Leaky Relu (128, 128, 128) (256, 256, 64) CONV(N3, K4×4, S1, P3)-BN-Leaky Relu (256, 256, 64) (256, 256,3)  下载: 导出CSV
下载: 导出CSV
表 2 判别器网络结构
Table 2 Discriminator network architecture
网络 层次 输入 输出 Input Layer CONV(N64, K3×3, S1, P1)-Leaky Relu (256, 256, 3) (256, 256, 64) CONV BLOCK (256, 256, 64) (256, 256, 64) CONV BLOCK (256, 256, 64) (128, 128 128) CONV BLOCK (128, 128 128) (64, 64 256) Inner Layer HIDDEN LAYER (64, 64 256) (32, 32 512) HIDDEN LAYER (32, 32 512) (32, 32 64) DECONV BLOCK (32, 32 64) (64, 64 64) DECONV BLOCK (64, 64 64) (128, 128, 64) DECONV BLOCK (128, 128, 64) (256, 256, 64) Output layer CONV(N64, K3×3, S1, P1)-Leaky Relu (256, 256, 64) (256, 256, 3) CONV(N64, K3×3, S1, P1)-Leaky Relu CONV(N3, K3×3, S1, P1)-Tanh
下载: 导出CSV
表 3 各模型Inception score统计表, 该指标越高表明模型性能越好
Table 3 Inception score of different models (For this metric, higher is better)
模型 DeepFashion Dayton ICG Lab6 all classes Top-1 class Top-5 class all classes Top-1 class Top-5 class all classes Top-1 class Top-5 class Pix2Pix 3.37 2.23 3.44 2.85 1.93 2.91 2.54 1.69 2.49 X-Fork 3.45 2.57 3.56 3.07 2.24 3.09 4.65 2.14 3.85 X-Seq 3.83 2.68 4.02 2.74 2.13 2.77 4.51 2.05 3.66 VariGAN 3.79 2.71 3.94 2.77 2.19 2.79 4.66 2.15 3.72 SelectionGAN 3.81 2.72 3.91 3.06 2.27 3.13 5.64 2.52 4.77 ViewGAN 4.10 2.95 4.32 3.18 2.27 3.36 5.92 2.71 4.91 Real Data 4.88 3.31 5.00 3.83 2.58 3.92 6.46 2.86 5.47
下载: 导出CSV
表 4 各模型Top-k预测准确率统计表, 该指标越高表明模型性能越好
Table 4 Accuracies of different models (For this metric, higher is better)
模型 DeepFashion Dayton ICG Lab6 Top-1 class Top-5 class Top-1 class Top-5 class Top-1 class Top-5 class Pix2Pix 7.34 9.28 25.79 32.68 6.80 9.15 23.55 27.00 1.33 1.62 5.43 6.79 X-Fork 20.68 31.35 50.45 64.12 30.00 48.68 61.57 78.84 5.94 10.36 20.83 30.45 X-Seq 16.03 24.31 42.97 54.52 30.16 49.85 62.59 80.70 4.87 8.94 17.13 24.47 VariGAN 25.67 31.43 55.52 63.70 32.21 52.69 67.95 84.31 10.44 20.49 33.45 41.62 SelectionGAN 41.57 64.55 72.30 88.65 42.11 68.12 77.74 92.89 28.35 54.67 62.91 76.44 ViewGAN 65.73 95.77 91.65 98.21 69.39 89.88 93.47 98.78 58.97 83.20 88.74 93.25
下载: 导出CSV
表 5 各模型SSIM, PSNR, SD和速度统计表, 其中FPS表示测试时每秒处理的图像数量,所有指标得分越高表明模型性能越好
Table 5 SSIM, PSNR, SD of different models. FPS is the number of images processed per second during testing(For all metrics, higher is better)
模型 DeepFashion Dayton ICG Lab6 速度 (帧/s) SSIM PSNR SD SSIM PSNR SD SSIM PSNR SD Pix2Pix 0.39 17.67 18.55 0.42 17.63 19.28 0.23 15.71 16.59 166±5 X-Fork 0.45 19.07 18.67 0.50 19.89 19.45 0.27 16.38 17.35 87±7 X-Seq 0.42 18.82 18.44 0.50 20.28 19.53 0.28 16.38 17.27 75±3 VariGAN 0.57 20.14 18.79 0.52 21.57 19.77 0.45 17.58 17.89 70±5 SelectionGAN 0.53 23.15 19.64 0.59 23.89 20.02 0.61 26.67 19.76 66±6 ViewGAN 0.70 26.47 21.63 0.74 25.97 21.37 0.80 28.61 21.77 62±2
下载: 导出CSV
表 6 最小数据量实验结果
Table 6 Minimum training data experimental results
数据量 (幅) SSIM PSNR SD 6000 (100%) 0.70 26.47 21.63 5400 (90%) 0.68 26.08 20.95 4800 (80%) 0.66 24.97 20.31 4200 (70%) 0.59 23.68 20.00 3600 (60%) 0.51 21.90 18.89
下载: 导出CSV
表 7 消融分析实验结果
Table 7 Ablations study of the proposed ViewGAN
模型 结构 SSIM PSNR SD A Pix2Pix 0.46 19.66 18.89 B A+由粗到精生成方法 0.53 22.90 19.31 C B+混合生成对抗网络 0.60 23.77 20.03 D C+类内损失 0.60 23.80 20.11 E D+惩罚机制 0.70 26.47 21.63
下载: 导出CSV
-
[1] Zhu X E, Yin Z C, Shi J P, Li H S, Lin D H. Generative adversarial frontal view to bird view synthesis. In: Proceedings of the 2018 International Conference on 3D Vision (3DV). Verona, Italy: IEEE, 2018. 454−463 [2] Regmi K, Borji A. Cross-view image synthesis using conditional GANs. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3501−3510 [3] Zhai M H, Bessinger Z, Workman S, Jacobs N. Predicting ground-level scene layout from aerial imagery. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 4132−4140 [4] Zhao B, Wu X, Cheng Z Q, Liu H, Jie Z Q, Feng J S. Multi-view image generation from a single-view. In: Proceedings of the 26th ACM International Conference on Multimedia. Seoul, Republic of Korea: ACM, 2018. 383−391 [5] Tang H, Xu D, Sebe N, Wang Y Z, Corso J J, Yan Y. Multi-channel attention selection GAN with cascaded semantic guidance for cross-view image translation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 2412−2421 [6] Kingma D P, Welling M. Auto-encoding variational bayes. In: Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014. Banff, Canada, 2014. [7] Park E, Yang J, Yumer E, Ceylan D, Berg A C. Transformation-grounded image generation network for novel 3D view synthesis. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 702−711 [8] Choy C B, Xu D F, Gwak J Y, Chen K, Savarese S. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 628−644 [9] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃. 生成式对抗网络GAN的研究进展与展望. 自动化学报, 2017, 43(3): 321−332Wang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks: The state of the art and beyond. Acta Automatica Sinica, 2017, 43(3): 321-332 [10] Browne C B, Powley E, Whitehouse D, Lucas S M, Cowling P I, Rohlfshagen P, et al. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games, 2012, 4(1): 1−43 doi: 10.1109/TCIAIG.2012.2186810 [11] Srivastava A, Valkov L, Russell C, Gutmann M U, Sutton C. VEEGAN: Reducing mode collapse in GANs using implicit variational learning. In: Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017). Long Beach, USA: Curran Associates, Inc., 2017. 3308−3318 [12] Isola P, Zhu J Y, Zhou T H, Efros A A. Image-to-image translation with conditional adversarial networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 1125−1134 [13] Yan X C, Yang J M, Sohn K, Lee H. Attribute2Image: Conditional image generation from visual attributes. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 776−791 [14] Gregor K, Danihelka I, Graves A, Rezende D, Wierstra D. DRAW: A recurrent neural network for image generation. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: PMLR, 2015. [15] 唐贤伦, 杜一铭, 刘雨微, 李佳歆, 马艺玮. 基于条件深度卷积生成对抗网络的图像识别方法. 自动化学报, 2018, 44(5): 855−864Tang Xian-Lun, Du Yi-Ming, Liu Yu-Wei, Li Jia-Xin, Ma Yi-Wei. Image recognition with conditional deep convolutional generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 855-864 [16] Dumoulin V, Belghazi I, Poole B, Mastropietro O, Lamb A, Arjovsky A, et al. Adversarially learned inference [Online], available: https://arxiv.gg363.site/abs/1606.00704, February 21, 2017 [17] Chen X, Duan Y, Houthooft R, Schulman J, Sutskever I, Abbeel P. InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates, Inc., 2016. 2180−2188 [18] Zhang H, Xu T, Li H S, Zhang S T, Wang X G, Huang X L, et al. StackGAN: Text to photo-realistic image synthesis with stacked generative adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 5907−5915 [19] Johnson J, Gupta A, Fei-Fei L. Image generation from scene graphs. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1219−1228 [20] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2242−2251 [21] Choi Y, Choi M, Kim M, Ha J W, Kim S, Choo J. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8789−8797 [22] Dosovitskiy A, Springenberg J T, Tatarchenko M, Brox T. Learning to generate chairs, tables and cars with convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 692−705 [23] Wu J J, Xue T F, Lim J J, Tian Y D, Tenenbaum J B, Torralba A, et al. Single image 3D interpreter network. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 365−382 [24] Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X. Improved techniques for training GANs. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates, Inc., 2016. 2234−2242 [25] Ronneberger O, Fischer P, Brox T. U-Net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich, Germany: Springer, 2015. 234−241 [26] Liu Z W, Luo P, Qiu S, Wang X G, Tang X O. DeepFashion: Powering robust clothes recognition and retrieval with rich annotations. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 1096−1104 [27] Vo N N, Hays J. Localizing and orienting street views using overhead imagery. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 494−509 [28] Possegger H, Sternig S, Mauthner T, Roth P M, Bischof H. Robust real-time tracking of multiple objects by volumetric mass densities. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE, 2013. 2395−2402 [29] Deng J, Dong W, Socher R, Li L J, Li K, Fei-Fei L. ImageNet: A large-scale hierarchical image database. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 248−255 [30] Zhou B L, Lapedriza A, Khosla A, Oliva A, Torralba A. Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1452−1464 doi: 10.1109/TPAMI.2017.2723009 [31] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: Curran Associates, Inc., 2012. 1097−1105 [32] Yamaguchi K, Kiapour M H, Berg T L. Paper doll parsing: Retrieving similar styles to parse clothing items. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 3519−3526 [33] Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, et al. Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 105−114 [34] 唐祎玲, 江顺亮, 徐少平, 刘婷云, 李崇禧. 基于眼优势的非对称失真立体图像质量评价. 自动化学报, 2019, 45(11): 2092−2106Tang Yi-Ling, Jiang Shun-Liang, Xu Shao-Ping, Liu Ting-Yun, Li Chong-Xi. Asymmetrically distorted stereoscopic image quality assessment based on ocular dominance. Acta Automatica Sinica, 2019, 45(11): 2092−2106 [35] Mathieu M, Couprie C, LeCun Y. Deep multi-scale video prediction beyond mean square error [Online], available: https://arxiv.gg363.site/abs/1511.05440, February 26, 2016 -

 下载:
下载:



计量
- 文章访问数: 2728
- HTML全文浏览量: 1083
- PDF下载量: 446
- 被引次数: 0
