

KPLS Robust Reconstruction Error Based Monitoring and Anomaly Identification ofFuel Ratio in Blast Furnace Ironmaking
-
摘要:
作为钢铁冶金制造的核心工序, 高炉炼铁是典型的高能耗过程, 其运行能耗约占钢铁总能耗的50%以上, 其中, 80%的能耗是焦炭和煤粉等燃料消耗. 因此, 对表征高炉燃料消耗的燃料比参数进行监测, 并尽可能早地识别影响燃料比异常波动的关键因素, 对于高炉炼铁过程的节能降耗具有重要意义. 本文针对先验故障知识少的高炉燃料比监测与异常识别难题, 提出一种基于核偏最小二乘(Kernel partial least squares, KPLS)鲁棒重构误差的故障识别方法. 该方法首先建立过程变量与监测变量的KPLS监测模型, 然后根据非线性映射空间的协方差矩阵和核空间Gram矩阵之间的关系, 反向估计原始空间变量的正常估值. 为了增强算法的鲁棒性, 采用迭代去噪算法减少异常数据对原始空间正常估值的影响. 通过利用原始空间正常估值和真实值来构造故障识别指标, 并给出故障识别指标的控制限. 基于实际工业数据的高炉数据实验表明所提方法不仅可以监测出正常工况下影响燃料比异常变化的潜在因素, 还可识别出异常工况下影响燃料比异常变化的关键因素, 具有很好的工程应用前景.
Abstract:As the core process of steel metallurgy manufacturing, blast furnace ironmaking is a typical process with high energy consumption, whose operating energy consumption accounts for more than 50% of the total energy consumption of steel, 80% of which is fuel consumption such as coke and pulverized coal. Therefore, it is important for energy saving and consumption reduction of blast furnace ironmaking process to monitor the fuel ratio parameter which characterizes the fuel consumption to identify the key factors that affect the abnormal fluctuation of fuel ratio as early as possible. Aiming at the problem of monitoring and identification of blast furnace fuel ratio with little knowledge of prior faults, this paper proposes a new fault identification method based on robust reconstruction error of kernel partial least squares (KPLS). Firstly, the KPLS-based monitoring model of process variables and monitored variable is established. According to the relationship between the covariance matrix of nonlinear mapping space and the Gram matrix of kernel space, the normal estimation of the original space variables is estimated inversely. And the iterative denoising algorithm is used to reduce the influence of the anomaly data on the normal estimation of the original space. The fault identification index is constructed by using the normal estimation and real value of the original space, and the control limit of the fault identification index is given. The experimental results based on actual industrial data show that the proposed method can not only monitor the potential factors affecting the abnormal change of fuel ratio under normal working conditions, but also identify the key factors affecting the abnormal change of fuel ratio under abnormal working conditions, which has a good engineering application prospects.
1) 收稿日期 2018-08-31 录用日期 2018-12-03 Manuscript received August 31, 2018; accepted December 3, 2018 国家自然科学基金项目 (61890934, 61790572), 辽宁省“兴辽英才计划”项目 (XLYC1907132), 中央高校基本科研业务费项目 (N180802003), 矿冶过程自动控制技术国家 (北京市) 重点实验室开放课题资助 (BGRIMM-KZSKL-2017-04) Supported by National Natural Science Foundation of China (61890934, 61790572), Liaoning Revitalization Talents Program2) (XLYC1907132), and Fundamental Research Funds for the CentralUniversities (N180802003). the State (Beijing) Key Laboratory of Process Automation in Mining & Metallurgy (BGRIMM-KZSKL-2017-04) 本文责任编委 曾志刚 Recommended by Associate Editor ZENG Zhi-Gang 1. 东北大学流程工业综合自动化国家重点实验室 沈阳 110819 1. State Key Laboratory of Synthetical Automation for Process Industries, Northeastern University, Shenyang 110819 -
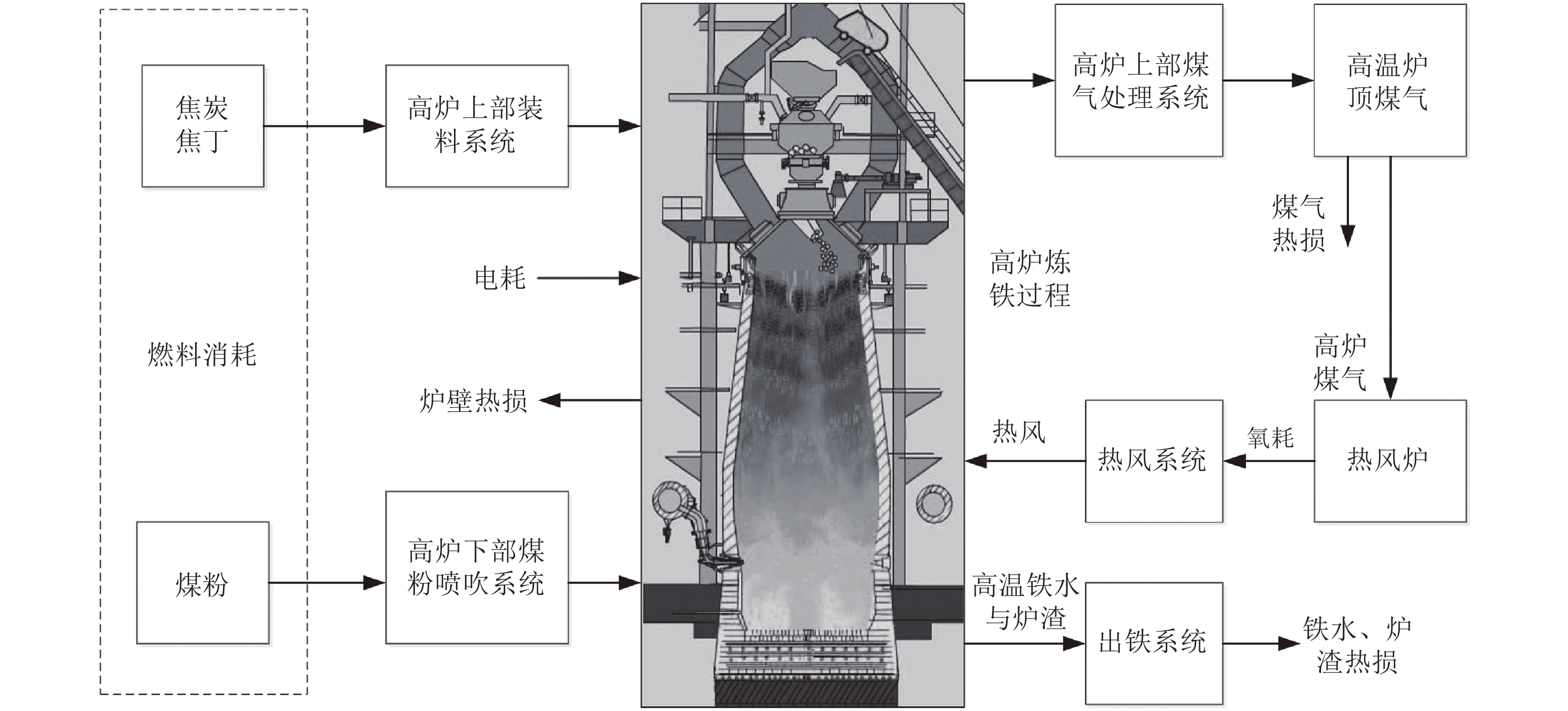
图 1 高炉炼铁过程能耗示意图
Fig. 1 Schematic diagram of energy consumption in blast furnace ironmaking process
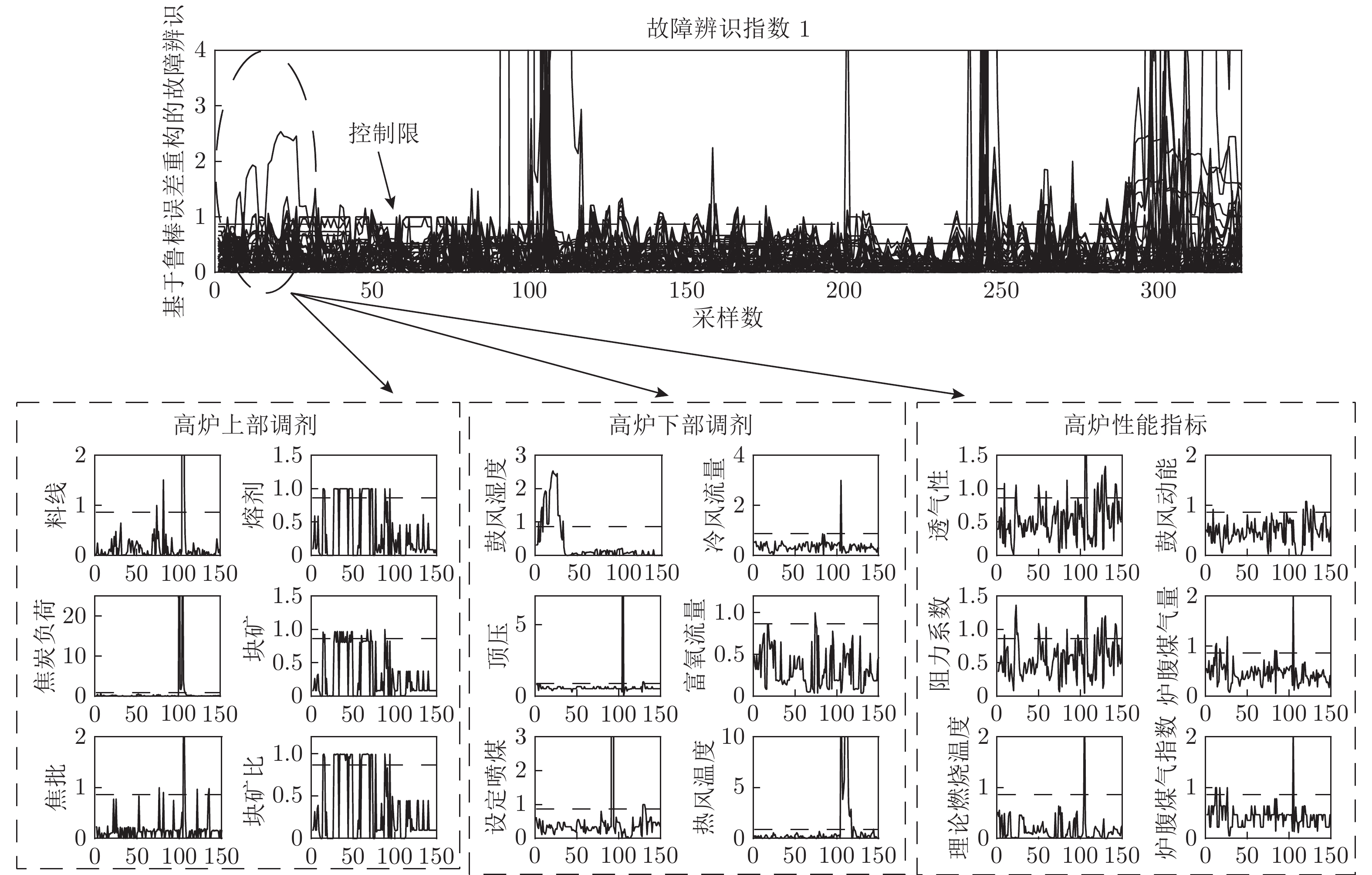
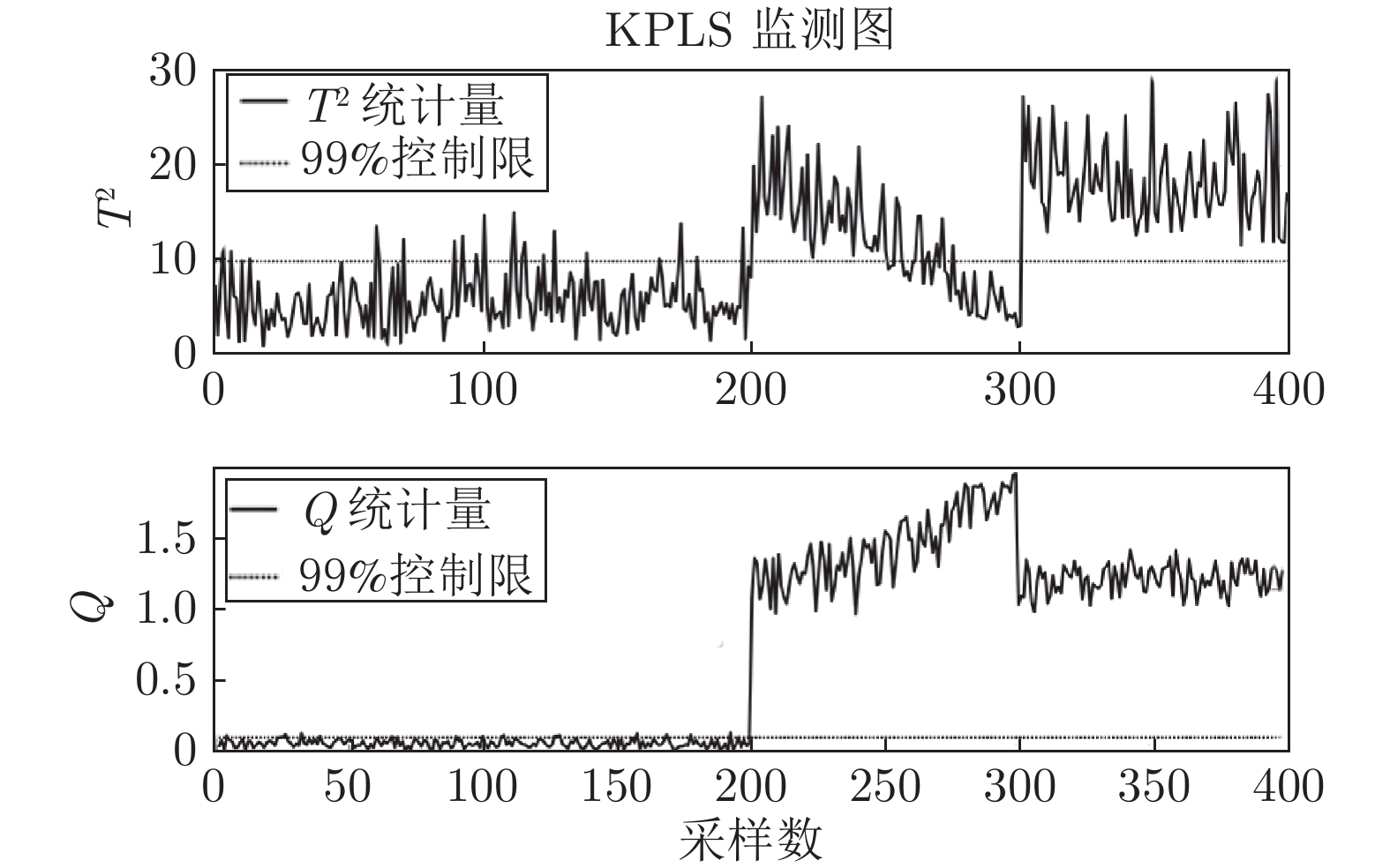
图 10 鼓风湿度异常时高炉燃料比异常识别曲线
Fig. 10 Blast furnace fuel ratio anomaly identification curve when blast humidity is abnormal
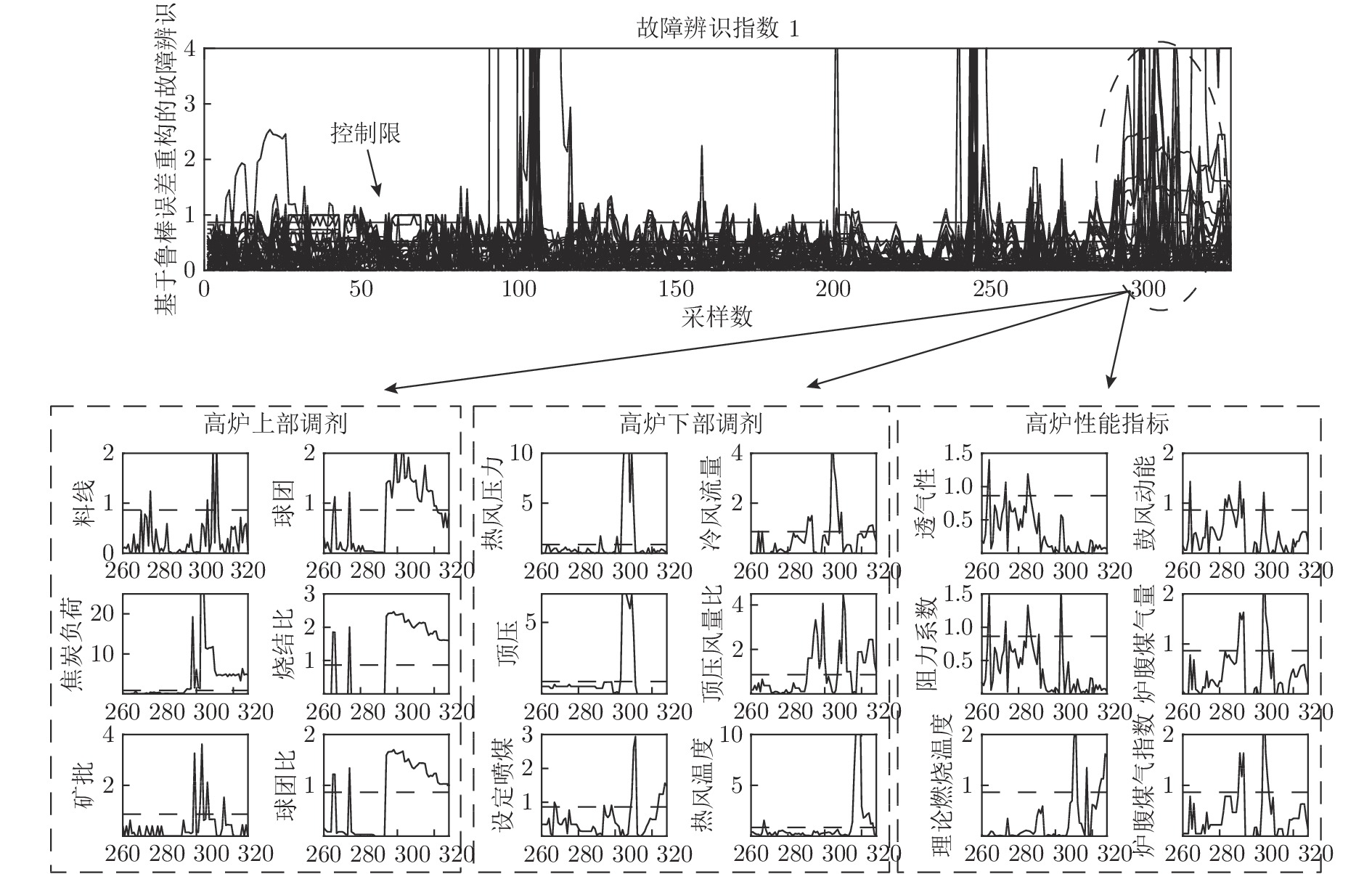
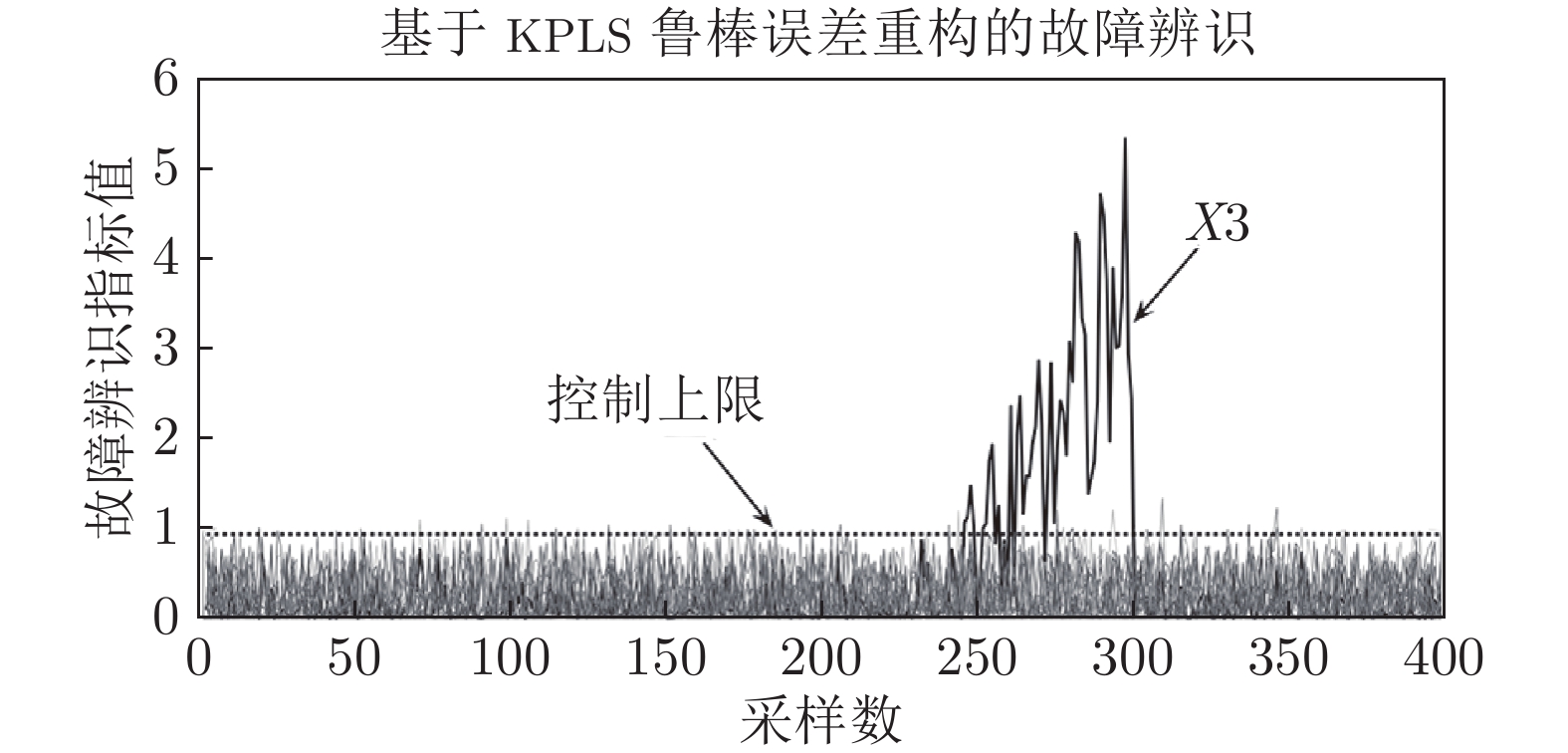
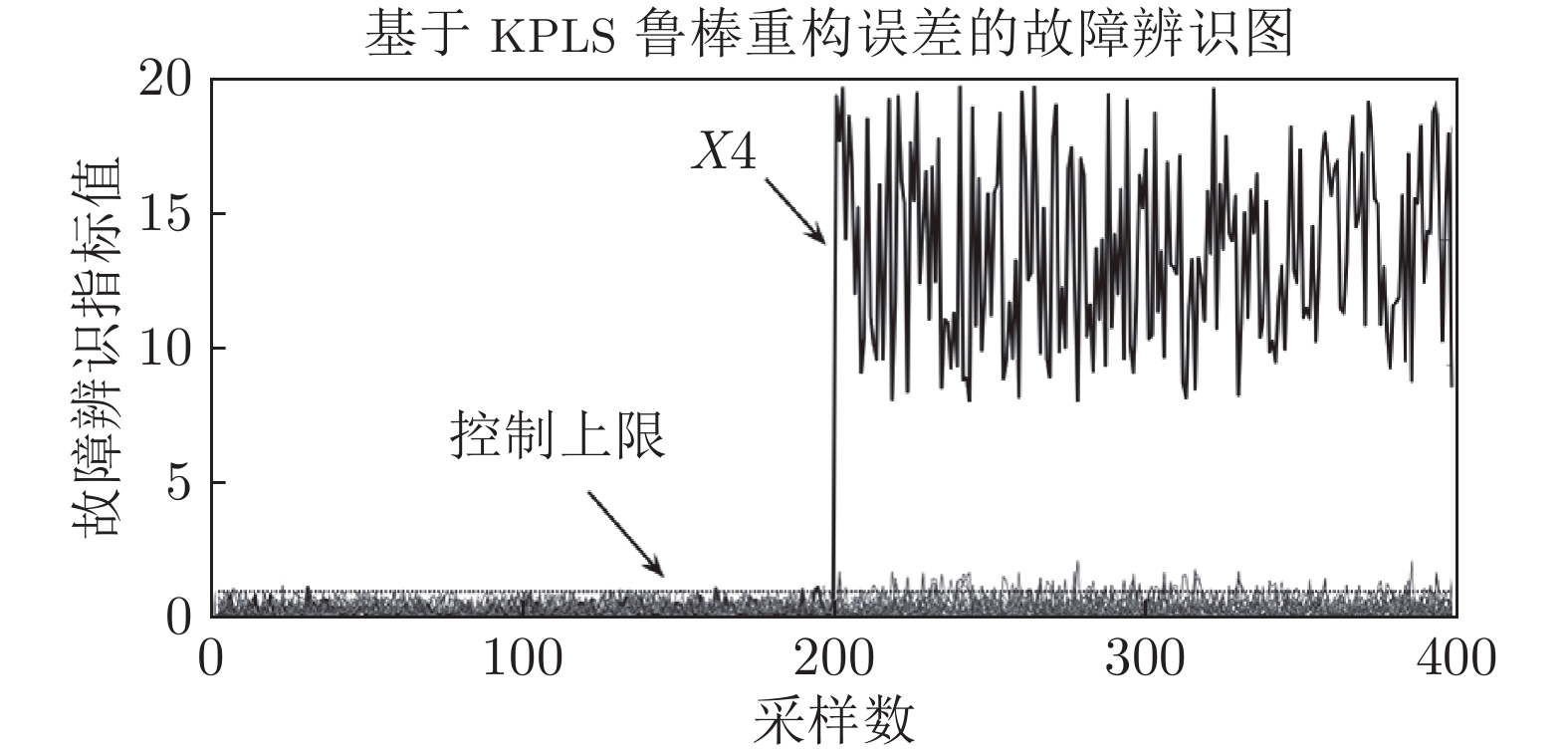
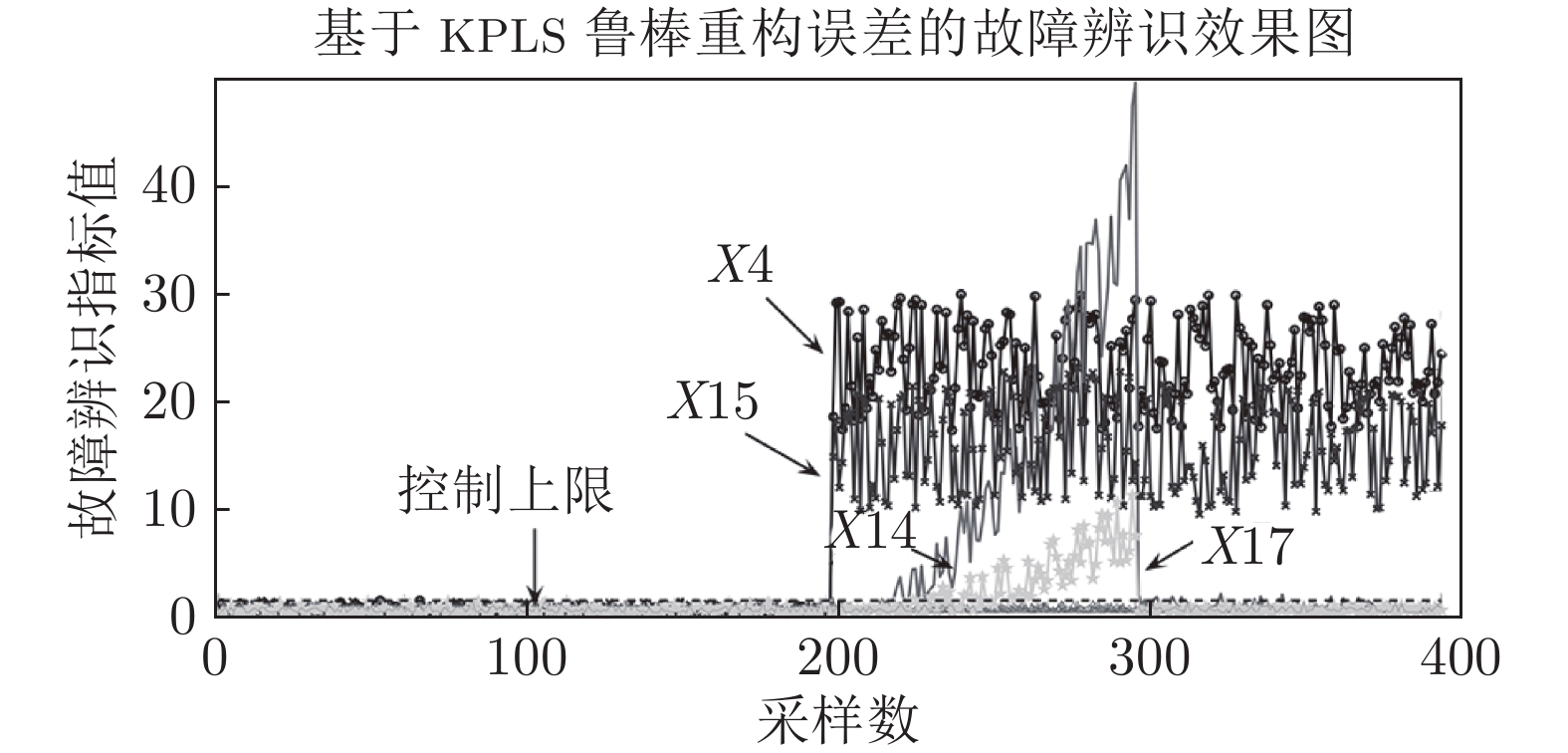
图 12 管道行程异常工况时高炉燃料比异常识别曲线
Fig. 12 Abnormal identification curve of blast furnace fuel ratio in abnormal pipeline condition
表 1 部分过程变量控制限与故障指标值的差值
Table 1 The value of the control limit is reduced to the value of the fault index for part process variables.
过程变量 时间 (1h) $T$290 $T$291 $T$292 $T$293 $T$294 $T$295 $T$296 $T$297 $T$298 $T$299 $T$300 焦炭负荷 0.618 0.692 0.692 0.692 0.095 −0.394 −0.306 −0.397 −18.397 −0.676 −5.217 球团 0.847 0.847 0.847 0.880 −0.533 −0.577 −0.581 −0.245 −0.611 −1.366 −0.552 烧结比 1.025 1.025 1.024 1.024 −1.464 −1.545 −1.557 −1.556 −1.599 −1.508 −1.504 球团比 0.869 0.871 0.870 0.870 −0.730 −0.793 −0.798 −0.801 −0.837 −0.768 −0.758 顶压风量比 0.372 −0.744 −0.744 −0.744 −1.818 −2.467 −1.816 −0.286 −0.722 −3.198 −0.731 标准风速 0.027 −0.654 −0.502 −0.654 0.861 0.790 0.861 0.909 0.909 0.184 0.068 鼓风动能 0.087 −0.569 0.156 −0.217 0.906 0.901 0.906 0.902 0.906 0.638 0.673 炉腹煤气指数 0.080 −0.771 −0.309 −0.771 0.933 0.929 0.933 0.864 0.932 0.694 0.690  下载: 导出CSV
下载: 导出CSV
-
[1] Zhou Ping, Song He-Da, Wang Hong, Chai Tian-You. Data-driven nonlinear subspace modeling for prediction and control of molten iron quality indices in blast furnace ironmaking. IEEE Trans. Control Systems Technology, 2017, 25(5): 1761−1774 doi: 10.1109/TCST.2016.2631124 [2] 蒋朝辉, 董梦林, 桂卫华, 阳春华, 谢永芳. 基于Bootstrap的高炉铁水硅含量二维预报. 自动化学报, 2016, 42(5): 715−723Jiang Zhao-Hui, Dong Meng-Lin, Gui Wei-Hua, Yang Chun-Hua, Xie Yong-Fang. Two-dimensional prediction for silicon content of hot metal of blast furnace based on bootstrap. Acta Automatica Sinica, 2016, 42(5): 715−723 [3] Jian Ling, Li Jun-dong, Luo Shi-Hua. Exploiting expertise rules for statistical data-driven modelling. IEEE Trans. Ind. Electron., 2017, 64(11): 8647−8656 doi: 10.1109/TIE.2017.2703659 [4] 周平, 刘记平. 基于数据驱动多输出ARMAX建模的高炉十字测温中心温度在线估计. 自动化学报, 2018, 44(3): 552−561Zhou Ping, Liu Ji-Ping. Data-driven multi-output ARMAX modeling for online estimation of central temperatures for cross temperature measuring in blast furnace ironmaking. Acta Automatica Sinica, 2018, 44(3): 552−561 [5] Xu Wan-Ren, Zhu Ren-Liang, Zhang Long-Lai, Zhang Yong-Zhong. Reason and control practice of hearth sidewall erosion of No.2 BF at Baosteel. Iron and Steel, 2007, 42(1): 8−12 [6] Gao Jian-Jun, Zhang Ying-Yi, Qi Yuan-Hong, Xu Hai-Chuan, Shi Xue-Feng. Energy consumption analysis on blast furnace ironmaking process using pre-reduced burden. Iron and Steel, 2014, 49(7): 61−65 [7] Liu Xiong, Chen Lin-Gen, Qin Xiao-Yong, Sun Feng-Rui. Exergy loss minimization for a blast furnace with comparative analyses for energy flows and exergy flows. Energy, 2015, 93: 10−19 doi: 10.1016/j.energy.2015.09.008 [8] Zhang Yan-Yan, Zhang Xiao-Lei, Tang Li-Xin. Energy consumption prediction in ironmaking process using hybrid algorithm of SVM and PSO. In: Proceedings of the International Conference on Advances in Neural Networks, IEEE, 2012. 1(4): 594−600 [9] Wei Na, Li Li, Zhu Jun, Li Na. Iron and steel process energy consumption prediction model based on selective ensemble. In: Proceedings of the International Conference on Advanced Mechatronic Systems. Luoyang, China: IEEE, 2013. 203−207 [10] Naito M, Takeda K, Matsui Y. Ironmaking technology for the last 100 years: deployment to advanced technologies from introduction of technological know-how, and evolution to next-generation process. ISIJ International, 2015, 55(1): 7−35 doi: 10.2355/isijinternational.55.7 [11] Lin Zhi-Ling, Yue You-Jun, Zhao Hui, Li Hong-Ru. Judging the states of blast furnace by ART2 neural network. International Symposium on Neural Networks, 2009, 56: 857−864 [12] Rajakarunakaran S, Venkumar P, Devaraj D, Rao K S P. Artificial neural network approach for fault detection in rotary system. Applied Soft Computing, 2008, 8(1): 740−748 doi: 10.1016/j.asoc.2007.06.002 [13] Dong Li-Xin, Xiao Deng-Ming, Liang Yi-Shan, Liu Yi-Lu. Rough set and fuzzy wavelet neural network integrated with least square weighted fusion algorithm based fault diagnosis research for power transformers. Electric Power Systems Research, 2008, 78(1): 129−136 doi: 10.1016/j.jpgr.2006.12.013 [14] Zhao Chun-Hui, Wang Fu-Li, Zhang Ying-Wei. Nonlinear process monitoring based on kernel dissimilarity analysis. Control Engineering Practice, 2009, 17(1): 221−230 doi: 10.1016/j.conengprac.2008.07.001 [15] Zhao Chun-Hui, Gao Fu-Rong. Fault-relevant principal component analysis (FPCA) method for multivariate statistical modeling and process monitoring. Chemometrics and Intelligent Laboratory Systems, 2014, 133: 1−16 doi: 10.1016/j.chemolab.2014.01.009 [16] Zhao Chun-Hui, Sun You-Xian. Multispace total projection to latent structures and its application to online process monitoring. IEEE Trans. Control Systems Technology, 2014, 22(3), 868−883 [17] Yao Li-Na, Qin Ji-Feng, Wang Hong, Jiang Bin. Design of new fault diagnosis and fault tolerant control scheme for non-Gaussian singular stochastic distribution systems. Automatica, 2012, 48(9): 2305−2313 doi: 10.1016/j.automatica.2012.06.036 [18] Qin S J. Statistical process monitoring: basics and beyond. Journal of Chemometrics, 2003, 17(8-9): 480−502 doi: 10.1002/cem.800 [19] Lee J M, Yoo C K, Choi S, Vanrolleghem P A, Lee I B. Nonlinear process monitoring using kernel principal component analysis. Chemical Engineering Science, 2004, 59(1): 223−234 doi: 10.1016/j.ces.2003.09.012 [20] Cho J H, Lee J M, Choi S W, Lee D, Lee I B. Fault identification for process monitoring using kernel principal component analysis. Chemical Engineering Science, 2005, 60(1): 279−288 doi: 10.1016/j.ces.2004.08.007 [21] Rosipal R, Trejo L J. Kernel partial least squares regression in reproducing kernel Hilbert space. Journal of Machine Learning Research, 2002, 2(2): 97−123 [22] Wold S, Kettaneh-Wold N, Skagerberg B. Nonlinear PLS modeling. Chemometrics and Intelligent Laboratory Systems, 1989, 7(1-2): 53−65 doi: 10.1016/0169-7439(89)80111-X [23] Qin S J, Mcavoy T J. Nonlinear PLS modeling using neural networks. Computers and Chemical Engineering, 1992, 16(4): 379−391 doi: 10.1016/0098-1354(92)80055-E [24] Baffi G, Martin E B, Morris A J. Non-linear projection to latent structures revisited (the neural network PLS algorithm). Computers and Chemical Engineering, 1999, 23(9): 1293−1307 doi: 10.1016/S0098-1354(99)00291-4 [25] Peng Kai-Xing, Zhang Kai, You Bo, Dong Jie, Wang Z D. A quality-based nonlinear fault diagnosis framework focusing on industrial multimode batch processes. IEEE Transactions on Industrial Electronics, 2016, 63(4): 2615−2624 [26] Shao R, Jia F, Martin E B, Morris A J. Wavelets and non-linear principal components analysis for process monitoring. Control Engineering Practice, 1997, 7(7): 865−879 [27] Dunia R, Qin S J, Edgar T F, McAvoy T J. Identification of faulty sensors using principal component analysis. AIChE Journal, 2010, 42(10): 2797−2812 [28] Sang W C, Lee C, Lee J M, Lee I B. Fault detection and identification of nonlinear processes based on kernel PCA. Chemometrics and Intelligent Laboratory Systems, 2005, 75(1): 55−67 doi: 10.1016/j.chemolab.2004.05.001 [29] Kim K, Lee J M, Lee I B. A novel multivariate regression approach based on kernel partial least squares with orthogonal signal correction. Chemometrics and Intelligent Laboratory Systems, 2005, 79(1-2): 22−30 doi: 10.1016/j.chemolab.2005.03.003 [30] Miller P, Swanson R E, Heckler C E. Contribution plots: a missing link in multivariate quality control. Applied Mathematics and Computer Science, 1998, 8(4): 775−792 [31] Struc V, Pavesic N. Gabor-based kernel partial-least-squares discrimination features for face recognition. Informatica, 2009, 20(1): 115−138 doi: 10.15388/Informatica.2009.240 [32] Mika S, Scholkopf B, Smola A, Muller K R, Scholz M, Ratsch G. Kernel PCA and de-noising in feature spaces. Advances in Neural Information Processing Systems, 1999, 11: 536−542 [33] Takahashi T, Kurita T. Robust de-noising by kernel PCA. International Conference on Artificial Neural Networks, 2002, 2415: 739−744 [34] Koc E K, Bozdogan H. Model selection in multivariate adaptive regression spines (MARS) using information complexity as the fitness function. Machine Learning, 2015, 101(1-3): 35−58 doi: 10.1007/s10994-014-5440-5 -

 下载:
下载:




计量
- 文章访问数: 1448
- HTML全文浏览量: 518
- PDF下载量: 207
- 被引次数: 0
