

An Entropy-based Approach for Measuring the Information Quantity of Small Lots Production in a Flow Shop
-
摘要: 流水车间生产中, 批量及批次的信息量测度意味着对描述不同批量及批次在工作站的状态所需信息量的度量, 即求解批量及批次的信息熵表达.现有批量及批次信息控制研究主要集中在批量调度问题上, 鲜有针对生产中的批量及批次与管理生产所需信息量关系的研究, 造成研究结论很难为决策者从信息管理角度选择生产方式提供理论依据.针对上述问题, 在分析信息熵度量特性基础上, 理论上首次建立流水车间生产线不同批次相同加工时间条件下的批量及批次的信息熵函数, 作为度量生产系统状态所需信息量的基础, 并由此提出生产批次与熵函数变化关系两个定理, 即:生产批次的信息熵函数单调递减; 批次趋于无穷大时, 系统信息熵趋于零.采用求导法与极值法分别对所提定理给予充分证明, 从而理论上证明了流水车间的加工批次增加(或批量减小), 则系统的信息熵降低.分别取工作站数量为10和20进行实证研究, 以图示表达的结果再次验证了所提定理的正确性.批量与批次的信息量测度理论研究, 对实际流水车间生产批量与批次的作业安排及最终生产方式的选择, 都具有重要的理论支撑和现实指导意义.Abstract: In the production of the flow shop, the measurement of information quantity on the number and size of lots means a measure of the information quantity required to describe the status of different numbers and sizes of lots at the workstations, i.e., to solve the information entropy representation of the number and size of lots. The existing information control research on the number and size of lots mainly focuses on the batch scheduling problem of the flow shop. There are few research on the relationship between the number and size of lots and the amount of information required to manage production, so its research conclusions are difficult to provide a theoretical basis for decision makers to choose production methods from the perspective of information management. Based on the analysis of the information entropy measurement characteristics, the entropy functions of the processing lots of a production line of a flow shop are first established theoretically for the first time, as the basis for measuring the states of production systems needed the amount of information. According to the established entropy functions, two theorems on the relationship between production lots and the entropy functions are proposed, namely: the entropy function of production lots decreases monotonically; the systematic entropy tends to zero when the number of lots approach to infinity. The derivation and the extremum methods are used to fully prove the theorems, respectively. As a result, it is theoretically demonstrated for the first time that the move toward larger number (or smaller size) of lots implies less information needs. In the empirical study, the number of workstations was taken as 10 and 20, respectively. The correctness of the theorem was verified again by the calculation results of the graphic representation. The theory research on the measurement of information quantity of the number and size of lots has important theoretical support and practical guiding significance for the actual flow shop batch and batch scheduling arrangement and final production mode selection.
-
Key words:
- Entropy function /
- small lots production /
- flow shop /
- information quantity
1) 本文责任编委 乔俊飞 -
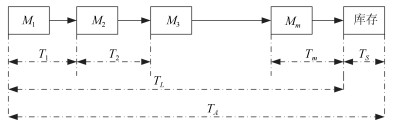
图 1 加工批次在工作站上的时间表示
Fig. 1 Time representation of the processing batch on the workstation
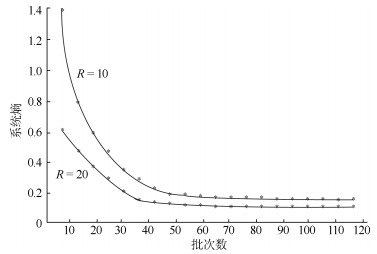
图 3 工作站数量为10和20的系统熵与批次函数关系曲线
Fig. 3 The entropy function curve of the size of lots with 10 and 20 workstations
-
[1] 王坤峰, 左旺孟, 谭营, 秦涛, 李立, 王飞跃.生成式对抗网络:从生成数据到创造智能.自动化学报, 2018, 44(5): 769-774 doi: 10.16383/j.aas.2018.y000001Wang Kun-Feng, Zuo Wang-Meng, Tang Ying, Qin Tao, Li Li, Wang Fei-Yue. Generative adversarial networks: from generating data to creating intelligence. Acta Automatica Sinica, 2018, 44(5): 769-774 doi: 10.16383/j.aas.2018.y000001 [2] 柴天佑.自动化科学与技术发展方向.自动化学报, 2018, 44(11): 1923-1930 doi: 10.16383/j.aas.2018.c180252Chai Tian-You. Development directions of automation science and technology. Acta Automatica Sinica, 2018, 44(11): 1923-1930 doi: 10.16383/j.aas.2018.c180252 [3] Alfred T, Kristofer B, Julien P, Michael L, Charlotta J, Thomas L, Bengt L. An event-driven manufacturing information system architecture for Industry 4.0. International Journal of Production Research, 2017, 55(5): 1297-1311 doi: 10.1080/00207543.2016.1201604 [4] Kuznetsov A P. Decision making in production on the basis of structure strategy theory. Russian Engineering Research, 2017, 37(9): 801-806 doi: 10.3103/S1068798X17090155 [5] Koren Y, Gu X, Guo W. Reconfigurable manufacturing systems: principles, design, and future trends. Frontiers of Mechanical Engineering, 2018, 13(2): 121-136 [6] Nujoom R, Wang Q, Mohammed A. Optimisation of a sustainable manufacturing system design using the multi-objective approach. International Journal of Advanced Manufacturing Technology, 2018, 96(5-8): 2539-2558 doi: 10.1007/s00170-018-1649-y [7] Klocke K, Arntz K, Heeschen D. Integrative technology chain design for small scale manufacturers. Production Engineering, 2015, 9(1): 109-117 doi: 10.1007/s11740-014-0590-7 [8] Cheng Y, Zhang Y P, Ji P, Xu W J, Zhou Z D, Tao F. Cyber-physical integration for moving digital factories forward towards smart manufacturing: a survey. International Journal of Advanced Manufacturing Technology, 2018, 97(1-4): 1209-1223 doi: 10.1007/s00170-018-2001-2 [9] Li C, Seeram R, Sunpreet S. A review of digital manufacturing-based hybrid additive manufacturing processes. International Journal of Advanced Manufacturing Technology, 2018, 95(5-8): 2281-2300 doi: 10.1007/s00170-017-1345-3 [10] Lu Y Q, Xu X. Resource virtualization: a core technology for developing cyber-physical production systems. Journal of Manufacturing Systems, 2018, 47(4): 128-140 http://www.sciencedirect.com/science/article/pii/S0278612518300657 [11] 李伯虎, 张霖, 任磊, 柴旭东, 陶飞, 王勇智, 等.云制造典型特征、关键技术与应用.计算机集成制造系统, 2012, 18(7): 1345-1356 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjjczzxt201207002tLi Bo-Hu, Zhang Li, Ren Lei, Chai Xu-Dong, Tao Fei, Wang Yong-Zhi, et al. Typical characteristics, technologies and applications of cloud manufacturing. Computer Integrated Manufacturing Systems, 2012, 18 (7): 1345-1356 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjjczzxt201207002t [12] Wang X V, Wang L H, Gördes R. Interoperability in cloud manufacturing: a case study on private cloud structure for SMEs. International Journal of Computer Integrated Manufacturing, 2018, 31(7): 653-663 doi: 10.1080/0951192X.2017.1407962 [13] Li C Y, Guan J H, Liu T T, Ma N, Zhang J. An autonomy-oriented method for service composition and optimal selection in cloud manufacturing. International Journal of Advanced Manufacturing Technology, 2018, 96(5-8): 2583-2604 doi: 10.1007/s00170-018-1746-y [14] Yin C, Deng P C, Li X B. Intelligent manufacturing mode for sophisticated equipment assembly workshop. Journal of Advanced Manufacturing Systems, 2018, 17(4): 533-549 doi: 10.1142/S0219686718500300 [15] Nouiri M, Bekrar A, Jemai A, Niar S, Ammari A C. An effective and distributed particle swarm optimization algorithm for flexible job-shop scheduling problem. Journal of Intelligent Manufacturing, 2018, 29(3): 603-615 doi: 10.1007/s10845-015-1039-3 [16] Ta Q C, Billaut J C, Bouquard J L. Matheuristic algorithms for minimizing total tardiness in the $m$-machine flow-shop scheduling problem. Journal of Intelligent Manufacturing, 2018, 29(3): 617-628 doi: 10.1007/s10845-015-1046-4 [17] Ding J Y, Song S J, Gupta J, Zhang R, Chiong R, Wu C. An improved iterated greedy algorithm with a Tabu-based reconstruction strategy for the no-wait flow shop scheduling problem. Applied Soft Computing, 2015, 30: 604-613 doi: 10.1016/j.asoc.2015.02.006 [18] Busogi M, Ransikarbum K, Oh Y G, Kim N. Computational modelling of manufacturing choice complexity in a mixed-model assembly line. International Journal of Production Research, 2017, 55(20): 5976-5990 doi: 10.1080/00207543.2017.1319088 [19] Defersha F, Chen M. Mathematical model and parallel genetic algorithm for hybrid flexible flowshop lot streaming problem. The International Journal of Advanced Manufacturing Technology, 2012, 62(1-4): 249-265 doi: 10.1007/s00170-011-3798-0 [20] Karaboga D. A comparative study of artificial bee colony algorithm. Applied Mathematics and Computation, 2009, 214(1): 108-132 http://www.ams.org/mathscinet-getitem?mr=2541051 [21] Pan Q, Ruiz R. An estimation of distribution algorithm for lot-streaming flow shop problems with setup times. OMEGA—International Journal of Management Science, 2012, 40(2): 166-180 doi: 10.1016/j.omega.2011.05.002 -

 下载:
下载:

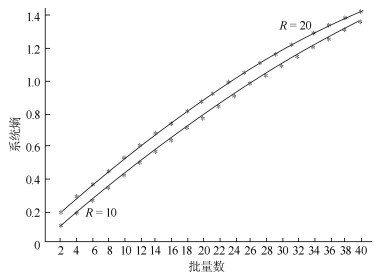

图(4)
计量
- 文章访问数: 1405
- HTML全文浏览量: 308
- PDF下载量: 157
- 被引次数: 0
