

Sampling Aggregate Network for Scene Depth Estimation
-
摘要: 针对现有场景深度估计方法中, 由于下采样操作引起的复杂物体边界定位不准确, 而造成物体边界处的场景深度估计模糊的问题, 受密集网络中特征汇集过程的启发, 本文提出一种针对上/下采样过程的汇集网络模型. 在下采样过程中, 使用尺度特征汇集策略, 兼顾不同尺寸物体的估计; 在上采样过程中, 使用上采样反卷积恢复图像分辨率; 同时, 引入采样跨层汇集策略, 提供下采样过程中保存的物体边界的有效定位信息. 本文提出的采样汇集网络 (Sampling aggregate network, SAN) 中使用的尺度特征汇集和采样跨层汇集, 都可以有效缩短特征图到输出损失之间的路径, 从而有利于避免模型的参数优化时陷入局部最优解. 在公认场景深度估计NYU-Depth-v2数据集上的实验说明, 本文方法能够有效改善复杂物体边界等干扰情况下的场景深度估计效果, 并在深度估计误差和准确性上, 优于当前场景深度估计的主流方法.Abstract: State-of-the-art approaches for scene depth estimation are built on downsampling strategy, which can lead to inaccurate location and ambiguous depth estimation for complicated boundary. Inspired with feature aggregation in DenseNets, we propose a novel feature aggregation strategy for upsample/downsample in our sampling aggregate network (SAN). Firstly, scale feature aggregation is used in downsample process to consider various scale object boundaries. Secondly, transposed convolution is applied in upsample process to restore image resolution. Thirdly, sample skip connection and aggregation is devoted to extract effective location of object boundary from downsample module with the same resolution. We adopt scale feature aggregation and sample skip aggregation to shorten the path from feature map to output loss, in order to avoid local optimal solution of our sampling aggregate network. Experiments in the recognized NYU-Depth-v2 database of scene depth estimation show that our model can improve the depth estimation result under complecated object boundaries and other disturbances. Our sampling aggregate network outperforms the state-of-the-art methods in error and accuracy evaluations.
-

图 5 采样汇集网络的消融模型对比实例图. (a)原始图像; (b) 真实场景深度; (c) SFAN-129结果; (d) NSN-129结果; (e) SAN-129结果
Fig. 5 Contrasting examples of ablation models for sampling aggregate network. (a) RGB image; (b) GT depth; (c) result of SFAN-129; (d) result of NSN-129; (e) result of SAN-129

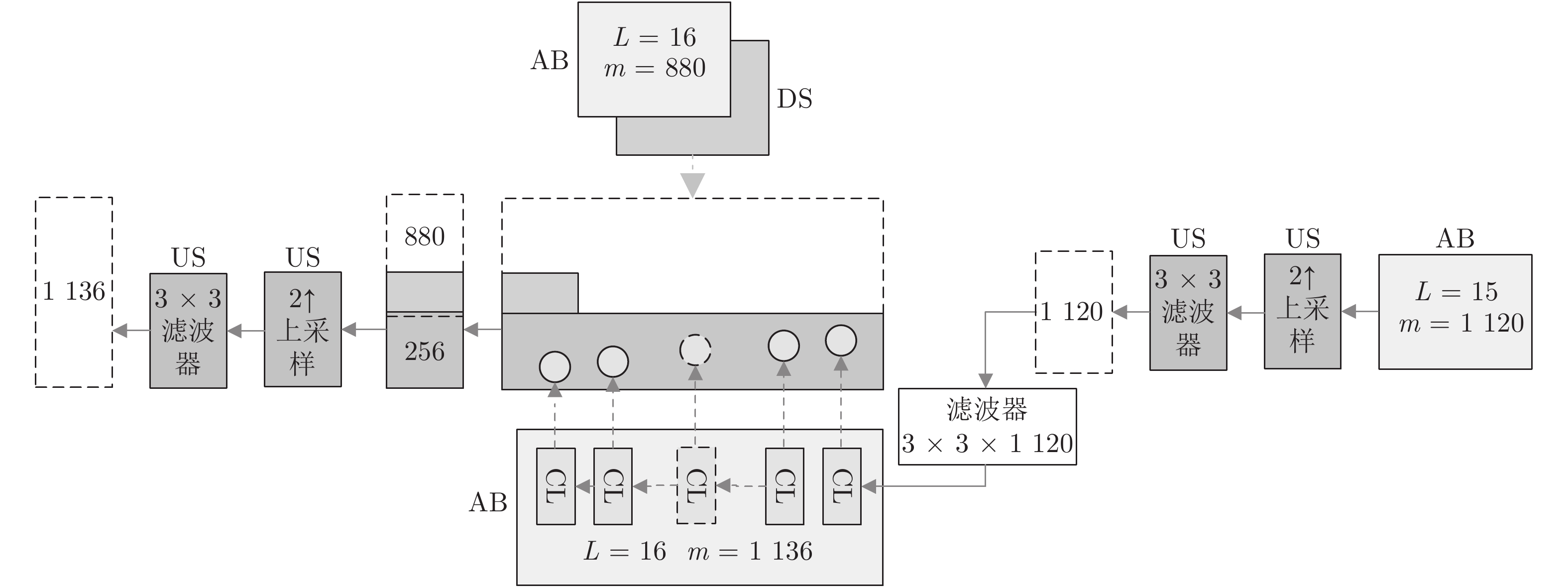
图 6 采样汇集网络中下采样次数定性结果,图6的原图和真实场景深度与图5中对应. (a) SAN-31结果; (b) SAN-47结果; (c) SAN-69结果; (d) SAN-95结果; (e) SAN-129结果
Fig. 6 Qualitative results of downsampling times in sampling aggregate network. Fig. 6 and Fig. 5 have the same RGB images and GT depth images. (a) result of SAN-31; (b) result of SAN-47; (c) result of SAN-69; (d) result of SAN-95; (e) result of SAN-129

图 7 场景估计中的困难实例,第1行小物体干扰,第2行复杂边界干扰,第3行光照干扰,第4行深度范围大干扰,第5行深度范围小的干扰. (a) 原始图像; (b)真实场景深度; (c) SAN-95结果; (d) SFAN-129结果; (e) SAN-129结果
Fig. 7 Challenge examples in depth estimation, including small object interference (Line 1), complex boundary interference (line 2), illumination interference (line 3), large depth range interference (line 4), small depth range interference (line 5). (a) RGB image; (b) GT depth; (c) result of SAN-95; (d) result of SFAN-129; (e) result of SAN-129
表 1 采样汇集网络的消融分析
Table 1 Ablation analysis of sampling aggregate network
消融模型 Error Accuracy (%) REL ${\rm{log}}_{10}$ RMS $\delta_1$ $\delta_2$ $\delta_3$ SFAN-129 0.165 0.072 0.586 75.70 93.70 98.10 NSN-129 0.163 0.070 0.583 76.00 94.10 98.20 SAN-129 0.158 0.067 0.567 77.60 95.20 98.80  下载: 导出CSV
下载: 导出CSV
表 2 采样汇集网络中下采样次数定量分析
Table 2 Quantitative analysis of downsampling times in sampling aggregate network
采样汇集网络模型 Error Accuracy (%) REL ${\rm{log}}_{10}$ RMS $\delta_1$ $\delta_2$ $\delta_3$ SAN-31 0.311 0.129 1.012 46.20 77.10 91.80 SAN-47 0.250 0.107 0.830 55.70 84.90 95.50 SAN-69 0.194 0.083 0.672 68.00 90.70 97.70 SAN-95 0.169 0.073 0.608 73.60 93.10 98.30 SAN-129 0.158 0.067 0.567 77.60 95.20 98.80
下载: 导出CSV
表 3 采样汇集网络中输入图像分辨率定量分析
Table 3 Quantitative analysis of image resolution in sampling aggregate network
采样汇集网络模型 图像分辨率 Error Accuracy (%) REL ${\rm{log}}_{10}$ RMS $\delta_1$ $\delta_2$ $\delta_3$ SAN-129 304 × 228 0.158 0.067 0.567 77.60 95.20 98.80 SAN-129 152 × 114 0.149 0.064 0.562 79.95 95.23 98.80
下载: 导出CSV
表 4 本文采样汇集网络与现有方法定量对比
Table 4 Quantitative analysis of our sampling aggregate network with state-of-the-art methods
对比方法 Error Accuracy (%) REL ${\rm{log}}_{10}$ RMS $\delta_1$ $\delta_2$ $\delta_3$ Su等[12] 0.302 0.128 0.937 − − − Laina等[23] 0.215 0.083 0.790 62.90 88.90 97.10 Liu等[9] 0.213 0.087 0.759 65.00 90.60 97.60 Wang等[8] 0.210 0.094 0.745 60.50 89.00 97.00 Roy等[6] 0.187 0.078 0.744 − − − Cao等[10] 0.187 0.071 0.681 71.20 92.30 98.00 Fu等[7] 0.160 − 0.586 76.50 95.00 99.10 Sharma-RMSE[26] 0.159 0.064 0.549 79.10 94.60 98.40 SAN-129 @ 304 × 228 0.158 0.067 0.567 77.60 95.20 98.80 Sharma-berHu[26] 0.153 0.062 0.549 79.90 95.00 98.50 SAN-129 @ 152 × 114 0.149 0.064 0.562 79.95 95.23 98.80
下载: 导出CSV
-
[1] Jégou S, Drozdzal M, Vazquez D, Romero A, Bengio Y. The one hundred layers tiramisu: fully convolutional densenets for semantic segmentation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA: IEEE, 2017. 1175−1183 [2] 2 Cheng Y H, Zhao X, Huang K Q, Tan T N. Semi-supervised learning and feature evaluation for rgb-d object recognition. Computer Vision and Image Understanding, 2015, 139: 149−160 doi: 10.1016/j.cviu.2015.05.007 [3] Borghi G, Venturelli M, Vezzani R, Cucchiara R. POSEidon: face-from-depth for driver pose estimation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA: IEEE, 2017. 5494−5503 [4] 4 Saxena A, Sun M, Ng A Y. Make3d: learning 3d scene structure from a single still image. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(5): 824−840 doi: 10.1109/TPAMI.2008.132 [5] Tateno K, Tombari F, Laina I, Navab N. CNN-SLAM: real-time dense monocular SLAM with learned depth prediction. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA: IEEE, 2017. 6565−6574 [6] Roy A, Todorovic S. Monocular depth estimation using neural regression forest. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA: IEEE, 2016. 5506−5514 [7] Fu H, Gong M M, Wang C H, Tao D. A compromise principle in deep monocular depth estimation. arXiv preprint arXiv: 1708.08267, 2017. 1−11 [8] Wang P, Shen X H, Lin Z, Cohen S, Price B, Yuille A. Towards unified depth and semantic prediction from a single image. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA: IEEE, 2015. 2800−2809 [9] 9 Liu F Y, Shen C H, Lin G S, Reid I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2024−2039 doi: 10.1109/TPAMI.2015.2505283 [10] 10 Cao Y, Wu Z, Shen C H. Estimating depth from monocular images as classification using deep fully convolutional residual networks. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 28(11): 1−11 [11] Huang G, Liu Z, Maaten L V D. Weinberger K Q. Densely connected convolutional networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA: IEEE, 2017. 2261−2269 [12] 12 Su C C, Cormack L K, Bovik A C. Bayesian depth estimation from monocular natural images. Journal of Vision, 2017, 17(5): 22−22 doi: 10.1167/17.5.22 [13] Liu B Y, Gould S, Koller D. Single image depth estimation from predicted semantic labels. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA: IEEE, 2010. 1253−1260 [14] 14 Karsch K, Liu C, Kang S B. Depth transfer: depth extraction from videos using nonparametric sampling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(11): 2144−2158 doi: 10.1109/TPAMI.2014.2316835 [15] Batra D and Saxena A. Learning the right model: efficient max-margin learning in laplacian CRFS. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA: IEEE, 2012. 2136−2143 [16] Saxena A, Chung S H, Ng A Y. Learning depth from single monocular images. In: Proceedings of the 2005 Advances in Neural Information Processing Systems, Vancouver, British Columbia, Canada: MIT Press, 2005. 1161−1168 [17] Eigen D, Puhrsch C, Fergus R. Depth map prediction from a single image using a multi-scale deep network. In: Proceedings of the 2014 Advances in Neural Information Processing Systems, Montreal, Quebec, Canada: MIT Press, 2014. 2366−2374 [18] Liu M M, Salzmann M, He X M. Discrete-continuous depth estimation from a single image. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA: IEEE, 2014. 716−723 [19] Liu F Y, Shen C H, Lin G S. Deep convolutional neural fields for depth estimation from a single image. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA: IEEE, 2015. 5162−5170 [20] Xu D, Ricci E, Ouyang W L, Wang X G, Sebe N. Multi-scale continuous crfs as sequential deep networks for monocular depth estimation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA: IEEE, 2017. 161−169 [21] Zhuo W, Salzmann M, He X M, Liu M M. Indoor scene structure analysis for single image depth estimation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA: IEEE, 2015. 614−622 [22] 22 Yan H, Zhang S L, Zhang Y, Zhang L. Monocular depth estimation with guidance of surface normal map. Neurocomputing, 2017, 280: 86−100 [23] Laina I, Rupprecht C, Belagiannis V, Tombari F, Navab N. Deeper depth prediction with fully convolutional residual networks. In: Proceedings of the 4th International Conference on 3D Vision, Stanford, CA, USA: IEEE, 2016. 239−248 [24] Godard C, Aodha O, Brostow G J. Unsupervised monocular depth estimation with left-right consistency. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA: IEEE, 2017. 6602−6611. [25] 25 Grigorev A, Jiang F, Rho S, Sori W J, Liu S H, Sai S. Depth estimation from single monocular images using deep hybrid network. Multimedia Tools and Applications, 2017, 76(18): 18585−18604 doi: 10.1007/s11042-016-4200-x [26] Sharma S, Padhy R P, Choudhury S K, Goswami N, Sa P K. DenseNet with pre-activated deconvolution for estimating depth map from single image. In: Proceeding of the 2017 British Machine Vision Conference, London, UK: BMVA, 2017. 1−12 [27] Zhu Y, Newsam S. Densenet for dense flow. In: Proceedings of the 2017 IEEE International Conference on Image Processing, Beijing, China: IEEE, 2017. 790−794 [28] Collobert R, Kavukcuoglu K, Farabet C. Torch7: a matlab-like environment for machine learning. In: Proceeding of the 2011 Advances in Neural Information Processing Systems, Granada, Spain: Springer, 2011. 1−6 [29] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: surpassing human-level performance on imagenet classification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile: IEEE, 2015. 1026−1034 [30] Silberman N, Hoiem D, Kohli P, Fergus R. Indoor segmentation and support inference from rgbd images. In: Proceedings of the 2012 European Conference on Computer Vision, Florence, Italy: IEEE, 2012. 746−760 -




















计量
- 文章访问数: 2000
- HTML全文浏览量: 763
- PDF下载量: 175
- 被引次数: 0
