

-
摘要: 汽车作为较高价值和个性化的消费品,使得用户购车决策过程较一般商品更为复杂.本文主要研究社交环境和评论文本两方面对用户购车决策过程的影响,提出了融合社交因素和评论文本卷积网络的汽车推荐模型(Social and comment text CNN model based automobile recommendation,SCTCMAR).SCTCMAR首先定义了基于购买用途需求的社交圈,在此基础上提出了个人偏好计算方法,并引入了偏好相似度;其次,设计了卷积网络模型学习汽车评论文本的隐特征;然后将社交影响量化因素和评论文本特征有机融合注入推荐模型,并采用低阶矩阵分解技术进行模型计算.另外,本文使用GloVe预训练词嵌入模型,产生了SCTCMAR的另一个版本SCTCMAR+.最后,将SCTCMAR、SCTCMAR、FMM(Flexible mixture model)、TR(Trust rank)、Random sampling在课题组爬取后经清理、去重和整合的266995个用户、702辆汽车信息的真实数据集上进行精确率、召回率和平均倒序排名三个指标的多粒度实验比较,结果表明本文提出的SCTCMAR+和SCTCMAR具有良好的推荐性能.Abstract: This paper mainly studies the influence of social environment and comment text on the user decision making process in purchasing an automobile, and proposes an automobile recommendation model named SCTCMAR (social and comment text CNN model based automobile recommendation). First, SCTCMAR defines a social circle of users in terms of user's purpose in choosing an automobile; on this basis, a method to calculate personal preference is put forward. and preference similarity is put forward. Second, a convolution neural network model is designed to learn the hidden features from the automobile comment texts. Afterwards, both the social circle and comment text features are integrated into the recommendation model, and low-rank matrix decomposition technology is used to solve the problem. In addition, by applying the GloVe pre-training word embedded model to SCTCMAR, an improved version, SCTCMAR+ is further proposed. Finally, a performance of comparison SCTCMAR+, SCTCMAR with FMM (flexible mixture model), TR (trust rank), and Random sampling is performed on a real dataset with 266995 users and 702 automobiles. Experimental results show that SCTCMAR+ and SCTCMAR models outperform other counterparts in precision, recall and ARHR (average reciprocal hit rank).1) 本文责任编委 周涛
-
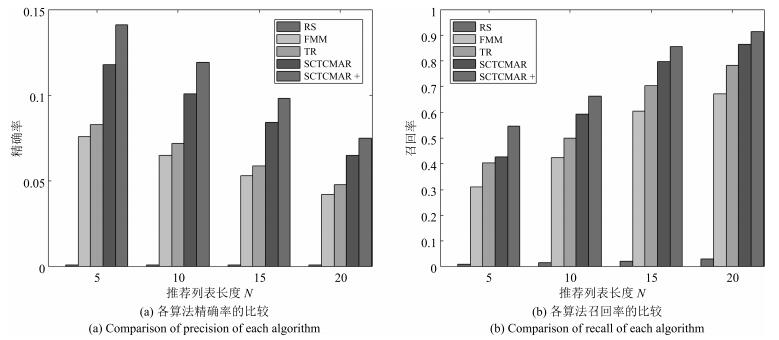
图 4 在精确率和召回率上本文提出的算法与其他算法的对比
Fig. 4 Precision and recall comparisons between our algorithm and other algorithms

图 6 本文算法多因素联合对平均倒序排名的影响
Fig. 6 ARHR line chart of impact of factors combination in our model
表 1 推荐框架的符号定义
Table 1 Notations in recommender framework
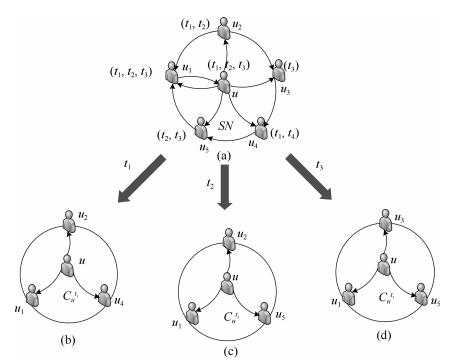
表示符号 概念描述 $U=\left\{ {{u}_{1}}, \cdots, {{u}_{N}} \right\}$ 用户集合 $F={{[{{F}_{u, v}}]}^{M\times M}}$ 偏好相似度矩阵 $V=\{{{i}_{1}}, \cdots, {{i}_{M}}\}$ 汽车集合 ${{F}_{u, v}}\in [0, 1]$ 用户$ u$和用户$ v$之间的偏好相似度 $R={{[{{R}_{u, i}}]}^{N\times M}}$ 评分矩阵 $Q={{[{{Q}_{u, i}}]}^{N\times M}}$ 用户个人偏好 ${{R}_{u, i}}$ 用户$ u$对汽车$ i$的评分 ${{Q}_{u, i}}\in [0, 1]$ 用户$ u$的偏好和汽车$ i$的主题之间的相关性 $W$ 卷积神经网络(CNN)中的内部权重  下载: 导出CSV
下载: 导出CSV
表 2 数据集信息列表
Table 2 The list of datasets
名称 来源/网址 用途 汽车之家 http://www.autohome.com.cn 汽车及用户的相关数据信息 网易汽车 http://auto.163.com 汽车及用户的相关数据信息 搜狗实验室 http://www.sogou.com/labs/ 语料数据集 汽车之家 http://www.autohome.com.cn 语料数据集 网易汽车 http://auto.163.com 语料数据集 腾讯汽车 http://auto.qq.com/ 语料数据集 新浪汽车 http://auto.sina.com.cn/ 语料数据集 数据堂 http://www.datatang.com/ 汽车领域字典 输入法字典 搜狗输入法 汽车领域字典
下载: 导出CSV
表 3 本文提出的算法与其他算法在推荐精确率上的比较及提升百分比
Table 3 Precision comparison and improvement between our algorithm and other algorithms
算法 $N=5$ $N=10$ $N=15$ $N=20$ FMM 0.076 0.065 0.053 0.042 46.10 % 45.38 % 45.92 % 44.00 % TR 0.083 0.072 0.059 0.048 41.13 % 39.50 % 39.80 % 36.00 % RS 0.001 0.001 0.001 0.001 99.29 % 99.16 % 98.98 % 98.67 % SCTCMAR 0.118 0.101 0.084 0.065 16.31 % 15.13 % 14.29 % 13.33 % SCTCMAR+ 0.141 0.119 0.098 0.075
下载: 导出CSV
表 4 本文提出的算法与其他算法在推荐召回率上的比较及提升百分比
Table 4 Recall comparison and improvement between our algorithm and other algorithms
算法 $N=5$ $N=10$ $N=15$ $N=20$ FMM 0.311 0.425 0.604 0.672 43.04 % 35.80 % 29.52 % 26.56 % TR 0.405 0.501 0.705 0.783 25.82 % 24.32 % 17.74 % 14.43 % RS 0.010 0.016 0.023 0.032 98.17 % 97.58 % 97.32 % 96.50 % SCTCMAR 0.472 0.593 0.798 0.864 13.55 % 10.42 % 6.88 % 5.57 % SCTCMAR+ 0.546 0.662 0.857 0.915
下载: 导出CSV
表 5 各算法在平均倒序排名上的对比
Table 5 ARHR comparison between our algorithm and other algorithms
算法 $N=5$ $N=10$ $N=15$ $N=20$ FMM 0.082 0.106 0.122 0.131 TR 0.119 0.137 0.148 0.154 RS 0.002 0.003 0.005 0.006 SCTCMAR 0.171 0.182 0.201 0.210 SCTCMAR+ 0.196 0.218 0.233 0.241
下载: 导出CSV
表 6 本文算法使用词嵌入模型在平均倒序排名上的影响
Table 6 ARHR comparison between our algorithm with pre-trained word embedding model
算法 pika mianbao small compact SCTCMAR 0.171 0.169 0.184 0.186 SCTCMAR+ 0.188 0.183 0.180 0.176 提升(%) 9.04 7.65 ${\bf-2.22}$ ${\bf-5.68}$
下载: 导出CSV
-
[1] Felfernig A, Burke R. Constraint-based recommender systems:technologies and research issues. In:Proceedings of the 10th International Conference on Electronic Commerce. Innsbruck, Austria:ACM, 2008. https://www.researchgate.net/publication/221550593_Constraint-based_recommender_systems_technologies_and_research_issues [2] Feng H, Qian X M. Recommendation via user's personality and social contextual. In:Proceedings of the 22nd ACM International Conference on Information and Knowledge Management. San Francisco, California, USA:ACM, 2013. 1521-1524 [3] Jamali M, Ester M. A matrix factorization technique with trust propagation for recommendation in social networks. In:Proceedings of the 4th ACM Conference on Recommender Systems. Barcelona, Spain:ACM, 2010. 135-142 https://www.researchgate.net/publication/221141035_A_matrix_factorization_technique_with_trust_propagation_for_recommendation_in_social_networks [4] 潘涛涛, 文锋, 刘勤让.基于矩阵填充和物品可预测性的协同过滤算法.自动化学报, 2017, 43(9):1597-1606 http://www.aas.net.cn/CN/abstract/abstract19136.shtmlPan Tao-Tao, Wen Feng, Liu Qin-Rang. Collaborative filtering recommendation algorithm based on rating matrix filling and item predictability. Acta Automatica Sinica, 2017, 43(9):1597-1606 http://www.aas.net.cn/CN/abstract/abstract19136.shtml [5] Yang X W, Steck H, Liu Y. Circle-based recommendation in online social networks. In:Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Beijing, China:ACM, 2012. 1267-1275 https://www.researchgate.net/publication/254464202_Circle-based_recommendation_in_online_social_networks [6] Salakhutdinov R, Mnih A. Probabilistic matrix factorization. In:Proceedings of the 20th International Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada:ACM, 2008. 1257-1264 [7] Jiang M, Cui P, Liu R, Yang Q. Social contextual recommendation. In:Proceedings of the 21st ACM international Conference on Information and Knowledge Management. Maui, Hawaii, USA:ACM, 2012. 45-54 [8] 张燕平, 张顺, 钱付兰, 张以文.基于用户声誉的鲁棒协同推荐算法.自动化学报, 2015, 41(5):1004-1012 http://www.aas.net.cn/CN/abstract/abstract18674.shtmlZhang Yan-Ping, Zhang Shun, Qian Fu-Lan, Zhang Yi-Wen. Robust collaborative recommendation algorithm based on user's reputation. Acta Automatica Sinica, 2015, 41(5):1004-1012 http://www.aas.net.cn/CN/abstract/abstract18674.shtml [9] Qian X M, Feng H, Zhao G S, Mei T. Personalized recommendation combining user interest and social circle. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(7):1763-1777 doi: 10.1109/TKDE.2013.168 [10] Wang Z, Sun L F, Zhu W W, Yang S Q, Li H Z, Wu D P. Joint social and content recommendation for user-generated videos in online social network. IEEE Transactions on Multimedia, 2013, 15(3):698-709 doi: 10.1109/TMM.2012.2237022 [11] Wang C, Blei D M. Collaborative topic modeling for recommending scientific articles. In:Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego, California, USA:ACM, 2011. 448-456 https://www.researchgate.net/publication/221654332_Collaborative_topic_modeling_for_recommending_scientific_articles [12] Ling G, Lyu M R, King I. Ratings meet reviews, a combined approach to recommend. In:Proceedings of the 8th ACM Conference on Recommender Systems. Foster City, Silicon Valley, California, USA:ACM, 2014. 105-112 [13] McAuley J, Leskovec J. Hidden factors and hidden topics:understanding rating dimensions with review text. In:Proceedings of the 7th ACM Conference on Recommender Systems. Hong Kong, China:ACM, 2013. 165-172 https://www.researchgate.net/publication/262205718_Hidden_factors_and_hidden_topics_Understanding_rating_dimensions_with_review_text [14] Wang H, Wang N Y, Yeung D Y. Collaborative deep learning for recommender systems. In:Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney, NSM, Australia:ACM, 2015. 1235-1244 http://www.oalib.com/paper/4068730#.XJ7Jlvk6uPI [15] Lecun Y, Bottou L, Bengio Y, Haffner F. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11):2278-2324 doi: 10.1109/5.726791 [16] 孙晓, 潘汀, 任福继.基于ROI-KNN卷积神经网络的面部表情识别.自动化学报, 2016, 42(6) 883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtmlSun Xiao, Pan Ting, Ren Fu-Ji. Facial expression recognition using ROI-KNN deep convolutional neural networks. Acta Automatica Sinica, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtml [17] Pennington J, Socher R, Manning C D. GloVe:global vectors for word representation. In:Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar:EMNLP, 2014. 1532-1543 [18] Kim D, Park C, Oh J, Lee S, Yu H. Convolutional matrix factorization for document context-aware recommendation. In:Proceedings of the 10th ACM Conference on Recommender Systems. Boston, Massachusetts, USA:ACM, 2016. 233-240 https://www.researchgate.net/publication/310818876_Convolutional_Matrix_Factorization_for_Document_Context-Aware_Recommendation [19] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. In:Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Lauderdale, USA:AISTATS, 2011. 315-323 [20] Maas A L, Hannun A Y, Ng A Y. Rectifier nonlinearities improve neural network acoustic models. In:Proceedings of the 30th International Conference on Machine Learning Workshop on Deep Learning for Audio Speech and Language Processing. Atlanta, Georgia, USA:ICML, 2013. [21] Deshpande M, Karypis G. Item-based top-N recommendation algorithms. ACM Transactions on Information Systems (TOIS), 2004, 22(1):143-177 doi: 10.1145/963770 [22] Si L, Jin R. Flexible mixture model for collaborative filtering. In:Proceedings of the 20th International Conference on Machine Learning (ICML-03). Washington, DC, USA:ICML, 2003. 704-711 [23] Zou H T, Gong Z G, Zhang N, Zhao W, Guo J Z. TrustRank:a Cold-Start tolerant recommender system. Enterprise Information Systems, 2015, 9(2):117-138 doi: 10.1080/17517575.2013.804587 [24] 奚雪峰, 周国栋.面向自然语言处理的深度学习研究.自动化学报, 2016, 42(10):1445-1465 http://www.aas.net.cn/CN/abstract/abstract18934.shtmlXi Xue-Feng, Zhou Guo-Dong. A survey on deep learning for natural language processing. Acta Automatica Sinica, 2016, 42(10):1445-1465 http://www.aas.net.cn/CN/abstract/abstract18934.shtml [25] 贺昱曜, 李宝奇.一种组合型的深度学习模型学习率策略.自动化学报, 2016, 42(6):953-958 http://www.aas.net.cn/CN/abstract/abstract18886.shtmlHe Yu-Yao, Li Bao-Qi. A combinatory form learning rate scheduling for deep learning model. Acta Automatica Sinica, 2016, 42(6):953-958 http://www.aas.net.cn/CN/abstract/abstract18886.shtml -

 下载:
下载:


计量
- 文章访问数: 1977
- HTML全文浏览量: 469
- PDF下载量: 557
- 被引次数: 0
