

-
摘要: 综述了近年来发展迅速的深度学习技术及其在游戏(或博弈)中的应用. 深度学习通过多层神经网络来构建端对端的从输入到输出的非线性映射, 相比传统的机器学习模型有显见的优势. 最近, 深度学习被成功地用于解决强化学习中的策略评估和策略优化的问题, 并于多种游戏的人工智能取得了突破性的提高. 本文详述了深度学习在常见游戏中的应用.Abstract: In this article, we present a survey of recent deep learning techniques and their applications to games. Deep learning aims to learn an end-to-end, non-linear mapping from the input to the output through multi-layer neural networks. Such architecture has several significant advantages as compared to traditional machine learning models. There has been a flurry of recent work on combining deep learning and reinforcement learning to better evaluate and optimize game policies, which has led to significant improvements of artificial intelligence in multiple games. We systematically review the use of deep learning in well-known games.
-
Key words:
- Deep learning /
- games /
- deep reinforcement learning /
- Go /
- artificial intelligence
-
[1] Werbos P. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences [Ph.D. dissertation], Harvard University, USA, 1974. [2] Parker D B. Learning Logic, Technical Report TR-47, MIT Press, Cambridge, 1985. [3] LeCun Y. Une procédure d'apprentissage pour Réseau á seuil assymétrique (a learning scheme for asymmetric threshold networks). In: Proceddings of the Cognitiva 85. Paris, France. 599-604 (in French) [4] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533-536 [5] Bengio Y. Learning Deep Architectures for AI. Hanover, MA: Now Publishers Inc, 2009. [6] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7): 1527-1554 [7] Ranzato M, Poultney C, Chopra S, LeCun Y. Efficient learning of sparse representations with an energy-based model. In: Proceedings of the 2007 Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2007. [8] Bengio Y, Lamblin P, Popovici D, Larochelle H. Greedy layer-wise training of deep networks. In: Proceedings of the 2007 Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2007. [9] Erhan D, Manzagol P A, Bengio Y, Bengio S, Vincent P. The difficulty of training deep architectures and the effect of unsupervised pre-training. In: Proceedings of the 12th International Conference on Artificial Intelligence and Statistics. Clearwater, Florida, USA: AISTATS, 2009. 153-160 [10] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Sardinia, Italy: ICAIS, 2010. [11] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, United States: ICAIS, 2011. [12] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 2014 International Conference on Learning Representations. Rimrock Resort Hotel, Banff, Canada: ICRR, 2014. [13] Sermanet P, Eigen D, Zhang X, Mathieu M, Fergus R, LeCun Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In: Proceedings of the 2013 International Conference on Learning Representations. Scottsdale, Arizona: ICLR, 2013. [14] Szegedy C, Toshev A, Erhan D. Deep neural networks for object detection. In: Proceedings of the 2013 Advances in Neural Information Processing Systems. Lake Tahoe, Nevada: NIPS, 2013. [15] Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Li F F. Large-scale video classification with convolutional neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. [16] Farabet C, Couprie C, Najman L, LeCun Y. Learning hierarchical features for scene labeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1915-1929 [17] Khan S H, Bennamoun M, Sohel F, Togneri R. Automatic feature learning for robust shadow detection. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH, USA: IEEE, 2014. [18] Amodei D, Anubhai R, Battenberg E, Case C, Casper J, Catanzaro B, Chen J D, Chrzanowski M, Coates A, Diamos G, Elsen E, Engel J, Fan L X, Fougner C, Han T, Hannun A, Jun B, LeGresley P, Lin L, Narang S, Ng A, Ozair S, Prenger R, Raiman J, Satheesh S, Seetapun D, Sengupta S, Wang Y, Wang Z Q, Wang C, Xiao B, Yogatama D, Zhan J, Zhu Z Y. Deep speech 2: End-to-end speech recognition in English and Mandarin. preprint arXiv:1512.02595, 2015. [19] Fernandez R, Rendel A, Ramabhadran B, Hoory R. Prosody contour prediction with long short-term memory, bi-directional, deep recurrent neural networks. In: Proceedings of the 15th Annual Conference of International Speech Communication Association. Singapore: Curran Associates, Inc., 2014. [20] Fan Y C, Qian Q, Xie F L, Soong F K. TTS synthesis with bidirectional LSTM based recurrent neural networks. In: Proceedings of the 15th Annual Conference of International Speech Communication Association. Singapore: Curran Associates, Inc., 2014. [21] Sak H, Vinyals O, Heigold G, Senior A, McDermott E, Monga R, Mao M. Sequence discriminative distributed training of long short-term memory recurrent neural networks. In: Proceedings of the 15th Annual Conference of the International Speech Communication Association. Singapore: Curran Associates, Inc., 2014. [22] Socher R, Bauer J, Manning C D, Ng A Y. Parsing with compositional vector grammars. In: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: ACL, 2013. [23] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 2014 Advances in Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. [24] Gao J F, He X D, Yih W T, Deng L. Learning continuous phrase representations for translation modeling. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore: ACL, 2014. [25] Gao J F, Deng L, Gamon M, He X D, Pantel P. Modeling Interestingness with Deep Neural Networks, US Patent 20150363688, December 17, 2015. [26] Socher R, Perelygin A, Wu J Y, Chuang J, Manning C D, Ng A Y, Potts C. Recursive deep models for semantic compositionality over a sentiment treebank. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP). Seattle, Washington: EMNLP, 2013. [27] Shen Y L, He X D, Gao J F, Deng L, Mesnil G. A latent semantic model with convolutional-pooling structure for information retrieval. In: Proceedings of the 23rd ACM International Conference on Information and Knowledge Management. New York, NY, USA: ACM, 2014. [28] Huang P S, He X D, Gao J F, Deng L, Acero A, Heck L. Learning deep structured semantic models for web search using clickthrough data. In: Proceedings of the 22nd ACM International Conference on Information & Knowledge Management. New York, NY, USA: ACM, 2013. [29] Bengio Y, Courville A, Vincent P. Representation learning: a review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013. 1798-1828, DOI: 10.1109/TPAMI.2013.50 [30] Schmidhuber J. Deep learning in neural networks: an overview. Neural Networks, 2015, 61: 85-117 [31] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436-444 [32] Lee H, Grosse R, Ranganath R, Ng A Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In: Proceedings of the 26th Annual International Conference on Machine Learning. New York, NY, USA: ACM, 2009. [33] Yao A C C. Separating the polynomial-time hierarchy by oracles. In: Proceedings of the 26th Annual Symposium on Foundations of Computer Science. Portland, OR, USA: IEEE, 1985. 1-10 [34] Hastad J. Almost optimal lower bounds for small depth circuits. In: Proceedings of the 18th Annual ACM Symposium on Theory of Computing. New York, NY, USA: ACM, 1986. [35] Braverman M. Poly-logarithmic independence fools bounded-depth Boolean circuits. Communications of the ACM, 2011, 54(4): 108-115 [36] Bengio Y, Delalleau O. On the expressive power of deep architectures. Algorithmic Learning Theory. Berlin Heidelberg: Springer, 2011. 18-36 [37] Le Cun Y, Boser B, Denker J S, Henderson D, Howard R E, Hubbard W, Jackel L D. Handwritten digit recognition with a back-propagation network. In: Proceedings of the 1990 Advances in Neural Information Processing Systems. San Francisco: Morgan Kaufmann, 1990. [38] Bengio Y, LeCun Y, DeCoste D, Weston J. Scaling learning algorithms towards AI. Large-Scale Kernel Machines. Cambridge: MIT Press, 2007. [39] Sutton R S, Barto A G. Reinforcement Learning: An Introduction. Cambridge: MIT Press, 1998. [40] Kaelbling L P, Littman M L, Moore A W. Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 1996, 4: 237-285 [41] Hausknecht M, Stone P. Deep recurrent q-learning for partially observable MDPS. In: Proceedings of the 2015 AAAI Fall Symposium Series. The Westin Arlington Gateway, Arlington, Virginia: AIAA, 2015. [42] Bakker B, Zhumatiy V, Gruener G, Schmidhuber J. A robot that reinforcement-learns to identify and memorize important previous observations. In: Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. Manno-Lugano, Switzerland: IEEE, 2003 [43] Wierstra D, Förster A, Peters J, Schmidhuber J. Recurrent policy gradients. Logic Journal of IGPL, 2010, 18(5): 620-634 [44] Bellemare M, Naddaf Y, Veness J, Bowling M. The arcade learning environment: an evaluation platform for general agents. Journal of Artificial Intelligence Research, 2013, 47: 253-279 [45] Watkins C J H, Dayan P. Technical note: Q-learning. Machine Learning, 1992, 8(3-4): 279-292 [46] Bellemare M G, Veness J, Bowling M. Investigating contingency awareness using Atari 2600 games. In: Proceedings of the 26th AAAI Conference on Artificial Intelligence. Toronto, Ontario: AIAA, 2012. [47] Bellemare M G, Veness J, Bowling M. Sketch-based linear value function approximation. In: Proceedings of the 26th Advances in Neural Information Processing Systems. Lake Tahoe, Nevada, USA: NIPS, 2012. [48] Tesauro G. TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural Computation, 1994, 6(2): 215-219 [49] Riedmiller M. Neural fitted Q iteration--first experiences with a data efficient neural reinforcement learning method. In: Proceedings of the 16th European Conference on Machine Learning. Porto, Portugal: Springer, 2005. [50] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, Graves A, Riedmiller M, Fidjeland A K, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 [51] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. In: Proceedings of the 2016 International Conference on Learning Representations. Caribe Hilton, San Juan, Puerto Rico: ICLR, 2016. [52] Ross S, Gordon G J, Bagnell J A. A reduction of imitation learning and structured prediction to no-regret online learning. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Ft. Lauderdale, FL, USA: AISTATS 2011. [53] Guo X X, Singh S, Lee H, Lewis R, Wang X S. Deep learning for real-time ATARI game play using offline Monte-Carlo tree search planning. In: Proceedings of the 2014 Advances in Neural Information Processing Systems. Cambridge: The MIT Press, 2014. [54] Schulman J, Levine S, Moritz P, Jordan M, Abbeel P. Trust region policy optimization. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ICML, 2015. [55] van Hasselt H, Guez A, Silver D. Deep reinforcement learning with double Q-learning. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, Arizona USA: AIAA, 2016. [56] Bellemare M G, Ostrovski G, Guez A, Thomas P S, Munos R. Increasing the action gap: new operators for reinforcement learning. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, Arizona USA: AIAA, 2016. [57] Wang Z Y, Schaul T, Hessel M, van Hasselt H, Lanctot M, de Freitas N. Dueling network architectures for deep reinforcement learning. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ICML, 2016. [58] Mnih V, Badia A P, Mirza M, Graves A, Lillicrap T P, Harley T, Silver D, Kavukcuoglu K. Asynchronous methods for deep reinforcement learning. preprint arXiv:1602.01783, 2016. [59] Rusu A A, Colmenarejo S G, Gulcehre C, Desjardins G, Kirkpatrick J, Pascanu R, Mnih V, Kavukcuoglu K, Hadsell R. Policy distillation. In: Proceedings of the 2016 International Conference on Learning Representations. Caribe Hilton, San Juan, Puerto Rico: ICLR, 2016. [60] Parisotto E, Ba J L, Salakhutdinov R. Actor-mimic: Deep multitask and transfer reinforcement learning. In: Proceedings of the 2016 International Conference on Learning Representations. Caribe Hilton, San Juan, Puerto Rico: ICLR, 2016. [61] Clark C, Storkey A. Training deep convolutional neural networks to play go. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ICML, 2015. [62] Maddison C J, Huang A, Sutskever I, Silver D. Move evaluation in Go using deep convolutional neural networks. In: Proceedings of the 2014 International Conference on Learning Representations. Rimrock Resort Hotel, Banff, Canada: ICRR, 2014. [63] Tian Y D, Zhu Y. Better computer go player with neural network and long-term prediction. In: Proceeding of the 2016 International Conference on Learning Representations. Caribe Hilton, San Juan, Puerto Rico: ICLR, 2016. [64] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, Dieleman S, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M, Dieleman S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Graepel T, Hassabis D. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484-489 [65] Bowling M, Burch N, Johanson M, Tammelin O. Heads-up limit hold'em poker is solved. Science, 2015, 347(6218): 145-149 [66] Yakovenko N, Cao L L, Raffel C, Fan J. Poker-CNN: a pattern learning strategy for making draws and bets in poker games. Tucson, Arizona: AIAA, 2005. [67] Heinrich J, Lanctot M, Silver D. Fictitious Self-Play in Extensive-Form Games. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ICML, 2015. [68] Schaeffer J, Lake R, Lu P, Bryant M. CHINOOK the world man-machine checkers champion. AI Magazine, 1996, 17(1): 21-29 -

 下载:
下载:

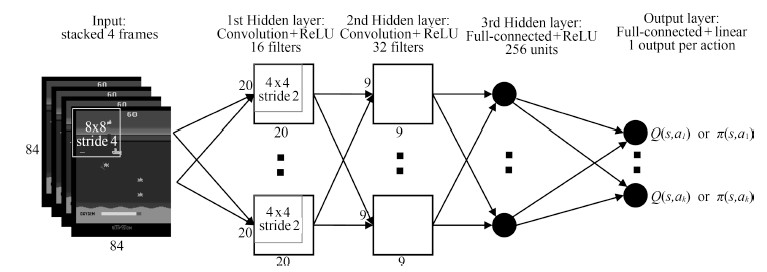
图(1)
计量
- 文章访问数: 5179
- HTML全文浏览量: 2382
- PDF下载量: 3710
- 被引次数: 0
