

-
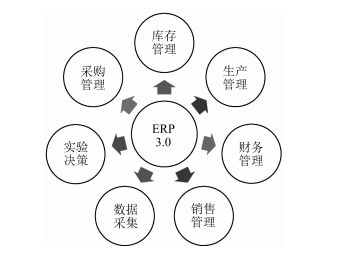
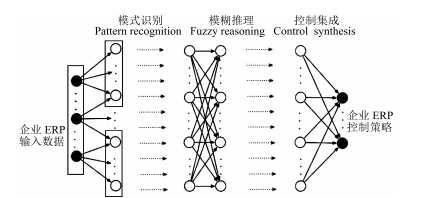
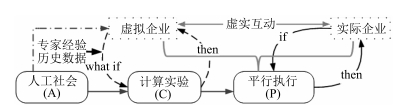
摘要: 传统的企业资源计划(Enterprise resource planning,ERP)采用静态化的业务流程设计理念,忽略了人的关键作用,且很少涉及系统性的过程模型,因此难以应对现代企业资源计划的复杂性要求.为实现现代企业资源计划的新范式,本文在ACP(人工社会(Artificial societies)、计算实验(Computational experiments)、平行执行(Parallel execution))方法框架下,以大数据为驱动,融合深度强化学习方法,构建基于平行管理的企业ERP系统.首先基于多Agent构建ERP整体建模框架,然后针对企业ERP的整个流程建立序贯博弈模型,最后运用基于深度强化学习的神经网络寻找最优策略,解决复杂企业ERP所面临的不确定性、多样性和复杂性.Abstract: Traditional enterprise resource planning (ERP) usually adopts static business processes design and does not take the key role of "human" into consideration. It rarely involves the systematic process modeling, which makes it impossible to tackle the management complexity of modern enterprises. Considering the big data driven environment of modern enterprises, we utilize the ACP (Artificial societies, computational experiments, parallel execution) theory integrated with deep reinforcement learning approaches to establish a parallel management system for modern ERP management. We first propose a framework for ERP systems based on multi-agent technology where a sequential game model is included. Then, we seek for the optimal strategy using a deep reinforcement learning based neural network. Our proposed framework and approaches can well deal with uncertainty, diversity and complexity of modern ERP systems.1) 本文责任编委 王飞跃
-
[1] Umble E J, Haft R R, Umble M M. Enterprise resource planning: implementation procedures and critical success factors. European Journal of Operational Research, 2003, 146(2): 241-257 doi: 10.1016/S0377-2217(02)00547-7 [2] 周玉清, 刘伯莹, 周强. ERP与企业管理:理论、方法、系统.北京:清华大学出版社, 2005.Zhou Yu-Qing, Liu Bo-Ying, Zhou Qiang. ERP and Enterprise Management: Theory, Method, System. Beijing: Tsinghua University Press, 2005. [3] 王飞跃.软件定义的系统与知识自动化:从牛顿到默顿的平行升华.自动化学报, 2015, 41(1): 1-8 http://www.aas.net.cn/CN/abstract/abstract18578.shtmlWang Fei-Yue. Software-defined systems and knowledge automation: a parallel paradigm shift from Newton to Merton. Acta Automatica Sinica, 2015, 41(1): 1-8 http://www.aas.net.cn/CN/abstract/abstract18578.shtml [4] 王飞跃.情报5.0:平行时代的平行情报体系.情报学报, 2015, 34(6): 563-574 http://d.wanfangdata.com.cn/Periodical/qbxb201506001Wang Fei-Yue. Intelligence 5.0: parallel intelligence in parallel age. Journal of the China Society for Scientific and Technical Information, 2015, 34(6): 563-574 http://d.wanfangdata.com.cn/Periodical/qbxb201506001 [5] Wang F Y. The emergence of intelligent enterprises: from CPS to CPSS. IEEE Intelligent Systems, 2010, 25(4): 85-88 doi: 10.1109/MIS.2010.104 [6] Chen J X. The evolution of computing: AlphaGo. Computing in Science and Engineering, 2016, 18(4): 4-7 doi: 10.1109/MCSE.2016.74 [7] Wang F Y, Zhang J J, Zheng X H, Wang X, Yuan Y, Dai X X, Zhang J, Yang L Q. Where does AlphaGo go: from church-turing thesis to AlphaGo thesis and beyond. IEEE/CAA Journal of Automatica Sinica, 2016, 3(2): 113-120 doi: 10.1109/JAS.2016.7471613 [8] 王飞跃.从alphaGo到平行智能:启示与展望.科技导报, 2016, 34(7): 72-74 http://www.cnki.com.cn/Article/CJFDTOTAL-KJDB201607022.htmWang Fei-Yue. Milestone to future: from alphaGo to parallel intelligence. Science and Technology Review, 2016, 34(7): 72-74 http://www.cnki.com.cn/Article/CJFDTOTAL-KJDB201607022.htm [9] 王飞跃.复杂性与智能化:从Church-Turning thesis到AlphaGo thesis及其展望(1).指挥与控制学报, 2016, 2(1): 1-4 http://www.cnki.com.cn/Article/CJFDTOTAL-ZHKZ201601001.htmWang Fei-Yue. Complexity and intelligence: from Church-Turning thesis to AlphaGo thesis and beyonds (1). Journal of Command and Control, 2016, 2(1): 1-4 http://www.cnki.com.cn/Article/CJFDTOTAL-ZHKZ201601001.htm [10] 王飞跃.人工社会、计算实验、平行系统—关于复杂社会经济系统计算研究的讨论.复杂系统与复杂性科学, 2004, 1(4): 25-35 http://www.cnki.com.cn/Article/CJFDTOTAL-FZXT200404001.htmWang Fei-Yue. Artificial societies, computational experiments, and parallel systems: a discussion on computational theory of complex social-economic systems. Complex Systems and Complexity Science, 2004, 1(4): 25-35 http://www.cnki.com.cn/Article/CJFDTOTAL-FZXT200404001.htm [11] Wen D, Yuan Y, Li X R. Artificial societies, computational experiments, and parallel systems: an investigation on a computational theory for complex socioeconomic systems. IEEE Transactions on Services Computing, 2013, 6(2): 177-185 doi: 10.1109/TSC.2012.24 [12] 王飞跃, 王晓, 袁勇, 王涛, 林懿伦.社会计算与计算社会:智慧社会的基础与必然.科学通报, 2015, 60(5-6): 460-469 http://www.cnki.com.cn/Article/CJFDTOTAL-KXTB2015Z1008.htmWang Fei-Yue, Wang Xiao, Yuan Yong, Wang Tao, Lin Yi-Lun. Social computing and computational societies: the foundation and consequence of smart societies. Chinese Science Bulletin, 2015, 60(5-6): 460-469 http://www.cnki.com.cn/Article/CJFDTOTAL-KXTB2015Z1008.htm [13] Ragowsky A, Somers T M. Enterprise resource planning. Journal of Management Information Systems, 2002, 19(1): 11-15 doi: 10.1080/07421222.2002.11045718 [14] Al-Mashari M, Al-Mudimigh A, Zairi M. Enterprise resource planning: a taxonomy of critical factors. European Journal of Operational Research, 2003, 146(2): 352-364 doi: 10.1016/S0377-2217(02)00554-4 [15] Jacobs F R, Ted'Weston Jr F C. Enterprise resource planning (ERP)—a brief history. Journal of Operations Management, 2007, 25(2): 357-363 doi: 10.1016/j.jom.2006.11.005 [16] McAfee A P. Enterprise 2.0: the dawn of emergent collaboration. IEEE Engineering Management Review, 2006, 34(3): 38-38 doi: 10.1109/EMR.2006.261380 [17] 李睿.企业2.0的发展及存在的问题.现代情报, 2008, 28(11): 170-174 doi: 10.3969/j.issn.1008-0821.2008.11.057Li Rui. The development of enterprise 2.0 and the related problems. Modern Information, 2008, 28(11): 170-174 doi: 10.3969/j.issn.1008-0821.2008.11.057 [18] Wang F Y. Toward a paradigm shift in social computing: the ACP approach. IEEE Intelligent Systems, 2007, 22(5): 65-67 doi: 10.1109/MIS.2007.4338496 [19] 王飞跃.平行系统方法与复杂系统的管理和控制.控制与决策, 2004, 19(5): 485-489 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC200405001.htmWang F Y. Parallel system methods for management and control of complex systems. Control and Decision, 2004, 19(5): 485-489 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC200405001.htm [20] 王飞跃.从平行宇宙到平行管理系统PMS.财经界·管理学家, 2007, 10: 48-51Wang Fei-Yue. From parallel universes to parallel management systems PMS. Money China: Management Scientists, 2007, 10: 48-51 [21] Balasubramanian S, Maturana F P, Norrie D H. Multi-agent planning and coordination for distributed concurrent engineering. International Journal of Cooperative Information Systems, 1996, 5(2-3): 153-179 doi: 10.1142/S0218843096000075 [22] Van Liedekerke M H, Avouris N M. Debugging multi-agent systems. Information and Software Technology, 1995, 37(2): 103-112 doi: 10.1016/0950-5849(95)93487-Y [23] 蒋丽娟. 基于多Agent的ERP系统研究与应用[硕士学位论文], 中南大学, 中国, 2008. http://cdmd.cnki.com.cn/Article/CDMD-10533-2008168179.htmJiang Li-Juan. Research and Application of ERP System based on Multi-Agent [Master dissertation], Central South University, China, 2008. http://cdmd.cnki.com.cn/Article/CDMD-10533-2008168179.htm [24] 袁勇, 王飞跃.不完全信息议价博弈的序贯均衡分析与计算实验.自动化学报, 2016, 42(5): 724-734 http://www.aas.net.cn/CN/abstract/abstract18862.shtmlYuan Yong, Wang Fei-Yue. Sequential equilibrium analysis and computational experiments of a bargaining game with incomplete information. Acta Automatica Sinica, 2016, 42(5): 724-734 http://www.aas.net.cn/CN/abstract/abstract18862.shtml [25] Kulkarni T D, Narasimhan K R, Saeedi A, Tenenbaum J B. Hierarchical deep reinforcement learning: integrating temporal abstraction and intrinsic motivation [Online], available: http://arxiv.org/abs/1604.06057, May 31, 2016 [26] Mnih V, Badia A P, Mirza M, Graves A, Lillicrap T P, Harley T, Silver D, Kavukcuoglu K. Asynchronous methods for deep reinforcement learning [Online], available: http://arxiv.org/abs/1602.01783, June 16, 2016 [27] 段艳杰, 吕宜生, 张杰, 赵学亮, 王飞跃.深度学习在控制领域的研究现状与展望.自动化学报, 2016, 42(5): 643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtmlDuan Yan-Jie, Lv Yi-Sheng, Zhang Jie, Zhao Xue-Liang, Wang Fei-Yue. Deep learning for control: the state of the art and prospects. Acta Automatica Sinica, 2016, 42(5): 643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtml [28] 陈兴国, 俞扬.强化学习及其在电脑围棋中的应用.自动化学报, 2016, 42(5): 685-695 http://www.aas.net.cn/CN/abstract/abstract18858.shtmlChen Xing-Guo, Yu Yang. Reinforcement learning and its application to the game of Go. Acta Automatica Sinica, 2016, 42(5): 685-695 http://www.aas.net.cn/CN/abstract/abstract18858.shtml [29] Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, Riedmiller M. Playing Atari with deep reinforcement learning [Online], available: http://arxiv.org/abs/1312.5602, December 19, 2013 [30] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, Graves A, Riedmiller M, Fidjeland A K, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 doi: 10.1038/nature14236 [31] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M, Dieleman S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Graepel T, Hassabis D. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484-489 doi: 10.1038/nature16961 [32] Heinrich J, Lanctot M, Silver D. Fictitious self-play in extensive-form games. In: Proceedings of the 32nd International Conference on Machine Learning, Lille. France: JMLR, 2015. 805-813 https://www.researchgate.net/publication/276395436_Fictitious_Self-Play_in_Extensive-Form_Games [33] Heinrich J, Silver D. Deep reinforcement learning from self-play in imperfect-information games [Online], available: http://arxiv.org/abs/1603.01121, June 28, 2016 http://arxiv.org/abs/1603.01121 -

 下载:
下载:


图(4)
计量
- 文章访问数: 3093
- HTML全文浏览量: 488
- PDF下载量: 1427
- 被引次数: 0
