

-
摘要: 复杂流程工业过程知识类型多样且含有多种不确定性,针对这些问题提出一种基于D-S融合的混合知识系统故障诊断方法.根据可利用信息的类型建立不同的专家知识系统并进行不确定性推理.通过分析当前信息的数据特点,自适应分配不同专家知识系统可靠性权重,通过权重D-S证据理论融合各专家知识系统的结论.这种方法不仅使用了专家的知识和经验,而且结合了生产过程积累的大量数据信息,提高了信息的利用率.通过融合多个专家知识系统的结论,提高了不确定性系统故障诊断的正确率.将该方法应用于某湿法冶金浓密过程故障诊断,取得了良好的诊断效果.Abstract: There are various types of process knowledge and multiple uncertainties in complex process industry. To address these issues, a fault diagnosis approach which employs D-S knowledge fusion and hybrid knowledge system is proposed. Based on the types of available information, we establish different expert knowledge systems and present uncertainty reasoning respectively. By analyzing the characteristics of the current available data, adaptive weights are calculated for different expert knowledge systems. Then D-S evidence theory is utilized for conclusion fusion. Not only the expert experience knowledge but also a large amount of accumulated data is utilized in this method, which improves the utilization rate of information. The fault diagnosis accuracy for uncertainty systems are increased by the use of D-S conclusion fusion. The proposed method is then applied to fault diagnosis of a thickener in a hydrometallurgy process and satisfactory diagnosis results are achieved.
-
Key words:
- Hybrid expert knowledge system /
- adaptive weight /
- D-S evidence theory /
- information fusion /
- thickener
-
随着过程工艺复杂性的提高, 过程故障诊断越来越重要.基于专家知识的方法[1-2]适用于机理模型难以获得数据规律性不强的情况.由于解决问题的思路更直观体现领域专家对过程工艺的了解, 专家系统[3-4]成为基于定性知识故障诊断方法中被广泛使用的方法, 因而也称为专家知识系统.按使用方法及处理信息类型划分, 专家系统[5]分为基于规则的、基于案例的、基于模型的和基于框架的专家系统等, 其中以基于规则的专家系统和基于案例的专家系统应用最广.流程工业过程运行可能产生多类型信息, 例如数据信息、声音图像信息和专家知识等, 考虑到这些信息或多或少包含有不确定性因素[6], 单纯使用一种方法来诊断过程运行状态并不可靠.根据这些过程信息和知识的特点, 建立不同的专家知识系统, 组成混合专家知识系统[7], 可以提高信息使用效率, 进而提高过程故障诊断准确率.可信度因子是处理不确定问题的常见方法, 结合规则推理, 可以处理专家给出的模糊定性信息.可信度因子符合专家表达习惯, 可以克服实际应用中事件先验概率和后验概率不可获得的难题, 被广泛应用于专家知识系统[6], 但可信度因子方法中证据的可信度赋值主观性较强.而基于案例推理的专家知识系统使用实时定量数据, 推理结果可靠性较高.但数据中的大量噪声可能导致其结论可靠性降低.
D-S证据理论[8-9]广泛应用于不确定性推理和信息融合, 但一般是单一专家系统中的多证据融合, 很少考虑将不同专家系统的推理结论进行融合.例如, 文献[10]使用D-S证据理论将多类型传感器采集的变量信息进行融合, 得到故障诊断结论.此外, D-S证据理论没有统一的基本概率分配函数赋值方法, 在证据理论的实用过程中, 基本概率分配函数生成往往与具体应用密切相关[11]. Valente等针对声音识别问题, 基于隶属度设计了生成基本概率分配函数的多种方法[12].邓鑫洋等面向决策问题设计并提出了基于信度马尔科夫模型的基本概率分配函数生成和推理方法[13]. D-S证据理论的证据融合规则可以将两条或者多条证据融合为一条证据, 本身就可以解决冲突问题, 避免了可能的结论冲突.但证据间冲突太大时会存在合成失效的情况, 目前相应的改进主要围绕两个主要方向: 1) 对其合成公式做改进; 2) 给不同可靠性的证据赋权重[11].有些改进的D-S证据理论如ER规则[14]同时考虑了证据的重要性和可靠性, 并提出了其证据融合公式, 已经相对完善, 然而ER证据理论并没有提出如何给证据源赋权重.很多学者对D-S证据理论中证据源可靠性问题进行了研究[11, 15], 但主要是在离线获得了大量证据后, 通过分析, 减小离群证据的权值, 增大集群证据的权值来实现, 而对于在线应用和证据数量不多的情况下难以使用.
综上所述, 针对信息来源和类型多样但信息不确定性程度较高的流程工业, 本文使用D-S证据理论将基于可信度因子规则推理和基于数据相似度案例推理的两个不同专家知识系统的结论进行融合并得到最终故障诊断结论.同时, 根据在线数据的准确程度自适应给两个专家系统的结论赋权值.最后, 将所提方法应用于某湿法冶金精炼厂浓密过程[16]的故障诊断中, 使用基于规则推理和基于案例推理的混合专家系统, 实验结果证明了该方法的有效性.
1. 混合专家知识系统
流程工业运行中产生的信息既包括大量数据, 也包括操作人员给出的定性知识.混合专家知识系统可以将这些知识充分利用, 对不同表达形式的知识使用不同方法加以利用.这些信息往往具有不同程度的不确定性.因此, 在专家知识系统的基础上需要引入处理不确定信息的相应方法来提高诊断准确率.本节重点介绍基于可信度因子的规则推理方法和基于数据相似度的案例推理方法, 并提出将它们的推理结论转化为D-S证据理论基本概率分配函数的方法.
1.1 基于可信度因子的规则推理知识系统
基于规则的故障诊断方法主要使用专家给出的模糊定性知识[17], 通过将故障诊断经验知识总结成规则, 进而推理得到结论.不同流程在提取专家知识和经验时的复杂性也各不相同.流程工业有些关键变量不能测量或者测量不准确, 但过程运行的粗略定性信息对故障诊断具有重要作用.这些粗略信息包括声音强度、物质色泽、矿浆是否起泡等.在很多情况下, 操作人员很难及时获得事件发生的先验概率, 对事件发生的概率大小往往凭主观给出定量描述.根据这种操作习惯, 在基于专家知识的规则推理中, 使用可信度因子方法来处理规则的不确定性问题.
产生式规则因为符合人们的逻辑思维习惯而被广泛使用.考虑到知识的不确定性, 带有规则不确定性的可信度因子产生式规则的表达形式为
$ \begin{align} {\rm if}\ E \ {\rm then}\ H \ {\rm with}\ cf({H}/{E}) \end{align} $
(1) 其中, $E$ 为规则的前件, 表示前提条件. $H$ 为规则的后件, 表示对应的结论. $cf(H/E)$ 表示是规则的可信度因子, 也叫规则强度.这些规则强度不仅可以通过分析历史数据得到, 也可以由专家凭经验主观给出.用 $e$ 表示现场实时观察给出的不准确信息, 其格式一般表示为 $e$ :规则前件 $E$ 成立, 成立的可信度因子是 $cf(E/e)$ .然后利用下式求取结论的可信度:
$ \begin{align} cf({H}/{e}) = cf({H}/{E})\times {\max }\{ cf({E}/{e}), 0\} \end{align} $
(2) 其中, $cf(H/e)$ 表示结论的可信度因子, 是由现场信息与规则前件的匹配度 $cf(E/e)$ 、规则强度 $cf(H/E)$ 求出的.
详细的可信度因子推理规则可参考文献[18].通过基于不确定性推理故障诊断知识系统得到各个事件发生的可信度, 假设有 $n$ 个事件的可信度 $c{f_1}$ , $c{f_2}$ , $\cdots$ , $c{f_n}$ 可以用第3节介绍的D-S证据理论构建统一的识别框架, 使用下式对这个可信度因子进行归一化:
$ \begin{align} \begin{cases} \dfrac{{c{f_1}}}{{{m_{11}}}} = \dfrac{{c{f_2}}}{{{m_{12}}}} = \cdots {\rm{ = }}\dfrac{{c{f_n}}}{{{m_{1n}}}} \\ {m_{11}} + {m_{12}} + \cdots + {m_{1n}} = 1 \end{cases} \end{align} $
(3) 其中, 为规则推理的识别框架中各个焦元的基本概率分布.
1.2 基于数据相似度的案例推理知识系统
案例推理[19-20]是人工智能领域问题求解和机器学习方法, 完整的案例推理理论包含匹配、复用、修正、学习等步骤.流程工业中通过传感器可获得大量生产数据, 这些数据能够反映生产的运行状态.正常生产状态及各类故障状态的数据特性不同, 因此, 可以提取不同类数据特性作为案例用于案例推理.一般通过数据相似度进行案例匹配, 而最近邻方法[21]是计算数据相似度中最常用的方法之一.其主要思想是在某种距离的定义下, 使得待识别案例与距离最近的源案例的相似度最大, 距离较远的案例之间相似度则较小.
基于案例推理的方法用于故障诊断时, 案例库中的源案例可表示为
$ \begin{align} {\pmb c_k} = ({x_{1k}}, {x_{2k}}, \cdots, {x_{ik}}, \cdots, {x_{jk}}), \ k = 1, 2, \cdots, p \end{align} $
(4) 其中, $p$ 是源案例总数; ${x_{ik}}$ , $i = 1, 2, \cdots, j$ 是第 $k$ 条源案例中第 $i$ 个变量值, $j$ 是变量个数.在获得待诊断案例后, 通过下式计算 ${\pmb x}$ 与中每个案例的最近邻相似度
$ \begin{align}{\rm sim}({\pmb x}, {\pmb c_k}) = \sum\limits_i^j {{w_i} \times {\rm sim}({x_i}, {x_{ik}})} \end{align} $
(5) 式(5) 表示待查询案例与源案例的相似度是所有变量相似度的加权和.其中 ${{w}_{i}}$ 为根据过程知识赋予变量 ${{x}_{i}}$ 的权重, 不同案例中各个变量的权重不同, 权重也保存在案例库中的相关案例中. 为变量 ${x_i}$ 与变量 ${x_{ik}}$ 的相似度, 其计算公式通过下式获得
$ \begin{align} {\rm sim}({x_i}, {x_{ik}})=1 - \frac{{\left| {{x_{ik}} - {x_i}} \right|}}{{\beta - \alpha }} \end{align} $
(6) 其中, ${x_i}$ , ${x_{ik}} \in [\alpha, \beta]$ , $\alpha $ , 分别为变量 ${x_i}$ 历史统计值中的最小值和最大值.
使用式(5) 计算待诊断案例与案例库中的每一案例的相似度, 分别求得当前案例与 $n$ 个源案例的相似度, 如果它们可以归进同一个识别框架, 需要通过下式对这 $n$ 个相似度数值进行归一化, 得到证据理论的基本概率分配函数
$ \begin{align} \begin{cases} \dfrac{{{\rm sim_1}}}{{{m_{21}}}} = \dfrac{{{\rm sim_2}}}{{{m_{22}}}} = \cdots =\dfrac{{\rm sim}_n}{{{m_{2n}}}}\\ {m_{21}} + {m_{22}} + \cdots + {m_{2n}} = 1 \end{cases} \end{align} $
(7) 其中, 为案例推理识别框架中各个焦元的基本概率分布.
2. 自适应权重D-S融合
D-S证据理论[22-23]可以融合多种推理方法得到的过程故障诊断结论, 减少多源知识推理后的结论分歧. D-S证据理论中最重要的概念是识别框架和基本概率分配函数.识别框架 $\theta $ 是一个由多个独立互斥的事件组成的集合. 的所有子集组成的集合叫做幂集, 用表示.基本概率分配函数 $m$ 是定义在 ${2^\theta }$ 上的映射函数, 使
$ \begin{align} \begin{cases} m(\Phi ) = 0\\ \sum\limits_{A \in {2^\theta }} { m(A) = 1} \end{cases} \end{align} $
(8) 其中, $\Phi $ 是空集, $A$ 是幂集中任一组成元素. $ m(A)$ 是事件 $A$ 在识别框架中的基本概率分配.
D-S证据理论的难点是如何确定各证据的基本概率分配函数的具体形式, 一般根据实际问题的不同而有不同的确定方式.在基于可信度因子规则专家系统和基于相似度的案例专家系统, 分别使用式(3) 和式(7) 求取其结论的证据形式.
如果两条证据有相同的识别框架 $\{ {A_1}$ , ${A_2}$ , $\cdots$ , ${A_n}\}$ , D-S证据理论最重要的融合公式可以定义为
$ \begin{align} m(C) = K\sum\limits_{{A_i} \cap {A_j} = C} {{m_1}({A_i}){m_2}({A_j})} \end{align} $
(9) 其中, ${m_1}$ 和 ${m_2}$ 是不同来源的两条证据. $1 \le i\le$ $n$ , , ${A_i} \cap {A_j} = C$ 表示事件 $C$ 可以由事件 ${A_i}$ 和 ${A_j}$ 相交得到. $K = ( 1-$ $\sum_{{A_i} \cap {A_j} = \Phi } {m_1}({A_i})$ $\times$ ${m_2}({A_j}) )^{ - 1}$ 是归一化因子, 是衡量证据 ${m_1}$ 和 ${m_2}$ 之间矛盾大小的重要指标.当证据间的矛盾和分歧较大时, 实际上是证据的可信度出现了差异, 应当考虑不同证据的权重问题.首先将 $q$ 条证据加权重平均得到平均证据, 平均证据计算如下:
$ \begin{align}\overline m (A) = \frac{1}{q}\sum\limits_i^q {w_i^e{m_i}(A)} \end{align} $
(10) 其中, $\overline m(A)$ 为平均证据中事件 $A$ 的基本概率分配, ${m_i}(A)$ 为第 $i$ 条证据中的基本概率分配, $w_i^e$ 为第 $i$ 条证据的权重.
然后再将平均证据进行融合, 记融合后的基本概率分配函数为 ${m_f}$ , 则通过式(9) 将平均证据融合为最终证据的过程表示为
$ \begin{align}{m_f} = \overline m \oplus \overline m \end{align} $
(11) 其中, 规定 $\oplus $ 是两个证据进行融合的符号, $\overline m $ 为通过式(10) 求出的平均证据.在线应用时, 不同信息源的可靠性是随时间变化的, 为了提高故障诊断的准确率, 本文提出一种通过分析数据特征来判断证据可靠性的自适应权重分配方法.该方法可以做到在数据准确时以案例推理结果为主, 在数据不准确时通过降低案例推理的权重来降低其在最终结论中的影响.规定当数据偏离正常波动范围较大时处于数据可靠性较低的状态.在线应用时, 取当前时刻之前的 $n$ 个采样的数据为时间窗, 求取窗口内每个变量的均值, 则待匹配案例偏离正常范围的总量可以由这 $j$ 个变量的偏移程度表示为
$ \begin{align}\sigma = \left| {{x_1} - {{\overline x_1}} } \right|{\rm{ + }}\left| {{x_2} - {{\overline x_2}} } \right| + \cdots + \left| {{x_j} - {{\overline x_j}} } \right| \end{align} $
(12) 其中, ${x_j}$ 为待匹配案例的第 $j$ 个变量, ${{\overline x_j}} $ 为采样窗口内的变量的平均值.使用指数表达案例推理知识来源的权重 ${w_{\rm data}}$ :
$ \begin{align}{w_{\rm data}} = {{\rm e}^{ - k\sigma }} \end{align} $
(13) 其中, $k$ 是系数, 根据实际情况取值不同.然后确定基于规则推理专家系统的权重:
$ \begin{align}{w_{\rm rule}} = 1 - {w_{\rm data}} \end{align} $
(14) 3. 基于D-S融合的混合专家知识系统故障诊断方法
本方法主要针对知识种类多样且运行数据准确度不高的流程系统.根据知识类型及特点建立不同类型的故障诊断专家知识系统, 提高了知识利用率.自适应地对不同的专家结论赋权重, 并使用D-S理论融合不同权重的专家证据, 提升了结论的准确度.
在故障诊断混合专家知识系统中, 常用的是基于规则的专家知识系统和基于案例的专家知识系统的混合.基于规则的故障诊断系统侧重将领域专家的知识经验提炼成规则, 其逻辑表达和解释性强, 便于理解.基于案例推理的故障诊断系统使用过程历史数据, 通过数据相似度寻找相似的诊断案例, 得到的结论有参照性, 直观可信.基于规则推理的专家知识系统使用操作人员提供的主观信息, 变化频率低, 但鲁棒性好.引入可信度因子处理推理过程中的不确定问题, 适合工人的操作习惯, 但误报漏报较多.而基于案例推理的专家知识系统使用实时定量数据, 推理结果可靠性较高.但数据中的大量噪声可能导致基于案例推理的结论可信度降低.而案例相似度某种程度上也包含由数据可靠性引起的不确定性.
基于D-S融合的混合知识系统故障诊断方法的算法流程如图 1所示.
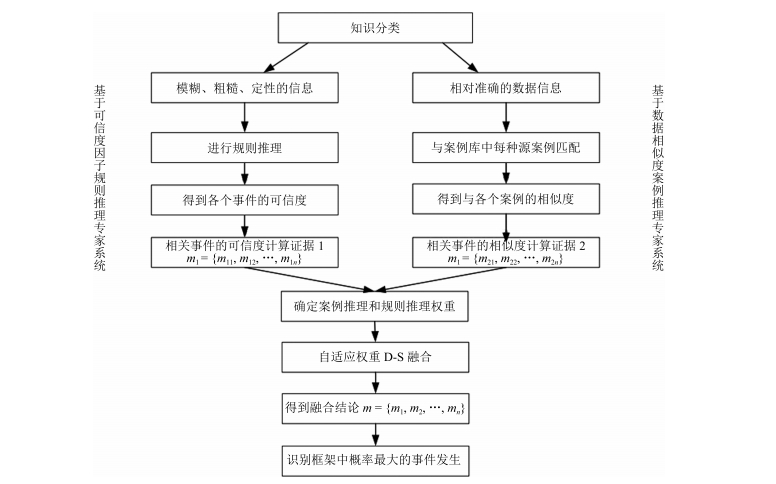 图 1 基于D-S融合的混合知识系统故障诊断算法流程Fig. 1 Fault diagnosis flowchart of method based on D-S fusion theory and hybrid expert knowledge system
图 1 基于D-S融合的混合知识系统故障诊断算法流程Fig. 1 Fault diagnosis flowchart of method based on D-S fusion theory and hybrid expert knowledge system故障诊断一般分为两步, 首先诊断故障, 然后追溯故障原因.两者都使用图 1中的算法, 但在具体操作上又有差别.故障诊断时, 需要为每种故障设定D-S理论形式的识别框架.这些故障诊断框架都包含两个元素, 如下式所示:
$ \begin{align} \begin{cases} \{故障1发生, 故障1未发生\} \\ \{故障2发生, 故障2未发生\} \\ \qquad \qquad\qquad \vdots \\ \{故障s发生, 故障s未发生 \} \end{cases} \end{align} $
(15) 其中, $s$ 为已知的故障种类数目.通过式(15), 可以判断过程所有已知故障是否发生.实际应用时, 在基于规则的知识系统和基于案例的知识系统中, 分别推理得到故障发生的可信度因子和故障相似度后, 通过对立事件概率公式求得故障未发生的可能性及相似度.当故障由深层原因导致且原因追溯的信息充分时, 可以进一步建立识别框架对故障原因进行追溯, 如下式所示:
$ \{ \text{故障原因1}, \text{故障原因2}, \cdots, \text{故障原因}t\} $
(16) 其中, $t$ 为导致某故障的原因数目, 不同的故障, $t$ 的取值并不一样.
故障诊断的步骤:
步骤1. 信息和知识分类.不同的专家系统处理不同类型的知识和数据.如果数据有缺失, 则通过历史数据补全.
步骤2. 分别进行规则推理和案例推理, 得到两条证据.
步骤3. 根据数据的准确程度赋予证据不同权重.
步骤4. 通过权重D-S融合得到最终结论, 认定分配的基本概率超过设定阈值的对应故障发生.
步骤5. 遍历法判断所有故障发生与否, 得到最终运行结论.
故障原因追溯的步骤与故障诊断的步骤基本相同, 在进行到步骤4, 相应推断出故障原因后, 故障原因追溯结束.
4. 仿真和分析
浓密机是基于重力沉降原理使矿浆富集且为下游工序提供均匀矿浆的设备.在采矿和冶金领域被广泛使用.过程运行时, 可以通过上位机实时获得过程运行的数据信息, 然而由于检测条件的限制导致一些数据不够准确.同时, 操作工人往往有一套行之有效的判断关键数据指标方法, 描述这些变量的都是模糊信息.这些不确定性导致单纯基于机理模型和数据模型的故障诊断往往不可靠.本文以某企业精炼厂湿法冶金浓密流程作为研究对象验证所提方法.该过程影响生产的主要故障有:压耙、压滤机前缓冲槽冒槽、底流流量故障、底流浓度故障等.
反映浓密机生产状态的可测量变量有10个, 分别是:耙底压力1、耙底压力2、中心搅拌电机电流、压滤机前缓冲槽液位、压滤机前缓冲槽液位变化率、渣浆泵电流、渣浆泵频率、溢流流量、溢流浊度和底流流量.案例库中存储着由这10个变量构成的用于故障诊断和故障原因追溯的案例.
此外, 操作人员也有一套判断关键过程运行指标的方法.根据领域专家和操作人员的经验和知识, 总结出浓密过程故障诊断专家规则.在此, 仅列举部分可用于仿真的故障诊断规则, 如表 1所示.
表 1 浓密机故障诊断规则Table 1 Fault diagnosis rules for thickener序号 规则前件 规则后件 规则强度 1 浓密机运转吃力,噪声大 浓密机压耙 0.8 2 底流流量比较小 底流管道堵塞 0.8 3 矿浆粘稠且起泡 浓度偏高 0.8 4 缓冲槽中液位离槽口过近 缓冲槽冒槽 0.8 为了验证所提故障诊断方法的有效性, 从该厂浓密流程采集2015年8月 $\sim$ 12月运行数据用于仿真实验, 样本数据均经过滤波处理.选取100组只存在浓度偏高故障样本进行故障诊断.故障诊断结果如图 2所示.图中纵坐标对应表 1中的各个规则序号, 0代表样本属于正常工况, 3代表浓度偏高故障.横坐标为采样序号.
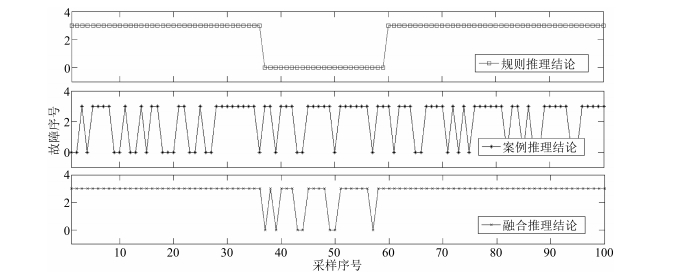 图 2 三种诊断方法对浓度偏高的识别效果对比Fig. 2 Effect comparison of three methods for high concentration fault
图 2 三种诊断方法对浓度偏高的识别效果对比Fig. 2 Effect comparison of three methods for high concentration fault理想情况下, 100个采样都是浓度偏高的故障样本, 是第3类.从图 2可以看出, 由于操作人员给出的信息变化频率较小, 所以基于规则推理的结论变化频率小且有大量数据被诊断为正常.而通过案例推理得到的结论是基于实时数据的, 数据变动较为频繁, 但也会出现多误报的情况.通过自适应权重D-S融合两个专家系统的结论, 只有少数采样被诊断为正常点, 结论准确率可以达到94%, 而单纯采用规则推理和案例推理, 其故障诊断的正确率都较低, 融合诊断准确率明显提高, 可以满足现场要求.
以某时刻压滤机前缓冲槽冒槽为例, 详细解释该方法在故障原因追溯过程中的应用.相应的不确定性规则如表 2所示.
表 2 压滤机前缓冲槽冒槽原因追溯规则Table 2 Reasons rules for tank overswelling in front of the fllter press序号 规则前件 规则后件 规则强度 5 冒槽,浓度不大,流量不大 其他原因致冒槽 0.8 6 冒槽,浓度偏大,流量不大 浓度高致冒槽 0.8 7 冒槽,浓度不大,流量偏大 流量大致冒槽 0.8 8 冒槽,浓度偏大,流量偏大 浓度高流量大致冒槽 0.8 1) 基于可信度因子规则的推理
首先液位超限是确定性事件.每条规则的可信度都定为0.8, 专家给出的初始证据可信度如表 3所示.计算导致冒槽的四种可能原因的可信度并归一化, 得到基于可信度因子规则推理的证据: $m_1 = $ {仅浓度偏高, 仅流量偏大, 浓度高且流量大, 其他原因} $=$ $\{0, 0, 1, 0\}$ .
表 3 专家给出的事件可信度Table 3 Certainty factors of cases given by expert事件 专家给出的可信度 浓度偏大 0.78 浓度不大 -0.78 流量偏大 0.81 流量不大 -0.81 2) 基于数据相似度的案例推理
首先确定与基于规则推理相同的故障原因识别框架.通过最近邻方法求取待诊断案例与各个故障原因案例的相似度并归一化, 求取其最后证据 $m_2 =$ $\{0.04$ , $0.23, 0.73, 0\}$ .
3) 权重融合结论分析数据.分别求取不同推理方法证据的权重, 此时刻过程运行正常, 所有可测变量都在历史数据正常范围内, 通过式(13) 和式(14), 参数 $k=1$ , 分别得到案例推理结论权重为0.9, 规则推理证据权重为0.1.通过式(10) 计算平均证据为 $\overline{m}= $ {仅浓度偏高, 仅流量偏大, 浓度高且流量大, 其他原因} .通过式(9) 对 $\overline m$ 进行融合.融合后的基本概率分配函数为 $m$ $=$ {仅浓度偏高, 仅流量偏大, 浓度高且流量大, 其他原因} $= \{ 0, 0.07, 0.93, 0\}$ .
单纯基于可信度因子的规则推理结论认为浓度高且流量大是导致冒槽故障的唯一原因.而基于数据相似度的案例推理则认为其他原因不同程度对故障有贡献, 这更加贴合实际情况, 能为后续的自愈控制提供更加准确的诊断结论.通过自适应权重D-S融合结论更加准确.
为了验证自适应权重D-S融合方法比固定权重融合的诊断效果更好.对200组已经判断出浓度偏高故障的样本进行故障原因追溯并将故障原因追溯结论与运行记录对比.统计故障原因追溯的误报率来比较两种融合方法的优劣.为表明自适应权重方法的泛化能力较好, 共分四种情况进行仿真试验.如表 4所示, 每种情况下, 自适应权重D-S融合后的结论误报率都有所降低.
表 4 自适应权重D-S与固定权重D-S融合对比(%)Table 4 Comparison of adaptive weight D-S and fixed weight D-S (%)固定权重误报 自适应权重误报 规则信息缺失 6.5 4.0 数据信息缺失 10 6.5 噪声10 % 5.25 4.0 数据较为准确 5 3.5 平均 6.69 4.50 混合系统故障诊断准确性的提高主要是由多来源信息的使用以及结论融合实现的, 相比于单一推理的专家知识系统, 混合系统对故障进行了双重的识别.虽然增加了计算量.但不会造成明显的诊断时间滞后.
5. 结论
针对过程知识类型多样和运行数据不准确的复杂工业流程, 提出一种基于D-S融合的混合知识系统故障诊断方法框架.通过不同的故障诊断知识系统利用多类型知识对过程的运行情况进行判断并给出诊断意见, 使用自适应权重的D-S证据理论将多专家系统的结论进行融合.这种方法依靠专家知识经验和过程数据, 实现了过程的智能故障诊断.将所提方法应用于湿法冶金浓密流程, 仿真结果证明了诊断方法的准确性和有效性.
-
图 1 基于D-S融合的混合知识系统故障诊断算法流程
Fig. 1 Fault diagnosis flowchart of method based on D-S fusion theory and hybrid expert knowledge system
图 2 三种诊断方法对浓度偏高的识别效果对比
Fig. 2 Effect comparison of three methods for high concentration fault
表 1 浓密机故障诊断规则
Table 1 Fault diagnosis rules for thickener
序号 规则前件 规则后件 规则强度 1 浓密机运转吃力,噪声大 浓密机压耙 0.8 2 底流流量比较小 底流管道堵塞 0.8 3 矿浆粘稠且起泡 浓度偏高 0.8 4 缓冲槽中液位离槽口过近 缓冲槽冒槽 0.8  下载: 导出CSV
下载: 导出CSV
表 2 压滤机前缓冲槽冒槽原因追溯规则
Table 2 Reasons rules for tank overswelling in front of the fllter press
序号 规则前件 规则后件 规则强度 5 冒槽,浓度不大,流量不大 其他原因致冒槽 0.8 6 冒槽,浓度偏大,流量不大 浓度高致冒槽 0.8 7 冒槽,浓度不大,流量偏大 流量大致冒槽 0.8 8 冒槽,浓度偏大,流量偏大 浓度高流量大致冒槽 0.8
下载: 导出CSV
表 3 专家给出的事件可信度
Table 3 Certainty factors of cases given by expert
事件 专家给出的可信度 浓度偏大 0.78 浓度不大 -0.78 流量偏大 0.81 流量不大 -0.81
下载: 导出CSV
表 4 自适应权重D-S与固定权重D-S融合对比(%)
Table 4 Comparison of adaptive weight D-S and fixed weight D-S (%)
固定权重误报 自适应权重误报 规则信息缺失 6.5 4.0 数据信息缺失 10 6.5 噪声10 % 5.25 4.0 数据较为准确 5 3.5 平均 6.69 4.50
下载: 导出CSV
-
[1] Gao Z W, Cecati C, Ding S X. A survey of fault diagnosis and fault-tolerant techniques—Part Ⅱ: fault diagnosis with knowledge-based and hybrid/active approaches. IEEE Transactions on Industrial Electronics, 2015, 62(6): 3768-3774 http://ieeexplore.ieee.org/document/7076586/ [2] 文成林, 吕菲亚, 包哲静, 刘妹琴.基于数据驱动的微小故障诊断方法综述.自动化学报, 2016, 42(9): 1285-1299 http://www.aas.net.cn/CN/abstract/abstract18918.shtmlWen Cheng-Lin, Lv Fei-Ya, Bao Zhe-Jing, Liu Mei-Qin. A review of data driven-based incipient fault diagnosis. Acta Automatica Sinica, 2016, 42(9): 1285-1299 http://www.aas.net.cn/CN/abstract/abstract18918.shtml [3] Koiwanit J, Supap T, Chan C, Gelowitz D, Idem R, Tontiwachwuthikul P. An expert system for monitoring and diagnosis of ammonia emissions from the post-combustion carbon dioxide capture process system. International Journal of Greenhouse Gas Control, 2014, 26(7): 158-168 http://www.sciencedirect.com/science/article/pii/S1750583614000991 [4] Azim T, Jaffar M A, Mirza A M. Fully automated real time fatigue detection of drivers through fuzzy expert systems. Applied Soft Computing, 2014, 18(1): 25-38 http://www.sciencedirect.com/science/article/pii/S1568494614000398 [5] 张煜东, 吴乐南, 王水花.专家系统发展综述.计算机工程与应用, 2010, 46(19): 43-47 doi: 10.3778/j.issn.1002-8331.2010.19.012Zhang Yu-Dong, Wu Le-Nan, Wang Shui-Hua. Survey on development of expert system. Computer Engineering and Applications, 2010, 46(19): 43-47 doi: 10.3778/j.issn.1002-8331.2010.19.012 [6] 陈翔. 专家系统中不精确推理的研究与应用[硕士学位论文], 安徽大学, 中国, 2006. http://cdmd.cnki.com.cn/Article/CDMD-10357-2006169564.htmChen Xiang. Research and Application of Uncertainty Inference in Expert System [Master dissertation], Anhui University, China, 2006. http://cdmd.cnki.com.cn/Article/CDMD-10357-2006169564.htm [7] Yu M, Wang D W, Luo M, Zhang D H, Chen Q J. Fault detection, isolation and identification for hybrid systems with unknown mode changes and fault patterns. Expert Systems with Applications, 2012, 39(11): 9955-9965 doi: 10.1016/j.eswa.2012.01.103 [8] Wang J W, Hu Y, Xiao F Y, Deng X Y, Deng Y. A novel method to use fuzzy soft sets in decision making based on ambiguity measure and Dempster-Shafer theory of evidence: an application in medical diagnosis. Artificial Intelligence in Medicine, 2016, 69(C): 1-11 http://www.ncbi.nlm.nih.gov/pubmed/27235800 [9] Fan X F, Zuo M J. Fault diagnosis of machines based on D-S evidence theory. Part 2: application of the improved D-S evidence theory in gearbox fault diagnosis. Pattern Recognition Letters, 2006, 27(5): 377-385 doi: 10.1016/j.patrec.2005.08.024 [10] Basir O, Yuan X H. Engine fault diagnosis based on multi-sensor information fusion using Dempster-Shafer evidence theory. Information Fusion, 2007, 8(4): 379-386 doi: 10.1016/j.inffus.2005.07.003 [11] 韩德强, 杨艺, 韩崇昭. DS证据理论研究进展及相关问题探讨.控制与决策, 2014, 29(1): 1-11 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201401001.htmHan De-Qiang, Yang Yi, Han Chong-Zhao. Advances in DS evidence theory and related discussions. Control and Decision, 2014, 29(1): 1-11 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201401001.htm [12] Valente F, Hermansky H. Combination of acoustic classifiers based on Dempster-Shafer theory of evidence. In: Proceedings of the 2006 IEEE International Conference on Acoustics. Honolulu, HI, USA: IEEE, 2006: Ⅳ-1129-Ⅳ-1132 http://ieeexplore.ieee.org/document/4218304/ [13] 邓鑫洋, 邓勇, 章雅娟, 刘琪.一种信度马尔科夫模型及应用.自动化学报, 2012, 38(4): 666-672 http://www.aas.net.cn/CN/abstract/abstract17722.shtmlDeng Xin-Yang, Deng Yong, Zhang Ya-Juan, Liu Qi. A belief Markov model and its application. Acta Automatica Sinica, 2012, 38(4): 666-672 http://www.aas.net.cn/CN/abstract/abstract17722.shtml [14] 柯小路, 马荔瑶, 李子懿, 王永.证据推理规则的性质研究及方法修正.信息与控制, 2016, 45(2): 165-170 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK201602007.htmKe Xiao-Lu, Ma Li-Yao, Li Zi-Yi, Wang Yong. Property research and approach modification of evidential reasoning rule. Information and Control, 2016, 45(2): 165-170 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK201602007.htm [15] Yang Y, Han D Q, Han C Z. Discounted combination of unreliable evidence using degree of disagreement. International Journal of Approximate Reasoning, 2013, 54(8): 1197-1216 doi: 10.1016/j.ijar.2013.04.002 [16] 李海波, 柴天佑, 赵大勇.混合选别浓密机底流矿浆浓度和流量区间智能切换控制方法.自动化学报, 2014, 40(9): 1967-1975 http://www.aas.net.cn/CN/abstract/abstract18467.shtmlLi Hai-Bo, Chai Tian-You, Zhao Da-Yong. Intelligent switching control of underflow slurry concentration and flowrate intervals in mixed separation thickener. Acta Automatica Sinica, 2014, 40(9): 1967-1975 http://www.aas.net.cn/CN/abstract/abstract18467.shtml [17] Sainz Palmero G I, Juez Santamaria J, de la Torre E J M, Perán González J R. Fault detection and fuzzy rule extraction in AC motors by a neuro-fuzzy ART-based system. Engineering Applications of Artificial Intelligence, 2005, 18(7): 867-874 doi: 10.1016/j.engappai.2005.02.005 [18] 黄元亮, 李冰.不确定性推理中确定性的传播.计算机仿真, 2008, 25(7): 133-136 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJZ200807035.htmHuang Yuan-Liang, Li Bing. Reliability's promulgating in uncertainty reasoning. Computer Simulation, 2008, 25(7): 133-136 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJZ200807035.htm [19] 张春晓, 严爱军, 王普.一种改进的案例推理分类方法研究.自动化学报, 2014, 40(9): 2015-2021 http://www.aas.net.cn/CN/abstract/abstract18473.shtmlZhang Chun-Xiao, Yan Ai-Jun, Wang Pu. An improved classification approach by case-based reasoning. Acta Automatica Sinica, 2014, 40(9): 2015-2021 http://www.aas.net.cn/CN/abstract/abstract18473.shtml [20] Suh M S, Jhee W C, Ko Y K, Lee A. A case-based expert system approach for quality design. Expert Systems with Applications, 1998, 15(2): 181-190 doi: 10.1016/S0957-4174(98)00022-0 [21] 余建波, 卢笑蕾, 宗卫周.基于局部与非局部线性判别分析和高斯混合模型动态集成的晶圆表面缺陷探测与识别.自动化学报, 2016, 42(1): 47-59 http://www.aas.net.cn/CN/abstract/abstract18795.shtmlYu Jian-Bo, Lu Xiao-Lei, Zong Wei-Zhou. Wafer defect detection and recognition based on local and nonlocal linear discriminant analysis and dynamic ensemble of Gaussian mixture models. Acta Automatica Sinica, 2016, 42(1): 47-59 http://www.aas.net.cn/CN/abstract/abstract18795.shtml [22] 汤永利, 李伟杰, 于金霞, 闫玺玺.基于改进D-S证据理论的网络安全态势评估方法.南京理工大学学报(自然科学版), 2015, 39(4): 405-411 http://www.cnki.com.cn/Article/CJFDTOTAL-NJLG201504005.htmTang Yong-Li, Li Wei-Jie, Yu Jin-Xia, Yan Xi-Xi. Network security situational assessment method based on improved D-S evidence theory. Journal of Nanjing University of Science and Technology, 2015, 39(4): 405-411 http://www.cnki.com.cn/Article/CJFDTOTAL-NJLG201504005.htm [23] 王俊华, 左祥麟, 左万利.基于证据理论的单词语义相似度度量.自动化学报, 2015, 41(6): 1173-1186 http://www.aas.net.cn/CN/abstract/abstract18692.shtmlWang Jun-Hua, Zuo Xiang-Lin, Zuo Wan-Li. Word semantic similarity measurement based on evidence theory. Acta Automatica Sinica, 2015, 41(6): 1173-1186 http://www.aas.net.cn/CN/abstract/abstract18692.shtml 期刊类型引用(37)
1. 李莎莎,崔铁军. 系统故障演化过程中事件状态联系数构建研究. 智能系统学报. 2024(02): 455-461 .  百度学术
百度学术2. 邓中乙. 面向磨煤机组故障诊断的聚类粗化图模型. 复杂系统与复杂性科学. 2024(01): 152-158 . 百度学术3. 谢苗苗,李华龙,詹凯. 基于多元数据的夏季鸡舍环境质量评价及其对产蛋性能的影响. 农业工程学报. 2024(08): 188-197 . 百度学术4. 王泽煜,张根才,赵振飞,袁华宇,董奇,李宝龙. 智慧管网下输气管道分输控制技术发展的认识与思考. 石油化工自动化. 2024(05): 1-10 . 百度学术5. 安雪,李少波,张仪宗,张安思. 无人机飞控系统故障诊断技术研究综述. 计算机工程与应用. 2023(24): 1-15 . 百度学术6. 马亮,施富中,彭开香. 数据驱动的热轧过程故障诊断研究现状与展望. 中国冶金. 2023(12): 12-17 . 百度学术7. 刘金富,黄頔,王文林. 无人机故障诊断研究进展. 控制工程. 2022(03): 428-434 . 百度学术8. 范莉萍,郎朗,肖晶晶,张诗慧,种银保,吕思敏. 基于故障树的多参数监护仪故障智能诊断专家系统研究. 生物医学工程学杂志. 2022(03): 586-595 . 百度学术9. 胥如迅,马军惠,孟建军,李德仓,陈晓强. 高速列车运行场景监测数据融合算法研究. 兰州交通大学学报. 2022(04): 76-81 . 百度学术10. 褚菲,鲍文超,傅逸灵,王佩,陈韬,马小平. 基于贝叶斯网络的重介质选煤过程自愈控制. 控制工程. 2022(10): 1866-1873 . 百度学术11. 齐咏生,白宇,高胜利,李永亭. 基于改进的数据融合滚动轴承故障诊断. 铁道学报. 2022(10): 24-32 . 百度学术12. 蒋仲安,郑登锋,曾发镔,付明福,张明星. 基于危险源理论的油气管道安全管理模型的研究. 湖南大学学报(自然科学版). 2021(04): 56-65 . 百度学术13. 范晓建,田建艳,杨英波,菅垄,杨胜强. 基于改进D-S证据理论的滚抛磨块融合决策模型. 表面技术. 2021(04): 393-401 . 百度学术14. 周志杰,唐帅文,胡昌华,曹友,王杰. 证据推理理论及其应用. 自动化学报. 2021(05): 970-984 . 本站查看15. 王晶,史雨茹,周萌. 基于状态集员估计的主动故障检测. 自动化学报. 2021(05): 1087-1097 . 本站查看16. 吴新忠,陈昌,耿柯,魏连江. 基于IFWA-BP神经网络的线风速数据融合研究. 电子测量与仪器学报. 2021(05): 16-23 . 百度学术17. 王海舰,黄梦蝶,高兴宇,卢士林,张强. 考虑截齿损耗的多传感信息融合煤岩界面感知识别. 煤炭学报. 2021(06): 1995-2008 . 百度学术18. 张境麟,姚钰鹏,冯银辉,刘清. 故障诊断预警系统在煤炭开采的应用. 煤炭科学技术. 2021(S1): 175-182 . 百度学术19. 高欣,任昺,张浩,刘蒙,李军良,徐建航. 基于信息差异图模型的电力调度自动化系统组件故障溯源方法. 电网技术. 2021(12): 4808-4817 . 百度学术20. 雷杰,徐晓滨,徐晓健,常雷雷. 基于置信规则库的并发故障诊断方法. 系统工程与电子技术. 2020(02): 497-504 . 百度学术21. 姚芳,姜涛,刘明宇,董超群,郑帅. 基于GWO-ELM的逆变器开路故障诊断. 电源学报. 2020(01): 45-53 . 百度学术22. 李英顺,江山青,陈悦峰,周建军,张银图. D-S证据融合的坦克火控系统混合故障诊断. 火炮发射与控制学报. 2020(01): 104-108 . 百度学术23. 张蓉,张澜. 图书情报领域知识融合研究现状分析. 科技创业月刊. 2020(02): 95-98 . 百度学术24. 刘元丰,毛凯敏. 轨道交通ATC设备模块装配自动调试故障诊断方法. 自动化与仪器仪表. 2020(08): 194-197 . 百度学术25. 徐耀松,王传为. 果蝇算法和改进D-S证据理论的四轴飞行器障碍辨识. 智能系统学报. 2020(03): 499-506 . 百度学术26. 李广建,陈瑜. 知识融合研究的现状分析及建议. 图书情报工作. 2019(01): 41-51 . 百度学术27. 薛大为,王永,高康凯. 基于规范分解的证据合成悖论分析. 北京邮电大学学报. 2019(01): 28-34 . 百度学术28. 翁钢民,潘越,李凌雁. “丝绸之路旅游带”景区区位优势等级测度与影响机理. 经济地理. 2019(04): 207-215 . 百度学术29. 王辉均,朱亦峰,董德浩,朱亮亮. 防空战车电气一体化检测工艺的优化. 机械制造. 2019(03): 71-75 . 百度学术30. 陈晓红,马智勇,李喜华. 证据视角下考虑多参考点的直觉模糊多属性决策模型. 运筹与管理. 2019(08): 1-9 . 百度学术31. 柴兴华,胡炎,雷耀麟,刘厦. 无人机智能测控技术研究综述. 无线电工程. 2019(10): 855-860 . 百度学术32. 李进. 基于规则和相似度的海洋石油设备智能诊断技术研究. 北京石油化工学院学报. 2019(03): 17-21 . 百度学术33. 宋威,施伟锋,卓金宝,谢嘉令. 多电平逆变器开关管故障诊断方法综述. 微电机. 2019(10): 110-117 . 百度学术34. 张懿,崔佳. 基于SVDD和D-S理论的曲轴轴承故障诊断. 重庆理工大学学报(自然科学). 2019(11): 89-94 . 百度学术35. 姜伟伟,姜学鹏. 基于退化失效阈值可能性分布的可靠性建模. 海军航空工程学院学报. 2018(02): 243-247+252 . 百度学术36. 李晓庆,唐昊,司加胜,苗刚中. 面向混合属性数据集的改进半监督FCM聚类方法. 自动化学报. 2018(12): 2259-2268 . 本站查看37. 周旖鋆,武凯,孙宇,杨晓燕,楼晓华. 基于数据挖掘与信息融合的制冷设备故障诊断. 振动.测试与诊断. 2021(02): 392-398+418 . 百度学术其他类型引用(101)
-

 下载:
下载:
计量
- 文章访问数: 2146
- HTML全文浏览量: 317
- PDF下载量: 943
- 被引次数: 138
