

-
摘要: 社交网络的飞速发展给用户带来了便捷,但是社交网络开放性的特点使得其容易受到虚假用户的影响.虚假用户借用社交网络传播虚假信息达到自身的目的,这种行为严重影响着社交网络的安全性和稳定性.目前社交网络虚假用户的检测方法主要通过用户的行为、文本和网络关系等特征对用户进行分类,由于人工标注用户数据需要的代价较大,导致分类器能够使用的标签样本不足.为解决此问题,本文提出一种基于双层采样主动学习的社交网络虚假用户检测方法,该方法使用样本不确定性、代表性和多样性3个指标评估未标记样本的价值,并使用排序和聚类相结合的双层采样算法对未标记样本进行筛选,选出最有价值的样本给专家标注,用于对分类模型的训练.在Twitter、Apontador和Youtube数据集上的实验说明本文所提方法在标签样本数量不足的情况下,只使用少量有标签样本就可以达到与有监督学习接近的检测效果;并且,对比其他主动学习方法,本文方法具有更高的准确率和召回率,需要的标签样本数量更少.Abstract: With the rapid development of social network, more and more people join in social network to make friends and share their views. However, social network is always suffering from fake accounts due to its openness. Fake accounts, also called spammers, always spread spam information to achieve their own purpose, which have destroyed the security and reliability of social network. Existing detection methods extract behaviour, text and relationship features of users, and then use machine learning algorithms to identify social spammers. But machine learning algorithms often suffer from insufficiently labeled training data. Aiming to solve this problem, we propose an efficient algorithm, called two-layer sampling active learning, to construct an accurate classifier with minimum labeled samples. We present three criteria (uncertainty, representative and diversity) to quantity the value of unlabeled samples, using the combination of sorting and clustering to actively select samples with max uncertainty, max representative and max diversity. Experimental results on Twitter, Apontador, and Youtube datasets prove the efficiency of our approach, and better precision and recall of our approach than other active learning methods.
-
Key words:
- Social network /
- spammer /
- active learning /
- diversity of samples
-

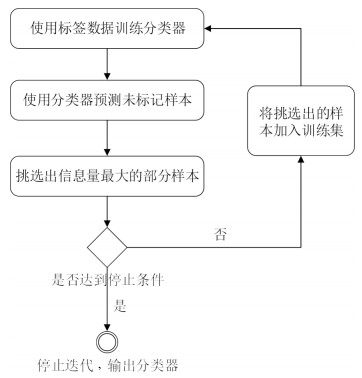
图 2 双层采样主动学习检测框架
Fig. 2 Detection framework based on active learning with two-layer sampling
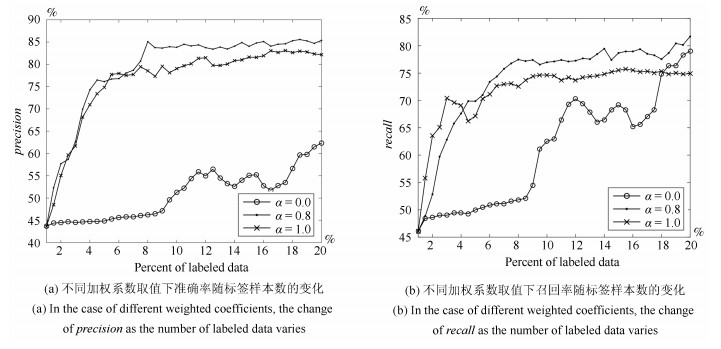
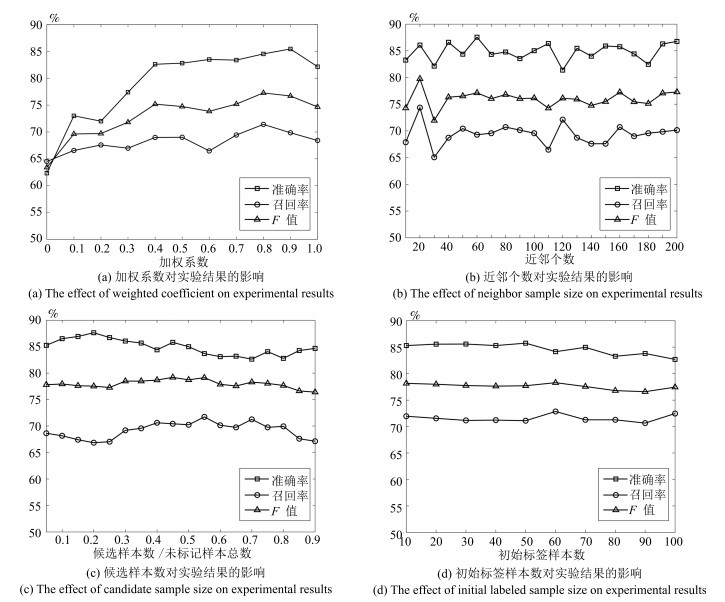
图 8 加权系数对双层采样算法效果的影响
Fig. 8 Influence of the weighted coefficient on experimental results
表 1 符号定义
Table 1 Definition of symbols
符号 含义 x 一个样本, 表示用户特征向量 y 用户标签 L, U 已标记样本集, 未标记样本集 $\ell ,\mu $ 已标记样本数目, 未标记样本数目 $H\left( x \right)$ 样本x的信息熵 $AS\left( x \right)$ 样本x的代表性 ${U_{candidates}}$ 候选样本集合 k 每轮迭代选择的样本数, $k \ll \mu $ $\Delta L$ 每轮迭代选择的样本集合  下载: 导出CSV
下载: 导出CSV
表 2 Apontador数据集用户特征 (粗体表示Apontador_49包含而Apontador_33不包含的特征)
Table 2 The user features of Apontador data set (Bold show features only in Apontador_49.)
特征类型 具体描述 属性特征 粉丝数、关注数 行为特征 注册地点个数、发表tip数、照片数、评论地点的总距离、发表过tip的地点数、地点点击数、tip数、评分、"Thumbs up"和"Thumbs down"点击数 内容特征 某用户所有tip中的1-gram、2-gram和3-gram、某用户每一个1-gram、2-gram、3-gram在该用户的所有的tip中出现的比例、文本中的垃圾词汇数量、大写字母的个数、数字字符的个数、出现电话号码的次数、出现邮箱地址的次数、URLs的个数、出现联系信息的次数、单词数、所有字母都是大写的单词数、攻击性词汇数、是否出现攻击性词汇 邻居特征 该用户的粉丝的关注数、该用户的关注者的地点个数 图特征 聚类系数、双向关注比、节点相关性、节点度/他的邻居节点平均度、节点出入度比、节点度、节点中心性、pagerank值
下载: 导出CSV
表 3 Twitter数据集用户特征
Table 3 The user features of Twitter data set
特征类型 具体描述 属性特征 昵称中是否存在垃圾词汇、关注数、粉丝数、账户年龄 行为特征 发表的推文数、被他人@的次数、被他人回复的次数、回复他人的次数、发表推文的时间间隔、每天发表推文的数目、每周发表推文的数目、推文被回复的比例、每篇推文的转发数 内容特征 含有垃圾词汇的推文占总推文的比例、含有URLs的推文占总推文的比例、'#'符号在每篇推文中所占的比重、URLs在每篇推文中所占的比重、每篇推文的字符数、每篇推文包含'#’符号的数目、每篇推文中包含符号'@’的数目、每篇推文中包含数字的数目、每篇推文中包含URLs的数量、每篇推文的单词数 邻居特征 该用户的粉丝的关注数、该用户的关注者的推文数 图特征 双向关注比
下载: 导出CSV
表 4 Youtube数据集用户特征
Table 4 The user features of Youtube data set
特征类型 具体描述 属性特征 朋友个数、订阅者数、订阅数 行为特征 发表的请求数、接收到的请求数、观看的视频数、下载的视频数、喜爱的视频数、24小时内最大视频下载量、下载视频的平均时长 内容特征 用户相关的视频 (下载、评分、收藏) 的视频的总观看量、平均观看量、总下载时间、平均下载时间、总观看时间、平均观看时间、总评分数、平均评分数、总评论数、平均评论数、总收藏数、平均收藏数 邻居特征 该用户的粉丝的关注数、该用户的关注者的推文数 图特征 聚类系数、节点相关性、节点出入度比、节点中心性、Pagerank值
下载: 导出CSV
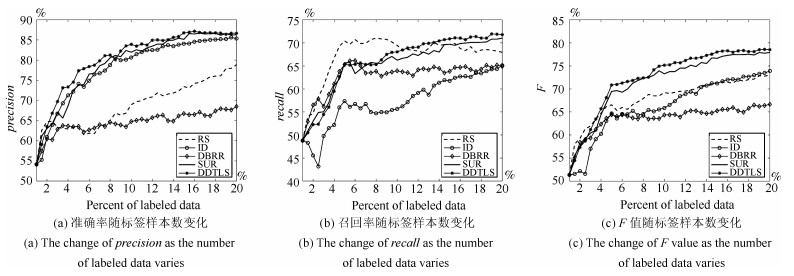
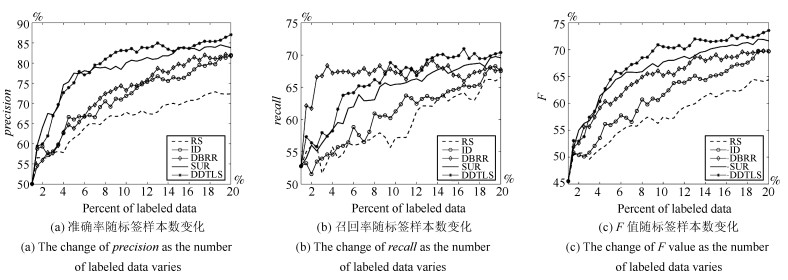
表 5 Twitter和Youtube数据集上的实验结果 (%)
Table 5 Experimental results on Twitter and Youtube data set
分类模型 算法 Supervised SUR_UNC SUR_QBC DDTLS_UNC DDTLS_QBC Twitter Youtube Twitter Youtube Twitter Youtube Twitter Youtube Twitter Youtube 准确率 90.58 77.48 86.27 75.69 85.54 73.82 85.45 74.53 88.00 77.05 支持向量机 召回率 70.42 62.23 66.08 65.61 73.80 69.57 70.99 62.74 72.56 70.40 F值 79.26 69.03 74.74 69.94 79.15 71.63 77.36 67.78 79.49 73.58 准确率 83.82 32.06 82.37 41.15 94.96 54.59 83.30 47.35 89.43 39.60 朴素贝叶斯 召回率 72.96 93.62 64.51 86.16 72.11 80.30 67.15 94.51 66.25 89.33 F值 78.01 47.76 72.26 55.66 81.97 63.42 74.36 63.09 76.12 53.37 准确率 87.20 74.55 83.03 69.07 86.21 78.52 82.10 80.04 87.30 73.32 决策树 召回率 70.99 65.43 67.61 66.33 70.70 62.66 68.08 62.64 69.39 61.12 F值 79.25 69.69 74.78 66.82 78.01 68.70 74.56 69.54 77.45 65.85 准确率 88.81 75.50 87.81 76.62 87.52 79.63 86.77 77.05 85.85 77.09 逻辑回归 召回率 71.55 60.64 69.29 71.26 74.36 67.04 73.01 67.06 72.30 66.49 F值 79.24 62.23 77.46 73.60 78.01 72.69 79.10 71.48 78.58 71.03
下载: 导出CSV
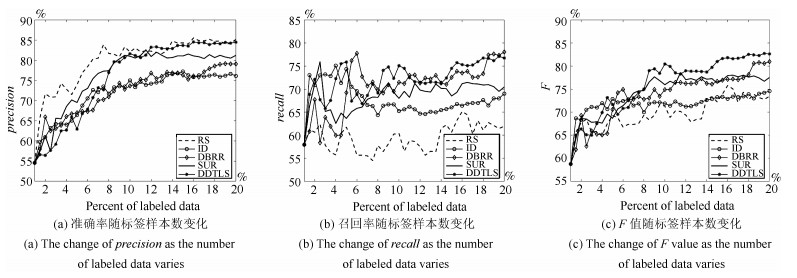
表 6 Apontador数据集上的实验结果 (%)
Table 6 Experimental results on Apontador data set (%)
分类模型 算法 Supervised SUR_UNC SUR_QBC DDTLS_UNC DDTLS_QBC _33 _49 _33 _49 _33 _49 _33 _49 _33 _49 准确率 87.70 89.18 83.73 86.45 86.22 88.34 83.14 86.26 89.50 87.27 支持向量机 召回率 75.38 79.88 74.22 70.12 70.45 72.80 76.63 81.89 76.76 80.55 F值 81.07 84.27 78.52 77.43 77.54 79.82 79.75 83.50 82.64 84.46 准确率 76.24 87.83 77.47 84.18 64.88 92.96 84.51 97.14 80.65 91. 15 朴素贝叶斯 召回率 60.17 81.18 70.16 74.51 72.27 73.51 64.73 51.39 66.18 45.90 F值 67.26 84.37 73.08 79.16 64.11 84.12 72.46 67.04 68.80 60.65 准确率 82.49 87.20 84.48 96.85 95.20 91.23 94.88 89.62 96.70 99.29 决策树 召回率 81.17 70.99 63.14 49.96 52.93 80.46 55.48 65.92 52.85 68.48 F值 81.82 79.25 67.59 66.92 68.00 85.51 69.44 74.25 68.17 80.86 准确率 85.25 87.83 82.33 87.67 86.59 87.52 86.53 86.26 85.53 87.04 逻辑回归 召回率 75.31 81.18 76.18 79.93 77.62 74.36 74.29 82.11 77.55 82.25 F值 79.97 84.37 79.04 83.46 81.79 78.01 79.80 84.10 81.31 84.56
下载: 导出CSV
-
[1] 黄震华, 张佳雯, 田春岐, 孙圣力, 向阳.基于排序学习的推荐算法研究综述.软件学报, 2016, 27(3): 691-713 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201603015.htmHuang Zhen-Hua, Zhang Jia-Wen, Tian Chun-Qi, Sun Sheng-Li, Xiang Yang. Survey on learning-to-rank based recommendatio algorithms. Journal of Software, 2016, 27(3): 691-713 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201603015.htm [2] 辛宇, 杨静, 谢志强.基于标签传播的语义重叠社区发现算法.自动化学报, 2014, 40(10): 2262-2275 http://www.aas.net.cn/CN/abstract/abstract18501.shtmlXin Yu, Yang Jing, Xie Zhi-Qiang. An overlapping semantic community structure detecting algorithm by label propagation. Acta Automatica Sinica, 2014, 40(10): 2262-2275 http://www.aas.net.cn/CN/abstract/abstract18501.shtml [3] Gao H Y, Hu J, Wilson C, Li Z C, Chen Y, Zhao B Y. Detecting and characterizing social spam campaigns. In: Proceedings of the 17th ACM Conference on Computer and Communications Security. Chicago, Illinois, USA: ACM, 2010. 681-683 [4] Wang G, Wilson C, Zhao X H, Zhu Y B, Mohanlal M, Zheng H T, Zhao B Y. Serf and turf: crowdturfing for fun and profit. In: Proceedings of the 21st International Conference on World Wide Web. Lyon, France: ACM, 2012. 679-688 [5] Stringhinl G, Wang G, Fgele M, Kruegel C, Vigna G, Zheng H T, Zhao B Y. Follow the green: growth and dynamics in Twitter follower markets. In: Proceedings of the 2013 Conference on Internet Measurement Conference. Barcelona, Spain: ACM, 2013. 163-176 [6] Ghosh S, Viswanath B, Kooti F, Sharma N K, Korlam G, Benevenuto F, Ganguly N, Gummadi K P. Understanding and combating link farming in the Twitter social network. In: Proceedings of the 21st International Conference on World Wide Web. Lyon, France: ACM, 2012. 61-70 [7] Gupta A, Kumaraguru P, Castillo C, Meier P. TweetCred: real-time credibility assessment of content on Twitter. In: Proceedings of the 6th International Conference on Social Informatics. Barcelona, Spain: Springer, 2014. 228-243 [8] Amleshwaram A A, Reddy N, Yadav S, Gu G F, Yang C. CATS: characterizing automation of Twitter spammers. In: Proceedings of the 5th International Conference on Communication Systems and Networks (COMSNETS). Bangalore, India: IEEE, 2013. 1-10 [9] Prasetyo P K, Lo D, Achananuparp P, Tian Y, Lim E P. Automatic classification of software related microblogs. In: Proceedings of the 28th IEEE International Conference on Software Maintenance (ICSM). Trento, Italy: IEEE, 2012. 596-599 [10] Hu X, Tang J L, Liu H. Online social spammer detection. In: Proceedings of the 28th Conference on Artificial Intelligence. Québec, Canada: AAAI, 2014. 59-65 [11] Hu X, Tang J L, Zhang Y C, Liu H. Social spammer detection in microblogging. In: Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Beijing, China: AAAI, 2013. 2633-2639 [12] Ravikumar S, Talamadupula K, Balakrishnan R, Kambhampati S. RAProp: ranking tweets by exploiting the tweet/user/web ecosystem and inter-tweet agreement. In: Proceedings of the 22nd ACM International Conference on Information and Knowledge Management. San Francisco, CA, USA: ACM, 2013. 2345-2350 [13] 程晓涛, 刘彩霞, 刘树新.基于关系图特征的微博水军发现方法.自动化学报, 2015, 41(9): 1533-1541 http://www.aas.net.cn/CN/abstract/abstract18728.shtmlCheng Xiao-Tao, Liu Cai-Xia, Liu Shu-Xin. Graph-based features for identifying spammers in microblog networks. Acta Automatica Sinica, 2015, 41(9): 1533-1541 http://www.aas.net.cn/CN/abstract/abstract18728.shtml [14] Li Z X, Zhang X C, Shen H, Liang W X, He Z Y. A semi-supervised framework for social spammer detection. In: Proceedings of the 19th Pacific-Asia Conference in Knowledge Discovery and Data Mining (PAKDD). Ho Chi Minh City, Vietnam: Springer, 2015. 177-188 [15] Cohn D A, Ghahramani Z, Jordan M I. Active learning with statistical models. Journal of Artificial Intelligence Research, 1996, 4: 129-145 http://www.academia.edu/1188308/Active_learning_with_statistical_models [16] Hajmohammadi M S, Ibrahim R, Selamat A, Fujita H. Combination of active learning and self-training for cross-lingual sentiment classification with density analysis of unlabelled samples. Information Sciences, 2015, 317: 67-77 doi: 10.1016/j.ins.2015.04.003 [17] Benevenuto F, Magno G, Rodrigues T, Almeida V. Detecting spammers on Twitter. In: Proceedings of the 7th Annual Collaboration, Electronic Messaging, Anti-Abuse and Spam Conference. Redmond, Washington, USA, 2010. [18] Jeong S, Noh G, Oh H, Kim C K. Follow spam detection based on cascaded social information. Information Sciences, 2016, 369: 481-499 doi: 10.1016/j.ins.2016.07.033 [19] Benevenuto F, Rodrigues T, Almeida V, Almeida J, Goçalves M A. Detecting spammers and content promoters in online video social networks. In: Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Boston, MA, USA: ACM, 2009. 620-627 [20] Lee K, Caverlee J, Webb S. Uncovering social spammers: social honeypots + machine learning. In: Proceeding of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Geneva, Switzerland: ACM, 2010. 435-442 [21] Song J, Lee S, Kim J. Spam filtering in Twitter using sender-receiver relationship. In: Proceedings of the 14th International Symposium, Recent Advances in Intrusion Detection. Menlo Park, CA, USA: Springer, 2011. 301-317 [22] 曹建平, 王晖, 夏友清, 乔凤才, 张鑫.基于LDA的双通道在线主题演化模型.自动化学报, 2014, 40(12): 2877-2886 http://www.aas.net.cn/CN/abstract/abstract18565.shtmlCao Jian-Ping, Wang Hui, Xia You-Qing, Qiao Feng-Cai, Zhang Xin. Bi-path evolution model for online topic model based on LDA. Acta Automatica Sinica, 2014, 40(12): 2877-2886 http://www.aas.net.cn/CN/abstract/abstract18565.shtml [23] Tan E H, Guo L, Chen S Q, Zhang X D, Zhao Y H. UNIK: unsupervised social network spam detection. In: Proceedings of the 22nd ACM International Conference on Information and Knowledge Management. San Francisco, USA: ACM, 2013. 479-488 [24] Zhao L, Chen F, Dai J, Hua T, Lu C T, Ramakrishnan N. Unsupervised spatial event detection in targeted domains with applications to civil unrest modeling. PLoS One, 2014, 9(10): e110206 doi: 10.1371/journal.pone.0110206 [25] 吴健, 盛胜利, 赵朋朋, 崔志明.最小差异采样的主动学习图像分类方法.通信学报, 2014, 35(1): 107-114 http://www.cnki.com.cn/Article/CJFDTOTAL-TXXB201401013.htmWu Jian, Sheng Sheng-Li, Zhao Peng-Peng, Cui Zhi-Ming. Minimal difference sampling for active learning image classification. Journal on Communications, 2014, 35(1): 107-114 http://www.cnki.com.cn/Article/CJFDTOTAL-TXXB201401013.htm [26] Zhu J B, Ma M. Uncertainty-based active learning with instability estimation for text classification. ACM Transactions on Speech and Language Processing, 2012, 8(4): Article No. 5 https://www.researchgate.net/publication/239761640_Uncertainty-based_active_learning_with_instability_estimation_for_text_classification [27] Tuia D, Ratle F, Pacifici F, Kanevski M F, Emery W J. Active learning methods for remote sensing image classification. IEEE Transactions on Geoscience and Remote Sensing, 2009, 47(7): 2218-2232 doi: 10.1109/TGRS.2008.2010404 [28] Settles B. Active Learning Literature Survey, Computer Sciences Technical Report 1648, University of Wisconsin-Madison, Wisconsin, 2010. [29] Zhang T, Oles F J. A probability analysis on the value of unlabeled data for classification problems. In: Proceedings of the 17th International Conference on Machine Learning. San Francisco, CA, USA: Morgan Kaufmann, 2000. 1191-1198 [30] Roy N, McCallum A. Toward optimal active learning through sampling estimation of error reduction. In: Proceedings of the 18th International Conference on Machine Learning. Williams College, Williamstown, MA, USA: Morgan Kaufmann Publishers Inc., 2001. 441-448 [31] Settles B, Craven M. An analysis of active learning strategies for sequence labeling tasks. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Honolulu, Hawaii, USA: ACL, 2008. 1070-1079 [32] Zhu J B, Wang H Z, Tsou B K, Ma M. Active learning with sampling by uncertainty and density for data annotations. IEEE Transactions on Audio, Speech, and Language Processing, 2010, 18(6): 1323-1331 doi: 10.1109/TASL.2009.2033421 [33] Xu Z, Yu K, Tresp V, Xu X W, Wang J Z. Representative sampling for text classification using support vector machines. In: Proceedings of the 25th European Conference on IR Research. Pisa, Italy: Springer, 2003. 393-407 [34] Yang C, Harkreader R, Gu G F. Empirical evaluation and new design for fighting evolving Twitter spammers. IEEE Transactions on Information Forensics and Security, 2013, 8(8): 1280-1293 doi: 10.1109/TIFS.2013.2267732 [35] Freitas C, Benevenuto F, Ghosh S, Veloso A. Reverse engineering socialbot infiltration strategies in Twitter. In: Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. Paris, France: ACM, 2015. 25-32 [36] 陈晋音, 何辉豪.基于密度的聚类中心自动确定的混合属性数据聚类算法研究.自动化学报, 2015, 41(10): 1798-1813 http://www.aas.net.cn/CN/abstract/abstract18754.shtmlChen Jin-Yin, He Hui-Hao. Research on density-based clustering algorithm for mixed data with determine cluster centers automatically. Acta Automatica Sinica, 2015, 41(10): 1798-1813 http://www.aas.net.cn/CN/abstract/abstract18754.shtml [37] Costa H, Benevenuto F, Merschmann C D. Detecting tip spam in location-based social networks. In: Proceedings of the 28th Annual ACM Symposium on Applied Computing. Coimbra, Portugal: ACM, 2013. 724-729 [38] Costa H, Merschmann L H C, Barth F, Benevenuto F. Pollution, bad-mouthing, and local marketing: the underground of location-based social networks. Information Sciences, 2014, 279: 123-137 doi: 10.1016/j.ins.2014.03.108 [39] Benevenuto F, Rodrigues T, Almeida J, Goncalves M, Almeida V. Detecting spammers and content promoters in online video social networks. In: Proceedings of the 28th IEEE International Conference on Computer Communications Workshops. Rio de Janeiro, Brazil: IEEE, 2009. 337-338 -

 下载:
下载:


计量
- 文章访问数: 2630
- HTML全文浏览量: 482
- PDF下载量: 1184
- 被引次数: 0
