

-
摘要: 现阶段, 语音交互技术日益在现实生活中得到广泛的应用, 然而, 由于干扰的存在, 现实环境中的语音交互技术远没有达到令人满意的程度. 针对加性噪音的语音分离技术是提高语音交互性能的有效途径, 几十年来, 全世界范围内的许多研究者为此投入了巨大的努力, 提出了很多实用的方法. 特别是近年来, 由于深度学习研究的兴起, 基于深度学习的语音分离技术日益得到了广泛关注和重视, 显露出了相当光明的应用前景, 逐渐成为语音分离中一个新的研究趋势. 目前已有很多基于深度学习的语音分离方法被提出, 但是, 对于深度学习语音分离技术一直以来都缺乏一个系统的分析和总结, 不同方法之间的联系和区分也很少被研究. 针对这个问题, 本文试图对语音分离的主要流程和整体框架进行细致的分析和总结, 从特征、模型以及目标三个方面对现有的前沿研究进展进行全面而深入的综述, 最后对语音分离技术进行展望.Abstract: Nowadays, speech interaction technology has been widely used in our daily life. However, due to the interferences, the performances of speech interaction systems in real-world environments are far from being satisfactory. Speech separation technology has been proven to be an effective way to improve the performance of speech interaction in noisy environments. To this end, decades of efforts have been devoted to speech separation. There have been many methods proposed and a lot of success achieved. Especially with the rise of deep learning, deep learning-based speech separation has been proposed and extensively studied, which has been shown considerable promise and become a main research line. So far, there have been many deep learning-based speech separation methods proposed. However, there is little systematic analysis and summary on the deep learning-based speech separation technology. We try to give a detail analysis and summary on the general procedures and components of speech separation in this regard. Moreover, we survey a wide range of supervised speech separation techniques from three aspects: 1) features, 2) targets, 3) models. And finally we give some views on its developments.
-
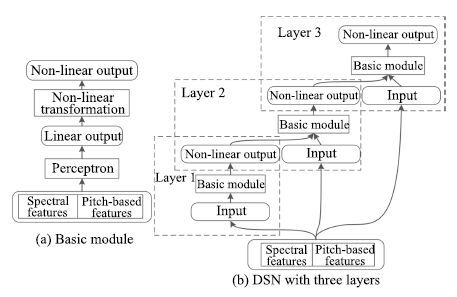
-
[1] Kim G, Lu Y, Hu Y, Loizou P C. An algorithm that improves speech intelligibility in noise for normal-hearing listeners. The Journal of the Acoustical Society of America, 2009, 126(3) : 1486-1494 [2] Dillon H. Hearing Aids. New York: Thieme, 2001. [3] Allen J B. Articulation and intelligibility. Synthesis Lectures on Speech and Audio Processing, 2005, 1(1) : 1-124 [4] Seltzer M L, Raj B, Stern R M. A Bayesian classifier for spectrographic mask estimation for missing feature speech recognition. Speech Communication, 2004, 43(4) : 379-393 [5] Weninger F, Erdogan H, Watanabe S, Vincent E, Le Roux J, Hershey J R, Schuller B. Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR. In: Proceedings of the 12th International Conference on Latent Variable Analysis and Signal Separation. Liberec, Czech Republic: Springer International Publishing, 2015. 91-99 [6] Weng C, Yu D, Seltzer M L, Droppo J. Deep neural networks for single-channel multi-talker speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(10) : 1670-1679 [7] Boll S F. Suppression of acoustic noise in speech using spectral subtraction. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1979, 27(2) : 113-120 [8] Chen J D, Benesty J, Huang Y T, Doclo S. New insights into the noise reduction wiener filter. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(4) : 1218-1234 [9] Loizou P C. Speech Enhancement: Theory and Practice. New York: CRC Press, 2007. [10] Liang S, Liu W J, Jiang W. A new Bayesian method incorporating with local correlation for IBM estimation. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(3) : 476-487 [11] Roweis S T. One microphone source separation. In: Proceedings of the 2000 Advances in Neural Information Processing Systems. Cambridge, MA: The MIT Press, 2000. 793-799 [12] Ozerov A, Vincent E, Bimbot F. A general flexible framework for the handling of prior information in audio source separation. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(4) : 1118-1133 [13] Reddy A M, Raj B. Soft mask methods for single-channel speaker separation. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(6) : 1766-1776 [14] Mohammadiha N, Smaragdis P, Leijon A. Supervised and unsupervised speech enhancement using nonnegative matrix factorization. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(10) : 2140-2151 [15] Virtanen T. Monaural sound source separation by nonnegative matrix factorization with temporal continuity and sparseness criteria. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(3) : 1066-1074 [16] Wang D L, Brown G J. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications. Piscataway: IEEE Press, 2006. [17] Wang Y X, Narayanan A, Wang D L. On training targets for supervised speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12) : 1849-1858 [18] Xu Y, Du J, Dai L R, Lee C H. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Processing Letters, 2014, 21(1) : 65-68 [19] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Deep learning for monaural speech separation. In: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing. Florence: IEEE, 2014. 1562-1566 [20] Weninger F, Hershey J R, Le Roux J, Schuller B. Discriminatively trained recurrent neural networks for single-channel speech separation. In: Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing. Atlanta, GA: IEEE, 2014. 577-581 [21] Wang Y X, Wang D L. A deep neural network for time-domain signal reconstruction. In: Proceedings of the 2015 IEEE International Conference on Acoustics, Speech, and Signal Processing. South Brisbane: IEEE, 2015. 4390-4394 [22] Simpson A J, Roma G, Plumbley M D. Deep karaoke: extracting vocals from musical mixtures using a convolutional deep neural network. In: Proceedings of the 12th International Conference on Latent Variable Analysis and Signal Separation. Liberec, Czech Republic: Springer International Publishing, 2015. 429-436 [23] Le Roux J, Hershey J R, Weninger F. Deep NMF for speech separation. In: Proceedings of the 2015 IEEE International Conference on Acoustics, Speech, and Signal Processing. South Brisbane: IEEE, 2015. 66-70 [24] Gabor D. Theory of communication. Part 1: the analysis of information. Journal of the Institution of Electrical Engineers����Part III: Radio and Communication Engineering, 1946, 93(26) : 429-441 [25] Patterson R, Nimmo-Smith I, Holdsworth J, Rice P. An efficient auditory filterbank based on the gammatone function. In: Proceedings of the 1987 Speech-Group Meeting of the Institute of Acoustics on Auditory Modelling. RSRE, Malvern, 1987. 2-18 [26] Wang Y X, Han K, Wang D L. Exploring monaural features for classification-based speech segregation. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(2) : 270-279 [27] Chen J T, Wang Y X, Wang D L. A feature study for classification-based speech separation at low signal-to-noise ratios. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12) : 1993-2002 [28] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Singing-voice separation from monaural recordings using deep recurrent neural networks. In: Proceedings of the 15th International Society for Music Information Retrieval. Taipei, China, 2014. [29] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(12) : 2136-2147 [30] Wang Y X, Wang D L. Towards scaling up classification-based speech separation. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(7) : 1381-1390 [31] Han K, Wang D L. A classification based approach to speech segregation. The Journal of the Acoustical Society of America, 2012, 132(5) : 3475-3483 [32] Han K, Wang D L. Towards generalizing classification based speech separation. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(1) : 168-177 [33] Nie S, Zhang H, Zhang X L, Liu W J. Deep stacking networks with time series for speech separation. In: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing. Florence: IEEE, 2014. 6667-6671 [34] Zhang H, Zhang X L, Nie S, Gao G L, Liu W J. A pairwise algorithm for pitch estimation and speech separation using deep stacking network. In: Proceedings of the 2015 IEEE International Conference on Acoustics, Speech, and Signal Processing. South Brisbane: IEEE, 2015. 246-250 [35] Han K, Wang Y X, Wang D L, Woods W S, Merks I, Zhang T. Learning spectral mapping for speech dereverberation and denoising. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(6) : 982-992 [36] Nie S, Xue W, Liang S, Zhang X L, Liu W J, Qiao L W, Li J P. Joint optimization of recurrent networks exploiting source auto-regression for source separation. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association. Dresden, Germany, 2015. [37] Dahl G E, Yu D, Deng L, Acero A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(1) : 30-42 [38] Wang Y X. Supervised Speech Separation Using Deep Neural Networks[Ph.D. dissertation], The Ohio State University, USA, 2015. [39] Weninger F, Eyben F, Schuller B. Single-channel speech separation with memory-enhanced recurrent neural networks. In: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing. Florence: IEEE, 2014. 3709-3713 [40] Hershey J R, Le Roux J, Weninger F. Deep unfolding: model-based inspiration of novel deep architectures. arXiv: 1409.2574, 2014. [41] Hsu C C, Chien J T, Chi T S. Layered nonnegative matrix factorization for speech separation. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association. Dresden, Germany: ICSA, 2015. 628-632 [42] Liang S, Liu W J, Jiang W, Xue W. The optimal ratio time-frequency mask for speech separation in terms of the signal-to-noise ratio. The Journal of the Acoustical Society of America, 2013, 134(5) : EL452-EL458 [43] Liang S, Liu W J, Jiang W, Xue W. The analysis of the simplification from the ideal ratio to binary mask in signal-to-noise ratio sense. Speech Communication, 2014, 59: 22-30 [44] Anzalone M C, Calandruccio L, Doherty K A, Carney L H. Determination of the potential benefit of time-frequency gain manipulation. Ear and Hearing, 2006, 27(5) : 480-492 [45] Brungart D S, Chang P S, Simpson B D, Wang D L. Isolating the energetic component of speech-on-speech masking with ideal time-frequency segregation. The Journal of the Acoustical Society of America, 2006, 120(6) : 4007-4018 [46] Li N, Loizou P C. Factors influencing intelligibility of ideal binary-masked speech: implications for noise reduction. The Journal of the Acoustical Society of America, 2008, 123(3) : 1673-1682 [47] Wang D L, Kjems U, Pedersen M S, Boldt J B, Lunner T. Speech intelligibility in background noise with ideal binary time-frequency masking. The Journal of the Acoustical Society of America, 2009, 125(4) : 2336-2347 [48] Hartmann W, Fosler-Lussier E. Investigations into the incorporation of the ideal binary mask in ASR. In: Proceedings of the 2011 IEEE International Conference on Acoustics, Speech, and Signal Processing. Prague: IEEE, 2011. 4804-4807 [49] Narayanan A, Wang D L. The role of binary mask patterns in automatic speech recognition in background noise. The Journal of the Acoustical Society of America, 2013, 133(5) : 3083-3093 [50] Paliwal K, Wójcicki K, Shannon B. The importance of phase in speech enhancement. Speech Communication, 2011, 53(4) : 465-494 [51] Mowlaee P, Saiedi R, Martin R. Phase estimation for signal reconstruction in single-channel speech separation. In: Proceedings of the 2012 International Conference on Spoken Language Processing. Portland, USA: ISCA, 2012. 1-4 [52] Krawczyk M, Gerkmann T. STFT phase reconstruction in voiced speech for an improved single-channel speech enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12) : 1931-1940 [53] Williamson D S, Wang Y X, Wang D L. Complex ratio masking for monaural speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(3) : 483-492 [54] Mallat S. A Wavelet Tour of Signal Processing. Burlington: Academic Press, 1999. [55] Hermansky H, Morgan N. Rasta processing of speech. IEEE Transactions on Speech and Audio Processing, 1994, 2(4) : 578-589 [56] Shao Y, Jin Z Z, Wang D L, Srinivasan S. An auditory-based feature for robust speech recognition. In: Proceedings of the 2009 IEEE International Conference on Acoustics, Speech, and Signal Processing. Taipei, China: IEEE, 2009. 4625-4628 [57] Hu G N, Wang D L. A tandem algorithm for pitch estimation and voiced speech segregation. IEEE Transactions on Audio, Speech, and Language Processing, 2010, 18(8) : 2067-2079 [58] Han K, Wang D L. An SVM based classification approach to speech separation. In: Proceedings of the 2011 IEEE International Conference on Acoustics, Speech, and Signal Processing. Prague: IEEE, 2011. 4632-4635 [59] Narayanan A, Wang D L. Investigation of speech separation as a front-end for noise robust speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(4) : 826-835 [60] Narayanan A, Wang D L. Improving robustness of deep neural network acoustic models via speech separation and joint adaptive training. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1) : 92-101 [61] Wang D L. On ideal binary mask as the computational goal of auditory scene analysis. Speech Separation by Humans and Machines. US: Springer, 2005. 181-197 [62] Healy E W, Yoho S E, Wang Y X, Wang D L. An algorithm to improve speech recognition in noise for hearing-impaired listeners. The Journal of the Acoustical Society of America, 2013, 134(4) : 3029-3038 [63] Kjems U, Boldt J B, Pedersen M S, Lunner T, Wang D L. Role of mask pattern in intelligibility of ideal binary-masked noisy speech. The Journal of the Acoustical Society of America, 2009, 126(3) : 1415-1426 [64] Srinivasan S, Roman N, Wang D L. Binary and ratio time-frequency masks for robust speech recognition. Speech Communication, 2006, 48(11) : 1486-1501 [65] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786) : 504-507 [66] Sprechmann P, Bruna J, LeCun Y. Audio source separation with discriminative scattering networks. In: Proceedings of the 12th International Conference on Latent Variable Analysis and Signal Separation. Liberec, Czech Republic: Springer International Publishing, 2015. 259-267 -

 下载:
下载:

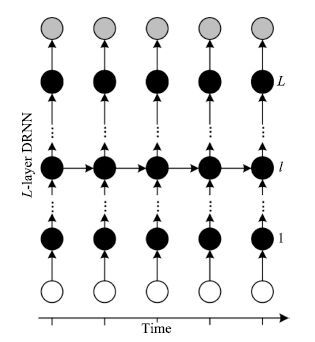

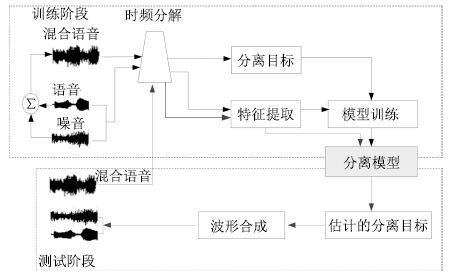
图(8)
计量
- 文章访问数: 5326
- HTML全文浏览量: 2376
- PDF下载量: 3745
- 被引次数: 0
