

-
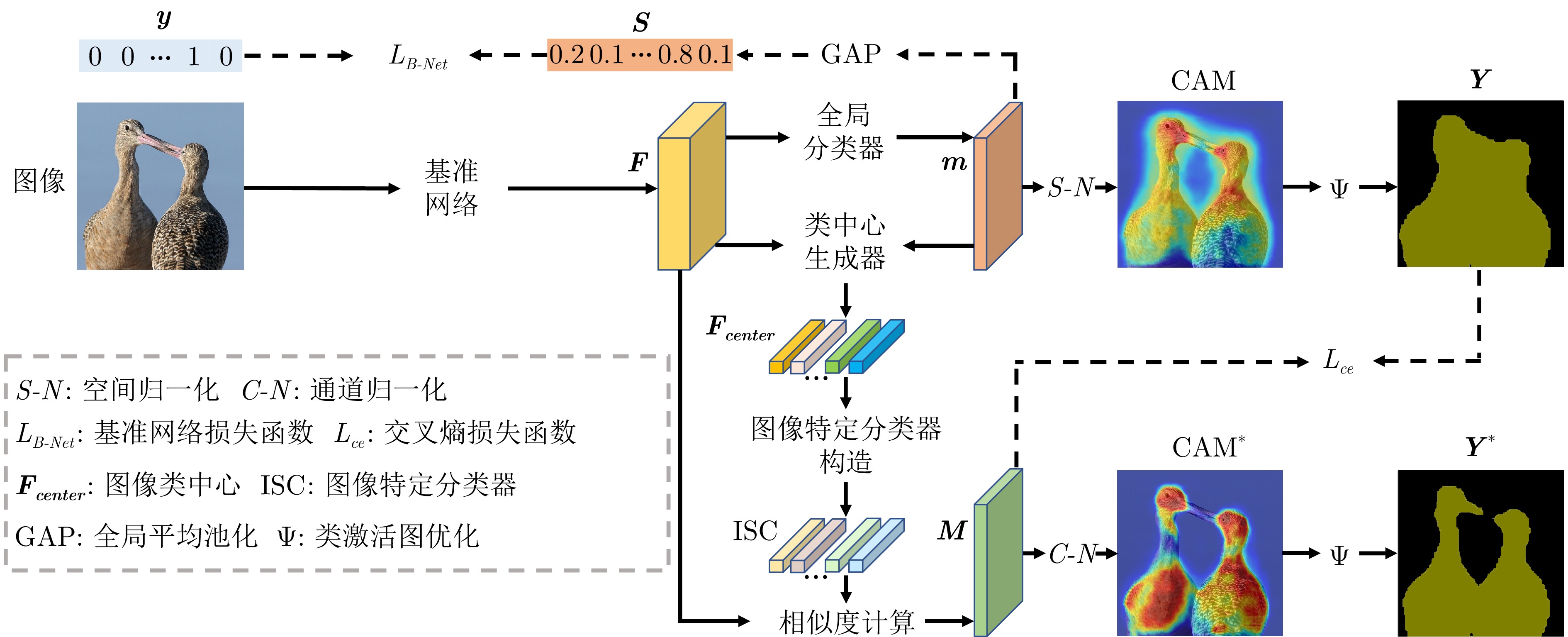
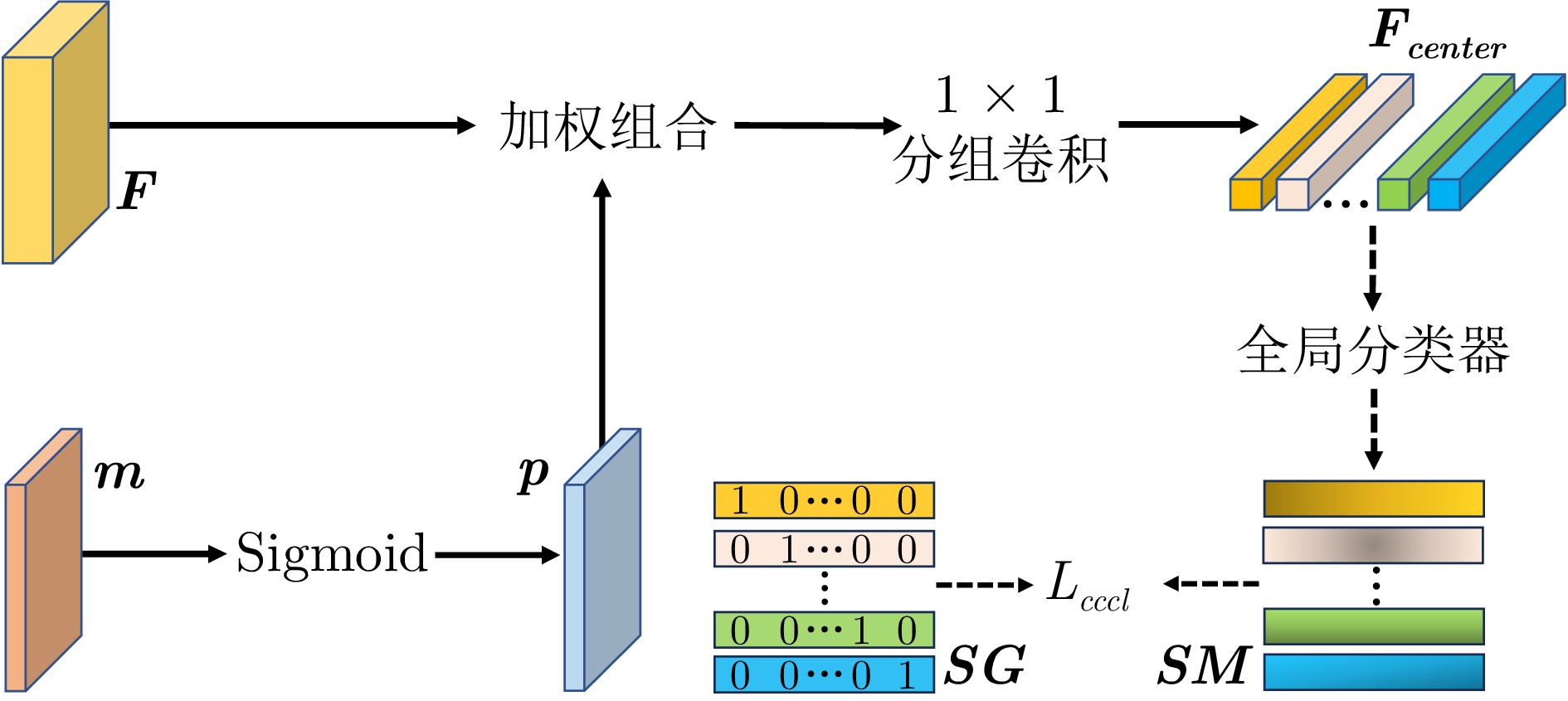
摘要: 基于图像级标签的弱监督语义分割算法因极低的标注成本引起学界广泛关注. 该领域的算法利用分类网络产生的类激活图实现从图像级标签到像素级标签的转化. 然而类激活图往往只关注于图像中最显著的区域, 致使基于类激活图产生的伪标签与真实标注存在较大差距, 主要包括前景未被有效激活的欠激活问题以及前景间预测混淆的错误激活问题. 欠激活源于数据集类内差异过大, 致使单一分类器不足以准确识别同一类别的所有像素; 错误激活则是数据集类间差异过小, 导致分类器不能有效区分不同类别的像素. 本文考虑到同一类别像素在图像内的差异小于在数据集中的差异, 设计基于类中心的图像特定分类器, 以提升对同类像素的识别能力, 从而改善欠激活, 同时考虑到类中心是类别在特征空间的代表, 设计类中心约束函数, 通过扩大类中心间的差距从而间接地疏远不同类别的特征分布, 以缓解错误激活现象. 图像特定分类器可以插入其他弱监督语义分割网络, 替代分类网络的分类器, 以产生更高质量的类激活图. 实验结果表明, 本文所提出的方案在两个基准数据集上均具有良好的表现, 证实了该方案的有效性.Abstract: Weakly supervised semantic segmentation algorithms based on image-level labels have garnered widespread attention due to their low annotation costs. These algorithms utilize class activation maps (CAMs) generated by classification networks to convert from image-level labels to pixel-level labels. However, CAMs only focus on the most discriminative regions in the image, resulting in a large gap between pseudo-labels generated by CAMs and ground truth. The gap includes under-activation and mis-activation issues. Under-activation arises from excessive intra-class differences in the dataset, making a single classifier insufficient to accurately identify all pixels of the same category, while mis-activation occurs when inter-class differences are too small, preventing the classifier from effectively distinguishing pixels of different categories. This paper considers that the intra-class difference for pixels of the same class within an image is smaller than that of the dataset, so we design the image-specific classifier based on the class center to enhance the recognition capability for pixels of the same class, thereby addressing the under-activation issue. Besides, considering that the class center serves as the representative of class in the feature space, we design the class center constrained loss function. By enlarging the distances of different class centers, this function indirectly pushes apart the feature distributions of different classes, thereby mitigating the issue of mis-activation. The proposed image-specific classifier can be plugged into other weakly supervised semantic segmentation networks, which can replace the classifiers of classification networks to generate higher quality CAMs. Experimental results demonstrate the superior performance of the proposed methods on two benchmark datasets, validating the effectiveness of this method.
-
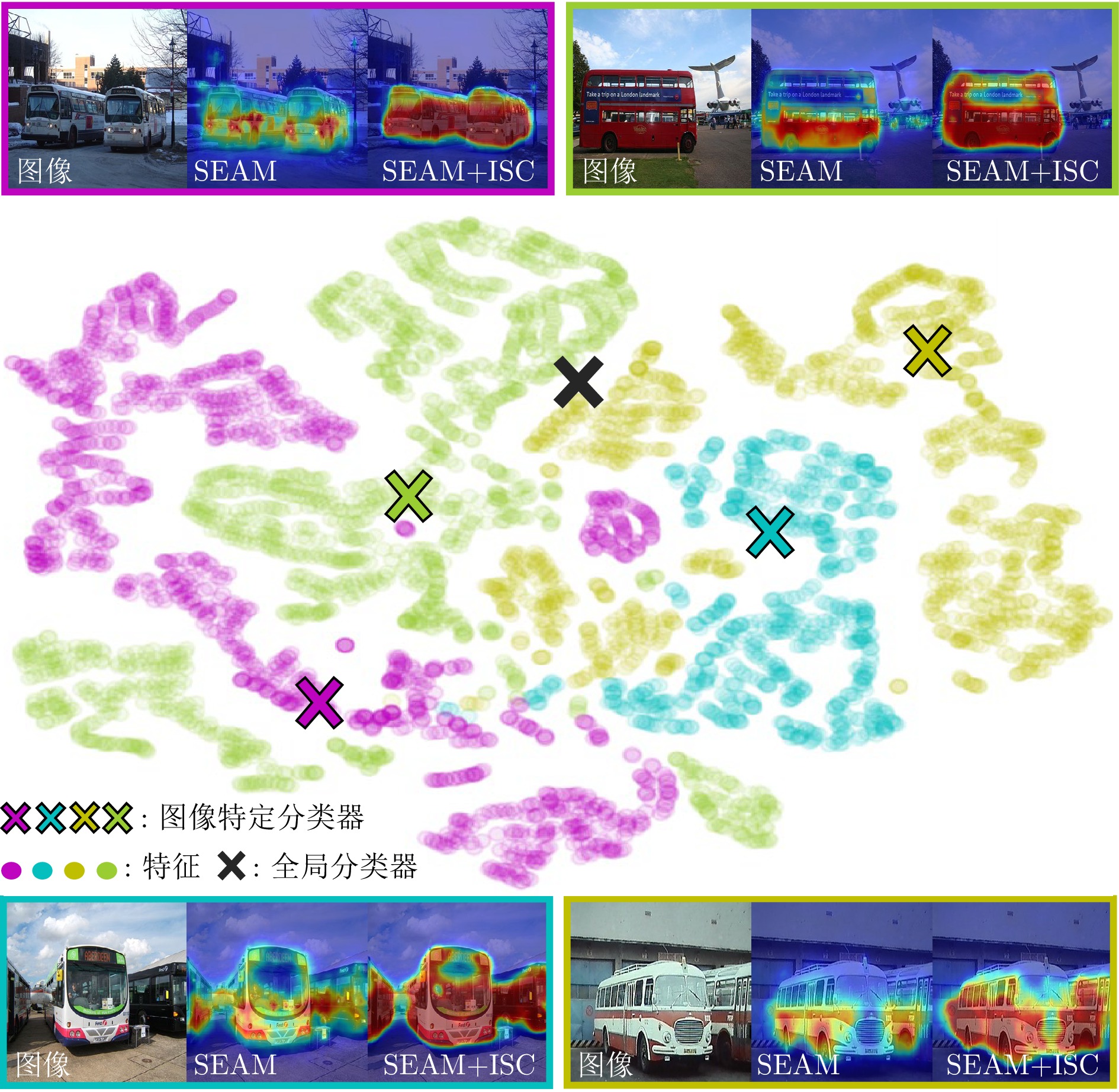
图 1 类激活图与特征、全局分类器以及图像特定分类器在t-SNE下的可视化结果
Fig. 1 The visualization results of CAMs, features, global classifier, and ISC under t-SNE
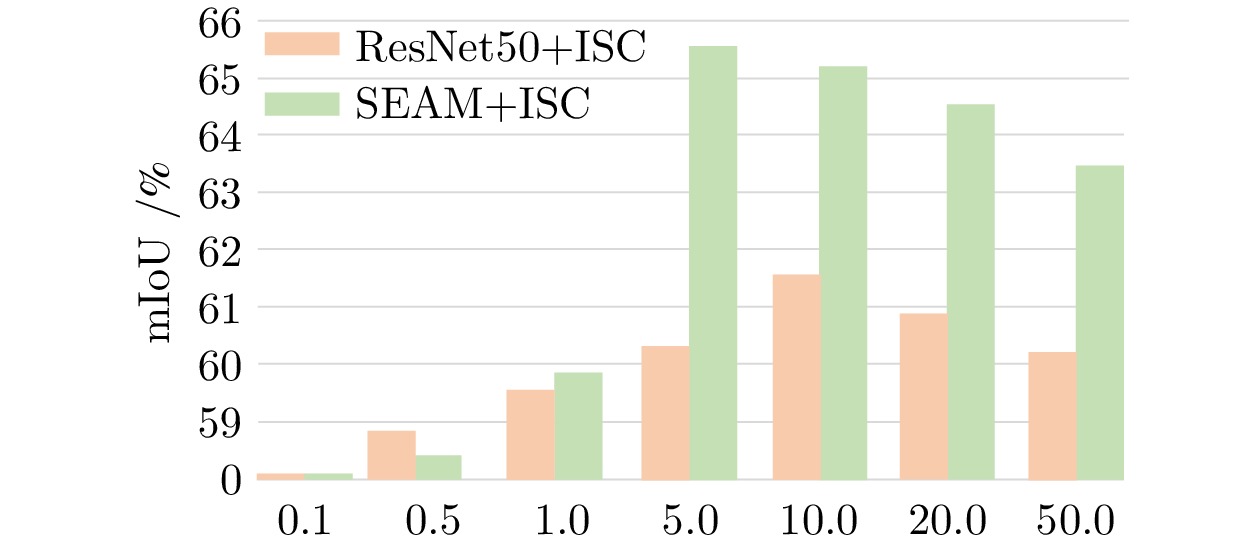
图 4 不同的$ \tau $对模型性能的影响
Fig. 4 The impact of different $ \tau $ values on the model's performance

图 5 不同方法产生的伪标签的可视化
Fig. 5 The visualization of the pseudo labels under different methods

图 6 DeepLabV2在PASCAL VOC 2012验证集上的预测结果与真实标签对比
Fig. 6 Comparison of the prediction results with the ground truth on the PASCAL VOC 2012 validation set
表 1 本方案中各组件性能对比
Table 1 Comparison of the performance about each component in this approach
R-50 ISC $ L_{cccl} $ 监督 优化 mIoU (%) CRF IRNet CRF IRNet $ \checkmark$ 48.5 $ \checkmark$ $ \checkmark$ 52.4 $ \checkmark$ $ \checkmark$ 66.5 $ \checkmark$ $ \checkmark$ $ \checkmark$ 54.3 $ \checkmark$ $ \checkmark$ $ \checkmark$ $ \checkmark$ 54.7 $ \checkmark$ $ \checkmark$ $ \checkmark$ 59.5 $ \checkmark$ $ \checkmark$ $ \checkmark$ $ \checkmark$ 61.5 $ \checkmark$ $ \checkmark$ $ \checkmark$ $ \checkmark$ 68.7 $ \checkmark$ $ \checkmark$ $ \checkmark$ $ \checkmark$ $ \checkmark$ 69.5  下载: 导出CSV
下载: 导出CSV
表 2 不同相似度度量算法对比
Table 2 Comparison of different similarity measurement algorithms
B-Net 距离 角度 卷积 mIoU ResNet50 51.3% 50.5% 54.3%
下载: 导出CSV
表 3 基于本文方法产生的类激活图以及伪标签与其他方法在PASCAL VOC 2012数据集上的对比 (%)
Table 3 Comparison about CAMs and pseudo labels generated by our method with those from other methods on the PASCAL VOC 2012 dataset (%)
方法 CAM 伪标签 SEAM[15] 55.4 63.6 IRNet[23] 48.3 66.5 CLIPES[41] 70.8 75.0 CLIPES+CPAL[42] 71.9 75.8 AdvCAM[43] 55.6 68.9 MCTformer[26] 61.7 69.1 FPR[44] 63.8 68.5 SEAM+OCR[45] 67.8 68.4 EPS*[24] 69.5 71.6 VIT-PCM†[46] 67.7 71.4 ToCo†[27] — 73.6 EPS*+PPC[14] 70.5 73.3 KTSE[47] 67.0 73.8 IRNet+Ours 61.5 69.5 SEAM+Ours 65.5 70.7 EPS*+Ours 71.9 74.4 CLIPES+SEAM+Ours 69.6 76.1 CLIPES+EPS*+Ours 73.5 76.8
下载: 导出CSV
表 4 与其他先进方法在PASCAL VOC 2012数据集上的分割性能对比
Table 4 Comparison of the segmentation performance with the state-of-the-art methods on the PASCAL VOC 2012 dataset
方法 监督 验证集(%) 测试集(%) IRNet[23] I 63.5 64.8 SEAM[15] I 64.5 65.7 SEAM+OCR[45] I 67.8 68.4 IRNet+ReCAM[37] I 68.7 68.5 IRNet+LPCAM[20] I 68.6 68.7 CLIMS[19] I+L 70.4 70.0 CLIPES[41] I+L 71.1 71.4 MCTformer[26] I 71.9 71.6 KTSE[47] I 73.0 72.9 CTI[48] I 74.1 73.8 CLIPES+CPAL[42] I+L 74.5 74.7 AuxSegNet[49] I+S 69.0 68.6 Yazhou Yao[50] I+S 70.4 70.2 EPS[24] I+S 70.9 70.8 SANCE[51] I+S 72.0 72.9 RCA[52] I+S 72.2 72.8 EPS+PPC[14] I+S 72.6 73.6 SEAM+Ours I 68.9 70.0 IRNet+Ours I 69.5 70.0 EPS+Ours I+S 73.1 73.5 CLIPES+SEAM+Ours I+L 74.1 74.1 CLIPES+EPS+Ours I+S+L 74.4 74.8
下载: 导出CSV
表 5 与其他先进方法在MS COCO 2014数据集上的分割性能对比
Table 5 Comparison of the segmentation performance with the state-of-the-art methods on the MS COCO 2014 dataset
方法 骨架网络 监督 验证集(%) PSA[9] ResNet38 I 29.5 SEAM[15] ResNet38 I 31.9 SEAM+OCR[45] ResNet38 I 33.2 CDA[53] ResNet38 I 33.2 URN[31] ResNet101 I 40.7 IRNet[23] ResNet101 I 42.0 IRNet+ReCAM[37] ResNet101 I 42.9 IRNet+LPCAM[20] ResNet101 I 44.5 RIB[54] ResNet101 I 44.5 BECO[32] ResNet101 I 45.1 EPS[24] ResNet101 I+S 35.7 RCA[52] ResNet101 I+S 36.8 L2G[55] ResNet101 I+S 44.2 IRNet+Ours ResNet101 I 44.6 BECO+Ours ResNet101 I 45.4
下载: 导出CSV
表 6 与其他可插入性方法的计算开销对比
Table 6 Comparison of computational overhead with other pluggable methods
下载: 导出CSV
表 7 不同形式的类中心约束函数对实验结果的影响, 其中基线代表ResNet50+ISC
Table 7 The impact of different forms of class center constrained loss function on experimental results, where the baseline represents ResNet50+ISC
方法 基线 $ L_{cccl} $ $ L_{info} $ $ {\boldsymbol{w}} $ $ {{\boldsymbol{w}}_{{\boldsymbol{aux}}}} $ mIoU (%) 59.5 61.5 61.0 60.4
下载: 导出CSV
-
[1] 徐鹏斌, 瞿安国, 王坤峰, 李大字. 全景分割研究综述. 自动化学报, 2021, 47(3): 549−568Xu Peng-Bin, Qu An-Guo, Wang Kun-Feng, Li Da-Zi. A survey of panoptic segmentation methods. Acta Automatica Sinica, 2021, 47(3): 549−568 [2] 张琳, 陆耀, 卢丽华, 周天飞, 史青宣. 一种改进的视频分割网络及其全局信息优化方法. 自动化学报, 2022, 48(3): 787−796Zhang Lin, Lu Yao, Lu Li-Hua, Zhou Tian-Fei, Shi Qing-Xuan. An improved video segmentation network and its global information optimization method. Acta Automatica Sinica, 2022, 48(3): 787−796 [3] 胡斌, 何克忠. 计算机视觉在室外移动机器人中的应用. 自动化学报, 2006, 32(5): 774−784Hu Bin, He Ke-Zhong. Applications of computer vision to outdoor mobile robot. Acta Automatica Sinica, 2006, 32(5): 774−784 [4] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 3431−3440 [5] Zheng S X, Lu J C, Zhao H S, Zhu X T, Luo Z K, Wang Y B, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with Transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 6881−6890 [6] Cordts M, Omran M, Ramos S, Rehfeld T, Enzweiler M, Benenson R, et al. The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 3213−3223 [7] Lee J, Yi J H, Shin C, Yoon S. BBAM: Bounding box attribution map for weakly supervised semantic and instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 2643−2652 [8] Lin D, Dai J F, Jia J Y, He K M, Sun J. ScribbleSup: Scribble-supervised convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 3159−3167 [9] Ahn J, Kwak S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 4981−4990 [10] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2921−2929 [11] Hou Q B, Jiang P T, Wei Y C, Cheng M M. Self-erasing network for integral object attention. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates, 2018. 549−559 [12] Kweon H, Yoon S H, Kim H, Park D, Yoon K J. Unlocking the potential of ordinary classifier: Class-specific adversarial erasing framework for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montréal, Canada: IEEE, 2021. 6994−7003 [13] Chen L Y, Wu W W, Fu C C, Han X, Zhang Y T. Weakly supervised semantic segmentation with boundary exploration. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 347−362 [14] Du Y, Fu Z H, Liu Q J, Wang Y H. Weakly supervised semantic segmentation by pixel-to-prototype contrast. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 4320−4329 [15] Wang Y D, Zhang J, Kan M N, Shan S G, Chen X L. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 12275−12284 [16] Everingham M, ali Eslami S M, van Gool L, Williams C K I, Winn J, Zisserman A. The PASCAL visual object classes challenge: A retrospective. International Journal of Computer Vision, 2015, 111(1): 98−136 doi: 10.1007/s11263-014-0733-5 [17] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 740−755 [18] Kim B, Han S, Kim J. Discriminative region suppression for weakly-supervised semantic segmentation. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI, 2021. 1754−1761 [19] Chen Q, Yang L X, Lai J H, Xie X H. Self-supervised image-specific prototype exploration for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 4288−4298 [20] Chen Z Z, Sun Q R. Extracting class activation maps from non-discriminative features as well. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 3135−3144 [21] Xie J H, Hou X X, Ye K, Shen L L. CLIMS: Cross language image matching for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 4483−4492 [22] Krähenbühl P, Koltun V. Efficient inference in fully connected CRFs with Gaussian edge potentials. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Granada, Spain: Curran Associates, 2011. 109−117 [23] Ahn J, Cho S, Kwak S. Weakly supervised learning of instance segmentation with inter-pixel relations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 2209−2218 [24] Lee S, Lee M, Lee J, Shim H. Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 5495−5505 [25] Wu T, Huang J S, Gao G Y, Wei X M, Wei X L, Luo X, et al. Embedded discriminative attention mechanism for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 16765−16774 [26] Xu L, Ouyang W L, Bennamoun M, Boussaid F, Xu D. Multi-class token Transformer for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 4310−4319 [27] Ru L X, Zheng H L, Zhan Y B, Du B. Token contrast for weakly-supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 3093−3102 [28] Chen L C, Papandreou G, Kokkinos I, Murphy K, Yuille A L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834−848 doi: 10.1109/TPAMI.2017.2699184 [29] Zhao H S, Shi J P, Qi X J, Wang X G, Jia J Y. Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 2881−2890 [30] Li Y, Kuang Z H, Liu L Y, Chen Y M, Zhang W. Pseudo-mask matters in weakly-supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montréal, Canada: IEEE, 2021. 6964−6973 [31] Li Y, Duan Y Q, Kuang Z H, Chen Y M, Zhang W, Li X M. Uncertainty estimation via response scaling for pseudo-mask noise mitigation in weakly-supervised semantic segmentation. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI, 2022. 1447−1455 [32] Rong S H, Tu B H, Wang Z L, Li J J. Boundary-enhanced co-training for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 19574−19584 [33] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [34] Zhang F, Chen Y Q, Li Z H, Hong Z B, Liu J T, Ma F F, et al. ACFNet: Attentional class feature network for semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, South Korea: IEEE, 2019. 6798−6807 [35] Yuan Y H, Chen X L, Wang J D. Object-contextual representations for semantic segmentation. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 173−190 [36] Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 8748−8763 [37] Chen Z Z, Wang T, Wu X W, Hua X S, Zhang H W, Sun Q R. Class re-activation maps for weakly-supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 969−978 [38] Hariharan B, Arbeláez P, Bourdev L, Maji S, Malik J. Semantic contours from inverse detectors. In: Proceedings of the International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 991−998 [39] Wu Z F, Shen C H, van den Hengel A. Wider or deeper: Revisiting the ResNet model for visual recognition. Pattern Recognition, 2019, 99: 119−133 [40] Deng J, Dong W, Socher R, Li L J, Li K, Li F F. ImageNet: A large-scale hierarchical image database. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 248−255 [41] Lin Y Q, Chen M H, Wang W X, Wu B X, Li K, Lin B B, et al. CLIP is also an efficient segmenter: A text-driven approach for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 15305−15314 [42] Tang F L, Xu Z X, Qu Z J, Feng W, Jiang X J, Ge Z Y. Hunting attributes: Context prototype-aware learning for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 3324−3334 [43] Lee J, Kim E, Yoon S. Anti-adversarially manipulated attributions for weakly and semi-supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 4071−4080 [44] Chen L Y, Lei C Y, Li R H, Li S, Zhang Z X, Zhang L. FPR: False positive rectification for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 1108−1118 [45] Cheng Z S, Qiao P C, Li K H, Li S H, Wei P X, Ji X Y, et al. Out-of-candidate rectification for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 23673−23684 [46] Rossetti S, Zappia D, Sanzari M, Schaerf M, Pirri F. Max pooling with vision Transformers reconciles class and shape in weakly supervised semantic segmentation. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 446−463 [47] Chen T, Jiang X R, Pei G S, Sun Z R, Wang Y C, Yao Y Z. Knowledge transfer with simulated inter-image erasing for weakly supervised semantic segmentation. In: Proceedings of the 18th European Conference on Computer Vision. Milan, Italy: Springer, 2025. 441−458 [48] Yoon S H, Kwon H, Kim H, Yoon K J. Class tokens infusion for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 3595−3605 [49] Xu L, Ouyang W L, Bennamoun M, Boussaid F, Sohel F, Xu D. Leveraging auxiliary tasks with affinity learning for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montréal, Canada: IEEE, 2021. 6984−6993 [50] Yao Y Z, Chen T, Xie G S, Zhang C Y, Shen F M, Wu Q, et al. Non-salient region object mining for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 2623−2632 [51] Li J, Fan J S, Zhang Z X. Towards noiseless object contours for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 16856−16865 [52] Zhou T F, Zhang M J, Zhao F, Li J W. Regional semantic contrast and aggregation for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 4299−4309 [53] Su Y K, Sun R Z, Lin G S, Wu Q Y. Context decoupling augmentation for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montréal, Canada: IEEE, 2021. 7004−7014 [54] Lee J, Choi J, Mok J, Yoon S. Reducing information bottleneck for weakly supervised semantic segmentation. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates, 2021. 27408−27421 [55] Jiang P T, Yang Y Q, Hou Q B, Wei Y C. L2G: A simple local-to-global knowledge transfer framework for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 16886−16896 [56] van den Oord A, Li Y Z, Vinyals O. Representation learning with contrastive predictive coding. arXiv preprint arXiv: 1807.03748, 2018. -

计量
- 文章访问数: 239
- HTML全文浏览量: 202
- PDF下载量: 47
- 被引次数: 0
