

Multi-USVs Cooperative Policy Optimization Method Based on Disturbed Input of Advantage Function
-
摘要: 多无人艇(Multiple unmanned surface vehicles, Multi-USVs)协同导航对于实现高效的海上作业至关重要, 而如何在开放未知海域处理多艇之间复杂的协作关系、实现多艇自主协同决策是当前亟待解决的难题. 近年来, 多智能体强化学习(Multi-agent reinforcement learning, MARL)在解决复杂的多体决策问题上展现出巨大的潜力, 被广泛应用于多无人艇协同导航任务中. 然而, 这种基于数据驱动的方法通常存在探索效率低、探索与利用难平衡、易陷入局部最优等问题. 因此, 在集中训练和分散执行(Centralized training and decentralized execution, CTDE)框架的基础上, 考虑从优势函数输入端注入扰动量来提升优势函数的泛化能力, 提出一种新的基于优势函数输入扰动的多智能体近端策略优化(Noise-advantage multi-agent proximal policy optimization, NA-MAPPO)方法, 从而提升多无人艇协同策略的探索效率. 实验结果表明, 与现有的基准算法相比, 所提方法能够有效提升多无人艇协同导航任务的成功率, 缩短策略的训练时间以及任务的完成时间, 从而提升多无人艇协同探索效率, 避免策略陷入局部最优.Abstract: Cooperative navigation of multiple unmanned surface vehicles (Multi-USVs) is crucial for achieving efficient maritime operations. However, it remains challenging to address the complex collaborative relationship of Multi-USVs and enable autonomous cooperative decision-making in open and unknown sea areas. In recent years, multi-agent reinforcement learning (MARL) has shown significant potential in addressing complex multi-agent decision-making problems and has been widely applied in the cooperative navigation tasks of Multi-USVs. Nevertheless, the data-driven method often encounters problems such as low exploration efficiency, difficulty in balancing exploration and utilization, and the likelihood of getting stuck in local optima. Therefore, under the centralized training and decentralized execution (CTDE) framework, this paper considers injecting disturbances into the advantage function and its input data to improve the generalization ability of the advantage function. Then, a novel noise-advantage multi-agent proximal policy optimization (NA-MAPPO) method is proposed, thereby enhancing the exploration efficiency of the cooperative policy for Multi-USVs. Experimental results demonstrate that compared to the existing benchmark algorithms, the proposed method can significantly improve the success rate of the cooperative navigation tasks, reduce the time of training policy and the time of completing task, thereby enhancing the cooperative exploration efficiency of the Multi-USVs system and preventing the policy from falling into local optimum.
-

图 2 无人艇的惯性坐标系和体固定坐标系
Fig. 2 The body-fixed coordinate system and inertial coordinate system of USV
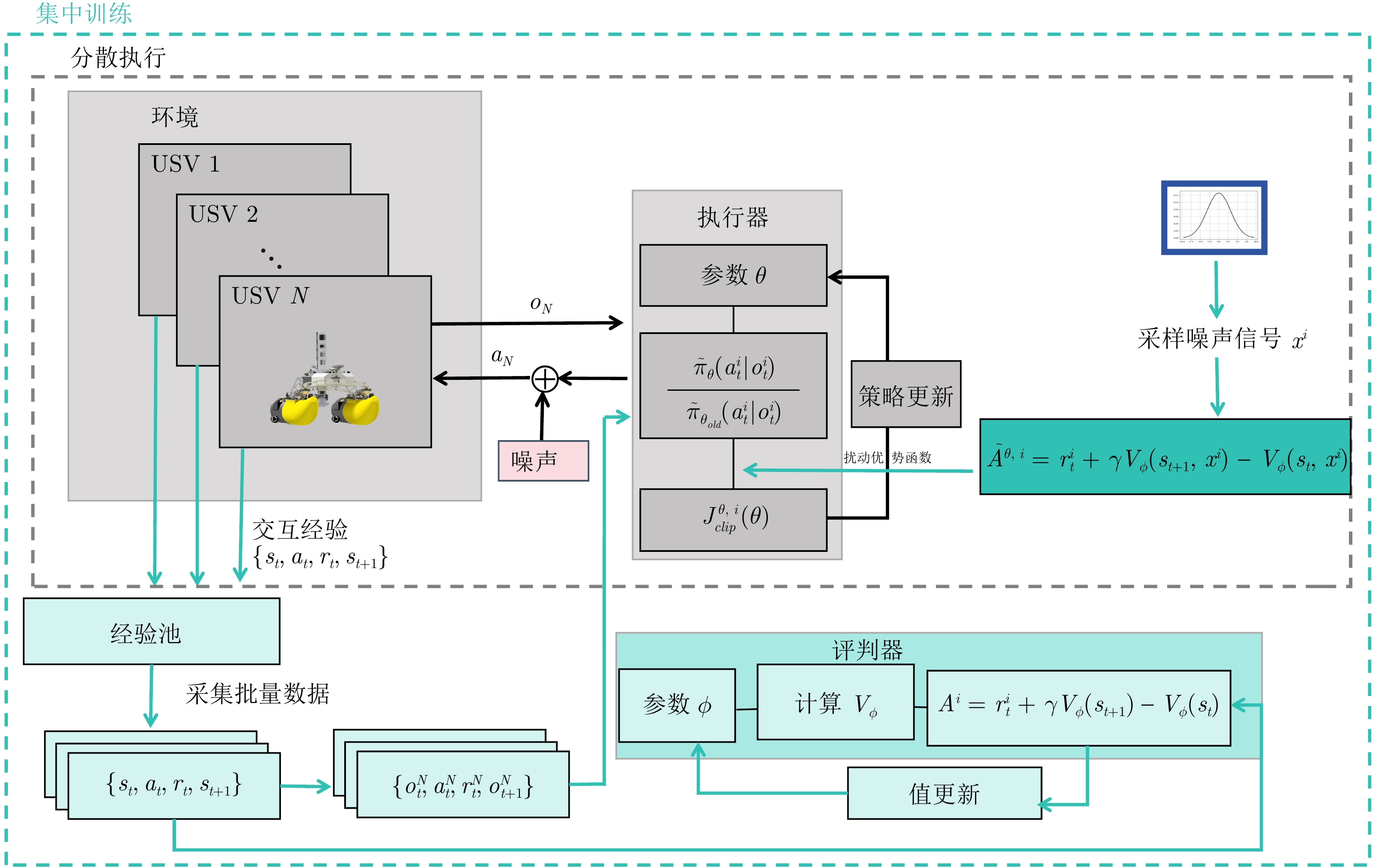
图 4 NA-MAPPO示意图, 灰色部分为分散执行部分, 蓝色部分为集中训练部分
Fig. 4 Diagram of NA-MAPPO, the gray section represents the decentralized execution part, while the blue section represents the centralized training part
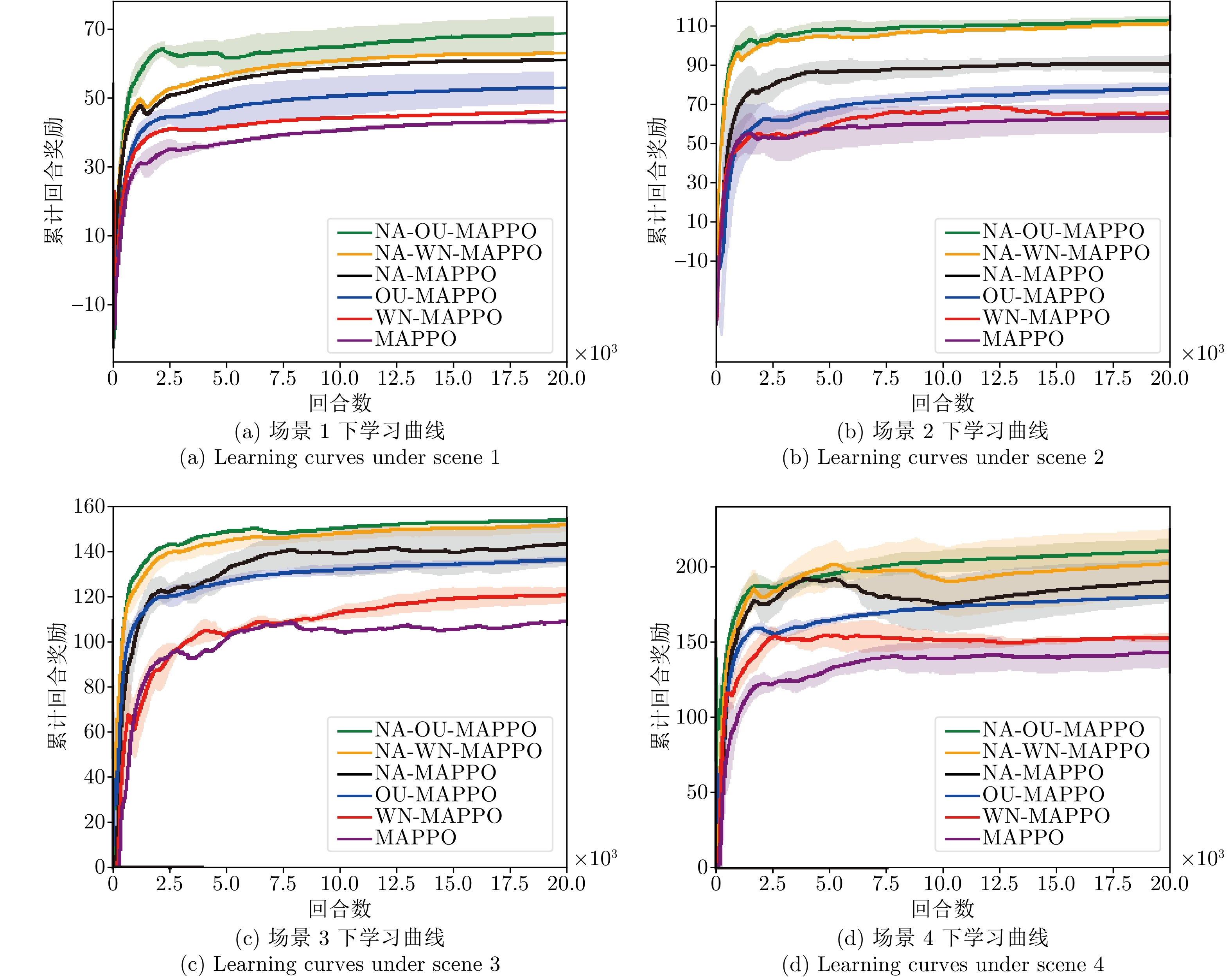
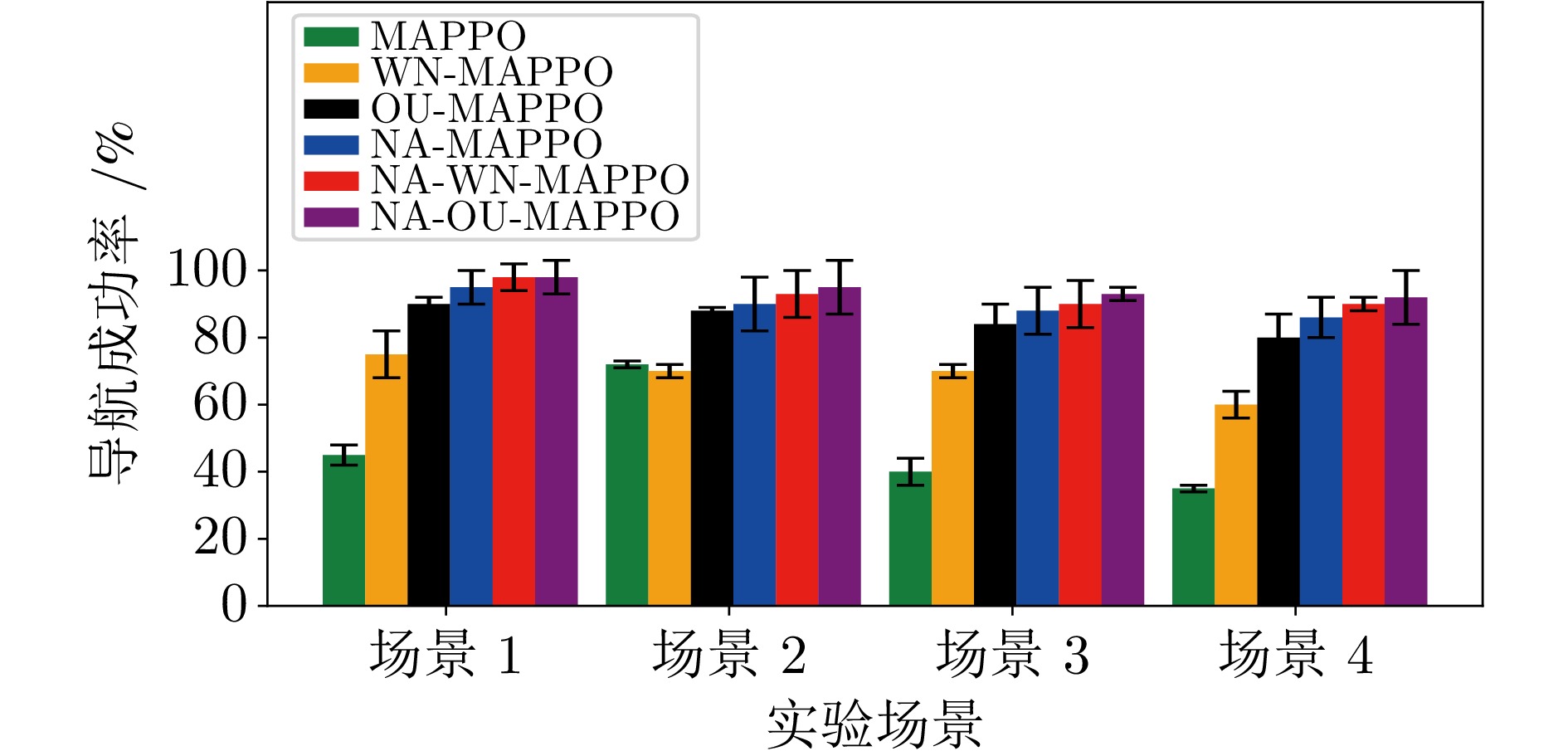
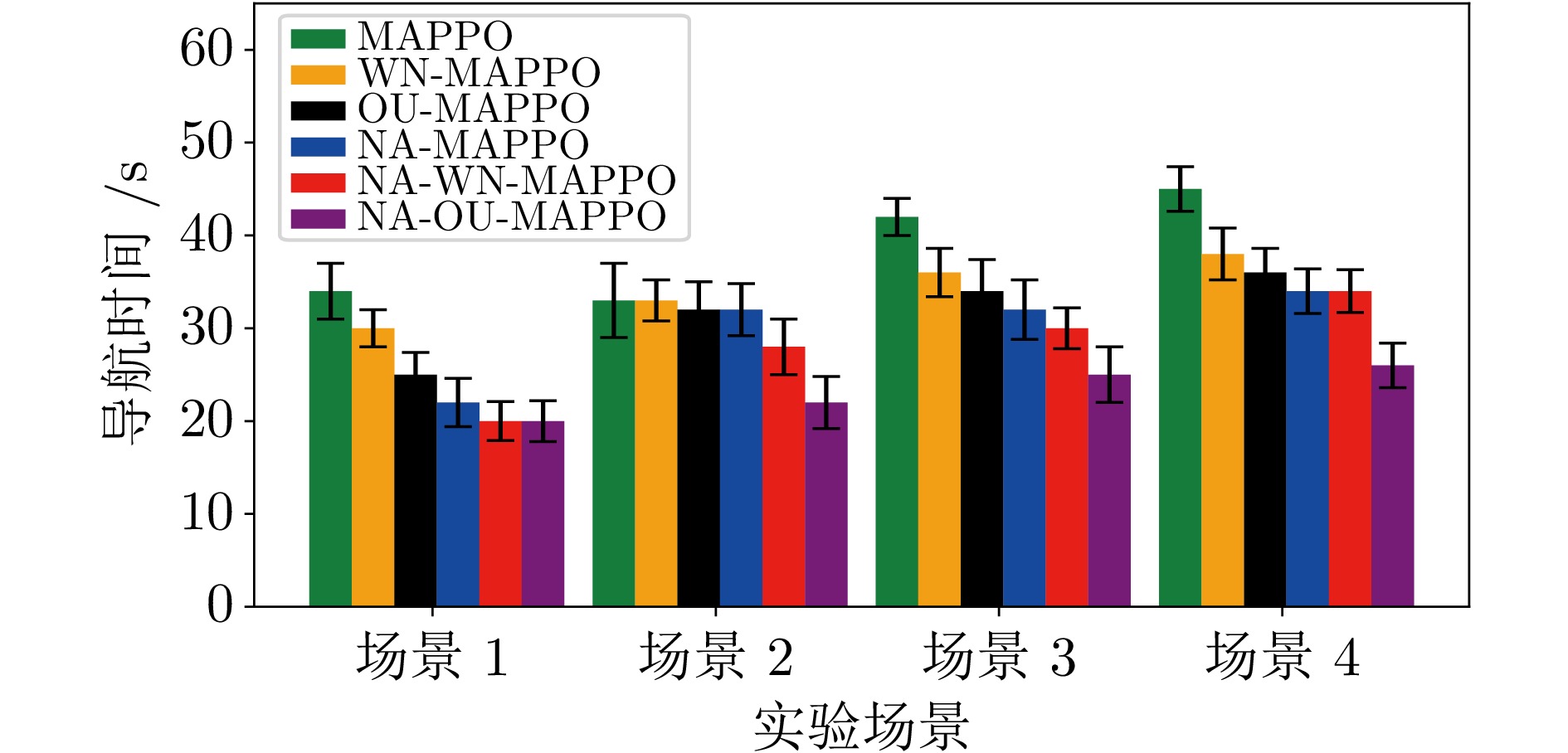
表 1 导航成功率、导航时间、累计回合奖励对比
Table 1 Comparison of navigation success rate, navigation time, and cumulative episode reward
导航成功率(%) MAPPO WN-MAPPO OU-MAPPO NA-MAPPO NA-WN-MAPPO NA-OU-MAPPO 场景1 45 75 90 95 98 98 场景2 72 70 88 90 93 95 场景3 40 70 84 88 90 93 场景4 35 60 80 86 90 92 导航时间(s) MAPPO WN-MAPPO OU-MAPPO NA-MAPPO NA-WN-MAPPO NA-OU-MAPPO 场景1 34 30 25 22 20 20 场景2 33 33 32 32 28 22 场景3 42 36 34 32 30 25 场景4 45 38 36 34 34 26 累积回合奖励 MAPPO WN-MAPPO OU-MAPPO NA-MAPPO NA-WN-MAPPO NA-OU-MAPPO 场景1 42.93 45.45 52.50 68.50 70 72.6 场景2 70.00 65.80 78.02 90.50 100 100.0 场景3 109.05 120.85 136.47 143.33 151 154.0 场景4 134.05 143.36 153.09 190.66 200 200.0  下载: 导出CSV
下载: 导出CSV
表 2 实验超参数设置
Table 2 Experimental hyperparameter setting
参数 值 折扣因子$ \gamma $ 0.9000 Critic网络的学习率$ {\alpha _w} $ 0.0010 Actor网络的学习率$ {\alpha _u} $ 0.0001 目标Critic网络的学习率$ {\alpha _{w'}} $ 0.0010 批量$ N _{\mathrm{batch}}$ 1024 缓冲器尺寸$ M_{\mathrm{buffer}} $ 10000 软更新因子$ \tau $ 0.0010 隐藏层1神经元数 128 隐藏层2神经元数 128
下载: 导出CSV
-
[1] Li J Q, Zhang G Q, Zhang X K, Zhang W D. Integrating dynamic event-triggered and sensor-tolerant control: Application to USV-UAVs cooperative formation system for maritime parallel search. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(5): 3986−3998 doi: 10.1109/TITS.2023.3326271 [2] Madeo D, Pozzebon A, Mocenni C, Bertoni D. A low-cost unmanned surface vehicle for pervasive water quality monitoring. IEEE Transactions on Instrumentation and Measurement, 2020, 69(4): 1433−1444 doi: 10.1109/TIM.2019.2963515 [3] Xie J J, Zhou R, Luo J, Peng Y, Liu Y, Xie S R, et al. Hybrid partition-based patrolling scheme for maritime area patrol with multiple cooperative unmanned surface vehicles. Journal of Marine Science and Engineering, 2020, 8(11): Article No. 936 doi: 10.3390/jmse8110936 [4] Zuo Z Y, Liu C J, Han Q L, Song J W. Unmanned aerial vehicles: Control methods and future challenges. IEEE/CAA Journal of Automatica Sinica, 2022, 9(4): 601−614 doi: 10.1109/JAS.2022.105410 [5] Zhang G Q, Han J, Li J Q, Zhang X K. APF-based intelligent navigation approach for USV in presence of mixed potential directions: Guidance and control design. Ocean Engineering, 2022, 260: Article No. 111972 doi: 10.1016/j.oceaneng.2022.111972 [6] Wang D, Chen H M, Lao S H, Drew S. Efficient path planning and dynamic obstacle avoidance in edge for safe navigation of USV. IEEE Internet of Things Journal, 2024, 11(6): 10084−10094 doi: 10.1109/JIOT.2023.3325234 [7] Zhang G Q, Shang X Y, Li J Q, Huang J S. A novel dynamic berthing scheme for an USV: DPFS guidance and two-dimensional event triggering ILC. IEEE Transactions on Intelligent Vehicles, DOI: 10.1109/TIV.2024.3402229 [8] Wang C C, Wang Y L, Han Q L, Xie W B. Multi-USV cooperative formation control via deep reinforcement learning with deceleration. IEEE Transactions on Intelligent Vehicles, DOI: 10.1109/TIV.2024.3437735 [9] Yu J B, Chen Z H, Zhao Z Y, Deng H, Wu J G, Xu J P. A cooperative hunting method for multi-USVs based on trajectory prediction by OR-LSTM. IEEE Transactions on Vehicular Technology, DOI: 10.1109/TVT.2024.3432739 [10] Wang Y D, Cao J Y, Sun J, Zou X S, Sun C Y. Path following control for unmanned surface vehicles: A reinforcement learning-based method with experimental validation. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2023.3313312 [11] Xi A, Mudiyanselage T W, Tao D C, Chen C. Balance control of a biped robot on a rotating platform based on efficient reinforcement learning. IEEE/CAA Journal of Automatica Sinica, 2019, 6(4): 938−951 doi: 10.1109/JAS.2019.1911567 [12] Yang H, Lin K, Xiao L, Zhao Y, Xiong Z, Han Z. Energy harvesting UAV-RIS-assisted maritime communications based on deep reinforcement learning against jamming. IEEE Transactions on Wireless Communications, 2024, 23(8): 1−15 doi: 10.1109/TWC.2024.3417154 [13] Wang C C, Wang Y L, Han Q L, Wu Y K. MUTS-based cooperative target stalking for a multi-USV system. IEEE/CAA Journal of Automatica Sinica, 2023, 10(7): 1582−1592 doi: 10.1109/JAS.2022.106007 [14] Feng Z K, Huang M X, Wu D, Wu E Q, Yuen C. Multi-agent reinforcement learning with policy clipping and average evaluation for UAV-assisted communication Markov game. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(12): 14281−14293 doi: 10.1109/TITS.2023.3296769 [15] Wu Q C, Lin R, Ren Z W. Distributed multirobot path planning based on MRDWA-MADDPG. IEEE Sensors Journal, 2023, 23(20): 25420−25432 doi: 10.1109/JSEN.2023.3310519 [16] Zhang H, Zhang X H, Feng Z, Xiao X H. Heterogeneous multi-robot cooperation with asynchronous multi-agent reinforcement learning. IEEE Robotics and Automation Letters, 2024, 9(1): 159−166 doi: 10.1109/LRA.2023.3328448 [17] Sunehag P, Lever G, Gruslys A, Czarnecki W M, Zambaldi V, Jaderberg M, et al. Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv: 1706.05296, 2017. [18] Rashid T, Samvelyan M, de Witt C S, Farquhar G, Foerster J, Whiteson S. QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. arXiv preprint arXiv: 1803.11485, 2018. [19] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. California, USA: Curran Associates Inc., 2017. 6382−6393 [20] Yu C, Velu A, Vinitsky E, Wang Y, Bayen A, Wu Y. The surprising effectiveness of PPO in cooperative multi-agent games. arXiv preprint arXiv: 2103.01955, 2021. [21] Foerster J N, Farquhar G, Afouras T, Nardelli N, Whiteson S. Counterfactual multi-agent policy gradients. arXiv preprint arXiv: 1705.08926, 2017. [22] Liu Y, Chen C, Qu D, Zhong Y X, Pu H Y, Luo J. Multi-USV system antidisturbance cooperative searching based on the reinforcement learning method. IEEE Journal of Oceanic Engineering, 2023, 48(4): 1019−1047 doi: 10.1109/JOE.2023.3281630 [23] Wang C C, Wang Y L, Shi P, Wang F. Scalable-MADDPG-based cooperative target invasion for a multi-USV system. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2023.3309689 [24] Xia J W, Luo Y S, Liu Z K, Zhang Y L, Shi H R, Liu Z. Cooperative multi-target hunting by unmanned surface vehicles based on multi-agent reinforcement learning. Defence Technology, 2023, 29: 80−94 doi: 10.1016/j.dt.2022.09.014 [25] Zhao Y J, Ma Y, Hu S L. USV formation and path-following control via deep reinforcement learning with random braking. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(12): 5468−5478 doi: 10.1109/TNNLS.2021.3068762 [26] Li F B, Yin M M, Wang T D, Huang T W, Yang C H, Gui W H. Distributed pursuit-evasion game of limited perception USV swarm based on multi-agent proximal policy optimization. IEEE Tansactions on Systems, Man, and Cybernetics: Systems, 2024, 54(10): 6435−6446 doi: 10.1109/TSMC.2024.3429467 [27] Gan W H, Qu X Q, Song D L, Yao P. Multi-USV cooperative chasing strategy based on obstacles assistance and deep reinforcement learning. IEEE Transactions on Automation Science and Engineering, 2024, 21(4): 5895−5910 doi: 10.1109/TASE.2023.3319510 [28] Eberhard O, Hollenstein J, Pinneri C, Martius G. Pink noise is all you need: Colored noise exploration in deep reinforcement learning. In: Proceedings of the 11th International Conference on Learning Representations. New Orleans, USA: OpenReview.net, 2019. [29] Raffin A, Hill A, Gleave A, Kanervisto A, Ernestus M, Dormann N. Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research, 2021, 22(268): 1−8 [30] Plappert M, Houthooft R, Dhariwal P, Sidor S, Chen R Y, Chen X, et al. Parameter space noise for exploration. arXiv preprint arXiv: 1706.01905, 2018. [31] Hu J, Hu S Y, Liao S W. Policy regularization via noisy advantage values for cooperative multi-agent actor-critic methods. arXiv preprint arXiv: 2106.14334, 2023. [32] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. arXiv preprint arXiv: 1509.02971, 2019. -



计量
- 文章访问数: 547
- HTML全文浏览量: 277
- PDF下载量: 111
- 被引次数: 0
