

-
摘要: 现有视觉缺陷检测技术通常基于传统电荷耦合器件(Charge-coupled device, CCD)或互补金属氧化物半导体(Complementary metal-oxide-semiconductor, CMOS)相机进行缺陷成像和后端检测算法开发. 然而, 现有技术存在成像速度慢、动态范围小、背景干扰大等问题, 难以实现对高反光产品表面弱小瑕疵的快速检测. 针对上述挑战, 创新性地提出了一套基于动态视觉传感器(Dynamic vision sensor, DVS)的缺陷检测新模式, 以实现对具有高反光特性的铝基盘片表面缺陷的高效检测. DVS是一种新型的仿生视觉传感器, 具有成像速度快、动态范围大、运动目标捕捉能力强等优势. 首先开展了面向铝基盘片高反光表面弱小瑕疵的DVS成像实验, 并分析总结了DVS缺陷成像的特性与优势. 随后, 构建了第一个基于DVS的缺陷检测数据集(Event-based defect detection dataset, EDD-10k), 包含划痕、点痕、污渍三类常见缺陷类型. 最后, 针对缺陷形态多变、纹理稀疏、噪声干扰等问题, 提出了一种基于时序不规则特征聚合框架的DVS缺陷检测算法(Temporal irregular feature aggregation framework for event-based defect detection, TIFF-EDD), 实现对缺陷目标的有效检测.Abstract: Current visual defect detection technologies usually rely on conventional charge-coupled device (CCD) or complementary metal-oxide-semiconductor (CMOS) cameras for defect imaging and the development of backend detection algorithms. However, these technologies encounter challenges such as slow imaging speed, limited dynamic range, and significant background interference, which hinder the rapid detection of minor defects on highly reflective product surfaces. To address these challenges, we innovatively propose a new defect detection mode based on dynamic vision sensor (DVS) to achieve efficient defect detection on the highly reflective surfaces of aluminum disks. DVS is a novel bio-inspired visual sensor with advantages such as fast imaging speed, high dynamic range, and excellent ability to capture moving objects. First, we conduct DVS imaging experiments for minor defects on the highly reflective surfaces of aluminum disk and analyze the characteristics and advantages of DVS on defect imaging. Then, we establish the first event-based defect detection dataset (EDD-10k) based on DVS, including three common defect types: Scratch, point and stain. Finally, to address the issues such as varying defect shapes, sparse textures, and noise interference, we propose a temporal irregular feature aggregation framework for event-based defect detection (TIFF-EDD), and realize the effective detection of defect targets.
-
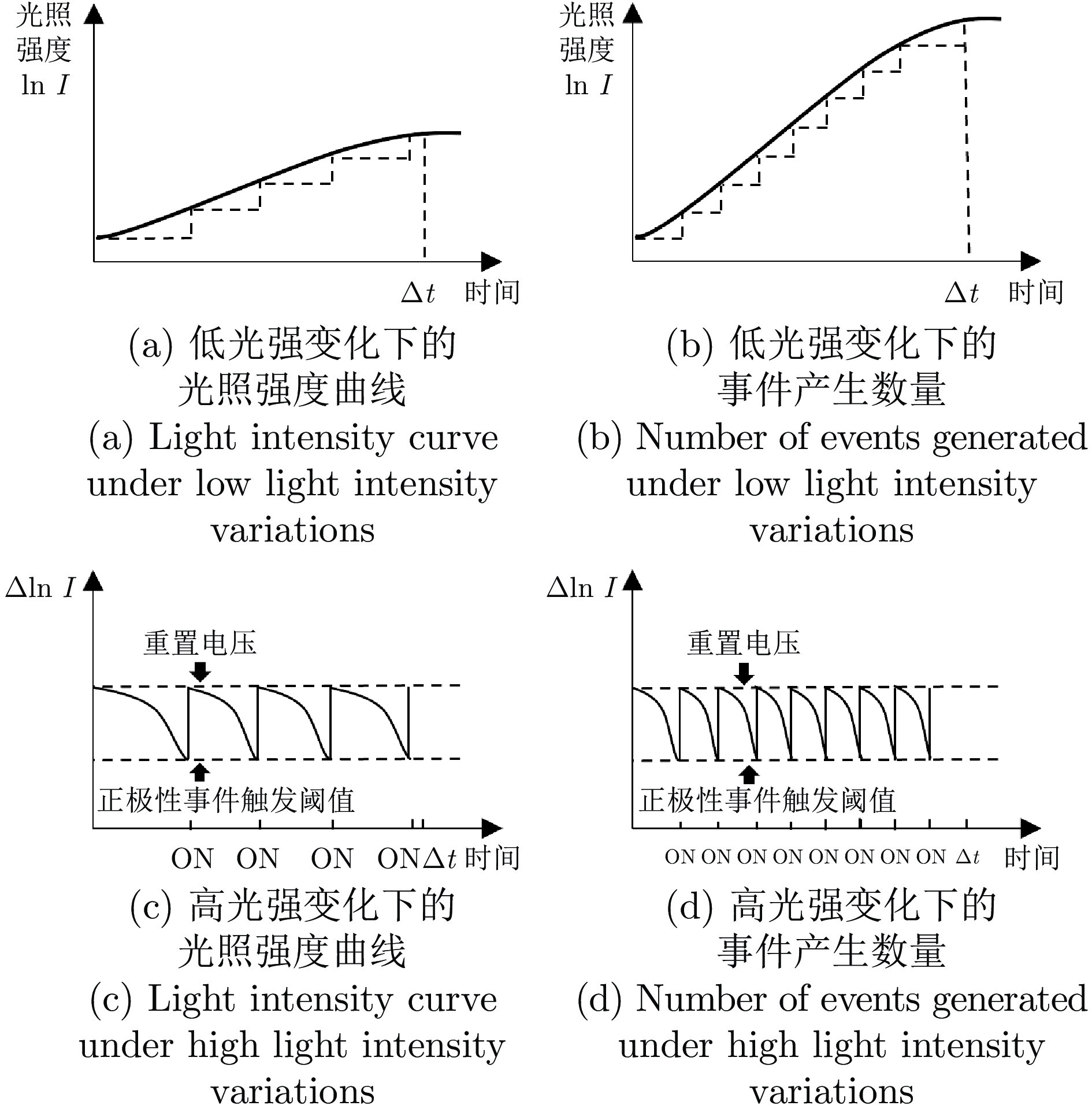
图 2 事件产生数量与光强变化大小的关系示意图
Fig. 2 Relationship diagram between the number of generated events and the magnitude of light intensity variations

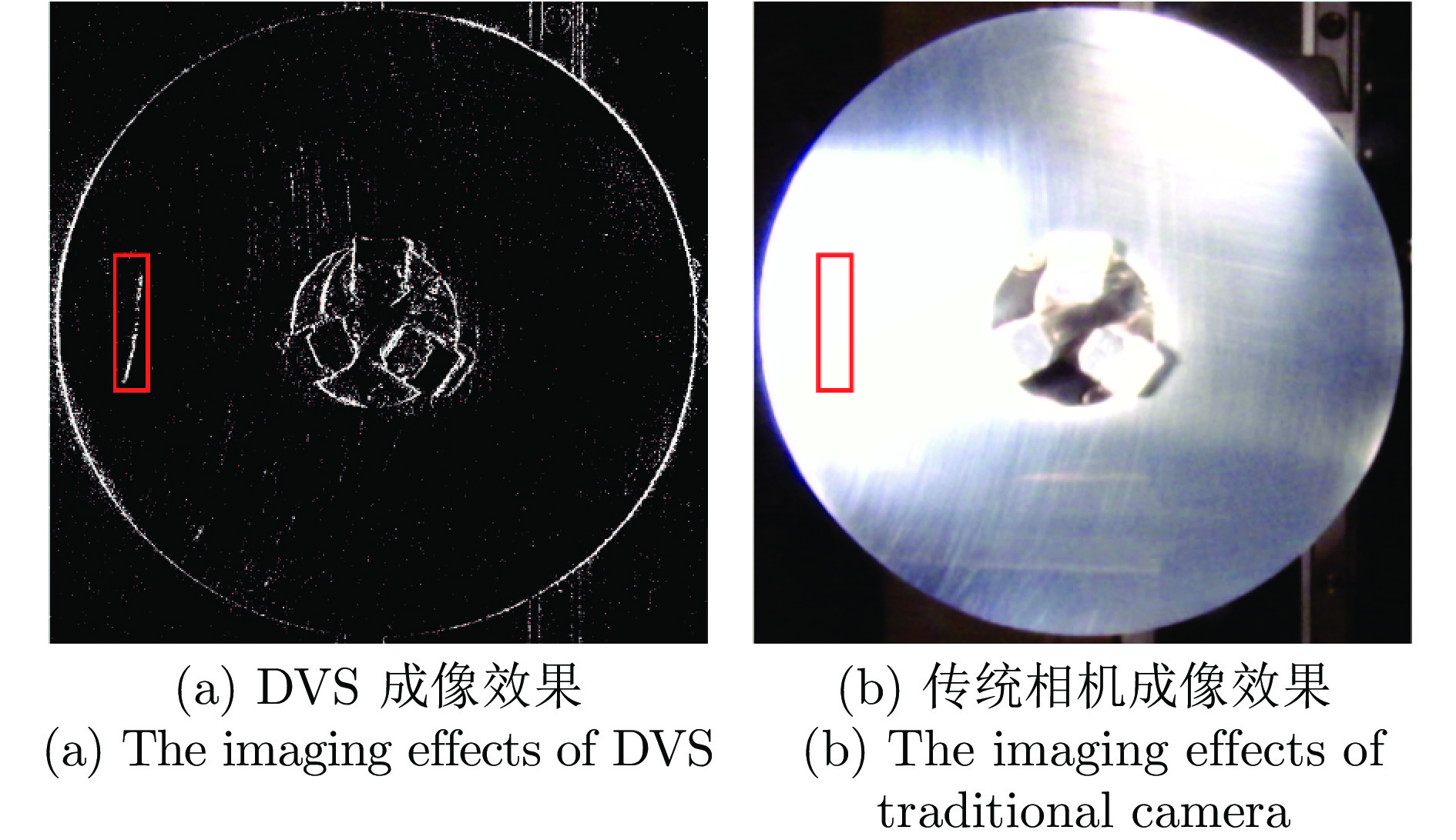
图 4 弱小缺陷、环境倒影的成像效果对比
Fig. 4 Comparison of imaging effects of small defects and environmental reflections
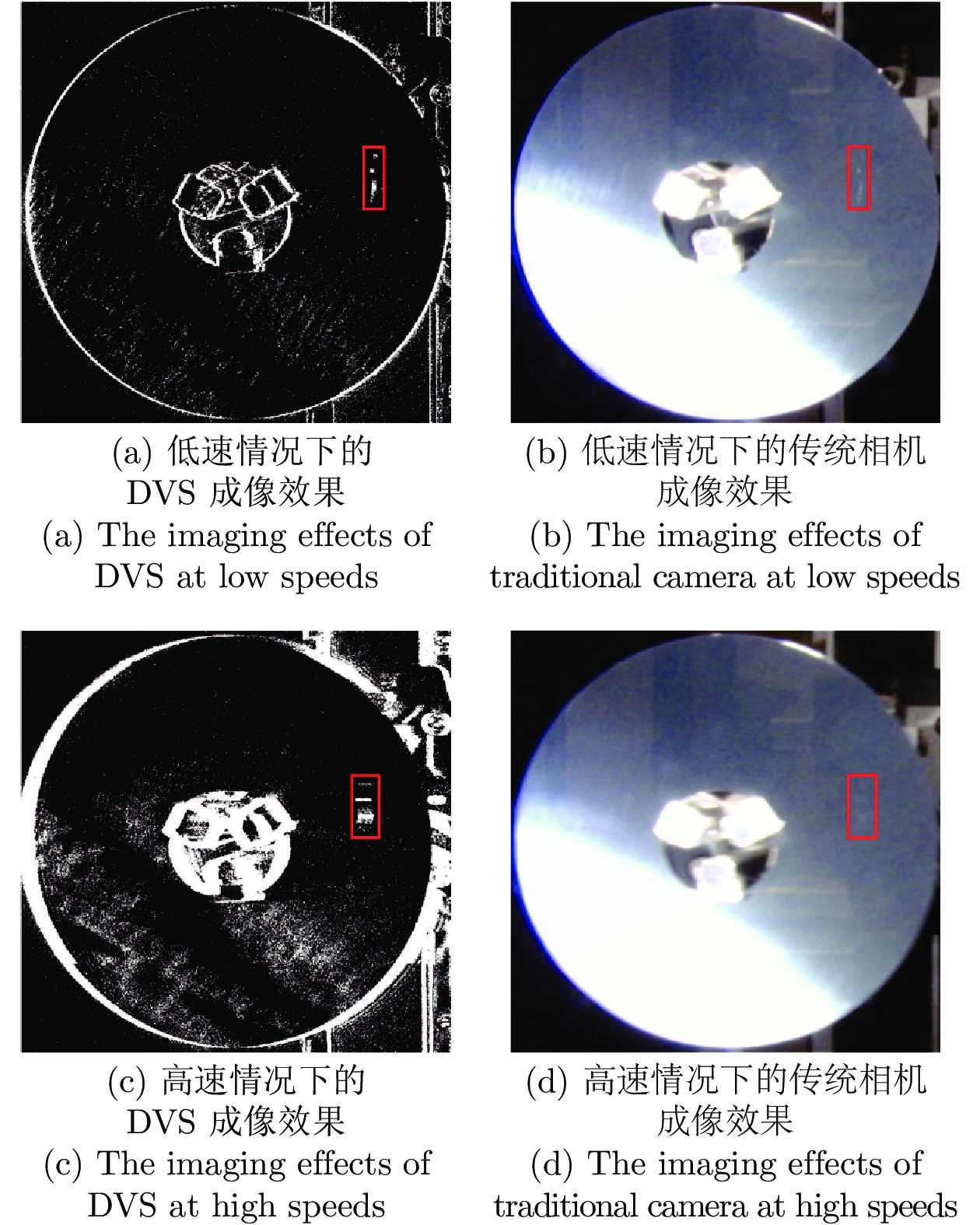
图 6 在不同运动速度下的缺陷成像效果对比
Fig. 6 Comparison of defect imaging effects under different motion speeds

图 7 不同缺陷类别的事件图像以及标注框的可视化结果 ((a)点痕; (b)划痕; (c)污渍)
Fig. 7 Visualization results of event images and annotation boxes for different defect categories ((a) Point; (b) Scratch; (c) Stain)
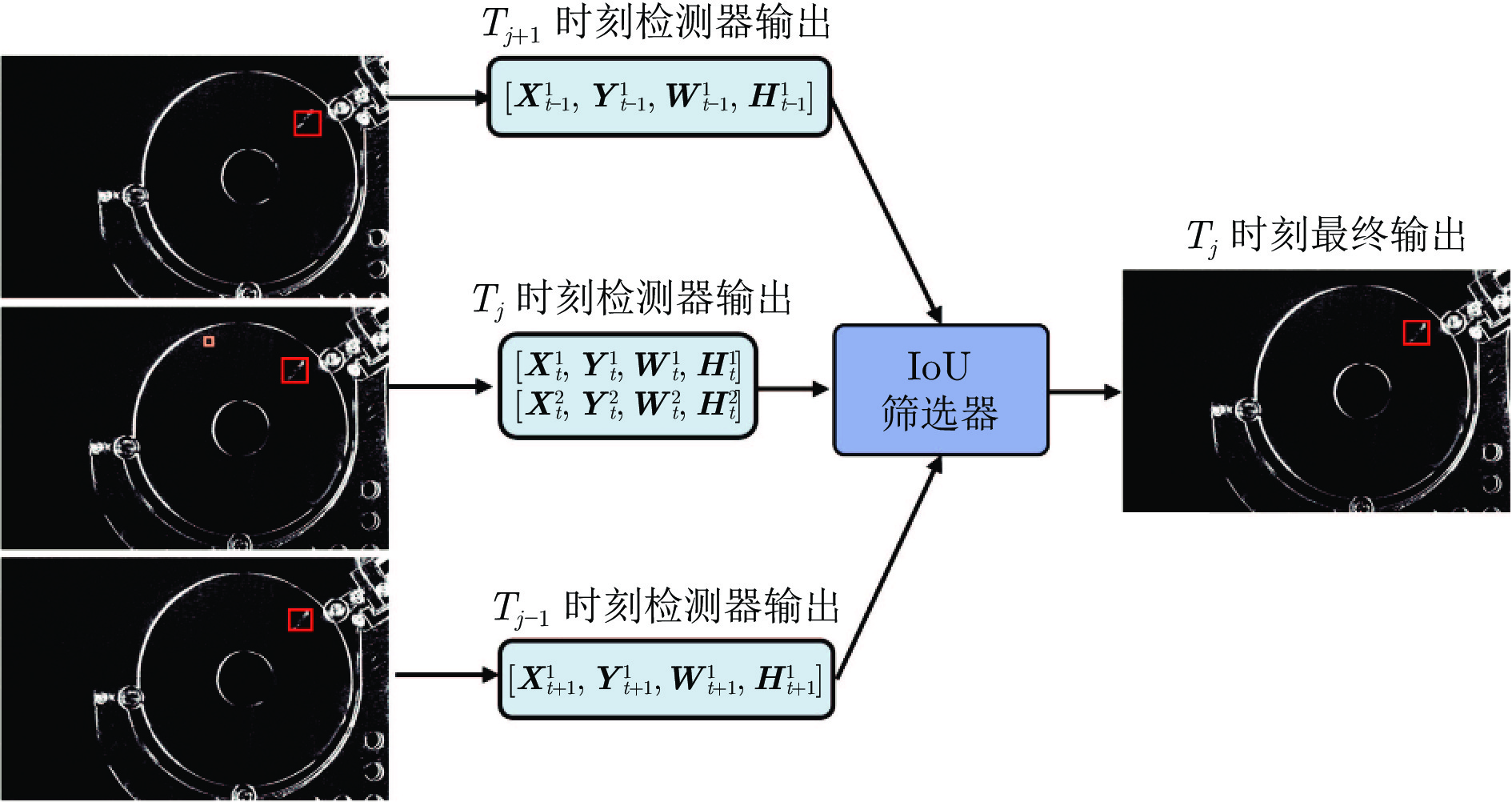
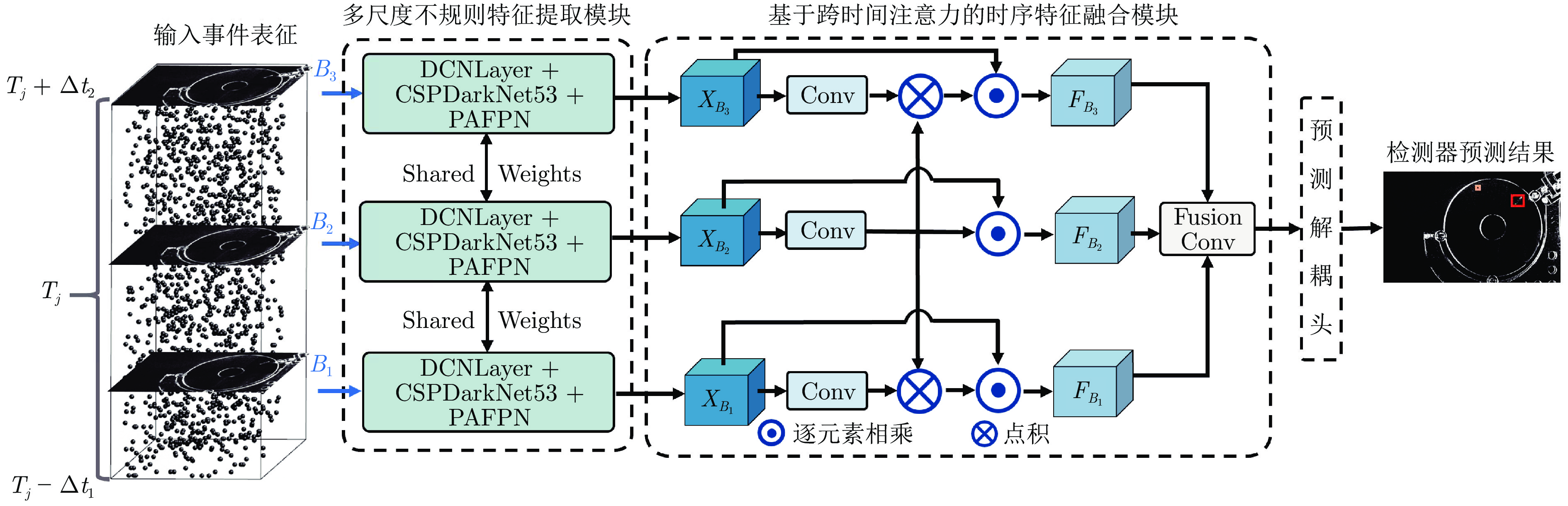
图 10 基于决策级时序预测融合的后处理模块工作流程图
Fig. 10 The workflow diagram of the post-processing module based on decision-level temporal prediction fusion
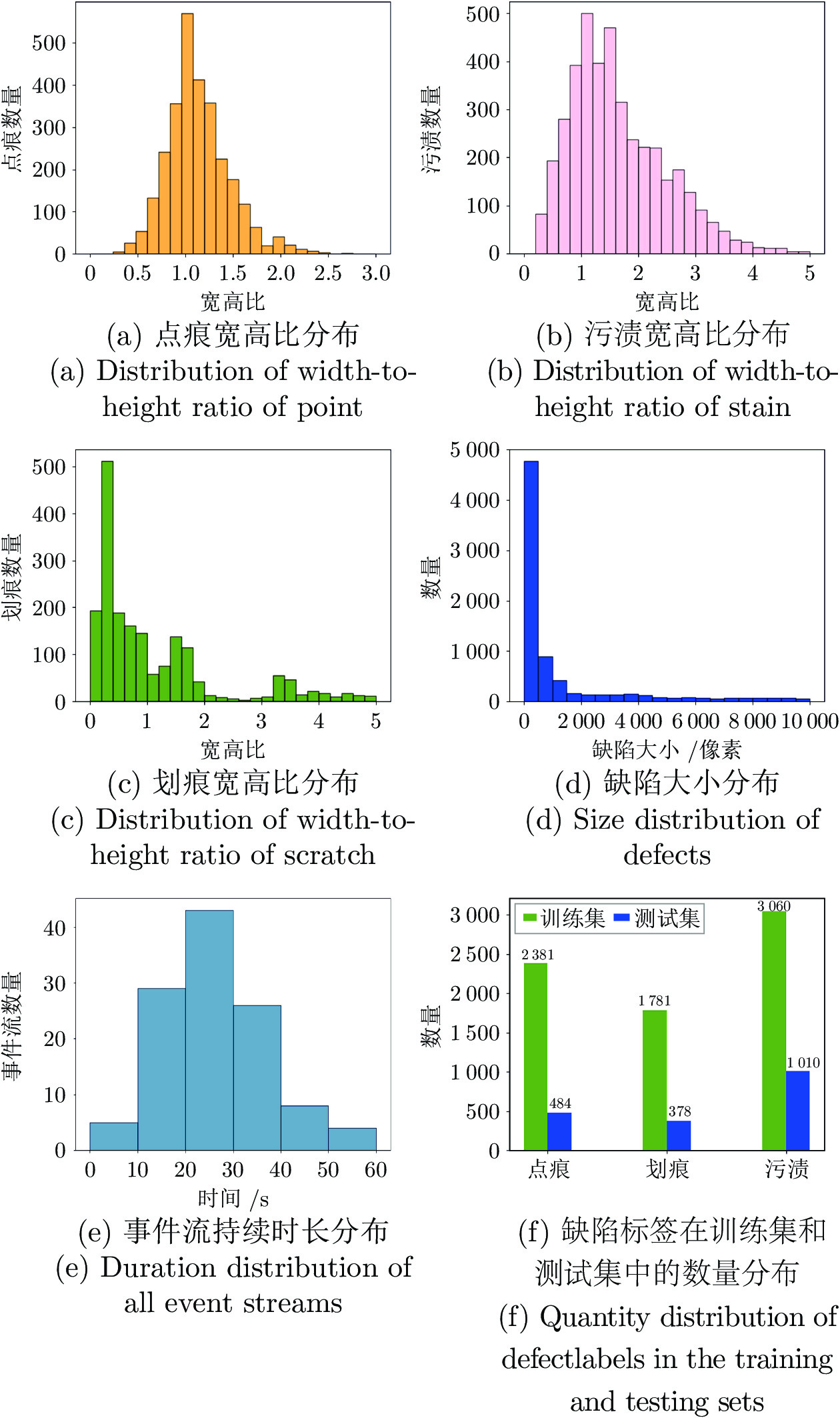
表 1 事件流在训练集和测试集中的数量分布
Table 1 Quantity distribution of event streams in the training set and testing set
类别 事件流总数 训练集事件流数量 测试集事件流数量 点痕 35 27 8 划痕 39 30 9 污渍 44 34 10 合格 4 2 2  下载: 导出CSV
下载: 导出CSV
表 2 EDD-10k数据集中每一类缺陷标签的数量
Table 2 The number of labels for each defect category in the EDD-10k dataset
类别 事件流总数 训练集事件流数量 测试集事件流数量 点痕 2865 2381 484 划痕 2159 1781 378 污渍 4070 3060 1010 合格 9094 7222 1872
下载: 导出CSV
表 3 与其他算法在EDD-10k数据集上的对比实验
Table 3 Comparison experiments with other algorithms on the EDD-10k dataset
方法 mAP@0.4 AP@点痕 AP@划痕 AP@污渍 Faster R-CNN[41] 0.210 0.000 0.536 0.095 YOLOv5 0.569 0.393 0.756 0.559 YOLOv7[42] 0.543 0.471 0.644 0.514 RDN[47] 0.512 0.553 0.476 0.507 MEGA[48] 0.401 0.356 0.509 0.349 YOLOV[49] 0.537 0.112 0.628 0.670 SSD-event[40] 0.236 0.087 0.626 0.138 SODformer-event[25] 0.394 0.363 0.161 0.495 TIFF-EDD 0.617 0.512 0.701 0.639
下载: 导出CSV
表 4 在EDD-10k数据集上的消融实验结果
Table 4 Ablation experimental results on the EDD-10k dataset
基线 MIFE CTAA VFLoss DPF mAP@0.4 TIFF-B $\checkmark$ 0.577 TIFF-MIFE $\checkmark$ $\checkmark$ 0.590 TIFF-CTAA $\checkmark$ $\checkmark$ $\checkmark$ 0.607 TIFF-VF $\checkmark$ $\checkmark$ $\checkmark$ $\checkmark$ 0.612 TIFF-EDD $\checkmark$ $\checkmark$ $\checkmark$ $\checkmark$ $\checkmark$ 0.617
下载: 导出CSV
-
[1] 金侠挺, 王耀南, 张辉, 刘理, 钟杭, 贺振东. 基于贝叶斯CNN和注意力网络的钢轨表面缺陷检测系统. 自动化学报, 2019, 45(12): 2312−2327Jin Xia-Ting, Wang Yao-Nan, Zhang Hui, Liu Li, Zhong Hang, He Zhen-Dong. DeepRail: Automatic visual detection system for railway surface defect using Bayesian CNN and attention network. Acta Automatica Sinica, 2019, 45(12): 2312−2327 [2] 陶显, 侯伟, 徐德. 基于深度学习的表面缺陷检测方法综述. 自动化学报, 2021, 47(5): 1017−1034Tao Xian, Hou Wei, Xu De. A survey of surface defect detection methods based on deep learning. Acta Automatica Sinica, 2021, 47(5): 1017−1034 [3] Chen Y Q, Pan J W, Lei J Y, Zeng D Y, Wu Z Z, Chen C S. EEE-Net: Efficient edge enhanced network for surface defect detection of glass. IEEE Transactions on Instrumentation and Measurement, 2023, 72: Article No. 5029013 [4] Jiang W B, Liu M, Peng Y N, Wu L H, Wang Y N. HDCB-Net: A neural network with the hybrid dilated convolution for pixel-level crack detection on concrete bridges. IEEE Transactions on Industrial Informatics, 2021, 17(8): 5485−5494 doi: 10.1109/TII.2020.3033170 [5] Zheng Y J, Zheng L X, Yu Z F, Shi B X, Tian Y H, Huang T J. High-speed image reconstruction through short-term plasticity for spiking cameras. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 6354−6363 [6] Xu X Y, Sun D Q, Pan J S, Zhang Y J, Pfister H, Yang M H. Learning to super-resolve blurry face and text images. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 251−260 [7] 李家宁, 田永鸿. 神经形态视觉传感器的研究进展及应用综述. 计算机学报, 2021, 44(6): 1258−1286Li Jia-Ning, Tian Yong-Hong. Recent advances in neuromorphic vision sensors: A survey. Chinese Journal of Computers, 2021, 44(6): 1258−1286 [8] Pan L Y, Hartley R, Scheerlinck C, Liu M M, Yu X, Dai Y C. High frame rate video reconstruction based on an event camera. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(5): 2519−2533 [9] Han J, Yang Y X, Duan P Q, Zhou C, Ma L, Xu C, et al. Hybrid high dynamic range imaging fusing neuromorphic and conventional images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(7): 8553−8565 doi: 10.1109/TPAMI.2022.3231334 [10] Hu Y H, Liu S C, Delbruck T. V2e: From video frames to realistic DVS events. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Nashville, USA: IEEE, 2021. 1312−1321 [11] 冯维, 徐仕楠, 王恒辉, 熊芝, 王选择, 翟中生. 逐像素调制的高反光表面三维测量方法. 中国光学, 2022, 15(3): 488−497 doi: 10.37188/CO.2021-0220Feng Wei, Xu Shi-Nan, Wang Heng-Hui, Xiong Zhi, Wang Xuan-Ze, Zhai Zhong-Sheng. Three-dimensional measurement method of highly reflective surface based on per-pixel modulation. Chinese Optics, 2022, 15(3): 488−497 doi: 10.37188/CO.2021-0220 [12] 王颖, 倪育博, 孟召宗, 高楠, 郭彤, 杨泽青, 等. 彩色高反光表面自适应编码条纹投影轮廓术. 光学学报, 2024, 44(7): Article No. 0712001Wang Ying, Ni Yu-Bo, Meng Zhao-Zong, Gao Nan, Guo Tong, Yang Ze-Qing, et al. Adaptive coding fringe projection profilometry on color reflective surfaces. Acta Optica Sinica, 2024, 44(7): Article No. 0712001 [13] Lichtsteiner P, Posch C, Delbruck T. A 128 × 128 120db 30mw asynchronous vision sensor that responds to relative intensity change. In: Proceedings of the IEEE International Solid State Circuits Conference-Digest of Technical Papers. San Francisco, USA: IEEE, 2006. 2060−2069 [14] Chen S S, Guo M H. Live demonstration: CeleX-V: A 1M pixel multi-mode event-based sensor. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Long Beach, USA: IEEE, 2019. 1682−1683 [15] Brandli C, Muller L, Delbruck T. Real-time, high-speed video decompression using a frame- and event-based DAVIS sensor. In: Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS). Melbourne, Australia: IEEE, 2014. 686−689 [16] Gallego G, Delbrück T, Orchard G, Bartolozzi C, Taba B, Censi A, et al. Event-based vision: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 154−180 doi: 10.1109/TPAMI.2020.3008413 [17] Lagorce X, Orchard G, Galluppi F, Shi B E, Benosman R B. HOTS: A hierarchy of event-based time-surfaces for pattern recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(7): 1346−1359 doi: 10.1109/TPAMI.2016.2574707 [18] Lazzaro J, Wawrzynek J, Mahowald M, Sivilotti M, Gillespie D. Silicon auditory processors as computer peripherals. In: Proceedings of the 5th International Conference on Neural Information Processing Systems. Denver, USA: ACM, 1992. 820−827 [19] 马艳阳, 叶梓豪, 刘坤华, 陈龙. 基于事件相机的定位与建图算法: 综述. 自动化学报, 2021, 47(7): 1484−1494Ma Yan-Yang, Ye Zi-Hao, Liu Kun-Hua, Chen Long. Event-based visual localization and mapping algorithms: A survey. Acta Automatica Sinica, 2021, 47(7): 1484−1494 [20] Li Y Z, Wang H L, Yuan S H, Liu M, Zhao D B, Guo Y W, et al. Myriad: Large multimodal model by applying vision experts for industrial anomaly detection. arXiv preprint arXiv: 2310.19070, 2023. [21] Song K C, Yan Y H. Micro surface defect detection method for silicon steel strip based on saliency convex active contour model. Mathematical Problems in Engineering, 2013, 2013: Article No. 429094 [22] Tabernik D, Šela S, Skvarč J, Skočaj D. Segmentation-based deep-learning approach for surface-defect detection. Journal of Intelligent Manufacturing, 2020, 31(3): 759−776 doi: 10.1007/s10845-019-01476-x [23] Bergmann P, Fauser M, Sattlegger D, Steger C. MVTec AD——A comprehensive real-world dataset for unsupervised anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 9584−9592 [24] Wang J L, Xu C Q, Yang Z L, Zhang J, Li X O. Deformable convolutional networks for efficient mixed-type wafer defect pattern recognition. IEEE Transactions on Semiconductor Manufacturing, 2020, 33(4): 587−596 doi: 10.1109/TSM.2020.3020985 [25] Li D Z, Tian Y H, Li J N. SODFormer: Streaming object detection with transformer using events and frames. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(11): 14020−14037 doi: 10.1109/TPAMI.2023.3298925 [26] Nguyen A, Do T T, Caldwell D G. Real-time 6DOF pose relocalization for event cameras with stacked spatial LSTM networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Long Beach, USA: IEEE, 2019. 1638−1645 [27] Kim J, Bae J, Park G. N-ImageNet: Towards robust, fine-grained object recognition with event cameras. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, USA: IEEE, 2021. 2126−2136 [28] Ge Z, Liu S T, Wang F, Li Z M, Sun J. YOLOX: Exceeding YOLO series in 2021. arXiv preprint arXiv: 2107.08430, 2021. [29] Duan K W, Bai S, Xie L X, Qi H G, Huang Q M, Tian Q. CenterNet: Keypoint triplets for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 6568−6577 [30] Xiong Y, Li Z, Chen Y, Wang F, Zhu X, Luo J, et al. Efficient deformable ConvNets: Rethinking dynamic and sparse operator for vision applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2024. 5652−5661 [31] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: Optimal speed and accuracy of object detection. arXiv preprint arXiv: 2004.10934, 2020. [32] Liu S, Qi L, Qin H F, Shi J P, Jia J Y. Path aggregation network for instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8759−8768 [33] Wang C Y, Liao H Y M, Wu Y H, Chen P Y, Hsieh J W, Yeh I H. CSPNet: A new backbone that can enhance learning capability of CNN. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2020. 1571−1580 [34] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [35] Lin T Y, Dollár P, Girshick R, He K M, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 936−944 [36] Liu B D, Xu C, Yang W, Yu H, Yu L. Motion robust high-speed light-weighted object detection with event camera. IEEE Transactions on Instrumentation and Measurement, 2023, 72: Article No. 5013113 [37] Li J N, Li J, Zhu L, Xiang X J, Huang T J, Tian Y H. Asynchronous spatio-temporal memory network for continuous event-based object detection. IEEE Transactions on Image Processing, 2022, 31: 2975−2987 doi: 10.1109/TIP.2022.3162962 [38] Wang X T, Chan K C K, Yu K, Dong C, Loy C C. EDVR: Video restoration with enhanced deformable convolutional networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Long Beach, USA: IEEE, 2019. 1954−1963 [39] Zhang H Y, Wang Y, Dayoub F, Sünderhauf N. VarifocalNet: An IoU-aware dense object detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 8510−8519 [40] Iacono M, Weber S, Glover A, Bartolozzi C. Towards event-driven object detection with off-the-shelf deep learning. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Madrid, Spain: IEEE, 2018. 1−9 [41] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: ACM, 2015. 91−99 [42] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 7464−7475 [43] Zhu X M, Wang S, Su J J, Liu F, Zeng L. High-speed and accurate cascade detection method for chip surface defects. IEEE Transactions on Instrumentation and Measurement, 2024, 73: Article No. 2506612 [44] Yuan M H, Zhou Y B, Ren X Y, Zhi H, Zhang J, Chen H J. YOLO-HMC: An improved method for PCB surface defect detection. IEEE Transactions on Instrumentation and Measurement, 2024, 73: Article No. 2001611 [45] Wang Y R, Song X K, Feng L L. MCI-GLA plug-in suitable for YOLO series models for transmission line insulator defect detection. IEEE Transactions on Instrumentation and Measurement, 2024, 73: Article No. 9002912 [46] Zhu J, Pang Q W, Li S S. ADDet: An efficient multiscale perceptual enhancement network for aluminum defect detection. IEEE Transactions on Instrumentation and Measurement, 2024, 73: Article No. 5004714 [47] Deng J J, Pan Y W, Yao T, Zhou W G, Li H Q, Mei T. Relation distillation networks for video object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 7022−7031 [48] Chen Y H, Cao Y, Hu H, Wang L W. Memory enhanced global-local aggregation for video object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 10334−10343 [49] Shi Y H, Wang N Y, Guo X J. YOLOV: Making still image object detectors great at video object detection. In: Proceedings of the 37th AAAI Conference on Artificial Intelligence. Washington, USA: AAAI, 2023. 2254−2262 [50] Jeong J, Park H, Kwak N. Enhancement of SSD by concatenating feature maps for object detection. arXiv preprint arXiv: 1705.09587, 2017. -

 下载:
下载:


计量
- 文章访问数: 1334
- HTML全文浏览量: 631
- PDF下载量: 326
- 被引次数: 0
