

-
摘要: 基于深度神经网络(Deep neutral networks, DNN)的分类方法因缺乏可解释性, 导致在金融、医疗、法律等关键领域难以获得完全信任, 极大限制了其应用. 现有多数研究主要关注单模态数据的可解释性, 多模态数据的可解释性方面仍存在挑战. 为解决这一问题, 提出一种基于视觉属性的多模态可解释图像分类方法, 该方法将可见光和深度图等不同视觉模态提取的属性融入模型的训练过程, 不仅能通过视觉属性和决策树对已有的神经网络黑盒模型进行解释, 而且能在训练过程中进一步提升模型解释信息的能力. 引入可解释性通常会造成模型精度的降低, 该方法在保持模型具有良好可解释性的同时, 仍具有较高的分类精度, 在NYUDv2、SUN RGB-D和RGB-NIR三个数据集上, 相比于单模态可解释方法, 该模型准确率明显提升, 并达到与多模态不可解释模型相媲美的性能.Abstract: The classification methods based on deep neutral networks (DNN) lack interpretability, which makes it difficult to gain complete trust in key fields such as finance, medical treatment, and law, greatly limiting their applications. Most existing research mainly focuses on the interpretability of uni-modal data, while there are still challenges in the interpretability of multimodal data. To address this issue, a multimodal interpretable image classification method based on visual attributes is proposed. This method incorporates attributes extracted from different visual modalities such as visible light and depth maps into the training process of the model. It not only interpret the existing black box model of neural networks through visual attributes and decision trees, but also further enhances the model's ability to interpret information during the training process. Introducing interpretability often leads to a decrease in model accuracy. This method maintains good interpretability while still maintaining high classification accuracy. Compared to uni-modal interpretable methods, the accuracy of this model is significantly improved on the NYUDv2, SUN RGB-D, and RGB-NIR datasets, and it achieves performance comparable to multi-modal uninterpretable models.
-
Key words:
- Interpretability /
- visual attributes /
- multimodal fusion /
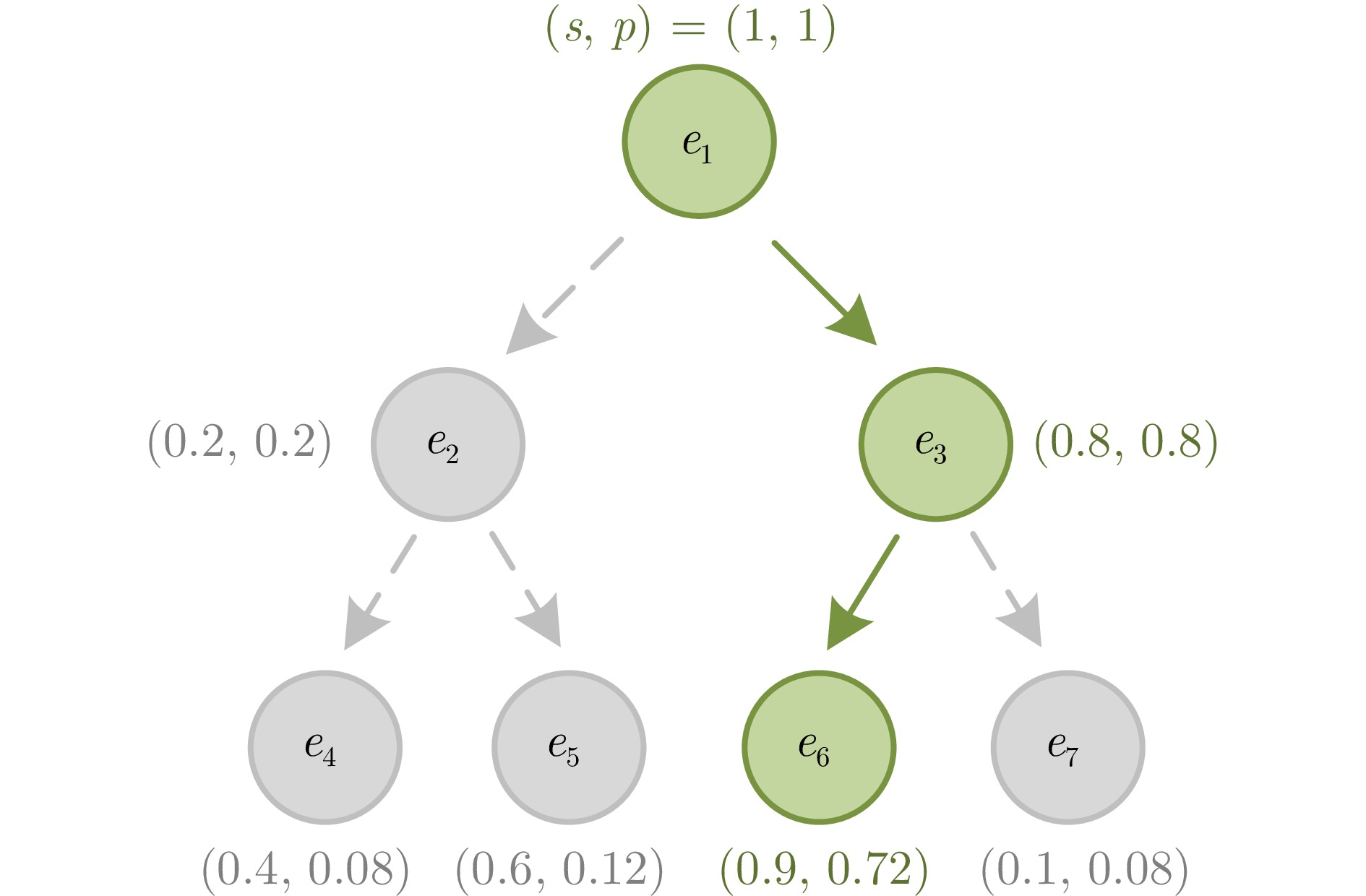
- decision tree /
- image classification
-
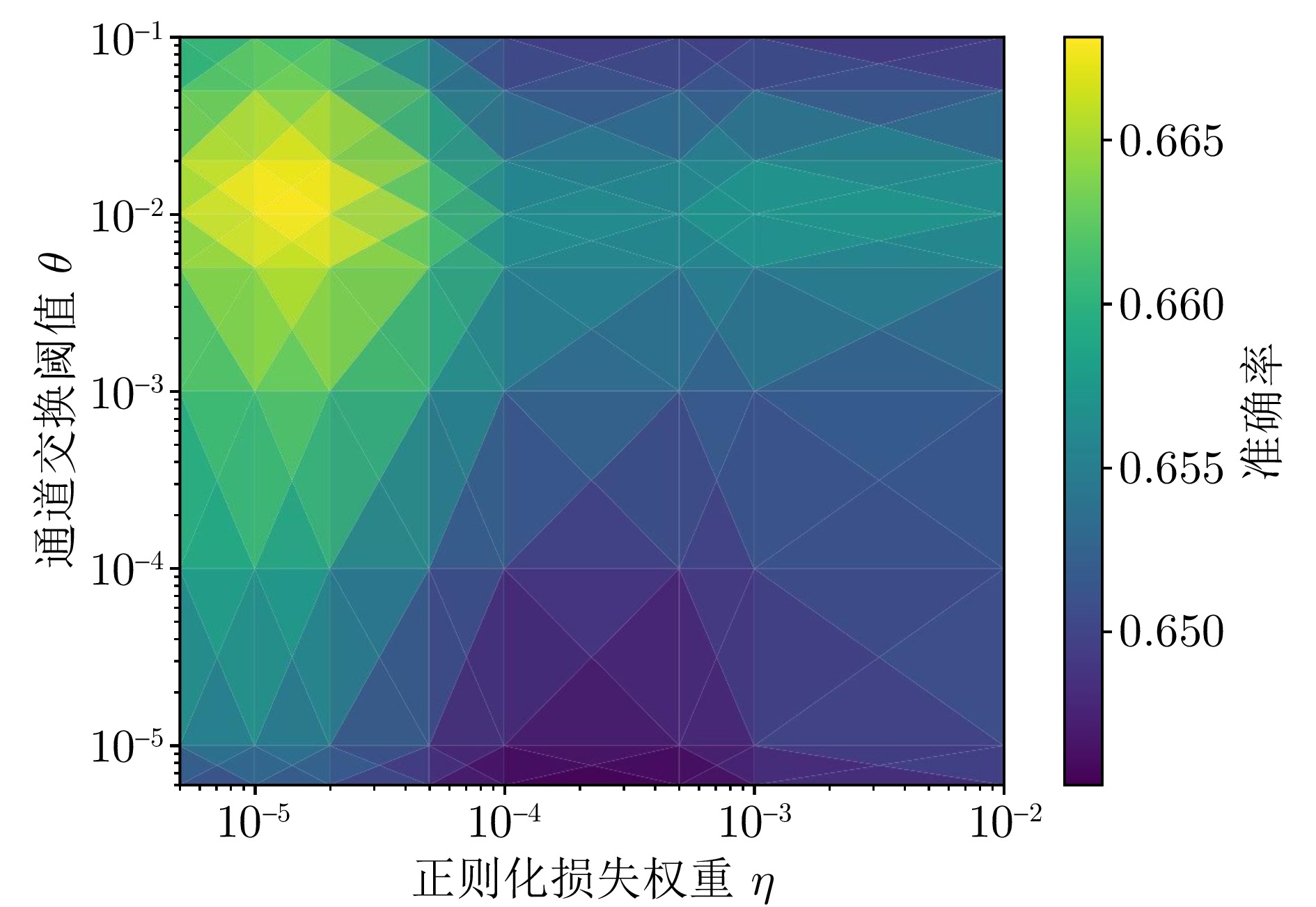
图 6 通道交换阈值$ \theta $、正则化损失权重$ \eta $与Top-1 准确率在SUN RGB-D数据集上的关系
Fig. 6 The relationship between channel exchange threshold$ \theta $, regularization loss parameters$ \eta $, Top-1 accuracy on SUN RGB-D

图 8 通过评估不确定度动态适应模态数据质量
Fig. 8 Dynamically adapt to modal data quality by evaluating uncertainty
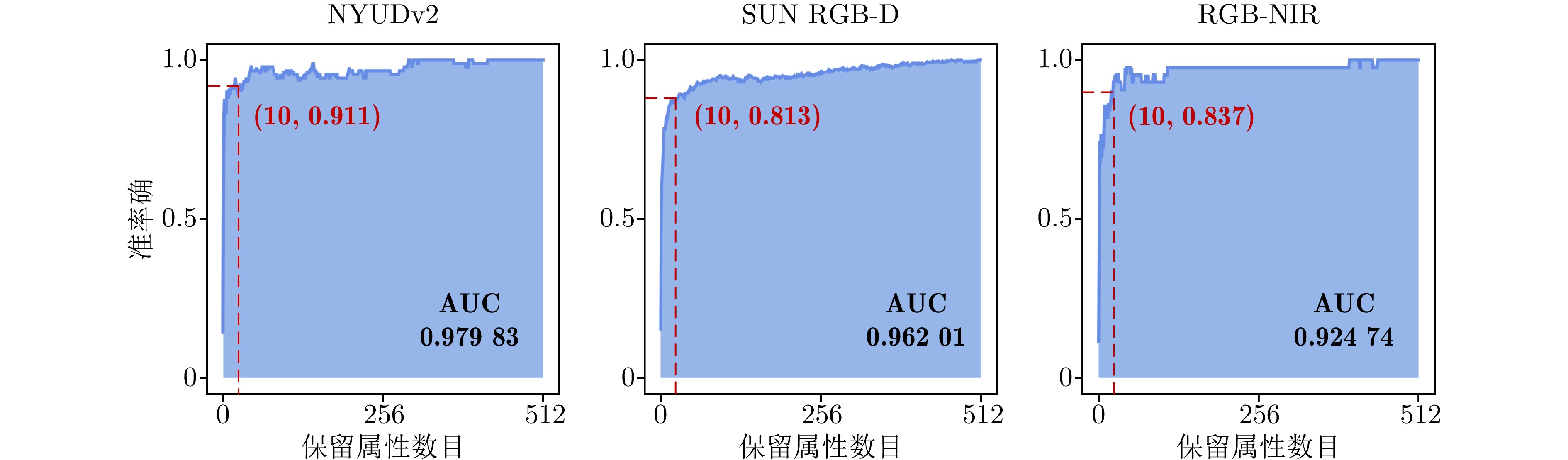
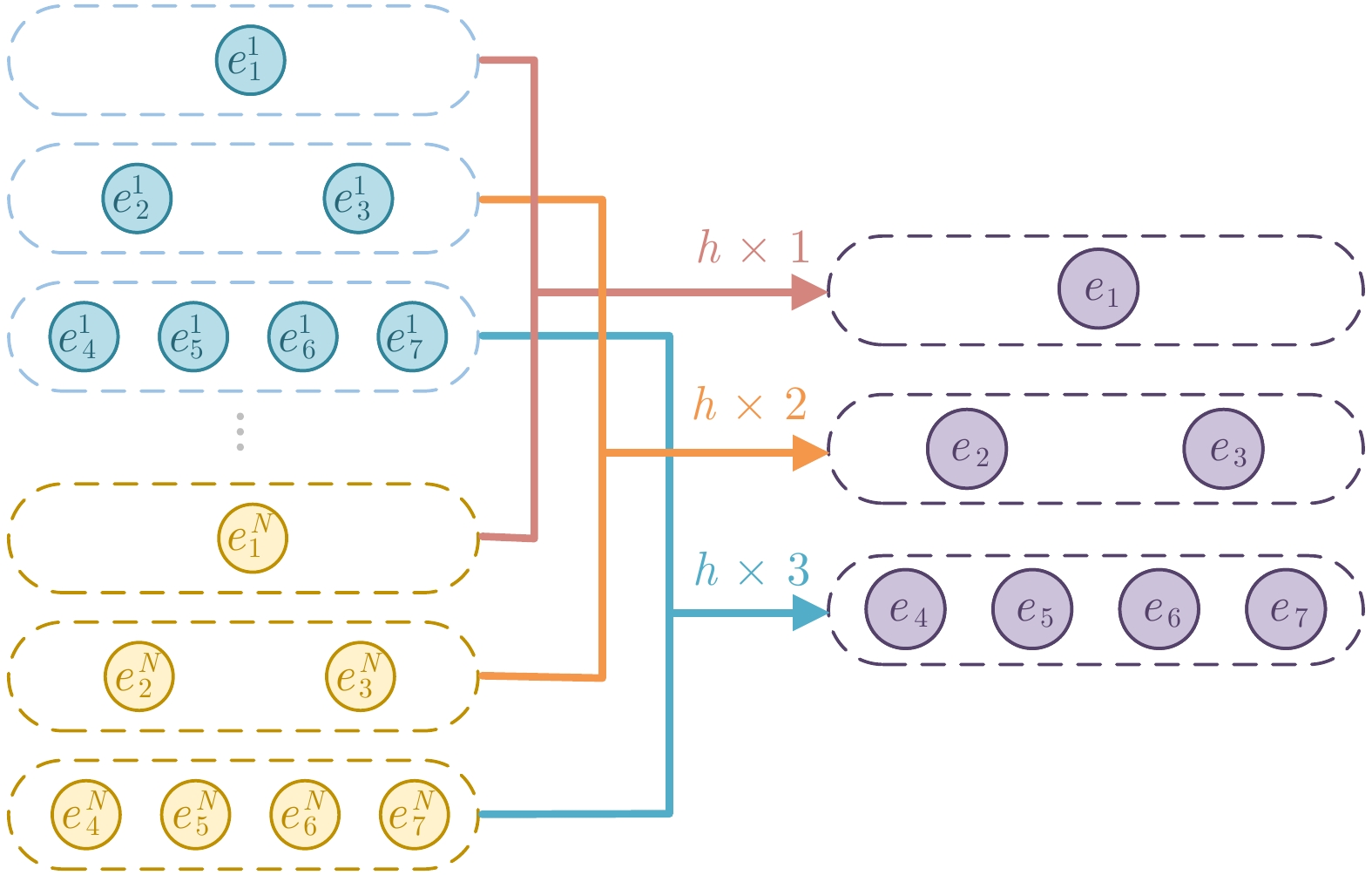
图 10 保留输入数据前$ k $强的属性
Fig. 10 Preserve the first$ k $strong attributes of the input data
表 1 不同模块在NYUDv2、SUN RGB-D和RGB-NIR数据集上的Top-1准确率 (%)
Table 1 Top-1 accuracies with different components on NYUDv2, SUN RGB-D and RGB-NIR (%)
树推理 树融合 通道交换 NYUDv2 SUN RGB-D RGB-NIR RGB Deep Fusion RGB Deep Fusion RGB NIR Fusion $ \times $ $ \times $ $ \times $ 43.08 59.26 71.98 52.10 38.49 62.19 58.33 52.08 77.78 $ \times $ $ \times $ √ $ 47.74^* $ $ 59.47^* $ 72.07 $ 54.29^* $ $ 47.05^* $ 66.28 $ 62.23^* $ $ 53.76^* $ 80.43 √ $ \times $ $ \times $ 46.28 57.68 72.41 50.98 36.00 58.99 58.68 53.47 79.17 √ √ $ \times $ 61.43 61.00 74.40 59.96 51.62 66.16 71.08 66.45 84.71 √ √ √ $ 71.14^* $ $ 70.99^* $ 74.74 $ 66.76^* $ $ 66.37^* $ 68.01 $ 78.85^* $ $ 77.37^* $ 85.54 注: * 表示使用通道交换为单个模态引入其他模态数据后的准确率, 加粗表示单模态或融合后最高准确率.  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在NYUDv2、SUN RGB-D和RGB-NIR数据集上的Top-1准确率 (%)
Table 2 Top-1 accuracies with different methods on NYUDv2, SUN RGB-D and RGB-NIR (%)
方法 解释性 NYUDv2 SUN RGB-D RGB-NIR RGB Deep Fusion RGB Deep Fusion RGB NIR Fusion ViT-S-16[51] $ \times $ 54.95 62.56 — 59.23 49.43 — 74.44 66.32 — ResNet-18[49] $ \times $ 65.28 65.93 — 66.04 57.85 — 78.83 75.70 — CBCL[52] $ \times $ 56.87 63.20 73.85 50.74 43.59 65.78 74.23 62.91 81.72 TMC[19] $ \times $ 60.14 62.19 74.57 60.89 52.95 66.69 72.76 68.77 84.29 TMNR[53] $ \times $ 56.61 64.50 74.10 60.60 53.53 66.30 69.50 65.26 82.20 dNDF[54] √ 61.86 65.76 — 64.78 57.30 — 78.61 72.11 — NBDT[27] √ 65.28 62.85 — 66.20 57.93 — 74.24 74.22 — HCN[20] √ 62.20 63.18 — 61.91 53.03 — 72.92 68.75 — Ours √ $ 71.14^* $ $ 70.99^* $ 74.74 $ 66.76^* $ $ 66.37^* $ 68.01 $ 78.85^* $ $ 77.37^* $ 85.54 注: * 表示使用通道交换为单个模态引入其他模态数据后的准确率, 加粗表示单模态或融合后最高准确率.
下载: 导出CSV
表 3 不同预训练骨干网络在NYUDv2、SUN RGB-D和RGB-NIR数据集中的Top-1准确率 (%)
Table 3 Top-1 accuracies with different pretrained backbones on NYUDv2, SUN RGB-D and RGB-NIR (%)
骨干网络 NYUDv2 SUN RGB-D RGB-NIR ResNet-18 80.90 73.50 90.15 ResNet-34 81.58 73.87 90.15 ResNet-50 81.92 73.88 90.58 ResNet-101 81.93 74.96 90.79
下载: 导出CSV
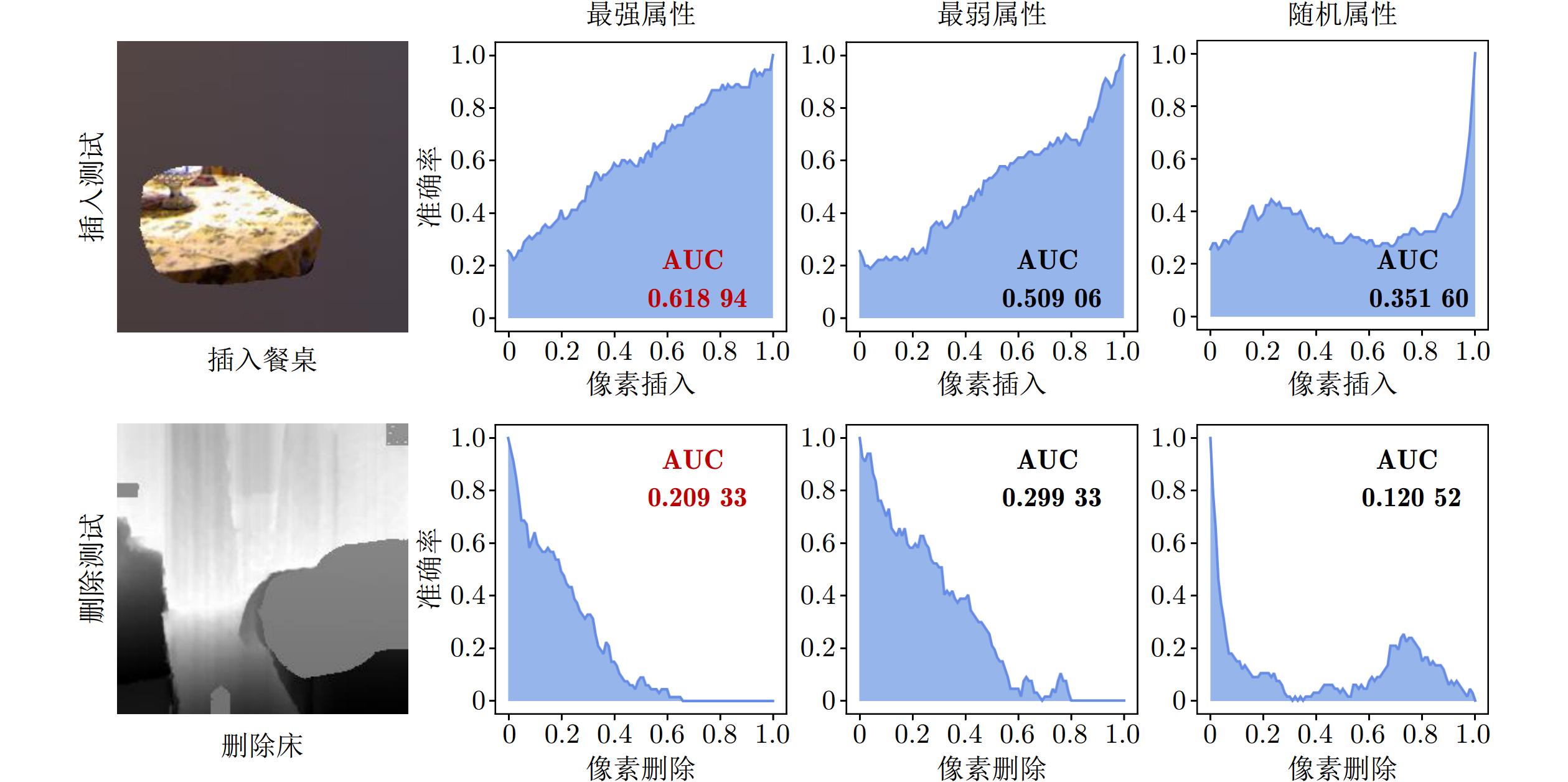
表 4 插入或删除不同属性在NYUDv2、SUN RGB-D和RGB-NIR数据集中的AUC
Table 4 AUC of different attributes inserted or deleted in NYUDv2, SUN RGB-D and RGB-NIR datasets
数据集 最强属性 最弱属性 随机 插入 删除 插入 删除 插入 删除 NYUDv2 0.619 0.209 0.509 0.299 0.351 0.121 SUN RGB-D 0.601 0.300 0.463 0.380 0.284 0.168 RGB-NIR 0.636 0.380 0.549 0.466 0.355 0.207
下载: 导出CSV
-
[1] 赵静, 裴子楠, 姜斌, 陆宁云, 赵斐, 陈树峰. 基于深度强化学习的无人机虚拟管道视觉避障. 自动化学报, 2024, 50(11): 1−14Zhao Jing, Pei Zi-Nan, Jiang Bin, Lu Ning-Yun, Zhao Fei, Chen Shu-Feng. Virtual tube visual obstacle avoidance for UAV based on deep reinforcement learning. Acta Automatica Sinica, 2024, 50(11): 1−14 [2] Miikkulainen R, Liang J, Meyerson E, Rawal A, Fink D, Francon O, et al. Evolving deep neural networks. Artificial Intelligence in the Age of Neural Networks and Brain Computing (Second edition). Amsterdam: Academic Press, 2024. 269−287 [3] Hassija V, Chamola V, Mahapatra A, Singal A, Goel D, Huang K Z, et al. Interpreting black-box models: A review on explainable artificial intelligence. Cognitive Computation, 2024, 16(1): 45−74 doi: 10.1007/s12559-023-10179-8 [4] Jung J, Lee H, Jung H, Kim H. Essential properties and explanation effectiveness of explainable artificial intelligence in healthcare: A systematic review. Heliyon, 2023, 9(5): Article No. e16110 doi: 10.1016/j.heliyon.2023.e16110 [5] Costa V G, Pedreira C E. Recent advances in decision trees: An updated survey. Artificial Intelligence Review, 2023, 56(5): 4765−4800 doi: 10.1007/s10462-022-10275-5 [6] Aksjonov A, Kyrki V. A safety-critical decision-making and control framework combining machine-learning-based and rule-based algorithms. SAE International Journal of Vehicle Dynamics, Stability, and NVH, 2023, 7(3): 287−299 [7] Kitson N K, Constantinou A C, Guo Z G, Liu Y, Chobtham K. A survey of Bayesian Network structure learning. Artificial Intelligence Review, 2023, 56(8): 8721−8814 doi: 10.1007/s10462-022-10351-w [8] Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In: Proceedings of the 2nd International Conference on Learning Representations (ICLR). Banff, Canada: ICLR, 2014. 1−8Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In: Proceedings of the 2nd International Conference on Learning Representations (ICLR). Banff, Canada: ICLR, 2014. 1−8 [9] Sundararajan M, Taly A, Yan Q Q. Axiomatic attribution for deep networks. In: Proceedings of the 34th International Conference on Machine Learning (ICML). Sydney, Australia: JMLR, 2017. 3319−3328 [10] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2921−2929 [11] Chattopadhay A, Sarkar A, Howlader P, Balasubramanian V N. Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, USA: IEEE, 2018. 839−847 [12] Ribeiro M T, Singh S, Guestrin C. “Why should I trust you?”: Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, USA: Association for Computing Machinery, 2016. 1135−1144 [13] Lundberg S M, Lee S I. A unified approach to interpreting model predictions. In: Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS). Long Beach, USA: Curran Associates Inc., 2017. 4768−4777 [14] Chen C F, Li O, Tao C F, Barnett A J, Su J, Rudin C. This looks like that: Deep learning for interpretable image recognition. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS). Vancouver, Canada: 2019. Article No. 801Chen C F, Li O, Tao C F, Barnett A J, Su J, Rudin C. This looks like that: Deep learning for interpretable image recognition. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS). Vancouver, Canada: 2019. Article No. 801 [15] Nauta M, van Bree R, Seifert C. Neural prototype trees for interpretable fine-grained image recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 14928−14938 [16] Biederman I. Recognition-by-components: A theory of human image understanding. Psychological Review, 1987, 94(2): 115−147 doi: 10.1037/0033-295X.94.2.115 [17] Cohen L G, Celnik P, Pascual-Leone A, Corwell B, Faiz L, Dambrosia J, et al. Functional relevance of cross-modal plasticity in blind humans. Nature, 1997, 389(6647): 180−183 doi: 10.1038/38278 [18] Wang Y K, Huang W B, Sun F C, Xu T Y, Rong Y, Huang J Z. Deep multimodal fusion by channel exchanging. In: Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS). Vancouver, Canada: Curran Associates Inc., 2020. Article No. 406 [19] Han Z B, Zhang C Q, Fu H Z, Zhou J T. Trusted multi-view classification with dynamic evidential fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2551−2566 doi: 10.1109/TPAMI.2022.3171983 [20] Liu H M, Wang R P, Shan S G, Chen X L. What is a tabby? Interpretable model decisions by learning attribute-based classification criteria. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(5): 1791−1807 doi: 10.1109/TPAMI.2019.2954501 [21] Selvaraju R R, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 618−626 [22] Shrikumar A, Greenside P, Kundaje A. Learning important features through propagating activation differences. In: Proceedings of the 34th International Conference on Machine Learning (ICML). Sydney, Australia: JMLR.org, 2017. 3145−3153 [23] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of the 13th European Conference on Computer Vision (ECCV). Zurich, Switzerland: Springer, 2014. 818−833 [24] Roberts L G. Machine Perception of Three-Dimensional Solids [Ph.D. dissertation], Massachusetts Institute of Technology, USA, 1963. [25] Farhadi A, Endres I, Hoiem D, Forsyth D. Describing objects by their attributes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Miami, USA: IEEE, 2009. 1778−1785 [26] Yang H M, Zhang X Y, Yin F, Liu C L. Robust classification with convolutional prototype learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 3474−3482 [27] Wan A, Dunlap L, Ho D, Yin J H, Lee S, Petryk S, et al. NBDT: Neural-backed decision tree. In: Proceedings of the 9th International Conference on Learning Representations (ICLR). Austria: OpenReview.net, 2021.Wan A, Dunlap L, Ho D, Yin J H, Lee S, Petryk S, et al. NBDT: Neural-backed decision tree. In: Proceedings of the 9th International Conference on Learning Representations (ICLR). Austria: OpenReview.net, 2021. [28] Han X Y, Zhu X B, Pedrycz W, Li Z W. A three-way classification with fuzzy decision trees. Applied Soft Computing, 2023, 132: Article No. 109788 doi: 10.1016/j.asoc.2022.109788 [29] Islam S, Haque M M, Karim A N M R. A rule-based machine learning model for financial fraud detection. International Journal of Electrical and Computer Engineering (IJECE), 2024, 14(1): 759−771 doi: 10.11591/ijece.v14i1.pp759-771 [30] Hotelling H. Relations between two sets of variates. Breakthroughs in Statistics: Methodology and Distribution. New York: Springer, 1992. 162−190 [31] Zhang J W, Yu Y, Tang S H, Wu J M, Li W. Variational autoencoder with CCA for audio——Visual cross-modal retrieval. ACM Transactions on Multimedia Computing, Communications and Applications, 2023, 19(3s): Article No. 130 [32] Sapkota R, Thapaliya B, Suresh P, Ray B, Calhoun V D, Liu J Y. Multimodal imaging feature extraction with reference canonical correlation analysis underlying intelligence. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Seoul, Korea: IEEE, 2024. 2071−2075 [33] Tang Q, Liang J, Zhu F Q. A comparative review on multi-modal sensors fusion based on deep learning. Signal Processing, 2023, 213: Article No. 109165 doi: 10.1016/j.sigpro.2023.109165 [34] Li X J, Ma S Q, Xu J H, Tang J J, He S F, Guo F. TranSiam: Aggregating multi-modal visual features with locality for medical image segmentation. Expert Systems With Applications, 2024, 237: Article No. 121574 doi: 10.1016/j.eswa.2023.121574 [35] Zheng X, Wang M H, Huang K, Zhu E. Global and cross-modal feature aggregation for multi-omics data classification and application on drug response prediction. Information Fusion, 2024, 102: Article No. 102077 doi: 10.1016/j.inffus.2023.102077 [36] Hou M X, Zhang Z, Liu C, Lu G M. Semantic alignment network for multi-modal emotion recognition. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(9): 5318−5329 doi: 10.1109/TCSVT.2023.3247822 [37] Song Z Y, Wei H Y, Bai L, Yang L, Jia C Y. GraphAlign: Enhancing accurate feature alignment by graph matching for multi-modal 3D object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 3335−3346 [38] Xue Z H, Marculescu R. Dynamic multimodal fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR). Vancouver, Canada: IEEE, 2023. 2575−2584 [39] de Vries H, Strub F, Mary J, Larochelle H, Pietquin O, Courville A. Modulating early visual processing by language. In: Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS). Long Beach, USA: Curran Associates Inc., 2017. 6597−6607 [40] Du C Z, Teng J Y, Li T L, Liu Y C, Yuan T Y, Wang Y, et al. On uni-modal feature learning in supervised multi-modal learning. In: Proceedings of the 40th International Conference on Machine Learning (ICML). Honolulu, USA: JMLR.org, 2023. Article No. 345 [41] Dempster A P. Upper and lower probabilities induced by a multivalued mapping. The Annals of Mathematical Statistics, 1967, 38(2): 325−339 doi: 10.1214/aoms/1177698950 [42] Jϕsang A. Subjective Logic: A Formalism for Reasoning Under Uncertainty. Cham: Springer Publishing Company, 2016. 1−326 [43] Sensoy M, Kaplan L, Kandemir M. Evidential deep learning to quantify classification uncertainty. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS). Montréal, Canada: Curran Associates Inc., 2018. 3183−3193 [44] Higgins I, Matthey L, Pal A, Burgess C P, Glorot X, Botvinick M M, et al. Beta-VAE: Learning basic visual concepts with a constrained variational framework. In: Proceedings of the 5th International Conference on Learning Representations (ICLR). Toulon, France: OpenReview.net, 2017. [45] İrsoy O, Yildiz O T, Alpaydın E. Soft decision trees. In: Proceedings of the 21st International Conference on Pattern Recognition (ICPR). Tsukuba, Japan: IEEE, 2012. 1819−1822 [46] Silberman N, Hoiem D, Kohli P, Fergus R. Indoor segmentation and support inference from RGBD images. In: Proceedings of the 12th European Conference on Computer Vision (ECCV). Florence, Italy: Springer, 2012. 746−760 [47] Song S R, Lichtenberg S P, Xiao J X. SUN RGB-D: A RGB-D scene understanding benchmark suite. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 567−576 [48] Brown M, Süsstrunk S. Multi-spectral SIFT for scene category recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Colorado Springs, USA: IEEE, 2011. 177−184 [49] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [50] Maas A L, Hannun A Y, Ng A Y. Rectifier nonlinearities improve neural network acoustic models. In: Proceedings of the 30th International Conference on Machine Learning (ICML). Atlanta, USA: JMLR, 2013. 3−8 [51] Lee S, Lee S, Song B C. Improving vision transformers to learn small-size dataset from scratch. IEEE Access, 2022, 10: 123212−123224 doi: 10.1109/ACCESS.2022.3224044 [52] Ayub A, Wagner A R. Centroid based concept learning for RGB-D indoor scene classification. In: Proceedings of the 31st British Machine Vision Conference (BMVC). Virtual Event: BMVA, 2020. 1−13Ayub A, Wagner A R. Centroid based concept learning for RGB-D indoor scene classification. In: Proceedings of the 31st British Machine Vision Conference (BMVC). Virtual Event: BMVA, 2020. 1−13 [53] Xu C, Zhang Y L, Guan Z Y, Zhao W. Trusted multi-view learning with label noise. In: Proceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI). Jeju Island, Korea: IJCAI, 2024. 5263−5271Xu C, Zhang Y L, Guan Z Y, Zhao W. Trusted multi-view learning with label noise. In: Proceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI). Jeju Island, Korea: IJCAI, 2024. 5263−5271 [54] Kontschieder P, Fiterau M, Criminisi A, Bulò S R. Deep neural decision forests. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1467−1475 [55] Petsiuk V, Das A, Saenko K. Rise: Randomized input sampling for explanation of black-box models. In: Proceedings of the British Machine Vision Conference (BMVC). Newcastle, UK: BMVA, 2018. 151−163 -

 下载:
下载:



计量
- 文章访问数: 2133
- HTML全文浏览量: 773
- PDF下载量: 744
- 被引次数: 0
