

-
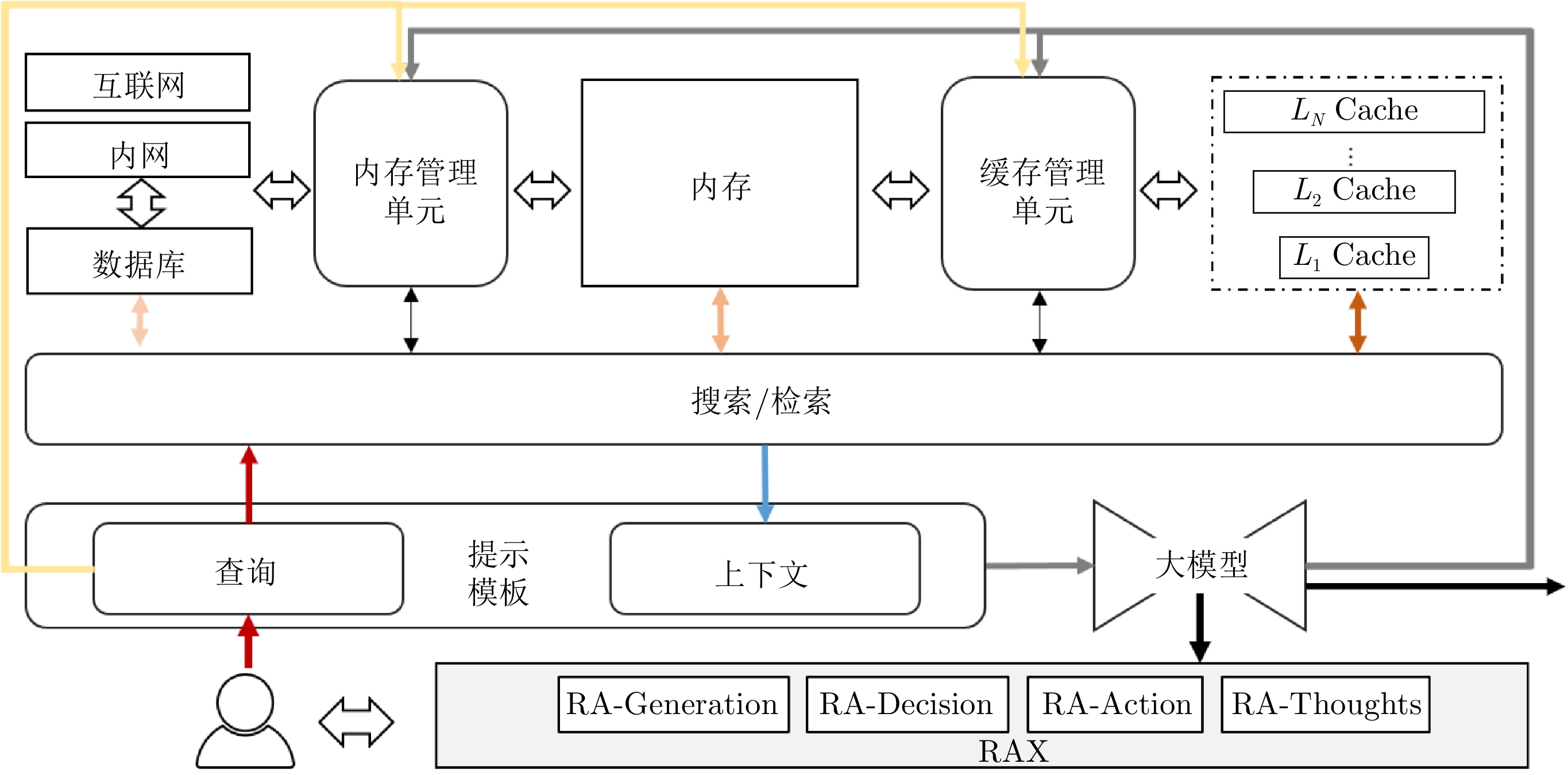
摘要: 大模型技术的兴起显著提升了人们获取和利用知识的效率, 但在实际应用中仍然面临着知识受限、迁移障碍和幻觉等挑战, 阻碍了可信可靠人工智能系统的构建. 检索增强生成(RAG)通过利用外接知识库和查询关联的检索有效增强大模型的能力水平, 为大模型掌握实时型、行业型及私有型知识提供有力支撑, 进而促进大模型技术向多样场景的快速推广和实施. 围绕RAG, 阐述其基本原理、发展现状及典型应用, 并分析其优势和面临的挑战. 在RAG的基础上, 通过结合搜索模块和多级缓存管理模块, 提出RAG的拓展框架SAGE, 以建立更加灵活和高效的大模型知识外挂工具链.Abstract: The emergence of large model technologies has significantly enhanced the efficiency with which humans acquire and utilize knowledge. However, in practical applications, they still confront challenges such as constrained knowledge, transfer obstacles, and hallucinations, which impede the construction of trustworthy and reliable artificial intelligence systems. Retrieval-augmented generation (RAG), by leveraging external knowledge bases and query-related retrieval, has effectively strengthened capability of large models and offers strong support for large models to master real-time, industry-specific, and private knowledge, thereby facilitating the rapid promotion and implementation of large model technologies across diverse scenarios. This paper focuses on RAG, detailing its basic principles, current development status, as well as exemplary applications, and analyzing its advantages and the challenges it faces. Based on RAG, we propose the extended framework of search-augmented generation and extension by incorporating the search module and multi-level cache management module, aiming to create a more flexible and efficient knowledge toolchain for large models.1)
1 1https://github.com/gkamradt/LLMTest_NeedleInAHaystack -
表 1 RAG综述文章总结与对比
Table 1 Summary and comparison of surveys on RAG
文献 年份 RAG技术点 RAG应用领域 RAG平台 新架构 文献[19] 2024 检索、生成 NLP $ \times $ $ \times $ 文献[12] 2024 架构、学习、检索 NLP及下游应用 $ \times $ $ \times $ 文献[20] 2023 检索、生成、搜索 NLP $ \times $ $ \times $ 文献[21] 2023 架构、检索、生成 NLP及下游应用 $ \times $ Module RAG 文献[22] 2022 检索、生成 NLP及下游应用 $ \times $ $ \times $ 文献[23] 2024 检索、生成 NLP及下游应用 $ \times $ $ \times $ 本文 2024 知识库、检索、生成 NLP、CV、垂直应用 $ \checkmark$ SAGE  下载: 导出CSV
下载: 导出CSV
表 2 基于RAG的应用案例
Table 2 RAG-based application cases
方法 应用领域 RAG作用 方法介绍 UniMS-RAG[87] 通用对话 个性化 知识库阶段, 构建人物角色库与上下文语料库 ERAGent[104] 通用对话 个性化 生成阶段, 使用人物角色资料作为提示构建的输入 HyKGE[105] 医疗问答 专业化 检索阶段, 基于医学知识图谱增强医学知识理解 CBR-RAG[106] 法律问答 专业化 数据库阶段, 基于法律案例库增强法学知识理解 uRAG[107], SEA[108] 通用对话 实时化 检索阶段, 基于搜索引擎的RAG系统 RA-VQA[109], KAT[110] 视觉问答 知识增强 生成阶段, 基于检索的知识增强视觉推理能力 Plug-and-Play[111], MuRAG[112] 图像描述 知识增强 生成阶段, 基于检索的知识增强视觉推理能力 RA-CM3[113], Re-Imagen[114] 图像生成 知识增强 生成阶段, 基于检索的知识丰富上下文信息 RAC[115] 图像分类 长尾分布 生成阶段, 融合原始图像和检索内容特征 文献[116], Make-an-Audio[117] 语音翻译 数据增强 基于检索构建多样化样本 RAG-Driver[118], 文献[119] 自动驾驶 可解释性 生成阶段, 基于RAG提取相似场景案例
下载: 导出CSV
表 3 RAG开源平台
Table 3 Open-source platforms of RAG
名称 发布日期 特点 链接 LangChain 2022年10月 功能多样, 可拓展性强 https://github.com/langchain-ai/langchain LlamaIndex 2023年05月 数据搜索检索效率高 https://github.com/jerryjliu/llama_index HayStack 2019年11月 侧重文本检索和问答应用开发 https://github.com/deepset-ai/haystack Embedchain 2023年07月 轻量化, 灵活, 可拓展性强 https://github.com/mem0ai/embedchainjs NeumAI 2023年12月 高吞吐分布式架构 https://github.com/NeumTry/NeumAI GraphRAG 2023年07月 知识图谱增强的全面信息理解 https://github.com/microsoft/graphrag Quivr 2023年05月 基于LangChain的知识库应用平台 https://github.com/QuivrHQ/quivr Dify 2023年05月 生成式AI开发框架 https://github.com/langgenius/dify RagFlow 2024年07月 自动化RAG构建, 流程精简 https://github.com/infiniflow/ragflow Open-WebUI 2024年02月 支持友好界面以及完全离线运行 https://github.com/open-webui/open-webui
下载: 导出CSV
表 4 中英文术语对照表
Table 4 Glossary of Chinese-English terms
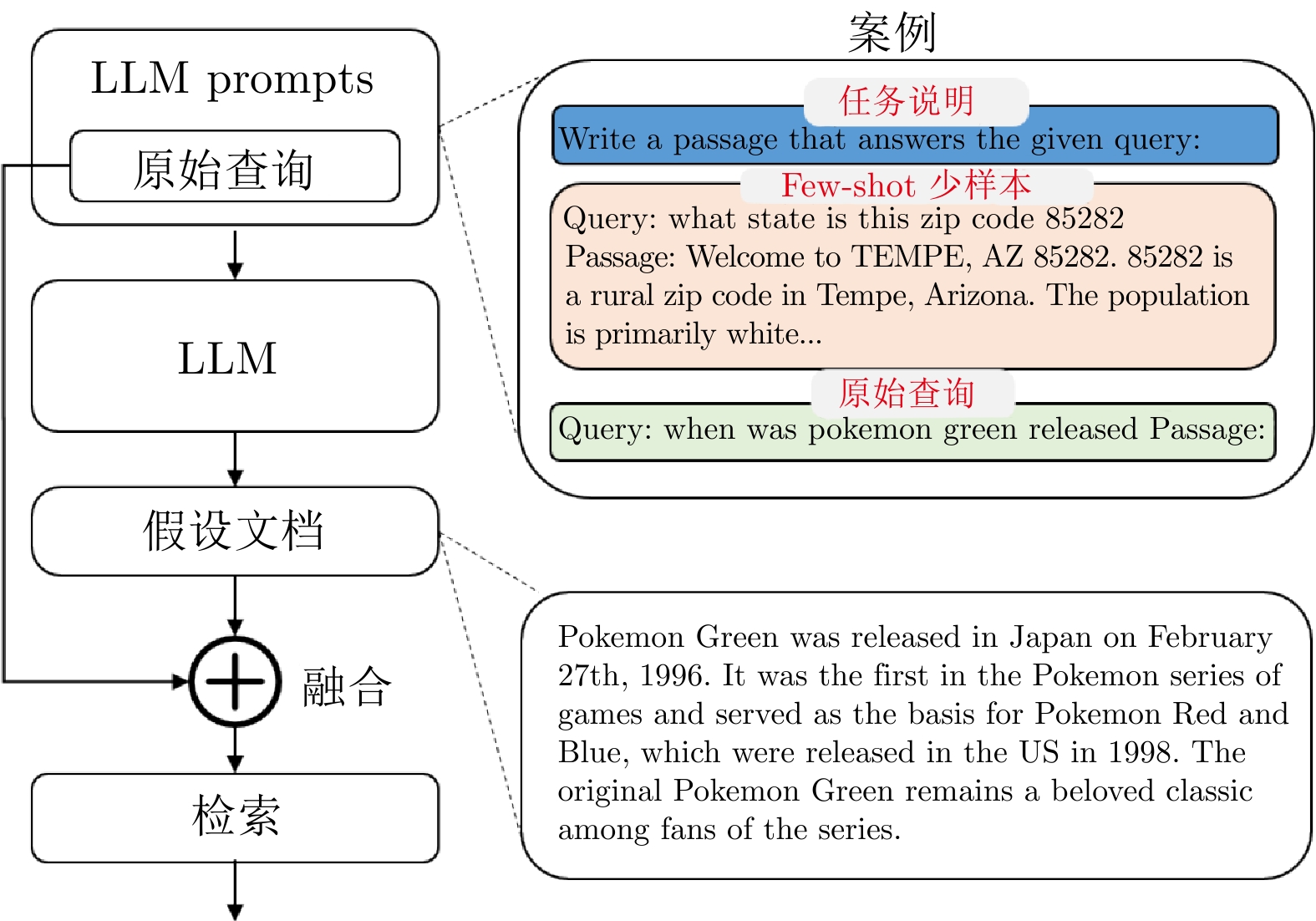
中文名称 英文名称 检索增强生成技术 Retrieval-augmented generation (RAG)[19−23] 大语言模型 Large language model (LLM)[5−8] 自然语言处理 Natural language processing (NLP) 计算机视觉 Computation vision (CV) 数据分块 Data chunking[38−41] 独热编码 One-hot encoding[49] 词袋模型 Bag of words (BOW)[50] 词频−逆向文件频率 Term frequency-inverse document frequency (TF-IDF)[51] N元模型 N-Gram[52] 海量文本语义向量基准测试 Massive text embedding benchmark (MTEB)[55] 退后提示 Step back prompting[81] 多路召回 Multi query retrieval[82] 假想文档嵌入 Hypothetical document embeddings (HyDE)[83−84] 外部知识视觉问答任务 Outside knowledge visual question answering (OKVQA)[110] 思维链 Chain of thought (CoT)[79] 搜索增强的生成与扩展技术 Search-augmented generation and extension (SAGE)
下载: 导出CSV
表 5 基于RAG的FLARE方法[86]与无检索基线方法的实验结果对比
Table 5 Comparison of experimental results between the RAG-based FLARE method[86] and the non-retrieval baseline method
指标 StrategyQA ASQA ASQA-hint WikiAsp EM EM D-F1 R-L DR EM D-F1 R-L DR UniEval[166] E-F1 R-L 无检索 72.9 33.8 24.2 33.3 28.4 40.1 32.5 36.4 34.4 47.1 14.1 26.4 FLARE 77.3 41.3 28.2 34.3 31.1 46.2 36.7 37.7 37.2 53.4 18.9 27.6
下载: 导出CSV
-
[1] 田永林, 王雨桐, 王建功, 王晓, 王飞跃. 视觉Transformer研究的关键问题: 现状及展望. 自动化学报, 2022, 48(4): 957−979Tian Yong-Lin, Wang Yu-Tong, Wang Jian-Gong, Wang Xiao, Wang Fei-Yue. Key problems and progress of vision transformers: The state of the art and prospects. Acta Automatica Sinica, 2022, 48(4): 957−979 [2] Casper S, Davies X, Shi C, Gilbert T K, Scheurer J, Rando J, et al. Open problems and fundamental limitations of reinforcement learning from human feedback. Transactions on Machine Learning Research, 2023. [3] Croitoru F A, Hondru V, Ionescu R T, Shah M. Diffusion models in vision: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(9): 10850−10869 doi: 10.1109/TPAMI.2023.3261988 [4] Muennighoff N, Rush A M, Barak B, le Scao T, Piktus A, Tazi N, et al. Scaling data-constrained language models. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: ACM, 2023. Article No. 2191 [5] Wang Y T, Pan Y H, Yan M, Su Z, Luan T H. A survey on ChatGPT: AI-generated contents, challenges, and solutions. IEEE Open Journal of the Computer Society, 2023, 4: 280−302 doi: 10.1109/OJCS.2023.3300321 [6] 王晓, 张翔宇, 周锐, 田永林, 王建功, 陈龙, 等. 基于平行测试的认知自动驾驶智能架构研究. 自动化学报, 2024, 50(2): 356−371Wang Xiao, Zhang Xiang-Yu, Zhou Rui, Tian Yong-Lin, Wang Jian-Gong, Chen Long, et al. An intelligent architecture for cognitive autonomous driving based on parallel testing. Acta Automatica Sinica, 2024, 50(2): 356−371 [7] Fan L L, Guo C, Tian Y L, Zhang H, Zhang J, Wang F Y. Sora for foundation robots with parallel intelligence: Three world models, three robotic systems. Frontiers of Information Technology and Electronic Engineering, 2024, 25(7): 917−923 [8] Moor M, Banerjee O, Abad Z S H, Krumholz H M, Leskovec J, Topol E J, et al. Foundation models for generalist medical artificial intelligence. Nature, 2023, 616(7956): 259−265 doi: 10.1038/s41586-023-05881-4 [9] 卢经纬, 郭超, 戴星原, 缪青海, 王兴霞, 杨静, 等. 问答ChatGPT之后: 超大预训练模型的机遇和挑战. 自动化学报, 2023, 49(4): 705−717Lu Jing-Wei, Guo Chao, Dai Xing-Yuan, Miao Qing-Hai, Wang Xing-Xia, Yang Jing, et al. The ChatGPT after: Opportunities and challenges of very large scale pre-trained models. Acta Automatica Sinica, 2023, 49(4): 705−717 [10] Currie G M. Academic integrity and artificial intelligence: Is ChatGPT hype, hero or heresy? Seminars in Nuclear Medicine, 2023, 53(5): 719−730 doi: 10.1053/j.semnuclmed.2023.04.008 [11] Hirano Y, Hanaoka S, Nakao T, Miki S, Kikuchi T, Nakamura Y, et al. GPT-4 Turbo with vision fails to outperform text-only GPT-4 Turbo in the Japan diagnostic radiology board examination. Japanese Journal of Radiology, 2024, 42(8): 918−926 doi: 10.1007/s11604-024-01561-z [12] Ding Y J, Fan W Q, Ning L B, Wang S J, Li H Y, Yin D W, et al. A survey on RAG meets LLMs: Towards retrieval-augmented large language models. arXiv preprint arXiv: 2405.06211, 2024. [13] Xiong G Z, Jin Q, Lu Z Y, Zhang A D. Benchmarking retrieval-augmented generation for medicine. In: Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024. Bangkok, Thailand: ACL, 2024. 6233−6251 [14] Zhao A, Huang D, Xu Q, Lin M, Liu Y J, Huang G. ExpeL: LLM agents are experiential learners. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 19632−19642 [15] Zhai Y X, Tong S B, Li X, Cai M, Qu Q, Lee Y J, et al. Investigating the catastrophic forgetting in multimodal large language model fine-tuning. In: Proceedings of the Conference on Parsimony and Learning. Hong Kong, China: PMLR, 2024. 202−227 [16] Gupta S, Jegelka S, Lopez-Paz D, Ahuja K. Context is environment. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. [17] Ji Z W, Yu T Z, Xu Y, Lee N, Ishii E, Fung P. Towards mitigating LLM hallucination via self reflection. In: Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023. Singapore, Singapore: ACL, 2023. 1827−1843 [18] Lewis P, Perez E, Piktus A, Petroni F, Karpukhin V, Goyal N, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: ACM, 2020. Article No. 793 [19] Huang Y Z, Huang J. A survey on retrieval-augmented text generation for large language models. arXiv preprint arXiv: 2404.10981, 2024. [20] Zhu Y T, Yuan H Y, Wang S T, Liu J N, Liu W H, Deng C L, et al. Large language models for information retrieval: A survey. arXiv preprint arXiv: 2308.07107, 2023. [21] Gao Y F, Xiong Y, Gao X Y, Jia K X, Pan J L, Bi Y X, et al. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv: 2312.10997, 2023. [22] Li H Y, Su Y X, Cai D, Wang Y, Liu L M. A survey on retrieval-augmented text generation. arXiv preprint arXiv: 2202.01110, 2022. [23] Hu Y C, Lu Y X. RAG and RAU: A survey on retrieval-augmented language model in natural language processing. arXiv preprint arXiv: 2404.19543, 2024. [24] 田永林, 王兴霞, 王雨桐, 王建功, 郭超, 范丽丽, 等. RAG-PHI: 检索增强生成驱动的平行人与平行智能. 智能科学与技术学报, 2024, 6(1): 41−51Tian Yong-Lin, Wang Xing-Xia, Wang Yu-Tong, Wang Jian-Gong, Guo Chao, Fan Li-Li, et al. RAG-PHI: RAG-driven parallel human and parallel intelligence. Chinese Journal of Intelligent Science and Technology, 2024, 6(1): 41−51 [25] Kaddour J, Harris J, Mozes M, Bradley H, Raileanu R, McHardy R. Challenges and applications of large language models. arXiv preprint arXiv: 2307.10169, 2023. [26] Dai X Y, Guo C, Tang Y, Li H C, Wang Y T, Huang J, et al. VistaRAG: Toward safe and trustworthy autonomous driving through retrieval-augmented generation. IEEE Transactions on Intelligent Vehicles, 2024, 9(4): 4579−4582 doi: 10.1109/TIV.2024.3396450 [27] Dave T, Athaluri S A, Singh S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Frontiers in Artificial Intelligence, 2023, 6: Article No. 1169595 doi: 10.3389/frai.2023.1169595 [28] Louis A, van Dijck G, Spanakis G. Interpretable long-form legal question answering with retrieval-augmented large language models. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 22266−22275 [29] Wu S J, Irsoy O, Lu S, Dabravolski V, Dredze M, Gehrmann S, et al. BloombergGPT: A large language model for finance. arXiv preprint arXiv: 2303.17564, 2023. [30] 王飞跃, 王艳芬, 陈薏竹, 田永林, 齐红威, 王晓, 等. 联邦生态: 从联邦数据到联邦智能. 智能科学与技术学报, 2020, 2(4): 305−311 doi: 10.11959/j.issn.2096-6652.202033Wang Fei-Yue, Wang Yan-Fen, Chen Yi-Zhu, Tian Yong-Lin, Qi Hong-Wei, Wang Xiao, et al. Federated ecology: From federated data to federated intelligence. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 305−311 doi: 10.11959/j.issn.2096-6652.202033 [31] Gemini Team Google. Gemini: A family of highly capable multimodal models. arXiv preprint arXiv: 2312.11805, 2023. [32] Lewis M, Liu Y H, Goyal N, Ghazvininejad M, Mohamed A, Levy O, et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Washington, USA: ACL, 2020. 7871−7880 [33] Devlin J, Chang M W, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, Minnesota: ACL, 2019. 4171−4186 [34] Wang Y X, Sun Q X. M3E: Moka massive mixed embedding model [Online], available: https://github.com/wangyuxinwhy/uniem. December 31, 2023 [35] Neelakantan A, Xu T, Puri R, Radford A, Han J M, Tworek J, et al. Text and code embeddings by contrastive pre-training. arXiv preprint arXiv: 2201.10005, 2022. [36] Karpukhin V, Oguz B, Min S, Lewis P, Wu L, Edunov S, et al. Dense passage retrieval for open-domain question answering. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Virtual Event: ACL, 2020. 6769−6781 [37] Yang Z L, Qi P, Zhang S Z, Bengio Y, Cohen W, Salakhutdinov R, et al. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: ACL, 2018. 2369−2380 [38] Yu H, Gan A R, Zhang K, Tong S W, Liu Q, Liu Z F. Evaluation of retrieval-augmented generation: A survey. In: Proceedings of the CCF Conference on Big Data. Singapore, Singapore: Springer Nature, 2024. 102−120 [39] Chen H Y, Yu H. Intent-based web page summarization with structure-aware chunking and generative language models. In: Proceedings of the ACM Web Conference 2023. Austin, USA: ACM, 2023. 310−313 [40] Xiao S T, Liu Z, Zhang P T, Muennighof N. C-pack: Packaged resources to advance general Chinese embedding. arXiv preprint arXiv: 2309.07597, 2023. [41] Chen T, Wang H W, Chen S H, Yu W H, Ma K X, Zhao X R, et al. Dense X retrieval: What retrieval granularity should we use? In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Miami, USA: ACL, 2024. 15159−15177 [42] Chung H W, Hou L, Longpre S, Zoph B, Tai Y, Fedus W, et al. Scaling instruction-finetuned language models. The Journal of Machine Learning Research, 2024, 25(1): Article No. 70 [43] Manning C D, Schütze H. Foundations of Statistical Natural Language Processing. Cambridge: MIT Press, 1999. [44] Zhang T, Damerau F, Johnson D. Text chunking based on a generalization of winnow. Journal of Machine Learning Research, 2002, 2(3): 615−637 [45] Barzilay R, Elhadad M. Using lexical chains for text summarization. In: Proceedings of the ACL Workshop on Intelligent Scalable Text Summarization. Madrid, Spain: ACL, 1997. 10−17 [46] Moens M F, Uyttendaele C, Dumortier J. Information extraction from legal texts: The potential of discourse analysis. International Journal of Human-Computer Studies, 1999, 51(6): 1155−1171 [47] Lin C Y. ROUGE: A package for automatic evaluation of summaries. In: Proceedings of the Text Summarization Branches Out. Barcelona, Spain: ACL, 2004. 74−81 [48] Wan X J. Using bilingual knowledge and ensemble techniques for unsupervised Chinese sentiment analysis. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Honolulu, USA: ACL, 2008. 553−561 [49] Rodríguez P, Bautista M A, González J, Escalera S. Beyond one-hot encoding: Lower dimensional target embedding. Image and Vision Computing, 2018, 75: 21−31 doi: 10.1016/j.imavis.2018.04.004 [50] Zhang Y, Jin R, Zhou Z H. Understanding bag-of-words model: A statistical framework. International Journal of Machine Learning and Cybernetics, 2010, 1(1−4): 43−52 doi: 10.1007/s13042-010-0001-0 [51] Chowdhury G. Introduction to Modern Information Retrieval (3rd edition). London: Facet Publishing, 2010. [52] Kondrak G. N-gram similarity and distance. In: Proceedings of the 12th International Symposium on String Processing and Information Retrieval. Buenos Aires, Argentina: Springer, 2005. 115−126 [53] Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. In: Proceedings of the 1st International Conference on Learning Representations. Scottsdale, USA: ICLR, 2013. [54] Pennington J, Socher R, Manning C. GloVe: Global vectors for word representation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: ACL, 2014. 1532−1543 [55] Muennighoff N, Tazi N, Magne L, Reimers N. MTEB: Massive text embedding benchmark. In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. Dubrovnik, Croatia: ACL, 2023. 2014−2037 [56] Meng R, Liu Y, Joty S, Xiong C M, Zhou Y B, Yavuz S. SFR-embedding-mistral: Enhance text retrieval with transfer learning [Online], available: https://www.salesforce.com/blog/sfr-embedding/#author-section, October 28, 2024 [57] Muennighoff N, Su H J, Wang L, Yang N, Wei F R, Yu T, et al. Generative representational instruction tuning. arXiv preprint arXiv: 2402.09906, 2024. [58] Wang L, Yang N, Huang X L, Yang L J, Majumder R, Wei F R. Improving text embeddings with large language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Bangkok, Thailand: ACL, 2024. 11897−11916 [59] Yang A Y, Xiao B, Wang B N, Zhang B R, Bian C, Yin C, et al. Baichuan 2: Open large-scale language models. arXiv preprint arXiv: 2309.10305, 2023. [60] Chen J L, Xiao S T, Zhang P T, Luo K, Lian D F, Liu Z. BGE M3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv: 2402.03216, 2024. [61] Xiao S T, Liu Z, Zhang P T, Muennighoff N, Lian D F, Nie J Y. C-pack: Packed resources for general Chinese embedding. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. Washington, USA: ACM, 2024. 641−649 [62] Chen J W, Lin H Y, Han X P, Sun L. Benchmarking large language models in retrieval-augmented generation. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Washington, USA: AAAI, 2024. 17754−17762 [63] Luo K, Liu Z, Xiao S T, Liu K. BGE landmark embedding: A chunking-free embedding method for retrieval augmented long-context large language models. arXiv preprint arXiv: 2402.11573, 2024. [64] Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M A, Lacroix T, et al. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv: 2302.13971, 2023. [65] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [66] Tan M X, Le Q V. EfficientNet: Rethinking model scaling for convolutional neural networks. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 6105−6114 [67] Wan X J. Using bilingual knowledge and ensemble techniques for unsupervised Chinese sentiment analysis. In: Proceedings of the Conference on Empirical methods in Natural language Processing. Virtual Event: ACL, 2008. [68] Tsalera E, Papadakis A, Samarakou M. Comparison of pre-trained CNNs for audio classification using transfer learning. Journal of Sensor and Actuator Networks, 2021, 10(4): Article No. 72 doi: 10.3390/jsan10040072 [69] Yuan Y, Xun G X, Suo Q L, Jia K B, Zhang A D. Wave2Vec: Learning deep representations for biosignals. In: Proceedings of the IEEE International Conference on Data Mining (ICDM). New Orleans, USA: IEEE, 2017. 1159−1164 [70] Lin G H, Zhang Y M, Xu G, Zhang Q X. Smoke detection on video sequences using 3D convolutional neural networks. Fire Technology, 2019, 55(5): 1827−1847 doi: 10.1007/s10694-019-00832-w [71] Bertasius G, Wang H, Torresani L. Is space-time attention all you need for video understanding? In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: ICML, 2021. 813−824 [72] Robertson S, Zaragoza H. The probabilistic relevance framework: BM25 and beyond. Foundations and Trends? In Information Retrieval, 2009, 3(4): 333−389 doi: 10.1561/1500000019 [73] McCandless M, Hatcher E, Gospodnetic O. Lucene in Action (2nd edition). Greenwich: Manning Publications, 2010. [74] Gormley C, Tong Z. Elasticsearch: The Definitive Guide: A Distributed Real-Time Search and Analytics Engine. Sebastopol: O'Reilly Media, Inc., 2015. [75] Chang X Y. The analysis of open source search engines. Highlights in Science, Engineering and Technology, 2023, 32: 32−42 doi: 10.54097/hset.v32i.4933 [76] Cuconasu F, Trappolini G, Siciliano F, Filice S, Campagnano C, Maarek Y, et al. The power of noise: Redefining retrieval for RAG systems. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. Washington, USA: ACM, 2024. 719−729 [77] Singh J, Prasad M, Prasad O K, Meng Joo E, Saxena A K, Lin C T. A novel fuzzy logic model for pseudo-relevance feedback-based query expansion. International Journal of Fuzzy Systems, 2016, 18(6): 980−989 doi: 10.1007/s40815-016-0254-1 [78] Kim L, Yahia E, Segonds F, Véron P, Mallet A. i-Dataquest: A heterogeneous information retrieval tool using data graph for the manufacturing industry. Computers in Industry, 2021, 132: Article No. 103527 doi: 10.1016/j.compind.2021.103527 [79] Wei J, Wang X Z, Schuurmans D, Bosma M, Ichter B, Xia F, et al. Chain-of-thought prompting elicits reasoning in large language models. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: ACM, 2022. Article No. 1800 [80] Ma X B, Gong Y Y, He P C, Zhao H, Duan N. Query rewriting in retrieval-augmented large language models. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Singapore, Singapore: ACL, 2023. 5303−5315 [81] Zheng H S, Mishra S, Chen X Y, Cheng H T. Take a step back: Evoking reasoning via abstraction in large language models. arXiv preprint arXiv: 2310.06117, 2023. [82] Wang Z Y, Wu Y, Narasimhan K, Russakovsky O. Multi-query video retrieval. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 233−249 [83] Gao L Y, Ma X G, Lin J, Callan J. Precise zero-shot dense retrieval without relevance labels. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Toronto, Canada: ACL, 2023. 1762−1777 [84] Wang L, Yang N, Wei F R. Query2doc: Query expansion with large language models. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Singapore, Singapore: ACL, 2023. 9414−9423 [85] Asai A, Wu Z Q, Wang Y Z, Sil A, Hajishirzi H. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. [86] Jiang Z B, Xu F, Gao L Y, Sun Z Q, Liu Q, Dwivedi-Yu J, et al. Active retrieval augmented generation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Singapore, Singapore: ACL, 2023. 7969−7992 [87] Wang H R, Huang W Y, Deng Y, Wang R, Wang Z Z, Wang Y F, et al. UniMS-RAG: A unified multi-source retrieval-augmented generation for personalized dialogue systems. arXiv preprint arXiv: 2401.13256, 2024. [88] Yuan Z Q, Zhang W K, Tian C Y, Mao Y Q, Zhou R X, Wang H Q, et al. MCRN: A multi-source cross-modal retrieval network for remote sensing. International Journal of Applied Earth Observation and Geoinformation, 2022, 115: Article No. 103071 doi: 10.1016/j.jag.2022.103071 [89] Bouchakwa M, Ayadi Y, Amous I. Multi-level diversification approach of semantic-based image retrieval results. Progress in Artificial Intelligence, 2020, 9(1): 1−30 doi: 10.1007/s13748-019-00195-x [90] Li W H, Yang S, Wang Y, Song D, Li X Y. Multi-level similarity learning for image-text retrieval. Information Processing and Management, 2021, 58(1): Article No. 102432 [91] Jeong S, Baek J, Cho S, Hwang S J, Park J. Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Mexico City, Mexico: ACL, 2024. 7036−7050 [92] Malkov Y A, Yashunin D A. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(4): 824−836 doi: 10.1109/TPAMI.2018.2889473 [93] Li W T, Li J K, Ma W Z, Liu Y. Citation-enhanced generation for LLM-based Chatbots. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Bangkok, Thailand: ACL, 2024. 1451−1466 [94] Glass M, Rossiello G, Chowdhury M F M, Naik A, Cai P S, Gliozzo A. Re2G: Retrieve, rerank, generate. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, USA: ACL, 2022. 2701−2715 [95] Wang S T, Xu X, Wang M, Chen W P, Zhu Y T, Dou Z C. RichRAG: Crafting rich responses for multi-faceted queries in retrieval-augmented generation. In: Proceedings of the 31st International Conference on Computational Linguistics. Abu Dhabi, UAE: ACL, 2025. 11317−11333 [96] Xu Z P, Liu Z H, Liu Y B, Xiong C Y, Yan Y K, Wang S, et al. ActiveRAG: Revealing the treasures of knowledge via active learning. arXiv preprint arXiv: 2402.13547, 2024. [97] Izacard G, Grave E. Leveraging passage retrieval with generative models for open domain question answering. In: Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. Virtual Event: ACL, 2021. 874−880 [98] Zhang J, Wang X, Zhang H Y, Sun H L, Liu X D. Retrieval-based neural source code summarization. In: Proceedings of the 42nd ACM/IEEE International Conference on Software Engineering. Seoul, South Korea: ACM, 2020. 1385−1397 [99] Khandelwal U, Levy O, Jurafsky D, Zettlemoyer L, Lewis M. Generalization through memorization: Nearest neighbor language models. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. [100] Poesia G, Polozov A, Le V, Tiwari A, Soares G, Meek C, et al. Synchromesh: Reliable code generation from pre-trained language models. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. [101] Joshi H, Sanchez J C, Gulwani S, Le V, Verbruggen G, Radiček I. Repair is nearly generation: Multilingual program repair with LLMs. In: Proceedings of the 37th AAAI Conference on Artificial Intelligence. Washington, USA: AAAI, 2023. 5131−5140 [102] Zheng L M, Chiang W L, Sheng Y, Li T L, Zhuang S Y, Wu Z H, et al. LMSYS-Chat-1M: A large-scale real-world LLM conversation dataset. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. [103] Zhu Y H, Ren C Y, Xie S Y, Liu S K, Ji H Y, Wang Z X, et al. REALM: RAG-driven enhancement of multimodal electronic health records analysis via large language models. arXiv preprint arXiv: 2402.07016, 2024. [104] Shi Y X, Zi X, Shi Z J, Zhang H M, Wu Q, Xu M. ERAGent: Enhancing retrieval-augmented language models with improved accuracy, efficiency, and personalization. arXiv preprint arXiv: 2405.06683, 2024. [105] Jiang X K, Zhang R Z, Xu Y X, Qiu R H, Fang Y, Wang Z Y, et al. Think and retrieval: A hypothesis knowledge graph enhanced medical large language models. arXiv preprint arXiv: 2312.15883, 2023. [106] Wiratunga N, Abeyratne R, Jayawardena L, Martin K, Massie S, Nkisi-Orji I, et al. CBR-RAG: Case-based reasoning for retrieval augmented generation in LLMs for legal question answering. In: Proceedings of the 32nd International Conference on Case-Based Reasoning Research and Development. Merida, Mexico: Springer, 2024. 445−460 [107] Salemi A, Zamani H. Towards a search engine for machines: Unified ranking for multiple retrieval-augmented large language models. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. Washington, USA: ACM, 2024. 741−751 [108] Komeili M, Shuster K, Weston J. Internet-augmented dialogue generation. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Dublin, Ireland: ACL, 2022. 8460−8478 [109] Lin W Z, Byrne B. Retrieval augmented visual question answering with outside knowledge. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: ACL, 2022. 11238−11254 [110] Gui L K, Wang B R, Huang Q Y, Hauptmann A, Bisk Y, Gao J F. KAT: A knowledge augmented transformer for vision-and-language. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, USA: ACL, 2022. 956−968 [111] Tiong A M H, Li J N, Li B Y, Savarese S, Hoi S C H. Plug-and-play VQA: Zero-shot VQA by conjoining large pretrained models with zero training. In: Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022. Abu Dhabi, United Arab Emirates: ACL, 2022. 951−967 [112] Chen W H, Hu H X, Chen X, Verga P, Cohen W. MuRAG: Multimodal retrieval-augmented generator for open question answering over images and text. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: ACL, 2022. 5558−5570 [113] Yasunaga M, Aghajanyan A, Shi W J, James R, Leskovec J, Liang P, et al. Retrieval-augmented multimodal language modeling. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: ACM, 2022. Article No. 1659 [114] Chen W H, Hu H X, Saharia C, Cohen W W. Re-Imagen: Retrieval-augmented text-to-image generator. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: ICLR, 2023. [115] Long A, Yin W, Ajanthan T, Nguyen V, Purkait P, Garg R, et al. Retrieval augmented classification for long-tail visual recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 6949−6959 [116] Zhao J, Haffar G, Shareghi E. Generating synthetic speech from spokenvocab for speech translation. In: Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023. Dubrovnik, Croatia: ACL, 2023. 1975−1981 [117] Huang R J, Huang J W, Yang D C, Ren Y, Liu L P, Li M Z, et al. Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: ICML, 2023. 13916−13932 [118] Yuan J H, Sun S Y, Omeiza D, Zhao B, Newman P, Kunze L, et al. RAG-driver: Generalisable driving explanations with retrieval-augmented in-context learning in multi-modal large language model. arXiv preprint arXiv: 2402.10828, 2024. [119] Hussien M M, Melo A N, Ballardini A L, Maldonado C S, Izquierdo R, Sotelo M Á. RAG-based explainable prediction of road users behaviors for automated driving using knowledge graphs and large language models. Expert Systems With Applications, 2025, 265: Article No. 125914 doi: 10.1016/j.eswa.2024.125914 [120] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: ACM, 2017. 6000−6010 [121] Chen M, Tworek J, Jun H, Yuan Q M, de Oliveira Pinto H P, Kaplan J, et al. Evaluating large language models trained on code. arXiv preprint arXiv: 2107.03374, 2021. [122] Ziegler A, Kalliamvakou E, Li X A, Rice A, Rifkin D, Simister S, et al. Productivity assessment of neural code completion. In: Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming. San Diego, USA: ACM, 2022. 21−29 [123] Li Y J, Choi D, Chung J, Kushman N, Schrittwieser J, Leblond R, et al. Competition-level code generation with AlphaCode. Science, 2022, 378(6624): 1092−1097 doi: 10.1126/science.abq1158 [124] Nijkamp E, Pang B, Hayashi H, Tu L F, Wang H, Zhou Y B, et al. A conversational paradigm for program synthesis. arXiv preprint arXiv: 2203.13474, 2022. [125] Fried D, Aghajanyan A, Lin J, Wang S D, Wallace E, Shi F, et al. InCoder: A generative model for code infilling and synthesis. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: ICLR, 2023. [126] Chowdhery A, Narang S, Devlin J, Bosma M, Mishra G, Roberts A, et al. PaLM: Scaling language modeling with pathways. The Journal of Machine Learning Research, 2023, 24(1): Article No. 240 [127] Zheng Q K, Xia X, Zou X, Dong Y X, Wang S, Xue Y F, et al. CodeGeeX: A pre-trained model for code generation with multilingual benchmarking on HumanEval-X. In: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Long Beach, USA: ACM, 2023. 5673−5684 [128] Selvaraju R R, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 618−626 [129] Yuan Z, Xi Q, Tan C Q, Zhao Z Y, Yuan H Y, Huang F, et al. RAMM: Retrieval-augmented biomedical visual question answering with multi-modal pre-training. In: Proceedings of the 31st ACM International Conference on Multimedia. Ottawa, Canada: ACM, 2023. 547−556 [130] Zhou Y C, Long G D. Style-aware contrastive learning for multi-style image captioning. In: Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023. Dubrovnik, Croatia: ACL, 2023. 2257−2267 [131] Shen S, Li C Y, Hu X W, Yang J W, Xie Y J, Zhang P C, et al. K-LITE: Learning transferable visual models with external knowledge. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: ACM, 2022. Article No. 1132 [132] Fellbaum C. WordNet: An Electronic Lexical Database. Cambridge: MIT Press, 1998. [133] Zesch T, Müller C, Gurevych I. Using wiktionary for computing semantic relatedness. In: Proceedings of the 23rd AAAI Conference on Artificial Intelligence. Chicago, USA: AAAI, 2008. 861−866 [134] Liu H T, Son K, Yang J W, Liu C, Gao J F, Lee Y J, et al. Learning customized visual models with retrieval-augmented knowledge. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 15148−15158 [135] Whitehead S, Ji H, Bansal M, Chang S F, Voss C. Incorporating background knowledge into video description generation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: ACL, 2018. 3992−4001 [136] Le H, Chen N, Hoi S. Vgnmn: Video-grounded neural module networks for video-grounded dialogue systems. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, USA: ACL, 2022. 3377−3393 [137] Kim M, Sung-Bin K, Oh T H. Prefix tuning for automated audio captioning. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Rhodes Island, Greece: IEEE, 2023. 1−5 [138] Mestre R, Middleton S E, Ryan M, Gheasi M, Norman T, Zhu J T. Augmenting pre-trained language models with audio feature embedding for argumentation mining in political debates. In: Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023. Dubrovnik, Croatia: ACL, 2023. 274−288 [139] Shu Y H, Yu Z W, Li Y H, Karlsson B, Ma T T, Qu Y Z, et al. TIARA: Multi-grained retrieval for robust question answering over large knowledge base. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: ACL, 2022. 8108−8121 [140] Pan F F, Canim M, Glass M, Gliozzo A, Fox P. CLTR: An end-to-end, transformer-based system for cell-level table retrieval and table question answering. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations. Bangkok, Thailand: ACL, 2021. 202−209 [141] Yang Z C, Qin J H, Chen J Q, Lin L, Liang X D. LogicSolver: Towards interpretable math word problem solving with logical prompt-enhanced learning. In: Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022. Abu Dhabi, United Arab Emirates: ACL, 2022. 1−13 [142] He H F, Zhang H M, Roth D. Rethinking with retrieval: Faithful large language model inference. arXiv preprint arXiv: 2301.00303, 2022. [143] Li X X, Zhao R C, Chia Y K, Ding B S, Bing L D, Joty S, et al. Chain of knowledge: A framework for grounding large language models with structured knowledge bases. arXiv preprint arXiv: 2305.13269, 2023. [144] Zhou H J, Gu B Y, Zou X Y, Li Y R, Chen S S, Zhou P L, et al. A survey of large language models in medicine: Progress, application, and challenge. arXiv preprint arXiv: 2311.05112, 2023. [145] Kang B, Kim J, Yun T R, Kim C E. Prompt-RAG: Pioneering vector embedding-free retrieval-augmented generation in niche domains, exemplified by Korean medicine. arXiv preprint arXiv: 2401.11246, 2024. [146] Quidwai M A, Lagana A. A RAG chatbot for precision medicine of multiple myeloma. medRxiv, DOI: 10.1101/2024.03.14.24304293 [147] Kim J, Min M. From RAG to QA-RAG: Integrating generative AI for pharmaceutical regulatory compliance process. arXiv preprint arXiv: 2402.01717, 2024. [148] Rafat M I. AI-powered Legal Virtual Assistant: Utilizing RAG-optimized LLM for Housing Dispute Resolution in Finland [Master thesis], Haaga-Helia University of Applied Sciences, Finland, 2024. [149] Li Y H, Wang S F, Ding H, Chen H. Large language models in finance: A survey. In: Proceedings of the 4th ACM International Conference on AI in Finance. Brooklyn, USA: ACM, 2023. 374−382 [150] Ryu C, Lee S, Pang S, Choi C, Choi H, Min M, et al. Retrieval-based evaluation for LLMs: A case study in Korean legal QA. In: Proceedings of the Natural Legal Language Processing Workshop 2023. Singapore, Singapore: ACL, 2023. 132−137 [151] Cui C, Ma Y S, Cao X, Ye W Q, Zhou Y, Liang K Z, et al. A survey on multimodal large language models for autonomous driving. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW). Waikoloa, USA: IEEE, 2024. 958−979 [152] Kim J, Rohrbach A, Darrell T, Canny J, Akata Z. Textual explanations for self-driving vehicles. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 577−593 [153] Papineni K, Roukos S, Ward T, Zhu W J. Bleu: A method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Philadelphia, USA: ACL, 2002. 311−318 [154] Elliott D, Keller F. Image description using visual dependency representations. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Seattle, USA: ACL, 2013. 1292−1302 [155] Vedantam R, Lawrence Zitnick C, Parikh D. Cider: Consensus-based image description evaluation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 4566−4575 [156] Xu Z H, Zhang Y J, Xie E Z, Zhao Z, Guo Y, Wong K Y K, et al. DriveGPT4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters, 2024, 9(10): 8186−8193 doi: 10.1109/LRA.2024.3440097 [157] Bornea A L, Ayed F, de Domenico A, Piovesan N, Maatouk A. Telco-RAG: Navigating the challenges of retrieval augmented language models for telecommunications. In: Proceedings of the IEEE Global Communications Conference. Cape Town, South Africa: IEEE, 2024. 2359−2364 [158] Gaddala V S. Unleashing the power of generative AI and RAG agents in supply chain management: A futuristic perspective. IRE Journals, 2023, 6(12): 1411−1417 [159] Gupta A, Shirgaonkar A, de Luis Balaguer A, Silva B, Holstein D, Li D W, et al. RAG vs fine-tuning: Pipelines, tradeoffs, and a case study on agriculture. arXiv preprint arXiv: 2401.08406, 2024. [160] Wang F Y. Foundation worlds for parallel intelligence: From foundation/infrastructure models to foundation/infrastructure intelligence. Alfred North Whitehead Laureate Lectures. Beijing: 2021. [161] Packer C, Fang V, Patil S G, Lin K, Wooders S, Gonzalez J E. MemGPT: Towards LLMs as operating systems. arXiv preprint arXiv: 2310.08560, 2023. [162] Pouplin T, Sun H, Holt S, van der Schaar M. Retrieval-augmented thought process as sequential decision making. arXiv preprint arXiv: 2402.07812, 2024. [163] Geva M, Khashabi D, Segal E, Khot T, Roth D, Berant J. Did Aristotle use a laptop? A question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 2021, 9: 346−361 doi: 10.1162/tacl_a_00370 [164] Stelmakh I, Luan Y, Dhingra B, Chang M W. ASQA: Factoid questions meet long-form answers. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: ACL, 2022. 8273−8288 [165] Hayashi H, Budania P, Wang P, Ackerson C, Neervannan R, Neubig G. WikiAsp: A dataset for multi-domain aspect-based summarization. Transactions of the Association for Computational Linguistics, 2021, 9: 211−225 doi: 10.1162/tacl_a_00362 [166] Zhong M, Liu Y, Yin D, Mao Y N, Jiao Y Z, Liu P F, et al. Towards a unified multi-dimensional evaluator for text generation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: ACL, 2022. 2023−2038 [167] Yu H, Gan A, Zhang K, Tong S W, Liu Q, Liu Z F. Evaluation of retrieval-augmented generation: A survey. arXiv preprint arXiv: 2405.07437, 2024. [168] Chen H T, Xu F Y, Arora S, Choi E. Understanding retrieval augmentation for long-form question answering. arXiv preprint arXiv: 2310.12150, 2023. [169] Chen W H, Hu H X, Saharia C, Cohen W W. Re-imagen: Retrieval-augmented text-to-image generator. arXiv preprint arXiv: 2209.14491, 2022. [170] Nashid N, Sintaha M, Mesbah A. Retrieval-based prompt selection for code-related few-shot learning. In: Proceedings of the 45th International Conference on Software Engineering (ICSE). Melbourne, Australia: IEEE, 2023. 2450−2462 [171] Yu W H. Retrieval-augmented generation across heterogeneous knowledge. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop. Washington, USA: ACL, 2022. 52−58 -

计量
- 文章访问数: 415
- HTML全文浏览量: 391
- PDF下载量: 116
- 被引次数: 0
