

Adaptive Timestep Improved Spiking Neural Network for Efficient Image Classification
-
摘要: 脉冲神经网络(Spiking neural network, SNN)由于具有相对人工神经网络(Artifcial neural network, ANN)更低的计算能耗而受到广泛关注. 然而, 现有SNN大多基于同步计算模式且往往采用多时间步的方式来模拟动态的信息整合过程, 因此带来了推理延迟增大和计算能耗增高等问题, 使其在边缘智能设备上的高效运行大打折扣. 针对这个问题, 本文提出一种自适应时间步脉冲神经网络(Adaptive timestep improved spiking neural network, ATSNN)算法. 该算法可以根据不同样本特征自适应选择合适的推理时间步, 并通过设计一个时间依赖的新型损失函数来约束不同计算时间步的重要性. 与此同时, 针对上述ATSNN特点设计一款低能耗脉冲神经网络加速器, 支持ATSNN算法在VGG和ResNet等成熟框架上的应用部署. 在CIFAR10、CIFAR100、CIFAR10-DVS等标准数据集上软硬件实验结果显示, 与当前固定时间步的SNN算法相比, ATSNN算法的精度基本不下降, 并且推理延迟减少36.7% ~ 58.7%, 计算复杂度减少33.0% ~ 57.0%. 在硬件模拟器上的运行结果显示, ATSNN的计算能耗仅为GPU RTX 3090Ti的4.43% ~ 7.88%. 显示出脑启发神经形态软硬件的巨大优势.Abstract: Spiking neural network (SNN) has received broad attention for its relatively lower computational energy consumption compared to artificial neural network (ANN). However, most conventional SNNs use a synchronous computation paradigm, whereby multiple timesteps are commonly used to simulate the dynamic process of information integration, resulting in some problems such as extended inference delay and increased computational energy consumption, which lead to a serious efficiency discount during the realistic application of edge intelligent devices. In this paper, we propose an adaptive timestep improved spiking neural network (ATSNN) algorithm, which can automatically choose a proper inference timestep based on different features of input samples, and regulate the importance of different timesteps by designing an innovative time-dependent loss function. Besides, a low energy consumption SNN accelerator is designed based on the characteristics of ATSNN mentioned above to support applications and deployments of ATSNN algorithm on some mature frameworks (such as VGG and ResNet). The results of software and hardware experiments on standard datasets such as CIFAR10, CIFAR100, and CIFAR10-DVS show that, compared to conventional SNN algorithms using static timesteps, the ATSNN algorithm can reach a comparable accuracy but with a decreased inference delay (around 36.7% ~ 58.7%) and reduced computational complexity (around 33.0% ~ 57.0%). Furthermore, the running results on the hardware simulator indicate that the computational energy consumption of ATSNN is only around 4.43% ~ 7.88% of GPU RTX 3090Ti. It shows great advantages of brain-inspired neuromorphic hardware and software.
-
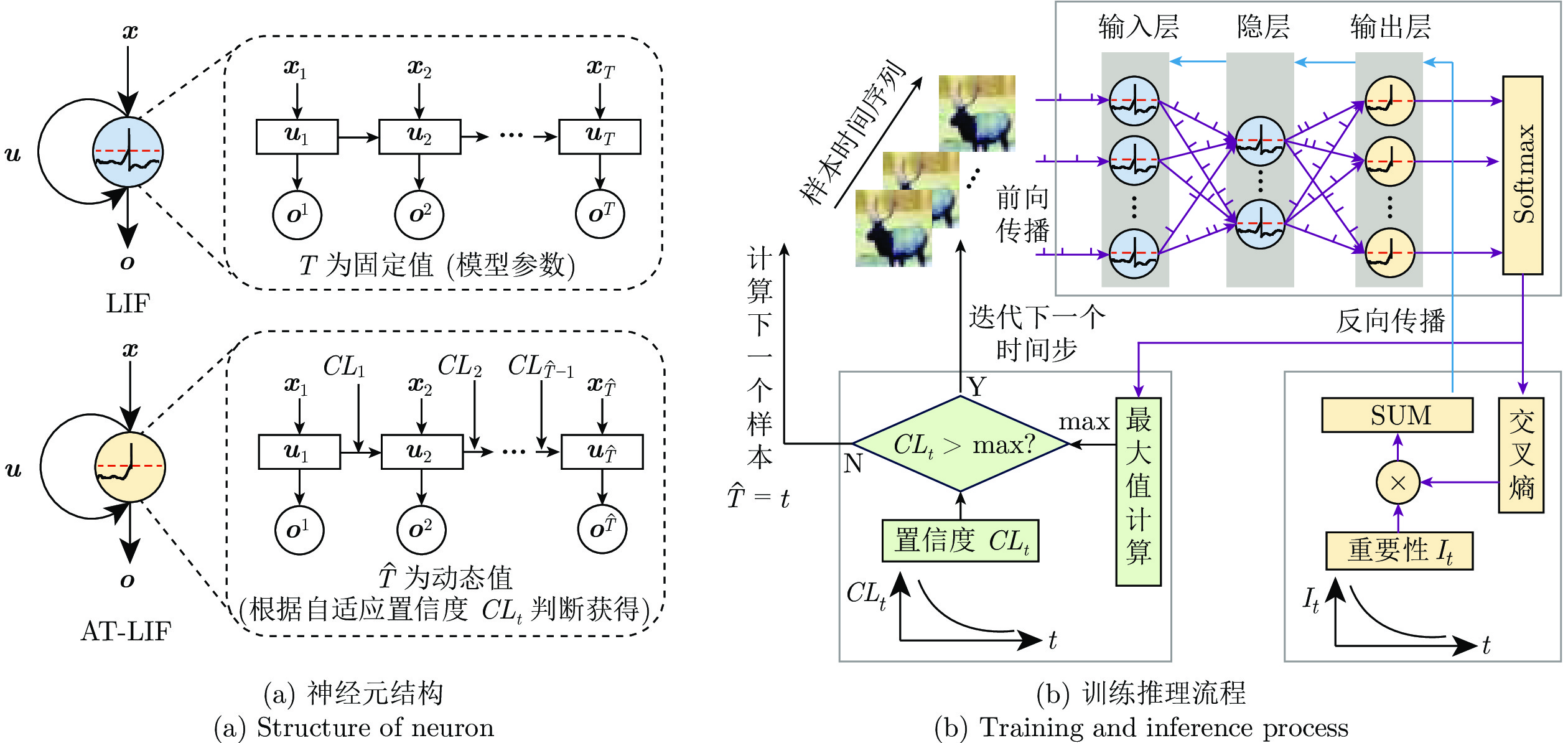
图 1 ATSNN结构及训练和动态时间推理流程图
Fig. 1 ATSNN structure and training and dynamic time inference flow chart
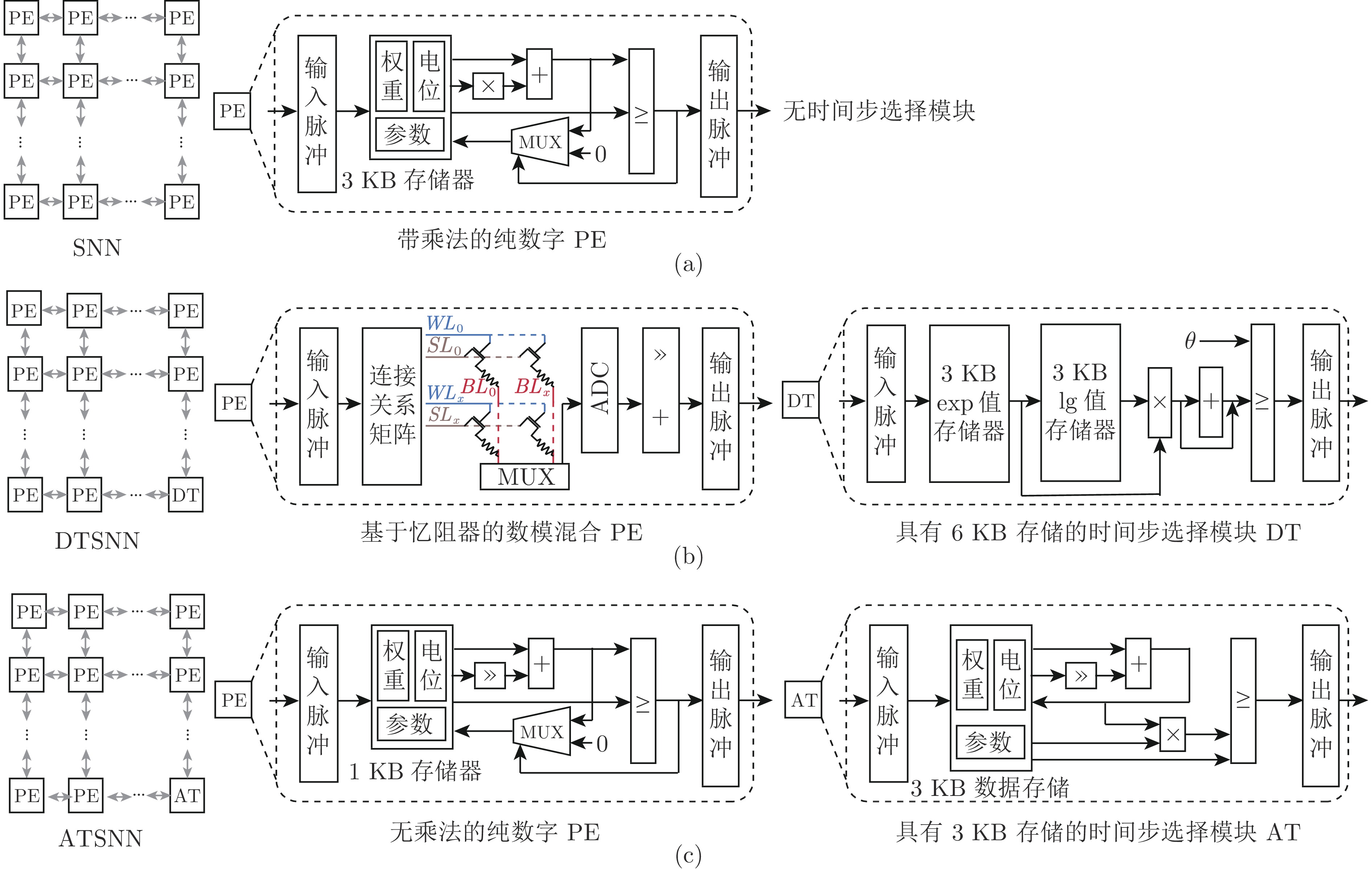
图 2 加速器架构((a)常规加速器; (b) DTSNN的加速器; (c)本文加速器)
Fig. 2 Accelerator architecture ((a) Conventional accelerator; (b) Accelerator of DTSNN; (c) Our accelerator)
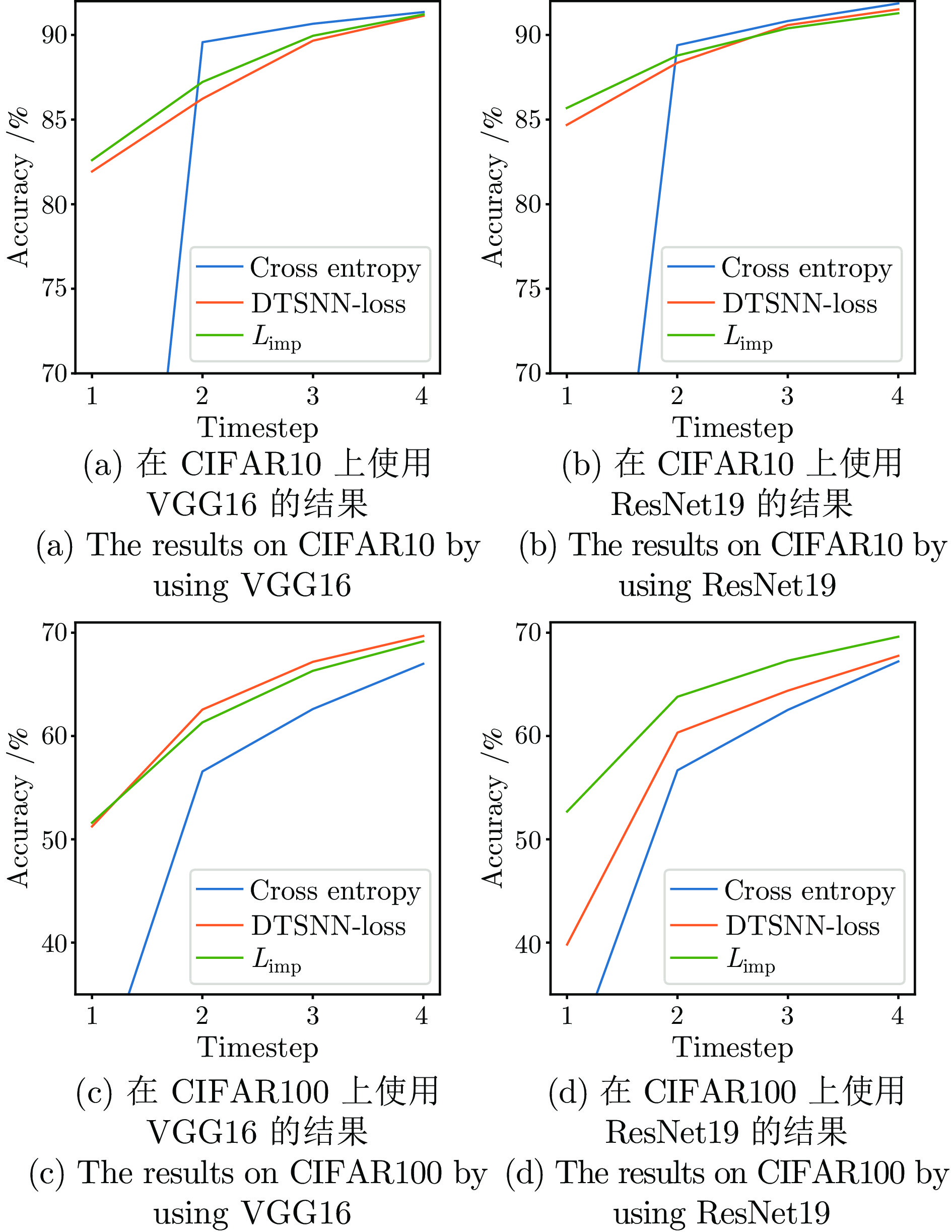
图 4 固定时间步时使用三种损失函数的准确率
Fig. 4 Accuracy by using three loss functions at fixed timestep
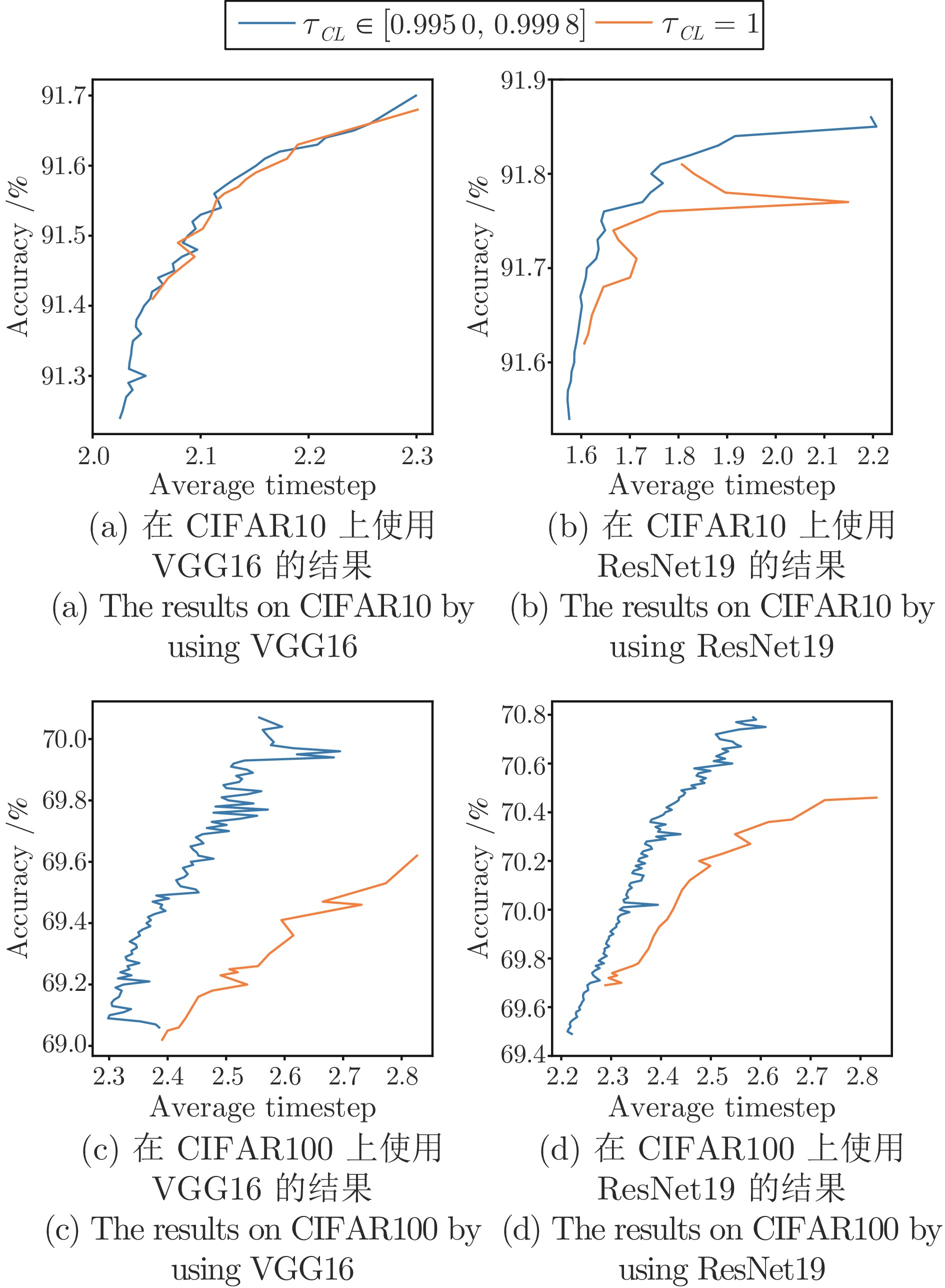
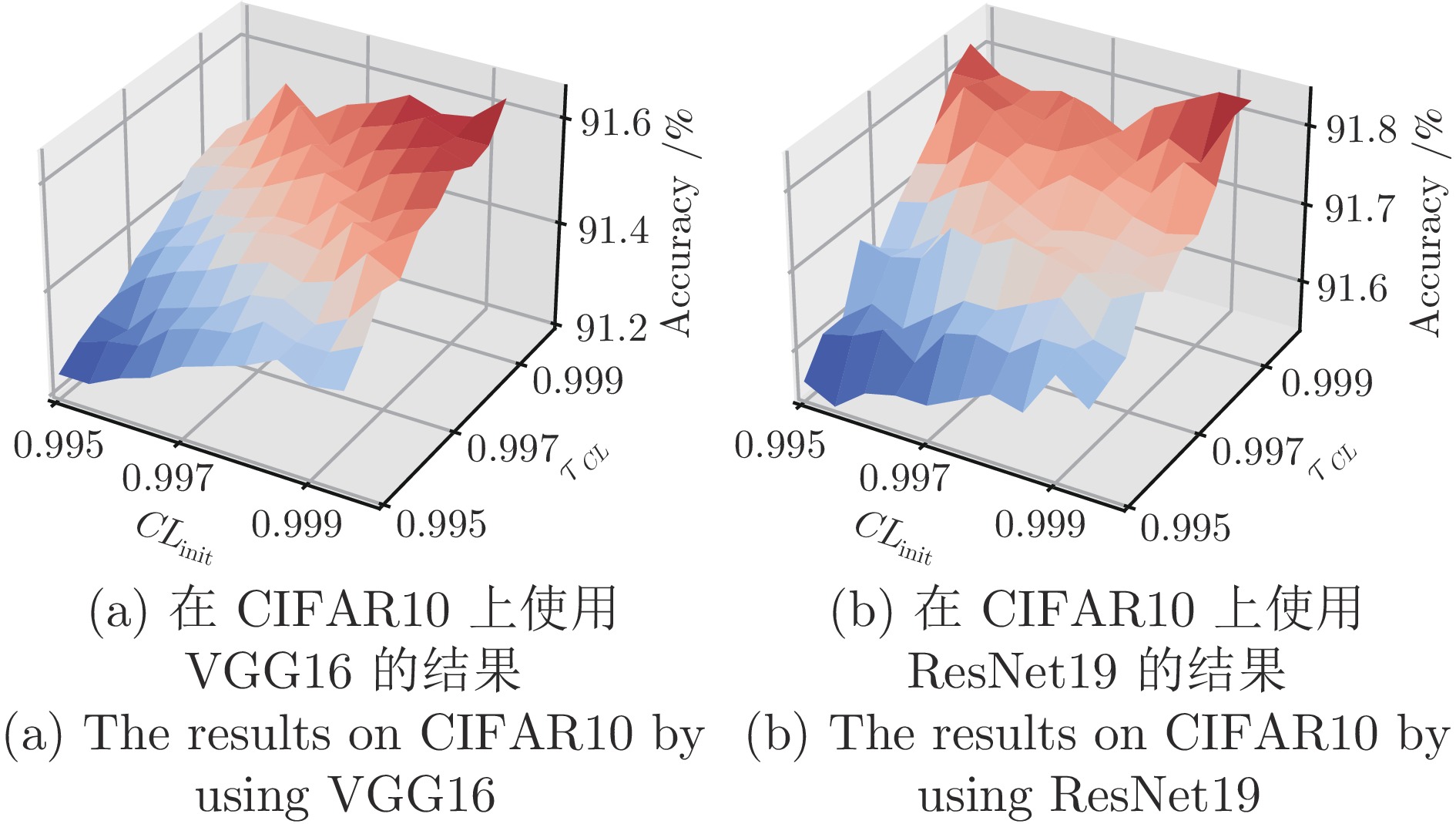
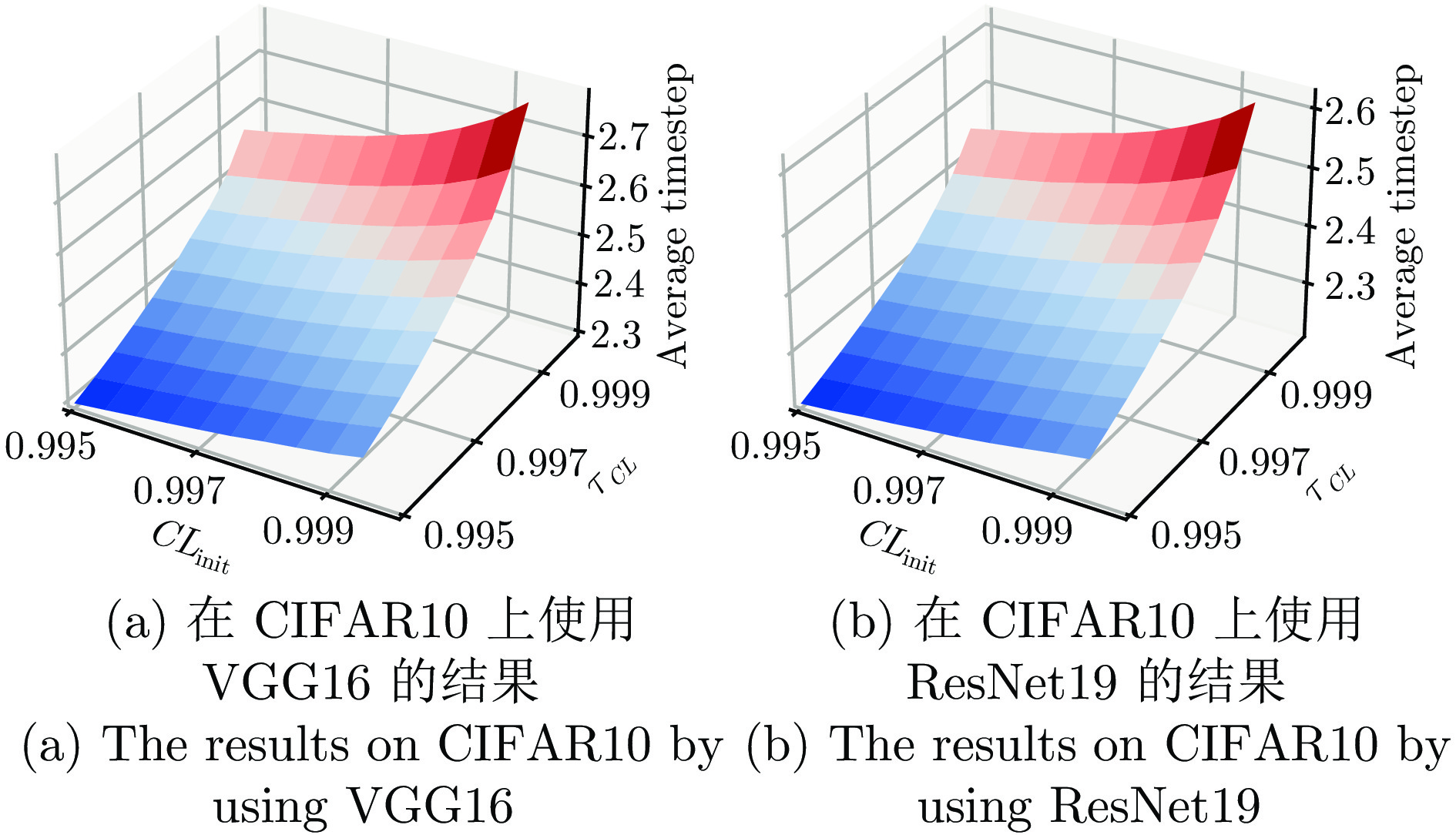
图 7 $ \tau_{CL}\ne1 $和$ \tau_{CL} =1$时的性能对比
Fig. 7 Performance comparison between $ \tau_{CL}\ne1 $ and $ \tau_{CL}= 1 $
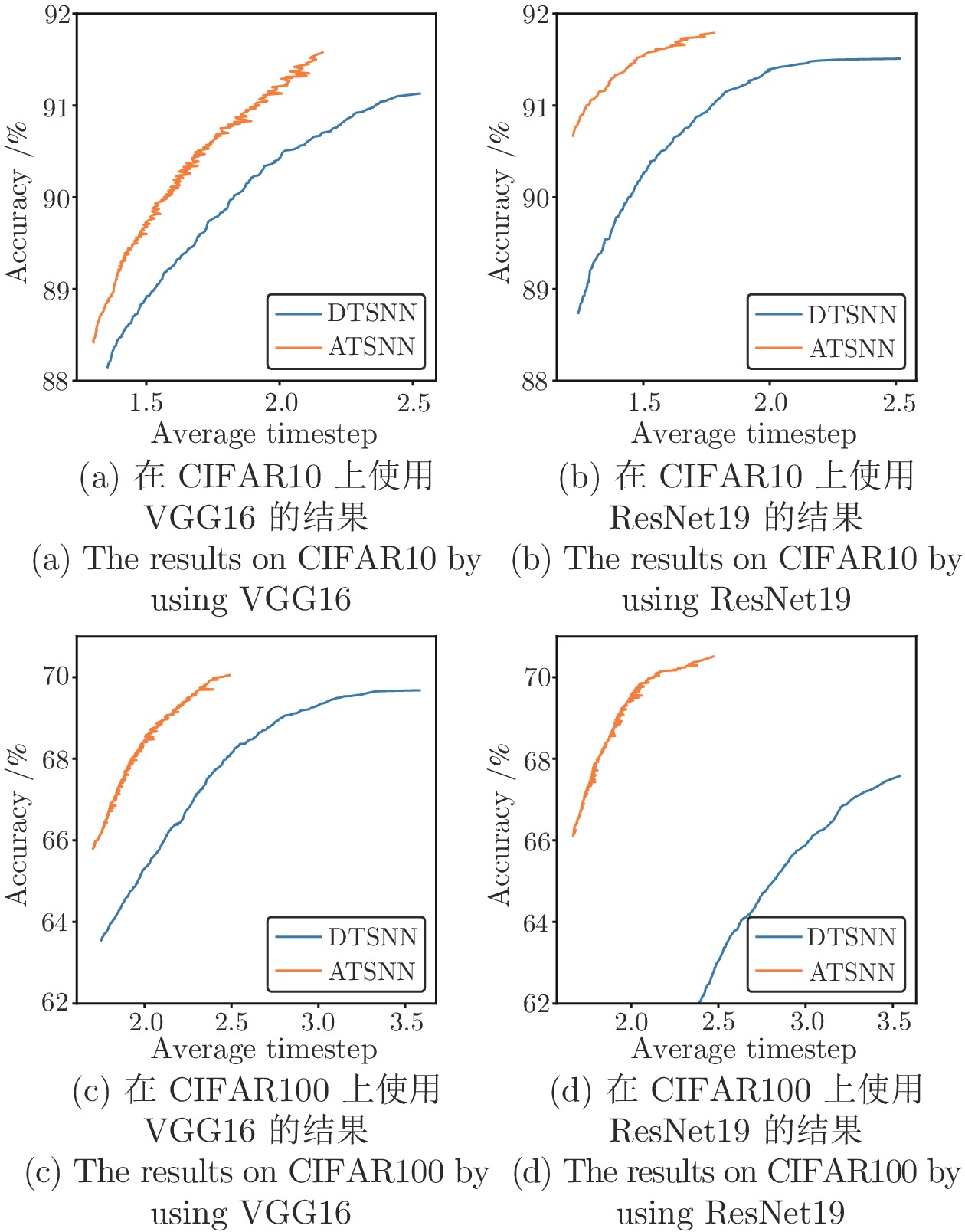
表 1 SNN、DTSNN和ATSNN在时间步、准确率和复杂度的对比
Table 1 Comparison of SNN, DTSNN and ATSNN in timestep, accuracy and complexity
网络结构 算法 CIFAR10 CIFAR100 CIFAR10-DVS 时间步 准确率(%) 复杂度 时间步 准确率(%) 复杂度 时间步 准确率(%) 复杂度 VGG16 SNN 4.00 91.35 1.00 4.00 66.99 1.00 10.00 72.60 1.00 DTSNN 2.53 (4) 91.13 0.79 3.58 (4) 69.68 0.96 5.70 (10) 73.30 0.56 ATSNN 2.19 (4) 91.61 0.67 2.49 (4) 70.05 0.63 4.13 (10) 73.00 0.43 ResNet19 SNN 4.00 91.86 1.00 4.00 67.22 1.00 10.00 70.00 1.00 DTSNN 2.52 (4) 91.51 0.88 3.54 (4) 67.58 1.02 6.95 (10) 70.50 0.94 ATSNN 2.00 (4) 91.84 0.67 2.53 (4) 70.64 0.64 5.57 (10) 69.50 0.63  下载: 导出CSV
下载: 导出CSV
表 2 每个时间步的相对计算复杂度及网络性能
Table 2 Relative computational complexity per timestep and network performance
数据集 T1 T2 T3 T4 T5 $\tilde{T}$ (%) $\Delta ACC$ (%) ImageNet-100 0.998 1.009 1.009 1.010 1.003 68.49 0.90 N-Caltech-101 0.959 0.977 0.978 0.959 0.989 68.32 0.45
下载: 导出CSV
表 3 加速器与GPU关于FPS、耗能对比
Table 3 Comparison of FPS and energy consumption between accelerator and GPU
网络结构 数据集 GPU 本文加速器 FPS 耗能(J) FPS 耗能(J) VGG16 CIFAR10 215 6814 248 537.6 (7.88%) CIFAR100 200 7499 228 543.6 (7.24%) ResNet19 CIFAR10 215 11088 212 606.1 (5.46%) CIFAR100 172 13914 180 617.2 (4.43%)
下载: 导出CSV
表 4 默认超参数的性能
Table 4 Performance with default hyperparameters
数据集 网络结构 时间步 准确率(%) CIFAR10 ResNet19 1.897 (4) 91.77 CIFAR10 VGG16 2.183 (4) 91.57 CIFAR100 ResNet19 2.501 (4) 70.46 CIFAR100 VGG16 2.642 (4) 69.58
下载: 导出CSV
表 5 ATSNN消融实验
Table 5 Ablation experiment of ATSNN
数据集 输出层神经元 损失函数 输出表征 T1 T2 T3 T4 CIFAR10 34.43 89.39 90.82 91.86 √ 47.26 89.85 90.52 91.38 √ 85.68 88.78 90.39 91.28 √ √ 86.93 89.96 91.63 91.79 √ √ √ 86.93 90.14 91.39 91.86 CIFAR100 27.13 56.68 62.53 67.22 √ 30.38 57.19 63.37 67.70 √ 52.69 63.80 67.29 69.61 √ √ 53.47 64.35 67.53 69.90 √ √ √ 53.47 65.23 68.17 70.25
下载: 导出CSV
表 6 ATSNN与低延迟算法的对比
Table 6 Comparison between ATSNN and low-latency algorithms
数据集 算法 算法类型 网络结构 时间步 准确率 (%) CIFAR10 Conversion[11] ANN转SNN VGG16 8 90.96 STDB[33] 转换+训练 VGG16 5 91.41 EfficientLIF-Net[10] 直接训练 VGG16 5 90.30 DTSNN[19] 直接训练 VGG16 2.53 (4) 91.13 本文 直接训练 VGG16 2.56 (10) 92.09 STBP-tdBN[14] 直接训练 ResNet19 6 93.16 DTSNN[19] 直接训练 ResNet19 2.51 (4) 91.51 本文 直接训练 ResNet19 2.71 (10) 92.38 CIFAR100 STDB[33] 转换+训练 VGG16 5 66.46 Diet-SNN[15] 直接训练 VGG16 5 69.67 Real Spike[34] 直接训练 VGG16 5 70.62 RecDis-SNN[35] 直接训练 VGG16 5 69.88 本文 直接训练 VGG16 3.86 (10) 71.37 DTSNN[19] 直接训练 ResNet19 3.54 (4) 67.58 本文 直接训练 ResNet19 2.53 (10) 70.64 CIFAR10-DVS STBP-tdBN[14] 直接训练 ResNet19 6 67.80 DTSNN[19] 直接训练 ResNet19 6.95 (10) 70.50 本文 直接训练 ResNet19 5.57 (10) 69.50 ImageNet-100 EfficientLIF-Net[10] 直接训练 ResNet19 5 79.44 LocalZO[36] 直接训练 SEW-ResNet34 4 81.56 本文 直接训练 ResNet19 1.76 (5) 81.96 TinyImageNet EfficientLIF-Net[10] 直接训练 ResNet19 5 55.44 DTSNN[19] 直接训练 ResNet19 3.71 (5) 57.18 本文 直接训练 ResNet19 2.47 (5) 57.61 N-Caltech-101 MC-SNN[37] 直接训练 VGG16 20 81.24 DTSNN[19] 直接训练 VGG16 3.21 (10) 82.26 本文 直接训练 VGG16 2.19 (10) 82.63 NDA[30] 直接训练 ResNet19 10 78.60 本文 直接训练 ResNet19 2.56 (10) 80.56
下载: 导出CSV
-
[1] Dampfhoffer M, Mesquida T, Valentian A, Anghel L. Are SNNs really more energy-efficient than ANNs? An in-depth hardware-aware study. IEEE Transactions on Emerging Topics in Computational Intelligence, 2023, 7(3): 731−741 doi: 10.1109/TETCI.2022.3214509 [2] Merolla P A, Arthur J V, Alvarez I R, Cassidy A S, Sawada J, Akopyan F, et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science, 2014, 345(6197): 668−673 doi: 10.1126/science.1254642 [3] Davies M, Srinivasa N, Lin T H, Chinya G, Cao Y Q, Choday S H, et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro, 2018, 38(1): 82−99 doi: 10.1109/MM.2018.112130359 [4] Pei J, Deng L, Song S, Zhao M G, Zhang Y H, Wu S, et al. Towards artificial general intelligence with hybrid Tianjic chip architecture. Nature, 2019, 572(7767): 106−111 doi: 10.1038/s41586-019-1424-8 [5] Bouvier M, Valentian A, Mesquida T, Rummens F, Reyboz M, Vianello E, et al. Spiking neural networks hardware implementations and challenges: A survey. ACM Journal on Emerging Technologies in Computing Systems, 2019, 15(2): Article No. 22 [6] Wu Y J, Deng L, Li G Q, Zhu J, Shi L P. Spatio-temporal backpropagation for training high-performance spiking neural networks. Frontiers in Neuroscience, DOI: 10.3389/fnins.2018.00331 [7] Izhikevich E M. Which model to use for cortical spiking neurons? IEEE Transactions on Neural Networks, 2004, 15(5): 1063−1070 doi: 10.1109/TNN.2004.832719 [8] Taherkhani A, Belatreche A, Li Y H, Cosma G, Maguire L P, McGinnity T M. A review of learning in biologically plausible spiking neural networks. Neural Networks, 2020, 122: 253−272 doi: 10.1016/j.neunet.2019.09.036 [9] Liang Z Z, Schwartz D, Ditzler G, Koyluoglu O O. The impact of encoding-decoding schemes and weight normalization in spiking neural networks. Neural Networks, 2018, 108: 365−378 doi: 10.1016/j.neunet.2018.08.024 [10] Kim Y, Li Y H, Moitra A, Yin R K, Panda P. Sharing leaky-integrate-and-fire neurons for memory-efficient spiking neural networks. Frontiers in Neuroscience, DOI: 10.3389/fnins.2023.1230002 [11] Bu T, Ding J H, Yu Z F, Huang T J. Optimized potential initialization for low-latency spiking neural networks. arXiv preprint arXiv: 2202.01440, 2022. [12] Jiang C M, Zhang Y L. KLIF: An optimized spiking neuron unit for tuning surrogate gradient slope and membrane potential. arXiv preprint arXiv: 2302.09238, 2023. [13] Fang W, Yu Z F, Chen Y Q, Huang T J, Masquelier T, Tian Y H. Deep residual learning in spiking neural networks. arXiv preprint arXiv: 2102.04159, 2021. [14] Zheng H L, Wu Y J, Deng L, Hu Y F, Li G Q. Going deeper with directly-trained larger spiking neural networks. arXiv preprint arXiv: 2011.05280, 2020. [15] Rathi N, Roy K. DIET-SNN: A low-latency spiking neural network with direct input encoding and leakage and threshold optimization. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(6): 3174−3182 doi: 10.1109/TNNLS.2021.3111897 [16] Guo Y F, Chen Y P, Zhang L W, Liu X D, Wang Y L, Huang X H, et al. IM-loss: Information maximization loss for spiking neural networks. In: Proceedings of the 36th Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. 156−166 [17] Teerapittayanon S, McDanel B, Kung H T. BranchyNet: Fast inference via early exiting from deep neural networks. In: Proceedings of the 23rd International Conference on Pattern Recognition (ICPR). Cancun, Mexico: IEEE, 2016. 2464−2469 [18] Kim Y, Panda P. Revisiting batch normalization for training low-latency deep spiking neural networks from scratch. Frontiers in Neuroscience, DOI: 10.3389/fnins.2021.773954 [19] Li Y H, Moitra A, Geller T, Panda P. Input-aware dynamic timestep spiking neural networks for efficient in-memory computing. In: Proceedings of the 60th ACM/IEEE Design Automation Conference (DAC). San Francisco, USA: IEEE, 2023. 1−6 [20] Deng L, Wu Y J, Hu Y F, Liang L, Li G Q, Hu X, et al. Comprehensive SNN compression using ADMM optimization and activity regularization. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(6): 2791−2805 doi: 10.1109/TNNLS.2021.3109064 [21] Stöckl C, Maass W. Optimized spiking neurons can classify images with high accuracy through temporal coding with two spikes. Nature Machine Intelligence, 2021, 3(3): 230−238 doi: 10.1038/s42256-021-00311-4 [22] Chen Y Q, Yu Z F, Fang W, Huang T J, Tian Y H. Pruning of deep spiking neural networks through gradient rewiring. arXiv preprint arXiv: 2105.04916, 2021. [23] Eshraghian J K, Lammie C, Azghadi M R, Lu W D. Navigating local minima in quantized spiking neural networks. In: Proceedings of the IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS). Incheon, South Korea: IEEE, 2022. 352−355 [24] Wang Y X, Xu Y, Yan R, Tang H J. Deep spiking neural networks with binary weights for object recognition. IEEE Transactions on Cognitive and Developmental Systems, 2021, 13(3): 514−523 doi: 10.1109/TCDS.2020.2971655 [25] Krizhevsky A. Learning Multiple Layers of Features From Tiny Images [Master thesis], University of Toronto, Canada, 2009. [26] Le Y, Yang X. Tiny imagenet visual recognition challenge [Online], available: http://cs231n.stanford.edu/tiny-imagenet-200.zip, June 11, 2023 [27] Deng J, Dong W, Socher R, Li L J, Li K, LI F F. ImageNet: A large-scale hierarchical image database. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 248−255 [28] Li H M, Liu H C, Ji X Y, Li G Q, Shi L P. CIFAR10-DVS: An event-stream dataset for object classification. Frontiers in Neuroscience, DOI: 10.3389/fnins.2017.00309 [29] Orchard G, Jayawant A, Cohen G K, Thakor N. Converting static image datasets to spiking neuromorphic datasets using saccades. Frontiers in Neuroscience, DOI: 10.3389/fnins.2015.00437 [30] Li Y H, Kim Y, Park H, Geller T, Panda P. Neuromorphic data augmentation for training spiking neural networks. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 631−649 [31] Fang W, Chen Y Q, Ding J H, Yu Z F, Masquelier T, Chen D, et al. SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence. Science Advances, 2023, 9(40): Article No. eadi1480 doi: 10.1126/sciadv.adi1480 [32] Yin R K, Moitra A, Bhattacharjee A, Kim Y, Panda P. SATA: Sparsity-aware training accelerator for spiking neural networks. IEEE Transactions on Computer-aided Design of Integrated Circuits and Systems, 2023, 42(6): 1926−1938 doi: 10.1109/TCAD.2022.3213211 [33] Datta G, Kundu S, Beerel P A. Training energy-efficient deep spiking neural networks with single-spike hybrid input encoding. In: Proceedings of the International Joint Conference on Neural Networks (IJCNN). Shenzhen, China: IEEE, 2021. 1−8 [34] Guo Y F, Zhang L W, Chen Y P, Tong X Y, Liu X D, Wang Y L, et al. Real spike: Learning real-valued spikes for spiking neural networks. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 52−68 [35] Guo Y F, Tong X Y, Chen Y P, Zhang L W, Liu X D, Ma Z, et al. RecDis-SNNS: Rectifying membrane potential distribution for directly training spiking neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 326−335 [36] Mukhoty B, Bojkovic V, Vazelhes W, Zhao X H, Masi G, Xiong H, et al. Direct training of SNN using local zeroth order method. In: Proceedings of the Thirty-seventh Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. 18994−19014 [37] Li X J, Tang J X, Lai J H. Learning high-performance spiking neural networks with multi-compartment spiking neurons. In: Proceedings of the 12th International Conference on Image and Graphics. Nanjing, China: Springer, 2023. 91−102 -

 下载:
下载:

计量
- 文章访问数: 953
- HTML全文浏览量: 575
- PDF下载量: 236
- 被引次数: 0
